diff --git a/.DS_Store b/.DS_Store
new file mode 100644
index 0000000..9e612d5
Binary files /dev/null and b/.DS_Store differ
diff --git a/README.md b/README.md
index c5a43d9..603d4df 100644
--- a/README.md
+++ b/README.md
@@ -176,3 +176,17 @@ Goal-orientied dialogue systems. Implemention of the multi-task model: intent cl
+### Week 13: *Dialogue Systems: Part 2*
+General conversation dialogue systems and DSSMs. Implementation of question answering model on SQuAD dataset and chit-chat model on OpenSubtitles dataset.
+
+
+
diff --git a/Week 13/README.md b/Week 13/README.md
new file mode 100644
index 0000000..b13817d
--- /dev/null
+++ b/Week 13/README.md
@@ -0,0 +1,6 @@
+# Разбалловка
+
+- Задания, сделанные на семинаре: 5 баллов
+- Реализовать hard negatives mining: +2 балла
+- Реализовать semi-hard negatives mining: +1.5 балла
+- Реализовать болталку: +3 балла
diff --git a/Week 13/Week_13_Dialogue_Systems_(Part_2).ipynb b/Week 13/Week_13_Dialogue_Systems_(Part_2).ipynb
new file mode 100644
index 0000000..e765498
--- /dev/null
+++ b/Week 13/Week_13_Dialogue_Systems_(Part_2).ipynb
@@ -0,0 +1,925 @@
+{
+ "nbformat": 4,
+ "nbformat_minor": 0,
+ "metadata": {
+ "colab": {
+ "name": "Week 13 - Dialogue Systems (Part 2).ipynb",
+ "version": "0.3.2",
+ "provenance": [],
+ "collapsed_sections": []
+ },
+ "kernelspec": {
+ "name": "python3",
+ "display_name": "Python 3"
+ },
+ "accelerator": "GPU"
+ },
+ "cells": [
+ {
+ "metadata": {
+ "id": "Z4WlMyJVRkzQ",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "!pip3 -qq install torch==0.4.1\n",
+ "!pip -qq install torchtext==0.3.1\n",
+ "!pip -qq install spacy==2.0.16\n",
+ "!pip install -qq gensim==3.6.0\n",
+ "!python -m spacy download en\n",
+ "!wget -O squad.zip -qq --no-check-certificate \"https://drive.google.com/uc?export=download&id=1h8dplcVzRkbrSYaTAbXYEAjcbApMxYQL\"\n",
+ "!unzip squad.zip\n",
+ "!wget -O opensubs.zip -qq --no-check-certificate \"https://drive.google.com/uc?export=download&id=1x1mNHweP95IeGFbDJPAI7zffgxrbqb7b\"\n",
+ "!unzip opensubs.zip"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "UvJKy3mtVOpw",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "import numpy as np\n",
+ "\n",
+ "import torch\n",
+ "import torch.nn as nn\n",
+ "import torch.nn.functional as F\n",
+ "import torch.optim as optim\n",
+ "\n",
+ "\n",
+ "if torch.cuda.is_available():\n",
+ " from torch.cuda import FloatTensor, LongTensor\n",
+ " DEVICE = torch.device('cuda')\n",
+ "else:\n",
+ " from torch import FloatTensor, LongTensor\n",
+ " DEVICE = torch.device('cpu')\n",
+ "\n",
+ "np.random.seed(42)"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "LKCD9Pt4Wupj",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "# General Conversation"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "C3fbABnaXFyk",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "Сегодня разбираем, как устроена болталка.\n",
+ "\n",
+ " \n",
+ "*From [«Алиса, за мной следит ФСБ?»: в соцсетях продолжают издеваться над голосовым помощником «Яндекса»](https://meduza.io/shapito/2017/10/11/alisa-za-mnoy-sledit-fsb-v-sotssetyah-prodolzhayut-izdevatsya-nad-golosovym-pomoschnikom-yandeksa)*\n",
+ "\n",
+ "Вообще, мы уже обсудили Seq2Seq модели, которые могут быть использованы для реализации болталки - однако, у них недостаток: высока вероятность сгенерировать что-то неграмматичное. Ну, как те пирожки.\n",
+ "\n",
+ "Поэтому почти всегда идут другим путем - вместо генерации применяют ранжирование. Нужно заранее составить большую базу ответов и просто выбирать наиболее подходящий к контексту каждый раз."
+ ]
+ },
+ {
+ "metadata": {
+ "id": "3mOxTaTjD0-p",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "## DSSM\n",
+ "\n",
+ "Для этого используют DSSM (Deep Structured Semantic Models):\n",
+ "\n",
+ " \n",
+ "*From [What are Siamese neural networks, what applications are they good for, and why?](https://www.quora.com/What-are-Siamese-neural-networks-what-applications-are-they-good-for-and-why)*\n",
+ "\n",
+ "Эта сеть состоит из (обычно) пары башен: левая кодирует запрос, правая - ответ. Задача - научиться считать близость между запросом и ответом.\n",
+ "\n",
+ "Дальше набирают большой корпус из пар запрос-ответ (запрос может быть как одним вопросом, так и контекстом - несколькими последними вопросами/ответами). \n",
+ "\n",
+ "Для ответов предпосчитывают их векторы, каждый новый запрос кодируют с помощью правой башни и находят среди предпосчитанных векторов ближайший."
+ ]
+ },
+ {
+ "metadata": {
+ "id": "JSz9ALe3w1v1",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "## Данные\n",
+ "\n",
+ "Будем использовать для начала [Stanford Question Answering Dataset (SQuAD)](https://rajpurkar.github.io/SQuAD-explorer/). Вообще, там задача - найти в тексте ответ на вопрос. Но мы будем просто выбирать среди предложений текста наиболее близкое к вопросу.\n",
+ "\n",
+ "*Эта часть ноутбука сильно основана на [шадовском ноутбуке](https://github.com/yandexdataschool/nlp_course/blob/master/week10_dialogue/seminar.ipynb)*."
+ ]
+ },
+ {
+ "metadata": {
+ "id": "_6OqXUJxjnX4",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "import pandas as pd\n",
+ "\n",
+ "train_data = pd.read_json('train.json')\n",
+ "test_data = pd.read_json('test.json')"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "s0DPvn5djkha",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "row = train_data.iloc[40]\n",
+ "print('QUESTION:', row.question, '\\n')\n",
+ "for i, cand in enumerate(row.options):\n",
+ " print('[ ]' if i not in row.correct_indices else '[v]', cand)"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "KIeJIQ7ex4nB",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "Токенизируем предложения:"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "udkrpaSHq7mg",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "import spacy\n",
+ "\n",
+ "spacy = spacy.load('en')\n",
+ "\n",
+ "train_data.question = train_data.question.apply(lambda text: [tok.text.lower() for tok in spacy.tokenizer(text)])\n",
+ "train_data.options = train_data.options.apply(lambda options: [[tok.text.lower() for tok in spacy.tokenizer(text)] for text in options])\n",
+ "\n",
+ "test_data.question = test_data.question.apply(lambda text: [tok.text.lower() for tok in spacy.tokenizer(text)])\n",
+ "test_data.options = test_data.options.apply(lambda options: [[tok.text.lower() for tok in spacy.tokenizer(text)] for text in options])"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "tU5jRHpax7Ot",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "У нас не так-то много данных, чтобы учить всё с нуля, поэтому будем сразу использовать предобученные эмбеддинги:"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "2mQjmbvs-jFQ",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "import gensim.downloader as api\n",
+ "\n",
+ "w2v_model = api.load('glove-wiki-gigaword-100')"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "dC8Db3DKyDSz",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "**Задание** Постройте матрицу предобученных эмбеддингов для самых частотных слов в выборке."
+ ]
+ },
+ {
+ "metadata": {
+ "id": "AinFu7nb6DSf",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "from collections import Counter\n",
+ "\n",
+ "\n",
+ "def build_word_embeddings(data, w2v_model, min_freq=5):\n",
+ " words = Counter()\n",
+ " \n",
+ " for text in data.question:\n",
+ " for word in text:\n",
+ " words[word] += 1\n",
+ " \n",
+ " for options in data.options:\n",
+ " for text in options:\n",
+ " for word in text:\n",
+ " words[word] += 1\n",
+ " \n",
+ " word2ind = {\n",
+ " '': 0,\n",
+ " '': 1\n",
+ " }\n",
+ " \n",
+ " embeddings = [\n",
+ " np.zeros(w2v_model.vectors.shape[1]),\n",
+ " np.zeros(w2v_model.vectors.shape[1])\n",
+ " ]\n",
+ " \n",
+ " \n",
+ "\n",
+ " return word2ind, np.array(embeddings)"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "rKJhqyV__jhl",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "word2ind, embeddings = build_word_embeddings(train_data, w2v_model, min_freq=8)\n",
+ "print('Vocab size =', len(word2ind))"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "M-_xdNG9yYka",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "Для генерации батчей будем использовать такой класс:"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "4IoQrJ5rTSSN",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "import random\n",
+ "import math\n",
+ "\n",
+ "\n",
+ "def to_matrix(lines, word2ind):\n",
+ " max_sent_len = max(len(line) for line in lines)\n",
+ " matrix = np.zeros((len(lines), max_sent_len))\n",
+ "\n",
+ " for batch_ind, line in enumerate(lines):\n",
+ " matrix[batch_ind, :len(line)] = [word2ind.get(word, 1) for word in line]\n",
+ "\n",
+ " return LongTensor(matrix)\n",
+ "\n",
+ "\n",
+ "class BatchIterator():\n",
+ " def __init__(self, data, batch_size, word2ind, shuffle=True):\n",
+ " self._data = data\n",
+ " self._num_samples = len(data)\n",
+ " self._batch_size = batch_size\n",
+ " self._word2ind = word2ind\n",
+ " self._shuffle = shuffle\n",
+ " self._batches_count = int(math.ceil(len(data) / batch_size))\n",
+ " \n",
+ " def __len__(self):\n",
+ " return self._batches_count\n",
+ " \n",
+ " def __iter__(self):\n",
+ " return self._iterate_batches()\n",
+ "\n",
+ " def _iterate_batches(self):\n",
+ " indices = np.arange(self._num_samples)\n",
+ " if self._shuffle:\n",
+ " np.random.shuffle(indices)\n",
+ "\n",
+ " for start in range(0, self._num_samples, self._batch_size):\n",
+ " end = min(start + self._batch_size, self._num_samples)\n",
+ "\n",
+ " batch_indices = indices[start: end]\n",
+ "\n",
+ " batch = self._data.iloc[batch_indices]\n",
+ " questions = batch['question'].values\n",
+ " correct_answers = np.array([\n",
+ " row['options'][random.choice(row['correct_indices'])]\n",
+ " for i, row in batch.iterrows()\n",
+ " ])\n",
+ " wrong_answers = np.array([\n",
+ " row['options'][random.choice(row['wrong_indices'])]\n",
+ " for i, row in batch.iterrows()\n",
+ " ])\n",
+ "\n",
+ " yield {\n",
+ " 'questions': to_matrix(questions, self._word2ind),\n",
+ " 'correct_answers': to_matrix(correct_answers, self._word2ind),\n",
+ " 'wrong_answers': to_matrix(wrong_answers, self._word2ind)\n",
+ " }"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "as5kgtjLyRE6",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "train_iter = BatchIterator(train_data, 64, word2ind)\n",
+ "test_iter = BatchIterator(test_data, 128, word2ind)"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "27zeQlTJzU1x",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "Он просто сэмплирует последовательности из вопросов, правильных и неправильных ответов на них:"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "F-ohzmkXzO0e",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "batch = next(iter(train_iter))\n",
