- TCP no está disponible para el sitio {{< region-param key="dd_site_name" >}} site. Para obtener más información, ponte en contacto con el servicio de asistencia.
+ TCP no está disponible para el sitio {{< region-param key="dd_site_name" >}}. Ponte en contacto con el servicio de asistencia para obtener más información.
{{% /site-region %}}
@@ -299,6 +301,5 @@ stream {
{{< partial name="whats-next/whats-next.html" >}}
-
[1]: /es/agent/logs/log_transport?tab=https
[2]: /es/agent/configuration/proxy/
\ No newline at end of file
diff --git a/content/es/agent/troubleshooting/integrations.md b/content/es/agent/troubleshooting/integrations.md
index 59e10c1dd12cf..dbe338a9246a9 100644
--- a/content/es/agent/troubleshooting/integrations.md
+++ b/content/es/agent/troubleshooting/integrations.md
@@ -1,6 +1,8 @@
---
aliases:
- /es/integrations/faq/issues-getting-integrations-working
+description: Soluciona problemas de configuración de la integración Datadog y resuelve
+ problemas relacionados con archivos YAML, checks de estado y métricas faltantes.
further_reading:
- link: /agent/troubleshooting/debug_mode/
tag: Documentación
diff --git a/content/es/agent/troubleshooting/site.md b/content/es/agent/troubleshooting/site.md
index 34bb6fab5046b..db2dd06e47fe5 100644
--- a/content/es/agent/troubleshooting/site.md
+++ b/content/es/agent/troubleshooting/site.md
@@ -1,4 +1,6 @@
---
+description: Configura el Datadog Agent para enviar datos al sitio de Datadog correcto
+ estableciendo el parámetro de sitio o la variable de entorno DD_SITE.
title: Problemas con el sitio del Agent
---
diff --git a/content/es/api/latest/_index.md b/content/es/api/latest/_index.md
index ce35dadb55014..9ffa0fbe0973b 100644
--- a/content/es/api/latest/_index.md
+++ b/content/es/api/latest/_index.md
@@ -62,7 +62,7 @@ Gradle - Añade esta dependencia al archivo de compilación de tu proyecto:
compile "com.datadoghq:datadog-api-client:{{< sdk-version "datadog-api-client-java" >}}"
```
-#### Uso
+#### Utilización
```java
import com.datadog.api.client.ApiClient;
@@ -126,7 +126,7 @@ Ejemplo de ejecución con el comando `gradle run`.
```sh
pip install datadog
```
-#### Uso
+#### Utilización
```python
import datadog
```
@@ -137,7 +137,7 @@ import datadog
```console
pip3 install datadog-api-client
```
-#### Uso
+#### Utilización
```python
import datadog_api_client
```
@@ -148,7 +148,7 @@ import datadog_api_client
```sh
gem install dogapi
```
-#### Uso
+#### Utilización
```ruby
require 'dogapi'
```
@@ -159,7 +159,7 @@ require 'dogapi'
```sh
gem install datadog_api_client -v {{< sdk-version "datadog-api-client-ruby" >}}
```
-#### Uso
+#### Utilización
```ruby
require 'datadog_api_client'
```
@@ -170,7 +170,7 @@ require 'datadog_api_client'
```sh
go mod init main && go get github.com/DataDog/datadog-api-client-go/v2/api/datadog
```
-#### Uso
+#### Utilización
```go
import (
"github.com/DataDog/datadog-api-client-go/v2/api/datadog"
@@ -192,7 +192,7 @@ npm install @datadog/datadog-api-client
yarn add @datadog/datadog-api-client
```
-#### Uso
+#### Utilización
```js
import {
- La lista no incluye todos los límites de tasa de las API de Datadog. Si experimentas limitaciones de tasa, ponte en contacto con el soporte para obtener más información sobre las API que utilizas y sus límites.
+La lista anterior no incluye todos los límites de velocidad de las APIs de Datadog. Si experimentas limitaciones de velocidad, ponte en contacto con el servicio de asistencia para obtener más información sobre las APIs que utilizas y sus límites.
| Cabeceras de límites de tasa | Descripción |
| ----------------------- | -------------------------------------------------------- |
@@ -223,4 +223,4 @@ Para obtener una visibilidad más detallada de la actividad de la API, considera
[1]: /es/help/
[2]: /es/api/v1/metrics/
[3]: /es/metrics/custom_metrics/
-[4]: /es/account_management/audit_trail/events/
+[4]: /es/account_management/audit_trail/events/
\ No newline at end of file
diff --git a/content/es/api/latest/scopes/_index.md b/content/es/api/latest/scopes/_index.md
index 9d23456bd27c0..bda1f40d2ee32 100644
--- a/content/es/api/latest/scopes/_index.md
+++ b/content/es/api/latest/scopes/_index.md
@@ -5,20 +5,20 @@ type: api
---
## Contextos de autorización para clientes OAuth
-Los contextos son un mecanismo de autorización que permite limitar y definir el acceso específico que tienen las aplicaciones a los datos de Datadog de una organización. Cuando se autoriza el acceso a los datos en nombre de un usuario o cuenta de servicio, las aplicaciones sólo pueden acceder a la información explícitamente permitida por su contexto asignado.
+Los contextos son un mecanismo de autorización que permite limitar y definir el acceso específico que tienen las aplicaciones a los datos de Datadog de una organización. Cuando se autoriza el acceso a los datos en nombre de un usuario o cuenta de servicio, las aplicaciones solo pueden acceder a la información explícitamente permitida por su contexto asignado.
-Esta página enumera únicamente los contextos de autorización que pueden asignarse a los clientes OAuth. Para ver la lista completa de permisos asignables para claves de aplicación delimitadas, consulta Permisos para roles Datadog.
+
+ + * Windows: Descarga la [versión Windows][2]. + +2. Ejecuta `datadog_mcp_cli login` manualmente para recorrer el flujo de inicio de sesión de OAuth. + + El servidor MCP inicia automáticamente el flujo de OAuth si un cliente lo necesita, pero hacerlo manualmente te permite elegir un [sitio Datadog][3] y evitar que el cliente de IA se desconecte. + +3. Configura tu cliente de IA para utilizar el Servidor MCP de Datadog. Sigue las instrucciones de configuración de tu cliente, ya que la configuración del Servidor MCP varía entre clientes de IA de terceros. + + Por ejemplo, para Claude Code, añade esto a `~/.claude.json`, asegúrate de sustituir `` en la ruta del comando:
+
+ ```json
+ {
+ "mcpServers": {
+ "datadog": {
+ "type": "stdio",
+ "command": "/Users//.local/bin/datadog_mcp_cli",
+ "args": [],
+ "env": {}
+ }
+ }
+ }
+ ```
+
+ Alternativamente, también puedes configurar Claude Code ejecutando lo siguiente:
+ ```bash
+ claude mcp add datadog --scope user -- ~/.local/bin/datadog_mcp_cli
+ ```
+
+[1]: https://modelcontextprotocol.io/specification/2025-03-26/basic/transports#stdio
+[2]: https://coterm.datadoghq.com/mcp-cli/datadog_mcp_cli.exe
+[3]: /es/getting_started/site/
+{{% /tab %}}
+{{< /tabs >}}
+
+### Autenticación
+
+El servidor MCP utiliza OAuth 2.0 para la [autenticación][2]. Si no puedes pasar por el flujo de OAuth (por ejemplo, en un servidor), puedes proporcionar una [clave de API y clave de aplicación][3] de Datadog como `DD_API_KEY` y `DD_APPLICATION_KEY` encabezados HTTP. Por ejemplo:
+
+{{< code-block lang="json" >}}
+{
+ "mcpServers": {
+ "datadog": {
+ "type": "http",
+ "url": "https://mcp.datadoghq.com/api/unstable/mcp-server/mcp",
+ "headers": {
+ "DD_API_KEY": "",
+ "DD_APPLICATION_KEY": ""
+ }
+ }
+ }
+}
+{{< /code-block >}}
+
+### Test de acceso al servidor MCP
+
+1. Instala el [inspector de MCP][4], una herramienta de desarrollo para testing y depuración de servidores MCP.
+
+ ```bash
+ npx @modelcontextprotocol/inspector
+ ```
+2. En la interfaz web del inspector, en **Transport Type** (Tipo de transmisión), selecciona **Streamable HTTP** (HTTP transmisible).
+3. En **URL**, introduce la [URL del servidor MCP](?tab=remoteauthentication#connect-in-supported-ai-clients) de tu sitio regional de Datadog.
+4. Haz clic en **Connect** (Conectar), luego ve a **Tools** (Herramientas) > **List Tools** (Enumerar herramientas).
+5. Check si aparecen las [herramientas disponibles](#available-tools).
+
+## Conjuntos de herramientas
+
+El servidor MCP de Datadog admite _conjuntos de herramientas_, que te permiten utilizar solo las herramientas que necesitas, ahorrando un valioso espacio en la ventana contextual. Estos conjuntos de herramientas están disponibles:
+
+- `core`: El conjunto de herramientas predeterminado
+- `synthetics`: Herramientas para interactuar con [tests de Synthetic Monitoring][21] de Datadog
+
+Para utilizar un conjunto de herramientas, incluye el parámetro de consulta `toolsets` en la URL del endpoint al conectarte al servidor MCP ([autenticación remota](?tab=remote-authentication#connect-in-supported-ai-clients) únicamente). Por ejemplo
+
+- `https://mcp.datadoghq.com/api/unstable/mcp-server/mcp` recupera solo las herramientas básicas (es el valor predeterminado si no se especifica `toolsets` ).
+- `https://mcp.datadoghq.com/api/unstable/mcp-server/mcp?toolsets=synthetics` recupera solo las herramientas relacionadas con tests de Synthetic Monitoring.
+- `https://mcp.datadoghq.com/api/unstable/mcp-server/mcp?toolsets=core,synthetics` recupera las herramientas de tests básicas y de Synthetic Monitoring.
+
+## Herramientas disponibles
+
+En esta sección se enumeran las herramientas disponibles en el servidor MCP de Datadog y se ofrecen avisos de cómo utilizarlas.
+
+ datadog/cloudprem \
+ -n \
+ -f datadog-values.yaml
+ ```
+
+3. Reinicia el pod de conserje (opcional, pero recomendado para un efecto inmediato):
+
+ ```shell
+ kubectl delete pod -l app.kubernetes.io/component=janitor -n
+ ```
+
+## Dashboards
+
+CloudPrem proporciona un dashboard predefinido que monitoriza las métricas clave de CloudPrem.
+
+### Configuración
+
+[DogStatsD][1] exporta estas métricas. Puedes:
+
+- Ejecutar DogStatsD como servicio independiente o
+- Ejecutar el Datadog Agent (que incluye DogStatsD en forma predeterminada)
+
+Configura cualquiera de las opciones con la clave de API de tu organización para exportar estas métricas. En cuanto tu clúster de CloudPrem se conecte a Datadog, se creará automáticamente el dashboard predefinido al que podrás acceder desde tu [Lista de dashboards][2].
+
+### Datos recopilados
+
+| Métrica | Descripción |
+|---|---|
+| **indexed_events.count**
(Contador) | Número de eventos indexados | +| **indexed_events_bytes.count**
(Contador) | Número de bytes indexados | +| **ingest_requests.count**
(Contador) | Número de solicitudes de ingesta | +| **object_storage_delete_requests.count**
(Contador) | Número de solicitudes de eliminación en el almacenamiento de objetos | +| **object_storage_get_requests.count**
(Contador) | Número de solicitudes de obtención en el almacenamiento de objetos | +| **object_storage_get_requests_bytes.count**
(Contador) | Total de bytes leídos del almacenamiento de objetos mediante solicitudes GET | +| **object_storage_put_requests.count**
(Contador) | Número de solicitudes PUT en el almacenamiento de objetos | +| **object_storage_put_requests_bytes.count**
(Contador) | Total de bytes escritos en el almacenamiento de objetos mediante solicitudes PUT | +| **pending_merge_ops.gauge**
(Gauge) | Número de operaciones de fusión pendientes | +| **search_requests.count**
(Contador) | Número de solicitudes de búsqueda | +| **search_requests.duration_seconds**
(Histograma) | Latencia de las solicitudes de búsqueda | +| **metastore_requests.count**
(Contador) | Número de solicitudes de metastore | +| **metastore_requests.duration_seconds**
(Histograma) | Latencia de las solicitudes de metastore | +| **cpu.usage.gauge**
(Gauge) | Porcentaje de uso de la CPU | +| **uptime.gauge**
(Gauge) | Tiempo de actividad del servicio en segundos | +| **memory.allocated_bytes.gauge**
(Gauge) | Memoria asignada en bytes | +| **disk.bytes_read.counter**
(Contador) | Total de bytes leídos desde el disco | +| **disk.bytes_written.counter**
(Contador) | Total de bytes escritos en el disco | +| **disk.available_space.gauge**
(Gauge) | Espacio disponible en disco en bytes | +| **disk.total_space.gauge**
(Gauge) | Capacidad total del disco en bytes | +| **network.bytes_recv.counter**
(Contador) | Total de bytes recibidos por la red | +| **network.bytes_sent.counter**
(Contador) | Total de bytes enviados por la red | + + + +[1]: https://docs.datadoghq.com/es/developers/dogstatsd/?tab=hostagent +[2]: https://app.datadoghq.com/dashboard/lists?q=cloudprem&p=1 \ No newline at end of file diff --git a/content/es/containers/amazon_ecs/_index.md b/content/es/containers/amazon_ecs/_index.md index e545b529fb431..b5ccab24745c3 100644 --- a/content/es/containers/amazon_ecs/_index.md +++ b/content/es/containers/amazon_ecs/_index.md @@ -4,6 +4,7 @@ algolia: - ecs aliases: - /es/agent/amazon_ecs/ +description: Instalar y configurar el Datadog Agent en Amazon Elastic Container Service further_reading: - link: /agent/amazon_ecs/logs/ tag: Documentación @@ -30,11 +31,21 @@ title: Amazon ECS Amazon ECS es un servicio escalable de orquestación de contenedores de alto rendimiento compatible con contenedores de Docker. Con el Datadog Agent, puedes monitorizar contenedores y tareas de ECS en cada instancia EC2 de tu clúster. +Para configurar Amazon ECS con Datadog, puedes utilizar **Fleet Automation** o la **instalación manual**. Si prefieres la instalación manual, ejecuta un contenedor del Agent por host de Amazon EC2 creando una definición de tarea del Datadog Agent e implementándola como servicio daemon. A continuación, cada Agent monitoriza los demás contenedores de tu host. Consulta la sección [Instalación manual](#install-manually) para obtener más detalles. + + +## Configuración de Fleet Automation +Sigue la [guía de instalación de la aplicación en Fleet Automation][32] para completar la configuración en ECS. Tras completar los pasos descritos en la guía de la aplicación, [Fleet Automation][33] genera una definición de tarea o plantilla de CloudFormation lista para usar, con tu clave de API preinyectada. + +{{< img src="agent/basic_agent_usage/ecs_install_page.png" alt="Pasos de instalación en la aplicación para el Datadog Agent en ECS." style="width:90%;">}} +
+ +## Configuración manual Para monitorizar tus contenedores y tareas de ECS, despliega el Datadog Agent como un contenedor **una vez en cada instancia de EC2** en tu clúster de ECS. Para ello, crea una definición de tarea para el contenedor de Datadog Agent y despliégala como servicio daemon. Cada contenedor de Datadog Agent luego monitoriza los otros contenedores en su respectiva instancia de EC2. @@ -211,10 +222,10 @@ Para recopilar la información de Live Process de todos tus contenedores y envia } {{< /highlight >}} -#### Cloud Network Monitoring +#### Monitorización de redes en la nube
site:
```
+ - Replace `` with a name for your cluster.
- Replace `` with your [Datadog site][2]. Your site is {{< region-param key="dd_site" code="true" >}}. (Ensure the correct SITE is selected on the right).
4. **Deploy Agent with the above configuration file**
@@ -152,11 +156,18 @@ Utiliza la página [Instalación en Kubernetes][16] de Datadog como guía para e
### Unprivileged installation
+To run an unprivileged installation, add the following `securityContext` to your configuration relative to your desired `` and ``:
+
+- Replace `` with the UID to run the Datadog Agent. Datadog recommends setting this value to `100` for the preexisting `dd-agent` user [for Datadog Agent v7.48+][26].
+- Replace `` with the group ID that owns the Docker or containerd socket.
+
+This sets the `securityContext` at the pod level for the Agent.
+
{{< tabs >}}
{{% tab "Datadog Operator" %}}
To run an unprivileged installation, add the following to `datadog-agent.yaml`:
-{{< highlight yaml "hl_lines=13-18" >}}
+{{< highlight yaml "hl_lines=14-19" >}}
apiVersion: datadoghq.com/v2alpha1
kind: DatadogAgent
metadata:
@@ -169,18 +180,14 @@ spec:
apiSecret:
secretName: datadog-secret
keyName: api-key
-agent:
- config:
- securityContext:
- runAsUser:
- supplementalGroups:
- -
-{{< /highlight >}}
-- Replace `` with the UID to run the Datadog Agent. Datadog recommends [setting this value to 100 since Datadog Agent v7.48+][1].
-- Replace `` with the group ID that owns the Docker or containerd socket.
-
-[1]: /es/data_security/kubernetes/#running-container-as-root-user
+ override:
+ nodeAgent:
+ securityContext:
+ runAsUser:
+ supplementalGroups:
+ -
+{{< /highlight >}}
Then, deploy the Agent:
@@ -192,19 +199,17 @@ kubectl apply -f datadog-agent.yaml
{{% tab "Helm" %}}
To run an unprivileged installation, add the following to your `datadog-values.yaml` file:
-{{< highlight yaml "hl_lines=4-7" >}}
+{{< highlight yaml "hl_lines=5-8" >}}
datadog:
apiKeyExistingSecret: datadog-secret
+ clusterName:
site:
securityContext:
- runAsUser:
- supplementalGroups:
- -
+ runAsUser:
+ supplementalGroups:
+ -
{{< /highlight >}}
-- Replace `` with the UID to run the Datadog Agent.
-- Replace `` with the group ID that owns the Docker or containerd socket.
-
Then, deploy the Agent:
```shell
@@ -307,7 +312,7 @@ La sección [Kubernetes][21] ofrece una visión general de todos tus recursos de
{{< nextlink href="/agent/kubernetes/configuration">}}Configuración adicional: Recopila eventos, sobrescribe parámetros de proxy, envía métricas personalizadas con DogStatsD, configura listas de autorizaciones y exclusiones de contenedores, y haz referencia a la lista completa de variables de entorno disponibles.{{< /nextlink >}}
{{< /whatsnext >}}
-## Para leer más
+## Referencias adicionales
{{< partial name="whats-next/whats-next.html" >}}
@@ -335,4 +340,5 @@ La sección [Kubernetes][21] ofrece una visión general de todos tus recursos de
[22]: https://app.datadoghq.com/orchestration/overview
[23]: https://app.datadoghq.com/orchestration/resource/pod
[24]: /es/infrastructure/containers/orchestrator_explorer
-[25]: /es/infrastructure/containers/kubernetes_resource_utilization
\ No newline at end of file
+[25]: /es/infrastructure/containers/kubernetes_resource_utilization
+[26]: /es/data_security/kubernetes/#running-container-as-root-user
\ No newline at end of file
diff --git a/content/es/containers/kubernetes/integrations.md b/content/es/containers/kubernetes/integrations.md
index ba08bf0f802bc..bc26810ff02a5 100644
--- a/content/es/containers/kubernetes/integrations.md
+++ b/content/es/containers/kubernetes/integrations.md
@@ -4,6 +4,8 @@ aliases:
- /es/guides/servicediscovery/
- /es/guides/autodiscovery/
- /es/agent/kubernetes/integrations
+description: Configura la monitorización de integraciones para aplicaciones que se
+ ejecutan en Kubernetes utilizando plantillas de Autodiscovery
further_reading:
- link: /agent/kubernetes/log/
tag: Documentación
@@ -29,7 +31,7 @@ Si utilizas Docker o Amazon ECS, consulta [Docker e integraciones][1].
/conf.d
+ name: confd
+ ```
+
+ Para Helm:
+ ```yaml
+ agents:
+ volumes:
+ - hostPath:
+ path: /conf.d
+ name: confd
+ volumeMounts:
+ - name: confd
+ mountPath: /conf.d
+ ```
+
{{% /tab %}}
{{% tab "ConfigMap" %}}
@@ -236,8 +261,9 @@ spec:
logs:
```
+
```
-Para monitorizar un [check de clústeres][3], define tu plantilla en `clusterAgent.confd`. Puedes encontrar ejemplos en línea en [values.yaml][2]. También debes habilitar el Cluster Agent, configurando `clusterAgent.enabled: true`, y habilitar los checks de clústeres, configurando `datadog.clusterChecks.enabled: true`.
+Para monitorizar un [check de clústeres][3], define tu plantilla en `clusterAgent.confd`. Puedes encontrar ejemplos en línea en [values.yaml][2]. También debes habilitar el Cluster Agent, configurando `clusterAgent.enabled: true`, y habilitar los checks de clústeres, configurando `datadog.clusterChecks.enabled: true`.
```yaml
datadog:
@@ -379,7 +405,7 @@ Aquí, `` corresponde a la contraseña del usuario `datadog` que has c
Para aplicar esta configuración a tus contenedores de Postgres:
{{< tabs >}}
-{{% tab "Anotaciones" %}}
+{{% tab "Annotations" %}}
En el manifiesto de tu pod:
@@ -393,7 +419,7 @@ metadata:
annotations:
ad.datadoghq.com/postgres.checks: |
{
- "postgresql": {
+ "postgres": {
"instances": [
{
"host": "%%host%%",
@@ -418,7 +444,7 @@ spec:
- name: postgres
```
-**Anotaciones de Autodiscovery v1**
+**Anotaciones de Autodiscovery v1**
```yaml
apiVersion: v1
@@ -426,7 +452,7 @@ kind: Pod
metadata:
name: postgres
annotations:
- ad.datadoghq.com/postgres.check_names: '["postgresql"]'
+ ad.datadoghq.com/postgres.check_names: '["postgres"]'
ad.datadoghq.com/postgres.init_configs: '[{}]'
ad.datadoghq.com/postgres.instances: |
[
@@ -452,7 +478,7 @@ spec:
```
{{% /tab %}}
-{{% tab "Archivo local" %}}
+{{% tab "Local file" %}}
1. Crea un archivo `conf.d/postgresql.d/conf.yaml` en tu host:
```yaml
@@ -472,6 +498,30 @@ spec:
```
2. Monta tu carpeta host `conf.d/` en la carpeta `conf.d` del Agent contenedorizado.
+
+ Para Datadog Operator:
+ ```yaml
+ spec:
+ override:
+ nodeAgent:
+ volumes:
+ - hostPath:
+ path: /conf.d
+ name: confd
+ ```
+
+ Para Helm:
+ ```yaml
+ agents:
+ volumes:
+ - hostPath:
+ path: /conf.d
+ name: confd
+ volumeMounts:
+ - name: confd
+ mountPath: /conf.d
+ ```
+
{{% /tab %}}
{{% tab "ConfigMap" %}}
@@ -527,7 +577,7 @@ Los siguientes comandos etcd crean una plantilla de integración con Postgres co
```conf
etcdctl mkdir /datadog/check_configs/postgres
-etcdctl set /datadog/check_configs/postgres/check_names '["postgresql"]'
+etcdctl set /datadog/check_configs/postgres/check_names '["postgres"]'
etcdctl set /datadog/check_configs/postgres/init_configs '[{}]'
etcdctl set /datadog/check_configs/postgres/instances '[{"host": "%%host%%","port":"5432","username":"datadog","password":"%%env_PG_PASSWORD%%"}]'
```
diff --git a/content/es/containers/kubernetes/log.md b/content/es/containers/kubernetes/log.md
index 78daa95ef57e9..7cc2f4b7cdc4c 100644
--- a/content/es/containers/kubernetes/log.md
+++ b/content/es/containers/kubernetes/log.md
@@ -1,6 +1,8 @@
---
aliases:
- /es/agent/kubernetes/log
+description: Configura la recopilación de logs de las aplicaciones en contenedores
+ que se ejecutan en Kubernetes utilizando el Datadog Agent
further_reading:
- link: /agent/kubernetes/apm/
tag: Documentación
@@ -139,13 +141,13 @@ datadog:
.logs` con una configuración `type: file` y `path`. Los logs recopilados de archivos con es´ta anotación se etiquetan automáticamente con el mismo conjunto de etiquetas (tags) que los logs procedentes del propio contenedor. Datadog recomienda que utilices los flujos de salida `stdout` y `stderr` para aplicaciones en contenedores, de modo que puedas configurar automáticamente la recopilación de logs. Para obtener más información, consulta las [configuraciones recomendadas](#recommended-configurations).
+Sin embargo, el Agent también puede recopilar directamente logs de un archivo basándose en una anotación. Para recopilar estos logs, utiliza `ad.datadoghq.com/.logs` con una configuración de `type: file` y `path`. Los logs recopilados de archivos con dicha anotación se etiquetan automáticamente con el mismo conjunto de etiquetas que los logs procedentes del propio contenedor. Datadog recomienda utilizar los flujos de salida `stdout` y `stderr` para las aplicaciones en contenedores, de modo que puedas configurar automáticamente la recopilación de logs. Para más información, consulta [Configuraciones recomendadas](#recommended-configurations).
Estas rutas de archivo son **relativas** al contenedor del Agent. Por lo tanto, el directorio que contiene el archivo de log debe montarse tanto en la aplicación como en el contenedor del Agent para que éste pueda tener la visibilidad adecuada.
diff --git a/content/es/containers/kubernetes/prometheus.md b/content/es/containers/kubernetes/prometheus.md
index 1475ee52249b0..95b29f2faa28c 100644
--- a/content/es/containers/kubernetes/prometheus.md
+++ b/content/es/containers/kubernetes/prometheus.md
@@ -5,6 +5,8 @@ aliases:
- /es/agent/openmetrics
- /es/agent/prometheus
- /es/agent/kubernetes/prometheus
+description: Recopila Prometheus y OpenMetrics de las cargas de trabajo de Kubernetes
+ utilizando el módulo Datadog Agent con Autodiscovery
further_reading:
- link: /agent/kubernetes/log/
tag: Documentación
diff --git a/content/es/continuous_integration/_index.md b/content/es/continuous_integration/_index.md
index 39324d2854de1..394dd203b3abd 100644
--- a/content/es/continuous_integration/_index.md
+++ b/content/es/continuous_integration/_index.md
@@ -42,10 +42,14 @@ further_reading:
- link: https://www.datadoghq.com/blog/datadog-detection-as-code/
tag: Blog
text: Cómo utilizamos Datadog para la detección como código
+- link: https://www.datadoghq.com/blog/cache-purge-ci-cd/
+ tag: Blog
+ text: Patrones para una purga de caché segura y eficaz en pipelines de Continuous
+ Integration Continuous Delivery
title: Continuous Integration Visibility
---
-
**Nota**: `Group by` solo es compatible con determinados widgets---Series temporales, Tabla, Mapa de árbol, Gráfico de barras, Comodín, Distribución, Lista principal, Mapa de calor, Gráfico circular, Geomapa, Cambio, Gráfico de dispersión, Valor de consulta, Mapa de hosts y Resumen de SLO. 1. (Opcional) Después de seleccionar una etiqueta, haz clic en el botón **+ Configure Dropdown Values** (+ Configurar valores desplegables), para cambiar el nombre de la variable y establecer valores predeterminados o disponibles. - {{< img src="dashboards/template_variables/add_template_variable_configure_dropdown_values.png" alt="Añadir ventana emergente de la variable que muestra el botón **+ Configure Dropdown Values** (+ Configurar valores desplegables)" style="width:80%;" >}} +1. Haz clic en **Save** (Guardar). +1. Para añadir más variables de plantilla, consulta [Editar una variable de plantilla](#edit-a-template-variable) + ## Editar una variable de plantilla -Para editar una variable de plantilla en un dashboard: -1. Haz clic en el botón **Edit** (Editar) del encabezado del dashboard. +Para editar una variable de plantilla o añadir variables: +1. Pasa el ratón por encima del encabezado del dashboard y haz clic en el botón **Edit** (Editar). 1. En el modo de edición, haz clic en una variable de plantilla y realiza cambios en la ventana emergente. 1. Para reorganizar las variables en el encabezado, pasa el cursor sobre una variable, y luego haz clic y arrastra el asa del icono de arrastre. +1. Haz clic en el icono **+ (plus)** (+ (más)) para añadir una nueva variable de plantilla. +1. (Opcional) Después de seleccionar una etiqueta, haz clic en el botón **+ Configure Dropdown Values** (+ Configurar valores desplegables), para cambiar el nombre de la variable y establecer valores predeterminados o disponibles. {{< img src="dashboards/template_variables/edit_template_variable_drag.png" alt="Ventana emergente del modo de edición de una variable de plantilla que muestra el icono de arrastre y te permite volver a acomodar el orden" style="width:100%;" >}} ## Aplicar una variable de plantilla a widgets @@ -77,7 +88,7 @@ Para añadir una variable de plantilla a las consultas de widgets: ### Crear 1. Haz clic en el menú desplegable **Saved Views** (Vistas guardadas) a la izquierda de las variables de plantilla en tu dashboard. Al actualizar el valor de una variable de plantilla, dicho valor no se guarda automáticamente en una vista. -1. Para guardar los valores actuales de variables de plantilla en una vista, selecciona **Guardar selecciones como vista** en el menú desplegable **Vistas guardadas**. +1. Para guardar los valores actuales de las variables de plantilla en una vista, selecciona **Save selections as view** (Guardar selecciones como vista) en el menú desplegable **Saved Views** (Vistas guardadas). 1. Introduce un nombre único para la vista con una descripción en opcional. 1. Haz clic en **Save** (Guardar). @@ -87,14 +98,14 @@ La vista guardada aparecerá en el menú desplegable. Haz clic en ella para recu ### Borrar -1. Haz clic en el menú desplegable de vistas guardadas y pasa el ratón por encima de la vista guardada deseada. +1. Haz clic en el menú desplegable de vistas guardadas y pasa el ratón por encima de la vista guardada que desees. 1. Haz clic en **Delete View** (Eliminar vista). ### Modificar La **vista por defecto** sólo puede editarse cambiando los valores por defecto de las variables de plantilla. Para editar la vista por defecto: 1. Pasa el ratón por encima de las plantillas. -1. Haz clic en **Edit** (Editar) cuando aparezca el botón. +1. Haz clic en **Edit** (Editar) cuando aparezca el botón. 1. Haz clic en **Done** (Listo) para guardar. Para modificar valores de variables de plantilla para otras vistas guardadas: @@ -125,7 +136,7 @@ En los widgets de log, APM y RUM, se pueden utilizar comodines en mitad de un va ### Widgets -Al crear o editar un widget, las variables de plantilla existentes se muestran como opciones en el campo `from`. Por ejemplo, si configuras la variable de plantilla `environment`, la opción `$environment` estará disponible como variable dinámica en el widget. +Al crear o editar un widget, las variables de plantilla de filtro existentes se muestran como opciones en el campo `from`, y las variables de plantilla de Agrupar por existentes se muestran como opciones a continuación del campo `by`. Por ejemplo, si configuras la variable de plantilla `environment`, la opción `$environment` estará disponible como variable dinámica en el widget. {{< img src="dashboards/template_variables/dynamic_template_variable.png" alt="La variable de plantilla puede definirse de forma dinámica en los widgets" style="width:100%;">}} diff --git a/content/es/dashboards/widgets/_index.md b/content/es/dashboards/widgets/_index.md index f256665096341..575480b1300be 100644 --- a/content/es/dashboards/widgets/_index.md +++ b/content/es/dashboards/widgets/_index.md @@ -3,215 +3,94 @@ aliases: - /es/graphing/dashboards/widgets - /es/graphing/faq/widgets - /es/graphing/widgets +description: Bloques de construcción de dashboard para visualizar y correlacionar + datos en toda la infraestructura con varios tipos de gráficos y visualizaciones. further_reading: -- link: /dashboards/guide/context-links/ +- link: /dashboards/ tag: Documentación - text: Enlaces personalizados -- link: https://www.datadoghq.com/blog/observability-pipelines-transform-and-enrich-logs/ - tag: Blog - text: Transformar y enriquecer tus logs con pipelines de observabilidad de datos + text: Más información sobre dashboards +- link: /dashboards/widgets/configuration + tag: Documentación + text: Conoce las opciones de configuración de los widgets y las mejores prácticas +- link: /dashboards/widgets/types/ + tag: Documentación + text: Explorar todos los tipos de widgets disponibles title: Widgets --- ## Información general -Los widgets son componentes básicos de tus dashboards. Te permiten visualizar y correlacionar los datos en tu infraestructura. - -### Gráficos -{{< whatsnext desc="Widgets genéricos para graficar datos a partir de productos Datadog: ">}} - {{< nextlink href="/dashboards/widgets/change" - img="dashboards/widgets/icons/change_light_large.png">}} Cambio {{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/distribution" - img="dashboards/widgets/icons/distribution_light_large.png">}} Distribución {{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/funnel" - img="dashboards/widgets/icons/funnel_light_large.png">}} Embudo {{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/geomap" - img="dashboards/widgets/icons/geomap_light_large.png">}} Geomap {{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/heat_map" - img="dashboards/widgets/icons/heatmap_light_large.png">}} Heatmap {{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/pie_chart" - img="dashboards/widgets/icons/pie_light_large.png">}} Gráfico circular {{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/query_value" - img="dashboards/widgets/icons/query-value_light_large.png">}} Valor de consulta {{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/sankey" img="dashboards/widgets/icons/sankey_light_large.svg">}} Sankey{{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/scatter_plot" - img="dashboards/widgets/icons/scatter-plot_light_large.png">}} Diagrama de dispersión {{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/table" - img="dashboards/widgets/icons/table_light_large.png">}} Tabla {{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/treemap" - img="dashboards/widgets/icons/treemap_light_large.png">}} Treemap {{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/timeseries" - img="dashboards/widgets/icons/timeseries_light_large.png">}} Series temporales {{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/top_list" - img="dashboards/widgets/icons/top-list_light_large.png">}} .Lista principal {{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/wildcard" - img="/dashboards/widgets/icons/wildcard_light_large.svg">}} Comodín {{< /nextlink >}} -{{< /whatsnext >}} - -### Groups (grupos) -{{< whatsnext desc="Muestra tus widgets en grupos: ">}} - {{< nextlink href="/dashboards/widgets/group" - img="dashboards/widgets/icons/group_default_light_large.svg">}} Grupo{{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/powerpack" - img="dashboards/widgets/icons/group_powerpack_light_large.svg">}} Powerpack{{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/split_graph" - img="dashboards/widgets/icons/group-split_light_small.svg">}} Gráfica dividida{{< /nextlink >}} -{{< /whatsnext >}} - -### Anotaciones y embeds -{{< whatsnext desc="Widgets de decoración para estructurar y comentar dashboards de manera visual: ">}} - {{< nextlink href="/dashboards/widgets/free_text" - img="dashboards/widgets/icons/free-text_light_large.png">}} Texto libre{{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/iframe" - img="dashboards/widgets/icons/iframe_light_large.png">}} Iframe{{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/image" - img="dashboards/widgets/icons/image_light_large.png">}} Imagen{{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/note" - img="dashboards/widgets/icons/notes_light_large.png">}} Notas y enlaces{{< /nextlink >}} -{{< /whatsnext >}} +Los widgets de dashboard son representaciones visuales de los datos. Sirven como bloques de construcción para tus [dashboards][2] para visualizar y correlacionar tus datos a través de tu infraestructura. Pueden contener distintos tipos de información, como gráficos, imágenes, logs y estados, para ofrecerte una visión general de tus sistemas y entornos. -### Listas y flujos -{{< whatsnext desc="Muestra una lista de eventos y problemas provenientes de diferentes fuentes: ">}} - {{< nextlink href="/dashboards/widgets/list" - img="dashboards/widgets/icons/change_light_large.png">}} Lista{{< /nextlink >}} -{{< /whatsnext >}} +## Para empezar -### Alerta y respuesta -{{< whatsnext desc="Widgets de resumen para mostrar información de monitorización: ">}} - {{< nextlink href="/dashboards/widgets/alert_graph" - img="dashboards/widgets/icons/alert-graph_light_large.png">}} Gráfica de alertas{{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/alert_value" - img="dashboards/widgets/icons/alert-value_light_large.png">}}Valor de alerta{{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/check_status" - img="dashboards/widgets/icons/check-status_light_large.png">}} Estado del check{{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/monitor_summary" - img="dashboards/widgets/icons/monitor-summary_light_large.png">}} Resumen de monitores{{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/run_workflow" - img="dashboards/widgets/icons/run-workflow_light_small.svg">}} Ejecutar flujo de trabajo{{< /nextlink >}} -{{< /whatsnext >}} +La forma más rápida de incorporar widgets relevantes para tus datos es clonar un dashboard de la [lista de preajustes][1], que incluye dashboards creados por otros miembros de tu organización y plantillas predefinidas para tus integraciones instaladas. Después de clonar un dashboard, puedes personalizar los widgets según tu caso de uso. -### Arquitectura -{{< whatsnext desc="Visualiza los datos de la infraestructura y la arquitectura: ">}} - {{< nextlink href="/dashboards/widgets/hostmap" - img="dashboards/widgets/icons/host-map_light_large.png">}} Mapa de host{{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/topology_map" - img="dashboards/widgets/icons/service-map_light_large.png">}} Mapa de topología{{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/service_summary" - img="dashboards/widgets/icons/service-summary_light_large.png">}} Resumen de servicio{{< /nextlink >}} -{{< /whatsnext >}} -### Rendimiento y fiabilidad -{{< whatsnext desc="Visualizaciones de fiabilidad del sitio: ">}} - {{< nextlink href="/dashboards/widgets/profiling_flame_graph" - img="dashboards/widgets/icons/profiling_flame_graph.svg">}} Gráfica de llamas de perfiles{{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/slo" - img="dashboards/widgets/icons/slo-summary_light_large.png">}} Resumen de objetivos de nivel de servicio (SLOs){{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/slo_list" - img="dashboards/widgets/icons/slo-list_light_large.png">}} Objetivo de nivel de servicio (SLO){{< /nextlink >}} +{{< whatsnext desc="Guías adicionales y cursos para conocer sobre widgets:" >}} + {{< nextlink href="/getting_started/dashboards/" >}}Introducción a dashboards: instrucciones para crear un dashboard con widgets{{< /nextlink >}} + {{< nextlink href="https://learn.datadoghq.com/courses/dashboard-graph-widgets" >}}Widgets de gráfico de dashboard: curso del centro de aprendizaje que explica cómo crear, configurar y usar widgets de gráfico de dashboard{{< /nextlink >}} + {{< nextlink href="https://learn.datadoghq.com/courses/intro-dashboards" >}}Introducción a dashboards: curso del centro de aprendizaje que explica cómo crear un dashboard en un entorno de pruebas{{< /nextlink >}} {{< /whatsnext >}} -## Pantalla completa - -Puedes ver la mayoría de los widgets en el modo de pantalla completa y hacer lo siguiente: - -* Cambiar los períodos -* Retroceder o avanzar en función del período de tiempo seleccionado -* Pausar la gráfica en el momento actual o visualizar la gráfica en directo -* Restablecer el período de tiempo -* Exportar la gráfica a un dashboard o notebook, o copiar la consulta -* Descargar los datos que producen la gráfica en formato CSV - -Para acceder directamente a la vista general del widget, haz clic en el botón de pantalla completa en la esquina superior derecha del widget. - -Hay opciones adicionales disponibles para los [widgets de serie temporal][1]. - -## Enlaces personalizados - -Los enlaces personalizados conectan valores de datos a URLs, como una página de Datadog o tu consola de AWS. - -Para personalizar las interacciones con los datos en línea de tus widgets genéricos, consulta la sección de [Enlaces personalizados][2]. - -## Anulación de unidad - -Personaliza los valores de las unidades que se muestran en los widgets para añadir contexto a tus datos. Para obtener más información y casos de uso, consulta la sección de [Personalizar las visualizaciones con anulaciones de unidades][3]. -- **Anulación de unidad**: elige mostrar unidades en la familia de la «memoria» y haz que Datadog se encargue de mostrar la escala adecuada en función de los datos (como megabytes o gigabytes). -- **Anulación de unidad y escala**: fija las unidades en una sola escala (muestra los datos en megabytes independientemente del valor). -- **Definir unidades personalizadas**: define unidades completamente personalizadas (como «pruebas» en lugar de un recuento genérico). - -Esta no es una alternativa para asignar unidades a tus datos. -{{< whatsnext desc="Establece unidades a nivel de la organización: ">}} - {{< nextlink href="/metrics/units/">}} Establecer unidades de métricas{{< /nextlink >}} - {{< nextlink href="/logs/explorer/facets/#units">}} Establecer unidades para consultas basadas en eventos{{< /nextlink >}} -{{< /whatsnext >}} - -## Selector de hora global - -Para utilizar el selector de hora global, al menos un widget basado en la hora debe tener configurado el uso de `Global Time`. Para ello, selecciona el widget en el editor de widgets, en **Set display preferences** (Configurar las preferencias de visualización), o añade un widget (la configuración de hora por defecto es la hora global). - -El selector de tiempo general establece el mismo período de tiempo para todos los widgets mediante la opción `Global Time` en el mismo dashboard. Selecciona un intervalo móvil en el pasado (por ejemplo, `Past 1 Hour` o `Past 1 Day`) o un período fijo con la opción `Select from calendar...`, o [ingresa un período de tiempo personalizado][11]. Si se elige un intervalo móvil, los widgets se actualizan para moverse junto con dicho intervalo. - -Los widgets no vinculados a la hora global muestran los datos de su periodo de tiempo local aplicados a la ventana global. Por ejemplo, si el selector de hora global está configurado del 1 de enero de 2019 al 2 de enero de 2019, un widget configurado con el marco de hora local para `Past 1 Minute` muestra el último minuto del 2 de enero de 2019 a partir de las 23:59. - -## Copiar y pegar widgets - -
(autoalojado, Amazon MSK, Confluent Cloud o cualquier otra plataforma de alojamiento) | {{< X >}} | {{< X >}} | {{< X >}} | {{< X >}} | {{< X >}} | +| Amazon Kinesis | {{< X >}} | {{< X >}} | {{< X >}} | {{< X >}} | | +| Amazon SNS | {{< X >}} | {{< X >}} | {{< X >}} | {{< X >}} | | +| Amazon SQS | {{< X >}} | {{< X >}} | {{< X >}} | {{< X >}} | | +| Azure Service Bus | | | {{< X >}} | | | +| Google Pub/Sub | {{< X >}} | | | {{< X >}} | | +| IBM MQ | | | {{< X >}} | | | +| RabbitMQ | {{< X >}} | {{< X >}} | {{< X >}} | {{< X >}} | | -Para empezar, sigue las instrucciones de instalación para configurar servicios con Data Streams Monitoring: +Data Streams Monitoring requiere versiones mínimas del rastreador Datadog. Para obtener más detalles, consulta cada página de configuración. + +#### Compatibilidad con OpenTelemetry +Data Streams Monitoring es compatible con OpenTelemetry. Si has configurado Datadog APM para que funcione con OpenTelemetry, no es necesaria ninguna configuración adicional para utilizar Data Streams Monitoring. Consulta [Compatibilidad de OpenTelemetry][11]. + +## Configuración + +### Por lenguaje {{< partial name="data_streams/setup-languages.html" >}} -
-| Tiempo de ejecución | Tecnologías compatibles | -|---|----| -| Java/Scala | Kafka (autoalojado, Amazon MSK, Confluent Cloud/Plataform), RabbitMQ, HTTP, gRPC, Amazon SQS | -| Python | Kafka (autoalojado, Amazon MSK, Confluent Cloud/Plataform), RabbitMQ, Amazon SQS | -| .NET | Kafka (autoalojado, Amazon MSK, Confluent Cloud/Plataform), RabbitMQ, Amazon SQS | -| Node.js | Kafka (autoalojado, Amazon MSK, Confluent Cloud/Plataform), RabbitMQ, Amazon SQS | -| Go | Todos (con [Instrumentación manual][1]) | +### Por tecnología + +{{< partial name="data_streams/setup-technologies.html" >}} + +
## Explorar Data Streams Monitoring +### Visualizar la arquitectura de tus pipelines de transmisión de datos + +{{< img src="data_streams/topology_map.png" alt="Visualización de un mapa de topología de DSM. " style="width:100%;" >}} + +Data Streams Monitoring proporciona un [mapa de topología[10] predefinido para que puedas visualizar el flujo de datos a través de tus pipelines e identificar los servicios productores/consumidores, las dependencias de las colas, la propiedad del servicio y las métricas de salud claves. + ### Medir el estado de los pipelines de extremo a extremo con las nuevas métricas -Una vez configurado Data Streams Monitoring, puedes medir el tiempo que suelen tardar los eventos en recorrer el trayecto entre dos puntos cualesquiera de tu sistema asíncrono: +Con Data Streams Monitoring, puedes medir el tiempo que suelen tardar los eventos en recorrer el trayecto entre dos puntos cualesquiera de tu sistema asíncrono: -| Nombre de la métrica | Etiquetas notables | Descripción | +| Nombre de la métrica | Etiquetas (tags) notables | Descripción | |---|---|-----| | data_streams.latency | `start`, `end`, `env` | Latencia de extremo a extremo de un trayecto desde un origen especificado hasta un servicio de destino. | | data_streams.kafka.lag_seconds | `consumer_group`, `partition`, `topic`, `env` | Retraso en segundos entre el productor y el consumidor. Requiere Java Agent v1.9.0 o posterior. | @@ -73,7 +108,7 @@ También puedes representar gráficamente y visualizar estas métricas en cualqu ### Monitorizar la latencia de extremo a extremo de cualquier ruta -Según cómo los eventos atraviesen tu sistema, diferentes rutas pueden conducir a un aumento de la latencia. Con la [pestaña **Measure** (Medir)][7], puedes seleccionar un servicio de inicio y un servicio final para obtener información sobre la latencia de extremo a extremo para identificar cuellos de botella y optimizar el rendimiento. Crea fácilmente un monitor para esa ruta o expórtalo a un dashboard. +Según cómo los eventos atraviesen tu sistema, diferentes rutas pueden conducir a un aumento de la latencia. Con la [pestaña **Medida**][7], puedes seleccionar un servicio de inicio y un servicio final para obtener información sobre la latencia de extremo a extremo para identificar cuellos de botella y optimizar el rendimiento. Crea fácilmente un monitor para esa ruta o expórtalo a un dashboard. También puedes hacer clic en un servicio para abrir un panel lateral detallado y ver la pestaña **Pathways** (Rutas) para conocer la latencia entre el servicio y servicios de flujo ascendente. @@ -81,30 +116,39 @@ También puedes hacer clic en un servicio para abrir un panel lateral detallado Las ralentizaciones causadas por un retraso elevado de los consumidores o por mensajes obsoletos pueden provocar fallos en cascada y aumentar la caída del sistema. Gracias a las alertas predefinidas, puedes determinar con precisión dónde se producen los cuellos de botella en tus pipelines y responder a ellos de inmediato. Para complementar métricas, Datadog proporciona integraciones adicionales para tecnologías de colas de mensajes como [Kafka][4] y [SQS][5]. -A través de monitores recomendados predefinidos de Data Streams Monitoring, puedes configurar monitores en métricas como el retraso del consumidor, el rendimiento y la latencia en un solo clic. +A través de las plantillas de monitor predefinidas de Data Stream Monitoring puedes configurar monitores de métricas como el retraso del consumidor, el rendimiento y la latencia en un solo clic. -{{< img src="data_streams/add_monitors_and_synthetic_tests.png" alt="Monitores recomendados de Datadog Data Streams Monitoring" style="width:100%;" caption="Click 'Add Monitors and Synthetic Tests' to view Recommended Monitors" >}} +{{< img src="data_streams/add_monitors_and_synthetic_tests.png" alt="Plantillas de monitor de Datadog Data Streams Monitoring" style="width:100%;" caption="Haz clic en 'Add Monitors and Synthetic Tests' (Añadir monitores y tests Synthetic para ver los monitores recomendados" >}} ### Atribuye los mensajes entrantes a cualquier cola, servicio o clúster Un retraso elevado en un servicio consumidor, un mayor uso de recursos en un intermediario de Kafka y un aumento del tamaño de la cola de RabbitMQ o Amazon SQS se explican con frecuencia por cambios en la forma en que los servicios adyacentes están produciendo o consumiendo estas entidades. -Haz clic en la pestaña **Throughput** (Rendimiento) en cualquier servicio o cola en Data Streams Monitoring para detectar rápidamente los cambios en el rendimiento y en qué servicio de flujo ascendente o descendente se originan estos cambios. Una vez configurado el [Catálogo de servicios][2], puedes pasar inmediatamente al canal de Slack del equipo correspondiente o al ingeniero de guardia. +Haz clic en la pestaña **Rendimiento** de cualquier servicio o cola en Data Streams Monitoring para detectar rápidamente cambios en el rendimiento y ver de qué servicio ascendente o descendente proceden los cambios. Una vez configurado el [Catálogo de software][2], puedes cambiar inmediatamente al canal Slack del equipo correspondiente o al ingeniero de turno. Al filtrar a un único clúster de Kafka, RabbitMQ o Amazon SQS, puedes detectar cambios en el tráfico entrante o saliente para todos los temas o colas detectados que se ejecuten en ese clúster: -### Pasa rápidamente para identificar las causas raíz en infraestructura, logs o trazas +### Cambiar rápidamente para identificar las causas raíz en la infraestructura, los logs o las trazas (traces) + +Datadog vincula automáticamente la infraestructura que alimenta tus servicios y los logs relacionados a través del [Etiquetado de servicios unificado][3], para que puedas localizar fácilmente los cuellos de botella. Haz clic en las pestañas **Infra**, **Logs** o **Trazas** para solucionar el problema de por qué ha aumentado la latencia de la ruta o el retraso del consumidor. + +### Monitorizar el rendimiento y el estado del conector +{{< img src="data_streams/connectors_topology.png" alt="A DSM topology (topología) map, showing a connector called 'analytics-sink'. The visualization indicates that the connector has a status of FAILED." style="width:100%;" >}} -Datadog vincula automáticamente la infraestructura que alimenta tus servicios y los logs relacionados a través del [Etiquetado de servicios unificado][3], para que puedas localizar fácilmente los cuellos de botella. Haz clic en las pestañas **Infra**, **Logs** o **Traces** (Trazas) para solucionar el problema de por qué ha aumentado la latencia de la ruta o el retraso del consumidor. +Datadog puede detectar automáticamente tus conectores gestionados de [Confluent Cloud][8] y visualizarlos en el mapa de Data Streams Monitoring topology (topología) . Instala y configura la [integración de Confluent Cloud][9] para recopilar información de tus conectores de Confluent Cloud, incluido el rendimiento, el estado y las dependencias de temas. -## Para leer más +## Referencias adicionales {{< partial name="whats-next/whats-next.html" >}} [1]: /es/data_streams/go#manual-instrumentation -[2]: /es/tracing/service_catalog/ +[2]: /es/tracing/software_catalog/ [3]: /es/getting_started/tagging/unified_service_tagging [4]: /es/integrations/kafka/ [5]: /es/integrations/amazon_sqs/ [6]: /es/tracing/trace_collection/runtime_config/ -[7]: https://app.datadoghq.com/data-streams/measure \ No newline at end of file +[7]: https://app.datadoghq.com/data-streams/measure +[8]: https://www.confluent.io/confluent-cloud/ +[9]: /es/integrations/confluent_cloud/ +[10]: https://app.datadoghq.com/data-streams/map +[11]: /es/opentelemetry/compatibility \ No newline at end of file diff --git a/content/es/database_monitoring/guide/_index.md b/content/es/database_monitoring/guide/_index.md index 0c2da5af5e6f3..a71b479fda1af 100644 --- a/content/es/database_monitoring/guide/_index.md +++ b/content/es/database_monitoring/guide/_index.md @@ -10,17 +10,18 @@ title: Guías de Database Monitoring --- {{< whatsnext desc="Guías generales:" >}} - {{< nextlink href="database_monitoring/guide/heroku-postgres" >}}Configurar Heroku Postgres para Database Monitoring{{< /nextlink >}} - {{< nextlink href="database_monitoring/guide/tag_database_statements" >}}Etiquetar sentencias de bases de datos{{< /nextlink >}} - {{< nextlink href="database_monitoring/guide/managed_authentication" >}}Conectar con Managed Authentication{{< /nextlink >}} - {{< nextlink href="database_monitoring/guide/aurora_autodiscovery" >}}Configurar Database Monitoring para clústeres de bases de datos Amazon Aurora{{< /nextlink >}} - {{< nextlink href="database_monitoring/guide/rds_autodiscovery" >}}Configurar Database Monitoring para instancias de bases de datos de Amazon RDS{{< /nextlink >}} - {{< nextlink href="database_monitoring/guide/database_identifier" >}}Especificar un identificador de bases de datos{{< /nextlink >}} + {{< nextlink href="database_monitoring/guide/tag_database_statements" >}}Etiquetado de afirmaciones de base de datos{{< /nextlink >}} + {{< nextlink href="database_monitoring/guide/managed_authentication" >}}Conexión con autenticación administrada{{< /nextlink >}} + {{< nextlink href="database_monitoring/guide/aurora_autodiscovery" >}}Configuración de la monitorización de base de datos para clústeres de base de datos de Amazon Aurora{{< /nextlink >}} + {{< nextlink href="database_monitoring/guide/rds_autodiscovery" >}}Configuración de la monitorización de base de datos para instancias de base de datos de Amazon RDS{{< /nextlink >}} + {{< nextlink href="database_monitoring/guide/database_identifier" >}}Especificación de un identificador de base de datos{{< /nextlink >}} {{< /whatsnext >}} {{< whatsnext desc="Guías de SQL Server:" >}} - {{< nextlink href="database_monitoring/guide/sql_alwayson" >}}Exploración de los grupos de disponibilidad AlwaysOn de SQL Server{{< /nextlink >}} - {{< nextlink href="database_monitoring/guide/sql_deadlock" >}}Configuración de Deadlock Monitoring en SQL Server{{< /nextlink >}} + {{< nextlink href="database_monitoring/guide/sql_alwayson" >}}Exploración de grupos de disponibilidad AlwaysOn de SQL Server{{< /nextlink >}} + {{< nextlink href="database_monitoring/guide/sql_deadlock" >}}Configuración de la monitorización de Deadlock en SQL Server{{< /nextlink >}} + {{< nextlink href="database_monitoring/guide/sql_extended_events" >}}Configuración de la finalización de consultas y la recopilación de errores de consulta en SQL Server{{< /nextlink >}} + {{< nextlink href="database_monitoring/guide/parameterized_queries" >}}Captura de los valores de parámetros de consultas SQL con Database Monitoring{{< /nextlink >}} {{< /whatsnext >}} {{< whatsnext desc="Guías de PostgreSQL:" >}} diff --git a/content/es/database_monitoring/setup_mysql/rds.md b/content/es/database_monitoring/setup_mysql/rds.md index bbfb87cc08242..e6af78c424d20 100644 --- a/content/es/database_monitoring/setup_mysql/rds.md +++ b/content/es/database_monitoring/setup_mysql/rds.md @@ -14,7 +14,7 @@ title: Configuración de la monitorización de bases de datos para MySQL gestion La monitorización de bases de datos proporciona una amplia visibilidad de tus bases de datos MySQL mediante la exposición de métricas de consultas, ejemplos de consultas, planes de explicación, datos de conexión, métricas de sistemas y telemetría para el motor de almacenamiento InnoDB. -El Agent recopila telemetría directamente de la base de datos iniciando sesión como usuario de sólo lectura. Realiza la siguiente configuración para habilitar la monitorización de bases de datos con tu base de datos MySQL: +El Agent recopila telemetría directamente de la base de datos iniciando sesión como usuario de solo lectura. Realiza la siguiente configuración para habilitar la monitorización de bases de datos con tu base de datos MySQL: 1. [Configura la integración AWS](#configure-the-aws-integration). 1. [Configura parámetros de bases de datos](#configure-mysql-settings). @@ -77,9 +77,9 @@ Configura lo siguiente en el [grupo de parámetros de base de datos][3] y luego ## Conceder acceso al Agent -El Datadog Agent requiere acceso de sólo lectura a la base de datos para poder recopilar estadísticas y realizar consultas. +El Datadog Agent requiere acceso de solo lectura a la base de datos para poder recopilar estadísticas y realizar consultas. -Las siguientes instrucciones conceden permiso al Agent para iniciar sesión desde cualquier host que utilice `datadog@'%'`. Puedes restringir al usuario `datadog` para que sólo pueda iniciar sesión desde el host local utilizando `datadog@'localhost'`. Para obtener más información, consulta la [documentación de MySQL][4]. +Las siguientes instrucciones conceden permiso al Agent para iniciar sesión desde cualquier host que utilice `datadog@'%'`. Puedes restringir al usuario `datadog` para que solo pueda iniciar sesión desde el host local utilizando `datadog@'localhost'`. Para obtener más información, consulta la [documentación de MySQL][4]. {{< tabs >}} {{% tab "MySQL ≥ 5.7" %}} @@ -175,7 +175,7 @@ GRANT EXECUTE ON PROCEDURE datadog.enable_events_statements_consumers TO datadog ## Instala y configura el Agent -Para monitorizar hosts de RDS, instala el Datadog Agent en tu infraestructura y configúralo para conectarse a cada endpoint de instancia de forma remota. El Agent no necesita ejecutarse en la base de datos, sólo necesita conectarse a ella. Para conocer otros métodos de instalación del Agent no mencionados aquí, consulta las [instrucciones de instalación del Agent][5]. +Para monitorizar hosts de RDS, instala el Datadog Agent en tu infraestructura y configúralo para conectarse a cada endpoint de instancia de forma remota. El Agent no necesita ejecutarse en la base de datos, solo necesita conectarse a ella. Para conocer otros métodos de instalación del Agent no mencionados aquí, consulta las [instrucciones de instalación del Agent][5]. {{< tabs >}} {{% tab "Host" %}} @@ -192,13 +192,14 @@ init_config: instances: - dbm: true host: ''
- port: 3306
+ port:
username: datadog
password: 'ENC[datadog_user_database_password]' # from the CREATE USER step earlier, stored as a secret
# After adding your project and instance, configure the Datadog AWS integration to pull additional cloud data such as CPU and Memory.
aws:
instance_endpoint: ''
+ region:
```
[Reinicia el Agent][3] para empezar a enviar métricas de MySQL a Datadog.
@@ -220,7 +221,7 @@ Ponte en marcha rápidamente con el siguiente comando para ejecutar el Agent des
```bash
export DD_API_KEY=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
-export DD_AGENT_VERSION=7.36.1
+export DD_AGENT_VERSION=
docker run -e "DD_API_KEY=${DD_API_KEY}" \
-v /var/run/docker.sock:/var/run/docker.sock:ro \
@@ -229,9 +230,13 @@ docker run -e "DD_API_KEY=${DD_API_KEY}" \
-l com.datadoghq.ad.instances='[{
"dbm": true,
"host": "",
- "port": 3306,
+ "port": ,
"username": "datadog",
- "password": ""
+ "password": "",
+ "aws": {
+ "instance_endpoint": "",
+ "region": ""
+ }
}]' \
gcr.io/datadoghq/agent:${DD_AGENT_VERSION}
```
@@ -241,11 +246,11 @@ docker run -e "DD_API_KEY=${DD_API_KEY}" \
Las etiquetas también pueden especificarse en un `Dockerfile`, por lo que puedes crear y desplegar un Agent personalizado sin cambiar la configuración de tu infraestructura:
```Dockerfile
-FROM gcr.io/datadoghq/agent:7.36.1
+FROM gcr.io/datadoghq/agent:
LABEL "com.datadoghq.ad.check_names"='["mysql"]'
LABEL "com.datadoghq.ad.init_configs"='[{}]'
-LABEL "com.datadoghq.ad.instances"='[{"dbm": true, "host": "", "port": 3306,"username": "datadog","password": "ENC[datadog_user_database_password]"}]'
+LABEL "com.datadoghq.ad.instances"='[{"dbm": true, "host": "", "port": ,"username": "datadog","password": "ENC[datadog_user_database_password]", "aws": {"instance_endpoint": "", "region": ""}}]'
```
[1]: /es/agent/docker/integrations/?tab=docker
@@ -256,11 +261,62 @@ Si tienes un clúster Kubernetes, utiliza el [Datadog Cluster Agent][1] para la
Sigue las instrucciones para [habilitar checks de clúster][2], si no están habilitados en tu clúster Kubernetes. Puedes declarar la configuración de MySQL mediante archivos estáticos integrados en el contenedor del Cluster Agent o utilizando anotaciones de servicios:
-### Helm
+### Operator
+
+Utilizando como referencia las [Instrucciones para operadores en Kubernetes e integraciones][3], sigue los pasos que se indican a continuación para configurar la integración de MySQL:
+
+1. Cree o actualice el archivo `datadog-agent.yaml` con la siguiente configuración:
+
+ ```yaml
+ apiVersion: datadoghq.com/v2alpha1
+ kind: DatadogAgent
+ metadata:
+ name: datadog
+ spec:
+ global:
+ clusterName:
+ site:
+ credentials:
+ apiSecret:
+ secretName: datadog-agent-secret
+ keyName: api-key
+
+ features:
+ clusterChecks:
+ enabled: true
+
+ override:
+ nodeAgent:
+ image:
+ name: agent
+ tag:
+
+ clusterAgent:
+ extraConfd:
+ configDataMap:
+ mysql.yaml: |-
+ cluster_check: true
+ init_config:
+ instances:
+ - host:
+ port:
+ username: datadog
+ password: 'ENC[datadog_user_database_password]'
+ dbm: true
+ aws:
+ instance_endpoint:
+ region:
+ ```
+
+2. Aplica los cambios al Datadog Operator utilizando el siguiente comando:
+
+ ```shell
+ kubectl apply -f datadog-agent.yaml
+ ```
-Realiza los siguientes pasos para instalar el [Datadog Cluster Agent][1] en tu clúster Kubernetes. Sustituye los valores para que coincidan con tu cuenta y tu entorno.
+### Helm
-1. Sigue las [instrucciones de instalación del Datadog Agent][3] para Helm.
+1. Complete las [instrucciones de instalación del Datadog Agent][4] para Helm.
2. Actualiza tu archivo de configuración YAML (`datadog-values.yaml` en las instrucciones de instalación del Cluster Agent) para incluir lo siguiente:
```yaml
clusterAgent:
@@ -270,16 +326,20 @@ Realiza los siguientes pasos para instalar el [Datadog Cluster Agent][1] en tu c
init_config:
instances:
- dbm: true
- host:
- port: 3306
+ host:
+ port:
username: datadog
password: 'ENC[datadog_user_database_password]'
+ aws:
+ instance_endpoint:
+ region:
clusterChecksRunner:
enabled: true
```
3. Despliega el Agent con el archivo de configuración anterior desde la línea de comandos:
+
```shell
helm install datadog-agent -f datadog-values.yaml datadog/datadog
```
@@ -288,10 +348,6 @@ Realiza los siguientes pasos para instalar el [Datadog Cluster Agent][1] en tu c
For Windows, append
-[1]: https://app.datadoghq.com/organization-settings/api-keys
-[2]: /es/getting_started/site
-[3]: /es/containers/kubernetes/installation/?tab=helm#installation
-
### Configuración con archivos integrados
Para configurar un check de clúster con un archivo de configuración integrado, integra el archivo de configuración del contenedor del Cluster Agent en la ruta `/conf.d/mysql.yaml`:
@@ -302,14 +358,17 @@ init_config:
instances:
- dbm: true
host: 'Esta página enumera solo los ámbitos de autorización que pueden asignarse a los clientes de OAuth. Para ver la lista completa de permisos asignables para claves de aplicación con ámbito, consulta Permisos de rol de Datadog.
-La práctica recomendada para delimitar las aplicaciones es seguir el principio del mínimo privilegio. Asigna sólo el mínimo contexto necesario para que una aplicación funcione según lo previsto. Esto mejora la seguridad y proporciona visibilidad de cómo interactúan las aplicaciones con los datos de tu organización. Por ejemplo, una aplicación de terceros que sólo lee dashboards no necesita permisos para eliminar o gestionar usuarios.
+La práctica recomendada para delimitar las aplicaciones es seguir el principio del mínimo privilegio. Asigna solo el mínimo contexto necesario para que una aplicación funcione según lo previsto. Esto mejora la seguridad y proporciona visibilidad de cómo interactúan las aplicaciones con los datos de tu organización. Por ejemplo, una aplicación de terceros que solo lee dashboards no necesita permisos para eliminar o gestionar usuarios.
Puede utilizar contextos de autorización con clientes OAuth2 para tus [aplicaciones Datadog][1].
{{< api-scopes >}}
-[1]: https://docs.datadoghq.com/es/developers/datadog_apps/#oauth-api-access
+[1]: https://docs.datadoghq.com/es/developers/datadog_apps/#oauth-api-access
\ No newline at end of file
diff --git a/content/es/bits_ai/mcp_server/setup/_index.md b/content/es/bits_ai/mcp_server/setup/_index.md
new file mode 100644
index 0000000000000..7cbe0a16bdc8f
--- /dev/null
+++ b/content/es/bits_ai/mcp_server/setup/_index.md
@@ -0,0 +1,433 @@
+---
+description: Aprende a instalar y configurar el servidor MCP de Datadog para conectar
+ tus agentes de IA a las herramientas y datos de capacidad de observación de Datadog.
+further_reading:
+- link: https://www.datadoghq.com/blog/datadog-remote-mcp-server/
+ tag: Blog
+ text: Conecta tus agentes de IA a las herramientas y el contexto de Datadog mediante
+ el servidor MCP de Datadog.
+- link: bits_ai/mcp_server
+ tag: Documentación
+ text: Servidor MCP de Datadog
+- link: developers/ide_plugins/vscode/?tab=cursor
+ tag: Documentación
+ text: Extensión para Cursor de Datadog
+- link: https://www.datadoghq.com/blog/datadog-cursor-extension/
+ tag: Blog
+ text: Depuración de problemas de producción en directo con la extensión Cursor de
+ Datadog
+- link: https://www.datadoghq.com/blog/openai-datadog-ai-devops-agent/
+ tag: Blog
+ text: 'Datadog + OpenAI: integración de Codex CLI para DevOps asistidos por IA'
+private: true
+title: Configurar el servidor MCP de Datadog
+---
+
+{{< callout url="https://www.datadoghq.com/product-preview/datadog-mcp-server/" >}}
+El servidor MCP de Datadog está en vista previa. El uso del servidor MCP de Datadog durante la vista previa es gratuito. Si estás interesado en esta función y necesitas acceso, completa este formulario. Más información sobre el servidor MCP en el blog de Datadog .
+{{< /callout >}}
+
+## Descargo de responsabilidad
+
+- El servidor MCP de Datadog no es compatible con el uso en producción durante la vista previa.
+- Solo las organizaciones de Datadog que hayan sido específicamente autorizadas pueden utilizar el Servidor MCP de Datadog. No está disponible para el público en general.
+- El servidor MCP de Datadog no está disponible para organizaciones que requieran el cumplimiento de HIPAA.
+- Datadog recopila determinada información sobre el uso que haces del Servidor MCP remoto de Datadog, incluida la forma en que interactúas con él, si se han producido errores al utilizarlo, cuál ha sido la causa de dichos errores e identificadores de usuario, de conformidad con la Política de privacidad de Datadog y el EULA de Datadog. Estos datos se utilizan para ayudar a mejorar el rendimiento y las funciones del servidor, incluidas las transiciones hacia y desde el servidor y la page (página) de inicio de sesión de Datadog aplicable para acceder a los Servicios y el contexto (por ejemplo, los avisos al usuario) que conducen al uso de las herramientas de MCP. Los datos se almacenan durante 120 días.
+
+## Información general
+
+El servidor MCP gestionado por Datadog actúa como puente entre tus datos de capacidad de observación en Datadog y los agentes de IA compatibles con el [Protocolo de Contexto de Modelo (MCP)][1]. Al proporcionar acceso estructurado a los contextos, funciones y herramientas pertinentes de Datadog, el servidor MCP te permite consultar y recuperar información de capacidad de observación directamente desde clientes de IA como Cursor, OpenAI Codex, Claude Code o tu propio agente de IA.
+
+Esta page (página) proporciona instrucciones para conectar tu agente de IA al servidor MCP de Datadog, enumera las herramientas disponibles e incluye ejemplos de avisos.
+
+Esta demostración muestra el Servidor MCP de Datadog mientras se utiliza en Cursor y Claude Code (desactiva el silencio para el audio):
+
+{{< img src="bits_ai/mcp_server/mcp_cursor_demo_3.mp4" alt="Demostración del servidor MCP de Datadog en Cursor y Claude Code" video="true" >}}
+
+## Compatibilidad con los clientes
+
+Los siguientes clientes de la IA son compatibles con el servidor MCP de Datadog.
+
+-
-
- Clientes OAuth → Sólo se les pueden asignar contextos de autorización (conjunto limitado). -
- Claves de aplicación delimitadas → Se les puede asignar cualquier permiso Datadog. +
- Clientes de OAuth → Solo se pueden asignar ámbitos de autorización (conjunto limitado). +
- Claves de aplicación de ámbito → Se les puede asignar cualquier permiso de Datadog.
El servidor MCP de Datadog se encuentra en fase de desarrollo, por lo que es posible que aparezcan otros clientes compatibles.
+
+| Cliente | Desarrollador | Notas |
+|--------|------|------|
+| [Cursor][8] | Anysphere | Se recomienda la [extensión Cursor y VS Code](#connect-in-cursor-and-vs-code) de Datadog. |
+| [Claude Code][5] | Anthropic | |
+| [Claude Desktop][6] | Anthropic | Compatibilidad limitada para la autenticación remota. Utiliza la [autenticación binaria local](?tab=localbinaryauthentication#connect-in-supported-ai-clients) según sea necesario. |
+| [Codex CLI][7] | OpenAI | |
+| [VS Code][11] | Microsoft | Se recomienda la [extensión Cursor y VS](#connect-in-cursor-and-vs-code) de Datadog. |
+| [Goose][9] | Bloque | |
+| [Q CLI][10] | Amazon | Para la autenticación remota, añade `"oauthScopes": []` a la [configuración] del servidor(?tab=remoteauthentication#example-configurations). |
+| [Cline][18] | Cline Bot | Compatibilidad limitada para la autenticación remota. Utiliza la [autenticación binaria local](?tab=localbinaryauthentication#connect-in-supported-ai-clients) según sea necesario. |
+
+## Requisitos
+
+Los usuarios de Datadog deben tener el [permiso][19] `Incidents Read` para utilizar el Servidor MCP.
+
+## Conectar en Cursor y VS Code
+
+La [extensión de Cursor y VS Code][12] de Datadog incluye acceso integrado al servidor MCP gestionado de Datadog. Las ventajas incluyen:
+
+* No es necesaria ninguna otra configuración del el servidor MCP después de instalar la extensión y conectarse a Datadog.
+* Transiciones con un solo clic entre varias organizaciones de Datadog.
+* [Solo Cursor] Mejores correcciones de **Fix in Chat** en Code Insights (problemas de Error Tracking, vulnerabilidades de código y vulnerabilidades de bibliotecas), informadas por contexto desde el Servidor MCP.
+
+Para instalar la extensión:
+
+1. Si previamente instalaste manualmente el Servidor MCP de Datadog, elimínalo de la configuración del IDE para evitar conflictos. Para encontrar la configuración del Servidor MCP:
+ - Cursor: Ve a **Cursor Settings** (Configuración de Cursor) (`Shift` + `Cmd/Ctrl` + `J`) y selecciona la pestaña **MCP**.
+ - VS Code: Abre la paleta de comandos (`Shift` + `Cmd/Ctrl` + `P`) y ejecuta `MCP: Open User Configuration`.
+2. Instala la extensión de Datadog siguiendo [estas instrucciones][14]. Si ya tienes instalada la extensión, asegúrate de que sea la última versión, ya que periódicamente se publican nuevas funciones.
+3. Inicia sesión en tu cuenta de Datadog. Si tienes varias cuentas, utiliza la cuenta incluida en tu vista previa del producto.
+ {{< img src="bits_ai/mcp_server/ide_sign_in.png" alt="Inicia sesión en Datadog desde la extensión del IDE" style="width:70%;" >}}
+4. **Reinicia el IDE.
+5. Confirma que el servidor MCP de Datadog esté disponible y que las [herramientas](#available-tools) aparezcan en tu IDE:
+ - Cursor: Ve a **Cursor Settings** (Configuración de Cursor) (`Shift` + `Cmd/Ctrl` + `J`) y selecciona la pestaña **MCP**.
+ - VS Code: Abre el panel del chat, selecciona el modo agente y haz clic en el botón **Configure Tools** (Configurar herramientas).
+ {{< img src="bits_ai/mcp_server/vscode_configure_tools_button.png" alt="Botón Configurar herramientas en VS Code" style="width:70%;" >}}
+
+## Conectar en clientes de IA compatibles
+
+Las siguientes instrucciones son para todos los [clientes compatibles con MCP](#client-compatibility). Para Cursor o VS Code, utiliza la [extensión de Datadog ](#connect-in-cursor-and-vs-code) para un acceso integrado al Servidor MCP de Datadog.
+
+{{< tabs >}}
+{{% tab "Autenticación remota" %}}
+Este método utiliza el mecanismo de transmisión [HTTP transmisible][1] de la especificación de MCP para conectarse al Servidor MCP.
+
+Dirige tu agente de IA al endpoint del servidor MCP para tu [sitio regional de Datadog ][2]. Por ejemplo, si utilizas `app.datadoghq.com` para acceder a Datadog, utiliza el endpoint del sitio US1.
+
+Si tu organización utiliza un [subdominio personalizado][3], utiliza el endpoint que corresponda a tu sitio regional de Datadog. Por ejemplo, si tu subdominio personalizado es `myorg.datadoghq.com`, utiliza el endpoint US1.
+
+| Sitio web de Datadog | Endpoint del servidor MCP |
+|--------|------|
+| **US1** (`app.datadoghq.com`) | `https://mcp.datadoghq.com/api/unstable/mcp-server/mcp` |
+| **US3** (`us3.datadoghq.com`) | `https://mcp.us3.datadoghq.com/api/unstable/mcp-server/mcp` |
+| **US5** (`us5.datadoghq.com`) | `https://mcp.us5.datadoghq.com/api/unstable/mcp-server/mcp` |
+| **UE1** (`app.datadoghq.eu`) | `https://mcp.datadoghq.eu/api/unstable/mcp-server/mcp` |
+| **AP1** (`ap1.datadoghq.com`) | `https://mcp.ap1.datadoghq.com/api/unstable/mcp-server/mcp` |
+| **AP2** (`ap2.datadoghq.com`) | `https://mcp.ap2.datadoghq.com/api/unstable/mcp-server/mcp` |
+
+### Ejemplos de configuraciones
+
+Estos ejemplos corresponden al sitio US1:
+
+* **Línea de comandos: Para Claude Code, ejecuta:
+ ```bash
+ claude mcp add --transport http datadog-mcp https://mcp.datadoghq.com/api/unstable/mcp-server/mcp
+ ```
+
+* **Archivo de configuración**: Edita el archivo de configuración de tu agente de IA:
+ * Codex CLI: `~/.codex/config.toml`
+ * Gemini CLI: `~/.gemini/settings.json`
+
+ ```json
+ {
+ "mcpServers": {
+ "datadog": {
+ "type": "http",
+ "url": "https://mcp.datadoghq.com/api/unstable/mcp-server/mcp"
+ }
+ }
+ }
+ ```
+ * Amazon Q CLI: `~/.aws/amazonq/default.json`
+
+ ```json
+ {
+ "mcpServers": {
+ "datadog": {
+ "type": "http",
+ "url": "https://mcp.datadoghq.com/api/unstable/mcp-server/mcp",
+ "oauthScopes": []
+ }
+ }
+ }
+ ```
+
+[1]: https://modelcontextprotocol.io/specification/2025-03-26/basic/transports#streamable-http
+[2]: /es/getting_started/site/
+[3]: /es/account_management/multi_organization/#custom-sub-domains
+{{% /tab %}}
+
+{{% tab "Autenticación binaria local" %}}
+
+Este método utiliza el mecanismo de transmisión [stdio][1] de la especificación de MCP para conectarse al servidor MCP.
+
+Utiliza esta opción si no dispones de autenticación remota directa. Tras la instalación, normalmente no es necesario actualizar el binario local para beneficiarse con las actualizaciones del servidor MCP, ya que las herramientas son remotas.
+
+1. Instala el binario del Servidor MCP de Datadog:
+ * macOS y Linux:
+ ```bash
+ curl -sSL https://coterm.datadoghq.com/mcp-cli/install.sh | bash
+ ```
+
+ Esto instala el binario del Servidor MCP en `~/.local/bin/datadog_mcp_cli` y entonces puedes utilizarlo como cualquier otro servidor MCP stdio.+ + * Windows: Descarga la [versión Windows][2]. + +2. Ejecuta `datadog_mcp_cli login` manualmente para recorrer el flujo de inicio de sesión de OAuth. + + El servidor MCP inicia automáticamente el flujo de OAuth si un cliente lo necesita, pero hacerlo manualmente te permite elegir un [sitio Datadog][3] y evitar que el cliente de IA se desconecte. + +3. Configura tu cliente de IA para utilizar el Servidor MCP de Datadog. Sigue las instrucciones de configuración de tu cliente, ya que la configuración del Servidor MCP varía entre clientes de IA de terceros. + + Por ejemplo, para Claude Code, añade esto a `~/.claude.json`, asegúrate de sustituir `
Las herramientas del servidor MCP de Datadog se encuentran en fase de desarrollo y están sujetas a cambios. Utiliza este formulario de comentarios para compartir cualquier comentario, casos de uso o problemas encontrados con sus avisos y consultas.
+
+### `search_datadog_docs`
+*Toolset: **core***\
+Devuelve respuestas generadas por IA a preguntas de Datadog, extraídas de la [documentación de Datadog][15].
+- ¿Cómo se activa la generación de perfiles de Datadog en Python?
+- ¿Cuál es la mejor manera de correlacionar logs y traces (trazas)?
+- ¿Cómo funciona la instrumentación automática de RUM?
+
+### `search_datadog_events`
+*Toolset: **core***\
+Busca eventos como alertas en monitor (noun), notificaciones de despliegue, cambios en la infraestructura, hallazgos de seguridad y cambios en el estado de los servicios.
+
+- Muestra todos los eventos de despliegue de las últimas 24 horas.
+- Busca eventos relacionados con nuestro entorno de producción con estado de error.
+- Obtén los eventos etiquetados con `service:api` de la última hora.
+
+**Nota**: Consulta la [API de Event Management][16] para obtener más detalles.
+
+### `get_datadog_incident`
+*Toolset: **core***\
+Recupera información detallada sobre un incident (incidente).
+
+- Obtén información detallada para el incident (incidente) ABC123.
+- ¿Cuál es la situación del incident (incidente) ABC123?
+- Recupera la información completa sobre el incident (incidente) Redis de ayer.
+
+**Nota**: La herramienta está operativa, pero no incluye datos cronológicos del incident (incidente).
+
+### `get_datadog_metric`
+*Toolset: **core***\
+Consulta y analiza datos de métricas históricas o en tiempo real, que admiten consultas y agregaciones personalizadas.
+
+- Muéstrame las métricas de utilización de CPU de todos los hosts en las últimas 4 horas.
+- Obtén métricas de latencia de Redis del entorno de producción.
+- Despliega las tendencias de uso de memoria de nuestros servidores de bases de datos.
+
+### `search_datadog_monitors`
+*Toolset: **core***\
+Recupera información sobre los monitores de Datadog, incluidos sus estados, umbrales y condiciones de alerta.
+
+- Enumera todos los monitores que están alertando actualmente.
+- Muéstrame monitores relacionados con nuestro servicio de pagos.
+- Busca monitores etiquetados con `team:infrastructure`.
+
+### `get_datadog_trace`
+*Toolset: **core***\
+Obtiene una trace (traza) completa de Datadog APM con un identificador de trace (traza).
+
+- Obtén la trace (traza) completa del identificador 7d5d747be160e280504c099d984bcfe0.
+- Muéstrame todos los spans (tramos) de la trace (traza) abc123 con información de tiempo.
+- Recupera detalles de trace (traza) que incluyen consultas a la base de datos del identificador xyz789.
+
+**Nota**: Las traces (trazas) grandes con miles de spans (tramos) pueden quedar truncadas (e indicarse como tales) sin una forma de recuperar todos los spans (tramos).
+
+### `search_datadog_dashboards`
+*Toolset: **core***\
+Enumera los dashboards disponibles y los detalles claves de Datadog.
+
+- Muéstrame todos los dashboards disponibles en nuestra cuenta.
+- Enumera los dashboards relacionados con la monitorización de la infraestructura.
+- Encuentra dashboards compartidos para el equipo de ingeniería.
+
+**Nota**: Esta herramienta enumera los dashboards pertinentes, pero ofrece detalles limitados sobre su contenido.
+
+### `search_datadog_hosts`
+*Toolset: **core***\
+Enumera y proporciona información sobre los hosts monitorizados, que admite filtrado y búsqueda.
+
+- Muéstrame todos los hosts de nuestro entorno de producción.
+- Enumera los hosts incorrectos que no han informado en la última hora.
+- Obtén todos los hosts etiquetados con `role:database`.
+
+### `search_datadog_incidents`
+*Toolset: **core***\
+Recupera una lista de incidentes de Datadog, incluido su estado, gravedad y metadatos.
+
+- Muéstrame todos los incidentes activos por gravedad.
+- Enumera los incidentes resueltos la semana pasada.
+- Encuentra incidentes que afecten a los clientes.
+
+### `search_datadog_metrics`
+*Toolset: **core***\
+Enumera las métricas disponibles, con opciones de filtrado y metadatos.
+
+- Muéstrame todas las métricas disponibles de Redis.
+- Enumera las métricas relacionadas con la CPU de nuestra infraestructura.
+- Busca métricas etiquetadas con `service:api`.
+
+### `search_datadog_services`
+*Toolset: **core***\
+Enumera los servicios del Software Catalog de Datadog con detalles e información del equipo.
+
+- Muéstrame todos los servicios de nuestra arquitectura de microservicios.
+- Enumera los servicios propiedad del equipo de la plataforma.
+- Busca servicios relacionados con el procesamiento de pagos.
+
+### `search_datadog_spans`
+*Toolset: **core***\
+Recupera spans (tramos) de las traces (trazas) de APM con filtros como servicio, hora, recurso, etc.
+
+- Muéstrame spans (tramos) con errores del servicio de pagos.
+- Busca consultas lentas a la base de datos en los últimos 30 minutos.
+- Obtén los spans (tramos) de las solicitudes de API fallidas a nuestro servicio de pagos.
+
+### `search_datadog_logs`
+*Toolset: **core***\
+Busca en logs con filtros (hora, consulta, servicio, host, nivel de almacenamiento, etc.) y devuelve los detalles de logs. Renombrado de `get_logs`.
+
+- Muéstrame logs de error del servicio NGINX en la última hora.
+- Busca logs que contengan 'tiempo de espera de la connection (conexión)' de nuestro servicio de API.
+- Obtén los 500 logs de códigos de estado de la producción.
+
+### `search_datadog_rum_events`
+*Toolset: **core***\
+Busca eventos de RUM de Datadog mediante la utilización de una sintaxis de consulta avanzada.
+
+- Muestra errores y advertencias de la consola de JavaScript en RUM.
+- Busca las páginas que se cargan lentamente (más de 3 segundos).
+- Muestra las interacciones recientes de los usuarios en las páginas de detalles de los productos.
+
+### `get_synthetics_tests`
+*Toolset **sintéticos***\
+Busca tests de Synthetic Monitoring de Datadog.
+
+- Ayúdame a comprender por qué el test de Synthetic Monitoring en el endpoint `/v1/my/tested/endpoint` está fallando.
+- Hay una interrupción; busca todos los tests de Synthetic Monitoring que fallan en el dominio `api.mycompany.com`.
+- ¿Siguen funcionando los tests de Synthetic Monitoring en mi sitio web `api.mycompany.com` en la última hora?
+
+### `edit_synthetics_tests`
+*Tooset: **sintética***\
+Edita tests de la API de HTTP de Synthetic Monitoring de Datadog.
+
+- Mejora las afirmaciones del test de Synthetic Monitoring definido en mi endpoint `/v1/my/tested/endpoint`.
+- Pon en pausa el test `aaa-bbb-ccc` y configura las ubicaciones solo en lugares europeos.
+- Añade la etiqueta de mi equipo al test `aaa-bbb-ccc` .
+
+### `synthetics_test_wizard`
+*Toolset: **synthetics***\
+Previsualiza y crea tests de la API de HTTP de Synthetic Monitoring de Datadog.
+
+- Crea tests de Synthetic Monitoring en cada endpoint definido en este archivo de código.
+- Crea un test de Synthetic Monitoring en `/path/to/endpoint`.
+- Crea un test de Synthetic Monitoring que compruebe si mi dominio `mycompany.com` permanece activo.
+
+## Eficiencia del contexto
+
+El servidor MCP de Datadog se optimiza para proporcionar respuestas de forma que los agentes de IA obtengan el contexto pertinente sin sobrecargarse con información innecesaria. Por ejemplo:
+
+- Las respuestas se truncan en función de la longitud estimada de las respuestas que proporciona cada herramienta. Las herramientas responden a los agentes de IA con instrucciones sobre cómo solicitar más información si la respuesta estaba truncada.
+- La mayoría de las herramientas tienen un parámetro `max_tokens` que permite a los agentes de IA solicitar menos o más información.
+
+## Rastrea las llamadas a herramientas en Audit Trail
+
+Puedes ver información sobre las llamadas realizadas por las herramientas del servidor MCP en [Audit Trail][17] de Datadog. Busca o filtra por el nombre del evento `MCP Server`.
+
+## Comentarios
+
+El servidor MCP de Datadog se encuentra en fase de desarrollo. Durante la vista previa, utiliza [este formulario de comentarios][20] para compartir comentarios, casos de uso o problemas encontrados con sus avisos y consultas.
+
+## Referencias adicionales
+
+{{< partial name="whats-next/whats-next.html" >}}
+
+[1]: https://modelcontextprotocol.io/
+[2]: https://modelcontextprotocol.io/specification/draft/basic/authorization
+[3]: /es/account_management/api-app-keys/
+[4]: https://github.com/modelcontextprotocol/inspector
+[5]: https://www.anthropic.com/claude-code
+[6]: https://claude.ai/download
+[7]: https://help.openai.com/en/articles/11096431-openai-codex-cli-getting-started
+[8]: https://www.cursor.com/
+[9]: https://github.com/block/goose
+[10]: https://github.com/aws/amazon-q-developer-cli
+[11]: https://code.visualstudio.com/
+[12]: /es/developers/ide_plugins/vscode/
+[13]: https://nodejs.org/en/about/previous-releases
+[14]: /es/developers/ide_plugins/vscode/?tab=cursor#installation
+[15]: /es/
+[16]: /es/api/latest/events/
+[17]: /es/account_management/audit_trail/
+[18]: https://cline.bot/
+[19]: /es/account_management/rbac/permissions/#case-and-incident-management
+[20]: https://docs.google.com/forms/d/e/1FAIpQLSeorvIrML3F4v74Zm5IIaQ_DyCMGqquIp7hXcycnCafx4htcg/viewform
+[21]: /es/synthetics/
\ No newline at end of file
diff --git a/content/es/cloud_cost_management/reports/_index.md b/content/es/cloud_cost_management/reports/_index.md
new file mode 100644
index 0000000000000..935e5ad260ca3
--- /dev/null
+++ b/content/es/cloud_cost_management/reports/_index.md
@@ -0,0 +1,110 @@
+---
+description: Realiza un seguimiento de los gastos de tu organización con los informes
+ de Cloud Cost Management.
+further_reading:
+- link: /cloud_cost_management/reports/scheduled_reports
+ tag: Documentación
+ text: Informes de costes programados
+- link: /cloud_cost_management/
+ tag: Documentación
+ text: Más información sobre Cloud Cost Management
+private: true
+title: Informes
+---
+
+## Información general
+
+Los informes de Cloud Cost Monitoring (CCM) de Datadog agilizan las operaciones financieras y permiten a los equipos de finanzas gestionar eficazmente los costes de la nube. Esta función proporciona una plataforma centralizada para el análisis detallado de los costes, que te permite explorar, analizar y compartir datos de costes o presupuestos de nube.
+
+Con los informes, puedes:
+
+- **Centralizar análisis de costes de nube**: Visualiza y gestiona los costes de [AWS][1], [Azure][2], [Google Cloud][3], [Oracle][12] y [proveedores de SaaS][4] en un solo lugar.
+- **Filtrar y agrupar**: Filtra por proveedor, etiquetas (tags), regiones y agrupa por servicio, proveedor o etiquetas personalizadas.
+- **Visualizar gráficos**: Utiliza gráficos de barras, resúmenes y vistas diarias para detectar tendencias y anomalías.
+- **Utilizar controles avanzados**: Cambia entre tipos de costes, alterna la asignación de contenedores y céntrate en los gastos de uso o en todos los gastos.
+- **Crear informes de presupuestos**: Elabora informes de presupuestos, además de informes de costes, para realizar un seguimiento de los gastos con respecto a los objetivos de presupuesto y anticipa costes futuros.
+- **Colaborar y compartir**: Guarda, marca, exporta y comparta informes con tu equipo.
+
+## Crear un informe de CCM
+
+1. Ve a [**Cloud Cost > Analyze > Reports** (Cloud Cost > Análisis > Informes)][5] en Datadog.
+1. Haz clic en **New Report** (Nuevo informe) para empezar desde cero, o selecciona una plantilla de la galería para acelerar tu flujo de trabajo.
+
+ {{< img src="cloud_cost/cost_reports/create-new-report.png" alt="Crear un informe nuevo o a partir de una plantilla." style="width:100%;" >}}
+
+ **Plantillas disponibles:**
+ - **Gasto de AWS por nombre de servicio**: Comprende tus costes de EC2, S3 y Lambda.
+ - **Gasto de Azure por nombre de servicio**: Desglosa los costes por servicios Azure como máquinas virtuales y monitor Azure.
+ - **Gasto de GCP por nombre de servicio**: Desglosa los costes por servicios GCP como Compute Engine, BigQuery y Kubernetes Engine.
+ - **Gasto por proveedor**: Compara costes en AWS, Azure, Google Cloud, etc.
+
+## Personalización del informe
+
+{{< img src="cloud_cost/cost_reports/customization-options-aws-1.png" alt="Personaliza tu informe seleccionando proveedores de nube, filtrando, agrupando, cambiando la visualización y utilizando opciones avanzadas." style="width:100%;" >}}
+
+### Seleccionar el tipo de informe
+
+Selecciona el tipo de informe que quieres crear:
+
+- **Coste**: Comprende en qué se gasta tu dinero en servicios, regiones, equipos, etc.
+- **Presupuesto**: Realiza un seguimiento de los gastos con respecto a los objetivos de presupuesto predefinidos y anticipa costes futuros.
+
+### Aplicar filtros
+
+Utiliza filtros para incluir solo los costes específicos que quieres asignar, como por proveedor, producto, etiqueta, región o tipo de coste, de modo que tu regla apunte exactamente al subconjunto adecuado de tus gastos de nube.
+
+| Filtrar por | Caso práctico |
+|--------|----------|
+| Proveedor de nube (como AWS, Azure, GCP, Snowflake) | Aplica tu regla de asignación solo a los costes de un proveedor de nube específico, como por ejemplo a las tarifas de asistencia de AWS, pero no a los costes de Azure o GCP. |
+| Producto o servicio (como EC2, S3, RDS) | Asigna costes relacionados con un producto o servicio específico. Por ejemplo, divide solo los costes de EC2 entre equipos, en lugar de todos los costes de AWS. |
+| Etiquetas (`env:prod`, `team:analytics`) | Incluye o excluye costes en función de las etiquetas de los recursos. Por ejemplo, asigna costes solo a los recursos de producción (`env:prod`) o solo a los recursos etiquetados para el equipo de análisis. |
+| Región | Asigna costes solo a los recursos de una región geográfica específica. Por ejemplo, divide los costes de los recursos de `us-east-1` separados de los de `eu-west-1`. |
+| Tipo de coste (uso, soporte, no etiquetado) | Asigna solo determinados tipos de costes, como cargos por uso, tarifas de soporte o costes no etiquetados. Por ejemplo, asigna solo costes no etiquetados para incentivar a los equipos a etiquetar sus recursos. |
+| Criterios personalizados | Cuando tengas un requisito empresarial único que combine varios filtros, crea un criterio personalizado. Por ejemplo, quieres asignar solo los costes de EC2 en una región específica `us-west-2`, etiquetados como `env:prod`. |
+
+### Datos del grupo
+- Agrupa por nombre de proveedor, nombre de servicio o etiquetas de recursos personalizadas para obtener información más detallada.
+
+### Cambia la forma de ver tus datos
+- Selecciona una **opción de visualización**:
+ - **Gráfico de barras**: Compara los costes de varias categorías para identificar los principales factores de coste.
+ - **Gráfico circular**: Muestra la cuota porcentual de cada segmento, ideal para comprender la proporción relativa de costes entre un número reducido de categorías.
+ - **Diagrama de árbol**: Muestra datos jerárquicos y el tamaño relativo de muchas categorías a la vez, para que puedas ver la estructura general y los mayores colaboradores en una sola vista.
+- Cambia la **vista de tabla**:
+ - **Resumen**: Una imagen consolidada y global de tus costes.
+ - **Día a día**, **semana a semana** o **mes a mes**: Analiza cómo cambian tus costes día a día, semana a semana o mes a mes, e identifica tendencias o fluctuaciones inusuales.
+- Actualiza el **marco temporal** para monitorizar tendencias sobre tus gastos en la nube.
+
+### Opciones avanzadas (opcionales)
+
+- **Mostrar solo gastos de uso**: Elige incluir todos los gastos (tarifas, impuestos, reembolsos) o centrarte solo en los gastos de uso.
+- **Tipo de coste**: Elige el tipo de coste que mejor se adapte a tus necesidades de elaboración de informes, análisis o gestión financiera. Revisa las definiciones de cada tipo de coste según tu proveedor: [AWS][7], [Azure][8], [Google Cloud][9], [Personalizado][10].
+
+ **Nota**: La disponibilidad de estas opciones varía en función del/de los proveedor(es) seleccionado(s).
+
+## Guardar y compartir tu informe
+
+Una vez creado y personalizado el informe, puedes guardarlo y compartirlo desde la página principal de informes y desde las vistas individuales de informes.
+
+- **Guarda tu informe** para que esté disponible para uso personal o del equipo.
+- **Comparte tu informe** copiando la URL o exportándolo a CSV o PNG.
+- **Programa informes** para que se envíen automáticamente a tu equipo. [Más información sobre la programación de informes][11].
+- **Exporta vistas de informes a dashboards** para realizar un seguimiento de los costes junto con otros widgets.
+- **Busca informes guardados** para encontrar lo que necesitas (solo disponible en la página de informes principales.
+
+## Referencias adicionales
+
+{{< partial name="whats-next/whats-next.html" >}}
+
+[1]: /es/cloud_cost_management/aws/
+[2]: /es/cloud_cost_management/azure/?tab=billingaccounts
+[3]: /es/cloud_cost_management/google_cloud/
+[4]: /es/cloud_cost_management/saas_costs/
+[5]: https://app.datadoghq.com/cost/analyze/reports
+[6]: /es/cloud_cost_management/container_cost_allocation/
+[7]: /es/cloud_cost_management/setup/aws/#cost-types
+[8]: /es/cloud_cost_management/setup/azure/#cost-types
+[9]: /es/cloud_cost_management/setup/google_cloud/#cost-types
+[10]: /es/cloud_cost_management/setup/custom/#cost-metric-types
+[11]: /es/cloud_cost_management/reports/scheduled_reports
+[12]: /es/cloud_cost_management/oracle/
\ No newline at end of file
diff --git a/content/es/cloudprem/manage/_index.md b/content/es/cloudprem/manage/_index.md
new file mode 100644
index 0000000000000..098788465e3fc
--- /dev/null
+++ b/content/es/cloudprem/manage/_index.md
@@ -0,0 +1,82 @@
+---
+description: Aprende a monitorizar, mantener y operar tu despliegue de CloudPrem.
+title: Gestiona y monitoriza CloudPrem
+---
+
+{{< callout btn_hidden="true" >}}
+ CloudPrem de Datadog está en vista previa.
+{{< /callout >}}
+
+## Política de retención
+
+La política de retención especifica cuánto tiempo se almacenan los datos antes de ser eliminados. En forma predeterminada, el periodo de retención está configurado en 30 días. Los datos se eliminan automáticamente en forma diaria por el conserje, que borra las divisiones (archivos de índice) más antiguas que el umbral de retención definido.
+
+Para cambiar el periodo de retención, actualiza el parámetro `cloudprem.index.retention` en el archivo de valores del gráfico de Helm, luego actualiza la versión de Helm y opcionalmente reinicia el pod de conserje para aplicar los cambios de inmediato:
+
+1. Actualiza el periodo de retención en el archivo de valores del gráfico de Helm con una cadena legible por humanos (por ejemplo, `15 days`, `6 months` o `3 years`):
+{{< code-block lang="yaml" filename="datadog-values.yaml">}}
+cloudprem:
+ índice:
+ retención: 6 meses
+{{< /code-block >}}
+
+2. Actualiza la versión del gráfico de Helm:
+
+ ```shell
+ helm upgrade (Contador) | Número de eventos indexados | +| **indexed_events_bytes.count**
(Contador) | Número de bytes indexados | +| **ingest_requests.count**
(Contador) | Número de solicitudes de ingesta | +| **object_storage_delete_requests.count**
(Contador) | Número de solicitudes de eliminación en el almacenamiento de objetos | +| **object_storage_get_requests.count**
(Contador) | Número de solicitudes de obtención en el almacenamiento de objetos | +| **object_storage_get_requests_bytes.count**
(Contador) | Total de bytes leídos del almacenamiento de objetos mediante solicitudes GET | +| **object_storage_put_requests.count**
(Contador) | Número de solicitudes PUT en el almacenamiento de objetos | +| **object_storage_put_requests_bytes.count**
(Contador) | Total de bytes escritos en el almacenamiento de objetos mediante solicitudes PUT | +| **pending_merge_ops.gauge**
(Gauge) | Número de operaciones de fusión pendientes | +| **search_requests.count**
(Contador) | Número de solicitudes de búsqueda | +| **search_requests.duration_seconds**
(Histograma) | Latencia de las solicitudes de búsqueda | +| **metastore_requests.count**
(Contador) | Número de solicitudes de metastore | +| **metastore_requests.duration_seconds**
(Histograma) | Latencia de las solicitudes de metastore | +| **cpu.usage.gauge**
(Gauge) | Porcentaje de uso de la CPU | +| **uptime.gauge**
(Gauge) | Tiempo de actividad del servicio en segundos | +| **memory.allocated_bytes.gauge**
(Gauge) | Memoria asignada en bytes | +| **disk.bytes_read.counter**
(Contador) | Total de bytes leídos desde el disco | +| **disk.bytes_written.counter**
(Contador) | Total de bytes escritos en el disco | +| **disk.available_space.gauge**
(Gauge) | Espacio disponible en disco en bytes | +| **disk.total_space.gauge**
(Gauge) | Capacidad total del disco en bytes | +| **network.bytes_recv.counter**
(Contador) | Total de bytes recibidos por la red | +| **network.bytes_sent.counter**
(Contador) | Total de bytes enviados por la red | + + + +[1]: https://docs.datadoghq.com/es/developers/dogstatsd/?tab=hostagent +[2]: https://app.datadoghq.com/dashboard/lists?q=cloudprem&p=1 \ No newline at end of file diff --git a/content/es/containers/amazon_ecs/_index.md b/content/es/containers/amazon_ecs/_index.md index e545b529fb431..b5ccab24745c3 100644 --- a/content/es/containers/amazon_ecs/_index.md +++ b/content/es/containers/amazon_ecs/_index.md @@ -4,6 +4,7 @@ algolia: - ecs aliases: - /es/agent/amazon_ecs/ +description: Instalar y configurar el Datadog Agent en Amazon Elastic Container Service further_reading: - link: /agent/amazon_ecs/logs/ tag: Documentación @@ -30,11 +31,21 @@ title: Amazon ECS Amazon ECS es un servicio escalable de orquestación de contenedores de alto rendimiento compatible con contenedores de Docker. Con el Datadog Agent, puedes monitorizar contenedores y tareas de ECS en cada instancia EC2 de tu clúster. +Para configurar Amazon ECS con Datadog, puedes utilizar **Fleet Automation** o la **instalación manual**. Si prefieres la instalación manual, ejecuta un contenedor del Agent por host de Amazon EC2 creando una definición de tarea del Datadog Agent e implementándola como servicio daemon. A continuación, cada Agent monitoriza los demás contenedores de tu host. Consulta la sección [Instalación manual](#install-manually) para obtener más detalles. + + +## Configuración de Fleet Automation +Sigue la [guía de instalación de la aplicación en Fleet Automation][32] para completar la configuración en ECS. Tras completar los pasos descritos en la guía de la aplicación, [Fleet Automation][33] genera una definición de tarea o plantilla de CloudFormation lista para usar, con tu clave de API preinyectada. + +{{< img src="agent/basic_agent_usage/ecs_install_page.png" alt="Pasos de instalación en la aplicación para el Datadog Agent en ECS." style="width:90%;">}} +
Si deseas monitorizar ECS en Fargate, consulta Amazon ECS en AWS Fargate.
-## Configuración
++ +## Configuración manual Para monitorizar tus contenedores y tareas de ECS, despliega el Datadog Agent como un contenedor **una vez en cada instancia de EC2** en tu clúster de ECS. Para ello, crea una definición de tarea para el contenedor de Datadog Agent y despliégala como servicio daemon. Cada contenedor de Datadog Agent luego monitoriza los otros contenedores en su respectiva instancia de EC2. @@ -211,10 +222,10 @@ Para recopilar la información de Live Process de todos tus contenedores y envia } {{< /highlight >}} -#### Cloud Network Monitoring +#### Monitorización de redes en la nube
-Esta función sólo está disponible para Linux.
+Esta función solo está disponible para Linux.
Consulta el archivo de ejemplo [datadog-agent-sysprobe-ecs.json][25].
@@ -355,4 +366,6 @@ Puedes ejecutar el Agent en modo `awsvpc`, pero Datadog no lo recomienda porque
[28]: #run-the-agent-as-a-daemon-service
[29]: #set-up-additional-agent-features
[30]: https://docs.aws.amazon.com/AmazonECS/latest/developerguide/task_definitions.html
-[31]: /es/network_monitoring/network_path
\ No newline at end of file
+[31]: /es/network_monitoring/network_path
+[32]: https://app.datadoghq.com/fleet/install-agent/latest?platform=ecs
+[33]:https://app.datadoghq.com/fleet/install-agent/latest?platform=ecs
\ No newline at end of file
diff --git a/content/es/containers/amazon_ecs/logs.md b/content/es/containers/amazon_ecs/logs.md
index b45c4a8b94f97..6f6b0a4a399b2 100644
--- a/content/es/containers/amazon_ecs/logs.md
+++ b/content/es/containers/amazon_ecs/logs.md
@@ -1,6 +1,8 @@
---
aliases:
- /es/agent/amazon_ecs/logs
+description: Configurar la recopilación de logs desde aplicaciones en contenedores
+ que se ejecutan en Amazon ECS con el Datadog Agent
further_reading:
- link: /agent/amazon_ecs/apm/
tag: Documentación
@@ -255,7 +257,7 @@ Consulta la [documentación sobre montajes de AWS Bind][6] para obtener más det
El atributo `source` sirve para identificar la integración que usar para cada contenedor. Sobrescríbelo directamente en tus etiquetas de contenedores para empezar a usar las [integraciones de logs de Datadog][2]. Para obtener más información sobre este proceso, lee la [guía de Autodiscovery para logs][1].
-## Leer más
+## Referencias adicionales
{{< partial name="whats-next/whats-next.html" >}}
diff --git a/content/es/containers/docker/log.md b/content/es/containers/docker/log.md
index 0ff8bb54e88b2..2c21627d42114 100644
--- a/content/es/containers/docker/log.md
+++ b/content/es/containers/docker/log.md
@@ -4,6 +4,8 @@ aliases:
- /es/logs/languages/docker
- /es/logs/log_collection/docker
- /es/agent/docker/log
+description: Configura la recopilación de logs de aplicaciones que se ejecutan en
+ contenedores de Docker utilizando el Datadog Agent
further_reading:
- link: logs/explorer
tag: Documentación
@@ -32,11 +34,11 @@ Datadog Agent v6 y posteriores recopila logs de contenedores. Hay dos tipos de i
La configuración de la recopilación de logs depende de tu entorno actual. Elige una de las siguientes instalaciones para empezar:
-- Si tu entorno escribe **todos** los logs en `stdout`/`stderr`, sigue la instalación del [Agent contenedorizado](?tab=containerized-agent#installation).
+- Si tu entorno escribe **todos** los logs en `stdout`/`stderr`, sigue la instalación del [containerized Agent](?tab=containerized-agent#installation).
-- Si no puedes desplegar el Agent contenedorizado y tu contenedor escribe **todos** los logs en `stdout`/`stderr`, sigue la instalación del [Agent de host](?tab=hostagent#installation) para activar la gestión de logs contenedorizados en tu archivo de configuración del Agent.
+- Si no puedes desplegar el Agent contenedorizado y tu contenedor escribe **todos** los logs en `stdout`/`stderr`, sigue la instalación del [host Agent](?tab=hostagent#installation) para activar la gestión de logs contenedorizados en tu archivo de configuración del Agent.
-- Si tu contenedor escribe logs en archivos (sólo escribe logs parcialmente en `stdout`/`stderr` y escribe logs en archivos O escribe logs en archivos completamente), sigue la instalación del [Agent de host con recopilación de logs personalizada](?tab=hostagentwithcustomlogging#installation) o sigue la instalación del [Agent contenedorizado](?tab=containerized-agent#installation) y comprueba la [recopilación de logs de archivos con el ejemplo de configuración de Autodiscovery](?tab=logcollectionfromfile#examples).
+- Si tu contenedor escribe logs en archivos (sólo escribe logs parcialmente en `stdout`/`stderr` y escribe logs en archivos O escribe logs en archivos completamente), sigue la instalación del [host Agent with custom log collection](?tab=hostagentwithcustomlogging#installation) o sigue la instalación del [containerized Agent](?tab=containerized-agent#installation) y comprueba la [recopilación de logs de archivos con el ejemplo de configuración de Autodiscovery](?tab=logcollectionfromfile#examples).
Los comandos CLI en esta página son para el tiempo de ejecución del Docker. Sustituye `docker` por `nerdctl` para el tiempo de ejecución de containerd, o por `podman`, para el tiempo de ejecución de Podman. La compatibilidad con la recopilación de logs containerd y Podman es limitada.
@@ -318,7 +320,7 @@ labels:
## Recopilación avanzada de logs
-Utiliza etiquetas de logs (labels) de Autodiscovery para aplicar la lógica de procesamiento de la recopilación avanzada de logs, por ejemplo:
+Utiliza etiquetas (labels) de logs de Autodiscovery para aplicar la lógica de procesamiento de la recopilación avanzada de logs, por ejemplo:
- [Filtra los logs antes de enviarlos a Datadog][7].
- [Limpia los datos confidenciales en tus logs][8].
@@ -363,4 +365,4 @@ Para entornos Kubernetes, consulta la [documentación de contendores de Kubernet
[9]: /es/agent/logs/advanced_log_collection/?tab=docker#multi-line-aggregation
[10]: /es/logs/guide/docker-logs-collection-troubleshooting-guide/
[11]: /es/agent/guide/autodiscovery-management/
-[12]: /es/agent/kubernetes/log/?tab=daemonset#short-lived-containers
+[12]: /es/agent/kubernetes/log/?tab=daemonset#short-lived-containers
\ No newline at end of file
diff --git a/content/es/containers/kubernetes/configuration.md b/content/es/containers/kubernetes/configuration.md
index 2b6d25d32f8ea..a68c2248e5435 100644
--- a/content/es/containers/kubernetes/configuration.md
+++ b/content/es/containers/kubernetes/configuration.md
@@ -3,6 +3,8 @@ aliases:
- /es/integrations/faq/gathering-kubernetes-events
- /es/agent/kubernetes/event_collection
- /es/agent/kubernetes/configuration
+description: Opciones de configuración adicionales para APM, logs, procesos, eventos
+ y otras funciones después de instalar el Datadog Agent
title: Configurar mejor el Datadog Agent en Kubernetes
---
diff --git a/content/es/containers/kubernetes/data_collected.md b/content/es/containers/kubernetes/data_collected.md
index 3fb168f042670..6d913f2d7fa90 100644
--- a/content/es/containers/kubernetes/data_collected.md
+++ b/content/es/containers/kubernetes/data_collected.md
@@ -2,6 +2,8 @@
aliases:
- /es/agent/kubernetes/metrics
- /es/agent/kubernetes/data_collected
+description: Guía de referencia para las métricas y eventos recopilados por el Datadog
+ Agent de clústeres de Kubernetes
further_reading:
- link: /agent/kubernetes/log/
tag: Documentación
diff --git a/content/es/containers/kubernetes/installation.md b/content/es/containers/kubernetes/installation.md
index dee639b0ed9a2..d04354d54a67f 100644
--- a/content/es/containers/kubernetes/installation.md
+++ b/content/es/containers/kubernetes/installation.md
@@ -3,6 +3,8 @@ aliases:
- /es/agent/kubernetes/daemonset_setup
- /es/agent/kubernetes/helm
- /es/agent/kubernetes/installation
+description: Instala y configura el Datadog Agent en Kubernetes utilizando el Datadog
+ OperatorHelm o kubectl
further_reading:
- link: /agent/kubernetes/configuration
tag: Documentación
@@ -28,7 +30,7 @@ Para obtener documentación específica y ejemplos de monitorización del plano
Algunas funciones relacionadas con versiones posteriores de Kubernetes requieren una versión mínima de Datadog Agent.
-| Versión de Kubernetes | Versión del Agent | Motivo |
+| Versión de Kubernetes | Agent version | Motivo |
| ------------------ | ------------- | ------------------------------------- |
| 1.16.0+ | 7.19.0+ | Obsolescencia de las métricas de Kubelet |
| 1.21.0+ | 7.36.0+ | Eliminación de recursos de Kubernetes |
@@ -84,7 +86,7 @@ Utiliza la página [Instalación en Kubernetes][16] de Datadog como guía para e
4. **Despliega el Agent con el archivo de configuración anterior**
- Ejecuta lo siguiente:
+ Ejecuta:
```shell
kubectl apply -f datadog-agent.yaml
```
@@ -112,9 +114,11 @@ Utiliza la página [Instalación en Kubernetes][16] de Datadog como guía para e
```yaml
datadog:
apiKeyExistingSecret: datadog-secret
+ clusterName:
Algunas integraciones de Datadog no funcionan con Autodiscovery, ya que requieren datos del árbol de procesos o un acceso a los sistemas de archivos: Ceph, Varnish, Postfix, nodetools Cassandra y Gunicorn.
-Para monitorizar integraciones que no son compatibles con Autodiscovery, puedes utilizar un exportador Prometheus en el pod, para exponer un endpoint HTTP, y luego puedes utilizar la integración con OpenMetrics (compatible con Autodiscovery) para encontrar el pod y consultar el endpoint. +Para monitorizar integraciones que no son compatibles con Autodiscovery, puedes utilizar un exportador Prometheus en el pod, para exponer un endpoint HTTP, y luego puedes utilizar la integración con OpenMetrics (compatible con Autodiscovery) para encontrar el pod y consultar el endpoint.
## Configurar tu integración
@@ -50,7 +52,7 @@ O:
3. [Proporciona valores](#placeholder-values) para estos parámetros.
{{< tabs >}}
-{{% tab "Anotaciones" %}}
+{{% tab "Annotations" %}}
Si defines tus pods de Kubernetes directamente con `kind: Pod`, añade las anotaciones de cada pod directamente bajo su sección `metadata`, como se muestra a continuación:
@@ -78,7 +80,7 @@ spec:
# (...)
```
-**Anotaciones de Autodiscovery v1**
+**Anotaciones de Autodiscovery v1**
```yaml
apiVersion: v1
@@ -101,7 +103,7 @@ spec:
Si defines pods indirectamente (con despliegues, ReplicaSets o ReplicationControllers), añade anotaciones de pod en `spec.template.metadata`.
{{% /tab %}}
-{{% tab "Archivo local" %}}
+{{% tab "Local file" %}}
Puedes almacenar plantillas de Autodiscovery como archivos locales en el directorio montado `conf.d` (`/etc/datadog-agent/conf.d`). Debes reiniciar tus contenedores del Agent cada vez que cambias, añades o eliminas plantillas.
@@ -122,6 +124,29 @@ Puedes almacenar plantillas de Autodiscovery como archivos locales en el directo
2. Monta tu carpeta host `conf.d/` en la carpeta `conf.d` del Agent contenedorizado.
+ Para Datadog Operator:
+ ```yaml
+ spec:
+ override:
+ nodeAgent:
+ volumes:
+ - hostPath:
+ path: -Para monitorizar integraciones que no son compatibles con Autodiscovery, puedes utilizar un exportador Prometheus en el pod, para exponer un endpoint HTTP, y luego puedes utilizar la integración con OpenMetrics (compatible con Autodiscovery) para encontrar el pod y consultar el endpoint. +Para monitorizar integraciones que no son compatibles con Autodiscovery, puedes utilizar un exportador Prometheus en el pod, para exponer un endpoint HTTP, y luego puedes utilizar la integración con OpenMetrics (compatible con Autodiscovery) para encontrar el pod y consultar el endpoint.
Cuando varios CRDs del
-Para monitorizar un [check de clústeres][1], añade una sobreescritura `extraConfd.configDataMap` al componente `clusterAgent`. También debes activar los checks de clústeres configurando `features.clusterChecks.enabled: true`.
+Para monitorizar un [check de clústeres][1], añade una sobreescritura `extraConfd.configDataMap` al componente `clusterAgent`. También debes activar los checks de clústeres configurando `features.clusterChecks.enabled: true`.
```yaml
apiVersion: datadoghq.com/v2alpha1
@@ -292,7 +318,7 @@ datadog:
DatadogAgent desplegados utilizan configDataMap, cada CRD escribe en un ConfigMap compartido llamado nodeagent-extra-confd. Esto puede provocar que las configuraciones se anulen entre sí.
Advertencia para instalaciones sin privilegios
-Cuando se ejecuta una instalación sin privilegios, el Agent necesita poder leer archivos de logs en
-Si estás utilizando el tiempo de ejecución contenedorizado, los archivos de logs en
-Si estás utilizando el tiempo de ejecución Docker, los archivos de logs en
-Para recopilar logs de
## Detección de logs
@@ -262,7 +264,7 @@ spec:
Puedes proporcionar archivos de configuración al Datadog Agent para que ejecute una integración especificada cuando detecte un contenedor que utiliza el identificador de imagen coincidente. Esto permite crear una configuración de log genérica que se aplica a un conjunto de imágenes de contenedor.
{{< tabs >}}
-{{% tab "Datadog Operador" %}}
+{{% tab "Datadog Operator" %}}
Puede personalizar la colección Logs por integración con un override en el `override.nodeAgent.extraConfd.configDataMap`. Este método crea el ConfigMap y monta el archivo Configuración deseado en el Agent Contenedor .
```yaml
@@ -392,7 +394,7 @@ Utiliza etiquetas (labels) de logs de Autodiscovery para aplicar la lógica de p
Datadog recomienda que utilices los flujos de salida `stdout` y `stderr` para aplicaciones en contenedores, de modo que puedas configurar más automáticamente la recopilación de logs.
-Sin embargo, el Agent también puede recopilar directamente logs de un archivo basándose en una anotación. Para recopilar estos logs, utiliza `ad.datadoghq.com/-Cuando se ejecuta una instalación sin privilegios, el Agent necesita poder leer archivos de logs en
/var/log/pods.
+Cuando se ejecuta una instalación sin privilegios, el Agent debe poder leer archivos de log en /var/log/pods.
-Si estás utilizando el tiempo de ejecución contenedorizado, los archivos de logs en
/var/log/pods son legibles por los miembros del grupo raíz. Con las instrucciones anteriores, el Agent se ejecuta con el grupo raíz. No es necesario realizar ninguna acción.
+Si estás utilizando el tiempo de ejecución de containerd, los archivos de log en /var/log/pods son legibles por los miembros del grupo raíz. Con las instrucciones anteriores, el Agent se ejecuta con el grupo raíz. No es necesario realizar ninguna acción.
-Si estás utilizando el tiempo de ejecución Docker, los archivos de logs en
/var/log/pods son enlaces simbólicos a /var/lib/docker/containers, que sólo puede recorrer el usuario raíz. Consecuentemente, con el tiempo de ejecución Docker, no es posible para un Agent no raíz leer logs en /var/log/pods. El socket Docker debe estar montado en el contenedor del Agent, para que pueda obtener logs de pod a través del Docker daemon.
+Si estás utilizando el tiempo de ejecución de Docker, los archivos de log en /var/log/pods son enlaces simbólicos a /var/lib/docker/containers que solo puede recorrer el usuario raíz. Consecuentemente, con el tiempo de ejecución de Docker, no es posible para un Agent que no raíz leer logs en /var/log/pods. El socket de Docker debe estar montado en contenedor del Agent, para que pueda obtener logs de pod a través del daemon de Docker.
-Para recopilar logs de
/var/log/pods cuando el socket Docker está montado, define la variable de entorno DD_LOGS_CONFIG_K8S_CONTAINER_USE_FILE (o logs_config.k8s_container_use_file en datadog.yaml) como true. Esto fuerza al Agent a utilizar el modo de recopilación de archivos.
+Para recopilar logs de /var/log/pods/ cuando el socket de Docker está montado, establece la variable entorno DD_LOGS_CONFIG_K8S_CONTAINER_USE_FILE (o logs_config.k8s_container_use_file en datadog.yaml) en true. Esto fuerza al Agent a utilizar el modo de recopilación de archivos.
Esta página trata sobre traer tus métricas y datos de Continuous Integration (CI) a dashboards de Datadog. Si deseas ejecutar tests de Continuous Testing en tus pipelines de CI, consulta la sección Continuous Testing y CI/CD.
+Esta página trata sobre traer tus métricas y datos de integración continua (CI) en dashboards de Datadog. Si deseas ejecutar tests de Continuous Testing en tus pipelines de CI, consulta la sección Continuous Testing y CI/CD.
{{< learning-center-callout header="Join an enablement webinar session" hide_image="true" btn_title="Sign Up" btn_url="https://www.datadoghq.com/technical-enablement/sessions/?etiquetas (tags).topics-0=CI">}}
Únete a la sesión de Introducción a CI Visibility para comprender cómo Datadog CI Visibility mejora la eficiencia de los pipelines de CI y cómo configurar los productos de Testing Visibility y Pipeline Visibility.
diff --git a/content/es/continuous_integration/guides/_index.md b/content/es/continuous_integration/guides/_index.md
index 059fd79d3d12e..43157485c15d8 100644
--- a/content/es/continuous_integration/guides/_index.md
+++ b/content/es/continuous_integration/guides/_index.md
@@ -9,9 +9,11 @@ private: true
title: Guías de CI Visibility
---
-{{< whatsnext desc="Pipeline Visibility Guides:" >}}
+{{< whatsnext desc="Guías de Pipeline Visibility:" >}}
{{< nextlink href="/continuous_integration/guides/ingestion_control" >}}Creación de filtros de exclusión para el control de ingesta{{< /nextlink >}}
{{< nextlink href="/continuous_integration/guides/pipeline_data_model" >}}Comprender el modelo de datos de pipeline y tipos de ejecución{{< /nextlink >}}
{{< nextlink href="/continuous_integration/guides/infrastructure_metrics_with_gitlab" >}}Correlación de métricas de infraestructura con trabajos de GitLab en Datadog{{< /nextlink >}}
{{< nextlink href="/account_management/billing/ci_visibility/" >}}Consideraciones de facturación de CI Visibility{{< /nextlink >}}
+ {{< nextlink href="/continuous_integration/guides/identify_highest_impact_jobs_with_critical_path/" >}}Identificación de trabajos de CI en la ruta crítica para reducir la duración del pipeline{{< /nextlink >}}
+ {{< nextlink href="/continuous_integration/guides/use_ci_jobs_failure_analysis/" >}} Uso de análisis de error de trabajos de CI para identificar causas raíz en trabajos fallidos{{< /nextlink >}}
{{< /whatsnext >}}
\ No newline at end of file
diff --git a/content/es/continuous_integration/troubleshooting.md b/content/es/continuous_integration/troubleshooting.md
index c8edf000f9649..92a0fc0a9b50a 100644
--- a/content/es/continuous_integration/troubleshooting.md
+++ b/content/es/continuous_integration/troubleshooting.md
@@ -38,16 +38,20 @@ La falta de etapas o tareas en la página _Detalles del pipeline_ puede deberse
[Las variables definidas por el usuario en Gitlab][16] deben ser informadas en el campo `@ci.parameters` en CI Visibility. Sin embargo, esta información sólo está presente en algunos casos, como los pipelines aguas abajo, y puede faltar en el resto de los casos, ya que Gitlab [no siempre proporciona esta información][17] a Datadog.
-### Limitaciones en la ejecución de pipelines
+## Limitaciones en la ejecución de pipelines
-#### La entrega de eventos de webhook no está garantizada por los proveedores de CI
+### La entrega de eventos de webhook no está garantizada por los proveedores de CI
El soporte para la ejecución de pipelines depende de los datos enviados por los proveedores de CI, indicando el estado de la ejecución. Si estos datos no están disponibles, es posible que las ejecuciones marcadas como `Running` en Datadog ya hayan finalizado.
-#### Duración máxima de la ejecución de un pipeline
+### Duración máxima de la ejecución de un pipeline
Una ejecución de pipeline puede conservar el estado `Running` durante un máximo de tres días. Si sigue en ejecución después de ese tiempo, la ejecución del pipeline no aparece en CI Visibility. Si una ejecución de pipeline finaliza después de tres días, la ejecución del pipeline finalizada aparece en CI Visibility con su correspondiente estado final (`Success`, `Error`, `Canceled`, `Skipped`) y con la duración correcta.
+## Limitaciones a los trabajos terminados de los pipelines
+
+Los datos de trabajo tienen un límite de tres días para ser procesados tras su finalización. Si un pipeline incluye trabajos que finalizan más de tres días antes de que se reciba el pipeline, esos trabajos no se procesan y no aparecen en CI Visibility.
+
## Referencias adicionales
{{< partial name="whats-next/whats-next.html" >}}
diff --git a/content/es/dashboards/functions/exclusion.md b/content/es/dashboards/functions/exclusion.md
index 687bc5c04acb9..b089f1cc61092 100644
--- a/content/es/dashboards/functions/exclusion.md
+++ b/content/es/dashboards/functions/exclusion.md
@@ -1,6 +1,8 @@
---
aliases:
- /es/graphing/functions/exclusion/
+description: Excluye los valores nulos y aplica un filtrado basado en umbrales utilizando
+ funciones de sujeción y corte en las métricas.
title: Exclusión
---
diff --git a/content/es/dashboards/functions/interpolation.md b/content/es/dashboards/functions/interpolation.md
index 89d6368aaad84..45018e504e442 100644
--- a/content/es/dashboards/functions/interpolation.md
+++ b/content/es/dashboards/functions/interpolation.md
@@ -1,6 +1,8 @@
---
aliases:
- /es/graphing/functions/interpolation/
+description: Rellena los valores de métricas faltantes utilizando métodos de interpolación
+ lineal, de último valor, cero o nulo en datos de series temporales.
further_reading:
- link: /dashboards/functions/
tag: Documentación
@@ -37,7 +39,7 @@ Lee la sección de [La interpolación y el modificador de relleno][1] para obten
La función `default_zero()` rellena los intervalos de tiempo vacíos con el valor 0 o, si la interpolación se encuentra habilitada, con la interpolación. **Nota**: La interpolación se encuentra habilitada por defecto para las métricas de tipo `GAUGE`. Como la mayoría de las funciones, `default_zero()` se aplica **después** de la [agregación temporal y espacial][2].
-### Casos de uso
+### Casos prácticos
La función `default_zero()` está destinada a abordar los siguientes casos de uso (aunque también puede servir para otros):
@@ -92,7 +94,7 @@ default_zero(avg:custom_metric{*})
+---------------------+-----------------------------+
```
-## Lectura adicional
+## Referencias adicionales
{{< partial name="whats-next/whats-next.html" >}}
diff --git a/content/es/dashboards/functions/rate.md b/content/es/dashboards/functions/rate.md
index 75d9a2b4df8ad..66b8e0cb35ebb 100644
--- a/content/es/dashboards/functions/rate.md
+++ b/content/es/dashboards/functions/rate.md
@@ -1,6 +1,8 @@
---
aliases:
- /es/graphing/functions/rate/
+description: Calcula tasas, derivadas y diferencias de tiempo para analizar cambios
+ en métricas por segundo, minuto u hora.
further_reading:
- link: /monitors/guide/alert-on-no-change-in-value/
tag: Documentación
@@ -75,6 +77,6 @@ Calcula la diferencia entre cada intervalo por intervalo. Por ejemplo, una métr
{{< nextlink href="/dashboards/functions/timeshift" >}}Cambio temporal: cambia el punto de datos de tu métrica dentro de la línea de tiempo. {{< /nextlink >}}
{{< /whatsnext >}}
-## Leer más
+## Referencias adicionales
{{< partial name="whats-next/whats-next.html" >}}
\ No newline at end of file
diff --git a/content/es/dashboards/functions/rollup.md b/content/es/dashboards/functions/rollup.md
index beb7e8a2016f5..5412d022f0d60 100644
--- a/content/es/dashboards/functions/rollup.md
+++ b/content/es/dashboards/functions/rollup.md
@@ -1,6 +1,8 @@
---
aliases:
- /es/graphing/functions/rollup/
+description: Controla la agregación temporal y los intervalos de puntos de datos mediante
+ funciones de rollup personalizadas y rollups móviles para métricas.
further_reading:
- link: /dashboards/guide/rollup-cardinality-visualizations
tag: Documentación
diff --git a/content/es/dashboards/functions/smoothing.md b/content/es/dashboards/functions/smoothing.md
index 99b93a63058b1..fbc7a7a2e5d16 100644
--- a/content/es/dashboards/functions/smoothing.md
+++ b/content/es/dashboards/functions/smoothing.md
@@ -1,6 +1,8 @@
---
aliases:
- /es/graphing/functions/smoothing/
+description: Reduce el ruido en los datos métricos utilizando autosmooth, medias móviles
+ ponderadas exponencialmente, filtros de mediana y funciones ponderadas.
title: Suavizado
---
diff --git a/content/es/dashboards/functions/timeshift.md b/content/es/dashboards/functions/timeshift.md
index 1586f08725f03..f951e55d0a0e7 100644
--- a/content/es/dashboards/functions/timeshift.md
+++ b/content/es/dashboards/functions/timeshift.md
@@ -1,6 +1,9 @@
---
aliases:
- /es/graphing/functions/timeshift/
+description: Compara los valores actuales de las métricas con los datos históricos
+ mediante las funciones de cambio temporal, desplazamiento de calendario y comparación
+ basada en el tiempo.
further_reading:
- link: /dashboards/faq/how-can-i-graph-the-percentage-change-between-an-earlier-value-and-a-current-value/
tag: FAQ
@@ -51,7 +54,7 @@ Este es un ejemplo de `system.load.1` con el valor `hour_before()` mostrado como
## Día anterior
-La función de día anterior está obsoleta. En su lugar, utiliza el desplazamiento del calendario con un valor de "-1d".
+La función de día anterior está obsoleta. En su lugar, utiliza el desplazamiento de calendario con un valor de "-1d".
| Función | Descripción | Ejemplo |
|:---------------|:---------------------------------------------------------------------|:-------------------------------|
@@ -63,7 +66,7 @@ Este es un ejemplo de `nginx.net.connections` con el valor de `day_before()` mos
## Semana anterior
-La función de semana anterior está obsoleta. En su lugar, utiliza el desplazamiento del calendario con un valor de "-7d".
+La función de semana anterior está obsoleta. En su lugar, utiliza el desplazamiento de calendario con un valor de "-7d".
| Función | Descripción | Ejemplo |
|:----------------|:-------------------------------------------------------------------------------|:--------------------------------|
diff --git a/content/es/dashboards/guide/custom_time_frames.md b/content/es/dashboards/guide/custom_time_frames.md
index 318287b3d173c..8c60ca746f5f3 100644
--- a/content/es/dashboards/guide/custom_time_frames.md
+++ b/content/es/dashboards/guide/custom_time_frames.md
@@ -1,4 +1,7 @@
---
+description: Utiliza sintaxis de marcos temporales personalizados, incluidas fechas
+ fijas, fechas relativas y periodos alineados con el calendario en los dashboards
+ de Datadog.
title: Marco temporal personalizadas
---
@@ -10,7 +13,7 @@ Muchas de las vistas de Datadog pueden ajustarse a un marco temporal específico
Para incrementar por mes, día, año, hora o minuto, resalta una parte del marco temporal y utiliza las teclas `[↑]` y `[↓]`:
-{{< img src="dashboards/guide/custom_time_frames/increment_with_arrow_keys.mp4" alt="Incrementar el tiempo con teclas de flechas" video="true" width="500" >}}
+{{< img src="dashboards/guide/custom_time_frames/increment_with_arrow_keys.mp4" video="true" alt="Incrementar el tiempo con teclas de flechas" width="500" >}}
## Sintaxis admitidas
diff --git a/content/es/dashboards/guide/how-to-graph-percentiles-in-datadog.md b/content/es/dashboards/guide/how-to-graph-percentiles-in-datadog.md
index e8bcbea2fb937..911c1661b18e9 100644
--- a/content/es/dashboards/guide/how-to-graph-percentiles-in-datadog.md
+++ b/content/es/dashboards/guide/how-to-graph-percentiles-in-datadog.md
@@ -2,6 +2,8 @@
aliases:
- /es/graphing/faq/how-to-graph-percentiles-in-datadog
- /es/graphing/guide/how-to-graph-percentiles-in-datadog
+description: Envía datos de histograma a través de DogStatsD para generar métricas
+ de percentiles, incluidos los percentiles 95 y 50, la media, el máximo y el recuento.
title: ¿Cómo representar gráficamente los percentiles en Datadog?
---
diff --git a/content/es/dashboards/guide/how-to-use-terraform-to-restrict-dashboard-edit.md b/content/es/dashboards/guide/how-to-use-terraform-to-restrict-dashboard-edit.md
index bfe54a367921d..f259fb45e818e 100644
--- a/content/es/dashboards/guide/how-to-use-terraform-to-restrict-dashboard-edit.md
+++ b/content/es/dashboards/guide/how-to-use-terraform-to-restrict-dashboard-edit.md
@@ -2,6 +2,8 @@
aliases:
- /es/dashboards/faq/how-to-use-terraform-to-restrict-dashboards
- /es/dashboards/guide/how-to-use-terraform-to-restrict-dashboards
+description: Utiliza el atributo restricted_roles en Terraform para controlar los
+ permisos de edición de dashboards para roles de usuario específicos.
title: Cómo utilizar Terraform para restringir la edición de un dashboard
---
@@ -23,7 +25,7 @@ recurso "datadog_dashboard" "ejemplo" {
## Restringir un dashboard utilizando una política de restricción
-Las políticas de restricción están en Vista previa. Para obtener acceso, ponte en contacto con el servicio de asistencia de Datadog o con tu asesor de clientes.
+Las políticas de restricción están en vista previa. Ponte en contacto con el servicio de asistencia de Datadog o con tu asesor de clientes para obtener acceso.
Las [políticas de restricción][1] te permiten restringir la edición de dashboards y otros recursos a responsables específicos, incluyendo roles, equipos, usuarios y cuentas de servicio.
diff --git a/content/es/dashboards/guide/query-to-the-graph.md b/content/es/dashboards/guide/query-to-the-graph.md
index 0112db00b637d..daedfd80a5c85 100644
--- a/content/es/dashboards/guide/query-to-the-graph.md
+++ b/content/es/dashboards/guide/query-to-the-graph.md
@@ -1,6 +1,8 @@
---
aliases:
- /es/dashboards/faq/query-to-the-graph
+description: Comprende cómo el sistema de gráficos de Datadog procesa las consultas
+ y las representa mediante líneas de gráficos con pasos de ejecución de backend.
title: Consulta al gráfico
---
@@ -103,7 +105,7 @@ Datadog ofrece 4 agregadores espaciales:
* `máx.`
* `mín.`
* `prom.`
-* `suma`
+* `sum`
## Aplica funciones (opcional)
diff --git a/content/es/dashboards/template_variables.md b/content/es/dashboards/template_variables.md
index 864597480f5ef..40fa85d1729f2 100644
--- a/content/es/dashboards/template_variables.md
+++ b/content/es/dashboards/template_variables.md
@@ -3,6 +3,9 @@ aliases:
- /es/graphing/dashboards/template_variables/correlate-metrics-and-events-using-dashboard-template-variables
- /es/graphing/dashboards/template_variables/how-do-i-overlay-events-onto-my-dashboards
- /es/graphing/dashboards/template_variables/
+description: Utiliza variables de plantilla para filtrar dinámicamente los widgets
+ del dashboard por etiquetas, atributos y facetas para una exploración flexible de
+ los datos.
further_reading:
- link: https://www.datadoghq.com/blog/template-variable-associated-values/
tag: Blog
@@ -29,7 +32,7 @@ title: Variables de plantilla
## Información general
-Las variables de plantilla te permiten filtrar dinámicamente uno o más widgets en un dashboard. Puedes crear vistas guardadas, a partir de tus selecciones de variables de plantilla, para organizar y navegar por tus visualizaciones a través de las selecciones desplegables.
+Las variables de plantilla permiten filtrar o agrupar dinámicamente los widgets de un dashboard. Puedes crear vistas guardadas a partir de tus selecciones de variables de plantilla para organizar y navegar por tus visualizaciones a través de las selecciones desplegables.
Una variable de plantilla se determina por:
@@ -43,20 +46,28 @@ Una variable de plantilla se determina por:
**Nota**: Si no ves la etiqueta o el atributo que buscas, puede deberse a que esos datos no se han informado a Datadog recientemente. Para obtener más información, consulta [Datos históricos][4].
## Añadir una variable de plantilla
+Si las variables de plantilla ya están definidas, consulta [Editar una variable de plantilla](#edit-a-template-variable). Si tu dashboard no tiene ninguna variable de plantilla, puedes hacer clic en el icono del signo de interrogación para abrir un modal de ayuda sobre cómo utilizar las variables del dashboard.
+
+{{< img src="/dashboards/template_variables/template_variable_menu.png" alt="Menú de Variable de entorno que muestra la opción Configurar los valores desplegables" style="width:70%;" >}}
Para añadir una variable de plantilla en un dashboard:
-1. Haz clic en **Add Variables** (Añadir variables).
-1. Si las variables de plantilla ya están definidas, pasa el cursor sobre el encabezado del dashboard y haz clic en el botón **Edit** (Editar) para acceder al modo de edición.
-1. En el modo de edición, haz clic en el icono **+ (más)** para crear una nueva variable de plantilla.
+1. Haz clic en **Add Variable** (Añadir variable).
+1. Puedes añadir tipos de variables **Filter** (Filtrar) y **Group by** (Agrupar por).
+ 1. Filtrar: añade una etiqueta o atributo para filtrar las consultas y visualizaciones del dashboard.
+ 1. Agrupar por: añade una etiqueta o atributo para mostrar un desglose de los grupos dentro de tus datos.**Nota**: `Group by` solo es compatible con determinados widgets---Series temporales, Tabla, Mapa de árbol, Gráfico de barras, Comodín, Distribución, Lista principal, Mapa de calor, Gráfico circular, Geomapa, Cambio, Gráfico de dispersión, Valor de consulta, Mapa de hosts y Resumen de SLO. 1. (Opcional) Después de seleccionar una etiqueta, haz clic en el botón **+ Configure Dropdown Values** (+ Configurar valores desplegables), para cambiar el nombre de la variable y establecer valores predeterminados o disponibles. - {{< img src="dashboards/template_variables/add_template_variable_configure_dropdown_values.png" alt="Añadir ventana emergente de la variable que muestra el botón **+ Configure Dropdown Values** (+ Configurar valores desplegables)" style="width:80%;" >}} +1. Haz clic en **Save** (Guardar). +1. Para añadir más variables de plantilla, consulta [Editar una variable de plantilla](#edit-a-template-variable) + ## Editar una variable de plantilla -Para editar una variable de plantilla en un dashboard: -1. Haz clic en el botón **Edit** (Editar) del encabezado del dashboard. +Para editar una variable de plantilla o añadir variables: +1. Pasa el ratón por encima del encabezado del dashboard y haz clic en el botón **Edit** (Editar). 1. En el modo de edición, haz clic en una variable de plantilla y realiza cambios en la ventana emergente. 1. Para reorganizar las variables en el encabezado, pasa el cursor sobre una variable, y luego haz clic y arrastra el asa del icono de arrastre. +1. Haz clic en el icono **+ (plus)** (+ (más)) para añadir una nueva variable de plantilla. +1. (Opcional) Después de seleccionar una etiqueta, haz clic en el botón **+ Configure Dropdown Values** (+ Configurar valores desplegables), para cambiar el nombre de la variable y establecer valores predeterminados o disponibles. {{< img src="dashboards/template_variables/edit_template_variable_drag.png" alt="Ventana emergente del modo de edición de una variable de plantilla que muestra el icono de arrastre y te permite volver a acomodar el orden" style="width:100%;" >}} ## Aplicar una variable de plantilla a widgets @@ -77,7 +88,7 @@ Para añadir una variable de plantilla a las consultas de widgets: ### Crear 1. Haz clic en el menú desplegable **Saved Views** (Vistas guardadas) a la izquierda de las variables de plantilla en tu dashboard. Al actualizar el valor de una variable de plantilla, dicho valor no se guarda automáticamente en una vista. -1. Para guardar los valores actuales de variables de plantilla en una vista, selecciona **Guardar selecciones como vista** en el menú desplegable **Vistas guardadas**. +1. Para guardar los valores actuales de las variables de plantilla en una vista, selecciona **Save selections as view** (Guardar selecciones como vista) en el menú desplegable **Saved Views** (Vistas guardadas). 1. Introduce un nombre único para la vista con una descripción en opcional. 1. Haz clic en **Save** (Guardar). @@ -87,14 +98,14 @@ La vista guardada aparecerá en el menú desplegable. Haz clic en ella para recu ### Borrar -1. Haz clic en el menú desplegable de vistas guardadas y pasa el ratón por encima de la vista guardada deseada. +1. Haz clic en el menú desplegable de vistas guardadas y pasa el ratón por encima de la vista guardada que desees. 1. Haz clic en **Delete View** (Eliminar vista). ### Modificar La **vista por defecto** sólo puede editarse cambiando los valores por defecto de las variables de plantilla. Para editar la vista por defecto: 1. Pasa el ratón por encima de las plantillas. -1. Haz clic en **Edit** (Editar) cuando aparezca el botón. +1. Haz clic en **Edit** (Editar) cuando aparezca el botón. 1. Haz clic en **Done** (Listo) para guardar. Para modificar valores de variables de plantilla para otras vistas guardadas: @@ -125,7 +136,7 @@ En los widgets de log, APM y RUM, se pueden utilizar comodines en mitad de un va ### Widgets -Al crear o editar un widget, las variables de plantilla existentes se muestran como opciones en el campo `from`. Por ejemplo, si configuras la variable de plantilla `environment`, la opción `$environment` estará disponible como variable dinámica en el widget. +Al crear o editar un widget, las variables de plantilla de filtro existentes se muestran como opciones en el campo `from`, y las variables de plantilla de Agrupar por existentes se muestran como opciones a continuación del campo `by`. Por ejemplo, si configuras la variable de plantilla `environment`, la opción `$environment` estará disponible como variable dinámica en el widget. {{< img src="dashboards/template_variables/dynamic_template_variable.png" alt="La variable de plantilla puede definirse de forma dinámica en los widgets" style="width:100%;">}} diff --git a/content/es/dashboards/widgets/_index.md b/content/es/dashboards/widgets/_index.md index f256665096341..575480b1300be 100644 --- a/content/es/dashboards/widgets/_index.md +++ b/content/es/dashboards/widgets/_index.md @@ -3,215 +3,94 @@ aliases: - /es/graphing/dashboards/widgets - /es/graphing/faq/widgets - /es/graphing/widgets +description: Bloques de construcción de dashboard para visualizar y correlacionar + datos en toda la infraestructura con varios tipos de gráficos y visualizaciones. further_reading: -- link: /dashboards/guide/context-links/ +- link: /dashboards/ tag: Documentación - text: Enlaces personalizados -- link: https://www.datadoghq.com/blog/observability-pipelines-transform-and-enrich-logs/ - tag: Blog - text: Transformar y enriquecer tus logs con pipelines de observabilidad de datos + text: Más información sobre dashboards +- link: /dashboards/widgets/configuration + tag: Documentación + text: Conoce las opciones de configuración de los widgets y las mejores prácticas +- link: /dashboards/widgets/types/ + tag: Documentación + text: Explorar todos los tipos de widgets disponibles title: Widgets --- ## Información general -Los widgets son componentes básicos de tus dashboards. Te permiten visualizar y correlacionar los datos en tu infraestructura. - -### Gráficos -{{< whatsnext desc="Widgets genéricos para graficar datos a partir de productos Datadog: ">}} - {{< nextlink href="/dashboards/widgets/change" - img="dashboards/widgets/icons/change_light_large.png">}} Cambio {{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/distribution" - img="dashboards/widgets/icons/distribution_light_large.png">}} Distribución {{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/funnel" - img="dashboards/widgets/icons/funnel_light_large.png">}} Embudo {{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/geomap" - img="dashboards/widgets/icons/geomap_light_large.png">}} Geomap {{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/heat_map" - img="dashboards/widgets/icons/heatmap_light_large.png">}} Heatmap {{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/pie_chart" - img="dashboards/widgets/icons/pie_light_large.png">}} Gráfico circular {{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/query_value" - img="dashboards/widgets/icons/query-value_light_large.png">}} Valor de consulta {{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/sankey" img="dashboards/widgets/icons/sankey_light_large.svg">}} Sankey{{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/scatter_plot" - img="dashboards/widgets/icons/scatter-plot_light_large.png">}} Diagrama de dispersión {{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/table" - img="dashboards/widgets/icons/table_light_large.png">}} Tabla {{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/treemap" - img="dashboards/widgets/icons/treemap_light_large.png">}} Treemap {{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/timeseries" - img="dashboards/widgets/icons/timeseries_light_large.png">}} Series temporales {{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/top_list" - img="dashboards/widgets/icons/top-list_light_large.png">}} .Lista principal {{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/wildcard" - img="/dashboards/widgets/icons/wildcard_light_large.svg">}} Comodín {{< /nextlink >}} -{{< /whatsnext >}} - -### Groups (grupos) -{{< whatsnext desc="Muestra tus widgets en grupos: ">}} - {{< nextlink href="/dashboards/widgets/group" - img="dashboards/widgets/icons/group_default_light_large.svg">}} Grupo{{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/powerpack" - img="dashboards/widgets/icons/group_powerpack_light_large.svg">}} Powerpack{{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/split_graph" - img="dashboards/widgets/icons/group-split_light_small.svg">}} Gráfica dividida{{< /nextlink >}} -{{< /whatsnext >}} - -### Anotaciones y embeds -{{< whatsnext desc="Widgets de decoración para estructurar y comentar dashboards de manera visual: ">}} - {{< nextlink href="/dashboards/widgets/free_text" - img="dashboards/widgets/icons/free-text_light_large.png">}} Texto libre{{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/iframe" - img="dashboards/widgets/icons/iframe_light_large.png">}} Iframe{{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/image" - img="dashboards/widgets/icons/image_light_large.png">}} Imagen{{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/note" - img="dashboards/widgets/icons/notes_light_large.png">}} Notas y enlaces{{< /nextlink >}} -{{< /whatsnext >}} +Los widgets de dashboard son representaciones visuales de los datos. Sirven como bloques de construcción para tus [dashboards][2] para visualizar y correlacionar tus datos a través de tu infraestructura. Pueden contener distintos tipos de información, como gráficos, imágenes, logs y estados, para ofrecerte una visión general de tus sistemas y entornos. -### Listas y flujos -{{< whatsnext desc="Muestra una lista de eventos y problemas provenientes de diferentes fuentes: ">}} - {{< nextlink href="/dashboards/widgets/list" - img="dashboards/widgets/icons/change_light_large.png">}} Lista{{< /nextlink >}} -{{< /whatsnext >}} +## Para empezar -### Alerta y respuesta -{{< whatsnext desc="Widgets de resumen para mostrar información de monitorización: ">}} - {{< nextlink href="/dashboards/widgets/alert_graph" - img="dashboards/widgets/icons/alert-graph_light_large.png">}} Gráfica de alertas{{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/alert_value" - img="dashboards/widgets/icons/alert-value_light_large.png">}}Valor de alerta{{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/check_status" - img="dashboards/widgets/icons/check-status_light_large.png">}} Estado del check{{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/monitor_summary" - img="dashboards/widgets/icons/monitor-summary_light_large.png">}} Resumen de monitores{{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/run_workflow" - img="dashboards/widgets/icons/run-workflow_light_small.svg">}} Ejecutar flujo de trabajo{{< /nextlink >}} -{{< /whatsnext >}} +La forma más rápida de incorporar widgets relevantes para tus datos es clonar un dashboard de la [lista de preajustes][1], que incluye dashboards creados por otros miembros de tu organización y plantillas predefinidas para tus integraciones instaladas. Después de clonar un dashboard, puedes personalizar los widgets según tu caso de uso. -### Arquitectura -{{< whatsnext desc="Visualiza los datos de la infraestructura y la arquitectura: ">}} - {{< nextlink href="/dashboards/widgets/hostmap" - img="dashboards/widgets/icons/host-map_light_large.png">}} Mapa de host{{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/topology_map" - img="dashboards/widgets/icons/service-map_light_large.png">}} Mapa de topología{{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/service_summary" - img="dashboards/widgets/icons/service-summary_light_large.png">}} Resumen de servicio{{< /nextlink >}} -{{< /whatsnext >}} -### Rendimiento y fiabilidad -{{< whatsnext desc="Visualizaciones de fiabilidad del sitio: ">}} - {{< nextlink href="/dashboards/widgets/profiling_flame_graph" - img="dashboards/widgets/icons/profiling_flame_graph.svg">}} Gráfica de llamas de perfiles{{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/slo" - img="dashboards/widgets/icons/slo-summary_light_large.png">}} Resumen de objetivos de nivel de servicio (SLOs){{< /nextlink >}} - {{< nextlink href="/dashboards/widgets/slo_list" - img="dashboards/widgets/icons/slo-list_light_large.png">}} Objetivo de nivel de servicio (SLO){{< /nextlink >}} +{{< whatsnext desc="Guías adicionales y cursos para conocer sobre widgets:" >}} + {{< nextlink href="/getting_started/dashboards/" >}}Introducción a dashboards: instrucciones para crear un dashboard con widgets{{< /nextlink >}} + {{< nextlink href="https://learn.datadoghq.com/courses/dashboard-graph-widgets" >}}Widgets de gráfico de dashboard: curso del centro de aprendizaje que explica cómo crear, configurar y usar widgets de gráfico de dashboard{{< /nextlink >}} + {{< nextlink href="https://learn.datadoghq.com/courses/intro-dashboards" >}}Introducción a dashboards: curso del centro de aprendizaje que explica cómo crear un dashboard en un entorno de pruebas{{< /nextlink >}} {{< /whatsnext >}} -## Pantalla completa - -Puedes ver la mayoría de los widgets en el modo de pantalla completa y hacer lo siguiente: - -* Cambiar los períodos -* Retroceder o avanzar en función del período de tiempo seleccionado -* Pausar la gráfica en el momento actual o visualizar la gráfica en directo -* Restablecer el período de tiempo -* Exportar la gráfica a un dashboard o notebook, o copiar la consulta -* Descargar los datos que producen la gráfica en formato CSV - -Para acceder directamente a la vista general del widget, haz clic en el botón de pantalla completa en la esquina superior derecha del widget. - -Hay opciones adicionales disponibles para los [widgets de serie temporal][1]. - -## Enlaces personalizados - -Los enlaces personalizados conectan valores de datos a URLs, como una página de Datadog o tu consola de AWS. - -Para personalizar las interacciones con los datos en línea de tus widgets genéricos, consulta la sección de [Enlaces personalizados][2]. - -## Anulación de unidad - -Personaliza los valores de las unidades que se muestran en los widgets para añadir contexto a tus datos. Para obtener más información y casos de uso, consulta la sección de [Personalizar las visualizaciones con anulaciones de unidades][3]. -- **Anulación de unidad**: elige mostrar unidades en la familia de la «memoria» y haz que Datadog se encargue de mostrar la escala adecuada en función de los datos (como megabytes o gigabytes). -- **Anulación de unidad y escala**: fija las unidades en una sola escala (muestra los datos en megabytes independientemente del valor). -- **Definir unidades personalizadas**: define unidades completamente personalizadas (como «pruebas» en lugar de un recuento genérico). - -Esta no es una alternativa para asignar unidades a tus datos. -{{< whatsnext desc="Establece unidades a nivel de la organización: ">}} - {{< nextlink href="/metrics/units/">}} Establecer unidades de métricas{{< /nextlink >}} - {{< nextlink href="/logs/explorer/facets/#units">}} Establecer unidades para consultas basadas en eventos{{< /nextlink >}} -{{< /whatsnext >}} - -## Selector de hora global - -Para utilizar el selector de hora global, al menos un widget basado en la hora debe tener configurado el uso de `Global Time`. Para ello, selecciona el widget en el editor de widgets, en **Set display preferences** (Configurar las preferencias de visualización), o añade un widget (la configuración de hora por defecto es la hora global). - -El selector de tiempo general establece el mismo período de tiempo para todos los widgets mediante la opción `Global Time` en el mismo dashboard. Selecciona un intervalo móvil en el pasado (por ejemplo, `Past 1 Hour` o `Past 1 Day`) o un período fijo con la opción `Select from calendar...`, o [ingresa un período de tiempo personalizado][11]. Si se elige un intervalo móvil, los widgets se actualizan para moverse junto con dicho intervalo. - -Los widgets no vinculados a la hora global muestran los datos de su periodo de tiempo local aplicados a la ventana global. Por ejemplo, si el selector de hora global está configurado del 1 de enero de 2019 al 2 de enero de 2019, un widget configurado con el marco de hora local para `Past 1 Minute` muestra el último minuto del 2 de enero de 2019 a partir de las 23:59. - -## Copiar y pegar widgets - -
Debes contar con los permisos
-
-Los widgets se pueden copiar en [dashboards][4], [notebooks][5], [servicios de APM][6] y la página de [recursos de APM][7] con `Ctrl + C` (`Cmd + C` para Mac), o al seleccionar el icono de compartir y elegir «Copy» (Copiar).
-
-Los widgets copiados se pueden pegar dentro de Datadog con `Ctrl + V` (`Cmd + V` para Mac) en:
-
-* **Dashboards**: añade un widget nuevo ubicado debajo del cursor del mouse.
-* **Notebooks**: añade una celda nueva al final del notebook.
-
-También puedes pegar el widget en tu programa de chat favorito que muestre previsualizaciones de enlaces (como Slack o Microsoft Teams). Esto muestra una imagen snapshot de tu gráfica junto con un enlace directo al widget.
+### Añadir un widget a tu dashboard
-### Grupos de widgets
+Para empezar a utilizar widgets en tus dashboards:
-Los widgets del grupo del timeboard se pueden copiar al colocar el cursor por encima de la zona del widget del grupo y al utilizar `Ctrl + C` (`Cmd + C` para Mac) o seleccionar el icono de compartir y elegir «Copy» (Copiar).
+1. Navega hasta la [Lista de dashboards][1] en Datadog.
+2. Haz clic en **New Dashboard** (Nuevo dashboards) o selecciona un dashboard existente para editarlo.
+3. Haz clic en **Add Widget** (Añadir widget). Elige entre una variedad de tipos de widgets como series de tiempo, gráfico de barras, tabla o flujo de eventos.
+4. Configurar tu widget:
+ - Seleccionar la fuente de datos: elija métricas, logs, trazas u otras fuentes de datos.
+ - Personalizar la visualización: ajusta la configuración de visualización, las unidades y los plazos para adaptarlos a tus necesidades.
+ - Añadir contexto: utiliza enlaces personalizados, formato condicional y agrupación para obtener información mejorada.
+5. Guarda tu dashboard y compártelo con tu equipo o externamente según sea necesario.
-**Nota**: Al pegar gráficas en screenboards o notebooks, se pegan widgets individuales en el grupo.
+Para más información, consulta [Configuración de widgets][3] y explora los [Tipos de widgets][4] disponibles.
-Para copiar varios widgets de screenboard (solo en el modo de edición), pulsa `shift + click` en los widgets y utiliza `Ctrl + C` (`Cmd + C` para Mac).
+## Fuentes de datos
-**Nota**: Esto solo funciona cuando se comparte dentro de Datadog. No genera una imagen de vista previa.
+Los widgets pueden visualizar datos de múltiples fuentes de Datadog, entre ellas:
-## Gráficas de widget
+- **Trazas de APM**: datos de monitorización del rendimiento de las aplicaciones
+- **Eventos**: eventos personalizados, despliegues y anotaciones.
+- **Logs**: eventos de log, análisis de logs y métricas basadas en logs
+- **Métricas**: infraestructura, aplicación y métricas personalizadas
+- **RUM**: Real User Monitoring y datos de synthetic test
+- **SLOs**: objetivos de nivel de servicio (SLO) y presupuestos de errores
+- **Seguridad**: señales de seguridad y datos de cumplimiento
-### Exportar
+## Casos de uso común
-| Formato | Instrucciones |
-| ----- | ----------------------- |
-| PNG | Para descargar un widget en formato PNG, haz clic en el botón de exportación en la parte superior derecha del widget y selecciona **Download as PNG** (Descargar como PNG). |
-| CSV | Para descargar los datos de un widget de lista de principales, serie temporal o tabla en formato CSV, haz clic en el botón de exportación en la parte superior derecha del widget y selecciona **Download as CSV** (Descargar como CSV).|
+{{% collapse-content title="Monitorización de infraestructura" level="h4" expanded=false %}}
+- Utiliza widgets **Series temporales** para las métricas de CPU, memoria y red a lo largo del tiempo
+- Utiliza widgets **Mapa de host** para visualizar el uso de recursos en toda tu infraestructura
+- Utiliza los widgets **Lista principal** para identificar los hosts o servicios que consumen más recursos.
+{{% /collapse-content %}}
-### Menú de gráficos
+{{% collapse-content title="Rendimiento de las aplicaciones" level="h4" expanded=false %}}
+- Utiliza widgets **Series temporales** para realizar un seguimiento de los tiempos de respuesta, las tasas de error y el rendimiento.
+- Utiliza los widgets **Resumen de servicios** para obtener una visión general del estado de los servicios.
+- Utiliza los widgets **Mapa de topología** para visualizar las dependencias de los servicios y el flujo de datos.
+{{% /collapse-content %}}
-Haz clic en cualquier gráfico del dashboard para abrir un menú de opciones:
+{{% collapse-content title="Inteligencia empresarial" level="h4" expanded=false %}}
+- Utiliza widgets **Valor de consulta** para indicadores clave de rendimiento y métricas empresariales.
+- Utiliza widgets **Embudo** para realizar un seguimiento de la conversión de los usuarios a través de tu aplicación.
+- Utiliza widgets de **Retención** para analizar el compromiso y la rotación de los usuarios.
+{{% /collapse-content %}}
-| Opción | Descripción |
-|------------------------|--------------------------------------------------------------------|
-| Send snapshot (Enviar snapshot) | Crea y envía un snapshot de tu gráfico. |
-| Find correlated metrics (Encontrar métricas correlacionadas)| Encuentra correlaciones de servicios de APM, integraciones y dashboards. |
-| View in full screen (Ver en pantalla completa) | Visualiza el gráfico en [modo pantalla completa][5]. |
-| Lock cursor (Bloquear el cursor) | Bloquea el cursor en la página. |
-| View related processes (Ver procesos relacionados) | Accede a la página [Live Processes][6] que se corresponde con tu gráfico. |
-| View related hosts (Ver hosts relacionados) | Accede a la página [Mapa del host][7] que se corresponde con tu gráfico. |
-| View related logs (Ver logs relacionados) | Accede a la página [Navegador de logs][8] que se corresponde con tu gráfico. |
-| View related traces (Ver trazas relacionadas) | Rellena un panel de [Trazas][9] que se corresponde con tu gráfico. |
-| View related profiles (Ver perfiles relacionados) | Accede a la página [Elaboración de perfiles][7] que se corresponde con tu gráfico. |
+{{% collapse-content title="Respuesta a incidentes" level="h4" expanded=false %}}
+- Utiliza los widgets **Gráfico de alertas** para mostrar el historial y las tendencias de las alertas
+- Utiliza los widgets **Resumen de monitor** para conocer el estado actual de las alertas en toda tu infraestructura.
+- Utiliza los widgets **Flujo de eventos** para controlar los eventos en tiempo real
+{{% /collapse-content %}}
## Referencias adicionales
{{< partial name="whats-next/whats-next.html" >}}
-[1]: /es/dashboards/widgets/timeseries/#full-screen
-[2]: /es/dashboards/guide/context-links/
-[3]: /es/dashboards/guide/unit-override
-[4]: /es/dashboards/
-[5]: /es/notebooks/
-[6]: /es/tracing/services/service_page/
-[7]: /es/tracing/services/resource_page/
-[8]: /es/logs/explorer/
-[9]: /es/tracing/trace_explorer/
-[10]: /es/profiler/profile_visualizations/
-[11]: /es/dashboards/guide/custom_time_frames/
\ No newline at end of file
+[1]: https://app.datadoghq.com/dashboard/lists/preset/1
+[2]: /es/dashboards/
+[3]: /es/dashboards/widgets/configuration/
+[4]: /es/dashboards/widgets/types/
\ No newline at end of file
diff --git a/content/es/dashboards/widgets/configuration/_index.md b/content/es/dashboards/widgets/configuration/_index.md
new file mode 100644
index 0000000000000..9a41815e222c8
--- /dev/null
+++ b/content/es/dashboards/widgets/configuration/_index.md
@@ -0,0 +1,193 @@
+---
+description: Aprende a configurar los widgets en los dashboards de Datadog, incluidas
+ las opciones de pantalla completa, enlaces personalizados, información sobre métricas
+ y anulaciones de unidades.
+further_reading:
+- link: /dashboards/widgets/
+ tag: Documentación
+ text: Información general del widget
+- link: /dashboards/widgets/types
+ tag: Documentación
+ text: Tipos de widgets
+title: Configuración del widget
+---
+
+## Información general
+
+La configuración de widgets es esencial para crear dashboards eficaces que proporcionen información significativa sobre tu infraestructura y aplicaciones. En esta guía se describen las principales opciones de configuración y las consideraciones que debes tener en cuenta a la hora de configurar los widgets.
+
+
+## Pantalla completa
+
+El modo de pantalla completa ofrece funciones mejoradas de visualización y análisis de tus widgets. Puedes ver la mayoría de los widgets en modo de pantalla completa y hacer lo siguiente:
+
+* Cambiar los períodos
+* Retroceder o avanzar en función del período de tiempo seleccionado
+* Pausar la gráfica en el momento actual o visualizar la gráfica en directo
+* Restablecer el período de tiempo
+* Exportar la gráfica a un dashboard o notebook, o copiar la consulta
+* Descargar los datos que producen la gráfica en formato CSV
+
+Para acceder directamente a la vista general del widget, haz clic en el botón de pantalla completa en la esquina superior derecha del widget.
+
+Hay opciones adicionales disponibles para los [widgets de serie temporal][1].
+
+## Vista previa de datos
+
+Puedes unir varias fuentes de datos en el editor de gráficos para enriquecer tus visualizaciones con contexto y metadatos adicionales. Con la vista previa de datos, puedes ver qué datos estás uniendo o si la consulta está funcionando como se esperaba. Esta función te ayuda a:
+
+- Confirmar estructura de datos y nombres de columnas
+- Identificar las claves coincidentes
+- Validar los resultados antes de ejecutar la consulta completa
+
+{{% collapse-content title="Ejemplo" level="h4" expanded=false %}}
+Podrías unir tus logs de pago con una tabla de referencia (tabla de búsqueda) que contenga detalles del producto para mostrar el precio de venta o la fecha de lanzamiento junto con los datos de la transacción. O bien, podrías enriquecer los datos de sesión de RUM uniéndolos a la información de cliente de una fuente externa, como Salesforce o Snowflake, para segmentar a los usuarios por nivel de cliente.
+
+Las fuentes de datos compatibles para las uniones incluyen (entre otras):
+
+- Logs
+- Métricas
+- RUM
+- Recomendaciones de costes en la nube
+- Netflow
+- Tramos de APM
+- Trazas de APM
+- Perfiles
+- Lotes de CI de Synthetic Monitoring
+- Ejecución de Synthetic Monitoring
+- Análisis estático
+- Tests CI
+- Conclusiones sobre el cumplimiento
+- Product Analytics
+- Tablas de referencia
+
+El uso de uniones y previsualizaciones de datos facilita la selección de los campos adecuados y enriquece tus gráficos con detalles relevantes, mejorando la calidad y utilidad de tus dashboards.
+
+
+{{% /collapse-content %}}
+
+## Enlaces personalizados
+
+Los enlaces personalizados mejoran la interacción con los datos conectando los valores de los datos del widget a URL relevantes, como las páginas de Datadog o tu consola de AWS.
+
+Para personalizar las interacciones con datos en línea de tus widgets genéricos, consulta [Enlaces contextuales][2].
+
+## Información de las métricas
+
+En el gráfico de una métrica, haz clic en el menú contextual (tres puntos verticales) para encontrar la opción **Metrics info** (Información de la métrica). Esto abre un panel con una descripción de la métrica. Al hacer clic en el nombre de la métrica en este panel, se abre la métrica en la página del resumen de métricas para su posterior análisis o edición.
+
+## Anulación de unidad
+
+Las modificaciones de unidad son una opción de visualización clave que te permiten personalizar la forma en que se presentan los valores de los datos en los widgets, añadiendo un contexto significativo a tus datos. Para obtener más información y casos de uso, consulta [Personaliza tus visualizaciones con modificaciones de unidad][3].
+- **Anulación de unidad**: elige mostrar unidades en la familia de la «memoria» y haz que Datadog se encargue de mostrar la escala adecuada en función de los datos (como megabytes o gigabytes).
+- **Anulación de unidad y escala**: fija las unidades en una sola escala (muestra los datos en megabytes independientemente del valor).
+- **Definir unidades personalizadas**: define unidades completamente personalizadas (como «pruebas» en lugar de un recuento genérico).
+
+Esta no es una alternativa para asignar unidades a tus datos.
+{{< whatsnext desc="Establece unidades a nivel de la organización: ">}}
+ {{< nextlink href="/metrics/units/">}} Establecer unidades de métricas{{< /nextlink >}}
+ {{< nextlink href="/logs/explorer/facets/#units">}} Establecer unidades para consultas basadas en eventos{{< /nextlink >}}
+{{< /whatsnext >}}
+
+## Selector de hora global
+
+El selector de hora global es una opción de configuración horaria fundamental que sincroniza todos los widgets de un dashboard para que utilicen el mismo marco temporal. Para utilizar el selector de hora global, al menos un widget basado en la hora debe estar configurado para utilizar `Global Time`. Haz la selección en el editor de widgets en **Set display preferences** (Configurar preferencias de visualización), o añade un widget (la hora global es la configuración horaria por defecto).
+
+El selector de tiempo global establece el mismo marco temporal para todos los widgets que utilicen la opción `Global Time` en el mismo dashboard. Selecciona un intervalo móvil en el pasado (por ejemplo, `Past 1 Hour` o `Past 1 Day`) o un periodo fijo con la opción `Select from calendar...` o [introduce un marco temporal personalizado][8]. Si se elige un intervalo móvil, los widgets se actualizan para moverse junto con el intervalo.
+
+Los widgets no vinculados a la hora global muestran los datos de su periodo de tiempo local aplicados a la ventana global. Por ejemplo, si el selector de hora global está configurado del 1 de enero de 2019 al 2 de enero de 2019, un widget configurado con el marco de hora local para `Past 1 Minute` muestra el último minuto del 2 de enero de 2019 a partir de las 23:59.
+
+## Copiar y pegar widgets
+
+Copiar y pegar es una función clave para compartir y colaborar que permite reutilizar widgets en distintos contextos de Datadog y herramientas externas.
+
+dashboard_public_share y habilitar el uso compartido de datos públicos estáticos en los parámetros de organización para utilizar esta característica.Activa Uso compartido de datos públicos estáticos en la Configuración de la organización para utilizar esta función.
+
+Los widgets pueden copiarse en [Dashboards][4], [Notebooks][5], [APM Service][6] y la page (página) del [recurso de APM][7] utilizando Ctrl/Cmd + C o seleccionando el ícono de compartir y seleccionando "Copiar".
+
+Los widgets copiados pueden pegarse en Datadog utilizando Ctrl/Cmd + V:
+
+* **Dashboards**: añade un widget nuevo ubicado debajo del cursor del mouse.
+* **Notebooks**: añade una celda nueva al final del notebook.
+
+También puedes pegar el widget en tu programa de chat favorito que muestre previsualizaciones de enlaces (como Slack o Microsoft Teams). Esto muestra una imagen snapshot de tu gráfica junto con un enlace directo al widget.
+
+Para obtener más información, consulta el [Portapapeles de Datadog][9].
+
+## Grupos de widgets
+
+Copia los widgets de grupos de timeboard pasando el ratón sobre el área del widget de grupo y utilizando Ctrl/Cmd + C o seleccionando el ícono de compartir y seleccionando "Copy" (Copiar).
+
+**Nota**: Al pegar gráficos en screenboard o notebook, Datadog pega cada widget del grupo individualmente.
+
+Para copiar varios widgets de screenboard (sólo en modo de edición), pulsa Mayúsculas + clic en los widgets y utiliza Ctrl/Cmd + C.
+
+**Nota**: Esto solo funciona cuando se comparte dentro de Datadog. No genera una imagen de vista previa.
+
+## Widget de menús gráficos
+
+Los menús de gráficos del widget proporcionan opciones esenciales para la interacción con los datos. Pasa el cursor sobre un gráfico para acceder a las siguientes opciones de menú.
+
+### View in full screen (Ver en pantalla completa)
+
+Ve el gráfico en [modo pantalla completa](#full-screen).
+
+### Exportar
+
+Haz clic en el icono de exportación de cualquier gráfico del dashboard para abrir un menú de opciones:
+
+| Opción | Descripción |
+|------------------------|--------------------------------------------------------------------|
+| Copia | Crea una copia del gráfico del dashboard. |
+| Compartir snapshot | Crea y envía un snapshot de tu gráfico. |
+
+#### Utilización en Datadog
+
+| Opción | Descripción |
+|------------------------|--------------------------------------------------------------------|
+| Declarar incidente | Declara un incidente del gráfico. |
+| Añadir al incidente | Añade el gráfico a una página existente del incidente. |
+| Crear incidencia | Crea una incidencia a partir del gráfico. |
+| Guardar en notebook | Guarda el gráfico en un notebook. |
+| Enlace al widget | Obtén un enlace al widget copiado en el portapapeles. |
+
+#### Compartir externamente
+
+| Formato | Descripción |
+| ----- | ----------------------- |
+| Descargar como PNG | Descarga el widget en formato PNG. |
+| Descargar como SVG | Descarga el widget en formato SVG. |
+| Descargar como CSV | Descarga el widget en formato CSV. |
+
+### Editar
+
+Haz clic en el icono del lápiz de cualquier gráfico del dashboard para realizar modificaciones.
+
+### Opciones adicionales
+
+Haz clic en el menú contextual (tres puntos verticales) de cualquier gráfico del dashboard para abrir un menú de opciones:
+
+| Opción | Descripción |
+|------------------------|--------------------------------------------------------------------|
+| Editar | Edita el gráfico. |
+| Clonar | Crea una copia adyacente del gráfico. |
+| Gráfica dividida | Crea un [gráfico dividido][10]. |
+| Crear enlaces personalizados | Crea [enlaces personalizados](#custom-links). |
+| Crear monitor | Crea un monitor preconfigurado con la consulta del gráfico. |
+| Información de la métrica (solo gráficos de métrica) | Obtén una descripción de las métricas en este gráfico. Puedes hacer clic en los nombres de las métricas para abrirlas en la página Resumen de métricas. |
+| Borrar | Borra el gráfico. |
+
+## Referencias adicionales
+
+{{< partial name="whats-next/whats-next.html" >}}
+
+[1]: /es/dashboards/widgets/timeseries/#full-screen
+[2]: /es/dashboards/guide/context-links/
+[3]: /es/dashboards/guide/unit-override
+[4]: /es/dashboards/
+[5]: /es/notebooks/
+[6]: /es/tracing/services/service_page/
+[7]: /es/tracing/services/resource_page/
+[8]: /es/dashboards/guide/custom_time_frames/
+[9]: /es/service_management/incident_management/datadog_clipboard/
+[10]: /es/dashboards/widgets/split_graph/
\ No newline at end of file
diff --git a/content/es/dashboards/widgets/table.md b/content/es/dashboards/widgets/table.md
index c74d56994f064..fa72c57821b2b 100644
--- a/content/es/dashboards/widgets/table.md
+++ b/content/es/dashboards/widgets/table.md
@@ -1,6 +1,8 @@
---
aliases:
- /es/graphing/widgets/table/
+description: Visualiza datos tabulares con columnas, filas y funciones de clasificación
+ para un análisis detallado de métricas y eventos.
further_reading:
- link: /dashboards/graphing_json/
tag: Documentación
@@ -22,7 +24,7 @@ La visualización de tablas muestra columnas de datos agregados agrupados por cl
### Configuración
-1. Elige los datos a graficar:
+1. Elige los datos para los que crear gráficas:
* Métrica: consulta la [Documentación principal de crear gráficas][1] para configurar una consulta a la métrica.
* Fuentes de datos no métrica: consulta la [Documentación de búsqueda de log][2] para configurar una consulta de evento.
@@ -34,18 +36,19 @@ La visualización de tablas muestra columnas de datos agregados agrupados por cl
* Configura si se muestra o no la barra de búsqueda. **Auto** es el valor predeterminado y muestra la barra de búsqueda según el tamaño del widget, esto significa que si tu pantalla se hace demasiado pequeña, prioriza la visualización de los datos en el widget y oculta la barra de búsqueda, pero sigue estando disponible en el modo de pantalla completa.
#### Formato de columnas
+
Personaliza la visualización de los valores de las celdas de cada columna con las Reglas de formato de columna. Crea códigos de color para tus datos para visualizar tendencias y cambios.
* Formato de umbral: resalta las celdas con colores cuando se cumplan determinados rangos de valores.
* Formato de rango: codifica por colores las celdas con un rango de valores.
* Formato de texto: sustituye las celdas por valores de texto de alias para mejorar la legibilidad.
+* Información de tendencias: visualiza las consultas de métricas y eventos.
-{{< img src="/dashboards/widgets/table/range_conditional_formatting.png" alt="Configuración del widget que muestra las opciones de formato de columna" style="width:90%;" >}}
+{{< img src="/dashboards/widgets/table/conditional_formatting_trends.png" alt="Widget de tabla que muestra el formato condicional con indicadores de tendencia" style="width:100%;" >}}
#### Enlaces contextuales
Los [enlaces contextuales][10] están activados por defecto y pueden activarse o desactivarse. Los enlaces contextuales sirven de puente entre widgets de dashboard con otras páginas de Datadog, o con aplicaciones de terceros.
-
## Valores N/A
Las columnas del widget de tabla se consultan independientemente unas de otras. Los grupos solapados con nombres coincidentes se unen en tiempo real para formar las filas de la tabla. Como resultado de dicho proceso, puede haber situaciones sin solapamiento total, por lo que se muestran celdas N/A. Para mitigar esto:
@@ -60,7 +63,7 @@ La [definición del esquema de widget JSON][9] dedicada al widget de la tabla es
{{< dashboards-widgets-api >}}
-## Leer más
+## Referencias adicionales
{{< partial name="whats-next/whats-next.html" >}}
diff --git a/content/es/dashboards/widgets/types/_index.md b/content/es/dashboards/widgets/types/_index.md
new file mode 100644
index 0000000000000..cfa2a0aa67cdc
--- /dev/null
+++ b/content/es/dashboards/widgets/types/_index.md
@@ -0,0 +1,118 @@
+---
+title: Tipos de widgets
+description: Descubre los tipos de widgets de dashboard disponibles en Datadog para visualizar y analizar tus datos, incluidos gráficos, tablas, grupos y widgets de análisis.
+further_reading:
+- link: /dashboards/widgets/
+ tag: Documentación
+ text: Información general del widget
+- link: dashboards/widgets/configuración
+ tag: Documentación
+ text: Configuraciones de widgets
+---
+
+## Gráficos
+{{< whatsnext desc="Widgets generales para graficar los datos desde productos de Datadog: ">}}
+ {{< nextlink href="/dashboards/widgets/bar_chart"
+ img="/dashboards/widgets/icons/bar-chart_light_large.svg">}}Gráfico de barras{{< /nextlink >}}
+ {{< nextlink href="/dashboards/widgets/change"
+ img="dashboards/widgets/icons/change_light_large.png">}} Cambio{{< /nextlink >}}
+ {{< nextlink href="/dashboards/widgets/distribution"
+ img="dashboards/widgets/icons/distribution_light_large.png">}} Distribución{{< /nextlink >}}
+ {{< nextlink href="/dashboards/widgets/geomap"
+ img="dashboards/widgets/icons/geomap_light_large.png">}} Mapa geográfico{{< /nextlink >}}
+ {{< nextlink href="/dashboards/widgets/heat_map"
+ img="dashboards/widgets/icons/heatmap_light_large.png">}} Mapa de calor{{< /nextlink >}}
+ {{< nextlink href="/dashboards/widgets/pie_chart"
+ img="dashboards/widgets/icons/pie_light_large.png">}} Gráfico de tortas{{< /nextlink >}}
+ {{< nextlink href="/dashboards/widgets/query_value"
+ img="dashboards/widgets/icons/query-value_light_large.png">}} Valor de consulta{{< /nextlink >}}
+ {{< nextlink href="/dashboards/widgets/scatter_plot"
+ img="dashboards/widgets/icons/scatter-plot_light_large.png">}} Diagrama de dispersión{{< /nextlink >}}
+ {{< nextlink href="/dashboards/widgets/table"
+ img="dashboards/widgets/icons/table_light_large.png">}} Tabla{{< /nextlink >}}
+ {{< nextlink href="/dashboards/widgets/treemap"
+ img="dashboards/widgets/icons/treemap_light_large.png">}} Mapa de árbol{{< /nextlink >}}
+ {{< nextlink href="/dashboards/widgets/timeseries"
+ img="dashboards/widgets/icons/timeseries_light_large.png">}} Serie temporal{{< /nextlink >}}
+ {{< nextlink href="/dashboards/widgets/top_list"
+ img="dashboards/widgets/icons/top-list_light_large.png">}} Lista de principales{{< /nextlink >}}
+ {{< nextlink href="/dashboards/widgets/wildcard"
+ img="/dashboards/widgets/icons/wildcard_light_large.svg">}} Comodín{{< /nextlink >}}
+{{< /whatsnext >}}
+
+## Grupos
+{{< whatsnext desc="Muestra tus widgets en grupos: ">}}
+ {{< nextlink href="/dashboards/widgets/group"
+ img="dashboards/widgets/icons/group_default_light_large.svg">}} Grupo{{< /nextlink >}}
+ {{< nextlink href="/dashboards/widgets/powerpack"
+ img="dashboards/widgets/icons/group_powerpack_light_large.svg">}} Powerpack{{< /nextlink >}}
+ {{< nextlink href="/dashboards/widgets/split_graph"
+ img="dashboards/widgets/icons/group-split_light_small.svg">}} Gráfica dividida{{< /nextlink >}}
+{{< /whatsnext >}}
+
+## Product Analytics
+{{< whatsnext desc="Visualizar datos de Product Analytics: ">}}
+ {{< nextlink href="/dashboards/widgets/sankey"
+ img="dashboards/widgets/icons/sankey_light_large.svg">}} Sankey{{< /nextlink >}}
+ {{< nextlink href="/dashboards/widgets/funnel"
+ img="dashboards/widgets/icons/funnel_light_large.png">}} Túnel{{< /nextlink >}}
+ {{< nextlink href="/dashboards/widgets/retention"
+ img="/dashboards/widgets/icons/cohort_light_small.svg">}} Retención{{< /nextlink >}}
+{{< /whatsnext >}}
+
+## Arquitectura
+{{< whatsnext desc="Visualizar datos de infraestructura y arquitectura: ">}}
+ {{< nextlink href="/dashboards/widgets/hostmap"
+ img="dashboards/widgets/icons/host-map_light_large.png">}} Mapa de host{{< /nextlink >}}
+ {{< nextlink href="/dashboards/widgets/topology_map"
+ img="dashboards/widgets/icons/service-map_light_large.png">}} Mapa de topología{{< /nextlink >}}
+ {{< nextlink href="/dashboards/widgets/service_summary"
+ img="dashboards/widgets/icons/service-summary_light_large.png">}} Resumen de servicio{{< /nextlink >}}
+{{< /whatsnext >}}
+
+## Anotaciones y embeds
+{{< whatsnext desc="Widgets de decoración para estructurar y anotar visualmente dashboards: ">}}
+ {{< nextlink href="/dashboards/widgets/free_text"
+ img="dashboards/widgets/icons/free-text_light_large.png">}} Texto libre{{< /nextlink >}}
+ {{< nextlink href="/dashboards/widgets/iframe"
+ img="dashboards/widgets/icons/iframe_light_large.png">}} Iframe{{< /nextlink >}}
+ {{< nextlink href="/dashboards/widgets/image"
+ img="dashboards/widgets/icons/image_light_large.png">}} Imagen{{< /nextlink >}}
+ {{< nextlink href="/dashboards/widgets/note"
+ img="dashboards/widgets/icons/notes_light_large.png">}} Notas y enlaces{{< /nextlink >}}
+{{< /whatsnext >}}
+
+## Listas y flujos
+{{< whatsnext desc="Muestra una lista de eventos y problemas provenientes de diferentes fuentes: ">}}
+ {{< nextlink href="/dashboards/widgets/list"
+ img="dashboards/widgets/icons/change_light_large.png">}} Lista{{< /nextlink >}}
+{{< /whatsnext >}}
+
+## Alerta y respuesta
+{{< whatsnext desc="Widgets de resumen para mostrar información de monitorización: ">}}
+ {{< nextlink href="/dashboards/widgets/alert_graph"
+ img="dashboards/widgets/icons/alert-graph_light_large.png">}} Gráfico de alertas{{< /nextlink >}}
+ {{< nextlink href="/dashboards/widgets/alert_value"
+ img="dashboards/widgets/icons/alert-value_light_large.png">}}Valor de alerta{{< /nextlink >}}
+ {{< nextlink href="/dashboards/widgets/check_status"
+ img="dashboards/widgets/icons/check-status_light_large.png">}} Comprobar estado{{< /nextlink >}}
+ {{< nextlink href="/dashboards/widgets/monitor_summary"
+ img="dashboards/widgets/icons/monitor-summary_light_large.png">}} Resumen de monitor{{< /nextlink >}}
+ {{< nextlink href="/dashboards/widgets/run_workflow"
+ img="dashboards/widgets/icons/run-workflow_light_small.svg">}} Ejecutar flujo de trabajo{{< /nextlink >}}
+{{< /whatsnext >}}
+
+## Rendimiento y fiabilidad
+{{< whatsnext desc="Visualizaciones de fiabilidad del sitio: ">}}
+ {{< nextlink href="/dashboards/widgets/profiling_flame_graph"
+ img="dashboards/widgets/icons/profiling_flame_graph.svg">}} Perfilado del gráfico de llamas{{< /nextlink >}}
+ {{< nextlink href="/dashboards/widgets/slo"
+ img="dashboards/widgets/icons/slo-summary_light_large.png">}} Resumen de objetivo de nivel de servicio (SLO){{< /nextlink >}}
+ {{< nextlink href="/dashboards/widgets/slo_list"
+ img="dashboards/widgets/icons/slo-list_light_large.png">}} Objetivo de nivel de servicio (SLO){{< /nextlink >}}
+{{< /whatsnext >}}
+
+
+## Referencias adicionales
+
+{{< partial name="whats-next/whats-next.html" >}}
diff --git a/content/es/data_security/logs.md b/content/es/data_security/logs.md
index 401a17fad5e12..0ee2fd50ee83a 100644
--- a/content/es/data_security/logs.md
+++ b/content/es/data_security/logs.md
@@ -7,11 +7,7 @@ further_reading:
text: Revisar las principales categorías de datos enviados a Datadog
- link: /data_security/pci_compliance/
tag: Documentación
- text: Establecer una organización de Datadog que cumpla el estándar PCI
-- link: https://www.datadoghq.com/blog/datadog-pci-compliance-log-management-apm/
- tag: Blog
- text: Datadog presenta los servicios de Log Management y APM compatibles con el
- PCI
+ text: Cumplimiento del estándar PCI DSS
title: Seguridad de los datos en Log Management
---
@@ -19,7 +15,9 @@ title: Seguridad de los datos en Log Management
El producto Log Management es compatible con múltiples [entornos y formatos][1], lo que te permite enviar a Datadog casi cualquier dato. En este artículo se describen las principales garantías de seguridad y los controles de filtrado disponibles al enviar logs a Datadog.
-**Nota**: Es posible ver logs en varios productos de Datadog. Todos los logs que se ven en la interfaz de usuario de Datadog, incluidos los que se ven en las páginas de trazas de APM, forman parte del producto Log Management.
+**Notas**:
+- Los logs pueden visualizarse en distintos productos de Datadog. Todos los logs visualizados en la interfaz de usuario de Datadog, incluidos los logs visualizados en las pages (páginas) de traces (trazas) de APM, forman parte del producto de Log Management.
+- Las herramientas y políticas de Datadog cumplen PCI v4.0. Para obtener más información, consulta [Cumplimiento de PCI DSS][10].
## Seguridad de la información
@@ -43,31 +41,6 @@ Sensitive Data Scanner también está disponible como [procesador][8] en [Observ
{{% hipaa-customers %}}
-## Cumplimiento del PCI DSS para Log Management
-
-{{< site-region region="us" >}}
-
-
-El cumplimiento del PCI DSS para Log Management sólo está disponible para organizaciones de Datadog en el sitio US1.
-
-
-Datadog permite a los clientes enviar logs a organizaciones de Datadog que cumplen el PCI DSS, si así lo solicitan. Para configurar una organización de Datadog que cumpla el PCI, sigue estos pasos:
-
-{{% pci-logs %}}
-
-Consulta [Cumplimiento del PCI DSS][1] para obtener más información. Para activar el cumplimiento del PCI para APM, consulte [Cumplimientol del PCI DSS para APM][1].
-
-[1]: /es/data_security/pci_compliance/
-[2]: /es/data_security/pci_compliance/?tab=apm
-
-{{< /site-region >}}
-
-{{< site-region region="us3,us5,eu,gov,ap1,ap2" >}}
-
-El cumplimiento del PCI DSS para Log Management no está disponible para el sitio {{< region-param key="dd_site_name" >}}.
-
-{{< /site-region >}}
-
## Cifrado de endpoints
Todos los endpoints de envío de logs están cifrados. Los siguientes endpoints heredados siguen siendo compatibles:
@@ -89,4 +62,5 @@ Todos los endpoints de envío de logs están cifrados. Los siguientes endpoints
[6]: https://www.datadoghq.com/legal/hipaa-eligible-services/
[7]: /es/security/sensitive_data_scanner/
[8]: /es/observability_pipelines/processors/sensitive_data_scanner
-[9]: /es/observability_pipelines/
\ No newline at end of file
+[9]: /es/observability_pipelines/
+[10]: /es/data_security/pci_compliance/
\ No newline at end of file
diff --git a/content/es/data_streams/_index.md b/content/es/data_streams/_index.md
index 0f33ce9203271..16da55649db10 100644
--- a/content/es/data_streams/_index.md
+++ b/content/es/data_streams/_index.md
@@ -1,4 +1,6 @@
---
+aliases:
+- /es/data_streams/troubleshooting
cascade:
algolia:
rank: 70
@@ -9,9 +11,9 @@ further_reading:
- link: /integrations/amazon_sqs/
tag: Documentación
text: Integración de Amazon SQS
-- link: /tracing/service_catalog/
+- link: /tracing/software_catalog/
tag: Documentación
- text: Catálogo de servicios
+ text: Catálogo de software
- link: https://www.datadoghq.com/blog/data-streams-monitoring/
tag: Blog
text: Controlar y mejorar el rendimiento de los pipelines de datos de transmisión
@@ -23,44 +25,77 @@ further_reading:
- link: https://www.datadoghq.com/blog/data-streams-monitoring-sqs/
tag: Blog
text: Monitorizar SQS con Data Streams Monitoring
+- link: https://www.datadoghq.com/blog/confluent-connector-dsm-autodiscovery/
+ tag: Blog
+ text: Detectar automáticamente conectores de Confluent Cloud y consultar fácilmente
+ el rendimiento de los monitores en Data Streams Monitoring
+- link: https://www.datadoghq.com/blog/data-observability/
+ tag: Blog
+ text: Garantizar la confianza durante todo el ciclo de vida de los datos con Datadog
+ Data Observability
title: Data Streams Monitoring
---
-{{% site-region region="gov,ap1" %}}
+{{% site-region region="gov" %}}
- Data Streams Monitoring no está disponible para el sitio de {{< region-param key="dd_site_name" >}}.
+ Data Streams Monitoring no está disponible para el sitio {{< region-param key="dd_site_name" >}}.
{{% /site-region %}}
+{{< img src="data_streams/map_view2.png" alt="Página de Data Streams Monitoring en Datadog, que muestra la vista Mapas. Se resalta un servicio llamado 'autenticador'. Visualización de un mapa de topología de flujos de datos de izquierda a derecha, donde el servicio autenticador se muestra en el centro con sus servicios y colas ascendentes y descendentes." style="width:100%;" >}}
+
Data Streams Monitoring proporciona un método estandarizado para que los equipos comprendan y gestionen los pipelines a escala y así facilita:
* Mide el estado de los pipelines con latencias de extremo a extremo para eventos que atraviesan tu sistema.
* Localiza los productores, consumidores o colas defectuosos y, a continuación, dirígete a logs o clústeres para solucionar los problemas con mayor rapidez.
* Evita los retrasos en cascada equipando a los propietarios de servicio para impedir que la acumulación de eventos desborde los servicios de flujo descendente.
-## Ajustes
+### Lenguajes y tecnologías compatibles
+
+Data Streams Monitoring instrumenta los _clientes_ de Kafka (consumidores/productores). Si puedes instrumentar tu infraestructura de clientes, puedes utilizar Data Streams Monitoring.
+
+| | Java | Python | .NET | Node.js | Go |
+| - | ---- | ------ | ---- | ------- | -- |
+| Apache Kafka (autoalojado, Amazon MSK, Confluent Cloud o cualquier otra plataforma de alojamiento) | {{< X >}} | {{< X >}} | {{< X >}} | {{< X >}} | {{< X >}} | +| Amazon Kinesis | {{< X >}} | {{< X >}} | {{< X >}} | {{< X >}} | | +| Amazon SNS | {{< X >}} | {{< X >}} | {{< X >}} | {{< X >}} | | +| Amazon SQS | {{< X >}} | {{< X >}} | {{< X >}} | {{< X >}} | | +| Azure Service Bus | | | {{< X >}} | | | +| Google Pub/Sub | {{< X >}} | | | {{< X >}} | | +| IBM MQ | | | {{< X >}} | | | +| RabbitMQ | {{< X >}} | {{< X >}} | {{< X >}} | {{< X >}} | | -Para empezar, sigue las instrucciones de instalación para configurar servicios con Data Streams Monitoring: +Data Streams Monitoring requiere versiones mínimas del rastreador Datadog. Para obtener más detalles, consulta cada página de configuración. + +#### Compatibilidad con OpenTelemetry +Data Streams Monitoring es compatible con OpenTelemetry. Si has configurado Datadog APM para que funcione con OpenTelemetry, no es necesaria ninguna configuración adicional para utilizar Data Streams Monitoring. Consulta [Compatibilidad de OpenTelemetry][11]. + +## Configuración + +### Por lenguaje {{< partial name="data_streams/setup-languages.html" >}} -
-| Tiempo de ejecución | Tecnologías compatibles | -|---|----| -| Java/Scala | Kafka (autoalojado, Amazon MSK, Confluent Cloud/Plataform), RabbitMQ, HTTP, gRPC, Amazon SQS | -| Python | Kafka (autoalojado, Amazon MSK, Confluent Cloud/Plataform), RabbitMQ, Amazon SQS | -| .NET | Kafka (autoalojado, Amazon MSK, Confluent Cloud/Plataform), RabbitMQ, Amazon SQS | -| Node.js | Kafka (autoalojado, Amazon MSK, Confluent Cloud/Plataform), RabbitMQ, Amazon SQS | -| Go | Todos (con [Instrumentación manual][1]) | +### Por tecnología + +{{< partial name="data_streams/setup-technologies.html" >}} + +
## Explorar Data Streams Monitoring +### Visualizar la arquitectura de tus pipelines de transmisión de datos + +{{< img src="data_streams/topology_map.png" alt="Visualización de un mapa de topología de DSM. " style="width:100%;" >}} + +Data Streams Monitoring proporciona un [mapa de topología[10] predefinido para que puedas visualizar el flujo de datos a través de tus pipelines e identificar los servicios productores/consumidores, las dependencias de las colas, la propiedad del servicio y las métricas de salud claves. + ### Medir el estado de los pipelines de extremo a extremo con las nuevas métricas -Una vez configurado Data Streams Monitoring, puedes medir el tiempo que suelen tardar los eventos en recorrer el trayecto entre dos puntos cualesquiera de tu sistema asíncrono: +Con Data Streams Monitoring, puedes medir el tiempo que suelen tardar los eventos en recorrer el trayecto entre dos puntos cualesquiera de tu sistema asíncrono: -| Nombre de la métrica | Etiquetas notables | Descripción | +| Nombre de la métrica | Etiquetas (tags) notables | Descripción | |---|---|-----| | data_streams.latency | `start`, `end`, `env` | Latencia de extremo a extremo de un trayecto desde un origen especificado hasta un servicio de destino. | | data_streams.kafka.lag_seconds | `consumer_group`, `partition`, `topic`, `env` | Retraso en segundos entre el productor y el consumidor. Requiere Java Agent v1.9.0 o posterior. | @@ -73,7 +108,7 @@ También puedes representar gráficamente y visualizar estas métricas en cualqu ### Monitorizar la latencia de extremo a extremo de cualquier ruta -Según cómo los eventos atraviesen tu sistema, diferentes rutas pueden conducir a un aumento de la latencia. Con la [pestaña **Measure** (Medir)][7], puedes seleccionar un servicio de inicio y un servicio final para obtener información sobre la latencia de extremo a extremo para identificar cuellos de botella y optimizar el rendimiento. Crea fácilmente un monitor para esa ruta o expórtalo a un dashboard. +Según cómo los eventos atraviesen tu sistema, diferentes rutas pueden conducir a un aumento de la latencia. Con la [pestaña **Medida**][7], puedes seleccionar un servicio de inicio y un servicio final para obtener información sobre la latencia de extremo a extremo para identificar cuellos de botella y optimizar el rendimiento. Crea fácilmente un monitor para esa ruta o expórtalo a un dashboard. También puedes hacer clic en un servicio para abrir un panel lateral detallado y ver la pestaña **Pathways** (Rutas) para conocer la latencia entre el servicio y servicios de flujo ascendente. @@ -81,30 +116,39 @@ También puedes hacer clic en un servicio para abrir un panel lateral detallado Las ralentizaciones causadas por un retraso elevado de los consumidores o por mensajes obsoletos pueden provocar fallos en cascada y aumentar la caída del sistema. Gracias a las alertas predefinidas, puedes determinar con precisión dónde se producen los cuellos de botella en tus pipelines y responder a ellos de inmediato. Para complementar métricas, Datadog proporciona integraciones adicionales para tecnologías de colas de mensajes como [Kafka][4] y [SQS][5]. -A través de monitores recomendados predefinidos de Data Streams Monitoring, puedes configurar monitores en métricas como el retraso del consumidor, el rendimiento y la latencia en un solo clic. +A través de las plantillas de monitor predefinidas de Data Stream Monitoring puedes configurar monitores de métricas como el retraso del consumidor, el rendimiento y la latencia en un solo clic. -{{< img src="data_streams/add_monitors_and_synthetic_tests.png" alt="Monitores recomendados de Datadog Data Streams Monitoring" style="width:100%;" caption="Click 'Add Monitors and Synthetic Tests' to view Recommended Monitors" >}} +{{< img src="data_streams/add_monitors_and_synthetic_tests.png" alt="Plantillas de monitor de Datadog Data Streams Monitoring" style="width:100%;" caption="Haz clic en 'Add Monitors and Synthetic Tests' (Añadir monitores y tests Synthetic para ver los monitores recomendados" >}} ### Atribuye los mensajes entrantes a cualquier cola, servicio o clúster Un retraso elevado en un servicio consumidor, un mayor uso de recursos en un intermediario de Kafka y un aumento del tamaño de la cola de RabbitMQ o Amazon SQS se explican con frecuencia por cambios en la forma en que los servicios adyacentes están produciendo o consumiendo estas entidades. -Haz clic en la pestaña **Throughput** (Rendimiento) en cualquier servicio o cola en Data Streams Monitoring para detectar rápidamente los cambios en el rendimiento y en qué servicio de flujo ascendente o descendente se originan estos cambios. Una vez configurado el [Catálogo de servicios][2], puedes pasar inmediatamente al canal de Slack del equipo correspondiente o al ingeniero de guardia. +Haz clic en la pestaña **Rendimiento** de cualquier servicio o cola en Data Streams Monitoring para detectar rápidamente cambios en el rendimiento y ver de qué servicio ascendente o descendente proceden los cambios. Una vez configurado el [Catálogo de software][2], puedes cambiar inmediatamente al canal Slack del equipo correspondiente o al ingeniero de turno. Al filtrar a un único clúster de Kafka, RabbitMQ o Amazon SQS, puedes detectar cambios en el tráfico entrante o saliente para todos los temas o colas detectados que se ejecuten en ese clúster: -### Pasa rápidamente para identificar las causas raíz en infraestructura, logs o trazas +### Cambiar rápidamente para identificar las causas raíz en la infraestructura, los logs o las trazas (traces) + +Datadog vincula automáticamente la infraestructura que alimenta tus servicios y los logs relacionados a través del [Etiquetado de servicios unificado][3], para que puedas localizar fácilmente los cuellos de botella. Haz clic en las pestañas **Infra**, **Logs** o **Trazas** para solucionar el problema de por qué ha aumentado la latencia de la ruta o el retraso del consumidor. + +### Monitorizar el rendimiento y el estado del conector +{{< img src="data_streams/connectors_topology.png" alt="A DSM topology (topología) map, showing a connector called 'analytics-sink'. The visualization indicates that the connector has a status of FAILED." style="width:100%;" >}} -Datadog vincula automáticamente la infraestructura que alimenta tus servicios y los logs relacionados a través del [Etiquetado de servicios unificado][3], para que puedas localizar fácilmente los cuellos de botella. Haz clic en las pestañas **Infra**, **Logs** o **Traces** (Trazas) para solucionar el problema de por qué ha aumentado la latencia de la ruta o el retraso del consumidor. +Datadog puede detectar automáticamente tus conectores gestionados de [Confluent Cloud][8] y visualizarlos en el mapa de Data Streams Monitoring topology (topología) . Instala y configura la [integración de Confluent Cloud][9] para recopilar información de tus conectores de Confluent Cloud, incluido el rendimiento, el estado y las dependencias de temas. -## Para leer más +## Referencias adicionales {{< partial name="whats-next/whats-next.html" >}} [1]: /es/data_streams/go#manual-instrumentation -[2]: /es/tracing/service_catalog/ +[2]: /es/tracing/software_catalog/ [3]: /es/getting_started/tagging/unified_service_tagging [4]: /es/integrations/kafka/ [5]: /es/integrations/amazon_sqs/ [6]: /es/tracing/trace_collection/runtime_config/ -[7]: https://app.datadoghq.com/data-streams/measure \ No newline at end of file +[7]: https://app.datadoghq.com/data-streams/measure +[8]: https://www.confluent.io/confluent-cloud/ +[9]: /es/integrations/confluent_cloud/ +[10]: https://app.datadoghq.com/data-streams/map +[11]: /es/opentelemetry/compatibility \ No newline at end of file diff --git a/content/es/database_monitoring/guide/_index.md b/content/es/database_monitoring/guide/_index.md index 0c2da5af5e6f3..a71b479fda1af 100644 --- a/content/es/database_monitoring/guide/_index.md +++ b/content/es/database_monitoring/guide/_index.md @@ -10,17 +10,18 @@ title: Guías de Database Monitoring --- {{< whatsnext desc="Guías generales:" >}} - {{< nextlink href="database_monitoring/guide/heroku-postgres" >}}Configurar Heroku Postgres para Database Monitoring{{< /nextlink >}} - {{< nextlink href="database_monitoring/guide/tag_database_statements" >}}Etiquetar sentencias de bases de datos{{< /nextlink >}} - {{< nextlink href="database_monitoring/guide/managed_authentication" >}}Conectar con Managed Authentication{{< /nextlink >}} - {{< nextlink href="database_monitoring/guide/aurora_autodiscovery" >}}Configurar Database Monitoring para clústeres de bases de datos Amazon Aurora{{< /nextlink >}} - {{< nextlink href="database_monitoring/guide/rds_autodiscovery" >}}Configurar Database Monitoring para instancias de bases de datos de Amazon RDS{{< /nextlink >}} - {{< nextlink href="database_monitoring/guide/database_identifier" >}}Especificar un identificador de bases de datos{{< /nextlink >}} + {{< nextlink href="database_monitoring/guide/tag_database_statements" >}}Etiquetado de afirmaciones de base de datos{{< /nextlink >}} + {{< nextlink href="database_monitoring/guide/managed_authentication" >}}Conexión con autenticación administrada{{< /nextlink >}} + {{< nextlink href="database_monitoring/guide/aurora_autodiscovery" >}}Configuración de la monitorización de base de datos para clústeres de base de datos de Amazon Aurora{{< /nextlink >}} + {{< nextlink href="database_monitoring/guide/rds_autodiscovery" >}}Configuración de la monitorización de base de datos para instancias de base de datos de Amazon RDS{{< /nextlink >}} + {{< nextlink href="database_monitoring/guide/database_identifier" >}}Especificación de un identificador de base de datos{{< /nextlink >}} {{< /whatsnext >}} {{< whatsnext desc="Guías de SQL Server:" >}} - {{< nextlink href="database_monitoring/guide/sql_alwayson" >}}Exploración de los grupos de disponibilidad AlwaysOn de SQL Server{{< /nextlink >}} - {{< nextlink href="database_monitoring/guide/sql_deadlock" >}}Configuración de Deadlock Monitoring en SQL Server{{< /nextlink >}} + {{< nextlink href="database_monitoring/guide/sql_alwayson" >}}Exploración de grupos de disponibilidad AlwaysOn de SQL Server{{< /nextlink >}} + {{< nextlink href="database_monitoring/guide/sql_deadlock" >}}Configuración de la monitorización de Deadlock en SQL Server{{< /nextlink >}} + {{< nextlink href="database_monitoring/guide/sql_extended_events" >}}Configuración de la finalización de consultas y la recopilación de errores de consulta en SQL Server{{< /nextlink >}} + {{< nextlink href="database_monitoring/guide/parameterized_queries" >}}Captura de los valores de parámetros de consultas SQL con Database Monitoring{{< /nextlink >}} {{< /whatsnext >}} {{< whatsnext desc="Guías de PostgreSQL:" >}} diff --git a/content/es/database_monitoring/setup_mysql/rds.md b/content/es/database_monitoring/setup_mysql/rds.md index bbfb87cc08242..e6af78c424d20 100644 --- a/content/es/database_monitoring/setup_mysql/rds.md +++ b/content/es/database_monitoring/setup_mysql/rds.md @@ -14,7 +14,7 @@ title: Configuración de la monitorización de bases de datos para MySQL gestion La monitorización de bases de datos proporciona una amplia visibilidad de tus bases de datos MySQL mediante la exposición de métricas de consultas, ejemplos de consultas, planes de explicación, datos de conexión, métricas de sistemas y telemetría para el motor de almacenamiento InnoDB. -El Agent recopila telemetría directamente de la base de datos iniciando sesión como usuario de sólo lectura. Realiza la siguiente configuración para habilitar la monitorización de bases de datos con tu base de datos MySQL: +El Agent recopila telemetría directamente de la base de datos iniciando sesión como usuario de solo lectura. Realiza la siguiente configuración para habilitar la monitorización de bases de datos con tu base de datos MySQL: 1. [Configura la integración AWS](#configure-the-aws-integration). 1. [Configura parámetros de bases de datos](#configure-mysql-settings). @@ -77,9 +77,9 @@ Configura lo siguiente en el [grupo de parámetros de base de datos][3] y luego ## Conceder acceso al Agent -El Datadog Agent requiere acceso de sólo lectura a la base de datos para poder recopilar estadísticas y realizar consultas. +El Datadog Agent requiere acceso de solo lectura a la base de datos para poder recopilar estadísticas y realizar consultas. -Las siguientes instrucciones conceden permiso al Agent para iniciar sesión desde cualquier host que utilice `datadog@'%'`. Puedes restringir al usuario `datadog` para que sólo pueda iniciar sesión desde el host local utilizando `datadog@'localhost'`. Para obtener más información, consulta la [documentación de MySQL][4]. +Las siguientes instrucciones conceden permiso al Agent para iniciar sesión desde cualquier host que utilice `datadog@'%'`. Puedes restringir al usuario `datadog` para que solo pueda iniciar sesión desde el host local utilizando `datadog@'localhost'`. Para obtener más información, consulta la [documentación de MySQL][4]. {{< tabs >}} {{% tab "MySQL ≥ 5.7" %}} @@ -175,7 +175,7 @@ GRANT EXECUTE ON PROCEDURE datadog.enable_events_statements_consumers TO datadog ## Instala y configura el Agent -Para monitorizar hosts de RDS, instala el Datadog Agent en tu infraestructura y configúralo para conectarse a cada endpoint de instancia de forma remota. El Agent no necesita ejecutarse en la base de datos, sólo necesita conectarse a ella. Para conocer otros métodos de instalación del Agent no mencionados aquí, consulta las [instrucciones de instalación del Agent][5]. +Para monitorizar hosts de RDS, instala el Datadog Agent en tu infraestructura y configúralo para conectarse a cada endpoint de instancia de forma remota. El Agent no necesita ejecutarse en la base de datos, solo necesita conectarse a ella. Para conocer otros métodos de instalación del Agent no mencionados aquí, consulta las [instrucciones de instalación del Agent][5]. {{< tabs >}} {{% tab "Host" %}} @@ -192,13 +192,14 @@ init_config: instances: - dbm: true host: '
--set targetSystem=windows to the helm install command.
-For Windows, append
-
-### Configuración con archivos integrados
-
-Para configurar un check de clúster con un archivo de configuración montado, monta el archivo de configuración en el contenedor del Cluster Agent en la ruta: `/conf.d/postgres.yaml`:
+Edita el archivo `conf.d/postgres.d/conf.yaml` del Agent para apuntar a la instancia Postgres que quieres monitorizar. Para ver una lista completa de las opciones de configuración, consulta el [ejemplo postgres.d/conf.yaml][9].
```yaml
-cluster_check: true # Make sure to include this flag
init_config:
instances:
- - dbm: true
- host: '--set targetSystem=windows to the helm install command.
-
-For Windows, append
### Configuración con archivos integrados
@@ -366,7 +369,7 @@ instances:
### Configuración con anotaciones de servicios de Kubernetes
-En lugar de montar un archivo, puedes declarar la configuración de la instancia como un servicio de Kubernetes. Para configurar este check para un Agent que se ejecuta en Kubernetes, crea un servicio en el mismo espacio de nombres que el Datadog Cluster Agent:
+En lugar de montar un archivo, puedes declarar la configuración de la instancia como servicio Kubernetes. Para configurar este check para un Agent que se ejecuta en Kubernetes, crea un servicio con la siguiente sintaxis:
```yaml
apiVersion: v1
diff --git a/content/es/database_monitoring/setup_sql_server/selfhosted.md b/content/es/database_monitoring/setup_sql_server/selfhosted.md
index de70170e51ec0..58350a597e9d7 100644
--- a/content/es/database_monitoring/setup_sql_server/selfhosted.md
+++ b/content/es/database_monitoring/setup_sql_server/selfhosted.md
@@ -10,6 +10,9 @@ further_reading:
- link: /database_monitoring/guide/sql_deadlock/
tag: Documentación
text: Configurar la Monitorización Deadlock
+- link: /database_monitoring/guide/sql_extended_events/
+ tag: Documentación
+ text: Configurar la finalización de consultas y la recopilación de errores de consulta
- link: https://www.datadoghq.com/blog/migrate-sql-workloads-to-azure-with-datadog/
tag: Blog
text: Establecer estrategias de migración Azure para cargas de trabajo SQL con Datadog
@@ -38,7 +41,7 @@ Versiones de SQL Server compatibles
El Datadog Agent requiere acceso de sólo lectura al servidor de la base de datos para recopilar estadísticas y consultas.
-Crea un inicio de sesión de solo lectura para conectarte a tu servidor y concede los permisos necesarios:
+Crea un inicio de sesión de solo lectura para conectarte a tu servidor y conceder los permisos necesarios:
{{< tabs >}}
{{% tab "SQL Server 2014 o posterior" %}}
@@ -75,8 +78,8 @@ Crea el usuario `datadog` en cada base de datos de aplicaciones adicional:
USE [database_name];
CREATE USER datadog FOR LOGIN datadog;
```
-{{% /tab%}}
-{{< /tabs>}}
+{{% /tab %}}
+{{< /tabs >}}
### Guarda tu contraseña de forma segura
{{% dbm-secret %}}
@@ -86,22 +89,14 @@ CREATE USER datadog FOR LOGIN datadog;
Se recomienda instalar el Agent directamente en el host de SQL Server, ya que esto permite al Agent recopilar una variedad de telemetrías del sistema (CPU, memoria, disco, red), además de la telemetría específica del SQL Server.
{{< tabs >}}
-{{% tab "Host de Windows" %}}
+{{% tab "Windows Host" %}}
{{% dbm-alwayson %}}
{{% dbm-sqlserver-agent-setup-windows %}}
{{% /tab %}}
-{{% tab "Host de Linux" %}}
+{{% tab "Linux Host" %}}
{{% dbm-alwayson %}}
{{% dbm-sqlserver-agent-setup-linux %}}
{{% /tab %}}
-{{% tab "Docker" %}}
-{{% dbm-alwayson %}}
-{{% dbm-sqlserver-agent-setup-docker %}}
-{{% /tab %}}
-{{% tab "Kubernetes" %}}
-{{% dbm-alwayson %}}
-{{% dbm-sqlserver-agent-setup-kubernetes %}}
-{{% /tab %}}
{{< /tabs >}}
## Configuraciones del Agent de ejemplo
diff --git a/content/es/datadog_cloudcraft/_index.md b/content/es/datadog_cloudcraft/_index.md
new file mode 100644
index 0000000000000..75cee2759a7f4
--- /dev/null
+++ b/content/es/datadog_cloudcraft/_index.md
@@ -0,0 +1,149 @@
+---
+description: Visualizar y analizar la infraestructura de la nube de AWS con diagramas
+ en directo de Cloudcraft en Datadog para solucionar los problemas, analizar la seguridad
+ y optimizar los costes
+further_reading:
+- link: https://www.datadoghq.com/blog/cloud-architecture-diagrams-cost-compliance-cloudcraft-datadog/
+ tag: Blog
+ text: Planificar nuevas arquitecturas y realiza un seguimiento de tu huella en la
+ nube con Cloudcraft (independiente)
+- link: https://www.datadoghq.com/blog/introducing-cloudcraft/
+ tag: Blog
+ text: Crear visualizaciones ricas y actualizadas de tu infraestructura AWS con Cloudcraft
+ en Datadog
+- link: https://www.datadoghq.com/blog/cloudcraft-security/
+ tag: Blog
+ text: Identificar y priorizar visualmente los riesgos de seguridad con Cloudcraft
+title: Cloudcraft en Datadog
+---
+
+## Información general
+
+Cloudcraft ofrece una potente herramienta de visualización en directo de solo lectura de la arquitectura de la nube que te permite explorar, analizar y gestionar tu infraestructura con facilidad. Esta guía, que no debe confundirse con la documentación de [Cloudcraft independiente][1], describe la funcionalidad, la configuración y los casos de uso de Cloudcraft *en Datadog*, detalla sus ventajas para varios usuarios y destaca las características y capacidades clave.
+
+--set targetSystem=windows to the helm install command.
+Para Windows, adjunta --set targetSystem=windows al comando de instalación de Helm.
Esta documentación se aplica al producto Cloudcraft en Datadog. Para obtener información sobre el producto Cloudcraft independiente, consulta la documentación Cloudcraft (independiente).
+
+La función central de Cloudcraft es su capacidad para generar diagramas de arquitectura detallados. Estos diagramas representan visualmente los recursos de la nube de AWS para permitirte explorar y analizar tus entornos. Los diagramas de Cloudcraft están optimizados para ofrecer claridad y rendimiento, y te proporcionan una interfaz intuitiva para navegar por despliegues a gran escala. Esto ayuda a los equipos a:
+
+- Rastrear las causas de los incidentes a través de dependencias de la infraestructura.
+- Determinar si la infraestructura es la causa de un incidente, como el tráfico entre regiones que genera latencia o mayores costes.
+- Analizar y abordar los errores de configuración de seguridad más relevantes.
+- Incorporar nuevos miembros al equipo.
+- Acelerar el MTTR de los incidentes y las tareas de gobernanza proactivas, simplificando la navegación por la infraestructura.
+
+{{< img src="datadog_cloudcraft/cloudcraft_with_ccm_2.mp4" alt="Cloudcraft en un vídeo de Datadog" video=true >}}
+
+Cloudcraft en Datadog solo está disponible actualmente para cuentas de AWS.
+
+### Requisitos previos
+
+- Para acceder a Cloudcraft en Datadog, necesitas el [permiso](#permissions) `cloudcraft_read`.
+- La [recopilación de recursos][2] debe estar activada para tus cuentas de AWS.
+- Para obtener la mejor experiencia, Datadog recomienda altamente utilizar la política [`SecurityAudit`][5] administrada por AWS o la política [`ReadOnlyAccess`][6] más permisiva.
+- La visualización de contenidos en la [superposición de seguridad][10] requiere la activación de productos adicionales:
+ - Para ver errores de configuración de seguridad y riesgos de identidad, se debe activar [Cloud Security][3].
+ - Para ver datos confidenciales, [Sensitive Data Scanner][12] debe estar activado. Para que un usuario active la capa, debe tener el permiso [`data_scanner_read`][13].
+
+**Nota**: Cloudcraft se adapta a los permisos restrictivos excluyendo los recursos inaccesibles. Por ejemplo, si no concedes permiso para enumerar buckets S3, el diagrama excluye esos buckets. Si los permisos bloquean ciertos recursos, se muestra una alerta en la interfaz de usuario.
+
+Activar la recopilación de recursos puede repercutir en los costes de AWS CloudWatch. Para evitar estos cargos, desactiva las métricas de uso en la pestaña Recopilación de métricas de la integración Datadog AWS.
+ +{{< img src="/infrastructure/resource_catalog/aws_usage_toggle.png" alt="Conmutador del uso de AWS en los parámetros de la cuenta" style="width:100%;" >}}
+
+## Empezando
+
+Para empezar a utilizar Cloudcraft, sigue estos pasos:
+1. Ve a [**Infrastructure > Resources > Cloudcraft** (Infraestructura > Recursos > Cloudcraft)][7].
+2. Se muestra un diagrama en tiempo real de los recursos de tu entorno.
+
+ **Nota**: Para entornos con más de 10.000 recursos, debes filtrar el diagrama por cuenta, región o etiquetas (tags) antes de poder mostrarlo.
+
+{{< img src="datadog_cloudcraft/getting_started_3.mp4" alt="Vídeo que muestra cómo empezar en Cloudcraft seleccionando la cuenta, la región y el recurso" video=true;" >}}
+
+**Nota**: El nombre de la cuenta en el desplegable **Account** (Cuenta) se origina a partir de las etiquetas de tu cuenta de AWS en el cuadro de integración de AWS.
+
+### Agrupar por
+
+Con la opción Agrupar por, Cloudcraft divide tu diagrama en distintas secciones basadas en diferentes tipos de grupos. Esta función ofrece una perspectiva clara y organizada de tus recursos, por lo que resulta especialmente útil para visualizar entornos de nube complejos.
+
+Activa la casilla **Show All Controls** (Mostrar todos los controles) para mostrar las opciones disponibles de **Agrupar por**. También puedes eliminar agrupaciones específicas desmarcando opciones como VPC y Región. Para ver la estructura de anidamiento actual y añadir la capa ACL de red (lista de control de acceso de red), haz clic en el desplegable **More** (Más).
+
+{{< img src="datadog_cloudcraft/cloudcraft_group_by_with_ccm.png" alt="Función Agrupar for en Cloudcraft, resaltando el menú Agrupar por" >}}
+
+#### Agrupar por etiquetas
+
+Puedes agrupar los recursos por etiquetas de AWS, como app, service, team o cost center, para organizar la vista por equipo o carga de trabajo.
+
+**Nota**: La agrupación por etiquetas solo es compatible con las etiquetas de AWS. Las etiquetas del Datadog Agent (por ejemplo, `env`, o `team` de la configuración local) no son compatibles.
+
+{{< img src="datadog_cloudcraft/group_by_tag.mp4" alt="Función Agrupar por etiqueta en Cloudcraft, donde se agrupa por equipo y centro de costes" video=true >}}
+
+### Vistas guardadas
+
+Las vistas guardadas te permiten guardar en tu diagrama los filtros específicos que son más importantes para ti. Esto permite una solución eficiente de los problemas con consultas delimitadas a tus cuentas, regiones, entornos y recursos.
+
+Para aplicar una vista guardada a tu diagrama:
+
+- Ve a [**Infrastructure > Resources > Cloudcraft** (Infraestructura > Recursos > Cloudcraft)][7]. Selecciona una o más cuentas, regiones y recursos. Aplica los filtros deseados a la vista guardada y haz clic en **+Save as new view** (+Guardar como nueva vista).
+- Selecciona la vista guardada deseada en el menú situado en la parte superior de la vista del diagrama. El diagrama se actualiza automáticamente para reflejar la vista elegida.
+
+{{< img src="datadog_cloudcraft/saved_views.png" alt="Captura de pantalla de las vistas guardadas" style="width:50%;" >}}
+
+### Explorar recursos
+
+Utiliza las funciones de ampliar y pasar el cursor por encima para localizar los recursos más importantes. A medida que se amplía la imagen, aparecen más nombres de recursos. Al pasar el cursor por encima de un recurso, aparece un panel con información básica, mientras que al hacer clic en un recurso se abre un panel lateral con datos de observabilidad, costes y seguridad, junto con enlaces cruzados a otros productos relevantes de Datadog.
+
+{{< img src="datadog_cloudcraft/cloudcraft_with_ccm_2.mp4" alt="Vídeo que muestra la función de ampliar y pasar el cursor por encima en Cloudcraft, y el clic en un recurso para abrir el panel lateral" video=true >}}
+
+#### Conmutador de proyección
+
+Cambia el conmutador de la proyección 3D (por defecto) a 2D para visualizar tus recursos desde arriba.
+
+{{< img src="datadog_cloudcraft/cloudcraft_2D.png" alt="Págiuna de inicio de Cloudcraft con el conmutador 2D activado" >}}
+
+
+### Filtrado y búsqueda
+
+Los diagramas pueden filtrarse por etiquetas, como team, application o service, lo que te permite concentrarte en los recursos pertinentes y conservar el contexto en los recursos conectados. Además, Cloudcraft ofrece una potente función de búsqueda y resaltado que facilita la localización de recursos o grupos de recursos específicos.
+
+Haz clic en el menú **\+Filter** (+Filtrar) para filtrar rápidamente tus recursos con las etiquetas más utilizadas, como service, team, region, etc. Además, haz clic en la opción **More Filters** (Más filtros) para filtrar por etiquetas AWS, etiquetas personalizadas y etiquetas Terraform. La opción de filtro vuelve a cargar el diagrama para mostrar solo la infraestructura que coincide con los criterios de filtrado.
+
+{{< img src="datadog_cloudcraft/cloudcraft_filter.png" alt="Filtrar funciones en Cloudcraft" >}}
+
+### Buscar y resaltar
+
+Utiliza la barra de búsqueda para localizar recursos en el diagrama por nombre, ID o etiqueta. Esta función es muy eficaz para encontrar recursos específicos dentro de tu arquitectura de nube. Resalta los criterios de búsqueda en el diagrama, sin crear un nuevo diagrama, poniendo en gris los elementos que no coinciden con los criterios de búsqueda.
+
+{{< img src="datadog_cloudcraft/search_highlight_2.mp4" alt="Vídeo que muestra la función de búsqueda y resaltado en Cloudcraft" video=true >}}
+
+## Permisos
+
+Para acceder a Cloudcraft en Datadog, necesitas el permiso `cloudcraft_read`. Este permiso está incluido por defecto en el rol de solo lectura de Datadog. Si tu organización utiliza roles personalizados, añade este permiso al rol apropiado. Para obtener más información sobre la gestión de permisos, consulta la [documentación de RBAC][14].
+
+## Siguientes pasos
+
+Aprende a navegar entre las [superposiciones integradas][4] para visualizar tu arquitectura desde diferentes perspectivas. Cada superposición está diseñada para respaldar objetivos operativos específicos, como:
+
+- [Infraestructura][8]: Vista clara de servicios y recursos.
+- [Observabilidad][9]: Indica qué hosts tienen instalado el Agent y qué características de observabilidad están activadas.
+- [Seguridad][10]: Visibilidad de IAM, cortafuegos y grupos de seguridad.
+- [Cloud Cost Management][11]: Seguimiento y optimización de gastos de recursos.
+
+## Referencias adicionales
+
+{{< partial name="whats-next/whats-next.html" >}}
+
+[1]: /es/cloudcraft
+[2]: /es/integrations/amazon_web_services/#resource-collection
+[3]: /es/security/cloud_security_management
+[4]: /es/datadog_cloudcraft/overlays
+[5]: https://docs.aws.amazon.com/aws-managed-policy/latest/reference/SecurityAudit.html
+[6]: https://docs.aws.amazon.com/aws-managed-policy/latest/reference/ReadOnlyAccess.html
+[7]: https://app.datadoghq.com/cloud-maps
+[8]: /es/datadog_cloudcraft/overlays#infrastructure
+[9]: /es/datadog_cloudcraft/overlays#observability
+[10]: /es/datadog_cloudcraft/overlays#security
+[11]: /es/datadog_cloudcraft/overlays#cloud-cost-management
+[12]: /es/security/sensitive_data_scanner
+[13]: /es/account_management/rbac/permissions/#compliance
+[14]: /es/account_management/rbac/
\ No newline at end of file
diff --git a/content/es/ddsql_reference/_index.md b/content/es/ddsql_reference/_index.md
new file mode 100644
index 0000000000000..2a29c507b7639
--- /dev/null
+++ b/content/es/ddsql_reference/_index.md
@@ -0,0 +1,856 @@
+---
+aliases:
+- /es/logs/workspaces/sql_reference
+- /es/ddsql_reference/ddsql_default
+description: Referencia completa de sintaxis, tipos de datos, funciones, operadores
+ y sentencias DDSQL para consultar datos de Datadog con SQL.
+further_reading:
+- link: /ddsql_editor/
+ tag: Documentación
+ text: Más información sobre DDSQL Editor
+products:
+- icon: ddsql
+ name: Editor DDSQL
+ url: /ddsql_editor/
+- icon: notebook
+ name: Notebooks
+ url: /notebooks/
+title: Referencia DDSQL
+---
+
+{{< product-availability >}}
+
+## Información general
+
+DDSQL es SQL para datos de Datadog. Implementa varias operaciones SQL estándar, como `SELECT`, y permite realizar consultas de datos no estructurados. Puedes realizar acciones, como obtener exactamente los datos que buscas, escribiendo tu propia sentencia `SELECT`, o consultar etiquetas (tags) como si fueran columnas de tablas estándar.
+
+Esta documentación cubre el soporte SQL disponible e incluye:
+- [Sintaxis compatible con PostgreSQL](#syntax)
+- [Tipos de datos](#data-types)
+- [Tipos literales](#type-literals)
+- [Funciones de SQL](#functions)
+- [Expresiones regulares](#regular-expressions)
+- [Funciones de ventana](#window-functions)
+- [Funciones JSON](#json-functions-and-operators)
+- [Funciones de tabla](#table-functions)
+- [Etiquetas](#tags)
+
+
+{{< img src="/logs/workspace/sql_reference/sql_syntax_analysis_cell.png" alt="Celda de Workspace de ejemplo con sintaxis de SQL" style="width:100%;" >}}
+
+## Sintaxis
+
+Se admite la siguiente sintaxis de SQL:
+
+`SELECT (DISTINCT)` (DISTINCT: Opcional)
+: Recupera filas de una base de datos, con `DISTINCT` filtrando los registros duplicados.
+
+ {{< code-block lang="sql" >}}SELECT DISTINCT customer_id
+FROM orders {{< /code-block >}}
+
+`JOIN`
+: Combina filas de dos o más tablas basándose en una columna relacionada entre ellas. Admite FULL JOIN, INNER JOIN, LEFT JOIN, RIGHT JOIN.
+
+ {{< code-block lang="sql" >}}SELECT orders.order_id, customers.customer_name
+FROM orders
+JOIN customers
+ON orders.customer_id = customers.customer_id {{< /code-block >}}
+
+`GROUP BY`
+: Agrupa las filas que tienen los mismos valores en las columnas especificadas en filas de resumen.
+
+ {{< code-block lang="sql" >}}SELECT product_id, SUM(quantity)
+FROM sales
+GROUP BY product_id {{< /code-block >}}
+
+`||` (concat)
+: Concatena dos o más cadenas.
+
+ {{< code-block lang="sql" >}}SELECT first_name || ' ' || last_name AS full_name
+FROM employees {{< /code-block >}}
+
+`WHERE` (Incluye compatibilidad con los filtros `LIKE`, `IN`, `ON`, `OR`)
+: Filtra los registros que cumplen una condición especificada.
+
+ {{< code-block lang="sql" >}}SELECT *
+FROM employees
+WHERE department = 'Sales' AND name LIKE 'J%' {{< /code-block >}}
+
+`CASE`
+: Proporciona una lógica condicional para devolver diferentes valores basados en condiciones especificadas.
+
+ {{< code-block lang="sql" >}}SELECT order_id,
+ CASE
+ WHEN quantity > 10 THEN 'Bulk Order'
+ ELSE 'Standard Order'
+ END AS order_type
+FROM orders {{< /code-block >}}
+
+`WINDOW`
+: Realiza un cálculo a través de un conjunto de filas de tabla relacionadas con la fila actual.
+
+ {{< code-block lang="sql" >}}SELECT
+ timestamp,
+ service_name,
+ cpu_usage_percent,
+ AVG(cpu_usage_percent) OVER (PARTITION BY service_name ORDER BY timestamp ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) AS moving_avg_cpu
+FROM
+ cpu_usage_data {{< /code-block >}}
+
+`IS NULL`/`IS NOT NULL`
+: Comprueba si un valor es nulo o no.
+
+ {{< code-block lang="sql" >}}SELECT *
+FROM orders
+WHERE delivery_date IS NULL {{< /code-block >}}
+
+`LIMIT`
+: Especifica el número máximo de registros a devolver.
+
+ {{< code-block lang="sql" >}}SELECT *
+FROM customers
+LIMIT 10 {{< /code-block >}}
+
+`OFFSET`
+: Omite un número especificado de registros antes de empezar a devolver registros de la consulta.
+
+ {{< code-block lang="sql" >}}SELECT *
+FROM employees
+OFFSET 20 {{< /code-block >}}
+
+`ORDER BY`
+: Ordena el conjunto de resultados de una consulta por una o varias columnas. Incluye ASC, DESC para el orden de clasificación.
+
+ {{< code-block lang="sql" >}}SELECT *
+FROM sales
+ORDER BY sale_date DESC {{< /code-block >}}
+
+`HAVING`
+: Filtra los registros que cumplen una condición especificada después de la agrupación.
+
+ {{< code-block lang="sql" >}}SELECT product_id, SUM(quantity)
+FROM sales
+GROUP BY product_id
+HAVING SUM(quantity) > 10 {{< /code-block >}}
+
+`IN`, `ON`, `OR`
+: Se utilizan para especificar condiciones en las consultas. Disponible en las cláusulas `WHERE`, `JOIN`.
+
+ {{< code-block lang="sql" >}}SELECT *
+FROM orders
+WHERE order_status IN ('Shipped', 'Pending') {{< /code-block >}}
+
+`USING`
+: Esta cláusula es una abreviatura para uniones en las que las columnas unidas tienen el mismo nombre en ambas tablas. Toma una lista separada por comas de esas columnas y crea una condición de igualdad independiente para cada par coincidente. Por ejemplo, unir `T1` y `T2` con `USING (a, b)` equivale a `ON T1.a = T2.a AND T1.b = T2.b`.
+
+ {{< code-block lang="sql" >}}SELECT orders.order_id, customers.customer_name
+FROM orders
+JOIN customers
+USING (customer_id) {{< /code-block >}}
+
+`AS`
+: Renombra una columna o tabla con un alias.
+
+ {{< code-block lang="sql" >}}SELECT first_name AS name
+FROM employees {{< /code-block >}}
+
+Operaciones aritméticas
+: Realiza cálculos básicos utilizando operadores como `+`, `-`, `*`, `/`.
+
+ {{< code-block lang="sql" >}}SELECT price, tax, (price * tax) AS total_cost
+FROM products {{< /code-block >}}
+
+`INTERVAL value unit`
+: Intervalo que representa una duración de tiempo especificada en una unidad determinada.
