how to make NCCL deterministic for different size for the same thing? #157
Comments
|
Hi, this is indeed expected. Floating point addition is not an associative operation. Therefore, depending on which rank starts the computation you get a different result. Note there is no good answer, there are n different possible results each with different rounding errors at each step of the addition. Having each rank start the sum at different offsets is better to ensure we use all links all the time, so this is needed to get best performance. If you want all results to be the same, you can use reduce + broadcast to a fixed root. This way, the reductions will always be done in the same order for all offsets, although performance might be slightly lower. |
|
Thank you for your quick reply! I get that how the rounding works here, but the confusion here is the fusion part. As you said, if the precision totally depends on which rank starts the computation first, we should observe totally different result each time, even for the no fusion part, but I actually found the output always the same among different runs (see below), it seems deterministic to me for fixed sizes. If we fuse the array a little bit (like the one I give above), the only thing changes is the reduced array size, which will impact the offset for each rank, but it has no impact to the computation order, right? first run: second run: |
|
Actually which ranks starts the sum at which offset is deterministic, and it depends on the buffer size as well. Basically, NCCL works like this (not considering LL) :
Here is an example with 4 ranks and min/max chunk sizes of 4K/1M :
As sizes increases from 16K to 4M, a value at offset 16K-1 will start from 3, then 2, then 1, then 0 (not well illustrated since we're not at scale). |

|
Thank you so much, very clear and detailed explanation! |
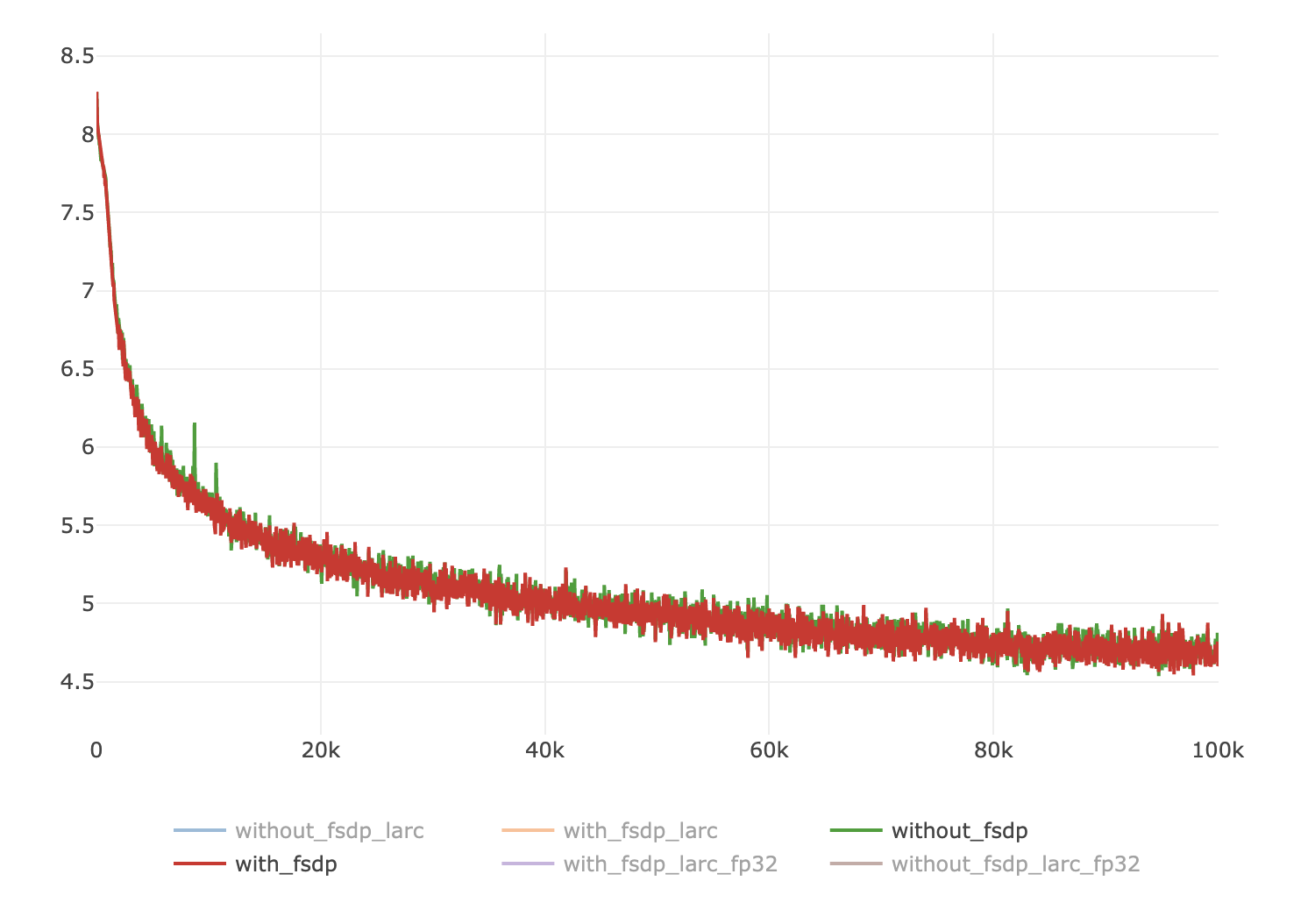
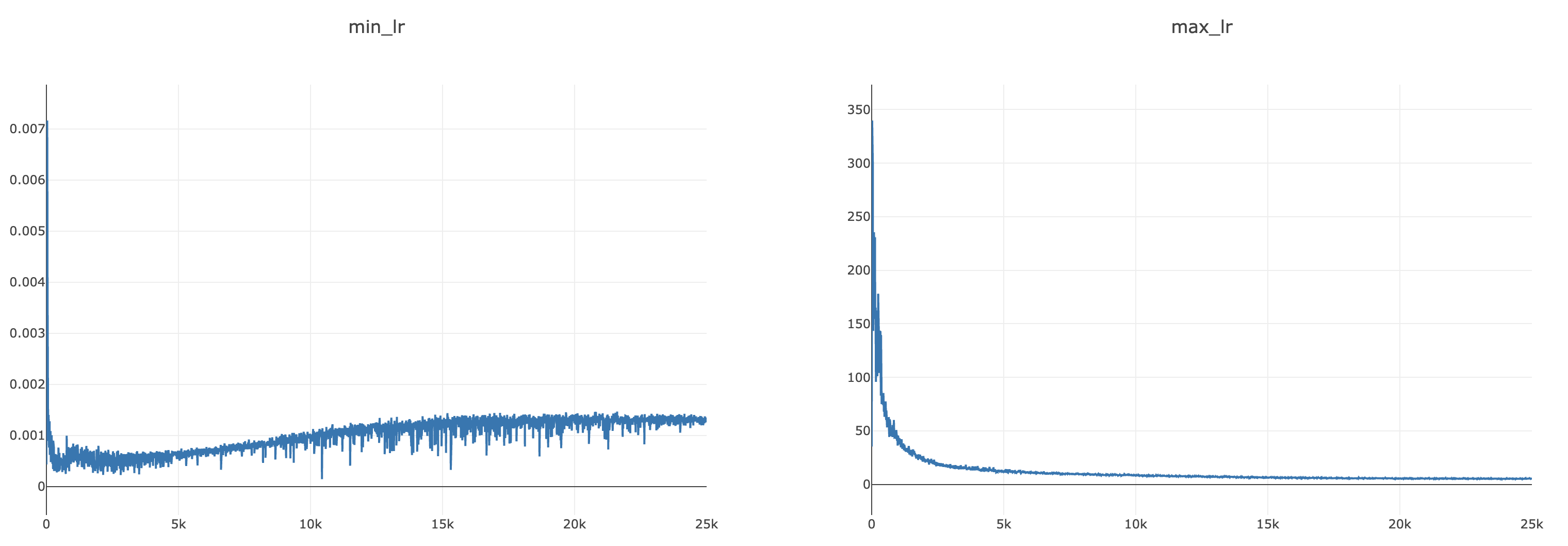
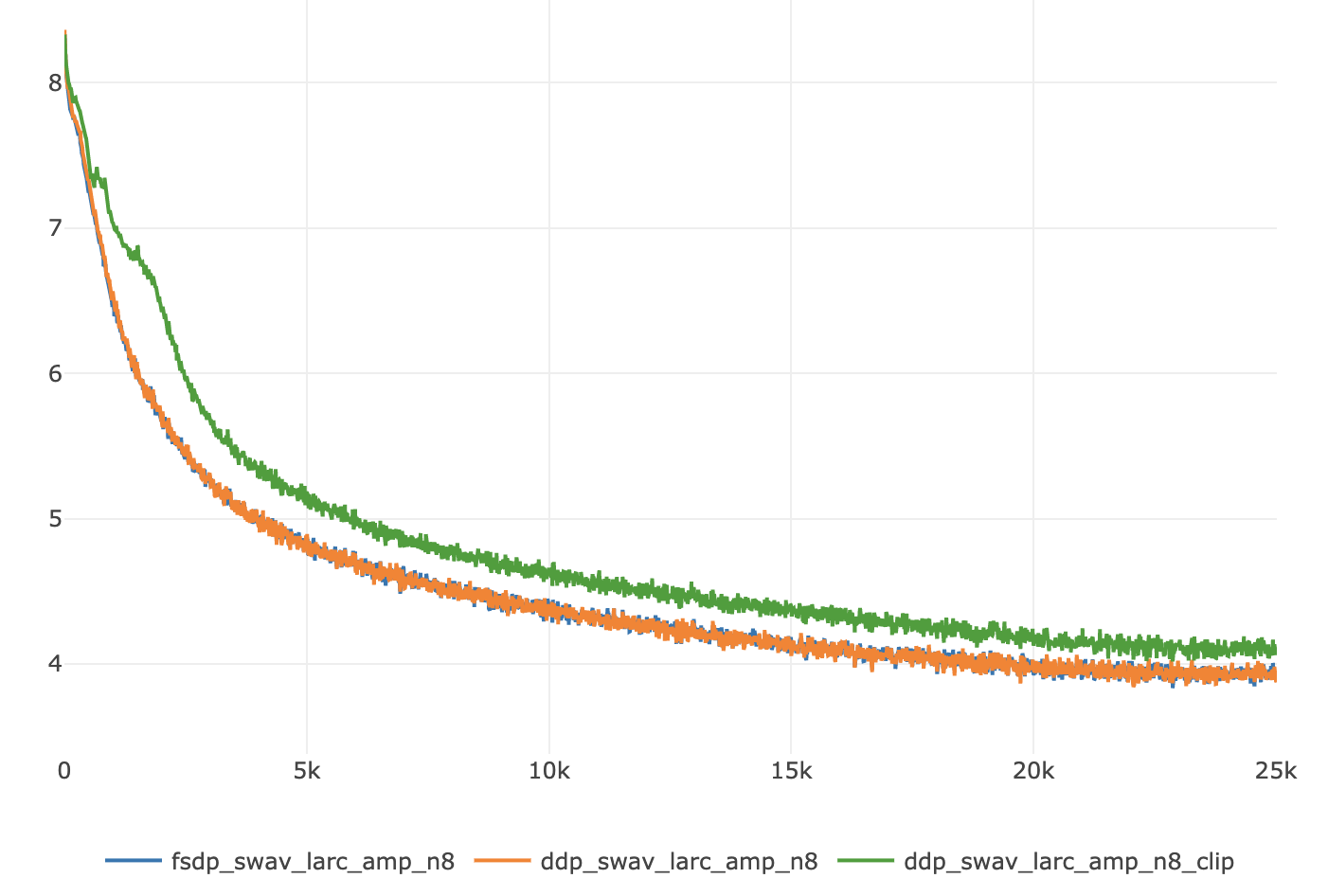
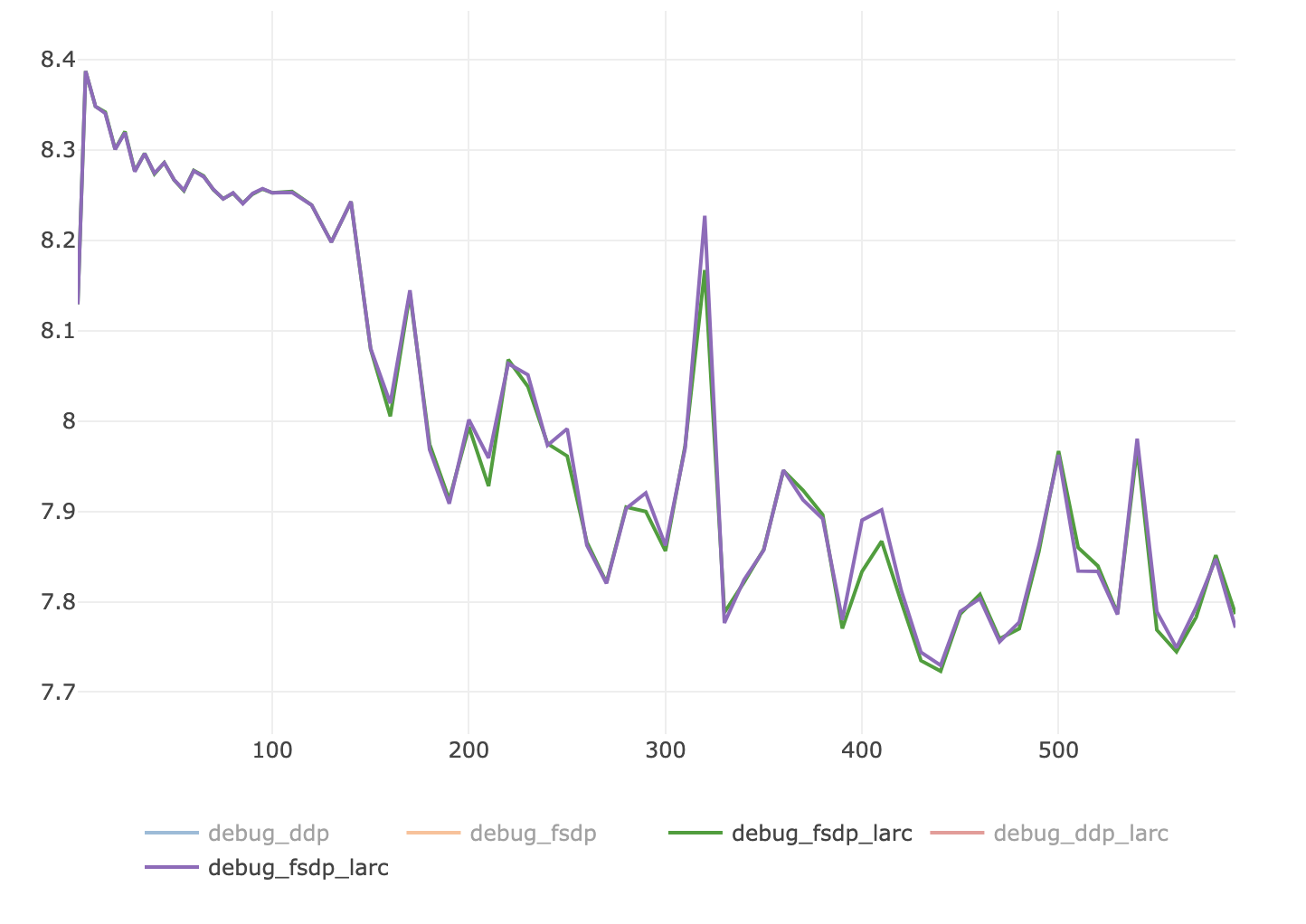
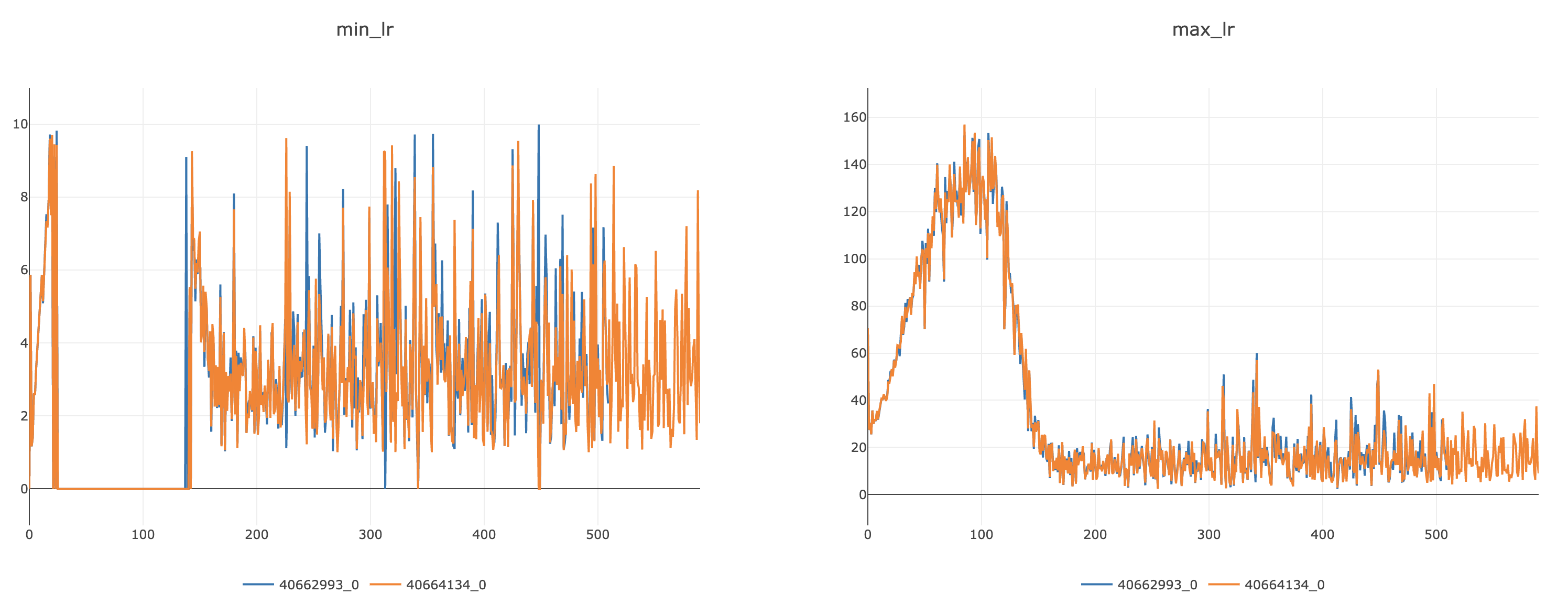
Summary: # LARC for FSDP A LARC version that is dedicated to FSDP sharded parameters and gradients: - the parameter norm and gradient norms are computed without summoning all parameters - getting the right parameter groups requires `flatten_parameters=False` in the `FSDP` wrapper ## Documentation To enable LARC for FSDP, use the following options: `config.OPTIMIZER.name=sgd_fsdp config.MODEL.FSDP_CONFIG.flatten_parameters=False config.OPTIMIZER.use_larc=True` The flag `config.MODEL.FSDP_CONFIG.flatten_parameters=False` is important as otherwise the parameter groups in FSDP are grouped together and so the layer-wise adaptation of the LR is not what's actually happening. Not setting `config.MODEL.FSDP_CONFIG.flatten_parameters=False` will therefore lead to bad numerical results. ## How it works The computation of the norm in normal LARC `torch.norm(p.data)` and `torch.norm(p.grad.data)` is decomposed into its constituent blocks: square, sum and then square root, so that the sum can be replaced by a local sum followed by a `all_reduce` NCCL call. In this first design, a variant of the `LARC` class from `apex` is introduced named `LARC_FSDP` and available through a new optimizer `sgd_fsdp`. ## Further improvements - [x] Plugging in the auto-deduction of FSDP parameters - [x] Understanding the small differences in convergence - [x] Convergence on longer runs - [x] Convergence together with AMP - [x] Impact on runtime - [x] Impact on memory - [x] Impact on communication Pull Request resolved: fairinternal/ssl_scaling#121 Test Plan: ### Unit tests A unit test has been introduced to check the convergence with and without FSDP when LARC is enabled. The first iterations match perfectly and diverge at the 5st decimal after the 4st iteration. ### Small debug runs (8 GPUs) Similarly, the curves are almost matching for DDP and FSDP on small test runs on imagenette: <img width="729" alt="Screenshot 2021-04-26 at 15 29 52" src="https://user-images.githubusercontent.com/7412790/116139685-48bb1680-a6a4-11eb-9c39-a4e53e6fc656.png"> ### Long runs (2 x 8 GPUs) The runs are not finished, but here are the first results: **Baseline: convergence without LARC** <img width="750" alt="Screenshot 2021-04-28 at 09 10 40" src="https://user-images.githubusercontent.com/7412790/116409459-dc562980-a801-11eb-808c-d19280dfaa84.png"> **Convergence with LARC in FP32** <img width="728" alt="Screenshot 2021-04-28 at 09 10 25" src="https://user-images.githubusercontent.com/7412790/116409414-d102fe00-a801-11eb-88ea-bfcb5283b8ef.png"> **Convergence with LARC in AMP (O1)** <img width="751" alt="Screenshot 2021-04-28 at 09 10 53" src="https://user-images.githubusercontent.com/7412790/116409354-c3e60f00-a801-11eb-9213-a3eef6e52def.png"> ### Long runs (8 x 8 GPUs) **Convergence with LARC in AMP (01)** <img width="726" alt="Screenshot 2021-04-29 at 09 08 46" src="https://user-images.githubusercontent.com/7412790/116556509-82ba3180-a8cb-11eb-9a62-12cb379d7dc2.png"> Tracking of the adaptative LR during the training shows that it settles down to stable values as the training progresses: <img width="1520" alt="Screenshot 2021-04-29 at 09 12 40" src="https://user-images.githubusercontent.com/7412790/116556771-d2006200-a8cb-11eb-957d-84b643a79a91.png"> So any difference between FSDP and DDP due to extreme values of adaptative LR will likely disappear past the initial training iterations. **Comparison with DDP with CLIPPING** <img width="701" alt="Screenshot 2021-04-29 at 09 11 15" src="https://user-images.githubusercontent.com/7412790/116556652-b09f7600-a8cb-11eb-9bd5-b7e38c8af037.png"> ### Impact on communication and runtime - Communication wise, 2 doubles are `all_reduce`d for each layer. The cost is negligible. - In terms of runtime, the main impact is due to `flatten_parameters=False` (without LARC, the cost was below 10%) ## Understanding the difference in convergence This implementation uses NCCL `all_reduce`. Floating point operations are not associative with addition and `all_reduce` does not guarantee that the operations will be executed in the same order (confer to NVIDIA/nccl#157) and does not guarantee which algorithm will be used (confer to NVIDIA/nccl#256). As a consequence, small numerical differences appear between different runs of FSDP with LARC: <img width="722" alt="Screenshot 2021-04-27 at 11 33 15" src="https://user-images.githubusercontent.com/7412790/116269689-6cd23280-a74c-11eb-8934-bba30511b2e5.png"> In addition to this, the result will also differ with LARC in DDP mode for LARC in DDP uses `torch.norm` which had a definite order of computation of the summations, while in the case of the tree algorithm of `all_reduce`, the ordering of the addition will not be from left to right and will therefore not result in the same norm being computed. These differences can have a big impact on the `adaptative_lr` computed in LARC which in turns has a big impact on convergence (since it is multiplied with the normal learning rate). The formula of `adaptative_lr` is indeed: ``` adaptive_lr = ( self.trust_coefficient * (param_norm) / (grad_norm + param_norm * weight_decay + self.eps) ) ``` This formula is sensitive to the choice of the trust coefficient (1e-3 in SwAV), the weight decay (1e-6 in SwAV) and even the epsilon value (1e-8 in SwAV) depending on the values of the parameter norm and gradient norms, especially when these go to extreme values. For instance, in unit tests, I have been able to match the values of DDP LARC with FSDP LARC by decreasing the epsilon values. We can indeed see that the LARC (both in DDP and FSDP) tends to produce big variations of the loss, when the gradients are actually small (small variation of the loss without LARC): <img width="745" alt="Screenshot 2021-04-27 at 11 30 54" src="https://user-images.githubusercontent.com/7412790/116270276-f2ee7900-a74c-11eb-885c-c06c93da9339.png"> ### Debugging information Indeed, measuring the minimum and maximum `adaptative_lr` on the two debug FSDP LARC runs above yields the following curves: <img width="1496" alt="Screenshot 2021-04-27 at 11 30 20" src="https://user-images.githubusercontent.com/7412790/116270110-ce929c80-a74c-11eb-8a64-a3faab272fed.png"> If we measure the parameter norms and gradient norms instead, we see while difference in range of values between these: ``` tensor(24.7898, device='cuda:0') tensor(0.0006, device='cuda:0') tensor(1.1607, device='cuda:0') tensor(4.2407e-05, device='cuda:0') tensor(49.6614, device='cuda:0') tensor(0.0023, device='cuda:0') tensor(35.0972, device='cuda:0') tensor(9.0357e-05, device='cuda:0') ``` Because of this, the significant digits of their ratio will be reduced and this will lead to relatively big variations (meaning variations at the 2nd or 3rd decimal) of the `adaptative_lr`. ### LARC clipping Using clipping of the adaptative LR, a lot of the convergence issues between DDP and FSDP seems to disappear: <img width="739" alt="Screenshot 2021-04-27 at 13 53 30" src="https://user-images.githubusercontent.com/7412790/116289278-5c2bb780-a760-11eb-90c7-3e5597087000.png"> ## Alternative designs ### All gathering A possible alternate design would be to use `all_gather` to summon the full parameters and then call `torch.norm` on each worker on the gathered norms and parameters. ``` staticmethod def _compute_norms(param_groups): def all_gather_norm(data): tensor_list = [torch.zeros_like(data) for _ in range(get_global_group().size())] dist.all_gather(tensor_list, data) tensor_list = torch.cat(tensor_list, dim=0) return torch.norm(tensor_list) param_norms = [] grad_norms = [] for group in param_groups: for p in group["params"]: if p.grad is not None: param_norms.append(all_gather_norm(p.data)) grad_norms.append(all_gather_norm(p.grad.data)) return param_norms, grad_norms ``` With this solution, we reach perfect convergence as tested on my side, but at a great cost in terms of communication: instead of exchanging 2 numbers for each layer, we exchange the full parameters and gradients. ### VISSL Hook Another design would be to play with he VISSL `hooks` to compute the norms of parameters and gradients after the call to `backward`. The position of the on_backward hook and on_update hook in `standard_train_step.py` is ideal: ``` task.amp_grad_scaler.scale(local_loss).backward() task.run_hooks(SSLClassyHookFunctions.on_backward.name) task.amp_grad_scaler.step(task.optimizer, where=task.where) task.run_hooks(SSLClassyHookFunctions.on_update.name) ``` - **on_backward**: - capture the weight decay - call `task.amp_grad_scaler.unscale_(task.optimizer)` before the computation of the gradient norms in case of AMP, otherwise the norms of the parameters and the norms of the gradient will not have the same scale - the compute the distributed norm and scale the gradient with it - **on_update**: - re-instate the weight decay ### FSDP Model hook Another design would be to play with FSDP backward `hooks` to compute the norms of parameters and gradients on the fly, while the gradients are still not sharded and inside the `summon_full_parameters`. However, this solution is full of flaws: - the backward hook is actually called after the resharding - even if it was called before the resharding, then it would not have underwent the reduce-scatter - even if it was called before the resharding, then it would not catch the sub-FSDP modules So the solution is either to wrap recursively the FSDP modules and push the hook before the resharding hook of FSDP, or to keep it after the resharding in which case it is not an improvement over the VISSL hook solution (it does the same at a different place). ## Interested parties CC: prigoyal min-xu-ai myleott Reviewed By: prigoyal Differential Revision: D28011463 Pulled By: QuentinDuval fbshipit-source-id: 84fd1996862889e60ff9e2aa841e613c97f8be88
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
hi,
first of all, It's not a bug!
we've found that NCCL seems non deterministic when we combine the reduced arrays first then split after reduced. check the below code snippet.
even I turned off the LL code path by setting NCCL_LL_THRESHOLD=0, the diff is small, but it also suggest that we can't do it this way when we want exactly the same results for those two scenarios.
did I miss something or is this by design, if it's the latter, is there any way to make it deterministic?
NCCL Version: 2.1.15
Torch Version: 0.4.1
The text was updated successfully, but these errors were encountered: