diff --git a/docs/integrations/containers-orchestration/opentelemetry/rabbitmq-opentelemetry.md b/docs/integrations/containers-orchestration/opentelemetry/rabbitmq-opentelemetry.md
index 0ed4870aa5..ac87f0a4c9 100644
--- a/docs/integrations/containers-orchestration/opentelemetry/rabbitmq-opentelemetry.md
+++ b/docs/integrations/containers-orchestration/opentelemetry/rabbitmq-opentelemetry.md
@@ -15,6 +15,10 @@ RabbitMQ logs are sent to Sumo Logic through the OpenTelemetry [filelog receiver
 +:::info
+This app includes [built-in monitors](#rabbitmq-alerts). For details on creating custom monitors, refer to the [Create monitors for RabbitMQ app](#create-monitors-for-rabbitmq-app).
+:::
+
## Fields creation in Sumo Logic for RabbitMQ
Following are the [Fields](/docs/manage/fields/) which will be created as part of RabbitMQ App install if not already present.
@@ -230,3 +234,20 @@ The **RabbitMQ - Logs** dashboard gives you an at-a-glance view of error message
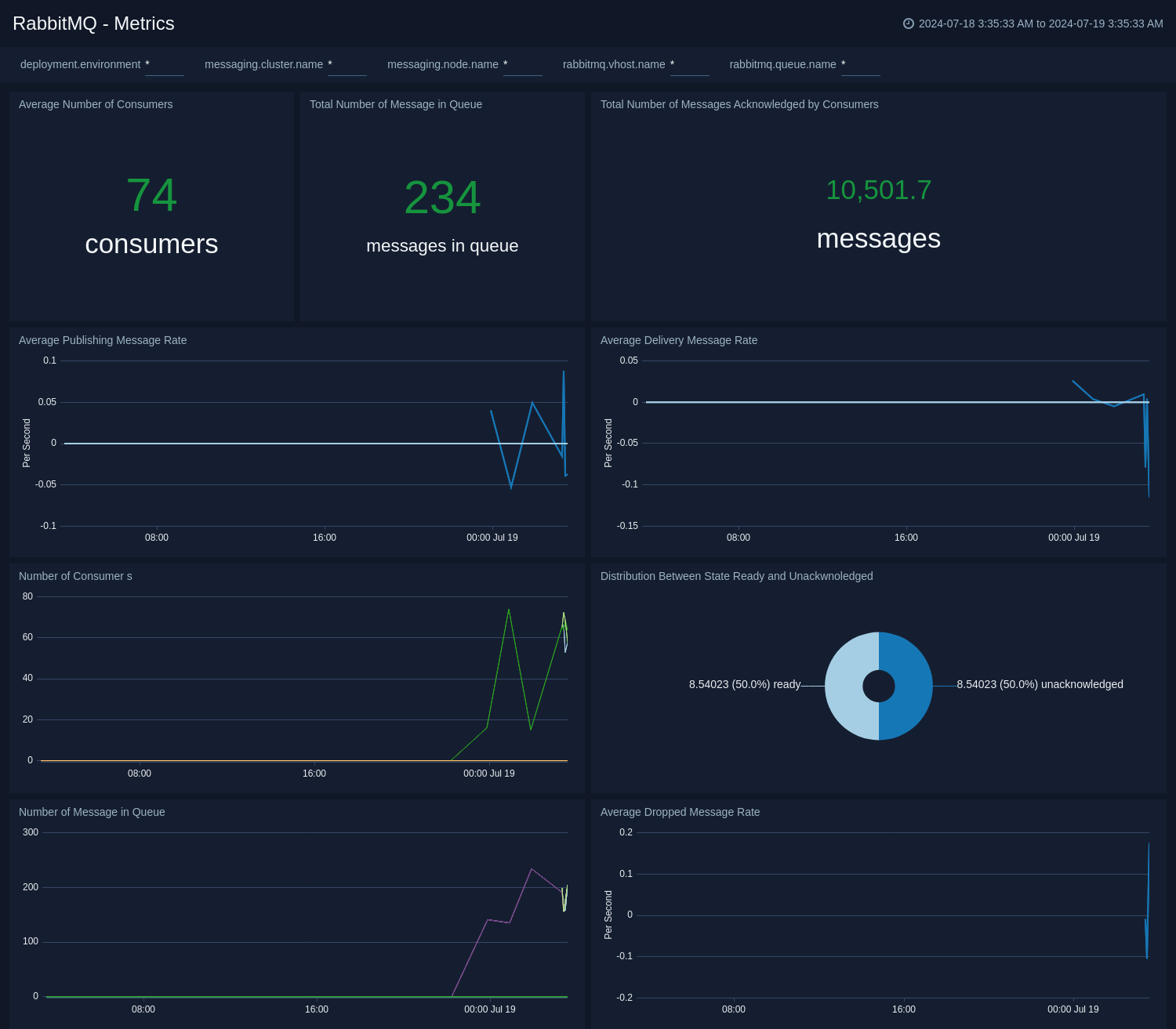
The **RabbitMQ - Metrics** dashboard gives you an at-a-glance view of your RabbitMQ deployment across brokers, queue, exchange, consumer, and messages.
+:::info
+This app includes [built-in monitors](#rabbitmq-alerts). For details on creating custom monitors, refer to the [Create monitors for RabbitMQ app](#create-monitors-for-rabbitmq-app).
+:::
+
## Fields creation in Sumo Logic for RabbitMQ
Following are the [Fields](/docs/manage/fields/) which will be created as part of RabbitMQ App install if not already present.
@@ -230,3 +234,20 @@ The **RabbitMQ - Logs** dashboard gives you an at-a-glance view of error message
The **RabbitMQ - Metrics** dashboard gives you an at-a-glance view of your RabbitMQ deployment across brokers, queue, exchange, consumer, and messages.
 +
+## Create monitors for RabbitMQ app
+
+import CreateMonitors from '../../../reuse/apps/create-monitors.md';
+
+
+
+### RabbitMQ alerts
+
+| Name | Description | Alert Condition | Recover Condition |
+|:--|:--|:--|:--|
+| `RabbitMQ - High Consumer Count` | This alert is triggered when consumers are higher than given value (Default 10000) in a queue. | Count `>=` 10000 | Count `<` 10000 |
+| `RabbitMQ - High Message Queue Size` | This alert is triggered when the number of messages in a queue exceeds a given threshold (Default 10000), indicating potential consumer issues or message processing bottlenecks. | Count `>=` 10000 | Count `<` 10000 |
+| `RabbitMQ - High Messages Count` | This alert is triggered when messages are higher than given value (Default 10000) in a queue. | Count `>=` 10000 | Count `<` 10000 |
+| `RabbitMQ - High Unacknowledged Messages` | This alert is triggered when there are too many unacknowledged messages (Default 5000), suggesting consumer processing issues. | Count `>=` 5000 | Count `<` 5000 |
+| `RabbitMQ - Node Down` | This alert is triggered when a node in the RabbitMQ cluster is down. | Count `>=` 1 | Count `<` 1 |
+| `RabbitMQ - Zero Consumers Alert` | This alert is triggered when a queue has no consumers, indicating potential service issues. | Count `<=` 0 | Count `>` 0 |
diff --git a/docs/integrations/databases/opentelemetry/cassandra-opentelemetry.md b/docs/integrations/databases/opentelemetry/cassandra-opentelemetry.md
index 1dbb93b407..935ecbd51c 100644
--- a/docs/integrations/databases/opentelemetry/cassandra-opentelemetry.md
+++ b/docs/integrations/databases/opentelemetry/cassandra-opentelemetry.md
@@ -2,7 +2,7 @@
id: cassandra-opentelemetry
title: Cassandra - OpenTelemetry Collector
sidebar_label: Cassandra - OTel Collector
-description: Learn about the Sumo Logic OpenTelemetry App for Cassandra.
+description: Learn about the Sumo Logic OpenTelemetry app for Cassandra.
---
import useBaseUrl from '@docusaurus/useBaseUrl';
@@ -15,10 +15,14 @@ The [Cassandra](https://cassandra.apache.org/_/cassandra-basics.html) app is a l
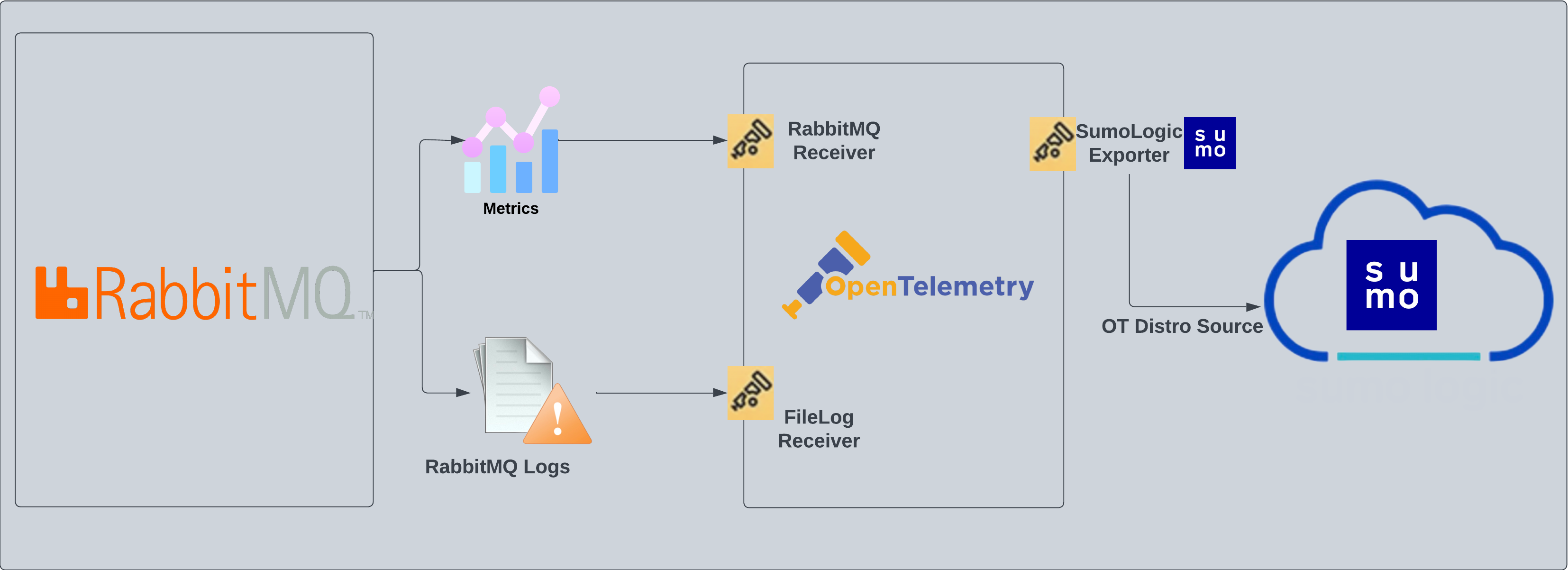
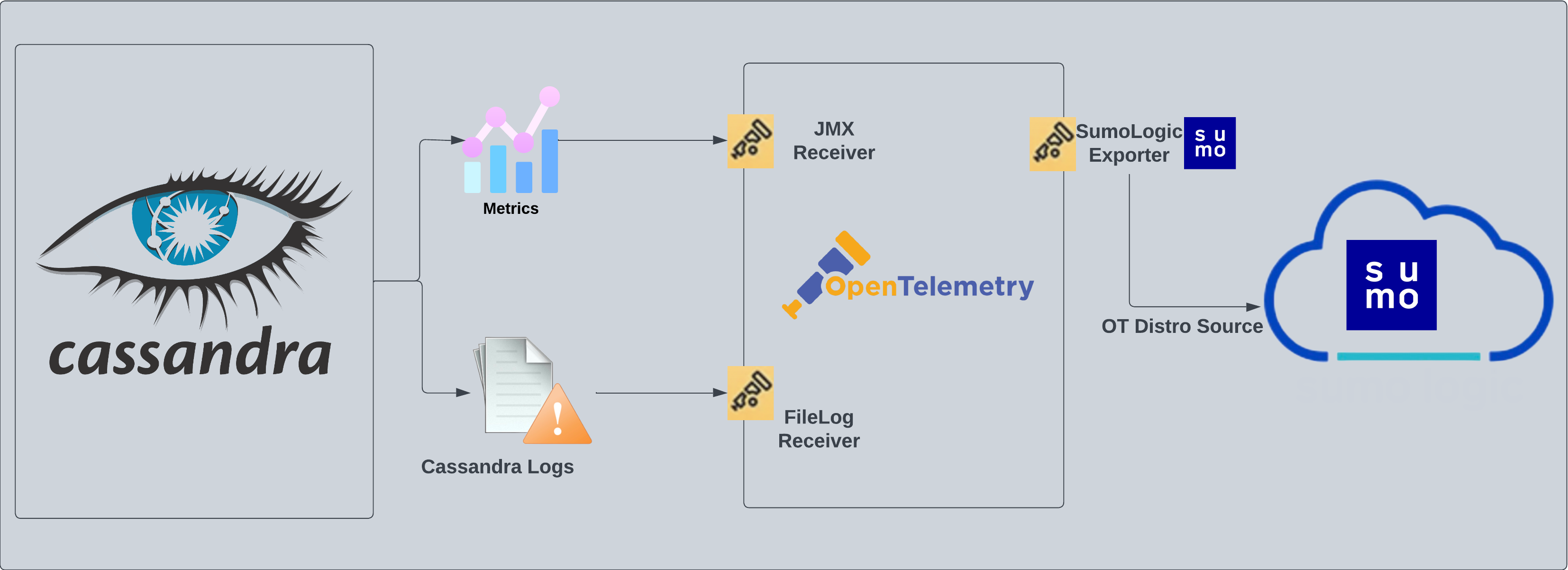
Cassandra logs are sent to Sumo Logic through OpenTelemetry [filelog receiver](https://github.com/open-telemetry/opentelemetry-collector-contrib/tree/main/receiver/filelogreceiver) and cassandra metrics are sent to Sumo Logic using [JMX opentelemetry receiver](https://github.com/open-telemetry/opentelemetry-collector-contrib/tree/main/receiver/jmxreceiver) with the `target_system` set as [`cassandra`](https://github.com/open-telemetry/opentelemetry-java-contrib/blob/main/jmx-metrics/docs/target-systems/cassandra.md).
-The app supports Logs from the open-source version of Cassandra. The App is tested on the 4.0.0 version of Cassandra.
+The app supports logs from the open-source version of Cassandra. The app is tested on the 4.0.0 version of Cassandra.
+
+## Create monitors for RabbitMQ app
+
+import CreateMonitors from '../../../reuse/apps/create-monitors.md';
+
+
+
+### RabbitMQ alerts
+
+| Name | Description | Alert Condition | Recover Condition |
+|:--|:--|:--|:--|
+| `RabbitMQ - High Consumer Count` | This alert is triggered when consumers are higher than given value (Default 10000) in a queue. | Count `>=` 10000 | Count `<` 10000 |
+| `RabbitMQ - High Message Queue Size` | This alert is triggered when the number of messages in a queue exceeds a given threshold (Default 10000), indicating potential consumer issues or message processing bottlenecks. | Count `>=` 10000 | Count `<` 10000 |
+| `RabbitMQ - High Messages Count` | This alert is triggered when messages are higher than given value (Default 10000) in a queue. | Count `>=` 10000 | Count `<` 10000 |
+| `RabbitMQ - High Unacknowledged Messages` | This alert is triggered when there are too many unacknowledged messages (Default 5000), suggesting consumer processing issues. | Count `>=` 5000 | Count `<` 5000 |
+| `RabbitMQ - Node Down` | This alert is triggered when a node in the RabbitMQ cluster is down. | Count `>=` 1 | Count `<` 1 |
+| `RabbitMQ - Zero Consumers Alert` | This alert is triggered when a queue has no consumers, indicating potential service issues. | Count `<=` 0 | Count `>` 0 |
diff --git a/docs/integrations/databases/opentelemetry/cassandra-opentelemetry.md b/docs/integrations/databases/opentelemetry/cassandra-opentelemetry.md
index 1dbb93b407..935ecbd51c 100644
--- a/docs/integrations/databases/opentelemetry/cassandra-opentelemetry.md
+++ b/docs/integrations/databases/opentelemetry/cassandra-opentelemetry.md
@@ -2,7 +2,7 @@
id: cassandra-opentelemetry
title: Cassandra - OpenTelemetry Collector
sidebar_label: Cassandra - OTel Collector
-description: Learn about the Sumo Logic OpenTelemetry App for Cassandra.
+description: Learn about the Sumo Logic OpenTelemetry app for Cassandra.
---
import useBaseUrl from '@docusaurus/useBaseUrl';
@@ -15,10 +15,14 @@ The [Cassandra](https://cassandra.apache.org/_/cassandra-basics.html) app is a l
Cassandra logs are sent to Sumo Logic through OpenTelemetry [filelog receiver](https://github.com/open-telemetry/opentelemetry-collector-contrib/tree/main/receiver/filelogreceiver) and cassandra metrics are sent to Sumo Logic using [JMX opentelemetry receiver](https://github.com/open-telemetry/opentelemetry-collector-contrib/tree/main/receiver/jmxreceiver) with the `target_system` set as [`cassandra`](https://github.com/open-telemetry/opentelemetry-java-contrib/blob/main/jmx-metrics/docs/target-systems/cassandra.md).
-The app supports Logs from the open-source version of Cassandra. The App is tested on the 4.0.0 version of Cassandra.
+The app supports logs from the open-source version of Cassandra. The app is tested on the 4.0.0 version of Cassandra.
 +:::info
+This app includes [built-in monitors](#cassandra-alerts). For details on creating custom monitors, refer to the [Create monitors for Cassandra app](#create-monitors-for-cassandra-app).
+:::
+
## Fields creation in Sumo Logic for Cassandra
Following are the [Fields](/docs/manage/fields/) which will be created as part of Cassandra App install if not already present:
@@ -36,7 +40,6 @@ Following are the [Fields](/docs/manage/fields/) which will be created as part o
JMX receiver collects Cassandra metrics from Cassandra server as part of the OpenTelemetry Collector (OTC).
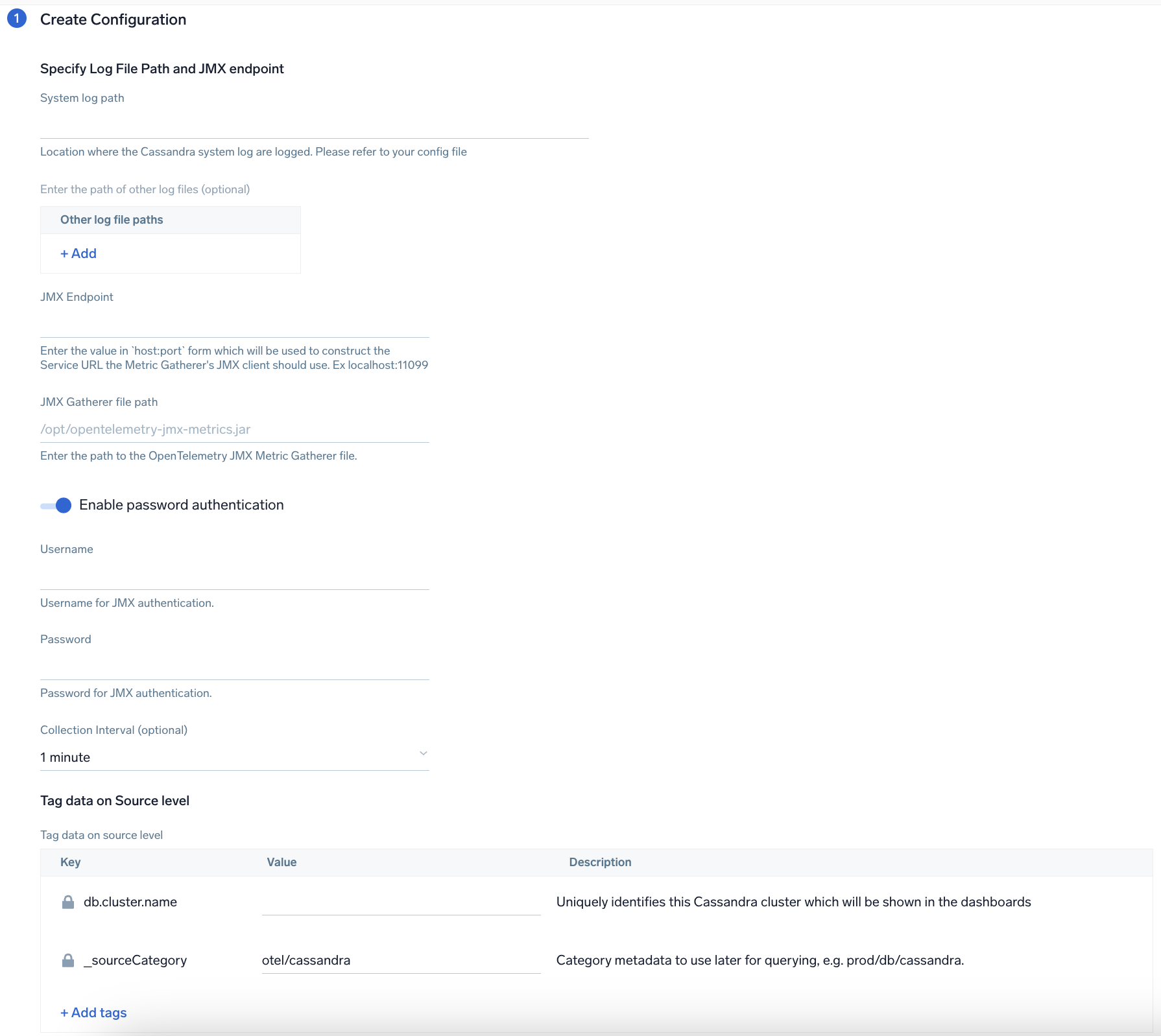
1. Follow the instructions in [JMX - OpenTelemetry's prerequisites section](/docs/integrations/app-development/opentelemetry/jmx-opentelemetry/#prerequisites) to download the [JMX Metric Gatherer](https://github.com/open-telemetry/opentelemetry-java-contrib/blob/main/jmx-metrics/README.md). This gatherer is used by the [JMX Receiver](https://github.com/open-telemetry/opentelemetry-collector-contrib/tree/main/receiver/jmxreceiver#details).
-
2. Set the JMX port as part of `JAVA_OPTS` for Tomcat startup. Usually, it is set in the `/etc/systemd/system/cassandra.service` or `C:\Program Files\apache-tomcat\bin\tomcat.bat` file.
```json
@@ -44,9 +47,10 @@ JMX receiver collects Cassandra metrics from Cassandra server as part of the Ope
```
#### For log collection
-Cassandra has three main logs: system.log, debug.log, and gc.log which hold general logging messages, debugging logging messages, and java garbage collection logs respectively.
-These logs by default live in `${CASSANDRA_HOME}/logs`, but most Linux distributions relocate logs to `/var/log/cassandra`. Operators can tune this location as well as what levels are logged using the provided logback.xml file. For more details on Cassandra logs, see[ this](https://cassandra.apache.org/doc/latest/troubleshooting/reading_logs.html) link.
+Cassandra has three main logs: `system.log`, `debug.log`, and `gc.log`, which hold general logging messages, debugging logging messages, and java garbage collection logs respectively.
+
+These logs by default live in `${CASSANDRA_HOME}/logs`, but most Linux distributions relocate logs to `/var/log/cassandra`. Operators can tune this location as well as what levels are logged using the provided logback.xml file. For more details on Cassandra logs, see [this](https://cassandra.apache.org/doc/latest/troubleshooting/reading_logs.html).
import LogsCollectionPrereqisites from '../../../reuse/apps/logs-collection-prereqisites.md';
@@ -78,7 +82,7 @@ You can add any custom fields which you want to be tagged with the data ingested
+:::info
+This app includes [built-in monitors](#cassandra-alerts). For details on creating custom monitors, refer to the [Create monitors for Cassandra app](#create-monitors-for-cassandra-app).
+:::
+
## Fields creation in Sumo Logic for Cassandra
Following are the [Fields](/docs/manage/fields/) which will be created as part of Cassandra App install if not already present:
@@ -36,7 +40,6 @@ Following are the [Fields](/docs/manage/fields/) which will be created as part o
JMX receiver collects Cassandra metrics from Cassandra server as part of the OpenTelemetry Collector (OTC).
1. Follow the instructions in [JMX - OpenTelemetry's prerequisites section](/docs/integrations/app-development/opentelemetry/jmx-opentelemetry/#prerequisites) to download the [JMX Metric Gatherer](https://github.com/open-telemetry/opentelemetry-java-contrib/blob/main/jmx-metrics/README.md). This gatherer is used by the [JMX Receiver](https://github.com/open-telemetry/opentelemetry-collector-contrib/tree/main/receiver/jmxreceiver#details).
-
2. Set the JMX port as part of `JAVA_OPTS` for Tomcat startup. Usually, it is set in the `/etc/systemd/system/cassandra.service` or `C:\Program Files\apache-tomcat\bin\tomcat.bat` file.
```json
@@ -44,9 +47,10 @@ JMX receiver collects Cassandra metrics from Cassandra server as part of the Ope
```
#### For log collection
-Cassandra has three main logs: system.log, debug.log, and gc.log which hold general logging messages, debugging logging messages, and java garbage collection logs respectively.
-These logs by default live in `${CASSANDRA_HOME}/logs`, but most Linux distributions relocate logs to `/var/log/cassandra`. Operators can tune this location as well as what levels are logged using the provided logback.xml file. For more details on Cassandra logs, see[ this](https://cassandra.apache.org/doc/latest/troubleshooting/reading_logs.html) link.
+Cassandra has three main logs: `system.log`, `debug.log`, and `gc.log`, which hold general logging messages, debugging logging messages, and java garbage collection logs respectively.
+
+These logs by default live in `${CASSANDRA_HOME}/logs`, but most Linux distributions relocate logs to `/var/log/cassandra`. Operators can tune this location as well as what levels are logged using the provided logback.xml file. For more details on Cassandra logs, see [this](https://cassandra.apache.org/doc/latest/troubleshooting/reading_logs.html).
import LogsCollectionPrereqisites from '../../../reuse/apps/logs-collection-prereqisites.md';
@@ -78,7 +82,7 @@ You can add any custom fields which you want to be tagged with the data ingested
 -### Step 3: Send logs to Sumo
+### Step 3: Send logs to Sumo Logic
import LogsIntro from '../../../reuse/apps/opentelemetry/send-logs-intro.md';
@@ -133,7 +137,7 @@ import LogsOutro from '../../../reuse/apps/opentelemetry/send-logs-outro.md';
-## Sample log messages
+## Sample log message
```sql
INFO [ScheduledTasks:1] 2023-01-08 09:18:47,347 StatusLogger.java:101 - system.schema_aggregates
@@ -176,7 +180,7 @@ import LogsOutro from '../../../reuse/apps/opentelemetry/send-logs-outro.md';
}
```
-## Sample log queries
+## Sample log query
Following is a query from the Cassandra app's **Cassandra - Overview** dashboard Nodes Up panel:
@@ -191,6 +195,7 @@ Following is a query from the Cassandra app's **Cassandra - Overview** dashboard
```
## Sample metrics query
+
Following is the query from Cassandra App's overview Dashboard's Number of Requests Panel:
```sql
@@ -205,20 +210,15 @@ The **Cassandra - Overview** dashboard provides an at-a-glance view of Cassandra
Use this dashboard to:
-- Identify number of nodes which are up and down
-- Gain insights into Memory - Init, used, Max and committed
-- Gain insights into the error and warning logs by thread and Node activity
+- Identify number of nodes which are up and down.
+- Gain insights into Memory - Init, used, Max, and committed.
+- Gain insights into the error and warning logs by thread and Node activity.
-### Step 3: Send logs to Sumo
+### Step 3: Send logs to Sumo Logic
import LogsIntro from '../../../reuse/apps/opentelemetry/send-logs-intro.md';
@@ -133,7 +137,7 @@ import LogsOutro from '../../../reuse/apps/opentelemetry/send-logs-outro.md';
-## Sample log messages
+## Sample log message
```sql
INFO [ScheduledTasks:1] 2023-01-08 09:18:47,347 StatusLogger.java:101 - system.schema_aggregates
@@ -176,7 +180,7 @@ import LogsOutro from '../../../reuse/apps/opentelemetry/send-logs-outro.md';
}
```
-## Sample log queries
+## Sample log query
Following is a query from the Cassandra app's **Cassandra - Overview** dashboard Nodes Up panel:
@@ -191,6 +195,7 @@ Following is a query from the Cassandra app's **Cassandra - Overview** dashboard
```
## Sample metrics query
+
Following is the query from Cassandra App's overview Dashboard's Number of Requests Panel:
```sql
@@ -205,20 +210,15 @@ The **Cassandra - Overview** dashboard provides an at-a-glance view of Cassandra
Use this dashboard to:
-- Identify number of nodes which are up and down
-- Gain insights into Memory - Init, used, Max and committed
-- Gain insights into the error and warning logs by thread and Node activity
+- Identify number of nodes which are up and down.
+- Gain insights into Memory - Init, used, Max, and committed.
+- Gain insights into the error and warning logs by thread and Node activity.
 ### Cache Stats
-The **Cassandra - Cache Stats** dashboard provides insight into the database cache status, schedule, and items.
-
-Use this dashboard to:
-
-- Monitor Cache performance.
-- Identify Cache usage statistics.
+The **Cassandra - Cache Stats** dashboard provides insight into the database cache status, schedule, and items. Use this dashboard to monitor cache performance and identify cache usage statistics.
### Cache Stats
-The **Cassandra - Cache Stats** dashboard provides insight into the database cache status, schedule, and items.
-
-Use this dashboard to:
-
-- Monitor Cache performance.
-- Identify Cache usage statistics.
+The **Cassandra - Cache Stats** dashboard provides insight into the database cache status, schedule, and items. Use this dashboard to monitor cache performance and identify cache usage statistics.
 @@ -246,32 +246,26 @@ Use this dashboard to:
### Memtable
-The **Cassandra - Memtable** dashboard provides insights into memtable statistics.
-
-Use this dashboard to:
-
-- Review flush activity and memtable status.
+The **Cassandra - Memtable** dashboard provides insights into memtable statistics. Use this dashboard to review flush activity and memtable status.
@@ -246,32 +246,26 @@ Use this dashboard to:
### Memtable
-The **Cassandra - Memtable** dashboard provides insights into memtable statistics.
-
-Use this dashboard to:
-
-- Review flush activity and memtable status.
+The **Cassandra - Memtable** dashboard provides insights into memtable statistics. Use this dashboard to review flush activity and memtable status.
 ### Resource Usage
-The **Cassandra - Resource Usage** dashboard provides details of resource utilization across Cassandra clusters.
-
-Use this dashboard to:
-
-- Identify resource utilization. This can help you to determine whether resources are over-allocated or under-allocated.
+The **Cassandra - Resource Usage** dashboard provides details of resource utilization across Cassandra clusters. Use this dashboard to identify resource utilization. This can help you to determine whether resources are over-allocated or under-allocated.
### Resource Usage
-The **Cassandra - Resource Usage** dashboard provides details of resource utilization across Cassandra clusters.
-
-Use this dashboard to:
-
-- Identify resource utilization. This can help you to determine whether resources are over-allocated or under-allocated.
+The **Cassandra - Resource Usage** dashboard provides details of resource utilization across Cassandra clusters. Use this dashboard to identify resource utilization. This can help you to determine whether resources are over-allocated or under-allocated.
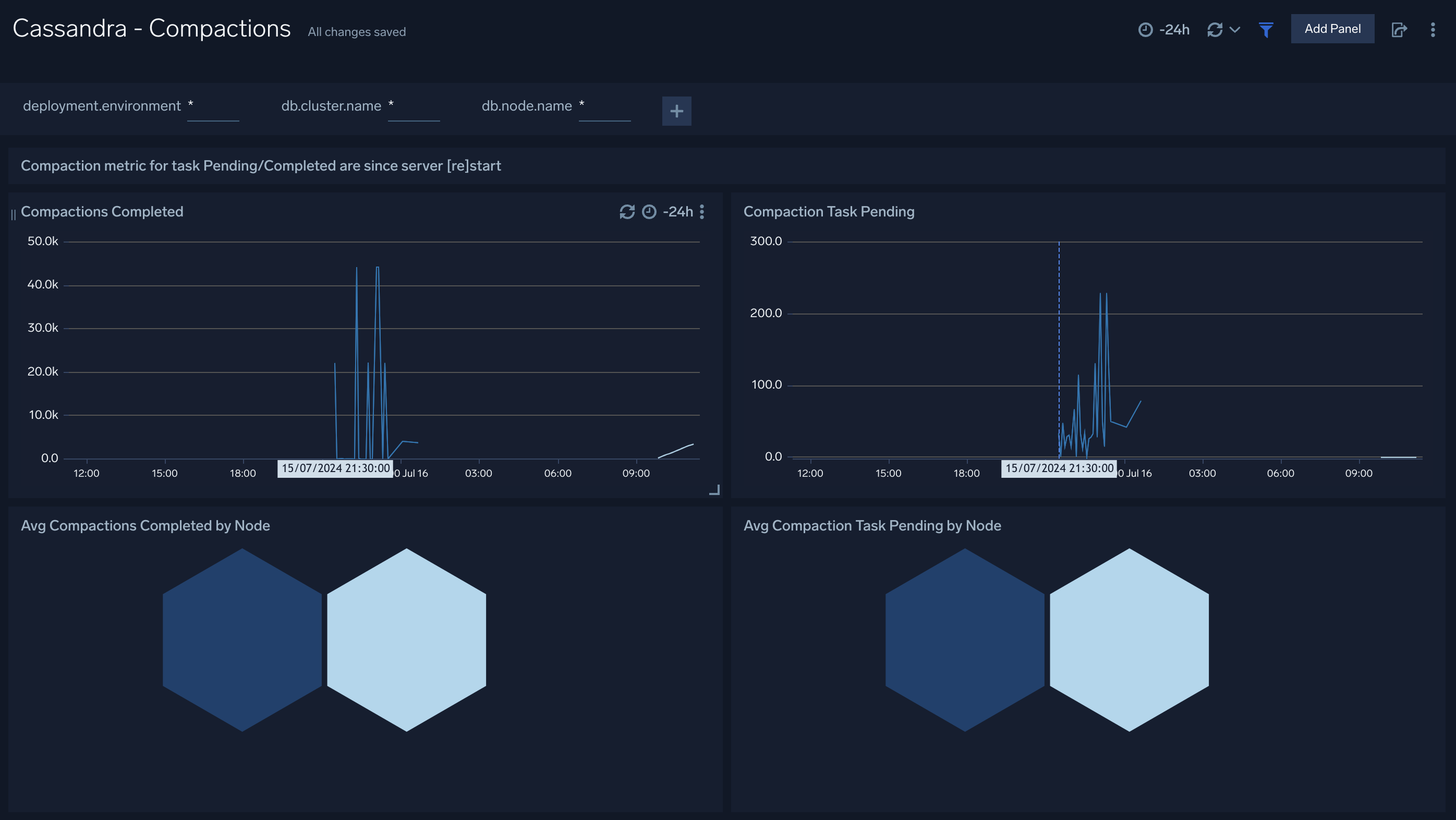
 ### Compaction
The **Cassandra - Compactions** dashboard provides insight into the completed and pending compaction tasks.
+
### Compaction
The **Cassandra - Compactions** dashboard provides insight into the completed and pending compaction tasks.
+
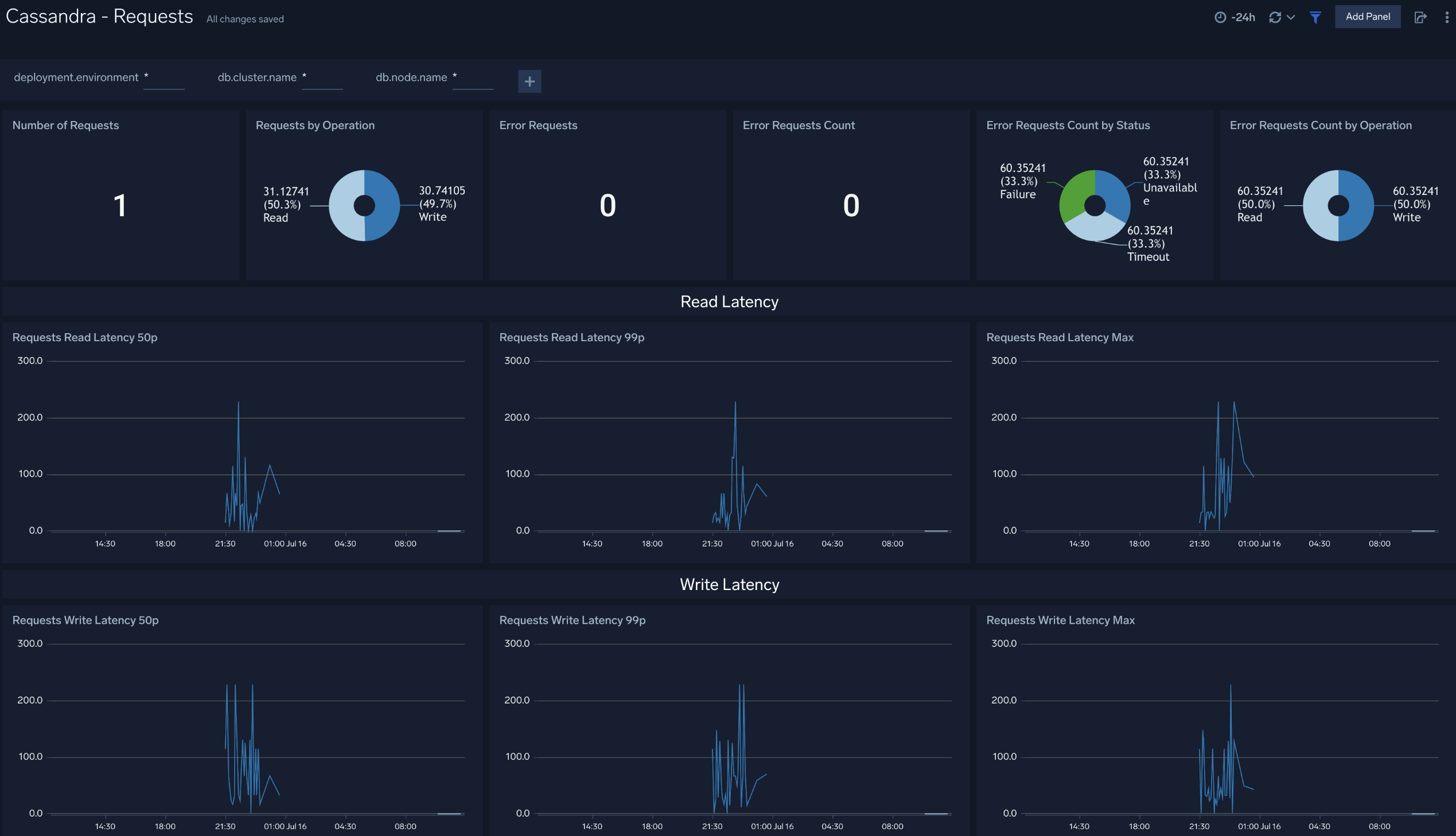
 ### Requests
The **Cassandra - Requests** dashboard provides insight into the number of request served, number of error request, and their distribution by status and operation. Also you can monitor the read and write latency of the cluster instance using this dashboard.
+
### Requests
The **Cassandra - Requests** dashboard provides insight into the number of request served, number of error request, and their distribution by status and operation. Also you can monitor the read and write latency of the cluster instance using this dashboard.
