Never re-use check containers #3079
Comments
|
I really like this idea. However I think this might be a good idea to rethink the way we model volume At the moment, a @vito thoughts? |
|
@pivotal-jwinters I wonder if the idea I threw around in #3025 (comment) meshes well with that. At least for now I would rather do this within the bounds of the current architecture, just because there seems to be a clear enough path. But it helps to discuss this stuff early on for potential post-5.x/6.x architecture changes! |
|
Spiking on some wild wild thoughts around this:
|
|
Adding this to the Core project as well, just because a lot of the concerns/gotchas regarding global resources would be greatly mitigated if we were to do this. Implementation-wise, there are probably more runtimey concerns though (especially regarding the cache volume lifecycle and container scheduling). Maybe it can be divided into separate steps that can be done by each team? Step 1 would be to eliminate check sessions entirely and just create a new Step 2 would be to measure container creation time to see how this change may impact worker load, and then see what we can do to mitigate any additional slowness. This testing should be done with cheap resources like Step 3 would then be to figure out the volume caching lifecycle, and how to schedule containers to best leverage it. I think this probably takes more thinking. Step 1 could probably be easily done by Core, and steps 2 and 3 are probably better left to Runtime. @topherbullock wdyt? |
|
I agree with the separation of work between Core and Runtime.
I think Core's implementation of Step 1 could even get away with ignoring
the fact that GC may reap those containers until Runtime picks up a
corresponding story to address GC.
We might want to spike on a quick resource check measurement now to see the
delta after Step 2 on low-state checks like `time`
…On Tue., Jan. 22, 2019, 2:01 p.m. Alex Suraci, ***@***.***> wrote:
Adding this to the Core project as well, just because a lot of the
concerns/gotchas regarding global resources would be greatly mitigated if
we were to do this. Implementation-wise, there are probably more runtimey
concerns though (especially regarding the cache volume lifecycle and
container scheduling).
Maybe it can be divided into separate steps that can be done by each team?
Step 1 would be to eliminate check sessions entirely and just create a new
check container every time. This would obviously be a huge regression for
big git repos and we shouldn't ship with only this much implemented, but
maybe we can start to see how this simplifies things. We would still need
to figure out a new lifecycle for these containers but it might be pretty
simple.
Step 2 would be to measure container creation time to see how this change
may impact worker load, and then see what we can do to mitigate any
additional slowness. This testing should be done with cheap resources like
time so that we're not measuring the known regression that Step 1
introduces.
Step 3 would then be to figure out the volume caching lifecycle, and how
to schedule containers to best leverage it. I think this probably takes
more thinking.
Step 1 could probably be easily done by Core, and steps 2 and 3 are
probably better left to Runtime.
@topherbullock <https://github.com/topherbullock> wdyt?
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#3079 (comment)>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/ABzt3MqHKktySWonUmligbD7X9jy8Rv6ks5vF1_xgaJpZM4aGEtu>
.
|
|
Did a bit more thinking on this with @clarafu and @pivotal-jwinters - we like the idea of creating a one-off container and not bothering with a complicated lifecycle, and allowing Garden's One gotcha however is that the container also has an associated volume for its copy-on-write rootfs. BaggageClaim supports TTLs but it won't keep it alive for you as it has no idea that it's "in use". So we tried thinking of ways to avoid defining the lifecycle for this volume, since it'd be just about as complicated as it would be for containers. One idea we had was to write a BaggageClaim image plugin for Guardian. Image plugins are executables that are configured in Guardian like so: We could ship Concourse with a BaggageClaim image plugin and auto-configure it when starting For phase 1 (Core spike), I think we can just leave the volumes around forever for now, or give them some arbitrary TTL. |
|
For the core spike, TODO list:
|
|
The current approach to this issue: Step 2. Core: remove resource config check sessions and all it's associates within the database and code base. Step 3. Runtime: measure container creation time with the new changes of ephemeral check containers to see how this change may impact worker load in a real deployment, and then see what we can do to mitigate any additional slowness. This testing should be done with cheap resources like Step 4. Runtime: would then be to figure out the volume caching lifecycle, and how to schedule containers to best leverage it. I think this probably takes more thinking. |
|
A goal of this is to remove the lock around checking, though currently this also locks around saving the versions. It looks like that code is idempotent but we should probably verify this by hand to make sure no funny business happens. Since it's never been exercised otherwise. |
|
Maybe related: I was looking at the "locks held" metric when a particular pipeline (strabo) kicked off, and it's quite interesting how that looks like:
|
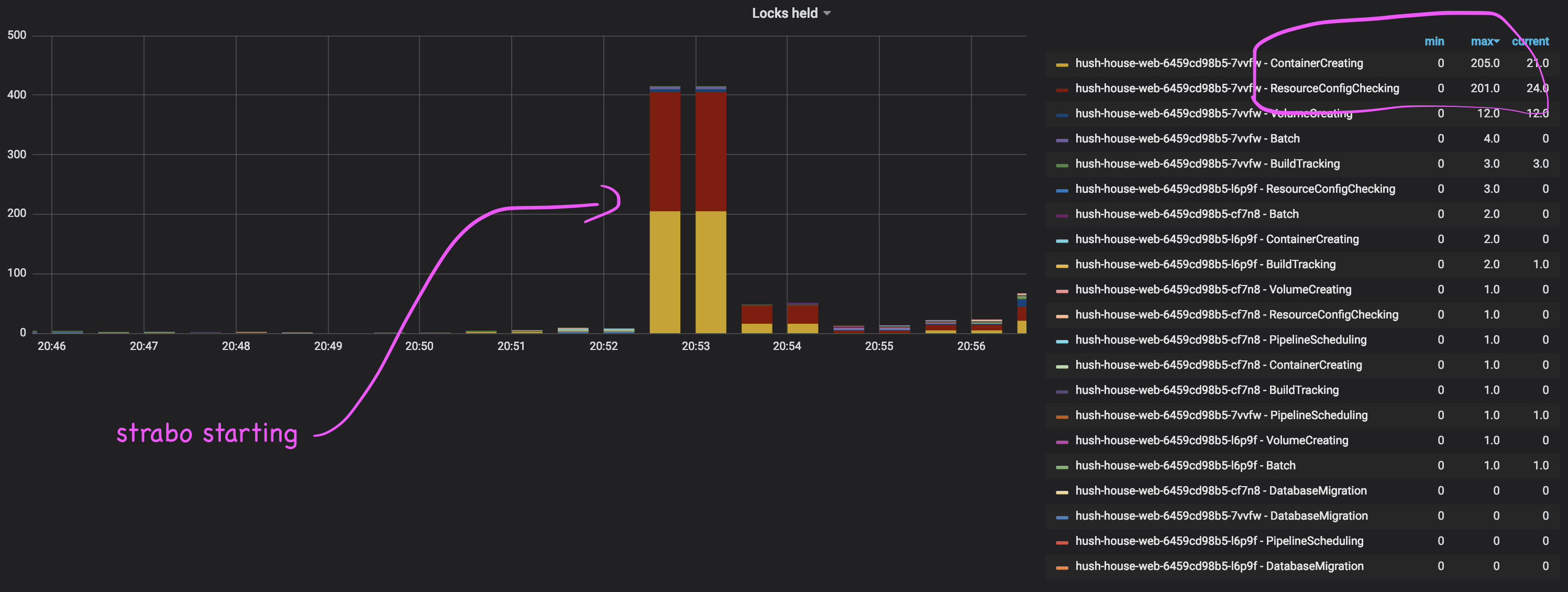
|
Work on this has resumed in #3424 |
What challenge are you facing?
Check containers are re-used for up to an hour (by default) so that resources can re-use cached state that they fetched (i.e. so a fresh
git clonedoesn't have to run all the time).We limit their re-use to an hour so that they get rebalanced across workers periodically. However that means every hour forces a fresh
git clone, which makes people want to extend their lifetime further (#2988).This also means that for a bunch of resources, there will always be a bunch of containers across all the workers, leading to desperate measures like #3054 and in general a ton of questions because people are almost always surprised to see so many
checkcontainers.We also are super careful to lock and make sure only one ATC is using a container at a time.
And we're careful about how these containers are re-used (e.g. across teams).
What would make this better?
Let's not do that!
Can we instead create a one-time-use container every time we need to run a
check, and use a volume to explicitly track the cached state between runs?This volume could work like task caches - there would be one persisted on each worker that the
checkruns on. A copy of it would be mounted to the container, and that copy would become the new cache for subsequent runs.Open questions:
Are you interested in implementing this yourself?
Yeah, actually, it sounds fun.
The text was updated successfully, but these errors were encountered: