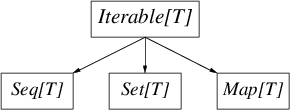
- Seq是一个有先后次序的值的序列,比如数组和列表。
- Set是一组没有先后次序的值。
- Map是一组键值对偶。
每个Scala集合特质或类都有一个带有apply方法的伴生对象,这个apply方法可以用来构建该集合的实例。例如
Iterable(Oxff, 0xff00, 0xff0000)
Set(Color.Red, Color.GREEN, Color.BLUE)
Map(Color.Red->0xff0000, Color.GREEN->0xff00, Color.BLUE->Oxff)
SortedSet("Hello", "World")这样的设计叫做“统一创建原则”。
object Run extends App {
val names = List("Peter", "Jeff", "Mary")
names.map(_.toUpperCase()) // List(PETER, JEFF, MARY)
names.flatMap(_.toUpperCase()) // List(P, E, T, E, R, J, E, F, F, M, A, R, Y)
names.collect{ case ("Jeff") => true; case _ => false} // List(false, true, false)
}object Run extends App {
List(1, 7, 2, 9).reduceLeft(_ - _) // -17
List(1, 7, 2, 9).reduceRight(_ - _) // -13
List(1, 7, 2, 9).foldLeft(0)(_ - _) // -19
List(1, 7, 2, 9).foldRight(0)(_ - _) // -13
List(1, 7, 2, 9).scanLeft(0)(_ - _) // List(0, -1, -8, -10, -19)
List(1, 7, 2, 9).scanRight(0)(_ - _) // List(-13, 14, -7, 9, 0)
}object Run extends App {
val prices = List(5.0, 20.0, 9.95)
val quantities = List(10, 2, 1)
prices.zip(quantities) // List((5.0,10), (20.0,2), (9.95,1))
prices.zip(quantities).map { p => p._1 * p._2 } // List(50.0, 40.0, 9.95)
(prices.zip(quantities).map { p => p._1 * p._2 }).sum // 99.95
List('a', 'b', 'c').zip(List(1, 2)) // List((a,1), (b,2))
List('a', 'b', 'c').zipAll(List(1, 2), 'x', 0) // List((a,1), (b,2), (c,0))
List('a', 'b').zipAll(List(1, 2, 3), 'x', 0) // List((a,1), (b,2), (x,3))
"scala".zipWithIndex // Vector((s,0), (c,1), (a,2), (l,3), (a,4))
"scala".zipWithIndex.max // (s,0)
"scala".zipWithIndex.max._2 // 0
}对于完整构造需要很大开销的集合来说,使用迭代器是个不错的想法。比如在用Source.fromFile读取文件的时候。使用迭代器时,只有在需要的时候才去取元素,所以不会一次性将文件全部读取到内存。
流,stream,是一个尾部被懒计算的不可变列表。流会缓存下中间计算过的值,所以可以重新访问已经访问过的值,这点是与迭代器不同的。
object Run extends App {
def numsFrom(n: BigInt): Stream[BigInt] = n #:: numsFrom(n + 1)
numsFrom(10) // Stream(10, ?)
numsFrom(10).tail.tail.tail // Stream(13, ?)
val squares = numsFrom(1).map(x=>x*x) // Stream(1, ?)
squares.take(5).force // Stream(1, 4, 9, 16, 25)
}流方法的懒执行,是在结果需要被计算时才计算,可以对其他集合应用view方法来得到类似的效果。
(0 to 1000).view.map(pow(10, _)).map(1 / _).force在上面的代码中,就避免了从pow方法中构建的中间集合map。
Java to Scala collections conversions:
scala.collection.Iterable <=> java.lang.Iterable
scala.collection.Iterable <=> java.util.Collection
scala.collection.Iterator <=> java.util.{ Iterator, Enumeration }
scala.collection.mutable.Buffer <=> java.util.List
scala.collection.mutable.Set <=> java.util.Set
scala.collection.mutable.Map <=> java.util.{ Map, Dictionary }
scala.collection.mutable.ConcurrentMap <=> java.util.concurrent.ConcurrentMap
One-way conversions:
scala.collection.Seq => java.util.List
scala.collection.mutable.Seq => java.util.List
scala.collection.Set => java.util.Set
scala.collection.Map => java.util.Map
java.util.Properties => scala.collection.mutable.Map[String, String]
可变集合可以混入特质来使集合的操作变为同步的。这样的特质共有六个,都以Synchronized开头:
SynchronizedBuffer
SynchronizedMap
SynchronizedPriorityQueue
SynchronizedQueue
SynchronizedSet
SynchronizedStack
val scores = new scala.collection.mutable.HashMap[String, Int] with scala.collection.mutable.SynchronizedMap[String, Int]需要注意的是,混入特质后,只是将操作变为同步的,并不能保证集合是线程安全的。(比如,并发进行修改和遍历集合。)通常可以使用java.util.concurrent包中的类来保证线程安全,而且可以将这些集合也转换成Scala集合来使用(使用JavaConversions)。
coll.par.sum上面的代码中coll是一个大型集合,而par方法会得到集合的并行实现——会尽可能地并行地执行结合方法。将上面的求和来说明,集合会被分成多个区块,然后由多个线程来对这些区块来进行求和,最后将区块的结果汇总得到最终的和。par方法返回的是ParIterable的子类型,但ParIterable并不是Iterable的子类型。可以使用ser方法将并行集合转换回串行集合。