

![]()
VLDT is an open-source Python library written in C++ that uses annotated dataclasses to create robust data models. It comes with built-in support for validation, parsing, and custom serialization/deserialization. Designed for scenarios where performance matters, VLDT streamlines data handling in Python applications without compromising on flexibility or correctness.
-
Type Validation:
Automatically checks that each field conforms to its expected type. -
Custom Validators:
- Field Validators: Run either before or after the main type validation, letting you adjust or verify individual field values.
- Model Validators: Validate or transform the entire model, either prior to or after type checks.
- Async Validators: Support asynchronous workflows via
AsyncDataModel.
-
Parsing Capabilities:
Easily convert Python dictionaries or JSON strings into validated models. -
Field Aliasing:
Define one or more alternate names for a field so that incoming data can use different keys. -
Custom Serialization/Deserialization:
Tailor how models are converted to and from dictionaries and JSON with a dedicated configuration system. -
Performance:
Thanks to its C++ implementation, VLDT delivers a significant speed boost in data parsing and validation.
VLDT is engineered for speed without sacrificing robust data validation. Our benchmarks focus on common operations - such as parsing, serialization, and list manipulation.
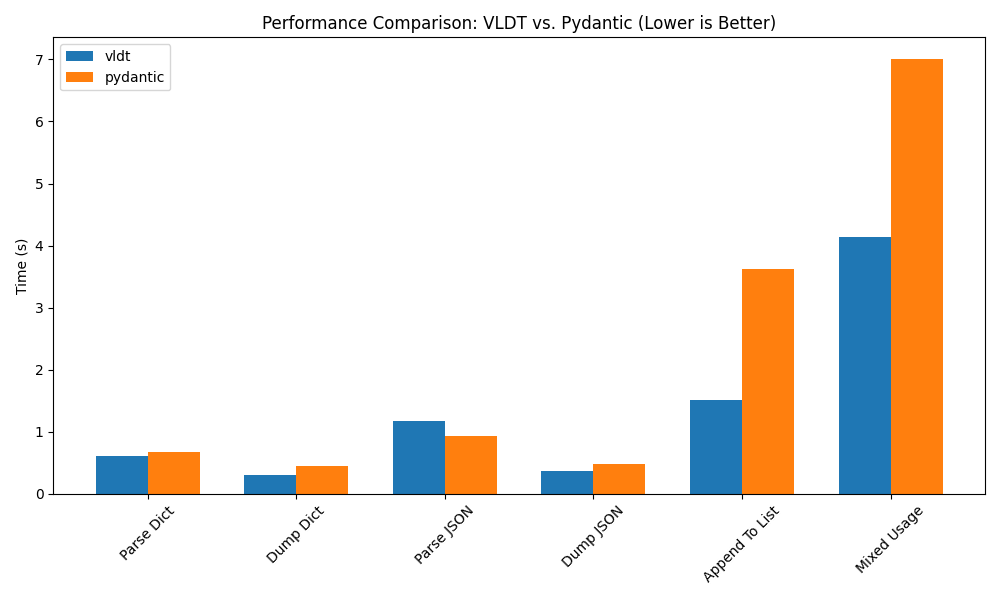
In our tests, VLDT demonstrated strong efficiency, making it well-suited for high-load or time-sensitive applications.
For those interested in reproducing these results, the complete load test script is available in the repository here.
Installing VLDT is simple. Use pip to install it:
pip install vldtThis section explains how to build, validate, and serialize data models using VLDT. The examples include everyday scenarios such as user profile management, order processing, and handling configuration data.
Define a model by subclassing DataModel and specifying type-annotated fields.
Example: User Profile
from vldt import DataModel
class UserProfile(DataModel):
username: str
email: str
age: int
# Create a simple user profile.
profile = UserProfile(username="alice123", email="alice@example.com", age=28)
print(profile.username, profile.email, profile.age) # Output: alice123 alice@example.com 28Assign default values so fields always have a value, even if not provided explicitly.
Example: Default Country in a User Profile
from vldt import DataModel
class UserProfile(DataModel):
username: str
email: str
country: str = "USA" # Defaults to "USA" if not provided.
profile = UserProfile(username="bob", email="bob@example.com")
print(profile.country) # Output: USAFor optional fields, the default is typically set to None.
from vldt import DataModel
from typing import Optional
class UserProfile(DataModel):
username: str
phone: Optional[str] # Optional phone number
profile = UserProfile(username="carol", phone=None)
print(profile.phone) # Output: NoneVLDT’s Field class offers fine-grained control over field behavior, including dynamic defaults and alternative aliases.
Example: Order Status
from vldt import DataModel, Field
class Order(DataModel):
order_id: int
status: str = Field(default="pending") # Defaults to "pending" if not specified.
order = Order(order_id=101)
print(order.status) # Output: pending
order2 = Order(order_id=102, status="shipped")
print(order2.status) # Output: shippedFor fields that require a fresh instance (like lists or dictionaries), use default_factory.
Example: Daily Log Entries
from vldt import DataModel, Field
class DailyLog(DataModel):
date: str
entries: list = Field(default_factory=list) # Creates a new empty list for each instance.
log1 = DailyLog(date="2025-03-01")
log1.entries.append("User login")
print(log1.entries) # Output: ['User login']
log2 = DailyLog(date="2025-03-02")
print(log2.entries) # Output: []Or use a factory for computed defaults:
from random import randint
from vldt import DataModel, Field
class Session(DataModel):
session_id: int = Field(default_factory=lambda: randint(1000, 9999))
session1 = Session()
session2 = Session()
print(session1.session_id, session2.session_id) # Likely different random IDs.Allow and single and multiple alternative names for a field, making it easier to work with data from different sources.
Example: Configuring a System
from vldt import DataModel, Field
class SystemConfig(DataModel):
timeout: int = Field(default=30, alias=["timeout_seconds", "t_timeout"])
# Input data might use different keys.
config = SystemConfig.from_dict({"t_timeout": 60})
print(config.timeout) # Output: 60Single aliases can be used as well:
from vldt import DataModel, Field
class SystemConfig(DataModel):
timeout: int = Field(default=30, alias="timeout_seconds")
config = SystemConfig.from_dict({"timeout_seconds": 45})
print(config.timeout) # Output: 45Converting a model to a dictionary and back retains the canonical field names and values.
Example: Product Data
from vldt import DataModel, Field
class Product(DataModel):
id: int = Field(default=0)
name: str = Field(default_factory=lambda: "Unknown")
price: float = Field(default=0.0, alias="cost")
data = {"id": 12, "name": "Gadget", "cost": 19.99}
product = Product.from_dict(data)
# Converting back to a dict returns the standard field names.
print(product.to_dict()) # Expected: {"id": 12, "name": "Gadget", "price": 19.99}VLDT accommodates fields that accept multiple types and supports nested models, useful for representing real-world objects like addresses or orders.
Example: Order with Shipping Address
from typing import Union, List, Optional
from vldt import DataModel
class Address(DataModel):
street: str
zipcode: Union[int, str]
country: str = "USA"
class Order(DataModel):
order_id: int
items: List[str]
shipping_address: Optional[Address] = None
# Creating an order with a shipping address.
address = Address(street="123 Main St", zipcode=90210)
order = Order(order_id=1001, items=["book", "pen"], shipping_address=address)
print(order.shipping_address.zipcode) # Output: 90210VLDT can validate elements inside containers like lists and dictionaries, ensuring every element meets the defined type.
Example: Validating an Inventory List
from typing import List, Dict
from vldt import DataModel
class Inventory(DataModel):
items: List[str]
quantities: Dict[str, int]
inventory = Inventory(items=["apple", "banana"], quantities={"apple": 10, "banana": 5})Or working with other containers:
from typing import Tuple, Set
from vldt import DataModel
class Metrics(DataModel):
dimensions: Tuple[int, int]
unique_values: Set[float]
metrics = Metrics(dimensions=(1920, 1080), unique_values={3.14, 2.718})Custom validators let you incorporate business logic into your model validation. They can adjust data before the main validation or check values afterward.
Example: Validating User Age and Name Format
from vldt import DataModel, field_validator, model_validator, ValidatorMode
class User(DataModel):
name: str
age: int
# Convert string age to int and enforce a minimum age.
@field_validator(mode=ValidatorMode.BEFORE)
@classmethod
def validate_age(cls, age):
if isinstance(age, str):
if not age.isdigit():
raise ValueError("Age must be a number")
age = int(age)
if age < 18:
raise ValueError("User must be at least 18 years old")
return age
# Ensure the name is properly capitalized.
@field_validator(mode=ValidatorMode.AFTER)
@classmethod
def format_name(cls, name):
return name.capitalize()
# Example of a model-level adjustment.
@model_validator(mode=ValidatorMode.BEFORE)
@classmethod
def adjust_user(cls, data: dict):
# For example, trim whitespace in the username.
if "name" in data:
data["name"] = data["name"].strip()
return data
user = User(name=" john ", age="25")
print(user.name, user.age) # Output: John 25For workflows involving asynchronous operations (like external API calls), VLDT provides async validators. In this case the AsyncDataModel class is used. Such models can be created using await.
Example: Validating an Async User Registration
from vldt import AsyncDataModel, async_field_validator, async_model_validator, ValidatorMode
import asyncio
class AsyncUser(AsyncDataModel):
name: str
age: int
@async_field_validator(mode=ValidatorMode.BEFORE)
@classmethod
async def check_age(cls, age):
if isinstance(age, str):
age = int(age)
min_age = await get_minimum_age() # Assume an async function to fetch the minimum age.
if age < min_age:
raise ValueError("User must be at least 18 years old")
return age
@async_field_validator(mode=ValidatorMode.AFTER)
@classmethod
async def check_name(cls, name):
if await name_already_taken(name): # Assume an async function to check if the name is taken.
raise ValueError("Name already taken")
return name
@async_model_validator(mode=ValidatorMode.BEFORE)
@classmethod
async def adjust_user(cls, data: dict):
is_correct = await check_user_data(data) # Calling an async function.
if not is_correct:
raise ValueError("Invalid user data")
return data
async def main():
user = await AsyncUser(name="alice", age="30") # await the model creation
print(user.name, user.age)
asyncio.run(main())VLDT ensures that models can be accurately converted to dictionaries or JSON strings and then re-instantiated without loss of information. This round-trip conversion is essential for data storage, transmission, and integration with other systems. In addition to standard conversion, you can define custom rules for handling specific data types.
Convert a model to a dictionary using the to_dict method and re-instantiate it using from_dict.
Example: Converting a Customer Order
from vldt import DataModel
class Address(DataModel):
street: str
city: str
postal_code: str
class CustomerOrder(DataModel):
order_id: int
customer: str
address: Address
notes: str
order_data = {
"order_id": 5001,
"customer": "Dana",
"address": {"street": "456 Elm St", "city": "Metropolis", "postal_code": "54321"},
"notes": "Leave package at the door.",
}
# Convert dictionary to model.
order_obj = CustomerOrder.from_dict(order_data)
# Serialize the model back to a dictionary.
order_dict = order_obj.to_dict()
print("Dictionary Conversion:", order_dict)VLDT also provides built-in methods for converting models to JSON strings and back, useful for API communication or configuration storage.
Example: Converting a Customer Order to JSON and Back
import json
from vldt import DataModel
class Address(DataModel):
street: str
city: str
postal_code: str
class CustomerOrder(DataModel):
order_id: int
customer: str
address: Address
notes: str
order_data = {
"order_id": 5001,
"customer": "Dana",
"address": {"street": "456 Elm St", "city": "Metropolis", "postal_code": "54321"},
"notes": "Leave package at the door.",
}
# Convert dictionary to model.
order_obj = CustomerOrder.from_dict(order_data)
# Serialize the model to a JSON string.
json_str = order_obj.to_json()
print("Serialized JSON:", json_str)
# Deserialize the JSON string back to a model.
order_obj2 = CustomerOrder.from_json(json_str)
print("Round-Trip JSON:", json.loads(order_obj2.to_json()))The Config class in VLDT provides a way to customize how data is serialized and deserialized. By defining a Config instance within a DataModel, you can control how specific data types are transformed when converting models to and from dictionaries or JSON.
The Config class allows you to specify:
- Custom serialization rules: Define how certain data types should be converted to dictionaries or JSON.
- Custom deserialization rules: Specify how incoming data should be transformed back into the appropriate Python objects.
To apply custom serialization and deserialization behavior, a Config instance is assigned to the __vldt_config__ attribute within a DataModel.
