Using "@language": "en-US" in context producing adverse affects #459
Comments
|
That's...interesting. It seems like that would be a problem for any converter/parser, even one that was working in JSON directly, if it didn't know which literals were human-readable and which were just strings. I wonder how that's been tackled by other users of JSON-LD. Well, the only other thing that comes immediately to mind would be to change all of the human-readable string properties to arrays of objects with one object each which contains a |
|
Nate, apparently, this is a long-standing problem with json-ld. Here is an issue (quite looong) from the json-ld repo (json-ld/json-ld.org#133) back in 2012. It is something that needs to be resolved. The ideal person (as you can tell from this thread) is Gregg Kellogg (who is currently recovering from very recent heart surgery). |
|
I was reading that very issue thread earlier today, along with other discussions and the language map section of the JSON-LD documentation (which is lacking in examples and not very useful). I really like the original proposal, as it is the most succinct: Though the use of as an option. But I don't think we'd necessarily need that for our purposes. Anyway yes, there does not seem to be any definitive answer on this - the thread being several years old doesn't help much. In the meantime, what should we do? The project is moving forward with or without a resolution to this. |
|
But, there has been more with multiple issues and notions intertwining including use of named graphs. Anyway, in these threads there are at least 4 familiar people with the necessary expertise, any one of which might cast some light on the issue:
|
|
Yes, this is not something that's a show stopper or should slow us down; but, it nevertheless needs to be resolved. |
|
I could also see the potential usefulness of another approach that seemed to show up in that thread; I think it was called property-mapped? Something like: Since it would scale pretty well, and have minimal impact in cases where only one language was in use: Instead of But then the problem becomes translating between that structure and an actual programming-friendly structure. You either have to do a lot of custom serialization/deserialization or give each class in the schema its own unique language container class, or one shared class but with some custom means of conveying rules about which properties are or aren't used in it...and then you also have to figure out how to handle it in the schema itself, if at all. So in the grand scheme of things the original proposal (properties as containers for languages rather than languages as containers for properties) ends up being easier to deal with, I think. |
I want to agree, but the handling of all human-readable string properties across the schema is far from trivial to change once we start building entire systems around it. It'll be especially hard once we start having data in the registry that is coming directly from other partners and isn't easy for us to just wipe out and republish with an updated format (in fact, it'll be impossible to do that legitimately, as it would violate third-party envelope signatures). In that sense, it kind of is a showstopper, now that I think about it some more. In the meantime, would it be worth creating a ceterms:LanguageMap class or something, and using that as the range of all relevant rdfs:literal properties? |
|
@siuc-nate, I'm jumping off to email to discuss options. |
|
The problem is that the use of ...where we should have The result is that when our current data is transformed to turtle, we get the following values falsely language tagged: where we should see: Alternatively, the types for these properties could be handled in the This does not handle the other two problematic language taggings in the Western Governs' degree CER record with If we had created and declared an xsd dataype for CTID, that would solve that And, for We do need to take steps to discover whether any other values in the CER data are being falsely languaged-tagged and make correction to the encoding process accordingly. |
|
Thanks, Stuart. I assume this applies not only to our schema serializations, but also the data we publish from the workit site, correct? |
|
Nate, I was just going to do a review of the schema serialization :-) Until I've done that, I can't say whether the problems are shared across schema and record encoding and thus on to Workit. As part of that schema review, I'll be looking for other properties that might fall in the basket of falsely [language] accused. |
|
Sorry, I should have been more clear - I meant that our workit serializations (specifically the literal fields) will also need to be altered to be more conversion-friendly (whatever that may entail). Though before we go doing that, I do wonder if there is a sufficiently valid use case for it. |
|
Well, the record I am working with is from Workit, so if you're asking
whether it would need to be corrected, I'd say 'yes'. Not sure what you
mean by "sufficiently valid use case for it"...being *not wrong* is a
sufficient use case for me. In the context of the Registry itself and it's
functioning, probably not. But when the data is in the wild, that's another
matter.
…On Fri, Sep 8, 2017 at 8:34 AM, siuc-nate ***@***.***> wrote:
Sorry, I should have been more clear - I meant that our workit
serializations (specifically the literal fields) will also need to be
altered to be more conversion-friendly (whatever that may entail). Though
before we go doing that, I do wonder if there is a sufficiently valid use
case for it.
—
You are receiving this because you were assigned.
Reply to this email directly, view it on GitHub
<#459 (comment)>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/ACzYpvqtdFUcDAM21VyLy-DyP0GpzFcxks5sgV6WgaJpZM4PQBK0>
.