+ "\n",
+ "batch"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "BSXFV1CTyfGo",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "## Модель\n",
+ "\n",
+ "**Задание** Реализуйте модель энкодера для текстов - башни DSSM модели.\n",
+ "\n",
+ "*Это не обязательно должна быть сложная модель, вполне сойдет сверточная, которая будет учиться гораздо быстрее.*"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "Ve7WZ4-dvbuw",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "class Encoder(nn.Module):\n",
+ " def __init__(self, embeddings, hidden_dim=128, output_dim=128):\n",
+ " super().__init__()\n",
+ " \n",
+ " \n",
+ " \n",
+ " def forward(self, inputs):\n",
+ " "
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "ZFBAUGGfzFwF",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "### Triplet Loss\n",
+ "\n",
+ "Мы хотим не просто научить энкодер строить эмбеддинги для предложений. Мы хотим, чтобы притягивать векторы правильных ответов к вопросам и отталкивать неправильные. Для этого используют, например, *Triplet Loss*:\n",
+ "\n",
+ "$$ L = \\frac 1N \\underset {q, a^+, a^-} \\sum max(0, \\space \\delta - sim[V_q(q), V_a(a^+)] + sim[V_q(q), V_a(a^-)] ),$$\n",
+ "\n",
+ "где\n",
+ "* $sim[a, b]$ функция похожести (например, dot product или cosine similarity)\n",
+ "* $\\delta$ - гиперпараметр модели. Если $sim[a, b]$ линейно по $b$, то все $\\delta > 0$ эквиватентны.\n",
+ "\n",
+ "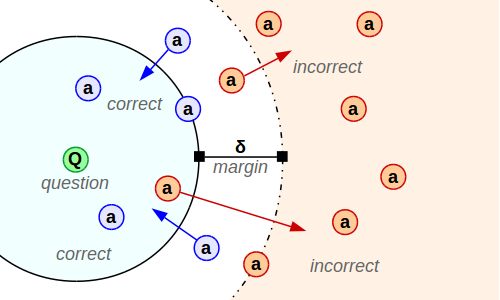\n",
+ "\n",
+ "**Задание** Реализуйте triplet loss, а также подсчет recall - процента случаев, когда правильный ответ был ближе неправильного."
+ ]
+ },
+ {
+ "metadata": {
+ "id": "GdHJK51dz0CB",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "class DSSM(nn.Module):\n",
+ " def __init__(self, question_encoder, answer_encoder):\n",
+ " super().__init__()\n",
+ " self.question_encoder = question_encoder\n",
+ " self.answer_encoder = answer_encoder\n",
+ " \n",
+ " def forward(self, questions, correct_answers, wrong_answers):\n",
+ " \n",
+ "\n",
+ " def calc_triplet_loss(self, question_embeddings, correct_answer_embeddings, wrong_answer_embeddings, delta=1.0):\n",
+ " \"\"\"Returns the triplet loss based on the equation above\"\"\"\n",
+ " \n",
+ " \n",
+ " def calc_recall_at_1(self, question_embeddings, correct_answer_embeddings, wrong_answer_embeddings):\n",
+ " \"\"\"Returns the number of cases when the correct answer were more similar than incorrect one\"\"\"\n",
+ " \n",
+ " \n",
+ " @staticmethod\n",
+ " def similarity(question_embeddings, answer_embeddings):\n",
+ " \"\"\"Returns sim[a, b]\"\"\"\n",
+ " "
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "ZWvlMTWpxTvJ",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "class ModelTrainer():\n",
+ " def __init__(self, model, optimizer):\n",
+ " self._model = model\n",
+ " self._optimizer = optimizer\n",
+ " \n",
+ " def on_epoch_begin(self, is_train, name, batches_count):\n",
+ " \"\"\"\n",
+ " Initializes metrics\n",
+ " \"\"\"\n",
+ " self._epoch_loss = 0\n",
+ " self._correct_count, self._total_count = 0, 0\n",
+ " self._is_train = is_train\n",
+ " self._name = name\n",
+ " self._batches_count = batches_count\n",
+ " \n",
+ " self._model.train(is_train)\n",
+ " \n",
+ " def on_epoch_end(self):\n",
+ " \"\"\"\n",
+ " Outputs final metrics\n",
+ " \"\"\"\n",
+ " return '{:>5s} Loss = {:.5f}, Recall@1 = {:.2%}'.format(\n",
+ " self._name, self._epoch_loss / self._batches_count, self._correct_count / self._total_count\n",
+ " )\n",
+ " \n",
+ " def on_batch(self, batch):\n",
+ " \"\"\"\n",
+ " Performs forward and (if is_train) backward pass with optimization, updates metrics\n",
+ " \"\"\"\n",
+ " \n",
+ " question_embs, correct_answer_embs, wrong_answer_embs = self._model(\n",
+ " batch['questions'], batch['correct_answers'], batch['wrong_answers']\n",
+ " )\n",
+ " loss = self._model.calc_triplet_loss(question_embs, correct_answer_embs, wrong_answer_embs)\n",
+ " correct_count = self._model.calc_recall_at_1(question_embs, correct_answer_embs, wrong_answer_embs)\n",
+ " total_count = len(batch['questions'])\n",
+ " \n",
+ " self._correct_count += correct_count\n",
+ " self._total_count += total_count\n",
+ " self._epoch_loss += loss.item()\n",
+ " \n",
+ " if self._is_train:\n",
+ " self._optimizer.zero_grad()\n",
+ " loss.backward()\n",
+ " nn.utils.clip_grad_norm_(self._model.parameters(), 1.)\n",
+ " self._optimizer.step()\n",
+ "\n",
+ " return '{:>5s} Loss = {:.5f}, Recall@1 = {:.2%}'.format(\n",
+ " self._name, loss.item(), correct_count / total_count\n",
+ " )"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "ecI_vVBgzpVn",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "import math\n",
+ "from tqdm import tqdm\n",
+ "tqdm.get_lock().locks = []\n",
+ "\n",
+ "\n",
+ "def do_epoch(trainer, data_iter, is_train, name=None):\n",
+ " trainer.on_epoch_begin(is_train, name, batches_count=len(data_iter))\n",
+ " \n",
+ " with torch.autograd.set_grad_enabled(is_train):\n",
+ " with tqdm(total=len(data_iter)) as progress_bar:\n",
+ " for i, batch in enumerate(data_iter):\n",
+ " batch_progress = trainer.on_batch(batch)\n",
+ "\n",
+ " progress_bar.update()\n",
+ " progress_bar.set_description(batch_progress)\n",
+ " \n",
+ " epoch_progress = trainer.on_epoch_end()\n",
+ " progress_bar.set_description(epoch_progress)\n",
+ " progress_bar.refresh()\n",
+ "\n",
+ " \n",
+ "def fit(trainer, train_iter, epochs_count=1, val_iter=None):\n",
+ " best_val_loss = None\n",
+ " for epoch in range(epochs_count):\n",
+ " name_prefix = '[{} / {}] '.format(epoch + 1, epochs_count)\n",
+ " do_epoch(trainer, train_iter, is_train=True, name=name_prefix + 'Train:')\n",
+ " \n",
+ " if not val_iter is None:\n",
+ " do_epoch(trainer, val_iter, is_train=False, name=name_prefix + ' Val:')"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "K1GvkkLh70S6",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "Запустим, наконец, учиться модель:"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "ipXj9pOD2afY",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "embeddings = FloatTensor(embeddings)\n",
+ "\n",
+ "model = DSSM(\n",
+ " Encoder(embeddings),\n",
+ " Encoder(embeddings)\n",
+ ").to(DEVICE)\n",
+ "\n",
+ "optimizer = optim.Adam(model.parameters())\n",
+ "\n",
+ "trainer = ModelTrainer(model, optimizer)\n",
+ "\n",
+ "fit(trainer, train_iter, epochs_count=30, val_iter=test_iter)"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "g_AHIoCB73XA",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "### Точность предсказаний\n",
+ "\n",
+ "Оценим, насколько хорошо модель предсказывает правильный ответ.\n",
+ "\n",
+ "**Задание** Для каждого вопроса найдите индекс ответа, генерируемого сетью:"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "QrA8N0zDJczj",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "predictions = []\n",
+ "\n",
+ " \n",
+ "accuracy = np.mean([\n",
+ " answer in correct_ind\n",
+ " for answer, correct_ind in zip(predictions, test_data['correct_indices'].values)\n",
+ "])\n",
+ "print(\"Accuracy: %0.5f\" % accuracy)"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "HZijVoOTLcCD",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "def draw_results(question, possible_answers, predicted_index, correct_indices):\n",
+ " print(\"Q:\", ' '.join(question), end='\\n\\n')\n",
+ " for i, answer in enumerate(possible_answers):\n",
+ " print(\"#%i: %s %s\" % (i, '[*]' if i == predicted_index else '[ ]', ' '.join(answer)))\n",
+ " \n",
+ " print(\"\\nVerdict:\", \"CORRECT\" if predicted_index in correct_indices else \"INCORRECT\", \n",
+ " \"(ref: %s)\" % correct_indices, end='\\n' * 3)"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "-_pYbNcsLfli",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "for i in [1, 100, 1000, 2000, 3000, 4000, 5000]:\n",
+ " draw_results(test_data.iloc[i].question, test_data.iloc[i].options,\n",
+ " predictions[i], test_data.iloc[i].correct_indices)"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "T5OC4EGt8HAo",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "## Hard-negatives mining\n",
+ "\n",
+ "На самом деле, в большинстве случаев у нас отрицательных примеров.\n",
+ "\n",
+ "Например, есть база диалогов - и где брать отрицательные примеры к ответам?\n",
+ "\n",
+ "Для этого используют *hard-negatives mining*. Берут в качестве отрицательного примера самый близкий из неправильных примеров в батче:\n",
+ "$$a^-_{hard} = \\underset {a^-} {argmax} \\space sim[V_q(q), V_a(a^-)]$$\n",
+ "\n",
+ "Неправильные в данном случае - все, кроме правильного :)\n",
+ "\n",
+ "Реализуется это как-то так:\n",
+ "* Батч состоит из правильных пар вопрос-ответ.\n",
+ "* Для всех вопросов и всех ответов считают эмбеддинги.\n",
+ "* Положительные примеры у нас есть - осталось найти для каждого вопроса наиболее похожие на него ответы, которые предназначались другим вопросам.\n",
+ "\n",
+ "**Задание** Обновите `DSSM`, чтобы делать hard-negatives mining внутри него.\n",
+ "\n",
+ "*Может понадобиться нормализовывать векторы с помощью `F.normalize` перед подсчетом `similarity`*"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "tY_BebgAOY70",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "class DSSM(nn.Module):\n",
+ " def __init__(self, question_encoder, answer_encoder):\n",
+ " super().__init__()\n",
+ " self.question_encoder = question_encoder\n",
+ " self.answer_encoder = answer_encoder\n",
+ " \n",
+ " def forward(self, questions, correct_answers, wrong_answers):\n",
+ " \"\"\"Ignore wrong_answers, they are here just for compatibility sake\"\"\"\n",
+ " \n",
+ "\n",
+ " def calc_triplet_loss(self, question_embeddings, answer_embeddings, delta=1.0):\n",
+ " \"\"\"Returns the triplet loss based on the equation above\"\"\"\n",
+ " \n",
+ " \n",
+ " def calc_recall_at_1(self, question_embeddings, correct_answer_embeddings, wrong_answer_embeddings):\n",
+ " \"\"\"Returns the number of cases when the correct answer were more similar than incorrect one\"\"\"\n",
+ " \n",
+ " \n",
+ " @staticmethod\n",
+ " def similarity(question_embeddings, answer_embeddings):\n",
+ " "
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "0AIvf3Zvtabs",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "model = DSSM(\n",
+ " question_encoder=Encoder(embeddings),\n",
+ " answer_encoder=Encoder(embeddings)\n",
+ ").to(DEVICE)\n",
+ "\n",
+ "optimizer = optim.Adam(model.parameters())\n",
+ "\n",
+ "trainer = ModelTrainer(model, optimizer)\n",
+ "\n",
+ "fit(trainer, train_iter, epochs_count=30, val_iter=test_iter)"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "pXaL1iRz-zEG",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "**Задание** Есть также вариант с semi-hard negatives - когда в качестве отрицательного примера берется наилучший среди тех, чья similarity меньше similarity вопроса с положительным примером. Попробуйте реализовать его."
+ ]
+ },
+ {
+ "metadata": {
+ "id": "edUVeXG0_lCa",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "# Болталка\n",
+ "\n",
+ "Чтобы реализовать болталку, нужен нормальный корпус с диалогами. Например, OpenSubtitles."
+ ]
+ },
+ {
+ "metadata": {
+ "id": "s3YmDo9Z_xG-",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "!head train.txt"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "A0R77ezW_1Wd",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "Ну, примерно нормальный.\n",
+ "\n",
+ "Считаем датасет."
+ ]
+ },
+ {
+ "metadata": {
+ "id": "SwHYmb28HPUn",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "from nltk import wordpunct_tokenize\n",
+ "\n",
+ "def read_dataset(path):\n",
+ " data = []\n",
+ " with open(path) as f:\n",
+ " for line in tqdm(f):\n",
+ " query, response = line.strip().split('\\t')\n",
+ " data.append((\n",
+ " wordpunct_tokenize(query.strip()),\n",
+ " wordpunct_tokenize(response.strip())\n",
+ " ))\n",
+ " return data\n",
+ "\n",
+ "train_data = read_dataset('train.txt')\n",
+ "val_data = read_dataset('valid.txt')\n",
+ "test_data = read_dataset('test.txt')"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "WTfkv17tHM3I",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "from torchtext.data import Field, Example, Dataset, BucketIterator\n",
+ "\n",
+ "query_field = Field(lower=True)\n",
+ "response_field = Field(lower=True)\n",
+ "\n",
+ "fields = [('query', query_field), ('response', response_field)]\n",
+ "\n",
+ "train_dataset = Dataset([Example.fromlist(example, fields) for example in train_data], fields)\n",
+ "val_dataset = Dataset([Example.fromlist(example, fields) for example in val_data], fields)\n",
+ "test_dataset = Dataset([Example.fromlist(example, fields) for example in test_data], fields)\n",
+ "\n",
+ "query_field.build_vocab(train_dataset, min_freq=5)\n",
+ "response_field.build_vocab(train_dataset, min_freq=5)\n",
+ "\n",
+ "print('Query vocab size =', len(query_field.vocab))\n",
+ "print('Response vocab size =', len(response_field.vocab))\n",
+ "\n",
+ "train_iter, val_iter, test_iter = BucketIterator.splits(\n",
+ " datasets=(train_dataset, val_dataset, test_dataset), batch_sizes=(512, 1024, 1024), \n",
+ " shuffle=True, device=DEVICE, sort=False\n",
+ ")"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "M-Ok7--NHUX0",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "**Задание** Реализовать болталку по аналогии с тем, что уже написали."
+ ]
+ },
+ {
+ "metadata": {
+ "id": "n2x9-j4oz08p",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "# Дополнительные материалы\n",
+ "\n",
+ "## Статьи\n",
+ "Learning Deep Structured Semantic Models for Web Search using Clickthrough Data, 2013 [[pdf]](https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/cikm2013_DSSM_fullversion.pdf) \n",
+ "Deep Learning and Continuous Representations for Natural Language Processing, Microsoft tutorial [[pdf]](https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/NAACL-HLT-2015_tutorial.pdf)\n",
+ "\n",
+ "## Блоги\n",
+ "[Neural conversational models: как научить нейронную сеть светской беседе](https://habr.com/company/yandex/blog/333912/) \n",
+ "[Искусственный интеллект в поиске. Как Яндекс научился применять нейронные сети, чтобы искать по смыслу, а не по словам](https://habr.com/company/yandex/blog/314222/) \n",
+ "[Triplet loss, Olivier Moindrot](https://omoindrot.github.io/triplet-loss)"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "gjkS1Kpkz4Aa",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "# Сдача\n",
+ "\n",
+ "[Форма для сдачи](https://goo.gl/forms/bf2auPe8FL5C0jzp2) \n",
+ "[Feedback](https://goo.gl/forms/9aizSzOUrx7EvGlG3)"
+ ]
+ }
+ ]
+}
\ No newline at end of file
 View source on GitHub
+
View source on GitHub
+