Integrate from upstream #282
Merged
Conversation
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Summary: Pull Request resolved: pytorch#12381 The workflow passes after D10150834, so we can restore strides. Reviewed By: ezyang Differential Revision: D10220313 fbshipit-source-id: aaf9edebf4ff739cbe45b2d32e77918fce47ba34
Summary: Fix pytorch#12624 . internal usecase of legacy `reduce`. Add test in test_nn Pull Request resolved: pytorch#12689 Reviewed By: ezyang Differential Revision: D10391195 Pulled By: ailzhang fbshipit-source-id: 1af2b258c4abb2b6527eaaeac63e8bf1762c66a1
…d49783 (pytorch#12676) Summary: Pull Request resolved: pytorch#12676 Previous import was 06f6d63d5529e3a94533c9f34c402be1793420b1 Included changes: - **[1cbe274](onnx/onnx@1cbe274)**: fix the optimizer (ROCm#1510) <Lu Fang> - **[481ad99](onnx/onnx@481ad99)**: Fix TensorProto int32_data comment (ROCm#1509) <Lutz Roeder> - **[f04fbe0](onnx/onnx@f04fbe0)**: fix ninja external (ROCm#1507) <Rui Zhu> Reviewed By: jamesr66a, wanchaol Differential Revision: D10388438 fbshipit-source-id: 298100589ce226c63d4e58edf185c9227fd52c85
Summary: Pull Request resolved: pytorch#12685 In this diff, we push the fake run of the net into the ONNXIFI transformer, because 1. We cannot do shape inference for every op 2. Since the net has been SSA rewritten, we cannot use shape info from outer workspace directly. In addition, this diff adds input shape info when querying the `onnxBackendCompatibility` function. Reviewed By: bddppq Differential Revision: D10390164 fbshipit-source-id: 80475444da2170c814678ed0ed3298e28a1fba92
Summary: Pull Request resolved: pytorch#12593 size() returns numel_, but what we really want is nbytes(), which is the capacity. Reviewed By: salexspb Differential Revision: D10354488 fbshipit-source-id: f7b37ad79ae78290ce96f37c65caa37d91686f95
Summary: There were two problems with SN + DP: 1. In SN, the updated _u vector is saved back to module via a `setattr`. However, in DP, everything is run on a replica, so those updates are lost. 2. In DP, the buffers are broadcast via a `broadcast_coalesced`, so on replicas they are all views. Therefore, the `detach_` call won't work. Fixes are: 1. Update _u vector in-place so, by the shared storage between 1st replica and the parallelized module, the update is retained 2. Do not call `detach_`. 3. Added comments in SN about the subtlety. 4. Added a note to the DP doc on this particular behavior of DP. cc crcrpar taesung89 The controller you requested could not be found. yaoshengfu Fixes pytorch#11476 Pull Request resolved: pytorch#12671 Differential Revision: D10410232 Pulled By: SsnL fbshipit-source-id: c447951844a30366d8c196bf9436340e88f3b6d9
Summary: Addressed Dima's feedback. The proposal is here: https://fb.quip.com/TbQmAuqIznCf Pull Request resolved: pytorch#12384 Reviewed By: dzhulgakov Differential Revision: D10246743 Pulled By: houseroad fbshipit-source-id: c80db0c35d60ca32965275da705f2b1dfb2a7265
Summary: This PR contains changes for: 1. Removing MIOpen softmax operator. Will be added later with the required functionality 2. Enabling softmax_ops_test on ROCm target Differential Revision: D10416079 Pulled By: bddppq fbshipit-source-id: 288099903aa9e0c3378e068fffe6e7d6a9a84841
Summary: Pull Request resolved: pytorch#12306 In a future diff, I'm going to introduce non-placement constructor and destructor to TypeMeta. To make it less ambigous, this diff is first renaming the existing ones to PlacementXXX. Reviewed By: dzhulgakov Differential Revision: D10184117 fbshipit-source-id: 119120ebc718048bdc1d66e0cc4d6a7840e666a4
Summary: The mapping protocol stipulates that when `__delitem__` is called, this is passed to `__setitem__` [(well, the same function in the C extension interface)](https://docs.python.org/3/c-api/typeobj.html#c.PyMappingMethods.mp_ass_subscript) with NULL data. PyTorch master crashes in this situation, with this patch, it does not anymore. Test code (careful, sefaults your interpreter): ```python import torch a = torch.randn(5) del a[2] ``` Pull Request resolved: pytorch#12726 Differential Revision: D10414244 Pulled By: colesbury fbshipit-source-id: c49716e1a0a3d9a117ce88fc394858f1df36ed79
pytorch#12691) Summary: Pull Request resolved: pytorch#12691 We check input(0) but not input(1) in BatchMatMul. This may result in a protobuf exception which won't be caught by upstream and causing termination of the program. Check that with `CAFFE_ENFORCE` will be caught by upstream inference function. Plus, it will print out clean stack tracing showing where went wrong. Reviewed By: bddppq, houseroad, BIT-silence Differential Revision: D10391130 fbshipit-source-id: daf8dcd8fcf9629a0626edad660dff54dd9aeae3
Summary:
- update docs examples at sparse tensor after print format changed
- update example to create empty sparse tensor:
```
>>> torch.sparse_coo_tensor(torch.LongTensor(size=[1,0]), [], torch.Size([1]))
tensor(indices=tensor([], size=(1, 0)),
values=tensor([], size=(0,)),
size=(1,), nnz=0, layout=torch.sparse_coo)
```
zou3519 SsnL yf225
Pull Request resolved: pytorch#12221
Differential Revision: D10412447
Pulled By: weiyangfb
fbshipit-source-id: 155b8cb0965f060e978f12239abdc1b3b41f6ab0
Summary: Pull Request resolved: pytorch#12696 In majority of the case, we use `InheritOnnxSchema(type_)`. This diff makes declaration of such case easier. Reviewed By: bddppq Differential Revision: D10395109 fbshipit-source-id: 914c1041387d5be386048d923eb832244fc506c3
Summary: Signed-off-by: Edward Z. Yang <ezyang@fb.com> Pull Request resolved: pytorch#12693 Differential Revision: D10419424 Pulled By: ezyang fbshipit-source-id: dc3999253f19b5615849619bd3e4a77ab3ca984e
Summary: Fixes pytorch#11683. Signed-off-by: Edward Z. Yang <ezyang@fb.com> Pull Request resolved: pytorch#11705 Differential Revision: D9833057 Pulled By: ezyang fbshipit-source-id: 18af9bcd77b088326738d567100fbe4a4c869dd6
Summary: Before and after coming after I run the tests on CI Signed-off-by: Edward Z. Yang <ezyang@fb.com> Pull Request resolved: pytorch#12610 Differential Revision: D10419483 Pulled By: ezyang fbshipit-source-id: 5543e971f8362e4cea64f332ba44a26c2145caea
Summary: This is for Caffe2 optimization. WIth this optimization, the following two ops can boost a lot. (Test with MaskRCNN, on SKX8180 one socket) BatchPermutation op: reduced from 8.296387 ms to 1.4501984 ms. Pull Request resolved: pytorch#12153 Differential Revision: D10362823 Pulled By: ezyang fbshipit-source-id: 04d1486f6c7db49270992cd8cde41092154e62ee
Summary: Module.to uses the Tensor.to parsing facility. It should not, however, accept "copy" as a keyword/fourth positional argument. See pytorch#12571 for discussion. Thank you SsnL for noticing. Pull Request resolved: pytorch#12617 Differential Revision: D10392053 Pulled By: ezyang fbshipit-source-id: b67a5def7993189b4b47193abc7b741b7d07512c
Summary: Optimize the UpsampleNearest Op. 1. Add OMP 2. revise the translated_idx method Pull Request resolved: pytorch#12151 Differential Revision: D10362856 Pulled By: ezyang fbshipit-source-id: 535a4b87c7423942217f2d79bedc463a0617c67a
Summary: This PR removes some duplication in `recurrent_op_cudnn.cc`. Instead of 4 of the same exact descriptor, should work fine with just 1. I don't see any other code that relies on those being 4 separate locations, but if that is what you need you can always allocate additional descriptors as necessary. Have not fully tested this thing out, just something I noticed when I was reading through the descriptor code. Cheers Pull Request resolved: pytorch#8321 Differential Revision: D10363744 Pulled By: ezyang fbshipit-source-id: 733c8242fb86866f1d64cfd79c54ee7bedb03b84
Summary: Add a mapping for conversion -- this will help with debugging as well but is directly used by the TUI stacked on top of this Reviewed By: duc0 Differential Revision: D10396130 fbshipit-source-id: cdd39278f0ed563bb828b1aebbbd228f486d89c8
Summary: Where is declared as: ``` where(Tensor condition, Tensor self, Tensor other) ``` Previously the compiler assumed that self must be the first argument. But this is not true in practice for `where` and for a few other exceptions. This changes the compiler to take an explicit self argument which gets matched to the `self` that appears in the schema. Note that this requires renaming a variant of pow, which referred to an exponent Tensor as `self` because otherwise that would cause `t^3` to match against `t` being the exponent. Pull Request resolved: pytorch#12385 Differential Revision: D10364658 Pulled By: zdevito fbshipit-source-id: 39e030c6912dd19b4b0b9e35fcbabc167b4cc255
Summary: - Fix broken sparse_coo_examples, update output - Tensor(...) to tensor(...) - Fix arguments to math.log to be floats While the last might be debateable, mypy currently complains when passing an int to math.log. As it is not essential for our examples, let's be clean w.r.t. other people's expectations. These popped up while checking examples in the context of pytorch#12500 . Pull Request resolved: pytorch#12707 Differential Revision: D10415256 Pulled By: SsnL fbshipit-source-id: c907b576b02cb0f89d8f261173dbf4b3175b4b8d
Summary: I struggled with yet another DataLoader hang for the entire evening. After numerous experiments, I realized that it is unsafe to do anything when Python is shutting down. We also unfortunately implement our DataLaoder cleaning-up logic in `__del__`, a function that may or may not be called during shutdown, and if called, may or may not be called before core library resources are freed. Fortunately, we are already setting all our workers and pin_memory_thread as daemonic. So in case of Python shutting down, we can just do a no-op in `__del__` and rely on the automatic termination of daemonic children. An `atexit` hook is used to detect Python exit. Pull Request resolved: pytorch#12700 Differential Revision: D10419027 Pulled By: SsnL fbshipit-source-id: 5753e70d03e69eb1c9ec4ae2154252d51e2f79b0
Summary: They are flaky in master. ashishfarmer petrex Pull Request resolved: pytorch#12749 Differential Revision: D10420265 Pulled By: bddppq fbshipit-source-id: cac58efb711941786b10b07ada58e0d59ab1db1d
Differential Revision: D10220313 Original commit changeset: aaf9edebf4ff fbshipit-source-id: 46c4d23d89d47be26c3f4967476271d8c2f95f11
Summary: include atomicAdd commentary as this is less well known There is some discussion in pytorch#12207 Unfortunately, I cannot seem to get the ..include working in `_tensor_docs.py` and `_torch_docs.py`. I could use a hint for that. Pull Request resolved: pytorch#12217 Differential Revision: D10419739 Pulled By: SsnL fbshipit-source-id: eecd04fb7486bd9c6ee64cd34859d61a0a97ec4e
Summary: Fixed the second example in NLLLoss. The LogSoftmax activation was missing after the convolution layer. Without this activation, the second example loss was sometimes negative. Pull Request resolved: pytorch#12703 Differential Revision: D10419694 Pulled By: ezyang fbshipit-source-id: 98bfefd1050290dd5b29d3ce18fe075103db4674
Summary: Pull Request resolved: pytorch#12307 This adds non-placement variants of New/Delete to TypeMeta. In a future diff, this is going to be used from Blob to destruct its contents. Reviewed By: dzhulgakov Differential Revision: D10184116 fbshipit-source-id: 7dc5592dbb9d7c4857c0ec7b8570329b33ce5017
Summary: Pull Request resolved: pytorch#11500 Since TypeMeta already stores a destructor, and we removed the ability from Blob to store a custom destructor in a diff stacked below this, there is now no reason for Blob to store it again. Reviewed By: ezyang Differential Revision: D9763423 fbshipit-source-id: d37a792ffd6928ed1906f5ba88bd4f1d1e2b3781
Differential Revision: D10457796 Original commit changeset: 9d1582c11c2e fbshipit-source-id: 9be38e999a2783dae4a387821806e6850b6a3671
Summary: As discussed in ROCm#1570, this adds a warning to the docstring of `tensor.resize_()` to prevent people from naively using it as an in-place view or reshape. For your convenience, the updated docstring renders as follows: 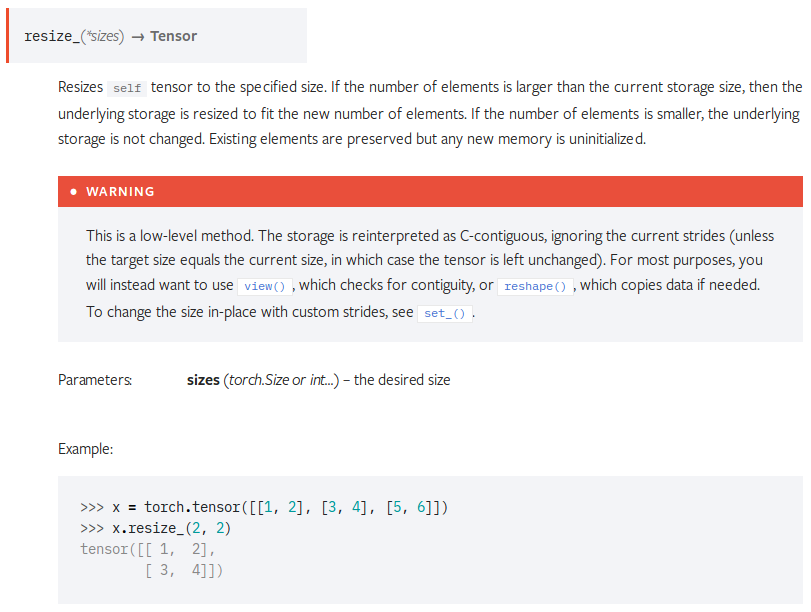 Fixes ROCm#1570. Pull Request resolved: pytorch#12816 Differential Revision: D10457755 Pulled By: ezyang fbshipit-source-id: dd4b3a821e8c76dc534d81c53084abdb336e690a
{kind=link}
Summary: trying again without xlocale.h Pull Request resolved: pytorch#12838 Differential Revision: D10453078 Pulled By: zdevito fbshipit-source-id: 760852c82e16acee7d1abb8a918822bf5ff59bca
Summary: I'm trying to do some transformations on Declarations.cwrap and this makes things overly difficult and doesn't do anything useful. Pull Request resolved: pytorch#12832 Reviewed By: ezyang Differential Revision: D10450771 Pulled By: gchanan fbshipit-source-id: 1abb1bce27b323dd3e93b52240e7627cd8e56566
Summary: Pull Request resolved: pytorch#12736 This updates UpsampleBilinearOp and UpsampleBilinearGradientOp to support scales to bring it inline with ResizeNearestOp pytorch#12720. Reviewed By: houseroad Differential Revision: D10416228 fbshipit-source-id: f339b7e06979c9c566afb4cee64a2d939b352957
Summary: Pull Request resolved: pytorch#12833 Differential Revision: D10464815 Pulled By: yf225 fbshipit-source-id: 06a6a673b6bb32f7c252a217f9ce59db35c75e9c
Summary: Pull Request resolved: pytorch#12667 Differential Revision: D10466661 Pulled By: yf225 fbshipit-source-id: a1a150d3b384eb88ba4c7e6d57e59d8ed834e53c
…ytorch#12849) Summary: I got annoyed at waiting for OSS to tell me my c10d builds were busted, so I also added support for building the test scripts in fbcode and fixed the warnings this uncovered. Pull Request resolved: pytorch#12849 Reviewed By: pietern Differential Revision: D10457671 fbshipit-source-id: 5b0e36c606e397323f313f09dfce64d2df88faed
Summary: Pull Request resolved: pytorch#12845 Attempting to do this again. Reallocation of strides_ if there's no change in dim seems to cause the error that broke internal flow last time. This fixes that. Found a potential race condition in caffe2 counter ops that might be the cause, we will investigate that. Reviewed By: ezyang Differential Revision: D10421896 fbshipit-source-id: b961ea0bca79757991013a2d60cfe51565689ee9
…2731) Summary: Add strings to our set of built-in types for annotations. This is used in the the functional library. Pull Request resolved: pytorch#12731 Differential Revision: D10453153 Pulled By: eellison fbshipit-source-id: f54177c0c529f2e09f7ff380ddb476c3545ba5b0
Summary: Pull Request resolved: pytorch#12844 Optimize GroupNormOp Reviewed By: houseroad Differential Revision: D10455567 fbshipit-source-id: aee211badd1e0c8ea6196843e3e77f7c612a74d5
pytorch#12836) Summary: `OMP_NUM_THREADS` and `MKL_NUM_THREADS` are set to 4 by default in the docker images, which causes `nproc` to only show 4 cores in the docker containers by default, and building PyTorch is slow in this default case. We likely don't need these two flags to be set, and this PR tests that hypothesis. Pull Request resolved: pytorch#12836 Differential Revision: D10468218 Pulled By: yf225 fbshipit-source-id: 7a57962c962e162a8d97f730626825aa1e371c7f
Differential Revision: D10421896 Original commit changeset: b961ea0bca79 fbshipit-source-id: 9d9d2ed0c2cb23a3fdf6bbfc9509539aeeb7e382
Summary: Pull Request resolved: pytorch#12717 Reviewed By: ilia-cher Differential Revision: D10408325 fbshipit-source-id: 82583d0ad4b8db094ee4c5c607b52500826328f7
Summary: Pull Request resolved: pytorch#12840 Add binding for delete_node Reviewed By: duc0 Differential Revision: D10453555 fbshipit-source-id: cdcaca8420a9a0c61479961d907ef6bb5478a41d
Summary: This fixes the issue for pytorch#12168 Pull Request resolved: pytorch#12694 Differential Revision: D10468717 Pulled By: teng-li fbshipit-source-id: 3df31d75eea19d6085af665f5350d3cb667a5048
Summary: Pull Request resolved: pytorch#12881 TSIA. This should not change any functionality. Remaining work: - change the build script to deprecate use of CAFFE2_USE_MINIMAL_GOOGLE_GLOG and use a C10 macro instead. - Unify the exception name (EnforceNotMet -> Error) - Unify the logging and warning APIs (like AT_WARNING) Reviewed By: dzhulgakov Differential Revision: D10441597 fbshipit-source-id: 4784dc0cd5af83dacb10c4952a2d1d7236b3f14d
Summary: This test flushes out the issue that IDEEP cannot handle tensor with dims like (0, 2), which is a valid tensor shape. Pull Request resolved: pytorch#8459 Differential Revision: D10419328 Pulled By: yinghai fbshipit-source-id: c5efcd152364a544180a8305c47a2a2d126ab070
Summary: Pull Request resolved: pytorch#12790 Add DFS based topological sort to nomnigraph. Reviewed By: duc0 Differential Revision: D10434645 fbshipit-source-id: aaf106b0cc37806b8ae61f065c1592a29993eb40
Summary: Pull Request resolved: pytorch#12864 Differential Revision: D10481669 Pulled By: SsnL fbshipit-source-id: 20831af41aaba75546e6ed6a99f011f0447b1acf
Summary: * Moves `weak_script` annotation to `torch/_jit_internal.py` folder to resolve dependency issue between `torch.jit` and `torch.nn` * Add `torch._jit.weak_script` to `tanhshrink` and `softsign`, their tests now pass instead of giving an `unknown builtin op` error * Blacklist converted `torch.nn.functional` functions from appearing in the builtin op list if they don't actually have corresponding `aten` ops Pull Request resolved: pytorch#12723 Differential Revision: D10452986 Pulled By: driazati fbshipit-source-id: c7842bc2d3ba0aaf7ca6e1e228523dbed3d63c36
Summary: For pytorch#10114 soumith fmassa Pull Request resolved: pytorch#12708 Differential Revision: D10444102 Pulled By: goldsborough fbshipit-source-id: 529e737e795bd8801beab2247be3dad296af5a3e
…2835) Summary: This is designed to make it easier to see how your codegen changes affected actual generated code. Limitations: A) This is NOT robust; if new directories are added that include generated files, they need to be added to tools/generated_dirs.txt. Note that subdirectories of the list are not included. B) This is particular to my workflow which I don't claim is generally applicable. Ideally we would have a script that pumped out a diff that could be attached to PRs. C) Only works on OSS and definitely won't work on windows. How to use: 1) python setup.py ... 2) tools/git_add_generated_dirs 3) Edit codegen 4) python setup.py ... 4) git diff to see changes 5) If satisfied: tools/git_reset_generated_dirs, commit, etc. If not satisfied: Go to 3) Pull Request resolved: pytorch#12835 Reviewed By: ezyang Differential Revision: D10452255 Pulled By: gchanan fbshipit-source-id: 294fc74d41d1b840c7a26d20e05efd0aff154635
Author
|
@pytorchbot retest this please |
amd-sriram
pushed a commit
that referenced
this pull request
Nov 24, 2025
Commit Messages: - Update README.md (#289) - Update version to 1.10.0 (#282) - add code to read BUILD_VERSION env variable, so that it is used instead of version.txt when creating a wheel (#278) PRs: - ROCm/apex#289 Fixes: - https://example.com/issue-289 - https://example.com/issue-282 - https://example.com/issue-278
amd-sriram
pushed a commit
that referenced
this pull request
Nov 25, 2025
Commit Messages: - Update README.md (#289) - Update version to 1.10.0 (#282) - add code to read BUILD_VERSION env variable, so that it is used instead of version.txt when creating a wheel (#278) PRs: - ROCm/apex#289 Fixes: - https://example.com/issue-278 - https://example.com/issue-289 - https://example.com/issue-282
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
19 participants
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
No description provided.