diff --git a/docs/lab-5/README.md b/docs/lab-5/README.md
index 9569c16..c417c2b 100644
--- a/docs/lab-5/README.md
+++ b/docs/lab-5/README.md
@@ -1,85 +1,117 @@
---
-title: Building a Local AI Assistant
-description: Build a Granite coding assistant
+title: Using AnythingLLM for a local RAG
+description: Learn how to build a simple local RAG
logo: images/ibm-blue-background.png
---
-Do you use LLMs in an enterprise-setting? There are usually three main barriers to adopting its use in an enterprise setting:
+## Configuration and Sanity Check
-- **Data Privacy:** Corporate privacy regulations that prohibit sending internal code or data to third party services.
-- **Generated Material Licensing:** Many models, even those with permissive usage licenses, don't disclose their training data and may produce output that is derived from material with licensing restrictions.
-- **Cost:** Many tools are paid solutions that require investment. For larger organizations, this would often include paid support and maintenance contracts which can be extremely costly and slow to
+Open up AnyThingLLM, and you should see something like the following:
+
-In this lab, we'll use a collection of open-source components to run a feature-rich developer code assistant in Visual Studio Code. Previously, we used `granite3.1-dense`, for general use cases like summarization, question-answering, and classification. Now, we'll try IBM's [Granite Code](https://github.com/ibm-granite/granite-code-models), which are geared towards code generation tasks.
+If you see this that means AnythingLLM is installed correctly, and we can continue configuration, if not, please find a workshop TA or
+raise your hand we'll be there to help you ASAP.
-This lab is a rendition of this [blogpost](https://developer.ibm.com/tutorials/awb-local-ai-copilot-ibm-granite-code-ollama-continue/).
+Next as a sanity check, run the following command to confirm you have the [granite3.1-dense](https://ollama.com/library/granite3.1-dense)
+model downloaded in `ollama`. This may take a bit, but we should have a way to copy it directly on your laptop.
-!!! note
- The following labs assume some programming experience/knowledge. If you don't have any, don't fret! Raise your hand and ask a TA for help! They'll be more than happy to.
+```bash
+ollama pull granite3.1-dense:8b
+```
-## Download the Model
+If you didn't know, the supported languages with `granite3.1-dense` now include:
-[Granite Code](https://github.com/ibm-granite/granite-code-models) was produced by IBM Research, with the goal of building an LLM that has only seen code which used enterprise-friendly licenses. According to section 2 of the , the IBM Granite Code models meticulously curated their training data for licenses, and to make sure that all text did not contain any hate, abuse, or profanity. You can read more about how they were built in its [paper](https://arxiv.org/pdf/2405.04324).
+- English, German, Spanish, French, Japanese, Portuguese, Arabic, Czech, Italian, Korean, Dutch, Chinese (Simplified)
-Many open LLMs available today license the model itself for derivative work, but because they bring in large amounts of training data without discriminating by license, most companies can't use the output of those models since it potentially presents intellectual property concerns.
+And the Capabilities also include:
-Granite Code comes in a wide range of sizes to fit your workstation's available resources. Generally, the bigger the model, the better the results, with a tradeoff: model responses will be slower, and it will take up more resources on your machine. In this lab, we'll try the 8b option for code generation. You could also use the `20b` version, if the wifi connection speed allows for it.
+- Summarization
+- Text classification
+- Text extraction
+- Question-answering
+- Retrieval Augmented Generation (RAG)
+- Code related tasks
+- Function-calling tasks
+- Multilingual dialog use cases
+- Long-context tasks including long document/meeting summarization, long document QA, etc.
-Open up a terminal, and run the following command:
+Next click on the `wrench` icon, and open up the settings. For now we are going to configure the global settings for `ollama`
+but you may want to change it in the future.
-```bash
-ollama pull granite-code:8b
-```
+
-## Set up Continue in VS Code
+Click on the "LLM" section, and select **Ollama** as the LLM Provider. Also select the `granite3.1-dense:8b` model. (You should be able to
+see all the models you have access to through `ollama` there.)
-Assuming you've already [installed `continue`](/docs/pre-work/README.md#installing-continue), you'll need to configure it.
+
-Open the extension in the sidebar and find the Local Assistant's gear icon.
+Click the "Back to workspaces" button where the wrench was. And Click "New Workspace."
-To open this config.yaml, you need to open the assistant's dropdown in the top-right portion of the chat input. On that dropdown beside the "Local Assistant" option, select the cog icon. It will open the local config.yaml.
+
-
+Name it something like "learning llm" or the name of the event we are right now, something so you know it's somewhere you are learning
+how to use this LLM.
-*The config.json can usually be found in `~/.continue/config.yaml`*
+
-You can add a section for each model you want to use in this file. For this lab, we'll register the Granite Code model we downloaded earlier. Replace the line `"models": []` with the following:
+Now we can test our connections _through_ AnythingLLM! I like the "Who is Batman?" question, as a sanity check on connections and that
+it knows _something_.
-```json
- "models": [
- {
- "title": "Granite Code 8b",
- "provider": "ollama",
- "model": "granite-code:8b"
- }
- ],
-```
+
-For inline code suggestions, it's generally recommended that you use smaller models since tab completion runs constantly as you type. This will reduce load on the machine. In the section that starts with `"tabAutocompleteModel"`, replace the whole section with the following:
+Now you may notice that the answer is slighty different then the screen shot above. That's expected and nothing to worry about. If
+you have more questions about it raise your hand and one of the helpers would love to talk you about it.
-```json
- "tabAutocompleteModel": {
- "title": "Granite Code 8b",
- "provider": "ollama",
- "model": "granite-code:8b"
- },
-```
+Congratulations! You have AnythingLLM running now, configured to work with `granite3.1-dense` and `ollama`!
+
+## Creating your own local RAG
+
+Now that you have everything set up, lets build our own RAG. You need a document, of some sort to questions to answer against
+it. Lets start with something fun. As of right now, our Granite model doesn't know about the US Federal Budget in 2024, so lets
+ask it a question about it to verify.
-## Sanity Check
+Create a new workspace, and call it whatever you want:
-Now that you have everything configured in VSCode, let's make sure that it works. Ensure that `ollama` is running in the background either as a status bar item or in the terminal using `ollama serve`.
+
-Open the Continue exension and test your local assistant.
+Now you have a new workspace, ask it a question like:
-```text
-What language is popular for backend development?
```
+What was the US federal budget for 2024?
+```
+
+You should come back with something like the following, it may be different, but the gist is there.
+
+
+
+Not great right? Well now we need to give it a way to look up this data, luckly, we have a backed up
+copy of the budget pdf [here](https://github.com/user-attachments/files/18510560/budget_fy2024.pdf).
+Go ahead and save it to your local machine, and be ready to grab it.
+
+Now spin up a **New Workspace**, (yes, please a new workspace, it seems that sometimes AnythingLLM has
+issues with adding things, so a clean environment is always easier to teach in) and call it
+something else.
+
+
+
+Click on the "upload a document" to get the pdf added.
+
+Next we need to add it to the workspace.
+
+
+
+Next click the upload or drag and drop and put the pdf in there, and then the arrow to move it to the
+workspace. Click Save and Embed.
+
+You have now added the pdf to the workspace.
-Additionally, if you open a file for editing you should see possible tab completions to the right of your cursor (it may take a few seconds to show up).
+Now when the chat comes back up ask the same question, and you should see some new answers!
-## Conclusion
+
-With your AI coding assistant now set up, move on to [Lab 6](https://ibm.github.io/opensource-ai-workshop/lab-6/) and actually use it!
+It won't be exactly what we are looking for, but it's enough to now see that the Granite model can
+leverage the local RAG and in turn can _look things up_ for you. You'll need some prompt engineering
+to get exactly what you want but this is just the start of leveraging the AI!
diff --git a/docs/lab-6/README.md b/docs/lab-6/README.md
index 44ea378..370ab24 100644
--- a/docs/lab-6/README.md
+++ b/docs/lab-6/README.md
@@ -1,117 +1,98 @@
---
-title: Coding with an AI Assistant
-description: Write code using Continue and Granite
+title: Using Open-WebUI for a local RAG
+description: Learn how to build a simple local RAG
logo: images/ibm-blue-background.png
---
-## Setup
+## Retrieval-Augmented Generation overview
+The LLMs we're using for these labs have been trained on billions of parameters, but they haven't been trained on everything, and the smaller models have less general knowledge to work with.
+For example, even the latest models are trained with aged data, and they couldn't know about current events or the unique data your use-case might need.
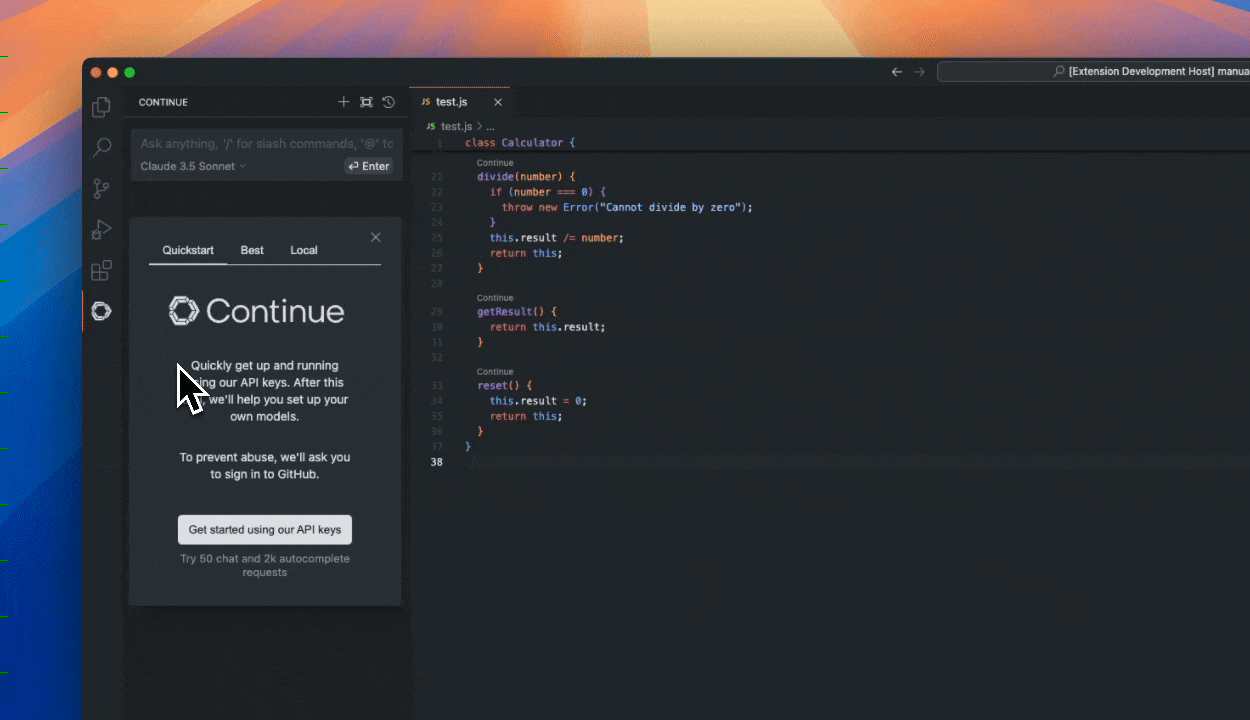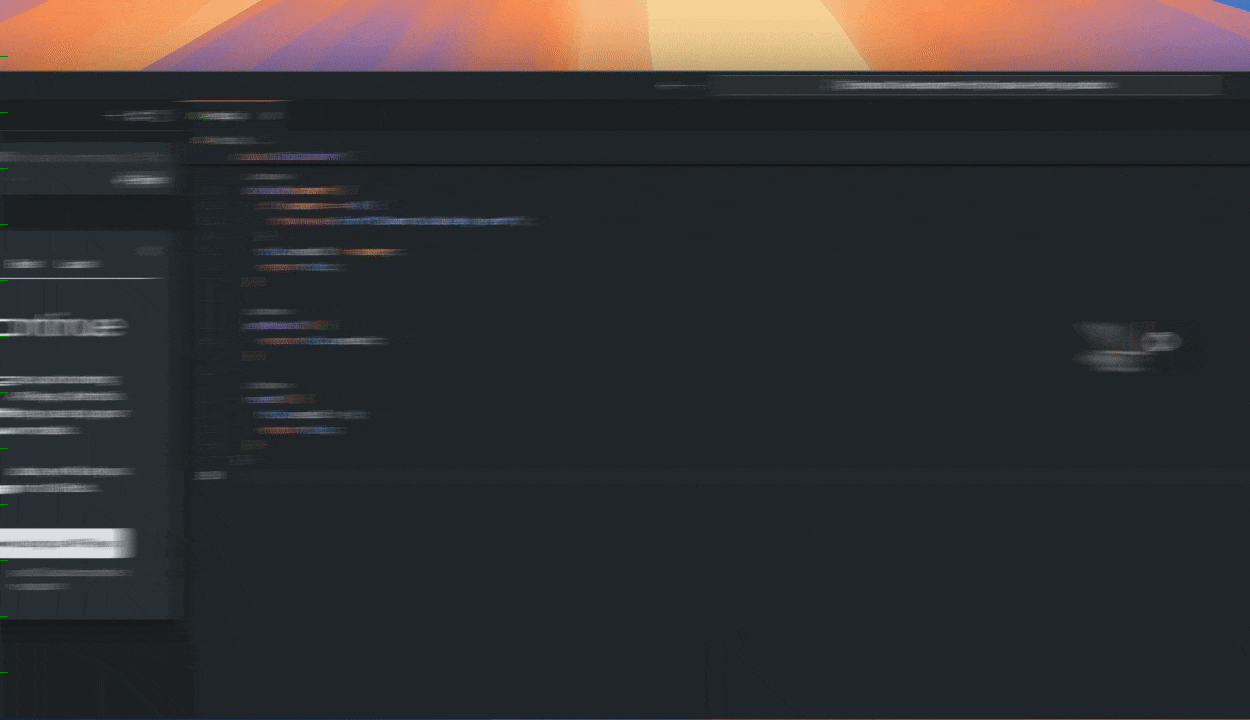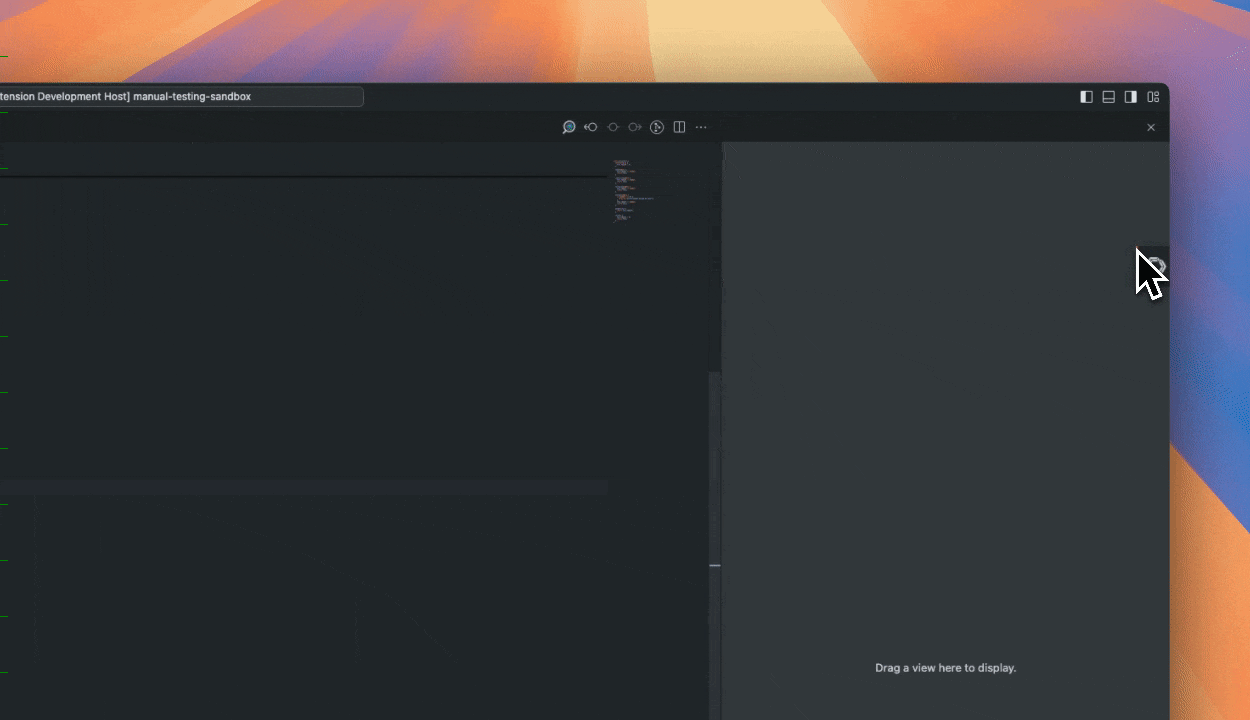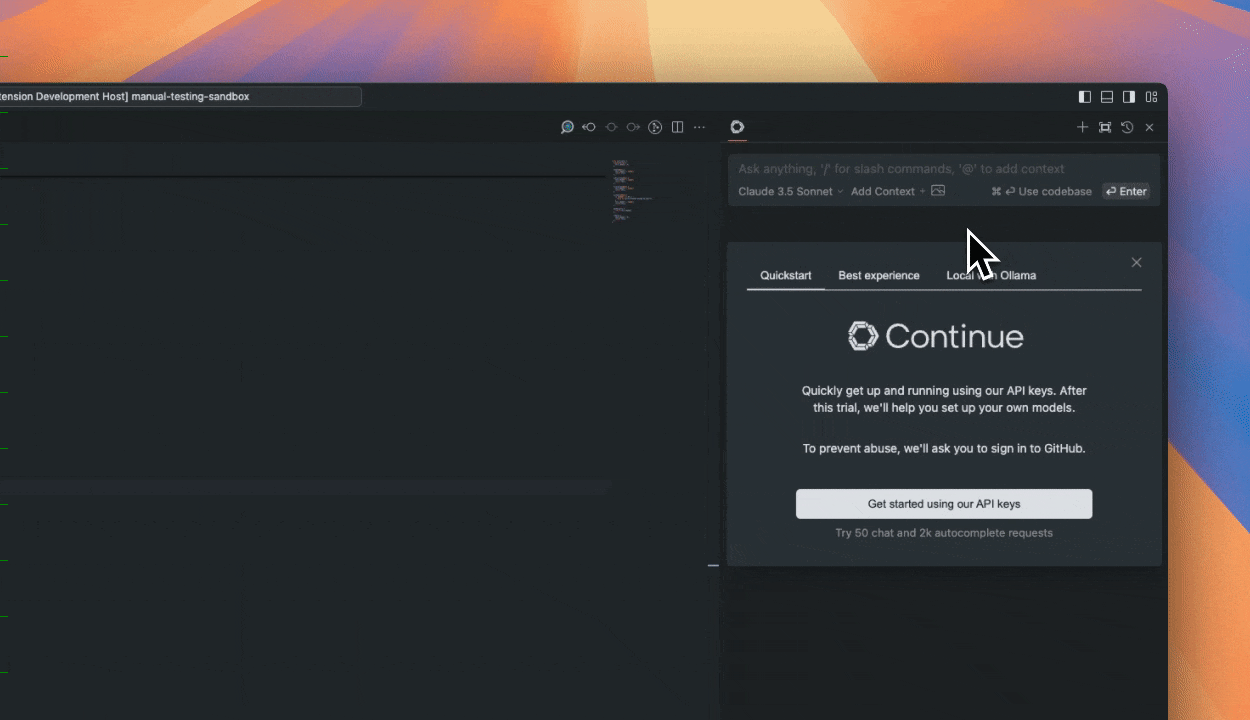
-First, get comfortable with Continue. For example, if you prefer that your local assistant have its own slice of the window, you can drag it to the right sidebar.
+RAG allows the user to supplement the LLM's data with up-to-date information from external sources, like databases and documents.
-
