converter = something::startsWith;
+String converted = converter.convert("Java");
+System.out.println(converted); // "J"
+```
+
+接下来看看构造函数是如何使用`::`关键字来引用的,首先我们定义一个包含多个构造函数的简单类:
+
+```java
+class Person {
+ String firstName;
+ String lastName;
+
+ Person() {}
+
+ Person(String firstName, String lastName) {
+ this.firstName = firstName;
+ this.lastName = lastName;
+ }
+}
+```
+接下来我们指定一个用来创建Person对象的对象工厂接口:
+
+```java
+interface PersonFactory {
+ P create(String firstName, String lastName);
+}
+```
+
+这里我们使用构造函数引用来将他们关联起来,而不是手动实现一个完整的工厂:
+
+```java
+PersonFactory personFactory = Person::new;
+Person person = personFactory.create("Peter", "Parker");
+```
+我们只需要使用 `Person::new` 来获取Person类构造函数的引用,Java编译器会自动根据`PersonFactory.create`方法的参数类型来选择合适的构造函数。
+
+### Lamda 表达式作用域(Lambda Scopes)
+
+#### 访问局部变量
+
+我们可以直接在 lambda 表达式中访问外部的局部变量:
+
+```java
+final int num = 1;
+Converter stringConverter =
+ (from) -> String.valueOf(from + num);
+
+stringConverter.convert(2); // 3
+```
+
+但是和匿名对象不同的是,这里的变量num可以不用声明为final,该代码同样正确:
+
+```java
+int num = 1;
+Converter stringConverter =
+ (from) -> String.valueOf(from + num);
+
+stringConverter.convert(2); // 3
+```
+
+不过这里的 num 必须不可被后面的代码修改(即隐性的具有final的语义),例如下面的就无法编译:
+
+```java
+int num = 1;
+Converter stringConverter =
+ (from) -> String.valueOf(from + num);
+num = 3;//在lambda表达式中试图修改num同样是不允许的。
+```
+
+#### 访问字段和静态变量
+
+与局部变量相比,我们对lambda表达式中的实例字段和静态变量都有读写访问权限。 该行为和匿名对象是一致的。
+
+```java
+class Lambda4 {
+ static int outerStaticNum;
+ int outerNum;
+
+ void testScopes() {
+ Converter stringConverter1 = (from) -> {
+ outerNum = 23;
+ return String.valueOf(from);
+ };
+
+ Converter stringConverter2 = (from) -> {
+ outerStaticNum = 72;
+ return String.valueOf(from);
+ };
+ }
+}
+```
+
+#### 访问默认接口方法
+
+还记得第一节中的 formula 示例吗? `Formula` 接口定义了一个默认方法`sqrt`,可以从包含匿名对象的每个 formula 实例访问该方法。 这不适用于lambda表达式。
+
+无法从 lambda 表达式中访问默认方法,故以下代码无法编译:
+
+```java
+Formula formula = (a) -> sqrt(a * 100);
+```
+
+### 内置函数式接口(Built-in Functional Interfaces)
+
+JDK 1.8 API包含许多内置函数式接口。 其中一些借口在老版本的 Java 中是比较常见的比如: `Comparator` 或`Runnable`,这些接口都增加了`@FunctionalInterface`注解以便能用在 lambda 表达式上。
+
+但是 Java 8 API 同样还提供了很多全新的函数式接口来让你的编程工作更加方便,有一些接口是来自 [Google Guava](https://code.google.com/p/guava-libraries/) 库里的,即便你对这些很熟悉了,还是有必要看看这些是如何扩展到lambda上使用的。
+
+#### Predicates
+
+Predicate 接口是只有一个参数的返回布尔类型值的 **断言型** 接口。该接口包含多种默认方法来将 Predicate 组合成其他复杂的逻辑(比如:与,或,非):
+
+**译者注:** Predicate 接口源码如下
+
+```java
+package java.util.function;
+import java.util.Objects;
+
+@FunctionalInterface
+public interface Predicate {
+
+ // 该方法是接受一个传入类型,返回一个布尔值.此方法应用于判断.
+ boolean test(T t);
+
+ //and方法与关系型运算符"&&"相似,两边都成立才返回true
+ default Predicate and(Predicate other) {
+ Objects.requireNonNull(other);
+ return (t) -> test(t) && other.test(t);
+ }
+ // 与关系运算符"!"相似,对判断进行取反
+ default Predicate negate() {
+ return (t) -> !test(t);
+ }
+ //or方法与关系型运算符"||"相似,两边只要有一个成立就返回true
+ default Predicate or(Predicate other) {
+ Objects.requireNonNull(other);
+ return (t) -> test(t) || other.test(t);
+ }
+ // 该方法接收一个Object对象,返回一个Predicate类型.此方法用于判断第一个test的方法与第二个test方法相同(equal).
+ static Predicate isEqual(Object targetRef) {
+ return (null == targetRef)
+ ? Objects::isNull
+ : object -> targetRef.equals(object);
+ }
+```
+
+示例:
+
+```java
+Predicate predicate = (s) -> s.length() > 0;
+
+predicate.test("foo"); // true
+predicate.negate().test("foo"); // false
+
+Predicate nonNull = Objects::nonNull;
+Predicate isNull = Objects::isNull;
+
+Predicate isEmpty = String::isEmpty;
+Predicate isNotEmpty = isEmpty.negate();
+```
+
+#### Functions
+
+Function 接口接受一个参数并生成结果。默认方法可用于将多个函数链接在一起(compose, andThen):
+
+**译者注:** Function 接口源码如下
+
+```java
+
+package java.util.function;
+
+import java.util.Objects;
+
+@FunctionalInterface
+public interface Function {
+
+ //将Function对象应用到输入的参数上,然后返回计算结果。
+ R apply(T t);
+ //将两个Function整合,并返回一个能够执行两个Function对象功能的Function对象。
+ default Function compose(Function before) {
+ Objects.requireNonNull(before);
+ return (V v) -> apply(before.apply(v));
+ }
+ //
+ default Function andThen(Function after) {
+ Objects.requireNonNull(after);
+ return (T t) -> after.apply(apply(t));
+ }
+
+ static Function identity() {
+ return t -> t;
+ }
+}
+```
+
+
+
+```java
+Function toInteger = Integer::valueOf;
+Function backToString = toInteger.andThen(String::valueOf);
+backToString.apply("123"); // "123"
+```
+
+#### Suppliers
+
+Supplier 接口产生给定泛型类型的结果。 与 Function 接口不同,Supplier 接口不接受参数。
+
+```java
+Supplier personSupplier = Person::new;
+personSupplier.get(); // new Person
+```
+
+#### Consumers
+
+Consumer 接口表示要对单个输入参数执行的操作。
+
+```java
+Consumer greeter = (p) -> System.out.println("Hello, " + p.firstName);
+greeter.accept(new Person("Luke", "Skywalker"));
+```
+
+#### Comparators
+
+Comparator 是老Java中的经典接口, Java 8在此之上添加了多种默认方法:
+
+```java
+Comparator comparator = (p1, p2) -> p1.firstName.compareTo(p2.firstName);
+
+Person p1 = new Person("John", "Doe");
+Person p2 = new Person("Alice", "Wonderland");
+
+comparator.compare(p1, p2); // > 0
+comparator.reversed().compare(p1, p2); // < 0
+```
+
+## Optionals
+
+Optionals不是函数式接口,而是用于防止 NullPointerException 的漂亮工具。这是下一节的一个重要概念,让我们快速了解一下Optionals的工作原理。
+
+Optional 是一个简单的容器,其值可能是null或者不是null。在Java 8之前一般某个函数应该返回非空对象但是有时却什么也没有返回,而在Java 8中,你应该返回 Optional 而不是 null。
+
+译者注:示例中每个方法的作用已经添加。
+
+```java
+//of():为非null的值创建一个Optional
+Optional optional = Optional.of("bam");
+// isPresent(): 如果值存在返回true,否则返回false
+optional.isPresent(); // true
+//get():如果Optional有值则将其返回,否则抛出NoSuchElementException
+optional.get(); // "bam"
+//orElse():如果有值则将其返回,否则返回指定的其它值
+optional.orElse("fallback"); // "bam"
+//ifPresent():如果Optional实例有值则为其调用consumer,否则不做处理
+optional.ifPresent((s) -> System.out.println(s.charAt(0))); // "b"
+```
+
+推荐阅读:[[Java8]如何正确使用Optional](https://blog.kaaass.net/archives/764)
+
+## Streams(流)
+
+`java.util.Stream` 表示能应用在一组元素上一次执行的操作序列。Stream 操作分为中间操作或者最终操作两种,最终操作返回一特定类型的计算结果,而中间操作返回Stream本身,这样你就可以将多个操作依次串起来。Stream 的创建需要指定一个数据源,比如` java.util.Collection` 的子类,List 或者 Set, Map 不支持。Stream 的操作可以串行执行或者并行执行。
+
+首先看看Stream是怎么用,首先创建实例代码的用到的数据List:
+
+```java
+List stringList = new ArrayList<>();
+stringList.add("ddd2");
+stringList.add("aaa2");
+stringList.add("bbb1");
+stringList.add("aaa1");
+stringList.add("bbb3");
+stringList.add("ccc");
+stringList.add("bbb2");
+stringList.add("ddd1");
+```
+
+Java 8扩展了集合类,可以通过 Collection.stream() 或者 Collection.parallelStream() 来创建一个Stream。下面几节将详细解释常用的Stream操作:
+
+### Filter(过滤)
+
+过滤通过一个predicate接口来过滤并只保留符合条件的元素,该操作属于**中间操作**,所以我们可以在过滤后的结果来应用其他Stream操作(比如forEach)。forEach需要一个函数来对过滤后的元素依次执行。forEach是一个最终操作,所以我们不能在forEach之后来执行其他Stream操作。
+
+```java
+ // 测试 Filter(过滤)
+ stringList
+ .stream()
+ .filter((s) -> s.startsWith("a"))
+ .forEach(System.out::println);//aaa2 aaa1
+```
+
+forEach 是为 Lambda 而设计的,保持了最紧凑的风格。而且 Lambda 表达式本身是可以重用的,非常方便。
+
+### Sorted(排序)
+
+排序是一个 **中间操作**,返回的是排序好后的 Stream。**如果你不指定一个自定义的 Comparator 则会使用默认排序。**
+
+```java
+ // 测试 Sort (排序)
+ stringList
+ .stream()
+ .sorted()
+ .filter((s) -> s.startsWith("a"))
+ .forEach(System.out::println);// aaa1 aaa2
+```
+
+需要注意的是,排序只创建了一个排列好后的Stream,而不会影响原有的数据源,排序之后原数据stringCollection是不会被修改的:
+
+```java
+ System.out.println(stringList);// ddd2, aaa2, bbb1, aaa1, bbb3, ccc, bbb2, ddd1
+```
+
+### Map(映射)
+
+中间操作 map 会将元素根据指定的 Function 接口来依次将元素转成另外的对象。
+
+下面的示例展示了将字符串转换为大写字符串。你也可以通过map来将对象转换成其他类型,map返回的Stream类型是根据你map传递进去的函数的返回值决定的。
+
+```java
+ // 测试 Map 操作
+ stringList
+ .stream()
+ .map(String::toUpperCase)
+ .sorted((a, b) -> b.compareTo(a))
+ .forEach(System.out::println);// "DDD2", "DDD1", "CCC", "BBB3", "BBB2", "AAA2", "AAA1"
+```
+
+
+
+### Match(匹配)
+
+Stream提供了多种匹配操作,允许检测指定的Predicate是否匹配整个Stream。所有的匹配操作都是 **最终操作** ,并返回一个 boolean 类型的值。
+
+```java
+ // 测试 Match (匹配)操作
+ boolean anyStartsWithA =
+ stringList
+ .stream()
+ .anyMatch((s) -> s.startsWith("a"));
+ System.out.println(anyStartsWithA); // true
+
+ boolean allStartsWithA =
+ stringList
+ .stream()
+ .allMatch((s) -> s.startsWith("a"));
+
+ System.out.println(allStartsWithA); // false
+
+ boolean noneStartsWithZ =
+ stringList
+ .stream()
+ .noneMatch((s) -> s.startsWith("z"));
+
+ System.out.println(noneStartsWithZ); // true
+```
+
+
+
+### Count(计数)
+
+计数是一个 **最终操作**,返回Stream中元素的个数,**返回值类型是 long**。
+
+```java
+ //测试 Count (计数)操作
+ long startsWithB =
+ stringList
+ .stream()
+ .filter((s) -> s.startsWith("b"))
+ .count();
+ System.out.println(startsWithB); // 3
+```
+
+### Reduce(规约)
+
+这是一个 **最终操作** ,允许通过指定的函数来讲stream中的多个元素规约为一个元素,规约后的结果是通过Optional 接口表示的:
+
+```java
+ //测试 Reduce (规约)操作
+ Optional reduced =
+ stringList
+ .stream()
+ .sorted()
+ .reduce((s1, s2) -> s1 + "#" + s2);
+
+ reduced.ifPresent(System.out::println);//aaa1#aaa2#bbb1#bbb2#bbb3#ccc#ddd1#ddd2
+```
+
+
+
+**译者注:** 这个方法的主要作用是把 Stream 元素组合起来。它提供一个起始值(种子),然后依照运算规则(BinaryOperator),和前面 Stream 的第一个、第二个、第 n 个元素组合。从这个意义上说,字符串拼接、数值的 sum、min、max、average 都是特殊的 reduce。例如 Stream 的 sum 就相当于`Integer sum = integers.reduce(0, (a, b) -> a+b);`也有没有起始值的情况,这时会把 Stream 的前面两个元素组合起来,返回的是 Optional。
+
+```java
+// 字符串连接,concat = "ABCD"
+String concat = Stream.of("A", "B", "C", "D").reduce("", String::concat);
+// 求最小值,minValue = -3.0
+double minValue = Stream.of(-1.5, 1.0, -3.0, -2.0).reduce(Double.MAX_VALUE, Double::min);
+// 求和,sumValue = 10, 有起始值
+int sumValue = Stream.of(1, 2, 3, 4).reduce(0, Integer::sum);
+// 求和,sumValue = 10, 无起始值
+sumValue = Stream.of(1, 2, 3, 4).reduce(Integer::sum).get();
+// 过滤,字符串连接,concat = "ace"
+concat = Stream.of("a", "B", "c", "D", "e", "F").
+ filter(x -> x.compareTo("Z") > 0).
+ reduce("", String::concat);
+```
+
+上面代码例如第一个示例的 reduce(),第一个参数(空白字符)即为起始值,第二个参数(String::concat)为 BinaryOperator。这类有起始值的 reduce() 都返回具体的对象。而对于第四个示例没有起始值的 reduce(),由于可能没有足够的元素,返回的是 Optional,请留意这个区别。更多内容查看: [IBM:Java 8 中的 Streams API 详解](https://www.ibm.com/developerworks/cn/java/j-lo-java8streamapi/index.html)
+
+## Parallel Streams(并行流)
+
+前面提到过Stream有串行和并行两种,串行Stream上的操作是在一个线程中依次完成,而并行Stream则是在多个线程上同时执行。
+
+下面的例子展示了是如何通过并行Stream来提升性能:
+
+首先我们创建一个没有重复元素的大表:
+
+```java
+int max = 1000000;
+List values = new ArrayList<>(max);
+for (int i = 0; i < max; i++) {
+ UUID uuid = UUID.randomUUID();
+ values.add(uuid.toString());
+}
+```
+
+我们分别用串行和并行两种方式对其进行排序,最后看看所用时间的对比。
+
+### Sequential Sort(串行排序)
+
+```java
+//串行排序
+long t0 = System.nanoTime();
+long count = values.stream().sorted().count();
+System.out.println(count);
+
+long t1 = System.nanoTime();
+
+long millis = TimeUnit.NANOSECONDS.toMillis(t1 - t0);
+System.out.println(String.format("sequential sort took: %d ms", millis));
+```
+
+```
+1000000
+sequential sort took: 709 ms//串行排序所用的时间
+```
+
+### Parallel Sort(并行排序)
+
+```java
+//并行排序
+long t0 = System.nanoTime();
+
+long count = values.parallelStream().sorted().count();
+System.out.println(count);
+
+long t1 = System.nanoTime();
+
+long millis = TimeUnit.NANOSECONDS.toMillis(t1 - t0);
+System.out.println(String.format("parallel sort took: %d ms", millis));
+
+```
+
+```java
+1000000
+parallel sort took: 475 ms//串行排序所用的时间
+```
+
+上面两个代码几乎是一样的,但是并行版的快了 50% 左右,唯一需要做的改动就是将 `stream()` 改为`parallelStream()`。
+
+## Maps
+
+前面提到过,Map 类型不支持 streams,不过Map提供了一些新的有用的方法来处理一些日常任务。Map接口本身没有可用的 `stream()`方法,但是你可以在键,值上创建专门的流或者通过 `map.keySet().stream()`,`map.values().stream()`和`map.entrySet().stream()`。
+
+此外,Maps 支持各种新的和有用的方法来执行常见任务。
+
+```java
+Map map = new HashMap<>();
+
+for (int i = 0; i < 10; i++) {
+ map.putIfAbsent(i, "val" + i);
+}
+
+map.forEach((id, val) -> System.out.println(val));//val0 val1 val2 val3 val4 val5 val6 val7 val8 val9
+```
+
+`putIfAbsent` 阻止我们在null检查时写入额外的代码;`forEach`接受一个 consumer 来对 map 中的每个元素操作。
+
+此示例显示如何使用函数在 map 上计算代码:
+
+```java
+map.computeIfPresent(3, (num, val) -> val + num);
+map.get(3); // val33
+
+map.computeIfPresent(9, (num, val) -> null);
+map.containsKey(9); // false
+
+map.computeIfAbsent(23, num -> "val" + num);
+map.containsKey(23); // true
+
+map.computeIfAbsent(3, num -> "bam");
+map.get(3); // val33
+```
+
+接下来展示如何在Map里删除一个键值全都匹配的项:
+
+```java
+map.remove(3, "val3");
+map.get(3); // val33
+map.remove(3, "val33");
+map.get(3); // null
+```
+
+另外一个有用的方法:
+
+```java
+map.getOrDefault(42, "not found"); // not found
+```
+
+对Map的元素做合并也变得很容易了:
+
+```java
+map.merge(9, "val9", (value, newValue) -> value.concat(newValue));
+map.get(9); // val9
+map.merge(9, "concat", (value, newValue) -> value.concat(newValue));
+map.get(9); // val9concat
+```
+
+Merge 做的事情是如果键名不存在则插入,否则则对原键对应的值做合并操作并重新插入到map中。
+
+## Date API(日期相关API)
+
+Java 8在 `java.time` 包下包含一个全新的日期和时间API。新的Date API与Joda-Time库相似,但它们不一样。以下示例涵盖了此新 API 的最重要部分。译者对这部分内容参考相关书籍做了大部分修改。
+
+**译者注(总结):**
+
+- Clock 类提供了访问当前日期和时间的方法,Clock 是时区敏感的,可以用来取代 `System.currentTimeMillis()` 来获取当前的微秒数。某一个特定的时间点也可以使用 `Instant` 类来表示,`Instant` 类也可以用来创建旧版本的`java.util.Date` 对象。
+
+- 在新API中时区使用 ZoneId 来表示。时区可以很方便的使用静态方法of来获取到。 抽象类`ZoneId`(在`java.time`包中)表示一个区域标识符。 它有一个名为`getAvailableZoneIds`的静态方法,它返回所有区域标识符。
+
+- jdk1.8中新增了 LocalDate 与 LocalDateTime等类来解决日期处理方法,同时引入了一个新的类DateTimeFormatter 来解决日期格式化问题。可以使用Instant代替 Date,LocalDateTime代替 Calendar,DateTimeFormatter 代替 SimpleDateFormat。
+
+
+
+### Clock
+
+Clock 类提供了访问当前日期和时间的方法,Clock 是时区敏感的,可以用来取代 `System.currentTimeMillis()` 来获取当前的微秒数。某一个特定的时间点也可以使用 `Instant` 类来表示,`Instant` 类也可以用来创建旧版本的`java.util.Date` 对象。
+
+```java
+Clock clock = Clock.systemDefaultZone();
+long millis = clock.millis();
+System.out.println(millis);//1552379579043
+Instant instant = clock.instant();
+System.out.println(instant);
+Date legacyDate = Date.from(instant); //2019-03-12T08:46:42.588Z
+System.out.println(legacyDate);//Tue Mar 12 16:32:59 CST 2019
+```
+
+### Timezones(时区)
+
+在新API中时区使用 ZoneId 来表示。时区可以很方便的使用静态方法of来获取到。 抽象类`ZoneId`(在`java.time`包中)表示一个区域标识符。 它有一个名为`getAvailableZoneIds`的静态方法,它返回所有区域标识符。
+
+```java
+//输出所有区域标识符
+System.out.println(ZoneId.getAvailableZoneIds());
+
+ZoneId zone1 = ZoneId.of("Europe/Berlin");
+ZoneId zone2 = ZoneId.of("Brazil/East");
+System.out.println(zone1.getRules());// ZoneRules[currentStandardOffset=+01:00]
+System.out.println(zone2.getRules());// ZoneRules[currentStandardOffset=-03:00]
+```
+
+### LocalTime(本地时间)
+
+LocalTime 定义了一个没有时区信息的时间,例如 晚上10点或者 17:30:15。下面的例子使用前面代码创建的时区创建了两个本地时间。之后比较时间并以小时和分钟为单位计算两个时间的时间差:
+
+```java
+LocalTime now1 = LocalTime.now(zone1);
+LocalTime now2 = LocalTime.now(zone2);
+System.out.println(now1.isBefore(now2)); // false
+
+long hoursBetween = ChronoUnit.HOURS.between(now1, now2);
+long minutesBetween = ChronoUnit.MINUTES.between(now1, now2);
+
+System.out.println(hoursBetween); // -3
+System.out.println(minutesBetween); // -239
+```
+
+LocalTime 提供了多种工厂方法来简化对象的创建,包括解析时间字符串.
+
+```java
+LocalTime late = LocalTime.of(23, 59, 59);
+System.out.println(late); // 23:59:59
+DateTimeFormatter germanFormatter =
+ DateTimeFormatter
+ .ofLocalizedTime(FormatStyle.SHORT)
+ .withLocale(Locale.GERMAN);
+
+LocalTime leetTime = LocalTime.parse("13:37", germanFormatter);
+System.out.println(leetTime); // 13:37
+```
+
+### LocalDate(本地日期)
+
+LocalDate 表示了一个确切的日期,比如 2014-03-11。该对象值是不可变的,用起来和LocalTime基本一致。下面的例子展示了如何给Date对象加减天/月/年。另外要注意的是这些对象是不可变的,操作返回的总是一个新实例。
+
+```java
+LocalDate today = LocalDate.now();//获取现在的日期
+System.out.println("今天的日期: "+today);//2019-03-12
+LocalDate tomorrow = today.plus(1, ChronoUnit.DAYS);
+System.out.println("明天的日期: "+tomorrow);//2019-03-13
+LocalDate yesterday = tomorrow.minusDays(2);
+System.out.println("昨天的日期: "+yesterday);//2019-03-11
+LocalDate independenceDay = LocalDate.of(2019, Month.MARCH, 12);
+DayOfWeek dayOfWeek = independenceDay.getDayOfWeek();
+System.out.println("今天是周几:"+dayOfWeek);//TUESDAY
+```
+
+从字符串解析一个 LocalDate 类型和解析 LocalTime 一样简单,下面是使用 `DateTimeFormatter` 解析字符串的例子:
+
+```java
+ String str1 = "2014==04==12 01时06分09秒";
+ // 根据需要解析的日期、时间字符串定义解析所用的格式器
+ DateTimeFormatter fomatter1 = DateTimeFormatter
+ .ofPattern("yyyy==MM==dd HH时mm分ss秒");
+
+ LocalDateTime dt1 = LocalDateTime.parse(str1, fomatter1);
+ System.out.println(dt1); // 输出 2014-04-12T01:06:09
+
+ String str2 = "2014$$$四月$$$13 20小时";
+ DateTimeFormatter fomatter2 = DateTimeFormatter
+ .ofPattern("yyy$$$MMM$$$dd HH小时");
+ LocalDateTime dt2 = LocalDateTime.parse(str2, fomatter2);
+ System.out.println(dt2); // 输出 2014-04-13T20:00
+
+```
+
+再来看一个使用 `DateTimeFormatter` 格式化日期的示例
+
+```java
+LocalDateTime rightNow=LocalDateTime.now();
+String date=DateTimeFormatter.ISO_LOCAL_DATE_TIME.format(rightNow);
+System.out.println(date);//2019-03-12T16:26:48.29
+DateTimeFormatter formatter=DateTimeFormatter.ofPattern("YYYY-MM-dd HH:mm:ss");
+System.out.println(formatter.format(rightNow));//2019-03-12 16:26:48
+```
+
+### LocalDateTime(本地日期时间)
+
+LocalDateTime 同时表示了时间和日期,相当于前两节内容合并到一个对象上了。LocalDateTime 和 LocalTime还有 LocalDate 一样,都是不可变的。LocalDateTime 提供了一些能访问具体字段的方法。
+
+```java
+LocalDateTime sylvester = LocalDateTime.of(2014, Month.DECEMBER, 31, 23, 59, 59);
+
+DayOfWeek dayOfWeek = sylvester.getDayOfWeek();
+System.out.println(dayOfWeek); // WEDNESDAY
+
+Month month = sylvester.getMonth();
+System.out.println(month); // DECEMBER
+
+long minuteOfDay = sylvester.getLong(ChronoField.MINUTE_OF_DAY);
+System.out.println(minuteOfDay); // 1439
+```
+
+只要附加上时区信息,就可以将其转换为一个时间点Instant对象,Instant时间点对象可以很容易的转换为老式的`java.util.Date`。
+
+```java
+Instant instant = sylvester
+ .atZone(ZoneId.systemDefault())
+ .toInstant();
+
+Date legacyDate = Date.from(instant);
+System.out.println(legacyDate); // Wed Dec 31 23:59:59 CET 2014
+```
+
+格式化LocalDateTime和格式化时间和日期一样的,除了使用预定义好的格式外,我们也可以自己定义格式:
+
+```java
+DateTimeFormatter formatter =
+ DateTimeFormatter
+ .ofPattern("MMM dd, yyyy - HH:mm");
+LocalDateTime parsed = LocalDateTime.parse("Nov 03, 2014 - 07:13", formatter);
+String string = formatter.format(parsed);
+System.out.println(string); // Nov 03, 2014 - 07:13
+```
+
+和java.text.NumberFormat不一样的是新版的DateTimeFormatter是不可变的,所以它是线程安全的。
+关于时间日期格式的详细信息在[这里](https://docs.oracle.com/javase/8/docs/api/java/time/format/DateTimeFormatter.html)。
+
+## Annotations(注解)
+
+在Java 8中支持多重注解了,先看个例子来理解一下是什么意思。
+首先定义一个包装类Hints注解用来放置一组具体的Hint注解:
+
+```java
+@interface Hints {
+ Hint[] value();
+}
+@Repeatable(Hints.class)
+@interface Hint {
+ String value();
+}
+```
+
+Java 8允许我们把同一个类型的注解使用多次,只需要给该注解标注一下`@Repeatable`即可。
+
+例 1: 使用包装类当容器来存多个注解(老方法)
+
+```java
+@Hints({@Hint("hint1"), @Hint("hint2")})
+class Person {}
+```
+
+例 2:使用多重注解(新方法)
+
+```java
+@Hint("hint1")
+@Hint("hint2")
+class Person {}
+```
+
+第二个例子里java编译器会隐性的帮你定义好@Hints注解,了解这一点有助于你用反射来获取这些信息:
+
+```java
+Hint hint = Person.class.getAnnotation(Hint.class);
+System.out.println(hint); // null
+Hints hints1 = Person.class.getAnnotation(Hints.class);
+System.out.println(hints1.value().length); // 2
+
+Hint[] hints2 = Person.class.getAnnotationsByType(Hint.class);
+System.out.println(hints2.length); // 2
+```
+
+即便我们没有在 `Person`类上定义 `@Hints`注解,我们还是可以通过 `getAnnotation(Hints.class) `来获取 `@Hints`注解,更加方便的方法是使用 `getAnnotationsByType` 可以直接获取到所有的`@Hint`注解。
+另外Java 8的注解还增加到两种新的target上了:
+
+```java
+@Target({ElementType.TYPE_PARAMETER, ElementType.TYPE_USE})
+@interface MyAnnotation {}
+```
+
+## Where to go from here?
+
+关于Java 8的新特性就写到这了,肯定还有更多的特性等待发掘。JDK 1.8里还有很多很有用的东西,比如`Arrays.parallelSort`, `StampedLock`和`CompletableFuture`等等。
+
+## 公众号
+
+如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
+
+**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
+
+**Java工程师必备学习资源:** 一些Java工程师常用学习资源[公众号](#公众号)后台回复关键字 **“1”** 即可免费无套路获取。
+
+
diff --git "a/docs/java/What's New in JDK8/Java8foreach\346\214\207\345\215\227.md" "b/docs/java/What's New in JDK8/Java8foreach\346\214\207\345\215\227.md"
new file mode 100644
index 00000000000..48cda3abfd9
--- /dev/null
+++ "b/docs/java/What's New in JDK8/Java8foreach\346\214\207\345\215\227.md"
@@ -0,0 +1,139 @@
+> 本文由 JavaGuide 翻译,原文地址:https://www.baeldung.com/foreach-java
+
+## 1 概述
+
+在Java 8中引入的*forEach*循环为程序员提供了一种新的,简洁而有趣的迭代集合的方式。
+
+在本文中,我们将看到如何将*forEach*与集合*一起*使用,它采用何种参数以及此循环与增强的*for*循环的不同之处。
+
+## 2 基础知识
+
+```Java
+public interface Collection extends Iterable
+```
+
+Collection 接口实现了 Iterable 接口,而 Iterable 接口在 Java 8开始具有一个新的 API:
+
+```java
+void forEach(Consumer action)//对 Iterable的每个元素执行给定的操作,直到所有元素都被处理或动作引发异常。
+```
+
+使用*forEach*,我们可以迭代一个集合并对每个元素执行给定的操作,就像任何其他*迭代器一样。*
+
+例如,迭代和打印字符串集合*的*for循环版本:
+
+```java
+for (String name : names) {
+ System.out.println(name);
+}
+```
+
+我们可以使用*forEach*写这个 :
+
+```java
+names.forEach(name -> {
+ System.out.println(name);
+});
+```
+
+## 3.使用forEach方法
+
+### 3.1 匿名类
+
+我们使用 *forEach*迭代集合并对每个元素执行特定操作。**要执行的操作包含在实现Consumer接口的类中,并作为参数传递给forEach 。**
+
+所述*消费者*接口是一个功能接口(具有单个抽象方法的接口)。它接受输入并且不返回任何结果。
+
+Consumer 接口定义如下:
+
+```java
+@FunctionalInterface
+public interface Consumer {
+ void accept(T t);
+}
+```
+任何实现,例如,只是打印字符串的消费者:
+
+```java
+Consumer printConsumer = new Consumer() {
+ public void accept(String name) {
+ System.out.println(name);
+ };
+};
+```
+
+可以作为参数传递给*forEach*:
+
+```java
+names.forEach(printConsumer);
+```
+
+但这不是通过消费者和使用*forEach* API 创建操作的唯一方法。让我们看看我们将使用*forEach*方法的另外2种最流行的方式:
+
+### 3.2 Lambda表达式
+
+Java 8功能接口的主要优点是我们可以使用Lambda表达式来实例化它们,并避免使用庞大的匿名类实现。
+
+由于 Consumer 接口属于函数式接口,我们可以通过以下形式在Lambda中表达它:
+
+```java
+(argument) -> { body }
+name -> System.out.println(name)
+names.forEach(name -> System.out.println(name));
+```
+
+### 3.3 方法参考
+
+我们可以使用方法引用语法而不是普通的Lambda语法,其中已存在一个方法来对类执行操作:
+
+```java
+names.forEach(System.out::println);
+```
+
+## 4.forEach在集合中的使用
+
+### 4.1.迭代集合
+
+**任何类型Collection的可迭代 - 列表,集合,队列 等都具有使用forEach的相同语法。**
+
+因此,正如我们已经看到的,迭代列表的元素:
+
+```java
+List names = Arrays.asList("Larry", "Steve", "James");
+
+names.forEach(System.out::println);
+```
+
+同样对于一组:
+
+```java
+Set uniqueNames = new HashSet<>(Arrays.asList("Larry", "Steve", "James"));
+
+uniqueNames.forEach(System.out::println);
+```
+
+或者让我们说一个*队列*也是一个*集合*:
+
+```java
+Queue namesQueue = new ArrayDeque<>(Arrays.asList("Larry", "Steve", "James"));
+
+namesQueue.forEach(System.out::println);
+```
+
+### 4.2.迭代Map - 使用Map的forEach
+
+Map没有实现Iterable接口,但它**提供了自己的forEach 变体,它接受BiConsumer**。*
+
+```java
+Map namesMap = new HashMap<>();
+namesMap.put(1, "Larry");
+namesMap.put(2, "Steve");
+namesMap.put(3, "James");
+namesMap.forEach((key, value) -> System.out.println(key + " " + value));
+```
+
+### 4.3.迭代一个Map - 通过迭代entrySet
+
+```java
+namesMap.entrySet().forEach(entry -> System.out.println(entry.getKey() + " " + entry.getValue()));
+```
\ No newline at end of file
diff --git "a/docs/java/What's New in JDK8/Java8\346\225\231\347\250\213\346\216\250\350\215\220.md" "b/docs/java/What's New in JDK8/Java8\346\225\231\347\250\213\346\216\250\350\215\220.md"
new file mode 100644
index 00000000000..7de58352a5f
--- /dev/null
+++ "b/docs/java/What's New in JDK8/Java8\346\225\231\347\250\213\346\216\250\350\215\220.md"
@@ -0,0 +1,18 @@
+### 书籍
+
+- **《Java8 In Action》**
+- **《写给大忙人看的Java SE 8》**
+
+上述书籍的PDF版本见 https://shimo.im/docs/CPB0PK05rP4CFmI2/ 中的 “Java 书籍推荐”。
+
+### 开源文档
+
+- **【译】Java 8 简明教程**:
+- **30 seconds of java8:**
+
+### 视频
+
+- **尚硅谷 Java 8 新特性**
+
+视频资源见: https://shimo.im/docs/CPB0PK05rP4CFmI2/ 。
+
diff --git a/docs/java/basic/Arrays,CollectionsCommonMethods.md b/docs/java/basic/Arrays,CollectionsCommonMethods.md
new file mode 100644
index 00000000000..0710de44a95
--- /dev/null
+++ b/docs/java/basic/Arrays,CollectionsCommonMethods.md
@@ -0,0 +1,383 @@
+
+
+- [Collections 工具类和 Arrays 工具类常见方法](#collections-工具类和-arrays-工具类常见方法)
+ - [Collections](#collections)
+ - [排序操作](#排序操作)
+ - [查找,替换操作](#查找替换操作)
+ - [同步控制](#同步控制)
+ - [Arrays类的常见操作](#arrays类的常见操作)
+ - [排序 : `sort()`](#排序--sort)
+ - [查找 : `binarySearch()`](#查找--binarysearch)
+ - [比较: `equals()`](#比较-equals)
+ - [填充 : `fill()`](#填充--fill)
+ - [转列表 `asList()`](#转列表-aslist)
+ - [转字符串 `toString()`](#转字符串-tostring)
+ - [复制 `copyOf()`](#复制-copyof)
+
+
+# Collections 工具类和 Arrays 工具类常见方法
+
+## Collections
+
+Collections 工具类常用方法:
+
+1. 排序
+2. 查找,替换操作
+3. 同步控制(不推荐,需要线程安全的集合类型时请考虑使用 JUC 包下的并发集合)
+
+### 排序操作
+
+```java
+void reverse(List list)//反转
+void shuffle(List list)//随机排序
+void sort(List list)//按自然排序的升序排序
+void sort(List list, Comparator c)//定制排序,由Comparator控制排序逻辑
+void swap(List list, int i , int j)//交换两个索引位置的元素
+void rotate(List list, int distance)//旋转。当distance为正数时,将list后distance个元素整体移到前面。当distance为负数时,将 list的前distance个元素整体移到后面。
+```
+
+**示例代码:**
+
+```java
+ ArrayList arrayList = new ArrayList();
+ arrayList.add(-1);
+ arrayList.add(3);
+ arrayList.add(3);
+ arrayList.add(-5);
+ arrayList.add(7);
+ arrayList.add(4);
+ arrayList.add(-9);
+ arrayList.add(-7);
+ System.out.println("原始数组:");
+ System.out.println(arrayList);
+ // void reverse(List list):反转
+ Collections.reverse(arrayList);
+ System.out.println("Collections.reverse(arrayList):");
+ System.out.println(arrayList);
+
+
+ Collections.rotate(arrayList, 4);
+ System.out.println("Collections.rotate(arrayList, 4):");
+ System.out.println(arrayList);
+
+ // void sort(List list),按自然排序的升序排序
+ Collections.sort(arrayList);
+ System.out.println("Collections.sort(arrayList):");
+ System.out.println(arrayList);
+
+ // void shuffle(List list),随机排序
+ Collections.shuffle(arrayList);
+ System.out.println("Collections.shuffle(arrayList):");
+ System.out.println(arrayList);
+
+ // void swap(List list, int i , int j),交换两个索引位置的元素
+ Collections.swap(arrayList, 2, 5);
+ System.out.println("Collections.swap(arrayList, 2, 5):");
+ System.out.println(arrayList);
+
+ // 定制排序的用法
+ Collections.sort(arrayList, new Comparator() {
+
+ @Override
+ public int compare(Integer o1, Integer o2) {
+ return o2.compareTo(o1);
+ }
+ });
+ System.out.println("定制排序后:");
+ System.out.println(arrayList);
+```
+
+### 查找,替换操作
+
+```java
+int binarySearch(List list, Object key)//对List进行二分查找,返回索引,注意List必须是有序的
+int max(Collection coll)//根据元素的自然顺序,返回最大的元素。 类比int min(Collection coll)
+int max(Collection coll, Comparator c)//根据定制排序,返回最大元素,排序规则由Comparatator类控制。类比int min(Collection coll, Comparator c)
+void fill(List list, Object obj)//用指定的元素代替指定list中的所有元素。
+int frequency(Collection c, Object o)//统计元素出现次数
+int indexOfSubList(List list, List target)//统计target在list中第一次出现的索引,找不到则返回-1,类比int lastIndexOfSubList(List source, list target).
+boolean replaceAll(List list, Object oldVal, Object newVal), 用新元素替换旧元素
+```
+
+**示例代码:**
+
+```java
+ ArrayList arrayList = new ArrayList();
+ arrayList.add(-1);
+ arrayList.add(3);
+ arrayList.add(3);
+ arrayList.add(-5);
+ arrayList.add(7);
+ arrayList.add(4);
+ arrayList.add(-9);
+ arrayList.add(-7);
+ ArrayList arrayList2 = new ArrayList();
+ arrayList2.add(-3);
+ arrayList2.add(-5);
+ arrayList2.add(7);
+ System.out.println("原始数组:");
+ System.out.println(arrayList);
+
+ System.out.println("Collections.max(arrayList):");
+ System.out.println(Collections.max(arrayList));
+
+ System.out.println("Collections.min(arrayList):");
+ System.out.println(Collections.min(arrayList));
+
+ System.out.println("Collections.replaceAll(arrayList, 3, -3):");
+ Collections.replaceAll(arrayList, 3, -3);
+ System.out.println(arrayList);
+
+ System.out.println("Collections.frequency(arrayList, -3):");
+ System.out.println(Collections.frequency(arrayList, -3));
+
+ System.out.println("Collections.indexOfSubList(arrayList, arrayList2):");
+ System.out.println(Collections.indexOfSubList(arrayList, arrayList2));
+
+ System.out.println("Collections.binarySearch(arrayList, 7):");
+ // 对List进行二分查找,返回索引,List必须是有序的
+ Collections.sort(arrayList);
+ System.out.println(Collections.binarySearch(arrayList, 7));
+```
+
+### 同步控制
+
+Collections提供了多个`synchronizedXxx()`方法·,该方法可以将指定集合包装成线程同步的集合,从而解决多线程并发访问集合时的线程安全问题。
+
+我们知道 HashSet,TreeSet,ArrayList,LinkedList,HashMap,TreeMap 都是线程不安全的。Collections提供了多个静态方法可以把他们包装成线程同步的集合。
+
+**最好不要用下面这些方法,效率非常低,需要线程安全的集合类型时请考虑使用 JUC 包下的并发集合。**
+
+方法如下:
+
+```java
+synchronizedCollection(Collection c) //返回指定 collection 支持的同步(线程安全的)collection。
+synchronizedList(List list)//返回指定列表支持的同步(线程安全的)List。
+synchronizedMap(Map m) //返回由指定映射支持的同步(线程安全的)Map。
+synchronizedSet(Set s) //返回指定 set 支持的同步(线程安全的)set。
+```
+
+### Collections还可以设置不可变集合,提供了如下三类方法:
+
+```java
+emptyXxx(): 返回一个空的、不可变的集合对象,此处的集合既可以是List,也可以是Set,还可以是Map。
+singletonXxx(): 返回一个只包含指定对象(只有一个或一个元素)的不可变的集合对象,此处的集合可以是:List,Set,Map。
+unmodifiableXxx(): 返回指定集合对象的不可变视图,此处的集合可以是:List,Set,Map。
+上面三类方法的参数是原有的集合对象,返回值是该集合的”只读“版本。
+```
+
+**示例代码:**
+
+```java
+ ArrayList arrayList = new ArrayList();
+ arrayList.add(-1);
+ arrayList.add(3);
+ arrayList.add(3);
+ arrayList.add(-5);
+ arrayList.add(7);
+ arrayList.add(4);
+ arrayList.add(-9);
+ arrayList.add(-7);
+ HashSet integers1 = new HashSet<>();
+ integers1.add(1);
+ integers1.add(3);
+ integers1.add(2);
+ Map scores = new HashMap();
+ scores.put("语文" , 80);
+ scores.put("Java" , 82);
+
+ //Collections.emptyXXX();创建一个空的、不可改变的XXX对象
+ List
 +
+
+## 目录
+
+- [Java](#java)
+ - [基础](#基础)
+ - [容器](#容器)
+ - [并发](#并发)
+ - [JVM](#jvm)
+ - [I/O](#io)
+ - [Java 8](#java-8)
+ - [编程规范](#编程规范)
+- [网络](#网络)
+- [操作系统](#操作系统)
+ - [Linux相关](#linux相关)
+- [数据结构与算法](#数据结构与算法)
+ - [数据结构](#数据结构)
+ - [算法](#算法)
+- [数据库](#数据库)
+ - [MySQL](#mysql)
+ - [Redis](#redis)
+- [系统设计](#系统设计)
+ - [设计模式(工厂模式、单例模式 ... )](#设计模式)
+ - [常用框架(Spring、Zookeeper ... )](#常用框架)
+ - [数据通信(消息队列、Dubbo ... )](#数据通信)
+ - [网站架构](#网站架构)
+- [面试指南](#面试指南)
+ - [备战面试](#备战面试)
+ - [常见面试题总结](#常见面试题总结)
+ - [面经](#面经)
+- [工具](#工具)
+ - [Git](#git)
+ - [Docker](#Docker)
+- [资料](#资料)
+ - [书单](#书单)
+ - [Github榜单](#Github榜单)
+- [待办](#待办)
+- [说明](#说明)
+
+## Java
+
+### 基础
+
+* [Java 基础知识回顾](java/Java基础知识.md)
+* [Java 基础知识疑难点总结](java/Java疑难点.md)
+* [J2EE 基础知识回顾](java/J2EE基础知识.md)
+
+### 容器
+
+* [Java容器常见面试题/知识点总结](java/collection/Java集合框架常见面试题.md)
+* [ArrayList 源码学习](java/collection/ArrayList.md)
+* [LinkedList 源码学习](java/collection/LinkedList.md)
+* [HashMap(JDK1.8)源码学习](java/collection/HashMap.md)
+
+### 并发
+
+* [Java 并发基础常见面试题总结](java/Multithread/JavaConcurrencyBasicsCommonInterviewQuestionsSummary.md)
+* [Java 并发进阶常见面试题总结](java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md)
+* [并发容器总结](java/Multithread/并发容器总结.md)
+* [乐观锁与悲观锁](essential-content-for-interview/面试必备之乐观锁与悲观锁.md)
+* [JUC 中的 Atomic 原子类总结](java/Multithread/Atomic.md)
+* [AQS 原理以及 AQS 同步组件总结](java/Multithread/AQS.md)
+
+### JVM
+* [一 Java内存区域](java/jvm/Java内存区域.md)
+* [二 JVM垃圾回收](java/jvm/JVM垃圾回收.md)
+* [三 JDK 监控和故障处理工具](java/jvm/JDK监控和故障处理工具总结.md)
+* [四 类文件结构](java/jvm/类文件结构.md)
+* [五 类加载过程](java/jvm/类加载过程.md)
+* [六 类加载器](java/jvm/类加载器.md)
+
+### I/O
+
+* [BIO,NIO,AIO 总结 ](java/BIO-NIO-AIO.md)
+* [Java IO 与 NIO系列文章](java/Java%20IO与NIO.md)
+
+### Java 8
+
+* [Java 8 新特性总结](java/What's%20New%20in%20JDK8/Java8Tutorial.md)
+* [Java 8 学习资源推荐](java/What's%20New%20in%20JDK8/Java8教程推荐.md)
+
+### 编程规范
+
+- [Java 编程规范](java/Java编程规范.md)
+
+## 网络
+
+* [计算机网络常见面试题](network/计算机网络.md)
+* [计算机网络基础知识总结](network/干货:计算机网络知识总结.md)
+* [HTTPS中的TLS](network/HTTPS中的TLS.md)
+
+## 操作系统
+
+### Linux相关
+
+* [后端程序员必备的 Linux 基础知识](operating-system/后端程序员必备的Linux基础知识.md)
+* [Shell 编程入门](operating-system/Shell.md)
+
+## 数据结构与算法
+
+### 数据结构
+
+- [数据结构知识学习与面试](dataStructures-algorithms/数据结构.md)
+
+### 算法
+
+- [算法学习资源推荐](dataStructures-algorithms/算法学习资源推荐.md)
+- [几道常见的字符串算法题总结 ](dataStructures-algorithms/几道常见的子符串算法题.md)
+- [几道常见的链表算法题总结 ](dataStructures-algorithms/几道常见的链表算法题.md)
+- [剑指offer部分编程题](dataStructures-algorithms/剑指offer部分编程题.md)
+- [公司真题](dataStructures-algorithms/公司真题.md)
+- [回溯算法经典案例之N皇后问题](dataStructures-algorithms/Backtracking-NQueens.md)
+
+## 数据库
+
+### MySQL
+
+* [MySQL 学习与面试](database/MySQL.md)
+* [一千行MySQL学习笔记](database/一千行MySQL命令.md)
+* [MySQL高性能优化规范建议](database/MySQL高性能优化规范建议.md)
+* [数据库索引总结](database/MySQL%20Index.md)
+* [事务隔离级别(图文详解)](database/事务隔离级别(图文详解).md)
+* [一条SQL语句在MySQL中如何执行的](database/一条sql语句在mysql中如何执行的.md)
+
+### Redis
+
+* [Redis 总结](database/Redis/Redis.md)
+* [Redlock分布式锁](database/Redis/Redlock分布式锁.md)
+* [如何做可靠的分布式锁,Redlock真的可行么](database/Redis/如何做可靠的分布式锁,Redlock真的可行么.md)
+
+## 系统设计
+
+### 设计模式
+
+- [设计模式系列文章](system-design/设计模式.md)
+
+### 常用框架
+
+#### Spring
+
+- [Spring 学习与面试](system-design/framework/spring/Spring.md)
+- [Spring 常见问题总结](system-design/framework/spring/SpringInterviewQuestions.md)
+- [Spring中bean的作用域与生命周期](system-design/framework/spring/SpringBean.md)
+- [SpringMVC 工作原理详解](system-design/framework/spring/SpringMVC-Principle.md)
+- [Spring中都用到了那些设计模式?](system-design/framework/spring/Spring-Design-Patterns.md)
+
+#### ZooKeeper
+
+- [ZooKeeper 相关概念总结](system-design/framework/ZooKeeper.md)
+- [ZooKeeper 数据模型和常见命令](system-design/framework/ZooKeeper数据模型和常见命令.md)
+
+### 数据通信
+
+- [数据通信(RESTful、RPC、消息队列)相关知识点总结](system-design/data-communication/summary.md)
+- [Dubbo 总结:关于 Dubbo 的重要知识点](system-design/data-communication/dubbo.md)
+- [消息队列总结](system-design/data-communication/message-queue.md)
+- [RabbitMQ 入门](system-design/data-communication/rabbitmq.md)
+- [RocketMQ的几个简单问题与答案](system-design/data-communication/RocketMQ-Questions.md)
+
+### 网站架构
+
+- [一文读懂分布式应该学什么](system-design/website-architecture/分布式.md)
+- [8 张图读懂大型网站技术架构](system-design/website-architecture/8%20张图读懂大型网站技术架构.md)
+- [【面试精选】关于大型网站系统架构你不得不懂的10个问题](system-design/website-architecture/【面试精选】关于大型网站系统架构你不得不懂的10个问题.md)
+
+## 面试指南
+
+### 备战面试
+
+* [【备战面试1】程序员的简历就该这样写](essential-content-for-interview/PreparingForInterview/程序员的简历之道.md)
+* [【备战面试2】初出茅庐的程序员该如何准备面试?](essential-content-for-interview/PreparingForInterview/interviewPrepare.md)
+* [【备战面试3】7个大部分程序员在面试前很关心的问题](essential-content-for-interview/PreparingForInterview/JavaProgrammerNeedKnow.md)
+* [【备战面试4】Github上开源的Java面试/学习相关的仓库推荐](essential-content-for-interview/PreparingForInterview/JavaInterviewLibrary.md)
+* [【备战面试5】如果面试官问你“你有什么问题问我吗?”时,你该如何回答](essential-content-for-interview/PreparingForInterview/如果面试官问你“你有什么问题问我吗?”时,你该如何回答.md)
+* [【备战面试6】美团面试常见问题总结(附详解答案)](essential-content-for-interview/PreparingForInterview/美团面试常见问题总结.md)
+
+### 常见面试题总结
+
+* [第一周(2018-8-7)](essential-content-for-interview/MostCommonJavaInterviewQuestions/第一周(2018-8-7).md) (为什么 Java 中只有值传递、==与equals、 hashCode与equals)
+* [第二周(2018-8-13)](essential-content-for-interview/MostCommonJavaInterviewQuestions/第二周(2018-8-13).md)(String和StringBuffer、StringBuilder的区别是什么?String为什么是不可变的?、什么是反射机制?反射机制的应用场景有哪些?......)
+* [第三周(2018-08-22)](java/collection/Java集合框架常见面试题.md) (Arraylist 与 LinkedList 异同、ArrayList 与 Vector 区别、HashMap的底层实现、HashMap 和 Hashtable 的区别、HashMap 的长度为什么是2的幂次方、HashSet 和 HashMap 区别、ConcurrentHashMap 和 Hashtable 的区别、ConcurrentHashMap线程安全的具体实现方式/底层具体实现、集合框架底层数据结构总结)
+* [第四周(2018-8-30).md](essential-content-for-interview/MostCommonJavaInterviewQuestions/第四周(2018-8-30).md) (主要内容是几道面试常问的多线程基础题。)
+
+### 面经
+
+- [5面阿里,终获offer(2018年秋招)](essential-content-for-interview/BATJrealInterviewExperience/5面阿里,终获offer.md)
+- [蚂蚁金服2019实习生面经总结(已拿口头offer)](essential-content-for-interview/BATJrealInterviewExperience/蚂蚁金服实习生面经总结(已拿口头offer).md)
+- [2019年蚂蚁金服、头条、拼多多的面试总结](essential-content-for-interview/BATJrealInterviewExperience/2019alipay-pinduoduo-toutiao.md)
+
+## 工具
+
+### Git
+
+* [Git入门](tools/Git.md)
+
+### Docker
+
+* [Docker 入门](tools/Docker.md)
+* [一文搞懂 Docker 镜像的常用操作!](tools/Docker-Image.md)
+
+## 资料
+
+### 书单
+
+- [Java程序员必备书单](data/java-recommended-books.md)
+
+### Github榜单
+
+- [Java 项目月榜单](github-trending/JavaGithubTrending.md)
+
+***
+
+## 待办
+
+- [x] [Java 8 新特性总结](./java/What's%20New%20in%20JDK8/Java8Tutorial.md)
+- [x] [Java 8 新特性详解](./java/What's%20New%20in%20JDK8/Java8教程推荐.md)
+- [ ] Java 多线程类别知识重构(---正在进行中---)
+- [x] [BIO,NIO,AIO 总结 ](./java/BIO-NIO-AIO.md)
+- [ ] Netty 总结(---正在进行中---)
+- [ ] 数据结构总结重构(---正在进行中---)
+
+## 公众号
+
+- 如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
+- 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本公众号后台回复 **"Java面试突击"** 即可免费领取!
+- 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
+
+
+
+
+## 目录
+
+- [Java](#java)
+ - [基础](#基础)
+ - [容器](#容器)
+ - [并发](#并发)
+ - [JVM](#jvm)
+ - [I/O](#io)
+ - [Java 8](#java-8)
+ - [编程规范](#编程规范)
+- [网络](#网络)
+- [操作系统](#操作系统)
+ - [Linux相关](#linux相关)
+- [数据结构与算法](#数据结构与算法)
+ - [数据结构](#数据结构)
+ - [算法](#算法)
+- [数据库](#数据库)
+ - [MySQL](#mysql)
+ - [Redis](#redis)
+- [系统设计](#系统设计)
+ - [设计模式(工厂模式、单例模式 ... )](#设计模式)
+ - [常用框架(Spring、Zookeeper ... )](#常用框架)
+ - [数据通信(消息队列、Dubbo ... )](#数据通信)
+ - [网站架构](#网站架构)
+- [面试指南](#面试指南)
+ - [备战面试](#备战面试)
+ - [常见面试题总结](#常见面试题总结)
+ - [面经](#面经)
+- [工具](#工具)
+ - [Git](#git)
+ - [Docker](#Docker)
+- [资料](#资料)
+ - [书单](#书单)
+ - [Github榜单](#Github榜单)
+- [待办](#待办)
+- [说明](#说明)
+
+## Java
+
+### 基础
+
+* [Java 基础知识回顾](java/Java基础知识.md)
+* [Java 基础知识疑难点总结](java/Java疑难点.md)
+* [J2EE 基础知识回顾](java/J2EE基础知识.md)
+
+### 容器
+
+* [Java容器常见面试题/知识点总结](java/collection/Java集合框架常见面试题.md)
+* [ArrayList 源码学习](java/collection/ArrayList.md)
+* [LinkedList 源码学习](java/collection/LinkedList.md)
+* [HashMap(JDK1.8)源码学习](java/collection/HashMap.md)
+
+### 并发
+
+* [Java 并发基础常见面试题总结](java/Multithread/JavaConcurrencyBasicsCommonInterviewQuestionsSummary.md)
+* [Java 并发进阶常见面试题总结](java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md)
+* [并发容器总结](java/Multithread/并发容器总结.md)
+* [乐观锁与悲观锁](essential-content-for-interview/面试必备之乐观锁与悲观锁.md)
+* [JUC 中的 Atomic 原子类总结](java/Multithread/Atomic.md)
+* [AQS 原理以及 AQS 同步组件总结](java/Multithread/AQS.md)
+
+### JVM
+* [一 Java内存区域](java/jvm/Java内存区域.md)
+* [二 JVM垃圾回收](java/jvm/JVM垃圾回收.md)
+* [三 JDK 监控和故障处理工具](java/jvm/JDK监控和故障处理工具总结.md)
+* [四 类文件结构](java/jvm/类文件结构.md)
+* [五 类加载过程](java/jvm/类加载过程.md)
+* [六 类加载器](java/jvm/类加载器.md)
+
+### I/O
+
+* [BIO,NIO,AIO 总结 ](java/BIO-NIO-AIO.md)
+* [Java IO 与 NIO系列文章](java/Java%20IO与NIO.md)
+
+### Java 8
+
+* [Java 8 新特性总结](java/What's%20New%20in%20JDK8/Java8Tutorial.md)
+* [Java 8 学习资源推荐](java/What's%20New%20in%20JDK8/Java8教程推荐.md)
+
+### 编程规范
+
+- [Java 编程规范](java/Java编程规范.md)
+
+## 网络
+
+* [计算机网络常见面试题](network/计算机网络.md)
+* [计算机网络基础知识总结](network/干货:计算机网络知识总结.md)
+* [HTTPS中的TLS](network/HTTPS中的TLS.md)
+
+## 操作系统
+
+### Linux相关
+
+* [后端程序员必备的 Linux 基础知识](operating-system/后端程序员必备的Linux基础知识.md)
+* [Shell 编程入门](operating-system/Shell.md)
+
+## 数据结构与算法
+
+### 数据结构
+
+- [数据结构知识学习与面试](dataStructures-algorithms/数据结构.md)
+
+### 算法
+
+- [算法学习资源推荐](dataStructures-algorithms/算法学习资源推荐.md)
+- [几道常见的字符串算法题总结 ](dataStructures-algorithms/几道常见的子符串算法题.md)
+- [几道常见的链表算法题总结 ](dataStructures-algorithms/几道常见的链表算法题.md)
+- [剑指offer部分编程题](dataStructures-algorithms/剑指offer部分编程题.md)
+- [公司真题](dataStructures-algorithms/公司真题.md)
+- [回溯算法经典案例之N皇后问题](dataStructures-algorithms/Backtracking-NQueens.md)
+
+## 数据库
+
+### MySQL
+
+* [MySQL 学习与面试](database/MySQL.md)
+* [一千行MySQL学习笔记](database/一千行MySQL命令.md)
+* [MySQL高性能优化规范建议](database/MySQL高性能优化规范建议.md)
+* [数据库索引总结](database/MySQL%20Index.md)
+* [事务隔离级别(图文详解)](database/事务隔离级别(图文详解).md)
+* [一条SQL语句在MySQL中如何执行的](database/一条sql语句在mysql中如何执行的.md)
+
+### Redis
+
+* [Redis 总结](database/Redis/Redis.md)
+* [Redlock分布式锁](database/Redis/Redlock分布式锁.md)
+* [如何做可靠的分布式锁,Redlock真的可行么](database/Redis/如何做可靠的分布式锁,Redlock真的可行么.md)
+
+## 系统设计
+
+### 设计模式
+
+- [设计模式系列文章](system-design/设计模式.md)
+
+### 常用框架
+
+#### Spring
+
+- [Spring 学习与面试](system-design/framework/spring/Spring.md)
+- [Spring 常见问题总结](system-design/framework/spring/SpringInterviewQuestions.md)
+- [Spring中bean的作用域与生命周期](system-design/framework/spring/SpringBean.md)
+- [SpringMVC 工作原理详解](system-design/framework/spring/SpringMVC-Principle.md)
+- [Spring中都用到了那些设计模式?](system-design/framework/spring/Spring-Design-Patterns.md)
+
+#### ZooKeeper
+
+- [ZooKeeper 相关概念总结](system-design/framework/ZooKeeper.md)
+- [ZooKeeper 数据模型和常见命令](system-design/framework/ZooKeeper数据模型和常见命令.md)
+
+### 数据通信
+
+- [数据通信(RESTful、RPC、消息队列)相关知识点总结](system-design/data-communication/summary.md)
+- [Dubbo 总结:关于 Dubbo 的重要知识点](system-design/data-communication/dubbo.md)
+- [消息队列总结](system-design/data-communication/message-queue.md)
+- [RabbitMQ 入门](system-design/data-communication/rabbitmq.md)
+- [RocketMQ的几个简单问题与答案](system-design/data-communication/RocketMQ-Questions.md)
+
+### 网站架构
+
+- [一文读懂分布式应该学什么](system-design/website-architecture/分布式.md)
+- [8 张图读懂大型网站技术架构](system-design/website-architecture/8%20张图读懂大型网站技术架构.md)
+- [【面试精选】关于大型网站系统架构你不得不懂的10个问题](system-design/website-architecture/【面试精选】关于大型网站系统架构你不得不懂的10个问题.md)
+
+## 面试指南
+
+### 备战面试
+
+* [【备战面试1】程序员的简历就该这样写](essential-content-for-interview/PreparingForInterview/程序员的简历之道.md)
+* [【备战面试2】初出茅庐的程序员该如何准备面试?](essential-content-for-interview/PreparingForInterview/interviewPrepare.md)
+* [【备战面试3】7个大部分程序员在面试前很关心的问题](essential-content-for-interview/PreparingForInterview/JavaProgrammerNeedKnow.md)
+* [【备战面试4】Github上开源的Java面试/学习相关的仓库推荐](essential-content-for-interview/PreparingForInterview/JavaInterviewLibrary.md)
+* [【备战面试5】如果面试官问你“你有什么问题问我吗?”时,你该如何回答](essential-content-for-interview/PreparingForInterview/如果面试官问你“你有什么问题问我吗?”时,你该如何回答.md)
+* [【备战面试6】美团面试常见问题总结(附详解答案)](essential-content-for-interview/PreparingForInterview/美团面试常见问题总结.md)
+
+### 常见面试题总结
+
+* [第一周(2018-8-7)](essential-content-for-interview/MostCommonJavaInterviewQuestions/第一周(2018-8-7).md) (为什么 Java 中只有值传递、==与equals、 hashCode与equals)
+* [第二周(2018-8-13)](essential-content-for-interview/MostCommonJavaInterviewQuestions/第二周(2018-8-13).md)(String和StringBuffer、StringBuilder的区别是什么?String为什么是不可变的?、什么是反射机制?反射机制的应用场景有哪些?......)
+* [第三周(2018-08-22)](java/collection/Java集合框架常见面试题.md) (Arraylist 与 LinkedList 异同、ArrayList 与 Vector 区别、HashMap的底层实现、HashMap 和 Hashtable 的区别、HashMap 的长度为什么是2的幂次方、HashSet 和 HashMap 区别、ConcurrentHashMap 和 Hashtable 的区别、ConcurrentHashMap线程安全的具体实现方式/底层具体实现、集合框架底层数据结构总结)
+* [第四周(2018-8-30).md](essential-content-for-interview/MostCommonJavaInterviewQuestions/第四周(2018-8-30).md) (主要内容是几道面试常问的多线程基础题。)
+
+### 面经
+
+- [5面阿里,终获offer(2018年秋招)](essential-content-for-interview/BATJrealInterviewExperience/5面阿里,终获offer.md)
+- [蚂蚁金服2019实习生面经总结(已拿口头offer)](essential-content-for-interview/BATJrealInterviewExperience/蚂蚁金服实习生面经总结(已拿口头offer).md)
+- [2019年蚂蚁金服、头条、拼多多的面试总结](essential-content-for-interview/BATJrealInterviewExperience/2019alipay-pinduoduo-toutiao.md)
+
+## 工具
+
+### Git
+
+* [Git入门](tools/Git.md)
+
+### Docker
+
+* [Docker 入门](tools/Docker.md)
+* [一文搞懂 Docker 镜像的常用操作!](tools/Docker-Image.md)
+
+## 资料
+
+### 书单
+
+- [Java程序员必备书单](data/java-recommended-books.md)
+
+### Github榜单
+
+- [Java 项目月榜单](github-trending/JavaGithubTrending.md)
+
+***
+
+## 待办
+
+- [x] [Java 8 新特性总结](./java/What's%20New%20in%20JDK8/Java8Tutorial.md)
+- [x] [Java 8 新特性详解](./java/What's%20New%20in%20JDK8/Java8教程推荐.md)
+- [ ] Java 多线程类别知识重构(---正在进行中---)
+- [x] [BIO,NIO,AIO 总结 ](./java/BIO-NIO-AIO.md)
+- [ ] Netty 总结(---正在进行中---)
+- [ ] 数据结构总结重构(---正在进行中---)
+
+## 公众号
+
+- 如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
+- 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本公众号后台回复 **"Java面试突击"** 即可免费领取!
+- 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
+
+ -
+如要进群或者请教问题,请[联系我](#联系我) (备注来自Github。请直入问题,工作时间不回复)。
-[](//shang.qq.com/wpa/qunwpa?idkey=f128b25264f43170c2721e0789b24b180fc482113b6f256928b6198ae07fe5d4)
+> JavaGuide 的Star数量虽然比较多,但是它的价值和含金量一定是不能和 Dubbo、Nacos这些优秀的国产开源项目比的。希望国内可以出更多优秀的开源项目!
+>
+> 另外,希望大家对面试不要抱有侥幸的心理,打铁还需自身硬! 我希望这个文档是为你学习 Java 指明方向,而不是用来应付面试用的。加油!奥利给!
+
+**开始阅读之前必看** :
+
+1. [完结撒花!JavaGuide面试突击版来啦!](./docs/javaguide面试突击版.md)
+2. [JavaGuide重大更新记录](./docs/update-history.md)
+
+
-
+如要进群或者请教问题,请[联系我](#联系我) (备注来自Github。请直入问题,工作时间不回复)。
-[](//shang.qq.com/wpa/qunwpa?idkey=f128b25264f43170c2721e0789b24b180fc482113b6f256928b6198ae07fe5d4)
+> JavaGuide 的Star数量虽然比较多,但是它的价值和含金量一定是不能和 Dubbo、Nacos这些优秀的国产开源项目比的。希望国内可以出更多优秀的开源项目!
+>
+> 另外,希望大家对面试不要抱有侥幸的心理,打铁还需自身硬! 我希望这个文档是为你学习 Java 指明方向,而不是用来应付面试用的。加油!奥利给!
+
+**开始阅读之前必看** :
+
+1. [完结撒花!JavaGuide面试突击版来啦!](./docs/javaguide面试突击版.md)
+2. [JavaGuide重大更新记录](./docs/update-history.md)
+
+

 +
+ +
+ +
+ +
+
 +
+
 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+**[我的第一本算法书](https://book.douban.com/subject/30357170/) (豆瓣评分 7.1,0.2K+人评价)**
+
+一本不那么“专业”的算法书籍。和下面两本推荐的算法书籍都是比较通俗易懂,“不那么深入”的算法书籍。我个人非常推荐,配图和讲解都非常不错!
+
+
+
+**[我的第一本算法书](https://book.douban.com/subject/30357170/) (豆瓣评分 7.1,0.2K+人评价)**
+
+一本不那么“专业”的算法书籍。和下面两本推荐的算法书籍都是比较通俗易懂,“不那么深入”的算法书籍。我个人非常推荐,配图和讲解都非常不错!
+
+ +
+**[《算法图解》](https://book.douban.com/subject/26979890/)(豆瓣评分 8.4,1.5K+人评价)**
+
+入门类型的书籍,读起来比较浅显易懂,非常适合没有算法基础或者说算法没学好的小伙伴用来入门。示例丰富,图文并茂,以让人容易理解的方式阐释了算法.读起来比较快,内容不枯燥!
+
+
+
+**[啊哈!算法](https://book.douban.com/subject/25894685/) (豆瓣评分 7.7,0.5K+人评价)**
+
+和《算法图解》类似的算法趣味入门书籍。
+
+### 经典
+
+
+
+**[《算法图解》](https://book.douban.com/subject/26979890/)(豆瓣评分 8.4,1.5K+人评价)**
+
+入门类型的书籍,读起来比较浅显易懂,非常适合没有算法基础或者说算法没学好的小伙伴用来入门。示例丰富,图文并茂,以让人容易理解的方式阐释了算法.读起来比较快,内容不枯燥!
+
+
+
+**[啊哈!算法](https://book.douban.com/subject/25894685/) (豆瓣评分 7.7,0.5K+人评价)**
+
+和《算法图解》类似的算法趣味入门书籍。
+
+### 经典
+
+ +
+**[《算法 第四版》](https://book.douban.com/subject/10432347/)(豆瓣评分 9.3,0.4K+人评价)**
+
+我在大二的时候被我们的一个老师强烈安利过!自己也在当时购买了一本放在宿舍,到离开大学的时候自己大概看了一半多一点。因为内容实在太多了!另外,这本书还提供了详细的Java代码,非常适合学习 Java 的朋友来看,可以说是 Java 程序员的必备书籍之一了。
+
+再来介绍一下这本书籍吧!这本书籍算的上是算法领域经典的参考书,全面介绍了关于算法和数据结构的必备知识,并特别针对排序、搜索、图处理和字符串处理进行了论述。
+
+> **下面这些书籍都是经典中的经典,但是阅读起来难度也比较大,不做太多阐述,神书就完事了!推荐先看 《算法》,然后再选下面的书籍进行进一步阅读。不需要都看,找一本好好看或者找某本书的某一个章节知识点好好看。**
+
+
+
+**[《算法 第四版》](https://book.douban.com/subject/10432347/)(豆瓣评分 9.3,0.4K+人评价)**
+
+我在大二的时候被我们的一个老师强烈安利过!自己也在当时购买了一本放在宿舍,到离开大学的时候自己大概看了一半多一点。因为内容实在太多了!另外,这本书还提供了详细的Java代码,非常适合学习 Java 的朋友来看,可以说是 Java 程序员的必备书籍之一了。
+
+再来介绍一下这本书籍吧!这本书籍算的上是算法领域经典的参考书,全面介绍了关于算法和数据结构的必备知识,并特别针对排序、搜索、图处理和字符串处理进行了论述。
+
+> **下面这些书籍都是经典中的经典,但是阅读起来难度也比较大,不做太多阐述,神书就完事了!推荐先看 《算法》,然后再选下面的书籍进行进一步阅读。不需要都看,找一本好好看或者找某本书的某一个章节知识点好好看。**
+
+ +
+**[编程珠玑](https://book.douban.com/subject/3227098/)(豆瓣评分 9.1,2K+人评价)**
+
+经典名著,被无数读者强烈推荐的书籍,几乎是顶级程序员必看的书籍之一了。这本书的作者也非常厉害,Java之父 James Gosling 就是他的学生。
+
+很多人都说这本书不是教你具体的算法,而是教你一种编程的思考方式。这种思考方式不仅仅在编程领域适用,在其他同样适用。
+
+
+
+
+
+**[编程珠玑](https://book.douban.com/subject/3227098/)(豆瓣评分 9.1,2K+人评价)**
+
+经典名著,被无数读者强烈推荐的书籍,几乎是顶级程序员必看的书籍之一了。这本书的作者也非常厉害,Java之父 James Gosling 就是他的学生。
+
+很多人都说这本书不是教你具体的算法,而是教你一种编程的思考方式。这种思考方式不仅仅在编程领域适用,在其他同样适用。
+
+
+
+ +
+**[《算法设计手册》](https://book.douban.com/subject/4048566/)(豆瓣评分9.1 , 45人评价)**
+
+被 [Teach Yourself Computer Science](https://teachyourselfcs.com/) 强烈推荐的一本算法书籍。
+
+
+
+**[《算法设计手册》](https://book.douban.com/subject/4048566/)(豆瓣评分9.1 , 45人评价)**
+
+被 [Teach Yourself Computer Science](https://teachyourselfcs.com/) 强烈推荐的一本算法书籍。
+
+ +
+**[《算法导论》](https://book.douban.com/subject/20432061/) (豆瓣评分 9.2,0.4K+人评价)**
+
+
+
+**[《计算机程序设计艺术(第1卷)》](https://book.douban.com/subject/1130500/)(豆瓣评分 9.4,0.4K+人评价)**
+
+### 面试
+
+
+
+**[《剑指Offer》](https://book.douban.com/subject/6966465/)(豆瓣评分 8.3,0.7K+人评价)**
+
+这本面试宝典上面涵盖了很多经典的算法面试题,如果你要准备大厂面试的话一定不要错过这本书。
+
+《剑指Offer》 对应的算法编程题部分的开源项目解析:[CodingInterviews](https://github.com/gatieme/CodingInterviews)
+
+
+
+
+
+
+
+**[《算法导论》](https://book.douban.com/subject/20432061/) (豆瓣评分 9.2,0.4K+人评价)**
+
+
+
+**[《计算机程序设计艺术(第1卷)》](https://book.douban.com/subject/1130500/)(豆瓣评分 9.4,0.4K+人评价)**
+
+### 面试
+
+
+
+**[《剑指Offer》](https://book.douban.com/subject/6966465/)(豆瓣评分 8.3,0.7K+人评价)**
+
+这本面试宝典上面涵盖了很多经典的算法面试题,如果你要准备大厂面试的话一定不要错过这本书。
+
+《剑指Offer》 对应的算法编程题部分的开源项目解析:[CodingInterviews](https://github.com/gatieme/CodingInterviews)
+
+
+
+
+
+ +
+**[程序员代码面试指南:IT名企算法与数据结构题目最优解(第2版)](https://book.douban.com/subject/30422021/) (豆瓣评分 8.7,0.2K+人评价)**
+
+题目相比于《剑指 offer》 来说要难很多,题目涵盖面相比于《剑指 offer》也更加全面。全书一共有将近300道真实出现过的经典代码面试题。
+
+
+
+
+
+**[程序员代码面试指南:IT名企算法与数据结构题目最优解(第2版)](https://book.douban.com/subject/30422021/) (豆瓣评分 8.7,0.2K+人评价)**
+
+题目相比于《剑指 offer》 来说要难很多,题目涵盖面相比于《剑指 offer》也更加全面。全书一共有将近300道真实出现过的经典代码面试题。
+
+
+
+ +
+
+
+**[编程之美](https://book.douban.com/subject/3004255/)(豆瓣评分 8.4,3K+人评价)**
+
+这本书收集了约60道算法和程序设计题目,这些题目大部分在近年的笔试、面试中出现过,或者是被微软员工热烈讨论过。作者试图从书中各种有趣的问题出发,引导读者发现问题,分析问题,解决问题,寻找更优的解法。
+
+## 网站推荐
+
+我比较推荐大家可以刷一下 Leetcode ,我自己平时没事也会刷一下,我觉得刷 Leetcode 不仅是为了能让你更从容地面对面试中的手撕算法问题,更可以提高你的编程思维能力、解决问题的能力以及你对某门编程语言 API 的熟练度。当然牛客网也有一些算法题,我下面也整理了一些。
+
+### [LeetCode](https://leetcode-cn.com/)
+
+[如何高效地使用 LeetCode](https://leetcode-cn.com/articles/%E5%A6%82%E4%BD%95%E9%AB%98%E6%95%88%E5%9C%B0%E4%BD%BF%E7%94%A8-leetcode/)
+
+- [《程序员代码面试指南》](https://leetcode-cn.com/problemset/lcci/)
+- [《剑指offer》](https://leetcode-cn.com/problemset/lcof/)
+
+
+### [牛客网](https://www.nowcoder.com)
+
+**[在线编程](https://www.nowcoder.com/activity/oj):**
+
+- [《剑指offer》](https://www.nowcoder.com/ta/coding-interviews)
+- [《程序员代码面试指南》](https://www.nowcoder.com/ta/programmer-code-interview-guide)
+- [2019 校招真题](https://www.nowcoder.com/ta/2019test)
+- [大一大二编程入门训练](https://www.nowcoder.com/ta/beginner-programmers)
+- .......
+
+**[大厂编程面试真题](https://www.nowcoder.com/contestRoom?filter=0&orderByHotValue=3&target=content&categories=-1&mutiTagIds=2491&page=1)**
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/docs/database/MySQL Index.md b/docs/database/MySQL Index.md
new file mode 100644
index 00000000000..df3f0a05149
--- /dev/null
+++ b/docs/database/MySQL Index.md
@@ -0,0 +1,185 @@
+## 为什么要使用索引?
+
+1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
+2. 可以大大加快 数据的检索速度(大大减少的检索的数据量), 这也是创建索引的最主要的原因。
+3. 帮助服务器避免排序和临时表。
+4. 将随机IO变为顺序IO
+5. 可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
+
+## 索引这么多优点,为什么不对表中的每一个列创建一个索引呢?
+
+1. 当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
+2. 索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
+3. 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
+
+## 使用索引的注意事项?
+
+1. 在经常需要搜索的列上,可以加快搜索的速度;
+
+2. 在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
+
+3. 在经常需要排序的列上创 建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;
+
+4. 对于中到大型表索引都是非常有效的,但是特大型表的话维护开销会很大,不适合建索引
+
+5. 在经常用在连接的列上,这 些列主要是一些外键,可以加快连接的速度;
+
+6. 避免 where 子句中对宇段施加函数,这会造成无法命中索引。
+
+7. 在使用InnoDB时使用与业务无关的自增主键作为主键,即使用逻辑主键,而不要使用业务主键。
+
+8. ~~将打算加索引的列设置为 NOT NULL ,否则将导致引擎放弃使用索引而进行全表扫描。~~
+
+ 订正,来自[issue758](https://github.com/Snailclimb/JavaGuide/issues/758) 。**将某一列设置为default null,where 是可以走索引,另外索引列是否设置 null 是不影响性能的。** 但是,还是不建议列上允许为空。最好限制not null,因为null需要更多的存储空间并且null值无法参与某些运算。
+
+ 《高性能MySQL》第四章如是说:And, in case you’re wondering, allowing NULL values in the index really doesn’t impact performance 。NULL 值的索引查找流程参考:https://juejin.im/post/5d5defc2518825591523a1db ,相关阅读:[MySQL中IS NULL、IS NOT NULL、!=不能用索引?胡扯!](https://juejin.im/post/5d5defc2518825591523a1db) 。
+
+9. 删除长期未使用的索引,不用的索引的存在会造成不必要的性能损耗 MySQL 5.7 可以通过查询 sys 库的 chema_unused_indexes 视图来查询哪些索引从未被使用
+
+10. 在使用 limit offset 查询缓慢时,可以借助索引来提高性能
+
+## Mysql索引主要使用的两种数据结构
+
+### 哈希索引
+
+对于哈希索引来说,底层的数据结构就是哈希表,因此在绝大多数需求为单条记录查询的时候,可以选择哈希索引,查询性能最快;其余大部分场景,建议选择BTree索引。
+
+### BTree索引
+
+## MyISAM和InnoDB实现BTree索引方式的区别
+
+### MyISAM
+
+B+Tree叶节点的data域存放的是数据记录的地址。在索引检索的时候,首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“非聚簇索引”。
+
+### InnoDB
+
+其数据文件本身就是索引文件。相比MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按B+Tree组织的一个索引结构,树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。这被称为“聚簇索引(或聚集索引)”,而其余的索引都作为辅助索引,辅助索引的data域存储相应记录主键的值而不是地址,这也是和MyISAM不同的地方。在根据主索引搜索时,直接找到key所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,在走一遍主索引。 因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。 PS:整理自《Java工程师修炼之道》
+
+## 覆盖索引介绍
+
+### 什么是覆盖索引
+
+如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为“覆盖索引”。我们知道InnoDB存储引擎中,如果不是主键索引,叶子节点存储的是主键+列值。最终还是要“回表”,也就是要通过主键再查找一次。这样就会比较慢覆盖索引就是把要查询出的列和索引是对应的,不做回表操作!
+
+### 覆盖索引使用实例
+
+现在我创建了索引(username,age),我们执行下面的 sql 语句
+
+```sql
+select username , age from user where username = 'Java' and age = 22
+```
+
+在查询数据的时候:要查询出的列在叶子节点都存在!所以,就不用回表。
+
+## 选择索引和编写利用这些索引的查询的3个原则
+
+1. 单行访问是很慢的。特别是在机械硬盘存储中(SSD的随机I/O要快很多,不过这一点仍然成立)。如果服务器从存储中读取一个数据块只是为了获取其中一行,那么就浪费了很多工作。最好读取的块中能包含尽可能多所需要的行。使用索引可以创建位置引,用以提升效率。
+2. 按顺序访问范围数据是很快的,这有两个原因。第一,顺序1/0不需要多次磁盘寻道,所以比随机I/O要快很多(特别是对机械硬盘)。第二,如果服务器能够按需要顺序读取数据,那么就不再需要额外的排序操作,并且GROUPBY查询也无须再做排序和将行按组进行聚合计算了。
+3. 索引覆盖查询是很快的。如果一个索引包含了查询需要的所有列,那么存储引擎就
+ 不需要再回表查找行。这避免了大量的单行访问,而上面的第1点已经写明单行访
+ 问是很慢的。
+
+## 为什么索引能提高查询速度
+
+> 以下内容整理自:
+> 地址: https://juejin.im/post/5b55b842f265da0f9e589e79
+> 作者 :Java3y
+
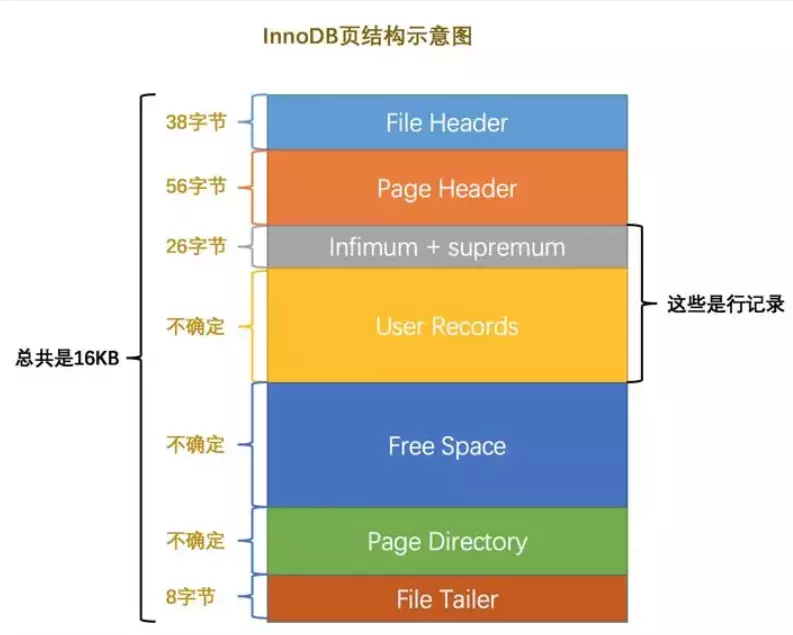
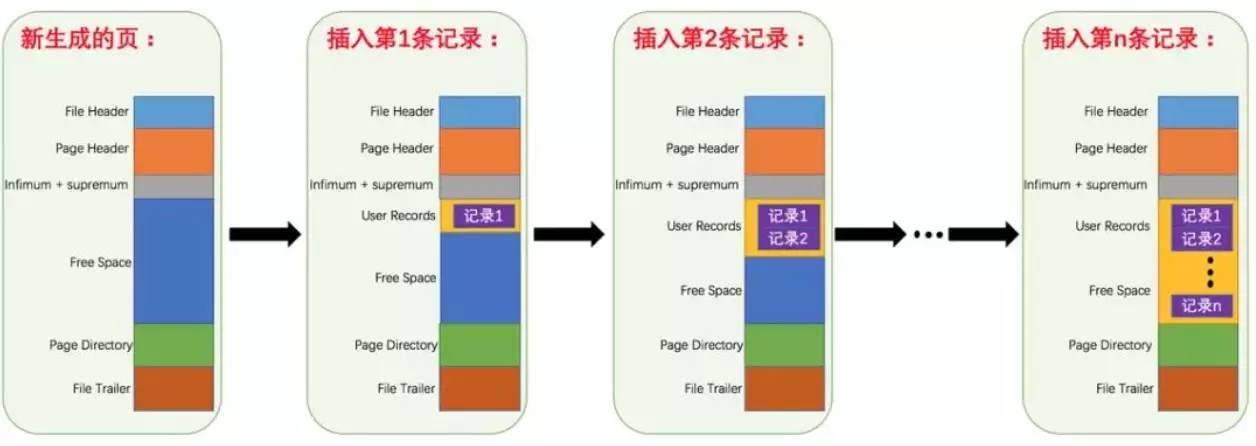
+### 先从 MySQL 的基本存储结构说起
+
+MySQL的基本存储结构是页(记录都存在页里边):
+
+
+
+
+
+ - **各个数据页可以组成一个双向链表**
+ - **每个数据页中的记录又可以组成一个单向链表**
+ - 每个数据页都会为存储在它里边儿的记录生成一个页目录,在通过主键查找某条记录的时候可以在页目录中使用二分法快速定位到对应的槽,然后再遍历该槽对应分组中的记录即可快速找到指定的记录
+ - 以其他列(非主键)作为搜索条件:只能从最小记录开始依次遍历单链表中的每条记录。
+
+所以说,如果我们写select * from user where indexname = 'xxx'这样没有进行任何优化的sql语句,默认会这样做:
+
+1. **定位到记录所在的页:需要遍历双向链表,找到所在的页**
+2. **从所在的页内中查找相应的记录:由于不是根据主键查询,只能遍历所在页的单链表了**
+
+很明显,在数据量很大的情况下这样查找会很慢!这样的时间复杂度为O(n)。
+
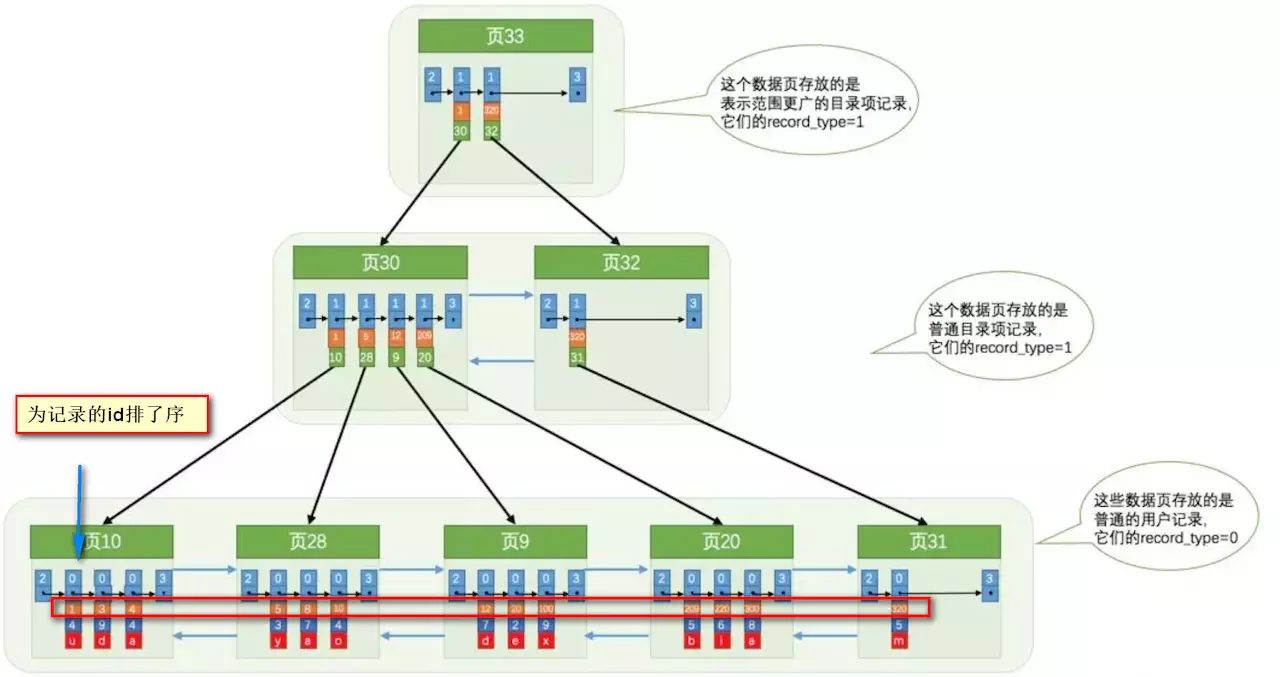
+
+### 使用索引之后
+
+索引做了些什么可以让我们查询加快速度呢?其实就是将无序的数据变成有序(相对):
+
+
+
+要找到id为8的记录简要步骤:
+
+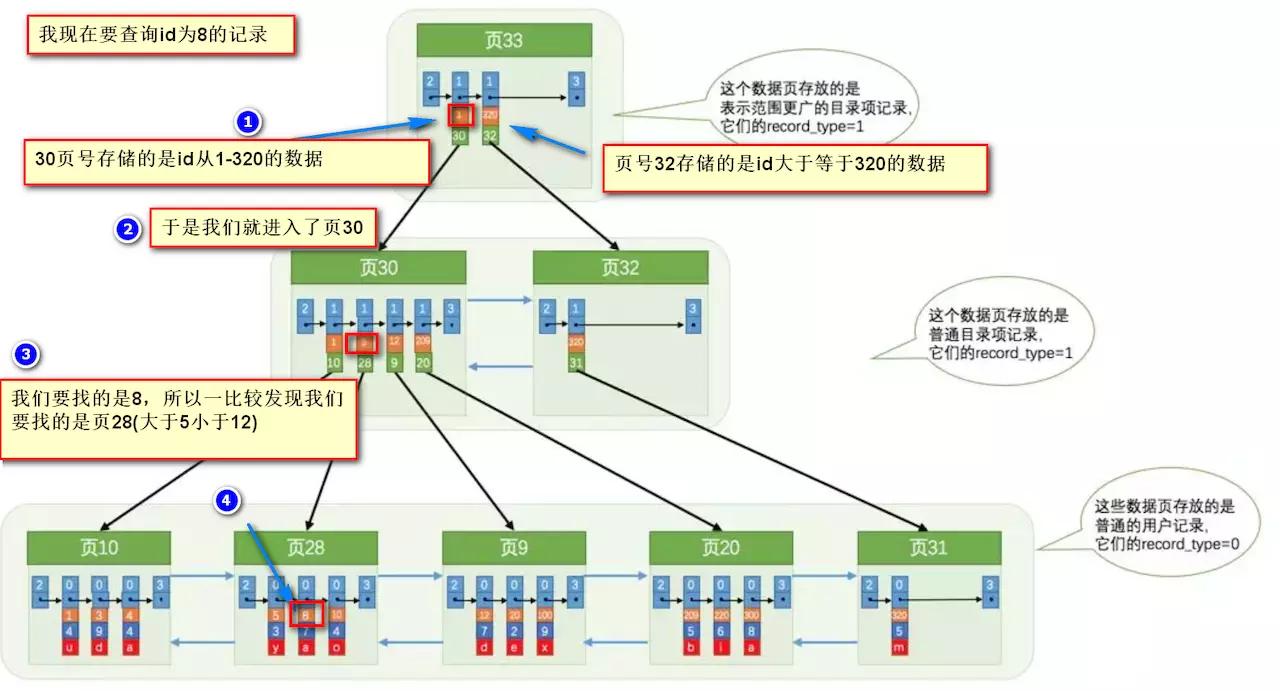
+
+很明显的是:没有用索引我们是需要遍历双向链表来定位对应的页,现在通过 **“目录”** 就可以很快地定位到对应的页上了!(二分查找,时间复杂度近似为O(logn))
+
+其实底层结构就是B+树,B+树作为树的一种实现,能够让我们很快地查找出对应的记录。
+
+## 关于索引其他重要的内容补充
+
+> 以下内容整理自:《Java工程师修炼之道》
+
+
+### 最左前缀原则
+
+MySQL中的索引可以以一定顺序引用多列,这种索引叫作联合索引。如User表的name和city加联合索引就是(name,city),而最左前缀原则指的是,如果查询的时候查询条件精确匹配索引的左边连续一列或几列,则此列就可以被用到。如下:
+
+```
+select * from user where name=xx and city=xx ; //可以命中索引
+select * from user where name=xx ; // 可以命中索引
+select * from user where city=xx ; // 无法命中索引
+```
+这里需要注意的是,查询的时候如果两个条件都用上了,但是顺序不同,如 `city= xx and name =xx`,那么现在的查询引擎会自动优化为匹配联合索引的顺序,这样是能够命中索引的。
+
+由于最左前缀原则,在创建联合索引时,索引字段的顺序需要考虑字段值去重之后的个数,较多的放前面。ORDER BY子句也遵循此规则。
+
+### 注意避免冗余索引
+
+冗余索引指的是索引的功能相同,能够命中 就肯定能命中 ,那么 就是冗余索引如(name,city )和(name )这两个索引就是冗余索引,能够命中后者的查询肯定是能够命中前者的 在大多数情况下,都应该尽量扩展已有的索引而不是创建新索引。
+
+MySQL 5.7 版本后,可以通过查询 sys 库的 `schema_redundant_indexes` 表来查看冗余索引
+
+### Mysql如何为表字段添加索引???
+
+1.添加PRIMARY KEY(主键索引)
+
+```
+ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` )
+```
+2.添加UNIQUE(唯一索引)
+
+```
+ALTER TABLE `table_name` ADD UNIQUE ( `column` )
+```
+
+3.添加INDEX(普通索引)
+
+```
+ALTER TABLE `table_name` ADD INDEX index_name ( `column` )
+```
+
+4.添加FULLTEXT(全文索引)
+
+```
+ALTER TABLE `table_name` ADD FULLTEXT ( `column`)
+```
+
+5.添加多列索引
+
+```
+ALTER TABLE `table_name` ADD INDEX index_name ( `column1`, `column2`, `column3` )
+```
+
+
+## 参考
+
+- 《Java工程师修炼之道》
+- 《MySQL高性能书籍_第3版》
+- https://juejin.im/post/5b55b842f265da0f9e589e79
+
diff --git a/docs/database/MySQL.md b/docs/database/MySQL.md
new file mode 100644
index 00000000000..8fd54b7d490
--- /dev/null
+++ b/docs/database/MySQL.md
@@ -0,0 +1,328 @@
+点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
+
+- [书籍推荐](#书籍推荐)
+- [文字教程推荐](#文字教程推荐)
+- [视频教程推荐](#视频教程推荐)
+- [常见问题总结](#常见问题总结)
+ - [什么是MySQL?](#什么是mysql)
+ - [存储引擎](#存储引擎)
+ - [一些常用命令](#一些常用命令)
+ - [MyISAM和InnoDB区别](#myisam和innodb区别)
+ - [字符集及校对规则](#字符集及校对规则)
+ - [索引](#索引)
+ - [查询缓存的使用](#查询缓存的使用)
+ - [什么是事务?](#什么是事务)
+ - [事物的四大特性(ACID)](#事物的四大特性acid)
+ - [并发事务带来哪些问题?](#并发事务带来哪些问题)
+ - [事务隔离级别有哪些?MySQL的默认隔离级别是?](#事务隔离级别有哪些mysql的默认隔离级别是)
+ - [锁机制与InnoDB锁算法](#锁机制与innodb锁算法)
+ - [大表优化](#大表优化)
+ - [1. 限定数据的范围](#1-限定数据的范围)
+ - [2. 读/写分离](#2-读写分离)
+ - [3. 垂直分区](#3-垂直分区)
+ - [4. 水平分区](#4-水平分区)
+ - [一条SQL语句在MySQL中如何执行的](#一条sql语句在mysql中如何执行的)
+ - [MySQL高性能优化规范建议](#mysql高性能优化规范建议)
+ - [一条SQL语句执行得很慢的原因有哪些?](#一条sql语句执行得很慢的原因有哪些)
+
+
+
+## 书籍推荐
+
+- 《SQL基础教程(第2版)》 (入门级)
+- 《高性能MySQL : 第3版》 (进阶)
+
+## 文字教程推荐
+
+- [SQL Tutorial](https://www.w3schools.com/sql/default.asp) (SQL语句学习,英文)、[SQL Tutorial](https://www.w3school.com.cn/sql/index.asp)(SQL语句学习,中文)、[SQL语句在线练习](https://www.w3schools.com/sql/exercise.asp) (非常不错)
+- [Github-MySQL入门教程(MySQL tutorial book)](https://github.com/jaywcjlove/mysql-tutorial) (从零开始学习MySQL,主要是面向MySQL数据库管理系统初学者)
+- [官方教程](https://dev.mysql.com/doc/refman/5.7/)
+- [MySQL 教程(菜鸟教程)](http://www.runoob.com/MySQL/MySQL-tutorial.html)
+
+## 相关资源推荐
+
+- [中国5级行政区域mysql库](https://github.com/kakuilan/china_area_mysql)
+
+## 视频教程推荐
+
+**基础入门:** [与MySQL的零距离接触-慕课网](https://www.imooc.com/learn/122)
+
+**MySQL开发技巧:** [MySQL开发技巧(一)](https://www.imooc.com/learn/398) [MySQL开发技巧(二)](https://www.imooc.com/learn/427) [MySQL开发技巧(三)](https://www.imooc.com/learn/449)
+
+**MySQL5.7新特性及相关优化技巧:** [MySQL5.7版本新特性](https://www.imooc.com/learn/533) [性能优化之MySQL优化](https://www.imooc.com/learn/194)
+
+[MySQL集群(PXC)入门](https://www.imooc.com/learn/993) [MyCAT入门及应用](https://www.imooc.com/learn/951)
+
+## 常见问题总结
+
+### 什么是MySQL?
+
+MySQL 是一种关系型数据库,在Java企业级开发中非常常用,因为 MySQL 是开源免费的,并且方便扩展。阿里巴巴数据库系统也大量用到了 MySQL,因此它的稳定性是有保障的。MySQL是开放源代码的,因此任何人都可以在 GPL(General Public License) 的许可下下载并根据个性化的需要对其进行修改。MySQL的默认端口号是**3306**。
+
+### 存储引擎
+
+#### 一些常用命令
+
+**查看MySQL提供的所有存储引擎**
+
+```sql
+mysql> show engines;
+```
+
+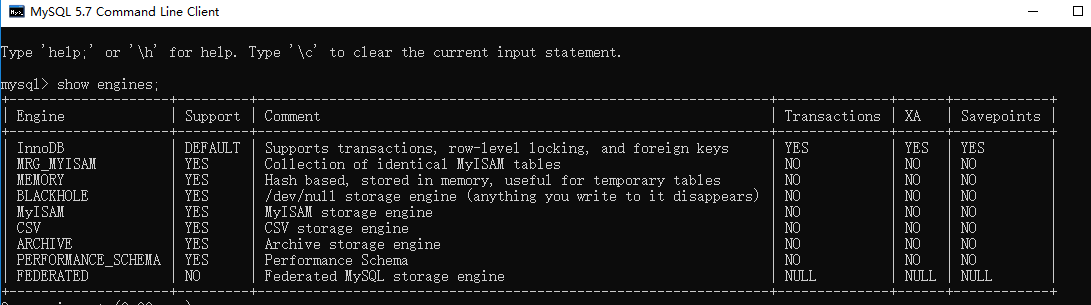
+
+从上图我们可以查看出 MySQL 当前默认的存储引擎是InnoDB,并且在5.7版本所有的存储引擎中只有 InnoDB 是事务性存储引擎,也就是说只有 InnoDB 支持事务。
+
+**查看MySQL当前默认的存储引擎**
+
+我们也可以通过下面的命令查看默认的存储引擎。
+
+```sql
+mysql> show variables like '%storage_engine%';
+```
+
+**查看表的存储引擎**
+
+```sql
+show table status like "table_name" ;
+```
+
+
+
+#### MyISAM和InnoDB区别
+
+MyISAM是MySQL的默认数据库引擎(5.5版之前)。虽然性能极佳,而且提供了大量的特性,包括全文索引、压缩、空间函数等,但MyISAM不支持事务和行级锁,而且最大的缺陷就是崩溃后无法安全恢复。不过,5.5版本之后,MySQL引入了InnoDB(事务性数据库引擎),MySQL 5.5版本后默认的存储引擎为InnoDB。
+
+大多数时候我们使用的都是 InnoDB 存储引擎,但是在某些情况下使用 MyISAM 也是合适的比如读密集的情况下。(如果你不介意 MyISAM 崩溃恢复问题的话)。
+
+**两者的对比:**
+
+1. **是否支持行级锁** : MyISAM 只有表级锁(table-level locking),而InnoDB 支持行级锁(row-level locking)和表级锁,默认为行级锁。
+2. **是否支持事务和崩溃后的安全恢复: MyISAM** 强调的是性能,每次查询具有原子性,其执行速度比InnoDB类型更快,但是不提供事务支持。但是**InnoDB** 提供事务支持事务,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
+3. **是否支持外键:** MyISAM不支持,而InnoDB支持。
+4. **是否支持MVCC** :仅 InnoDB 支持。应对高并发事务, MVCC比单纯的加锁更高效;MVCC只在 `READ COMMITTED` 和 `REPEATABLE READ` 两个隔离级别下工作;MVCC可以使用 乐观(optimistic)锁 和 悲观(pessimistic)锁来实现;各数据库中MVCC实现并不统一。推荐阅读:[MySQL-InnoDB-MVCC多版本并发控制](https://segmentfault.com/a/1190000012650596)
+5. ......
+
+《MySQL高性能》上面有一句话这样写到:
+
+> 不要轻易相信“MyISAM比InnoDB快”之类的经验之谈,这个结论往往不是绝对的。在很多我们已知场景中,InnoDB的速度都可以让MyISAM望尘莫及,尤其是用到了聚簇索引,或者需要访问的数据都可以放入内存的应用。
+
+一般情况下我们选择 InnoDB 都是没有问题的,但是某些情况下你并不在乎可扩展能力和并发能力,也不需要事务支持,也不在乎崩溃后的安全恢复问题的话,选择MyISAM也是一个不错的选择。但是一般情况下,我们都是需要考虑到这些问题的。
+
+### 字符集及校对规则
+
+字符集指的是一种从二进制编码到某类字符符号的映射。校对规则则是指某种字符集下的排序规则。MySQL中每一种字符集都会对应一系列的校对规则。
+
+MySQL采用的是类似继承的方式指定字符集的默认值,每个数据库以及每张数据表都有自己的默认值,他们逐层继承。比如:某个库中所有表的默认字符集将是该数据库所指定的字符集(这些表在没有指定字符集的情况下,才会采用默认字符集) PS:整理自《Java工程师修炼之道》
+
+详细内容可以参考: [MySQL字符集及校对规则的理解](https://www.cnblogs.com/geaozhang/p/6724393.html#MySQLyuzifuji)
+
+### 索引
+
+MySQL索引使用的数据结构主要有**BTree索引** 和 **哈希索引** 。对于哈希索引来说,底层的数据结构就是哈希表,因此在绝大多数需求为单条记录查询的时候,可以选择哈希索引,查询性能最快;其余大部分场景,建议选择BTree索引。
+
+MySQL的BTree索引使用的是B树中的B+Tree,但对于主要的两种存储引擎的实现方式是不同的。
+
+- **MyISAM:** B+Tree叶节点的data域存放的是数据记录的地址。在索引检索的时候,首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“非聚簇索引”。
+- **InnoDB:** 其数据文件本身就是索引文件。相比MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按B+Tree组织的一个索引结构,树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。这被称为“聚簇索引(或聚集索引)”。而其余的索引都作为辅助索引,辅助索引的data域存储相应记录主键的值而不是地址,这也是和MyISAM不同的地方。**在根据主索引搜索时,直接找到key所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,再走一遍主索引。** **因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。** PS:整理自《Java工程师修炼之道》
+
+**更多关于索引的内容可以查看文档首页MySQL目录下关于索引的详细总结。**
+
+### 查询缓存的使用
+
+> 执行查询语句的时候,会先查询缓存。不过,MySQL 8.0 版本后移除,因为这个功能不太实用
+
+my.cnf加入以下配置,重启MySQL开启查询缓存
+```properties
+query_cache_type=1
+query_cache_size=600000
+```
+
+MySQL执行以下命令也可以开启查询缓存
+
+```properties
+set global query_cache_type=1;
+set global query_cache_size=600000;
+```
+如上,**开启查询缓存后在同样的查询条件以及数据情况下,会直接在缓存中返回结果**。这里的查询条件包括查询本身、当前要查询的数据库、客户端协议版本号等一些可能影响结果的信息。因此任何两个查询在任何字符上的不同都会导致缓存不命中。此外,如果查询中包含任何用户自定义函数、存储函数、用户变量、临时表、MySQL库中的系统表,其查询结果也不会被缓存。
+
+缓存建立之后,MySQL的查询缓存系统会跟踪查询中涉及的每张表,如果这些表(数据或结构)发生变化,那么和这张表相关的所有缓存数据都将失效。
+
+**缓存虽然能够提升数据库的查询性能,但是缓存同时也带来了额外的开销,每次查询后都要做一次缓存操作,失效后还要销毁。** 因此,开启缓存查询要谨慎,尤其对于写密集的应用来说更是如此。如果开启,要注意合理控制缓存空间大小,一般来说其大小设置为几十MB比较合适。此外,**还可以通过sql_cache和sql_no_cache来控制某个查询语句是否需要缓存:**
+```sql
+select sql_no_cache count(*) from usr;
+```
+
+### 什么是事务?
+
+**事务是逻辑上的一组操作,要么都执行,要么都不执行。**
+
+事务最经典也经常被拿出来说例子就是转账了。假如小明要给小红转账1000元,这个转账会涉及到两个关键操作就是:将小明的余额减少1000元,将小红的余额增加1000元。万一在这两个操作之间突然出现错误比如银行系统崩溃,导致小明余额减少而小红的余额没有增加,这样就不对了。事务就是保证这两个关键操作要么都成功,要么都要失败。
+
+### 事物的四大特性(ACID)
+
+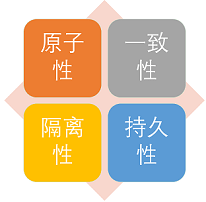
+
+1. **原子性(Atomicity):** 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
+2. **一致性(Consistency):** 执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是相同的;
+3. **隔离性(Isolation):** 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
+4. **持久性(Durability):** 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
+
+### 并发事务带来哪些问题?
+
+在典型的应用程序中,多个事务并发运行,经常会操作相同的数据来完成各自的任务(多个用户对同一数据进行操作)。并发虽然是必须的,但可能会导致以下的问题。
+
+- **脏读(Dirty read):** 当一个事务正在访问数据并且对数据进行了修改,而这种修改还没有提交到数据库中,这时另外一个事务也访问了这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据,那么另外一个事务读到的这个数据是“脏数据”,依据“脏数据”所做的操作可能是不正确的。
+- **丢失修改(Lost to modify):** 指在一个事务读取一个数据时,另外一个事务也访问了该数据,那么在第一个事务中修改了这个数据后,第二个事务也修改了这个数据。这样第一个事务内的修改结果就被丢失,因此称为丢失修改。 例如:事务1读取某表中的数据A=20,事务2也读取A=20,事务1修改A=A-1,事务2也修改A=A-1,最终结果A=19,事务1的修改被丢失。
+- **不可重复读(Unrepeatableread):** 指在一个事务内多次读同一数据。在这个事务还没有结束时,另一个事务也访问该数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改导致第一个事务两次读取的数据可能不太一样。这就发生了在一个事务内两次读到的数据是不一样的情况,因此称为不可重复读。
+- **幻读(Phantom read):** 幻读与不可重复读类似。它发生在一个事务(T1)读取了几行数据,接着另一个并发事务(T2)插入了一些数据时。在随后的查询中,第一个事务(T1)就会发现多了一些原本不存在的记录,就好像发生了幻觉一样,所以称为幻读。
+
+**不可重复读和幻读区别:**
+
+不可重复读的重点是修改比如多次读取一条记录发现其中某些列的值被修改,幻读的重点在于新增或者删除比如多次读取一条记录发现记录增多或减少了。
+
+### 事务隔离级别有哪些?MySQL的默认隔离级别是?
+
+**SQL 标准定义了四个隔离级别:**
+
+- **READ-UNCOMMITTED(读取未提交):** 最低的隔离级别,允许读取尚未提交的数据变更,**可能会导致脏读、幻读或不可重复读**。
+- **READ-COMMITTED(读取已提交):** 允许读取并发事务已经提交的数据,**可以阻止脏读,但是幻读或不可重复读仍有可能发生**。
+- **REPEATABLE-READ(可重复读):** 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,**可以阻止脏读和不可重复读,但幻读仍有可能发生**。
+- **SERIALIZABLE(可串行化):** 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,**该级别可以防止脏读、不可重复读以及幻读**。
+
+------
+
+| 隔离级别 | 脏读 | 不可重复读 | 幻影读 |
+| :--------------: | :--: | :--------: | :----: |
+| READ-UNCOMMITTED | √ | √ | √ |
+| READ-COMMITTED | × | √ | √ |
+| REPEATABLE-READ | × | × | √ |
+| SERIALIZABLE | × | × | × |
+
+MySQL InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)**。我们可以通过`SELECT @@tx_isolation;`命令来查看,MySQL 8.0 该命令改为`SELECT @@transaction_isolation;`
+
+```sql
+mysql> SELECT @@tx_isolation;
++-----------------+
+| @@tx_isolation |
++-----------------+
+| REPEATABLE-READ |
++-----------------+
+```
+
+这里需要注意的是:与 SQL 标准不同的地方在于 InnoDB 存储引擎在 **REPEATABLE-READ(可重读)**
+事务隔离级别下使用的是Next-Key Lock 锁算法,因此可以避免幻读的产生,这与其他数据库系统(如 SQL Server)
+是不同的。所以说InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)** 已经可以完全保证事务的隔离性要求,即达到了
+ SQL标准的 **SERIALIZABLE(可串行化)** 隔离级别。因为隔离级别越低,事务请求的锁越少,所以大部分数据库系统的隔离级别都是 **READ-COMMITTED(读取提交内容)** ,但是你要知道的是InnoDB 存储引擎默认使用 **REPEAaTABLE-READ(可重读)** 并不会有任何性能损失。
+
+InnoDB 存储引擎在 **分布式事务** 的情况下一般会用到 **SERIALIZABLE(可串行化)** 隔离级别。
+
+### 锁机制与InnoDB锁算法
+
+**MyISAM和InnoDB存储引擎使用的锁:**
+
+- MyISAM采用表级锁(table-level locking)。
+- InnoDB支持行级锁(row-level locking)和表级锁,默认为行级锁
+
+**表级锁和行级锁对比:**
+
+- **表级锁:** MySQL中锁定 **粒度最大** 的一种锁,对当前操作的整张表加锁,实现简单,资源消耗也比较少,加锁快,不会出现死锁。其锁定粒度最大,触发锁冲突的概率最高,并发度最低,MyISAM和 InnoDB引擎都支持表级锁。
+- **行级锁:** MySQL中锁定 **粒度最小** 的一种锁,只针对当前操作的行进行加锁。 行级锁能大大减少数据库操作的冲突。其加锁粒度最小,并发度高,但加锁的开销也最大,加锁慢,会出现死锁。
+
+详细内容可以参考: MySQL锁机制简单了解一下:[https://blog.csdn.net/qq_34337272/article/details/80611486](https://blog.csdn.net/qq_34337272/article/details/80611486)
+
+**InnoDB存储引擎的锁的算法有三种:**
+
+- Record lock:单个行记录上的锁
+- Gap lock:间隙锁,锁定一个范围,不包括记录本身
+- Next-key lock:record+gap 锁定一个范围,包含记录本身
+
+**相关知识点:**
+
+1. innodb对于行的查询使用next-key lock
+2. Next-locking keying为了解决Phantom Problem幻读问题
+3. 当查询的索引含有唯一属性时,将next-key lock降级为record key
+4. Gap锁设计的目的是为了阻止多个事务将记录插入到同一范围内,而这会导致幻读问题的产生
+5. 有两种方式显式关闭gap锁:(除了外键约束和唯一性检查外,其余情况仅使用record lock) A. 将事务隔离级别设置为RC B. 将参数innodb_locks_unsafe_for_binlog设置为1
+
+### 大表优化
+
+当MySQL单表记录数过大时,数据库的CRUD性能会明显下降,一些常见的优化措施如下:
+
+#### 1. 限定数据的范围
+
+务必禁止不带任何限制数据范围条件的查询语句。比如:我们当用户在查询订单历史的时候,我们可以控制在一个月的范围内;
+
+#### 2. 读/写分离
+
+经典的数据库拆分方案,主库负责写,从库负责读;
+
+#### 3. 垂直分区
+
+ **根据数据库里面数据表的相关性进行拆分。** 例如,用户表中既有用户的登录信息又有用户的基本信息,可以将用户表拆分成两个单独的表,甚至放到单独的库做分库。
+
+ **简单来说垂直拆分是指数据表列的拆分,把一张列比较多的表拆分为多张表。** 如下图所示,这样来说大家应该就更容易理解了。
+ 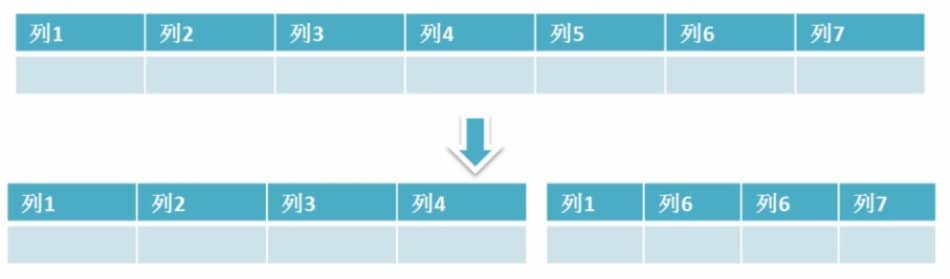
+
+- **垂直拆分的优点:** 可以使得列数据变小,在查询时减少读取的Block数,减少I/O次数。此外,垂直分区可以简化表的结构,易于维护。
+- **垂直拆分的缺点:** 主键会出现冗余,需要管理冗余列,并会引起Join操作,可以通过在应用层进行Join来解决。此外,垂直分区会让事务变得更加复杂;
+
+#### 4. 水平分区
+
+**保持数据表结构不变,通过某种策略存储数据分片。这样每一片数据分散到不同的表或者库中,达到了分布式的目的。 水平拆分可以支撑非常大的数据量。**
+
+ 水平拆分是指数据表行的拆分,表的行数超过200万行时,就会变慢,这时可以把一张的表的数据拆成多张表来存放。举个例子:我们可以将用户信息表拆分成多个用户信息表,这样就可以避免单一表数据量过大对性能造成影响。
+
+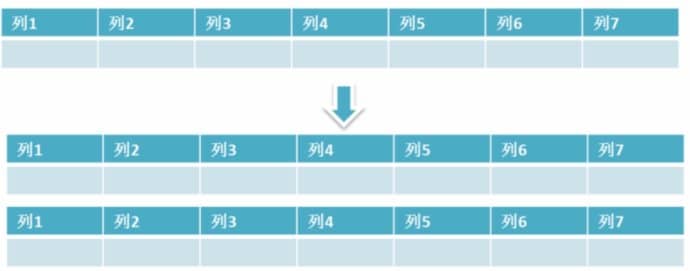
+
+水平拆分可以支持非常大的数据量。需要注意的一点是:分表仅仅是解决了单一表数据过大的问题,但由于表的数据还是在同一台机器上,其实对于提升MySQL并发能力没有什么意义,所以 **水平拆分最好分库** 。
+
+水平拆分能够 **支持非常大的数据量存储,应用端改造也少**,但 **分片事务难以解决** ,跨节点Join性能较差,逻辑复杂。《Java工程师修炼之道》的作者推荐 **尽量不要对数据进行分片,因为拆分会带来逻辑、部署、运维的各种复杂度** ,一般的数据表在优化得当的情况下支撑千万以下的数据量是没有太大问题的。如果实在要分片,尽量选择客户端分片架构,这样可以减少一次和中间件的网络I/O。
+
+**下面补充一下数据库分片的两种常见方案:**
+
+- **客户端代理:** **分片逻辑在应用端,封装在jar包中,通过修改或者封装JDBC层来实现。** 当当网的 **Sharding-JDBC** 、阿里的TDDL是两种比较常用的实现。
+- **中间件代理:** **在应用和数据中间加了一个代理层。分片逻辑统一维护在中间件服务中。** 我们现在谈的 **Mycat** 、360的Atlas、网易的DDB等等都是这种架构的实现。
+
+详细内容可以参考: MySQL大表优化方案: [https://segmentfault.com/a/1190000006158186](https://segmentfault.com/a/1190000006158186)
+
+### 解释一下什么是池化设计思想。什么是数据库连接池?为什么需要数据库连接池?
+
+池化设计应该不是一个新名词。我们常见的如java线程池、jdbc连接池、redis连接池等就是这类设计的代表实现。这种设计会初始预设资源,解决的问题就是抵消每次获取资源的消耗,如创建线程的开销,获取远程连接的开销等。就好比你去食堂打饭,打饭的大妈会先把饭盛好几份放那里,你来了就直接拿着饭盒加菜即可,不用再临时又盛饭又打菜,效率就高了。除了初始化资源,池化设计还包括如下这些特征:池子的初始值、池子的活跃值、池子的最大值等,这些特征可以直接映射到java线程池和数据库连接池的成员属性中。这篇文章对[池化设计思想](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485679&idx=1&sn=57dbca8c9ad49e1f3968ecff04a4f735&chksm=cea24724f9d5ce3212292fac291234a760c99c0960b5430d714269efe33554730b5f71208582&token=1141994790&lang=zh_CN#rd)介绍的还不错,直接复制过来,避免重复造轮子了。
+
+数据库连接本质就是一个 socket 的连接。数据库服务端还要维护一些缓存和用户权限信息之类的 所以占用了一些内存。我们可以把数据库连接池是看做是维护的数据库连接的缓存,以便将来需要对数据库的请求时可以重用这些连接。为每个用户打开和维护数据库连接,尤其是对动态数据库驱动的网站应用程序的请求,既昂贵又浪费资源。**在连接池中,创建连接后,将其放置在池中,并再次使用它,因此不必建立新的连接。如果使用了所有连接,则会建立一个新连接并将其添加到池中**。 连接池还减少了用户必须等待建立与数据库的连接的时间。
+
+### 分库分表之后,id 主键如何处理?
+
+因为要是分成多个表之后,每个表都是从 1 开始累加,这样是不对的,我们需要一个全局唯一的 id 来支持。
+
+生成全局 id 有下面这几种方式:
+
+- **UUID**:不适合作为主键,因为太长了,并且无序不可读,查询效率低。比较适合用于生成唯一的名字的标示比如文件的名字。
+- **数据库自增 id** : 两台数据库分别设置不同步长,生成不重复ID的策略来实现高可用。这种方式生成的 id 有序,但是需要独立部署数据库实例,成本高,还会有性能瓶颈。
+- **利用 redis 生成 id :** 性能比较好,灵活方便,不依赖于数据库。但是,引入了新的组件造成系统更加复杂,可用性降低,编码更加复杂,增加了系统成本。
+- **Twitter的snowflake算法** :Github 地址:https://github.com/twitter-archive/snowflake。
+- **美团的[Leaf](https://tech.meituan.com/2017/04/21/mt-leaf.html)分布式ID生成系统** :Leaf 是美团开源的分布式ID生成器,能保证全局唯一性、趋势递增、单调递增、信息安全,里面也提到了几种分布式方案的对比,但也需要依赖关系数据库、Zookeeper等中间件。感觉还不错。美团技术团队的一篇文章:https://tech.meituan.com/2017/04/21/mt-leaf.html 。
+- ......
+
+### 一条SQL语句在MySQL中如何执行的
+
+[一条SQL语句在MySQL中如何执行的](
+
+
+
+**[编程之美](https://book.douban.com/subject/3004255/)(豆瓣评分 8.4,3K+人评价)**
+
+这本书收集了约60道算法和程序设计题目,这些题目大部分在近年的笔试、面试中出现过,或者是被微软员工热烈讨论过。作者试图从书中各种有趣的问题出发,引导读者发现问题,分析问题,解决问题,寻找更优的解法。
+
+## 网站推荐
+
+我比较推荐大家可以刷一下 Leetcode ,我自己平时没事也会刷一下,我觉得刷 Leetcode 不仅是为了能让你更从容地面对面试中的手撕算法问题,更可以提高你的编程思维能力、解决问题的能力以及你对某门编程语言 API 的熟练度。当然牛客网也有一些算法题,我下面也整理了一些。
+
+### [LeetCode](https://leetcode-cn.com/)
+
+[如何高效地使用 LeetCode](https://leetcode-cn.com/articles/%E5%A6%82%E4%BD%95%E9%AB%98%E6%95%88%E5%9C%B0%E4%BD%BF%E7%94%A8-leetcode/)
+
+- [《程序员代码面试指南》](https://leetcode-cn.com/problemset/lcci/)
+- [《剑指offer》](https://leetcode-cn.com/problemset/lcof/)
+
+
+### [牛客网](https://www.nowcoder.com)
+
+**[在线编程](https://www.nowcoder.com/activity/oj):**
+
+- [《剑指offer》](https://www.nowcoder.com/ta/coding-interviews)
+- [《程序员代码面试指南》](https://www.nowcoder.com/ta/programmer-code-interview-guide)
+- [2019 校招真题](https://www.nowcoder.com/ta/2019test)
+- [大一大二编程入门训练](https://www.nowcoder.com/ta/beginner-programmers)
+- .......
+
+**[大厂编程面试真题](https://www.nowcoder.com/contestRoom?filter=0&orderByHotValue=3&target=content&categories=-1&mutiTagIds=2491&page=1)**
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/docs/database/MySQL Index.md b/docs/database/MySQL Index.md
new file mode 100644
index 00000000000..df3f0a05149
--- /dev/null
+++ b/docs/database/MySQL Index.md
@@ -0,0 +1,185 @@
+## 为什么要使用索引?
+
+1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
+2. 可以大大加快 数据的检索速度(大大减少的检索的数据量), 这也是创建索引的最主要的原因。
+3. 帮助服务器避免排序和临时表。
+4. 将随机IO变为顺序IO
+5. 可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
+
+## 索引这么多优点,为什么不对表中的每一个列创建一个索引呢?
+
+1. 当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
+2. 索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
+3. 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
+
+## 使用索引的注意事项?
+
+1. 在经常需要搜索的列上,可以加快搜索的速度;
+
+2. 在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
+
+3. 在经常需要排序的列上创 建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;
+
+4. 对于中到大型表索引都是非常有效的,但是特大型表的话维护开销会很大,不适合建索引
+
+5. 在经常用在连接的列上,这 些列主要是一些外键,可以加快连接的速度;
+
+6. 避免 where 子句中对宇段施加函数,这会造成无法命中索引。
+
+7. 在使用InnoDB时使用与业务无关的自增主键作为主键,即使用逻辑主键,而不要使用业务主键。
+
+8. ~~将打算加索引的列设置为 NOT NULL ,否则将导致引擎放弃使用索引而进行全表扫描。~~
+
+ 订正,来自[issue758](https://github.com/Snailclimb/JavaGuide/issues/758) 。**将某一列设置为default null,where 是可以走索引,另外索引列是否设置 null 是不影响性能的。** 但是,还是不建议列上允许为空。最好限制not null,因为null需要更多的存储空间并且null值无法参与某些运算。
+
+ 《高性能MySQL》第四章如是说:And, in case you’re wondering, allowing NULL values in the index really doesn’t impact performance 。NULL 值的索引查找流程参考:https://juejin.im/post/5d5defc2518825591523a1db ,相关阅读:[MySQL中IS NULL、IS NOT NULL、!=不能用索引?胡扯!](https://juejin.im/post/5d5defc2518825591523a1db) 。
+
+9. 删除长期未使用的索引,不用的索引的存在会造成不必要的性能损耗 MySQL 5.7 可以通过查询 sys 库的 chema_unused_indexes 视图来查询哪些索引从未被使用
+
+10. 在使用 limit offset 查询缓慢时,可以借助索引来提高性能
+
+## Mysql索引主要使用的两种数据结构
+
+### 哈希索引
+
+对于哈希索引来说,底层的数据结构就是哈希表,因此在绝大多数需求为单条记录查询的时候,可以选择哈希索引,查询性能最快;其余大部分场景,建议选择BTree索引。
+
+### BTree索引
+
+## MyISAM和InnoDB实现BTree索引方式的区别
+
+### MyISAM
+
+B+Tree叶节点的data域存放的是数据记录的地址。在索引检索的时候,首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“非聚簇索引”。
+
+### InnoDB
+
+其数据文件本身就是索引文件。相比MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按B+Tree组织的一个索引结构,树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。这被称为“聚簇索引(或聚集索引)”,而其余的索引都作为辅助索引,辅助索引的data域存储相应记录主键的值而不是地址,这也是和MyISAM不同的地方。在根据主索引搜索时,直接找到key所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,在走一遍主索引。 因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。 PS:整理自《Java工程师修炼之道》
+
+## 覆盖索引介绍
+
+### 什么是覆盖索引
+
+如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为“覆盖索引”。我们知道InnoDB存储引擎中,如果不是主键索引,叶子节点存储的是主键+列值。最终还是要“回表”,也就是要通过主键再查找一次。这样就会比较慢覆盖索引就是把要查询出的列和索引是对应的,不做回表操作!
+
+### 覆盖索引使用实例
+
+现在我创建了索引(username,age),我们执行下面的 sql 语句
+
+```sql
+select username , age from user where username = 'Java' and age = 22
+```
+
+在查询数据的时候:要查询出的列在叶子节点都存在!所以,就不用回表。
+
+## 选择索引和编写利用这些索引的查询的3个原则
+
+1. 单行访问是很慢的。特别是在机械硬盘存储中(SSD的随机I/O要快很多,不过这一点仍然成立)。如果服务器从存储中读取一个数据块只是为了获取其中一行,那么就浪费了很多工作。最好读取的块中能包含尽可能多所需要的行。使用索引可以创建位置引,用以提升效率。
+2. 按顺序访问范围数据是很快的,这有两个原因。第一,顺序1/0不需要多次磁盘寻道,所以比随机I/O要快很多(特别是对机械硬盘)。第二,如果服务器能够按需要顺序读取数据,那么就不再需要额外的排序操作,并且GROUPBY查询也无须再做排序和将行按组进行聚合计算了。
+3. 索引覆盖查询是很快的。如果一个索引包含了查询需要的所有列,那么存储引擎就
+ 不需要再回表查找行。这避免了大量的单行访问,而上面的第1点已经写明单行访
+ 问是很慢的。
+
+## 为什么索引能提高查询速度
+
+> 以下内容整理自:
+> 地址: https://juejin.im/post/5b55b842f265da0f9e589e79
+> 作者 :Java3y
+
+### 先从 MySQL 的基本存储结构说起
+
+MySQL的基本存储结构是页(记录都存在页里边):
+
+
+
+
+
+ - **各个数据页可以组成一个双向链表**
+ - **每个数据页中的记录又可以组成一个单向链表**
+ - 每个数据页都会为存储在它里边儿的记录生成一个页目录,在通过主键查找某条记录的时候可以在页目录中使用二分法快速定位到对应的槽,然后再遍历该槽对应分组中的记录即可快速找到指定的记录
+ - 以其他列(非主键)作为搜索条件:只能从最小记录开始依次遍历单链表中的每条记录。
+
+所以说,如果我们写select * from user where indexname = 'xxx'这样没有进行任何优化的sql语句,默认会这样做:
+
+1. **定位到记录所在的页:需要遍历双向链表,找到所在的页**
+2. **从所在的页内中查找相应的记录:由于不是根据主键查询,只能遍历所在页的单链表了**
+
+很明显,在数据量很大的情况下这样查找会很慢!这样的时间复杂度为O(n)。
+
+
+### 使用索引之后
+
+索引做了些什么可以让我们查询加快速度呢?其实就是将无序的数据变成有序(相对):
+
+
+
+要找到id为8的记录简要步骤:
+
+
+
+很明显的是:没有用索引我们是需要遍历双向链表来定位对应的页,现在通过 **“目录”** 就可以很快地定位到对应的页上了!(二分查找,时间复杂度近似为O(logn))
+
+其实底层结构就是B+树,B+树作为树的一种实现,能够让我们很快地查找出对应的记录。
+
+## 关于索引其他重要的内容补充
+
+> 以下内容整理自:《Java工程师修炼之道》
+
+
+### 最左前缀原则
+
+MySQL中的索引可以以一定顺序引用多列,这种索引叫作联合索引。如User表的name和city加联合索引就是(name,city),而最左前缀原则指的是,如果查询的时候查询条件精确匹配索引的左边连续一列或几列,则此列就可以被用到。如下:
+
+```
+select * from user where name=xx and city=xx ; //可以命中索引
+select * from user where name=xx ; // 可以命中索引
+select * from user where city=xx ; // 无法命中索引
+```
+这里需要注意的是,查询的时候如果两个条件都用上了,但是顺序不同,如 `city= xx and name =xx`,那么现在的查询引擎会自动优化为匹配联合索引的顺序,这样是能够命中索引的。
+
+由于最左前缀原则,在创建联合索引时,索引字段的顺序需要考虑字段值去重之后的个数,较多的放前面。ORDER BY子句也遵循此规则。
+
+### 注意避免冗余索引
+
+冗余索引指的是索引的功能相同,能够命中 就肯定能命中 ,那么 就是冗余索引如(name,city )和(name )这两个索引就是冗余索引,能够命中后者的查询肯定是能够命中前者的 在大多数情况下,都应该尽量扩展已有的索引而不是创建新索引。
+
+MySQL 5.7 版本后,可以通过查询 sys 库的 `schema_redundant_indexes` 表来查看冗余索引
+
+### Mysql如何为表字段添加索引???
+
+1.添加PRIMARY KEY(主键索引)
+
+```
+ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` )
+```
+2.添加UNIQUE(唯一索引)
+
+```
+ALTER TABLE `table_name` ADD UNIQUE ( `column` )
+```
+
+3.添加INDEX(普通索引)
+
+```
+ALTER TABLE `table_name` ADD INDEX index_name ( `column` )
+```
+
+4.添加FULLTEXT(全文索引)
+
+```
+ALTER TABLE `table_name` ADD FULLTEXT ( `column`)
+```
+
+5.添加多列索引
+
+```
+ALTER TABLE `table_name` ADD INDEX index_name ( `column1`, `column2`, `column3` )
+```
+
+
+## 参考
+
+- 《Java工程师修炼之道》
+- 《MySQL高性能书籍_第3版》
+- https://juejin.im/post/5b55b842f265da0f9e589e79
+
diff --git a/docs/database/MySQL.md b/docs/database/MySQL.md
new file mode 100644
index 00000000000..8fd54b7d490
--- /dev/null
+++ b/docs/database/MySQL.md
@@ -0,0 +1,328 @@
+点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
+
+- [书籍推荐](#书籍推荐)
+- [文字教程推荐](#文字教程推荐)
+- [视频教程推荐](#视频教程推荐)
+- [常见问题总结](#常见问题总结)
+ - [什么是MySQL?](#什么是mysql)
+ - [存储引擎](#存储引擎)
+ - [一些常用命令](#一些常用命令)
+ - [MyISAM和InnoDB区别](#myisam和innodb区别)
+ - [字符集及校对规则](#字符集及校对规则)
+ - [索引](#索引)
+ - [查询缓存的使用](#查询缓存的使用)
+ - [什么是事务?](#什么是事务)
+ - [事物的四大特性(ACID)](#事物的四大特性acid)
+ - [并发事务带来哪些问题?](#并发事务带来哪些问题)
+ - [事务隔离级别有哪些?MySQL的默认隔离级别是?](#事务隔离级别有哪些mysql的默认隔离级别是)
+ - [锁机制与InnoDB锁算法](#锁机制与innodb锁算法)
+ - [大表优化](#大表优化)
+ - [1. 限定数据的范围](#1-限定数据的范围)
+ - [2. 读/写分离](#2-读写分离)
+ - [3. 垂直分区](#3-垂直分区)
+ - [4. 水平分区](#4-水平分区)
+ - [一条SQL语句在MySQL中如何执行的](#一条sql语句在mysql中如何执行的)
+ - [MySQL高性能优化规范建议](#mysql高性能优化规范建议)
+ - [一条SQL语句执行得很慢的原因有哪些?](#一条sql语句执行得很慢的原因有哪些)
+
+
+
+## 书籍推荐
+
+- 《SQL基础教程(第2版)》 (入门级)
+- 《高性能MySQL : 第3版》 (进阶)
+
+## 文字教程推荐
+
+- [SQL Tutorial](https://www.w3schools.com/sql/default.asp) (SQL语句学习,英文)、[SQL Tutorial](https://www.w3school.com.cn/sql/index.asp)(SQL语句学习,中文)、[SQL语句在线练习](https://www.w3schools.com/sql/exercise.asp) (非常不错)
+- [Github-MySQL入门教程(MySQL tutorial book)](https://github.com/jaywcjlove/mysql-tutorial) (从零开始学习MySQL,主要是面向MySQL数据库管理系统初学者)
+- [官方教程](https://dev.mysql.com/doc/refman/5.7/)
+- [MySQL 教程(菜鸟教程)](http://www.runoob.com/MySQL/MySQL-tutorial.html)
+
+## 相关资源推荐
+
+- [中国5级行政区域mysql库](https://github.com/kakuilan/china_area_mysql)
+
+## 视频教程推荐
+
+**基础入门:** [与MySQL的零距离接触-慕课网](https://www.imooc.com/learn/122)
+
+**MySQL开发技巧:** [MySQL开发技巧(一)](https://www.imooc.com/learn/398) [MySQL开发技巧(二)](https://www.imooc.com/learn/427) [MySQL开发技巧(三)](https://www.imooc.com/learn/449)
+
+**MySQL5.7新特性及相关优化技巧:** [MySQL5.7版本新特性](https://www.imooc.com/learn/533) [性能优化之MySQL优化](https://www.imooc.com/learn/194)
+
+[MySQL集群(PXC)入门](https://www.imooc.com/learn/993) [MyCAT入门及应用](https://www.imooc.com/learn/951)
+
+## 常见问题总结
+
+### 什么是MySQL?
+
+MySQL 是一种关系型数据库,在Java企业级开发中非常常用,因为 MySQL 是开源免费的,并且方便扩展。阿里巴巴数据库系统也大量用到了 MySQL,因此它的稳定性是有保障的。MySQL是开放源代码的,因此任何人都可以在 GPL(General Public License) 的许可下下载并根据个性化的需要对其进行修改。MySQL的默认端口号是**3306**。
+
+### 存储引擎
+
+#### 一些常用命令
+
+**查看MySQL提供的所有存储引擎**
+
+```sql
+mysql> show engines;
+```
+
+
+
+从上图我们可以查看出 MySQL 当前默认的存储引擎是InnoDB,并且在5.7版本所有的存储引擎中只有 InnoDB 是事务性存储引擎,也就是说只有 InnoDB 支持事务。
+
+**查看MySQL当前默认的存储引擎**
+
+我们也可以通过下面的命令查看默认的存储引擎。
+
+```sql
+mysql> show variables like '%storage_engine%';
+```
+
+**查看表的存储引擎**
+
+```sql
+show table status like "table_name" ;
+```
+
+
+
+#### MyISAM和InnoDB区别
+
+MyISAM是MySQL的默认数据库引擎(5.5版之前)。虽然性能极佳,而且提供了大量的特性,包括全文索引、压缩、空间函数等,但MyISAM不支持事务和行级锁,而且最大的缺陷就是崩溃后无法安全恢复。不过,5.5版本之后,MySQL引入了InnoDB(事务性数据库引擎),MySQL 5.5版本后默认的存储引擎为InnoDB。
+
+大多数时候我们使用的都是 InnoDB 存储引擎,但是在某些情况下使用 MyISAM 也是合适的比如读密集的情况下。(如果你不介意 MyISAM 崩溃恢复问题的话)。
+
+**两者的对比:**
+
+1. **是否支持行级锁** : MyISAM 只有表级锁(table-level locking),而InnoDB 支持行级锁(row-level locking)和表级锁,默认为行级锁。
+2. **是否支持事务和崩溃后的安全恢复: MyISAM** 强调的是性能,每次查询具有原子性,其执行速度比InnoDB类型更快,但是不提供事务支持。但是**InnoDB** 提供事务支持事务,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
+3. **是否支持外键:** MyISAM不支持,而InnoDB支持。
+4. **是否支持MVCC** :仅 InnoDB 支持。应对高并发事务, MVCC比单纯的加锁更高效;MVCC只在 `READ COMMITTED` 和 `REPEATABLE READ` 两个隔离级别下工作;MVCC可以使用 乐观(optimistic)锁 和 悲观(pessimistic)锁来实现;各数据库中MVCC实现并不统一。推荐阅读:[MySQL-InnoDB-MVCC多版本并发控制](https://segmentfault.com/a/1190000012650596)
+5. ......
+
+《MySQL高性能》上面有一句话这样写到:
+
+> 不要轻易相信“MyISAM比InnoDB快”之类的经验之谈,这个结论往往不是绝对的。在很多我们已知场景中,InnoDB的速度都可以让MyISAM望尘莫及,尤其是用到了聚簇索引,或者需要访问的数据都可以放入内存的应用。
+
+一般情况下我们选择 InnoDB 都是没有问题的,但是某些情况下你并不在乎可扩展能力和并发能力,也不需要事务支持,也不在乎崩溃后的安全恢复问题的话,选择MyISAM也是一个不错的选择。但是一般情况下,我们都是需要考虑到这些问题的。
+
+### 字符集及校对规则
+
+字符集指的是一种从二进制编码到某类字符符号的映射。校对规则则是指某种字符集下的排序规则。MySQL中每一种字符集都会对应一系列的校对规则。
+
+MySQL采用的是类似继承的方式指定字符集的默认值,每个数据库以及每张数据表都有自己的默认值,他们逐层继承。比如:某个库中所有表的默认字符集将是该数据库所指定的字符集(这些表在没有指定字符集的情况下,才会采用默认字符集) PS:整理自《Java工程师修炼之道》
+
+详细内容可以参考: [MySQL字符集及校对规则的理解](https://www.cnblogs.com/geaozhang/p/6724393.html#MySQLyuzifuji)
+
+### 索引
+
+MySQL索引使用的数据结构主要有**BTree索引** 和 **哈希索引** 。对于哈希索引来说,底层的数据结构就是哈希表,因此在绝大多数需求为单条记录查询的时候,可以选择哈希索引,查询性能最快;其余大部分场景,建议选择BTree索引。
+
+MySQL的BTree索引使用的是B树中的B+Tree,但对于主要的两种存储引擎的实现方式是不同的。
+
+- **MyISAM:** B+Tree叶节点的data域存放的是数据记录的地址。在索引检索的时候,首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“非聚簇索引”。
+- **InnoDB:** 其数据文件本身就是索引文件。相比MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按B+Tree组织的一个索引结构,树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。这被称为“聚簇索引(或聚集索引)”。而其余的索引都作为辅助索引,辅助索引的data域存储相应记录主键的值而不是地址,这也是和MyISAM不同的地方。**在根据主索引搜索时,直接找到key所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,再走一遍主索引。** **因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。** PS:整理自《Java工程师修炼之道》
+
+**更多关于索引的内容可以查看文档首页MySQL目录下关于索引的详细总结。**
+
+### 查询缓存的使用
+
+> 执行查询语句的时候,会先查询缓存。不过,MySQL 8.0 版本后移除,因为这个功能不太实用
+
+my.cnf加入以下配置,重启MySQL开启查询缓存
+```properties
+query_cache_type=1
+query_cache_size=600000
+```
+
+MySQL执行以下命令也可以开启查询缓存
+
+```properties
+set global query_cache_type=1;
+set global query_cache_size=600000;
+```
+如上,**开启查询缓存后在同样的查询条件以及数据情况下,会直接在缓存中返回结果**。这里的查询条件包括查询本身、当前要查询的数据库、客户端协议版本号等一些可能影响结果的信息。因此任何两个查询在任何字符上的不同都会导致缓存不命中。此外,如果查询中包含任何用户自定义函数、存储函数、用户变量、临时表、MySQL库中的系统表,其查询结果也不会被缓存。
+
+缓存建立之后,MySQL的查询缓存系统会跟踪查询中涉及的每张表,如果这些表(数据或结构)发生变化,那么和这张表相关的所有缓存数据都将失效。
+
+**缓存虽然能够提升数据库的查询性能,但是缓存同时也带来了额外的开销,每次查询后都要做一次缓存操作,失效后还要销毁。** 因此,开启缓存查询要谨慎,尤其对于写密集的应用来说更是如此。如果开启,要注意合理控制缓存空间大小,一般来说其大小设置为几十MB比较合适。此外,**还可以通过sql_cache和sql_no_cache来控制某个查询语句是否需要缓存:**
+```sql
+select sql_no_cache count(*) from usr;
+```
+
+### 什么是事务?
+
+**事务是逻辑上的一组操作,要么都执行,要么都不执行。**
+
+事务最经典也经常被拿出来说例子就是转账了。假如小明要给小红转账1000元,这个转账会涉及到两个关键操作就是:将小明的余额减少1000元,将小红的余额增加1000元。万一在这两个操作之间突然出现错误比如银行系统崩溃,导致小明余额减少而小红的余额没有增加,这样就不对了。事务就是保证这两个关键操作要么都成功,要么都要失败。
+
+### 事物的四大特性(ACID)
+
+
+
+1. **原子性(Atomicity):** 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
+2. **一致性(Consistency):** 执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是相同的;
+3. **隔离性(Isolation):** 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
+4. **持久性(Durability):** 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
+
+### 并发事务带来哪些问题?
+
+在典型的应用程序中,多个事务并发运行,经常会操作相同的数据来完成各自的任务(多个用户对同一数据进行操作)。并发虽然是必须的,但可能会导致以下的问题。
+
+- **脏读(Dirty read):** 当一个事务正在访问数据并且对数据进行了修改,而这种修改还没有提交到数据库中,这时另外一个事务也访问了这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据,那么另外一个事务读到的这个数据是“脏数据”,依据“脏数据”所做的操作可能是不正确的。
+- **丢失修改(Lost to modify):** 指在一个事务读取一个数据时,另外一个事务也访问了该数据,那么在第一个事务中修改了这个数据后,第二个事务也修改了这个数据。这样第一个事务内的修改结果就被丢失,因此称为丢失修改。 例如:事务1读取某表中的数据A=20,事务2也读取A=20,事务1修改A=A-1,事务2也修改A=A-1,最终结果A=19,事务1的修改被丢失。
+- **不可重复读(Unrepeatableread):** 指在一个事务内多次读同一数据。在这个事务还没有结束时,另一个事务也访问该数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改导致第一个事务两次读取的数据可能不太一样。这就发生了在一个事务内两次读到的数据是不一样的情况,因此称为不可重复读。
+- **幻读(Phantom read):** 幻读与不可重复读类似。它发生在一个事务(T1)读取了几行数据,接着另一个并发事务(T2)插入了一些数据时。在随后的查询中,第一个事务(T1)就会发现多了一些原本不存在的记录,就好像发生了幻觉一样,所以称为幻读。
+
+**不可重复读和幻读区别:**
+
+不可重复读的重点是修改比如多次读取一条记录发现其中某些列的值被修改,幻读的重点在于新增或者删除比如多次读取一条记录发现记录增多或减少了。
+
+### 事务隔离级别有哪些?MySQL的默认隔离级别是?
+
+**SQL 标准定义了四个隔离级别:**
+
+- **READ-UNCOMMITTED(读取未提交):** 最低的隔离级别,允许读取尚未提交的数据变更,**可能会导致脏读、幻读或不可重复读**。
+- **READ-COMMITTED(读取已提交):** 允许读取并发事务已经提交的数据,**可以阻止脏读,但是幻读或不可重复读仍有可能发生**。
+- **REPEATABLE-READ(可重复读):** 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,**可以阻止脏读和不可重复读,但幻读仍有可能发生**。
+- **SERIALIZABLE(可串行化):** 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,**该级别可以防止脏读、不可重复读以及幻读**。
+
+------
+
+| 隔离级别 | 脏读 | 不可重复读 | 幻影读 |
+| :--------------: | :--: | :--------: | :----: |
+| READ-UNCOMMITTED | √ | √ | √ |
+| READ-COMMITTED | × | √ | √ |
+| REPEATABLE-READ | × | × | √ |
+| SERIALIZABLE | × | × | × |
+
+MySQL InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)**。我们可以通过`SELECT @@tx_isolation;`命令来查看,MySQL 8.0 该命令改为`SELECT @@transaction_isolation;`
+
+```sql
+mysql> SELECT @@tx_isolation;
++-----------------+
+| @@tx_isolation |
++-----------------+
+| REPEATABLE-READ |
++-----------------+
+```
+
+这里需要注意的是:与 SQL 标准不同的地方在于 InnoDB 存储引擎在 **REPEATABLE-READ(可重读)**
+事务隔离级别下使用的是Next-Key Lock 锁算法,因此可以避免幻读的产生,这与其他数据库系统(如 SQL Server)
+是不同的。所以说InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)** 已经可以完全保证事务的隔离性要求,即达到了
+ SQL标准的 **SERIALIZABLE(可串行化)** 隔离级别。因为隔离级别越低,事务请求的锁越少,所以大部分数据库系统的隔离级别都是 **READ-COMMITTED(读取提交内容)** ,但是你要知道的是InnoDB 存储引擎默认使用 **REPEAaTABLE-READ(可重读)** 并不会有任何性能损失。
+
+InnoDB 存储引擎在 **分布式事务** 的情况下一般会用到 **SERIALIZABLE(可串行化)** 隔离级别。
+
+### 锁机制与InnoDB锁算法
+
+**MyISAM和InnoDB存储引擎使用的锁:**
+
+- MyISAM采用表级锁(table-level locking)。
+- InnoDB支持行级锁(row-level locking)和表级锁,默认为行级锁
+
+**表级锁和行级锁对比:**
+
+- **表级锁:** MySQL中锁定 **粒度最大** 的一种锁,对当前操作的整张表加锁,实现简单,资源消耗也比较少,加锁快,不会出现死锁。其锁定粒度最大,触发锁冲突的概率最高,并发度最低,MyISAM和 InnoDB引擎都支持表级锁。
+- **行级锁:** MySQL中锁定 **粒度最小** 的一种锁,只针对当前操作的行进行加锁。 行级锁能大大减少数据库操作的冲突。其加锁粒度最小,并发度高,但加锁的开销也最大,加锁慢,会出现死锁。
+
+详细内容可以参考: MySQL锁机制简单了解一下:[https://blog.csdn.net/qq_34337272/article/details/80611486](https://blog.csdn.net/qq_34337272/article/details/80611486)
+
+**InnoDB存储引擎的锁的算法有三种:**
+
+- Record lock:单个行记录上的锁
+- Gap lock:间隙锁,锁定一个范围,不包括记录本身
+- Next-key lock:record+gap 锁定一个范围,包含记录本身
+
+**相关知识点:**
+
+1. innodb对于行的查询使用next-key lock
+2. Next-locking keying为了解决Phantom Problem幻读问题
+3. 当查询的索引含有唯一属性时,将next-key lock降级为record key
+4. Gap锁设计的目的是为了阻止多个事务将记录插入到同一范围内,而这会导致幻读问题的产生
+5. 有两种方式显式关闭gap锁:(除了外键约束和唯一性检查外,其余情况仅使用record lock) A. 将事务隔离级别设置为RC B. 将参数innodb_locks_unsafe_for_binlog设置为1
+
+### 大表优化
+
+当MySQL单表记录数过大时,数据库的CRUD性能会明显下降,一些常见的优化措施如下:
+
+#### 1. 限定数据的范围
+
+务必禁止不带任何限制数据范围条件的查询语句。比如:我们当用户在查询订单历史的时候,我们可以控制在一个月的范围内;
+
+#### 2. 读/写分离
+
+经典的数据库拆分方案,主库负责写,从库负责读;
+
+#### 3. 垂直分区
+
+ **根据数据库里面数据表的相关性进行拆分。** 例如,用户表中既有用户的登录信息又有用户的基本信息,可以将用户表拆分成两个单独的表,甚至放到单独的库做分库。
+
+ **简单来说垂直拆分是指数据表列的拆分,把一张列比较多的表拆分为多张表。** 如下图所示,这样来说大家应该就更容易理解了。
+ 
+
+- **垂直拆分的优点:** 可以使得列数据变小,在查询时减少读取的Block数,减少I/O次数。此外,垂直分区可以简化表的结构,易于维护。
+- **垂直拆分的缺点:** 主键会出现冗余,需要管理冗余列,并会引起Join操作,可以通过在应用层进行Join来解决。此外,垂直分区会让事务变得更加复杂;
+
+#### 4. 水平分区
+
+**保持数据表结构不变,通过某种策略存储数据分片。这样每一片数据分散到不同的表或者库中,达到了分布式的目的。 水平拆分可以支撑非常大的数据量。**
+
+ 水平拆分是指数据表行的拆分,表的行数超过200万行时,就会变慢,这时可以把一张的表的数据拆成多张表来存放。举个例子:我们可以将用户信息表拆分成多个用户信息表,这样就可以避免单一表数据量过大对性能造成影响。
+
+
+
+水平拆分可以支持非常大的数据量。需要注意的一点是:分表仅仅是解决了单一表数据过大的问题,但由于表的数据还是在同一台机器上,其实对于提升MySQL并发能力没有什么意义,所以 **水平拆分最好分库** 。
+
+水平拆分能够 **支持非常大的数据量存储,应用端改造也少**,但 **分片事务难以解决** ,跨节点Join性能较差,逻辑复杂。《Java工程师修炼之道》的作者推荐 **尽量不要对数据进行分片,因为拆分会带来逻辑、部署、运维的各种复杂度** ,一般的数据表在优化得当的情况下支撑千万以下的数据量是没有太大问题的。如果实在要分片,尽量选择客户端分片架构,这样可以减少一次和中间件的网络I/O。
+
+**下面补充一下数据库分片的两种常见方案:**
+
+- **客户端代理:** **分片逻辑在应用端,封装在jar包中,通过修改或者封装JDBC层来实现。** 当当网的 **Sharding-JDBC** 、阿里的TDDL是两种比较常用的实现。
+- **中间件代理:** **在应用和数据中间加了一个代理层。分片逻辑统一维护在中间件服务中。** 我们现在谈的 **Mycat** 、360的Atlas、网易的DDB等等都是这种架构的实现。
+
+详细内容可以参考: MySQL大表优化方案: [https://segmentfault.com/a/1190000006158186](https://segmentfault.com/a/1190000006158186)
+
+### 解释一下什么是池化设计思想。什么是数据库连接池?为什么需要数据库连接池?
+
+池化设计应该不是一个新名词。我们常见的如java线程池、jdbc连接池、redis连接池等就是这类设计的代表实现。这种设计会初始预设资源,解决的问题就是抵消每次获取资源的消耗,如创建线程的开销,获取远程连接的开销等。就好比你去食堂打饭,打饭的大妈会先把饭盛好几份放那里,你来了就直接拿着饭盒加菜即可,不用再临时又盛饭又打菜,效率就高了。除了初始化资源,池化设计还包括如下这些特征:池子的初始值、池子的活跃值、池子的最大值等,这些特征可以直接映射到java线程池和数据库连接池的成员属性中。这篇文章对[池化设计思想](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485679&idx=1&sn=57dbca8c9ad49e1f3968ecff04a4f735&chksm=cea24724f9d5ce3212292fac291234a760c99c0960b5430d714269efe33554730b5f71208582&token=1141994790&lang=zh_CN#rd)介绍的还不错,直接复制过来,避免重复造轮子了。
+
+数据库连接本质就是一个 socket 的连接。数据库服务端还要维护一些缓存和用户权限信息之类的 所以占用了一些内存。我们可以把数据库连接池是看做是维护的数据库连接的缓存,以便将来需要对数据库的请求时可以重用这些连接。为每个用户打开和维护数据库连接,尤其是对动态数据库驱动的网站应用程序的请求,既昂贵又浪费资源。**在连接池中,创建连接后,将其放置在池中,并再次使用它,因此不必建立新的连接。如果使用了所有连接,则会建立一个新连接并将其添加到池中**。 连接池还减少了用户必须等待建立与数据库的连接的时间。
+
+### 分库分表之后,id 主键如何处理?
+
+因为要是分成多个表之后,每个表都是从 1 开始累加,这样是不对的,我们需要一个全局唯一的 id 来支持。
+
+生成全局 id 有下面这几种方式:
+
+- **UUID**:不适合作为主键,因为太长了,并且无序不可读,查询效率低。比较适合用于生成唯一的名字的标示比如文件的名字。
+- **数据库自增 id** : 两台数据库分别设置不同步长,生成不重复ID的策略来实现高可用。这种方式生成的 id 有序,但是需要独立部署数据库实例,成本高,还会有性能瓶颈。
+- **利用 redis 生成 id :** 性能比较好,灵活方便,不依赖于数据库。但是,引入了新的组件造成系统更加复杂,可用性降低,编码更加复杂,增加了系统成本。
+- **Twitter的snowflake算法** :Github 地址:https://github.com/twitter-archive/snowflake。
+- **美团的[Leaf](https://tech.meituan.com/2017/04/21/mt-leaf.html)分布式ID生成系统** :Leaf 是美团开源的分布式ID生成器,能保证全局唯一性、趋势递增、单调递增、信息安全,里面也提到了几种分布式方案的对比,但也需要依赖关系数据库、Zookeeper等中间件。感觉还不错。美团技术团队的一篇文章:https://tech.meituan.com/2017/04/21/mt-leaf.html 。
+- ......