By default, datetime objects may not serialize into JSON-friendly formats. With Config, we can ensure they are stored as ISO-formatted strings and correctly parsed back when deserializing.
from datetime import datetime
from vldt import DataModel, Config
def serialize_datetime(dt: datetime) -> str:
return dt.isoformat()
def deserialize_datetime(value: str) -> datetime:
return datetime.fromisoformat(value)
class Event(DataModel):
name: str
start_time: datetime
__vldt_config__ = Config(
dict_serializer={datetime: serialize_datetime},
json_serializer={datetime: serialize_datetime},
deserializer={
datetime: {
str: deserialize_datetime,
}
}
)
event = Event(name="Conference", start_time=datetime(2025, 3, 15, 9, 0))
print("Serialized Event Dict:", event.to_dict())
json_str_event = event.to_json()
print("Serialized Event JSON:", json_str_event)
# Deserialize the JSON string back to an Event model.
event2 = Event.from_json(json_str_event)
print("Deserialized Event:", event2.name, event2.start_time)Explanation:
- The
serialize_datetimefunction converts adatetimeobject to an ISO 8601 string. - The
deserialize_datetimefunction converts the string back into adatetimeobject. - The
Configclass is used to ensure this transformation is applied whenever the model is serialized or deserialized.
In financial applications, floating-point numbers are often displayed as formatted currency strings. The following example demonstrates how to format a float as a currency string when serializing and convert it back when deserializing.
from vldt import DataModel, Config
def serialize_currency(amount: float) -> str:
return f"${amount:,.2f}"
def deserialize_currency(value: str) -> float:
return float(value.replace("$", "").replace(",", ""))
class Invoice(DataModel):
invoice_number: int
total: float
__vldt_config__ = Config(
dict_serializer={float: serialize_currency},
json_serializer={float: serialize_currency},
deserializer={
float: {
str: deserialize_currency,
}
}
)
invoice = Invoice(invoice_number=2025, total=1234.56)
print("Serialized Invoice Dict:", invoice.to_dict())
json_invoice = invoice.to_json()
print("Serialized Invoice JSON:", json_invoice)
# Deserialize the JSON back to an Invoice model.
invoice2 = Invoice.from_json(json_invoice)
print("Deserialized Invoice:", invoice2.invoice_number, invoice2.total)Explanation:
- The
serialize_currencyfunction converts a float into a formatted string with a dollar sign and comma separators. - The
deserialize_currencyfunction reverses this transformation to extract a float value. - The
Configclass ensures that these transformations happen automatically whenever the model is serialized or deserialized.
VLDT is capable of handling deeply nested data and complex models, which is common in real-world applications like configuration files or comprehensive business data.
Example: Inventory Management System
from typing import List, Dict, Union
from vldt import DataModel
class Warehouse(DataModel):
name: str
location: str
class InventoryItem(DataModel):
sku: str
quantity: int
class Inventory(DataModel):
warehouses: Dict[str, Warehouse]
items: List[InventoryItem]
inventory_data = {
"warehouses": {
"WH1": {"name": "Main Warehouse", "location": "New York"},
"WH2": {"name": "Secondary Warehouse", "location": "Los Angeles"}
},
"items": [
{"sku": "A123", "quantity": 100},
{"sku": "B456", "quantity": 200}
]
}
inventory = Inventory.from_dict(inventory_data)
print(inventory.warehouses["WH2"].location) # Output: Los AngelesExample: Complex Model with Class Variables
from typing import ClassVar, List, Dict, Any, Optional
from vldt import DataModel
class ComplexModel(DataModel):
MAX_ITEMS: ClassVar[int] = 100 # Example constant for business rules.
TIMEOUT: ClassVar[float] = 5.0
id: int
metadata: Dict[str, Any]
products: List[dict] # Assume a product is represented as a dictionary.
address: Optional[dict] = None
history: List[int] = []
complex_obj = ComplexModel(
id=1,
metadata={"version": 1.0},
products=[{"id": 1, "name": "Widget", "price": 9.99}],
address={"street": "123 Main St", "zipcode": 90210}
)VLDT uses rapidjson for JSON serialization and deserialization. The library is included as a submodule in the repository.
Minimal Python version is 3.11