+
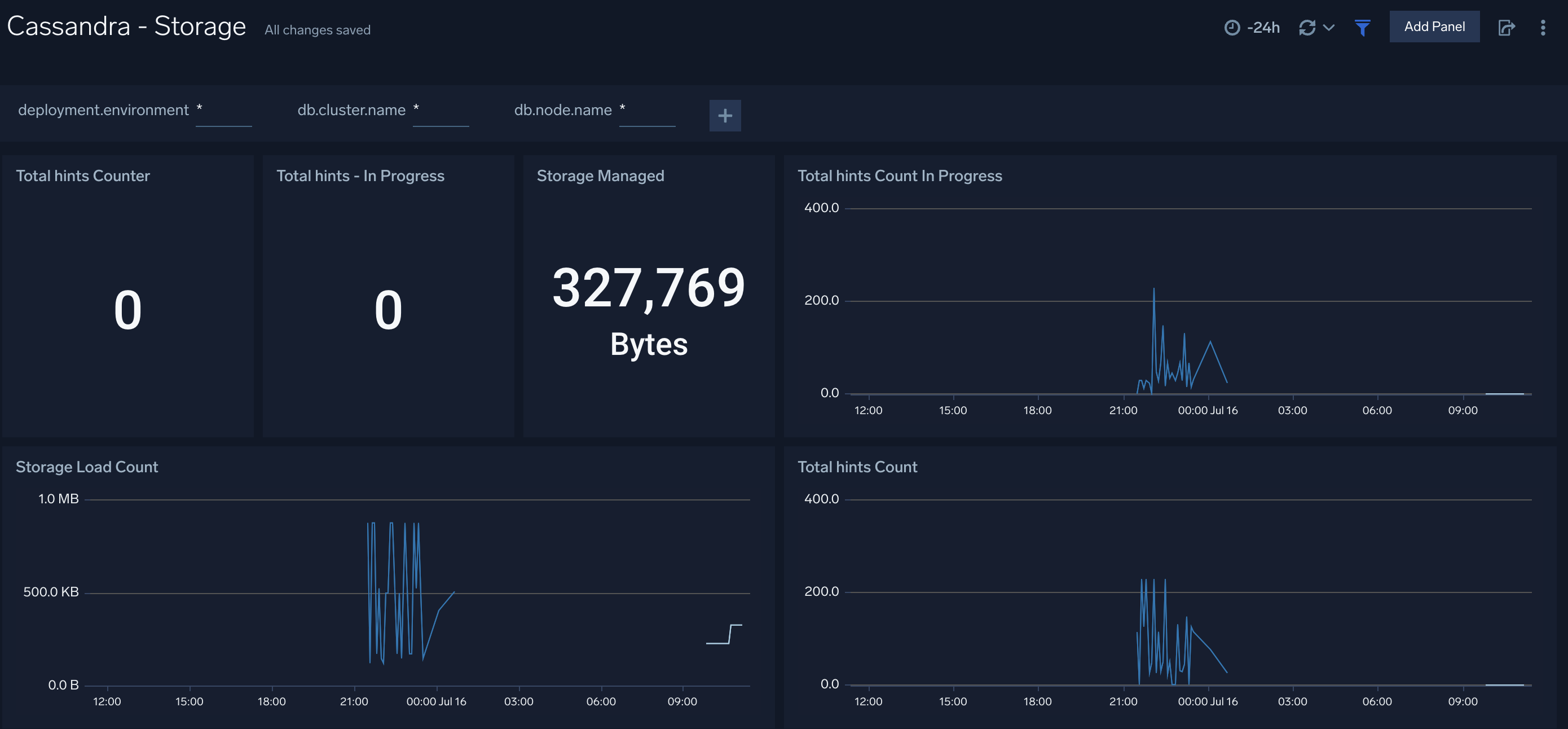
 ### Storage
@@ -279,3 +273,23 @@ The **Cassandra - Requests** dashboard provides insight into the number of reque
The **Cassandra - Storage** dashboard provides insight into the current value of total hints of your Cassandra cluster along with storage managed by the cluster.
### Storage
@@ -279,3 +273,23 @@ The **Cassandra - Requests** dashboard provides insight into the number of reque
The **Cassandra - Storage** dashboard provides insight into the current value of total hints of your Cassandra cluster along with storage managed by the cluster.
 +
+## Create monitors for Cassandra app
+
+import CreateMonitors from '../../../reuse/apps/create-monitors.md';
+
+
+
+### Cassandra alerts
+
+| Name | Description | Alert Condition | Recover Condition |
+|:--|:--|:--|:--|
+| `Cassandra - Compaction Task Pending` | This alert is triggered when there are more than 15 pending Compaction tasks. | Count > = 15 | Count < 15 |
+| `Cassandra - High Hints Backlog` | This alert is triggered when the number of in-progress hints exceeds the given value for 5 minutes. | Count > = 5000 | Count < 5000 |
+| `Cassandra - High Memory Usage` | This alert is triggered when memory used exceeds 85% of committed memory for more than 10 minutes. | Count > = 1 | Count < 1 |
+| `Cassandra - Node Down Alert` | This alert is triggered when a Cassandra node status changes to DOWN for more than 5 minutes. | Count > = 1 | Count < 1 |
+| `Cassandra - Operation Error Rate High` | This alert is triggered when the error rate of operations exceeds given value (Default 5%) for 5 minutes. | Count > 5 | Count < = 5 |
+| `Cassandra - Range Query Latency High (99th Percentile)` | This alert is triggered when the 99th percentile of range query latency exceeds the given value (Default 2 seconds) for 5 minutes. | Count > = 2000000 | Count < 2000000 |
+| `Cassandra - Read Latency High (99th Percentile)` | This alert is triggered when the 99th percentile of read latency exceeds given value (Default 500ms) for 5 minutes. | Count > = 500000 | Count < 500000 |
+| `Cassandra - Storage Growth Rate Abnormal` | This alert is triggered when the storage growth rate exceeds given value (Default 25MB/minute) for 5 minutes. | Count > = 26214400 | Count < 26214400 |
+| `Cassandra - Write Latency High (99th Percentile)` | This alert is triggered when the 99th percentile of write latency exceeds given value (Default 200ms) for 5 minutes. | Count > = 200000 | Count < 200000 |
diff --git a/docs/integrations/databases/opentelemetry/memcached-opentelemetry.md b/docs/integrations/databases/opentelemetry/memcached-opentelemetry.md
index ade5501398..47944ec3b4 100644
--- a/docs/integrations/databases/opentelemetry/memcached-opentelemetry.md
+++ b/docs/integrations/databases/opentelemetry/memcached-opentelemetry.md
@@ -19,17 +19,20 @@ Memcached logs are sent to Sumo Logic through the OpenTelemetry [filelog receive
+
+## Create monitors for Cassandra app
+
+import CreateMonitors from '../../../reuse/apps/create-monitors.md';
+
+
+
+### Cassandra alerts
+
+| Name | Description | Alert Condition | Recover Condition |
+|:--|:--|:--|:--|
+| `Cassandra - Compaction Task Pending` | This alert is triggered when there are more than 15 pending Compaction tasks. | Count > = 15 | Count < 15 |
+| `Cassandra - High Hints Backlog` | This alert is triggered when the number of in-progress hints exceeds the given value for 5 minutes. | Count > = 5000 | Count < 5000 |
+| `Cassandra - High Memory Usage` | This alert is triggered when memory used exceeds 85% of committed memory for more than 10 minutes. | Count > = 1 | Count < 1 |
+| `Cassandra - Node Down Alert` | This alert is triggered when a Cassandra node status changes to DOWN for more than 5 minutes. | Count > = 1 | Count < 1 |
+| `Cassandra - Operation Error Rate High` | This alert is triggered when the error rate of operations exceeds given value (Default 5%) for 5 minutes. | Count > 5 | Count < = 5 |
+| `Cassandra - Range Query Latency High (99th Percentile)` | This alert is triggered when the 99th percentile of range query latency exceeds the given value (Default 2 seconds) for 5 minutes. | Count > = 2000000 | Count < 2000000 |
+| `Cassandra - Read Latency High (99th Percentile)` | This alert is triggered when the 99th percentile of read latency exceeds given value (Default 500ms) for 5 minutes. | Count > = 500000 | Count < 500000 |
+| `Cassandra - Storage Growth Rate Abnormal` | This alert is triggered when the storage growth rate exceeds given value (Default 25MB/minute) for 5 minutes. | Count > = 26214400 | Count < 26214400 |
+| `Cassandra - Write Latency High (99th Percentile)` | This alert is triggered when the 99th percentile of write latency exceeds given value (Default 200ms) for 5 minutes. | Count > = 200000 | Count < 200000 |
diff --git a/docs/integrations/databases/opentelemetry/memcached-opentelemetry.md b/docs/integrations/databases/opentelemetry/memcached-opentelemetry.md
index ade5501398..47944ec3b4 100644
--- a/docs/integrations/databases/opentelemetry/memcached-opentelemetry.md
+++ b/docs/integrations/databases/opentelemetry/memcached-opentelemetry.md
@@ -19,17 +19,20 @@ Memcached logs are sent to Sumo Logic through the OpenTelemetry [filelog receive
 +:::info
+This app includes [built-in monitors](#memcached-alerts). For details on creating custom monitors, refer to the [Create monitors for Memcached app](#create-monitors-for-memcached-app).
+:::
+
## Fields creation in Sumo Logic for Memcached
Following are the [Fields](/docs/manage/fields/) which will be created as part of Memcached App install if not already present.
- **`sumo.datasource`**. Has a fixed value of **memcached**.
-- **`db.system`**. Has a fixed value of **memcached**
-- **`deployment.environment`**. User configured. This is the deployment environment where the Memcache cluster resides. For example: dev, prod or qa.
+- **`db.system`**. Has a fixed value of **memcached**.
+- **`deployment.environment`**. User configured. This is the deployment environment where the Memcache cluster resides. For example: dev, prod, or qa.
- **`db.cluster.name`**. User configured. Enter a name to identify this Memcached cluster. This cluster name will be shown in the Sumo Logic dashboards.
- **`db.node.name`**. This has value of the FQDN of the machine where OpenTelemetry collector is collecting logs and metrics from.
-
## Prerequisites
1. Configure logging in Memcached: By default, the installation of Memcached will not write any request logs to disk. To add a log file for Memcached, you can use the following syntax:
@@ -221,13 +224,12 @@ Following is the query from Errors panel of Memcached app's overview Dashboard:
| sum(ERROR) as ERROR by _timeslice
```
## Sample metrics queries
-**Total Get**
-```
+```sql title="Total Get"
sumo.datasource=memcached deployment.environment=* db.cluster.name=* db.node.name=* metric=memcached.commands command=get | sum
```
-## Viewing Memcached Dashboards
+## Viewing the Memcached dashboards
### Overview
@@ -237,7 +239,7 @@ The **Memcached - Overview** dashboard provides an at-a-glance view of the Memca
### Operations
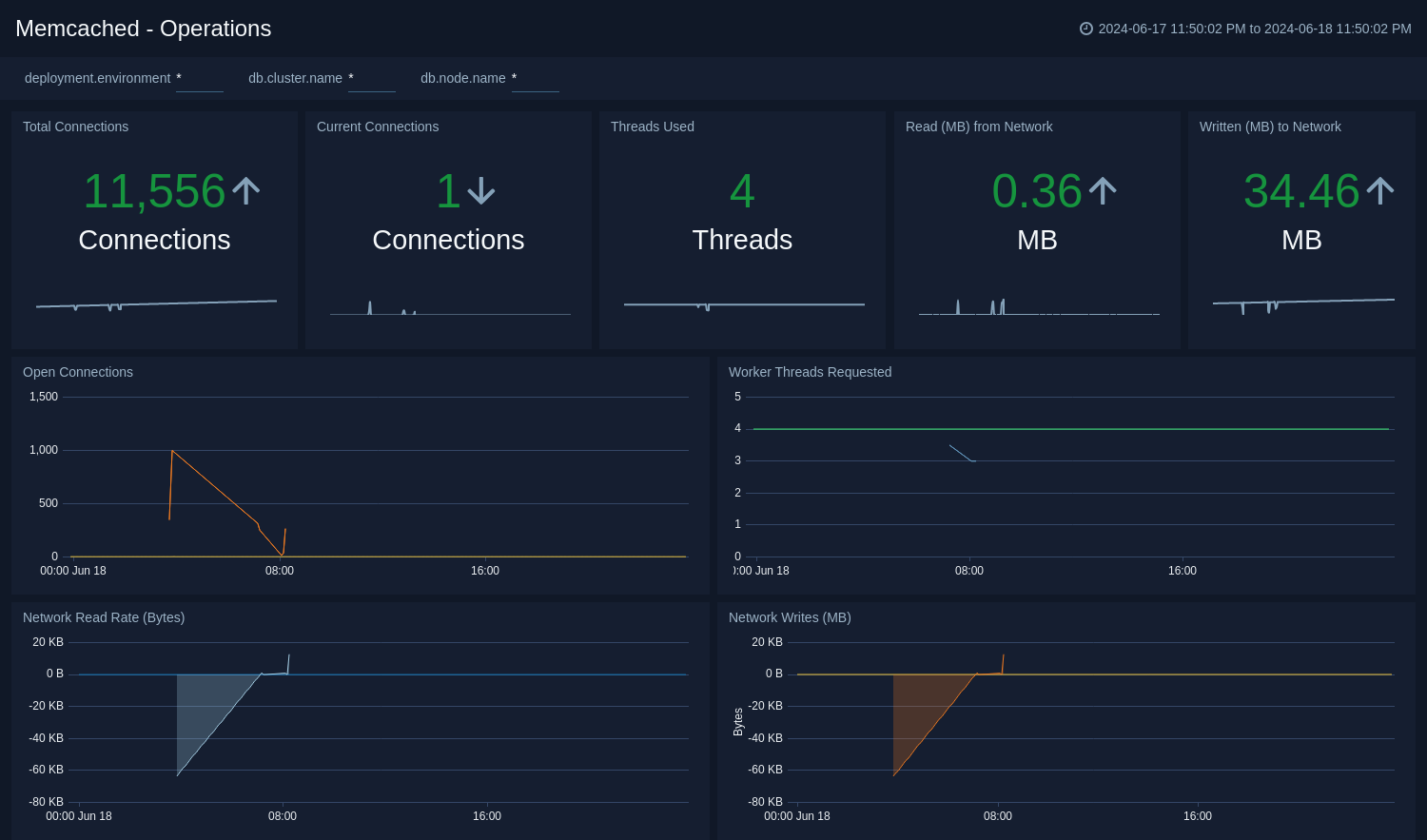
-The **Memcached - Operations** Dashboard provides detailed analysis on connections, thread requested, network bytes, table size.
+The **Memcached - Operations** Dashboard provides detailed analysis on connections, thread requested, network bytes, and table size.
+:::info
+This app includes [built-in monitors](#memcached-alerts). For details on creating custom monitors, refer to the [Create monitors for Memcached app](#create-monitors-for-memcached-app).
+:::
+
## Fields creation in Sumo Logic for Memcached
Following are the [Fields](/docs/manage/fields/) which will be created as part of Memcached App install if not already present.
- **`sumo.datasource`**. Has a fixed value of **memcached**.
-- **`db.system`**. Has a fixed value of **memcached**
-- **`deployment.environment`**. User configured. This is the deployment environment where the Memcache cluster resides. For example: dev, prod or qa.
+- **`db.system`**. Has a fixed value of **memcached**.
+- **`deployment.environment`**. User configured. This is the deployment environment where the Memcache cluster resides. For example: dev, prod, or qa.
- **`db.cluster.name`**. User configured. Enter a name to identify this Memcached cluster. This cluster name will be shown in the Sumo Logic dashboards.
- **`db.node.name`**. This has value of the FQDN of the machine where OpenTelemetry collector is collecting logs and metrics from.
-
## Prerequisites
1. Configure logging in Memcached: By default, the installation of Memcached will not write any request logs to disk. To add a log file for Memcached, you can use the following syntax:
@@ -221,13 +224,12 @@ Following is the query from Errors panel of Memcached app's overview Dashboard:
| sum(ERROR) as ERROR by _timeslice
```
## Sample metrics queries
-**Total Get**
-```
+```sql title="Total Get"
sumo.datasource=memcached deployment.environment=* db.cluster.name=* db.node.name=* metric=memcached.commands command=get | sum
```
-## Viewing Memcached Dashboards
+## Viewing the Memcached dashboards
### Overview
@@ -237,7 +239,7 @@ The **Memcached - Overview** dashboard provides an at-a-glance view of the Memca
### Operations
-The **Memcached - Operations** Dashboard provides detailed analysis on connections, thread requested, network bytes, table size.
+The **Memcached - Operations** Dashboard provides detailed analysis on connections, thread requested, network bytes, and table size.
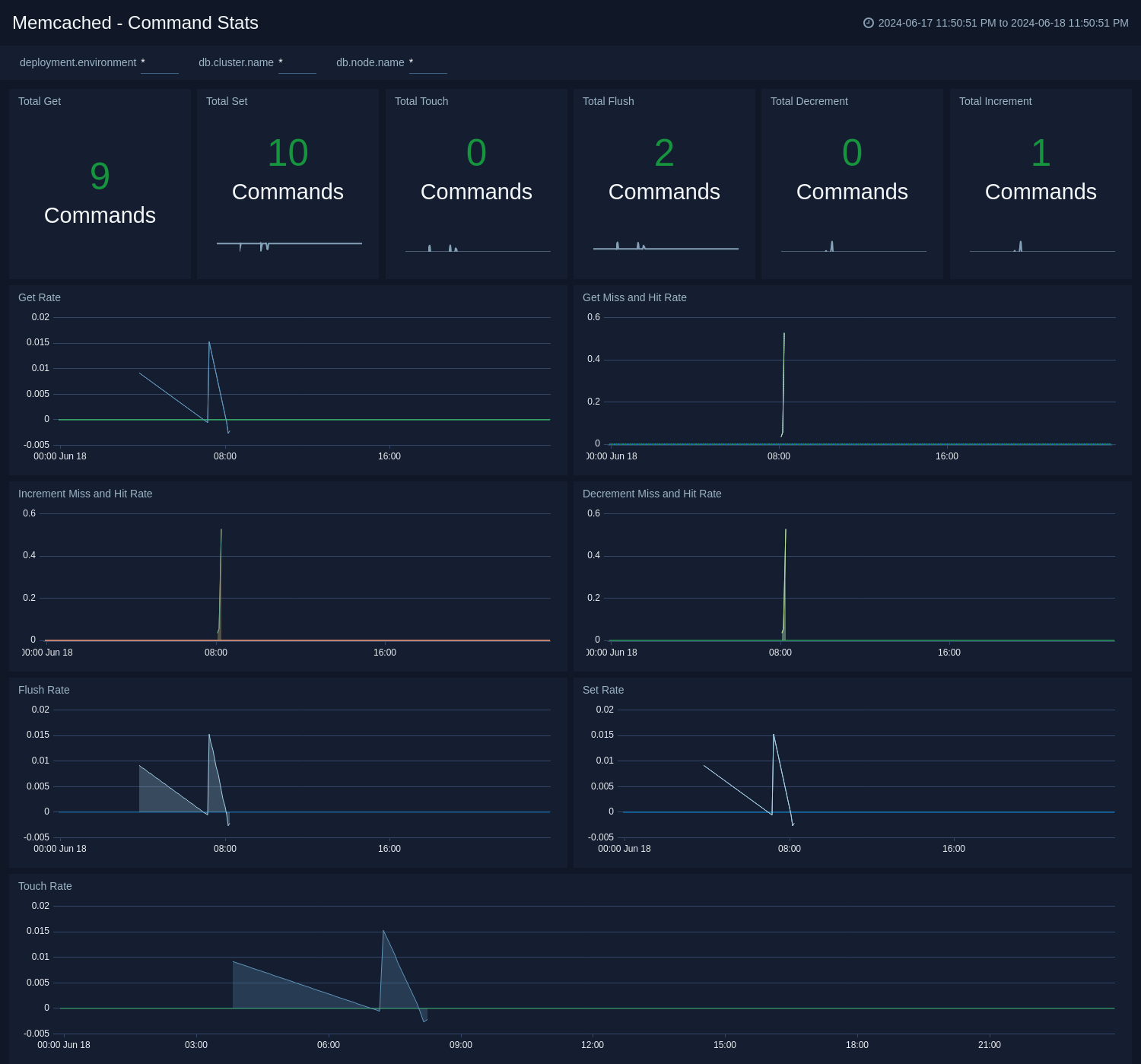
 @@ -247,7 +249,6 @@ The **Memcached - Command Stats** dashboard provides detailed insights into the
@@ -247,7 +249,6 @@ The **Memcached - Command Stats** dashboard provides detailed insights into the
 -
### Cache Information
The **Memcached - Cache Information** dashboard provides insight into cache states, cache hit, and miss rate over time.
@@ -258,4 +259,21 @@ The **Memcached - Cache Information** dashboard provides insight into cache stat
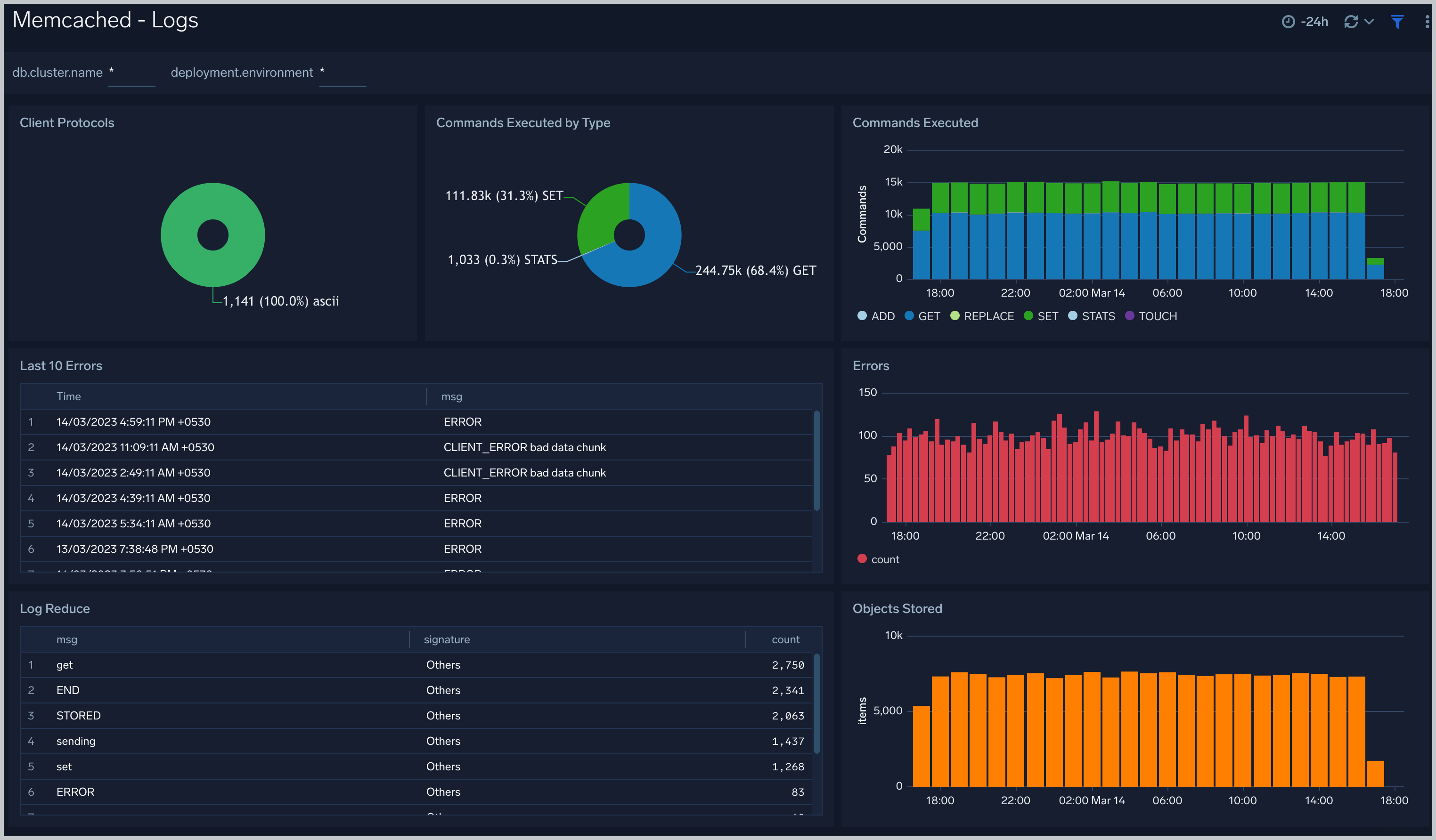
The **Memcached - Logs** dashboard helps you quickly analyze your Memcached error logs, commands executed, and objects stored.
-
-
### Cache Information
The **Memcached - Cache Information** dashboard provides insight into cache states, cache hit, and miss rate over time.
@@ -258,4 +259,21 @@ The **Memcached - Cache Information** dashboard provides insight into cache stat
The **Memcached - Logs** dashboard helps you quickly analyze your Memcached error logs, commands executed, and objects stored.
- \ No newline at end of file
+
+
+
+## Create monitors for Memcached app
+
+import CreateMonitors from '../../../reuse/apps/create-monitors.md';
+
+
+
+### Memcached alerts
+
+| Name | Description | Alert Condition | Recover Condition |
+|:--|:--|:--|:--|
+| `Memcached - Cache Hit Ratio` | This alert is triggered when low cache hit ratio is less than 50%. The hit rate is one of the most important indicators of Memcached performance. A high hit rate means faster responses to your users. If the hit rate is falling, you need quick visibility into why. | Count < = 50% | Count > 50% |
+| `Memcached - Commands Error` | This alert is triggered when Memcached has error commands. | Count > 0 | Count < = 0 |
+| `Memcached - Current Connections` | This alert is triggered when current connections to Memcached are zero. | Count < = 0 | Count > 0 |
+| `Memcached - High Memory Usage` | This alert is triggered when the Memcached exceed given threshold memory usage (in GB). | Count > 5 | Count < = 5 |
+| `Memcached - High Number of Connections` | This alert is triggered when the number of current connection for Memcached exceed given threshold. | Count > = 1000 | Count < 1000 |
diff --git a/docs/integrations/databases/opentelemetry/mongodb-opentelemetry.md b/docs/integrations/databases/opentelemetry/mongodb-opentelemetry.md
index 6102111565..c1f85d3c94 100644
--- a/docs/integrations/databases/opentelemetry/mongodb-opentelemetry.md
+++ b/docs/integrations/databases/opentelemetry/mongodb-opentelemetry.md
@@ -23,13 +23,17 @@ This app supports logs and metrics for MongoDB instance. The MongoDB logs are ge
The app supports metrics generated by the [MongoDB Receiver](https://github.com/open-telemetry/opentelemetry-collector-contrib/blob/main/receiver/mongodbreceiver/documentation.md).
+:::info
+This app includes [built-in monitors](#mongodb-alerts). For details on creating custom monitors, refer to the [Create monitors for MongoDB app](#create-monitors-for-mongodb-app).
+:::
+
## Fields creation in Sumo Logic for MongoDB
Following are the [Fields](/docs/manage/fields/) which will be created as part of MongoDB App install if not already present.
- **`db.cluster.name`**. User configured. Enter a name to identify this MongoDb cluster. This cluster name will be shown in the Sumo Logic dashboards.
- **`db.system`**. Has fixed value of **mongodb**.
-- **`deployment.environment`**. User configured. This is the deployment environment where the Mongodb cluster resides. For example: dev, prod or qa.
+- **`deployment.environment`**. User configured. This is the deployment environment where the Mongodb cluster resides. For example: dev, prod, or qa.
- **`sumo.datasource`**. has a fixed value of **mongodb**.
* **`db.node.name`**. Has the value of host name of the machine which is being monitored.
@@ -238,7 +242,7 @@ deployment.environment=* db.cluster.name=* sumo.datasource=mongodb | json "log
| count by component
```
-## Viewing MongoDB dashboards
+## Viewing the MongoDB dashboards
import ViewDashboards from '../../../reuse/apps/view-dashboards.md';
@@ -258,11 +262,7 @@ Use this dashboard to:
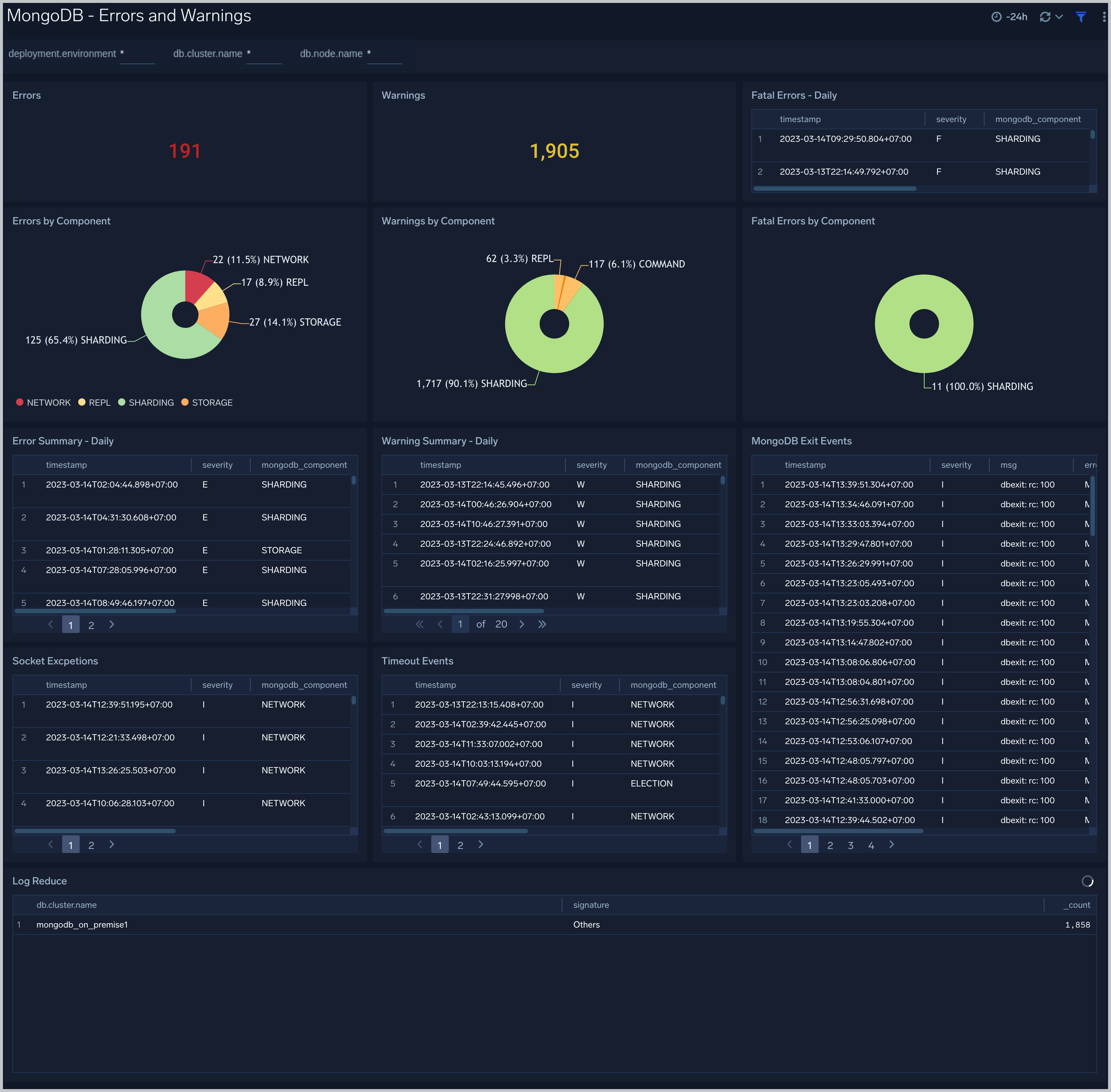
### Errors and Warnings
-The **MongoDB - Errors and Warnings** dashboard shows errors and warnings by the MongoDB component.
-
-Use this dashboard to:
-
-- Determine components producing multiple errors or warnings.
+The **MongoDB - Errors and Warnings** dashboard shows errors and warnings by the MongoDB component. Use this dashboard to determine the components producing multiple errors or warnings.
\ No newline at end of file
+
+
+
+## Create monitors for Memcached app
+
+import CreateMonitors from '../../../reuse/apps/create-monitors.md';
+
+
+
+### Memcached alerts
+
+| Name | Description | Alert Condition | Recover Condition |
+|:--|:--|:--|:--|
+| `Memcached - Cache Hit Ratio` | This alert is triggered when low cache hit ratio is less than 50%. The hit rate is one of the most important indicators of Memcached performance. A high hit rate means faster responses to your users. If the hit rate is falling, you need quick visibility into why. | Count < = 50% | Count > 50% |
+| `Memcached - Commands Error` | This alert is triggered when Memcached has error commands. | Count > 0 | Count < = 0 |
+| `Memcached - Current Connections` | This alert is triggered when current connections to Memcached are zero. | Count < = 0 | Count > 0 |
+| `Memcached - High Memory Usage` | This alert is triggered when the Memcached exceed given threshold memory usage (in GB). | Count > 5 | Count < = 5 |
+| `Memcached - High Number of Connections` | This alert is triggered when the number of current connection for Memcached exceed given threshold. | Count > = 1000 | Count < 1000 |
diff --git a/docs/integrations/databases/opentelemetry/mongodb-opentelemetry.md b/docs/integrations/databases/opentelemetry/mongodb-opentelemetry.md
index 6102111565..c1f85d3c94 100644
--- a/docs/integrations/databases/opentelemetry/mongodb-opentelemetry.md
+++ b/docs/integrations/databases/opentelemetry/mongodb-opentelemetry.md
@@ -23,13 +23,17 @@ This app supports logs and metrics for MongoDB instance. The MongoDB logs are ge
The app supports metrics generated by the [MongoDB Receiver](https://github.com/open-telemetry/opentelemetry-collector-contrib/blob/main/receiver/mongodbreceiver/documentation.md).
+:::info
+This app includes [built-in monitors](#mongodb-alerts). For details on creating custom monitors, refer to the [Create monitors for MongoDB app](#create-monitors-for-mongodb-app).
+:::
+
## Fields creation in Sumo Logic for MongoDB
Following are the [Fields](/docs/manage/fields/) which will be created as part of MongoDB App install if not already present.
- **`db.cluster.name`**. User configured. Enter a name to identify this MongoDb cluster. This cluster name will be shown in the Sumo Logic dashboards.
- **`db.system`**. Has fixed value of **mongodb**.
-- **`deployment.environment`**. User configured. This is the deployment environment where the Mongodb cluster resides. For example: dev, prod or qa.
+- **`deployment.environment`**. User configured. This is the deployment environment where the Mongodb cluster resides. For example: dev, prod, or qa.
- **`sumo.datasource`**. has a fixed value of **mongodb**.
* **`db.node.name`**. Has the value of host name of the machine which is being monitored.
@@ -238,7 +242,7 @@ deployment.environment=* db.cluster.name=* sumo.datasource=mongodb | json "log
| count by component
```
-## Viewing MongoDB dashboards
+## Viewing the MongoDB dashboards
import ViewDashboards from '../../../reuse/apps/view-dashboards.md';
@@ -258,11 +262,7 @@ Use this dashboard to:
### Errors and Warnings
-The **MongoDB - Errors and Warnings** dashboard shows errors and warnings by the MongoDB component.
-
-Use this dashboard to:
-
-- Determine components producing multiple errors or warnings.
+The **MongoDB - Errors and Warnings** dashboard shows errors and warnings by the MongoDB component. Use this dashboard to determine the components producing multiple errors or warnings.
 @@ -339,3 +339,27 @@ Use this dashboard to:
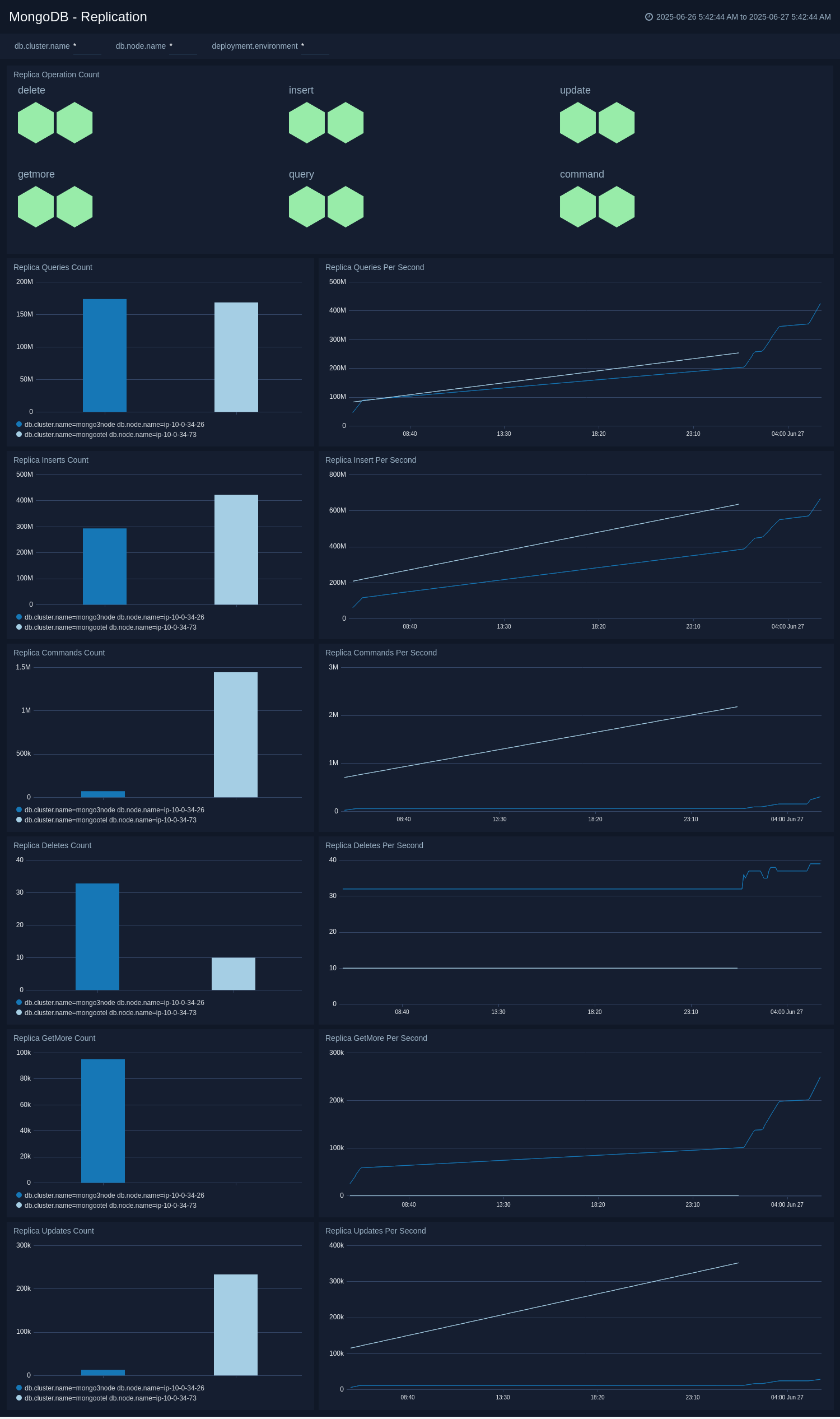
* Operation count like query, insert, and delete.
@@ -339,3 +339,27 @@ Use this dashboard to:
* Operation count like query, insert, and delete.
 +
+
+## Create monitors for MongoDB app
+
+import CreateMonitors from '../../../reuse/apps/create-monitors.md';
+
+
+
+### MongoDB alerts
+
+| Name | Description | Alert Condition | Recover Condition |
+|:--|:--|:--|:--|
+| `MongoDB - Instance Down` | This alert is triggered when we detect that the MongoDB instance is down. | Missing Data | Data Found |
+| `MongoDB - Replication Error` | This alert is triggered when we detect errors in MongoDB replication operations. | Count > 0 | Count < = 0 |
+| `MongoDB - Replication Heartbeat Error` | This alert is triggered when we detect that the MongoDB Replication Heartbeat request has errors, which indicates replication is not working as expected. | Count > 0 | Count < = 0 |
+| `MongoDB - Secondary Node Replication Failure` | This alert is triggered when we detect that a MongoDB secondary node is out of sync for replication. | Count > 0 | Count < = 0 |
+| `MongoDB - Sharding Balancer Failure` | This alert is triggered when we detect that data balancing failed on a MongoDB Cluster with 1 mongos instance and 3 mongod instances. | Count > 0 | Count < = 0 |
+| `MongoDB - Sharding Chunk Split Failure` | This alert is triggered when we detect that a MongoDB chunk not been split during sharding. | Count > 0 | Count < = 0 |
+| `MongoDB - Sharding Error` | This alert is triggered when we detect errors in MongoDB sharding operations. | Count > 0 | Count < = 0 |
+| `MongoDB - Sharding Warning` | This alert is triggered when we detect warnings in MongoDB sharding operations. | Count > 0 | Count < = 0 |
+| `MongoDB - Slow Queries` | This alert is triggered when we detect that a MongoDB cluster is executing slow queries. | Count > 0 | Count < = 0 |
+| `MongoDB - Too Many Connections` | This alert is triggered when we detect a given MongoDB server has too many connections (over 80% of capacity). | Count > = 80% | Count < 80% |
+| `MongoDB - Too Many Cursors Open` | This alert is triggered when we detect that there are too many cursors (>10K) opened by MongoDB. | Count > = 10000 | Count < 10000 |
+| `MongoDB - Too Many Cursors Timeouts` | This alert is triggered when we detect that there are too many cursors (100) timing out on a MongoDB server within a 5 minute time interval. | Count > = 100 | Count < 100 |
diff --git a/docs/integrations/databases/opentelemetry/redis-opentelemetry.md b/docs/integrations/databases/opentelemetry/redis-opentelemetry.md
index 84b7d5e6d5..64eac0af57 100644
--- a/docs/integrations/databases/opentelemetry/redis-opentelemetry.md
+++ b/docs/integrations/databases/opentelemetry/redis-opentelemetry.md
@@ -25,13 +25,17 @@ This app supports metrics and logs for Redis in Cluster mode or Standalone mode.
The app supports metrics generated by the [Redis Receiver](https://github.com/open-telemetry/opentelemetry-collector-contrib/blob/main/receiver/redisreceiver/documentation.md).
+:::info
+This app includes [built-in monitors](#redis-alerts). For details on creating custom monitors, refer to the [Create monitors for Redis app](#create-monitors-for-redis-app).
+:::
+
## Creating fields in Sumo Logic for Redis
The following are [fields](/docs/manage/fields/) that will be created as part of the Redis App install if not already present.
* **`db.cluster.name`**. User configured. Enter a name to identify this Redis cluster. This cluster name will be shown in the Sumo Logic dashboards.
* **`db.system`**. Has fixed value of redis.
-* **`deployment.environment`**. User configured. This is the deployment environment where the Redis cluster resides. For example: dev, prod or qa.
+* **`deployment.environment`**. User configured. This is the deployment environment where the Redis cluster resides. For example: dev, prod, or qa.
* **`db.node.name`**. Has the value of host name of the machine which is being monitored.
* **`sumo.datasource`**. Has fixed value of redis.
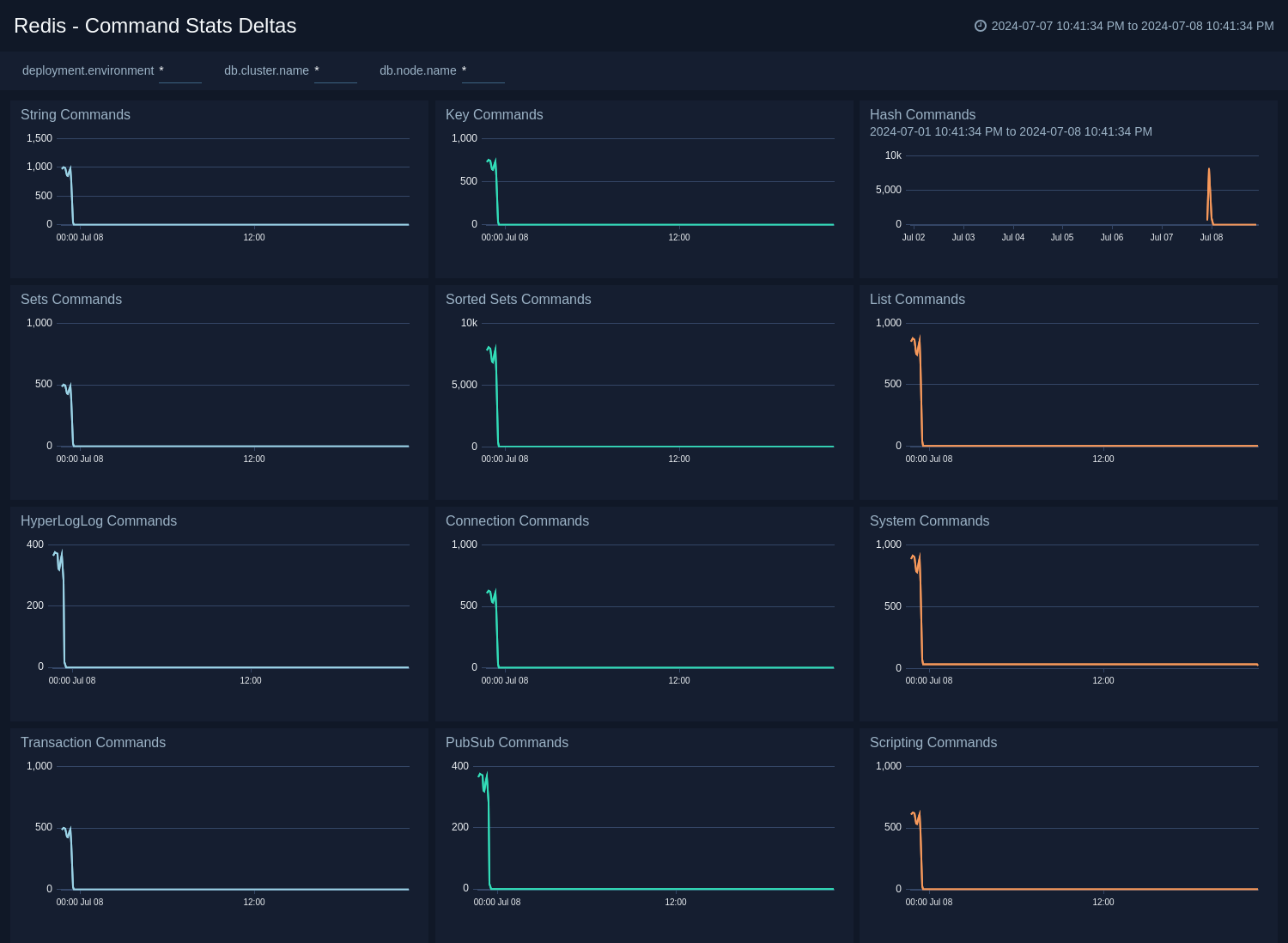
@@ -243,3 +247,19 @@ Use this dashboard to review String Commands, Key Commands, Hash Commands, Sets
+
+
+## Create monitors for MongoDB app
+
+import CreateMonitors from '../../../reuse/apps/create-monitors.md';
+
+
+
+### MongoDB alerts
+
+| Name | Description | Alert Condition | Recover Condition |
+|:--|:--|:--|:--|
+| `MongoDB - Instance Down` | This alert is triggered when we detect that the MongoDB instance is down. | Missing Data | Data Found |
+| `MongoDB - Replication Error` | This alert is triggered when we detect errors in MongoDB replication operations. | Count > 0 | Count < = 0 |
+| `MongoDB - Replication Heartbeat Error` | This alert is triggered when we detect that the MongoDB Replication Heartbeat request has errors, which indicates replication is not working as expected. | Count > 0 | Count < = 0 |
+| `MongoDB - Secondary Node Replication Failure` | This alert is triggered when we detect that a MongoDB secondary node is out of sync for replication. | Count > 0 | Count < = 0 |
+| `MongoDB - Sharding Balancer Failure` | This alert is triggered when we detect that data balancing failed on a MongoDB Cluster with 1 mongos instance and 3 mongod instances. | Count > 0 | Count < = 0 |
+| `MongoDB - Sharding Chunk Split Failure` | This alert is triggered when we detect that a MongoDB chunk not been split during sharding. | Count > 0 | Count < = 0 |
+| `MongoDB - Sharding Error` | This alert is triggered when we detect errors in MongoDB sharding operations. | Count > 0 | Count < = 0 |
+| `MongoDB - Sharding Warning` | This alert is triggered when we detect warnings in MongoDB sharding operations. | Count > 0 | Count < = 0 |
+| `MongoDB - Slow Queries` | This alert is triggered when we detect that a MongoDB cluster is executing slow queries. | Count > 0 | Count < = 0 |
+| `MongoDB - Too Many Connections` | This alert is triggered when we detect a given MongoDB server has too many connections (over 80% of capacity). | Count > = 80% | Count < 80% |
+| `MongoDB - Too Many Cursors Open` | This alert is triggered when we detect that there are too many cursors (>10K) opened by MongoDB. | Count > = 10000 | Count < 10000 |
+| `MongoDB - Too Many Cursors Timeouts` | This alert is triggered when we detect that there are too many cursors (100) timing out on a MongoDB server within a 5 minute time interval. | Count > = 100 | Count < 100 |
diff --git a/docs/integrations/databases/opentelemetry/redis-opentelemetry.md b/docs/integrations/databases/opentelemetry/redis-opentelemetry.md
index 84b7d5e6d5..64eac0af57 100644
--- a/docs/integrations/databases/opentelemetry/redis-opentelemetry.md
+++ b/docs/integrations/databases/opentelemetry/redis-opentelemetry.md
@@ -25,13 +25,17 @@ This app supports metrics and logs for Redis in Cluster mode or Standalone mode.
The app supports metrics generated by the [Redis Receiver](https://github.com/open-telemetry/opentelemetry-collector-contrib/blob/main/receiver/redisreceiver/documentation.md).
+:::info
+This app includes [built-in monitors](#redis-alerts). For details on creating custom monitors, refer to the [Create monitors for Redis app](#create-monitors-for-redis-app).
+:::
+
## Creating fields in Sumo Logic for Redis
The following are [fields](/docs/manage/fields/) that will be created as part of the Redis App install if not already present.
* **`db.cluster.name`**. User configured. Enter a name to identify this Redis cluster. This cluster name will be shown in the Sumo Logic dashboards.
* **`db.system`**. Has fixed value of redis.
-* **`deployment.environment`**. User configured. This is the deployment environment where the Redis cluster resides. For example: dev, prod or qa.
+* **`deployment.environment`**. User configured. This is the deployment environment where the Redis cluster resides. For example: dev, prod, or qa.
* **`db.node.name`**. Has the value of host name of the machine which is being monitored.
* **`sumo.datasource`**. Has fixed value of redis.
@@ -243,3 +247,19 @@ Use this dashboard to review String Commands, Key Commands, Hash Commands, Sets
 +## Create monitors for Redis app
+
+import CreateMonitors from '../../../reuse/apps/create-monitors.md';
+
+
+
+### Redis alerts
+
+| Name | Description | Alert Condition | Recover Condition |
+|:--|:--|:--|:--|
+| `Redis - High Memory Fragmentation Ratio` | This alert is triggered when the ratio of Redis memory usage to Linux virtual memory pages (mapped to physical memory chunks) is higher than 1.5. A high ratio will lead to swapping and can adversely affect performance. | Count > 1.5 | Count < = 1.5 |
+| `Redis - Instance Down` | This alert is triggered if the Redis instance is down for 5 minutes. | Missing Data | Data Found |
+| `Redis - Rejected Connections` | This alert is triggered when some connections to a Redis cluster have been rejected. | Count > 0 | Count < = 0 |
+| `Redis - Replication Broken` | This alert is triggered when a Redis instance has lost all slaves. This will affect the redundancy of data stored in Redis. We suggest you to review how replication has been configured. | Count < 1 | Count > = 1 |
+| `Redis - Replication Offset` | This alert is triggered when the replication offset in a given Redis cluster is greater than 1 MB for last 5 minutes. We suggest you to review how replication has been configured. | Count > = 1 | Count < 1 |
+| `Redis - Too Many Connections` | This alert is triggered when a given Redis server has too many connections (default is 100). | Count > 100 | Count < = 100 |
diff --git a/docs/integrations/web-servers/opentelemetry/haproxy-opentelemetry.md b/docs/integrations/web-servers/opentelemetry/haproxy-opentelemetry.md
index 24c5df3504..cba874ef1c 100644
--- a/docs/integrations/web-servers/opentelemetry/haproxy-opentelemetry.md
+++ b/docs/integrations/web-servers/opentelemetry/haproxy-opentelemetry.md
@@ -19,10 +19,14 @@ The OpenTelemetry collector runs on the same host as HAProxy, where it uses the
## HAProxy log types
-The app supports Logs from the open source version of HAProxy. The App is tested on the 2.3.9 version of HAProxy.
+The app supports logs from the open source version of HAProxy. This app is tested on the `2.3.9` version of HAProxy.
The HAProxy logs are generated in files as configured in the configuration file `/etc/haproxy/haproxy.cfg` ([learn more](https://www.haproxy.com/blog/introduction-to-haproxy-logging/)).
+:::info
+This app includes [built-in monitors](#haproxy-alerts). For details on creating custom monitors, refer to the [Create monitors for HAProxy app](#create-monitors-for-haproxy-app).
+:::
+
## Fields Create in Sumo Logic for HAProxy
Following are the [Fields](/docs/manage/fields/) which will be created as part of HAProxy App install if not already present.
@@ -185,6 +189,24 @@ May 13 08:24:43 localhost haproxy[21813]:
27.2.81.92:64274 [13/May/2021:08:24:43.921] web-edupia.vn-4
```
+## Sample metrics
+
+```json
+{
+ "Query": "A",
+ "metric": "avg",
+ "haproxy.proxy_name": "stats",
+ "webengine.cluster.name": "haproxy_otel_cluster",
+ "webengine.node.name": "node1",
+ "min": 3385124.8,
+ "max": 3553632,
+ "latest": 3553632,
+ "avg": 3469494.86851211,
+ "sum": 1002684017.0,
+ "count": 289,
+}
+```
+
## Sample queries
### Logs
@@ -220,25 +242,7 @@ sumo.datasource=haproxy metric=haproxy.requests.total status_code=* haproxy.serv
| avg by webengine.cluster.name,webengine.node.name,haproxy.proxy_name,code
```
-## Sample metrics
-
-```json
-{
- "Query": "A",
- "metric": "avg",
- "haproxy.proxy_name": "stats",
- "webengine.cluster.name": "haproxy_otel_cluster",
- "webengine.node.name": "node1",
- "min": 3385124.8,
- "max": 3553632,
- "latest": 3553632,
- "avg": 3469494.86851211,
- "sum": 1002684017.0,
- "count": 289,
-}
-```
-
-## Viewing HAProxy dashboards
+## Viewing the HAProxy dashboards
### Overview
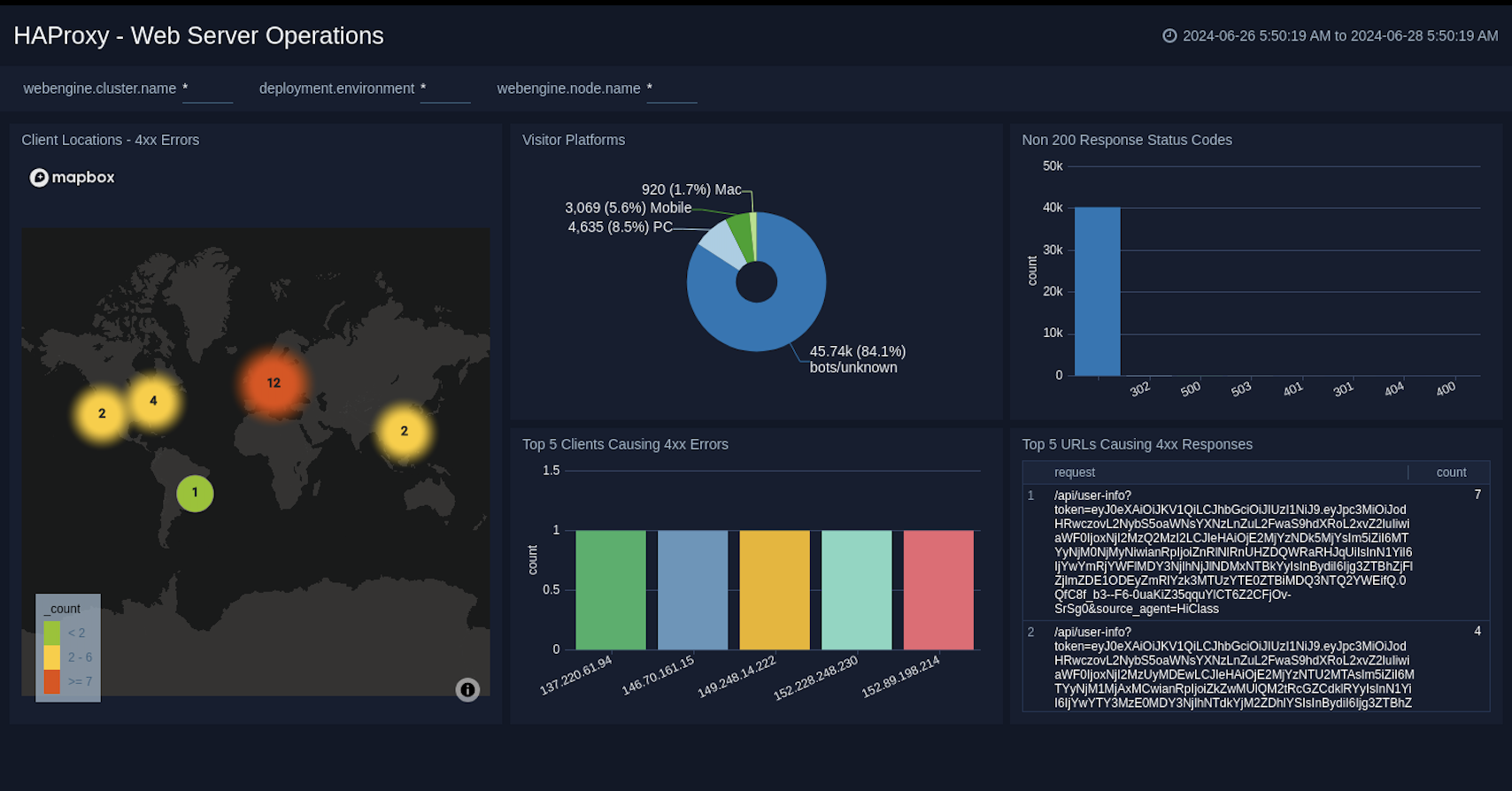
@@ -348,4 +352,21 @@ Use this dashboard to:
- Gain insights into Client, Server Responses on HAProxy Server. This helps you identify errors in HAProxy Server.
- To identify geo locations of all Client errors. This helps you identify client location causing errors and helps you to block client IPs.
-
+## Create monitors for Redis app
+
+import CreateMonitors from '../../../reuse/apps/create-monitors.md';
+
+
+
+### Redis alerts
+
+| Name | Description | Alert Condition | Recover Condition |
+|:--|:--|:--|:--|
+| `Redis - High Memory Fragmentation Ratio` | This alert is triggered when the ratio of Redis memory usage to Linux virtual memory pages (mapped to physical memory chunks) is higher than 1.5. A high ratio will lead to swapping and can adversely affect performance. | Count > 1.5 | Count < = 1.5 |
+| `Redis - Instance Down` | This alert is triggered if the Redis instance is down for 5 minutes. | Missing Data | Data Found |
+| `Redis - Rejected Connections` | This alert is triggered when some connections to a Redis cluster have been rejected. | Count > 0 | Count < = 0 |
+| `Redis - Replication Broken` | This alert is triggered when a Redis instance has lost all slaves. This will affect the redundancy of data stored in Redis. We suggest you to review how replication has been configured. | Count < 1 | Count > = 1 |
+| `Redis - Replication Offset` | This alert is triggered when the replication offset in a given Redis cluster is greater than 1 MB for last 5 minutes. We suggest you to review how replication has been configured. | Count > = 1 | Count < 1 |
+| `Redis - Too Many Connections` | This alert is triggered when a given Redis server has too many connections (default is 100). | Count > 100 | Count < = 100 |
diff --git a/docs/integrations/web-servers/opentelemetry/haproxy-opentelemetry.md b/docs/integrations/web-servers/opentelemetry/haproxy-opentelemetry.md
index 24c5df3504..cba874ef1c 100644
--- a/docs/integrations/web-servers/opentelemetry/haproxy-opentelemetry.md
+++ b/docs/integrations/web-servers/opentelemetry/haproxy-opentelemetry.md
@@ -19,10 +19,14 @@ The OpenTelemetry collector runs on the same host as HAProxy, where it uses the
## HAProxy log types
-The app supports Logs from the open source version of HAProxy. The App is tested on the 2.3.9 version of HAProxy.
+The app supports logs from the open source version of HAProxy. This app is tested on the `2.3.9` version of HAProxy.
The HAProxy logs are generated in files as configured in the configuration file `/etc/haproxy/haproxy.cfg` ([learn more](https://www.haproxy.com/blog/introduction-to-haproxy-logging/)).
+:::info
+This app includes [built-in monitors](#haproxy-alerts). For details on creating custom monitors, refer to the [Create monitors for HAProxy app](#create-monitors-for-haproxy-app).
+:::
+
## Fields Create in Sumo Logic for HAProxy
Following are the [Fields](/docs/manage/fields/) which will be created as part of HAProxy App install if not already present.
@@ -185,6 +189,24 @@ May 13 08:24:43 localhost haproxy[21813]:
27.2.81.92:64274 [13/May/2021:08:24:43.921] web-edupia.vn-4
```
+## Sample metrics
+
+```json
+{
+ "Query": "A",
+ "metric": "avg",
+ "haproxy.proxy_name": "stats",
+ "webengine.cluster.name": "haproxy_otel_cluster",
+ "webengine.node.name": "node1",
+ "min": 3385124.8,
+ "max": 3553632,
+ "latest": 3553632,
+ "avg": 3469494.86851211,
+ "sum": 1002684017.0,
+ "count": 289,
+}
+```
+
## Sample queries
### Logs
@@ -220,25 +242,7 @@ sumo.datasource=haproxy metric=haproxy.requests.total status_code=* haproxy.serv
| avg by webengine.cluster.name,webengine.node.name,haproxy.proxy_name,code
```
-## Sample metrics
-
-```json
-{
- "Query": "A",
- "metric": "avg",
- "haproxy.proxy_name": "stats",
- "webengine.cluster.name": "haproxy_otel_cluster",
- "webengine.node.name": "node1",
- "min": 3385124.8,
- "max": 3553632,
- "latest": 3553632,
- "avg": 3469494.86851211,
- "sum": 1002684017.0,
- "count": 289,
-}
-```
-
-## Viewing HAProxy dashboards
+## Viewing the HAProxy dashboards
### Overview
@@ -348,4 +352,21 @@ Use this dashboard to:
- Gain insights into Client, Server Responses on HAProxy Server. This helps you identify errors in HAProxy Server.
- To identify geo locations of all Client errors. This helps you identify client location causing errors and helps you to block client IPs.
- \ No newline at end of file
+
+
+
+## Create monitors for HAProxy app
+
+import CreateMonitors from '../../../reuse/apps/create-monitors.md';
+
+
+
+### HAProxy alerts
+
+| Name | Description | Alert Condition | Recover Condition |
+|:--|:--|:--|:--|
+| `HAProxy - Access from Highly Malicious Sources` | This alert is triggered when an HAProxy is accessed from highly malicious IP addresses. | Count > 0 | Count < = 0 |
+| `HAProxy - Backend Error` | This alert is triggered when backend server error is detected. | Count > 0 | Count < = 0 |
+| `HAProxy - Backend Server Down` | This alert is triggered when a backend server for a given HAProxy server is down. | Count > 0 | Count < = 0 |
+| `HAProxy - High Client (HTTP 4xx) Error Rate` | This alert is triggered when there are too many HTTP requests (>5%) with a response status of 4xx. | Count > 0 | Count < = 0 |
+| `HAProxy - High Server (HTTP 5xx) Error Rate` | This alert fires when there are too many HTTP requests (>5%) with a response status of 5xx. | Count > 0 | Count < = 0 |
\ No newline at end of file
+
+
+
+## Create monitors for HAProxy app
+
+import CreateMonitors from '../../../reuse/apps/create-monitors.md';
+
+
+
+### HAProxy alerts
+
+| Name | Description | Alert Condition | Recover Condition |
+|:--|:--|:--|:--|
+| `HAProxy - Access from Highly Malicious Sources` | This alert is triggered when an HAProxy is accessed from highly malicious IP addresses. | Count > 0 | Count < = 0 |
+| `HAProxy - Backend Error` | This alert is triggered when backend server error is detected. | Count > 0 | Count < = 0 |
+| `HAProxy - Backend Server Down` | This alert is triggered when a backend server for a given HAProxy server is down. | Count > 0 | Count < = 0 |
+| `HAProxy - High Client (HTTP 4xx) Error Rate` | This alert is triggered when there are too many HTTP requests (>5%) with a response status of 4xx. | Count > 0 | Count < = 0 |
+| `HAProxy - High Server (HTTP 5xx) Error Rate` | This alert fires when there are too many HTTP requests (>5%) with a response status of 5xx. | Count > 0 | Count < = 0 |