Why is the 'training' parameter of dropout in Prenet set to True? #247
Comments
|
This is mentioned in the original Tacotron2 paper.
The code just follows the specification. |
|
@yuxinyuan Hi, I noticed that this is mentioned in Tacotron2 paper: 'to introduce output variation at inference time'. But why the model output noise after I set this to False when inference? I don't understand why the model can only work with dropout set to True. |
|
@yuxinyuan When I'm testing with the pre-trained model, even if I set training=True and change the drop rate to some other value, for example, 0.3. The model also generates noise. That's weird. The pre-trained model only works with training=True and droprate=0.5. |
|
@jjl1994 Full information(dropout(0.0)) of previous mel make the decoder hard to correct prediction. Since Full information is too much for prenet that consist of (fc, dropout(0.5))×2. |
|
@Yeongtae I think the framework should have already automatically ×2 if the dropout is set to true because if the framework don't (fc, dropout(0.5))×2, it will not get the correct loss and update the network. This mechanism has been mentioned in the course from Fei-Fei Li. Also If model only learned from half information. We should always use dropout when inference. But actually we don't do that. We only use drop during training(maybe in 99% of the case). |
|
If u set droprate to 0.15 from 0.5 and training=self.training, u can solve this problem. Text to mel model can always make some audio given a same utterance. |
|
@Yeongtae Hi, maybe (0.15 and disable dropout) when reference will let the prenet give simillar results as (0.5 and enable dropout). It seems the autoregressive decoder is extremely sensitive to its input. A dropout before the layer will not affect the output of some conventional layers(such as dense layer), but do will affect the output of the autoregressive decoder. |
|
@jjl1994 you can run an experiment and train the model from scratch without dropout on the prenet |
|
@jjl1994 You are right. Using dropout in inference is not wised. The mozilla version of tacotron2 is working as your wish. Moreover, using small dropout on overmany parameters is not wised too. The original model structure is just a reference, you can optimize it. |
|
any experiment result of set training=self.training to train the model? |
|
Closing due to inactivity. |
|
@terryyizhong I can share valid loss of setting |
thanks for your information. I tried before and counter the same problem. The loss keep going up after several steps. |
have you solved the problem? I encountered the same problem when set training=self.training, the valid loss keeps going up after some steps, especially when the reductor factor = 1. |
|
no, I think this issue should keep open gain |
|
@terryyizhong |
I am training. But it is really hard to converge with a reduce fator r =1. So, usually how many steps does it take to pick up a alignment for the LJspeech dataset? |
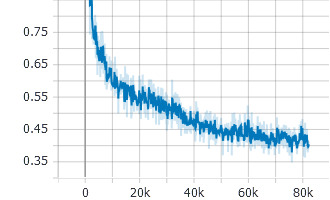
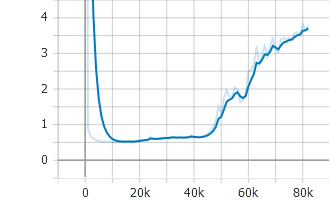
When training with prenet dropout=self.training, the process is same as before, so it also converges and get an alignment. But the valid loss is easy to overfit with dropout disabled. It rises up quickly after several epochs. As a result, the model can not work with the prenet dropout disabled when infering. However, setting the prenet dropout=True solves the problem with a non-overfiting valid loss. As discussed above, maybe (p = 0.15 and disable dropout) when infering will let the prenet give simillar results as (p = 0.5 and enable dropout). traing loss: |
In the code of Prenet
Why is 'training=True'? Shouldn't it be 'training=self.training'? Does that mean we apply dropout when inference? I changed this to 'training=self.training' and the pre-trained model is unable to generate correct audio.
The text was updated successfully, but these errors were encountered: