In the world of Machine Learning, Neural Networks have been successful to achieve state-of-art accuracy in multiple domains like image classification, voice recognition, autonomous driving and so on. In this project, I focus on training various neural network models for classifying images. The Datasets that were used are MNIST, FMNIST, CIFAR 10, and SVHN. Studied Various regularization techniques their effect while training. During the training phase, there are mulitple parameters which influence the validation accuracy. The algorithmic community is coming out with different optimization strategies to reduce the validation loss. My goal is to study the most recently used optimization strategies and observe their influence over the accuracy of the network.
When the range of the data varies, training might get harder while updating the weights in the backpropagation stage. It is best to scale all the inputs to lie in in the range of 0 to 1 so that we have smaller values of weights. There are different ways to normalize the data and few of them are as follows:
- Dividing all the data points in the input by the maximum possible value, this scales the data in the range of 0 to 1.
- Subtracting minimum value and dividing the diffrence of maximum and minimum from data(d-min/(max-min)) is another way to normalize the data that lies in the range of 0 to 1.
- Most commonly used data normalization is to calculate the mean and standard deviation of the data. Subtract the mean and divide the value by the standard deviation ((d- mean)/std) to make the data have a normal distribution with mean 0 and standard deviation 1.
Overfiting occurs when a network fits the training set with a very high accuracy i.e it gets over trained only for the training datasets but cannot be generalized on test or validation sets. One of the reason for a network to overfit in a deeper network is when the number of parameters to be learned are a lot more than data available. On the other hand, when we reduce the network size, there is a high impact on the performance since all the features cannot be learnt. Therefore, there is a need to find a balance of having a deeper network but preventing overfitting. Following regularization techniques can be used to overcome the problem of overfitting
When a network is overfitting, the weights have a high magnitude in order to fit all the training data perfectly. Regularization penalizes the weights by a factor and prevents overfitting.
Huge amount of data is required to train to design a good model. But, often the data available in the dataset is not enough to support a bigger network without overfitting. Data Augmentation solves this problem by generating more data from the given data in real-time. This is done by applying various operations such as rotation, cropping, flipping, and scaling.
During training, some of the nodes are ignored. This results in the training of different networks on the same dataset without increasing the number of parameters to be trained.
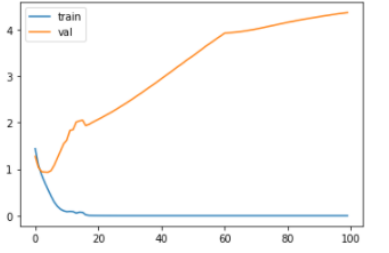
Training and testing loss over epochs when no regularization is applied.

Training and testing loss over epochs when L2 regularization is used while training.
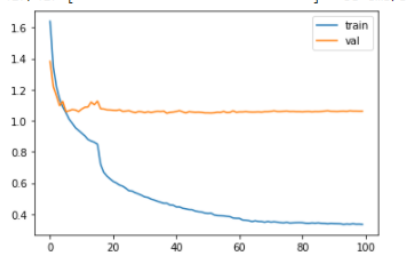
Training and testing loss over epochs when L2 regularization and Dropout are used while training.
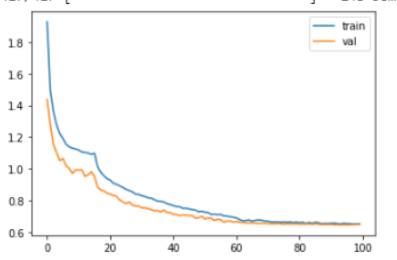
Training and testing loss over epochs when L2 Regularization, Dropout and Data Augmentation are used while training.
This dataset contains Handwritten digits from (0 to 9), 60,000 images are available for training and 10,000 for testing. Images are black white and contain 28x28 pixels which has a value of its intensity.
This dataset contains images of 10 different kinds of clothing. These images also are black white and have a single channel of 28x28 pixels.
This is a real-world dataset of house numbers from google street view images. There are 10 classes for each digit. There is a lot of noise in these images and cropped to fit in a single digit of 32 x32 pixels. Unlike MNISt dataset this has 3 channels for each image representing the intensity of each primary colour(R, G, B).[1]
This dataset consists of coloured images of 10 different classes. Each image has 3 channels (R,G,B) and 32x32 pixels.
LENET is one of the first CNN's that were introduced. It is a simple neural network with 2 convolutional layers, downsampling and follwed by 1 densely connected layers and output layer [2]
VGG is a very deep neural network that was implemented for ImageNet. It is deep neural network with kernel size as 3x3 as opposed to the larger kernel sizes of 5x5, 7x7. The authors of the papers showed that large kernel sizes are not necessary for training. Using 3x3 kernel size also reduces the number of parameters to be trained by a good factor [3].
In NiN more non-linearity is introduced using mpl convolutions layer(convolution layer with 1x1 kernel) and Global Average pooling instead of a dense layer. The authors of the paper showed that the non-linaerity and global averaging prevents overfitting globally [4].
- MNIST: With two hidden dense layers 98.35% test accuracy. LENET with 5x5 as kernel size 99.61% and 3x3 as kerne size 99.3%.
- Fashion_MNIST: LENET with 5x5 as kernel size 93.65% and 3x3 as kernel size it is 92.79%.
- SVHN: LENET with 5x5 as kernel size accuracy is 93.97% and with 3x3 as kernel size it is 93.85. With NiN the accuracy 95.25% is with VGG11 96.06% it is and with VGG13 it is 96.76%.
- CIFAR10: LENET with 5x5 as kernel size accuracy is 82.72%. With NiN the accuracy is 88.68% with VGG11 it is 82.56% and with VGG13 it is 86.29%.