The Synthetic Data Generator is a tool for generating IID (Independent and Identically Distributed) and Non-IID datasets with customisable parameters. Built with Python and Streamlit, this app enables users to create structured synthetic data for machine learning, research, and data exploration.
- Generate IID Data: Features are drawn independently from a standard normal distribution.
- Generate Non-IID Data: Feature distributions are adjusted to depend on the target variable.
- Customisable Data Generation:
- Select the number of samples.
- Choose number of features and target classes.
- Introduce class imbalance (optional).
- Set a random seed for reproducibility.
- Automated Validation:
- Chi-Square Test: Checks feature dependence on the target.
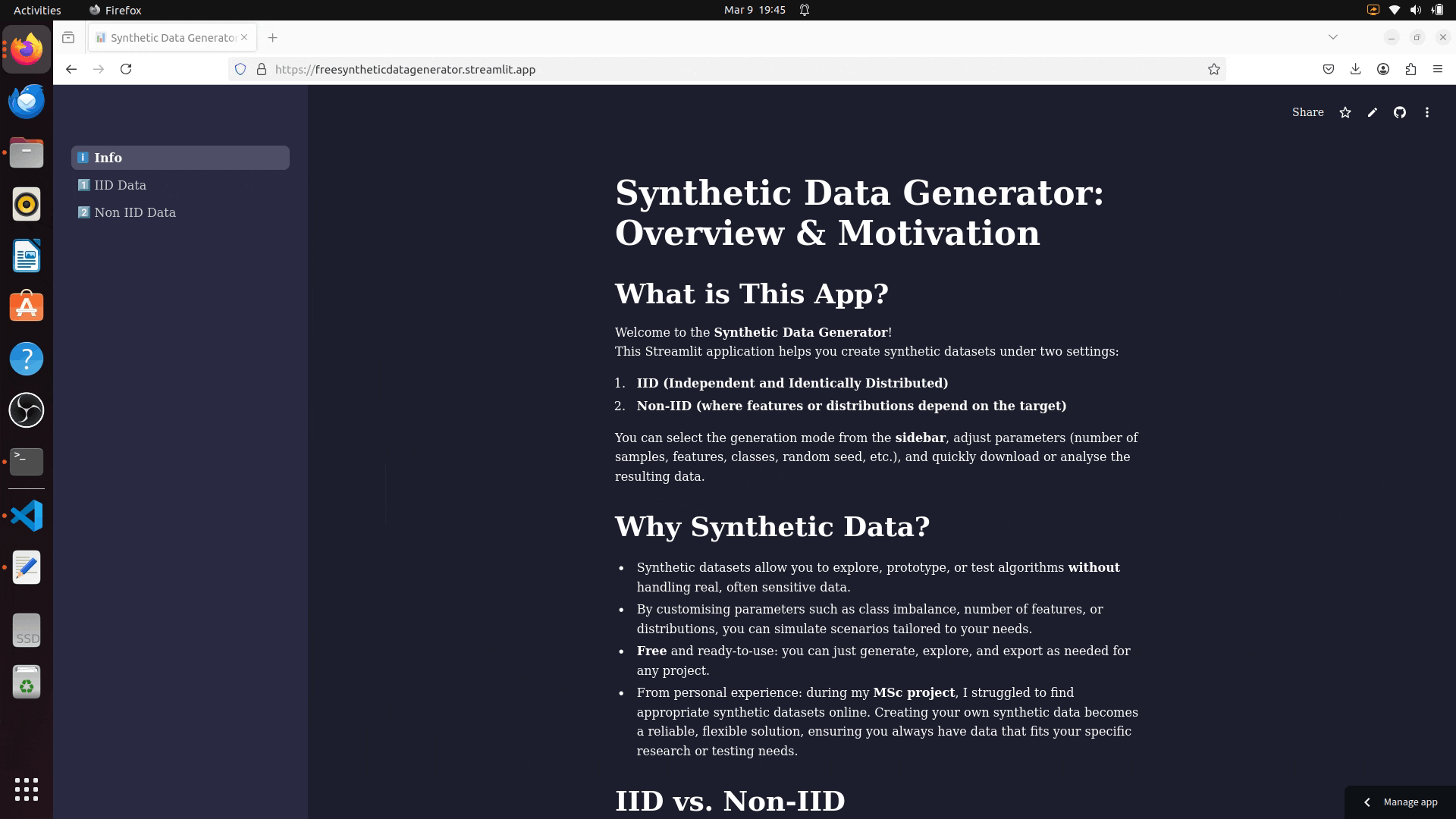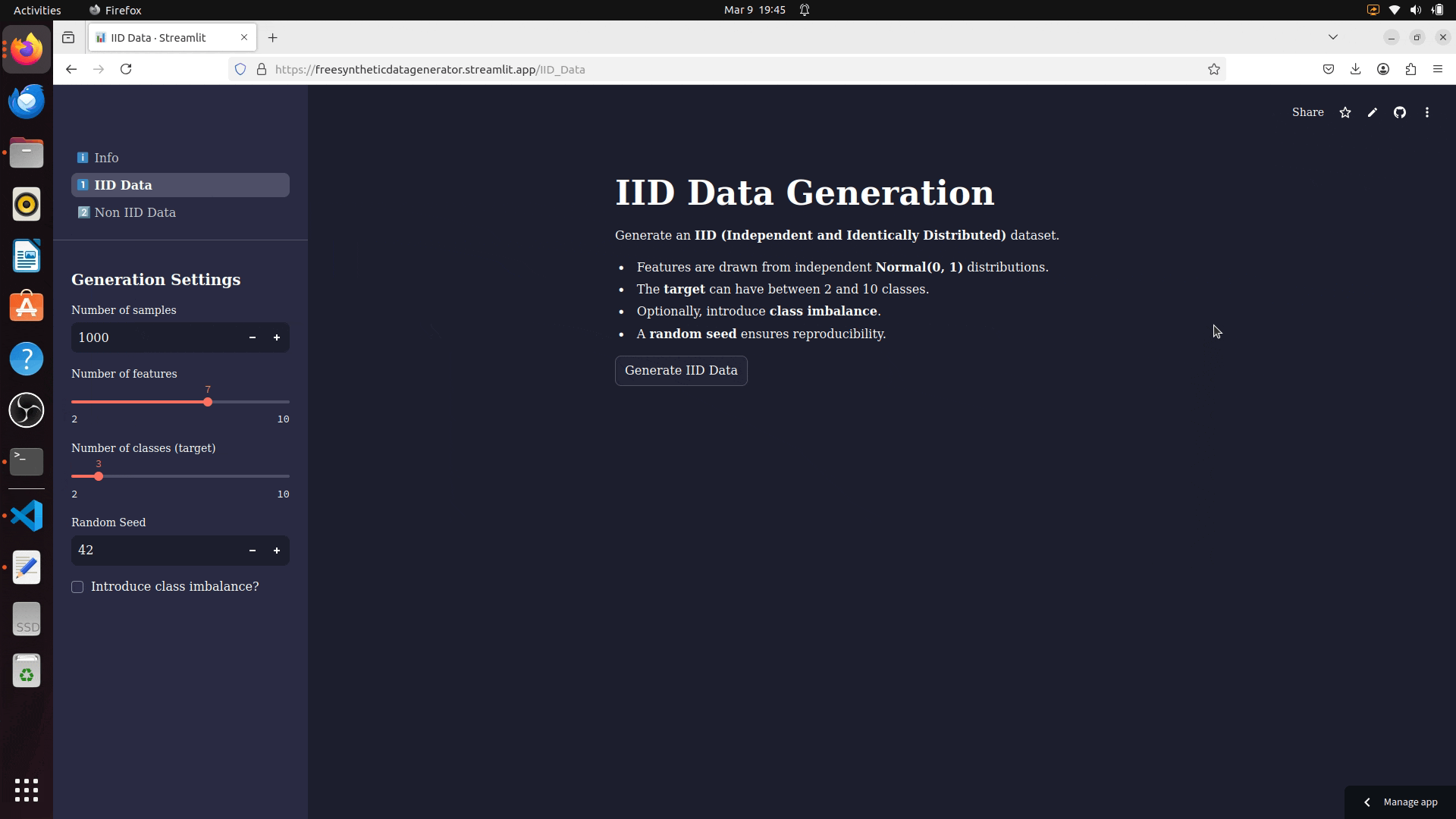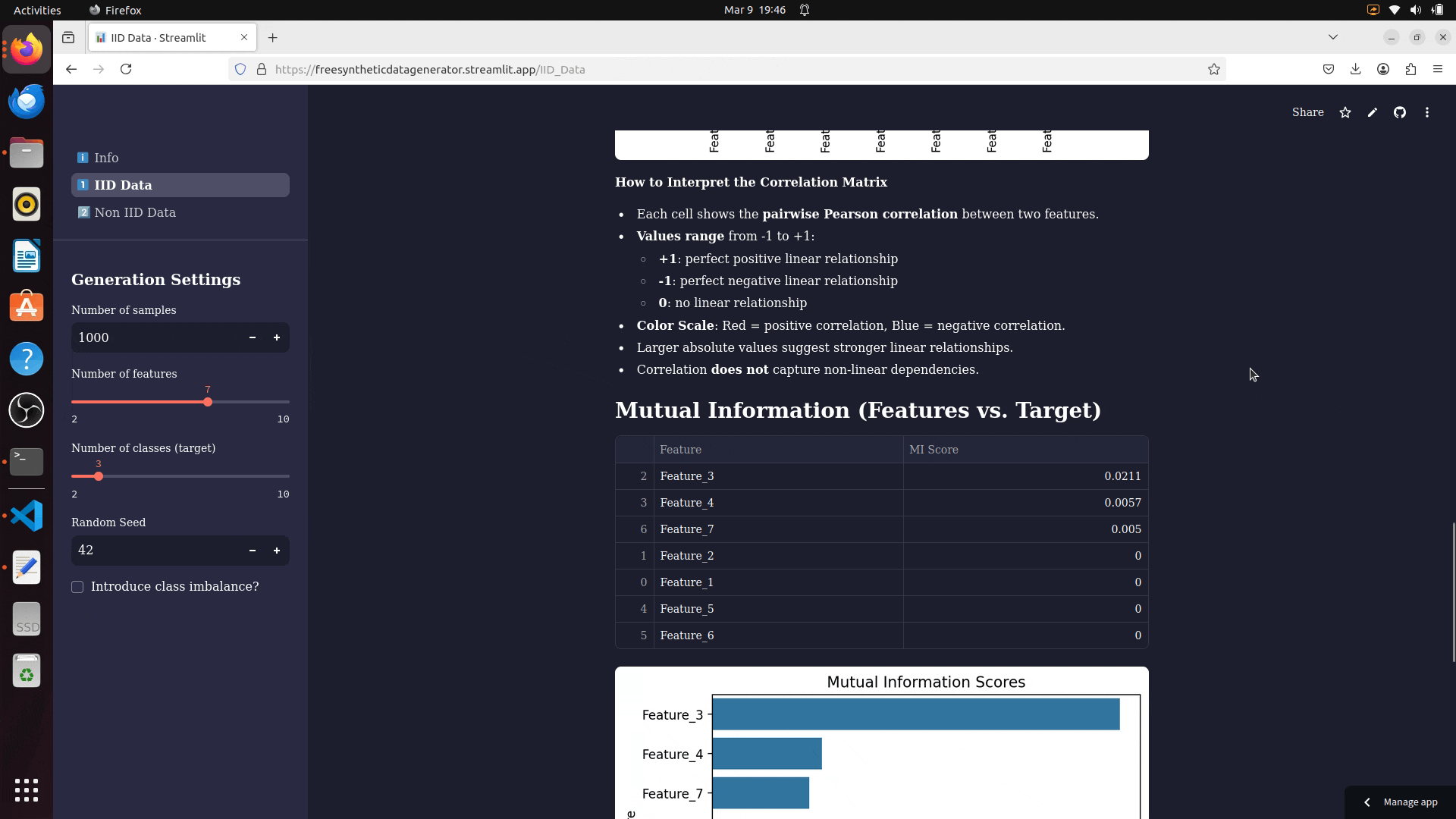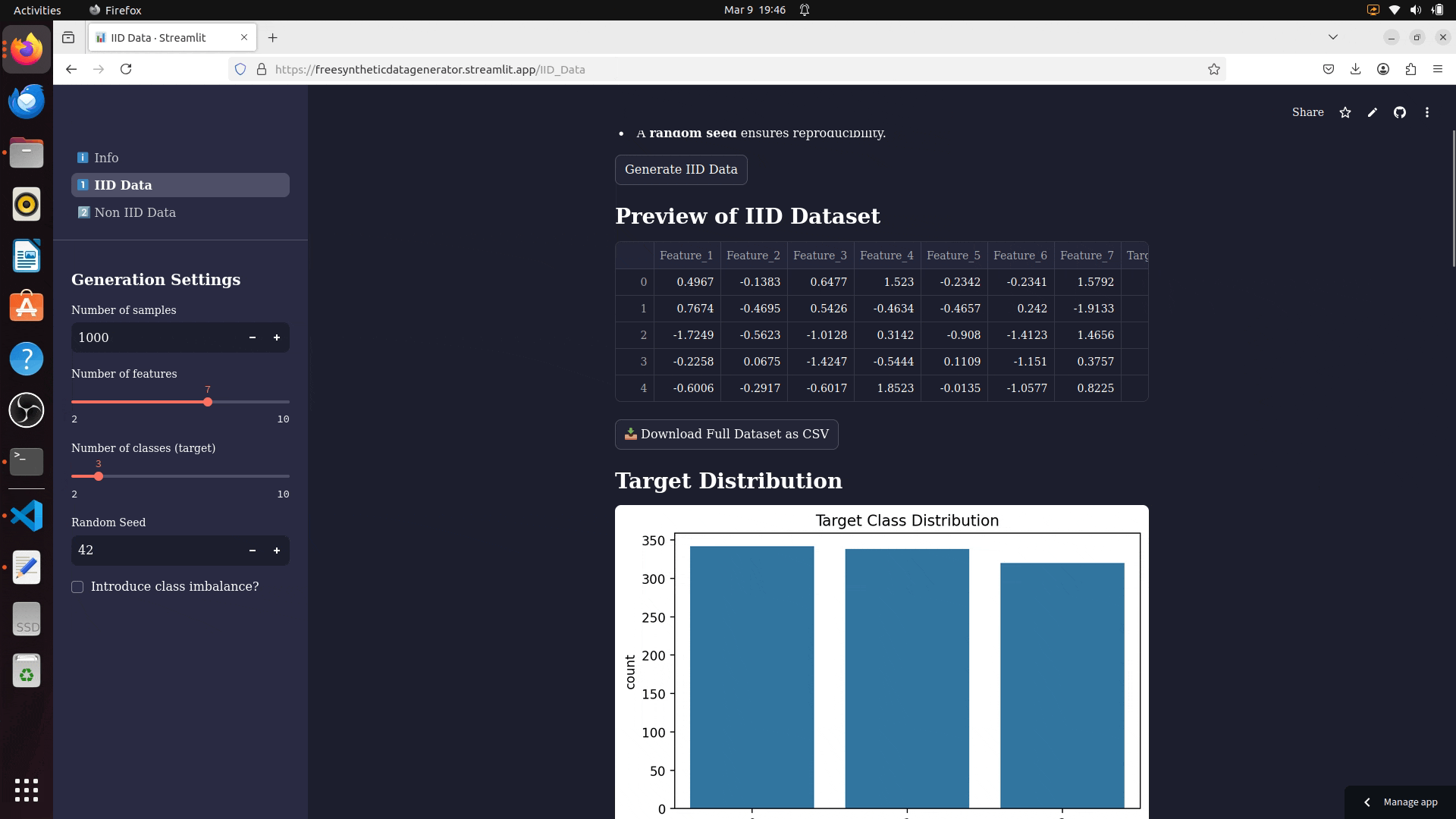
- Mutual Information Analysis: Measures how much features reduce uncertainty about the target.
