diff --git a/Jenkinsfile b/Jenkinsfile
index 7b0716a6407f..1958a3f8e054 100644
--- a/Jenkinsfile
+++ b/Jenkinsfile
@@ -17,12 +17,6 @@ pipeline {
}
}
- stage('Uninstall torchtext') {
- steps {
- sh 'pip uninstall -y torchtext'
- }
- }
-
stage('Install test requirements') {
steps {
sh 'apt-get update && apt-get install -y bc && pip install -r requirements/requirements_test.txt'
diff --git a/README.rst b/README.rst
index 585064f17e5d..b0fe918f4ab9 100644
--- a/README.rst
+++ b/README.rst
@@ -93,19 +93,17 @@ Documentation
:scale: 100%
:target: https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/stable/
-+---------+-------------+----------------------------------------------------------------------------------------------------------------------------------+
-| Version | Status | Description |
-+=========+=============+==================================================================================================================================+
-| Latest | |main| | `Documentation of the latest (i.e. main) branch. `_ |
-+---------+-------------+----------------------------------------------------------------------------------------------------------------------------------+
-| Next | |v1.0.2| | `Documentation of the most recent release: v1.0.2 `_ |
-+---------+-------------+----------------------------------------------------------------------------------------------------------------------------------+
-| Stable | |stable| | `Documentation of the stable (i.e. stable) branch. `_ |
-+---------+-------------+----------------------------------------------------------------------------------------------------------------------------------+
++---------+-------------+------------------------------------------------------------------------------------------------------------------------------------------+
+| Version | Status | Description |
++=========+=============+==========================================================================================================================================+
+| Latest | |main| | `Documentation of the latest (i.e. main) branch. `_ |
++---------+-------------+------------------------------------------------------------------------------------------------------------------------------------------+
+| Stable | |stable| | `Documentation of the stable (i.e. most recent release) branch. `_ |
++---------+-------------+------------------------------------------------------------------------------------------------------------------------------------------+
Tutorials
---------
-A great way to start with NeMo is by checking `one of our tutorials `_.
+A great way to start with NeMo is by checking `one of our tutorials `_.
Getting help with NeMo
----------------------
@@ -147,6 +145,16 @@ Use this installation mode if you are contributing to NeMo.
cd NeMo
./reinstall.sh
+RNNT
+~~~~
+Note that RNNT requires numba to be installed from conda.
+
+.. code-block:: bash
+
+ conda remove numba
+ pip uninstall numba
+ conda install -c conda conda
+
Docker containers:
~~~~~~~~~~~~~~~~~~
@@ -161,14 +169,14 @@ If you chose to work with main branch, we recommend using NVIDIA's PyTorch conta
Examples
--------
-Many example can be found under `"Examples" `_ folder.
+Many example can be found under `"Examples" `_ folder.
Contributing
------------
-We welcome community contributions! Please refer to the `CONTRIBUTING.md `_ CONTRIBUTING.md for the process.
+We welcome community contributions! Please refer to the `CONTRIBUTING.md `_ CONTRIBUTING.md for the process.
License
-------
-NeMo is under `Apache 2.0 license `_.
+NeMo is under `Apache 2.0 license `_.
diff --git a/docs/source/asr/asr_language_modeling.rst b/docs/source/asr/asr_language_modeling.rst
index 2df9994c4ac9..5d68b3b963cb 100644
--- a/docs/source/asr/asr_language_modeling.rst
+++ b/docs/source/asr/asr_language_modeling.rst
@@ -42,7 +42,7 @@ Train N-gram LM
===============
The script to train an N-gram language model with KenLM can be found at
-`scripts/asr_language_modeling/ngram_lm/train_kenlm.py `__.
+`scripts/asr_language_modeling/ngram_lm/train_kenlm.py `__.
This script would train an N-gram language model with KenLM library which can be used with the beam search decoders
on top of the ASR models. This script supports both character level and BPE level encodings and models which is
@@ -95,7 +95,7 @@ Evaluate by Beam Search Decoding and N-gram LM
NeMo's beam search decoders are capable of using the KenLM's N-gram models to find the best candidates.
The script to evaluate an ASR model with beam search decoding and N-gram models can be found at
-`scripts/asr_language_modeling/ngram_lm/eval_beamsearch_ngram.py `__.
+`scripts/asr_language_modeling/ngram_lm/eval_beamsearch_ngram.py `__.
You may evaluate an ASR model as the following:
@@ -169,7 +169,7 @@ Width of the beam search (`--beam_width`) specifies the number of top candidates
would search for. Larger beams result in more accurate but slower predictions.
There is also a tutorial to learn more about evaluating the ASR models with N-gram LM here:
-`Offline ASR Inference with Beam Search and External Language Model Rescoring `_
+`Offline ASR Inference with Beam Search and External Language Model Rescoring `_
Hyperparameter Grid Search
--------------------------
@@ -202,7 +202,7 @@ This score is usually combined with the scores from the beam search decoding to
Train Neural Rescorer
=====================
-An example script to train such a language model with Transformer can be found at `examples/nlp/language_modeling/transformer_lm.py `__.
+An example script to train such a language model with Transformer can be found at `examples/nlp/language_modeling/transformer_lm.py `__.
It trains a TransformerLMModel which can be used as a neural rescorer for an ASR system.
@@ -210,11 +210,11 @@ Evaluation
==========
Given a trained TransformerLMModel `.nemo` file, the script available at
-`scripts/asr_language_modeling/neural_rescorer/eval_neural_rescorer.py `__
+`scripts/asr_language_modeling/neural_rescorer/eval_neural_rescorer.py `__
can be used to re-score beams obtained with ASR model. You need the `.tsv` file containing the candidates produced
by the acoustic model and the beam search decoding to use this script. The candidates can be the result of just the beam
search decoding or the result of fusion with an N-gram LM. You may generate this file by specifying `--preds_output_folder' for
-`scripts/asr_language_modeling/ngram_lm/eval_beamsearch_ngram.py `__.
+`scripts/asr_language_modeling/ngram_lm/eval_beamsearch_ngram.py `__.
The neural rescorer would rescore the beams/candidates by using two parameters of `rescorer_alpha` and `rescorer_beta` as the following:
@@ -231,9 +231,9 @@ You may follow the following steps to evaluate a neural LM:
#. Obtain `.tsv` file with beams and their corresponding scores. Scores can be from a regular beam search decoder or
in fusion with an N-gram LM scores. For a given beam size `beam_size` and a number of examples
for evaluation `num_eval_examples`, it should contain (`num_eval_examples` x `beam_size`) lines of
- form `beam_candidate_text \t score`. This file can be generated by `scripts/asr_language_modeling/ngram_lm/eval_beamsearch_ngram.py `__
+ form `beam_candidate_text \t score`. This file can be generated by `scripts/asr_language_modeling/ngram_lm/eval_beamsearch_ngram.py `__
-#. Rescore the candidates by `scripts/asr_language_modeling/neural_rescorer/eval_neural_rescorer.py `__.
+#. Rescore the candidates by `scripts/asr_language_modeling/neural_rescorer/eval_neural_rescorer.py `__.
.. code::
python eval_neural_rescorer.py
diff --git a/docs/source/nemo_text_processing/intro.rst b/docs/source/nemo_text_processing/intro.rst
index c3be9a896489..1e631ced44a9 100644
--- a/docs/source/nemo_text_processing/intro.rst
+++ b/docs/source/nemo_text_processing/intro.rst
@@ -5,7 +5,7 @@ Text Processing
See :doc:`NeMo Introduction <../starthere/intro>` for installation details.
-Additional requirements can be found in `setup.sh `_.
+Additional requirements can be found in `setup.sh `_.
.. toctree::
:maxdepth: 1
diff --git a/docs/source/nemo_text_processing/inverse_text_normalization.rst b/docs/source/nemo_text_processing/inverse_text_normalization.rst
index 0e828c78bfe5..1a04a63768f3 100644
--- a/docs/source/nemo_text_processing/inverse_text_normalization.rst
+++ b/docs/source/nemo_text_processing/inverse_text_normalization.rst
@@ -13,7 +13,7 @@ See :doc:`Text Procesing Deployment <../tools/text_processing_deployment>` for d
.. note::
- For more details, see the tutorial `NeMo/tutorials/text_processing/Inverse_Text_Normalization.ipynb `__ in `Google's Colab `_.
+ For more details, see the tutorial `NeMo/tutorials/text_processing/Inverse_Text_Normalization.ipynb `__ in `Google's Colab `_.
diff --git a/docs/source/nemo_text_processing/text_normalization.rst b/docs/source/nemo_text_processing/text_normalization.rst
index 3f225cacd761..f75c2370cfdd 100644
--- a/docs/source/nemo_text_processing/text_normalization.rst
+++ b/docs/source/nemo_text_processing/text_normalization.rst
@@ -15,7 +15,7 @@ See :doc:`Text Procesing Deployment <../tools/text_processing_deployment>` for d
.. note::
- For more details, see the tutorial `NeMo/tutorials/text_processing/Text_Normalization.ipynb `__ in `Google's Colab `_.
+ For more details, see the tutorial `NeMo/tutorials/text_processing/Text_Normalization.ipynb `__ in `Google's Colab `_.
diff --git a/docs/source/nlp/bert_pretraining.rst b/docs/source/nlp/bert_pretraining.rst
index eee23bd55077..efa5766b1ec2 100755
--- a/docs/source/nlp/bert_pretraining.rst
+++ b/docs/source/nlp/bert_pretraining.rst
@@ -61,8 +61,8 @@ and specify the path to the created hd5f files.
Training the BERT model
-----------------------
-Example of model configuration for on-the-fly data preprocessing: `NeMo/examples/nlp/language_modeling/conf/bert_pretraining_from_text_config.yaml `__.
-Example of model configuration for offline data preprocessing: `NeMo/examples/nlp/language_modeling/conf/bert_pretraining_from_preprocessed_config.yaml `__.
+Example of model configuration for on-the-fly data preprocessing: `NeMo/examples/nlp/language_modeling/conf/bert_pretraining_from_text_config.yaml `__.
+Example of model configuration for offline data preprocessing: `NeMo/examples/nlp/language_modeling/conf/bert_pretraining_from_preprocessed_config.yaml `__.
The specification can be grouped into three categories:
diff --git a/docs/source/nlp/glue_benchmark.rst b/docs/source/nlp/glue_benchmark.rst
index 37e091252081..849a49ea1a12 100644
--- a/docs/source/nlp/glue_benchmark.rst
+++ b/docs/source/nlp/glue_benchmark.rst
@@ -3,8 +3,8 @@
GLUE Benchmark
==============
-We recommend you try the GLUE Benchmark model in a Jupyter notebook (can run on `Google's Colab `_): `NeMo/tutorials/nlp/GLUE_Benchmark.ipynb `__.
+We recommend you try the GLUE Benchmark model in a Jupyter notebook (can run on `Google's Colab `_): `NeMo/tutorials/nlp/GLUE_Benchmark.ipynb `__.
Connect to an instance with a GPU (**Runtime** -> **Change runtime type** -> select **GPU** for the hardware accelerator).
-An example script on how to train the model can be found here: `NeMo/examples/nlp/glue_benchmark/glue_benchmark.py `__.
+An example script on how to train the model can be found here: `NeMo/examples/nlp/glue_benchmark/glue_benchmark.py `__.
diff --git a/docs/source/nlp/information_retrieval.rst b/docs/source/nlp/information_retrieval.rst
index e4c047a40b0a..d4620335209c 100644
--- a/docs/source/nlp/information_retrieval.rst
+++ b/docs/source/nlp/information_retrieval.rst
@@ -3,7 +3,7 @@
Information Retrieval
=====================
-We recommend you try the Information Retrieval model in a Jupyter notebook (can run on `Google's Colab `_): `NeMo/tutorials/nlp/Information_Retrieval_MSMARCO.ipynb `__.
+We recommend you try the Information Retrieval model in a Jupyter notebook (can run on `Google's Colab `_): `NeMo/tutorials/nlp/Information_Retrieval_MSMARCO.ipynb `__.
Connect to an instance with a GPU (**Runtime** -> **Change runtime type** -> select **GPU** for hardware the accelerator),
diff --git a/docs/source/nlp/joint_intent_slot.rst b/docs/source/nlp/joint_intent_slot.rst
index 5dc00430a2bf..87756d1b3ef8 100644
--- a/docs/source/nlp/joint_intent_slot.rst
+++ b/docs/source/nlp/joint_intent_slot.rst
@@ -14,7 +14,7 @@ Our BERT-based model implementation allows you to train and detect both of these
.. note::
- We recommend you try the Joint Intent and Slot Classification model in a Jupyter notebook (can run on `Google's Colab `_.): `NeMo/tutorials/nlp/Joint_Intent_and_Slot_Classification.ipynb `__.
+ We recommend you try the Joint Intent and Slot Classification model in a Jupyter notebook (can run on `Google's Colab `_.): `NeMo/tutorials/nlp/Joint_Intent_and_Slot_Classification.ipynb `__.
Connect to an instance with a GPU (**Runtime** -> **Change runtime type** -> select **GPU** for the hardware accelerator).
@@ -115,7 +115,7 @@ For each query, the model classifies it as one the intents from the intent dicti
it as one of the slots from the slot dictionary, including out of scope slot for all the remaining words in the query which does not
fall in another slot category. Out of scope slot (``O``) is a part of slot dictionary that the model is trained on.
-Example of model configuration file for training the model can be found at: `NeMo/examples/nlp/intent_slot_classification/conf/intent_slot_classification.yaml `__.
+Example of model configuration file for training the model can be found at: `NeMo/examples/nlp/intent_slot_classification/conf/intent_slot_classification.yaml `__.
In the configuration file, define the parameters of the training and the model, although most of the default values will work well.
The specification can be roughly grouped into three categories:
@@ -152,7 +152,7 @@ More details about parameters in the spec file can be found below:
| **test_ds.prefix** | string | ``test`` | A prefix for the test file names. |
+-------------------------------------------+-----------------+----------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------+
-For additional config parameters common to all NLP models, refer to the `nlp_model doc `__.
+For additional config parameters common to all NLP models, refer to the `nlp_model doc `__.
The following is an example of the command for training the model:
diff --git a/docs/source/nlp/machine_translation.rst b/docs/source/nlp/machine_translation.rst
index 3635fad5174f..3c943fb98f42 100644
--- a/docs/source/nlp/machine_translation.rst
+++ b/docs/source/nlp/machine_translation.rst
@@ -478,7 +478,7 @@ custom configuration under the ``encoder`` configuration.
HuggingFace
^^^^^^^^^^^
-We have provided a `HuggingFace config file `__
+We have provided a `HuggingFace config file `__
to use with HuggingFace encoders.
To use the config file from CLI:
@@ -508,7 +508,7 @@ Note the ``+`` symbol is needed if we're not adding the arguments to the YAML co
Megatron
^^^^^^^^
-We have provided a `Megatron config file `__
+We have provided a `Megatron config file `__
to use with Megatron encoders.
To use the config file from CLI:
@@ -561,6 +561,17 @@ To train a Megatron 345M BERT, we would use
model.encoder.num_layers=24 \
model.encoder.max_position_embeddings=512 \
+If the pretrained megatron model used a custom vocab file, then set:
+
+.. code::
+
+ model.encoder_tokenizer.vocab_file=/path/to/your/megatron/vocab_file.txt
+ model.encoder.vocab_file=/path/to/your/megatron/vocab_file.txt
+
+
+Use ``encoder.model_name=megatron_bert_uncased`` for uncased models with custom vocabularies and
+use ``encoder.model_name=megatron_bert_cased`` for cased models with custom vocabularies.
+
References
----------
diff --git a/docs/source/nlp/megatron_finetuning.rst b/docs/source/nlp/megatron_finetuning.rst
index fec82f2d1d4e..9f7a09df4330 100644
--- a/docs/source/nlp/megatron_finetuning.rst
+++ b/docs/source/nlp/megatron_finetuning.rst
@@ -51,7 +51,7 @@ BioMegatron has the same network architecture as the Megatron-LM, but is pretrai
a large biomedical text corpus, which achieves better performance in biomedical downstream tasks than the original Megatron-LM.
Examples of using BioMegatron on biomedical downstream tasks can be found at (can be executed with `Google's Colab `_):
-`NeMo/tutorials/nlp/Relation_Extraction-BioMegatron.ipynb `__ and `NeMo/tutorials/nlp/Token_Classification-BioMegatron.ipynb `__.
+`NeMo/tutorials/nlp/Relation_Extraction-BioMegatron.ipynb `__ and `NeMo/tutorials/nlp/Token_Classification-BioMegatron.ipynb `__.
Model Parallelism
-----------------
diff --git a/docs/source/nlp/punctuation_and_capitalization.rst b/docs/source/nlp/punctuation_and_capitalization.rst
index 4cce7b34ced1..9db4ba5e72b8 100755
--- a/docs/source/nlp/punctuation_and_capitalization.rst
+++ b/docs/source/nlp/punctuation_and_capitalization.rst
@@ -39,15 +39,15 @@ language model, such as `BERT: Pre-training of Deep Bidirectional Transformers f
.. note::
- We recommend you try this model in a Jupyter notebook (run on `Google's Colab `_.): `NeMo/tutorials/nlp/Punctuation_and_Capitalization.ipynb `__.
+ We recommend you try this model in a Jupyter notebook (run on `Google's Colab `_.): `NeMo/tutorials/nlp/Punctuation_and_Capitalization.ipynb `__.
Connect to an instance with a GPU (**Runtime** -> **Change runtime type** -> select **GPU** for the hardware accelerator).
- An example script on how to train the model can be found at: `NeMo/examples/nlp/token_classification/punctuation_capitalization_train.py `__.
+ An example script on how to train the model can be found at: `NeMo/examples/nlp/token_classification/punctuation_capitalization_train.py `__.
- An example script on how to run evaluation and inference can be found at: `NeMo/examples/nlp/token_classification/punctuation_capitalization_evaluate.py `__.
+ An example script on how to run evaluation and inference can be found at: `NeMo/examples/nlp/token_classification/punctuation_capitalization_evaluate.py `__.
- The default configuration file for the model can be found at: `NeMo/examples/nlp/token_classification/conf/punctuation_capitalization_config.yaml `__.
+ The default configuration file for the model can be found at: `NeMo/examples/nlp/token_classification/conf/punctuation_capitalization_config.yaml `__.
.. _raw_data_format_punct:
@@ -162,7 +162,7 @@ Training Punctuation and Capitalization Model
---------------------------------------------
The language model is initialized with the pre-trained model from `HuggingFace Transformers `__,
-unless the user provides a pre-trained checkpoint for the language model. Example of model configuration file for training the model can be found at: `NeMo/examples/nlp/token_classification/conf/punctuation_capitalization_config.yaml `__.
+unless the user provides a pre-trained checkpoint for the language model. Example of model configuration file for training the model can be found at: `NeMo/examples/nlp/token_classification/conf/punctuation_capitalization_config.yaml `__.
The specification is roughly grouped into the following categories:
@@ -170,7 +170,7 @@ The specification is roughly grouped into the following categories:
- Parameters that describe the datasets: **model.dataset**, **model.train_ds**, **model.validation_ds**
- Parameters that describe the model: **model**
-More details about parameters in the config file can be found below and in the `model's config file `__:
+More details about parameters in the config file can be found below and in the `model's config file `__:
+-------------------------------------------+-----------------+--------------------------------------------------------------------------------------------------------------+
| **Parameter** | **Data Type** | **Description** |
@@ -248,7 +248,7 @@ Required Arguments for Training
Inference
---------
-An example script on how to run inference on a few examples, can be found at `examples/nlp/token_classification/punctuation_capitalization_evaluate.py `_.
+An example script on how to run inference on a few examples, can be found at `examples/nlp/token_classification/punctuation_capitalization_evaluate.py `_.
To start inference with a pre-trained model on a few examples, run:
@@ -261,7 +261,7 @@ To start inference with a pre-trained model on a few examples, run:
Model Evaluation
----------------
-An example script on how to evaluate the pre-trained model, can be found at `examples/nlp/token_classification/punctuation_capitalization_evaluate.py `_.
+An example script on how to evaluate the pre-trained model, can be found at `examples/nlp/token_classification/punctuation_capitalization_evaluate.py `_.
To start evaluation of the pre-trained model, run:
diff --git a/docs/source/nlp/question_answering.rst b/docs/source/nlp/question_answering.rst
index 567be7dc622b..75ced9f0daea 100644
--- a/docs/source/nlp/question_answering.rst
+++ b/docs/source/nlp/question_answering.rst
@@ -38,13 +38,13 @@ Quick Start Guide
.. note::
We recommend you try Question Answering model in a Jupyter notebook (can run on `Google's Colab `_.):
- `NeMo/tutorials/nlp/Question_Answering_Squad.ipynb `__.
+ `NeMo/tutorials/nlp/Question_Answering_Squad.ipynb `__.
Connect to an instance with a GPU (**Runtime** -> **Change runtime type** -> select **GPU** for the hardware accelerator).
- An example script on how to train and evaluate the model can be found here: `NeMo/examples/nlp/question_answering/question_answering_squad.py `__.
+ An example script on how to train and evaluate the model can be found here: `NeMo/examples/nlp/question_answering/question_answering_squad.py `__.
- The default configuration file for the model can be found at: `NeMo/examples/nlp/question_answering/conf/question_answering_squad.yaml `__.
+ The default configuration file for the model can be found at: `NeMo/examples/nlp/question_answering/conf/question_answering_squad.yaml `__.
@@ -174,7 +174,7 @@ In the Question Answering Model, we are training a span prediction head on top o
Unless the user provides a pre-trained checkpoint for the language model, the language model is initialized with the pre-trained model
from `HuggingFace Transformers `__.
-Example of model configuration file for training the model can be found at: `NeMo/examples/nlp/question_answering/conf/question_answering_squad_config.yaml `__.
+Example of model configuration file for training the model can be found at: `NeMo/examples/nlp/question_answering/conf/question_answering_squad_config.yaml `__.
The specification can be grouped into three categories:
@@ -243,7 +243,7 @@ that is initially loaded from a previously trained checkpoint, e.g. by specifyin
Inference
---------
-An example script on how to run inference can be found at `examples/nlp/question_answering/question_answering_squad.py `_.
+An example script on how to run inference can be found at `examples/nlp/question_answering/question_answering_squad.py `_.
To run inference with the pre-trained model, run:
@@ -264,7 +264,7 @@ Required Arguments for inference:
Model Evaluation
----------------
-An example script on how to evaluate the pre-trained model, can be found at `examples/nlp/question_answering/question_answering_squad.py `_.
+An example script on how to evaluate the pre-trained model, can be found at `examples/nlp/question_answering/question_answering_squad.py `_.
To run evaluation of the pre-trained model, run:
diff --git a/docs/source/nlp/sgd_qa.rst b/docs/source/nlp/sgd_qa.rst
index 351ffe520ea1..db9de8e97b94 100644
--- a/docs/source/nlp/sgd_qa.rst
+++ b/docs/source/nlp/sgd_qa.rst
@@ -5,7 +5,7 @@ Dialogue State Tracking - SGD-QA Model
More details can be found in the paper
`SGD-QA: Fast Schema-Guided Dialogue State Tracking for Unseen Services `__ :cite:`nlp-sgdqa-zhang2021sgdqa`.
-An example script on how to train the model can be found here: `NeMo/examples/nlp/dialogue_state_tracking/sgd_qa.py `__.
+An example script on how to train the model can be found here: `NeMo/examples/nlp/dialogue_state_tracking/sgd_qa.py `__.
References
diff --git a/docs/source/nlp/text_classification.rst b/docs/source/nlp/text_classification.rst
index ea90c8503a5e..f7ff1d2f3686 100644
--- a/docs/source/nlp/text_classification.rst
+++ b/docs/source/nlp/text_classification.rst
@@ -8,11 +8,11 @@ variety of tasks like text classification, sentiment analysis, domain/intent det
The model takes a text input and predicts a label/class for the whole sequence. Megatron-LM and most of the BERT-based encoders
supported by HuggingFace including BERT, RoBERTa, and DistilBERT.
-An example script on how to train the model can be found here: `NeMo/examples/nlp/text_classification/text_classification_with_bert.py `__.
-The default configuration file for the model can be found at: `NeMo/examples/nlp/text_classification/conf/text_classification_config.yaml `__.
+An example script on how to train the model can be found here: `NeMo/examples/nlp/text_classification/text_classification_with_bert.py `__.
+The default configuration file for the model can be found at: `NeMo/examples/nlp/text_classification/conf/text_classification_config.yaml `__.
There is also a Jupyter notebook which explains how to work with this model. We recommend you try this model in the Jupyter notebook (can run on `Google's Colab `_.):
-`NeMo/tutorials/nlp/Text_Classification_Sentiment_Analysis.ipynb `__.
+`NeMo/tutorials/nlp/Text_Classification_Sentiment_Analysis.ipynb `__.
This tutorial shows an example of how run the Text Classification model on a sentiment analysis task. You may connect to an instance with a GPU (**Runtime** -> **Change runtime type** -> select **GPU** for the hardware accelerator) to run the notebook.
Data Format
@@ -79,7 +79,7 @@ Some datasets do not have the test set or their test set does not have any label
Model Training
--------------
-You may find an example of a config file to be used for training of the Text Classification model at `NeMo/examples/nlp/text_classification/conf/text_classification_config.yaml `__.
+You may find an example of a config file to be used for training of the Text Classification model at `NeMo/examples/nlp/text_classification/conf/text_classification_config.yaml `__.
You can change any of these parameters directly from the config file or update them with the command-line arguments.
The config file of the Text Classification model contains three main sections of ``trainer``, ``exp_manager``, and ``model``. You can
@@ -158,7 +158,7 @@ Model Evaluation and Inference
------------------------------
After saving the model in ``.nemo`` format, you can load the model and perform evaluation or inference on the model. You can find
-some examples in the example script: `NeMo/examples/nlp/text_classification/text_classification_with_bert.py `__.
+some examples in the example script: `NeMo/examples/nlp/text_classification/text_classification_with_bert.py `__.
References
----------
diff --git a/docs/source/nlp/token_classification.rst b/docs/source/nlp/token_classification.rst
index cab12eda1210..cca2e68055f3 100755
--- a/docs/source/nlp/token_classification.rst
+++ b/docs/source/nlp/token_classification.rst
@@ -30,15 +30,15 @@ Quick Start Guide
.. note::
We recommend you try this model in a Jupyter notebook (run on `Google's Colab `_.):
- `NeMo/tutorials/nlp/Token_Classification_Named_Entity_Recognition.ipynb `__.
+ `NeMo/tutorials/nlp/Token_Classification_Named_Entity_Recognition.ipynb `__.
Connect to an instance with a GPU (**Runtime** -> **Change runtime type** -> select **GPU** for the hardware accelerator).
- An example script on how to train the model can be found here: `NeMo/examples/nlp/token_classification/token_classification_train.py `__.
+ An example script on how to train the model can be found here: `NeMo/examples/nlp/token_classification/token_classification_train.py `__.
- An example script on how to run evaluation and inference can be found here: `NeMo/examples/nlp/token_classification/token_classification_evaluate.py `__.
+ An example script on how to run evaluation and inference can be found here: `NeMo/examples/nlp/token_classification/token_classification_evaluate.py `__.
- The default configuration file for the model can be found here: `NeMo/examples/nlp/token_classification/conf/token_classification_config.yaml `__.
+ The default configuration file for the model can be found here: `NeMo/examples/nlp/token_classification/conf/token_classification_config.yaml `__.
.. _dataset_token_classification:
@@ -68,7 +68,7 @@ Dataset Conversion
------------------
To convert an `IOB format `__ (short for inside, outside, beginning) data to the format required for training, use
-`examples/nlp/token_classification/data/import_from_iob_format.py `_.
+`examples/nlp/token_classification/data/import_from_iob_format.py `_.
.. code::
@@ -101,7 +101,7 @@ In the Token Classification model, we are jointly training a classifier on top o
Unless the user provides a pre-trained checkpoint for the language model, the language model is initialized with the pre-trained model
from `HuggingFace Transformers `__.
-Example of model configuration file for training the model can be found at: `NeMo/examples/nlp/token_classification/conf/token_classification_config.yaml `__.
+Example of model configuration file for training the model can be found at: `NeMo/examples/nlp/token_classification/conf/token_classification_config.yaml `__.
The specification can be roughly grouped into three categories:
@@ -165,7 +165,7 @@ Required Arguments for Training
Inference
---------
-An example script on how to run inference can be found at `examples/nlp/token_classification/token_classification_evaluate.py `_.
+An example script on how to run inference can be found at `examples/nlp/token_classification/token_classification_evaluate.py `_.
To run inference with the pre-trained model, run:
@@ -182,7 +182,7 @@ Required Arguments for Inference
Model Evaluation
----------------
-An example script on how to evaluate the pre-trained model can be found at `examples/nlp/token_classification/token_classification_evaluate.py `_.
+An example script on how to evaluate the pre-trained model can be found at `examples/nlp/token_classification/token_classification_evaluate.py `_.
To start evaluation of the pre-trained model, run:
diff --git a/docs/source/starthere/best-practices.rst b/docs/source/starthere/best-practices.rst
index 2c0d1238edcf..972c27c4d575 100644
--- a/docs/source/starthere/best-practices.rst
+++ b/docs/source/starthere/best-practices.rst
@@ -112,7 +112,7 @@ appear to be correct?**
A: Because our pre-trained models can only output lowercase letters and apostrophe, everything else is dropped. So the model will
transcribe 10 as ten. The best way forward is to prepare the training data first by transforming everything to lowercase and convert
the numbers from digit representation to word representation using a simple library such as `inflect `_. Then, add the uppercase letters
-and punctuation back using the NLP punctuation model. Here is an example of how this is incorporated: `NeMo voice swap demo `_.
+and punctuation back using the NLP punctuation model. Here is an example of how this is incorporated: `NeMo voice swap demo `_.
**Q: What languages are supported in NeMo currently?**
A: Along with English, we provide pre-trained models for Zh, Es, Fr, De, Ru, It, Ca and Pl languages.
@@ -133,7 +133,7 @@ For example, processing a single sample involves:
- Impulse perturbation
- Time stretch augmentation (batch level, neural module)
-A simple tutorial guides users on how to use these utilities provided in `GitHub: NeMo `_.
+A simple tutorial guides users on how to use these utilities provided in `GitHub: NeMo `_.
Speech Data Explorer
--------------------
@@ -193,8 +193,8 @@ BioMegatron is a large language model (Megatron-LM) trained on larger domain tex
It achieves state-of-the-art results for certain tasks such as Relationship Extraction, Named Entity Recognition and Question &
Answering. Follow these tutorials to learn how to train and fine tune BioMegatron; pretrained models are provided on NGC:
-- `Relation Extraction BioMegatron `_
-- `Token Classification BioMegatron `_
+- `Relation Extraction BioMegatron `_
+- `Token Classification BioMegatron `_
Efficient Training With NeMo
----------------------------
diff --git a/docs/source/starthere/intro.rst b/docs/source/starthere/intro.rst
index d80a3dfac980..e55a701c6f25 100644
--- a/docs/source/starthere/intro.rst
+++ b/docs/source/starthere/intro.rst
@@ -47,10 +47,10 @@ This NeMo Quick Start Guide is a starting point for users who want to try out Ne
If you're new to NeMo, the best way to get started is to take a look at the following tutorials:
-* `Text Classification (Sentiment Analysis) `__ - demonstrates the Text Classification model using the NeMo NLP collection.
-* `NeMo Primer `__ - introduces NeMo, PyTorch Lightning, and OmegaConf, and shows how to use, modify, save, and restore NeMo models.
-* `NeMo Models `__ - explains the fundamental concepts of the NeMo model.
-* `NeMo voice swap demo `__ - demonstrates how to swap a voice in the audio fragment with a computer generated one using NeMo.
+* `Text Classification (Sentiment Analysis) `__ - demonstrates the Text Classification model using the NeMo NLP collection.
+* `NeMo Primer `__ - introduces NeMo, PyTorch Lightning, and OmegaConf, and shows how to use, modify, save, and restore NeMo models.
+* `NeMo Models `__ - explains the fundamental concepts of the NeMo model.
+* `NeMo voice swap demo `__ - demonstrates how to swap a voice in the audio fragment with a computer generated one using NeMo.
Below we is the code snippet of Audio Translator application.
@@ -149,9 +149,9 @@ Have a look at our `discussions board `_ file for the process.
+We welcome community contributions! Refer to the `CONTRIBUTING.md `_ file for the process.
License
-------
-NeMo is under `Apache 2.0 license `_.
\ No newline at end of file
+NeMo is under `Apache 2.0 license `_.
\ No newline at end of file
diff --git a/docs/source/starthere/tutorials.rst b/docs/source/starthere/tutorials.rst
index a8e0eb98cc33..a0b0f0ad3583 100644
--- a/docs/source/starthere/tutorials.rst
+++ b/docs/source/starthere/tutorials.rst
@@ -21,100 +21,100 @@ To run a tutorial:
- GitHub URL
* - General
- Getting Started: Exploring Nemo Fundamentals
- - `NeMo Fundamentals `_
+ - `NeMo Fundamentals `_
* - General
- Getting Started: Sample Conversational AI application
- - `Audio translator example `_
+ - `Audio translator example `_
* - General
- Getting Started: Voice swap application
- - `Voice swap example `_
+ - `Voice swap example `_
* - General
- Exploring NeMo Model Construction
- - `NeMo Models `_
+ - `NeMo Models `_
* - ASR
- ASR with NeMo
- - `ASR with NeMo `_
+ - `ASR with NeMo `_
* - ASR
- ASR with Subword Tokenization
- - `ASR with Subword Tokenization `_
+ - `ASR with Subword Tokenization `_
* - ASR
- Offline ASR Inference with Beam Search and External Language Model Rescoring
- - `Offline ASR `_
+ - `Offline ASR `_
* - ASR
- Online ASR inference with Microphone
- - `Online ASR Microphone `_
+ - `Online ASR Microphone `_
* - ASR
- Fine-tuning CTC Models on New Languages
- - `ASR CTC Language Fine-Tuning `_
+ - `ASR CTC Language Fine-Tuning `_
* - ASR
- Speech Commands
- - `Speech Commands `_
+ - `Speech Commands `_
* - ASR
- Online and Offline Speech Commands Inference
- - `Online Offline Microphone Speech Commands `_
+ - `Online Offline Microphone Speech Commands `_
* - ASR
- - Voice Activiy Detection (VAD)
- - `Voice Activiy Detection `_
+ - Voice Activity Detection (VAD)
+ - `Voice Activity Detection `_
* - ASR
- Online and Offline VAD Inference
- - `Online Offline Microphone VAD `_
+ - `Online Offline Microphone VAD `_
* - ASR
- Speaker Recognition and Verification
- - `Speaker Recognition and Verification `_
+ - `Speaker Recognition and Verification `_
* - ASR
- Speaker Diarization Inference
- - `Speaker Diarization Inference `_
+ - `Speaker Diarization Inference `_
* - ASR
- ASR with Speaker Diarization
- - `ASR with Speaker Diarization `_
+ - `ASR with Speaker Diarization `_
* - ASR
- Online Noise Augmentation
- - `Online Noise Augmentation `_
+ - `Online Noise Augmentation `_
* - ASR
- ASR for Telephony Speech
- `ASR for Telephony Speech `_
* - NLP
- Using Pretrained Language Models for Downstream Tasks
- - `Pretrained Language Models for Downstream Tasks `_
+ - `Pretrained Language Models for Downstream Tasks `_
* - NLP
- Exploring NeMo NLP Tokenizers
- - `NLP Tokenizers `_
+ - `NLP Tokenizers `_
* - NLP
- Text Classification (Sentiment Analysis) with BERT
- - `Text Classification (Sentiment Analysis) `_
+ - `Text Classification (Sentiment Analysis) `_
* - NLP
- Question Answering with SQuAD
- - `Question Answering Squad `_
+ - `Question Answering Squad `_
* - NLP
- Token Classification (Named Entity Recognition)
- - `Token Classification: Named Entity Recognition `_
+ - `Token Classification: Named Entity Recognition `_
* - NLP
- Joint Intent Classification and Slot Filling
- - `Joint Intent and Slot Classification `_
+ - `Joint Intent and Slot Classification `_
* - NLP
- GLUE Benchmark
- - `GLUE Benchmark `_
+ - `GLUE Benchmark `_
* - NLP
- Punctuation and Capitalization
- - `Punctuation and Capitalization `_
+ - `Punctuation and Capitalization `_
* - NLP
- Named Entity Recognition - BioMegatron
- - `Named Entity Recognition - BioMegatron `_
+ - `Named Entity Recognition - BioMegatron `_
* - NLP
- Relation Extraction - BioMegatron
- - `Relation Extraction - BioMegatron `_
+ - `Relation Extraction - BioMegatron `_
* - TTS
- Speech Synthesis
- - `TTS Inference `_
+ - `TTS Inference `_
* - TTS
- Speech Synthesis
- - `Tacotron2 Training `_
+ - `Tacotron2 Training `_
* - Tools
- CTC Segmentation
- - `CTC Segmentation `_
+ - `CTC Segmentation `_
* - Text Processing
- Text Normalization for TTS
- - `Text Normalization `_
+ - `Text Normalization `_
* - Text Processing
- Inverse Text Normalization for ASR
- - `Inverse Text Normalization `_
+ - `Inverse Text Normalization `_
diff --git a/docs/source/tools/ctc_segmentation.rst b/docs/source/tools/ctc_segmentation.rst
index 80e4f6cf85e8..c9729e266323 100644
--- a/docs/source/tools/ctc_segmentation.rst
+++ b/docs/source/tools/ctc_segmentation.rst
@@ -4,7 +4,7 @@ Dataset Creation Tool Based on CTC-Segmentation
This tool provides functionality to align long audio files and the corresponding transcripts into shorter fragments
that are suitable for an Automatic Speech Recognition (ASR) model training.
-More details could be found in `NeMo/tutorials/tools/CTC_Segmentation_Tutorial.ipynb `__ (can be executed with `Google's Colab `_).
+More details could be found in `NeMo/tutorials/tools/CTC_Segmentation_Tutorial.ipynb `__ (can be executed with `Google's Colab `_).
The tool is based on the `CTC-Segmentation `__ package and
`CTC-Segmentation of Large Corpora for German End-to-end Speech Recognition
diff --git a/nemo/collections/nlp/models/machine_translation/mt_enc_dec_model.py b/nemo/collections/nlp/models/machine_translation/mt_enc_dec_model.py
index 6e2bb30e1368..cd444bb22f79 100644
--- a/nemo/collections/nlp/models/machine_translation/mt_enc_dec_model.py
+++ b/nemo/collections/nlp/models/machine_translation/mt_enc_dec_model.py
@@ -84,7 +84,8 @@ def __init__(self, cfg: MTEncDecModelConfig, trainer: Trainer = None):
if cfg.encoder_tokenizer.get('bpe_dropout', 0.0) is not None
else 0.0,
encoder_model_name=cfg.encoder.get('model_name') if hasattr(cfg.encoder, 'model_name') else None,
- decoder_tokenizer_library=self.decoder_tokenizer_library,
+ encoder_tokenizer_vocab_file=cfg.encoder_tokenizer.get('vocab_file', None),
+ decoder_tokenizer_library=cfg.decoder_tokenizer.get('library', 'yttm'),
decoder_tokenizer_model=cfg.decoder_tokenizer.tokenizer_model,
decoder_bpe_dropout=cfg.decoder_tokenizer.get('bpe_dropout', 0.0)
if cfg.decoder_tokenizer.get('bpe_dropout', 0.0) is not None
@@ -381,6 +382,7 @@ def setup_enc_dec_tokenizers(
encoder_tokenizer_model=None,
encoder_bpe_dropout=0.0,
encoder_model_name=None,
+ encoder_tokenizer_vocab_file=None,
decoder_tokenizer_library=None,
decoder_tokenizer_model=None,
decoder_bpe_dropout=0.0,
@@ -399,7 +401,7 @@ def setup_enc_dec_tokenizers(
tokenizer_model=self.register_artifact("encoder_tokenizer.tokenizer_model", encoder_tokenizer_model),
bpe_dropout=encoder_bpe_dropout,
model_name=encoder_model_name,
- vocab_file=None,
+ vocab_file=self.register_artifact("encoder_tokenizer.vocab_file", encoder_tokenizer_vocab_file),
special_tokens=None,
use_fast=False,
)
diff --git a/nemo/collections/nlp/modules/common/tokenizer_utils.py b/nemo/collections/nlp/modules/common/tokenizer_utils.py
index 36d953e807c0..b3a1087b4944 100644
--- a/nemo/collections/nlp/modules/common/tokenizer_utils.py
+++ b/nemo/collections/nlp/modules/common/tokenizer_utils.py
@@ -96,6 +96,9 @@ def get_tokenizer(
elif tokenizer_name == 'char':
return CharTokenizer(vocab_file=vocab_file, **special_tokens_dict)
+ logging.info(
+ f"Getting HuggingFace AutoTokenizer with pretrained_model_name: {tokenizer_name}, vocab_file: {vocab_file}, special_tokens_dict: {special_tokens_dict}, and use_fast: {use_fast}"
+ )
return AutoTokenizer(
pretrained_model_name=tokenizer_name, vocab_file=vocab_file, **special_tokens_dict, use_fast=use_fast
)
@@ -144,7 +147,7 @@ def get_nmt_tokenizer(
return ByteLevelTokenizer()
elif library == 'megatron':
logging.info(
- f'Getting Megatron tokenizer with pretrained model name: {model_name} and custom vocab file: {vocab_file}'
+ f'Getting Megatron tokenizer for pretrained model name: {model_name} and custom vocab file: {vocab_file}'
)
return get_tokenizer(tokenizer_name=model_name, vocab_file=vocab_file)
else:
diff --git a/nemo/package_info.py b/nemo/package_info.py
index cb39b87bf6bf..72039b675825 100644
--- a/nemo/package_info.py
+++ b/nemo/package_info.py
@@ -14,8 +14,8 @@
MAJOR = 1
-MINOR = 0
-PATCH = 2
+MINOR = 1
+PATCH = 0
PRE_RELEASE = ''
# Use the following formatting: (major, minor, patch, pre-release)
diff --git a/requirements/requirements.txt b/requirements/requirements.txt
index ac7d1a3dd472..fc33f07cc769 100644
--- a/requirements/requirements.txt
+++ b/requirements/requirements.txt
@@ -3,6 +3,7 @@ onnx>=1.7.0
pytorch-lightning>=1.3.0
python-dateutil
torch
+torchmetrics>=0.4.1rc0
wget
wrapt
ruamel.yaml
diff --git a/tutorials/01_NeMo_Models.ipynb b/tutorials/01_NeMo_Models.ipynb
index 089646053c92..04b800a34b16 100644
--- a/tutorials/01_NeMo_Models.ipynb
+++ b/tutorials/01_NeMo_Models.ipynb
@@ -115,7 +115,7 @@
"\n",
"NeMo comes with several state-of-the-art pre-trained Conversational AI models for users to quickly be able to start training and fine-tuning on their own datasets. \n",
"\n",
- "In the previous [NeMo Primer](https://colab.research.google.com/github/NVIDIA/NeMo/blob/main/tutorials/00_NeMo_Primer.ipynb) notebook, we learned how to download pretrained checkpoints with NeMo and we also discussed the fundamental concepts of the NeMo Model. The previous tutorial showed us how to use, modify, save, and restore NeMo Models.\n",
+ "In the previous [NeMo Primer](https://colab.research.google.com/github/NVIDIA/NeMo/blob/stable/tutorials/00_NeMo_Primer.ipynb) notebook, we learned how to download pretrained checkpoints with NeMo and we also discussed the fundamental concepts of the NeMo Model. The previous tutorial showed us how to use, modify, save, and restore NeMo Models.\n",
"\n",
"In this tutorial we will learn how to develop a non-trivial NeMo model from scratch. This helps us to understand the underlying components and how they interact with the overall PyTorch ecosystem.\n"
]
diff --git a/tutorials/AudioTranslationSample.ipynb b/tutorials/AudioTranslationSample.ipynb
index 4507c4ceb965..ee1cdbf10e1e 100644
--- a/tutorials/AudioTranslationSample.ipynb
+++ b/tutorials/AudioTranslationSample.ipynb
@@ -239,11 +239,11 @@
"\n",
"**NeMo is built for training.** You can fine-tune, or train from scratch on your data all models used in this example. We recommend you checkout the following, more in-depth, tutorials next:\n",
"\n",
- "* [NeMo fundamentals](https://colab.research.google.com/github/NVIDIA/NeMo/blob/v1.0.2/tutorials/00_NeMo_Primer.ipynb)\n",
- "* [NeMo models](https://colab.research.google.com/github/NVIDIA/NeMo/blob/v1.0.2/tutorials/01_NeMo_Models.ipynb)\n",
- "* [Speech Recognition](https://colab.research.google.com/github/NVIDIA/NeMo/blob/v1.0.2/tutorials/asr/01_ASR_with_NeMo.ipynb)\n",
- "* [Punctuation and Capitalization](https://colab.research.google.com/github/NVIDIA/NeMo/blob/v1.0.2/tutorials/nlp/Punctuation_and_Capitalization.ipynb)\n",
- "* [Speech Synthesis](https://colab.research.google.com/github/NVIDIA/NeMo/blob/v1.0.2/tutorials/tts/1_TTS_inference.ipynb)\n",
+ "* [NeMo fundamentals](https://colab.research.google.com/github/NVIDIA/NeMo/blob/stable/tutorials/00_NeMo_Primer.ipynb)\n",
+ "* [NeMo models](https://colab.research.google.com/github/NVIDIA/NeMo/blob/stable/tutorials/01_NeMo_Models.ipynb)\n",
+ "* [Speech Recognition](https://colab.research.google.com/github/NVIDIA/NeMo/blob/stable/tutorials/asr/01_ASR_with_NeMo.ipynb)\n",
+ "* [Punctuation and Capitalization](https://colab.research.google.com/github/NVIDIA/NeMo/blob/stable/tutorials/nlp/Punctuation_and_Capitalization.ipynb)\n",
+ "* [Speech Synthesis](https://colab.research.google.com/github/NVIDIA/NeMo/blob/stable/tutorials/tts/1_TTS_inference.ipynb)\n",
"\n",
"\n",
"You can find scripts for training and fine-tuning ASR, NLP and TTS models [here](https://github.com/NVIDIA/NeMo/tree/v1.0.2/examples). "
diff --git a/tutorials/VoiceSwapSample.ipynb b/tutorials/VoiceSwapSample.ipynb
index b94cf57eea23..892d2dc72bf1 100644
--- a/tutorials/VoiceSwapSample.ipynb
+++ b/tutorials/VoiceSwapSample.ipynb
@@ -273,11 +273,11 @@
"\n",
"**NeMo is built for training.** You can fine-tune, or train from scratch on your data all models used in this example. We recommend you checkout the following, more in-depth, tutorials next:\n",
"\n",
- "* [NeMo fundamentals](https://colab.research.google.com/github/NVIDIA/NeMo/blob/main/tutorials/00_NeMo_Primer.ipynb)\n",
- "* [NeMo models](https://colab.research.google.com/github/NVIDIA/NeMo/blob/main/tutorials/01_NeMo_Models.ipynb)\n",
- "* [Speech Recognition](https://colab.research.google.com/github/NVIDIA/NeMo/blob/main/tutorials/asr/01_ASR_with_NeMo.ipynb)\n",
- "* [Punctuation and Capitalization](https://colab.research.google.com/github/NVIDIA/NeMo/blob/main/tutorials/nlp/Punctuation_and_Capitalization.ipynb)\n",
- "* [Speech Synthesis](https://colab.research.google.com/github/NVIDIA/NeMo/blob/main/tutorials/tts/1_TTS_inference.ipynb)\n",
+ "* [NeMo fundamentals](https://colab.research.google.com/github/NVIDIA/NeMo/blob/stable/tutorials/00_NeMo_Primer.ipynb)\n",
+ "* [NeMo models](https://colab.research.google.com/github/NVIDIA/NeMo/blob/stable/tutorials/01_NeMo_Models.ipynb)\n",
+ "* [Speech Recognition](https://colab.research.google.com/github/NVIDIA/NeMo/blob/stable/tutorials/asr/01_ASR_with_NeMo.ipynb)\n",
+ "* [Punctuation and Capitalization](https://colab.research.google.com/github/NVIDIA/NeMo/blob/stable/tutorials/nlp/Punctuation_and_Capitalization.ipynb)\n",
+ "* [Speech Synthesis](https://colab.research.google.com/github/NVIDIA/NeMo/blob/stable/tutorials/tts/1_TTS_inference.ipynb)\n",
"\n",
"\n",
"You can find scripts for training and fine-tuning ASR, NLP and TTS models [here](https://github.com/NVIDIA/NeMo/tree/main/examples). "
@@ -322,4 +322,4 @@
},
"nbformat": 4,
"nbformat_minor": 1
-}
+}
\ No newline at end of file
diff --git a/tutorials/asr/01_ASR_with_NeMo.ipynb b/tutorials/asr/01_ASR_with_NeMo.ipynb
index 3dd4b23b6224..06c4b03d393e 100644
--- a/tutorials/asr/01_ASR_with_NeMo.ipynb
+++ b/tutorials/asr/01_ASR_with_NeMo.ipynb
@@ -126,7 +126,7 @@
"\n",
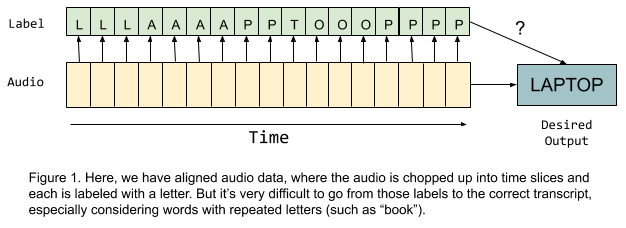
"Earlier speech recognition approaches relied on **temporally-aligned data**, in which each segment of time in an audio file was matched up to a corresponding speech sound such as a phoneme or word. However, if we would like to have the flexibility to predict letter-by-letter to prevent OOV (out of vocabulary) issues, then each time step in the data would have to be labeled with the letter sound that the speaker is making at that point in the audio file. With that information, it seems like we should simply be able to try to predict the correct letter for each time step and then collapse the repeated letters (e.g. the prediction output `LLLAAAAPPTOOOPPPP` would become `LAPTOP`). It turns out that this idea has some problems: not only does alignment make the dataset incredibly labor-intensive to label, but also, what do we do with words like \"book\" that contain consecutive repeated letters? Simply squashing repeated letters together would not work in that case!\n",
"\n",
- "\n",
+ "\n",
"\n",
"Modern end-to-end approaches get around this using methods that don't require manual alignment at all, so that the input-output pairs are really just the raw audio and the transcript--no extra data or labeling required. Let's briefly go over two popular approaches that allow us to do this, Connectionist Temporal Classification (CTC) and sequence-to-sequence models with attention.\n",
"\n",
@@ -972,7 +972,7 @@
"# Of course, you can combine these flags as well.\n",
"```\n",
"\n",
- "Finally, have a look at [example scripts in NeMo repository](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/speech_to_text.py) which can handle mixed precision and distributed training using command-line arguments."
+ "Finally, have a look at [example scripts in NeMo repository](https://github.com/NVIDIA/NeMo/blob/stable/examples/asr/speech_to_text.py) which can handle mixed precision and distributed training using command-line arguments."
]
},
{
@@ -983,9 +983,12 @@
"source": [
"### Deployment\n",
"\n",
+ "Note: It is recommended to run the deployment code from the NVIDIA PyTorch container.\n",
+ "\n",
"Let's get back to our pre-trained model and see how easy it can be exported to an ONNX file\n",
"in order to run it in an inference engine like TensorRT or ONNXRuntime.\n",
- "If you don't have one, let's install it:"
+ "\n",
+ "If you are running in an environment outside of the NVIDIA PyTorch container (like Google Colab for example) then you will have to build the onnxruntime and onnxruntime-gpu. The cell below gives an example of how to build those runtimes but the example may have to be adapted depending on your environment."
]
},
{
@@ -994,15 +997,15 @@
"id": "I4WRcmakjQnj"
},
"source": [
- "!mkdir -p ort\n",
- "%cd ort\n",
- "!git clean -xfd\n",
- "!git clone --depth 1 --branch v1.5.2 https://github.com/microsoft/onnxruntime.git .\n",
- "!./build.sh --skip_tests --config Release --build_shared_lib --parallel --use_cuda --cuda_home /usr/local/cuda --cudnn_home /usr/lib/x86_64-linux-gnu --build_wheel\n",
- "!pip uninstall -y onnxruntime\n",
- "!pip uninstall -y onnxruntime-gpu\n",
- "!pip install --upgrade --force-reinstall ./build/Linux/Release/dist/onnxruntime*.whl\n",
- "%cd .."
+ "#!mkdir -p ort\n",
+ "#%cd ort\n",
+ "#!git clean -xfd\n",
+ "#!git clone --depth 1 --branch v1.8.0 https://github.com/microsoft/onnxruntime.git .\n",
+ "#!./build.sh --skip_tests --config Release --build_shared_lib --parallel --use_cuda --cuda_home /usr/local/cuda --cudnn_home /usr/lib/#x86_64-linux-gnu --build_wheel\n",
+ "#!pip uninstall -y onnxruntime\n",
+ "#!pip uninstall -y onnxruntime-gpu\n",
+ "#!pip install --upgrade --force-reinstall ./build/Linux/Release/dist/onnxruntime*.whl\n",
+ "#%cd .."
],
"execution_count": null,
"outputs": []
@@ -1164,9 +1167,7 @@
"metadata": {
"id": "V3ERGX86lR0V"
},
- "source": [
- ""
- ],
+ "source": [],
"execution_count": null,
"outputs": []
}
diff --git a/tutorials/asr/04_Online_Offline_Speech_Commands_Demo.ipynb b/tutorials/asr/04_Online_Offline_Speech_Commands_Demo.ipynb
index a3531222492d..bd30873c041e 100644
--- a/tutorials/asr/04_Online_Offline_Speech_Commands_Demo.ipynb
+++ b/tutorials/asr/04_Online_Offline_Speech_Commands_Demo.ipynb
@@ -673,7 +673,7 @@
"source": [
"!mkdir -p ort\n",
"%cd ort\n",
- "!git clone --depth 1 --branch v1.5.1 https://github.com/microsoft/onnxruntime.git .\n",
+ "!git clone --depth 1 --branch v1.8.0 https://github.com/microsoft/onnxruntime.git .\n",
"!./build.sh --skip_tests --config Release --build_shared_lib --parallel --use_cuda --cuda_home /usr/local/cuda --cudnn_home /usr/lib/x86_64-linux-gnu --build_wheel\n",
"!pip install ./build/Linux/Release/dist/onnxruntime*.whl\n",
"%cd .."
diff --git a/tutorials/asr/06_Voice_Activiy_Detection.ipynb b/tutorials/asr/06_Voice_Activity_Detection.ipynb
similarity index 98%
rename from tutorials/asr/06_Voice_Activiy_Detection.ipynb
rename to tutorials/asr/06_Voice_Activity_Detection.ipynb
index f2d5927413b2..737282bae22d 100644
--- a/tutorials/asr/06_Voice_Activiy_Detection.ipynb
+++ b/tutorials/asr/06_Voice_Activity_Detection.ipynb
@@ -564,7 +564,7 @@
"Experiment with increasing the number of epochs or with batch size to see how much you can improve the score! \n",
"\n",
"**NOTE:** Noise robustness is quite important for VAD task. Below we list the augmentation we used in this demo. \n",
- "Please refer to [05_Online_Noise_Augmentation.ipynb](https://github.com/NVIDIA/NeMo/blob/v1.0.2/tutorials/asr/05_Online_Noise_Augmentation.ipynb) for understanding noise augmentation in NeMo.\n",
+ "Please refer to [05_Online_Noise_Augmentation.ipynb](https://github.com/NVIDIA/NeMo/blob/stable/tutorials/asr/05_Online_Noise_Augmentation.ipynb) for understanding noise augmentation in NeMo.\n",
"\n",
"\n"
]
@@ -1109,9 +1109,9 @@
"metadata": {},
"source": [
"# Transfer Leaning & Fine-tuning on a new dataset\n",
- "For transfer learning, please refer to [**Transfer learning** part of ASR tutorial](https://github.com/NVIDIA/NeMo/blob/v1.0.2/tutorials/asr/01_ASR_with_NeMo.ipynb)\n",
+ "For transfer learning, please refer to [**Transfer learning** part of ASR tutorial](https://github.com/NVIDIA/NeMo/blob/stable/tutorials/asr/01_ASR_with_NeMo.ipynb)\n",
"\n",
- "More details on saving and restoring checkpoint, and exporting a model in its entirety, please refer to [**Fine-tuning on a new dataset** & **Advanced Usage parts** of Speech Command tutorial](https://github.com/NVIDIA/NeMo/blob/v1.0.2/tutorials/asr/03_Speech_Commands.ipynb)\n",
+ "More details on saving and restoring checkpoint, and exporting a model in its entirety, please refer to [**Fine-tuning on a new dataset** & **Advanced Usage parts** of Speech Command tutorial](https://github.com/NVIDIA/NeMo/blob/stable/tutorials/asr/03_Speech_Commands.ipynb)\n",
"\n",
"\n",
"\n"
@@ -1125,7 +1125,7 @@
},
"source": [
"# Inference and more\n",
- "If you are interested in **pretrained** model and **streaming inference**, please have a look at our [VAD inference tutorial](https://github.com/NVIDIA/NeMo/blob/v1.0.2/tutorials/asr/07_Online_Offline_Microphone_VAD_Demo.ipynb) and script [vad_infer.py](https://github.com/NVIDIA/NeMo/blob/v1.0.2/examples/asr/vad_infer.py)\n"
+ "If you are interested in **pretrained** model and **streaming inference**, please have a look at our [VAD inference tutorial](https://github.com/NVIDIA/NeMo/blob/stable/tutorials/asr/07_Online_Offline_Microphone_VAD_Demo.ipynb) and script [vad_infer.py](https://github.com/NVIDIA/NeMo/blob/stable/examples/asr/vad_infer.py)\n"
]
}
],
diff --git a/tutorials/asr/07_Online_Offline_Microphone_VAD_Demo.ipynb b/tutorials/asr/07_Online_Offline_Microphone_VAD_Demo.ipynb
index 2e606d3d6740..21d73c21a4a7 100644
--- a/tutorials/asr/07_Online_Offline_Microphone_VAD_Demo.ipynb
+++ b/tutorials/asr/07_Online_Offline_Microphone_VAD_Demo.ipynb
@@ -229,7 +229,7 @@
"metadata": {},
"source": [
"### Finetune\n",
- "You might need to finetune on your data for better performance. For finetuning/transfer learning, please refer to [**Transfer learning** part of ASR tutorial](https://github.com/NVIDIA/NeMo/blob/v1.0.2/tutorials/asr/01_ASR_with_NeMo.ipynb)"
+ "You might need to finetune on your data for better performance. For finetuning/transfer learning, please refer to [**Transfer learning** part of ASR tutorial](https://github.com/NVIDIA/NeMo/blob/stable/tutorials/asr/01_ASR_with_NeMo.ipynb)"
]
},
{
@@ -756,7 +756,7 @@
"source": [
"!mkdir -p ort\n",
"%cd ort\n",
- "!git clone --depth 1 --branch v1.5.1 https://github.com/microsoft/onnxruntime.git .\n",
+ "!git clone --depth 1 --branch v1.8.0 https://github.com/microsoft/onnxruntime.git .\n",
"!./build.sh --skip_tests --config Release --build_shared_lib --parallel --use_cuda --cuda_home /usr/local/cuda --cudnn_home /usr/lib/x86_64-linux-gnu --build_wheel\n",
"!pip install ./build/Linux/Release/dist/onnxruntime*.whl\n",
"%cd .."
diff --git a/tutorials/asr/08_ASR_with_Subword_Tokenization.ipynb b/tutorials/asr/08_ASR_with_Subword_Tokenization.ipynb
index f273659cd8b8..c103b2907d79 100644
--- a/tutorials/asr/08_ASR_with_Subword_Tokenization.ipynb
+++ b/tutorials/asr/08_ASR_with_Subword_Tokenization.ipynb
@@ -65,7 +65,7 @@
"source": [
"# Automatic Speech Recognition with Subword Tokenization\r\n",
"\r\n",
- "In the [ASR with NeMo notebook](https://colab.research.google.com/github/NVIDIA/NeMo/blob/v1.0.2/tutorials/asr/01_ASR_with_NeMo.ipynb), we discuss the pipeline necessary for Automatic Speech Recognition (ASR), and then use the NeMo toolkit to construct a functioning speech recognition model.\r\n",
+ "In the [ASR with NeMo notebook](https://colab.research.google.com/github/NVIDIA/NeMo/blob/stable/tutorials/asr/01_ASR_with_NeMo.ipynb), we discuss the pipeline necessary for Automatic Speech Recognition (ASR), and then use the NeMo toolkit to construct a functioning speech recognition model.\r\n",
"\r\n",
"In this notebook, we take a step further and look into subword tokenization as a useful encoding scheme for ASR models, and why they are necessary. We then construct a custom tokenizer from the dataset, and use it to construct and train an ASR model on the [AN4 dataset from CMU](http://www.speech.cs.cmu.edu/databases/an4/) (with processing using `sox`)."
]
@@ -1378,7 +1378,7 @@
"# Of course, you can combine these flags as well.\r\n",
"```\r\n",
"\r\n",
- "Finally, have a look at [example scripts in NeMo repository](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/speech_to_text_bpe.py) which can handle mixed precision and distributed training using command-line arguments."
+ "Finally, have a look at [example scripts in NeMo repository](https://github.com/NVIDIA/NeMo/blob/stable/examples/asr/speech_to_text_bpe.py) which can handle mixed precision and distributed training using command-line arguments."
]
},
{
@@ -1442,4 +1442,4 @@
]
}
]
-}
\ No newline at end of file
+}
diff --git a/tutorials/nlp/01_Pretrained_Language_Models_for_Downstream_Tasks.ipynb b/tutorials/nlp/01_Pretrained_Language_Models_for_Downstream_Tasks.ipynb
index 36d8f79ebe92..8872ea61fa51 100644
--- a/tutorials/nlp/01_Pretrained_Language_Models_for_Downstream_Tasks.ipynb
+++ b/tutorials/nlp/01_Pretrained_Language_Models_for_Downstream_Tasks.ipynb
@@ -146,7 +146,7 @@
"id": "jEgEo0aPj3Ws"
},
"source": [
- "All NeMo [NLP models](https://github.com/NVIDIA/NeMo/tree/main/examples/nlp) have an associated config file. As an example, let's examine the config file for the Named Entity Recognition (NER) model (more details about the model and the NER task could be found [here](https://github.com/NVIDIA/NeMo/blob/main/tutorials/nlp/Token_Classification_Named_Entity_Recognition.ipynb))."
+ "All NeMo [NLP models](https://github.com/NVIDIA/NeMo/tree/main/examples/nlp) have an associated config file. As an example, let's examine the config file for the Named Entity Recognition (NER) model (more details about the model and the NER task could be found [here](https://github.com/NVIDIA/NeMo/blob/stable/tutorials/nlp/Token_Classification_Named_Entity_Recognition.ipynb))."
]
},
{
diff --git a/tutorials/nlp/02_NLP_Tokenizers.ipynb b/tutorials/nlp/02_NLP_Tokenizers.ipynb
index 7724ca9f94f2..bfd096c80558 100644
--- a/tutorials/nlp/02_NLP_Tokenizers.ipynb
+++ b/tutorials/nlp/02_NLP_Tokenizers.ipynb
@@ -98,7 +98,7 @@
"\n",
"Hugging Face and Megatron tokenizers (which uses Hugging Face underneath) can be automatically instantiated by only `tokenizer_name`, which downloads the corresponding `vocab_file` from the internet. \n",
"\n",
- "For SentencePieceTokenizer, WordTokenizer, and CharTokenizers `tokenizer_model` or/and `vocab_file` can be generated offline in advance using [`scripts/tokenizers/process_asr_text_tokenizer.py`](https://github.com/NVIDIA/NeMo/blob/main/scripts/process_asr_text_tokenizer.py)\n",
+ "For SentencePieceTokenizer, WordTokenizer, and CharTokenizers `tokenizer_model` or/and `vocab_file` can be generated offline in advance using [`scripts/tokenizers/process_asr_text_tokenizer.py`](https://github.com/NVIDIA/NeMo/blob/stable/scripts/process_asr_text_tokenizer.py)\n",
"\n",
"The tokenizers in NeMo are designed to be used interchangeably, especially when\n",
"used in combination with a BERT-based model.\n",
@@ -379,7 +379,7 @@
"id": "ykwKmREuPQE-"
},
"source": [
- "We use the [`scripts/tokenizers/process_asr_text_tokenizer.py`](https://github.com/NVIDIA/NeMo/blob/main/scripts/process_asr_text_tokenizer.py) script to create a custom tokenizer model with its own vocabulary from an input file"
+ "We use the [`scripts/tokenizers/process_asr_text_tokenizer.py`](https://github.com/NVIDIA/NeMo/blob/stable/scripts/process_asr_text_tokenizer.py) script to create a custom tokenizer model with its own vocabulary from an input file"
]
},
{
diff --git a/tutorials/nlp/GLUE_Benchmark.ipynb b/tutorials/nlp/GLUE_Benchmark.ipynb
index 818bab153a8c..b3b1bef3f0c7 100644
--- a/tutorials/nlp/GLUE_Benchmark.ipynb
+++ b/tutorials/nlp/GLUE_Benchmark.ipynb
@@ -143,7 +143,7 @@
"\n",
"After running the above commands, you will have a folder `glue_data` with data folders for every GLUE task. For example, data for MRPC task would be under glue_data/MRPC.\n",
"\n",
- "This tutorial and [examples/nlp/glue_benchmark/glue_benchmark.py](https://github.com/NVIDIA/NeMo/blob/main/examples/nlp/glue_benchmark/glue_benchmark.py) work with all GLUE tasks without any modifications. For this tutorial, we are going to use MRPC task.\n",
+ "This tutorial and [examples/nlp/glue_benchmark/glue_benchmark.py](https://github.com/NVIDIA/NeMo/blob/stable/examples/nlp/glue_benchmark/glue_benchmark.py) work with all GLUE tasks without any modifications. For this tutorial, we are going to use MRPC task.\n",
"\n",
"\n",
"\n"
@@ -513,7 +513,7 @@
"source": [
"## Training Script\n",
"\n",
- "If you have NeMo installed locally, you can also train the model with [examples/nlp/glue_benchmark/glue_benchmark.py](https://github.com/NVIDIA/NeMo/blob/main/examples/nlp/glue_benchmark/glue_benchmark.py).\n",
+ "If you have NeMo installed locally, you can also train the model with [examples/nlp/glue_benchmark/glue_benchmark.py](https://github.com/NVIDIA/NeMo/blob/stable/examples/nlp/glue_benchmark/glue_benchmark.py).\n",
"\n",
"To run training script, use:\n",
"\n",
diff --git a/tutorials/nlp/Punctuation_and_Capitalization.ipynb b/tutorials/nlp/Punctuation_and_Capitalization.ipynb
index 3d2f503ed30d..3702c95591fa 100644
--- a/tutorials/nlp/Punctuation_and_Capitalization.ipynb
+++ b/tutorials/nlp/Punctuation_and_Capitalization.ipynb
@@ -212,7 +212,7 @@
"colab_type": "text"
},
"source": [
- "In this notebook we are going to use a subset of English examples from the [Tatoeba collection of sentences](https://tatoeba.org/eng) this script will download and preprocess the Tatoeba data [NeMo/examples/nlp/token_classification/get_tatoeba_data.py](https://github.com/NVIDIA/NeMo/blob/main/examples/nlp/token_classification/data/get_tatoeba_data.py). Note, for further experiments with the model, set NUM_SAMPLES=-1 and consider including other datasets to improve model performance. \n"
+ "In this notebook we are going to use a subset of English examples from the [Tatoeba collection of sentences](https://tatoeba.org/eng) this script will download and preprocess the Tatoeba data [NeMo/examples/nlp/token_classification/get_tatoeba_data.py](https://github.com/NVIDIA/NeMo/blob/stable/examples/nlp/token_classification/data/get_tatoeba_data.py). Note, for further experiments with the model, set NUM_SAMPLES=-1 and consider including other datasets to improve model performance. \n"
]
},
{
@@ -679,7 +679,7 @@
"source": [
"## Training Script\n",
"\n",
- "If you have NeMo installed locally, you can also train the model with [nlp/token_classification/punctuation_capitalization_train.py](https://github.com/NVIDIA/NeMo/blob/main/examples/nlp/token_classification/punctuation_capitalization_train.py).\n",
+ "If you have NeMo installed locally, you can also train the model with [nlp/token_classification/punctuation_capitalization_train.py](https://github.com/NVIDIA/NeMo/blob/stable/examples/nlp/token_classification/punctuation_capitalization_train.py).\n",
"\n",
"To run training script, use:\n",
"\n",
diff --git a/tutorials/nlp/Question_Answering_Squad.ipynb b/tutorials/nlp/Question_Answering_Squad.ipynb
index 3b3c6c275ff8..c298e2428492 100755
--- a/tutorials/nlp/Question_Answering_Squad.ipynb
+++ b/tutorials/nlp/Question_Answering_Squad.ipynb
@@ -196,7 +196,7 @@
"In this notebook we are going download the [SQuAD](https://rajpurkar.github.io/SQuAD-explorer/) dataset to showcase how to do training and inference. There are two datasets, SQuAD1.0 and SQuAD2.0. SQuAD 1.1, the previous version of the SQuAD dataset, contains 100,000+ question-answer pairs on 500+ articles. SQuAD2.0 dataset combines the 100,000 questions in SQuAD1.1 with over 50,000 unanswerable questions written adversarially by crowdworkers to look similar to answerable ones. \n",
"\n",
"\n",
- "To download both datasets, we use [NeMo/examples/nlp/question_answering/get_squad.py](https://github.com/NVIDIA/NeMo/blob/main/examples/nlp/question_answering/get_squad.py). \n",
+ "To download both datasets, we use [NeMo/examples/nlp/question_answering/get_squad.py](https://github.com/NVIDIA/NeMo/blob/stable/examples/nlp/question_answering/get_squad.py). \n",
"\n",
"\n"
]
@@ -279,7 +279,7 @@
"\" [CLS] query [SEP] context [SEP]\".\n",
"This is the tokenization used for BERT, i.e. [WordPiece](https://arxiv.org/pdf/1609.08144.pdf) Tokenizer, which uses the [Google's BERT vocabulary](https://github.com/google-research/bert). This tokenizer is configured with `model.tokenizer.tokenizer_name=bert-base-uncased` and is automatically instantiated using [Huggingface](https://huggingface.co/)'s API. \n",
"The benefit of this tokenizer is that this is compatible with a pretrained BERT model, from which we can finetune instead of training the question answering model from scratch. However, we also support other tokenizers, such as `model.tokenizer.tokenizer_name=sentencepiece`. Unlike the BERT WordPiece tokenizer, the [SentencePiece](https://github.com/google/sentencepiece) tokenizer model needs to be first created from a text file.\n",
- "See [02_NLP_Tokenizers.ipynb](https://colab.research.google.com/github/NVIDIA/NeMo/blob/main/tutorials/nlp/02_NLP_Tokenizers.ipynb) for more details on how to use NeMo Tokenizers."
+ "See [02_NLP_Tokenizers.ipynb](https://colab.research.google.com/github/NVIDIA/NeMo/blob/stable/tutorials/nlp/02_NLP_Tokenizers.ipynb) for more details on how to use NeMo Tokenizers."
]
},
{
@@ -711,7 +711,7 @@
},
"source": [
"If you have NeMo installed locally, you can also train the model with \n",
- "[NeMo/examples/nlp/question_answering/get_squad.py](https://github.com/NVIDIA/NeMo/blob/main/examples/nlp/question_answering/question_answering_squad.py).\n",
+ "[NeMo/examples/nlp/question_answering/get_squad.py](https://github.com/NVIDIA/NeMo/blob/stable/examples/nlp/question_answering/question_answering_squad.py).\n",
"\n",
"To run training script, use:\n",
"\n",
diff --git a/tutorials/nlp/Relation_Extraction-BioMegatron.ipynb b/tutorials/nlp/Relation_Extraction-BioMegatron.ipynb
index 61ea73541b51..c5d3f27cc694 100644
--- a/tutorials/nlp/Relation_Extraction-BioMegatron.ipynb
+++ b/tutorials/nlp/Relation_Extraction-BioMegatron.ipynb
@@ -78,7 +78,7 @@
"The model size of Megatron-LM can be larger than BERT, up to multi-billion parameters, compared to 345 million parameters of BERT-large.\n",
"There are some alternatives of BioMegatron, most notably [BioBERT](https://arxiv.org/abs/1901.08746). Compared to BioBERT BioMegatron is larger by model size and pre-trained on larger text corpus.\n",
"\n",
- "A more general tutorial of using BERT-based models, including Megatron-LM, for downstream natural language processing tasks can be found [here](https://github.com/NVIDIA/NeMo/blob/main/tutorials/nlp/01_Pretrained_Language_Models_for_Downstream_Tasks.ipynb)."
+ "A more general tutorial of using BERT-based models, including Megatron-LM, for downstream natural language processing tasks can be found [here](https://github.com/NVIDIA/NeMo/blob/stable/tutorials/nlp/01_Pretrained_Language_Models_for_Downstream_Tasks.ipynb)."
]
},
{
@@ -184,7 +184,7 @@
"metadata": {},
"source": [
"## Pre-process dataset\n",
- "Let's convert the dataset into the format that is compatible for [NeMo text-classification module](https://github.com/NVIDIA/NeMo/blob/main/examples/nlp/text_classification/text_classification_with_bert.py)."
+ "Let's convert the dataset into the format that is compatible for [NeMo text-classification module](https://github.com/NVIDIA/NeMo/blob/stable/examples/nlp/text_classification/text_classification_with_bert.py)."
]
},
{
diff --git a/tutorials/nlp/Text_Classification_Sentiment_Analysis.ipynb b/tutorials/nlp/Text_Classification_Sentiment_Analysis.ipynb
index e449538d6615..11d473324529 100644
--- a/tutorials/nlp/Text_Classification_Sentiment_Analysis.ipynb
+++ b/tutorials/nlp/Text_Classification_Sentiment_Analysis.ipynb
@@ -95,7 +95,7 @@
"source": [
"# NeMo Text Classification Data Format\n",
"\n",
- "[TextClassificationModel](https://github.com/NVIDIA/NeMo/blob/main/nemo/collections/nlp/models/text_classification/text_classification_model.py) in NeMo supports text classification problems such as sentiment analysis or domain/intent detection for dialogue systems, as long as the data follows the format specified below. \n",
+ "[TextClassificationModel](https://github.com/NVIDIA/NeMo/blob/stable/nemo/collections/nlp/models/text_classification/text_classification_model.py) in NeMo supports text classification problems such as sentiment analysis or domain/intent detection for dialogue systems, as long as the data follows the format specified below. \n",
"\n",
"TextClassificationModel requires the data to be stored in TAB separated files (.tsv) with two columns of sentence and label. Each line of the data file contains text sequences, where words are separated with spaces and label separated with [TAB], i.e.: \n",
"\n",
@@ -693,7 +693,7 @@
"!mkdir -p ort\n",
"%cd ort\n",
"!git clean -xfd\n",
- "!git clone --depth 1 --branch v1.5.2 https://github.com/microsoft/onnxruntime.git .\n",
+ "!git clone --depth 1 --branch v1.8.0 https://github.com/microsoft/onnxruntime.git .\n",
"!./build.sh --skip_tests --config Release --build_shared_lib --parallel --use_cuda --cuda_home /usr/local/cuda --cudnn_home /usr/lib/x86_64-linux-gnu --build_wheel\n",
"!pip uninstall -y onnxruntime\n",
"!pip uninstall -y onnxruntime-gpu\n",
diff --git a/tutorials/nlp/Token_Classification-BioMegatron.ipynb b/tutorials/nlp/Token_Classification-BioMegatron.ipynb
index d96ca50c2c30..55149a7369d1 100644
--- a/tutorials/nlp/Token_Classification-BioMegatron.ipynb
+++ b/tutorials/nlp/Token_Classification-BioMegatron.ipynb
@@ -75,7 +75,7 @@
"The model size of Megatron-LM can be larger than BERT, up to multi-billion parameters, compared to 345 million parameters of BERT-large.\n",
"There are some alternatives of BioMegatron, most notably [BioBERT](https://arxiv.org/abs/1901.08746). Compared to BioBERT BioMegatron is larger by model size and pre-trained on larger text corpus.\n",
"\n",
- "A more general tutorial of using BERT-based models, including Megatron-LM, for downstream natural language processing tasks can be found [here](https://github.com/NVIDIA/NeMo/blob/main/tutorials/nlp/01_Pretrained_Language_Models_for_Downstream_Tasks.ipynb).\n",
+ "A more general tutorial of using BERT-based models, including Megatron-LM, for downstream natural language processing tasks can be found [here](https://github.com/NVIDIA/NeMo/blob/stable/tutorials/nlp/01_Pretrained_Language_Models_for_Downstream_Tasks.ipynb).\n",
"\n",
"# Task Description\n",
"**Named entity recognition (NER)**, also referred to as entity chunking, identification or extraction, is the task of detecting and classifying key information (entities) in text.\n",
@@ -83,7 +83,7 @@
"For instance, **given sentences from medical abstracts, what diseases are mentioned?**
\n",
"In this case, our data input is sentences from the abstracts, and our labels are the precise locations of the named disease entities. Take a look at the information provided for the dataset.\n",
"\n",
- "For more details and general examples on Named Entity Recognition, please refer to the [Token Classification and Named Entity Recognition tutorial notebook](https://github.com/NVIDIA/NeMo/blob/main/tutorials/nlp/Token_Classification_Named_Entity_Recognition.ipynb).\n",
+ "For more details and general examples on Named Entity Recognition, please refer to the [Token Classification and Named Entity Recognition tutorial notebook](https://github.com/NVIDIA/NeMo/blob/stable/tutorials/nlp/Token_Classification_Named_Entity_Recognition.ipynb).\n",
"\n",
"# Dataset\n",
"\n",
@@ -191,7 +191,7 @@
"id": "powerful-donor",
"metadata": {},
"source": [
- "Convert these to a format that is compatible with [NeMo Token Classification module](https://github.com/NVIDIA/NeMo/blob/main/examples/nlp/token_classification/token_classification_train.py), using the [conversion script](https://github.com/NVIDIA/NeMo/blob/main/examples/nlp/token_classification/data/import_from_iob_format.py)."
+ "Convert these to a format that is compatible with [NeMo Token Classification module](https://github.com/NVIDIA/NeMo/blob/stable/examples/nlp/token_classification/token_classification_train.py), using the [conversion script](https://github.com/NVIDIA/NeMo/blob/stable/examples/nlp/token_classification/data/import_from_iob_format.py)."
]
},
{
diff --git a/tutorials/nlp/Token_Classification_Named_Entity_Recognition.ipynb b/tutorials/nlp/Token_Classification_Named_Entity_Recognition.ipynb
index a4dbfe7714dd..47d6a32baaee 100644
--- a/tutorials/nlp/Token_Classification_Named_Entity_Recognition.ipynb
+++ b/tutorials/nlp/Token_Classification_Named_Entity_Recognition.ipynb
@@ -150,7 +150,7 @@
"source": [
"# NeMo Token Classification Data Format\n",
"\n",
- "[TokenClassification Model](https://github.com/NVIDIA/NeMo/blob/main/nemo/collections/nlp/models/token_classification/token_classification_model.py) in NeMo supports NER and other token level classification tasks, as long as the data follows the format specified below. \n",
+ "[TokenClassification Model](https://github.com/NVIDIA/NeMo/blob/stable/nemo/collections/nlp/models/token_classification/token_classification_model.py) in NeMo supports NER and other token level classification tasks, as long as the data follows the format specified below. \n",
"\n",
"Token Classification Model requires the data to be split into 2 files: \n",
"* text.txt and \n",
@@ -183,7 +183,7 @@
"colab_type": "text"
},
"source": [
- "To convert an IOB format data to the format required for training, run [examples/nlp/token_classification/data/import_from_iob_format.py](https://github.com/NVIDIA/NeMo/blob/main/examples/nlp/token_classification/data/import_from_iob_format.py) on your train and dev files, as follows:\n",
+ "To convert an IOB format data to the format required for training, run [examples/nlp/token_classification/data/import_from_iob_format.py](https://github.com/NVIDIA/NeMo/blob/stable/examples/nlp/token_classification/data/import_from_iob_format.py) on your train and dev files, as follows:\n",
"\n",
"\n",
"\n",
@@ -794,7 +794,7 @@
"source": [
"## Training Script\n",
"\n",
- "If you have NeMo installed locally, you can also train the model with [nlp/token_classification/token_classification_train.py](https://github.com/NVIDIA/NeMo/blob/main/examples/nlp/token_classification/token_classification_train.py).\n",
+ "If you have NeMo installed locally, you can also train the model with [nlp/token_classification/token_classification_train.py](https://github.com/NVIDIA/NeMo/blob/stable/examples/nlp/token_classification/token_classification_train.py).\n",
"\n",
"To run training script, use:\n",
"\n",
diff --git a/tutorials/speaker_recognition/ASR_with_SpeakerDiarization.ipynb b/tutorials/speaker_recognition/ASR_with_SpeakerDiarization.ipynb
index 0fbcf1b6702f..aed1ea72b949 100644
--- a/tutorials/speaker_recognition/ASR_with_SpeakerDiarization.ipynb
+++ b/tutorials/speaker_recognition/ASR_with_SpeakerDiarization.ipynb
@@ -54,7 +54,7 @@
"\n",
"In this tutorial we demonstrate how one can get ASR transcriptions combined with Speaker labels along with voice activity time stamps using NeMo asr collections. \n",
"\n",
- "For detailed understanding of transcribing words with ASR refer to this [ASR tutorial](https://github.com/NVIDIA/NeMo/blob/main/tutorials/asr/01_ASR_with_NeMo.ipynb), and for detailed understanding of speaker diarizing an audio refer to this [Diarization inference](https://github.com/NVIDIA/NeMo/blob/main/tutorials/speaker_recognition/Speaker_Diarization_Inference.ipynb) tutorial"
+ "For detailed understanding of transcribing words with ASR refer to this [ASR tutorial](https://github.com/NVIDIA/NeMo/blob/stable/tutorials/asr/01_ASR_with_NeMo.ipynb), and for detailed understanding of speaker diarizing an audio refer to this [Diarization inference](https://github.com/NVIDIA/NeMo/blob/stable/tutorials/speaker_recognition/Speaker_Diarization_Inference.ipynb) tutorial"
]
},
{
@@ -427,7 +427,7 @@
"from omegaconf import OmegaConf\n",
"MODEL_CONFIG = os.path.join(data_dir,'speaker_diarization.yaml')\n",
"if not os.path.exists(MODEL_CONFIG):\n",
- " config_url = \"https://raw.githubusercontent.com/NVIDIA/NeMo/main/examples/speaker_recognition/conf/speaker_diarization.yaml\"\n",
+ " config_url = \"https://raw.githubusercontent.com/NVIDIA/NeMo/stable/examples/speaker_recognition/conf/speaker_diarization.yaml\"\n",
" MODEL_CONFIG = wget.download(config_url,data_dir) \n",
" \n",
"config = OmegaConf.load(MODEL_CONFIG)\n",
@@ -545,4 +545,4 @@
},
"nbformat": 4,
"nbformat_minor": 4
-}
+}
\ No newline at end of file
diff --git a/tutorials/speaker_recognition/Speaker_Diarization_Inference.ipynb b/tutorials/speaker_recognition/Speaker_Diarization_Inference.ipynb
index 675f6f3ceede..7cb220f66408 100644
--- a/tutorials/speaker_recognition/Speaker_Diarization_Inference.ipynb
+++ b/tutorials/speaker_recognition/Speaker_Diarization_Inference.ipynb
@@ -40,9 +40,9 @@
"\n",
"In NeMo we support both **oracle VAD** and **non-oracle VAD** diarization. \n",
"\n",
- "In this tutorial, we shall first demonstrate how to perform diarization with a oracle VAD time stamps (we assume we already have speech time stamps) and pretrained speaker verification model which can be found in tutorial for [Speaker and Recognition and Verification in NeMo](https://github.com/NVIDIA/NeMo/blob/main/tutorials/speaker_recognition/Speaker_Recognition_Verification.ipynb).\n",
+ "In this tutorial, we shall first demonstrate how to perform diarization with a oracle VAD time stamps (we assume we already have speech time stamps) and pretrained speaker verification model which can be found in tutorial for [Speaker and Recognition and Verification in NeMo](https://github.com/NVIDIA/NeMo/blob/stable/tutorials/speaker_recognition/Speaker_Recognition_Verification.ipynb).\n",
"\n",
- "In [second part](#ORACLE-VAD-DIARIZATION) we show how to perform VAD and then diarization if ground truth timestamped speech were not available (non-oracle VAD). We also have tutorials for [VAD training in NeMo](https://github.com/NVIDIA/NeMo/blob/main/tutorials/asr/06_Voice_Activiy_Detection.ipynb) and [online offline microphone inference](https://github.com/NVIDIA/NeMo/blob/main/tutorials/asr/07_Online_Offline_Microphone_VAD_Demo.ipynb), where you can custom your model and training/finetuning on your own data.\n",
+ "In [second part](#ORACLE-VAD-DIARIZATION) we show how to perform VAD and then diarization if ground truth timestamped speech were not available (non-oracle VAD). We also have tutorials for [VAD training in NeMo](https://github.com/NVIDIA/NeMo/blob/stable/tutorials/asr/06_Voice_Activity_Detection.ipynb) and [online offline microphone inference](https://github.com/NVIDIA/NeMo/blob/stable/tutorials/asr/07_Online_Offline_Microphone_VAD_Demo.ipynb), where you can custom your model and training/finetuning on your own data.\n",
"\n",
"For demonstration purposes we would be using simulated audio from [an4 dataset](http://www.speech.cs.cmu.edu/databases/an4/)"
]
@@ -255,7 +255,7 @@
"from omegaconf import OmegaConf\n",
"MODEL_CONFIG = os.path.join(data_dir,'speaker_diarization.yaml')\n",
"if not os.path.exists(MODEL_CONFIG):\n",
- " config_url = \"https://raw.githubusercontent.com/NVIDIA/NeMo/main/examples/speaker_recognition/conf/speaker_diarization.yaml\"\n",
+ " config_url = \"https://raw.githubusercontent.com/NVIDIA/NeMo/stable/examples/speaker_recognition/conf/speaker_diarization.yaml\"\n",
" MODEL_CONFIG = wget.download(config_url,data_dir)\n",
"config = OmegaConf.load(MODEL_CONFIG)\n",
"print(OmegaConf.to_yaml(config))"
@@ -471,9 +471,9 @@
"source": [
"To generate VAD predicted time step. We perform VAD inference to have frame level prediction → (optional: use decision smoothing) → given `threshold`, write speech segment to RTTM-like time stamps manifest.\n",
"\n",
- "we use vad decision smoothing (87.5% overlap median) as described [here](https://github.com/NVIDIA/NeMo/blob/v1.0.2/nemo/collections/asr/parts/vad_utils.py)\n",
+ "we use vad decision smoothing (87.5% overlap median) as described [here](https://github.com/NVIDIA/NeMo/blob/stable/nemo/collections/asr/parts/vad_utils.py)\n",
"\n",
- "you can also tune the threshold on your dev set. Use this provided [script](https://github.com/NVIDIA/NeMo/blob/v1.0.2/scripts/voice_activity_detection/vad_tune_threshold.py)"
+ "you can also tune the threshold on your dev set. Use this provided [script](https://github.com/NVIDIA/NeMo/blob/stable/scripts/voice_activity_detection/vad_tune_threshold.py)"
]
},
{
@@ -629,4 +629,4 @@
},
"nbformat": 4,
"nbformat_minor": 4
-}
+}
\ No newline at end of file
diff --git a/tutorials/speaker_recognition/Speaker_Recognition_Verification.ipynb b/tutorials/speaker_recognition/Speaker_Recognition_Verification.ipynb
index e2eeedf6c88b..b4577514d30e 100644
--- a/tutorials/speaker_recognition/Speaker_Recognition_Verification.ipynb
+++ b/tutorials/speaker_recognition/Speaker_Recognition_Verification.ipynb
@@ -58,7 +58,7 @@
"source": [
"In this tutorial, we shall first train these embeddings on speaker-related datasets, and then get speaker embeddings from a pretrained network for a new dataset. Since Google Colab has very slow read-write speeds, I'll be demonstrating this tutorial using [an4](http://www.speech.cs.cmu.edu/databases/an4/). \n",
"\n",
- "Instead, if you'd like to try on a bigger dataset like [hi-mia](https://arxiv.org/abs/1912.01231) use the [get_hi-mia-data.py](https://github.com/NVIDIA/NeMo/blob/v1.0.2/scripts/dataset_processing/get_hi-mia_data.py) script to download the necessary files, extract them, also re-sample to 16Khz if any of these samples are not at 16Khz. "
+ "Instead, if you'd like to try on a bigger dataset like [hi-mia](https://arxiv.org/abs/1912.01231) use the [get_hi-mia-data.py](https://github.com/NVIDIA/NeMo/blob/stable/scripts/dataset_processing/get_hi-mia_data.py) script to download the necessary files, extract them, also re-sample to 16Khz if any of these samples are not at 16Khz. "
]
},
{
diff --git a/tutorials/text_processing/Inverse_Text_Normalization.ipynb b/tutorials/text_processing/Inverse_Text_Normalization.ipynb
index ce5378022897..10e3d2f5e24d 100755
--- a/tutorials/text_processing/Inverse_Text_Normalization.ipynb
+++ b/tutorials/text_processing/Inverse_Text_Normalization.ipynb
@@ -138,7 +138,7 @@
"DATE, CARDINAL, MEASURE, DECIMAL, ORDINAL, MONEY, TIME, PLAIN. \n",
"We additionally added the class `WHITELIST` for all whitelisted tokens whose verbalizations are directly looked up from a user-defined list.\n",
"\n",
- "The toolkit is modular, easily extendable, and can be adapted to other languages and tasks like [text normalization](https://github.com/NVIDIA/NeMo/blob/main/tutorials/text_processing/Text_Normalization.ipynb). The Python environment enables an easy combination of text covering grammars with NNs. \n",
+ "The toolkit is modular, easily extendable, and can be adapted to other languages and tasks like [text normalization](https://github.com/NVIDIA/NeMo/blob/stable/tutorials/text_processing/Text_Normalization.ipynb). The Python environment enables an easy combination of text covering grammars with NNs. \n",
"\n",
"The rule-based system is divided into a classifier and a verbalizer following [Google's Kestrel](https://www.researchgate.net/profile/Richard_Sproat/publication/277932107_The_Kestrel_TTS_text_normalization_system/links/57308b1108aeaae23f5cc8c4/The-Kestrel-TTS-text-normalization-system.pdf) design: the classifier is responsible for detecting and classifying semiotic classes in the underlying text, the verbalizer the verbalizes the detected text segment. \n",
"\n",
diff --git a/tutorials/text_processing/Text_Normalization.ipynb b/tutorials/text_processing/Text_Normalization.ipynb
index 607bad00b99a..a11c668fa812 100755
--- a/tutorials/text_processing/Text_Normalization.ipynb
+++ b/tutorials/text_processing/Text_Normalization.ipynb
@@ -127,7 +127,7 @@
"Currently, NeMo TN provides support for English and the following semiotic classes from the [Google Text normalization dataset](https://www.kaggle.com/richardwilliamsproat/text-normalization-for-english-russian-and-polish):\n",
"DATE, CARDINAL, MEASURE, DECIMAL, ORDINAL, MONEY, TIME, TELEPHONE, ELECTRONIC, PLAIN. We additionally added the class `WHITELIST` for all whitelisted tokens whose verbalizations are directly looked up from a user-defined list.\n",
"\n",
- "The toolkit is modular, easily extendable, and can be adapted to other languages and tasks like [inverse text normalization](https://github.com/NVIDIA/NeMo/blob/main/tutorials/text_processing/Inverse_Text_Normalization.ipynb). The Python environment enables an easy combination of text covering grammars with NNs. \n",
+ "The toolkit is modular, easily extendable, and can be adapted to other languages and tasks like [inverse text normalization](https://github.com/NVIDIA/NeMo/blob/stable/tutorials/text_processing/Inverse_Text_Normalization.ipynb). The Python environment enables an easy combination of text covering grammars with NNs. \n",
"\n",
"The rule-based system is divided into a classifier and a verbalizer following [Google's Kestrel](https://www.researchgate.net/profile/Richard_Sproat/publication/277932107_The_Kestrel_TTS_text_normalization_system/links/57308b1108aeaae23f5cc8c4/The-Kestrel-TTS-text-normalization-system.pdf) design: the classifier is responsible for detecting and classifying semiotic classes in the underlying text, the verbalizer the verbalizes the detected text segment. \n",
"In the example `The alarm goes off at 10:30 a.m.`, the tagger for TIME detects `10:30 a.m.` as a valid time data with `hour=10`, `minutes=30`, `suffix=a.m.`, the verbalizer then turns this into `ten thirty a m`.\n",
@@ -372,7 +372,7 @@
"source": [
"# WFST and Common Pynini Operations\n",
"\n",
- "See [NeMo Text Inverse Normalization Tutorial](https://github.com/NVIDIA/NeMo/blob/main/tutorials/text_processing/Inverse_Text_Normalization.ipynb) for details."
+ "See [NeMo Text Inverse Normalization Tutorial](https://github.com/NVIDIA/NeMo/blob/stable/tutorials/text_processing/Inverse_Text_Normalization.ipynb) for details."
]
},
{
diff --git a/tutorials/tools/CTC_Segmentation_Tutorial.ipynb b/tutorials/tools/CTC_Segmentation_Tutorial.ipynb
index 597dd41c2f10..3d57fc5cf1c1 100644
--- a/tutorials/tools/CTC_Segmentation_Tutorial.ipynb
+++ b/tutorials/tools/CTC_Segmentation_Tutorial.ipynb
@@ -305,7 +305,7 @@
"* to specify additional punctuation marks to split the text into fragments, use `--additional_split_symbols` argument. If segments produced after splitting the original text based on the end of sentence punctuation marks is longer than `--max_length`, `--additional_split_symbols` are going to be used to shorten the segments. Use `|` as a separator between symbols, for example: `--additional_split_symbols=;|:|` \n",
"* out-of-vocabulary words will be removed based on pre-trained ASR model vocabulary, (optionally) text will be changed to lowercase \n",
"* sentences for alignment with the original punctuation and capitalization will be stored under `$OUTPUT_DIR/processed/*_with_punct.txt`\n",
- "* numbers will be converted from written to their spoken form with `num2words` package. To use NeMo normalization tool use `--use_nemo_normalization` argument (not supported if running this segmentation tutorial in Colab, see [the text normalization tutorial](https://github.com/NVIDIA/NeMo/blob/main/tutorials/tools/Text_Normalization_Tutorial.ipynb) for more details). Such normalization is usually enough for proper segmentation but to build a high-quality training dataset, all out-vocabulary symbols should be replaced with their actual spoken representations.\n",
+ "* numbers will be converted from written to their spoken form with `num2words` package. To use NeMo normalization tool use `--use_nemo_normalization` argument (not supported if running this segmentation tutorial in Colab, see [the text normalization tutorial](https://github.com/NVIDIA/NeMo/blob/stable/tutorials/tools/Text_Normalization_Tutorial.ipynb) for more details). Such normalization is usually enough for proper segmentation but to build a high-quality training dataset, all out-vocabulary symbols should be replaced with their actual spoken representations.\n",
"\n",
"Audio preprocessing:\n",
"* `.mp3` files will be converted to `.wav` files\n",
diff --git a/tutorials/tools/DefinedCrowd_x_NeMo_ASR_Training_Tutorial.ipynb b/tutorials/tools/DefinedCrowd_x_NeMo_ASR_Training_Tutorial.ipynb
index a1691bba455e..4ee727500c47 100644
--- a/tutorials/tools/DefinedCrowd_x_NeMo_ASR_Training_Tutorial.ipynb
+++ b/tutorials/tools/DefinedCrowd_x_NeMo_ASR_Training_Tutorial.ipynb
@@ -528,7 +528,7 @@
"\n",
"NVIDIA NeMo is a toolkit built by NVIDIA for **creating conversational AI applications**. This toolkit includes collections of pre-trained modules for **Automatic Speech Recognition (ASR)**, Natural Language Processing (NLP), and Texto-to-Speech (TTS), enabling researchers and data scientists to easily compose complex neural network architectures and focus on designing their applications.\n",
"\n",
- "In this tutorial, we want to demonstrate how to **connect DefinedCrowd Speech Workflows** to **train and improve an ASR model** using NVIDIA NeMo. The tutorial re-uses parts of a previous [ASR tutorial from NeMo](https://colab.research.google.com/github/NVIDIA/NeMo/blob/r1.0.0b3/tutorials/asr/01_ASR_with_NeMo.ipynb)."
+ "In this tutorial, we want to demonstrate how to **connect DefinedCrowd Speech Workflows** to **train and improve an ASR model** using NVIDIA NeMo. The tutorial re-uses parts of a previous [ASR tutorial from NeMo](https://colab.research.google.com/github/NVIDIA/NeMo/blob/stable/tutorials/asr/01_ASR_with_NeMo.ipynb)."
]
},
{
@@ -1464,7 +1464,7 @@
"source": [
"## Download the config we'll use in this example\n",
"!mkdir configs\n",
- "!wget -P configs/ https://raw.githubusercontent.com/NVIDIA/NeMo/main/examples/asr/conf/config.yaml &> /dev/null\n",
+ "!wget -P configs/ https://raw.githubusercontent.com/NVIDIA/NeMo/stable/examples/asr/conf/config.yaml &> /dev/null\n",
"\n",
"# --- Config Information ---#\n",
"from ruamel.yaml import YAML\n",
diff --git a/tutorials/tools/label-studio/setup-asr-preannotations.ipynb b/tutorials/tools/label-studio/setup-asr-preannotations.ipynb
index e377c1a3eeb5..b11487c8e62f 100644
--- a/tutorials/tools/label-studio/setup-asr-preannotations.ipynb
+++ b/tutorials/tools/label-studio/setup-asr-preannotations.ipynb
@@ -221,7 +221,7 @@
"id": "alike-realtor",
"metadata": {},
"source": [
- "Then you can start to annotate your audio files by correcting the text areas prepopulated by NeMo ASR's output. After you finish labeling, you can export results in the `ASR_MANIFEST` format ready to use for [training a NeMo ASR model](https://colab.research.google.com/github/NVIDIA/NeMo/blob/r1.0.0b3/tutorials/asr/01_ASR_with_NeMo.ipynb)"
+ "Then you can start to annotate your audio files by correcting the text areas prepopulated by NeMo ASR's output. After you finish labeling, you can export results in the `ASR_MANIFEST` format ready to use for [training a NeMo ASR model](https://colab.research.google.com/github/NVIDIA/NeMo/blob/stable/tutorials/asr/01_ASR_with_NeMo.ipynb)"
]
}
],
@@ -246,4 +246,4 @@
},
"nbformat": 4,
"nbformat_minor": 5
-}
+}
\ No newline at end of file
diff --git a/tutorials/tts/3_TTS_TalkNet_Training.ipynb b/tutorials/tts/3_TTS_TalkNet_Training.ipynb
index 312109fae395..352e113bfd64 100644
--- a/tutorials/tts/3_TTS_TalkNet_Training.ipynb
+++ b/tutorials/tts/3_TTS_TalkNet_Training.ipynb
@@ -162,14 +162,14 @@
"metadata": {},
"outputs": [],
"source": [
- "!wget https://raw.githubusercontent.com/NVIDIA/NeMo/main/examples/tts/talknet_durs.py\n",
- "!wget https://raw.githubusercontent.com/NVIDIA/NeMo/main/examples/tts/talknet_pitch.py\n",
- "!wget https://raw.githubusercontent.com/NVIDIA/NeMo/main/examples/tts/talknet_spect.py\n",
+ "!wget https://raw.githubusercontent.com/NVIDIA/NeMo/stable/examples/tts/talknet_durs.py\n",
+ "!wget https://raw.githubusercontent.com/NVIDIA/NeMo/stable/examples/tts/talknet_pitch.py\n",
+ "!wget https://raw.githubusercontent.com/NVIDIA/NeMo/stable/examples/tts/talknet_spect.py\n",
"\n",
"!mkdir -p conf && cd conf \\\n",
- "&& wget https://raw.githubusercontent.com/NVIDIA/NeMo/main/examples/tts/conf/talknet-durs.yaml \\\n",
- "&& wget https://raw.githubusercontent.com/NVIDIA/NeMo/main/examples/tts/conf/talknet-pitch.yaml \\\n",
- "&& wget https://raw.githubusercontent.com/NVIDIA/NeMo/main/examples/tts/conf/talknet-spect.yaml \\\n",
+ "&& wget https://raw.githubusercontent.com/NVIDIA/NeMo/stable/examples/tts/conf/talknet-durs.yaml \\\n",
+ "&& wget https://raw.githubusercontent.com/NVIDIA/NeMo/stable/examples/tts/conf/talknet-pitch.yaml \\\n",
+ "&& wget https://raw.githubusercontent.com/NVIDIA/NeMo/stable/examples/tts/conf/talknet-spect.yaml \\\n",
"&& cd .."
]
},
@@ -496,4 +496,4 @@
},
"nbformat": 4,
"nbformat_minor": 5
-}
+}
\ No newline at end of file