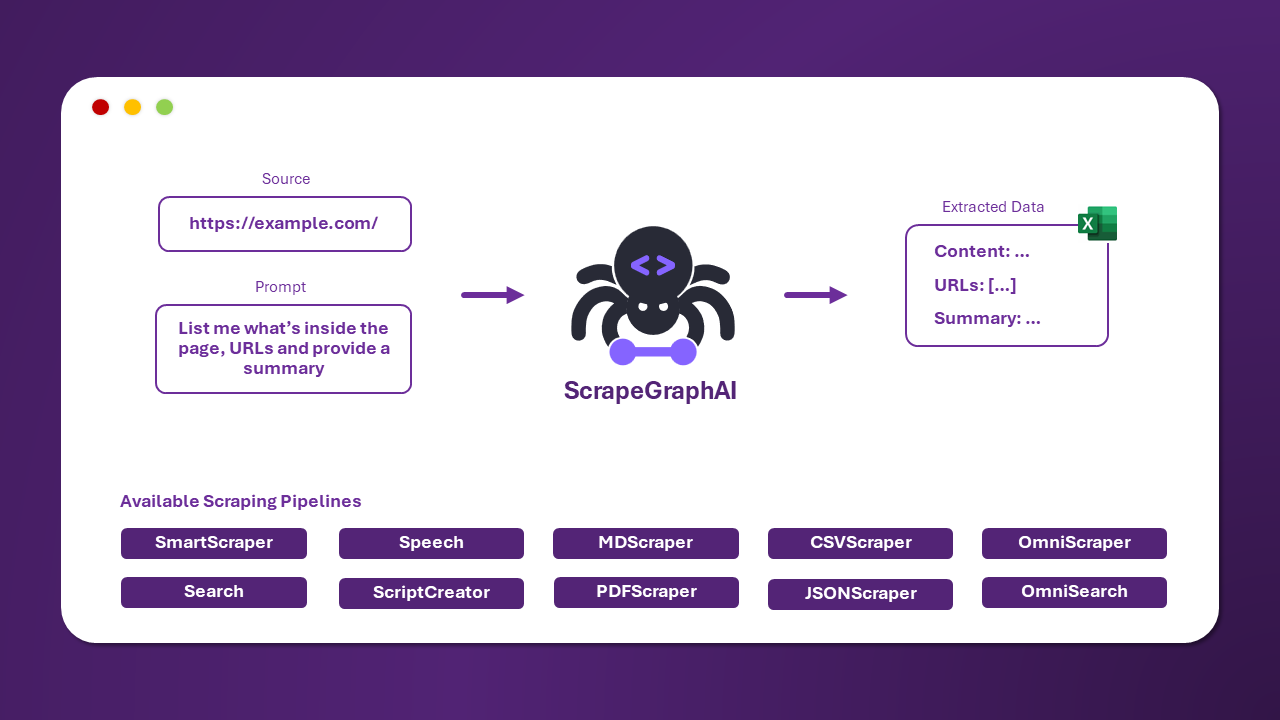
ScrapeGraphAIは、大規模言語モデルと直接グラフロジックを使用して、ウェブサイトやローカルドキュメント(XML、HTML、JSONなど)のクローリングパイプラインを作成するPythonライブラリです。
クロールしたい情報をライブラリに伝えるだけで、残りはすべてライブラリが行います!
Scrapegraph-aiの参照ページはPyPIの公式サイトで見ることができます: pypi。
pip install scrapegraphai注意: 他のライブラリとの競合を避けるため、このライブラリは仮想環境でのインストールを推奨します 🐱
公式のStreamlitデモ:
Google Colabで直接試す:
ScrapeGraphAIのドキュメントはこちらで見ることができます。
Docusaurusのバージョンもご覧ください。
ウェブサイト(またはローカルファイル)から情報を抽出するための3つの主要なクローリングパイプラインがあります:
SmartScraperGraph: 単一ページのクローラー。ユーザープロンプトと入力ソースのみが必要です。SearchGraph: 複数ページのクローラー。検索エンジンの上位n個の検索結果から情報を抽出します。SpeechGraph: 単一ページのクローラー。ウェブサイトから情報を抽出し、音声ファイルを生成します。SmartScraperMultiGraph: 複数ページのクローラー。プロンプトを与えると、 OpenAI、Groq、Azure、Geminiなどの異なるLLMをAPI経由で使用することができます。また、Ollamaのローカルモデルを使用することもできます。
Ollamaがインストールされていること、およびollama pullコマンドでモデルがダウンロードされていることを確認してください。
from scrapegraphai.graphs import SmartScraperGraph
graph_config = {
"llm": {
"model": "ollama/mistral",
"temperature": 0,
"format": "json", # Ollamaではフォーマットを明示的に指定する必要があります
"base_url": "http://localhost:11434", # OllamaのURLを設定
},
"embeddings": {
"model": "ollama/nomic-embed-text",
"base_url": "http://localhost:11434", # OllamaのURLを設定
},
"verbose": True,
}
smart_scraper_graph = SmartScraperGraph(
prompt="すべてのプロジェクトとその説明をリストしてください",
# ダウンロード済みのHTMLコードの文字列も受け付けます
source="https://perinim.github.io/projects",
config=graph_config
)
result = smart_scraper_graph.run()
print(result)出力は、プロジェクトとその説明のリストになります:
{'projects': [{'title': 'Rotary Pendulum RL', 'description': 'Open Source project aimed at controlling a real life rotary pendulum using RL algorithms'}, {'title': 'DQN Implementation from scratch', 'description': 'Developed a Deep Q-Network algorithm to train a simple and double pendulum'}, ...]}GroqをLLMとして、Ollamaを埋め込みモデルとして使用します。
from scrapegraphai.graphs import SearchGraph
# グラフの設定を定義
graph_config = {
"llm": {
"model": "groq/gemma-7b-it",
"api_key": "GROQ_API_KEY",
"temperature": 0
},
"embeddings": {
"model": "ollama/nomic-embed-text",
"base_url": "http://localhost:11434", # OllamaのURLを任意に設定
},
"max_results": 5,
}
# SearchGraphインスタンスを作成
search_graph = SearchGraph(
prompt="Chioggiaの伝統的なレシピをすべてリストしてください",
config=graph_config
)
# グラフを実行
result = search_graph.run()
print(result)出力は、レシピのリストになります:
{'recipes': [{'name': 'Sarde in Saòre'}, {'name': 'Bigoli in salsa'}, {'name': 'Seppie in umido'}, {'name': 'Moleche frite'}, {'name': 'Risotto alla pescatora'}, {'name': 'Broeto'}, {'name': 'Bibarasse in Cassopipa'}, {'name': 'Risi e bisi'}, {'name': 'Smegiassa Ciosota'}]}OpenAI APIキーとモデル名を渡すだけです。
from scrapegraphai.graphs import SpeechGraph
graph_config = {
"llm": {
"api_key": "OPENAI_API_KEY",
"model": "openai/gpt-3.5-turbo",
},
"tts_model": {
"api_key": "OPENAI_API_KEY",
"model": "tts-1",
"voice": "alloy"
},
"output_path": "audio_summary.mp3",
}
# ************************************************
# SpeechGraphインスタンスを作成して実行
# ************************************************
speech_graph = SpeechGraph(
prompt="プロジェクトの詳細な音声要約を作成してください。",
source="https://perinim.github.io/projects/",
config=graph_config,
)
result = speech_graph.run()
print(result)出力は、ページ上のプロジェクトの要約を含む音声ファイルになります。

貢献を歓迎し、Discordサーバーで改善や提案について話し合います!
貢献ガイドをご覧ください。
こちらでプロジェクトのロードマップをご覧ください! 🚀
よりインタラクティブな方法でロードマップを視覚化したいですか?markmapをチェックして、マークダウンの内容をエディタにコピー&ペーストして視覚化してください!
研究目的で当社のライブラリを使用する場合は、以下の参考文献を引用してください:
@misc{scrapegraph-ai,
author = {, Lorenzo Padoan, Marco Vinciguerra},
title = {Scrapegraph-ai},
year = {2024},
url = {https://github.com/VinciGit00/Scrapegraph-ai},
note = {A Python library for scraping leveraging large language models}
}
![]()
| 連絡先 | |
|---|---|
| Marco Vinciguerra | |
| Lorenzo Padoan |
ScrapeGraphAIはMITライセンスの下で提供されています。詳細はLICENSEファイルをご覧ください。
- プロジェクトの貢献者とオープンソースコミュニティのサポートに感謝します。
- ScrapeGraphAIはデータ探索と研究目的のみに使用されます。このライブラリの不正使用については一切責任を負いません。