+In this lab we're going to use one of the smallest IBM Granite models and show that it's answer is not complete. Then we'll add a small RAG document and allow it render a much better answer
+utilizing both it's internal data combined with the RAG data you give it.
-You can also take a look at the [Continue documentation](https://docs.continue.dev/chat/how-to-use-it), or at least have it open in case you want to refer to it.
+## Configuration and Sanity Check
-Now that our local AI co-pilot is up and running, let’s put it to work. The following examples will focus on `python`, but the same approach applies to other languages like `go`, `javascript`, or `rust`.
+Open up [Open-WebUI](http://localhost:8080/), and you should see something like the following:
+
-A key part of learning to use this technology effectively is exploring the boundaries of what it can and can’t do.
+If you see this that means Open-WebUI is installed correctly, and we can continue configuration, if not, please find a workshop TA or
+raise your hand we'll be there to help you ASAP.
-As you work through this lab, keep in mind: this assistant is here to support your workflow — not to do the work for you!
-
-!!! tip
- If you lose the Continue pane in VSCode, you can re-enable it in VSCode by clicking at the top of the screen under "View --> Appearance --> Secondary Side Bar" and then the Continue window will be visible again.
-
-## Writing a `main.py`
-
-Clear the Continue window using `cmd+l` so we can start with a clean slate and create a new file called `main.py` in a new directory.
-
-
-
-With your `main.py` open, use the `cmd+i` to open up the `Generate Code` command palette. You should see some information about what file and line will be edited. Give it the following prompt:
+Next as a sanity check, run the following command to confirm you have the [granite3.3:2b](https://ollama.com/library/granite3.3:2b)
+model downloaded in `ollama`. This may take a bit, but we should have a way to copy it directly on your laptop.
+```bash
+ollama pull granite3.3:2b
```
-Write the code for conway's game of life using pygame
-```
-
-!!! note
- [What is Conway's Game of Life?](https://en.wikipedia.org/wiki/Conway's_Game_of_Life)
-
-After a few moments, the model should start writing code in the file, it might look something like:
-
-## AI-Generated Code
+If you didn't know, the supported languages with `granite3.3:2b` now include:
-You can try to run it... *but would it work?* Do you see any potential errors in this code? If the code you generated worked, then consider yourself lucky! You can see below that this instance of generated code doesn't provide any output.
+- English, German, Spanish, French, Japanese, Portuguese, Arabic, Czech, Italian, Korean, Dutch, Chinese (Simplified)
-
+And the Capabilities also include:
-This is an important lesson for using _any_ AI co-pilot code assistants. While they can provide a lot of helpful code towards what you need, it often won't get you across the finish line.
+- Thinking
+- Summarization
+- Text classification
+- Text extraction
+- Question-answering
+- Retrieval Augmented Generation (RAG)
+- Code related tasks
+- Function-calling tasks
+- Multilingual dialog use cases
+- Fill-in-the-middle
+- Long-context tasks including long document/meeting summarization, long document QA, etc.
-## Cleaning up the AI-Generated Code
-At this point, you can practice debugging or refactoring code with the AI co-pilot. Maybe it's a missing indent or the functions could be better organized for your understanding.
+Next click on the down arrow at the top and select the "granite3.3:2b" if it's not already selected.
-!!! note
- You can try using the built-in autocomplete and code assistant functions to generate any missing code.
- In the example generated code, a "main" entry point to the script is missing. In this case, using `cmd+I` again and trying the prompt: "write a main function for my game that plays ten rounds of Conway's
- game of life using the `board()` function." might help. What happens?
+
-It's hard to read the generated code in the example case, making it difficult to understand the logic. To clean it up, I'll define a `main` function so the entry point exists. There's also a `tkinter` section in the generated code, I decided to put the main game loop there:
-
-```python
-if __name__ == '__main__':
- root = tkinter.Tk()
- game_of_life(tkinter.Canvas(root))
- root.mainloop()
+Click on the "New Chat" icon to clear the context. Then, ask the model for:
+```bash
+List all the past and current CEOs of the IBM corporation in order of their term as CEO
```
+For example:
+
-In this generated code, there are also missing imports:
+At first glance, the list looks pretty good. But if you know your IBM CEOs, you'll notice that it misses a few of them, and sometimes adds new names that weren't ever IBM CEOs!
+(Note: the larger granite3.3:8b does a much better job on the IBM CEOs, you can try it later)
+But we can provide the small LLM with a RAG document that supplements the model's missing informaiton with a correct list, so it will generate a better answer.
-```python
-import tkinter
-import time
-```
+Click on the "New Chat" icon to clear the context. Then download a small text file with the correct list of IBM CEOs to your Downloads folder:
-It looks like the code is improving:
+[IBM.txt](../resources/IBM.txt)
-
+Right click on the IBM.txt URL and select "Save Link As" and save it as IBM in your Downloads folder.
-## Explaining the Code
+In your Open-WebUI browser, click on the "+" under the "send a message" prompt and then select "Upload files"
-To debug further, use Granite-Code to explain what the different functions do. Simply highlight one of them, use `cmd+L` to add it to the context window of your assistant and write a prompt similar to:
+Select the IBM.txt file that you just downloaded in your Downloads folder and press Open.
-```text
-what does this function do?
-```
-
-
-
-Asking for an explanation of portions of code can be very helpful with understanding logic that isn't clear right away. The model might even catch or highlight problems in the code if your prompt encourages it to.
-
-## Creating Tests
-
-One of the most effective ways to streamline your workflow as a developer is by writing tests for your code. Tests act as a safety net, helping you catch unintended changes. Tests can be time-consuming to write, and Granite Code can help generate them for you.
+
-Assuming you still have a function you wanted explained above in the context-window for your local assistant, you can use the prompt:
-
-```text
-write a pytest test for this function
+Now ask it our question about the CEOs of IBM:
+```bash
+List all the past and current CEOs of the IBM corporation in order of their term as CEO
```
+The answer should now be correct. (For example, always before it forgets John Akers)
-The model generated a great framework for a test here:
-
-
-Notice that the test only spans what is provided in the context, so it isn't integrated into my project yet. But, the code provides a good start. I'll need to create a new test file and integrate `pytest` into my project to use it.
+
-## Adding Comments
+We can also find and download information to pdf from Wikipedia:
+For example: [History of IBM](https://en.wikipedia.org/wiki/History_of_IBM)
-Continue also provides the ability to automatically add comments to code. Try it out!
+On the right of the Wikipedia page, click on "Tools" and click on "Download as PDF"
-
+Then use this History_of_IBM.pdf as a RAG by clicking on the + and select "History_of_IBM.pdf" as a file from your Downloads folder.
-## Conclusion
-
-This lab was all about using our local, open-source AI co-pilot to write complex code in Python. By combining Continue and Granite-Code, we were able to generate code, explain functions, write tests, and add comments to our code!
+Next, use the Open-WebUI to ask more questions about IBM, or have it summarize the document itself. For example:
+```bash
+Write a short 300 word summary of the History_of_IBM.pdf
+```
+
-
+Congratulations, you've completed the Open-WebUI RAG example.
diff --git a/docs/lab-7.5/README.md b/docs/lab-7.5/README.md
deleted file mode 100644
index 99ec25f..0000000
--- a/docs/lab-7.5/README.md
+++ /dev/null
@@ -1,98 +0,0 @@
----
-title: Using Open-WebUI for a local RAG
-description: Learn how to build a simple local RAG
-logo: images/ibm-blue-background.png
----
-
-## Retrieval-Augmented Generation overview
-The LLMs we're using for these labs have been trained on billions of parameters, but they haven't been trained on everything, and the smaller models have less general knowledge to work with.
-For example, even the latest models are trained with aged data, and they couldn't know about current events or the unique data your use-case might need.
-
-RAG allows the user to supplement the LLM's data with up-to-date information from external sources, like databases and documents.
-
-In this lab we're going to use one of the smallest IBM Granite models and show that it's answer is not complete. Then we'll add a small RAG document and allow it render a much better answer
-utilizing both it's internal data combined with the RAG data you give it.
-
-## Configuration and Sanity Check
-
-Open up [Open-WebUI](http://localhost:8080/), and you should see something like the following:
-
-
-If you see this that means Open-WebUI is installed correctly, and we can continue configuration, if not, please find a workshop TA or
-raise your hand we'll be there to help you ASAP.
-
-Next as a sanity check, run the following command to confirm you have the [granite3.3:2b](https://ollama.com/library/granite3.3:2b)
-model downloaded in `ollama`. This may take a bit, but we should have a way to copy it directly on your laptop.
-
-```bash
-ollama pull granite3.3:2b
-```
-
-If you didn't know, the supported languages with `granite3.3:2b` now include:
-
-- English, German, Spanish, French, Japanese, Portuguese, Arabic, Czech, Italian, Korean, Dutch, Chinese (Simplified)
-
-And the Capabilities also include:
-
-- Thinking
-- Summarization
-- Text classification
-- Text extraction
-- Question-answering
-- Retrieval Augmented Generation (RAG)
-- Code related tasks
-- Function-calling tasks
-- Multilingual dialog use cases
-- Fill-in-the-middle
-- Long-context tasks including long document/meeting summarization, long document QA, etc.
-
-
-Next click on the down arrow at the top and select the "granite3.3:2b" if it's not already selected.
-
-
-
-Click on the "New Chat" icon to clear the context. Then, ask the model for:
-```bash
-List all the past and current CEOs of the IBM corporation in order of their term as CEO
-```
-For example:
-
-
-At first glance, the list looks pretty good. But if you know your IBM CEOs, you'll notice that it misses a few of them, and sometimes adds new names that weren't ever IBM CEOs!
-(Note: the larger granite3.3:8b does a much better job on the IBM CEOs, you can try it later)
-But we can provide the small LLM with a RAG document that supplements the model's missing informaiton with a correct list, so it will generate a better answer.
-
-Click on the "New Chat" icon to clear the context. Then download a small text file with the correct list of IBM CEOs to your Downloads folder:
-
-[IBM.txt](../resources/IBM.txt)
-
-Right click on the IBM.txt URL and select "Save Link As" and save it as IBM in your Downloads folder.
-
-In your Open-WebUI browser, click on the "+" under the "send a message" prompt and then select "Upload files"
-
-Select the IBM.txt file that you just downloaded in your Downloads folder and press Open.
-
-
-
-Now ask it our question about the CEOs of IBM:
-```bash
-List all the past and current CEOs of the IBM corporation in order of their term as CEO
-```
-The answer should now be correct. (For example, always before it forgets John Akers)
-
-
-
-We can also find and download information to pdf from Wikipedia:
-For example: [History of IBM](https://en.wikipedia.org/wiki/History_of_IBM)
-
-On the right of the Wikipedia page, click on "Tools" and click on "Download as PDF"
-
-Then use this History_of_IBM.pdf as a RAG by clicking on the + and select "History_of_IBM.pdf" as a file from your Downloads folder.
-
-Next, use the Open-WebUI to ask more questions about IBM, or have it summarize the document itself. For example:
-```bash
-Write a short 300 word summary of the History_of_IBM.pdf
-```
-
-
-Congratulations, you've completed the Open-WebUI RAG example.
diff --git a/docs/lab-7/README.md b/docs/lab-7/README.md
index c417c2b..c1e546a 100644
--- a/docs/lab-7/README.md
+++ b/docs/lab-7/README.md
@@ -1,117 +1,235 @@
---
-title: Using AnythingLLM for a local RAG
-description: Learn how to build a simple local RAG
+title: Using Mellea to help with Generative Computing
+description: Learn how to leverage Mellea for Advanced AI situations
logo: images/ibm-blue-background.png
---
-## Configuration and Sanity Check
-
-Open up AnyThingLLM, and you should see something like the following:
-
-
-If you see this that means AnythingLLM is installed correctly, and we can continue configuration, if not, please find a workshop TA or
-raise your hand we'll be there to help you ASAP.
-
-Next as a sanity check, run the following command to confirm you have the [granite3.1-dense](https://ollama.com/library/granite3.1-dense)
-model downloaded in `ollama`. This may take a bit, but we should have a way to copy it directly on your laptop.
-
+# What is Generative Computing?
+
+A generative program is any computer program that contains calls to an LLM.
+As we will see throughout the documentation, LLMs can be incorporated into
+software in a wide variety of ways. Some ways of incorporating LLMs into
+programs tend to result in robust and performant systems, while others
+result in software that is brittle and error-prone.
+Generative programs are distinguished from classical programs by their use of
+functions that invoke generative models. These generative calls can produce
+many different data types — strings, booleans, structured data, code,
+images/video, and so on. The model(s) and software underlying generative
+calls can be combined and composed in certain situations and in certain
+ways (e.g., LoRA adapters as a special case). In addition to invoking
+generative calls, generative programs can invoke other functions, written
+in languages that do not have an LLM in their base, so that we can, for
+example, pass the output of a generative function into a DB retrieval system
+and feed the output of that into another generator. Writing generative
+programs is difficult because generative programs interleave deterministic
+and stochastic operations.
+
+If you would like to read more about this, please don't hesitate to take a
+look [here](https://docs.mellea.ai/overview/project-mellea).
+
+# Mellea
+
+[Mellea](https://github.com/generative-computing/mellea) is a library for
+writing generative programs. Generative programming replaces flaky agents
+and brittle prompts with structured, maintainable, robust, and efficient AI workflows.
+
+## Features
+
+* A standard library of opinionated prompting patterns.
+* Sampling strategies for inference-time scaling.
+* Clean integration between verifiers and samplers.
+ - Batteries-included library of verifiers.
+ - Support for efficient checking of specialized requirements using
+ activated LoRAs.
+ - Train your own verifiers on proprietary classifier data.
+* Compatible with many inference services and model families. Control cost
+ and quality by easily lifting and shifting workloads between:
+ - inference providers
+ - model families
+ - model sizes
+* Easily integrate the power of LLMs into legacy code-bases (mify).
+* Sketch applications by writing specifications and letting `mellea` fill in
+ the details (generative slots).
+* Get started by decomposing your large unwieldy prompts into structured and maintainable mellea problems.
+
+## Let's setup Mellea to work locally
+
+1. Open up a terminal, and run the following commands:
```bash
-ollama pull granite3.1-dense:8b
+python3.11 -m venv venv
+source venv/bin/activate
+pip install mellea
```
+Note: If you see something about the Rust compiler, please confirm you are using python3.11, or python3.12
+anything above that has a Rust dependency.
+2. Run a simple Mellea session:
+```python
+import mellea
+
+m = mellea.start_session()
+print(m.chat("What is the etymology of mellea?").content)
+```
+You can either add this to a file like `main.py` or run it in the python REPL, if you get output
+you are set up to dig deeper with Mellea.
-If you didn't know, the supported languages with `granite3.1-dense` now include:
-
-- English, German, Spanish, French, Japanese, Portuguese, Arabic, Czech, Italian, Korean, Dutch, Chinese (Simplified)
-
-And the Capabilities also include:
-
-- Summarization
-- Text classification
-- Text extraction
-- Question-answering
-- Retrieval Augmented Generation (RAG)
-- Code related tasks
-- Function-calling tasks
-- Multilingual dialog use cases
-- Long-context tasks including long document/meeting summarization, long document QA, etc.
-
-Next click on the `wrench` icon, and open up the settings. For now we are going to configure the global settings for `ollama`
-but you may want to change it in the future.
-
-
-
-Click on the "LLM" section, and select **Ollama** as the LLM Provider. Also select the `granite3.1-dense:8b` model. (You should be able to
-see all the models you have access to through `ollama` there.)
-
-
-
-Click the "Back to workspaces" button where the wrench was. And Click "New Workspace."
-
-
-
-Name it something like "learning llm" or the name of the event we are right now, something so you know it's somewhere you are learning
-how to use this LLM.
-
-
-
-Now we can test our connections _through_ AnythingLLM! I like the "Who is Batman?" question, as a sanity check on connections and that
-it knows _something_.
-
-
-
-Now you may notice that the answer is slighty different then the screen shot above. That's expected and nothing to worry about. If
-you have more questions about it raise your hand and one of the helpers would love to talk you about it.
-
-Congratulations! You have AnythingLLM running now, configured to work with `granite3.1-dense` and `ollama`!
-
-## Creating your own local RAG
-
-Now that you have everything set up, lets build our own RAG. You need a document, of some sort to questions to answer against
-it. Lets start with something fun. As of right now, our Granite model doesn't know about the US Federal Budget in 2024, so lets
-ask it a question about it to verify.
-
-Create a new workspace, and call it whatever you want:
+## Simple email examples
-
+Note: The following work should be done via a text editor, there should be a couple installed on your
+laptop, if you aren't sure raise your hand and a helper will help you out.
-Now you have a new workspace, ask it a question like:
+Let's leverage Mellea to do some email generation for us, the first example is a simple example:
+```python
+import mellea
+m = mellea.start_session()
+email = m.instruct("Write an email inviting interns to an office party at 3:30pm.")
+print(str(email))
```
-What was the US federal budget for 2024?
+As you can see, it outputs a standard email with only a couple lines of code, lets expand on this:
+```python
+import mellea
+m = mellea.start_session()
+
+def write_email(m: mellea.MelleaSession, name: str, notes: str) -> str:
+ email = m.instruct(
+ "Write an email to {{name}} using the notes following: {{notes}}.",
+ )
+ return email.value # str(email) also works.
+
+
+print(
+ write_email(
+ m,
+ "Olivia",
+ "Olivia helped the lab over the last few weeks by organizing intern events, advertising the speaker series, and handling issues with snack delivery.",
+ )
+) user_variables={"name": name, "notes": notes},
+```
+With this more advance example we now have the ability to customize the email to be more directed and
+personalized for the recipient. But this is just a more programmatic prompt engineering, lets see where
+Mellea really shines.
+
+### Simple email with boundries and requirements
+
+The first step with the power of Mellea, is adding requirements to something like this email, take a look at this first
+example:
+```python
+import mellea
+m = mellea.start_session()
+
+def write_email_with_requirements(
+ m: mellea.MelleaSession, name: str, notes: str
+) -> str:
+ email = m.instruct(
+ "Write an email to {{name}} using the notes following: {{notes}}.",
+ requirements=[
+ "The email should have a salutation",
+ "Use only lower-case letters",
+ ],
+ user_variables={"name": name, "notes": notes},
+ )
+ return str(email)
+
+
+print(
+ write_email_with_requirements(
+ m,
+ name="Olivia",
+ notes="Olivia helped the lab over the last few weeks by organizing intern events, advertising the speaker series, and handling issues with snack delivery.",
+ )
+)
+```
+As you can see with this output now, you force the Mellea framework to start checking itself to create what you need.
+Imagine this possibility, now you can start making sure your LLMs only generate things that you want. Test this theory
+by changing from "only lower-case" to "only upper-case" and see that it will follow your instructions.
+
+Pretty neat eh? Lets go even deeper.
+
+Let's create an email with some sampling and have Mellea, find the best option for what we are looking for:
+We add two requirements to the instruction which will be added to the model request.
+But we don't check yet if these requirements are satisfied, we add a strategy for validating the requirements.
+
+This sampling strategy (`RejectionSamplingStrategy()`) checks if all requirements are met and if any requirement fails, the sampling strategy will sample a new email from the LLM.
+```python
+import mellea
+m = mellea.start_session()
+
+from mellea.stdlib.sampling import RejectionSamplingStrategy
+
+
+def write_email_with_strategy(m: mellea.MelleaSession, name: str, notes: str) -> str:
+ email_candidate = m.instruct(
+ "Write an email to {{name}} using the notes following: {{notes}}.",
+ requirements=[
+ "The email should have a salutation",
+ "Use only lower-case letters",
+ ],
+ strategy=RejectionSamplingStrategy(loop_budget=5),
+ user_variables={"name": name, "notes": notes},
+ return_sampling_results=True,
+ )
+ if email_candidate.success:
+ return str(email_candidate.result)
+ else:
+ print("Expect sub-par result.")
+ return email_candidate.sample_generations[0].value
+
+
+print(
+ write_email_with_strategy(
+ m,
+ "Olivia",
+ "Olivia helped the lab over the last few weeks by organizing intern events, advertising the speaker series, and handling issues with snack delivery.",
+ )
+)
+```
+You might notice it fails with the above example, just remove the `"Use only lower-case letters",` line, and
+it should pass on the first re-run. This brings up some interesting opportunities, so make sure that the
+writing you expect is within the boundaries and it'll keep trying till it gets it right.
+
+## Instruct Validate Repair
+
+The first `instruct-validate-repair` pattern is as follows:
+
+```python
+import mellea
+from mellea.stdlib.requirement import req, check, simple_validate
+from mellea.stdlib.sampling import RejectionSamplingStrategy
+
+def write_email(m: mellea.MelleaSession, name: str, notes: str) -> str:
+ email_candidate = m.instruct(
+ "Write an email to {{name}} using the notes following: {{notes}}.",
+ requirements=[
+ req("The email should have a salutation"), # == r1
+ req(
+ "Use only lower-case letters",
+ validation_fn=simple_validate(lambda x: x.lower() == x),
+ ), # == r2
+ check("Do not mention purple elephants."), # == r3
+ ],
+ strategy=RejectionSamplingStrategy(loop_budget=5),
+ user_variables={"name": name, "notes": notes},
+ return_sampling_results=True,
+ )
+ if email_candidate.success:
+ return str(email_candidate.result)
+ else:
+ return email_candidate.sample_generations[0].value
+
+
+m = mellea.start_session()
+print(write_email(m, "Olivia",
+ "Olivia helped the lab over the last few weeks by organizing intern events, advertising the speaker series, and handling issues with snack delivery."))
```
-You should come back with something like the following, it may be different, but the gist is there.
-
-
-
-Not great right? Well now we need to give it a way to look up this data, luckly, we have a backed up
-copy of the budget pdf [here](https://github.com/user-attachments/files/18510560/budget_fy2024.pdf).
-Go ahead and save it to your local machine, and be ready to grab it.
-
-Now spin up a **New Workspace**, (yes, please a new workspace, it seems that sometimes AnythingLLM has
-issues with adding things, so a clean environment is always easier to teach in) and call it
-something else.
-
-
-
-Click on the "upload a document" to get the pdf added.
-
-Next we need to add it to the workspace.
-
-
-
-Next click the upload or drag and drop and put the pdf in there, and then the arrow to move it to the
-workspace. Click Save and Embed.
-
-You have now added the pdf to the workspace.
-
-Now when the chat comes back up ask the same question, and you should see some new answers!
-
-
+Most of this should look familiar by now, but the `validation_fn` and `check` should be new.
+We create 3 requirements:
+- First requirement (r1) will be validated by LLM-as-a-judge on the output of the instruction. This is the default behavior.
+- Second requirement (r2) uses a function that takes the output of a sampling step and returns a boolean value indicating successful or unsuccessful validation. While the validation_fn parameter requires to run validation on the full session context, Mellea provides a wrapper for simpler validation functions (simple_validate(fn: Callable[[str], bool])) that take the output string and return a boolean as seen in this case.
+- Third requirement is a check(). Checks are only used for validation, not for generation. Don't think mention purple elephants.
-It won't be exactly what we are looking for, but it's enough to now see that the Granite model can
-leverage the local RAG and in turn can _look things up_ for you. You'll need some prompt engineering
-to get exactly what you want but this is just the start of leveraging the AI!
+Run this in your local instance, and you'll see it working, and ideally no purple elephants! :)
-
+Hopefully you felt like you've learned a bunch about AI and engaging with our open source models through this journey. Never hesitate
+to give us any feedback, and remember all of this stuff is free, open source, Apache 2 licensed, and designed to work in the
+Enterprise ecosystem. Thanks for reading and joining us!