--
Stuart A. Sutton, Metadata Consultant
Associate Professor Emeritus, University of Washington
Information School
Email: stuartasutton@gmail.com
Skype: sasutton
|
|
The functionality of the Registry is what I was referring to, yes - records are only ever JSON there, and the registry is meant to facilitate interoperability between systems (that would presumably speak JSON). You are right about cases where the data is in the wild, but does complicate the serialization/deserialization process significantly. This will likely be a deterrent to adoption - if developers are able to create and get a more streamlined JSON record, they are less likely to have problems figuring out how to deal with its data. The schema documentation will tell them what the datatypes are; the data itself doesn't need to (and if it tries to, then the schema documentation becomes less immediately useful, since the values of many "literals" will actually be objects). In other words, it's a lot easier to get developer buy-in if they only need to output and import instead of As a [third-party/partner] developer, I would balk at the latter, and wonder why we need a standalone schema at all if every property is going to tell me its type anyway. So, I think we need to be very careful in how we solve this. The primary use case we need to serve is the communication of data between systems coded to understand CTDL; I would think that worrying about whether or not the data also converts smoothly to other formats should be an important, but secondary, concern. That's just my opinion, though; I can be swayed. |
|
Nate, this is a BIG point. First, the conversion to other RDF formats is not a "secondary concern" , it is both: (1) the test of how well the CTDL encoding conforms to RDF; and (2) necessary to full functioning on the open web where everyone in the Semantic Web context does not rely on JSON-LD. So, JSON-LD data that can't translate into flavors of RDF without rendering incorrect data doesn't seem to me to fit the goals of this project. As for developers, the data standing alone has to carry (one way or another) the data necessary to proper handling and that includes both datatyping and language-tagging. Downstream systems should not have to reference a schema to figure out how to process the data. Remember that there are usually developers on both ends of that transaction. The goal is smart, complete data. What's the price of sending incomplete, "dumb" data? |
|
I will accept your point about the data on the open web. However, I still think it is a greater burden to developers to code for a data model that is so much more complex. I'm not sure I understand your point about "not having to reference a schema". If the data carries all of the typing needed to process it, then what is the function of a schema? Does it only serve to define which properties go with which class? As a developer, I would think that the schema (or more specifically, a profile thereof) should tell me everything I need to know about how to process the data, so that I can write efficient code that handles "dumb" data by being a smarter system. Consider a simple (pseudocode) class for the example: Compared to what would be needed to handle the fully described example: If my code knows what types of values to expect for which properties in the data, it would know that your example contains faulty information (specifically the non-boolean boolean) and reject it. It is much more cumbersome to write code that must check each property for its type, and then determine what to do with it. If the schema (and therefore the types of the data) are known already, then it is also redundant to have to check. It also means processing a deeper, more complicated data structure for each property - and the data itself is bigger and much harder to read (as a human). All of that also leads to documentation that is more confusing to write and read (again, discouraging developer buy-in), which in turn leads to a larger number and variety of chances for errors to occur. Perhaps this is a point of friction between the world of RDF and the world of object-oriented programming. It is definitely possible to write code that handles fully-described data, but it is also unnecessary if the value types are known from the schema. In the second example above, I now have to ensure against null objects for each property, dive into each object to set or get its value, and write handlers that can render, serialize, deserialize, store, query, load, etc., the additional pieces properly. The additional complication is an order of magnitude greater this way, and for no benefit since I already know what the types are from the schema. At the very least, I have to convert to and from this more complex format and something simpler used in the rest of my code - again without benefit due to already knowing the types. It also introduces the chance for typo-based errors (i.e., In other words, given a well-documented schema, the price for producing and processing "dumb" data is lower than the price of producing and processing "smart" data. Having said that, there is one case where having the data type embedded in the data is necessary - when the range contains more than one type of data. If the range for a given property includes two different types of objects, then there is no avoiding writing code that must check the data first and then determine how to process it. We have some properties like this in CTDL. I'm not sure where this leaves us in terms of solutions. I'm prepared to accept that we have to use the more complex format, in the end, regardless - but we must be prepared to answer developers who want us to explain it. Perhaps the Registry Assistant API should be a two-way street? That is, not only should it convert from simplified classes to full CTDL, but also from CTDL back to simplified classes (give it a CTID, it fetches the record from the registry, converts it, and gives it to you)? Is that a possible solution? |
|
@siuc-nate, I'm sympathetic to the implementation issues of trying to make the solution stack behave like a triplestore |
|
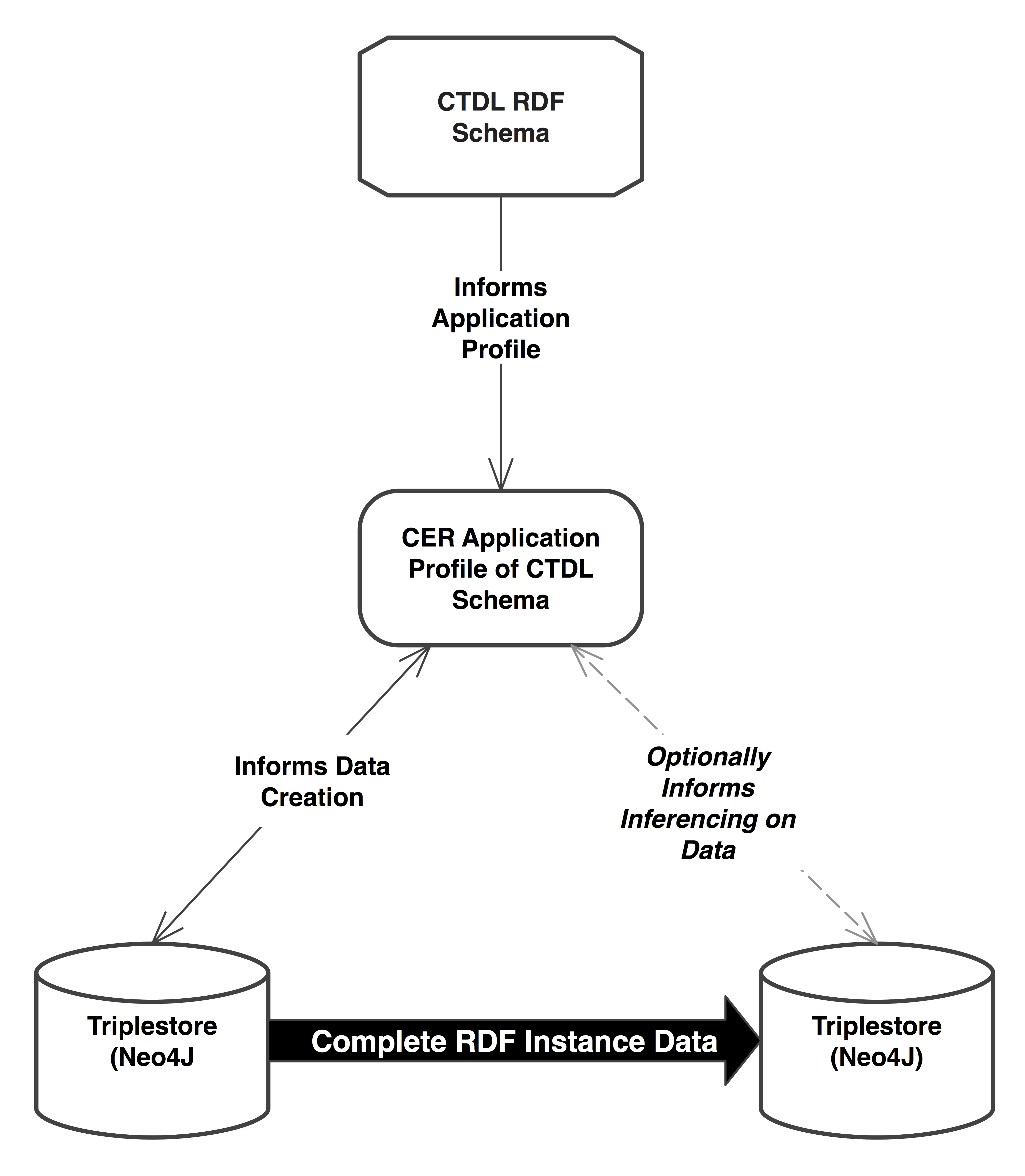
@siuc-nate and @jkitchensSIUC, let me see if I can summarize (and characterize) the points so far.