+Unidades admitidas:+ +{{< img src="/infrastructure/resource_catalog/aws_usage_toggle.png" alt="Conmutador del uso de AWS en los parámetros de la cuenta" style="width:100%;" >}}
- `milliseconds`/`millisecond`
- `seconds`/`second`
- `minutes`/`minute`
- `hours`/`hour`
- `days`/`day` + +## Tipos de datos + +DDSQL admite los siguientes tipos de datos: + +| Tipo de datos | Descripción | +|-----------|-------------| +| `BIGINT` | Enteros con signo de 64 bits. | +| `BOOLEAN` | Valores `true` o `false`. | +| `DOUBLE` | Números de coma flotante de doble precisión. | +| `INTERVAL` | Valores de duración. | +| `JSON` | Datos JSON. | +| `TIMESTAMP` | Valores de fecha y hora. | +| `VARCHAR` | Cadenas de caracteres de longitud variable. | + +### Tipos de matrices + +Todos los tipos de datos admiten tipos de matrices. Las matrices pueden contener varios valores del mismo tipo de datos. + +## Tipos literales + +DDSQL admite tipos literales explícitos utilizando la sintaxis `[TYPE] [value]`. + +| Tipo | Sintaxis | Ejemplo | +|------|--------|---------| +| `BIGINT` | `BIGINT value` | `BIGINT 1234567` | +| `BOOLEAN` | `BOOLEAN value` | `BOOLEAN true` | +| `DOUBLE` | `DOUBLE value` | `DOUBLE 3.14159` | +| `INTERVAL` | `INTERVAL 'value unit'` | `INTERVAL '30 minutes'` | +| `JSON` | `JSON 'value'` | `JSON '{"key": "value", "count": 42}'` | +| `TIMESTAMP` | `TIMESTAMP 'value'` | `TIMESTAMP '2023-12-25 10:30:00'` | +| `VARCHAR` | `VARCHAR 'value'` | `VARCHAR 'hello world'` | + +El prefijo del tipo puede omitirse y el tipo se deduce automáticamente del valor. Por ejemplo, `'hello world'` se deduce como `VARCHAR`, `123` como `BIGINT` y `true` como `BOOLEAN`. Utiliza prefijos de tipo explícitos cuando los valores puedan ser ambiguos. Por ejemplo,`TIMESTAMP '2025-01-01'` se deduciría como `VARCHAR` sin el prefijo. + +### Matrices literales + +Las matrices literales utilizan la sintaxis `ARRAY[value1, value2, ...]`. El tipo de matriz se deduce automáticamente de los valores. + +{{< code-block lang="sql" >}} +SELECT ARRAY['apple', 'banana', 'cherry'] AS fruits; -- Inferred as VARCHAR array +SELECT ARRAY[1, 2, 3] AS numbers; -- Inferred as BIGINT array +SELECT ARRAY[true, false, true] AS flags; -- Inferred as BOOLEAN array +SELECT ARRAY[1.1, 2.2, 3.3] AS decimals; -- Inferred as DOUBLE array +{{< /code-block >}} + +### Ejemplo + +{{< code-block lang="sql" >}} +-- Using type literals in queries +SELECT + VARCHAR 'Product Name: ' || name AS labeled_name, + price * DOUBLE 1.08 AS price_with_tax, + created_at + INTERVAL '7 days' AS expiry_date +FROM products +WHERE created_at > TIMESTAMP '2025-01-01'; +{{< /code-block >}} + +## Funciones + +Se admiten las siguientes funciones de SQL. Para la función de ventana, consulta la sección [función de ventana](#window-functions) de esta documentación. + +| Función | Tipo de retorno | Descripción | +|--------------------------------------------------|---------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------| +| `MIN(variable v)` | Variable typeof | Devuelve el valor más pequeño de un conjunto de datos. | +| `MAX(variable v)` | Variable typeof | Devuelve el valor máximo de todos los valores de entrada. | +| `COUNT(any a)` | numérico | Devuelve el número de valores de entrada que no son nulos. | +| `SUM(numeric n)` | numérico | Devuelve la suma de todos los valores de entrada. | +| `AVG(numeric n)` | numérico | Devuelve el valor medio (media aritmética) de todos los valores de entrada. | +| `BOOL_AND(boolean b)` | booleano | Devuelve si todos los valores de entrada no nulos son verdaderos. | +| `BOOL_OR(boolean b)` | booleano | Devuelve si cualquier valor de entrada no nulo es verdadero. | +| `CEIL(numeric n)` | numérico | Devuelve el valor redondeado al entero más próximo. | +| `FLOOR(numeric n)` | numérico | Devuelve el valor redondeado al entero más próximo. | +| `ROUND(numeric n)` | numérico | Devuelve el valor redondeado al entero más próximo. | +| `POWER(numeric base, numeric exponent)` | numérico | Devuelve el valor de la base elevado a la potencia del exponente. | +| `LOWER(string s)` | cadena | Devuelve la cadena en minúsculas. | +| `UPPER(string s)` | cadena | Devuelve la cadena en mayúsculas. | +| `ABS(numeric n)` | numérico | Devuelve el valor absoluto. | +| `COALESCE(args a)` | typeof first non-null a OR null | Devuelve el primer valor no nulo o nulo si todos son nulos. | +| `CAST(value AS type)` | tipo | Convierte el valor dado al tipo de datos especificado. | +| `LENGTH(string s)` | entero | Devuelve el número de caracteres de la cadena. | +| `TRIM(string s)` | cadena | Elimina los espacios en blanco iniciales y finales de la cadena. | +| `REPLACE(string s, string from, string to)` | cadena | Sustituye las apariciones de una subcadena dentro de una cadena por otra subcadena. | +| `SUBSTRING(string s, int start, int length)` | cadena | Extrae una subcadena de una cadena, comenzando en una posición dada y para una longitud especificada. | +| `STRPOS(string s, string substring)` | entero | Devuelve la primera posición del índice de la subcadena en una cadena dada, o 0 si no hay coincidencia. | +| `SPLIT_PART(string s, string delimiter, integer index)` | cadena | Divide la cadena en el delimitador dado y devuelve la cadena en la posición dada contando desde uno. | +| `EXTRACT(unit from timestamp/interval)` | numérico | Extrae una parte de un campo de fecha u hora (como el año o el mes) de una marca temporal o intervalo. | +| `TO_TIMESTAMP(string timestamp, string format)` | marca de tiempo | Convierte una cadena en una marca de tiempo según el formato dado. | +| `TO_CHAR(timestamp t, string format)` | cadena | Convierte una marca de tiempo en una cadena según el formato dado. | +| `DATE_BIN(interval stride, timestamp source, timestamp origin)` | marca de tiempo | Alinea una marca de tiempo (fuente) en buckets de longitud par (stride). Devuelve el inicio del bucket que contiene la fuente, calculado como la mayor marca de tiempo que es menor o igual que la fuente y es un múltiplo de longitudes de stride desde el origen. | +| `DATE_TRUNC(string unit, timestamp t)` | marca de tiempo | Trunca una marca de tiempo a una precisión especificada basada en la unidad proporcionada. | +| `CURRENT_SETTING(string setting_name)` | cadena | Devuelve el valor actual del parámetro especificado. Admite los parámetros `dd.time_frame_start` y `dd.time_frame_end`, que devuelven el inicio y el final del marco temporal global, respectivamente. | +| `NOW()` | marca de tiempo | Devuelve la marca de tiempo actual al inicio de la consulta actual. | +| `CARDINALITY(array a)` | entero | Devuelve el número de elementos de la matriz. | +| `ARRAY_POSITION(array a, typeof_array value)` | entero | Devuelve el índice de la primera aparición del valor encontrado en la matriz, o null (nulo) si no se encuentra el valor. | +| `STRING_TO_ARRAY(string s, string delimiter)` | matriz de cadenas | Divide la cadena dada en una matriz de cadenas utilizando el delimitador dado. | +| `ARRAY_AGG(expression e)` | matriz de tipo de entrada | Crea una matriz al recopilar todos los valores de entrada. | +| `UNNEST(array a [, array b...])` | filas de a [, b...] | Expande matrices en un conjunto de filas. Esta forma sólo se permite en una cláusula FROM. | + +{{% collapse-content title="Ejemplos" level="h3" %}} + +### `MIN` +{{< code-block lang="sql" >}} +SELECT MIN(response_time) AS min_response_time +FROM logs +WHERE status_code = 200 +{{< /code-block >}} + +### `MAX` +{{< code-block lang="sql" >}} +SELECT MAX(response_time) AS max_response_time +FROM logs +WHERE status_code = 200 +{{< /code-block >}} + +### `COUNT` +{{< code-block lang="sql" >}}SELECT COUNT(request_id) AS total_requests +FROM logs +WHERE status_code = 200 {{< /code-block >}} + +### `SUM` +{{< code-block lang="sql" >}}SELECT SUM(bytes_transferred) AS total_bytes +FROM logs +GROUP BY service_name +{{< /code-block >}} + +### `AVG` +{{< code-block lang="sql" >}}SELECT AVG(response_time) +AS avg_response_time +FROM logs +WHERE status_code = 200 +GROUP BY service_name +{{< /code-block >}} + +### `BOOL_AND` +{{< code-block lang="sql" >}}SELECT BOOL_AND(status_code = 200) AS all_success +FROM logs +{{< /code-block >}} + +### `BOOL_OR` +{{< code-block lang="sql" >}}SELECT BOOL_OR(status_code = 200) AS some_success +FROM logs +{{< /code-block >}} + +### `CEIL` +{{< code-block lang="sql" >}} +SELECT CEIL(price) AS rounded_price +FROM products +{{< /code-block >}} + +### `FLOOR` +{{< code-block lang="sql" >}} +SELECT FLOOR(price) AS floored_price +FROM products +{{< /code-block >}} + +### `ROUND` +{{< code-block lang="sql" >}} +SELECT ROUND(price) AS rounded_price +FROM products +{{< /code-block >}} + +### `POWER` +{{< code-block lang="sql" >}} +SELECT POWER(response_time, 2) AS squared_response_time +FROM logs +{{< /code-block >}} + +### `LOWER` +{{< code-block lang="sql" >}} +SELECT LOWER(customer_name) AS lowercase_name +FROM customers +{{< /code-block >}} + +### `UPPER` +{{< code-block lang="sql" >}} +SELECT UPPER(customer_name) AS uppercase_name +FROM customers +{{< /code-block >}} + +### `ABS` +{{< code-block lang="sql" >}} +SELECT ABS(balance) AS absolute_balance +FROM accounts +{{< /code-block >}} + +### `COALESCE` +{{< code-block lang="sql" >}} +SELECT COALESCE(phone_number, email) AS contact_info +FROM users +{{< /code-block >}} + +### `CAST` + +Tipos de objetivos de cast admitidos: +- `BIGINT` +- `DECIMAL` +- `TIMESTAMP` +- `VARCHAR` + +{{< code-block lang="sql" >}} +SELECT + CAST(order_id AS VARCHAR) AS order_id_string, + 'Order-' || CAST(order_id AS VARCHAR) AS order_label +FROM + orders +{{< /code-block >}} + +### `LENGTH` +{{< code-block lang="sql" >}} +SELECT + customer_name, + LENGTH(customer_name) AS name_length +FROM + customers +{{< /code-block >}} + +### `INTERVAL` +{{< code-block lang="sql" >}} +SELECT + TIMESTAMP '2023-10-01 10:00:00' + INTERVAL '30 days' AS future_date, + INTERVAL '1 MILLISECOND 2 SECONDS 3 MINUTES 4 HOURS 5 DAYS' +{{< /code-block >}} + +### `TRIM` +{{< code-block lang="sql" >}} +SELECT + TRIM(name) AS trimmed_name +FROM + users +{{< /code-block >}} + +### `REPLACE` +{{< code-block lang="sql" >}} +SELECT + REPLACE(description, 'old', 'new') AS updated_description +FROM + products +{{< /code-block >}} + +### `SUBSTRING` +{{< code-block lang="sql" >}} +SELECT + SUBSTRING(title, 1, 10) AS short_title +FROM + books +{{< /code-block >}} + +### `STRPOS` +{{< code-block lang="sql" >}} +SELECT + STRPOS('foobar', 'bar') +{{< /code-block >}} + +### `SPLIT_PART` +{{< code-block lang="sql" >}} +SELECT + SPLIT_PART('aaa-bbb-ccc', '-', 2) +{{< /code-block >}} + +### `EXTRACT` + +Unidades de extracción compatibles: +| Literal | Tipo de entrada | Descripción | +| ------------------| ------------------------ | -------------------------------------------- | +| `day` | `timestamp` / `interval` | día del mes | +| `dow` | `timestamp` | día de la semana `1` (lunes) a `7` (domingo) | +| `doy` | `timestamp` | día del año (`1` - `366`) | +| `hour` | `timestamp` / `interval` | hora del día (`0` - `23`) | +| `minute` | `timestamp` / `interval` | minuto de la hora (`0` - `59`) | +| `second` | `timestamp` / `interval` | segundo del minuto (`0` - `59`) | +| `week` | `timestamp` | semana del año (`1` - `53`) | +| `month` | `timestamp` | mes del año (`1` - `12`) | +| `quarter` | `timestamp` | trimestre del año (`1` - `4`) | +| `year` | `timestamp` | año | +| `timezone_hour` | `timestamp` | hora del inicio del huso horario | +| `timezone_minute` | `timestamp` | minuto del inicio del huso horario | + +{{< code-block lang="sql" >}} +SELECT + EXTRACT(year FROM purchase_date) AS purchase_year +FROM + sales +{{< /code-block >}} + +### `TO_TIMESTAMP` + +Patrones compatibles para el formato fecha/hora: +| Patrón | Descripción | +| ----------- | ------------------------------------ | +| `YYYY` | año (4 dígitos) | +| `YY` | año (2 dígitos) | +| `MM` | número de mes (01 - 12) | +| `DD` | día del mes (01 - 31) | +| `HH24` | hora del día (00 - 23) | +| `HH12` | hora del día (01 - 12) | +| `HH` | hora del día (01 - 12) | +| `MI` | minuto (00 - 59) | +| `SS` | segundo (00 - 59) | +| `MS` | milisegundo (000 - 999) | +| `TZ` | abreviatura del huso horario | +| `OF` | inicio del huso horario desde UTC | +| `AM` / `am` | indicador del meridiano (sin puntos) | +| `PM` / `pm` | indicador del meridiano (sin puntos) | + +{{< code-block lang="sql" >}} +SELECT + TO_TIMESTAMP('25/12/2025 04:23 pm', 'DD/MM/YYYY HH:MI am') AS ts +{{< /code-block >}} + +### `TO_CHAR` + +Patrones compatibles para el formato fecha/hora: +| Patrón | Descripción | +| ----------- | ------------------------------------ | +| `YYYY` | año (4 dígitos) | +| `YY` | año (2 dígitos) | +| `MM` | número de mes (01 - 12) | +| `DD` | día del mes (01 - 31) | +| `HH24` | hora del día (00 - 23) | +| `HH12` | hora del día (01 - 12) | +| `HH` | hora del día (01 - 12) | +| `MI` | minuto (00 - 59) | +| `SS` | segundo (00 - 59) | +| `MS` | milisegundo (000 - 999) | +| `TZ` | abreviatura del huso horario | +| `OF` | inicio del huso horario desde UTC | +| `AM` / `am` | indicador del meridiano (sin puntos) | +| `PM` / `pm` | indicador del meridiano (sin puntos) | + +{{< code-block lang="sql" >}} +SELECT + TO_CHAR(order_date, 'MM-DD-YYYY') AS formatted_date +FROM + orders +{{< /code-block >}} + +### `DATE_BIN` +{{< code-block lang="sql" >}} +SELECT DATE_BIN('15 minutes', TIMESTAMP '2025-09-15 12:34:56', TIMESTAMP '2025-01-01') +-- Returns 2025-09-15 12:30:00 + +SELECT DATE_BIN('1 day', TIMESTAMP '2025-09-15 12:34:56', TIMESTAMP '2025-01-01') +-- Returns 2025-09-15 00:00:00 +{{< /code-block >}} + +### `DATE_TRUNC` + +Truncamientos admitidos: +- `milliseconds` +- `seconds` / `second` +- `minutes` / `minute` +- `hours` / `hour` +- `days` / `day` +- `weeks` / `week ` +- `months` / `month` +- `quarters` / `quarter` +- `years` / `year` + +{{< code-block lang="sql" >}} +SELECT + DATE_TRUNC('month', event_time) AS month_start +FROM + events +{{< /code-block >}} + +### `CURRENT_SETTING` + +Parámetros de configuración admitidos: +- `dd.time_frame_start`: Devuelve el inicio de la marca de tiempo seleccionada en formato RFC 3339 (`YYYY-MM-DD HH:mm:ss.sss±HH:mm`). +- `dd.time_frame_end`: Devuelve el final de la marca de tiempo seleccionada en formato RFC 3339 (`YYYY-MM-DD HH:mm:ss.sss±HH:mm`). + +{{< code-block lang="sql" >}} +-- Define the current analysis window +WITH bounds AS ( + SELECT CAST(CURRENT_SETTING('dd.time_frame_start') AS TIMESTAMP) AS time_frame_start, + CAST(CURRENT_SETTING('dd.time_frame_end') AS TIMESTAMP) AS time_frame_end +), +-- Define the immediately preceding window of equal length + previous_bounds AS ( + SELECT time_frame_start - (time_frame_end - time_frame_start) AS prev_time_frame_start, + time_frame_start AS prev_time_frame_end + FROM bounds +) +SELECT * FROM bounds, previous_bounds +{{< /code-block >}} + +### `NOW` +{{< code-block lang="sql" >}} +SELECT + * +FROM + sales +WHERE + purchase_date > NOW() - INTERVAL '1 hour' +{{< /code-block >}} + +### `CARDINALITY` +{{< code-block lang="sql" >}} +SELECT + CARDINALITY(recipients) +FROM + emails +{{< /code-block >}} + +### `ARRAY_POSITION` +{{< code-block lang="sql" >}} +SELECT + ARRAY_POSITION(recipients, 'hello@example.com') +FROM + emails +{{< /code-block >}} + +### `STRING_TO_ARRAY` +{{< code-block lang="sql" >}} +SELECT + STRING_TO_ARRAY('a,b,c,d,e,f', ',') +{{< /code-block >}} + +### `ARRAY_AGG` +{{< code-block lang="sql" >}} +SELECT + sender, + ARRAY_AGG(subject) subjects, + ARRAY_AGG(ALL subject) all_subjects, + ARRAY_AGG(DISTINCT subject) distinct_subjects +FROM + emails +GROUP BY + sender +{{< /code-block >}} + +### `UNNEST` +{{< code-block lang="sql" >}} +SELECT + sender, + recipient +FROM + emails, + UNNEST(recipients) AS recipient +{{< /code-block >}} + +{{% /collapse-content %}} + +## Expresiones regulares + +### Sabor + +Todas las funciones de expresión regular (regex) utilizan el formato ICU (International Components for Unicode): + +- [Metacaracteres][5] +- [Operadores][6] +- [Expresiones de conjuntos (clases de caracteres)][7] +- [Opciones de marcadores para marcadores en patrones][8]. Consulta la [sección sobre marcadores a continuación](#function-level-flags) para conocer los marcadores a nivel de función. +- [Buscar y reemplazar (utilizando grupos de captura)][9] + +### Funciones + +| Función | Tipo de retorno | Descripción | +|------------------------------------------------------------------------------------------------------------------|------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------| +| `REGEXP_LIKE(string input, string pattern)` | Booleano | Evalúa si una cadena coincide con un patrón de expresión regular. | +| `REGEXP_MATCH(string input, string pattern [, string flags ])` | matriz de cadenas | Devuelve las subcadenas de la primera coincidencia de patrón en la cadena.
Esta función busca en la cadena de entrada utilizando el patrón dado y devuelve las subcadenas capturadas (grupos de captura) de la primera coincidencia. Si no hay grupos de captura, devuelve la coincidencia completa. | +| `REGEXP_REPLACE(string input, string pattern, string replacement [, string flags ])` | cadena | Sustituye la subcadena que es la primera coincidencia con el patrón, o todas las coincidencias si utilizas el [marcador opcional `g` ](#function-level-flags). | +| `REGEXP_REPLACE (string input, string pattern, string replacement, integer start, integer N [, string flags ] )` | cadena | Sustituye la subcadena que es la enésima coincidencia con el patrón, o todas las coincidencias si `N` es cero, empezando por `start`. | + +{{% collapse-content title="Ejemplos" level="h3" %}} + +### `REGEXP_LIKE` +{{< code-block lang="sql" >}} +SELECT + * +FROM + emails +WHERE + REGEXP_LIKE(email_address, '@example\.com$') +{{< /code-block >}} + +### `REGEXP_MATCH` +{{< code-block lang="sql" >}} +SELECT regexp_match('foobarbequebaz', '(bar)(beque)'); +-- {bar,beque} + +SELECT regexp_match('foobarbequebaz', 'barbeque'); +-- {barbeque} + +SELECT regexp_match('abc123xyz', '([a-z]+)(\d+)(x(.)z)'); +-- {abc,123,xyz,y} +{{< /code-block >}} + +### `REGEXP_REPLACE` +{{< code-block lang="sql" >}} +SELECT regexp_replace('Auth success token=abc123XYZ789', 'token=\w+', 'token=***'); +-- Auth success token=*** + +SELECT regexp_replace('status=200 method=GET', 'status=(\d+) method=(\w+)', '$2: $1'); +-- GET: 200 + +SELECT regexp_replace('INFO INFO INFO', 'INFO', 'DEBUG', 1, 2); +-- INFO DEBUG INFO +{{< /code-block >}} + +{{% /collapse-content %}} + +### Marcadores de función + +Puedes utilizar los siguientes marcadores con [funciones de expresión regular](#regular-expressions): + +`i` +: Coincidencia que no distingue mayúsculas y minúsculas + +`n` o `m` +: Coincidencia que reconoce nuevas líneas + +`g` +: Global; sustiyuye _todas_ las subcadenas coincidentes en lugar de solo la primera + +{{% collapse-content title="Ejemplos" level="h3" %}} + +### Marcador `i` + +{{< code-block lang="sql" >}} +SELECT regexp_match('INFO', 'info') +-- NULL + +SELECT regexp_match('INFO', 'info', 'i') +-- ['INFO'] +{{< /code-block >}} + +### Marcador `n` + +{{< code-block lang="sql" >}} +SELECT regexp_match('a +b', '^b'); +-- NULL + +SELECT regexp_match('a +b', '^b', 'n'); +-- ['b'] +{{< /code-block >}} + +### Marcador `g` + +{{< code-block lang="sql" >}} +SELECT icu_regexp_replace('Request id=12345 completed, id=67890 pending', 'id=\d+', 'id=XXX'); +-- Request id=XXX completed, id=67890 pending + +SELECT regexp_replace('Request id=12345 completed, id=67890 pending', 'id=\d+', 'id=XXX', 'g'); +-- Request id=XXX completed, id=XXX pending +{{< /code-block >}} + +{{% /collapse-content %}} + +## Funciones de ventana + +Esta tabla proporciona información general de las funciones de ventana admitidas. Para ver más detalles y ejemplos, consulte la [documentación de PostgreSQL][2]. + +| Función | Tipo de retorno | Descripción | +|-------------------------|-------------------|------------------------------------------------------------------------| +| `OVER` | N/A | Define una ventana para un conjunto de filas sobre las que pueden operar otras funciones de ventana. | +| `PARTITION BY` | N/A | Divide el conjunto de resultados en particiones, específicamente para aplicar funciones de ventana. | +| `RANK()` | entero | Asigna un rango a cada fila dentro de una partición, con espacios para los empates. | +| `ROW_NUMBER()` | entero | Asigna un número secuencial único a cada fila dentro de una partición. | +| `LEAD(column n)` | columna typeof | Devuelve el valor de la siguiente fila de la partición. | +| `LAG(column n)` | columna typeof | Devuelve el valor de la fila anterior de la partición. | +| `FIRST_VALUE(column n)` | columna typeof | Devuelve el primer valor de un conjunto ordenado de valores. | +| `LAST_VALUE(column n)` | columna typeof | Devuelve el último valor de un conjunto ordenado de valores. | +| `NTH_VALUE(column n, offset)`| columna typeof | Devuelve el valor en el desplazamiento especificado en un conjunto ordenado de valores. | + + +## Funciones y operadores JSON + +| Nombre | Tipo de devolución | Descripción | +|-----------------------------------------------|--------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------| +| json_extract_path_text(text json, text path...) | texto | Extrae un subobjeto JSON como texto, definido por la ruta. Su comportamiento es equivalente a la [función Postgres del mismo nombre][3]. Por ejemplo, `json_extract_path_text(col, ‘forest')` devuelve el valor de la clave `forest` para cada objeto JSON en `col`. Consulta el ejemplo siguiente para ver la sintaxis de una matriz JSON. | +| json_extract_path(text json, text path...) | JSON | Misma funcionalidad que `json_extract_path_text`, pero devuelve una columna de tipo JSON en lugar de tipo texto. | +| json_array_elements(text json) | filas de JSON | Expande una matriz JSON en un conjunto de filas. Esta forma solo se permite en una cláusula FROM. | +| json_array_elements_text(text json) | filas de texto | Expande una matriz JSON en un conjunto de filas. Esta forma solo se permite en una cláusula FROM. | + +## Funciones de tabla + +{{< callout url="https://www.datadoghq.com/product-preview/logs-metrics-support-in-ddsql-editor/" >}} +La consulta de logs y métricas mediante DDSQL está en vista previa. Utiliza este formulario para solicitar accesso. +{{< /callout >}} + +Las funciones de tabla se utilizan para consultar logs y métricas. + +
| Función | +Descripción | +Ejemplo | +
|---|---|---|
+ +dd.logs( + filter => varchar, + columns => array < varchar >, + indexes => array < varchar >, + from_timestamp => timestamp, + to_timestamp => timestamp +) AS (column_name type [, ...])+ |
+ Devuelve los datos de logs en forma de tabla. El parámetro de columna especifica qué campos de log extraer, y la cláusula AS define el esquema de la tabla devuelta. Opcional: Filtrado por índice o rango temporal. Si no se especifica la hora, se utilizará por defecto la última hora de los datos. | ++ {{< code-block lang="sql" >}} +SELECT timestamp, host, service, message +FROM dd.logs( + filter => 'source (fuente):java', + columns => ARRAY['timestamp','host', 'service','message'] +) AS ( + timestamp TIMESTAMP, + host VARCHAR, + service VARCHAR, + message VARCHAR +){{< /code-block >}} + | +
+ +dd.metric_scalar( + query varchar + reducer varchar [, from_timestamp timestamp, to_timestamp timestamp] +)+ |
+ Devuelve datos de métricas como un valor escalar. La función acepta una consulta de métricas (con agrupación opcional), un reductor para determinar cómo se agregan los valores (medio, máx, etc.) y parámetros opcionales de fecha y hora (por defecto 1 hora) para definir el intervalo de tiempo. | ++ {{< code-block lang="sql" >}} +SELECT * +FROM dd.metric_scalar( + 'avg:system.cpu.user{*} by {service}', + 'avg', + TIMESTAMP '2025-07-10 00:00:00.000-04:00', + TIMESTAMP '2025-07-17 00:00:00.000-04:00' +) +ORDER BY value DESC;{{< /code-block >}} + | +
Nota: El script de instalación del Agent crea el archivo de socket con los permisos correctos, y
+use_dogstatsd: true y dogstatsd_socket: "/var/run/datadog/dsd.socket" se establecen por defecto. El script de instalación del Agent crea automáticamente el archivo de socket con los permisos correctos, y
1. Crea un archivo de socket para que DogStatsD lo utilice como socket de escucha. Por ejemplo:
```shell
diff --git a/content/es/getting_started/feature_flags/_index.md b/content/es/getting_started/feature_flags/_index.md
new file mode 100644
index 0000000000000..1a34564e27f2d
--- /dev/null
+++ b/content/es/getting_started/feature_flags/_index.md
@@ -0,0 +1,139 @@
+---
+description: Gestiona la entrega de funciones con capacidad de observación integrada,
+ métricas en tiempo real y lanzamientos graduales compatibles con OpenFeature.
+further_reading:
+- link: https://openfeature.dev/docs/reference/technologies/client/web/
+ tag: Sitio externo
+ text: Documentación del kit de desarrollo de software (SDK) de OpenFeature Web
+- link: https://www.datadoghq.com/blog/feature-flags/
+ tag: Blog
+ text: Envía funciones de forma más rápida y segura con Datadog Feature Flags
+site_support_id: getting_started_feature_flags
+title: Empezando con los Feature Flags
+---
+
+{{< callout url="http://datadoghq.com/product-preview/feature-flags/" >}}
+Feature Flags está en vista previa. Completa el formulario para solicitar acceso.
+{{< /callout >}}
+
+## Información general
+
+Los marcadores de funciones de Datadog ofrecen una forma potente e integrada de gestionar la entrega de funciones, con capacidad de observación incorporada y una integración perfecta en toda la plataforma.
+
+* **Métricas en tiempo real:** Conoce quién recibe cada variante y la manera en que tu marcador afecta al estado y al rendimiento de tu aplicación, todo en tiempo real.
+
+* **Admite cualquier tipo de datos:** Utiliza booleanos, cadenas, números u objetos completos de JSON, el que necesite tu uso en case (incidencia).
+
+* **Creado para la experimentación:** Dirígete a audiencias específicas para tests A/B, lanza funciones gradualmente con versiones canarias y retrocede automáticamente cuando se detecten regresiones.
+
+* **Compatible con OpenFeature:** Se basa en la norma de OpenFeature, lo que garantiza la compatibilidad con las implementaciones existentes de OpenFeature y proporciona un enfoque independiente del proveedor para la gestión de marcadores de funciones.
+
+## Configura tus entornos
+
+Es probable que tu organización ya disponga de entornos preconfigurados para Desarrollo, Escenificación y Producción. Si necesitas configurar estos u otros entornos, ve a la page (página) [**Entornos**][3] para crear consultas de etiquetas para cada entorno. También puedes identificar qué entorno debe considerarse como entorno de Producción.
+
+{{< img src="getting_started/feature_flags/environments-list.png" alt="Lista de entornos" style="width:100%;" >}}
+
+## Crea tu primer marcador de funciones
+
+### Step (UI) / paso (generic) 1: Importar e inicializar el kit de desarrollo de software (SDK)
+
+En primer lugar, instala `@datadog/openfeature-browser`, `@openfeature/web-sdk`, y `@openfeature/core` como dependencias en tu project (proyecto):
+
+
+```
+yarn add @datadog/openfeature-browser@preview @openfeature/web-sdk @openfeature/core
+```
+
+A continuación, añade lo siguiente a tu project (proyecto) para inicializar el kit de desarrollo de software (SDK):
+
+```js
+import { DatadogProvider } from '@datadog/openfeature-browser';
+import { OpenFeature } from '@openfeature/web-sdk';
+
+// Initialize the provider
+const provider = new DatadogProvider({
+ clientToken: 'use_dogstatsd: true y dogstatsd_socket: "/var/run/datadog/dsd.socket" están configurados por defecto.
+Como práctica general, los cambios deben implementarse en un entorno de pruebas antes de implementarlos en producción.
+
+
+En la sección **Reglas de orientación y lanzamientos**, cambia el entorno seleccionado a **Activado**.
+
+{{< img src="getting_started/feature_flags/publish-targeting-rules.png" alt="Publicar reglas de orientación" style="width:100%;" >}}
+
+El marcador sirve tus reglas de orientación en este entorno. Puedes seguir editando estas reglas de orientación para controlar dónde se sirven las variantes.
+
+### Step (UI) / paso (generic) 6: Monitorizar tu despliegue
+
+Monitoriza el despliegue de la función desde la page (página) de detalles del marcador de función, en que se proporciona un rastreo de la exposición en tiempo real y métricas como **la tasa de errores** y **el tiempo de carga de la page (página) **. A medida que vayas lanzando la función con el marcador, consulta el panel **Real-Time Metric Overview** (Información general de métricas en tiempo real) de la interfaz de usuario de Datadog para ver cómo afecta la función al rendimiento de la aplicación.
+
+{{< img src="getting_started/feature_flags/real-time-flag-metrics.png" alt="Panel de métricas de marcadores en tiempo real" style="width:100%;" >}}
+
+## Referencias adicionales
+
+{{< partial name="whats-next/whats-next.html" >}}
+
+[1]: https://openfeature.dev/docs/reference/technologies/client/web/
+[2]: https://app.datadoghq.com/feature-flags/create
+[3]: https://app.datadoghq.com/feature-flags/environments
+[4]: https://docs.datadoghq.com/es/account_management/api-app-keys/#client-tokens
\ No newline at end of file
diff --git a/content/es/getting_started/learning_center.md b/content/es/getting_started/learning_center.md
index 11e466530a856..a88303a173aa0 100644
--- a/content/es/getting_started/learning_center.md
+++ b/content/es/getting_started/learning_center.md
@@ -36,6 +36,8 @@ aliases:
- /es/videos/apm
- /es/videos/aws
- /es/videos/host-map
+description: Accede a cursos prácticos y tutoriales para conocer las funciones de
+ la plataforma Datadog, las prácticas recomendadas y las estrategias de implementación.
title: Centro de aprendizaje de Datadog
---
diff --git a/content/es/getting_started/serverless/_index.md b/content/es/getting_started/serverless/_index.md
index 786255008953f..234652ce5ffb5 100644
--- a/content/es/getting_started/serverless/_index.md
+++ b/content/es/getting_started/serverless/_index.md
@@ -1,8 +1,10 @@
---
+description: Monitoriza aplicaciones sin servidor con métricas, trazas y logs de Lambda
+ mejorados para solucionar problemas de rendimiento y errores.
further_reading:
-- link: /agent/basic_agent_usage/
+- link: agent/
tag: Documentación
- text: Uso básico del Agent
+ text: El Datadog Agent
- link: https://dtdg.co/fe
tag: Habilitar los fundamentos
text: Participa en una sesión interactiva para saber más sobre monitorización serverless.
diff --git a/content/es/getting_started/synthetics/_index.md b/content/es/getting_started/synthetics/_index.md
index a22da5fa2740b..f46683e148f10 100644
--- a/content/es/getting_started/synthetics/_index.md
+++ b/content/es/getting_started/synthetics/_index.md
@@ -2,16 +2,21 @@
algolia:
tags:
- synthetics
+description: Monitoriza el rendimiento del sistema con solicitudes simuladas de API,
+ navegador y tests móviles en ubicaciones globales.
further_reading:
-- link: https://learn.datadoghq.com/courses/intro-to-synthetic-tests
+- link: https://learn.datadoghq.com/courses/getting-started-with-synthetic-browser-testing
tag: Centro de aprendizaje
- text: Introducción a los tests Synthetic
+ text: Primeros pasos con Synthetic Monitoring Browser Testing
- link: /synthetics/api_tests
tag: Documentación
text: Más información sobre los tests de API
- link: /synthetics/multistep
tag: Documentación
text: Más información sobre los tests de API multipaso
+- link: /synthetics/mobile_app_testing
+ tag: Documentación
+ text: Más información sobre tests de móviles
- link: /synthetics/browser_tests
tag: Documentación
text: Más información sobre los tests de navegador
@@ -20,12 +25,12 @@ further_reading:
text: Más información sobre las localizaciones privadas
- link: /continuous_testing/cicd_integrations
tag: Documentación
- text: Más información sobre los tests Synthetic en el pipeline de integración continua
- (CI)
+ text: Más información sobre los tests Synthetic en la canalización de integración
+ continua (CI)
- link: https://dtdg.co/fe
- tag: Habilitar los fundamentos
- text: Participa en una sesión interactiva para mejorar tus capacidades de synthetic
- testing
+ tag: Habilitación de los fundamentos
+ text: Participa en una sesión interactiva para mejorar tus capacidades de ejecutar
+ tests synthetic
title: Empezando con la monitorización Synthetic
---
@@ -37,9 +42,9 @@ Las pruebas Synthetic te permiten observar el rendimiento de tus sistemas y apli
## Tipos de tests Synthetic
-Datadog ofrece **tests de API**, **tests de API multipaso** y **tests de navegador**.
+Datadog ofrece **tests de API**, **tests de API multipaso**, **tests de navegador** y **tests de móviles**.
-Para monitorizar aplicaciones internas, lleva a cabo tus tests desde localizaciones gestionadas o privadas. Los tests Synthetic pueden activarse manualmente, de manera programada o directamente desde tus pipelines de integración/distribución continuas (CI/CD).
+Para monitorizar aplicaciones internas, ejecute tus tests desde localizaciones gestionadas o privadas. Los tests Synthetic se pueden activar manualmente, en un horario, o [directamente desde tus pipelines CI/CD][7].
## Requisitos previos
@@ -52,9 +57,32 @@ Para configurar tu primer test Synthetic con Datadog, elige alguna de las siguie
- [Crea un test de API][2] para empezar a monitorizar el tiempo de actividad de los endpoints de tu API.
- [Crea un test de API multipaso][3] para vincular varias solicitudes HTTP y empezar a monitorizar flujos de trabajo clave en la API.
- [Crea un test de navegador][4] para empezar a testar transacciones empresariales críticas en tus aplicaciones.
+- [Crea un test de móvil][6] para empezar a probar flujos de trabajo empresariales clave en tus aplicaciones Android e iOS.
- [Crea una localización privada][5] para empezar a monitorizar aplicaciones internas con todos los tipos de tests Synthetic.
-## Leer más
+## Notificaciones de Synthetic Monitoring
+
+Utiliza y mejora los monitores de Synthetic para enviar notificaciones cuando un test de Synthetic Monitoring esté fallando. Están disponibles los siguientes casos de uso:
+
+Mensajes de monitor prerellenados
+: los mensajes de monitor prerellenados proporcionan un punto de partida estructurado para las alertas de Synthetic test. Cada mensaje incluye un título normalizado, un resumen y un pie de página con metadatos de test, lo que facilita la comprensión de la alerta de un vistazo.
+
+Variables de plantilla
+: las variables de plantilla permiten inyectar datos específicos de test en las notificaciones de monitor de forma dinámica. Estas variables se extraen del objeto `synthetics.attributes`.
+
+Uso avanzado
+: el uso avanzado incluye técnicas para profundizar en el test o estructurar mensajes complejos utilizando plantillas de identificadores.
+
+Alerta condicional
+: las alertas condicionales te permiten cambiar el contenido de una notificación de monitor en función de resultados específicos de test o de condiciones de fallo.
+
+Para más información, consulta [notificaciones de Synthetic Monitoring][9].
+
+## Historial de versiones
+
+Utiliza [Historial de versiones en Synthetic Monitoring][8] para ejecutar una versión anterior de un test, restaurar tu test a cualquier versión guardada o clonar una versión para crear un nuevo test de Synthetic Monitoring.
+
+## Referencias adicionales
{{< partial name="whats-next/whats-next.html" >}}
@@ -62,4 +90,8 @@ Para configurar tu primer test Synthetic con Datadog, elige alguna de las siguie
[2]: /es/getting_started/synthetics/api_test/
[3]: /es/getting_started/synthetics/api_test/#create-a-multistep-api-test
[4]: /es/getting_started/synthetics/browser_test/
-[5]: /es/getting_started/synthetics/private_location/
\ No newline at end of file
+[5]: /es/getting_started/synthetics/private_location/
+[6]: /es/getting_started/synthetics/mobile_app_testing/
+[7]: /es/getting_started/continuous_testing/
+[8]: /es/synthetics/guide/version_history/
+[9]: /es/synthetics/notifications/
\ No newline at end of file
diff --git a/content/es/getting_started/synthetics/private_location.md b/content/es/getting_started/synthetics/private_location.md
index 4860c9d35ceac..fc5666c0f0e68 100644
--- a/content/es/getting_started/synthetics/private_location.md
+++ b/content/es/getting_started/synthetics/private_location.md
@@ -1,17 +1,17 @@
---
+description: Configura localizaciones privadas para monitorizar aplicaciones internas
+ y URL privadas. Crea localizaciones personalizadas para áreas de misión crítica
+ y entornos de pruebas internos.
further_reading:
- link: https://www.datadoghq.com/blog/synthetic-private-location-monitoring-datadog/
tag: Blog
text: Monitoriza tus localizaciones privadas Synthetic con Datadog
-- link: /getting_started/synthetics/api_test
- tag: Documentación
- text: Crea tu primer test de API
-- link: /getting_started/synthetics/browser_test
- tag: Documentación
- text: Crea tu primer test de navegador
- link: /synthetics/private_locations
tag: Documentación
text: Más información sobre las localizaciones privadas
+- link: /synthetics/guide/kerberos-authentication/
+ tag: Guía
+ text: Autenticación Kerberos para la monitorización Synthetic
title: Empezando con las localizaciones privadas
---
@@ -19,13 +19,14 @@ title: Empezando con las localizaciones privadas
Las localizaciones privadas te permiten **monitorizar aplicaciones internas** o direcciones URL privadas que no son accesibles a través de la red pública de Internet.
-{{< img src="synthetics/private_locations/private_locations_worker_1.png" alt="Diagrama de arquitectura que muestra cómo funciona una localización privada durante la monitorización de Synthetic" style="width:100%;">}}
+{{< img src="synthetics/private_locations/private_locations_worker_1.png" alt="Diagrama de arquitectura que muestra cómo funciona una localización privada durante la monitorización Synthetic" style="width:100%;">}}
También puedes utilizar las localizaciones privadas para:
- **Crear localizaciones personalizadas** en áreas consideradas críticas para el desarrollo de tu negocio.
- **Verificar el rendimiento de la aplicación en tu entorno de testeo interno** antes de lanzar nuevas funciones a la fase de producción con [tests Synthetic en tus pipelines de integración/distribución continuas (CI/CD)][1].
- **Comparar el rendimiento de la aplicación** desde dentro y fuera de tu red interna.
+- **[Autenticar tests de monitorización Synthetic utilizando el inicio de sesión único de Kerberos][16]** para sitios y API internos basados en Windows.
Las localizaciones privadas son contenedores Docker o servicios Windows que puedes instalar en cualquier lugar dentro de tu red privada. Busca la imagen Docker en [Google Container Registry][2] o descarga el [instalador de Windows][13].**\***
@@ -87,10 +88,10 @@ Los resultados de los tests de las localizaciones privadas se muestran de forma
## Ejecuta tests Synthetic con tu localización privada
-Utiliza tu nueva localización privada como si fuese una localización gestionada en tus test de Synthetic.
+Utiliza tu nueva localización privada como si fuese una localización gestionada en tus tests Synthetic.
1. Crea un [test de API][2], un [test de API multipaso][8] o un [test de navegador][9] en cualquier endpoint interno o aplicación que quieras monitorizar.
-2. En la sección **Private Locations**, selecciona tu nueva localización privada:
+2. En la sección **Private Locations** (Localizaciones privadas), selecciona tu nueva localización privada:
{{< img src="synthetics/private_locations/assign-test-pl-2.png" alt="Asignar un test Synthetic a una localización privada" style="width:100%;">}}
@@ -116,4 +117,5 @@ Utiliza tu nueva localización privada como si fuese una localización gestionad
[12]: /es/synthetics/private_locations?tab=windows#install-your-private-location
[13]: https://ddsynthetics-windows.s3.amazonaws.com/datadog-synthetics-worker-{{< synthetics-worker-version "synthetics-windows-pl" >}}.amd64.msi
[14]: https://www.datadoghq.com/legal/eula/
-[15]: https://www.datadoghq.com/support/
\ No newline at end of file
+[15]: https://www.datadoghq.com/support/
+[16]: /es/synthetics/guide/kerberos-authentication/
\ No newline at end of file
diff --git a/content/es/getting_started/tagging/_index.md b/content/es/getting_started/tagging/_index.md
index 1e41c66bfe544..04da88be4c309 100644
--- a/content/es/getting_started/tagging/_index.md
+++ b/content/es/getting_started/tagging/_index.md
@@ -1,4 +1,7 @@
---
+algolia:
+ tags:
+ - etiquetado
aliases:
- /es/getting_started/getting_started_with_tags
- /es/guides/getting_started/tagging/
@@ -27,7 +30,12 @@ title: Empezando con las etiquetas (tags)
Las etiquetas son una forma de añadir dimensiones a las telemetrías de Datadog para que puedan filtrarse, agregarse y compararse en las visualizaciones de Datadog. [Usar etiquetas][1] te permite observar el rendimiento conjunto en varios hosts y, de manera opcional, reducir ese conjunto en función de ciertos elementos. En resumen, el etiquetado es un método para observar puntos de datos de manera conjunta.
-El etiquetado vincula distintos tipos de datos en Datadog, lo cual hace posible la correlación y la llamada a la acción entre métricas, trazas y logs. Esto se logra con claves de etiquetas **reservadas**.
+Las etiquetas son pares `key:value` que contienen dos partes:
+
+- La clave de etiqueta es el identificador. La clave de etiqueta sólo puede existir una vez en cada recurso y distingue entre mayúsculas y minúsculas.
+- El valor de etiqueta son los datos específicos o la información asociada a la clave. Los valores de etiqueta no son únicos por recurso y pueden utilizarse en muchos recursos en un par `key-value`.
+
+El etiquetado vincula distintos tipos de datos en Datadog, lo que permite la correlación y las llamadas a la acción entre métricas, trazas (traces) y logs. Esto se consigue con claves de etiqueta **reservadas**:
| Clave de etiqueta | Qué permite |
| --------- | --------------------------------------------------------------------- |
@@ -37,6 +45,7 @@ El etiquetado vincula distintos tipos de datos en Datadog, lo cual hace posible
| `service` | Control sobre datos específicos de la aplicación en métricas, trazas y logs. |
| `env` | Control sobre datos específicos de la aplicación en métricas, trazas y logs. |
| `version` | Control sobre datos específicos de la aplicación en métricas, trazas y logs. |
+| `team` | Asignar una propiedad a cualquier recurso |
Datadog recomienda analizar los contenedores, las máquinas virtuales y la infraestructura en la nube de forma conjunta a nivel de `service`. Por ejemplo, puedes observar el uso de la CPU en una serie de hosts que represente un servicio, en lugar del uso de la CPU para el servidor A o B por separado.
@@ -57,7 +66,7 @@ Estos son los requisitos de etiquetado de Datadog:
Los demás caracteres especiales se convertirán en guiones bajos.
-2. Las etiquetas (tags) pueden tener **hasta 200 caracteres** y admiten letras Unicode (que incluyen la mayoría de conjuntos de caracteres, incluidos idiomas como el japonés).
+2. Las etiquetas pueden tener **hasta 200 caracteres** y admiten letras Unicode (que incluyen la mayoría de conjuntos de caracteres, incluidos idiomas como el japonés).
3. Las etiquetas se cambiarán a minúsculas. Por tanto, no se recomiendan las etiquetas `CamelCase`. Las integraciones basadas en (un rastreador de) autenticación convierten ese tipo de ortografía en guiones bajos. Ejemplo: `TestTag` --> `test_tag`.
4. Una etiqueta puede estar en formato `value` o `Nota: La variable de entorno
+OTEL_SERVICE_NAME tiene prioridad sobre el atributo service.name de la variable de entorno OTEL_RESOURCE_ATTRIBUTES.La variable de entorno
##### Configuración parcial
@@ -210,7 +213,7 @@ containers:
Puedes utilizar la etiqueta (tag) `version` en APM para [monitorizar despliegues][7] e identificar despliegues de código fallidos mediante la [detección automática de despliegues fallidos][8].
-Para los datos de APM, Datadog configura la etiqueta (tag) `version` en el siguiente orden de prioridad. Si configuras `version` manualmente, Datadog no anula su valor `version`.
+Para datos de APM, Datadog configura la etiqueta (tag) `version` en el siguiente orden de prioridad. Si configuras `version` manualmente, Datadog no anula su valor `version`.
| Prioridad | Valor de versión |
|--------------|------------|
@@ -287,7 +290,7 @@ Como se explica en la configuración completa, estas etiquetas (labels) se puede
Puedes utilizar la etiqueta (tag) `version` en APM para [monitorizar despliegues][1] e identificar despliegues de código fallidos mediante la [detección automática de despliegues fallidos][2].
-Para los datos de APM, Datadog configura la etiqueta (tag) `version` en el siguiente orden de prioridad. Si configuras `version` manualmente, Datadog no anula su valor `version`.
+Para datos de APM, Datadog configura la etiqueta (tag) `version` en el siguiente orden de prioridad. Si configuras `version` manualmente, Datadog no anula su valor `version`.
| Prioridad | Valor de versión |
|--------------|------------|
@@ -310,7 +313,7 @@ Requisitos:
{{% tab "ECS" %}}
OTEL_SERVICE_NAME tiene prioridad sobre el atributo service.name de la variable de entorno OTEL_RESOURCE_ATTRIBUTES.
-En ECS Fargate que utiliza Fluent Bit o FireLens, el etiquetado de servicios unificado sólo está disponible para métricas y trazas, no para la recopilación de logs.
+En ECS Fargate con Fluent Bit o FireLens, el etiquetado de servicios unificado solo está disponible para métricas y trazas, no para la recopilación de logs.
##### Configuración completa
@@ -339,6 +342,9 @@ Configura las variables de entorno `DD_ENV`, `DD_SERVICE` y `DD_VERSION` (con el
"com.datadoghq.tags.version": "
+En ECS Fargate, debes añadir estas etiquetas a tu contenedor de aplicaciones, no al contenedor del Datadog Agent.
+
##### Configuración parcial
@@ -407,14 +413,14 @@ Para crear un único punto de configuración de toda la telemetría emitida dire
[1]: /es/tracing/setup/
[2]: /es/developers/dogstatsd/
-{{% /tab %}}
+ {{% /tab %}}
{{% tab "Logs" %}}
Si utilizas [trazas y logs conectados][1], activa la introducción automática de logs siempre que tu rastreador de APM lo permita. De esta forma, el rastreador de APM introducirá automáticamente `env`, `service` y `version` en tus logs, lo que significa que no tendrás que configurar esos campos manualmente en otros lugares.
[1]: /es/tracing/other_telemetry/connect_logs_and_traces/
-{{% /tab %}}
+ {{% /tab %}}
{{% tab "RUM y Session Replay" %}}
@@ -423,9 +429,9 @@ Si utilizas [RUM y trazas conectados][1], especifica la aplicación de navegador
Cuando [crees una aplicación de RUM][2], confirma los nombres de `env` y `service`.
-[1]: /es/real_user_monitoring/platform/connect_rum_and_traces/
-[2]: /es/real_user_monitoring/browser/setup
-{{% /tab %}}
+[1]: /es/real_user_monitoring/correlate_with_other_telemetry/apm/
+[2]: /es/real_user_monitoring/browser/setup/
+ {{% /tab %}}
{{% tab "Synthetics" %}}
@@ -435,7 +441,7 @@ Si utilizas [trazas y tests conectados del navegador Synthetic][1], especifica u
[1]: /es/synthetics/apm/
[2]: https://app.datadoghq.com/synthetics/settings/integrations
-{{% /tab %}}
+ {{% /tab %}}
{{% tab "Métricas personalizadas" %}}
@@ -446,7 +452,7 @@ Si tu servicio tiene acceso a `DD_ENV`, `DD_SERVICE` y `DD_VERSION`, el cliente
**Nota**: Los clientes DogStatsD de Datadog en .NET y PHP no admiten esta funcionalidad.
[1]: /es/metrics/
-{{% /tab %}}
+ {{% /tab %}}
{{% tab "Métricas de sistema" %}}
@@ -498,7 +504,7 @@ instances:
### Entorno serverless
-Para obtener más información sobre las funciones de AWS Lambda, consulta [cómo conectar tu telemetría de Lambda mediante el uso de etiquetas (tags))][15].
+Para obtener más información sobre las funciones de AWS Lambda, consulta [cómo conectar tu telemetría de Lambda mediante el uso de etiquetas (tags)][15].
### OpenTelemetry
@@ -514,10 +520,10 @@ Cuando utilices OpenTelemetry, asigna los siguientes [atributos de recursos][16]
1: `deployment.environment` queda obsoleto en favor de `deployment.environment.name` en [convenciones semánticas de OpenTelemetry v1.27.0][17].
2: `deployment.environment.name` es compatible con el Datadog Agent v7.58.0 o posterior y con Datadog Exporter v0.110.0 o posterior.
-Algunas variables de entorno específicas de Datadog como
+DD_SERVICE, DD_ENV o DD_VERSION no son compatibles de forma predefinida en tu configuración de OpenTelemetry.Las variables de entorno específicas de Datadog como
{{< tabs >}}
-{{% tab "Variables de entorno" %}}
+{{% tab "Environment variables" %}}
Para definir atributos de recursos utilizando variables de entorno, configura `OTEL_RESOURCE_ATTRIBUTES` con los valores adecuados:
@@ -581,7 +587,7 @@ processors:
[7]: /es/agent/docker/?tab=standard#optional-collection-agents
[8]: /es/getting_started/tracing/
[9]: /es/getting_started/logs/
-[10]: /es/real_user_monitoring/platform/connect_rum_and_traces/
+[10]: /es/real_user_monitoring/correlate_with_other_telemetry/apm/
[11]: /es/getting_started/synthetics/
[12]: /es/integrations/statsd/
[13]: https://www.chef.io/
diff --git a/content/es/gpu_monitoring/_index.md b/content/es/gpu_monitoring/_index.md
new file mode 100644
index 0000000000000..66e2553b6e4a1
--- /dev/null
+++ b/content/es/gpu_monitoring/_index.md
@@ -0,0 +1,52 @@
+---
+further_reading:
+- link: /gpu_monitoring/setup
+ tag: Documentación
+ text: Configurar GPU Monitoring
+- link: https://www.datadoghq.com/blog/datadog-gpu-monitoring/
+ tag: Blog
+ text: Optimiza y soluciona los problemas de la infraestructura de IA con Datadog
+ GPU Monitoring
+private: true
+title: GPU Monitoring
+---
+
+{{< callout url="https://www.datadoghq.com/product-preview/gpu-monitoring/" >}}
+GPU Monitoring está en vista previa. Para unirse a la vista previa, haz clic en Solicitar acceso y completa el formulario.
+{{< /callout >}}
+
+## Información general
+[GPU Monitoring][1] de Datadog proporciona una visión centralizada del estado, costo y rendimiento de la flota de GPU. GPU Monitoring permite a los equipos tomar mejores decisiones de aprovisionamiento, solucionar problemas de cargas de trabajo fallidas y eliminar costos de GPU inactiva sin tener que configurar manualmente herramientas de proveedores individuales (como DCGM de NVIDIA). Puedes acceder a la información de tu flota de GPU mediante el despliegue del Datadog Agent.
+
+Para obtener instrucciones de configuración, consulta [Configurar GPU Monitoring][2].
+
+### Tomar decisiones de asignación y aprovisionamiento de GPU basadas en datos
+Gracias a la visibilidad de la utilización de la GPU por el host, nodo o pod, es posible identificar los puntos conflictivos o la subutilización de la costosa infraestructura de GPU.
+
+{{< img src="gpu_monitoring/funnel-2.png" alt="Visualización del embudo titulada 'Tu flota de GPU de un vistazo.' Muestra dispositivos totales, asignados, activos y eficaces. Pone de relieve los núcleos de GPU subutilizados y los dispositivos inactivos." style="width:100%;" >}}
+
+### Solucionar cargas de trabajo fallidas debido a la contención de recursos
+Conoce tu disponibilidad actual de dispositivos y prevé cuántos dispositivos se necesitan para determinados equipos o cargas de trabajo para evitar cargas de trabajo fallidas por contención de recursos.
+
+{{< img src="gpu_monitoring/device_allocation.png" alt="Gráficos para ayudar a visualizar la asignación de GPU. Gráfica lineal titulada 'Asignación de dispositivos en el tiempo', en la que se grafican counts de dispositivos totales/asignados/activos, incluida una previsión futura a 4 semanas. Un gráfico de anillos titulado 'Desglose de instancias de proveedores en la nube', en que se muestra el predominio de instancias de proveedores en la nube en toda la flota. Un 'Desglose por tipo de dispositivo' en que se muestran dispositivos asignados/totales para distintas GPU." style="width:100%;" >}}
+
+### Identificar y eliminar los costos de GPU desperdiciada e inactiva
+Identifica el gasto total en infraestructura de GPU y atribuye esos costos a cargas de trabajo e instancias específicas. Correlaciona directamente el uso de la GPU con los pods o procesos relacionados.
+
+{{< img src="gpu_monitoring/fleet_costs.png" alt="Vista detallada de un clúster, en el que se muestra la visualización de embudo de dispositivos (totales/asignados/activos/eficaces), el costo total de la nube, el costo de la nube inactiva y la visualización y los detalles de distintas entidades conectadas (pods, procesadores, trabajos SLURM)." style="width:100%;" >}}
+
+### Maximizar el rendimiento del modelo y la aplicación
+Con la telemetría de recursos de GPU Monitoring, puedes analizar las tendencias de los recursos y las métricas de la GPU (incluida la utilización de la GPU, la potencia y la memoria) a lo largo del tiempo, lo que te ayudará a comprender sus efectos en el rendimiento de tu modelo y tu aplicación.
+
+{{< img src="gpu_monitoring/device_metrics.png" alt="Vista detallada de un dispositivo, en la que se muestran visualizaciones de series temporales configurables de la actividad de SM, la utilización de la memoria, la potencia y la actividad del motor." style="width:100%;" >}}
+
+## ¿Estás listo para comenzar?
+
+Consulta [Configurar GPU Monitoring][2] para obtener instrucciones sobre cómo configurar GPU Monitoring de Datadog.
+
+## Referencias adicionales
+
+{{< partial name="whats-next/whats-next.html" >}}
+
+[1]: https://app.datadoghq.com/gpu-monitoring
+[2]: /es/gpu_monitoring/setup
\ No newline at end of file
diff --git a/content/es/infrastructure/list.md b/content/es/infrastructure/list.md
index ad7cd4ee3dd05..0c4b9a52da046 100644
--- a/content/es/infrastructure/list.md
+++ b/content/es/infrastructure/list.md
@@ -17,7 +17,7 @@ title: Lista de infraestructuras
## Información general
-La lista de infraestructuras muestra todos tus hosts con actividad durante las últimas dos horas (por defecto) y hasta una semana, monitorizados por Datadog. Busca tus hosts o agrúpalos por etiquetas (tags). En Datadog, ve a [**infraestructura > Hosts**][10] para ver la lista de infraestructuras. Esta lista no debe utilizarse para estimar tu facturación por el host de la infraestructura. Para obtener más información sobre facturación, consulta la página [Facturación][11].
+La lista de infraestructuras te ofrece un inventario en tiempo real de todos los hosts que se comunican con Datadog a través de las integraciones en el Agent o en la nube. En forma predeterminada, muestra los hosts con actividad en las últimas dos horas, pero puedes ampliar la vista para cubrir hasta una semana. Busca tus hosts o agrúpalos por etiquetas. En Datadog, ve a [**Infraestructure > Hosts**][10] (Infraestructura > Hosts) para ver la lista de infraestructuras. Esta lista no debe utilizarse para estimar la facturación de tu host de infraestructura. Consulta la page (página) de [facturación][11] para obtener más información sobre la facturación.
## Hosts
@@ -47,7 +47,7 @@ Carga 15
Aplicaciones
: Las integraciones de Datadog que informan métricas del host.
-Sistema operativo
+Sistema operativo
: El sistema operativo rastreado.
Plataforma en la nube
@@ -74,6 +74,7 @@ Haz clic en un host para ver más detalles, incluido:
- [contenedores][4]
- [logs][5] (si se encuentra habilitado)
- [Configuración del Agent](#agent-configuration) (si se encuentra habilitado)
+- [Configuración del recopilador de OpenTelemetry](#OpenTelemetry-collector-configuration) (si está activada)
{{< img src="infrastructure/index/infra-list2.png" alt="Detalles del host de la lista de infraestructuras" style="width:100%;">}}
@@ -85,17 +86,26 @@ Datadog crea alias para nombres de host cuando hay varios nombres unívocos para
#### Configuración del Agent
-El Agent puede enviar su propia configuración a Datadog para que se muestre en la sección `Agent Configuration` del panel de detalles del host.
+Puedes ver y gestionar las configuraciones del Agent en toda tu infraestructura utilizando [Fleet Automation][12].
-La configuración del Agent no incluye información confidencial y sólo contiene la configuración que has establecido mediante el archivo de configuración o las variables de entorno. Los cambios de configuración se actualizan cada 10 minutos.
+Para ver las configuraciones del Agent:
+1. Haz clic en **Open Host** (Abrir host) en la esquina superior derecha del panel de detalles del host.
+2. Selecciona **View Agent Configurations** (Ver configuraciones del Agent) en el menú desplegable para ir directamente a Fleet Automation.
-La vista de la configuración del Agent está activada en forma predeterminada en el Agent versión >= 7.47.0/6.47.0. En el Agent versiones >= 7.39/6.39, puedes activarla manualmente:
+{{< img src="infrastructure/index/infra-list-config-4.png" alt="Ver configuraciones del Agent en Fleet Automation" style="width:100%;">}}
-Para activar o desactivar la vista de la configuración:
-- Configura el valor de `inventories_configuration_enabled` en tu [archivo de configuración del Agent][6] en `true` para activar la vista de configuración o `false` para desactivarla.
-- También puedes utilizar la variable de entorno`DD_INVENTORIES_CONFIGURATION_ENABLED` para activar o desactivar la vista de configuración.
+#### Configuración de OpenTelemetry Collector
+
+Cuando la [extensión de Datadog][14] está configurada con tu recopilador de OpenTelemetry, puedes ver la configuración del recopilador y la información de creación directamente en el panel de detalles del host de la lista de infraestructuras. La extensión de Datadog proporciona visibilidad de tu flota de recopiladores desde la interfaz de usuario de Datadog, lo que te ayuda a gestionar y depurar tus despliegues de recopiladores de OpenTelemetry.
+
+Para ver las configuraciones del recopilador de OpenTelemetry:
+1. Haz clic en un host que ejecute el recopilador de OpenTelemetry en la lista Infraestructuras.
+2. En el panel de detalles del host, selecciona la pestaña **OpenTelemetry Collector** (Recopilador de OpenTelemetry) para ver la información de creación y la configuración completa del recopilador.
+
+Para obtener instrucciones y requisitos de configuración detallados, como la coincidencia de nombres de host y la configuración de pipeline, consulta la [documentación principal de la extensión de Datadog][14].
+
+{{< img src="infrastructure/index/infra-list-config-OpenTelemetry.png" alt="Ver configuraciones del recopilador de OpenTelemetry en la lista de infraestructuras" style="width:100%;">}}
-{{< img src="infrastructure/index/infra-list-config3.png" alt="La vista de configuración del Agent" style="width:100%;">}}
### Exportar
@@ -106,7 +116,7 @@ Para obtener una lista con formato JSON de tus hosts que informan a Datadog, uti
#### Agent version
-En ciertas ocasiones, también puede resultar útil auditar tus versiones del Agent para asegurarte de que estás ejecutando la última versión. Para ello, utiliza el [script get_host_agent_list][9], que aprovecha el enlace permanente de JSON para generar los Agents en ejecución actuales con sus números de versión. También puedes utilizar el script `json_to_csv` para convertir el resultado JSON en un archivo CSV.
+Puede ser útil auditar tus versiones del Agent para asegurarte de que estés ejecutando la última versión. Para ello, utiliza el [script get_host_agent_list][9], que aprovecha el vínculo permanente a JSON para mostrar los Agents que se están ejecutando con los números de versión. También hay un script `json_to_csv` para convertir la salida JSON en un archivo CSV.
#### Sin Agent
@@ -142,7 +152,6 @@ for host in infra['rows']:
{{< partial name="whats-next/whats-next.html" >}}
-
[1]: /es/agent/faq/how-datadog-agent-determines-the-hostname/
[2]: /es/getting_started/tagging/
[3]: /es/metrics/
@@ -153,4 +162,7 @@ for host in infra['rows']:
[8]: /es/developers/guide/query-the-infrastructure-list-via-the-api/
[9]: https://github.com/DataDog/Miscellany/tree/master/get_hostname_agentversion
[10]: https://app.datadoghq.com/infrastructure
-[11]: https://docs.datadoghq.com/es/account_management/billing/
\ No newline at end of file
+[11]: https://docs.datadoghq.com/es/account_management/billing/
+[12]: https://app.datadoghq.com/release-notes/fleet-automation-is-now-generally-available
+[13]: /es/agent/fleet_automation
+[14]: /es/opentelemetry/integrations/datadog_extension/
\ No newline at end of file
diff --git a/content/es/infrastructure/process/increase_process_retention.md b/content/es/infrastructure/process/increase_process_retention.md
index 4342f212ff4b3..5742b4eafcb2a 100644
--- a/content/es/infrastructure/process/increase_process_retention.md
+++ b/content/es/infrastructure/process/increase_process_retention.md
@@ -40,7 +40,7 @@ Puedes generar una nueva métrica basada en procesos directamente a partir de co
{{< img src="infrastructure/process/process2metrics_create.png" alt="Crear una métrica basada en procesos" style="width:80%;">}}
-1. **Selecciona etiquetas (tags) para filtrar tu consulta**: Las etiquetas (tags) disponibles son las mismas que para [Procesos activos][2]. Sólo se tendrán en cuenta para la agregación los procesos que coincidan con el ámbito de tus filtros. Los filtros de búsqueda de texto sólo se admiten en la page (página) Procesos activos.
+1. **Selecciona etiquetas para filtrar tu consulta**: Las etiquetas disponibles son las mismas que para [Procesos activos][2]. Sólo se tendrán en cuenta para la agregación los procesos que coincidan con el ámbito de tus filtros. Los filtros de búsqueda de texto sólo se admiten en la page (página) Procesos activos.
2. **Seleccionar la medida de la que deseas realizar un seguimiento**: ingresa una medida como `Total CPU %` para agregar un valor numérico y crear sus métricas agregadas `count`, `min`, `max`, `sum` y `avg` correspondientes.
3. **Añadir etiquetas a `group by`**: selecciona etiquetas que se añadirán como dimensiones a tus métricas, para que se puedan filtrar, agregar y comparar. De manera predeterminada, las métricas generadas a partir de procesos no tienen etiquetas a menos que se añadan de manera explícita. En este campo se puede utilizar cualquier etiqueta disponible para consultas de Live Processes.
4. **Nombrar la métrica**: completa el nombre de tu métrica. Las métricas basadas en procesos siempre tienen el prefijo _proc._ y el sufijo _[selección_de_medida]_.
diff --git a/content/es/integrations/guide/source-code-integration.md b/content/es/integrations/guide/source-code-integration.md
index 4ef643d0e6615..1139b3bb1d606 100644
--- a/content/es/integrations/guide/source-code-integration.md
+++ b/content/es/integrations/guide/source-code-integration.md
@@ -1,6 +1,6 @@
---
description: Configura la integración del código fuente que se integra con APM para
- vincular tu telemetría con tus repositorios, incorporar información git en artefactos
+ vincular tu telemetría con tus repositorios, incorporar información Git en artefactos
de tu pipeline CI y utilizar la integración GitHub para generar fragmentos de código
en línea.
further_reading:
@@ -18,7 +18,7 @@ further_reading:
text: Más información sobre Serverless Monitoring
- link: /tests/developer_workflows/
tag: Documentación
- text: Más información sobre la optimización de test
+ text: Más información sobre Test Optimization
- link: /security/code_security/
tag: Documentación
text: Más información sobre Code Security
@@ -43,7 +43,7 @@ La integración del código fuente en Datadog te permite conectar tus repositori
## Conectar tus repositorios Git con Datadog
-Para utilizar la mayoría de las funciones relacionadas con el código fuente, debes conectar tus repositorios Git con Datadog. Por defecto, al sincronizar tus repositorios, Datadog no almacena el contenido real de los archivos de tu repositorio, sólo los objetos Git commit y tree.
+Para utilizar la mayoría de las funciones relacionadas con el código fuente, debes conectar tus repositorios Git con Datadog. Por defecto, al sincronizar tus repositorios, Datadog no almacena el contenido real de los archivos de tu repositorio, solo los objetos Git commit y tree.
### Proveedores de gestión de código fuente
@@ -58,7 +58,7 @@ Datadog admite las siguientes funciones para los siguientes proveedores de gesti
| **Comentarios en solicitudes pull** | Sí | Sí | Sí | No |
{{< tabs >}}
-{{% tab "GitHub (SaaS & On-Prem)" %}}
+{{% tab "GitHub (SaaS y On-Prem)" %}}
DD_SERVICE, DD_ENV o DD_VERSION no se admiten predefinidas en la configuración de OpenTelemetry.
Los repositorios de las instancias de GitHub son compatibles con GitHub.com, GitHub Enterprise Cloud (SaaS) y GitHub Enterprise Server (On-Prem). Para GitHub Enterprise Server, tu instancia debe ser accesible desde Internet. Si es necesario, puedes permitir direcciones IP de
webhooks de Datadog para que Datadog pueda conectarse a tu instancia.
@@ -70,10 +70,10 @@ Instala la [integración GitHub][101] de Datadog utilizando el [cuadro de la int
[102]: https://app.datadoghq.com/integrations/github/
{{% /tab %}}
-{{% tab "GitLab (SaaS & On-Prem)" %}}
+{{% tab "GitLab (SaaS y On-Prem)" %}}
-Los repositorios de las instancias de GitLab son compatibles con la vista previa cerrada. Los repositorios de las instancias de GitLab son compatibles tanto con GitLab.com (SaaS) como con GitLab Self-Managed/Dedicated (On-Prem). Para GitLab Self-Managed, tu instancia debe ser accesible desde Internet. Si es necesario, puedes permitir direcciones IP de
Instala la [integración del código fuente de GitHub][101] de Datadog utilizando el [cuadro de la integración][102] o mientras accedes a otros productos de Datadog para conectarte a tus repositorios de GitHub.
@@ -82,21 +82,22 @@ Instala la [integración del código fuente de GitHub][101] de Datadog utilizand
[102]: https://app.datadoghq.com/integrations/gitlab-source-code/
{{% /tab %}}
-{{% tab "Azure DevOps (SaaS Only)" %}}
+{{% tab "Azure DevOps (solo SaaS)" %}}
webhooks de Datadog para que Datadog pueda conectarse a tu instancia. Únete a la vista previa.
+Los repositorios de las instancias de GitLab son compatibles con la vista previa cerrada. Los repositorios de las instancias de GitLab son compatibles tanto con GitLab.com (SaaS) como con GitLab Self-Managed/Dedicated (On-Prem). Para GitLab Self-Managed, tu instancia debe ser accesible desde Internet. Si es necesario, puedes permitir direcciones IP de webhooks de Datadog para permitir que Datadog se conecte a tu instancia. Únete a la vista previa.
Los repositorios de Azure DevOps son compatibles con la vista previa cerrada. Únete a la vista previa.
-Instala la integración del código fuente de Azure DevOps de Datadog mientras accedes a [Datadog Code Security][101]. La funcionalidad de esta integración se limita a Code Security.
+Instala la integración de código fuente de Azure DevOps de Datadog utilizando el [cuadro de integración][102] o mientras se incorpora a [Datadog Code Security][101].
[101]: https://app.datadoghq.com/security/configuration/code-security/setup?provider=azure-devops&steps=static
+[102]: https://app.datadoghq.com/integrations/azure-devops-source-code/
{{% /tab %}}
-{{% tab "Other SCM Providers" %}}
+{{% tab "Otros proveedores de SCM" %}}
-Los repositorios en instancias autoalojadas o URL privadas no son compatibles de forma predefinida. Para activar esta función, ponte en contacto con el servicio de asistencia.
+Los repositorios en instancias autoalojadas o URL privadas no son compatibles de forma predeterminada. Para activar esta función, ponte en contacto con el servicio de asistencia.
Si estás utilizando cualquier otro proveedor SCM, aún puedes vincular manualmente la telemetría con tu código fuente. Para ello, carga los metadatos de tu repositorio con el comando [`datadog-ci git-metadata upload`][1]. Se requiere `datadog-ci v2.10.0` o posterior.
@@ -120,7 +121,7 @@ Successfully synced git DB in 3.579 seconds.
✅ Uploaded in 5.207 seconds.
```
-[1]: https://github.com/DataDog/datadog-ci/tree/master/src/commands/git-metadata
+[1]: https://github.com/DataDog/datadog-ci/tree/master/packages/base/src/commands/git-metadata
{{% /tab %}}
{{< /tabs >}}
@@ -128,7 +129,7 @@ Successfully synced git DB in 3.579 seconds.
Se requiere el Datadog Agent v7.35.0 o posterior.
-Si ya tienes [APM][6] configurado, ve a [**Integrations** > **Link Source Code**][7] y configura la integración del código fuente para tus servicios de backend.
+Si ya tienes [APM][6] configurado, ve a [**Integrations** > **Link Source Code** (Integraciones > Vincular código fuente)][7] y configura la integración del código fuente para tus servicios de backend.
Tu telemetría debe estar etiquetada con información Git que vincule la versión de la aplicación en ejecución con un repositorio y una confirmación concretos.
@@ -145,11 +146,11 @@ Selecciona uno de los siguientes lenguajes que sea compatible con la integració
{{< tabs >}}
{{% tab "Go" %}}
-Se requiere la librería del cliente Go versión 1.48.0 o posterior.
+Se requiere la biblioteca del cliente Go versión 1.48.0 o posterior.
#### Contenedores
-Si utilizas contenedores Docker, tienes tres opciones: utilizar Docker, utilizar la librería de rastreo de Datadog o configurar tu aplicación con variables de entorno `DD_GIT_*`.
+Si utilizas contenedores Docker, tienes tres opciones: utilizar Docker, utilizar la biblioteca de rastreo de Datadog o configurar tu aplicación con variables de entorno `DD_GIT_*`.
##### Opción 1: Docker
@@ -179,7 +180,7 @@ Si utilizas la opción serverless, tienes tres opciones en función de la config
{{% sci-dd-git-env-variables %}}
-#### host
+#### Host
Si utilizas un host, tienes dos opciones.
@@ -200,11 +201,11 @@ Si utilizas un host, tienes dos opciones.
{{% tab "Python" %}}
-Se requiere la librería del cliente Python versión 1.12.0 o posterior.
+Se requiere la biblioteca del cliente Python versión 1.12.0 o posterior.
#### Contenedores
-Si utilizas contenedores Docker, tienes tres opciones: utilizar Docker, utilizar la librería de rastreo de Datadog o configurar tu aplicación con variables de entorno `DD_GIT_*`.
+Si utilizas contenedores Docker, tienes tres opciones: utilizar Docker, utilizar la biblioteca de rastreo de Datadog o configurar tu aplicación con variables de entorno `DD_GIT_*`.
##### Opción 1: Docker
@@ -237,7 +238,7 @@ Si utilizas la opción serverless, tienes tres opciones en función de la config
{{% sci-dd-git-env-variables %}}
-#### host
+#### Host
Si utilizas un host, tienes dos opciones.
@@ -252,14 +253,14 @@ Si utilizas un host, tienes dos opciones.
{{% /tab %}}
{{% tab ".NET" %}}
-Se requiere la librería del cliente .NET versión 2.24.1 o posterior.
+Se requiere la biblioteca del cliente .NET versión 2.24.1 o posterior.
Como primer paso, asegúrate de que tus archivos `.pdb` se despliegan junto con tus ensamblados .NET (`.dll` o `.exe`) en la misma carpeta.
A continuación, sigue el resto de las instrucciones en función de tu modelo de despliegue específico:
#### Contenedores
-Si utilizas contenedores Docker, tienes tres opciones: utilizar Docker, utilizar la librería de rastreo de Datadog o configurar tu aplicación con variables de entorno `DD_GIT_*`.
+Si utilizas contenedores Docker, tienes tres opciones: utilizar Docker, utilizar la biblioteca de rastreo de Datadog o configurar tu aplicación con variables de entorno `DD_GIT_*`.
##### Opción 1: Docker
@@ -289,7 +290,7 @@ Si utilizas la opción serverless, tienes tres opciones en función de la config
{{% sci-dd-git-env-variables %}}
-#### host
+#### Host
Si utilizas un host, tienes dos opciones: utilizar Microsoft SourceLink o configurar tu aplicación con variables de entorno `DD_GIT_*`.
@@ -305,7 +306,7 @@ Si utilizas un host, tienes dos opciones: utilizar Microsoft SourceLink o config
{{% tab "Node.js" %}}
- Se requiere la librería de cliente de Node.js versión 3.21.0 o posterior.
+ Se requiere la biblioteca de cliente de Node.js versión 3.21.0 o posterior.
Para aplicaciones de Node.js transpiladas (por ejemplo, TypeScript), asegúrate de generar y publicar mapas de fuentes con la aplicación desplegada, y de ejecutar Node.js con la opción ` | `{"source": "journald", "service": ""}` |
-[1]: https://docs.datadoghq.com/es/agent/kubernetes/integrations/
-[2]: https://docs.datadoghq.com/es/agent/kubernetes/log/?tab=containerinstallation#setup
{{% /tab %}}
-{{< /tabs >}}
+{{< /tabs >}}
#### Funciones avanzadas
-##### Cambiar la localización del diario
+##### Cambiar la localización del registro
-Por defecto, el Agent busca el diario en las siguientes localizaciones:
+Por defecto, el Agent busca el registro en las siguientes localizaciones:
- `/var/log/journal`
- `/run/log/journal`
-Si tu diario se encuentra en otro lugar, añade un parámetro `path` con la ruta del diario correspondiente.
+Si tu registro se encuentra en otro lugar, añade un parámetro `path` con la ruta del registro correspondiente.
-##### Filtrar unidades del diario
+##### Filtrar unidades del registro
Puedes filtrar unidades específicas _a nivel de sistema_ utilizando estos parámetros:
- `include_units`: incluye todas las unidades de nivel de sistema especificadas.
- `exclude_units`: excluye todas las unidades de nivel de sistema especificadas.
-
Ejemplo:
```yaml
@@ -177,14 +128,13 @@ logs:
- '*'
```
-##### Filtrar los mensajes del diario
+##### Filtrar los mensajes del registro
En el Datadog Agent versión `7.39.0`+, puedes filtrar mensajes arbitrarios utilizando pares de clave-valor con estos parámetros:
- `include_matches`: incluye mensajes coincidentes con `key=value`
- `exclude_matches`: excluye los mensajes que coinciden con `key=value`
-
Ejemplo:
```yaml
@@ -195,11 +145,11 @@ logs:
- _TRANSPORT=kernel
```
-##### Seguimiento del mismo diario varias veces
+##### Seguimiento del mismo registro varias veces
Si deseas informar de unidades con diferentes fuentes o etiquetas de servicio, éstas deben aparecer en configuraciones de journald separadas.
-Para ello debes identificar unívocamente la configuración del diario con un `config_id` (disponible en Agent `7.41.0` +).
+Para ello debes identificar unívocamente la configuración del registro con un `config_id` (disponible en Agent `7.41.0` +).
```yaml
logs:
@@ -222,34 +172,28 @@ logs:
Las etiquetas son fundamentales para encontrar información en entornos en contenedores altamente dinámicos, por lo que el Agent puede recopilar etiquetas de contenedor en logs de journald.
-Esto funciona automáticamente cuando el Agent se está ejecutando desde el host. Si estás utilizando la versión en contenedores del Datadog Agent, integra la ruta de tu diario y el siguiente archivo:
+Esto funciona automáticamente cuando el Agent se está ejecutando desde el host. Si estás utilizando la versión en contenedores del Datadog Agent, integra la ruta de tu registro y el siguiente archivo:
-- `/etc/machine-id`: esto asegura que el Agent puede consultar el diario almacenado en el host.
+- `/etc/machine-id`: esto asegura que el Agent puede consultar el registro almacenado en el host.
### Validación
-Ejecuta el [subcomando de estado][3] del Agent y busca `journald` en la sección Logs del Agent.
+[Ejecuta el [subcomando de estado del Agent](https://docs.datadoghq.com/agent/guide/agent-commands/#agent-status-and-information) y busca `journald` en la sección Checks.
## Datos recopilados
### Métricas
-journald no incluye ninguna métrica.
+Journald no incluye métricas.
### Checks de servicio
-journald no incluye ningún check de servicio.
+Journald no incluye checks de servicio.
### Eventos
-journald no incluye ningún evento.
+Journald no incluye eventos.
## Solucionar problemas
-¿Necesitas ayuda? Ponte en contacto con el [soporte de Datadog][4].
-
-
-[1]: https://docs.datadoghq.com/es/agent/guide/agent-commands/#start-stop-and-restart-the-agent
-[2]: https://app.datadoghq.com/account/settings/agent/latest
-[3]: https://docs.datadoghq.com/es/agent/guide/agent-commands/#agent-status-and-information
-[4]: https://docs.datadoghq.com/es/help/
\ No newline at end of file
+¿Necesitas ayuda? Ponte en contacto con el [servicio de asistencia de Datadog](https://docs.datadoghq.com/help/).
\ No newline at end of file
diff --git a/content/es/integrations/lambdatest.md b/content/es/integrations/lambdatest.md
index 96682ea60748d..74cac5fe97178 100644
--- a/content/es/integrations/lambdatest.md
+++ b/content/es/integrations/lambdatest.md
@@ -1,78 +1,21 @@
---
app_id: lambdatest
-app_uuid: 8d4556af-b5e8-4608-a4ca-4632111931c1
-assets:
- dashboards:
- LambdaTest: assets/dashboards/overview.json
- integration:
- auto_install: true
- configuration: {}
- events:
- creates_events: false
- metrics:
- check: []
- metadata_path: metadata.csv
- prefix: lambdatest.
- service_checks:
- metadata_path: assets/service_checks.json
- source_type_id: 10243
- source_type_name: LambdaTest
- logs:
- source: lambdatest
- oauth: assets/oauth_clients.json
-author:
- homepage: https://github.com/DataDog/integrations-extras
- name: LambdaTest
- sales_email: prateeksaini@lambdatest.com
- support_email: prateeksaini@lambdatest.com
categories:
- automatización
- contenedores
- rum
- seguimiento de problemas
- tests
-custom_kind: integration
-dependencies:
-- https://github.com/DataDog/integrations-extras/blob/master/lambdatest/README.md
-display_on_public_website: true
-draft: false
-git_integration_title: lambdatest
-integration_id: lambdatest
-integration_title: LambdaTest
-integration_version: ''
-is_public: true
-manifest_version: 2.0.0
-name: lambdatest
-public_title: LambdaTest
-short_description: La plataforma de tests de automatización más potente
+custom_kind: integración
+description: La plataforma de tests de automatización más potente
+integration_version: 1.0.0
+media: []
supported_os:
- Linux
- Windows
- macOS
-tile:
- changelog: CHANGELOG.md
- classifier_tags:
- - Categoría::Automatización
- - Categoría::Contenedores
- - Categoría::Incidentes
- - Categoría::Seguimiento de problemas
- - Categoría::Tests
- - Sistema operativo compatible::Linux
- - Sistema operativo compatible::Windows
- - Sistema operativo compatible::macOS
- - Oferta::Integración
- configuration: README.md#Configuración
- description: La plataforma de tests de automatización más potente
- media: []
- overview: README.md#Información general
- support: README.md#Soporte
- title: LambdaTest
- uninstallation: README.md#Desinstalación
+title: LambdaTest
---
-
-
-
-
## Información general
Realiza una integración con LambdaTest y permite a tus equipos colaborar y realizar tests de forma eficaz. LambdaTest es una plataforma de tests en la nube que permite a los usuarios ejecutar tests manuales y automatizados en sus sitios web y aplicaciones web en más de 2000 navegadores, versiones de navegadores y sistemas operativos.
@@ -92,31 +35,28 @@ A continuación podrás ver todo lo que puedes hacer con LambdaTest:
## Configuración
-Toda la configuración ocurre en el dashboard de LambdaTest. Consulta la documentación de configuración de la [integración de LambdaTest en Datadog][1].
+Toda la configuración ocurre en el dashboard de LambdaTest. Consulta la documentación de configuración de la [integración LambdaTest-Datadog](https://www.lambdatest.com/support/docs/datadog-integration/).
### Configuración
A continuación se explica cómo realizar un seguimiento de los problemas en Datadog con LambdaTest:
1. Haz clic en **Connect Accounts** (Conectar cuentas) para iniciar la autorización de la integración de LambdaTest desde la página de inicio de sesión en LambdaTest.
-2. Inicia sesión en tu cuenta de LambdaTest, en el sitio web de LambdaTest, para que se te redirija a la página de autorización de Datadog.
-3. Haz clic en **Authorize** (Autorizar) para completar el proceso de integración.
-4. Una vez que se haya completado la configuración de la integración se enviará un correo electrónico de confirmación.
-5. Una vez que Datadog esté integrado en tu cuenta de LambdaTest, comienza a registrar errores y a realizar tests entre navegadores.
+1. Inicia sesión en tu cuenta de LambdaTest, en el sitio web de LambdaTest, para que se te redirija a la página de autorización de Datadog.
+1. Haz clic en **Authorize** (Autorizar) para completar el proceso de integración.
+1. Una vez que se haya completado la configuración de la integración se enviará un correo electrónico de confirmación.
+1. Una vez que Datadog esté integrado en tu cuenta de LambdaTest, comienza a registrar errores y a realizar tests entre navegadores.
## Desinstalación
-Una vez que se desinstala esta integración, se revocan todas las autorizaciones anteriores.
+Una vez que desinstales esta integración, se revocarán todas las autorizaciones anteriores.
-Además, asegúrate de que todas las claves de API asociadas a esta integración se han deshabilitado, buscando el nombre de la integración en la [página de gestión de las claves de API][2].
+Además, asegúrate de que todas las claves de API asociadas a esta integración se han desactivado, buscando el nombre de la integración en la [página de gestión de claves de API](/organization-settings/api-keys?filter=LambdaTest).
-## Compatibilidad
+## Soporte
Para recibir asistencia o solicitar funciones, ponte en contacto con LambdaTest a través de los siguientes canales:
Correo electrónico: support@lambdatest.com
Teléfono: +1-(866)-430-7087
-Sitio web: https://www.lambdatest.com/
-
-[1]: https://www.lambdatest.com/support/docs/datadog-integration/
-[2]: https://app.datadoghq.com/organization-settings/api-keys?filter=LambdaTest
\ No newline at end of file
+Sitio web: https://www.lambdatest.com/
\ No newline at end of file
diff --git a/content/es/integrations/microsoft_365.md b/content/es/integrations/microsoft_365.md
index aaf2afba0d135..530ba3dbebe12 100644
--- a/content/es/integrations/microsoft_365.md
+++ b/content/es/integrations/microsoft_365.md
@@ -1,36 +1,23 @@
---
+app_id: microsoft_365
categories:
- recopilación de logs
- seguridad
-custom_kind: integration
-dependencies: []
-description: Conéctate a Microsoft 365 para extraer los logs de auditoría de una organización
- a la plataforma de registro de Datadog.
-doc_link: https://docs.datadoghq.com/integrations/microsoft_365/
-draft: false
+custom_kind: integración
+description: 'Visualiza los logs de auditoría de Microsoft 365 en Datadog desde servicios
+ como: Microsoft Teams, Power BI, Azure Active Directory, Dynamics 365 y más'
further_reading:
- link: https://www.datadoghq.com/blog/microsoft-365-integration/
tag: Blog
text: Recopilar y monitorizar logs de auditoría de Microsoft 365 con Datadog
-git_integration_title: microsoft_365
-has_logo: true
-integration_id: ''
-integration_title: Logs de auditoría y seguridad de Microsoft 365
-integration_version: ''
-is_public: true
-manifest_version: '1.0'
-name: microsoft_365
-public_title: Logs de auditoría y seguridad de Microsoft 365 y Datadog
-short_description: 'Visualiza los logs de auditoría de Microsoft 365 en Datadog desde
- servicios como: Microsoft Teams, Power BI, Azure Active Directory, Dynamics 365
- y más'
-team: web-integrations
-version: '1.0'
+title: Logs de auditoría y seguridad de Microsoft 365
---
-
-
## Información general
+"}]'
```
-Consulta las [variables de plantilla de Autodiscovery][2] para obtener más detalles sobre cómo usar `` como una variable de entorno en lugar de una etiqueta (label).
+Consulta [variables de plantillas de Autodiscovery](https://docs.datadoghq.com/agent/faq/template_variables/) para obtener más detalles sobre el uso de `` como variable de entorno en lugar de una etiqueta.
#### Recopilación de logs
+La recopilación de logs está desactivada en forma predeterminada en el Datadog Agent . Para activarla, consulta [Recopilación de logs de Docker](https://docs.datadoghq.com/agent/docker/log/?tab=containerinstallation#installation).
-La recopilación de logs está desactivada por defecto en el Datadog Agent. Para activarla, consulta [recopilación de logs de Docker][3].
-
-A continuación, establece [integraciones de log][4] como etiquetas de Docker:
+A continuación, configura [Integraciones de logs](https://docs.datadoghq.com/agent/docker/log/?tab=containerinstallation#log-integrations) como etiquetas de Docker:
```yaml
LABEL "com.datadoghq.ad.logs"='[{"source":"mysql","service":"mysql"}]'
```
-[1]: https://docs.datadoghq.com/agent/docker/integrations/?tab=docker
-[2]: https://docs.datadoghq.com/agent/faq/template_variables/
-[3]: https://docs.datadoghq.com/agent/docker/log/?tab=containerinstallation#installation
-[4]: https://docs.datadoghq.com/agent/docker/log/?tab=containerinstallation#log-integrations
{{% /tab %}}
+
{{% tab "Kubernetes" %}}
#### Kubernetes
-Para configurar este check para un Agent que se ejecuta en Kubernetes:
+Para Configurar este check para un Agent que se ejecuta en Kubernetes:
##### Recopilación de métricas
-Establece [plantillas de integraciones de Autodiscovery][1] como anotaciones de pod en tu contenedor de aplicación. Alternativamente, puedes configurar plantillas con un [archivo, configmap, o almacén de clave-valor][2].
+Configura [Plantillas de integraciones de Autodiscovery](https://docs.datadoghq.com/agent/kubernetes/integrations/?tab=kubernetes) como anotaciones de pod en tu contenedor de aplicaciones. Alternativamente, puedes configurar plantillas con un [archivo, mapa de configuración o almacenamiento de valores de claves](https://docs.datadoghq.com/agent/kubernetes/integrations/?tab=kubernetes#configuration).
-**Anotaciones v1** (para el Datadog Agent v7.36 o anterior)
+**Annotations v1** (para el Datadog Agent \< v7.36)
```yaml
apiVersion: v1
@@ -405,16 +351,15 @@ spec:
- name: mysql
```
-Consulta las [variables de plantilla de Autodiscovery][3] para obtener más detalles sobre cómo usar `` como una variable de entorno en lugar de una etiqueta.
+Consulta [variables de plantilla de Autodiscovery](https://docs.datadoghq.com/agent/faq/template_variables/) para más detalles sobre el uso de `` como variable de entorno en lugar de una etiqueta.
#### Recopilación de logs
+La recopilación de logs está desactivada por defecto en el Datadog Agent. Para activarla, consulta [Recopilación de logs de Kubernetes](https://docs.datadoghq.com/agent/kubernetes/log/?tab=containerinstallation#setup).
-La recopilación de logs está desactivada por defecto en el Datadog Agent. Para activarla, consulta [Recopilación de logs de Kubernetes][4].
+A continuación, configura [Integraciones de logs](https://docs.datadoghq.com/agent/docker/log/?tab=containerinstallation#log-integrations) como anotaciones del pod. Alternativamente, puedes configurar esto con un [archivo, mapa de configuración o almacenamiento de valores de claves](https://docs.datadoghq.com/agent/kubernetes/log/?tab=daemonset#configuration).
-A continuación, establece [integraciones de log][5] como anotaciones del pod. Alternativamente, puedes configurar esto con un [archivo, configmap, o almacén de clave-valor][6].
-
-**Anotaciones v1/v2**
+**Annotations v1/v2**
```yaml
apiVersion: v1
@@ -427,13 +372,8 @@ metadata:
name: mysql
```
-[1]: https://docs.datadoghq.com/agent/kubernetes/integrations/?tab=kubernetes
-[2]: https://docs.datadoghq.com/agent/kubernetes/integrations/?tab=kubernetes#configuration
-[3]: https://docs.datadoghq.com/agent/faq/template_variables/
-[4]: https://docs.datadoghq.com/agent/kubernetes/log/?tab=containerinstallation#setup
-[5]: https://docs.datadoghq.com/agent/docker/log/?tab=containerinstallation#log-integrations
-[6]: https://docs.datadoghq.com/agent/kubernetes/log/?tab=daemonset#configuration
{{% /tab %}}
+
{{% tab "ECS" %}}
#### ECS
@@ -442,7 +382,7 @@ Para configurar este check para un Agent que se ejecuta en ECS:
##### Recopilación de métricas
-Establece las [plantillas de integraciones de Autodiscovery][1] como etiquetas de Docker en el contenedor de tu aplicación:
+Configura [Plantillas de integraciones de Autodiscovery](https://docs.datadoghq.com/agent/docker/integrations/?tab=docker) como etiquetas de Docker en el contenedor de tu aplicación:
```json
{
@@ -458,15 +398,15 @@ Establece las [plantillas de integraciones de Autodiscovery][1] como etiquetas d
}
```
-Consulta las [variables de plantilla de Autodiscovery][2] para obtener más detalles sobre cómo usar `` como una variable de entorno en lugar de una etiqueta.
+Consulta [variables de plantilla de Autodiscovery](https://docs.datadoghq.com/agent/faq/template_variables/) para obtener más detalles sobre el uso de `` como variable de entorno en lugar de una etiqueta.
##### Recopilación de logs
-_Disponible para el Agent versión 6.0 o posterior_
+_Disponible para las versiones 6.0 o posteriores del Agent_
-La recopilación de logs está desactivada por defecto en el Datadog Agent. Para activarla, consulta [recopilación de logs de ECS][3].
+La recopilación de logs está desactivada en forma predeterminada en el Datadog Agent. Para activarla, consulta [Recopilación de logs de ECS](https://docs.datadoghq.com/agent/amazon_ecs/logs/?tab=linux).
-A continuación, establece [integraciones de log][4] como etiquetas de Docker:
+A continuación, configura [Integraciones de logs](https://docs.datadoghq.com/agent/docker/log/?tab=containerinstallation#log-integrations) como etiquetas de Docker:
```yaml
{
@@ -479,22 +419,260 @@ A continuación, establece [integraciones de log][4] como etiquetas de Docker:
}]
}
```
-[1]: https://docs.datadoghq.com/agent/docker/integrations/?tab=docker
-[2]: https://docs.datadoghq.com/agent/faq/template_variables/
-[3]: https://docs.datadoghq.com/agent/amazon_ecs/logs/?tab=linux
-[4]: https://docs.datadoghq.com/agent/docker/log/?tab=containerinstallation#log-integrations
+
{{% /tab %}}
+
{{< /tabs >}}
### Validación
-[Ejecuta el subcomando de estado del Agent][7] y busca `mysql` en la sección Checks.
+[Ejecuta el subcomando de estado del Agent(https://docs.datadoghq.com/agent/guide/agent-commands/#agent-status-and-information) y busca `MySQL` en la sección Checks.
## Datos recopilados
### Métricas
-{{< get-metrics-from-git "mysql" >}}
+| | |
+| --- | --- |
+| **mysql.binlog.cache_disk_use**
(gauge) | El número de transacciones que utilizaron la caché temporal de logs binarios, pero que excedieron el valor de `binlog_cache_size` y utilizaron un archivo temporal para almacenar sentencias de la transacción.
_Mostrado como transacción_ | +| **mysql.binlog.cache_use**
(gauge) | El número de transacciones que utilizaron la caché de logs binarios.
_Mostrado como transacción_ | +| **mysql.binlog.disk_use**
(gauge) | Tamaño total del archivo de log binario.
_Mostrado como byte_ | +| **mysql.galera.wsrep_cert_deps_distance**
(gauge) | Muestra la distancia media entre los valores más bajos y más altos del número de secuencia, o seqno, que el nodo puede aplicar en paralelo.| +| **mysql.galera.wsrep_cluster_size**
(gauge) | El número actual de nodos en el clúster Galera.
_Mostrado como nodo_ | +| **mysql.galera.wsrep_flow_control_paused**
(gauge) | Muestra la fracción de tiempo, desde la última vez que se llamó a FLUSH STATUS, que el nodo estuvo en pausa debido al control de flujo.
_Mostrado como fracción_ | +| **mysql.galera.wsrep_flow_control_paused_ns**
(count) | Muestra el tiempo de pausa debido al control de flujo, en nanosegundos.
_Mostrado como nanosegundo_ | +| **mysql.galera.wsrep_flow_control_recv**
(count) | Muestra el número de veces que el nodo galera ha recibido un mensaje de control de flujo en pausa de otros| +| **mysql.galera.wsrep_flow_control_sent**
(count) | Muestra el número de veces que el nodo galera ha enviado un mensaje de control de flujo en pausa a otros| +| **mysql.galera.wsrep_local_cert_failures**
(count) | Número total de transacciones locales que no han superado el test de certificación.| +| **mysql.galera.wsrep_local_recv_queue**
(gauge) | Muestra el tamaño actual (instantáneo) de la cola de recepción local.| +| **mysql.galera.wsrep_local_recv_queue_avg**
(gauge) | Muestra el tamaño medio de la cola de recepción local desde la última consulta de FLUSH STATUS.| +| **mysql.galera.wsrep_local_send_queue**
(gauge) | Muestra el tamaño actual (instantáneo) de la longitud de la cola de envío desde la última consulta de FLUSH STATUS.| +| **mysql.galera.wsrep_local_send_queue_avg**
(gauge) | Muestra un promedio de la longitud de la cola de envío desde la última consulta de FLUSH STATUS.| +| **mysql.galera.wsrep_local_state**
(gauge) | Número de estado interno del clúster Galera| +| **mysql.galera.wsrep_received**
(gauge) | Número total de conjuntos de escritura recibidos de otros nodos.| +| **mysql.galera.wsrep_received_bytes**
(gauge) | Tamaño total (en bytes) de los conjuntos de escritura recibidos de otros nodos.| +| **mysql.galera.wsrep_replicated_bytes**
(gauge) | Tamaño total (en bytes) de los conjuntos de escritura enviados a otros nodos.| +| **mysql.index.deletes**
(gauge) | Número de operaciones de borrado que utilizan un índice. Se restablece a 0 al reiniciar la base de datos.
_Mostrado como operación_. | +| **mysql.index.reads**
(gauge) | Número de operaciones de lectura que utilizan un índice. Se restablece a 0 al reiniciar la base de datos.
_Mostrado como operación_. | +| **mysql.index.size**
(gauge) | Tamaño del índice en bytes
_Se muestra como byte_ | +| **mysql.index.updates**
(gauge) | Número de operaciones de actualización que utilizan un índice. Se restablece a 0 al reiniciar la base de datos.
_Mostrado como operación_ | +| **mysql.info.schema.size**
(gauge) | Tamaño de los esquemas en MiB
_Se muestra como mebibyte_ | +| **mysql.info.table.data_size**
(gauge) | Tamaño de los datos de las tablas en MiB
_Se muestra como mebibyte_ | +| **mysql.info.table.index_size**
(gauge) | Tamaño del índice de las tablas en MiB
_Se muestra como mebibyte_ | +| **mysql.info.table.rows.changed**
(count) | Número total de filas modificadas por tabla (solo estado de usuario de Percona)
_Mostrado como fila_ | +| **mysql.info.table.rows.read**
(count) | Número total de filas leídas por tabla (solo estado de usuario de Percona)
_Mostrado como fila_ | +| **mysql.innodb.active_transactions**
(gauge) | El número de transacciones activas en tablas de InnoDB.
_Mostrado como operación_ | +| **mysql.innodb.buffer_pool_data**
(gauge) | El número total de bytes en la reserva de búferes de InnoDB que contienen datos. El número incluye tanto las páginas sucias como las limpias.
_Mostrado como byte_ | +| **mysql.innodb.buffer_pool_dirty**
(gauge) | El número total actual de bytes retenidos en páginas sucias en la reserva de búferes de InnoDB.
_Mostrado como byte_ | +| **mysql.innodb.buffer_pool_free**
(gauge) | El número de bytes libres en la reserva de búferes de InnoDB.
_Mostrado como byte_ | +| **mysql.innodb.buffer_pool_pages_data**
(gauge) | El número de páginas en la reserva de búferes de InnoDB que contienen datos. El número incluye tanto las páginas sucias como las limpias.
_Mostrado como page (página)_ | +| **mysql.innodb.buffer_pool_pages_dirty**
(gauge) | El número actual de páginas sucias en la reserva de búferes de InnoDB.
_Mostrado como page (página)_ | +| **mysql.innodb.buffer_pool_pages_flushed**
(gauge) | El número de solicitudes para vaciar páginas de la reserva de búferes de InnoDB.
_Mostrado como page (página)_ | +| **mysql.innodb.buffer_pool_pages_free**
(gauge) | Número de páginas libres en la reserva de búferes de InnoDB.
_Mostrado como page (página)_ | +| **mysql.innodb.buffer_pool_pages_total**
(gauge) | El tamaño total de la reserva de búferes de InnoDB, en páginas.
_Mostrado como page (página)_ | +| **mysql.innodb.buffer_pool_read_ahead**
(gauge) | El número de páginas leídas en la reserva de búferes de InnoDB por el hilo de lectura en segundo plano.
_Mostrado como page (página)_ | +| **mysql.innodb.buffer_pool_read_ahead_evicted**
(gauge) | El número de páginas leídas en la reserva de búferes de InnoDB por el hilo de lectura en segundo plano que fueron desalojadas posteriormente sin haber sido accedidas por las consultas.
_Mostrado como page (página)_ | +| **mysql.innodb.buffer_pool_read_ahead_rnd**
(gauge) | El número de lecturas aleatorias iniciadas por InnoDB. Esto ocurre cuando una consulta explora una gran parte de una tabla, pero en orden aleatorio.
_Mostrado como operación_. | +| **mysql.innodb.buffer_pool_read_requests**
(gauge) | El número de solicitudes de lecturas lógicas.
_Mostrado como lectura_ | +| **mysql.innodb.buffer_pool_reads**
(gauge) | El número de lecturas lógicas que InnoDB no pudo satisfacer desde la reserva de búferes y tuvo que leer directamente del disco.
_Mostrado como lectura_ | +| **mysql.innodb.buffer_pool_total**
(gauge) | El número total de bytes en la reserva de búferes de InnoDB.
_Mostrado como byte_ | +| **mysql.innodb.buffer_pool_used**
(gauge) | El número de bytes utilizados en la reserva de búferes de InnoDB.
_Mostrado como byte_ | +| **mysql.innodb.buffer_pool_utilization**
(gauge) | La utilización de la reserva de búferes de InnoDB.
_Mostrado como fracción_ | +| **mysql.innodb.buffer_pool_wait_free**
(count) | Cuando InnoDB necesita leer o crear un page (página) y no hay páginas limpias disponibles, InnoDB vacía primero algunas páginas sucias y espera a que termine la operación. Este contador cuenta las instancias de estas esperas.
_Mostrado como espera_ | +| **mysql.innodb.buffer_pool_write_requests**
(gauge) | Número de escrituras realizadas en la reserva de búferes de InnoDB.
_Mostrado como escritura_ | +| **mysql.innodb.checkpoint_age**
(gauge) | Edad del punto de control como se muestra en la sección LOG de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.current_row_locks**
(gauge) | El número de bloqueos de filas actuales.
_Shown as bloqueo_ | +| **mysql.innodb.current_transactions**
(gauge) | Transacciones actuales de InnoDB
_Mostrado como transacción_ | +| **mysql.innodb.data_fsyncs**
(gauge) | El número de operaciones fsync() por segundo.
_Mostrado como operación_ | +| **mysql.innodb.data_pending_fsyncs**
(gauge) | El número actual de operaciones fsync() pendientes.
_Mostrado como operación_ | +| **mysql.innodb.data_pending_reads**
(gauge) | El número actual de lecturas pendientes.
_Shown as lectura_ | +| **mysql.innodb.data_pending_writes**
(gauge) | El número actual de escrituras pendientes.
_Shown as escritura_ | +| **mysql.innodb.data_read**
(gauge) | La cantidad de datos leídos por segundo.
_Se muestra como byte_ | +| **mysql.innodb.data_reads**
(gauge) | La tasa de lecturas de datos.
_Shown as lectura_ | +| **mysql.innodb.data_writes**
(gauge) | La tasa de escrituras de datos.
_Shown as escritura_ | +| **mysql.innodb.data_written**
(gauge) | La cantidad de datos escritos por segundo.
_Se muestra como byte_ | +| **mysql.innodb.dblwr_pages_written**
(gauge) | El número de páginas escritas por segundo en el búfer de doble escritura.
_Shown as page (página)_ | +| **mysql.innodb.dblwr_writes**
(gauge) | El número de operaciones de doble escritura realizadas por segundo.
_Mostrado como byte_ | +| **mysql.innodb.deadlocks**
(count) | El número de bloqueos.
_Shown as bloqueo_ | +| **mysql.innodb.hash_index_cells_total**
(gauge) | Número total de celdas del índice hash adaptativo| +| **mysql.innodb.hash_index_cells_used**
(gauge) | Número de celdas utilizadas del índice hash adaptativo| +| **mysql.innodb.history_list_length**
(gauge) | Longitud de la lista de historial como se muestra en la sección TRANSACTIONS de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.ibuf_free_list**
(gauge) | Lista libre de búferes de inserción, como se muestra en la sección INSERT BUFFER AND ADAPTIVE HASH INDEX de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.ibuf_merged**
(gauge) | Búfer de inserción e índice hash adaptativo fusionados
_Mostrado como operación_ | +| **mysql.innodb.ibuf_merged_delete_marks**
(gauge) | Marcas de borrado de búfer de inserción e índice hash adaptativo fusionados
_Mostrado como operación_ | +| **mysql.innodb.ibuf_merged_deletes**
(gauge) | Búfer de inserción e índice hash adaptativo fusionados borrados
_Mostrado como operación_ | +| **mysql.innodb.ibuf_merged_inserts**
(gauge) | Inserciones de búfer de inserción e índice hash adaptativo fusionados
_Mostrado como operación_ | +| **mysql.innodb.ibuf_merges**
(gauge) | Fusiones de búfer de inserción e índice hash adaptativo
_Mostrado como operación_ | +| **mysql.innodb.ibuf_segment_size**
(gauge) | Tamaño del segmento del búfer de inserción, como se muestra en la sección INSERT BUFFER AND ADAPTIVE HASH INDEX de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.ibuf_size**
(gauge) | Tamaño del búfer de inserción, como se muestra en la sección INSERT BUFFER AND ADAPTIVE HASH INDEX de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.lock_structs**
(gauge) | Estructuras de bloqueo
_Mostrado como operación_ | +| **mysql.innodb.locked_tables**
(gauge) | Tablas bloqueadas
_Mostrado como operación_ | +| **mysql.innodb.log_waits**
(gauge) | Número de veces que el búfer de log era demasiado pequeño y fue necesario esperar a que se vaciara antes de continuar.
_Mostrado como espera_ | +| **mysql.innodb.log_write_requests**
(gauge) | El número de solicitudes de escritura para el log de rehacer de InnoDB.
_Mostrado como escritura_ | +| **mysql.innodb.log_writes**
(gauge) | El número de escrituras físicas en el archivo de log de rehacer de InnoDB.
_Mostrado como escritura_ | +| **mysql.innodb.lsn_current**
(gauge) | Número de secuencia de logs como se muestra en la sección LOGS de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.lsn_flushed**
(gauge) | Vaciado hasta el número de secuencia de logs como se muestra en la sección LOG de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.lsn_last_checkpoint**
(gauge) | Último punto de control del número de secuencia de logs como se muestra en la sección LOG de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.mem_adaptive_hash**
(gauge) | Como se muestra en la sección BUFFER POOL AND MEMORY de la salida SHOW ENGINE INNODB STATUS.
_Mostrado como byte_ | +| **mysql.innodb.mem_additional_pool**
(gauge) | Como se muestra en la sección BUFFER POOL AND MEMORY de la salida SHOW ENGINE INNODB STATUS. Solo disponible en MySQL 5.6.
_Mostrado como byte_ | +| **mysql.innodb.mem_dictionary**
(gauge) | Como se muestra en la sección BUFFER POOL AND MEMORY de la salida SHOW ENGINE INNODB STATUS.
_Mostrado como byte_ | +| **mysql.innodb.mem_file_system**
(gauge) | Como se muestra en la sección BUFFER POOL AND MEMORY de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.mem_lock_system**
(gauge) | Como se muestra en la sección BUFFER POOL AND MEMORY de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.mem_page_hash**
(gauge) | Como se muestra en la sección BUFFER POOL AND MEMORY de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.mem_recovery_system**
(gauge) | Como se muestra en la sección BUFFER POOL AND MEMORY de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.mem_total**
(gauge) | Como se muestra en la sección BUFFER POOL AND MEMORY de la salida SHOW ENGINE INNODB STATUS.
_Mostrado como byte_ | +| **mysql.innodb.mutex_os_waits**
(gauge) | La tasa de esperas del sistema operativo mutex. Solo disponible en MySQL 5.6 y 5.7.
_Mostrado como evento_. | +| **mysql.innodb.mutex_spin_rounds**
(gauge) | La tasa de rondas de giro del mutex. Solo disponible en MySQL 5.6 y 5.7.
_Mostrado como evento_. | +| **mysql.innodb.mutex_spin_waits**
(gauge) | La tasa de esperas de giro del mutex. Solo disponible en MySQL 5.6 y 5.7.
_Mostrado como evento_. | +| **mysql.innodb.os_file_fsyncs**
(gauge) | (Delta) Número total de operaciones fsync() realizadas por InnoDB.
_Mostrado como operación_ | +| **mysql.innodb.os_file_reads**
(gauge) | (Delta) El número total de lecturas de archivos realizadas por hilos de lectura en InnoDB.
_Mostrado como operación_ | +| **mysql.innodb.os_file_writes**
(gauge) | (Delta) El número total de escrituras de archivos realizadas por hilos de escritura en InnoDB.
_Mostrado como operación_ | +| **mysql.innodb.os_log_fsyncs**
(gauge) | La tasa de escrituras fsync en el archivo de log.
_Mostrado como escritura_ | +| **mysql.innodb.os_log_pending_fsyncs**
(gauge) | Número de solicitudes fsync (sincronización con disco) de log de InnoDBpendientes.
_Mostrado como operación_ | +| **mysql.innodb.os_log_pending_writes**
(gauge) | Número de escrituras de logs de InnoDB pendientes.
_Mostrado como escritura_ | +| **mysql.innodb.os_log_written**
(gauge) | Número de bytes escritos en log de InnoDB.
_Mostrado como byte_ | +| **mysql.innodb.pages_created**
(gauge) | Número de páginas de InnoDB creadas.
_Mostrado como page (página)_ | +| **mysql.innodb.pages_read**
(gauge) | Número de páginas InnoDB leídas.
_Mostrado como page (página)_ | +| **mysql.innodb.pages_written**
(gauge) | Número de páginas InnoDB escritas.
_Mostrado como page (página)_ | +| **mysql.innodb.pending_aio_log_ios**
(gauge) | Como se muestra en la sección FILE I/O de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.pending_aio_sync_ios**
(gauge) | Como se muestra en la sección FILE I/O de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.pending_buffer_pool_flushes**
(gauge) | Como se muestra en la sección FILE I/O de la salida SHOW ENGINE INNODB STATUS.
_Mostrado como vaciado_ | +| **mysql.innodb.pending_checkpoint_writes**
(gauge) | Como se muestra en la sección FILE I/O de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.pending_ibuf_aio_reads**
(gauge) | Como se muestra en la sección FILE I/O de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.pending_log_flushes**
(gauge) | Como se muestra en la sección FILE I/O de la salida SHOW ENGINE INNODB STATUS. Solo disponible en MySQL 5.6 y 5.7.
_Mostrado como vaciado_. | +| **mysql.innodb.pending_log_writes**
(gauge) | Como se muestra en la sección FILE I/O de la salida SHOW ENGINE INNODB STATUS. Solo disponible en MySQL 5.6 y 5.7.
_Mostrado como escritura_. | +| **mysql.innodb.pending_normal_aio_reads**
(gauge) | Como se muestra en la sección FILE I/O de la salida SHOW ENGINE INNODB STATUS.
_Mostrado como lectura_ | +| **mysql.innodb.pending_normal_aio_writes**
(gauge) | Como se muestra en la sección FILE I/O de la salida SHOW ENGINE INNODB STATUS.
_Mostrado como escritura_ | +| **mysql.innodb.queries_inside**
(gauge) | Como se muestra en la sección FILE I/O de la salida SHOW ENGINE INNODB STATUS.
_Mostrado como consulta_ | +| **mysql.innodb.queries_queued**
(gauge) | Como se muestra en la sección FILE I/O de la salida SHOW ENGINE INNODB STATUS.
_Mostrado como consulta_ | +| **mysql.innodb.read_views**
(gauge) | Como se muestra en la sección FILE I/O de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.row_lock_current_waits**
(gauge) | El número de bloqueos de fila actualmente en espera por operaciones en tablas de InnoDB.| +| **mysql.innodb.row_lock_time**
(gauge) | El tiempo empleado en adquirir bloqueos de fila.
_Mostrado como milisegundo_ | +| **mysql.innodb.row_lock_waits**
(gauge) | El número de veces por segundo que se ha tenido que esperar un bloqueo de fila.
_Mostrado como evento_ | +| **mysql.innodb.rows_deleted**
(gauge) | Número de filas eliminadas de las tablas de InnoDB.
_Mostrado como fila_ | +| **mysql.innodb.rows_inserted**
(gauge) | Número de filas insertadas en tablas de InnoDB.
_Mostrado como fila_ | +| **mysql.innodb.rows_read**
(gauge) | Número de filas leídas de las tablas de InnoDB.
_Mostrado como fila_ | +| **mysql.innodb.rows_updated**
(gauge) | Número de filas actualizadas en tablas de InnoDB.
_Mostrado como fila_ | +| **mysql.innodb.s_lock_os_waits**
(gauge) | Como se muestra en la sección SEMÁFOROS de la salida SHOW ENGINE INNODB STATUS| +| **mysql.innodb.s_lock_spin_rounds**
(gauge) | Como se muestra en la sección SEMÁFOROS de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.s_lock_spin_waits**
(gauge) | Como se muestra en la sección SEMAPHORES de la salida SHOW ENGINE INNODB STATUS.
_Mostrado como espera_ | +| **mysql.innodb.semaphore_wait_time**
(gauge) | Tiempo de espera en semáforo| +| **mysql.innodb.semaphore_waits**
(gauge) | El número de semáforos actualmente en espera por operaciones en tablas de InnoDB.| +| **mysql.innodb.tables_in_use**
(gauge) | Tablas en uso
_Mostrado como operación_ | +| **mysql.innodb.x_lock_os_waits**
(gauge) | Como se muestra en la sección SEMAPHORES de la salida SHOW ENGINE INNODB STATUS.
_Mostrado como espera_ | +| **mysql.innodb.x_lock_spin_rounds**
(gauge) | Como se muestra en la sección SEMAPHORES de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.x_lock_spin_waits**
(gauge) | Como se muestra en la sección SEMAPHORES de la salida SHOW ENGINE INNODB STATUS.
_Mostrado como espera_ | +| **mysql.myisam.key_buffer_bytes_unflushed**
(gauge) | Bytes del búfer de claves de MyISAM sin vaciar.
_Mostrado como byte_ | +| **mysql.myisam.key_buffer_bytes_used**
(gauge) | Bytes del búfer de claves de MyISAM utilizados.
_Mostrado como byte_ | +| **mysql.myisam.key_buffer_size**
(gauge) | Tamaño del búfer utilizado para los bloques de índice.
_Mostrado como byte_ | +| **mysql.myisam.key_read_requests**
(gauge) | Número de solicitudes para leer un bloque de claves de la caché de claves de MyISAM.
_Mostrado como leído_ | +| **mysql.myisam.key_reads**
(gauge) | El número de lecturas físicas de un bloque de claves desde el disco a la caché de claves de MyISAM. Si `key_reads` es grande, es probable que el valor de clave_bpufer_tamaño sea demasiado pequeño. La tasa de fallos de la caché puede calcularse como `key_reads`/`key_read_requests`.
_Mostrado como lectura_. | +| **mysql.myisam.key_write_requests**
(gauge) | Número de solicitudes para escribir un bloque de claves en la caché de claves de MyISAM.
_Mostrado como escritura_ | +| **mysql.myisam.key_writes**
(gauge) | Número de escrituras físicas de un bloque de claves desde la caché de claves de MyISAM al disco.
_Mostrado como escritura_ | +| **mysql.net.aborted_clients**
(gauge) | El número de conexiones que se abortaron porque el cliente murió sin cerrar la connection (conexión) correctamente.
_Mostrado como connection (conexión)_ | +| **mysql.net.aborted_connects**
(gauge) | Número de intentos fallidos de conexión con el servidor de MySQL.
_Mostrado como connection (conexión)_ | +| **mysql.net.connections**
(gauge) | La tasa de conexiones al servidor.
_Mostrado como connection (conexión)_ | +| **mysql.net.max_connections**
(gauge) | El número máximo de conexiones que han estado en uso simultáneamente desde que se inició el servidor.
_Mostrado como connection (conexión) | +| **mysql.net.max_connections_available**
(gauge) | El número máximo permitido de conexiones simultáneas del cliente.
_Mostrado como connection (conexión)_ | +| **mysql.performance.bytes_received**
(gauge) | El número de bytes recibidos de todos los clientes.
_Mostrado como byte_ | +| **mysql.performance.bytes_sent**
(gauge) | El número de bytes enviados a todos los clientes.
_Mostrado como byte_ | +| **mysql.performance.com_delete**
(gauge) | La tasa de sentencias de borrado.
_Shown as consulta_ | +| **mysql.performance.com_delete_multi**
(gauge) | La tasa de sentencias de borrado múltiple.
_Mostrado como consulta_ | +| **mysql.performance.com_insert**
(gauge) | La tasa de sentencias de inserción.
_Shown as consulta_ | +| **mysql.performance.com_insert_select**
(gauge) | La tasa de sentencias inserción y selección.
_Mostrado como consulta_ | +| **mysql.performance.com_load**
(gauge) | La tasa de sentencias de carga.
_Mostrado como consulta_ | +| **mysql.performance.com_replace**
(gauge) | La tasa de sentencias de sustitución.
_Mostrado como consulta_ | +| **mysql.performance.com_replace_select**
(gauge) | La tasa de sentencias de sustituir y seleccionar.
_Mostrado como consulta_ | +| **mysql.performance.com_select**
(gauge) | La tasa de sentencias de selección.
_Shown as consulta_ | +| **mysql.performance.com_update**
(gauge) | La tasa de sentencias de actualización.
_Mostrado como consulta_ | +| **mysql.performance.com_update_multi**
(gauge) | La tasa de actualización múltiple.
_Mostrado como consulta_ | +| **mysql.performance.cpu_time**
(gauge) | Porcentaje de tiempo de CPU empleado por MySQL.
_Mostrado como porcentaje_ | +| **mysql.performance.created_tmp_disk_tables**
(gauge) | Tasa de tablas temporales internas en disco creadas por segundo por el servidor durante la ejecución de sentencias.
_Mostrado como tabla_ | +| **mysql.performance.created_tmp_files**
(gauge) | La tasa de archivos temporales creados por segundo.
_Mostrado como archivo_ | +| **mysql.performance.created_tmp_tables**
(gauge) | Tasa de tablas temporales internas creadas por segundo por el servidor durante la ejecución de sentencias.
_Mostrado como tabla_ | +| **mysql.performance.digest_95th_percentile.avg_us**
(gauge) | Percentil 95 por esquema de tiempo de respuesta de consulta.
_Mostrado en microsegundos_ | +| **mysql.performance.handler_commit**
(gauge) | El número de sentencias COMMIT internas.
_Mostrado como operación_ | +| **mysql.performance.handler_delete**
(gauge) | El número de sentencias DELETE internas.
_Mostrado como operación_ | +| **mysql.performance.handler_prepare**
(gauge) | El número de sentencias PREPARE internas.
_Mostrado como operación_ | +| **mysql.performance.handler_read_first**
(gauge) | El número de sentencias internas READ_FIRST.
_Mostrado como operación_ | +| **mysql.performance.handler_read_key**
(gauge) | El número de sentencias internas READ_KEY.
_Mostrado como operación_ | +| **mysql.performance.handler_read_next**
(gauge) | El número de sentencias internas READ_NEXT.
_Mostrado como operación_ | +| **mysql.performance.handler_read_prev**
(gauge) | El número de sentencias internas READ_PREV.
_Mostrado como operación_ | +| **mysql.performance.handler_read_rnd**
(gauge) | El número de sentencias internas READ_RND.
_Mostrado como operación_ | +| **mysql.performance.handler_read_rnd_next**
(gauge) | El número de sentencias internas READ_RND_NEXT.
_Mostrado como operación_ | +| **mysql.performance.handler_rollback**
(gauge) | El número de sentencias ROLLBACK internas.
_Mostrado como operación_ | +| **mysql.performance.handler_update**
(gauge) | El número de sentencias UPDATE internas.
_Mostrado como operación_ | +| **mysql.performance.handler_write**
(gauge) | El número de sentencias WRITE internas.
_Mostrado como operación_ | +| **mysql.performance.kernel_time**
(gauge) | Porcentaje de tiempo de CPU empleado en el espacio del núcleo por MySQL.
_Mostrado como porcentaje_. | +| **mysql.performance.key_cache_utilization**
(gauge) | La relación de utilización de la caché de claves.
_Mostrado como fracción_ | +| **mysql.performance.max_prepared_stmt_count**
(gauge) | El máximo permitido de sentencias preparadas en el servidor.| +| **mysql.performance.open_files**
(gauge) | El número de archivos abiertos.
_Mostrado como archivo_ | +| **mysql.performance.open_tables**
(gauge) | El número de tablas que están abiertas.
_Mostrado como tabla_ | +| **mysql.performance.opened_tables**
(gauge) | El número de tablas que se han abierto. Si `opened_tables` es grande, su valor `table_open_cache` es probablemente demasiado pequeño.
_Mostrado como tabla_. | +| **mysql.performance.performance_schema_digest_lost**
(gauge) | El número de instancias de compendio que no pudieron instrumentarse en la tabla eventos_sentencias_resumen_por_compendio. Puede ser distinto de cero si el valor de rendimiento_esquema_compendios_tamaño es demasiado pequeño.| +| **mysql.performance.prepared_stmt_count**
(gauge) | El número actual de sentencias preparadas.
_Mostrado como consulta_ | +| **mysql.performance.qcache.utilization**
(gauge) | Fracción de la memoria caché de consultas que se está utilizando actualmente.
_Mostrado como fracción_ | +| **mysql.performance.qcache_free_blocks**
(gauge) | El número de bloques de memoria libres en la caché de consulta.
_Mostrado como bloque_ | +| **mysql.performance.qcache_free_memory**
(gauge) | La cantidad de memoria libre para la caché de consultas.
_Mostrado como byte_ | +| **mysql.performance.qcache_hits**
(gauge) | Tasa de aciertos en la caché de consultas.
_Mostrado como acierto_ | +| **mysql.performance.qcache_inserts**
(gauge) | Número de consultas añadidas a la caché de consultas.
_Mostrado como consulta_ | +| **mysql.performance.qcache_lowmem_prunes**
(gauge) | Número de consultas borradas de la caché de consultas por falta de memoria.
_Mostrado como consulta_ | +| **mysql.performance.qcache_not_cached**
(gauge) | El número de consultas no almacenadas en caché (no almacenables en caché o no almacenadas en caché debido a la configuración de `query_cache_type`).
_Mostrado como consulta_ | +| **mysql.performance.qcache_queries_in_cache**
(gauge) | Número de consultas registradas en la caché de consultas.
_Mostrado como consulta_ | +| **mysql.performance.qcache_size**
(gauge) | La cantidad de memoria asignada para almacenar en caché los resultados de la consulta.
_Mostrado como byte_ | +| **mysql.performance.qcache_total_blocks**
(gauge) | Número total de bloques en la caché de consultas.
_Mostrado como bloque_ | +| **mysql.performance.queries**
(gauge) | La tasa de consultas.
_Mostrado como consulta_ | +| **mysql.performance.query_run_time.avg**
(gauge) | Tiempo medio de respuesta de consulta por esquema.
_Mostrado en microsegundos_ | +| **mysql.performance.questions**
(gauge) | La tasa de sentencias ejecutadas por el servidor.
_Mostrado como consulta_ | +| **mysql.performance.select_full_join**
(gauge) | El número de uniones que realizan exploraciones de tablas porque no utilizan índices. Si este valor no es 0, debes comprobar cuidadosamente los índices de tus tablas.
_Mostrado como operación_. | +| **mysql.performance.select_full_range_join**
(gauge) | El número de uniones que utilizaron una búsqueda de rango en una tabla de referencia.
_Mostrado como operación_ | +| **mysql.performance.select_range**
(gauge) | El número de uniones que utilizaron rangos en la primera tabla. Normalmente, este no es un problema crítico, incluso si el valor es bastante grande.
_Mostrado como operación_. | +| **mysql.performance.select_range_check**
(gauge) | El número de uniones sin claves que comprueban el uso de claves después de cada fila. Si no es 0, debes comprobar cuidadosamente los índices de tus tablas.
_Mostrado como operación_. | +| **mysql.performance.select_scan**
(gauge) | El número de uniones que hicieron una exploración completa de la primera tabla.
_Mostrado como operación_ | +| **mysql.performance.slow_queries**
(gauge) | La tasa de consultas lentas (consultas de logs que superan un tiempo de ejecución determinado).
_Mostrado como consulta_ | +| **mysql.performance.sort_merge_passes**
(gauge) | El número de pasadas de fusión que ha tenido que hacer el algoritmo de clasificación. Si este valor es grande, debes considerar aumentar el valor de la variable del sistema `sort_buffer_size`.
_Mostrado como operación_. | +| **mysql.performance.sort_range**
(gauge) | El número de clasificaciones que se han realizado utilizando rangos.
_Mostrado como operación_ | +| **mysql.performance.sort_rows**
(gauge) | El número de filas ordenadas.
_Mostrado como operación_ | +| **mysql.performance.sort_scan**
(gauge) | El número de clasificaciones que se han realizado explorando la tabla.
_Mostrado como operación_ | +| **mysql.performance.table_cache_hits**
(gauge) | Número de aciertos en las búsquedas de la caché de tablas abiertas.
_Mostrado como acierto_ | +| **mysql.performance.table_cache_misses**
(gauge) | Número de fallos en las búsquedas de la caché de tablas abiertas.
_Mostrado como fallo_ | +| **mysql.performance.table_locks_immediate**
(gauge) | El número de veces que una solicitud de bloqueo de una tabla podría concederse inmediatamente.| +| **mysql.performance.table_locks_immediate.rate**
(gauge) | Porcentaje de veces que una solicitud de bloqueo de una tabla puede concederse inmediatamente.| +| **mysql.performance.table_locks_waited**
(gauge) | Número total de veces que una solicitud de bloqueo de tabla no pudo concederse inmediatamente y fue necesario esperar.| +| **mysql.performance.table_locks_waited.rate**
(gauge) | Porcentaje de veces que una solicitud de bloqueo de una tabla no pudo concederse inmediatamente y fue necesario esperar.| +| **mysql.performance.table_open_cache**
(gauge) | El número de tablas abiertas para todos los hilos. Incrementar este valor incrementa el número de descriptores de archivo que requiere mysqld.| +| **mysql.performance.thread_cache_size**
(gauge) | Cuántos hilos debe almacenar en caché el servidor para su reutilización. Cuando un cliente se desconecta, los hilos del cliente se ponen en la caché si hay menos de `thread_cache_size` hilos allí.
_Mostrado como byte_. | +| **mysql.performance.threads_cached**
(gauge) | El número de hilos en la caché de hilos.
_Mostrado como hilo_ | +| **mysql.performance.threads_connected**
(gauge) | El número de conexiones abiertas actualmente.
_Mostrado como connection (conexión)_ | +| **mysql.performance.threads_created**
(count) | El número de hilos creados para manejar las conexiones. Si `threads_created` es grande, es posible que desees aumentar el valor de `thread_cache_size`.
_Mostrado como hilo_. | +| **mysql.performance.threads_running**
(gauge) | El número de hilos que no están inactivos.
_Mostrado como hilo_ | +| **mysql.performance.user_connections**
(gauge) | El número de conexiones de usuario. Etiquetas: `processlist_db`, `processlist_host`, `processlist_state`, `processlist_user`
_Mostrado como connection (conexión)_ | +| **mysql.performance.user_time**
(gauge) | Porcentaje de tiempo de CPU empleado en el espacio de usuario por MySQL.
_Mostrado como porcentaje_. | +| **mysql.queries.count**
(count) | El count total de consultas ejecutadas por consulta normalizada y esquema. (Solo DBM)
_Mostrado como consulta_. | +| **mysql.queries.errors**
(count) | El count total de consultas ejecutadas con un error por consulta y esquema normalizados. (Solo DBM)
_Mostrado como error_. | +| **mysql.queries.lock_time**
(count) | Tiempo total de espera de bloqueos por consulta y esquema normalizados. (Solo DBM)
_Mostrado como nanosegundo_. | +| **mysql.queries.no_good_index_used**
(count) | El count total de consultas que utilizaron un índice menor que el óptimo por consulta y esquema normalizados. (Solo DBM)
_Mostrado como consulta_. | +| **mysql.queries.no_index_used**
(count) | El count total de consultas que no utilizan un índice por consulta y esquema normalizados. (Solo DBM)
_Mostrado como consulta_. | +| **mysql.queries.rows_affected**
(count) | Número de filas mutadas por consulta y esquema normalizados. (Solo DBM)
_Mostrado como fila_. | +| **mysql.queries.rows_examined**
(count) | Número de filas examinadas por consulta y esquema normalizados. (Solo DBM)
_Mostrado como fila_. | +| **mysql.queries.rows_sent**
(count) | Número de filas enviadas por consulta y esquema normalizados. (Solo DBM)
_Mostrado como fila_. | +| **mysql.queries.select_full_join**
(count) | El count total de exploraciones de tabla completa en una tabla unida por consulta y esquema normalizados. (Solo DBM)| +| **mysql.queries.select_scan**
(count) | El count total de exploraciones de tabla completa en la primera tabla por consulta y esquema normalizados. (Solo DBM)| +| **mysql.queries.time**
(count) | El tiempo total de ejecución de la consulta por consulta y esquema normalizados. (Solo DBM)
_Mostrado como nanosegundo_. | +| **mysql.replication.group.conflicts_detected**
(gauge) | Número de transacciones que no han pasado el check de detección de conflictos.
_Mostrado como transacción_ | +| **mysql.replication.group.member_status**
(gauge) | Información sobre el estado del nodo en un entorno de replicación de grupo, siempre igual a 1.| +| **mysql.replication.group.transactions**
(gauge) | El número de transacciones en la cola pendientes de checks de detección de conflictos.
_Mostrado como transacción_ | +| **mysql.replication.group.transactions_applied**
(gauge) | Número de transacciones que este miembro ha recibido del grupo y ha aplicado.
_Mostrado como transacción_ | +| **mysql.replication.group.transactions_check**
(gauge) | El número de transacciones que se han comprobado en busca de conflictos.
_Mostrado como transacción_ | +| **mysql.replication.group.transactions_in_applier_queue**
(gauge) | El número de transacciones que este miembro ha recibido del grupo de replicación y que están a la espera de ser aplicadas.
_Mostrado como transacción_ | +| **mysql.replication.group.transactions_proposed**
(gauge) | Número de transacciones que se originaron en este miembro y se enviaron al grupo.
_Mostrado como transacción_ | +| **mysql.replication.group.transactions_rollback**
(gauge) | Número de transacciones que se originaron en este miembro y fueron revertidas por el grupo.
_Mostrado como transacción_ | +| **mysql.replication.group.transactions_validating**
(gauge) | Número de filas de transacciones que pueden utilizarse para la certificación, pero que no se han recolectado de la basura.
_Mostrado como transacción_ | +| **mysql.replication.replicas_connected**
(gauge) | Número de réplicas conectadas a una source (fuente) de réplicas.| +| **mysql.replication.seconds_behind_master**
(gauge) | El desfase en segundos entre el patrón y el esclavo.
_Mostrado como segundo_ | +| **mysql.replication.seconds_behind_source**
(gauge) | El desfase en segundos entre la source (fuente) y la réplica.
_Mostrado como segundo_ | +| **mysql.replication.slave_running**
(gauge) | Obsoleto. Utiliza un check de servicios mysql.replication.replica_running en su lugar. Un booleano que muestra si este servidor es un esclavo/patrón de réplica que se está ejecutando.| +| **mysql.replication.slaves_connected**
(gauge) | Obsoleto. Utiliza `MySQL.replication.replicas_connected` en su lugar. Número de esclavos conectados a un patrón de réplica.| El check no recopila todas las métricas por defecto. Establece las siguientes opciones de configuración booleanas en `true` para activar las respectivas métricas: @@ -644,42 +822,45 @@ El check no recopila todas las métricas por defecto. Establece las siguientes o El check de MySQL no incluye eventos. ### Checks de servicio -{{< get-service-checks-from-git "mysql" >}} +**mysql.can_connect** + +Devuelve `CRITICAL` si el Agent no puede conectarse a la instancia MySQL monitorizada. En caso contrario, devuelve `OK`. + +_Estados: ok, crítico_ + +**mysql.replication.slave_running** + +Obsoleto. Devuelve CRÍTICO para una réplica que no esté ejecutando Esclavo_IO_En ejecución ni Esclavo_SQL_En ejecución, ADVERTENCIA si una de las dos no está ejecutándose. En caso contrario, devuelve `OK`. + +_Estados: ok, advertencia, crítico_ + +**mysql.replication.replica_running** + +Devuelve CRÍTICO para una réplica que no esté ejecutando Réplica_IO_En ejecución ni Réplica_SQL_En ejeución, ADVERTENCIA si una de las dos no está ejecutándose. En caso contrario, devuelve `OK`. + +_Estados: ok, advertencia, crítico_ + +**mysql.replication.group.status** + +Devuelve `OK` si el estado del host es EN LÍNEA, devuelve `CRITICAL` en caso contrario. + +_Estados: ok, crítico_ ## Solucionar problemas -- [Problemas de conexión con la integración de SQL Server][8] -- [Error de host local de MySQL: host local VS 127.0.0.1][9] -- [¿Puedo utilizar una instancia con nombre en la integración de SQL Server?][10] -- [¿Puedo configurar el check de MySQL dd-agent en mi Google CloudSQL?][11] -- [Consultas personalizadas de MySQL][12] -- [Utilizar WMI para recopilar más métricas de rendimiento de SQL Server][13] -- [¿Cómo puedo recopilar más métricas de mi integración de SQL Server?][14] -- [El usuario de la base de datos carece de privilegios][15] -- [¿Cómo se recopilan las métricas con un procedimiento almacenado de SQL?][16] +- [Problemas de connection (conexión) con la integración del servidor de SQL](https://docs.datadoghq.com/integrations/guide/connection-issues-with-the-sql-server-integration/) +- [Error del host local de MySQL - Host local VS 127.0.0.1](https://docs.datadoghq.com/integrations/faq/mysql-localhost-error-localhost-vs-127-0-0-1/) +- [¿Puedo utilizar una instancia con nombre en la integración del servidor de SQL?](https://docs.datadoghq.com/integrations/faq/can-i-use-a-named-instance-in-the-sql-server-integration/) +- [Puedo configurar el check de MySQL del dd-agent en mi Google CloudSQL?](https://docs.datadoghq.com/integrations/faq/can-i-set-up-the-dd-agent-mysql-check-on-my-google-cloudsql/) +- [Consultas personalizadas de MySQL](https://docs.datadoghq.com/integrations/faq/how-to-collect-metrics-from-custom-mysql-queries/) +- [Utiliza WMI para recopilar más métricas de rendimiento del servidor de SQL](https://docs.datadoghq.com/integrations/guide/use-wmi-to-collect-more-sql-server-performance-metrics/) +- [¿Cómo puedo recopilar más métricas de mi integración del servidor de SQL?](https://docs.datadoghq.com/integrations/faq/how-can-i-collect-more-metrics-from-my-sql-server-integration/) +- [Usuario de base de datos sin privilegios](https://docs.datadoghq.com/integrations/faq/database-user-lacks-privileges/) +- [Cómo recopilar métricas con un procedimiento almacenado de SQL](https://docs.datadoghq.com/integrations/guide/collect-sql-server-custom-metrics/#collecting-metrics-from-a-custom-procedure) ## Referencias adicionales -Más enlaces, artículos y documentación útiles: - -- [Monitorización de métricas de rendimiento de MySQL][17] - - -[1]: https://raw.githubusercontent.com/DataDog/integrations-core/master/mysql/images/mysql-dash-dd-2.png -[2]: https://docs.datadoghq.com/database_monitoring/ -[3]: https://app.datadoghq.com/account/settings/agent/latest -[4]: https://docs.datadoghq.com/database_monitoring/#mysql -[5]: https://dev.mysql.com/doc/refman/8.0/en/creating-accounts.html -[6]: https://github.com/DataDog/integrations-core/blob/master/mysql/datadog_checks/mysql/data/conf.yaml.example -[7]: https://docs.datadoghq.com/agent/guide/agent-commands/#agent-status-and-information -[8]: https://docs.datadoghq.com/integrations/guide/connection-issues-with-the-sql-server-integration/ -[9]: https://docs.datadoghq.com/integrations/faq/mysql-localhost-error-localhost-vs-127-0-0-1/ -[10]: https://docs.datadoghq.com/integrations/faq/can-i-use-a-named-instance-in-the-sql-server-integration/ -[11]: https://docs.datadoghq.com/integrations/faq/can-i-set-up-the-dd-agent-mysql-check-on-my-google-cloudsql/ -[12]: https://docs.datadoghq.com/integrations/faq/how-to-collect-metrics-from-custom-mysql-queries/ -[13]: https://docs.datadoghq.com/integrations/guide/use-wmi-to-collect-more-sql-server-performance-metrics/ -[14]: https://docs.datadoghq.com/integrations/faq/how-can-i-collect-more-metrics-from-my-sql-server-integration/ -[15]: https://docs.datadoghq.com/integrations/faq/database-user-lacks-privileges/ -[16]: https://docs.datadoghq.com/integrations/guide/collect-sql-server-custom-metrics/#collecting-metrics-from-a-custom-procedure -[17]: https://www.datadoghq.com/blog/monitoring-mysql-performance-metrics +Documentación útil adicional, enlaces y artículos: + +- [Monitorización de métricas de rendimiento de MySQL](https://www.datadoghq.com/blog/monitoring-mysql-performance-metrics) \ No newline at end of file diff --git a/content/es/integrations/n2ws.md b/content/es/integrations/n2ws.md index 06781039057ab..bd55cda967547 100644 --- a/content/es/integrations/n2ws.md +++ b/content/es/integrations/n2ws.md @@ -1,75 +1,18 @@ --- app_id: n2ws -app_uuid: 6c0176c4-b878-43e0-a5a8-d280b0fa123e -assets: - dashboards: - N2WSBackup&Recovery-EntitiesSpecificDashboard: assets/dashboards/N2WSBackup&Recovery-EntityTypesDetails.json - N2WSBackup&Recovery-EntitiesSpecificDashboardV4.0: assets/dashboards/N2WSBackup&Recoveryv4.1-EntityTypesDetails.json - N2WSBackup&Recovery-GraphicalVersion: assets/dashboards/N2WSBackup&Recovery-BackupSuccessRates(ColumnGraphs).json - N2WSBackup&Recovery-GraphicalVersion-Areas: assets/dashboards/N2WSBackup&Recovery-BackupSuccessRates(AreasGraphs).json - N2WSBackup&Recovery-GraphicalVersionV4.0: assets/dashboards/N2WSBackup&Recoveryv4.1-BackupSuccessRates(ColumnGraphs).json - integration: - auto_install: true - configuration: {} - events: - creates_events: false - metrics: - check: cpm_metric.dashboard_activity.backup_success_num - metadata_path: metadata.csv - prefix: cpm_metric. - service_checks: - metadata_path: assets/service_checks.json - source_type_id: 10129 - source_type_name: N2WS Backup & Recovery -author: - homepage: https://github.com/DataDog/integrations-extras - name: N2WS - sales_email: eliad.eini@n2ws.com - support_email: eliad.eini@n2ws.com categories: - nube -custom_kind: integration -dependencies: -- https://github.com/DataDog/integrations-extras/blob/master/n2ws/README.md -display_on_public_website: true -draft: false -git_integration_title: n2ws -integration_id: n2ws -integration_title: N2WS -integration_version: '' -is_public: true -manifest_version: 2.0.0 -name: n2ws -public_title: N2WS -short_description: Ver datos resumidos de todos los hosts conectados de N2WS Backup - & Recovery +custom_kind: integración +description: Ver datos resumidos de todos los hosts conectados de N2WS Backup & Recovery +media: [] supported_os: - linux - macos - windows -tile: - changelog: CHANGELOG.md - classifier_tags: - - Supported OS::Linux - - Supported OS::macOS - - Supported OS::Windows - - Category::Cloud - - Offering::Integration - configuration: README.md#Setup - description: Ver datos resumidos de todos los hosts conectados de N2WS Backup & - Recovery - media: [] - overview: README.md#Overview - support: README.md#Support - title: N2WS +title: N2WS --- - - - - ## Información general - N2WS Backup & Recovery (CPM), conocido como N2WS, es una solución empresarial de copia de seguridad, recuperación y recuperación de desastres para Amazon Web Services (AWS) y Microsoft Azure. N2WS utiliza tecnologías nativas en la nube (snapshots) para brindar capacidades de copia de seguridad y restauración en AWS y Azure. Tu instancia de N2WS Backup and Recovery admite la monitorización de copias de seguridad, recuperación de desastres, copia a S3, alertas, @@ -79,39 +22,42 @@ y mucho más con el servicio d emonitorización de Datadog. Esta integración pe ### Instalación -1. Instala la [integración de Python][1]. +1. Instala la [integración de Python](https://app.datadoghq.com/account/settings#integrations/python). + +1. Habilita la compatibilidad con Datadog en tu instancia de N2WS: -2. Habilita la compatibilidad con Datadog en tu instancia de N2WS: - - Conéctate a tu instancia de N2WS Backup and Recovery con SSH. - - Añade las líneas siguientes a `/cpmdata/conf/cpmserver.cfg`. Es posible que necesites privilegios `sudo` para realizar esta acción. - ``` - [external_monitoring] - enabled=True - ``` - - Ejecuta `service apache2 restart` + - Conéctate a tu instancia de N2WS Backup and Recovery con SSH. + - Añade las líneas siguientes a `/cpmdata/conf/cpmserver.cfg`. Es posible que necesites privilegios `sudo` para realizar esta acción. + ``` + [external_monitoring] + enabled=True + ``` + - Ejecuta `service apache2 restart` -3. Instala el Datadog Agent en tu instancia de N2WS. - - Inicia sesión en Datadog y ve a Integrations -> Agent -> Ubuntu (Integraciones -> Agent -> Ubuntu) - - Copia el comando de instalación en un solo paso del Agent. - - Conéctate a tu instancia de N2WS Backup and Recovery con SSH y ejecuta el comando. Es posible que necesites privilegios `sudo` para realizar esta acción. +1. Instala el Datadog Agent en tu instancia de N2WS. -4. Configura las métricas de dashboard de Datadog: - - Ve a [**Metrics** -> **Explorer**][2] (Métricas -> Explorador) + - Inicia sesión en Datadog y ve a Integrations -> Agent -> Ubuntu (Integraciones -> Agent -> Ubuntu) + - Copia el comando de instalación en un solo paso del Agent. + - Conéctate a tu instancia de N2WS Backup and Recovery con SSH y ejecuta el comando. Es posible que necesites privilegios `sudo` para realizar esta acción. - **Gráfico**: selecciona tu métrica en la lista. Todas las métricas de N2WS comienzan con la cadena `cpm_metric`. +1. Configura las métricas de dashboard de Datadog: - **Sobre**: selecciona los datos de la lista. Todos los datos de los usuarios de N2WS comienzan con la cadena `cpm:user:`.
- Puedes seleccionar un usuario específico o toda la instancia de N2WS.
+ - Ve a [**Metrics** -> **Explorer** (Métricas -> Explorer)](https://app.datadoghq.com/metric/explorer)
+ **Gráfico**: selecciona tu métrica en la lista. Todas las métricas de N2WS comienzan con la cadena `cpm_metric`.
-5. Obtén dashboards de N2WS
- - En [Integraciones de Datadog][3], busca el cuadro `N2WS` e instálalo.
- - Cinco dashboards están instalados en tu cuenta:
- `N2WSBackup&Recovery-Graphicalversion`, `N2WSBackup&Recovery-Graphicalversion-areas` y `N2WSBackup&Recovery-EntitiesSpecificDashboard` para N2WS Backup & Recovery v3.2.1
- **Nota**: Estos dashboards solo están disponibles para los usuarios de AWS.
- `N2WSBackup&Recovery-EntitiesSpecificDashboardV4.1` y `N2WSBackup&Recovery-GraphicalVersionV4.1` para N2WS Backup & Recovery v4.1
+ **Sobre**: selecciona los datos de la lista. Todos los datos de los usuarios de N2WS comienzan con la cadena `cpm:user:`.
+ Puedes seleccionar un usuario específico o toda la instancia de N2WS.
- Alternativamente, puedes [importar plantillas JSON desde N2WS][4] para crear tus dashboards.
+1. Obtén dashboards de N2WS
+
+ - En [Integraciones de Datadog](https://app.datadoghq.com/account/settings#integrations/n2ws), busca el ícono `N2WS` e instálalo.
+ - Cinco dashboards están instalados en tu cuenta:
+ `N2WSBackup&Recovery-Graphicalversion`, `N2WSBackup&Recovery-Graphicalversion-areas` y `N2WSBackup&Recovery-EntitiesSpecificDashboard` para N2WS Backup & Recovery v3.2.1
+ **Nota**: Estos dashboards solo están disponibles para los usuarios de AWS.
+ `N2WSBackup&Recovery-EntitiesSpecificDashboardV4.1` y `N2WSBackup&Recovery-GraphicalVersionV4.1` para N2WS Backup & Recovery v4.1
+
+ Alternativamente, puedes [importar plantillas JSON desde N2WS](https://support.n2ws.com/portal/en/kb/articles/datadog-templates) para crear tus dashboards.
## Datos recopilados
@@ -125,8 +71,44 @@ Datadog recopila los siguientes datos sobre las copias de seguridad de N2WS Back
- Datos sobre la capacidad del volumen (solo AWS), alertas, etc.
### Métricas
-{{< get-metrics-from-git "n2ws" >}}
+| | |
+| --- | --- |
+| **cpm_metric.dashboard_activity.backup_success_num**
(gauge) | Número total de copias de seguridad realizadas con éxito (de todos los tipos)| +| **cpm_metric.dashboard_activity.backup_fail_num**
(gauge) | Número total de copias de seguridad fallidas (de todos los tipos)| +| **cpm_metric.dashboard_activity.backup_partial_num**
(gauge) | Número total de copias de seguridad parcialmente correctas (de todos los tipos)| +| **cpm_metric.dashboard_activity.backup_dr_success_num**
(gauge) | Número total de copias de seguridad DR realizadas con éxito (de todos los tipos)| +| **cpm_metric.dashboard_activity.backup_dr_fail_num**
(gauge) | Número total de copias de seguridad DR fallidas (de todos los tipos)| +| **cpm_metric.dashboard_activity.backup_dr_partial_num**
(gauge) | Número total de copias de seguridad de RD parcialmente correctas (de todos los tipos)| +| **cpm_metric.dashboard_activity.backup_s3_success_num**
(gauge) | Número total de copias de seguridad realizadas con éxito en S3| +| **cpm_metric.dashboard_activity.backup_s3_fail_num**
(gauge) | Número total de copias de seguridad fallidas en S3| +| **cpm_metric.dashboard_activity.backup_s3_partial_num**
(gauge) | Número total de copias de seguridad parcialmente correctas en S3| +| **cpm_metric.dashboard_state.policies_num**
(gauge) | Número total de políticas en todos los hosts| +| **cpm_metric.dashboard_state.accounts_num**
(gauge) | Número total de cuentas en todos los hosts| +| **cpm_metric.dashboard_state.snapshots_volume_num**
(gauge) | Número total de instantáneas de volúmenes| +| **cpm_metric.dashboard_state.snapshots_only_ami_num**
(gauge) | Número total de instantáneas de instancia solo AMI| +| **cpm_metric.dashboard_state.snapshots_dr_volume_num**
(gauge) | Número total de instantáneas DR de volúmenes| +| **cpm_metric.dashboard_state.snapshots_rds_num**
(gauge) | Número total de instantáneas de bases de datos RDS| +| **cpm_metric.dashboard_state.snapshots_dr_rds_num**
(gauge) | Número total de instantáneas DR de bases de datos RDS| +| **cpm_metric.dashboard_state.snapshots_redshift_num**
(gauge) | Número total de instantáneas de bases de datos de Redshift| +| **cpm_metric.dashboard_state.snapshots_rds_clus_num**
(gauge) | Número total de instantáneas de los clústeres de Aurora| +| **cpm_metric.dashboard_state.snapshots_dr_rds_clus_num**
(gauge) | Número total de instantáneas DR de los clústeres de Aurora| +| **cpm_metric.dashboard_state.snapshots_ddb_num**
(gauge) | Número total de instantáneas de DynamoDB| +| **cpm_metric.dashboard_state.snapshots_efs_num**
(gauge) | Número total de instantáneas DR de sistemas de archivos EFS| +| **cpm_metric.dashboard_state.snapshots_dr_efs_num**
(gauge) | Número total de instantáneas de Azure Disks| +| **cpm_metric.dashboard_state.snapshots_disk_num**
(gauge) | Número total de instantáneas de sistemas de archivos EFS| +| **cpm_metric.dashboard_state.protected_instances_num**
(gauge) | Número total de recursos de instancias protegidas| +| **cpm_metric.dashboard_state.protected_volumes_num**
(gauge) | Número total de recursos de volúmenes protegidos| +| **cpm_metric.dashboard_state.protected_rds_db_num**
(gauge) | Número total de recursos RDS protegidos| +| **cpm_metric.dashboard_state.protected_ddb_num**
(gauge) | Número total de recursos de DynamoDB protegidos| +| **cpm_metric.dashboard_state.protected_efs_num**
(gauge) | Número total de recursos EFS protegidos| +| **cpm_metric.dashboard_state.protected_rds_clus_num**
(gauge) | Número total de recursos de Aurora protegidos| +| **cpm_metric.dashboard_state.protected_redshift_num**
(gauge) | Número total de recursos de máquinas virtuales de Azure protegidas| +| **cpm_metric.dashboard_state.protected_virtual_machines_num**
(gauge) | Número total de recursos de Redshift protegidos| +| **cpm_metric.dashboard_state.protected_disks_num**
(gauge) | Número total de recursos de Redshift protegidos| +| **cpm_metric.dashboard_state.volumes_above_high_watermark_num**
(gauge) | Número de volúmenes con capacidad superior a la marca de agua| +| **cpm_metric.dashboard_state.volumes_below_low_watermark_num**
(gauge) | Número de volúmenes con capacidad inferior a la marca de agua| +| **cpm_metric.dashboard_state.volumes_usage_percentage_num**
(gauge) | Uso total de la capacidad para todos los volúmenes de todos los hosts
_Mostrado como porcentaje_ | ### Eventos @@ -138,16 +120,6 @@ La integración de N2WS Backup & Recovery no incluye ningún check de servicio. ## Solucionar problemas -- [Guía del usuario y documentación de N2WS][6] -- [Soporte de N2WS][7] -- [Soporte de Datadog][8] - - -[1]: https://app.datadoghq.com/account/settings#integrations/python -[2]: https://app.datadoghq.com/metric/explorer -[3]: https://app.datadoghq.com/account/settings#integrations/n2ws -[4]: https://support.n2ws.com/portal/en/kb/articles/datadog-templates -[5]: https://github.com/DataDog/integrations-extras/blob/master/n2ws/metadata.csv -[6]: https://n2ws.com/support/documentation -[7]: https://n2ws.com/support -[8]: https://docs.datadoghq.com/es/help/ \ No newline at end of file +- [Guía del usuario y documentación de N2WS](https://n2ws.com/support/documentation) +- [Asistencia técnica de N2WS](https://n2ws.com/support) +- [Asistencia técnica de Datadog](https://docs.datadoghq.com/help/) \ No newline at end of file diff --git a/content/es/integrations/neo4j.md b/content/es/integrations/neo4j.md index 87f3d11bffa48..55f1eef6834ea 100644 --- a/content/es/integrations/neo4j.md +++ b/content/es/integrations/neo4j.md @@ -1,94 +1,42 @@ --- app_id: neo4j -app_uuid: f2657bb8-ded4-48f3-8095-f703cc203149 -assets: - dashboards: - Neo4j V4 Dashboard: assets/dashboards/Neo4j4.xDefaultDashboard.json - Neo4j V5 Cluster Dashboard: assets/dashboards/Neo4j5ClusterDashboard.json - Neo4j V5 Dashboard: assets/dashboards/Neo4j5DefaultDashboard.json - integration: - auto_install: true - configuration: - spec: assets/configuration/spec.yaml - events: - creates_events: false - metrics: - check: neo4j.dbms.page_cache.hits - metadata_path: metadata.csv - prefix: neo4j. - service_checks: - metadata_path: assets/service_checks.json - source_type_id: 10202 - source_type_name: Neo4j -author: - homepage: https://github.com/DataDog/integrations-extras - name: Neo4j - sales_email: support@neotechnology.com - support_email: support@neotechnology.com categories: - almacenes de datos -custom_kind: integration -dependencies: -- https://github.com/DataDog/integrations-extras/blob/master/neo4j/README.md -display_on_public_website: true -draft: false -git_integration_title: neo4j -integration_id: neo4j -integration_title: Neo4j -integration_version: 3.0.3 -is_public: true -manifest_version: 2.0.0 -name: neo4j -public_title: Neo4j -short_description: Recopila métricas de Neo4j +custom_kind: integración +description: Recopila métricas de Neo4j +integration_version: 3.0.4 +media: +- caption: Dashboard de Neo4j 5 + image_url: images/Neo4j_5_Dashboard.png + media_type: imagen +- caption: Base de datos de Neo4j 5 + image_url: images/neo4j_graph.png + media_type: imagen supported_os: - linux - macos - windows -tile: - changelog: CHANGELOG.md - classifier_tags: - - Supported OS::Linux - - Supported OS::macOS - - Supported OS::Windows - - Category::Data Stores - - Offering::Integration - configuration: README.md#Setup - description: Recopila métricas de Neo4j - media: - - caption: Dashboard de Neo4j 5 - image_url: images/Neo4j_5_Dashboard.png - media_type: imagen - - caption: Base de datos de Neo4j 5 - image_url: images/neo4j_graph.png - media_type: imagen - overview: README.md#Overview - support: README.md#Support - title: Neo4j +title: Neo4j --- - - - - ## Información general -[Neo4j][1] es una base de datos gráfica empresarial que combina almacenamiento gráfico nativo, seguridad avanzada, arquitectura escalable de velocidad optimizada y conformidad con ACID para asegurar la previsibilidad y la integridad de las consultas basadas en relaciones. Neo4j almacena y gestiona los datos en su estado más natural y conectado, mediante relaciones de datos que ofrecen consultas ultrarrápidas, un contexto más detallado para el análisis y un modelo de datos modificable sin complicaciones. +[Neo4j](https://neo4j.com/) es una base de datos gráfica empresarial que combina almacenamiento gráfico nativo, seguridad avanzada, arquitectura escalable de velocidad optimizada y conformidad con ACID para garantizar la previsibilidad y la integridad de las consultas basadas en relaciones. Neo4j almacena y gestiona los datos en su estado más natural y conectado y mantiene relaciones de datos que ofrecen consultas ultrarrápidas, un contexto más profundo para el análisis y un modelo de datos modificable sin complicaciones. -Las métricas de Neo4j permite a los administradores de bases de datos monitorizar sus despliegues de Neo4j. Los administradores de bases de datos desean conocer el uso de la memoria (caché de heap y páginas), el número de transacciones, el estado del clúster, el tamaño de la base de datos (incluido el número de nodos, relaciones y propiedades) y el rendimiento de las consultas. - -Con esta integración, visualiza importantes métricas de Neo4j en nuestros dashboards predefinidos y permite a tus DBAs solucionar problemas y monitorizar el estado de tus bases de datos Neo4j. +Las métricas de Neo4j permiten a los administradores de bases de datos monitorizar sus despliegues de Neo4j. Los administradores de bases de datos desean conocer el uso de la memoria (caché de montón y de page (página)), el número de transacciones, el estado del clúster, el tamaño de la base de datos (incluidos el número de nodos, relaciones y propiedades) y el rendimiento de las consultas. +Con esta integración, visualiza importantes métricas de Neo4j en nuestros dashboards predefinidos y permite a tus bases de datos solucionar problemas y monitorizar el estado de tus bases de datos Neo4j. ## Configuración -Sigue las instrucciones a continuación para instalar y configurar este check para un Agent que se ejecuta en un host. Para entornos en contenedores, consulta las [plantillas de integración de Autodiscovery][2] para obtener orientación sobre la aplicación de estas instrucciones. +Sigue las siguientes instrucciones para instalar y configurar este check para un Agent que se ejecute en un host. Para entornos en contenedores, consulta las [Plantillas de integración de Autodiscovery](https://docs.datadoghq.com/agent/autodiscovery/integrations) para obtener orientación sobre la aplicación de estas instrucciones. ### Instalación Para instalar el check de neo4j en tu host: -1. Descarga e instala el [Datadog Agent][3]. -2. Para instalar el check de neo4j en tu host: +1. Descarga e instala el [Datadog Agent](https://app.datadoghq.com/account/settings/agent/latest). + +1. Para instalar el check de neo4j en tu host: ```shell datadog-agent integration install -t datadog-neo4j==
@@ -96,21 +44,495 @@ Para instalar el check de neo4j en tu host:
### Configuración
-1. Edita el archivo `neo4j.d/conf.yaml`, en la carpeta `conf.d/` en la raíz del directorio de configuración del Agent para comenzar a recopilar tus datos de rendimiento de neo4j. Consulta el [neo4j.d/conf.yaml de ejemplo][4] para todas las opciones disponibles de configuración.
+1. Edita el archivo `neo4j.d/conf.yaml`, en la carpeta `conf.d/` en la raíz de tu directorio de configuración del Agent para comenzar a recopilar tus datos de rendimiento de neo4j. Consulta el [ejemplo neo4j.d/conf.yaml](https://github.com/DataDog/integrations-extras/blob/master/neo4j/datadog_checks/neo4j/data/conf.yaml.example) para conocer todas las opciones de configuración disponibles.
-2. Datadog escucha en el puerto 5000 para dogstatsd_stats_port y expvar_port. En tu archivo neo4j.conf, tendrás que cambiar server.discovery.listen_address y el server.discovery.advertised_address para utilizar un puerto distinto de 5000.
+1. Datadog escucha en el puerto 5000 para dogstatsd_stats_port y expvar_port. En tu archivo neo4j.conf, tendrás que cambiar server.discovery.listen_address y el server.discovery.advertised_address para utilizar un puerto distinto de 5000.
-3. [Reinicia el Agent][5].
+1. [Reinicia el Agent](https://docs.datadoghq.com/agent/guide/agent-commands/#start-stop-and-restart-the-agent).
### Validación
-[Ejecuta el subcomando de estado del Agent][6] y busca `neo4j` en la sección Checks.
+[Ejecuta el subcomando de estado del Agent(https://docs.datadoghq.com/agent/guide/agent-commands/#agent-status-and-information) y busca `neo4j` en la sección Checks.
## Datos recopilados
### Métricas
-{{< get-metrics-from-git "neo4j" >}}
+| | |
+| --- | --- |
+| **neo4j.causal_clustering.catchup_tx_pull_requests_received**
(gauge) | Número total de solicitudes de extracción de transacciones recibidas. (Neo4j 4)| +| **neo4j.causal_clustering.core.append_index**
(gauge) | Índice de anexión del log de RAFT. (Neo4j 4)| +| **neo4j.causal_clustering.core.commit_index**
(gauge) | Índice de confirmación del log de RAFT. (Neo4j 4)| +| **neo4j.causal_clustering.core.discovery.cluster.converged**
(gauge) | Convergencia del clúster de descubrimiento. (Neo4j 4)| +| **neo4j.causal_clustering.core.discovery.cluster.members**
(gauge) | Tamaño de los miembros del clúster de descubrimiento. (Neo4j 4)| +| **neo4j.causal_clustering.core.discovery.cluster.unreachable**
(gauge) | Tamaño inalcanzable del clúster de descubrimiento. (Neo4j 4)| +| **neo4j.causal_clustering.core.discovery.replicated_data.cluster_id.per_db_name.invisible**
(gauge) | Identificador oculto del clúster. (Neo4j 4)| +| **neo4j.causal_clustering.core.discovery.replicated_data.cluster_id.per_db_name.visible**
(gauge) | Identificador compartido del clúster. (Neo4j 4)| +| **neo4j.causal_clustering.core.discovery.replicated_data.member_data.invisible**
(gauge) | Estructura de datos invisible que contiene metadatos sobre los miembros del clúster. (Neo4j 4)| +| **neo4j.causal_clustering.core.discovery.replicated_data.member_data.visible**
(gauge) | Estructura de datos visible que contiene metadatos sobre los miembros del clúster. (Neo4j 4)| +| **neo4j.causal_clustering.core.discovery.replicated_data.member_db_state.invisible**
(gauge) | La parte oculta de la estructura de datos utilizada con fines internos. (Neo4j 4)| +| **neo4j.causal_clustering.core.discovery.replicated_data.member_db_state.visible**
(gauge) | La parte visible de la estructura de datos utilizada con fines internos. (Neo4j 4)| +| **neo4j.causal_clustering.core.discovery.replicated_data.per_db.leader_name.invisible**
(gauge) | El número total de cambios de liderazgo. (Neo4j 4)| +| **neo4j.causal_clustering.core.discovery.replicated_data.per_db.leader_name.visible**
(gauge) | Número de líderes del clúster. (Neo4j 4)| +| **neo4j.causal_clustering.core.discovery.replicated_data.raft_id.published_by_member.invisible**
(gauge) | Identificador de Raft visible publicado por el miembro. (Neo4j 4)| +| **neo4j.causal_clustering.core.discovery.replicated_data.raft_id.published_by_member.visible**
(gauge) | Identificador de Raft oculto publicado por el miembro. (Neo4j 4)| +| **neo4j.causal_clustering.core.in_flight_cache_element_count**
(gauge) | Recuento de elementos de la caché en vuelo. (Neo4j 4)| +| **neo4j.causal_clustering.core.in_flight_cache.hits**
(gauge) | Aciertos de la caché en vuelo. (Neo4j 4)| +| **neo4j.causal_clustering.core.in_flight_cache.max_bytes**
(gauge) | Bytes máximos de caché en vuelo. (Neo4j 4)| +| **neo4j.causal_clustering.core.in_flight_cache.max_elements**
(gauge) | Elementos máximos de caché en vuelo. (Neo4j 4)| +| **neo4j.causal_clustering.core.in_flight_cache.misses**
(gauge) | Fallos de caché en vuelo. (Neo4j 4)| +| **neo4j.causal_clustering.core.in_flight_cache.total_bytes**
(gauge) | Total de bytes de la caché en vuelo. (Neo4j 4)| +| **neo4j.causal_clustering.core.is_leader**
(gauge) | ¿Es este servidor el líder? (Neo4j 4)| +| **neo4j.causal_clustering.core.message_processing_delay**
(gauge) | Retraso entre la recepción y el procesamiento de mensajes de RAFT. (Neo4j 4)| +| **neo4j.causal_clustering.core.message_processing_timer**
(gauge) | Temporizador para el procesamiento de mensajes de RAFT. (Neo4j 4)| +| **neo4j.causal_clustering.core.message_processing_timer.append_entries_request**
(gauge) | Solicitudes invocadas por el líder de RAFT para replicar entradas de logs. (Neo4j 4)| +| **neo4j.causal_clustering.core.message_processing_timer.append_entries_response**
(gauge) | Respuestas de los seguidores a las solicitudes del líder de RAFT para replicar las entradas de logs. (Neo4j 4)| +| **neo4j.causal_clustering.core.message_processing_timer.election_timeout**
(gauge) | Eventos de tiempo de espera para el procesamiento de mensajes de RAFT. (Neo4j 4)| +| **neo4j.causal_clustering.core.message_processing_timer.heartbeat**
(gauge) | Solicitudes de Heartbeat recibidas por los seguidores en el clúster de RAFT. (Neo4j 4)| +| **neo4j.causal_clustering.core.message_processing_timer.heartbeat_response**
(gauge) | Respuestas de Heartbeat recibidas por el líder en el clúster de RAFT. (Neo4j 4)| +| **neo4j.causal_clustering.core.message_processing_timer.heartbeat_timeout**
(gauge) | Eventos de tiempo de espera para solicitudes de latido. (Neo4j 4)| +| **neo4j.causal_clustering.core.message_processing_timer.log_compaction_info**
(gauge) | Compactación de logs (Neo4j 4)| +| **neo4j.causal_clustering.core.message_processing_timer.new_batch_request**
(gauge) | Nuevas solicitudes por lotes (Neo4j 4)| +| **neo4j.causal_clustering.core.message_processing_timer.new_entry_request**
(gauge) | Nuevas solicitudes de entrada (Neo4j 4)| +| **neo4j.causal_clustering.core.message_processing_timer.pre_vote_request**
(gauge) | Solicitudes previas a la votación (Neo4j 4)| +| **neo4j.causal_clustering.core.message_processing_timer.pre_vote_response**
(gauge) | Respuestas previas a la votación (Neo4j 4)| +| **neo4j.causal_clustering.core.message_processing_timer.prune_request**
(gauge) | Solicitudes de poda (Neo4j 4)| +| **neo4j.causal_clustering.core.message_processing_timer.vote_request**
(gauge) | Solicitudes de votación (Neo4j 4)| +| **neo4j.causal_clustering.core.message_processing_timer.vote_response**
(gauge) | Respuestas a las votaciones (Neo4j 4)| +| **neo4j.causal_clustering.core.replication_attempt**
(gauge) | Count de intentos de réplica de la Raft. (Neo4j 4)| +| **neo4j.causal_clustering.core.replication_fail**
(gauge) | Count de fallos en la réplica de Raft. (Neo4j 4)| +| **neo4j.causal_clustering.core.replication_new**
(gauge) | Nuevo count de solicitudes de réplica de Raft. (Neo4j 4)| +| **neo4j.causal_clustering.core.replication_success**
(gauge) | Count de éxitos de réplica de Raft. (Neo4j 4)| +| **neo4j.causal_clustering.core.term**
(gauge) | Término de RAFT de este servidor (Neo4j 4)| +| **neo4j.causal_clustering.core.tx_retries**
(gauge) | Reintentos de transacción. (Neo4j 4)| +| **neo4j.causal_clustering.read_replica.pull_update_highest_tx_id_received**
(gauge) | El identificador de transacción más alto que se ha extraído en la última actualización de extracción por esta instancia. (Neo4j 4)| +| **neo4j.causal_clustering.read_replica.pull_update_highest_tx_id_requested**
(gauge) | El identificador de transacción más alto solicitado en una actualización de incorporación de cambios por esta instancia. (Neo4j 4)| +| **neo4j.causal_clustering.read_replica.pull_updates**
(gauge) | El número total de solicitudes de incorporación de cambios realizadas por esta instancia. (Neo4j 4)| +| **neo4j.database.dbname.check_point.duration**
(gauge) | La duración, en milisegundos, del último evento de punto de control. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.check_point.events**
(count) | El número total de eventos de punto de control ejecutados hasta el momento. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.check_point.io_limit**
(gauge) | El límite de entrada/salida utilizado durante el último evento de punto de control. (Neo4j 5)| +| **neo4j.database.dbname.check_point.io_performed**
(gauge) | El número de entradas/salidas desde la perspectiva de Neo4j realizadas durante el último evento de punto de control. (Neo4j 5)| +| **neo4j.database.dbname.check_point.limit_millis**
(gauge) | (Neo4j 5)| +| **neo4j.database.dbname.check_point.limit_times**
(gauge) | (Neo4j 5)| +| **neo4j.database.dbname.check_point.pages_flushed**
(gauge) | El número de páginas que se vaciaron durante el último evento de punto de control. (Neo4j 5)| +| **neo4j.database.dbname.check_point.total_time**
(count) | El tiempo total, en milisegundos, empleado en el punto de control hasta ahora. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.cluster.catchup.tx_pull_requests_received**
(count) | Solicitudes de incorporación de cambios de TX recibidas de secundarios. (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.append_index**
(count) | El índice de anexión del log de Raft (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.applied_index**
(count) | El índice aplicado del log de Raft (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.commit_index**
(count) | El índice de confirmación del log de Raft (Neo4j 4)| +| **neo4j.database.dbname.cluster.core.in_flight_cache.element_count**
(gauge) | Count de elementos en caché en vuelo. (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.in_flight_cache.hits**
(count) | Aciertos de caché en vuelo. (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.in_flight_cache.max_bytes**
(gauge) | Bytes máximos de caché en vuelo. (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.in_flight_cache.max_elements**
(gauge) | Elementos máximos de la caché en vuelo. (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.in_flight_cache.misses**
(count) | Fallos de caché en vuelo. (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.in_flight_cache.total_bytes**
(count) | Total de bytes de la caché en vuelo. (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.is_leader**
(count) | ¿Es este servidor el líder? (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.last_leader_message**
(count) | El tiempo transcurrido desde el último mensaje de un líder en milisegundos.| +| **neo4j.database.dbname.cluster.core.message_processing_delay**
(count) | Retraso entre la recepción y el procesamiento del mensaje de Raft.| +| **neo4j.database.dbname.cluster.core.message_processing_timer**
(count) | Temporizador para el procesamiento de mensajes de Raft. (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.message_processing_timer.append_entries_request**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.message_processing_timer.append_entries_response**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.message_processing_timer.election_timeout**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.message_processing_timer.heartbeat**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.message_processing_timer.heartbeat_response**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.message_processing_timer.heartbeat_timeout**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.message_processing_timer.leadership_transfer_proposal**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.message_processing_timer.leadership_transfer_rejection**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.message_processing_timer.leadership_transfer_request**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.message_processing_timer.log_compaction_info**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.message_processing_timer.new_batch_request**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.message_processing_timer.new_entry_request**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.message_processing_timer.pre_vote_request**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.message_processing_timer.pre_vote_response**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.message_processing_timer.prune_request**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.message_processing_timer.status_response**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.message_processing_timer.vote_request**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.message_processing_timer.vote_response**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.raft_log_entry_prefetch_buffer.async_put**
(count) | Puts asíncronas de búfer de acceso previo de entrada de logs de Raft (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.raft_log_entry_prefetch_buffer.bytes**
(count) | Bytes totales de acceso previo de entrada de logs de Raft. (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.raft_log_entry_prefetch_buffer.lag**
(count) | Retraso de acceso previo de entrada de logs de Raft. (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.raft_log_entry_prefetch_buffer.size**
(count) | Tamaño del búfer de acceso previo de entrada de logs de Raft (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.raft_log_entry_prefetch_buffer.sync_put**
(count) | Puts asíncronas de búfer de acceso previo de entrada de logs de Raft (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.replication_attempt**
(count) | El número total de intentos de solicitudes de réplicas de Raft. Es mayor o igual que las solicitudes de réplicas.| +| **neo4j.database.dbname.cluster.core.replication_fail**
(count) | El número total de intentos de réplica de Raft que han fallado. (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.replication_maybe**
(count) | La réplica de Raft tal vez cuente. (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.replication_new**
(count) | La réplica de Raft tal vez cuente. (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.replication_success**
(count) | El número total de solicitudes de réplicas de Raft que han tenido éxito. (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.term**
(count) | El término de Raft de este servidor. Aumenta en forma monótona si no se desvincula el estado del clúster. (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.tx_retries**
(count) | Reintentos de transacción. (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.append_index**
(count) | El índice de anexión del log de Raft. Cada índice representa una transacción de escritura (posiblemente interna) propuesta para confirmación. Los valores aumentan en su mayoría, pero a veces pueden disminuir como consecuencia de cambios de líder. El índice de anexión siempre debe ser menor o igual al índice de confirmación. (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.applied_index**
(count) | El índice aplicado del log de Raft. Representa la aplicación de las entradas de logs de Raft confirmadas a la base de datos y al estado interno. El índice aplicado siempre debe ser mayor o igual que el índice de confirmación. La diferencia entre este y el índice de confirmación se puede utilizar para monitorizar para saber cuán actualizada está la base de datos de seguimiento. (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.commit_index**
(count) | El índice de confirmación de logs de Raft. Representa el compromiso de las entradas añadidas previamente. Su valor aumenta en forma monótona si no se desvincula el estado del clúster. El índice de confirmación siempre debe ser mayor o igual que el índice de anexión. (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.in_flight_cache.element_count**
(count) | Count de elementos en caché en vuelo. (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.in_flight_cache.hits**
(count) | Aciertos de la caché en vuelo. (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.in_flight_cache.max_bytes**
(count) | Bytes máximos de caché en vuelo. (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.in_flight_cache.max_elements**
(count) | Elementos máximos de la caché en vuelo. (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.in_flight_cache.misses**
(count) | Fallos de caché en vuelo. (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.in_flight_cache.total_bytes**
(count) | Total de bytes de la caché en vuelo. (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.is_leader**
(count) | ¿Es este servidor el líder? (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.last_leader_message**
(count) | El tiempo transcurrido desde el último mensaje de un líder en milisegundos. Debe reiniciarse periódicamente. (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_delay**
(count) | Retraso entre la recepción y el procesamiento del mensaje de Raft. (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer**
(count) | Temporizador para el procesamiento de mensajes de Raft. (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer.append_entries_request**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer.append_entries_response**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer.election_timeout**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer.heartbeat**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer.heartbeat_response**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer.heartbeat_timeout**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer.leadership_transfer_proposal**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer.leadership_transfer_rejection**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer.leadership_transfer_request**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer.log_compaction_info**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer.new_batch_request**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer.new_entry_request**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer.pre_vote_request**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer.pre_vote_response**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer.prune_request**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer.status_response**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer.vote_request**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer.vote_response**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.raft_log_entry_prefetch_buffer.async_put**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.raft_log_entry_prefetch_buffer.bytes**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.raft_log_entry_prefetch_buffer.lag**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.raft_log_entry_prefetch_buffer.size**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.raft_log_entry_prefetch_buffer.sync_put**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.replication_attempt**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.replication_fail**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.replication_maybe**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.replication_new**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.replication_success**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.term**
(count) | El término de Raft de este servidor. Aumenta en forma monótona si no se desvincula el estado del clúster. (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.tx_retries**
(count) | Reintentos de transacción. (Neo4j 5)| +| **neo4j.database.dbname.count.node**
(gauge) | El número total de nodos en las bases de datos. (Neo4j 4)| +| **neo4j.database.dbname.cypher.cache.ast.entries**
(gauge) | Número de entradas de AST en la caché de cifrado (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.executable_query.cache_flushes**
(gauge) | Número de descargas de la caché de consultas ejecutables de la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.executable_query.compiled**
(gauge) | El número de entradas compiladas de consultas ejecutables de la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.executable_query.discards**
(gauge) | El número de descartes de consultas ejecutables de la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.executable_query.entries**
(gauge) | Número de entradas de consultas ejecutables en la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.executable_query.hits**
(gauge) | Número de aciertos de consultas ejecutables en la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.executable_query.misses**
(gauge) | El número de consultas ejecutables fallidas de la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.executable_query.stale_entries**
(gauge) | Número de entradas de consultas obsoletas ejecutables en la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.execution_plan.cache_flushes**
(gauge) | El número de vaciados de caché del plan de ejecución de la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.execution_plan.compiled**
(gauge) | El número de entradas compiladas del plan de ejecución de la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.execution_plan.discards**
(gauge) | El número de descartes del plan de ejecución de la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.execution_plan.entries**
(gauge) | El número de entradas del plan de ejecución de la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.execution_plan.hits**
(gauge) | Número de aciertos en el plan de ejecución de la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.execution_plan.misses**
(gauge) | El número de fallos en el plan de ejecución de la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.execution_plan.stale_entries**
(gauge) | Número de entradas de consultas obsoletas ejecutables en la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.logical_plan.cache_flushes**
(gauge) | El número de vaciados de la caché de planes lógicos de la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.logical_plan.compiled**
(gauge) | El número de entradas compiladas del plan lógico de la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.logical_plan.discards**
(gauge) | El número de descartes del plan lógico de la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.logical_plan.entries**
(gauge) | El número de entradas del plan lógico de la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.logical_plan.hits**
(gauge) | Número de aciertos del plan lógico de la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.logical_plan.misses**
(gauge) | Número de faltas del plan lógico de la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.logical_plan.stale_entries**
(gauge) | Número de entradas de consultas obsoletas ejecutables en la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.pre_parser.entries**
(gauge) | El número de entradas del analizador previo de la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.replan_events**
(count) | El número total de veces que Cypher ha decidido volver a planificar una consulta. Neo4j almacena 1000 planes en forma predeterminada. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.cypher.replan_wait_time**
(count) | El número total de segundos esperados entre nuevas planificaciones de consultas. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.db.query.execution.failure**
(count) | Count de consultas fallidas ejecutadas. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.db.query.execution.latency.millis**
(gauge) | Tiempo de ejecución en milisegundos de las consultas ejecutadas con éxito. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.db.query.execution.success**
(count) | Count de consultas ejecutadas con éxito. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.ids_in_use.node**
(gauge) | El número total de nodos almacenados en la base de datos. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.ids_in_use.property**
(gauge) | El número total de nombres de propiedades diferentes utilizados en la base de datos. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.ids_in_use.relationship**
(gauge) | El número total de relaciones almacenadas en la base de datos. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.ids_in_use.relationship_type**
(gauge) | El número total de diferentes tipos de relaciones almacenadas en la base de datos. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.log.append_batch_size**
(gauge) | El tamaño del último lote de anexiones de transacciones. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.log.appended_bytes**
(count) | El número total de bytes añadidos al log de transacción. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.log.flushes**
(count) | El número total de vaciados de logs de transacciones. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.log.rotation_duration**
(count) | La duración, en milisegundos, del último evento de rotación de logs. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.log.rotation_events**
(count) | El número total de rotaciones de logs de transacciones ejecutadas hasta el momento. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.log.rotation_total_time**
(count) | El tiempo total, en milisegundos, empleado en rotar logs de transacciones hasta el momento. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.neo4j.count.node**
(count) | El número total de nodos en la base de datos. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.neo4j.count.relationship**
(gauge) | El número total de relaciones en la base de datos. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.neo4j.count.relationship_types**
(gauge) | Número total de identificadores generados internamente para los diferentes tipos de relaciones almacenados en la base de datos. (Neo4j 5)| +| **neo4j.database.dbname.pool.other.neo4j.free**
(count) | Cantidad estimada de memoria libre en bytes para este grupo. (Neo4j 4)| +| **neo4j.database.dbname.pool.other.neo4j.total_size**
(count) | Cantidad estimada de memoria disponible en bytes para este grupo. (Neo4j 4)| +| **neo4j.database.dbname.pool.other.neo4j.total_used**
(count) | Cantidad estimada de memoria total utilizada en bytes para este grupo. (Neo4j 4)| +| **neo4j.database.dbname.pool.other.neo4j.used_heap**
(count) | Cantidad estimada de montón utilizado en bytes para este grupo. (Neo4j 4)| +| **neo4j.database.dbname.pool.other.neo4j.used_native**
(count) | Cantidad estimada de memoria nativa utilizada para este grupo. (Neo4j 4)| +| **neo4j.database.dbname.pool.transaction.neo4j.free**
(count) | Cantidad estimada de memoria libre en bytes para este grupo.| +| **neo4j.database.dbname.pool.transaction.neo4j.total_size**
(count) | Cantidad estimada de memoria disponible en bytes para este grupo.| +| **neo4j.database.dbname.pool.transaction.neo4j.total_used**
(count) | Cantidad estimada de memoria total utilizada en bytes para este pool.| +| **neo4j.database.dbname.pool.transaction.neo4j.used_heap**
(count) | Cantidad estimada del montón utilizado en bytes para este grupo.| +| **neo4j.database.dbname.pool.transaction.neo4j.used_native**
(count) | Cantidad estimada de memoria nativa utilizada para este grupo.| +| **neo4j.database.dbname.store.size.database**
(gauge) | El tamaño de la base de datos, en bytes. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.store.size.total**
(gauge) | El tamaño total de la base de datos y de los logs de transacciones, en bytes. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.transaction.active**
(gauge) | El número de transacciones actualmente activas. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.transaction.active_read**
(gauge) | El número de transacciones de lectura actualmente activas. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.transaction.active_write**
(gauge) | El número de transacciones de escritura actualmente activas. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.transaction.committed**
(count) | El número total de transacciones confirmadas. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.transaction.committed_read**
(count) | El número total de transacciones de lectura confirmadas. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.transaction.committed_write**
(count) | El número total de transacciones de escritura confirmadas. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.transaction.last_closed_tx_id**
(gauge) | El identificador de la última transacción cerrada. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.transaction.last_committed_tx_id**
(gauge) | El identificador de la última transacción confirmada. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.transaction.peak_concurrent**
(count) | El pico más alto de transacciones concurrentes. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.transaction.rollbacks**
(count) | El número total de transacciones revertidas. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.transaction.rollbacks_read**
(count) | El número total de transacciones de lectura revertidas. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.transaction.rollbacks_write**
(count) | El número total de transacciones de escritura revertidas. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.transaction.started**
(count) | El número total de transacciones iniciadas.| +| **neo4j.database.dbname.transaction.terminated**
(count) | El número total de transacciones finalizadas.| +| **neo4j.database.dbname.transaction.terminated_read**
(count) | El número total de transacciones de lectura terminadas. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.transaction.terminated_write**
(count) | Número total de transacciones de escritura finalizadas.| +| **neo4j.database.dbname.transaction.tx_size_heap**
(count) | El tamaño de las transacciones en el montón en bytes.| +| **neo4j.database.dbname.transaction.tx_size_native**
(count) | El tamaño de las transacciones en la memoria nativa en bytes. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.bolt.accumulated_processing_time**
(count) | La cantidad total de tiempo en milisegundos que los subprocesos de worker han estado procesando mensajes. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.bolt.accumulated_queue_time**
(count) | Cuando internal.server.bolt.thread_pool_queue_size está activado, el tiempo total en milisegundos que un mensaje de Bolt espera en la cola de procesamiento antes de que un subproceso de worker de Bolt esté disponible para procesarlo. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.bolt.connections_closed**
(gauge) | El número total de conexiones de Bolt cerradas desde que se inició esta instancia. Esto incluye tanto las conexiones finalizadas correctamente como las anormalmente finalizadas. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.bolt.connections_idle**
(gauge) | El número total de conexiones de Bolt que no están ejecutando actualmente Cypher ni devolviendo resultados. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.bolt.connections_opened**
(count) | El número total de conexiones de Bolt abiertas desde el inicio. Esto incluye tanto las conexiones finalizadas con éxito como las fallidas. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.bolt.connections_running**
(gauge) | El número total de conexiones de Bolt que están ejecutando actualmente Cypher y devolviendo resultados. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.bolt.messages_done**
(count) | El número total de mensajes de Bolt que han terminado de procesarse, ya sea con éxito o sin éxito. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.bolt.messages_failed**
(count) | El número total de mensajes que han fallado durante el procesamiento. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.bolt.messages_received**
(count) | El número total de mensajes recibidos a través de Bolt desde el inicio. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.bolt.messages_started**
(count) | El número total de mensajes que han comenzado a procesarse desde que se recibieron. Un mensaje recibido puede haber comenzado a ser procesado hasta que un hilo de worker de Bolt esté disponible. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.bolt.response_failed**
(count) | El número total de respuestas de Bolt que han fallado durante el procesamiento. (Neo4j 5)| +| **neo4j.dbms.bolt.response_ignored**
(count) | Número total de respuestas de Bolt que se han ignorado durante el procesamiento. (Neo4j 5)| +| **neo4j.dbms.bolt.response_success**
(count) | Número total de respuestas de Bolt que se han procesado correctamente. (Neo4j 5)| +| **neo4j.dbms.bolt_driver.api.managed_transaction_function_calls**
(count) | Número total de llamadas a funciones de transacciones gestionadas. (Neo4j 5)| +| **neo4j.dbms.bolt_driver.api.unmanaged_transaction_calls**
(count) | El número total de llamadas a funciones de transacción no gestionadas. (Neo4j 5)| +| **neo4j.dbms.bolt_driver.api.implicit_transaction_calls**
(count) | Número total de llamadas implícitas a funciones de transacción. (Neo4j 5)| +| **neo4j.dbms.bolt_driver.api.execute_calls**
(count) | Número total de llamadas a funciones de ejecución a nivel de controlador. . (Neo4j 5)| +| **neo4j.dbms.cluster.catchup.tx_pull_requests_received**
(count) | Solicitudes de incorporación de cambios de TX recibidas de réplicas de lectura. (Neo4j 4)| +| **neo4j.dbms.cluster.core.append_index**
(gauge) | El índice de anexión del log de Raft (Neo4j 4)| +| **neo4j.dbms.cluster.core.applied_index**
(gauge) | El índice aplicado del log de Raft (Neo4j 4)| +| **neo4j.dbms.cluster.core.commit_index**
(gauge) | El índice de confirmación del log de Raft (Neo4j 4)| +| **neo4j.dbms.cluster.core.in_flight_cache_element_count**
(gauge) | Recuento de elementos de la caché en vuelo. (Neo4j 4)| +| **neo4j.dbms.cluster.core.in_flight_cache.hits**
(count) | Aciertos de la caché en vuelo. (Neo4j 4)| +| **neo4j.dbms.cluster.core.in_flight_cache.max_bytes**
(gauge) | Número máximo de bytes de caché en vuelo. (Neo4j 4)| +| **neo4j.dbms.cluster.core.in_flight_cache.max_elements**
(gauge) | Elementos máximos de caché en vuelo. (Neo4j 4)| +| **neo4j.dbms.cluster.core.in_flight_cache.misses**
(count) | Fallos de caché en vuelo. (Neo4j 4)| +| **neo4j.dbms.cluster.core.in_flight_cache.total_bytes**
(gauge) | Total de bytes de la caché en vuelo. (Neo4j 4)| +| **neo4j.dbms.cluster.core.is_leader**
(gauge) | ¿Es este servidor el líder? (Neo4j 4)| +| **neo4j.dbms.cluster.core.last_leader_message**
(gauge) | El tiempo transcurrido desde el último mensaje de un líder en milisegundos. (Neo4j 4)| +| **neo4j.dbms.cluster.core.message_processing_delay**
(gauge) | Retraso entre la recepción y el procesamiento de mensajes de RAFT. (Neo4j 4)| +| **neo4j.dbms.cluster.core.message_processsing_timer**
(count) | Temporizador para el procesamiento de mensajes de RAFT. (Neo4j 4)| +| **neo4j.dbms.cluster.core.raft_log_entry_prefetch_buffer.async_put**
(gauge) | Puts asíncronas de búfer de acceso previo de entrada de logs de Raft (Neo4j 4)| +| **neo4j.dbms.cluster.core.raft_log_entry_prefetch_buffer.bytes**
(gauge) | Bytes totales de acceso previo de entrada de logs de Raft. (Neo4j 4)| +| **neo4j.dbms.cluster.core.raft_log_entry_prefetch_buffer.lag**
(gauge) | Retraso de acceso previo de entrada de logs de Raft. (Neo4j 4)| +| **neo4j.dbms.cluster.core.raft_log_entry_prefetch_buffer.size**
(gauge) | Tamaño del búfer de acceso previo de entrada de logs de Raft. (Neo4j 4)| +| **neo4j.dbms.cluster.core.raft_log_entry_prefetch_buffer.sync_put**
(gauge) | Puts asíncronas de búfer de acceso previo de entrada de logs de Raft (Neo4j 4)| +| **neo4j.dbms.cluster.core.replication_attempt**
(count) | El número total de intentos de réplica de solicitudes de Raft. (Neo4j 4)| +| **neo4j.dbms.cluster.core.replication_fail**
(count) | El número total de intentos de réplicas de Raft que han fallado. (Neo4j 4)| +| **neo4j.dbms.cluster.core.replication_maybe**
(count) | Réplica de Raft tal vez cuenta. (Neo4j 4)| +| **neo4j.dbms.cluster.core.replication_new**
(count) | El número total de solicitudes de réplicas de Raft. (Neo4j 4)| +| **neo4j.dbms.cluster.core.replication_success**
(count) | Count de éxitos de réplicas de Raft. (Neo4j 4)| +| **neo4j.dbms.cluster.core.term**
(gauge) | El término de RAFT de este servidor. (Neo4j 4)| +| **neo4j.dbms.cluster.core.tx_retries**
(count) | Reintentos de transacción. (Neo4j 4)| +| **neo4j.dbms.cluster.discovery.cluster.converged**
(gauge) | Convergencia del clúster de descubrimiento. (Neo4j 5)| +| **neo4j.dbms.cluster.discovery.cluster.members**
(gauge) | Tamaño de los miembros del clúster de descubrimiento. (Neo4j 5)| +| **neo4j.dbms.cluster.discovery.cluster.unreachable**
(gauge) | Tamaño inalcanzable del clúster de descubrimiento. (Neo4j 5)| +| **neo4j.dbms.cluster.discovery.replicated_data**
(gauge) | Tamaño de las estructuras de datos replicadas. (Neo4j 5)| +| **neo4j.dbms.cluster.discovery.replicated_data.bootstrap_data.invisible**
(count) | (Neo4j 5)| +| **neo4j.dbms.cluster.discovery.replicated_data.bootstrap_data.visible**
(count) | (Neo4j 5)| +| **neo4j.dbms.cluster.discovery.replicated_data.component_versions.invisible**
(count) | (Neo4j 5)| +| **neo4j.dbms.cluster.discovery.replicated_data.component_versions.visible**
(count) | (Neo4j 5)| +| **neo4j.dbms.cluster.discovery.replicated_data.database_data.invisible**
(count) | (Neo4j 5)| +| **neo4j.dbms.cluster.discovery.replicated_data.database_data.visible**
(count) | (Neo4j 5)| +| **neo4j.dbms.cluster.discovery.replicated_data.leader_data.invisible**
(count) | (Neo4j 5)| +| **neo4j.dbms.cluster.discovery.replicated_data.leader_data.visible**
(count) | (Neo4j 5)| +| **neo4j.dbms.cluster.discovery.replicated_data.server_data.invisible**
(count) | (Neo4j 5)| +| **neo4j.dbms.cluster.discovery.replicated_data.server_data.visible**
(count) | (Neo4j 5)| +| **neo4j.dbms.cluster.discovery.restart.failed_count**
(count) | (Neo4j 5)| +| **neo4j.dbms.cluster.discovery.restart.success_count**
(count) | (Neo4j 5)| +| **neo4j.dbms.cluster.read_replica.pull_update_highest_tx_id_received**
(count) | El identificador de transacción más alto que ha sido extraído en la última actualización de incorporación de cambios por esta instancia. (Neo4j 4)| +| **neo4j.dbms.cluster.read_replica.pull_update_highest_tx_id_requested**
(count) | El identificador de transacción más alto solicitado en una actualización incorporación de cambios por esta instancia. (Neo4j 4)| +| **neo4j.dbms.cluster.read_replica.pull_updates**
(count) | El número total de solicitudes de incorporación de cambios realizadas por esta instancia. (Neo4j 4)| +| **neo4j.dbms.db.operation.count.create**
(count) | Count de operaciones de creación realizadas con éxito. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.db.operation.count.drop**
(count) | Count de operaciones de eliminación de bases de datos realizadas con éxito. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.db.operation.count.failed**
(count) | Count de operaciones fallidas en la base de datos. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.db.operation.count.recovered**
(count) | Count de operaciones de base de datos que fallaron anteriormente, pero se han recuperado. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.db.operation.count.start**
(count) | Count de operaciones de inicio de base de datos realizadas con éxito. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.db.operation.count.stop**
(count) | Count de operaciones de parada de la base de datos realizadas con éxito. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.page_cache.bytes_read**
(count) | El número total de bytes leídos por la caché de page (página). (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.page_cache.bytes_written**
(count) | El número total de bytes escritos por la caché de la page (página). (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.page_cache.eviction_exceptions**
(count) | El número total de excepciones vistas durante el proceso de desalojo en la caché de la page (página). (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.page_cache.evictions**
(count) | El número total de desalojos de la page (página) ejecutados por la caché Page ( página). (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.page_cache.evictions.cooperative**
(count) | El número total de desalojos cooperativos de la page (página) ejecutados por la caché de la page (página) debido a la escasez de páginas disponibles. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.page_cache.evictions.flushes**
(count) | El número total de páginas vaciadas por el desalojo de la page (página). (Neo4j 5)| +| **neo4j.dbms.page_cache.evictions.cooperative.flushes**
(count) | El número total de páginas cooperativas vaciadas por el desalojo de la page (página). (Neo4j 5)| +| **neo4j.dbms.page_cache.flushes**
(count) | El número total de descargas ejecutadas por la caché de la page (página). (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.page_cache.hit_ratio**
(gauge) | Relación de aciertos respecto al número total de búsquedas en la caché de la page (página). (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.page_cache.hits**
(count) | El número total de aciertos de page (página) que se han producido en la caché de page (página). (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.page_cache.iops**
(count) | El número total de operaciones entrada/salida realizadas por la caché de page (página). (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.page_cache.merges**
(count) | El número total de fusiones de page (página) ejecutadas por la caché de page (página). (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.page_cache.page_cancelled_faults**
(count) | El número total de fallos cancelados de page (página) ocurridos en la caché de page (página). (Neo4j 5)| +| **neo4j.dbms.page_cache.page_fault_failures**
(count) | El número total de fallos de page (página) ocurridos en la caché de page (página). (Neo4j 5)| +| **neo4j.dbms.page_cache.page_faults**
(count) | El número total de fallos de page (página) ocurridos en la caché de page (página). (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.page_cache.page_no_pin_page_faults**
(count) | (Neo4j 5)| +| **neo4j.dbms.page_cache.page_vectored_faults**
(count) | (Neo4j 5)| +| **neo4j.dbms.page_cache.page_vectored_faults_failures**
(count) | (Neo4j 5)| +| **neo4j.dbms.page_cache.pages_copied**
(count) | El número total de copias de page (página) que se han producido en la caché de page (página). (Neo4j 5)| +| **neo4j.dbms.page_cache.pins**
(count) | El número total de pasadores de page (página) ejecutados por la caché de page (página). (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.page_cache.throttled_millis**
(count) | El número total del limitador de entradas/salidas de vaciado de caché de page (página) de millones se alternó durante operaciones de entrada/salida en curso. (Neo4j 4)| +| **neo4j.dbms.page_cache.throttled.times**
(count) | El número total de veces que el limitador de vaciado de caché de page (página) cache se alternó durante operaciones de entrada/salida en curso. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.page_cache.unpins**
(count) | El número total de desclavados de page (página) ejecutados por la caché de page (página). (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.page_cache.usage_ratio**
(gauge) | Relación entre el número de páginas utilizadas y el número total de páginas disponibles. (Neo4j 5)| +| **neo4j.dbms.pool.backup.free**
(count) | Cantidad estimada de memoria libre en bytes para este grupo.| +| **neo4j.dbms.pool.backup.total_size**
(count) | Cantidad estimada de memoria disponible en bytes para este grupo.| +| **neo4j.dbms.pool.backup.total_used**
(count) | Cantidad estimada de memoria total utilizada en bytes para este grupo.| +| **neo4j.dbms.pool.backup.used_heap**
(count) | Cantidad estimada de montón usado en bytes para este grupo.| +| **neo4j.dbms.pool.backup.used_native**
(count) | Cantidad estimada de memoria nativa utilizada para este grupo.| +| **neo4j.dbms.pool.bolt.free**
(count) | Cantidad estimada de memoria libre en bytes para este grupo. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.bolt.total_size**
(count) | Cantidad estimada de memoria disponible en bytes para este grupo. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.bolt.total_used**
(count) | Cantidad estimada de memoria total utilizada en bytes para este grupo (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.bolt.used_heap**
(count) | Cantidad estimada de montón utilizado en bytes para este grupo. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.bolt.used_native**
(count) | Cantidad estimada de memoria nativa utilizada para este grupo.| +| **neo4j.dbms.pool.cluster.free**
(count) | Cantidad estimada de memoria libre en bytes para este grupo.| +| **neo4j.dbms.pool.cluster.total_size**
(count) | Cantidad estimada de memoria disponible en bytes para este grupo.| +| **neo4j.dbms.pool.cluster.total_used**
(count) | Cantidad estimada de memoria total utilizada en bytes para este grupo.| +| **neo4j.dbms.pool.cluster.used_heap**
(count) | Cantidad estimada de montón utilizado en bytes para este grupo.| +| **neo4j.dbms.pool.cluster.used_native**
(count) | Cantidad estimada de memoria nativa utilizada para este grupo.| +| **neo4j.dbms.pool.http_transaction.free**
(count) | Cantidad estimada de memoria libre en bytes para este grupo.| +| **neo4j.dbms.pool.http_transaction.total_size**
(count) | Cantidad estimada de memoria disponible en bytes para este grupo.| +| **neo4j.dbms.pool.http_transaction.total_used**
(count) | Cantidad estimada de memoria total utilizada en bytes para este grupo.| +| **neo4j.dbms.pool.http_transaction.used_heap**
(count) | Cantidad estimada de montón usado en bytes para este grupo.| +| **neo4j.dbms.pool.http_transaction.used_native**
(count) | Cantidad estimada de memoria nativa utilizada para este grupo.| +| **neo4j.dbms.pool.http.free**
(count) | Cantidad estimada de memoria libre en bytes para este grupo.| +| **neo4j.dbms.pool.http.total_size**
(count) | Cantidad estimada de memoria disponible en bytes para este grupo.| +| **neo4j.dbms.pool.http.total_used**
(count) | Cantidad estimada de memoria total utilizada en bytes para este grupo.| +| **neo4j.dbms.pool.http.used_heap**
(count) | Cantidad estimada de montón utilizado en bytes para este grupo.| +| **neo4j.dbms.pool.http.used_native**
(count) | Cantidad estimada de memoria nativa utilizada para este grupo.| +| **neo4j.dbms.pool.other.free**
(count) | Cantidad estimada de memoria libre en bytes para este grupo.| +| **neo4j.dbms.pool.other.total_size**
(count) | Cantidad estimada de memoria disponible en bytes para este grupo.| +| **neo4j.dbms.pool.other.total_used**
(count) | Cantidad estimada de memoria total utilizada en bytes para este grupo (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.other.used_heap**
(count) | Cantidad estimada de montón utilizado en bytes para este grupo. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.other.used_native**
(count) | Cantidad estimada de memoria nativa utilizada para este grupo. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.page_cache.free**
(count) | Cantidad estimada de memoria libre en bytes para este grupo. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.page_cache.total_size**
(count) | Cantidad estimada de memoria disponible en bytes para este grupo. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.page_cache.total_used**
(count) | Cantidad estimada de memoria total utilizada en bytes para este grupo (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.page_cache.used_heap**
(count) | Cantidad estimada de montón utilizado en bytes para este grupo. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.page_cache.used_native**
(count) | Cantidad estimada de memoria nativa utilizada para este grupo. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.pool.database.free**
(gauge) | Memoria no utilizada disponible en el grupo, en bytes. (Neo4j 4)| +| **neo4j.dbms.pool.pool.database.total_size**
(gauge) | Suma total de tamaño de la capacidad del montón y/o del grupo de memoria nativa. (Neo4j 4)| +| **neo4j.dbms.pool.pool.database.total_used**
(gauge) | Suma total de memoria de montón y nativa utilizada en bytes. (Neo4j 4)| +| **neo4j.dbms.pool.pool.database.used_heap**
(gauge) | Memoria de montón utilizada o reservada en bytes. (Neo4j 4)| +| **neo4j.dbms.pool.pool.database.used_native**
(gauge) | Memoria nativa utilizada o reservada en bytes. (Neo4j 4)| +| **neo4j.dbms.pool.pool.free**
(gauge) | Memoria no utilizada disponible en el grupo, en bytes. (Neo4j 4)| +| **neo4j.dbms.pool.pool.total_size**
(gauge) | Suma total del tamaño de la capacidad del montón y/o del grupo de memoria nativa. (Neo4j 4)| +| **neo4j.dbms.pool.pool.total_used**
(gauge) | Suma total de la memoria de montón y nativa utilizada en bytes. (Neo4j 4)| +| **neo4j.dbms.pool.pool.used_heap**
(gauge) | Memoria de montón utilizada o reservada en bytes. (Neo4j 4)| +| **neo4j.dbms.pool.pool.used_native**
(gauge) | Memoria nativa utilizada o reservada en bytes. (Neo4j 4)| +| **neo4j.dbms.pool.recent_query_buffer.free**
(count) | Cantidad estimada de memoria libre en bytes para este grupo. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.recent_query_buffer.total_size**
(count) | Cantidad estimada de memoria disponible en bytes para este grupo. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.recent_query_buffer.total_used**
(count) | Cantidad estimada de memoria total utilizada en bytes para este grupo (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.recent_query_buffer.used_heap**
(count) | Cantidad estimada de montón utilizado en bytes para este grupo. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.recent_query_buffer.used_native**
(count) | Cantidad estimada de memoria nativa utilizada para este grupo. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.transaction.free**
(count) | Cantidad estimada de memoria libre en bytes para este grupo. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.transaction.total_size**
(count) | Cantidad estimada de memoria disponible en bytes para este grupo. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.transaction.total_used**
(count) | Cantidad estimada de memoria total utilizada en bytes para este grupo (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.transaction.used_heap**
(count) | Cantidad estimada de montón utilizado en bytes para este grupo. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.transaction.used_native**
(count) | Cantidad estimada de memoria nativa utilizada para este grupo. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.routing.query.count.local**
(count) | Número de consultas redirigidas localmente. (Neo4j 5)| +| **neo4j.dbms.routing.query.count.remote_internal**
(count) | Número de consultas redirigidas internamente. (Neo4j 5)| +| **neo4j.dbms.routing.query.count.remote_external**
(count) | Número de consultas redirigidas externamente. (Neo4j 5)| +| **neo4j.dbms.server.threads.jetty.all**
(gauge) | El número total de subprocesos (tanto inactivos como ocupados) en el grupo de jetty. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.server.threads.jetty.idle**
(gauge) | El número total de subprocesos inactivos en el grupo de jetty. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.file.descriptors.count**
(gauge) | El número actual de descriptores de archivo abiertos (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.file.descriptors.maximum**
(gauge) | (Configuración del sistema operativo) El número máximo de descriptores de archivo abiertos. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.gc.count.g1_old_generation**
(count) | (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.gc.count.g1_young_generation**
(count) | (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.gc.count.gc**
(count) | Número total de recolecciones de basura.| +| **neo4j.dbms.vm.gc.time.g1_old_generation**
(count) | (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.gc.time.g1_young_generation**
(count) | (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.gc.time.gc**
(count) | Tiempo acumulado de recolección de basura en milisegundos.| +| **neo4j.dbms.vm.heap.committed**
(gauge) | Cantidad de memoria (en bytes) que se garantiza que está disponible para ser utilizada por la JVM. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.heap.max**
(gauge) | Cantidad máxima de memoria de montón (en bytes) que se puede utilizar. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.heap.used**
(gauge) | Cantidad de memoria (en bytes) utilizada actualmente. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.memory.buffer.bufferpool.capacity**
(gauge) | Capacidad total estimada de los búferes asignados en el grupo.| +| **neo4j.dbms.vm.memory.buffer.bufferpool.count**
(gauge) | Número estimado de búferes asignados en el grupo.| +| **neo4j.dbms.vm.memory.buffer.bufferpool.used**
(gauge) | Cantidad estimada de memoria asignada utilizada por el grupo.| +| **neo4j.dbms.vm.memory.buffer.direct.capacity**
(count) | Capacidad total estimada de búferes en el grupo (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.memory.buffer.direct.count**
(count) | Número estimado de búferes en el grupo (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.memory.buffer.direct.used**
(count) | Cantidad estimada de memoria utilizada por el grupo (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.memory.buffer.mapped_non_volatile_memory.capacity**
(count) | Capacidad total estimada de los búferes en el grupo.| +| **neo4j.dbms.vm.memory.buffer.mapped_non_volatile_memory.count**
(count) | Número estimado de búferes en el grupo.| +| **neo4j.dbms.vm.memory.buffer.mapped_non_volatile_memory.used**
(count) | Cantidad estimada de memoria utilizada por el grupo.| +| **neo4j.dbms.vm.memory.buffer.mapped.capacity**
(count) | Capacidad total estimada de búferes en el grupo (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.memory.buffer.mapped.count**
(count) | Número estimado de búferes en el grupo (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.memory.buffer.mapped.used**
(count) | Cantidad estimada de memoria utilizada por el grupo (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.memory.pool.codeheap_non_nmethods**
(count) | | +| **neo4j.dbms.vm.memory.pool.codeheap_non_profiled_nmethods**
(count) | | +| **neo4j.dbms.vm.memory.pool.codeheap_profiled_nmethods**
(count) | | +| **neo4j.dbms.vm.memory.pool.compressed_class_space**
(count) | (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.memory.pool.g1_eden_space**
(count) | (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.memory.pool.g1_old_gen**
(count) | (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.memory.pool.g1_survivor_space**
(count) | (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.memory.pool.metaspace**
(count) | (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.memory.pool.pool**
(gauge) | Cantidad estimada de memoria en bytes utilizada por el grupo.| +| **neo4j.dbms.vm.pause_time**
(count) | Tiempo de pausa detectado acumulado de máquinas virtuales (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.threads**
(gauge) | El número total de subprocesos activos, incluidos los subprocesos daemon y no daemon. (Neo4j 5)| +| **neo4j.transaction.terminated**
(count) | El número total de transacciones finalizadas. (Neo4j 4)| +| **neo4j.transaction.terminated_read**
(count) | Número total de transacciones de lectura finalizadas.| +| **neo4j.transaction.terminated_write**
(count) | Número total de transacciones de escritura finalizadas.| +| **neo4j.transaction.tx_size_heap**
(gauge) | El tamaño de las transacciones en el montón en bytes.| +| **neo4j.transaction.tx_size_native**
(gauge) | El tamaño de las transacciones en memoria nativa en bytes.| +| **neo4j.vm.thread.count**
(gauge) | Número estimado de subprocesos activos en el grupo de subprocesos actual. (Neo4j 4)| +| **neo4j.vm.thread.total**
(gauge) | El número total de subprocesos en tiempo real, incluidos subprocesos daemon y no daemon. (Neo4j 4)| +| **neo4j.bolt.accumulated_processing_time**
(gauge) | El tiempo acumulado que los subprocesos de worker han pasado procesando mensajes. (neo4j 4)| +| **neo4j.bolt.accumulated_queue_time**
(gauge) | El tiempo acumulado que han pasado los mensajes esperando un subproceso de worker. (neo4j 4)| +| **neo4j.bolt.connections_closed**
(gauge) | El número total de conexiones de Bolt cerradas desde que se inició esta instancia. Esto incluye tanto las conexiones finalizadas correctamente como las anormalmente finalizadas (neo4j 4).| +| **neo4j.bolt.connections_idle**
(gauge) | Número total de conexiones de Bolt inactivas (neo4j 4)| +| **neo4j.bolt.connections_opened**
(gauge) | El número total de conexiones de Bolt abiertas desde que se inició esta instancia. Esto incluye tanto las conexiones exitosas como las fallidas (neo4j 4)| +| **neo4j.bolt.connections_running**
(gauge) | Número total de conexiones de Bolt ejecutadas actualmente (neo4j 4)| +| **neo4j.bolt.messages_done**
(gauge) | El número total de mensajes que se han procesado desde que se inició esta instancia. Esto incluye mensajes de Bolt exitosos y fallidos e ignorados (neo4j 4).| +| **neo4j.bolt.messages_failed**
(gauge) | Número total de mensajes que no se han podido procesar desde que se inició esta instancia (neo4j 4)| +| **neo4j.bolt.messages_received**
(gauge) | Número total de mensajes recibidos a través de Bolt desde que se inició esta instancia (neo4j 4)| +| **neo4j.bolt.messages_started**
(gauge) | El número total de mensajes que comenzaron a procesarse desde que se inició esta instancia. Esto es diferente de los mensajes recibidos en que este contador rastrea cuántos de los mensajes recibidos han sido tomados por un subproceso de worker (neo4j 4)| +| **neo4j.check_point.events**
(gauge) | El número total de eventos de punto de control ejecutados hasta el momento. (neo4j 4)| +| **neo4j.check_point.total_time**
(gauge) | El tiempo total empleado hasta ahora en el punto de control. (neo4j 4)| +| **neo4j.check_point.duration**
(gauge) | La duración del último evento de punto de control. (neo4j 4)| +| **neo4j.cypher.replan_events**
(gauge) | Número total de veces que Cypher ha decidido planificar nuevamente una consulta. (neo4j 4)| +| **neo4j.cypher.replan_wait_time**
(gauge) | El número total de segundos esperados entre nuevas planificaciones de consultas. (neo4j 4)| +| **neo4j.node_count**
(gauge) | El número total de nodos. (neo4j 4)| +| **neo4j.relationship_count**
(gauge) | El número total de relaciones. (neo4j 4)| +| **neo4j.ids_in_use.node**
(gauge) | El número total de nodos almacenados en la base de datos. (neo4j 4)| +| **neo4j.ids_in_use.property**
(gauge) | Número total de nombres de propiedades diferentes utilizados en la base de datos. (neo4j 4)| +| **neo4j.ids_in_use.relationship**
(gauge) | Número total de relaciones almacenadas en la base de datos. (neo4j 4)| +| **neo4j.ids_in_use.relationship_type**
(gauge) | Número total de tipos de relación diferentes almacenados en la base de datos. (neo4j 4)| +| **neo4j.store.size.total**
(gauge) | El tamaño total de la base de datos y los logs de transacciones. (neo4j 4)| +| **neo4j.store.size.database**
(gauge) | El tamaño en disco de la base de datos. (neo4j 4)| +| **neo4j.log.appended_bytes**
(gauge) | El número total de bytes añadidos al log de la transacción. (neo4j 4)| +| **neo4j.log.rotation_events**
(gauge) | El número total de rotaciones de transacciones de logs ejecutadas hasta el momento. (neo4j 4)| +| **neo4j.log.rotation_total_time**
(gauge) | El tiempo total empleado en rotar los logs de transacción hasta ahora. (neo4j 4)| +| **neo4j.log.rotation_duration**
(gauge) | La duración del último evento de rotación de logs. (neo4j 4)| +| **neo4j.page_cache.eviction_exceptions**
(gauge) | El número total de excepciones vistas durante el proceso de desalojo en la caché de page (página). (neo4j 4)| +| **neo4j.page_cache.evictions**
(gauge) | El número total de desalojos de page (página) ejecutados por la caché de page (página). (neo4j 4)| +| **neo4j.page_cache.flushes**
(gauge) | El número total de descargas ejecutadas por la caché de page (página). (neo4j 4)| +| **neo4j.page_cache.hits**
(gauge) | El número total de aciertos de la page (página) ocurridos en la caché de page (página). (neo4j 4)| +| **neo4j.page_cache_hits_total**
(gauge) | El número total de aciertos de page (página) ocurridos en la caché de page (página). (neo4j 4)| +| **neo4j.page_cache.page_faults**
(gauge) | El número total de fallos de page (página) ocurridos en la caché de page (página). (neo4j 4)| +| **neo4j.page_cache.pins**
(gauge) | El número total de pines de page (página) ejecutados por la caché de page (página). (neo4j 4)| +| **neo4j.page_cache.unpins**
(gauge) | El número total de desclavados de page (página) ejecutados por la caché de page (página). (neo4j 4)| +| **neo4j.server.threads.jetty.all**
(gauge) | El número total de subprocesos (tanto inactivos como ocupados) en el grupo jetty. (neo4j 4)| +| **neo4j.server.threads.jetty.idle**
(gauge) | El número total de subprocesos inactivos en el grupo jetty. (neo4j 4)| +| **neo4j.transaction.active**
(gauge) | Número de transacciones activas actualmente. (neo4j 4)| +| **neo4j.transaction.active_read**
(gauge) | Número de transacciones de lectura actualmente activas. (neo4j 4)| +| **neo4j.transaction.active_write**
(gauge) | El número de transacciones de escritura actualmente activas. (neo4j 4)| +| **neo4j.transaction.committed_read**
(gauge) | Número total de transacciones confirmadas. (neo4j 4)| +| **neo4j.transaction.committed**
(gauge) | Número total de transacciones de lectura confirmadas. (neo4j 4)| +| **neo4j.transaction.committed_write**
(gauge) | Número total de transacciones de escritura confirmadas. (neo4j 4)| +| **neo4j.transaction.last_closed_tx_id**
(gauge) | El identificador de la última transacción cerrada. (neo4j 4)| +| **neo4j.transaction.last_committed_tx_id**
(gauge) | Identificador de la última transacción confirmada. (neo4j 4)| +| **neo4j.transaction.peak_concurrent**
(gauge) | El pico más alto de transacciones concurrentes. (neo4j 4)| +| **neo4j.transaction.rollbacks_read**
(gauge) | Número total de transacciones de lectura revertidas. (neo4j 4)| +| **neo4j.transaction.rollbacks**
(gauge) | Número total de transacciones revertidas. (neo4j 4)| +| **neo4j.transaction.rollbacks_write**
(gauge) | Número total de transacciones de escritura revertidas. (neo4j 4)| +| **neo4j.transaction.started**
(gauge) | Número total de transacciones iniciadas. (neo4j 4)| +| **neo4j.vm.gc.count.g1_old_generation**
(gauge) | Número total de recolecciones de basura para la antigua generación. (neo4j 4)| +| **neo4j.vm.gc.count.g1_young_generation**
(gauge) | Número total de recolecciones de basura para la generación joven. (neo4j 4)| +| **neo4j.vm.gc.time.g1_old_generation**
(gauge) | Tiempo acumulado de recolección de basura en milisegundos para la generación antigua. (neo4j 4)| +| **neo4j.vm.gc.time.g1_young_generation**
(gauge) | Tiempo acumulado de recolección de basura en milisegundos para la generación joven. (neo4j 4)| +| **neo4j.vm.memory.buffer.direct_capacity**
(gauge) | Capacidad total estimada de los búferes directos del grupo (neo4j 4)| +| **neo4j.vm.memory.buffer.direct_count**
(gauge) | Número estimado de búferes directos en el grupo. (neo4j 4)| +| **neo4j.vm.memory.buffer.direct_used**
(gauge) | Cantidad estimada de memoria directa utilizada por el grupo. (neo4j 4)| +| **neo4j.vm.memory.buffer.mapped_capacity**
(gauge) | Capacidad total estimada de los búferes asignados en el grupo. (neo4j 4)| +| **neo4j.vm.memory.buffer.mapped_count**
(gauge) | Número estimado de búferes asignados en el grupo. (neo4j 4)| +| **neo4j.vm.memory.buffer.mapped_used**
(gauge) | Cantidad estimada de memoria asignada utilizada por el grupo. (neo4j 4)| +| **neo4j.vm.memory.pool.compressed_class_space**
(gauge) | Número estimado de búferes en el grupo de espacio de clase comprimido. (neo4j 4)| +| **neo4j.vm.memory.pool.g1_eden_space**
(gauge) | Número estimado de búferes en el grupo de espacio de g1 eden. (neo4j 4)| +| **neo4j.vm.memory.pool.g1_old_gen**
(gauge) | Número estimado de búferes en el grupo de la generación antigua g1. (neo4j 4)| +| **neo4j.vm.memory.pool.g1_survivor_space**
(gauge) | Número estimado de búferes en el grupo de espacio de supervivencia g1. (neo4j 4)| +| **neo4j.vm.memory.pool.metaspace**
(gauge) | Número estimado de búferes en el grupo de metaespacios (neo4j 4)| ### Checks de servicio @@ -120,18 +542,6 @@ El check de servicio `neo4j.prometheus.health` se presenta en el check base Neo4j no incluye ningún evento. - ## Solucionar problemas -¿Necesitas ayuda? Ponte en contacto con el [soporte de Neo4j][10]. - -[1]: https://neo4j.com/ -[2]: https://docs.datadoghq.com/es/agent/autodiscovery/integrations -[3]: https://app.datadoghq.com/account/settings/agent/latest -[4]: https://github.com/DataDog/integrations-extras/blob/master/neo4j/datadog_checks/neo4j/data/conf.yaml.example -[5]: https://docs.datadoghq.com/es/agent/guide/agent-commands/#start-stop-and-restart-the-agent -[6]: https://docs.datadoghq.com/es/agent/guide/agent-commands/#agent-status-and-information -[7]: https://neo4j.com/docs/operations-manual/4.4/monitoring/metrics/reference/ -[8]: https://neo4j.com/docs/operations-manual/5/monitoring/metrics/reference/ -[9]: https://github.com/DataDog/integrations-extras/blob/master/neo4j/metadata.csv -[10]: mailto:support@neo4j.com \ No newline at end of file +¿Necesitas ayuda? Ponte en contacto con [asistencia técnica de Neo4j](mailto:support@neo4j.com). \ No newline at end of file diff --git a/content/es/integrations/node.md b/content/es/integrations/node.md new file mode 100644 index 0000000000000..752425a5d1fd5 --- /dev/null +++ b/content/es/integrations/node.md @@ -0,0 +1,126 @@ +--- +app_id: nodo +categories: +- languages +- log collection +- tracing +custom_kind: integración +description: Recopila métricas, trazas y logs de tus aplicaciones Node.js. +further_reading: +- link: https://www.datadoghq.com/blog/node-logging-best-practices/ + tag: blog + text: Cómo recopilar, personalizar y centralizar los logs de Node.js +- link: https://www.datadoghq.com/blog/node-monitoring-apm/ + tag: blog + text: Monitorización de Node.js con Datadog APM y rastreo distribuido +media: [] +title: Node +--- +## Información general + +La integración de Node.js te permite recopilar y monitorizar tus logs de aplicación, trazas (traces) y métricas personalizadas de Node.js. + +## Configuración + +### Recopilación de métricas + +La integración de Node.js te permite monitorizar una métrica personalizada al instrumentar unas pocas líneas de código. Por ejemplo, puedes tener una métrica que devuelva el número de páginas vistas o el tiempo de llamada a una función. + +Para obtener información adicional sobre la integración de Node.js, consulta la [guía sobre el envío de métricas](https://docs.datadoghq.com/metrics/custom_metrics/dogstatsd_metrics_submission/?code-lang=nodejs). + +```js +// Require dd-trace +const tracer = require('dd-trace').init(); + +// Increment a counter +tracer.dogstatsd.increment('page.views'); +``` + +Ten en cuenta que, para que las métricas personalizadas funcionen, es necesario habilitar DogStatsD en Agent. La recopilación está habilitada por defecto, pero el Agent solo escucha métricas desde el host local. Para permitir métricas externas, necesitas establecer una variable de entorno o actualizar el archivo de configuración: + +```sh +DD_USE_DOGSTATSD=true # default +DD_DOGSTATSD_PORT=8125 # default +DD_DOGSTATSD_NON_LOCAL_TRAFFIC=true # if expecting external metrics +``` + +```yaml +use_dogstatsd: true # default +dogstatsd_port: 8125 # default +dogstatsd_non_local_traffic: true # if expecting external metrics +``` + +También necesitarás configurar para que tu aplicación utilice el recopilador de DogStatsD del Agent: + +```sh +DD_DOGSTATSD_HOSTNAME=localhost DD_DOGSTATSD_PORT=8125 node app.js +``` + +### Recopilación de trazas + +Consulta la documentación dedicada para [instrumentar tu aplicación Node.js](https://docs.datadoghq.com/tracing/setup/nodejs/) para enviar traces (trazas) a Datadog. + +### Recopilación de logs + +_Disponible para la versión 6.0 o posterior del Agent_ + +Consulta la documentación específica para configurar [recopilación de logs de Node.js](https://docs.datadoghq.com/logs/log_collection/nodejs/) para reenviar tus logs a Datadog. + +### Recopilación de perfiles + +Consulta la documentación dedicada para [activar el perfilador de Node.js](https://github.com/DataDog/dogweb/blob/prod/node/node_metadata.csv). + +## Datos recopilados + +### Métricas + +| | | +| --- | --- | +| **runtime.node.cpu.user**
(medidor) | Uso de la CPU en código de usuario
_Mostrado en porcentaje_. | +| **runtime.node.cpu.system**
(medidor) | Uso de la CPU en el código del sistema
_Mostrado en porcentaje_. | +| **runtime.node.cpu.total**
(medidor) | Uso total de la CPU
_Mostrado como porcentaje_. | +| **runtime.node.mem.rss**
(medidor) | Tamaño del conjunto residente
_Mostrado como byte_ | +| **runtime.node.mem.heap_total**
(medidor) | Memoria heap total
_Mostrado como byte_ | +| **runtime.node.mem.heap_used**
(medidor) | Uso de memoria Heap
_Mostrado como byte_ | +| **runtime.node.mem.external**
(medidor) | Memoria externa
_Mostrado como byte_ | +| **runtime.node.heap.total_heap_size**
(medidor) | Tamaño total de heap
_Mostrado como byte_ | +| **runtime.node.heap.total_heap_size_executable**
(medidor) | Tamaño total de heap ejecutable
_Mostrado como byte_ | +| **runtime.node.heap.total_physical_size**
(mediidor) | Tamaño físico total de heap
_Mostrado como byte_ | +| **runtime.node.heap.used_heap_size**
(medidor) | Tamaño de heap utilizado
_Mostrado como byte_ | +| **runtime.node.heap.heap_size_limit**
(medidor) | Límite de tamaño de heap
_Mostrado como byte_ | +| **runtime.node.heap.malloced_memory**
(medidor) | Memoria malgastada
_Mostrado como byte_ | +| **runtime.node.heap.peak_malloced_memory**
(medidor) | Pico de memoria asignada
_Mostrado como byte_ | +| **runtime.node.heap.size.by.space**
(medidor) | Tamaño del espacio de heap
_Mostrado como byte_ | +| **runtime.node.heap.used_size.by.space**
(medidor) | Tamaño de espacio heap utilizado
_Mostrado como byte_ | +| **runtime.node.heap.available_size.by.space**
(medidor) | Tamaño del espacio disponible en heap
_Mostrado como byte_ | +| **runtime.node.heap.physical_size.by.space**
(medidor) | Tamaño físico del espacio heap
_Mostrado como byte_ | +| **runtime.node.process.uptime**
(medidor) | Tiempo de actividad del proceso
_Mostrado en segundos_ | +| **runtime.node.event_loop.delay.max**
(medidor) | Retardo máximo del bucle de eventos
_Mostrado en nanosegundos_ | +| **runtime.node.event_loop.delay.min**
(medidor) | Retardo mínimo del bucle de eventos
_Mostrado en nanosegundos_ | +| **runtime.node.event_loop.delay.avg**
(medidor) | Retardo medio del bucle de eventos
_Mostrado en nanosegundos_ | +| **runtime.node.event_loop.delay.sum**
(tasa) | Retardo total del bucle de eventos
_Mostrado en nanosegundos_ | +| **runtime.node.event_loop.delay.median**
(medidor) | Mediana del retardo del bucle de eventos
_Mostrado en nanosegundos_ | +| **runtime.node.event_loop.delay.95percentile**
(medidor) | Percentil 95 del retardo del bucle de eventos
_Mostrado en nanosegundos_ | +| **runtime.node.event_loop.delay.count**
(tasa) | Count de iteraciones del bucle de eventos donde se detecta un retardo
_Mostrado como ejecución_ | +| **runtime.node.gc.pause.max**
(medidor) | Pausa máxima de recolección de basura
_Mostrado en nanosegundos_ | +| **runtime.node.gc.pause.min**
(medidor) | Pausa mínima de recolección de basura
_Mostrado en nanosegundos_ | +| **runtime.node.gc.pause.avg**
(medidor) | Pausa media de recolección de basura
_Mostrado en nanosegundos_ | +| **runtime.node.gc.pause.sum**
(tasa) | Pausa total de recolección de basura
_Mostrado en nanosegundos_ | +| **runtime.node.gc.pause.median**
(medidor) | Mediana de la pausa de recolección de basura
_Mostrado en nanosegundos_ | +| **runtime.node.gc.pause.95percentile**
(medidor) | Pausa de recolección de basura del percentil 95
_Mostrado en nanosegundos_ | +| **runtime.node.gc.pause.count**
(tasa) | Número de recolecciones de basura
_Mostrado como recolección de basura_ | +| **runtime.node.gc.pause.by.type.max**
(medidor) | Pausa máxima de recolección de basura por tipo
_Mostrado como nanosegundo_ | +| **runtime.node.gc.pause.by.type.min**
(medidor) | Pausa mínima de recolección de basura por tipo
_Mostrado en nanosegundos_ | +| **runtime.node.gc.pause.by.type.avg**
(medidor) | Pausa media de recolección de basura por tipo
_Mostrado en nanosegundos_ | +| **runtime.node.gc.pause.by.type.sum**
(tasa) | Pausa total de recolección de basura por tipo
_Mostrado en nanosegundos_ | +| **runtime.node.gc.pause.by.type.median**
(medidor) | Mediana de la pausa de recolección de basura por tipo
_Mostrado en nanosegundos_ | +| **runtime.node.gc.pause.by.type.95percentile**
(medidor) | Pausa de recopilación de basura del percentil 95 por tipo
_Mostrado en nanosegundos_ | +| **runtime.node.gc.pause.by.type.count**
(tasa) | Número de recolecciones de basura por tipo
_Mostrado como recolección de basura_ | + +## Solucionar problemas + +¿Necesitas ayuda? Ponte en contacto con el [servicio de asistencia de Datadog](https://docs.datadoghq.com/help/). + +## Referencias adicionales + +{{< partial name="whats-next/whats-next.html" >}} \ No newline at end of file diff --git a/content/es/integrations/nvml.md b/content/es/integrations/nvml.md index 5149f66c7f3b0..08f6da31c8812 100644 --- a/content/es/integrations/nvml.md +++ b/content/es/integrations/nvml.md @@ -1,150 +1,101 @@ --- app_id: nvml -app_uuid: 2c7a8b1e-9343-4b4a-bada-5091e37c4806 -assets: - integration: - auto_install: true - configuration: - spec: assets/configuration/spec.yaml - events: - creates_events: false - metrics: - check: nvml.device_count - metadata_path: metadata.csv - prefix: nvml. - service_checks: - metadata_path: assets/service_checks.json - source_type_id: 10177 - source_type_name: nvml -author: - homepage: https://github.com/DataDog/integrations-extras - name: Comunidad - sales_email: help@datadoghq.com - support_email: help@datadoghq.com categories: - ia/ml - kubernetes - sistema operativo y sistema -custom_kind: integration -dependencies: -- https://github.com/DataDog/integrations-extras/blob/master/nvml/README.md -display_on_public_website: true -draft: false -git_integration_title: nvml -integration_id: nvml -integration_title: NVIDIA NVML +custom_kind: integración +description: Admite métricas de GPU Nvidia en k8s integration_version: 1.0.9 -is_public: true -manifest_version: 2.0.0 -name: nvml -public_title: NVIDIA NVML -short_description: Admite métricas de GPU NVIDIA en k8s +media: [] supported_os: - linux - windows - macos -tile: - changelog: CHANGELOG.md - classifier_tags: - - Category::AI/ML - - Category::Kubernetes - - Category::OS & System - - Supported OS::Linux - - Supported OS::Windows - - Supported OS::macOS - - Offering::Integration - configuration: README.md#Setup - description: Admite métricas de GPU NVIDIA en k8s - media: [] - overview: README.md#Overview - support: README.md#Support - title: NVIDIA NVML +title: Nvidia NVML --- - - - - ## Información general -Este check monitoriza métricas de [NVIDIA Management Library (NVML)][1] expuestas a través del Datadog Agent y puede correlacionarlas con los [dispositivos expuestos de Kubernetes][2]. +Este check monitoriza las métricas expuestas de [NVIDIA Management Library (NVML)](https://pypi.org/project/pynvml/) a través del Datadog Agent y puede correlacionarlas con los [dispositivos expuestos de Kubernetes](https://kubernetes.io/docs/concepts/extend-kubernetes/compute-storage-net/device-plugins/#monitoring-device-plugin-resources). ## Configuración -El check de NVML no está incluido en el paquete del [Datadog Agent][3], por lo que es necesario instalarlo. +El check de NVML no está incluido en el paquete del [Datadog Agent](https://app.datadoghq.com/account/settings/agent/latest), por lo que es necesario instalarlo. ### Instalación -Para el Agent v7.21+/v6.21+, sigue las instrucciones a continuación para instalar el check de NVML en tu host. Consulta [Usar integraciones de comunidad][4] para realizar la instalación con Agent de Docker o versiones anteriores del Agent. +Para el Agent v7.21+ / v6.21+, sigue las instrucciones siguientes para instalar el check de NVML en tu host. Consulta [Usar integraciones de la comunidad](https://docs.datadoghq.com/agent/guide/use-community-integrations/) para realizar la instalación con el Docker Agent o versiones anteriores del Agent. 1. Ejecuta el siguiente comando para instalar la integración del Agent: Para Linux: + ```shell datadog-agent integration install -t datadog-nvml==
# You may also need to install dependencies since those aren't packaged into the wheel
sudo -u dd-agent -H /opt/datadog-agent/embedded/bin/pip3 install grpcio pynvml
```
+
Para Windows (con Powershell ejecutado como administrador):
+
```shell
& "$env:ProgramFiles\Datadog\Datadog Agent\bin\agent.exe" integration install -t datadog-nvml==
# You may also need to install dependencies since those aren't packaged into the wheel
& "$env:ProgramFiles\Datadog\Datadog Agent\embedded3\python" -m pip install grpcio pynvml
```
-2. Configura tu integración como si fuese una [integración][5] de base.
+1. Configura tu integración de forma similar a las [integraciones](https://docs.datadoghq.com/getting_started/integrations/) centrales.
-Si utilizas Docker, existe un [archivo Docker de ejemplo][6] en el repositorio NVML.
+Si utilizas Docker, hay un [Dockerfile de ejemplo](https://github.com/DataDog/integrations-extras/blob/master/nvml/tests/Dockerfile) en el repositorio de NVML.
- ```shell
- docker build -t dd-agent-nvml .
- ```
+```shell
+docker build -t dd-agent-nvml .
+```
Si utilizas Docker y Kubernetes, deberás exponer las variables de entorno `NVIDIA_VISIBLE_DEVICES` y `NVIDIA_DRIVER_CAPABILITIES`. Consulta el archivo Docker incluido para ver un ejemplo.
-Para correlacionar los dispositivos reservados de NVIDIA Kubernetes con el pod de Kubernetes que utiliza el dispositivo, monta el socket de dominio de Unix `/var/lib/kubelet/pod-resources/kubelet.sock` en tu configuración del Agent. Más información sobre este socket en el [sitio web de Kubernetes][2]. **Nota**: Este dispositivo tiene compatibilidad en fase beta para la versión 1.15.
+Para correlacionar los dispositivos NVIDIA reservados de Kubernetes con el pod de Kubernetes que utiliza el dispositivo, monta el socket de dominio Unix `/var/lib/kubelet/pod-resources/kubelet.sock` en tu configuración del Agent. Encontrarás más información sobre este socket en el sitio web de [Kubernetes](https://kubernetes.io/docs/concepts/extend-kubernetes/compute-storage-net/device-plugins/#monitoring-device-plugin-resources). **Nota**: Este dispositivo está en soporte beta para la versión 1.15.
### Configuración
-1. Edita el archivo `nvml.d/conf.yaml`, en la carpeta `conf.d/` en la raíz del directorio de configuración del Agent para comenzar a recopilar tus datos de rendimiento de NVML. Consulta el [nvml.d/conf.yaml de ejemplo][7] para todas las opciones disponibles de configuración.
+1. Edita el archivo `nvml.d/conf.yaml`, en la carpeta `conf.d/` en la raíz de tu directorio de configuración del Agent para comenzar a recopilar tus datos de rendimiento de NVML. Consulta [el nvml.d/conf.yaml de ejemplo](https://github.com/DataDog/integrations-extras/blob/master/nvml/datadog_checks/nvml/data/conf.yaml.example) para conocer todas las opciones de configuración disponibles.
-2. [Reinicia el Agent][8].
+1. [Reinicia el Agent](https://docs.datadoghq.com/agent/guide/agent-commands/#start-stop-and-restart-the-agent).
### Validación
-[Ejecuta el subcomando de estado del Agent][9] y busca `nvml` en la sección Checks.
+[Ejecuta el subcomando de estado del Agent](https://docs.datadoghq.com/agent/guide/agent-commands/#agent-status-and-information) y busca `nvml` en la sección Checks.
## Datos recopilados
### Métricas
-{{< get-metrics-from-git "nvml" >}}
- La documentación autorizada de métricas se encuentra en el [sitio web de NVIDIA][11].
-Se ha intentado, en la medida de lo posible, que los nombres de métrica coincidan con el exportador [Data Center GPU Manager (DCGM)][12] de NVIDIA.
+| | |
+| --- | --- |
+| **nvml.device_count**
(gauge) | Número de GPU en esta instancia.| +| **nvml.gpu_utilization**
(gauge) | Porcentaje de tiempo durante el último periodo de muestreo en el que uno o más kernels se ejecutaron en la GPU.
_Se muestra como porcentaje_ | +| **nvml.mem_copy_utilization**
(gauge) | Porcentaje de tiempo durante el último periodo de muestreo en el que la memoria global (dispositivo) se estaba leyendo o escribiendo.
_Se muestra como porcentaje_ | +| **nvml.fb_free**
(gauge) | Memoria FB no asignada.
_Se muestra como byte_ | +| **nvml.fb_used**
(gauge) | Memoria FB asignada.
_Se muestra como byte_ | +| **nvml.fb_total**
(gauge) | Memoria FB total instalada.
_Se muestra como byte_ | +| **nvml.power_usage**
(gauge) | Consumo de energía de esta GPU en milivatios y sus circuitos asociados (por ejemplo, la memoria).| +| **nvml.total_energy_consumption**
(count) | Consumo total de energía de esta GPU en milijulios (mJ) desde la última recarga del controlador.| +| **nvml.enc_utilization**
(gauge) | Utilización actual del codificador
_Se muestra en porcentaje_ | +| **nvml.dec_utilization**
(gauge) | La utilización actual del decodificador
_Se muestra en porcentaje_. | +| **nvml.pcie_tx_throughput**
(gauge) | Utilización de PCIe TX
_Se muestra como kibibyte_ | +| **nvml.pcie_rx_throughput**
(gauge) | Utilización de PCIe RX
_Se muestra como kibibyte_ | +| **nvml.temperature**
(gauge) | Temperatura actual de esta GPU en grados centígrados| +| **nvml.fan_speed**
(gauge) | Utilización actual del ventilador
_Se muestra en porcentaje_ | +| **nvml.compute_running_process**
(gauge) | El uso actual de la memoria gpu por el proceso
_Se muestra como byte_ | ### Eventos NVML no incluye eventos. ### Checks de servicio -{{< get-service-checks-from-git "nvml" >}} +Consulta [service_checks.json](https://github.com/DataDog/integrations-extras/blob/master/nvml/assets/service_checks.json) para obtener una lista de los checks de servicio proporcionados por esta integración. ## Solucionar problemas -¿Necesitas ayuda? Ponte en contacto con el [soporte de Datadog][14]. - - -[1]: https://pypi.org/project/pynvml/ -[2]: https://kubernetes.io/docs/concepts/extend-kubernetes/compute-storage-net/device-plugins/#monitoring-device-plugin-resources -[3]: https://app.datadoghq.com/account/settings/agent/latest -[4]: https://docs.datadoghq.com/es/agent/guide/use-community-integrations/ -[5]: https://docs.datadoghq.com/es/getting_started/integrations/ -[6]: https://github.com/DataDog/integrations-extras/blob/master/nvml/tests/Dockerfile -[7]: https://github.com/DataDog/integrations-extras/blob/master/nvml/datadog_checks/nvml/data/conf.yaml.example -[8]: https://docs.datadoghq.com/es/agent/guide/agent-commands/#start-stop-and-restart-the-agent -[9]: https://docs.datadoghq.com/es/agent/guide/agent-commands/#agent-status-and-information -[10]: https://github.com/DataDog/integrations-extras/blob/master/nvml/metadata.csv -[11]: https://docs.nvidia.com/deploy/nvml-api/group__nvmlDeviceQueries.html -[12]: https://github.com/NVIDIA/dcgm-exporter -[13]: https://github.com/DataDog/integrations-extras/blob/master/nvml/assets/service_checks.json -[14]: https://docs.datadoghq.com/es/help +¿Necesitas ayuda? Ponte en contacto con el [soporte de Datadog](https://docs.datadoghq.com/help). \ No newline at end of file diff --git a/content/es/integrations/oke.md b/content/es/integrations/oke.md index c1dc4931776c1..c39301d3ccafb 100644 --- a/content/es/integrations/oke.md +++ b/content/es/integrations/oke.md @@ -1,88 +1,52 @@ --- app_id: oke -app_uuid: c3361861-32be-4ed4-a138-d68b85b8d88b -assets: - integration: - auto_install: true - configuration: {} - events: - creates_events: false - service_checks: - metadata_path: assets/service_checks.json - source_type_id: 10255 - source_type_name: 'Oracle Container Engine para Kubernetes: OKE' -author: - homepage: https://www.datadoghq.com - name: Datadog - sales_email: info@datadoghq.com - support_email: help@datadoghq.com categories: -- contenedores -- kubernetes +- configuración y despliegue +- rastreo +- Kubernetes +- métricas - oracle - orquestación -custom_kind: integration -dependencies: -- https://github.com/DataDog/integrations-core/blob/master/oke/README.md -display_on_public_website: true -draft: false -git_integration_title: oke -integration_id: oke -integration_title: Oracle Container Engine para Kubernetes -integration_version: '' -is_public: true -manifest_version: 2.0.0 -name: oke -public_title: Oracle Container Engine para Kubernetes -short_description: OKE es un servicio de orquestación de contenedores gestionado por - Oracle. +custom_kind: integración +description: OKE es un servicio de orquestación de contenedores gestionado por OCI. +further_reading: +- link: https://www.datadoghq.com/blog/monitor-oracle-kubernetes-engine/ + tag: blog + text: Cómo monitorizar el motor de Kubernetes de Oracle con Datadog +integration_version: 1.0.0 +media: [] supported_os: - linux - windows - macos -tile: - changelog: CHANGELOG.md - classifier_tags: - - Category::Containers - - Category::Kubernetes - - Category::Oracle - - Category::Orchestration - - Supported OS::Linux - - Supported OS::Windows - - Supported OS::macOS - - Offering::Integration - configuration: README.md#Setup - description: OKE es un servicio de orquestación de contenedores gestionado por Oracle. - media: [] - overview: README.md#Overview - resources: - - resource_type: Blog - url: https://www.datadoghq.com/blog/monitor-oracle-kubernetes-engine/ - support: README.md#Support - title: Oracle Container Engine para Kubernetes +title: Oracle Container Engine para Kubernetes --- +## Información general - +Oracle Cloud Infrastructure Container Engine para Kubernetes (OKE) es un servicio gestionado de Kubernetes que simplifica las operaciones de Kubernetes a escala empresarial. +Esta integración recopila métricas y etiquetas del espacio de nombres [`oci_oke`](https://docs.oracle.com/en-us/iaas/Content/ContEng/Reference/contengmetrics.htm) para ayudarte a monitorizar tu plano de control de Kubernetes, clústeres y estados de nodos. -## Información general +El despliegue del [Datadog Agent](https://docs.datadoghq.com/agent/kubernetes/#installation) en tu clúster de OKE también puede ayudarte a realizar un seguimiento de la carga en tus clústeres, pods y nodos individuales para obtener mejores conocimientos sobre cómo aprovisionar y desplegar tus recursos. + +Además de la monitorización de tus nodos, pods y contenedores, el Agent también puede recopilar e informar métricas de los servicios que se ejecutan en tu clúster, para que puedas: -Oracle Cloud Infrastructure Container Engine para Kubernetes (OKE) es un servicio totalmente gestionado de Kubernetes para desplegar y ejecutar tus aplicaciones en contenedores en Oracle Cloud. Datadog te proporciona una visibilidad completa de tus clústeres de Kubernetes gestionados por OKE. Una vez que hayas habilitado tu integración de Datadog, puedes ver tu infraestructura de Kubernetes, monitorizar Live Processes y realizar un seguimiento de métricas clave de todos tus pods y contenedores en un solo lugar. +- Explora tus clústeres de OKE con [dashboards preconfigurados de Kubernetes](https://app.datadoghq.com/dashboard/lists/preset/3?q=kubernetes) +- Monitorizar contenedores y procesos en tiempo real +- Hacer un seguimiento automático y monitorizar servicios en contenedores ## Configuración -Dado que Datadog ya se integra con Kubernetes, está preparado para monitorizar OKE. Si estás ejecutando el Agent en un clúster de Kubernetes y planeas migrar a OKE, puedes continuar con la monitorización de tu clúster con Datadog. +Una vez configurada la integración de [Oracle Cloud Infrastructure](https://docs.datadoghq.com/integrations/oracle_cloud_infrastructure/), asegúrate de que el espacio de nombres `oci_oke` está incluido en tu [Connector Hub](https://cloud.oracle.com/connector-hub/service-connectors). -Además, se admiten grupos de nodos de OKE. +Dado que Datadog ya se integra con Kubernetes, está preparado para monitorizar OKE. Si estás ejecutando el Agent en un clúster de Kubernetes y planeas migrar a OKE, puedes continuar con la monitorización de tu clúster con Datadog. +Desplegar el Agent como un DaemonSet con el [Helm chart](https://docs.datadoghq.com/agent/kubernetes/?tab=helm) es el método más directo (y recomendado), ya que asegura que el Agent se ejecutará como un pod en cada nodo dentro de tu clúster y que cada nuevo nodo tendrá automáticamente el Agent instalado. También puedes configurar el Agent para recopilar datos de procesos, trazas y logs añadiendo unas pocas líneas adicionales a un archivo de valores Helm. Adicionalmente, los grupos de nodos de OKE son compatibles. ## Solucionar problemas -¿Necesitas ayuda? Contacta con el [equipo de soporte de Datadog][1]. +¿Necesitas ayuda? Ponte en contacto con el [soporte de Datadog](https://docs.datadoghq.com/help/). ## Referencias adicionales -- [Cómo monitorizar OKE con Datadog][2] - -[1]: https://docs.datadoghq.com/es/help/ -[2]: https://www.datadoghq.com/blog/monitor-oracle-kubernetes-engine/ \ No newline at end of file +- [Cómo monitorizar OKE con Datadog](https://www.datadoghq.com/blog/monitor-oracle-kubernetes-engine/) \ No newline at end of file diff --git a/content/es/integrations/openmetrics.md b/content/es/integrations/openmetrics.md index 962d52ee8266a..d3ecf5cb3fbad 100644 --- a/content/es/integrations/openmetrics.md +++ b/content/es/integrations/openmetrics.md @@ -1,87 +1,45 @@ --- app_id: openmetrics -app_uuid: 302b841e-8270-4ecd-948e-f16317a316bc -assets: - integration: - auto_install: true - configuration: - spec: assets/configuration/spec.yaml - events: - creates_events: false - service_checks: - metadata_path: assets/service_checks.json - source_type_id: 10045 - source_type_name: OpenMetrics -author: - homepage: https://www.datadoghq.com - name: Datadog - sales_email: info@datadoghq.com - support_email: help@datadoghq.com categories: - métricas custom_kind: integración -dependencies: -- https://github.com/DataDog/integrations-core/blob/master/openmetrics/README.md -display_on_public_website: true -draft: false -git_integration_title: openmetrics -integration_id: openmetrics -integration_title: OpenMetrics -integration_version: 6.1.0 -is_public: true -manifest_version: 2.0.0 -name: openmetrics -public_title: OpenMetrics -short_description: OpenMetrics es un estándar abierto para exponer datos de métricas +description: OpenMetrics es un estándar abierto para exponer datos de métricas +further_reading: +- link: https://docs.datadoghq.com/agent/openmetrics/ + tag: documentación + text: Documentación sobre OpenMetrics +- link: https://docs.datadoghq.com/developers/openmetrics/ + tag: documentación + text: Documentación sobre OpenMetrics +integration_version: 7.0.0 +media: [] supported_os: - linux - windows - macos -tile: - changelog: CHANGELOG.md - classifier_tags: - - Supported OS::Linux - - Supported OS::Windows - - Category::Metrics - - Supported OS::macOS - - Offering::Integration - configuration: README.md#Setup - description: OpenMetrics es un estándar abierto para exponer datos de métricas - media: [] - overview: README.md#Overview - resources: - - resource_type: documentación - url: https://docs.datadoghq.com/agent/openmetrics/ - - resource_type: documentación - url: https://docs.datadoghq.com/developers/openmetrics/ - support: README.md#Support - title: OpenMetrics +title: OpenMetrics --- - - - - ## Información general Extrae métricas personalizadas de cualquier endpoint de OpenMetrics o Prometheus. -
--enable-source-maps. De lo contrario, los enlaces de código y fragmentos no funcionarán.
@@ -313,38 +314,52 @@ Si utilizas un host, tienes dos opciones: utilizar Microsoft SourceLink o config
#### Contenedores
-Si utilizas contenedores Docker, tienes dos opciones: utilizar Docker o configurar tu aplicación con variables de entorno `DD_GIT_*`.
+Si utilizas contenedores de Docker, tienes varias opciones: utilizar un complemento si tu aplicación está empaquetada, utilizar Docker, o configurar tu aplicación con variables de entorno `DD_GIT_*`.
-##### Opción 1: Docker
+##### Opción 1: Complemento empaquetador
+
+{{% sci-dd-tags-bundled-node-js %}}
+
+##### Opción 2: Docker
{{% sci-docker %}}
-##### Opción 2: Variables de entorno `DD_GIT_*`
+##### Opción 3: Variables de entorno `DD_GIT_*`
{{% sci-dd-git-env-variables %}}
#### Serverless
-Si utilizas la opción serverless, tienes dos opciones en función de la configuración de tu aplicación serverless.
+Si estás utilizando Serverless, tienes varias opciones dependiendo de la configuración de tu aplicación serverless.
-##### Opción 1: Herramientas de Datadog
+##### Opción 1: Complemento empaquetador
+
+{{% sci-dd-tags-bundled-node-js %}}
+
+##### Opción 2: Herramientas de Datadog
{{% sci-dd-serverless %}}
-##### Opción 2: Variables de entorno `DD_GIT_*`
+##### Opción 3: Variables de entorno `DD_GIT_*`
{{% sci-dd-git-env-variables %}}
-#### host
+#### Host
-Si utilizas un host, configura tu aplicación con variables de entorno `DD_GIT_*`.
+Para entornos basados en host, tienes dos opciones basadas en tu configuración de compilación y despliegue.
+
+##### Opción 1: Complemento empaquetador
+
+{{% sci-dd-tags-bundled-node-js %}}
+
+##### Opción 2: Variables de entorno `DD_GIT_*`
{{% sci-dd-git-env-variables %}}
{{% /tab %}}
{{% tab "Ruby" %}}
-Se requiere la librería del cliente Ruby versión 1.6.0 o posterior.
+Se requiere la biblioteca del cliente Ruby versión 1.6.0 o posterior.
#### Contenedores
@@ -370,7 +385,7 @@ Si utilizas la opción serverless, tienes dos opciones en función de la configu
{{% sci-dd-tags-env-variable %}}
-#### host
+#### Host
Si utilizas un host, configura tu aplicación con la variable de entorno `DD_TAGS`.
@@ -379,7 +394,7 @@ Si utilizas un host, configura tu aplicación con la variable de entorno `DD_TAG
{{% /tab %}}
{{% tab "Java" %}}
-Se requiere la librería del cliente Java versión 1.12.0 o posterior.
+Se requiere la biblioteca del cliente Java versión 1.12.0 o posterior.
#### Contenedores
@@ -405,7 +420,7 @@ Si utilizas la opción serverless, tienes dos opciones en función de la configu
{{% sci-dd-git-env-variables %}}
-#### host
+#### Host
Si utilizas un host, configura tu aplicación con variables de entorno `DD_GIT_*`.
@@ -414,7 +429,7 @@ Si utilizas un host, configura tu aplicación con variables de entorno `DD_GIT_*
{{% /tab %}}
{{% tab "PHP" %}}
-Se requiere la librería del cliente PHP versión 1.2.0 o posterior.
+Se requiere la biblioteca del cliente PHP versión 1.2.0 o posterior.
#### Contenedores
@@ -428,7 +443,7 @@ Si utilizas contenedores Docker, tienes dos opciones: utilizar Docker o configur
{{% sci-dd-git-env-variables %}}
-#### host
+#### Host
Si utilizas un host, configura tu aplicación con variables de entorno `DD_GIT_*`.
@@ -468,8 +483,8 @@ Para los lenguajes no compatibles, utiliza las etiquetas `git.commit.sha` y `git
En [Error Tracking][1], puedes ver los enlaces de los marcos de stack tecnológico hasta su repositorio de origen.
1. Ve a [**APM** > **Error Tracking**][2].
-2. Haz clic en un problema. El panel **Issue Details** aparece a la derecha.
-3. En **Último evento**, si utilizas las integraciones GitHub o GitLab, haz clic en **Connect to preview** (Conectar para previsualizar) en los marcos de stack tecnológico. Puedes ver fragmentos de código en línea directamente en la traza de stack tecnológico. De lo contrario, puedes hacer clic en el botón **View** (Ver) a la derecha de un marco o seleccionar **View file** (Ver archivo), **View Git blame* (Ver Git blame) o **View commit** (Ver commit) para ser redirigido a tu herramienta de gestión de código fuente.
+2. Haz clic en un problema. El panel **Issue Details** (información del incidente) aparece a la derecha.
+3. En **Latest Event** (Último evento), si utilizas las integraciones GitHub o GitLab, haz clic en **Connect to preview** (Conectar para previsualizar) en los marcos de stack tecnológico. Puedes ver fragmentos de código en línea directamente en la traza de stack tecnológico. De lo contrario, puedes hacer clic en el botón **View** (Ver) a la derecha de un marco o seleccionar **View file** (Ver archivo), **View Git blame* (Ver Git blame) o **View commit** (Ver commit) para ser redirigido a tu herramienta de gestión de código fuente.
{{< img src="integrations/guide/source_code_integration/error-tracking-panel-full.png" alt="Botón de visualización de repositorio con tres opciones (ver archivo, ver blame y ver confirmación) disponibles a la derecha de una stack trace de error en Error Tracking, junto con fragmentos de código en línea en la stack trace" style="width:100%;">}}
@@ -479,22 +494,17 @@ En [Error Tracking][1], puedes ver los enlaces de los marcos de stack tecnológi
{{% /tab %}}
{{% tab "Continuous Profiler" %}}
-En [Continuous Profiler][1], puedes ver una vista previa del código fuente de los marcos de perfiles.
-
-1. Ve a [**APM** > **Profile Search**][2].
-2. Pasa el cursor sobre un método en el gráfico de llamas.
-3. Si es necesario, pulsa `Opt` o `Alt` para habilitar la vista previa.
-4. Si utilizas las integraciones GitHub o GitLab, haz clic en **Connect to preview** (Conectar para previsualizar) para ver fragmentos de código en línea directamente en el gráfico de llamas.
-
-{{< img src="integrations/guide/source_code_integration/profiler-source-code-preview.png" alt="Vista previa del código fuente en Continuous Profiler" style="width:100%;">}}
-
-También puedes ver los enlaces de los marcos de perfiles hasta su repositorio de origen. Esto es compatible con los perfiles desglosados por línea, método o archivo.
+Puedes ver vistas previas del código fuente directamente en gráficas de llamas de [Continuous Profiler][1].
-1. Ve a [**APM** > **Profile Search**][2].
-2. Pasa el cursor sobre un método en el gráfico de llamas. A la derecha aparece un icono con tres puntos con la etiqueta **More actions**.
-3. Haz clic en **More actions** > **View in repo** para abrir la traza en su repositorio de código fuente.
+1. Ve a [**APM** > **Profiles** > **Explorer**][2] (APM > Perfiles > Explorador).
+2. Selecciona el servicio que deseas investigar.
+3. Pasa el cursor sobre un método en el gráfico de llamas.
+4. Pulsa `Opt` (en macOS) o `Ctrl` (en otros sistemas operativos) para bloquear la información sobre herramientas y poder interactuar con su contenido.
+5. Si se te solicita, haz clic en **Connect to preview** (Conectar para previsualizar). La primera vez que hagas esto para un repositorio, serás redirigido a GitHub para **Authorize** (Autorizar) la aplicación de Datadog.
+6. Después de autorizar, la vista previa del código fuente aparece en el tooltip.
+7. Haz clic en el enlace de archivo en el tooltip para abrir el archivo de código fuente completo en tu repositorio.
-{{< img src="integrations/guide/source_code_integration/profiler-link-to-git.png" alt="Enlace a GitHub desde Continuous Profiler" style="width:100%;">}}
+{{< img src="integrations/guide/source_code_integration/profiler-source-code-preview-2.png" alt="Vista previa de código fuente en el Continuous Profiler" style="width:100%;">}}
[1]: /es/profiler/
[2]: https://app.datadoghq.com/profiling/explorer
@@ -503,8 +513,8 @@ También puedes ver los enlaces de los marcos de perfiles hasta su repositorio d
En **Serverless Monitoring**, puedes ver los enlaces de los errores en tus stack traces, asociadas a funciones Lambda, hasta su repositorio de origen.
-1. Ve a [**Infrastructure** > **Serverless**][101] y haz clic en la pestaña **AWS**.
-2. Haz clic en una función Lambda y luego en el botón **Open Trace** para una invocación con una stack trace asociada.
+1. Ve a [**Infrastructure** > **Serverless** (Infraestructura > Serverless)][101] y haz clic en la pestaña **AWS**.
+2. Haz clic en una función Lambda y luego en el botón **Open Trace** (Abrir traza) para una invocación con una stack trace asociada.
3. Si utilizas las integraciones GitHub o GitLab, haz clic en **Connect to preview** (Conectar para previsualizar) en los marcos de stack tecnológico. Puedes ver fragmentos de código en línea directamente en la traza de stack tecnológico. De lo contrario, puedes hacer clic en el botón **View** (Ver) a la derecha de un marco o seleccionar **View file** (Ver archivo), **View Git blame* (Ver Git blame) o **View commit** (Ver commit) para ser redirigido a tu herramienta de gestión de código fuente.
{{< img src="integrations/guide/source_code_integration/serverless-aws-function-errors.mp4" alt="Enlace a GitHub desde Serverless Monitoring" video="true" >}}
@@ -512,11 +522,11 @@ En **Serverless Monitoring**, puedes ver los enlaces de los errores en tus stack
[101]: https://app.datadoghq.com/functions?cloud=aws&entity_view=lambda_functions
{{% /tab %}}
-{{% tab "Optimización de test" %}}
+{{% tab "Test Optimization" %}}
-Puedes ver los enlaces de los tests fallidos a tu repositorio fuente en **Optimización de test**.
+Puedes ver los enlaces de los tests fallidos a tu repositorio fuente en **Test Optimization**.
-1. Ve a [**Software Delivery** > **Test Optimization** > **Test Runs**][101] (Entrega de software > Optimización de test > Ejecuciones de test) y selecciona un test fallido.
+1. Ve a [**Software Delivery** > **Test Optimization** > **Test Runs**][101] (Entrega de software > Test Optimization > Ejecuciones de test) y selecciona un test fallido.
2. Si utilizas las integraciones GitHub o GitLab, haz clic en **Connect to preview** (Conectar para previsualizar) en los marcos de stack tecnológico. Puedes ver fragmentos de código en línea directamente en la traza de stack tecnológico. De lo contrario, puedes hacer clic en el botón **View** (Ver) a la derecha de un marco o seleccionar **View file** (Ver archivo), **View Git blame* (Ver Git blame) o **View commit** (Ver commit) para ser redirigido a tu herramienta de gestión de código fuente.
{{< img src="integrations/guide/source_code_integration/test_run_blurred.png" alt="Enlace a GitHub desde CI Visibility Explorer" style="width:100%;">}}
@@ -531,8 +541,8 @@ Para obtener más información, consulta [Mejora de los flujos de trabajo de los
Puedes ver los enlaces de los escaneos fallidos de Static Analysis y Software Composition Analysis a tu repositorio de fuentes en **Code Security**.
-1. Navega hasta [**Software Delivery** > **Code Security**][101] y selecciona un repositorio.
-2. En la vista **Vulnerabilidades de código** o **Code Quality**, haz clic en una vulnerabilidad o infracción de código. En la sección **Detalles**, si utilizas las integraciones GitHub, GitLab o Azure DevOps, haga clic en **Connect to preview** (Conectar para previsualizar). Puedes ver fragmentos de código en línea que resaltan las líneas exactas de código que desencadenaron la vulnerabilidad o infracción. De lo contrario, puedes hacer clic en el botón **View** (Ver) a la derecha de un marco o seleccionar **View file** (Ver archivo), **View Git blame* (Ver Git blame) o **View commit** (Ver commit) para ser redirigido a tu herramienta de gestión de código fuente.
+1. Ve a [**Software Delivery** > **Code Security** (Entrega de software > Code Security)][101] y selecciona un repositorio.
+2. En la vista **Code Vulnerabilities** (Vulnerabilidades de código) o **Code Quality** (Callidad del còdigo), haz clic en una vulnerabilidad o infracción de código. En la sección **Detalles**, si utilizas las integraciones GitHub, GitLab o Azure DevOps, haga clic en **Connect to preview** (Conectar para previsualizar). Puedes ver fragmentos de código en línea que resaltan las líneas exactas de código que desencadenaron la vulnerabilidad o infracción. De lo contrario, puedes hacer clic en el botón **View** (Ver) a la derecha de un marco o seleccionar **View file** (Ver archivo), **View Git blame* (Ver Git blame) o **View commit** (Ver commit) para ser redirigido a tu herramienta de gestión de código fuente.
{{< img src="integrations/guide/source_code_integration/code-analysis-scan.png" alt="Enlace a GitHub desde la vista Code Security Code Vulnerabilities" style="width:100%;">}}
@@ -546,28 +556,28 @@ Para más información, consulta la [Documentación sobre Code Security][102].
Puedes ver los enlaces de los errores en los stack traces asociados de tus señales de seguridad a tu repositorio fuente en **App and API Protection Monitoring**.
-1. Navega a [**Security** > **App and API Protection**][101] (Seguridad > App and API Protection) y selecciona una señal de seguridad.
-2. Desplázate hasta la sección **Traces**, en la pestaña **Related Signals**, y haz clic en una stack trace asociada.
+1. Ve a [**Security** > **App and API Protection** (Seguridad > Protección de aplicaciones y API)][101] y selecciona una señal de seguridad.
+2. Desplázate hasta la sección **Traces**, en la pestaña **Señales relacionadas**, y haz clic en una stack trace asociada.
3. Si utilizas las integraciones GitHub o GitLab, haz clic en **Connect to preview** (Conectar para previsualizar) en los marcos de stack tecnológico. Puedes ver fragmentos de código en línea directamente en la traza de stack tecnológico. De lo contrario, puedes hacer clic en el botón **View** (Ver) a la derecha de un marco o seleccionar **View file** (Ver archivo), **View Git blame* (Ver Git blame) o **View commit** (Ver commit) para ser redirigido a tu herramienta de gestión de código fuente.
-{{< img src="integrations/guide/source_code_integration/asm-signal-trace-blur.png" alt="Enlace a GitHub desde App and API Protection Monitoring" style="width:100%;">}}
+{{< img src="integrations/guide/source_code_integration/asm-signal-trace-blur.png" alt="Enlace a GitHub desde Monitorización de la protección de aplicaciones y API" style="width:100%;">}}
[101]: https://app.datadoghq.com/security/appsec
{{% /tab %}}
{{% tab "Dynamic Instrumentation" %}}
-Puedes ver los archivos de código fuente completos en [**Dynamic Instrumentation**][102] al crear o editar una instrumentación (log dinámico, métrica, tramo o span tags).
+Puedes ver los archivos de código fuente completos en [**Dynamic Instrumentation**][102] (Instrumentación dinámica) al crear o editar una instrumentación (log dinámico, métrica, tramo o etiquetas de tramo).
#### Crear nueva instrumentación
-1. Ve a [**APM** > **Dynamic Instrumentation**][101].
+1. Ve a [**APM** > **Dynamic Instrumentation** (APM > Instrumentación dinámica)][101].
2. Selecciona **Create New Instrumentation** (Crear nueva instrumentación) y elige un servicio a instrumentar.
3. Busca y selecciona un nombre de archivo o método de código fuente.
#### Ver o editar instrumentación
-1. Ve a [**APM** > **Dynamic Instrumentation**][101].
+1. Ve a [**APM** > **Dynamic Instrumentation** (APM > Instrumentación dinámica)][101].
2. Selecciona una instrumentación existente en la lista y haz clic en **View Events** (Ver eventos).
3. Selecciona la tarjeta de instrumentación para ver su localización en el código fuente.
@@ -585,9 +595,9 @@ Para más información, consulta la [documentación de Dynamic Instrumentation][
{{< tabs >}}
{{% tab "CI Visibility" %}}
-Los comentarios en solicitudes pull están habilitados por defecto cuando se accede por primera vez a CI Visibility, si la integración GitHub o GitLab está instalada correctamente. Estas integraciones publican un comentario resumiendo los trabajos fallidos detectados en tu solicitud pull.
+Los comentarios de solicitud pull están habilitados por defecto cuando se accede por primera vez a CI Visibility si la integración con GitHub o GitLab está instalada correctamente. Estas integraciones publican un comentario resumiendo los trabajos fallidos detectados en tu solicitud pull.
-{{< img src="integrations/guide/source_code_integration/ci-visibility-pr-comment.png" alt="Comentario en solicitud pull que resume los trabajos fallidos detectados por CI Visibility" style="width:100%;">}}
+{{< img src="integrations/guide/source_code_integration/ci-visibility-pr-comment.png" alt="Comentario en solicitud pull que resume los trabajos fallidos detectados por CI Visibility" style="width:100%;">}}
Para desactivar los comentarios en solicitudes pull para CI Visibility, ve a los [parámetros de repositorios de CI Visibility][101].
@@ -596,9 +606,9 @@ Para desactivar los comentarios en solicitudes pull para CI Visibility, ve a los
{{% /tab %}}
{{% tab "Code Security" %}}
-Los comentarios en solicitudes pull están habilitados por defecto cuando se accede por primera vez a Code Security, si la integración GitHub, GitLab o Azure DevOps está instalada correctamente. Estas integraciones publican dos tipos de comentarios en tus solicitudes pull.
+Los comentarios de solicitud pull están habilitados por defecto al acceder por primera vez a Code Security si la integración con GitHub, GitLab o Azure DevOps está instalada correctamente. Estas integraciones publican dos tipos de comentarios en tus solicitudes pull:
-1. Un único comentario que resume las nuevas infracciones detectadas en tu solicitud pull.
+1. Un único comentario que resuma las nuevas infracciones detectadas en tu solicitud pull.
{{< img src="integrations/guide/source_code_integration/code-security-summary-pr-comment.png" alt="Comentario en solicitud pull que resume las nuevas infracciones detectadas por Code Security" style="width:100%;">}}
@@ -611,9 +621,9 @@ Para desactivar los comentarios en solicitudes pull para Code Security, ve a los
[101]: https://app.datadoghq.com/security/configuration/code-security/settings
{{% /tab %}}
-{{% tab "Optimización de test" %}}
+{{% tab "Test Optimization" %}}
-Los comentarios en solicitudes pull están habilitados por defecto cuando se accede por primera vez a Test Optimization, si la integración GitHub o GitLab está instalada correctamente. Estas integraciones publican un comentario resumiendo los tests fallidos o defectuosos detectados en tu solicitud pull.
+Los comentarios de solicitud pull están habilitados por defecto cuando se accede por primera vez a Test Optimization (optimización de tests) si la integración con GitHub o GitLab está instalada correctamente. La integración publica un comentario en el que se resumen los tests fallidos y defectuosos detectados en tu solicitud pull.
{{< img src="integrations/guide/source_code_integration/test-optimization-pr-comment.png" alt="Comentario en solicitud pull que resume los tests fallidos y defectuosos detectados por Test Optimization" style="width:100%;">}}
@@ -635,4 +645,4 @@ Para desactivar los comentarios en solicitudes pull para Test Optimization, ve a
[6]: /es/tracing/
[7]: https://app.datadoghq.com/source-code/setup/apm
[8]: /es/tracing/error_tracking/
-[9]: /es/tracing/trace_collection/dd_libraries/
+[9]: /es/tracing/trace_collection/dd_libraries/
\ No newline at end of file
diff --git a/content/es/integrations/honeybadger.md b/content/es/integrations/honeybadger.md
index a357548c779cc..cf45eebce406f 100644
--- a/content/es/integrations/honeybadger.md
+++ b/content/es/integrations/honeybadger.md
@@ -1,54 +1,15 @@
---
app_id: honeybadger
-app_uuid: 385c386e-6394-41f4-8c92-5944e6b203f5
-assets:
- integration:
- auto_install: true
- events:
- creates_events: true
- service_checks:
- metadata_path: assets/service_checks.json
- source_type_id: 130
- source_type_name: Honeybadger
-author:
- homepage: https://www.datadoghq.com
- name: Datadog
- sales_email: info@datadoghq.com
- support_email: help@datadoghq.com
categories:
- event management
- issue tracking
custom_kind: integración
-dependencies: []
-display_on_public_website: true
-draft: false
-git_integration_title: honeybadger
-integration_id: honeybadger
-integration_title: Honeybadger
-integration_version: ''
-is_public: true
-manifest_version: 2.0.0
-name: honeybadger
-public_title: Honeybadger
-short_description: Visualiza, busca y analiza excepciones de Honeybadger en tu flujo
- de eventos.
-supported_os: []
-tile:
- changelog: CHANGELOG.md
- classifier_tags:
- - Category::Event Management
- - Category::Issue Tracking
- - Offering::Integration
- configuration: README.md#Configuración
- description: Visualiza, busca y analiza excepciones de Honeybadger en tu flujo de
- eventos.
- media: []
- overview: README.md#Información general
- support: README.md#Soporte
- title: Honeybadger
+description: Visualizar, buscar y discutir excepciones de Honeybadger en tu evento
+ stream.
+integration_version: 1.0.0
+media: []
+title: Honeybadger
---
-
-
## Información general
Honeybadger proporciona monitorización de excepciones y tiempo de actividad para mantener tus aplicaciones web libres de errores. Conecta Honeybadger a Datadog para recibir alertas de Honeybadger en tu flujo de eventos de Datadog.
@@ -59,13 +20,13 @@ Honeybadger proporciona monitorización de excepciones y tiempo de actividad par
Para capturar errores de Honeybadger:
-1. Abre tu [lista de proyectos][1] de Honeybadger.
-2. Haz clic en «Settings» (Configuración) del proyecto que deseas monitorizar.
-3. Haz clic en «Alerts & Integrations» (Alertas e integraciones).
-4. Selecciona «Datadog» como integración nueva.
-5. Añade tu [clave de API][2].
-6. Guarda la integración.
-7. Haz clic en el botón **Install Integration** (Instalar integración) del [cuadro de integración de Honeybadger][3].
+1. Abre tu [lista de proyectos](https://app.honeybadger.io/users/sign_in). de Honeybadger.
+1. Haz clic en «Settings» (Configuración) del proyecto que deseas monitorizar.
+1. Haz clic en «Alerts & Integrations» (Alertas e integraciones).
+1. Selecciona «Datadog» como integración nueva.
+1. Añade tu [clave de API](https://app.datadoghq.com/organization-settings/api-keys).
+1. Guarda la integración.
+1. Haz clic en el botón **Install Integration** (Instalar integración) del [cuadro de integración de Honeybadger](https://app.datadoghq.com/account/settings#integrations/honeybadger).
## Datos recopilados
@@ -83,9 +44,4 @@ La integración de Honeybadger no incluye checks de servicio.
## Solucionar problemas
-¿Necesitas ayuda? Ponte en contacto con el [servicio de asistencia de Datadog][4].
-
-[1]: https://app.honeybadger.io/users/sign_in
-[2]: https://app.datadoghq.com/organization-settings/api-keys
-[3]: https://app.datadoghq.com/account/settings#integrations/honeybadger
-[4]: https://docs.datadoghq.com/es/help/
\ No newline at end of file
+¿Necesitas ayuda? Ponte en contacto con el [servicio de asistencia de Datadog](https://docs.datadoghq.com/help/).
\ No newline at end of file
diff --git a/content/es/integrations/jenkins.md b/content/es/integrations/jenkins.md
index 27753bf7ad23a..ee9dd83d51bcc 100644
--- a/content/es/integrations/jenkins.md
+++ b/content/es/integrations/jenkins.md
@@ -1,21 +1,11 @@
---
-categories:
-- configuration & deployment
+app_id: jenkins
custom_kind: integración
-dependencies:
-- https://github.com/jenkinsci/datadog-plugin/blob/master/README.md
description: Reenvía automáticamente tus métricas, eventos y checks de servicio de
Jenkins to Datadog.
-doc_link: https://docs.datadoghq.com/integrations/jenkins/
-git_integration_title: jenkins
-has_logo: true
-integration_title: Jenkins
-is_public: true
-name: jenkins
-public_title: Integración de Datadog y Jenkins
-short_description: Reenvía automáticamente tus métricas, eventos y servicios de Jenkins
- checks to Datadog.
+title: Jenkins
---
+
Un complemento de Jenkins para reenviar automáticamente métricas, eventos y checks de servicio a una cuenta de Datadog.
![Dashboard de Jenkins Datadog][16]
@@ -274,7 +264,7 @@ pipeline {
datadog(testOptimization: [
enabled: true,
serviceName: "my-service", // the name of service or library being tested
- languages: ["JAVA"], // languages that should be instrumented (available options are "JAVA", "JAVASCRIPT", "PYTHON", "DOTNET", "RUBY")
+ languages: ["JAVA"], // languages that should be instrumented (available options are "JAVA", "JAVASCRIPT", "PYTHON", "DOTNET", "RUBY", "GO")
additionalVariables: ["my-var": "value"] // additional tracer configuration settings (optional)
])
}
@@ -425,7 +415,7 @@ NOTA: Como se menciona en la sección [personalización del trabajo](#job-custom
**Nota**: Esta configuración sólo se aplica a aquellos que utilizan la [configuración del Datadog Agent](#plugin-user-interface).
-1. La recopilación de logs está deshabilitada por defecto en el Datadog Agent; habilítala en tu archivo `datadog.yaml`:
+1. La recopilación de logs está desactivada en forma predeterminada en el Datadog Agent, actívala en tu archivo `datadog.yaml`:
```yaml
logs_enabled: true
@@ -449,7 +439,7 @@ NOTA: Como se menciona en la sección [personalización del trabajo](#job-custom
Crea el estado `jenkins.job.status` con las siguientes etiquetas predeterminadas: `jenkins_url`, `job`, `node`, `user_id`
-## Resolución de problemas
+## Solucionar problemas
### Generación de un flare de diagnóstico.
diff --git a/content/es/integrations/journald.md b/content/es/integrations/journald.md
index 2c1e7c86e959e..441020a791fa4 100644
--- a/content/es/integrations/journald.md
+++ b/content/es/integrations/journald.md
@@ -1,89 +1,46 @@
---
app_id: journald
-app_uuid: 2ee4cbe2-2d88-435b-9ed9-dbe07ca1d059
-assets:
- integration:
- auto_install: true
- configuration:
- spec: assets/configuration/spec.yaml
- events:
- creates_events: false
- service_checks:
- metadata_path: assets/service_checks.json
- source_type_id: 10167
- source_type_name: journald
-author:
- homepage: https://www.datadoghq.com
- name: Datadog
- sales_email: info@datadoghq.com
- support_email: help@datadoghq.com
categories:
- recopilación de logs
custom_kind: integración
-dependencies:
-- https://github.com/DataDog/integrations-core/blob/master/journald/README.md
-display_on_public_website: true
-draft: false
-git_integration_title: journald
-integration_id: journald
-integration_title: journald
+description: Monitoriza tus logs systemd-journald con Datadog.
integration_version: 3.0.0
-is_public: true
-manifest_version: 2.0.0
-name: journald
-public_title: journald
-short_description: Monitoriza tus logs systemd-journald con Datadog.
+media: []
supported_os:
- linux
- macos
- windows
-tile:
- changelog: CHANGELOG.md
- classifier_tags:
- - Supported OS::Linux
- - Supported OS::macOS
- - Supported OS::Windows
- - Category::Log Collection
- - Offering::Integration
- configuration: README.md#Setup
- description: Monitoriza tus logs systemd-journald con Datadog.
- media: []
- overview: README.md#Overview
- support: README.md#Support
- title: journald
+title: journald
---
-
-
-
-
## Información general
-Systemd-journald es un servicio de sistema que recopila y almacena datos de registro.
-Crea y mantiene diarios estructurados e indexados basados en información de registro procedente de diversas fuentes.
+Systemd-journald es un servicio de sistema que recopila y almacena datos de generación de logs.
+Este servicio crea y conserva registros estructurados e indexados basados en la información de generación de logs procedente de diversas fuentes.
## Configuración
### Instalación
-El check de journald está incluido en el paquete del [Datadog Agent ][1].
+El check de journald está incluido en el paquete del [Datadog Agent](https://docs.datadoghq.com/agent/guide/agent-commands/#start-stop-and-restart-the-agent).
No es necesaria ninguna instalación adicional en tu servidor.
### Configuración
-Los archivos del diario, por defecto, son propiedad del grupo del sistema systemd-journal y pueden ser leidos por él. Para empezar a recopilar tus logs de diario, debes hacer lo siguiente:
+Los archivos del registro, por defecto, son propiedad del grupo del sistema systemd-journal y pueden ser leidos por él. Para empezar a recopilar tus logs de registro, debes hacer lo siguiente:
-1. [Instala el Agent][2] en la instancia que ejecuta el diario.
-2. Añade el usuario `dd-agent` al grupo `systemd-journal` ejecutando:
- ```text
- usermod -a -G systemd-journal dd-agent
- ```
+1. [Instala el Agent](https://app.datadoghq.com/account/settings/agent/latest) en la instancia que ejecuta el registro.
+1. Añade el usuario `dd-agent` al grupo `systemd-journal` ejecutando:
+ ```text
+ usermod -a -G systemd-journal dd-agent
+ ```
{{< tabs >}}
+
{{% tab "Host" %}}
Para configurar este check para un Agent que se ejecuta en un host:
-Edita el archivo `journald.d/conf.yaml`, en la carpeta `conf.d/` en la raíz de tu [directorio de configuración del Agent][1] para empezar a recopilar logs.
+Edita el archivo `journald.d/conf.yaml`, que se encuentra en la carpeta `conf.d/` en la raíz de tu [directorio de configuración del Agent](https://docs.datadoghq.com/agent/guide/agent-configuration-files/#agent-configuration-directory) para empezar a recopilar logs.
#### Recopilación de logs
@@ -105,50 +62,44 @@ Para rellenar los atributos `source` y `service`, el Agent recopila `SYSLOG_IDEN
**Nota**: Con Agent 7.17+, si `container_mode` se establece en `true`, el comportamiento por defecto cambia para logs procedentes de contenedores de Docker. El atributo `source` de tus logs se establecen automáticamente en el nombre corto de imagen correspondiente del contenedor en lugar de simplemente `docker`.
-[Reinicia el Agent][2].
+[Reinicia el Agent](https://docs.datadoghq.com/agent/guide/agent-commands/#start-stop-and-restart-the-agent).
-
-[1]: https://docs.datadoghq.com/es/agent/guide/agent-configuration-files/#agent-configuration-directory
-[2]: https://docs.datadoghq.com/es/agent/guide/agent-commands/#start-stop-and-restart-the-agent
{{% /tab %}}
-{{% tab "Contenedorizado" %}}
-Para entornos en contenedores, consulta las [plantillas de integración de Autodiscovery][1] para obtener orientación sobre la aplicación de los parámetros que se indican a continuación.
+{{% tab "En contenedores" %}}
-#### Recopilación de logs
+Para entornos en contenedores, consulta las [plantillas de integración de Autodiscovery](https://docs.datadoghq.com/agent/kubernetes/integrations/) para obtener orientación sobre la aplicación de los parámetros que se indican a continuación.
+#### Recopilación de logs
-La recopilación de logs está desactivada por defecto en Datadog Agent. Para activarla, consulta [recopilación de logs de Kubernetes][2].
+La recopilación de logs está desactivada en forma predeterminada en el Datadog Agent. Para activarla, consulta [Recopilación de logs de Kubernetes](https://docs.datadoghq.com/agent/kubernetes/log/?tab=containerinstallation#setup).
| Parámetro | Valor |
| -------------- | ------------------------------------------------------ |
| `
+Si utilizas Cloud SIEM, Datadog recomienda utilizar la integración de Microsoft Entra ID para una mejor cobertura de detección de seguridad.
+
+
Integra con Microsoft 365 para:
- Ver y analizar los logs de auditoría con el producto de registro de Datadog
@@ -41,19 +28,19 @@ Integra con Microsoft 365 para:
### Instalación
-Usa el [cuadro de Microsoft 365 y Datadog][1] para instalar la integración.
+Utiliza el [ícono de Datadog Microsoft 365](https://app.datadoghq.com/integrations/microsoft-365) para instalar la integración.
Haz clic en **Install a New Tenant** (Instalar un inquilino nuevo). Esto te indicará que debes iniciar sesión en tu cuenta de Microsoft 365 para obtener autorización. Debes iniciar sesión con una cuenta de administrador.
De manera opcional, añade etiquetas (tags) personalizadas separadas por comas que se adjunten a cada log para este inquilino recién configurado, por ejemplo, `environment:prod,team:us`. Estas etiquetas se pueden usar para filtrar o analizar logs.
-**Nota**: Tu organización debe tener el [registro de auditoría habilitado][2] para usar el registro de auditoría de Datadog.
+**Nota**: Tu organización debe tener [activado el registro de auditoría](https://docs.microsoft.com/en-us/microsoft-365/compliance/turn-audit-log-search-on-or-off?view=o365-worldwide#turn-on-audit-log-search) para utilizar el registro de auditoría de Datadog.
## Datos recopilados
### Logs
-Puedes recopilar logs de auditoría para todos los servicios que se mencionan en los [esquemas de la API de gestión de Office 365][3], como:
+Puedes recopilar logs de auditoría de todos los servicios mencionados en los [esquemas de la API de gestión de Office 365](https://learn.microsoft.com/en-us/office/office-365-management-api/office-365-management-activity-api-schema#office-365-management-api-schemas), como:
- Microsoft Teams
- Power BI
@@ -65,90 +52,90 @@ Puedes recopilar logs de auditoría para todos los servicios que se mencionan en
La integración de Microsoft 365 produce un evento de log por log de auditoría. Los logs recopilados se etiquetan con la fuente `microsoft-365`. Haz clic a continuación para obtener una lista de fuentes de log comunes con resúmenes y enlaces a consultas de log preestablecidas en Datadog.
-
-Consulta los [esquemas de la API de gestión de Office 365][3] para obtener la lista completa de posibles fuentes de log.
+Consulta [Esquemas de la API de gestión de Office 365](https://learn.microsoft.com/en-us/office/office-365-management-api/office-365-management-activity-api-schema#office-365-management-api-schemas) para ver la lista completa de posibles sources (fuentes) de logs.
### Seguridad
-Puedes usar [Cloud SIEM][28] de Datadog para detectar amenazas en tiempo real en tu entorno con logs de auditoría de Microsoft 365. Consulta la lista completa de [reglas de detección de Microsoft 365 predefinidas][29] o [crea una regla de detección personalizada][30].
+Puedes utilizar [Cloud SIEM] de Datadog (https://docs.datadoghq.com/security/#cloud-siem) para detectar amenazas en tiempo real en tu entorno con logs de auditoría de Microsoft 365. Consulte la lista completa de [reglas de detección predefinidas de Microsoft 365](https://docs.datadoghq.com/security/default_rules/?category=cat-cloud-siem-log-detection&search=microsoft+365) o [crea una regla de detección personalizada](https://docs.datadoghq.com/security/detection_rules/#create-detection-rules).
{{< img src="integrations/microsoft_365/microsoft_365_rules.png" alt="La página de reglas de seguridad predefinidas con Cloud SIEM seleccionado y Microsoft 365 ingresado en la barra de búsqueda" style="width:80;" popup="true">}}
@@ -156,50 +143,18 @@ Puedes usar [Cloud SIEM][28] de Datadog para detectar amenazas en tiempo real en
La integración de Microsoft 365 no recopila métricas.
-### Checks de servicios
+### Checks de servicio
La integración de Microsoft 365 no recopila checks de servicio.
-## Resolución de problemas
+## Solucionar problemas
La entrada de logs de Datadog solo permite retrotraer eventos de log hasta 18 horas atrás. Se descartan los eventos de log con una marca de tiempo anterior.
Datadog no es compatible con los inquilinos de DoD, gobierno de CCG o gobierno de GCC High, porque requieren diferentes endpoints de Microsoft.
-¿Necesitas ayuda? Ponte en contacto con el [servicio de asistencia de Datadog][31].
-
-## Leer más
-
-{{< partial name="whats-next/whats-next.html" >}}
-
-[1]: https://app.datadoghq.com/integrations/microsoft-365
-[2]: https://docs.microsoft.com/en-us/microsoft-365/compliance/turn-audit-log-search-on-or-off?view=o365-worldwide#turn-on-audit-log-search
-[3]: https://learn.microsoft.com/en-us/office/office-365-management-api/office-365-management-activity-api-schema#office-365-management-api-schemas
-[4]: https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3AAirInvestigation%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true
-[5]: https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3AAzureActiveDirectory%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true
-[6]: https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3AExchange%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true
-[7]: https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true
-[8]: https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3AMicrosoftForms%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true
-[9]: https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3AMicrosoftStream%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true
-[10]: https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3AMicrosoftTeams%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true
-[11]: https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3AOneDrive%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true
-[12]: https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3APowerBI%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true
-[13]: https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3AProject%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true
-[14]: https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3ASharePoint%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true
-[15]: https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3ASkypeForBusiness%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true
-[16]: https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3AYammer%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true
-[17]: https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3AComplianceManager%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true
-[18]: https://learn.microsoft.com/dynamics365/
-[19]: https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3AMicrosoftFlow%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true
-[20]: https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3AMip%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true
-[21]: https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3AMyAnalytics%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true
-[22]: https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3APowerApps%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true
-[23]: https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3AQuarantine%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true
-[24]: https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3ARdl%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true
-[25]: https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3ASecurityComplianceCenter%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true
-[26]: https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3ASecurityMonitoringEntityReducer%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true
-[27]: https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3AThreatIntelligence%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true
-[28]: https://docs.datadoghq.com/es/security/#cloud-siem
-[29]: https://docs.datadoghq.com/es/security/default_rules/?category=cat-cloud-siem-log-detection&search=microsoft+365
-[30]: https://docs.datadoghq.com/es/security/detection_rules/#create-detection-rules
-[31]: https://docs.datadoghq.com/es/help/
\ No newline at end of file
+¿Necesitas ayuda? Ponte en contacto con [asistencia técnica de Datadog](https://docs.datadoghq.com/help/).
+
+## Referencias adicionales
+
+{{< partial name="whats-next/whats-next.html" >}}
\ No newline at end of file
diff --git a/content/es/integrations/mysql.md b/content/es/integrations/mysql.md
index b106ffc6b73ca..4da709691e412 100644
--- a/content/es/integrations/mysql.md
+++ b/content/es/integrations/mysql.md
@@ -1,110 +1,50 @@
---
-app_id: "mysql"
-app_uuid: "f6177896-da1e-4bc4-ab19-fd32e8868647"
-assets:
- dashboards:
- mysql: "assets/dashboards/overview.json"
- mysql-screenboard: "assets/dashboards/overview-screenboard.json"
- integration:
- auto_install: true
- configuration:
- spec: "assets/configuration/spec.yaml"
- events:
- creates_events: true
- metrics:
- check: "mysql.net.connections"
- metadata_path: "metadata.csv"
- prefix: "mysql."
- process_signatures:
- - "mysqld"
- service_checks:
- metadata_path: "assets/service_checks.json"
- source_type_id: !!int "18"
- source_type_name: "MySQL"
- monitors:
- MySQL database replica is not running properly: "assets/monitors/replica_running.json"
- SELECT query volume is dropping: "assets/monitors/select_query_rate.json"
- saved_views:
- mysql_processes: "assets/saved_views/mysql_processes.json"
- operations: "assets/saved_views/operations.json"
- operations_overview: "assets/saved_views/operations_overview.json"
- slow_operations: "assets/saved_views/slow_operations.json"
-author:
- homepage: "https://www.datadoghq.com"
- name: "Datadog"
- sales_email: "info@datadoghq.com"
- support_email: "help@datadoghq.com"
+app_id: mysql
categories:
-- "data stores"
-- "log collection"
-custom_kind: "integración"
-dependencies:
-- "https://github.com/DataDog/integrations-core/blob/master/mysql/README.md"
-display_on_public_website: true
-draft: false
-git_integration_title: "mysql"
-integration_id: "mysql"
-integration_title: "MySQL"
-integration_version: "14.3.0"
-is_public: true
-manifest_version: "2.0.0"
-name: "mysql"
-public_title: "MySQL"
-short_description: "Recopila métricas de esquema de rendimiento, rendimiento de consultas, métricas personalizadas y mucho más."
+- data stores
+- log collection
+custom_kind: integración
+description: Recopila métricas de esquemas de rendimiento, rendimiento de consultas
+ y métricas personalizadas, and more.
+further_reading:
+- link: https://www.datadoghq.com/blog/monitoring-mysql-performance-metrics
+ tag: blog
+ text: Monitorización de las métricas de rendimiento de MySQL
+integration_version: 15.7.1
+media: []
supported_os:
-- "linux"
-- "macos"
-- "windows"
-tile:
- changelog: "CHANGELOG.md"
- classifier_tags:
- - "Supported OS::Linux"
- - "Supported OS::macOS"
- - "Supported OS::Windows"
- - "Category::Data Stores"
- - "Category::Log Collection"
- - "Offering::Integration"
- configuration: "README.md#Setup"
- description: "Recopila métricas de esquema de rendimiento, rendimiento de consultas, métricas personalizadas y mucho más."
- media: []
- overview: "README.md#Overview"
- resources:
- resource_type: "blog"
- url: "https://www.datadoghq.com/blog/monitoring-mysql-performance-metrics"
- support: "README.md#Support"
- title: "MySQL"
+- linux
+- macos
+- windows
+title: MySQL
---
-
-
-
-
-![Dashboard de MySQL][1]
+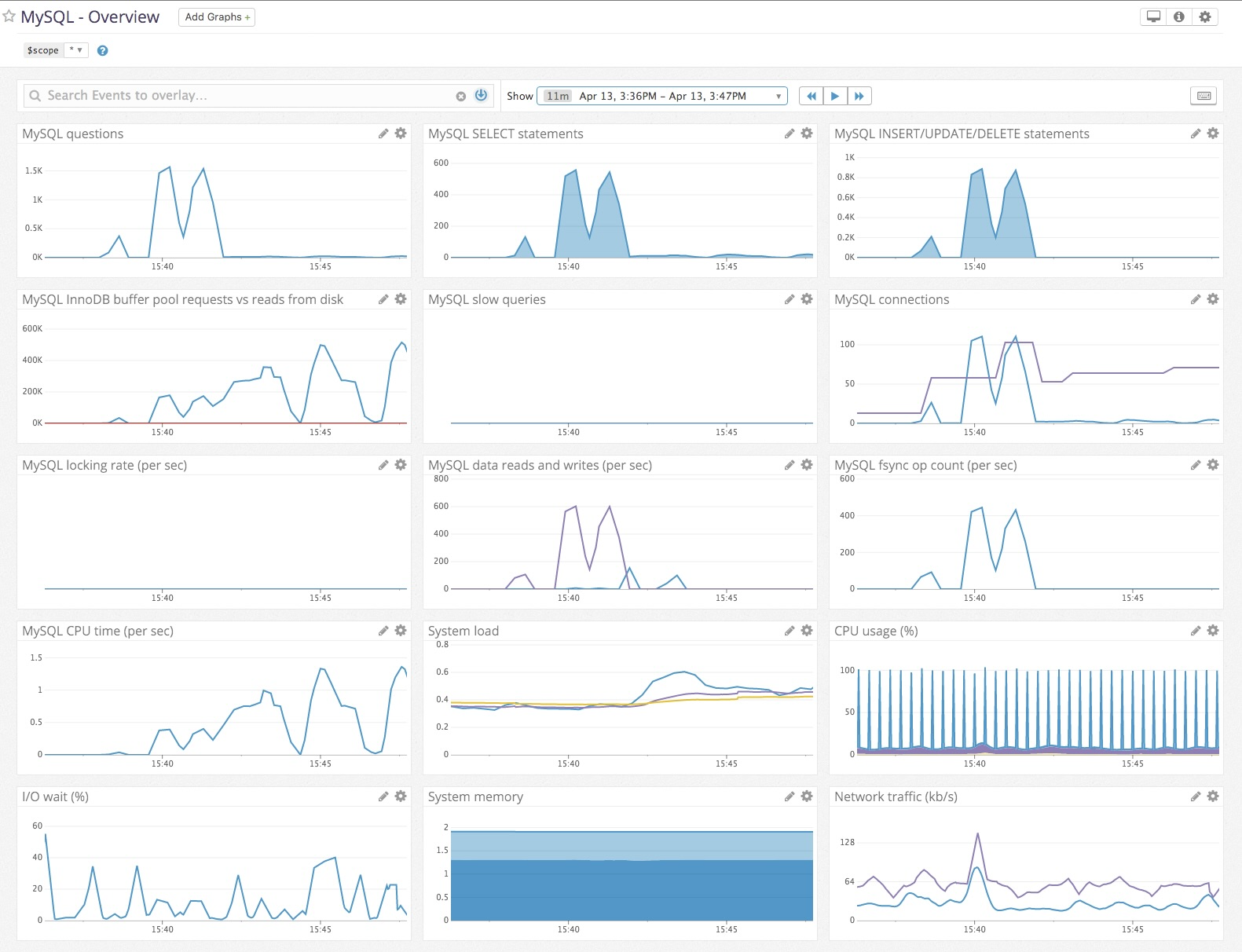
## Información general
La integración de MySQL controla el rendimiento de tus instancias de MySQL. Recopila métricas en relación con el rendimiento, las conexiones, los errores y métricas de InnoDB.
-Activa la [Monitorización de base de datos][2] (DBM) para obtener información mejorada sobre el rendimiento de las consultas y el estado de la base de datos. Además de la integración estándar, Datadog DBM proporciona métricas a nivel de consulta, snapshots de consultas en tiempo real e históricas, análisis de eventos en espera, carga de la base de datos y planes de explicación de consultas.
+Activa [Database Monitoring](https://docs.datadoghq.com/database_monitoring/) (DBM) para obtener información mejorada sobre el rendimiento de las consultas y el estado de la base de datos. Además de la integración estándar, DBM de Datadog proporciona métricas a nivel de consulta, instantáneas de consultas históricas y en tiempo real, análisis de eventos de espera, carga de base de datos y planes de explicación de consultas.
-Se admiten las versiones 5.6, 5.7 y 8.0 de MySQL, y las versiones 10.5, 10.6, 10.11 y 11.1 de MariaDB.
+Se admiten las versiones 5.6, 5.7 y 8.0 de MySQL y las versiones 10.5, 10.6, 10.11 y 11.1 de MariaDB.
## Configuración
-Haz clic para ver las fuentes de log comunes
+Haz clic para ver las sources (fuentes) de logs habituales
-[`AirInvestigation`][4] -: Relacionado con las investigaciones de Advanced eDiscovery y Advanced Threat Protection (ATP) dentro de Microsoft 365. Estos logs contienen información sobre incidencias de seguridad, investigaciones y acciones tomadas para mitigar amenazas, como alertas, pasos de corrección y datos forenses. +[`AirInvestigation`](https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3AAirInvestigation%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true) +: Relacionado con investigaciones de Advanced eDiscovery y Advanced Threat Protection (ATP) en Microsoft 365. Estos logs contienen información sobre incidents (incidentes) de seguridad, investigaciones y medidas tomadas para mitigar amenazas, como alertas, steps (UI) / pasos (generic) de corrección y datos forenses. -[`Audit.AzureActiveDirectory`][5] -: Representa a los logs que genera Azure Active Directory (Azure AD), el servicio de gestión de identidad y acceso basado en la nube de Microsoft. Los logs de Azure AD proporcionan información sobre las actividades de inicio de sesión de los usuarios, la gestión de directorios y grupos, el acceso a las aplicaciones, y los eventos relacionados con la seguridad. Permite a las organizaciones gestionar el acceso de los usuarios y detectar posibles riesgos de seguridad. +[`Audit.AzureActiveDirectory`](https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3AAzureActiveDirectory%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true) +: Representa logs generados Azure Active Directory (Azure AD), identidad basada en la nube de Microsoft y servicio de gestión de acceso. Los logs de Azure AD brindan información sobre las actividades de inicio de sesión del usuario, gestión de grupos y directorios, acceso a aplicaciones y eventos relacionados con la seguridad. Permite que las organizaciones gestionen el acceso del usuario y detecten posibles riesgos de seguridad. -[`Audit.Exchange`][6] -: Se refiere a los logs que genera Microsoft Exchange Server. Los logs de Exchange contienen información sobre la entrega de correos electrónicos, el acceso al buzón, las conexiones de clientes y las acciones administrativas dentro del entorno de Exchange. Ayuda a las organizaciones a monitorizar y solucionar problemas relacionados con correos electrónicos. +[`Audit.Exchange`](https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3AExchange%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true) +: Se relaciona con logs generados por Microsoft Exchange Server. Los logs de Exchange contienen información sobre entrega de correo electrónico, acceso al buzón, conexiones de clientes y acciones administrativas en el entorno de Exchange. Ayda a las organizaciones a monitorizar y solucionar problemas relacionados con el correo electrónico. -[`Audit.General`][7] -: Contiene información sobre diversas actividades y eventos que se producen en tu entorno de Microsoft 365, como actividades de usuarios y administradores, eventos del sistema, incidencias de seguridad y otras acciones que no están directamente asociadas con servicios específicos como Exchange o SharePoint. +[`Audit.General`](https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true) +: Contiene información sobre distintas actividades y eventos que se producen en tu entorno de Microsoft 365, como actividades del usuario y del administrador, eventos del sistema, incidents (incidentes) de seguridad y otras medidas que no se relacionan directamente con servicios específicos como Exchange o SharePoint. -[`Audit.MicrosoftForms`][8] -: Representa a los logs que genera Microsoft Forms, una herramienta para crear encuestas, cuestionarios y formularios. Los logs de Forms incluyen información sobre la creación de formularios, el acceso, las respuestas y las actividades de los usuarios. Ayuda a las organizaciones a rastrear y proteger los datos de sus formularios. +[`Audit.MicrosoftForms`](https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3AMicrosoftForms%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true) +: Representa logs generados por Microsoft Forms, una herramienta para crear encuestas, cuestionarios y formularios. Los logs de formularios incluyen información sobre creación de formularios, acceso, respuestas y actividades del usuario. Brinda asistencia a las organizaciones en el rastreo y la obtención de datos de sus formularios. -[`Audit.MicrosoftStream`][9] -: Hace referencia a los logs que genera Microsoft Stream, una plataforma para compartir vídeos dentro del ecosistema de Microsoft. Los logs de Stream contienen información sobre las cargas de vídeos, el acceso, el uso compartido y las actividades de los usuarios. Ayuda a las organizaciones a rastrear y proteger su contenido de vídeos. +[`Audit.MicrosoftStream`](https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3AMicrosoftStream%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true) +: Se refiere a logs generados por Microsoft Stream, una plataforma para compartir videos en el ecosistema de Microsoft. Los logs de Stream contienen información sobre cargas de videos, acceso, compartir y actividades del usuario. Ayuda a las organizaciones a rastrear y obtener su contenido de video. -[`Audit.MicrosoftTeams`][10] -: Incluye los logs que genera Microsoft Teams, una plataforma de colaboración y comunicación. Los logs de Teams incluyen información sobre las actividades de los usuarios, la gestión de equipos y canales, el uso compartido de archivos, y los eventos de reuniones. Ayuda a las organizaciones a monitorizar las interacciones de los usuarios y garantizar una colaboración segura. +[`Audit.MicrosoftTeams`](https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3AMicrosoftTeams%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true) +: Comprende logs producidos por Microsoft Teams, una plataforma de colaboración y comunicación. Los logs de Teams incluyen información sobre actividades del usuario, gestión de equipos y canales, archivos compartidos y eventos de reuniones. Ayuda a las organizaciones a monitorizar interacciones de usuarios y garantizar una colaboración segura. -[`Audit.OneDrive`][11] -: Hace referencia a los logs que genera OneDrive, el servicio de sincronización y almacenamiento de archivos basado en la nube de Microsoft. Los logs de OneDrive incluyen información sobre el acceso a los archivos, el uso compartido, las modificaciones y las actividades de los usuarios. Ayuda a las organizaciones a monitorizar y proteger sus datos basados en la nube. +[`Audit.OneDrive`](https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3AOneDrive%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true) +: Se refiere a logs generados por OneDrive, el servicio de almacenamiento y sincronización de archivos basado en la nube de Microsoft. Los logs de OneDrive incluyen información sobre acceso a archivos, compartida, modificaciones y actividades del usuario. Ayuda a las organizaciones a monitorizar y obtener datos basados en la nube. -[`Audit.PowerBI`][12] -: Hace referencia a los logs que genera Power BI, la herramienta de análisis empresarial y visualización de datos de Microsoft. Los logs de Power BI contienen información sobre el acceso a los datos, la generación de informes, las actividades del dashboard y las interacciones de los usuarios. Ayuda a las organizaciones a monitorizar y proteger sus datos de inteligencia empresarial. +[`Audit.PowerBI`](https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3APowerBI%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true) +: Se refiere a logs producidos por Power BI, la herramienta de análisis comerciales y visualización de datos de Microsoft. Los logs de Power BI contienen información sobre acceso a datos, generación de informes, actividades de dashboard e interacciones de usuarios. Ayuda a las organizaciones a monitorizar y obtener sus datos de inteligencia comercial. -[`Audit.Project`][13] -: Hace referencia a los logs de auditoría de Microsoft Project, una herramienta de gestión de proyectos dentro del conjunto de aplicaciones de Microsoft 365. Estos logs capturan eventos relacionados con actividades de los usuarios, acciones administrativas y eventos del sistema dentro de Microsoft Project, como la creación de proyectos, actualizaciones de tareas, asignación de recursos y cambios de permisos. +[`Audit.Project`](https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3AProject%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true) +: Se refiere a logs de auditoría de Microsoft Project, una herramienta de gestión de projects (proyectos) en la serie Microsoft 365. Estos logs capturan eventos relacionados con actividades del usuario, medidas administrativas y eventos del sistema en Microsoft Project, como creación de projects (proyectos), actualizaciones de tareas, asignación de recursos y cambios de permisos. -[`Audit.SharePoint`][14] -: Hace referencia a los logs que genera Microsoft SharePoint. Los logs de SharePoint registran el acceso de los usuarios, las modificaciones de documentos, la administración del sitio y los eventos relacionados con la seguridad. Permite a las organizaciones mantener la integridad de los datos y proteger sus sitios y contenidos de SharePoint. +[`Audit.SharePoint`](https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3ASharePoint%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true) +: Se refiere a logs producidos por Microsoft SharePoint. Los logs de SharePoint registran el acceso del usuario, modificaciones de documentos, administración de sitios y eventos relacionados con la seguridad. Permite que las organizaciones mantengan la integridad de los datos y obtengan sus sitios y contenido de SharePoint. -[`Audit.SkypeForBusiness`][15] -: Hace referencia a los logs de auditoría de las actividades de Skype Empresarial. Estos logs capturan eventos relacionados con acciones administrativas y de usuarios dentro del servicio de Skype Empresarial, como registros de detalles de llamadas, registros de detalles de conferencias, actividades de mensajería y acciones de administración, como la administración de usuarios y actualizaciones de políticas. +[`Audit.SkypeForBusiness`](https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3ASkypeForBusiness%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true) +: Se refiere a los logs de auditoría de actividades de Skype for Business. Estos logs capturan eventos relacionados con acciones del usuario y administrativas en el servicio de Skype for Business, como registros de detalles de llamadas, registros de detalles de conferencias, actividades de mensajería y medidas administrativas como actualizaciones de gestión y políticas del usuario. -[`Audit.Yammer`][16] -: Representa a los logs que genera Yammer, una plataforma de redes sociales para empresas. Los logs de Yammer incluyen información sobre las actividades de los usuarios, la gestión de grupos y comunidades, y el uso compartido de contenido. Ayuda a las organizaciones a monitorizar y proteger sus redes sociales internas. +[`Audit.Yammer`](https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3AYammer%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true) +: Representa logs producidos por Yammer, una plataforma de redes sociales para empresas. Los logs de Yammer incluyen información sobre actividades del usuario, gestión de grupos y comunidades y contenido compartido. Ayuda a las organizaciones a monitorizar y obtener sus redes sociales internas. -[`ComplianceManager`][17] -: Relacionado con la herramienta Microsoft Compliance Manager, que ayuda a las organizaciones a evaluar, gestionar y rastrear sus actividades de cumplimiento en Microsoft 365. Estos logs contienen información sobre evaluaciones de cumplimiento, tareas, acciones de mejora y progreso hacia el cumplimiento de los requisitos normativos. +[`ComplianceManager`](https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3AComplianceManager%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true) +: Se relaciona con la herramienta Microsoft Compliance Manager, que ayuda a las organizaciones a evaluar, gestionar y rastrear sus actividades de cumplimiento en Microsoft 365. Estos logs contienen información sobre evaluaciones de complimiento, tareas, medidas de mejoramiento y progreso hacia requisitos regulatorios de reuniones. `DLP.All` -: Captura eventos relacionados con políticas, detecciones y acciones de DLP en todos los servicios de Microsoft 365, incluidos Exchange, SharePoint, OneDrive, Microsoft Teams y otros. Estos logs proporcionan información sobre infracciones de políticas, detecciones de información confidencial y acciones tomadas para proteger los datos, como bloquear contenido, notificar a usuarios o administradores, y más. +: Captura eventos relacionados con políticas de DLP, detecciones y acciones en todos los servicios de Microsoft 365, incluidos Exchange, SharePoint, OneDrive, Microsoft Teams y otros. Estos logs brindan información sobre incumplimientos de políticas detecciones de información confidencial y las medidas tomadas para proteger los datos, como bloqueo de contenido, notificación a usuarios o administradores y más. `Dynamics365` -: Recopila eventos de cualquiera de tus servicios y aplicaciones de [Microsoft Dynamics 365][18]. +: Recopila eventos de cualquiera de tus servicios y aplicaciones de [Microsoft Dynamics 365](https://learn.microsoft.com/dynamics365/). -[`MicrosoftFlow`][19] -: Asociado con el servicio de Microsoft Power Automate (antes conocido como Microsoft Flow), una plataforma basada en la nube que permite a los usuarios crear y gestionar flujos de trabajo automatizados entre varias aplicaciones y servicios. Estos logs capturan eventos relacionados con ejecuciones de flujos de trabajo, errores y acciones administrativas, como la creación, actualización o eliminación de flujos. +[`MicrosoftFlow`](https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3AMicrosoftFlow%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true) +: Asociado con el servicio Microsoft Power Automate (anteriormente denominado Microsoft Flow), una plataforma basada en la nube que permite que los usuarios creen y gestionen workflows (UI) / procesos (generic) automatizados entre distintas aplicaciones y servicios. Estos logs capturan eventos relacionados con ejecuciones de workflows, errores y medidas administrativas, como la creación, actualización o eliminación de flujos. -[`Mip`][20] -: Se refiere a los logs que genera Microsoft Information Protection (MIP), un conjunto de herramientas y servicios para clasificar, etiquetar y proteger datos confidenciales. Los logs de MIP proporcionan información sobre la clasificación de datos, el acceso y los eventos de protección. Permite a las organizaciones gestionar y proteger su información confidencial. +[`Mip`](https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3AMip%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true) +: Se relaciona con logs generados por Microsoft Information Protection (MIP), una serie de herramientas y servicios para clasificar, etiquetar y proteger datos confidenciales. Los logs de MIP brindan información sobre eventos de clasificación, acceso y protección de datos. Permite que las organizaciones gestionen y aseguren su información confidencial. -[`MyAnalytics`][21] -: Relacionado con el servicio de Microsoft MyAnalytics, que proporciona información sobre los hábitos de trabajo y las tendencias de productividad de una persona dentro del conjunto de aplicaciones de Microsoft 365. Estos logs contienen información sobre las actividades de los usuarios, como el tiempo dedicado a reuniones, correos electrónicos, colaboración y tiempo de concentración. +[`MyAnalytics`](https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3AMyAnalytics%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true) +: Relacionado con el servicio Microsoft MyAnalytics, que brinda información sobre los hábitos laborales y las tendencias de productividad de una persona en la serie Microsoft 365. Estos logs contienen información sobre actividades de usuarios, el tiempo transcurrido en reuniones, correos electrónico, colaboración y tiempo de concentración. -[`PowerApps`][22] -: Hace referencia a los logs que genera Power Apps, la plataforma de desarrollo de aplicaciones de poco código de Microsoft. Los logs de Power Apps contienen información sobre la creación de aplicaciones, el acceso, el uso y las actividades del usuario. +[`PowerApps`](https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3APowerApps%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true) +: Se refiere a logs generados por Power Apps, la plataforma de código mínimo para el desarrollo de aplicaciones de Microsoft. Los logs de Power Apps contienen información sobre creación de aplicaciones, acceso, uso y actividades del usuario. -[`Quarantine`][23] -: Representa a los logs que generan los sistemas de cuarentena de correos electrónicos que se usan para aislar y revisar los correos electrónicos potencialmente maliciosos o no deseados. Los logs de cuarentena incluyen información sobre los correos electrónicos en cuarentena, los detalles del remitente y el destinatario, y las medidas adoptadas. Ayuda a las organizaciones a gestionar la seguridad de los correos electrónicos y a prevenir amenazas. +[`Quarantine`](https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3AQuarantine%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true) +: Representa logs generados por sistemas de cuarentena de correo electrónico utilizados para aislar y revisar correos electrónicos posiblemente maliciosos o no deseados. Los logs de cuarentena incluyen información sobre correos electrónicos en cuarentena, datos del remitente y del destinatario y medidas tomadas. Ayuda a las organizaciones a gestionar la seguridad del correo electrónico email y a protegerse de amenazas. -[`Rdl`][24] -: Relacionado con SQL Server Reporting Services (SSRS), una plataforma de generación de informes basada en servidores que permite a los usuarios crear, publicar y gestionar informes en varios formatos. La fuente de log Rdl captura eventos relacionados con la ejecución de informes, el acceso y las acciones administrativas, como la generación, actualización o eliminación de informes. +[`Rdl`](https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3ARdl%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true) +: Relacionado con SQL Server Reporting Services (SSRS), una plataforma de informes basada en el servidor que permite que los usuarios creen, publiquen y gestionen informes en distintos formatos. La source (fuente) de logs de Rdl captura eventos relacionados con la ejecución de informes, el acceso y las medidas administrativas, como generar, actualizar o eliminar informes. -[`SecurityComplianceCenter`][25] -: Se refiere a los logs que genera el Centro de seguridad y cumplimiento de Microsoft, una plataforma centralizada para gestionar las funciones de seguridad y cumplimiento en todos los servicios de Microsoft 365. Estos logs proporcionan información sobre incidencias de seguridad, infracciones de políticas y actividades de gestión del cumplimiento. Ayuda a las organizaciones a mantener un entorno de TI seguro y que cumpla con las normas. +[`SecurityComplianceCenter`](https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3ASecurityComplianceCenter%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true) +: Se refiere a logs generados por Microsoft's Security & Compliance Center, una plataforma centralizada para gestionar funciones de seguridad y cumplimiento en todos los servicios de Microsoft 365. Estos logs brindan información sobre incidents (ncidentes) de seguridad, incumplimientos de políticas y actividades de gestión de cumplimiento. Ayuda a las organizaciones a mantener un entorno seguro y cumplidor de TI. -[`SecurityMonitoringEntityReducer`][26] -: Asociado con logs de eventos de seguridad y actividades de agregación de alertas en Microsoft 365. Estos logs proporcionan información sobre eventos de seguridad, anomalías y posibles amenazas detectadas en el entorno de Microsoft 365. +[`SecurityMonitoringEntityReducer`](https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3ASecurityMonitoringEntityReducer%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true) +: Asociado con logs de eventos de seguridad y actividades de agregación de alertas en Microsoft 365. Estos logs brindan informaciones sobre eventos de seguridad, anomalías y posibles amenazas detectadas en todo el entorno de Microsoft 365. -[`ThreatIntelligence`][27] -: Incluye logs que generan los sistemas o herramientas de inteligencia de amenazas que recopilan, analizan y comparten información sobre amenazas de seguridad emergentes. Los logs de inteligencia de amenazas proporcionan información sobre posibles amenazas, vulnerabilidades e indicadores de riesgo. Ayuda a las organizaciones a defenderse de manera proactiva contra los ciberataques. +[`ThreatIntelligence`](https://app.datadoghq.com/logs?query=source%3Amicrosoft-365%20service%3AThreatIntelligence%20&cols=host%2Cservice&index=%2A&messageDisplay=inline&stream_sort=desc&viz=stream&live=true) +: Comprende logs generados por sistemas o herramientas de inteligencia de amenazas que recopilan, analizan y comparten información sobre amenazas a la seguridad surgidas. Los logs de inteligencia de amenazas brindan información sobre posibles amenazas, vulnerabilidades e indicadores de compromiso. Ayuda a las organizaciones a defenderse en forma proactiva de ciberataques.En esta página, se describe la integración estándar del Agent de MySQL. Si buscas el producto de Monitorización de base de datos para MySQL, consulta Monitorización de base de datos de Datadog.
+En esta page (página), se describe la integración estándar del Agent de MySQL. Si buscas el producto de Database Monitoring para MySQL, consulta Database Monitoring de Datadog.
### Instalación
-El check de MySQL está incluido en el paquete del [Datadog Agent ][3]. No es necesaria ninguna instalación adicional en tu servidor de MySQL.
+El check de MySQL está incluido en el paquete del [Datadog Agent ](https://app.datadoghq.com/account/settings/agent/latest). No es necesaria ninguna instalación adicional en tu servidor de MySQL.
#### Preparar MySQL
-**Nota**: Para instalar la Monitorización de base de datos para MySQL, selecciona tu solución de alojamiento en la [documentación de Monitorización de base de datos][4] para obtener instrucciones.
+**Nota**: Para instalar Database Monitoring para MySQL, selecciona tu solución de alojamiento en la [documentación de Database Monitoring](https://docs.datadoghq.com/database_monitoring/#mysql) para obtener instrucciones.
-Procede con los siguientes pasos de esta guía solo si vas a instalar únicamente la integración estándar.
+Procede con los siguientes pasos de esta guía solo si vas a instalar la integración estándar únicamente.
En cada servidor MySQL, crea un usuario de base de datos para el Datadog Agent.
-Las siguientes instrucciones conceden al Agent permiso para iniciar sesión desde cualquier host mediante `datadog@'%'`. Puedes restringir al usuario `datadog` para que sólo pueda iniciar sesión desde el host local mediante `datadog@'localhost'`. Consulta [Añadir cuentas de MySQL, asignar privilegios y eliminar cuentas][5] para obtener más información.
+Las siguientes instrucciones conceden al Agent permiso para iniciar sesión desde cualquier host mediante `datadog@'%'`. Puedes restringir al usuario `datadog` para que solo pueda iniciar sesión desde un host local mediante `datadog@'localhost'`. Consulta [Añadir cuentas, asignar privilegios y eliminar cuentas de MySQL](https://dev.mysql.com/doc/refman/8.0/en/creating-accounts.html) para obtener más información.
Crea el usuario `datadog` con el siguiente comando:
@@ -169,22 +109,31 @@ mysql> GRANT SELECT ON performance_schema.* TO 'datadog'@'%';
Query OK, 0 rows affected (0.00 sec)
```
+Para recopilar métricas de índices, concede al usuario `datadog` un privilegio adicional:
+
+```shell
+
+mysql> GRANT SELECT ON mysql.innodb_index_stats TO 'datadog'@'%';
+Query OK, 0 rows affected (0.00 sec)
+```
+
### Configuración
-Sigue las instrucciones a continuación para configurar este check para un Agent que se ejecuta en un host. Para entornos en contenedores, consulta las secciones de [Docker](?tab=docker#docker), [Kubernetes](?tab=kubernetes#kubernetes), o [ECS](?tab=ecs#ecs).
+Sigue las instrucciones a continuación para configurar este check para un Agent que se ejecuta en un host. Para entornos en contenedores, consulta las secciones [Docker](?tab=docker#docker), [Kubernetes](?tab=kubernetes#kubernetes) o [ECS](?tab=ecs#ecs).
-**Nota**: Para obtener una lista completa de las opciones de configuración disponibles, consulta el [mysql.d/conf.yaml de ejemplo][6].
+**Nota**: Para obtener una lista completa de las opciones de configuración disponibles, consulta el [ejemplo mysql.d/conf.yaml](https://github.com/DataDog/integrations-core/blob/master/mysql/datadog_checks/mysql/data/conf.yaml.example).
{{< tabs >}}
+
{{% tab "Host" %}}
#### Host
Para configurar este check para un Agent que se ejecuta en un host:
-Edita el archivo `mysql.d/conf.yaml`, en la carpeta `conf.d/` en la raíz de tu [directorio de configuración del Agent][1] para iniciar la recopilación de tus [métricas](#métrica-collection) y [logs](#log-collection) de MySQL.
+Edita el archivo `MySQL.d/conf.yaml`, en la carpeta `conf.d/` en la raíz de tu [directorio de configuración del Agent](https://docs.datadoghq.com/agent/guide/agent-configuration-files/#agent-configuration-directory) para empezar a recopilar tus [métricas](#metric-collection) y [logs](#log-collection) de MySQL.
-Para obtener una lista completa de las opciones de configuración disponibles, consulta el [`mysql.d/conf.yaml` de ejemplo][2].
+Para obtener una lista completa de las opciones de configuración disponibles, consulta el [ejemplo `mysql.d/conf.yaml`](https://github.com/DataDog/integrations-core/blob/master/mysql/datadog_checks/mysql/data/conf.yaml.example).
##### Recopilación de métricas
@@ -209,19 +158,20 @@ Para obtener una lista completa de las opciones de configuración disponibles, c
**Nota**: Escribe tu contraseña entre comillas simples en caso de que haya un carácter especial.
-Para recopilar `extra_performance_metrics`, tu servidor de MySQL debe tener habilitado `performance_schema`; de lo contrario, configura `extra_performance_metrics` en `false`. Para obtener más información sobre `performance_schema`, consulta [inicio rápido del esquema de rendimiento de MySQL][3].
+Para recopilar `extra_performance_metrics`, tu servidor de MySQL debe tener `performance_schema` activado, de lo contrario, configura `extra_performance_metrics` en `false`. Para obtener más información sobre `performance_schema`, consulta [Inicio rápido del esquema de rendimiento de MySQL](https://dev.mysql.com/doc/refman/5.7/en/performance-schema-quick-start.html).
**Nota**: El usuario `datadog` debe establecerse en la configuración de la integración de MySQL como `host: 127.0.0.1` en lugar de `localhost`. Como alternativa, también puedes utilizar `sock`.
-[Reinicia el Agent][4] para empezar a enviar métricas de MySQL a Datadog.
+[Reinicia el Agent](https://docs.datadoghq.com/agent/guide/agent-commands/#start-stop-and-restart-the-agent) para empezar a enviar métricas de MySQL a Datadog.
##### Recopilación de logs
-_Disponible para el Agent versión 6.0 o posterior_
+_Disponible para las versiones 6.0 o posteriores del Agent_
-1. Por defecto, MySQL loguea todo en `/var/log/syslog` que requiere acceso raíz para la lectura. Para que los logs sean más accesibles, sigue estos pasos:
+1. De manera predeterminada, MySQL registra todo en `/var/log/syslog` que requiere acceso raíz para la lectura. Para que los logs sean más accesibles, sigue estos pasos:
- Edita `/etc/mysql/conf.d/mysqld_safe_syslog.cnf` y elimina o comenta las líneas.
+
- Edita `/etc/mysql/my.cnf` y añade las siguientes líneas para activar los logs de consultas generales, de error y lentas:
```conf
@@ -239,7 +189,9 @@ _Disponible para el Agent versión 6.0 o posterior_
- Guarda el archivo y reinicia MySQL con los siguientes comandos:
`service mysql restart`
+
- Asegúrate de que el Agent tiene acceso de lectura al directorio `/var/log/mysql` y a todos los archivos que contiene. Vuelve a controlar tu configuración de logrotate para asegurarte de que esos archivos se tienen en cuenta y que los permisos se establecen correctamente allí también.
+
- En `/etc/logrotate.d/mysql-server` debería haber algo parecido a:
```text
@@ -252,13 +204,13 @@ _Disponible para el Agent versión 6.0 o posterior_
}
```
-2. La recopilación de logs está desactivada por defecto en el Datadog Agent, actívala en tu archivo `datadog.yaml`:
+1. La recopilación de logs está desactivada en forma predeterminada en el Datadog Agent, actívala en tu archivo `datadog.yaml`:
```yaml
logs_enabled: true
```
-3. Añade este bloque de configuración en tu archivo `mysql.d/conf.yaml` para empezar a recopilar tus logs de MySQL:
+1. Añade este bloque de configuración a tu archivo `mysql.d/conf.yaml` para empezar a recopilar logs de MySQL:
```yaml
logs:
@@ -301,23 +253,21 @@ _Disponible para el Agent versión 6.0 o posterior_
# pattern: \t\t\s*\d+\s+|\d{6}\s+\d{,2}:\d{2}:\d{2}\t\s*\d+\s+
```
- Para conocer todas las opciones de configuración disponibles, incluidas las de métricas personalizadas, consulta el [mysql.yaml de ejemplo][2].
+ Consulta el [ejemplo mysql.yaml](https://github.com/DataDog/integrations-core/blob/master/mysql/datadog_checks/mysql/data/conf.yaml.example) para conocer todas las opciones de configuración disponibles, incluidas las de métricas personalizadas.
-4. [Reinicia el Agent][4].
+1. [Reinicia el Agent](https://docs.datadoghq.com/agent/guide/agent-commands/#start-stop-and-restart-the-agent).
-[1]: https://docs.datadoghq.com/agent/guide/agent-configuration-files/#agent-configuration-directory
-[2]: https://github.com/DataDog/integrations-core/blob/master/mysql/datadog_checks/mysql/data/conf.yaml.example
-[3]: https://dev.mysql.com/doc/refman/5.7/en/performance-schema-quick-start.html
-[4]: https://docs.datadoghq.com/agent/guide/agent-commands/#start-stop-and-restart-the-agent
{{% /tab %}}
+
{{% tab "Docker" %}}
+
#### Docker
Para configurar este check para un Agent que se ejecuta en un contenedor:
##### Recopilación de métricas
-Establece [plantillas de integración de Autodiscovery][1] como etiquetas de Docker en tu contenedor de aplicación:
+Configura [Plantillas de integración de Autodiscovery](https://docs.datadoghq.com/agent/docker/integrations/?tab=docker) como etiquetas de Docker en tu contenedor de aplicaciones:
```yaml
LABEL "com.datadoghq.ad.check_names"='["mysql"]'
@@ -325,35 +275,31 @@ LABEL "com.datadoghq.ad.init_configs"='[{}]'
LABEL "com.datadoghq.ad.instances"='[{"server": "%%host%%", "username": "datadog","password": "(gauge) | El número de transacciones que utilizaron la caché temporal de logs binarios, pero que excedieron el valor de `binlog_cache_size` y utilizaron un archivo temporal para almacenar sentencias de la transacción.
_Mostrado como transacción_ | +| **mysql.binlog.cache_use**
(gauge) | El número de transacciones que utilizaron la caché de logs binarios.
_Mostrado como transacción_ | +| **mysql.binlog.disk_use**
(gauge) | Tamaño total del archivo de log binario.
_Mostrado como byte_ | +| **mysql.galera.wsrep_cert_deps_distance**
(gauge) | Muestra la distancia media entre los valores más bajos y más altos del número de secuencia, o seqno, que el nodo puede aplicar en paralelo.| +| **mysql.galera.wsrep_cluster_size**
(gauge) | El número actual de nodos en el clúster Galera.
_Mostrado como nodo_ | +| **mysql.galera.wsrep_flow_control_paused**
(gauge) | Muestra la fracción de tiempo, desde la última vez que se llamó a FLUSH STATUS, que el nodo estuvo en pausa debido al control de flujo.
_Mostrado como fracción_ | +| **mysql.galera.wsrep_flow_control_paused_ns**
(count) | Muestra el tiempo de pausa debido al control de flujo, en nanosegundos.
_Mostrado como nanosegundo_ | +| **mysql.galera.wsrep_flow_control_recv**
(count) | Muestra el número de veces que el nodo galera ha recibido un mensaje de control de flujo en pausa de otros| +| **mysql.galera.wsrep_flow_control_sent**
(count) | Muestra el número de veces que el nodo galera ha enviado un mensaje de control de flujo en pausa a otros| +| **mysql.galera.wsrep_local_cert_failures**
(count) | Número total de transacciones locales que no han superado el test de certificación.| +| **mysql.galera.wsrep_local_recv_queue**
(gauge) | Muestra el tamaño actual (instantáneo) de la cola de recepción local.| +| **mysql.galera.wsrep_local_recv_queue_avg**
(gauge) | Muestra el tamaño medio de la cola de recepción local desde la última consulta de FLUSH STATUS.| +| **mysql.galera.wsrep_local_send_queue**
(gauge) | Muestra el tamaño actual (instantáneo) de la longitud de la cola de envío desde la última consulta de FLUSH STATUS.| +| **mysql.galera.wsrep_local_send_queue_avg**
(gauge) | Muestra un promedio de la longitud de la cola de envío desde la última consulta de FLUSH STATUS.| +| **mysql.galera.wsrep_local_state**
(gauge) | Número de estado interno del clúster Galera| +| **mysql.galera.wsrep_received**
(gauge) | Número total de conjuntos de escritura recibidos de otros nodos.| +| **mysql.galera.wsrep_received_bytes**
(gauge) | Tamaño total (en bytes) de los conjuntos de escritura recibidos de otros nodos.| +| **mysql.galera.wsrep_replicated_bytes**
(gauge) | Tamaño total (en bytes) de los conjuntos de escritura enviados a otros nodos.| +| **mysql.index.deletes**
(gauge) | Número de operaciones de borrado que utilizan un índice. Se restablece a 0 al reiniciar la base de datos.
_Mostrado como operación_. | +| **mysql.index.reads**
(gauge) | Número de operaciones de lectura que utilizan un índice. Se restablece a 0 al reiniciar la base de datos.
_Mostrado como operación_. | +| **mysql.index.size**
(gauge) | Tamaño del índice en bytes
_Se muestra como byte_ | +| **mysql.index.updates**
(gauge) | Número de operaciones de actualización que utilizan un índice. Se restablece a 0 al reiniciar la base de datos.
_Mostrado como operación_ | +| **mysql.info.schema.size**
(gauge) | Tamaño de los esquemas en MiB
_Se muestra como mebibyte_ | +| **mysql.info.table.data_size**
(gauge) | Tamaño de los datos de las tablas en MiB
_Se muestra como mebibyte_ | +| **mysql.info.table.index_size**
(gauge) | Tamaño del índice de las tablas en MiB
_Se muestra como mebibyte_ | +| **mysql.info.table.rows.changed**
(count) | Número total de filas modificadas por tabla (solo estado de usuario de Percona)
_Mostrado como fila_ | +| **mysql.info.table.rows.read**
(count) | Número total de filas leídas por tabla (solo estado de usuario de Percona)
_Mostrado como fila_ | +| **mysql.innodb.active_transactions**
(gauge) | El número de transacciones activas en tablas de InnoDB.
_Mostrado como operación_ | +| **mysql.innodb.buffer_pool_data**
(gauge) | El número total de bytes en la reserva de búferes de InnoDB que contienen datos. El número incluye tanto las páginas sucias como las limpias.
_Mostrado como byte_ | +| **mysql.innodb.buffer_pool_dirty**
(gauge) | El número total actual de bytes retenidos en páginas sucias en la reserva de búferes de InnoDB.
_Mostrado como byte_ | +| **mysql.innodb.buffer_pool_free**
(gauge) | El número de bytes libres en la reserva de búferes de InnoDB.
_Mostrado como byte_ | +| **mysql.innodb.buffer_pool_pages_data**
(gauge) | El número de páginas en la reserva de búferes de InnoDB que contienen datos. El número incluye tanto las páginas sucias como las limpias.
_Mostrado como page (página)_ | +| **mysql.innodb.buffer_pool_pages_dirty**
(gauge) | El número actual de páginas sucias en la reserva de búferes de InnoDB.
_Mostrado como page (página)_ | +| **mysql.innodb.buffer_pool_pages_flushed**
(gauge) | El número de solicitudes para vaciar páginas de la reserva de búferes de InnoDB.
_Mostrado como page (página)_ | +| **mysql.innodb.buffer_pool_pages_free**
(gauge) | Número de páginas libres en la reserva de búferes de InnoDB.
_Mostrado como page (página)_ | +| **mysql.innodb.buffer_pool_pages_total**
(gauge) | El tamaño total de la reserva de búferes de InnoDB, en páginas.
_Mostrado como page (página)_ | +| **mysql.innodb.buffer_pool_read_ahead**
(gauge) | El número de páginas leídas en la reserva de búferes de InnoDB por el hilo de lectura en segundo plano.
_Mostrado como page (página)_ | +| **mysql.innodb.buffer_pool_read_ahead_evicted**
(gauge) | El número de páginas leídas en la reserva de búferes de InnoDB por el hilo de lectura en segundo plano que fueron desalojadas posteriormente sin haber sido accedidas por las consultas.
_Mostrado como page (página)_ | +| **mysql.innodb.buffer_pool_read_ahead_rnd**
(gauge) | El número de lecturas aleatorias iniciadas por InnoDB. Esto ocurre cuando una consulta explora una gran parte de una tabla, pero en orden aleatorio.
_Mostrado como operación_. | +| **mysql.innodb.buffer_pool_read_requests**
(gauge) | El número de solicitudes de lecturas lógicas.
_Mostrado como lectura_ | +| **mysql.innodb.buffer_pool_reads**
(gauge) | El número de lecturas lógicas que InnoDB no pudo satisfacer desde la reserva de búferes y tuvo que leer directamente del disco.
_Mostrado como lectura_ | +| **mysql.innodb.buffer_pool_total**
(gauge) | El número total de bytes en la reserva de búferes de InnoDB.
_Mostrado como byte_ | +| **mysql.innodb.buffer_pool_used**
(gauge) | El número de bytes utilizados en la reserva de búferes de InnoDB.
_Mostrado como byte_ | +| **mysql.innodb.buffer_pool_utilization**
(gauge) | La utilización de la reserva de búferes de InnoDB.
_Mostrado como fracción_ | +| **mysql.innodb.buffer_pool_wait_free**
(count) | Cuando InnoDB necesita leer o crear un page (página) y no hay páginas limpias disponibles, InnoDB vacía primero algunas páginas sucias y espera a que termine la operación. Este contador cuenta las instancias de estas esperas.
_Mostrado como espera_ | +| **mysql.innodb.buffer_pool_write_requests**
(gauge) | Número de escrituras realizadas en la reserva de búferes de InnoDB.
_Mostrado como escritura_ | +| **mysql.innodb.checkpoint_age**
(gauge) | Edad del punto de control como se muestra en la sección LOG de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.current_row_locks**
(gauge) | El número de bloqueos de filas actuales.
_Shown as bloqueo_ | +| **mysql.innodb.current_transactions**
(gauge) | Transacciones actuales de InnoDB
_Mostrado como transacción_ | +| **mysql.innodb.data_fsyncs**
(gauge) | El número de operaciones fsync() por segundo.
_Mostrado como operación_ | +| **mysql.innodb.data_pending_fsyncs**
(gauge) | El número actual de operaciones fsync() pendientes.
_Mostrado como operación_ | +| **mysql.innodb.data_pending_reads**
(gauge) | El número actual de lecturas pendientes.
_Shown as lectura_ | +| **mysql.innodb.data_pending_writes**
(gauge) | El número actual de escrituras pendientes.
_Shown as escritura_ | +| **mysql.innodb.data_read**
(gauge) | La cantidad de datos leídos por segundo.
_Se muestra como byte_ | +| **mysql.innodb.data_reads**
(gauge) | La tasa de lecturas de datos.
_Shown as lectura_ | +| **mysql.innodb.data_writes**
(gauge) | La tasa de escrituras de datos.
_Shown as escritura_ | +| **mysql.innodb.data_written**
(gauge) | La cantidad de datos escritos por segundo.
_Se muestra como byte_ | +| **mysql.innodb.dblwr_pages_written**
(gauge) | El número de páginas escritas por segundo en el búfer de doble escritura.
_Shown as page (página)_ | +| **mysql.innodb.dblwr_writes**
(gauge) | El número de operaciones de doble escritura realizadas por segundo.
_Mostrado como byte_ | +| **mysql.innodb.deadlocks**
(count) | El número de bloqueos.
_Shown as bloqueo_ | +| **mysql.innodb.hash_index_cells_total**
(gauge) | Número total de celdas del índice hash adaptativo| +| **mysql.innodb.hash_index_cells_used**
(gauge) | Número de celdas utilizadas del índice hash adaptativo| +| **mysql.innodb.history_list_length**
(gauge) | Longitud de la lista de historial como se muestra en la sección TRANSACTIONS de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.ibuf_free_list**
(gauge) | Lista libre de búferes de inserción, como se muestra en la sección INSERT BUFFER AND ADAPTIVE HASH INDEX de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.ibuf_merged**
(gauge) | Búfer de inserción e índice hash adaptativo fusionados
_Mostrado como operación_ | +| **mysql.innodb.ibuf_merged_delete_marks**
(gauge) | Marcas de borrado de búfer de inserción e índice hash adaptativo fusionados
_Mostrado como operación_ | +| **mysql.innodb.ibuf_merged_deletes**
(gauge) | Búfer de inserción e índice hash adaptativo fusionados borrados
_Mostrado como operación_ | +| **mysql.innodb.ibuf_merged_inserts**
(gauge) | Inserciones de búfer de inserción e índice hash adaptativo fusionados
_Mostrado como operación_ | +| **mysql.innodb.ibuf_merges**
(gauge) | Fusiones de búfer de inserción e índice hash adaptativo
_Mostrado como operación_ | +| **mysql.innodb.ibuf_segment_size**
(gauge) | Tamaño del segmento del búfer de inserción, como se muestra en la sección INSERT BUFFER AND ADAPTIVE HASH INDEX de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.ibuf_size**
(gauge) | Tamaño del búfer de inserción, como se muestra en la sección INSERT BUFFER AND ADAPTIVE HASH INDEX de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.lock_structs**
(gauge) | Estructuras de bloqueo
_Mostrado como operación_ | +| **mysql.innodb.locked_tables**
(gauge) | Tablas bloqueadas
_Mostrado como operación_ | +| **mysql.innodb.log_waits**
(gauge) | Número de veces que el búfer de log era demasiado pequeño y fue necesario esperar a que se vaciara antes de continuar.
_Mostrado como espera_ | +| **mysql.innodb.log_write_requests**
(gauge) | El número de solicitudes de escritura para el log de rehacer de InnoDB.
_Mostrado como escritura_ | +| **mysql.innodb.log_writes**
(gauge) | El número de escrituras físicas en el archivo de log de rehacer de InnoDB.
_Mostrado como escritura_ | +| **mysql.innodb.lsn_current**
(gauge) | Número de secuencia de logs como se muestra en la sección LOGS de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.lsn_flushed**
(gauge) | Vaciado hasta el número de secuencia de logs como se muestra en la sección LOG de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.lsn_last_checkpoint**
(gauge) | Último punto de control del número de secuencia de logs como se muestra en la sección LOG de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.mem_adaptive_hash**
(gauge) | Como se muestra en la sección BUFFER POOL AND MEMORY de la salida SHOW ENGINE INNODB STATUS.
_Mostrado como byte_ | +| **mysql.innodb.mem_additional_pool**
(gauge) | Como se muestra en la sección BUFFER POOL AND MEMORY de la salida SHOW ENGINE INNODB STATUS. Solo disponible en MySQL 5.6.
_Mostrado como byte_ | +| **mysql.innodb.mem_dictionary**
(gauge) | Como se muestra en la sección BUFFER POOL AND MEMORY de la salida SHOW ENGINE INNODB STATUS.
_Mostrado como byte_ | +| **mysql.innodb.mem_file_system**
(gauge) | Como se muestra en la sección BUFFER POOL AND MEMORY de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.mem_lock_system**
(gauge) | Como se muestra en la sección BUFFER POOL AND MEMORY de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.mem_page_hash**
(gauge) | Como se muestra en la sección BUFFER POOL AND MEMORY de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.mem_recovery_system**
(gauge) | Como se muestra en la sección BUFFER POOL AND MEMORY de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.mem_total**
(gauge) | Como se muestra en la sección BUFFER POOL AND MEMORY de la salida SHOW ENGINE INNODB STATUS.
_Mostrado como byte_ | +| **mysql.innodb.mutex_os_waits**
(gauge) | La tasa de esperas del sistema operativo mutex. Solo disponible en MySQL 5.6 y 5.7.
_Mostrado como evento_. | +| **mysql.innodb.mutex_spin_rounds**
(gauge) | La tasa de rondas de giro del mutex. Solo disponible en MySQL 5.6 y 5.7.
_Mostrado como evento_. | +| **mysql.innodb.mutex_spin_waits**
(gauge) | La tasa de esperas de giro del mutex. Solo disponible en MySQL 5.6 y 5.7.
_Mostrado como evento_. | +| **mysql.innodb.os_file_fsyncs**
(gauge) | (Delta) Número total de operaciones fsync() realizadas por InnoDB.
_Mostrado como operación_ | +| **mysql.innodb.os_file_reads**
(gauge) | (Delta) El número total de lecturas de archivos realizadas por hilos de lectura en InnoDB.
_Mostrado como operación_ | +| **mysql.innodb.os_file_writes**
(gauge) | (Delta) El número total de escrituras de archivos realizadas por hilos de escritura en InnoDB.
_Mostrado como operación_ | +| **mysql.innodb.os_log_fsyncs**
(gauge) | La tasa de escrituras fsync en el archivo de log.
_Mostrado como escritura_ | +| **mysql.innodb.os_log_pending_fsyncs**
(gauge) | Número de solicitudes fsync (sincronización con disco) de log de InnoDBpendientes.
_Mostrado como operación_ | +| **mysql.innodb.os_log_pending_writes**
(gauge) | Número de escrituras de logs de InnoDB pendientes.
_Mostrado como escritura_ | +| **mysql.innodb.os_log_written**
(gauge) | Número de bytes escritos en log de InnoDB.
_Mostrado como byte_ | +| **mysql.innodb.pages_created**
(gauge) | Número de páginas de InnoDB creadas.
_Mostrado como page (página)_ | +| **mysql.innodb.pages_read**
(gauge) | Número de páginas InnoDB leídas.
_Mostrado como page (página)_ | +| **mysql.innodb.pages_written**
(gauge) | Número de páginas InnoDB escritas.
_Mostrado como page (página)_ | +| **mysql.innodb.pending_aio_log_ios**
(gauge) | Como se muestra en la sección FILE I/O de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.pending_aio_sync_ios**
(gauge) | Como se muestra en la sección FILE I/O de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.pending_buffer_pool_flushes**
(gauge) | Como se muestra en la sección FILE I/O de la salida SHOW ENGINE INNODB STATUS.
_Mostrado como vaciado_ | +| **mysql.innodb.pending_checkpoint_writes**
(gauge) | Como se muestra en la sección FILE I/O de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.pending_ibuf_aio_reads**
(gauge) | Como se muestra en la sección FILE I/O de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.pending_log_flushes**
(gauge) | Como se muestra en la sección FILE I/O de la salida SHOW ENGINE INNODB STATUS. Solo disponible en MySQL 5.6 y 5.7.
_Mostrado como vaciado_. | +| **mysql.innodb.pending_log_writes**
(gauge) | Como se muestra en la sección FILE I/O de la salida SHOW ENGINE INNODB STATUS. Solo disponible en MySQL 5.6 y 5.7.
_Mostrado como escritura_. | +| **mysql.innodb.pending_normal_aio_reads**
(gauge) | Como se muestra en la sección FILE I/O de la salida SHOW ENGINE INNODB STATUS.
_Mostrado como lectura_ | +| **mysql.innodb.pending_normal_aio_writes**
(gauge) | Como se muestra en la sección FILE I/O de la salida SHOW ENGINE INNODB STATUS.
_Mostrado como escritura_ | +| **mysql.innodb.queries_inside**
(gauge) | Como se muestra en la sección FILE I/O de la salida SHOW ENGINE INNODB STATUS.
_Mostrado como consulta_ | +| **mysql.innodb.queries_queued**
(gauge) | Como se muestra en la sección FILE I/O de la salida SHOW ENGINE INNODB STATUS.
_Mostrado como consulta_ | +| **mysql.innodb.read_views**
(gauge) | Como se muestra en la sección FILE I/O de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.row_lock_current_waits**
(gauge) | El número de bloqueos de fila actualmente en espera por operaciones en tablas de InnoDB.| +| **mysql.innodb.row_lock_time**
(gauge) | El tiempo empleado en adquirir bloqueos de fila.
_Mostrado como milisegundo_ | +| **mysql.innodb.row_lock_waits**
(gauge) | El número de veces por segundo que se ha tenido que esperar un bloqueo de fila.
_Mostrado como evento_ | +| **mysql.innodb.rows_deleted**
(gauge) | Número de filas eliminadas de las tablas de InnoDB.
_Mostrado como fila_ | +| **mysql.innodb.rows_inserted**
(gauge) | Número de filas insertadas en tablas de InnoDB.
_Mostrado como fila_ | +| **mysql.innodb.rows_read**
(gauge) | Número de filas leídas de las tablas de InnoDB.
_Mostrado como fila_ | +| **mysql.innodb.rows_updated**
(gauge) | Número de filas actualizadas en tablas de InnoDB.
_Mostrado como fila_ | +| **mysql.innodb.s_lock_os_waits**
(gauge) | Como se muestra en la sección SEMÁFOROS de la salida SHOW ENGINE INNODB STATUS| +| **mysql.innodb.s_lock_spin_rounds**
(gauge) | Como se muestra en la sección SEMÁFOROS de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.s_lock_spin_waits**
(gauge) | Como se muestra en la sección SEMAPHORES de la salida SHOW ENGINE INNODB STATUS.
_Mostrado como espera_ | +| **mysql.innodb.semaphore_wait_time**
(gauge) | Tiempo de espera en semáforo| +| **mysql.innodb.semaphore_waits**
(gauge) | El número de semáforos actualmente en espera por operaciones en tablas de InnoDB.| +| **mysql.innodb.tables_in_use**
(gauge) | Tablas en uso
_Mostrado como operación_ | +| **mysql.innodb.x_lock_os_waits**
(gauge) | Como se muestra en la sección SEMAPHORES de la salida SHOW ENGINE INNODB STATUS.
_Mostrado como espera_ | +| **mysql.innodb.x_lock_spin_rounds**
(gauge) | Como se muestra en la sección SEMAPHORES de la salida SHOW ENGINE INNODB STATUS.| +| **mysql.innodb.x_lock_spin_waits**
(gauge) | Como se muestra en la sección SEMAPHORES de la salida SHOW ENGINE INNODB STATUS.
_Mostrado como espera_ | +| **mysql.myisam.key_buffer_bytes_unflushed**
(gauge) | Bytes del búfer de claves de MyISAM sin vaciar.
_Mostrado como byte_ | +| **mysql.myisam.key_buffer_bytes_used**
(gauge) | Bytes del búfer de claves de MyISAM utilizados.
_Mostrado como byte_ | +| **mysql.myisam.key_buffer_size**
(gauge) | Tamaño del búfer utilizado para los bloques de índice.
_Mostrado como byte_ | +| **mysql.myisam.key_read_requests**
(gauge) | Número de solicitudes para leer un bloque de claves de la caché de claves de MyISAM.
_Mostrado como leído_ | +| **mysql.myisam.key_reads**
(gauge) | El número de lecturas físicas de un bloque de claves desde el disco a la caché de claves de MyISAM. Si `key_reads` es grande, es probable que el valor de clave_bpufer_tamaño sea demasiado pequeño. La tasa de fallos de la caché puede calcularse como `key_reads`/`key_read_requests`.
_Mostrado como lectura_. | +| **mysql.myisam.key_write_requests**
(gauge) | Número de solicitudes para escribir un bloque de claves en la caché de claves de MyISAM.
_Mostrado como escritura_ | +| **mysql.myisam.key_writes**
(gauge) | Número de escrituras físicas de un bloque de claves desde la caché de claves de MyISAM al disco.
_Mostrado como escritura_ | +| **mysql.net.aborted_clients**
(gauge) | El número de conexiones que se abortaron porque el cliente murió sin cerrar la connection (conexión) correctamente.
_Mostrado como connection (conexión)_ | +| **mysql.net.aborted_connects**
(gauge) | Número de intentos fallidos de conexión con el servidor de MySQL.
_Mostrado como connection (conexión)_ | +| **mysql.net.connections**
(gauge) | La tasa de conexiones al servidor.
_Mostrado como connection (conexión)_ | +| **mysql.net.max_connections**
(gauge) | El número máximo de conexiones que han estado en uso simultáneamente desde que se inició el servidor.
_Mostrado como connection (conexión) | +| **mysql.net.max_connections_available**
(gauge) | El número máximo permitido de conexiones simultáneas del cliente.
_Mostrado como connection (conexión)_ | +| **mysql.performance.bytes_received**
(gauge) | El número de bytes recibidos de todos los clientes.
_Mostrado como byte_ | +| **mysql.performance.bytes_sent**
(gauge) | El número de bytes enviados a todos los clientes.
_Mostrado como byte_ | +| **mysql.performance.com_delete**
(gauge) | La tasa de sentencias de borrado.
_Shown as consulta_ | +| **mysql.performance.com_delete_multi**
(gauge) | La tasa de sentencias de borrado múltiple.
_Mostrado como consulta_ | +| **mysql.performance.com_insert**
(gauge) | La tasa de sentencias de inserción.
_Shown as consulta_ | +| **mysql.performance.com_insert_select**
(gauge) | La tasa de sentencias inserción y selección.
_Mostrado como consulta_ | +| **mysql.performance.com_load**
(gauge) | La tasa de sentencias de carga.
_Mostrado como consulta_ | +| **mysql.performance.com_replace**
(gauge) | La tasa de sentencias de sustitución.
_Mostrado como consulta_ | +| **mysql.performance.com_replace_select**
(gauge) | La tasa de sentencias de sustituir y seleccionar.
_Mostrado como consulta_ | +| **mysql.performance.com_select**
(gauge) | La tasa de sentencias de selección.
_Shown as consulta_ | +| **mysql.performance.com_update**
(gauge) | La tasa de sentencias de actualización.
_Mostrado como consulta_ | +| **mysql.performance.com_update_multi**
(gauge) | La tasa de actualización múltiple.
_Mostrado como consulta_ | +| **mysql.performance.cpu_time**
(gauge) | Porcentaje de tiempo de CPU empleado por MySQL.
_Mostrado como porcentaje_ | +| **mysql.performance.created_tmp_disk_tables**
(gauge) | Tasa de tablas temporales internas en disco creadas por segundo por el servidor durante la ejecución de sentencias.
_Mostrado como tabla_ | +| **mysql.performance.created_tmp_files**
(gauge) | La tasa de archivos temporales creados por segundo.
_Mostrado como archivo_ | +| **mysql.performance.created_tmp_tables**
(gauge) | Tasa de tablas temporales internas creadas por segundo por el servidor durante la ejecución de sentencias.
_Mostrado como tabla_ | +| **mysql.performance.digest_95th_percentile.avg_us**
(gauge) | Percentil 95 por esquema de tiempo de respuesta de consulta.
_Mostrado en microsegundos_ | +| **mysql.performance.handler_commit**
(gauge) | El número de sentencias COMMIT internas.
_Mostrado como operación_ | +| **mysql.performance.handler_delete**
(gauge) | El número de sentencias DELETE internas.
_Mostrado como operación_ | +| **mysql.performance.handler_prepare**
(gauge) | El número de sentencias PREPARE internas.
_Mostrado como operación_ | +| **mysql.performance.handler_read_first**
(gauge) | El número de sentencias internas READ_FIRST.
_Mostrado como operación_ | +| **mysql.performance.handler_read_key**
(gauge) | El número de sentencias internas READ_KEY.
_Mostrado como operación_ | +| **mysql.performance.handler_read_next**
(gauge) | El número de sentencias internas READ_NEXT.
_Mostrado como operación_ | +| **mysql.performance.handler_read_prev**
(gauge) | El número de sentencias internas READ_PREV.
_Mostrado como operación_ | +| **mysql.performance.handler_read_rnd**
(gauge) | El número de sentencias internas READ_RND.
_Mostrado como operación_ | +| **mysql.performance.handler_read_rnd_next**
(gauge) | El número de sentencias internas READ_RND_NEXT.
_Mostrado como operación_ | +| **mysql.performance.handler_rollback**
(gauge) | El número de sentencias ROLLBACK internas.
_Mostrado como operación_ | +| **mysql.performance.handler_update**
(gauge) | El número de sentencias UPDATE internas.
_Mostrado como operación_ | +| **mysql.performance.handler_write**
(gauge) | El número de sentencias WRITE internas.
_Mostrado como operación_ | +| **mysql.performance.kernel_time**
(gauge) | Porcentaje de tiempo de CPU empleado en el espacio del núcleo por MySQL.
_Mostrado como porcentaje_. | +| **mysql.performance.key_cache_utilization**
(gauge) | La relación de utilización de la caché de claves.
_Mostrado como fracción_ | +| **mysql.performance.max_prepared_stmt_count**
(gauge) | El máximo permitido de sentencias preparadas en el servidor.| +| **mysql.performance.open_files**
(gauge) | El número de archivos abiertos.
_Mostrado como archivo_ | +| **mysql.performance.open_tables**
(gauge) | El número de tablas que están abiertas.
_Mostrado como tabla_ | +| **mysql.performance.opened_tables**
(gauge) | El número de tablas que se han abierto. Si `opened_tables` es grande, su valor `table_open_cache` es probablemente demasiado pequeño.
_Mostrado como tabla_. | +| **mysql.performance.performance_schema_digest_lost**
(gauge) | El número de instancias de compendio que no pudieron instrumentarse en la tabla eventos_sentencias_resumen_por_compendio. Puede ser distinto de cero si el valor de rendimiento_esquema_compendios_tamaño es demasiado pequeño.| +| **mysql.performance.prepared_stmt_count**
(gauge) | El número actual de sentencias preparadas.
_Mostrado como consulta_ | +| **mysql.performance.qcache.utilization**
(gauge) | Fracción de la memoria caché de consultas que se está utilizando actualmente.
_Mostrado como fracción_ | +| **mysql.performance.qcache_free_blocks**
(gauge) | El número de bloques de memoria libres en la caché de consulta.
_Mostrado como bloque_ | +| **mysql.performance.qcache_free_memory**
(gauge) | La cantidad de memoria libre para la caché de consultas.
_Mostrado como byte_ | +| **mysql.performance.qcache_hits**
(gauge) | Tasa de aciertos en la caché de consultas.
_Mostrado como acierto_ | +| **mysql.performance.qcache_inserts**
(gauge) | Número de consultas añadidas a la caché de consultas.
_Mostrado como consulta_ | +| **mysql.performance.qcache_lowmem_prunes**
(gauge) | Número de consultas borradas de la caché de consultas por falta de memoria.
_Mostrado como consulta_ | +| **mysql.performance.qcache_not_cached**
(gauge) | El número de consultas no almacenadas en caché (no almacenables en caché o no almacenadas en caché debido a la configuración de `query_cache_type`).
_Mostrado como consulta_ | +| **mysql.performance.qcache_queries_in_cache**
(gauge) | Número de consultas registradas en la caché de consultas.
_Mostrado como consulta_ | +| **mysql.performance.qcache_size**
(gauge) | La cantidad de memoria asignada para almacenar en caché los resultados de la consulta.
_Mostrado como byte_ | +| **mysql.performance.qcache_total_blocks**
(gauge) | Número total de bloques en la caché de consultas.
_Mostrado como bloque_ | +| **mysql.performance.queries**
(gauge) | La tasa de consultas.
_Mostrado como consulta_ | +| **mysql.performance.query_run_time.avg**
(gauge) | Tiempo medio de respuesta de consulta por esquema.
_Mostrado en microsegundos_ | +| **mysql.performance.questions**
(gauge) | La tasa de sentencias ejecutadas por el servidor.
_Mostrado como consulta_ | +| **mysql.performance.select_full_join**
(gauge) | El número de uniones que realizan exploraciones de tablas porque no utilizan índices. Si este valor no es 0, debes comprobar cuidadosamente los índices de tus tablas.
_Mostrado como operación_. | +| **mysql.performance.select_full_range_join**
(gauge) | El número de uniones que utilizaron una búsqueda de rango en una tabla de referencia.
_Mostrado como operación_ | +| **mysql.performance.select_range**
(gauge) | El número de uniones que utilizaron rangos en la primera tabla. Normalmente, este no es un problema crítico, incluso si el valor es bastante grande.
_Mostrado como operación_. | +| **mysql.performance.select_range_check**
(gauge) | El número de uniones sin claves que comprueban el uso de claves después de cada fila. Si no es 0, debes comprobar cuidadosamente los índices de tus tablas.
_Mostrado como operación_. | +| **mysql.performance.select_scan**
(gauge) | El número de uniones que hicieron una exploración completa de la primera tabla.
_Mostrado como operación_ | +| **mysql.performance.slow_queries**
(gauge) | La tasa de consultas lentas (consultas de logs que superan un tiempo de ejecución determinado).
_Mostrado como consulta_ | +| **mysql.performance.sort_merge_passes**
(gauge) | El número de pasadas de fusión que ha tenido que hacer el algoritmo de clasificación. Si este valor es grande, debes considerar aumentar el valor de la variable del sistema `sort_buffer_size`.
_Mostrado como operación_. | +| **mysql.performance.sort_range**
(gauge) | El número de clasificaciones que se han realizado utilizando rangos.
_Mostrado como operación_ | +| **mysql.performance.sort_rows**
(gauge) | El número de filas ordenadas.
_Mostrado como operación_ | +| **mysql.performance.sort_scan**
(gauge) | El número de clasificaciones que se han realizado explorando la tabla.
_Mostrado como operación_ | +| **mysql.performance.table_cache_hits**
(gauge) | Número de aciertos en las búsquedas de la caché de tablas abiertas.
_Mostrado como acierto_ | +| **mysql.performance.table_cache_misses**
(gauge) | Número de fallos en las búsquedas de la caché de tablas abiertas.
_Mostrado como fallo_ | +| **mysql.performance.table_locks_immediate**
(gauge) | El número de veces que una solicitud de bloqueo de una tabla podría concederse inmediatamente.| +| **mysql.performance.table_locks_immediate.rate**
(gauge) | Porcentaje de veces que una solicitud de bloqueo de una tabla puede concederse inmediatamente.| +| **mysql.performance.table_locks_waited**
(gauge) | Número total de veces que una solicitud de bloqueo de tabla no pudo concederse inmediatamente y fue necesario esperar.| +| **mysql.performance.table_locks_waited.rate**
(gauge) | Porcentaje de veces que una solicitud de bloqueo de una tabla no pudo concederse inmediatamente y fue necesario esperar.| +| **mysql.performance.table_open_cache**
(gauge) | El número de tablas abiertas para todos los hilos. Incrementar este valor incrementa el número de descriptores de archivo que requiere mysqld.| +| **mysql.performance.thread_cache_size**
(gauge) | Cuántos hilos debe almacenar en caché el servidor para su reutilización. Cuando un cliente se desconecta, los hilos del cliente se ponen en la caché si hay menos de `thread_cache_size` hilos allí.
_Mostrado como byte_. | +| **mysql.performance.threads_cached**
(gauge) | El número de hilos en la caché de hilos.
_Mostrado como hilo_ | +| **mysql.performance.threads_connected**
(gauge) | El número de conexiones abiertas actualmente.
_Mostrado como connection (conexión)_ | +| **mysql.performance.threads_created**
(count) | El número de hilos creados para manejar las conexiones. Si `threads_created` es grande, es posible que desees aumentar el valor de `thread_cache_size`.
_Mostrado como hilo_. | +| **mysql.performance.threads_running**
(gauge) | El número de hilos que no están inactivos.
_Mostrado como hilo_ | +| **mysql.performance.user_connections**
(gauge) | El número de conexiones de usuario. Etiquetas: `processlist_db`, `processlist_host`, `processlist_state`, `processlist_user`
_Mostrado como connection (conexión)_ | +| **mysql.performance.user_time**
(gauge) | Porcentaje de tiempo de CPU empleado en el espacio de usuario por MySQL.
_Mostrado como porcentaje_. | +| **mysql.queries.count**
(count) | El count total de consultas ejecutadas por consulta normalizada y esquema. (Solo DBM)
_Mostrado como consulta_. | +| **mysql.queries.errors**
(count) | El count total de consultas ejecutadas con un error por consulta y esquema normalizados. (Solo DBM)
_Mostrado como error_. | +| **mysql.queries.lock_time**
(count) | Tiempo total de espera de bloqueos por consulta y esquema normalizados. (Solo DBM)
_Mostrado como nanosegundo_. | +| **mysql.queries.no_good_index_used**
(count) | El count total de consultas que utilizaron un índice menor que el óptimo por consulta y esquema normalizados. (Solo DBM)
_Mostrado como consulta_. | +| **mysql.queries.no_index_used**
(count) | El count total de consultas que no utilizan un índice por consulta y esquema normalizados. (Solo DBM)
_Mostrado como consulta_. | +| **mysql.queries.rows_affected**
(count) | Número de filas mutadas por consulta y esquema normalizados. (Solo DBM)
_Mostrado como fila_. | +| **mysql.queries.rows_examined**
(count) | Número de filas examinadas por consulta y esquema normalizados. (Solo DBM)
_Mostrado como fila_. | +| **mysql.queries.rows_sent**
(count) | Número de filas enviadas por consulta y esquema normalizados. (Solo DBM)
_Mostrado como fila_. | +| **mysql.queries.select_full_join**
(count) | El count total de exploraciones de tabla completa en una tabla unida por consulta y esquema normalizados. (Solo DBM)| +| **mysql.queries.select_scan**
(count) | El count total de exploraciones de tabla completa en la primera tabla por consulta y esquema normalizados. (Solo DBM)| +| **mysql.queries.time**
(count) | El tiempo total de ejecución de la consulta por consulta y esquema normalizados. (Solo DBM)
_Mostrado como nanosegundo_. | +| **mysql.replication.group.conflicts_detected**
(gauge) | Número de transacciones que no han pasado el check de detección de conflictos.
_Mostrado como transacción_ | +| **mysql.replication.group.member_status**
(gauge) | Información sobre el estado del nodo en un entorno de replicación de grupo, siempre igual a 1.| +| **mysql.replication.group.transactions**
(gauge) | El número de transacciones en la cola pendientes de checks de detección de conflictos.
_Mostrado como transacción_ | +| **mysql.replication.group.transactions_applied**
(gauge) | Número de transacciones que este miembro ha recibido del grupo y ha aplicado.
_Mostrado como transacción_ | +| **mysql.replication.group.transactions_check**
(gauge) | El número de transacciones que se han comprobado en busca de conflictos.
_Mostrado como transacción_ | +| **mysql.replication.group.transactions_in_applier_queue**
(gauge) | El número de transacciones que este miembro ha recibido del grupo de replicación y que están a la espera de ser aplicadas.
_Mostrado como transacción_ | +| **mysql.replication.group.transactions_proposed**
(gauge) | Número de transacciones que se originaron en este miembro y se enviaron al grupo.
_Mostrado como transacción_ | +| **mysql.replication.group.transactions_rollback**
(gauge) | Número de transacciones que se originaron en este miembro y fueron revertidas por el grupo.
_Mostrado como transacción_ | +| **mysql.replication.group.transactions_validating**
(gauge) | Número de filas de transacciones que pueden utilizarse para la certificación, pero que no se han recolectado de la basura.
_Mostrado como transacción_ | +| **mysql.replication.replicas_connected**
(gauge) | Número de réplicas conectadas a una source (fuente) de réplicas.| +| **mysql.replication.seconds_behind_master**
(gauge) | El desfase en segundos entre el patrón y el esclavo.
_Mostrado como segundo_ | +| **mysql.replication.seconds_behind_source**
(gauge) | El desfase en segundos entre la source (fuente) y la réplica.
_Mostrado como segundo_ | +| **mysql.replication.slave_running**
(gauge) | Obsoleto. Utiliza un check de servicios mysql.replication.replica_running en su lugar. Un booleano que muestra si este servidor es un esclavo/patrón de réplica que se está ejecutando.| +| **mysql.replication.slaves_connected**
(gauge) | Obsoleto. Utiliza `MySQL.replication.replicas_connected` en su lugar. Número de esclavos conectados a un patrón de réplica.| El check no recopila todas las métricas por defecto. Establece las siguientes opciones de configuración booleanas en `true` para activar las respectivas métricas: @@ -644,42 +822,45 @@ El check no recopila todas las métricas por defecto. Establece las siguientes o El check de MySQL no incluye eventos. ### Checks de servicio -{{< get-service-checks-from-git "mysql" >}} +**mysql.can_connect** + +Devuelve `CRITICAL` si el Agent no puede conectarse a la instancia MySQL monitorizada. En caso contrario, devuelve `OK`. + +_Estados: ok, crítico_ + +**mysql.replication.slave_running** + +Obsoleto. Devuelve CRÍTICO para una réplica que no esté ejecutando Esclavo_IO_En ejecución ni Esclavo_SQL_En ejecución, ADVERTENCIA si una de las dos no está ejecutándose. En caso contrario, devuelve `OK`. + +_Estados: ok, advertencia, crítico_ + +**mysql.replication.replica_running** + +Devuelve CRÍTICO para una réplica que no esté ejecutando Réplica_IO_En ejecución ni Réplica_SQL_En ejeución, ADVERTENCIA si una de las dos no está ejecutándose. En caso contrario, devuelve `OK`. + +_Estados: ok, advertencia, crítico_ + +**mysql.replication.group.status** + +Devuelve `OK` si el estado del host es EN LÍNEA, devuelve `CRITICAL` en caso contrario. + +_Estados: ok, crítico_ ## Solucionar problemas -- [Problemas de conexión con la integración de SQL Server][8] -- [Error de host local de MySQL: host local VS 127.0.0.1][9] -- [¿Puedo utilizar una instancia con nombre en la integración de SQL Server?][10] -- [¿Puedo configurar el check de MySQL dd-agent en mi Google CloudSQL?][11] -- [Consultas personalizadas de MySQL][12] -- [Utilizar WMI para recopilar más métricas de rendimiento de SQL Server][13] -- [¿Cómo puedo recopilar más métricas de mi integración de SQL Server?][14] -- [El usuario de la base de datos carece de privilegios][15] -- [¿Cómo se recopilan las métricas con un procedimiento almacenado de SQL?][16] +- [Problemas de connection (conexión) con la integración del servidor de SQL](https://docs.datadoghq.com/integrations/guide/connection-issues-with-the-sql-server-integration/) +- [Error del host local de MySQL - Host local VS 127.0.0.1](https://docs.datadoghq.com/integrations/faq/mysql-localhost-error-localhost-vs-127-0-0-1/) +- [¿Puedo utilizar una instancia con nombre en la integración del servidor de SQL?](https://docs.datadoghq.com/integrations/faq/can-i-use-a-named-instance-in-the-sql-server-integration/) +- [Puedo configurar el check de MySQL del dd-agent en mi Google CloudSQL?](https://docs.datadoghq.com/integrations/faq/can-i-set-up-the-dd-agent-mysql-check-on-my-google-cloudsql/) +- [Consultas personalizadas de MySQL](https://docs.datadoghq.com/integrations/faq/how-to-collect-metrics-from-custom-mysql-queries/) +- [Utiliza WMI para recopilar más métricas de rendimiento del servidor de SQL](https://docs.datadoghq.com/integrations/guide/use-wmi-to-collect-more-sql-server-performance-metrics/) +- [¿Cómo puedo recopilar más métricas de mi integración del servidor de SQL?](https://docs.datadoghq.com/integrations/faq/how-can-i-collect-more-metrics-from-my-sql-server-integration/) +- [Usuario de base de datos sin privilegios](https://docs.datadoghq.com/integrations/faq/database-user-lacks-privileges/) +- [Cómo recopilar métricas con un procedimiento almacenado de SQL](https://docs.datadoghq.com/integrations/guide/collect-sql-server-custom-metrics/#collecting-metrics-from-a-custom-procedure) ## Referencias adicionales -Más enlaces, artículos y documentación útiles: - -- [Monitorización de métricas de rendimiento de MySQL][17] - - -[1]: https://raw.githubusercontent.com/DataDog/integrations-core/master/mysql/images/mysql-dash-dd-2.png -[2]: https://docs.datadoghq.com/database_monitoring/ -[3]: https://app.datadoghq.com/account/settings/agent/latest -[4]: https://docs.datadoghq.com/database_monitoring/#mysql -[5]: https://dev.mysql.com/doc/refman/8.0/en/creating-accounts.html -[6]: https://github.com/DataDog/integrations-core/blob/master/mysql/datadog_checks/mysql/data/conf.yaml.example -[7]: https://docs.datadoghq.com/agent/guide/agent-commands/#agent-status-and-information -[8]: https://docs.datadoghq.com/integrations/guide/connection-issues-with-the-sql-server-integration/ -[9]: https://docs.datadoghq.com/integrations/faq/mysql-localhost-error-localhost-vs-127-0-0-1/ -[10]: https://docs.datadoghq.com/integrations/faq/can-i-use-a-named-instance-in-the-sql-server-integration/ -[11]: https://docs.datadoghq.com/integrations/faq/can-i-set-up-the-dd-agent-mysql-check-on-my-google-cloudsql/ -[12]: https://docs.datadoghq.com/integrations/faq/how-to-collect-metrics-from-custom-mysql-queries/ -[13]: https://docs.datadoghq.com/integrations/guide/use-wmi-to-collect-more-sql-server-performance-metrics/ -[14]: https://docs.datadoghq.com/integrations/faq/how-can-i-collect-more-metrics-from-my-sql-server-integration/ -[15]: https://docs.datadoghq.com/integrations/faq/database-user-lacks-privileges/ -[16]: https://docs.datadoghq.com/integrations/guide/collect-sql-server-custom-metrics/#collecting-metrics-from-a-custom-procedure -[17]: https://www.datadoghq.com/blog/monitoring-mysql-performance-metrics +Documentación útil adicional, enlaces y artículos: + +- [Monitorización de métricas de rendimiento de MySQL](https://www.datadoghq.com/blog/monitoring-mysql-performance-metrics) \ No newline at end of file diff --git a/content/es/integrations/n2ws.md b/content/es/integrations/n2ws.md index 06781039057ab..bd55cda967547 100644 --- a/content/es/integrations/n2ws.md +++ b/content/es/integrations/n2ws.md @@ -1,75 +1,18 @@ --- app_id: n2ws -app_uuid: 6c0176c4-b878-43e0-a5a8-d280b0fa123e -assets: - dashboards: - N2WSBackup&Recovery-EntitiesSpecificDashboard: assets/dashboards/N2WSBackup&Recovery-EntityTypesDetails.json - N2WSBackup&Recovery-EntitiesSpecificDashboardV4.0: assets/dashboards/N2WSBackup&Recoveryv4.1-EntityTypesDetails.json - N2WSBackup&Recovery-GraphicalVersion: assets/dashboards/N2WSBackup&Recovery-BackupSuccessRates(ColumnGraphs).json - N2WSBackup&Recovery-GraphicalVersion-Areas: assets/dashboards/N2WSBackup&Recovery-BackupSuccessRates(AreasGraphs).json - N2WSBackup&Recovery-GraphicalVersionV4.0: assets/dashboards/N2WSBackup&Recoveryv4.1-BackupSuccessRates(ColumnGraphs).json - integration: - auto_install: true - configuration: {} - events: - creates_events: false - metrics: - check: cpm_metric.dashboard_activity.backup_success_num - metadata_path: metadata.csv - prefix: cpm_metric. - service_checks: - metadata_path: assets/service_checks.json - source_type_id: 10129 - source_type_name: N2WS Backup & Recovery -author: - homepage: https://github.com/DataDog/integrations-extras - name: N2WS - sales_email: eliad.eini@n2ws.com - support_email: eliad.eini@n2ws.com categories: - nube -custom_kind: integration -dependencies: -- https://github.com/DataDog/integrations-extras/blob/master/n2ws/README.md -display_on_public_website: true -draft: false -git_integration_title: n2ws -integration_id: n2ws -integration_title: N2WS -integration_version: '' -is_public: true -manifest_version: 2.0.0 -name: n2ws -public_title: N2WS -short_description: Ver datos resumidos de todos los hosts conectados de N2WS Backup - & Recovery +custom_kind: integración +description: Ver datos resumidos de todos los hosts conectados de N2WS Backup & Recovery +media: [] supported_os: - linux - macos - windows -tile: - changelog: CHANGELOG.md - classifier_tags: - - Supported OS::Linux - - Supported OS::macOS - - Supported OS::Windows - - Category::Cloud - - Offering::Integration - configuration: README.md#Setup - description: Ver datos resumidos de todos los hosts conectados de N2WS Backup & - Recovery - media: [] - overview: README.md#Overview - support: README.md#Support - title: N2WS +title: N2WS --- - - - - ## Información general - N2WS Backup & Recovery (CPM), conocido como N2WS, es una solución empresarial de copia de seguridad, recuperación y recuperación de desastres para Amazon Web Services (AWS) y Microsoft Azure. N2WS utiliza tecnologías nativas en la nube (snapshots) para brindar capacidades de copia de seguridad y restauración en AWS y Azure. Tu instancia de N2WS Backup and Recovery admite la monitorización de copias de seguridad, recuperación de desastres, copia a S3, alertas, @@ -79,39 +22,42 @@ y mucho más con el servicio d emonitorización de Datadog. Esta integración pe ### Instalación -1. Instala la [integración de Python][1]. +1. Instala la [integración de Python](https://app.datadoghq.com/account/settings#integrations/python). + +1. Habilita la compatibilidad con Datadog en tu instancia de N2WS: -2. Habilita la compatibilidad con Datadog en tu instancia de N2WS: - - Conéctate a tu instancia de N2WS Backup and Recovery con SSH. - - Añade las líneas siguientes a `/cpmdata/conf/cpmserver.cfg`. Es posible que necesites privilegios `sudo` para realizar esta acción. - ``` - [external_monitoring] - enabled=True - ``` - - Ejecuta `service apache2 restart` + - Conéctate a tu instancia de N2WS Backup and Recovery con SSH. + - Añade las líneas siguientes a `/cpmdata/conf/cpmserver.cfg`. Es posible que necesites privilegios `sudo` para realizar esta acción. + ``` + [external_monitoring] + enabled=True + ``` + - Ejecuta `service apache2 restart` -3. Instala el Datadog Agent en tu instancia de N2WS. - - Inicia sesión en Datadog y ve a Integrations -> Agent -> Ubuntu (Integraciones -> Agent -> Ubuntu) - - Copia el comando de instalación en un solo paso del Agent. - - Conéctate a tu instancia de N2WS Backup and Recovery con SSH y ejecuta el comando. Es posible que necesites privilegios `sudo` para realizar esta acción. +1. Instala el Datadog Agent en tu instancia de N2WS. -4. Configura las métricas de dashboard de Datadog: - - Ve a [**Metrics** -> **Explorer**][2] (Métricas -> Explorador) + - Inicia sesión en Datadog y ve a Integrations -> Agent -> Ubuntu (Integraciones -> Agent -> Ubuntu) + - Copia el comando de instalación en un solo paso del Agent. + - Conéctate a tu instancia de N2WS Backup and Recovery con SSH y ejecuta el comando. Es posible que necesites privilegios `sudo` para realizar esta acción. - **Gráfico**: selecciona tu métrica en la lista. Todas las métricas de N2WS comienzan con la cadena `cpm_metric`. +1. Configura las métricas de dashboard de Datadog: - **Sobre**: selecciona los datos de la lista. Todos los datos de los usuarios de N2WS comienzan con la cadena `cpm:user:
(gauge) | Número total de copias de seguridad realizadas con éxito (de todos los tipos)| +| **cpm_metric.dashboard_activity.backup_fail_num**
(gauge) | Número total de copias de seguridad fallidas (de todos los tipos)| +| **cpm_metric.dashboard_activity.backup_partial_num**
(gauge) | Número total de copias de seguridad parcialmente correctas (de todos los tipos)| +| **cpm_metric.dashboard_activity.backup_dr_success_num**
(gauge) | Número total de copias de seguridad DR realizadas con éxito (de todos los tipos)| +| **cpm_metric.dashboard_activity.backup_dr_fail_num**
(gauge) | Número total de copias de seguridad DR fallidas (de todos los tipos)| +| **cpm_metric.dashboard_activity.backup_dr_partial_num**
(gauge) | Número total de copias de seguridad de RD parcialmente correctas (de todos los tipos)| +| **cpm_metric.dashboard_activity.backup_s3_success_num**
(gauge) | Número total de copias de seguridad realizadas con éxito en S3| +| **cpm_metric.dashboard_activity.backup_s3_fail_num**
(gauge) | Número total de copias de seguridad fallidas en S3| +| **cpm_metric.dashboard_activity.backup_s3_partial_num**
(gauge) | Número total de copias de seguridad parcialmente correctas en S3| +| **cpm_metric.dashboard_state.policies_num**
(gauge) | Número total de políticas en todos los hosts| +| **cpm_metric.dashboard_state.accounts_num**
(gauge) | Número total de cuentas en todos los hosts| +| **cpm_metric.dashboard_state.snapshots_volume_num**
(gauge) | Número total de instantáneas de volúmenes| +| **cpm_metric.dashboard_state.snapshots_only_ami_num**
(gauge) | Número total de instantáneas de instancia solo AMI| +| **cpm_metric.dashboard_state.snapshots_dr_volume_num**
(gauge) | Número total de instantáneas DR de volúmenes| +| **cpm_metric.dashboard_state.snapshots_rds_num**
(gauge) | Número total de instantáneas de bases de datos RDS| +| **cpm_metric.dashboard_state.snapshots_dr_rds_num**
(gauge) | Número total de instantáneas DR de bases de datos RDS| +| **cpm_metric.dashboard_state.snapshots_redshift_num**
(gauge) | Número total de instantáneas de bases de datos de Redshift| +| **cpm_metric.dashboard_state.snapshots_rds_clus_num**
(gauge) | Número total de instantáneas de los clústeres de Aurora| +| **cpm_metric.dashboard_state.snapshots_dr_rds_clus_num**
(gauge) | Número total de instantáneas DR de los clústeres de Aurora| +| **cpm_metric.dashboard_state.snapshots_ddb_num**
(gauge) | Número total de instantáneas de DynamoDB| +| **cpm_metric.dashboard_state.snapshots_efs_num**
(gauge) | Número total de instantáneas DR de sistemas de archivos EFS| +| **cpm_metric.dashboard_state.snapshots_dr_efs_num**
(gauge) | Número total de instantáneas de Azure Disks| +| **cpm_metric.dashboard_state.snapshots_disk_num**
(gauge) | Número total de instantáneas de sistemas de archivos EFS| +| **cpm_metric.dashboard_state.protected_instances_num**
(gauge) | Número total de recursos de instancias protegidas| +| **cpm_metric.dashboard_state.protected_volumes_num**
(gauge) | Número total de recursos de volúmenes protegidos| +| **cpm_metric.dashboard_state.protected_rds_db_num**
(gauge) | Número total de recursos RDS protegidos| +| **cpm_metric.dashboard_state.protected_ddb_num**
(gauge) | Número total de recursos de DynamoDB protegidos| +| **cpm_metric.dashboard_state.protected_efs_num**
(gauge) | Número total de recursos EFS protegidos| +| **cpm_metric.dashboard_state.protected_rds_clus_num**
(gauge) | Número total de recursos de Aurora protegidos| +| **cpm_metric.dashboard_state.protected_redshift_num**
(gauge) | Número total de recursos de máquinas virtuales de Azure protegidas| +| **cpm_metric.dashboard_state.protected_virtual_machines_num**
(gauge) | Número total de recursos de Redshift protegidos| +| **cpm_metric.dashboard_state.protected_disks_num**
(gauge) | Número total de recursos de Redshift protegidos| +| **cpm_metric.dashboard_state.volumes_above_high_watermark_num**
(gauge) | Número de volúmenes con capacidad superior a la marca de agua| +| **cpm_metric.dashboard_state.volumes_below_low_watermark_num**
(gauge) | Número de volúmenes con capacidad inferior a la marca de agua| +| **cpm_metric.dashboard_state.volumes_usage_percentage_num**
(gauge) | Uso total de la capacidad para todos los volúmenes de todos los hosts
_Mostrado como porcentaje_ | ### Eventos @@ -138,16 +120,6 @@ La integración de N2WS Backup & Recovery no incluye ningún check de servicio. ## Solucionar problemas -- [Guía del usuario y documentación de N2WS][6] -- [Soporte de N2WS][7] -- [Soporte de Datadog][8] - - -[1]: https://app.datadoghq.com/account/settings#integrations/python -[2]: https://app.datadoghq.com/metric/explorer -[3]: https://app.datadoghq.com/account/settings#integrations/n2ws -[4]: https://support.n2ws.com/portal/en/kb/articles/datadog-templates -[5]: https://github.com/DataDog/integrations-extras/blob/master/n2ws/metadata.csv -[6]: https://n2ws.com/support/documentation -[7]: https://n2ws.com/support -[8]: https://docs.datadoghq.com/es/help/ \ No newline at end of file +- [Guía del usuario y documentación de N2WS](https://n2ws.com/support/documentation) +- [Asistencia técnica de N2WS](https://n2ws.com/support) +- [Asistencia técnica de Datadog](https://docs.datadoghq.com/help/) \ No newline at end of file diff --git a/content/es/integrations/neo4j.md b/content/es/integrations/neo4j.md index 87f3d11bffa48..55f1eef6834ea 100644 --- a/content/es/integrations/neo4j.md +++ b/content/es/integrations/neo4j.md @@ -1,94 +1,42 @@ --- app_id: neo4j -app_uuid: f2657bb8-ded4-48f3-8095-f703cc203149 -assets: - dashboards: - Neo4j V4 Dashboard: assets/dashboards/Neo4j4.xDefaultDashboard.json - Neo4j V5 Cluster Dashboard: assets/dashboards/Neo4j5ClusterDashboard.json - Neo4j V5 Dashboard: assets/dashboards/Neo4j5DefaultDashboard.json - integration: - auto_install: true - configuration: - spec: assets/configuration/spec.yaml - events: - creates_events: false - metrics: - check: neo4j.dbms.page_cache.hits - metadata_path: metadata.csv - prefix: neo4j. - service_checks: - metadata_path: assets/service_checks.json - source_type_id: 10202 - source_type_name: Neo4j -author: - homepage: https://github.com/DataDog/integrations-extras - name: Neo4j - sales_email: support@neotechnology.com - support_email: support@neotechnology.com categories: - almacenes de datos -custom_kind: integration -dependencies: -- https://github.com/DataDog/integrations-extras/blob/master/neo4j/README.md -display_on_public_website: true -draft: false -git_integration_title: neo4j -integration_id: neo4j -integration_title: Neo4j -integration_version: 3.0.3 -is_public: true -manifest_version: 2.0.0 -name: neo4j -public_title: Neo4j -short_description: Recopila métricas de Neo4j +custom_kind: integración +description: Recopila métricas de Neo4j +integration_version: 3.0.4 +media: +- caption: Dashboard de Neo4j 5 + image_url: images/Neo4j_5_Dashboard.png + media_type: imagen +- caption: Base de datos de Neo4j 5 + image_url: images/neo4j_graph.png + media_type: imagen supported_os: - linux - macos - windows -tile: - changelog: CHANGELOG.md - classifier_tags: - - Supported OS::Linux - - Supported OS::macOS - - Supported OS::Windows - - Category::Data Stores - - Offering::Integration - configuration: README.md#Setup - description: Recopila métricas de Neo4j - media: - - caption: Dashboard de Neo4j 5 - image_url: images/Neo4j_5_Dashboard.png - media_type: imagen - - caption: Base de datos de Neo4j 5 - image_url: images/neo4j_graph.png - media_type: imagen - overview: README.md#Overview - support: README.md#Support - title: Neo4j +title: Neo4j --- - - - - ## Información general -[Neo4j][1] es una base de datos gráfica empresarial que combina almacenamiento gráfico nativo, seguridad avanzada, arquitectura escalable de velocidad optimizada y conformidad con ACID para asegurar la previsibilidad y la integridad de las consultas basadas en relaciones. Neo4j almacena y gestiona los datos en su estado más natural y conectado, mediante relaciones de datos que ofrecen consultas ultrarrápidas, un contexto más detallado para el análisis y un modelo de datos modificable sin complicaciones. +[Neo4j](https://neo4j.com/) es una base de datos gráfica empresarial que combina almacenamiento gráfico nativo, seguridad avanzada, arquitectura escalable de velocidad optimizada y conformidad con ACID para garantizar la previsibilidad y la integridad de las consultas basadas en relaciones. Neo4j almacena y gestiona los datos en su estado más natural y conectado y mantiene relaciones de datos que ofrecen consultas ultrarrápidas, un contexto más profundo para el análisis y un modelo de datos modificable sin complicaciones. -Las métricas de Neo4j permite a los administradores de bases de datos monitorizar sus despliegues de Neo4j. Los administradores de bases de datos desean conocer el uso de la memoria (caché de heap y páginas), el número de transacciones, el estado del clúster, el tamaño de la base de datos (incluido el número de nodos, relaciones y propiedades) y el rendimiento de las consultas. - -Con esta integración, visualiza importantes métricas de Neo4j en nuestros dashboards predefinidos y permite a tus DBAs solucionar problemas y monitorizar el estado de tus bases de datos Neo4j. +Las métricas de Neo4j permiten a los administradores de bases de datos monitorizar sus despliegues de Neo4j. Los administradores de bases de datos desean conocer el uso de la memoria (caché de montón y de page (página)), el número de transacciones, el estado del clúster, el tamaño de la base de datos (incluidos el número de nodos, relaciones y propiedades) y el rendimiento de las consultas. +Con esta integración, visualiza importantes métricas de Neo4j en nuestros dashboards predefinidos y permite a tus bases de datos solucionar problemas y monitorizar el estado de tus bases de datos Neo4j. ## Configuración -Sigue las instrucciones a continuación para instalar y configurar este check para un Agent que se ejecuta en un host. Para entornos en contenedores, consulta las [plantillas de integración de Autodiscovery][2] para obtener orientación sobre la aplicación de estas instrucciones. +Sigue las siguientes instrucciones para instalar y configurar este check para un Agent que se ejecute en un host. Para entornos en contenedores, consulta las [Plantillas de integración de Autodiscovery](https://docs.datadoghq.com/agent/autodiscovery/integrations) para obtener orientación sobre la aplicación de estas instrucciones. ### Instalación Para instalar el check de neo4j en tu host: -1. Descarga e instala el [Datadog Agent][3]. -2. Para instalar el check de neo4j en tu host: +1. Descarga e instala el [Datadog Agent](https://app.datadoghq.com/account/settings/agent/latest). + +1. Para instalar el check de neo4j en tu host: ```shell datadog-agent integration install -t datadog-neo4j==
(gauge) | Número total de solicitudes de extracción de transacciones recibidas. (Neo4j 4)| +| **neo4j.causal_clustering.core.append_index**
(gauge) | Índice de anexión del log de RAFT. (Neo4j 4)| +| **neo4j.causal_clustering.core.commit_index**
(gauge) | Índice de confirmación del log de RAFT. (Neo4j 4)| +| **neo4j.causal_clustering.core.discovery.cluster.converged**
(gauge) | Convergencia del clúster de descubrimiento. (Neo4j 4)| +| **neo4j.causal_clustering.core.discovery.cluster.members**
(gauge) | Tamaño de los miembros del clúster de descubrimiento. (Neo4j 4)| +| **neo4j.causal_clustering.core.discovery.cluster.unreachable**
(gauge) | Tamaño inalcanzable del clúster de descubrimiento. (Neo4j 4)| +| **neo4j.causal_clustering.core.discovery.replicated_data.cluster_id.per_db_name.invisible**
(gauge) | Identificador oculto del clúster. (Neo4j 4)| +| **neo4j.causal_clustering.core.discovery.replicated_data.cluster_id.per_db_name.visible**
(gauge) | Identificador compartido del clúster. (Neo4j 4)| +| **neo4j.causal_clustering.core.discovery.replicated_data.member_data.invisible**
(gauge) | Estructura de datos invisible que contiene metadatos sobre los miembros del clúster. (Neo4j 4)| +| **neo4j.causal_clustering.core.discovery.replicated_data.member_data.visible**
(gauge) | Estructura de datos visible que contiene metadatos sobre los miembros del clúster. (Neo4j 4)| +| **neo4j.causal_clustering.core.discovery.replicated_data.member_db_state.invisible**
(gauge) | La parte oculta de la estructura de datos utilizada con fines internos. (Neo4j 4)| +| **neo4j.causal_clustering.core.discovery.replicated_data.member_db_state.visible**
(gauge) | La parte visible de la estructura de datos utilizada con fines internos. (Neo4j 4)| +| **neo4j.causal_clustering.core.discovery.replicated_data.per_db.leader_name.invisible**
(gauge) | El número total de cambios de liderazgo. (Neo4j 4)| +| **neo4j.causal_clustering.core.discovery.replicated_data.per_db.leader_name.visible**
(gauge) | Número de líderes del clúster. (Neo4j 4)| +| **neo4j.causal_clustering.core.discovery.replicated_data.raft_id.published_by_member.invisible**
(gauge) | Identificador de Raft visible publicado por el miembro. (Neo4j 4)| +| **neo4j.causal_clustering.core.discovery.replicated_data.raft_id.published_by_member.visible**
(gauge) | Identificador de Raft oculto publicado por el miembro. (Neo4j 4)| +| **neo4j.causal_clustering.core.in_flight_cache_element_count**
(gauge) | Recuento de elementos de la caché en vuelo. (Neo4j 4)| +| **neo4j.causal_clustering.core.in_flight_cache.hits**
(gauge) | Aciertos de la caché en vuelo. (Neo4j 4)| +| **neo4j.causal_clustering.core.in_flight_cache.max_bytes**
(gauge) | Bytes máximos de caché en vuelo. (Neo4j 4)| +| **neo4j.causal_clustering.core.in_flight_cache.max_elements**
(gauge) | Elementos máximos de caché en vuelo. (Neo4j 4)| +| **neo4j.causal_clustering.core.in_flight_cache.misses**
(gauge) | Fallos de caché en vuelo. (Neo4j 4)| +| **neo4j.causal_clustering.core.in_flight_cache.total_bytes**
(gauge) | Total de bytes de la caché en vuelo. (Neo4j 4)| +| **neo4j.causal_clustering.core.is_leader**
(gauge) | ¿Es este servidor el líder? (Neo4j 4)| +| **neo4j.causal_clustering.core.message_processing_delay**
(gauge) | Retraso entre la recepción y el procesamiento de mensajes de RAFT. (Neo4j 4)| +| **neo4j.causal_clustering.core.message_processing_timer**
(gauge) | Temporizador para el procesamiento de mensajes de RAFT. (Neo4j 4)| +| **neo4j.causal_clustering.core.message_processing_timer.append_entries_request**
(gauge) | Solicitudes invocadas por el líder de RAFT para replicar entradas de logs. (Neo4j 4)| +| **neo4j.causal_clustering.core.message_processing_timer.append_entries_response**
(gauge) | Respuestas de los seguidores a las solicitudes del líder de RAFT para replicar las entradas de logs. (Neo4j 4)| +| **neo4j.causal_clustering.core.message_processing_timer.election_timeout**
(gauge) | Eventos de tiempo de espera para el procesamiento de mensajes de RAFT. (Neo4j 4)| +| **neo4j.causal_clustering.core.message_processing_timer.heartbeat**
(gauge) | Solicitudes de Heartbeat recibidas por los seguidores en el clúster de RAFT. (Neo4j 4)| +| **neo4j.causal_clustering.core.message_processing_timer.heartbeat_response**
(gauge) | Respuestas de Heartbeat recibidas por el líder en el clúster de RAFT. (Neo4j 4)| +| **neo4j.causal_clustering.core.message_processing_timer.heartbeat_timeout**
(gauge) | Eventos de tiempo de espera para solicitudes de latido. (Neo4j 4)| +| **neo4j.causal_clustering.core.message_processing_timer.log_compaction_info**
(gauge) | Compactación de logs (Neo4j 4)| +| **neo4j.causal_clustering.core.message_processing_timer.new_batch_request**
(gauge) | Nuevas solicitudes por lotes (Neo4j 4)| +| **neo4j.causal_clustering.core.message_processing_timer.new_entry_request**
(gauge) | Nuevas solicitudes de entrada (Neo4j 4)| +| **neo4j.causal_clustering.core.message_processing_timer.pre_vote_request**
(gauge) | Solicitudes previas a la votación (Neo4j 4)| +| **neo4j.causal_clustering.core.message_processing_timer.pre_vote_response**
(gauge) | Respuestas previas a la votación (Neo4j 4)| +| **neo4j.causal_clustering.core.message_processing_timer.prune_request**
(gauge) | Solicitudes de poda (Neo4j 4)| +| **neo4j.causal_clustering.core.message_processing_timer.vote_request**
(gauge) | Solicitudes de votación (Neo4j 4)| +| **neo4j.causal_clustering.core.message_processing_timer.vote_response**
(gauge) | Respuestas a las votaciones (Neo4j 4)| +| **neo4j.causal_clustering.core.replication_attempt**
(gauge) | Count de intentos de réplica de la Raft. (Neo4j 4)| +| **neo4j.causal_clustering.core.replication_fail**
(gauge) | Count de fallos en la réplica de Raft. (Neo4j 4)| +| **neo4j.causal_clustering.core.replication_new**
(gauge) | Nuevo count de solicitudes de réplica de Raft. (Neo4j 4)| +| **neo4j.causal_clustering.core.replication_success**
(gauge) | Count de éxitos de réplica de Raft. (Neo4j 4)| +| **neo4j.causal_clustering.core.term**
(gauge) | Término de RAFT de este servidor (Neo4j 4)| +| **neo4j.causal_clustering.core.tx_retries**
(gauge) | Reintentos de transacción. (Neo4j 4)| +| **neo4j.causal_clustering.read_replica.pull_update_highest_tx_id_received**
(gauge) | El identificador de transacción más alto que se ha extraído en la última actualización de extracción por esta instancia. (Neo4j 4)| +| **neo4j.causal_clustering.read_replica.pull_update_highest_tx_id_requested**
(gauge) | El identificador de transacción más alto solicitado en una actualización de incorporación de cambios por esta instancia. (Neo4j 4)| +| **neo4j.causal_clustering.read_replica.pull_updates**
(gauge) | El número total de solicitudes de incorporación de cambios realizadas por esta instancia. (Neo4j 4)| +| **neo4j.database.dbname.check_point.duration**
(gauge) | La duración, en milisegundos, del último evento de punto de control. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.check_point.events**
(count) | El número total de eventos de punto de control ejecutados hasta el momento. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.check_point.io_limit**
(gauge) | El límite de entrada/salida utilizado durante el último evento de punto de control. (Neo4j 5)| +| **neo4j.database.dbname.check_point.io_performed**
(gauge) | El número de entradas/salidas desde la perspectiva de Neo4j realizadas durante el último evento de punto de control. (Neo4j 5)| +| **neo4j.database.dbname.check_point.limit_millis**
(gauge) | (Neo4j 5)| +| **neo4j.database.dbname.check_point.limit_times**
(gauge) | (Neo4j 5)| +| **neo4j.database.dbname.check_point.pages_flushed**
(gauge) | El número de páginas que se vaciaron durante el último evento de punto de control. (Neo4j 5)| +| **neo4j.database.dbname.check_point.total_time**
(count) | El tiempo total, en milisegundos, empleado en el punto de control hasta ahora. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.cluster.catchup.tx_pull_requests_received**
(count) | Solicitudes de incorporación de cambios de TX recibidas de secundarios. (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.append_index**
(count) | El índice de anexión del log de Raft (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.applied_index**
(count) | El índice aplicado del log de Raft (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.commit_index**
(count) | El índice de confirmación del log de Raft (Neo4j 4)| +| **neo4j.database.dbname.cluster.core.in_flight_cache.element_count**
(gauge) | Count de elementos en caché en vuelo. (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.in_flight_cache.hits**
(count) | Aciertos de caché en vuelo. (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.in_flight_cache.max_bytes**
(gauge) | Bytes máximos de caché en vuelo. (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.in_flight_cache.max_elements**
(gauge) | Elementos máximos de la caché en vuelo. (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.in_flight_cache.misses**
(count) | Fallos de caché en vuelo. (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.in_flight_cache.total_bytes**
(count) | Total de bytes de la caché en vuelo. (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.is_leader**
(count) | ¿Es este servidor el líder? (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.last_leader_message**
(count) | El tiempo transcurrido desde el último mensaje de un líder en milisegundos.| +| **neo4j.database.dbname.cluster.core.message_processing_delay**
(count) | Retraso entre la recepción y el procesamiento del mensaje de Raft.| +| **neo4j.database.dbname.cluster.core.message_processing_timer**
(count) | Temporizador para el procesamiento de mensajes de Raft. (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.message_processing_timer.append_entries_request**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.message_processing_timer.append_entries_response**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.message_processing_timer.election_timeout**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.message_processing_timer.heartbeat**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.message_processing_timer.heartbeat_response**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.message_processing_timer.heartbeat_timeout**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.message_processing_timer.leadership_transfer_proposal**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.message_processing_timer.leadership_transfer_rejection**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.message_processing_timer.leadership_transfer_request**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.message_processing_timer.log_compaction_info**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.message_processing_timer.new_batch_request**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.message_processing_timer.new_entry_request**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.message_processing_timer.pre_vote_request**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.message_processing_timer.pre_vote_response**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.message_processing_timer.prune_request**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.message_processing_timer.status_response**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.message_processing_timer.vote_request**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.message_processing_timer.vote_response**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.raft_log_entry_prefetch_buffer.async_put**
(count) | Puts asíncronas de búfer de acceso previo de entrada de logs de Raft (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.raft_log_entry_prefetch_buffer.bytes**
(count) | Bytes totales de acceso previo de entrada de logs de Raft. (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.raft_log_entry_prefetch_buffer.lag**
(count) | Retraso de acceso previo de entrada de logs de Raft. (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.raft_log_entry_prefetch_buffer.size**
(count) | Tamaño del búfer de acceso previo de entrada de logs de Raft (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.raft_log_entry_prefetch_buffer.sync_put**
(count) | Puts asíncronas de búfer de acceso previo de entrada de logs de Raft (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.replication_attempt**
(count) | El número total de intentos de solicitudes de réplicas de Raft. Es mayor o igual que las solicitudes de réplicas.| +| **neo4j.database.dbname.cluster.core.replication_fail**
(count) | El número total de intentos de réplica de Raft que han fallado. (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.replication_maybe**
(count) | La réplica de Raft tal vez cuente. (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.replication_new**
(count) | La réplica de Raft tal vez cuente. (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.replication_success**
(count) | El número total de solicitudes de réplicas de Raft que han tenido éxito. (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.term**
(count) | El término de Raft de este servidor. Aumenta en forma monótona si no se desvincula el estado del clúster. (Neo4j 5)| +| **neo4j.database.dbname.cluster.core.tx_retries**
(count) | Reintentos de transacción. (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.append_index**
(count) | El índice de anexión del log de Raft. Cada índice representa una transacción de escritura (posiblemente interna) propuesta para confirmación. Los valores aumentan en su mayoría, pero a veces pueden disminuir como consecuencia de cambios de líder. El índice de anexión siempre debe ser menor o igual al índice de confirmación. (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.applied_index**
(count) | El índice aplicado del log de Raft. Representa la aplicación de las entradas de logs de Raft confirmadas a la base de datos y al estado interno. El índice aplicado siempre debe ser mayor o igual que el índice de confirmación. La diferencia entre este y el índice de confirmación se puede utilizar para monitorizar para saber cuán actualizada está la base de datos de seguimiento. (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.commit_index**
(count) | El índice de confirmación de logs de Raft. Representa el compromiso de las entradas añadidas previamente. Su valor aumenta en forma monótona si no se desvincula el estado del clúster. El índice de confirmación siempre debe ser mayor o igual que el índice de anexión. (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.in_flight_cache.element_count**
(count) | Count de elementos en caché en vuelo. (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.in_flight_cache.hits**
(count) | Aciertos de la caché en vuelo. (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.in_flight_cache.max_bytes**
(count) | Bytes máximos de caché en vuelo. (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.in_flight_cache.max_elements**
(count) | Elementos máximos de la caché en vuelo. (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.in_flight_cache.misses**
(count) | Fallos de caché en vuelo. (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.in_flight_cache.total_bytes**
(count) | Total de bytes de la caché en vuelo. (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.is_leader**
(count) | ¿Es este servidor el líder? (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.last_leader_message**
(count) | El tiempo transcurrido desde el último mensaje de un líder en milisegundos. Debe reiniciarse periódicamente. (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_delay**
(count) | Retraso entre la recepción y el procesamiento del mensaje de Raft. (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer**
(count) | Temporizador para el procesamiento de mensajes de Raft. (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer.append_entries_request**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer.append_entries_response**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer.election_timeout**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer.heartbeat**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer.heartbeat_response**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer.heartbeat_timeout**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer.leadership_transfer_proposal**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer.leadership_transfer_rejection**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer.leadership_transfer_request**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer.log_compaction_info**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer.new_batch_request**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer.new_entry_request**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer.pre_vote_request**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer.pre_vote_response**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer.prune_request**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer.status_response**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer.vote_request**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.message_processing_timer.vote_response**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.raft_log_entry_prefetch_buffer.async_put**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.raft_log_entry_prefetch_buffer.bytes**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.raft_log_entry_prefetch_buffer.lag**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.raft_log_entry_prefetch_buffer.size**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.raft_log_entry_prefetch_buffer.sync_put**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.replication_attempt**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.replication_fail**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.replication_maybe**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.replication_new**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.replication_success**
(count) | (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.term**
(count) | El término de Raft de este servidor. Aumenta en forma monótona si no se desvincula el estado del clúster. (Neo4j 5)| +| **neo4j.database.dbname.cluster.raft.tx_retries**
(count) | Reintentos de transacción. (Neo4j 5)| +| **neo4j.database.dbname.count.node**
(gauge) | El número total de nodos en las bases de datos. (Neo4j 4)| +| **neo4j.database.dbname.cypher.cache.ast.entries**
(gauge) | Número de entradas de AST en la caché de cifrado (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.executable_query.cache_flushes**
(gauge) | Número de descargas de la caché de consultas ejecutables de la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.executable_query.compiled**
(gauge) | El número de entradas compiladas de consultas ejecutables de la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.executable_query.discards**
(gauge) | El número de descartes de consultas ejecutables de la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.executable_query.entries**
(gauge) | Número de entradas de consultas ejecutables en la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.executable_query.hits**
(gauge) | Número de aciertos de consultas ejecutables en la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.executable_query.misses**
(gauge) | El número de consultas ejecutables fallidas de la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.executable_query.stale_entries**
(gauge) | Número de entradas de consultas obsoletas ejecutables en la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.execution_plan.cache_flushes**
(gauge) | El número de vaciados de caché del plan de ejecución de la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.execution_plan.compiled**
(gauge) | El número de entradas compiladas del plan de ejecución de la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.execution_plan.discards**
(gauge) | El número de descartes del plan de ejecución de la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.execution_plan.entries**
(gauge) | El número de entradas del plan de ejecución de la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.execution_plan.hits**
(gauge) | Número de aciertos en el plan de ejecución de la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.execution_plan.misses**
(gauge) | El número de fallos en el plan de ejecución de la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.execution_plan.stale_entries**
(gauge) | Número de entradas de consultas obsoletas ejecutables en la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.logical_plan.cache_flushes**
(gauge) | El número de vaciados de la caché de planes lógicos de la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.logical_plan.compiled**
(gauge) | El número de entradas compiladas del plan lógico de la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.logical_plan.discards**
(gauge) | El número de descartes del plan lógico de la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.logical_plan.entries**
(gauge) | El número de entradas del plan lógico de la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.logical_plan.hits**
(gauge) | Número de aciertos del plan lógico de la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.logical_plan.misses**
(gauge) | Número de faltas del plan lógico de la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.logical_plan.stale_entries**
(gauge) | Número de entradas de consultas obsoletas ejecutables en la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.cache.pre_parser.entries**
(gauge) | El número de entradas del analizador previo de la caché de cifrado. (Neo4j 5)| +| **neo4j.database.dbname.cypher.replan_events**
(count) | El número total de veces que Cypher ha decidido volver a planificar una consulta. Neo4j almacena 1000 planes en forma predeterminada. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.cypher.replan_wait_time**
(count) | El número total de segundos esperados entre nuevas planificaciones de consultas. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.db.query.execution.failure**
(count) | Count de consultas fallidas ejecutadas. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.db.query.execution.latency.millis**
(gauge) | Tiempo de ejecución en milisegundos de las consultas ejecutadas con éxito. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.db.query.execution.success**
(count) | Count de consultas ejecutadas con éxito. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.ids_in_use.node**
(gauge) | El número total de nodos almacenados en la base de datos. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.ids_in_use.property**
(gauge) | El número total de nombres de propiedades diferentes utilizados en la base de datos. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.ids_in_use.relationship**
(gauge) | El número total de relaciones almacenadas en la base de datos. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.ids_in_use.relationship_type**
(gauge) | El número total de diferentes tipos de relaciones almacenadas en la base de datos. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.log.append_batch_size**
(gauge) | El tamaño del último lote de anexiones de transacciones. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.log.appended_bytes**
(count) | El número total de bytes añadidos al log de transacción. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.log.flushes**
(count) | El número total de vaciados de logs de transacciones. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.log.rotation_duration**
(count) | La duración, en milisegundos, del último evento de rotación de logs. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.log.rotation_events**
(count) | El número total de rotaciones de logs de transacciones ejecutadas hasta el momento. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.log.rotation_total_time**
(count) | El tiempo total, en milisegundos, empleado en rotar logs de transacciones hasta el momento. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.neo4j.count.node**
(count) | El número total de nodos en la base de datos. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.neo4j.count.relationship**
(gauge) | El número total de relaciones en la base de datos. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.neo4j.count.relationship_types**
(gauge) | Número total de identificadores generados internamente para los diferentes tipos de relaciones almacenados en la base de datos. (Neo4j 5)| +| **neo4j.database.dbname.pool.other.neo4j.free**
(count) | Cantidad estimada de memoria libre en bytes para este grupo. (Neo4j 4)| +| **neo4j.database.dbname.pool.other.neo4j.total_size**
(count) | Cantidad estimada de memoria disponible en bytes para este grupo. (Neo4j 4)| +| **neo4j.database.dbname.pool.other.neo4j.total_used**
(count) | Cantidad estimada de memoria total utilizada en bytes para este grupo. (Neo4j 4)| +| **neo4j.database.dbname.pool.other.neo4j.used_heap**
(count) | Cantidad estimada de montón utilizado en bytes para este grupo. (Neo4j 4)| +| **neo4j.database.dbname.pool.other.neo4j.used_native**
(count) | Cantidad estimada de memoria nativa utilizada para este grupo. (Neo4j 4)| +| **neo4j.database.dbname.pool.transaction.neo4j.free**
(count) | Cantidad estimada de memoria libre en bytes para este grupo.| +| **neo4j.database.dbname.pool.transaction.neo4j.total_size**
(count) | Cantidad estimada de memoria disponible en bytes para este grupo.| +| **neo4j.database.dbname.pool.transaction.neo4j.total_used**
(count) | Cantidad estimada de memoria total utilizada en bytes para este pool.| +| **neo4j.database.dbname.pool.transaction.neo4j.used_heap**
(count) | Cantidad estimada del montón utilizado en bytes para este grupo.| +| **neo4j.database.dbname.pool.transaction.neo4j.used_native**
(count) | Cantidad estimada de memoria nativa utilizada para este grupo.| +| **neo4j.database.dbname.store.size.database**
(gauge) | El tamaño de la base de datos, en bytes. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.store.size.total**
(gauge) | El tamaño total de la base de datos y de los logs de transacciones, en bytes. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.transaction.active**
(gauge) | El número de transacciones actualmente activas. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.transaction.active_read**
(gauge) | El número de transacciones de lectura actualmente activas. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.transaction.active_write**
(gauge) | El número de transacciones de escritura actualmente activas. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.transaction.committed**
(count) | El número total de transacciones confirmadas. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.transaction.committed_read**
(count) | El número total de transacciones de lectura confirmadas. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.transaction.committed_write**
(count) | El número total de transacciones de escritura confirmadas. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.transaction.last_closed_tx_id**
(gauge) | El identificador de la última transacción cerrada. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.transaction.last_committed_tx_id**
(gauge) | El identificador de la última transacción confirmada. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.transaction.peak_concurrent**
(count) | El pico más alto de transacciones concurrentes. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.transaction.rollbacks**
(count) | El número total de transacciones revertidas. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.transaction.rollbacks_read**
(count) | El número total de transacciones de lectura revertidas. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.transaction.rollbacks_write**
(count) | El número total de transacciones de escritura revertidas. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.transaction.started**
(count) | El número total de transacciones iniciadas.| +| **neo4j.database.dbname.transaction.terminated**
(count) | El número total de transacciones finalizadas.| +| **neo4j.database.dbname.transaction.terminated_read**
(count) | El número total de transacciones de lectura terminadas. (Neo4j 4 y Neo4j 5)| +| **neo4j.database.dbname.transaction.terminated_write**
(count) | Número total de transacciones de escritura finalizadas.| +| **neo4j.database.dbname.transaction.tx_size_heap**
(count) | El tamaño de las transacciones en el montón en bytes.| +| **neo4j.database.dbname.transaction.tx_size_native**
(count) | El tamaño de las transacciones en la memoria nativa en bytes. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.bolt.accumulated_processing_time**
(count) | La cantidad total de tiempo en milisegundos que los subprocesos de worker han estado procesando mensajes. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.bolt.accumulated_queue_time**
(count) | Cuando internal.server.bolt.thread_pool_queue_size está activado, el tiempo total en milisegundos que un mensaje de Bolt espera en la cola de procesamiento antes de que un subproceso de worker de Bolt esté disponible para procesarlo. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.bolt.connections_closed**
(gauge) | El número total de conexiones de Bolt cerradas desde que se inició esta instancia. Esto incluye tanto las conexiones finalizadas correctamente como las anormalmente finalizadas. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.bolt.connections_idle**
(gauge) | El número total de conexiones de Bolt que no están ejecutando actualmente Cypher ni devolviendo resultados. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.bolt.connections_opened**
(count) | El número total de conexiones de Bolt abiertas desde el inicio. Esto incluye tanto las conexiones finalizadas con éxito como las fallidas. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.bolt.connections_running**
(gauge) | El número total de conexiones de Bolt que están ejecutando actualmente Cypher y devolviendo resultados. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.bolt.messages_done**
(count) | El número total de mensajes de Bolt que han terminado de procesarse, ya sea con éxito o sin éxito. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.bolt.messages_failed**
(count) | El número total de mensajes que han fallado durante el procesamiento. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.bolt.messages_received**
(count) | El número total de mensajes recibidos a través de Bolt desde el inicio. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.bolt.messages_started**
(count) | El número total de mensajes que han comenzado a procesarse desde que se recibieron. Un mensaje recibido puede haber comenzado a ser procesado hasta que un hilo de worker de Bolt esté disponible. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.bolt.response_failed**
(count) | El número total de respuestas de Bolt que han fallado durante el procesamiento. (Neo4j 5)| +| **neo4j.dbms.bolt.response_ignored**
(count) | Número total de respuestas de Bolt que se han ignorado durante el procesamiento. (Neo4j 5)| +| **neo4j.dbms.bolt.response_success**
(count) | Número total de respuestas de Bolt que se han procesado correctamente. (Neo4j 5)| +| **neo4j.dbms.bolt_driver.api.managed_transaction_function_calls**
(count) | Número total de llamadas a funciones de transacciones gestionadas. (Neo4j 5)| +| **neo4j.dbms.bolt_driver.api.unmanaged_transaction_calls**
(count) | El número total de llamadas a funciones de transacción no gestionadas. (Neo4j 5)| +| **neo4j.dbms.bolt_driver.api.implicit_transaction_calls**
(count) | Número total de llamadas implícitas a funciones de transacción. (Neo4j 5)| +| **neo4j.dbms.bolt_driver.api.execute_calls**
(count) | Número total de llamadas a funciones de ejecución a nivel de controlador. . (Neo4j 5)| +| **neo4j.dbms.cluster.catchup.tx_pull_requests_received**
(count) | Solicitudes de incorporación de cambios de TX recibidas de réplicas de lectura. (Neo4j 4)| +| **neo4j.dbms.cluster.core.append_index**
(gauge) | El índice de anexión del log de Raft (Neo4j 4)| +| **neo4j.dbms.cluster.core.applied_index**
(gauge) | El índice aplicado del log de Raft (Neo4j 4)| +| **neo4j.dbms.cluster.core.commit_index**
(gauge) | El índice de confirmación del log de Raft (Neo4j 4)| +| **neo4j.dbms.cluster.core.in_flight_cache_element_count**
(gauge) | Recuento de elementos de la caché en vuelo. (Neo4j 4)| +| **neo4j.dbms.cluster.core.in_flight_cache.hits**
(count) | Aciertos de la caché en vuelo. (Neo4j 4)| +| **neo4j.dbms.cluster.core.in_flight_cache.max_bytes**
(gauge) | Número máximo de bytes de caché en vuelo. (Neo4j 4)| +| **neo4j.dbms.cluster.core.in_flight_cache.max_elements**
(gauge) | Elementos máximos de caché en vuelo. (Neo4j 4)| +| **neo4j.dbms.cluster.core.in_flight_cache.misses**
(count) | Fallos de caché en vuelo. (Neo4j 4)| +| **neo4j.dbms.cluster.core.in_flight_cache.total_bytes**
(gauge) | Total de bytes de la caché en vuelo. (Neo4j 4)| +| **neo4j.dbms.cluster.core.is_leader**
(gauge) | ¿Es este servidor el líder? (Neo4j 4)| +| **neo4j.dbms.cluster.core.last_leader_message**
(gauge) | El tiempo transcurrido desde el último mensaje de un líder en milisegundos. (Neo4j 4)| +| **neo4j.dbms.cluster.core.message_processing_delay**
(gauge) | Retraso entre la recepción y el procesamiento de mensajes de RAFT. (Neo4j 4)| +| **neo4j.dbms.cluster.core.message_processsing_timer**
(count) | Temporizador para el procesamiento de mensajes de RAFT. (Neo4j 4)| +| **neo4j.dbms.cluster.core.raft_log_entry_prefetch_buffer.async_put**
(gauge) | Puts asíncronas de búfer de acceso previo de entrada de logs de Raft (Neo4j 4)| +| **neo4j.dbms.cluster.core.raft_log_entry_prefetch_buffer.bytes**
(gauge) | Bytes totales de acceso previo de entrada de logs de Raft. (Neo4j 4)| +| **neo4j.dbms.cluster.core.raft_log_entry_prefetch_buffer.lag**
(gauge) | Retraso de acceso previo de entrada de logs de Raft. (Neo4j 4)| +| **neo4j.dbms.cluster.core.raft_log_entry_prefetch_buffer.size**
(gauge) | Tamaño del búfer de acceso previo de entrada de logs de Raft. (Neo4j 4)| +| **neo4j.dbms.cluster.core.raft_log_entry_prefetch_buffer.sync_put**
(gauge) | Puts asíncronas de búfer de acceso previo de entrada de logs de Raft (Neo4j 4)| +| **neo4j.dbms.cluster.core.replication_attempt**
(count) | El número total de intentos de réplica de solicitudes de Raft. (Neo4j 4)| +| **neo4j.dbms.cluster.core.replication_fail**
(count) | El número total de intentos de réplicas de Raft que han fallado. (Neo4j 4)| +| **neo4j.dbms.cluster.core.replication_maybe**
(count) | Réplica de Raft tal vez cuenta. (Neo4j 4)| +| **neo4j.dbms.cluster.core.replication_new**
(count) | El número total de solicitudes de réplicas de Raft. (Neo4j 4)| +| **neo4j.dbms.cluster.core.replication_success**
(count) | Count de éxitos de réplicas de Raft. (Neo4j 4)| +| **neo4j.dbms.cluster.core.term**
(gauge) | El término de RAFT de este servidor. (Neo4j 4)| +| **neo4j.dbms.cluster.core.tx_retries**
(count) | Reintentos de transacción. (Neo4j 4)| +| **neo4j.dbms.cluster.discovery.cluster.converged**
(gauge) | Convergencia del clúster de descubrimiento. (Neo4j 5)| +| **neo4j.dbms.cluster.discovery.cluster.members**
(gauge) | Tamaño de los miembros del clúster de descubrimiento. (Neo4j 5)| +| **neo4j.dbms.cluster.discovery.cluster.unreachable**
(gauge) | Tamaño inalcanzable del clúster de descubrimiento. (Neo4j 5)| +| **neo4j.dbms.cluster.discovery.replicated_data**
(gauge) | Tamaño de las estructuras de datos replicadas. (Neo4j 5)| +| **neo4j.dbms.cluster.discovery.replicated_data.bootstrap_data.invisible**
(count) | (Neo4j 5)| +| **neo4j.dbms.cluster.discovery.replicated_data.bootstrap_data.visible**
(count) | (Neo4j 5)| +| **neo4j.dbms.cluster.discovery.replicated_data.component_versions.invisible**
(count) | (Neo4j 5)| +| **neo4j.dbms.cluster.discovery.replicated_data.component_versions.visible**
(count) | (Neo4j 5)| +| **neo4j.dbms.cluster.discovery.replicated_data.database_data.invisible**
(count) | (Neo4j 5)| +| **neo4j.dbms.cluster.discovery.replicated_data.database_data.visible**
(count) | (Neo4j 5)| +| **neo4j.dbms.cluster.discovery.replicated_data.leader_data.invisible**
(count) | (Neo4j 5)| +| **neo4j.dbms.cluster.discovery.replicated_data.leader_data.visible**
(count) | (Neo4j 5)| +| **neo4j.dbms.cluster.discovery.replicated_data.server_data.invisible**
(count) | (Neo4j 5)| +| **neo4j.dbms.cluster.discovery.replicated_data.server_data.visible**
(count) | (Neo4j 5)| +| **neo4j.dbms.cluster.discovery.restart.failed_count**
(count) | (Neo4j 5)| +| **neo4j.dbms.cluster.discovery.restart.success_count**
(count) | (Neo4j 5)| +| **neo4j.dbms.cluster.read_replica.pull_update_highest_tx_id_received**
(count) | El identificador de transacción más alto que ha sido extraído en la última actualización de incorporación de cambios por esta instancia. (Neo4j 4)| +| **neo4j.dbms.cluster.read_replica.pull_update_highest_tx_id_requested**
(count) | El identificador de transacción más alto solicitado en una actualización incorporación de cambios por esta instancia. (Neo4j 4)| +| **neo4j.dbms.cluster.read_replica.pull_updates**
(count) | El número total de solicitudes de incorporación de cambios realizadas por esta instancia. (Neo4j 4)| +| **neo4j.dbms.db.operation.count.create**
(count) | Count de operaciones de creación realizadas con éxito. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.db.operation.count.drop**
(count) | Count de operaciones de eliminación de bases de datos realizadas con éxito. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.db.operation.count.failed**
(count) | Count de operaciones fallidas en la base de datos. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.db.operation.count.recovered**
(count) | Count de operaciones de base de datos que fallaron anteriormente, pero se han recuperado. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.db.operation.count.start**
(count) | Count de operaciones de inicio de base de datos realizadas con éxito. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.db.operation.count.stop**
(count) | Count de operaciones de parada de la base de datos realizadas con éxito. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.page_cache.bytes_read**
(count) | El número total de bytes leídos por la caché de page (página). (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.page_cache.bytes_written**
(count) | El número total de bytes escritos por la caché de la page (página). (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.page_cache.eviction_exceptions**
(count) | El número total de excepciones vistas durante el proceso de desalojo en la caché de la page (página). (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.page_cache.evictions**
(count) | El número total de desalojos de la page (página) ejecutados por la caché Page ( página). (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.page_cache.evictions.cooperative**
(count) | El número total de desalojos cooperativos de la page (página) ejecutados por la caché de la page (página) debido a la escasez de páginas disponibles. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.page_cache.evictions.flushes**
(count) | El número total de páginas vaciadas por el desalojo de la page (página). (Neo4j 5)| +| **neo4j.dbms.page_cache.evictions.cooperative.flushes**
(count) | El número total de páginas cooperativas vaciadas por el desalojo de la page (página). (Neo4j 5)| +| **neo4j.dbms.page_cache.flushes**
(count) | El número total de descargas ejecutadas por la caché de la page (página). (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.page_cache.hit_ratio**
(gauge) | Relación de aciertos respecto al número total de búsquedas en la caché de la page (página). (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.page_cache.hits**
(count) | El número total de aciertos de page (página) que se han producido en la caché de page (página). (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.page_cache.iops**
(count) | El número total de operaciones entrada/salida realizadas por la caché de page (página). (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.page_cache.merges**
(count) | El número total de fusiones de page (página) ejecutadas por la caché de page (página). (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.page_cache.page_cancelled_faults**
(count) | El número total de fallos cancelados de page (página) ocurridos en la caché de page (página). (Neo4j 5)| +| **neo4j.dbms.page_cache.page_fault_failures**
(count) | El número total de fallos de page (página) ocurridos en la caché de page (página). (Neo4j 5)| +| **neo4j.dbms.page_cache.page_faults**
(count) | El número total de fallos de page (página) ocurridos en la caché de page (página). (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.page_cache.page_no_pin_page_faults**
(count) | (Neo4j 5)| +| **neo4j.dbms.page_cache.page_vectored_faults**
(count) | (Neo4j 5)| +| **neo4j.dbms.page_cache.page_vectored_faults_failures**
(count) | (Neo4j 5)| +| **neo4j.dbms.page_cache.pages_copied**
(count) | El número total de copias de page (página) que se han producido en la caché de page (página). (Neo4j 5)| +| **neo4j.dbms.page_cache.pins**
(count) | El número total de pasadores de page (página) ejecutados por la caché de page (página). (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.page_cache.throttled_millis**
(count) | El número total del limitador de entradas/salidas de vaciado de caché de page (página) de millones se alternó durante operaciones de entrada/salida en curso. (Neo4j 4)| +| **neo4j.dbms.page_cache.throttled.times**
(count) | El número total de veces que el limitador de vaciado de caché de page (página) cache se alternó durante operaciones de entrada/salida en curso. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.page_cache.unpins**
(count) | El número total de desclavados de page (página) ejecutados por la caché de page (página). (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.page_cache.usage_ratio**
(gauge) | Relación entre el número de páginas utilizadas y el número total de páginas disponibles. (Neo4j 5)| +| **neo4j.dbms.pool.backup.free**
(count) | Cantidad estimada de memoria libre en bytes para este grupo.| +| **neo4j.dbms.pool.backup.total_size**
(count) | Cantidad estimada de memoria disponible en bytes para este grupo.| +| **neo4j.dbms.pool.backup.total_used**
(count) | Cantidad estimada de memoria total utilizada en bytes para este grupo.| +| **neo4j.dbms.pool.backup.used_heap**
(count) | Cantidad estimada de montón usado en bytes para este grupo.| +| **neo4j.dbms.pool.backup.used_native**
(count) | Cantidad estimada de memoria nativa utilizada para este grupo.| +| **neo4j.dbms.pool.bolt.free**
(count) | Cantidad estimada de memoria libre en bytes para este grupo. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.bolt.total_size**
(count) | Cantidad estimada de memoria disponible en bytes para este grupo. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.bolt.total_used**
(count) | Cantidad estimada de memoria total utilizada en bytes para este grupo (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.bolt.used_heap**
(count) | Cantidad estimada de montón utilizado en bytes para este grupo. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.bolt.used_native**
(count) | Cantidad estimada de memoria nativa utilizada para este grupo.| +| **neo4j.dbms.pool.cluster.free**
(count) | Cantidad estimada de memoria libre en bytes para este grupo.| +| **neo4j.dbms.pool.cluster.total_size**
(count) | Cantidad estimada de memoria disponible en bytes para este grupo.| +| **neo4j.dbms.pool.cluster.total_used**
(count) | Cantidad estimada de memoria total utilizada en bytes para este grupo.| +| **neo4j.dbms.pool.cluster.used_heap**
(count) | Cantidad estimada de montón utilizado en bytes para este grupo.| +| **neo4j.dbms.pool.cluster.used_native**
(count) | Cantidad estimada de memoria nativa utilizada para este grupo.| +| **neo4j.dbms.pool.http_transaction.free**
(count) | Cantidad estimada de memoria libre en bytes para este grupo.| +| **neo4j.dbms.pool.http_transaction.total_size**
(count) | Cantidad estimada de memoria disponible en bytes para este grupo.| +| **neo4j.dbms.pool.http_transaction.total_used**
(count) | Cantidad estimada de memoria total utilizada en bytes para este grupo.| +| **neo4j.dbms.pool.http_transaction.used_heap**
(count) | Cantidad estimada de montón usado en bytes para este grupo.| +| **neo4j.dbms.pool.http_transaction.used_native**
(count) | Cantidad estimada de memoria nativa utilizada para este grupo.| +| **neo4j.dbms.pool.http.free**
(count) | Cantidad estimada de memoria libre en bytes para este grupo.| +| **neo4j.dbms.pool.http.total_size**
(count) | Cantidad estimada de memoria disponible en bytes para este grupo.| +| **neo4j.dbms.pool.http.total_used**
(count) | Cantidad estimada de memoria total utilizada en bytes para este grupo.| +| **neo4j.dbms.pool.http.used_heap**
(count) | Cantidad estimada de montón utilizado en bytes para este grupo.| +| **neo4j.dbms.pool.http.used_native**
(count) | Cantidad estimada de memoria nativa utilizada para este grupo.| +| **neo4j.dbms.pool.other.free**
(count) | Cantidad estimada de memoria libre en bytes para este grupo.| +| **neo4j.dbms.pool.other.total_size**
(count) | Cantidad estimada de memoria disponible en bytes para este grupo.| +| **neo4j.dbms.pool.other.total_used**
(count) | Cantidad estimada de memoria total utilizada en bytes para este grupo (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.other.used_heap**
(count) | Cantidad estimada de montón utilizado en bytes para este grupo. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.other.used_native**
(count) | Cantidad estimada de memoria nativa utilizada para este grupo. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.page_cache.free**
(count) | Cantidad estimada de memoria libre en bytes para este grupo. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.page_cache.total_size**
(count) | Cantidad estimada de memoria disponible en bytes para este grupo. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.page_cache.total_used**
(count) | Cantidad estimada de memoria total utilizada en bytes para este grupo (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.page_cache.used_heap**
(count) | Cantidad estimada de montón utilizado en bytes para este grupo. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.page_cache.used_native**
(count) | Cantidad estimada de memoria nativa utilizada para este grupo. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.pool.database.free**
(gauge) | Memoria no utilizada disponible en el grupo, en bytes. (Neo4j 4)| +| **neo4j.dbms.pool.pool.database.total_size**
(gauge) | Suma total de tamaño de la capacidad del montón y/o del grupo de memoria nativa. (Neo4j 4)| +| **neo4j.dbms.pool.pool.database.total_used**
(gauge) | Suma total de memoria de montón y nativa utilizada en bytes. (Neo4j 4)| +| **neo4j.dbms.pool.pool.database.used_heap**
(gauge) | Memoria de montón utilizada o reservada en bytes. (Neo4j 4)| +| **neo4j.dbms.pool.pool.database.used_native**
(gauge) | Memoria nativa utilizada o reservada en bytes. (Neo4j 4)| +| **neo4j.dbms.pool.pool.free**
(gauge) | Memoria no utilizada disponible en el grupo, en bytes. (Neo4j 4)| +| **neo4j.dbms.pool.pool.total_size**
(gauge) | Suma total del tamaño de la capacidad del montón y/o del grupo de memoria nativa. (Neo4j 4)| +| **neo4j.dbms.pool.pool.total_used**
(gauge) | Suma total de la memoria de montón y nativa utilizada en bytes. (Neo4j 4)| +| **neo4j.dbms.pool.pool.used_heap**
(gauge) | Memoria de montón utilizada o reservada en bytes. (Neo4j 4)| +| **neo4j.dbms.pool.pool.used_native**
(gauge) | Memoria nativa utilizada o reservada en bytes. (Neo4j 4)| +| **neo4j.dbms.pool.recent_query_buffer.free**
(count) | Cantidad estimada de memoria libre en bytes para este grupo. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.recent_query_buffer.total_size**
(count) | Cantidad estimada de memoria disponible en bytes para este grupo. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.recent_query_buffer.total_used**
(count) | Cantidad estimada de memoria total utilizada en bytes para este grupo (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.recent_query_buffer.used_heap**
(count) | Cantidad estimada de montón utilizado en bytes para este grupo. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.recent_query_buffer.used_native**
(count) | Cantidad estimada de memoria nativa utilizada para este grupo. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.transaction.free**
(count) | Cantidad estimada de memoria libre en bytes para este grupo. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.transaction.total_size**
(count) | Cantidad estimada de memoria disponible en bytes para este grupo. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.transaction.total_used**
(count) | Cantidad estimada de memoria total utilizada en bytes para este grupo (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.transaction.used_heap**
(count) | Cantidad estimada de montón utilizado en bytes para este grupo. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.pool.transaction.used_native**
(count) | Cantidad estimada de memoria nativa utilizada para este grupo. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.routing.query.count.local**
(count) | Número de consultas redirigidas localmente. (Neo4j 5)| +| **neo4j.dbms.routing.query.count.remote_internal**
(count) | Número de consultas redirigidas internamente. (Neo4j 5)| +| **neo4j.dbms.routing.query.count.remote_external**
(count) | Número de consultas redirigidas externamente. (Neo4j 5)| +| **neo4j.dbms.server.threads.jetty.all**
(gauge) | El número total de subprocesos (tanto inactivos como ocupados) en el grupo de jetty. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.server.threads.jetty.idle**
(gauge) | El número total de subprocesos inactivos en el grupo de jetty. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.file.descriptors.count**
(gauge) | El número actual de descriptores de archivo abiertos (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.file.descriptors.maximum**
(gauge) | (Configuración del sistema operativo) El número máximo de descriptores de archivo abiertos. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.gc.count.g1_old_generation**
(count) | (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.gc.count.g1_young_generation**
(count) | (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.gc.count.gc**
(count) | Número total de recolecciones de basura.| +| **neo4j.dbms.vm.gc.time.g1_old_generation**
(count) | (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.gc.time.g1_young_generation**
(count) | (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.gc.time.gc**
(count) | Tiempo acumulado de recolección de basura en milisegundos.| +| **neo4j.dbms.vm.heap.committed**
(gauge) | Cantidad de memoria (en bytes) que se garantiza que está disponible para ser utilizada por la JVM. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.heap.max**
(gauge) | Cantidad máxima de memoria de montón (en bytes) que se puede utilizar. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.heap.used**
(gauge) | Cantidad de memoria (en bytes) utilizada actualmente. (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.memory.buffer.bufferpool.capacity**
(gauge) | Capacidad total estimada de los búferes asignados en el grupo.| +| **neo4j.dbms.vm.memory.buffer.bufferpool.count**
(gauge) | Número estimado de búferes asignados en el grupo.| +| **neo4j.dbms.vm.memory.buffer.bufferpool.used**
(gauge) | Cantidad estimada de memoria asignada utilizada por el grupo.| +| **neo4j.dbms.vm.memory.buffer.direct.capacity**
(count) | Capacidad total estimada de búferes en el grupo (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.memory.buffer.direct.count**
(count) | Número estimado de búferes en el grupo (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.memory.buffer.direct.used**
(count) | Cantidad estimada de memoria utilizada por el grupo (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.memory.buffer.mapped_non_volatile_memory.capacity**
(count) | Capacidad total estimada de los búferes en el grupo.| +| **neo4j.dbms.vm.memory.buffer.mapped_non_volatile_memory.count**
(count) | Número estimado de búferes en el grupo.| +| **neo4j.dbms.vm.memory.buffer.mapped_non_volatile_memory.used**
(count) | Cantidad estimada de memoria utilizada por el grupo.| +| **neo4j.dbms.vm.memory.buffer.mapped.capacity**
(count) | Capacidad total estimada de búferes en el grupo (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.memory.buffer.mapped.count**
(count) | Número estimado de búferes en el grupo (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.memory.buffer.mapped.used**
(count) | Cantidad estimada de memoria utilizada por el grupo (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.memory.pool.codeheap_non_nmethods**
(count) | | +| **neo4j.dbms.vm.memory.pool.codeheap_non_profiled_nmethods**
(count) | | +| **neo4j.dbms.vm.memory.pool.codeheap_profiled_nmethods**
(count) | | +| **neo4j.dbms.vm.memory.pool.compressed_class_space**
(count) | (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.memory.pool.g1_eden_space**
(count) | (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.memory.pool.g1_old_gen**
(count) | (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.memory.pool.g1_survivor_space**
(count) | (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.memory.pool.metaspace**
(count) | (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.memory.pool.pool**
(gauge) | Cantidad estimada de memoria en bytes utilizada por el grupo.| +| **neo4j.dbms.vm.pause_time**
(count) | Tiempo de pausa detectado acumulado de máquinas virtuales (Neo4j 4 y Neo4j 5)| +| **neo4j.dbms.vm.threads**
(gauge) | El número total de subprocesos activos, incluidos los subprocesos daemon y no daemon. (Neo4j 5)| +| **neo4j.transaction.terminated**
(count) | El número total de transacciones finalizadas. (Neo4j 4)| +| **neo4j.transaction.terminated_read**
(count) | Número total de transacciones de lectura finalizadas.| +| **neo4j.transaction.terminated_write**
(count) | Número total de transacciones de escritura finalizadas.| +| **neo4j.transaction.tx_size_heap**
(gauge) | El tamaño de las transacciones en el montón en bytes.| +| **neo4j.transaction.tx_size_native**
(gauge) | El tamaño de las transacciones en memoria nativa en bytes.| +| **neo4j.vm.thread.count**
(gauge) | Número estimado de subprocesos activos en el grupo de subprocesos actual. (Neo4j 4)| +| **neo4j.vm.thread.total**
(gauge) | El número total de subprocesos en tiempo real, incluidos subprocesos daemon y no daemon. (Neo4j 4)| +| **neo4j.bolt.accumulated_processing_time**
(gauge) | El tiempo acumulado que los subprocesos de worker han pasado procesando mensajes. (neo4j 4)| +| **neo4j.bolt.accumulated_queue_time**
(gauge) | El tiempo acumulado que han pasado los mensajes esperando un subproceso de worker. (neo4j 4)| +| **neo4j.bolt.connections_closed**
(gauge) | El número total de conexiones de Bolt cerradas desde que se inició esta instancia. Esto incluye tanto las conexiones finalizadas correctamente como las anormalmente finalizadas (neo4j 4).| +| **neo4j.bolt.connections_idle**
(gauge) | Número total de conexiones de Bolt inactivas (neo4j 4)| +| **neo4j.bolt.connections_opened**
(gauge) | El número total de conexiones de Bolt abiertas desde que se inició esta instancia. Esto incluye tanto las conexiones exitosas como las fallidas (neo4j 4)| +| **neo4j.bolt.connections_running**
(gauge) | Número total de conexiones de Bolt ejecutadas actualmente (neo4j 4)| +| **neo4j.bolt.messages_done**
(gauge) | El número total de mensajes que se han procesado desde que se inició esta instancia. Esto incluye mensajes de Bolt exitosos y fallidos e ignorados (neo4j 4).| +| **neo4j.bolt.messages_failed**
(gauge) | Número total de mensajes que no se han podido procesar desde que se inició esta instancia (neo4j 4)| +| **neo4j.bolt.messages_received**
(gauge) | Número total de mensajes recibidos a través de Bolt desde que se inició esta instancia (neo4j 4)| +| **neo4j.bolt.messages_started**
(gauge) | El número total de mensajes que comenzaron a procesarse desde que se inició esta instancia. Esto es diferente de los mensajes recibidos en que este contador rastrea cuántos de los mensajes recibidos han sido tomados por un subproceso de worker (neo4j 4)| +| **neo4j.check_point.events**
(gauge) | El número total de eventos de punto de control ejecutados hasta el momento. (neo4j 4)| +| **neo4j.check_point.total_time**
(gauge) | El tiempo total empleado hasta ahora en el punto de control. (neo4j 4)| +| **neo4j.check_point.duration**
(gauge) | La duración del último evento de punto de control. (neo4j 4)| +| **neo4j.cypher.replan_events**
(gauge) | Número total de veces que Cypher ha decidido planificar nuevamente una consulta. (neo4j 4)| +| **neo4j.cypher.replan_wait_time**
(gauge) | El número total de segundos esperados entre nuevas planificaciones de consultas. (neo4j 4)| +| **neo4j.node_count**
(gauge) | El número total de nodos. (neo4j 4)| +| **neo4j.relationship_count**
(gauge) | El número total de relaciones. (neo4j 4)| +| **neo4j.ids_in_use.node**
(gauge) | El número total de nodos almacenados en la base de datos. (neo4j 4)| +| **neo4j.ids_in_use.property**
(gauge) | Número total de nombres de propiedades diferentes utilizados en la base de datos. (neo4j 4)| +| **neo4j.ids_in_use.relationship**
(gauge) | Número total de relaciones almacenadas en la base de datos. (neo4j 4)| +| **neo4j.ids_in_use.relationship_type**
(gauge) | Número total de tipos de relación diferentes almacenados en la base de datos. (neo4j 4)| +| **neo4j.store.size.total**
(gauge) | El tamaño total de la base de datos y los logs de transacciones. (neo4j 4)| +| **neo4j.store.size.database**
(gauge) | El tamaño en disco de la base de datos. (neo4j 4)| +| **neo4j.log.appended_bytes**
(gauge) | El número total de bytes añadidos al log de la transacción. (neo4j 4)| +| **neo4j.log.rotation_events**
(gauge) | El número total de rotaciones de transacciones de logs ejecutadas hasta el momento. (neo4j 4)| +| **neo4j.log.rotation_total_time**
(gauge) | El tiempo total empleado en rotar los logs de transacción hasta ahora. (neo4j 4)| +| **neo4j.log.rotation_duration**
(gauge) | La duración del último evento de rotación de logs. (neo4j 4)| +| **neo4j.page_cache.eviction_exceptions**
(gauge) | El número total de excepciones vistas durante el proceso de desalojo en la caché de page (página). (neo4j 4)| +| **neo4j.page_cache.evictions**
(gauge) | El número total de desalojos de page (página) ejecutados por la caché de page (página). (neo4j 4)| +| **neo4j.page_cache.flushes**
(gauge) | El número total de descargas ejecutadas por la caché de page (página). (neo4j 4)| +| **neo4j.page_cache.hits**
(gauge) | El número total de aciertos de la page (página) ocurridos en la caché de page (página). (neo4j 4)| +| **neo4j.page_cache_hits_total**
(gauge) | El número total de aciertos de page (página) ocurridos en la caché de page (página). (neo4j 4)| +| **neo4j.page_cache.page_faults**
(gauge) | El número total de fallos de page (página) ocurridos en la caché de page (página). (neo4j 4)| +| **neo4j.page_cache.pins**
(gauge) | El número total de pines de page (página) ejecutados por la caché de page (página). (neo4j 4)| +| **neo4j.page_cache.unpins**
(gauge) | El número total de desclavados de page (página) ejecutados por la caché de page (página). (neo4j 4)| +| **neo4j.server.threads.jetty.all**
(gauge) | El número total de subprocesos (tanto inactivos como ocupados) en el grupo jetty. (neo4j 4)| +| **neo4j.server.threads.jetty.idle**
(gauge) | El número total de subprocesos inactivos en el grupo jetty. (neo4j 4)| +| **neo4j.transaction.active**
(gauge) | Número de transacciones activas actualmente. (neo4j 4)| +| **neo4j.transaction.active_read**
(gauge) | Número de transacciones de lectura actualmente activas. (neo4j 4)| +| **neo4j.transaction.active_write**
(gauge) | El número de transacciones de escritura actualmente activas. (neo4j 4)| +| **neo4j.transaction.committed_read**
(gauge) | Número total de transacciones confirmadas. (neo4j 4)| +| **neo4j.transaction.committed**
(gauge) | Número total de transacciones de lectura confirmadas. (neo4j 4)| +| **neo4j.transaction.committed_write**
(gauge) | Número total de transacciones de escritura confirmadas. (neo4j 4)| +| **neo4j.transaction.last_closed_tx_id**
(gauge) | El identificador de la última transacción cerrada. (neo4j 4)| +| **neo4j.transaction.last_committed_tx_id**
(gauge) | Identificador de la última transacción confirmada. (neo4j 4)| +| **neo4j.transaction.peak_concurrent**
(gauge) | El pico más alto de transacciones concurrentes. (neo4j 4)| +| **neo4j.transaction.rollbacks_read**
(gauge) | Número total de transacciones de lectura revertidas. (neo4j 4)| +| **neo4j.transaction.rollbacks**
(gauge) | Número total de transacciones revertidas. (neo4j 4)| +| **neo4j.transaction.rollbacks_write**
(gauge) | Número total de transacciones de escritura revertidas. (neo4j 4)| +| **neo4j.transaction.started**
(gauge) | Número total de transacciones iniciadas. (neo4j 4)| +| **neo4j.vm.gc.count.g1_old_generation**
(gauge) | Número total de recolecciones de basura para la antigua generación. (neo4j 4)| +| **neo4j.vm.gc.count.g1_young_generation**
(gauge) | Número total de recolecciones de basura para la generación joven. (neo4j 4)| +| **neo4j.vm.gc.time.g1_old_generation**
(gauge) | Tiempo acumulado de recolección de basura en milisegundos para la generación antigua. (neo4j 4)| +| **neo4j.vm.gc.time.g1_young_generation**
(gauge) | Tiempo acumulado de recolección de basura en milisegundos para la generación joven. (neo4j 4)| +| **neo4j.vm.memory.buffer.direct_capacity**
(gauge) | Capacidad total estimada de los búferes directos del grupo (neo4j 4)| +| **neo4j.vm.memory.buffer.direct_count**
(gauge) | Número estimado de búferes directos en el grupo. (neo4j 4)| +| **neo4j.vm.memory.buffer.direct_used**
(gauge) | Cantidad estimada de memoria directa utilizada por el grupo. (neo4j 4)| +| **neo4j.vm.memory.buffer.mapped_capacity**
(gauge) | Capacidad total estimada de los búferes asignados en el grupo. (neo4j 4)| +| **neo4j.vm.memory.buffer.mapped_count**
(gauge) | Número estimado de búferes asignados en el grupo. (neo4j 4)| +| **neo4j.vm.memory.buffer.mapped_used**
(gauge) | Cantidad estimada de memoria asignada utilizada por el grupo. (neo4j 4)| +| **neo4j.vm.memory.pool.compressed_class_space**
(gauge) | Número estimado de búferes en el grupo de espacio de clase comprimido. (neo4j 4)| +| **neo4j.vm.memory.pool.g1_eden_space**
(gauge) | Número estimado de búferes en el grupo de espacio de g1 eden. (neo4j 4)| +| **neo4j.vm.memory.pool.g1_old_gen**
(gauge) | Número estimado de búferes en el grupo de la generación antigua g1. (neo4j 4)| +| **neo4j.vm.memory.pool.g1_survivor_space**
(gauge) | Número estimado de búferes en el grupo de espacio de supervivencia g1. (neo4j 4)| +| **neo4j.vm.memory.pool.metaspace**
(gauge) | Número estimado de búferes en el grupo de metaespacios (neo4j 4)| ### Checks de servicio @@ -120,18 +542,6 @@ El check de servicio `neo4j.prometheus.health` se presenta en el check base Neo4j no incluye ningún evento. - ## Solucionar problemas -¿Necesitas ayuda? Ponte en contacto con el [soporte de Neo4j][10]. - -[1]: https://neo4j.com/ -[2]: https://docs.datadoghq.com/es/agent/autodiscovery/integrations -[3]: https://app.datadoghq.com/account/settings/agent/latest -[4]: https://github.com/DataDog/integrations-extras/blob/master/neo4j/datadog_checks/neo4j/data/conf.yaml.example -[5]: https://docs.datadoghq.com/es/agent/guide/agent-commands/#start-stop-and-restart-the-agent -[6]: https://docs.datadoghq.com/es/agent/guide/agent-commands/#agent-status-and-information -[7]: https://neo4j.com/docs/operations-manual/4.4/monitoring/metrics/reference/ -[8]: https://neo4j.com/docs/operations-manual/5/monitoring/metrics/reference/ -[9]: https://github.com/DataDog/integrations-extras/blob/master/neo4j/metadata.csv -[10]: mailto:support@neo4j.com \ No newline at end of file +¿Necesitas ayuda? Ponte en contacto con [asistencia técnica de Neo4j](mailto:support@neo4j.com). \ No newline at end of file diff --git a/content/es/integrations/node.md b/content/es/integrations/node.md new file mode 100644 index 0000000000000..752425a5d1fd5 --- /dev/null +++ b/content/es/integrations/node.md @@ -0,0 +1,126 @@ +--- +app_id: nodo +categories: +- languages +- log collection +- tracing +custom_kind: integración +description: Recopila métricas, trazas y logs de tus aplicaciones Node.js. +further_reading: +- link: https://www.datadoghq.com/blog/node-logging-best-practices/ + tag: blog + text: Cómo recopilar, personalizar y centralizar los logs de Node.js +- link: https://www.datadoghq.com/blog/node-monitoring-apm/ + tag: blog + text: Monitorización de Node.js con Datadog APM y rastreo distribuido +media: [] +title: Node +--- +## Información general + +La integración de Node.js te permite recopilar y monitorizar tus logs de aplicación, trazas (traces) y métricas personalizadas de Node.js. + +## Configuración + +### Recopilación de métricas + +La integración de Node.js te permite monitorizar una métrica personalizada al instrumentar unas pocas líneas de código. Por ejemplo, puedes tener una métrica que devuelva el número de páginas vistas o el tiempo de llamada a una función. + +Para obtener información adicional sobre la integración de Node.js, consulta la [guía sobre el envío de métricas](https://docs.datadoghq.com/metrics/custom_metrics/dogstatsd_metrics_submission/?code-lang=nodejs). + +```js +// Require dd-trace +const tracer = require('dd-trace').init(); + +// Increment a counter +tracer.dogstatsd.increment('page.views'); +``` + +Ten en cuenta que, para que las métricas personalizadas funcionen, es necesario habilitar DogStatsD en Agent. La recopilación está habilitada por defecto, pero el Agent solo escucha métricas desde el host local. Para permitir métricas externas, necesitas establecer una variable de entorno o actualizar el archivo de configuración: + +```sh +DD_USE_DOGSTATSD=true # default +DD_DOGSTATSD_PORT=8125 # default +DD_DOGSTATSD_NON_LOCAL_TRAFFIC=true # if expecting external metrics +``` + +```yaml +use_dogstatsd: true # default +dogstatsd_port: 8125 # default +dogstatsd_non_local_traffic: true # if expecting external metrics +``` + +También necesitarás configurar para que tu aplicación utilice el recopilador de DogStatsD del Agent: + +```sh +DD_DOGSTATSD_HOSTNAME=localhost DD_DOGSTATSD_PORT=8125 node app.js +``` + +### Recopilación de trazas + +Consulta la documentación dedicada para [instrumentar tu aplicación Node.js](https://docs.datadoghq.com/tracing/setup/nodejs/) para enviar traces (trazas) a Datadog. + +### Recopilación de logs + +_Disponible para la versión 6.0 o posterior del Agent_ + +Consulta la documentación específica para configurar [recopilación de logs de Node.js](https://docs.datadoghq.com/logs/log_collection/nodejs/) para reenviar tus logs a Datadog. + +### Recopilación de perfiles + +Consulta la documentación dedicada para [activar el perfilador de Node.js](https://github.com/DataDog/dogweb/blob/prod/node/node_metadata.csv). + +## Datos recopilados + +### Métricas + +| | | +| --- | --- | +| **runtime.node.cpu.user**
(medidor) | Uso de la CPU en código de usuario
_Mostrado en porcentaje_. | +| **runtime.node.cpu.system**
(medidor) | Uso de la CPU en el código del sistema
_Mostrado en porcentaje_. | +| **runtime.node.cpu.total**
(medidor) | Uso total de la CPU
_Mostrado como porcentaje_. | +| **runtime.node.mem.rss**
(medidor) | Tamaño del conjunto residente
_Mostrado como byte_ | +| **runtime.node.mem.heap_total**
(medidor) | Memoria heap total
_Mostrado como byte_ | +| **runtime.node.mem.heap_used**
(medidor) | Uso de memoria Heap
_Mostrado como byte_ | +| **runtime.node.mem.external**
(medidor) | Memoria externa
_Mostrado como byte_ | +| **runtime.node.heap.total_heap_size**
(medidor) | Tamaño total de heap
_Mostrado como byte_ | +| **runtime.node.heap.total_heap_size_executable**
(medidor) | Tamaño total de heap ejecutable
_Mostrado como byte_ | +| **runtime.node.heap.total_physical_size**
(mediidor) | Tamaño físico total de heap
_Mostrado como byte_ | +| **runtime.node.heap.used_heap_size**
(medidor) | Tamaño de heap utilizado
_Mostrado como byte_ | +| **runtime.node.heap.heap_size_limit**
(medidor) | Límite de tamaño de heap
_Mostrado como byte_ | +| **runtime.node.heap.malloced_memory**
(medidor) | Memoria malgastada
_Mostrado como byte_ | +| **runtime.node.heap.peak_malloced_memory**
(medidor) | Pico de memoria asignada
_Mostrado como byte_ | +| **runtime.node.heap.size.by.space**
(medidor) | Tamaño del espacio de heap
_Mostrado como byte_ | +| **runtime.node.heap.used_size.by.space**
(medidor) | Tamaño de espacio heap utilizado
_Mostrado como byte_ | +| **runtime.node.heap.available_size.by.space**
(medidor) | Tamaño del espacio disponible en heap
_Mostrado como byte_ | +| **runtime.node.heap.physical_size.by.space**
(medidor) | Tamaño físico del espacio heap
_Mostrado como byte_ | +| **runtime.node.process.uptime**
(medidor) | Tiempo de actividad del proceso
_Mostrado en segundos_ | +| **runtime.node.event_loop.delay.max**
(medidor) | Retardo máximo del bucle de eventos
_Mostrado en nanosegundos_ | +| **runtime.node.event_loop.delay.min**
(medidor) | Retardo mínimo del bucle de eventos
_Mostrado en nanosegundos_ | +| **runtime.node.event_loop.delay.avg**
(medidor) | Retardo medio del bucle de eventos
_Mostrado en nanosegundos_ | +| **runtime.node.event_loop.delay.sum**
(tasa) | Retardo total del bucle de eventos
_Mostrado en nanosegundos_ | +| **runtime.node.event_loop.delay.median**
(medidor) | Mediana del retardo del bucle de eventos
_Mostrado en nanosegundos_ | +| **runtime.node.event_loop.delay.95percentile**
(medidor) | Percentil 95 del retardo del bucle de eventos
_Mostrado en nanosegundos_ | +| **runtime.node.event_loop.delay.count**
(tasa) | Count de iteraciones del bucle de eventos donde se detecta un retardo
_Mostrado como ejecución_ | +| **runtime.node.gc.pause.max**
(medidor) | Pausa máxima de recolección de basura
_Mostrado en nanosegundos_ | +| **runtime.node.gc.pause.min**
(medidor) | Pausa mínima de recolección de basura
_Mostrado en nanosegundos_ | +| **runtime.node.gc.pause.avg**
(medidor) | Pausa media de recolección de basura
_Mostrado en nanosegundos_ | +| **runtime.node.gc.pause.sum**
(tasa) | Pausa total de recolección de basura
_Mostrado en nanosegundos_ | +| **runtime.node.gc.pause.median**
(medidor) | Mediana de la pausa de recolección de basura
_Mostrado en nanosegundos_ | +| **runtime.node.gc.pause.95percentile**
(medidor) | Pausa de recolección de basura del percentil 95
_Mostrado en nanosegundos_ | +| **runtime.node.gc.pause.count**
(tasa) | Número de recolecciones de basura
_Mostrado como recolección de basura_ | +| **runtime.node.gc.pause.by.type.max**
(medidor) | Pausa máxima de recolección de basura por tipo
_Mostrado como nanosegundo_ | +| **runtime.node.gc.pause.by.type.min**
(medidor) | Pausa mínima de recolección de basura por tipo
_Mostrado en nanosegundos_ | +| **runtime.node.gc.pause.by.type.avg**
(medidor) | Pausa media de recolección de basura por tipo
_Mostrado en nanosegundos_ | +| **runtime.node.gc.pause.by.type.sum**
(tasa) | Pausa total de recolección de basura por tipo
_Mostrado en nanosegundos_ | +| **runtime.node.gc.pause.by.type.median**
(medidor) | Mediana de la pausa de recolección de basura por tipo
_Mostrado en nanosegundos_ | +| **runtime.node.gc.pause.by.type.95percentile**
(medidor) | Pausa de recopilación de basura del percentil 95 por tipo
_Mostrado en nanosegundos_ | +| **runtime.node.gc.pause.by.type.count**
(tasa) | Número de recolecciones de basura por tipo
_Mostrado como recolección de basura_ | + +## Solucionar problemas + +¿Necesitas ayuda? Ponte en contacto con el [servicio de asistencia de Datadog](https://docs.datadoghq.com/help/). + +## Referencias adicionales + +{{< partial name="whats-next/whats-next.html" >}} \ No newline at end of file diff --git a/content/es/integrations/nvml.md b/content/es/integrations/nvml.md index 5149f66c7f3b0..08f6da31c8812 100644 --- a/content/es/integrations/nvml.md +++ b/content/es/integrations/nvml.md @@ -1,150 +1,101 @@ --- app_id: nvml -app_uuid: 2c7a8b1e-9343-4b4a-bada-5091e37c4806 -assets: - integration: - auto_install: true - configuration: - spec: assets/configuration/spec.yaml - events: - creates_events: false - metrics: - check: nvml.device_count - metadata_path: metadata.csv - prefix: nvml. - service_checks: - metadata_path: assets/service_checks.json - source_type_id: 10177 - source_type_name: nvml -author: - homepage: https://github.com/DataDog/integrations-extras - name: Comunidad - sales_email: help@datadoghq.com - support_email: help@datadoghq.com categories: - ia/ml - kubernetes - sistema operativo y sistema -custom_kind: integration -dependencies: -- https://github.com/DataDog/integrations-extras/blob/master/nvml/README.md -display_on_public_website: true -draft: false -git_integration_title: nvml -integration_id: nvml -integration_title: NVIDIA NVML +custom_kind: integración +description: Admite métricas de GPU Nvidia en k8s integration_version: 1.0.9 -is_public: true -manifest_version: 2.0.0 -name: nvml -public_title: NVIDIA NVML -short_description: Admite métricas de GPU NVIDIA en k8s +media: [] supported_os: - linux - windows - macos -tile: - changelog: CHANGELOG.md - classifier_tags: - - Category::AI/ML - - Category::Kubernetes - - Category::OS & System - - Supported OS::Linux - - Supported OS::Windows - - Supported OS::macOS - - Offering::Integration - configuration: README.md#Setup - description: Admite métricas de GPU NVIDIA en k8s - media: [] - overview: README.md#Overview - support: README.md#Support - title: NVIDIA NVML +title: Nvidia NVML --- - - - - ## Información general -Este check monitoriza métricas de [NVIDIA Management Library (NVML)][1] expuestas a través del Datadog Agent y puede correlacionarlas con los [dispositivos expuestos de Kubernetes][2]. +Este check monitoriza las métricas expuestas de [NVIDIA Management Library (NVML)](https://pypi.org/project/pynvml/) a través del Datadog Agent y puede correlacionarlas con los [dispositivos expuestos de Kubernetes](https://kubernetes.io/docs/concepts/extend-kubernetes/compute-storage-net/device-plugins/#monitoring-device-plugin-resources). ## Configuración -El check de NVML no está incluido en el paquete del [Datadog Agent][3], por lo que es necesario instalarlo. +El check de NVML no está incluido en el paquete del [Datadog Agent](https://app.datadoghq.com/account/settings/agent/latest), por lo que es necesario instalarlo. ### Instalación -Para el Agent v7.21+/v6.21+, sigue las instrucciones a continuación para instalar el check de NVML en tu host. Consulta [Usar integraciones de comunidad][4] para realizar la instalación con Agent de Docker o versiones anteriores del Agent. +Para el Agent v7.21+ / v6.21+, sigue las instrucciones siguientes para instalar el check de NVML en tu host. Consulta [Usar integraciones de la comunidad](https://docs.datadoghq.com/agent/guide/use-community-integrations/) para realizar la instalación con el Docker Agent o versiones anteriores del Agent. 1. Ejecuta el siguiente comando para instalar la integración del Agent: Para Linux: + ```shell datadog-agent integration install -t datadog-nvml==
(gauge) | Número de GPU en esta instancia.| +| **nvml.gpu_utilization**
(gauge) | Porcentaje de tiempo durante el último periodo de muestreo en el que uno o más kernels se ejecutaron en la GPU.
_Se muestra como porcentaje_ | +| **nvml.mem_copy_utilization**
(gauge) | Porcentaje de tiempo durante el último periodo de muestreo en el que la memoria global (dispositivo) se estaba leyendo o escribiendo.
_Se muestra como porcentaje_ | +| **nvml.fb_free**
(gauge) | Memoria FB no asignada.
_Se muestra como byte_ | +| **nvml.fb_used**
(gauge) | Memoria FB asignada.
_Se muestra como byte_ | +| **nvml.fb_total**
(gauge) | Memoria FB total instalada.
_Se muestra como byte_ | +| **nvml.power_usage**
(gauge) | Consumo de energía de esta GPU en milivatios y sus circuitos asociados (por ejemplo, la memoria).| +| **nvml.total_energy_consumption**
(count) | Consumo total de energía de esta GPU en milijulios (mJ) desde la última recarga del controlador.| +| **nvml.enc_utilization**
(gauge) | Utilización actual del codificador
_Se muestra en porcentaje_ | +| **nvml.dec_utilization**
(gauge) | La utilización actual del decodificador
_Se muestra en porcentaje_. | +| **nvml.pcie_tx_throughput**
(gauge) | Utilización de PCIe TX
_Se muestra como kibibyte_ | +| **nvml.pcie_rx_throughput**
(gauge) | Utilización de PCIe RX
_Se muestra como kibibyte_ | +| **nvml.temperature**
(gauge) | Temperatura actual de esta GPU en grados centígrados| +| **nvml.fan_speed**
(gauge) | Utilización actual del ventilador
_Se muestra en porcentaje_ | +| **nvml.compute_running_process**
(gauge) | El uso actual de la memoria gpu por el proceso
_Se muestra como byte_ | ### Eventos NVML no incluye eventos. ### Checks de servicio -{{< get-service-checks-from-git "nvml" >}} +Consulta [service_checks.json](https://github.com/DataDog/integrations-extras/blob/master/nvml/assets/service_checks.json) para obtener una lista de los checks de servicio proporcionados por esta integración. ## Solucionar problemas -¿Necesitas ayuda? Ponte en contacto con el [soporte de Datadog][14]. - - -[1]: https://pypi.org/project/pynvml/ -[2]: https://kubernetes.io/docs/concepts/extend-kubernetes/compute-storage-net/device-plugins/#monitoring-device-plugin-resources -[3]: https://app.datadoghq.com/account/settings/agent/latest -[4]: https://docs.datadoghq.com/es/agent/guide/use-community-integrations/ -[5]: https://docs.datadoghq.com/es/getting_started/integrations/ -[6]: https://github.com/DataDog/integrations-extras/blob/master/nvml/tests/Dockerfile -[7]: https://github.com/DataDog/integrations-extras/blob/master/nvml/datadog_checks/nvml/data/conf.yaml.example -[8]: https://docs.datadoghq.com/es/agent/guide/agent-commands/#start-stop-and-restart-the-agent -[9]: https://docs.datadoghq.com/es/agent/guide/agent-commands/#agent-status-and-information -[10]: https://github.com/DataDog/integrations-extras/blob/master/nvml/metadata.csv -[11]: https://docs.nvidia.com/deploy/nvml-api/group__nvmlDeviceQueries.html -[12]: https://github.com/NVIDIA/dcgm-exporter -[13]: https://github.com/DataDog/integrations-extras/blob/master/nvml/assets/service_checks.json -[14]: https://docs.datadoghq.com/es/help +¿Necesitas ayuda? Ponte en contacto con el [soporte de Datadog](https://docs.datadoghq.com/help). \ No newline at end of file diff --git a/content/es/integrations/oke.md b/content/es/integrations/oke.md index c1dc4931776c1..c39301d3ccafb 100644 --- a/content/es/integrations/oke.md +++ b/content/es/integrations/oke.md @@ -1,88 +1,52 @@ --- app_id: oke -app_uuid: c3361861-32be-4ed4-a138-d68b85b8d88b -assets: - integration: - auto_install: true - configuration: {} - events: - creates_events: false - service_checks: - metadata_path: assets/service_checks.json - source_type_id: 10255 - source_type_name: 'Oracle Container Engine para Kubernetes: OKE' -author: - homepage: https://www.datadoghq.com - name: Datadog - sales_email: info@datadoghq.com - support_email: help@datadoghq.com categories: -- contenedores -- kubernetes +- configuración y despliegue +- rastreo +- Kubernetes +- métricas - oracle - orquestación -custom_kind: integration -dependencies: -- https://github.com/DataDog/integrations-core/blob/master/oke/README.md -display_on_public_website: true -draft: false -git_integration_title: oke -integration_id: oke -integration_title: Oracle Container Engine para Kubernetes -integration_version: '' -is_public: true -manifest_version: 2.0.0 -name: oke -public_title: Oracle Container Engine para Kubernetes -short_description: OKE es un servicio de orquestación de contenedores gestionado por - Oracle. +custom_kind: integración +description: OKE es un servicio de orquestación de contenedores gestionado por OCI. +further_reading: +- link: https://www.datadoghq.com/blog/monitor-oracle-kubernetes-engine/ + tag: blog + text: Cómo monitorizar el motor de Kubernetes de Oracle con Datadog +integration_version: 1.0.0 +media: [] supported_os: - linux - windows - macos -tile: - changelog: CHANGELOG.md - classifier_tags: - - Category::Containers - - Category::Kubernetes - - Category::Oracle - - Category::Orchestration - - Supported OS::Linux - - Supported OS::Windows - - Supported OS::macOS - - Offering::Integration - configuration: README.md#Setup - description: OKE es un servicio de orquestación de contenedores gestionado por Oracle. - media: [] - overview: README.md#Overview - resources: - - resource_type: Blog - url: https://www.datadoghq.com/blog/monitor-oracle-kubernetes-engine/ - support: README.md#Support - title: Oracle Container Engine para Kubernetes +title: Oracle Container Engine para Kubernetes --- +## Información general - +Oracle Cloud Infrastructure Container Engine para Kubernetes (OKE) es un servicio gestionado de Kubernetes que simplifica las operaciones de Kubernetes a escala empresarial. +Esta integración recopila métricas y etiquetas del espacio de nombres [`oci_oke`](https://docs.oracle.com/en-us/iaas/Content/ContEng/Reference/contengmetrics.htm) para ayudarte a monitorizar tu plano de control de Kubernetes, clústeres y estados de nodos. -## Información general +El despliegue del [Datadog Agent](https://docs.datadoghq.com/agent/kubernetes/#installation) en tu clúster de OKE también puede ayudarte a realizar un seguimiento de la carga en tus clústeres, pods y nodos individuales para obtener mejores conocimientos sobre cómo aprovisionar y desplegar tus recursos. + +Además de la monitorización de tus nodos, pods y contenedores, el Agent también puede recopilar e informar métricas de los servicios que se ejecutan en tu clúster, para que puedas: -Oracle Cloud Infrastructure Container Engine para Kubernetes (OKE) es un servicio totalmente gestionado de Kubernetes para desplegar y ejecutar tus aplicaciones en contenedores en Oracle Cloud. Datadog te proporciona una visibilidad completa de tus clústeres de Kubernetes gestionados por OKE. Una vez que hayas habilitado tu integración de Datadog, puedes ver tu infraestructura de Kubernetes, monitorizar Live Processes y realizar un seguimiento de métricas clave de todos tus pods y contenedores en un solo lugar. +- Explora tus clústeres de OKE con [dashboards preconfigurados de Kubernetes](https://app.datadoghq.com/dashboard/lists/preset/3?q=kubernetes) +- Monitorizar contenedores y procesos en tiempo real +- Hacer un seguimiento automático y monitorizar servicios en contenedores ## Configuración -Dado que Datadog ya se integra con Kubernetes, está preparado para monitorizar OKE. Si estás ejecutando el Agent en un clúster de Kubernetes y planeas migrar a OKE, puedes continuar con la monitorización de tu clúster con Datadog. +Una vez configurada la integración de [Oracle Cloud Infrastructure](https://docs.datadoghq.com/integrations/oracle_cloud_infrastructure/), asegúrate de que el espacio de nombres `oci_oke` está incluido en tu [Connector Hub](https://cloud.oracle.com/connector-hub/service-connectors). -Además, se admiten grupos de nodos de OKE. +Dado que Datadog ya se integra con Kubernetes, está preparado para monitorizar OKE. Si estás ejecutando el Agent en un clúster de Kubernetes y planeas migrar a OKE, puedes continuar con la monitorización de tu clúster con Datadog. +Desplegar el Agent como un DaemonSet con el [Helm chart](https://docs.datadoghq.com/agent/kubernetes/?tab=helm) es el método más directo (y recomendado), ya que asegura que el Agent se ejecutará como un pod en cada nodo dentro de tu clúster y que cada nuevo nodo tendrá automáticamente el Agent instalado. También puedes configurar el Agent para recopilar datos de procesos, trazas y logs añadiendo unas pocas líneas adicionales a un archivo de valores Helm. Adicionalmente, los grupos de nodos de OKE son compatibles. ## Solucionar problemas -¿Necesitas ayuda? Contacta con el [equipo de soporte de Datadog][1]. +¿Necesitas ayuda? Ponte en contacto con el [soporte de Datadog](https://docs.datadoghq.com/help/). ## Referencias adicionales -- [Cómo monitorizar OKE con Datadog][2] - -[1]: https://docs.datadoghq.com/es/help/ -[2]: https://www.datadoghq.com/blog/monitor-oracle-kubernetes-engine/ \ No newline at end of file +- [Cómo monitorizar OKE con Datadog](https://www.datadoghq.com/blog/monitor-oracle-kubernetes-engine/) \ No newline at end of file diff --git a/content/es/integrations/openmetrics.md b/content/es/integrations/openmetrics.md index 962d52ee8266a..d3ecf5cb3fbad 100644 --- a/content/es/integrations/openmetrics.md +++ b/content/es/integrations/openmetrics.md @@ -1,87 +1,45 @@ --- app_id: openmetrics -app_uuid: 302b841e-8270-4ecd-948e-f16317a316bc -assets: - integration: - auto_install: true - configuration: - spec: assets/configuration/spec.yaml - events: - creates_events: false - service_checks: - metadata_path: assets/service_checks.json - source_type_id: 10045 - source_type_name: OpenMetrics -author: - homepage: https://www.datadoghq.com - name: Datadog - sales_email: info@datadoghq.com - support_email: help@datadoghq.com categories: - métricas custom_kind: integración -dependencies: -- https://github.com/DataDog/integrations-core/blob/master/openmetrics/README.md -display_on_public_website: true -draft: false -git_integration_title: openmetrics -integration_id: openmetrics -integration_title: OpenMetrics -integration_version: 6.1.0 -is_public: true -manifest_version: 2.0.0 -name: openmetrics -public_title: OpenMetrics -short_description: OpenMetrics es un estándar abierto para exponer datos de métricas +description: OpenMetrics es un estándar abierto para exponer datos de métricas +further_reading: +- link: https://docs.datadoghq.com/agent/openmetrics/ + tag: documentación + text: Documentación sobre OpenMetrics +- link: https://docs.datadoghq.com/developers/openmetrics/ + tag: documentación + text: Documentación sobre OpenMetrics +integration_version: 7.0.0 +media: [] supported_os: - linux - windows - macos -tile: - changelog: CHANGELOG.md - classifier_tags: - - Supported OS::Linux - - Supported OS::Windows - - Category::Metrics - - Supported OS::macOS - - Offering::Integration - configuration: README.md#Setup - description: OpenMetrics es un estándar abierto para exponer datos de métricas - media: [] - overview: README.md#Overview - resources: - - resource_type: documentación - url: https://docs.datadoghq.com/agent/openmetrics/ - - resource_type: documentación - url: https://docs.datadoghq.com/developers/openmetrics/ - support: README.md#Support - title: OpenMetrics +title: OpenMetrics --- - - - - ## Información general Extrae métricas personalizadas de cualquier endpoint de OpenMetrics o Prometheus. -
Todas las métricas recuperadas por esta integración se consideran métricas personalizadas.
+Todas las métricas recuperadas por esta integración se consideran métricas personalizadas.
-La integración es compatible tanto con el [formato de exposición de Prometheus][1] como con la [especificación de OpenMetrics][2].
+La integración es compatible tanto con el [formato de exposición de Prometheus](https://prometheus.io/docs/instrumenting/exposition_formats/#text-based-format) como con la [especificación de OpenMetrics](https://github.com/OpenObservability/OpenMetrics/blob/main/specification/OpenMetrics.md#suffixes).
## Configuración
-Sigue las instrucciones a continuación para instalar y configurar este check para un Agent que se ejecuta en un host. Para entornos en contenedores, consulta las [plantillas de integración de Autodiscovery][3] para obtener orientación sobre la aplicación de estas instrucciones.
+Sigue las instrucciones siguientes para instalar y configurar este check para un Agent que se ejecute en un host. Para entornos en contenedores, consulta las [Plantillas de integración de Autodiscovery](https://docs.datadoghq.com/agent/kubernetes/integrations/) para obtener orientación sobre la aplicación de estas instrucciones.
-Esta integración basada en OpenMetrics tiene un modo más reciente (que se habilita al configurar `openmetrics_endpoint` de modo que apunte hacia el endpoint de destino) y un modo heredado (que se habilita al configurar `prometheus_url` en su lugar). Para obtener todas las características más actualizadas, Datadog recomienda habilitar el modo más reciente. Para obtener más información, consulta [Control de versiones más reciente y heredado para las integraciones basadas en OpenMetrics][4].
+Esta integración tiene un modo más reciente (que se activa configurando `openmetrics_endpoint` para que apunte al endpoint de destino) y un modo heredado (que se activa configurando `prometheus_url` en su lugar). Para obtener todas las características más actualizadas, Datadog recomienda activar el modo más reciente. Para obtener más información, consulta [Última versión y versión heredada para integraciones basadas en OpenMetrics](https://docs.datadoghq.com/integrations/guide/versions-for-openmetrics-based-integrations).
### Instalación
-El check de OpenMetrics viene empaquetado con [Datadog Agent v6.6.0 o posterior][5].
+El check de OpenMetrics se incluye en el paquete del [Datadog Agent v6.6.0 o posterior](https://docs.datadoghq.com/getting_started/integrations/prometheus/?tab=docker#configuration).
### Configuración
-Edita el archivo `conf.d/openmetrics.d/conf.yaml` en la raíz de tu [directorio de configuración del Agent][6]. Consulta el [openmetrics.d/conf.yaml de ejemplo][7] para todas las opciones disponibles de configuración. Este es el ejemplo más reciente del check de OpenMetrics a partir de la versión 7.32.0 de Datadog Agent. Si previamente implementaste esta integración, consulta el [ejemplo de legacy][8].
+Edita el archivo `conf.d/openmetrics.d/conf.yaml` en la raíz de tu [directorio de configuración del Agent](https://docs.datadoghq.com/agent/guide/agent-configuration-files/#agent-configuration-directory). Ve el [openmetrics.d/conf.yaml de ejemplo](https://github.com/DataDog/integrations-core/blob/master/openmetrics/datadog_checks/openmetrics/data/conf.yaml.example) para todas las opciones de configuración disponibles. Este es el último ejemplo de check de OpenMetrics a partir del Datadog Agent versión 7.32.0. Si anteriormente implementaste esta integración, consulta el [ejemplo heredado](https://github.com/DataDog/integrations-core/blob/7.30.x/openmetrics/datadog_checks/openmetrics/data/conf.yaml.example).
Para cada instancia, se requieren los siguientes parámetros:
@@ -91,15 +49,15 @@ Para cada instancia, se requieren los siguientes parámetros:
| `namespace` | El espacio de nombres se añade a todas las métricas. |
| `metrics` | Una lista de métricas para recuperar como métricas personalizadas. Añade cada métrica a la lista como `metric_name` o `metric_name: renamed` para renombrarla. Las métricas se interpretan como expresiones regulares. Utiliza `".*"` como comodín (`metric.*`) para recuperar todas las métricas que coincidan. **Nota**: Las expresiones regulares pueden enviar muchas métricas personalizadas. |
-A partir del Datadog Agent v7.32.0, de acuerdo con el [estándar de especificación de OpenMetrics][2], los nombres de contador que terminan en `_total` deben especificarse sin el sufijo `_total`. Por ejemplo, para recopilar `promhttp_metric_handler_requests_total`, especifica el nombre de métrica `promhttp_metric_handler_requests`. Esto envía a Datadog el nombre de métrica con `.count`, `promhttp_metric_handler_requests.count`.
+A partir del Datadog Agent v7.32.0, de conformidad con el [estándar de especificación de OpenMetrics](https://github.com/OpenObservability/OpenMetrics/blob/main/specification/OpenMetrics.md#suffixes), los nombres de contador que terminan en `_total` deben especificarse sin el sufijo `_total`. Por ejemplo, para recopilar `promhttp_metric_handler_requests_total`, especifica el nombre de la métrica `promhttp_metric_handler_requests`. Esto envía a Datadog el nombre de la métrica con el sufijo `.count`, `promhttp_metric_handler_requests.count`.
-Este check tiene un límite de 2000 métricas por instancia. El número de métricas devueltas se indica al ejecutar el [comando de estado][9] del Datadog Agent. Puedes especificar las métricas que te interesan editando la configuración. Para saber cómo personalizar las métricas a recopilar, consulta [Recopilación de métricas de Prometheus y OpenMetrics][10].
+Este check tiene un límite de 2000 métricas por instancia. El número de métricas devueltas se indica al ejecutar el [comando de estado] del Datadog Agent(https://docs.datadoghq.com/agent/guide/agent-commands/#agent-status-and-information). Puedes especificar las métricas que te interesan editando la configuración. Para saber cómo personalizar las métricas a recopilar, consulta [Recopilación de métricas de Prometheus y OpenMetrics](https://docs.datadoghq.com/getting_started/integrations/prometheus/).
-Si necesitas monitorizar más métricas, ponte en contacto con el [soporte de Datadog][11].
+Si necesitas monitorizar más métricas, ponte en contacto con el [soporte de Datadog](https://docs.datadoghq.com/help/).
### Validación
-[Ejecuta el subcomando de estado del Agent][9] y busca `openmetrics` en la sección Checks.
+[Ejecuta el subcomando de estado del Agent(https://docs.datadoghq.com/agent/guide/agent-commands/#agent-status-and-information) y busca `openmetrics` en la sección Checks.
## Datos recopilados
@@ -143,7 +101,7 @@ Las versiones anteriores utilizaban por defecto `text/plain`, lo que normalmente
Aunque el comportamiento debería seguir siendo el mismo en la mayoría de las circunstancias, algunas aplicaciones devuelven métricas en un formato que no es totalmente compatible con OpenMetrics, a pesar de configurar `Content-Type` para indicar el uso del formato estándar de OpenMetrics. Esto puede hacer que nuestra integración informe de errores durante el parseo de la carga útil de métricas.
-Si observas errores en el parseo al seleccionar el endpoint de OpenMetrics con esta nueva versión, puedes forzar el uso del formato menos estricto de Prometheus, al configurar manualmente el encabezado `Accept` que la integración envía a `text/plain` mediante la opción `headers` en el [archivo de configuración][12]. Por ejemplo:
+Si observas errores de parseo al escanear el endpoint de OpenMetrics con esta nueva versión, puedes forzar el uso del formato menos estricto de Prometheus configurando manualmente el encabezado `Accept` que la integración envía a `text/plain` mediante la opción `headers` del [archivo de configuración](https://github.com/DataDog/integrations-core/blob/7.46.x/openmetrics/datadog_checks/openmetrics/data/conf.yaml.example#L537-L546). Por ejemplo:
```yaml
## All options defined here are available to all instances.
@@ -157,24 +115,9 @@ instances:
Accept: text/plain
```
-¿Necesitas ayuda? Contacta con el [equipo de asistencia de Datadog][11].
+¿Necesitas ayuda? Ponte en contacto con el [soporte de Datadog](https://docs.datadoghq.com/help/).
## Referencias adicionales
-- [Configuración del check de OpenMetrics][13]
-- [Escribir un check de OpenMetrics personalizado][14]
-
-[1]: https://prometheus.io/docs/instrumenting/exposition_formats/#text-based-format
-[2]: https://github.com/OpenObservability/OpenMetrics/blob/main/specification/OpenMetrics.md#suffixes
-[3]: https://docs.datadoghq.com/es/agent/kubernetes/integrations/
-[4]: https://docs.datadoghq.com/es/integrations/guide/versions-for-openmetrics-based-integrations
-[5]: https://docs.datadoghq.com/es/getting_started/integrations/prometheus/?tab=docker#configuration
-[6]: https://docs.datadoghq.com/es/agent/guide/agent-configuration-files/#agent-configuration-directory
-[7]: https://github.com/DataDog/integrations-core/blob/master/openmetrics/datadog_checks/openmetrics/data/conf.yaml.example
-[8]: https://github.com/DataDog/integrations-core/blob/7.30.x/openmetrics/datadog_checks/openmetrics/data/conf.yaml.example
-[9]: https://docs.datadoghq.com/es/agent/guide/agent-commands/#agent-status-and-information
-[10]: https://docs.datadoghq.com/es/getting_started/integrations/prometheus/
-[11]: https://docs.datadoghq.com/es/help/
-[12]: https://github.com/DataDog/integrations-core/blob/7.46.x/openmetrics/datadog_checks/openmetrics/data/conf.yaml.example#L537-L546
-[13]: https://docs.datadoghq.com/es/agent/openmetrics/
-[14]: https://docs.datadoghq.com/es/developers/openmetrics/
\ No newline at end of file
+- [Configuración de un check de OpenMetrics](https://docs.datadoghq.com/agent/openmetrics/)
+- [Escribir un check personalizado de OpenMetrics](https://docs.datadoghq.com/developers/openmetrics/)
\ No newline at end of file
diff --git a/content/es/integrations/openshift.md b/content/es/integrations/openshift.md
index bcb2d5a395eae..3fc9d58ba7d91 100644
--- a/content/es/integrations/openshift.md
+++ b/content/es/integrations/openshift.md
@@ -1,27 +1,5 @@
---
app_id: openshift
-app_uuid: e92e309f-7bdc-4ff4-91d4-975497526325
-assets:
- integration:
- auto_install: true
- configuration: {}
- events:
- creates_events: false
- metrics:
- check:
- - openshift.clusterquota.cpu.requests.used
- - openshift.clusterquota.cpu.used
- metadata_path: metadata.csv
- prefix: openshift.
- service_checks:
- metadata_path: assets/service_checks.json
- source_type_id: 10024
- source_type_name: OpenShift
-author:
- homepage: https://www.datadoghq.com
- name: Datadog
- sales_email: info@datadoghq.com
- support_email: help@datadoghq.com
categories:
- contenedores
- kubernetes
@@ -29,47 +7,19 @@ categories:
- la red
- orquestación
- suministrar
-custom_kind: integration
-dependencies:
-- https://github.com/DataDog/integrations-core/blob/master/openshift/README.md
-display_on_public_website: true
-draft: false
-git_integration_title: openshift
-integration_id: openshift
-integration_title: OpenShift
-integration_version: ''
-is_public: true
-manifest_version: 2.0.0
-name: openshift
-public_title: OpenShift
-short_description: La plataforma de Kubernetes para grandes ideas
+custom_kind: integración
+description: La plataforma de Kubernetes para grandes ideas
+integration_version: 1.0.0
+media: []
supported_os:
- linux
-tile:
- changelog: CHANGELOG.md
- classifier_tags:
- - Category::Containers
- - Category::Kubernetes
- - Category::Log Collection
- - Category::Network
- - Category::Orchestration
- - Category::Provisioning
- - Supported OS::Linux
- - Offering::Integration
- configuration: README.md#Setup
- description: La plataforma de Kubernetes para grandes ideas
- media: []
- overview: README.md#Overview
- support: README.md#Support
- title: OpenShift
+title: OpenShift
---
-
-
## Información general
Red Hat OpenShift es una plataforma de aplicaciones en contenedores de código abierto basada en el orquestador de contenedores de Kubernetes para el desarrollo y despliegue de aplicaciones empresariales.
-> Este README describe la configuración necesaria para permitir la recopilación de métricas específicas de OpenShift en el Agent. Los datos aquí descritos son recopilados por el check de [`kubernetes_apiserver`][1]. Debes configurar el check para recopilar las métricas `openshift.*`.
+> Este archivo README describe la configuración necesaria para permitir la recopilación de métricas específicas de OpenShift en el Agent. Los datos descritos aquí son recopilados por el [check de `kubernetes_apiserver`](https://github.com/DataDog/datadog-agent/blob/master/cmd/agent/dist/conf.d/kubernetes_apiserver.d/conf.yaml.example). Debes configurar el check para recopilar las métricas de `openshift.*`.
## Configuración
@@ -77,27 +27,26 @@ Red Hat OpenShift es una plataforma de aplicaciones en contenedores de código a
Esta configuración central es compatible con OpenShift 3.11 y OpenShift 4, pero funciona mejor con OpenShift 4.
-Para instalar el Agent, consulta las [instrucciones de instalación del Agent][2] para obtener instrucciones generales de Kubernetes y la [página de distribuciones de Kubernetes][3] para obtener ejemplos de la configuración de OpenShift.
+Para instalar el Agent, consulta las [instrucciones de instalación del Agent](https://docs.datadoghq.com/containers/kubernetes/installation) para obtener instrucciones generales de Kubernetes y la [página de distribución de Kubernetes](https://docs.datadoghq.com/containers/kubernetes/distributions/?tab=datadogoperator#Openshift) para obtener ejemplos de configuración de OpenShift.
-Como alternativa, puede utilizarse [Datadog Operator][4] para instalar y gestionar el Datadog Agent. El Datadog Operator puede instalarse mediante el [OperatorHub][5] de OpenShift.
+Como alternativa, puede utilizarse el [Datadog Operator](https://github.com/DataDog/datadog-operator/) para instalar y gestionar el Datadog Agent. El Datadog Operator puede instalarse utilizando [OperatorHub](https://docs.openshift.com/container-platform/4.10/operators/understanding/olm-understanding-operatorhub.html) de OpenShift.
### Configuración de las restricciones del contexto de seguridad
Si estás desplegando el Datadog Agent utilizando cualquiera de los métodos vinculados en las instrucciones de instalación anteriores, debes incluir restricciones de contexto de seguridad (SCC) para el Agent y el Cluster Agent para recopilar datos. Sigue las instrucciones que se indican a continuación en relación con tu despliegue.
{{< tabs >}}
+
{{% tab "Operator" %}}
-Para obtener instrucciones sobre cómo instalar el Datadog Operator y el recurso `DatadogAgent` en OpenShift, consulta la [Guía de instalación de OpenShift][1].
+Para obtener instrucciones sobre cómo instalar el Datadog Operator y el recurso `DatadogAgent` en OpenShift, consulta la [Guía de instalación de OpenShift](https://github.com/DataDog/datadog-operator/blob/main/docs/install-openshift.md).
Si despliegas el Operator con Operator Lifecycle Manager (OLM), los SCC predeterminados necesarios de OpenShift se asocian automáticamente a la cuenta de servicio `datadog-agent-scc`. A continuación, puedes desplegar los componentes de Datadog con la CustomResourceDefinition `DatadogAgent`, haciendo referencia a esta cuenta de servicio en los pods del Node Agent y Cluster Agent.
-Consulta la página [Distribuciones][2] y el [repositorio del Operator][3] para ver más ejemplos.
+Consulta la página [Distribuciones](https://docs.datadoghq.com/containers/kubernetes/distributions/?tab=datadogoperator#Openshift) y [el repositorio del Operator](https://github.com/DataDog/datadog-operator/blob/main/examples/datadogagent/datadog-agent-on-openshift.yaml) para ver más ejemplos.
-[1]: https://github.com/DataDog/datadog-operator/blob/main/docs/install-openshift.md
-[2]: https://docs.datadoghq.com/es/containers/kubernetes/distributions/?tab=datadogoperator#Openshift
-[3]: https://github.com/DataDog/datadog-operator/blob/main/examples/datadogagent/datadog-agent-on-openshift.yaml
{{% /tab %}}
+
{{% tab "Helm" %}}
Puedes crear el SCC directamente dentro de tu `values.yaml` del Datadog Agent. Añade los siguientes parámetros de bloque en la sección `agents` y `clusterAgent` para crear sus respectivos SCC.
@@ -117,16 +66,15 @@ clusterAgent:
create: true
```
-Puedes aplicar esto cuando despliegues inicialmente el Agent, o puedes ejecutar un `helm upgrade` después de hacer este cambio para aplicar el SCC.
+Puedes aplicar esto cuando despliegues inicialmente el Agent, o puedes ejecutar un `helm upgrade` después de hacer este cambio para aplicar el SCC.
-Consulta la página [Distribuciones][1] y el [repositorio de Helm][2] para más ejemplos.
+Consulta la página de [Distribuciones](https://docs.datadoghq.com/containers/kubernetes/distributions/?tab=datadogoperator#Openshift) y el [repositorio de Helm](https://github.com/DataDog/helm-charts/blob/main/examples/datadog/agent_on_openshift_values.yaml) para más ejemplos.
-[1]: https://docs.datadoghq.com/es/containers/kubernetes/distributions/?tab=datadogoperator#Openshift
-[2]: https://github.com/DataDog/helm-charts/blob/main/examples/datadog/agent_on_openshift_values.yaml
{{% /tab %}}
+
{{% tab "Daemonset" %}}
-Según tus necesidades y las [restricciones de seguridad][1] de tu clúster, se admiten tres escenarios de despliegue:
+En función de tus necesidades y de las [restricciones de seguridad](https://docs.openshift.com/enterprise/3.0/admin_guide/manage_scc.html) de tu clúster, se admiten tres escenarios de despliegue:
- [Operaciones SCC restringidas](#restricted-scc-operations)
- [Operaciones SCC de red de host](#host)
@@ -147,7 +95,7 @@ Según tus necesidades y las [restricciones de seguridad][1] de tu clúster, se
#### Operaciones restringidas de SCC
-Este modo no requiere conceder permisos especiales al [DaemonSet del `datadog-agent`][2], aparte de los permisos [RBAC][3] necesarios para acceder al kubelet y al APIserver. Puedes empezar con esta [plantilla kubelet-only][4].
+Este modo no requiere conceder permisos especiales al [DaemonSet del `datadog-agent`](https://docs.datadoghq.com/agent/kubernetes/daemonset_setup/), aparte de los permisos [RBAC](https://docs.datadoghq.com/agent/kubernetes/daemonset_setup/?tab=k8sfile#configure-rbac-permissions) necesarios para acceder al kubelet y al servidor de la API. Puedes empezar con esta [plantilla solo de kubelet](https://github.com/DataDog/datadog-agent/blob/master/Dockerfiles/manifests/agent-kubelet-only.yaml).
El método de ingesta recomendado para DogStatsD, APM y logs consiste en vincular el Datadog Agent a un puerto de host. De esta forma, la IP de destino es constante y fácilmente detectable por tus aplicaciones. La SCC por defecto de OpenShift no permite la vinculación al puerto de host. Puedes configurar el Agent para que escuche en su propia IP, pero tendrás que gestionar la detección de esa IP desde tu aplicación.
@@ -167,11 +115,8 @@ ports:
protocol: TCP
```
-[1]: https://docs.openshift.com/enterprise/3.0/admin_guide/manage_scc.html
-[2]: https://docs.datadoghq.com/es/agent/kubernetes/daemonset_setup/
-[3]: https://docs.datadoghq.com/es/agent/kubernetes/daemonset_setup/?tab=k8sfile#configure-rbac-permissions
-[4]: https://github.com/DataDog/datadog-agent/blob/master/Dockerfiles/manifests/agent-kubelet-only.yaml
{{% /tab %}}
+
{{< /tabs >}}
#### SCC personalizado de Datadog para todas las funciones
@@ -179,18 +124,18 @@ ports:
El Helm Chart y Datadog Operator gestionan el SCC por ti de forma predeterminada. Para gestionarlo tú mismo en su lugar, asegúrate de incluir las configuraciones correctas en función de las características que hayas habilitado.
Si SELinux está en modo permisivo o deshabilitado, habilita el SCC `hostaccess` para beneficiarte de todas las características.
-Si SELinux está en modo obligatorio, es recomendado conceder [el tipo `spc_t`][6] al pod datadog-agent. Para desplegar el Agent, puedes utilizar el siguiente [SCC datadog-agent][7] que se puede aplicar después de [crear la cuenta de servicio datadog-agent][8]. Concede los siguientes permisos:
+Si SELinux está en modo enforcing, se recomienda conceder [el tipo `spc_t`](https://developers.redhat.com/blog/2014/11/06/introducing-a-super-privileged-container-concept) al pod del datadog-agent. Para desplegar el Agent puedes utilizar el siguiente [SCC de datadog-agent](https://github.com/DataDog/datadog-agent/blob/master/Dockerfiles/manifests/openshift/scc.yaml) que puede aplicarse después de [crear la cuenta de servicio del datadog-agent](https://docs.datadoghq.com/agent/kubernetes/daemonset_setup/?tab=k8sfile#configure-rbac-permissions). Concede los siguientes permisos:
- `allowHostPorts: true`: vincula las entradas de DogStatsD/APM/logs a la IP del nodo.
- `allowHostPID: true`: activa la Detección de origen para las métricas de DogStatsD enviadas por Unix Socket.
- `volumes: hostPath`: accede al socker de Docker y a las carpetas `proc` y `cgroup` de host, para la recopilación de métricas.
-- `SELinux type: spc_t`: accede al socket de Docker y a las carpetas `proc` y `cgroup` de todos los procesos, para la recopilación de métricas. Consulta [Introducción al concepto de Contenedor con súper privilegios][6] para más detalles.
+- `SELinux type: spc_t`: accede al socket de Docker y a las carpetas `proc` y `cgroup` de todos los procesos, para la recopilación de métricas. Ver [Introducing a Super Privileged Container Concept](https://developers.redhat.com/blog/2014/11/06/introducing-a-super-privileged-container-concept) para más detalles.
No olvides añadir una cuenta de servicio datadog-agent a un SCC datadog-agent recientemente creado al añadir
-system:serviceaccount:: a la sección usuarios.
+
(gauge) | Límite fijo para cpu por cuota de recursos de clúster y espacio de nombres
_Se muestra como cpu_ | +| **openshift.appliedclusterquota.cpu.remaining**
(gauge) | Cpu disponible restante por cuota de recursos de clúster y espacio de nombres
_Se muestra como cpu_ | +| **openshift.appliedclusterquota.cpu.used**
(gauge) | Uso de cpu observado por cuota de recursos de clúster y espacio de nombres
_Se muestra como cpu_ | +| **openshift.appliedclusterquota.memory.limit**
(gauge) | Límite fijo de memoria por cuota de recursos de clúster y espacio de nombres
_Se muestra como byte_ | +| **openshift.appliedclusterquota.memory.remaining**
(gauge) | Memoria disponible restante por cuota de recursos de clúster y espacio de nombres
_Se muestra como byte_ | +| **openshift.appliedclusterquota.memory.used**
(gauge) | Uso de memoria observado por cuota de recursos de clúster y espacio de nombres
_Se muestra como byte_ | +| **openshift.appliedclusterquota.persistentvolumeclaims.limit**
(gauge) | Límite fijo para reclamaciones de volúmenes persistentes por cuota de recursos de clúster y espacio de nombres| +| **openshift.appliedclusterquota.persistentvolumeclaims.remaining**
(gauge) | Reclamaciones de volúmenes persistentes disponibles por cuota de recursos de clúster y espacio de nombres| +| **openshift.appliedclusterquota.persistentvolumeclaims.used**
(gauge) | Uso observado de reclamaciones de volumen persistente por cuota de recursos de clúster y espacio de nombres| +| **openshift.appliedclusterquota.pods.limit**
(gauge) | Límite fijo para pods por cuota de recursos de clúster y espacio de nombres| +| **openshift.appliedclusterquota.pods.remaining**
(gauge) | Pods disponibles por cuota de recursos de clúster y espacio de nombres| +| **openshift.appliedclusterquota.pods.used**
(gauge) | Uso de pods observado por cuota de recursos de clúster y espacio de nombres| +| **openshift.appliedclusterquota.services.limit**
(gauge) | Límite fijo para servicios por cuota de recursos de clúster y espacio de nombres| +| **openshift.appliedclusterquota.services.loadbalancers.limit**
(gauge) | Límite fijo para equilibradores de carga de servicios por cuota de recursos de clúster y espacio de nombres| +| **openshift.appliedclusterquota.services.loadbalancers.remaining**
(gauge) | Equilibradores de carga de servicios disponibles por cuota de recursos de clúster y espacio de nombres| +| **openshift.appliedclusterquota.services.loadbalancers.used**
(gauge) | Uso observado de los equilibradores de carga de servicios por cuota de recursos de clúster y espacio de nombres| +| **openshift.appliedclusterquota.services.nodeports.limit**
(gauge) | Límite fijo para puertos de nodo de servicio por cuota de recursos de clúster y espacio de nombres| +| **openshift.appliedclusterquota.services.nodeports.remaining**
(gauge) | Puertos de nodo de servicio disponibles por cuota de recursos de clúster y espacio de nombres| +| **openshift.appliedclusterquota.services.nodeports.used**
(gauge) | Uso observado de puertos de nodos de servicio por cuota de recursos de clúster y espacio de nombres| +| **openshift.appliedclusterquota.services.remaining**
(gauge) | Servicios disponibles restantes por cuota de recursos de clúster y espacio de nombres| +| **openshift.appliedclusterquota.services.used**
(gauge) | Utilización de servicios observada por cuota de recursos de clúster y espacio de nombres| +| **openshift.clusterquota.cpu.limit**
(gauge) | Límite fijo de cpu por cuota de recursos de clúster para todos los espacios de nombres
_Se muestra como cpu_ | +| **openshift.clusterquota.cpu.remaining**
(gauge) | Cpu disponible restante por cuota de recursos de clúster para todos los espacios de nombres
_Se muestra como cpu_ | +| **openshift.clusterquota.cpu.requests.used**
(gauge) | Uso de cpu observado por recurso de clúster para solicitud| +| **openshift.clusterquota.cpu.used**
(gauge) | Uso de cpu observado por cuota de recursos de clúster para todos los espacios de nombres
_Se muestra como cpu_ | +| **openshift.clusterquota.memory.limit**
(gauge) | Límite fijo de memoria por cuota de recursos de clúster para todos los espacios de nombres
_Se muestra como byte_ | +| **openshift.clusterquota.memory.remaining**
(gauge) | Memoria disponible restante por cuota de recursos de clúster para todos los espacios de nombres
_Se muestra como byte_ | +| **openshift.clusterquota.memory.used**
(gauge) | Uso de memoria observado por cuota de recursos de clúster para todos los espacios de nombres
_Se muestra como byte_ | +| **openshift.clusterquota.persistentvolumeclaims.limit**
(gauge) | Límite fija para las reclamaciones de volúmenes persistentes por cuota de recursos de clúster para todos los espacios de nombres.| +| **openshift.clusterquota.persistentvolumeclaims.remaining**
(gauge) | Reclamaciones de volumen persistente disponibles restantes por cuota de recursos de clúster para todos los espacios de nombres.| +| **openshift.clusterquota.persistentvolumeclaims.used**
(gauge) | Uso de reclamaciones de volumen persistente observado por cuota de recursos de clúster para todos los espacios de nombres| +| **openshift.clusterquota.pods.limit**
(gauge) | Límite duro para pods por cuota de recursos de clúster para todos los espacios de nombres| +| **openshift.clusterquota.pods.remaining**
(gauge) | Pods disponibles restantes por cuota de recursos de clúster para todos los espacios de nombres| +| **openshift.clusterquota.pods.used**
(gauge) | Uso de pods observado por cuota de recursos de clúster para todos los espacios de nombres| +| **openshift.clusterquota.services.limit**
(gauge) | Límite fijo para servicios por cuota de recursos de clúster para todos los espacios de nombres| +| **openshift.clusterquota.services.loadbalancers.limit**
(gauge) | Límite fijo para los equilibradores de carga de servicios por cuota de recursos de clúster para todos los espacios de nombres.| +| **openshift.clusterquota.services.loadbalancers.remaining**
(gauge) | Equilibradores de carga de servicio disponibles restantes por cuota de recursos de clúster para todos los espacios de nombres.| +| **openshift.clusterquota.services.loadbalancers.used**
(gauge) | Uso observado de los equilibradores de carga de servicios por cuota de recursos de clúster para todos los espacios de nombres| +| **openshift.clusterquota.services.nodeports.limit**
(gauge) | Límite fijo para puertos de nodo de servicio por cuota de recursos de clúster para todos los espacios de nombres.| +| **openshift.clusterquota.services.nodeports.remaining**
(gauge) | Puertos de nodo de servicio disponibles restantes por cuota de recursos de clúster para todos los espacios de nombres| +| **openshift.clusterquota.services.nodeports.used**
(gauge) | Uso observado de puertos de nodo de servicio por cuota de recursos de clúster para todos los espacios de nombres| +| **openshift.clusterquota.services.remaining**
(gauge) | Servicios disponibles restantes por cuota de recursos de clúster para todos los espacios de nombres| +| **openshift.clusterquota.services.used**
(gauge) | Utilización de servicios observada por cuota de recursos de clúster para todos los espacios de nombres| ### Eventos @@ -235,17 +224,4 @@ El check de OpenShift no incluye ningún check de servicio. ## Solucionar problemas -¿Necesitas ayuda? Contacta con el [equipo de asistencia de Datadog][11]. - - -[1]: https://github.com/DataDog/datadog-agent/blob/master/cmd/agent/dist/conf.d/kubernetes_apiserver.d/conf.yaml.example -[2]: https://docs.datadoghq.com/es/containers/kubernetes/installation -[3]: https://docs.datadoghq.com/es/containers/kubernetes/distributions/?tab=datadogoperator#Openshift -[4]: https://github.com/DataDog/datadog-operator/ -[5]: https://docs.openshift.com/container-platform/4.10/operators/understanding/olm-understanding-operatorhub.html -[6]: https://developers.redhat.com/blog/2014/11/06/introducing-a-super-privileged-container-concept -[7]: https://github.com/DataDog/datadog-agent/blob/master/Dockerfiles/manifests/openshift/scc.yaml -[8]: https://docs.datadoghq.com/es/agent/kubernetes/daemonset_setup/?tab=k8sfile#configure-rbac-permissions -[9]: https://docs.datadoghq.com/es/agent/kubernetes/log/?tab=daemonset -[10]: https://docs.datadoghq.com/es/containers/kubernetes/apm -[11]: https://docs.datadoghq.com/es/help/ \ No newline at end of file +¿Necesitas ayuda? Ponte en contacto con el [soporte de Datadog](https://docs.datadoghq.com/help/). \ No newline at end of file diff --git a/content/es/integrations/openstack.md b/content/es/integrations/openstack.md new file mode 100644 index 0000000000000..63e6fb9bda43d --- /dev/null +++ b/content/es/integrations/openstack.md @@ -0,0 +1,263 @@ +--- +app_id: openstack +categories: +- cloud +- log collection +- network +- provisioning +- configuration & deployment +custom_kind: integración +description: Seguimiento del uso de recursos a nivel de hipervisor y VM, además de + métricas de Neutron. +further_reading: +- link: https://www.datadoghq.com/blog/openstack-monitoring-nova + tag: blog + text: Monitorización de OpenStack Nova +- link: https://www.datadoghq.com/blog/install-openstack-in-two-commands + tag: blog + text: Instalar OpenStack en dos comandos para dev y test +- link: https://www.datadoghq.com/blog/openstack-host-aggregates-flavors-availability-zones + tag: blog + text: 'OpenStack: agregados de hosts, opciones y zonas de disponibilidad' +integration_version: 4.0.1 +media: [] +supported_os: +- linux +- windows +- macos +title: OpenStack (heredado) +--- +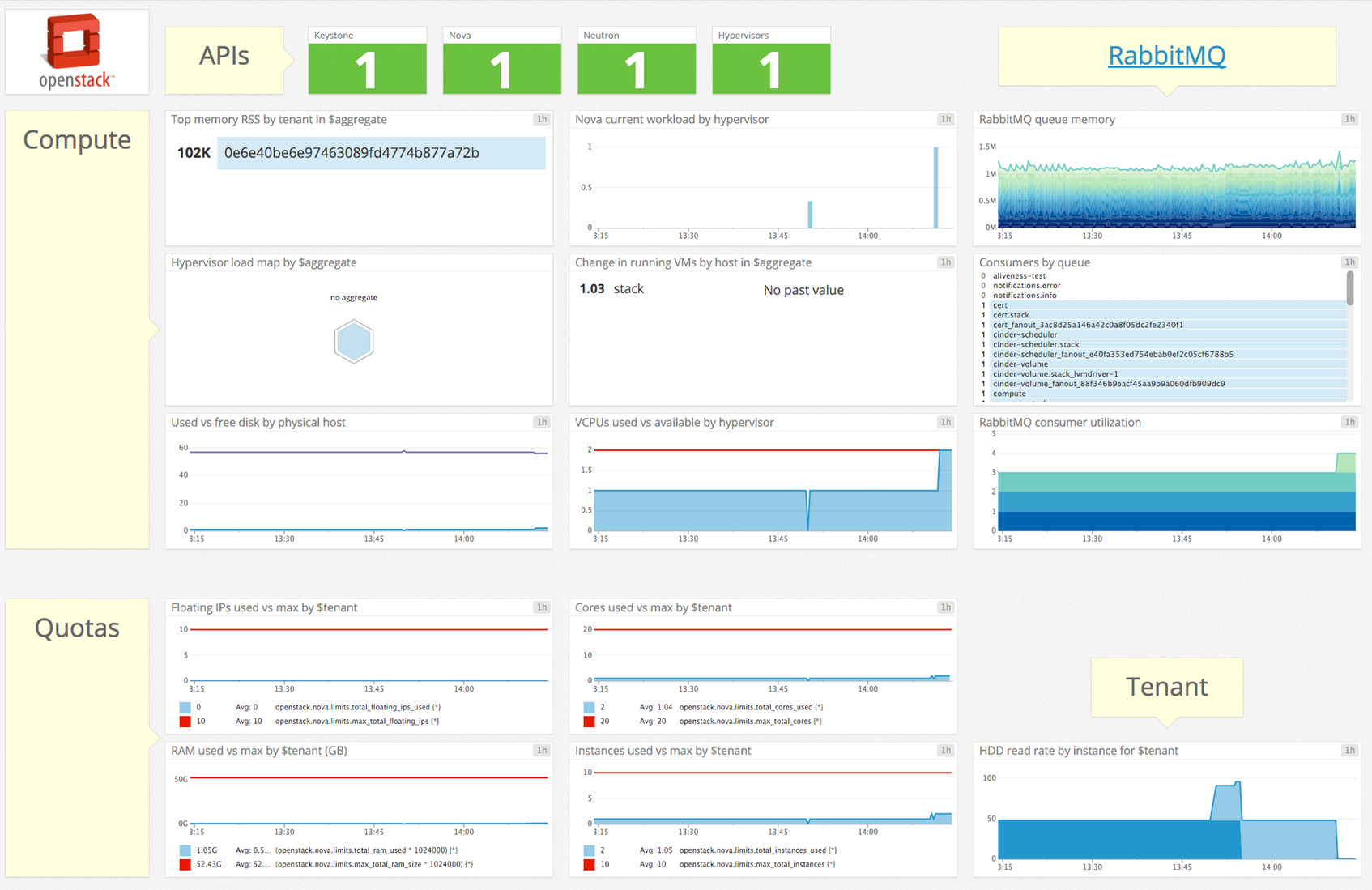 + +## Información general + +**Nota**: Esta integración solo se aplica a OpenStack v12 e inferiores. Si deseas recopilar métricas de OpenStack v13+, utiliza la [integración de OpenStack Controller](https://docs.datadoghq.com/integrations/openstack_controller). + +Obtén métricas del servicio OpenStack en tiempo real para: + +- Visualizar y monitorizar estados de OpenStack. +- Recibir notificaciones sobre fallos y eventos de OpenStack. + +## Configuración + +### Instalación + +Para capturar tus métricas de OpenStack, [instala el Agent](https://app.datadoghq.com/account/settings/agent/latest) en tus hosts que ejecutan hipervisores. + +### Configuración + +#### Preparar OpenStack + +Configura un rol y un usuario de Datadog con tu servidor de identidad: + +```console +openstack role create datadog_monitoring +openstack user create datadog \ + --password my_password \ + --project my_project_name +openstack role add datadog_monitoring \ + --project my_project_name \ + --user datadog +``` + +A continuación, actualiza tus archivos `policy.json` para conceder los permisos necesarios. `role:datadog_monitoring` requiere acceso a las siguientes operaciones: + +**Nova** + +```json +{ + "compute_extension": "aggregates", + "compute_extension": "hypervisors", + "compute_extension": "server_diagnostics", + "compute_extension": "v3:os-hypervisors", + "compute_extension": "v3:os-server-diagnostics", + "compute_extension": "availability_zone:detail", + "compute_extension": "v3:availability_zone:detail", + "compute_extension": "used_limits_for_admin", + "os_compute_api:os-aggregates:index": "rule:admin_api or role:datadog_monitoring", + "os_compute_api:os-aggregates:show": "rule:admin_api or role:datadog_monitoring", + "os_compute_api:os-hypervisors": "rule:admin_api or role:datadog_monitoring", + "os_compute_api:os-server-diagnostics": "rule:admin_api or role:datadog_monitoring", + "os_compute_api:os-used-limits": "rule:admin_api or role:datadog_monitoring" +} +``` + +**Neutron** + +```json +{ + "get_network": "rule:admin_or_owner or rule:shared or rule:external or rule:context_is_advsvc or role:datadog_monitoring" +} +``` + +**Keystone** + +```json +{ + "identity:get_project": "rule:admin_required or project_id:%(target.project.id)s or role:datadog_monitoring", + "identity:list_projects": "rule:admin_required or role:datadog_monitoring" +} +``` + +Es posible que tengas que reiniciar tus servicios de API de Keystone, Neutron y Nova para asegurarte de que los cambios de política se llevan a cabo. + +**Nota**: La instalación de la integración de OpenStack podría aumentar el número de máquinas virtuales que Datadog monitoriza. Para obtener más información sobre cómo esto puede afectar a tu facturación, consulta las FAQ de facturación. + +#### Configuración del Agent + +1. Configura el Datadog Agent para conectarte a tu servidor Keystone, y especifica proyectos individuales para monitorizar. Edita el archivo `openstack.d/conf.yaml` en la carpeta `conf.d/` en la raíz del [directorio de configuración del Agent](https://docs.datadoghq.com/agent/guide/agent-configuration-files/#agent-configuration-directory) con la configuración de abajo. Consulta el [openstack.d/conf.yaml de ejemplo](https://github.com/DataDog/integrations-core/blob/master/openstack/datadog_checks/openstack/data/conf.yaml.example) para conocer todas las opciones de configuración disponibles: + + ```yaml + init_config: + ## @param keystone_server_url - string - required + ## Where your identity server lives. + ## Note that the server must support Identity API v3 + # + keystone_server_url: "https://:/"
+
+ instances:
+ ## @param name - string - required
+ ## Unique identifier for this instance.
+ #
+ - name: ""
+
+ ## @param user - object - required
+ ## User credentials
+ ## Password authentication is the only auth method supported.
+ ## `user` object expects the parameter `username`, `password`,
+ ## and `user.domain.id`.
+ ##
+ ## `user` should resolve to a structure like:
+ ##
+ ## {'password': '', 'name': '', 'domain': {'id': ''}}
+ #
+ user:
+ password: ""
+ name: datadog
+ domain:
+ id: ""
+ ```
+
+1. [Reinicia el Agent](https://docs.datadoghq.com/agent/guide/agent-commands/#start-stop-and-restart-the-agent).
+
+##### Recopilación de logs
+
+1. La recopilación de logs está desactivada por defecto en el Datadog Agent, puedes activarla en `datadog.yaml`:
+
+ ```yaml
+ logs_enabled: true
+ ```
+
+1. Añade este bloque de configuración a tu archivo `openstack.d/conf.yaml` para empezar a recopilar tus logs de Openstack:
+
+ ```yaml
+ logs:
+ - type: file
+ path: ""
+ source: openstack
+ ```
+
+ Cambia el valor de los parámetros de `path` y configúralos para tu entorno. Consulta el [openstack.d/conf.yaml de ejemplo](https://github.com/DataDog/integrations-core/blob/master/openstack/datadog_checks/openstack/data/conf.yaml.example) para conocer todas las opciones de configuración disponibles.
+
+### Validación
+
+Ejecuta el subcomando [de estado del Agent](https://docs.datadoghq.com/agent/guide/agent-commands/#agent-status-and-information) y busca `openstack` en la sección Checks.
+
+## Datos recopilados
+
+### Métricas
+
+| | |
+| --- | --- |
+| **openstack.nova.current_workload**
(gauge) | Carga de trabajo actual en el hipervisor de Nova| +| **openstack.nova.disk_available_least**
(gauge) | Disco disponible para el hipervisor de Nova
_Se muestra como gibibyte_ | +| **openstack.nova.free_disk_gb**
(gauge) | Disco libre en el hipervisor de Nova
_Se muestra como gibibyte_ | +| **openstack.nova.free_ram_mb**
(gauge) | RAM libre en el hipervisor de Nova
_Se muestra como mebibyte_ | +| **openstack.nova.hypervisor_load.1**
(gauge) | La carga media del hipervisor durante un minuto.| +| **openstack.nova.hypervisor_load.15**
(gauge) | La carga media del hipervisor en quince minutos.| +| **openstack.nova.hypervisor_load.5**
(gauge) | La carga media del hipervisor en cinco minutos.| +| **openstack.nova.limits.max_image_meta**
(gauge) | El máximo permitido de definiciones de metadatos de imagen para este inquilino| +| **openstack.nova.limits.max_personality**
(gauge) | Las personalidades máximas permitidas para este inquilino| +| **openstack.nova.limits.max_personality_size**
(gauge) | El tamaño máximo de una sola personalidad permitido para este inquilino.| +| **openstack.nova.limits.max_security_group_rules**
(gauge) | El número máximo de reglas de grupo de seguridad permitidas para este inquilino.| +| **openstack.nova.limits.max_security_groups**
(gauge) | Número máximo de grupos de seguridad permitidos para este inquilino| +| **openstack.nova.limits.max_server_meta**
(gauge) | El máximo permitido de definiciones de metadatos de servicio para este inquilino| +| **openstack.nova.limits.max_total_cores**
(gauge) | El máximo de núcleos permitidos para este inquilino| +| **openstack.nova.limits.max_total_floating_ips**
(gauge) | El máximo permitido de IPs flotantes para este inquilino| +| **openstack.nova.limits.max_total_instances**
(gauge) | Número máximo de instancias permitidas para este inquilino| +| **openstack.nova.limits.max_total_keypairs**
(gauge) | Los pares de claves máximos permitidos para este inquilino| +| **openstack.nova.limits.max_total_ram_size**
(gauge) | El tamaño máximo de RAM permitido para este inquilino en megabytes (MB)
_Se muestra como mebibyte_ | +| **openstack.nova.limits.total_cores_used**
(gauge) | El total de núcleos utilizados por este inquilino| +| **openstack.nova.limits.total_floating_ips_used**
(gauge) | El total de IPs flotantes utilizadas por este inquilino| +| **openstack.nova.limits.total_instances_used**
(gauge) | El total de instancias utilizadas por este inquilino| +| **openstack.nova.limits.total_ram_used**
(gauge) | La RAM actual utilizada por este inquilino en megabytes (MB)
_Se muestra como mebibyte_ | +| **openstack.nova.limits.total_security_groups_used**
(gauge) | Número total de grupos de seguridad utilizados por este inquilino| +| **openstack.nova.local_gb**
(gauge) | El tamaño en GB del disco efímero presente en este host hipervisor
_Se muestra como gibibyte_ | +| **openstack.nova.local_gb_used**
(gauge) | El tamaño en GB del disco utilizado en este host hipervisor
_Se muestra como gibibyte_ | +| **openstack.nova.memory_mb**
(gauge) | El tamaño en MB de la RAM presente en este host hipervisor
_Se muestra como mebibyte_ | +| **openstack.nova.memory_mb_used**
(gauge) | El tamaño en MB de la RAM utilizada en este host hipervisor
_Se muestra como mebibyte_ | +| **openstack.nova.running_vms**
(gauge) | Número de máquinas virtuales en ejecución en este host de hipervisor| +| **openstack.nova.server.cpu0_time**
(gauge) | Tiempo de CPU en nanosegundos de esta CPU virtual
_Se muestra como nanosegundo_ | +| **openstack.nova.server.hdd_errors**
(gauge) | Número de errores observados por el servidor al acceder a un dispositivo HDD| +| **openstack.nova.server.hdd_read**
(gauge) | Número de bytes leídos desde un dispositivo HDD por este servidor
_Se muestra como byte_ | +| **openstack.nova.server.hdd_read_req**
(gauge) | Número de solicitudes de lectura realizadas a un dispositivo HDD por este servidor| +| **openstack.nova.server.hdd_write**
(gauge) | Número de bytes escritos en un dispositivo HDD por este servidor
_Se muestra como byte_ | +| **openstack.nova.server.hdd_write_req**
(gauge) | El número de solicitudes de escritura realizadas a un dispositivo HDD por este servidor| +| **openstack.nova.server.memory**
(gauge) | La cantidad de memoria en MB aprovisionada para este servidor
_Se muestra como mebibyte_ | +| **openstack.nova.server.memory_actual**
(gauge) | La cantidad de memoria en MB aprovisionada para este servidor
_Se muestra como mebibyte_ | +| **openstack.nova.server.memory_rss**
(gauge) | La cantidad de memoria utilizada por los procesos de este servidor que no está asociada a páginas de disco, como el stack tecnológico y la memoria heap
_Se muestra como mebibyte_ | +| **openstack.nova.server.vda_errors**
(gauge) | Número de errores observados por el servidor al acceder a un dispositivo VDA.| +| **openstack.nova.server.vda_read**
(gauge) | Número de bytes leídos desde un dispositivo VDA por este servidor
_Se muestra como byte_ | +| **openstack.nova.server.vda_read_req**
(gauge) | Número de solicitudes de lectura realizadas a un dispositivo VDA por este servidor.| +| **openstack.nova.server.vda_write**
(gauge) | Número de bytes escritos en un dispositivo VDA por este servidor
_Se muestra como byte_ | +| **openstack.nova.server.vda_write_req**
(gauge) | Número de solicitudes de escritura realizadas a un dispositivo VDA por este servidor| +| **openstack.nova.vcpus**
(gauge) | Número de vCPUs disponibles en este host hipervisor| +| **openstack.nova.vcpus_used**
(gauge) | Número de vCPUS utilizados en este host hipervisor| + +### Eventos + +El check de OpenStack no incluye ningún evento. + +### Checks de servicio + +**openstack.neutron.api.up** + +Devuelve `CRITICAL` si el Agent no puede consultar la API de Neutron, `UNKNOWN` si hay un problema con la API de Keystone. En caso contrario, devuelve `OK`. + +_Estados: ok, critical, unknown_ + +**openstack.nova.api.up** + +Devuelve `CRITICAL` si el Agent no puede consultar la API de Nova, `UNKNOWN` si hay un problema con la API de Keystone. En caso contrario, devuelve `OK`. + +_Estados: ok, critical, unknown_ + +**openstack.keystone.api.up** + +Devuelve `CRITICAL` si el Agent no puede consultar la API de Keystone. En caso contrario, devuelve `OK`. + +_Estados: ok, critical_ + +**openstack.nova.hypervisor.up** + +Devuelve `UNKNOWN` si el Agent no puede obtener el estado del hipervisor, `CRITICAL` si el hipervisor está caído. Devuelve `OK` en caso contrario. + +_Estados: ok, critical, unknown_ + +**openstack.neutron.network.up** + +Devuelve `UNKNOWN` si el Agent no puede obtener el estado de la red, `CRITICAL` si la red está caída. En caso contrario, devuelve `OK`. + +_Estados: ok, critical, unknown_ + +## Solucionar problemas + +¿Necesitas ayuda? Ponte en contacto con el [soporte de Datadog](https://docs.datadoghq.com/help/). + +## Referencias adicionales + +Documentación útil adicional, enlaces y artículos: + +- [Monitorización de OpenStack Nova](https://www.datadoghq.com/blog/openstack-monitoring-nova) +- [Instalar OpenStack en dos comandos para dev y test](https://www.datadoghq.com/blog/install-openstack-in-two-commands) +- [OpenStack: agregados de hosts, opciones y zonas de disponibilidad](https://www.datadoghq.com/blog/openstack-host-aggregates-flavors-availability-zones) \ No newline at end of file diff --git a/content/es/integrations/opsgenie.md b/content/es/integrations/opsgenie.md new file mode 100644 index 0000000000000..46a94cdf71ea4 --- /dev/null +++ b/content/es/integrations/opsgenie.md @@ -0,0 +1,105 @@ +--- +app_id: opsgenie +categories: +- collaboration +- notifications +custom_kind: integración +description: Reenvía alertas desde Datadog y notifica a los usuarios por teléfono. +further_reading: +- link: https://docs.datadoghq.com/tracing/service_catalog/integrations/#opsgenie-integration + tag: blog + text: Blog de Opsgenie +- link: https://registry.terraform.io/providers/DataDog/datadog/latest/docs/resources/integration_opsgenie_service_object + tag: otros + text: Opsgenie +media: [] +title: Opsgenie +--- +## Información general + +Crea alertas en Opsgenie utilizando `@opsgenie-{service-name}`: + +- Al tomar una snapshot +- Cuando se activa una alerta de métrica + +## Configuración + +### Configuración + +#### Crear una integración de Datadog en Opsgenie + +1. Inicia sesión en tu cuenta de Opsgenie y ve a la page (página) [Integraciones de Opsgenie](https://app.opsgenie.com/settings/integration/integration-list). +1. Busca Datadog y haz clic en cuadro. +1. Completa el Nombre de la integración y, si lo deseas, configura el Equipo asignado. +1. Después de hacer clic en **Enviar**, permanece en la page (página) y guarda la clave de API de la integración recién creada. La necesitarás para finalizar la configuración. +1. Añade más integraciones de Datadog en Opsgenie yendo a la page (página) [Integraciones de Opsgenie](https://app.opsgenie.com/settings/integration/integration-list) y repitiendo los pasos anteriores. + +#### Registra las integraciones que has realizado en Opsgenie en Datadog + +1. En Datadog, ve a la [page (página) Integraciones](https://app.datadoghq.com/integrations), luego busca y selecciona el ícono Opsgenie. +1. Check que estés en la pestaña Configuración del cuadro de diálogo que aparece. +1. Haz clic en **Nuevo servicio de integración**. +1. Pega la clave de API guardada anteriormente de la integración de Datadog (creada en Opsgenie) en el campo **Clave de API de Opsgenie** e introduce un **Nombre de servicio**. + 1. El nombre del servicio debe ser descriptivo y único. Sólo se permiten valores alfanuméricos, guiones, guiones bajos y puntos. No se admiten espacios. + {{< img src="integrations/opsgenie/datadog-add-opsgenie-api-key.png" alt="Ícono de integración de Opsgenie que muestra la configuración para un nuevo servicio de integración" popup="true">}} +1. En el menú desplegable **Región**, selecciona Estados Unidos o Europa, según dónde opere tu cuenta de Opsgenie. +1. Haz clic en **Save** (Guardar). + +## Ejemplo de uso + +### El monitor de ruta alerta a Opsgenie + +1. Crea cualquier monitor (noun) en la [Page (página) Monitores](https://app.datadoghq.com/monitors/manage). +1. En el cuerpo de monitor (noun), pega `@opsgenie-{service-name}` (sustituye `{service-name}` por el nombre del servicio definido en el ícono de integración de Opsgenie). +1. Guarda el monitor. +1. Ve a la Page (página) Editar del monitor (noun) y haz clic en "Test notificaciones" para emitir una alerta de ejemplo utilizando tu integración. Debería crearse una alerta correspondiente en Opsgenie. +1. Para notificar a varios servicios, pega `@opsgenie-{service-name} @opsgenie-{service-name-2}` en el cuerpo del monitor (noun) y test con los mismos pasos. + +#### Permisos + +En forma predeterminada, todos los usuarios tienen acceso completo a los servicios de Opsgenie. + +Utiliza [Control de acceso granular](https://docs.datadoghq.com/account_management/rbac/granular_access/) para limitar los roles que pueden editar un servicio específico: + +1. Mientras visualizas un servicio, haz clic en el icono de engranaje de la esquina superior derecha para abrir el menú de configuración. +1. Selecciona **Configurar permisos**. +1. Haz clic en **Restrict Access** (Acceso restringido). El cuadro de diálogo se actualiza para mostrar que los miembros de tu organización tienen acceso de **Visor** por defecto. +1. Utiliza el menú desplegable para seleccionar uno o más roles, equipos o usuarios que pueden editar el servicio Opsgenie. +1. Haz clic en **Add** (Añadir). El cuadro de diálogo se actualiza para mostrar que el rol seleccionado tiene el permiso de **Editor**. +1. Haz clic en **Save** (Guardar). + +**Nota:** Para mantener tu acceso de edición al servicio, incluye al menos un rol al que pertenezcas antes de guardar. + +Si tienes acceso de edición, puedes restaurar el acceso general a un servicio restringido siguiendo los siguientes pasos: + +1. Mientras visualizas el servicio, haz clic en el icono de engranaje de la esquina superior derecha para abrir el menú de configuración. +1. Selecciona **Configurar permisos**. +1. Haz clic en **Restore Full Access** (Restablecer acceso completo). +1. Haz clic en **Save** (Guardar). + +Para editar los permisos de servicio a través de la API: + +1. Obtén los ID de servicio de Opsgenie utilizando la [API de integración de Opsgenie](https://docs.datadoghq.com/api/latest/opsgenie-integration/). +1. Utiliza la [API de políticas de restricción](https://docs.datadoghq.com/api/latest/restriction-policies/), donde el tipo es `integration-service` y el ID es `opsgenie:`.
+
+## Datos recopilados
+
+### Métricas
+
+La integración de Opsgenie no incluye ninguna métrica.
+
+### Eventos
+
+La integración Opsgenie no incluye ningún evento.
+
+### Checks de servicio
+
+La integración de Opsgenie no incluye ningún check de servicio.
+
+## Solucionar problemas
+
+¿Necesitas ayuda? Ponte en contacto con el [servicio de asistencia de Datadog](https://docs.datadoghq.com/help/).
+
+## Referencias adicionales
+
+{{< partial name="whats-next/whats-next.html" >}}
\ No newline at end of file
diff --git a/content/es/integrations/opsmatic.md b/content/es/integrations/opsmatic.md
new file mode 100644
index 0000000000000..4ca11cfe2949b
--- /dev/null
+++ b/content/es/integrations/opsmatic.md
@@ -0,0 +1,48 @@
+---
+app_id: opsmatic
+categories:
+- notifications
+custom_kind: integración
+description: Visualiza alertas de Opsmatic y confirma su recepción desde tu flujo
+ (stream) de eventos Datadog.
+title: Opsmatic
+---
+## Información general
+
+Conecta Opsmatic a Datadog para obtener:
+
+- Conocimiento instantáneo de cualquier cambio crítico
+- Visibilidad completa del estado en directo y del historial de todos tus hosts
+
+## Configuración
+
+### Instalación
+
+Para ver eventos de Opsmatic en tu flujo (stream) de Datadog:
+
+1. Añade tu clave de API de Datadog a tu página de integraciones de Opsmatic .
+1. Configura tus notificaciones de Opsmatic para Datadog.
+
+Consulta los [documentos del sitio web de Opsmatic para obtener más información](https://opsmatic.com/app/docs/datadog-integration).
+
+### Configuración
+
+Haz clic en el botón **Install Integration** (Instalar integración) del cuadro de integración de Opsmatic. Para ello es necesario seguir los pasos de configuración de esta integración.
+
+## Datos recopilados
+
+### Métricas
+
+La integración de Opsmatic no incluye ninguna métrica.
+
+### Eventos
+
+La integración de Opsmatic no incluye ningún evento.
+
+### Checks de servicio
+
+La integración de Opsmatic no incluye ningún check de servicio.
+
+## Solucionar problemas
+
+¿Necesitas ayuda? Ponte en contacto con el [servicio de asistencia de Datadog](https://docs.datadoghq.com/help/).
\ No newline at end of file
diff --git a/content/es/integrations/oracle.md b/content/es/integrations/oracle.md
index 6882011947396..7a0f250352d52 100644
--- a/content/es/integrations/oracle.md
+++ b/content/es/integrations/oracle.md
@@ -1,82 +1,27 @@
---
app_id: oracle
-app_uuid: 34835d2b-a812-4aac-8cc2-d298db851b80
-assets:
- dashboards:
- DBM Oracle Database Overview: assets/dashboards/dbm_oracle_database_overview.json
- oracle: assets/dashboards/oracle_overview.json
- integration:
- auto_install: true
- configuration:
- spec: assets/configuration/spec.yaml
- events:
- creates_events: false
- metrics:
- check: oracle.session_count
- metadata_path: metadata.csv
- prefix: oracle.
- service_checks:
- metadata_path: assets/service_checks.json
- source_type_id: 10000
- source_type_name: Oracle Database
-author:
- homepage: https://www.datadoghq.com
- name: Datadog
- sales_email: info@datadoghq.com
- support_email: help@datadoghq.com
categories:
- data stores
- network
- oracle
-custom_kind: integration
-dependencies:
-- https://github.com/DataDog/integrations-core/blob/master/oracle/README.md
-display_on_public_website: true
-draft: false
-git_integration_title: oracle
-integration_id: oracle
-integration_title: Oracle Database
+custom_kind: integración
+description: Sistema de base de datos relacional Oracle diseñado para la computación
+ en red de la empresa
integration_version: 6.0.0
-is_public: true
-manifest_version: 2.0.0
-name: oracle
-public_title: Oracle Database
-short_description: Sistema de base de datos relacional Oracle diseñado para la computación
- enterprise grid
+media: []
supported_os:
- linux
- windows
- macos
-tile:
- changelog: CHANGELOG.md
- classifier_tags:
- - Category::Data Stores
- - Category::Network
- - Category::Oracle
- - Supported OS::Linux
- - Supported OS::Windows
- - Supported OS::macOS
- - Offering::Integration
- configuration: README.md#Setup
- description: Sistema de base de datos relacional Oracle diseñado para la computación
- enterprise grid
- media: []
- overview: README.md#Overview
- support: README.md#Support
- title: Oracle Database
+title: Oracle Database
---
-
-
-
-
-![Dashboard de Oracle][1]
+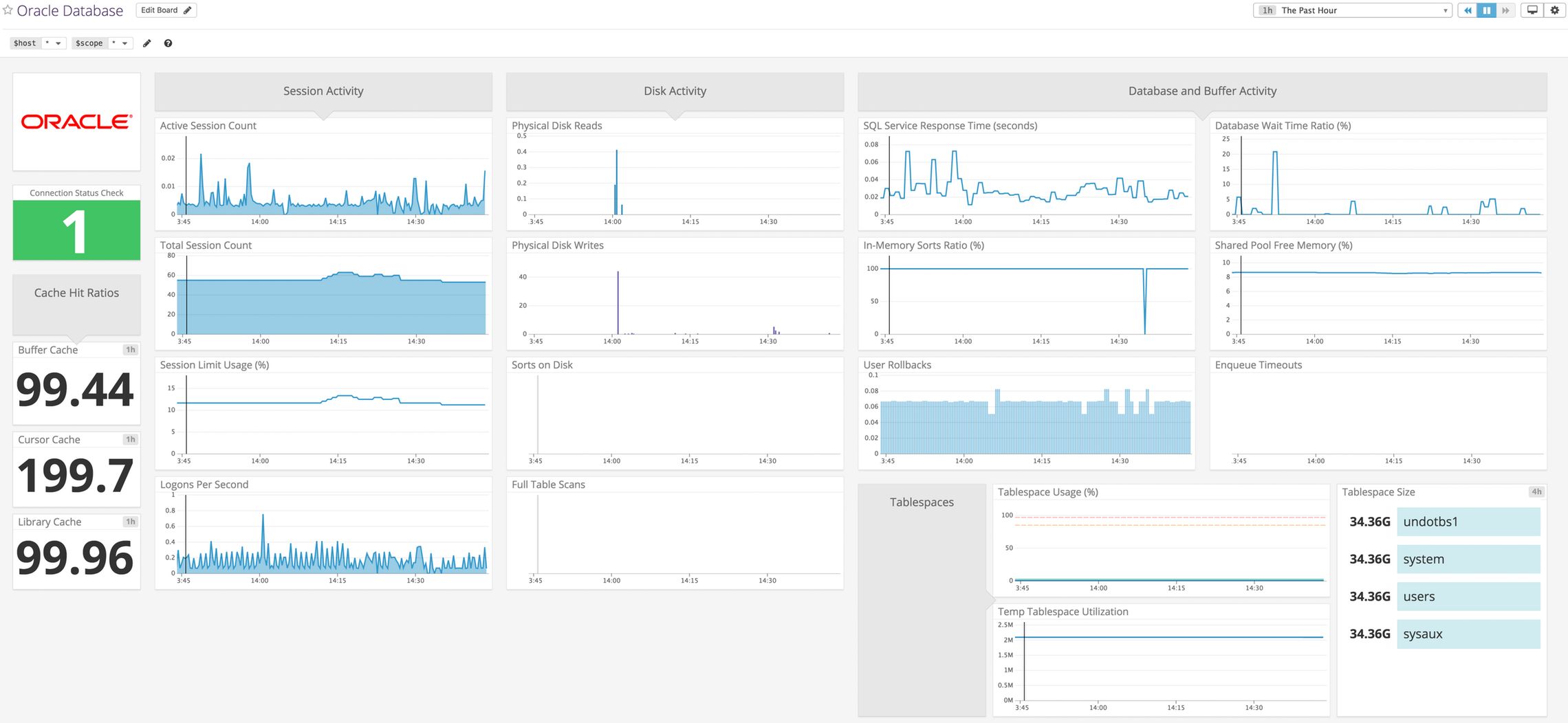
## Información general
La integración de Oracle proporciona métricas del estado y el rendimiento de tu base de datos de Oracle casi en tiempo real. Visualiza estas métricas con el dashboard proporcionado y crea monitores para alertar a tu equipo sobre los estados de base de datos de Oracle.
-Activa la [Monitorización de base de datos][2] (DBM) para obtener información mejorada sobre el rendimiento de las consultas y el estado de la base de datos. Además de las funciones estándar de integración, Datadog DBM proporciona métricas a nivel de consulta, snapshots de consultas en tiempo real e históricas, análisis de evento de espera, carga de la base de datos, planes de explicación de consultas e información de consultas de bloqueo.
-
+Activa [Database Monitoring](https://docs.datadoghq.com/database_monitoring/) (DBM) para obtener información mejorada sobre el rendimiento de las consultas y el estado de las bases de datos. Además de las funciones de la integración estándar, Datadog DBM proporciona métricas a nivel de consulta, snapshots de consultas históricas y actuales, análisis de eventos de espera, carga de bases de datos, explain plans de consultas e información sobre bloqueos de consultas.
## Configuración
@@ -84,7 +29,7 @@ Activa la [Monitorización de base de datos][2] (DBM) para obtener información
#### Requisito previo
-Para utilizar la integración de Oracle, puedes utilizar el cliente nativo (no requiere pasos adicionales de instalación) o Oracle Instant Client.
+Para utilizar la integración de Oracle puedes utilizar el cliente nativo (no se requieren pasos adicionales de instalación) o el Oracle Instant Client.
##### Oracle Instant Client
@@ -93,53 +38,53 @@ Omite este paso si no utilizas Instant Client.
{{< tabs >}}
{{% tab "Linux" %}}
+
###### Linux
-1. Sigue las instrucciones de [Instalación de Oracle Instant Client para Linux][1].
+1. Sigue las instrucciones de [Instalación de Oracle Instant Client para Linux](https://docs.oracle.com/en/database/oracle/oracle-database/19/mxcli/installing-and-removing-oracle-database-client.html).
-2. Comprueba que el paquete *Instant Client Basic* está instalado. Encuéntralo en la [página de descargas][2] de Oracle.
+1. Comprueba que el paquete *Instant Client Basic* está instalado. Búscalo en la [página de descargas](https://www.oracle.com/ch-de/database/technologies/instant-client/downloads.html). de Oracle.
- Una vez instaladas las bibliotecas de Instant Client, asegúrate de que el enlazador de tiempo de ejecución pueda encontrar las bibliotecas, por ejemplo:
+ Una vez instaladas las bibliotecas de Instant Client, asegúrate de que el enlazador de tiempo de ejecución puede encontrar las bibliotecas, por ejemplo:
- ```shell
- # Put the library location in the /etc/datadog-agent/environment file.
+ ```shell
+ # Put the library location in the /etc/datadog-agent/environment file.
- echo "LD_LIBRARY_PATH=/u01/app/oracle/product/instantclient_19" \
- >> /etc/datadog-agent/environment
- ```
+ echo "LD_LIBRARY_PATH=/u01/app/oracle/product/instantclient_19" \
+ >> /etc/datadog-agent/environment
+ ```
-[1]: https://docs.oracle.com/en/database/oracle/oracle-database/19/mxcli/installing-and-removing-oracle-database-client.html
-[2]: https://www.oracle.com/ch-de/database/technologies/instant-client/downloads.html
{{% /tab %}}
{{% tab "Windows" %}}
+
###### Windows
-1. Sigue la [Guía de instalación de Oracle Windows][1] para configurar tu Oracle Instant Client.
+1. Sigue la [guía de instalación de Oracle Windows](https://www.oracle.com/database/technologies/instant-client/winx64-64-downloads.html#ic_winx64_inst) para configurar tu Oracle Instant Client.
-2. Verifica lo siguiente:
- - Se ha instalado [Microsoft Visual Studio 2017 Redistributable][2] o la versión adecuada para Oracle Instant Client.
+1. Comprueba lo siguiente:
- - El paquete *Instant Client Basic* de la [página de descargas][3] de Oracle está instalado y disponible para todos los usuarios de la máquina en cuestión (por ejemplo, `C:\oracle\instantclient_19`).
+ - Se ha instalado [Microsoft Visual Studio 2017 Redistributable](https://support.microsoft.com/en-us/topic/the-latest-supported-visual-c-downloads-2647da03-1eea-4433-9aff-95f26a218cc0) o la versión adecuada para el Oracle Instant Client.
- - La variable de entorno `PATH` contiene el directorio con el Instant Client (por ejemplo, `C:\oracle\instantclient_19`).
+ - Se ha instalado el paquete *Instant Client Basic* de la [página de descargas](https://www.oracle.com/ch-de/database/technologies/instant-client/downloads.html) de Oracle y está disponible para todos los usuarios de la máquina en cuestión (por ejemplo, `C:\oracle\instantclient_19`).
+ - La variable de entorno `PATH` contiene el directorio con el Instant Client (por ejemplo, `C:\oracle\instantclient_19`).
-[1]: https://www.oracle.com/database/technologies/instant-client/winx64-64-downloads.html#ic_winx64_inst
-[2]: https://support.microsoft.com/en-us/topic/the-latest-supported-visual-c-downloads-2647da03-1eea-4433-9aff-95f26a218cc0
-[3]: https://www.oracle.com/ch-de/database/technologies/instant-client/downloads.html
{{% /tab %}}
+
{{< /tabs >}}
#### Creación de usuarios de Datadog
{{< tabs >}}
-{{% tab "Multiinquilino" %}}
+
+{{% tab "Multi-tenant" %}}
+
##### Multiinquilino
###### Crear usuario
-Crea un inicio de sesión de solo lectura para conectarte a tu servidor y concede los permisos necesarios:
+Crea un inicio de sesión de solo lectura para conectarte a tu servidor y conceder los permisos necesarios:
```SQL
CREATE USER c##datadog IDENTIFIED BY &password CONTAINER = ALL ;
@@ -200,11 +145,12 @@ grant set container to c##datadog ;
{{% /tab %}}
{{% tab "Sin CDB" %}}
+
##### Sin CDB
###### Crear usuario
-Crea un inicio de sesión de solo lectura para conectarte a tu servidor y concede los permisos necesarios:
+Crea un inicio de sesión de solo lectura para conectarte a tu servidor y conceder los permisos necesarios:
```SQL
CREATE USER datadog IDENTIFIED BY &password ;
@@ -255,17 +201,18 @@ grant select on dba_data_files to datadog;
{{% /tab %}}
{{% tab "RDS" %}}
+
##### RDS
###### Crear usuario
-Crea un inicio de sesión de solo lectura para conectarte a tu servidor y concede los permisos necesarios:
+Crea un inicio de sesión de solo lectura para conectarte a tu servidor y conceder los permisos necesarios:
```SQL
CREATE USER datadog IDENTIFIED BY your_password ;
```
-###### Conceder permisos
+###### Conceder permisos
```SQL
grant create session to datadog ;
@@ -309,17 +256,18 @@ exec rdsadmin.rdsadmin_util.grant_sys_object('DBA_DATA_FILES','DATADOG','SELECT'
{{% /tab %}}
{{% tab "Oracle Autonomous Database" %}}
+
##### Oracle Autonomous Database
###### Crear usuario
-Crea un inicio de sesión de solo lectura para conectarte a tu servidor y concede los permisos necesarios:
+Crea un inicio de sesión de solo lectura para conectarte a tu servidor y conceder los permisos necesarios:
```SQL
CREATE USER datadog IDENTIFIED BY your_password ;
```
-###### Conceder permisos
+###### Conceder permisos
```SQL
grant create session to datadog ;
@@ -367,7 +315,7 @@ grant select on dba_data_files to datadog;
Para configurar este check para un Agent que se ejecuta en un host:
-1. Edita el archivo `oracle.d/conf.yaml`, en la carpeta `conf.d/` en la raíz de tu [directorio de configuración del Agent][3]. Actualiza `server` y `port` para establecer el nodo maestro a monitorizar. Consulta el [oracle.d/conf.yaml de ejemplo][4] para conocer todas las opciones disponibles de configuración.
+1. Edita el archivo `oracle.d/conf.yaml`, en la carpeta `conf.d/` en la raíz de tu [directorio de configuración del Agent](https://docs.datadoghq.com/agent/guide/agent-configuration-files/#agent-configuration-directory). Actualiza `server` y `port` para configurar los masters que se van a monitorizar. Consulta el [ejemplo oracle.d/conf.yaml](https://github.com/DataDog/datadog-agent/blob/main/cmd/agent/dist/conf.d/oracle.d/conf.yaml.example) para conocer todas las opciones de configuración disponibles.
```yaml
init_config:
@@ -397,60 +345,62 @@ Para configurar este check para un Agent que se ejecuta en un host:
**Nota:** Para las versiones del Agent comprendidas entre `7.50.1` (incluido) y `7.53.0` (excluido), el subdirectorio de configuración es `oracle-dbm.d`. Para todas las demás versiones del Agent, el directorio de configuración es `oracle.d`.
-**Nota**: Los clientes de Oracle Real Application Cluster (RAC) deben configurar el Agent para cada nodo RAC, porque el Agent recopila información de cada nodo por separado consultando las vistas `V$`. El Agent no consulta ninguna vista `GV$` para evitar generar tráfico de interconexión.
+**Nota**: Los clientes de Oracle Real Application Cluster (RAC) deben configurar el Agent para cada nodo RAC, ya que el Agent recopila información de cada nodo por separado, consultando vistas `V$`. El Agent no consulta ninguna vista `GV$` para evitar generar tráfico de interconexión.
-2. [Reinicia el Agent][5].
+2. [Reinicia el Agent](https://docs.datadoghq.com/agent/guide/agent-commands/#start-stop-and-restart-the-agent).
#### Conexión a Oracle a través de TCPS
-Para conectarte a Oracle a través de TCPS (TCP con SSL), elimina los comentarios de la opción de configuración `protocol` y selecciona `TCPS`. Actualiza la opción `server` para establecer el servidor TCPS a monitorizar.
-
- ```yaml
- init_config:
-
- instances:
- ## @param server - string - required
- ## L dirección IP o el nombre de host del Oracle Database Server.
- #
- - server: localhost:1522
-
- ## @param service_name - string - required
- ## El nombre de servicio de Oracle Database. Para ver los servicios disponibles en tu servidor,
- ## ejecuta la siguiente consulta:
- #
- service_name: ""
-
- ## @param username - string - required
- ## El nombre de usuario de la cuenta de usuario.
- #
- username:
-
- ## @param password - string - required
- ## La contraseña para la cuenta de usuario.
- #
- password: ""
+Para conectarte a Oracle a través de TCPS (TCP con SSL), quita la marca de comentario de la opción de configuración `protocol` y selecciona `TCPS`. Actualiza la opción `server` para configurar el servidor TCPS en el monitor.
- ## @param protocol - string - optional - default: TCP
- ## El protocolo para conectarte al Oracle Database Server. Los protocolos válids son TCP y TCPS.
- ##
- #
- protocol: TCPS
- ```
+````
+```yaml
+init_config:
+
+instances:
+ ## @param server - string - required
+ ## The IP address or hostname of the Oracle Database Server.
+ #
+ - server: localhost:1522
+
+ ## @param service_name - string - required
+ ## The Oracle Database service name. To view the services available on your server,
+ ## run the following query:
+ #
+ service_name: ""
+
+ ## @param username - string - required
+ ## The username for the user account.
+ #
+ username:
+
+ ## @param password - string - required
+ ## The password for the user account.
+ #
+ password: ""
+
+ ## @param protocol - string - optional - default: TCP
+ ## The protocol to connect to the Oracle Database Server. Valid protocols include TCP and TCPS.
+ ##
+ #
+ protocol: TCPS
+```
+````
### Validación
-[Ejecuta el subcomando de estado del Agent][6] y busca `oracle` en la sección Checks.
+[Ejecuta el subcomando de estado del Agent](https://docs.datadoghq.com/agent/guide/agent-commands/#agent-status-and-information) y busca `oracle` en la sección Checks.
### Consulta personalizada
También es posible realizar consultas personalizadas. Cada consulta debe tener dos parámetros:
-| Parámetro | Descripción |
-| --------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
-| `query` | Este es el SQL a ejecutar. Puede ser una sentencia simple o un script de varias líneas. Se evalúan todas las filas del resultado. |
-| `columns` | Se trata de una lista que representa cada columna, ordenada secuencialmente de izquierda a derecha. Hay dos datos obligatorios:
a. `type`: es el método de envío (`gauge`, `count`, etc.).
b. name (nombre): es el sufijo utilizado para formar el nombre completo de la métrica. Si `type` es `tag`, esta columna se considera una etiqueta que se aplica a cada métrica recopilada por esta consulta en particular. | +| Parámetro | Descripción | +| --------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |\ +| `query` | Este es el SQL a ejecutar. Puede ser una sentencia simple o un script de varias líneas. Se evalúan todas las filas del resultado. | +| `columns` | Esta es una lista que representa cada columna, ordenada secuencialmente de izquierda a derecha. Hay dos datos obligatorios:
a. `type` - Es el método de envío (`gauge`, `count`, etc.).
b. name - Es el sufijo utilizado para formar el nombre completo de la métrica. Si `type` es `tag`, esta columna se considera en cambio como una etiqueta que se aplica a cada métrica recopilada por esta consulta en particular. | -Opcionalmente, utiliza el parámetro `tags` para aplicar una lista de etiquetas a cada métrica recopilada. +Opcionalmente, utiliza el parámetro `tags` para aplicar una lista de etiquetas (tags) a cada métrica recopilada. Lo siguiente: @@ -462,12 +412,12 @@ self.count('oracle.custom_query.metric2', value, tags=['tester:oracle', 'tag1:va es en lo que se convertiría el siguiente ejemplo de configuración: ```yaml -- query: | # Usa el pipe si necesitas un script de múltiples líneas. +- query: | # Use the pipe if you require a multi-line script. SELECT columns FROM tester.test_table WHERE conditions columns: - # Coloca esto en cualquier columna que deseas omitir: + # Put this for any column you wish to skip: - {} - name: metric1 type: gauge @@ -479,31 +429,67 @@ es en lo que se convertiría el siguiente ejemplo de configuración: - tester:oracle ``` -Consulta el [oracle.d/conf.yaml de ejemplo][4] para ver todas las opciones disponibles de configuración. +Consulta el [ejemplo oracle.d/conf.yaml](https://github.com/DataDog/datadog-agent/blob/main/cmd/agent/dist/conf.d/oracle.d/conf.yaml.example) para conocer todas las opciones de configuración disponibles. ## Datos recopilados ### Métricas -{{< get-metrics-from-git "oracle" >}} +| | | +| --- | --- | +| **oracle.active_sessions**
(gauge) | Número de sesiones activas| +| **oracle.asm_diskgroup.free_mb**
(gauge) | Capacidad no utilizada de un grupo de discos en megabytes, etiquetada por `state` (solo DBM)| +| **oracle.asm_diskgroup.offline_disks**
(gauge) | Número de discos de un grupo de discos ASM que están fuera de línea, etiquetados por `state` (solo DBM)| +| **oracle.asm_diskgroup.total_mb**
(gauge) | Capacidad total utilizable del grupo de discos, etiquetada por `state` (solo DBM)| +| **oracle.buffer_cachehit_ratio**
(gauge) | Ratio de accesos a la caché del buffer
_Se muestra como porcentaje_ | +| **oracle.cache_blocks_corrupt**
(gauge) | Bloques de caché corruptos
_Se muestra como bloque_ | +| **oracle.cache_blocks_lost**
(gauge) | Bloques de caché perdidos
_Se muestra como bloque_ | +| **oracle.cursor_cachehit_ratio**
(gauge) | Ratio de accesos a la caché del cursor
_Se muestra como porcentaje_. | +| **oracle.database_wait_time_ratio**
(gauge) | Ordenaciones de memoria por segundo
_Se muestra como porcentaje_. | +| **oracle.disk_sorts**
(gauge) | Ordenaciones de disco por segundo
_Se muestra como operación_ | +| **oracle.enqueue_timeouts**
(gauge) | Tiempos de espera en cola excedidos por segundo
_Se muestra como tiempo de espera excedido_ | +| **oracle.gc_cr_block_received**
(gauge) | Bloque CR de recolección de basura recibido
_Se muestra como bloque_ | +| **oracle.library_cachehit_ratio**
(gauge) | Ratio de accesos a la caché de la biblioteca
_Se muestra como porcentaje_ | +| **oracle.logons**
(gauge) | Número de intentos de inicio de sesión| +| **oracle.long_table_scans**
(gauge) | Número de análisis extensos de tablas por segundo
_Se muestra como análisis_ | +| **oracle.memory_sorts_ratio**
(gauge) | Ratio de ordenaciones de la memoria
_Se muestra como porcentaje_ | +| **oracle.physical_reads**
(gauge) | Lecturas físicas por segundo
_Se muestra como lectura_ | +| **oracle.physical_writes**
(gauge) | Escrituras físicas por segundo
_Se muestra como escritura_ | +| **oracle.process.pga_allocated_memory**
(gauge) | Memoria PGA asignada por el proceso
_Se muestra como bytes_ | +| **oracle.process.pga_freeable_memory**
(gauge) | Memoria PGA liberable por proceso
_Se muestra como bytes_ | +| **oracle.process.pga_maximum_memory**
(gauge) | Memoria PGA máxima asignada por el proceso
_Se muestra como bytes_ | +| **oracle.process.pga_used_memory**
(gauge) | Memoria PGA utilizada por el proceso
_Se muestra como bytes_ | +| **oracle.rows_per_sort**
(gauge) | Filas por clasificación
_Se muestra como fila_ | +| **oracle.service_response_time**
(gauge) | Tiempo de respuesta del servicio
_Se muestra como segundos_ | +| **oracle.session_count**
(gauge) | Recuento de sesiones| +| **oracle.session_limit_usage**
(gauge) | Uso del límite de sesión
_Se muestra como porcentaje_. | +| **oracle.shared_pool_free**
(gauge) | % de memoria libre del grupo compartido
_Se muestra como porcentaje_ | +| **oracle.sorts_per_user_call**
(gauge) | Clasificación por llamadas de usuario| +| **oracle.tablespace.in_use**
(gauge) | Espacio de tabla en uso
_Se muestra como porcentaje_. | +| **oracle.tablespace.offline**
(gauge) | Espacio de tabla fuera de línea| +| **oracle.tablespace.size**
(gauge) | Tamaño del espacio de tabla
_Se muestra como bytes_ | +| **oracle.tablespace.used**
(gauge) | Espacio de tabla utilizado
_Se muestra como bytes_ | +| **oracle.temp_space_used**
(gauge) | Espacio temporal utilizado
_Se muestra como bytes_ | +| **oracle.user_rollbacks**
(gauge) | Número de reversiones de usuarios
_Se muestra como operación_ | ### Eventos El check de Oracle Database no incluye ningún evento. ### Checks de servicio -{{< get-service-checks-from-git "oracle" >}} +**oracle.can_connect** -## Solucionar problemas +Devuelve OK si la integración puede conectarse a Oracle Database, CRITICAL en caso contrario -¿Necesitas ayuda? Ponte en contacto con el [soporte de Datadog][7]. +_Estados: ok, crítico_ +**oracle.can_query** + +Devuelve OK si la integración puede ejecutar todas las consultas, CRITICAL en caso contrario + +_Estados: ok, crítico_ + +## Solucionar problemas -[1]: https://raw.githubusercontent.com/DataDog/integrations-core/master/oracle/images/oracle_dashboard.png -[2]: https://docs.datadoghq.com/es/database_monitoring/ -[3]: https://docs.datadoghq.com/es/agent/guide/agent-configuration-files/#agent-configuration-directory -[4]: https://github.com/DataDog/datadog-agent/blob/main/cmd/agent/dist/conf.d/oracle.d/conf.yaml.example -[5]: https://docs.datadoghq.com/es/agent/guide/agent-commands/#start-stop-and-restart-the-agent -[6]: https://docs.datadoghq.com/es/agent/guide/agent-commands/#agent-status-and-information -[7]: https://docs.datadoghq.com/es/help/ \ No newline at end of file +¿Necesitas ayuda? Ponte en contacto con el [servicio de asistencia de Datadog](https://docs.datadoghq.com/help/). \ No newline at end of file diff --git a/content/es/integrations/oracle_cloud_infrastructure.md b/content/es/integrations/oracle_cloud_infrastructure.md index 3222e81e8cfa8..d83faaaca997a 100644 --- a/content/es/integrations/oracle_cloud_infrastructure.md +++ b/content/es/integrations/oracle_cloud_infrastructure.md @@ -8,11 +8,6 @@ assets: auto_install: false events: creates_events: false - metrics: - check: - - oci.mediastreams.egress_bytes - metadata_path: metadata.csv - prefix: oci. service_checks: metadata_path: assets/service_checks.json source_type_id: 310 @@ -55,33 +50,123 @@ tile: a una serie de aplicaciones en un entorno alojado. media: [] overview: README.md#Overview + resources: + - resource_type: blog + url: https://www.datadoghq.com/blog/monitor-oci-with-datadog/ + - resource_type: blog + url: https://www.datadoghq.com/blog/datadog-oci-quickstart/ support: README.md#Support title: Oracle Cloud Infrastructure --- - -## Información general + +{{% site-region region="gov" %}} +
+ **Nota**: Despliega este stack tecnológico sólo una vez por tenencia. + +#### Stack tecnológico de ORM + +1. Acepta las Condiciones de uso de Oracle. +2. Deja sin marcar la opción de utilizar proveedores personalizados de Terraform. +3. Utiliza el directorio de trabajo predeterminado para desplegar el stack tecnológico u opcionalmente elige uno diferente. +4. Haz clic en **Siguiente** y **Siguiente** de nuevo.
+5. Haz clic en **Crear** y espera hasta 15 minutos a que se complete el despliegue. + +[1]: https://app.datadoghq.com/integrations/oracle-cloud-infrastructure +[2]: https://docs.oracle.com/iaas/Content/General/Concepts/servicelimits.htm#Requesti +{{% /tab %}} + +{{% tab "Manual setup" %}} + +Para reenviar tus métricas de OCI a Datadog: - [Ingresa la información de la tenencia](#enter-tenancy-info). - - [Crea un stack tecnológico de políticas de OCI](#create-oci-policy-stack) en la región de origen de tu tenencia para crear un usuario de autenticación, un grupo y políticas de Datadog. - - [Ingresa la información del DatadogAuthUser](#enter-datadogauthuser-info) en Datadog. - - [Crea un stack tecnológico de reenvío de métricas de OCI](#create-oci-metric-forwarding-stack) para cada región de la tenencia desde la que quieras reenviar métricas. + - [Despliega el stack tecnológico de políticas OCI (#create-oci-policy-stack) en la región de origen de tu tenencia para crear un usuario, grupo y políticas de sólo lectura en Datadog. + - [Introduce DatadogROAuthUser info](#enter-datadogroauthuser-info) en Datadog + - [Despliega un stack tecnológico de reenvío de métricas OCI (#create-oci-metric-forwarding-stack) para cada región de tenencia desde la que desees reenviar métricas. + - [Completa la configuración en Datadog](#complete-the-setup-in-datadog) + - [Valida las métricas que fluyen](#validation) + - [Configura la recopilación de métricas (opcional)](#configuration) + - [Configura la recopilación de logs (opcional)](#log-collection) Para ver una representación visual de esta arquitectura, consulta la sección [Arquitectura](#architecture). #### Ingresar la información de la tenencia {{% collapse-content title="Requisitos para esta sección" level="h5" %}} -- Tu cuenta de usuario de OCI necesita el rol **Cloud Administrator** (Administrador de la nube) para completar estos pasos. +- Tu cuenta de usuario OCI necesita el rol de **Administrador de la nube** para completar estos pasos - OCID de la tenencia - Región de origen {{% /collapse-content %}} @@ -93,61 +178,61 @@ Ingresa el OCID y la región de origen de la tenencia que deseas monitorizar en #### Crear un stack tecnológico de políticas de OCI {{% collapse-content title="Requisitos para esta sección" level="h5" %}} -- Tu cuenta de usuario debe poder [crear políticas y grupos dinámicos][4] en el dominio predeterminado. -- Debes estar en la región de origen de la tenencia. +- Tu cuenta de usuario OCI debe poder [crear grupos y políticas dinámicas][4] en el dominio predeterminado +- Debes estar en la región de origen de la tenencia {{% /collapse-content %}} -
+ a. En la esquina inferior izquierda de la pantalla, en **Recursos**, haz clic en **Claves de API**.
+ b. Haz clic en **Añadir clave de API**.
+ c. Haz clic en **Descargar clave privada**.
+ d. Haz clic en **Añadir**.
e. Aparece una ventana emergente **Configuration file preview** (Vista previa del archivo de configuración), pero no es necesario realizar ninguna acción; cierra la ventana emergente. -![La página Add API Key (Añadir clave de API) en la consola de OCI][5] +![La página Añadir clave de API en la consola de OCI][5] -5. Copia el valor de la huella digital y pégalo en el campo **Fingerprint** (Huella digital) del [cuadro de integración de Datadog y OCI][1]. +5. Copia el valor de la huella digital y pégalo en el campo **Huella digital** del [cuadro de integración de Datadog y OCI][1]. 6. Copia el valor de la clave privada con estos pasos: a. Abre el archivo de clave privada `.pem` descargado en un editor de texto, o utiliza un comando de terminal como `cat` para mostrar el contenido del archivo. b. Copia todo el contenido, incluidos `-----BEGIN PRIVATE KEY-----` y `-----END PRIVATE KEY-----`. 7. Pega el valor de la clave privada en el campo **Private Key** (Clave privada) del cuadro de integración de Datadog y OCI. -#### Crear un stack tecnológico de reenvío de métricas de OCI +#### Crea un stack tecnológico de reenvío de métricas de OCI {{% collapse-content title="Requisitos para esta sección" level="h5" %}} -- Tu cuenta de usuario debe poder crear recursos en el compartimento. +- Tu cuenta de usuario OCI debe poder crear recursos en el compartimento - Valor de la [clave de API de Datadog][6]. -- Nombre de usuario y token de autenticación para un usuario con los permisos `REPOSITORY_READ` y `REPOSITORY_UPDATE`, de modo que se puedan extraer y enviar imágenes a un repositorio de Docker. +- Nombre de usuario y token de autenticación para un usuario con los permisos `REPOSITORY_READ` y `REPOSITORY_UPDATE` para extraer e insertar imágenes en un repositorio Docker - Consulta [Cómo obtener un token de autenticación][7] para saber cómo crear un token de autenticación. - - Consulta [Políticas para controlar el acceso a repositorios][8] para obtener más información sobre las políticas requeridas. + - Consulta [Políticas para controlar el acceso a repositorios][8] para obtener más información sobre las políticas necesarias -**Nota**: Para comprobar que el inicio de sesión en el registro de Docker es el correcto, consulta [Inicio de sesión en el registro de Oracle Cloud Infrastructure][9]. +**Nota**: Para comprobar que el inicio de sesión en el registro de Docker sea el correcto, consulta [Inicio de sesión en el registro de Oracle Cloud Infrastructure][9]. {{% /collapse-content %}} -El stack tecnológico de reenvío métricas debe desplegarse para **cada combinación de tenencia y región** que se va a monitorizar. Para la configuración más sencilla, Datadog recomienda crear todos los recursos de OCI necesarios con el stack tecnológico de ORM que se facilita a continuación. Como alternativa, puedes usar tu infraestructura de redes de OCI existente. +El stack tecnológico de reenvío de métricas debe desplegarse para **cada combinación de tenencia y región** que se debe monitorizar. Para la configuración más sencilla, Datadog recomienda crear todos los recursos OCI necesarios con el stack tecnológico de Oracle Resource Manager (ORM) que se proporciona a continuación. Como alternativa, puedes utilizar tu infraestructura de red OCI existente. Todos los recursos creados a partir del stack tecnológico de ORM de Datadog se despliegan en el compartimento especificado y para la región seleccionada actualmente en la parte superior derecha de la pantalla. @@ -155,119 +240,132 @@ Todos los recursos creados a partir del stack tecnológico de ORM de Datadog se 2. Acepta las Condiciones de uso de Oracle. 3. Deja sin marcar la opción **Custom providers** (Proveedores personalizados). 4. Asigna un nombre al stack tecnológico y selecciona el compartimento en el que se desplegará. -5. Haz clic en **Next** (Siguiente). +5. Haz clic en **Siguiente**. 6. En el campo **Datadog API Key** (Clave de API de Datadog), ingresa el valor de tu [clave de API de Datadog][6]. +7. En la sección **Network options** (Opciones de red), deja marcada la opción `Create VCN`. +{{% collapse-content title="(Opcional) Utilizar el VCN existente en su lugar" level="h4" %}} +Si utilizas una Red de Nube Virtual (VCN) existente, debes proporcionar el OCID de la subred al stack tecnológico. Asegúrate de que la VCN: + - Tenga permiso para realizar llamadas de salida HTTP a través de la puerta de NAT + - Sea capaz de extraer imágenes del registro de contenedores OCI mediante la puerta de servicios. + - Tenga las reglas de tabla de rutas para permitir la puerta de NAT y la puerta de servicio + - Tenga las reglas de seguridad para enviar solicitudes HTTP + +7. En la sección **Opciones de red**, deja sin marcar la opción `Create VCN` e introduce la información de tu VCN:
+ a. En el campo **Compartimento de VCN**, selecciona tu compartimento.
+ b. En la sección **VCN existente**, selecciona tu VCN existente.
+ c. En la sección **Function Subnet OCID** (OCID de subred de función), introduce el OCID de la subred que se va a utilizar. +{{% /collapse-content %}} -{{< tabs >}} -{{% tab "Creaf VCN con ORM (recomendado)" %}} -8. En la sección **Network options** (Opciones de red), deja marcada la opción `Create VCN`. -{{% /tab %}} -{{% tab "Usar una VCN existente" %}} -Si utilizas una VCN existente, debes indicar el OCID de la subred en el stack tecnológico. Asegúrate de que la VCN cumpla los siguientes requisitos: - - Se le permite hacer llamadas de salida HTTP a través de la gateway NAT. - - Puede extraer imágenes del registro de contenedores de OCI mediante la gateway de servicio. - - Tiene las reglas de la tabla de enrutamiento para permitir la gateway NAT y la gateway de servicio. - - Tiene las reglas de seguridad para enviar solicitudes HTTP. - -8. En la sección **Network options** (Opciones de red), desmarca la opción `Create VCN` e ingresa la información de tu VCN: - a. En el campo **vcnCompartment**, selecciona tu compartimento. - b. En la sección **existingVcn**, selecciona tu VCN existente. - c. En la sección **Function Subnet OCID** (OCID de subred de función), ingresa el OCID de la subred que se va a utilizar. +8. De manera opcional, en la sección **Metrics settings** (Parámetros de las métricas), elimina cualquier espacio de nombres de métrica de la recopilación. +9. En la sección **Metrics compartments** (Compartimentos de las métricas), ingresa una lista separada por comas de los OCID de compartimentos que se van a monitorizar. Los filtros de espacio de nombres de métrica seleccionados en el paso anterior se aplican a cada compartimento. +10. En la sección **Configuración de funciones**, selecciona `GENERIC_ARM`. Selecciona `GENERIC_X86` si realizas el despliegue en una región de Japón. +11. Haz clic en **Siguiente**. +12. Haz clic en **Create** (Crear). +13. Vuelve a la página del [cuadro de integración de Datadog y OCI][1] y haz clic en **Create configuration** (Crear configuración). + +**Notas**: +- En forma predeterminada, sólo se selecciona el compartimento raíz y se activan todos los espacios de nombres de métricas del Paso 8 presentes en el compartimento (se admiten hasta 50 espacios de nombres por concentrador de conectores). Si eliges monitorizar compartimentos adicionales, los espacios de nombres añadidos a ellos son una intersección de los espacios de nombres seleccionados y los espacios de nombres presentes en el compartimento. +- Debes gestionar quién tiene acceso a los archivos de estado de Terraform de los stacks tecnológicos del gestor de recursos. Consulta la [sección Archivos de estado de Terraform][10] de la página Obtener el gestor de recursos para obtener más información. + +[1]: https://app.datadoghq.com/integrations/oracle-cloud-infrastructure +[2]: https://cloud.oracle.com/tenancy +[3]: https://docs.oracle.com/iaas/Content/General/Concepts/regions.htm +[4]: https://docs.oracle.com/en/cloud/paas/weblogic-container/user/create-dynamic-groups-and-policies.html +[5]: images/add_api_key.png +[6]: https://app.datadoghq.com/organization-settings/api-keys +[7]: https://docs.oracle.com/iaas/Content/Registry/Tasks/registrygettingauthtoken.htm +[8]: https://docs.oracle.com/iaas/Content/Registry/Concepts/registrypolicyrepoaccess.htm#Policies_to_Control_Repository_Access +[9]: https://docs.oracle.com/iaas/Content/Functions/Tasks/functionslogintoocir.htm +[10]: https://docs.oracle.com/iaas/Content/Security/Reference/resourcemanager_security.htm#confidentiality__terraform-state {{% /tab %}} + {{< /tabs >}} -9. De manera opcional, en la sección **Metrics settings** (Parámetros de las métricas), elimina cualquier espacio de nombres de métrica de la colección. -10. En la sección **Metrics compartments** (Compartimentos de las métricas), ingresa una lista separada por comas de los OCID de compartimentos que se van a monitorizar. Los filtros de espacio de nombres de métrica seleccionados en el paso anterior se aplican a cada compartimento. -11. En la sección **Function settings** (Parámetros de la función), indica un nombre de usuario de registro de OCI Docker y un token de autenticación en sus campos respectivos. Consulta [Cómo obtener un token de autenticación][7] para obtener más información. -12. Haz clic en **Next** (Siguiente). -13. Haz clic en **Create** (Crear). -14. Vuelve a la página del [cuadro de integración de Datadog y OCI][1] y haz clic en **Create configuration** (Crear configuración). +#### Completar la configuración en Datadog -**Notas**: -- De forma predeterminada, solo se selecciona el compartimento raíz y se activan todos los espacios de nombres de métrica compatibles con la integración de Datadog y OCI (se admiten hasta 50 espacios de nombres por hub de conectores). Si eliges monitorizar compartimentos adicionales, se aplica cualquier filtro de exclusión de espacio de nombres de métrica a cada compartimento. -- Debes gestionar quién tiene acceso a los archivos de estado de Terraform de los stacks tecnológicos del gestor de recursos. Consulta la sección [Archivos de estado de Terraform][10] de la página Seguridad del gestor de recursos para obtener más información. +Vuelve al [ícono de integración de OCI de Datadog][1] y haz clic en **¡Listo!**. #### Validación -Consulta las métricas de `oci.*` en el [dashboard de información general de la integración de OCI][11] o en la [página del explorador de métricas][12] en Datadog. +Consulta las métricas de `oci.*` en el [dashboard de información general de integración de OCI][2] o la [página Metrics Explorer][3] en Datadog. - to read metrics in tenancy
-Allow dynamic-group to use fn-function in tenancy
-Allow dynamic-group to use fn-invocation in tenancy
-Allow dynamic-group Default/ to read metrics in tenancy
-Allow dynamic-group Default/ to use fn-function in tenancy
-Allow dynamic-group Default/ to use fn-invocation in tenancy
-Allow group Default/ to read all-resources in tenancy
-```
+Utiliza uno de los siguientes métodos para enviar tus logs de OCI a Datadog:
-### Espacios de nombre de métrica
+{{< tabs >}}
-| Integración | Espacio de nombre de métrica |
-|-------------------------------------| ---------------------------------------------------------------------------------------------------------------------------------------- |
-| [Base de datos autónoma][18] | [oci_autonomous_database][19] |
-| Block Storage | [oci_blockstore][20] |
-| [Computación][21] | [oci_computeagent][22], [rdma_infrastructure_health][23], [gpu_infrastructure_health][24], [oci_compute_infrastructure_health][25] |
-| [Instancias de contenedor (versión preliminar)][26] | [oci_computecontainerinstance][27] |
-| [Base de datos][28] | [oci_database][29], [oci_database_cluster][30] |
-| Gateway de enrutamiento dinámico | [oci_dynamic_routing_gateway][31] |
-| FastConnect | [oci_fastconnect][32] |
-| File Storage | [oci_filestorage][33] |
-| [Funciones (versión preliminar)][34] | [oci_faas][35] |
-| [HeatWave MySQL][36] | [oci_mysql_database][37] |
-| Motor de Kubernetes | [oci_oke][38] |
-| [Equilibrador de carga][39] | [oci_lbaas][40], [oci_nlb][41] |
-| [Gateway NAT][42] | [oci_nat_gateway][43] |
-| Object Storage | [oci_objectstorage][44] |
-| Cola | [oci_queue][45] |
-| Hub de conectores de servicio | [oci_service_connector_hub][46] |
-| Gateway de servicio | [oci_service_gateway][47] |
-| [VCN][48] | [oci_vcn][49] |
-| [VPN][50] | [oci_vpn][51] |
-| Firewall de aplicaciones web | [oci_waf][52] |
+{{% tab "OCI QuickStart (Preview; recommended)" %}}
-### Recopilación de logs
+1. Sigue los pasos de la [sección de configuración](#setup) para crear la infraestructura necesaria para reenviar las métricas y los logs a Datadog.
+2. Haz clic en el conmutador **Habilitar Recopilación de logs** en la pestaña **Recopilación de logs** del [ícono de integración de OCI de Datadog][1].
-Envía logs desde tu infraestructura en la nube de Oracle a Datadog siguiendo alguno de estos procesos:
+[1]: https://app.datadoghq.com/integrations/oracle-cloud-infrastructure
+{{% /tab %}}
-{{< tabs >}}
-{{% tab "Hub de conectores de servicio" %}}
+{{% tab "Service Connector Hub" %}}
1. Configura un log de OCI.
2. Crea una función de OCI.
@@ -277,34 +375,34 @@ Las siguientes instrucciones utilizan el portal de OCI para configurar la integr
#### Registro de OCI
-1. En el portal de OCI, navega hasta *Logging -> Log Groups* (Registro > Grupos de logs).
-2. Selecciona tu compartimento y haz clic en **Create Log Group**. Se abre un panel lateral.
+1. En el portal de OCI, ve a *Logging -> Log Groups* (Registro > Grupos de logs).
+2. Selecciona tu compartimento y haz clic en **Crear un grupo de logs**. Se abre un panel lateral.
3. Introduce `data_log_group` para el nombre y, opcionalmente, proporciona una descripción y etiquetas (tags).
4. Haz clic en **Create** (Crear) para configurar tu nuevo grupo de logs.
5. En **Resources** (Recursos), haz clic en **Logs**.
6. Haz clic en **Create custom log** (Crear log personalizado) o **Enable service log** (Habilitar log de servicio) según lo desees.
7. Haz clic en **Enable Log** (Habilitar log), para crear tu nuevo log de OCI.
-Para más información sobre logs de OCI, consulta [Activación del registro para un recurso][1].
+Para obtener más información sobre logs de OCI, consulta [Activación del registro para un recurso][1].
#### Función de OCI
1. En el portal de OCI, ve a *Functions** (Funciones).
2. Selecciona una aplicación existente o haz clic en **Create Application** (Crear aplicación).
3. Crea una nueva función de OCI dentro de tu aplicación. Consulta [Información general de funciones de Oracle][2] para obtener más detalles.
-4. Es recomendado para crear una función boilerplate de Python primero y reemplazar los archivos autogenerados con el código fuente de Datadog:
- - Sustituye `func.py` por código del [repositorio de Datadog OCI][3].
- - Sustituye `func.yaml` por el código del [repositorio de Datadog OCI][4]. `DATADOG_TOKEN` y `DATADOG_HOST` deben sustituirse por tu clave de API de Datadog y el enlace de entrada de logs de la región.
- - Sustituye `requirements.txt` por código del [repositorio de Datadog OCI][5].
+4. Se recomienda crear primero una función boilerplate en Python y sustituir los archivos generados automáticamente por el código fuente de Datadog:
+ - Sustituye `func.py` por el código del [repositorio de OCI de Datadog][3]
+ - Sustituye `func.yaml` por el código del [repositorio de OCI de Datadog][4]. `DATADOG_TOKEN` y `DATADOG_HOST` deben sustituirse por tu clave API Datadog y el enlace de admisión de logs de la región
+ - Sustituye `requirements.txt` por el código del [repositorio de OCI de Datadog][5]
#### Hub de conectores de servicio de OCI
-1. En el portal de OCI, navega hasta *Logging -> Service Connectors* (Registro > Conectores de servicio).
+1. En el portal de OCI, ve a *Logging -> Service Connectors* (Registro > Conectores de servicio).
2. Haz clic en **Create Service Connector** (Crear conector de servicio) para ser redireccionado a la página **Create Service Connector** (Crear conector de servicio).
3. Selecciona **Source** (Origen) como Logging (Registro) y **Target** (Destino) como Functions (Funciones).
4. En **Configure Source Connection** (Configurar conexión de origen) selecciona **Compartment name** (Nombre de compartimento), **Log Group** (Grupo de logs) y **Log**. (El **Log Group** (Grupo de logs) y **Log** creados en el primer paso).
-5. Si también deseas enviar **Audit Logs** (Logs de auditoría), haz clic en **+Another Log** (+ otro log) y selecciona el mismo **Compartment** (Compartimento) y reemplaza "_Audit" (_Auditoría) como tu **Log Group** (Grupo de logs).
-6. En **Configure target** (Configurar destino) selecciona **Compartment** (Compartimento), **Function application** (Aplicación de función) y **Function** (Función). (La **Function Application** (Aplicación de función) y **Function** (Función) creadas en el paso anterior.
+5. Si también deseas enviar **Audit Logs** (Logs de auditoría), haz clic en **+Another Log** (+ otro log) y selecciona el mismo **Compartment** (Compartimento) y sustituye "_Auditoría" como tu **Log Group** (Grupo de logs).
+6. En **Configure target** (Configurar destino) selecciona **Compartment** (Compartimento), **Function application** (Aplicación de función) y **Function** (Función). (La **Function Application** (Aplicación de función) y la **Function** (Función) creadas en el paso anterior.)
7. Si se te pide que crees una política, haz clic en **Create** (Crear) en la pantalla.
8. Haz clic en **Create** (Crear) en la parte inferior para terminar de crear tu conector de servicio.
@@ -317,7 +415,8 @@ Para obtener más información sobre OCI Object Storage, consulta [la entrada de
[5]: https://github.com/DataDog/Oracle_Logs_Integration/blob/master/Service%20Connector%20%20Hub/requirements.txt
[6]: https://blogs.oracle.com/cloud-infrastructure/oracle-cloud-infrastructure-service-connector-hub-now-generally-available
{{% /tab %}}
-{{% tab "Almacén de objectos" %}}
+
+{{% tab "Object store" %}}
1. Configura un log de OCI.
2. Crea un almacén de objetos de OCI y habilita el acceso de lectura/escritura para logs de OCI.
@@ -339,41 +438,41 @@ Las siguientes instrucciones utilizan el portal de OCI para configurar la integr
9. Establece el tipo de entrada en **Log Path** (Ruta de log), introduce el nombre de entrada que prefieras y utiliza "/" para las rutas de los archivos.
10. Haz clic en **Create Custom Log** (Crear log personalizado), entonces tu log de OCI se creará y estará disponible en la página de logs.
-Para más información sobre logs de OCI, consulta [Activación del registro para un recurso][1].
+Para obtener más información sobre logs de OCI, consulta [Activación del registro para un recurso][1].
-#### OCI object storage
+#### Almacén de objetos de OCI
-1. En el portal de OCI, ve a *Core Infrastructure -> Object Storage -> Object Storage* (Infraestructura central > Object Storage > Object Storage).
+1. En el portal de OCI, ve a *Core Infrastructure -> Object Storage -> Object Storage* (Infraestructura central > Almacén de objetos > Almacén de objetos).
2. Haz clic en **Create Bucket** (Crear bucket) para acceder al formulario **Create bucket** (Crear bucket).
3. Selecciona **Standard** (Estándar) para tu nivel de almacenamiento y marca **Emit Object Events** (Emitir eventos de objeto).
-4. Rellena el resto del formulario según tus preferencias.
+4. Completa el resto del formulario según tus preferencias.
5. Haz clic en **Create Bucket** (Crear bucket), tu bucket se creará y estará disponible en la lista de buckets.
6. Selecciona tu nuevo bucket en la lista de buckets activos y haz clic en **Logs** en recursos.
-7. Activa **read** (leer), lo que te lleva al menú lateral **Enable Log** (Habilitar log).
+7. Activa **leer**, lo que te dirige a un menú lateral **Habilitar log**.
8. Selecciona un **Compartment** (Compartimento) y un **Log Group** (Grupo de logs) (utiliza las mismas selecciones que en tu log de OCI).
9. Introduce un nombre para el **Log Name** (Nombre de log) y selecciona tu retención de log preferida.
-Para más información sobre OCI Object Storage, consulta [Poner datos en Object Storage][2].
+Para obtener más información sobre OCI Object Storage, consulta [Poner datos en Object Storage][2].
#### Función de OCI
1. En el portal de OCI, ve a *Solutions and Platform -> Developer Services -> Functions* (Soluciones y plataforma > Servicios de desarrollador > Funciones).
2. Selecciona una aplicación existente o haz clic en **Create Application** (Crear aplicación).
3. Crea una nueva función de OCI dentro de tu aplicación. Para más detalles, consulta [Información general de funciones de Oracle][3].
-4. Es recomendado para crear una función boilerplate de Python primero y reemplazar los archivos autogenerados con el código fuente de Datadog:
- - Sustituye `func.py` por código del [repositorio de Datadog OCI][4].
- - Sustituye `func.yaml` por el código del [repositorio de Datadog OCI][5]. `DATADOG_TOKEN` y `DATADOG_HOST` deben sustituirse por tu clave de API de Datadog y el enlace de entrada de logs de la región.
- - Sustituye `requirements.txt` por código del [repositorio de Datadog OCI][6].
+4. Se recomienda crear primero una función boilerplate en Python y sustituir los archivos generados automáticamente por el código fuente de Datadog:
+ - Sustituye `func.py` por el código del [repositorio de OCI de Datadog][4]
+ - Sustituye `func.yaml` por el código del [repositorio de OCI de Datadog][5]. `DATADOG_TOKEN` y `DATADOG_HOST` deben sustituirse por tu clave de API Datadog y el enlace de admisión de logs de la región
+ - Sustituye `requirements.txt` por el código del [repositorio de OCI de Datadog][6]
#### Evento de OCI
1. En el portal de OCI, ve a *Solutions and Platform -> Application Integration -> Event Service* (Soluciones y plataforma > Integración de aplicaciones > Servicio de eventos).
2. Haz clic en **Create Rule** (Crear regla) para acceder a la página **Create Rule** (Crear regla).
3. Asigna un nombre y una descripción a tu regla de evento.
-4. Establece tu condición como **Event Type** (Tipo de evento), el nombre de servicio como **Object Storage** y el tipo de evento como **Object - Create** (Objeto: crear).
+4. Establece tu condición como **Tipo de evento**, el nombre de servicio como **Almacén de objetos** y el tipo de evento como **Objeto - Crear**.
5. Establece tu tipo de acción como **Functions** (Funciones).
6. Asegúrate de que tu compartimento de función sea la misma selección que hiciste para Log de OCI, Bucket de OCI y Función de OCI.
-7. Selecciona tu aplicación de función y función (según el paso de instalación anterior).
+7. Selecciona tu aplicación y función (según el paso de instalación anterior).
8. Haz clic en **Create Rule** (Crear regla), tu regla se creará y estará disponible en la lista de reglas.
Para más información sobre OCI Object Storage, consulta [Empezando con eventos][7].
@@ -386,13 +485,123 @@ Para más información sobre OCI Object Storage, consulta [Empezando con eventos
[6]: https://github.com/DataDog/Oracle_Logs_Integration/blob/master/Object%20Store/requirements.txt
[7]: https://docs.cloud.oracle.com/iaas/Content/Events/Concepts/eventsgetstarted.htm
{{% /tab %}}
+
+{{< /tabs >}}
+
+### Recopilación de recursos
+
+En la pestaña **Recopilación de recursos** del [ícono de integración de OCI de Datadog][1], haz clic en el conmutador **Habilitar recopilación de recursos**. Los recursos son visibles en el [Catálogo de recursos de Datadog][60].
+
+## Arquitectura
+
+{{< tabs >}}
+
+{{% tab "OCI QuickStart (Preview; recommended)" %}}
+
+### Recursos de reenvío de métricas y logs
+
+![Un diagrama de los recursos de reenvío de métricas y logs de OCI mencionados para esta opción de configuración y que muestra el flujo de datos][1].
+
+Para cada región monitorizada, esta opción de configuración crea la siguiente infraestructura dentro de esa región para reenviar métricas y logs a Datadog:
+
+- Aplicación de funciones (`dd-function-app`)
+- Dos funciones:
+ - Reenvío de métricas (`dd-metrics-forwarder`)
+ - Reenvío de logs (`dd-logs-forwarder`)
+- VCN (`dd-vcn`) con infraestructura de red segura:
+ - Subred privada (`dd-vcn-private-subnet`)
+ - Puerta NAT (`dd-vcn-natgateway`) para acceso externo a Internet
+ - Puerta de servicios (`dd-vcn-servicegateway`) para el acceso interno a los servicios OCI
+- Vault del Servicio de Gestión de Claves (KMS) (`datadog-vault`) para almacenar la clave de la API Datadog
+- Compartimento dedicado **Datadog** (`Datadog`)
+
+Todos los recursos están etiquetados con `ownedby = "datadog"`.
+
+### Recursos de IAM
+
+![Un diagrama de los recursos OCI IAM mencionados para esta opción de configuración y que muestra el flujo de datos][2].
+
+Esta opción de configuración crea los siguientes recursos IAM para habilitar el reenvío de datos a Datadog:
+
+- Usuario del servicio (`dd-svc`)
+- Grupo (`dd-svc-admin`) al que pertenece el usuario del servicio
+- Par de claves RSA para la autenticación de la API
+- Clave de la API OCI para el usuario del servicio
+- Grupo dinámico (`dd-dynamic-group-connectorhubs`) que incluye todos los conectores de servicio del compartimento Datadog
+- Grupo dinámico (`dd-dynamic-group-function`) que incluye todas las funciones del compartimento de Datadog
+- Política (`dd-svc-policy`) para dar al usuario del servicio acceso de lectura a los recursos de la tenencia y acceso para gestionar OCI Service Connector Hubs y OCI Functions en el compartimento creado y gestionado por Datadog
+{{% collapse-content title="Consultar la política" level="h6" %}}
+```text
+- Permitir que dd-svc-admin lea todos los recursos en tenencia
+- Permitir que dd-svc-admin gestione conectores de servicios en el compartimento Datadog
+- Permitir que dd-svc-admin gestione una familia de funciones en el compartimento Datadog con permisos específicos:
+ * FN_FUNCIÓN_ACTUALIZACIÓN
+ * FN_FUNCIÓN_LISTA
+ * FN_APLICACIONES_LISTA
+- Autorizar a dd-svc-admin a leer objetos en el informe de uso de la tenencia
+```
+{{% /collapse-content %}}
+
+- Política `dd-dynamic-group-policy` para permitir que los conectores de servicio lean datos (logs y métricas) e interactúen con las funciones. Esta política también permite que las funciones lean secretos en el compartimento Datadog (la API Datadog y las claves de aplicaciones almacenadas en el vault de KMS).
+
+{{% collapse-content title="Consultar la política" level="h6" %}}
+```text
+ - Allow dd-dynamic-group-connectorhubs to read log-content in tenancy
+ - Allow dd-dynamic-group-connectorhubs to read metrics in tenancy
+ - Allow dd-dynamic-group-connectorhubs to use fn-function in Datadog compartment
+ - Allow dd-dynamic-group-connectorhubs to use fn-invocation in Datadog compartment
+ - Allow dd-dynamic-group-functions to read secret-bundles in Datadog compartment
+```
+{{% /collapse-content %}}
+
+[1]: images/oci_quickstart_infrastructure_diagram.png
+[2]: images/oci_quickstart_iam_diagram.png
+{{% /tab %}}
+
+{{% tab "Manual setup" %}}
+
+### Recursos de reenvío de métricas
+
+![Diagrama de los recursos OCI mencionados para esta opción de configuración y visualización del flujo de datos][1].
+
+Esta opción de configuración crea un [hub de conectores][2] OCI, una [aplicación de función][3] y una infraestructura de red segura para reenviar métricas OCI a Datadog. El stack tecnológico de ORM para estos recursos crea un repositorio de contenedor de función para la región en la tenencia y la imagen Docker se envía a este para ser utilizada por la función.
+
+### Recursos de IAM
+
+![Diagrama de los recursos OCI y flujo de trabajo utilizados para la autenticación de la integración][4]
+
+Esta opción de configuración crea:
+
+- Grupo dinámico con `resource.type = 'serviceconnectors'`, para permitir el acceso al hub de conectores
+- Usuario denominado **DatadogROAuthUser**, que Datadog utiliza para leer los recursos de la tenencia.
+- Grupo al que se añade el usuario creado para el acceso a la política
+- Usuario llamado **DatadogAuthWriteUser**, que se utiliza para insertar imágenes Docker para la función
+- Grupo de acceso de escritura al que se añade `DatadogAuthWriteUser`, para insertar imágenes a través de la política de acceso
+- Política en el compartimento raíz para permitir que los hubs de conectores lean métricas e invoquen funciones. Esta política también otorga al grupo de usuarios creado acceso de lectura tanto a los recursos de tenencia como al grupo de acceso de escritura, para insertar imágenes
+
+{{% collapse-content title="Consultar la política" level="h6" %}}
+```text
+Allow dynamic-group Default/ to read metrics in tenancy
+Allow dynamic-group Default/ to use fn-function in tenancy
+Allow dynamic-group Default/ to use fn-invocation in tenancy
+Allow group Default/ to read all-resources in tenancy
+Allow group Default/ to manage repos in tenancy where ANY {request.permission = 'REPOSITORY_READ', request.permission = 'REPOSITORY_UPDATE', request.permission = 'REPOSITORY_CREATE'}
+```
+{{% /collapse-content %}}
+
+[1]: images/OCI_metrics_integration_diagram.png
+[2]: https://docs.oracle.com/iaas/Content/connector-hub/home.htm
+[3]: https://docs.oracle.com/iaas/Content/Functions/Concepts/functionsconcepts.htm#applications
+[4]: images/OCI_auth_workflow_diagram.png
+{{% /tab %}}
+
{{< /tabs >}}
## Datos recopilados
### Métricas
-{{< get-metrics-from-git "oracle-cloud-infrastructure" >}}
+Consulta [metadata.csv][61] para obtener una lista de las métricas proporcionadas por esta integración.
### Checks de servicio
@@ -402,68 +611,79 @@ La integración de OCI no incluye ningún check de servicio.
La integración de OCI no incluye ningún evento.
-## Resolución de problemas
+## Solucionar problemas
-¿Necesitas ayuda? Ponte en contacto con el [servicio de asistencia de Datadog][53].
+¿Necesitas ayuda? Ponte en contacto con [Asistencia técnica de Datadog][62].
-## Para leer más
+## Referencias adicionales
-Más enlaces, artículos y documentación útiles:
+Documentación útil adicional, enlaces y artículos:
-- [Monitorizar Oracle Cloud Infrastructure con Datadog][54]
+- [Monitoriza Oracle Cloud Infrastructure con Datadog][63]
+- [Acelerar la monitorización de Oracle Cloud Infrastructure con Datadog OCI QuickStart][64]
[1]: https://app.datadoghq.com/integrations/oracle-cloud-infrastructure
-[2]: https://cloud.oracle.com/tenancy
-[3]: https://docs.oracle.com/iaas/Content/General/Concepts/regions.htm
-[4]: https://docs.oracle.com/en/cloud/paas/weblogic-container/user/create-dynamic-groups-and-policies.html
-[5]: images/add_api_key.png
-[6]: https://app.datadoghq.com/organization-settings/api-keys
-[7]: https://docs.oracle.com/iaas/Content/Registry/Tasks/registrygettingauthtoken.htm
-[8]: https://docs.oracle.com/en-us/iaas/Content/Registry/Concepts/registrypolicyrepoaccess.htm#Policies_to_Control_Repository_Access
-[9]: https://docs.oracle.com/iaas/Content/Functions/Tasks/functionslogintoocir.htm
-[10]: https://docs.oracle.com/iaas/Content/Security/Reference/resourcemanager_security.htm#confidentiality__terraform-state
-[11]: https://app.datadoghq.com/dash/integration/31417/oracle-cloud-infrastructure-oci-overview
-[12]: https://app.datadoghq.com/metric/explorer
-[13]: https://cloud.oracle.com/connector-hub/service-connectors
-[14]: images/OCI_metrics_integration_diagram.png
-[15]: https://docs.oracle.com/iaas/Content/connector-hub/home.htm
-[16]: https://docs.oracle.com/iaas/Content/Functions/Concepts/functionsconcepts.htm#applications
-[17]: images/OCI_auth_workflow_diagram.png
-[18]: https://app.datadoghq.com/integrations/oci-autonomous-database
-[19]: https://docs.oracle.com/iaas/autonomous-database-serverless/doc/autonomous-monitor-metrics-list.html
-[20]: https://docs.oracle.com/iaas/Content/Block/References/volumemetrics.htm
-[21]: https://app.datadoghq.com/integrations/oci-compute
-[22]: https://docs.oracle.com/iaas/Content/Compute/References/computemetrics.htm#Availabl
-[23]: https://docs.oracle.com/iaas/Content/Compute/References/computemetrics.htm#computemetrics_topic-Available_Metrics_oci_compute_rdma_network
-[24]: https://docs.oracle.com/iaas/Content/Compute/References/computemetrics.htm#computemetrics_topic-Available_Metrics_oci_high_performance_compute
-[25]: https://docs.oracle.com/iaas/Content/Compute/References/infrastructurehealthmetrics.htm
-[26]: https://app.datadoghq.com/integrations/oci-container-instances
-[27]: https://docs.oracle.com/iaas/Content/container-instances/container-instance-metrics.htm
-[28]: https://app.datadoghq.com/integrations/oci-database
-[29]: https://docs.oracle.com/iaas/base-database/doc/available-metrics-base-database-service-resources.html#DBSCB-GUID-57B7B9B1-288B-4DCB-82AE-D53B2BD9C78F
-[30]: https://docs.oracle.com/iaas/base-database/doc/available-metrics-base-database-service-resources.html#DBSCB-GUID-A42CF0E3-EE65-4A66-B8A3-C89B62AFE489
-[31]: https://docs.oracle.com/iaas/Content/Network/Reference/drgmetrics.htm
-[32]: https://docs.oracle.com/iaas/Content/Network/Reference/fastconnectmetrics.htm
-[33]: https://docs.oracle.com/iaas/Content/File/Reference/filemetrics.htm
-[34]: https://app.datadoghq.com/integrations/oci-functions
-[35]: https://docs.oracle.com/iaas/Content/Functions/Reference/functionsmetrics.htm
-[36]: https://app.datadoghq.com/integrations/oci-mysql-database
-[37]: https://docs.oracle.com/iaas/mysql-database/doc/metrics.html
-[38]: https://docs.oracle.com/iaas/Content/ContEng/Reference/contengmetrics.htm
-[39]: https://app.datadoghq.com/integrations/oci-load-balancer
-[40]: https://docs.oracle.com/iaas/Content/Balance/Reference/loadbalancermetrics.htm
-[41]: https://docs.oracle.com/iaas/Content/NetworkLoadBalancer/Metrics/metrics.htm
-[42]: https://app.datadoghq.com/integrations/oci-nat-gateway
-[43]: https://docs.oracle.com/iaas/Content/Network/Reference/nat-gateway-metrics.htm
-[44]: https://docs.oracle.com/iaas/Content/Object/Reference/objectstoragemetrics.htm
-[45]: https://docs.oracle.com/iaas/Content/queue/metrics.htm
-[46]: https://docs.oracle.com/iaas/Content/connector-hub/metrics-reference.htm
-[47]: https://docs.oracle.com/iaas/Content/Network/Reference/SGWmetrics.htm
-[48]: https://app.datadoghq.com/integrations/oci-vcn
-[49]: https://docs.oracle.com/iaas/Content/Network/Reference/vnicmetrics.htm
-[50]: https://app.datadoghq.com/integrations/oci-vpn
-[51]: https://docs.oracle.com/iaas/Content/Network/Reference/ipsecmetrics.htm
-[52]: https://docs.oracle.com/iaas/Content/WAF/Reference/metricsalarms.htm
-[53]: https://docs.datadoghq.com/es/help/
-[54]: https://www.datadoghq.com/blog/monitor-oci-with-datadog/
\ No newline at end of file
+[2]: https://app.datadoghq.com/dash/integration/31417/oracle-cloud-infrastructure-oci-overview
+[3]: https://app.datadoghq.com/metric/explorer
+[4]: images/oci_configuration_tab.png
+[5]: https://docs.datadoghq.com/es/integrations/oci_api_gateway/
+[6]: https://docs.oracle.com/iaas/Content/APIGateway/Reference/apigatewaymetrics.htm
+[7]: https://docs.datadoghq.com/es/integrations/oci_autonomous_database/
+[8]: https://docs.oracle.com/iaas/autonomous-database-serverless/doc/autonomous-monitor-metrics-list.html
+[9]: https://docs.datadoghq.com/es/integrations/oci_block_storage/
+[10]: https://docs.oracle.com/iaas/Content/Block/References/volumemetrics.htm
+[11]: https://docs.datadoghq.com/es/integrations/oci_compute/
+[12]: https://docs.oracle.com/iaas/Content/Compute/References/computemetrics.htm#Availabl
+[13]: https://docs.oracle.com/iaas/Content/Compute/References/computemetrics.htm#computemetrics_topic-Available_Metrics_oci_compute_rdma_network
+[14]: https://docs.oracle.com/iaas/Content/Compute/References/computemetrics.htm#computemetrics_topic-Available_Metrics_oci_high_performance_compute
+[15]: https://docs.oracle.com/iaas/Content/Compute/References/infrastructurehealthmetrics.htm
+[16]: https://docs.datadoghq.com/es/integrations/oci_container_instances/
+[17]: https://docs.oracle.com/iaas/Content/container-instances/container-instance-metrics.htm
+[18]: https://docs.datadoghq.com/es/integrations/oci_database/
+[19]: https://docs.oracle.com/iaas/base-database/doc/available-metrics-base-database-service-resources.html#DBSCB-GUID-57B7B9B1-288B-4DCB-82AE-D53B2BD9C78F
+[20]: https://docs.oracle.com/iaas/base-database/doc/available-metrics-base-database-service-resources.html#DBSCB-GUID-A42CF0E3-EE65-4A66-B8A3-C89B62AFE489
+[21]: https://docs.oracle.com/iaas/Content/Network/Reference/drgmetrics.htm
+[22]: https://docs.datadoghq.com/es/integrations/oci_ebs/
+[23]: https://docs.oracle.com/iaas/stack-monitoring/doc/metric-reference.html#STMON-GUID-4E859CA3-1CAB-43FB-8DC7-0AA17E6B52EC
+[24]: https://docs.datadoghq.com/es/integrations/oci_fastconnect/
+[25]: https://docs.oracle.com/iaas/Content/Network/Reference/fastconnectmetrics.htm
+[26]: https://docs.datadoghq.com/es/integrations/oci_file_storage/
+[27]: https://docs.oracle.com/iaas/Content/File/Reference/filemetrics.htm
+[28]: https://docs.datadoghq.com/es/integrations/oci_functions/
+[29]: https://docs.oracle.com/iaas/Content/Functions/Reference/functionsmetrics.htm
+[30]: https://docs.datadoghq.com/es/integrations/oci_gpu/
+[31]: https://docs.datadoghq.com/es/integrations/oci_mysql_database/
+[32]: https://docs.oracle.com/iaas/mysql-database/doc/metrics.html
+[33]: https://docs.datadoghq.com/es/integrations/oke/
+[34]: https://docs.oracle.com/iaas/Content/ContEng/Reference/contengmetrics.htm
+[35]: https://docs.datadoghq.com/es/integrations/oci_load_balancer/
+[36]: https://docs.oracle.com/iaas/Content/Balance/Reference/loadbalancermetrics.htm
+[37]: https://docs.oracle.com/iaas/Content/NetworkLoadBalancer/Metrics/metrics.htm
+[38]: https://docs.datadoghq.com/es/integrations/oci_media_streams/
+[39]: https://docs.oracle.com/iaas/Content/dms-mediastream/mediastreams_metrics.htm?
+[40]: https://docs.datadoghq.com/es/integrations/oci_nat_gateway/
+[41]: https://docs.oracle.com/iaas/Content/Network/Reference/nat-gateway-metrics.htm
+[42]: https://docs.datadoghq.com/es/integrations/oci_network_firewall/
+[43]: https://docs.oracle.com/iaas/Content/network-firewall/metrics.htm
+[44]: https://docs.datadoghq.com/es/integrations/oci_object_storage/
+[45]: https://docs.oracle.com/iaas/Content/Object/Reference/objectstoragemetrics.htm
+[46]: https://docs.datadoghq.com/es/integrations/oci_postgresql/
+[47]: https://docs.oracle.com/iaas/Content/postgresql/metrics.htm
+[48]: https://docs.datadoghq.com/es/integrations/oci_queue/
+[49]: https://docs.oracle.com/iaas/Content/queue/metrics.htm
+[50]: https://docs.datadoghq.com/es/integrations/oci_service_connector_hub/
+[51]: https://docs.oracle.com/iaas/Content/connector-hub/metrics-reference.htm
+[52]: https://docs.datadoghq.com/es/integrations/oci_service_gateway/
+[53]: https://docs.oracle.com/iaas/Content/Network/Reference/SGWmetrics.htm
+[54]: https://docs.datadoghq.com/es/integrations/oci_vcn/
+[55]: https://docs.oracle.com/iaas/Content/Network/Reference/vnicmetrics.htm
+[56]: https://docs.datadoghq.com/es/integrations/oci_vpn/
+[57]: https://docs.oracle.com/iaas/Content/Network/Reference/ipsecmetrics.htm
+[58]: https://docs.datadoghq.com/es/integrations/oci_waf/
+[59]: https://docs.oracle.com/iaas/Content/WAF/Reference/metricsalarms.htm
+[60]: https://docs.datadoghq.com/es/infrastructure/resource_catalog/
+[61]: https://github.com/DataDog/integrations-internal-core/blob/main/oracle_cloud_infrastructure/metadata.csv
+[62]: https://docs.datadoghq.com/es/help/
+[63]: https://www.datadoghq.com/blog/monitor-oci-with-datadog/
+[64]: https://www.datadoghq.com/blog/datadog-oci-quickstart/
\ No newline at end of file
diff --git a/content/es/integrations/pagerduty.md b/content/es/integrations/pagerduty.md
index 31e7fb7732b91..66f24413b7d92 100644
--- a/content/es/integrations/pagerduty.md
+++ b/content/es/integrations/pagerduty.md
@@ -1,55 +1,44 @@
---
+app_id: pagerduty
categories:
- collaboration
- incidents
- notifications
-custom_kind: integration
-dependencies: []
-description: Generar alertas PagerDuty a partir de métricas y eventos de Datadog
-doc_link: https://docs.datadoghq.com/integrations/pagerduty/
-draft: false
+custom_kind: integración
+description: PagerDuty añade alertas por teléfono y SMS a tus herramientas de monitorización
+ existentes.
further_reading:
- link: https://www.datadoghq.com/blog/mobile-incident-management-datadog/
- tag: Blog
- text: Gestionar los incidentes sobre la marcha con la aplicación móvil de Datadog
+ tag: blog
+ text: Gestionar incidentes sobre la marcha con la aplicación móvil Datadog
- link: https://www.datadoghq.com/blog/how-pagerduty-deploys-safely-with-datadog/
- tag: Blog
- text: Para desplegar PagerDuty de forma segura con Datadog
+ tag: blog
+ text: Cómo se despliega PagerDuty de forma segura con Datadog
- link: https://docs.datadoghq.com/tracing/service_catalog/integrations/#pagerduty-integration
- tag: Blog
- text: Uso de integraciones con el catálogo de servicios
+ tag: blog
+ text: Blog de PagerDuty
- link: https://registry.terraform.io/providers/DataDog/datadog/latest/docs/resources/integration_pagerduty
- tag: Terraform
- text: Crear y gestionar la integración Pagerduty en Datadog con Terraform
-git_integration_title: pagerduty
-has_logo: true
-integration_id: ''
-integration_title: PagerDuty
-integration_version: ''
-is_public: true
-manifest_version: '1.0'
-name: pagerduty
-public_title: Integración de PagerDuty en Datadog
-short_description: Generar alertas PagerDuty a partir de métricas y eventos de Datadog
-version: '1.0'
+ tag: otros
+ text: PagerDuty
+media: []
+title: PagerDuty
---
-
-
{{< site-region region="gov" >}}
-
```
-2. Instala el binario `ping` en función de tu sistema operativo. Por ejemplo, ejecuta el siguiente comando para Ubuntu:
+
+1. Instala el binario `ping` en función de tu sistema operativo. Por ejemplo, ejecuta el siguiente comando para Ubuntu:
+
```shell
apt-get install iputils-ping
```
-3. Configura tu integración como si fuese una [integración][4] de base.
+1. Configura tu integración de forma similar a las [integraciones] centrales (https://docs.datadoghq.com/getting_started/integrations/).
### Configuración
-1. Edita el archivo `ping.d/conf.yaml`, que se encuentra en la carpeta `conf.d/` en la raíz del directorio de configuración del Agent, para empezar a recopilar los datos de rendimiento de tu ping. Para conocer todas las opciones de configuración disponibles, consulta el [ignite.d/conf.yaml de ejemplo][5].
+1. Edita el archivo `ping.d/conf.yaml`, en la carpeta `conf.d/` en la raíz de tu directorio de configuración del Agent para empezar a recopilar tus datos de rendimiento de Ping. Consulta el [ejemplo ping.d/conf.yaml](https://github.com/DataDog/integrations-extras/blob/master/ping/datadog_checks/ping/data/conf.yaml.example) para conocer todas las opciones de configuración disponibles.
-2. [Reinicia el Agent][6].
+1. [Reinicia el Agent](https://docs.datadoghq.com/agent/guide/agent-commands/#start-stop-and-restart-the-agent).
### Validación
-Ejecuta el [subcomando de estado del Agent][7] y busca `ping` en la sección Checks.
+Ejecuta el [subcomando de estado del Agent](https://docs.datadoghq.com/agent/guide/agent-commands/#service-status) y busca `ping` en la sección Checks.
## Datos recopilados
### Métricas
-{{< get-metrics-from-git "ping" >}}
+| | |
+| --- | --- |
+| **network.ping.response_time**
(gauge) | Tiempo de respuesta de un host y un puerto de ping determinados, etiquetado con url, por ejemplo, 'host:192.168.1.100'.
_Se muestra como milisegundos_ | +| **network.ping.can_connect**
(gauge) | Valor de 1 si el Agent puede comunicarse con éxito con el host de destino, 0 en caso contrario| ### Eventos -El check ping no incluye eventos. +El check de Ping no incluye eventos. ### Checks de servicio -{{< get-service-checks-from-git "ping" >}} +**network.ping.can_connect** + +Devuelve CRITICAL si el Agent no puede comunicarse con el host de destino. Devuelve OK si el ping tiene éxito. + +_Estados: ok, crítico_ ## Solucionar problemas ### Error `SubprocessOutputEmptyError: get_subprocess_output expected output but had none` -Mientras ejecutas la integración del ping, puedes ver un error como el siguiente: + +Mientras ejecutas la integración Ping, puedes ver un error como el siguiente: ``` Traceback (most recent call last): @@ -138,19 +100,6 @@ Mientras ejecutas la integración del ping, puedes ver un error como el siguient _util.SubprocessOutputEmptyError: get_subprocess_output expected output but had none. ``` -Debido a que la integración del ping no está incluida por defecto en el Agent, el binario `ping` tampoco está incluido en el Agent. Para poder ejecutar la integración con éxito, debes instalar el binario `ping`. - - -¿Necesitas ayuda? Ponte en contacto con el [equipo de asistencia de Datadog][10]. - +Debido a que la integración Ping no está incluida por defecto en el Agent, el binario `ping` tampoco está incluido con el Agent. Debes instalar el binario `ping` para poder ejecutar la integración con éxito. -[1]: https://en.wikipedia.org/wiki/Ping_%28networking_utility%29 -[2]: https://app.datadoghq.com/account/settings/agent/latest -[3]: https://docs.datadoghq.com/es/agent/guide/use-community-integrations/ -[4]: https://docs.datadoghq.com/es/getting_started/integrations/ -[5]: https://github.com/DataDog/integrations-extras/blob/master/ping/datadog_checks/ping/data/conf.yaml.example -[6]: https://docs.datadoghq.com/es/agent/guide/agent-commands/#start-stop-and-restart-the-agent -[7]: https://docs.datadoghq.com/es/agent/guide/agent-commands/#service-status -[8]: https://github.com/DataDog/integrations-extras/blob/master/ping/metadata.csv -[9]: https://github.com/DataDog/integrations-extras/blob/master/ping/assets/service_checks.json -[10]: https://docs.datadoghq.com/es/help/ \ No newline at end of file +¿Necesitas ayuda? Ponte en contacto con el [servicio de asistencia de Datadog](https://docs.datadoghq.com/help/). \ No newline at end of file diff --git a/content/es/integrations/pingdom_v3.md b/content/es/integrations/pingdom_v3.md index 4b5918ca243c1..890faf8e88a0f 100644 --- a/content/es/integrations/pingdom_v3.md +++ b/content/es/integrations/pingdom_v3.md @@ -23,7 +23,7 @@ author: categories: - métricas - notificaciones -custom_kind: integration +custom_kind: integración dependencies: [] display_on_public_website: true draft: false @@ -66,26 +66,26 @@ Realiza un seguimiento de las métricas de rendimiento de Pingdom basadas en usu La integración Pingdom V3 actúa de forma similar a la [integración Pingdom en Datadog (obsoleta)][1], pero utiliza la versión 3.1 de la [API Pingdom][2]. -{{< img src="integrations/pingdom/pingdom_dashboard.png" alt="Gráficos de Pingdom en un dashboard de Datadog" popup="true">}} +![Gráficos Pingdom en un dashboard de Datadog][3] ## Configuración ### Generar token de API -1. Inicia sesión en tu [cuenta de Pingdom][3]. +1. Inicia sesión en tu [cuenta de Pingdom][4]. 2. Ve a Settings > Pingdom API (Configuración > API Pingdom). 3. Haz clic en Add API token (Añadir token de API). Dale un nombre y permisos de lectura-escritura al token. Guarda el token en algún sitio, ya que no podrás volver a acceder a él. ### Instalación y configuración -1. Abre el [cuadro de la integración Pingdom V3][4]. +1. Abre el [cuadro de integración de Pingdom V3][5]. 2. Introduce el nombre y el token de API en los campos correspondientes. Las métricas y los checks configurados en Pingdom se recopilan en Datadog. 3. Administra etiquetas (tags) de checks en Pingdom. Las etiquetas añadidas a un check en Pingdom se añaden automáticamente a un check en Datadog. Excluya checks añadiendo la etiqueta `datadog-exclude`. ## Datos recopilados ### Métricas -{{< get-metrics-from-git "pingdom-v3" >}} +{{< get-metrics-from-git "pingdom_v3" >}} ### Eventos @@ -107,11 +107,12 @@ En el caso del check `pingdom.status`, los resultados de los checks de transacci ## Solucionar problemas -¿Necesitas ayuda? Ponte en contacto con el [servicio de asistencia de Datadog][6]. +¿Necesitas ayuda? Ponte en contacto con el [soporte de Datadog][7]. [1]: https://docs.datadoghq.com/es/integrations/pingdom/ [2]: https://docs.pingdom.com/api/ -[3]: https://my.pingdom.com/ -[4]: https://app.datadoghq.com/account/settings#integrations/pingdom-v3 -[5]: https://github.com/DataDog/integrations-internal-core/blob/main/pingdom/metadata.csv -[6]: https://docs.datadoghq.com/es/help \ No newline at end of file +[3]: images/pingdom_dashboard.png +[4]: https://my.pingdom.com/ +[5]: https://app.datadoghq.com/account/settings#integrations/pingdom-v3 +[6]: https://github.com/DataDog/integrations-internal-core/blob/main/pingdom/metadata.csv +[7]: https://docs.datadoghq.com/es/help \ No newline at end of file diff --git a/content/es/integrations/pivotal.md b/content/es/integrations/pivotal.md index 4743d7ba99063..411075dcfd0b4 100644 --- a/content/es/integrations/pivotal.md +++ b/content/es/integrations/pivotal.md @@ -1,62 +1,22 @@ --- -"app_id": "pivotal" -"app_uuid": "c28e887f-43e0-4b99-aa2b-3f02d4f10763" -"assets": - "integration": - "auto_install": false - "events": - "creates_events": true - "service_checks": - "metadata_path": "assets/service_checks.json" - "source_type_id": !!int "9" - "source_type_name": "Pivotal" -"author": - "homepage": "https://www.datadoghq.com" - "name": "Datadog" - "sales_email": "info@datadoghq.com" - "support_email": "help@datadoghq.com" -"categories": -- "collaboration" -- "issue tracking" -"custom_kind": "integration" -"dependencies": [] -"display_on_public_website": true -"draft": false -"git_integration_title": "pivotal" -"integration_id": "pivotal" -"integration_title": "Pivotal" -"integration_version": "" -"is_public": true -"manifest_version": "2.0.0" -"name": "pivotal" -"public_title": "Pivotal" -"short_description": "Pivotal Tracker es un software como servicio (SaaS) de colaboración y gestión de proyectos ágiles" -"supported_os": -- "linux" -- "windows" -- "macos" -"tile": - "changelog": "CHANGELOG.md" - "classifier_tags": - - "Category::Collaboration" - - "Category::Issue Tracking" - - "Offering::Integration" - - "Submitted Data Type::Events" - - "Supported OS::Linux" - - "Supported OS::Windows" - - "Supported OS::macOS" - "configuration": "README.md#Setup" - "description": "Pivotal Tracker es un software como servicio (SaaS) de colaboración y gestión de proyectos ágiles" - "media": [] - "overview": "README.md#Overview" - "support": "README.md#Support" - "title": "Pivotal" +app_id: pivotal +categories: +- collaboration +- issue tracking +custom_kind: integración +description: Pivotal Tracker es un software como servicio (SaaS) para la gestión ágil + de proyectos and collaboration. +integration_version: 1.0.0 +media: [] +supported_os: +- linux +- windows +- macos +title: Pivotal --- - - ## Información general -[Pivotal Tracker][1] utiliza historias para ayudar a los equipos a realizar un seguimiento de los proyectos y colaborar a lo largo de las diferentes etapas del ciclo de desarrollo, como la creación de nuevas funciones, la resolución de errores o el tratamiento de la deuda técnica. Conecta Pivotal Tracker a Datadog para: +[Pivotal Tracker](https://www.pivotaltracker.com/features) utiliza historias para ayudar a los equipos a realizar un seguimiento de los proyectos y colaborar a lo largo de las distintas partes del ciclo de desarrollo, como la creación de nuevas funciones, la resolución de errores o el tratamiento de la deuda técnica. Conecta Pivotal Tracker a Datadog para: - Ver y discutir el progreso de tus historias en el Explorador de eventos de Datadog. - Correlacionar y graficar la finalización de historias con otros eventos y otras métricas en tu sistema. @@ -66,9 +26,9 @@ ### Instalación -Para obtener eventos Pivotal en en el Explorador de eventos de Datadog, introduce el token de API generado desde la [página de tu perfil] de Pivotal[2]. +Para obtener eventos de Pivotal en el Explorador de eventos de Datadog, introduce el token de API generado de tu [página de perfil](https://www.pivotaltracker.com/signin) de Pivotal. -![token de pivotal][3] + ## Datos recopilados @@ -84,12 +44,6 @@ La integración Pivotal Tracker no incluye eventos. La integración Pivotal Tracker no incluye checks de servicio. -## Resolución de problemas - -¿Necesitas ayuda? Ponte en contacto con el [soporte de Datadog][4]. - -[1]: https://www.pivotaltracker.com/features -[2]: https://www.pivotaltracker.com/signin -[3]: images/pivotal_token.png -[4]: https://docs.datadoghq.com/help/ +## Solucionar problemas +¿Necesitas ayuda? Ponte en contacto con el [servicio de asistencia de Datadog](https://docs.datadoghq.com/help/). \ No newline at end of file diff --git a/content/es/integrations/postgres.md b/content/es/integrations/postgres.md index 9051993d03e98..4671ed581b6ea 100644 --- a/content/es/integrations/postgres.md +++ b/content/es/integrations/postgres.md @@ -1,107 +1,44 @@ --- app_id: postgres -app_uuid: e6b3c5ec-b293-4a22-9145-277a12a9abd4 -assets: - dashboards: - postgresql: assets/dashboards/postgresql_dashboard.json - postgresql_screenboard: assets/dashboards/postgresql_screenboard_dashboard.json - integration: - auto_install: true - configuration: - spec: assets/configuration/spec.yaml - events: - creates_events: false - metrics: - check: - - postgresql.connections - - postgresql.max_connections - metadata_path: metadata.csv - prefix: postgresql. - process_signatures: - - postgres -D - - pg_ctl start -l logfile - - postgres -c 'pg_ctl start -D -l - service_checks: - metadata_path: assets/service_checks.json - source_type_id: !!int 28 - source_type_name: Postgres - monitors: - Connection pool is reaching saturation point: assets/monitors/percent_usage_connections.json - Replication delay is high: assets/monitors/replication_delay.json - saved_views: - operations: assets/saved_views/operations.json - postgres_pattern: assets/saved_views/postgres_pattern.json - postgres_processes: assets/saved_views/postgres_processes.json - sessions_by_host: assets/saved_views/sessions_by_host.json - slow_operations: assets/saved_views/slow_operations.json -author: - homepage: https://www.datadoghq.com - name: Datadog - sales_email: info@datadoghq.com - support_email: help@datadoghq.com categories: - data stores - log collection - notifications - tracing custom_kind: integración -dependencies: -- https://github.com/DataDog/integrations-core/blob/master/postgres/README.md -display_on_public_website: true -draft: false -git_integration_title: postgres -integration_id: postgres -integration_title: Postgres -integration_version: 22.0.1 -is_public: true -manifest_version: 2.0.0 -name: postgres -public_title: Postgres -short_description: Recopila una importante cantidad de métricas del rendimiento y el estado de las bases de datos. +description: Recopila una importante cantidad de métricas del rendimiento y el estado + de las bases de datos. +further_reading: +- link: https://docs.datadoghq.com/integrations/faq/postgres-custom-metric-collection-explained/ + tag: documentación + text: Recopilación de métricas personalizadas de Postgres +- link: https://www.datadoghq.com/blog/100x-faster-postgres-performance-by-changing-1-line + tag: blog + text: Rendimiento de Postgres 100 veces más rápido cambiando 1 línea +- link: https://www.datadoghq.com/blog/postgresql-monitoring + tag: blog + text: Métricas clave para la monitorización de PostgreSQL +- link: https://www.datadoghq.com/blog/postgresql-monitoring-tools + tag: blog + text: Recopilación de métricas con herramientas de monitorización PostgreSQL +- link: https://www.datadoghq.com/blog/collect-postgresql-data-with-datadog + tag: blog + text: Recopilación y monitorización de datos PostgreSQL con Datadog +integration_version: 22.15.0 +media: [] supported_os: - linux - windows - macos -tile: - changelog: CHANGELOG.md - classifier_tags: - - Category::Almacenes de datos - - Category::Recopilación de logs - - Category::Notificaciones - - Category::Rastreo - - Supported OS::Linux - - Supported OS::Windows - - Supported OS::macOS - - Offering::Integración - configuration: README.md#Configuración - description: Recopila una importante cantidad de métricas del rendimiento y el estado de las bases de datos. - media: [] - overview: README.md#Información general - resources: - - resource_type: documentación - url: https://docs.datadoghq.com/integrations/faq/postgres-custom-metric-collection-explained/ - - resource_type: blog - url: https://www.datadoghq.com/blog/100x-faster-postgres-performance-by-changing-1-line - - resource_type: blog - url: https://www.datadoghq.com/blog/postgresql-monitoring - - resource_type: blog - url: https://www.datadoghq.com/blog/postgresql-monitoring-tools - - resource_type: blog - url: https://www.datadoghq.com/blog/collect-postgresql-data-with-datadog - support: README.md#Soporte - title: Postgres +title: Postgres --- - - - - -[Gráfico de PostgreSQL][1] +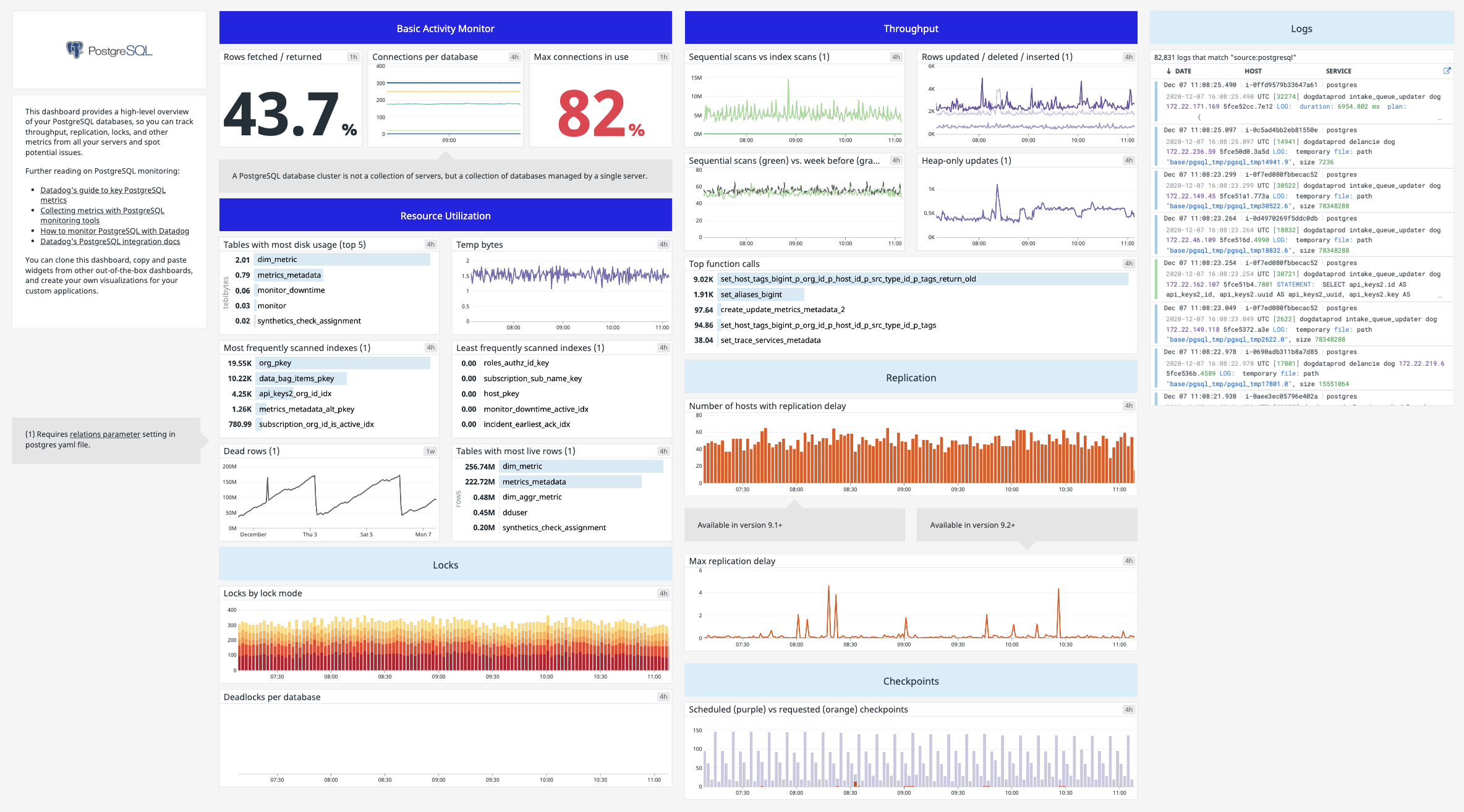 ## Información general La integración Postgres proporciona métricas del estado y el rendimiento de tu base de datos Postgres casi en tiempo real. Visualiza estos métricas con el dashboard proporcionado y crea monitores para alertar a tu equipo sobre los estados de PostgreSQL. -Habilita [Database Monitoring][2] (DBM) para obtener información mejorada sobre el rendimiento de las consultas y el estado de las bases de datos. Además de la integración estándar, Datadog DBM proporciona métricas a nivel de consulta, snapshots de consultas históricas y actuales, análisis de eventos de espera, carga de bases de datos, planes de explicación de consultas e información sobre bloqueos de consultas. +Activa [Database Monitoring](https://docs.datadoghq.com/database_monitoring/) (DBM) para obtener información mejorada sobre el rendimiento de las consultas y el estado de las bases de datos. Además de la integración estándar, Datadog DBM proporciona métricas a nivel de consulta, snapshots de consultas históricas y actuales, análisis de eventos de espera, carga de bases de datos, explain plans de consultas e información sobre bloqueos de consultas. Se admiten las versiones 9.6-16 de Postgres. @@ -111,13 +48,13 @@ Se admiten las versiones 9.6-16 de Postgres. ### Instalación -El check de PostgreSQL viene en el mismo paquete que el Agent. Para empezar a reunir tus métricas y logs de PostgreSQL, [instala el Agent][3]. +El check de PostgreSQL viene en el mismo paquete que el Agent. Para empezar a recopilar tus métricas y logs de PostgreSQL, [instala el Agent](https://app.datadoghq.com/account/settings/agent/latest). ### Configuración -**Nota**: Para instalar Database Monitoring para PostgreSQL, selecciona tu solución de alojamiento en la [documentación de Database Monitoring][4] para obtener instrucciones. +**Nota**: Para instalar Database Monitoring para PostgreSQL, selecciona tu solución de alojamiento en la [documentación de Database Monitoring](https://docs.datadoghq.com/database_monitoring/#postgres) para obtener instrucciones. -Procede con los siguientes pasos de esta guía, sólo si vas a instalar la integración estándar únicamente. +Procede con los siguientes pasos de esta guía solo si vas a instalar la integración estándar únicamente. #### Preparación de Postgres @@ -161,9 +98,10 @@ grant SELECT ON pg_stat_activity_dd to datadog; ``` {{< tabs >}} + {{% tab "Host" %}} -**Nota**: Al generar métricas personalizadas que requieren que se consulten tablas adicionales, puede que sea necesario conceder el permiso `SELECT` al usuario `datadog` para acceder a esas tablas. Ejemplo: `grant SELECT on to datadog;`. Para obtener más información, consulta la [sección FAQ][1].
+**Nota**: Al generar métricas personalizadas que requieren que se consulten tablas adicionales, puede que sea necesario conceder el permiso `SELECT` al usuario `datadog` para acceder a esas tablas. Ejemplo: `grant SELECT on to datadog;`. Para obtener más información, consulta la [sección FAQ](https://docs.datadoghq.com/integrations/postgres/?tab=host#faq).
#### Host
@@ -171,105 +109,104 @@ Para configurar este check para un Agent que se ejecuta en un host:
##### Recopilación de métricas
-1. Edita el archivo `postgres.d/conf.yaml` para que apunte a tu `host` / `port` y define los maestros que se van a monitorizar. Para ver todas las opciones de configuración disponibles, consulta el [postgres.d/conf.yaml de ejemplo][2].
-
- ```yaml
- init_config:
-
- instances:
- ## @param host - string - required
- ## The hostname to connect to.
- ## NOTE: Even if the server name is "localhost", the agent connects to
- ## PostgreSQL using TCP/IP, unless you also provide a value for the sock key.
- #
- - host: localhost
-
- ## @param port - integer - optional - default: 5432
- ## The port to use when connecting to PostgreSQL.
- #
- # port: 5432
-
- ## @param username - string - required
- ## The Datadog username created to connect to PostgreSQL.
- #
- username: datadog
-
- ## @param password - string - optional
- ## The password associated with the Datadog user.
- #
- # password:
-
- ## @param dbname - string - optional - default: postgres
- ## The name of the PostgresSQL database to monitor.
- ## Note: If omitted, the default system Postgres database is queried.
- #
- # dbname:
-
- # @param disable_generic_tags - boolean - optional - default: false
- # The integration will stop sending server tag as is redundant with host tag
- disable_generic_tags: true
- ```
-
-2. Para recopilar métricas de relación, conecta el Agent a cada base de datos lógica. Estas bases de datos se pueden detectar automáticamente o cada una de ellas puede estar explícitamente listada en la configuración.
-
- - Para detectar bases de datos lógicas automáticamente en una instancia determinada, habilita la detección automática en esa instancia:
-
- ```yaml
- instances:
- - host: localhost
- # port: 5432
- database_autodiscovery:
- enabled: true
- # Optionally, set the include field to specify
- # a set of databases you are interested in discovering
- include:
- - mydb.*
- - example.*
- relations:
- - relation_regex: .*
- ```
-
- - También puedes listar cada base de datos lógica como una instancia en la configuración:
-
- ```yaml
- instances:
- - host: example-service-primary.example-host.com
- # port: 5432
- username: datadog
- password: ''
- relations:
- - relation_name: products
- - relation_name: external_seller_products
- - host: example-service-replica-1.example-host.com
- # port: 5432
- username: datadog
- password: ''
- relations:
- - relation_regex: inventory_.*
- relkind:
- - r
- - i
- - host: example-service-replica-2.example-host.com
- # port: 5432
- username: datadog
- password: ''
- relations:
- - relation_regex: .*
- ```
-3. [Reinicia el Agent][3].
-
-##### Recopilación de trazas (traces)
-
-Datadog APM se integra con Postgres para visualizar trazas a través de tu sistema distribuido. La recopilación de trazas está habilitada por defecto en el Datadog Agent v6 o posteriores. Para empezar a recopilar trazas:
-
-1. [Habilita la recopilación de trazas en Datadog][4].
-2. [Instrumenta la aplicación que realiza solicitudes a Postgres][5].
+1. Edita el archivo `postgres.d/conf.yaml` para que apunte a tu `host`/`port` y define los principales para monitorizar. Consulta el [ejemplo de postgres.d/conf.yaml](https://github.com/DataDog/integrations-core/blob/master/postgres/datadog_checks/postgres/data/conf.yaml.example) para ver todas las opciones de configuración disponibles.
-##### Recopilación de logs
+ ```yaml
+ init_config:
+
+ instances:
+ ## @param host - string - required
+ ## The hostname to connect to.
+ ## NOTE: Even if the server name is "localhost", the agent connects to
+ ## PostgreSQL using TCP/IP, unless you also provide a value for the sock key.
+ #
+ - host: localhost
+
+ ## @param port - integer - optional - default: 5432
+ ## The port to use when connecting to PostgreSQL.
+ #
+ # port: 5432
+
+ ## @param username - string - required
+ ## The Datadog username created to connect to PostgreSQL.
+ #
+ username: datadog
+
+ ## @param password - string - optional
+ ## The password associated with the Datadog user.
+ #
+ # password:
+
+ ## @param dbname - string - optional - default: postgres
+ ## The name of the PostgresSQL database to monitor.
+ ## Note: If omitted, the default system Postgres database is queried.
+ #
+ # dbname:
+
+ # @param disable_generic_tags - boolean - optional - default: false
+ # The integration will stop sending server tag as is redundant with host tag
+ disable_generic_tags: true
+ ```
+
+1. Para recopilar métricas de relación, conecta el Agent a cada base de datos lógica. Estas bases de datos pueden ser detectadas automáticamente o cada una puede estar enumerada explícitamente en la configuración.
+
+ - Para detectar bases de datos lógicas automáticamente en una instancia determinada, activa la detección automática en esa instancia:
-Disponible para la versión 6.0 o posteriores del Agent
+ ```yaml
+ instances:
+ - host: localhost
+ # port: 5432
+ database_autodiscovery:
+ enabled: true
+ # Optionally, set the include field to specify
+ # a set of databases you are interested in discovering
+ include:
+ - mydb.*
+ - example.*
+ relations:
+ - relation_regex: .*
+ ```
-La generación de logs por defecto de PostgreSQL es para `stderr` y los logs no incluyen información detallada. Se recomienda generar logs en un archivo con detalles adicionales especificados en el prefijo de línea de los logs. Para obtener más información, consulta la documentación de PostgreSQL sobre [informes de error y generación de logs][6].
+ - También puedes listar cada base de datos lógica como una instancia en la configuración:
+
+ ```yaml
+ instances:
+ - host: example-service-primary.example-host.com
+ # port: 5432
+ username: datadog
+ password: ''
+ relations:
+ - relation_name: products
+ - relation_name: external_seller_products
+ - host: example-service-replica-1.example-host.com
+ # port: 5432
+ username: datadog
+ password: ''
+ relations:
+ - relation_regex: inventory_.*
+ relkind:
+ - r
+ - i
+ - host: example-service-replica-2.example-host.com
+ # port: 5432
+ username: datadog
+ password: ''
+ relations:
+ - relation_regex: .*
+ ```
+
+1. [Reinicia el Agent](https://docs.datadoghq.com/agent/guide/agent-commands/#start-stop-and-restart-the-agent).
+
+##### Recopilación de trazas
+
+Datadog APM se integra con Postgres para visualizar trazas (traces) a través de tu sistema distribuido. La recopilación de trazas está activada por defecto en el Datadog Agent v6 o posteriores. Para empezar a recopilar trazas:
+
+1. [Activa la recopilación de trazas en Datadog](https://docs.datadoghq.com/tracing/send_traces/).
+1. [Instrumenta tu aplicación que realiza solicitudes a Postgres](https://docs.datadoghq.com/tracing/setup/).
+
+##### Recopilación de logs
+
+La generación de logs por defecto de PostgreSQL es para `stderr` y los logs no incluyen información detallada. Se recomienda generar logs en un archivo con detalles adicionales especificados en el prefijo de línea de los logs. Para obtener más información, consulta la documentación de PostgreSQL sobre [informes de error y generación de logs](https://www.postgresql.org/docs/11/runtime-config-logging.html).
1. La generación de logs se configura en el archivo `/etc/postgresql//main/postgresql.conf`. Para obtener resultados regulares en logs, incluidos los resultados de sentencias, descomenta los siguientes parámetros en la sección de logs:
@@ -286,7 +223,7 @@ La generación de logs por defecto de PostgreSQL es para `stderr` y los logs no
#log_destination = 'eventlog'
```
-2. Para recopilar métricas de duración detallada y permitir su búsqueda en la interfaz de Datadog, deben configurarse en línea con la propia sentencia. Consulta a continuación las diferencias de configuración recomendadas con respecto a las anteriores. **Nota**: Las opciones `log_statement` y `log_duration` están comentadas. Para ver una discusión sobre este tema, consulta [Sentencia/duración de la generación de logs en la misma línea][7].
+1. Para recopilar métricas de duración detallada y permitir su búsqueda en la interfaz de Datadog, deben configurarse en línea con la propia sentencia. Consulta a continuación las diferencias de configuración recomendadas con respecto a las anteriores. **Nota**: Las opciones `log_statement` y `log_duration` están comentadas. Para ver una discusión sobre este tema, consulta [Sentencia/duración de la generación de logs en la misma línea](https://www.postgresql.org/message-id/20100210180532.GA20138@depesz.com).
Esta configuración registra todas las sentencias. Para reducir los resultados en función de la duración, ajusta el valor `log_min_duration_statement` a la duración mínima deseada (en milisegundos):
@@ -299,13 +236,13 @@ La generación de logs por defecto de PostgreSQL es para `stderr` y los logs no
#log_duration = on
```
-3. La recopilación de logs se encuentra deshabilitada de manera predeterminada en el Datadog Agent. Habilítala en tu archivo `datadog.yaml`:
+1. La recopilación de logs está desactivada en forma predeterminada en el Datadog Agent, actívala en tu archivo `datadog.yaml`:
```yaml
logs_enabled: true
```
-4. Añade y edita este bloque de configuración a tu archivo `postgres.d/conf.yaml` para empezar a recopilar tus logs de PostgreSQL:
+1. Añade y edita este bloque de configuración a tu archivo `postgres.d/conf.yaml` para empezar a recopilar tus logs de PostgreSQL:
```yaml
logs:
@@ -320,18 +257,12 @@ La generación de logs por defecto de PostgreSQL es para `stderr` y los logs no
# name: new_log_start_with_date
```
- Cambia los valores de los parámetros `service` y `path` a fin de configurarlos para tu entorno. Para ver todas las opciones de configuración disponibles, consulta el [postgres.d/conf.yaml de ejemplo][2].
+ Cambia los valores de los parámetros `service` y `path` y configúralos para tu entorno. Consulta el [ejemplo de postgres.d/conf.yaml](https://github.com/DataDog/integrations-core/blob/master/postgres/datadog_checks/postgres/data/conf.yaml.example) para ver todas las opciones de configuración disponibles.
-5. [Reinicia el Agent][3].
+1. [Reinicia el Agent](https://docs.datadoghq.com/agent/guide/agent-commands/#start-stop-and-restart-the-agent).
-[1]: https://docs.datadoghq.com/integrations/postgres/?tab=host#faq
-[2]: https://github.com/DataDog/integrations-core/blob/master/postgres/datadog_checks/postgres/data/conf.yaml.example
-[3]: https://docs.datadoghq.com/agent/guide/agent-commands/#start-stop-and-restart-the-agent
-[4]: https://docs.datadoghq.com/tracing/send_traces/
-[5]: https://docs.datadoghq.com/tracing/setup/
-[6]: https://www.postgresql.org/docs/11/runtime-config-logging.html
-[7]: https://www.postgresql.org/message-id/20100210180532.GA20138@depesz.com
{{% /tab %}}
+
{{% tab "Docker" %}}
#### Docker
@@ -340,7 +271,7 @@ Para configurar este check para un Agent que se ejecuta en un contenedor:
##### Recopilación de métricas
-Configura [plantillas de integraciones Autodiscovery][1] como etiquetas (labels) Docker en el contenedor de tu aplicación:
+Configura [plantillas de integración de Autodiscovery](https://docs.datadoghq.com/agent/docker/integrations/?tab=docker) como etiquetas (labels) de Docker en el contenedor de tu aplicación:
```yaml
LABEL "com.datadoghq.ad.check_names"='["postgres"]'
@@ -350,10 +281,9 @@ LABEL "com.datadoghq.ad.instances"='[{"host":"%%host%%", "port":5432,"username":
##### Recopilación de logs
+La recopilación de logs está desactivada por defecto en el Datadog Agent. Para activarla, consulta [Recopilación de logs de Docker](https://docs.datadoghq.com/agent/docker/log/?tab=containerinstallation#installation).
-La recopilación de logs se encuentra deshabilitada de manera predeterminada en el Datadog Agent. Para habilitarla, consulta la [recopilación de logs de Docker][2].
-
-Luego, configura [integraciones de logs][3] como etiquetas Docker:
+A continuación, configura [integraciones de logs](https://docs.datadoghq.com/agent/docker/log/?tab=containerinstallation#log-integrations) como etiquetas de Docker:
```yaml
LABEL "com.datadoghq.ad.logs"='[{"source":"postgresql","service":"postgresql"}]'
@@ -361,9 +291,9 @@ LABEL "com.datadoghq.ad.logs"='[{"source":"postgresql","service":"postgresql"}]'
##### Recopilación de trazas
-APM para aplicaciones en contenedores es compatible con la versión 6 o posteriores del Agent, pero requiere una configuración adicional a fin de empezar a recopilar trazas.
+APM para aplicaciones en contenedores es compatible con el Agent v6 o posterior, pero requiere configuración adicional para empezar a recopilar trazas.
-Variables de entorno necesarias en el contenedor del Agent:
+Variables de entorno requeridas en el contenedor del Agent:
| Parámetro | Valor |
| -------------------- | -------------------------------------------------------------------------- |
@@ -371,27 +301,23 @@ Variables de entorno necesarias en el contenedor del Agent:
| `` | verdadero |
| `` | verdadero |
-Para ver una lista completa de las variables de entorno y la configuración disponibles, consulta [Rastreo de aplicaciones Docker][4].
-
-Luego, [instrumenta el contenedor de tu aplicación que realiza solicitudes a Postgres][3] y configura `DD_AGENT_HOST` con el nombre del contenedor de tu Agent.
+Para ver una lista completa de las variables de entorno y la configuración disponibles, consulta [Rastreo de aplicaciones Docker](https://docs.datadoghq.com/agent/amazon_ecs/logs/?tab=linux).
+A continuación, [instrumenta el contenedor de tu aplicación que realiza solicitudes a Postgres](https://docs.datadoghq.com/agent/docker/log/?tab=containerinstallation#log-integrations) y configura `DD_AGENT_HOST` con el nombre del contenedor de tu Agent.
-[1]: https://docs.datadoghq.com/agent/docker/integrations/?tab=docker
-[2]: https://docs.datadoghq.com/agent/docker/log/?tab=containerinstallation#installation
-[3]: https://docs.datadoghq.com/agent/docker/log/?tab=containerinstallation#log-integrations
-[4]: https://docs.datadoghq.com/agent/amazon_ecs/logs/?tab=linux
{{% /tab %}}
+
{{% tab "Kubernetes" %}}
#### Kubernetes
-Para configurar este check para un Agent que se ejecuta en Kubernetes:
+Para Configurar este check para un Agent que se ejecuta en Kubernetes:
##### Recopilación de métricas
-Configura [plantillas de integraciones de Autodiscovery][1] como anotaciones de pod en el contenedor de tu aplicación. Además de esto, las plantillas también se pueden configurar con [un archivo, un mapa de configuración o un almacén de clave-valor][2].
+Configura [plantillas de integración de Autodiscovery](https://docs.datadoghq.com/agent/kubernetes/integrations/?tab=kubernetes) como anotaciones de pod en el contenedor de tu aplicación. Aparte de esto, las plantillas también se pueden configurar con [un archivo, un mapa de configuración o un almacén clave-valor](https://docs.datadoghq.com/agent/kubernetes/integrations/?tab=kubernetes#configuration).
-**Anotaciones v1** (para la versión 7.36 o anterior del Datadog Agent)
+**Anotaciones v1** (para el Datadog Agent \< v7.36)
```yaml
apiVersion: v1
@@ -415,7 +341,7 @@ spec:
- name: postgres
```
-**Anotaciones v2** (para la versión 7.36 o posterior del Datadog Agent)
+**Anotaciones v2** (para el Datadog Agent v7.36 o posterior)
```yaml
apiVersion: v1
@@ -444,10 +370,9 @@ spec:
##### Recopilación de logs
+La recopilación de logs está desactivada por defecto en el Datadog Agent. Para activarla, consulta [Recopilación de logs de Kubernetes](https://docs.datadoghq.com/agent/kubernetes/log/?tab=containerinstallation#setup).
-La recopilación de logs se encuentra deshabilitada de manera predeterminada en el Datadog Agent. Para habilitarla, consulta la [recopilación de logs de Kubernetes][3].
-
-Luego, configura las [integraciones de logs][4] como anotaciones de pod. Esto también se puede configurar con [un archivo, un mapa de configuración o un almacén de clave-valor][5].
+A continuación, configura [integraciones de logs](https://docs.datadoghq.com/agent/docker/log/?tab=containerinstallation#log-integrations) como anotaciones de pod. Esto también se puede configurar con [un archivo, un mapa de configuración o un almacén clave-valor](https://docs.datadoghq.com/agent/kubernetes/log/?tab=daemonset#configuration).
**Anotaciones v1/v2**
@@ -465,9 +390,9 @@ spec:
##### Recopilación de trazas
-APM para aplicaciones en contenedores es compatible con hosts que se ejecutan en la versión 6 o posteriores del Agent, pero requiere una configuración adicional a fin de empezar a recopilar trazas.
+APM para aplicaciones en contenedores es compatible con hosts que se ejecutan en la versión 6 o posteriores del Agent, pero requiere configuración adicional para empezar a recopilar trazas.
-Variables de entorno necesarias en el contenedor del Agent:
+Variables de entorno requeridas en el contenedor del Agent:
| Parámetro | Valor |
| -------------------- | -------------------------------------------------------------------------- |
@@ -475,18 +400,12 @@ Variables de entorno necesarias en el contenedor del Agent:
| `` | verdadero |
| `` | verdadero |
-Para ver una lista completa de las variables de entorno y la configuración disponibles, consulta [Rastreo de aplicaciones Kubernetes][6] y la [configuración del DaemonSet de Kubernetes][7].
+Consulta [Rastreo de aplicaciones Kubernetes](https://docs.datadoghq.com/agent/amazon_ecs/apm/?tab=ec2metadataendpoint#setup) y [Configuración de Kubernetes DaemonSet](https://github.com/DataDog/integrations-core/blob/master/postgres/assets/service_checks.json) para obtener una lista completa de las variables de entorno y la configuración disponibles.
-A continuación, [instrumenta el contenedor de tu aplicación que realiza solicitudes a Postgres][4].
+A continuación, [instrumenta el contenedor de tu aplicación que realiza solicitudes a Postgres](https://docs.datadoghq.com/agent/docker/log/?tab=containerinstallation#log-integrations).
-[1]: https://docs.datadoghq.com/agent/kubernetes/integrations/?tab=kubernetes
-[2]: https://docs.datadoghq.com/agent/kubernetes/integrations/?tab=kubernetes#configuration
-[3]: https://docs.datadoghq.com/agent/kubernetes/log/?tab=containerinstallation#setup
-[4]: https://docs.datadoghq.com/agent/docker/log/?tab=containerinstallation#log-integrations
-[5]: https://docs.datadoghq.com/agent/kubernetes/log/?tab=daemonset#configuration
-[6]: https://docs.datadoghq.com/agent/amazon_ecs/apm/?tab=ec2metadataendpoint#setup
-[7]: https://github.com/DataDog/integrations-core/blob/master/postgres/assets/service_checks.json
{{% /tab %}}
+
{{% tab "ECS" %}}
#### ECS
@@ -495,7 +414,9 @@ Para configurar este check para un Agent que se ejecuta en ECS:
##### Recopilación de métricas
-Configura [plantillas de integraciones Autodiscovery][1] como etiquetas Docker en el contenedor de tu aplicación:
+Configura [plantillas de integración de Autodiscovery](https://docs.datadoghq.com/agent/docker/integrations/?tab=docker) como etiquetas de Docker en el contenedor de tu aplicación:
+
+**Anotaciones v1** (para el Datadog Agent \< v7.36)
```json
{
@@ -511,12 +432,25 @@ Configura [plantillas de integraciones Autodiscovery][1] como etiquetas Docker e
}
```
-##### Recopilación de logs
+**Anotaciones v2** (para el Datadog Agent v7.36 o posterior)
+```json
+{
+ "containerDefinitions": [{
+ "name": "postgres",
+ "image": "postgres:latest",
+ "dockerLabels": {
+ "com.datadoghq.ad.checks": "{\"postgres\": {\"instances\": [{\"host\":\"%%host%%\", \"port\":5432, \"username\":\"postgres\", \"password\":\"\"}]}}"
+ }
+ }]
+}
+```
-La recopilación de logs se encuentra deshabilitada de manera predeterminada en el Datadog Agent. Para habilitarla, consulta la [recopilación de logs de ECS][2].
+##### Recopilación de logs
-Luego, configura [integraciones de logs][3] como etiquetas Docker:
+La recopilación de logs está desactivada por defecto en el Datadog Agent. Para activarla, consulta [Recopilación de logs de ECS](https://docs.datadoghq.com/agent/amazon_ecs/logs/?tab=linux).
+
+A continuación, configura [integraciones de logs](https://docs.datadoghq.com/agent/docker/log/?tab=containerinstallation#log-integrations) como etiquetas de Docker:
```json
{
@@ -532,9 +466,9 @@ Luego, configura [integraciones de logs][3] como etiquetas Docker:
##### Recopilación de trazas
-APM para aplicaciones en contenedores es compatible con la versión 6 o posteriores del Agent, pero requiere una configuración adicional a fin de empezar a recopilar trazas.
+APM para aplicaciones en contenedores es compatible con el Agent v6 o posterior, pero requiere configuración adicional para empezar a recopilar trazas.
-Variables de entorno necesarias en el contenedor del Agent:
+Variables de entorno requeridas en el contenedor del Agent:
| Parámetro | Valor |
| -------------------- | -------------------------------------------------------------------------- |
@@ -542,69 +476,293 @@ Variables de entorno necesarias en el contenedor del Agent:
| `` | verdadero |
| `` | verdadero |
-Para ver una lista completa de las variables de entorno y la configuración disponibles, consulta [Rastreo de aplicaciones Docker][4].
+Para ver una lista completa de las variables de entorno y la configuración disponibles, consulta [Rastreo de aplicaciones Docker](https://docs.datadoghq.com/agent/docker/apm/).
-Luego, [instrumenta el contenedor de tu aplicación que realiza solicitudes a Postgres][3] y configura `DD_AGENT_HOST` en la [dirección IP privada de EC2][5].
+A continuación, [instrumenta el contenedor de tu aplicación que realiza solicitudes a Postgres](https://docs.datadoghq.com/agent/docker/log/?tab=containerinstallation#log-integrations) y configura `DD_AGENT_HOST` con la [dirección IP privada de EC2](https://docs.datadoghq.com/agent/amazon_ecs/apm/?tab=ec2metadataendpoint#setup).
-[1]: https://docs.datadoghq.com/agent/docker/integrations/?tab=docker
-[2]: https://docs.datadoghq.com/agent/amazon_ecs/logs/?tab=linux
-[3]: https://docs.datadoghq.com/agent/docker/log/?tab=containerinstallation#log-integrations
-[4]: https://docs.datadoghq.com/agent/docker/apm/
-[5]: https://docs.datadoghq.com/agent/amazon_ecs/apm/?tab=ec2metadataendpoint#setup
{{% /tab %}}
+
{{< /tabs >}}
### Validación
-[Ejecuta el subcomando de estado del Agent][5] y busca `postgres` en la sección Checks.
+[Ejecuta el subcomando de estado del Agent(https://docs.datadoghq.com/agent/guide/agent-commands/#agent-status-and-information) y busca `postgres` en la sección Checks.
## Datos recopilados
-Algunas de las métricas enumeradas a continuación requieren una configuración adicional. Para ver todas las opciones configurables, consulta el [postgres.d/conf.yaml de ejemplo][6].
+Algunas de las métricas enumeradas a continuación requieren configuración adicional. Consulta el [ejemplo de postgres.d/conf.yaml](https://github.com/DataDog/integrations-core/blob/master/postgres/datadog_checks/postgres/data/conf.yaml.example) para ver todas las opciones de configuración disponibles.
### Métricas
-{{< get-metrics-from-git "postgres" >}}
-
-Para la versión `7.32.0` y posteriores del Agent, si tienes Database Database Monitoring habilitado, la métrica `postgresql.connections` se etiqueta (tag) con `state`, `app`, `db` y `user`.
+| | |
+| --- | --- |
+| **postgresql.active_queries**
(gauge) | Activado con `collect_activity_metrics`. Número de consultas activas en esta base de datos. Esta métrica (por defecto) está etiquetada con db, app, user.| +| **postgresql.active_waiting_queries**
(gauge) | Activado con `collect_activity_metrics`. Número de consultas en espera en esta base de datos en estado activo. Esta métrica (por defecto) está etiquetada con db, app, user.| +| **postgresql.activity.backend_xid_age**
(gauge) | Antigüedad del xid del backend más antiguo en relación con el último xid estable. Esta métrica (por defecto) está etiquetada con db, app, user.
_Se muestra como transacción_ | +| **postgresql.activity.backend_xmin_age**
(gauge) | Antigüedad del horizonte xmin del backend más antiguo en relación con el último xid estable. Esta métrica (por defecto) está etiquetada con db, app, user.
_Se muestra como transacción_ | +| **postgresql.activity.wait_event**
(gauge) | Número de eventos de espera en el momento de la comprobación. Esta métrica está etiquetada por usuario. Esta métrica está etiquetada por user, db, app y backend_type.| +| **postgresql.activity.xact_start_age**
(gauge) | Antigüedad de las transacciones activas más antiguas. Esta métrica (por defecto) está etiquetada con db, app, user.
_Se muestra como segundos_. | +| **postgresql.analyze.child_tables_done**
(gauge) | Número de tablas secundarias analizadas. Este contador solo avanza cuando la fase está adquiriendo filas de ejemplo heredadas. Esta métrica está etiquetada con db, table, child_relation, phase.| +| **postgresql.analyze.child_tables_total**
(gauge) | Número de tablas secundarias. Esta métrica está etiquetada con db, table, child_relation, phase.| +| **postgresql.analyze.ext_stats_computed**
(gauge) | Número de estadísticas ampliadas calculadas. Este contador solo avanza cuando la fase está calculando estadísticas ampliadas. Esta métrica está etiquetada con db, table, child_relation, phase.| +| **postgresql.analyze.ext_stats_total**
(gauge) | Número de estadísticas ampliadas. Esta métrica está etiquetada con db, table, child_relation, phase.| +| **postgresql.analyze.sample_blks_scanned**
(gauge) | Número de bloques heap analizados. Esta métrica está etiquetada con db, table, child_relation, phase.
_Se muestra como bloque_. | +| **postgresql.analyze.sample_blks_total**
(gauge) | Número total de bloques heap que se muestrearán. Esta métrica está etiquetada con db, table, child_relation, phase.
_Se muestra como bloque_. | +| **postgresql.analyzed**
(count) | Activado con `relations`. Número de veces que se ha analizado manualmente esta tabla. Esta métrica está etiquetada con db, schema, table.| +| **postgresql.archiver.archived_count**
(count) | Número de archivos WAL que se han archivado correctamente.| +| **postgresql.archiver.failed_count**
(count) | Número de intentos fallidos para archivar archivos WAL.| +| **postgresql.autoanalyzed**
(count) | Activado con `relations`. Número de veces que esta tabla ha sido analizada por el daemon de autovaciado. Esta métrica está etiquetada con db, schema, table.| +| **postgresql.autovacuumed**
(count) | Activado con `relations`. Número de veces que esta tabla ha sido vaciada por el daemon de autovaciado. Esta métrica está etiquetada con db, schema, table.| +| **postgresql.before_xid_wraparound**
(gauge) | Número de transacciones que pueden ocurrir hasta que se agote el ID de una transacción. Esta métrica está etiquetada con db.
_Se muestra como transacción_ | +| **postgresql.bgwriter.buffers_alloc**
(count) | Número de buffers asignados| +| **postgresql.bgwriter.buffers_backend**
(count) | Número de buffers escritos directamente por un backend.
_Se muestra como buffer_ | +| **postgresql.bgwriter.buffers_backend_fsync**
(count) | Cantidad de veces que un backend ha tenido que ejecutar su propia llamada fsync en lugar del escritor en segundo plano.| +| **postgresql.bgwriter.buffers_checkpoint**
(count) | Número de buffers escritos durante los puntos de control.| +| **postgresql.bgwriter.buffers_clean**
(count) | Número de buffers escritos por el escritor en segundo plano.| +| **postgresql.bgwriter.checkpoints_requested**
(count) | Número de puntos de control solicitados que se han realizado.| +| **postgresql.bgwriter.checkpoints_timed**
(count) | Número de puntos de control programados que se han realizado.| +| **postgresql.bgwriter.maxwritten_clean**
(count) | Número de veces que el escritor en segundo plano ha detenido una exploración de limpieza debido a la escritura de demasiados buffers.| +| **postgresql.bgwriter.sync_time**
(count) | Cantidad total de tiempo de procesamiento del punto de control dedicado a sincronizar los archivos con el disco.
_Se muestra como milisegundos_ | +| **postgresql.bgwriter.write_time**
(count) | Cantidad total de tiempo de procesamiento del punto de control dedicado a escribir archivos en el disco.
_Se muestra como milisegundos_ | +| **postgresql.blk_read_time**
(count) | Tiempo dedicado a leer bloques de archivos de datos por los backends en esta base de datos si track_io_timing está activado. Esta métrica está etiquetada con db.
_Se muestra como milisegundos_. | +| **postgresql.blk_write_time**
(count) | Tiempo dedicado a escribir bloques de archivos de datos por los backends en esta base de datos si track_io_timing está activado. Esta métrica está etiquetada con db.
_Se muestra como milisegundos_. | +| **postgresql.buffer_hit**
(rate) | Número de veces que se han encontrado bloques del disco en la caché del buffer, evitando la necesidad de leer desde la base de datos. Esta métrica está etiquetada con db.
_Se muestra como solicitud_. | +| **postgresql.buffercache.dirty_buffers**
(gauge) | Número de buffers sucios compartidos. Es necesario instalar la extensión pg_buffercache. Esta métrica está etiquetada por db, esquema y relación.
_Se muestra como buffer_ | +| **postgresql.buffercache.pinning_backends**
(gauge) | Número de backends que utilizan buffers compartidos. Es necesario instalar la extensión pg_buffercache. Esta métrica está etiquetada por db, schema y relation.| +| **postgresql.buffercache.unused_buffers**
(gauge) | Número de buffers compartidos no utilizados. Es necesario instalar la extensión pg_buffercache.
_Se muestra como buffer_ | +| **postgresql.buffercache.usage_count**
(gauge) | Suma de usage_count de buffers compartidos. Es necesario instalar la extensión pg_buffercache. Esta métrica está etiquetada por por db, schema y relation.| +| **postgresql.buffercache.used_buffers**
(gauge) | Número de buffers compartidos. Es necesario instalar la extensión pg_buffercache. Esta métrica está etiquetada por db, schema y relation.
_Se muestra como buffer_ | +| **postgresql.checksums.checksum_failures**
(count) | Número de fallos de suma de comprobación en esta base de datos. Esta métrica está etiquetada con db.| +| **postgresql.checksums.enabled**
(count) | Si están activadas las sumas de comprobación de bases de datos. El valor es siempre 1 y está etiquetado con enabled:true o enabled:false. Esta métrica está etiquetada con db.| +| **postgresql.cluster_vacuum.heap_blks_scanned**
(gauge) | Número de bloques heap analizados. Este contador solo avanza cuando la fase es heap de análisis secuencial. Solo disponible con PostgreSQL v12 y posteriores. Esta métrica está etiquetada con db, table, command, phase, index.
_Se muestra como bloque_ | +| **postgresql.cluster_vacuum.heap_blks_total**
(gauge) | Número total de bloques heap en la tabla. Este número se informa desde el inicio del heap de análisis secuencial. Solo disponible con PostgreSQL v12 y posteriores. Esta métrica está etiquetada con db, table, command, phase, index.
_Se muestra como bloque_ | +| **postgresql.cluster_vacuum.heap_tuples_scanned**
(gauge) | Número de tuplas heap analizadas. Este contador solo avanza cuando la fase es heap de análisis secuencial, heap de análisis de índices o nuevo heap de escritura. Solo disponible con PostgreSQL v12 y posteriores. Esta métrica está etiquetada con db, table, command, phase, index.| +| **postgresql.cluster_vacuum.heap_tuples_written**
(gauge) | Número de tuplas heap escritas. Este contador solo avanza cuando la fase es heap de análisis secuencial, heap de análisis de índices o nuevo heap de escritura. Solo disponible con PostgreSQL v12 y posteriores. Esta métrica está etiquetada con db, table, command, phase, index.| +| **postgresql.cluster_vacuum.index_rebuild_count**
(gauge) | Número de índices reconstruidos. Este contador solo avanza cuando la fase es de reconstrucción de índices. Solo disponible con PostgreSQL v12 y posteriores. Esta métrica está etiquetada con db, table, command, phase, index.| +| **postgresql.commits**
(rate) | Número de transacciones que se han confirmado en esta base de datos. Esta métrica está etiquetada con db.
_Se muestra como transacción_ | +| **postgresql.conflicts.bufferpin**
(count) | Número de consultas en esta base de datos que han sido canceladas debido a buffers anclados. Los conflictos de pin de buffer ocurrirán cuando el proceso walreceiver intente aplicar una limpieza de buffer como el pruning de cadena HOT. Esto requiere un bloqueo completo del buffer y cualquier consulta que lo tenga anclado entrará en conflicto con la limpieza. Esta métrica está etiquetada con db.
_Se muestra como consulta_ | +| **postgresql.conflicts.deadlock**
(count) | Número de consultas en esta base de datos que han sido canceladas debido a bloqueos. Los conflictos de bloqueo ocurrirán cuando el proceso walreceiver intente aplicar un buffer como pruning de cadena HOT. Si el conflicto dura más de deadlock_timeout segundos, se activará una comprobación de bloqueo y las consultas en conflicto se cancelarán hasta que se desancle el buffer. Esta métrica está etiquetada con db.
_Se muestra como consulta_ | +| **postgresql.conflicts.lock**
(count) | Número de consultas en esta base de datos que se han cancelado debido a tiempos de espera de bloqueo. Esto ocurrirá cuando el proceso walreceiver intente aplicar un cambio que requiera un bloqueo ACCESS EXCLUSIVE mientras una consulta en la réplica está leyendo la tabla. La consulta en conflicto será eliminada después de esperar hasta max_standby_streaming_delay segundos. Esta métrica está etiquetada con db.
_Se muestra como consulta_ | +| **postgresql.conflicts.snapshot**
(count) | Número de consultas en esta base de datos que se han cancelado debido a snapshots demasiado antiguos. Se producirá un conflicto de snapshots cuando se reproduzca un VACUUM, eliminando las tuplas leídas actualmente en una espera. Esta métrica está etiquetada con db.
_Se muestra como consulta_ | +| **postgresql.conflicts.tablespace**
(count) | Número de consultas en esta base de datos que se han cancelado debido a espacios en tablas eliminados. Esto ocurrirá cuando se elimine un temp_tablespace temporal mientras se utiliza en una espera. Esta métrica está etiquetada con db.
_Se muestra como consulta_ | +| **postgresql.connections**
(gauge) | Número de conexiones activas a esta base de datos.
_Se muestra como conexión_ | +| **postgresql.connections_by_process**
(gauge) | Número de conexiones activas a esta base de datos, desglosado por atributos a nivel de proceso. Esta métrica está etiquetada con state, application, user y db. (Solo DBM)
_Se muestra como conexión_. | +| **postgresql.control.checkpoint_delay**
(gauge) | Tiempo transcurrido desde el último punto de control.
_Se muestra como segundos_ | +| **postgresql.control.checkpoint_delay_bytes**
(gauge) | Cantidad de bytes WAL escritos desde el último punto de control.
_Se muestra como bytes_ | +| **postgresql.control.redo_delay_bytes**
(gauge) | Cantidad de bytes WAL escritos desde el último punto de rehacer.
_Se muestra como bytes_ | +| **postgresql.control.timeline_id**
(gauge) | ID actual de la línea de tiempo.| +| **postgresql.create_index.blocks_done**
(gauge) | Número de bloques procesados en la fase actual. Solo disponible con PostgreSQL v12 y posteriores. Esta métrica está etiquetada con db, table, index, command, phase.| +| **postgresql.create_index.blocks_total**
(gauge) | Número total de bloques a procesar en la fase actual. Solo disponible con PostgreSQL v12 y posteriores. Esta métrica está etiquetada con db, table, index, command, phase.| +| **postgresql.create_index.lockers_done**
(gauge) | Número de casilleros esperados. Solo disponible con PostgreSQL v12 y posteriores. Esta métrica está etiquetada con db, table, index, command, phase.| +| **postgresql.create_index.lockers_total**
(gauge) | Número total de casilleros a esperar, cuando corresponda. Solo disponible con PostgreSQL v12 y posteriores. Esta métrica está etiquetada con db, table, index, command, phase.| +| **postgresql.create_index.partitions_done**
(gauge) | Cuando se crea un índice en una tabla particionada, esta columna se configura según el número de particiones en que se ha creado el índice. Este campo es 0 durante un REINDEX. Solo disponible con PostgreSQL v12 y posteriores. Esta métrica está etiquetada con db, table, index, command, phase.| +| **postgresql.create_index.partitions_total**
(gauge) | Cuando se crea un índice en una tabla particionada, esta columna se configura según el número de particiones en que se ha creado el índice. Este campo es 0 durante un REINDEX. Solo disponible con PostgreSQL v12 y posteriores. Esta métrica está etiquetada con db, table, index, command, phase.| +| **postgresql.create_index.tuples_done**
(gauge) | Número de tuplas procesadas en la fase actual. Solo disponible con PostgreSQL v12 y posteriores. Esta métrica está etiquetada con db, table, index, command, phase.| +| **postgresql.create_index.tuples_total**
(gauge) | Número total de tuplas a procesar en la fase actual. Solo disponible con PostgreSQL v12 y posteriores. Esta métrica está etiquetada con db, table, index, command, phase.| +| **postgresql.database_size**
(gauge) | Espacio en disco utilizado por esta base de datos. Esta métrica está etiquetada con db.
_Se muestra como bytes_ | +| **postgresql.db.count**
(gauge) | Número de bases de datos disponibles.
_Se muestra como elemento_ | +| **postgresql.dead_rows**
(gauge) | Activado con `relations`. Número estimado de filas inactivas. Esta métrica está etiquetada con db, schema, table.
_Se muestra como fila_ | +| **postgresql.deadlocks**
(rate) | Tasa de bloqueos detectados en esta base de datos. Esta métrica está etiquetada con db.
_Se muestra como bloqueo_ | +| **postgresql.deadlocks.count**
(count) | Número de bloqueos detectados en esta base de datos. Esta métrica está etiquetada con db.
_Se muestra como bloqueo_ | +| **postgresql.disk_read**
(rate) | Número de bloques de disco leídos en esta base de datos. Esta métrica está etiquetada con db.
_Se muestra como bloque_ | +| **postgresql.function.calls**
(rate) | Activado con `collect_function_metrics`. Número de llamadas realizadas a una función. Esta métrica está etiquetada con db, schema, function.| +| **postgresql.function.self_time**
(rate) | Activado con `collect_function_metrics`. Tiempo total dedicado a esta función, sin incluir otras funciones llamadas por ella. Esta métrica está etiquetada con db, schema, function.| +| **postgresql.function.total_time**
(rate) | Activado con `collect_function_metrics`. Tiempo total dedicado a esta función y en todas las demás funciones llamadas por ella. Esta métrica está etiquetada con db, schema, function.| +| **postgresql.heap_blocks_hit**
(gauge) | Activado con `relations`. Número de hits de buffer de esta tabla. Esta métrica está etiquetada con db, schema, table.
_Se muestra como hit_ | +| **postgresql.heap_blocks_read**
(gauge) | Activado con `relations`. Número de bloques de disco leídos de esta tabla. Esta métrica está etiquetada con db, schema, table.
_Se muestra como bloque_. | +| **postgresql.index.index_blocks_hit**
(gauge) | Activado con `relations`. Número de hits de buffer para un índice específico. Esta métrica está etiquetada con db, schema, table, index.
_Se muestra como hit_ | +| **postgresql.index.index_blocks_read**
(gauge) | Activado con `relations`. El número de bloques de disco para un índice específico. Esta métrica está etiquetada con db, schema, table, index.
_Se muestra como bloque_ | +| **postgresql.index_bloat**
(gauge) | Activado con `collect_bloat_metrics`. Porcentaje estimado de sobrecarga del índice. Esta métrica está etiquetada con db, schema, table, index.
_Se muestra como porcentaje_. | +| **postgresql.index_blocks_hit**
(gauge) | Activado con `relations`. Número de hits de buffer en todos los índices de esta tabla. Esta métrica está etiquetada con db, schema, table.
_Se muestra como hit_ | +| **postgresql.index_blocks_read**
(gauge) | Activado con `relations`. Número de bloques de disco leídos de todos los índices de esta tabla. Esta métrica está etiquetada con db, schema, table.
_Se muestra como bloque_ | +| **postgresql.index_rel_rows_fetched**
(gauge) | Activado con `relations`. Número de filas activas obtenidas por análisis de índices. Esta métrica está etiquetada con db, schema, table.
_Se muestra como fila_ | +| **postgresql.index_rel_scans**
(gauge) | Activado con `relations`. Número total de análisis de índices iniciados de esta tabla. Esta métrica está etiquetada con db, schema, table.
_Se muestra como análisis_ | +| **postgresql.index_rows_fetched**
(gauge) | Activado con `relations`. Número de filas activas obtenidas por análisis de índices. Esta métrica está etiquetada con db, schema, table, index.
_Se muestra como fila_ | +| **postgresql.index_rows_read**
(gauge) | Activado con `relations`. Número de entradas de índice devueltas por análisis de este índice. Esta métrica está etiquetada con db, schema, table, index.
_Se muestra como fila_ | +| **postgresql.index_scans**
(gauge) | Activado con `relations`. Número de análisis de índices iniciadas de esta tabla. Esta métrica está etiquetada con db, schema, table, index
_Se muestra como análisis_ | +| **postgresql.index_size**
(gauge) | Activado con `relations`. Espacio total en disco utilizado por los índices adjuntos a la tabla especificada. Esta métrica está etiquetada con db, schema, table.
_Se muestra como bytes_ | +| **postgresql.individual_index_size**
(gauge) | Espacio en disco utilizado por un índice especificado. Esta métrica está etiquetada con db, schema, table, index.
_Se muestra como bytes_ | +| **postgresql.io.evictions**
(count) | Número de veces que un bloque se ha escrito desde un buffer compartido o local para que esté disponible para otro uso. Esta métrica está etiquetada con backend_type, context, object. Solo disponible con PostgreSQL v16 y posteriores. (Solo DBM)
_Se muestra como milisegundos_ | +| **postgresql.io.extend_time**
(count) | Tiempo dedicado a operaciones extend (si track_io_timing está activado, de lo contrario cero). Esta métrica está etiquetada con backend_type, context, object. Solo disponible con PostgreSQL v16 y posteriores. (Solo DBM)
_Se muestra como milisegundos_ | +| **postgresql.io.extends**
(count) | Número de operaciones extend de relaciones. Esta métrica está etiquetada con backend_type, context, object. Solo disponible con PostgreSQL v16 y posteriores. (Solo DBM)| +| **postgresql.io.fsync_time**
(count) | Tiempo dedicado a operaciones fsync (si track_io_timing está activado, de lo contrario cero). Esta métrica está etiquetada con backend_type, context, object. Solo disponible con PostgreSQL v16 y posteriores. (Solo DBM)
_Se muestra como milisegundos_ | +| **postgresql.io.fsyncs**
(count) | Número de llamadas fsync. Esta métrica está etiquetada con backend_type, context, object. Solo disponible con PostgreSQL v16 y posteriores. (Solo DBM)| +| **postgresql.io.hits**
(count) | Número de veces que se ha encontrado un bloque deseado en un buffer compartido. Esta métrica está etiquetada con backend_type, context, object. Solo disponible con PostgreSQL v16 y posteriores. (Solo DBM)
_Se muestra como milisegundos_ | +| **postgresql.io.read_time**
(count) | Tiempo dedicado a operaciones de lectura (si track_io_timing está activado, de lo contrario cero). Esta métrica está etiquetada con backend_type, context, object. Solo disponible con PostgreSQL v16 y posteriores. (Solo DBM)
_Se muestra como milisegundos_ | +| **postgresql.io.reads**
(count) | Número de operaciones de lectura. Esta métrica está etiquetada con backend_type, context, object. Solo disponible con PostgreSQL v16 y posteriores. (Solo DBM)| +| **postgresql.io.write_time**
(count) | Tiempo dedicado a operaciones de escritura (si track_io_timing está activado, de lo contrario cero). Esta métrica está etiquetada con backend_type, context, object. Solo disponible con PostgreSQL v16 y posteriores. (Solo DBM)
_Se muestra como milisegundos_ | +| **postgresql.io.writes**
(count) | Número de operaciones de escritura. Esta métrica está etiquetada con backend_type, context, object. Solo disponible con PostgreSQL v16 y posteriores. (Solo DBM)| +| **postgresql.last_analyze_age**
(gauge) | Última vez que esta tabla fue analizada manualmente. Esta métrica está etiquetada con db, schema, table.
_Se muestra como segundos_ | +| **postgresql.last_autoanalyze_age**
(gauge) | Última vez que esta tabla fue analizada por el daemon de autovaciado. Esta métrica está etiquetada con db, schema, table.
_Se muestra como segundos_ | +| **postgresql.last_autovacuum_age**
(gauge) | Última vez que esta tabla ha sido vaciada por el daemon de autovaciado. Esta métrica está etiquetada con db, schema, table.
_Se muestra como segundos_ | +| **postgresql.last_vacuum_age**
(gauge) | Última vez que esta tabla ha sido vaciada manualmente (sin contar VACUUM FULL). Esta métrica está etiquetada con db, schema, table.
_Se muestra como segundos_ | +| **postgresql.live_rows**
(gauge) | Activado con `relations`. Número estimado de filas activas. Esta métrica está etiquetada con db, schema, table.
_Se muestra como fila_ | +| **postgresql.locks**
(gauge) | Activado con `relations`. Número de bloqueos activos para esta base de datos. Esta métrica está etiquetada con db, lock_mode, lock_type, schema, table, granted.
_Se muestra como bloqueo_ | +| **postgresql.max_connections**
(gauge) | Número máximo de conexiones de cliente permitidas a esta base de datos.
_Se muestra como conexión_ | +| **postgresql.percent_usage_connections**
(gauge) | Número de conexiones a esta base de datos como fracción del número máximo de conexiones permitidas.
_Se muestra como fracción_ | +| **postgresql.pg_stat_statements.dealloc**
(count) | Número de veces que pg_stat_statements tuvo que desalojar las consultas menos ejecutadas porque se alcanzó pg_stat_statements.max.| +| **postgresql.queries.blk_read_time**
(count) | Tiempo total dedicado a leer bloques por query_signature, base de datos y usuario. (Solo DBM)
_Se muestra como nanosegundos_ | +| **postgresql.queries.blk_write_time**
(count) | Tiempo total dedicado a escribir bloques por query_signature, base de datos y usuario. (Solo DBM)
_Se muestra como nanosegundos_ | +| **postgresql.queries.count**
(count) | Recuento total de ejecución de consultas por query_signature, base de datos y usuario. (Solo DBM)
_Se muestra como consulta_ | +| **postgresql.queries.duration.max**
(gauge) | Antigüedad de la consulta en ejecución más larga por usuario, base de datos y aplicación. (Solo DBM)
_Se muestra como nanosegundos_ | +| **postgresql.queries.duration.sum**
(gauge) | Suma de la antigüedad de todas las consultas en ejecución por usuario, base de datos y aplicación. (Solo DBM)
_Se muestra como nanosegundos_ | +| **postgresql.queries.local_blks_dirtied**
(count) | Número total de bloques locales ensuciados por query_signature, base de datos y usuario. (Solo DBM)
_Se muestra como bloque_ | +| **postgresql.queries.local_blks_hit**
(count) | Número total de hits en la caché de bloques locales por query_signature, base de datos y usuario. (Solo DBM)
_Se muestra como bloque_ | +| **postgresql.queries.local_blks_read**
(count) | Número total de bloques locales leídos por query_signature, base de datos y usuario. (Solo DBM)
_Se muestra como bloque_ | +| **postgresql.queries.local_blks_written**
(count) | Número total de bloques locales escritos por query_signature, base de datos y usuario. (Solo DBM)
_Se muestra como bloque_ | +| **postgresql.queries.rows**
(count) | Número total de filas recuperadas o afectadas por query_signature, base de datos y usuario. (Solo DBM)
_Se muestra como fila_ | +| **postgresql.queries.shared_blks_dirtied**
(count) | Número total de bloques compartidos ensuciados por query_signature, base de datos y usuario. (Solo DBM)
_Se muestra como bloque_ | +| **postgresql.queries.shared_blks_hit**
(count) | Número total de hits en la caché de bloques compartidos por query_signature, base de datos y usuario. (Solo DBM)
_Se muestra como bloque_ | +| **postgresql.queries.shared_blks_read**
(count) | Número total de bloques compartidos leídos por query_signature, base de datos y usuario. (Solo DBM)
_Se muestra como bloque_ | +| **postgresql.queries.shared_blks_written**
(count) | Número total de bloques compartidos escritos por query_signature, base de datos y usuario. (Solo DBM)
_Se muestra como bloque_ | +| **postgresql.queries.temp_blks_read**
(count) | Número total de bloques temporales leídos por query_signature, base de datos y usuario. (Solo DBM)
_Se muestra como bloque_ | +| **postgresql.queries.temp_blks_written**
(count) | Número total de bloques temporales escritos por query_signature, base de datos y usuario. (Solo DBM)
_Se muestra como bloque_ | +| **postgresql.queries.time**
(count) | Tiempo total de ejecución de la consulta por query_signature, base de datos y usuario. (Solo DBM)
_Se muestra como nanosegundos_ | +| **postgresql.recovery_prefetch.block_distance**
(gauge) | Cuántos bloques por delante está buscando el prefetcher.
_Se muestra como bloque_ | +| **postgresql.recovery_prefetch.hit**
(count) | Número de bloques no precargados porque ya estaban en el grupo de buffers.
_Se muestra como bloque_ | +| **postgresql.recovery_prefetch.io_depth**
(gauge) | Cuántas precargas se han iniciado pero aún no se sabe si han finalizado.| +| **postgresql.recovery_prefetch.prefetch**
(count) | Número de bloques precargados porque no estaban en el grupo de buffers.
_Se muestra como bloque_ | +| **postgresql.recovery_prefetch.skip_fpw**
(count) | Número de bloques no precargados porque se ha incluido una imagen de página completa en el WAL.
_Se muestra como bloque_ | +| **postgresql.recovery_prefetch.skip_init**
(count) | Número de bloques no precargados porque se inicializarían a cero.
_Se muestra como bloque_ | +| **postgresql.recovery_prefetch.skip_new**
(count) | Número de bloques no precargados porque aún no existían.
_Se muestra como bloque_ | +| **postgresql.recovery_prefetch.skip_rep**
(count) | Número de bloques no precargados porque ya se habían precargado recientemente.
_Se muestra como bloque_ | +| **postgresql.recovery_prefetch.wal_distance**
(gauge) | Cuántos bytes por delante está buscando el prefetcher.
_Se muestra como bytes_ | +| **postgresql.relation.all_visible**
(gauge) | Número de páginas que están marcadas como todas visibles en el mapa de visibilidad de la tabla. Se trata únicamente de una estimación utilizada por el planificador y se actualiza mediante VACUUM o ANALYZE. Esta métrica está etiquetada con db, schema, table, partition_of.| +| **postgresql.relation.pages**
(gauge) | Tamaño de una tabla en páginas (1 página = 8KB por defecto). Se trata únicamente de una estimación utilizada por el planificador y se actualiza mediante VACUUM o ANALYZE. Esta métrica está etiquetada con db, schema, table, partition_of.| +| **postgresql.relation.tuples**
(gauge) | Número de filas activas en la tabla. Se trata únicamente de una estimación utilizada por el planificador y se actualiza mediante VACUUM o ANALYZE. Si la tabla nunca ha sido vaciada o analizada, se informará -1. Esta métrica está etiquetada con db, schema, table, partition_of.| +| **postgresql.relation.xmin**
(gauge) | ID de transacción de la última modificación de la relación en pg_class. Esta métrica está etiquetada con db, schema, table.| +| **postgresql.relation_size**
(gauge) | Espacio en disco utilizado por la tabla especificada. No se incluyen datos TOAST, índices, mapa de espacio libre o mapa de visibilidad. Esta métrica está etiquetada con db, schema, table.
_Se muestra como bytes_ | +| **postgresql.replication.backend_xmin_age**
(gauge) | Antigüedad del horizonte xmin del servidor en espera (en relación con el último xid estable) informada por hot_standby_feedback.| +| **postgresql.replication.wal_flush_lag**
(gauge) | Tiempo transcurrido entre el vaciado local de WAL reciente y la recepción de la notificación de que este servidor en espera la ha escrito y vaciado (pero aún no la ha aplicado). Esto puede utilizarse para medir el retraso en el que incurre el nivel synchronous_commit al confirmar si este servidor está configurado como servidor en espera síncrono. Solo disponible con PostgreSQL v10 y posteriores.
_Se muestra como segundos_ | +| **postgresql.replication.wal_replay_lag**
(gauge) | Tiempo transcurrido entre el vaciado local de WAL reciente y la recepción de la notificación de que este servidor en espera la ha escrito, vaciado y aplicado. Esto puede utilizarse para medir el retraso en el que incurre el nivel synchronous_commit al confirmar si este servidor está configurado como servidor en espera síncrono. Solo disponible con PostgreSQL v10 y posteriores.
_Se muestra como segundos_ | +| **postgresql.replication.wal_write_lag**
(gauge) | Tiempo transcurrido entre el vaciado local de WAL reciente y la recepción de la notificación de que este servidor en espera la ha escrito (pero no la ha vaciado ni aplicado). Esto puede utilizarse para medir el retraso en el que incurre el nivel synchronous_commit al confirmar si este servidor está configurado como servidor en espera síncrono. Solo disponible con PostgreSQL v10 y posteriores.
_Se muestra como segundos_ | +| **postgresql.replication_delay**
(gauge) | Retraso de replicación actual en segundos. Solo disponible con PostgreSQL v9.1 y posteriores
_Se muestra como segundos_ | +| **postgresql.replication_delay_bytes**
(gauge) | Retraso de replicación actual en bytes. Solo disponible con PostgreSQL v9.2 y posteriores
_Se muestra como bytes_ | +| **postgresql.replication_slot.catalog_xmin_age**
(gauge) | Antigüedad de la transacción más antigua que afecta a los catálogos del sistema que este slot necesita que la base de datos conserve. VACUUM no puede eliminar tuplas de catálogo eliminadas por una transacción posterior. Esta métrica está etiquetada con slot_name, slot_type, slot_persistence, slot_state.
_Se muestra como transacción_ | +| **postgresql.replication_slot.confirmed_flush_delay_bytes**
(gauge) | Retraso en bytes entre la posición actual de WAL y la última posición confirmada por el consumidor de este slot. Solo está disponible para slots de replicación lógica. Esta métrica está etiquetada con slot_name, slot_type, slot_persistence, slot_state.
_Se muestra como bytes_ | +| **postgresql.replication_slot.restart_delay_bytes**
(gauge) | Cantidad de bytes WAL que el consumidor de este slot puede requerir y no se eliminará automáticamente durante los puntos de control a menos que exceda el parámetro max_slot_wal_keep_size. No se informa de nada si no hay reserva de WAL para este slot. Esta métrica está etiquetada con slot_name, slot_type, slot_persistence, slot_state.
_Se muestra como bytes_ | +| **postgresql.replication_slot.spill_bytes**
(count) | Cantidad de datos de transacción decodificados vertidos al disco mientras se realiza la decodificación de cambios de WAL para este slot. Este y otros contadores de vertido pueden ser utilizados para medir las E/S ocurridas durante la decodificación lógica y permitir el ajuste de logical_decoding_work_mem. Extraído de pg_stat_replication_slots. Solo disponible con PostgreSQL v14 y posteriores. Esta métrica está etiquetada con slot_name, slot_type, slot_state.
_Se muestra como bytes_ | +| **postgresql.replication_slot.spill_count**
(count) | Número de veces que las transacciones fueron vertidas al disco mientras se decodificaban los cambios de WAL para este slot. Este contador se incrementa cada vez que una transacción es vertida, y la misma transacción puede ser vertida múltiples veces. Extraído de pg_stat_replication_slots. Solo disponible con PostgreSQL v14 y posteriores. Esta métrica está etiquetada con slot_name, slot_type, slot_state.| +| **postgresql.replication_slot.spill_txns**
(count) | Número de transacciones vertidas al disco una vez que la memoria utilizada por la decodificación lógica para decodificar los cambios de WAL excede logical_decoding_work_mem. El contador se incrementa tanto para las transacciones de nivel superior como para las subtransacciones. Extraído de pg_stat_replication_slots. Solo disponible con PostgreSQL v14 y posteriores. Esta métrica está etiquetada con slot_name, slot_type, slot_state.
_Se muestra como transacción_ | +| **postgresql.replication_slot.stream_bytes**
(count) | Cantidad de datos de transacciones decodificados para transmitir transacciones en curso al complemento de salida de decodificación mientras se decodifican los cambios de WAL para este slot. Extraído de pg_stat_replication_slots. Solo disponible con PostgreSQL v14 y posteriores. Esta métrica está etiquetada con slot_name, slot_type, slot_state.
_Se muestra como bytes_ | +| **postgresql.replication_slot.stream_count**
(count) | Número de veces que las transacciones en curso fueron transmitidas al complemento de salida de decodificación mientras se decodificaban los cambios de WAL para este slot. Extraído de pg_stat_replication_slots. Solo disponible con PostgreSQL v14 y posteriores. Esta métrica está etiquetada con slot_name, slot_type, slot_state.| +| **postgresql.replication_slot.stream_txns**
(count) | Número de transacciones en curso transmitidas al complemento de salida de decodificación después de que la memoria utilizada por la decodificación lógica para decodificar cambios de WAL para este slot exceda logical_decoding_work_mem. Extraído de pg_stat_replication_slots. Solo disponible con PostgreSQL v14 y posteriores. Esta métrica está etiquetada con slot_name, slot_type, slot_state.
_Se muestra como transacción_ | +| **postgresql.replication_slot.total_bytes**
(count) | Cantidad de datos de transacciones decodificados para enviar transacciones al complemento de salida de decodificación mientras se decodifican cambios de WAL para este slot. Extraído de pg_stat_replication_slots. Solo disponible con PostgreSQL v14 y posteriores. Esta métrica está etiquetada con slot_name, slot_type, slot_state.
_Se muestra como bytes_ | +| **postgresql.replication_slot.total_txns**
(count) | Número de transacciones decodificadas enviadas al complemento de salida de decodificación para este slot. Extraído de pg_stat_replication_slots. Solo disponible con PostgreSQL v14 y posteriores. Esta métrica está etiquetada con slot_name, slot_type, slot_state.
_Se muestra como transacción_ | +| **postgresql.replication_slot.xmin_age**
(gauge) | Antigüedad de la transacción más antigua que este slot necesita que la base de datos retenga. Solo el slot de replicación física tendrá un xmin. El slot de replicación huérfano (no hay consumidor o el consumidor no está conectado) impedirá que avance el horizonte xmin. Esta métrica está etiquetada con slot_name, slot_type, slot_persistence, slot_state.
_Se muestra como transacción_ | +| **postgresql.rollbacks**
(rate) | Número de transacciones que se han revertido en esta base de datos. Esta métrica está etiquetada con db.
_Se muestra como transacción_ | +| **postgresql.rows_deleted**
(rate) | Activado con `relations`. Número de filas eliminadas por consultas en esta base de datos. Esta métrica está etiquetada con db.
_Se muestra como fila_ | +| **postgresql.rows_fetched**
(tasa) | Número de filas obtenidas por consultas en esta base de datos. Esta métrica está etiquetada con db.
_Se muestra como fila_ | +| **postgresql.rows_hot_updated**
(rate) | Activado con `relations`. Número de filas HOT actualizadas, lo que significa que no fue necesaria una actualización de índice separada. Esta métrica está etiquetada con db, schema, table.
_Se muestra como fila_ | +| **postgresql.rows_inserted**
(rate) | Activado con `relations`. Número de filas insertadas por consultas en esta base de datos. Esta métrica está etiquetada con db.
_Se muestra como fila_ | +| **postgresql.rows_returned**
(rate) | Número de filas devueltas por consultas en esta base de datos. Esta métrica está etiquetada con db.
_Se muestra como fila_ | +| **postgresql.rows_updated**
(rate) | Activado con `relations`. Número de filas actualizadas por consultas en esta base de datos. Esta métrica está etiquetada con db.
_Se muestra como fila_ | +| **postgresql.running**
(gauge) | Número de instancias en ejecución.| +| **postgresql.seq_rows_read**
(gauge) | Activado con `relations`. Número de filas activas obtenidas por análisis secuenciales. Esta métrica está etiquetada con db, schema, table.
_Se muestra como fila_ | +| **postgresql.seq_scans**
(gauge) | Activado con `relations`. Número de análisis secuenciales iniciados de esta tabla. Esta métrica está etiquetada con db, schema, table.
_Se muestra como análisis_ | +| **postgresql.sessions.abandoned**
(count) | Número de sesiones de base de datos en esta base de datos que fueron finalizados porque se perdió la conexión con el cliente. Esta métrica está etiquetada con db.
_Se muestra como sesión_ | +| **postgresql.sessions.active_time**
(count) | Tiempo dedicado a ejecutar sentencias SQL en esta base de datos, en milisegundos (corresponde a los estados active y fastpath de la llamada a la función en pg_stat_activity). Esta métrica está etiquetada con db.
_Se muestra como milisegundos_ | +| **postgresql.sessions.count**
(count) | Número total de sesiones establecidas en esta base de datos. Esta métrica está etiquetada con db.
_Se muestra como sesión_ | +| **postgresql.sessions.fatal**
(count) | Número de sesiones de esta base de datos que fueron finalizados por errores fatales. Esta métrica está etiquetada con db.
_Se muestra como sesión_ | +| **postgresql.sessions.idle_in_transaction_time**
(count) | Tiempo de inactividad durante una transacción en esta base de datos, en milisegundos (corresponde a los estados inactivo en transacción e inactivo en transacción (abortada) en pg_stat_activity). Esta métrica está etiquetada con db.
_Se muestra como milisegundos_ | +| **postgresql.sessions.killed**
(count) | Número de sesiones de esta base de datos que fueron finalizados por intervención del operador. Esta métrica está etiquetada con db.
_Se muestra como sesión_ | +| **postgresql.sessions.session_time**
(count) | Tiempo empleado por las sesiones de base de datos en esta base de datos, en milisegundos (ten en cuenta que las estadísticas solo se actualizan cuando cambia el estado de una sesión, por lo que si las sesiones han estado inactivas durante mucho tiempo, este tiempo de inactividad no será incluido). Esta métrica está etiquetada con db.
_Se muestra como milisegundos_ | +| **postgresql.slru.blks_exists**
(count) | Número de bloques en que se comprueba la existencia de la caché SLRU (simple menos utilizada recientemente). Solo las cachés CommitTs y MultiXactOffset comprueban si los bloques ya están presentes en el disco. Esta métrica está etiquetada con slru_name.
_Se muestra como bloque_ | +| **postgresql.slru.blks_hit**
(count) | Número de veces que se han encontrado bloques de disco ya en la caché SLRU (simple menos utilizada recientemente), por lo que no fue necesaria una lectura (esto solo incluye hits en la SLRU, no en la caché del sistema de archivos del sistema operativo). Esta métrica está etiquetada con slru_name.
_Se muestra como bloque_ | +| **postgresql.slru.blks_read**
(count) | Número de bloques de disco leídos para la caché SLRU (simple menos utilizada recientemente). Las cachés SLRU se crean con un número fijo de páginas. Cuando se utilizan todas las páginas, el bloque utilizado menos recientemente se desaloja del disco para crear espacio. El acceso al bloque desalojado requerirá que los datos se lean del disco y se vuelvan a cargar en una página de caché SLRU, aumentando el recuento de lectura de bloques. Esta métrica está etiquetada con slru_name.
_Se muestra como bloque_ | +| **postgresql.slru.blks_written**
(count) | Número de bloques de disco escritos para la caché SLRU (simple menos utilizada recientemente). Las cachés SLRU se crean con un número fijo de páginas. Cuando se utilizan todas las páginas, el bloque utilizado menos recientemente se desaloja del disco para crear espacio. Un desalojo de bloque no genera necesariamente una escritura en disco, ya que el bloque podría haberse escrito en un desalojo anterior. Esta métrica está etiquetada con slru_name.
_Se muestra como bloque_ | +| **postgresql.slru.blks_zeroed**
(count) | Número de bloques puestos a cero durante las inicializaciones de la caché SLRU (simple menos utilizada recientemente). Las cachés SLRU se crean con un número fijo de páginas. Para las cachés Subtrans, Xact y CommitTs, se utiliza el transactionId global para obtener el número de página. Por lo tanto, aumentará con el rendimiento de la transacción. Esta métrica está etiquetada con slru_name.
_Se muestra como bloque_ | +| **postgresql.slru.flushes**
(count) | Número de vaciados de datos sucios de la caché SLRU (simple menos utilizada recientemente). El vaciado de las cachés CommitTs, MultiXact, Subtrans y Xact tendrá lugar durante el punto de control. El vaciado de la caché MultiXact puede ocurrir durante el vaciado. Esta métrica está etiquetada con slru_name.| +| **postgresql.slru.truncates**
(count) | Número de truncamientos de la caché SLRU (simple menos utilizada recientemente). Para las cachés CommitTs, Xact y MultiXact, los truncamientos se producirán cuando progrese el frozenID. Para la caché Subtrans, un truncamiento puede ocurrir durante un punto de reinicio y un punto de control. Esta métrica está etiquetada con slru_name.| +| **postgresql.snapshot.xip_count**
(gauge) | Informa del número de transacciones activas basadas en pg_snapshot_xip(pg_current_snapshot()).| +| **postgresql.snapshot.xmax**
(gauge) | Informa del siguiente ID de transacción que será asignado basado en pg_snapshot_xmax(pg_current_snapshot()).| +| **postgresql.snapshot.xmin**
(gauge) | Informa del ID de transacción más bajo aún activo basado en pg_snapshot_xmin(pg_current_snapshot()). Todos los ID de transacciones menores que xmin son confirmados y visibles, o revertidos y eliminados.| +| **postgresql.subscription.apply_error**
(count) | Número de errores que se han producido al aplicar los cambios. Extraído de pg_stat_subscription_stats. Solo disponible en PostgreSQL v15 o posteriores. Esta métrica está etiquetada con subscription_name.| +| **postgresql.subscription.last_msg_receipt_age**
(gauge) | Antigüedad de recepción del último mensaje recibido del remitente WAL de origen. Extraído de pg_stat_subscription. Solo disponible en PostgreSQL v12 o posteriores. Esta métrica está etiquetada con subscription_name.
_Se muestra como segundos_ | +| **postgresql.subscription.last_msg_send_age**
(gauge) | Antigüedad de recepción del último mensaje recibido del remitente WAL de origen. Extraído de pg_stat_subscription. Solo disponible en PostgreSQL v12 o posteriores. Esta métrica está etiquetada con subscription_name.
_Se muestra como segundos_ | +| **postgresql.subscription.latest_end_age**
(gauge) | Antigüedad de la última ubicación de escritura de log anticipada informada al remitente WAL de origen. Extraído de pg_stat_subscription. Solo disponible en PostgreSQL v12 o posteriores. Esta métrica está etiquetada con subscription_name.
_Se muestra como segundos_ | +| **postgresql.subscription.state**
(gauge) | Estado de una suscripción por relación y suscripción. Extraído de pg_subscription_rel. Solo disponible en PostgreSQL v14 o posteriores. Esta métrica está etiquetada con subscription_name, relation, state.| +| **postgresql.subscription.sync_error**
(count) | Número de errores producidos durante la sincronización inicial de la tabla. Extraído de pg_stat_subscription_stats. Solo disponible en PostgreSQL v15 o posteriores. Esta métrica está etiquetada con subscription_name.| +| **postgresql.table.count**
(gauge) | Número de tablas de usuario en esta base de datos. Esta métrica está etiquetada con db, schema.
_Se muestra como tabla_ | +| **postgresql.table_bloat**
(gauge) | Activado con `collect_bloat_metrics`. Porcentaje estimado de sobrecarga de las tablas. Esta métrica está etiquetada con db, schema, table.
_Se muestra como porcentaje_ | +| **postgresql.table_size**
(gauge) | Activado con `relations`. Espacio en disco utilizado por la tabla especificada con datos TOAST. No se incluyen el mapa de espacio libre ni el mapa de visibilidad. Esta métrica está etiquetada con db, schema, table.
_Se muestra como bytes_ | +| **postgresql.temp_bytes**
(rate) | Cantidad de datos escritos en archivos temporales por las consultas en esta base de datos. Esta métrica está etiquetada con db.
_Se muestra como bytes_ | +| **postgresql.temp_files**
(rate) | Número de archivos temporales creados por consultas en esta base de datos. Esta métrica está etiquetada con db.
_Se muestra como archivo_ | +| **postgresql.toast.autovacuumed**
(count) | Activado con `relations`. Número de veces que la tabla TOAST de una relación ha sido autovaciada. Esta métrica está etiquetada con db, schema, table.| +| **postgresql.toast.dead_rows**
(gauge) | Activado con `relations`. Número de filas inactivas en la tabla TOAST de una relación. Esta métrica está etiquetada con db, schema, table.| +| **postgresql.toast.index_scans**
(count) | Activado con `relations`. Número de análisis de índices realizados en la tabla TOAST de una relación. Esta métrica está etiquetada con db, schema, table.| +| **postgresql.toast.last_autovacuum_age**
(gauge) | Última vez que el daemon de autovaciado ha vaciado la tabla TOAST de esta tabla. Esta métrica está etiquetada con db, schema, table.
_Se muestra como segundos_ | +| **postgresql.toast.last_vacuum_age**
(gauge) | Última vez que se ha vaciado manualmente la tabla TOAST de esta tabla (sin contar VACUUM FULL). Esta métrica está etiquetada con db, schema, table.
_Se muestra como segundos_ | +| **postgresql.toast.live_rows**
(gauge) | Activado con `relations`. Número de filas activas en la tabla TOAST de una relación. Esta métrica está etiquetada con db, schema, table.| +| **postgresql.toast.rows_deleted**
(count) | Activado con `relations`. Número de filas eliminadas en la tabla TOAST de una relación. Esta métrica está etiquetada con db, schema, table.| +| **postgresql.toast.rows_fetched**
(count) | Activado con `relations`. Número de filas obtenidas en la tabla TOAST de una relación. Esta métrica está etiquetada con db, schema, table.| +| **postgresql.toast.rows_inserted**
(count) | Activado con `relations`. Número de filas insertadas en la tabla TOAST de una relación. Esta métrica está etiquetada con db, schema, table.| +| **postgresql.toast.vacuumed**
(count) | Activado con `relations`. Número de veces que se ha vaciado la tabla TOAST de una relación. Esta métrica está etiquetada con db, schema, table.| +| **postgresql.toast_blocks_hit**
(gauge) | Activado con `relations`. Número de accesos al buffer en la tabla TOAST de esta tabla. Esta métrica está etiquetada con db, schema, table.
_Se muestra como hit_ | +| **postgresql.toast_blocks_read**
(gauge) | Activado con `relations`. Número de bloques de disco leídos de la tabla TOAST de esta tabla. Esta métrica está etiquetada con db, schema, table.
_Se muestra como bloque_ | +| **postgresql.toast_index_blocks_hit**
(gauge) | Activado con `relations`. Número de accesos al buffer en el índice de la tabla TOAST de esta tabla. Esta métrica está etiquetada con db, schema, table.
_Se muestra como bloque_ | +| **postgresql.toast_index_blocks_read**
(gauge) | Activado con `relations`. Número de bloques de disco leídos desde el índice de la tabla TOAST de esta tabla. Esta métrica está etiquetada con db, schema, table.
_Se muestra como bloque_ | +| **postgresql.toast_size**
(gauge) | Espacio total en disco utilizado por la tabla TOAST adjunta a la tabla especificada. Esta métrica está etiquetada con db, schema, table.
_Se muestra como bytes_ | +| **postgresql.total_size**
(gauge) | Activado con `relations`. Espacio total en disco utilizado por la tabla, incluidos los índices y los datos TOAST. Esta métrica está etiquetada con db, schema, table.
_Se muestra como bytes_ | +| **postgresql.transactions.duration.max**
(gauge) | Antigüedad de la transacción en ejecución más larga por usuario, base de datos y aplicación. (Solo DBM)
_Se muestra como nanosegundos_ | +| **postgresql.transactions.duration.sum**
(gauge) | Suma de la antigüedad de todas las transacciones en ejecución por usuario, base de datos y aplicación. (Solo DBM)
_Se muestra como nanosegundos_ | +| **postgresql.transactions.idle_in_transaction**
(gauge) | Activado con `collect_activity_metrics`. Número de transacciones 'inactivas en transacción' en esta base de datos. Esta métrica (por defecto) está etiquetada con db, app, user.
_Se muestra como transacción_ | +| **postgresql.transactions.open**
(gauge) | Activado con `collect_activity_metrics`. Número de transacciones abiertas en esta base de datos. Esta métrica (por defecto) está etiquetada con db, app, user.
_Se muestra como transacción_ | +| **postgresql.uptime**
(gauge) | Tiempo de actividad del servidor en segundos.
_Se muestra como segundos_ | +| **postgresql.vacuum.heap_blks_scanned**
(gauge) | Número de bloques heap analizados. Debido a que el mapa de visibilidad se utiliza para optimizar los análisis, algunos bloques serán omitidos sin inspección. Los bloques omitidos se incluyen en este total, de modo que este número eventualmente se volverá igual a heap_blks_total cuando el vaciado finalice. Este contador solo avanza cuando la fase está analizando heap. Esta métrica está etiquetada con db, table, phase.
_Se muestra como bloque_ | +| **postgresql.vacuum.heap_blks_total**
(gauge) | Número total de bloques heap en la tabla. Este número se informa al inicio del análisis. Los bloques añadidos posteriormente no serán (y no necesitan ser) visitados por este VACUUM. Esta métrica está etiquetada con db, table, phase.
_Se muestra como bloque_ | +| **postgresql.vacuum.heap_blks_vacuumed**
(gauge) | Número de bloques heap vaciados. A menos que la tabla no tenga índices, este contador solo avanza cuando la fase está aspirando heap. Los bloques que no contienen tuplas inactivas se omiten, por lo que el contador a veces puede saltar hacia adelante en grandes incrementos. Esta métrica está etiquetada con db, table, phase.
_Se muestra como bloques_ | +| **postgresql.vacuum.index_vacuum_count**
(gauge) | Número de ciclos de vacío de índices completados. Esta métrica está etiquetada con db, table, phase.
_Se muestra como bloque_ | +| **postgresql.vacuum.max_dead_tuples**
(gauge) | Número de tuplas inactivas que podemos almacenar antes de necesitar realizar un ciclo de vaciado de índices, basado en maintenance_work_mem. Esta métrica está etiquetada con db, table, phase.| +| **postgresql.vacuum.num_dead_tuples**
(gauge) | Número de tuplas inactivas recopiladas desde el último ciclo de vaciado de índices. Esta métrica está etiquetada con db, table, phase.| +| **postgresql.vacuumed**
(count) | Activado con `relations`. Número de veces que esta tabla ha sido vaciada manualmente. Esta métrica está etiquetada con db, schema, table.| +| **postgresql.waiting_queries**
(gauge) | Activado con `collect_activity_metrics`. Número de consultas en espera en esta base de datos. Esta métrica (por defecto) está etiquetada con db, app, user.| +| **postgresql.wal.buffers_full**
(count) | Número de veces que los datos de WAL fueron escritos en el disco porque los buffers de WAL se llenaron. Los cambios de WAL se almacenan primero en los buffers de WAL. Si el buffer está lleno, las inserciones de WAL se bloquean hasta que se vacía el buffer. El tamaño de este buffer se define mediante la configuración de wal_buffers. Por defecto, utilizará el 3% del valor de shared_buffers.| +| **postgresql.wal.bytes**
(count) | Cantidad total de WAL generada en bytes.
_Se muestra como bytes_ | +| **postgresql.wal.full_page_images**
(count) | Número total de imágenes de páginas completas de WAL generadas. La escritura de páginas completas se producirá cuando un bloque se modifique por primera vez después de un punto de control.
_Se muestra como página_ | +| **postgresql.wal.records**
(count) | Número total de registros WAL generados.
_Se muestra como registro_ | +| **postgresql.wal.sync**
(count) | Número de veces que los archivos WAL fueron sincronizados con el disco.| +| **postgresql.wal.sync_time**
(count) | Cantidad total de tiempo dedicado a sincronizar los archivos WAL con el disco, en milisegundos (si track_wal_io_timing está activado, fsync está activado y wal_sync_method es fdatasync, fsync o fsync_writethrough, de lo contrario cero).
_Se muestra como milisegundos_ | +| **postgresql.wal.write**
(count) | Número de veces que los buffers de WAL se han escrito en disco.
_Se muestra como escritura_ | +| **postgresql.wal.write_time**
(count) | Cantidad total de tiempo dedicado a escribir buffers de WAL en el disco, en milisegundos (si track_wal_io_timing está activado, de lo contrario cero).
_Se muestra como milisegundos_ | +| **postgresql.wal_age**
(gauge) | Activado con `collect_wal_metrics`. Antigüedad en segundos del archivo WAL más antiguo.
_Se muestra como segundos_ | +| **postgresql.wal_count**
(gauge) | Número de archivos WAL en disco.| +| **postgresql.wal_receiver.connected**
(gauge) | Estado del receptor WAL. Esta métrica se configurará en 1 con una etiqueta (tag) 'status:disconnected' si la instancia no tiene un receptor WAL en ejecución. En caso contrario, utilizará el valor de estado de pg_stat_wal_receiver. Esta métrica está etiquetada con status.| +| **postgresql.wal_receiver.last_msg_receipt_age**
(gauge) | Tiempo transcurrido desde la recepción del último mensaje del remitente WAL. Esta métrica está etiquetada con el status.
_Se muestra como segundos_ | +| **postgresql.wal_receiver.last_msg_send_age**
(gauge) | Antigüedad del envío del último mensaje recibido del remitente WAL. Esta métrica está etiquetada con status.
_Se muestra como segundos_ | +| **postgresql.wal_receiver.latest_end_age**
(gauge) | Tiempo transcurrido desde la recepción del último mensaje del remitente WAL con una actualización de la ubicación de WAL. Esta métrica está etiquetada con status.
_Se muestra como segundos_ | +| **postgresql.wal_receiver.received_timeline**
(gauge) | Número de línea de tiempo de la última ubicación de escritura anticipada de logs recibida y vaciada al disco. El valor inicial de este campo es el número de línea de tiempo de la ubicación del primer log utilizada cuando se inicia el receptor WAL. Esta métrica está etiquetada con status.| +| **postgresql.wal_size**
(gauge) | Suma de todos los archivos WAL en disco.
_Se muestra como bytes_ | + +Para la versión `7.32.0` y posteriores del Agent, si tienes Database Database Monitoring activado, la métrica `postgresql.connections` se etiqueta (tag) con `state`, `app`, `db` y `user`. ### Eventos El check de PostgreSQL no incluye eventos. ### Checks de servicio -{{< get-service-checks-from-git "postgres" >}} +**postgres.can_connect** + +Devuelve `CRITICAL` si el Agent no puede conectarse a la instancia PostgreSQL monitorizada. Devuelve `OK` en caso contrario. + +_Estados: ok, crítico_ ## Solucionar problemas -¿Necesitas ayuda? Ponte en contacto con el [servicio de asistencia de Datadog][7]. +¿Necesita ayuda? Póngase en contacto con [Datadog support](https://docs.datadoghq.com/help). ## Referencias adicionales -Más enlaces, artículos y documentación útiles: +Documentación útil adicional, enlaces y artículos: ### FAQ -- [Explicación de la recopilación de métricas personalizadas de PostgreSQL][8] +- [Explicación de la recopilación de métricas personalizadas de PostgreSQL](https://docs.datadoghq.com/integrations/faq/postgres-custom-metric-collection-explained/) ### Entradas de blog -- [Postgres 100 veces más rápido cambiando 1 línea][9] -- [Monitorización de métricas clave para PostgreSQL][10] -- [Recopilación de métricas con herramientas de monitorización PostgreSQL][11] -- [Para recopilar y monitorizar datos de PostgreSQL con Datadog][12] - - -[1]: https://raw.githubusercontent.com/DataDog/integrations-core/master/postgres/images/postgresql_dashboard.png -[2]: https://docs.datadoghq.com/database_monitoring/ -[3]: https://app.datadoghq.com/account/settings/agent/latest -[4]: https://docs.datadoghq.com/database_monitoring/#postgres -[5]: https://docs.datadoghq.com/agent/guide/agent-commands/#agent-status-and-information -[6]: https://github.com/DataDog/integrations-core/blob/master/postgres/datadog_checks/postgres/data/conf.yaml.example -[7]: https://docs.datadoghq.com/help -[8]: https://docs.datadoghq.com/integrations/faq/postgres-custom-metric-collection-explained/ -[9]: https://www.datadoghq.com/blog/100x-faster-postgres-performance-by-changing-1-line -[10]: https://www.datadoghq.com/blog/postgresql-monitoring -[11]: https://www.datadoghq.com/blog/postgresql-monitoring-tools -[12]: https://www.datadoghq.com/blog/collect-postgresql-data-with-datadog +- [Rendimiento de Postgres 100 veces más rápido cambiando 1 línea](https://www.datadoghq.com/blog/100x-faster-postgres-performance-by-changing-1-line) +- [Métricas clave para la monitorización de PostgreSQL](https://www.datadoghq.com/blog/postgresql-monitoring) +- [Recopilación de métricas con herramientas de monitorización de PostgreSQL](https://www.datadoghq.com/blog/postgresql-monitoring-tools) +- [Recopilación y monitorización de datos PostgreSQL con Datadog](https://www.datadoghq.com/blog/collect-postgresql-data-with-datadog) \ No newline at end of file diff --git a/content/es/integrations/process.md b/content/es/integrations/process.md index f762697d2b8f4..152b13c0352ca 100644 --- a/content/es/integrations/process.md +++ b/content/es/integrations/process.md @@ -1,83 +1,39 @@ --- app_id: sistema -app_uuid: 43bff15c-c943-4153-a0dc-25bb557ac763 -assets: - integration: - configuration: - spec: assets/configuration/spec.yaml - events: - creates_events: false - metrics: - check: system.processes.cpu.pct - metadata_path: metadata.csv - prefix: sistema - service_checks: - metadata_path: assets/service_checks.json - source_type_name: Proceso -author: - homepage: https://www.datadoghq.com - name: Datadog - sales_email: info@datadoghq.com - support_email: help@datadoghq.com categories: - os & system -custom_kind: integration -dependencies: -- https://github.com/DataDog/integrations-core/blob/master/process/README.md -display_on_public_website: true -draft: false -git_integration_title: proceso -integration_id: sistema -integration_title: Procesos -integration_version: 5.0.0 -is_public: true -manifest_version: 2.0.0 -name: proceso -public_title: Procesos -short_description: Captura métricas y monitoriza el estado de procesos en ejecución. +custom_kind: integración +description: Captura métricas y monitoriza el estado de los procesos en ejecución. +further_reading: +- link: https://www.datadoghq.com/blog/process-check-monitoring + tag: blog + text: Monitorizar el consumo de recursos por parte de los procesos de un vistazo +integration_version: 5.1.0 +media: [] supported_os: - linux - macos - windows -tile: - changelog: CHANGELOG.md - classifier_tags: - - Supported OS::Linux - - Supported OS::macOS - - Supported OS::Windows - - Category::Sistema operativo y sistema - - Offering::Integración - configuration: README.md#Configuración - description: Captura métricas y monitoriza el estado de procesos en ejecución. - media: [] - overview: README.md#Información general - resources: - - resource_type: blog - url: https://www.datadoghq.com/blog/process-check-monitoring - support: README.md#Soporte - title: Procesos +title: Procesos --- - - - - ## Información general -El check de proceso te permite: +El check de procesos te permite: + - Recopila métricas del uso de recursos para procesos en ejecución específicos en cualquier host. Por ejemplo, CPU, memoria, E/S y número de subprocesos. -- Utiliza [monitores de procesos][1] para configurar umbrales de cuántas instancias de un proceso específico deben ejecutarse y recibe alertas cuando no se cumplen los umbrales (consulta **Checks de servicio* a continuación). +- Utiliza [monitores de procesos](https://docs.datadoghq.com/monitors/create/types/process_check/?tab=checkalert) para configurar umbrales sobre cuántas instancias de un proceso específico deben ejecutarse y recibir alertas cuando los umbrales no se cumplen (consulta **Checks de servicio** más abajo). ## Configuración ### Instalación -El check de procesos está incluido en el paquete del [Datadog Agent][2], por lo que no necesitas instalar nada más en tu servidor. +El check de procesos está incluido en el paquete del [Datadog Agent](https://app.datadoghq.com/account/settings/agent/latest), por lo que no necesitas instalar nada más en tu servidor. ### Configuración A diferencia de muchos checks, el check de procesos no monitoriza nada útil por defecto. Debes configurar los procesos que quieres monitorizar. -Aunque no hay una configuración de check por defecto, aquí hay un ejemplo de `process.d/conf.yaml` que monitoriza procesos SSH/SSHD. Para ver todas las opciones de configuración disponibles, consulta el [process.d/conf.yaml de ejemplo][3]: +Si bien no existe una configuración de check estándar por defecto, aquí hay un ejemplo de `process.d/conf.yaml` que monitoriza los procesos SSH/SSHD. Consulta el [ejemplo process.d/conf.yaml](https://github.com/DataDog/integrations-core/blob/master/process/datadog_checks/process/data/conf.yaml.example) para conocer todas las opciones de configuración disponibles: ```yaml init_config: @@ -88,9 +44,9 @@ instances: - sshd ``` -**Nota**: Asegúrate de [reiniciar el Agent][4] después de realizar cambios de configuración. +**Nota**: Después de realizar cambios en la configuración, asegúrate de [reiniciar el Agent](https://docs.datadoghq.com/agent/guide/agent-commands/#start-stop-and-restart-the-agent). -La recuperación de algunas métricas de procesos requiere que el recopilador de Datadog se ejecute como el usuario del proceso monitorizado o con acceso privilegiado. Para la métrica`open_file_descriptors` en plataformas Unix, existe una opción de configuración adicional. Configurar `try_sudo` como `true` en el archivo `conf.yaml` permite que el El check de procesos intente utilizar `sudo` para recopilar la métrica `open_file_descriptors`. El uso de esta opción de configuración requiere definir reglas para sudoers apropiadas en `/etc/sudoers`: +La recuperación de algunas métricas de procesos requiere que el recopilador de Datadog se ejecute como el usuario del proceso monitorizado o con acceso privilegiado. Para la métrica`open_file_descriptors` en plataformas Unix, existe una opción de configuración adicional. Configurar `try_sudo` como `true` en el archivo `conf.yaml` permite que el check de procesos intente utilizar `sudo` para recopilar la métrica `open_file_descriptors`. El uso de esta opción de configuración requiere definir reglas para sudoers apropiadas en `/etc/sudoers`: ```shell dd-agent ALL=NOPASSWD: /bin/ls /proc/*/fd/ @@ -98,14 +54,16 @@ dd-agent ALL=NOPASSWD: /bin/ls /proc/*/fd/ ### Validación -Ejecuta el [subcomando de estado del Agent][5] y busca `process` en la sección Checks. +Ejecuta el [subcomando de estado del Agent](https://docs.datadoghq.com/agent/guide/agent-commands/#agent-status-and-information) y busca `process` en la sección Checks. ### Notas de métricas Las siguientes métricas no están disponibles en Linux o macOS: -- Las métricas de I/O de procesos **no** están disponibles en Linux o macOS, ya que los archivos que lee el Agent (`/proc//io`) sólo pueden ser leídos por el propietario del proceso. Para obtener más información, [lee las FAQ del Agent][6]. + +- Las métricas de E/S del proceso **no** están disponibles en Linux o macOS, ya que los archivos que lee el Agent (`/proc//io`) solo son legibles por el propietario del proceso. Para obtener más información, [lee las FAQ del Agent](https://docs.datadoghq.com/agent/faq/why-don-t-i-see-the-system-processes-open-file-descriptors-metric/).
Las siguientes métricas no están disponibles en Windows:
+
- `system.cpu.iowait`
- `system.processes.mem.page_faults.minor_faults`
- `system.processes.mem.page_faults.children_minor_faults`
@@ -113,50 +71,68 @@ Las siguientes métricas no están disponibles en Windows:
- `system.processes.mem.page_faults.children_major_faults`
- `system.processes.mem.real`
-**Nota**: Utiliza un [check de WMI][7] para reunir métricas de fallos de páginas en Windows.
+**Nota**: Utiliza un [check de WMI](https://docs.datadoghq.com/integrations/wmi_check/) para recopilar métricas de fallos de páginas en Windows.
+
+**Nota**: En la versión 6.11 o posteriores en Windows, el Agent se ejecuta como `ddagentuser` en lugar de `Local System`. Debido a [esto](https://docs.datadoghq.com/agent/guide/windows-agent-ddagent-user/#process-check), no tiene acceso a la línea de comandos completa de los procesos que se ejecutan bajo otros usuarios y al usuario de los procesos de otros usuarios. Esto provoca que las siguientes opciones del check no funcionen:
-**Nota**: En la versión 6.11 o posteriores en Windows, el Agent se ejecuta como `ddagentuser` en lugar de `Local System`. Debido a [esto][8], no tiene acceso a la línea de comandos completa de los procesos que se ejecutan bajo otros usuarios y al usuario de otros procesos de usuarios. Esto provoca que las siguientes opciones de check no funcionen:
- `exact_match`, cuando se configura como `false`
- `user`, que permite seleccionar los procesos que pertenecen a un usuario específico
Todas las métricas se configuran por `instance` en process.yaml y están etiquetados como `process_name:`.
-La métrica `system.processes.cpu.pct` enviada por este check sólo es exacta en procesos que duran más
-de 30 segundos. No esperes que tu valor sea exacto en procesos con duraciones más cortas.
+La métrica `system.processes.cpu.pct` enviada por este check solo es precisa para los procesos que viven más de
+de 30 segundos. No esperes que su valor sea exacto para procesos de vida más corta.
Para ver la lista completa de métricas, consulta la sección [Métricas](#metrics).
## Datos recopilados
### Métricas
-{{< get-metrics-from-git "process" >}}
+| | |
+| --- | --- |
+| **system.processes.cpu.pct**
(gauge) | Uso de CPU de un proceso.
_Se muestra como porcentaje_ | +| **system.processes.cpu.normalized_pct**
(gauge) | Uso normalizado de CPU de un proceso.
_Se muestra como porcentaje_ | +| **system.processes.involuntary_ctx_switches**
(gauge) | Número de cambios de contexto involuntarios realizados por este proceso.
_Se muestra como evento_ | +| **system.processes.ioread_bytes**
(gauge) | Número de bytes leídos del disco por este proceso. En Windows: el número de bytes leídos.
_Se muestra como bytes_ | +| **system.processes.ioread_bytes_count**
(count) | Número de bytes leídos del disco por este proceso. En Windows: el número de bytes leídos.
_Se muestra como bytes_ | +| **system.processes.ioread_count**
(gauge) | Número de lecturas del disco realizadas por este proceso. En Windows: el número de lecturas realizadas por este proceso.
_Se muestra como lectura_ | +| **system.processes.iowrite_bytes**
(gauge) | Número de bytes escritos en el disco por este proceso. En Windows: el número de bytes escritos por este proceso.
_Se muestra como bytes_ | +| **system.processes.iowrite_bytes_count**
(count) | Número de bytes escritos en el disco por este proceso. En Windows: el número de bytes escritos por este proceso.
_Se muestra como bytes_ | +| **system.processes.iowrite_count**
(gauge) | Número de escrituras en el disco realizadas por este proceso. En Windows: el número de escrituras de este proceso.
_Se muestra como escritura_ | +| **system.processes.mem.page_faults.minor_faults**
(gauge) | En Unix/Linux y macOS: el número de fallos menores de página por segundo para este proceso.
_Se muestra como caso_ | +| **system.processes.mem.page_faults.children_minor_faults**
(gauge) | En Unix/Linux y macOS: el número de fallos menores de página por segundo por cada elemento secundario para este proceso.
_Se muestra como caso_ | +| **system.processes.mem.page_faults.major_faults**
(gauge) | En Unix/Linux y macOS: el número de fallos mayores de página por segundo para este proceso.
_Se muestra como caso_ | +| **system.processes.mem.page_faults.children_major_faults**
(gauge) | En Unix/Linux y macOS: el número de fallos mayores de página por segundo por cada elemento secundario para este proceso.
_Se muestra como caso_ | +| **system.processes.mem.pct**
(gauge) | Consumo de memoria del proceso.
_Se muestra como porcentaje_ | +| **system.processes.mem.real**
(gauge) | Memoria física no intercambiada que un proceso ha utilizado y no puede ser compartida con otro proceso (solo Linux).
_Se muestra como bytes_ | +| **system.processes.mem.rss**
(gauge) | Memoria física no intercambiada que un proceso ha utilizado. también conocido como "Tamaño del conjunto residente".
_Se muestra como bytes_ | +| **system.processes.mem.vms**
(gauge) | Cantidad total de memoria virtual utilizada por el proceso. también conocido como "Tamaño de memoria virtual".
_Se muestra como bytes_ | +| **system.processes.number**
(gauge) | Número de procesos.
_Se muestra como proceso_ | +| **system.processes.open_file_descriptors**
(gauge) | Número de descriptores de archivos utilizados por este proceso (solo disponible para procesos ejecutados como usuario dd-agent)| +| **system.processes.open_handles**
(gauge) | Número de manejadores utilizados por este proceso.| +| **system.processes.threads**
(gauge) | Número de subprocesos utilizados por este proceso.
_Se muestra como subproceso_ | +| **system.processes.voluntary_ctx_switches**
(gauge) | Número de cambios de contexto voluntarios realizados por este proceso.
_Se muestra como evento_ | +| **system.processes.run_time.avg**
(gauge) | Tiempo medio de ejecución de todas las instancias de este proceso
_Se muestra como segundos_ | +| **system.processes.run_time.max**
(gauge) | Tiempo más largo de ejecución de todas las instancias de este proceso
_Se muestra como segundos_ | +| **system.processes.run_time.min**
(gauge) | Tiempo más corto de ejecución de todas las instancias de este proceso
_Se muestra como segundos_ | ### Eventos El check de procesos no incluye eventos. ### Checks de servicio -{{< get-service-checks-from-git "process" >}} +**process.up** + +Devuelve OK si el check está dentro de los umbrales de advertencia, CRITICAL si está fuera de los umbrales críticos y WARNING si está fuera de los umbrales de advertencia. + +_Estados: ok, advertencia, crítico_ ## Solucionar problemas -¿Necesitas ayuda? Ponte en contacto con el [servicio de asistencia de Datadog][11]. +¿Necesitas ayuda? Ponte en contacto con el [servicio de asistencia de Datadog](https://docs.datadoghq.com/help/). ## Referencias adicionales -Para hacerse una mejor idea de cómo (o por qué) monitorizar el consumo de recursos de los proceso con Datadog, consulta esta [serie de entradas de blog][12]. - -[1]: https://docs.datadoghq.com/es/monitors/create/types/process_check/?tab=checkalert -[2]: https://app.datadoghq.com/account/settings/agent/latest -[3]: https://github.com/DataDog/integrations-core/blob/master/process/datadog_checks/process/data/conf.yaml.example -[4]: https://docs.datadoghq.com/es/agent/guide/agent-commands/#start-stop-and-restart-the-agent -[5]: https://docs.datadoghq.com/es/agent/guide/agent-commands/#agent-status-and-information -[6]: https://docs.datadoghq.com/es/agent/faq/why-don-t-i-see-the-system-processes-open-file-descriptors-metric/ -[7]: https://docs.datadoghq.com/es/integrations/wmi_check/ -[8]: https://docs.datadoghq.com/es/agent/guide/windows-agent-ddagent-user/#process-check -[9]: https://github.com/DataDog/integrations-core/blob/master/process/metadata.csv -[10]: https://github.com/DataDog/integrations-core/blob/master/process/assets/service_checks.json -[11]: https://docs.datadoghq.com/es/help/ -[12]: https://www.datadoghq.com/blog/process-check-monitoring \ No newline at end of file +Para hacerte una mejor idea de cómo (o por qué) monitorizar el consumo de recursos por parte de los proceso con Datadog, consulta esta [serie de entradas de blog](https://www.datadoghq.com/blog/process-check-monitoring). \ No newline at end of file diff --git a/content/es/integrations/pulsar.md b/content/es/integrations/pulsar.md index 69d7cab3c8dc1..843c79459d1cf 100644 --- a/content/es/integrations/pulsar.md +++ b/content/es/integrations/pulsar.md @@ -1,138 +1,277 @@ --- app_id: pulsar -app_uuid: 2a3a1555-3c19-42a9-b954-ce16c4aa6308 -assets: - integration: - auto_install: true - configuration: - spec: assets/configuration/spec.yaml - events: - creates_events: false - metrics: - check: pulsar.active_connections - metadata_path: metadata.csv - prefix: pulsar. - process_signatures: - - java org.apache.pulsar.PulsarStandaloneStarter - service_checks: - metadata_path: assets/service_checks.json - source_type_id: 10143 - source_type_name: pulsar -author: - homepage: https://www.datadoghq.com - name: Datadog - sales_email: info@datadoghq.com - support_email: help@datadoghq.com categories: - recopilación de logs - colas de mensajes custom_kind: integración -dependencies: -- https://github.com/DataDog/integrations-core/blob/master/pulsar/README.md -display_on_public_website: true -draft: false -git_integration_title: pulsar -integration_id: pulsar -integration_title: Pulsar +description: Monitoriza tus clústeres Pulsar. integration_version: 3.2.0 -is_public: true -manifest_version: 2.0.0 -name: pulsar -public_title: Pulsar -short_description: Monitoriza tus clústeres Pulsar. +media: [] supported_os: - Linux - Windows - macOS -tile: - changelog: CHANGELOG.md - classifier_tags: - - Categoría::Recopilación de logs - - Categoría::Colas de mensajes - - Sistema operativo compatible::Linux - - Sistema operativo compatible::Windows - - Sistema operativo compatible::macOS - - Oferta::Integración - configuration: README.md#Configuración - description: Monitoriza tus clústeres Pulsar. - media: [] - overview: README.md#Información general - support: README.md#Soporte - title: Pulsar +title: Pulsar --- - - - - ## Información general -Este check monitoriza [Pulsar][1] a través del Datadog Agent. +Este check monitoriza [Pulsar](https://pulsar.apache.org) a través del Datadog Agent. ## Configuración -Sigue las instrucciones a continuación para instalar y configurar este check para un Agent que se ejecuta en un host. Para entornos en contenedores, consulta las [plantillas de integración de Autodiscovery][2] para obtener orientación sobre la aplicación de estas instrucciones. +Sigue las instrucciones a continuación para instalar y configurar este check para un Agent que se ejecute en un host. Para entornos en contenedores, consulta las [plantillas de integración de Autodiscovery](https://docs.datadoghq.com/agent/kubernetes/integrations/) para obtener orientación sobre la aplicación de estas instrucciones. ### Instalación -El check de Pulsar está incluido en el paquete del [Datadog Agent ][3]. +El check de Pulsar está incluido en el paquete del [Datadog Agent](https://app.datadoghq.com/account/settings/agent/latest). No es necesaria ninguna instalación adicional en tu servidor. ### Configuración -1. Edita el archivo `pulsar.d/conf.yaml`, que se encuentra en la carpeta `conf.d/` en la raíz del directorio de configuración del Agent, para empezar a recopilar los datos de rendimiento de tu Pulsar. Para conocer todas las opciones de configuración disponibles, consulta el [pulsar.d/conf.yaml de ejemplo][4]. +1. Edita el archivo `pulsar.d/conf.yaml`, en la carpeta `conf.d/` en la raíz de tu directorio de configuración del Agent para empezar a recopilar tus datos de rendimiento de Pulsar. Consulta el [ejemplo pulsar.d/conf.yaml](https://github.com/DataDog/integrations-core/blob/master/pulsar/datadog_checks/pulsar/data/conf.yaml.example) para conocer todas las opciones de configuración disponibles. -2. [Reinicia el Agent][5]. +1. [Reinicia el Agent](https://docs.datadoghq.com/agent/guide/agent-commands/#start-stop-and-restart-the-agent). ### Validación -[Ejecuta el subcomando de estado del Agent][6] y busca `pulsar` en la sección Checks. +[Ejecuta el subcomando de estado del Agent] (https://docs.datadoghq.com/agent/guide/agent-commands/#agent-status-and-information) y busca `pulsar` en la sección Checks. ## Datos recopilados ### Métricas -{{< get-metrics-from-git "pulsar" >}} - +| | | +| --- | --- | +| **pulsar.active_connections**
(gauge) | Número de conexiones activas.
_Se muestra como conexión_ | +| **pulsar.authentication_failures_count.count**
(count) | Número de operaciones de autenticación fallidas.| +| **pulsar.authentication_success_count.count**
(count) | Número de operaciones de autenticación realizadas con éxito.| +| **pulsar.bookie_DELETED_LEDGER_COUNT.count**
(count) | Número total de ledgers eliminados desde que fue iniciado el bookie.| +| **pulsar.bookie_READ_BYTES.count**
(count) | Número total de bytes leídos del bookie.
_Se muestra como bytes_ | +| **pulsar.bookie_SERVER_STATUS**
(gauge) | Estado del servidor del bookie server. 1: el bookie se ejecuta en modo de escritura.0: el bookie se ejecuta en modo de solo lectura.| +| **pulsar.bookie_WRITE_BYTES.count**
(count) | Número total de bytes escritos en el bookie.
_Se muestra como bytes_ | +| **pulsar.bookie_entries_count**
(gauge) | Número total de entradas almacenadas en el bookie.| +| **pulsar.bookie_flush**
(gauge) | Latencia de descarga de la tabla de la memoria del bookie.| +| **pulsar.bookie_journal_JOURNAL_CB_QUEUE_SIZE**
(gauge) | Número total de devoluciones de llamada pendientes en la cola de devoluciones de llamada.| +| **pulsar.bookie_journal_JOURNAL_FORCE_WRITE_QUEUE_SIZE**
(gauge) | Número total de solicitudes de escritura forzada (fsync) pendientes en la cola de escritura forzada.
_Se muestra como solicitud_ | +| **pulsar.bookie_journal_JOURNAL_QUEUE_SIZE**
(gauge) | Número total de solicitudes pendientes en la cola de registros.
_Se muestra como solicitud_ | +| **pulsar.bookie_journal_JOURNAL_SYNC_count.count**
(count) | Número total de operaciones fsync de diario que se producen en el bookie. La etiqueta de éxito se utiliza para distinguir éxitos y fracasos.| +| **pulsar.bookie_ledger_writable_dirs**
(gauge) | Número de directorios con permisos de escritura en el bookie.| +| **pulsar.bookie_ledgers_count**
(gauge) | Número total de ledgers almacenados en el bookie.| +| **pulsar.bookie_read_cache_size**
(gauge) | Tamaño de la caché de lectura del bookie (en bytes).
_Se muestra como bytes_ | +| **pulsar.bookie_throttled_write_requests.count**
(count) | Número de solicitudes de escritura que se deben limitar.
_Se muestra como solicitud_ | +| **pulsar.bookie_write_cache_size**
(gauge) | Tamaño de la caché de escritura del bookie (en bytes).
_Se muestra como bytes_ | +| **pulsar.bookkeeper_server_ADD_ENTRY_count.count**
(count) | Número total de solicitudes ADD_ENTRY recibidas en el bookie. La etiqueta de éxito se utiliza para distinguir éxitos y fracasos.
_Se muestra como solicitud_. | +| **pulsar.bookkeeper_server_BOOKIE_QUARANTINE_count.count**
(count) | Número de clientes de bookie que deben colocarse en cuarentena.| +| **pulsar.bookkeeper_server_READ_ENTRY_count.count**
(count) | Número total de solicitudes READ_ENTRY recibidas en el bookie. La etiqueta de éxito se utiliza para distinguir éxitos y fracasos.
_Se muestra como solicitud_ | +| **pulsar.brk_ml_cursor_nonContiguousDeletedMessagesRange**
(gauge) | Número de rangos de mensajes no contiguos eliminados.| +| **pulsar.brk_ml_cursor_persistLedgerErrors**
(gauge) | Número de errores de ledger ocurridos cuando los estados de reconocimiento no logran ser persistentes en el ledger.
_Se muestra como error_ | +| **pulsar.brk_ml_cursor_persistLedgerSucceed**
(gauge) | Número de estados de reconocimiento persistentes en un ledger.| +| **pulsar.brk_ml_cursor_persistZookeeperErrors**
(gauge) | Número de errores del ledger cuando los estados de reconocimiento no logran ser persistentes en ZooKeeper.
_Se muestra como error_ | +| **pulsar.brk_ml_cursor_persistZookeeperSucceed**
(gauge) | Número de estados de reconocimiento persistentes en ZooKeeper.| +| **pulsar.brk_ml_cursor_readLedgerSize**
(gauge) | Tamaño de la lectura del ledger.| +| **pulsar.brk_ml_cursor_writeLedgerLogicalSize**
(gauge) | Tamaño de la escritura en el ledger (teniendo en cuenta sin réplicas).| +| **pulsar.brk_ml_cursor_writeLedgerSize**
(gauge) | Tamaño de la escritura en el ledger.| +| **pulsar.broker_load_manager_bundle_assignment**
(gauge) | Resumen de la latencia de las operaciones de propiedad de paquetes.| +| **pulsar.broker_lookup.count**
(count) | Número de muestras de la latencia de todas las operaciones de búsqueda.| +| **pulsar.broker_lookup.quantle**
(count) | Latencia de todas las operaciones de búsqueda.| +| **pulsar.broker_lookup.sum**
(count) | Latencia total de todas las operaciones de búsqueda.| +| **pulsar.broker_lookup_answers.count**
(count) | Número de respuestas de búsqueda (es decir, solicitudes no redirigidas).
_Se muestra como respuesta_ | +| **pulsar.broker_lookup_failures.count**
(count) | Número de errores de búsqueda.| +| **pulsar.broker_lookup_pending_requests**
(gauge) | Número de búsquedas pendientes en el broker. Cuando alcanza el umbral, se rechazan las nuevas solicitudes.
_Se muestra como solicitud_ | +| **pulsar.broker_lookup_redirects.count**
(count) | Número de solicitudes de búsqueda redirigidas.
_Se muestra como solicitud_ | +| **pulsar.broker_throttled_connections**
(gauge) | Número de conexiones limitadas.
_Se muestra como conexión_ | +| **pulsar.broker_throttled_connections_global_limit**
(gauge) | Número de conexiones limitadas debido al límite por conexión.
_Se muestra como conexión_ | +| **pulsar.broker_topic_load_pending_requests**
(gauge) | Carga de operaciones de temas pendientes.| +| **pulsar.bundle_consumer_count**
(gauge) | Recuento de consumidores de temas de este paquete.| +| **pulsar.bundle_msg_rate_in**
(gauge) | Tasa total de mensajes que llegan a los temas de este paquete (mensajes/segundo).| +| **pulsar.bundle_msg_rate_out**
(gauge) | Tasa total de mensajes que salen de los temas de este paquete (mensajes/segundo).| +| **pulsar.bundle_msg_throughput_in**
(gauge) | Rendimiento total que entra en los temas de este paquete (bytes/segundo).| +| **pulsar.bundle_msg_throughput_out**
(gauge) | Rendimiento total que sale de los temas de este paquete (bytes/segundo).| +| **pulsar.bundle_producer_count**
(gauge) | Recuento de productores de los temas de este paquete.| +| **pulsar.bundle_topics_count**
(gauge) | Recuento de temas de este paquete.| +| **pulsar.compaction_compacted_entries_count**
(gauge) | Número total de entradas compactadas.| +| **pulsar.compaction_compacted_entries_size**
(gauge) | Tamaño total de las entradas compactadas.| +| **pulsar.compaction_duration_time_in_mills**
(gauge) | Duración de la compactación.| +| **pulsar.compaction_failed_count**
(gauge) | Número total de fallos de la compactación.| +| **pulsar.compaction_read_throughput**
(gauge) | Rendimiento de lectura de la compactación.| +| **pulsar.compaction_removed_event_count**
(gauge) | Número total de eventos eliminados de la compactación.| +| **pulsar.compaction_succeed_count**
(gauge) | Número total de éxitos de la compactación.| +| **pulsar.compaction_write_throughput**
(gauge) | Rendimiento de escritura de la compactación.| +| **pulsar.connection_closed_total_count**
(gauge) | Número total de conexiones cerradas.
_Se muestra como conexión_ | +| **pulsar.connection_create_fail_count**
(gauge) | Número de conexiones fallidas.
_Se muestra como conexión_ | +| **pulsar.connection_create_success_count**
(gauge) | Número de conexiones creadas con éxito.
_Se muestra como conexión_ | +| **pulsar.connection_created_total_count**
(gauge) | Número total de conexiones.
_Se muestra como conexión_ | +| **pulsar.consumer_available_permits**
(gauge) | Permisos disponibles para un consumidor.| +| **pulsar.consumer_blocked_on_unacked_messages**
(gauge) | Indica si un consumidor está bloqueado en mensajes no reconocidos o no. 1 significa que el consumidor está bloqueado a la espera de que los mensajes no reconocidos sean reconocidos, acked.0 significa que el consumidor no está bloqueado a la espera de que los mensajes no reconocidos sean reconocidos.| +| **pulsar.consumer_msg_rate_out**
(gauge) | Tasa total de envío de mensajes de un consumidor (mensajes/segundo).| +| **pulsar.consumer_msg_rate_redeliver**
(gauge) | Tasa total de mensajes que se vuelven a entregar (mensajes/segundo).| +| **pulsar.consumer_msg_throughput_out**
(gauge) | Rendimiento total de envío de mensajes a un consumidor (bytes/segundo).| +| **pulsar.consumer_unacked_messages**
(gauge) | Número total de mensajes no reconocidos de un consumidor (mensajes).
_Se muestra como mensaje_ | +| **pulsar.consumers_count**
(gauge) | Número de consumidores activos del espacio de nombres conectados a este broker.| +| **pulsar.expired_token_count.count**
(count) | Número de tokens caducados en Pulsar.| +| **pulsar.function_last_invocation**
(gauge) | Marca de tiempo de la última invocación de la función.| +| **pulsar.function_processed_successfully_total.count**
(count) | Número total de mensajes procesados con éxito.
_Se muestra como mensaje_ | +| **pulsar.function_processed_successfully_total_1min.count**
(count) | Número total de mensajes procesados con éxito en el último minuto.
_Se muestra como mensaje_ | +| **pulsar.function_received_total.count**
(count) | Número total de mensajes recibidos de la fuente.
_Se muestra como mensaje_ | +| **pulsar.function_received_total_1min.count**
(count) | Número total de mensajes recibidos de la fuente en el último minuto.
_Se muestra como mensaje_ | +| **pulsar.function_system_exceptions_total.count**
(count) | Número total de excepciones del sistema.| +| **pulsar.function_system_exceptions_total_1min.count**
(count) | Número total de excepciones del sistema en el último minuto.| +| **pulsar.function_user_exceptions_total.count**
(count) | Número total de excepciones de usuarios.| +| **pulsar.function_user_exceptions_total_1min.count**
(count) | Número total de excepciones de usuarios en el último minuto.| +| **pulsar.in_bytes_total**
(gauge) | Número de mensajes en bytes recibidos de este tema.
_Se muestra como byte_ | +| **pulsar.in_messages_total**
(gauge) | Número total de mensajes recibidos de este tema.
_Se muestra como mensaje_ | +| **pulsar.jetty_async_dispatches_total.count**
(count) | Número de solicitudes que se han enviado de forma asíncrona.| +| **pulsar.jetty_async_requests_total.count**
(count) | Número total de solicitudes asíncronas.
_Se muestra como solicitud_ | +| **pulsar.jetty_async_requests_waiting**
(gauge) | Actualmente esperando solicitudes asíncronas.
_Se muestra como solicitud_ | +| **pulsar.jetty_async_requests_waiting_max**
(gauge) | Número máximo de peticiones solicitudes en espera.
_Se muestra como solicitud_ | +| **pulsar.jetty_dispatched_active**
(gauge) | Número de envíos activos actualmente.| +| **pulsar.jetty_dispatched_active_max**
(gauge) | Número máximo de envíos activos que se están gestionando.| +| **pulsar.jetty_dispatched_time_max**
(gauge) | Tiempo máximo dedicado a la gestión de envíos.| +| **pulsar.jetty_dispatched_time_seconds_total.count**
(count) | Tiempo total dedicado a la gestión del envío.
_Se muestra como segundos_ | +| **pulsar.jetty_dispatched_total.count**
(count) | Número de envíos.| +| **pulsar.jetty_expires_total.count**
(count) | Número de solicitudes asíncronas que han caducado.
_Se muestra como solicitud_ | +| **pulsar.jetty_request_time_max_seconds**
(gauge) | Tiempo máximo dedicado a la gestión de solicitudes.
_Se muestra como segundos_ | +| **pulsar.jetty_request_time_seconds_total.count**
(count) | Tiempo total dedicado a la gestión de todas las solicitudes.
_Se muestra como segundos_ | +| **pulsar.jetty_requests_active**
(gauge) | Número de solicitudes activas actualmente.
_Se muestra como solicitud_ | +| **pulsar.jetty_requests_active_max**
(gauge) | Número máximo de solicitudes que han estado activas a la vez.
_Se muestra como solicitud_ | +| **pulsar.jetty_requests_total.count**
(count) | Número de solicitudes.
_Se muestra como solicitud_ | +| **pulsar.jetty_responses_bytes_total.count**
(count) | Número total de bytes en todas las respuestas.
_Se muestra como bytes_ | +| **pulsar.jetty_responses_total.count**
(count) | Número de respuestas, etiquetadas por código de estado. La etiqueta del código puede ser "1xx", "2xx", "3xx", "4xx" o "5xx".
_Se muestra como respuesta_ | +| **pulsar.jetty_stats_seconds**
(gauge) | Tiempo en segundos durante el que se han recopilado estadísticas.
_Se muestra como segundos_ | +| **pulsar.lb_bandwidth_in_usage**
(gauge) | Uso de ancho de banda entrante del broker (en porcentaje).| +| **pulsar.lb_bandwidth_out_usage**
(gauge) | Uso de ancho de banda saliente del broker (en porcentaje).| +| **pulsar.lb_bundles_split_count.count**
(count) | Recuento de división de paquetes en este intervalo de comprobación de división de paquetes| +| **pulsar.lb_cpu_usage**
(gauge) | Uso de cpu del broker (en porcentaje).| +| **pulsar.lb_directMemory_usage**
(gauge) | Uso de memoria directa del proceso de broker (en porcentaje).| +| **pulsar.lb_memory_usage**
(gauge) | Uso de memoria del proceso del broker (en porcentaje).| +| **pulsar.lb_unload_broker_count.count**
(count) | Recuento de brokers de descarga en esta descarga de paquetes| +| **pulsar.lb_unload_bundle_count.count**
(count) | Recuento de descarga de paquetes en esta descarga de paquetes| +| **pulsar.ml_AddEntryBytesRate**
(gauge) | Tasa de bytes/s de mensajes añadidos| +| **pulsar.ml_AddEntryErrors**
(gauge) | Número de solicitudes addEntry fallidas
_Se muestra como solicitud_ | +| **pulsar.ml_AddEntryMessagesRate**
(gauge) | Tasa de msg/s de mensajes añadidos| +| **pulsar.ml_AddEntrySucceed**
(gauge) | Número de solicitudes de addEntry exitosas
_Se muestra como solicitud_ | +| **pulsar.ml_AddEntryWithReplicasBytesRate**
(gauge) | Tasa de bytes/s de mensajes añadidos con réplicas| +| **pulsar.ml_MarkDeleteRate**
(gauge) | Tasa de operaciones/s de marcado-eliminación| +| **pulsar.ml_NumberOfMessagesInBacklog**
(gauge) | Número de mensajes pendientes para todos los consumidores
_Se muestra como mensaje_ | +| **pulsar.ml_ReadEntriesBytesRate**
(gauge) | Tasa de bytes/s de mensajes leídos| +| **pulsar.ml_ReadEntriesErrors**
(gauge) | Número de solicitudes readEntries fallidas
_Se muestra como solicitud_ | +| **pulsar.ml_ReadEntriesRate**
(gauge) | Tasa de msg/s de mensajes leídos| +| **pulsar.ml_ReadEntriesSucceeded**
(gauge) | Número de solicitudes readEntries exitosas
_Se muestra como solicitud_ | +| **pulsar.ml_StoredMessagesSize**
(gauge) | Tamaño total de los mensajes en ledgers activos (teniendo en cuenta las múltiples copias almacenadas).| +| **pulsar.ml_cache_evictions**
(gauge) | Número de desalojos de la caché durante el último minuto.
_Se muestra como desalojo_ | +| **pulsar.ml_cache_hits_rate**
(gauge) | Número de accesos a la caché por segundo en el lado del broker.
_Se muestra como hit_ | +| **pulsar.ml_cache_hits_throughput**
(gauge) | Cantidad de datos que se recuperan de la caché en el lado del broker (en bytes/s).| +| **pulsar.ml_cache_misses_rate**
(gauge) | Número de fallos de caché por segundo en el lado del broker.
_Se muestra como fallo_ | +| **pulsar.ml_cache_misses_throughput**
(gauge) | Cantidad de datos que no se recuperan de la caché en el lado del broker (en byte/s).| +| **pulsar.ml_cache_pool_active_allocations**
(gauge) | Número de asignaciones actualmente activas en el ámbito directo| +| **pulsar.ml_cache_pool_active_allocations_huge**
(gauge) | Número de grandes asignaciones actualmente activas en el ámbito directo| +| **pulsar.ml_cache_pool_active_allocations_normal**
(gauge) | Número de asignaciones normales actualmente activas en el ámbito directo| +| **pulsar.ml_cache_pool_active_allocations_small**
(gauge) | Número de pequeñas asignaciones actualmente activas en el ámbito directo| +| **pulsar.ml_cache_pool_allocated**
(gauge) | Memoria total asignada a las listas de fragmentos en el ámbito directo| +| **pulsar.ml_cache_pool_used**
(gauge) | Memoria total utilizada de las listas de fragmentos en el ámbito directo| +| **pulsar.ml_cache_used_size**
(gauge) | Tamaño en bytes utilizado para almacenar las cargas útiles de las entradas
_Se muestra como bytes_ | +| **pulsar.ml_count**
(gauge) | Número de ledgers gestionados actualmente abiertos| +| **pulsar.out_bytes_total**
(gauge) | Número total de mensajes en bytes leídos de este tema.
_Se muestra como bytes_ | +| **pulsar.out_messages_total**
(gauge) | Número total de mensajes leídos de este tema.
_Se muestra como mensaje_ | +| **pulsar.producers_count**
(gauge) | Número de productores activos del espacio de nombres conectados a este broker.| +| **pulsar.proxy_active_connections**
(gauge) | Número de conexiones activas actualmente en el proxy.
_Se muestra como conexión_ | +| **pulsar.proxy_binary_bytes.count**
(count) | Contador de bytes proxy.
_Se muestra como bytes_ | +| **pulsar.proxy_binary_ops.count**
(count) | Contador de operaciones proxy.| +| **pulsar.proxy_new_connections.count**
(count) | Contador de conexiones que se están abriendo en el proxy.
_Se muestra como conexión_ | +| **pulsar.proxy_rejected_connections.count**
(count) | Contador de conexiones rechazadas por limitación.
_Se muestra como conexión_ | +| **pulsar.rate_in**
(gauge) | Tasa total de mensajes del espacio de nombres que llegan a este broker (mensajes/segundo).| +| **pulsar.rate_out**
(gauge) | Tasa total de mensajes del espacio de nombres que salen de este broker (mensajes/segundo).| +| **pulsar.replication_backlog**
(gauge) | Backlog total del espacio de nombres que replica al clúster remoto (mensajes).
_Se muestra como mensaje_ | +| **pulsar.replication_connected_count**
(gauge) | Recuento de suscriptores de replicación en funcionamiento para replicar al clúster remoto.| +| **pulsar.replication_delay_in_seconds**
(gauge) | Tiempo en segundos desde el momento en que se produjo un mensaje hasta el momento en que está a punto de ser replicado.
_Se muestra como segundos_ | +| **pulsar.replication_rate_expired**
(gauge) | Tasa total de mensajes caducados (mensajes/segundo).| +| **pulsar.replication_rate_in**
(gauge) | Tasa total de mensajes del espacio de nombres que replica desde el clúster remoto (mensajes/segundo).| +| **pulsar.replication_rate_out**
(gauge) | Tasa total de mensajes del espacio de nombres que replica al clúster remoto (mensajes/segundo).| +| **pulsar.replication_throughput_in**
(gauge) | Rendimiento total del espacio de nombres que replica desde el clúster remoto (bytes/segundo).| +| **pulsar.replication_throughput_out**
(gauge) | Rendimiento total del espacio de nombres que replica al clúster remoto (bytes/segundo).| +| **pulsar.sink_last_invocation**
(gauge) | Marca de tiempo de la última invocación del sumidero.| +| **pulsar.sink_received_total.count**
(count) | Número total de registros que un sumidero ha recibido de temas Pulsar.| +| **pulsar.sink_received_total_1min.count**
(count) | Número total de mensajes que un sumidero ha recibido de temas Pulsar en el último minuto.
_Se muestra como mensaje_ | +| **pulsar.sink_sink_exception**
(gauge) | Excepción de un sumidero.| +| **pulsar.sink_sink_exceptions_total.count**
(count) | Número total de excepciones de sumidero.| +| **pulsar.sink_sink_exceptions_total_1min.count**
(count) | Número total de excepciones de sumidero en el último minuto.| +| **pulsar.sink_system_exception**
(gauge) | Excepción del código del sistema.| +| **pulsar.sink_system_exceptions_total.count**
(count) | Número total de excepciones del sistema.| +| **pulsar.sink_system_exceptions_total_1min.count**
(count) | Número total de excepciones del sistema en el último minuto.| +| **pulsar.sink_written_total.count**
(count) | Número total de registros procesados por un sumidero.| +| **pulsar.sink_written_total_1min.count**
(count) | Número total de registros procesados por un sumidero en el último minuto.| +| **pulsar.source_last_invocation**
(gauge) | Marca de tiempo de la última invocación de la fuente.| +| **pulsar.source_received_total.count**
(count) | Número total de registros recibidos de la fuente.| +| **pulsar.source_received_total_1min.count**
(count) | Número total de registros recibidos de la fuente en el último minuto.| +| **pulsar.source_source_exception**
(gauge) | Excepción de una fuente.| +| **pulsar.source_source_exceptions_total.count**
(count) | Número total de excepciones de una fuente.| +| **pulsar.source_source_exceptions_total_1min.count**
(count) | Número total de excepciones de una fuente en el último minuto.| +| **pulsar.source_system_exception**
(gauge) | Excepción del código del sistema.| +| **pulsar.source_system_exceptions_total.count**
(count) | Número total de excepciones del sistema.| +| **pulsar.source_system_exceptions_total_1min.count**
(count) | Número total de excepciones del sistema en el último minuto.| +| **pulsar.source_written_total.count**
(count) | Número total de registros escritos en un tema Pulsar.| +| **pulsar.source_written_total_1min.count**
(count) | Número total de registros escritos en un tema Pulsar en el último minuto.| +| **pulsar.split_bytes_read.count**
(count) | Número de bytes leídos desde BookKeeper.
_Se muestra como bytes_ | +| **pulsar.split_num_messages_deserialized.count**
(count) | Número de mensajes deserializados.
_Se muestra como mensaje_ | +| **pulsar.split_num_record_deserialized.count**
(count) | Número de registros deserializados.| +| **pulsar.storage_backlog_quota_limit**
(gauge) | Cantidad total de datos en este tema que limitan la cuota de backlog (bytes).
_Se muestra como bytes_ | +| **pulsar.storage_backlog_size**
(gauge) | Tamaño total del backlog de temas de este espacio de nombres propiedad de este broker (mensajes).| +| **pulsar.storage_logical_size**
(gauge) | Tamaño de almacenamiento delos temas en el espacio de nombres propiedad del broker sin réplicas (en bytes).| +| **pulsar.storage_offloaded_size**
(gauge) | Cantidad total de datos de este espacio de nombres descargados al almacenamiento por niveles (bytes).| +| **pulsar.storage_read_rate**
(gauge) | Total de lotes de mensajes (entradas) leídos del almacenamiento para este espacio de nombres (lotes de mensajes/segundo).| +| **pulsar.storage_size**
(gauge) | Tamaño total de almacenamiento de los temas en este espacio de nombres propiedad de este broker (bytes).| +| **pulsar.storage_write_rate**
(gauge) | Total de lotes de mensajes (entradas) escritos en el almacenamiento para este espacio de nombres (lotes de mensajes/segundo).| +| **pulsar.subscription_back_log**
(gauge) | Backlog total de una suscripción (mensajes).
_Se muestra como mensaje_ | +| **pulsar.subscription_blocked_on_unacked_messages**
(gauge) | Indica si una suscripción está bloqueada en los mensajes no reconocidos o no. 1 significa que la suscripción está bloqueada a la espera de que los mensajes no reconocidos sean reconocidos, 0 significa que la suscripción no está bloqueada a la espera de que los mensajes no reconocidos sean reconocidos.| +| **pulsar.subscription_delayed**
(gauge) | Total de lotes de mensajes (entradas) cuyo envío se retrasa.| +| **pulsar.subscription_msg_rate_out**
(gauge) | Tasa total de envío de mensajes de una suscripción (mensajes/segundo).| +| **pulsar.subscription_msg_rate_redeliver**
(gauge) | Tasa total de mensajes que se vuelven a entregar (mensajes/segundo).| +| **pulsar.subscription_msg_throughput_out**
(gauge) | Rendimiento total de envío de mensajes de una suscripción (bytes/segundo).| +| **pulsar.subscription_unacked_messages**
(gauge) | Número total de mensajes no reconocidos para una suscripción (mensajes).
_Se muestra como mensaje_ | +| **pulsar.subscriptions_count**
(gauge) | Número de suscripciones Pulsar del espacio de nombres servidas por este broker.| +| **pulsar.throughput_in**
(gauge) | Rendimiento total del espacio de nombres que entra en este broker (bytes/segundo).| +| **pulsar.throughput_out**
(gauge) | Rendimiento total del espacio de nombres que sale de este broker (bytes/segundo).| +| **pulsar.topics_count**
(gauge) | Número de temas Pulsar del espacio de nombres propiedad de este broker.| +| **pulsar.txn_aborted_count.count**
(count) | Número de transacciones abortadas de este coordinador.
_Se muestra como transacción_ | +| **pulsar.txn_active_count**
(gauge) | Número de transacciones activas.
_Se muestra como transacción_ | +| **pulsar.txn_append_log_count.count**
(count) | Número de logs de transacciones anexas.| +| **pulsar.txn_committed_count.count**
(count) | Número de transacciones confirmadas.
_Se muestra como transacción_ | +| **pulsar.txn_created_count.count**
(count) | Número de transacciones creadas.
_Se muestra como transacción_ | +| **pulsar.txn_timeout_count.count**
(count) | Número de transacciones con tiempo de espera agotado.
_Se muestra como transacción_ | ### Recopilación de logs -1. La integración de logs de Pulsar admite el [formato de logs por defecto][8] de Pulsar. Clona y edita el [pipeline de la integración][9] si tienes un formato diferente. +1. La integración de logs de Pulsar admite el [formato de log por defecto](https://pulsar.apache.org/docs/en/reference-configuration/#log4j) de Pulsar. Clona y edita el [pipeline de la integración](https://docs.datadoghq.com/logs/processing/#integration-pipelines) si tienes un formato diferente. + +1. La recopilación de logs está desactivada por defecto en el Datadog Agent. Actívala en tu archivo `datadog.yaml`: -2. La recopilación de logs se encuentra deshabilitada de manera predeterminada en el Datadog Agent. Habilítala en tu archivo `datadog.yaml`: ```yaml logs_enabled: true ``` -3. Deselecciona y edita el bloque de configuración de logs en tu archivo `pulsar.d/conf.yaml`. Cambia el valor de los parámetros de ruta según tu entorno. Consulta el [pulsar.d/conf.yaml de ejemplol][4] para ver todas las opciones de configuración disponibles. +1. Descomenta y edita el bloque de configuración de logs en tu archivo `pulsar.d/conf.yaml`. Cambia el valor del parámetro de ruta en función de tu entorno. Consulta el [ejemplo pulsar.d/conf.yaml](https://github.com/DataDog/integrations-core/blob/master/pulsar/datadog_checks/pulsar/data/conf.yaml.example) para ver todas las opciones de configuración disponibles. + ```yaml logs: - type: file path: /pulsar/logs/pulsar.log source: pulsar ``` -4. [Reiniciar el Agent][5] + +1. [Reinicia el Agent](https://docs.datadoghq.com/agent/guide/agent-commands/#start-stop-and-restart-the-agent) ### Eventos La integración Pulsar no incluye eventos. ### Checks de servicio -{{< get-service-checks-from-git "pulsar" >}} +**pulsar.openmetrics.health** -## Solucionar problemas +Devuelve `CRITICAL` si el Agent no puede conectarse al endpoint de OpenMetrics o `OK` en caso contrario. -¿Necesitas ayuda? Contacta con el [equipo de asistencia de Datadog][11]. +_Estados: ok, crítico_ +## Solucionar problemas -[1]: https://pulsar.apache.org -[2]: https://docs.datadoghq.com/es/agent/kubernetes/integrations/ -[3]: https://app.datadoghq.com/account/settings/agent/latest -[4]: https://github.com/DataDog/integrations-core/blob/master/pulsar/datadog_checks/pulsar/data/conf.yaml.example -[5]: https://docs.datadoghq.com/es/agent/guide/agent-commands/#start-stop-and-restart-the-agent -[6]: https://docs.datadoghq.com/es/agent/guide/agent-commands/#agent-status-and-information -[7]: https://github.com/DataDog/integrations-core/blob/master/pulsar/metadata.csv -[8]: https://pulsar.apache.org/docs/en/reference-configuration/#log4j -[9]: https://docs.datadoghq.com/es/logs/processing/#integration-pipelines -[10]: https://github.com/DataDog/integrations-core/blob/master/pulsar/assets/service_checks.json -[11]: https://docs.datadoghq.com/es/help/ \ No newline at end of file +¿Necesitas ayuda? Ponte en contacto con el [servicio de asistencia de Datadog](https://docs.datadoghq.com/help/). \ No newline at end of file diff --git a/content/es/integrations/purefa.md b/content/es/integrations/purefa.md index fa67e7d691a97..af298eb5785c0 100644 --- a/content/es/integrations/purefa.md +++ b/content/es/integrations/purefa.md @@ -1,82 +1,30 @@ --- app_id: purefa -app_uuid: a2d8f393-62cd-4ece-bfab-e30797698b12 -assets: - dashboards: - purefa_overview: assets/dashboards/purefa_overview.json - purefa_overview_legacy: assets/dashboards/purefa_overview_legacy.json - integration: - auto_install: true - configuration: - spec: assets/configuration/spec.yaml - events: - creates_events: false - metrics: - check: purefa.info - metadata_path: metadata.csv - prefix: purefa. - service_checks: - metadata_path: assets/service_checks.json - source_type_id: 10256 - source_type_name: PureFA -author: - homepage: https://purestorage.com - name: Pure Storage - sales_email: sales@purestorage.com - support_email: pure-observability@purestorage.com categories: - almacenes de datos - sistema operativo y sistema -custom_kind: integration -dependencies: -- https://github.com/DataDog/integrations-extras/blob/master/purefa/README.md -display_on_public_website: true -draft: false -git_integration_title: purefa -integration_id: purefa -integration_title: FlashArray Pure Storage -integration_version: 1.2.0 -is_public: true -manifest_version: 2.0.0 -name: purefa -public_title: FlashArray Pure Storage -short_description: Monitorización del rendimiento y el uso de FlashArrays Pure Storage +custom_kind: integración +description: Monitorización del rendimiento y el uso de FlashArrays Pure Storage +integration_version: 1.3.0 +media: +- caption: Dashboard de FlashArray Pure Storage - Información general (arriba) + image_url: images/FA-overview-1.png + media_type: imagen +- caption: Dashboard de FlashArray Pure Storage - Información general (arriba) + image_url: images/FA-overview-2.png + media_type: imagen +- caption: Dashboard de FlashArray Pure Storage - Información general (abajo) + image_url: images/FA-overview-3.png + media_type: imagen supported_os: - Linux - Windows - macOS -tile: - changelog: CHANGELOG.md - classifier_tags: - - Categoría::Almacenes de datos - - Categoría::Sistema operativo y sistema - - Oferta::Integración - - Sistema operativo compatible::Linux - - Sistema operativo compatible::Windows - - Sistema operativo compatible::macOS - configuration: README.md#Configuración - description: Monitorización del rendimiento y el uso de FlashArrays Pure Storage - media: - - caption: Dashboard de FlashArray Pure Storage - Información general (arriba) - image_url: images/FA-overview-1.png - media_type: imagen - - caption: Dashboard de FlashArray Pure Storage - Información general (arriba) - image_url: images/FA-overview-2.png - media_type: imagen - - caption: Dashboard de FlashArray Pure Storage - Información general (abajo) - image_url: images/FA-overview-3.png - media_type: imagen - overview: README.md#Información general - support: README.md#Soporte - title: FlashArray Pure Storage +title: FlashArray Pure Storage --- - - - - ## Información general -Este check monitoriza el [FlashArray Pure Storage][1] a través del [Datadog Agent][2] y el [exportador OpenMetrics Pure Storage][3]. +Este check monitoriza [Pure Storage FlashArray](https://www.purestorage.com/products.html) a través del [Datadog Agent](https://app.datadoghq.com/account/settings/agent/latest) y el [exportador OpenMetrics de Pure Storage](https://github.com/PureStorage-OpenConnect/pure-fa-openmetrics-exporter). La integración puede proporcionar datos de rendimiento a nivel de matriz, host, volumen y pod, así como información muy clara sobre capacidad y configuración. @@ -84,9 +32,10 @@ Puedes monitorizar múltiples FlashArrays y agregarlos en un único dashboard o **Esta integración requiere lo siguiente**: - - Agent v7.26.x o posterior para utilizar OpenMetrics BaseCheckV2 - - Python 3 - - El exportador OpenMetrics Pure Storage se instala y ejecuta en un entorno contenedorizado. Para obtener instrucciones de instalación, consulta el [repositorio de GitHub][3]. +- Agent v7.26.x o posterior para utilizar OpenMetrics BaseCheckV2 +- Python 3 +- El exportador OpenMetrics de Pure Storage se instala y ejecuta en un entorno contenedorizado. Consulta el [repositorio de GitHub](https://github.com/PureStorage-OpenConnect/pure-fa-openmetrics-exporter) para obtener instrucciones de instalación. + - En FlashArrays que ejecutan Purity//FA versión 6.7.0 y posteriores, el exportador OpenMetrics se ejecuta de forma nativa en la matriz. Consulta Configuración para obtener más información. ## Configuración @@ -94,24 +43,93 @@ Sigue las instrucciones a continuación para instalar y configurar este check pa ### Instalación -1. [Descarga e inicia el Datadog Agent][2]. -2. Instala manualmente la integración Pure FlashArray. Para obtener más detalles en función de tu entorno, consulta [Uso de integraciones de la comunidad][4]. - +1. [Descarga e inicia el Datadog Agent](https://app.datadoghq.com/account/settings/agent/latest). +1. Instala manualmente la integración Pure FlashArray. Consulta [Uso de integraciones comunitarias](https://docs.datadoghq.com/agent/guide/community-integrations-installation-with-docker-agent) para obtener más información en función de tu entorno. #### Host Para configurar este check para un Agent que se ejecuta en un host, ejecuta `sudo -u dd-agent -- datadog-agent integration install -t datadog-purefa==`.
-Nota: `` se puede encontrar dentro del [CHANGELOG.md][5] de integraciones adicionales de Datadog.
- * Por ejemplo `sudo -u dd-agent -- datadog-agent integration install -t datadog-purefa==1.2.0`
+Nota: `` se puede encontrar dentro del [CHANGELOG.md](https://github.com/DataDog/integrations-extras/blob/master/purefa/CHANGELOG.md) para Datadog Integration Extras.
+
+- Por ejemplo `sudo -u dd-agent -- datadog-agent integration install -t datadog-purefa==1.3.0`
### Configuración
1. Crea un usuario local en tu FlashArray con el rol de sólo lectura y genera un token de API para este usuario.
- ![Generación de una clave de API][6]
-2. Añade el siguiente bloque de configuración al archivo `purefa.d/conf.yaml`, que se encuentra en la carpeta `conf.d/` en la raíz del directorio de configuración del Agent para comenzar a recopilar tus datos de rendimiento de PureFA. Para conocer todas las opciones de configuración disponibles, consulta el [purefa.d/conf.yaml de ejemplo][7].
+ 
+1. Añade el siguiente bloque de configuración al archivo `purefa.d/conf.yaml`, en la carpeta `conf.d/` en la raíz del directorio de configuración de tu Agent para empezar a recopilar tus datos de rendimiento de PureFA. Consulta el ejemplo [purefa.d/conf.yaml](https://github.com/datadog/integrations-extras/blob/master/purefa/datadog_checks/purefa/data/conf.yaml.example) para conocer todas las opciones de configuración disponibles.
+
+> **Nota**: La creación de tu archivo de configuración requiere el endpoint `/array` como mínimo absoluto.
+
+#### (Preferido) Para uso con el exportador nativo OpenMetrics de Pure Storage (Purity//FA v6.7.0 o posteriores)
+
+```yaml
+init_config:
+ timeout: 60
+
+instances:
+
+ - openmetrics_endpoint: https:///metrics/array?namespace=purefa
+ tags:
+ - env:
+ - fa_array_name:
+ - host:
+ headers:
+ Authorization: Bearer
+ min_collection_interval: 120
+ # If you have not configured your Purity management TLS certifcate, you may skip TLS verification. For other TLS options, please see conf.yaml.example.
+ # tls_verify: false
+ # tls_ignore_warning: true
+
+ - openmetrics_endpoint: https:///metrics/volumes?namespace=purefa
+ tags:
+ - env:
+ - fa_array_name:
+ headers:
+ Authorization: Bearer
+ min_collection_interval: 120
+ # If you have not configured your Purity management TLS certifcate, you may skip TLS verification. For other TLS options, please see conf.yaml.example.
+ # tls_verify: false
+ # tls_ignore_warning: true
+
+ - openmetrics_endpoint: https:///metrics/hosts?namespace=purefa
+ tags:
+ - env:
+ - fa_array_name:
+ headers:
+ Authorization: Bearer
+ min_collection_interval: 120
+ # If you have not configured your Purity management TLS certifcate, you may skip TLS verification. For other TLS options, please see conf.yaml.example.
+ # tls_verify: false
+ # tls_ignore_warning: true
-**Nota**: La creación de tu archivo de configuración requiere el endpoint `/array` como mínimo absoluto.
+ - openmetrics_endpoint: https:///metrics/pods?namespace=purefa
+ tags:
+ - env:
+ - fa_array_name:
+ - host:
+ headers:
+ Authorization: Bearer
+ min_collection_interval: 120
+ # If you have not configured your Purity management TLS certifcate, you may skip TLS verification. For other TLS options, please see conf.yaml.example.
+ # tls_verify: false
+ # tls_ignore_warning: true
+
+ - openmetrics_endpoint: https:///metrics/directories?namespace=purefa
+ tags:
+ - env:
+ - fa_array_name:
+ - host:
+ headers:
+ Authorization: Bearer
+ min_collection_interval: 120
+ # If you have not configured your Purity management TLS certifcate, you may skip TLS verification. For other TLS options, please see conf.yaml.example.
+ # tls_verify: false
+ # tls_ignore_warning: true
+```
+
+#### Para su uso con el exportador externo [OpenMetrics de Pure Storage(https://github.com/PureStorage-OpenConnect/pure-fa-openmetrics-exporter) (Purity //FA v\<6.7.0)
```yaml
init_config:
@@ -163,29 +181,27 @@ instances:
min_collection_interval: 120
```
-2. [Reinicia el Agent][8].
+2. [Reinicia el Agent](https://docs.datadoghq.com/agent/guide/agent-commands/#start-stop-and-restart-the-agent).
### Validación
-[Ejecuta el subcomando de estado del Agent][9] y busca `purefa` en la sección Checks.
-
-
+[Ejecuta el subcomando de estado del Agent] (https://docs.datadoghq.com/agent/guide/agent-commands/#agent-status-and-information) y busca `purefa` en la sección Checks.
### Actualización a nuevas versiones de esta integración
#### A partir del check del Agent PureFA v1.0.x a v1.1.x
-La versión 1.1.x admite tanto el [exportador OpenMetrics Pure Storage][3] y el [exportador Prometheus Pure Storage][10] obsoleto.
+1.1.x admite tanto el [exportador OpenMetrics de Pure Storage](https://github.com/PureStorage-OpenConnect/pure-fa-openmetrics-exporter) como el obsoleto [exportador Prometheus de Pure Storage](https://github.com/PureStorage-OpenConnect/pure-exporter).
-El dashboard para el [exportador Prometheus Pure Storage][10] obsoleto ha sido renombrado `Pure FlashArray - Overview (Legacy Exporter)`.
+El dashboard del obsoleto [exportador Prometheus de Pure Storage](https://github.com/PureStorage-OpenConnect/pure-exporter) ha sido renombrado como `Pure FlashArray - Overview (Legacy Exporter)`.
-En [metrics.py][11] se muestra un listado de métricas, tanto compartidas como exclusivas, de los distintos exportadores. Al migrar del [exportador Prometheus Pure Storage][10] al [exportador OpenMetrics Pure Storage][3], es posible que tengas que actualizar tus dashboards o tus alertas para que coincidan con los nuevos nombres de métricas. Si tienes alguna pregunta, ponte en contacto con Pure Storage con la información de la pestaña de asistencia.
+En [metrics.py](https://github.com/datadog/integrations-extras/blob/master/purefa/datadog_checks/purefa/metrics.py) encontrarás una lista de métricas compartidas y exclusivas de los distintos exportadores. Es posible que tengas que actualizar tus dashboards o tus alertas para que coincidan con los nuevos nombres de métricas al migrar del [exportador Prometheus de Pure Storage](https://github.com/PureStorage-OpenConnect/pure-exporter) al [exportador OpenMetrics de Pure Storage](https://github.com/PureStorage-OpenConnect/pure-fa-openmetrics-exporter). Si tienes alguna pregunta, ponte en contacto con Pure Storage con la información de la pestaña Asistencia.
-Al migrar del [exportador Prometheus Pure Storage][10] al [exportador OpenMetrics Pure Storage][3], los endpoints ya no tendrán `/flasharray` en el URI del endpoint.
+Al migrar del [exportador Prometheus de Pure Storage](https://github.com/PureStorage-OpenConnect/pure-exporter) al [exportador OpenMetrics de Pure Storage](https://github.com/PureStorage-OpenConnect/pure-fa-openmetrics-exporter), los endpoints ya no tendrán `/flasharray` en el URI del endpoint.
En futuras versiones del check del Agent PureFA, se eliminarán los nombres de métricas del exportador Prometheus Pure Storage.
-### Resolución de problemas
+### Solucionar problemas
#### Las matrices no se muestran en el dashboard
@@ -206,12 +222,90 @@ El check de FlashArray Pure Storage configura `min_collection_interval` como `12
min_collection_interval: 120
```
-
## Datos recopilados
### Métricas
-{{< get-metrics-from-git "purefa" >}}
+| | |
+| --- | --- |
+| **purefa.alerts.open**
(gauge) | Eventos de alerta de FlashArray abiertos.| +| **purefa.alerts.total**
(gauge) | (Legacy) Número de eventos de alerta.| +| **purefa.array.performance_average_bytes**
(gauge) | Tamaño medio de las operaciones de la matriz FlashArray en bytes.
_Se muestra como bytes_ | +| **purefa.array.performance_avg_block_bytes**
(gauge) | (Legacy) Tamaño medio de bloque de FlashArray.
_Se muestra como bytes_ | +| **purefa.array.performance_bandwidth_bytes**
(gauge) | Rendimiento de la matriz FlashArray en bytes por segundo.
_Se muestra como bytes_ | +| **purefa.array.performance_iops**
(gauge) | (Legacy) IOPS FlashArray.
_Se muestra como operación_ | +| **purefa.array.performance_latency_usec**
(gauge) | Latencia de la matriz FlashArray en microsegundos.
_Se muestra como microsegundos_ | +| **purefa.array.performance_qdepth**
(gauge) | (Legacy) Profundidad de la cola de FlashArray.| +| **purefa.array.performance_queue_depth_ops**
(gauge) | Tamaño de la profundidad de la cola de la matriz FlashArray.
_Se muestra como operación_ | +| **purefa.array.performance_throughput_iops**
(gauge) | Rendimiento de la matriz FlashArray en IOPS.
_Se muestra como operación_ | +| **purefa.array.space_bytes**
(gauge) | Espacio de la matriz FlashArray en bytes.
_Se muestra como bytes_ | +| **purefa.array.space_capacity_bytes**
(gauge) | (Legacy) Capacidad de espacio total de FlashArray.
_Se muestra como bytes_ | +| **purefa.array.space_data_reduction_ratio**
(gauge) | Reducción de datos del espacio de la matriz FlashArray.| +| **purefa.array.space_datareduction_ratio**
(gauge) | (Legacy) Reducción global de datos de FlashArray.| +| **purefa.array.space_provisioned_bytes**
(gauge) | (Legacy) Espacio total aprovisionado de FlashArray.
_Se muestra como bytes_ | +| **purefa.array.space_used_bytes**
(gauge) | (Legacy) Espacio total utilizado de FlashArray.
_Se muestra como bytes_ | +| **purefa.array.space_utilization**
(gauge) | Uso del espacio de la matriz FlashArray en porcentaje.
_Se muestra como porcentaje_ | +| **purefa.directory.performance_average_bytes**
(gauge) | Tamaño medio de las operaciones del directorio FlashArray en bytes.
_Se muestra como bytes_ | +| **purefa.directory.performance_bandwidth_bytes**
(gauge) | Rendimiento del directorio FlashArray en bytes por segundo.
_Se muestra como bytes_ | +| **purefa.directory.performance_latency_usec**
(gauge) | Latencia del directorio FlashArray en microsegundos.
_Se muestra como microsegundos_ | +| **purefa.directory.performance_throughput_iops**
(gauge) | Rendimiento del directorio FlashArray en IOPS.
_Se muestra como operación_ | +| **purefa.directory.space_bytes**
(gauge) | Espacio del directorio FlashArray en bytes.
_Se muestra como bytes_ | +| **purefa.directory.space_data_reduction_ratio**
(gauge) | Reducción de datos del espacio del directorio FlashArray.| +| **purefa.drive.capacity_bytes**
(gauge) | Capacidad de la unidad FlashArray en bytes.
_Se muestra como bytes_ | +| **purefa.hardware.chassis_health**
(gauge) | (Legacy) Estado de salud del chasis de hardware de FlashArray.| +| **purefa.hardware.component_health**
(gauge) | (Legacy) Estado de salud del componente de hardware de FlashArray.| +| **purefa.hardware.controller_health**
(gauge) | (Legacy) Estado de salud del controlador de hardware de FlashArray.| +| **purefa.hardware.power_volts**
(gauge) | (Legacy) Tensión de alimentación del hardware de FlashArray.
_Se muestra como voltios_ | +| **purefa.hardware.temperature_celsius**
(gauge) | (Legacy) Sensores de temperatura del hardware de FlashArray.
_Se muestra como grados celsius_ | +| **purefa.host.connections_info**
(gauge) | Conexiones de volúmenes del host FlashArray.| +| **purefa.host.connectivity_info**
(gauge) | Información de conectividad del host FlashArray.| +| **purefa.host.performance_average_bytes**
(gauge) | Tamaño medio de las operaciones del host FlashArray en bytes.
_Se muestra como bytes_ | +| **purefa.host.performance_bandwidth_bytes**
(gauge) | Ancho de banda del host FlashArray en bytes por segundo.
_Se muestra como bytes_ | +| **purefa.host.performance_iops**
(gauge) | (Legacy) IOPS de host FlashArray.
_Se muestra como operación_ | +| **purefa.host.performance_latency_usec**
(gauge) | Latencia del host FlashArray en microsegundos.
_Se muestra como microsegundos_ | +| **purefa.host.performance_throughput_iops**
(gauge) | Rendimiento del host FlashArray en IOPS.
_Se muestra como operación_ | +| **purefa.host.space_bytes**
(gauge) | Espacio del host FlashArray en bytes.
_Se muestra como bytes_ | +| **purefa.host.space_data_reduction_ratio**
(gauge) | Reducción de datos del espacio del host FlashArray.| +| **purefa.host.space_datareduction_ratio**
(gauge) | (Legacy) Ratio de reducción de datos de los volúmenes del host FlashArray.| +| **purefa.host.space_size_bytes**
(gauge) | Tamaño de los volúmenes del host FlashArray.
_Se muestra como bytes_ | +| **purefa.hw.component_status**
(gauge) | Estado del componente de hardware de FlashArray.| +| **purefa.hw.component_temperature_celsius**
(gauge) | Temperatura del componente de hardware de FlashArray en °C.
_Se muestra como grados celsius_ | +| **purefa.hw.component_voltage_volt**
(gauge) | Tensión del componente de hardware de FlashArray.
_Se muestra como voltios_ | +| **purefa.hw.controller_info**
(gauge) | Información del controlador FlashArray| +| **purefa.hw.controller_mode_since_timestamp_seconds**
(gauge) | Tiempo de actividad del controlador de hardware de FlashArray en segundos
_Se muestra como segundos_ | +| **purefa.info**
(gauge) | Información del sistema FlashArray.| +| **purefa.network.interface_performance_bandwidth_bytes**
(gauge) | Ancho de banda de la interfaz de red de FlashArray en bytes por segundo
_Se muestra como bytes_ | +| **purefa.network.interface_performance_errors**
(gauge) | Errores de la interfaz de red de FlashArray en errores por segundo
_Se muestra como error_ | +| **purefa.network.interface_performance_throughput_pkts**
(gauge) | Rendimiento de la interfaz de red de FlashArray en paquetes por segundo.
_Se muestra como paquete_ | +| **purefa.network.interface_speed_bandwidth_bytes**
(gauge) | Velocidad de la interfaz de red de FlashArray en bytes por segundo
_Se muestra como bytes_ | +| **purefa.network.port_info**
(gauge) | Información del puerto de red de FlashArray| +| **purefa.pod.mediator_status**
(gauge) | (Legacy) Estado del mediador de pods de FlashArray.| +| **purefa.pod.performance_average_bytes**
(gauge) | Tamaño medio de las operaciones de pods de FlashArray.
_Se muestra como bytes_ | +| **purefa.pod.performance_bandwidth_bytes**
(gauge) | Rendimiento de pods de FlashArray en bytes por segundo.
_Se muestra como bytes_ | +| **purefa.pod.performance_iops**
(gauge) | (Legacy) IOPS de pods de FlashArray.
_Se muestra como operación_ | +| **purefa.pod.performance_latency_usec**
(gauge) | Latencia de pods de FlashArray en microsegundos.
_Se muestra como microsegundos_ | +| **purefa.pod.performance_replication_bandwidth_bytes**
(gauge) | Ancho de banda de replicación de pods de FlashArray.
_Se muestra como bytes_ | +| **purefa.pod.performance_throughput_iops**
(gauge) | Rendimiento de pods de FlashArray en IOPS.
_Se muestra como operación_ | +| **purefa.pod.replica_links_lag_average_msec**
(gauge) | Retraso medio de enlaces de pods de FlashArray en milisegundos.
_Se muestra como segundos_ | +| **purefa.pod.replica_links_lag_average_sec**
(gauge) | Retraso medio de enlaces de pods de FlashArray en milisegundos.
_Se muestra como segundos_ | +| **purefa.pod.replica_links_lag_max_msec**
(gauge) | Retraso máximo de enlaces de pods de FlashArray en milisegundos.
_Se muestra como segundos_ | +| **purefa.pod.replica_links_lag_max_sec**
(gauge) | Retraso máximo de enlaces de pods de FlashArray en milisegundos.
_Se muestra como segundos_ | +| **purefa.pod.replica_links_performance_bandwidth_bytes**
(gauge) | Ancho de banda de enlaces de pods de FlashArray.
_Se muestra como bytes_ | +| **purefa.pod.space_bytes**
(gauge) | Espacio de pods de FlashArray en bytes.
_Se muestra como bytes_ | +| **purefa.pod.space_data_reduction_ratio**
(gauge) | Reducción de datos en el espacio de pods de FlashArray.| +| **purefa.pod.space_datareduction_ratio**
(gauge) | (Legacy) Ratio de reducción de datos de pods de FlashArray.| +| **purefa.pod.space_size_bytes**
(gauge) | (Legacy) Tamaño de pods de FlashArray.
_Se muestra como bytes_ | +| **purefa.pod.status**
(gauge) | (Legacy) Estado de pods de FlashArray.| +| **purefa.volume.performance_average_bytes**
(gauge) | Tamaño medio de las operaciones de volúmenes de FlashArray en bytes.
_Se muestra como bytes_ | +| **purefa.volume.performance_bandwidth_bytes**
(gauge) | Rendimiento de volúmenes de FlashArray en bytes por segundo.
_Se muestra como bytes_ | +| **purefa.volume.performance_iops**
(gauge) | (Legacy) IOPS de volúmenes de FlashArray.
_Se muestra como operación_ | +| **purefa.volume.performance_latency_usec**
(gauge) | Latencia de volúmenes de FlashArray en microsegundos.
_Se muestra como microsegundos_ | +| **purefa.volume.performance_throughput_bytes**
(gauge) | (Legacy) Rendimiento de volúmenes de FlashArray.
_Se muestra como bytes_ | +| **purefa.volume.performance_throughput_iops**
(gauge) | Rendimiento de volúmenes de FlashArray en IOPS.
_Se muestra como operación_ | +| **purefa.volume.space_bytes**
(gauge) | Espacio de volúmenes de FlashArray en bytes.
_Se muestra como bytes_ | +| **purefa.volume.space_data_reduction_ratio**
(gauge) | Reducción del espacio de datos de volúmenes de FlashArray.| +| **purefa.volume.space_datareduction_ratio**
(gauge) | (Legacy) Ratio de reducción de datos de volúmenes de FlashArray.| +| **purefa.volume.space_size_bytes**
(gauge) | (Legacy) Tamaño de volúmenes de FlashArray.
_Se muestra como bytes_ | ### Eventos @@ -219,25 +313,15 @@ La integración PureFA no incluye eventos. ### Checks de servicio -Para ver una lista de los checks de servicio proporcionados por esta integración, consulta [service_checks.json][13]. +**purefa.openmetrics.health** -## Agent +Devuelve `CRITICAL` si el Agent no puede conectarse al endpoint de OpenMetrics o `OK` en caso contrario. + +_Estados: ok, crítico_ + +## Soporte Para obtener asistencia o realizar solicitudes de funciones, ponte en contacto con Pure Storage utilizando los siguientes métodos: -* Correo electrónico: pure-observability@purestorage.com -* Slack: [Código Storage Code//Canal de observabilidad][14]. - -[1]: https://www.purestorage.com/products.html -[2]: https://app.datadoghq.com/account/settings/agent/latest -[3]: https://github.com/PureStorage-OpenConnect/pure-fa-openmetrics-exporter -[4]: https://docs.datadoghq.com/es/agent/guide/community-integrations-installation-with-docker-agent -[5]: https://github.com/DataDog/integrations-extras/blob/master/purefa/CHANGELOG.md -[6]: https://raw.githubusercontent.com/DataDog/integrations-extras/master/purefa/images/API.png -[7]: https://github.com/datadog/integrations-extras/blob/master/purefa/datadog_checks/purefa/data/conf.yaml.example -[8]: https://docs.datadoghq.com/es/agent/guide/agent-commands/#start-stop-and-restart-the-agent -[9]: https://docs.datadoghq.com/es/agent/guide/agent-commands/#agent-status-and-information -[10]: https://github.com/PureStorage-OpenConnect/pure-exporter -[11]: https://github.com/datadog/integrations-extras/blob/master/purefa/datadog_checks/purefa/metrics.py -[12]: https://github.com/DataDog/integrations-extras/blob/master/purefa/metadata.csv -[13]: https://github.com/DataDog/integrations-extras/blob/master/purefa/assets/service_checks.json -[14]: https://code-purestorage.slack.com/messages/C0357KLR1EU \ No newline at end of file + +- Correo electrónico: pure-observability@purestorage.com +- Slack: [Código Pure Storage//Canal de observabilidad](https://code-purestorage.slack.com/messages/C0357KLR1EU). \ No newline at end of file diff --git a/content/es/integrations/python.md b/content/es/integrations/python.md new file mode 100644 index 0000000000000..94c952dc0ed3a --- /dev/null +++ b/content/es/integrations/python.md @@ -0,0 +1,67 @@ +--- +app_id: python +categories: +- languages +- log collection +- tracing +custom_kind: integración +description: Recopila métricas, trazas (traces) y logs de tus aplicaciones Python. +further_reading: +- link: https://www.datadoghq.com/blog/tracing-async-python-code/ + tag: blog + text: Rastreo de código Python asíncrono con Datadog APM +- link: https://www.datadoghq.com/blog/python-logging-best-practices/ + tag: blog + text: 'Formatos de generación de logs de Python: Cómo recopilar y centralizar logs + de Python' +media: [] +title: Python +--- +## Información general + +La integración Python te permite recopilar y monitorizar tus logs de aplicaciones, trazas y métricas personalizadas de Python. + +## Configuración + +### Recopilación de métricas + +Consulta la documentación exclusiva para [recopilar métricas personalizadas de Python con DogStatsD](https://docs.datadoghq.com/developers/dogstatsd/?tab=python). + +### Recopilación de trazas + +Consulta la documentación exclusiva para [instrumentar tu aplicación Python](https://docs.datadoghq.com/tracing/setup/python/) para enviar tus trazas a Datadog. + +### Recopilación de logs + +_Disponible para la versión 6.0 o posterior del Agent_ + +Consulta la documentación exclusiva sobre cómo [configurar la recopilación de logs Python](https://docs.datadoghq.com/logs/log_collection/python/) para reenviar tus logs a Datadog. + +### Recopilación de perfiles + +Consulta la documentación exclusiva para [habilitar el generador de perfiles Python](https://docs.datadoghq.com/profiler/enabling/python/). + +## Datos recopilados + +### Métricas + +| | | +| --- | --- | +| **runtime.python.cpu.time.sys**
(gauge) | Número de segundos de ejecución en el kernel
_Se muestra como segundos_ | +| **runtime.python.cpu.time.user**
(gauge) | Número de segundos de ejecución fuera del núcleo
_Se muestra como segundos_ | +| **runtime.python.cpu.percent**
(gauge) | Porcentaje de uso de CPU
_Se muestra como porcentaje_ | +| **runtime.python.cpu.ctx_switch.voluntary**
(gauge) | Número de cambios de contexto voluntarios
_Se muestra como invocación_ | +| **runtime.python.cpu.ctx_switch.involuntary**
(gauge) | Número de cambios de contexto involuntarios
_Se muestra como invocación_ | +| **runtime.python.gc.count.gen0**
(gauge) | Número de objetos de generación 0
_Se muestra como recurso_ | +| **runtime.python.gc.count.gen1**
(gauge) | Número de objetos de generación 1
_Se muestra como recurso_ | +| **runtime.python.gc.count.gen2**
(gauge) | Número de objetos de generación 2
_Se muestra como recurso_ | +| **runtime.python.mem.rss**
(gauge) | Memoria de conjunto residente
_Se muestra como bytes_ | +| **runtime.python.thread_count**
(gauge) | Número de subprocesos
_Se muestra como subproceso_ | + +## Solucionar problemas + +¿Necesitas ayuda? Ponte en contacto con el [servicio de asistencia de Datadog](https://docs.datadoghq.com/help/). + +## Referencias adicionales + +{{< partial name="whats-next/whats-next.html" >}} \ No newline at end of file diff --git a/content/es/integrations/rabbitmq.md b/content/es/integrations/rabbitmq.md new file mode 100644 index 0000000000000..6f6e86236cabb --- /dev/null +++ b/content/es/integrations/rabbitmq.md @@ -0,0 +1,538 @@ +--- +app_id: rabbitmq +categories: +- log collection +- message queues +custom_kind: integración +description: Seguimiento del tamaño de las colas, del recuento de consumidores, de + mensajes no reconocidos, etc. +further_reading: +- link: https://www.datadoghq.com/blog/rabbitmq-monitoring + tag: blog + text: Métricas clave para la monitorización de RabbitMQ +- link: https://www.datadoghq.com/blog/rabbitmq-monitoring-tools + tag: blog + text: Recopilación de métricas utilizando las herramientas de monitorización de + RabbitMQ +- link: https://www.datadoghq.com/blog/monitoring-rabbitmq-performance-with-datadog + tag: blog + text: Monitorización de RabbitMQ con Datadog +integration_version: 8.0.0 +media: [] +supported_os: +- linux +- windows +- macos +title: RabbitMQ +--- + + +## Información general + +Este check monitoriza [RabbitMQ](https://www.rabbitmq.com) a través del Datadog Agent. Te permite: + +- Realizar un seguimiento de estadísticas basadas en colas: tamaño de la cola, recuento de consumidores, mensajes no reconocidos, mensajes reenviados, etc. +- Realizar un de estadísticas basadas en nodos: procesos en espera, sockets utilizados, descriptores de archivos utilizados, etc. +- Monitoriza vhosts para comprobar la disponibilidad y el número de conexiones. + +Considerar [Data Streams Monitoring](https://docs.datadoghq.com/data_streams/) para mejorar tu integración con RabbitMQ. Esta solución permite la visualización de pipelines y el seguimiento de retrasos, ayudándote a identificar y resolver cuellos de botella. + +## Configuración + +### Instalación + +El check de RabbitMQ se incluye en el paquete del [Datadog Agent](https://app.datadoghq.com/account/settings/agent/latest). No es necesaria ninguna instalación adicional en tu servidor. + +### Configuración + +RabbitMQ expone métricas de dos formas: el [complemento de gestión de RabbitMQ](https://www.rabbitmq.com/management.html) y el [complemento RabbitMQ Prometheus](https://www.rabbitmq.com/prometheus.html). La integración de Datadog admite ambas versiones. Sigue las instrucciones de configuración de este archivo correspondientes a la versión que quieres utilizar. La integración Datadog también viene con un dashboard y monitores predefinidos para cada versión, como se indica en los títulos Dashboard y Monitor. + +#### Preparación de RabbitMQ + +##### [Complemento RabbitMQ Prometheus](https://www.rabbitmq.com/prometheus.html). + +*A partir de la versión 3.8 de RabbitMQ, el [complemento RabbitMQ Prometheus](https://www.rabbitmq.com/prometheus.html) está activado por defecto.* + +*La versión del complemento Prometheus de RabbitMQ requiere el soporte de Python 3 del Datadog Agent, por lo que sólo es compatible con el Agent v6 o posterior. Asegúrate de que tu Agent está actualizado, antes de configurar la versión del complemento Prometheus de la integración.* + +Configura la sección `prometheus_plugin` en la configuración de tu instancia. Cuando se utiliza la opción `prometheus_plugin`, se ignoran los parámetros relacionados con el complemento de gestión. + +```yaml +instances: + - prometheus_plugin: + url: http://:15692
+```
+
+Esto permite el scraping del [endpoint `/metrics`](https://www.rabbitmq.com/prometheus.html#default-endpoint) en un nodo RabbitMQ. Datadog también puede recopilar datos del [endpoint `/metrics/detailed`](https://www.rabbitmq.com/prometheus.html#detailed-endpoint). Las métricas recopiladas dependen de las familias que se incluyen.
+
+```yaml
+ instances:
+ - prometheus_plugin:
+ url: http://:15692
+ unaggregated_endpoint: detailed?family=queue_coarse_metrics&family=queue_consumer_count&family=channel_exchange_metrics&family=channel_queue_exchange_metrics&family=node_coarse_metrics
+```
+
+Esta configuración recopila métricas de cada cola, intercambio y nodo. Para obtener más información sobre las métricas proporcionadas por cada familia, consulta la [documentación de la API `/metrics/detailed`](https://www.rabbitmq.com/prometheus.html#detailed-endpoint).
+
+##### [Complemento de gestión de RabbitMQ](https://www.rabbitmq.com/management.html).
+
+Habilita el complemento. El usuario del Agent necesita al menos la etiqueta (tag) `monitoring` y los siguientes permisos obligatorios:
+
+| Permiso | Comando |
+| ---------- | ------------------ |
+| **conf** | `^aliveness-test$` |
+| **write** | `^amq\.default$` |
+| **read** | `.*` |
+
+Crea un usuario del Agent para tu vhost predeterminado con los siguientes comandos:
+
+```text
+rabbitmqctl add_user datadog
+rabbitmqctl set_permissions -p / datadog "^aliveness-test$" "^amq\.default$" ".*"
+rabbitmqctl set_user_tags datadog monitoring
+```
+
+Aquí, `/` se refiere al host por defecto. Defínelo para tu nombre de host virtual especificado. Consulta la [documentación de RabbitMQ](https://www.rabbitmq.com/rabbitmqctl.8.html#set_permissions) para obtener más información.
+
+{{< tabs >}}
+
+{{% tab "Host" %}}
+
+#### host
+
+Para configurar este check para un Agent que se ejecuta en un host:
+
+##### Recopilación de métricas
+
+1. Edita el archivo `rabbitmq.d/conf.yaml`, en la carpeta `conf.d/` en la raíz de tu [directorio de configuración del Agent](https://docs.datadoghq.com/agent/guide/agent-configuration-files/#agent-configuration-directory) para comenzar a recopilar tus métricas de RabbitMQ. Consulta el [ejemplo de rabbitmq.d/conf.yaml](https://github.com/DataDog/integrations-core/blob/master/rabbitmq/datadog_checks/rabbitmq/data/conf.yaml.example) para ver todas las opciones de configuración disponibles.
+
+ **Nota**: El Agent comprueba todas las colas, vhosts y nodos por defecto, pero puedes proporcionar listas o expresiones regulares para limitar esto. Para ver ejemplos, consulta [rabbitmq.d/conf.yaml](https://github.com/DataDog/integrations-core/blob/master/rabbitmq/datadog_checks/rabbitmq/data/conf.yaml.example).
+
+1. [Reinicia el Agent](https://docs.datadoghq.com/agent/guide/agent-commands/#start-stop-and-restart-the-agent).
+
+##### Recopilación de logs
+
+_Disponible para las versiones 6.0 o posteriores del Agent_
+
+1. Para modificar la ubicación predeterminada del archivo de log, define la variable de entorno `RABBITMQ_LOGS` o añade lo siguiente a tu archivo de configuración de RabbitMQ (`/etc/rabbitmq/rabbitmq.conf`):
+
+ ```conf
+ log.dir = /var/log/rabbit
+ log.file = rabbit.log
+ ```
+
+1. La recopilación de logs está desactivada en forma predeterminada en el Datadog Agent, actívala en tu archivo `datadog.yaml`:
+
+ ```yaml
+ logs_enabled: true
+ ```
+
+1. Edita la sección `logs` de tu archivo `rabbitmq.d/conf.yaml` para empezar a recopilar tus logs de RabbitMQ:
+
+ ```yaml
+ logs:
+ - type: file
+ path: /var/log/rabbit/*.log
+ source: rabbitmq
+ service: myservice
+ log_processing_rules:
+ - type: multi_line
+ name: logs_starts_with_equal_sign
+ pattern: "="
+ ```
+
+1. [Reinicia el Agent](https://docs.datadoghq.com/agent/guide/agent-commands/#start-stop-and-restart-the-agent).
+
+{{% /tab %}}
+
+{{% tab "Containerized" %}}
+
+#### En contenedores
+
+Puedes aprovechar la [detección automática de contenedores de Docker](https://docs.datadoghq.com/containers/docker/integrations/?tab=dockeradv2), de Datadog. Para ver parámetros específicos de RabbitMQ, consulta el ejemplo de configuración `auto_conf.yaml`.
+
+Para entornos en contenedores, como Kubernetes, consulta las [plantillas de integración de Autodiscovery](https://docs.datadoghq.com/agent/kubernetes/integrations/) para obtener orientación sobre la aplicación de los parámetros que se indican a continuación.
+
+##### Recopilación de métricas
+
+| Parámetro | Valor |
+| -------------------- | -------------------------------------------- |
+| `` | `rabbitmq` |
+| `` | en blanco o `{}` |
+| `` | `{"prometheus_plugin": {"url": "http://%%host%%:15692"}}` |
+
+##### Recopilación de logs
+
+Disponible para la versión 6.0 o posteriores del Agent
+
+La recopilación de logs está desactivada de forma predeterminada en el Datadog Agent. Para activarla, consulta [Recopilación de logs de Kubernetes](https://docs.datadoghq.com/agent/kubernetes/log/).
+
+| Parámetro | Valor |
+| -------------- | --------------------------------------------------------------------------------------------------------------------------------------------------- |
+| `` | `{"source": "rabbitmq", "service": "rabbitmq", "log_processing_rules": [{"type":"multi_line","name":"logs_starts_with_equal_sign", "pattern": "="}]}` |
+
+{{% /tab %}}
+
+{{< /tabs >}}
+
+### Validación
+
+[Ejecuta el subcomando de estado del Agent](https://docs.datadoghq.com/agent/guide/agent-commands/#agent-status-and-information) y busca `rabbitmq` en la sección Checks.
+
+## Datos recopilados
+
+### Métricas
+
+| | |
+| --- | --- |
+| **rabbitmq.alarms.file_descriptor_limit**
(gauge) | \[OpenMetrics\] es 1 si la alarma de límite del descriptor de archivo está activa| +| **rabbitmq.alarms.free_disk_space.watermark**
(gauge) | \[OpenMetrics\] es 1 si la alarma de marca de agua del espacio libre en disco está activa| +| **rabbitmq.alarms.memory_used_watermark**
(gauge) | \[OpenMetrics\] es 1 si la alarma de marca de agua de memoria de la máquina virtual está vigente| +| **rabbitmq.auth_attempts.count**
(count) | \[OpenMetrics\] Número total de intentos de autenticación| +| **rabbitmq.auth_attempts.failed.count**
(count) | \[OpenMetrics\] Número total de intentos de autenticación fallidos| +| **rabbitmq.auth_attempts.succeeded.count**
(count) | \[OpenMetrics\] Número total de intentos de autenticación exitosos| +| **rabbitmq.build_info**
(gauge) | \[OpenMetrics\] Información de la versión RabbitMQ & Erlang/OTP| +| **rabbitmq.channel.acks_uncommitted**
(gauge) | \[OpenMetrics\] Reconocimientos de mensajes en una transacción aún no confirmada| +| **rabbitmq.channel.consumers**
(gauge) | \[OpenMetrics\] Consumidores en un canal| +| **rabbitmq.channel.get.ack.count**
(count) | \[OpenMetrics\] Número total de mensajes obtenidos con basic.get en modo de reconocimiento manual| +| **rabbitmq.channel.get.count**
(count) | \[OpenMetrics\] Número total de mensajes obtenidos con basic.get en modo de reconocimiento automático
_Se muestra como mensaje_ | +| **rabbitmq.channel.get.empty.count**
(count) | \[OpenMetrics\] Número total de veces que las operaciones basic.get no obtuvieron ningún mensaje.| +| **rabbitmq.channel.messages.acked.count**
(count) | \[OpenMetrics\] Número total de mensajes reconocidos por los consumidores
_Se muestra como mensaje_ | +| **rabbitmq.channel.messages.confirmed.count**
(count) | \[OpenMetrics\] Número total de mensajes publicados en un intercambio y confirmados en el canal
_Se muestra como mensaje_ | +| **rabbitmq.channel.messages.delivered.ack.count**
(count) | \[OpenMetrics\] Número total de mensajes entregados a los consumidores en modo de reconocimiento manual
_Se muestra como mensaje_ | +| **rabbitmq.channel.messages.delivered.count**
(count) | \[OpenMetrics\] Número total de mensajes entregados a los consumidores en modo de reconocimiento automático
_Se muestra como mensaje_ | +| **rabbitmq.channel.messages.published.count**
(count) | \[OpenMetrics\] Número total de mensajes publicados en un intercambio en un canal
_Se muestra como mensaje_ | +| **rabbitmq.channel.messages.redelivered.count**
(count) | \[OpenMetrics\] Número total de mensajes reenviados a los consumidores
_Se muestra como mensaje_ | +| **rabbitmq.channel.messages.unacked**
(gauge) | \[OpenMetrics\] Mensajes entregados pero aún no reconocidos
_Se muestra como mensaje_ | +| **rabbitmq.channel.messages.uncommitted**
(gauge) | \[OpenMetrics\] Mensajes recibidos en una transacción pero aún no confirmados
_Se muestra como mensaje_ | +| **rabbitmq.channel.messages.unconfirmed**
(gauge) | \[OpenMetrics\] Mensajes publicados pero aún no confirmados
_Se muestra como mensaje_ | +| **rabbitmq.channel.messages.unroutable.dropped.count**
(count) | \[OpenMetrics\] Número total de mensajes publicados como no obligatorios en un intercambio y descartados como no enrutables
_Se muestra como mensaje_ | +| **rabbitmq.channel.messages.unroutable.returned.count**
(count) | \[OpenMetrics\] Número total de mensajes publicados como obligatorios en un intercambio y devueltos al publicador como no enrutables
_Se muestra como mensaje_ | +| **rabbitmq.channel.prefetch**
(gauge) | \[OpenMetrics\] Límite total de mensajes no reconocidos para todos los consumidores en un canal
_Se muestra como mensaje_ | +| **rabbitmq.channel.process_reductions.count**
(count) | \[OpenMetrics\] Número total de reducciones de procesos de canal| +| **rabbitmq.channels**
(gauge) | \[OpenMetrics\] Canales actualmente abiertos| +| **rabbitmq.channels.closed.count**
(count) | \[OpenMetrics\] Número total de canales cerrados| +| **rabbitmq.channels.opened.count**
(count) | \[OpenMetrics\] Número total de canales abiertos| +| **rabbitmq.cluster.exchange_bindings**
(gauge) | \[OpenMetrics\] Número de enlaces de un intercambio. Este valor es válido para todo el clúster.| +| **rabbitmq.cluster.exchange_name**
(gauge) | \[OpenMetrics\] Enumera los intercambios sin información adicional. Este valor es válido para todo el clúster. Una alternativa más económica a `exchange_bindings`| +| **rabbitmq.cluster.vhost_status**
(gauge) | \[OpenMetrics\] Si se está ejecutando un vhost determinado| +| **rabbitmq.connection.channels**
(gauge) | \[OpenMetrics\] Canales en un conexión| +| **rabbitmq.connection.incoming_bytes.count**
(count) | \[OpenMetrics\] Número total de bytes recibidos en un conexión
_Se muestra como byte_ | +| **rabbitmq.connection.incoming_packets.count**
(count) | \[OpenMetrics\] Número total de paquetes recibidos en un conexión
_Se muestra como paquete_ | +| **rabbitmq.connection.outgoing_bytes.count**
(count) | \[OpenMetrics\] Número total de bytes enviados en una conexión
_Se muestra como bytes_ | +| **rabbitmq.connection.outgoing_packets.count**
(count) | \[OpenMetrics\] Número total de paquetes enviados en una conexión
_Se muestra como paquete_ | +| **rabbitmq.connection.pending_packets**
(gauge) | \[OpenMetrics\] Número de paquetes a la espera de ser enviados en una conexión
_Se muestra como paquete_ | +| **rabbitmq.connection.process_reductions.count**
(count) | \[OpenMetrics\] Número total de reducciones de procesos de conexión| +| **rabbitmq.connections**
(gauge) | \[OpenMetrics, CLI de gestión\] Número de conexiones actuales a un vhost rabbitmq dado, etiquetado 'rabbitmq_vhost:\' Conexiones actualmente abiertas
_Se muestra como conexión_ | +| **rabbitmq.connections.closed.count**
(count) | \[OpenMetrics\] Número total de conexiones cerradas o terminadas| +| **rabbitmq.connections.opened.count**
(count) | \[OpenMetrics\] Número total de conexiones abiertas| +| **rabbitmq.connections.state**
(gauge) | Número de conexiones en el estado de conexión especificado
_Se muestra como conexión_ | +| **rabbitmq.consumer_prefetch**
(gauge) | \[OpenMetrics\] Límite de mensajes no reconocidos para cada consumidor.| +| **rabbitmq.consumers**
(gauge) | \[OpenMetrics\] Consumidores actualmente conectados| +| **rabbitmq.disk_space.available_bytes**
(gauge) | \[OpenMetrics\] Espacio en disco disponible en bytes
_Se muestra como bytes_ | +| **rabbitmq.disk_space.available_limit_bytes**
(gauge) | \[OpenMetrics\] Marca de agua baja del espacio libre en disco en bytes
_Se muestra como bytes_ | +| **rabbitmq.erlang.gc.reclaimed_bytes.count**
(count) | \[OpenMetrics\] Número total de bytes de memoria recuperados por el recolector de basura Erlang
_Se muestra como bytes_ | +| **rabbitmq.erlang.gc.runs.count**
(count) | \[OpenMetrics\] Número total de ejecuciones del recolector de basura Erlang| +| **rabbitmq.erlang.mnesia.committed_transactions.count**
(count) | \[OpenMetrics\] Número de transacciones confirmadas.
_Se muestra como transacción_ | +| **rabbitmq.erlang.mnesia.failed_transactions.count**
(count) | \[OpenMetrics\] Número de transacciones fallidas (es decir, abortadas).
_Se muestra como transacción_ | +| **rabbitmq.erlang.mnesia.held_locks**
(gauge) | \[OpenMetrics\] Número de bloqueos mantenidos.| +| **rabbitmq.erlang.mnesia.lock_queue**
(gauge) | \[OpenMetrics\] Número de transacciones a la espera de un bloqueo.
_Se muestra como transacción_ | +| **rabbitmq.erlang.mnesia.logged_transactions.count**
(count) | \[OpenMetrics\] Número de transacciones registradas.
_Se muestra como transacción_ | +| **rabbitmq.erlang.mnesia.memory_usage_bytes**
(gauge) | \[OpenMetrics\] Número total de bytes asignados por todas las tablas de mnesia
_Se muestra como bytes_ | +| **rabbitmq.erlang.mnesia.restarted_transactions.count**
(count) | \[OpenMetrics\] Número total de reinicios de transacciones.
_Se muestra como transacción_ | +| **rabbitmq.erlang.mnesia.tablewise_memory_usage_bytes**
(gauge) | \[OpenMetrics\] Número de bytes asignados por la tabla de mnesia
_Se muestra como byte_ | +| **rabbitmq.erlang.mnesia.tablewise_size**
(gauge) | \[OpenMetrics\] Número de filas presentes por tabla| +| **rabbitmq.erlang.mnesia.transaction_coordinators**
(gauge) | \[OpenMetrics\] Número de transacciones de coordinadores.
_Se muestra como transacción_ | +| **rabbitmq.erlang.mnesia.transaction_participants**
(gauge) | \[OpenMetrics\] Número de transacciones de participantes.
_Se muestra como transacción_ | +| **rabbitmq.erlang.net.ticktime_seconds**
(gauge) | \[OpenMetrics\] Intervalo de latidos entre nodos
_Se muestra como segundos_ | +| **rabbitmq.erlang.processes_limit**
(gauge) | \[OpenMetrics\] Límite de procesos Erlang
_Se muestra como proceso_ | +| **rabbitmq.erlang.processes_used**
(gauge) | \[OpenMetrics\] Procesos Erlang utilizados
_Se muestra como proceso_ | +| **rabbitmq.erlang.scheduler.context_switches.count**
(count) | \[OpenMetrics\] Número total de cambios de contexto del programador Erlang| +| **rabbitmq.erlang.scheduler.run_queue**
(gauge) | \[OpenMetrics\] Cola de ejecución del programador Erlang| +| **rabbitmq.erlang.uptime_seconds**
(gauge) | \[OpenMetrics\] Tiempo de actividad del nodo
_Se muestra como segundos_ | +| **rabbitmq.erlang.vm.allocators**
(gauge) | \[OpenMetrics\] Memoria asignada (carriers_size) y utilizada (blocks_size) para los diferentes asignadores en la máquina virtual. Consulta erts_alloc(3).| +| **rabbitmq.erlang.vm.atom_count**
(gauge) | \[OpenMetrics\] Número de átomos existentes actualmente en el nodo local.| +| **rabbitmq.erlang.vm.atom_limit**
(gauge) | \[OpenMetrics\] Número máximo de átomos existentes simultáneamente en el nodo local.| +| **rabbitmq.erlang.vm.dirty_cpu_schedulers**
(gauge) | \[OpenMetrics\] Número de subprocesos sucios del programador de CPU utilizados por el emulador.
_Se muestra como subproceso_ | +| **rabbitmq.erlang.vm.dirty_cpu_schedulers_online**
(gauge) | \[OpenMetrics\] Número de subprocesos sucios del programador de CPU en línea.
_Se muestra como subproceso_ | +| **rabbitmq.erlang.vm.dirty_io_schedulers**
(gauge) | \[OpenMetrics\] Número de subprocesos sucios del programador de E/S utilizados por el emulador.
_Se muestra como subproceso_ | +| **rabbitmq.erlang.vm.dist.node_queue_size_bytes**
(gauge) | \[OpenMetrics\] Número de bytes en la cola de distribución de salida. Esta cola se sitúa entre el código Erlang y el controlador del puerto.
_Se muestra como bytes_ | +| **rabbitmq.erlang.vm.dist.node_state**
(gauge) | \[OpenMetrics\] Estado actual del enlace de distribución. El estado se representa como un valor numérico donde `pending=1', `up_pending=2' y `up=3'.| | **rabbitmq.erlang.vm.dist.port_input_bytes**
(gauge) | [OpenMetrics] Número total de bytes leídos desde el puerto.
_Se muestra como bytes_ | | **rabbitmq.erlang.vm.dist.port_memory_bytes**
(gauge) | [OpenMetrics] Número total de bytes asignados a este puerto por el sistema en tiempo de ejecución. El propio puerto puede tener memoria asignada que no está incluida.
_Se muestra como byte_ | | **rabbitmq.erlang.vm.dist.port_output_bytes**
(gauge) | [OpenMetrics] Número total de bytes escritos en el puerto.
_Se muestra como bytes_ | | **rabbitmq.erlang.vm.dist.port_queue.size_bytes**
(gauge) | [OpenMetrics] Número total de bytes puestos en cola por el puerto utilizando la implementación de colas del controlador ERTS.
_Se muestra como bytes_ | | **rabbitmq.erlang.vm.dist.proc.heap_size_words**
(gauge) | [OpenMetrics] Tamaño en palabras de la generación heap más joven del proceso. Esta generación incluye el stack tecnplógico del proceso. Esta información es altamente dependiente de la implementación y puede cambiar si la implementación cambia.| | **rabbitmq.erlang.vm.dist.proc.memory_bytes**
(gauge) | [OpenMetrics] Tamaño en bytes del proceso. Esto incluye el stack tecnológico de llamadas, heap y las estructuras internas.
_Se muestra como bytes_ | | **rabbitmq.erlang.vm.dist.proc.message_queue_len**
(gauge) | [OpenMetrics] Número de mensajes actualmente en la cola de mensajes del proceso.
_Se muestra como mensaje_ | | **rabbitmq.erlang.vm.dist.proc.min_bin_vheap_size_words**
(gauge) | [OpenMetrics] Tamaño mínimo de heap virtual binario para el proceso.| | **rabbitmq.erlang.vm.dist.proc.min_heap_size_words**
(gauge) | [OpenMetrics] Tamaño mínimo de heap para el proceso.| | **rabbitmq.erlang.vm.dist.proc.reductions**
(gauge) | [OpenMetrics] Número de reducciones ejecutadas por el proceso.| | **rabbitmq.erlang.vm.dist.proc.stack_size_words**
(gauge) | [OpenMetrics] Tamaño del stack tecnológico del proceso, en palabras.| | **rabbitmq.erlang.vm.dist.proc.status**
(gauge) | [OpenMetrics] Estado actual del proceso de distribución. El estado se representa como un valor numérico donde `exiting=1', `suspended=2', `runnable=3', `garbage_collecting=4', `running=5' and \`waiting=6'.| +| **rabbitmq.erlang.vm.dist.proc.total_heap_size_words**
(gauge) | \[OpenMetrics\] Tamaño total, en palabras, de todos los fragmentos de heap del proceso. Esto incluye el stack tecnológico del proceso y cualquier mensaje no recibido que se considere parte del heap.| +| **rabbitmq.erlang.vm.dist.recv.avg_bytes**
(gauge) | \[OpenMetrics\] Tamaño medio de los paquetes, en bytes, recibidos por el socket.
_Se muestra como bytes_ | +| **rabbitmq.erlang.vm.dist.recv.cnt**
(gauge) | \[OpenMetrics\] Número de paquetes recibidos por el socket.| +| **rabbitmq.erlang.vm.dist.recv.dvi_bytes**
(gauge) | \[OpenMetrics\] Desviación media del tamaño del paquete, en bytes, recibido por el socket.
_Se muestra como bytes_ | +| **rabbitmq.erlang.vm.dist.recv.max_bytes**
(gauge) | \[OpenMetrics\] Tamaño del paquete más grande, en bytes, recibido por el socket.
_Se muestra como bytes_ | +| **rabbitmq.erlang.vm.dist.recv_bytes**
(gauge) | \[OpenMetrics\] Número de bytes recibidos por el socket.
_Se muestra como bytes_ | +| **rabbitmq.erlang.vm.dist.send.avg_bytes**
(gauge) | \[OpenMetrics\] Tamaño medio de los paquetes, en bytes, enviados desde el socket.
_Se muestra como bytes_ | +| **rabbitmq.erlang.vm.dist.send.cnt**
(gauge) | \[OpenMetrics\] Número de paquetes enviados desde el socket.| +| **rabbitmq.erlang.vm.dist.send.max_bytes**
(gauge) | \[OpenMetrics\] Tamaño del paquete más grande, en bytes, enviado desde el socket.
_Se muestra como bytes_ | +| **rabbitmq.erlang.vm.dist.send.pend_bytes**
(gauge) | \[OpenMetrics\] Número de bytes a la espera de ser enviados por el socket.
_Se muestra como bytes_ | +| **rabbitmq.erlang.vm.dist.send_bytes**
(gauge) | \[OpenMetrics\] Número de bytes enviados desde el socket.
_Se muestra como bytes_ | +| **rabbitmq.erlang.vm.ets_limit**
(gauge) | \[OpenMetrics\] Número máximo de tablas ETS permitidas.| +| **rabbitmq.erlang.vm.logical_processors**
(gauge) | \[OpenMetrics\] Número detectado de procesadores lógicos configurados en el sistema.| +| **rabbitmq.erlang.vm.logical_processors.available**
(gauge) | \[OpenMetrics\] Número detectado de procesadores lógicos disponibles para el sistema de tiempo de ejecución Erlang.| +| **rabbitmq.erlang.vm.logical_processors.online**
(gauge) | \[OpenMetrics\] Número detectado de procesadores lógicos en línea en el sistema.| +| **rabbitmq.erlang.vm.memory.atom_bytes_total**
(gauge) | \[OpenMetrics\] Cantidad total de memoria actualmente asignada para los átomos. Esta memoria es parte de la memoria presentada como memoria del sistema.
_Se muestra como bytes_ | +| **rabbitmq.erlang.vm.memory.bytes_total**
(gauge) | \[OpenMetrics\] Cantidad total de memoria asignada actualmente. Es igual a la suma del tamaño de memoria de los procesos y del sistema.
_Se muestra como bytes_ | +| **rabbitmq.erlang.vm.memory.dets_tables**
(gauge) | \[OpenMetrics\] Recuento de tablas DETS de máquinas virtuales Erlang.| +| **rabbitmq.erlang.vm.memory.ets_tables**
(gauge) | \[OpenMetrics\] Recuento de tablas ETS de máquinas virtuales Erlang.| +| **rabbitmq.erlang.vm.memory.processes_bytes_total**
(gauge) | \[OpenMetrics\] Cantidad total de memoria actualmente asignada para los procesos Erlang.
_Se muestra como bytes_ | +| **rabbitmq.erlang.vm.memory.system_bytes_total**
(gauge) | \[OpenMetrics\] Cantidad total de memoria actualmente asignada para el emulador que no está directamente relacionada con un proceso Erlang. La memoria presentada como procesos no está incluida en esta memoria.
_Se muestra como bytes_ | +| **rabbitmq.erlang.vm.msacc.alloc_seconds.count**
(count) | \[OpenMetrics\] Tiempo total en segundos dedicado a gestionar la memoria. Sin estados adicionales, este tiempo se reparte entre todos los demás estados.
_Se muestra como segundos_ | +| **rabbitmq.erlang.vm.msacc.aux_seconds.count**
(count) | \[OpenMetrics\] Tiempo total en segundos dedicado a gestionar trabajos auxiliares.
_Se muestra como segundos_ | +| **rabbitmq.erlang.vm.msacc.bif_seconds.count**
(count) | \[OpenMetrics\] Tiempo total en segundos dedicado a BIF. Sin estados adicionales, este tiempo forma parte del estado 'emulador'.
_Se muestra como segundos_ | +| **rabbitmq.erlang.vm.msacc.busy_wait_seconds.count**
(count) | \[OpenMetrics\] Tiempo total en segundos de espera ocupada. Sin estados adicionales, este tiempo forma parte del estado 'otros'.
_Se muestra como segundos_ | +| **rabbitmq.erlang.vm.msacc.check_io_seconds.count**
(count) | \[OpenMetrics\] Tiempo total en segundos dedicado a comprobar si hay nuevos eventos de E/S.
_Se muestra como segundos_ | +| **rabbitmq.erlang.vm.msacc.emulator_seconds.count**
(count) | \[OpenMetrics\] Tiempo total en segundos dedicado a ejecutar procesos Erlang.
_Se muestra como segundos_ | +| **rabbitmq.erlang.vm.msacc.ets_seconds.count**
(count) | \[OpenMetrics\] Tiempo total en segundos dedicado a ejecutar BIF ETS. Sin estados adicionales, este tiempo forma parte del estado 'emulador'.
_Se muestra como segundos_ | +| **rabbitmq.erlang.vm.msacc.gc_full_seconds.count**
(count) | \[OpenMetrics\] Tiempo total en segundos dedicado a la recolección de basura fullsweep. Sin estados adicionales, este tiempo es parte del estado 'recolección de basura'.
_Se muestra como segundos_ | +| **rabbitmq.erlang.vm.msacc.gc_seconds.count**
(count) | \[OpenMetrics\] Tiempo total en segundos dedicado a la recolección de basura. Cuando los estados adicionales están activados, este es el tiempo dedicado a recolectar basura non-fullsweep.
_Se muestra como segundos_ | +| **rabbitmq.erlang.vm.msacc.nif_seconds.count**
(count) | \[OpenMetrics\] Tiempo total en segundos dedicado a NIF. Sin estados adicionales, este tiempo forma parte del estado 'emulador'.
_Se muestra como segundos_ | +| **rabbitmq.erlang.vm.msacc.other_seconds.count**
(count) | \[OpenMetrics\] Tiempo total en segundos dedicado a hacer cosas no explicadas.
_Se muestra como segundos_ | +| **rabbitmq.erlang.vm.msacc.port_seconds.count**
(count) | \[OpenMetrics\] Tiempo total en segundos dedicado a ejecutar puertos.
_Se muestra como segundos_ | +| **rabbitmq.erlang.vm.msacc.send_seconds.count**
(count) | \[OpenMetrics\] Tiempo total en segundos dedicado a enviar mensajes (solo procesos). Sin estados adicionales, este tiempo forma parte del estado 'emulador'.
_Se muestra como segundos_ | +| **rabbitmq.erlang.vm.msacc.sleep_seconds.count**
(count) | \[OpenMetrics\] Tiempo total en segundos que pasó durmiendo.
_Se muestra como segundos_ | +| **rabbitmq.erlang.vm.msacc.timers_seconds.count**
(count) | \[OpenMetrics\] Tiempo total en segundos dedicado a gestionar temporizadores. Sin estados adicionales, este tiempo forma parte del estado 'otros'.
_Se muestra como segundos_ | +| **rabbitmq.erlang.vm.port_count**
(gauge) | \[OpenMetrics\] Número de puertos existentes actualmente en el nodo local.| +| **rabbitmq.erlang.vm.port_limit**
(gauge) | \[OpenMetrics\] Número máximo de puertos existentes simultáneamente en el nodo local.| +| **rabbitmq.erlang.vm.process_count**
(gauge) | \[OpenMetrics\] Número de procesos existentes actualmente en el nodo local.
_Se muestra como proceso_ | +| **rabbitmq.erlang.vm.process_limit**
(gauge) | \[OpenMetrics\] Número máximo de procesos existentes simultáneamente en el nodo local.
_Se muestra como proceso_ | +| **rabbitmq.erlang.vm.schedulers**
(gauge) | \[OpenMetrics\] Número de procesos del programador utilizados por el emulador.| +| **rabbitmq.erlang.vm.schedulers_online**
(gauge) | \[OpenMetrics\] Número de programadores en línea.| +| **rabbitmq.erlang.vm.smp_support**
(gauge) | \[OpenMetrics\] 1 si el emulador ha sido compilado con soporte SMP, en caso contrario 0.| +| **rabbitmq.erlang.vm.statistics.bytes_output.count**
(count) | \[OpenMetrics\] Número total de bytes emitidos a los puertos.
_Se muestra como bytes_ | +| **rabbitmq.erlang.vm.statistics.bytes_received.count**
(count) | \[OpenMetrics\] Número total de bytes recibidos a través de los puertos.
_Se muestra como bytes_ | +| **rabbitmq.erlang.vm.statistics.context_switches.count**
(count) | \[OpenMetrics\] Número total de cambios de contexto desde que se inició el sistema.| +| **rabbitmq.erlang.vm.statistics.dirty_cpu_run_queue_length**
(gauge) | \[OpenMetrics\] Longitud de la cola de ejecución de CPU sucia.| +| **rabbitmq.erlang.vm.statistics.dirty_io_run_queue_length**
(gauge) | \[OpenMetrics\] Longitud de la cola de ejecución de E/S sucia.| +| **rabbitmq.erlang.vm.statistics.garbage_collection.bytes_reclaimed.count**
(count) | \[OpenMetrics\] Recolección de basura: bytes recuperados.
_Se muestra como bytes_ | +| **rabbitmq.erlang.vm.statistics.garbage_collection.number_of_gcs.count**
(count) | \[OpenMetrics\] Recolección de basura: número de recolecciones de basura.| +| **rabbitmq.erlang.vm.statistics.garbage_collection.words_reclaimed.count**
(count) | \[OpenMetrics\] Recolección de basura: palabras recuperadas.| +| **rabbitmq.erlang.vm.statistics.reductions.count**
(count) | \[OpenMetrics\] Reducciones totales.| +| **rabbitmq.erlang.vm.statistics.run_queues_length**
(gauge) | \[OpenMetrics\] Longitud de las colas de ejecución normales.| +| **rabbitmq.erlang.vm.statistics.runtime_milliseconds.count**
(count) | \[OpenMetrics\] Suma del tiempo de ejecución de todos los subprocesos en el sistema de tiempo de ejecución Erlang. Puede ser mayor que el tiempo del reloj de pared.
_Se muestra como milisegundos_ | +| **rabbitmq.erlang.vm.statistics.wallclock_time_milliseconds.count**
(count) | \[OpenMetrics\] Información sobre el reloj de pared. Igual que erlang_vm_statistics_runtime_milliseconds excepto que se mide el tiempo real.
_Se muestra como milisegundos_ | +| **rabbitmq.erlang.vm.thread_pool_size**
(gauge) | \[OpenMetrics\] Número de subprocesos asíncronos en el grupo de subprocesos asíncronos utilizados en llamadas asíncronas al controlador.| +| **rabbitmq.erlang.vm.threads**
(gauge) | \[OpenMetrics\] 1 si el emulador ha sido compilado con soporte para subprocesos, 0 en caso contrario.| +| **rabbitmq.erlang.vm.time_correction**
(gauge) | \[OpenMetrics\] 1 si la corrección de tiempo está activada, 0 en caso contrario.| +| **rabbitmq.erlang.vm.wordsize_bytes**
(gauge) | \[OpenMetrics\] Tamaño de las palabras de términos Erlang en bytes.
_Se muestra como bytes_ | +| **rabbitmq.exchange.messages.ack.count**
(gauge) | Número de mensajes en intercambios entregados a clientes y reconocidos
_Se muestra como mensaje_ | +| **rabbitmq.exchange.messages.ack.rate**
(gauge) | Tasa de mensajes en intercambios entregados a clientes y reconocidos por segundo
_Se muestra como mensaje_ | +| **rabbitmq.exchange.messages.confirm.count**
(gauge) | Recuento de mensajes en intercambios confirmados
_Se muestra como mensaje_ | +| **rabbitmq.exchange.messages.confirm.rate**
(gauge) | Tasa de mensajes en intercambios confirmados por segundo
_Se muestra como mensaje_ | +| **rabbitmq.exchange.messages.deliver_get.count**
(gauge) | Suma de mensajes en intercambios entregados en modo de reconocimiento a los consumidores, en modo sin reconocimiento a los consumidores, en modo de reconocimiento en respuesta a basic.get y en modo sin reconocimiento en respuesta a basic.get
_Se muestra como mensaje_ | +| **rabbitmq.exchange.messages.deliver_get.rate**
(gauge) | Tasa por segundo de la suma de mensajes en intercambios entregados en modo de reconocimiento a los consumidores, en modo sin reconocimiento a los consumidores, en modo de reconocimiento en respuesta a basic.get y en modo sin reconocimiento en respuesta a basic.get
_Se muestra como mensaje_ | +| **rabbitmq.exchange.messages.publish.count**
(gauge) | Recuento de mensajes en intercambios publicados
_Se muestra como mensaje_ | +| **rabbitmq.exchange.messages.publish.rate**
(gauge) | Tasa de mensajes en intercambios publicados por segundo
_Se muestra como mensaje_ | +| **rabbitmq.exchange.messages.publish_in.count**
(gauge) | Recuento de mensajes publicados desde canales en este intercambio
_Se muestra como mensaje_ | +| **rabbitmq.exchange.messages.publish_in.rate**
(gauge) | Tasa de mensajes publicados desde los canales a esta central por segundo
_Se muestra como mensaje_ | +| **rabbitmq.exchange.messages.publish_out.count**
(gauge) | Recuento de mensajes publicados desde este intercambio en colas
_Se muestra como mensaje_ | +| **rabbitmq.exchange.messages.publish_out.rate**
(gauge) | Tasa de mensajes publicados desde este intercambio a las colas por segundo
_Se muestra como mensaje_ | +| **rabbitmq.exchange.messages.redeliver.count**
(gauge) | Recuento del subconjunto de mensajes en intercambios en deliver_get que tenían el indicador de reenviado activado
_Se muestra como mensaje_ | +| **rabbitmq.exchange.messages.redeliver.rate**
(gauge) | Tasa del subconjunto de mensajes en intercambios en deliver_get que tenían el indicador de reenviado activado por segundo
_Se muestra como mensaje_ | +| **rabbitmq.exchange.messages.return_unroutable.count**
(gauge) | Recuento de mensajes en intercambios devueltos al publicador como no enrutables
_Se muestra como mensaje_ | +| **rabbitmq.exchange.messages.return_unroutable.rate**
(gauge) | Tasa de mensajes en intercambios devueltos al publicador como no enrutables por segundo
_Se muestra como mensaje_ | +| **rabbitmq.global.consumers**
(gauge) | \[OpenMetrics\] Número actual de consumidores| +| **rabbitmq.global.messages.acknowledged.count**
(count) | \[OpenMetrics\] Número total de mensajes reconocidos por los consumidores
_Se muestra como mensaje_ | +| **rabbitmq.global.messages.confirmed.count**
(count) | \[OpenMetrics\] Número total de mensajes confirmados a los publicadores
_Se muestra como mensaje_ | +| **rabbitmq.global.messages.dead_lettered.confirmed.count**
(count) | \[OpenMetrics\] Número total de mensajes fallidos y confirmados por colas de destino
_Se muestra como mensaje_ | +| **rabbitmq.global.messages.dead_lettered.delivery_limit.count**
(count) | \[OpenMetrics\] Número total de mensajes fallidos por exceder el límite de entrega
_Se muestra como mensaje_ | +| **rabbitmq.global.messages.dead_lettered.expired.count**
(count) | \[OpenMetrics\] Número total de mensajes fallidos por exceder el ciclo de vida del mensaje
_Se muestra como mensaje_ | +| **rabbitmq.global.messages.dead_lettered.maxlen.count**
(count) | \[OpenMetrics\] Número total de mensajes fallidos por desbordamiento drop-head o reject-publish-dlx
_Se muestra como mensaje_ | +| **rabbitmq.global.messages.dead_lettered.rejected.count**
(count) | \[OpenMetrics\] Número total de mensajes fallidos debido a basic.reject o basic.nack
_Se muestra como mensaje_ | +| **rabbitmq.global.messages.delivered.consume_auto_ack.count**
(count) | \[OpenMetrics\] Número total de mensajes entregados a los consumidores utilizando basic.consume con reconocimiento automático
_Se muestra como mensaje_ | +| **rabbitmq.global.messages.delivered.consume_manual_ack.count**
(count) | \[OpenMetrics\] Número total de mensajes entregados a los consumidores utilizando basic.consume con reconocimiento manual
_Se muestra como mensaje_ | +| **rabbitmq.global.messages.delivered.count**
(count) | \[OpenMetrics\] Número total de mensajes entregados a los consumidores
_Se muestra como mensaje_ | +| **rabbitmq.global.messages.delivered.get_auto_ack.count**
(count) | \[OpenMetrics\] Número total de mensajes entregados a los consumidores utilizando basic.get con reconocimiento automático
_Se muestra como mensaje_ | +| **rabbitmq.global.messages.delivered.get_manual_ack.count**
(count) | \[OpenMetrics\] Número total de mensajes entregados a los consumidores utilizando basic.get con reconocimiento manual
_Se muestra como mensaje_ | +| **rabbitmq.global.messages.get_empty.count**
(count) | \[OpenMetrics\] Número total de veces que las operaciones basic.get no han obtenido ningún mensaje.| +| **rabbitmq.global.messages.received.count**
(count) | \[OpenMetrics\] Número total de mensajes recibidos de los publicadores
_Se muestra como mensaje_ | +| **rabbitmq.global.messages.received_confirm.count**
(count) | \[OpenMetrics\] Número total de mensajes recibidos de publicadores que esperan confirmaciones
_Se muestra como mensaje_ | +| **rabbitmq.global.messages.redelivered.count**
(count) | \[OpenMetrics\] Número total de mensajes reenviados a los consumidores
_Se muestra como mensaje_ | +| **rabbitmq.global.messages.routed.count**
(count) | \[OpenMetrics\] Número total de mensajes enrutados a colas o flujos
_Se muestra como mensaje_ | +| **rabbitmq.global.messages.unroutable.dropped.count**
(count) | \[OpenMetrics\] Número total de mensajes publicados como no obligatorios en un intercambio y descartados como no enrutables
_Se muestra como mensaje_ | +| **rabbitmq.global.messages.unroutable.returned.count**
(count) | \[OpenMetrics\] Número total de mensajes publicados como obligatorios en un intercambio y devueltos al publicador como no enrutables
_Se muestra como mensaje_ | +| **rabbitmq.global.publishers**
(gauge) | \[OpenMetrics\] Número actual de publicadores| +| **rabbitmq.identity_info**
(gauge) | \[OpenMetrics\] Información de la identidad de nodos y clústeres RabbitMQ| +| **rabbitmq.io.read_bytes.count**
(count) | \[OpenMetrics\] Número total de bytes de E/S leídos
_Se muestra como bytes_ | +| **rabbitmq.io.read_ops.count**
(count) | \[OpenMetrics\] Número total de operaciones de lectura de E/S
_Se muestra como operación_ | +| **rabbitmq.io.read_time_seconds.count**
(count) | \[OpenMetrics\] Tiempo total de lectura de E/S
_Se muestra en segundos_ | +| **rabbitmq.io.reopen_ops.count**
(count) | \[OpenMetrics\] Número total de veces que se han reabierto archivos| +| **rabbitmq.io.seek_ops.count**
(count) | \[OpenMetrics\] Número total de operaciones de búsqueda de E/S
_Se muestra como operación_ | +| **rabbitmq.io.seek_time_seconds.count**
(count) | \[OpenMetrics\] Tiempo total de búsqueda de E/S
_Se muestra como segundos_ | +| **rabbitmq.io.sync_ops.count**
(count) | \[OpenMetrics\] Número total de operaciones de sincronización de E/S
_Se muestra como operación_ | +| **rabbitmq.io.sync_time_seconds.count**
(count) | \[OpenMetrics\] Tiempo total de sincronización de E/S
_Se muestra como segundos_ | +| **rabbitmq.io.write_bytes.count**
(count) | \[OpenMetrics\] Número total de bytes de E/S escritos
_Se muestra como bytes_ | +| **rabbitmq.io.write_ops.count**
(count) | \[OpenMetrics\] Número total de operaciones de escritura de E/S
_Se muestra como operación_ | +| **rabbitmq.io.write_time_seconds.count**
(count) | \[OpenMetrics\] Tiempo total de escritura de E/S
_Se muestra en segundos_ | +| **rabbitmq.msg_store.read.count**
(count) | \[OpenMetrics\] Número total de operaciones de lectura del almacén de mensajes
_Se muestra como operación_ | +| **rabbitmq.msg_store.write.count**
(count) | \[OpenMetrics\] Número total de operaciones de escritura del almacén de mensajes
_Se muestra como operación_ | +| **rabbitmq.node.disk_alarm**
(gauge) | ¿Tiene el nodo alarma de disco?| +| **rabbitmq.node.disk_free**
(gauge) | Espacio libre actual en disco
_Se muestra como bytes_ | +| **rabbitmq.node.fd_used**
(gauge) | Descriptores de archivo utilizados| +| **rabbitmq.node.mem_alarm**
(gauge) | ¿Tiene el host alarma de memoria?| +| **rabbitmq.node.mem_limit**
(gauge) | Marca de agua alta del uso de memoria en bytes
_Se muestra como bytes_ | +| **rabbitmq.node.mem_used**
(gauge) | Memoria utilizada en bytes
_Se muestra como bytes_ | +| **rabbitmq.node.partitions**
(gauge) | Número de particiones de red que ve este nodo| +| **rabbitmq.node.run_queue**
(gauge) | Número medio de procesos Erlang a la espera de ejecución
_Se muestra como proceso_ | +| **rabbitmq.node.running**
(gauge) | ¿Se está ejecutando el nodo o no?| +| **rabbitmq.node.sockets_used**
(gauge) | Número de descriptores de archivo utilizados como sockets| +| **rabbitmq.overview.messages.ack.count**
(gauge) | Número de mensajes entregados a los clientes y reconocidos
_Se muestra como mensaje_ | +| **rabbitmq.overview.messages.ack.rate**
(gauge) | Tasa de mensajes entregados a clientes y reconocidos por segundo
_Se muestra como mensaje_ | +| **rabbitmq.overview.messages.confirm.count**
(gauge) | Recuento de mensajes confirmados
_Se muestra como mensaje_ | +| **rabbitmq.overview.messages.confirm.rate**
(gauge) | Tasa de mensajes confirmados por segundo
_Se muestra como mensaje_ | +| **rabbitmq.overview.messages.deliver_get.count**
(gauge) | Suma de mensajes entregados en modo de reconocimiento a los consumidores, en modo sin reconocimiento a los consumidores, en modo de reconocimiento en respuesta a basic.get y en modo sin reconocimiento en respuesta a basic.get
_Se muestra como mensaje_ | +| **rabbitmq.overview.messages.deliver_get.rate**
(gauge) | Tasa por segundo de la suma de mensajes entregados en modo de reconocimiento a los consumidores, en modo sin reconocimiento a los consumidores, en modo de reconocimiento en respuesta a basic.get y en modo sin reconocimiento en respuesta a basic.get
_Se muestra como mensaje_ | +| **rabbitmq.overview.messages.drop_unroutable.count**
(gauge) | Recuento de mensajes descartados como no enrutables
_Se muestra como mensaje_ | +| **rabbitmq.overview.messages.drop_unroutable.rate**
(gauge) | Tasa de mensajes descartados como no enrutables por segundo
_Se muestra como mensaje_ | +| **rabbitmq.overview.messages.publish.count**
(gauge) | Recuento de mensajes publicados
_Se muestra como mensaje_ | +| **rabbitmq.overview.messages.publish.rate**
(gauge) | Tasa de mensajes publicados por segundo
_Se muestra como mensaje_ | +| **rabbitmq.overview.messages.publish_in.count**
(gauge) | Recuento de mensajes publicados desde canales en este resumen
_Se muestra como mensaje_ | +| **rabbitmq.overview.messages.publish_in.rate**
(gauge) | Tasa de mensajes publicados desde canales en este resumen por segundo
_Se muestra como mensaje_ | +| **rabbitmq.overview.messages.publish_out.count**
(gauge) | Recuento de mensajes publicados desde este resumen en colas
_Se muestra como mensaje_ | +| **rabbitmq.overview.messages.publish_out.rate**
(gauge) | Tasa de mensajes publicados desde este resumen en colas por segundo
_Se muestra como mensaje_ | +| **rabbitmq.overview.messages.redeliver.count**
(gauge) | Recuento del subconjunto de mensajes en deliver_get que tenían el indicador de reenviado activado
_Se muestra como mensaje_ | +| **rabbitmq.overview.messages.redeliver.rate**
(gauge) | Tasa del subconjunto de mensajes en deliver_get que tenían el indicador de reenviado activado por segundo
__Se muestra como mensaje_ | +| **rabbitmq.overview.messages.return_unroutable.count**
(gauge) | Recuento de mensajes devueltos al publicador como no enrutables
_Se muestra como mensaje_ | +| **rabbitmq.overview.messages.return_unroutable.rate**
(gauge) | Tasa de mensajes devueltos al publicador como no enrutables por segundo
_Se muestra como mensaje_ | +| **rabbitmq.overview.object_totals.channels**
(gauge) | Número total de canales
_Se muestra como elemento_ | +| **rabbitmq.overview.object_totals.connections**
(gauge) | Número total de conexiones
_Se muestra como conexión_ | +| **rabbitmq.overview.object_totals.consumers**
(gauge) | Número total de consumidores
_Se muestra como elemento_ | +| **rabbitmq.overview.object_totals.queues**
(gauge) | Número total de colas
_Se muestra como elemento_ | +| **rabbitmq.overview.queue_totals.messages.count**
(gauge) | Número total de mensajes (listos más no reconocidos)
_Se muestra como mensaje_ | +| **rabbitmq.overview.queue_totals.messages.rate**
(gauge) | Tasa del número de mensajes (listos más no reconocidos)
_Se muestra como mensaje_ | +| **rabbitmq.overview.queue_totals.messages_ready.count**
(gauge) | Número de mensajes listos para su entrega
_Se muestra como mensaje_ | +| **rabbitmq.overview.queue_totals.messages_ready.rate**
(gauge) | Tasa del número de mensajes listos para su entrega
_Se muestra como mensaje_ | +| **rabbitmq.overview.queue_totals.messages_unacknowledged.count**
(gauge) | Número de mensajes no reconocidos
_Se muestra como mensaje_ | +| **rabbitmq.overview.queue_totals.messages_unacknowledged.rate**
(gauge) | Tasa del número de mensajes no reconocidos
_Se muestra como mensaje_ | +| **rabbitmq.process.max_fds**
(gauge) | \[OpenMetrics\] Límite de descriptores de archivo abiertos| +| **rabbitmq.process.max_tcp_sockets**
(gauge) | \[OpenMetrics\] Límite de sockets TCP abiertos| +| **rabbitmq.process.open_fds**
(gauge) | \[OpenMetrics\] Descriptores de archivo abiertos| +| **rabbitmq.process.open_tcp_sockets**
(gauge) | \[OpenMetrics\] Sockets TCP abiertos| +| **rabbitmq.process.resident_memory_bytes**
(gauge) | \[OpenMetrics\] Memoria utilizada en bytes
_Se muestra como bytes_ | +| **rabbitmq.process_start_time_seconds**
(gauge) | \[OpenMetrics\] Tiempo de inicio del proceso desde unix epoch en segundos.
_Se muestra como segundos_ | +| **rabbitmq.queue.active_consumers**
(gauge) | Número de consumidores activos, consumidores que pueden recibir inmediatamente cualquier mensaje enviado a la cola.| +| **rabbitmq.queue.bindings.count**
(gauge) | Número de enlaces para una cola específica| +| **rabbitmq.queue.consumer_capacity**
(gauge) | \[OpenMetrics\] Capacidad de consumo| +| **rabbitmq.queue.consumer_utilisation**
(gauge) | Proporción de tiempo durante el que los consumidores de una cola pueden tomar nuevos mensajes
_Se muestra como fracción_ | +| **rabbitmq.queue.consumers**
(gauge) | Número de consumidores| +| **rabbitmq.queue.disk_reads.count**
(count) | \[OpenMetrics\] Número total de veces que la cola ha leído mensajes del disco| +| **rabbitmq.queue.disk_writes.count**
(count) | \[OpenMetrics\] Número total de veces que la cola ha escrito mensajes en el disco| +| **rabbitmq.queue.get.ack.count**
(count) | \[OpenMetrics\] Número total de mensajes obtenidos de una cola con basic.get en modo de reconocimiento manual.| +| **rabbitmq.queue.get.count**
(count) | \[OpenMetrics\] Número total de mensajes obtenidos de una cola con basic.get en modo de reconocimiento automático.| +| **rabbitmq.queue.get.empty.count**
(count) | \[OpenMetrics\] Número total de veces que las operaciones basic.get no han obtenido ningún mensaje en una cola.| +| **rabbitmq.queue.head_message_timestamp**
(gauge) | \[OpenMetrics, CLI de gestión\] Marca de tiempo del mensaje de cabecera de la marca de tiempo de la cola del primer mensaje de la cola, si lo hay
_Se muestra como milisegundos_ | +| **rabbitmq.queue.index.read_ops.count**
(count) | \[OpenMetrics\] Número total de operaciones de lectura de índices de cola
_Se muestra como operación_ | +| **rabbitmq.queue.index.write_ops.count**
(count) | \[OpenMetrics\] Número total de operaciones de escritura de índices de cola
_Se muestra como operación_ | +| **rabbitmq.queue.memory**
(gauge) | Bytes de memoria consumidos por el proceso Erlang asociado a la cola, incluyendo stack tecnológico, heap y estructuras internas
_Se muestra como bytes_ | +| **rabbitmq.queue.message_bytes**
(gauge) | Número de bytes de mensajes listos para ser entregados a los clientes
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages**
(gauge) | \[OpenMetrics, CLI de gestión\] Recuento del total de mensajes en la cola, que es la suma de mensajes listos y no reconocidos (profundidad total de la cola)
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages.ack.count**
(gauge) | Número de mensajes en cola entregados a clientes y reconocidos
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages.ack.rate**
(gauge) | Número por segundo de mensajes entregados a clientes y reconocidos
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages.acked.count**
(count) | \[OpenMetrics\] Número total de mensajes reconocidos por los consumidores en una cola| +| **rabbitmq.queue.messages.bytes**
(gauge) | \[OpenMetrics\] Tamaño en bytes de los mensajes listos y no reconocidos
_Se muestra como bytes_ | +| **rabbitmq.queue.messages.deliver.count**
(gauge) | Recuento de mensajes entregados en modo de reconocimiento a los consumidores
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages.deliver.rate**
(gauge) | Tasa de mensajes entregados en modo de reconocimiento a los consumidores
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages.deliver_get.count**
(gauge) | Suma de mensajes en colas entregados en modo de reconocimiento a los consumidores, en modo sin reconocimiento a los consumidores, en modo de reconocimiento en respuesta a basic.get y en modo sin reconocimiento en respuesta a basic.get.
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages.deliver_get.rate**
(gauge) | Tasa por segundo de la suma de mensajes en colas entregados en modo de reconocimiento a los consumidores, en modo sin reconocimiento a los consumidores, en modo de reconocimiento en respuesta a basic.get y en modo sin reconocimiento en respuesta a basic.get.
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages.delivered.ack.count**
(count) | \[OpenMetrics\] Número total de mensajes entregados desde una cola a los consumidores en modo de reconocimiento automático.| +| **rabbitmq.queue.messages.delivered.count**
(count) | \[OpenMetrics\] Número total de mensajes entregados desde una cola a los consumidores en modo de reconocimiento automático.| +| **rabbitmq.queue.messages.paged_out**
(gauge) | \[OpenMetrics\] Mensajes paginados al disco| +| **rabbitmq.queue.messages.paged_out_bytes**
(gauge) | \[OpenMetrics\] Tamaño en bytes de los mensajes paginados al disco
_Se muestra como bytes_ | +| **rabbitmq.queue.messages.persistent**
(gauge) | \[OpenMetrics\] Mensajes persistentes
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages.persistent_bytes**
(gauge) | \[OpenMetrics\] Tamaño en bytes de los mensajes persistentes
_Se muestra como bytes_ | +| **rabbitmq.queue.messages.publish.count**
(gauge) | Recuento de mensajes en colas publicados
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages.publish.rate**
(gauge) | Tasa por segundo de mensajes publicados
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages.published.count**
(count) | \[OpenMetrics\] Número total de mensajes publicados en colas
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages.ram**
(gauge) | \[OpenMetrics\] Mensajes listos y no reconocidos almacenados en memoria
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages.ram_bytes**
(gauge) | \[OpenMetrics\] Tamaño de los mensajes listos y no reconocidos almacenados en memoria
_Se muestra como byte_ | +| **rabbitmq.queue.messages.rate**
(gauge) | Recuento por segundo del total de mensajes en la cola
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages.ready**
(gauge) | \[OpenMetrics\] Mensajes listos para ser entregados a los consumidores
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages.ready_bytes**
(gauge) | \[OpenMetrics\] Tamaño en bytes de los mensajes listos
_Se muestra como bytes_ | +| **rabbitmq.queue.messages.ready_ram**
(gauge) | \[OpenMetrics\] Mensajes listos almacenados en memoria
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages.redeliver.count**
(gauge) | Recuento del subconjunto de mensajes en colas en deliver_get que tenían el indicador de reenviado activado
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages.redeliver.rate**
(gauge) | Tasa por segundo del subconjunto de mensajes en deliver_get que tenían el indicador de reenviado activado
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages.redelivered.count**
(count) | \[OpenMetrics\] Número total de mensajes redistribuidos desde una cola a los consumidores| +| **rabbitmq.queue.messages.unacked**
(gauge) | \[OpenMetrics\] Mensajes entregados a los consumidores pero aún no reconocidos
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages.unacked_bytes**
(gauge) | \[OpenMetrics\] Tamaño en bytes de todos los mensajes no reconocidos
_Se muestra como bytes_ | +| **rabbitmq.queue.messages.unacked_ram**
(gauge) | \[OpenMetrics\] Mensajes no reconocidos almacenados en memoria
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages_ready**
(gauge) | Número de mensajes listos para ser entregados a los clientes
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages_ready.rate**
(gauge) | Número por segundo de mensajes listos para ser entregados a los clientes
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages_unacknowledged**
(gauge) | Número de mensajes entregados a clientes pero aún no reconocidos
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages_unacknowledged.rate**
(gauge) | Número por segundo de mensajes entregados a clientes pero aún no reconocidos
_Se muestra como mensaje_ | +| **rabbitmq.queue.process_memory_bytes**
(gauge) | \[OpenMetrics\] Memoria en bytes utilizada por el proceso de cola Erlang
_Se muestra como bytes_ | +| **rabbitmq.queue.process_reductions.count**
(count) | \[OpenMetrics\] Número total de reducciones de procesos de cola| +| **rabbitmq.queues**
(gauge) | \[OpenMetrics\] Colas disponibles| +| **rabbitmq.queues.created.count**
(count) | \[OpenMetrics\] Número total de colas creadas| +| **rabbitmq.queues.declared.count**
(count) | \[OpenMetrics\] Número total de colas declaradas| +| **rabbitmq.queues.deleted.count**
(count) | \[OpenMetrics\] Número total de colas eliminadas| +| **rabbitmq.raft.entry_commit_latency_seconds**
(gauge) | \[OpenMetrics\] Tiempo que tarda en confirmarse una entrada de log
_Se muestra como segundos_ | +| **rabbitmq.raft.log.commit_index**
(gauge) | \[OpenMetrics] Índice de confirmación de logs Raft| +| **rabbitmq.raft.log.last_applied_index**
(gauge) | \[OpenMetrics\] Último índice de logs Raft aplicado| +| **rabbitmq.raft.log.last_written_index**
(gauge) | \[OpenMetrics\] Último índice de logs Raft escrito| +| **rabbitmq.raft.log.snapshot_index**
(gauge) | \[OpenMetrics\] Índice de snapshots de logs Raft| +| **rabbitmq.raft.term.count**
(count) | \[OpenMetrics\] Número de término Raft actual| +| **rabbitmq.resident_memory_limit_bytes**
(gauge) | \[OpenMetrics\] Marca de agua alta de memoria en bytes
_Se muestra como bytes_ | +| **rabbitmq.schema.db.disk_tx.count**
(count) | \[OpenMetrics\] Número total de transacciones de disco Schema DB
_Se muestra como transacción_ | +| **rabbitmq.schema.db.ram_tx.count**
(count) | \[OpenMetrics\] Número total de transacciones de memoria Schema DB
_Se muestra como transacción_ | +| **rabbitmq.telemetry.scrape.duration_seconds.count**
(count) | \[OpenMetrics\] Duración del raspado
_Se muestra como segundos_ | +| **rabbitmq.telemetry.scrape.duration_seconds.sum**
(count) | \[OpenMetrics\] Duración del raspado
_Se muestra como segundos_ | +| **rabbitmq.telemetry.scrape.encoded_size_bytes.count**
(count) | \[OpenMetrics\] Tamaño de raspado, codificado
_Se muestra como bytes_ | +| **rabbitmq.telemetry.scrape.encoded_size_bytes.sum**
(count) | \[OpenMetrics\] Tamaño de raspado, codificado
_Se muestra como bytes_ | +| **rabbitmq.telemetry.scrape.size_bytes.count**
(count) | \[OpenMetrics\] Tamaño de raspado, no codificado
_Se muestra como bytes_ | +| **rabbitmq.telemetry.scrape.size_bytes.sum**
(count) | \[OpenMetrics\] Tamaño de raspado, no codificado
_Se muestra como bytes_ | + +### Eventos + +### Checks de servicio + +**rabbitmq.aliveness** + +Solo disponible con el complemento de gestión de RabbitMQ. Devuelve el estado de un vhost basado en la [API Aliveness](https://github.com/rabbitmq/rabbitmq-management/blob/rabbitmq_v3_6_8/priv/www/api/index.html) de RabbitMQ. La API Aliveness crea una cola de test, luego publica y consume un mensaje de esa cola. Devuelve `OK` si el código de estado de la API es 200 y `CRITICAL` en caso contrario. + +_Estados: ok, crítico_ + +**rabbitmq.status** + +Solo disponible con el complemento de gestión de RabbitMQ. Devuelve el estado del servidor RabbitMQ. Devuelve `OK` si el Agent ha podido contactar con la API y `CRITICAL` en caso contrario. + +_Estados: ok, crítico_ + +**rabbitmq.openmetrics.health** + +Solo disponible con el complemento RabbitMQ Prometheus. Devuelve `CRITICAL` si el Agent no puede conectarse al endpoint de OpenMetrics y `OK` en caso contrario. + +_Estados: ok, crítico_ + +## Solucionar problemas + +### Migración al complemento Prometheus + +El complemento Prometheus expone un conjunto diferente de métricas del complemento de gestión. +Esto es lo que debes tener en cuenta al migrar del complemento de gestión a Prometheus. + +- Busca tus métricas en [esta tabla](https://docs.datadoghq.com/integrations/rabbitmq/?tab=host#metrics).. Si la descripción de una métrica contiene una etiqueta `[OpenMetrics]`, significa que está disponible en el complemento Prometheus. Las métricas que solo están disponibles en el complemento de gestión no tienen etiquetas en sus descripciones. +- Todos los dashboards y monitores que utilizan métricas del complemento de gestión no funcionarán. Cambia a los dashboards y a los monitores marcados como *OpenMetrics Version*. +- La configuración por defecto recopila métricas agregadas. Esto significa, por ejemplo, que no hay métricas etiquetadas por cola. Configura la opción `prometheus_plugin.unaggregated_endpoint` para obtener métricas sin agregación. +- El check de servicio `rabbitmq.status` se sustituye por `rabbitmq.openmetrics.health`. El check de servicio `rabbitmq.aliveness` no tiene equivalente en el complemento Prometheus. + +El complemento Prometheus modifica algunas etiquetas. En la siguiente tabla se describen los cambios de las etiquetas más comunes. + +| Gestión | Prometheus | +|:--------------------|:-----------------------------------------| +| `queue_name` | `queue` | +| `rabbitmq_vhost` | `vhost`, `exchange_vhost`, `queue_vhost` | +| `rabbitmq_exchange` | `exchange` | + +Para obtener más información, consulta [Etiquetado de colas RabbitMQ por familia de etiquetas](https://docs.datadoghq.com/integrations/faq/tagging-rabbitmq-queues-by-tag-family/). + +¿Necesitas ayuda? Ponte en contacto con el [servicio de asistencia de Datadog](https://docs.datadoghq.com/help/). + +## Referencias adicionales + +Documentación útil adicional, enlaces y artículos: + +- [Métricas clave para la monitorización de RabbitMQ](https://www.datadoghq.com/blog/rabbitmq-monitoring) +- [Recopilación de métricas con las herramientas de monitorización de RabbitMQ](https://www.datadoghq.com/blog/rabbitmq-monitoring-tools) +- [Monitorización del rendimiento de RabbitMQ con Datadog](https://www.datadoghq.com/blog/monitoring-rabbitmq-performance-with-datadog) \ No newline at end of file diff --git a/content/es/integrations/solr.md b/content/es/integrations/solr.md new file mode 100644 index 0000000000000..f2c8e86a2d02c --- /dev/null +++ b/content/es/integrations/solr.md @@ -0,0 +1,324 @@ +--- +"app_id": "solr" +"app_uuid": "3733c24e-8466-4f3b-8411-59ef85c28302" +"assets": + "dashboards": + "solr": "assets/dashboards/solr_overview.json" + "integration": + "auto_install": true + "configuration": + "spec": "assets/configuration/spec.yaml" + "events": + "creates_events": false + "metrics": + "check": "solr.searcher.numdocs" + "metadata_path": "metadata.csv" + "prefix": "solr." + "process_signatures": + - "solr start" + "service_checks": + "metadata_path": "assets/service_checks.json" + "source_type_id": !!int "42" + "source_type_name": "Solr" + "saved_views": + "solr_processes": "assets/saved_views/solr_processes.json" +"author": + "homepage": "https://www.datadoghq.com" + "name": "Datadog" + "sales_email": "info@datadoghq.com" + "support_email": "help@datadoghq.com" +"categories": +- "caching" +- "data stores" +- "log collection" +"custom_kind": "integración" +"dependencies": +- "https://github.com/DataDog/integrations-core/blob/master/solr/README.md" +"display_on_public_website": true +"draft": false +"git_integration_title": "solr" +"integration_id": "solr" +"integration_title": "Solr" +"integration_version": "2.1.0" +"is_public": true +"manifest_version": "2.0.0" +"name": "solr" +"public_title": "Solr" +"short_description": "Monitoriza tasa de solicitudes, errores de gestor, fallos de caché y desalojos y más." +"supported_os": +- "linux" +- "windows" +- "macos" +"tile": + "changelog": "CHANGELOG.md" + "classifier_tags": + - "Category::Caching" + - "Category::Data Stores" + - "Category::Log Collection" + - "Supported OS::Linux" + - "Supported OS::Windows" + - "Supported OS::macOS" + - "Offering::Integration" + "configuration": "README.md#Setup" + "description": "Monitoriza tasa de solicitudes, errores de gestor, fallos de caché y desalojos y más." + "media": [] + "overview": "README.md#Overview" + "support": "README.md#Support" + "title": "Solr" +--- + + + + +![Gráfico de Solr][1] + +## Información general + +El check de Solr realiza un seguimiento del estado y el rendimiento de un clúster de Solr. Recopila métricas del número de documentos indexados, los aciertos y desalojos de la caché, los tiempos medios de solicitud, las solicitudes medias por segundo, etc. + +## Configuración + +### Instalación + +El check de Solr está incluido en el paquete del [Datadog Agent][2], por lo que no necesitas instalar nada más en tus nodos de Solr. + +Este check está basado en JMX, por lo que necesitas habilitar JMX Remote en tus servidores de Solr. Consulta la [documentación del check de JMX][3] para obtener más información. + +### Configuración + +{{< tabs >}} +{{% tab "Host" %}} + +#### Host + +Para configurar este check para un Agent que se ejecuta en un host: + +1. Edita el archivo `solr.d/conf.yaml` en la carpeta `conf.d/` en la raíz del [directorio de configuración de tu Agent][1]. Para conocer todas las opciones de configuración disponibles, consulta el [solr.d/conf.yaml de ejemplo][2]. + + ```yaml + init_config: + + ## @param is_jmx - boolean - required + ## Whether or not this file is a configuration for a JMX integration. + # + is_jmx: true + + ## @param collect_default_metrics - boolean - required + ## Whether or not the check should collect all default metrics. + # + collect_default_metrics: true + + instances: + ## @param host - string - required + ## Solr host to connect to. + - host: localhost + + ## @param port - integer - required + ## Solr port to connect to. + port: 9999 + ``` + +2. [Reinicia el Agent][3]. + +#### Lista de métricas + +El parámetro `conf` es una lista de métricas que recopilará la integración. Solo se admiten 2 claves: + +- `include` (**obligatorio**): un diccionario de filtros, cualquier atributo que coincida con estos filtros se recopila a menos que también coincida con los filtros `exclude` (ver más abajo). +- `exclude` (**opcional**): un diccionario de filtros, los atributos que coinciden con estos filtros no se recopilan. + +Para un bean dado, las métricas se etiquetan de la siguiente manera: + +```text +mydomain:attr0=val0,attr1=val1 +``` + +En este ejemplo, tu métrica es `mydomain` (o alguna variación según el atributo dentro del bean) y tiene las etiquetas `attr0:val0`, `attr1:val1` y `domain:mydomain`. + +Si especificas un alias en una clave `include` con formato _camel case_, se convierte a _snake case_. Por ejemplo, `MyMetricName` aparece en Datadog como `my_metric_name`. + +##### El filtro de atributos + +El filtro `attribute` puede aceptar dos tipos de valores: + +- Un diccionario cuyas claves son nombres de atributos (ver más adelante). Para este caso, puedes especificar un alias para la métrica que se convierte en el nombre de métrica en Datadog. También puedes especificar el tipo de métrica como gauge o count. Si eliges count, se calcula una tasa por segundo para la métrica. + + ```yaml + conf: + - include: + attribute: + maxThreads: + alias: tomcat.threads.max + metric_type: gauge + currentThreadCount: + alias: tomcat.threads.count + metric_type: gauge + bytesReceived: + alias: tomcat.bytes_rcvd + metric_type: counter + ``` + +- Una lista de nombres de atributos (ver más abajo). Para este caso, el tipo de métrica es un gauge y el nombre de métrica es `jmx.\[DOMAIN_NAME].\[ATTRIBUTE_NAME]`. + + ```yaml + conf: + - include: + domain: org.apache.cassandra.db + attribute: + - BloomFilterDiskSpaceUsed + - BloomFilterFalsePositives + - BloomFilterFalseRatio + - Capacity + - CompressionRatio + - CompletedTasks + - ExceptionCount + - Hits + - RecentHitRate + ``` + +#### Versiones anteriores + +La lista de filtros solo se admite en el Datadog Agent > 5.3.0. Si utilizas una versión anterior, utiliza singletons y varias sentencias `include` en su lugar. + +```yaml +# Datadog Agent > 5.3.0 + conf: + - include: + domain: domain_name + bean: + - first_bean_name + - second_bean_name +# Older Datadog Agent versions + conf: + - include: + domain: domain_name + bean: first_bean_name + - include: + domain: domain_name + bean: second_bean_name +``` + +[1]: https://docs.datadoghq.com/agent/guide/agent-configuration-files/#agent-configuration-directory +[2]: https://github.com/DataDog/integrations-core/blob/master/solr/datadog_checks/solr/data/conf.yaml.example +[3]: https://docs.datadoghq.com/agent/guide/agent-commands/#start-stop-and-restart-the-agent +{{% /tab %}} +{{% tab "Contenedorizado" %}} + +#### Contenedores + +Para obtener información sobre entornos en contenedores, consulta la guía [Autodiscovery con JMX][1]. + +##### Recopilación de logs + +1. La recopilación de logs está desactivada por defecto en el Datadog Agent, actívala en tu archivo `datadog.yaml`: + + ```yaml + logs_enabled: true + ``` + +2. Solr utiliza el registrador `log4j` por defecto. Para personalizar el formato de registro, edita el archivo [`server/resources/log4j2.xml`][2]. Por defecto, el pipeline de la integración de Datadog admite el siguiente [patrón][3] de conversión: + + ```text + %maxLen{%d{yyyy-MM-dd HH:mm:ss.SSS} %-5p (%t) [%X{collection} %X{shard} %X{replica} %X{core}] %c{1.} %m%notEmpty{ =>%ex{short}}}{10240}%n + ``` + + Clona y edita el [pipeline de integración][4] si tienes un formato diferente. + + +3. Anula los comentarios y edita el bloque de configuración de logs en tu archivo `solr.d/conf.yaml`. Cambia los valores de los parámetros `type`, `path` y `service` en función de tu entorno. Consulta [solr.d/solr.yaml de ejemplo][5] para conocer todas las opciones disponibles de configuración. + + ```yaml + logs: + - type: file + path: /var/solr/logs/solr.log + source: solr + # To handle multi line that starts with yyyy-mm-dd use the following pattern + # log_processing_rules: + # - type: multi_line + # pattern: \d{4}\-(0?[1-9]|1[012])\-(0?[1-9]|[12][0-9]|3[01]) + # name: new_log_start_with_date + ``` + +4. [Reinicia el Agent][6]. + +Para habilitar logs para entornos de Kubernetes, consulta [Recopilación de log de Kubernetes][7]. + +[1]: https://docs.datadoghq.com/agent/guide/autodiscovery-with-jmx/?tab=containerizedagent +[2]: https://lucene.apache.org/solr/guide/configuring-logging.html#permanent-logging-settings +[3]: https://logging.apache.org/log4j/2.x/manual/layouts.html#Patterns +[4]: https://docs.datadoghq.com/logs/processing/#integration-pipelines +[5]: https://github.com/DataDog/integrations-core/blob/master/solr/datadog_checks/solr/data/conf.yaml.example +[6]: https://docs.datadoghq.com/agent/guide/agent-commands/#start-stop-and-restart-the-agent +[7]: https://docs.datadoghq.com/agent/docker/log/ +{{% /tab %}} +{{< /tabs >}} + +### Validación + +[Ejecuta el subcomando de estado del Agent][4] y busca `solr` en la sección Checks. + +## Datos recopilados + +### Métricas +{{< get-metrics-from-git "solr" >}} + + +### Eventos + +El check de Solr no incluye ningún evento. + +### Checks de servicio +{{< get-service-checks-from-git "solr" >}} + + +## Solucionar problemas + +### Comandos para ver las métricas disponibles + +El comando `datadog-agent jmx` se añadió en la versión 4.1.0. + +- Mostrar una lista de atributos que coincidan con, al menos, una de tus configuraciones de instancias: + `sudo datadog-agent jmx list matching` +- Mostrar una lista de atributos que coinciden con una de tus configuraciones de instancias, pero no se recopilan porque se superaría el número de métricas que es posible recopilar. + `sudo datadog-agent jmx list limited` +- Mostrar una lista de atributos que se espera que recopile tu configuración de instancias actual: + `sudo datadog-agent jmx list collected` +- Mostrar una lista de atributos que no coincidan con ninguna de tus configuraciones de instancias: + `sudo datadog-agent jmx list not-matching` +- Mostrar cada atributo disponible que tenga un tipo compatible con JMXFetch: + `sudo datadog-agent jmx list everything` +- Iniciar la recopilación de métricas según tu configuración actual y mostrarlas en la consola: + `sudo datadog-agent jmx collect` + +¿Necesitas ayuda? Ponte en contacto con el [servicio de asistencia de Datadog][5]. + +## Referencias adicionales + +### Parseo de un valor de cadena en un número + +Si tu jmxfetch devuelve solo valores de cadena como **false** y **true** y quieres transformarlo en una métrica gauge de Datadog para usos avanzados. Por ejemplo, si deseas la siguiente equivalencia para tu jmxfetch: + +```text +"myJmxfetch:false" = myJmxfetch:0 +"myJmxfetch:true" = myJmxfetch:1 +``` + +Puedes utilizar el filtro `attribute` como se indica a continuación: + +```yaml +# ... +attribute: + myJmxfetch: + alias: your_metric_name + metric_type: gauge + values: + "false": 0 + "true": 1 +``` + + +[1]: https://raw.githubusercontent.com/DataDog/integrations-core/master/solr/images/solrgraph.png +[2]: https://app.datadoghq.com/account/settings/agent/latest +[3]: https://docs.datadoghq.com/integrations/java/ +[4]: https://docs.datadoghq.com/agent/guide/agent-commands/#agent-status-and-information +[5]: https://docs.datadoghq.com/help/ diff --git a/content/es/integrations/spark.md b/content/es/integrations/spark.md new file mode 100644 index 0000000000000..df281b7de5933 --- /dev/null +++ b/content/es/integrations/spark.md @@ -0,0 +1,232 @@ +--- +"app_id": "spark" +"app_uuid": "5cb22455-9ae2-44ee-ae05-ec21c27b3292" +"assets": + "dashboards": + "Databricks Spark Overview": "assets/dashboards/databricks_overview.json" + "spark": "assets/dashboards/spark_dashboard.json" + "integration": + "auto_install": true + "configuration": + "spec": "assets/configuration/spec.yaml" + "events": + "creates_events": false + "metrics": + "check": "spark.job.count" + "metadata_path": "metadata.csv" + "prefix": "spark." + "process_signatures": + - "java org.apache.spark.deploy.SparkSubmit" + - "java org.apache.spark.deploy.worker.Worker" + - "java org.apache.spark.deploy.master.Master" + "service_checks": + "metadata_path": "assets/service_checks.json" + "source_type_id": !!int "142" + "source_type_name": "Spark" +"author": + "homepage": "https://www.datadoghq.com" + "name": "Datadog" + "sales_email": "info@datadoghq.com" + "support_email": "help@datadoghq.com" +"categories": +- "log collection" +"custom_kind": "integración" +"dependencies": +- "https://github.com/DataDog/integrations-core/blob/master/spark/README.md" +"display_on_public_website": true +"draft": false +"git_integration_title": "spark" +"integration_id": "spark" +"integration_title": "Spark" +"integration_version": "6.4.0" +"is_public": true +"manifest_version": "2.0.0" +"name": "spark" +"public_title": "Spark" +"short_description": "Rastrea los índices de tareas fallidas, bytes aleatorios y mucho más." +"supported_os": +- "linux" +- "windows" +- "macos" +"tile": + "changelog": "CHANGELOG.md" + "classifier_tags": + - "Category::Log Collection" + - "Supported OS::Linux" + - "Supported OS::Windows" + - "Supported OS::macOS" + - "Offering::Integration" + "configuration": "README.md#Setup" + "description": "Rastrea los índices de tareas fallidas, bytes aleatorios y mucho más." + "media": [] + "overview": "README.md#Overview" + "resources": + - "resource_type": "blog" + "url": "https://www.datadoghq.com/blog/data-jobs-monitoring/" + - "resource_type": "blog" + "url": "https://www.datadoghq.com/blog/data-observability-monitoring/" + - "resource_type": "blog" + "url": "https://www.datadoghq.com/blog/monitoring-spark" + - "resource_type": "blog" + "url": "https://www.datadoghq.com/blog/spark-emr-monitoring/" + "support": "README.md#Support" + "title": "Spark" +--- + + + + +:5050 # Mesos master web UI
+ # spark_url: http://:8088 # YARN ResourceManager address
+
+ spark_cluster_mode: spark_yarn_mode # default
+ # spark_cluster_mode: spark_mesos_mode
+ # spark_cluster_mode: spark_yarn_mode
+ # spark_cluster_mode: spark_driver_mode
+
+ # required; adds a tag 'cluster_name:' to all metrics
+ cluster_name: ""
+ # spark_pre_20_mode: true # if you use Standalone Spark < v2.0
+ # spark_proxy_enabled: true # if you have enabled the spark UI proxy
+ ```
+
+2. [Reinicia el Agent][3].
+
+[1]: https://docs.datadoghq.com/agent/guide/agent-configuration-files/#agent-configuration-directory
+[2]: https://github.com/DataDog/integrations-core/blob/master/spark/datadog_checks/spark/data/conf.yaml.example
+[3]: https://docs.datadoghq.com/agent/guide/agent-commands/#start-stop-and-restart-the-agent
+{{% /tab %}}
+{{% tab "Contenedorizado" %}}
+
+#### Contenedores
+
+Para entornos en contenedores, consulta las plantillas de integración de Autodiscovery, ya sea para [Docker][1] o [Kubernetes][2], para obtener orientación sobre la aplicación de los parámetros que se indican a continuación.
+
+| Parámetro | Valor |
+| -------------------- | ----------------------------------------------------------------- |
+| `` | `spark` |
+| `` | en blanco o `{}` |
+| `` | `{"spark_url": "%%host%%:8080", "cluster_name":""}` |
+
+[1]: https://docs.datadoghq.com/containers/docker/integrations/
+[2]: https://docs.datadoghq.com/agent/kubernetes/integrations/
+{{% /tab %}}
+{{< /tabs >}}
+
+### Recopilación de logs
+
+1. La recopilación de logs está desactivada por defecto en el Datadog Agent, actívala en tu archivo `datadog.yaml`:
+
+ ```yaml
+ logs_enabled: true
+ ```
+
+2. Anula los comentarios y edita el bloque de configuración de logs en tu archivo `spark.d/conf.yaml`. Cambia los valores de los parámetros `type`, `path` y `service` en función de tu entorno. Consulta [spark.d/.yaml de ejemplo][4] para conocer todas las opciones disponibles de configuración.
+
+ ```yaml
+ logs:
+ - type: file
+ path:
+ source: spark
+ service:
+ # To handle multi line that starts with yyyy-mm-dd use the following pattern
+ # log_processing_rules:
+ # - type: multi_line
+ # pattern: \d{4}\-(0?[1-9]|1[012])\-(0?[1-9]|[12][0-9]|3[01])
+ # name: new_log_start_with_date
+ ```
+
+3. [Reinicia el Agent][5].
+
+Para habilitar los logs para entornos de Docker, consulta [recopilación de logs de Docker][6].
+
+### Validación
+
+[Ejecuta el subcomando de estado del Agent][7] y busca `spark` en la sección Checks.
+
+## Datos recopilados
+
+### Métricas
+{{< get-metrics-from-git "spark" >}}
+
+
+### Eventos
+
+El check de Spark no incluye ningún evento.
+
+### Checks de servicio
+{{< get-service-checks-from-git "spark" >}}
+
+
+## Solucionar problemas
+
+### Spark en Amazon EMR
+
+Para recibir métricas para Spark en Amazon EMR, [utiliza acciones de arranque][8] para instalar el [Agent][9]:
+
+Para Agent v5, crea el archivo de configuración `/etc/dd-agent/conf.d/spark.yaml` con los [valores adecuados en cada nodo de EMR][10].
+
+Para Agent v6/7, crea el archivo de configuración `/etc/datadog-agent/conf.d/spark.d/conf.yaml` con los [valores adecuados en cada nodo de EMR][10].
+
+### Check finalizado con éxito, pero no se recopilaron métricas
+
+La integración de Spark solo recopila métricas sobre las aplicaciones en ejecución. Si no tienes ninguna aplicación en ejecución, el check se limitará a enviar un check de estado.
+
+## Referencias adicionales
+
+Más enlaces, artículos y documentación útiles:
+
+- [Monitorización de Hadoop y Spark con Datadog][11]
+- [Monitorización de aplicaciones de Apache Spark ejecutadas en Amazon EMR][12]
+
+
+[1]: https://raw.githubusercontent.com/DataDog/integrations-core/master/spark/images/sparkgraph.png
+[2]: https://spark.apache.org/
+[3]: https://app.datadoghq.com/account/settings/agent/latest
+[4]: https://github.com/DataDog/integrations-core/blob/master/spark/datadog_checks/spark/data/conf.yaml.example
+[5]: https://docs.datadoghq.com/agent/guide/agent-commands/#start-stop-and-restart-the-agent
+[6]: https://docs.datadoghq.com/agent/docker/log/
+[7]: https://docs.datadoghq.com/agent/guide/agent-commands/#agent-status-and-information
+[8]: https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-plan-bootstrap.html
+[9]: https://docs.datadoghq.com/agent/
+[10]: https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-connect-master-node-ssh.html
+[11]: https://www.datadoghq.com/blog/monitoring-spark
+[12]: https://www.datadoghq.com/blog/spark-emr-monitoring/
diff --git a/content/es/integrations/sqlserver.md b/content/es/integrations/sqlserver.md
new file mode 100644
index 0000000000000..475e04d2e0e4e
--- /dev/null
+++ b/content/es/integrations/sqlserver.md
@@ -0,0 +1,314 @@
+---
+"app_id": "sql-server"
+"app_uuid": "bfa2f276-da05-4153-b8d4-48d4e41f5e40"
+"assets":
+ "dashboards":
+ "SQLServer-AlwaysOn": "assets/dashboards/SQLServer-AlwaysOn_dashboard.json"
+ "SQLServer-Overview": "assets/dashboards/SQLServer-Overview_dashboard.json"
+ "sqlserver": "assets/dashboards/sqlserver_dashboard.json"
+ "integration":
+ "auto_install": true
+ "configuration":
+ "spec": "assets/configuration/spec.yaml"
+ "events":
+ "creates_events": false
+ "metrics":
+ "check": "sqlserver.stats.connections"
+ "metadata_path": "metadata.csv"
+ "prefix": "sqlserver."
+ "service_checks":
+ "metadata_path": "assets/service_checks.json"
+ "source_type_id": !!int "45"
+ "source_type_name": "SQL Server"
+ "monitors":
+ "Auto-parameterization attempts are failing": "assets/monitors/sqlserver_high_number_failed_auto_param.json"
+ "Availability Group is not healthy": "assets/monitors/sqlserver_ao_not_healthy.json"
+ "Availability group failover detected": "assets/monitors/sqlserver_ao_failover.json"
+ "Database is not online": "assets/monitors/sqlserver_db_not_online.json"
+ "Database not in sync": "assets/monitors/sqlserver_db_not_sync.json"
+ "Processes are blocked": "assets/monitors/sqlserver_high_processes_blocked.json"
+"author":
+ "homepage": "https://www.datadoghq.com"
+ "name": "Datadog"
+ "sales_email": "info@datadoghq.com"
+ "support_email": "help@datadoghq.com"
+"categories":
+- "data stores"
+- "log collection"
+"custom_kind": "integración"
+"dependencies":
+- "https://github.com/DataDog/integrations-core/blob/master/sqlserver/README.md"
+"display_on_public_website": verdadero
+"draft": falso
+"git_integration_title": "sqlserver"
+"integration_id": "sql-server"
+"integration_title": "SQL Server"
+"integration_version": "22.7.0"
+"is_public": verdadero
+"manifest_version": "2.0.0"
+"name": "sqlserver"
+"public_title": "SQL Server"
+"short_description": "Recopila métricas de rendimiento y estado importantes de SQL Server."
+"supported_os":
+- "linux"
+- "macos"
+- "windows"
+"tile":
+ "changelog": "CHANGELOG.md"
+ "classifier_tags":
+ - "Supported OS::Linux"
+ - "Supported OS::macOS"
+ - "Supported OS::Windows"
+ - "Category::Almacenes de datos"
+ - "Category::Recopilación de logs"
+ - "Offering::Integration"
+ "configuration": "README.md#Setup"
+ "description": "Recopila métricas de rendimiento y estado importantes de SQL Server."
+ "media": []
+ "overview": "README.md#Overview"
+ "resources":
+ - "resource_type": "blog"
+ "url": "https://www.datadoghq.com/blog/monitor-azure-sql-databases-datadog"
+ - "resource_type": "blog"
+ "url": "https://www.datadoghq.com/blog/sql-server-monitoring"
+ - "resource_type": "blog"
+ "url": "https://www.datadoghq.com/blog/sql-server-monitoring-tools"
+ - "resource_type": "blog"
+ "url": "https://www.datadoghq.com/blog/sql-server-performance"
+ - "resource_type": "blog"
+ "url": "https://www.datadoghq.com/blog/sql-server-metrics"
+ - "resource_type": "blog"
+ "url": "https://www.datadoghq.com/blog/migrate-sql-workloads-to-azure-with-datadog/"
+ "support": "README.md#Support"
+ "title": "SQL Server"
+---
+
+
+
+
+![Gráfico de SQL Server][1]
+
+## Información general
+
+La integración de SQL Server realiza un seguimiento del rendimiento de las instancias de SQL Server. Recopila métricas para el número de conexiones de usuario, la tasa de compilaciones de SQL y mucho más.
+
+Activa la [Monitorización de base de datos][2] (DBM) para obtener una visión mejorada del rendimiento de las consultas y del estado de la base de datos. Además de la integración estándar, Datadog DBM proporciona métricas a nivel de consulta, snapshots de consultas en tiempo real e históricas, análisis de eventos de espera, carga de la base de datos, planes de explicación de consultas e información sobre consultas de bloqueo.
+
+SQL Server 2012, 2014, 2016, 2017, 2019 y 2022 son compatibles.
+
+## Configuración
+
+';
+ USE master;
+ CREATE USER datadog FOR LOGIN datadog;
+ GRANT SELECT on sys.dm_os_performance_counters to datadog;
+ GRANT VIEW SERVER STATE to datadog;
+ ```
+
+ Para recopilar métricas del tamaño del archivo por base de datos, asegúrate de que el usuario que has creado (`datadog`) tiene [acceso con permiso de conexión][6] a tus bases de datos ejecutando:
+
+ ```SQL
+ GRANT CONNECT ANY DATABASE to datadog;
+ ```
+
+2. (Necesario para AlwaysOn y métricas `sys.master_files`) Para reunir AlwaysOn y métricas `sys.master_files`, concede el siguiente permiso adicional:
+
+ ```SQL
+ GRANT VIEW ANY DEFINITION to datadog;
+ ```
+
+### Configuración
+
+{{< tabs >}}
+{{% tab "Host" %}}
+
+#### host
+
+Para configurar este check para un Agent que se ejecuta en un host:
+
+1. Edita el archivo `sqlserver.d/conf.yaml` en la carpeta `conf.d/` en la raíz del [directorio de configuración de tu Agent][1]. Para conocer todas las opciones de configuración disponibles, consulta el [sqlserver.d/conf.yaml de ejemplo][2].
+
+ ```yaml
+ init_config:
+
+ instances:
+ - host: ","
+ username: datadog
+ password: ""
+ connector: adodbapi
+ adoprovider: MSOLEDBSQL19 # Replace with MSOLEDBSQL for versions 18 and previous
+ ```
+
+ Si utilizas el Autodiscovery de puerto, utiliza `0` para `SQL_PORT`. Consulta la [configuración de check de ejemplo][2] para obtener una descripción completa de todas las opciones, incluido cómo utilizar consultas personalizadas para crear tus propias métricas.
+
+ Utiliza [controladores compatibles][3] en función de tu configuración de SQL Server.
+
+ **Nota**: También es posible utilizar la autenticación de Windows y no especificar el nombre de usuario/contraseña con:
+
+ ```yaml
+ connection_string: "Trusted_Connection=yes"
+ ```
+
+
+2. [Reinicia el Agent][4].
+
+##### Linux
+
+Se requieren pasos adicionales en la configuración para que la integración de SQL Server funcione en el host de Linux:
+
+1. Instala un controlador ODBC SQL Server, por ejemplo el [controlador ODBC de Microsoft][5] o el [controlador FreeTDS][6].
+2. Copia los archivos `odbc.ini` y `odbcinst.ini` en la carpeta `/opt/datadog-agent/embedded/etc`.
+3. Configura el archivo `conf.yaml` para utilizar el conector `odbc` y especifica el controlador adecuado como se indica en el archivo `odbcinst.ini`.
+
+##### Recopilación de logs
+
+_Disponible para las versiones 6.0 o posteriores del Agent_
+
+1. La recopilación de logs está desactivada en forma predeterminada en el Datadog Agent, actívala en tu archivo `datadog.yaml`:
+
+ ```yaml
+ logs_enabled: true
+ ```
+
+2. Añade este bloque de configuración a tu archivo `sqlserver.d/conf.yaml` para empezar a recopilar tus logs de SQL Server:
+
+ ```yaml
+ logs:
+ - type: file
+ encoding: utf-16-le
+ path: ""
+ source: sqlserver
+ service: ""
+ ```
+
+ Cambia los valores de los parámetros `path` y `service` en función de tu entorno. Consulta el [sqlserver.d/conf.yaml de ejemplo][2] para ver todas las opciones disponibles de configuración.
+
+3. [Reinicia el Agent][4].
+
+[1]: https://docs.datadoghq.com/agent/guide/agent-configuration-files/#agent-configuration-directory
+[2]: https://github.com/DataDog/integrations-core/blob/master/sqlserver/datadog_checks/sqlserver/data/conf.yaml.example
+[3]: https://docs.datadoghq.com/database_monitoring/setup_sql_server/selfhosted/#supported-drivers
+[4]: https://docs.datadoghq.com/agent/guide/agent-commands/#start-stop-and-restart-the-agent
+[5]: https://docs.microsoft.com/en-us/sql/connect/odbc/linux-mac/installing-the-microsoft-odbc-driver-for-sql-server?view=sql-server-2017
+[6]: http://www.freetds.org/
+{{% /tab %}}
+{{% tab "Contenedores" %}}
+
+#### En contenedores
+
+Para entornos en contenedores, consulta las [plantillas de integración de Autodiscovery][1] para obtener orientación sobre la aplicación de los parámetros que se indican a continuación.
+
+##### Recopilación de métricas
+
+| Parámetro | Valor |
+| -------------------- | -------------------------------------------------------------------------------------------------------------------------------- |
+| `` | `sqlserver` |
+| `` | en blanco o `{}` |
+| `` | `{"host": "%%host%%,%%port%%", "username": "datadog", "password": "", "connector": "odbc", "driver": "FreeTDS"}` |
+
+Consulta [Variables de plantilla de Autodiscovery][2] para obtener más detalles sobre cómo pasar `` como una variable de entorno en lugar de una etiqueta (label).
+
+##### Recopilación de logs
+
+_Disponible para las versiones 6.0 o posteriores del Agent_
+
+La recopilación de logs se encuentra deshabilitada de manera predeterminada en el Datadog Agent. Para habilitarla, consulta la [recopilación de logs de Kubernetes][3].
+
+| Parámetro | Valor |
+| -------------- | ------------------------------------------------- |
+| `` | `{"source": "sqlserver", "service": "sqlserver"}` |
+
+[1]: https://docs.datadoghq.com/agent/kubernetes/integrations/
+[2]: https://docs.datadoghq.com/agent/faq/template_variables/
+[3]: https://docs.datadoghq.com/agent/kubernetes/log/
+{{% /tab %}}
+{{< /tabs >}}
+
+### Validación
+
+[Ejecuta el subcomando de estado del Agent][9] y busca `sqlserver` en la sección Checks.
+
+## Datos recopilados
+
+### Métricas
+{{< get-metrics-from-git "sqlserver" >}}
+
+
+La mayoría de estas métricas proceden de la tabla `sys.dm_os_performance_counters` de tu SQL Server.
+
+### Eventos
+
+El check de SQL Server no incluye ningún evento.
+
+### Checks de servicio
+{{< get-service-checks-from-git "sqlserver" >}}
+
+
+## Solucionar problemas
+
+¿Necesitas ayuda? Ponte en contacto con el [servicio de asistencia de Datadog][8].
+
+Si estás ejecutando el Agent en un procesador ARM aarch64, existe un problema conocido que comienza en la versión 14.0.0 de este check, que se incluye con el Agent versión 7.48.0. Una dependencia de Python falla al cargarse y verás el siguiente mensaje al ejecutar [el subcomando de estado del Agent][7]:
+
+```
+Loading Errors
+ ==============
+ sqlserver
+ ---------
+ Core Check Loader:
+ Check sqlserver not found in Catalog
+ JMX Check Loader:
+ check is not a jmx check, or unable to determine if it's so
+ Python Check Loader:
+ unable to import module 'sqlserver': No module named 'sqlserver'
+```
+
+Esto se ha solucionado en la versión 15.2.0 del check y en las versiones 7.49.1 y posteriores del Agent.
+
+## Referencias adicionales
+
+- [Monitoriza tus bases de datos de Azure SQL con Datadog][9]
+- [Métricas clave para la monitorización de SQL Server][10]
+- [Herramientas de monitorización de SQL Server][11]
+- [Monitorizar el rendimiento de SQL Server con Datadog][12]
+- [Métricas personalizadas de SQL Server para una monitorización detallada][13]
+- [Hacer una estrategia para tu migración de Azure para cargas de trabajo de SQL con Datadog][14]
+- [Optimizar el rendimiento de SQL Server con la monitorización de base de datos de Datadog][15]
+
+
+[1]: https://raw.githubusercontent.com/DataDog/integrations-core/master/sqlserver/images/sqlserver_dashboard_02_2024.png
+[2]: https://docs.datadoghq.com/database_monitoring/
+[3]: https://app.datadoghq.com/account/settings/agent/latest
+[4]: https://docs.datadoghq.com/database_monitoring/#sqlserver
+[5]: https://docs.datadoghq.com/database_monitoring/setup_sql_server/
+[6]: https://docs.microsoft.com/en-us/sql/t-sql/statements/grant-server-permissions-transact-sql?view=sql-server-ver15
+[7]: https://docs.datadoghq.com/agent/guide/agent-commands/#agent-status-and-information
+[8]: https://docs.datadoghq.com/help/
+[9]: https://www.datadoghq.com/blog/monitor-azure-sql-databases-datadog
+[10]: https://www.datadoghq.com/blog/sql-server-monitoring
+[11]: https://www.datadoghq.com/blog/sql-server-monitoring-tools
+[12]: https://www.datadoghq.com/blog/sql-server-performance
+[13]: https://www.datadoghq.com/blog/sql-server-metrics
+[14]: https://www.datadoghq.com/blog/migrate-sql-workloads-to-azure-with-datadog/
+[15]: https://www.datadoghq.com/blog/optimize-sql-server-performance-with-datadog/
diff --git a/content/es/integrations/teamcity.md b/content/es/integrations/teamcity.md
new file mode 100644
index 0000000000000..f55a731d52de0
--- /dev/null
+++ b/content/es/integrations/teamcity.md
@@ -0,0 +1,316 @@
+---
+"app_id": "teamcity"
+"app_uuid": "8dd65d36-9cb4-4295-bb0c-68d67c0cdd4b"
+"assets":
+ "dashboards":
+ "TeamCity Overview": "assets/dashboards/overview.json"
+ "integration":
+ "auto_install": true
+ "configuration":
+ "spec": "assets/configuration/spec.yaml"
+ "events":
+ "creates_events": true
+ "metrics":
+ "check":
+ - "teamcity.builds"
+ - "teamcity.build_duration"
+ "metadata_path": "metadata.csv"
+ "prefix": "teamcity."
+ "process_signatures":
+ - "teamcity-server.sh"
+ - "teamcity-server"
+ "service_checks":
+ "metadata_path": "assets/service_checks.json"
+ "source_type_id": !!int "109"
+ "source_type_name": "Teamcity"
+ "monitors":
+ "Builds are failing": "assets/monitors/build_status.json"
+ "saved_views":
+ "teamcity_processes": "assets/saved_views/teamcity_processes.json"
+"author":
+ "homepage": "https://www.datadoghq.com"
+ "name": "Datadog"
+ "sales_email": "info@datadoghq.com"
+ "support_email": "help@datadoghq.com"
+"categories":
+- "configuration & deployment"
+- "log collection"
+- "notifications"
+"custom_kind": "integración"
+"dependencies":
+- "https://github.com/DataDog/integrations-core/blob/master/teamcity/README.md"
+"display_on_public_website": true
+"draft": false
+"git_integration_title": "teamcity"
+"integration_id": "teamcity"
+"integration_title": "TeamCity"
+"integration_version": "6.1.0"
+"is_public": true
+"manifest_version": "2.0.0"
+"name": "teamcity"
+"public_title": "TeamCity"
+"short_description": "Realiza un seguimiento de las compilaciones y comprende el impacto en el rendimiento de cada despliegue."
+"supported_os":
+- "linux"
+- "windows"
+- "macos"
+"tile":
+ "changelog": "CHANGELOG.md"
+ "classifier_tags":
+ - "Category::Configuration & Deployment"
+ - "Category::Log Collection"
+ - "Category::Notifications"
+ - "Supported OS::Linux"
+ - "Supported OS::Windows"
+ - "Supported OS::macOS"
+ - "Offering::Integration"
+ "configuration": "README.md#Setup"
+ "description": "Realiza un seguimiento de las compilaciones y comprende el impacto en el rendimiento de cada despliegue."
+ "media": []
+ "overview": "README.md#Overview"
+ "resources":
+ - "resource_type": "blog"
+ "url": "https://www.datadoghq.com/blog/track-performance-impact-of-code-changes-with-teamcity-and-datadog"
+ "support": "README.md#Support"
+ "title": "TeamCity"
+---
+
+
+
+
+## Información general
+
+Esta integración se conecta a tu servidor de TeamCity para enviar métricas, checks de servicio y eventos, lo que te permite monitorizar el estado de las configuraciones de compilación de tus proyectos de TeamCity, las ejecuciones de compilación, los recursos del servidor y mucho más.
+
+## Configuración
+
+### Instalación
+
+El check de TeamCity está incluido en el paquete del [Datadog Agent][1], por lo que no necesitas instalar nada más en tus servidores de TeamCity.
+
+### Configuración
+
+#### Preparar TeamCity
+
+Puedes activar el [inicio de sesión de invitado](#guest-login), o identificar [credenciales de usuario](#user-credentials) para la autenticación HTTP básica.
+
+##### Inicio de sesión de invitado
+
+1. [Activar el inicio de sesión de invitado][2].
+
+2. Habilita `Per-project permissions` para permitir la asignación de permisos basados en proyectos al usuario invitado. Consulta [Cambiar el modo de autorización][3].
+![Activar inicio de sesión de invitado][4]
+3. Utiliza un rol existente o crea uno nuevo de solo lectura y añade el permiso `View Usage Statistics` al rol. Consulta [Gestión de roles y permisos][5].
+![Crear rol de solo lectura][6]
+
+3. _[Opcional]_ Para permitir que el check detecte automáticamente el tipo de configuración de la compilación durante la recopilación de eventos, añade el permiso `View Build Configuration Settings` al rol de solo lectura.
+![Asignar permiso de configuración de vista de compilación][7]
+
+4. Asigna el rol de solo lectura al usuario invitado. Consulta [Asignación de roles a los usuarios][8].
+![Configuración del usuario invitado][9]
+![Asignar rol][10]
+
+##### Credenciales de usuario
+
+Para la autenticación HTTP básica
+- Especifica un `username` identificado y `password` en el archivo `teamcity.d/conf.yaml` en la carpeta `conf.d/` de tu [directorio de configuración del Agent][11].
+- Si encuentras un error `Access denied. Enable guest authentication or check user permissions.`, asegúrate de que el usuario tiene los permisos correctos:
+ - Permisos Por proyecto y Ver estadísticas de uso activados.
+ - Si estás recopilando estadísticas de carga útil del Agent, asigna también los permisos Ver detalles del Agent y Ver estadísticas de uso del Agent.
+
+{{< tabs >}}
+{{% tab "Host" %}}
+
+#### Host
+
+Para configurar este check para un Agent que se ejecuta en un host:
+
+Edita el archivo `teamcity.d/conf.yaml` en la carpeta `conf.d/` en la raíz del [directorio de configuración de tu Agent][1]. Para conocer todas las opciones de configuración disponibles, consulta el [teamcity.d/conf.yaml de ejemplo][2]:
+
+El check de TeamCity ofrece dos métodos de recopilación de datos. Para optimizar la monitorización de tu entorno de TeamCity, configura dos instancias separadas para recopilar métricas de cada método.
+
+1. Método de OpenMetrics (requiere Python versión 3):
+
+ Habilita `use_openmetrics: true` para recopilar métricas desde el endpoint de Prometheus`/metrics` de TeamCity.
+
+ ```yaml
+ init_config:
+
+ instances:
+ - use_openmetrics: true
+
+ ## @param server - string - required
+ ## Specify the server name of your TeamCity instance.
+ ## Enable Guest Authentication on your instance or specify `username` and `password` to
+ ## enable basic HTTP authentication.
+ #
+ server: http://teamcity..com
+ ```
+
+ Para recopilar métricas de histograma y resumen [conformes con OpenMetrics][3] (disponible a partir de TeamCity Server 2022.10+), añade la propiedad interna, `teamcity.metrics.followOpenMetricsSpec=true`. Consulta [Propiedades internas de TeamCity][4].
+
+2. Método API REST de TeamCity Server (requiere Python versión 3):
+
+ Configura una instancia separada en el archivo `teamcity.d/conf.yaml` para recopilar métricas específicas de la compilación, checks de servicio y eventos de estado de la compilación de la API REST del servidor TeamCity. Especifica tus proyectos y configuraciones de compilación utilizando la opción `projects`.
+
+ ```yaml
+ init_config:
+
+ instances:
+ - server: http://teamcity..com
+
+ ## @param projects - mapping - optional
+ ## Mapping of TeamCity projects and build configurations to
+ ## collect events and metrics from the TeamCity REST API.
+ #
+ projects:
+ :
+ include:
+ -
+ -
+ exclude:
+ -
+ :
+ include:
+ -
+ : {}
+ ```
+
+Personaliza la monitorización de la configuración de compilación de cada proyecto utilizando los filtros opcionales `include` y `exclude` para especificar IDs de configuración de la compilación para incluir o excluir de la monitorización, respectivamente. Se admiten patrones de expresión regular en las claves `include` y `exclude` para especificar patrones de coincidencia de ID de la configuración de la compilación. Si se omiten los filtros `include` y `exclude`, todas las configuraciones de compilación se monitorean para el proyecto especificado.
+
+Para Python versión 2, configura un ID de configuración de compilación por instancia utilizando la opción `build_configuration`:
+
+```yaml
+init_config:
+
+instances:
+ - server: http://teamcity..com
+
+ ## @param projects - mapping - optional
+ ## Mapping of TeamCity projects and build configurations to
+ ## collect events and metrics from the TeamCity REST API.
+ #
+ build_configuration:
+```
+
+[Reinicia el Agent][5] para empezar a recopilar y enviar eventos de TeamCity a Datadog.
+
+##### Recopilación de logs
+
+1. Establecer la [configuración de registro][6] de TeamCity.
+
+2. Por defecto, el pipeline de la integración de Datadog admite el siguiente tipo de formato de log:
+
+ ```text
+ [2020-09-10 21:21:37,486] INFO - jetbrains.buildServer.STARTUP - Current stage: System is ready
+ ```
+
+ Clona y edita el [pipeline de integración][7] si has definido diferentes [patrones] de conversión[8].
+
+3. La recopilación de logs está desactivada por defecto en el Datadog Agent. Actívala en tu archivo `datadog.yaml`:
+
+ ```yaml
+ logs_enabled: true
+ ```
+
+4. Anula los comentarios del bloque de configuración siguiente en tu archivo `teamcity.d/conf.yaml`. Cambia el valor de los parámetros `path` según tu entorno. Consulta el [teamcity.d/conf.yaml de ejemplol][2] para ver todas las opciones de configuración disponibles.
+
+ ```yaml
+ logs:
+ - type: file
+ path: /opt/teamcity/logs/teamcity-server.log
+ source: teamcity
+ - type: file
+ path: /opt/teamcity/logs/teamcity-activities.log
+ source: teamcity
+ - type: file
+ path: /opt/teamcity/logs/teamcity-vcs.log
+ source: teamcity
+ - type: file
+ path: /opt/teamcity/logs/teamcity-cleanup.log
+ source: teamcity
+ - type: file
+ path: /opt/teamcity/logs/teamcity-notifications.log
+ source: teamcity
+ - type: file
+ path: /opt/teamcity/logs/teamcity-ws.log
+ source: teamcity
+ ```
+
+5. [Reinicia el Agent][5].
+
+[1]: https://docs.datadoghq.com/agent/guide/agent-configuration-files/#agent-configuration-directory
+[2]: https://github.com/DataDog/integrations-core/blob/master/teamcity/datadog_checks/teamcity/data/conf.yaml.example
+[3]: https://github.com/OpenObservability/OpenMetrics/blob/main/specification/OpenMetrics.md
+[4]: https://www.jetbrains.com/help/teamcity/server-startup-properties.html#TeamCity+Internal+Properties
+[5]: https://docs.datadoghq.com/agent/guide/agent-commands/#start-stop-and-restart-the-agent
+[6]: https://www.jetbrains.com/help/teamcity/teamcity-server-logs.html
+[7]: https://docs.datadoghq.com/logs/log_configuration/pipelines/#integration-pipelines
+[8]: https://logging.apache.org/log4j/2.x/manual/layouts.html#Patterns
+{{% /tab %}}
+{{% tab "Contenedorizado" %}}
+
+#### Contenedores
+
+Para entornos en contenedores, consulta las [plantillas de integración de Autodiscovery][1] para obtener orientación sobre la aplicación de los parámetros que se indican a continuación.
+
+| Parámetro | Valor |
+| -------------------- | ------------------------------------------------------------------------------------------------- |
+| `` | `teamcity` |
+| `` | en blanco o `{}` |
+| `` | `{"server": "%%host%%", "use_openmetrics": "true"}` |
+
+##### Recopilación de logs
+
+La recopilación de logs está deshabilitada por defecto en el Datadog Agent. Para activarla, consulta [Recopilación de logs de Kubernetes][2].
+
+| Parámetro | Valor |
+| -------------- | ---------------------------------------------------- |
+| `` | `{"source": "teamcity"}` |
+
+[1]: https://docs.datadoghq.com/agent/kubernetes/integrations/
+[2]: https://docs.datadoghq.com/agent/kubernetes/log/
+{{% /tab %}}
+{{< /tabs >}}
+
+### Validación
+
+[Ejecuta el subcomando `status` del Agent][12] y busca `teamcity` en la sección Checks.
+
+## Datos recopilados
+
+### Métricas
+{{< get-metrics-from-git "teamcity" >}}
+
+
+### Eventos
+
+Los eventos de TeamCity que representan las compilaciones exitosas y fallidas se envían a Datadog.
+
+### Checks de servicio
+{{< get-service-checks-from-git "teamcity" >}}
+
+
+## Solucionar problemas
+
+¿Necesitas ayuda? Ponte en contacto con el [soporte de Datadog][13].
+
+## Referencias adicionales
+
+- [Seguimiento del impacto en el rendimiento de los cambios de código con TeamCity y Datadog][14]
+
+
+[1]: https://app.datadoghq.com/account/settings/agent/latest
+[2]: https://www.jetbrains.com/help/teamcity/enabling-guest-login.html
+[3]: https://www.jetbrains.com/help/teamcity/managing-roles-and-permissions.html#Changing+Authorization+Mode
+[4]: https://raw.githubusercontent.com/DataDog/integrations-core/master/teamcity/images/authentication.jpg
+[5]: https://www.jetbrains.com/help/teamcity/managing-roles-and-permissions.html
+[6]: https://raw.githubusercontent.com/DataDog/integrations-core/master/teamcity/images/create_role.jpg
+[7]: https://raw.githubusercontent.com/DataDog/integrations-core/master/teamcity/images/build_config_permissions.jpg
+[8]: https://www.jetbrains.com/help/teamcity/creating-and-managing-users.html#Assigning+Roles+to+Users
+[9]: https://raw.githubusercontent.com/DataDog/integrations-core/master/teamcity/images/guest_user_settings.jpg
+[10]: https://raw.githubusercontent.com/DataDog/integrations-core/master/teamcity/images/assign_role.jpg
+[11]: https://docs.datadoghq.com/agent/guide/agent-configuration-files/#agent-configuration-directory
+[12]: https://docs.datadoghq.com/agent/guide/agent-commands/#agent-status-and-information
+[13]: https://docs.datadoghq.com/help/
+[14]: https://www.datadoghq.com/blog/track-performance-impact-of-code-changes-with-teamcity-and-datadog
diff --git a/content/es/integrations/tyk.md b/content/es/integrations/tyk.md
index 6046b49e6992f..417c9421f54c5 100644
--- a/content/es/integrations/tyk.md
+++ b/content/es/integrations/tyk.md
@@ -29,7 +29,7 @@ author:
support_email: yaara@tyk.io
categories:
- métricas
-custom_kind: integration
+custom_kind: integración
dependencies:
- https://github.com/DataDog/integrations-extras/blob/master/tyk/README.md
display_on_public_website: true
@@ -118,7 +118,7 @@ pump.conf:
"dogstatsd": {
"type": "dogstatsd",
"meta": {
- "address": "dd-agent:8126",
+ "address": "dd-agent:8125",
"namespace": "tyk",
"async_uds": true,
"async_uds_write_timeout_seconds": 2,
diff --git a/content/es/integrations/win32_event_log.md b/content/es/integrations/win32_event_log.md
index 925da26f13745..e86a092ddd369 100644
--- a/content/es/integrations/win32_event_log.md
+++ b/content/es/integrations/win32_event_log.md
@@ -33,7 +33,7 @@ draft: false
git_integration_title: win32_event_log
integration_id: event-viewer
integration_title: Log de eventos de Windows
-integration_version: 5.0.0
+integration_version: 5.2.1
is_public: true
manifest_version: 2.0.0
name: win32_event_log
@@ -188,7 +188,7 @@ Para recopilar logs de eventos de Windows como eventos de Datadog, configura can
```yaml
init_config:
instances:
- - # API de logs de eventos
+ - # Event Log API
path: Security
legacy_mode: false
filters: {}
@@ -204,7 +204,7 @@ Las versiones 7.49 y posteriores del Agent permiten configurar `legacy_mode` en
init_config:
legacy_mode: false
instances:
- - # API de logs de eventos
+ - # Event Log API
path: Security
filters: {}
@@ -225,7 +225,7 @@ Para recopilar logs de eventos de Windows como eventos de Datadog, configura can
```yaml
init_config:
instances:
- - # WMI (por defecto)
+ - # WMI (default)
legacy_mode: true
log_file:
- Security
diff --git a/content/es/llm_observability/instrumentation/_index.md b/content/es/llm_observability/instrumentation/_index.md
new file mode 100644
index 0000000000000..8605190d6558a
--- /dev/null
+++ b/content/es/llm_observability/instrumentation/_index.md
@@ -0,0 +1,76 @@
+---
+further_reading:
+- link: /llm_observability/auto_instrumentation
+ tag: Instrumentación automática
+ text: Empezar rápidamente con la instrumentación automática
+title: Instrumentación de LLM Observability
+---
+
+
+Para empezar con Datadog LLM Observability, instrumenta tus aplicaciones o agente(s) LLM eligiendo entre varias estrategias basadas en tu lenguaje de programación y configuración. Datadog proporciona opciones de instrumentación completas diseñadas para capturar trazas (traces), métricas y evaluaciones detalladas de tus aplicaciones y agentes LLM con cambios mínimos en el código.
+
+## Opciones de instrumentación
+Puedes instrumentar tu aplicación con los SDK de Python, Node.js o Java, o utilizando la API de LLM Observability.
+
+### Instrumentación basada en SDK (recomendado)
+Datadog proporciona SDK nativos que ofrecen las funciones de LLM Observability más completas:
+| Lenguaje | SDK disponible | Instrumentación automática | Instrumentación personalizada | .
+| -------- | ------------- | -------------------- | ---------------------- |
+| Python | Python v3.7 o posterior {{< X >}} | {{< X >}} |
+| Node.js | Node.js v16 o posterior {{< X >}} | {{< X >}} |
+| Java | Java 8 o posterior {{< X >}} |
+
+
+Para instrumentar una aplicación LLM con el SDK:
+1. Instala el SDK de LLM Observability.
+2. Configura el SDK proporcionando [las variables de entorno necesarias][6] en el comando de inicio de tu aplicación o [en el código][7] mediante programación. Asegúrate de haber configurado tu clave de API Datadog, el sitio Datadog y el nombre de la aplicación de machine learning (ML).
+
+#### Instrumentación automática
+La instrumentación automática captura llamadas LLM de aplicaciones Python y Node.js sin requerir cambios en el código. Te permite obtener trazas predefinidas y una observabilidad de marcos y proveedores populares. Para obtener más información y una lista completa de marcos y proveedores compatibles, consulta la documentación [Instrumentación automática][1].
+
+La instrumentación automática captura automáticamente:
+- Solicitudes de entradas y finalizaciones de salidas
+- Uso y costes de los tokens
+- Información sobre latencia y errores
+- Parámetros del modelo (temperatura, max_tokens, etc.)
+- Metadatos específicos del marco
+
+` en el ejemplo de configuración anterior por {{< region-param key="dd_site" code="true" >}}.
+Para todas las opciones de configuración y detalles, incluyendo [Despliegue multiregión][205], consulta la [documentación del módulo][201].
-[101]: https://www.terraform.io/docs/providers/aws/r/cloudformation_stack
-[102]: https://app.datadoghq.com/organization-settings/api-keys
-[103]: https://docs.datadoghq.com/es/logs/guide/send-aws-services-logs-with-the-datadog-lambda-function/#set-up-triggers
-[104]: https://docs.datadoghq.com/es/getting_started/site/#access-the-datadog-site
+[201]: https://registry.terraform.io/modules/DataDog/log-lambda-forwarder-datadog/aws/latest
+[202]: https://docs.datadoghq.com/es/logs/guide/send-aws-services-logs-with-the-datadog-lambda-function/#set-up-triggers
+[203]: https://docs.datadoghq.com/es/getting_started/site/#access-the-datadog-site
+[204]: https://app.datadoghq.com/organization-settings/api-keys
+[205]: https://registry.terraform.io/modules/DataDog/log-lambda-forwarder-datadog/aws/latest#multi-region-deployments
{{% /tab %}}
{{% tab "Manual" %}}
@@ -112,7 +84,7 @@ resource "aws_cloudformation_stack" "datadog_forwarder" {
Si no puedes instalar el Forwarder utilizando la plantilla de CloudFormation proporcionada, puedes instalarlo manualmente siguiendo los pasos que se indican a continuación. No dudes en abrir una incidencia o en crear una solicitud de extracción para hacernos saber si hay algo que podríamos mejorar para que la plantilla funcione.
-1. Crea una función Lambda de Python 3.12 utilizando `aws-dd-forwarder-.zip` de las últimas [versiones][101].
+1. Crea una función Lambda de Python 3.13 utilizando `aws-dd-forwarder-.zip` de las últimas [versiones][101].
2. Guarda tu [clave de API de Datadog][102] en AWS Secrets Manager, configura la variable de entorno `DD_API_KEY_SECRET_ARN` con el ARN de secretos en la función Lambda y añade el permiso `secretsmanager:GetSecretValue` al rol de ejecución Lambda.
3. Si necesitas reenviar logs desde buckets S3, añade el permiso `s3:GetObject` al rol de ejecución Lambda.
4. Configura la variable de entorno `DD_ENHANCED_METRICS` como `false` en el Forwarder. Esto evita que el Forwarder genere métricas mejoradas por sí mismo, aunque seguirá reenviando métricas personalizadas desde otras lambdas.DdFetchLambdaTags.
@@ -125,8 +97,8 @@ Si no puedes instalar el Forwarder utilizando la plantilla de CloudFormation pro
aws lambda invoke --function-name --payload '{"retry":"true"}' out
```
-
OpenShift 4.0+: Si has utilizado el instalador de OpenShift en un proveedor de nube compatible, debes desplegar el SCC con
@@ -205,7 +150,7 @@ runAsUser:
La recopilación de logs del Datadog Agent se configura en OpenShift en gran medida igual que otros clústeres de Kubernetes. El Datadog Operator y Helm Chart se montan en el directorio `/var/log/pods`, que el pod de Datadog Agent utiliza para monitorizar los logs de los pods y contenedores en sus respectivos hosts. Sin embargo, con el Datadog Operator, es necesario aplicar opciones de SELinux adicionales para dar al Agent permisos para leer estos archivos de log.
-Consulta [Recopilación de logs de Kubernetes][9] para obtener más información general y la página [Distribuciones][3] para ver ejemplos de configuración.
+Consulta la [recopilación de logs de Kubernetes](https://docs.datadoghq.com/agent/kubernetes/log/?tab=daemonset) para obtener más información general y la página [Distribuciones](https://docs.datadoghq.com/containers/kubernetes/distributions/?tab=datadogoperator#Openshift) para ver ejemplos de configuración.
### APM
@@ -213,17 +158,61 @@ En Kubernetes, hay tres opciones principales para enrutar los datos desde el pod
Datadog recomienda deshabilitar la opción de UDS explícitamente para evitar esto y para evitar que el Admission Controller (Controlador de admisión) inyecte esta configuración.
-Consulta [Recopilación de trazas, APM de Kubernetes][10] para más información general y la página [Distribuciones][3] para ver ejemplos de configuración.
+Consulta [recopilación de APM y trazas de Kubernetes](https://docs.datadoghq.com/containers/kubernetes/apm) para más información general y la página [Distribuciones](https://docs.datadoghq.com/containers/kubernetes/distributions/?tab=datadogoperator#Openshift) para ejemplos de configuración.
### Validación
-Ver [kubernetes_apiserver][1]
+Consulta [kubernetes_apiserver](https://github.com/DataDog/datadog-agent/blob/master/cmd/agent/dist/conf.d/kubernetes_apiserver.d/conf.yaml.example)
## Datos recopilados
### Métricas
-{{< get-metrics-from-git "openshift" >}}
+| | |
+| --- | --- |
+| **openshift.appliedclusterquota.cpu.limit** allowHostNetwork: true en el manifiesto scc.yaml, así como hostNetwork: true en la configuración del Agent para obtener etiquetas (tags) de host y alias. Por lo demás, el acceso a los servidores de metadatos desde la red de pod está restringido.
(gauge) | Límite fijo para cpu por cuota de recursos de clúster y espacio de nombres
_Se muestra como cpu_ | +| **openshift.appliedclusterquota.cpu.remaining**
(gauge) | Cpu disponible restante por cuota de recursos de clúster y espacio de nombres
_Se muestra como cpu_ | +| **openshift.appliedclusterquota.cpu.used**
(gauge) | Uso de cpu observado por cuota de recursos de clúster y espacio de nombres
_Se muestra como cpu_ | +| **openshift.appliedclusterquota.memory.limit**
(gauge) | Límite fijo de memoria por cuota de recursos de clúster y espacio de nombres
_Se muestra como byte_ | +| **openshift.appliedclusterquota.memory.remaining**
(gauge) | Memoria disponible restante por cuota de recursos de clúster y espacio de nombres
_Se muestra como byte_ | +| **openshift.appliedclusterquota.memory.used**
(gauge) | Uso de memoria observado por cuota de recursos de clúster y espacio de nombres
_Se muestra como byte_ | +| **openshift.appliedclusterquota.persistentvolumeclaims.limit**
(gauge) | Límite fijo para reclamaciones de volúmenes persistentes por cuota de recursos de clúster y espacio de nombres| +| **openshift.appliedclusterquota.persistentvolumeclaims.remaining**
(gauge) | Reclamaciones de volúmenes persistentes disponibles por cuota de recursos de clúster y espacio de nombres| +| **openshift.appliedclusterquota.persistentvolumeclaims.used**
(gauge) | Uso observado de reclamaciones de volumen persistente por cuota de recursos de clúster y espacio de nombres| +| **openshift.appliedclusterquota.pods.limit**
(gauge) | Límite fijo para pods por cuota de recursos de clúster y espacio de nombres| +| **openshift.appliedclusterquota.pods.remaining**
(gauge) | Pods disponibles por cuota de recursos de clúster y espacio de nombres| +| **openshift.appliedclusterquota.pods.used**
(gauge) | Uso de pods observado por cuota de recursos de clúster y espacio de nombres| +| **openshift.appliedclusterquota.services.limit**
(gauge) | Límite fijo para servicios por cuota de recursos de clúster y espacio de nombres| +| **openshift.appliedclusterquota.services.loadbalancers.limit**
(gauge) | Límite fijo para equilibradores de carga de servicios por cuota de recursos de clúster y espacio de nombres| +| **openshift.appliedclusterquota.services.loadbalancers.remaining**
(gauge) | Equilibradores de carga de servicios disponibles por cuota de recursos de clúster y espacio de nombres| +| **openshift.appliedclusterquota.services.loadbalancers.used**
(gauge) | Uso observado de los equilibradores de carga de servicios por cuota de recursos de clúster y espacio de nombres| +| **openshift.appliedclusterquota.services.nodeports.limit**
(gauge) | Límite fijo para puertos de nodo de servicio por cuota de recursos de clúster y espacio de nombres| +| **openshift.appliedclusterquota.services.nodeports.remaining**
(gauge) | Puertos de nodo de servicio disponibles por cuota de recursos de clúster y espacio de nombres| +| **openshift.appliedclusterquota.services.nodeports.used**
(gauge) | Uso observado de puertos de nodos de servicio por cuota de recursos de clúster y espacio de nombres| +| **openshift.appliedclusterquota.services.remaining**
(gauge) | Servicios disponibles restantes por cuota de recursos de clúster y espacio de nombres| +| **openshift.appliedclusterquota.services.used**
(gauge) | Utilización de servicios observada por cuota de recursos de clúster y espacio de nombres| +| **openshift.clusterquota.cpu.limit**
(gauge) | Límite fijo de cpu por cuota de recursos de clúster para todos los espacios de nombres
_Se muestra como cpu_ | +| **openshift.clusterquota.cpu.remaining**
(gauge) | Cpu disponible restante por cuota de recursos de clúster para todos los espacios de nombres
_Se muestra como cpu_ | +| **openshift.clusterquota.cpu.requests.used**
(gauge) | Uso de cpu observado por recurso de clúster para solicitud| +| **openshift.clusterquota.cpu.used**
(gauge) | Uso de cpu observado por cuota de recursos de clúster para todos los espacios de nombres
_Se muestra como cpu_ | +| **openshift.clusterquota.memory.limit**
(gauge) | Límite fijo de memoria por cuota de recursos de clúster para todos los espacios de nombres
_Se muestra como byte_ | +| **openshift.clusterquota.memory.remaining**
(gauge) | Memoria disponible restante por cuota de recursos de clúster para todos los espacios de nombres
_Se muestra como byte_ | +| **openshift.clusterquota.memory.used**
(gauge) | Uso de memoria observado por cuota de recursos de clúster para todos los espacios de nombres
_Se muestra como byte_ | +| **openshift.clusterquota.persistentvolumeclaims.limit**
(gauge) | Límite fija para las reclamaciones de volúmenes persistentes por cuota de recursos de clúster para todos los espacios de nombres.| +| **openshift.clusterquota.persistentvolumeclaims.remaining**
(gauge) | Reclamaciones de volumen persistente disponibles restantes por cuota de recursos de clúster para todos los espacios de nombres.| +| **openshift.clusterquota.persistentvolumeclaims.used**
(gauge) | Uso de reclamaciones de volumen persistente observado por cuota de recursos de clúster para todos los espacios de nombres| +| **openshift.clusterquota.pods.limit**
(gauge) | Límite duro para pods por cuota de recursos de clúster para todos los espacios de nombres| +| **openshift.clusterquota.pods.remaining**
(gauge) | Pods disponibles restantes por cuota de recursos de clúster para todos los espacios de nombres| +| **openshift.clusterquota.pods.used**
(gauge) | Uso de pods observado por cuota de recursos de clúster para todos los espacios de nombres| +| **openshift.clusterquota.services.limit**
(gauge) | Límite fijo para servicios por cuota de recursos de clúster para todos los espacios de nombres| +| **openshift.clusterquota.services.loadbalancers.limit**
(gauge) | Límite fijo para los equilibradores de carga de servicios por cuota de recursos de clúster para todos los espacios de nombres.| +| **openshift.clusterquota.services.loadbalancers.remaining**
(gauge) | Equilibradores de carga de servicio disponibles restantes por cuota de recursos de clúster para todos los espacios de nombres.| +| **openshift.clusterquota.services.loadbalancers.used**
(gauge) | Uso observado de los equilibradores de carga de servicios por cuota de recursos de clúster para todos los espacios de nombres| +| **openshift.clusterquota.services.nodeports.limit**
(gauge) | Límite fijo para puertos de nodo de servicio por cuota de recursos de clúster para todos los espacios de nombres.| +| **openshift.clusterquota.services.nodeports.remaining**
(gauge) | Puertos de nodo de servicio disponibles restantes por cuota de recursos de clúster para todos los espacios de nombres| +| **openshift.clusterquota.services.nodeports.used**
(gauge) | Uso observado de puertos de nodo de servicio por cuota de recursos de clúster para todos los espacios de nombres| +| **openshift.clusterquota.services.remaining**
(gauge) | Servicios disponibles restantes por cuota de recursos de clúster para todos los espacios de nombres| +| **openshift.clusterquota.services.used**
(gauge) | Utilización de servicios observada por cuota de recursos de clúster para todos los espacios de nombres| ### Eventos @@ -235,17 +224,4 @@ El check de OpenShift no incluye ningún check de servicio. ## Solucionar problemas -¿Necesitas ayuda? Contacta con el [equipo de asistencia de Datadog][11]. - - -[1]: https://github.com/DataDog/datadog-agent/blob/master/cmd/agent/dist/conf.d/kubernetes_apiserver.d/conf.yaml.example -[2]: https://docs.datadoghq.com/es/containers/kubernetes/installation -[3]: https://docs.datadoghq.com/es/containers/kubernetes/distributions/?tab=datadogoperator#Openshift -[4]: https://github.com/DataDog/datadog-operator/ -[5]: https://docs.openshift.com/container-platform/4.10/operators/understanding/olm-understanding-operatorhub.html -[6]: https://developers.redhat.com/blog/2014/11/06/introducing-a-super-privileged-container-concept -[7]: https://github.com/DataDog/datadog-agent/blob/master/Dockerfiles/manifests/openshift/scc.yaml -[8]: https://docs.datadoghq.com/es/agent/kubernetes/daemonset_setup/?tab=k8sfile#configure-rbac-permissions -[9]: https://docs.datadoghq.com/es/agent/kubernetes/log/?tab=daemonset -[10]: https://docs.datadoghq.com/es/containers/kubernetes/apm -[11]: https://docs.datadoghq.com/es/help/ \ No newline at end of file +¿Necesitas ayuda? Ponte en contacto con el [soporte de Datadog](https://docs.datadoghq.com/help/). \ No newline at end of file diff --git a/content/es/integrations/openstack.md b/content/es/integrations/openstack.md new file mode 100644 index 0000000000000..63e6fb9bda43d --- /dev/null +++ b/content/es/integrations/openstack.md @@ -0,0 +1,263 @@ +--- +app_id: openstack +categories: +- cloud +- log collection +- network +- provisioning +- configuration & deployment +custom_kind: integración +description: Seguimiento del uso de recursos a nivel de hipervisor y VM, además de + métricas de Neutron. +further_reading: +- link: https://www.datadoghq.com/blog/openstack-monitoring-nova + tag: blog + text: Monitorización de OpenStack Nova +- link: https://www.datadoghq.com/blog/install-openstack-in-two-commands + tag: blog + text: Instalar OpenStack en dos comandos para dev y test +- link: https://www.datadoghq.com/blog/openstack-host-aggregates-flavors-availability-zones + tag: blog + text: 'OpenStack: agregados de hosts, opciones y zonas de disponibilidad' +integration_version: 4.0.1 +media: [] +supported_os: +- linux +- windows +- macos +title: OpenStack (heredado) +--- + + +## Información general + +**Nota**: Esta integración solo se aplica a OpenStack v12 e inferiores. Si deseas recopilar métricas de OpenStack v13+, utiliza la [integración de OpenStack Controller](https://docs.datadoghq.com/integrations/openstack_controller). + +Obtén métricas del servicio OpenStack en tiempo real para: + +- Visualizar y monitorizar estados de OpenStack. +- Recibir notificaciones sobre fallos y eventos de OpenStack. + +## Configuración + +### Instalación + +Para capturar tus métricas de OpenStack, [instala el Agent](https://app.datadoghq.com/account/settings/agent/latest) en tus hosts que ejecutan hipervisores. + +### Configuración + +#### Preparar OpenStack + +Configura un rol y un usuario de Datadog con tu servidor de identidad: + +```console +openstack role create datadog_monitoring +openstack user create datadog \ + --password my_password \ + --project my_project_name +openstack role add datadog_monitoring \ + --project my_project_name \ + --user datadog +``` + +A continuación, actualiza tus archivos `policy.json` para conceder los permisos necesarios. `role:datadog_monitoring` requiere acceso a las siguientes operaciones: + +**Nova** + +```json +{ + "compute_extension": "aggregates", + "compute_extension": "hypervisors", + "compute_extension": "server_diagnostics", + "compute_extension": "v3:os-hypervisors", + "compute_extension": "v3:os-server-diagnostics", + "compute_extension": "availability_zone:detail", + "compute_extension": "v3:availability_zone:detail", + "compute_extension": "used_limits_for_admin", + "os_compute_api:os-aggregates:index": "rule:admin_api or role:datadog_monitoring", + "os_compute_api:os-aggregates:show": "rule:admin_api or role:datadog_monitoring", + "os_compute_api:os-hypervisors": "rule:admin_api or role:datadog_monitoring", + "os_compute_api:os-server-diagnostics": "rule:admin_api or role:datadog_monitoring", + "os_compute_api:os-used-limits": "rule:admin_api or role:datadog_monitoring" +} +``` + +**Neutron** + +```json +{ + "get_network": "rule:admin_or_owner or rule:shared or rule:external or rule:context_is_advsvc or role:datadog_monitoring" +} +``` + +**Keystone** + +```json +{ + "identity:get_project": "rule:admin_required or project_id:%(target.project.id)s or role:datadog_monitoring", + "identity:list_projects": "rule:admin_required or role:datadog_monitoring" +} +``` + +Es posible que tengas que reiniciar tus servicios de API de Keystone, Neutron y Nova para asegurarte de que los cambios de política se llevan a cabo. + +**Nota**: La instalación de la integración de OpenStack podría aumentar el número de máquinas virtuales que Datadog monitoriza. Para obtener más información sobre cómo esto puede afectar a tu facturación, consulta las FAQ de facturación. + +#### Configuración del Agent + +1. Configura el Datadog Agent para conectarte a tu servidor Keystone, y especifica proyectos individuales para monitorizar. Edita el archivo `openstack.d/conf.yaml` en la carpeta `conf.d/` en la raíz del [directorio de configuración del Agent](https://docs.datadoghq.com/agent/guide/agent-configuration-files/#agent-configuration-directory) con la configuración de abajo. Consulta el [openstack.d/conf.yaml de ejemplo](https://github.com/DataDog/integrations-core/blob/master/openstack/datadog_checks/openstack/data/conf.yaml.example) para conocer todas las opciones de configuración disponibles: + + ```yaml + init_config: + ## @param keystone_server_url - string - required + ## Where your identity server lives. + ## Note that the server must support Identity API v3 + # + keystone_server_url: "https://
(gauge) | Carga de trabajo actual en el hipervisor de Nova| +| **openstack.nova.disk_available_least**
(gauge) | Disco disponible para el hipervisor de Nova
_Se muestra como gibibyte_ | +| **openstack.nova.free_disk_gb**
(gauge) | Disco libre en el hipervisor de Nova
_Se muestra como gibibyte_ | +| **openstack.nova.free_ram_mb**
(gauge) | RAM libre en el hipervisor de Nova
_Se muestra como mebibyte_ | +| **openstack.nova.hypervisor_load.1**
(gauge) | La carga media del hipervisor durante un minuto.| +| **openstack.nova.hypervisor_load.15**
(gauge) | La carga media del hipervisor en quince minutos.| +| **openstack.nova.hypervisor_load.5**
(gauge) | La carga media del hipervisor en cinco minutos.| +| **openstack.nova.limits.max_image_meta**
(gauge) | El máximo permitido de definiciones de metadatos de imagen para este inquilino| +| **openstack.nova.limits.max_personality**
(gauge) | Las personalidades máximas permitidas para este inquilino| +| **openstack.nova.limits.max_personality_size**
(gauge) | El tamaño máximo de una sola personalidad permitido para este inquilino.| +| **openstack.nova.limits.max_security_group_rules**
(gauge) | El número máximo de reglas de grupo de seguridad permitidas para este inquilino.| +| **openstack.nova.limits.max_security_groups**
(gauge) | Número máximo de grupos de seguridad permitidos para este inquilino| +| **openstack.nova.limits.max_server_meta**
(gauge) | El máximo permitido de definiciones de metadatos de servicio para este inquilino| +| **openstack.nova.limits.max_total_cores**
(gauge) | El máximo de núcleos permitidos para este inquilino| +| **openstack.nova.limits.max_total_floating_ips**
(gauge) | El máximo permitido de IPs flotantes para este inquilino| +| **openstack.nova.limits.max_total_instances**
(gauge) | Número máximo de instancias permitidas para este inquilino| +| **openstack.nova.limits.max_total_keypairs**
(gauge) | Los pares de claves máximos permitidos para este inquilino| +| **openstack.nova.limits.max_total_ram_size**
(gauge) | El tamaño máximo de RAM permitido para este inquilino en megabytes (MB)
_Se muestra como mebibyte_ | +| **openstack.nova.limits.total_cores_used**
(gauge) | El total de núcleos utilizados por este inquilino| +| **openstack.nova.limits.total_floating_ips_used**
(gauge) | El total de IPs flotantes utilizadas por este inquilino| +| **openstack.nova.limits.total_instances_used**
(gauge) | El total de instancias utilizadas por este inquilino| +| **openstack.nova.limits.total_ram_used**
(gauge) | La RAM actual utilizada por este inquilino en megabytes (MB)
_Se muestra como mebibyte_ | +| **openstack.nova.limits.total_security_groups_used**
(gauge) | Número total de grupos de seguridad utilizados por este inquilino| +| **openstack.nova.local_gb**
(gauge) | El tamaño en GB del disco efímero presente en este host hipervisor
_Se muestra como gibibyte_ | +| **openstack.nova.local_gb_used**
(gauge) | El tamaño en GB del disco utilizado en este host hipervisor
_Se muestra como gibibyte_ | +| **openstack.nova.memory_mb**
(gauge) | El tamaño en MB de la RAM presente en este host hipervisor
_Se muestra como mebibyte_ | +| **openstack.nova.memory_mb_used**
(gauge) | El tamaño en MB de la RAM utilizada en este host hipervisor
_Se muestra como mebibyte_ | +| **openstack.nova.running_vms**
(gauge) | Número de máquinas virtuales en ejecución en este host de hipervisor| +| **openstack.nova.server.cpu0_time**
(gauge) | Tiempo de CPU en nanosegundos de esta CPU virtual
_Se muestra como nanosegundo_ | +| **openstack.nova.server.hdd_errors**
(gauge) | Número de errores observados por el servidor al acceder a un dispositivo HDD| +| **openstack.nova.server.hdd_read**
(gauge) | Número de bytes leídos desde un dispositivo HDD por este servidor
_Se muestra como byte_ | +| **openstack.nova.server.hdd_read_req**
(gauge) | Número de solicitudes de lectura realizadas a un dispositivo HDD por este servidor| +| **openstack.nova.server.hdd_write**
(gauge) | Número de bytes escritos en un dispositivo HDD por este servidor
_Se muestra como byte_ | +| **openstack.nova.server.hdd_write_req**
(gauge) | El número de solicitudes de escritura realizadas a un dispositivo HDD por este servidor| +| **openstack.nova.server.memory**
(gauge) | La cantidad de memoria en MB aprovisionada para este servidor
_Se muestra como mebibyte_ | +| **openstack.nova.server.memory_actual**
(gauge) | La cantidad de memoria en MB aprovisionada para este servidor
_Se muestra como mebibyte_ | +| **openstack.nova.server.memory_rss**
(gauge) | La cantidad de memoria utilizada por los procesos de este servidor que no está asociada a páginas de disco, como el stack tecnológico y la memoria heap
_Se muestra como mebibyte_ | +| **openstack.nova.server.vda_errors**
(gauge) | Número de errores observados por el servidor al acceder a un dispositivo VDA.| +| **openstack.nova.server.vda_read**
(gauge) | Número de bytes leídos desde un dispositivo VDA por este servidor
_Se muestra como byte_ | +| **openstack.nova.server.vda_read_req**
(gauge) | Número de solicitudes de lectura realizadas a un dispositivo VDA por este servidor.| +| **openstack.nova.server.vda_write**
(gauge) | Número de bytes escritos en un dispositivo VDA por este servidor
_Se muestra como byte_ | +| **openstack.nova.server.vda_write_req**
(gauge) | Número de solicitudes de escritura realizadas a un dispositivo VDA por este servidor| +| **openstack.nova.vcpus**
(gauge) | Número de vCPUs disponibles en este host hipervisor| +| **openstack.nova.vcpus_used**
(gauge) | Número de vCPUS utilizados en este host hipervisor| + +### Eventos + +El check de OpenStack no incluye ningún evento. + +### Checks de servicio + +**openstack.neutron.api.up** + +Devuelve `CRITICAL` si el Agent no puede consultar la API de Neutron, `UNKNOWN` si hay un problema con la API de Keystone. En caso contrario, devuelve `OK`. + +_Estados: ok, critical, unknown_ + +**openstack.nova.api.up** + +Devuelve `CRITICAL` si el Agent no puede consultar la API de Nova, `UNKNOWN` si hay un problema con la API de Keystone. En caso contrario, devuelve `OK`. + +_Estados: ok, critical, unknown_ + +**openstack.keystone.api.up** + +Devuelve `CRITICAL` si el Agent no puede consultar la API de Keystone. En caso contrario, devuelve `OK`. + +_Estados: ok, critical_ + +**openstack.nova.hypervisor.up** + +Devuelve `UNKNOWN` si el Agent no puede obtener el estado del hipervisor, `CRITICAL` si el hipervisor está caído. Devuelve `OK` en caso contrario. + +_Estados: ok, critical, unknown_ + +**openstack.neutron.network.up** + +Devuelve `UNKNOWN` si el Agent no puede obtener el estado de la red, `CRITICAL` si la red está caída. En caso contrario, devuelve `OK`. + +_Estados: ok, critical, unknown_ + +## Solucionar problemas + +¿Necesitas ayuda? Ponte en contacto con el [soporte de Datadog](https://docs.datadoghq.com/help/). + +## Referencias adicionales + +Documentación útil adicional, enlaces y artículos: + +- [Monitorización de OpenStack Nova](https://www.datadoghq.com/blog/openstack-monitoring-nova) +- [Instalar OpenStack en dos comandos para dev y test](https://www.datadoghq.com/blog/install-openstack-in-two-commands) +- [OpenStack: agregados de hosts, opciones y zonas de disponibilidad](https://www.datadoghq.com/blog/openstack-host-aggregates-flavors-availability-zones) \ No newline at end of file diff --git a/content/es/integrations/opsgenie.md b/content/es/integrations/opsgenie.md new file mode 100644 index 0000000000000..46a94cdf71ea4 --- /dev/null +++ b/content/es/integrations/opsgenie.md @@ -0,0 +1,105 @@ +--- +app_id: opsgenie +categories: +- collaboration +- notifications +custom_kind: integración +description: Reenvía alertas desde Datadog y notifica a los usuarios por teléfono. +further_reading: +- link: https://docs.datadoghq.com/tracing/service_catalog/integrations/#opsgenie-integration + tag: blog + text: Blog de Opsgenie +- link: https://registry.terraform.io/providers/DataDog/datadog/latest/docs/resources/integration_opsgenie_service_object + tag: otros + text: Opsgenie +media: [] +title: Opsgenie +--- +## Información general + +Crea alertas en Opsgenie utilizando `@opsgenie-{service-name}`: + +- Al tomar una snapshot +- Cuando se activa una alerta de métrica + +## Configuración + +### Configuración + +#### Crear una integración de Datadog en Opsgenie + +1. Inicia sesión en tu cuenta de Opsgenie y ve a la page (página) [Integraciones de Opsgenie](https://app.opsgenie.com/settings/integration/integration-list). +1. Busca Datadog y haz clic en cuadro. +1. Completa el Nombre de la integración y, si lo deseas, configura el Equipo asignado. +1. Después de hacer clic en **Enviar**, permanece en la page (página) y guarda la clave de API de la integración recién creada. La necesitarás para finalizar la configuración. +1. Añade más integraciones de Datadog en Opsgenie yendo a la page (página) [Integraciones de Opsgenie](https://app.opsgenie.com/settings/integration/integration-list) y repitiendo los pasos anteriores. + +#### Registra las integraciones que has realizado en Opsgenie en Datadog + +1. En Datadog, ve a la [page (página) Integraciones](https://app.datadoghq.com/integrations), luego busca y selecciona el ícono Opsgenie. +1. Check que estés en la pestaña Configuración del cuadro de diálogo que aparece. +1. Haz clic en **Nuevo servicio de integración**. +1. Pega la clave de API guardada anteriormente de la integración de Datadog (creada en Opsgenie) en el campo **Clave de API de Opsgenie** e introduce un **Nombre de servicio**. + 1. El nombre del servicio debe ser descriptivo y único. Sólo se permiten valores alfanuméricos, guiones, guiones bajos y puntos. No se admiten espacios. + {{< img src="integrations/opsgenie/datadog-add-opsgenie-api-key.png" alt="Ícono de integración de Opsgenie que muestra la configuración para un nuevo servicio de integración" popup="true">}} +1. En el menú desplegable **Región**, selecciona Estados Unidos o Europa, según dónde opere tu cuenta de Opsgenie. +1. Haz clic en **Save** (Guardar). + +## Ejemplo de uso + +### El monitor de ruta alerta a Opsgenie + +1. Crea cualquier monitor (noun) en la [Page (página) Monitores](https://app.datadoghq.com/monitors/manage). +1. En el cuerpo de monitor (noun), pega `@opsgenie-{service-name}` (sustituye `{service-name}` por el nombre del servicio definido en el ícono de integración de Opsgenie). +1. Guarda el monitor. +1. Ve a la Page (página) Editar del monitor (noun) y haz clic en "Test notificaciones" para emitir una alerta de ejemplo utilizando tu integración. Debería crearse una alerta correspondiente en Opsgenie. +1. Para notificar a varios servicios, pega `@opsgenie-{service-name} @opsgenie-{service-name-2}` en el cuerpo del monitor (noun) y test con los mismos pasos. + +#### Permisos + +En forma predeterminada, todos los usuarios tienen acceso completo a los servicios de Opsgenie. + +Utiliza [Control de acceso granular](https://docs.datadoghq.com/account_management/rbac/granular_access/) para limitar los roles que pueden editar un servicio específico: + +1. Mientras visualizas un servicio, haz clic en el icono de engranaje de la esquina superior derecha para abrir el menú de configuración. +1. Selecciona **Configurar permisos**. +1. Haz clic en **Restrict Access** (Acceso restringido). El cuadro de diálogo se actualiza para mostrar que los miembros de tu organización tienen acceso de **Visor** por defecto. +1. Utiliza el menú desplegable para seleccionar uno o más roles, equipos o usuarios que pueden editar el servicio Opsgenie. +1. Haz clic en **Add** (Añadir). El cuadro de diálogo se actualiza para mostrar que el rol seleccionado tiene el permiso de **Editor**. +1. Haz clic en **Save** (Guardar). + +**Nota:** Para mantener tu acceso de edición al servicio, incluye al menos un rol al que pertenezcas antes de guardar. + +Si tienes acceso de edición, puedes restaurar el acceso general a un servicio restringido siguiendo los siguientes pasos: + +1. Mientras visualizas el servicio, haz clic en el icono de engranaje de la esquina superior derecha para abrir el menú de configuración. +1. Selecciona **Configurar permisos**. +1. Haz clic en **Restore Full Access** (Restablecer acceso completo). +1. Haz clic en **Save** (Guardar). + +Para editar los permisos de servicio a través de la API: + +1. Obtén los ID de servicio de Opsgenie utilizando la [API de integración de Opsgenie](https://docs.datadoghq.com/api/latest/opsgenie-integration/). +1. Utiliza la [API de políticas de restricción](https://docs.datadoghq.com/api/latest/restriction-policies/), donde el tipo es `integration-service` y el ID es `opsgenie:
a. `type`: es el método de envío (`gauge`, `count`, etc.).
b. name (nombre): es el sufijo utilizado para formar el nombre completo de la métrica. Si `type` es `tag`, esta columna se considera una etiqueta que se aplica a cada métrica recopilada por esta consulta en particular. | +| Parámetro | Descripción | +| --------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |\ +| `query` | Este es el SQL a ejecutar. Puede ser una sentencia simple o un script de varias líneas. Se evalúan todas las filas del resultado. | +| `columns` | Esta es una lista que representa cada columna, ordenada secuencialmente de izquierda a derecha. Hay dos datos obligatorios:
a. `type` - Es el método de envío (`gauge`, `count`, etc.).
b. name - Es el sufijo utilizado para formar el nombre completo de la métrica. Si `type` es `tag`, esta columna se considera en cambio como una etiqueta que se aplica a cada métrica recopilada por esta consulta en particular. | -Opcionalmente, utiliza el parámetro `tags` para aplicar una lista de etiquetas a cada métrica recopilada. +Opcionalmente, utiliza el parámetro `tags` para aplicar una lista de etiquetas (tags) a cada métrica recopilada. Lo siguiente: @@ -462,12 +412,12 @@ self.count('oracle.custom_query.metric2', value, tags=['tester:oracle', 'tag1:va es en lo que se convertiría el siguiente ejemplo de configuración: ```yaml -- query: | # Usa el pipe si necesitas un script de múltiples líneas. +- query: | # Use the pipe if you require a multi-line script. SELECT columns FROM tester.test_table WHERE conditions columns: - # Coloca esto en cualquier columna que deseas omitir: + # Put this for any column you wish to skip: - {} - name: metric1 type: gauge @@ -479,31 +429,67 @@ es en lo que se convertiría el siguiente ejemplo de configuración: - tester:oracle ``` -Consulta el [oracle.d/conf.yaml de ejemplo][4] para ver todas las opciones disponibles de configuración. +Consulta el [ejemplo oracle.d/conf.yaml](https://github.com/DataDog/datadog-agent/blob/main/cmd/agent/dist/conf.d/oracle.d/conf.yaml.example) para conocer todas las opciones de configuración disponibles. ## Datos recopilados ### Métricas -{{< get-metrics-from-git "oracle" >}} +| | | +| --- | --- | +| **oracle.active_sessions**
(gauge) | Número de sesiones activas| +| **oracle.asm_diskgroup.free_mb**
(gauge) | Capacidad no utilizada de un grupo de discos en megabytes, etiquetada por `state` (solo DBM)| +| **oracle.asm_diskgroup.offline_disks**
(gauge) | Número de discos de un grupo de discos ASM que están fuera de línea, etiquetados por `state` (solo DBM)| +| **oracle.asm_diskgroup.total_mb**
(gauge) | Capacidad total utilizable del grupo de discos, etiquetada por `state` (solo DBM)| +| **oracle.buffer_cachehit_ratio**
(gauge) | Ratio de accesos a la caché del buffer
_Se muestra como porcentaje_ | +| **oracle.cache_blocks_corrupt**
(gauge) | Bloques de caché corruptos
_Se muestra como bloque_ | +| **oracle.cache_blocks_lost**
(gauge) | Bloques de caché perdidos
_Se muestra como bloque_ | +| **oracle.cursor_cachehit_ratio**
(gauge) | Ratio de accesos a la caché del cursor
_Se muestra como porcentaje_. | +| **oracle.database_wait_time_ratio**
(gauge) | Ordenaciones de memoria por segundo
_Se muestra como porcentaje_. | +| **oracle.disk_sorts**
(gauge) | Ordenaciones de disco por segundo
_Se muestra como operación_ | +| **oracle.enqueue_timeouts**
(gauge) | Tiempos de espera en cola excedidos por segundo
_Se muestra como tiempo de espera excedido_ | +| **oracle.gc_cr_block_received**
(gauge) | Bloque CR de recolección de basura recibido
_Se muestra como bloque_ | +| **oracle.library_cachehit_ratio**
(gauge) | Ratio de accesos a la caché de la biblioteca
_Se muestra como porcentaje_ | +| **oracle.logons**
(gauge) | Número de intentos de inicio de sesión| +| **oracle.long_table_scans**
(gauge) | Número de análisis extensos de tablas por segundo
_Se muestra como análisis_ | +| **oracle.memory_sorts_ratio**
(gauge) | Ratio de ordenaciones de la memoria
_Se muestra como porcentaje_ | +| **oracle.physical_reads**
(gauge) | Lecturas físicas por segundo
_Se muestra como lectura_ | +| **oracle.physical_writes**
(gauge) | Escrituras físicas por segundo
_Se muestra como escritura_ | +| **oracle.process.pga_allocated_memory**
(gauge) | Memoria PGA asignada por el proceso
_Se muestra como bytes_ | +| **oracle.process.pga_freeable_memory**
(gauge) | Memoria PGA liberable por proceso
_Se muestra como bytes_ | +| **oracle.process.pga_maximum_memory**
(gauge) | Memoria PGA máxima asignada por el proceso
_Se muestra como bytes_ | +| **oracle.process.pga_used_memory**
(gauge) | Memoria PGA utilizada por el proceso
_Se muestra como bytes_ | +| **oracle.rows_per_sort**
(gauge) | Filas por clasificación
_Se muestra como fila_ | +| **oracle.service_response_time**
(gauge) | Tiempo de respuesta del servicio
_Se muestra como segundos_ | +| **oracle.session_count**
(gauge) | Recuento de sesiones| +| **oracle.session_limit_usage**
(gauge) | Uso del límite de sesión
_Se muestra como porcentaje_. | +| **oracle.shared_pool_free**
(gauge) | % de memoria libre del grupo compartido
_Se muestra como porcentaje_ | +| **oracle.sorts_per_user_call**
(gauge) | Clasificación por llamadas de usuario| +| **oracle.tablespace.in_use**
(gauge) | Espacio de tabla en uso
_Se muestra como porcentaje_. | +| **oracle.tablespace.offline**
(gauge) | Espacio de tabla fuera de línea| +| **oracle.tablespace.size**
(gauge) | Tamaño del espacio de tabla
_Se muestra como bytes_ | +| **oracle.tablespace.used**
(gauge) | Espacio de tabla utilizado
_Se muestra como bytes_ | +| **oracle.temp_space_used**
(gauge) | Espacio temporal utilizado
_Se muestra como bytes_ | +| **oracle.user_rollbacks**
(gauge) | Número de reversiones de usuarios
_Se muestra como operación_ | ### Eventos El check de Oracle Database no incluye ningún evento. ### Checks de servicio -{{< get-service-checks-from-git "oracle" >}} +**oracle.can_connect** -## Solucionar problemas +Devuelve OK si la integración puede conectarse a Oracle Database, CRITICAL en caso contrario -¿Necesitas ayuda? Ponte en contacto con el [soporte de Datadog][7]. +_Estados: ok, crítico_ +**oracle.can_query** + +Devuelve OK si la integración puede ejecutar todas las consultas, CRITICAL en caso contrario + +_Estados: ok, crítico_ + +## Solucionar problemas -[1]: https://raw.githubusercontent.com/DataDog/integrations-core/master/oracle/images/oracle_dashboard.png -[2]: https://docs.datadoghq.com/es/database_monitoring/ -[3]: https://docs.datadoghq.com/es/agent/guide/agent-configuration-files/#agent-configuration-directory -[4]: https://github.com/DataDog/datadog-agent/blob/main/cmd/agent/dist/conf.d/oracle.d/conf.yaml.example -[5]: https://docs.datadoghq.com/es/agent/guide/agent-commands/#start-stop-and-restart-the-agent -[6]: https://docs.datadoghq.com/es/agent/guide/agent-commands/#agent-status-and-information -[7]: https://docs.datadoghq.com/es/help/ \ No newline at end of file +¿Necesitas ayuda? Ponte en contacto con el [servicio de asistencia de Datadog](https://docs.datadoghq.com/help/). \ No newline at end of file diff --git a/content/es/integrations/oracle_cloud_infrastructure.md b/content/es/integrations/oracle_cloud_infrastructure.md index 3222e81e8cfa8..d83faaaca997a 100644 --- a/content/es/integrations/oracle_cloud_infrastructure.md +++ b/content/es/integrations/oracle_cloud_infrastructure.md @@ -8,11 +8,6 @@ assets: auto_install: false events: creates_events: false - metrics: - check: - - oci.mediastreams.egress_bytes - metadata_path: metadata.csv - prefix: oci. service_checks: metadata_path: assets/service_checks.json source_type_id: 310 @@ -55,33 +50,123 @@ tile: a una serie de aplicaciones en un entorno alojado. media: [] overview: README.md#Overview + resources: + - resource_type: blog + url: https://www.datadoghq.com/blog/monitor-oci-with-datadog/ + - resource_type: blog + url: https://www.datadoghq.com/blog/datadog-oci-quickstart/ support: README.md#Support title: Oracle Cloud Infrastructure --- - -## Información general + +{{% site-region region="gov" %}} +
La integración de Oracle Cloud Infrastructure no es compatible con el Datadog site seleccionado ({{< region-param key="dd_site_name" >}}).
