这篇是 《和 lvgo 一起学设计模式》 系列的最后一个设计模式了,这篇就轻松一些吧。
给定一个语言,定义它的文法的一种表示,并定义一个解释器,这个解释器使用该表示来解释语言中的句子。
因为时代的发展、技术的更替等等原因(你想做的解释器都有人做好了,且开源)吧,可能这个是我们很长一段时间都用不到的一种设计模式了。
还记得那些年看过的影视剧吗?或是表情包吗?


你能看懂柯镇恶和“老婆”的眼色吗?
反正我是看不懂,单是看这情况,完全看不懂是什么意思。
但如果我提前给你说下规则呢?
柯镇恶图
- 柯镇恶往左摆头,冲!
- 柯镇恶往右摆头,撤!
“老婆”图
- “老婆”坐在坐垫上,生气!
- “老婆”坐在摩的后面架子上,开心!
那这个时候再看他们的“眼色”,你能看懂了吗?如果有了上面的定义,我便知道了:
- 柯镇恶的意思是冲!(假设是往左摆头了)
- “老婆”很开心!
给定一个语言,定义它的文法的一种表示,并定义一个解释器,这个解释器使用该表示来解释语言中的句子。
定义一个语言:“眼色”
定义他的文法表示:“摆头”、“坐的位置”
定义解释器:“规则”
这样我们就可以通过这个解释器来了解TA了。
给定一个”眼色“,定义”摆头“或”坐的位置“,并定义一个规则,这样就可以解释图中的柯镇恶和”老婆“了。
{kind=link}
{kind=link}
{kind=link}
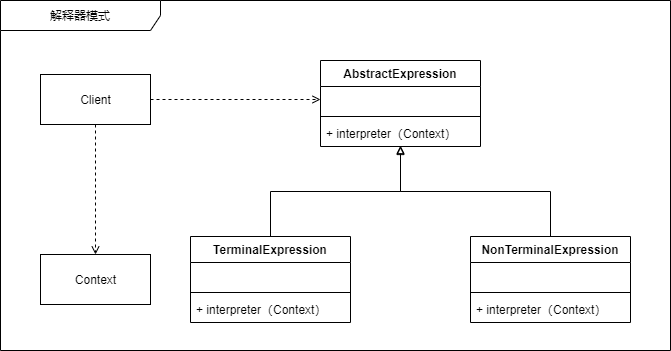
这个结构比较简单,定义一个解释接口,然后就是两个具体的解释器
- 最终解释器
- 非最终解释器
- 环境
这两个有点像组合模式中的子节点和叶节点的意思。这里的 NonTerminalExpression 是可以有多个的;
这里最麻烦的其实是 Context 环境。
我们来看看代码来实现上面的”眼色“
完整代码关注回复“源码”获取。
@Test
void getType() {
EyeColor eyeColor = null;
Context context = new Context("柯镇恶往左摆头 | 老婆坐在了架子上");
String content = context.getContent();
String[] strings = content.split("\\|");
for (int i = 0; i < strings.length; i++) {
String string = strings[i];
context.setContent(string);
if (string.contains("柯镇恶")) {
eyeColor = new KeZhenE();
} else if (string.contains("老婆")) {
eyeColor = new Wife();
}
assert eyeColor != null;
eyeColor.interpreter(context);
}
}public class KeZhenE implements EyeColor {
@Override
public void interpreter(Context context) {
if (context.getContent().contains("左摆头")) {
System.out.println("冲!");
} else if (context.getContent().contains("右摆头")) {
System.out.println("撤!");
}
}
}public class Wife implements EyeColor {
@Override
public void interpreter(Context context) {
if (context.getContent().contains("座椅")) {
System.out.println("生气!");
} else if (context.getContent().contains("架子")) {
System.out.println("开心!");
}
}
}冲!
开心!通过上面的内容我们了解到,解释器可以自己定义一些规则和对应的解释规则,来完成一些复杂的事情,这样就使得可以用一个简单的“动作”来达成一件复杂的事情。你看柯镇恶一个眼色,我就知道他想冲,他省去了复杂的“张嘴”过程。
其实解释器模式就像是我们现在用高级语言来开发软件程序一样,是怎么才能让计算机知道我们在说什么呢?其实这就是解释器的作用,我们按照一定规则(语法)来编写代码,然后解释器按照定义好的规则来将我们的代码翻译成机器认识的 01 代码。
对于解释器,它将复杂的事自己“包揽”了,但是一旦发生新的规则,你就不得不去修改“包揽”的复杂解析过程。
在今天,解释器模式应该很少会在我们的应用自己去设计了,毕竟这如同设计一门语言一样,过程很复杂,还记得我们正在用的正则表达式吗?他就是一个轻量级的语言,如果有能力有机会的时候,也可以挑战一下,开发一个自己的语言。
关注星尘的一个朋友欢迎加群一起交流学习🤓。
