Bu repoda Vision Transformer mimarisinin Pytorch kütühanesi ile implementasyonu bulunmaktadır. İncelemek isterseniz vision_transformers_implementation.py koduna bakabilirsiniz.
- Torch
- Numpy
- Tqdm
- Matplotlib
Aşağıdaki görselde mimarinin tamamı gösterilmektedir. Genel anlamda özetlersek ilk olarak görüntü alınarak patch'lere ayrılır. Elde edilen patch'ler vektörlere çevrilerek bir dizi elde edilir ve bu dizinin en başına öğrenilebilir bir parametre olan classification token eklenir. Encoder'a girdi olarak verilmeden önce bu diziye bir de konum bilgisi (positional encoding) eklenir. Bu aşamalardan sonra artık girdi Encoder'a verilmek için uygun hale getirilmiş olur ve dizi Transformer Encoder'a girer. Transformer Encoder içerisinde MSA(Multi-Head Self Attention) ve MLP(Multi Layer Perceptron) olmak üzere 2 temel kısım bulunur. MSA kısmında attention skorları elde edilir. MLP kısmında da classification token ile sınıflandırma işlemi gerçekleştirilir.
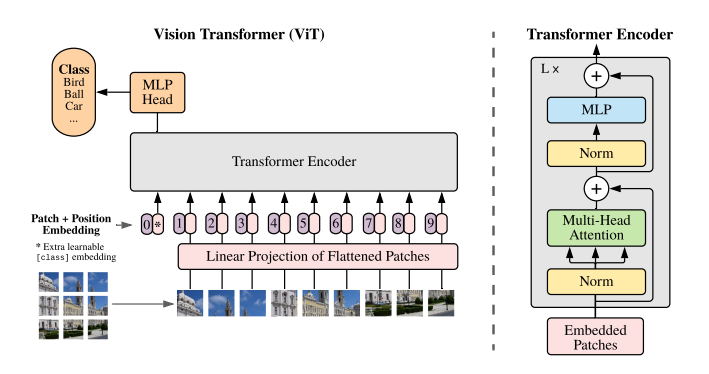
Vision Transformer Model Mimarisi
Bu kısımda görüntü belli bir patch (parça) sayısına göre parçalara ayrılır. NxNxC'lik bir görüntü için patch boyutunu PxP olarak belirlediğimizde elde edilen toplam patch sayısı (H*W*C)/(P*P) olur. Örneğin elimizde 28x28x1 boyutunda bir görsel olsun. Eğer patch boyutunu 7x7 olarak belirlersek elde edeceğimiz toplam patch sayısı 16 olur ve oluşan her bir patch'in boyutu da 4x4x1 olur. Daha iyi anlamak için aşağıdaki şekildeki görselleştirmeye bakılabilir. Ayrıca patch'lere ayırma ve görselleştirme için patchifying.ipynb kodu da incelenebilir.
Sonrasında 2D olan her bir patch 1D haline getirilir. Bu da P*P*C işlemi ile gerçekleştirilir. Önceki örneğimizi düşündüğümüzde vektörün uzunluğu 4x4x1'den 16 olur. Elde edilen vektör linear mapping ile istenilen boyuta eşlenebilir. Kodda hidden_d ile belirtilen değer aslında dizinin embedding size olarak kaça eşleneceğini belirtir.

Classification token elde edilen dizinin başına eklenir. Bu eklenen token değeri öğrenilebilir bir parametredir. Bu Vision Transformer modelindeki amacımız sınıflandırma olduğu için böyle bir parametre ekleriz.
Positional encoding ile elde edilen bu patch embedding dizisine konum bilgisi eklenir. Transformer yapıları girdilerin sırasını hatırlama yeteneğine sahip değildir. Bu nedenle görüntüdeki patch'lerin sırasının değişmesi demek görüntünün anlamının kaybolması demektir. Bundan dolayı positional encoding'e ihtiyaç duyarız. Positional encoding için kullanılan formüller aşağıdaki görselde verilmiştir. O satırdaki indis çift ise sin fonskiyonu tek ise cos fonskiyonu kullanılmaktadır.