It seems that your position, Nate, is that the JSON-LD credential instance data generated need not include language tags or datatypes because the necessary information regarding them is embodied in the RDF schema for CTDL and that systems can just look it up. If this is a correct reading, it would look like this:
There are a couple of issues here. First it's a "closed systems" view that assumes that the CER datastore is merely passing a record to some 3rd party system and that the 3rd party system looks up the schema and fills in the blanks in the incomplete record. This is somewhat of a misunderstanding of the role of the RDF schema. When a 3rd party triplestore ingests RDF data in this manner, it could (but doesn't have to) use the RDF schema to infer new data in terms of the defined semantics in the schema such as creating an inferred triple from a declaration of
But the problem of "closed system" thinking is that closed systems are just one scenario of concern to us. It does not take into account Linked Data and how it works. There are two fundamental linking contexts where: (1) a system uses linked data to reach out through a link to a second system to retrieve some data that it uses in a mashup; and (2) an end user clicks on a link in a browser to retrieve a credential description to display. In the latter scenario, the browser assumes the instance data it gets is "complete". It does not look up anything, it just presents. It looks like this:
So, my take is that the JSON-LD data in the CER that is presented to the world has to be complete and done so that it translates accurately into other RDF serializations. Of course, lesser quality data could be produced in JSON-LD without either language tags or datatypes identified if the Registry somehow does the addition of datatypes and language tags in the exposed data. Just don't assume that some consuming systems is going to do the job of completing those records by looking up datatypes and inferring appropriate language tags.
@siuc-nate If your assumption that technical powers that be will not buy-in or balk, then the Registry would need to ingest the incomplete data and fill in the blanks before quality data could be exposed, exported or linked to. I do find it interesting that tech folks like JSON-LD so much if they don't like "excessive" encoding when it is the most verbose language available for encoding linked data. If you take the CER's JSON-LD record for the Western Governors BS in Information Technology encoding and translate it into other serializations including datatypes etc., here are the stats:
Nate, you state:
This in essence says that producing valid RDF data through transformation of the JSON-LD serialization is a secondary concern. I don't agree. It basically says that it's OK for data transformations to generate poor or incomplete RDF. I think that both are primary concerns; however, we need to leave a decision here to Jeanne and others. |


|
In the end, Nate, the biggest issue in the instance data is with language tags since JSON handing of other datatypes is already extremely limited (e.g., no datatypes for forms of dates etc.) so the full expressiveness of CTDL isn't available anyway. In conversion, it handles primitive conversions of number/integer. Which brings us full circle back to the fact that the @language does not work for us in @context because it tags every literal in double quotes as So, we are back at square one. |
|
Nate, you asked:
There is something we can do at the declaration level in the tables and the JSON-LD and Turtle of the schema; but not at all sure how that helps us with a JSON-LD encoding. All literals are datatyped. We can declare those that have language tags as being of the datatype So a faked schema definition example here would looking the following: TurtleRDF/XMLJSON-LD |
|
Nate, in the sentence: "Anything not defined as having the |
|
So if I'm understanding correctly, you're saying we'd replace all current instances of rdfs:Literal in the schema currently with the appropriate subclass (xsd:string, rdf:langString, etc)? It would be interesting to see how that impacts conversion. I wonder if there is anything in the JSON-LD specification that would specify how to treat langString vs Literal when converting/handling
It seems like a two-step problem/solution. I think it's more valuable to solve the schema problem first; once we have a concrete indication at the schema level of which properties are language-dependent, we can handle that in any number of ways in the JSON-LD we generate. |
|
Not exactly, but very close. We'd change the rangeIncludes for those needing to include a language tag to Change rangeIncludes to rdf:langString
Remove rdfs:Literal (no rangeIncludes designation)
|
|
Why no range at all? It seems like that would create a lot of problems (particularly for developers - a property that can't hold data isn't a property, and is just confusing). |
|
I see one reference to rdf:langString in the JSON discussions at json-ld/json-ld.org#133 ... search the page for langString. In answer to your question, any property in RDF that is not declared as a datatype or rdf:langString is treated in RDF as an xsd:string. If there is no declaration of range, surely |
|
I wouldn't alter the schema like that just to handle the |
|
Perhaps not, but the change to rdf:langString where it is intended would be
much more precise and useful.
…On Mon, Sep 11, 2017 at 10:55 AM, siuc-nate ***@***.***> wrote:
I wouldn't alter the schema like that just to handle the @language in the
context doing odd things during conversion - there are other ways to solve
that. I think the schema should reflect the actual range, because that is
incredibly useful for generating the documentation. If the range is string,
we should declare it as such.
—
You are receiving this because you modified the open/close state.
Reply to this email directly, view it on GitHub
<#459 (comment)>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/ACzYph8sB4a8fpo59xFs68HvG9l3wx6Nks5shXLRgaJpZM4PQBK0>
.
--
Stuart A. Sutton, Metadata Consultant
Associate Professor Emeritus, University of Washington
Information School
Email: stuartasutton@gmail.com
Skype: sasutton
|
|
I agree, we should use langString. I strongly feel we should change the range of the other properties to the appropriate value as well (xsd:string in most cases; maybe we do something different for latitude/longitude? Shouldn't those be xsd:float anyway?) |
|
Per our 9/19/2017 conversation: We will explore using the language map as defined in https://json-ld.org/spec/latest/json-ld/#string-internationalization example 36 in addition to the assignment of rdf:langString and xsd:string as discussed above. First, we will create a few tests and try them with http://www.easyrdf.org/converter and http://rdf-translator.appspot.com/ |
|
@stuartasutton Here is an example, based on https://credentialfinder.org/credential/1306/A_A_S__in_Dental_Assisting (with some extra locations removed). Some experiments with this:
I'll test this with the converters above. If you have other tests, Stuart, go ahead. |
|
Results: Conversion to Turtle via http://www.easyrdf.org/converter : Everything appears to have succeeded, with the exception of there not being a type value for the ConditionProfile. This is certainly encouraging. Same tool, but with XML: Again, it all appears to have worked, except for the ConditionProfile type. Conversion to N3 via http://rdf-translator.appspot.com/ : I'm not 100% sure I'm reading it correctly, but it appears to have the same result as above. Conversion to JSON-LD (or rather, expansion I suppose) via the same tool: Again, same result - everything but the I think we may have a viable approach here. If I add the Well, @stuartasutton, what do you think? Does this solve the problem? Are there any other |
|
Just to identify the steps I think we can/should make at this point (and in roughly the order we should make them):
@cwd-mparsons, @stuartasutton, @jkitchenssiuc if you can think of any other changes, please let me know. |
|
Here is a tentative list of affected properties (relevant portions based on Stuart's list in a previous post): Schema serialization rdf:langString
CTDL rdf:langString
CTDL xsd:string
CTDL xsd:float
For rdf:object above, how would the When converted, it appears to work if the data is either a literal or an object, but not both: Is there an alternate way of encoding history changes such that the object uses rdf:object for URIs and rdf:langString for language-strings? |
|
@siuc-nate, looks good. In your original, you have the following
I manually tagged it to align with how it is declared in the
This means that the structure defined in the context works with language tagged data; but, it does not enforce the addition of such a language tag. So prepping for use of the language tag as you have done in the context does not compel such use. For me, this is a good thing. Whether including a language tag gets enforced as a requirement in an implementation (CER?) issue --i.e., the value of the description property must have a language tag-- has to be an outcome of some other validation process on the data. |
|
Thanks, Stuart. I was mid-edit of the post above yours when you replied, and I added the information about the use of rdf:object with langString - can you review that and let me know your thoughts? One potential solution would be to leave rdf:object out of the I would wonder how the JSON-LD folks would handle such a situation. |
|
Not sure what's the issue.
When is an object ever a string? I think I am not getting this. |
|
In the encodings for history tracking, when a definition or whatever gets changed, the rdf:object is a (lang)string. Otherwise it's a URI to something (when a domain or range changes, for example). Compare: The question is, what, if anything, should the |
|
After discussing this with @stuartasutton, the current approach is to use rdf:object for non-language strings and a new property, meta:objectText, for language strings. This property will be declared to be a subproperty of rdf:object: |
|
Nate, we need to keep thinking about this since parsers will not recognize the following as a triple, and that's key: So, both of these are legal: |
|
@stuartasutton I was afraid of that. That's why I conducted the experiment referenced in #459 (comment) after the property list (and with the name property rather than the object property). Basically, it doesn't work to have a That means we would need to fall back to leaving Given that it only applies to one property and that property only shows up in history tracking, this may be an acceptable compromise - however, it means we won't have a consistent implementation of langString properties and that could come back to bite us if we add |
|
@siuc-nate , can you provide me with a complete As is above, the snippet does validate. So I added a I got this far: But translation to turtle looks like this: |
|
The context in your example seems to fit, though perhaps the translator doesn't assume the rdf:subject and rdf:predicate properties are actually URI pointers (which I assume a triple store would). Is that what you're referring to? I'm not sure where there is missing information in your post. |
|
Yes, that's what I am referring to. |
|
So something like this?: |
|
Bingo! RDF/XMLTURTLE |
|
These changes have been made in pending CTDL and noted in history tracking. |
Nate, the use of
"@language": "en-US"in the json-ld is resulting in every instance of a literal being tagged asen-USeven where it shouldn't. For example:In Turtle:
ceterms:ctid "ce-CB8EB8D0-208D-4DA0-9F50-7003F8A39ED6"@en-US ;and in RDF/XML:
<ceterms:ctid xml:lang="en-US">ce-CB8EB8D0-208D-4DA0-9F50-7003F8A39ED6</ceterms:ctid>The text was updated successfully, but these errors were encountered: