I have previously worked with this road classification dataset and you can find it in my repository. I stumbled on knowledge distillation in a challenge and I decided to explore it in a simple classification problem such as this but before I go on, let me talk about knowledge distillation.
Knowlege distillation is the process of transfering knowledge from a large model to a smaller model. Usually, the large model is referred to as the teacher model while the smaller model is reffered to as the student model. The purpose of knowledge distillation is to have a smaller model for deployment to smaller devices like mobile phone. Large models are sometimes very complex and take a lot of space and time for processing but a smaller model would have a lower size and become faster, achieving similar performance as the large model.
The teacher model is first of all trained to ensure a high accuracy or low error, then the student model is also trained(shallow or deep). The distiller class in this file shows the knowledge distillation process. I used image augmentation methods to improve accuracy of all models and i also used pretrained models in the last phase.
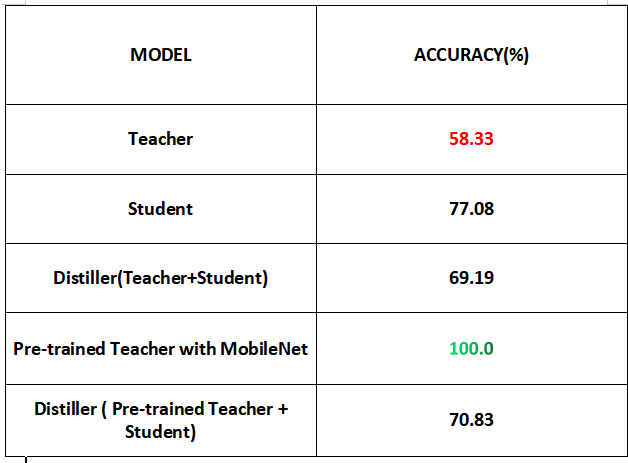
The table above shows the result of each model. I realized that it is always a good option to always train the teacher very well before distilling the knowledge to a student. As shown, the teacher model had a poor result, hence it affected the result of the distiller. A good practice is to train for longer epochs, restructure the architecture or even do some hyperparameter tuning to ensure the teacher is well trained.
The teacher was redesigned with a pretrained model(mobilev2) and the knowledge was distilled to the student. Although the output of the distiller that was pretrained is a bit lower than the accuracy of the teacher, the ultimate goal is to reduce the size of the teacher for deployment.