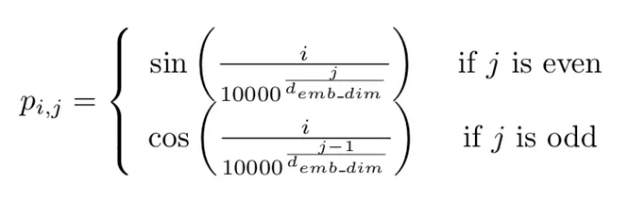
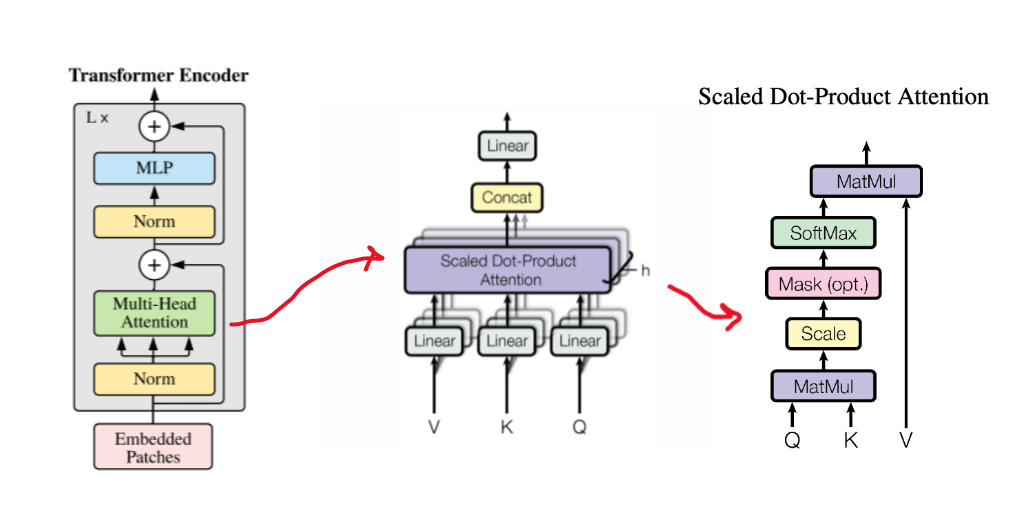
Transformer Encoder detaylı gösterimi
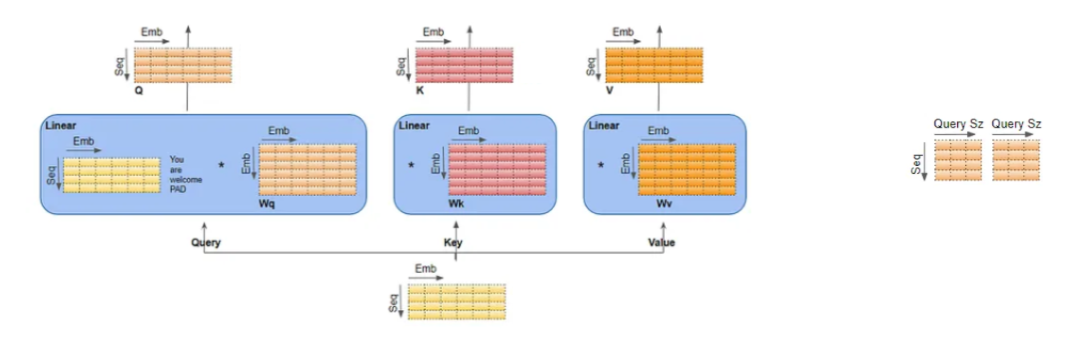
Transformer mimarisinin en önemli kısmı diyebiliriz. Bu kısımda kolaylık olması açısından sadece tek bir görüntü üzerinden ilerlenmektedir. Elimizdeki (seq, emb_size) şeklinde bir matrisimiz mevcut. Bu aşamada Query(Q), Key(K) ve Value(V) matrislerimizi oluşturmak için öncelikle (seq, emb_size) matrisimiz her birinin ağırlıkları birbirinden farklı olan Wq, Wk ve Wv matrisleri ile çarpılır. Bu çarpım sonucunda Q, K ve V matrislerimizi elde ederiz (aşağıdaki görselde sol taraf). Bu kısımda aslında bahsetmemiz gereken bir diğer kavram da head kavramıdır. Bu elde ettiğimiz Q, K ve V matrislerinin her biri sonraki işlemler için head'lere ayrılırlar. Q matrisi için şekildeki sağ taraftaki kısmı inceleyelim. Head sayısı 2 ise eğer artık emb_size kısmı her bir head için emb_size/n_head ile 3 olacaktır. Bizim kendi kodumuzda emb_size değeri 8 ve n_heads değeri 2 olarak belirlendiğinden elde edilen değer 4 olmaktadır. Sonrasında bu matrislerden Q ile K matrisi dot product yapılarak head sayısının kareköküne bölünür. Ardından ise elde edilen matris softmax fonskiyonundan geçirilir ve V matrisi ile çarpılır. Bu işlem sonucunda aslında bir head için attention score elde etmiş olunur. Bu attention score'lar ise en sonda birleştirilerek tek bir matris haline getirilirler.
MLP, iki tane Linear katman ve bunların arasına eklenen GELU aktivasyon fonksiyonundan oluşan bir kısımdır. Bir de en sonda sınıflandırma için kullanılan bir diğer MLP daha bulunur. Tüm bunlara ek olarak hem MSA hem de MLP katmanlarından önce layer normalization işlemi gerçekleştirilir. Ayrıca, mimaride bulunan residual connection'lar da eklenerek ağ daha güçlü hale getirilmeye çalışılır.
- https://arxiv.org/pdf/2010.11929.pdf
- https://medium.com/mlearning-ai/vision-transformers-from-scratch-pytorch-a-step-by-step-guide-96c3313c2e0c
- https://medium.com/swlh/visual-transformers-a-new-computer-vision-paradigm-aa78c2a2ccf2
- https://medium.com/machine-intelligence-and-deep-learning-lab/vit-vision-transformer-cc56c8071a20
- https://towardsdatascience.com/transformers-explained-visually-part-3-multi-head-attention-deep-dive-1c1ff1024853#:~:text=This%20logical%20split%20is%20done%20by%20partitioning%20the%20input%20data%20as%20well%20as%20the%20Linear%20layer%20weights%20uniformly%20across%20the%20Attention%20heads.%20We%20can%20achieve%20this%20by%20choosing%20the%20Query%20Size%20as%20below%3A
- https://mertcobanov.medium.com/vision-transformers-nedir-vits-nedir-14dce4d1c6d7