Performance Investigations
I started with this flamegraph, which is a reverse graph of a run over 2 minutes of 50/50 HTTPS and DNS traffic:
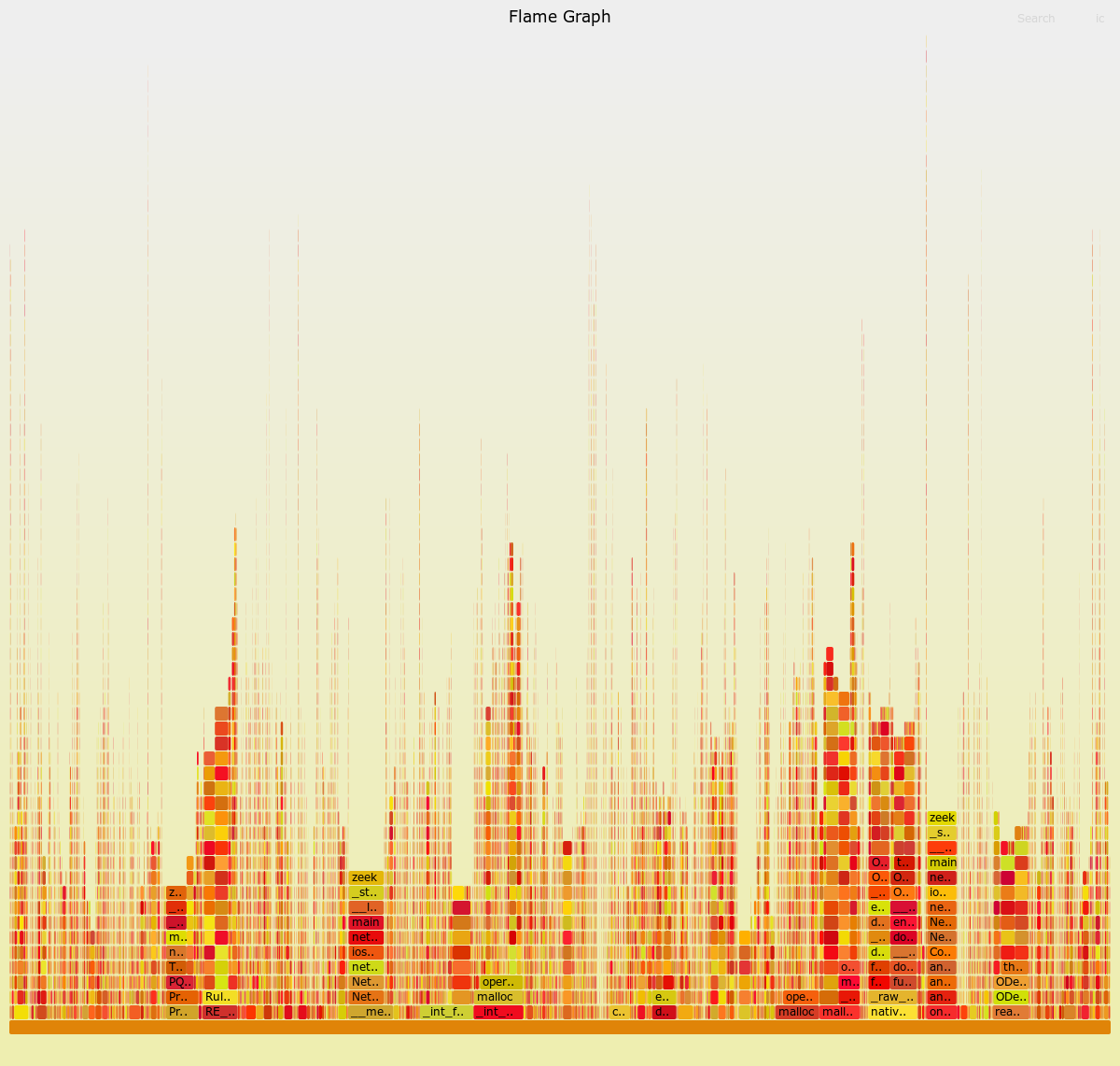
I know this is a bit of an eye chart, so I’ll point out some highlights mainly in the larger of the bars on the bottom row. These are where the initial efforts focused so far and a few other ideas:
- PriorityQueue::BubbleDown
- Ones_complement_checksum
- Large amounts of mallocs in general
- RE_State_Match::Match
- realloc in ODesc (because of logging)
Also included, but not in the bars there, is siphash24.
- It’s difficult to measure the overall impact of siphash24 in a flamegraph because it’s called everywhere we use a Dict and those uses are spread across a large swath of code.
- We’re currently using basically the reference implementation of siphash24, and while it’s concise and follows the algorithm exactly, it’s also not necessarily the fastest implementation of the hash. There’s minor wins to be had here, mostly depending on how much the hash is called. Since we moved away from using our internal dictionary types for Connections, it’s called less than it used to be. There are definitely faster implementations of the siphash24 algorithm. We merged https://github.com/zeek/zeek/pull/819 that includes a new version from https://github.com/majek/csiphash/. Details of the performance gains are in that PR.
- There might be more room for improvement here by moving to a different hashing algorithm. Google’s highwayhash is supposedly ~5x faster than siphash24 and offers roughly the same security guarantees. More detail about that is at https://github.com/google/highwayhash/.
-
We spend about 3% of our runtime doing priority queue operations.
-
Our implementation of a priority queue is surprisingly fast. Inserting 100000 randomly-timed entries into the queue and then removing them in ordered sequence results in the following timing:
PQ: add_time: 0.081542 remove_time: 0.862934 total: 0.944476The time is entirely dominated by removing the elements from the queue because of how the elements are moved around in the queue in order to remove it. Elements are stored in the array in order of time, with the next elements to be popped at the head of the array. This makes the BubbleUp operation quite fast: insert at the end, and bubble that element up until it finds a place where it can’t move any further. To remove an element, we do the opposite. We look at the element at the head, and then call BubbleDown to move it to the end of the array so it can be easily removed. Unfortunately, this operation is really slow because it involves recursively trying to move an element through the array and re-sorting the elements around it as it moves.
-
Testing using both std::set and std::priority_queue were failures. Both are considerably slower than our implementation. Set is ~1.25x slower and priority_queue was ~1.5x slower. Note that std::priority_queue is basically a std::vector using std::make_heap. I tested doing that myself and it was as slow as expected. Timing output using std::multiset (which is roughly the same timing as std::set):
std::multiset: add_time: 0.964570 (11.83x) remove_time: 0.225333 (0.26x) total: 1.189903 (1.26x) -
Testing using abseil’s btree_set looked promising. It’s ~0.8x the speed of our priority queue. That said, it’s abseil and we definitely don’t want to bring that dependency in. Thankfully there is a 3rd-party reimplementation of it (with less abseil-ness) available at https://github.com/greg7mdp/parallel-hashmap. I haven’t tried bringing that into a full zeek build to see how it performs. Timing output for the same test as above:
absl::btree_set: add_time: 0.650935 (7.98x) remove_time: 0.094129 (0.11x) total: 0.745064 (0.79x) -
There might also be the possibility of some wins with an implementation that uses std::vector underneath the PriorityQueue, and automatically sorting the vector in the reverse order of how it is now. That would allow popping directly off the back of the vector and to use vector’s built-in resizing. I tested just using std::sort directly and it was abysmally slower. There’s no indication that this could be faster than just continuing to use an array and sorting in reverse though.
-
(UPDATE Mar 4): Unrolling the recursion by hand into a while loop results in a very slight performance gain where the runtime is about 95% of the current version. This includes a number of changes to remove extra function calls, but doesn’t seem to have much effect.
-
We spend about 2.5% of the runtime doing checksums. From the flamegraph, most of that is during the TCP Analyzer.
-
The one’s complement checksum method was changed years ago (in https://github.com/zeek/zeek/commit/24f74cb52e4020703f47cd35769e08dd54098a1c) to process bytes at a time. This was because of an issue with gcc 6.2.1 that broke the ability to do words at a time (which would be faster).
-
Some quick investigation with ubsan indicates that part of the above problem is some misalignment with some of the variables used in the icmp6_method. Fixing those allows switching back to 16-bit mode on most platforms. There’s unfortunately still a bug on Ubuntu 18 with gcc 7.4.0 and any optimization level that causes test failures with Teredo tunnels and inverse DNS requests. Building in debug mode works correctly.
-
On a platform that does build correctly at all optimization levels (CentOS 8), the performance gain is fairly good. Over the same data used to build the flame graph:
Master: Time spent: 99.45 seconds Max memory usage: 2211880 bytes Branch: Time spent: 96.35 seconds Max memory usage: 2209568 bytes -
I considered switching the checksumming over to use SSE/AVX/SIMD/etc, but in testing separate from the Zeek code it didn’t appear to increase performance at the data sizes we’re processing. It only started being a performance gain above about 1KB, where most of the time we’re processing sub-500-byte blocks of memory. I also attempted to use std::accumulate and std::reduce instead of doing the sum by hand but both were considerably slower.
-
One possible route for more investigation is caching sums for things like IP Addresses that may repeat a lot, and then just adding the sums in as one value instead of 4.
-
Another route could be using hardware checksumming and not doing our own checksums if the kernel indicates that it already succeeded. Unfortunately the kernel will only indicate that a packet passed checksumming, and not that it attempted to checksum and the packet failed. In that case we’d have to do the checksum again ourselves. This functionality may only be available on Linux, but there may be similar methods on the other platforms.
- In the flamegraph above, int_malloc, malloc, and malloc_consolidate account for roughly 12% of the overall runtime. Obviously a bit of this is focused heavily during startup, and there are already efforts underway to reduce that (see Max’s PRs for example).
- I spent a small amount of time looking through the Expr code for places where we could possibly skip allocations, but don’t have anything concrete to share about it yet.