- Feature Correlation Matrix: Evaluates relationships between generated features.
- Download Full Dataset: Export your generated dataset in CSV format.
- User-Friendly UI: Built with Streamlit for seamless interaction.
SyntheticDataGeneratorApp
├── .streamlit/
│ └── config.toml
├── assets/
│ └── gifs/
│ └── dataGeneratorApp.gif
├── streamlit_app/
│ ├── pages/
│ │ ├── 01_1️⃣_IID_Data.py
│ │ └── 02_2️⃣_Non_IID_Data.py
│ └── 00_ℹ️_Info.py
├── LICENSE
├── README.md
└── requirements.txt Finding synthetic data for machine learning experiments can be challenging, especially for research projects.
This tool was created after experiencing difficulties in finding high-quality synthetic datasets during my MSc project.
With this app, you can generate and download free synthetic data instantly, tailored to your needs.
The Synthetic Data Generator leverages the following Python libraries:
- Streamlit – Interactive UI for dataset generation.
- NumPy – Random number generation and data structuring.
- Pandas – Dataframe handling and CSV export.
- Seaborn & Matplotlib – Data visualisation.
- SciPy – Chi-Square tests for statistical independence.
- Scikit-learn – Mutual Information analysis.
| Type | Characteristics |
|---|---|
| IID (Independent and Identically Distributed) | Features are generated independently from a normal distribution. No feature is related to the target. |
| Non-IID (Non-Independent and Identically Distributed) | Feature distributions shift based on the target class (different mean & scale per class). This ensures dependence between features and target. |
✅ Chi-Square Test – Ensures features in Non-IID datasets are dependent on the target.
✅ Mutual Information – Measures feature-target relationships.
✅ Feature Correlation – Examines relationships between generated features.
- Navigate to the Homepage (ℹ️ Info) to understand the differences between IID & Non-IID.
- Go to "📊 IID Data" to generate an independent dataset.
- Go to "📊 Non-IID Data" to generate a dataset where features depend on the target.
- Adjust Parameters:
- Select sample size, features, and classes.
- Optionally, introduce class imbalance.
- Set a random seed for reproducibility.
- Generate & Visualise Data:
- View feature distributions, correlation heatmaps, and mutual information scores.
- Download Full Dataset as CSV.
| Issue | Cause | Solution |
|---|---|---|
| Theme not working in deployment | .streamlit/config.toml is ignored by Streamlit Cloud |
Move config.toml to ~/.streamlit/config.toml or apply st.set_page_config() directly. |
| Only 5 rows downloaded | Streamlit’s default table download only exports preview rows | Added st.download_button() for full dataset export. |
| Page refresh when downloading CSV | Streamlit re-runs on interaction | Implemented st.session_state to persist generated datasets. |
- More Data Distributions: Support for uniform, exponential, and categorical distributions.
- Custom Feature Relationships: Users define correlations between features.
- Time-Series Synthetic Data: Generate sequential synthetic data.
🔹 Have an idea to improve the app? Feel free to fork the repo and submit a pull request!
🔹 If you encounter any issues, report them on the GitHub Issues page.