NOTE: FUTURE DEVELOPMENT WILL HAPPEN THROUGH GITLAB!
As of June, 6th 2018 this project moved to Gitlab that's why this repository is archived and thus read-only until it is entirely removed from Github. Repository removal is scheduled for September, 15th 2018.
Please report issues and request your merges through the new project home. All further discussion - even for existing issues - will take place there.
Thank you,
rc0r

afl-utils is a collection of utilities to assist fuzzing with american-fuzzy-lop (afl). afl-utils includes tools for:
- automated crash sample collection, verification, reduction and analysis (
afl-collect,afl-vcrash) - easy management of parallel (multi-core) fuzzing jobs (
afl-multicore,afl-multikill) - corpus optimization (
afl-minimize) - fuzzer stats supervision (
afl-stats) - fuzzer queue synchronisation (
afl-sync) - autonomous utility execution (
afl-cron)
Various screenshots of the tools in action can be found at the end of this file.
For installation instructions see docs/INSTALL.md.
afl-collect basically copies all crash sample files from an afl synchronisation directory
(used by multiple afl instances when run in parallel) into a single location providing
easy access for further crash analysis. Beyond that afl-collect has some more advanced
features like invalid crash sample removing (see afl-vcrash) as well as generating and
executing gdb scripts that make use of Exploitable.
The purpose of these scripts is to automate crash sample classification (see screenshot below)
and reduction.
Version 1.01a introduced crash sample de-duplication using backtrace hashes calculated by
exploitable. To use this feature invoke afl-collect with -e <gdb_script> switch for
automatic gdb+exploitable script generation and execution. For each backtrace hash only a
single crash sample file will be kept.
afl-collect is quite slow when operating on large sample sets and using gdb+exploitable
script execution, so be patient!
When invoked with -d <database>, sample information will be stored in the database. This
will only be done when the gdb-script execution step is selected (-e). If database is an
existing database containing sample info, afl-collect will skip all samples that already
have a database entry during sample processing. This will work also when -e is not requested.
This makes subsequent afl-collect runs more efficient, since only unseen samples are
processed (and added to the database).
Usage examples:
Simply collect all crashes from ./afl_sync_dir into a collection directory removing
non-crashing samples:
$ afl-collect -r ./afl_sync_dir ./collection_dir -- /path/to/target --target-opts
Collect crashes, execute exploitable on them and remove uninteresting crashes. Info
for all processed samples will be stored in an SQLite DB. The gdb script used to run
exploitable on all samples will be saved in gdb_script. We're using eight threads
here:
$ afl-collect -d crashes.db -e gdb_script -r -rr ./afl_sync_dir ./collection_dir \
-j 8 -- /path/to/target --target-opts
During sample verification (enabled using -r) afl-collect uses a default time of
10 seconds to allow the target process to finish processing a single sample. This ensures
that afl-collect continues to run even if you happen to encounter some DoS condition
in the target. If you want to tweak this value use -r in conjunction with
-rt <timeout> to specify the timeout in seconds.
The purpose of afl-cron is to run different afl-utils tasks periodically. Example
use cases include grabbing afl-stats or syncing fuzzing queues using afl-sync
repeatedly. afl-cron is not limited to run top-level tools from the afl-utils
collection. For a much finer granularity you may specify an arbitrary function from
any afl-utils module to be executed once the timer runs out.
Running afl-cron with the following configuration will execute afl-stats.main()
every 60 minutes in quiet mode using the provided sample config:
{
"interval": 60,
"jobs": [
{
"name": "afl-stats",
"description": "Job description here",
"module": "afl_utils.afl_stats",
"function": "main",
"params": "--quiet -c config/afl-stats.conf.sample"
}
]
}You may have multiple job definitions in your configuration. Once the interval timer is up, all jobs are executed sequentially.
Helps to create a minimized corpus from samples of a parallel fuzzing job. It basically works as follows:
- Collect all queue samples from an afl synchronisation directory in
collection_dir. - Run
afl-cminon the collected corpus, save minimized corpus incollection_dir.cmin. - Run
afl-tminon the remaining samples to reduce them in size. Save results incollection_dir.tminif step two was omitted orcollection_dir.cmin.tminotherwise. - Perform a "dry-run" for each sample and move crashes/timeouts out of the corpus. This
step will be useful prior to starting a new or resuming a parallel fuzzing job on a
corpus containing intermittent crashes. Crashes will be moved to a
.crashesdirectory, if one of steps 1, 2 or 3 were performed. If only "dry-run" is requested, crashing samples will be moved from thequeueto thecrashesdirs within an afl sync dir. For timeouts the behavior is similar: When operating on a collection directory timeouts will be moved to a.hangsdirectory. When operating on the original afl synchronisation directory timeouts will go intohangsdir within the corresponding afl fuzzer dir.
As already indicated, all these steps are optional, making the tool quite flexible. E.g.
running only step four can be handy before resuming a parallel fuzzing session. In order
to skip step one, simply provide a directory containing fuzzing samples. Then afl-minimize
will not collect any samples, instead afl-cmin and/or afl-tmin are run on the samples
in the provided directory.
When operating on corpora with many samples use --tmin with caution. Running thousands
of files through afl-tmin can take very long. So make sure the results are as expected
and worth the effort. You don't want to waste days of CPU time just to reduce your corpus
size by a few bytes, don't you?!
Performing the "dry-run" step after running afl-cmin might seem pointless, but my
experience showed that sometimes crashes remain in the minimized corpus. So this is just
an additional step to get rid of them. But don't expect "dry-run" to always clear your
corpus from crashes with a 100% success rate!
Brandon Perry described a common fuzzing workflow in his
blog post.
It incorporates corpus pruning and reseeding afl-fuzz with optimized corpora. The
collection and minimization steps taken in afl-minimize automate the pruning process
of the presented workflow. To feed the minimized, pruned corpus back into the different
instances of afl-fuzz you may use the --reseed option that comes with afl-minimize.
This effectively moves the original queue directories of all fuzzing instances
out of the way (to queue.YYYY-MM-DD-HH:MM:SS). Next, the optimized corpus is copied
into the queue dirs of your fuzzing instances.
After reseeding, all fuzzing instances may be resumed on the same, optimized corpus.
So with afl-utils the pruning/reseeding process is just a matter of afl-multicoreing,
afl-multikilling and afl-minimizeing.
Usage examples:
Minimize the entire corpus of all fuzzers in ./afl_sync_dir using afl-cmin and
afl-cmin utilizing eight threads:
$ afl-minimize -c new_corpus --cmin --cmin-mem-limit=500 --tmin --tmin-mem-limit=500 \
-j 8 ./afl_sync_dir -- /path/to/target --target-opts
Minimize the entire corpus using afl-cmin and reseed the fuzzers:
$ afl-minimize -c new_corpus --cmin --cmin-mem-limit=500 --reseed ./afl_sync_dir \
-- /path/to/target --target-opts
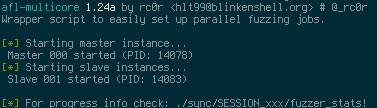
afl-multicore starts several parallel fuzzing jobs in the background using nohup (Note:
So afl's fancy interface is gone). Fuzzer outputs (stdout and stderr) will be redirected
to /dev/null. Use --verbose to turn output redirection off. This is particularly useful
when debugging afl-fuzz invocations. The auto-generated file nohup.out might also contain
some useful info.
Another way to debug afl-fuzz invocations is test mode. Just start afl-multicore and
provide the --test flag to perform a test run. afl-multicore will start a single fuzzing
instance in interactive mode using a test output directory <out-dir>_test. The interactive
setting in your config file will be ignored.
Note: After running a test you will have to clean up the test output directory
<out-dir>_test yourself!
Note: For interactive test runs screen is not required!
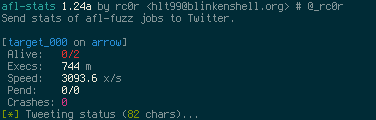
If you want to check the fuzzers' progress see fuzzer_stats in the respective fuzzer
directory in the synchronisation dir (sync_dir/SESSION###/fuzzer_stats)! Another way to monitor
fuzzing progress is to use afl-stats. You may also want to check out afl-stats database dumping
feature. An afl-multicore session can (and should!) easily be aborted with the help of
afl-multikill (see below).
If you prefer to work with afl's UI instead of background processes and stat files, screen
mode is for you. "Interactive" screen mode can be enabled using the interactive setting
in the config file (see below). In order to use it, start afl-multicore from inside a
screen session. A new screen window is created for every afl instance. Though screen mode is
not supported by afl-multikill.
Attention: When using screen mode be sure to set necessary environment variables in your
afl-multicore configuration! Alternatively run
screen -X setenv <var_name> <var_value> from inside screen before running afl-multicore.
Both ways the environment is inherited by all subsequently created screen windows.
Usage examples:
$ afl-multicore -c target-multicore.conf start 16
$ afl-multicore -c target-multicore.conf add 4
$ afl-multicore -c target-multicore.conf resume 20
In case you want to resume just a few fuzzers you may use selective resume. Let's say you've had 20 afl instances running, killed all but the first one (the master instance) and now you want to resume all slave instances without interrupting master:
$ afl-multicore -c target-multicore.conf resume number_of_jobs_to_resume,job_offset
$ afl-multicore -c target-multicore.conf resume 19,1
This afl-multicore invocation will resume 19 instances starting at offset 1. Of course other
ranges are possible too. However, when using an offset greater than master_instances (description
below) only slave instances will be resumed!
Target settings and afl options are configured in a JSON configuration file. The most simple configuration may look something like:
{
"input": "./in",
"output": "./out",
"target": "~/bin/target",
"cmdline": "--target-opt"
}Of course a lot more settings can be configured, some of these settings are:
- afl options: timeout, memory limit, dictionary, CPU affinity, ...
- job options: session name, interactive mode
- environment variables for interactive screen mode
For a complete list of options see afl-multicore.conf.sample. Their descriptions
are documented in section Configuration Settings below.
To start four fuzzing instances simply do:
$ afl-multicore -c target.conf start 4
Now, if you want to add two more instances because afl-gotcpu states you've
got some spare CPU cycles available, use the add command:
$ afl-multicore -c target.conf add 2
Interrupted fuzzing jobs can be resumed the same way using the resume command.
Note: It is possible to tell afl-multicore to resume more jobs for a
specific target than were previously started. Obviously afl-multicore can
resume just as many afl instances as it finds output directories for! Use the
add command to start additional afl instances!
afl-fuzz can be run using its -f <file> argument to specify the location of
the generated sample. When using multiple afl-fuzz instances a single file
obviously can't do the trick, because multiple fuzzers running in parallel would
need separate files to store their data. For that reason afl-multicore extends
the provided filename with the instance number similar to the session naming
scheme: cur_input would be extended into cur_input_000, cur_input_001 and
so on. In order to use these files just use %% in the target command line
specification within the config file. afl-multicore will then do all the magic
and use the correct files for the different instances of afl-fuzz.
Example config:
{
"target": "/your/app/here",
"cmdline": "--some-target-opts --input-file %%",
"#": "^- translates to:",
"#": "--some-target-opts --input-file /path/to/cur_input_000",
"#": "--some-target-opts --input-file /path/to/cur_input_001",
"#": "...",
"file": "/path/to/cur_input"
}Real life fuzzing experience showed that starting or resuming many afl-fuzz
instances at once can be problematic. Especially during initialization these
fuzzers may heavily interfere with each other causing intermittent afl-fuzz
aborts. In case you are facing such a scenario you might want to give the delayed
startup feature (-s <delay> option) a try! Chose the startup delay with caution
depending on your corpus size. For small corpora a few seconds should work well,
for corpora containing tens or hundreds of thousands of files much greater delays
(minutes, hours or even days) are needed to have an effect.
If you have no clue what to chose or you're simply lazy, try auto. This will
estimate a delay based on the chosen afl timeout and the number of samples in the
input dir (for initial start ups) or in the queue dirs of the individual fuzzers
(for resumes).
$ afl-multicore -c target.conf -s 120 resume 64
$ afl-multicore -c target.conf -s auto resume 64
As already noted there are only four settings that are required in every config
file. These are afl-fuzz directory specifications input and output, the
path to the target binary target and target command line arguments cmdline:
If you want to run afl-multicore on different afl-fuzz binaries you may
specify the fuzzer explicitly:
"fuzzer": "afl-fuzz-fast"Make sure the provided fuzzer binary is in your path! The default is to use afl-fuzz.
afl-fuzz directory specifications:
"input": "./in",
"output": "./out"Target binary and command line settings:
"target": "/usr/bin/target",
"cmdline": "-a -b -c -d"Location read by the fuzzed program. Valid options are:
- a file name
@@(see afl-fuzz manual)
"file": "@@"Timeout in ms for each fuzzing run:
"timeout": "200+"Memory limit in MB for target processes. To avoid hiccups make sure to provide the desired memory limit value as a string!
"mem_limit": "150"Use afl QEMU mode?
"qemu": trueUse afl_margs to provide additional cmdline arguments for afl. These
arguments will directly be passed to afl! This way you may provide new,
hacked or experimental cmdline args to afl-fuzz.
"afl_margs": "-T banner"Skip afl deterministic steps:
"dirty": trueFuzz without instrumentation:
"dumb": trueSpecify a fuzzing dictionary:
"dict": "dict/target.dict"Provide a name for the fuzzing session. Master outputs
will be written to output/SESSION000!
"session": "SESSION"The optional master_instances configuration option controls how many master instances should be started:
master_instances = 1or omitted: run in default single-master modemaster_instances <= 0: run in slave-only modemaster_instances > 1: run in experimental multi-master mode
"master_instances": 1Interactive screen mode. Starts every afl instance in a separate
screen window. Run afl-multicore from inside screen!
"interactive": trueEnvironment variables afl-multicore will set when using interactive screen mode.
"environment": [
"AFL_PERSISTENT=1",
"LD_PRELOAD=desock.so"
]Aborts all afl-fuzz instances belonging to an active non-interactive afl-multicore
session. afl-multicore sessions that were started in screen mode can not be aborted!
Usage example:
$ afl-multikill -S target_session
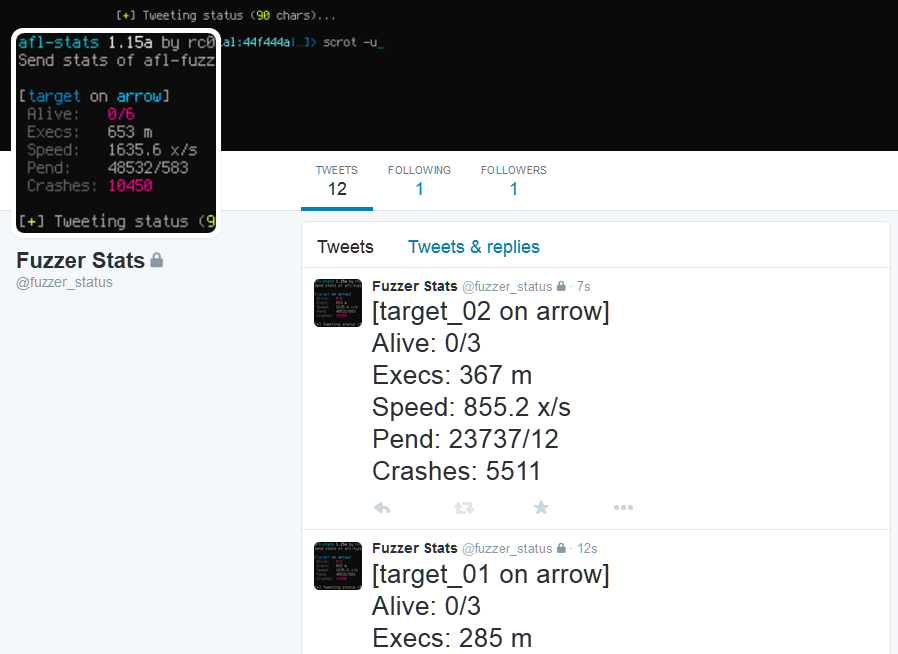
Prints fuzzing statistics similar to afl-whatsup -s and optionally posts (tweets) them
to Twitter. This is especially useful when fuzzing on multiple machines. Regularly ssh-ing
into all of your boxes to check fuzzer_stats quickly becomes a PITA...
Additionally afl-stats may dump the current contents of fuzzer_stats into a database.
So upon later inspection you have historical stats information in one place for analysis.
For twitter setup instructions, please see
docs/INSTALL.md!
Screenshots of sample tweets can be found in the final section of this document.
Usage example:
$ afl-stats -c target-stats.conf -d stats.db -t
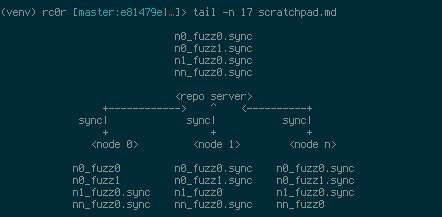
Using afl-sync you may distribute fuzzing corpora of multiple afl-fuzz instances
across node boundaries. It allows to backup, restore or synchronise afl-fuzz instance
directories to, from or with a remote destination. Under the hood afl-sync uses
rsync with enabled compression and tries to avoid unnecessary data transfers. During
a push operation afl-sync takes an afl-fuzz synchronisation directory and transfers
all contained fuzzer directories to a remote location appending the .sync extension.
When pulling afl-sync downloads all fuzzer directories from the remote location to
the synchronisation dir. Fuzzer instances already located in the local sync dir that
previously were used for pushing will not be downloaded! In order to download these
fuzzer directories provide a clean sync dir.
The synchronisation operation simply issues a pull followed by push command.
Specific fuzzing jobs may be selected from a sync dir by providing their respective
session name (-S session). See afl-multicore for more info about session naming.
Usage examples:
$ afl-sync push ./afl_sync_dir rc0r@remote.fuzzer_instance_repo.com:/repo/target/
$ afl-sync pull ./afl_sync_dir rc0r@remote.fuzzer_instance_repo.com:/repo/target/
$ afl-sync sync ./afl_sync_dir rc0r@remote.fuzzer_instance_repo.com:/repo/target/
afl-vcrash verifies that afl-fuzz crash samples really lead to crashes in the target
binary and optionally removes these samples automatically.
Note: afl-vcrash functionality is incorporated into afl-collect. If afl-collect is
invoked with switch -r, it runs afl-vcrash -qr to quietly remove invalid samples from
the collected files.
To enable parallel crash sample verification provide -j followed by the desired number
of threads afl-vcrash will utilize. Depending on the target process you're fuzzing,
running multiple threads in parallel can significantly improve verification speeds.
Usage example:
$ afl-vcrash -r -j 8 ./dir_with_crashes -- /path/to/target --target-opt
Sample output:
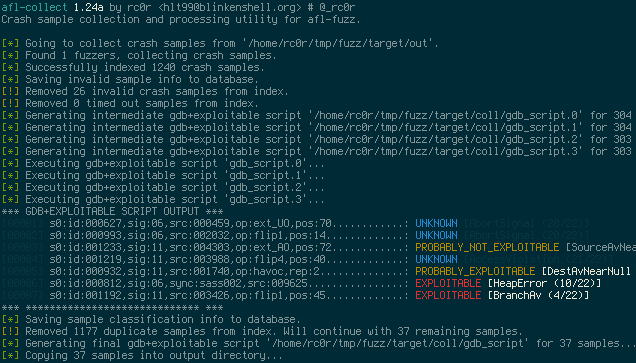
Sample output (normal mode):