Home
Compare to kylin architechture, the main changes include the following:
- Query engine
Can submit query task to cluster with spark - Cube build engine Spark as the only build engine
- Metadata
There's a little difference with kylin metadata, see more from MetadataConverter.scala - Storage
- Cuboids are saved into HDFS(or other file system, no longer need HBase)
- HBase only store metadata and is not the only option

Currently, Kylin uses Apache HBase as the storage for OLAP cubes. HBase is very fast, while it also has some drawbacks:
- HBase is not real columnar storage;
- HBase has no secondary index; Rowkey is the only index;
- HBase has no encoding, Kylin has to do the encoding by itself;
- HBase does not fit for cloud deployment and auto-scaling;
- HBase has different API versions and has compatible issues (e.g, 0.98, 1.0, 1.1, 2.0);
- HBase has different vendor releases and has compatible issues (e.g, Cloudera's is not compatible with others);
This proposal is to use Apache Parquet + Spark to replace HBase:
- Parquet is an open-source columnar file format;
- Parquet is more cloud-friendly, can work with most FS including HDFS, S3, Azure Blob store, Ali OSS, etc;
- Parquet can integrate very well with Hadoop, Hive, Spark, Impala, and others;
- Support custom index;
- It is mature and stable;
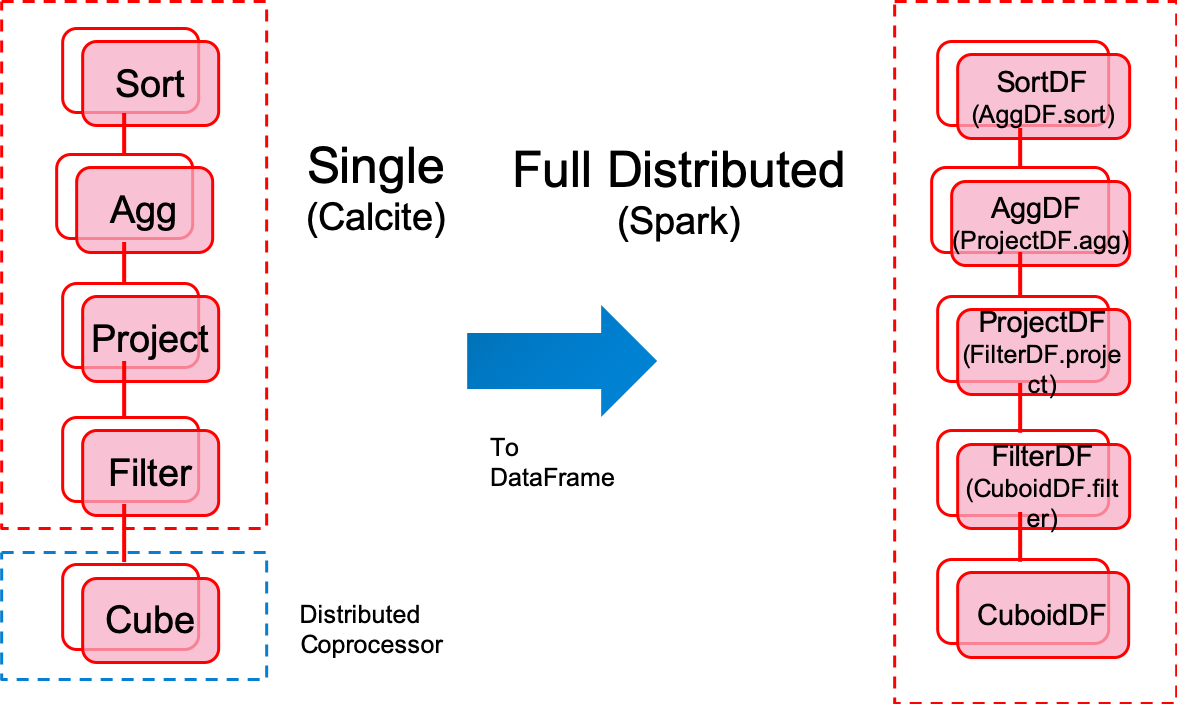
- Query node calculate pressure, single bottleneck
- Hard to debug the code generated by Calcite

- Fully Distributed
- Easy to debug and add breakpoint in each DataFrame
- Parquet cloud-friendly
New cube build engine is faster and cost less storage space in file system.



- SparkCubingJob
Extends CubingJob to create batch job steps for spark cubing, including the two steps -- Resource detect and Cubing. It must extends class CubingJob, so that JobMonitor can collect job information and showing on front end. - NSparkExecutable To submit spark job to local or cluster.
- SparkApplication The execatly executed instance on Spark
- ResourceDetectStep
- Dump kylin metadata to working fs
- Specify the class name of the spark task execution
- SparkCubingStep
- Dump kylin metadata to working fs
- Specify the class name of the spark task execution
- Update metadata after the building job done
- ResourceDetectBeforeCubingJob
- Collect and dump source tables info
- Adaptively adjust spark parameters
- Create flat table and build Global dictionary(if needed)
- CubeBuildJob
- Build cuboids by layer
- Save cuboids to FS as parquet format

- SparkMergingJob Extends CubingJob to create batch job steps for spark cubing, including the three steps -- Resource detect, Merging and Cleanup temp files.
- If contains COUNT_DISTINCT measure(Boolean)
- Resource paths(Array) we can using ResourceDetectUtils to Get source table infor(like source size, etc).
- Table RDD leaf task numbers(Map). It's used for the next step -- Adaptively adjust spark parameters
- Turned on by default
- Cluster mode only
- Affect spark configuration property
kylin.engine.spark-conf.spark.executor.instances kylin.engine.spark-conf.spark.executor.cores kylin.engine.spark-conf.spark.executor.memory kylin.engine.spark-conf.spark.executor.memoryOverhead kylin.engine.spark-conf.spark.sql.shuffle.partitions kylin.engine.spark-conf.spark.driver.memory kylin.engine.spark-conf.spark.driver.memoryOverhead kylin.engine.spark-conf.spark.driver.cores
- Driver memory base is 1024M, it will adujst by the number of cuboids. The adjust strategy is define in KylinConfigBase.java
public int[] getSparkEngineDriverMemoryStrategy() { String[] dft = { "2", "20", "100" }; return getOptionalIntArray("kylin.engine.driver-memory-strategy", dft); }

- Distributed encoding
- Using Roaring64NavigableMap, support canditary higher than Integer.MAX_VALUE
- Group by FlatTable RDD then distinct
- Repartion RDD, Using DictionaryBuilderHelper.calculateBucketSize()
- MapPartiton RDD, using DictHelper.genDict()
- Save encoded dict file to FS, using NGlobalDictHDFSStore.writeBucketDict()
- The bucket is used to store dictionaries. The number of bucket is just the RDD partitions(task parallelism). It has two import member variables -- relativeDictMap and absoluteDictMap.
- At one segment building job, dictionaries are encoded parallelized and stored into RelativeDictionary and after segment building job done, dictionaries will be reencoded with buckets offsets. And this global dictionry will save to FS and tags as one version(If there's no global dictionary built before, version is 0).
- When the next segment job starts, it will get the lastest vertion of dictionary and loaded to buckets and add new distinct values to buckts.


- Reduced build steps
- From ten-twenty steps to only two steps
- Build Engine
- Simple and clear architecture
- Spark as the only build engine
- All builds are done via spark
- Adaptively adjust spark parameters
- Dictionary of dimensions no longer needed
- Supported measures
- Sum
- Count
- Min
- Max
- TopN
- CountDictinct(Bitmap, HyperLogLog)
The flowing is the tree of parquet storage dictory in FS. As we can see, cuboids are saved into path spliced by Cube Name, Segment Name and Cuboid Id, which is processed by PathManager.java .

If there is a dimension combination of [d1, d2, d3] and measures of [m1, m2],then a parquet file like this will be generated: Columns 1, 2, and 3 correspond to Dimension d1, d2, and d3, respectivelyColumn 11 and 12 respectively correspond to Measure m1, m2

- How do you encode the data into a parquet?
- Kylin no longer needs to encode columns
- Parquet will encode needed columns
- All data types can be accurately mapped to Parquet
- Support with ParquetWriteSupport
- StructType ArrayType MapType
- Direct mapping transformation
| Type | Spark | Parquet |
|---|---|---|
| Numeric types | ByteType | INT32 |
| Numeric types | ShortType | INT32 |
| Numeric types | IntegerType | INT32 |
| Numeric types | LongType | INT64 |
| Numeric types | FloatType | FLOAT |
| Numeric types | DoubleType | DOUBLE |
| Numeric types | DecimalType | INT32,INT64,BinaryType,FIXED_LEN_BYTE_ARRAY |
| String type | StringType | Binary |
| Binary type | BinaryType | Binary |
| Boolean type | BooleanType | BOOLEAN |
| Datetime type | TimestampType | INT96 |
| Datetime type | DateType | INT32 |
- How computed columns are stored
- Bitmap: Binary
- TopN: Binary
- Prune segment with partition column(Date type)
- Prune cuboid parquet files with shard by columns
- Prune with paritition column will auto analyse date range to prune segments
- Prune shard columns
-
Identify the columns that need shard by. It's usually the column that used after where. For example: "select count from kylin_sales left join kylin_order where seller_id = '100041'", the "shard by" column is seller_id.
-
Edit cube. The shard by column should set as normal column not derived column.
-
Set "Shard by" to true in "Cube edit" -> "Advanced Setting" -> "Rowkey"
-
Set "kylin.storage.columnar.shard-rowcount" in kylin.properties, the default value is 2500000. The property is used to cut the cuboid file into multiple files and then filter out unwanted files when query.
-
Limit:
As for now, the shard by is set by cube leve, so there should only be one shard by column. In the future, we may support multi shard by columns with cuboid level. And community users can also give more suggestions.