+{{% /site-region %}}
-Oracle Cloud Infrastructure (OCI) es una infraestructura como servicio (IaaS) y plataforma como servicio (PaaS) utilizada por empresas. Con un completo conjunto de servicios gestionados para alojamiento, almacenamiento, redes, bases de datos y mucho más.
+{{< jqmath-vanilla >}}
-Utiliza la integración de OCI de Datadog para reenviar tus logs y métricas a Datadog, donde pueden servir para dashboards, pueden ayudar a solucionar problemas y ser monitorizados para la seguridad y la postura de cumplimiento.
+## Visión general
+
+Oracle Cloud Infrastructure (OCI) es una infraestructura como servicio (IaaS) y plataforma como servicio (PaaS) utilizada por empresas de gran escala. Incluye un conjunto completo de más de 30 servicios gestionados de alojamiento, almacenamiento, redes, bases de datos, etc.
+
+Utilice la integración OCI de Datadog para obtener una visibilidad completa de su entorno OCI a través de métricas, logy datos de recursos. Estos datos le permiten crear cuadros de mando, le ayudan a solucionar problemas y pueden supervisarse para garantizar la seguridad y el cumplimiento de las normativas.
## Configuración
### Recopilación de métricas
-Para enviar tus métricas de OCI a Datadog:
+{{< tabs >}}
+
+{{% tab "OCI QuickStart (Preview; recommended)" %}}
+
+
+OCI QuickStart está en Vista previa. Utilice este formulario para enviar su solicitud hoy mismo.
+
+
+OCI QuickStart de Datadog es una experiencia de configuración totalmente gestionada y de flujo único que te ayuda a monitorizar tu infraestructura y aplicaciones OCI en tan sólo unos clics. OCI QuickStart crea la infraestructura necesaria para reenviar métricas, logs y datos de recursos a Datadog y descubre automáticamente nuevos recursos o compartimentos OCI para la recopilación de datos.
+
+**Nota**: En forma predeterminada sólo se envían métricas. Habilita la recopilación de logs y de datos de recursos desde el [ícono de integración de OCI de Datadog][1] después de completar esta configuración.
+
+Para configurar la infraestructura de reenvío de métricas y logs a Datadog:
+ - [Configura el ícono de integración OCI de Datadog](#datadog-oci-integration-tile)
+ - [Despliega el stack tecnológico QuickStart](#orm-stack)
+ - [Completa la configuración en Datadog](#complete-the-setup-in-datadog)
+ - [Valida las métricas que fluyen](#validation)
+ - [Configura la recopilación de métricas (opcional)](#configuration)
+ - [Configura la recopilación de logs (opcional)](#log-collection)
+
+La integración requiere el uso de Oracle Service Connector Hubs para reenviar datos a Datadog. Se recomienda [solicitar un aumento del límite del servicio][2] antes de completar la configuración. El número aproximado de Service Connector Hubs que necesitas es:
+
+$$\\text"Service Connector Hubs" = \text"Número de compartimentos en tenencia" / \text"5"\$$
+
+{{% collapse-content title="Requisitos previos para esta configuración" level="h4" %}}
+- Tu cuenta de usuario OCI necesita el rol de **Administrador de la nube** para completar estos pasos
+- Debes iniciar sesión en OCI en la tenencia con la que deseas integrarte
+- Debes iniciar sesión en OCI con la Región de origen seleccionada en la parte superior derecha de la pantalla
+- Tu cuenta de usuario OCI debe estar en el Dominio de identidad predeterminado
+- Tu cuenta de usuario de OCI debe poder crear un usuario, un grupo de usuarios y un grupo dinámico en el dominio de identidad predeterminado.
+- Tu cuenta de usuario OCI debe poder crear políticas en el compartimento raíz
+{{% /collapse-content %}}
+
+{{% collapse-content title="Regiones admitidas" level="h4" %}}
+- us-ashburn-1
+- ap-tokyo-1
+- sa-saopaulo-1
+- us-phoenix-1
+- eu-frankfurt-1
+- eu-stockholm-1
+- ap-singapur-1
+- us-sanjose-1
+- ca-toronto-1
+- sa-santiago-1
+- uk-london-1
+- eu-madrid-1
+- me-jeddah-1
+- us-chicago-1
+
+Ponte en contacto a través de este formulario para solicitar regiones adicionales.
+
+{{% /collapse-content %}}
+
+#### Ícono de integración de OCI de Datadog
+
+1. Ve al [ícono de integración de OCI de Datadog][1] y haz clic en **Añadir nueva tenencia**.
+2. Selecciona o crea una clave de la API Datadog para utilizarla para la integración.
+3. Crea una clave de la aplicación Datadog.
+4. Haz clic en **Crear stack tecnológico de OCI**. Esto te llevará a un stack tecnológico de Oracle Resource Manager (ORM) para finalizar el despliegue.+ **Nota**: Despliega este stack tecnológico sólo una vez por tenencia. + +#### Stack tecnológico de ORM + +1. Acepta las Condiciones de uso de Oracle. +2. Deja sin marcar la opción de utilizar proveedores personalizados de Terraform. +3. Utiliza el directorio de trabajo predeterminado para desplegar el stack tecnológico u opcionalmente elige uno diferente. +4. Haz clic en **Siguiente** y **Siguiente** de nuevo.
+5. Haz clic en **Crear** y espera hasta 15 minutos a que se complete el despliegue. + +[1]: https://app.datadoghq.com/integrations/oracle-cloud-infrastructure +[2]: https://docs.oracle.com/iaas/Content/General/Concepts/servicelimits.htm#Requesti +{{% /tab %}} + +{{% tab "Manual setup" %}} + +Para reenviar tus métricas de OCI a Datadog: - [Ingresa la información de la tenencia](#enter-tenancy-info). - - [Crea un stack tecnológico de políticas de OCI](#create-oci-policy-stack) en la región de origen de tu tenencia para crear un usuario de autenticación, un grupo y políticas de Datadog. - - [Ingresa la información del DatadogAuthUser](#enter-datadogauthuser-info) en Datadog. - - [Crea un stack tecnológico de reenvío de métricas de OCI](#create-oci-metric-forwarding-stack) para cada región de la tenencia desde la que quieras reenviar métricas. + - [Despliega el stack tecnológico de políticas OCI (#create-oci-policy-stack) en la región de origen de tu tenencia para crear un usuario, grupo y políticas de sólo lectura en Datadog. + - [Introduce DatadogROAuthUser info](#enter-datadogroauthuser-info) en Datadog + - [Despliega un stack tecnológico de reenvío de métricas OCI (#create-oci-metric-forwarding-stack) para cada región de tenencia desde la que desees reenviar métricas. + - [Completa la configuración en Datadog](#complete-the-setup-in-datadog) + - [Valida las métricas que fluyen](#validation) + - [Configura la recopilación de métricas (opcional)](#configuration) + - [Configura la recopilación de logs (opcional)](#log-collection) Para ver una representación visual de esta arquitectura, consulta la sección [Arquitectura](#architecture). #### Ingresar la información de la tenencia {{% collapse-content title="Requisitos para esta sección" level="h5" %}} -- Tu cuenta de usuario de OCI necesita el rol **Cloud Administrator** (Administrador de la nube) para completar estos pasos. +- Tu cuenta de usuario OCI necesita el rol de **Administrador de la nube** para completar estos pasos - OCID de la tenencia - Región de origen {{% /collapse-content %}} @@ -93,61 +178,61 @@ Ingresa el OCID y la región de origen de la tenencia que deseas monitorizar en #### Crear un stack tecnológico de políticas de OCI {{% collapse-content title="Requisitos para esta sección" level="h5" %}} -- Tu cuenta de usuario debe poder [crear políticas y grupos dinámicos][4] en el dominio predeterminado. -- Debes estar en la región de origen de la tenencia. +- Tu cuenta de usuario OCI debe poder [crear grupos y políticas dinámicas][4] en el dominio predeterminado +- Debes estar en la región de origen de la tenencia {{% /collapse-content %}} -
Asegúrate de que la región de origen de la tenencia esté seleccionada en la parte superior derecha de la pantalla.
+Asegúrate de que la región de origen de la tenencia esté seleccionada en la parte superior derecha de la pantalla.
-Este stack tecnológico de políticas solo debe desplegarse una vez por tenencia.
+Este stack tecnológico de políticas de Oracle Resource Manager (ORM) sólo debe desplegarse una vez por tenencia.
1. Haz clic en el botón **Create Policy Stack** (Crear un stack tecnológico de políticas) en el cuadro de integración de Datadog y OCI.
2. Acepta las Condiciones de uso de Oracle.
-3. Deja la opción de utilizar proveedores de Terraform personalizados **desmarcada**.
+3. Deja la opción de utilizar proveedores de Terraform personalizados **sin marcar**.
4. Utiliza el nombre y el compartimento predeterminados para el stack tecnológico. De manera opcional, indica tu propio nombre descriptivo o compartimento.
-5. Haz clic en **Next** (Siguiente).
-6. Asigna un nombre al grupo dinámico, el grupo de usuarios y a la política que se van a crear, o usa los nombres predeterminados proporcionados.
-7. Haz clic en **Next** (Siguiente).
+5. Haz clic en **Siguiente**.
+6. Deja el campo de tenencia y el campo de usuario actual como están.
+7. Haz clic en **Siguiente**.
8. Haz clic en **Create** (Crear).
-#### Ingresar la información del DatadogAuthUser
+#### Introduce DatadogROAuthUser info
{{% collapse-content title="Requisitos para esta sección" level="h5" %}}
-- OCID del `DatadogAuthUser`
+- OCID del `DatadogROAuthUser`
- Clave de la API de OCI y valor de la huella digital
{{% /collapse-content %}}
-1. En la barra de búsqueda de la consola de OCI, busca `DatadogAuthUser` y haz clic en el recurso de usuario que aparece.
+1. En la barra de búsqueda de la consola OCI, busca `DatadogROAuthUser` y haz clic en el recurso de Usuario que aparece.
2. Copia el valor del OCID del usuario.
3. Pega el valor en el campo **User OCID** (OCID del usuario) del [cuadro de integración de Datadog y OCI][1].
-4. Vuelve a la consola de OCI y genera una clave de API con estos pasos:
- a. En la esquina inferior izquierda de la pantalla, en **Resources** (Recursos), haz clic en **API keys** (Claves de API).
- b. Haz clic en **Add API key** (Añadir clave de API).
- c. Haz clic en **Download private key** (Descargar clave privada).
- d. Haz clic en **Add** (Añadir).
+4. Al volver a la consola OCI, genera una clave de API con estos pasos:+ a. En la esquina inferior izquierda de la pantalla, en **Recursos**, haz clic en **Claves de API**.
+ b. Haz clic en **Añadir clave de API**.
+ c. Haz clic en **Descargar clave privada**.
+ d. Haz clic en **Añadir**.
e. Aparece una ventana emergente **Configuration file preview** (Vista previa del archivo de configuración), pero no es necesario realizar ninguna acción; cierra la ventana emergente. -![La página Add API Key (Añadir clave de API) en la consola de OCI][5] +![La página Añadir clave de API en la consola de OCI][5] -5. Copia el valor de la huella digital y pégalo en el campo **Fingerprint** (Huella digital) del [cuadro de integración de Datadog y OCI][1]. +5. Copia el valor de la huella digital y pégalo en el campo **Huella digital** del [cuadro de integración de Datadog y OCI][1]. 6. Copia el valor de la clave privada con estos pasos: a. Abre el archivo de clave privada `.pem` descargado en un editor de texto, o utiliza un comando de terminal como `cat` para mostrar el contenido del archivo. b. Copia todo el contenido, incluidos `-----BEGIN PRIVATE KEY-----` y `-----END PRIVATE KEY-----`. 7. Pega el valor de la clave privada en el campo **Private Key** (Clave privada) del cuadro de integración de Datadog y OCI. -#### Crear un stack tecnológico de reenvío de métricas de OCI +#### Crea un stack tecnológico de reenvío de métricas de OCI {{% collapse-content title="Requisitos para esta sección" level="h5" %}} -- Tu cuenta de usuario debe poder crear recursos en el compartimento. +- Tu cuenta de usuario OCI debe poder crear recursos en el compartimento - Valor de la [clave de API de Datadog][6]. -- Nombre de usuario y token de autenticación para un usuario con los permisos `REPOSITORY_READ` y `REPOSITORY_UPDATE`, de modo que se puedan extraer y enviar imágenes a un repositorio de Docker. +- Nombre de usuario y token de autenticación para un usuario con los permisos `REPOSITORY_READ` y `REPOSITORY_UPDATE` para extraer e insertar imágenes en un repositorio Docker - Consulta [Cómo obtener un token de autenticación][7] para saber cómo crear un token de autenticación. - - Consulta [Políticas para controlar el acceso a repositorios][8] para obtener más información sobre las políticas requeridas. + - Consulta [Políticas para controlar el acceso a repositorios][8] para obtener más información sobre las políticas necesarias -**Nota**: Para comprobar que el inicio de sesión en el registro de Docker es el correcto, consulta [Inicio de sesión en el registro de Oracle Cloud Infrastructure][9]. +**Nota**: Para comprobar que el inicio de sesión en el registro de Docker sea el correcto, consulta [Inicio de sesión en el registro de Oracle Cloud Infrastructure][9]. {{% /collapse-content %}} -El stack tecnológico de reenvío métricas debe desplegarse para **cada combinación de tenencia y región** que se va a monitorizar. Para la configuración más sencilla, Datadog recomienda crear todos los recursos de OCI necesarios con el stack tecnológico de ORM que se facilita a continuación. Como alternativa, puedes usar tu infraestructura de redes de OCI existente. +El stack tecnológico de reenvío de métricas debe desplegarse para **cada combinación de tenencia y región** que se debe monitorizar. Para la configuración más sencilla, Datadog recomienda crear todos los recursos OCI necesarios con el stack tecnológico de Oracle Resource Manager (ORM) que se proporciona a continuación. Como alternativa, puedes utilizar tu infraestructura de red OCI existente. Todos los recursos creados a partir del stack tecnológico de ORM de Datadog se despliegan en el compartimento especificado y para la región seleccionada actualmente en la parte superior derecha de la pantalla. @@ -155,119 +240,132 @@ Todos los recursos creados a partir del stack tecnológico de ORM de Datadog se 2. Acepta las Condiciones de uso de Oracle. 3. Deja sin marcar la opción **Custom providers** (Proveedores personalizados). 4. Asigna un nombre al stack tecnológico y selecciona el compartimento en el que se desplegará. -5. Haz clic en **Next** (Siguiente). +5. Haz clic en **Siguiente**. 6. En el campo **Datadog API Key** (Clave de API de Datadog), ingresa el valor de tu [clave de API de Datadog][6]. +7. En la sección **Network options** (Opciones de red), deja marcada la opción `Create VCN`. +{{% collapse-content title="(Opcional) Utilizar el VCN existente en su lugar" level="h4" %}} +Si utilizas una Red de Nube Virtual (VCN) existente, debes proporcionar el OCID de la subred al stack tecnológico. Asegúrate de que la VCN: + - Tenga permiso para realizar llamadas de salida HTTP a través de la puerta de NAT + - Sea capaz de extraer imágenes del registro de contenedores OCI mediante la puerta de servicios. + - Tenga las reglas de tabla de rutas para permitir la puerta de NAT y la puerta de servicio + - Tenga las reglas de seguridad para enviar solicitudes HTTP + +7. En la sección **Opciones de red**, deja sin marcar la opción `Create VCN` e introduce la información de tu VCN:
+ a. En el campo **Compartimento de VCN**, selecciona tu compartimento.
+ b. En la sección **VCN existente**, selecciona tu VCN existente.
+ c. En la sección **Function Subnet OCID** (OCID de subred de función), introduce el OCID de la subred que se va a utilizar. +{{% /collapse-content %}} -{{< tabs >}} -{{% tab "Creaf VCN con ORM (recomendado)" %}} -8. En la sección **Network options** (Opciones de red), deja marcada la opción `Create VCN`. -{{% /tab %}} -{{% tab "Usar una VCN existente" %}} -Si utilizas una VCN existente, debes indicar el OCID de la subred en el stack tecnológico. Asegúrate de que la VCN cumpla los siguientes requisitos: - - Se le permite hacer llamadas de salida HTTP a través de la gateway NAT. - - Puede extraer imágenes del registro de contenedores de OCI mediante la gateway de servicio. - - Tiene las reglas de la tabla de enrutamiento para permitir la gateway NAT y la gateway de servicio. - - Tiene las reglas de seguridad para enviar solicitudes HTTP. - -8. En la sección **Network options** (Opciones de red), desmarca la opción `Create VCN` e ingresa la información de tu VCN: - a. En el campo **vcnCompartment**, selecciona tu compartimento. - b. En la sección **existingVcn**, selecciona tu VCN existente. - c. En la sección **Function Subnet OCID** (OCID de subred de función), ingresa el OCID de la subred que se va a utilizar. +8. De manera opcional, en la sección **Metrics settings** (Parámetros de las métricas), elimina cualquier espacio de nombres de métrica de la recopilación. +9. En la sección **Metrics compartments** (Compartimentos de las métricas), ingresa una lista separada por comas de los OCID de compartimentos que se van a monitorizar. Los filtros de espacio de nombres de métrica seleccionados en el paso anterior se aplican a cada compartimento. +10. En la sección **Configuración de funciones**, selecciona `GENERIC_ARM`. Selecciona `GENERIC_X86` si realizas el despliegue en una región de Japón. +11. Haz clic en **Siguiente**. +12. Haz clic en **Create** (Crear). +13. Vuelve a la página del [cuadro de integración de Datadog y OCI][1] y haz clic en **Create configuration** (Crear configuración). + +**Notas**: +- En forma predeterminada, sólo se selecciona el compartimento raíz y se activan todos los espacios de nombres de métricas del Paso 8 presentes en el compartimento (se admiten hasta 50 espacios de nombres por concentrador de conectores). Si eliges monitorizar compartimentos adicionales, los espacios de nombres añadidos a ellos son una intersección de los espacios de nombres seleccionados y los espacios de nombres presentes en el compartimento. +- Debes gestionar quién tiene acceso a los archivos de estado de Terraform de los stacks tecnológicos del gestor de recursos. Consulta la [sección Archivos de estado de Terraform][10] de la página Obtener el gestor de recursos para obtener más información. + +[1]: https://app.datadoghq.com/integrations/oracle-cloud-infrastructure +[2]: https://cloud.oracle.com/tenancy +[3]: https://docs.oracle.com/iaas/Content/General/Concepts/regions.htm +[4]: https://docs.oracle.com/en/cloud/paas/weblogic-container/user/create-dynamic-groups-and-policies.html +[5]: images/add_api_key.png +[6]: https://app.datadoghq.com/organization-settings/api-keys +[7]: https://docs.oracle.com/iaas/Content/Registry/Tasks/registrygettingauthtoken.htm +[8]: https://docs.oracle.com/iaas/Content/Registry/Concepts/registrypolicyrepoaccess.htm#Policies_to_Control_Repository_Access +[9]: https://docs.oracle.com/iaas/Content/Functions/Tasks/functionslogintoocir.htm +[10]: https://docs.oracle.com/iaas/Content/Security/Reference/resourcemanager_security.htm#confidentiality__terraform-state {{% /tab %}} + {{< /tabs >}} -9. De manera opcional, en la sección **Metrics settings** (Parámetros de las métricas), elimina cualquier espacio de nombres de métrica de la colección. -10. En la sección **Metrics compartments** (Compartimentos de las métricas), ingresa una lista separada por comas de los OCID de compartimentos que se van a monitorizar. Los filtros de espacio de nombres de métrica seleccionados en el paso anterior se aplican a cada compartimento. -11. En la sección **Function settings** (Parámetros de la función), indica un nombre de usuario de registro de OCI Docker y un token de autenticación en sus campos respectivos. Consulta [Cómo obtener un token de autenticación][7] para obtener más información. -12. Haz clic en **Next** (Siguiente). -13. Haz clic en **Create** (Crear). -14. Vuelve a la página del [cuadro de integración de Datadog y OCI][1] y haz clic en **Create configuration** (Crear configuración). +#### Completar la configuración en Datadog -**Notas**: -- De forma predeterminada, solo se selecciona el compartimento raíz y se activan todos los espacios de nombres de métrica compatibles con la integración de Datadog y OCI (se admiten hasta 50 espacios de nombres por hub de conectores). Si eliges monitorizar compartimentos adicionales, se aplica cualquier filtro de exclusión de espacio de nombres de métrica a cada compartimento. -- Debes gestionar quién tiene acceso a los archivos de estado de Terraform de los stacks tecnológicos del gestor de recursos. Consulta la sección [Archivos de estado de Terraform][10] de la página Seguridad del gestor de recursos para obtener más información. +Vuelve al [ícono de integración de OCI de Datadog][1] y haz clic en **¡Listo!**. #### Validación -Consulta las métricas de `oci.*` en el [dashboard de información general de la integración de OCI][11] o en la [página del explorador de métricas][12] en Datadog. +Consulta las métricas de `oci.*` en el [dashboard de información general de integración de OCI][2] o la [página Metrics Explorer][3] en Datadog. -
Las métricas de la función de OCI (espacio de nombres
+oci.faas) y las métricas de la instancia del contenedor (espacio de nombres oci_computecontainerinstance) se encuentran en versión preliminar.Las métricas de la función de OCI (espacio de nombres
#### Configuración
-##### Añadir regiones
+![La pestaña de configuración de una tenencia de OCI en Datadog][4]!
-Para monitorizar una región adicional en una tenencia, navega hasta esa tenencia en el cuadro de integración de OCI.
- 1. En la sección **Configure an Additional Region** (Configurar una región adicional), haz clic en **Create Metric Stack** (Crear un stack tecnológico de métricas).
- 2. Cambia a la región que deseas monitorizar en la parte superior derecha de la pantalla.
- 3. Completa los pasos de [Crear un stack tecnológico de reenvío de métricas de OCI](#create-oci-metric-forwarding-stack) en la región nueva.
+Una vez completada la configuración, aparecerá una pestaña de configuración para la tenencia en la parte izquierda del [ícono de integración de OCI de Datadog][1]. Aplica las configuraciones de recopilación de datos de toda la tenencia como se indica en las secciones siguientes.
-##### Añadir compartimentos o espacios de nombres de métrica
+##### Añadir regiones
-Para añadir compartimentos o editar la lista de los espacios de nombres de métrica activados, haz clic en **Edit** (Editar) en el [hub de conectores][13] recién creado.
- - Haz clic en **+ Another compartment** (+ otro compartimento) para añadir compartimentos.
- - En la sección **Configure source** (Configurar origen), añade o elimina espacios de nombres del menú desplegable **Namespaces** (Espacios de nombres).
+En la pestaña **General**, selecciona las regiones para la recopilación de datos en la lista de casillas de verificación **Regiones**. Las selecciones de regiones se aplican a toda la tenencia, tanto para las métricas como para logs.
-#### Arquitectura
+**Nota**: Si has utilizado el método de configuración QuickStart y después te has suscrito a una nueva región OCI, vuelve a aplicar el stack tecnológico de configuración inicial en ORM. La nueva región estará entonces disponible en el ícono de OCI de Datadog.
-##### Recursos de reenvío de métricas
+##### Recopilación de métricas y logs
-![Un diagrama de los recursos de OCI mencionados en esta página, en el que se muestra el flujo de datos][14]
+Utiliza las pestañas **Recopilación de métricas** y **Recopilación de logs** para configurar qué métricas y logs se envían a Datadog:
-Esta integración crea un [hub de conectores][15] de OCI, una [aplicación de función][16] y una infraestructura de redes segura para reenviar métricas de OCI a Datadog. El stack tecnológico de ORM de estos recursos crea un repositorio de contenedores de la función para la región en la tenencia, y la imagen de Docker se envía a él para que la función la utilice.
+- **Activar** o **desactivar** la recopilación de métricas o logs para toda la tenencia.
+- **Incluir** o **excluir** compartimentos específicos basándose en las etiquetas (tags) de compartimentos del formato `key:value`. Por ejemplo:
+ - `datadog:monitored,env:prod*` incluye compartimentos si **alguna** de estas etiquetas (tags) está presente
+ - `!env:staging,!testing` excluye los compartimentos sólo si **ambas** etiquetas (tags) están presentes
+ - `datadog:monitored,!region:us-phoenix-1` incluye los compartimentos que tienen la etiqueta (tag) `datadog:monitored` y los que no tienen la etiqueta (tag) `region:us-phoenix-1`
+- **Activar** o **desactivar** la recopilación para servicios OCI específicos.
-##### Recursos de IAM
+**Notas**:
+- Tras modificar las etiquetas (tags) en OCI, los cambios pueden tardar hasta 15 minutos en aparecer en Datadog
+- En OCI, las etiquetas (tags) no son heredadas por los compartimentos secundarios; cada compartimento se debe etiquetar individualmente.
-![Un diagrama de los recursos y el flujo de trabajo de OCI utilizados para la autenticación de la integración][17]
+{{% collapse-content title="Consulta la lista completa de espacios de nombres de métricas" level="h4" %}}
+### Espacios de nombre de métricas
-Esta integración crea lo siguiente:
+| Integración | Espacio de nombres de métricas |
+|-------------------------------------| ---------------------------------------------------------------------------------------------------------------------------------------- |
+| [Puerta de API][5] | [oci_apigateway][6] |
+| [Base de datos autónoma][7] | [base de datos_autónoma_oci][8] |
+| [Almacenamiento en bloque][9] | [oci_blockstore][10] |
+| [Cómputo][11] | [oci_computeagent][12], [rdma_infraestructura_estado][13], [gpu_infraestructura_estado][14], [oci_cómputo_infraestructura_estado][15] |
+| [Instancias de contenedor (vista previa)][16] | [oci_computecontainerinstance][17] |
+| [Base de datos][18] | [oci_base de datos][19], [oci_base de datos_clúster][20] |
+| Puerta de enrutamiento dinámico | [oci_puerta_enrutamiento_dinámico][21] |
+| [E-Business Suite (EBS)][22] | [oracle_appmgmt][23] |
+| [FastConnect][24] | [oci_fastconnect][25] |
+| [Almacenamiento de archivos][26] | [oci_filestorage][27] |
+| [Funciones (Vista previa)][28] | [oci_faas][29] |
+| [GPU][30] | [gpu_infraestructura_estado][14] |
+| [HeatWave MySQL][31] | [oci_mysql_base de datos][32] |
+| [Motor de Kubernetes][33] | [oci_oke][34] |
+| [Equilibrador de carga][35] | [oci_lbaas][36], [oci_nlb][37] |
+| [Flujos de comunicación][38] | [oci_mediastreams][39] |
+| [Puerta NAT][40] | [oci_nat_gateway][41] |
+| [Cortafuegos de red][42] | [oci_red_cortafuegos][43] |
+| [Almacenamiento de objetos][44] | [oci_objectstorage][45] |
+| [PostgreSQL][46] | [oci_postgresql][47] |
+| [Cola] [48] | [oci_cola][49] |
+| [Service Connector Hub][50] | [oci_service_connector_hub][51] |
+| [Puerta de servicios][52] | [oci_puerta_servicios][53] |
+| [VCN][54] | [oci_vcn][55] |
+| [VPN][56] | [oci_vpn][57] |
+| [Web Application Firewall][58] | [oci_waf][59]
+{{% /collapse-content %}}
- * Un grupo dinámico con `resource.type = 'serviceconnectors'`, para permitir el acceso al hub de conectores.
- * Un usuario llamado **DatadogAuthUser**, que Datadog usa para leer recursos de tenencia.
- * Un grupo al que se añade el usuario creado para acceder a la política.
- * Una política en el compartimento raíz para permitir que los hubs de conectores lean métricas e invoquen funciones. Además, otorga al grupo de usuarios creado acceso de lectura a los recursos de la tenencia. Se añaden las siguientes instrucciones a la política:
+### Recopilación de logs
-```text
-Allow dynamic-group oci.faas) y las métricas de la instancia del contenedor (espacio de nombres oci_computecontainerinstance) se encuentran en versión preliminar.La integración de PagerDuty en Datadog tiene soporte limitado en el sitio de Datadog para el gobierno. La integración del catálogo de servicios y la resolución automática de la Gestión de Incidentes y la Automatización de flujos (flows) de trabajo no son compatibles.
+
+La integración de PagerDuty en Datadog tiene soporte limitado en el sitio de Datadog para el gobierno. La integración del catálogo de servicios y la resolución automática de la Gestión de Incidentes y la Automatización de flujos de trabajo no son compatibles.
{{< /site-region >}}
## Información general
Conecta PagerDuty a Datadog para:
-- Activar y resolver incidentes de tu flujo mencionando `@pagerduty` en tu mensaje
+- Activar y resolver incidentes de tu flujo (stream) mencionando `@pagerduty` en tu mensaje
- Visualizar los incidentes y las escaladas en tu flujo a medida que se producen
- Recibir un recordatorio diario de quién está de guardia
## Configuración
-Consulta la [guía de la integración en Datadog][1] de Pagerduty.
+Consulta la [guía de integración de Datadog](http://www.pagerduty.com/docs/guides/datadog-integration-guide) de PagerDuty.
{{< site-region region="us" >}}
Una vez que tengas Pagerduty integrado, puedes verificar tendencias personalizadas de incidentes de PagerDuty.
@@ -63,13 +52,13 @@ La integración de PagerDuty no incluye métricas.
### Eventos
-Tus eventos PagerDuty activados/resueltos aparecen en el [Explorador de eventos][2].
+Tus eventos de PagerDuty activados/resueltos aparecen en el [Explorador de eventos](https://docs.datadoghq.com/events/explorer/).
### Checks de servicio
La integración de PagerDuty no incluye checks de servicio.
-## Resolución de problemas
+## Solucionar problemas
### Enviar una notificación a un servicio de PagerDuty específico
@@ -98,9 +87,6 @@ Por ejemplo, si el monitor pasa de `OK` a `WARNING` y notifica un `@pagerduty-[s
Datadog tiene un límite superior para la longitud de los notificaciones del monitor enviadas a PagerDuty. El límite es de **1024 caracteres**.
-## Leer más
-
-{{< partial name="whats-next/whats-next.html" >}}
+## Referencias adicionales
-[1]: http://www.pagerduty.com/docs/guides/datadog-integration-guide
-[2]: https://docs.datadoghq.com/es/events/explorer/
\ No newline at end of file
+{{< partial name="whats-next/whats-next.html" >}}
\ No newline at end of file
diff --git a/content/es/integrations/papertrail.md b/content/es/integrations/papertrail.md
index 54f2096682e24..4935a8f8b2b77 100644
--- a/content/es/integrations/papertrail.md
+++ b/content/es/integrations/papertrail.md
@@ -1,55 +1,16 @@
---
app_id: papertrail
-app_uuid: 630c6ff6-e853-4ef7-8be4-371a55269208
-assets:
- integration:
- auto_install: true
- events:
- creates_events: true
- service_checks:
- metadata_path: assets/service_checks.json
- source_type_id: 147
- source_type_name: PaperTrail
-author:
- homepage: https://www.datadoghq.com
- name: Datadog
- sales_email: info@datadoghq.com
- support_email: help@datadoghq.com
categories:
- event management
- notifications
custom_kind: integración
-dependencies: []
-display_on_public_website: true
-draft: false
-git_integration_title: papertrail
-integration_id: papertrail
-integration_title: Papertrail
-integration_version: ''
-is_public: true
-manifest_version: 2.0.0
-name: papertrail
-public_title: Papertrail
-short_description: Visualiza, realiza búsquedas y discute sobre logs de Papertrail
- en tu flujo (stream) de eventos de Datadog.
-supported_os: []
-tile:
- changelog: CHANGELOG.md
- classifier_tags:
- - Category::Gestión de eventos
- - Category::Notificaciones
- - Offering::Integración
- configuration: README.md#Configuración
- description: Visualiza, realiza búsquedas y discute sobre logs de Papertrail en
- tu flujo de eventos de Datadog.
- media: []
- overview: README.md#Información general
- support: README.md#Soporte
- title: Papertrail
+description: Visualiza, realiza búsquedas y discute sobre logs de Papertrail en tu
+ flujo (stream) de eventos de Datadog.
+integration_version: 1.0.0
+media: []
+title: Papertrail
---
-
-
-![Ejemplo de Papertrail][1]
+
## Información general
@@ -64,16 +25,19 @@ Utiliza Papertrail y Datadog para:
Para capturar métricas de Papertrail:
-1. En el [visor de eventos][2] de Papertrail, guarda una búsqueda de los eventos de logs que deben ser graficados.
-2. Ingresa el nombre de la búsqueda y haz clic en el botón **Save & Setup an Alert** (Guardar y configurar una alerta).
-3. En Gráficas y métricas, elige Datadog.
- ![Notificaciones de Papertrail][3]
+1. En el [visor de eventos](https://papertrailapp.com/events) de Papertrail, guarda una búsqueda de los evento de log que deben ser graficados.
+
+1. Ingresa el nombre de la búsqueda y haz clic en el botón **Save & Setup an Alert** (Guardar y configurar una alerta).
+
+1. En Gráficas y métricas, elige Datadog.
+ 
-4. Elige la frecuencia de tus alertas y otros detalles.
-5. Proporciona tu clave de API Datadog, introduce el nombre elegido para tu métrica y, opcionalmente, introduce algunas etiquetas (tags) para asociar a la métrica.
- ![Notificaciones de Papertrail][4]
+1. Elige la frecuencia de tus alertas y otros detalles.
-6. Haz clic en el botón **Create Alert** (Crear alerta).
+1. Proporciona tu clave de API Datadog, introduce el nombre elegido para tu métrica y, opcionalmente, introduce algunas etiquetas (tags) para asociar a la métrica.
+ 
+
+1. Haz clic en el botón **Create Alert** (Crear alerta).
Papertrail actualiza Datadog según el intervalo elegido.
@@ -97,10 +61,4 @@ La integración de Papertrail no incluye checks de servicio.
## Solucionar problemas
-¿Necesitas ayuda? Ponte en contacto con el [servicio de asistencia de Datadog][5].
-
-[1]: images/papertrailexample.png
-[2]: https://papertrailapp.com/events
-[3]: images/papertrailnotify.png
-[4]: images/papertraildetails.png
-[5]: https://docs.datadoghq.com/es/help/
\ No newline at end of file
+¿Necesitas ayuda? Ponte en contacto con el [servicio de asistencia de Datadog](https://docs.datadoghq.com/help/).
\ No newline at end of file
diff --git a/content/es/integrations/php.md b/content/es/integrations/php.md
index c940dca5a54e0..4f2d0e6cd07a5 100644
--- a/content/es/integrations/php.md
+++ b/content/es/integrations/php.md
@@ -1,69 +1,49 @@
---
+app_id: php
categories:
- languages
- log collection
- tracing
-custom_kind: integration
-dependencies: []
-description: Recopila métricas, trazas, logs y datos de perfil de tus aplicaciones PHP.
-doc_link: https://docs.datadoghq.com/integrations/php/
-draft: false
+custom_kind: integración
+description: Recopila métricas, trazas (traces) y logs de tus aplicaciones PHP.
further_reading:
- link: https://www.datadoghq.com/blog/monitor-php-performance/
- tag: Blog
- text: Monitorización de PHP con Datadog APM y rastreo distribuido.
+ tag: blog
+ text: Monitorización PHP con Datadog APM y rastreo distribuido
- link: https://www.datadoghq.com/blog/php-logging-guide/
- tag: Blog
- text: Cómo recopilar, personalizar y analizar logs de PHP.
-git_integration_title: php
-has_logo: true
-integration_id: php
-integration_title: PHP
-integration_version:
-is_public: true
-manifest_version: 1.0
-name: php
-public_title: Integración de Datadog y PHP
-short_description: Recopila métricas, trazas, logs y datos de perfil de tus aplicaciones PHP.
-version: 1.0
+ tag: blog
+ text: 'Generación de logs PHP: cómo recopilar, personalizar y analizar logs PHP'
+media: []
+title: PHP
---
-
-
## Información general
-La integración de Datadog y PHP te permite recopilar y monitorizar logs, trazas (traces) y métricas personalizadas de tu aplicación de PHP.
+La integración de Datadog y PHP te permite recopilar y monitorizar logs, trazas y métricas personalizadas de tu aplicación PHP.
## Configuración
### Recopilación de métricas
-Consulta la documentación dedicada a [recopilar métricas personalizadas de PHP con DogStatsD][1].
+Consulta la documentación exclusiva para [recopilar métricas personalizadas de PHP con DogStatsD](https://docs.datadoghq.com/developers/dogstatsd/?tab=php).
### Recopilación de trazas
-Consulta la documentación dedicada a [instrumentar tu aplicación PHP][2] para enviar sus trazas (traces) a Datadog.
+Consulta la documentación exclusiva para [instrumentar tu aplicación PHP](https://docs.datadoghq.com/tracing/setup/php/) para enviar tus trazas a Datadog.
-### APM
+### Recopilación de logs
*Disponible para Agent v6.0+*
-Consulta la documentación específica sobre cómo [configurar la recopilación de logs de PHP][3] para reenviar tus logs a Datadog.
+Consulta la documentación exclusiva sobre cómo [configurar la recopilación de logs PHP](https://docs.datadoghq.com/logs/log_collection/php/) para reenviar tus logs a Datadog.
### Recopilación de perfiles
-Consulta la documentación específica para [activar el perfilador PHP][4].
-
-## Resolución de problemas
-
-¿Necesitas ayuda? Ponte en contacto con el [soporte de Datadog][5].
+Consulta la documentación exclusiva para [habilitar el generador de perfiles PHP](https://docs.datadoghq.com/profiler/enabling/php/).
-## Leer más
+## Solucionar problemas
-{{< partial name="whats-next/whats-next.html" >}}
+¿Necesitas ayuda? Ponte en contacto con el [servicio de asistencia de Datadog](https://docs.datadoghq.com/help/).
-[1]: https://docs.datadoghq.com/developers/dogstatsd/?tab=php
-[2]: https://docs.datadoghq.com/tracing/setup/php/
-[3]: https://docs.datadoghq.com/logs/log_collection/php/
-[4]: https://docs.datadoghq.com/profiler/enabling/php/
-[5]: https://docs.datadoghq.com/help/
+## Referencias adicionales
+{{< partial name="whats-next/whats-next.html" >}}
\ No newline at end of file
diff --git a/content/es/integrations/ping.md b/content/es/integrations/ping.md
index 002186ee24be4..83ac4f8744299 100644
--- a/content/es/integrations/ping.md
+++ b/content/es/integrations/ping.md
@@ -1,72 +1,24 @@
---
app_id: ping
-app_uuid: 841c9313-628f-4861-ad0b-2d12c37ee571
-assets:
- integration:
- auto_install: true
- configuration: {}
- events:
- creates_events: false
- metrics:
- check: network.ping.response_time
- metadata_path: metadata.csv
- prefix: red.
- service_checks:
- metadata_path: assets/service_checks.json
- source_type_id: 10200
- source_type_name: Ping
-author:
- homepage: https://github.com/DataDog/integrations-extras
- name: Comunidad
- sales_email: jim.stanton@datadoghq.com
- support_email: jim.stanton@datadoghq.com
categories:
- herramientas de desarrollo
- la red
-custom_kind: integration
-dependencies:
-- https://github.com/DataDog/integrations-extras/blob/master/ping/README.md
-display_on_public_website: true
-draft: false
-git_integration_title: ping
-integration_id: ping
-integration_title: Ping
+custom_kind: integración
+description: Monitoriza la conectividad a hosts remotos.
integration_version: 1.0.2
-is_public: true
-manifest_version: 2.0.0
-name: ping
-public_title: Ping
-short_description: Monitoriza la conectividad a hosts remotos.
+media: []
supported_os:
- Linux
- Windows
- macOS
-tile:
- changelog: CHANGELOG.md
- classifier_tags:
- - Categoría::Herramientas de desarrollo
- - Categoría::Red
- - Sistema operativo compatible::Linux
- - Sistema operativo compatible::Windows
- - Sistema operativo compatible::macOS
- - Oferta::Integración
- configuration: README.md#Configuración
- description: Monitoriza la conectividad a hosts remotos.
- media: []
- overview: README.md#Información general
- support: README.md#Soporte
- title: Ping
+title: Ping
---
-
-
-
-
## Información general
-Este check utiliza el comando [ping][1] del sistema para comprobar la accesibilidad de un host.
+Este check utiliza el comando [ping](https://en.wikipedia.org/wiki/Ping_%28networking_utility%29) del sistema para comprobar la accesibilidad de un host.
También mide opcionalmente el tiempo de ida y vuelta de los mensajes enviados desde el check al host de destino.
-El ping funciona enviando paquetes de solicitud de eco del Protocolo de mensajes de control de Internet (ICMP) al host de destino y esperando una respuesta de eco ICMP.
+Ping funciona enviando paquetes de solicitud de eco del Protocolo de mensajes de control de Internet (ICMP) al host de destino y esperando una respuesta de eco ICMP.
Este check utiliza el comando ping del sistema, en lugar de generar la solicitud de eco del ICMP, ya que la creación de un paquete ICMP requiere un socket sin procesar. La creación de sockets sin procesar requiere privilegios raíz que el Agent no tiene. El comando ping utiliza el marcador de acceso `setuid` para ejecutarse con privilegios elevados y evitar este inconveniente.
@@ -74,11 +26,11 @@ Este check utiliza el comando ping del sistema, en lugar de generar la solicitud
## Configuración
-El check ping no está incluido en el paquete del [Datadog Agent][2], por lo que es necesario instalarlo.
+El check de Ping no está incluido en el paquete del [Datadog Agent](https://app.datadoghq.com/account/settings/agent/latest), por lo que es necesario instalarlo.
### Instalación
-Para versiones 7.21/6.21 o posteriores del Agent, sigue las siguientes instrucciones para instalar el check ping en tu host. Para instalarlo con el Agent Docker o versiones anteriores del Agent, consulta [Uso de integraciones de la comunidad][3].
+Para el Agent v7.21/v6.21 o posteriores, sigue las instrucciones a continuación para instalar el check de Ping en tu host. Consulta [Uso de integraciones comunitarias](https://docs.datadoghq.com/agent/guide/use-community-integrations/) para instalar con el Docker Agent o versiones anteriores del Agent.
1. Ejecuta el siguiente comando para instalar la integración del Agent:
@@ -89,41 +41,51 @@ Para versiones 7.21/6.21 o posteriores del Agent, sigue las siguientes instrucci
# Windows
agent.exe integration install -t datadog-ping==(gauge) | Tiempo de respuesta de un host y un puerto de ping determinados, etiquetado con url, por ejemplo, 'host:192.168.1.100'.
_Se muestra como milisegundos_ | +| **network.ping.can_connect**
(gauge) | Valor de 1 si el Agent puede comunicarse con éxito con el host de destino, 0 en caso contrario| ### Eventos -El check ping no incluye eventos. +El check de Ping no incluye eventos. ### Checks de servicio -{{< get-service-checks-from-git "ping" >}} +**network.ping.can_connect** + +Devuelve CRITICAL si el Agent no puede comunicarse con el host de destino. Devuelve OK si el ping tiene éxito. + +_Estados: ok, crítico_ ## Solucionar problemas ### Error `SubprocessOutputEmptyError: get_subprocess_output expected output but had none` -Mientras ejecutas la integración del ping, puedes ver un error como el siguiente: + +Mientras ejecutas la integración Ping, puedes ver un error como el siguiente: ``` Traceback (most recent call last): @@ -138,19 +100,6 @@ Mientras ejecutas la integración del ping, puedes ver un error como el siguient _util.SubprocessOutputEmptyError: get_subprocess_output expected output but had none. ``` -Debido a que la integración del ping no está incluida por defecto en el Agent, el binario `ping` tampoco está incluido en el Agent. Para poder ejecutar la integración con éxito, debes instalar el binario `ping`. - - -¿Necesitas ayuda? Ponte en contacto con el [equipo de asistencia de Datadog][10]. - +Debido a que la integración Ping no está incluida por defecto en el Agent, el binario `ping` tampoco está incluido con el Agent. Debes instalar el binario `ping` para poder ejecutar la integración con éxito. -[1]: https://en.wikipedia.org/wiki/Ping_%28networking_utility%29 -[2]: https://app.datadoghq.com/account/settings/agent/latest -[3]: https://docs.datadoghq.com/es/agent/guide/use-community-integrations/ -[4]: https://docs.datadoghq.com/es/getting_started/integrations/ -[5]: https://github.com/DataDog/integrations-extras/blob/master/ping/datadog_checks/ping/data/conf.yaml.example -[6]: https://docs.datadoghq.com/es/agent/guide/agent-commands/#start-stop-and-restart-the-agent -[7]: https://docs.datadoghq.com/es/agent/guide/agent-commands/#service-status -[8]: https://github.com/DataDog/integrations-extras/blob/master/ping/metadata.csv -[9]: https://github.com/DataDog/integrations-extras/blob/master/ping/assets/service_checks.json -[10]: https://docs.datadoghq.com/es/help/ \ No newline at end of file +¿Necesitas ayuda? Ponte en contacto con el [servicio de asistencia de Datadog](https://docs.datadoghq.com/help/). \ No newline at end of file diff --git a/content/es/integrations/pingdom_v3.md b/content/es/integrations/pingdom_v3.md index 4b5918ca243c1..890faf8e88a0f 100644 --- a/content/es/integrations/pingdom_v3.md +++ b/content/es/integrations/pingdom_v3.md @@ -23,7 +23,7 @@ author: categories: - métricas - notificaciones -custom_kind: integration +custom_kind: integración dependencies: [] display_on_public_website: true draft: false @@ -66,26 +66,26 @@ Realiza un seguimiento de las métricas de rendimiento de Pingdom basadas en usu La integración Pingdom V3 actúa de forma similar a la [integración Pingdom en Datadog (obsoleta)][1], pero utiliza la versión 3.1 de la [API Pingdom][2]. -{{< img src="integrations/pingdom/pingdom_dashboard.png" alt="Gráficos de Pingdom en un dashboard de Datadog" popup="true">}} +![Gráficos Pingdom en un dashboard de Datadog][3] ## Configuración ### Generar token de API -1. Inicia sesión en tu [cuenta de Pingdom][3]. +1. Inicia sesión en tu [cuenta de Pingdom][4]. 2. Ve a Settings > Pingdom API (Configuración > API Pingdom). 3. Haz clic en Add API token (Añadir token de API). Dale un nombre y permisos de lectura-escritura al token. Guarda el token en algún sitio, ya que no podrás volver a acceder a él. ### Instalación y configuración -1. Abre el [cuadro de la integración Pingdom V3][4]. +1. Abre el [cuadro de integración de Pingdom V3][5]. 2. Introduce el nombre y el token de API en los campos correspondientes. Las métricas y los checks configurados en Pingdom se recopilan en Datadog. 3. Administra etiquetas (tags) de checks en Pingdom. Las etiquetas añadidas a un check en Pingdom se añaden automáticamente a un check en Datadog. Excluya checks añadiendo la etiqueta `datadog-exclude`. ## Datos recopilados ### Métricas -{{< get-metrics-from-git "pingdom-v3" >}} +{{< get-metrics-from-git "pingdom_v3" >}} ### Eventos @@ -107,11 +107,12 @@ En el caso del check `pingdom.status`, los resultados de los checks de transacci ## Solucionar problemas -¿Necesitas ayuda? Ponte en contacto con el [servicio de asistencia de Datadog][6]. +¿Necesitas ayuda? Ponte en contacto con el [soporte de Datadog][7]. [1]: https://docs.datadoghq.com/es/integrations/pingdom/ [2]: https://docs.pingdom.com/api/ -[3]: https://my.pingdom.com/ -[4]: https://app.datadoghq.com/account/settings#integrations/pingdom-v3 -[5]: https://github.com/DataDog/integrations-internal-core/blob/main/pingdom/metadata.csv -[6]: https://docs.datadoghq.com/es/help \ No newline at end of file +[3]: images/pingdom_dashboard.png +[4]: https://my.pingdom.com/ +[5]: https://app.datadoghq.com/account/settings#integrations/pingdom-v3 +[6]: https://github.com/DataDog/integrations-internal-core/blob/main/pingdom/metadata.csv +[7]: https://docs.datadoghq.com/es/help \ No newline at end of file diff --git a/content/es/integrations/pivotal.md b/content/es/integrations/pivotal.md index 4743d7ba99063..411075dcfd0b4 100644 --- a/content/es/integrations/pivotal.md +++ b/content/es/integrations/pivotal.md @@ -1,62 +1,22 @@ --- -"app_id": "pivotal" -"app_uuid": "c28e887f-43e0-4b99-aa2b-3f02d4f10763" -"assets": - "integration": - "auto_install": false - "events": - "creates_events": true - "service_checks": - "metadata_path": "assets/service_checks.json" - "source_type_id": !!int "9" - "source_type_name": "Pivotal" -"author": - "homepage": "https://www.datadoghq.com" - "name": "Datadog" - "sales_email": "info@datadoghq.com" - "support_email": "help@datadoghq.com" -"categories": -- "collaboration" -- "issue tracking" -"custom_kind": "integration" -"dependencies": [] -"display_on_public_website": true -"draft": false -"git_integration_title": "pivotal" -"integration_id": "pivotal" -"integration_title": "Pivotal" -"integration_version": "" -"is_public": true -"manifest_version": "2.0.0" -"name": "pivotal" -"public_title": "Pivotal" -"short_description": "Pivotal Tracker es un software como servicio (SaaS) de colaboración y gestión de proyectos ágiles" -"supported_os": -- "linux" -- "windows" -- "macos" -"tile": - "changelog": "CHANGELOG.md" - "classifier_tags": - - "Category::Collaboration" - - "Category::Issue Tracking" - - "Offering::Integration" - - "Submitted Data Type::Events" - - "Supported OS::Linux" - - "Supported OS::Windows" - - "Supported OS::macOS" - "configuration": "README.md#Setup" - "description": "Pivotal Tracker es un software como servicio (SaaS) de colaboración y gestión de proyectos ágiles" - "media": [] - "overview": "README.md#Overview" - "support": "README.md#Support" - "title": "Pivotal" +app_id: pivotal +categories: +- collaboration +- issue tracking +custom_kind: integración +description: Pivotal Tracker es un software como servicio (SaaS) para la gestión ágil + de proyectos and collaboration. +integration_version: 1.0.0 +media: [] +supported_os: +- linux +- windows +- macos +title: Pivotal --- - - ## Información general -[Pivotal Tracker][1] utiliza historias para ayudar a los equipos a realizar un seguimiento de los proyectos y colaborar a lo largo de las diferentes etapas del ciclo de desarrollo, como la creación de nuevas funciones, la resolución de errores o el tratamiento de la deuda técnica. Conecta Pivotal Tracker a Datadog para: +[Pivotal Tracker](https://www.pivotaltracker.com/features) utiliza historias para ayudar a los equipos a realizar un seguimiento de los proyectos y colaborar a lo largo de las distintas partes del ciclo de desarrollo, como la creación de nuevas funciones, la resolución de errores o el tratamiento de la deuda técnica. Conecta Pivotal Tracker a Datadog para: - Ver y discutir el progreso de tus historias en el Explorador de eventos de Datadog. - Correlacionar y graficar la finalización de historias con otros eventos y otras métricas en tu sistema. @@ -66,9 +26,9 @@ ### Instalación -Para obtener eventos Pivotal en en el Explorador de eventos de Datadog, introduce el token de API generado desde la [página de tu perfil] de Pivotal[2]. +Para obtener eventos de Pivotal en el Explorador de eventos de Datadog, introduce el token de API generado de tu [página de perfil](https://www.pivotaltracker.com/signin) de Pivotal. -![token de pivotal][3] + ## Datos recopilados @@ -84,12 +44,6 @@ La integración Pivotal Tracker no incluye eventos. La integración Pivotal Tracker no incluye checks de servicio. -## Resolución de problemas - -¿Necesitas ayuda? Ponte en contacto con el [soporte de Datadog][4]. - -[1]: https://www.pivotaltracker.com/features -[2]: https://www.pivotaltracker.com/signin -[3]: images/pivotal_token.png -[4]: https://docs.datadoghq.com/help/ +## Solucionar problemas +¿Necesitas ayuda? Ponte en contacto con el [servicio de asistencia de Datadog](https://docs.datadoghq.com/help/). \ No newline at end of file diff --git a/content/es/integrations/postgres.md b/content/es/integrations/postgres.md index 9051993d03e98..4671ed581b6ea 100644 --- a/content/es/integrations/postgres.md +++ b/content/es/integrations/postgres.md @@ -1,107 +1,44 @@ --- app_id: postgres -app_uuid: e6b3c5ec-b293-4a22-9145-277a12a9abd4 -assets: - dashboards: - postgresql: assets/dashboards/postgresql_dashboard.json - postgresql_screenboard: assets/dashboards/postgresql_screenboard_dashboard.json - integration: - auto_install: true - configuration: - spec: assets/configuration/spec.yaml - events: - creates_events: false - metrics: - check: - - postgresql.connections - - postgresql.max_connections - metadata_path: metadata.csv - prefix: postgresql. - process_signatures: - - postgres -D - - pg_ctl start -l logfile - - postgres -c 'pg_ctl start -D -l - service_checks: - metadata_path: assets/service_checks.json - source_type_id: !!int 28 - source_type_name: Postgres - monitors: - Connection pool is reaching saturation point: assets/monitors/percent_usage_connections.json - Replication delay is high: assets/monitors/replication_delay.json - saved_views: - operations: assets/saved_views/operations.json - postgres_pattern: assets/saved_views/postgres_pattern.json - postgres_processes: assets/saved_views/postgres_processes.json - sessions_by_host: assets/saved_views/sessions_by_host.json - slow_operations: assets/saved_views/slow_operations.json -author: - homepage: https://www.datadoghq.com - name: Datadog - sales_email: info@datadoghq.com - support_email: help@datadoghq.com categories: - data stores - log collection - notifications - tracing custom_kind: integración -dependencies: -- https://github.com/DataDog/integrations-core/blob/master/postgres/README.md -display_on_public_website: true -draft: false -git_integration_title: postgres -integration_id: postgres -integration_title: Postgres -integration_version: 22.0.1 -is_public: true -manifest_version: 2.0.0 -name: postgres -public_title: Postgres -short_description: Recopila una importante cantidad de métricas del rendimiento y el estado de las bases de datos. +description: Recopila una importante cantidad de métricas del rendimiento y el estado + de las bases de datos. +further_reading: +- link: https://docs.datadoghq.com/integrations/faq/postgres-custom-metric-collection-explained/ + tag: documentación + text: Recopilación de métricas personalizadas de Postgres +- link: https://www.datadoghq.com/blog/100x-faster-postgres-performance-by-changing-1-line + tag: blog + text: Rendimiento de Postgres 100 veces más rápido cambiando 1 línea +- link: https://www.datadoghq.com/blog/postgresql-monitoring + tag: blog + text: Métricas clave para la monitorización de PostgreSQL +- link: https://www.datadoghq.com/blog/postgresql-monitoring-tools + tag: blog + text: Recopilación de métricas con herramientas de monitorización PostgreSQL +- link: https://www.datadoghq.com/blog/collect-postgresql-data-with-datadog + tag: blog + text: Recopilación y monitorización de datos PostgreSQL con Datadog +integration_version: 22.15.0 +media: [] supported_os: - linux - windows - macos -tile: - changelog: CHANGELOG.md - classifier_tags: - - Category::Almacenes de datos - - Category::Recopilación de logs - - Category::Notificaciones - - Category::Rastreo - - Supported OS::Linux - - Supported OS::Windows - - Supported OS::macOS - - Offering::Integración - configuration: README.md#Configuración - description: Recopila una importante cantidad de métricas del rendimiento y el estado de las bases de datos. - media: [] - overview: README.md#Información general - resources: - - resource_type: documentación - url: https://docs.datadoghq.com/integrations/faq/postgres-custom-metric-collection-explained/ - - resource_type: blog - url: https://www.datadoghq.com/blog/100x-faster-postgres-performance-by-changing-1-line - - resource_type: blog - url: https://www.datadoghq.com/blog/postgresql-monitoring - - resource_type: blog - url: https://www.datadoghq.com/blog/postgresql-monitoring-tools - - resource_type: blog - url: https://www.datadoghq.com/blog/collect-postgresql-data-with-datadog - support: README.md#Soporte - title: Postgres +title: Postgres --- - - - - -[Gráfico de PostgreSQL][1] + ## Información general La integración Postgres proporciona métricas del estado y el rendimiento de tu base de datos Postgres casi en tiempo real. Visualiza estos métricas con el dashboard proporcionado y crea monitores para alertar a tu equipo sobre los estados de PostgreSQL. -Habilita [Database Monitoring][2] (DBM) para obtener información mejorada sobre el rendimiento de las consultas y el estado de las bases de datos. Además de la integración estándar, Datadog DBM proporciona métricas a nivel de consulta, snapshots de consultas históricas y actuales, análisis de eventos de espera, carga de bases de datos, planes de explicación de consultas e información sobre bloqueos de consultas. +Activa [Database Monitoring](https://docs.datadoghq.com/database_monitoring/) (DBM) para obtener información mejorada sobre el rendimiento de las consultas y el estado de las bases de datos. Además de la integración estándar, Datadog DBM proporciona métricas a nivel de consulta, snapshots de consultas históricas y actuales, análisis de eventos de espera, carga de bases de datos, explain plans de consultas e información sobre bloqueos de consultas. Se admiten las versiones 9.6-16 de Postgres. @@ -111,13 +48,13 @@ Se admiten las versiones 9.6-16 de Postgres. ### Instalación -El check de PostgreSQL viene en el mismo paquete que el Agent. Para empezar a reunir tus métricas y logs de PostgreSQL, [instala el Agent][3]. +El check de PostgreSQL viene en el mismo paquete que el Agent. Para empezar a recopilar tus métricas y logs de PostgreSQL, [instala el Agent](https://app.datadoghq.com/account/settings/agent/latest). ### Configuración -**Nota**: Para instalar Database Monitoring para PostgreSQL, selecciona tu solución de alojamiento en la [documentación de Database Monitoring][4] para obtener instrucciones. +**Nota**: Para instalar Database Monitoring para PostgreSQL, selecciona tu solución de alojamiento en la [documentación de Database Monitoring](https://docs.datadoghq.com/database_monitoring/#postgres) para obtener instrucciones. -Procede con los siguientes pasos de esta guía, sólo si vas a instalar la integración estándar únicamente. +Procede con los siguientes pasos de esta guía solo si vas a instalar la integración estándar únicamente. #### Preparación de Postgres @@ -161,9 +98,10 @@ grant SELECT ON pg_stat_activity_dd to datadog; ``` {{< tabs >}} + {{% tab "Host" %}} -**Nota**: Al generar métricas personalizadas que requieren que se consulten tablas adicionales, puede que sea necesario conceder el permiso `SELECT` al usuario `datadog` para acceder a esas tablas. Ejemplo: `grant SELECT on
(gauge) | Activado con `collect_activity_metrics`. Número de consultas activas en esta base de datos. Esta métrica (por defecto) está etiquetada con db, app, user.| +| **postgresql.active_waiting_queries**
(gauge) | Activado con `collect_activity_metrics`. Número de consultas en espera en esta base de datos en estado activo. Esta métrica (por defecto) está etiquetada con db, app, user.| +| **postgresql.activity.backend_xid_age**
(gauge) | Antigüedad del xid del backend más antiguo en relación con el último xid estable. Esta métrica (por defecto) está etiquetada con db, app, user.
_Se muestra como transacción_ | +| **postgresql.activity.backend_xmin_age**
(gauge) | Antigüedad del horizonte xmin del backend más antiguo en relación con el último xid estable. Esta métrica (por defecto) está etiquetada con db, app, user.
_Se muestra como transacción_ | +| **postgresql.activity.wait_event**
(gauge) | Número de eventos de espera en el momento de la comprobación. Esta métrica está etiquetada por usuario. Esta métrica está etiquetada por user, db, app y backend_type.| +| **postgresql.activity.xact_start_age**
(gauge) | Antigüedad de las transacciones activas más antiguas. Esta métrica (por defecto) está etiquetada con db, app, user.
_Se muestra como segundos_. | +| **postgresql.analyze.child_tables_done**
(gauge) | Número de tablas secundarias analizadas. Este contador solo avanza cuando la fase está adquiriendo filas de ejemplo heredadas. Esta métrica está etiquetada con db, table, child_relation, phase.| +| **postgresql.analyze.child_tables_total**
(gauge) | Número de tablas secundarias. Esta métrica está etiquetada con db, table, child_relation, phase.| +| **postgresql.analyze.ext_stats_computed**
(gauge) | Número de estadísticas ampliadas calculadas. Este contador solo avanza cuando la fase está calculando estadísticas ampliadas. Esta métrica está etiquetada con db, table, child_relation, phase.| +| **postgresql.analyze.ext_stats_total**
(gauge) | Número de estadísticas ampliadas. Esta métrica está etiquetada con db, table, child_relation, phase.| +| **postgresql.analyze.sample_blks_scanned**
(gauge) | Número de bloques heap analizados. Esta métrica está etiquetada con db, table, child_relation, phase.
_Se muestra como bloque_. | +| **postgresql.analyze.sample_blks_total**
(gauge) | Número total de bloques heap que se muestrearán. Esta métrica está etiquetada con db, table, child_relation, phase.
_Se muestra como bloque_. | +| **postgresql.analyzed**
(count) | Activado con `relations`. Número de veces que se ha analizado manualmente esta tabla. Esta métrica está etiquetada con db, schema, table.| +| **postgresql.archiver.archived_count**
(count) | Número de archivos WAL que se han archivado correctamente.| +| **postgresql.archiver.failed_count**
(count) | Número de intentos fallidos para archivar archivos WAL.| +| **postgresql.autoanalyzed**
(count) | Activado con `relations`. Número de veces que esta tabla ha sido analizada por el daemon de autovaciado. Esta métrica está etiquetada con db, schema, table.| +| **postgresql.autovacuumed**
(count) | Activado con `relations`. Número de veces que esta tabla ha sido vaciada por el daemon de autovaciado. Esta métrica está etiquetada con db, schema, table.| +| **postgresql.before_xid_wraparound**
(gauge) | Número de transacciones que pueden ocurrir hasta que se agote el ID de una transacción. Esta métrica está etiquetada con db.
_Se muestra como transacción_ | +| **postgresql.bgwriter.buffers_alloc**
(count) | Número de buffers asignados| +| **postgresql.bgwriter.buffers_backend**
(count) | Número de buffers escritos directamente por un backend.
_Se muestra como buffer_ | +| **postgresql.bgwriter.buffers_backend_fsync**
(count) | Cantidad de veces que un backend ha tenido que ejecutar su propia llamada fsync en lugar del escritor en segundo plano.| +| **postgresql.bgwriter.buffers_checkpoint**
(count) | Número de buffers escritos durante los puntos de control.| +| **postgresql.bgwriter.buffers_clean**
(count) | Número de buffers escritos por el escritor en segundo plano.| +| **postgresql.bgwriter.checkpoints_requested**
(count) | Número de puntos de control solicitados que se han realizado.| +| **postgresql.bgwriter.checkpoints_timed**
(count) | Número de puntos de control programados que se han realizado.| +| **postgresql.bgwriter.maxwritten_clean**
(count) | Número de veces que el escritor en segundo plano ha detenido una exploración de limpieza debido a la escritura de demasiados buffers.| +| **postgresql.bgwriter.sync_time**
(count) | Cantidad total de tiempo de procesamiento del punto de control dedicado a sincronizar los archivos con el disco.
_Se muestra como milisegundos_ | +| **postgresql.bgwriter.write_time**
(count) | Cantidad total de tiempo de procesamiento del punto de control dedicado a escribir archivos en el disco.
_Se muestra como milisegundos_ | +| **postgresql.blk_read_time**
(count) | Tiempo dedicado a leer bloques de archivos de datos por los backends en esta base de datos si track_io_timing está activado. Esta métrica está etiquetada con db.
_Se muestra como milisegundos_. | +| **postgresql.blk_write_time**
(count) | Tiempo dedicado a escribir bloques de archivos de datos por los backends en esta base de datos si track_io_timing está activado. Esta métrica está etiquetada con db.
_Se muestra como milisegundos_. | +| **postgresql.buffer_hit**
(rate) | Número de veces que se han encontrado bloques del disco en la caché del buffer, evitando la necesidad de leer desde la base de datos. Esta métrica está etiquetada con db.
_Se muestra como solicitud_. | +| **postgresql.buffercache.dirty_buffers**
(gauge) | Número de buffers sucios compartidos. Es necesario instalar la extensión pg_buffercache. Esta métrica está etiquetada por db, esquema y relación.
_Se muestra como buffer_ | +| **postgresql.buffercache.pinning_backends**
(gauge) | Número de backends que utilizan buffers compartidos. Es necesario instalar la extensión pg_buffercache. Esta métrica está etiquetada por db, schema y relation.| +| **postgresql.buffercache.unused_buffers**
(gauge) | Número de buffers compartidos no utilizados. Es necesario instalar la extensión pg_buffercache.
_Se muestra como buffer_ | +| **postgresql.buffercache.usage_count**
(gauge) | Suma de usage_count de buffers compartidos. Es necesario instalar la extensión pg_buffercache. Esta métrica está etiquetada por por db, schema y relation.| +| **postgresql.buffercache.used_buffers**
(gauge) | Número de buffers compartidos. Es necesario instalar la extensión pg_buffercache. Esta métrica está etiquetada por db, schema y relation.
_Se muestra como buffer_ | +| **postgresql.checksums.checksum_failures**
(count) | Número de fallos de suma de comprobación en esta base de datos. Esta métrica está etiquetada con db.| +| **postgresql.checksums.enabled**
(count) | Si están activadas las sumas de comprobación de bases de datos. El valor es siempre 1 y está etiquetado con enabled:true o enabled:false. Esta métrica está etiquetada con db.| +| **postgresql.cluster_vacuum.heap_blks_scanned**
(gauge) | Número de bloques heap analizados. Este contador solo avanza cuando la fase es heap de análisis secuencial. Solo disponible con PostgreSQL v12 y posteriores. Esta métrica está etiquetada con db, table, command, phase, index.
_Se muestra como bloque_ | +| **postgresql.cluster_vacuum.heap_blks_total**
(gauge) | Número total de bloques heap en la tabla. Este número se informa desde el inicio del heap de análisis secuencial. Solo disponible con PostgreSQL v12 y posteriores. Esta métrica está etiquetada con db, table, command, phase, index.
_Se muestra como bloque_ | +| **postgresql.cluster_vacuum.heap_tuples_scanned**
(gauge) | Número de tuplas heap analizadas. Este contador solo avanza cuando la fase es heap de análisis secuencial, heap de análisis de índices o nuevo heap de escritura. Solo disponible con PostgreSQL v12 y posteriores. Esta métrica está etiquetada con db, table, command, phase, index.| +| **postgresql.cluster_vacuum.heap_tuples_written**
(gauge) | Número de tuplas heap escritas. Este contador solo avanza cuando la fase es heap de análisis secuencial, heap de análisis de índices o nuevo heap de escritura. Solo disponible con PostgreSQL v12 y posteriores. Esta métrica está etiquetada con db, table, command, phase, index.| +| **postgresql.cluster_vacuum.index_rebuild_count**
(gauge) | Número de índices reconstruidos. Este contador solo avanza cuando la fase es de reconstrucción de índices. Solo disponible con PostgreSQL v12 y posteriores. Esta métrica está etiquetada con db, table, command, phase, index.| +| **postgresql.commits**
(rate) | Número de transacciones que se han confirmado en esta base de datos. Esta métrica está etiquetada con db.
_Se muestra como transacción_ | +| **postgresql.conflicts.bufferpin**
(count) | Número de consultas en esta base de datos que han sido canceladas debido a buffers anclados. Los conflictos de pin de buffer ocurrirán cuando el proceso walreceiver intente aplicar una limpieza de buffer como el pruning de cadena HOT. Esto requiere un bloqueo completo del buffer y cualquier consulta que lo tenga anclado entrará en conflicto con la limpieza. Esta métrica está etiquetada con db.
_Se muestra como consulta_ | +| **postgresql.conflicts.deadlock**
(count) | Número de consultas en esta base de datos que han sido canceladas debido a bloqueos. Los conflictos de bloqueo ocurrirán cuando el proceso walreceiver intente aplicar un buffer como pruning de cadena HOT. Si el conflicto dura más de deadlock_timeout segundos, se activará una comprobación de bloqueo y las consultas en conflicto se cancelarán hasta que se desancle el buffer. Esta métrica está etiquetada con db.
_Se muestra como consulta_ | +| **postgresql.conflicts.lock**
(count) | Número de consultas en esta base de datos que se han cancelado debido a tiempos de espera de bloqueo. Esto ocurrirá cuando el proceso walreceiver intente aplicar un cambio que requiera un bloqueo ACCESS EXCLUSIVE mientras una consulta en la réplica está leyendo la tabla. La consulta en conflicto será eliminada después de esperar hasta max_standby_streaming_delay segundos. Esta métrica está etiquetada con db.
_Se muestra como consulta_ | +| **postgresql.conflicts.snapshot**
(count) | Número de consultas en esta base de datos que se han cancelado debido a snapshots demasiado antiguos. Se producirá un conflicto de snapshots cuando se reproduzca un VACUUM, eliminando las tuplas leídas actualmente en una espera. Esta métrica está etiquetada con db.
_Se muestra como consulta_ | +| **postgresql.conflicts.tablespace**
(count) | Número de consultas en esta base de datos que se han cancelado debido a espacios en tablas eliminados. Esto ocurrirá cuando se elimine un temp_tablespace temporal mientras se utiliza en una espera. Esta métrica está etiquetada con db.
_Se muestra como consulta_ | +| **postgresql.connections**
(gauge) | Número de conexiones activas a esta base de datos.
_Se muestra como conexión_ | +| **postgresql.connections_by_process**
(gauge) | Número de conexiones activas a esta base de datos, desglosado por atributos a nivel de proceso. Esta métrica está etiquetada con state, application, user y db. (Solo DBM)
_Se muestra como conexión_. | +| **postgresql.control.checkpoint_delay**
(gauge) | Tiempo transcurrido desde el último punto de control.
_Se muestra como segundos_ | +| **postgresql.control.checkpoint_delay_bytes**
(gauge) | Cantidad de bytes WAL escritos desde el último punto de control.
_Se muestra como bytes_ | +| **postgresql.control.redo_delay_bytes**
(gauge) | Cantidad de bytes WAL escritos desde el último punto de rehacer.
_Se muestra como bytes_ | +| **postgresql.control.timeline_id**
(gauge) | ID actual de la línea de tiempo.| +| **postgresql.create_index.blocks_done**
(gauge) | Número de bloques procesados en la fase actual. Solo disponible con PostgreSQL v12 y posteriores. Esta métrica está etiquetada con db, table, index, command, phase.| +| **postgresql.create_index.blocks_total**
(gauge) | Número total de bloques a procesar en la fase actual. Solo disponible con PostgreSQL v12 y posteriores. Esta métrica está etiquetada con db, table, index, command, phase.| +| **postgresql.create_index.lockers_done**
(gauge) | Número de casilleros esperados. Solo disponible con PostgreSQL v12 y posteriores. Esta métrica está etiquetada con db, table, index, command, phase.| +| **postgresql.create_index.lockers_total**
(gauge) | Número total de casilleros a esperar, cuando corresponda. Solo disponible con PostgreSQL v12 y posteriores. Esta métrica está etiquetada con db, table, index, command, phase.| +| **postgresql.create_index.partitions_done**
(gauge) | Cuando se crea un índice en una tabla particionada, esta columna se configura según el número de particiones en que se ha creado el índice. Este campo es 0 durante un REINDEX. Solo disponible con PostgreSQL v12 y posteriores. Esta métrica está etiquetada con db, table, index, command, phase.| +| **postgresql.create_index.partitions_total**
(gauge) | Cuando se crea un índice en una tabla particionada, esta columna se configura según el número de particiones en que se ha creado el índice. Este campo es 0 durante un REINDEX. Solo disponible con PostgreSQL v12 y posteriores. Esta métrica está etiquetada con db, table, index, command, phase.| +| **postgresql.create_index.tuples_done**
(gauge) | Número de tuplas procesadas en la fase actual. Solo disponible con PostgreSQL v12 y posteriores. Esta métrica está etiquetada con db, table, index, command, phase.| +| **postgresql.create_index.tuples_total**
(gauge) | Número total de tuplas a procesar en la fase actual. Solo disponible con PostgreSQL v12 y posteriores. Esta métrica está etiquetada con db, table, index, command, phase.| +| **postgresql.database_size**
(gauge) | Espacio en disco utilizado por esta base de datos. Esta métrica está etiquetada con db.
_Se muestra como bytes_ | +| **postgresql.db.count**
(gauge) | Número de bases de datos disponibles.
_Se muestra como elemento_ | +| **postgresql.dead_rows**
(gauge) | Activado con `relations`. Número estimado de filas inactivas. Esta métrica está etiquetada con db, schema, table.
_Se muestra como fila_ | +| **postgresql.deadlocks**
(rate) | Tasa de bloqueos detectados en esta base de datos. Esta métrica está etiquetada con db.
_Se muestra como bloqueo_ | +| **postgresql.deadlocks.count**
(count) | Número de bloqueos detectados en esta base de datos. Esta métrica está etiquetada con db.
_Se muestra como bloqueo_ | +| **postgresql.disk_read**
(rate) | Número de bloques de disco leídos en esta base de datos. Esta métrica está etiquetada con db.
_Se muestra como bloque_ | +| **postgresql.function.calls**
(rate) | Activado con `collect_function_metrics`. Número de llamadas realizadas a una función. Esta métrica está etiquetada con db, schema, function.| +| **postgresql.function.self_time**
(rate) | Activado con `collect_function_metrics`. Tiempo total dedicado a esta función, sin incluir otras funciones llamadas por ella. Esta métrica está etiquetada con db, schema, function.| +| **postgresql.function.total_time**
(rate) | Activado con `collect_function_metrics`. Tiempo total dedicado a esta función y en todas las demás funciones llamadas por ella. Esta métrica está etiquetada con db, schema, function.| +| **postgresql.heap_blocks_hit**
(gauge) | Activado con `relations`. Número de hits de buffer de esta tabla. Esta métrica está etiquetada con db, schema, table.
_Se muestra como hit_ | +| **postgresql.heap_blocks_read**
(gauge) | Activado con `relations`. Número de bloques de disco leídos de esta tabla. Esta métrica está etiquetada con db, schema, table.
_Se muestra como bloque_. | +| **postgresql.index.index_blocks_hit**
(gauge) | Activado con `relations`. Número de hits de buffer para un índice específico. Esta métrica está etiquetada con db, schema, table, index.
_Se muestra como hit_ | +| **postgresql.index.index_blocks_read**
(gauge) | Activado con `relations`. El número de bloques de disco para un índice específico. Esta métrica está etiquetada con db, schema, table, index.
_Se muestra como bloque_ | +| **postgresql.index_bloat**
(gauge) | Activado con `collect_bloat_metrics`. Porcentaje estimado de sobrecarga del índice. Esta métrica está etiquetada con db, schema, table, index.
_Se muestra como porcentaje_. | +| **postgresql.index_blocks_hit**
(gauge) | Activado con `relations`. Número de hits de buffer en todos los índices de esta tabla. Esta métrica está etiquetada con db, schema, table.
_Se muestra como hit_ | +| **postgresql.index_blocks_read**
(gauge) | Activado con `relations`. Número de bloques de disco leídos de todos los índices de esta tabla. Esta métrica está etiquetada con db, schema, table.
_Se muestra como bloque_ | +| **postgresql.index_rel_rows_fetched**
(gauge) | Activado con `relations`. Número de filas activas obtenidas por análisis de índices. Esta métrica está etiquetada con db, schema, table.
_Se muestra como fila_ | +| **postgresql.index_rel_scans**
(gauge) | Activado con `relations`. Número total de análisis de índices iniciados de esta tabla. Esta métrica está etiquetada con db, schema, table.
_Se muestra como análisis_ | +| **postgresql.index_rows_fetched**
(gauge) | Activado con `relations`. Número de filas activas obtenidas por análisis de índices. Esta métrica está etiquetada con db, schema, table, index.
_Se muestra como fila_ | +| **postgresql.index_rows_read**
(gauge) | Activado con `relations`. Número de entradas de índice devueltas por análisis de este índice. Esta métrica está etiquetada con db, schema, table, index.
_Se muestra como fila_ | +| **postgresql.index_scans**
(gauge) | Activado con `relations`. Número de análisis de índices iniciadas de esta tabla. Esta métrica está etiquetada con db, schema, table, index
_Se muestra como análisis_ | +| **postgresql.index_size**
(gauge) | Activado con `relations`. Espacio total en disco utilizado por los índices adjuntos a la tabla especificada. Esta métrica está etiquetada con db, schema, table.
_Se muestra como bytes_ | +| **postgresql.individual_index_size**
(gauge) | Espacio en disco utilizado por un índice especificado. Esta métrica está etiquetada con db, schema, table, index.
_Se muestra como bytes_ | +| **postgresql.io.evictions**
(count) | Número de veces que un bloque se ha escrito desde un buffer compartido o local para que esté disponible para otro uso. Esta métrica está etiquetada con backend_type, context, object. Solo disponible con PostgreSQL v16 y posteriores. (Solo DBM)
_Se muestra como milisegundos_ | +| **postgresql.io.extend_time**
(count) | Tiempo dedicado a operaciones extend (si track_io_timing está activado, de lo contrario cero). Esta métrica está etiquetada con backend_type, context, object. Solo disponible con PostgreSQL v16 y posteriores. (Solo DBM)
_Se muestra como milisegundos_ | +| **postgresql.io.extends**
(count) | Número de operaciones extend de relaciones. Esta métrica está etiquetada con backend_type, context, object. Solo disponible con PostgreSQL v16 y posteriores. (Solo DBM)| +| **postgresql.io.fsync_time**
(count) | Tiempo dedicado a operaciones fsync (si track_io_timing está activado, de lo contrario cero). Esta métrica está etiquetada con backend_type, context, object. Solo disponible con PostgreSQL v16 y posteriores. (Solo DBM)
_Se muestra como milisegundos_ | +| **postgresql.io.fsyncs**
(count) | Número de llamadas fsync. Esta métrica está etiquetada con backend_type, context, object. Solo disponible con PostgreSQL v16 y posteriores. (Solo DBM)| +| **postgresql.io.hits**
(count) | Número de veces que se ha encontrado un bloque deseado en un buffer compartido. Esta métrica está etiquetada con backend_type, context, object. Solo disponible con PostgreSQL v16 y posteriores. (Solo DBM)
_Se muestra como milisegundos_ | +| **postgresql.io.read_time**
(count) | Tiempo dedicado a operaciones de lectura (si track_io_timing está activado, de lo contrario cero). Esta métrica está etiquetada con backend_type, context, object. Solo disponible con PostgreSQL v16 y posteriores. (Solo DBM)
_Se muestra como milisegundos_ | +| **postgresql.io.reads**
(count) | Número de operaciones de lectura. Esta métrica está etiquetada con backend_type, context, object. Solo disponible con PostgreSQL v16 y posteriores. (Solo DBM)| +| **postgresql.io.write_time**
(count) | Tiempo dedicado a operaciones de escritura (si track_io_timing está activado, de lo contrario cero). Esta métrica está etiquetada con backend_type, context, object. Solo disponible con PostgreSQL v16 y posteriores. (Solo DBM)
_Se muestra como milisegundos_ | +| **postgresql.io.writes**
(count) | Número de operaciones de escritura. Esta métrica está etiquetada con backend_type, context, object. Solo disponible con PostgreSQL v16 y posteriores. (Solo DBM)| +| **postgresql.last_analyze_age**
(gauge) | Última vez que esta tabla fue analizada manualmente. Esta métrica está etiquetada con db, schema, table.
_Se muestra como segundos_ | +| **postgresql.last_autoanalyze_age**
(gauge) | Última vez que esta tabla fue analizada por el daemon de autovaciado. Esta métrica está etiquetada con db, schema, table.
_Se muestra como segundos_ | +| **postgresql.last_autovacuum_age**
(gauge) | Última vez que esta tabla ha sido vaciada por el daemon de autovaciado. Esta métrica está etiquetada con db, schema, table.
_Se muestra como segundos_ | +| **postgresql.last_vacuum_age**
(gauge) | Última vez que esta tabla ha sido vaciada manualmente (sin contar VACUUM FULL). Esta métrica está etiquetada con db, schema, table.
_Se muestra como segundos_ | +| **postgresql.live_rows**
(gauge) | Activado con `relations`. Número estimado de filas activas. Esta métrica está etiquetada con db, schema, table.
_Se muestra como fila_ | +| **postgresql.locks**
(gauge) | Activado con `relations`. Número de bloqueos activos para esta base de datos. Esta métrica está etiquetada con db, lock_mode, lock_type, schema, table, granted.
_Se muestra como bloqueo_ | +| **postgresql.max_connections**
(gauge) | Número máximo de conexiones de cliente permitidas a esta base de datos.
_Se muestra como conexión_ | +| **postgresql.percent_usage_connections**
(gauge) | Número de conexiones a esta base de datos como fracción del número máximo de conexiones permitidas.
_Se muestra como fracción_ | +| **postgresql.pg_stat_statements.dealloc**
(count) | Número de veces que pg_stat_statements tuvo que desalojar las consultas menos ejecutadas porque se alcanzó pg_stat_statements.max.| +| **postgresql.queries.blk_read_time**
(count) | Tiempo total dedicado a leer bloques por query_signature, base de datos y usuario. (Solo DBM)
_Se muestra como nanosegundos_ | +| **postgresql.queries.blk_write_time**
(count) | Tiempo total dedicado a escribir bloques por query_signature, base de datos y usuario. (Solo DBM)
_Se muestra como nanosegundos_ | +| **postgresql.queries.count**
(count) | Recuento total de ejecución de consultas por query_signature, base de datos y usuario. (Solo DBM)
_Se muestra como consulta_ | +| **postgresql.queries.duration.max**
(gauge) | Antigüedad de la consulta en ejecución más larga por usuario, base de datos y aplicación. (Solo DBM)
_Se muestra como nanosegundos_ | +| **postgresql.queries.duration.sum**
(gauge) | Suma de la antigüedad de todas las consultas en ejecución por usuario, base de datos y aplicación. (Solo DBM)
_Se muestra como nanosegundos_ | +| **postgresql.queries.local_blks_dirtied**
(count) | Número total de bloques locales ensuciados por query_signature, base de datos y usuario. (Solo DBM)
_Se muestra como bloque_ | +| **postgresql.queries.local_blks_hit**
(count) | Número total de hits en la caché de bloques locales por query_signature, base de datos y usuario. (Solo DBM)
_Se muestra como bloque_ | +| **postgresql.queries.local_blks_read**
(count) | Número total de bloques locales leídos por query_signature, base de datos y usuario. (Solo DBM)
_Se muestra como bloque_ | +| **postgresql.queries.local_blks_written**
(count) | Número total de bloques locales escritos por query_signature, base de datos y usuario. (Solo DBM)
_Se muestra como bloque_ | +| **postgresql.queries.rows**
(count) | Número total de filas recuperadas o afectadas por query_signature, base de datos y usuario. (Solo DBM)
_Se muestra como fila_ | +| **postgresql.queries.shared_blks_dirtied**
(count) | Número total de bloques compartidos ensuciados por query_signature, base de datos y usuario. (Solo DBM)
_Se muestra como bloque_ | +| **postgresql.queries.shared_blks_hit**
(count) | Número total de hits en la caché de bloques compartidos por query_signature, base de datos y usuario. (Solo DBM)
_Se muestra como bloque_ | +| **postgresql.queries.shared_blks_read**
(count) | Número total de bloques compartidos leídos por query_signature, base de datos y usuario. (Solo DBM)
_Se muestra como bloque_ | +| **postgresql.queries.shared_blks_written**
(count) | Número total de bloques compartidos escritos por query_signature, base de datos y usuario. (Solo DBM)
_Se muestra como bloque_ | +| **postgresql.queries.temp_blks_read**
(count) | Número total de bloques temporales leídos por query_signature, base de datos y usuario. (Solo DBM)
_Se muestra como bloque_ | +| **postgresql.queries.temp_blks_written**
(count) | Número total de bloques temporales escritos por query_signature, base de datos y usuario. (Solo DBM)
_Se muestra como bloque_ | +| **postgresql.queries.time**
(count) | Tiempo total de ejecución de la consulta por query_signature, base de datos y usuario. (Solo DBM)
_Se muestra como nanosegundos_ | +| **postgresql.recovery_prefetch.block_distance**
(gauge) | Cuántos bloques por delante está buscando el prefetcher.
_Se muestra como bloque_ | +| **postgresql.recovery_prefetch.hit**
(count) | Número de bloques no precargados porque ya estaban en el grupo de buffers.
_Se muestra como bloque_ | +| **postgresql.recovery_prefetch.io_depth**
(gauge) | Cuántas precargas se han iniciado pero aún no se sabe si han finalizado.| +| **postgresql.recovery_prefetch.prefetch**
(count) | Número de bloques precargados porque no estaban en el grupo de buffers.
_Se muestra como bloque_ | +| **postgresql.recovery_prefetch.skip_fpw**
(count) | Número de bloques no precargados porque se ha incluido una imagen de página completa en el WAL.
_Se muestra como bloque_ | +| **postgresql.recovery_prefetch.skip_init**
(count) | Número de bloques no precargados porque se inicializarían a cero.
_Se muestra como bloque_ | +| **postgresql.recovery_prefetch.skip_new**
(count) | Número de bloques no precargados porque aún no existían.
_Se muestra como bloque_ | +| **postgresql.recovery_prefetch.skip_rep**
(count) | Número de bloques no precargados porque ya se habían precargado recientemente.
_Se muestra como bloque_ | +| **postgresql.recovery_prefetch.wal_distance**
(gauge) | Cuántos bytes por delante está buscando el prefetcher.
_Se muestra como bytes_ | +| **postgresql.relation.all_visible**
(gauge) | Número de páginas que están marcadas como todas visibles en el mapa de visibilidad de la tabla. Se trata únicamente de una estimación utilizada por el planificador y se actualiza mediante VACUUM o ANALYZE. Esta métrica está etiquetada con db, schema, table, partition_of.| +| **postgresql.relation.pages**
(gauge) | Tamaño de una tabla en páginas (1 página = 8KB por defecto). Se trata únicamente de una estimación utilizada por el planificador y se actualiza mediante VACUUM o ANALYZE. Esta métrica está etiquetada con db, schema, table, partition_of.| +| **postgresql.relation.tuples**
(gauge) | Número de filas activas en la tabla. Se trata únicamente de una estimación utilizada por el planificador y se actualiza mediante VACUUM o ANALYZE. Si la tabla nunca ha sido vaciada o analizada, se informará -1. Esta métrica está etiquetada con db, schema, table, partition_of.| +| **postgresql.relation.xmin**
(gauge) | ID de transacción de la última modificación de la relación en pg_class. Esta métrica está etiquetada con db, schema, table.| +| **postgresql.relation_size**
(gauge) | Espacio en disco utilizado por la tabla especificada. No se incluyen datos TOAST, índices, mapa de espacio libre o mapa de visibilidad. Esta métrica está etiquetada con db, schema, table.
_Se muestra como bytes_ | +| **postgresql.replication.backend_xmin_age**
(gauge) | Antigüedad del horizonte xmin del servidor en espera (en relación con el último xid estable) informada por hot_standby_feedback.| +| **postgresql.replication.wal_flush_lag**
(gauge) | Tiempo transcurrido entre el vaciado local de WAL reciente y la recepción de la notificación de que este servidor en espera la ha escrito y vaciado (pero aún no la ha aplicado). Esto puede utilizarse para medir el retraso en el que incurre el nivel synchronous_commit al confirmar si este servidor está configurado como servidor en espera síncrono. Solo disponible con PostgreSQL v10 y posteriores.
_Se muestra como segundos_ | +| **postgresql.replication.wal_replay_lag**
(gauge) | Tiempo transcurrido entre el vaciado local de WAL reciente y la recepción de la notificación de que este servidor en espera la ha escrito, vaciado y aplicado. Esto puede utilizarse para medir el retraso en el que incurre el nivel synchronous_commit al confirmar si este servidor está configurado como servidor en espera síncrono. Solo disponible con PostgreSQL v10 y posteriores.
_Se muestra como segundos_ | +| **postgresql.replication.wal_write_lag**
(gauge) | Tiempo transcurrido entre el vaciado local de WAL reciente y la recepción de la notificación de que este servidor en espera la ha escrito (pero no la ha vaciado ni aplicado). Esto puede utilizarse para medir el retraso en el que incurre el nivel synchronous_commit al confirmar si este servidor está configurado como servidor en espera síncrono. Solo disponible con PostgreSQL v10 y posteriores.
_Se muestra como segundos_ | +| **postgresql.replication_delay**
(gauge) | Retraso de replicación actual en segundos. Solo disponible con PostgreSQL v9.1 y posteriores
_Se muestra como segundos_ | +| **postgresql.replication_delay_bytes**
(gauge) | Retraso de replicación actual en bytes. Solo disponible con PostgreSQL v9.2 y posteriores
_Se muestra como bytes_ | +| **postgresql.replication_slot.catalog_xmin_age**
(gauge) | Antigüedad de la transacción más antigua que afecta a los catálogos del sistema que este slot necesita que la base de datos conserve. VACUUM no puede eliminar tuplas de catálogo eliminadas por una transacción posterior. Esta métrica está etiquetada con slot_name, slot_type, slot_persistence, slot_state.
_Se muestra como transacción_ | +| **postgresql.replication_slot.confirmed_flush_delay_bytes**
(gauge) | Retraso en bytes entre la posición actual de WAL y la última posición confirmada por el consumidor de este slot. Solo está disponible para slots de replicación lógica. Esta métrica está etiquetada con slot_name, slot_type, slot_persistence, slot_state.
_Se muestra como bytes_ | +| **postgresql.replication_slot.restart_delay_bytes**
(gauge) | Cantidad de bytes WAL que el consumidor de este slot puede requerir y no se eliminará automáticamente durante los puntos de control a menos que exceda el parámetro max_slot_wal_keep_size. No se informa de nada si no hay reserva de WAL para este slot. Esta métrica está etiquetada con slot_name, slot_type, slot_persistence, slot_state.
_Se muestra como bytes_ | +| **postgresql.replication_slot.spill_bytes**
(count) | Cantidad de datos de transacción decodificados vertidos al disco mientras se realiza la decodificación de cambios de WAL para este slot. Este y otros contadores de vertido pueden ser utilizados para medir las E/S ocurridas durante la decodificación lógica y permitir el ajuste de logical_decoding_work_mem. Extraído de pg_stat_replication_slots. Solo disponible con PostgreSQL v14 y posteriores. Esta métrica está etiquetada con slot_name, slot_type, slot_state.
_Se muestra como bytes_ | +| **postgresql.replication_slot.spill_count**
(count) | Número de veces que las transacciones fueron vertidas al disco mientras se decodificaban los cambios de WAL para este slot. Este contador se incrementa cada vez que una transacción es vertida, y la misma transacción puede ser vertida múltiples veces. Extraído de pg_stat_replication_slots. Solo disponible con PostgreSQL v14 y posteriores. Esta métrica está etiquetada con slot_name, slot_type, slot_state.| +| **postgresql.replication_slot.spill_txns**
(count) | Número de transacciones vertidas al disco una vez que la memoria utilizada por la decodificación lógica para decodificar los cambios de WAL excede logical_decoding_work_mem. El contador se incrementa tanto para las transacciones de nivel superior como para las subtransacciones. Extraído de pg_stat_replication_slots. Solo disponible con PostgreSQL v14 y posteriores. Esta métrica está etiquetada con slot_name, slot_type, slot_state.
_Se muestra como transacción_ | +| **postgresql.replication_slot.stream_bytes**
(count) | Cantidad de datos de transacciones decodificados para transmitir transacciones en curso al complemento de salida de decodificación mientras se decodifican los cambios de WAL para este slot. Extraído de pg_stat_replication_slots. Solo disponible con PostgreSQL v14 y posteriores. Esta métrica está etiquetada con slot_name, slot_type, slot_state.
_Se muestra como bytes_ | +| **postgresql.replication_slot.stream_count**
(count) | Número de veces que las transacciones en curso fueron transmitidas al complemento de salida de decodificación mientras se decodificaban los cambios de WAL para este slot. Extraído de pg_stat_replication_slots. Solo disponible con PostgreSQL v14 y posteriores. Esta métrica está etiquetada con slot_name, slot_type, slot_state.| +| **postgresql.replication_slot.stream_txns**
(count) | Número de transacciones en curso transmitidas al complemento de salida de decodificación después de que la memoria utilizada por la decodificación lógica para decodificar cambios de WAL para este slot exceda logical_decoding_work_mem. Extraído de pg_stat_replication_slots. Solo disponible con PostgreSQL v14 y posteriores. Esta métrica está etiquetada con slot_name, slot_type, slot_state.
_Se muestra como transacción_ | +| **postgresql.replication_slot.total_bytes**
(count) | Cantidad de datos de transacciones decodificados para enviar transacciones al complemento de salida de decodificación mientras se decodifican cambios de WAL para este slot. Extraído de pg_stat_replication_slots. Solo disponible con PostgreSQL v14 y posteriores. Esta métrica está etiquetada con slot_name, slot_type, slot_state.
_Se muestra como bytes_ | +| **postgresql.replication_slot.total_txns**
(count) | Número de transacciones decodificadas enviadas al complemento de salida de decodificación para este slot. Extraído de pg_stat_replication_slots. Solo disponible con PostgreSQL v14 y posteriores. Esta métrica está etiquetada con slot_name, slot_type, slot_state.
_Se muestra como transacción_ | +| **postgresql.replication_slot.xmin_age**
(gauge) | Antigüedad de la transacción más antigua que este slot necesita que la base de datos retenga. Solo el slot de replicación física tendrá un xmin. El slot de replicación huérfano (no hay consumidor o el consumidor no está conectado) impedirá que avance el horizonte xmin. Esta métrica está etiquetada con slot_name, slot_type, slot_persistence, slot_state.
_Se muestra como transacción_ | +| **postgresql.rollbacks**
(rate) | Número de transacciones que se han revertido en esta base de datos. Esta métrica está etiquetada con db.
_Se muestra como transacción_ | +| **postgresql.rows_deleted**
(rate) | Activado con `relations`. Número de filas eliminadas por consultas en esta base de datos. Esta métrica está etiquetada con db.
_Se muestra como fila_ | +| **postgresql.rows_fetched**
(tasa) | Número de filas obtenidas por consultas en esta base de datos. Esta métrica está etiquetada con db.
_Se muestra como fila_ | +| **postgresql.rows_hot_updated**
(rate) | Activado con `relations`. Número de filas HOT actualizadas, lo que significa que no fue necesaria una actualización de índice separada. Esta métrica está etiquetada con db, schema, table.
_Se muestra como fila_ | +| **postgresql.rows_inserted**
(rate) | Activado con `relations`. Número de filas insertadas por consultas en esta base de datos. Esta métrica está etiquetada con db.
_Se muestra como fila_ | +| **postgresql.rows_returned**
(rate) | Número de filas devueltas por consultas en esta base de datos. Esta métrica está etiquetada con db.
_Se muestra como fila_ | +| **postgresql.rows_updated**
(rate) | Activado con `relations`. Número de filas actualizadas por consultas en esta base de datos. Esta métrica está etiquetada con db.
_Se muestra como fila_ | +| **postgresql.running**
(gauge) | Número de instancias en ejecución.| +| **postgresql.seq_rows_read**
(gauge) | Activado con `relations`. Número de filas activas obtenidas por análisis secuenciales. Esta métrica está etiquetada con db, schema, table.
_Se muestra como fila_ | +| **postgresql.seq_scans**
(gauge) | Activado con `relations`. Número de análisis secuenciales iniciados de esta tabla. Esta métrica está etiquetada con db, schema, table.
_Se muestra como análisis_ | +| **postgresql.sessions.abandoned**
(count) | Número de sesiones de base de datos en esta base de datos que fueron finalizados porque se perdió la conexión con el cliente. Esta métrica está etiquetada con db.
_Se muestra como sesión_ | +| **postgresql.sessions.active_time**
(count) | Tiempo dedicado a ejecutar sentencias SQL en esta base de datos, en milisegundos (corresponde a los estados active y fastpath de la llamada a la función en pg_stat_activity). Esta métrica está etiquetada con db.
_Se muestra como milisegundos_ | +| **postgresql.sessions.count**
(count) | Número total de sesiones establecidas en esta base de datos. Esta métrica está etiquetada con db.
_Se muestra como sesión_ | +| **postgresql.sessions.fatal**
(count) | Número de sesiones de esta base de datos que fueron finalizados por errores fatales. Esta métrica está etiquetada con db.
_Se muestra como sesión_ | +| **postgresql.sessions.idle_in_transaction_time**
(count) | Tiempo de inactividad durante una transacción en esta base de datos, en milisegundos (corresponde a los estados inactivo en transacción e inactivo en transacción (abortada) en pg_stat_activity). Esta métrica está etiquetada con db.
_Se muestra como milisegundos_ | +| **postgresql.sessions.killed**
(count) | Número de sesiones de esta base de datos que fueron finalizados por intervención del operador. Esta métrica está etiquetada con db.
_Se muestra como sesión_ | +| **postgresql.sessions.session_time**
(count) | Tiempo empleado por las sesiones de base de datos en esta base de datos, en milisegundos (ten en cuenta que las estadísticas solo se actualizan cuando cambia el estado de una sesión, por lo que si las sesiones han estado inactivas durante mucho tiempo, este tiempo de inactividad no será incluido). Esta métrica está etiquetada con db.
_Se muestra como milisegundos_ | +| **postgresql.slru.blks_exists**
(count) | Número de bloques en que se comprueba la existencia de la caché SLRU (simple menos utilizada recientemente). Solo las cachés CommitTs y MultiXactOffset comprueban si los bloques ya están presentes en el disco. Esta métrica está etiquetada con slru_name.
_Se muestra como bloque_ | +| **postgresql.slru.blks_hit**
(count) | Número de veces que se han encontrado bloques de disco ya en la caché SLRU (simple menos utilizada recientemente), por lo que no fue necesaria una lectura (esto solo incluye hits en la SLRU, no en la caché del sistema de archivos del sistema operativo). Esta métrica está etiquetada con slru_name.
_Se muestra como bloque_ | +| **postgresql.slru.blks_read**
(count) | Número de bloques de disco leídos para la caché SLRU (simple menos utilizada recientemente). Las cachés SLRU se crean con un número fijo de páginas. Cuando se utilizan todas las páginas, el bloque utilizado menos recientemente se desaloja del disco para crear espacio. El acceso al bloque desalojado requerirá que los datos se lean del disco y se vuelvan a cargar en una página de caché SLRU, aumentando el recuento de lectura de bloques. Esta métrica está etiquetada con slru_name.
_Se muestra como bloque_ | +| **postgresql.slru.blks_written**
(count) | Número de bloques de disco escritos para la caché SLRU (simple menos utilizada recientemente). Las cachés SLRU se crean con un número fijo de páginas. Cuando se utilizan todas las páginas, el bloque utilizado menos recientemente se desaloja del disco para crear espacio. Un desalojo de bloque no genera necesariamente una escritura en disco, ya que el bloque podría haberse escrito en un desalojo anterior. Esta métrica está etiquetada con slru_name.
_Se muestra como bloque_ | +| **postgresql.slru.blks_zeroed**
(count) | Número de bloques puestos a cero durante las inicializaciones de la caché SLRU (simple menos utilizada recientemente). Las cachés SLRU se crean con un número fijo de páginas. Para las cachés Subtrans, Xact y CommitTs, se utiliza el transactionId global para obtener el número de página. Por lo tanto, aumentará con el rendimiento de la transacción. Esta métrica está etiquetada con slru_name.
_Se muestra como bloque_ | +| **postgresql.slru.flushes**
(count) | Número de vaciados de datos sucios de la caché SLRU (simple menos utilizada recientemente). El vaciado de las cachés CommitTs, MultiXact, Subtrans y Xact tendrá lugar durante el punto de control. El vaciado de la caché MultiXact puede ocurrir durante el vaciado. Esta métrica está etiquetada con slru_name.| +| **postgresql.slru.truncates**
(count) | Número de truncamientos de la caché SLRU (simple menos utilizada recientemente). Para las cachés CommitTs, Xact y MultiXact, los truncamientos se producirán cuando progrese el frozenID. Para la caché Subtrans, un truncamiento puede ocurrir durante un punto de reinicio y un punto de control. Esta métrica está etiquetada con slru_name.| +| **postgresql.snapshot.xip_count**
(gauge) | Informa del número de transacciones activas basadas en pg_snapshot_xip(pg_current_snapshot()).| +| **postgresql.snapshot.xmax**
(gauge) | Informa del siguiente ID de transacción que será asignado basado en pg_snapshot_xmax(pg_current_snapshot()).| +| **postgresql.snapshot.xmin**
(gauge) | Informa del ID de transacción más bajo aún activo basado en pg_snapshot_xmin(pg_current_snapshot()). Todos los ID de transacciones menores que xmin son confirmados y visibles, o revertidos y eliminados.| +| **postgresql.subscription.apply_error**
(count) | Número de errores que se han producido al aplicar los cambios. Extraído de pg_stat_subscription_stats. Solo disponible en PostgreSQL v15 o posteriores. Esta métrica está etiquetada con subscription_name.| +| **postgresql.subscription.last_msg_receipt_age**
(gauge) | Antigüedad de recepción del último mensaje recibido del remitente WAL de origen. Extraído de pg_stat_subscription. Solo disponible en PostgreSQL v12 o posteriores. Esta métrica está etiquetada con subscription_name.
_Se muestra como segundos_ | +| **postgresql.subscription.last_msg_send_age**
(gauge) | Antigüedad de recepción del último mensaje recibido del remitente WAL de origen. Extraído de pg_stat_subscription. Solo disponible en PostgreSQL v12 o posteriores. Esta métrica está etiquetada con subscription_name.
_Se muestra como segundos_ | +| **postgresql.subscription.latest_end_age**
(gauge) | Antigüedad de la última ubicación de escritura de log anticipada informada al remitente WAL de origen. Extraído de pg_stat_subscription. Solo disponible en PostgreSQL v12 o posteriores. Esta métrica está etiquetada con subscription_name.
_Se muestra como segundos_ | +| **postgresql.subscription.state**
(gauge) | Estado de una suscripción por relación y suscripción. Extraído de pg_subscription_rel. Solo disponible en PostgreSQL v14 o posteriores. Esta métrica está etiquetada con subscription_name, relation, state.| +| **postgresql.subscription.sync_error**
(count) | Número de errores producidos durante la sincronización inicial de la tabla. Extraído de pg_stat_subscription_stats. Solo disponible en PostgreSQL v15 o posteriores. Esta métrica está etiquetada con subscription_name.| +| **postgresql.table.count**
(gauge) | Número de tablas de usuario en esta base de datos. Esta métrica está etiquetada con db, schema.
_Se muestra como tabla_ | +| **postgresql.table_bloat**
(gauge) | Activado con `collect_bloat_metrics`. Porcentaje estimado de sobrecarga de las tablas. Esta métrica está etiquetada con db, schema, table.
_Se muestra como porcentaje_ | +| **postgresql.table_size**
(gauge) | Activado con `relations`. Espacio en disco utilizado por la tabla especificada con datos TOAST. No se incluyen el mapa de espacio libre ni el mapa de visibilidad. Esta métrica está etiquetada con db, schema, table.
_Se muestra como bytes_ | +| **postgresql.temp_bytes**
(rate) | Cantidad de datos escritos en archivos temporales por las consultas en esta base de datos. Esta métrica está etiquetada con db.
_Se muestra como bytes_ | +| **postgresql.temp_files**
(rate) | Número de archivos temporales creados por consultas en esta base de datos. Esta métrica está etiquetada con db.
_Se muestra como archivo_ | +| **postgresql.toast.autovacuumed**
(count) | Activado con `relations`. Número de veces que la tabla TOAST de una relación ha sido autovaciada. Esta métrica está etiquetada con db, schema, table.| +| **postgresql.toast.dead_rows**
(gauge) | Activado con `relations`. Número de filas inactivas en la tabla TOAST de una relación. Esta métrica está etiquetada con db, schema, table.| +| **postgresql.toast.index_scans**
(count) | Activado con `relations`. Número de análisis de índices realizados en la tabla TOAST de una relación. Esta métrica está etiquetada con db, schema, table.| +| **postgresql.toast.last_autovacuum_age**
(gauge) | Última vez que el daemon de autovaciado ha vaciado la tabla TOAST de esta tabla. Esta métrica está etiquetada con db, schema, table.
_Se muestra como segundos_ | +| **postgresql.toast.last_vacuum_age**
(gauge) | Última vez que se ha vaciado manualmente la tabla TOAST de esta tabla (sin contar VACUUM FULL). Esta métrica está etiquetada con db, schema, table.
_Se muestra como segundos_ | +| **postgresql.toast.live_rows**
(gauge) | Activado con `relations`. Número de filas activas en la tabla TOAST de una relación. Esta métrica está etiquetada con db, schema, table.| +| **postgresql.toast.rows_deleted**
(count) | Activado con `relations`. Número de filas eliminadas en la tabla TOAST de una relación. Esta métrica está etiquetada con db, schema, table.| +| **postgresql.toast.rows_fetched**
(count) | Activado con `relations`. Número de filas obtenidas en la tabla TOAST de una relación. Esta métrica está etiquetada con db, schema, table.| +| **postgresql.toast.rows_inserted**
(count) | Activado con `relations`. Número de filas insertadas en la tabla TOAST de una relación. Esta métrica está etiquetada con db, schema, table.| +| **postgresql.toast.vacuumed**
(count) | Activado con `relations`. Número de veces que se ha vaciado la tabla TOAST de una relación. Esta métrica está etiquetada con db, schema, table.| +| **postgresql.toast_blocks_hit**
(gauge) | Activado con `relations`. Número de accesos al buffer en la tabla TOAST de esta tabla. Esta métrica está etiquetada con db, schema, table.
_Se muestra como hit_ | +| **postgresql.toast_blocks_read**
(gauge) | Activado con `relations`. Número de bloques de disco leídos de la tabla TOAST de esta tabla. Esta métrica está etiquetada con db, schema, table.
_Se muestra como bloque_ | +| **postgresql.toast_index_blocks_hit**
(gauge) | Activado con `relations`. Número de accesos al buffer en el índice de la tabla TOAST de esta tabla. Esta métrica está etiquetada con db, schema, table.
_Se muestra como bloque_ | +| **postgresql.toast_index_blocks_read**
(gauge) | Activado con `relations`. Número de bloques de disco leídos desde el índice de la tabla TOAST de esta tabla. Esta métrica está etiquetada con db, schema, table.
_Se muestra como bloque_ | +| **postgresql.toast_size**
(gauge) | Espacio total en disco utilizado por la tabla TOAST adjunta a la tabla especificada. Esta métrica está etiquetada con db, schema, table.
_Se muestra como bytes_ | +| **postgresql.total_size**
(gauge) | Activado con `relations`. Espacio total en disco utilizado por la tabla, incluidos los índices y los datos TOAST. Esta métrica está etiquetada con db, schema, table.
_Se muestra como bytes_ | +| **postgresql.transactions.duration.max**
(gauge) | Antigüedad de la transacción en ejecución más larga por usuario, base de datos y aplicación. (Solo DBM)
_Se muestra como nanosegundos_ | +| **postgresql.transactions.duration.sum**
(gauge) | Suma de la antigüedad de todas las transacciones en ejecución por usuario, base de datos y aplicación. (Solo DBM)
_Se muestra como nanosegundos_ | +| **postgresql.transactions.idle_in_transaction**
(gauge) | Activado con `collect_activity_metrics`. Número de transacciones 'inactivas en transacción' en esta base de datos. Esta métrica (por defecto) está etiquetada con db, app, user.
_Se muestra como transacción_ | +| **postgresql.transactions.open**
(gauge) | Activado con `collect_activity_metrics`. Número de transacciones abiertas en esta base de datos. Esta métrica (por defecto) está etiquetada con db, app, user.
_Se muestra como transacción_ | +| **postgresql.uptime**
(gauge) | Tiempo de actividad del servidor en segundos.
_Se muestra como segundos_ | +| **postgresql.vacuum.heap_blks_scanned**
(gauge) | Número de bloques heap analizados. Debido a que el mapa de visibilidad se utiliza para optimizar los análisis, algunos bloques serán omitidos sin inspección. Los bloques omitidos se incluyen en este total, de modo que este número eventualmente se volverá igual a heap_blks_total cuando el vaciado finalice. Este contador solo avanza cuando la fase está analizando heap. Esta métrica está etiquetada con db, table, phase.
_Se muestra como bloque_ | +| **postgresql.vacuum.heap_blks_total**
(gauge) | Número total de bloques heap en la tabla. Este número se informa al inicio del análisis. Los bloques añadidos posteriormente no serán (y no necesitan ser) visitados por este VACUUM. Esta métrica está etiquetada con db, table, phase.
_Se muestra como bloque_ | +| **postgresql.vacuum.heap_blks_vacuumed**
(gauge) | Número de bloques heap vaciados. A menos que la tabla no tenga índices, este contador solo avanza cuando la fase está aspirando heap. Los bloques que no contienen tuplas inactivas se omiten, por lo que el contador a veces puede saltar hacia adelante en grandes incrementos. Esta métrica está etiquetada con db, table, phase.
_Se muestra como bloques_ | +| **postgresql.vacuum.index_vacuum_count**
(gauge) | Número de ciclos de vacío de índices completados. Esta métrica está etiquetada con db, table, phase.
_Se muestra como bloque_ | +| **postgresql.vacuum.max_dead_tuples**
(gauge) | Número de tuplas inactivas que podemos almacenar antes de necesitar realizar un ciclo de vaciado de índices, basado en maintenance_work_mem. Esta métrica está etiquetada con db, table, phase.| +| **postgresql.vacuum.num_dead_tuples**
(gauge) | Número de tuplas inactivas recopiladas desde el último ciclo de vaciado de índices. Esta métrica está etiquetada con db, table, phase.| +| **postgresql.vacuumed**
(count) | Activado con `relations`. Número de veces que esta tabla ha sido vaciada manualmente. Esta métrica está etiquetada con db, schema, table.| +| **postgresql.waiting_queries**
(gauge) | Activado con `collect_activity_metrics`. Número de consultas en espera en esta base de datos. Esta métrica (por defecto) está etiquetada con db, app, user.| +| **postgresql.wal.buffers_full**
(count) | Número de veces que los datos de WAL fueron escritos en el disco porque los buffers de WAL se llenaron. Los cambios de WAL se almacenan primero en los buffers de WAL. Si el buffer está lleno, las inserciones de WAL se bloquean hasta que se vacía el buffer. El tamaño de este buffer se define mediante la configuración de wal_buffers. Por defecto, utilizará el 3% del valor de shared_buffers.| +| **postgresql.wal.bytes**
(count) | Cantidad total de WAL generada en bytes.
_Se muestra como bytes_ | +| **postgresql.wal.full_page_images**
(count) | Número total de imágenes de páginas completas de WAL generadas. La escritura de páginas completas se producirá cuando un bloque se modifique por primera vez después de un punto de control.
_Se muestra como página_ | +| **postgresql.wal.records**
(count) | Número total de registros WAL generados.
_Se muestra como registro_ | +| **postgresql.wal.sync**
(count) | Número de veces que los archivos WAL fueron sincronizados con el disco.| +| **postgresql.wal.sync_time**
(count) | Cantidad total de tiempo dedicado a sincronizar los archivos WAL con el disco, en milisegundos (si track_wal_io_timing está activado, fsync está activado y wal_sync_method es fdatasync, fsync o fsync_writethrough, de lo contrario cero).
_Se muestra como milisegundos_ | +| **postgresql.wal.write**
(count) | Número de veces que los buffers de WAL se han escrito en disco.
_Se muestra como escritura_ | +| **postgresql.wal.write_time**
(count) | Cantidad total de tiempo dedicado a escribir buffers de WAL en el disco, en milisegundos (si track_wal_io_timing está activado, de lo contrario cero).
_Se muestra como milisegundos_ | +| **postgresql.wal_age**
(gauge) | Activado con `collect_wal_metrics`. Antigüedad en segundos del archivo WAL más antiguo.
_Se muestra como segundos_ | +| **postgresql.wal_count**
(gauge) | Número de archivos WAL en disco.| +| **postgresql.wal_receiver.connected**
(gauge) | Estado del receptor WAL. Esta métrica se configurará en 1 con una etiqueta (tag) 'status:disconnected' si la instancia no tiene un receptor WAL en ejecución. En caso contrario, utilizará el valor de estado de pg_stat_wal_receiver. Esta métrica está etiquetada con status.| +| **postgresql.wal_receiver.last_msg_receipt_age**
(gauge) | Tiempo transcurrido desde la recepción del último mensaje del remitente WAL. Esta métrica está etiquetada con el status.
_Se muestra como segundos_ | +| **postgresql.wal_receiver.last_msg_send_age**
(gauge) | Antigüedad del envío del último mensaje recibido del remitente WAL. Esta métrica está etiquetada con status.
_Se muestra como segundos_ | +| **postgresql.wal_receiver.latest_end_age**
(gauge) | Tiempo transcurrido desde la recepción del último mensaje del remitente WAL con una actualización de la ubicación de WAL. Esta métrica está etiquetada con status.
_Se muestra como segundos_ | +| **postgresql.wal_receiver.received_timeline**
(gauge) | Número de línea de tiempo de la última ubicación de escritura anticipada de logs recibida y vaciada al disco. El valor inicial de este campo es el número de línea de tiempo de la ubicación del primer log utilizada cuando se inicia el receptor WAL. Esta métrica está etiquetada con status.| +| **postgresql.wal_size**
(gauge) | Suma de todos los archivos WAL en disco.
_Se muestra como bytes_ | + +Para la versión `7.32.0` y posteriores del Agent, si tienes Database Database Monitoring activado, la métrica `postgresql.connections` se etiqueta (tag) con `state`, `app`, `db` y `user`. ### Eventos El check de PostgreSQL no incluye eventos. ### Checks de servicio -{{< get-service-checks-from-git "postgres" >}} +**postgres.can_connect** + +Devuelve `CRITICAL` si el Agent no puede conectarse a la instancia PostgreSQL monitorizada. Devuelve `OK` en caso contrario. + +_Estados: ok, crítico_ ## Solucionar problemas -¿Necesitas ayuda? Ponte en contacto con el [servicio de asistencia de Datadog][7]. +¿Necesita ayuda? Póngase en contacto con [Datadog support](https://docs.datadoghq.com/help). ## Referencias adicionales -Más enlaces, artículos y documentación útiles: +Documentación útil adicional, enlaces y artículos: ### FAQ -- [Explicación de la recopilación de métricas personalizadas de PostgreSQL][8] +- [Explicación de la recopilación de métricas personalizadas de PostgreSQL](https://docs.datadoghq.com/integrations/faq/postgres-custom-metric-collection-explained/) ### Entradas de blog -- [Postgres 100 veces más rápido cambiando 1 línea][9] -- [Monitorización de métricas clave para PostgreSQL][10] -- [Recopilación de métricas con herramientas de monitorización PostgreSQL][11] -- [Para recopilar y monitorizar datos de PostgreSQL con Datadog][12] - - -[1]: https://raw.githubusercontent.com/DataDog/integrations-core/master/postgres/images/postgresql_dashboard.png -[2]: https://docs.datadoghq.com/database_monitoring/ -[3]: https://app.datadoghq.com/account/settings/agent/latest -[4]: https://docs.datadoghq.com/database_monitoring/#postgres -[5]: https://docs.datadoghq.com/agent/guide/agent-commands/#agent-status-and-information -[6]: https://github.com/DataDog/integrations-core/blob/master/postgres/datadog_checks/postgres/data/conf.yaml.example -[7]: https://docs.datadoghq.com/help -[8]: https://docs.datadoghq.com/integrations/faq/postgres-custom-metric-collection-explained/ -[9]: https://www.datadoghq.com/blog/100x-faster-postgres-performance-by-changing-1-line -[10]: https://www.datadoghq.com/blog/postgresql-monitoring -[11]: https://www.datadoghq.com/blog/postgresql-monitoring-tools -[12]: https://www.datadoghq.com/blog/collect-postgresql-data-with-datadog +- [Rendimiento de Postgres 100 veces más rápido cambiando 1 línea](https://www.datadoghq.com/blog/100x-faster-postgres-performance-by-changing-1-line) +- [Métricas clave para la monitorización de PostgreSQL](https://www.datadoghq.com/blog/postgresql-monitoring) +- [Recopilación de métricas con herramientas de monitorización de PostgreSQL](https://www.datadoghq.com/blog/postgresql-monitoring-tools) +- [Recopilación y monitorización de datos PostgreSQL con Datadog](https://www.datadoghq.com/blog/collect-postgresql-data-with-datadog) \ No newline at end of file diff --git a/content/es/integrations/process.md b/content/es/integrations/process.md index f762697d2b8f4..152b13c0352ca 100644 --- a/content/es/integrations/process.md +++ b/content/es/integrations/process.md @@ -1,83 +1,39 @@ --- app_id: sistema -app_uuid: 43bff15c-c943-4153-a0dc-25bb557ac763 -assets: - integration: - configuration: - spec: assets/configuration/spec.yaml - events: - creates_events: false - metrics: - check: system.processes.cpu.pct - metadata_path: metadata.csv - prefix: sistema - service_checks: - metadata_path: assets/service_checks.json - source_type_name: Proceso -author: - homepage: https://www.datadoghq.com - name: Datadog - sales_email: info@datadoghq.com - support_email: help@datadoghq.com categories: - os & system -custom_kind: integration -dependencies: -- https://github.com/DataDog/integrations-core/blob/master/process/README.md -display_on_public_website: true -draft: false -git_integration_title: proceso -integration_id: sistema -integration_title: Procesos -integration_version: 5.0.0 -is_public: true -manifest_version: 2.0.0 -name: proceso -public_title: Procesos -short_description: Captura métricas y monitoriza el estado de procesos en ejecución. +custom_kind: integración +description: Captura métricas y monitoriza el estado de los procesos en ejecución. +further_reading: +- link: https://www.datadoghq.com/blog/process-check-monitoring + tag: blog + text: Monitorizar el consumo de recursos por parte de los procesos de un vistazo +integration_version: 5.1.0 +media: [] supported_os: - linux - macos - windows -tile: - changelog: CHANGELOG.md - classifier_tags: - - Supported OS::Linux - - Supported OS::macOS - - Supported OS::Windows - - Category::Sistema operativo y sistema - - Offering::Integración - configuration: README.md#Configuración - description: Captura métricas y monitoriza el estado de procesos en ejecución. - media: [] - overview: README.md#Información general - resources: - - resource_type: blog - url: https://www.datadoghq.com/blog/process-check-monitoring - support: README.md#Soporte - title: Procesos +title: Procesos --- - - - - ## Información general -El check de proceso te permite: +El check de procesos te permite: + - Recopila métricas del uso de recursos para procesos en ejecución específicos en cualquier host. Por ejemplo, CPU, memoria, E/S y número de subprocesos. -- Utiliza [monitores de procesos][1] para configurar umbrales de cuántas instancias de un proceso específico deben ejecutarse y recibe alertas cuando no se cumplen los umbrales (consulta **Checks de servicio* a continuación). +- Utiliza [monitores de procesos](https://docs.datadoghq.com/monitors/create/types/process_check/?tab=checkalert) para configurar umbrales sobre cuántas instancias de un proceso específico deben ejecutarse y recibir alertas cuando los umbrales no se cumplen (consulta **Checks de servicio** más abajo). ## Configuración ### Instalación -El check de procesos está incluido en el paquete del [Datadog Agent][2], por lo que no necesitas instalar nada más en tu servidor. +El check de procesos está incluido en el paquete del [Datadog Agent](https://app.datadoghq.com/account/settings/agent/latest), por lo que no necesitas instalar nada más en tu servidor. ### Configuración A diferencia de muchos checks, el check de procesos no monitoriza nada útil por defecto. Debes configurar los procesos que quieres monitorizar. -Aunque no hay una configuración de check por defecto, aquí hay un ejemplo de `process.d/conf.yaml` que monitoriza procesos SSH/SSHD. Para ver todas las opciones de configuración disponibles, consulta el [process.d/conf.yaml de ejemplo][3]: +Si bien no existe una configuración de check estándar por defecto, aquí hay un ejemplo de `process.d/conf.yaml` que monitoriza los procesos SSH/SSHD. Consulta el [ejemplo process.d/conf.yaml](https://github.com/DataDog/integrations-core/blob/master/process/datadog_checks/process/data/conf.yaml.example) para conocer todas las opciones de configuración disponibles: ```yaml init_config: @@ -88,9 +44,9 @@ instances: - sshd ``` -**Nota**: Asegúrate de [reiniciar el Agent][4] después de realizar cambios de configuración. +**Nota**: Después de realizar cambios en la configuración, asegúrate de [reiniciar el Agent](https://docs.datadoghq.com/agent/guide/agent-commands/#start-stop-and-restart-the-agent). -La recuperación de algunas métricas de procesos requiere que el recopilador de Datadog se ejecute como el usuario del proceso monitorizado o con acceso privilegiado. Para la métrica`open_file_descriptors` en plataformas Unix, existe una opción de configuración adicional. Configurar `try_sudo` como `true` en el archivo `conf.yaml` permite que el El check de procesos intente utilizar `sudo` para recopilar la métrica `open_file_descriptors`. El uso de esta opción de configuración requiere definir reglas para sudoers apropiadas en `/etc/sudoers`: +La recuperación de algunas métricas de procesos requiere que el recopilador de Datadog se ejecute como el usuario del proceso monitorizado o con acceso privilegiado. Para la métrica`open_file_descriptors` en plataformas Unix, existe una opción de configuración adicional. Configurar `try_sudo` como `true` en el archivo `conf.yaml` permite que el check de procesos intente utilizar `sudo` para recopilar la métrica `open_file_descriptors`. El uso de esta opción de configuración requiere definir reglas para sudoers apropiadas en `/etc/sudoers`: ```shell dd-agent ALL=NOPASSWD: /bin/ls /proc/*/fd/ @@ -98,14 +54,16 @@ dd-agent ALL=NOPASSWD: /bin/ls /proc/*/fd/ ### Validación -Ejecuta el [subcomando de estado del Agent][5] y busca `process` en la sección Checks. +Ejecuta el [subcomando de estado del Agent](https://docs.datadoghq.com/agent/guide/agent-commands/#agent-status-and-information) y busca `process` en la sección Checks. ### Notas de métricas Las siguientes métricas no están disponibles en Linux o macOS: -- Las métricas de I/O de procesos **no** están disponibles en Linux o macOS, ya que los archivos que lee el Agent (`/proc//io`) sólo pueden ser leídos por el propietario del proceso. Para obtener más información, [lee las FAQ del Agent][6]. + +- Las métricas de E/S del proceso **no** están disponibles en Linux o macOS, ya que los archivos que lee el Agent (`/proc/
(gauge) | Uso de CPU de un proceso.
_Se muestra como porcentaje_ | +| **system.processes.cpu.normalized_pct**
(gauge) | Uso normalizado de CPU de un proceso.
_Se muestra como porcentaje_ | +| **system.processes.involuntary_ctx_switches**
(gauge) | Número de cambios de contexto involuntarios realizados por este proceso.
_Se muestra como evento_ | +| **system.processes.ioread_bytes**
(gauge) | Número de bytes leídos del disco por este proceso. En Windows: el número de bytes leídos.
_Se muestra como bytes_ | +| **system.processes.ioread_bytes_count**
(count) | Número de bytes leídos del disco por este proceso. En Windows: el número de bytes leídos.
_Se muestra como bytes_ | +| **system.processes.ioread_count**
(gauge) | Número de lecturas del disco realizadas por este proceso. En Windows: el número de lecturas realizadas por este proceso.
_Se muestra como lectura_ | +| **system.processes.iowrite_bytes**
(gauge) | Número de bytes escritos en el disco por este proceso. En Windows: el número de bytes escritos por este proceso.
_Se muestra como bytes_ | +| **system.processes.iowrite_bytes_count**
(count) | Número de bytes escritos en el disco por este proceso. En Windows: el número de bytes escritos por este proceso.
_Se muestra como bytes_ | +| **system.processes.iowrite_count**
(gauge) | Número de escrituras en el disco realizadas por este proceso. En Windows: el número de escrituras de este proceso.
_Se muestra como escritura_ | +| **system.processes.mem.page_faults.minor_faults**
(gauge) | En Unix/Linux y macOS: el número de fallos menores de página por segundo para este proceso.
_Se muestra como caso_ | +| **system.processes.mem.page_faults.children_minor_faults**
(gauge) | En Unix/Linux y macOS: el número de fallos menores de página por segundo por cada elemento secundario para este proceso.
_Se muestra como caso_ | +| **system.processes.mem.page_faults.major_faults**
(gauge) | En Unix/Linux y macOS: el número de fallos mayores de página por segundo para este proceso.
_Se muestra como caso_ | +| **system.processes.mem.page_faults.children_major_faults**
(gauge) | En Unix/Linux y macOS: el número de fallos mayores de página por segundo por cada elemento secundario para este proceso.
_Se muestra como caso_ | +| **system.processes.mem.pct**
(gauge) | Consumo de memoria del proceso.
_Se muestra como porcentaje_ | +| **system.processes.mem.real**
(gauge) | Memoria física no intercambiada que un proceso ha utilizado y no puede ser compartida con otro proceso (solo Linux).
_Se muestra como bytes_ | +| **system.processes.mem.rss**
(gauge) | Memoria física no intercambiada que un proceso ha utilizado. también conocido como "Tamaño del conjunto residente".
_Se muestra como bytes_ | +| **system.processes.mem.vms**
(gauge) | Cantidad total de memoria virtual utilizada por el proceso. también conocido como "Tamaño de memoria virtual".
_Se muestra como bytes_ | +| **system.processes.number**
(gauge) | Número de procesos.
_Se muestra como proceso_ | +| **system.processes.open_file_descriptors**
(gauge) | Número de descriptores de archivos utilizados por este proceso (solo disponible para procesos ejecutados como usuario dd-agent)| +| **system.processes.open_handles**
(gauge) | Número de manejadores utilizados por este proceso.| +| **system.processes.threads**
(gauge) | Número de subprocesos utilizados por este proceso.
_Se muestra como subproceso_ | +| **system.processes.voluntary_ctx_switches**
(gauge) | Número de cambios de contexto voluntarios realizados por este proceso.
_Se muestra como evento_ | +| **system.processes.run_time.avg**
(gauge) | Tiempo medio de ejecución de todas las instancias de este proceso
_Se muestra como segundos_ | +| **system.processes.run_time.max**
(gauge) | Tiempo más largo de ejecución de todas las instancias de este proceso
_Se muestra como segundos_ | +| **system.processes.run_time.min**
(gauge) | Tiempo más corto de ejecución de todas las instancias de este proceso
_Se muestra como segundos_ | ### Eventos El check de procesos no incluye eventos. ### Checks de servicio -{{< get-service-checks-from-git "process" >}} +**process.up** + +Devuelve OK si el check está dentro de los umbrales de advertencia, CRITICAL si está fuera de los umbrales críticos y WARNING si está fuera de los umbrales de advertencia. + +_Estados: ok, advertencia, crítico_ ## Solucionar problemas -¿Necesitas ayuda? Ponte en contacto con el [servicio de asistencia de Datadog][11]. +¿Necesitas ayuda? Ponte en contacto con el [servicio de asistencia de Datadog](https://docs.datadoghq.com/help/). ## Referencias adicionales -Para hacerse una mejor idea de cómo (o por qué) monitorizar el consumo de recursos de los proceso con Datadog, consulta esta [serie de entradas de blog][12]. - -[1]: https://docs.datadoghq.com/es/monitors/create/types/process_check/?tab=checkalert -[2]: https://app.datadoghq.com/account/settings/agent/latest -[3]: https://github.com/DataDog/integrations-core/blob/master/process/datadog_checks/process/data/conf.yaml.example -[4]: https://docs.datadoghq.com/es/agent/guide/agent-commands/#start-stop-and-restart-the-agent -[5]: https://docs.datadoghq.com/es/agent/guide/agent-commands/#agent-status-and-information -[6]: https://docs.datadoghq.com/es/agent/faq/why-don-t-i-see-the-system-processes-open-file-descriptors-metric/ -[7]: https://docs.datadoghq.com/es/integrations/wmi_check/ -[8]: https://docs.datadoghq.com/es/agent/guide/windows-agent-ddagent-user/#process-check -[9]: https://github.com/DataDog/integrations-core/blob/master/process/metadata.csv -[10]: https://github.com/DataDog/integrations-core/blob/master/process/assets/service_checks.json -[11]: https://docs.datadoghq.com/es/help/ -[12]: https://www.datadoghq.com/blog/process-check-monitoring \ No newline at end of file +Para hacerte una mejor idea de cómo (o por qué) monitorizar el consumo de recursos por parte de los proceso con Datadog, consulta esta [serie de entradas de blog](https://www.datadoghq.com/blog/process-check-monitoring). \ No newline at end of file diff --git a/content/es/integrations/pulsar.md b/content/es/integrations/pulsar.md index 69d7cab3c8dc1..843c79459d1cf 100644 --- a/content/es/integrations/pulsar.md +++ b/content/es/integrations/pulsar.md @@ -1,138 +1,277 @@ --- app_id: pulsar -app_uuid: 2a3a1555-3c19-42a9-b954-ce16c4aa6308 -assets: - integration: - auto_install: true - configuration: - spec: assets/configuration/spec.yaml - events: - creates_events: false - metrics: - check: pulsar.active_connections - metadata_path: metadata.csv - prefix: pulsar. - process_signatures: - - java org.apache.pulsar.PulsarStandaloneStarter - service_checks: - metadata_path: assets/service_checks.json - source_type_id: 10143 - source_type_name: pulsar -author: - homepage: https://www.datadoghq.com - name: Datadog - sales_email: info@datadoghq.com - support_email: help@datadoghq.com categories: - recopilación de logs - colas de mensajes custom_kind: integración -dependencies: -- https://github.com/DataDog/integrations-core/blob/master/pulsar/README.md -display_on_public_website: true -draft: false -git_integration_title: pulsar -integration_id: pulsar -integration_title: Pulsar +description: Monitoriza tus clústeres Pulsar. integration_version: 3.2.0 -is_public: true -manifest_version: 2.0.0 -name: pulsar -public_title: Pulsar -short_description: Monitoriza tus clústeres Pulsar. +media: [] supported_os: - Linux - Windows - macOS -tile: - changelog: CHANGELOG.md - classifier_tags: - - Categoría::Recopilación de logs - - Categoría::Colas de mensajes - - Sistema operativo compatible::Linux - - Sistema operativo compatible::Windows - - Sistema operativo compatible::macOS - - Oferta::Integración - configuration: README.md#Configuración - description: Monitoriza tus clústeres Pulsar. - media: [] - overview: README.md#Información general - support: README.md#Soporte - title: Pulsar +title: Pulsar --- - - - - ## Información general -Este check monitoriza [Pulsar][1] a través del Datadog Agent. +Este check monitoriza [Pulsar](https://pulsar.apache.org) a través del Datadog Agent. ## Configuración -Sigue las instrucciones a continuación para instalar y configurar este check para un Agent que se ejecuta en un host. Para entornos en contenedores, consulta las [plantillas de integración de Autodiscovery][2] para obtener orientación sobre la aplicación de estas instrucciones. +Sigue las instrucciones a continuación para instalar y configurar este check para un Agent que se ejecute en un host. Para entornos en contenedores, consulta las [plantillas de integración de Autodiscovery](https://docs.datadoghq.com/agent/kubernetes/integrations/) para obtener orientación sobre la aplicación de estas instrucciones. ### Instalación -El check de Pulsar está incluido en el paquete del [Datadog Agent ][3]. +El check de Pulsar está incluido en el paquete del [Datadog Agent](https://app.datadoghq.com/account/settings/agent/latest). No es necesaria ninguna instalación adicional en tu servidor. ### Configuración -1. Edita el archivo `pulsar.d/conf.yaml`, que se encuentra en la carpeta `conf.d/` en la raíz del directorio de configuración del Agent, para empezar a recopilar los datos de rendimiento de tu Pulsar. Para conocer todas las opciones de configuración disponibles, consulta el [pulsar.d/conf.yaml de ejemplo][4]. +1. Edita el archivo `pulsar.d/conf.yaml`, en la carpeta `conf.d/` en la raíz de tu directorio de configuración del Agent para empezar a recopilar tus datos de rendimiento de Pulsar. Consulta el [ejemplo pulsar.d/conf.yaml](https://github.com/DataDog/integrations-core/blob/master/pulsar/datadog_checks/pulsar/data/conf.yaml.example) para conocer todas las opciones de configuración disponibles. -2. [Reinicia el Agent][5]. +1. [Reinicia el Agent](https://docs.datadoghq.com/agent/guide/agent-commands/#start-stop-and-restart-the-agent). ### Validación -[Ejecuta el subcomando de estado del Agent][6] y busca `pulsar` en la sección Checks. +[Ejecuta el subcomando de estado del Agent] (https://docs.datadoghq.com/agent/guide/agent-commands/#agent-status-and-information) y busca `pulsar` en la sección Checks. ## Datos recopilados ### Métricas -{{< get-metrics-from-git "pulsar" >}} - +| | | +| --- | --- | +| **pulsar.active_connections**
(gauge) | Número de conexiones activas.
_Se muestra como conexión_ | +| **pulsar.authentication_failures_count.count**
(count) | Número de operaciones de autenticación fallidas.| +| **pulsar.authentication_success_count.count**
(count) | Número de operaciones de autenticación realizadas con éxito.| +| **pulsar.bookie_DELETED_LEDGER_COUNT.count**
(count) | Número total de ledgers eliminados desde que fue iniciado el bookie.| +| **pulsar.bookie_READ_BYTES.count**
(count) | Número total de bytes leídos del bookie.
_Se muestra como bytes_ | +| **pulsar.bookie_SERVER_STATUS**
(gauge) | Estado del servidor del bookie server. 1: el bookie se ejecuta en modo de escritura.0: el bookie se ejecuta en modo de solo lectura.| +| **pulsar.bookie_WRITE_BYTES.count**
(count) | Número total de bytes escritos en el bookie.
_Se muestra como bytes_ | +| **pulsar.bookie_entries_count**
(gauge) | Número total de entradas almacenadas en el bookie.| +| **pulsar.bookie_flush**
(gauge) | Latencia de descarga de la tabla de la memoria del bookie.| +| **pulsar.bookie_journal_JOURNAL_CB_QUEUE_SIZE**
(gauge) | Número total de devoluciones de llamada pendientes en la cola de devoluciones de llamada.| +| **pulsar.bookie_journal_JOURNAL_FORCE_WRITE_QUEUE_SIZE**
(gauge) | Número total de solicitudes de escritura forzada (fsync) pendientes en la cola de escritura forzada.
_Se muestra como solicitud_ | +| **pulsar.bookie_journal_JOURNAL_QUEUE_SIZE**
(gauge) | Número total de solicitudes pendientes en la cola de registros.
_Se muestra como solicitud_ | +| **pulsar.bookie_journal_JOURNAL_SYNC_count.count**
(count) | Número total de operaciones fsync de diario que se producen en el bookie. La etiqueta de éxito se utiliza para distinguir éxitos y fracasos.| +| **pulsar.bookie_ledger_writable_dirs**
(gauge) | Número de directorios con permisos de escritura en el bookie.| +| **pulsar.bookie_ledgers_count**
(gauge) | Número total de ledgers almacenados en el bookie.| +| **pulsar.bookie_read_cache_size**
(gauge) | Tamaño de la caché de lectura del bookie (en bytes).
_Se muestra como bytes_ | +| **pulsar.bookie_throttled_write_requests.count**
(count) | Número de solicitudes de escritura que se deben limitar.
_Se muestra como solicitud_ | +| **pulsar.bookie_write_cache_size**
(gauge) | Tamaño de la caché de escritura del bookie (en bytes).
_Se muestra como bytes_ | +| **pulsar.bookkeeper_server_ADD_ENTRY_count.count**
(count) | Número total de solicitudes ADD_ENTRY recibidas en el bookie. La etiqueta de éxito se utiliza para distinguir éxitos y fracasos.
_Se muestra como solicitud_. | +| **pulsar.bookkeeper_server_BOOKIE_QUARANTINE_count.count**
(count) | Número de clientes de bookie que deben colocarse en cuarentena.| +| **pulsar.bookkeeper_server_READ_ENTRY_count.count**
(count) | Número total de solicitudes READ_ENTRY recibidas en el bookie. La etiqueta de éxito se utiliza para distinguir éxitos y fracasos.
_Se muestra como solicitud_ | +| **pulsar.brk_ml_cursor_nonContiguousDeletedMessagesRange**
(gauge) | Número de rangos de mensajes no contiguos eliminados.| +| **pulsar.brk_ml_cursor_persistLedgerErrors**
(gauge) | Número de errores de ledger ocurridos cuando los estados de reconocimiento no logran ser persistentes en el ledger.
_Se muestra como error_ | +| **pulsar.brk_ml_cursor_persistLedgerSucceed**
(gauge) | Número de estados de reconocimiento persistentes en un ledger.| +| **pulsar.brk_ml_cursor_persistZookeeperErrors**
(gauge) | Número de errores del ledger cuando los estados de reconocimiento no logran ser persistentes en ZooKeeper.
_Se muestra como error_ | +| **pulsar.brk_ml_cursor_persistZookeeperSucceed**
(gauge) | Número de estados de reconocimiento persistentes en ZooKeeper.| +| **pulsar.brk_ml_cursor_readLedgerSize**
(gauge) | Tamaño de la lectura del ledger.| +| **pulsar.brk_ml_cursor_writeLedgerLogicalSize**
(gauge) | Tamaño de la escritura en el ledger (teniendo en cuenta sin réplicas).| +| **pulsar.brk_ml_cursor_writeLedgerSize**
(gauge) | Tamaño de la escritura en el ledger.| +| **pulsar.broker_load_manager_bundle_assignment**
(gauge) | Resumen de la latencia de las operaciones de propiedad de paquetes.| +| **pulsar.broker_lookup.count**
(count) | Número de muestras de la latencia de todas las operaciones de búsqueda.| +| **pulsar.broker_lookup.quantle**
(count) | Latencia de todas las operaciones de búsqueda.| +| **pulsar.broker_lookup.sum**
(count) | Latencia total de todas las operaciones de búsqueda.| +| **pulsar.broker_lookup_answers.count**
(count) | Número de respuestas de búsqueda (es decir, solicitudes no redirigidas).
_Se muestra como respuesta_ | +| **pulsar.broker_lookup_failures.count**
(count) | Número de errores de búsqueda.| +| **pulsar.broker_lookup_pending_requests**
(gauge) | Número de búsquedas pendientes en el broker. Cuando alcanza el umbral, se rechazan las nuevas solicitudes.
_Se muestra como solicitud_ | +| **pulsar.broker_lookup_redirects.count**
(count) | Número de solicitudes de búsqueda redirigidas.
_Se muestra como solicitud_ | +| **pulsar.broker_throttled_connections**
(gauge) | Número de conexiones limitadas.
_Se muestra como conexión_ | +| **pulsar.broker_throttled_connections_global_limit**
(gauge) | Número de conexiones limitadas debido al límite por conexión.
_Se muestra como conexión_ | +| **pulsar.broker_topic_load_pending_requests**
(gauge) | Carga de operaciones de temas pendientes.| +| **pulsar.bundle_consumer_count**
(gauge) | Recuento de consumidores de temas de este paquete.| +| **pulsar.bundle_msg_rate_in**
(gauge) | Tasa total de mensajes que llegan a los temas de este paquete (mensajes/segundo).| +| **pulsar.bundle_msg_rate_out**
(gauge) | Tasa total de mensajes que salen de los temas de este paquete (mensajes/segundo).| +| **pulsar.bundle_msg_throughput_in**
(gauge) | Rendimiento total que entra en los temas de este paquete (bytes/segundo).| +| **pulsar.bundle_msg_throughput_out**
(gauge) | Rendimiento total que sale de los temas de este paquete (bytes/segundo).| +| **pulsar.bundle_producer_count**
(gauge) | Recuento de productores de los temas de este paquete.| +| **pulsar.bundle_topics_count**
(gauge) | Recuento de temas de este paquete.| +| **pulsar.compaction_compacted_entries_count**
(gauge) | Número total de entradas compactadas.| +| **pulsar.compaction_compacted_entries_size**
(gauge) | Tamaño total de las entradas compactadas.| +| **pulsar.compaction_duration_time_in_mills**
(gauge) | Duración de la compactación.| +| **pulsar.compaction_failed_count**
(gauge) | Número total de fallos de la compactación.| +| **pulsar.compaction_read_throughput**
(gauge) | Rendimiento de lectura de la compactación.| +| **pulsar.compaction_removed_event_count**
(gauge) | Número total de eventos eliminados de la compactación.| +| **pulsar.compaction_succeed_count**
(gauge) | Número total de éxitos de la compactación.| +| **pulsar.compaction_write_throughput**
(gauge) | Rendimiento de escritura de la compactación.| +| **pulsar.connection_closed_total_count**
(gauge) | Número total de conexiones cerradas.
_Se muestra como conexión_ | +| **pulsar.connection_create_fail_count**
(gauge) | Número de conexiones fallidas.
_Se muestra como conexión_ | +| **pulsar.connection_create_success_count**
(gauge) | Número de conexiones creadas con éxito.
_Se muestra como conexión_ | +| **pulsar.connection_created_total_count**
(gauge) | Número total de conexiones.
_Se muestra como conexión_ | +| **pulsar.consumer_available_permits**
(gauge) | Permisos disponibles para un consumidor.| +| **pulsar.consumer_blocked_on_unacked_messages**
(gauge) | Indica si un consumidor está bloqueado en mensajes no reconocidos o no. 1 significa que el consumidor está bloqueado a la espera de que los mensajes no reconocidos sean reconocidos, acked.0 significa que el consumidor no está bloqueado a la espera de que los mensajes no reconocidos sean reconocidos.| +| **pulsar.consumer_msg_rate_out**
(gauge) | Tasa total de envío de mensajes de un consumidor (mensajes/segundo).| +| **pulsar.consumer_msg_rate_redeliver**
(gauge) | Tasa total de mensajes que se vuelven a entregar (mensajes/segundo).| +| **pulsar.consumer_msg_throughput_out**
(gauge) | Rendimiento total de envío de mensajes a un consumidor (bytes/segundo).| +| **pulsar.consumer_unacked_messages**
(gauge) | Número total de mensajes no reconocidos de un consumidor (mensajes).
_Se muestra como mensaje_ | +| **pulsar.consumers_count**
(gauge) | Número de consumidores activos del espacio de nombres conectados a este broker.| +| **pulsar.expired_token_count.count**
(count) | Número de tokens caducados en Pulsar.| +| **pulsar.function_last_invocation**
(gauge) | Marca de tiempo de la última invocación de la función.| +| **pulsar.function_processed_successfully_total.count**
(count) | Número total de mensajes procesados con éxito.
_Se muestra como mensaje_ | +| **pulsar.function_processed_successfully_total_1min.count**
(count) | Número total de mensajes procesados con éxito en el último minuto.
_Se muestra como mensaje_ | +| **pulsar.function_received_total.count**
(count) | Número total de mensajes recibidos de la fuente.
_Se muestra como mensaje_ | +| **pulsar.function_received_total_1min.count**
(count) | Número total de mensajes recibidos de la fuente en el último minuto.
_Se muestra como mensaje_ | +| **pulsar.function_system_exceptions_total.count**
(count) | Número total de excepciones del sistema.| +| **pulsar.function_system_exceptions_total_1min.count**
(count) | Número total de excepciones del sistema en el último minuto.| +| **pulsar.function_user_exceptions_total.count**
(count) | Número total de excepciones de usuarios.| +| **pulsar.function_user_exceptions_total_1min.count**
(count) | Número total de excepciones de usuarios en el último minuto.| +| **pulsar.in_bytes_total**
(gauge) | Número de mensajes en bytes recibidos de este tema.
_Se muestra como byte_ | +| **pulsar.in_messages_total**
(gauge) | Número total de mensajes recibidos de este tema.
_Se muestra como mensaje_ | +| **pulsar.jetty_async_dispatches_total.count**
(count) | Número de solicitudes que se han enviado de forma asíncrona.| +| **pulsar.jetty_async_requests_total.count**
(count) | Número total de solicitudes asíncronas.
_Se muestra como solicitud_ | +| **pulsar.jetty_async_requests_waiting**
(gauge) | Actualmente esperando solicitudes asíncronas.
_Se muestra como solicitud_ | +| **pulsar.jetty_async_requests_waiting_max**
(gauge) | Número máximo de peticiones solicitudes en espera.
_Se muestra como solicitud_ | +| **pulsar.jetty_dispatched_active**
(gauge) | Número de envíos activos actualmente.| +| **pulsar.jetty_dispatched_active_max**
(gauge) | Número máximo de envíos activos que se están gestionando.| +| **pulsar.jetty_dispatched_time_max**
(gauge) | Tiempo máximo dedicado a la gestión de envíos.| +| **pulsar.jetty_dispatched_time_seconds_total.count**
(count) | Tiempo total dedicado a la gestión del envío.
_Se muestra como segundos_ | +| **pulsar.jetty_dispatched_total.count**
(count) | Número de envíos.| +| **pulsar.jetty_expires_total.count**
(count) | Número de solicitudes asíncronas que han caducado.
_Se muestra como solicitud_ | +| **pulsar.jetty_request_time_max_seconds**
(gauge) | Tiempo máximo dedicado a la gestión de solicitudes.
_Se muestra como segundos_ | +| **pulsar.jetty_request_time_seconds_total.count**
(count) | Tiempo total dedicado a la gestión de todas las solicitudes.
_Se muestra como segundos_ | +| **pulsar.jetty_requests_active**
(gauge) | Número de solicitudes activas actualmente.
_Se muestra como solicitud_ | +| **pulsar.jetty_requests_active_max**
(gauge) | Número máximo de solicitudes que han estado activas a la vez.
_Se muestra como solicitud_ | +| **pulsar.jetty_requests_total.count**
(count) | Número de solicitudes.
_Se muestra como solicitud_ | +| **pulsar.jetty_responses_bytes_total.count**
(count) | Número total de bytes en todas las respuestas.
_Se muestra como bytes_ | +| **pulsar.jetty_responses_total.count**
(count) | Número de respuestas, etiquetadas por código de estado. La etiqueta del código puede ser "1xx", "2xx", "3xx", "4xx" o "5xx".
_Se muestra como respuesta_ | +| **pulsar.jetty_stats_seconds**
(gauge) | Tiempo en segundos durante el que se han recopilado estadísticas.
_Se muestra como segundos_ | +| **pulsar.lb_bandwidth_in_usage**
(gauge) | Uso de ancho de banda entrante del broker (en porcentaje).| +| **pulsar.lb_bandwidth_out_usage**
(gauge) | Uso de ancho de banda saliente del broker (en porcentaje).| +| **pulsar.lb_bundles_split_count.count**
(count) | Recuento de división de paquetes en este intervalo de comprobación de división de paquetes| +| **pulsar.lb_cpu_usage**
(gauge) | Uso de cpu del broker (en porcentaje).| +| **pulsar.lb_directMemory_usage**
(gauge) | Uso de memoria directa del proceso de broker (en porcentaje).| +| **pulsar.lb_memory_usage**
(gauge) | Uso de memoria del proceso del broker (en porcentaje).| +| **pulsar.lb_unload_broker_count.count**
(count) | Recuento de brokers de descarga en esta descarga de paquetes| +| **pulsar.lb_unload_bundle_count.count**
(count) | Recuento de descarga de paquetes en esta descarga de paquetes| +| **pulsar.ml_AddEntryBytesRate**
(gauge) | Tasa de bytes/s de mensajes añadidos| +| **pulsar.ml_AddEntryErrors**
(gauge) | Número de solicitudes addEntry fallidas
_Se muestra como solicitud_ | +| **pulsar.ml_AddEntryMessagesRate**
(gauge) | Tasa de msg/s de mensajes añadidos| +| **pulsar.ml_AddEntrySucceed**
(gauge) | Número de solicitudes de addEntry exitosas
_Se muestra como solicitud_ | +| **pulsar.ml_AddEntryWithReplicasBytesRate**
(gauge) | Tasa de bytes/s de mensajes añadidos con réplicas| +| **pulsar.ml_MarkDeleteRate**
(gauge) | Tasa de operaciones/s de marcado-eliminación| +| **pulsar.ml_NumberOfMessagesInBacklog**
(gauge) | Número de mensajes pendientes para todos los consumidores
_Se muestra como mensaje_ | +| **pulsar.ml_ReadEntriesBytesRate**
(gauge) | Tasa de bytes/s de mensajes leídos| +| **pulsar.ml_ReadEntriesErrors**
(gauge) | Número de solicitudes readEntries fallidas
_Se muestra como solicitud_ | +| **pulsar.ml_ReadEntriesRate**
(gauge) | Tasa de msg/s de mensajes leídos| +| **pulsar.ml_ReadEntriesSucceeded**
(gauge) | Número de solicitudes readEntries exitosas
_Se muestra como solicitud_ | +| **pulsar.ml_StoredMessagesSize**
(gauge) | Tamaño total de los mensajes en ledgers activos (teniendo en cuenta las múltiples copias almacenadas).| +| **pulsar.ml_cache_evictions**
(gauge) | Número de desalojos de la caché durante el último minuto.
_Se muestra como desalojo_ | +| **pulsar.ml_cache_hits_rate**
(gauge) | Número de accesos a la caché por segundo en el lado del broker.
_Se muestra como hit_ | +| **pulsar.ml_cache_hits_throughput**
(gauge) | Cantidad de datos que se recuperan de la caché en el lado del broker (en bytes/s).| +| **pulsar.ml_cache_misses_rate**
(gauge) | Número de fallos de caché por segundo en el lado del broker.
_Se muestra como fallo_ | +| **pulsar.ml_cache_misses_throughput**
(gauge) | Cantidad de datos que no se recuperan de la caché en el lado del broker (en byte/s).| +| **pulsar.ml_cache_pool_active_allocations**
(gauge) | Número de asignaciones actualmente activas en el ámbito directo| +| **pulsar.ml_cache_pool_active_allocations_huge**
(gauge) | Número de grandes asignaciones actualmente activas en el ámbito directo| +| **pulsar.ml_cache_pool_active_allocations_normal**
(gauge) | Número de asignaciones normales actualmente activas en el ámbito directo| +| **pulsar.ml_cache_pool_active_allocations_small**
(gauge) | Número de pequeñas asignaciones actualmente activas en el ámbito directo| +| **pulsar.ml_cache_pool_allocated**
(gauge) | Memoria total asignada a las listas de fragmentos en el ámbito directo| +| **pulsar.ml_cache_pool_used**
(gauge) | Memoria total utilizada de las listas de fragmentos en el ámbito directo| +| **pulsar.ml_cache_used_size**
(gauge) | Tamaño en bytes utilizado para almacenar las cargas útiles de las entradas
_Se muestra como bytes_ | +| **pulsar.ml_count**
(gauge) | Número de ledgers gestionados actualmente abiertos| +| **pulsar.out_bytes_total**
(gauge) | Número total de mensajes en bytes leídos de este tema.
_Se muestra como bytes_ | +| **pulsar.out_messages_total**
(gauge) | Número total de mensajes leídos de este tema.
_Se muestra como mensaje_ | +| **pulsar.producers_count**
(gauge) | Número de productores activos del espacio de nombres conectados a este broker.| +| **pulsar.proxy_active_connections**
(gauge) | Número de conexiones activas actualmente en el proxy.
_Se muestra como conexión_ | +| **pulsar.proxy_binary_bytes.count**
(count) | Contador de bytes proxy.
_Se muestra como bytes_ | +| **pulsar.proxy_binary_ops.count**
(count) | Contador de operaciones proxy.| +| **pulsar.proxy_new_connections.count**
(count) | Contador de conexiones que se están abriendo en el proxy.
_Se muestra como conexión_ | +| **pulsar.proxy_rejected_connections.count**
(count) | Contador de conexiones rechazadas por limitación.
_Se muestra como conexión_ | +| **pulsar.rate_in**
(gauge) | Tasa total de mensajes del espacio de nombres que llegan a este broker (mensajes/segundo).| +| **pulsar.rate_out**
(gauge) | Tasa total de mensajes del espacio de nombres que salen de este broker (mensajes/segundo).| +| **pulsar.replication_backlog**
(gauge) | Backlog total del espacio de nombres que replica al clúster remoto (mensajes).
_Se muestra como mensaje_ | +| **pulsar.replication_connected_count**
(gauge) | Recuento de suscriptores de replicación en funcionamiento para replicar al clúster remoto.| +| **pulsar.replication_delay_in_seconds**
(gauge) | Tiempo en segundos desde el momento en que se produjo un mensaje hasta el momento en que está a punto de ser replicado.
_Se muestra como segundos_ | +| **pulsar.replication_rate_expired**
(gauge) | Tasa total de mensajes caducados (mensajes/segundo).| +| **pulsar.replication_rate_in**
(gauge) | Tasa total de mensajes del espacio de nombres que replica desde el clúster remoto (mensajes/segundo).| +| **pulsar.replication_rate_out**
(gauge) | Tasa total de mensajes del espacio de nombres que replica al clúster remoto (mensajes/segundo).| +| **pulsar.replication_throughput_in**
(gauge) | Rendimiento total del espacio de nombres que replica desde el clúster remoto (bytes/segundo).| +| **pulsar.replication_throughput_out**
(gauge) | Rendimiento total del espacio de nombres que replica al clúster remoto (bytes/segundo).| +| **pulsar.sink_last_invocation**
(gauge) | Marca de tiempo de la última invocación del sumidero.| +| **pulsar.sink_received_total.count**
(count) | Número total de registros que un sumidero ha recibido de temas Pulsar.| +| **pulsar.sink_received_total_1min.count**
(count) | Número total de mensajes que un sumidero ha recibido de temas Pulsar en el último minuto.
_Se muestra como mensaje_ | +| **pulsar.sink_sink_exception**
(gauge) | Excepción de un sumidero.| +| **pulsar.sink_sink_exceptions_total.count**
(count) | Número total de excepciones de sumidero.| +| **pulsar.sink_sink_exceptions_total_1min.count**
(count) | Número total de excepciones de sumidero en el último minuto.| +| **pulsar.sink_system_exception**
(gauge) | Excepción del código del sistema.| +| **pulsar.sink_system_exceptions_total.count**
(count) | Número total de excepciones del sistema.| +| **pulsar.sink_system_exceptions_total_1min.count**
(count) | Número total de excepciones del sistema en el último minuto.| +| **pulsar.sink_written_total.count**
(count) | Número total de registros procesados por un sumidero.| +| **pulsar.sink_written_total_1min.count**
(count) | Número total de registros procesados por un sumidero en el último minuto.| +| **pulsar.source_last_invocation**
(gauge) | Marca de tiempo de la última invocación de la fuente.| +| **pulsar.source_received_total.count**
(count) | Número total de registros recibidos de la fuente.| +| **pulsar.source_received_total_1min.count**
(count) | Número total de registros recibidos de la fuente en el último minuto.| +| **pulsar.source_source_exception**
(gauge) | Excepción de una fuente.| +| **pulsar.source_source_exceptions_total.count**
(count) | Número total de excepciones de una fuente.| +| **pulsar.source_source_exceptions_total_1min.count**
(count) | Número total de excepciones de una fuente en el último minuto.| +| **pulsar.source_system_exception**
(gauge) | Excepción del código del sistema.| +| **pulsar.source_system_exceptions_total.count**
(count) | Número total de excepciones del sistema.| +| **pulsar.source_system_exceptions_total_1min.count**
(count) | Número total de excepciones del sistema en el último minuto.| +| **pulsar.source_written_total.count**
(count) | Número total de registros escritos en un tema Pulsar.| +| **pulsar.source_written_total_1min.count**
(count) | Número total de registros escritos en un tema Pulsar en el último minuto.| +| **pulsar.split_bytes_read.count**
(count) | Número de bytes leídos desde BookKeeper.
_Se muestra como bytes_ | +| **pulsar.split_num_messages_deserialized.count**
(count) | Número de mensajes deserializados.
_Se muestra como mensaje_ | +| **pulsar.split_num_record_deserialized.count**
(count) | Número de registros deserializados.| +| **pulsar.storage_backlog_quota_limit**
(gauge) | Cantidad total de datos en este tema que limitan la cuota de backlog (bytes).
_Se muestra como bytes_ | +| **pulsar.storage_backlog_size**
(gauge) | Tamaño total del backlog de temas de este espacio de nombres propiedad de este broker (mensajes).| +| **pulsar.storage_logical_size**
(gauge) | Tamaño de almacenamiento delos temas en el espacio de nombres propiedad del broker sin réplicas (en bytes).| +| **pulsar.storage_offloaded_size**
(gauge) | Cantidad total de datos de este espacio de nombres descargados al almacenamiento por niveles (bytes).| +| **pulsar.storage_read_rate**
(gauge) | Total de lotes de mensajes (entradas) leídos del almacenamiento para este espacio de nombres (lotes de mensajes/segundo).| +| **pulsar.storage_size**
(gauge) | Tamaño total de almacenamiento de los temas en este espacio de nombres propiedad de este broker (bytes).| +| **pulsar.storage_write_rate**
(gauge) | Total de lotes de mensajes (entradas) escritos en el almacenamiento para este espacio de nombres (lotes de mensajes/segundo).| +| **pulsar.subscription_back_log**
(gauge) | Backlog total de una suscripción (mensajes).
_Se muestra como mensaje_ | +| **pulsar.subscription_blocked_on_unacked_messages**
(gauge) | Indica si una suscripción está bloqueada en los mensajes no reconocidos o no. 1 significa que la suscripción está bloqueada a la espera de que los mensajes no reconocidos sean reconocidos, 0 significa que la suscripción no está bloqueada a la espera de que los mensajes no reconocidos sean reconocidos.| +| **pulsar.subscription_delayed**
(gauge) | Total de lotes de mensajes (entradas) cuyo envío se retrasa.| +| **pulsar.subscription_msg_rate_out**
(gauge) | Tasa total de envío de mensajes de una suscripción (mensajes/segundo).| +| **pulsar.subscription_msg_rate_redeliver**
(gauge) | Tasa total de mensajes que se vuelven a entregar (mensajes/segundo).| +| **pulsar.subscription_msg_throughput_out**
(gauge) | Rendimiento total de envío de mensajes de una suscripción (bytes/segundo).| +| **pulsar.subscription_unacked_messages**
(gauge) | Número total de mensajes no reconocidos para una suscripción (mensajes).
_Se muestra como mensaje_ | +| **pulsar.subscriptions_count**
(gauge) | Número de suscripciones Pulsar del espacio de nombres servidas por este broker.| +| **pulsar.throughput_in**
(gauge) | Rendimiento total del espacio de nombres que entra en este broker (bytes/segundo).| +| **pulsar.throughput_out**
(gauge) | Rendimiento total del espacio de nombres que sale de este broker (bytes/segundo).| +| **pulsar.topics_count**
(gauge) | Número de temas Pulsar del espacio de nombres propiedad de este broker.| +| **pulsar.txn_aborted_count.count**
(count) | Número de transacciones abortadas de este coordinador.
_Se muestra como transacción_ | +| **pulsar.txn_active_count**
(gauge) | Número de transacciones activas.
_Se muestra como transacción_ | +| **pulsar.txn_append_log_count.count**
(count) | Número de logs de transacciones anexas.| +| **pulsar.txn_committed_count.count**
(count) | Número de transacciones confirmadas.
_Se muestra como transacción_ | +| **pulsar.txn_created_count.count**
(count) | Número de transacciones creadas.
_Se muestra como transacción_ | +| **pulsar.txn_timeout_count.count**
(count) | Número de transacciones con tiempo de espera agotado.
_Se muestra como transacción_ | ### Recopilación de logs -1. La integración de logs de Pulsar admite el [formato de logs por defecto][8] de Pulsar. Clona y edita el [pipeline de la integración][9] si tienes un formato diferente. +1. La integración de logs de Pulsar admite el [formato de log por defecto](https://pulsar.apache.org/docs/en/reference-configuration/#log4j) de Pulsar. Clona y edita el [pipeline de la integración](https://docs.datadoghq.com/logs/processing/#integration-pipelines) si tienes un formato diferente. + +1. La recopilación de logs está desactivada por defecto en el Datadog Agent. Actívala en tu archivo `datadog.yaml`: -2. La recopilación de logs se encuentra deshabilitada de manera predeterminada en el Datadog Agent. Habilítala en tu archivo `datadog.yaml`: ```yaml logs_enabled: true ``` -3. Deselecciona y edita el bloque de configuración de logs en tu archivo `pulsar.d/conf.yaml`. Cambia el valor de los parámetros de ruta según tu entorno. Consulta el [pulsar.d/conf.yaml de ejemplol][4] para ver todas las opciones de configuración disponibles. +1. Descomenta y edita el bloque de configuración de logs en tu archivo `pulsar.d/conf.yaml`. Cambia el valor del parámetro de ruta en función de tu entorno. Consulta el [ejemplo pulsar.d/conf.yaml](https://github.com/DataDog/integrations-core/blob/master/pulsar/datadog_checks/pulsar/data/conf.yaml.example) para ver todas las opciones de configuración disponibles. + ```yaml logs: - type: file path: /pulsar/logs/pulsar.log source: pulsar ``` -4. [Reiniciar el Agent][5] + +1. [Reinicia el Agent](https://docs.datadoghq.com/agent/guide/agent-commands/#start-stop-and-restart-the-agent) ### Eventos La integración Pulsar no incluye eventos. ### Checks de servicio -{{< get-service-checks-from-git "pulsar" >}} +**pulsar.openmetrics.health** -## Solucionar problemas +Devuelve `CRITICAL` si el Agent no puede conectarse al endpoint de OpenMetrics o `OK` en caso contrario. -¿Necesitas ayuda? Contacta con el [equipo de asistencia de Datadog][11]. +_Estados: ok, crítico_ +## Solucionar problemas -[1]: https://pulsar.apache.org -[2]: https://docs.datadoghq.com/es/agent/kubernetes/integrations/ -[3]: https://app.datadoghq.com/account/settings/agent/latest -[4]: https://github.com/DataDog/integrations-core/blob/master/pulsar/datadog_checks/pulsar/data/conf.yaml.example -[5]: https://docs.datadoghq.com/es/agent/guide/agent-commands/#start-stop-and-restart-the-agent -[6]: https://docs.datadoghq.com/es/agent/guide/agent-commands/#agent-status-and-information -[7]: https://github.com/DataDog/integrations-core/blob/master/pulsar/metadata.csv -[8]: https://pulsar.apache.org/docs/en/reference-configuration/#log4j -[9]: https://docs.datadoghq.com/es/logs/processing/#integration-pipelines -[10]: https://github.com/DataDog/integrations-core/blob/master/pulsar/assets/service_checks.json -[11]: https://docs.datadoghq.com/es/help/ \ No newline at end of file +¿Necesitas ayuda? Ponte en contacto con el [servicio de asistencia de Datadog](https://docs.datadoghq.com/help/). \ No newline at end of file diff --git a/content/es/integrations/purefa.md b/content/es/integrations/purefa.md index fa67e7d691a97..af298eb5785c0 100644 --- a/content/es/integrations/purefa.md +++ b/content/es/integrations/purefa.md @@ -1,82 +1,30 @@ --- app_id: purefa -app_uuid: a2d8f393-62cd-4ece-bfab-e30797698b12 -assets: - dashboards: - purefa_overview: assets/dashboards/purefa_overview.json - purefa_overview_legacy: assets/dashboards/purefa_overview_legacy.json - integration: - auto_install: true - configuration: - spec: assets/configuration/spec.yaml - events: - creates_events: false - metrics: - check: purefa.info - metadata_path: metadata.csv - prefix: purefa. - service_checks: - metadata_path: assets/service_checks.json - source_type_id: 10256 - source_type_name: PureFA -author: - homepage: https://purestorage.com - name: Pure Storage - sales_email: sales@purestorage.com - support_email: pure-observability@purestorage.com categories: - almacenes de datos - sistema operativo y sistema -custom_kind: integration -dependencies: -- https://github.com/DataDog/integrations-extras/blob/master/purefa/README.md -display_on_public_website: true -draft: false -git_integration_title: purefa -integration_id: purefa -integration_title: FlashArray Pure Storage -integration_version: 1.2.0 -is_public: true -manifest_version: 2.0.0 -name: purefa -public_title: FlashArray Pure Storage -short_description: Monitorización del rendimiento y el uso de FlashArrays Pure Storage +custom_kind: integración +description: Monitorización del rendimiento y el uso de FlashArrays Pure Storage +integration_version: 1.3.0 +media: +- caption: Dashboard de FlashArray Pure Storage - Información general (arriba) + image_url: images/FA-overview-1.png + media_type: imagen +- caption: Dashboard de FlashArray Pure Storage - Información general (arriba) + image_url: images/FA-overview-2.png + media_type: imagen +- caption: Dashboard de FlashArray Pure Storage - Información general (abajo) + image_url: images/FA-overview-3.png + media_type: imagen supported_os: - Linux - Windows - macOS -tile: - changelog: CHANGELOG.md - classifier_tags: - - Categoría::Almacenes de datos - - Categoría::Sistema operativo y sistema - - Oferta::Integración - - Sistema operativo compatible::Linux - - Sistema operativo compatible::Windows - - Sistema operativo compatible::macOS - configuration: README.md#Configuración - description: Monitorización del rendimiento y el uso de FlashArrays Pure Storage - media: - - caption: Dashboard de FlashArray Pure Storage - Información general (arriba) - image_url: images/FA-overview-1.png - media_type: imagen - - caption: Dashboard de FlashArray Pure Storage - Información general (arriba) - image_url: images/FA-overview-2.png - media_type: imagen - - caption: Dashboard de FlashArray Pure Storage - Información general (abajo) - image_url: images/FA-overview-3.png - media_type: imagen - overview: README.md#Información general - support: README.md#Soporte - title: FlashArray Pure Storage +title: FlashArray Pure Storage --- - - - - ## Información general -Este check monitoriza el [FlashArray Pure Storage][1] a través del [Datadog Agent][2] y el [exportador OpenMetrics Pure Storage][3]. +Este check monitoriza [Pure Storage FlashArray](https://www.purestorage.com/products.html) a través del [Datadog Agent](https://app.datadoghq.com/account/settings/agent/latest) y el [exportador OpenMetrics de Pure Storage](https://github.com/PureStorage-OpenConnect/pure-fa-openmetrics-exporter). La integración puede proporcionar datos de rendimiento a nivel de matriz, host, volumen y pod, así como información muy clara sobre capacidad y configuración. @@ -84,9 +32,10 @@ Puedes monitorizar múltiples FlashArrays y agregarlos en un único dashboard o **Esta integración requiere lo siguiente**: - - Agent v7.26.x o posterior para utilizar OpenMetrics BaseCheckV2 - - Python 3 - - El exportador OpenMetrics Pure Storage se instala y ejecuta en un entorno contenedorizado. Para obtener instrucciones de instalación, consulta el [repositorio de GitHub][3]. +- Agent v7.26.x o posterior para utilizar OpenMetrics BaseCheckV2 +- Python 3 +- El exportador OpenMetrics de Pure Storage se instala y ejecuta en un entorno contenedorizado. Consulta el [repositorio de GitHub](https://github.com/PureStorage-OpenConnect/pure-fa-openmetrics-exporter) para obtener instrucciones de instalación. + - En FlashArrays que ejecutan Purity//FA versión 6.7.0 y posteriores, el exportador OpenMetrics se ejecuta de forma nativa en la matriz. Consulta Configuración para obtener más información. ## Configuración @@ -94,24 +43,93 @@ Sigue las instrucciones a continuación para instalar y configurar este check pa ### Instalación -1. [Descarga e inicia el Datadog Agent][2]. -2. Instala manualmente la integración Pure FlashArray. Para obtener más detalles en función de tu entorno, consulta [Uso de integraciones de la comunidad][4]. - +1. [Descarga e inicia el Datadog Agent](https://app.datadoghq.com/account/settings/agent/latest). +1. Instala manualmente la integración Pure FlashArray. Consulta [Uso de integraciones comunitarias](https://docs.datadoghq.com/agent/guide/community-integrations-installation-with-docker-agent) para obtener más información en función de tu entorno. #### Host Para configurar este check para un Agent que se ejecuta en un host, ejecuta `sudo -u dd-agent -- datadog-agent integration install -t datadog-purefa==
(gauge) | Eventos de alerta de FlashArray abiertos.| +| **purefa.alerts.total**
(gauge) | (Legacy) Número de eventos de alerta.| +| **purefa.array.performance_average_bytes**
(gauge) | Tamaño medio de las operaciones de la matriz FlashArray en bytes.
_Se muestra como bytes_ | +| **purefa.array.performance_avg_block_bytes**
(gauge) | (Legacy) Tamaño medio de bloque de FlashArray.
_Se muestra como bytes_ | +| **purefa.array.performance_bandwidth_bytes**
(gauge) | Rendimiento de la matriz FlashArray en bytes por segundo.
_Se muestra como bytes_ | +| **purefa.array.performance_iops**
(gauge) | (Legacy) IOPS FlashArray.
_Se muestra como operación_ | +| **purefa.array.performance_latency_usec**
(gauge) | Latencia de la matriz FlashArray en microsegundos.
_Se muestra como microsegundos_ | +| **purefa.array.performance_qdepth**
(gauge) | (Legacy) Profundidad de la cola de FlashArray.| +| **purefa.array.performance_queue_depth_ops**
(gauge) | Tamaño de la profundidad de la cola de la matriz FlashArray.
_Se muestra como operación_ | +| **purefa.array.performance_throughput_iops**
(gauge) | Rendimiento de la matriz FlashArray en IOPS.
_Se muestra como operación_ | +| **purefa.array.space_bytes**
(gauge) | Espacio de la matriz FlashArray en bytes.
_Se muestra como bytes_ | +| **purefa.array.space_capacity_bytes**
(gauge) | (Legacy) Capacidad de espacio total de FlashArray.
_Se muestra como bytes_ | +| **purefa.array.space_data_reduction_ratio**
(gauge) | Reducción de datos del espacio de la matriz FlashArray.| +| **purefa.array.space_datareduction_ratio**
(gauge) | (Legacy) Reducción global de datos de FlashArray.| +| **purefa.array.space_provisioned_bytes**
(gauge) | (Legacy) Espacio total aprovisionado de FlashArray.
_Se muestra como bytes_ | +| **purefa.array.space_used_bytes**
(gauge) | (Legacy) Espacio total utilizado de FlashArray.
_Se muestra como bytes_ | +| **purefa.array.space_utilization**
(gauge) | Uso del espacio de la matriz FlashArray en porcentaje.
_Se muestra como porcentaje_ | +| **purefa.directory.performance_average_bytes**
(gauge) | Tamaño medio de las operaciones del directorio FlashArray en bytes.
_Se muestra como bytes_ | +| **purefa.directory.performance_bandwidth_bytes**
(gauge) | Rendimiento del directorio FlashArray en bytes por segundo.
_Se muestra como bytes_ | +| **purefa.directory.performance_latency_usec**
(gauge) | Latencia del directorio FlashArray en microsegundos.
_Se muestra como microsegundos_ | +| **purefa.directory.performance_throughput_iops**
(gauge) | Rendimiento del directorio FlashArray en IOPS.
_Se muestra como operación_ | +| **purefa.directory.space_bytes**
(gauge) | Espacio del directorio FlashArray en bytes.
_Se muestra como bytes_ | +| **purefa.directory.space_data_reduction_ratio**
(gauge) | Reducción de datos del espacio del directorio FlashArray.| +| **purefa.drive.capacity_bytes**
(gauge) | Capacidad de la unidad FlashArray en bytes.
_Se muestra como bytes_ | +| **purefa.hardware.chassis_health**
(gauge) | (Legacy) Estado de salud del chasis de hardware de FlashArray.| +| **purefa.hardware.component_health**
(gauge) | (Legacy) Estado de salud del componente de hardware de FlashArray.| +| **purefa.hardware.controller_health**
(gauge) | (Legacy) Estado de salud del controlador de hardware de FlashArray.| +| **purefa.hardware.power_volts**
(gauge) | (Legacy) Tensión de alimentación del hardware de FlashArray.
_Se muestra como voltios_ | +| **purefa.hardware.temperature_celsius**
(gauge) | (Legacy) Sensores de temperatura del hardware de FlashArray.
_Se muestra como grados celsius_ | +| **purefa.host.connections_info**
(gauge) | Conexiones de volúmenes del host FlashArray.| +| **purefa.host.connectivity_info**
(gauge) | Información de conectividad del host FlashArray.| +| **purefa.host.performance_average_bytes**
(gauge) | Tamaño medio de las operaciones del host FlashArray en bytes.
_Se muestra como bytes_ | +| **purefa.host.performance_bandwidth_bytes**
(gauge) | Ancho de banda del host FlashArray en bytes por segundo.
_Se muestra como bytes_ | +| **purefa.host.performance_iops**
(gauge) | (Legacy) IOPS de host FlashArray.
_Se muestra como operación_ | +| **purefa.host.performance_latency_usec**
(gauge) | Latencia del host FlashArray en microsegundos.
_Se muestra como microsegundos_ | +| **purefa.host.performance_throughput_iops**
(gauge) | Rendimiento del host FlashArray en IOPS.
_Se muestra como operación_ | +| **purefa.host.space_bytes**
(gauge) | Espacio del host FlashArray en bytes.
_Se muestra como bytes_ | +| **purefa.host.space_data_reduction_ratio**
(gauge) | Reducción de datos del espacio del host FlashArray.| +| **purefa.host.space_datareduction_ratio**
(gauge) | (Legacy) Ratio de reducción de datos de los volúmenes del host FlashArray.| +| **purefa.host.space_size_bytes**
(gauge) | Tamaño de los volúmenes del host FlashArray.
_Se muestra como bytes_ | +| **purefa.hw.component_status**
(gauge) | Estado del componente de hardware de FlashArray.| +| **purefa.hw.component_temperature_celsius**
(gauge) | Temperatura del componente de hardware de FlashArray en °C.
_Se muestra como grados celsius_ | +| **purefa.hw.component_voltage_volt**
(gauge) | Tensión del componente de hardware de FlashArray.
_Se muestra como voltios_ | +| **purefa.hw.controller_info**
(gauge) | Información del controlador FlashArray| +| **purefa.hw.controller_mode_since_timestamp_seconds**
(gauge) | Tiempo de actividad del controlador de hardware de FlashArray en segundos
_Se muestra como segundos_ | +| **purefa.info**
(gauge) | Información del sistema FlashArray.| +| **purefa.network.interface_performance_bandwidth_bytes**
(gauge) | Ancho de banda de la interfaz de red de FlashArray en bytes por segundo
_Se muestra como bytes_ | +| **purefa.network.interface_performance_errors**
(gauge) | Errores de la interfaz de red de FlashArray en errores por segundo
_Se muestra como error_ | +| **purefa.network.interface_performance_throughput_pkts**
(gauge) | Rendimiento de la interfaz de red de FlashArray en paquetes por segundo.
_Se muestra como paquete_ | +| **purefa.network.interface_speed_bandwidth_bytes**
(gauge) | Velocidad de la interfaz de red de FlashArray en bytes por segundo
_Se muestra como bytes_ | +| **purefa.network.port_info**
(gauge) | Información del puerto de red de FlashArray| +| **purefa.pod.mediator_status**
(gauge) | (Legacy) Estado del mediador de pods de FlashArray.| +| **purefa.pod.performance_average_bytes**
(gauge) | Tamaño medio de las operaciones de pods de FlashArray.
_Se muestra como bytes_ | +| **purefa.pod.performance_bandwidth_bytes**
(gauge) | Rendimiento de pods de FlashArray en bytes por segundo.
_Se muestra como bytes_ | +| **purefa.pod.performance_iops**
(gauge) | (Legacy) IOPS de pods de FlashArray.
_Se muestra como operación_ | +| **purefa.pod.performance_latency_usec**
(gauge) | Latencia de pods de FlashArray en microsegundos.
_Se muestra como microsegundos_ | +| **purefa.pod.performance_replication_bandwidth_bytes**
(gauge) | Ancho de banda de replicación de pods de FlashArray.
_Se muestra como bytes_ | +| **purefa.pod.performance_throughput_iops**
(gauge) | Rendimiento de pods de FlashArray en IOPS.
_Se muestra como operación_ | +| **purefa.pod.replica_links_lag_average_msec**
(gauge) | Retraso medio de enlaces de pods de FlashArray en milisegundos.
_Se muestra como segundos_ | +| **purefa.pod.replica_links_lag_average_sec**
(gauge) | Retraso medio de enlaces de pods de FlashArray en milisegundos.
_Se muestra como segundos_ | +| **purefa.pod.replica_links_lag_max_msec**
(gauge) | Retraso máximo de enlaces de pods de FlashArray en milisegundos.
_Se muestra como segundos_ | +| **purefa.pod.replica_links_lag_max_sec**
(gauge) | Retraso máximo de enlaces de pods de FlashArray en milisegundos.
_Se muestra como segundos_ | +| **purefa.pod.replica_links_performance_bandwidth_bytes**
(gauge) | Ancho de banda de enlaces de pods de FlashArray.
_Se muestra como bytes_ | +| **purefa.pod.space_bytes**
(gauge) | Espacio de pods de FlashArray en bytes.
_Se muestra como bytes_ | +| **purefa.pod.space_data_reduction_ratio**
(gauge) | Reducción de datos en el espacio de pods de FlashArray.| +| **purefa.pod.space_datareduction_ratio**
(gauge) | (Legacy) Ratio de reducción de datos de pods de FlashArray.| +| **purefa.pod.space_size_bytes**
(gauge) | (Legacy) Tamaño de pods de FlashArray.
_Se muestra como bytes_ | +| **purefa.pod.status**
(gauge) | (Legacy) Estado de pods de FlashArray.| +| **purefa.volume.performance_average_bytes**
(gauge) | Tamaño medio de las operaciones de volúmenes de FlashArray en bytes.
_Se muestra como bytes_ | +| **purefa.volume.performance_bandwidth_bytes**
(gauge) | Rendimiento de volúmenes de FlashArray en bytes por segundo.
_Se muestra como bytes_ | +| **purefa.volume.performance_iops**
(gauge) | (Legacy) IOPS de volúmenes de FlashArray.
_Se muestra como operación_ | +| **purefa.volume.performance_latency_usec**
(gauge) | Latencia de volúmenes de FlashArray en microsegundos.
_Se muestra como microsegundos_ | +| **purefa.volume.performance_throughput_bytes**
(gauge) | (Legacy) Rendimiento de volúmenes de FlashArray.
_Se muestra como bytes_ | +| **purefa.volume.performance_throughput_iops**
(gauge) | Rendimiento de volúmenes de FlashArray en IOPS.
_Se muestra como operación_ | +| **purefa.volume.space_bytes**
(gauge) | Espacio de volúmenes de FlashArray en bytes.
_Se muestra como bytes_ | +| **purefa.volume.space_data_reduction_ratio**
(gauge) | Reducción del espacio de datos de volúmenes de FlashArray.| +| **purefa.volume.space_datareduction_ratio**
(gauge) | (Legacy) Ratio de reducción de datos de volúmenes de FlashArray.| +| **purefa.volume.space_size_bytes**
(gauge) | (Legacy) Tamaño de volúmenes de FlashArray.
_Se muestra como bytes_ | ### Eventos @@ -219,25 +313,15 @@ La integración PureFA no incluye eventos. ### Checks de servicio -Para ver una lista de los checks de servicio proporcionados por esta integración, consulta [service_checks.json][13]. +**purefa.openmetrics.health** -## Agent +Devuelve `CRITICAL` si el Agent no puede conectarse al endpoint de OpenMetrics o `OK` en caso contrario. + +_Estados: ok, crítico_ + +## Soporte Para obtener asistencia o realizar solicitudes de funciones, ponte en contacto con Pure Storage utilizando los siguientes métodos: -* Correo electrónico: pure-observability@purestorage.com -* Slack: [Código Storage Code//Canal de observabilidad][14]. - -[1]: https://www.purestorage.com/products.html -[2]: https://app.datadoghq.com/account/settings/agent/latest -[3]: https://github.com/PureStorage-OpenConnect/pure-fa-openmetrics-exporter -[4]: https://docs.datadoghq.com/es/agent/guide/community-integrations-installation-with-docker-agent -[5]: https://github.com/DataDog/integrations-extras/blob/master/purefa/CHANGELOG.md -[6]: https://raw.githubusercontent.com/DataDog/integrations-extras/master/purefa/images/API.png -[7]: https://github.com/datadog/integrations-extras/blob/master/purefa/datadog_checks/purefa/data/conf.yaml.example -[8]: https://docs.datadoghq.com/es/agent/guide/agent-commands/#start-stop-and-restart-the-agent -[9]: https://docs.datadoghq.com/es/agent/guide/agent-commands/#agent-status-and-information -[10]: https://github.com/PureStorage-OpenConnect/pure-exporter -[11]: https://github.com/datadog/integrations-extras/blob/master/purefa/datadog_checks/purefa/metrics.py -[12]: https://github.com/DataDog/integrations-extras/blob/master/purefa/metadata.csv -[13]: https://github.com/DataDog/integrations-extras/blob/master/purefa/assets/service_checks.json -[14]: https://code-purestorage.slack.com/messages/C0357KLR1EU \ No newline at end of file + +- Correo electrónico: pure-observability@purestorage.com +- Slack: [Código Pure Storage//Canal de observabilidad](https://code-purestorage.slack.com/messages/C0357KLR1EU). \ No newline at end of file diff --git a/content/es/integrations/python.md b/content/es/integrations/python.md new file mode 100644 index 0000000000000..94c952dc0ed3a --- /dev/null +++ b/content/es/integrations/python.md @@ -0,0 +1,67 @@ +--- +app_id: python +categories: +- languages +- log collection +- tracing +custom_kind: integración +description: Recopila métricas, trazas (traces) y logs de tus aplicaciones Python. +further_reading: +- link: https://www.datadoghq.com/blog/tracing-async-python-code/ + tag: blog + text: Rastreo de código Python asíncrono con Datadog APM +- link: https://www.datadoghq.com/blog/python-logging-best-practices/ + tag: blog + text: 'Formatos de generación de logs de Python: Cómo recopilar y centralizar logs + de Python' +media: [] +title: Python +--- +## Información general + +La integración Python te permite recopilar y monitorizar tus logs de aplicaciones, trazas y métricas personalizadas de Python. + +## Configuración + +### Recopilación de métricas + +Consulta la documentación exclusiva para [recopilar métricas personalizadas de Python con DogStatsD](https://docs.datadoghq.com/developers/dogstatsd/?tab=python). + +### Recopilación de trazas + +Consulta la documentación exclusiva para [instrumentar tu aplicación Python](https://docs.datadoghq.com/tracing/setup/python/) para enviar tus trazas a Datadog. + +### Recopilación de logs + +_Disponible para la versión 6.0 o posterior del Agent_ + +Consulta la documentación exclusiva sobre cómo [configurar la recopilación de logs Python](https://docs.datadoghq.com/logs/log_collection/python/) para reenviar tus logs a Datadog. + +### Recopilación de perfiles + +Consulta la documentación exclusiva para [habilitar el generador de perfiles Python](https://docs.datadoghq.com/profiler/enabling/python/). + +## Datos recopilados + +### Métricas + +| | | +| --- | --- | +| **runtime.python.cpu.time.sys**
(gauge) | Número de segundos de ejecución en el kernel
_Se muestra como segundos_ | +| **runtime.python.cpu.time.user**
(gauge) | Número de segundos de ejecución fuera del núcleo
_Se muestra como segundos_ | +| **runtime.python.cpu.percent**
(gauge) | Porcentaje de uso de CPU
_Se muestra como porcentaje_ | +| **runtime.python.cpu.ctx_switch.voluntary**
(gauge) | Número de cambios de contexto voluntarios
_Se muestra como invocación_ | +| **runtime.python.cpu.ctx_switch.involuntary**
(gauge) | Número de cambios de contexto involuntarios
_Se muestra como invocación_ | +| **runtime.python.gc.count.gen0**
(gauge) | Número de objetos de generación 0
_Se muestra como recurso_ | +| **runtime.python.gc.count.gen1**
(gauge) | Número de objetos de generación 1
_Se muestra como recurso_ | +| **runtime.python.gc.count.gen2**
(gauge) | Número de objetos de generación 2
_Se muestra como recurso_ | +| **runtime.python.mem.rss**
(gauge) | Memoria de conjunto residente
_Se muestra como bytes_ | +| **runtime.python.thread_count**
(gauge) | Número de subprocesos
_Se muestra como subproceso_ | + +## Solucionar problemas + +¿Necesitas ayuda? Ponte en contacto con el [servicio de asistencia de Datadog](https://docs.datadoghq.com/help/). + +## Referencias adicionales + +{{< partial name="whats-next/whats-next.html" >}} \ No newline at end of file diff --git a/content/es/integrations/rabbitmq.md b/content/es/integrations/rabbitmq.md new file mode 100644 index 0000000000000..6f6e86236cabb --- /dev/null +++ b/content/es/integrations/rabbitmq.md @@ -0,0 +1,538 @@ +--- +app_id: rabbitmq +categories: +- log collection +- message queues +custom_kind: integración +description: Seguimiento del tamaño de las colas, del recuento de consumidores, de + mensajes no reconocidos, etc. +further_reading: +- link: https://www.datadoghq.com/blog/rabbitmq-monitoring + tag: blog + text: Métricas clave para la monitorización de RabbitMQ +- link: https://www.datadoghq.com/blog/rabbitmq-monitoring-tools + tag: blog + text: Recopilación de métricas utilizando las herramientas de monitorización de + RabbitMQ +- link: https://www.datadoghq.com/blog/monitoring-rabbitmq-performance-with-datadog + tag: blog + text: Monitorización de RabbitMQ con Datadog +integration_version: 8.0.0 +media: [] +supported_os: +- linux +- windows +- macos +title: RabbitMQ +--- + + +## Información general + +Este check monitoriza [RabbitMQ](https://www.rabbitmq.com) a través del Datadog Agent. Te permite: + +- Realizar un seguimiento de estadísticas basadas en colas: tamaño de la cola, recuento de consumidores, mensajes no reconocidos, mensajes reenviados, etc. +- Realizar un de estadísticas basadas en nodos: procesos en espera, sockets utilizados, descriptores de archivos utilizados, etc. +- Monitoriza vhosts para comprobar la disponibilidad y el número de conexiones. + +Considerar [Data Streams Monitoring](https://docs.datadoghq.com/data_streams/) para mejorar tu integración con RabbitMQ. Esta solución permite la visualización de pipelines y el seguimiento de retrasos, ayudándote a identificar y resolver cuellos de botella. + +## Configuración + +### Instalación + +El check de RabbitMQ se incluye en el paquete del [Datadog Agent](https://app.datadoghq.com/account/settings/agent/latest). No es necesaria ninguna instalación adicional en tu servidor. + +### Configuración + +RabbitMQ expone métricas de dos formas: el [complemento de gestión de RabbitMQ](https://www.rabbitmq.com/management.html) y el [complemento RabbitMQ Prometheus](https://www.rabbitmq.com/prometheus.html). La integración de Datadog admite ambas versiones. Sigue las instrucciones de configuración de este archivo correspondientes a la versión que quieres utilizar. La integración Datadog también viene con un dashboard y monitores predefinidos para cada versión, como se indica en los títulos Dashboard y Monitor. + +#### Preparación de RabbitMQ + +##### [Complemento RabbitMQ Prometheus](https://www.rabbitmq.com/prometheus.html). + +*A partir de la versión 3.8 de RabbitMQ, el [complemento RabbitMQ Prometheus](https://www.rabbitmq.com/prometheus.html) está activado por defecto.* + +*La versión del complemento Prometheus de RabbitMQ requiere el soporte de Python 3 del Datadog Agent, por lo que sólo es compatible con el Agent v6 o posterior. Asegúrate de que tu Agent está actualizado, antes de configurar la versión del complemento Prometheus de la integración.* + +Configura la sección `prometheus_plugin` en la configuración de tu instancia. Cuando se utiliza la opción `prometheus_plugin`, se ignoran los parámetros relacionados con el complemento de gestión. + +```yaml +instances: + - prometheus_plugin: + url: http://
(gauge) | \[OpenMetrics\] es 1 si la alarma de límite del descriptor de archivo está activa| +| **rabbitmq.alarms.free_disk_space.watermark**
(gauge) | \[OpenMetrics\] es 1 si la alarma de marca de agua del espacio libre en disco está activa| +| **rabbitmq.alarms.memory_used_watermark**
(gauge) | \[OpenMetrics\] es 1 si la alarma de marca de agua de memoria de la máquina virtual está vigente| +| **rabbitmq.auth_attempts.count**
(count) | \[OpenMetrics\] Número total de intentos de autenticación| +| **rabbitmq.auth_attempts.failed.count**
(count) | \[OpenMetrics\] Número total de intentos de autenticación fallidos| +| **rabbitmq.auth_attempts.succeeded.count**
(count) | \[OpenMetrics\] Número total de intentos de autenticación exitosos| +| **rabbitmq.build_info**
(gauge) | \[OpenMetrics\] Información de la versión RabbitMQ & Erlang/OTP| +| **rabbitmq.channel.acks_uncommitted**
(gauge) | \[OpenMetrics\] Reconocimientos de mensajes en una transacción aún no confirmada| +| **rabbitmq.channel.consumers**
(gauge) | \[OpenMetrics\] Consumidores en un canal| +| **rabbitmq.channel.get.ack.count**
(count) | \[OpenMetrics\] Número total de mensajes obtenidos con basic.get en modo de reconocimiento manual| +| **rabbitmq.channel.get.count**
(count) | \[OpenMetrics\] Número total de mensajes obtenidos con basic.get en modo de reconocimiento automático
_Se muestra como mensaje_ | +| **rabbitmq.channel.get.empty.count**
(count) | \[OpenMetrics\] Número total de veces que las operaciones basic.get no obtuvieron ningún mensaje.| +| **rabbitmq.channel.messages.acked.count**
(count) | \[OpenMetrics\] Número total de mensajes reconocidos por los consumidores
_Se muestra como mensaje_ | +| **rabbitmq.channel.messages.confirmed.count**
(count) | \[OpenMetrics\] Número total de mensajes publicados en un intercambio y confirmados en el canal
_Se muestra como mensaje_ | +| **rabbitmq.channel.messages.delivered.ack.count**
(count) | \[OpenMetrics\] Número total de mensajes entregados a los consumidores en modo de reconocimiento manual
_Se muestra como mensaje_ | +| **rabbitmq.channel.messages.delivered.count**
(count) | \[OpenMetrics\] Número total de mensajes entregados a los consumidores en modo de reconocimiento automático
_Se muestra como mensaje_ | +| **rabbitmq.channel.messages.published.count**
(count) | \[OpenMetrics\] Número total de mensajes publicados en un intercambio en un canal
_Se muestra como mensaje_ | +| **rabbitmq.channel.messages.redelivered.count**
(count) | \[OpenMetrics\] Número total de mensajes reenviados a los consumidores
_Se muestra como mensaje_ | +| **rabbitmq.channel.messages.unacked**
(gauge) | \[OpenMetrics\] Mensajes entregados pero aún no reconocidos
_Se muestra como mensaje_ | +| **rabbitmq.channel.messages.uncommitted**
(gauge) | \[OpenMetrics\] Mensajes recibidos en una transacción pero aún no confirmados
_Se muestra como mensaje_ | +| **rabbitmq.channel.messages.unconfirmed**
(gauge) | \[OpenMetrics\] Mensajes publicados pero aún no confirmados
_Se muestra como mensaje_ | +| **rabbitmq.channel.messages.unroutable.dropped.count**
(count) | \[OpenMetrics\] Número total de mensajes publicados como no obligatorios en un intercambio y descartados como no enrutables
_Se muestra como mensaje_ | +| **rabbitmq.channel.messages.unroutable.returned.count**
(count) | \[OpenMetrics\] Número total de mensajes publicados como obligatorios en un intercambio y devueltos al publicador como no enrutables
_Se muestra como mensaje_ | +| **rabbitmq.channel.prefetch**
(gauge) | \[OpenMetrics\] Límite total de mensajes no reconocidos para todos los consumidores en un canal
_Se muestra como mensaje_ | +| **rabbitmq.channel.process_reductions.count**
(count) | \[OpenMetrics\] Número total de reducciones de procesos de canal| +| **rabbitmq.channels**
(gauge) | \[OpenMetrics\] Canales actualmente abiertos| +| **rabbitmq.channels.closed.count**
(count) | \[OpenMetrics\] Número total de canales cerrados| +| **rabbitmq.channels.opened.count**
(count) | \[OpenMetrics\] Número total de canales abiertos| +| **rabbitmq.cluster.exchange_bindings**
(gauge) | \[OpenMetrics\] Número de enlaces de un intercambio. Este valor es válido para todo el clúster.| +| **rabbitmq.cluster.exchange_name**
(gauge) | \[OpenMetrics\] Enumera los intercambios sin información adicional. Este valor es válido para todo el clúster. Una alternativa más económica a `exchange_bindings`| +| **rabbitmq.cluster.vhost_status**
(gauge) | \[OpenMetrics\] Si se está ejecutando un vhost determinado| +| **rabbitmq.connection.channels**
(gauge) | \[OpenMetrics\] Canales en un conexión| +| **rabbitmq.connection.incoming_bytes.count**
(count) | \[OpenMetrics\] Número total de bytes recibidos en un conexión
_Se muestra como byte_ | +| **rabbitmq.connection.incoming_packets.count**
(count) | \[OpenMetrics\] Número total de paquetes recibidos en un conexión
_Se muestra como paquete_ | +| **rabbitmq.connection.outgoing_bytes.count**
(count) | \[OpenMetrics\] Número total de bytes enviados en una conexión
_Se muestra como bytes_ | +| **rabbitmq.connection.outgoing_packets.count**
(count) | \[OpenMetrics\] Número total de paquetes enviados en una conexión
_Se muestra como paquete_ | +| **rabbitmq.connection.pending_packets**
(gauge) | \[OpenMetrics\] Número de paquetes a la espera de ser enviados en una conexión
_Se muestra como paquete_ | +| **rabbitmq.connection.process_reductions.count**
(count) | \[OpenMetrics\] Número total de reducciones de procesos de conexión| +| **rabbitmq.connections**
(gauge) | \[OpenMetrics, CLI de gestión\] Número de conexiones actuales a un vhost rabbitmq dado, etiquetado 'rabbitmq_vhost:\
_Se muestra como conexión_ | +| **rabbitmq.connections.closed.count**
(count) | \[OpenMetrics\] Número total de conexiones cerradas o terminadas| +| **rabbitmq.connections.opened.count**
(count) | \[OpenMetrics\] Número total de conexiones abiertas| +| **rabbitmq.connections.state**
(gauge) | Número de conexiones en el estado de conexión especificado
_Se muestra como conexión_ | +| **rabbitmq.consumer_prefetch**
(gauge) | \[OpenMetrics\] Límite de mensajes no reconocidos para cada consumidor.| +| **rabbitmq.consumers**
(gauge) | \[OpenMetrics\] Consumidores actualmente conectados| +| **rabbitmq.disk_space.available_bytes**
(gauge) | \[OpenMetrics\] Espacio en disco disponible en bytes
_Se muestra como bytes_ | +| **rabbitmq.disk_space.available_limit_bytes**
(gauge) | \[OpenMetrics\] Marca de agua baja del espacio libre en disco en bytes
_Se muestra como bytes_ | +| **rabbitmq.erlang.gc.reclaimed_bytes.count**
(count) | \[OpenMetrics\] Número total de bytes de memoria recuperados por el recolector de basura Erlang
_Se muestra como bytes_ | +| **rabbitmq.erlang.gc.runs.count**
(count) | \[OpenMetrics\] Número total de ejecuciones del recolector de basura Erlang| +| **rabbitmq.erlang.mnesia.committed_transactions.count**
(count) | \[OpenMetrics\] Número de transacciones confirmadas.
_Se muestra como transacción_ | +| **rabbitmq.erlang.mnesia.failed_transactions.count**
(count) | \[OpenMetrics\] Número de transacciones fallidas (es decir, abortadas).
_Se muestra como transacción_ | +| **rabbitmq.erlang.mnesia.held_locks**
(gauge) | \[OpenMetrics\] Número de bloqueos mantenidos.| +| **rabbitmq.erlang.mnesia.lock_queue**
(gauge) | \[OpenMetrics\] Número de transacciones a la espera de un bloqueo.
_Se muestra como transacción_ | +| **rabbitmq.erlang.mnesia.logged_transactions.count**
(count) | \[OpenMetrics\] Número de transacciones registradas.
_Se muestra como transacción_ | +| **rabbitmq.erlang.mnesia.memory_usage_bytes**
(gauge) | \[OpenMetrics\] Número total de bytes asignados por todas las tablas de mnesia
_Se muestra como bytes_ | +| **rabbitmq.erlang.mnesia.restarted_transactions.count**
(count) | \[OpenMetrics\] Número total de reinicios de transacciones.
_Se muestra como transacción_ | +| **rabbitmq.erlang.mnesia.tablewise_memory_usage_bytes**
(gauge) | \[OpenMetrics\] Número de bytes asignados por la tabla de mnesia
_Se muestra como byte_ | +| **rabbitmq.erlang.mnesia.tablewise_size**
(gauge) | \[OpenMetrics\] Número de filas presentes por tabla| +| **rabbitmq.erlang.mnesia.transaction_coordinators**
(gauge) | \[OpenMetrics\] Número de transacciones de coordinadores.
_Se muestra como transacción_ | +| **rabbitmq.erlang.mnesia.transaction_participants**
(gauge) | \[OpenMetrics\] Número de transacciones de participantes.
_Se muestra como transacción_ | +| **rabbitmq.erlang.net.ticktime_seconds**
(gauge) | \[OpenMetrics\] Intervalo de latidos entre nodos
_Se muestra como segundos_ | +| **rabbitmq.erlang.processes_limit**
(gauge) | \[OpenMetrics\] Límite de procesos Erlang
_Se muestra como proceso_ | +| **rabbitmq.erlang.processes_used**
(gauge) | \[OpenMetrics\] Procesos Erlang utilizados
_Se muestra como proceso_ | +| **rabbitmq.erlang.scheduler.context_switches.count**
(count) | \[OpenMetrics\] Número total de cambios de contexto del programador Erlang| +| **rabbitmq.erlang.scheduler.run_queue**
(gauge) | \[OpenMetrics\] Cola de ejecución del programador Erlang| +| **rabbitmq.erlang.uptime_seconds**
(gauge) | \[OpenMetrics\] Tiempo de actividad del nodo
_Se muestra como segundos_ | +| **rabbitmq.erlang.vm.allocators**
(gauge) | \[OpenMetrics\] Memoria asignada (carriers_size) y utilizada (blocks_size) para los diferentes asignadores en la máquina virtual. Consulta erts_alloc(3).| +| **rabbitmq.erlang.vm.atom_count**
(gauge) | \[OpenMetrics\] Número de átomos existentes actualmente en el nodo local.| +| **rabbitmq.erlang.vm.atom_limit**
(gauge) | \[OpenMetrics\] Número máximo de átomos existentes simultáneamente en el nodo local.| +| **rabbitmq.erlang.vm.dirty_cpu_schedulers**
(gauge) | \[OpenMetrics\] Número de subprocesos sucios del programador de CPU utilizados por el emulador.
_Se muestra como subproceso_ | +| **rabbitmq.erlang.vm.dirty_cpu_schedulers_online**
(gauge) | \[OpenMetrics\] Número de subprocesos sucios del programador de CPU en línea.
_Se muestra como subproceso_ | +| **rabbitmq.erlang.vm.dirty_io_schedulers**
(gauge) | \[OpenMetrics\] Número de subprocesos sucios del programador de E/S utilizados por el emulador.
_Se muestra como subproceso_ | +| **rabbitmq.erlang.vm.dist.node_queue_size_bytes**
(gauge) | \[OpenMetrics\] Número de bytes en la cola de distribución de salida. Esta cola se sitúa entre el código Erlang y el controlador del puerto.
_Se muestra como bytes_ | +| **rabbitmq.erlang.vm.dist.node_state**
(gauge) | \[OpenMetrics\] Estado actual del enlace de distribución. El estado se representa como un valor numérico donde `pending=1', `up_pending=2' y `up=3'.| | **rabbitmq.erlang.vm.dist.port_input_bytes**
(gauge) | [OpenMetrics] Número total de bytes leídos desde el puerto.
_Se muestra como bytes_ | | **rabbitmq.erlang.vm.dist.port_memory_bytes**
(gauge) | [OpenMetrics] Número total de bytes asignados a este puerto por el sistema en tiempo de ejecución. El propio puerto puede tener memoria asignada que no está incluida.
_Se muestra como byte_ | | **rabbitmq.erlang.vm.dist.port_output_bytes**
(gauge) | [OpenMetrics] Número total de bytes escritos en el puerto.
_Se muestra como bytes_ | | **rabbitmq.erlang.vm.dist.port_queue.size_bytes**
(gauge) | [OpenMetrics] Número total de bytes puestos en cola por el puerto utilizando la implementación de colas del controlador ERTS.
_Se muestra como bytes_ | | **rabbitmq.erlang.vm.dist.proc.heap_size_words**
(gauge) | [OpenMetrics] Tamaño en palabras de la generación heap más joven del proceso. Esta generación incluye el stack tecnplógico del proceso. Esta información es altamente dependiente de la implementación y puede cambiar si la implementación cambia.| | **rabbitmq.erlang.vm.dist.proc.memory_bytes**
(gauge) | [OpenMetrics] Tamaño en bytes del proceso. Esto incluye el stack tecnológico de llamadas, heap y las estructuras internas.
_Se muestra como bytes_ | | **rabbitmq.erlang.vm.dist.proc.message_queue_len**
(gauge) | [OpenMetrics] Número de mensajes actualmente en la cola de mensajes del proceso.
_Se muestra como mensaje_ | | **rabbitmq.erlang.vm.dist.proc.min_bin_vheap_size_words**
(gauge) | [OpenMetrics] Tamaño mínimo de heap virtual binario para el proceso.| | **rabbitmq.erlang.vm.dist.proc.min_heap_size_words**
(gauge) | [OpenMetrics] Tamaño mínimo de heap para el proceso.| | **rabbitmq.erlang.vm.dist.proc.reductions**
(gauge) | [OpenMetrics] Número de reducciones ejecutadas por el proceso.| | **rabbitmq.erlang.vm.dist.proc.stack_size_words**
(gauge) | [OpenMetrics] Tamaño del stack tecnológico del proceso, en palabras.| | **rabbitmq.erlang.vm.dist.proc.status**
(gauge) | [OpenMetrics] Estado actual del proceso de distribución. El estado se representa como un valor numérico donde `exiting=1', `suspended=2', `runnable=3', `garbage_collecting=4', `running=5' and \`waiting=6'.| +| **rabbitmq.erlang.vm.dist.proc.total_heap_size_words**
(gauge) | \[OpenMetrics\] Tamaño total, en palabras, de todos los fragmentos de heap del proceso. Esto incluye el stack tecnológico del proceso y cualquier mensaje no recibido que se considere parte del heap.| +| **rabbitmq.erlang.vm.dist.recv.avg_bytes**
(gauge) | \[OpenMetrics\] Tamaño medio de los paquetes, en bytes, recibidos por el socket.
_Se muestra como bytes_ | +| **rabbitmq.erlang.vm.dist.recv.cnt**
(gauge) | \[OpenMetrics\] Número de paquetes recibidos por el socket.| +| **rabbitmq.erlang.vm.dist.recv.dvi_bytes**
(gauge) | \[OpenMetrics\] Desviación media del tamaño del paquete, en bytes, recibido por el socket.
_Se muestra como bytes_ | +| **rabbitmq.erlang.vm.dist.recv.max_bytes**
(gauge) | \[OpenMetrics\] Tamaño del paquete más grande, en bytes, recibido por el socket.
_Se muestra como bytes_ | +| **rabbitmq.erlang.vm.dist.recv_bytes**
(gauge) | \[OpenMetrics\] Número de bytes recibidos por el socket.
_Se muestra como bytes_ | +| **rabbitmq.erlang.vm.dist.send.avg_bytes**
(gauge) | \[OpenMetrics\] Tamaño medio de los paquetes, en bytes, enviados desde el socket.
_Se muestra como bytes_ | +| **rabbitmq.erlang.vm.dist.send.cnt**
(gauge) | \[OpenMetrics\] Número de paquetes enviados desde el socket.| +| **rabbitmq.erlang.vm.dist.send.max_bytes**
(gauge) | \[OpenMetrics\] Tamaño del paquete más grande, en bytes, enviado desde el socket.
_Se muestra como bytes_ | +| **rabbitmq.erlang.vm.dist.send.pend_bytes**
(gauge) | \[OpenMetrics\] Número de bytes a la espera de ser enviados por el socket.
_Se muestra como bytes_ | +| **rabbitmq.erlang.vm.dist.send_bytes**
(gauge) | \[OpenMetrics\] Número de bytes enviados desde el socket.
_Se muestra como bytes_ | +| **rabbitmq.erlang.vm.ets_limit**
(gauge) | \[OpenMetrics\] Número máximo de tablas ETS permitidas.| +| **rabbitmq.erlang.vm.logical_processors**
(gauge) | \[OpenMetrics\] Número detectado de procesadores lógicos configurados en el sistema.| +| **rabbitmq.erlang.vm.logical_processors.available**
(gauge) | \[OpenMetrics\] Número detectado de procesadores lógicos disponibles para el sistema de tiempo de ejecución Erlang.| +| **rabbitmq.erlang.vm.logical_processors.online**
(gauge) | \[OpenMetrics\] Número detectado de procesadores lógicos en línea en el sistema.| +| **rabbitmq.erlang.vm.memory.atom_bytes_total**
(gauge) | \[OpenMetrics\] Cantidad total de memoria actualmente asignada para los átomos. Esta memoria es parte de la memoria presentada como memoria del sistema.
_Se muestra como bytes_ | +| **rabbitmq.erlang.vm.memory.bytes_total**
(gauge) | \[OpenMetrics\] Cantidad total de memoria asignada actualmente. Es igual a la suma del tamaño de memoria de los procesos y del sistema.
_Se muestra como bytes_ | +| **rabbitmq.erlang.vm.memory.dets_tables**
(gauge) | \[OpenMetrics\] Recuento de tablas DETS de máquinas virtuales Erlang.| +| **rabbitmq.erlang.vm.memory.ets_tables**
(gauge) | \[OpenMetrics\] Recuento de tablas ETS de máquinas virtuales Erlang.| +| **rabbitmq.erlang.vm.memory.processes_bytes_total**
(gauge) | \[OpenMetrics\] Cantidad total de memoria actualmente asignada para los procesos Erlang.
_Se muestra como bytes_ | +| **rabbitmq.erlang.vm.memory.system_bytes_total**
(gauge) | \[OpenMetrics\] Cantidad total de memoria actualmente asignada para el emulador que no está directamente relacionada con un proceso Erlang. La memoria presentada como procesos no está incluida en esta memoria.
_Se muestra como bytes_ | +| **rabbitmq.erlang.vm.msacc.alloc_seconds.count**
(count) | \[OpenMetrics\] Tiempo total en segundos dedicado a gestionar la memoria. Sin estados adicionales, este tiempo se reparte entre todos los demás estados.
_Se muestra como segundos_ | +| **rabbitmq.erlang.vm.msacc.aux_seconds.count**
(count) | \[OpenMetrics\] Tiempo total en segundos dedicado a gestionar trabajos auxiliares.
_Se muestra como segundos_ | +| **rabbitmq.erlang.vm.msacc.bif_seconds.count**
(count) | \[OpenMetrics\] Tiempo total en segundos dedicado a BIF. Sin estados adicionales, este tiempo forma parte del estado 'emulador'.
_Se muestra como segundos_ | +| **rabbitmq.erlang.vm.msacc.busy_wait_seconds.count**
(count) | \[OpenMetrics\] Tiempo total en segundos de espera ocupada. Sin estados adicionales, este tiempo forma parte del estado 'otros'.
_Se muestra como segundos_ | +| **rabbitmq.erlang.vm.msacc.check_io_seconds.count**
(count) | \[OpenMetrics\] Tiempo total en segundos dedicado a comprobar si hay nuevos eventos de E/S.
_Se muestra como segundos_ | +| **rabbitmq.erlang.vm.msacc.emulator_seconds.count**
(count) | \[OpenMetrics\] Tiempo total en segundos dedicado a ejecutar procesos Erlang.
_Se muestra como segundos_ | +| **rabbitmq.erlang.vm.msacc.ets_seconds.count**
(count) | \[OpenMetrics\] Tiempo total en segundos dedicado a ejecutar BIF ETS. Sin estados adicionales, este tiempo forma parte del estado 'emulador'.
_Se muestra como segundos_ | +| **rabbitmq.erlang.vm.msacc.gc_full_seconds.count**
(count) | \[OpenMetrics\] Tiempo total en segundos dedicado a la recolección de basura fullsweep. Sin estados adicionales, este tiempo es parte del estado 'recolección de basura'.
_Se muestra como segundos_ | +| **rabbitmq.erlang.vm.msacc.gc_seconds.count**
(count) | \[OpenMetrics\] Tiempo total en segundos dedicado a la recolección de basura. Cuando los estados adicionales están activados, este es el tiempo dedicado a recolectar basura non-fullsweep.
_Se muestra como segundos_ | +| **rabbitmq.erlang.vm.msacc.nif_seconds.count**
(count) | \[OpenMetrics\] Tiempo total en segundos dedicado a NIF. Sin estados adicionales, este tiempo forma parte del estado 'emulador'.
_Se muestra como segundos_ | +| **rabbitmq.erlang.vm.msacc.other_seconds.count**
(count) | \[OpenMetrics\] Tiempo total en segundos dedicado a hacer cosas no explicadas.
_Se muestra como segundos_ | +| **rabbitmq.erlang.vm.msacc.port_seconds.count**
(count) | \[OpenMetrics\] Tiempo total en segundos dedicado a ejecutar puertos.
_Se muestra como segundos_ | +| **rabbitmq.erlang.vm.msacc.send_seconds.count**
(count) | \[OpenMetrics\] Tiempo total en segundos dedicado a enviar mensajes (solo procesos). Sin estados adicionales, este tiempo forma parte del estado 'emulador'.
_Se muestra como segundos_ | +| **rabbitmq.erlang.vm.msacc.sleep_seconds.count**
(count) | \[OpenMetrics\] Tiempo total en segundos que pasó durmiendo.
_Se muestra como segundos_ | +| **rabbitmq.erlang.vm.msacc.timers_seconds.count**
(count) | \[OpenMetrics\] Tiempo total en segundos dedicado a gestionar temporizadores. Sin estados adicionales, este tiempo forma parte del estado 'otros'.
_Se muestra como segundos_ | +| **rabbitmq.erlang.vm.port_count**
(gauge) | \[OpenMetrics\] Número de puertos existentes actualmente en el nodo local.| +| **rabbitmq.erlang.vm.port_limit**
(gauge) | \[OpenMetrics\] Número máximo de puertos existentes simultáneamente en el nodo local.| +| **rabbitmq.erlang.vm.process_count**
(gauge) | \[OpenMetrics\] Número de procesos existentes actualmente en el nodo local.
_Se muestra como proceso_ | +| **rabbitmq.erlang.vm.process_limit**
(gauge) | \[OpenMetrics\] Número máximo de procesos existentes simultáneamente en el nodo local.
_Se muestra como proceso_ | +| **rabbitmq.erlang.vm.schedulers**
(gauge) | \[OpenMetrics\] Número de procesos del programador utilizados por el emulador.| +| **rabbitmq.erlang.vm.schedulers_online**
(gauge) | \[OpenMetrics\] Número de programadores en línea.| +| **rabbitmq.erlang.vm.smp_support**
(gauge) | \[OpenMetrics\] 1 si el emulador ha sido compilado con soporte SMP, en caso contrario 0.| +| **rabbitmq.erlang.vm.statistics.bytes_output.count**
(count) | \[OpenMetrics\] Número total de bytes emitidos a los puertos.
_Se muestra como bytes_ | +| **rabbitmq.erlang.vm.statistics.bytes_received.count**
(count) | \[OpenMetrics\] Número total de bytes recibidos a través de los puertos.
_Se muestra como bytes_ | +| **rabbitmq.erlang.vm.statistics.context_switches.count**
(count) | \[OpenMetrics\] Número total de cambios de contexto desde que se inició el sistema.| +| **rabbitmq.erlang.vm.statistics.dirty_cpu_run_queue_length**
(gauge) | \[OpenMetrics\] Longitud de la cola de ejecución de CPU sucia.| +| **rabbitmq.erlang.vm.statistics.dirty_io_run_queue_length**
(gauge) | \[OpenMetrics\] Longitud de la cola de ejecución de E/S sucia.| +| **rabbitmq.erlang.vm.statistics.garbage_collection.bytes_reclaimed.count**
(count) | \[OpenMetrics\] Recolección de basura: bytes recuperados.
_Se muestra como bytes_ | +| **rabbitmq.erlang.vm.statistics.garbage_collection.number_of_gcs.count**
(count) | \[OpenMetrics\] Recolección de basura: número de recolecciones de basura.| +| **rabbitmq.erlang.vm.statistics.garbage_collection.words_reclaimed.count**
(count) | \[OpenMetrics\] Recolección de basura: palabras recuperadas.| +| **rabbitmq.erlang.vm.statistics.reductions.count**
(count) | \[OpenMetrics\] Reducciones totales.| +| **rabbitmq.erlang.vm.statistics.run_queues_length**
(gauge) | \[OpenMetrics\] Longitud de las colas de ejecución normales.| +| **rabbitmq.erlang.vm.statistics.runtime_milliseconds.count**
(count) | \[OpenMetrics\] Suma del tiempo de ejecución de todos los subprocesos en el sistema de tiempo de ejecución Erlang. Puede ser mayor que el tiempo del reloj de pared.
_Se muestra como milisegundos_ | +| **rabbitmq.erlang.vm.statistics.wallclock_time_milliseconds.count**
(count) | \[OpenMetrics\] Información sobre el reloj de pared. Igual que erlang_vm_statistics_runtime_milliseconds excepto que se mide el tiempo real.
_Se muestra como milisegundos_ | +| **rabbitmq.erlang.vm.thread_pool_size**
(gauge) | \[OpenMetrics\] Número de subprocesos asíncronos en el grupo de subprocesos asíncronos utilizados en llamadas asíncronas al controlador.| +| **rabbitmq.erlang.vm.threads**
(gauge) | \[OpenMetrics\] 1 si el emulador ha sido compilado con soporte para subprocesos, 0 en caso contrario.| +| **rabbitmq.erlang.vm.time_correction**
(gauge) | \[OpenMetrics\] 1 si la corrección de tiempo está activada, 0 en caso contrario.| +| **rabbitmq.erlang.vm.wordsize_bytes**
(gauge) | \[OpenMetrics\] Tamaño de las palabras de términos Erlang en bytes.
_Se muestra como bytes_ | +| **rabbitmq.exchange.messages.ack.count**
(gauge) | Número de mensajes en intercambios entregados a clientes y reconocidos
_Se muestra como mensaje_ | +| **rabbitmq.exchange.messages.ack.rate**
(gauge) | Tasa de mensajes en intercambios entregados a clientes y reconocidos por segundo
_Se muestra como mensaje_ | +| **rabbitmq.exchange.messages.confirm.count**
(gauge) | Recuento de mensajes en intercambios confirmados
_Se muestra como mensaje_ | +| **rabbitmq.exchange.messages.confirm.rate**
(gauge) | Tasa de mensajes en intercambios confirmados por segundo
_Se muestra como mensaje_ | +| **rabbitmq.exchange.messages.deliver_get.count**
(gauge) | Suma de mensajes en intercambios entregados en modo de reconocimiento a los consumidores, en modo sin reconocimiento a los consumidores, en modo de reconocimiento en respuesta a basic.get y en modo sin reconocimiento en respuesta a basic.get
_Se muestra como mensaje_ | +| **rabbitmq.exchange.messages.deliver_get.rate**
(gauge) | Tasa por segundo de la suma de mensajes en intercambios entregados en modo de reconocimiento a los consumidores, en modo sin reconocimiento a los consumidores, en modo de reconocimiento en respuesta a basic.get y en modo sin reconocimiento en respuesta a basic.get
_Se muestra como mensaje_ | +| **rabbitmq.exchange.messages.publish.count**
(gauge) | Recuento de mensajes en intercambios publicados
_Se muestra como mensaje_ | +| **rabbitmq.exchange.messages.publish.rate**
(gauge) | Tasa de mensajes en intercambios publicados por segundo
_Se muestra como mensaje_ | +| **rabbitmq.exchange.messages.publish_in.count**
(gauge) | Recuento de mensajes publicados desde canales en este intercambio
_Se muestra como mensaje_ | +| **rabbitmq.exchange.messages.publish_in.rate**
(gauge) | Tasa de mensajes publicados desde los canales a esta central por segundo
_Se muestra como mensaje_ | +| **rabbitmq.exchange.messages.publish_out.count**
(gauge) | Recuento de mensajes publicados desde este intercambio en colas
_Se muestra como mensaje_ | +| **rabbitmq.exchange.messages.publish_out.rate**
(gauge) | Tasa de mensajes publicados desde este intercambio a las colas por segundo
_Se muestra como mensaje_ | +| **rabbitmq.exchange.messages.redeliver.count**
(gauge) | Recuento del subconjunto de mensajes en intercambios en deliver_get que tenían el indicador de reenviado activado
_Se muestra como mensaje_ | +| **rabbitmq.exchange.messages.redeliver.rate**
(gauge) | Tasa del subconjunto de mensajes en intercambios en deliver_get que tenían el indicador de reenviado activado por segundo
_Se muestra como mensaje_ | +| **rabbitmq.exchange.messages.return_unroutable.count**
(gauge) | Recuento de mensajes en intercambios devueltos al publicador como no enrutables
_Se muestra como mensaje_ | +| **rabbitmq.exchange.messages.return_unroutable.rate**
(gauge) | Tasa de mensajes en intercambios devueltos al publicador como no enrutables por segundo
_Se muestra como mensaje_ | +| **rabbitmq.global.consumers**
(gauge) | \[OpenMetrics\] Número actual de consumidores| +| **rabbitmq.global.messages.acknowledged.count**
(count) | \[OpenMetrics\] Número total de mensajes reconocidos por los consumidores
_Se muestra como mensaje_ | +| **rabbitmq.global.messages.confirmed.count**
(count) | \[OpenMetrics\] Número total de mensajes confirmados a los publicadores
_Se muestra como mensaje_ | +| **rabbitmq.global.messages.dead_lettered.confirmed.count**
(count) | \[OpenMetrics\] Número total de mensajes fallidos y confirmados por colas de destino
_Se muestra como mensaje_ | +| **rabbitmq.global.messages.dead_lettered.delivery_limit.count**
(count) | \[OpenMetrics\] Número total de mensajes fallidos por exceder el límite de entrega
_Se muestra como mensaje_ | +| **rabbitmq.global.messages.dead_lettered.expired.count**
(count) | \[OpenMetrics\] Número total de mensajes fallidos por exceder el ciclo de vida del mensaje
_Se muestra como mensaje_ | +| **rabbitmq.global.messages.dead_lettered.maxlen.count**
(count) | \[OpenMetrics\] Número total de mensajes fallidos por desbordamiento drop-head o reject-publish-dlx
_Se muestra como mensaje_ | +| **rabbitmq.global.messages.dead_lettered.rejected.count**
(count) | \[OpenMetrics\] Número total de mensajes fallidos debido a basic.reject o basic.nack
_Se muestra como mensaje_ | +| **rabbitmq.global.messages.delivered.consume_auto_ack.count**
(count) | \[OpenMetrics\] Número total de mensajes entregados a los consumidores utilizando basic.consume con reconocimiento automático
_Se muestra como mensaje_ | +| **rabbitmq.global.messages.delivered.consume_manual_ack.count**
(count) | \[OpenMetrics\] Número total de mensajes entregados a los consumidores utilizando basic.consume con reconocimiento manual
_Se muestra como mensaje_ | +| **rabbitmq.global.messages.delivered.count**
(count) | \[OpenMetrics\] Número total de mensajes entregados a los consumidores
_Se muestra como mensaje_ | +| **rabbitmq.global.messages.delivered.get_auto_ack.count**
(count) | \[OpenMetrics\] Número total de mensajes entregados a los consumidores utilizando basic.get con reconocimiento automático
_Se muestra como mensaje_ | +| **rabbitmq.global.messages.delivered.get_manual_ack.count**
(count) | \[OpenMetrics\] Número total de mensajes entregados a los consumidores utilizando basic.get con reconocimiento manual
_Se muestra como mensaje_ | +| **rabbitmq.global.messages.get_empty.count**
(count) | \[OpenMetrics\] Número total de veces que las operaciones basic.get no han obtenido ningún mensaje.| +| **rabbitmq.global.messages.received.count**
(count) | \[OpenMetrics\] Número total de mensajes recibidos de los publicadores
_Se muestra como mensaje_ | +| **rabbitmq.global.messages.received_confirm.count**
(count) | \[OpenMetrics\] Número total de mensajes recibidos de publicadores que esperan confirmaciones
_Se muestra como mensaje_ | +| **rabbitmq.global.messages.redelivered.count**
(count) | \[OpenMetrics\] Número total de mensajes reenviados a los consumidores
_Se muestra como mensaje_ | +| **rabbitmq.global.messages.routed.count**
(count) | \[OpenMetrics\] Número total de mensajes enrutados a colas o flujos
_Se muestra como mensaje_ | +| **rabbitmq.global.messages.unroutable.dropped.count**
(count) | \[OpenMetrics\] Número total de mensajes publicados como no obligatorios en un intercambio y descartados como no enrutables
_Se muestra como mensaje_ | +| **rabbitmq.global.messages.unroutable.returned.count**
(count) | \[OpenMetrics\] Número total de mensajes publicados como obligatorios en un intercambio y devueltos al publicador como no enrutables
_Se muestra como mensaje_ | +| **rabbitmq.global.publishers**
(gauge) | \[OpenMetrics\] Número actual de publicadores| +| **rabbitmq.identity_info**
(gauge) | \[OpenMetrics\] Información de la identidad de nodos y clústeres RabbitMQ| +| **rabbitmq.io.read_bytes.count**
(count) | \[OpenMetrics\] Número total de bytes de E/S leídos
_Se muestra como bytes_ | +| **rabbitmq.io.read_ops.count**
(count) | \[OpenMetrics\] Número total de operaciones de lectura de E/S
_Se muestra como operación_ | +| **rabbitmq.io.read_time_seconds.count**
(count) | \[OpenMetrics\] Tiempo total de lectura de E/S
_Se muestra en segundos_ | +| **rabbitmq.io.reopen_ops.count**
(count) | \[OpenMetrics\] Número total de veces que se han reabierto archivos| +| **rabbitmq.io.seek_ops.count**
(count) | \[OpenMetrics\] Número total de operaciones de búsqueda de E/S
_Se muestra como operación_ | +| **rabbitmq.io.seek_time_seconds.count**
(count) | \[OpenMetrics\] Tiempo total de búsqueda de E/S
_Se muestra como segundos_ | +| **rabbitmq.io.sync_ops.count**
(count) | \[OpenMetrics\] Número total de operaciones de sincronización de E/S
_Se muestra como operación_ | +| **rabbitmq.io.sync_time_seconds.count**
(count) | \[OpenMetrics\] Tiempo total de sincronización de E/S
_Se muestra como segundos_ | +| **rabbitmq.io.write_bytes.count**
(count) | \[OpenMetrics\] Número total de bytes de E/S escritos
_Se muestra como bytes_ | +| **rabbitmq.io.write_ops.count**
(count) | \[OpenMetrics\] Número total de operaciones de escritura de E/S
_Se muestra como operación_ | +| **rabbitmq.io.write_time_seconds.count**
(count) | \[OpenMetrics\] Tiempo total de escritura de E/S
_Se muestra en segundos_ | +| **rabbitmq.msg_store.read.count**
(count) | \[OpenMetrics\] Número total de operaciones de lectura del almacén de mensajes
_Se muestra como operación_ | +| **rabbitmq.msg_store.write.count**
(count) | \[OpenMetrics\] Número total de operaciones de escritura del almacén de mensajes
_Se muestra como operación_ | +| **rabbitmq.node.disk_alarm**
(gauge) | ¿Tiene el nodo alarma de disco?| +| **rabbitmq.node.disk_free**
(gauge) | Espacio libre actual en disco
_Se muestra como bytes_ | +| **rabbitmq.node.fd_used**
(gauge) | Descriptores de archivo utilizados| +| **rabbitmq.node.mem_alarm**
(gauge) | ¿Tiene el host alarma de memoria?| +| **rabbitmq.node.mem_limit**
(gauge) | Marca de agua alta del uso de memoria en bytes
_Se muestra como bytes_ | +| **rabbitmq.node.mem_used**
(gauge) | Memoria utilizada en bytes
_Se muestra como bytes_ | +| **rabbitmq.node.partitions**
(gauge) | Número de particiones de red que ve este nodo| +| **rabbitmq.node.run_queue**
(gauge) | Número medio de procesos Erlang a la espera de ejecución
_Se muestra como proceso_ | +| **rabbitmq.node.running**
(gauge) | ¿Se está ejecutando el nodo o no?| +| **rabbitmq.node.sockets_used**
(gauge) | Número de descriptores de archivo utilizados como sockets| +| **rabbitmq.overview.messages.ack.count**
(gauge) | Número de mensajes entregados a los clientes y reconocidos
_Se muestra como mensaje_ | +| **rabbitmq.overview.messages.ack.rate**
(gauge) | Tasa de mensajes entregados a clientes y reconocidos por segundo
_Se muestra como mensaje_ | +| **rabbitmq.overview.messages.confirm.count**
(gauge) | Recuento de mensajes confirmados
_Se muestra como mensaje_ | +| **rabbitmq.overview.messages.confirm.rate**
(gauge) | Tasa de mensajes confirmados por segundo
_Se muestra como mensaje_ | +| **rabbitmq.overview.messages.deliver_get.count**
(gauge) | Suma de mensajes entregados en modo de reconocimiento a los consumidores, en modo sin reconocimiento a los consumidores, en modo de reconocimiento en respuesta a basic.get y en modo sin reconocimiento en respuesta a basic.get
_Se muestra como mensaje_ | +| **rabbitmq.overview.messages.deliver_get.rate**
(gauge) | Tasa por segundo de la suma de mensajes entregados en modo de reconocimiento a los consumidores, en modo sin reconocimiento a los consumidores, en modo de reconocimiento en respuesta a basic.get y en modo sin reconocimiento en respuesta a basic.get
_Se muestra como mensaje_ | +| **rabbitmq.overview.messages.drop_unroutable.count**
(gauge) | Recuento de mensajes descartados como no enrutables
_Se muestra como mensaje_ | +| **rabbitmq.overview.messages.drop_unroutable.rate**
(gauge) | Tasa de mensajes descartados como no enrutables por segundo
_Se muestra como mensaje_ | +| **rabbitmq.overview.messages.publish.count**
(gauge) | Recuento de mensajes publicados
_Se muestra como mensaje_ | +| **rabbitmq.overview.messages.publish.rate**
(gauge) | Tasa de mensajes publicados por segundo
_Se muestra como mensaje_ | +| **rabbitmq.overview.messages.publish_in.count**
(gauge) | Recuento de mensajes publicados desde canales en este resumen
_Se muestra como mensaje_ | +| **rabbitmq.overview.messages.publish_in.rate**
(gauge) | Tasa de mensajes publicados desde canales en este resumen por segundo
_Se muestra como mensaje_ | +| **rabbitmq.overview.messages.publish_out.count**
(gauge) | Recuento de mensajes publicados desde este resumen en colas
_Se muestra como mensaje_ | +| **rabbitmq.overview.messages.publish_out.rate**
(gauge) | Tasa de mensajes publicados desde este resumen en colas por segundo
_Se muestra como mensaje_ | +| **rabbitmq.overview.messages.redeliver.count**
(gauge) | Recuento del subconjunto de mensajes en deliver_get que tenían el indicador de reenviado activado
_Se muestra como mensaje_ | +| **rabbitmq.overview.messages.redeliver.rate**
(gauge) | Tasa del subconjunto de mensajes en deliver_get que tenían el indicador de reenviado activado por segundo
__Se muestra como mensaje_ | +| **rabbitmq.overview.messages.return_unroutable.count**
(gauge) | Recuento de mensajes devueltos al publicador como no enrutables
_Se muestra como mensaje_ | +| **rabbitmq.overview.messages.return_unroutable.rate**
(gauge) | Tasa de mensajes devueltos al publicador como no enrutables por segundo
_Se muestra como mensaje_ | +| **rabbitmq.overview.object_totals.channels**
(gauge) | Número total de canales
_Se muestra como elemento_ | +| **rabbitmq.overview.object_totals.connections**
(gauge) | Número total de conexiones
_Se muestra como conexión_ | +| **rabbitmq.overview.object_totals.consumers**
(gauge) | Número total de consumidores
_Se muestra como elemento_ | +| **rabbitmq.overview.object_totals.queues**
(gauge) | Número total de colas
_Se muestra como elemento_ | +| **rabbitmq.overview.queue_totals.messages.count**
(gauge) | Número total de mensajes (listos más no reconocidos)
_Se muestra como mensaje_ | +| **rabbitmq.overview.queue_totals.messages.rate**
(gauge) | Tasa del número de mensajes (listos más no reconocidos)
_Se muestra como mensaje_ | +| **rabbitmq.overview.queue_totals.messages_ready.count**
(gauge) | Número de mensajes listos para su entrega
_Se muestra como mensaje_ | +| **rabbitmq.overview.queue_totals.messages_ready.rate**
(gauge) | Tasa del número de mensajes listos para su entrega
_Se muestra como mensaje_ | +| **rabbitmq.overview.queue_totals.messages_unacknowledged.count**
(gauge) | Número de mensajes no reconocidos
_Se muestra como mensaje_ | +| **rabbitmq.overview.queue_totals.messages_unacknowledged.rate**
(gauge) | Tasa del número de mensajes no reconocidos
_Se muestra como mensaje_ | +| **rabbitmq.process.max_fds**
(gauge) | \[OpenMetrics\] Límite de descriptores de archivo abiertos| +| **rabbitmq.process.max_tcp_sockets**
(gauge) | \[OpenMetrics\] Límite de sockets TCP abiertos| +| **rabbitmq.process.open_fds**
(gauge) | \[OpenMetrics\] Descriptores de archivo abiertos| +| **rabbitmq.process.open_tcp_sockets**
(gauge) | \[OpenMetrics\] Sockets TCP abiertos| +| **rabbitmq.process.resident_memory_bytes**
(gauge) | \[OpenMetrics\] Memoria utilizada en bytes
_Se muestra como bytes_ | +| **rabbitmq.process_start_time_seconds**
(gauge) | \[OpenMetrics\] Tiempo de inicio del proceso desde unix epoch en segundos.
_Se muestra como segundos_ | +| **rabbitmq.queue.active_consumers**
(gauge) | Número de consumidores activos, consumidores que pueden recibir inmediatamente cualquier mensaje enviado a la cola.| +| **rabbitmq.queue.bindings.count**
(gauge) | Número de enlaces para una cola específica| +| **rabbitmq.queue.consumer_capacity**
(gauge) | \[OpenMetrics\] Capacidad de consumo| +| **rabbitmq.queue.consumer_utilisation**
(gauge) | Proporción de tiempo durante el que los consumidores de una cola pueden tomar nuevos mensajes
_Se muestra como fracción_ | +| **rabbitmq.queue.consumers**
(gauge) | Número de consumidores| +| **rabbitmq.queue.disk_reads.count**
(count) | \[OpenMetrics\] Número total de veces que la cola ha leído mensajes del disco| +| **rabbitmq.queue.disk_writes.count**
(count) | \[OpenMetrics\] Número total de veces que la cola ha escrito mensajes en el disco| +| **rabbitmq.queue.get.ack.count**
(count) | \[OpenMetrics\] Número total de mensajes obtenidos de una cola con basic.get en modo de reconocimiento manual.| +| **rabbitmq.queue.get.count**
(count) | \[OpenMetrics\] Número total de mensajes obtenidos de una cola con basic.get en modo de reconocimiento automático.| +| **rabbitmq.queue.get.empty.count**
(count) | \[OpenMetrics\] Número total de veces que las operaciones basic.get no han obtenido ningún mensaje en una cola.| +| **rabbitmq.queue.head_message_timestamp**
(gauge) | \[OpenMetrics, CLI de gestión\] Marca de tiempo del mensaje de cabecera de la marca de tiempo de la cola del primer mensaje de la cola, si lo hay
_Se muestra como milisegundos_ | +| **rabbitmq.queue.index.read_ops.count**
(count) | \[OpenMetrics\] Número total de operaciones de lectura de índices de cola
_Se muestra como operación_ | +| **rabbitmq.queue.index.write_ops.count**
(count) | \[OpenMetrics\] Número total de operaciones de escritura de índices de cola
_Se muestra como operación_ | +| **rabbitmq.queue.memory**
(gauge) | Bytes de memoria consumidos por el proceso Erlang asociado a la cola, incluyendo stack tecnológico, heap y estructuras internas
_Se muestra como bytes_ | +| **rabbitmq.queue.message_bytes**
(gauge) | Número de bytes de mensajes listos para ser entregados a los clientes
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages**
(gauge) | \[OpenMetrics, CLI de gestión\] Recuento del total de mensajes en la cola, que es la suma de mensajes listos y no reconocidos (profundidad total de la cola)
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages.ack.count**
(gauge) | Número de mensajes en cola entregados a clientes y reconocidos
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages.ack.rate**
(gauge) | Número por segundo de mensajes entregados a clientes y reconocidos
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages.acked.count**
(count) | \[OpenMetrics\] Número total de mensajes reconocidos por los consumidores en una cola| +| **rabbitmq.queue.messages.bytes**
(gauge) | \[OpenMetrics\] Tamaño en bytes de los mensajes listos y no reconocidos
_Se muestra como bytes_ | +| **rabbitmq.queue.messages.deliver.count**
(gauge) | Recuento de mensajes entregados en modo de reconocimiento a los consumidores
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages.deliver.rate**
(gauge) | Tasa de mensajes entregados en modo de reconocimiento a los consumidores
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages.deliver_get.count**
(gauge) | Suma de mensajes en colas entregados en modo de reconocimiento a los consumidores, en modo sin reconocimiento a los consumidores, en modo de reconocimiento en respuesta a basic.get y en modo sin reconocimiento en respuesta a basic.get.
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages.deliver_get.rate**
(gauge) | Tasa por segundo de la suma de mensajes en colas entregados en modo de reconocimiento a los consumidores, en modo sin reconocimiento a los consumidores, en modo de reconocimiento en respuesta a basic.get y en modo sin reconocimiento en respuesta a basic.get.
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages.delivered.ack.count**
(count) | \[OpenMetrics\] Número total de mensajes entregados desde una cola a los consumidores en modo de reconocimiento automático.| +| **rabbitmq.queue.messages.delivered.count**
(count) | \[OpenMetrics\] Número total de mensajes entregados desde una cola a los consumidores en modo de reconocimiento automático.| +| **rabbitmq.queue.messages.paged_out**
(gauge) | \[OpenMetrics\] Mensajes paginados al disco| +| **rabbitmq.queue.messages.paged_out_bytes**
(gauge) | \[OpenMetrics\] Tamaño en bytes de los mensajes paginados al disco
_Se muestra como bytes_ | +| **rabbitmq.queue.messages.persistent**
(gauge) | \[OpenMetrics\] Mensajes persistentes
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages.persistent_bytes**
(gauge) | \[OpenMetrics\] Tamaño en bytes de los mensajes persistentes
_Se muestra como bytes_ | +| **rabbitmq.queue.messages.publish.count**
(gauge) | Recuento de mensajes en colas publicados
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages.publish.rate**
(gauge) | Tasa por segundo de mensajes publicados
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages.published.count**
(count) | \[OpenMetrics\] Número total de mensajes publicados en colas
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages.ram**
(gauge) | \[OpenMetrics\] Mensajes listos y no reconocidos almacenados en memoria
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages.ram_bytes**
(gauge) | \[OpenMetrics\] Tamaño de los mensajes listos y no reconocidos almacenados en memoria
_Se muestra como byte_ | +| **rabbitmq.queue.messages.rate**
(gauge) | Recuento por segundo del total de mensajes en la cola
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages.ready**
(gauge) | \[OpenMetrics\] Mensajes listos para ser entregados a los consumidores
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages.ready_bytes**
(gauge) | \[OpenMetrics\] Tamaño en bytes de los mensajes listos
_Se muestra como bytes_ | +| **rabbitmq.queue.messages.ready_ram**
(gauge) | \[OpenMetrics\] Mensajes listos almacenados en memoria
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages.redeliver.count**
(gauge) | Recuento del subconjunto de mensajes en colas en deliver_get que tenían el indicador de reenviado activado
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages.redeliver.rate**
(gauge) | Tasa por segundo del subconjunto de mensajes en deliver_get que tenían el indicador de reenviado activado
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages.redelivered.count**
(count) | \[OpenMetrics\] Número total de mensajes redistribuidos desde una cola a los consumidores| +| **rabbitmq.queue.messages.unacked**
(gauge) | \[OpenMetrics\] Mensajes entregados a los consumidores pero aún no reconocidos
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages.unacked_bytes**
(gauge) | \[OpenMetrics\] Tamaño en bytes de todos los mensajes no reconocidos
_Se muestra como bytes_ | +| **rabbitmq.queue.messages.unacked_ram**
(gauge) | \[OpenMetrics\] Mensajes no reconocidos almacenados en memoria
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages_ready**
(gauge) | Número de mensajes listos para ser entregados a los clientes
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages_ready.rate**
(gauge) | Número por segundo de mensajes listos para ser entregados a los clientes
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages_unacknowledged**
(gauge) | Número de mensajes entregados a clientes pero aún no reconocidos
_Se muestra como mensaje_ | +| **rabbitmq.queue.messages_unacknowledged.rate**
(gauge) | Número por segundo de mensajes entregados a clientes pero aún no reconocidos
_Se muestra como mensaje_ | +| **rabbitmq.queue.process_memory_bytes**
(gauge) | \[OpenMetrics\] Memoria en bytes utilizada por el proceso de cola Erlang
_Se muestra como bytes_ | +| **rabbitmq.queue.process_reductions.count**
(count) | \[OpenMetrics\] Número total de reducciones de procesos de cola| +| **rabbitmq.queues**
(gauge) | \[OpenMetrics\] Colas disponibles| +| **rabbitmq.queues.created.count**
(count) | \[OpenMetrics\] Número total de colas creadas| +| **rabbitmq.queues.declared.count**
(count) | \[OpenMetrics\] Número total de colas declaradas| +| **rabbitmq.queues.deleted.count**
(count) | \[OpenMetrics\] Número total de colas eliminadas| +| **rabbitmq.raft.entry_commit_latency_seconds**
(gauge) | \[OpenMetrics\] Tiempo que tarda en confirmarse una entrada de log
_Se muestra como segundos_ | +| **rabbitmq.raft.log.commit_index**
(gauge) | \[OpenMetrics] Índice de confirmación de logs Raft| +| **rabbitmq.raft.log.last_applied_index**
(gauge) | \[OpenMetrics\] Último índice de logs Raft aplicado| +| **rabbitmq.raft.log.last_written_index**
(gauge) | \[OpenMetrics\] Último índice de logs Raft escrito| +| **rabbitmq.raft.log.snapshot_index**
(gauge) | \[OpenMetrics\] Índice de snapshots de logs Raft| +| **rabbitmq.raft.term.count**
(count) | \[OpenMetrics\] Número de término Raft actual| +| **rabbitmq.resident_memory_limit_bytes**
(gauge) | \[OpenMetrics\] Marca de agua alta de memoria en bytes
_Se muestra como bytes_ | +| **rabbitmq.schema.db.disk_tx.count**
(count) | \[OpenMetrics\] Número total de transacciones de disco Schema DB
_Se muestra como transacción_ | +| **rabbitmq.schema.db.ram_tx.count**
(count) | \[OpenMetrics\] Número total de transacciones de memoria Schema DB
_Se muestra como transacción_ | +| **rabbitmq.telemetry.scrape.duration_seconds.count**
(count) | \[OpenMetrics\] Duración del raspado
_Se muestra como segundos_ | +| **rabbitmq.telemetry.scrape.duration_seconds.sum**
(count) | \[OpenMetrics\] Duración del raspado
_Se muestra como segundos_ | +| **rabbitmq.telemetry.scrape.encoded_size_bytes.count**
(count) | \[OpenMetrics\] Tamaño de raspado, codificado
_Se muestra como bytes_ | +| **rabbitmq.telemetry.scrape.encoded_size_bytes.sum**
(count) | \[OpenMetrics\] Tamaño de raspado, codificado
_Se muestra como bytes_ | +| **rabbitmq.telemetry.scrape.size_bytes.count**
(count) | \[OpenMetrics\] Tamaño de raspado, no codificado
_Se muestra como bytes_ | +| **rabbitmq.telemetry.scrape.size_bytes.sum**
(count) | \[OpenMetrics\] Tamaño de raspado, no codificado
_Se muestra como bytes_ | + +### Eventos + +### Checks de servicio + +**rabbitmq.aliveness** + +Solo disponible con el complemento de gestión de RabbitMQ. Devuelve el estado de un vhost basado en la [API Aliveness](https://github.com/rabbitmq/rabbitmq-management/blob/rabbitmq_v3_6_8/priv/www/api/index.html) de RabbitMQ. La API Aliveness crea una cola de test, luego publica y consume un mensaje de esa cola. Devuelve `OK` si el código de estado de la API es 200 y `CRITICAL` en caso contrario. + +_Estados: ok, crítico_ + +**rabbitmq.status** + +Solo disponible con el complemento de gestión de RabbitMQ. Devuelve el estado del servidor RabbitMQ. Devuelve `OK` si el Agent ha podido contactar con la API y `CRITICAL` en caso contrario. + +_Estados: ok, crítico_ + +**rabbitmq.openmetrics.health** + +Solo disponible con el complemento RabbitMQ Prometheus. Devuelve `CRITICAL` si el Agent no puede conectarse al endpoint de OpenMetrics y `OK` en caso contrario. + +_Estados: ok, crítico_ + +## Solucionar problemas + +### Migración al complemento Prometheus + +El complemento Prometheus expone un conjunto diferente de métricas del complemento de gestión. +Esto es lo que debes tener en cuenta al migrar del complemento de gestión a Prometheus. + +- Busca tus métricas en [esta tabla](https://docs.datadoghq.com/integrations/rabbitmq/?tab=host#metrics).. Si la descripción de una métrica contiene una etiqueta `[OpenMetrics]`, significa que está disponible en el complemento Prometheus. Las métricas que solo están disponibles en el complemento de gestión no tienen etiquetas en sus descripciones. +- Todos los dashboards y monitores que utilizan métricas del complemento de gestión no funcionarán. Cambia a los dashboards y a los monitores marcados como *OpenMetrics Version*. +- La configuración por defecto recopila métricas agregadas. Esto significa, por ejemplo, que no hay métricas etiquetadas por cola. Configura la opción `prometheus_plugin.unaggregated_endpoint` para obtener métricas sin agregación. +- El check de servicio `rabbitmq.status` se sustituye por `rabbitmq.openmetrics.health`. El check de servicio `rabbitmq.aliveness` no tiene equivalente en el complemento Prometheus. + +El complemento Prometheus modifica algunas etiquetas. En la siguiente tabla se describen los cambios de las etiquetas más comunes. + +| Gestión | Prometheus | +|:--------------------|:-----------------------------------------| +| `queue_name` | `queue` | +| `rabbitmq_vhost` | `vhost`, `exchange_vhost`, `queue_vhost` | +| `rabbitmq_exchange` | `exchange` | + +Para obtener más información, consulta [Etiquetado de colas RabbitMQ por familia de etiquetas](https://docs.datadoghq.com/integrations/faq/tagging-rabbitmq-queues-by-tag-family/). + +¿Necesitas ayuda? Ponte en contacto con el [servicio de asistencia de Datadog](https://docs.datadoghq.com/help/). + +## Referencias adicionales + +Documentación útil adicional, enlaces y artículos: + +- [Métricas clave para la monitorización de RabbitMQ](https://www.datadoghq.com/blog/rabbitmq-monitoring) +- [Recopilación de métricas con las herramientas de monitorización de RabbitMQ](https://www.datadoghq.com/blog/rabbitmq-monitoring-tools) +- [Monitorización del rendimiento de RabbitMQ con Datadog](https://www.datadoghq.com/blog/monitoring-rabbitmq-performance-with-datadog) \ No newline at end of file diff --git a/content/es/integrations/solr.md b/content/es/integrations/solr.md new file mode 100644 index 0000000000000..f2c8e86a2d02c --- /dev/null +++ b/content/es/integrations/solr.md @@ -0,0 +1,324 @@ +--- +"app_id": "solr" +"app_uuid": "3733c24e-8466-4f3b-8411-59ef85c28302" +"assets": + "dashboards": + "solr": "assets/dashboards/solr_overview.json" + "integration": + "auto_install": true + "configuration": + "spec": "assets/configuration/spec.yaml" + "events": + "creates_events": false + "metrics": + "check": "solr.searcher.numdocs" + "metadata_path": "metadata.csv" + "prefix": "solr." + "process_signatures": + - "solr start" + "service_checks": + "metadata_path": "assets/service_checks.json" + "source_type_id": !!int "42" + "source_type_name": "Solr" + "saved_views": + "solr_processes": "assets/saved_views/solr_processes.json" +"author": + "homepage": "https://www.datadoghq.com" + "name": "Datadog" + "sales_email": "info@datadoghq.com" + "support_email": "help@datadoghq.com" +"categories": +- "caching" +- "data stores" +- "log collection" +"custom_kind": "integración" +"dependencies": +- "https://github.com/DataDog/integrations-core/blob/master/solr/README.md" +"display_on_public_website": true +"draft": false +"git_integration_title": "solr" +"integration_id": "solr" +"integration_title": "Solr" +"integration_version": "2.1.0" +"is_public": true +"manifest_version": "2.0.0" +"name": "solr" +"public_title": "Solr" +"short_description": "Monitoriza tasa de solicitudes, errores de gestor, fallos de caché y desalojos y más." +"supported_os": +- "linux" +- "windows" +- "macos" +"tile": + "changelog": "CHANGELOG.md" + "classifier_tags": + - "Category::Caching" + - "Category::Data Stores" + - "Category::Log Collection" + - "Supported OS::Linux" + - "Supported OS::Windows" + - "Supported OS::macOS" + - "Offering::Integration" + "configuration": "README.md#Setup" + "description": "Monitoriza tasa de solicitudes, errores de gestor, fallos de caché y desalojos y más." + "media": [] + "overview": "README.md#Overview" + "support": "README.md#Support" + "title": "Solr" +--- + + + + +![Gráfico de Solr][1] + +## Información general + +El check de Solr realiza un seguimiento del estado y el rendimiento de un clúster de Solr. Recopila métricas del número de documentos indexados, los aciertos y desalojos de la caché, los tiempos medios de solicitud, las solicitudes medias por segundo, etc. + +## Configuración + +### Instalación + +El check de Solr está incluido en el paquete del [Datadog Agent][2], por lo que no necesitas instalar nada más en tus nodos de Solr. + +Este check está basado en JMX, por lo que necesitas habilitar JMX Remote en tus servidores de Solr. Consulta la [documentación del check de JMX][3] para obtener más información. + +### Configuración + +{{< tabs >}} +{{% tab "Host" %}} + +#### Host + +Para configurar este check para un Agent que se ejecuta en un host: + +1. Edita el archivo `solr.d/conf.yaml` en la carpeta `conf.d/` en la raíz del [directorio de configuración de tu Agent][1]. Para conocer todas las opciones de configuración disponibles, consulta el [solr.d/conf.yaml de ejemplo][2]. + + ```yaml + init_config: + + ## @param is_jmx - boolean - required + ## Whether or not this file is a configuration for a JMX integration. + # + is_jmx: true + + ## @param collect_default_metrics - boolean - required + ## Whether or not the check should collect all default metrics. + # + collect_default_metrics: true + + instances: + ## @param host - string - required + ## Solr host to connect to. + - host: localhost + + ## @param port - integer - required + ## Solr port to connect to. + port: 9999 + ``` + +2. [Reinicia el Agent][3]. + +#### Lista de métricas + +El parámetro `conf` es una lista de métricas que recopilará la integración. Solo se admiten 2 claves: + +- `include` (**obligatorio**): un diccionario de filtros, cualquier atributo que coincida con estos filtros se recopila a menos que también coincida con los filtros `exclude` (ver más abajo). +- `exclude` (**opcional**): un diccionario de filtros, los atributos que coinciden con estos filtros no se recopilan. + +Para un bean dado, las métricas se etiquetan de la siguiente manera: + +```text +mydomain:attr0=val0,attr1=val1 +``` + +En este ejemplo, tu métrica es `mydomain` (o alguna variación según el atributo dentro del bean) y tiene las etiquetas `attr0:val0`, `attr1:val1` y `domain:mydomain`. + +Si especificas un alias en una clave `include` con formato _camel case_, se convierte a _snake case_. Por ejemplo, `MyMetricName` aparece en Datadog como `my_metric_name`. + +##### El filtro de atributos + +El filtro `attribute` puede aceptar dos tipos de valores: + +- Un diccionario cuyas claves son nombres de atributos (ver más adelante). Para este caso, puedes especificar un alias para la métrica que se convierte en el nombre de métrica en Datadog. También puedes especificar el tipo de métrica como gauge o count. Si eliges count, se calcula una tasa por segundo para la métrica. + + ```yaml + conf: + - include: + attribute: + maxThreads: + alias: tomcat.threads.max + metric_type: gauge + currentThreadCount: + alias: tomcat.threads.count + metric_type: gauge + bytesReceived: + alias: tomcat.bytes_rcvd + metric_type: counter + ``` + +- Una lista de nombres de atributos (ver más abajo). Para este caso, el tipo de métrica es un gauge y el nombre de métrica es `jmx.\[DOMAIN_NAME].\[ATTRIBUTE_NAME]`. + + ```yaml + conf: + - include: + domain: org.apache.cassandra.db + attribute: + - BloomFilterDiskSpaceUsed + - BloomFilterFalsePositives + - BloomFilterFalseRatio + - Capacity + - CompressionRatio + - CompletedTasks + - ExceptionCount + - Hits + - RecentHitRate + ``` + +#### Versiones anteriores + +La lista de filtros solo se admite en el Datadog Agent > 5.3.0. Si utilizas una versión anterior, utiliza singletons y varias sentencias `include` en su lugar. + +```yaml +# Datadog Agent > 5.3.0 + conf: + - include: + domain: domain_name + bean: + - first_bean_name + - second_bean_name +# Older Datadog Agent versions + conf: + - include: + domain: domain_name + bean: first_bean_name + - include: + domain: domain_name + bean: second_bean_name +``` + +[1]: https://docs.datadoghq.com/agent/guide/agent-configuration-files/#agent-configuration-directory +[2]: https://github.com/DataDog/integrations-core/blob/master/solr/datadog_checks/solr/data/conf.yaml.example +[3]: https://docs.datadoghq.com/agent/guide/agent-commands/#start-stop-and-restart-the-agent +{{% /tab %}} +{{% tab "Contenedorizado" %}} + +#### Contenedores + +Para obtener información sobre entornos en contenedores, consulta la guía [Autodiscovery con JMX][1]. + +##### Recopilación de logs + +1. La recopilación de logs está desactivada por defecto en el Datadog Agent, actívala en tu archivo `datadog.yaml`: + + ```yaml + logs_enabled: true + ``` + +2. Solr utiliza el registrador `log4j` por defecto. Para personalizar el formato de registro, edita el archivo [`server/resources/log4j2.xml`][2]. Por defecto, el pipeline de la integración de Datadog admite el siguiente [patrón][3] de conversión: + + ```text + %maxLen{%d{yyyy-MM-dd HH:mm:ss.SSS} %-5p (%t) [%X{collection} %X{shard} %X{replica} %X{core}] %c{1.} %m%notEmpty{ =>%ex{short}}}{10240}%n + ``` + + Clona y edita el [pipeline de integración][4] si tienes un formato diferente. + + +3. Anula los comentarios y edita el bloque de configuración de logs en tu archivo `solr.d/conf.yaml`. Cambia los valores de los parámetros `type`, `path` y `service` en función de tu entorno. Consulta [solr.d/solr.yaml de ejemplo][5] para conocer todas las opciones disponibles de configuración. + + ```yaml + logs: + - type: file + path: /var/solr/logs/solr.log + source: solr + # To handle multi line that starts with yyyy-mm-dd use the following pattern + # log_processing_rules: + # - type: multi_line + # pattern: \d{4}\-(0?[1-9]|1[012])\-(0?[1-9]|[12][0-9]|3[01]) + # name: new_log_start_with_date + ``` + +4. [Reinicia el Agent][6]. + +Para habilitar logs para entornos de Kubernetes, consulta [Recopilación de log de Kubernetes][7]. + +[1]: https://docs.datadoghq.com/agent/guide/autodiscovery-with-jmx/?tab=containerizedagent +[2]: https://lucene.apache.org/solr/guide/configuring-logging.html#permanent-logging-settings +[3]: https://logging.apache.org/log4j/2.x/manual/layouts.html#Patterns +[4]: https://docs.datadoghq.com/logs/processing/#integration-pipelines +[5]: https://github.com/DataDog/integrations-core/blob/master/solr/datadog_checks/solr/data/conf.yaml.example +[6]: https://docs.datadoghq.com/agent/guide/agent-commands/#start-stop-and-restart-the-agent +[7]: https://docs.datadoghq.com/agent/docker/log/ +{{% /tab %}} +{{< /tabs >}} + +### Validación + +[Ejecuta el subcomando de estado del Agent][4] y busca `solr` en la sección Checks. + +## Datos recopilados + +### Métricas +{{< get-metrics-from-git "solr" >}} + + +### Eventos + +El check de Solr no incluye ningún evento. + +### Checks de servicio +{{< get-service-checks-from-git "solr" >}} + + +## Solucionar problemas + +### Comandos para ver las métricas disponibles + +El comando `datadog-agent jmx` se añadió en la versión 4.1.0. + +- Mostrar una lista de atributos que coincidan con, al menos, una de tus configuraciones de instancias: + `sudo datadog-agent jmx list matching` +- Mostrar una lista de atributos que coinciden con una de tus configuraciones de instancias, pero no se recopilan porque se superaría el número de métricas que es posible recopilar. + `sudo datadog-agent jmx list limited` +- Mostrar una lista de atributos que se espera que recopile tu configuración de instancias actual: + `sudo datadog-agent jmx list collected` +- Mostrar una lista de atributos que no coincidan con ninguna de tus configuraciones de instancias: + `sudo datadog-agent jmx list not-matching` +- Mostrar cada atributo disponible que tenga un tipo compatible con JMXFetch: + `sudo datadog-agent jmx list everything` +- Iniciar la recopilación de métricas según tu configuración actual y mostrarlas en la consola: + `sudo datadog-agent jmx collect` + +¿Necesitas ayuda? Ponte en contacto con el [servicio de asistencia de Datadog][5]. + +## Referencias adicionales + +### Parseo de un valor de cadena en un número + +Si tu jmxfetch devuelve solo valores de cadena como **false** y **true** y quieres transformarlo en una métrica gauge de Datadog para usos avanzados. Por ejemplo, si deseas la siguiente equivalencia para tu jmxfetch: + +```text +"myJmxfetch:false" = myJmxfetch:0 +"myJmxfetch:true" = myJmxfetch:1 +``` + +Puedes utilizar el filtro `attribute` como se indica a continuación: + +```yaml +# ... +attribute: + myJmxfetch: + alias: your_metric_name + metric_type: gauge + values: + "false": 0 + "true": 1 +``` + + +[1]: https://raw.githubusercontent.com/DataDog/integrations-core/master/solr/images/solrgraph.png +[2]: https://app.datadoghq.com/account/settings/agent/latest +[3]: https://docs.datadoghq.com/integrations/java/ +[4]: https://docs.datadoghq.com/agent/guide/agent-commands/#agent-status-and-information +[5]: https://docs.datadoghq.com/help/ diff --git a/content/es/integrations/spark.md b/content/es/integrations/spark.md new file mode 100644 index 0000000000000..df281b7de5933 --- /dev/null +++ b/content/es/integrations/spark.md @@ -0,0 +1,232 @@ +--- +"app_id": "spark" +"app_uuid": "5cb22455-9ae2-44ee-ae05-ec21c27b3292" +"assets": + "dashboards": + "Databricks Spark Overview": "assets/dashboards/databricks_overview.json" + "spark": "assets/dashboards/spark_dashboard.json" + "integration": + "auto_install": true + "configuration": + "spec": "assets/configuration/spec.yaml" + "events": + "creates_events": false + "metrics": + "check": "spark.job.count" + "metadata_path": "metadata.csv" + "prefix": "spark." + "process_signatures": + - "java org.apache.spark.deploy.SparkSubmit" + - "java org.apache.spark.deploy.worker.Worker" + - "java org.apache.spark.deploy.master.Master" + "service_checks": + "metadata_path": "assets/service_checks.json" + "source_type_id": !!int "142" + "source_type_name": "Spark" +"author": + "homepage": "https://www.datadoghq.com" + "name": "Datadog" + "sales_email": "info@datadoghq.com" + "support_email": "help@datadoghq.com" +"categories": +- "log collection" +"custom_kind": "integración" +"dependencies": +- "https://github.com/DataDog/integrations-core/blob/master/spark/README.md" +"display_on_public_website": true +"draft": false +"git_integration_title": "spark" +"integration_id": "spark" +"integration_title": "Spark" +"integration_version": "6.4.0" +"is_public": true +"manifest_version": "2.0.0" +"name": "spark" +"public_title": "Spark" +"short_description": "Rastrea los índices de tareas fallidas, bytes aleatorios y mucho más." +"supported_os": +- "linux" +- "windows" +- "macos" +"tile": + "changelog": "CHANGELOG.md" + "classifier_tags": + - "Category::Log Collection" + - "Supported OS::Linux" + - "Supported OS::Windows" + - "Supported OS::macOS" + - "Offering::Integration" + "configuration": "README.md#Setup" + "description": "Rastrea los índices de tareas fallidas, bytes aleatorios y mucho más." + "media": [] + "overview": "README.md#Overview" + "resources": + - "resource_type": "blog" + "url": "https://www.datadoghq.com/blog/data-jobs-monitoring/" + - "resource_type": "blog" + "url": "https://www.datadoghq.com/blog/data-observability-monitoring/" + - "resource_type": "blog" + "url": "https://www.datadoghq.com/blog/monitoring-spark" + - "resource_type": "blog" + "url": "https://www.datadoghq.com/blog/spark-emr-monitoring/" + "support": "README.md#Support" + "title": "Spark" +--- + + + + +
+Data Jobs Monitoring te ayuda a observar, solucionar problemas y optimizar los costes de tus trabajos de Spark y Databricks y clústeres.
+Esta página solo documenta cómo ingerir métricas y logs de Spark. +
+
+![Gráfico de Spark][1]
+
+## Información general
+
+Este check monitoriza [Spark][2] a través del Datadog Agent. Recopila métricas de Spark para:
+
+- Controladores y ejecutores: bloques RDD, memoria utilizada, disco utilizado, duración, etc.
+- RDDs: recuento de particiones, memoria utilizada y disco utilizado.
+- Tareas: número de tareas activas, omitidas, fallidas y totales.
+- Estado del trabajo: número de trabajos activos, completados, omitidos y fallidos.
+
+## Configuración
+
+### Instalación
+
+El check de Spark está incluido en el paquete del [Datadog Agent][3]. No es necesaria ninguna instalación adicional en tu nodo maestro de Mesos (para Spark on Mesos), YARN ResourceManager (para Spark on YARN), o nodo maestro de Spark (para Spark Standalone).
+
+### Configuración
+
+{{< tabs >}}
+{{% tab "Host" %}}
+
+#### Host
+
+Para configurar este check para un Agent que se ejecuta en un host:
+
+1. Edita el archivo `spark.d/conf.yaml`, que se encuentra en la carpeta `conf.d/` en la [raíz del directorio de configuración del Agent][1]. Puede que sea necesario actualizar los siguientes parámetros. Para conocer todas las opciones de configuración disponibles, consulta el [spark.d/conf.yaml de ejemplo][2].
+
+ ```yaml
+ init_config:
+
+ instances:
+ - spark_url: http://localhost:8080 # Spark master web UI
+ # spark_url: http://+Esta página solo documenta cómo ingerir métricas y logs de Spark. +
En esta página, se describe la integración estándar del Agent de SQL Server. Si buscas el producto de Monitorización de base de datos para SQL Server, consulta Monitorización de base de datos de Datadog.
+
+### Instalación
+
+El check de SQL Server se incluye en el paquete del [Datadog Agent][3]. No es necesaria ninguna instalación adicional en tus instancias de SQL Server.
+
+Asegúrate de que tu instancia de SQL Server admite la autenticación de SQL Server activando el "Modo de autenticación de SQL Server y Windows" en las propiedades del servidor:
+
+_Propiedades del servidor_ -> _Seguridad_ -> _Modo de autenticación de SQL Server y Windows_
+
+### Requisito previo
+
+**Nota**: Para instalar la Monitorización de base de datos para SQL Server, selecciona tu solución de alojamiento en el [sitio de documentación][4] para obtener instrucciones.
+
+Las versiones de SQL Server admitidas para el check de SQL Server son las mismas que para la Monitorización de base de datos. Visita la página [Configuración de SQL Server][5] para ver las versiones soportadas actualmente bajo el título **Autoalojado**.
+
+Procede con los siguientes pasos de esta guía solo si vas a instalar la integración estándar únicamente.
+
+1. Crea un inicio de sesión de sólo lectura para conectarse a tu servidor:
+
+ ```SQL
+ CREATE LOGIN datadog WITH PASSWORD = 'Cuando se utilizan marcos compatibles, no es necesario crear manualmente tramos (spans) para las llamadas LLM. El SDK crea automáticamente los tramos adecuados con metadatos enriquecidos.
+
+#### Instrumentación personalizada
+Todos los SDK compatibles proporcionan capacidades avanzadas para la instrumentación personalizada de tus aplicaciones LLM, además de la instrumentación automática, incluyendo:
+- Creación manual de tramos mediante decoradores de funciones o gestores de contextos
+- Rastreo de flujos de trabajo complejos para aplicaciones LLM de varios pasos
+- Monitorización de agentes para agentes LLM autónomos
+- Evaluaciones personalizadas y mediciones de calidad
+- Seguimiento de la sesión para ver interacciones de usuarios
+
+Para obtener más información, consulta la [documentación de referencia del SDK][2].
+
+### Instrumentación de la API HTTP
+Si tu lenguaje no es compatible con los SDK o si utilizas integraciones personalizadas, puedes instrumentar tu aplicación utilizando la API HTTP de Datadog.
+
+La API te permite:
+- Enviar tramos directamente a través de endpoints HTTP
+- Enviar evaluaciones personalizadas asociadas a tramos
+- Incluir jerarquías completas de trazas de aplicaciones complejas
+- Anotar tramos con entradas, salidas, metadatos y métricas
+
+Endpoints de API:
+- [API de tramos][4]: `POST` `https://api.{{< region-param key="dd_site" code="true" >}}/api/intake/llm-obs/v1/trace/spans`
+- [API de evaluaciones][5]: `POST` `https://api.{{< region-param key="dd_site" code="true" >}}/api/intake/llm-obs/v2/eval-metric`
+
+Para obtener más información, consulta la [documentación de la API HTTP][3].
+
+## Referencias adicionales
+
+{{< partial name="whats-next/whats-next.html" >}}
+
+
+[1]: /es/llm_observability/auto_instrumentation
+[2]: /es/llm_observability/instrumentation/sdk
+[3]: /es/llm_observability/setup/api
+[4]: /es/llm_observability/instrumentation/api/?tab=model#spans-api
+[5]: /es/llm_observability/instrumentation/api/?tab=model#evaluations-api
+[6]: /es/llm_observability/instrumentation/sdk#command-line-setup
+[7]: /es/llm_observability/instrumentation/sdk#in-code-setup
\ No newline at end of file
diff --git a/content/es/llm_observability/monitoring/_index.md b/content/es/llm_observability/monitoring/_index.md
index e172c52b080f9..a992656a90dec 100644
--- a/content/es/llm_observability/monitoring/_index.md
+++ b/content/es/llm_observability/monitoring/_index.md
@@ -1,9 +1,77 @@
---
+description: Explorar aún más tu aplicación en LLM Observability.
title: Monitorización
---
-{{< whatsnext desc="Esta sección incluye los siguientes temas:">}}
- {{< nextlink href="/llm_observability/monitoring/llm_observability_and_apm">}}Conecta LLM Observability con APM: vincular tramos de LLM Observability con tramos de Datadog APM{{< /nextlink >}}
- {{< nextlink href="/llm_observability/monitoring/cluster_map">}}Mapa de clúster: uso de la visualización del Mapa de clúster de LLM Observability{{< /nextlink >}}
- {{< nextlink href="/llm_observability/monitoring/agent_monitoring">}}Monitorización del Agent: monitorización de aplicaciones de Agentic LLM{{< /nextlink >}}
-{{< /whatsnext >}}
\ No newline at end of file
+## Información general
+
+Explora y analiza tus aplicaciones LLM en producción con herramientas para consultar, visualizar, correlacionar e investigar datos en trazas (traces), clústeres y otros recursos.
+
+Monitoriza el rendimiento, corrige los problemas, evalúa la calidad y protege tus sistemas basados en LLM con una visibilidad unificada de trazas, métricas y evaluaciones en línea.
+
+### Monitorización del rendimiento en tiempo real
+
+Monitoriza el estado operativo de tu aplicación LLM con métricas y dashboards integrados:
+
+{{< img src="llm_observability/index/llm_dashboard_light.png" alt="Dashboard de información operativa de LLM Observability, que muestra diversas métricas y visualizaciones. Incluye una sección de información general con el número total de trazas y tramos (spans), índices de acierto y error, etc., y una sección de llamadas LLM con un gráfico circular del uso de modelos, la media de tokens de entrada y salida por llamada, etc." style="width:100%">}}
+
+- **Volumen y latencia de solicitudes**: Realiza un seguimiento de las solicitudes por segundo, los tiempos de respuesta y los cuellos de botella de rendimiento en diferentes modelos, operaciones y endpoints.
+- **Seguimiento de errores**: Monitoriza errores HTTP, tiempos de espera del modelo y solicitudes fallidas con el contexto de error detallado.
+- **Consumo de tokens**: Realiza un seguimiento de los tokens de solicitudes, los tokens almacenados en caché, los tokens de finalización y el uso total para optimizar los costes.
+- **Análisis del uso de modelos**: Monitoriza qué modelos están siendo llamandos, sus frecuencias y sus características de rendimiento.
+
+El [dashboard de información operativa de LLM Observability][6] proporciona vistas consolidadas de métricas a nivel de traza y de tramo, índices de error, desgloses de latencia, tendencias de consumo de tokens y monitores activados.
+
+### Corrección y resolución de problemas de producción
+
+Depura flujos de trabajo LLM complejos con una visibilidad detallada de la ejecución:
+
+{{< img src="llm_observability/index/llm_trace_light.png" alt="Vista detallada de una traza en LLM Observability, que muestra un gráfico de llama que representa visualmente cada llamada a un servicio. 'OpenAI.createResponse' está seleccionado y se muestra una vista detallada del tramo, que incluye los mensajes de entrada y los mensajes de salida." style="width:100%">}}
+
+- **Análisis de trazas de extremo a extremo**: Visualiza los flujos completos de solicitudes, desde la entrada del usuario hasta las llamadas al modelo, las llamadas a las herramientas y la generación de respuestas.
+- **Depuración a nivel de tramo**: Examina las operaciones individuales dentro de las cadenas, incluyendo los pasos de preprocesamiento, las llamadas al modelo y la lógica de postprocesamiento.
+- **Identificación de las causas de error**: Identifica los puntos de fallo en las cadenas de varios pasos, los flujos de trabajo o las operaciones agénticas con información detallada del contexto y el momento del error.
+- **Identificación de los cuellos de botella**: Busca las operaciones lentas y optimízalas en función de los desgloses de latencia de los componentes de flujos de trabajo.
+
+### Evaluaciones de calidad y seguridad
+
+{{< img src="llm_observability/index/llm_example_eval_light.png" alt="Vista detallada de un tramo en la pestaña Evaluations (Evaluaciones) de LLM Observability, que muestra una evaluación de alucinaciones con 'Contradicción confirmada', la salida marcada, la cuota de contexto y una explicación de pr qué se ha marcado." style="width:100%">}}
+
+Asegúrate de que tus agentes o aplicaciones LLM cumplen las normas de calidad con evaluaciones en línea. Para obtener información completa sobre las evaluaciones alojadas y gestionadas en Datadog, la ingesta de evaluaciones personalizadas y las funciones de monitorización de la seguridad, consults la [documentación sobre evaluaciones][5].
+
+### Consultar trazas y tramos de tu aplicación LLM
+
+{{< img src="llm_observability/index/llm_query_example_light.png" alt="Vista LLM Observability > Trazas, donde el usuario ha ingresado la consulta`ml_app:shopist-chat-v2 'purchase' -'discount' @trace.total_tokens:>=20` y se muestran varias trazas." style="width:100%">}}
+
+Aprende a utilizar la interfaz de consulta de LLM Observability de Datadog para buscar, filtrar y analizar las trazas y los tramos generados por tus aplicaciones LLM. La [documentación sobre consultas][1] explica cómo hacerlo:
+
+- Utiliza la barra de búsqueda para filtrar las trazas y los tramos por atributos como modelo, usuario o estado de error.
+- Aplica filtros avanzados para centrarte en operaciones o plazos específicos de LLM.
+- Visualiza e inspecciona detalles de trazas para solucionar problemas y optimizar tus flujos de trabajo LLM.
+
+Esto te permite identificar rápidamente los problemas, monitorizar el rendimiento y obtener información sobre el comportamiento de tu aplicación LLM en producción.
+
+
+### Correlacionar APM y LLM Observability
+
+{{< img src="llm_observability/index/llm_apm_example_light.png" alt="Una traza en Datadog APM. La pestaña Overview (Información general) muestra una sección llamada LLM Observability, con un enlace para visualizar el tramo en LLM Observability, así como el texto de entrada y salida." style="width:100%">}}
+
+Para aplicaciones instrumentadas con Datadog APM, puedes [correlacionar APM y LLM Observability][2] a través del SDK. Correlacionar APM con LLM Observability proporciona visibilidad completa de extremo a extremo y análisis exhaustivos, desde problemas de aplicaciones hasta causas raíz específicas de LLM.
+
+### Mapa de clústeres
+
+{{< img src="llm_observability/index/llm_cluster_example.png" alt="Un mapa de clústeres de ejemplo qie muestra más de 1000 entradas de trazas, coloreadas por la métrica 'no hubo respuesta'. En el mapa se ve un estado de punto suspendido, que muestra una clasificación de la traza como 'Opciones económicas', así como texto de entrada y salida y un enlace para ver más detalles." style="width:100%">}}
+
+El [mapa de clústeres][3] proporciona información general de cómo se agrupan y relacionan las solicitudes de tu aplicación LLM. Te ayuda a identificar patrones, grupos de actividad similar y outliers en trazas LLM, lo que facilita la investigación de problemas y optimiza el rendimiento.
+
+### Monitorizar tus sistemas agénticos
+
+Aprende cómo monitorizar aplicaciones LLM agénticas que utilizan múltiples herramientas o cadenas de razonamiento con [Agent Monitoring][4] de Datadog. Esta característica te ayuda a realizar un seguimiento de las acciones de los agentes, el uso de herramientas y los pasos de razonamiento, proporcionándote una visibilidad de complejos flujos de trabajo LLM y permitiéndote solucionar problemas y optimizar los sistemas agénticos de manera efectiva. Consulta la [documentación de Agent Monitoring][4] para ver más detalles.
+
+
+[1]: /es/llm_observability/monitoring/querying
+[2]: /es/llm_observability/monitoring/llm_observability_and_apm
+[3]: /es/llm_observability/monitoring/cluster_map/
+[4]: /es/llm_observability/monitoring/agent_monitoring
+[5]: /es/llm_observability/evaluations/
+[6]: https://app.datadoghq.com/dash/integration/llm_operational_insights?fromUser=false&refresh_mode=sliding&from_ts=1758905575629&to_ts=1758909175629&live=true
\ No newline at end of file
diff --git a/content/es/logs/explorer/search_syntax.md b/content/es/logs/explorer/search_syntax.md
index ae5ac07dfb20b..a91250504b295 100644
--- a/content/es/logs/explorer/search_syntax.md
+++ b/content/es/logs/explorer/search_syntax.md
@@ -4,18 +4,24 @@ aliases:
- /es/logs/search_syntax/
description: Busca a través de todos tus logs.
further_reading:
+- link: /getting_started/search/
+ tag: Documentación
+ text: Introducción a la búsqueda en Datadog
- link: /logs/explorer/#visualize
tag: Documentación
text: Aprende a visualizar logs
- link: /logs/explorer/#patterns
tag: Documentación
- text: Detecta patrones dentro de tus logs
+ text: Detecta patrones en tus logs
- link: /logs/log_configuration/processors
tag: Documentación
- text: Aprende a procesar tus logs
+ text: Aprender a procesar tus logs
- link: /logs/explorer/saved_views/
tag: Documentación
- text: Información sobre las vistas guardadas
+ text: Más información sobre las vistas guardadas
+- link: /logs/explorer/calculated_fields/expression_language
+ tag: Documentación
+ text: Más información sobre el lenguaje de expresión de campos calculados
title: Sintaxis de búsqueda de logs
---
@@ -25,62 +31,55 @@ Un filtro de consulta se compone de términos y operadores.
Existen dos tipos de términos:
-* Un **término único** es una sola palabra, como `test` o `hello`.
+* Un **término único** es una sola palabra como `test` o `hello`.
-* Una **secuencia** es un grupo de palabras delimitadas por comillas dobles, como `"hello dolly"`.
+* Una **secuencia** es un grupo de palabras rodeadas de comillas dobles, como `"hello dolly"`.
Para combinar varios términos en una consulta compleja, puedes utilizar cualquiera de los siguientes operadores booleanos que distinguen entre mayúsculas y minúsculas:
| | | |
|--------------|--------------------------------------------------------------------------------------------------------|------------------------------|
| **Operador** | **Descripción** | **Ejemplo** |
-| `AND` | **Intersección**: ambos términos están en los eventos seleccionados (si no se añade nada, se toma AND por defecto). | autenticación AND error |
-| `OR` | **Unión**: cualquiera de los dos términos está en los eventos seleccionados. | autenticación OR contraseña |
-| `-` | **Exclusión**: el término siguiente NO figura en el evento (se aplica a cada búsqueda individual de texto sin formato). | autenticación AND -contraseña |
+| `AND` | **Intersección**: ambos términos están en los eventos seleccionados (si no se añade nada, se toma AND por defecto). | autenticación Y fallo |
+| `OR` | **Unión**: cualquiera de los dos términos está en los eventos seleccionados. | autenticación O contraseña |
+| `-` | **Exclusión**: el siguiente término NO figura en el evento (se aplica a cada búsqueda de texto sin formato individual). | autenticación Y contraseña |
## Búsqueda de texto completo
-La función de búsqueda de texto completo solo está disponible en Log Management y funciona en las consultas de monitor, dashboard y notebook. La sintaxis de búsqueda de texto completo no puede utilizarse para definir filtros de índice, filtros de archivo, filtros de pipeline de log ni en Live Tail.
+La función de búsqueda de texto completo solo está disponible en Log Management y funciona en las consultas de monitor, dashboard y notebook. La sintaxis de búsqueda de texto completo no puede utilizarse para definir filtros de índice, filtros de archivo, filtros de pipeline de log, filtros de rehidratación ni en Live tail.
Utiliza la sintaxis `*:search_term` para realizar una búsqueda de texto completo en todos los atributos de log, incluido el mensaje de log.
### Ejemplo de término único
-| Sintaxis de búsqueda | Tipo de búsqueda | Descripción |
-| ------------- | ----------- | ----------------------------------------------------- |
-| `*:hello` | Texto completo | Busca todos los atributos de log para el término `hello`. |
-| `hello` | Texto libre | Busca solo en el mensaje de log el término `hello`. |
+| Sintaxis de búsqueda | Tipo de búsqueda | Descripción |
+| ------------- | ----------- | --------------------------------------------------------- |
+| `*:hello` | Texto completo | Busca en todos los atributos de log la cadena exacta `hello`. |
+| `hello` | Texto libre | Busca la cadena exacta `hello` solo en los atributos `message`, `@title`, `@error.message` y `@error.stack`. |
### Ejemplo de término de búsqueda con comodín
-| Sintaxis de búsqueda | Tipo de búsqueda | Descripción |
-| ------------- | ----------- | -------------------------------------------------------------------------------------------- |
-| `*:hello` | Texto completo | Busca en todos los atributos de log la cadena exacta `hello`. |
-| `*:hello*`| Texto completo | Busca en todos los atributos de log cadenas que empiecen por `hello`. Por ejemplo, `hello_world`.|
+| Sintaxis de búsqueda | Tipo de búsqueda | Descripción |
+| ------------- | ----------- | ------------------------------------------------------------------------------------------- |
+| `*:hello` | Texto completo | Busca en todos los atributos de log la cadena exacta `hello`. |
+| `*:hello*` | Texto completo | Busca en todos los atributos de log las cadenas que empiecen por `hello`. Por ejemplo, `hello_world`. |
### Ejemplo de términos múltiples con coincidencia exacta
-| Sintaxis de búsqueda | Tipo de búsqueda | Descripción |
-| ------------------- | ----------- |------------------------------------------------------- |
-| `*:"hello world"` | Texto completo | Busca todos los atributos de log para el término `hello world`. |
-| `hello world` | Texto libre | Busca solo en el mensaje de log el término `hello`. |
-
-### Ejemplo de términos múltiples sin coincidencia exacta
-
-La sintaxis de búsqueda de texto completo `*:hello world` es equivalente a `*:hello *:world`. Busca en todos los atributos de log los términos `hello` y `world`.
-
-### Ejemplo de términos múltiples con un espacio en blanco
-
-La sintaxis de búsqueda de texto completo `*:"hello world" "i am here"` es equivalente a `*:"hello world" *:"i am here"`. Busca en todos los atributos de log los términos `hello world` y `i am here`.
+| Sintaxis de búsqueda | Tipo de búsqueda | Descripción |
+| ------------------- | ----------- |--------------------------------------------------------------------------------------------------- |
+| `*:"hello world"` | Texto completo | Busca en todos los atributos de log la cadena exacta `hello world`. |
+| `hello world` | Texto libre | Busca sólo en el mensaje de log las palabras `hello` y `world`. Por ejemplo `hello beautiful world`. |
## Caracteres especiales de escape y espacios
-Los siguientes caracteres, que se consideran especiales: `+` `-` `=` `&&` `||` `>` `<` `!` `(` `)` `{` `}` `[` `]` `^` `"` `“` `”` `~` `*` `?` `:` `\` `#` y los espacios que requieren ser de escape con el carácter `\`.
-`/` no se considera un carácter especial y no necesita ser de escape.
+Los siguientes caracteres se consideran especiales y deben escaparse con el carácter `\`: `-` `!` `&&` `||` `>` `>=` `<` `<=` `(` `)` `{` `}` `[` `]` `"` `*` `?` `:` `\` `#` y espacios.
+- `/` no se considera un carácter especial y no necesita escape.
+- `@` no puede utilizarse en las consultas de búsqueda dentro del Log Explorer porque está reservado para la [búsqueda de atributos](#attributes-search).
No se pueden buscar caracteres especiales en un mensaje de log. Puedes buscar caracteres especiales cuando están dentro de un atributo.
-Para buscar caracteres especiales, analízalos en un atributo con el [Analizador Grok][1], y busca los logs que contengan ese atributo.
+Para buscar caracteres especiales, analízalos en un atributo con el [Analizador Grok][1] y busca los logs que contengan ese atributo.
## Búsqueda de atributos
@@ -102,7 +101,7 @@ Por ejemplo, si el nombre de tu atributo es **url** y quieres filtrar por el val
3. La búsqueda de un valor de atributo que contenga caracteres especiales requiere un carácter de escape o comillas dobles.
- Por ejemplo, para un atributo `my_attribute` con el valor `hello:world`, busca utilizando: `@my_attribute:hello\:world` o `@my_attribute:"hello:world"`.
- - Para que coincida con un único carácter especial o espacio, utiliza el comodín `?`. Por ejemplo, para un atributo `my_attribute` con el valor `hello world`, busca utilizando: `@my_attribute:hello?world`.
+ - Para buscar una coincidencia con un único carácter especial o espacio, utiliza el comodín `?`. Por ejemplo, para un atributo `my_attribute` con los valores `hello world`, realiza la búsqueda utilizando: `@my_attribute:hello?world`.
Ejemplos:
@@ -134,11 +133,11 @@ Puedes utilizar comodines con la búsqueda de texto libre. Sin embargo, solo bus
Para realizar una búsqueda de comodín de varios caracteres en el mensaje de log (la columna `content` en Log Explorer), utiliza el símbolo `*` como se indica a continuación:
-* `service:web*` coincide con cada mensaje de log que tenga un servicio que empiece por `web`.
+* `service:web*` coincide con cada mensaje de log que tenga un servicio que empiece con `web`.
* `web*` coincide con todos los mensajes de log que empiecen con `web`.
* `*web` coincide con todos los mensajes de log que terminan con `web`.
-**Nota**: Los comodines solo funcionan fuera de las comillas dobles. Por ejemplo, `"*test*"` coincide con un log que tenga la cadena `*test*` en su mensaje. `*test*` coincide con un log que tenga la test de cadena en cualquier parte de su mensaje.
+**Nota**: Los comodines solo funcionan fuera de las comillas dobles. Por ejemplo, `"*test*"` coincide con un log que tenga la cadena `*test*` en su mensaje. `*test*` coincide con un log que tenga el test de cadena en cualquier parte de su mensaje.
Las búsquedas con comodines funcionan dentro de etiquetas y atributos (con o sin facetas) con esta sintaxis. Esta consulta devuelve todos los servicios que terminan con la cadena `mongo`:
@@ -163,7 +162,7 @@ Cuando busques un valor de atributo o etiqueta que contenga caracteres especiale ## Valores numéricos -Para buscar en un atributo numérico, primero [añádelo como faceta][2]. A continuación, puedes utilizar operadores numéricos (`<`,`>`, `<=`, o `>=`) para realizar una búsqueda sobre facetas numéricas. +Para buscar en un atributo numérico, primero [añádelo como faceta][2]. A continuación, puedes utilizar operadores numéricos (`<`,`>`, `<=` o `>=`) para realizar una búsqueda sobre facetas numéricas. Por ejemplo, recupera todos los logs que tengan un tiempo de respuesta superior a 100ms con:
@@ -204,11 +203,17 @@ En el siguiente ejemplo, los logs de CloudWatch para Windows contienen una matri {{< img src="logs/explorer/search/facetless_query_json_arrray2.png" alt="Consulta sin facetas en una matriz de objetos JSON" style="width:80%;">}}
+## Campos calculados + +Los campos calculados función como atributos de log y pueden utilizarse para la búsqueda, agregación, visualización y definición de otros campos calculados. Utiliza el prefijo `#` cuando hagas referencia a nombres de campos calculados. + +{{< img src="logs/explorer/calculated_fields/calculated_field.png" alt="Un campo calculado llamado request_duration que se utiliza para filtrar resultados en el Log Explorer" style="width:100%;" >}} + ## Búsquedas guardadas Las [Vistas guardadas][6] contienen tu consulta de búsqueda, columnas, horizonte temporal y faceta. -## Leer más +## Referencias adicionales {{< partial name="whats-next/whats-next.html" >}} diff --git a/content/es/logs/guide/forwarder.md b/content/es/logs/guide/forwarder.md index 1b9978fcfb271..a002be874e060 100644 --- a/content/es/logs/guide/forwarder.md +++ b/content/es/logs/guide/forwarder.md @@ -24,6 +24,8 @@ Para obtener más información sobre el envío de logs de servicios AWS con el D Datadog recomienda utilizar [CloudFormation](#cloudformation) para instalar automáticamente el Forwarder. También puedes completar el proceso de configuración utilizando [Terraform](#terraform) o [manualmente](#manually). Una vez instalado, puedes asignar fuentes de logs al Forwarder, como buckets S3 o grupos de logs CloudWatch [setting up triggers][4]. +**Nota**: Forwarder v4.1.0+ no es compatible con la arquitectura x86_64. Si utilizas x86_64, debes migrar a ARM64 para poder utilizar Datadog Forwarder. + {{< tabs >}} {{% tab "CloudFormation" %}} @@ -50,60 +52,30 @@ Si ya habías habilitado tu integración AWS utilizando la [siguiente plantilla ### Terraform -Instala el Forwarder utilizando el recurso Terraform [`aws_cloudformation_stack`][101] como encapsulador, además de la plantilla de CloudFormation proporcionada. - -Datadog recomienda crear configuraciones de Terraform separadas: - -- Utiliza la primera para almacenar la [clave de API de Datadog][102] en el AWS Secrets Manager y anota el ARN de secretos de la salida de aplicación -- A continuación, crea una configuración para el Forwarder y proporciona el ARN de secretos a través del parámetro `DdApiKeySecretArn`. -- Por último, crea una configuración para [configurar los activadores en el Forwarder][103]. - -Al separar las configuraciones de la clave de API y del Forwarder, no es necesario proporcionar la clave de API de Datadog al actualizar el Forwarder. Para actualizar o mejorar el Forwarder en el futuro, vuelve a aplicar la configuración del Forwarder. +Instala el Forwarder utilizando el módulo de Datadog Terraform público disponible en [https://registry.terraform.io/modules/DataDog/log-lambda-forwarder-datadog/aws/latest][201]. Una vez desplegada la función Lambda, [configura activadores en el Forwarder][202]. #### Ejemplo de configuración ```tf +module "datadog_forwarder" { + source = "DataDog/log-lambda-forwarder-datadog/aws" + version = "~> 1.0" -variable "dd_api_key" { - type = string - description = "Datadog API key" -} - -resource "aws_secretsmanager_secret" "dd_api_key" { - name = "datadog_api_key" - description = "Encrypted Datadog API Key" -} - -resource "aws_secretsmanager_secret_version" "dd_api_key" { - secret_id = aws_secretsmanager_secret.dd_api_key.id - secret_string = var.dd_api_key -} - -output "dd_api_key" { - value = aws_secretsmanager_secret.dd_api_key.arn + dd_api_key = var.dd_api_key + dd_site = var.dd_site } ``` -```tf -# Use the Datadog Forwarder to ship logs from S3 and CloudWatch, as well as observability data from Lambda functions to Datadog. For more information, see https://github.com/DataDog/datadog-serverless-functions/tree/master/aws/logs_monitoring -resource "aws_cloudformation_stack" "datadog_forwarder" { - name = "datadog-forwarder" - capabilities = ["CAPABILITY_IAM", "CAPABILITY_NAMED_IAM", "CAPABILITY_AUTO_EXPAND"] - parameters = { - DdApiKeySecretArn = "REPLACE WITH DATADOG SECRETS ARN", - DdSite = "REPLACE WITH DATADOG SITE", - FunctionName = "datadog-forwarder" - } - template_url = "https://datadog-cloudformation-template.s3.amazonaws.com/aws/forwarder/latest.yaml" -} -``` +**Nota**: Asegúrate de que el parámetro `dd_site` coincide con tu [sitio de Datadog][203]. Selecciona tu sitio en la parte derecha de este página. Tu sitio de Datadog es {{< region-param key="dd_site" code="true" >}}. +Encontrarás tu [clave de API de Datadog][204] para `dd_api_key` en **Organization Settings** > **API Keys** (Configuración de la organización > Claves de API). -**Nota**: Asegúrate de que el parámetro `DdSite` coincide con tu [sitio Datadog][104]. Selecciona tu sitio en la parte derecha de esta página. Sustituye `
-Las variables de entorno proporcionadas en esta página tienen un formato para CloudFormation y Terraform. Si estás instalando el Forwarder manualmente, convierte estos nombres de parámetros de PascalCase a Screaming Snake Case. Por ejemplo,
DdApiKey se convierte en DD_API_KEY, y ExcludeAtMatch se convierte en EXCLUDE_AT_MATCH.
+
+Las variables de entorno proporcionadas en esta página están formateadas para CloudFormation. Si estás instalando el Forwarder manualmente, convierte estos nombres de parámetros de caso Pascal a un caso screaming snake. Por ejemplo,
[101]: https://github.com/DataDog/datadog-serverless-functions/releases
@@ -145,8 +117,11 @@ Las variables de entorno proporcionadas en
Si tienes problemas para actualizar a la última versión, consulta la sección Solucionar problemas.
-### Actualizar una versión anterior a v4.3.0 o posterior
-A partir de la versión 4.3.0, el Forwarder Lambda admitirá una única versión de Python. La versión de Python admitida en esta versión es la v3.12.
+### Actualizar una versión anterior a 4.13.0+
+A partir de la versión 4.13.0+, la función Lambda se ha actualizado para requerir **Python 3.13**. Si actualizas una instalación de forwarder anterior a 4.13.0+, asegúrate de que la función de AWS Lambda está configurada para utilizar Python 3.13.
+
+### Actualizar una versión anterior a 4.3.0+
+A partir de la versión 4.3.0 el Lambda forwarder admitirá una única versión de python. La versión de Python admitida en esta versión es la 3.12.
### Actualizar una versión anterior a v4.0.0
A partir de la versión 4.0.0, la lógica de identificación de `source`, `service` y `host` se extraerá del código del Forwarder Lambda y se instalará directamente en el backend de Datadog. La primera fuente de logs migrada es `RDS`.
@@ -286,7 +261,7 @@ Nos encantan las solicitudes de extracción. Aquí tienes una guía rápida.
Si necesitas enviar logs a varias organizaciones Datadog u otros destinos, configura el parámetro `AdditionalTargetLambdaArns` de CloudFormation para que el Datadog Forwarder copie los logs entrantes en las funciones Lambda especificadas. Estas funciones Lambda adicionales se llaman de forma asíncrona con exactamente el mismo `event` que recibe el Datadog Forwarder.
-DdApiKey se convierte en DD_API_KEY, y ExcludeAtMatch se convierte en EXCLUDE_AT_MATCH.
+:3834` o `https://:3834`.
@@ -338,11 +313,10 @@ En cambio, si utilizas el proxy web:
El Datadog Forwarder está firmado por Datadog. Para verificar la integridad del Forwarder, utiliza el método de instalación manual. [Crea una configuración para la firma de códigos][19] que incluya el ARN del perfil de firma de Datadog (`arn:aws:signer:us-east-1:464622532012:/signing-profiles/DatadogLambdaSigningProfile/9vMI9ZAGLc`) y asócialo a la función Lambda del Forwarder antes de cargar el archivo ZIP del Forwarder.
-## Parámetros de CloudFormation
+## Parámetros
-
-**Predeterminado**: `true`
-Habilitado de manera predeterminada al usar el registro de logs sin Agent a partir de la versión 2.7.0 del rastreador. +: permite [conectar logs y trazas][9]:
+**Por defecto**: `true`
+Activado por defecto desde la versión 3.24.0 de rastreador. `DD_LOGS_DIRECT_SUBMISSION_INTEGRATIONS` : Permite el registro de logs sin Agent. Habilita esta funcionalidad en tu marco de registro de logs al establecer `Serilog`, `NLog`, `Log4Net` o `ILogger` (para `Microsoft.Extensions.Logging`). Si usas varios marcos de registro de logs, usa una lista de variables separadas por punto y coma.
**Ejemplo**: `Serilog;Log4Net;NLog`
**Predeterminado**: `1` -Si usas la integración `Microsoft.Extensions.Logging`, puedes filtrar los logs enviados a Datadog con ayuda de las funcionalidades estándar integradas en `ILogger`. Usa la clave `"Datadog"` para identificar al proveedor de envío directo, y establece los niveles mínimos del log para un espacio de nombres. Por ejemplo, si añades lo siguiente a tu `appSettings.json`, evitarías que se envíen logs con un nivel inferior a `Warning` a Datadog. Disponible a partir de la versión 2.20.0 de la librería del rastreador de .NET. +Si usas la integración `Microsoft.Extensions.Logging`, puedes filtrar los logs enviados a Datadog con ayuda de las funcionalidades estándar integradas en `ILogger`. Usa la clave `"Datadog"` para identificar al proveedor de envío directo, y establece los niveles mínimos del log para un espacio de nombres. Por ejemplo, si añades lo siguiente a tu `appSettings.json`, evitarías que se envíen logs con un nivel inferior a `Warning` a Datadog. Disponible a partir de la versión 2.20.0 de la biblioteca del rastreador de .NET. ```json { @@ -571,4 +571,4 @@ Ahora los logs nuevos se envían directamente a Datadog. [17]: /es/logs/log_configuration/pipelines/?tab=source [18]: /es/api/latest/logs/#send-logs [19]: https://www.nuget.org/packages/Serilog.Sinks.Datadog.Logs -[20]: /es/glossary/#tail +[20]: /es/glossary/#tail \ No newline at end of file diff --git a/content/es/logs/log_collection/ios.md b/content/es/logs/log_collection/ios.md index 352ce6d03b490..5d054ce196f52 100644 --- a/content/es/logs/log_collection/ios.md +++ b/content/es/logs/log_collection/ios.md @@ -11,18 +11,18 @@ title: Recopilación de logs de iOS --- ## Información general -Envía logs a Datadog desde tus aplicaciones de iOS con [la librería de registro del cliente `dd-sdk-ios` de Datadog][1] y aprovecha las siguientes características: +Envía logs a Datadog desde tus aplicaciones de iOS con [la biblioteca de registro del cliente `dd-sdk-ios` de Datadog][1] y aprovecha las siguientes características: * Loguear en Datadog en formato JSON de forma nativa. * Utilizar los atributos predeterminados y añadir atributos personalizados a cada log enviado. * Registrar las direcciones IP reales de los clientes y los Agents de usuario. * Aprovechar el uso optimizado de red con publicaciones masivas automáticas. -La librería `dd-sdk-ios` es compatible con todas las versiones de iOS 11 o posteriores. +La biblioteca `dd-sdk-ios` es compatible con todas las versiones de iOS 11 o posteriores. ## Configuración -1. Declara la librería como una dependencia dependiente de tu gestor de paquete. Se recomienda el gestor de paquete Swift. +1. Declara la biblioteca como una dependencia dependiente de tu gestor de paquete. Se recomienda el gestor de paquete Swift. {{< tabs >}} {{% tab "Swift Package Manager (SPM)" %}} @@ -69,7 +69,7 @@ DatadogLogs.xcframework {{% /tab %}} {{< /tabs >}} -2. Inicializa la librería con el contexto de tu aplicación y tu [token de cliente de Datadog][2]. Por razones de seguridad, debes utilizar un token de cliente: no puedes utilizar [claves de API de Datadog][3] para configurar la librería `dd-sdk-ios`, ya que estarían expuestas del lado del cliente en el código de bytes IPA de la aplicación iOS. +2. Inicializa la biblioteca con el contexto de tu aplicación y tu [token de cliente de Datadog][2]. Por razones de seguridad, debes utilizar un token de cliente: no puedes utilizar [claves de API de Datadog][3] para configurar la biblioteca `dd-sdk-ios`, ya que estarían expuestas del lado del cliente en el código de bytes IPA de la aplicación iOS. Para obtener más información sobre cómo configurar un token de cliente, consulta la [documentación sobre el token de cliente][2]. @@ -349,7 +349,7 @@ El SDK cambia su comportamiento según el nuevo valor. Por ejemplo, si el consen Antes de que los datos se carguen en Datadog, se almacenan en texto claro en el directorio de caché (`Library/Caches`) de tu [entorno de prueba de aplicaciones][6]. El directorio de caché no puede ser leído por ninguna otra aplicación instalada en el dispositivo. -Al redactar tu aplicación, habilita los logs de desarrollo para loguear en consola todos los mensajes internos del SDK con una prioridad igual o superior al nivel proporcionado. +Al redactar tu aplicación, habilita los logs de desarrollo para registrar en consola todos los mensajes internos del SDK con una prioridad igual o superior al nivel proporcionado. {{< tabs >}} {{% tab "Swift" %}} @@ -500,7 +500,7 @@ Para más información, consulta [Empezando con etiquetas][5]. Por defecto, los siguientes atributos se añaden a todos los logs enviados por un registrador: -* `http.useragent` y sus propiedades extraídas `device` y `OS` +* `http.useragent` y sus propiedades extraídas `device` y `OS` * `network.client.ip` y sus propiedades geográficas extraídas (`country`, `city`) * `logger.version`, versión del SDK de Datadog * `logger.thread_name`(`main`, `background`) @@ -512,7 +512,7 @@ Utiliza el método `addAttribute(forKey:value:)` para añadir un atributo person {{< tabs >}} {{% tab "Swift" %}} ```swift -// Esto añade un atributo "device-model" con un valor de cadena +// This adds an attribute "device-model" with a string value for this logger instance. logger.addAttribute(forKey: "device-model", value: UIDevice.current.model) ``` {{% /tab %}} @@ -523,6 +523,22 @@ logger.addAttribute(forKey: "device-model", value: UIDevice.current.model) {{% /tab %}} {{< /tabs >}} +Los atributos pueden añadirse globalmente en todas las instancias de logs (por ejemplo: nombre del servicio, entorno) utilizando: + +{{< tabs >}} +{{% tab "Swift" %}} +```swift +// This adds an attribute "device-model" with a string value in all Logs instances. +Logs.addAttribute(forKey: "device-model", value: UIDevice.current.model) +``` +{{% /tab %}} +{{% tab "Objective-C" %}} +```objective-c +[Logs addAttributeForKey:@"device-model" value:UIDevice.currentDevice.model]; +``` +{{% /tab %}} +{{< /tabs >}} + `` puede ser cualquier elemento que se ajuste a `Encodable`, como `String`, `Date`, modelo de datos personalizado `Codable`, etc.
##### Eliminar atributos
@@ -532,7 +548,7 @@ Utiliza el método `removeAttribute(forKey:)` para eliminar un atributo personal
{{< tabs >}}
{{% tab "Swift" %}}
```swift
-// Esto elimina el atributo "device-model" de todos los logs enviados en el futuro.
+// This removes the attribute "device-model" from all further logs sent from this logger instance.
logger.removeAttribute(forKey: "device-model")
```
{{% /tab %}}
@@ -543,6 +559,22 @@ logger.removeAttribute(forKey: "device-model")
{{% /tab %}}
{{< /tabs >}}
+Para eliminar un atributo global de todas las instancias de logs:
+
+{{< tabs >}}
+{{% tab "Swift" %}}
+```swift
+// This removes the attribute "device-model" from all further logs sent from all logger instances.
+Logs.removeAttribute(forKey: "device-model")
+```
+{{% /tab %}}
+{{% tab "Objective-C" %}}
+```objective-c
+[Logs removeAttributeForKey:@"device-model"];
+```
+{{% /tab %}}
+{{< /tabs >}}
+
## Referencias adicionales
{{< partial name="whats-next/whats-next.html" >}}
@@ -552,4 +584,4 @@ logger.removeAttribute(forKey: "device-model")
[3]: /es/account_management/api-app-keys/#api-keys
[4]: /es/logs/processing/attributes_naming_convention/
[5]: /es/getting_started/tagging/
-[6]: https://support.apple.com/guide/security/security-of-runtime-process-sec15bfe098e/web
+[6]: https://support.apple.com/guide/security/security-of-runtime-process-sec15bfe098e/web
\ No newline at end of file
diff --git a/content/es/logs/log_collection/javascript.md b/content/es/logs/log_collection/javascript.md
index 5c24ed01311bc..2d8294abb64be 100644
--- a/content/es/logs/log_collection/javascript.md
+++ b/content/es/logs/log_collection/javascript.md
@@ -17,413 +17,289 @@ Con el SDK de logs del navegador, puedes enviar logs directamente a Datadog desd
- Reenvía errores del frontend.
- Registra las direcciones IP reales de los clientes y los agentes de usuario.
- Uso de red optimizado con envíos masivos automáticos.
+- Uso en entornos de worker y worker de servicios.
**Notas**:
+
- **Independiente del SDK de RUM**: el SDK de logs de navegador se puede utilizar sin el SDK de RUM.
+- **Entornos de worker**: el SDK de logs de navegador funcionan en entornos de worker y worker de servicio utilizando los mismos métodos de configuración. Sin embargo, los logs enviados desde entornos de worker no incluyen automáticamente información de sesión.
## Configuración
-**Token de cliente de Datadog**: Por motivos de seguridad, las [claves de la API][1] no pueden utilizarse para configurar el SDK de logs del navegador, ya que quedarían expuestas del lado del cliente en el código JavaScript. Para recopilar logs de los navegadores web, se debe utilizar un [token de cliente][2]. Consulta la [documentación del token de cliente][2] para más detalles.
+### Paso 1: Crear un token de cliente
-**SKD de logs del navegador de Datadog**: Configura el SDK a través de [NPM](#npm) o utiliza los fragmentos de código [CDN asíncrono](#cdn-async) o [CDN síncrono](#cdn-sync) en la etiqueta (tag) del encabezado.
+En Datadog, ve a [**Organization Settings > New Client Tokens**][1] (Configuración de la organización > Nuevos tokens de cliente).
-**Navegadores compatibles**: el SDK de logs de navegador es compatible con todos los navegadores modernos de escritorio y móviles. Consulta la tabla de [Compatibilidad de navegadores][4].
+**Entornos compatibles**: el SDK de logs de navegador son compatibles con todos los navegadores modernos de escritorio y móviles, así como con los entornos de worker y worker de servicio. Consulta la tabla [Soporte del navegador][4].
-### Elegir el método de instalación adecuado
+',
- site: '',
- forwardErrorsToLogs: true,
- sessionSampleRate: 100,
-})
-```
+Añade [`@datadog/browser-logs`][13] a tu archivo `package.json`. Por ejemplo, si utilizas npm cli.
+
+[13]: https://www.npmjs.com/package/@datadog/browser-logs
+
+{{% /tab %}}
+{{% tab "CDN asíncrono" %}}
-### CDN asíncrono
+Las aplicaciones web con objetivos de rendimiento deben instalarse a través de CDN asíncronas. El SDK de navegador se carga desde la CDN de Datadog de forma asíncrona, lo que garantiza que no afecte al rendimiento de carga de la página. Sin embargo, es posible que el SDK no capture errores o logs de consola que se produzcan antes de que se inicialice el SDK.
-Carga y configura el SDK en la sección de encabezado de tus páginas. Para el sitio **{{}}**:
+Añade el fragmento de código generado a la etiqueta head de cada página HTML que desees monitorizar en tu aplicación.
{{< site-region region="us" >}}
-```html
-
-
- Example to send logs to Datadog
-
-
-
-```
-{{}}
+
+```javascript
+
+```
+
+{{< /site-region >}}
+{{< site-region region="eu" >}}
+
+```javascript
+
+```
+
+{{< /site-region >}}
{{< site-region region="ap1" >}}
-```html
-
-
- Example to send logs to Datadog
-
-
-
-```
-{{}}
+
+```javascript
+
+```
+
+{{< /site-region >}}
{{< site-region region="ap2" >}}
-```html
-
-
- Example to send logs to Datadog
-
-
-
-```
-{{}}
-{{< site-region region="eu" >}}
-```html
-
-
- Example to send logs to Datadog
-
-
-
-```
-{{}}
+
+```javascript
+
+```
+
+{{< /site-region >}}
{{< site-region region="us3" >}}
-```html
-
-
- Example to send logs to Datadog
-
-
-
-```
-{{}}
+
+```javascript
+
+```
+
+{{< /site-region >}}
{{< site-region region="us5" >}}
-```html
-
-
- Example to send logs to Datadog
-
-
-
-```
-{{}}
+
+```javascript
+
+```
+
+{{< /site-region >}}
{{< site-region region="gov" >}}
-```html
-
-
- Example to send logs to Datadog
-
-
-
-```
-{{}}
+```javascript
+
+```
-**Nota**: Las primeras llamadas a la API deben incluirse en la devolución de llamada de `window.DD_LOGS.onReady()`. Esto asegura que el código solo se ejecute una vez que el SDK se cargue correctamente.
+{{< /site-region >}}
-### CDN síncrono
+{{% /tab %}}
+{{% tab "CDN síncrono" %}}
-Para recibir todos los logs y errores, carga y configura el SDK al principio de la sección de encabezado de tus páginas. Para el sitio **{{}}**:
+Para recopilar todos los eventos, debes instalar a través de CDN síncronas. El SDK de navegador se carga desde la CDN de Datadog de forma sincrónica, lo que garantiza que el SDK se carga primero y recopila todos los errores, recursos y acciones del usuario. Este método puede afectar al rendimiento de carga de la página.
+
+Añade el fragmento de código generado a la etiqueta head (delante de cualquier otra etiqueta script) de cada página HTML que desees monitorizar en tu aplicación. Colocar la etiqueta script más arriba y cargarla de forma sincrónica garantiza que Datadog RUM pueda recopilar todos los datos de rendimiento y errores.
{{< site-region region="us" >}}
-```html
-
-
- Example to send logs to Datadog
-
-
-
-
-```
-{{}}
+
+```javascript
+
+```
+
+{{< /site-region >}}
+{{< site-region region="eu" >}}
+
+```javascript
+
+```
+
+{{< /site-region >}}
{{< site-region region="ap1" >}}
-```html
-
-
- Example to send logs to Datadog
-
-
-
-
-```
-{{}}
+
+```javascript
+
+```
+
+{{< /site-region >}}
{{< site-region region="ap2" >}}
-```html
-
-
- Example to send logs to Datadog
-
-
-
-
-```
-{{}}
-{{< site-region region="eu" >}}
-```html
-
-
- Example to send logs to Datadog
-
-
-
-
-```
-{{}}
+
+```javascript
+
+```
+
+{{< /site-region >}}
{{< site-region region="us3" >}}
-```html
-
-
- Example to send logs to Datadog
-
-
-
-
-```
-{{}}
+
+```javascript
+
+```
+
+{{< /site-region >}}
{{< site-region region="us5" >}}
-```html
-
-
- Example to send logs to Datadog
-
-
-
-
-```
-{{}}
+
+```javascript
+
+```
+
+{{< /site-region >}}
{{< site-region region="gov" >}}
-```html
-
-
- Example to send logs to Datadog
-
-
-
-
-```
-{{}}
-**Nota**: El check `window.DD_LOGS` evita problemas cuando se produce un fallo de carga con el SDK.
+```javascript
+
+```
-### TypeScript
+{{< /site-region >}}
-Los tipos son compatibles con TypeScript >= 3.8.2. Para las versiones anteriores, importa fuentes JS y utiliza variables globales para evitar problemas de compilación:
+{{% /tab %}}
+{{< /tabs >}}
-```typescript
-import '@datadog/browser-logs/bundle/datadog-logs'
+### Paso 3: Inicializar el SDK del navegador
+
+El SDK debe inicializarse lo antes posible en el ciclo de vida de la aplicación. Esto garantiza que todos los logs se capturen correctamente.
+
+En el fragmento de inicialización, establece el token de cliente y el sitio. Consulta la lista completa de [parámetros de inicialización][4].
-window.DD_LOGS.init({
+{{< tabs >}}
+{{% tab "NPM" %}}
+
+```javascript
+import { datadogLogs } from '@datadog/browser-logs';
+
+datadogLogs.init({
clientToken: '',
+ // `site` refers to the Datadog site parameter of your organization
+ // see https://docs.datadoghq.com/getting_started/site/
site: '',
forwardErrorsToLogs: true,
sessionSampleRate: 100,
-})
+});
+
```
-## Configuración
+{{% /tab %}}
+{{% tab "CDN asíncrono" %}}
+
+```javascript
+
+```
-### Integración de la política de seguridad de contenido
+{{% /tab %}}
+{{% tab "CDN síncrono" %}}
-Si utilizas la integración de política de seguridad de contenido (CSP) de Datadog en tu sitio, consulta [la sección RUM de la documentación de CSP][14] para conocer los pasos a seguir en la configuración.
+```javascript
+
+```
+
+{{% /tab %}}
+{{< /tabs >}}
-### Parámetros de inicialización
+#### Configurar el consentimiento de seguimiento (cumplimiento de GDPR)
-Los siguientes parámetros están disponibles para configurar el SDK de logs de navegador de Datadog para enviar logs a Datadog:
+Para cumplir con GDPR, CCPA y normativas similares, el KIT de navegador de RUM te permite proporcionar el [valor de consentimiento de seguimiento en la inicialización][5].
-| Parámetro | Tipo | Obligatorio | Valor predeterminado | Descripción |
-|----------------------------|---------------------------------------------------------------------------|----------|-----------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
-| `clientToken` | Cadena | Sí | | Un [token de cliente de Datadog][2]. |
-| `site` | Cadena | Sí | `datadoghq.com` | El [parámetro del sitio de Datadog de tu organización][9]. |
-| `service` | Cadena | No | | El nombre de servicio para tu aplicación. Debes seguir los [requisitos de sintaxis de etiqueta][7]. |
-| `env` | Cadena | No | | El entorno de la aplicación, por ejemplo: producción, preproducción, preparación, etc. Debe seguir los [requisitos de sintaxis de etiqueta][7]. |
-| `version` | Cadena | No | | La versión de la aplicación, por ejemplo: 1.2.3, 6c44da20, 2020.02.13, etc. Debe seguir los [requisitos de sintaxis de etiqueta][7]. |
-| `forwardErrorsToLogs` | Booleano | No | `true` | Configúralo en `false` para dejar de reenviar logs console.error, excepciones no capturadas y errores de red a Datadog. |
-| `forwardConsoleLogs` | `"all"` o una matriz de `"log"` `"debug"` `"info"` `"warn"` `"error"` | No | `[]` | Reenvía logs de `console.*` a Datadog. Utiliza `"all"` para reenviar todo o una matriz de nombres de la API de consola para reenviar solo un subconjunto. |
-| `forwardReports` | `"all"` o una matriz de `"intervention"` `"deprecation"` `"csp_violation"` | No | `[]` | Reenvía informes de la [API de informes][8] a Datadog. Utiliza `"all"` para reenviar todo o una matriz de tipos de informes para reenviar solo un subconjunto. |
-| `sampleRate` | Número | No | `100` | **Obsoleto**: Consulta `sessionSampleRate`. |
-| `sessionSampleRate` | Número | No | `100` | El porcentaje de sesiones a rastrear: `100` para todas, `0` para ninguna. Sólo las sesiones rastreadas envían logs. Sólo se aplica a los logs recopilados a través del SDK de logs de navegador y es independiente de los datos de RUM. |
-| `trackingConsent` | `"granted"` o `"not-granted"` | No | `"granted"` | Establece el estado inicial del consentimiento de rastreo del usuario. Consulta [Consentimiento de rastreo del usuario][15]. |
-| `silentMultipleInit` | Booleano | No | | Evita errores de registro al tener múltiples inicios. |
-| `proxy` | Cadena | No | | URL proxy opcional (ej: `https://www.proxy.com/path`). Para obtener más información, consulta la [guía completa para la configuración de proxies][6]. |
-| `telemetrySampleRate` | Número | No | `20` | Los datos de telemetría (error, logs de depuración) sobre la ejecución del SDK se envían a Datadog para detectar y resolver posibles problemas. Configura esta opción en `0` si te quieres excluir de la recopilación de datos telemétricos. |
-| `storeContextsAcrossPages` | Booleano | No | | Almacena el contexto global y el contexto de usuario en `localStorage` para preservarlos a lo largo de la navegación del usuario. Consulta [Ciclos de vida de los contextos][11] para obtener más detalles y limitaciones específicas. |
-| `allowUntrustedEvents` | Booleano | No | | Permite la captura de [eventos no confiables][13], por ejemplo, en tests automatizados de interfaz de usuario. |
-| `allowedTrackingOrigins` | Matriz | No | | Lista de orígenes en los que el kit de desarrollo de software (SDK) puede funcionar. |
+#### Configurar la política de seguridad de contenidos (CSP)
+Si utilizas la integración de la Política de seguridad de contenidos (CSP) de Datadog en tu sitio, consulta [la documentación de la CSP][6] para conocer los pasos adicionales de configuración.
-Opciones que deben tener una configuración coincidente cuando utilices el SDK `RUM`:
+### Paso 4: Visualizar tus datos
+Ahora que has completado la configuración básica de logs, tu aplicación está recopilando logs del navegador y puedes empezar a monitorizar y depurar problemas en tiempo real.
-| Parámetro | Tipo | Obligatorio | Valor predeterminado | Descripción |
-| -------------------------------------- | ------------------------------- | -------- | ---------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
-| `sessionPersistence` | `"cookie"` o `"local-storage"` | No | `"cookie"` | Qué estrategia de almacenamiento utilizar para persistir las sesiones. Puede ser `cookie` o `local-storage`. |
-| `trackAnonymousUser` | Booleano | No | `true` | Permite la recopilación del identificador de usuario anónimo en todas las sesiones. |
-| `trackSessionAcrossSubdomains` | Booleano | No | `false` | Preserva la sesión a través de subdominios para el mismo sitio. |
-| `useSecureSessionCookie` | Booleano | No | `false` | Utiliza una cookie de sesión segura. Esto desactiva logs enviados en conexiones inseguras (no HTTPS). |
-| `usePartitionedCrossSiteSessionCookie` | Booleano | No | `false` | Utiliza una cookie de sesión segura particionada entre sitios. Esto permite que el SDK de logs se ejecute cuando el sitio se carga desde otro (iframe). Implica `useSecureSessionCookie`. |
+Visualiza los logs en el [Log Explorer][7].
## Utilización
@@ -431,11 +307,12 @@ Opciones que deben tener una configuración coincidente cuando utilices el SDK `
Una vez inicializado el SDK de logs de navegador de Datadog, envía una entrada de log personalizado directamente a Datadog con la API:
-```
+```typescript
logger.debug | info | warn | error (message: string, messageContext?: Context, error?: Error)
```
-#### NPM
+{{< tabs >}}
+{{% tab "NPM" %}}
```javascript
import { datadogLogs } from '@datadog/browser-logs'
@@ -443,7 +320,8 @@ import { datadogLogs } from '@datadog/browser-logs'
datadogLogs.logger.info('Button clicked', { name: 'buttonName', id: 123 })
```
-#### CDN asíncrono
+{{% /tab %}}
+{{% tab "CDN asíncrono" %}}
```javascript
window.DD_LOGS.onReady(function () {
@@ -453,7 +331,8 @@ window.DD_LOGS.onReady(function () {
**Nota**: Las primeras llamadas a la API deben incluirse en la devolución de llamada de `window.DD_LOGS.onReady()`. Esto asegura que el código solo se ejecute una vez que el SDK se cargue correctamente.
-#### CDN síncrono
+{{% /tab %}}
+{{% tab "CDN síncrono" %}}
```javascript
window.DD_LOGS && window.DD_LOGS.logger.info('Button clicked', { name: 'buttonName', id: 123 })
@@ -461,6 +340,9 @@ window.DD_LOGS && window.DD_LOGS.logger.info('Button clicked', { name: 'buttonNa
**Nota**: El check `window.DD_LOGS` evita problemas cuando se produce un fallo de carga con el SDK.
+{{% /tab %}}
+{{< /tabs >}}
+
#### Resultados
Los resultados son los mismos cuando se utiliza NPM, CDN asíncrono o CDN síncrono:
@@ -505,13 +387,14 @@ El backend de Datadog añade más campos, como:
### Rastreo de errores
-El SDK de logs de navegador de Datadog permite el rastreo manual de errores mediante el parámetro opcional `error` (disponible en SDK v4.36.0+). Cuando se proporciona una instancia de un [error de JavaScript][10], el SDK extrae información relevante (tipo, mensaje, traza (trace) de stack tecnológico) del error.
+El SDK de logs de navegador de Datadog permite el rastreo de error manual mediante el parámetro opcional `error` (disponible en el SDK v4.36.0+). Cuando se proporciona una instancia de un [error JavaScript][8], el SDK extrae información relevante (tipo, mensaje, stack trace) del error.
-```
-logger.debug | info | warn | error (message: string, messageContext?: Context, error?: Error)
+```typescript
+logger.{debug|info|warn|error}(message: string, messageContext?: Context, error?: Error)
```
-#### NPM
+{{< tabs >}}
+{{% tab "NPM" %}}
```javascript
import { datadogLogs } from '@datadog/browser-logs'
@@ -525,7 +408,8 @@ try {
}
```
-#### CDN asíncrono
+{{% /tab %}}
+{{% tab "CDN asíncrono" %}}
```javascript
try {
@@ -541,7 +425,8 @@ try {
**Nota**: Las primeras llamadas a la API deben incluirse en la devolución de llamada de `window.DD_LOGS.onReady()`. Esto asegura que el código solo se ejecute una vez que el SDK se cargue correctamente.
-#### CDN síncrono
+{{% /tab %}}
+{{% tab "CDN síncrono" %}}
```javascript
try {
@@ -555,6 +440,9 @@ try {
**Nota**: El check `window.DD_LOGS` evita problemas cuando se produce un fallo de carga con el SDK.
+{{% /tab %}}
+{{< /tabs >}}
+
#### Resultados
Los resultados son los mismos cuando se utiliza NPM, CDN asíncrono o CDN síncrono:
@@ -579,13 +467,12 @@ Los resultados son los mismos cuando se utiliza NPM, CDN asíncrono o CDN síncr
El SDK de logs de navegador de Datadog añade las funciones abreviadas (`.debug`, `.info`, `.warn`, `.error`) a los generadores de logs para mayor comodidad. También está disponible una función de generador de logs genérico, que expone el parámetro `status`:
+```typescript
+log(message: string, messageContext?: Context, status? = 'debug' | 'info' | 'warn' | 'error', error?: Error)
```
-log (message: string, messageContext?: Context, status? = 'debug' | 'info' | 'warn' | 'error', error?: Error)
-```
-
-#### NPM
-Para NPM, utiliza:
+{{< tabs >}}
+{{% tab "NPM" %}}
```javascript
import { datadogLogs } from '@datadog/browser-logs';
@@ -593,9 +480,8 @@ import { datadogLogs } from '@datadog/browser-logs';
datadogLogs.logger.log(,,,);
```
-#### CDN asíncrono
-
-Para CDN asíncrono, utiliza:
+{{% /tab %}}
+{{% tab "CDN asíncrono" %}}
```javascript
window.DD_LOGS.onReady(function() {
@@ -605,14 +491,18 @@ window.DD_LOGS.onReady(function() {
**Nota**: Las primeras llamadas a la API deben incluirse en la devolución de llamada de `window.DD_LOGS.onReady()`. Esto asegura que el código solo se ejecute una vez que el SDK se cargue correctamente.
-#### CDN síncrono
-
-Para CDN síncrono, utiliza:
+{{% /tab %}}
+{{% tab "CDN síncrono" %}}
```javascript
window.DD_LOGS && window.DD_LOGS.logger.log(,,,);
```
+**Nota**: El check `window.DD_LOGS` evita problemas cuando se produce un fallo de carga con el SDK.
+
+{{% /tab %}}
+{{< /tabs >}}
+
#### Parámetros
A continuación se describen los parámetros de los ejemplos anteriores:
@@ -622,7 +512,7 @@ A continuación se describen los parámetros de los ejemplos anteriores:
| `` | El mensaje de tu log que está totalmente indexado por Datadog. |
| `` | Un objeto JSON válido, que incluye todos los atributos adjuntos al ``. |
| `` | El estado de tu log; los valores de estado aceptados son `debug`, `info`, `warn` o `error`. |
-| `` | Una instancia de un objeto de [error de JavaScript][10]. |
+| `` | Una instancia de un objeto [error JavaScript][8]. |
## Uso avanzado
@@ -630,7 +520,7 @@ A continuación se describen los parámetros de los ejemplos anteriores:
Si tus logs de navegador contienen información confidencial que debe redactarse, configura el SDK del navegador para limpiar secuencias confidenciales utilizando la devolución de llamada `beforeSend` cuando inicialices el Collector de logs del navegador.
-La función callback `beforeSend` puede invocarse con dos argumentos: evento de `log` y `context`. Esta función te proporciona acceso a cada log recopilado por el SDK del navegador, antes de ser enviado a Datadog, y te permite utilizar el contexto para ajustar cualquier propiedad del log. El contexto contiene información adicional relacionada con el evento, que podría no estar necesariamente incluida en el evento. Por lo general, puedes utilizar esta información para [enriquecer][18] o [descartar][19] tu evento.
+La función de devolución de llamada `beforeSend` puede invocarse con dos argumentos: el evento `log` y `context`. Esta función te da acceso a cada log recopilado por el SDK de navegador antes de ser enviado a Datadog, y te permite utilizar el contexto para ajustar cualquier propiedad de log. El contexto contiene información adicional relacionada con el evento, pero no necesariamente incluida en el mismo. Normalmente puedes utilizar esta información para [enriquecer][11] tu evento o [descartarlo][12].
```javascript
function beforeSend(log, context)
@@ -641,11 +531,12 @@ Los valores posibles de `context` son:
| Valor | Tipo de datos | Caso de uso |
|-------|---------|------------|
| `isAborted` | Booleano | En el caso de los eventos de logs de red, esta propiedad te indica si la aplicación abortó la solicitud fallida. En este caso es posible que no quieras enviar este evento, ya que podría haber sido abortado intencionalmente. |
-| `handlingStack` | Cadena | Una traza de stack tecnológico de donde se gestionó el evento de log. Puede utilizarse para identificar desde qué [micro-frontend][17] se envió el log. |
+| `handlingStack` | Cadena | Un atack trace de dónde se gestionó el evento de log. Se puede utilizar para identificar desde qué [micro-frontend][9] se envió el log. |
Para eliminar las direcciones de correo electrónico de las URLs de tus aplicaciones web:
-#### NPM
+{{< tabs >}}
+{{% tab "NPM" %}}
```javascript
import { datadogLogs } from '@datadog/browser-logs'
@@ -660,7 +551,8 @@ datadogLogs.init({
});
```
-#### CDN asíncrono
+{{% /tab %}}
+{{% tab "CDN asíncrono" %}}
```javascript
window.DD_LOGS.onReady(function() {
@@ -675,7 +567,10 @@ window.DD_LOGS.onReady(function() {
})
```
-#### CDN síncrono
+**Nota**: Las primeras llamadas a la API deben incluirse en la devolución de llamada de `window.DD_LOGS.onReady()`. Esto asegura que el código solo se ejecute una vez que el SDK se cargue correctamente.
+
+{{% /tab %}}
+{{% tab "CDN síncrono" %}}
```javascript
window.DD_LOGS &&
@@ -689,6 +584,11 @@ window.DD_LOGS &&
});
```
+**Nota**: El check `window.DD_LOGS` evita problemas cuando se produce un fallo de carga con el SDK.
+
+{{% /tab %}}
+{{< /tabs >}}
+
El SDK recopila automáticamente las siguientes propiedades que podrían contener datos confidenciales:
| Atributo | Tipo | Descripción |
@@ -705,7 +605,8 @@ La función de devolución de la llamada `beforeSend` permite también descartar
Para descartar errores de red si su estado es 404:
-#### NPM
+{{< tabs >}}
+{{% tab "NPM" %}}
```javascript
import { datadogLogs } from '@datadog/browser-logs'
@@ -722,7 +623,8 @@ datadogLogs.init({
});
```
-#### CDN asíncrono
+{{% /tab %}}
+{{% tab "CDN asíncrono" %}}
```javascript
window.DD_LOGS.onReady(function() {
@@ -739,7 +641,10 @@ window.DD_LOGS.onReady(function() {
})
```
-#### CDN síncrono
+**Nota**: Las primeras llamadas a la API deben incluirse en la devolución de llamada de `window.DD_LOGS.onReady()`. Esto asegura que el código solo se ejecute una vez que el SDK se cargue correctamente.
+
+{{% /tab %}}
+{{% tab "CDN síncrono" %}}
```javascript
window.DD_LOGS &&
@@ -755,6 +660,11 @@ window.DD_LOGS &&
});
```
+**Nota**: El check `window.DD_LOGS` evita problemas cuando se produce un fallo de carga con el SDK.
+
+{{% /tab %}}
+{{< /tabs >}}
+
### Definir varios generadores de logs
El SDK de logs de navegador de Datadog contiene un generador de logs por defecto, pero es posible definir diferentes generadores de logs.
@@ -781,7 +691,8 @@ Tras la creación de un generador de logs, accede a él en cualquier parte de tu
getLogger(name: string)
```
-##### NPM
+{{< tabs >}}
+{{% tab "NPM" %}}
Por ejemplo, supongamos que hay un `signupLogger`, definido con todos los demás generadores de logs:
@@ -804,7 +715,8 @@ const signupLogger = datadogLogs.getLogger('signupLogger')
signupLogger.info('Test sign up completed')
```
-##### CDN asíncrono
+{{% /tab %}}
+{{% tab "CDN asíncrono" %}}
Por ejemplo, supongamos que hay un `signupLogger`, definido con todos los demás generadores de logs:
@@ -829,7 +741,8 @@ window.DD_LOGS.onReady(function () {
**Nota**: Las primeras llamadas a la API deben incluirse en la devolución de llamada de `window.DD_LOGS.onReady()`. Esto asegura que el código solo se ejecute una vez que el SDK se cargue correctamente.
-##### CDN síncrono
+{{% /tab %}}
+{{% tab "CDN síncrono" %}}
Por ejemplo, supongamos que hay un `signupLogger`, definido con todos los demás generadores de logs:
@@ -854,6 +767,9 @@ if (window.DD_LOGS) {
**Nota**: El check `window.DD_LOGS` evita problemas cuando se produce un fallo de carga con el SDK.
+{{% /tab %}}
+{{< /tabs >}}
+
### Sobrescribir contexto
#### Contexto global
@@ -873,7 +789,8 @@ Una vez inicializado el SDK de logs de navegador de Datadog, es posible:
> - `setGlobalContextProperty` en lugar de `addLoggerGlobalContext`
> - `removeGlobalContextProperty` en lugar de `removeLoggerGlobalContext`
-##### NPM
+{{< tabs >}}
+{{% tab "NPM" %}}
Para NPM, utiliza:
@@ -895,7 +812,8 @@ datadogLogs.clearGlobalContext()
datadogLogs.getGlobalContext() // => {}
```
-##### CDN asíncrono
+{{% /tab %}}
+{{% tab "CDN asíncrono" %}}
Para CDN asíncrono, utiliza:
@@ -931,7 +849,8 @@ window.DD_LOGS.onReady(function () {
**Nota**: Las primeras llamadas a la API deben incluirse en la devolución de llamada de `window.DD_LOGS.onReady()`. Esto asegura que el código solo se ejecute una vez que el SDK se cargue correctamente.
-##### CDN síncrono
+{{% /tab %}}
+{{% tab "CDN síncrono" %}}
Para CDN síncrono, utiliza:
@@ -953,6 +872,9 @@ window.DD_LOGS && window.DD_LOGS.getGlobalContext() // => {}
**Nota**: El check `window.DD_LOGS` evita problemas cuando se produce un fallo de carga con el SDK.
+{{% /tab %}}
+{{< /tabs >}}
+
#### Contexto de usuario
El SDK de logs de Datadog ofrece la posibilidad de asociar un `User` a logs generados.
@@ -965,7 +887,8 @@ El SDK de logs de Datadog ofrece la posibilidad de asociar un `User` a logs gene
**Nota**: El contexto de usuario se aplica antes que el contexto global. Por lo tanto, cada propiedad de usuario incluida en el contexto global anulará el contexto de usuario al generar logs.
-##### NPM
+{{< tabs >}}
+{{% tab "NPM" %}}
Para NPM, utiliza:
@@ -983,7 +906,8 @@ datadogLogs.clearUser()
datadogLogs.getUser() // => {}
```
-##### CDN asíncrono
+{{% /tab %}}
+{{% tab "CDN asíncrono" %}}
Para CDN asíncrono, utiliza:
@@ -1019,7 +943,8 @@ window.DD_LOGS.onReady(function () {
**Nota**: Las primeras llamadas a la API deben incluirse en la devolución de llamada de `window.DD_LOGS.onReady()`. Esto asegura que el código solo se ejecute una vez que el SDK se cargue correctamente.
-##### CDN síncrono
+{{% /tab %}}
+{{% tab "CDN síncrono" %}}
Para CDN síncrono, utiliza:
@@ -1041,6 +966,9 @@ window.DD_LOGS && window.DD_LOGS.getUser() // => {}
**Nota**: El check `window.DD_LOGS` evita problemas cuando se produce un fallo de carga con el SDK.
+{{% /tab %}}
+{{< /tabs >}}
+
#### Contexto de la cuenta
El SDK de logs de Datadog ofrece la posibilidad de asociar una `Account`a los logs generados.
@@ -1053,9 +981,8 @@ El SDK de logs de Datadog ofrece la posibilidad de asociar una `Account`a los lo
**Nota**: El contexto de cuenta se aplica antes que el contexto global. Por lo tanto, cada propiedad de cuenta incluida en el contexto global anulará el contexto de cuenta al generar logs.
-##### NPM
-
-Para NPM, utiliza:
+{{< tabs >}}
+{{% tab "NPM" %}}
```javascript
import { datadogLogs } from '@datadog/browser-logs'
@@ -1071,9 +998,8 @@ datadogLogs.clearAccount()
datadogLogs.getAccount() // => {}
```
-##### CDN asíncrono
-
-Para CDN asíncrono, utiliza:
+{{% /tab %}}
+{{% tab "CDN asíncrono" %}}
```javascript
window.DD_LOGS.onReady(function () {
@@ -1107,9 +1033,8 @@ window.DD_LOGS.onReady(function () {
**Nota**: Las primeras llamadas a la API deben incluirse en la devolución de llamada de `window.DD_LOGS.onReady()`. Esto asegura que el código solo se ejecute una vez que el SDK se cargue correctamente.
-##### CDN síncrono
-
-Para CDN síncrono, utiliza:
+{{% /tab %}}
+{{% tab "CDN síncrono" %}}
```javascript
window.DD_LOGS && window.DD_LOGS.setAccount({ id: '1234', name: 'My Company Name' })
@@ -1129,6 +1054,9 @@ window.DD_LOGS && window.DD_LOGS.getAccount() // => {}
**Nota**: El check `window.DD_LOGS` evita problemas cuando se produce un fallo de carga con el SDK.
+{{% /tab %}}
+{{< /tabs >}}
+
#### Ciclo de vida de los contextos
Por defecto, los contextos se almacenan en la memoria de la página actual, lo que significa que no están:
@@ -1138,7 +1066,7 @@ Por defecto, los contextos se almacenan en la memoria de la página actual, lo q
Para añadirlas a todos los eventos de la sesión, deben adjuntarse a cada página.
-Con la introducción de la opción de configuración `storeContextsAcrossPages` en la v4.49.0 del SDK del navegador, esos contextos pueden almacenarse en [`localStorage`][12], permitiendo los siguientes comportamientos:
+Con la introducción de la opción de configuración `storeContextsAcrossPages` en la v4.49.0 del SDK de navegador, esos contextos pueden ser almacenados en [`localStorage`][9], permitiendo los siguientes comportamientos:
- Los contextos se conservan tras una recarga completa.
- Los contextos se sincronizan entre pestañas abiertas en el mismo origen.
@@ -1156,9 +1084,8 @@ Una vez creado un generador de logs, es posible:
- Configurar el contexto completo para tu generador de logs con la API `setContext (context: object)`.
- Configurar una propiedad de contexto en tu generador de logs con la API `setContextProperty (key: string, value: any)`:
-##### NPM
-
-Para NPM, utiliza:
+{{< tabs >}}
+{{% tab "NPM" %}}
```javascript
import { datadogLogs } from '@datadog/browser-logs'
@@ -1168,9 +1095,8 @@ datadogLogs.setContext("{'env': 'staging'}")
datadogLogs.setContextProperty('referrer', document.referrer)
```
-##### CDN asíncrono
-
-Para CDN asíncrono, utiliza:
+{{% /tab %}}
+{{% tab "CDN asíncrono" %}}
```javascript
window.DD_LOGS.onReady(function () {
@@ -1184,9 +1110,8 @@ window.DD_LOGS.onReady(function () {
**Nota**: Las primeras llamadas a la API deben incluirse en la devolución de llamada de `window.DD_LOGS.onReady()`. Esto asegura que el código solo se ejecute una vez que el SDK se cargue correctamente.
-##### CDN síncrono
-
-Para CDN síncrono, utiliza:
+{{% /tab %}}
+{{% tab "CDN síncrono" %}}
```javascript
window.DD_LOGS && window.DD_LOGS.setContext("{'env': 'staging'}")
@@ -1196,19 +1121,21 @@ window.DD_LOGS && window.DD_LOGS.setContextProperty('referrer', document.referre
**Nota**: El check `window.DD_LOGS` evita problemas cuando se produce un fallo de carga con el SDK.
+{{% /tab %}}
+{{< /tabs >}}
+
### Filtrar por estado
Una vez inicializado el SDK de logs de navegador de Datadog, el nivel mínimo de log para tu generador de logs se configura con la API:
-```
+```typescript
setLevel (level?: 'debug' | 'info' | 'warn' | 'error')
```
Solo se envían logs con un estado igual o superior al nivel especificado.
-#### NPM
-
-Para NPM, utiliza:
+{{< tabs >}}
+{{% tab "NPM" %}}
```javascript
import { datadogLogs } from '@datadog/browser-logs'
@@ -1216,9 +1143,8 @@ import { datadogLogs } from '@datadog/browser-logs'
datadogLogs.logger.setLevel('')
```
-#### CDN asíncrono
-
-Para CDN asíncrono, utiliza:
+{{% /tab %}}
+{{% tab "CDN asíncrono" %}}
```javascript
window.DD_LOGS.onReady(function () {
@@ -1228,9 +1154,8 @@ window.DD_LOGS.onReady(function () {
**Nota**: Las primeras llamadas a la API deben incluirse en la devolución de llamada de `window.DD_LOGS.onReady()`. Esto asegura que el código solo se ejecute una vez que el SDK se cargue correctamente.
-#### CDN síncrono
-
-Para CDN síncrono, utiliza:
+{{% /tab %}}
+{{% tab "CDN síncrono" %}}
```javascript
window.DD_LOGS && window.DD_LOGS.logger.setLevel('')
@@ -1238,6 +1163,9 @@ window.DD_LOGS && window.DD_LOGS.logger.setLevel('')
**Nota**: El check `window.DD_LOGS` evita problemas cuando se produce un fallo de carga con el SDK.
+{{% /tab %}}
+{{< /tabs >}}
+
### Cambiar el destino
Por defecto, los generadores de logs creados por el SDK de logs de navegador de Datadog envían logs a Datadog. Una vez inicializado el SDK de logs de navegador de Datadog, es posible configurar el generador de logs para que:
@@ -1246,13 +1174,12 @@ Por defecto, los generadores de logs creados por el SDK de logs de navegador de
- envíe logs solo a `console`
- no envíe logs en absoluto (`silent`)
-```
+```typescript
setHandler (handler?: 'http' | 'console' | 'silent' | Array)
```
-#### NPM
-
-Para NPM, utiliza:
+{{< tabs >}}
+{{% tab "NPM" %}}
```javascript
import { datadogLogs } from '@datadog/browser-logs'
@@ -1261,9 +1188,9 @@ datadogLogs.logger.setHandler('')
datadogLogs.logger.setHandler(['', ''])
```
-#### CDN asíncrono
+{{% /tab %}}
-Para CDN asíncrono, utiliza:
+{{% tab "CDN asíncrono" %}}
```javascript
window.DD_LOGS.onReady(function () {
@@ -1274,7 +1201,8 @@ window.DD_LOGS.onReady(function () {
**Nota**: Las primeras llamadas a la API deben incluirse en la devolución de llamada de `window.DD_LOGS.onReady()`. Esto asegura que el código solo se ejecute una vez que el SDK se cargue correctamente.
-#### CDN síncrono
+{{% /tab %}}
+{{% tab "CDN síncrono" %}}
Para CDN síncrono, utiliza:
@@ -1285,6 +1213,9 @@ window.DD_LOGS && window.DD_LOGS.logger.setHandler(['', ''])
**Nota**: El check `window.DD_LOGS` evita problemas cuando se produce un fallo de carga con el SDK.
+{{% /tab %}}
+{{< /tabs >}}
+
### Consentimiento de rastreo del usuario
Para cumplir con GDPR, CCPA y normativas similares, el SDK del navegador de logs te permite proporcionar el valor de consentimiento de rastreo en la inicialización.
@@ -1296,16 +1227,15 @@ El parámetro de inicialización `trackingConsent` puede ser uno de los siguient
Para cambiar el valor del consentimiento de rastreo una vez inicializado el SDK del navegador de logs, utiliza la llamada a la API `setTrackingConsent()`. El SDK del navegador de logs cambia su comportamiento según el nuevo valor:
-* cuando se cambia de `"granted"` a `"not-granted"`, la sesión de logs se detiene y ya no se envían datos a Datadog.
-* cuando se cambia de `"not-granted"` a `"granted"`, se crea una nueva sesión de logs si no hay ninguna sesión anterior activa y se reanuda la recopilación de datos.
+- cuando se cambia de `"granted"` a `"not-granted"`, la sesión de logs se detiene y ya no se envían datos a Datadog.
+- cuando se cambia de `"not-granted"` a `"granted"`, se crea una nueva sesión de logs si no hay ninguna sesión anterior activa y se reanuda la recopilación de datos.
Este estado no se sincroniza entre pestañas ni persiste entre navegaciones. Es tu responsabilidad proporcionar la decisión del usuario durante la inicialización del SDK de navegador de logs o mediante el uso de `setTrackingConsent()`.
Cuando se utiliza `setTrackingConsent()` antes que `init()`, el valor proporcionado tiene prioridad sobre el parámetro de inicialización.
-#### NPM
-
-Para NPM, utiliza:
+{{< tabs >}}
+{{% tab "NPM" %}}
```javascript
import { datadogLogs } from '@datadog/browser-logs';
@@ -1320,9 +1250,8 @@ acceptCookieBannerButton.addEventListener('click', function() {
});
```
-#### CDN asíncrono
-
-Para CDN asíncrono, utiliza:
+{{% /tab %}}
+{{% tab "CDN asíncrono" %}}
```javascript
window.DD_LOGS.onReady(function() {
@@ -1339,9 +1268,8 @@ acceptCookieBannerButton.addEventListener('click', () => {
});
```
-#### CDN síncrono
-
-Para CDN síncrono, utiliza:
+{{% /tab %}}
+{{% tab "CDN síncrono" %}}
```javascript
window.DD_LOGS && window.DD_LOGS.init({
@@ -1354,19 +1282,21 @@ acceptCookieBannerButton.addEventListener('click', () => {
});
```
+{{% /tab %}}
+{{< /tabs >}}
+
### Acceder al contexto interno
Una vez inicializado el SDK de logs de navegador de Datadog, puedes acceder al contexto interno del SDK. Esto te permite acceder al `session_id`.
-```
+```typescript
getInternalContext (startTime?: 'number' | undefined)
```
También puedes utilizar el parámetro `startTime` para obtener el contexto de un momento específico. Si se omite el parámetro, se regresa el contexto actual.
-#### NPM
-
-Para NPM, utiliza:
+{{< tabs >}}
+{{% tab "NPM" %}}
```javascript
import { datadogLogs } from '@datadog/browser-logs'
@@ -1374,9 +1304,9 @@ import { datadogLogs } from '@datadog/browser-logs'
datadogLogs.getInternalContext() // { session_id: "xxxx-xxxx-xxxx-xxxx" }
```
-#### CDN asíncrono
+{{% /tab %}}
-Para CDN asíncrono, utiliza:
+{{% tab "CDN asíncrono" %}}
```javascript
window.DD_LOGS.onReady(function () {
@@ -1384,31 +1314,24 @@ window.DD_LOGS.onReady(function () {
})
```
-#### CDN síncrono
-
-Para CDN síncrono, utiliza:
+{{% /tab %}}
+{{% tab "CDN síncrono" %}}
```javascript
window.DD_LOGS && window.DD_LOGS.getInternalContext() // { session_id: "xxxx-xxxx-xxxx-xxxx" }
```
+{{% /tab %}}
+{{< /tabs >}}
+
-[1]: https://docs.datadoghq.com/es/account_management/api-app-keys/#api-keys
-[2]: https://docs.datadoghq.com/es/account_management/api-app-keys/#client-tokens
-[3]: https://www.npmjs.com/package/@datadog/browser-logs
-[4]: https://github.com/DataDog/browser-sdk/blob/main/packages/logs/BROWSER_SUPPORT.md
-[5]: https://docs.datadoghq.com/es/real_user_monitoring/guide/enrich-and-control-rum-data/
-[6]: https://docs.datadoghq.com/es/real_user_monitoring/faq/proxy_rum_data/
-[7]: https://docs.datadoghq.com/es/getting_started/tagging/#define-tags
-[8]: https://developer.mozilla.org/en-US/docs/Web/API/Reporting_API
-[9]: https://docs.datadoghq.com/es/getting_started/site/
-[10]: https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Error
-[11]: https://docs.datadoghq.com/es/logs/log_collection/javascript/#contexts-life-cycle
-[12]: https://developer.mozilla.org/en-US/docs/Web/API/Window/localStorage
-[13]: https://developer.mozilla.org/en-US/docs/Web/API/Event/isTrusted
-[14]: /es/integrations/content_security_policy_logs/#use-csp-with-real-user-monitoring-and-session-replay
-[15]: #user-tracking-consent
-[17]: /es/real_user_monitoring/browser/advanced_configuration/?tab=npm#micro-frontend
-[18]: /es/real_user_monitoring/browser/advanced_configuration/?tab=npm#enrich-and-control-rum-data
-[19]: /es/real_user_monitoring/browser/advanced_configuration/?tab=npm#discard-a-rum-event
\ No newline at end of file
+[1]: https://app.datadoghq.com/organization-settings/client-tokens
+[4]: https://datadoghq.dev/browser-sdk/interfaces/_datadog_browser-logs.LogsInitConfiguration.html
+[5]: /es/logs/log_collection/javascript/#user-tracking-consent
+[6]: /es/integrations/content_security_policy_logs/#use-csp-with-real-user-monitoring-and-session-replay
+[7]: /es/logs/explorer/
+[8]:
+[9]: https://developer.mozilla.org/en-US/docs/Web/API/Window/localStorage
+[11]: /es/real_user_monitoring/browser/advanced_configuration/?tab=npm#enrich-and-control-rum-data
+[12]: /es/real_user_monitoring/browser/advanced_configuration/?tab=npm#discard-a-rum-event
\ No newline at end of file
diff --git a/content/es/logs/log_configuration/logs_to_metrics.md b/content/es/logs/log_configuration/logs_to_metrics.md
index 67a956cc4def0..906fe9dc2f9e0 100644
--- a/content/es/logs/log_configuration/logs_to_metrics.md
+++ b/content/es/logs/log_configuration/logs_to_metrics.md
@@ -46,7 +46,7 @@ También puedes crear métricas a partir de una búsqueda de Analytics, seleccio
{{< img src="logs/processing/logs_to_metrics/create_custom_metrics2.png" alt="Crear logs para métricas" style="width:80%;">}}
-1. **Introduce una consulta para filtrar el flujo de logs**: la sintaxis de la consulta es la misma que la de las [búsquedas del Explorador de logs][6]. Para la agregación, sólo se tienen en cuenta los logs con marcas de tiempo, consumidos en los últimos 20 minutos.
+1. **Introduce una consulta para filtrar el flujo de logs**: la sintaxis de la consulta es la misma que la de las [búsquedas del Log Explorer][6]. Para la agregación, solo se tienen en cuenta los logs con marcas de tiempo, consumidos en los últimos 20 minutos. El índice debe excluirse de la consulta.
2. **Selecciona el campo del que quieres realizar el seguimiento**: selecciona `*` para generar un recuento de todos los logs que coinciden con tu consulta o introduce un atributo de log (por ejemplo, `@network.bytes_written`), para agregar un valor numérico y crear sus correspondientes métricas agregadas `count`, `min`, `max`, `sum` y `avg`. Si la faceta del atributo de log es una [medida][7], el valor de la métrica es el valor del atributo de log.
3. **Añade dimensiones a `group by`**: por defecto, las métricas generadas a partir de logs no tienen ninguna etiqueta (tags), a menos que se añadan explícitamente. Cualquier atributo o dimensión de etiqueta presente en tus logs (por ejemplo, `@network.bytes_written`, `env`) puede utilizarse para crear [etiquetas][8] de métricas. Los nombres de etiquetas de métricas son iguales al atributo o nombre de etiqueta de origen, sin el símbolo @.
4. **Añade agregaciones de percentiles**: para las métricas de distribución, también puedes generar los percentiles p50, p75, p90, p95 y p99. Las métricas de percentiles también se consideran métricas personalizadas y se [facturan en consecuencia][9].
@@ -56,7 +56,7 @@ También puedes crear métricas a partir de una búsqueda de Analytics, seleccio
{{< img src="logs/processing/logs_to_metrics/count_unique.png" alt="Página de configuración del gráfico de series temporales con el parámetro de consulta de recuento único resaltado" style="width:80%;">}}
-
diff --git a/content/es/logs/log_configuration/processors.md b/content/es/logs/log_configuration/processors.md index a4adbc9d90c3a..86ca5068a9f35 100644 --- a/content/es/logs/log_configuration/processors.md +++ b/content/es/logs/log_configuration/processors.md @@ -686,7 +686,7 @@ El procesador de búsqueda realiza las siguientes acciones: * Opcionalmente, si no encuentra el valor en la tabla de asignación, crea un atributo de destino con el valor de la tabla de referencia. Puedes seleccionar un valor para una [tabla de referencias][101] en la pestaña **Reference Table** (Tabla de referencia). - {{< img src="logs/log_configuration/processor/lookup_processor_reference_table.png" alt="Procesador de búsqueda" >}} + {{< img src="logs/log_configuration/processor/lookup_processor_reference_table.png" alt="Procesador de búsqueda" style="width:80%;">}} @@ -829,7 +829,7 @@ Define el procesador de matrices en la página [**Pipelines**][1]. Extrae un valor específico de un objeto dentro de una matriz cuando coincide con una condición. {{< tabs >}} -{{% tab "UI (IU)" %}} +{{% tab "UI" %}} {{< img src="logs/log_configuration/processor/array_processor_select_value.png" alt="Procesador de matrices - Seleccionar el valor de un elemento" style="width:80%;" >}} @@ -864,6 +864,38 @@ Extrae un valor específico de un objeto dentro de una matriz cuando coincide co } ``` +{{% /tab %}} +{{% tab "API" %}} + +Utiliza el [endpoint de API del pipeline de logs de Datadog][1] con la siguiente carga útil JSON del procesador de matrices: + +```json +{ + "type": "array-processor", + "name": "Extract Referrer URL", + "is_enabled": true, + "operation" : { + "type" : "select", + "source": "httpRequest.headers", + "target": "referrer", + "filter": "name:Referrer", + "value_to_extract": "value" + } +} +``` + +| Parámetro | Tipo | Obligatorio | Descripción | +|--------------|------------------|----------|---------------------------------------------------------------| +| `type` | Cadena | Sí | Tipo de procesador. | +| `name` | Cadena | No | Nombre del procesador. | +| `is_enabled` | Booleano | No | Si el procesador está activado. Por defecto: `false`. | +| `operation.type` | Cadena | Sí | Tipo de funcionamiento del procesador de matrices. | +| `operation.source` | Cadena | Sí | Ruta de la matriz de la que quieres seleccionar. | +| `operation.target` | Cadena | Sí | Atributo objetivo. | +| `operation.filter` | Cadena | Sí | Expresión que coincide con un elemento de la matriz. Se selecciona el primer elemento coincidente. | +| `operation.value_to_extract` | Cadena | Sí | Atributo a leer en el elemento seleccionado. | + +[1]: /es/api/v1/logs-pipelines/ {{% /tab %}} {{< /tabs >}} @@ -872,7 +904,7 @@ Extrae un valor específico de un objeto dentro de una matriz cuando coincide co Calcula el número de elementos de una matriz. {{< tabs >}} -{{% tab "UI (IU)" %}} +{{% tab "UI" %}} {{< img src="logs/log_configuration/processor/array_processor_length.png" alt="Procesador de matrices - Longitud" style="width:80%;" >}} @@ -898,6 +930,34 @@ Calcula el número de elementos de una matriz. } ``` {{% /tab %}} +{{% tab "API" %}} + +Utiliza el [endpoint de API del pipeline de logs de Datadog][1] con la siguiente carga útil JSON del procesador de matrices: + +```json +{ + "type": "array-processor", + "name": "Compute number of tags", + "is_enabled": true, + "operation" : { + "type" : "length", + "source": "tags", + "target": "tagCount" + } +} +``` + +| Parámetro | Tipo | Obligatorio | Descripción | +|---------------------|-----------|----------|---------------------------------------------------------------| +| `type` | Cadena | Sí | Tipo de procesador. | +| `name` | Cadena | No | Nombre del procesador. | +| `is_enabled` | Booleano | No | Si el procesador está activado. Por defecto: `false`. | +| `operation.type` | Cadena | Sí | Tipo de funcionamiento del procesador de matrices. | +| `operation.source` | Cadena | Sí | Ruta de la matriz de la que quieres seleccionar. | +| `operation.target` | Cadena | Sí | Atributo objetivo. | + +[1]: /es/api/v1/logs-pipelines/ +{{% /tab %}} {{< /tabs >}} ### Añadir a la matriz @@ -908,7 +968,7 @@ Añade un valor de atributo al final de un atributo de matriz de destino en el l {{< tabs >}} -{{% tab "UI (IU)" %}} +{{% tab "UI" %}} {{< img src="logs/log_configuration/processor/array_processor_append.png" alt="Procesador de matrices - Añadir" style="width:80%;" >}} @@ -942,6 +1002,60 @@ Añade un valor de atributo al final de un atributo de matriz de destino en el l "sourceIps": ["203.0.113.1", "198.51.100.23"] } ``` +{{% /tab %}} +{{% tab "API" %}} + +Utiliza el [endpoint de API del pipeline de logs de Datadog][1] con la siguiente carga útil JSON del procesador de matrices: + +```json +{ + "type": "array-processor", + "name": "Append client IP to sourceIps", + "is_enabled": true, + "operation" : { + "type" : "append", + "source": "network.client.ip", + "target": "sourceIps" + } +} +``` + +| Parámetro | Tipo | Obligatorio | Descripción | +|------------------------------|------------|----------|--------------------------------------------------------------------| +| `type` | Cadena | Sí | Tipo de procesador. | +| `name` | Cadena | No | Nombre del procesador. | +| `is_enabled` | Booleano | No | Si el procesador está activado. Por defecto: `false`. | +| `operation.type` | Cadena | Sí | Tipo de funcionamiento del procesador de matrices. | +| `operation.source` | Cadena | Sí | Atributo a añadir. | +| `operation.target` | Cadena | Sí | Atributo de matriz al que añadir. | +| `operation.preserve_source` | Booleano | No | Si se conserva la fuente original después de la reasignación. Por defecto: `false`. | + +[1]: /es/api/v1/logs-pipelines/ +{{% /tab %}} +{{< /tabs >}} + +## Procesador decodificador + +El procesador decodificador traduce los campos de cadena codificados de binario a texto (como Base64 o Hex/Base16) a su representación original. Esto permite interpretar los datos en su contexto nativo, ya sea como cadena UTF-8, comando ASCII o valor numérico (por ejemplo, un número entero derivado de una cadena hexadecimal). El procesador decodificador es especialmente útil para analizar comandos codificados, logs de sistemas específicos o técnicas de evasión utilizadas por actores de amenazas. + +**Notas**: + +- Cadenas truncadas: El procesador maneja las cadenas Base64/Base16 parcialmente truncadas con elegancia, recortándolas o rellenándolas según sea necesario. + +- Formato hexadecimal: La entrada hexadecimal puede descodificarse en una cadena (UTF-8) o en un número entero. + +- Gestión de fallos: Si la descodificación falla (debido a una entrada no válida), el procesador omite la transformación y el log permanece inalterado. + +{{< tabs >}} +{{% tab "UI" %}} + +1. Configura el atributo de origen: Proporciona la ruta del atributo que contiene la cadena codificada, como `encoded.base64`. +2. Selecciona la codificación de origen: Elige la codificación binaria a texto de la fuente: `base64` o `base16/hex`. +2. Para `Base16/Hex`: Elige el formato de salida: `string (UTF-8)` o `integer`. +3. Configura el atributo de destino: Introduce la ruta del atributo para almacenar el resultado decodificado. + +{{< img src="logs/log_configuration/processor/decoder-processor.png" alt="Procesador decodificador - Adjuntar" style="width:80%;" >}} + {{% /tab %}} {{< /tabs >}} @@ -959,7 +1073,7 @@ Para más información, véase [Inteligencia sobre amenazas][9]. *Logging without Limits es una marca registrada de Datadog, Inc. [1]: /es/logs/log_configuration/pipelines/ -[2]: /es/logs/log_configuration/parsing/ +[2]: /es/agent/logs/advanced_log_collection/?tab=configurationfile#scrub-sensitive-data-from-your-logs [3]: /es/logs/log_configuration/parsing/?tab=matchers#parsing-dates [4]: https://en.wikipedia.org/wiki/Syslog#Severity_level [5]: /es/logs/log_collection/?tab=host#attributes-and-tags diff --git a/content/es/metrics/metrics-without-limits.md b/content/es/metrics/metrics-without-limits.md index 8c7a7d62e5a3d..a7e27aeabe336 100644 --- a/content/es/metrics/metrics-without-limits.md +++ b/content/es/metrics/metrics-without-limits.md @@ -5,6 +5,7 @@ algolia: aliases: - /es/metrics/faq/metrics-without-limits/ - /es/metrics/guide/metrics-without-limits-getting-started/ +- /es/metrics/faq/why-is-my-save-button-disabled/ further_reading: - link: https://www.datadoghq.com/blog/metrics-without-limits tag: Blog @@ -21,57 +22,85 @@ title: Metrics without LimitsTM Metrics without LimitsTM proporciona flexibilidad y control sobre tus volúmenes de métricas personalizadas al desvincular la ingesta e indexación de métricas personalizadas. Solo pagas por las etiquetas (tags) de las métricas personalizadas que son valiosas para tu organización. -Metrics without LimitsTM te permite configurar etiquetas en todos los tipos de métricas de la aplicación. También puedes personalizar las agregaciones en counts, tasas y medidores sin tener que volver a desplegar o cambiar código. Con Metrics without LimitsTM, puedes configurar una lista de etiquetas permitidas en la aplicación para que se puedan consultar en toda la plataforma de Datadog; esto elimina de manera automática las etiquetas que no son esenciales asociadas a métricas de nivel de aplicación o empresariales (por ejemplo, `host`). De manera alternativa, puedes configurar una lista de etiquetas bloqueadas en la aplicación para eliminar y excluir con rapidez las etiquetas; esto conserva de manera automática las etiquetas esenciales restantes que brindan valor empresarial a tus equipos. Estas funcionalidades de configuración se encuentran en la página de [Resumen de métricas][1]. +Metrics without LimitsTM te permite configurar las etiquetas de todos los tipos de métricas en la aplicación seleccionando una lista de etiquetas permitidas que se pueden consultar en Datadog; de este modo, se eliminan automáticamente las etiquetas no esenciales asociadas a métricas empresariales o de nivel de aplicación (por ejemplo, `host`). Como alternativa, puedes configurar una lista de bloqueo de etiquetas en la aplicación para eliminar y excluir etiquetas; de este modo, se conservan automáticamente las etiquetas esenciales restantes que aportan valor empresarial a tus equipos. Estas funciones de configuración se encuentran en la página [Resumen de métricas][1]. En esta página se identifican los componentes clave de Metrics without LimitsTM que pueden ayudarte a gestionar los volúmenes de métricas personalizadas dentro de tu presupuesto de observabilidad. -### Configuración de etiquetas +### Configuración de etiquetas para una única métrica #### Lista de etiquetas permitidas + 1. Haz clic en el nombre de cualquier métrica para abrir su panel lateral de detalles. -2. Haz clic en **Manage Tags** (Gestionar etiquetas) -> **«Include Tags...»** (Incluir etiquetas...) para configurar las etiquetas que quieras que se puedan consultar en dashboards, notebooks, monitores y otros productos de Datadog. +2. Haz clic en **Manage Tags** (Gestionar etiquetas), luego en **Include tags** (Incluir etiquetas) para configurar las etiquetas que quieras que se puedan consultar en dashboards, notebooks, monitores y otros productos de Datadog. 3. Define tu lista de etiquetas permitidas. -De manera predeterminada, el modal de configuración de etiquetas se completa previamente con una lista de etiquetas permitidas recomendadas por Datadog que se consultaron de manera activa en dashboards, notebooks, monitores o a través de la API en los últimos 30 días. Las etiquetas recomendadas se distinguen con un icono de línea de gráfica. +De manera predeterminada, el modal de configuración de etiquetas se completa previamente con una lista de etiquetas permitidas recomendadas por Datadog que se consultaron de manera activa en dashboards, notebooks, monitores o a través de la API en los últimos 30 días. Las etiquetas recomendadas se distinguen con un icono de gráficos de línea. + a. Además, incluye las etiquetas que se utilizan en los activos (dashboards, monitores, notebooks y SLOs). Estas etiquetas se utilizan en los activos, pero no se consultan activamente y están marcadas con un icono de objetivo. Si las añades, te asegurarás de no perder visibilidad de tus activos críticos. 4. Revisa el *Estimated New Volume* (Nuevo volumen estimado) de métricas personalizadas indexadas que resultan de esta posible configuración de etiquetas. -5. Haz clic en **Guardar**. +5. Haz clic en **Save** (Guardar). + +{{< img src="metrics/mwl_example_include_tags-compressed_03182025.mp4" alt="Configuración de etiquetas con la lista de permitidos" video="true" style="width:100%" >}} -{{< img src="metrics/mwl_example_include_tags-compressed.mp4" alt="Configuración de etiquetas con la lista de permitidas" video=true style="width:100%" >}} +{{< img src="metrics/tags_used_assets.png" alt="Mostrar a los clientes que pueden añadir etiquetas utilizadas en activos en su configuración de MWL" style="width:100%" >}} Puedes [crear][2], [editar][3], [eliminar][4] y [estimar el impacto][5] de la configuración de tu etiqueta a través de las APIs de Metrics. #### Lista de etiquetas bloqueadas + 1. Haz clic en el nombre de cualquier métrica para abrir su panel lateral de detalles. -2. Haz clic en **Manage Tags** (Gestionar etiquetas) -> **«Exclude Tags...»** (Excluir etiquetas...) para eliminar las etiquetas que no quieres consultar. -3. Define tu lista de etiquetas bloqueadas. Las etiquetas que se definan en la lista de bloqueadas **no** se pueden consultar en dashboards ni monitores. Las etiquetas que se han consultado de manera activa en dashboards, notebooks, monitores y a través de la API en los últimos 30 días se distinguen con un icono de línea de gráfica. -5. Revisa el *Estimated New Volume* (Nuevo volumen estimado) de métricas personalizadas indexadas que resultan de esta posible configuración de etiquetas. -6. Haz clic en **Guardar**. +2. Haz clic en **Manage Tags** (Administrar etiquetas), luego, en **Exclude Tags** (Excluir etiquetas). +3. Define tu lista de etiquetas bloqueadas. Las etiquetas que se definan en la lista de bloqueadas **no** se pueden consultar en dashboards ni monitores. Las etiquetas que se han consultado de manera activa en dashboards, notebooks, monitores y a través de la API en los últimos 30 días se distinguen con un icono del gráfico de líneas. +4. Revisa el *Estimated New Volume* (Nuevo volumen estimado) de métricas personalizadas indexadas que resultan de esta posible configuración de etiquetas. +5. Haz clic en **Save** (Guardar). -{{< img src="metrics/mwl-example-tag-exclusion-compressed.mp4" alt="Configuración de etiquetas con exclusión de etiquetas" video=true style="width:100%" >}} +{{< img src="metrics/mwl-example-tag-exclusion-compressed_04032025.mp4" alt="Configuración de etiquetas con exclusión de etiquetas" video="true" style="width:100%" >}} Establece el parámetro `exclude_tags_mode: true` en la API de Metrics para [crear][2] y [editar][3] una lista de etiquetas bloqueadas. -Al configurar etiquetas para counts, tasas y medidores, la combinación de agregación de tiempo/espacio consultada con mayor frecuencia se encuentra disponible para consultar de manera predeterminada. +**Nota:** Para que las etiquetas se gestionen en una métrica, ésta debe tener un tipo declarado. Esto se hace normalmente cuando se envía una métrica, pero también puede hacerse manualmente utilizando el botón `Edit` para una métrica en Resumen de métricas. + +#### En la API + +Puedes [crear][2], [editar][3], [eliminar][4] y [estimar el impacto][5] de la configuración de tu etiqueta a través de las APIs de Metrics. ### Configurar varias métricas a la vez -Optimiza los volúmenes de métricas personalizadas mediante la [función de configuración masiva de etiquetas de métricas][7]. A fin de especificar un espacio de nombres para tus métricas, haz clic en **Configure Tags*** (Configurar etiquetas) en Resumen de métricas. Puedes configurar todas las métricas que coincidan con ese prefijo de espacio de nombres con la misma lista de etiquetas permitidas en ***Include tags...*** (Incluir tags...) o la misma lista de etiquetas bloqueadas en ***Exclude tags...*** (Excluir etiquetas...). +Optimiza tus volúmenes de métricas personalizadas utilizando la [función de configuración en bloque de etiquetas de métricas][7]. Para especificar las métricas que deseas configurar, haz clic en **Configure Metrics** (Configurar métricas) y, a continuación, en **Manage Tags*** (Gestionar etiquetas) en la página de resumen de métricas. Selecciona la métrica o el espacio de nombres de métricas que desees configurar y, a continuación, elige una de las siguientes opciones: + - [Permitir todas las etiquetas](#allow-all-tags) para anular cualquier configuración de etiquetas anterior y hacer que todas las etiquetas se puedan consultar. + - [Incluir o excluir etiquetas](#include-or-exclude-tags) para definir etiquetas consultables y no consultables, respectivamente. + +#### Permitir todas las etiquetas + +{{< img src="metrics/bulk_allow_all_tags.png" alt="La opción Administrar etiquetas con Permitir todas las etiquetas seleccionada en la sección Configurar etiquetas" style="width:100%" >}} + +Esta opción está seleccionada por defecto y anula las configuraciones de etiquetas establecidas previamente para que todas las etiquetas sean consultables. + +#### Incluir o excluir etiquetas + +Cuando selecciones etiquetas para incluir o excluir, elige entre [anular las configuraciones de etiquetas existentes](#override-existing-tag-configurations) o [mantener las configuraciones de etiquetas existentes](#keep-existing-tag-configurations). + +##### Anular configuraciones de etiquetas existentes + +{{< img src="metrics/bulk_include_tags.png" alt="La opción Administrar etiquetas con Incluir etiquetas y Anular seleccionada en la sección Configurar etiquetas. Las opciones para incluir etiquetas consultadas de forma activa en dashboards y monitores en los últimos 90 días y Etiquetas específicas están seleccionadas" style="width:100%" >}} + +Se anulan todas las configuraciones de etiquetas existentes para las métricas seleccionadas y se define una nueva configuración de etiquetas. Esto te permite hacer que todas las etiquetas se puedan consultar en todos los nombres de métricas. Si eliges **incluir etiquetas**, puedes incluir una o ambas de las siguientes opciones: + - Etiquetas consultadas activamente en Datadog en los últimos 30, 60 o 90 días. + - Un conjunto específico de etiquetas que defines. -Puedes [configurar][13] y [eliminar][14] etiquetas para varias métricas a través de la API. A fin de [configurar una lista de etiquetas bloqueadas][13] para varias métricas, establece el parámetro `exclude_tags_mode: true` en la API. +##### Mantener las configuraciones de etiquetas existentes -### Refinar y optimizar las agregaciones +{{< img src="metrics/bulk_exclude_tags.png" alt="La opción Administrar etiquetas con Excluir etiquetas y Mantener seleccionadas en la sección Configurar etiquetas" style="width:100%" >}} -Puedes ajustar aún más tus filtros de métricas personalizadas si optas por más [agregaciones de métricas][6] en tus métricas de medidor, count o tasa. A fin de preservar la precisión matemática de tus consultas, Datadog solo almacena la combinación de agregación de tiempo/espacio consultada con mayor frecuencia para un tipo de métrica determinado: +Se conservan las configuraciones de etiquetas existentes y se definen las nuevas etiquetas que se añadirán a la configuración. -- Los counts y tasas configurados se pueden consultar en tiempo/espacio con SUM -- Los medidores configurados se pueden consultar en tiempo/espacio con AVG +#### En la API -Puedes añadir o eliminar agregaciones en cualquier momento sin necesidad de realizar cambios en el nivel de código o Agent. +Puedes [configurar][13] y [eliminar][14] etiquetas para múltiples métricas a través de la API. -El modal de configuración de etiquetas se completa previamente con una lista de agregaciones permitidas que se han consultado de manera activa en dashboards, notebooks, monitores y a través de la API en los últimos 30 días (de color azul con un icono). También puedes incluir tus propias agregaciones adicionales. +**Nota**: Utiliza el atributo `include_actively_queried_tags_window` para incluir sólo las etiquetas consultadas activamente en un periodo determinado. ## Facturación de Metrics without LimitsTM -La configuración de las etiquetas y agregaciones te permite controlar qué métricas personalizadas se pueden consultar, lo que en última instancia reduce la cantidad facturable de métricas personalizadas. Metrics without LimitsTM desvincula los costes de ingesta de los costes de indexación. Puedes continuar enviando a Datadog todos los datos (se ingiere todo) y puedes especificar una lista de etiquetas permitidas que quieras que se puedan consultar en la plataforma de Datadog. Si el volumen de datos que Datadog ingiere para las métricas configuradas difiere del volumen restante más pequeño que indexas, puedes ver dos volúmenes distintos en la página de Uso, así como en la página de Resumen de métricas. +La configuración de tus etiquetas te permite controlar qué métricas personalizadas pueden consultarse, lo que reduce el número de métricas personalizadas facturables. Metrics without LimitsTM desvincula los costes de ingesta de los costes de indexación. Puedes seguir enviando a Datadog todos tus datos (todo se ingiere) y puedes especificar una lista de etiquetas permitidas que deseas que sigan siendo consultables en la plataforma de Datadog. Si el volumen de datos que Datadog está ingiriendo para tus métricas configuradas difiere del volumen restante más pequeño que indexas, puedes ver dos volúmenes distintos en tu pagina de Uso, así como en la página Resumen de métricas. - **Métricas personalizadas ingeridas**: el volumen original de métricas personalizadas basadas en todas las etiquetas ingeridas. - **Métricas personalizadas indexadas**: el volumen de métricas personalizadas de tipo consultable que queda en la plataforma de Datadog (en función de las configuraciones de Metrics without LimitsTM) @@ -103,7 +132,7 @@ Obtén más información sobre la [Facturación de métricas personalizadas][8]. - El [control de acceso basado en roles][11] para Metrics without LimitsTM también se encuentra disponible a fin de controlar qué usuarios tienen permisos para usar esta función que tiene implicaciones de facturación. -- Los eventos de auditoría te permiten realizar un seguimiento de las configuraciones de etiquetas o las agregaciones de percentiles que se hayan realizado y que puedan correlacionarse con picos de métricas personalizadas. Busca «tags:audit» y «configuración de etiquetas consultable» o «agregaciones de percentiles» en tu [Flujo de eventos][12] +- Los eventos de auditoría te permiten realizar un seguimiento de las configuraciones de etiquetas o las agregaciones de percentiles que se hayan realizado y que puedan correlacionarse con picos de métricas personalizadas. Busca "tags:audit" y "configuración de etiquetas consultable" o "agregaciones de percentiles" en tu [Flujo de eventos][12]. \*Metrics without Limits es una marca registrada de Datadog, Inc. diff --git a/content/es/metrics/summary.md b/content/es/metrics/summary.md index bdb19d672ea99..a19dd8ebf3577 100644 --- a/content/es/metrics/summary.md +++ b/content/es/metrics/summary.md @@ -21,9 +21,9 @@ Busca tus métricas por nombre de métrica o etiqueta (tag) utilizando los campo {{< img src="metrics/summary/tag_advanced_filtering.png" alt="Página de resumen de métricas SIN equipo:* ingresado en la barra de búsqueda por etiquetas" style="width:75%;">}} -También puede descubrir métricas relevantes utilizando el soporte mejorado de concordancia difusa en el campo de búsqueda de métricas: +También puedes detectar métricas relevantes utilizando la compatibilidad mejorada de concordancia difusa en el campo de búsqueda de métricas: -{{< img src="metrics/summary/metric_advanced_filtering_fuzzy.png" alt="The metrics summary Page ( página) with fuzzy search searching shopist checkout" style="width:75%;">}} +{{< img src="metrics/summary/metric_advanced_filtering_fuzzy.png" alt="La página de resumen de métricas con búsqueda difusa que busca el pago en Shopist" style="width:75%;">}} El filtrado por etiquetas admite la sintaxis booleana y de comodín para que puedas identificar: * Métricas que están etiquetadas con una clave de etiqueta concreta, por ejemplo, `team`: `team:*` @@ -149,12 +149,13 @@ Para cualquier clave concreta de etiqueta, puedes: ### Activos relacionados con métricas -{{< img src="metrics/summary/related_assets_dashboards.png" alt="Activos relacionados para un nombre de métricas especificado" style="width:80%;">}} +{{< img src="metrics/summary/related_assets_dashboards_08_05_2025.png" alt="Activos relacionados para un nombre de métricas específico" style="width:80%;">}} Para determinar el valor de cualquier nombre de métrica para tu organización, utiliza Activos relacionados de métricas. Los activos relacionados de métricas se refieren a cualquier dashboard, notebook, monitor, o SLO que consulta una métrica en particular. 1. Desplázate hasta la parte inferior del panel lateral de detalles de la métrica, hasta la sección **Recursos relacionados**. 2. Haz clic en el botón desplegable para ver el tipo de recurso relacionado que te interesa en (dashboards, monitores, notebooks, SLOs). Además, puedes utilizar la barra de búsqueda para validar activos específicos. +3. La columna **Tags** (Etiquetas) muestra exactamente qué etiquetas se utilizan en cada activo. ## Explorador de la cardinalidad de etiquetas de métricas personalizadas diff --git a/content/es/metrics/units.md b/content/es/metrics/units.md index 48e8103bd3fae..a2efe23549279 100644 --- a/content/es/metrics/units.md +++ b/content/es/metrics/units.md @@ -25,9 +25,13 @@ Por ejemplo, si tienes un punto de datos que es 3.000.000.000: * Si no has especificado una unidad para este punto de datos, aparecerá "3G". * Si has especificado que este punto de datos está en bytes, aparecerá "3GB". -Las unidades también se muestran en la parte inferior de las gráficas de timeboard, y las descripciones de métricas están disponibles al seleccionar **Metrics Info** del menú desplegable: +Haz clic en el botón de pantalla completa situado en la esquina superior derecha del gráfico para ver las unidades que aparecen en la parte inferior: -{{< img src="metrics/units/annotated_ops.png" alt="Operaciones anotadas" style="width:100%;">}} +{{< img src="metrics/units/metrics_units.png" alt="Las unidades de un gráfico de métricas en el modo pantalla completa" style="width:100%;">}} + +En el gráfico de una métrica, haz clic en el menú contextual (tres puntos verticales) para encontrar la opción **Metrics info** (Información de la métrica). Esto abre un panel con una descripción de la métrica. Al hacer clic en el nombre de la métrica en este panel, se abre la métrica en la página del resumen de métricas para su posterior análisis o edición. + +{{< img src="metrics/units/metrics_info.png" alt="La opción Información de métricas en el menú de contexto ampliado (tres puntos verticales)" style="width:100%;">}} Para cambiar una unidad de métrica, ve a la página de [resumen de métricas][1] y selecciona una métrica. Haz clic en **Edit** en **Metadata** y selecciona una unidad, como `bit` o `byte` del menú desplegable. diff --git a/content/es/monitors/guide/how-to-set-up-rbac-for-monitors.md b/content/es/monitors/guide/how-to-set-up-rbac-for-monitors.md index 62912e4bf47c7..7a4cf8085848a 100644 --- a/content/es/monitors/guide/how-to-set-up-rbac-for-monitors.md +++ b/content/es/monitors/guide/how-to-set-up-rbac-for-monitors.md @@ -1,4 +1,7 @@ --- +description: Configura el control de acceso basado en roles (RBAC) para monitores + con el fin de restringir los permisos de edición a roles específicos y evitar cambios + no autorizados. further_reading: - link: /account_management/rbac/permissions/#monitors tag: Documentación @@ -133,7 +136,7 @@ Puedes actualizar la definición de los monitores que se gestionan mediante API Para obtener más información, consulta [Editar un endpoint de API de monitor][3] y [API de políticas de restricción][4]. -### IU +### Interfaz de usuario Todos los nuevos monitores creados desde la interfaz de usuario utilizan el parámetro `restricted_roles`. Todos los monitores muestran también la opción de restricción de roles independientemente del mecanismo subyacente: diff --git a/content/es/monitors/guide/monitor_api_options.md b/content/es/monitors/guide/monitor_api_options.md index 7990a257e7d6d..46cd62b789215 100644 --- a/content/es/monitors/guide/monitor_api_options.md +++ b/content/es/monitors/guide/monitor_api_options.md @@ -1,4 +1,7 @@ --- +description: Referencia completa para las opciones de configuración de la API monitores + (noun), incluidos los parámetros comunes, los permisos, las alertas de anomalías + y las alertas de métricas. title: Opciones de la API Monitor --- diff --git a/content/es/monitors/guide/template-variable-evaluation.md b/content/es/monitors/guide/template-variable-evaluation.md index 02d39e49b7c10..d0126af08beda 100644 --- a/content/es/monitors/guide/template-variable-evaluation.md +++ b/content/es/monitors/guide/template-variable-evaluation.md @@ -1,4 +1,7 @@ --- +description: Modifica la salida de variables de plantilla en las notificaciones de + monitor utilizando operaciones matemáticas, funciones y manipulación de cadenas + con la sintaxis eval. title: Evaluación de variables de plantilla --- diff --git a/content/es/monitors/notify/_index.md b/content/es/monitors/notify/_index.md index b6f7df339f3ea..508f40fafd2fb 100644 --- a/content/es/monitors/notify/_index.md +++ b/content/es/monitors/notify/_index.md @@ -112,7 +112,7 @@ Cuando se crea un incidente a partir de un monitor, los [valores de campo][13] d Las notificaciones del monitor incluyen contenidos como la consulta de monitor, las @-mentions utilizadas, las snapshots de métrica (para monitores de métrica) y enlaces a páginas relevantes en Datadog. Tienes la opción de elegir qué contenido deseas incluir o excluir de notificaciones para monitores individuales. -` no existe o si está vacío, utiliza `is_exact_match`. Consulta la pestaña `is_exact_match` para más detalles.
+**Nota**: Para comprobar si uns `` no existe o si está vacía, utiliza `is_exact_match`. Consulta la pestaña `is_exact_match` para más detalles.
{{% /tab %}}
{{% tab "is_exact_match" %}}
@@ -197,7 +197,7 @@ La variable condicional `is_exact_match` también admite una cadena vacía para
```text
{{#is_exact_match "host.datacenter" ""}}
This displays if the attribute or tag does not exist or if it's empty
-{{/is_match}}
+{{/is_exact_match}}
```
@@ -264,7 +264,7 @@ Atributos
### Variables de alerta múltiple
-Configura variables de multialertas en [monitores de multialertas][1] en función de la dimensión seleccionada en el cuadro de grupo de multialertas. Mejora las notificaciones incluyendo dinámicamente en cada alerta el valor asociado a la dimensión agrupada.
+Configura variables de multialertas en [monitores de multialertas][1] en función de la dimensión seleccionada en el cuadro de grupo de multialertas. Enriquece las notificaciones incluyendo dinámicamente en cada alerta el valor asociado a la dimensión agrupada.
**Nota**: Cuando se utiliza el campo `group_by` en la agregación, las etiquetas y alertas adicionales del monitor pueden heredarse automáticamente. Esto significa que cualquier alerta o configuración establecida en el endpoint supervisado podría aplicarse a cada grupo resultante de la agregación.
@@ -381,31 +381,23 @@ Para documentos y enlaces también puedes acceder a un elemento específico con
```
{{% /collapse-content %}}
+### Unión de variables de atributo/etiqueta
+Puedes incluir cualquier atributo o etiqueta de un log, tramo de traza, evento RUM, CI pipeline, o evento de CI test que coincida con la consulta de monitor. La siguiente tabla muestra ejemplos de atributos y variables que puedes añadir de diferentes tipos de monitor.
-### Unión de variables de atributo/etiqueta
+
+
+
## Gráficos de resumen
@@ -207,16 +265,19 @@ Están disponibles las siguientes métricas TCP:
| Métrica | Descripción |
|---|---|
-| **Retransmisiones TCP** | Las retransmisiones TCP representan los fallos detectados que se retransmiten para garantizar la entrega, medidas como recuento de retransmisiones del cliente. |
-| **Latencia TCP** | Medida como tiempo de ida y vuelta suavizado por TCP, es decir, el tiempo transcurrido entre el envío y el acuse de recibo de un marco TCP. |
-| **Jitter TCP** | Medido como variación del tiempo de ida y vuelta suavizada por TCP. |
-| **Tiempos de espera TCP** | Número de conexiones TCP que han expirado desde la perspectiva del sistema operativo. Esto puede indicar problemas generales de conectividad y latencia. |
-| **Rechazos de TCP** | Número de conexiones TCP rechazadas por el servidor. Normalmente esto indica un intento de conexión a una IP/puerto que no está recibiendo conexiones o una mala configuración de cortafuegos/seguridad. |
-| **Reinicios de TCP** | Número de conexiones TCP reiniciadas por el servidor. |
-| **Conexiones establecidas** | Número de conexiones TCP en estado establecido, medidas en conexiones por segundo del cliente. |
| **Conexiones finalizadas** | Número de conexiones TCP en estado finalizado, medidas en conexiones por segundo del cliente. |
+| **Conexiones establecidas** | Número de conexiones TCP en estado establecido, medidas en conexiones por segundo del cliente. |
+| **No se puede alcanzar el host** | Indica cuando el host de destino está fuera de línea o el tráfico está bloqueado por routers o firewall. Disponible en el **Agent 7.68+**. |
+| **No se puede alcanzar la red** | Indica problemas de red local en el equipo host del Agent. Disponible en el **Agent 7.68+**. |
+| **Cancelaciones de la conexión** | Rastrea las cancelaciones de conexión de TCP y los tiempos de espera de la conexión del espacio de usuario en tiempos de ejecución de lenguajes como `Go` y `Node.js`. Disponible en el **Agent 7.70+**. |
+| **Jitter TCP** | Medido como variación del tiempo de ida y vuelta suavizada por TCP. |
+| **Latencia TCP** | Medida como tiempo de ida y vuelta suavizado por TCP, es decir, el tiempo transcurrido entre el envío y el acuse de recibo de un marco TCP. |
+| **Rechazos de TCP** | Número de conexiones de TCP rechazadas por el servidor. Por lo general, esto indica un intento de conexión a una IP/puerto que no está recibiendo conexiones, o una mala configuración del firewall/seguridad. |
+| **Reinicios de TCP** | Número de conexiones de TCP reiniciadas por el servidor. |
+| **Retransmisiones TCP** | Las retransmisiones TCP representan los fallos detectados que se retransmiten para garantizar la entrega, medidas como recuento de retransmisiones del cliente. |
+| **Tiempos de espera TCP** | Número de conexiones de TCP vencidas desde la perspectiva del sistema operativo. Esto puede indicar problemas generales de conectividad y latencia. |
-Todas las métricas se instrumentan desde la perspectiva del lado del `client` de la conexión, cuando está disponible, o del servidor en caso contrario.
+Todas las métricas se miden desde el lado `client` de la conexión cuando están disponibles; en caso contrario, desde el lado del servidor.
### Detección automática de servicios en la nube
diff --git a/content/es/network_monitoring/devices/_index.md b/content/es/network_monitoring/devices/_index.md
index d72d03fe4f515..8ac53a0e7960c 100644
--- a/content/es/network_monitoring/devices/_index.md
+++ b/content/es/network_monitoring/devices/_index.md
@@ -37,11 +37,12 @@ title: Network Device Monitoring
Network Device Monitoring (NDM) te ofrece visibilidad de tus dispositivos de red on-premises y virtuales, como enrutadores, conmutadores y cortafuegos. Detecta automáticamente dispositivos en cualquier red y empieza a recopilar métricas como el uso del ancho de banda, el volumen de bytes enviados y determina si los dispositivos están activos o inactivos.
{{< whatsnext desc="Esta sección incluye los siguientes temas:">}}
- {{< nextlink href="network_monitoring/devices/getting_started" >}}Empezando: Empezando con Network Device Monitoring{{< /nextlink >}}
- {{< nextlink href="network_monitoring/devices/supported_devices" >}}Dispositivos compatibles: Ver los dispositivos NDM compatibles{{< /nextlink >}}
- {{< nextlink href="network_monitoring/devices/snmp_metrics?tab=snmpv2" >}}Métricas de SNMP: Recopilar métricas de SNMP de tus dispositivos de red {{< /nextlink >}}
- {{< nextlink href="network_monitoring/devices/device_topology_map" >}}Mapa de topología de dispositivos: Visualiza las conexiones físicas de tu red{{< /nextlink >}}
- {{< nextlink href="network_monitoring/devices/guide/device_profiles/" >}}Gestor de perfiles SNMP: Empezando con los perfiles de dispositivos{{< /nextlink >}}
+ {{< nextlink href="network_monitoring/devices/getting_started" >}}Introducción: comenzar con Network Device Monitoring{{< /nextlink >}}
+ {{< nextlink href="network_monitoring/devices/supported_devices" >}}Dispositivos compatibles: ver los dispositivos de NDM compatibles{{< /nextlink >}}
+ {{< nextlink href="network_monitoring/devices/snmp_metrics?tab=snmpv2" >}}Métricas de SNMP: recopilar métricas de SNMP desde tus dispositivos de red{{< /nextlink >}}
+ {{< nextlink href="network_monitoring/devices/device_topology_map" >}}Mapa de topología de dispositivo: ver tus conexiones físicas de red{{< /nextlink >}}
+ {{< nextlink href="network_monitoring/devices/guide/device_profiles/" >}}Gestor de perfiles de SNMP: introducción a perfiles de dispositivos{{< /nextlink >}}
+ {{< nextlink href="network_monitoring/devices/integrations/" >}}Integraciones : integraciones de NDM compatibles{{< /nextlink >}}
{{< /whatsnext >}}
diff --git a/content/es/network_monitoring/devices/troubleshooting.md b/content/es/network_monitoring/devices/troubleshooting.md
index 89a691e75ad1a..61a97b7ee4dae 100644
--- a/content/es/network_monitoring/devices/troubleshooting.md
+++ b/content/es/network_monitoring/devices/troubleshooting.md
@@ -149,6 +149,8 @@ Si ves un error de permiso denegado mientras enlazas puertos en logs del Agent,
Si faltan trampas SNMP o tráfico NetFlow, una causa común son las reglas del cortafuegos que bloquean los paquetes UDP antes de que lleguen al Agent. Tanto las trampas SNMP como el tráfico NetFlow dependen de UDP y utilizan los puertos definidos en tu configuración de [datadog.yaml][9].
+
+**Nota**: Si buscas una fuente de datos y no está disponible, solicítala [aquí][5]. 3. Introduce tu consulta. Los atributos reservados de los logs filtrados se añaden automáticamente como columnas. -**Desde el [Log Explorer][1]**: +**Desde el [Explorador de logs][1]**: -1. Introduce tu consulta en el Log Explorer. -2. Haz clic en **Analyze in Notebooks** (Analizar en notebooks). -3. Marca la casilla **Use as a computational data source** (Utilizar como fuente de datos computacionales) y selecciona el notebook que deseas utilizar. -4. Se añade una celda de fuente de datos al notebook seleccionado con la misma consulta introducida en el Log Explorer. Por defecto, las columnas mostradas en el Log Explorer se incluyen en la celda de fuente de datos. +1. Introduce tu consulta en el Explorador de logs. +2. Haz clic en **Analyze in Notebooks** (Analizar en notebooks). +3. Marca la casilla **Use as a computational data source** (Utilizar como fuente de datos de cálculo) y selecciona el notebook que quieres utilizar. +4. Se añade una celda de fuente de datos al notebook seleccionado con la misma consulta introducida en el Explorador de logs. Por defecto, las columnas mostradas en el Explorador de logs se incluyen en la celda de fuente de datos. ## Configuración de una celda de fuente de datos -Después de añadir una celda de fuente de datos a un notebook, puedes seguir modificándola para estructurar los datos de forma que se adapten a tus necesidades de análisis. +Después de añadir una celda de fuente de datos a un notebook, puedes seguir modificándola para estructurar los datos según tus necesidades de análisis. ### Cambiar el marco temporal de los datos -Por defecto, las celdas de fuente de datos creadas a partir de notebooks utilizan el marco temporal global del notebook. Las celdas de fuente de datos creadas a partir del Log Explorer utilizan una hora local fijada al marco temporal en el momento de la exportación. +Por defecto, las celdas de fuente de datos creadas a partir de notebooks utilizan el marco temporal global del notebook. Las celdas de fuente de datos creadas a partir del Explorador de logs utilizan una hora local fijada al marco temporal en el momento de la exportación. -Puedes cambiar cualquier celda de fuente de datos entre un marco temporal local o global utilizando el botón de alternancia situado en la esquina superior derecha de la celda. +Puedes cambiar cualquier celda de fuente de datos entre un marco temporal local o global, utilizando el botón conmutador situado en la esquina superior derecha de la celda. ### Filtrar la fuente de datos -Independientemente de cómo crees la celda de fuente de datos, puedes modificar la consulta utilizando la barra de búsqueda. Cualquier cambio en la consulta reejecuta automáticamente la celda de fuente de datos y cualquier celda posterior, actualizando la vista previa de los datos. +Independientemente de cómo crees la celda de fuente de datos, puedes modificar la consulta utilizando la barra de búsqueda. Cualquier cambio en la consulta vuelve a ejecutar automáticamente la celda de fuente de datos y cualquier celda posterior, actualizando la vista previa de los datos. ### Añadir o modificar una columna Puedes añadir o modificar columnas en tu celda de fuente de datos. Hay dos formas de ajustar las columnas: -- En la sección de vista previa, haz clic en **columnas** para buscar entre los atributos disponibles para tus fuente de datos. +- En la sección de vista previa, haz clic en **columns** (columnas) para buscar entre los atributos disponibles para tu fuente de datos. - En la vista previa, haz clic en una fila para abrir el panel lateral de detalles. Haz clic en el atributo que desees añadir como columna y, en la opción emergente, selecciona "@your_column" a tu conjunto de datos "@your_datasource". {{< img src="/notebooks/analysis_features/add_column_to_dataset.png" alt="Panel lateral de detalles abierto con la opción para añadir una columna de atributos a la celda de fuente de datos" style="width:100%;" >}} ### Consultas de campos calculados -Puedes tomar consultas existentes del Log Explorer que incluyan [Campos calculados][4] y abrirlas en notebooks. Para transferir estas consultas desde el Log Explorer, haz clic en **More** (Más) y selecciona **Analyze in Notebooks** (Analizar en notebooks). Los campos calculados se convierten automáticamente en una celda de transformación. +Puedes tomar consultas existentes del Explorador de logs que incluyan [Campos calculados][4] y abrirlas en notebooks. Para transferir estas consultas desde el Explorador de logs, haz clic en **More** (Más) y selecciona **Analyze in Notebooks** (Analizar en notebooks). Los campos calculados se convierten automáticamente en una celda de transformación. También puedes crear campos calculados directamente en un notebook para definir un campo calculado a partir de fuentes de datos existentes. Estos campos pueden reutilizarse en análisis posteriores: 1. Abre un Workspace con una fuente de datos. @@ -85,7 +91,7 @@ Puedes añadir varios tipos de celdas para mejorar tus capacidades de análisis. Añade una celda de transformación para filtrar, agrupar, unir o extraer datos definidos en una celda de fuente de datos. -1. Escribe `/transformation` y pulsa Enter (Intro), o bien haz clic en el cuadro del conjunto de datos de transformación situado en la parte inferior de la página. +1. Escribe `/transformation` y presiona Intro o haz clic en el cuadro del conjunto de datos de transformación situado en la parte inferior de la página. 2. Selecciona la fuente de datos que quieres transformar en el menú desplegable del conjunto de datos fuente. Después de añadir la celda de transformación, puedes añadir cualquier número de operaciones de transformación dentro de la celda. Elige una operación de la lista de transformaciones admitidas: @@ -104,9 +110,9 @@ Después de añadir la celda de transformación, puedes añadir cualquier númer También puedes transformar tus datos utilizando SQL añadiendo una celda de análisis a tu notebook. -1. Escribe `/sql` o `/analysis` y pulsa Enter (Intro), o haz clic en el cuadro **SQL Query** (Consulta SQL) situada en la parte inferior de la página. -2. En el desplegable del conjunto de datos fuente, selecciona la fuente de datos que deseas transformar. -3. Escribe tu consulta SQL. Para conocer la sintaxis SQL compatible, consulta la [Referencia de DDSQL][4]. +1. Escribe `/sql` o `/analysis` y presiona Intro o haz clic en el cuadro **SQL Query** (Consulta SQL) situado en la parte inferior de la página. +2. En el desplegable del conjunto de datos de la fuente, selecciona la fuente de datos que quieres transformar. +3. Escribe tu consulta SQL. Para conocer la sintaxis SQL compatible, consulta la [referencia de DDSQL][4]. 4. Haz clic en **Run** (Ejecutar) en la esquina superior derecha de la celda de análisis para ejecutar la consulta. {{< img src="/notebooks/analysis_features/analysis_cell_example.png" alt="Ejemplo de una celda de análisis con datos de transformación de consulta SQL en un notebook" style="width:100%;" >}} @@ -117,9 +123,9 @@ Puedes representar gráficamente los datos que has transformado utilizando celda Para representar gráficamente los datos: -1. Escribe `/graph` y pulsa Enter (Intro), o haz clic en el cuadro **graph dataset** (Conjunto de datos de gráfico) situado en la parte inferior de página. -2. Escribe o selecciona la fuente de datos deseada en el menú desplegable y pulsa Enter (Intro). -3. Selecciona el tipo de visualización en el menú de gráficos y pulsa Enter (Intro). +1. Escribe `/graph` y presiona Intro o haz clic en el cuadro **Graph Dataset** (Graficar conjunto de datos) situado en la parte inferior de la página. +2. Escribe o selecciona tu fuente de datos deseada en el menú desplegable y presiona Intro. +3. Selecciona el tipo de visualización en el menú de gráficos y presiona Intro. ## Visualización y exportación de datos @@ -153,4 +159,5 @@ Para descargar tu conjunto de datos como archivo CSV: [1]: https://app.datadoghq.com/logs [2]: /es/logs/log_configuration/parsing/ [3]: /es/logs/explorer/calculated_fields/expression_language/ -[4]: /es/ddsql_reference/ \ No newline at end of file +[4]: /es/ddsql_reference/ +[5]: https://www.datadoghq.com/product-preview/additional-advanced-querying-data-sources/ \ No newline at end of file diff --git a/content/es/opentelemetry/setup/_index.md b/content/es/opentelemetry/setup/_index.md index 41299a70354f0..11c04adee3e5b 100644 --- a/content/es/opentelemetry/setup/_index.md +++ b/content/es/opentelemetry/setup/_index.md @@ -1,5 +1,4 @@ --- -aliases: null further_reading: - link: /opentelemetry/instrument/ tag: Documentación @@ -7,16 +6,50 @@ further_reading: - link: https://www.datadoghq.com/blog/otel-deployments/ tag: Blog text: Seleccionar el depsliegue de OpenTelemetry -title: Enviar datos a Datadog +title: Enviar datos de OpenTelemetry a Datadog --- -Existen varias formas de enviar datos de OpenTelemetry a Datadog. Elige el método que mejor se adapte a tu infraestructura y a tus requisitos: +En esta página se describen todas las formas de enviar datos de OpenTelemetry (OTel) a Datadog. -| Método | Lo mejor para | Principales ventajas | Documentación | -|---------------------------------|--------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------| -| Recopilador de OTel | Usuarios nuevos o existentes de OTel que quieren una configuración neutral con respecto al proveedor | }}
+
+1. Configura las funciones del producto escogidas en la interfaz de usuario de Datadog.
+2. La configuración de las funciones del producto se almacenan en condiciones seguras en Datadog.
+3. Los componentes de Datadog habilitados por configuración remota en tus entornos sondean, reciben y aplican automáticamente actualizaciones de configuración de forma segura desde Datadog. Las bibliotecas de rastreo que se despliegan en tus entornos se comunican con los Agents para solicitar y recibir actualizaciones de configuración desde Datadog, en lugar de sondear Datadog directamente.
+
+## Entornos compatibles
+
+La configuración remota funciona en entornos en los que están instalados los componentes compatibles de Datadog. Entre los componentes compatibles de Datadog se incluyen:
+- Agents
+- Rastreadores (indirectamente)
+- Observability Pipeline Workers
+- Ejecutores de acciones privadas y servicios de nube de contenedores sin servidor como AWS Fargate
+
+La configuración remota no es compatible con aplicaciones sin servidor gestionadas por contenedores, como AWS App Runner, Azure Container Apps, Google Cloud Run, ni con funciones desplegadas con paquetes de contenedores, como AWS Lambda, Azure Functions y Google Cloud Functions.
+
+## Productos y funciones compatibles
+
+Los siguientes productos y funciones son compatibles con la configuración remota.
+
+Fleet Automation
+: - [Envía flares][27] directamente desde el sitio Datadog. Soluciona sin problemas incidentes del Datadog Agent sin acceder directamente al host.
+: - [Actualiza tus Agents][29] (Vista previa).
+
+App and API Protection (AAP)
+: - [Activación de AAP en 1 clic][33]: Activa AAP en 1 clic desde la interfaz de usuario de Datadog.
+: - [Actualizaciones de patrones de ataque en la aplicación][34]: Recibe automáticamente los patrones de ataque más recientes de Web Application Firewall (WAF) a medida que Datadog los publica, siguiendo vulnerabilidades o vectores de ataque recientemente revelados.
+: - [Protección][34]: Bloquea las IP de los atacantes, los usuarios autenticados y las solicitudes sospechosas indicadas en señales y rastros de seguridad de AAP de forma temporal o permanente a través de la interfaz de usuario de Datadog.
+
+Application Performance Monitoring (APM)
+: - Configuración en tiempo de ejecución (Vista previa): Cambia la frecuencia de muestreo del rastreo de un servicio, la activación de la inyección de logs y las etiquetas (tags) de encabezados HTTP desde la interfaz de usuario del Catálogo de software, sin tener que reiniciar el servicio. Consulta [Configuración en tiempo de ejecución][22] para obtener más información.
+: - [Configura de forma remota la frecuencia de muestreo del Agent][35] (Vista previa): Configura de forma remota el Datadog Agent para cambiar sus frecuencias de muestreo del rastreo y configura reglas para escalar la ingesta de trazas (traces) de tu organización según tus necesidades, sin necesidad de reiniciar tu Datadog Agent.
+
+[Dynamic Instrumentation][36]
+: - Envía métricas, trazas y logs críticos de tus aplicaciones en directo sin cambios en el código.
+
+Workload Protection
+: - Actualizaciones automáticas de reglas predeterminadas del Agent: Recibe y actualiza automáticamente las reglas predeterminadas del Agent mantenidas por Datadog a medida que se publican nuevas detecciones y mejoras del Agent. Consulta [Configuración de Workload Protection][3] para obtener más información.
+: - Despliegue automático de reglas personalizadas del Agent: Despliega automáticamente tus reglas personalizadas del Agent en los hosts designados (todos los hosts o un subconjunto definido de hosts).
+
+Observability Pipelines
+: - Despliega y actualiza de forma remota [Observability Pipelines Workers][4] (OPW): Crea y edita pipelines en la interfaz de usuario de Datadog, desplegando tus cambios de configuración en las instancias OPW que se ejecutan en tu entorno.
+
+Ejecutor de acciones privadas
+: - Ejecuta flujos de trabajo y aplicaciones de Datadog que interactúan con servicios alojados en tu red privada sin exponer tus servicios a la Internet pública. Para obtener más información, consulta [Private Actions][30].
+
+## Cuestiones de seguridad
+
+Datadog implementa las siguientes medidas de seguridad para proteger la confidencialidad, la integridad y la disponibilidad de las configuraciones que reciben y aplican los componentes de Datadog:
+
+- Los componentes de Datadog habilitados por configuración remota y desplegados en tu infraestructura necesitan configuraciones de Datadog.
+
}}
+
+1. Configura las funciones del producto escogidas en la interfaz de usuario de Datadog.
+2. La configuración de las funciones del producto se almacenan en condiciones seguras en Datadog.
+3. Los componentes de Datadog habilitados por configuración remota en tus entornos sondean, reciben y aplican automáticamente actualizaciones de configuración de forma segura desde Datadog. Las bibliotecas de rastreo que se despliegan en tus entornos se comunican con los Agents para solicitar y recibir actualizaciones de configuración desde Datadog, en lugar de sondear Datadog directamente.
+
+## Entornos compatibles
+
+La configuración remota funciona en entornos en los que están instalados los componentes compatibles de Datadog. Entre los componentes compatibles de Datadog se incluyen:
+- Agents
+- Rastreadores (indirectamente)
+- Observability Pipeline Workers
+- Ejecutores de acciones privadas y servicios de nube de contenedores sin servidor como AWS Fargate
+
+La configuración remota no es compatible con aplicaciones sin servidor gestionadas por contenedores, como AWS App Runner, Azure Container Apps, Google Cloud Run, ni con funciones desplegadas con paquetes de contenedores, como AWS Lambda, Azure Functions y Google Cloud Functions.
+
+## Productos y funciones compatibles
+
+Los siguientes productos y funciones son compatibles con la configuración remota.
+
+Fleet Automation
+: - [Envía flares][27] directamente desde el sitio Datadog. Soluciona sin problemas incidentes del Datadog Agent sin acceder directamente al host.
+: - [Actualiza tus Agents][29] (Vista previa).
+
+App and API Protection (AAP)
+: - [Activación de AAP en 1 clic][33]: Activa AAP en 1 clic desde la interfaz de usuario de Datadog.
+: - [Actualizaciones de patrones de ataque en la aplicación][34]: Recibe automáticamente los patrones de ataque más recientes de Web Application Firewall (WAF) a medida que Datadog los publica, siguiendo vulnerabilidades o vectores de ataque recientemente revelados.
+: - [Protección][34]: Bloquea las IP de los atacantes, los usuarios autenticados y las solicitudes sospechosas indicadas en señales y rastros de seguridad de AAP de forma temporal o permanente a través de la interfaz de usuario de Datadog.
+
+Application Performance Monitoring (APM)
+: - Configuración en tiempo de ejecución (Vista previa): Cambia la frecuencia de muestreo del rastreo de un servicio, la activación de la inyección de logs y las etiquetas (tags) de encabezados HTTP desde la interfaz de usuario del Catálogo de software, sin tener que reiniciar el servicio. Consulta [Configuración en tiempo de ejecución][22] para obtener más información.
+: - [Configura de forma remota la frecuencia de muestreo del Agent][35] (Vista previa): Configura de forma remota el Datadog Agent para cambiar sus frecuencias de muestreo del rastreo y configura reglas para escalar la ingesta de trazas (traces) de tu organización según tus necesidades, sin necesidad de reiniciar tu Datadog Agent.
+
+[Dynamic Instrumentation][36]
+: - Envía métricas, trazas y logs críticos de tus aplicaciones en directo sin cambios en el código.
+
+Workload Protection
+: - Actualizaciones automáticas de reglas predeterminadas del Agent: Recibe y actualiza automáticamente las reglas predeterminadas del Agent mantenidas por Datadog a medida que se publican nuevas detecciones y mejoras del Agent. Consulta [Configuración de Workload Protection][3] para obtener más información.
+: - Despliegue automático de reglas personalizadas del Agent: Despliega automáticamente tus reglas personalizadas del Agent en los hosts designados (todos los hosts o un subconjunto definido de hosts).
+
+Observability Pipelines
+: - Despliega y actualiza de forma remota [Observability Pipelines Workers][4] (OPW): Crea y edita pipelines en la interfaz de usuario de Datadog, desplegando tus cambios de configuración en las instancias OPW que se ejecutan en tu entorno.
+
+Ejecutor de acciones privadas
+: - Ejecuta flujos de trabajo y aplicaciones de Datadog que interactúan con servicios alojados en tu red privada sin exponer tus servicios a la Internet pública. Para obtener más información, consulta [Private Actions][30].
+
+## Cuestiones de seguridad
+
+Datadog implementa las siguientes medidas de seguridad para proteger la confidencialidad, la integridad y la disponibilidad de las configuraciones que reciben y aplican los componentes de Datadog:
+
+- Los componentes de Datadog habilitados por configuración remota y desplegados en tu infraestructura necesitan configuraciones de Datadog.
+ :/info`, normalmente `http://localhost:8126/info`.
- Asegúrate de que no hay errores de transmisión del Agent relacionados con tramos (spans) en los [logs de tu rastreador][7].
-- Si el Agent se instala en una máquina independiente, comprueba que `DD_AGENT_HOST` y, opcionalmente, `DD_TRACE_AGENT_PORT` están configurados, o que `DD_TRACE_AGENT_URL` está configurado para la librería de rastreo de aplicaciones.
+- Si el Agent se instala en una máquina independiente, comprueba que `DD_AGENT_HOST` y, opcionalmente, `DD_TRACE_AGENT_PORT` están configurados, o que `DD_TRACE_AGENT_URL` está configurado para la biblioteca de rastreo de aplicaciones.
### Comprobar si los tramos se transmiten correctamente a Datadog
@@ -270,7 +270,7 @@ A continuación se indican los pasos adicionales para solucionar problemas para
{{< programming-lang-wrapper langs="java,.NET,go,ruby,PHP,Node.js,python" >}}
{{< programming-lang lang="java" >}}
-La librería Java utiliza [SLF4J][1] para la generación de logs. Añade las siguientes marcas de tiempo de ejecución para que el rastreador genere logs en un archivo:
+La biblioteca Java utiliza [SLF4J][1] para la generación de logs. Añade las siguientes marcas de tiempo de ejecución para que el rastreador genere logs en un archivo:
```java
-Ddatadog.slf4j.simpleLogger.defaultLogLevel=info
@@ -283,7 +283,7 @@ Luego de que se inicia el servicio, el rastreador genera logs en un archivo espe
{{< /programming-lang >}}
{{< programming-lang lang=".NET" >}}
-La librería .NET genera logs en un archivo, pero no puede generar logs en `stdout`/`stderr`. El nivel de logs por defecto es `INFO`. Para habilitar logs `DEBUG`, configura `DD_TRACE_DEBUG=true`.
+La biblioteca .NET genera logs en un archivo, pero no puede generar logs en `stdout`/`stderr`. El nivel de logs por defecto es `INFO`. Para habilitar logs `DEBUG`, configura `DD_TRACE_DEBUG=true`.
Los archivos de log están disponibles en los siguientes directorios:
@@ -363,9 +363,9 @@ Por ejemplo, el siguiente log de inicio muestra que AAP está deshabilitado:
#### Activa logs de depuración
-Habilita logs de depuración con la variable de entorno `DD_TRACE_DEBUG=1`. La librería AAP generará logs para el resultado de error estándar.
+Habilita logs de depuración con la variable de entorno `DD_TRACE_DEBUG=1`. La biblioteca AAP generará logs para el resultado de error estándar.
-**Nota:** AAP sólo envía logs cuando está habilitado. Utiliza la variable de entorno `DD_APPSEC_ENABLED=1` para habilitar AAP.
+**Nota:** AAP solo envía logs cuando está habilitado. Utiliza la variable de entorno `DD_APPSEC_ENABLED=1` para habilitar AAP.
[1]: /es/tracing/troubleshooting/tracer_startup_logs/
{{< /programming-lang >}}
@@ -540,7 +540,7 @@ Espera un minuto a que el Agent reenvíe las trazas y luego comprueba que estas
Para comprobar si AAP se está ejecutando, puedes utilizar la métrica `datadog.apm.appsec_host`.
-1. Ve a **Métricas > Resumen** en Datadog.
+1. Ve a **Metrics > Summary** (Métricas > Resumen) en Datadog.
2. Busca la métrica `datadog.apm.appsec_host` . Si la métrica no existe, entonces no hay servicios ejecutando AAP. Si la métrica existe, los servicios se informan mediante las etiquetas de métricas `host` y `service`.
3. Selecciona la métrica y busca `service` en la sección **Etiquetas** para ver qué servicios están ejecutando AAP.
@@ -550,7 +550,7 @@ Los datos de AAP se envían con trazas de APM. Consulta [Solucionar problemas de
### Confirmar que las versiones del rastreador están actualizadas
-Consulta la documentación de configuración del producto App and API Protection para confirmar que estás utilizando la versión correcta del rastreador. Estas versiones mínimas son necesarias para comenzar a enviar datos de telemetría que incluyan información de la librería.
+Consulta la documentación de configuración del producto App and API Protection para confirmar que estás utilizando la versión correcta del rastreador. Estas versiones mínimas son necesarias para comenzar a enviar datos de telemetría que incluyan información de la biblioteca.
### Garantizar la comunicación de los datos de telemetría
@@ -560,6 +560,9 @@ Asegúrate de que la variable de entorno `DD_INSTRUMENTATION_TELEMETRY_ENABLED`
Para desactivar AAP, utiliza uno de los siguientes métodos.
+Si habilitaste AAP utilizando la variable de entorno `DD_APPSEC_ENABLED=true`, utiliza la sección DD_APPSEC_ENABLED a continuación.
+Si habilitaste AAP mediante la [Configuración remota][16], utiliza el método de configuración remota que se indica a continuación.
+
### DD_APPSEC_ENABLED
Si la variable de entorno `DD_APPSEC_ENABLED=true` está configurada para tu servicio, elimina la variable de entorno `DD_APPSEC_ENABLED=true` de la configuración de tu aplicación y reinicia tu servicio.
@@ -568,22 +571,22 @@ Si tu servicio es un servicio PHP, define explícitamente la variable de entorno
### Configuración remota
-Si AAP se habilitó mediante [configuración remota][16], haz lo siguiente:
- 1. Ve a [Servicios][15].
- 2. Selecciona **Gestión de amenazas en modo monitorización**.
- 3. En la faceta **Gestión de amenazas**, activa **Monitoring Only**, **No data**, and **Ready to block** (Sólo monitorización, Sin datos y Listo para el bloqueo).
+Si AAP se habilitó mediante [configuración remota][16], haz lo siguiente:
+ 1. Ve a [Services (Servicios)][15].
+ 2. Selecciona **App & API Protection in Monitoring Mode** (App & API Protection en modo de monitorización).
+ 3. En la faceta **App & API Protection**, activa **Monitoring Only** (Solo monitorización), **No data** (Sin datos) y **Ready to block** (Listo para bloquear).
4. Haz clic en un servicio.
- 5. En los detalles del servicio, en **Detección de amenazas**, haz clic en **Deactivate** (Desactivar).
+ 5. En los detalles del servicio, en **App & API Protection**, haz clic en **Deactivate** (Desactivar).
/
+ curl -H 'My-AAP-Test-Header: acunetix-product' https:///
```
Unos minutos después de habilitar tu aplicación y enviar los patrones de ataque, **la información sobre las amenazas aparece en el [Application Signals Explorer][41]**.
@@ -89,7 +92,7 @@ datadog-ci lambda instrument \
{{% /tab %}}
{{% tab "Serverless Framework" %}}
-Asegúrate de usar la última versión del complemento [Datadog Serverless Plugin][1] y aplica las etiquetas con los parámetros `env`, `service`, `version` y `tags`. Por ejemplo:
+Asegúrate de usar la última versión del [complemento sin servidor Datadog][1] y aplica las etiquetas con los parámetros `env`, `service`, `version` y `tags`. Por ejemplo:
```yaml
custom:
@@ -123,13 +126,13 @@ Transform:
[1]: https://docs.datadoghq.com/es/serverless/serverless_integrations/macro
{{% /tab %}}
-{{% tab "CDK AWS" %}}
+{{% tab "AWS CDK" %}}
Asegúrate de usar la última versión de la [construcción del CDK serverless de Datadog][1] y aplica las etiquetas con los parámetros `env`, `service`, `version` y `tags`. Por ejemplo:
```typescript
-const datadog = new Datadog(this, "Datadog", {
- // ... otros parámetros obligatorios, como el sitio de Datadog y la clave de la API
+const datadog = new DatadogLambda(this, "Datadog", {
+ // ... other required parameters, such as the Datadog site and API key
env: "dev",
service: "web",
version: "v1.2.3",
@@ -140,7 +143,7 @@ datadog.addLambdaFunctions([]);
[1]: https://github.com/DataDog/datadog-cdk-constructs
{{% /tab %}}
-{{% tab "Others" %}}
+{{% tab "Otros" %}}
Si vas a recopilar la telemetría de tus funciones de Lambda mediante la [Datadog Lambda Extension][1], define las siguientes variables de entorno en tus funciones de Lambda. Por ejemplo:
- DD_ENV: dev
@@ -210,13 +213,13 @@ Transform:
[1]: https://docs.datadoghq.com/es/serverless/serverless_integrations/macro
{{% /tab %}}
-{{% tab "CDK AWS" %}}
+{{% tab "AWS CDK" %}}
Asegúrate de usar la última versión de la [construcción del CDK serverless de Datadog][1] y define el parámetro `captureLambdaPayload` como `true`. Por ejemplo:
```typescript
-const datadog = new Datadog(this, "Datadog", {
- // ... otros parámetros obligatorios, como el sitio de Datadog y la clave de la API
+const datadog = new DatadogLambda(this, "Datadog", {
+ // ... other required parameters, such as the Datadog site and API key
captureLambdaPayload: true
});
datadog.addLambdaFunctions([]);
@@ -224,7 +227,7 @@ datadog.addLambdaFunctions([]);
[1]: https://github.com/DataDog/datadog-cdk-constructs
{{% /tab %}}
-{{% tab "Others" %}}
+{{% tab "Otros" %}}
Define la variable de entorno `DD_CAPTURE_LAMBDA_PAYLOAD` como `true` en tus funciones de Lambda.
@@ -274,11 +277,11 @@ DD_APM_REPLACE_TAGS=[
]
```
+Para recopilar cargas útiles de los servicios de AWS, consulta [Capturar solicitudes y respuestas de los servicios de AWS][54].
-## Recopilar trazas procedentes de recursos distintos de Lambda
-.hits` se calculan en función de las invocaciones muestreadas *sólo* en Lambda.
Para los servicios de alto rendimiento, normalmente no es necesario que recopiles todas las solicitudes, porque los datos de las trazas son muy repetitivos. Los problemas suficientemente graves siempre deberían poder detectarse en varias trazas. Los [controles de ingesta][18] te permiten solucionar los problemas sin salirte del presupuesto.
@@ -372,7 +377,7 @@ Para borrar atributos de trazas por razones de seguridad de los datos, consulta
## Habilitar y deshabilitar la recopilación de trazas
-La recopilación de trazas a través de la Datadog Lambda Extension está habilitada de forma predeterminada.
+La recopilación de trazas (traces) a través de la extensión Datadog Lambda está activada por defecto.
Si quieres empezar a recopilar las trazas de tus funciones de Lambda, aplica las configuraciones que se indican a continuación:
@@ -407,18 +412,18 @@ Transform:
```
{{% /tab %}}
-{{% tab "CDK AWS" %}}
+{{% tab "AWS CDK" %}}
```typescript
-const datadog = new Datadog(this, "Datadog", {
- // ... otros parámetros obligatorios, como el sitio de Datadog y la clave de la API
+const datadog = new DatadogLambda(this, "Datadog", {
+ // ... other required parameters, such as the Datadog site and API key
enableDatadogTracing: true
});
datadog.addLambdaFunctions([]);
```
{{% /tab %}}
-{{% tab "Others" %}}
+{{% tab "Otros" %}}
Define la variable de entorno `DD_TRACE_ENABLED` como `true` en tus funciones de Lambda.
@@ -460,18 +465,18 @@ Transform:
```
{{% /tab %}}
-{{% tab "CDK AWS" %}}
+{{% tab "AWS CDK" %}}
```typescript
-const datadog = new Datadog(this, "Datadog", {
- // ... otros parámetros obligatorios, como el sitio de Datadog y la clave de la API
+const datadog = new DatadogLambda(this, "Datadog", {
+ // ... other required parameters, such as the Datadog site and API key
enableDatadogTracing: false
});
datadog.addLambdaFunctions([]);
```
{{% /tab %}}
-{{% tab "Others" %}}
+{{% tab "Otros" %}}
Define la variable de entorno `DD_TRACE_ENABLED` como `false` en tus funciones de Lambda.
@@ -482,7 +487,7 @@ Define la variable de entorno `DD_TRACE_ENABLED` como `false` en tus funciones d
Si usas la [extensión de Lambda][2] para recopilar trazas y logs, Datadog añade automáticamente el ID de solicitud de AWS Lambda al tramo `aws.lambda` en la etiqueta `request_id`. Además, los logs de Lambda para la misma solicitud se añaden en el atributo `lambda.request_id`. Las vistas de trazas y logs de Datadog se vinculan mediante el uso del ID de solicitud de AWS Lambda.
-Si usas la [función de Lambda del Forwarder][4] para recopilar trazas y logs, `dd.trace_id` se inserta automáticamente en los logs (habilitada por la variable de entorno `DD_LOGS_INJECTION`). Las vistas de trazas y logs de Datadog se conectan mediante el ID de traza de Datadog. Esta característica es compatible con la mayoría de aplicaciones que utilizan tiempos de ejecución y loggers populares (consulta la [compatibilidad por tiempo de ejecución][24]).
+Si estás utilizando la [función del Forwarder Lambda][4] para recopilar trazas y logs, `dd.trace_id` se inyecta automáticamente en logs (habilitado por defecto con la variable de entorno `DD_LOGS_INJECTION`). Las vistas de traza y log de Datadog se conectan utilizando el ID de traza de Datadog. Esta característica es compatible con la mayoría de las aplicaciones que utilizan un tiempo de ejecución y un registrador populares (ver [compatibilidad por tiempo de ejecución][24]).
Si usas un tiempo de ejecución o un logger personalizado no compatible, sigue estos pasos:
- Al generar logs en JSON, debes obtener el ID de traza de Datadog mediante `dd-trace` y añadirlo a tus logs en el campo `dd.trace_id`:
@@ -503,7 +508,7 @@ Si usas un tiempo de ejecución o un logger personalizado no compatible, sigue e
## Vincular errores al código fuente
-La [integración del código fuente de Datadog][26] te permite vincular tu telemetría (como stack traces) al código fuente de tus funciones de Lambda en los repositorios de Git.
+La [integración del código fuente de Datadog][26] te permite vincular tu telemetría (como trazas de stack tecnológico) al código fuente de tus funciones Lambda en tus repositorios Git.
Para obtener instrucciones sobre cómo configurar la integración del código fuente en tus aplicaciones serverless, consulta la [sección Integrar información de Git en los artefactos de compilación][101].
@@ -531,13 +536,13 @@ Si quieres enviar datos a varias organizaciones, puedes habilitar el envío múl
Puedes habilitar el envío múltiple con una clave de API de texto sin formato al configurar las siguientes variables de entorno en tu función de Lambda.
```bash
-# Habilitar el envío doble para métricas
+# Enable dual shipping for metrics
DD_ADDITIONAL_ENDPOINTS={"https://app.datadoghq.com": ["", ""], "https://app.datadoghq.eu": [""]}
-# Habilitar el envío doble para APM (trazas)
+# Enable dual shipping for APM (traces)
DD_APM_ADDITIONAL_ENDPOINTS={"https://trace.agent.datadoghq.com": ["", ""], "https://trace.agent.datadoghq.eu": [""]}
-# Habilitar el envío doble para APM (perfilado)
+# Enable dual shipping for APM (profiling)
DD_APM_PROFILING_ADDITIONAL_ENDPOINTS={"https://trace.agent.datadoghq.com": ["", ""], "https://trace.agent.datadoghq.eu": [""]}
-# Habilitar el envío doble para logs
+# Enable dual shipping for logs
DD_LOGS_CONFIG_FORCE_USE_HTTP=true
DD_LOGS_CONFIG_ADDITIONAL_ENDPOINTS=[{"api_key": "", "Host": "agent-http-intake.logs.datadoghq.com", "Port": 443, "is_reliable": true}]
```
@@ -578,6 +583,40 @@ La extensión de Datadog es compatible con el descifrado automático de valores
Para obtener información sobre un uso más avanzado, consulta la [guía de Envío múltiple][32].
+## Habilitar el cumplimiento FIPS
+
+:002406178527:layer:Datadog-Extension-FIPS:{{< latest-lambda-layer-version layer="extension" >}}
+ arn:aws-us-gov:lambda::002406178527:layer:Datadog-Extension-ARM-FIPS:{{< latest-lambda-layer-version layer="extension" >}}
+ ```
+{{% /tab %}}
+{{% tab "AWS Commercial" %}}
+ ```sh
+ arn:aws:lambda:
El envío de logs a dos o más destinos implica el uso de dos o más funciones Lambda que pueden empezar a generar logs entre sí en un bucle infinito. Utiliza
@@ -299,7 +274,7 @@ Puedes ejecutar el Forwarder en una subred privada de VPC y enviar datos a Datad
3. Al instalar el Forwarder con la plantilla de CloudFormation:
1. Configurar `DdUseVPC` como `true`.
2. Configura `VPCSecurityGroupIds` y `VPCSubnetIds` en función de la configuración de tu VPC.
- 3. Configura `DdFetchLambdaTags` como `false`, ya que la API de etiquetado de AWS Resource Groups no admite PrivateLink.
+ 3. Establece `DdFetchLambdaTags`, `DdFetchStepFunctionsTags` y `DdFetchS3Tags` en `false`, porque la API de etiquetado de grupos de recursos de AWS no admite PrivateLink.
#### DdUsePrivateLink está obsoleto
@@ -320,7 +295,7 @@ Si necesitas desplegar el Forwarder en una VPC sin acceso público directo a Int
1. A menos que el Forwarder esté desplegado en una subred pública, sigue las [instrucciones][15] para añadir endpoints para Secrets Manager y S3 a la VPC, de modo que el Forwarder pueda acceder a esos servicios.
2. Actualiza tu proxy con las siguientes configuraciones ([HAproxy][17] o [NGINX][18]). Si estás utilizando otro proxy o proxy web, autoriza el dominio Datadog, por ejemplo: `.{{< region-param key="dd_site" code="true" >}}`.
3. Al instalar el Forwarder con la plantilla de CloudFormation, configura `DdUseVPC`, `VPCSecurityGroupIds` y `VPCSubnetIds`.
-4. Asegúrate de que la opción `DdFetchLambdaTags` está deshabilitada, ya que la VPC de AWS aún no ofrece un endpoint para la API de etiquetado de AWS Resource Groups.
+4. Asegúrate de que las opciones `DdFetchLambdaTags`, `DdFetchStepFunctionsTags` y `DdFetchS3Tags` están desactivadas, ya que AWS VPC aún no ofrece un endpoint para la API de etiquetado de grupos de recursos.
5. Si utilizas HAproxy o NGINX:
- Configura `DdApiUrl` como `http://ExcludeAtMatch para filtrar logs de Lambda y evitar este bucle infinito. Consulta la sección Filtrado de logs para obtener más información.
-Los siguientes parámetros se utilizan en CloudFormation y Terraform. Si estás instalando el Forwarder manualmente, convierte estos nombres de parámetros de PascalCase a Screaming Snake Case. Por ejemplo,
+{{< tabs >}}
+{{% tab "CloudFormation" %}}
### Obligatorio
@@ -451,8 +425,11 @@ Para probar diferentes patrones en tus logs, activa la [limpieza de logs](#troub
`DdFetchStepFunctionsTags`
: Permite que Forwarder recupere tags de funciones Step mediante llamadas a la API GetResources y las aplique a logs y trazas (si está habilitado el rastreo de funciones Step). Si se configura como true (verdadero), el permiso `tag:GetResources` se añadirá automáticamente al rol IAM de ejecución de Lambda.
-`DdStepFunctionTraceEnabled`
-: Establécelo como verdadero para habilitar el seguimiento de todas las etiquetas de Step Functions.
+`DdFetchS3Tags`
+: Permite que el forwarder recupere etiquetas de S3 mediante llamadas a la API GetResources y las aplique a logs y trazas. Si se establece en true, el permiso `tag:GetResources` se añadirá automáticamente al rol de IAM de ejecución de Lambda.
+
+`DdStepFunctionsTraceEnabled`
+: Establécelo como true para activar el rastreo de todas Step Functions.
`SourceZipUrl`
: No lo cambies a menos que sepas lo que estás haciendo. Sustituye la localización predeterminada del código fuente de la función.
@@ -484,6 +461,180 @@ Para probar diferentes patrones en tus logs, activa la [limpieza de logs](#troub
`LayerARN`
: ARN de la capa que contiene el código del Forwarder. Si está vacío, el script utilizará la versión de la capa con la que se ha publicado el Forwarder. Por defecto está vacío.
+
+[20]: https://app.datadoghq.com/organization-settings/api-keys
+[13]: https://docs.datadoghq.com/es/getting_started/site/
+[21]: https://docs.datadoghq.com/es/logs/processing/pipelines/
+[2]: https://docs.datadoghq.com/es/logs/guide/send-aws-services-logs-with-the-datadog-lambda-function/
+{{% /tab %}}
+{{% tab "Terraform" %}}
+
+### Obligatorio
+
+`dd_api_key`
+: Tu [clave de API de Datadog][204], que puedes encontrar en **Organization Settings** > **API Keys** (Configuración de la organización > Claves de API). La clave de API se almacena en AWS Secrets Manager. Si ya tienes una clave de API de Datadog almacenada en el Secret Manager, utiliza `dd_api_key_secret_arn` en su lugar.
+
+`dd_site`
+: El [sitio Datadog][203] al que se enviarán tus métricas y logs. Tu sitio de Datadog es {{< region-param key="dd_site" code="true" >}}.
+
+Para todas las opciones de configuración y detalles, incluyendo [Despliegue multiregión][205], consulta la [documentación del módulo][201].
+
+[201]: https://registry.terraform.io/modules/DataDog/log-lambda-forwarder-datadog/aws/latest
+[203]: https://docs.datadoghq.com/es/getting_started/site/#access-the-datadog-site
+[204]: https://app.datadoghq.com/organization-settings/api-keys
+[205]: https://registry.terraform.io/modules/DataDog/log-lambda-forwarder-datadog/aws/latest#multi-region-deployments
+{{% /tab %}}
+{{% tab "Manual" %}}
+
+Si estás instalando el Forwarder manualmente, convierte los nombres de los parámetros de caso Pascal a un caso screaming snake.
+
+### Obligatorio
+
+`DD_API_KEY`
+: Tu [clave de API de Datadog][20], que puedes encontrar en **Organization Settings** > **API Keys** (Configuración de la organización > Claves de API). La clave de API se almacena en AWS Secrets Manager. Si ya tienes una clave de API de Datadog almacenada en el Secrets Manager, utiliza `DD_API_KEY_SECRET_ARN` en su lugar.
+
+`DD_API_KEY_SECRET_ARN`
+: el ARN del secreto que almacena la clave de la API de Datadog, si ya la tienes almacenada en el Secrets Manager. Debes almacenar el secreto como texto sin formato, en lugar de como un par clave-valor.
+
+`DD_SITE`
+: El [sitio de Datadog][13] al que se enviarán tus métricas y logs. Tu sitio de Datadog es {{< region-param key="dd_site" code="true" >}}.
+
+### Función Lambda (opcional)
+
+`FUNCTION_NAME`
+: El nombre de la función Lambda del Datadog Forwarder. No cambies esto cuando actualices un stack tecnológico de CloudFormation existente, de lo contrario se sustituirá la función del forwarder actual y se perderán todos los activadores.
+
+`MEMORY_SIZE`
+: Tamaño de memoria para la función Lambda del Datadog Forwarder.
+
+`TIMEOUT`
+: Tiempo de espera para la función Lambda del Datadog Forwarder.
+
+`RESERVED_CONCURRENCY`
+: Concurrencia reservada para la función Lambda del Datadog Forwarder. Si está vacío, utiliza la concurrencia no reservada de la cuenta.
+Datadog recomienda utilizar al menos 10 de concurrencia reservada, pero este valor predeterminado es 0, ya que puede que necesites aumentar tus límites. Si utilizas concurrencia de cuenta no reservada, puedes limitar otras funciones Lambda en tu entorno.
+
+`LOG_RETENTION_IN_DAYS`
+: retención de logs de CloudWatch para logs generada por la función Lambda de Datadog Forwarder.
+
+### Reenvío de logs (opcional)
+
+`DD_TAGS`
+: Añade etiquetas personalizadas a los logs reenviados, cadena delimitada por comas, sin coma final, como `env:prod,stack:classic`.
+
+`DD_MULTILINE_LOG_REGEX_PATTERN`
+: Utiliza la expresión regular suministrada para detectar una nueva línea de log para logs multilíneas de S3, como `\d{2}\/\d{2}\/\d{4}` para logs multilíneas que comienzan con el patrón "11/10/2014".
+
+`DD_USE_TCP`
+: Por defecto, el forwarder envía logs utilizando HTTPS a través del puerto 443. Para enviar logs a través de una
+conexión TCP con cifrado SSL, establece este parámetro en true.
+
+`DD_NO_SSL`
+: Desactivar SSL al reenviar logs, poner en true al reenviar logs a través de un proxy.
+
+`DD_URL`
+: La URL del endpoint al que reenviar los logs, útil para reenviar logs a través de un proxy.
+
+`DD_PORT`
+: El puerto del endpointal que reenviar los logs, útil para reenviar logs a través de un proxy.
+
+`DD_SKIP_SSL_VALIDATION`
+: Enviar logs a través de HTTPS, sin validar el certificado proporcionado por el endpoint. Esto seguirá cifrando el tráfico entre el forwarder y el endpoint de entrada de log, pero no verificará si el certificado SSL de destino es válido.
+
+`DD_USE_COMPRESSION`
+: Establécelo en false para desactivar la compresión de log. Solo es válido al enviar logs a través de HTTP.
+
+`DD_COMPRESSION_LEVEL`
+: Ajusta el nivel de compresión de 0 (sin compresión) a 9 (mejor compresión). El nivel de compresión por defecto es 6. Si aumentas el nivel de compresión, es posible que se reduzca el tráfico de salida de la red, a expensas de que aumente la duración de ejecución del forwarder.
+
+`DD_FORWARD_LOG`
+: Establécelo en false para desactivar el reenvío de log, mientras se siguen reenviando otros datos de observabilidad, como métricas y trazas de funciones Lambda.
+
+### Limpieza de logs (opcional)
+
+`REDACT_IP`
+: Sustituye el texto que coincida con `\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}` por `xxx.xxx.xxx.xxx`.
+
+`REDACT_EMAIL`
+: Sustituye el texto que coincida con `[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+` por `xxxxx@xxxxx.com`.
+
+`DD_SCRUBBING_RULE`
+: Sustituye el texto que coincida con la expresión regular suministrada por `xxxxx` (por defecto) o `DD_SCRUBBING_RULE_REPLACEMENT` (si se suministra). La regla de depuración de log se aplica a todo el log con formato JSON, incluidos los metadatos añadidos automáticamente por la función Lambda. Cada instancia de una coincidencia de patrón se sustituye hasta que no se encuentran más coincidencias en cada log. El uso de expresiones regulares ineficientes, como `.*`, puede ralentizar la función Lambda.
+
+`DD_SCRUBBING_RULE_REPLACEMENT`
+: Sustituye el texto que coincida con DD_SCRUBBING_RULE por el texto suministrado.
+
+### Filtrado de logs (opcional)
+
+`EXCLUDE_AT_MATCH`
+: No envíes logs que coincidan con la expresión regular suministrada. Si un log coincide tanto con `EXCLUDE_AT_MATCH` como con `INCLUDE_AT_MATCH`, se excluye.
+
+`INCLUDE_AT_MATCH`
+: Solo envía logs que coincidan con la expresión regular suministrada, y no excluidos por `EXCLUDE_AT_MATCH`.
+
+Las reglas de filtrado se aplican a todo el log con formato JSON, incluidos los metadatos que el Forwarder. añade automáticamente Sin embargo, las transformaciones aplicadas por [pipelines de logs][21], que se producen después del envío de logs a Datadog, no pueden utilizarse para filtrar logs en el Forwarder. El uso de una expresión regular ineficaz, como `.*`, puede ralentizar el Forwarder.
+
+Los siguientes son algunos ejemplos de expresiones regulares que pueden utilizarse para el filtrado de logs:
+
+- Incluye (o excluye) logs de la plataforma Lambda: `"(START|END) RequestId:\s`. El precedente `"` es necesario para que coincida con el inicio del mensaje del log, que está en un blob JSON (`{"message": "START RequestId...."}`). Datadog recomienda conservar los logs de `REPORT`, ya que se utilizan para rellenar la lista de invocaciones en las vistas de funciones serverless.
+- Incluye sólo mensajes de error de CloudTrail: `errorMessage`.
+- Incluye sólo logs que contienen un código de error HTTP 4XX o 5XX: `\b[4|5][0-9][0-9]\b`.
+- Incluye sólo logs de CloudWatch cuando el campo `message` contiene un par clave/valor JSON específico: `\"awsRegion\":\"us-east-1\"`.
+ - El campo de mensaje de un evento de log de CloudWatch se codifica como una cadena. Por ejemplo,`{"awsRegion": "us-east-1"}` se codifica como `{\"awsRegion\":\"us-east-1\"}`. Por lo tanto, el patrón que proporciones debe incluir `\` caracteres de escape, como en el siguiente ejemplo: `\"awsRegion\":\"us-east-1\"`.
+
+Para probar diferentes patrones en tus logs, activa la [limpieza de logs](#troubleshooting).
+
+### Avanzado (opcional)
+
+`DD_FETCH_LAMBDA_TAGS`
+: Permite que el forwarder obtenga etiquetas Lambda mediante llamadas a la API GetResources y las aplique a logs, métricas y rastros. Si se establece en true, el permiso `tag:GetResources` se añadirá automáticamente al rol de IAM de ejecución de Lambda.
+
+`DD_FETCH_LOG_GROUP_TAGS`
+: Permite que el forwarder obtenga etiquetas de grupo de log mediante ListTagsLogGroup y las aplique a logs, métricas y trazas. Si se establece en true, el permiso `logs:ListTagsForResource` se añadirá automáticamente al rol de IAM de ejecución de Lambda.
+
+`DD_FETCH_STEP_FUNCTIONS_TAGS`
+: Permite que el Forwarder recupere etiquetas de Step Functions mediante llamadas a la API GetResources y las aplique a logs y trazas (si está habilitado el rastreo de Step Functions). Si se configura como true (verdadero), el permiso `tag:GetResources` se añadirá automáticamente al rol de IAM de ejecución de Lambda.
+
+`DD_STEP_FUNCTION_TRACE_ENABLED`
+: Establécelo como true para activar el seguimiento de todas las Step Functions.
+
+`SOURCE_ZIP_URL`
+: No lo cambies a menos que sepas lo que estás haciendo. Anula la ubicación predeterminada del código fuente de la función.
+
+`PERMISSIONS_BOUNDARY_ARN`
+: ARN para la política de límites de permisos.
+
+`DD_USE_PRIVATE_LINK` (OBSOLETO)
+: Establecer en true para permitir el envío de logs y métricas a través de AWS PrivateLink. Consulta [Conectarte a Datadog a través de AWS PrivateLink][2].
+
+`DD_HTTP_PROXY_URL`
+: Establece las variables de entorno estándar del proxy web HTTP_PROXY y HTTPS_PROXY. Estos son los endpoints de URL que expone tu servidor proxy. No utilices esto en combinación con AWS Private Link. Asegúrate también de establecer `DD_SKIP_SSL_VALIDATION` a true.
+
+`DD_NO_PROXY`
+: Establece la variable de entorno del proxy web estándar `NO_PROXY`. Es una lista separada por comas de nombres de dominio que deben excluirse del proxy web.
+
+`VPC_SECURITY_GROUP_IDS`
+: Lista separada por comas de IDs de grupos de seguridad de VPC. Se utiliza cuando AWS PrivateLink está activado.
+
+`VPC_SUBNET_IDS`
+: Lista separada por comas de IDs de subred de VPC. Se utiliza cuando AWS PrivateLink está activado.
+
+`ADDITIONAL_TARGET_LAMBDA_ARNS`
+: Lista separada por comas de ARNs de Lambda que se llamarán de forma asíncrona con el mismo `event` que recibe el Datadog Forwarder.
+
+`INSTALL_AS_LAYER`
+: Si se utiliza el flujo de instalación basado en capas. Establécelo en false para utilizar el flujo de instalación heredado, que instala una segunda función que copia el código del forwarder desde GitHub a un bucket de S3. Por defecto es true.
+
+`LAYER_ARN`
+: ARN de la capa que contiene el código del forwarder. Si está vacío, el script utilizará la versión de la capa con la que se publicó el forwarder. Por defecto está vacío.
+
+[20]: https://app.datadoghq.com/organization-settings/api-keys
+[13]: https://docs.datadoghq.com/es/getting_started/site/
+[21]: https://docs.datadoghq.com/es/logs/processing/pipelines/
+[2]: https://docs.datadoghq.com/es/logs/guide/send-aws-services-logs-with-the-datadog-lambda-function/
+{{% /tab %}}
+{{< /tabs >}}
+
## Permisos
Para desplegar el stack tecnológico de CloudFormation con las opciones predeterminadas, necesitas tener los permisos que se indican a continuación. Estos sirven para guardar tu clave de API Datadog como secreto, crear un bucket S3 para almacenar el código del Forwarder (archivo ZIP) y crear funciones Lambda (incluidos los roles de ejecución y los grupos de logs).
@@ -589,7 +740,7 @@ El valor de la etiqueta `service` se determina en función de varias entradas. E
1. Etiquetas personalizadas de mensajes de logs: Si el mensaje de log tiene una clave `ddtags` que contiene un valor de etiqueta `service`, se utilizará para anular la etiqueta `service` en el evento de log.
2. Caché de etiquetas Lambda (aplicable sólo a logs de Lambda): La activación de `DdFetchLambdaTags` obtendrá y almacenará todas las etiquetas de las funciones Lambda y anulará la etiqueta `service` si no se configuró previamente o si se configuró con un valor predeterminado, es decir, el valor `source (fuente)`.
3. Caché de etiquetas de grupo de logs de Cloudwatch (aplicable sólo a logs de Cloudwatch): La activación `DdFetchLogGroupTags` obtendrá y almacenará todas las etiquetas de grupos de logs de Cloudwatch que se añadan a la entrada `ddtags` en el evento de log. Si el valor de la etiqueta `service` se configuró en el caché de etiquetas, se utilizará para configurar la etiqueta `service` para el evento de log.
-4. Definir directamente un valor de etiqueta `service` en la var. de ENT. `ddtags` del Forwarder.
+4. Establecer directamente un valor de etiqueta `service` en la variable de entorno `ddtags` del forwarder.
5. Valor por defecto igual a la etiqueta `source (fuente)`.
diff --git a/content/es/logs/guide/how-to-set-up-only-logs.md b/content/es/logs/guide/how-to-set-up-only-logs.md
index 900bde0eeb31a..99af650b11d3e 100644
--- a/content/es/logs/guide/how-to-set-up-only-logs.md
+++ b/content/es/logs/guide/how-to-set-up-only-logs.md
@@ -11,7 +11,7 @@ further_reading:
title: Uso exclusivo del Datadog Agent para la recopilación de logs
---
-DdApiKey se convierte en DD_API_KEY, y ExcludeAtMatch se convierte en EXCLUDE_AT_MATCH.
-La Monitorización de la infraestructura es un requisito previo para usar APM. Si eres cliente de APM, no desactives la recopilación de métricas o podrías perder información importante de telemetría y recopilación de métricas.
+La monitorización de la infraestructura es un requisito previo para utilizar APM. Si eres cliente de APM, no desactives la recopilación de métricas, ya que podrías perder información importante de telemetría y recopilación de métricas.
Para deshabilitar las cargas útiles, debes ejecutar la versión 6.4 o posterior del Agent. Esto deshabilita el envío de datos de métricas (incluidas las métricas personalizadas) para que los hosts dejen de aparecer en Datadog. Sigue estos pasos:
diff --git a/content/es/logs/guide/setting-file-permissions-for-rotating-logs.md b/content/es/logs/guide/setting-file-permissions-for-rotating-logs.md
index 73219fa13a8a6..0346f78d7f477 100644
--- a/content/es/logs/guide/setting-file-permissions-for-rotating-logs.md
+++ b/content/es/logs/guide/setting-file-permissions-for-rotating-logs.md
@@ -47,7 +47,7 @@ setfacl -m u:dd-agent:rx /var/log/apache
### Configuración de permisos para la rotación de archivos de logs
-[Configurar los permisos][4] una vez no servirá para la rotación de logs, ya que logrotate no vuelve a aplicar la configuración de ACL. Para obtener una solución más permanente, añade una regla a logrotate para restablecer la ACL en un nuevo archivo:
+Configurar los permisos una vez no persistirá para rotar logs, ya que logrotate no vuelve a aplicar la configuración ACL. Para una solución más permanente, añade una regla a logrotate para restablecer la ACL en un nuevo archivo:
```shell
sudo touch /etc/logrotate.d/dd-agent_ACLs
@@ -113,5 +113,4 @@ Cada aplicación existente seguirá una nomenclatura similar. La ventaja es que
[1]: https://help.ubuntu.com/community/FilePermissionsACLs
[2]: https://www.tecmint.com/secure-files-using-acls-in-linux
-[3]: http://xmodulo.com/configure-access-control-lists-acls-linux.html
-[4]: http://bencane.com/2012/05/27/acl-using-access-control-lists-on-linux
\ No newline at end of file
+[3]: http://xmodulo.com/configure-access-control-lists-acls-linux.html
\ No newline at end of file
diff --git a/content/es/logs/log_collection/csharp.md b/content/es/logs/log_collection/csharp.md
index c6d5d5073058c..159dc7c59daf5 100644
--- a/content/es/logs/log_collection/csharp.md
+++ b/content/es/logs/log_collection/csharp.md
@@ -123,7 +123,7 @@ Para instalar NLog con NuGet, ejecuta el siguiente comando en la consola del adm
PM> Install-Package NLog
```
-Una vez tengas la librería en tu classpath, adjunta el siguiente formato a cualquier destino. Edita o añade un archivo `NLog.config` a la ruta raíz del proyecto. Luego copia y pega el siguiente código en él (*los logs que se graban en el archivo `application-logs.json`*):
+Una vez tengas la biblioteca en tu classpath, adjunta el siguiente formato a cualquier destino. Edita o añade un archivo `NLog.config` a la ruta raíz del proyecto. Luego copia y pega el siguiente código en él (*los logs que se graban en el archivo `application-logs.json`*):
```xml
@@ -187,7 +187,7 @@ PM> Install-Package log4net
PM> Install-Package log4net.Ext.Json
```
-Una vez instalada la librería, adjunta el siguiente formato a cualquier destino. Edita la `App.config` de tu proyecto y añade la siguiente sección:
+Una vez instalada la biblioteca, adjunta el siguiente formato a cualquier destino. Edita la `App.config` de tu proyecto y añade la siguiente sección:
```xml
@@ -313,7 +313,7 @@ Si tienes APM habilitado para esta aplicación, conecta tus logs y trazas al añ
## Registro de logs sin Agent con APM
-Gracias a la librería de instrumentación automática de APM y .NET, es posible crear un flujo de logs desde tu aplicación directamente a Datadog, sin hacer cambios en el código. De esta forma, los logs se envían directamente a Datadog, por lo que no se beneficia de [funciones como la limpieza de datos confidenciales][10] que ofrece el Datadog Agent. Por esta razón, recomendamos que registres los logs en un archivo que puedas supervisar siempre que sea posible, aunque es cierto que resulta útil en entornos no compatibles con este método (por ejemplo, si usas [Azure App Service][11]). Cabe destacar que podrás seguir limpiando los datos confidenciales en el servidor con la ayuda de [Sensitive Data Scanner][12].
+Gracias a la biblioteca de instrumentación automática de APM y .NET, es posible crear un flujo de logs desde tu aplicación directamente a Datadog, sin hacer cambios en el código. De esta forma, los logs se envían directamente a Datadog, por lo que no se beneficia de [funciones como la limpieza de datos confidenciales][10] que ofrece el Datadog Agent. Por esta razón, recomendamos que registres los logs en un archivo que puedas supervisar siempre que sea posible, aunque es cierto que resulta útil en entornos no compatibles con este método (por ejemplo, si usas [Azure App Service][11]). Cabe destacar que podrás seguir limpiando los datos confidenciales en el servidor con la ayuda de [Sensitive Data Scanner][12].
El registro de logs sin Agent (también denominado «envío directo de logs») es compatible con los siguientes marcos:
- Serilog (versión 1.0 o posterior)
@@ -324,11 +324,11 @@ El registro de logs sin Agent (también denominado «envío directo de logs») e
No es necesario que modifiques el código de tu aplicación ni que instales dependencias adicionales.
- Nota: Si usas log4net o NLog, debes configurar un adicionador (log4net) o un registrador (NLog) para poder habilitar el registro de logs sin Agent. En esos casos, puedes añadir dependencias adicionales o usar el registro de logs sin Agent con el receptor Serilog.
+ Nota: Si utilizas log4net o NLog, un anexador (log4net) o un registrador (NLog) deben estar configurados para que el registro sin Agent esté habilitado. En estos casos, pueded añadir estas dependencias adicionales, o utilizar el registro sin agent con el sink de Serilog en su lugar.
-### Configurar la librería de APM
+### Configurar la biblioteca de APM
El registro de logs sin Agent solo está disponible cuando se usa APM con la instrumentación automática. Para empezar, instrumenta tu aplicación según se describe en los siguientes documentos:
@@ -350,16 +350,16 @@ Para habilitar el registro de logs sin Agent, define las siguientes variables de
**Predeterminado**: `datadoghq.com` (US1)
`DD_LOGS_INJECTION`
-: Habilita la [conexión de logs y trazas][9]:-**Predeterminado**: `true`
-Habilitado de manera predeterminada al usar el registro de logs sin Agent a partir de la versión 2.7.0 del rastreador. +: permite [conectar logs y trazas][9]:
+**Por defecto**: `true`
+Activado por defecto desde la versión 3.24.0 de rastreador. `DD_LOGS_DIRECT_SUBMISSION_INTEGRATIONS` : Permite el registro de logs sin Agent. Habilita esta funcionalidad en tu marco de registro de logs al establecer `Serilog`, `NLog`, `Log4Net` o `ILogger` (para `Microsoft.Extensions.Logging`). Si usas varios marcos de registro de logs, usa una lista de variables separadas por punto y coma.
**Ejemplo**: `Serilog;Log4Net;NLog`
- Nota: Si usas un marco de registro de logs junto con
Reinicia tu aplicación después de establecer las variables de entorno.
@@ -455,7 +455,7 @@ Por lo general, los siguientes valores de configuración no se modifican, pero p
: Define el tiempo de espera (en segundos) antes de comprobar si hay logs nuevos para enviar.Microsoft.Extensions.Logging, lo normal es que debas usar el nombre del marco. Por ejemplo, si usas Serilog.Extensions.Logging, deberías establecer DD_LOGS_DIRECT_SUBMISSION_INTEGRATIONS=Serilog.
+ Nota: Si estás utilizando un marco de registro en conjunto con Microsoft.Extensions.Logging, en general necesitarás el nombre de marco. Por ejemplo, si estás usando Serilog.Extensions.Logging, debes configurar DD_LOGS_DIRECT_SUBMISSION_INTEGRATIONS=Serilog.
**Predeterminado**: `1` -Si usas la integración `Microsoft.Extensions.Logging`, puedes filtrar los logs enviados a Datadog con ayuda de las funcionalidades estándar integradas en `ILogger`. Usa la clave `"Datadog"` para identificar al proveedor de envío directo, y establece los niveles mínimos del log para un espacio de nombres. Por ejemplo, si añades lo siguiente a tu `appSettings.json`, evitarías que se envíen logs con un nivel inferior a `Warning` a Datadog. Disponible a partir de la versión 2.20.0 de la librería del rastreador de .NET. +Si usas la integración `Microsoft.Extensions.Logging`, puedes filtrar los logs enviados a Datadog con ayuda de las funcionalidades estándar integradas en `ILogger`. Usa la clave `"Datadog"` para identificar al proveedor de envío directo, y establece los niveles mínimos del log para un espacio de nombres. Por ejemplo, si añades lo siguiente a tu `appSettings.json`, evitarías que se envíen logs con un nivel inferior a `Warning` a Datadog. Disponible a partir de la versión 2.20.0 de la biblioteca del rastreador de .NET. ```json { @@ -571,4 +571,4 @@ Ahora los logs nuevos se envían directamente a Datadog. [17]: /es/logs/log_configuration/pipelines/?tab=source [18]: /es/api/latest/logs/#send-logs [19]: https://www.nuget.org/packages/Serilog.Sinks.Datadog.Logs -[20]: /es/glossary/#tail +[20]: /es/glossary/#tail \ No newline at end of file diff --git a/content/es/logs/log_collection/ios.md b/content/es/logs/log_collection/ios.md index 352ce6d03b490..5d054ce196f52 100644 --- a/content/es/logs/log_collection/ios.md +++ b/content/es/logs/log_collection/ios.md @@ -11,18 +11,18 @@ title: Recopilación de logs de iOS --- ## Información general -Envía logs a Datadog desde tus aplicaciones de iOS con [la librería de registro del cliente `dd-sdk-ios` de Datadog][1] y aprovecha las siguientes características: +Envía logs a Datadog desde tus aplicaciones de iOS con [la biblioteca de registro del cliente `dd-sdk-ios` de Datadog][1] y aprovecha las siguientes características: * Loguear en Datadog en formato JSON de forma nativa. * Utilizar los atributos predeterminados y añadir atributos personalizados a cada log enviado. * Registrar las direcciones IP reales de los clientes y los Agents de usuario. * Aprovechar el uso optimizado de red con publicaciones masivas automáticas. -La librería `dd-sdk-ios` es compatible con todas las versiones de iOS 11 o posteriores. +La biblioteca `dd-sdk-ios` es compatible con todas las versiones de iOS 11 o posteriores. ## Configuración -1. Declara la librería como una dependencia dependiente de tu gestor de paquete. Se recomienda el gestor de paquete Swift. +1. Declara la biblioteca como una dependencia dependiente de tu gestor de paquete. Se recomienda el gestor de paquete Swift. {{< tabs >}} {{% tab "Swift Package Manager (SPM)" %}} @@ -69,7 +69,7 @@ DatadogLogs.xcframework {{% /tab %}} {{< /tabs >}} -2. Inicializa la librería con el contexto de tu aplicación y tu [token de cliente de Datadog][2]. Por razones de seguridad, debes utilizar un token de cliente: no puedes utilizar [claves de API de Datadog][3] para configurar la librería `dd-sdk-ios`, ya que estarían expuestas del lado del cliente en el código de bytes IPA de la aplicación iOS. +2. Inicializa la biblioteca con el contexto de tu aplicación y tu [token de cliente de Datadog][2]. Por razones de seguridad, debes utilizar un token de cliente: no puedes utilizar [claves de API de Datadog][3] para configurar la biblioteca `dd-sdk-ios`, ya que estarían expuestas del lado del cliente en el código de bytes IPA de la aplicación iOS. Para obtener más información sobre cómo configurar un token de cliente, consulta la [documentación sobre el token de cliente][2]. @@ -349,7 +349,7 @@ El SDK cambia su comportamiento según el nuevo valor. Por ejemplo, si el consen Antes de que los datos se carguen en Datadog, se almacenan en texto claro en el directorio de caché (`Library/Caches`) de tu [entorno de prueba de aplicaciones][6]. El directorio de caché no puede ser leído por ninguna otra aplicación instalada en el dispositivo. -Al redactar tu aplicación, habilita los logs de desarrollo para loguear en consola todos los mensajes internos del SDK con una prioridad igual o superior al nivel proporcionado. +Al redactar tu aplicación, habilita los logs de desarrollo para registrar en consola todos los mensajes internos del SDK con una prioridad igual o superior al nivel proporcionado. {{< tabs >}} {{% tab "Swift" %}} @@ -500,7 +500,7 @@ Para más información, consulta [Empezando con etiquetas][5]. Por defecto, los siguientes atributos se añaden a todos los logs enviados por un registrador: -* `http.useragent` y sus propiedades extraídas `device` y `OS` +* `http.useragent` y sus propiedades extraídas `device` y `OS` * `network.client.ip` y sus propiedades geográficas extraídas (`country`, `city`) * `logger.version`, versión del SDK de Datadog * `logger.thread_name`(`main`, `background`) @@ -512,7 +512,7 @@ Utiliza el método `addAttribute(forKey:value:)` para añadir un atributo person {{< tabs >}} {{% tab "Swift" %}} ```swift -// Esto añade un atributo "device-model" con un valor de cadena +// This adds an attribute "device-model" with a string value for this logger instance. logger.addAttribute(forKey: "device-model", value: UIDevice.current.model) ``` {{% /tab %}} @@ -523,6 +523,22 @@ logger.addAttribute(forKey: "device-model", value: UIDevice.current.model) {{% /tab %}} {{< /tabs >}} +Los atributos pueden añadirse globalmente en todas las instancias de logs (por ejemplo: nombre del servicio, entorno) utilizando: + +{{< tabs >}} +{{% tab "Swift" %}} +```swift +// This adds an attribute "device-model" with a string value in all Logs instances. +Logs.addAttribute(forKey: "device-model", value: UIDevice.current.model) +``` +{{% /tab %}} +{{% tab "Objective-C" %}} +```objective-c +[Logs addAttributeForKey:@"device-model" value:UIDevice.currentDevice.model]; +``` +{{% /tab %}} +{{< /tabs >}} + `
Por motivos de seguridad, las claves de API no pueden utilizarse para configurar el SDK de logs del navegador, ya que quedarían expuestas del lado del cliente en el código de JavaScript. Para recopilar losg de los navegadores web, debe utilizarse un token de cliente.
-| Método de instalación | Caso práctico |
-| -------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
-| npm (node package manager) | Este método se recomienda para las aplicaciones web modernas. El SDK de logs del navegador se empaqueta con el resto de tu código frontend de JavaScript. No tiene ningún efecto en el rendimiento de la carga de la página. Sin embargo, el SDK puede omitir errores, recursos y acciones del usuario activadas antes de que el SDK se inicialice. **Nota**: Se recomienda utilizar una versión coincidente con el SDK de RUM si se utiliza. |
-| CDN asíncrono | Este método se recomienda para aplicaciones web con objetivos de rendimiento. El SDK de logs de navegador se carga desde nuestra CDN de forma asíncrona: este método garantiza que la descarga del SDK no afecte al rendimiento de carga de la página. Sin embargo, el SDK podría omitir errores, recursos y acciones del usuario activados antes de que se inicialice el SDK. |
-| CDN síncrono | Este método se recomienda para recopilar todos los eventos de RUM. El SDK de logs de navegador se carga desde nuestra CDN de forma sincrónica: este método garantiza que el SDK se cargue primero y recopile todos los errores, recursos y acciones del usuario. Este método puede afectar al rendimiento de carga de la página. |
+### Paso 2: Instalar el SDK de logs de navegador
-### NPM
+Elige el método de instalación del SDK de navegador.
-Después de añadir [`@datadog/browser-logs`][3] a tu archivo `package.json`, inicialízalo con:
+{{< tabs >}}
+{{% tab "NPM" %}}
-```javascript
-import { datadogLogs } from '@datadog/browser-logs'
+Para aplicaciones web modernas, Datadog recomienda la instalación a través de Node Package Manager (npm). El SDK de navegador se empaqueta con el resto de tu código JavaScript de frontend. No tiene ningún impacto en el rendimiento de carga de la página. Sin embargo, es posible que el SDK no capture errores o logs de consola que se produzcan antes de que se inicialice el SDK. Datadog recomienda utilizar una versión que coincida con el SDK de logs del navegador.
-datadogLogs.init({
- clientToken: 'Las métricas basadas en logs se consideran métricas personalizadas y se facturan en consecuencia. Evita agrupar por atributos no limitados o de cardinalidad extremadamente alta, como marcas de tiempo, ID de usuario, ID de solicitud o ID de sesión, para no afectar a tu facturación.
+Las métricas basadas en logs se consideran métricas personalizadas y se facturan en consecuencia. Evita agrupar por atributos no limitados o de cardinalidad extremadamente alta, como marcas de tiempo, IDs de usuario, IDs de solicitud o IDs de sesión, para no afectar a tu facturación.
### Actualizar una métrica basada en logs
@@ -87,9 +87,11 @@ Las métricas de uso de Log Management vienen con tres etiquetas que se pueden u
| `datadog_is_excluded` | Indica si un log coincide o no con una consulta de exclusión. |
| `service` | El atributo servicio del evento de log. |
+**Nota**: Los campos `datadog_is_excluded` y `datadog_index` pueden tener un valor de `N/A`. Esto indica que los logs fueros ingeridos, pero no coincidió con ningún criterio de inclusión o exclusión para ser enrutado explícitamente a un índice.
+
Existe una etiqueta `status` adicional disponible en la métrica `datadog.estimated_usage.logs.ingested_events` para reflejar el estado del log (`info`, `warning`, etc.).
-## Leer más
+## Referencias adicionales
{{< partial name="whats-next/whats-next.html" >}}
diff --git a/content/es/logs/log_configuration/processors.md b/content/es/logs/log_configuration/processors.md index a4adbc9d90c3a..86ca5068a9f35 100644 --- a/content/es/logs/log_configuration/processors.md +++ b/content/es/logs/log_configuration/processors.md @@ -686,7 +686,7 @@ El procesador de búsqueda realiza las siguientes acciones: * Opcionalmente, si no encuentra el valor en la tabla de asignación, crea un atributo de destino con el valor de la tabla de referencia. Puedes seleccionar un valor para una [tabla de referencias][101] en la pestaña **Reference Table** (Tabla de referencia). - {{< img src="logs/log_configuration/processor/lookup_processor_reference_table.png" alt="Procesador de búsqueda" >}} + {{< img src="logs/log_configuration/processor/lookup_processor_reference_table.png" alt="Procesador de búsqueda" style="width:80%;">}} @@ -829,7 +829,7 @@ Define el procesador de matrices en la página [**Pipelines**][1]. Extrae un valor específico de un objeto dentro de una matriz cuando coincide con una condición. {{< tabs >}} -{{% tab "UI (IU)" %}} +{{% tab "UI" %}} {{< img src="logs/log_configuration/processor/array_processor_select_value.png" alt="Procesador de matrices - Seleccionar el valor de un elemento" style="width:80%;" >}} @@ -864,6 +864,38 @@ Extrae un valor específico de un objeto dentro de una matriz cuando coincide co } ``` +{{% /tab %}} +{{% tab "API" %}} + +Utiliza el [endpoint de API del pipeline de logs de Datadog][1] con la siguiente carga útil JSON del procesador de matrices: + +```json +{ + "type": "array-processor", + "name": "Extract Referrer URL", + "is_enabled": true, + "operation" : { + "type" : "select", + "source": "httpRequest.headers", + "target": "referrer", + "filter": "name:Referrer", + "value_to_extract": "value" + } +} +``` + +| Parámetro | Tipo | Obligatorio | Descripción | +|--------------|------------------|----------|---------------------------------------------------------------| +| `type` | Cadena | Sí | Tipo de procesador. | +| `name` | Cadena | No | Nombre del procesador. | +| `is_enabled` | Booleano | No | Si el procesador está activado. Por defecto: `false`. | +| `operation.type` | Cadena | Sí | Tipo de funcionamiento del procesador de matrices. | +| `operation.source` | Cadena | Sí | Ruta de la matriz de la que quieres seleccionar. | +| `operation.target` | Cadena | Sí | Atributo objetivo. | +| `operation.filter` | Cadena | Sí | Expresión que coincide con un elemento de la matriz. Se selecciona el primer elemento coincidente. | +| `operation.value_to_extract` | Cadena | Sí | Atributo a leer en el elemento seleccionado. | + +[1]: /es/api/v1/logs-pipelines/ {{% /tab %}} {{< /tabs >}} @@ -872,7 +904,7 @@ Extrae un valor específico de un objeto dentro de una matriz cuando coincide co Calcula el número de elementos de una matriz. {{< tabs >}} -{{% tab "UI (IU)" %}} +{{% tab "UI" %}} {{< img src="logs/log_configuration/processor/array_processor_length.png" alt="Procesador de matrices - Longitud" style="width:80%;" >}} @@ -898,6 +930,34 @@ Calcula el número de elementos de una matriz. } ``` {{% /tab %}} +{{% tab "API" %}} + +Utiliza el [endpoint de API del pipeline de logs de Datadog][1] con la siguiente carga útil JSON del procesador de matrices: + +```json +{ + "type": "array-processor", + "name": "Compute number of tags", + "is_enabled": true, + "operation" : { + "type" : "length", + "source": "tags", + "target": "tagCount" + } +} +``` + +| Parámetro | Tipo | Obligatorio | Descripción | +|---------------------|-----------|----------|---------------------------------------------------------------| +| `type` | Cadena | Sí | Tipo de procesador. | +| `name` | Cadena | No | Nombre del procesador. | +| `is_enabled` | Booleano | No | Si el procesador está activado. Por defecto: `false`. | +| `operation.type` | Cadena | Sí | Tipo de funcionamiento del procesador de matrices. | +| `operation.source` | Cadena | Sí | Ruta de la matriz de la que quieres seleccionar. | +| `operation.target` | Cadena | Sí | Atributo objetivo. | + +[1]: /es/api/v1/logs-pipelines/ +{{% /tab %}} {{< /tabs >}} ### Añadir a la matriz @@ -908,7 +968,7 @@ Añade un valor de atributo al final de un atributo de matriz de destino en el l {{< tabs >}} -{{% tab "UI (IU)" %}} +{{% tab "UI" %}} {{< img src="logs/log_configuration/processor/array_processor_append.png" alt="Procesador de matrices - Añadir" style="width:80%;" >}} @@ -942,6 +1002,60 @@ Añade un valor de atributo al final de un atributo de matriz de destino en el l "sourceIps": ["203.0.113.1", "198.51.100.23"] } ``` +{{% /tab %}} +{{% tab "API" %}} + +Utiliza el [endpoint de API del pipeline de logs de Datadog][1] con la siguiente carga útil JSON del procesador de matrices: + +```json +{ + "type": "array-processor", + "name": "Append client IP to sourceIps", + "is_enabled": true, + "operation" : { + "type" : "append", + "source": "network.client.ip", + "target": "sourceIps" + } +} +``` + +| Parámetro | Tipo | Obligatorio | Descripción | +|------------------------------|------------|----------|--------------------------------------------------------------------| +| `type` | Cadena | Sí | Tipo de procesador. | +| `name` | Cadena | No | Nombre del procesador. | +| `is_enabled` | Booleano | No | Si el procesador está activado. Por defecto: `false`. | +| `operation.type` | Cadena | Sí | Tipo de funcionamiento del procesador de matrices. | +| `operation.source` | Cadena | Sí | Atributo a añadir. | +| `operation.target` | Cadena | Sí | Atributo de matriz al que añadir. | +| `operation.preserve_source` | Booleano | No | Si se conserva la fuente original después de la reasignación. Por defecto: `false`. | + +[1]: /es/api/v1/logs-pipelines/ +{{% /tab %}} +{{< /tabs >}} + +## Procesador decodificador + +El procesador decodificador traduce los campos de cadena codificados de binario a texto (como Base64 o Hex/Base16) a su representación original. Esto permite interpretar los datos en su contexto nativo, ya sea como cadena UTF-8, comando ASCII o valor numérico (por ejemplo, un número entero derivado de una cadena hexadecimal). El procesador decodificador es especialmente útil para analizar comandos codificados, logs de sistemas específicos o técnicas de evasión utilizadas por actores de amenazas. + +**Notas**: + +- Cadenas truncadas: El procesador maneja las cadenas Base64/Base16 parcialmente truncadas con elegancia, recortándolas o rellenándolas según sea necesario. + +- Formato hexadecimal: La entrada hexadecimal puede descodificarse en una cadena (UTF-8) o en un número entero. + +- Gestión de fallos: Si la descodificación falla (debido a una entrada no válida), el procesador omite la transformación y el log permanece inalterado. + +{{< tabs >}} +{{% tab "UI" %}} + +1. Configura el atributo de origen: Proporciona la ruta del atributo que contiene la cadena codificada, como `encoded.base64`. +2. Selecciona la codificación de origen: Elige la codificación binaria a texto de la fuente: `base64` o `base16/hex`. +2. Para `Base16/Hex`: Elige el formato de salida: `string (UTF-8)` o `integer`. +3. Configura el atributo de destino: Introduce la ruta del atributo para almacenar el resultado decodificado. + +{{< img src="logs/log_configuration/processor/decoder-processor.png" alt="Procesador decodificador - Adjuntar" style="width:80%;" >}} + {{% /tab %}} {{< /tabs >}} @@ -959,7 +1073,7 @@ Para más información, véase [Inteligencia sobre amenazas][9]. *Logging without Limits es una marca registrada de Datadog, Inc. [1]: /es/logs/log_configuration/pipelines/ -[2]: /es/logs/log_configuration/parsing/ +[2]: /es/agent/logs/advanced_log_collection/?tab=configurationfile#scrub-sensitive-data-from-your-logs [3]: /es/logs/log_configuration/parsing/?tab=matchers#parsing-dates [4]: https://en.wikipedia.org/wiki/Syslog#Severity_level [5]: /es/logs/log_collection/?tab=host#attributes-and-tags diff --git a/content/es/metrics/metrics-without-limits.md b/content/es/metrics/metrics-without-limits.md index 8c7a7d62e5a3d..a7e27aeabe336 100644 --- a/content/es/metrics/metrics-without-limits.md +++ b/content/es/metrics/metrics-without-limits.md @@ -5,6 +5,7 @@ algolia: aliases: - /es/metrics/faq/metrics-without-limits/ - /es/metrics/guide/metrics-without-limits-getting-started/ +- /es/metrics/faq/why-is-my-save-button-disabled/ further_reading: - link: https://www.datadoghq.com/blog/metrics-without-limits tag: Blog @@ -21,57 +22,85 @@ title: Metrics without LimitsTM Metrics without LimitsTM proporciona flexibilidad y control sobre tus volúmenes de métricas personalizadas al desvincular la ingesta e indexación de métricas personalizadas. Solo pagas por las etiquetas (tags) de las métricas personalizadas que son valiosas para tu organización. -Metrics without LimitsTM te permite configurar etiquetas en todos los tipos de métricas de la aplicación. También puedes personalizar las agregaciones en counts, tasas y medidores sin tener que volver a desplegar o cambiar código. Con Metrics without LimitsTM, puedes configurar una lista de etiquetas permitidas en la aplicación para que se puedan consultar en toda la plataforma de Datadog; esto elimina de manera automática las etiquetas que no son esenciales asociadas a métricas de nivel de aplicación o empresariales (por ejemplo, `host`). De manera alternativa, puedes configurar una lista de etiquetas bloqueadas en la aplicación para eliminar y excluir con rapidez las etiquetas; esto conserva de manera automática las etiquetas esenciales restantes que brindan valor empresarial a tus equipos. Estas funcionalidades de configuración se encuentran en la página de [Resumen de métricas][1]. +Metrics without LimitsTM te permite configurar las etiquetas de todos los tipos de métricas en la aplicación seleccionando una lista de etiquetas permitidas que se pueden consultar en Datadog; de este modo, se eliminan automáticamente las etiquetas no esenciales asociadas a métricas empresariales o de nivel de aplicación (por ejemplo, `host`). Como alternativa, puedes configurar una lista de bloqueo de etiquetas en la aplicación para eliminar y excluir etiquetas; de este modo, se conservan automáticamente las etiquetas esenciales restantes que aportan valor empresarial a tus equipos. Estas funciones de configuración se encuentran en la página [Resumen de métricas][1]. En esta página se identifican los componentes clave de Metrics without LimitsTM que pueden ayudarte a gestionar los volúmenes de métricas personalizadas dentro de tu presupuesto de observabilidad. -### Configuración de etiquetas +### Configuración de etiquetas para una única métrica #### Lista de etiquetas permitidas + 1. Haz clic en el nombre de cualquier métrica para abrir su panel lateral de detalles. -2. Haz clic en **Manage Tags** (Gestionar etiquetas) -> **«Include Tags...»** (Incluir etiquetas...) para configurar las etiquetas que quieras que se puedan consultar en dashboards, notebooks, monitores y otros productos de Datadog. +2. Haz clic en **Manage Tags** (Gestionar etiquetas), luego en **Include tags** (Incluir etiquetas) para configurar las etiquetas que quieras que se puedan consultar en dashboards, notebooks, monitores y otros productos de Datadog. 3. Define tu lista de etiquetas permitidas. -De manera predeterminada, el modal de configuración de etiquetas se completa previamente con una lista de etiquetas permitidas recomendadas por Datadog que se consultaron de manera activa en dashboards, notebooks, monitores o a través de la API en los últimos 30 días. Las etiquetas recomendadas se distinguen con un icono de línea de gráfica. +De manera predeterminada, el modal de configuración de etiquetas se completa previamente con una lista de etiquetas permitidas recomendadas por Datadog que se consultaron de manera activa en dashboards, notebooks, monitores o a través de la API en los últimos 30 días. Las etiquetas recomendadas se distinguen con un icono de gráficos de línea. + a. Además, incluye las etiquetas que se utilizan en los activos (dashboards, monitores, notebooks y SLOs). Estas etiquetas se utilizan en los activos, pero no se consultan activamente y están marcadas con un icono de objetivo. Si las añades, te asegurarás de no perder visibilidad de tus activos críticos. 4. Revisa el *Estimated New Volume* (Nuevo volumen estimado) de métricas personalizadas indexadas que resultan de esta posible configuración de etiquetas. -5. Haz clic en **Guardar**. +5. Haz clic en **Save** (Guardar). + +{{< img src="metrics/mwl_example_include_tags-compressed_03182025.mp4" alt="Configuración de etiquetas con la lista de permitidos" video="true" style="width:100%" >}} -{{< img src="metrics/mwl_example_include_tags-compressed.mp4" alt="Configuración de etiquetas con la lista de permitidas" video=true style="width:100%" >}} +{{< img src="metrics/tags_used_assets.png" alt="Mostrar a los clientes que pueden añadir etiquetas utilizadas en activos en su configuración de MWL" style="width:100%" >}} Puedes [crear][2], [editar][3], [eliminar][4] y [estimar el impacto][5] de la configuración de tu etiqueta a través de las APIs de Metrics. #### Lista de etiquetas bloqueadas + 1. Haz clic en el nombre de cualquier métrica para abrir su panel lateral de detalles. -2. Haz clic en **Manage Tags** (Gestionar etiquetas) -> **«Exclude Tags...»** (Excluir etiquetas...) para eliminar las etiquetas que no quieres consultar. -3. Define tu lista de etiquetas bloqueadas. Las etiquetas que se definan en la lista de bloqueadas **no** se pueden consultar en dashboards ni monitores. Las etiquetas que se han consultado de manera activa en dashboards, notebooks, monitores y a través de la API en los últimos 30 días se distinguen con un icono de línea de gráfica. -5. Revisa el *Estimated New Volume* (Nuevo volumen estimado) de métricas personalizadas indexadas que resultan de esta posible configuración de etiquetas. -6. Haz clic en **Guardar**. +2. Haz clic en **Manage Tags** (Administrar etiquetas), luego, en **Exclude Tags** (Excluir etiquetas). +3. Define tu lista de etiquetas bloqueadas. Las etiquetas que se definan en la lista de bloqueadas **no** se pueden consultar en dashboards ni monitores. Las etiquetas que se han consultado de manera activa en dashboards, notebooks, monitores y a través de la API en los últimos 30 días se distinguen con un icono del gráfico de líneas. +4. Revisa el *Estimated New Volume* (Nuevo volumen estimado) de métricas personalizadas indexadas que resultan de esta posible configuración de etiquetas. +5. Haz clic en **Save** (Guardar). -{{< img src="metrics/mwl-example-tag-exclusion-compressed.mp4" alt="Configuración de etiquetas con exclusión de etiquetas" video=true style="width:100%" >}} +{{< img src="metrics/mwl-example-tag-exclusion-compressed_04032025.mp4" alt="Configuración de etiquetas con exclusión de etiquetas" video="true" style="width:100%" >}} Establece el parámetro `exclude_tags_mode: true` en la API de Metrics para [crear][2] y [editar][3] una lista de etiquetas bloqueadas. -Al configurar etiquetas para counts, tasas y medidores, la combinación de agregación de tiempo/espacio consultada con mayor frecuencia se encuentra disponible para consultar de manera predeterminada. +**Nota:** Para que las etiquetas se gestionen en una métrica, ésta debe tener un tipo declarado. Esto se hace normalmente cuando se envía una métrica, pero también puede hacerse manualmente utilizando el botón `Edit` para una métrica en Resumen de métricas. + +#### En la API + +Puedes [crear][2], [editar][3], [eliminar][4] y [estimar el impacto][5] de la configuración de tu etiqueta a través de las APIs de Metrics. ### Configurar varias métricas a la vez -Optimiza los volúmenes de métricas personalizadas mediante la [función de configuración masiva de etiquetas de métricas][7]. A fin de especificar un espacio de nombres para tus métricas, haz clic en **Configure Tags*** (Configurar etiquetas) en Resumen de métricas. Puedes configurar todas las métricas que coincidan con ese prefijo de espacio de nombres con la misma lista de etiquetas permitidas en ***Include tags...*** (Incluir tags...) o la misma lista de etiquetas bloqueadas en ***Exclude tags...*** (Excluir etiquetas...). +Optimiza tus volúmenes de métricas personalizadas utilizando la [función de configuración en bloque de etiquetas de métricas][7]. Para especificar las métricas que deseas configurar, haz clic en **Configure Metrics** (Configurar métricas) y, a continuación, en **Manage Tags*** (Gestionar etiquetas) en la página de resumen de métricas. Selecciona la métrica o el espacio de nombres de métricas que desees configurar y, a continuación, elige una de las siguientes opciones: + - [Permitir todas las etiquetas](#allow-all-tags) para anular cualquier configuración de etiquetas anterior y hacer que todas las etiquetas se puedan consultar. + - [Incluir o excluir etiquetas](#include-or-exclude-tags) para definir etiquetas consultables y no consultables, respectivamente. + +#### Permitir todas las etiquetas + +{{< img src="metrics/bulk_allow_all_tags.png" alt="La opción Administrar etiquetas con Permitir todas las etiquetas seleccionada en la sección Configurar etiquetas" style="width:100%" >}} + +Esta opción está seleccionada por defecto y anula las configuraciones de etiquetas establecidas previamente para que todas las etiquetas sean consultables. + +#### Incluir o excluir etiquetas + +Cuando selecciones etiquetas para incluir o excluir, elige entre [anular las configuraciones de etiquetas existentes](#override-existing-tag-configurations) o [mantener las configuraciones de etiquetas existentes](#keep-existing-tag-configurations). + +##### Anular configuraciones de etiquetas existentes + +{{< img src="metrics/bulk_include_tags.png" alt="La opción Administrar etiquetas con Incluir etiquetas y Anular seleccionada en la sección Configurar etiquetas. Las opciones para incluir etiquetas consultadas de forma activa en dashboards y monitores en los últimos 90 días y Etiquetas específicas están seleccionadas" style="width:100%" >}} + +Se anulan todas las configuraciones de etiquetas existentes para las métricas seleccionadas y se define una nueva configuración de etiquetas. Esto te permite hacer que todas las etiquetas se puedan consultar en todos los nombres de métricas. Si eliges **incluir etiquetas**, puedes incluir una o ambas de las siguientes opciones: + - Etiquetas consultadas activamente en Datadog en los últimos 30, 60 o 90 días. + - Un conjunto específico de etiquetas que defines. -Puedes [configurar][13] y [eliminar][14] etiquetas para varias métricas a través de la API. A fin de [configurar una lista de etiquetas bloqueadas][13] para varias métricas, establece el parámetro `exclude_tags_mode: true` en la API. +##### Mantener las configuraciones de etiquetas existentes -### Refinar y optimizar las agregaciones +{{< img src="metrics/bulk_exclude_tags.png" alt="La opción Administrar etiquetas con Excluir etiquetas y Mantener seleccionadas en la sección Configurar etiquetas" style="width:100%" >}} -Puedes ajustar aún más tus filtros de métricas personalizadas si optas por más [agregaciones de métricas][6] en tus métricas de medidor, count o tasa. A fin de preservar la precisión matemática de tus consultas, Datadog solo almacena la combinación de agregación de tiempo/espacio consultada con mayor frecuencia para un tipo de métrica determinado: +Se conservan las configuraciones de etiquetas existentes y se definen las nuevas etiquetas que se añadirán a la configuración. -- Los counts y tasas configurados se pueden consultar en tiempo/espacio con SUM -- Los medidores configurados se pueden consultar en tiempo/espacio con AVG +#### En la API -Puedes añadir o eliminar agregaciones en cualquier momento sin necesidad de realizar cambios en el nivel de código o Agent. +Puedes [configurar][13] y [eliminar][14] etiquetas para múltiples métricas a través de la API. -El modal de configuración de etiquetas se completa previamente con una lista de agregaciones permitidas que se han consultado de manera activa en dashboards, notebooks, monitores y a través de la API en los últimos 30 días (de color azul con un icono). También puedes incluir tus propias agregaciones adicionales. +**Nota**: Utiliza el atributo `include_actively_queried_tags_window` para incluir sólo las etiquetas consultadas activamente en un periodo determinado. ## Facturación de Metrics without LimitsTM -La configuración de las etiquetas y agregaciones te permite controlar qué métricas personalizadas se pueden consultar, lo que en última instancia reduce la cantidad facturable de métricas personalizadas. Metrics without LimitsTM desvincula los costes de ingesta de los costes de indexación. Puedes continuar enviando a Datadog todos los datos (se ingiere todo) y puedes especificar una lista de etiquetas permitidas que quieras que se puedan consultar en la plataforma de Datadog. Si el volumen de datos que Datadog ingiere para las métricas configuradas difiere del volumen restante más pequeño que indexas, puedes ver dos volúmenes distintos en la página de Uso, así como en la página de Resumen de métricas. +La configuración de tus etiquetas te permite controlar qué métricas personalizadas pueden consultarse, lo que reduce el número de métricas personalizadas facturables. Metrics without LimitsTM desvincula los costes de ingesta de los costes de indexación. Puedes seguir enviando a Datadog todos tus datos (todo se ingiere) y puedes especificar una lista de etiquetas permitidas que deseas que sigan siendo consultables en la plataforma de Datadog. Si el volumen de datos que Datadog está ingiriendo para tus métricas configuradas difiere del volumen restante más pequeño que indexas, puedes ver dos volúmenes distintos en tu pagina de Uso, así como en la página Resumen de métricas. - **Métricas personalizadas ingeridas**: el volumen original de métricas personalizadas basadas en todas las etiquetas ingeridas. - **Métricas personalizadas indexadas**: el volumen de métricas personalizadas de tipo consultable que queda en la plataforma de Datadog (en función de las configuraciones de Metrics without LimitsTM) @@ -103,7 +132,7 @@ Obtén más información sobre la [Facturación de métricas personalizadas][8]. - El [control de acceso basado en roles][11] para Metrics without LimitsTM también se encuentra disponible a fin de controlar qué usuarios tienen permisos para usar esta función que tiene implicaciones de facturación. -- Los eventos de auditoría te permiten realizar un seguimiento de las configuraciones de etiquetas o las agregaciones de percentiles que se hayan realizado y que puedan correlacionarse con picos de métricas personalizadas. Busca «tags:audit» y «configuración de etiquetas consultable» o «agregaciones de percentiles» en tu [Flujo de eventos][12] +- Los eventos de auditoría te permiten realizar un seguimiento de las configuraciones de etiquetas o las agregaciones de percentiles que se hayan realizado y que puedan correlacionarse con picos de métricas personalizadas. Busca "tags:audit" y "configuración de etiquetas consultable" o "agregaciones de percentiles" en tu [Flujo de eventos][12]. \*Metrics without Limits es una marca registrada de Datadog, Inc. diff --git a/content/es/metrics/summary.md b/content/es/metrics/summary.md index bdb19d672ea99..a19dd8ebf3577 100644 --- a/content/es/metrics/summary.md +++ b/content/es/metrics/summary.md @@ -21,9 +21,9 @@ Busca tus métricas por nombre de métrica o etiqueta (tag) utilizando los campo {{< img src="metrics/summary/tag_advanced_filtering.png" alt="Página de resumen de métricas SIN equipo:* ingresado en la barra de búsqueda por etiquetas" style="width:75%;">}} -También puede descubrir métricas relevantes utilizando el soporte mejorado de concordancia difusa en el campo de búsqueda de métricas: +También puedes detectar métricas relevantes utilizando la compatibilidad mejorada de concordancia difusa en el campo de búsqueda de métricas: -{{< img src="metrics/summary/metric_advanced_filtering_fuzzy.png" alt="The metrics summary Page ( página) with fuzzy search searching shopist checkout" style="width:75%;">}} +{{< img src="metrics/summary/metric_advanced_filtering_fuzzy.png" alt="La página de resumen de métricas con búsqueda difusa que busca el pago en Shopist" style="width:75%;">}} El filtrado por etiquetas admite la sintaxis booleana y de comodín para que puedas identificar: * Métricas que están etiquetadas con una clave de etiqueta concreta, por ejemplo, `team`: `team:*` @@ -149,12 +149,13 @@ Para cualquier clave concreta de etiqueta, puedes: ### Activos relacionados con métricas -{{< img src="metrics/summary/related_assets_dashboards.png" alt="Activos relacionados para un nombre de métricas especificado" style="width:80%;">}} +{{< img src="metrics/summary/related_assets_dashboards_08_05_2025.png" alt="Activos relacionados para un nombre de métricas específico" style="width:80%;">}} Para determinar el valor de cualquier nombre de métrica para tu organización, utiliza Activos relacionados de métricas. Los activos relacionados de métricas se refieren a cualquier dashboard, notebook, monitor, o SLO que consulta una métrica en particular. 1. Desplázate hasta la parte inferior del panel lateral de detalles de la métrica, hasta la sección **Recursos relacionados**. 2. Haz clic en el botón desplegable para ver el tipo de recurso relacionado que te interesa en (dashboards, monitores, notebooks, SLOs). Además, puedes utilizar la barra de búsqueda para validar activos específicos. +3. La columna **Tags** (Etiquetas) muestra exactamente qué etiquetas se utilizan en cada activo. ## Explorador de la cardinalidad de etiquetas de métricas personalizadas diff --git a/content/es/metrics/units.md b/content/es/metrics/units.md index 48e8103bd3fae..a2efe23549279 100644 --- a/content/es/metrics/units.md +++ b/content/es/metrics/units.md @@ -25,9 +25,13 @@ Por ejemplo, si tienes un punto de datos que es 3.000.000.000: * Si no has especificado una unidad para este punto de datos, aparecerá "3G". * Si has especificado que este punto de datos está en bytes, aparecerá "3GB". -Las unidades también se muestran en la parte inferior de las gráficas de timeboard, y las descripciones de métricas están disponibles al seleccionar **Metrics Info** del menú desplegable: +Haz clic en el botón de pantalla completa situado en la esquina superior derecha del gráfico para ver las unidades que aparecen en la parte inferior: -{{< img src="metrics/units/annotated_ops.png" alt="Operaciones anotadas" style="width:100%;">}} +{{< img src="metrics/units/metrics_units.png" alt="Las unidades de un gráfico de métricas en el modo pantalla completa" style="width:100%;">}} + +En el gráfico de una métrica, haz clic en el menú contextual (tres puntos verticales) para encontrar la opción **Metrics info** (Información de la métrica). Esto abre un panel con una descripción de la métrica. Al hacer clic en el nombre de la métrica en este panel, se abre la métrica en la página del resumen de métricas para su posterior análisis o edición. + +{{< img src="metrics/units/metrics_info.png" alt="La opción Información de métricas en el menú de contexto ampliado (tres puntos verticales)" style="width:100%;">}} Para cambiar una unidad de métrica, ve a la página de [resumen de métricas][1] y selecciona una métrica. Haz clic en **Edit** en **Metadata** y selecciona una unidad, como `bit` o `byte` del menú desplegable. diff --git a/content/es/monitors/guide/how-to-set-up-rbac-for-monitors.md b/content/es/monitors/guide/how-to-set-up-rbac-for-monitors.md index 62912e4bf47c7..7a4cf8085848a 100644 --- a/content/es/monitors/guide/how-to-set-up-rbac-for-monitors.md +++ b/content/es/monitors/guide/how-to-set-up-rbac-for-monitors.md @@ -1,4 +1,7 @@ --- +description: Configura el control de acceso basado en roles (RBAC) para monitores + con el fin de restringir los permisos de edición a roles específicos y evitar cambios + no autorizados. further_reading: - link: /account_management/rbac/permissions/#monitors tag: Documentación @@ -133,7 +136,7 @@ Puedes actualizar la definición de los monitores que se gestionan mediante API Para obtener más información, consulta [Editar un endpoint de API de monitor][3] y [API de políticas de restricción][4]. -### IU +### Interfaz de usuario Todos los nuevos monitores creados desde la interfaz de usuario utilizan el parámetro `restricted_roles`. Todos los monitores muestran también la opción de restricción de roles independientemente del mecanismo subyacente: diff --git a/content/es/monitors/guide/monitor_api_options.md b/content/es/monitors/guide/monitor_api_options.md index 7990a257e7d6d..46cd62b789215 100644 --- a/content/es/monitors/guide/monitor_api_options.md +++ b/content/es/monitors/guide/monitor_api_options.md @@ -1,4 +1,7 @@ --- +description: Referencia completa para las opciones de configuración de la API monitores + (noun), incluidos los parámetros comunes, los permisos, las alertas de anomalías + y las alertas de métricas. title: Opciones de la API Monitor --- diff --git a/content/es/monitors/guide/template-variable-evaluation.md b/content/es/monitors/guide/template-variable-evaluation.md index 02d39e49b7c10..d0126af08beda 100644 --- a/content/es/monitors/guide/template-variable-evaluation.md +++ b/content/es/monitors/guide/template-variable-evaluation.md @@ -1,4 +1,7 @@ --- +description: Modifica la salida de variables de plantilla en las notificaciones de + monitor utilizando operaciones matemáticas, funciones y manipulación de cadenas + con la sintaxis eval. title: Evaluación de variables de plantilla --- diff --git a/content/es/monitors/notify/_index.md b/content/es/monitors/notify/_index.md index b6f7df339f3ea..508f40fafd2fb 100644 --- a/content/es/monitors/notify/_index.md +++ b/content/es/monitors/notify/_index.md @@ -112,7 +112,7 @@ Cuando se crea un incidente a partir de un monitor, los [valores de campo][13] d Las notificaciones del monitor incluyen contenidos como la consulta de monitor, las @-mentions utilizadas, las snapshots de métrica (para monitores de métrica) y enlaces a páginas relevantes en Datadog. Tienes la opción de elegir qué contenido deseas incluir o excluir de notificaciones para monitores individuales. -
Las métricas de distribución con agregadores de percentil (como `p50`, `p75`, `p95`, o `p99`) no generan un gráfico de snapshot en notificaciones.
+Las métricas de distribución con agregadores de percentiles (como `p50`, `p75`, `p95` o `p99`) no generan un gráfico de snapshot en las notificaciones.
{{< img src="monitors/notifications/monitor_notification_presets.png" alt="Establecer una configuración previa de un monitor" style="width:70%;" >}}
diff --git a/content/es/monitors/notify/variables.md b/content/es/monitors/notify/variables.md
index cd3a88fff5c70..fcf9d9515394f 100644
--- a/content/es/monitors/notify/variables.md
+++ b/content/es/monitors/notify/variables.md
@@ -146,7 +146,7 @@ O utiliza el parámetro `{{else}}` del primer ejemplo:
@slack-example
{{/is_match}}
```
-**Nota**: Para comprobar si un `Para ver la lista completa de variables disponibles para tu monitor, en la parte inferior de la configuración de notificaciones, haz clic en Add Variable (Añadir variable) y selecciona una de las opciones del menú desplegado.
-Disponible para
- monitores de log,
- monitores de Trace Analytics (APM),
- monitores de Error Tracking,
- monitores RUM,
- monitores de CI y
- monitores de Database Monitoring.
-
-
-Para incluir **cualquier** atributo o etiqueta de un log, un tramo (span) de traza (trace), un evento RUM, un CI Pipeline, o un evento de CI Test que coincida con la consulta del monitor, utiliza las siguientes variables:
-
-| Tipo de monitor | Sintaxis de la variable |
-|-----------------|--------------------------------------------------|
-| Log | `{{log.attributes.key}}` o `{{log.tags.key}}` |
-| Trace Analytics | `{{span.attributes.key}}` o `{{span.tags.key}}` |
-| Error Tracking | `{{issue.attributes.key}}` |
-| RUM | `{{rum.attributes.key}}` o `{{rum.tags.key}}` |
-| Audit Trail | `{{audit.attributes.key}}` o `{{audit.message}}` |
-| CI Pipeline | `{{cipipeline.attributes.key}}` |
-| CI Test | `{{citest.attributes.key}}` |
-| Database Monitoring | `{{databasemonitoring.attributes.key}}` |
+| Tipo de monitor | Sintaxis de la variable |
+|--------------------------|--------------------------------------------------------|
+| [Audit Trail][16] | `{{audit.attributes.key}}` o `{{audit.message}}` |
+| [CI Pipeline][17] | `{{cipipeline.attributes.key}}` |
+| [CI Test][18] | `{{citest.attributes.key}}` |
+| [Database Monitoring][19]| `{{databasemonitoring.attributes.key}}` |
+| [Error Tracking][14] | `{{issue.attributes.key}}` |
+| [Log][12] | `{{log.attributes.key}}` o `{{log.tags.key}}` |
+| [RUM][15] | `{{rum.attributes.key}}` o `{{rum.tags.key}}` |
+| [Synthetic Monitoring][20]| `{{synthetics.attributes.key}}` |
+| [Trace Analytics][13] | `{{span.attributes.key}}` o `{{span.tags.key}}` |
{{% collapse-content title="Ejemplo de uso de sintaxis" level="h4" %}}
- Para cualquier par `key:value`, la variable `{{log.tags.key}}` se convierte en `value` en el mensaje de alerta.
@@ -425,10 +417,8 @@ Para incluir **cualquier** atributo o etiqueta de un log, un tramo (span) de tra
{{ event.tags.[dot.key.test] }}
```
-
{{% /collapse-content %}}
-
#### Notas importantes
- Si el evento seleccionado no incluye la clave de atributo o etiqueta, la variable aparece vacía en el mensaje de notificación. Para evitar que se pierdan notificaciones, evita utilizar estas variables para enrutar notificaciones con indicadores `{{#is_match}}`.
@@ -515,7 +505,7 @@ Las variables de plantilla de monitor `{{first_triggered_at}}`, `{{first_trigger
{{< img src="monitors/notifications/triggered_variables.png" alt="Muestra cuatro transiciones con marcas temporales A: 1419 OK a WARN, B: 1427 WARN a ALERT, C: 1445 ALERT a NO DATA, D: 1449 NO DATA a OK" style="width:90%;">}}
-**Ejemplo**: Cuando el monitor pasa de `OK` → `WARN`, los valores de `{{first_triggered_at}}` y `{{last_triggered_at}}` tienen ambos la marca temporal A. La tabla siguiente muestra los valores hasta que el monitor se recupera.
+**Ejemplo**: Cuando el monitor pasa de `OK` → `WARN`, los valores de `{{first_triggered_at}}` y `{{last_triggered_at}}` tienen ambos la marca temporal A. La tabla siguiente muestra los valores hasta que el monitor se recupere.
| Transición | first_triggered_at | last_triggered_at | triggered_duration_sec |
|------------------ |-------------------------------- |-------------------------------- |-------------------------------- |
@@ -716,4 +706,13 @@ https://app.datadoghq.com/services/{{urlencode "service.name"}}
[8]: https://en.wikipedia.org/wiki/List_of_tz_database_time_zones
[9]: /es/monitors/types/error_tracking/
[10]: /es/software_catalog/service_definitions/
-[11]: https://docs.datadoghq.com/es/software_catalog/service_definitions/v2-2/#example-yaml
\ No newline at end of file
+[11]: https://docs.datadoghq.com/es/software_catalog/service_definitions/v2-2/#example-yaml
+[12]: /es/monitors/types/log/
+[13]: /es/monitors/types/apm/?tab=analytics
+[14]: /es/monitors/types/error_tracking/
+[15]: /es/monitors/types/real_user_monitoring/
+[16]: /es/monitors/types/audit_trail/
+[17]: /es/monitors/types/ci/?tab=tests
+[18]: /es/monitors/types/ci/?tab=pipelines
+[19]: /es/monitors/types/database_monitoring/
+[20]: /es/synthetics/notifications/template_variables/
\ No newline at end of file
diff --git a/content/es/network_monitoring/cloud_network_monitoring/_index.md b/content/es/network_monitoring/cloud_network_monitoring/_index.md
index 8585bf61270d8..0727a7b621ffa 100644
--- a/content/es/network_monitoring/cloud_network_monitoring/_index.md
+++ b/content/es/network_monitoring/cloud_network_monitoring/_index.md
@@ -56,8 +56,8 @@ Además, la [ruta de red][5], una función de CNM, está disponible en Vista pre
{{< whatsnext desc="Esta sección incluye los siguientes temas:">}}
{{< nextlink href="network_monitoring/cloud_network_monitoring/setup" >}}Configuración: configura el Agent para recopilar datos de red.{{< /nextlink >}}
{{< nextlink href="network_monitoring/cloud_network_monitoring/network_analytics" >}}Análisis de red: grafica tus datos de red entre cada cliente y servidor disponible.{{< /nextlink >}}
- {{< nextlink href="network_monitoring/cloud_network_monitoring/network_map" >}}Mapa de redes: asigna tus datos de red entre tus etiquetas.{{< /nextlink >}}
- {{< nextlink href="monitors/types/cloud_network_monitoring/" >}}Monitores recomendados : configura los monitores de CNM recomendados.{{< /nextlink >}}
+ {{< nextlink href="network_monitoring/cloud_network_monitoring/network_map" >}}Mapa de red: asigna tus datos de red entre tus etiquetas.{{< /nextlink >}}
+ {{< nextlink href="monitors/types/cloud_network_monitoring/#common-monitors" >}}Monitores comunes: configura monitores de CNM comunes.{{< /nextlink >}}
{{< /whatsnext >}}
## Referencias adicionales
diff --git a/content/es/network_monitoring/cloud_network_monitoring/network_analytics.md b/content/es/network_monitoring/cloud_network_monitoring/network_analytics.md
index aa13b7919f1f0..f216f65a31b8e 100644
--- a/content/es/network_monitoring/cloud_network_monitoring/network_analytics.md
+++ b/content/es/network_monitoring/cloud_network_monitoring/network_analytics.md
@@ -144,22 +144,80 @@ Las etiquetas neutras no son específicas de un cliente o servidor, sino que se
La siguiente lista muestra etiquetas neutras disponibles para su uso:
-| Etiqueta | Descripción |
-|-------------------------|-----------------------------------------------------------------------------------------------|
-| `is_agent_traffic` | Indica si el tráfico fue generado por el Datadog Agent. |
-| `tls_encrypted` | Especifica si la conexión está cifrada mediante TLS. |
-| `tls_cipher_suite` | Identifica el conjunto de cifrado TLS utilizado (por ejemplo, `tls_ecdhe_rsa_with_aes_128_gcm_sha256`). |
-| `tls_cipher_insecure` | Indica si el cifrado utilizado se considera seguro. |
-| `tls_version` | Versión de TLS utilizada (`tls_1.2` o `tls_1.3`). |
-| `tls_client_version` | Versiones de TLS compatibles con el cliente (`tls_1.2` o `tls_1.3`). |
-| `gateway_id` | Identificador único del recurso de pasarela AWS. |
-| `gateway_type` | Tipo de puerta de enlace AWS (Internet, NAT o Tránsito). |
-| `gateway_region` | Región AWS de la puerta de enlace (por ejemplo, `us-east-1`). |
-| `gateway_availability-zone` | Zona de disponibilidad que aloja la puerta de enlace (por ejemplo, `us-east-1a`). |
-| `gateway_public_ip` | Dirección IP pública asignada a la puerta de enlace NAT. |
-| `tgw_attachment_id` | Identificador único de la conexión de AWS Transit Gateway. |
-| `tgw_attachment_type` | Tipo de adjunto de la puerta de enlace de tránsito (por ejemplo, VPC, VPN, Direct Connect). |
-| `vpc_endpoint_id` | Identificador único del endpoint de la VPC. |
+| Etiqueta | +Descripción | +
|---|---|
gateway_availability-zone |
+Zona de disponibilidad que aloja la gateway (por ejemplo, us-east-1a). |
+
gateway_id |
+Identificador único para el recurso gateway de AWS. | +
gateway_public_ip |
+Dirección IP pública asignada a la gateway NAT. | +
gateway_region |
+Región de AWS de la gateway (por ejemplo, us-east-1). |
+
gateway_type |
+Tipo de gateway de AWS (internet, NAT o Transit). | +
intra_availability_zone |
+Indica si los flujos de red están dentro de la zona de disponibilidad (true), zona entre disponibilidad (false) o no determinado (unknown). Nota: No se aplica para Azure. |
+
intra_region |
+Indica si los flujos de red están dentro de una región (true), entre regiones (false), o no determinado (unknown). |
+
is_agent_traffic |
+Indica si al tráfico lo generó el Datadog Agent. | +
tgw_attachment_id |
+Identificador único para el adjunto de AWS Transit Gateway. | +
tgw_attachment_type |
+Tipo de adjunto de Transit Gateway (por ejemplo, VPC, VPN, Direct Connect). | +
tls_cipher_insecure |
+Indica si eli cipher se considera seguro. | +
tls_cipher_suite |
+Identifica si el conjunto de cipher TLS utilizado (por ejemplo, tls_ecdhe_rsa_with_aes_128_gcm_sha256). |
+
tls_client_version |
+La versión de TLS admitida por el cliente (tls_1.2 o tls_1.3). |
+
tls_encrypted |
+Especifica si la conexión está cifrada con TLS. | +
tls_version |
+La versión de TLS utilizada (tls_1.2 o tls_1.3). |
+
vpc_endpoint_id |
+Identificador único para el endpoint de VPC. | +
Los firewalls locales como Uncomplicated Firewall (UFW) pueden bloquear el tráfico incluso cuando están configurados con parámetros permisivos. Comprueba los logs del sistema en busca de entradas de paquetes bloqueados, que suelen indicar que el tráfico llegó a la interfaz de red pero se bloqueó antes de llegar al sistema operativo.
+
Utiliza los siguientes comandos específicos de la plataforma para buscar reglas de cortafuegos que puedan estar bloqueando el tráfico y evitando que llegue al Agent.
{{< tabs >}}
diff --git a/content/es/network_monitoring/netflow/_index.md b/content/es/network_monitoring/netflow/_index.md
index fff4db619a0e7..435665da8c9ab 100644
--- a/content/es/network_monitoring/netflow/_index.md
+++ b/content/es/network_monitoring/netflow/_index.md
@@ -225,7 +225,7 @@ Para visualizar los bytes/paquetes sin procesar (muestreados) enviados por tus d
Los datos de NetFlow se conservan durante 30 días por defecto, con opciones de conservación de 15, 30, 60 y 90 días.
-Para conservar los datos de NetFlow durante más tiempo, ponte en contacto con tu representante de cuenta.
+Para conservar los datos de NetFlow durante más tiempo, ponte en contacto con el representante de tu cuenta.
## Solucionar problemas
diff --git a/content/es/network_monitoring/network_path/_index.md b/content/es/network_monitoring/network_path/_index.md
index bb8e6492c4848..cb977ad23b0ed 100644
--- a/content/es/network_monitoring/network_path/_index.md
+++ b/content/es/network_monitoring/network_path/_index.md
@@ -4,6 +4,9 @@ further_reading:
- link: https://www.datadoghq.com/blog/datadog-network-path-monitoring/
tag: Blog
text: Obtener visibilidad de extremo a extremo de la red con la Ruta de red de Datadog
+- link: https://www.datadoghq.com/blog/network-path/
+ tag: Blog
+ text: Identifica las ralentizaciones en toda la red con Datadog Network Path
is_beta: true
title: Ruta de red
---
@@ -13,7 +16,7 @@ title: Ruta de red
La Ruta de red ilustra la ruta que sigue el tráfico de red desde su origen hasta su destino. Esto proporciona a los administradores de red la capacidad de identificar con precisión el origen de los problemas de red, ya sean internos o de un proveedor de servicios de Internet (ISP), o debido a otros problemas como un enrutamiento erróneo. Cada fila significa una ruta desde un origen hasta su destino, como se muestra en el panel de facetas `source` y `destination`.
-{{< img src="network_performance_monitoring/network_path/network_path_default_view_3.png" alt="La vista predeterminada de Ruta de red, que muestra la ruta desde el origen al destino" >}}
+{{< img src="network_performance_monitoring/network_path/network_path_default_view_4.png" alt="La vista predeterminada de Network Path, que muestra la ruta desde la fuente al destino, con la leyenda ampliada" >}}
## Cómo funciona
diff --git a/content/es/notebooks/advanced_analysis/_index.md b/content/es/notebooks/advanced_analysis/_index.md
index 940376acd7177..ffb981551b76a 100644
--- a/content/es/notebooks/advanced_analysis/_index.md
+++ b/content/es/notebooks/advanced_analysis/_index.md
@@ -1,4 +1,9 @@
---
+aliases:
+- /es/logs/workspaces/
+- /es/logs/workspaces/export/
+description: Realiza análisis avanzados de datos en notebooks con consultas SQL, transformaciones
+ de datos, uniones y visualizaciones en varios conjuntos de datos.
further_reading:
- link: /notebooks
tag: Documentación
@@ -11,7 +16,7 @@ title: Analysis Features
{{% site-region region="gov" %}}
-Analysis Features para notebooks no está disponible en el sitio de Datadog ({{< region-param key="dd_site_name" >}}).
+Los análisis avanzados en notebooks no están disponibles en el sitio Datadog ({{< region-param key="dd_site_name" >}}).
{{% /site-region %}}
@@ -21,53 +26,54 @@ La función de análisis de los notebooks permite realizar análisis avanzados d
Los notebooks son editores de texto colaborativos que permiten incrustar gráficos de Datadog directamente en los documentos. Aunque esto es ideal para explorar y narrar, las investigaciones más profundas pueden requerir un control más avanzado sobre las consultas de datos. Las funciones de análisis te permiten realizar consultas que te ayudarán a:
-* Consultar en cadena, como la agregación de datos agregados existentes o la unión de dos conjuntos de datos agregados.
+* Encadena consultas, como la agregación de datos agregados existentes o la unión de dos conjuntos de datos agregados.
* Unir datos de múltiples fuentes de logs y otros conjuntos de datos.
-* Realizar parseos avanzados, extraer datos y añadir campos calculados en el momento de la consulta.
+* Realiza análisis avanzados, extrae datos y añade campos calculados en el momento de la consulta.
* Visualizar conjuntos de datos transformados con gráficos.
## Añadir datos a tu notebook
-Para ejecutar consultas complejas en un notebook, añade primero una celda **Data Source** (Fuente de datos). Hay dos maneras de hacerlo:
+Para ejecutar consultas complejas en un notebook, añade primero una celda **Fuente de datos**. Hay dos maneras de hacerlo:
**Desde un notebook**:
-1. Escribe `/datasource` y pulsa Enter (Intro), o haz clic en el cuadro **Data Source** (Fuente de datos) situado en la parte inferior de página.
-2. Escribe o selecciona la fuente de datos deseada en el menú desplegable y pulsa Enter (Intro).
+1. Escribe `/datasource` y presiona Intro o haz clic en el cuadro **Data Source** (Fuente de datos) situado en la parte inferior de la página.
+2. Escribe o seleccione tu fuente de datos deseada en el menú desplegable y presiona Intro.+**Nota**: Si buscas una fuente de datos y no está disponible, solicítala [aquí][5]. 3. Introduce tu consulta. Los atributos reservados de los logs filtrados se añaden automáticamente como columnas. -**Desde el [Log Explorer][1]**: +**Desde el [Explorador de logs][1]**: -1. Introduce tu consulta en el Log Explorer. -2. Haz clic en **Analyze in Notebooks** (Analizar en notebooks). -3. Marca la casilla **Use as a computational data source** (Utilizar como fuente de datos computacionales) y selecciona el notebook que deseas utilizar. -4. Se añade una celda de fuente de datos al notebook seleccionado con la misma consulta introducida en el Log Explorer. Por defecto, las columnas mostradas en el Log Explorer se incluyen en la celda de fuente de datos. +1. Introduce tu consulta en el Explorador de logs. +2. Haz clic en **Analyze in Notebooks** (Analizar en notebooks). +3. Marca la casilla **Use as a computational data source** (Utilizar como fuente de datos de cálculo) y selecciona el notebook que quieres utilizar. +4. Se añade una celda de fuente de datos al notebook seleccionado con la misma consulta introducida en el Explorador de logs. Por defecto, las columnas mostradas en el Explorador de logs se incluyen en la celda de fuente de datos. ## Configuración de una celda de fuente de datos -Después de añadir una celda de fuente de datos a un notebook, puedes seguir modificándola para estructurar los datos de forma que se adapten a tus necesidades de análisis. +Después de añadir una celda de fuente de datos a un notebook, puedes seguir modificándola para estructurar los datos según tus necesidades de análisis. ### Cambiar el marco temporal de los datos -Por defecto, las celdas de fuente de datos creadas a partir de notebooks utilizan el marco temporal global del notebook. Las celdas de fuente de datos creadas a partir del Log Explorer utilizan una hora local fijada al marco temporal en el momento de la exportación. +Por defecto, las celdas de fuente de datos creadas a partir de notebooks utilizan el marco temporal global del notebook. Las celdas de fuente de datos creadas a partir del Explorador de logs utilizan una hora local fijada al marco temporal en el momento de la exportación. -Puedes cambiar cualquier celda de fuente de datos entre un marco temporal local o global utilizando el botón de alternancia situado en la esquina superior derecha de la celda. +Puedes cambiar cualquier celda de fuente de datos entre un marco temporal local o global, utilizando el botón conmutador situado en la esquina superior derecha de la celda. ### Filtrar la fuente de datos -Independientemente de cómo crees la celda de fuente de datos, puedes modificar la consulta utilizando la barra de búsqueda. Cualquier cambio en la consulta reejecuta automáticamente la celda de fuente de datos y cualquier celda posterior, actualizando la vista previa de los datos. +Independientemente de cómo crees la celda de fuente de datos, puedes modificar la consulta utilizando la barra de búsqueda. Cualquier cambio en la consulta vuelve a ejecutar automáticamente la celda de fuente de datos y cualquier celda posterior, actualizando la vista previa de los datos. ### Añadir o modificar una columna Puedes añadir o modificar columnas en tu celda de fuente de datos. Hay dos formas de ajustar las columnas: -- En la sección de vista previa, haz clic en **columnas** para buscar entre los atributos disponibles para tus fuente de datos. +- En la sección de vista previa, haz clic en **columns** (columnas) para buscar entre los atributos disponibles para tu fuente de datos. - En la vista previa, haz clic en una fila para abrir el panel lateral de detalles. Haz clic en el atributo que desees añadir como columna y, en la opción emergente, selecciona "@your_column" a tu conjunto de datos "@your_datasource". {{< img src="/notebooks/analysis_features/add_column_to_dataset.png" alt="Panel lateral de detalles abierto con la opción para añadir una columna de atributos a la celda de fuente de datos" style="width:100%;" >}} ### Consultas de campos calculados -Puedes tomar consultas existentes del Log Explorer que incluyan [Campos calculados][4] y abrirlas en notebooks. Para transferir estas consultas desde el Log Explorer, haz clic en **More** (Más) y selecciona **Analyze in Notebooks** (Analizar en notebooks). Los campos calculados se convierten automáticamente en una celda de transformación. +Puedes tomar consultas existentes del Explorador de logs que incluyan [Campos calculados][4] y abrirlas en notebooks. Para transferir estas consultas desde el Explorador de logs, haz clic en **More** (Más) y selecciona **Analyze in Notebooks** (Analizar en notebooks). Los campos calculados se convierten automáticamente en una celda de transformación. También puedes crear campos calculados directamente en un notebook para definir un campo calculado a partir de fuentes de datos existentes. Estos campos pueden reutilizarse en análisis posteriores: 1. Abre un Workspace con una fuente de datos. @@ -85,7 +91,7 @@ Puedes añadir varios tipos de celdas para mejorar tus capacidades de análisis. Añade una celda de transformación para filtrar, agrupar, unir o extraer datos definidos en una celda de fuente de datos. -1. Escribe `/transformation` y pulsa Enter (Intro), o bien haz clic en el cuadro del conjunto de datos de transformación situado en la parte inferior de la página. +1. Escribe `/transformation` y presiona Intro o haz clic en el cuadro del conjunto de datos de transformación situado en la parte inferior de la página. 2. Selecciona la fuente de datos que quieres transformar en el menú desplegable del conjunto de datos fuente. Después de añadir la celda de transformación, puedes añadir cualquier número de operaciones de transformación dentro de la celda. Elige una operación de la lista de transformaciones admitidas: @@ -104,9 +110,9 @@ Después de añadir la celda de transformación, puedes añadir cualquier númer También puedes transformar tus datos utilizando SQL añadiendo una celda de análisis a tu notebook. -1. Escribe `/sql` o `/analysis` y pulsa Enter (Intro), o haz clic en el cuadro **SQL Query** (Consulta SQL) situada en la parte inferior de la página. -2. En el desplegable del conjunto de datos fuente, selecciona la fuente de datos que deseas transformar. -3. Escribe tu consulta SQL. Para conocer la sintaxis SQL compatible, consulta la [Referencia de DDSQL][4]. +1. Escribe `/sql` o `/analysis` y presiona Intro o haz clic en el cuadro **SQL Query** (Consulta SQL) situado en la parte inferior de la página. +2. En el desplegable del conjunto de datos de la fuente, selecciona la fuente de datos que quieres transformar. +3. Escribe tu consulta SQL. Para conocer la sintaxis SQL compatible, consulta la [referencia de DDSQL][4]. 4. Haz clic en **Run** (Ejecutar) en la esquina superior derecha de la celda de análisis para ejecutar la consulta. {{< img src="/notebooks/analysis_features/analysis_cell_example.png" alt="Ejemplo de una celda de análisis con datos de transformación de consulta SQL en un notebook" style="width:100%;" >}} @@ -117,9 +123,9 @@ Puedes representar gráficamente los datos que has transformado utilizando celda Para representar gráficamente los datos: -1. Escribe `/graph` y pulsa Enter (Intro), o haz clic en el cuadro **graph dataset** (Conjunto de datos de gráfico) situado en la parte inferior de página. -2. Escribe o selecciona la fuente de datos deseada en el menú desplegable y pulsa Enter (Intro). -3. Selecciona el tipo de visualización en el menú de gráficos y pulsa Enter (Intro). +1. Escribe `/graph` y presiona Intro o haz clic en el cuadro **Graph Dataset** (Graficar conjunto de datos) situado en la parte inferior de la página. +2. Escribe o selecciona tu fuente de datos deseada en el menú desplegable y presiona Intro. +3. Selecciona el tipo de visualización en el menú de gráficos y presiona Intro. ## Visualización y exportación de datos @@ -153,4 +159,5 @@ Para descargar tu conjunto de datos como archivo CSV: [1]: https://app.datadoghq.com/logs [2]: /es/logs/log_configuration/parsing/ [3]: /es/logs/explorer/calculated_fields/expression_language/ -[4]: /es/ddsql_reference/ \ No newline at end of file +[4]: /es/ddsql_reference/ +[5]: https://www.datadoghq.com/product-preview/additional-advanced-querying-data-sources/ \ No newline at end of file diff --git a/content/es/opentelemetry/setup/_index.md b/content/es/opentelemetry/setup/_index.md index 41299a70354f0..11c04adee3e5b 100644 --- a/content/es/opentelemetry/setup/_index.md +++ b/content/es/opentelemetry/setup/_index.md @@ -1,5 +1,4 @@ --- -aliases: null further_reading: - link: /opentelemetry/instrument/ tag: Documentación @@ -7,16 +6,50 @@ further_reading: - link: https://www.datadoghq.com/blog/otel-deployments/ tag: Blog text: Seleccionar el depsliegue de OpenTelemetry -title: Enviar datos a Datadog +title: Enviar datos de OpenTelemetry a Datadog --- -Existen varias formas de enviar datos de OpenTelemetry a Datadog. Elige el método que mejor se adapte a tu infraestructura y a tus requisitos: +En esta página se describen todas las formas de enviar datos de OpenTelemetry (OTel) a Datadog. -| Método | Lo mejor para | Principales ventajas | Documentación | -|---------------------------------|--------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------| -| Recopilador de OTel | Usuarios nuevos o existentes de OTel que quieren una configuración neutral con respecto al proveedor |
- Neutralidad total con respecto al proveedor
- Envío de trazas (traces), métricas y logs a Datadog sin necesidad de instalar bibliotecas del Datadog Agent o de rastreo
- Capacidades de procesamiento avanzadas (por ejemplo, [muestreo basado en colas][4])
- [Recopilador de DDOT][5]: Recomendado para entornos Kubernetes
- [Ingesta de OTLP][1]: Recomendado para todos los demás entornos
- Acceso a todas las funciones del Datadog Agent
- Capacidades de monitorización mejoradas que incluyen:
- Automatización de flotas
- Live Container Monitoring
- Explorador Kubernetes
- Live Processes
- Cloud Network Monitoring
- Universal Service Monitoring
- {{< translate key="integration_count" >}}+ integraciones Datadog
- Transmisión directa de datos
- No se necesitan componentes adicionales
Instala el Datadog distribution of OpenTelemetry (DDOT) Collector
+ Sigue nuestra configuración guiada para instalar el Collector y comenzar a enviar tus datos de OpenTelemetry a Datadog. + {{< /nextlink >}} +{{< /whatsnext >}} + +## Otras opciones de configuración + +Existen métodos alternativos para casos de uso específicos, como el mantenimiento de un pipeline de proveedor neutral o la ejecución en entornos que no sean Kubernetes. + +{{< whatsnext desc=" " >}} + {{< nextlink href="/opentelemetry/setup/collector_exporter/" >}} +OpenTelemetry Collector independiente
+ Útil para usuarios que prefieran usar distribuciones del OTel Collector desde la comunidad de código abierto de OpenTelemetry o que requieran funciones de procesamiento avanzadas como el muestreo basado en el seguimiento de logs. + {{< /nextlink >}} + {{< nextlink href="/opentelemetry/setup/otlp_ingest_in_the_agent" >}} +Ingesta OTLP en el Agent
+ Útil para usuarios en plataformas que no sean Kubernetes Linux, o aquellos que prefieran una configuración mínima sin administrar los pipelines del Collector. + {{< /nextlink >}} + {{< nextlink href="/opentelemetry/setup/agentless" >}} +Ingesta directa de OTLP (Vista previa)
+ Útil para situaciones que requieren la trasmisión directa de datos al endpoint de entrada de Datadog sin componentes intermediarios. + {{< /nextlink >}} +{{< /whatsnext >}}¿Aún no sabes cuál es la configuración más adecuada para ti?
Consulta la tabla de compatibilidad de funciones para saber qué funciones de Datadog son compatibles.
@@ -26,7 +59,7 @@ Existen varias formas de enviar datos de OpenTelemetry a Datadog. Elige el méto
[1]: /es/opentelemetry/setup/agent
[2]: /es/opentelemetry/setup/collector_exporter/
-[3]: /es/opentelemetry/setup/intake_endpoint
+[3]: /es/opentelemetry/setup/agentless
[4]: /es/opentelemetry/ingestion_sampling#tail-based-sampling
[5]: /es/opentelemetry/agent
[6]: /es/opentelemetry/setup/otlp_ingest_in_the_agent
\ No newline at end of file
diff --git a/content/es/opentelemetry/setup/collector_exporter/_index.md b/content/es/opentelemetry/setup/collector_exporter/_index.md
index 0e8787635ceda..f77bf6426b5bf 100644
--- a/content/es/opentelemetry/setup/collector_exporter/_index.md
+++ b/content/es/opentelemetry/setup/collector_exporter/_index.md
@@ -1,300 +1,62 @@
---
-aliases:
-- /es/tracing/setup_overview/open_standards/otel_collector_datadog_exporter/
-- /es/tracing/trace_collection/open_standards/otel_collector_datadog_exporter/
-- /es/opentelemetry/otel_collector_datadog_exporter/
-- /es/opentelemetry/collector_exporter/
-- /es/opentelemetry/collector_exporter/otel_collector_datadog_exporter
description: Envío de datos de OpenTelemetry al OpenTelemetry Collector y el Datadog
Exporter
further_reading:
-- link: https://opentelemetry.io/docs/collector/
- tag: Sitio externo
- text: Documentación del Collector
-- link: https://www.datadoghq.com/blog/ingest-opentelemetry-traces-metrics-with-datadog-exporter/
- tag: Blog
- text: Envío de métricas, trazas (traces) y logs desde OpenTelemetry Collector a
- Datadog con el Datadog Exporter
-title: Configurar el OpenTelemetry Collector
+- link: /opentelemetry/setup/ddot_collector/install/
+ tag: Documentación
+ text: Instala el Datadog distribution of OpenTelemetry (DDOT) Collector (Recomendado)
+- link: /opentelemetry/compatibility/
+ tag: Documentación
+ text: Compatibilidad de funciones
+title: Instalación y configuración del OpenTelemetry Collector
---
## Información general
-El OpenTelemetry Collector te permite recopilar, procesar y exportar datos de telemetría de tus aplicaciones de una manera independiente del proveedor. Cuando se configura con el [Datadog Exporter][1] y el [Datadog Connector][29], puedes enviar tus trazas, logs y métricas a Datadog sin necesidad del Datadog Agent.
+En esta página se proporcionan guías para instalar y configurar un OpenTelemetry Collector independiente para enviar datos de telemetría a Datadog.
-- **Datadog Exporter**: Reenvía datos de trazas, métricas y logs de los SDK de OpenTelemetry a Datadog (sin necesidad del Datadog Agent)
-- **Datadog Connector**: Calcula métricas de rastreo a partir de los datos de tramos recopilados
+Este método es el mejor para los usuarios que prefieren utilizar distribuciones del OpenTelemetry Collector de la comunidad de código abierto de OpenTelemetry o que requieren capacidades de procesamiento avanzadas no disponibles en otras configuraciones. Para la mayoría de los casos de uso, el [Datadog Distribution of OTel Collector (DDOT)][1] es el método recomendado.
-{{< img src="/opentelemetry/setup/otel-collector.png" alt="Diagrama: El SDK de OpenTelemetry en código envía datos a través de OTLP al host que ejecuta el OpenTelemetry Collector con el Datadog Exporter, que los reenvía a la plataforma de observabilidad de Datadog." style="width:100%;" >}}
+## Configuración
-Consulta la tabla de compatibilidad de funciones para saber qué funciones de Datadog son compatibles.
Para ver qué funciones de Datadog son compatibles con esta configuración, consulta la tabla de compatibilidad de funciones en OTel completo.
+Para empezar, instala el OpenTelemetry Collector y configúralo con el Datadog Exporter. Esta guía te indicará la configuración inicial necesaria antes de pasar a temas de configuración más específicos.
-## Instalar y configurar
-
-### 1 - Descargar el OpenTelemetry Collector
-
-Descarga la última versión de la distribución OpenTelemetry Collector Contrib, desde [el repositorio del proyecto][3].
-
-### 2 - Configurar el Datadog Exporter y el Datadog Connector
-
-Para utilizar el Datadog Exporter y el Datadog Connector, defínelos en tu [configuración del [OpenTelemetry Collector[4]:
-
-1. Crea un archivo de configuración llamado `collector.yaml`.
-1. Utiliza el siguiente archivo de ejemplo para empezar.
-1. Configura tu clave de API Datadog como la variable de entorno `DD_API_KEY`.
-
-{{% otel-endpoint-note %}}
-
-```yaml
-receivers:
- otlp:
- protocols:
- http:
- endpoint: 0.0.0.0:4318
- grpc:
- endpoint: 0.0.0.0:4317
- # The hostmetrics receiver is required to get correct infrastructure metrics in Datadog.
- hostmetrics:
- collection_interval: 10s
- scrapers:
- paging:
- metrics:
- system.paging.utilization:
- enabled: true
- cpu:
- metrics:
- system.cpu.utilization:
- enabled: true
- disk:
- filesystem:
- metrics:
- system.filesystem.utilization:
- enabled: true
- load:
- memory:
- network:
- processes:
- # The prometheus receiver scrapes metrics needed for the OpenTelemetry Collector Dashboard.
- prometheus:
- config:
- scrape_configs:
- - job_name: 'otelcol'
- scrape_interval: 10s
- static_configs:
- - targets: ['0.0.0.0:8888']
-
- filelog:
- include_file_path: true
- poll_interval: 500ms
- include:
- - /var/log/**/*example*/*.log
-
-processors:
- batch:
- send_batch_max_size: 100
- send_batch_size: 10
- timeout: 10s
-
-connectors:
- datadog/connector:
-
-exporters:
- datadog/exporter:
- api:
- site: {{< region-param key="dd_site" >}}
- key: ${env:DD_API_KEY}
-
-service:
- pipelines:
- metrics:
- receivers: [hostmetrics, prometheus, otlp, datadog/connector]
- processors: [batch]
- exporters: [datadog/exporter]
- traces:
- receivers: [otlp]
- processors: [batch]
- exporters: [datadog/connector, datadog/exporter]
- logs:
- receivers: [otlp, filelog]
- processors: [batch]
- exporters: [datadog/exporter]
-```
-
-Esta configuración básica permite recibir datos de OTLP a través de HTTP y gRPC, y configura un [procesador por lotes][5].
-
-Si quieres consultar la lista completa de opciones de configuración del Datadog Exporter, consulta el [archivo de configuración de ejemplo completamente documentado][8]. Opciones adicionales como `api::site` y `host_metadata` pueden ser relevantes, dependiendo de tu despliegue.
-
-#### Configuración del procesador por lotes
-
-El procesador por lotes se requiere en entornos que no son de desarrollo. La configuración exacta depende de tu carga de trabajo específica y de los tipos de señales.
-
-Configura el procesador por lotes basándote en los límites de ingesta de Datadog:
-
-- Ingreso de trazas: 3,2MB
-- Ingesta de log: [5MB sin comprimir][6]
-- Ingesta de métricas V2: [500 KB o 5 MB tras la descompresión][7]
-
-Pueden producirse errores en `413 - Request Entity Too Large`, si se introducen demasiados datos de telemetría en el procesador por lotes.
-
-### 3 - Configurar tu aplicación
-
-Para obtener mejores metadatos para trazas y para simplificar la integración con Datadog:
-
-- **Utiliza detectores de recursos**: si los proporciona el SDK del lenguaje, adjunta información de contenedor como atributos de recurso. Por ejemplo, en Go, utiliza la opción de recurso [`WithContainer()`][9].
-
-- **Aplica [etiquetado de servicios unificado][10]**: asegúrate de haber configurado tu aplicación con los atributos de recursos apropiados para el etiquetado de servicios unificado. Esto vincula la telemetría de Datadog con etiquetas (tags) para nombre de servicio, entorno de despliegue y versión de servicio. La aplicación debe establecer estas etiquetas utilizando las convenciones semánticas de OpenTelemetry: `service.name`, `deployment.environment` y `service.version`.
-
-### 4 - Configurar el generador de logs para tu aplicación
-
-{{< img src="logs/log_collection/otel_collector_logs.png" alt="Un diagrama con el host, contenedor o aplicación que envía datos al receptor de log de archivo en el Collector y el Datadog Exporter en el Collector que envía los datos al backend de Datadog" style="width:100%;">}}
-
-Dado que la funcionalidad de generación de logs del SDK de OpenTelemetry no es totalmente compatible (consulta tu lenguaje específico en la [documentación de OpenTelemetry][11] para más información), Datadog recomienda el uso de una biblioteca de generación de logs estándar para tu aplicación. Sigue la [documentación de recopilación de logs][12] específica del lenguaje para configurar el generador de logs adecuado en tu aplicación. Datadog recomienda especialmente la configuración de tu biblioteca de registro para la salida de logs en JSON, a fin de evitar la necesidad de [reglas de análisis personalizadas][13].
-
-#### Configurar el receptor de log de archivo
-
-Configura el receptor de log de archivo utilizando [operadores][14]. Por ejemplo, si hay un servicio `checkoutservice` que está escribiendo logs en `/var/log/pods/services/checkout/0.log`, un ejemplo de log podría tener este aspecto:
-
-```
-{"level":"info","message":"order confirmation email sent to \"jack@example.com\"","service":"checkoutservice","span_id":"197492ff2b4e1c65","timestamp":"2022-10-10T22:17:14.841359661Z","trace_id":"e12c408e028299900d48a9dd29b0dc4c"}
-```
-
-Ejemplo de configuración de log de archivo:
-
-```
-filelog:
- include:
- - /var/log/pods/**/*checkout*/*.log
- start_at: end
- poll_interval: 500ms
- operators:
- - id: parse_log
- type: json_parser
- parse_from: body
- - id: trace
- type: trace_parser
- trace_id:
- parse_from: attributes.trace_id
- span_id:
- parse_from: attributes.span_id
- attributes:
- ddtags: env:staging
-```
-
-- `include`: Lista de archivos que el receptor rastrea
-- `start_at: end`: Indica que se lea el nuevo contenido que se está escribiendo
-- `poll_internal`: Define la frecuencia de sondeo
-- Operadores:
- - `json_parser`: analiza los logs JSON. Por defecto, el receptor de log de archivos convierte cada línea de log en un registro de log, que es el `body` del [modelo de datos][15] de logs. A continuación, el `json_parser` convierte el cuerpo JSON en atributos del modelo de datos.
- - `trace_parser`: Extrae `trace_id` y `span_id` del log para correlacionar logs y trazas en Datadog.
-
-#### Reasignar el atributo `service.name` de OTel a `service` para logs
-
-Para las versiones 0.83.0 y posteriores del Datadog Exporter, el campo `service` de logs de OTel se rellena como la [convención semántica de OTel][25] `service.name`. Sin embargo, `service.name` no es uno de los [atributos de servicio][26] predeterminados en el preprocesamiento de logs de Datadog.
-
-Para que el campo `service` se rellene correctamente en tus logs, puedes especificar que `service.name` sea la fuente de un servicio de log estableciendo un [procesador de reasignación de servicio de log][27].
-
-{{% collapse-content title="Optional: Using Kubernetes" level="h4" %}}
-
-Hay múltiples maneras de desplegar el OpenTelemetry Collector y el Datadog Exporter en una infraestructura Kubernetes. Para que el receptor filelog funcione, el [despliegue del Agent/DaemonSet][16] es el método de despliegue recomendado.
-
-En entornos contenedorizados, las aplicaciones escriben logs en `stdout` o `stderr`. Kubernetes recopila los logs y los escribe en una localización estándar. Es necesario montar la localización en el nodo host del Collector para el receptor filelog. A continuación se muestra un [ejemplo de extensión][17] con los montajes necesarios para enviar logs.
-
-```
-apiVersion: apps/v1
-metadata:
- name: otel-agent
- labels:
- app: opentelemetry
- component: otel-collector
-spec:
- template:
- metadata:
- labels:
- app: opentelemetry
- component: otel-collector
- spec:
- containers:
- - name: collector
- command:
- - "/otelcol-contrib"
- - "--config=/conf/otel-agent-config.yaml"
- image: otel/opentelemetry-collector-contrib:0.71.0
- env:
- - name: POD_IP
- valueFrom:
- fieldRef:
- fieldPath: status.podIP
- # The k8s.pod.ip is used to associate pods for k8sattributes
- - name: OTEL_RESOURCE_ATTRIBUTES
- value: "k8s.pod.ip=$(POD_IP)"
- ports:
- - containerPort: 4318 # default port for OpenTelemetry HTTP receiver.
- hostPort: 4318
- - containerPort: 4317 # default port for OpenTelemetry gRPC receiver.
- hostPort: 4317
- - containerPort: 8888 # Default endpoint for querying metrics.
- volumeMounts:
- - name: otel-agent-config-vol
- mountPath: /conf
- - name: varlogpods
- mountPath: /var/log/pods
- readOnly: true
- - name: varlibdockercontainers
- mountPath: /var/lib/docker/containers
- readOnly: true
- volumes:
- - name: otel-agent-config-vol
- configMap:
- name: otel-agent-conf
- items:
- - key: otel-agent-config
- path: otel-agent-config.yaml
- # Mount nodes log file location.
- - name: varlogpods
- hostPath:
- path: /var/log/pods
- - name: varlibdockercontainers
- hostPath:
- path: /var/lib/docker/containers
-```
-
-{{% /collapse-content %}}
+{{< whatsnext desc=" " >}}
+ {{< nextlink href="/opentelemetry/setup/collector_exporter/install" >}}
+ Instala y configura el Collector
+ Sigue los pasos de configuración inicial para obtener un Collector que se ejecuta con el Datadog Exporter. + {{< /nextlink >}} +{{< /whatsnext >}} -## Configuración del Datadog Exporter predefinida +## Configuración -Puedes encontrar ejemplos de configuración predefinida del Datadog Exporter en la [carpeta`exporter/datadogexporter/examples`][31] en el proyecto OpenTelemetry Collector Contrib. Consulta el archivo de ejemplo de configuración completo, [`ootb-ec2.yaml`][30]. Configura cada uno de los siguientes componentes para adaptarlos a tus necesidades: +Una vez que el Collector esté en funcionamiento, utiliza estas guías para configurar receptores y procesadores específicos para recopilar y enriquecer los datos de telemetría. {{< whatsnext desc=" " >}} - {{< nextlink href="/opentelemetry/collector_exporter/otlp_receiver/" >}}Receptor OTLP{{< /nextlink >}} - {{< nextlink href="/opentelemetry/collector_exporter/hostname_tagging/" >}}Nombre de host y etiquetas{{< /nextlink >}} - {{< nextlink href="/opentelemetry/collector_exporter/collector_batch_memory/" >}}Configuración de lote y memoria{{< /nextlink >}} + {{< nextlink href="/opentelemetry/setup/collector_exporter/deploy" >}} +Desplegar el Collector
+ Aprende cómo ejecutar el Collector en varios entornos, incluido en un host, en Docker, o como un DaemonSet o Gateway en Kubernetes. + {{< /nextlink >}} + {{< nextlink href="/opentelemetry/config/hostname_tagging" >}} +Configurar el nombre de host y el etiquetado
+ Usa la detección de recursos y los procesadores de atributos de Kubernetes para asegurar la resolución correcta de nombres de host y aplicar las etiquetas críticas para correlacionar la telemetría en Datadog. + {{< /nextlink >}} + {{< nextlink href="/opentelemetry/config/log_collection" >}} +Configurar la recopilación de logs
+ Configura el receptor de logs de archivo para recopilar logs desde archivos y reenviarlos a Datadog, lo que admite los logs, métricas y trazas unificados. + {{< /nextlink >}} + {{< nextlink href="/opentelemetry/config/otlp_receiver" >}} +Permitir un receptor OTLP
+ Configura el receptor OTLP para aceptar trazas, métricas y logs desde tus aplicaciones instrumentadas por OpenTelemetry mediante gRPC o HTTP. + {{< /nextlink >}} + {{< nextlink href="/opentelemetry/config/collector_batch_memory" >}} +Ajustar la configuración de lotes y memoria
+ Optimiza el rendimiento y el consumo de recursos de tu Collector al configurar el procesador de lotes y el delimitador de memoria. + {{< /nextlink >}} {{< /whatsnext >}} ## Referencias adicionales {{< partial name="whats-next/whats-next.html" >}} -[1]: https://github.com/open-telemetry/opentelemetry-collector-contrib/tree/main/exporter/datadogexporter -[3]: https://github.com/open-telemetry/opentelemetry-collector-releases/releases/latest -[4]: https://opentelemetry.io/docs/collector/configuration/ -[5]: https://github.com/open-telemetry/opentelemetry-collector/blob/main/processor/batchprocessor/README.md -[6]: /es/api/latest/logs/ -[7]: /es/api/latest/metrics/#submit-metrics -[8]: https://github.com/open-telemetry/opentelemetry-collector-contrib/blob/main/internal/e2e/examples/collector.yaml -[9]: https://pkg.go.dev/go.opentelemetry.io/otel/sdk/resource#WithContainer -[10]: /es/getting_started/tagging/unified_service_tagging/ -[11]: https://opentelemetry.io/docs/instrumentation/ -[12]: /es/logs/log_collection/?tab=host -[13]: /es/logs/log_configuration/parsing/ -[14]: https://github.com/open-telemetry/opentelemetry-collector-contrib/tree/main/pkg/stanza/docs/operators -[15]: https://opentelemetry.io/docs/reference/specification/logs/data-model/ -[16]: https://opentelemetry.io/docs/collector/deployment/#agent -[17]: https://github.com/open-telemetry/opentelemetry-collector-contrib/blob/main/exporter/datadogexporter/examples/k8s-chart/daemonset.yaml -[25]: https://opentelemetry.io/docs/specs/semconv/resource/#service -[26]: /es/logs/log_configuration/pipelines/?tab=service#service-attribute -[27]: /es/logs/log_configuration/processors/?tab=ui#service-remapper -[28]: /es/opentelemetry/schema_semantics/hostname/ -[29]: https://github.com/open-telemetry/opentelemetry-collector-contrib/tree/main/connector/datadogconnector -[30]: https://github.com/open-telemetry/opentelemetry-collector-contrib/blob/main/exporter/datadogexporter/examples/ootb-ec2.yaml -[31]: https://github.com/open-telemetry/opentelemetry-collector-contrib/blob/main/exporter/datadogexporter/examples/ -[32]: /es/opentelemetry/compatibility/ \ No newline at end of file +[1]: /es/opentelemetry/setup/ddot_collector/install/ \ No newline at end of file diff --git a/content/es/opentelemetry/setup/otlp_ingest/_index.md b/content/es/opentelemetry/setup/otlp_ingest/_index.md index 8143b494e277a..f11ee87673cdd 100644 --- a/content/es/opentelemetry/setup/otlp_ingest/_index.md +++ b/content/es/opentelemetry/setup/otlp_ingest/_index.md @@ -9,10 +9,6 @@ further_reading: title: Endpoint de ingreso del OTLP de Datadog --- -{{< callout header="false" btn_hidden="true">}} - El endpoint de ingreso del OTLP de Datadog está en Vista previa. Para solicitar acceso, ponte en contacto con tu representante de cuenta. -{{< /callout >}} - ## Información general El endpoint de la API de ingreso del protocolo OpenTelemetry (OTLP) de Datadog te permite enviar datos de observabilidad directamente a Datadog. Con esta función, no necesitas ejecutar el [Agent][1] u [OpenTelemetry Collector + Datadog Exporter][2]. diff --git a/content/es/profiler/enabling/java.md b/content/es/profiler/enabling/java.md index 17bdc070f3bc4..83e0e72faad5b 100644 --- a/content/es/profiler/enabling/java.md +++ b/content/es/profiler/enabling/java.md @@ -6,7 +6,7 @@ code_lang_weight: 10 further_reading: - link: getting_started/profiler tag: Documentación - text: Empezando con el generador de perfiles + text: Empezando con Profiler - link: profiler/profile_visualizations tag: Documentación text: Más información sobre las visualizaciones de perfiles disponibles @@ -17,13 +17,13 @@ title: Activación de Java Profiler type: multi-code-lang --- -El generador de perfiles se incluye en las bibliotecas de rastreo de Datadog. Si ya estás utilizando [APM para recopilar trazas (traces)][1] para tu aplicación, puedes omitir la instalación de librería e ir directamente a habilitar el generador de perfiles. +El generador de perfiles se incluye en las bibliotecas de rastreo de Datadog. Si ya estás utilizando [APM para recopilar trazas (traces)][1] para tu aplicación, puedes omitir la instalación de biblioteca e ir directamente a habilitar el generador de perfiles. ## Requisitos Para obtener un resumen de las versiones mínimas y recomendadas del tiempo de ejecución y del rastreador en todos los lenguajes, consulta [Versiones de lenguaje y rastreadores compatibles][13]. -A partir de dd-trace-java 1.0.0, tienes dos opciones para el motor que genera datos de perfil para las aplicaciones de Java: [Java Flight Recorder (JFR)][2] o el Datadog Profiler. A partir de dd-trace-java 1.7.0, Datadog Profiler es el predeterminado. Cada motor de perfil tiene diferentes efectos secundarios, requisitos, configuraciones disponibles y limitaciones, y esta página describe cada uno. Puedes activar uno o ambos motores. Activando ambos se capturan los dos tipos de perfil al mismo tiempo. +A partir de dd-trace-java 1.0.0, tienes dos opciones para el motor que genera datos de perfil para las aplicaciones de Java: [Java Flight Recorder (JFR)][2] o el Datadog Profiler. A partir de dd-trace-java 1.7.0, Datadog Profiler es el predeterminado. Cada motor de generador de perfiles tiene diferentes efectos secundarios, requisitos, configuraciones disponibles y limitaciones, y esta página describe cada uno. Puedes activar uno o ambos motores. Activando ambos se capturan los dos tipos de perfil al mismo tiempo. {{< tabs >}} {{% tab "Datadog Profiler" %}} @@ -32,15 +32,17 @@ Sistemas operativos compatibles: - Linux Versiones mínimas de JDK: -- OpenJDK 8u352+, 11.0.17+, 17.0.5+, 21+ (incluidas las primeras compilaciones: Amazon Corretto, Azul Zulu y otras). -- Oracle JDK 8u351+, 11.0.17+, 17.0.5+, 21+ -- OpenJ9 JDK 8u372+, 11.0.18+, 17.0.6+ (utilizado en Eclipse OpenJ9, IBM JDK, IBM Semeru Runtime). El generador de perfiles está deshabilitado por defecto para OpenJ9 debido a la posibilidad de que la JVM se bloquee a causa de un sutil error en la implementación de JVTMI. Si no experimentas ningún error, puedes activar el generador de perfiles añadiendo `-Ddd.profiling.ddprof.enabled=true`. -- Azul Platform Prime 23.05.0.0+ (antes Azul Zing) +- OpenJDK 8u352 o posterior, 11.0.17 o posterior, 17.0.5 o posterior, 21 o posterior (incluidas las primeras compilaciones: Amazon Corretto, Azul Zulu y otras). +- Oracle JDK 8u351 o posterior, 11.0.17 o posterior, 17.0.5 o posterior, 21 o posterior +- OpenJ9 JDK 8u372 o posterior, 11.0.18 o posterior, 17.0.6 o posterior (utilizado en Eclipse OpenJ9, IBM JDK, IBM Semeru Runtime). + +**Nota:** El generador de perfiles está deshabilitado por defecto para OpenJ9 debido a la posibilidad de fallos de la JVM causados por un sutil error en la implementación de JVTMI. Si **no** experimentas ningún fallo, puedes habilitar el generador de perfiles añadiendo `-Ddd.profiling.ddprof.enabled=true` o `DD_PROFILING_DDPROF_ENABLED=true`. +- Azul Platform Prime 23.05.0.0 o posterior (antes Azul Zing) **Nota:** El Datadog Profiler está inactivado en el compilador GraalVM (JVMCI) y necesita ser habilitado explícitamente con `-Ddd.profiling.ddprof.enabled=true` o `DD_PROFILING_DDPROF_ENABLED=true`. -Datadog Profiler utiliza la función `AsyncGetCallTrace` de JVMTI, en la que existe un [problema conocido][1] anterior a la versión 17.0.5 del JDK. Esta corrección se ha trasladado a la versión 11.0.17 y 8u352. Datadog Profiler no está habilitado a menos que la JVM en la que se despliega el generador de perfiles tenga esta corrección. Actualiza al menos a 8u352, 11.0.17, 17.0.5 o a la última versión de JVM que no sea LTS para utilizar Datadog Profiler. +El Datadog Profiler utiliza la función `AsyncGetCallTrace` de JVMTI, en la que existe un [problema conocido][1] anterior a la versión 17.0.5 del JDK. Esta corrección se ha trasladado a la versión 11.0.17 y 8u352. El Datadog Profiler no está habilitado a menos que la JVM en la que se despliega el generador de perfiles tenga esta corrección. Actualiza al menos a 8u352, 11.0.17, 17.0.5 o a la última versión de JVM que no sea LTS para utilizar el Datadog Profiler. [1]: https://bugs.openjdk.org/browse/JDK-8283849 {{% /tab %}} @@ -52,20 +54,20 @@ Sistemas operativos compatibles: - Windows Versiones mínimas de JDK: -- OpenJDK [1.8.0.262/8u262+][3], 11+ (incluidas las versiones basadas en él: Amazon Corretto y otras) -- Oracle JDK 11+ (la activación del JFR puede requerir una licencia comercial de Oracle. Ponte en contacto con tu representante de Oracle para confirmar si esto forma parte de tu licencia). -- Azul Zulu 8 (versión 1.8.0.212/8u212+), 11+ -- GraalVM 17+ - ambas versiones, JIT y AOT (imagen nativa) +- OpenJDK [1.8.0.262/8u262 o posterior][3], 11+ (incluidas las versiones basadas en él: Amazon Corretto y otras) +- Oracle JDK 11 o posterior (la activación del JFR puede requerir una licencia comercial de Oracle. Ponte en contacto con tu representante de Oracle para confirmar si esto forma parte de tu licencia). +- Azul Zulu 8 (versión 1.8.0.212/8u212 o posterior), 11 o posterior +- GraalVM 17 o posterior - ambas versiones, JIT y AOT (imagen nativa) -Dado que las versiones de JDK que no son LTS pueden no contener correcciones de estabilidad y rendimiento relacionadas con la librería de Datadog Profiler, utiliza las versiones 8, 11 y 17 del JDK de soporte a largo plazo. +Dado que las versiones de JDK que no son LTS pueden no contener correcciones de estabilidad y rendimiento relacionadas con la biblioteca del Datadog Profiler, utiliza las versiones 8, 11 y 17 del JDK de soporte a largo plazo. Requisitos adicionales para la formación de perfiles [trace (traza) to integración de perfil][12]: - - OpenJDK 17.0.5+ y `dd-trace (traza)-java` versión 1.17.0+. - - OpenJDK 11.0.17+ y `dd-trace (traza)-java` versión 1.17.0+ - - OpenJDK 8 8u352+ y `dd-trace (traza)-java` versión 1.17.0+ - - OpenJ9 17.0.6+ y `dd-trace (traza)-java` versión 1.17.0+ - - OpenJ9 11.0.18+ y `dd-trace (traza)-java` versión 1.17.0+ - - OpenJ9 8.0.362+ y `dd-trace (traza)-java` versión 1.17.0+ + - OpenJDK 17.0.5 o posterior y `dd-trace (traza)-java` versión 1.17.0 o posterior. + - OpenJDK 11.0.17 o posterior y `dd-trace (traza)-java` versión 1.17.0 o posterior + - OpenJDK 8 8u352 o posterior y `dd-trace (traza)-java` versión 1.17.0 o posterior + - OpenJ9 17.0.6 o posterior y `dd-trace (traza)-java` versión 1.17.0 o posterior + - OpenJ9 11.0.18 o posterior y `dd-trace (traza)-java` versión 1.17.0 o posterior + - OpenJ9 8.0.362 o posterior y `dd-trace (traza)-java` versión 1.17.0 o posterior [3]: /es/profiler/profiler_troubleshooting/java/#java-8-support [12]: /es/profiler/connect_traces_and_profiles/#identify-code-hotspots-in-slow-traces @@ -81,7 +83,7 @@ Continuous Profiler no es compatible con algunas plataformas serverless, como AW Para empezar a crear perfiles de aplicaciones: -1. Asegúrate de que Datadog Agent v6+ está instalado y en ejecución. Datadog recomienda utilizar [Datadog Agent v7+][4]. Si no tienes APM habilitado para configurar tu aplicación para enviar datos a Datadog, en tu Agent, configura la variable de entorno `DD_APM_ENABLED` en `true` y escuchando en el puerto `8126/TCP`. +1. Asegúrate de que Datadog Agent v6 o posterior está instalado y en ejecución. Datadog recomienda utilizar [Datadog Agent v7 o posterior][4]. Si no tienes APM habilitado para configurar tu aplicación para enviar datos a Datadog, en tu Agent, configura la variable de entorno `DD_APM_ENABLED` en `true` y escuchando en el puerto `8126/TCP`. 2. Descarga `dd-java-agent.jar`, que contiene los archivos de clase de Java Agent: @@ -103,7 +105,7 @@ Para empezar a crear perfiles de aplicaciones: {{% /tab %}} {{< /tabs >}} - **Nota**: El generador de perfiles está disponible en la librería `dd-java-agent.jar` para las versiones 0.55+. + **Nota**: Profiler está disponible en la biblioteca `dd-java-agent.jar` para las versiones 0.55 o posterior. 3. Habilita el generador de perfiles configurando el indicador `-Ddd.profiling.enabled` o la variable de entorno `DD_PROFILING_ENABLED` en `true`. Especifica `dd.service`, `dd.env` y `dd.version` para poder filtrar y agrupar tus perfiles a través de estas dimensiones: {{< tabs >}} @@ -159,16 +161,16 @@ Cuando se crea el archivo binario de servicio, puedes utilizar variables de ento Desde la versión 1.5.0 de dd-trace-java, tienes dos opciones para el generador de perfiles de CPU utilizado, Datadog o Java Flight Recorder (JFR). Desde la versión 1.7.0, Datadog es el predeterminado, pero también puedes habilitar opcionalmente JFR para los perfiles de CPU. Puedes activar uno o ambos motores. Activando ambos se capturan los dos tipos de perfiles al mismo tiempo. -El perfilador Datadog registra el span (tramo) activo en cada muestra, lo que mejora la fidelidad de la integración de la trace (traza) a Profiling y las funciones de perfilado de endpoint. Habilitar este motor admite una integración mucho mejor con el rastreo de APM. +El Datadog Profiler registra el span (tramo) activo en cada muestra, lo que mejora la fidelidad de la integración de la trace (traza) a Profiling y las funciones de perfilado de endpoint. Habilitar este motor admite una integración mucho mejor con el rastreo de APM. El Datadog Profiler consta de varios motores de perfiles, incluidos los generadores de perfiles de CPU, tiempo real, asignación y fugas de memoria. {{< tabs >}} {{% tab "Datadog Profiler" %}} -_Consulta los requisitos mínimos de la versión JDK para activar el perfilador DataDog._ +_Consulta los requisitos mínimos de la versión JDK para activar el Datadog Profiler._ -El Datadog Profiler está activado por defecto en las versiones 1.7.0+ de dd-trace-java. El perfil de CPU de Datadog se programa a través de eventos perf y es más preciso que el perfil de CPU de JFR. Para habilitar la generación de perfiles de CPU: +El Datadog Profiler está activado por defecto en las versiones 1.7.0 o posterior de dd-trace-java. El perfil de CPU de Datadog se programa a través de eventos perf y es más preciso que el perfil de CPU de JFR. Para habilitar la generación de perfiles de CPU: ``` export DD_PROFILING_DDPROF_ENABLED=true # this is the default in v1.7.0+ @@ -196,7 +198,7 @@ sudo sh -c 'echo 2 >/proc/sys/kernel/perf_event_paranoid' {{% tab "JFR" %}} -Para la versión 1.7.0+, para cambiar del perfil por defecto de Datadog al perfil de CPU de JFR: +Para la versión 1.7.0 o posterior, para cambiar del perfil por defecto de Datadog al perfil de CPU de JFR: ``` export DD_PROFILING_DDPROF_CPU_ENABLED=false @@ -220,7 +222,7 @@ El motor de perfil de tiempo real es útil para perfilar la latencia y se integr -Ddd.profiling.ddprof.wall.enabled=true ``` -Para la versión 1.7.0+, para desactivar el perfil de tiempo real: +Para la versión 1.7.0 o posterior, para desactivar el generador de perfiles de tiempo real: ``` export DD_PROFILING_DDPROF_WALL_ENABLED=false @@ -234,7 +236,7 @@ Para los usuarios de JMC, el evento `datadog.MethodSample` se emite para las mue El motor de tiempo real no depende de la configuración de `/proc/sys/kernel/perf_event_paranoid`. -### Motor de asignación de perfiles +### Motor de asignación del generador de perfiles {{< tabs >}} {{% tab "JFR" %}} @@ -274,16 +276,16 @@ o: Para los usuarios de JMC, los eventos de asignación de Datadog son `datadog.ObjectAllocationInNewTLAB` y `datadog.ObjectAllocationOutsideTLAB`. -El motor de perfiles de asignación no depende de la configuración de `/proc/sys/kernel/perf_event_paranoid`. +El motor del generador de perfiles de asignación no depende de la configuración de `/proc/sys/kernel/perf_event_paranoid`. {{% /tab %}} {{< /tabs >}} -### Motor de perfilado Live-heap +### Motor del generador de perfiles live-heap -_Desde: v1.39.0. Requiere JDK 11.0.23+, 17.0.11+, 21.0.3+, o 22+._ +_A partir de: v1.39.0. Requiere JDK 11.0.23 o posterior, 17.0.11 o posterior, 21.0.3 o posterior, o 22 o posterior._ -El motor de perfiles de heap en directo es útil para investigar el uso general de memoria de tu servicio e identificar posibles fugas de memoria. +El motor del generador de perfiles live-heap en directo es útil para investigar el uso general de memoria de tu servicio e identificar posibles fugas de memoria. El motor muestrea las asignaciones y mantiene un registro de si esas muestras sobrevivieron al ciclo de recopilación de elementos no usados más reciente. El número de muestras que sobreviven se utiliza para estimar el número de objetos activos en el stack. El número de muestras rastreadas está limitado para evitar un crecimiento ilimitado del uso de memoria del generador de perfiles. @@ -305,21 +307,21 @@ El motor de asignación no depende de la configuración de `/proc/sys/kernel/per ### Recopilación de stack traces nativas -Si los motores de CPU o tiempo real de Datadog Profiler están activados, puedes recopilar stack traces nativas. Estas incluyen cosas como las internas de la JVM, las bibliotecas nativas utilizadas por tu aplicación o la JVM, y syscalls. +Si los motores de CPU o tiempo real del Datadog Profiler están activados, puedes recopilar stack traces nativas. Estas incluyen cosas como las internas de la JVM, las bibliotecas nativas utilizadas por tu aplicación o la JVM, y syscalls. -Las stack traces nativas no se recopilan de forma predeterminada porque normalmente no proporcionan información procesable y analizarlas puede afectar potencialmente a la estabilidad de la aplicación. Prueba esta configuración en un entorno que no sea de producción antes de intentar utilizarla en producción.
+Las stack traces nativas no se recopilan de forma predeterminada, ya que normalmente no proporcionan información procesable y analizarlas puede afectar potencialmente a la estabilidad de la aplicación. Prueba esta configuración en un entorno que no sea de producción antes de intentar utilizarla en producción.
Para habilitar la recopilación de stack traces nativas, entendiendo que puede desestabilizar tu aplicación, establece:
```
-export DD_PROFILING_DDPROF_ENABLED=true # predeterminado en v1.7.0+
+export DD_PROFILING_DDPROF_ENABLED=true # this is the default in v1.7.0+
export DD_PROFILING_DDPROF_CSTACK=dwarf
```
o:
```
--Ddd.profiling.ddprof.enabled=true # predeterminado en v1.7.0+
+-Ddd.profiling.ddprof.enabled=true # this is the default in v1.7.0+
-Ddd.profiling.ddprof.cstack=dwarf
```
@@ -332,7 +334,7 @@ Puedes configurar el generador de perfiles utilizando las siguientes variables d
| Variable de entorno | Tipo | Descripción |
| ------------------------------------------------ | ------------- | ------------------------------------------------------------------------------------------------ |
| `DD_PROFILING_ENABLED` | Booleano | Alternativa para el argumento `-Ddd.profiling.enabled`. Establece la opción en `true` para habilitar el generador de perfiles. |
-| `DD_PROFILING_ALLOCATION_ENABLED` | Booleano | Alternativa para el argumento `-Ddd.profiling.allocation.enabled`. Establece la opción en `true` para habilitar el perfil de asignación. Requiere que el generador de perfiles ya esté habilitado. |
+| `DD_PROFILING_ALLOCATION_ENABLED` | Booleano | Alternativa para el argumento `-Ddd.profiling.allocation.enabled`. Establece la opción en `true` para habilitar el generador de perfiles de asignación. Requiere que el generador de perfiles ya esté habilitado. |
| `DD_ENV` | Cadena | El nombre de [entorno][10], por ejemplo: `production`. |
| `DD_SERVICE` | Cadena | El nombre de [servicio][10], por ejemplo, `web-backend`. |
| `DD_VERSION` | Cadena | La [versión][10] de tu servicio. |
@@ -340,7 +342,7 @@ Puedes configurar el generador de perfiles utilizando las siguientes variables d
## ¿No sabes qué hacer a continuación?
-La guía [Empezando con el generador de perfiles][11] toma un ejemplo de servicio con un problema de rendimiento y te muestra cómo utilizar Continuous Profiler para comprender y solucionar el problema.
+La guía [Empezando con el Profiler][11] toma un ejemplo de servicio con un problema de rendimiento y te muestra cómo utilizar Continuous Profiler para comprender y solucionar el problema.
## Referencias adicionales
@@ -360,4 +362,4 @@ La guía [Empezando con el generador de perfiles][11] toma un ejemplo de servici
[12]: /es/profiler/connect_traces_and_profiles/#identify-code-hotspots-in-slow-traces
[13]: /es/profiler/enabling/supported_versions/
[14]: /es/tracing/trace_collection/compatibility/java/?tab=graalvm#setup
-[15]: https://docs.datadoghq.com/es/profiler/enabling/java/?tab=datadogprofiler#
+[15]: https://docs.datadoghq.com/es/profiler/enabling/java/?tab=datadogprofiler#
\ No newline at end of file
diff --git a/content/es/real_user_monitoring/browser/frustration_signals.md b/content/es/real_user_monitoring/browser/frustration_signals.md
index 16d488990e480..5a583b0daeda3 100644
--- a/content/es/real_user_monitoring/browser/frustration_signals.md
+++ b/content/es/real_user_monitoring/browser/frustration_signals.md
@@ -1,6 +1,9 @@
---
aliases:
- /es/real_user_monitoring/frustration_signals
+description: Identifica los puntos de fricción del usuario con las señales de frustración
+ de RUM (incluidos los clics repetidos, los clics sin resultados y los clics de error)
+ para mejorar la experiencia del usuario y reducir el abandono.
further_reading:
- link: https://www.datadoghq.com/blog/analyze-user-experience-frustration-signals-with-rum/
tag: Blog
@@ -23,10 +26,10 @@ Las señales de frustración te permiten identificar los puntos de mayor fricci
RUM recopila tres tipos de señales de frustración:
-Clics de Furia
+Clics de rabia
: Un usuario hace clic en un elemento más de tres veces en una ventana deslizante de un segundo.
-Clics Muertos
+Clics muertos
: Un usuario hace clic en un elemento estático que no produce ninguna acción en la página.
Clics de error
@@ -63,13 +66,13 @@ window.DD_RUM.init({
Las señales de frustración requieren acciones. Activar `trackFrustrations` activa automáticamente `trackUserInteractions`.
-## Uso
+## Utilización
Las señales de frustración aparecen como puntos de datos claros que representan las fuentes de frustración del usuario en la [página **Aplicaciones RUM**][1]. Para mostrar una lista de recuentos de casos de frustración en el [Explorador RUM][2], haz clic en el botón **Options** (Opciones) y añade una columna para `@session.frustration.count`.
### Lista de aplicaciones
-Colócate sobre lista de las sesiones del navegador y haz clic en una sesión para observar el comportamiento de clics frustrados de un usuario. O bien haz clic en **Sesiones frustradas** para acceder a las sesiones con una señal de frustración.
+Colócate sobre lista de las sesiones del navegador y haz clic en una sesión para observar el comportamiento de clics frustrados de un usuario. O bien haz clic en **Frustrated Sessions** (Sesiones frustradas) para acceder a las sesiones con una señal de frustración.
### Explora el dashboard de señales de frustración
@@ -148,7 +151,7 @@ Las señales de frustración se generan a partir de los clics del ratón, no al
Si una sesión está en vivo, está obteniendo información y puede hacer que los banners reflejen un número diferente a los de la línea de tiempo.
-Para hacernos llegar tus comentarios o solicitar una función, ponte en contacto con el Servicio de asistencia de Datadog .
+Para hacernos llegar tus comentarios o solicitar una función, ponte en contacto con el servicio de asistencia de Datadog.
## Referencias adicionales
diff --git a/content/es/real_user_monitoring/browser/monitoring_resource_performance.md b/content/es/real_user_monitoring/browser/monitoring_resource_performance.md
index 053a841d55eeb..0e6be6b1b5cc9 100644
--- a/content/es/real_user_monitoring/browser/monitoring_resource_performance.md
+++ b/content/es/real_user_monitoring/browser/monitoring_resource_performance.md
@@ -1,4 +1,7 @@
---
+description: Rastrea el rendimiento de los recursos web, incluidos los activos de
+ XHR, Fetch, imágenes, CSS y JavaScript, con datos de temporización detallados e
+ identificación del proveedor.
further_reading:
- link: https://www.datadoghq.com/blog/real-user-monitoring-with-datadog/
tag: Blog
@@ -31,7 +34,7 @@ Consultar [Conectar RUM y trazas ][2] para obtener información sobre cómo conf
{{< img src="real_user_monitoring/browser/resource_performance_graph.png" alt="Información de trazas de APM para un recurso de RUM" >}}
-## Tiempos y métricas de recursos
+## Atributos del recurso
Los datos de tiempo de red detallados para recursos se recopilan con los métodos de navegador nativos Fetch y XHR y con la [API de Performance Resource Timing][3].
@@ -40,7 +43,7 @@ Los datos de tiempo de red detallados para recursos se recopilan con los método
| `resource.duration` | número | Tiempo total empleado en cargar el recurso. |
| `resource.size` | número (bytes) | Tamaño del recurso. |
| `resource.connect.duration` | número (ns) | Tiempo empleado en establecer una conexión con el servidor (connectEnd - connectStart). |
-| `resource.ssl.duration` | número (ns) | Tiempo empleado por el protocolo TLS. Si la última solicitud no es en HTTPS, esta métrica no aparece (connectEnd - secureConnectionStart). |
+| `resource.ssl.duration` | número (ns) | Tiempo transcurrido para el apretón de manos de TLS. Si la última solicitud no es en HTTPS, este atributo no aparece (connectEnd - secureConnectionStart). |
| `resource.dns.duration` | número (ns) | Tiempo empleado en resolver el nombre DNS de la última solicitud (domainLookupEnd - domainLookupStart). |
| `resource.redirect.duration` | número (ns) | Tiempo empleado en las siguientes solicitudes HTTP (redirectEnd - redirectStart). |
| `resource.first_byte.duration` | número (ns) | Tiempo de espera empleado para recibir el primer byte de respuesta (responseStart - RequestStart). |
@@ -58,7 +61,7 @@ Los datos de tiempo de red detallados para recursos se recopilan con los método
| `resource.url` | cadena | La URL del recurso. |
| `resource.url_host` | cadena | La parte de host de la URL. |
| `resource.url_path` | cadena | La parte de ruta de la URL. |
-| `resource.url_query` | objecto | Las partes de la cadena de consulta de la URL desglosadas como atributos de clave/valor de parámetros de consulta. |
+| `resource.url_query` | objeto | Las partes de la cadena de consulta de la URL desglosadas como atributos de clave/valor de parámetros de consulta. |
| `resource.url_scheme` | cadena | El nombre del protocolo de la URL (HTTP o HTTPS). |
| `resource.provider.name` | cadena | El nombre del proveedor de recursos. Por defecto es `unknown`. |
| `resource.provider.domain` | cadena | El dominio del proveedor del recurso. |
diff --git a/content/es/real_user_monitoring/browser/tracking_user_actions.md b/content/es/real_user_monitoring/browser/tracking_user_actions.md
index f152119a7a795..1e510da5e063c 100644
--- a/content/es/real_user_monitoring/browser/tracking_user_actions.md
+++ b/content/es/real_user_monitoring/browser/tracking_user_actions.md
@@ -2,6 +2,9 @@
algolia:
tags:
- acciones del usuario
+description: Realiza un seguimiento automático de las interacciones de los usuarios
+ y las acciones personalizadas en las aplicaciones web para comprender el comportamiento
+ de los usuarios, el rendimiento y la adopción de funciones.
further_reading:
- link: https://www.datadoghq.com/blog/real-user-monitoring-with-datadog/
tag: Blog
@@ -28,34 +31,32 @@ Puedes alcanzar los siguientes objetivos:
* Cuantificar la adopción de las funciones
* Identificar los pasos que llevaron a un error específico en el navegador
+Aunque no hay un límite explícito en el número total de acciones que pueden ser recopiladas por el SDK del RUM Browser durante una sesión, hay limitaciones técnicas en los tamaños de los eventos individuales y la carga útil enviada. Para más detalles sobre las limitaciones de las acciones, consulta la [documentación de resolución de problemas del RUM Browser][1].
+
## Administrar la información recopilada
El parámetro de inicialización `trackUserInteractions` activa la recopilación de los clics del usuario en tu aplicación, lo que significa que se pueden incluir datos confidenciales y privados presentes en tus páginas para identificar los elementos con los que ha interactuado un usuario.
-Para controlar qué información se envía a Datadog, puedes [enmascarar nombres de acciones con opciones de privacidad][6], [configurar manualmente un nombre de acción](#declare-a-name-for-click-actions) o [implementar una regla de limpieza global en el SDK del navegador de Datadog para RUM][1].
+Para controlar qué información se envía a Datadog, puedes [enmascarar nombres de acciones con opciones de privacidad][2], [configurar manualmente un nombre de acción](#declare-a-name-for-click-actions) o [implementar una regla de limpieza global en el SDK de Datadog Browser para RUM][3].
## Administrar las interacciones de los usuarios
-El SDK del RUM Browser realiza un rastreo automático de los clics. Se crea una acción de clic cuando se cumplen **todas las siguientes** condiciones:
-
-* Se detecta la actividad posterior al clic. Consulta [Cómo se calcula la actividad de la página][2] para obtener más información.
-* El clic no genera que se cargue una nueva página, en cuyo caso, el SDK del navegador de Datadog genera otro evento de vista de RUM.
-* Se puede calcular un nombre para la acción. Consulta [Declarar un nombre para las acciones de clics](#declare-a-name-for-click-actions) para obtener más información.
+El SDK de RUM Browser rastrea automáticamente los clics para generar acciones de clic. Una acción de un solo clic representa generalmente un clic del usuario, excepto cuando se hace clic varias veces seguidas en el mismo elemento, y en ese caso se considera una sola acción (consulta [Señales de frustración "clics repetidos"][4]).
-## Métricas del tiempo de acción
+## Telemetría de tiempos de acción
-Para obtener información sobre los atributos predeterminados para todos los tipos de eventos de RUM, consulta [Datos de RUM Browser recopilados][3].
+Para obtener información sobre los atributos predeterminados para todos los tipos de eventos RUM, consulta [Datos recopilados del RUM Browser][5].
-| Métrica | Tipo | Descripción |
+| Telemetría | Tipo | Descripción |
|--------------|--------|--------------------------|
| `action.loading_time` | número (ns) | El tiempo de carga de la acción. |
| `action.long_task.count` | número | Número de tareas largas recopiladas para esta acción. |
| `action.resource.count` | número | Número de recursos recopilados para esta acción. |
| `action.error.count` | número | Número de errores recopilados para esta acción.|
-El SDK del navegador de Datadog para RUM calcula el tiempo de carga de la acción monitorizando la actividad de la página después de cada clic. Una acción se considera completa cuando la página no tiene más actividad. Consulta [Cómo se calcula la actividad de la página][2] para obtener más información.
+El SDK de Datadog Browser para RUM calcula el tiempo de carga de la acción monitorizando la actividad de la página después de cada clic. Una acción se considera completa cuando la página no tiene más actividad. Consulta [Cómo se calcula la actividad de la página][2] para obtener más información.
-Para obtener más información sobre la configuración para el muestreo o el contexto global, consulta [Modificar los datos y el contexto de RUM][1].
+Para obtener más información sobre la configuración para el muestreo o el contexto global, consulta [Modificación de datos y contexto RUM][3].
## Atributos de las acciones
@@ -78,11 +79,11 @@ Por ejemplo:
Error:
- Ingresar una dirección de correo electrónico válida
+ Enter a valid email address
```
-A partir de la [versión 2.16.0][4], mediante el parámetro de inicialización `actionNameAttribute`, es posible especificar un atributo personalizado que se emplee para dar un nombre a la acción.
+A partir de la [versión 2.16.0][7], con el parámetro de inicialización `actionNameAttribute`, puedes especificar un atributo personalizado que se utiliza para dar nombre a acción.
Por ejemplo:
@@ -113,15 +114,26 @@ El SDK del navegador de Datadog utiliza diferentes estrategias para calcular los
Para aumentar la recopilación de interacciones del usuario, envía tus acciones personalizadas mediante la API `addAction`. Estas acciones personalizadas envían información sobre un evento que se produce durante el recorrido de un usuario.
-Para más información, consulta [Enviar acciones personalizadas][5].
+Para obtener más información, consulta [Enviar acciones personalizadas][8].
+
+## Límites y muestreo de acciones
+
+No existe un límite estricto en el número de acciones del usuario, como clics o acciones personalizadas, que el SDK de Datadog RUM Browser puede rastrear por sesión o página. Sin embargo, debes tener en cuenta lo siguiente:
+
+- **Muestreo**: puedes configurar el SDK para que muestree un porcentaje de las acciones del usuario utilizando las opciones `sampleRate` y `trackInteractions`. Esto ayuda a controlar el volumen de datos enviados a Datadog. Para más información, consulta [Configuración avanzada][1].
+- **Rendimiento**: el SDK agrupa y envía eventos periódicamente. En casos de acciones de alta frecuencia, como clics repetidos, el SDK puede deduplicar o agrupar acciones, por ejemplo, mediante la detección de clics repetidos para evitar inundaciones.
+
+Como mejor práctica, si esperas un alto volumen de acciones de usuario, considera ajustar tu configuración de muestreo y monitorizar tu uso de eventos de Datadog.
## Referencias adicionales
{{< partial name="whats-next/whats-next.html" >}}
-[1]: /es/real_user_monitoring/browser/advanced_configuration/
-[2]: /es/real_user_monitoring/browser/monitoring_page_performance/#how-page-activity-is-calculated
-[3]: /es/real_user_monitoring/browser/data_collected/#default-attributes
-[4]: https://github.com/DataDog/browser-sdk/blob/main/CHANGELOG.md#v2160
-[5]: /es/real_user_monitoring/guide/send-rum-custom-actions
-[6]: /es/data_security/real_user_monitoring/#mask-action-names
\ No newline at end of file
+[1]: /es/real_user_monitoring/browser/troubleshooting/
+[2]: /es/data_security/real_user_monitoring/#mask-action-names
+[3]: /es/real_user_monitoring/browser/advanced_configuration/
+[4]: /es/real_user_monitoring/browser/frustration_signals/
+[5]: /es/real_user_monitoring/browser/data_collected/#default-attributes
+[6]: /es/real_user_monitoring/browser/monitoring_page_performance/#how-page-activity-is-calculated
+[7]: https://github.com/DataDog/browser-sdk/blob/main/CHANGELOG.md#v2160
+[8]: /es/real_user_monitoring/guide/send-rum-custom-actions
\ No newline at end of file
diff --git a/content/es/real_user_monitoring/browser/troubleshooting.md b/content/es/real_user_monitoring/browser/troubleshooting.md
index f453200105535..d9e4d033f471d 100644
--- a/content/es/real_user_monitoring/browser/troubleshooting.md
+++ b/content/es/real_user_monitoring/browser/troubleshooting.md
@@ -1,4 +1,6 @@
---
+description: Solucionar problemas comunes con el SDK de RUM Browser incluyendo datos
+ perdidos, bloqueadores de anuncios, restricciones de red y problemas de configuración.
further_reading:
- link: https://www.datadoghq.com/blog/real-user-monitoring-with-datadog/
tag: Blog
@@ -9,7 +11,7 @@ further_reading:
title: Solucionar problemas
---
-Si experimentas algún comportamiento inesperado con Datadog Browser RUM, utiliza esta guía para resolver los problemas rápidamente. Si sigues teniendo problemas, contacta con el [equipo de asistencia de Datadog][1] para obtener más ayuda. Actualiza con regularidad el [RUM Browser SDK][2] a la última versión, ya que cada nueva versión contiene mejoras y correcciones.
+Si experimentas algún comportamiento inesperado con Datadog Browser RUM, utiliza esta guía para resolver los problemas rápidamente. Si sigues teniendo problemas, contacta con el [equipo de asistencia de Datadog][1] para obtener más ayuda. Actualiza con regularidad el [SDK del RUM Browser][2] a la última versión, ya que cada nueva versión contiene mejoras y correcciones.
## Datos faltantes
@@ -19,16 +21,20 @@ Si no puedes ver ningún dato en RUM o si faltan datos de algún usuario:
| ----------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| Los bloqueadores de anuncios impiden que el SDK del RUM Browser se descargue o envíe datos a Datadog. | Algunos bloqueadores de anuncios amplían sus restricciones a las herramientas de rastreo de rendimiento y marketing. Consulta los documentos [Instalar el SDK del RUM Browser con npm][3] y [reenviar los datos recopilados a través de un proxy][4]. |
| Las reglas de red, las VPN o el software antivirus pueden impedir que se descargue el SDK del RUM Browser o que se envíen datos a Datadog. | Permite el acceso a los endpoints necesarios para descargar el SDK del RUM Browser o para enviar datos. La lista de endpoints está disponible en la [documentación sobre la Política de seguridad de contenido][5]. |
-| Los scripts, paquetes y clientes inicializados antes del SDK del RUM Browser pueden provocar que se pierdan logs, recursos y acciones del usuario. Por ejemplo, inicializar ApolloClient antes que el SDK del RUM Browser puede provocar que las solicitudes `graphql` no se registren como recursos XHR en el navegador RUM. | Check dónde se inicializa el SDK de RUM Browser y plantéate adelantar este paso en la ejecución del código de tu aplicación. |
-| Si has configurado `trackViewsManually: true` y observas que no hay sesiones, es posible que la aplicación haya dejado de enviar información RUM repentinamente aunque no haya errores red. | Asegúrate de iniciar una vista inicial una vez que hayas inicializado RUM para evitar cualquier pérdida de datos. Consulta [Configuración avanzada][6] para obtener más información.|
+| Los scripts, paquetes y clientes inicializados antes del SDK del RUM Browser pueden provocar que se pierdan logs, recursos y acciones del usuario. Por ejemplo, inicializar ApolloClient antes que el SDK del RUM Browser puede provocar que las solicitudes `graphql` no se registren como recursos XHR en el RUM Explorer. | Check dónde se inicializa el SDK de RUM Browser y plantéate adelantar este paso en la ejecución del código de tu aplicación. |
+| Si has configurado `trackViewsManually: true` y observas que no hay sesiones, es posible que la aplicación haya dejado de enviar información RUM repentinamente aunque no haya errores de red. | Asegúrate de iniciar una vista inicial una vez que hayas inicializado RUM para evitar cualquier pérdida de datos. Consulta [Configuración avanzada][6] para obtener más información.|
-Lee las [directrices de la política de seguridad de contenidos][5] y asegúrate de que tu sitio web permita el acceso al CDN del SDK del RUM Browser y al endpoint de ingesta.
+Lee las [directrices de la política de seguridad de contenido][5] y asegúrate de que tu sitio web permita el acceso al CDN del SDK del RUM Browser y al endpoint de ingesta.
+
+## Problemas al ejecutar varias herramientas RUM en la misma aplicación
+
+Datadog solo admite un SDK por aplicación. Para garantizar una recopilación de datos óptima y la plena funcionalidad de todas las características del SDK de Datadog RUM, utiliza únicamente el SDK de Datadog RUM.
### Inicialización del SDK del RUM Browser
Check si el SDK del RUM Browser se inicializa ejecutando `window.DD_RUM.getInternalContext()` en la consola de tu navegador y verifica que se devuelvan `application_id`, `session_id` y el objeto de vista:
-{{< img src="real_user_monitoring/browser/troubleshooting/success_rum_internal_context.png" alt="Comando de obtención de contexto interno ejecutado correctamente">}}
+{{< img src="real_user_monitoring/browser/troubleshooting/success_rum_internal_context.png" alt="El comando de obtención de contexto interno se ejecutó correctamente">}}
Si el SDK del RUM Browser no está instalado o si no se inicializa correctamente, puedes ver el error `ReferenceError: DD_RUM is not defined` como el que se muestra a continuación:
@@ -44,13 +50,13 @@ También puedes check la consola de herramientas de desarrollo de tu navegador o
El SDK de RUM envía lotes de datos de eventos a la ingesta de Datadog cada vez que se cumple una de estas condiciones:
- Cada 30 segundos
-- Cuando se hayan alcanzado 50 eventos
-- Cuando la carga útil sea >16 kB
+- Cuando se hayan alcanzado 50 eventos
+- Cuando la carga útil sea >16 kB
- En `visibility:hidden` o `beforeUnload`
-Si se están enviando datos, deberías ver solicitudes de redes dirigidas a `/v1/input` (la parte del origen de la URL puede diferir debido a la configuración de RUM) en la sección de red de las herramientas de desarrollo del navegador:
+Si se están enviando datos, deberías ver las solicitudes de red dirigidas a `api/v2/rum` (la parte del origen de la URL puede diferir debido a la configuración de RUM) en la sección Red de las herramientas de desarrollo de tu navegador:
-{{< img src="real_user_monitoring/browser/troubleshooting/network_intake.png" alt="Solicitudes de RUM a la ingesta de Datadog">}}
+{{< img src="real_user_monitoring/browser/troubleshooting/network_intake-1.png" alt="Solicitudes de RUM a la entrada de Datadog">}}
## Cookies de RUM
@@ -120,16 +126,20 @@ El SDK del navegador RUM permite configurar el [contexto global][10], la [inform
Para minimizar el impacto en el ancho de banda del usuario, el SDK del navegador RUM limita los datos enviados a la ingesta de Datadog. Sin embargo, el envío de grandes volúmenes de datos puede afectar al rendimiento de los usuarios con conexiones a Internet lentas.
-Para una mejor experiencia de usuario, Datadog recomienda mantener el tamaño del contexto global, la información del usuario y las marcas de funciones por debajo de 3 KiB. Si los datos superan este límite, se muestra una advertencia: `The data exceeds the recommended 3KiB threshold.`
+Para una mejor experiencia de usuario, Datadog recomienda mantener el tamaño del contexto global, la información del usuario y las marcas de funciones por debajo de 3 KiB. Si los datos superan este límite, se mostrará una advertencia: `The data exceeds the recommended 3KiB threshold.`
Desde v5.3.0, el SDK del RUM Browser admite la compresión de datos a través de `compressIntakeRequest` [parámetro de inicialización][13]. Cuando está activado, este límite recomendado se amplía de 3 KiB a 16 KiB.
## Advertencia de bloqueo de lectura de origen cruzado
-En los navegadores basados en Chromium, cuando el SDK del RUM Browser envía datos a la ingesta de Datadog, se muestra una advertencia CORB en la consola: `Cross-Origin Read Blocking (CORB) blocked cross-origin response`.
+En los navegadores de Chromium, cuando el SDK del RUM Browser envía datos a la ingesta de Datadog, se muestra una advertencia CORB en la consola: `Cross-Origin Read Blocking (CORB) blocked cross-origin response`.
La advertencia se muestra porque la ingesta devuelve un objeto JSON no vacío. Este comportamiento es un problema reportado [de Chromium][8]. No afecta al SDK del RUM Browser y se lo puede ignorar en forma segura.
+## Advertencia "Deobfuscation failed"
+
+Aparece una advertencia cuando falla el desenmascaramiento de un stack trace. Si el stack trace no está enmascarado para empezar, puedes ignorar esta advertencia. De lo contrario, utiliza la [página Símbolos de depuración de RUM][14] para ver todos tus mapas fuente subidos. Consulta [Investigar stack traces enmascarados con símbolos de depuración de RUM][15].
+
## Referencias adicionales
{{< partial name="whats-next/whats-next.html" >}}
@@ -146,4 +156,6 @@ La advertencia se muestra porque la ingesta devuelve un objeto JSON no vacío. E
[10]: /es/real_user_monitoring/browser/advanced_configuration/?tab=npm#global-context
[11]: /es/real_user_monitoring/browser/advanced_configuration/?tab=npm#user-session
[12]: /es/real_user_monitoring/guide/setup-feature-flag-data-collection/?tab=browser
-[13]: /es/real_user_monitoring/browser/setup/#initialization-parameters
\ No newline at end of file
+[13]: /es/real_user_monitoring/browser/setup/#initialization-parameters
+[14]: https://app.datadoghq.com/source-code/setup/rum
+[15]: /es/real_user_monitoring/guide/debug-symbols
\ No newline at end of file
diff --git a/content/es/real_user_monitoring/correlate_with_other_telemetry/llm_observability/_index.md b/content/es/real_user_monitoring/correlate_with_other_telemetry/llm_observability/_index.md
new file mode 100644
index 0000000000000..b316668aa337f
--- /dev/null
+++ b/content/es/real_user_monitoring/correlate_with_other_telemetry/llm_observability/_index.md
@@ -0,0 +1,127 @@
+---
+algolia:
+ tags:
+ - llmobs
+ - agentes ia
+ - llm
+description: Conecta sesiones RUM con LLM Observability para realizar un seguimiento
+ de las interacciones de los usuarios con los agentes de IA y comprender el recorrido
+ completo del usuario.
+further_reading:
+- link: /llm_observability/sdk
+ tag: Documentación
+ text: Referencia del SDK de LLM Observability
+title: Correlacionar LLM Observability con RUM
+---
+
+## Información general
+Correlaciona sesiones RUM y LLM Observability para obtener más visibilidad sobre cómo interactúa tu aplicación web con los agentes de IA. Esta correlación te ayuda a comprender el recorrido completo del usuario conectando las interacciones del usuario frontend con el procesamiento de IA backend.
+
+El enlace entre RUM y LLM Observability se crea reenviando el ID de la sesión RUM al SDK de LLM Observability.
+
+## Requisitos previos
+
+Antes de empezar, asegúrate de que tienes:
+- El [SDK del navegador RUM][1] instalado y configurado en tu aplicación web
+- El [SDK de LLM Observability][2] instalado en tu servicio backend
+- Datadog cuenta con [RUM][3] y [LLM Observability][4] activados
+- El endpoint del agente de IA al que tu aplicación web puede llamar
+
+## Configuración
+### Paso 1: Configurar el SDK de tu navegador RUM
+
+Asegúrate de que el SDK de tu navegador RUM está correctamente inicializado en tu aplicación web. Para obtener instrucciones de configuración detalladas, consulta la [guía de configuración del navegador RUM][1].
+
+Necesitas enviar tu ID de sesión RUM en cada llamada desde tu aplicación web a un agente de IA. Consulta los ejemplos siguientes.
+
+```javascript
+import { datadogRum } from '@datadog/browser-rum'
+
+datadogRum.init({
+ /* RUM Browser SDK configuration */
+});
+```
+
+### Paso 2: Modificar las llamadas a tu IA frontend
+
+Actualiza tu aplicación web para incluir el ID de sesión RUM en cada llamada a tu agente de IA. Para obtener más información sobre la gestión de sesiones RUM, consulta la [documentación del navegador RUM][3].
+
+```javascript
+ /**
+ * Example call to an AI Agent.
+ *
+ * We send the `session_id` in the body of the request. If the call to the AI agent
+ * needs to be a GET request, the `session_id` can be sent as a query param.
+ */
+ const response = await fetch("/ai-agent-endpoint", {
+ method: "POST",
+ headers: {
+ "Content-Type": "application/json",
+ },
+ body: JSON.stringify({ message, session_id: datadogRum.getInternalContext().session_id }),
+});
+```
+
+### Paso 3: Actualizar tu manejador backend
+
+Modifica tu código del lado del servidor para extraer el ID de sesión y trasladarlo al SDK de LLM Observability. Para una configuración detallada de LLM Observability, consulta la [guía de configuración de LLM Observability][4].
+
+```python
+# Read the session_id from the incoming request
+class MessagesHandler:
+ def __init__(self, handler):
+ try:
+ post_data = handler.rfile.read(content_length)
+
+ # Parse the JSON message
+ message_data = json.loads(post_data.decode('utf-8'))
+ message = message_data.get('message', '')
+
+ # Read the session_id
+ current_session_id = message_data.get('session_id', None)
+
+ # Call AI Agent and pass the session_id
+ await agent_loop(
+ messages=messages,
+ model="claude-3-7-sonnet-20250219",
+ provider="anthropic",
+ api_key=os.getenv("ANTHROPIC_API_KEY"),
+ max_tokens=4096,
+ session_id=current_session_id,
+ # Other kwargs your agent might need
+ )
+ except Exception as e:
+ handler.send_error(500, str(e))
+```
+
+Utiliza el SDK de LLM Observability para instrumentar tu agente y tus herramientas e indica al SDK de LLM Observability cuál debe ser el `session_id`.
+
+### Paso 4: Instrumentar tu agente de IA
+
+Utiliza el SDK de LLM Observability para instrumentar tu agente y asociarlo a la sesión RUM. Para una referencia detallada, consulta la [documentación del SDK de LLM Observability][4].
+```python
+async def agent_loop(
+ session_id,
+ # Other kwargs
+):
+ LLMObs.annotate(
+ span=None,
+ tags={"session_id": session_id},
+ )
+ # Rest of your agent code
+```
+
+## Navegación entre RUM y LLM Observability
+Una vez finalizada la configuración, podrás navegar entre los datos correlacionados:
+
+- **De RUM a LLM**: En una sesión RUM, haz clic en el botón "LLM Traces" (Trazas de LLM) en la cabecera del panel lateral para ver las interacciones de IA asociadas.
+- **De LLM a RUM**: En una traza de LLM, haz clic en el enlace "RUM Session" (Sesión RUM) para ver la repetición de la sesión de usuario correspondiente.
+
+## Referencias adicionales
+
+{{< partial name="whats-next/whats-next.html" >}}
+
+[1]: /es/real_user_monitoring/browser/setup/
+[2]: /es/llm_observability/setup/
+[3]: /es/real_user_monitoring/browser/
+[4]: /es/llm_observability/
\ No newline at end of file
diff --git a/content/es/real_user_monitoring/explorer/visualize.md b/content/es/real_user_monitoring/explorer/visualize.md
index 298e94bd45b53..32b1dc2a7b3e5 100644
--- a/content/es/real_user_monitoring/explorer/visualize.md
+++ b/content/es/real_user_monitoring/explorer/visualize.md
@@ -1,4 +1,7 @@
---
+description: Crea visualizaciones a partir de los datos de RUM, incluyendo listas,
+ series temporales, tablas y gráficos para analizar el rendimiento y las tendencias
+ de comportamiento de los usuarios.
further_reading:
- link: /real_user_monitoring/explorer/search/
tag: Documentación
@@ -12,11 +15,11 @@ Las visualizaciones definen los resultados de los filtros y agregados mostrados
## Listas
-Las listas son resultados paginados de eventos y son ideales cuando son importantes los resultados individuales. Para utilizar las listas no es necesario tener conocimientos previos de lo que define un resultado coincidente.
+Las listas son resultados paginados de eventos y son ideales cuando importan los resultados individuales. Para utilizar las listas no es necesario tener conocimientos previos de lo que define un resultado coincidente.
{{< img src="real_user_monitoring/explorer/visualize/rum_explorer_lists-1.mp4" alt="Listas en el Explorador RUM" video="true" style="width:70%;" >}}
-La información que buscas se muestra en columnas. Puedes administrar lo siguiente:
+La información que buscas se muestra en columnas. Puedes gestionar lo siguiente:
- La tabla con las interacciones disponibles en la primera fila. Puedes ordenar, reorganizar y eliminar columnas.
- El panel de facetas de la izquierda o el [panel lateral de eventos][2] RUM de la derecha. Puedes añadir una columna para un campo.
@@ -43,8 +46,8 @@ El gráfico de series temporales muestra la evolución del número de páginas v
Puedes elegir opciones de visualización adicionales como:
-- Visualización: Los resultados se muestran en forma de barras (recomendado para recuentos y recuentos únicos), líneas (recomendado para agregaciones estadísticas), áreas. Hay varios conjuntos de colores disponibles.
-- Intervalo de roll-up: Determina la anchura de los buckets en las barras.
+- Visualización: Los resultados se muestran en forma de barras (recomendado para counts y counts únicos), líneas (recomendado para agregaciones estadísticas), áreas y se dispone de varios conjuntos de colores.
+- El intervalo de acumulación: determina el ancho de los buckets en las barras.
## Lista principal
@@ -52,16 +55,16 @@ Visualiza los principales valores de una faceta en función de la medida elegida
{{< img src="real_user_monitoring/explorer/visualize/top-list-2.png" alt="Gráfico de barras de la lista principal en el Explorador RUM" style="width:90%;" >}}
-La lista principal incluye los principales navegadores utilizados para visitar el sitio web de Shopist durante el último día.
+La lista de principales incluye los principales navegadores utilizados para visitar el sitio web de Shopist durante el último día.
## Tablas anidadas
Visualiza los principales valores de hasta tres [facetas][5] según la [medida][5] elegida (la primera medida que elijas en lista) y visualiza el valor de las medidas adicionales para los elementos que aparecen en la tabla anidada. Actualiza la consulta de búsqueda o investiga los eventos RUM correspondientes a cualquiera de las dos dimensiones.
-* Cuando hay varias medidas, la lista principal o inferior se determina en función de la primera medida.
-* El subtotal puede diferir de la suma real de valores de un grupo, ya que sólo se muestra un subconjunto (principal o inferior). Los eventos con un valor nulo o vacío para esta dimensión no se muestran como subgrupo.
+* Cuando haya varias medidas, la lista superior o inferior se determina en función de la primera medida.
+* El subtotal puede diferir de la suma real de valores de un grupo, ya que sólo se muestra un subconjunto (superior o inferior). Los eventos con un valor nulo o vacío para esta dimensión no se muestran como subgrupo.
- **Nota**: Una visualización de tabla utilizada para una sola medida y una sola dimensión es lo mismo que una [lista principal](#top-list), sólo que con una visualización diferente.
+ **Nota**: Una visualización de tabla utilizada para una sola medida y una sola dimensión es lo mismo que una [lista de principales](#top-list), sólo que con una visualización diferente.
La siguiente tabla de RUM Analytics muestra las **5 principales rutas URL** para **dos países**, EE.UU. y Japón, agrupadas por navegador, durante el último día:
@@ -69,11 +72,11 @@ Visualiza los principales valores de hasta tres [facetas][5] según la [medida][
## Distribuciones
-Puedes visualizar la distribución de los atributos de medida a lo largo del periodo de tiempo seleccionado para ver la fluctuación de los valores.
+Puedes visualizar la distribución de los atributos de medidas a lo largo del periodo de tiempo seleccionado para ver la fluctuación de los valores.
{{< img src="real_user_monitoring/explorer/visualize/distribution-2.png" alt="Gráfico de distribución en el Explorador RUM" style="width:90%;">}}
-El gráfico de distribución muestra la distribución del Largest Contentful Paint que mide la experiencia de usuario de la página de inicio de Shopist.
+En el gráfico de distribución, se muestra la distribución de la pintura de mayor contenido que mide la experiencia de usuario de la página de destino de Shopist.
## Geomapas
@@ -85,11 +88,11 @@ El geomapa de RUM Analytics muestra el percentil 75 del **Largest Contentful Pai
## Embudos
-El análisis del embudo te ayuda a realizar un seguimiento de las tasas de conversión en los flujos de trabajo clave para identificar y abordar los cuellos de botella en los recorridos integrales de los usuarios. En concreto, puedes:
+El análisis del embudo te ayuda a realizar un seguimiento de las tasas de conversión en flujos de trabajo clave, para identificar y abordar los cuellos de botella en recorridos de extremo a extremo de los usuarios. En concreto, puedes:
-- Comprobar si los clientes abandonan el sitio web en un momento determinado debido a un rendimiento deficiente
-- Rastrear la evolución de la tasa de conversión a medida que se incorporan nuevas funciones
-- Medir cómo afecta a la tasa de abandono la adición de nuevos pasos a un flujo de trabajo
+- Ver si los clientes abandonan el sitio web en un momento determinado debido a un rendimiento deficiente.
+- Realizar un seguimiento de la evolución de la tasa de conversión a medida que se incorporan nuevas funciones.
+- Medir cómo afecta a la tasa de abandono la adición de nuevos pasos a un flujo de trabajo.
**Nota**: La tasa de conversión es el número de visitantes de tu sitio web que completaron un objetivo deseado (una conversión) del número total de visitantes.
@@ -101,9 +104,9 @@ Para construir un embudo, elige tu vista o acción inicial y haz clic en el icon
### Próximos pasos sugeridos
-Cuando tengas un punto de partida en mente, pero no estés seguro de lo que tus usuarios hicieron después, despliega el panel **Quickly add a step** (Añadir rápidamente un paso) (disponible en un cajón a la derecha) para ver los siguientes pasos sugeridos. Después de introducir los pasos, este panel carga automáticamente las cinco **vistas** y **acciones** más comunes que los usuarios suelen ver y realizar a continuación. Esto te permite construir embudos más rápido sabiendo los caminos que tus usuarios están tomando en secuencia.
+Cuando tengas un punto de partida en mente, pero no estés seguro de lo que tus usuarios hicieron a continuación, haz clic en el cuadro de búsqueda donde dice "Search for View or Action Name" (Búsqueda por nombre de vista o acción) para ver los siguientes pasos sugeridos. Este cuadro de entrada carga automáticamente las **vistas** y **acciones** más comunes que los usuarios suelen ver y realizar a continuación. Esto te permite crear embudos más rápido sabiendo los caminos que tus usuarios están tomando en secuencia.
-{{< img src="real_user_monitoring/funnel_analysis/funnel-analysis-suggested-next-steps.jpg" alt="Crear un embudo" style="width:90%;" >}}
+{{< img src="real_user_monitoring/funnel_analysis/funnel-analysis-suggested-next-steps-1.png" alt="Crear un túnel" style="width:90%;" >}}
**Nota**: Cualquier acción o vista que ocurra entre dos pasos de un embudo no afecta a la tasa de conversión paso a paso o global. Mientras el paso 1 y el paso 2 ocurran en el orden correcto en una sesión dada al menos una vez, cuentan como una única sesión convertida.
@@ -129,7 +132,7 @@ Después de crear un embudo, haz clic en **View Funnel Insights** (Ver informaci
## Gráficos circulares
Un gráfico circular te ayuda a organizar y mostrar los datos como un porcentaje del total. Resulta útil cuando se compara la relación entre diferentes dimensiones como servicios, usuarios, hosts, países, etc. dentro de tus datos de logs.
-El siguiente gráfico circular muestra el desglose porcentual por **Ruta de vista**.
+En el siguiente gráfico circular se muestra el desglose porcentual por **Ruta de vista**.
{{< img src="real_user_monitoring/explorer/visualize/pie-chart.png" alt="Gráfico circular en el Explorador RUM" style="width:90%;">}}
@@ -139,13 +142,12 @@ Para todas las visualizaciones, selecciona una sección del gráfico o haz clic
{{< img src="real_user_monitoring/explorer/visualize/related-events-2.png" alt="Enlace de eventos relacionados cuando se hace clic en el gráfico" width="90%" >}}
-Para el resto de las opciones de visualización, haz clic en el gráfico y luego en **Ver eventos**, para ver una lista de los eventos que corresponden a tu selección.
+Para el resto de las opciones de visualización, haz clic en el gráfico y en **Ver eventos** para ver una lista de eventos que correspondan a tu selección.
## Referencias adicionales
{{< partial name="whats-next/whats-next.html" >}}
-
[1]: /es/real_user_monitoring/explorer/
[2]: /es/real_user_monitoring/explorer/events/
[3]: /es/logs/explorer/facets/
diff --git a/content/es/real_user_monitoring/guide/_index.md b/content/es/real_user_monitoring/guide/_index.md
index 03268cde01882..183226c81443f 100644
--- a/content/es/real_user_monitoring/guide/_index.md
+++ b/content/es/real_user_monitoring/guide/_index.md
@@ -4,6 +4,8 @@ cascade:
category: Guía
rank: 20
subcategory: Guías de RUM y Session Replay
+description: Guías completas para la implementación, optimización y mejores prácticas
+ de RUM y Session Replay para aplicaciones web y móviles.
disable_toc: true
private: true
title: Guías de Real User Monitoring y Session Replay
diff --git a/content/es/real_user_monitoring/guide/send-rum-custom-actions.md b/content/es/real_user_monitoring/guide/send-rum-custom-actions.md
index 8ecc66b8c1508..4a278602c1bab 100644
--- a/content/es/real_user_monitoring/guide/send-rum-custom-actions.md
+++ b/content/es/real_user_monitoring/guide/send-rum-custom-actions.md
@@ -1,4 +1,7 @@
---
+algolia:
+ tags:
+ - addaction
aliases:
- /es/real_user_monitoring/guide/send-custom-user-actions/
beta: true
@@ -17,7 +20,7 @@ Real User Monitoring [recopila acciones automáticamente][1] en tu aplicación w
Las acciones RUM personalizadas te permiten monitorizar eventos interesantes con todo su contexto relevante adjunto. Por ejemplo, el SDK del Navegador Datadog puede recopilar la información de pago de un usuario (como la cantidad de artículos en el carro de compras, la lista de artículos y su precio) cuando hace clic en el botón de pago en un sitio web de comercio electrónico.
-## Instrumentación de tu código
+## Instrumentar tu código
Crea una acción RUM utilizando la API `addAction`. Dale un nombre a tu acción y adjunta atributos de contexto en forma de objeto de JavaScript.
diff --git a/content/es/real_user_monitoring/rum_without_limits/_index.md b/content/es/real_user_monitoring/rum_without_limits/_index.md
new file mode 100644
index 0000000000000..d0bdebb081bb8
--- /dev/null
+++ b/content/es/real_user_monitoring/rum_without_limits/_index.md
@@ -0,0 +1,108 @@
+---
+description: Conserva solo los datos RUM que necesites, manteniendo una visibilidad
+ total de las métricas de rendimiento para tus aplicaciones.
+further_reading:
+- link: /real_user_monitoring/rum_without_limits/retention_filters
+ tag: Documentación
+ text: Conservar datos con filtros de retención
+- link: /real_user_monitoring/guide/retention_filter_best_practices/
+ tag: Guía
+ text: Mejores prácticas para los filtros de retención
+- link: /real_user_monitoring/rum_without_limits/metrics
+ tag: Documentación
+ text: Analizar el rendimiento con métricas
+- link: https://www.datadoghq.com/blog/rum-without-limits/
+ tag: Blog
+ text: 'Presentamos RUM without LimitsTM: captura todo, conserva lo que importa'
+title: RUM without Limits
+---
+
+RUM without Limits se activa automáticamente para los clientes con planes de RUM no comprometidos. Ponte en contacto con tu equipo de cuentas o con el servicio de asistencia de Datadog para activar esta función.
+
+{{< img src="real_user_monitoring/rum_without_limits/rum-without-limits-overview.png" alt="Página de panel lateral de las métricas de uso estimado" style="width:90%" >}}
+
+## Información general
+
+RUM without Limits te proporciona flexibilidad sobre tus volúmenes de sesiones RUM al desacoplar la ingesta de datos de sesión de la indexación. Esto te permite:
+
+- Establecer filtros de retención dinámicamente desde la interfaz de usuario de Datadog sin tener que tomar decisiones de muestreo previas ni cambiar el código.
+- Conservar las sesiones con errores o problemas de rendimiento y descartar las menos significativas, como las que tienen pocas interacciones con el usuario.
+
+Aunque solo se conserve una fracción de las sesiones, Datadog proporciona [métricas de rendimiento][1] para todas las sesiones ingestadas. Esto garantiza una visión general precisa y a largo plazo del estado y el rendimiento de la aplicación, incluso si solo se conserva una fracción de los datos de sesión.
+
+**Nota**: En el modo RUM without Limits, solo puedes utilizar los filtros predeterminados en la [página de Resumen de monitorización del rendimiento][7]. Esto te permite ver todo el conjunto de datos y evita métricas de rendimiento sesgadas, ya que los datos se muestrean y hay menos etiquetas disponibles que en los atributos de eventos.
+
+Esta página identifica los componentes clave de RUM without Limits que pueden ayudarte a gestionar los volúmenes de tus sesiones RUM dentro de tu presupuesto de observabilidad.
+
+### Para nuevas aplicaciones
+
+Para empezar a trabajar con RUM without Limits para nuevas aplicaciones, en el paso de [instrumentación][2]:
+
+1. Asegúrate de que `sessionSampleRate` está configurado al 100%. Datadog recomienda configurarlo a este porcentaje para una visibilidad óptima y precisión de las métricas.
+
+2. Elige una `sessionReplaySampleRate` que satisfaga tus necesidades de observabilidad.
+
+3. Para aplicaciones con la integración [APM activada][3], configura el porcentaje de sesiones para las que deseas asegurarte de que las trazas de backend de APM se ingieren con `traceSampleRate` (navegador), `traceSampler` (Android) o `sampleRate` (iOS).
+
+4. Habilita `traceContextInjection: sampled` para permitir que las bibliotecas de rastreo de backend tomen sus propias decisiones de muestreo para las sesiones en las que el SDK de RUM decida no conservar la traza.
+
+ Los pasos 1, 3 y 4 pueden afectar a la ingesta de trazas de APM. Para garantizar que los volúmenes ingestados de tramos permanezcan estables, configura
+
+5. Despliega tu aplicación para aplicar la configuración.
+
+### Para aplicaciones existentes
+Los usuarios existentes de RUM deben volver a desplegar las aplicaciones para utilizar plenamente RUM without Limits. Asegúrate de que la frecuencia de muestreo de la sesión es del 100 % para todas las aplicaciones.
+
+#### Paso 1: Ajustar la frecuencia de muestreo
+Si ya estás recopilando repeticiones, para aumentar la frecuencia de muestreo de la sesión es necesario reducir la frecuencia de muestreo de las repeticiones para recopilar el mismo número de repeticiones (consulta el ejemplo siguiente). La frecuencia de muestreo de repetición se basa en la frecuencia de muestreo de sesión existente.
+
+Antes:
+
+```java
+ sessionSampleRate: 20,
+ sessionReplaySampleRate: 10,
+```
+
+Después:
+
+```java
+ sessionSampleRate: 100,
+ sessionReplaySampleRate: 2,
+```
+
+1. Ve a [**Digital Experiences > Real User Monitoring > Manage Applications**][4] (Experiencias digitales > Real User Monitoring > Gestionar aplicaciones).
+1. Haz clic en la aplicación que deseas migrar.
+1. Haz clic en la pestaña **SDK Configuration** (Configuración del SDK).
+1. Asegúrate de que `sessionSampleRate` está ajustado al 100 %.
+1. Establece `sessionReplaySampleRate` a una velocidad que resulte en el mismo número de repeticiones antes de aumentar la velocidad de muestreo de la sesión.
+1. Utiliza el fragmento de código generado para actualizar tu código fuente y volver a desplegar tus aplicaciones para asegurarte de que se aplica la nueva configuración.
+
+#### Paso 2: Ajustar el rastreo
+
+Si has aumentado `sessionSampleRate`, podrías aumentar el número de tramos de APM ingestados, ya que el SDK de RUM tiene la capacidad de anular las decisiones de muestreo de las trazas de backend para realizar la correlación.
+
+Para simplificar esto, establece `traceSampleRate` en un porcentaje inferior al 100 % (a la `sessionSampleRate` establecida anteriormente) y establece `traceContextInjection: sampled` para permitir que las bibliotecas de rastreo de backend tomen sus propias decisiones de muestreo para las sesiones en las que el SDK de RUM decida no mantener la traza.
+
+#### Paso 3: Crear filtros de retención
+
+En las aplicaciones móviles, pueden convivir muchas versiones concurrentes. Sin embargo, las versiones existentes no envían necesariamente el 100 % de las sesiones, lo que significa que la creación de nuevos filtros de retención reduce los datos disponibles en Datadog para estas versiones de aplicaciones.
+
+Datadog recomienda crear los mismos filtros de retención para todas las versiones de la aplicación, independientemente de si la tasa de muestreo del SDK está configurada al 100 % o no. En última instancia, todas las sesiones valiosas se siguen recopilando aunque algunas sesiones no se ingieran para algunas versiones antiguas.
+
+Consulta los filtros de retención y casos de uso sugeridos en [Prácticas recomendadas del filtro de retención][5].
+
+## Siguientes pasos
+
+Crea y configura [filtros de retención][6].
+
+## Referencias adicionales
+
+{{< partial name="whats-next/whats-next.html" >}}
+
+[1]: /es/real_user_monitoring/rum_without_limits/metrics
+[2]: /es/real_user_monitoring/browser/setup/
+[3]: /es/real_user_monitoring/platform/connect_rum_and_traces/
+[4]: https://app.datadoghq.com/rum/list
+[5]: /es/real_user_monitoring/guide/retention_filter_best_practices/
+[6]: /es/real_user_monitoring/rum_without_limits/retention_filters
+[7]: https://app.datadoghq.com/rum/performance-monitoring
\ No newline at end of file
diff --git a/content/es/remote_configuration/_index.md b/content/es/remote_configuration/_index.md
new file mode 100644
index 0000000000000..27361d6c75997
--- /dev/null
+++ b/content/es/remote_configuration/_index.md
@@ -0,0 +1,176 @@
+---
+algolia:
+ tags:
+ - configuración remota
+ - configuración remota
+aliases:
+- /es/agent/guide/how_rc_works
+- /es/agent/guide/how_remote_config_works
+- /es/agent/remote_config
+description: Configura y cambia de forma remota el comportamiento de los componentes
+ de Datadog como Agents, bibliotecas de rastreo y Observability Pipelines Workers
+ desplegados en tu infraestructura.
+further_reading:
+- link: /security/application_security/how-appsec-works/#built-in-protection
+ tag: Documentación
+ text: Como funciona Application Security Monitoring
+- link: /dynamic_instrumentation/?tab=configurationyaml#enable-remote-configuration
+ tag: Documentación
+ text: Dynamic Instrumentation
+- link: /security/workload_protection/
+ tag: Documentación
+ text: Configuración de Workload Protection
+- link: https://www.datadoghq.com/blog/compliance-governance-transparency-with-datadog-audit-trail/
+ tag: Blog
+ text: Como usar Datadog Audit Trail
+- link: https://www.datadoghq.com/blog/remote-configuration-for-datadog/
+ tag: Blog
+ text: Aplicar actualizaciones en tiempo real a los componentes de Datadog con la
+ configuración remota
+title: Configuración remota
+---
+
+## Información general
+
+La configuración remota es una función de Datadog que te permite configurar y cambiar de forma remota el comportamiento de los componentes de Datadog (por ejemplo, Agents, bibliotecas de rastreo y Observability Pipelines Workers) desplegados en tu infraestructura. Utiliza la configuración remota para aplicar configuraciones a componentes de Datadog de tu entorno, disminuyendo los costes de gestión, reduciendo la fricción entre equipos y acelerando los tiempos de resolución de problemas.
+
+Para productos de seguridad de Datadog, App and API Protection y Workload Protection, los Agents habilitados por configuración remota y bibliotecas de rastreo compatibles proporcionan actualizaciones y respuestas de seguridad en tiempo real, lo que mejora la situación de seguridad de tus aplicaciones y la infraestructura de la nube.
+
+## Cómo funciona
+
+Cuando la configuración remota está activada, los componentes de Datadog como el Datadog Agent sondean de forma segura el [sitio Datadog][1] configurado en busca de cambios de configuración que estén listos para ser aplicados. Los cambios pendientes se aplican automáticamente a los componentes de Datadog. Por ejemplo, después de enviar cambios de configuración en la interfaz de usuario de Datadog para una función de producto habilitada por configuración remota, los cambios se almacenan en Datadog.
+
+El siguiente diagrama muestra como funciona la configuración remota:
+
+{{traceSampleRate con el valor de sessionSampleRate configurado anteriormente. Por ejemplo, si solías tener configurado sessionSampleRate al 10 % y lo aumentas al 100 % para RUM without Limits, reduce traceSampleRate del 100 % al 10 % para ingerir la misma cantidad de trazas.}}
+
+1. Configura las funciones del producto escogidas en la interfaz de usuario de Datadog.
+2. La configuración de las funciones del producto se almacenan en condiciones seguras en Datadog.
+3. Los componentes de Datadog habilitados por configuración remota en tus entornos sondean, reciben y aplican automáticamente actualizaciones de configuración de forma segura desde Datadog. Las bibliotecas de rastreo que se despliegan en tus entornos se comunican con los Agents para solicitar y recibir actualizaciones de configuración desde Datadog, en lugar de sondear Datadog directamente.
+
+## Entornos compatibles
+
+La configuración remota funciona en entornos en los que están instalados los componentes compatibles de Datadog. Entre los componentes compatibles de Datadog se incluyen:
+- Agents
+- Rastreadores (indirectamente)
+- Observability Pipeline Workers
+- Ejecutores de acciones privadas y servicios de nube de contenedores sin servidor como AWS Fargate
+
+La configuración remota no es compatible con aplicaciones sin servidor gestionadas por contenedores, como AWS App Runner, Azure Container Apps, Google Cloud Run, ni con funciones desplegadas con paquetes de contenedores, como AWS Lambda, Azure Functions y Google Cloud Functions.
+
+## Productos y funciones compatibles
+
+Los siguientes productos y funciones son compatibles con la configuración remota.
+
+Fleet Automation
+: - [Envía flares][27] directamente desde el sitio Datadog. Soluciona sin problemas incidentes del Datadog Agent sin acceder directamente al host.
+: - [Actualiza tus Agents][29] (Vista previa).
+
+App and API Protection (AAP)
+: - [Activación de AAP en 1 clic][33]: Activa AAP en 1 clic desde la interfaz de usuario de Datadog.
+: - [Actualizaciones de patrones de ataque en la aplicación][34]: Recibe automáticamente los patrones de ataque más recientes de Web Application Firewall (WAF) a medida que Datadog los publica, siguiendo vulnerabilidades o vectores de ataque recientemente revelados.
+: - [Protección][34]: Bloquea las IP de los atacantes, los usuarios autenticados y las solicitudes sospechosas indicadas en señales y rastros de seguridad de AAP de forma temporal o permanente a través de la interfaz de usuario de Datadog.
+
+Application Performance Monitoring (APM)
+: - Configuración en tiempo de ejecución (Vista previa): Cambia la frecuencia de muestreo del rastreo de un servicio, la activación de la inyección de logs y las etiquetas (tags) de encabezados HTTP desde la interfaz de usuario del Catálogo de software, sin tener que reiniciar el servicio. Consulta [Configuración en tiempo de ejecución][22] para obtener más información.
+: - [Configura de forma remota la frecuencia de muestreo del Agent][35] (Vista previa): Configura de forma remota el Datadog Agent para cambiar sus frecuencias de muestreo del rastreo y configura reglas para escalar la ingesta de trazas (traces) de tu organización según tus necesidades, sin necesidad de reiniciar tu Datadog Agent.
+
+[Dynamic Instrumentation][36]
+: - Envía métricas, trazas y logs críticos de tus aplicaciones en directo sin cambios en el código.
+
+Workload Protection
+: - Actualizaciones automáticas de reglas predeterminadas del Agent: Recibe y actualiza automáticamente las reglas predeterminadas del Agent mantenidas por Datadog a medida que se publican nuevas detecciones y mejoras del Agent. Consulta [Configuración de Workload Protection][3] para obtener más información.
+: - Despliegue automático de reglas personalizadas del Agent: Despliega automáticamente tus reglas personalizadas del Agent en los hosts designados (todos los hosts o un subconjunto definido de hosts).
+
+Observability Pipelines
+: - Despliega y actualiza de forma remota [Observability Pipelines Workers][4] (OPW): Crea y edita pipelines en la interfaz de usuario de Datadog, desplegando tus cambios de configuración en las instancias OPW que se ejecutan en tu entorno.
+
+Ejecutor de acciones privadas
+: - Ejecuta flujos de trabajo y aplicaciones de Datadog que interactúan con servicios alojados en tu red privada sin exponer tus servicios a la Internet pública. Para obtener más información, consulta [Private Actions][30].
+
+## Cuestiones de seguridad
+
+Datadog implementa las siguientes medidas de seguridad para proteger la confidencialidad, la integridad y la disponibilidad de las configuraciones que reciben y aplican los componentes de Datadog:
+
+- Los componentes de Datadog habilitados por configuración remota y desplegados en tu infraestructura necesitan configuraciones de Datadog.
+ Algunos componentes, como los ejecutores de acciones privadas, están siempre habilitados por configuración remota. Otros, como el Agent, pueden activarse o desactivarse mediante opciones de configuración en el disco.
+- Datadog nunca envía cambios de configuración a menos que se lo soliciten componentes de Datadog. Si envía cambios de configuración, Datadog solo envía aquellos relevantes para el componente solicitante.
+- Las solicitudes de configuración se inician desde tu infraestructura a Datadog a través de HTTPS (puerto 443). Este es el mismo puerto que el Agent utiliza por defecto para enviar datos de observabilidad.
+- La comunicación entre tus componentes de Datadog y Datadog se cifra mediante HTTPS y se autentica y autoriza utilizando tu clave de API Datadog, excepto en el caso de los ejecutores de acciones privadas donde se utiliza un token JWT en su lugar.
+- Solo los usuarios con el permiso [`api_keys_write`][5] están autorizados a activar o desactivar la función de configuración remota en las claves de API y a utilizar las funciones compatibles del producto.
+- Los cambios de configuración enviados a través de la interfaz de usuario de Datadog son firmados y validados por el componente de Datadog solicitante, lo que verifica la integridad de la configuración.
+
+## Activar la configuración remota
+
+En la mayoría de los casos, la configuración remota está activada por defecto para tu organización. Puedes comprobar si la configuración remota está activada en tu organización desde la página de parámetros de [Configuración remota][8]. Si necesitas activarla:
+1. Asegúrate de que los permisos de RBAC incluyan [`org_management`][7], para poder habilitar la configuración remota en tu organización.
+1. Desde la página Parámetros de tu organización, activa [Configuración remota][8]. Esto permite que los componentes de Datadog de toda la organización reciban configuraciones de Datadog.
+1. Sigue las instrucciones de [configuración específicas del producto](#product-specific-configuration) que se indican a continuación para finalizar la configuración remota.
+
+### Configuración específica del producto
+
+Consulta la documentación a continuación para obtener instrucciones específicas para el producto que estás configurando.
+
+| Producto | Instrucciones de instalación |
+| ------- | --------------------- |
+| Automatización de flotas | [Configurar Fleet Automation][31] |
+| APM | [Configuración en tiempo de ejecución](/tracing/guide/remote_config/) |
+| Dynamic Instrumentation | [Empezando con Dynamic Instrumentation](/dynamic_instrumentation/#getting-started) |
+| Workload Protection | [Workload Protection][3] |
+| Observability Pipelines | Asegúrate de que has [activado la configuración remota en la clave de API][32] que estás utilizando para Observability Pipelines. |
+| Sensitive Data Scanner | [Almacenamiento en la nube](/security/sensitive_data_scanner/setup/cloud_storage/?tab=newawsaccount) |
+| Ejecutor de acciones privadas | [Información general sobre acciones privadas](/actions/private_actions/) |
+
+## Prácticas recomendadas
+
+### Audit Trail de Datadog
+
+Utiliza [Audit Trail de Datadog][13] para monitorizar el acceso a la organización y a eventos habilitados por configuración remota. Audit Trail permite a los administradores y equipos de seguridad realizar un seguimiento de la creación, eliminación y modificación de la API de Datadog y las claves de aplicación. Una vez configurado Audit Trail, podrás ver los eventos relacionados con las funciones habilitadas por configuración remota y quién ha solicitado estos cambios. Audit Trail permite reconstruir secuencias de eventos y establecer una monitorización sólida de Datadog para la configuración remota.
+
+### Monitores
+
+Configurar los [monitores][14] para recibir notificaciones cuando se encuentre un evento de interés.
+
+## Exclusión de la configuración remota
+
+En lugar de desactivar la configuración remota de forma global, Datadog recomienda optar por desactivarla en productos específicos de Datadog. Para obtener más información, consulta la [documentación del producto en cuestión](#product-specific-configuration).
+
+## Referencias adicionales
+
+{{< partial name="whats-next/whats-next.html" >}}
+
+[1]: /es/getting_started/site/
+[3]: /es/security/workload_protection/
+[4]: /es/observability_pipelines/#observability-pipelines-worker
+[5]: /es/account_management/rbac/permissions#api-and-application-keys
+[6]: /es/security/application_security/threats/setup/compatibility/
+[7]: /es/account_management/rbac/permissions#access-management
+[8]: https://app.datadoghq.com/organization-settings/remote-config
+[9]: /es/security/default_rules/#cat-workload-security
+[10]: /es/tracing/trace_pipeline/ingestion_controls/#managing-ingestion-for-all-services-at-the-agent-level
+[11]: /es/dynamic_instrumentation/?tab=configurationyaml#enable-remote-configuration
+[12]: /es/security/application_security/how-appsec-works/#built-in-protection
+[13]: /es/account_management/audit_trail
+[14]: /es/monitors/
+[15]: /es/help/
+[16]: /es/remote_configuration
+[17]: /es/agent/configuration/network
+[18]: /es/agent/configuration/proxy/
+[19]: /es/tracing/software_catalog/
+[20]: /es/dynamic_instrumentation/?tab=configurationyaml#prerequisites
+[21]: /es/agent/configuration/agent-configuration-files/?tab=agentv6v7#agent-main-configuration-file
+[22]: /es/tracing/trace_collection/runtime_config/
+[23]: /es/remote_configuration#opting-out-of-remote-configuration
+[24]: https://app.datadoghq.com/organization-settings/api-keys
+[25]: /es/agent/guide/
+[26]: https://app.datadoghq.com/organization-settings/remote-config/setup?page_id=org-enablement-step
+[27]: /es/agent/fleet_automation/#send-a-remote-flare
+[28]: /es/security/sensitive_data_scanner/?tab=usingtheagent
+[29]: /es/agent/fleet_automation/remote_management#remotely-upgrade-your-agents
+[30]: /es/actions/private_actions/use_private_actions/
+[31]: /es/agent/guide/setup_remote_config
+[32]: https://app.datadoghq.com/organization-settings/remote-config/setup?page_id=api-key-enablement-step&standalone=1
+[33]: /es/security/application_security/setup/
+[34]: /es/security/application_security/
+[35]: /es/tracing/trace_pipeline/adaptive_sampling/
+[36]: /es/tracing/dynamic_instrumentation/#explore-dynamic-instrumentation
\ No newline at end of file
diff --git a/content/es/security/application_security/setup/nodejs/_index.md b/content/es/security/application_security/setup/nodejs/_index.md
new file mode 100644
index 0000000000000..d8e495ce71a93
--- /dev/null
+++ b/content/es/security/application_security/setup/nodejs/_index.md
@@ -0,0 +1,51 @@
+---
+aliases:
+- /es/security_platform/application_security/getting_started/nodejs
+- /es/security/application_security/getting_started/nodejs
+- /es/security/application_security/enabling/tracing_libraries/threat_detection/nodejs/
+- /es/security/application_security/threats/setup/threat_detection/nodejs
+- /es/security/application_security/threats_detection/nodejs
+- /es/security/application_security/setup/aws/fargate/nodejs
+further_reading:
+- link: /security/application_security/add-user-info/
+ tag: Documentación
+ text: Añadir información del usuario a trazas (traces)
+- link: https://github.com/DataDog/dd-trace-js
+ tag: Código fuente
+ text: Código fuente de la biblioteca Node.js de Datadog
+- link: /security/default_rules/?category=cat-application-security
+ tag: Documentación
+ text: Reglas de protección de aplicaciones y API predefinidas
+- link: /security/application_security/troubleshooting
+ tag: Documentación
+ text: Solucionar problemas con la protección de aplicaciones y API
+title: Activar App and API Protection para Node.js
+---
+{{< partial name="app_and_api_protection/callout.html" >}}
+
+{{% aap/aap_and_api_protection_nodejs_overview showSetup="false" %}}
+
+## Entornos
+
+### Hosts
+{{< appsec-integrations >}}
+{{< appsec-integration name="Linux" avatar="linux" link="./linux" >}}
+{{< appsec-integration name="macOS" avatar="apple" link="./macos" >}}
+{{< appsec-integration name="Windows" avatar="windows" link="./windows" >}}
+{{< /appsec-integrations >}}
+
+### Plataformas de nube y contenedores
+{{< appsec-integrations >}}
+{{< appsec-integration name="Docker" avatar="docker" link="./docker" >}}
+{{< appsec-integration name="Kubernetes" avatar="kubernetes" link="./kubernetes" >}}
+{{< /appsec-integrations >}}
+
+### AWS
+{{< appsec-integrations >}}
+{{< appsec-integration name="AWS Fargate" avatar="aws-fargate" link="./aws-fargate" >}}
+{{< /appsec-integrations >}}
+
+## Recursos adicionales
+
+- [Guía de resolución de problemas](./troubleshooting)
+- [Información de compatibilidad(./compatibility)
\ No newline at end of file
diff --git a/content/es/security/application_security/terms.md b/content/es/security/application_security/terms.md
index e67c23c1bae5c..72ffabec61646 100644
--- a/content/es/security/application_security/terms.md
+++ b/content/es/security/application_security/terms.md
@@ -23,14 +23,14 @@ Intento de ataque
Biblioteca de Datadog
: _también_ rastreador, biblioteca de rastreo
-: una biblioteca específica del lenguaje de programación incrustada en aplicaciones web. Datadog App and API Protection utiliza la librería para monitorizar y proteger. APM utiliza la misma biblioteca para instrumentar código para rastrear telemetría.
+: una biblioteca específica del lenguaje de programación incrustada en aplicaciones web. Datadog App and API Protection utiliza la biblioteca para monitorizar y proteger. APM utiliza la misma biblioteca para instrumentar código para rastrear telemetría.
Regla de detección
: Definición de lógica condicional que se aplica a los datos ingeridos y a las configuraciones de la nube. Cuando coincide al menos un caso definido en una regla durante un periodo de tiempo determinado, Datadog genera una _señal de seguridad_.
: Consulta [Reglas de detección][10].
Lista de permisos (antiguo filtro de exclusión)
-: Mecanismo para descartar las trazas de seguridad marcadas por la librería de Datadog App and API Protection y las reglas WAF en la aplicación. La lista de permisos se aplica a medida que las solicitudes se ingieren en Datadog (admisión), y ayuda a gestionar los falsos positivos y los costes de admisión.
+: Mecanismo para descartar las trazas de seguridad marcadas por la biblioteca de Datadog App and API Protection y las reglas WAF en la aplicación. La lista de permisos se aplica a medida que las solicitudes se ingieren en Datadog (admisión), y ayuda a gestionar los falsos positivos y los costes de admisión.
: Consulta [Filtros de exclusión][11] en la aplicación.
Reglas WAF en la aplicación (antiguas reglas de eventos)
@@ -74,12 +74,12 @@ Información sobre amenazas
: Consulta [Información sobre amenazas][16].
atacantes sospechosos
-: Precursor de las IP marcadas. Las IPs sospechosas han alcanzado un umbral mínimo de tráfico de ataque para ser clasificadas como sospechosas, pero no el umbral para Flagged. Los umbrales no son configurables por el usuario.
-: Véase [Atacantes Explorer][17]
+: un precursor de las IPs marcadas. Las IPs sospechosas han alcanzado un umbral mínimo de tráfico de ataque para ser clasificadas como sospechosas, pero no el umbral para Flagged (Marcadas). Los umbrales no son configurables por el usuario.
+: Consulta [Attackers Explorer][17]
atacantes marcados
-: IPs que envían grandes cantidades de tráfico de ataque. Se recomienda revisar y bloquear las IP marcadas. Los umbrales no son configurables por el usuario.
-: Ver [Atacantes Explorer][17]
+: IPs que envían grandes cantidades de tráfico de ataque. Se recomienda revisar y bloquear las IPs marcadas. Los umbrales no son configurables por el usuario.
+: Consulta [Attackers Explorer][17]
huella digital del atacante
: identificadores calculados a partir de las características de la solicitud para rastrear a un atacante a través de múltiples solicitudes.
@@ -134,7 +134,7 @@ Inyección de OGNLi (Object-Graph Navigation Language Injection)
[5]: https://owasp.org/Top10/A10_2021-Server-Side_Request_Forgery_%28SSRF%29/
[6]: https://owasp.org/www-project-web-security-testing-guide/v42/4-Web_Application_Security_Testing/07-Input_Validation_Testing/11.1-Testing_for_Local_File_Inclusion
[7]: https://owasp.org/www-project-top-ten/2017/A1_2017-Injection
-[8]: /es/agent/remote_config/
+[8]: /es/remote_configuration
[10]: /es/security/detection_rules/
[11]: https://app.datadoghq.com/security/appsec/exclusions
[12]: /es/security/application_security/policies/inapp_waf_rules/
@@ -144,4 +144,4 @@ Inyección de OGNLi (Object-Graph Navigation Language Injection)
[16]: /es/security/application_security/how-it-works/threat-intelligence/
[17]: /es/security/application_security/security_signals/attacker-explorer/
[18]: /es/security/application_security/security_signals/attacker_fingerprint/
-[19]: /es/security/application_security/security_signals/attacker_clustering/
+[19]: /es/security/application_security/security_signals/attacker_clustering/
\ No newline at end of file
diff --git a/content/es/security/application_security/troubleshooting.md b/content/es/security/application_security/troubleshooting.md
index 5166510f50885..3a6aa1ca16661 100644
--- a/content/es/security/application_security/troubleshooting.md
+++ b/content/es/security/application_security/troubleshooting.md
@@ -27,7 +27,7 @@ Existe una serie de pasos que deben ejecutarse correctamente para que la informa
Para comprobar si AAP se está ejecutando, puedes utilizar la métrica `datadog.apm.appsec_host`.
-1. Ve a **Métricas > Resumen** en Datadog.
+1. Ve a **Metrics > Summary** (Métricas > Resumen) en Datadog.
2. Busca la métrica `datadog.apm.appsec_host` . Si la métrica no existe, entonces no hay servicios ejecutando AAP. Si la métrica existe, los servicios se informan mediante las etiquetas (tags) de métricas `host` y `service`.
3. Selecciona la métrica y busca `service` en la sección **Etiquetas** para ver qué servicios están ejecutando AAP.
@@ -248,7 +248,7 @@ Para resolver este paso del proceso, haz lo siguiente:
- Comprueba los detalles del Agent que se está ejecutando en esta dirección `http://Si AAP se habilitó mediante configuración remota, puedes utilizar el botón Deactivate (Desactivar). Si AAP se habilitó mediante configuración local, el botón Deactivate (Desactivar) no es una opción.
### Desactivar en bloque
-Para deshabilitar AAP en tus servicios de forma masiva, haz lo siguiente:
- 1. Ve a [Servicios][15].
- 2. En la faceta **Gestión de amenazas**, activa **Monitoring Only**, **No data**, and **Ready to block** (Sólo monitorización, Sin datos y Listo para el bloqueo).
+Para deshabilitar AAP en tus servicios de forma masiva, haz lo siguiente:
+ 1. Ve a [Services (Servicios)][15].
+ 3. En la faceta **App & API Protection**, activa **Monitoring Only** (Solo monitorización), **No data** (Sin datos) y **Ready to block** (Listo para bloquear).
3. Selecciona las casillas de verificación de servicios en las que quieres deshabilitar la detección de amenazas.
- 4. En **Acciones masivas**, selecciona **Desactivar detección de amenazas en (número) servicios**.
+ 4. En **Bulk Actions** (Acciones en bloque), selecciona **Deactivate Threat detection on (number of) services** (Desactivar detección de amenazas en (número) servicios).
## ¿Necesitas más ayuda?
@@ -612,4 +615,4 @@ Si sigues teniendo problemas con AAP, ponte en contacto con el [servicio de asis
[14]: /es/security/code_security/software_composition_analysis
[15]: https://app.datadoghq.com/security/configuration/asm/services-config
[16]: https://app.datadoghq.com/organization-settings/remote-config
-[17]: https://ddtrace.readthedocs.io/en/stable/integrations.html#flask
+[17]: https://ddtrace.readthedocs.io/en/stable/integrations.html#flask
\ No newline at end of file
diff --git a/content/es/security/cloud_siem/_index.md b/content/es/security/cloud_siem/_index.md
index de1ee1b809abd..1413250b4d132 100644
--- a/content/es/security/cloud_siem/_index.md
+++ b/content/es/security/cloud_siem/_index.md
@@ -12,6 +12,10 @@ further_reading:
tag: Blog
text: Automatiza tareas de seguridad habituales y protégete frente a las amenazas
con Datadog Workflows y Cloud SIEM
+- link: https://www.datadoghq.com/blog/soar/
+ tag: Blog
+ text: Automatizar la protección de identidades, la contención de amenazas y la inteligencia
+ sobre amenazas con los flujos de trabajo SOAR de Datadog
- link: https://www.datadoghq.com/blog/compliance-governance-transparency-with-datadog-audit-trail/
tag: Blog
text: Mejora el control, la gestión y la transparencia en todos tus equipos con
@@ -28,41 +32,244 @@ further_reading:
text: Crear una cobertura de seguridad suficiente para tu entorno en la nube
- link: https://www.datadoghq.com/blog/monitor-dns-logs-for-network-and-security-datadog/
tag: Blog
- text: Monitorización de logs DNS para la red y los análisis de seguridad
+ text: Monitorizar logs de DNS para análisis de red y seguridad
- link: https://www.datadoghq.com/blog/akamai-zero-trust-application-security/
tag: Blog
- text: Monitoriza Akamai Zero Trust y Application Security con Datadog Cloud SIEM
+ text: Monitorizar Akamai Zero Trust y Application Security con Datadog Cloud SIEM
+- link: https://www.datadoghq.com/blog/microsoft-365-detections/
+ tag: Blog
+ text: Cómo se aprovechan los atacantes de los servicios de Microsoft 365
+- link: https://www.datadoghq.com/blog/monitor-security-metrics/
+ tag: Blog
+ text: Monitorizar la postura de seguridad de tu organización con Datadog
+- link: https://www.datadoghq.com/blog/risky-behavior-cloud-environments/
+ tag: Blog
+ text: Identificar comportamientos de riesgo en entornos de la nube
+- link: https://www.datadoghq.com/blog/detect-phishing-activity-amazon-ses/
+ tag: Blog
+ text: 'Monitorización de Amazon SES: Detectar campañas de phishing en la nube'
+- link: https://www.datadoghq.com/blog/detection-as-code-cloud-siem/
+ tag: Blog
+ text: Crea, prueba y escala detecciones como código con Datadog Cloud SIEM
title: Cloud SIEM
---
-{{< learning-center-callout header="Join an enablement webinar session" hide_image="true" btn_title="Sign Up" btn_url="https://www.datadoghq.com/technical-enablement/sessions/?tags.topics-0=Security">}}
- Descubre cómo Datadog Cloud SIEM y Cloud Security Management mejoran la detección de amenazas de tu organización e investigación de entornos dinámicos a escala en la nube.
+{{< learning-center-callout header="'Unete a una sesión web de capacitación" hide_image="true" btn_title="Inscríbete" btn_url="https://www.datadoghq.com/technical-enablement/sessions/?tags.topics-0=Security">}}
+ Descubre cómo Datadog Cloud SIEM y Cloud Security aumentan el nivel de detección e investigación de amenazas de tu organización en entornos dinámicos a escala de la nube.
{{< /learning-center-callout >}}
## Información general
-Datadog Cloud SIEM (Security Information y Event Management) unifica los equipos de desarrollo, operaciones y seguridad en una sola plataforma. Utiliza un único dashboard para visualizar el contenido de DevOps, las métricas empresariales y la información de seguridad. Cloud SIEM detecta en tiempo real las amenazas a tus aplicaciones y tu infraestructura, como ataques dirigidos, comunicaciones desde direcciones IP incluidas en la lista de amenazas y configuraciones inseguras. Notifica estos problemas de seguridad a tu equipo por correo electrónico, Slack, Jira, PagerDuty o webhooks.
+Datadog Cloud SIEM (Información de seguridad y Event Management) es un sistema de análisis y correlación de datos de seguridad. Permite a todo el equipo de operaciones de seguridad ver, detectar, investigar y responder a los problemas de seguridad. Aprovechando la plataforma escalable de Datadog, Cloud SIEM ingiere telemetría tanto de sistemas en la nube como de sistemas on-premises mediante el Datadog Agent e integraciones basadas en la API.
+
+Una respuesta de seguridad eficaz requiere velocidad, contexto, conocimiento y automatización. Cloud SIEM analiza continuamente los datos entrantes para detectar amenazas, generar señales de seguridad procesables y correlacionarlas a través de múltiples fuentes. Esto permite a tu equipo investigar incidentes y responder con rapidez.
+
+Para mantener a tu equipo al tanto de los últimos ataques, Datadog también cuenta con un equipo de investigadores de amenazas que analizan petabytes de telemetría a través de sistemas en la nube y on-premises para identificar amenazas emergentes y comportamientos de atacantes. Consulta [Datadog Security Labs][1] para leer artículos sobre sus investigaciones recientes.
+
+### Seguridad y observabilidad
+
+Cloud SIEM integra la telemetría en la nube y on-premises directamente en los flujos de trabajo de seguridad para acelerar la investigación y la respuesta. Y con una plataforma compartida que une los equipos de DevOps y seguridad, las organizaciones pueden acabar con los silos y responder a las amenazas de forma colaborativa y eficiente.
+
+### Control flexible de los costes de los datos de seguridad
+
+A medida que tu organización crece, es fundamental controlar el coste de ingesta de los logs de seguridad sin comprometer la visibilidad. Cloud SIEM está integrado con Datadog Log Management para que puedas elegir la capacidad de retención y consulta adecuada para tus logs de seguridad. Esta flexibilidad te ayuda a equilibrar la rentabilidad con tus necesidades de detección de amenazas.
-{{< img src="security/security_monitoring/cloud_siem_overview_2.png" alt="Página principal de Cloud SIEM que muestra la sección de información general de seguridad con widgets para señales importantes, actores sospechosos, recursos afectados, información sobre amenazas y tendencias de señales" >}}
+Almacena logs utilizando una de las opciones disponibles:
+- [Indexación estándar][6] para logs que deben consultarse frecuentemente con el mayor número de cálculos.
+- [Logs flexibles][7] para logs que deben conservarse a largo plazo, pero que a veces deben consultarse con urgencia.
+- [Archivos de logs][8] para logs que se consultan con poca frecuencia y deben almacenarse a largo plazo.
-Las amenazas aparecen en Datadog como señales de seguridad y se pueden correlacionar y clasificar en el [Security Signals Explorer][1]. Las señales de seguridad son generadas por Datadog Cloud SIEM con [Reglas de detección][2]. Las Reglas de detección detectan amenazas a través de diferentes fuentes y están disponibles para su uso inmediato. Puedes clonar cualquiera de las reglas de detección proporcionadas para cambiar la configuración. También puedes añadir una [nueva regla][3] desde cero para adaptarla a tu caso de uso específico.
+### Incorporación guiada de datos de seguridad
+
+Los [paquetes de contenido][9] de Cloud SIEM son un conjunto de integraciones de Datadog diseñados para los equipos de seguridad. Cada paquete de contenido contiene instrucciones sobre cómo configurar la integración y qué incluye, como reglas de detección, dashboards predefinidos interactivos, parseos y flujos de trabajo SOAR. Los paquetes de contenido resaltan información práctica específica de cada integración para ayudarte a investigar los problemas de seguridad.
+
+### Monitorización del estado del paquete de contenido
+
+Una vez activado un paquete de contenido, te informa del estado de la integración y te ofrece pasos para solucionar problemas si algo va mal, para que puedas volver a estar operativo lo antes posible.
+
+### Búsqueda y análisis de logs
+
+Crea búsquedas en el Log Explorer utilizando facetas o haciendo clic en los campos directamente en los logs. O utiliza Bits AI y la búsqueda en lenguaje natural para encontrar eventos de seguridad importantes. Con las funciones integradas de búsqueda por grupos y tablas, así como el análisis de patrones y las visualizaciones, los equipos de seguridad pueden obtener información sobre seguridad a partir de sus datos. Consulta [Log Explorer][11] y [Sintaxis de búsqueda de logs][10] para obtener más información.
## Para empezar
-{{< whatsnext desc="See the following documents to get started with Cloud SIEM:" >}}
- {{< nextlink href="/getting_started/cloud_siem/">}}Empezando con la Guía de Cloud SIEM{{< /nextlink >}}
- {{< nextlink href="/security/cloud_siem/guide/aws-config-guide-for-cloud-siem/">}}Configurar AWS para Cloud SIEM{{< /nextlink >}}
- {{< nextlink href="/security/cloud_siem/guide/google-cloud-config-guide-for-cloud-siem/">}}Configurar Google Cloud para Cloud SIEM{{< /nextlink >}}
- {{< nextlink href="/security/cloud_siem/guide/azure-config-guide-for-cloud-siem/">}}Configurar Azure para Cloud SIEM{{< /nextlink >}}
- {{< nextlink href="/integrations/">}}Buscar integraciones específicas para configurar la recopilación de logs en ellas{{< /nextlink >}}
- {{< nextlink href="/security/default_rules#cat-cloud-siem-log-detection">}}Comenzar a usar reglas de detección predefinidas de Cloud SIEM{{< /nextlink >}}
- {{< nextlink href="/security/detection_rules">}}Crear tus propias reglas de detección personalizadas{{< /nextlink >}}
-{{< /whatsnext >}}
+Si aún no tienes una cuenta en Datadog, regístrate para obtener una [prueba gratuita][2]. Después de acceder a tu cuenta de Datadog:
+
+1. Navega hasta [Cloud SIEM][3].
+1. Haz clic en **Enable Cloud SIEM** (Habilitar Cloud SIEM).
+1. Sigue los pasos de incorporación.
+
+Consulta la [Guía de introducción][4] para obtener instrucciones de configuración más detalladas.
+
+## Página de información general de Cloud SIEM
+
+Navega hasta la [página de información general de Cloud SIEM][3]. Utiliza esta página para ver las perspectivas clave de seguridad y actuar sobre flujos de trabajo comunes para analistas de seguridad, ingenieros de seguridad y detección, y gerentes del Centro de Operaciones de Seguridad (SOC). Desde la página de información general, puedes:
+- Acceder a señales importantes, casos abiertos y entidades de alto riesgo.
+- Completar las tareas de incorporación y revisar el estado del paquete de contenido.
+- Ver e investigar las principales señales por geografía o proveedor de servicios de Internet (ISP).
+- Analizar señales y reglas mediante tácticas de MITRE ATT&CK.
+- Seguimiento del rendimiento de la detección (tiempo medio hasta la detección (MTTD), tasas de falsos positivos).
+- Leer las últimas investigaciones y notas de la versión de [Security Labs][1].
+
+Haz clic en **Customize Page** (Personalizar página) para reordenar u ocultar los módulos de modo que puedas ver lo que es importante para ti.
+
+Obtén más información sobre cada una de las secciones de página de información general de Cloud SIEM.
+
+### Cobertura de seguridad
+
+{{< img src="security/security_monitoring/landing/01_security_coverage.png" alt="Secciones de cobertura de código que muestra 11 paquetes de contenido y 1 paquete de contenido roto y un gráfico de barras de los logs analizados por Cloud SIEM" style="width:100%;" >}}
+
+Está atento a cualquier problema de tratamiento de datos o laguna en la cobertura.
+
+#### Paquetes de contenido e integraciones habilitados
+
+Ve los paquetes de contenido y las integraciones habilitados en las categorías críticas para proporcionar una cobertura de seguridad completa. Pasa el ratón por encima de cada sección de la barra horizontal para ver qué paquetes de contenido están activados en cada categoría.
+
+#### Paquete de contenido y KPIs de estado del log
+
+Comprueba si algún paquete de contenido o integración se encuentra en estado de advertencia o roto para poder resolver las brechas de cobertura. Haz clic en un cuadro de estado para ver los paquetes de contenido afectados.
+
+#### Logs analizados
+
+Consulta las tendencias de registro en tus principales fuentes de log e identifica cualquier pico o caída inusual. Haz clic en la leyenda de la parte inferior para explorar las tendencias por fuente.
+
+### Señales y casos importantes
+
+{{< img src="security/security_monitoring/landing/02_important_signals_cases.png" alt="" style="width:100%;" >}}
+
+Ve los acontecimientos importantes que ocurren en tu entorno, como:
+
+#### Señales abiertas recientes agrupadas por regla
+
+Ve las señales agrupadas por nombre de regla y ordenadas por gravedad para obtener una visión general de las señales más importantes de tu entorno. Haz clic en una señal o en un conjunto de gravedad para ver más detalles en una vista filtrada en el Signal Explorer.
+
+#### Casos de seguridad abiertos recientemente
+
+Utiliza [Case Management][5] para realizar un seguimiento de las señales que requieren un análisis más detallado. Ve los casos de seguridad activos en tu entorno y haz clic en una incidencia para ver más detalles.
+
+### Información sobre riesgos
+
+{{< img src="security/security_monitoring/landing/03_risk_insights.png" alt="" style="width:100%;" >}}
+
+Revisa las entidades de riesgo de tu entorno.
+
+#### Entidades de mayor riesgo
+
+Ve las entidades con las puntuaciones de riesgo más altas. Haz clic en una entidad para ver más detalles y tomar acción.
+
+#### Desglose por tipo de entidad
+
+Ve los tipos de entidades más comunes en tu entorno. Haz clic en una parte del gráfico circular para filtrar la lista de entidades por tipo.
+
+#### Desglose de la puntuación de riesgo de las entidades
+
+Ver entidades por gravedad. Haz clic en un cuadro de gravedad para ver una lista de entidades con esa gravedad.
+
+### Mapa de amenazas
+
+{{< img src="security/security_monitoring/landing/04_threat_map.png" alt="" style="width:100%;" >}}
+
+Obtén información sobre dónde se generan las señales en tu entorno.
+
+#### Principales IPs por distribución de países
+
+Ve qué IPs están generando más señales con un desglose de señales importantes y menos importantes. Utiliza también el mapa para ver una lista de señales por país.
+
+#### Señales por país
+
+Ve el desglose proporcional de dónde se originan las señales. Haz clic en una parte del gráfico circular para filtrar por país y estado o provincia, e identificar las señales procedentes de lugares inesperados.
+
+#### Señales por proveedor de ISP
+
+Revisa qué ISPs están enviando señales. Haz clic en una parte del gráfico circular para desglosarlo por proveedor y ubicación.
+
+### Información general de seguridad
+
+{{< img src="security/security_monitoring/landing/05_security_overview.png" alt="" style="width:100%;" >}}
+
+Información general superficial de todas las señales.
+
+#### Distribución de señales
+
+En la parte izquierda de la sección, ve las señales agrupadas por gravedad y tendencia a lo largo de la ventana temporal seleccionada.
+En la parte derecha, puedes ver un desglose de la actividad de las señales por gravedad, fuente y resolución. Haz clic en un nodo del diagrama de Sankey para ver las señales en Signal Explorer filtradas según las características específicas de ese nodo.
+
+#### Tiempo medio de respuesta a las señales
+
+Ve los KPIs de la rapidez de respuesta de tu equipo. Haz clic en un cuadro de gravedad para ver las señales configuradas en `under review` o `archive` y filtradas según la gravedad seleccionada.
+
+### Cobertura de MITRE ATT&CK
+
+{{< img src="security/security_monitoring/landing/06_mitre_coverage.png" alt="" style="width:100%;" >}}
+
+Cobertura de reglas de detección y actividad de señales mediante tácticas y técnicas de MITRE ATT&CK.
+
+#### Técnicas con al menos 1 regla
+
+Ve cuántas técnicas están cubiertas por las reglas de detección activadas en tu entorno.
+
+#### KPIs de densidad de reglas
+
+Ve cuántas técnicas tienen una densidad alta, media o baja, o no tienen ninguna regla. Haz clic en un cuadro para ver un mapa de MITRE filtrado.
+
+#### Señales por vista táctica
+
+Ve qué tácticas de MITRE ATT&CK están generando señales. Haz clic en una parte del gráfico circular para ver el Signal Explorer filtrado por esa táctica. Haz clic en el menú desplegable y selecciona **Rules count** (Conteo de reglas) para ver qué tácticas tienen más reglas asignadas. Cuando se visualiza por recuento de reglas, al hacer clic en una parte del gráfico circular se crea una vista del Explorer de la regla de detección filtrada por esa táctica.
+
+#### Señales por vista técnica
+
+Ve qué técnicas de MITRE ATT&CK están generando señales. Haz clic en una parte del gráfico circular para ver el Signal Explorer filtrado por técnicas. Haz clic en el menú desplegable y selecciona **Rules count** (Conteo de reglas) para ver qué técnicas tienen más reglas asignadas. Cuando se visualiza por recuento de reglas, al hacer clic en una parte del gráfico circular se puede ver el Explorer de la regla de detección filtrado por esa técnicas.
+
+### Rendimiento de las reglas de detección
+
+{{< img src="security/security_monitoring/landing/07_detection_rule_performance.png" alt="" style="width:100%;" >}}
+
+Obtén una comprensión más profunda del rendimiento de las reglas de detección. Esta sección funciona mejor si realiza el triaje de señales en Cloud SIEM.
+
+#### KPIs de MTTD para Cloud SIEM
+
+Ve el tiempo medio de detección (MTTD) de todas las señales. Los cuadros de abajo muestran el MTTD para señales críticas, altas y medias. Haz clic en un cuadro para ver las señales con esa gravedad en Signal Explorer.
+
+#### Actividad de las señales
+
+Ve las tendencias de la señal en la ventana de tiempo seleccionada. Selecciona las casillas de verificación de gravedad en la parte inferior del gráfico de barras para ampliar el alcance por gravedad, lo que puede ser útil para identificar picos o caídas inusuales.
+
+#### Reglas por cambio de señal importante (1 semana)
+
+Ve qué reglas han aumentado la actividad de señales importantes en comparación con la semana anterior. Haz clic en el nombre de una regla para ver las señales en Signal Explorer filtradas por ese nombre de regla.
+
+#### Señales por cambio de gravedad (1 semana)
+
+Ve cómo han cambiado las gravedades de todas las señales en comparación con la semana anterior. Haz clic en una gravedad para ver las señales con esa gravedad en Signal Explorer.
+
+#### Señales importantes por motivo de archivo
+
+Ve cuántas señales se archivaron por motivo de archivo. Haz clic en un motivo para ver el Signal Explorer filtrado por ese motivo de archivo.
+
+#### Reglas archivadas con verdadero positivo (malicioso)
+
+Ve qué reglas se han archivado en `True Positive: Malicious`. Haz clic en una regla para ver las señales en Signal Explorer.
+
+#### Reglas archivadas con verdadero positivo (benigno)
+
+Ve qué reglas se han archivado en `True Positive: Benign`. Haz clic en una regla para ver las señales en Signal Explorer.
+
+#### Reglas por tasa de falsos positivos
+
+Ve qué reglas son las más ruidosas calculando el porcentaje de señales que se marcan como falsos positivos de todas las señales generadas por una regla. Haz clic en una regla para ver las señales correspondientes en Signal Explorer.
## Referencias adicionales
{{< partial name="whats-next/whats-next.html" >}}
-[1]: /es/security/cloud_siem/investigate_security_signals
-[2]: /es/security/default_rules#cat-cloud-siem
-[3]: /es/security/detection_rules
\ No newline at end of file
+[1]: https://securitylabs.datadoghq.com/
+[2]: https://www.datadoghq.com/product/cloud-siem/
+[3]: https://app.datadoghq.com/security/home?
+[4]: /es/getting_started/security/cloud_siem/
+[5]: /es/security/cloud_siem/investigate_security_signals/#case-management
+[6]: /es/logs/log_configuration/indexes
+[7]: /es/logs/log_configuration/flex_logs/
+[8]: /es/logs/log_configuration/archives/
+[9]: /es/security/cloud_siem/content_packs/
+[10]: /es/logs/explorer/search_syntax/
+[11]: /es/logs/explorer/
\ No newline at end of file
diff --git a/content/es/security/cloud_siem/detect_and_monitor/custom_detection_rules/create_rule/_index.md b/content/es/security/cloud_siem/detect_and_monitor/custom_detection_rules/create_rule/_index.md
new file mode 100644
index 0000000000000..26c93965eefc7
--- /dev/null
+++ b/content/es/security/cloud_siem/detect_and_monitor/custom_detection_rules/create_rule/_index.md
@@ -0,0 +1,4 @@
+---
+title: Crear una regla personalizada
+type: multi-code-lang
+---
diff --git a/content/es/security/code_security/dev_tool_int/pull_request_comments/_index.md b/content/es/security/code_security/dev_tool_int/pull_request_comments/_index.md
new file mode 100644
index 0000000000000..bbb21efdd4d2f
--- /dev/null
+++ b/content/es/security/code_security/dev_tool_int/pull_request_comments/_index.md
@@ -0,0 +1,140 @@
+---
+aliases:
+- /es/static_analysis/github_pull_requests
+- /es/code_analysis/github_pull_requests/
+- /es/security/code_security/dev_tool_int/github_pull_requests/
+description: Aprende a configurar comentarios de solicitudes de incorporación de cambios
+ para repositorios explorados por Code Security.
+title: Comentarios de solicitudes de incorporación de cambios
+---
+
+## Información general
+Code Security puede publicar comentarios directamente en las solicitudes de incorporación de cambios de tu sistema de gestión de código (SCM) source (fuente) cuando se detecten vulnerabilidades. Esto te ayuda a ver y solucionar los problemas en contexto antes de fusionar el código. Los comentarios tienen reconocimiento diferente, lo que significa que solo marcan los nuevos problemas introducidos en las líneas modificadas en la solicitud de incorporación de cambios.
+
+Existen dos tipos de comentarios de solicitudes de incorporación de cambios:
+- **Comentario en línea**: Marca una conclusión individual de Code Security en líneas específicas de código y sugiere una corrección (si está disponible).
+
+ {{< img src="/code_security/github_inline_pr_comment_light.png" alt="A Datadog bot has posted an inline comment on a GitHub pull request flagging a \"Critical: Code Vulnerability\". Este comentario sugiere sustituir el código os.system(command) con os.system(shlex.quote(command)) para depurar la llamada de proceso." style="width:100%;" >}}
+- **Comentario resumido**: Combina todas las conclusiones de Datadog en un único comentario.
+
+ {{< img src="/code_security/github_summary_comment_injections_light.png" alt="Un bot de Datadog ha publicado un comentario resumido en una solicitud de incorporación de cambios de GitHub. El comentario tiene una sección \"Warnings\" (Advertencias) en la que se enumeran vulnerabilidades críticas de código, como SQL e inserciones de comandos, con vínculos a los archivos y líneas específicas de código." style="width:100%;" >}}
+
+Puedes configurar los comentarios de PR a nivel de la organización o del repositorio en [Configuración del repositorio][7], con los siguientes controles:
+- Activación/desactivación de comentarios de PR por tipo de exploración (pruebas de seguridad de aplicaciones estáticas (SAST), SCA estático, secretos, IaC)
+- Configuración de umbrales de gravedad para cada tipo de exploración
+- Exclusión de los resultados de los archivos test o de las dependencias desarrollo/test
+
+**Nota**: Los comentarios de PR no son checks de PR. Para configurar las checks, consulta [Quality Gates][10].
+
+## Requisitos previos
+- Debes tener activada la integración de código source (fuente) de Datadog para tu proveedor. Los comentarios de PR son compatibles con los repositorios de [GitHub][2], [GitLab][8] y Azure DevOps ([en vista previa][9]).
+- Tus repositorios deben tener activados los productos Code Security correspondientes. Para actvar Code Security en la aplicación, ve a la [page (página) de configuración de **Code Security**][4].
+
+## Configurar comentarios de solicitud de incorporación de cambios
+Sigue los pasos que se indican a continuación en función de tu proveedor de gestión de códigos source (fuente).
+
+{{< tabs >}}
+{{% tab "GitHub" %}}
+
+Si utilizas la exploración alojada en Datadog, activa la alternancia del tipo de exploración que desees (por ejemplo, Análisis estático de código (pruebas de seguridad de aplicaciones estáticas (SAST))) una vez completados los pasos de configuración de GitHub.
+Si utilizas Acciones de GitHub para ejecutar tus exploraciones, activa la opción acción en
+
+### Conecta tu(s) cuenta(s) de GitHub a Datadog
+Para obtener instrucciones de configuración, lee la documentación de [integración de código source (fuente) de Datadog y GitHub][2].
+
+### Crear o actualizar una aplicación de GitHub
+Si ya tienes una aplicación de GitHub conectada a Datadog, actualízala. De lo contrario, crea una nueva aplicación de GitHub.
+
+inserción para que aparezcan los comentarios una vez completada la configuración de GitHub.Los permisos que concedas a la aplicación de GitHub determinan qué funciones de integración de GitHub están disponibles para la configuración.
+
+#### Crear e instalar una aplicación GitHub
+
+1. En Datadog, ve a [**Integraciones** > **Aplicaciones GitHub** > **Añadir una nueva aplicación GitHub**][3].
+2. Rellena los datos necesarios, como el nombre de la organización GitHub.
+3. En **Seleccionar función**, marca la casilla **Code Security: Comentarios de revisión de solicitudes de extracción**.
+4. En **Editar permisos**, comprueba que el permiso **Solicitudes de extracción** está configurado para **Lectura y escritura**.
+5. Haz clic en **Create App in GitHub** (Crear aplicación en GitHub).
+6. Introduce un nombre para tu aplicación y envíalo.
+7. Haz clic en **Install GitHub App** (Instalar aplicación GitHub).
+8. Elige en qué repositorios debe instalarse la aplicación y luego haz clic en **Install & Authorize** (Instalar y autorizar).
+
+ {{< img src="ci/static-analysis-install-github-app.png" alt="Pantalla de instalación de la aplicación de GitHub" style="width:50%;" >}}
+
+#### Actualizar una GitHub App existente
+
+1. En Datadog, ve a [**Integraciones > Aplicaciones GitHub**][5] y busca la aplicación GitHub que quieres utilizar para la seguridad del código.
+ {{< img src="ci/static-analysis-existing-github-app.png" alt="Ejemplo de comentario de Static Code Analysis en una solicitud de extracción" style="width:90%;" >}}
+2. En la pestaña **Características**, observa la sección **Code Security: Comentarios de solicitudes de extracción** para determinar si tu aplicación GitHub necesita permisos adicionales. Si es así, haz clic en **Update permissions in GitHub** (Actualizar permisos en GitHub) para editar la configuración de la aplicación.
+3. En **Permisos de repositorio**, configura el acceso a **Solicitudes de extracción** como **Lectura y escritura**.
+ {{< img src="ci/static-analysis-pr-read-write-permissions.png" alt="Desplegable correspondiente al permiso de lectura y escritura en solicitudes de extracción" style="width:90%;" >}}
+4. Bajo el título **Suscribirse a eventos**, marca la casilla **Solicitud de extracción**.
+ {{< img src="ci/static-analysis-pr-review-comment.png" alt="Casilla correspondiente al permiso para comentarios de revisión en solicitudes de extracción" style="width:90%;" >}}
+
+
+[2]: /es/integrations/github/
+[3]: https://app.datadoghq.com/integrations/github/add
+[5]: https://app.datadoghq.com/integrations/github/configuration
+
+{{% /tab %}}
+{{% tab "GitLab" %}}
+
+Consulta las instrucciones de configuración de l[Código source (fuente) de GitLab][8] para conectar GitLab a Datadog.
+
+[8]: /es/integrations/gitlab-source-code/
+
+{{% /tab %}}
+{{% tab "Azure DevOps" %}}
+
+Azure DevOps para Code Security está en vista previa. [Solicita acceso para unirte a la vista previa][9].
+
+[9]: https://www.datadoghq.com/product-preview/azure-devops-integration-code-security/
+
+{{% /tab %}}
+{{< /tabs >}}
+
+## Opciones de configuración
+
+Antes de activar los comentarios de PR, asegúrate de que **al menos una capacidad de exploración de Code Security esté activada en el repositorio.** Incluso si los comentarios de PR están configurados a nivel de la organización, solo se añaden en repositorios donde está activo un tipo de exploración admitido (por ejemplo, pruebas de seguridad de aplicaciones estáticas (SAST), SCA o IaC). Los repositorios sin ningún tipo de exploración activado no recibirán comentarios de PR.
+
+Los comentarios de PR pueden configurarse a nivel de la organización o a nivel del repositorio:
+- **Nivel de la organización:** La configuración se aplica a todos los repositorios de la organización que tengan activada al menos una capacidad de exploración.
+- **Nivel del repositorio:** La configuración sustituye los valores predeterminados de la organización para el repositorio seleccionado.
+
+Al configurar los comentarios de PR, puedes:
+- Activar o desactivar comentarios para tipos específicos de exploración (pruebas de seguridad de aplicaciones estáticas (SAST), SCA, IaC).
+- Configura umbrales mínimos de gravedad para controlar cuándo aparecen los comentarios.
+- Excluye los comentarios de los resultados en los archivos test o en las dependencias desarrollo/test para evitar el ruido de los problemas de baja prioridad.
+
+## Configurar los comentarios de PR a nivel de la organización
+
+1. En Datadog, ve a [**Seguridad** > **Code Security** > **Configuración**][7].
+1. En **Configuración del repositorio**, haz clic en **Global PR Comment Configuration** (Configuración global de comentarios en solicitudes de extracción).
+1. Configura los parámetros:
+ - **Activar comentarios en solicitudes de extracción para todos los tipos y gravedades de análisis**: Habilita esta opción para aplicar comentarios en solicitudes de extracción para todos los tipos y gravedades.
+ - **Activar para Static Analysis (SAST)**: Activa esta opción para habilitar comentarios en solicitudes de extracción para SAST. Si está activada, especifica un umbral de gravedad mínimo. Además, selecciona **Excluir comentarios en solicitudes de extracción, si se detectan infracciones en archivos de test** para evitar comentarios sobre problemas encontrados en archivos de test.
+ - **Activar para Software Composition Analysis (SCA)**: Activa esta opción para habilitar comentarios en solicitudes de extracción para SCA. Si está activada, especifica un umbral de gravedad mínimo. Además, selecciona **Excluir comentarios en solicitudes de extracción, si se detectan infracciones en dependencias de test o desarrollo** para evitar comentarios sobre problemas encontrados en dependencias existentes, sólo en entornos de test o desarrollo.
+ - **Activar para Infrastructure-as-Code (IaC)**: Activa esta opción para habilitar comentarios en solicitudes de extracción para IaC. Si está activada, especifica un umbral de gravedad mínimo.
+1. Haz clic en **Save** (Guardar).
+
+## Configurar comentarios de PR a nivel del repositorio
+
+1. En Datadog, ve a [**Seguridad** > **Code Security** > **Configuración**][7].
+1. En **Configuración del repositorio**, selecciona un repositorio de la lista.
+1. Configura los parámetros:
+ - **Activar comentarios en solicitudes de extracción para todos los tipos y gravedades de análisis**: Habilita esta opción para aplicar comentarios en solicitudes de extracción para todos los tipos y gravedades.
+ - **Activar para Static Analysis (SAST)**: Activa esta opción para habilitar comentarios en solicitudes de extracción para SAST. Si está activada, especifica un umbral de gravedad mínimo. Además, selecciona **Excluir comentarios en solicitudes de extracción, si se detectan infracciones en archivos de test** para evitar comentarios sobre problemas encontrados en archivos de test.
+ - **Activar para Software Composition Analysis (SCA)**: Activa esta opción para habilitar comentarios en solicitudes de extracción para SCA. Si está activada, especifica un umbral de gravedad mínimo. Además, selecciona **Excluir comentarios en solicitudes de extracción, si se detectan infracciones en dependencias de test o desarrollo** para evitar comentarios sobre problemas encontrados en dependencias existentes, sólo en entornos de test o desarrollo.
+ - **Activar para Infrastructure-as-Code (IaC)**: Activa esta opción para habilitar comentarios en solicitudes de extracción para IaC. Si está activada, especifica un umbral de gravedad mínimo.
+ - **Bloquear todos los comentarios en este repositorio**: Activa esta opción para desactivar todos los comentarios de este repositorio, anulando la configuración global.
+1. Haz clic en **Save configuration** (Guardar configuración).
+
+[1]: /es/security/code_security/
+[2]: /es/integrations/github/
+[3]: https://app.datadoghq.com/integrations/github/add
+[4]: https://app.datadoghq.com/security/configuration/code-security/setup
+[5]: https://app.datadoghq.com/integrations/github/configuration
+[6]: /es/security/code_security/static_analysis/github_actions/
+[7]: https://app.datadoghq.com/security/configuration/code-security/settings
+[8]: /es/integrations/gitlab-source-code/
+[9]: https://www.datadoghq.com/product-preview/azure-devops-integration-code-security/
+[10]: /es/quality_gates/?tab=staticanalysis#setup
\ No newline at end of file
diff --git a/content/es/security/code_security/iac_security/_index.md b/content/es/security/code_security/iac_security/_index.md
new file mode 100644
index 0000000000000..f573c85711504
--- /dev/null
+++ b/content/es/security/code_security/iac_security/_index.md
@@ -0,0 +1,89 @@
+---
+aliases:
+- /es/security/cloud_security_management/iac_scanning/
+further_reading:
+- link: https://www.datadoghq.com/blog/datadog-iac-security/
+ tag: Blog
+ text: Evitar que los errores de configuración de la nube lleguen a la producción
+ con Datadog IaC Security
+- link: /security/code_security/iac_security/setup
+ tag: Documentación
+ text: Configurar IaC Security
+- link: /security/code_security/iac_security/exclusions
+ tag: Documentación
+ text: Configurar exclusiones de IaC Security
+- link: /security/code_security/iac_security/iac_rules/
+ tag: Documentación
+ text: Reglas de IaC Security
+title: Infrastructure as Code (IaC) Security
+---
+
+Datadog Infrastructure as Code (IaC) Security detecta errores de configuración en el código de Terraform antes de su despliegue. Señala problemas como la falta de cifrado o el acceso demasiado permisivo en los archivos almacenados en los repositorios de GitHub conectados. Los tipos de archivos compatibles incluyen archivos Terraform independientes y módulos locales.
+
+{{< img src="/security/infrastructure_as_code/iac_misconfiguration_side_panel.png" alt="Panel lateral de errores de configuración de IaC en el que se muestran detalles del problema de alta gravedad activado por IMDSv1, incluidos un resumen de seguridad, un fragmento de código, marcas de tiempo de detección y pasos de corrección." width="100%">}}
+
+## Cómo funciona
+
+IaC Security se integra con tus repositorios de GitHub para buscar continuamente errores de configuración. Analiza cada commit en todas las ramas y realiza un análisis diario completo de cada repositorio configurado. Los hallazgos aparecen cuando se detectan infracciones y se asocian con el repositorio, la rama y la ruta de archivo relevantes. Esto te permite identificar, priorizar y corregir errores de configuración directamente en el origen.
+
+## Capacidades clave
+
+### Revisar y corregir infracciones en solicitudes de extracción
+
+Cuando una solicitud de extracción de GitHub incluye cambios en la infraestructura como código, Datadog añade comentarios en línea para señalar cualquier infracción. Cuando corresponde, también sugiere correcciones de código que pueden aplicarse directamente en la solicitud de extracción. También puedes abrir una nueva solicitud de extracción desde Datadog para corregir un hallazgo. Para obtener más información, consulta [Solicitudes de extracción de GitHub][5].
+
+### Ver y filtrar los hallazgos
+
+Después de configurar IaC Security, cada commit de un repositorio analizado activa un análisis. Los hallazgos se resumen en la página [Vulnerabilidades de Code Security][3] y se agrupan por repositorio en la página [Repositorios de Code Security][6].
+
+Utiliza filtros para delimitar los resultados:
+
+- Gravedad
+- Estado (abierto, silenciado, fijo)
+- Resource type
+- Proveedor de la nube
+- Ruta del archivo
+- Equipo
+- Repositorio
+
+Haz clic en cualquier hallazgo para abrir un panel lateral que muestra:
+
+- **Detalles**: Una descripción y el código relevante que ha activado el hallazgo. (Para ver fragmentos de código, [instala la aplicación GitHub][9]).
+- **Solución**: Si están disponibles, se sugieren correcciones de código para los hallazgos que admiten la corrección.
+
+### Crear tickets de Jira a partir de hallazgos
+
+Puedes crear un ticket bidireccional de Jira directamente desde cualquier hallazgo para realizar un seguimiento de los problemas y solucionarlos en tus flujos de trabajo existentes. El estado del ticket permanece sincronizado entre Datadog y Jira. Para obtener más información, consulta [Sincronización bidireccional de tickets con Jira][4].
+
+### Silenciar los hallazgos
+
+Para eliminar un hallazgo, haz clic en **Mute** (Silenciar) en el panel de detalles del hallazgo. Se abre un flujo de trabajo, donde puedes [crear una regla de silenciado][10] para el filtrado contextual por valores de etiqueta (tag) (por ejemplo, por `service` o `environment`). Silenciar un hallazgo lo oculta y lo excluye de los informes.
+
+Para restaurar un hallazgo silenciado, haz clic en **Unmute** (Anular el modo de silencio) en el panel de detalles. También puedes utilizar el filtro **Estado** en la página [Vulnerabilidades de Code Security][3] para revisar los hallazgos silenciados.
+
+### Excluir reglas, archivos o recursos específicos
+
+Puedes configurar exclusiones para evitar que ciertos hallazgos aparezcan en los resultados del análisis. Las exclusiones pueden basarse en el ID de la regla, la ruta del archivo, el tipo de recurso, la gravedad o la etiqueta.
+
+Las exclusiones se gestionan a través de un archivo de configuración o comentarios en línea en tu código IaC. Para ver los formatos compatibles y ejemplos de uso, consulta [Configurar exclusiones de IaC Security][7].
+
+## Siguientes pasos
+
+1. [Configura IaC Security][1] en tu entorno.
+2. Configura [exclusiones de análisis][2] para reducir los falsos positivos o ignorar los resultados esperados.
+3. Revisa y clasifica los hallazgos en la página [Vulnerabilidades de Code Security][3].
+
+## Referencias adicionales
+
+{{< partial name="whats-next/whats-next.html" >}}
+
+[1]: /es/security/code_security/iac_security/setup
+[2]: /es/security/code_security/iac_security/exclusions
+[3]: https://app.datadoghq.com/security/code-security/iac
+[4]: /es/security/ticketing_integrations#bidirectional-ticket-syncing-with-jira
+[5]: /es/security/code_security/dev_tool_int/github_pull_requests/
+[6]: https://app.datadoghq.com/ci/code-analysis?
+[7]: /es/security/code_security/iac_security/exclusions/?tab=yaml
+[8]: /es/security/automation_pipelines/mute
+[9]: https://app.datadoghq.com/integrations/github/
+[10]: /es/security/automation_pipelines/
\ No newline at end of file
diff --git a/content/es/security/code_security/static_analysis/static_analysis_rules/_index.md b/content/es/security/code_security/static_analysis/static_analysis_rules/_index.md
index 28e1a962ec9eb..a2fb222db89c5 100644
--- a/content/es/security/code_security/static_analysis/static_analysis_rules/_index.md
+++ b/content/es/security/code_security/static_analysis/static_analysis_rules/_index.md
@@ -9,214 +9,177 @@ aliases:
is_beta: false
type: static-analysis
rulesets:
+ apex-code-style:
+ title: Reglas para hacer cumplir el estilo de código Apex y las mejores prácticas.
+ description: Code Security para escribir reglas Apex que sigan los estándares de codificación establecidos.
+ apex-security:
+ title: Reglas de seguridad para Apex
+ description: Reglas enfocadas a encontrar problemas de seguridad en tu código Apex.
csharp-best-practices:
title: "Prácticas recomendadas para C#"
- description: |
- Reglas para aplicar las prácticas recomendadas de C#.
+ description: Reglas para aplicar las prácticas recomendadas de C#.
csharp-code-style:
title: "Seguir los patrones del estilo de código de C#"
- description: |
- Reglas para aplicar el código de estilo de C#.
+ description: Reglas para aplicar el código de estilo de C#.
csharp-inclusive:
title: "Usar lenguaje inclusivo en C#"
- description: |
- Reglas para que tu código de C# sea más inclusivo.
+ description: Reglas para que tu código de C# sea más inclusivo.
csharp-security:
title: "Escribir código de C# seguro y protegido"
- description: |
- Reglas centradas en encontrar problemas de seguridad en tu código de C#.
+ description: Reglas centradas en encontrar problemas de seguridad en tu código de C#.
docker-best-practices:
title: Seguir las prácticas recomendadas con el uso de Docker
- description: |
- Prácticas recomendadas para el uso de Docker.
+ description: Prácticas recomendadas para el uso de Docker.
github-actions:
title: Proteger las GitHub Actions
- description: |
- Reglas para verificar tus GitHub Actions y detectar patrones inseguros, como permisos o fijación de versiones.
+ description: Reglas para verificar tus GitHub Actions y detectar patrones inseguros, como permisos o fijación de versiones.
go-best-practices:
title: Prácticas recomendadas para Go
- description: |
- Reglas para que sea más rápido y sencillo escribir código de Go. Desde el estilo de código hasta la prevención de errores, este conjunto de reglas ayuda a los desarrolladores a escribir código de Go eficiente, fácil de mantener y de alto rendimiento.
+ description: Reglas para que sea más rápido y sencillo escribir código de Go. Desde el estilo de código hasta la prevención de errores, este conjunto de reglas ayuda a los desarrolladores a escribir código de Go eficiente, fácil de mantener y de alto rendimiento.
go-inclusive:
title: Usar lenguaje inclusivo en Go
- description: |
- Verifica el código de Go para detectar problemas de redacción.
+ description: Verifica el código de Go para detectar problemas de redacción.
go-security:
title: Garantizar que el código de Go esté protegido y seguro
- description: |
- Detecta problemas de seguridad comunes (como la inyección de SQL, XSS o inyección de shell) en tu base de código de Go.
+ description: Detecta problemas de seguridad comunes (como la inyección de SQL, XSS o inyección de shell) en tu base de código de Go.
java-best-practices:
title: Seguir las prácticas recomendadas en Java
- description: |
- Reglas para aplicar las prácticas recomendadas de Java.
+ description: Reglas para aplicar las prácticas recomendadas de Java.
java-code-style:
title: Seguir los patrones del estilo de código de Java
- description: |
- Reglas para aplicar el código de estilo de Java.
+ description: Reglas para aplicar el código de estilo de Java.
java-inclusive:
title: Usar lenguaje inclusivo en Java
- description: |
- Reglas de Java para evitar redactar textos inadecuados en el código y los comentarios.
+ description: Reglas de Java para evitar redactar textos inadecuados en el código y los comentarios.
java-security:
title: Garantizar que el código de Java sea seguro
- description: |
- Reglas centradas en encontrar problemas de seguridad en código de Java.
+ description: Reglas centradas en encontrar problemas de seguridad en código de Java.
javascript-best-practices:
title: Seguir las mejores prácticas para escribir código de JavaScript
- description: |
- Reglas para aplicar las prácticas recomendadas de JavaScript.
+ description: Reglas para aplicar las prácticas recomendadas de JavaScript.
javascript-browser-security:
title: Reglas de seguridad para aplicaciones web de JavaScript
- description: |
- Reglas centradas en encontrar problemas de seguridad en tus aplicaciones web de JavaScript.
+ description: Reglas centradas en encontrar problemas de seguridad en tus aplicaciones web de JavaScript.
javascript-code-style:
title: Aplicar el estilo de código de JavaScript
- description: |
- Reglas para aplicar el código de estilo de JavaScript.
+ description: Reglas para aplicar el código de estilo de JavaScript.
javascript-common-security:
title: Reglas de seguridad comunes para JavaScript
- description: |
- Reglas centradas en encontrar problemas de seguridad en tu código de JavaScript.
+ description: Reglas centradas en encontrar problemas de seguridad en tu código de JavaScript.
javascript-express:
title: Consultar las prácticas recomendadas y seguridad de Express.js
- description: |
- Reglas específicas para las prácticas recomendadas y seguridad de Express.js.
+ description: Reglas específicas para las prácticas recomendadas y seguridad de Express.js.
javascript-inclusive:
title: Verifica el código de JavaScript para detectar problemas de redacción.
- description: |
- Reglas de JavaScript para evitar redactar textos inadecuados en el código y los comentarios.
+ description: Reglas de JavaScript para evitar redactar textos inadecuados en el código y los comentarios.
javascript-node-security:
title: Identificar posibles puntos críticos de seguridad en Node
- description: |
- Reglas para identificar posibles puntos críticos de seguridad en Node. Esto puede incluir falsos positivos que requieren una evaluación más exhaustiva.
+ description: Reglas para identificar posibles puntos críticos de seguridad en Node. Esto puede incluir falsos positivos que requieren una evaluación más exhaustiva.
jsx-react:
title: Reglas de linting específicas de React
- description: |
- Este complemento exporta una configuración `recommended` que aplica las prácticas recomendadas de React.
+ description: Este complemento exporta una configuración `recommended` que aplica las prácticas recomendadas de React.
kotlin-best-practices:
title: Seguir las mejores prácticas para escribir código de Kotlin
- description: |
- Reglas para aplicar las prácticas recomendadas de Kotlin.
+ description: Reglas para aplicar las prácticas recomendadas de Kotlin.
kotlin-code-style:
title: Aplicar el estilo de código de Kotlin
- description: |
- Reglas para aplicar el código de estilo de Kotlin.
+ description: Reglas para aplicar el código de estilo de Kotlin.
kotlin-security:
title: Aplicar la codificación segura de Kotlin
- description: |
- Reglas enfocadas a encontrar problemas de seguridad en tu código Kotlin.
+ description: Reglas enfocadas a encontrar problemas de seguridad en tu código Kotlin.
php-best-practices:
title: Seguir las mejores prácticas para escribir código de PHP
- description: |
- Reglas para aplicar las prácticas recomendadas de PHP, mejorar el estilo de código, prevenir errores, y promover un código de PHP de alto rendimiento, fácil de mantener y eficiente.
+ description: Reglas para aplicar las prácticas recomendadas de PHP, mejorar el estilo de código, prevenir errores, y promover un código de PHP de alto rendimiento, fácil de mantener y eficiente.
php-code-style:
title: Aplicar el estilo de código de PHP
- description: |
- Reglas para aplicar el código de estilo de PHP.
+ description: Reglas para aplicar el código de estilo de PHP.
php-security:
title: Reglas de seguridad para PHP
- description: |
- Reglas centradas en encontrar problemas de seguridad en tu código de PHP.
+ description: Reglas centradas en encontrar problemas de seguridad en tu código de PHP.
python-best-practices:
title: Seguir las mejores prácticas para escribir código de Python
- description: |
- Prácticas recomendadas de Python para escribir código eficiente y sin errores.
+ description: Prácticas recomendadas de Python para escribir código eficiente y sin errores.
python-code-style:
title: Aplicar el estilo de código de Python
- description: |
- Reglas para aplicar el código de estilo de Python.
+ description: Reglas para aplicar el código de estilo de Python.
python-design:
title: Verificar la estructura de programa de Python
- description: |
- Reglas para verificar la estructura de programa de Python, incluido cosas como bucles anidados.
+ description: Reglas para verificar la estructura de programa de Python, incluido cosas como bucles anidados.
python-django:
title: Consultar las prácticas recomendadas y seguridad de Django
- description: |
- Reglas específicas para las prácticas recomendadas y seguridad de Django.
+ description: Reglas específicas para las prácticas recomendadas y seguridad de Django.
python-flask:
title: Consultar las prácticas recomendadas y seguridad de Flask
- description: |
- Reglas específicas para las prácticas recomendadas y seguridad de Flask.
+ description: Reglas específicas para las prácticas recomendadas y seguridad de Flask.
python-inclusive:
title: Verifica el código de Python para detectar problemas de redacción.
- description: |
- Reglas de Python para evitar redactar textos inadecuados en el código y los comentarios.
+ description: Reglas de Python para evitar redactar textos inadecuados en el código y los comentarios.
python-pandas:
title: Prácticas recomendadas para la ciencia de datos con pandas
- description: |
- Un conjunto de reglas para verificar que el código de pandas se use de forma adecuada.
+ description: Un conjunto de reglas para verificar que el código de pandas se use de forma adecuada.
- - Garantiza que las declaraciones `import` sigan las pautas de codificación.
- - Evita códigos y métodos obsoletos.
- - Evita el código ineficiente siempre que sea posible.
+ - Garantiza que las declaraciones `import` sigan las pautas de codificación.
+ - Evita códigos y métodos obsoletos.
+ - Evita el código ineficiente siempre que sea posible.
python-security:
title: Garantizar que el código de Python esté protegido y seguro
- description: |
- Reglas centradas en encontrar problemas de seguridad y vulnerabilidad en tu código de Python, incluidos aquellos que se encuentran en OWASP10 y SANS25.
+ description: Reglas centradas en encontrar problemas de seguridad y vulnerabilidad en tu código de Python, incluidos aquellos que se encuentran en OWASP10 y SANS25.
- - Uso de protocolos de cifrado y hash incorrectos
- - Falta de control de acceso
- - Configuración errónea de seguridad
- - Inyecciones de SQL
- - Credenciales codificadas
- - Inyección de shell
- - Deserialización insegura
+ - Uso de protocolos de cifrado y hash incorrectos
+ - Falta de control de acceso
+ - Configuración errónea de seguridad
+ - Inyecciones de SQL
+ - Credenciales codificadas
+ - Inyección de shell
+ - Deserialización insegura
rails-best-practices:
title: Patrones ampliamente adoptados por la comunidad de Ruby on Rails
- description: |
- Prácticas recomendadas para escribir código de Ruby on Rails.
+ description: Prácticas recomendadas para escribir código de Ruby on Rails.
ruby-best-practices:
title: Seguir las prácticas recomendadas en Ruby
- description: |
- Reglas para aplicar las prácticas recomendadas de Ruby.
+ description: Reglas para aplicar las prácticas recomendadas de Ruby.
ruby-code-style:
title: Reglas para aplicar el código de estilo de Ruby.
- description: |
- Codifica las reglas de seguridad para escribir reglas de Ruby que sigan las normas de codificación establecidas.
+ description: Codifica las reglas de seguridad para escribir reglas de Ruby que sigan las normas de codificación establecidas.
ruby-inclusive:
title: Reglas para código de Ruby inclusivo
- description: |
- Escribir código de Ruby inclusivo
+ description: Escribir código de Ruby inclusivo
ruby-security:
title: Reglas de seguridad para Ruby
- description: |
- Reglas centradas en encontrar problemas de seguridad en tu código de Ruby.
+ description: Reglas centradas en encontrar problemas de seguridad en tu código de Ruby.
+ swift-code-style:
+ title: Reglas para imponer el estilo y las buenas prácticas del código Swift.
+ description: Code Security para escribir reglas Swift que sigan los estándares de codificación establecidos.
+ swift-security:
+ title: Reglas de seguridad para Swift
+ description: Reglas centradas en encontrar problemas de seguridad en tu código Swift.
terraform-aws:
title: Terraform AWS
- description: |
- Reglas a fin de aplicar las prácticas recomendadas de Terraform para AWS.
+ description: Reglas a fin de aplicar las prácticas recomendadas de Terraform para AWS.
tsx-react:
title: Calidad del código de TypeScript con React
- description: |
- Este complemento exporta una configuración `recommended` que aplica las prácticas recomendadas de React.
+ description: Este complemento exporta una configuración `recommended` que aplica las prácticas recomendadas de React.
typescript-best-practices:
title: Seguir las mejores prácticas para escribir código de TypeScript
- description: |
- Reglas para aplicar las prácticas recomendadas de TypeScript.
+ description: Reglas para aplicar las prácticas recomendadas de TypeScript.
typescript-browser-security:
title: Reglas de seguridad para aplicaciones web de TypeScript
- description: |
- Reglas centradas en encontrar problemas de seguridad en tus aplicaciones web de TypeScript.
+ description: Reglas centradas en encontrar problemas de seguridad en tus aplicaciones web de TypeScript.
typescript-code-style:
title: Patrones de código con opiniones de TypeScript
- description: |
- Reglas que se consideran las prácticas recomendadas para las bases de código de TypeScript modernas, pero que no afectan la lógica del programa. Por lo general, estas reglas tienen como objetivo aplicar patrones de código más simples.
+ description: Reglas que se consideran las prácticas recomendadas para las bases de código de TypeScript modernas, pero que no afectan la lógica del programa. Por lo general, estas reglas tienen como objetivo aplicar patrones de código más simples.
typescript-common-security:
title: Reglas de seguridad comunes para TypeScript
- description: |
- Reglas centradas en encontrar problemas de seguridad en tu código de TypeScript.
+ description: Reglas centradas en encontrar problemas de seguridad en tu código de TypeScript.
typescript-express:
title: Consultar las prácticas recomendadas y seguridad de Express.js con TypeScript
- description: |
- Reglas específicas para las prácticas recomendadas y seguridad de Express.js con TypeScript.
+ description: Reglas específicas para las prácticas recomendadas y seguridad de Express.js con TypeScript.
typescript-inclusive:
title: Verifica el código de TypeScript para detectar problemas de redacción.
- description: |
- Reglas de TypeScript para evitar redactar textos inadecuados en el código y los comentarios.
+ description: Reglas de TypeScript para evitar redactar textos inadecuados en el código y los comentarios.
typescript-node-security:
title: Identificar posibles puntos críticos de seguridad en Node
- description: |
- Reglas para identificar posibles puntos críticos de seguridad en Node. Esto puede incluir falsos positivos que requieren una evaluación más exhaustiva.
+ description: Reglas para identificar posibles puntos críticos de seguridad en Node. Esto puede incluir falsos positivos que requieren una evaluación más exhaustiva.
cascade:
modal:
title: Prueba esta regla y analiza tu código con Datadog Code Security
diff --git a/content/es/security/detection_rules/_index.md b/content/es/security/detection_rules/_index.md
index 8e5fa216e48c4..8dce40f46d3a6 100644
--- a/content/es/security/detection_rules/_index.md
+++ b/content/es/security/detection_rules/_index.md
@@ -28,6 +28,9 @@ products:
- icon: app-sec
name: App and API Protection
url: /security/application_security/
+- icon: cloud-security-management
+ name: Workload Protection
+ url: /security/workload_protection/
title: Reglas de detección
---
@@ -44,10 +47,31 @@ Las reglas predefinidas están disponibles para los siguientes productos de segu
- [Cloud SIEM][3] utiliza la detección de logs para analizar logs ingeridos en tiempo real.
- Cloud Security:
- [Cloud Security Misconfigurations][4] utiliza reglas de detección de configuración en la nube y configuración de infraestructura para analizar el estado de tu entorno en la nube.
- - [Workload Protection][5] utiliza las reglas del Agent y de detección para monitorizar activamente y evaluar la actividad del sistema.
- [Cloud Security Identity Risks][6] utiliza reglas de detección para detectar riesgos basados en IAM en tu infraestructura de nube.
+- [Workload Protection][5] utiliza las reglas del Agent y de detección para monitorizar activamente y evaluar la actividad del sistema.
- [App and API Protection][7] (AAP) aprovecha Datadog [APM][8], el [Datadog Agent][9] y las reglas de detección para detectar amenazas en el entorno de tu aplicación.
+## Mapa de MITRE ATT&CK
+
+{{< product-availability names="Cloud SIEM,App and API Protection,Workload Protection" >}}
+
+MITRE ATT&CK es un marco que ayuda a las organizaciones a comprender cómo actúan los ciberatacantes. Mapea lo siguiente:
+
+- **Táctica:** el "por qué" de un ataque. Son los objetivos generales, como obtener acceso inicial, ejecutar código malicioso o robar datos.
+- **Técnicas:** el "cómo" de un ataque. Son las acciones específicas que realiza un atacante para lograr una táctica, como utilizar el phishing para entrar en un sistema o explotar una vulnerabilidad en el software.
+
+Mediante el mapeo de tácticas y técnicas, MITRE ATT&CK proporciona a los equipos de seguridad un lenguaje común para comunicar las amenazas y preparar mejor las defensas.
+
+Para utilizar el mapa de ATT&CK de MITRE, haz lo siguiente:
+
+1. Abrir reglas de detección en [SIEM][16] o [Workload Protection][17].
+2. Selecciona el mapa **MITRE ATT&CK**.
+3. Selecciona uno o varios productos en el filtro .
+4. Revisa el mapa para ver lo siguiente:
+ - Evaluar la cobertura: determina qué técnicas de ataque están bien cubiertas y cuáles están poco vigiladas.
+ - Priorizar la creación de reglas: centrarse en la creación de reglas de detección para técnicas con baja o nula cobertura.
+ - Racionalización de la gestión de reglas: gestionar y actualizar las reglas de detección, asegurándote de que se ajustan a la información sobre amenazas más reciente.
+El mapa de ATT&CK de MITRE está disponible en SIEM o Workload Protection, pero puedes seleccionar Application and API Protection en el filtro. Application and API Protection se incluye en el mapa de MITRE ATT&CK para una cobertura de seguridad integral.
## Reglas de detección beta
El equipo de investigación de seguridad de Datadog añade continuamente nuevas reglas de detección de seguridad predefinidas. Aunque el objetivo es ofrecer detecciones de alta calidad con el lanzamiento de integraciones u otras nuevas funciones, a menudo es necesario observar el rendimiento de la detección a escala antes de poner la regla a disposición general. De este modo, el equipo de investigación de seguridad de Datadog dispone del tiempo necesario para perfeccionar o eliminar las posibilidades de detección que no cumplan nuestras normas.
@@ -111,12 +135,12 @@ Para eliminar una regla personalizada, haz clic en el menú vertical de tres pun
### Consultar el historial de versiones de una regla
-{{< img src="/security/security_monitoring/detection_rules/rule_version_history_20250207.png" alt="Historial de versiones del compromiso de un token de acceso GitHub OAuth" style="width:80%;" >}}
+{{< img src="/security/security_monitoring/detection_rules/rule_version_history_20250207.png" alt="Historial de versiones de un compromiso de token de acceso GitHub OAuth" style="width:80%;" >}}
Utiliza el historial de versiones de reglas para:
-- Ver las versiones anteriores de una regla de detección y comprender los cambios a lo largo del tiempo.
-- Ver quién realizó los cambios para mejorar la colaboración.
-- Comparar versiones con diferencias para analizar las modificaciones y el impacto de los cambios.
+- Consulta las versiones anteriores de una regla de detección y entiende los cambios a lo largo del tiempo.
+- Descubre quién realizó los cambios para mejorar la colaboración.
+- Compara versiones con diferencias para analizar las modificaciones y el impacto de los cambios.
Para ver el historial de versiones de una regla:
1. Ve a la página [Parámetros de seguridad][15]. En el panel de navegación izquierdo:
@@ -171,8 +195,10 @@ El proceso de obsolescencia de las reglas es el siguiente:
[8]: /es/tracing/
[9]: /es/agent/
[10]: https://app.datadoghq.com/security/configuration/
-[11]: /es/security/cloud_siem/detection_rules/
+[11]: /es/security/cloud_siem/detect_and_monitor/custom_detection_rules/
[12]: /es/security/application_security/policies/custom_rules/
[13]: /es/security/cloud_security_management/misconfigurations/custom_rules
[14]: /es/security/workload_protection/workload_security_rules?tab=host#create-custom-rules
-[15]: https://app.datadoghq.com/security/configuration/
\ No newline at end of file
+[15]: https://app.datadoghq.com/security/configuration/
+[16]: https://app.datadoghq.com/security/rules
+[17]: https://app.datadoghq.com/security/workload-protection/detection-rules
\ No newline at end of file
diff --git a/content/es/security/workload_protection/_index.md b/content/es/security/workload_protection/_index.md
index 8a6b5bf22ab43..c8ebf89ee9563 100644
--- a/content/es/security/workload_protection/_index.md
+++ b/content/es/security/workload_protection/_index.md
@@ -13,21 +13,21 @@ cascade:
aliases:
- /security/threats/agent_expressions
- _target:
- path: /seguridad/carga_protección/backend_linux
+ path: /security/workload_protection/backend_linux
aliases:
- - /seguridad/amenazas/backend_linux
+ - /security/threats/backend_linux
- _target:
path: /security/workload_protection/backend_windows
aliases:
- /security/threats/backend_windows
- _target:
- path: /seguridad/carga_proteccion/expresiones_linux
+ path: /security/workload_protection/linux_expressions
aliases:
- - /seguridad/amenazas/expresiones_linux
+ - /security/threats/linux_expressions
- _target:
- path: /seguridad/carga_protección/expresiones_windows
+ path: /security/workload_protection/windows_expressions
aliases:
- - /seguridad/amenazas/expresiones_windows
+ - /security/threats/windows_expressions
title: Workload Protection
---
@@ -56,7 +56,7 @@ Por defecto, todas las reglas de detección de amenazas de minería de criptomon
Workload Protection Threats viene con más de 50 reglas de detección predefinidas que son mantenidas por un equipo de expertos en seguridad. Las reglas identifican los riesgos más importantes para que puedas tomar medidas correctivas de inmediato. Las reglas de expresión del Agent definen las actividades de carga de trabajo que deben recopilarse para el análisis, mientras que las reglas de detección de backend analizan las actividades e identifican técnicas de ataque y otros patrones de comportamiento peligrosos.
-Utiliza la [configuración remota][7] para desplegar automáticamente reglas nuevas y actualizadas en el Agent. [Personaliza las reglas][5] definiendo cómo cada regla monitoriza la actividad de proceso, red y archivos, [crea reglas personalizadas][6], y [configura notificaciones en tiempo real](#set-up-real-time-notifications) para nuevas señales.
+Configura [Cloud Security][1] con {{< tooltip glossary="Configuración remota" case="title" >}} para desplegar automáticamente reglas nuevas y actualizadas en el Agent. [Personaliza las reglas][5] definiendo cómo cada regla monitoriza la actividad de procesos, redes y archivos, [crea reglas personalizadas][6] y [configura notificaciones en tiempo real](#set-up-real-time-notifications) para nuevas señales.
@@ -80,20 +80,19 @@ Datadog está introduciendo una nueva función llamada Active Protection para ha
## Para empezar
{{< whatsnext >}}
- {{< nextlink href="/security/threats/setup">}}Instalación y configuración completas{{< /nextlink >}}
+ {{< nextlink href="/security/cloud_security_management/setup/">}}Finalizar la configuración{{< /nextlink >}}
{{< nextlink href="/account_management/rbac/permissions/#cloud-security-platform">}}Permisos de roles de Datadog para Workload Protection{{< /nextlink >}}
- {{< nextlink href="/security/workload_protection/workload_security_rules">}}Más información sobre las reglas de detección de Workload Protection{{< /nextlink >}}
- {{< nextlink href="/security/default_rules/#cat-workload-security">}}Empieza a utilizar reglas de detección de Workload Protection predefinidas{{< /nextlink >}}
+ {{< nextlink href="/security/workload_protection/workload_security_rules">}}Más información sobre reglas de detección de Workload Protection{{< /nextlink >}}
+ {{< nextlink href="/security/default_rules/#cat-workload-security">}}Empezar a utilizar reglas de detección de Workload Protection predefinidas{{< /nextlink >}}
{{< nextlink href="/getting_started/cloud_security_management">}}Empezando con Cloud Security Management{{< /nextlink >}}
{{< /whatsnext >}}
-[1]: /es/security/threats/setup/?tab=kuberneteshelm#prerequisites
+[1]: /es/security/cloud_security_management/setup/
[2]: /es/agent/
[3]: /es/security/notifications/
[4]: /es/security/notifications/#notification-channels
[5]: /es/security/notifications/#detection-rule-notifications
[6]: /es/security/workload_protection/agent_expressions
-[7]: /es/security/threats/setup
[8]: /es/security/workload_protection/security_signals
[9]: /es/network_monitoring/performance/
[10]: /es/security/workload_protection/guide/active-protection
\ No newline at end of file
diff --git a/content/es/serverless/_index.md b/content/es/serverless/_index.md
index 5d6e3f28edf2d..38600b5f589db 100644
--- a/content/es/serverless/_index.md
+++ b/content/es/serverless/_index.md
@@ -86,13 +86,13 @@ La extensión de Datadog para Azure App Service proporciona capacidades de rastr
Azure Container Apps es una plataforma serverless totalmente gestionada para desplegar y escalar aplicaciones basadas en contenedores. Datadog proporciona la monitorización y la recopilación de log para Container Apps a través de la [integración Azure][9].
-Datadog también ofrece una solución, ahora en Vista previa, para [instrumentar tus aplicaciones de contenedor][10] con un Agent diseñado específicamente para permitir el rastreo, las métricas personalizadas y la recopilación directa de logs.
+Datadog también ofrece una solución para [instrumentar tus aplicaciones de Container Apps][10] con un Agent específico para permitir el rastreo, las métricas personalizadas y la recopilación directa de logs.
### Google Cloud Run
Google Cloud Run es una solución informática asíncrona, liviana y basada en eventos que te permite crear funciones pequeñas con un solo propósito. Para monitorizar las funciones serverless que se ejecutan en Google Cloud Platform, habilita la [integración de Google Cloud Platform][11].
-Datadog también ofrece una solución, ahora en Vista previa, para [instrumentar tus aplicaciones Cloud Run][12] con un Agent especialmente diseñado para permitir el rastreo, las métricas personalizadas y la recopilación directa de logs.
+Datadog también ofrece una solución para [instrumentar tus aplicaciones de Cloud Run][12] con un Agent específico para permitir el rastreo, las métricas personalizadas y la recopilación directa de logs.
## Referencias adicionales
@@ -104,7 +104,7 @@ Datadog también ofrece una solución, ahora en Vista previa, para [instrumentar
[4]: /es/serverless/custom_metrics
[5]: /es/serverless/distributed_tracing
[6]: /es/serverless/deployment_tracking
-[7]: /es/infrastructure/serverless/azure_app_services/#overview
+[7]: /es/serverless/azure_app_service/#overview
[8]: https://app.datadoghq.com/functions?cloud=azure&config_serverless-azure-app=true&group=service
[9]: /es/integrations/azure/#log-collection
[10]: /es/serverless/azure_container_apps
diff --git a/content/es/serverless/aws_lambda/configuration.md b/content/es/serverless/aws_lambda/configuration.md
index 418634d3d673d..156db221f6e4d 100644
--- a/content/es/serverless/aws_lambda/configuration.md
+++ b/content/es/serverless/aws_lambda/configuration.md
@@ -33,6 +33,7 @@ Primero, [instala][1] Datadog Serverless Monitoring para comenzar a recopilar m
- [Recopilar datos de perfiles](#collect-profiling-data)
- [Enviar la telemetría a través de PrivateLink o un proxy](#send-telemetry-over-privatelink-or-proxy)
- [Enviar la telemetría a varias organizaciones de Datadog](#send-telemetry-to-multiple-datadog-organizations)
+- [Activar el cumplimiento de FIPS](#enable-fips-compliance)
- [Propagar el contexto de las trazas en los recursos de AWS](#propagate-trace-context-over-aws-resources)
- [Fusionar las trazas de X-Ray y Datadog](#merge-x-ray-and-datadog-traces)
- [Habilitar la firma de código para AWS Lambda](#enable-aws-lambda-code-signing)
@@ -40,13 +41,17 @@ Primero, [instala][1] Datadog Serverless Monitoring para comenzar a recopilar m
- [Migrar de x86 a arm64 con la Datadog Lambda Extension](#migrating-between-x86-to-arm64-with-the-datadog-lambda-extension)
- [Configurar la Datadog Lambda Extension para hacer tests locales](#configure-the-datadog-lambda-extension-for-local-testing)
- [Instrumentar AWS Lambda con la API de OpenTelemetry](#Instrumentar-AWS-lambda-with-the-opentelemetry-api)
+- [Uso de Datadog Lambda Extension v67+](#using-datadog-lambda-extension-v67)
+- [Configuración del enlace automático para PutItem de DynamoDB](#configure-auto-linking-for-dynamodb-putitem)
+- [Visualización y modelado correcto de los servicios de AWS](#visualize-and-model-aws-services-by-resource-name)
+- [Envío de logs a Observability Pipelines](#sending-data-to-observability-pipelines)
- [Solucionar problemas](#troubleshoot)
- [Referencias adicionales](#further-reading)
## Habilitar la detección de amenazas para observar los intentos de ataque
-Recibe alertas sobre atacantes que tengan como objetivo tus aplicaciones serverless y responde con rapidez.
+Recibe alertas sobre los atacantes que apuntan a tus aplicaciones sin servidor y responde rápidamente.
Para empezar, asegúrate de tener el [rastreo habilitado][43] para tus funciones.
@@ -57,13 +62,11 @@ Para habilitar la monitorización de amenazas, añade las siguientes variables d
AWS_LAMBDA_EXEC_WRAPPER: /opt/datadog_wrapper
```
-Vuelve a desplegar la función e invócala. Al cabo de unos minutos, aparecerá en las [vistas ASM][3].
+Vuelve a desplegar la función e invócala. Al cabo de unos minutos, aparece en las [vistas AAP][49].
-[3]: https://app.datadoghq.com/security/appsec?column=time&order=desc
-
-Para ver la detección de amenazas de Application Security Management en acción, envía patrones de ataque conocidos a tu aplicación. Por ejemplo, envía un encabezado HTTP con el valor `acunetix-product` para activar un intento de [ataque de escaneo de seguridad][44]:
+Para ver en acción la detección de amenazas a las aplicaciones y las API, envía patrones de ataque conocidos a tu aplicación. Por ejemplo, envía una cabecera HTTP con el valor `acunetix-product` para activar un intento de [ataque al analizador de seguridad][44]:
```sh
- curl -H 'My-ASM-Test-Header: acunetix-product' https://En estos momentos, esta característica es compatible con Python, Node.js, Java y .NET.
+## Recopilar trazas procedentes de recursos distintos de Lambda
Datadog puede inferir tramos de APM en función de los eventos de Lambda entrantes para los recursos gestionados de AWS que activan la función de Lambda. Esto puede ayudarte a visualizar la relación entre los recursos gestionados de AWS e identificar problemas de rendimiento en tus aplicaciones serverless. Consulta [más detalles sobre el producto][12].
@@ -319,6 +322,7 @@ Para cambiar el nombre de todos los servicios anteriores asociados a una integra
| `lambda_kinesis` | `"lambda_kinesis:newServiceName"` |
| `lambda_dynamodb` | `"lambda_dynamodb:newServiceName"` |
| `lambda_url` | `"lambda_url:newServiceName"` |
+| `lambda_msk` | `"lambda_msk:newServiceName"` |
#### Cambiar el nombre de servicios específicos
@@ -334,6 +338,7 @@ Para un enfoque más granular, utiliza estos identificadores específicos de los
| Kinesis | Nombre del flujo | `"MyStream:newServiceName"` |
| DynamoDB | Nombre de la tabla | `"ExampleTableWithStream:newServiceName"` |
| URL de Lambda | ID de la API | `"a8hyhsshac:newServiceName"` |
+| MSK | Nombre del clúster | `"ExampleCluster:newServiceName"` |
#### Ejemplos con descripción
@@ -350,11 +355,11 @@ Para ver qué bibliotecas y marcos instrumenta de forma automática el cliente d
## Seleccionar las frecuencias de muestreo para la ingesta de tramos de APM
-Para gestionar la [frecuencia de muestreo de las invocaciones rastreadas de APM][17] para las funciones serverless, define la variable de entorno `DD_TRACE_SAMPLING_RULES` en una función con un valor entre 0,000 (no se rastrea ninguna invocación de la función de Lambda) y 1,000 (se rastrean todas las invocaciones).
+Para gestionar la [frecuencia de muestreo de invocaciones de APM rastreadas][17] de las funciones sin servidor, configura la variable de entorno `DD_TRACE_SAMPLING_RULES` en la función con un valor entre 0.000 (sin rastreo de invocaciones de funciones Lambda) y 1.000 (con rastreo de todas las invocaciones de funciones Lambda).
-Nota: El uso de DD_TRACE_SAMPLE_RATE está obsoleto. Utiliza DD_TRACE_SAMPLING_RULES en su lugar. Por ejemplo, si ya has establecido DD_TRACE_SAMPLE_RATE en 0.1, estableceDD_TRACE_SAMPLING_RULES en [{"sample_rate":0.1}] en su lugar.
-
-Las métricas se calculan en función del 100 % del tráfico de la aplicación, y son precisas independientemente de la configuración del muestreo.
+**Notas**:
+ - El uso de `DD_TRACE_SAMPLE_RATE` está obsoleto. Utiliza `DD_TRACE_SAMPLING_RULES` en su lugar. Por ejemplo, si ya configuraste `DD_TRACE_SAMPLE_RATE` como `0.1`, configura `DD_TRACE_SAMPLING_RULES` como `[{"sample_rate":0.1}]` en su lugar.
+ - Las métricas de tráfico globales como `trace (traza).Para obtener una descripción completa del cumplimiento de FIPS de las funciones AWS Lambda, consulta la página de Cumplimiento de FIPS para AWS Lambda exclusiva.
+
+Para habilitar el cumplimiento de FIPS de las funciones AWS Lambda, sigue estos pasos:
+
+1. Utiliza una capa de extensión que cumpla con FIPS haciendo referencia al ARN apropiado:
+
+{{< tabs >}}
+{{% tab "AWS GovCLoud" %}}
+ ```sh
+ arn:aws-us-gov:lambda: