The CUDA API encompasses a suite of libraries designed for GPU-accelerated computations, with powerful features such as cuBLAS, cuDNN, and cuBLASmp. These libraries offer optimized routines for linear algebra, deep learning, and more, but they come as opaque structures, meaning you interact with them via documented function calls, without access to the underlying implementation.
The term opaque in the context of CUDA APIs refers to the abstraction provided by these libraries. You interact with precompiled binaries, such as .so (shared object) files, that contain highly optimized machine code. However, the source code is not exposed, making the internal workings of the library invisible to the user.
While these libraries come with extensive documentation, the actual source code is hidden for performance reasons. For instance, when working with libraries like cuFFT, cuDNN, or cuBLAS, you deal with API functions but not the implementation details of those functions. These libraries are pre-compiled for maximum throughput, and the structure types within them are treated as opaque types.
In cuBLAS, cublasLtHandle_t is an opaque type used to manage the context of cuBLAS Lt operations. You do not have access to its internal structure, but you can interact with it using the documented functions.
To get the fastest possible inference for your GPU applications, especially in production environments like clusters, it is essential to understand the intricacies of the CUDA API. Here are some tips to help you explore the API effectively:
- A real-time search engine that provides up-to-date information about the CUDA ecosystem.
- A classic approach, though it may not always yield the most current results. Use it for general inquiries.
- For general knowledge and guidance that is less likely to be outdated, as it provides a stable knowledge base.
- Always refer to the NVIDIA documentation for detailed explanations and reference material.
One of the crucial aspects of working with CUDA APIs is error checking. Using macros to ensure the proper execution of functions can save you from hard-to-debug errors and silent failures. Here are some examples for cuBLAS and cuDNN:
#define CUBLAS_CHECK(call) \
do { \
cublasStatus_t status = call; \
if (status != CUBLAS_STATUS_SUCCESS) { \
fprintf(stderr, "cuBLAS error at %s:%d: %d\n", __FILE__, __LINE__, status); \
exit(EXIT_FAILURE); \
} \
} while(0)#define CUDNN_CHECK(call) \
do { \
cudnnStatus_t status = call; \
if (status != CUDNN_STATUS_SUCCESS) { \
fprintf(stderr, "cuDNN error at %s:%d: %s\n", __FILE__, __LINE__, \
cudnnGetErrorString(status)); \
exit(EXIT_FAILURE); \
} \
} while(0)When you call a function in a CUDA API, it operates within a context that you configure. The error checking macros help monitor the status of these operations by validating the result of each API call. If an error occurs (such as an out-of-memory error or invalid configuration), you get a detailed error message instead of facing issues like segmentation faults or silent failures.
The above error-checking macros are just a starting point. Many other CUDA APIs, such as cuFFT and cuSOLVER, have their own error-checking mechanisms. To dive deeper into this topic, refer to this guide: Proper CUDA Error Checking.
Matrix multiplication is a key operation in many GPU-accelerated tasks, such as deep learning. CUDA provides optimized libraries like cuDNN and cuBLAS for performing these operations.
-
cuDNN implicitly supports matrix multiplication as part of its convolution and deep learning operations. However, matrix multiplication is not the primary focus of cuDNN, and it is not presented as a standalone feature.
-
For matrix multiplication, cuBLAS is the go-to library. cuBLAS is highly optimized for linear algebra operations, including matrix multiplication, and is fine-tuned for high-throughput performance on GPUs.
Side note: While cuDNN and cuBLAS are optimized for different use cases (deep learning vs linear algebra), understanding one often makes it easy to transfer knowledge to the other. Both libraries share similar principles in how you configure and call operations.
- CUDA Library Samples: Explore CUDA library examples and sample code to see real-world implementations of these APIs.
The CUDA programming model breaks down the GPU into grids of thread blocks, each consisting of threads. Here’s a visual representation of the hierarchy:
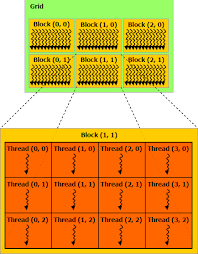
CUDA Thread Hierarchy
Understanding the memory hierarchy is essential for optimizing your code. CUDA provides different memory types for various levels of access speed:
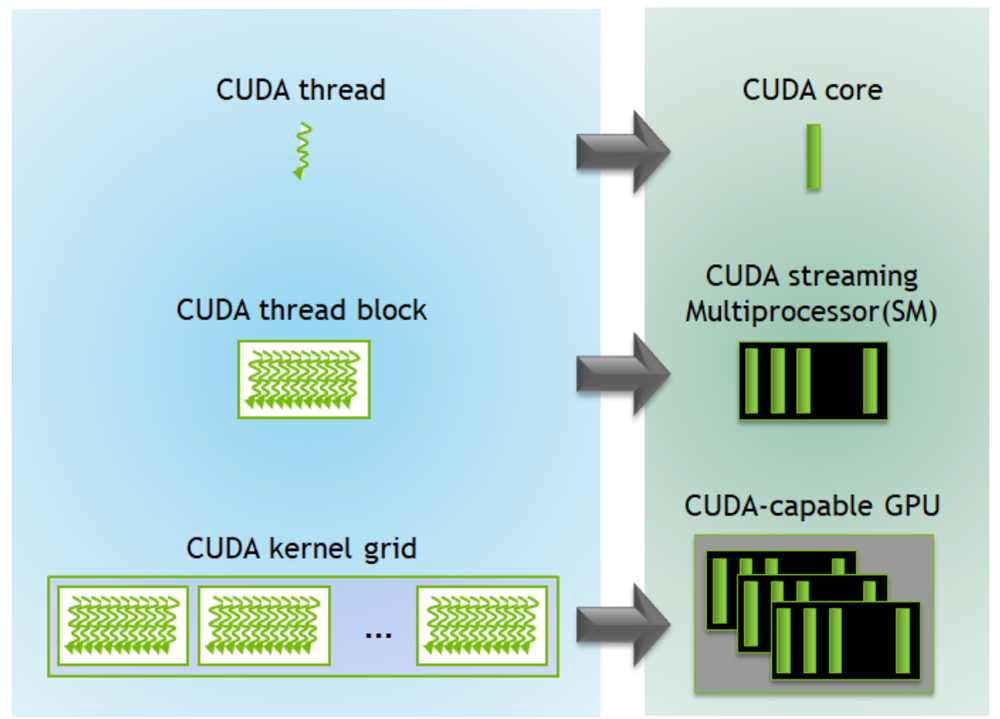
CUDA Memory Hierarchy
| Memory Type | Scope | Lifetime | Speed |
|---|---|---|---|
| Registers | Thread | Thread | Fastest |
| Shared Memory | Block | Block | Very Fast |
| Global Memory | Grid | Application | Slow |
| Constant Memory | Grid | Application | Fast (cached) |
Tools like NVIDIA Nsight and nvprof allow you to analyze and optimize GPU performance. Here’s an example of GPU statistics profiling:
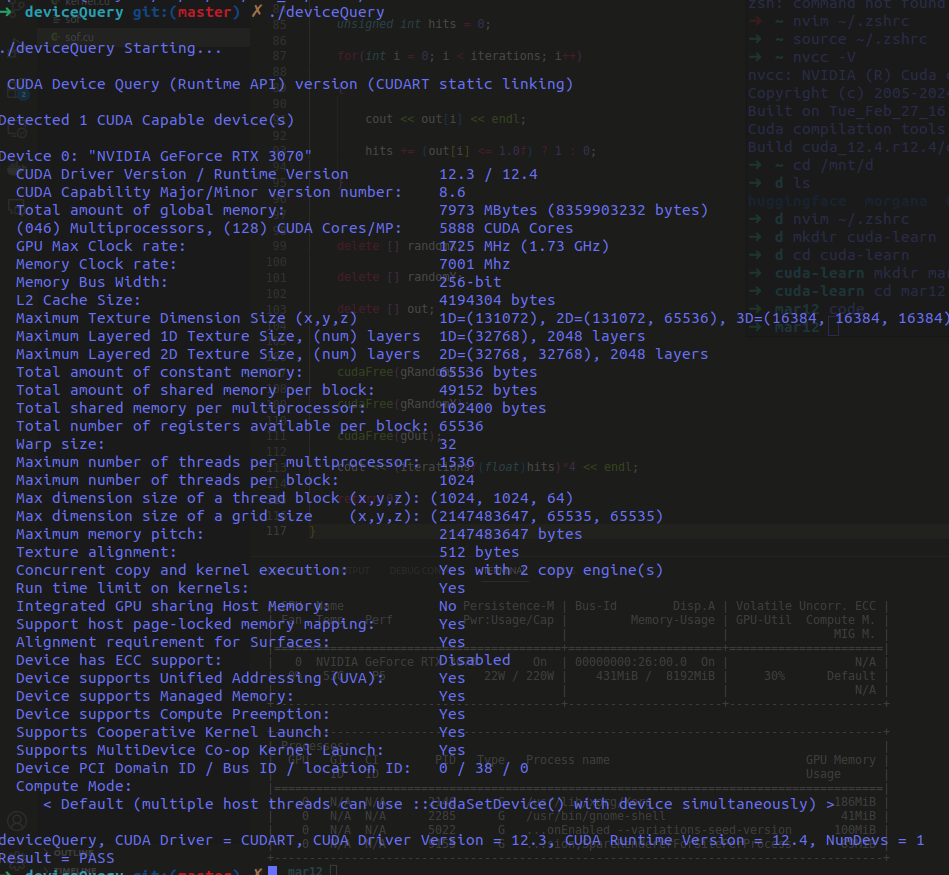
GPU Performance Stats