+
+### 一条SQL语句在MySQL中如何执行的
+
+[一条SQL语句在MySQL中如何执行的](实例.jpg) +
+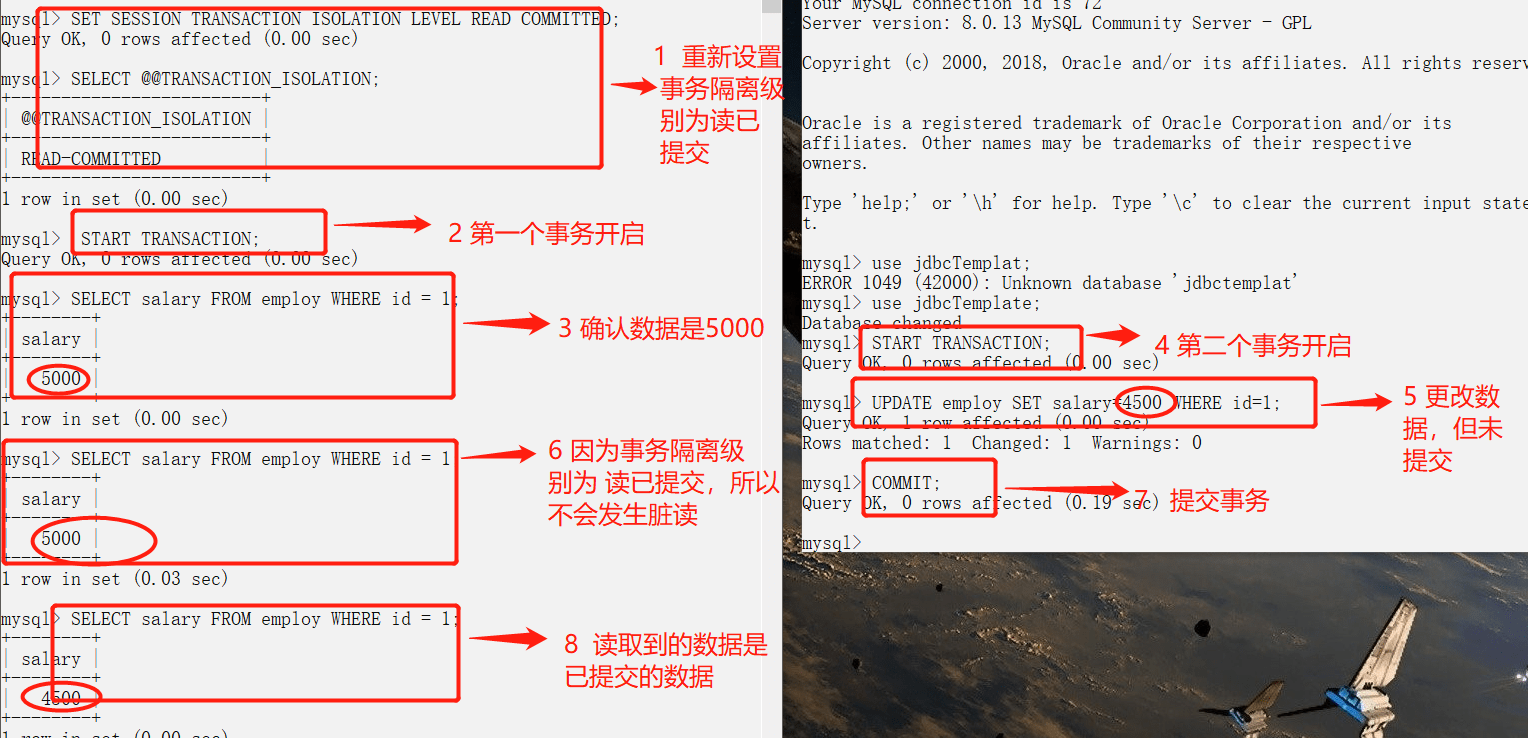 +
+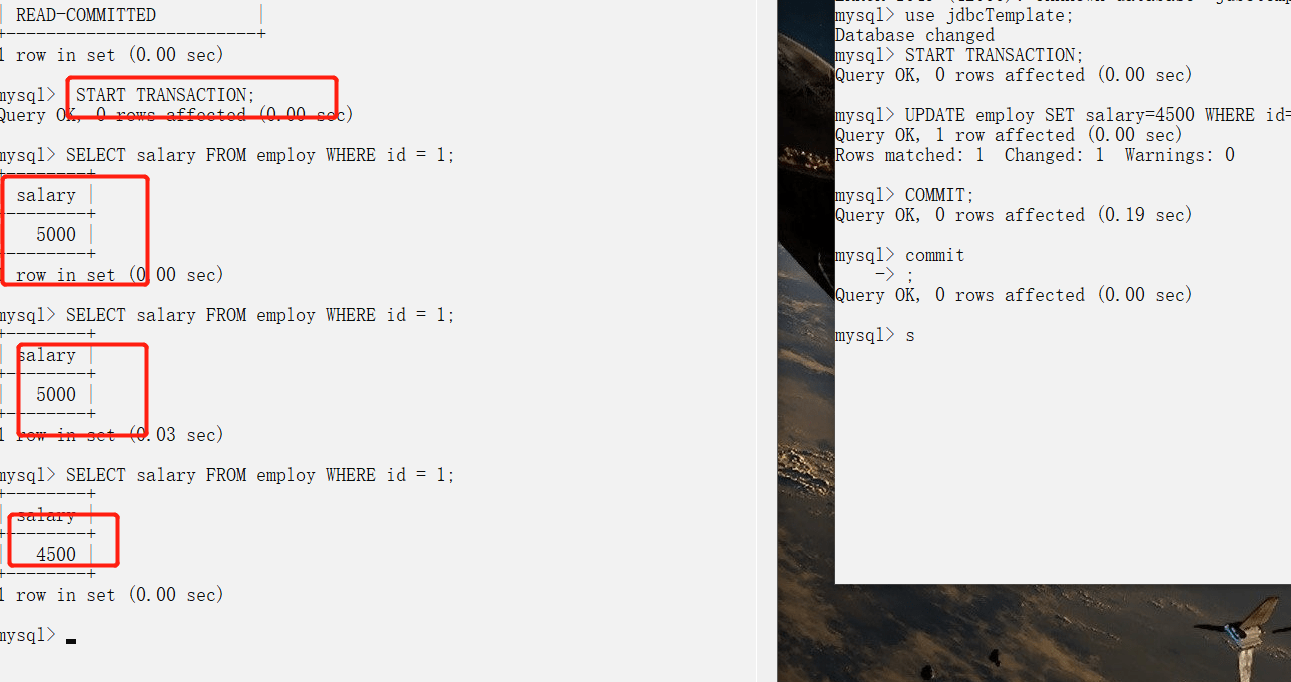 +
+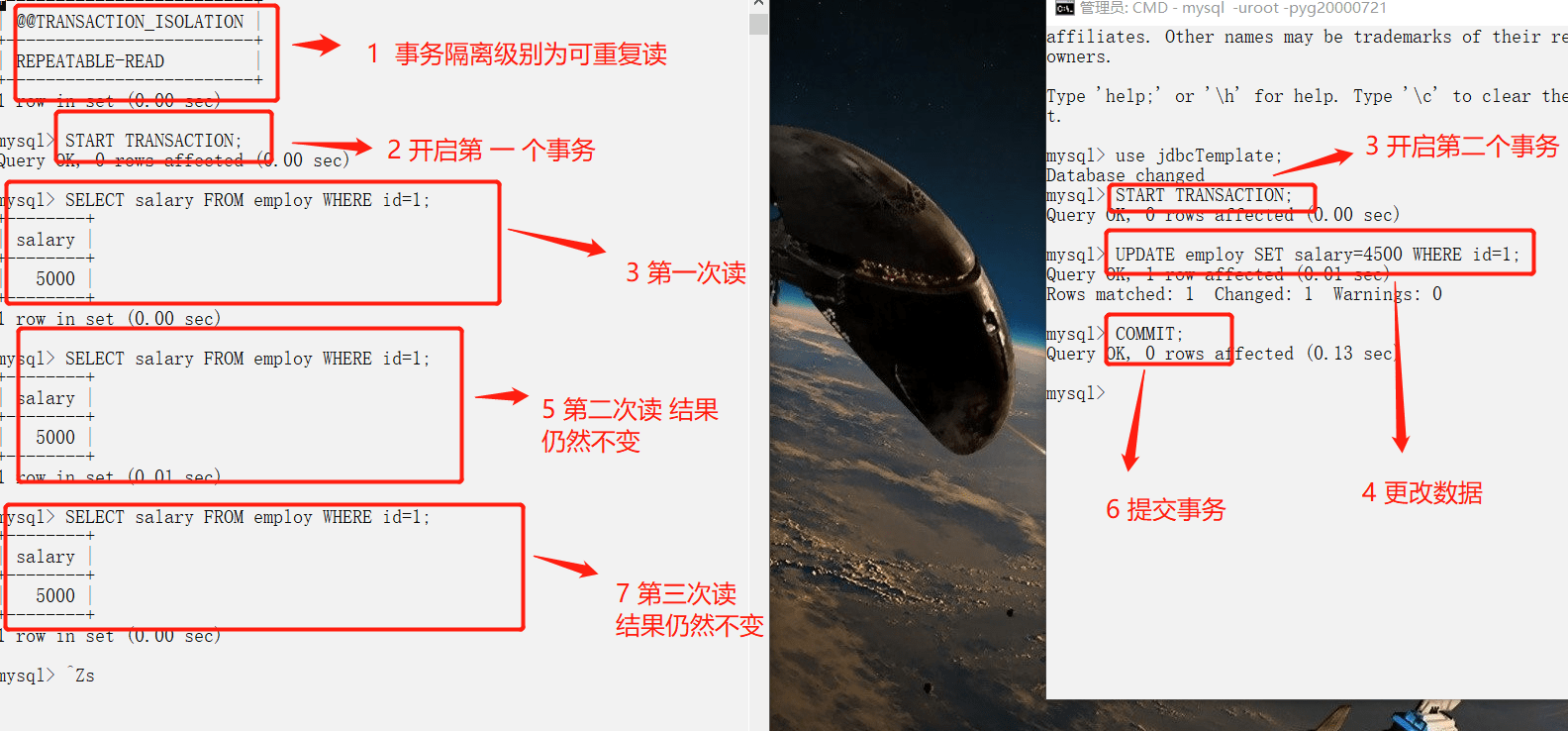 +
+.jpg) +
+ +
+每种方式都有各自的优势,根据实际场景才是王道。下面再对这三种方式做一个简单的对比,以供大家实际开发中选择正确的存放时间的数据类型:
+
+
+
+每种方式都有各自的优势,根据实际场景才是王道。下面再对这三种方式做一个简单的对比,以供大家实际开发中选择正确的存放时间的数据类型:
+
+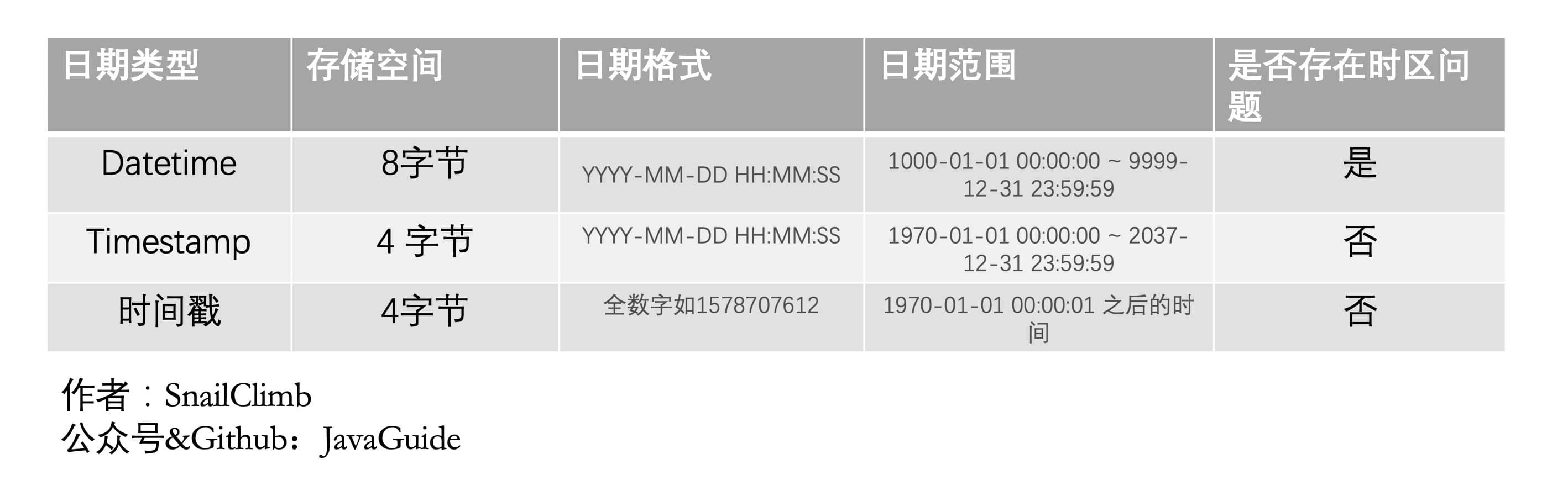 +
+如果还有什么问题欢迎给我留言!如果文章有什么问题的话,也劳烦指出,Guide 哥感激不尽!
+
+后面的文章我会介绍:
+
+- [ ] Java8 对日期的支持以及为啥不能用 SimpleDateFormat。
+- [ ] SpringBoot 中如何实际使用(JPA 为例)
\ No newline at end of file
diff --git "a/docs/database/\346\225\260\346\215\256\345\272\223\347\264\242\345\274\225.md" "b/docs/database/\346\225\260\346\215\256\345\272\223\347\264\242\345\274\225.md"
new file mode 100644
index 00000000000..568ba833fab
--- /dev/null
+++ "b/docs/database/\346\225\260\346\215\256\345\272\223\347\264\242\345\274\225.md"
@@ -0,0 +1,225 @@
+## 什么是索引?
+**索引是一种用于快速查询和检索数据的数据结构。常见的索引结构有: B树, B+树和Hash。**
+
+索引的作用就相当于目录的作用。打个比方: 我们在查字典的时候,如果没有目录,那我们就只能一页一页的去找我们需要查的那个字,速度很慢。如果有目录了,我们只需要先去目录里查找字的位置,然后直接翻到那一页就行了。
+
+## 为什么要用索引?索引的优缺点分析
+
+### 索引的优点
+**可以大大加快 数据的检索速度(大大减少的检索的数据量), 这也是创建索引的最主要的原因。毕竟大部分系统的读请求总是大于写请求的。 ** 另外,通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
+
+### 索引的缺点
+1. **创建索引和维护索引需要耗费许多时间**:当对表中的数据进行增删改的时候,如果数据有索引,那么索引也需要动态的修改,会降低SQL执行效率。
+2. **占用物理存储空间** :索引需要使用物理文件存储,也会耗费一定空间。
+
+## B树和B+树区别
+
+* B树的所有节点既存放 键(key) 也存放 数据(data);而B+树只有叶子节点存放 key 和 data,其他内节点只存放key。
+* B树的叶子节点都是独立的;B+树的叶子节点有一条引用链指向与它相邻的叶子节点。
+* B树的检索的过程相当于对范围内的每个节点的关键字做二分查找,可能还没有到达叶子节点,检索就结束了。而B+树的检索效率就很稳定了,任何查找都是从根节点到叶子节点的过程,叶子节点的顺序检索很明显。
+
+
+
+## Hash索引和 B+树索引优劣分析
+
+**Hash索引定位快**
+
+Hash索引指的就是Hash表,最大的优点就是能够在很短的时间内,根据Hash函数定位到数据所在的位置,这是B+树所不能比的。
+
+**Hash冲突问题**
+
+知道HashMap或HashTable的同学,相信都知道它们最大的缺点就是Hash冲突了。不过对于数据库来说这还不算最大的缺点。
+
+**Hash索引不支持顺序和范围查询(Hash索引不支持顺序和范围查询是它最大的缺点。**
+
+试想一种情况:
+
+````text
+SELECT * FROM tb1 WHERE id < 500;
+````
+
+B+树是有序的,在这种范围查询中,优势非常大,直接遍历比500小的叶子节点就够了。而Hash索引是根据hash算法来定位的,难不成还要把 1 - 499的数据,每个都进行一次hash计算来定位吗?这就是Hash最大的缺点了。
+
+---
+
+## 索引类型
+
+### 主键索引(Primary Key)
+**数据表的主键列使用的就是主键索引。**
+
+**一张数据表有只能有一个主键,并且主键不能为null,不能重复。**
+
+**在mysql的InnoDB的表中,当没有显示的指定表的主键时,InnoDB会自动先检查表中是否有唯一索引的字段,如果有,则选择该字段为默认的主键,否则InnoDB将会自动创建一个6Byte的自增主键。**
+
+### 二级索引(辅助索引)
+**二级索引又称为辅助索引,是因为二级索引的叶子节点存储的数据是主键。也就是说,通过二级索引,可以定位主键的位置。**
+
+唯一索引,普通索引,前缀索引等索引属于二级索引。
+
+**PS:不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,也可以自行搜索。**
+
+1. **唯一索引(Unique Key)** :唯一索引也是一种约束。**唯一索引的属性列不能出现重复的数据,但是允许数据为NULL,一张表允许创建多个唯一索引。**建立唯一索引的目的大部分时候都是为了该属性列的数据的唯一性,而不是为了查询效率。
+2. **普通索引(Index)** :**普通索引的唯一作用就是为了快速查询数据,一张表允许创建多个普通索引,并允许数据重复和NULL。**
+3. **前缀索引(Prefix)** :前缀索引只适用于字符串类型的数据。前缀索引是对文本的前几个字符创建索引,相比普通索引建立的数据更小,
+ 因为只取前几个字符。
+4. **全文索引(Full Text)** :全文索引主要是为了检索大文本数据中的关键字的信息,是目前搜索引擎数据库使用的一种技术。Mysql5.6之前只有MYISAM引擎支持全文索引,5.6之后InnoDB也支持了全文索引。
+
+二级索引:
+.png)
+
+## 聚集索引与非聚集索引
+
+### 聚集索引
+**聚集索引即索引结构和数据一起存放的索引。主键索引属于聚集索引。**
+
+在 Mysql 中,InnoDB引擎的表的 `.ibd`文件就包含了该表的索引和数据,对于 InnoDB 引擎表来说,该表的索引(B+树)的每个非叶子节点存储索引,叶子节点存储索引和索引对应的数据。
+
+#### 聚集索引的优点
+聚集索引的查询速度非常的快,因为整个B+树本身就是一颗多叉平衡树,叶子节点也都是有序的,定位到索引的节点,就相当于定位到了数据。
+
+#### 聚集索引的缺点
+1. **依赖于有序的数据** :因为B+树是多路平衡树,如果索引的数据不是有序的,那么就需要在插入时排序,如果数据是整型还好,否则类似于字符串或UUID这种又长又难比较的数据,插入或查找的速度肯定比较慢。
+2. **更新代价大** : 如果对索引列的数据被修改时,那么对应的索引也将会被修改,
+ 而且况聚集索引的叶子节点还存放着数据,修改代价肯定是较大的,
+ 所以对于主键索引来说,主键一般都是不可被修改的。
+
+### 非聚集索引
+
+**非聚集索引即索引结构和数据分开存放的索引。**
+
+**二级索引属于非聚集索引。**
+
+>MYISAM引擎的表的.MYI文件包含了表的索引,
+>该表的索引(B+树)的每个叶子非叶子节点存储索引,
+>叶子节点存储索引和索引对应数据的指针,指向.MYD文件的数据。
+>
+**非聚集索引的叶子节点并不一定存放数据的指针,
+因为二级索引的叶子节点就存放的是主键,根据主键再回表查数据。**
+
+#### 非聚集索引的优点
+**更新代价比聚集索引要小** 。非聚集索引的更新代价就没有聚集索引那么大了,非聚集索引的叶子节点是不存放数据的
+
+#### 非聚集索引的缺点
+1. 跟聚集索引一样,非聚集索引也依赖于有序的数据
+2. **可能会二次查询(回表)** :这应该是非聚集索引最大的缺点了。 当查到索引对应的指针或主键后,可能还需要根据指针或主键再到数据文件或表中查询。
+
+这是Mysql的表的文件截图:
+
+
+
+聚集索引和非聚集索引:
+
+
+
+### 非聚集索引一定回表查询吗(覆盖索引)?
+**非聚集索引不一定回表查询。**
+
+>试想一种情况,用户准备使用SQL查询用户名,而用户名字段正好建立了索引。
+
+````text
+ SELECT name FROM table WHERE username='guang19';
+````
+
+>那么这个索引的key本身就是name,查到对应的name直接返回就行了,无需回表查询。
+
+**即使是MYISAM也是这样,虽然MYISAM的主键索引确实需要回表,
+因为它的主键索引的叶子节点存放的是指针。但是如果SQL查的就是主键呢?**
+
+```text
+SELECT id FROM table WHERE id=1;
+```
+
+主键索引本身的key就是主键,查到返回就行了。这种情况就称之为覆盖索引了。
+
+## 覆盖索引
+
+如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为“覆盖索引”。我们知道在InnoDB存储引擎中,如果不是主键索引,叶子节点存储的是主键+列值。最终还是要“回表”,也就是要通过主键再查找一次。这样就会比较慢覆盖索引就是把要查询出的列和索引是对应的,不做回表操作!
+
+**覆盖索引即需要查询的字段正好是索引的字段,那么直接根据该索引,就可以查到数据了,
+而无需回表查询。**
+
+>如主键索引,如果一条SQL需要查询主键,那么正好根据主键索引就可以查到主键。
+>
+>再如普通索引,如果一条SQL需要查询name,name字段正好有索引,
+>那么直接根据这个索引就可以查到数据,也无需回表。
+
+覆盖索引:
+
+
+---
+
+## 索引创建原则
+
+### 单列索引
+单列索引即由一列属性组成的索引。
+
+### 联合索引(多列索引)
+联合索引即由多列属性组成索引。
+
+### 最左前缀原则
+
+假设创建的联合索引由三个字段组成:
+
+```text
+ALTER TABLE table ADD INDEX index_name (num,name,age)
+```
+
+那么当查询的条件有为:num / (num AND name) / (num AND name AND age)时,索引才生效。所以在创建联合索引时,尽量把查询最频繁的那个字段作为最左(第一个)字段。查询的时候也尽量以这个字段为第一条件。
+
+> 但可能由于版本原因(我的mysql版本为8.0.x),我创建的联合索引,相当于在联合索引的每个字段上都创建了相同的索引:
+
+.png)
+
+无论是否符合最左前缀原则,每个字段的索引都生效:
+
+
+
+## 索引创建注意点
+
+### 最左前缀原则
+
+虽然我目前的Mysql版本较高,好像不遵守最左前缀原则,索引也会生效。
+但是我们仍应遵守最左前缀原则,以免版本更迭带来的麻烦。
+
+### 选择合适的字段
+
+#### 1.不为NULL的字段
+
+索引字段的数据应该尽量不为NULL,因为对于数据为NULL的字段,数据库较难优化。如果字段频繁被查询,但又避免不了为NULL,建议使用0,1,true,false这样语义较为清晰的短值或短字符作为替代。
+
+#### 2.被频繁查询的字段
+
+我们创建索引的字段应该是查询操作非常频繁的字段。
+
+#### 3.被作为条件查询的字段
+
+被作为WHERE条件查询的字段,应该被考虑建立索引。
+
+#### 4.被经常频繁用于连接的字段
+
+经常用于连接的字段可能是一些外键列,对于外键列并不一定要建立外键,只是说该列涉及到表与表的关系。对于频繁被连接查询的字段,可以考虑建立索引,提高多表连接查询的效率。
+
+### 不合适创建索引的字段
+
+#### 1.被频繁更新的字段应该慎重建立索引
+
+虽然索引能带来查询上的效率,但是维护索引的成本也是不小的。
+如果一个字段不被经常查询,反而被经常修改,那么就更不应该在这种字段上建立索引了。
+
+#### 2.不被经常查询的字段没有必要建立索引
+
+#### 3.尽可能的考虑建立联合索引而不是单列索引
+
+因为索引是需要占用磁盘空间的,可以简单理解为每个索引都对应着一颗B+树。如果一个表的字段过多,索引过多,那么当这个表的数据达到一个体量后,索引占用的空间也是很多的,且修改索引时,耗费的时间也是较多的。如果是联合索引,多个字段在一个索引上,那么将会节约很大磁盘空间,且修改数据的操作效率也会提升。
+
+#### 4.注意避免冗余索引
+
+冗余索引指的是索引的功能相同,能够命中 就肯定能命中 ,那么 就是冗余索引如(name,city )和(name )这两个索引就是冗余索引,能够命中后者的查询肯定是能够命中前者的 在大多数情况下,都应该尽量扩展已有的索引而不是创建新索引。
+
+#### 5.考虑在字符串类型的字段上使用前缀索引代替普通索引
+
+前缀索引仅限于字符串类型,较普通索引会占用更小的空间,所以可以考虑使用前缀索引带替普通索引。
+
+### 使用索引一定能提高查询性能吗?
+
+大多数情况下,索引查询都是比全表扫描要快的。但是如果数据库的数据量不大,那么使用索引也不一定能够带来很大提升。
\ No newline at end of file
diff --git "a/docs/database/\346\225\260\346\215\256\345\272\223\350\277\236\346\216\245\346\261\240.md" "b/docs/database/\346\225\260\346\215\256\345\272\223\350\277\236\346\216\245\346\261\240.md"
new file mode 100644
index 00000000000..3e84dfc8efd
--- /dev/null
+++ "b/docs/database/\346\225\260\346\215\256\345\272\223\350\277\236\346\216\245\346\261\240.md"
@@ -0,0 +1,21 @@
+- 公众号和Github待发文章:[数据库:数据库连接池原理详解与自定义连接池实现](https://www.fangzhipeng.com/javainterview/2019/07/15/mysql-connector-pool.html)
+- [基于JDBC的数据库连接池技术研究与应用](http://blog.itpub.net/9403012/viewspace-111794/)
+- [数据库连接池技术详解](https://juejin.im/post/5b7944c6e51d4538c86cf195)
+
+数据库连接本质就是一个 socket 的连接。数据库服务端还要维护一些缓存和用户权限信息之类的 所以占用了一些内存
+
+连接池是维护的数据库连接的缓存,以便将来需要对数据库的请求时可以重用这些连接。为每个用户打开和维护数据库连接,尤其是对动态数据库驱动的网站应用程序的请求,既昂贵又浪费资源。**在连接池中,创建连接后,将其放置在池中,并再次使用它,因此不必建立新的连接。如果使用了所有连接,则会建立一个新连接并将其添加到池中。**连接池还减少了用户必须等待建立与数据库的连接的时间。
+
+操作过数据库的朋友应该都知道数据库连接池这个概念,它几乎每天都在和我们打交道,但是你真的了解 **数据库连接池** 吗?
+
+### 没有数据库连接池之前
+
+我相信你一定听过这样一句话:**Java语言中,JDBC(Java DataBase Connection)是应用程序与数据库沟通的桥梁**。
+
+
+
+
+
+
+
+
diff --git "a/docs/database/\351\230\277\351\207\214\345\267\264\345\267\264\345\274\200\345\217\221\346\211\213\345\206\214\346\225\260\346\215\256\345\272\223\351\203\250\345\210\206\347\232\204\344\270\200\344\272\233\346\234\200\344\275\263\345\256\236\350\267\265.md" "b/docs/database/\351\230\277\351\207\214\345\267\264\345\267\264\345\274\200\345\217\221\346\211\213\345\206\214\346\225\260\346\215\256\345\272\223\351\203\250\345\210\206\347\232\204\344\270\200\344\272\233\346\234\200\344\275\263\345\256\236\350\267\265.md"
new file mode 100644
index 00000000000..abd9331d6f7
--- /dev/null
+++ "b/docs/database/\351\230\277\351\207\214\345\267\264\345\267\264\345\274\200\345\217\221\346\211\213\345\206\214\346\225\260\346\215\256\345\272\223\351\203\250\345\210\206\347\232\204\344\270\200\344\272\233\346\234\200\344\275\263\345\256\236\350\267\265.md"
@@ -0,0 +1,41 @@
+# 阿里巴巴Java开发手册数据库部分的一些最佳实践总结
+
+## 模糊查询
+
+对于模糊查询阿里巴巴开发手册这样说到:
+
+> 【强制】页面搜索严禁左模糊或者全模糊,如果需要请走搜索引擎来解决。
+>
+> 说明:索引文件具有 B-Tree 的最左前缀匹配特性,如果左边的值未确定,那么无法使用此索引。
+
+## 外键和级联
+
+对于外键和级联,阿里巴巴开发手册这样说到:
+
+>【强制】不得使用外键与级联,一切外键概念必须在应用层解决。
+>
+>说明:以学生和成绩的关系为例,学生表中的 student_id 是主键,那么成绩表中的 student_id 则为外键。如果更新学生表中的 student_id,同时触发成绩表中的 student_id 更新,即为级联更新。外键与级联更新适用于单机低并发,不适合分布式、高并发集群;级联更新是强阻塞,存在数据库更新风暴的风 险;外键影响数据库的插入速度
+
+为什么不要用外键呢?大部分人可能会这样回答:
+
+> 1. **增加了复杂性:** a.每次做DELETE 或者UPDATE都必须考虑外键约束,会导致开发的时候很痛苦,测试数据极为不方便;b.外键的主从关系是定的,假如那天需求有变化,数据库中的这个字段根本不需要和其他表有关联的话就会增加很多麻烦。
+> 2. **增加了额外工作**: 数据库需要增加维护外键的工作,比如当我们做一些涉及外键字段的增,删,更新操作之后,需要触发相关操作去检查,保证数据的的一致性和正确性,这样会不得不消耗资源;(个人觉得这个不是不用外键的原因,因为即使你不使用外键,你在应用层面也还是要保证的。所以,我觉得这个影响可以忽略不计。)
+> 3. 外键还会因为需要请求对其他表内部加锁而容易出现死锁情况;
+> 4. **对分库分表不友好** :因为分库分表下外键是无法生效的。
+> 5. ......
+
+我个人觉得上面这种回答不是特别的全面,只是说了外键存在的一个常见的问题。实际上,我们知道外键也是有很多好处的,比如:
+
+1. 保证了数据库数据的一致性和完整性;
+2. 级联操作方便,减轻了程序代码量;
+3. ......
+
+所以说,不要一股脑的就抛弃了外键这个概念,既然它存在就有它存在的道理,如果系统不涉及分不分表,并发量不是很高的情况还是可以考虑使用外键的。
+
+我个人是不太喜欢外键约束,比较喜欢在应用层去进行相关操作。
+
+## 关于@Transactional注解
+
+对于`@Transactional`事务注解,阿里巴巴开发手册这样说到:
+
+>【参考】@Transactional事务不要滥用。事务会影响数据库的QPS,另外使用事务的地方需要考虑各方面的回滚方案,包括缓存回滚、搜索引擎回滚、消息补偿、统计修正等。
diff --git a/docs/essential-content-for-interview/BATJrealInterviewExperience/2019alipay-pinduoduo-toutiao.md b/docs/essential-content-for-interview/BATJrealInterviewExperience/2019alipay-pinduoduo-toutiao.md
new file mode 100644
index 00000000000..183a1852a90
--- /dev/null
+++ b/docs/essential-content-for-interview/BATJrealInterviewExperience/2019alipay-pinduoduo-toutiao.md
@@ -0,0 +1,294 @@
+作者: rhwayfun,原文地址:https://mp.weixin.qq.com/s/msYty4vjjC0PvrwasRH5Bw ,JavaGuide 已经获得作者授权并对原文进行了重新排版。
+
+
+- [写在2019年后的蚂蚁、头条、拼多多的面试总结](#写在2019年后的蚂蚁头条拼多多的面试总结)
+ - [准备过程](#准备过程)
+ - [蚂蚁金服](#蚂蚁金服)
+ - [一面](#一面)
+ - [二面](#二面)
+ - [三面](#三面)
+ - [四面](#四面)
+ - [五面](#五面)
+ - [小结](#小结)
+ - [拼多多](#拼多多)
+ - [面试前](#面试前)
+ - [一面](#一面-1)
+ - [二面](#二面-1)
+ - [三面](#三面-1)
+ - [小结](#小结-1)
+ - [字节跳动](#字节跳动)
+ - [面试前](#面试前-1)
+ - [一面](#一面-2)
+ - [二面](#二面-2)
+ - [小结](#小结-2)
+ - [总结](#总结)
+
+
+
+# 2019年蚂蚁金服、头条、拼多多的面试总结
+
+文章有点长,请耐心看完,绝对有收获!不想听我BB直接进入面试分享:
+
+- 准备过程
+- 蚂蚁金服面试分享
+- 拼多多面试分享
+- 字节跳动面试分享
+- 总结
+
+说起来开始进行面试是年前倒数第二周,上午9点,我还在去公司的公交上,突然收到蚂蚁的面试电话,其实算不上真正的面试。面试官只是和我聊了下他们在做的事情(主要是做双十一这里大促的稳定性保障,偏中间件吧),说的很详细,然后和我沟通了下是否有兴趣,我表示有兴趣,后面就收到正式面试的通知,最后没选择去蚂蚁表示抱歉。
+
+当时我自己也准备出去看看机会,顺便看看自己的实力。当时我其实挺纠结的,一方面现在部门也正需要我,还是可以有一番作为的,另一方面觉得近一年来进步缓慢,没有以前飞速进步的成就感了,而且业务和技术偏于稳定,加上自己也属于那种比较懒散的人,骨子里还是希望能够突破现状,持续在技术上有所精进。
+
+在开始正式的总结之前,还是希望各位同仁能否听我继续发泄一会,抱拳!
+
+我翻开自己2018年初立的flag,觉得甚是惭愧。其中就有一条是保持一周写一篇博客,奈何中间因为各种原因没能坚持下去。细细想来,主要是自己没能真正静下来心认真投入到技术的研究和学习,那么为什么会这样?说白了还是因为没有确定目标或者目标不明确,没有目标或者目标不明确都可能导致行动的失败。
+
+那么问题来了,目标是啥?就我而言,短期目标是深入研究某一项技术,比如最近在研究mysql,那么深入研究一定要动手实践并且有所产出,这就够了么?还需要我们能够举一反三,结合实际开发场景想一想日常开发要注意什么,这中间有没有什么坑?可以看出,要进步真的不是一件简单的事,这种反人类的行为需要我们克服自我的弱点,逐渐形成习惯。真正牛逼的人,从不觉得认真学习是一件多么难的事,因为这已经形成了他的习惯,就喝早上起床刷牙洗脸那么自然简单。
+
+扯了那么多,开始进入正题,先后进行了蚂蚁、拼多多和字节跳动的面试。
+
+## 准备过程
+
+先说说我自己的情况,我2016先在蚂蚁实习了将近三个月,然后去了我现在的老东家,2.5年工作经验,可以说毕业后就一直老老实实在老东家打怪升级,虽说有蚂蚁的实习经历,但是因为时间太短,还是有点虚的。所以面试官看到我简历第一个问题绝对是这样的。
+
+“哇,你在蚂蚁待过,不错啊”,面试官笑嘻嘻地问到。“是的,还好”,我说。“为啥才三个月?”,面试官脸色一沉问到。“哗啦啦解释一通。。。”,我解释道。“哦,原来如此,那我们开始面试吧”,面试官一本正经说到。
+
+尼玛,早知道不写蚂蚁的实习经历了,后面仔细一想,当初写上蚂蚁不就给简历加点料嘛。
+
+言归正传,准备过程其实很早开始了(当然这不是说我工作时老想着跳槽,因为我明白现在的老东家并不是终点,我还需要不断提升),具体可追溯到从蚂蚁离职的时候,当时出来也面了很多公司,没啥大公司,面了大概5家公司,都拿到offer了。
+
+工作之余常常会去额外研究自己感兴趣的技术以及工作用到的技术,力求把原理搞明白,并且会自己实践一把。此外,买了N多书,基本有时间就会去看,补补基础,什么操作系统、数据结构与算法、MySQL、JDK之类的源码,基本都好好温习了(文末会列一下自己看过的书和一些好的资料)。**我深知基础就像“木桶效应”的短板,决定了能装多少水。**
+
+此外,在正式决定看机会之前,我给自己列了一个提纲,主要包括Java要掌握的核心要点,有不懂的就查资料搞懂。我给自己定位还是Java工程师,所以Java体系是一定要做到心中有数的,很多东西没有常年的积累面试的时候很容易露馅,学习要对得起自己,不要骗人。
+
+剩下的就是找平台和内推了,除了蚂蚁,头条和拼多多都是找人内推的,感谢蚂蚁面试官对我的欣赏,以后说不定会去蚂蚁咯😄。
+
+平台:脉脉、GitHub、v2
+
+## 蚂蚁金服
+
+
+
+- 一面
+- 二面
+- 三面
+- 四面
+- 五面
+- 小结
+
+### 一面
+
+一面就做了一道算法题,要求两小时内完成,给了长度为N的有重复元素的数组,要求输出第10大的数。典型的TopK问题,快排算法搞定。
+
+算法题要注意的是合法性校验、边界条件以及异常的处理。另外,如果要写测试用例,一定要保证测试覆盖场景尽可能全。加上平时刷刷算法题,这种考核应该没问题的。
+
+### 二面
+
+- 自我介绍下呗
+- 开源项目贡献过代码么?(Dubbo提过一个打印accesslog的bug算么)
+- 目前在部门做什么,业务简单介绍下,内部有哪些系统,作用和交互过程说下
+- Dubbo踩过哪些坑,分别是怎么解决的?(说了异常处理时业务异常捕获的问题,自定义了一个异常拦截器)
+- 开始进入正题,说下你对线程安全的理解(多线程访问同一个对象,如果不需要考虑额外的同步,调用对象的行为就可以获得正确的结果就是线程安全)
+- 事务有哪些特性?(ACID)
+- 怎么理解原子性?(同一个事务下,多个操作要么成功要么失败,不存在部分成功或者部分失败的情况)
+- 乐观锁和悲观锁的区别?(悲观锁假定会发生冲突,访问的时候都要先获得锁,保证同一个时刻只有线程获得锁,读读也会阻塞;乐观锁假设不会发生冲突,只有在提交操作的时候检查是否有冲突)这两种锁在Java和MySQL分别是怎么实现的?(Java乐观锁通过CAS实现,悲观锁通过synchronize实现。mysql乐观锁通过MVCC,也就是版本实现,悲观锁可以通过select... for update加上排它锁)
+- HashMap为什么不是线程安全的?(多线程操作无并发控制,顺便说了在扩容的时候多线程访问时会造成死锁,会形成一个环,不过扩容时多线程操作形成环的问题再JDK1.8已经解决,但多线程下使用HashMap还会有一些其他问题比如数据丢失,所以多线程下不应该使用HashMap,而应该使用ConcurrentHashMap)怎么让HashMap变得线程安全?(Collections的synchronize方法包装一个线程安全的Map,或者直接用ConcurrentHashMap)两者的区别是什么?(前者直接在put和get方法加了synchronize同步,后者采用了分段锁以及CAS支持更高的并发)
+- jdk1.8对ConcurrentHashMap做了哪些优化?(插入的时候如果数组元素使用了红黑树,取消了分段锁设计,synchronize替代了Lock锁)为什么这样优化?(避免冲突严重时链表多长,提高查询效率,时间复杂度从O(N)提高到O(logN))
+- redis主从机制了解么?怎么实现的?
+- 有过GC调优的经历么?(有点虚,答得不是很好)
+- 有什么想问的么?
+
+### 三面
+
+- 简单自我介绍下
+- 监控系统怎么做的,分为哪些模块,模块之间怎么交互的?用的什么数据库?(MySQL)使用什么存储引擎,为什么使用InnnoDB?(支持事务、聚簇索引、MVCC)
+- 订单表有做拆分么,怎么拆的?(垂直拆分和水平拆分)
+- 水平拆分后查询过程描述下
+- 如果落到某个分片的数据很大怎么办?(按照某种规则,比如哈希取模、range,将单张表拆分为多张表)
+- 哈希取模会有什么问题么?(有的,数据分布不均,扩容缩容相对复杂 )
+- 分库分表后怎么解决读写压力?(一主多从、多主多从)
+- 拆分后主键怎么保证惟一?(UUID、Snowflake算法)
+- Snowflake生成的ID是全局递增唯一么?(不是,只是全局唯一,单机递增)
+- 怎么实现全局递增的唯一ID?(讲了TDDL的一次取一批ID,然后再本地慢慢分配的做法)
+- Mysql的索引结构说下(说了B+树,B+树可以对叶子结点顺序查找,因为叶子结点存放了数据结点且有序)
+- 主键索引和普通索引的区别(主键索引的叶子结点存放了整行记录,普通索引的叶子结点存放了主键ID,查询的时候需要做一次回表查询)一定要回表查询么?(不一定,当查询的字段刚好是索引的字段或者索引的一部分,就可以不用回表,这也是索引覆盖的原理)
+- 你们系统目前的瓶颈在哪里?
+- 你打算怎么优化?简要说下你的优化思路
+- 有什么想问我么?
+
+### 四面
+
+- 介绍下自己
+- 为什么要做逆向?
+- 怎么理解微服务?
+- 服务治理怎么实现的?(说了限流、压测、监控等模块的实现)
+- 这个不是中间件做的事么,为什么你们部门做?(当时没有单独的中间件团队,微服务刚搞不久,需要进行监控和性能优化)
+- 说说Spring的生命周期吧
+- 说说GC的过程(说了young gc和full gc的触发条件和回收过程以及对象创建的过程)
+- CMS GC有什么问题?(并发清除算法,浮动垃圾,短暂停顿)
+- 怎么避免产生浮动垃圾?(记得有个VM参数设置可以让扫描新生代之前进行一次young gc,但是因为gc是虚拟机自动调度的,所以不保证一定执行。但是还有参数可以让虚拟机强制执行一次young gc)
+- 强制young gc会有什么问题?(STW停顿时间变长)
+- 知道G1么?(了解一点 )
+- 回收过程是怎么样的?(young gc、并发阶段、混合阶段、full gc,说了Remember Set)
+- 你提到的Remember Set底层是怎么实现的?
+- 有什么想问的么?
+
+### 五面
+
+五面是HRBP面的,和我提前预约了时间,主要聊了之前在蚂蚁的实习经历、部门在做的事情、职业发展、福利待遇等。阿里面试官确实是具有一票否决权的,很看重你的价值观是否match,一般都比较喜欢皮实的候选人。HR面一定要诚实,不要说谎,只要你说谎HR都会去证实,直接cut了。
+
+- 之前蚂蚁实习三个月怎么不留下来?
+- 实习的时候主管是谁?
+- 实习做了哪些事情?(尼玛这种也问?)
+- 你对技术怎么看?平时使用什么技术栈?(阿里HR真的是既当爹又当妈,😂)
+- 最近有在研究什么东西么
+- 你对SRE怎么看
+- 对待遇有什么预期么
+
+最后HR还对我说目前稳定性保障部挺缺人的,希望我尽快回复。
+
+### 小结
+
+蚂蚁面试比较重视基础,所以Java那些基本功一定要扎实。蚂蚁的工作环境还是挺赞的,因为我面的是稳定性保障部门,还有许多单独的小组,什么三年1班,很有青春的感觉。面试官基本水平都比较高,基本都P7以上,除了基础还问了不少架构设计方面的问题,收获还是挺大的。
+
+## 拼多多
+
+
+
+- 面试前
+- 一面
+- 二面
+- 三面
+- 小结
+
+### 面试前
+
+面完蚂蚁后,早就听闻拼多多这个独角兽,决定也去面一把。首先我在脉脉找了一个拼多多的HR,加了微信聊了下,发了简历便开始我的拼多多面试之旅。这里要非常感谢拼多多HR小姐姐,从面试内推到offer确认一直都在帮我,人真的很nice。
+
+### 一面
+
+- 为啥蚂蚁只待了三个月?没转正?(转正了,解释了一通。。。)
+- Java中的HashMap、TreeMap解释下?(TreeMap红黑树,有序,HashMap无序,数组+链表)
+- TreeMap查询写入的时间复杂度多少?(O(logN))
+- HashMap多线程有什么问题?(线程安全,死锁)怎么解决?( jdk1.8用了synchronize + CAS,扩容的时候通过CAS检查是否有修改,是则重试)重试会有什么问题么?(CAS(Compare And Swap)是比较和交换,不会导致线程阻塞,但是因为重试是通过自旋实现的,所以仍然会占用CPU时间,还有ABA的问题)怎么解决?(超时,限定自旋的次数,ABA可以通过原理变量AtomicStampedReference解决,原理利用版本号进行比较)超过重试次数如果仍然失败怎么办?(synchronize互斥锁)
+- CAS和synchronize有什么区别?都用synchronize不行么?(CAS是乐观锁,不需要阻塞,硬件级别实现的原子性;synchronize会阻塞,JVM级别实现的原子性。使用场景不同,线程冲突严重时CAS会造成CPU压力过大,导致吞吐量下降,synchronize的原理是先自旋然后阻塞,线程冲突严重仍然有较高的吞吐量,因为线程都被阻塞了,不会占用CPU
+)
+- 如果要保证线程安全怎么办?(ConcurrentHashMap)
+- ConcurrentHashMap怎么实现线程安全的?(分段锁)
+- get需要加锁么,为什么?(不用,volatile关键字)
+- volatile的作用是什么?(保证内存可见性)
+- 底层怎么实现的?(说了主内存和工作内存,读写内存屏障,happen-before,并在纸上画了线程交互图)
+- 在多核CPU下,可见性怎么保证?(思考了一会,总线嗅探技术)
+- 聊项目,系统之间是怎么交互的?
+- 系统并发多少,怎么优化?
+- 给我一张纸,画了一个九方格,都填了数字,给一个M*N矩阵,从1开始逆时针打印这M*N个数,要求时间复杂度尽可能低(内心OS:之前貌似碰到过这题,最优解是怎么实现来着)思考中。。。
+- 可以先说下你的思路(想起来了,说了什么时候要变换方向的条件,向右、向下、向左、向上,依此循环)
+- 有什么想问我的?
+
+### 二面
+
+- 自我介绍下
+- 手上还有其他offer么?(拿了蚂蚁的offer)
+- 部门组织结构是怎样的?(这轮不是技术面么,不过还是老老实实说了)
+- 系统有哪些模块,每个模块用了哪些技术,数据怎么流转的?(面试官有点秃顶,一看级别就很高)给了我一张纸,我在上面简单画了下系统之间的流转情况
+- 链路追踪的信息是怎么传递的?(RpcContext的attachment,说了Span的结构:parentSpanId + curSpanId)
+- SpanId怎么保证唯一性?(UUID,说了下内部的定制改动)
+- RpcContext是在什么维度传递的?(线程)
+- Dubbo的远程调用怎么实现的?(讲了读取配置、拼装url、创建Invoker、服务导出、服务注册以及消费者通过动态代理、filter、获取Invoker列表、负载均衡等过程(哗啦啦讲了10多分钟),我可以喝口水么)
+- Spring的单例是怎么实现的?(单例注册表)
+- 为什么要单独实现一个服务治理框架?(说了下内部刚搞微服务不久,主要对服务进行一些监控和性能优化)
+- 谁主导的?内部还在使用么?
+- 逆向有想过怎么做成通用么?
+- 有什么想问的么?
+
+### 三面
+
+二面老大面完后就直接HR面了,主要问了些职业发展、是否有其他offer、以及入职意向等问题,顺便说了下公司的福利待遇等,都比较常规啦。不过要说的是手上有其他offer或者大厂经历会有一定加分。
+
+### 小结
+
+拼多多的面试流程就简单许多,毕竟是一个成立三年多的公司。面试难度中规中矩,只要基础扎实应该不是问题。但不得不说工作强度很大,开始面试前HR就提前和我确认能否接受这样强度的工作,想来的老铁还是要做好准备
+
+## 字节跳动
+
+
+
+- 面试前
+- 一面
+- 二面
+- 小结
+
+### 面试前
+
+头条的面试是三家里最专业的,每次面试前有专门的HR和你约时间,确定OK后再进行面试。每次都是通过视频面试,因为都是之前都是电话面或现场面,所以视频面试还是有点不自然。也有人觉得视频面试体验很赞,当然萝卜青菜各有所爱。最坑的二面的时候对方面试官的网络老是掉线,最后很冤枉的挂了(当然有一些点答得不好也是原因之一)。所以还是有点遗憾的。
+
+### 一面
+
+- 先自我介绍下
+- 聊项目,逆向系统是什么意思
+- 聊项目,逆向系统用了哪些技术
+- 线程池的线程数怎么确定?
+- 如果是IO操作为主怎么确定?
+- 如果计算型操作又怎么确定?
+- Redis熟悉么,了解哪些数据结构?(说了zset) zset底层怎么实现的?(跳表)
+- 跳表的查询过程是怎么样的,查询和插入的时间复杂度?(说了先从第一层查找,不满足就下沉到第二层找,因为每一层都是有序的,写入和插入的时间复杂度都是O(logN))
+- 红黑树了解么,时间复杂度?(说了是N叉平衡树,O(logN))
+- 既然两个数据结构时间复杂度都是O(logN),zset为什么不用红黑树(跳表实现简单,踩坑成本低,红黑树每次插入都要通过旋转以维持平衡,实现复杂)
+- 点了点头,说下Dubbo的原理?(说了服务注册与发布以及消费者调用的过程)踩过什么坑没有?(说了dubbo异常处理的和打印accesslog的问题)
+- CAS了解么?(说了CAS的实现)还了解其他同步机制么?(说了synchronize以及两者的区别,一个乐观锁,一个悲观锁)
+- 那我们做一道题吧,数组A,2*n个元素,n个奇数、n个偶数,设计一个算法,使得数组奇数下标位置放置的都是奇数,偶数下标位置放置的都是偶数
+- 先说下你的思路(从0下标开始遍历,如果是奇数下标判断该元素是否奇数,是则跳过,否则从该位置寻找下一个奇数)
+- 下一个奇数?怎么找?(有点懵逼,思考中。。)
+- 有思路么?(仍然是先遍历一次数组,并对下标进行判断,如果下标属性和该位置元素不匹配从当前下标的下一个遍历数组元素,然后替换)
+- 你这样时间复杂度有点高,如果要求O(N)要怎么做(思考一会,答道“定义两个指针,分别从下标0和1开始遍历,遇见奇数位是是偶数和偶数位是奇数就停下,交换内容”)
+- 时间差不多了,先到这吧。你有什么想问我的?
+
+### 二面
+
+- 面试官和蔼很多,你先介绍下自己吧
+- 你对服务治理怎么理解的?
+- 项目中的限流怎么实现的?(Guava ratelimiter,令牌桶算法)
+- 具体怎么实现的?(要点是固定速率且令牌数有限)
+- 如果突然很多线程同时请求令牌,有什么问题?(导致很多请求积压,线程阻塞)
+- 怎么解决呢?(可以把积压的请求放到消息队列,然后异步处理)
+- 如果不用消息队列怎么解决?(说了RateLimiter预消费的策略)
+- 分布式追踪的上下文是怎么存储和传递的?(ThreadLocal + spanId,当前节点的spanId作为下个节点的父spanId)
+- Dubbo的RpcContext是怎么传递的?(ThreadLocal)主线程的ThreadLocal怎么传递到线程池?(说了先在主线程通过ThreadLocal的get方法拿到上下文信息,在线程池创建新的ThreadLocal并把之前获取的上下文信息设置到ThreadLocal中。这里要注意的线程池创建的ThreadLocal要在finally中手动remove,不然会有内存泄漏的问题)
+- 你说的内存泄漏具体是怎么产生的?(说了ThreadLocal的结构,主要分两种场景:主线程仍然对ThreadLocal有引用和主线程不存在对ThreadLocal的引用。第一种场景因为主线程仍然在运行,所以还是有对ThreadLocal的引用,那么ThreadLocal变量的引用和value是不会被回收的。第二种场景虽然主线程不存在对ThreadLocal的引用,且该引用是弱引用,所以会在gc的时候被回收,但是对用的value不是弱引用,不会被内存回收,仍然会造成内存泄漏)
+- 线程池的线程是不是必须手动remove才可以回收value?(是的,因为线程池的核心线程是一直存在的,如果不清理,那么核心线程的threadLocals变量会一直持有ThreadLocal变量)
+- 那你说的内存泄漏是指主线程还是线程池?(主线程 )
+- 可是主线程不是都退出了,引用的对象不应该会主动回收么?(面试官和内存泄漏杠上了),沉默了一会。。。
+- 那你说下SpringMVC不同用户登录的信息怎么保证线程安全的?(刚才解释的有点懵逼,一下没反应过来,居然回答成锁了。大脑有点晕了,此时已经一个小时过去了,感觉情况不妙。。。)
+- 这个直接用ThreadLocal不就可以么,你见过SpringMVC有锁实现的代码么?(有点晕菜。。。)
+- 我们聊聊mysql吧,说下索引结构(说了B+树)
+- 为什么使用B+树?( 说了查询效率高,O(logN),可以充分利用磁盘预读的特性,多叉树,深度小,叶子结点有序且存储数据)
+- 什么是索引覆盖?(忘记了。。。 )
+- Java为什么要设计双亲委派模型?
+- 什么时候需要自定义类加载器?
+- 我们做一道题吧,手写一个对象池
+- 有什么想问我的么?(感觉我很多点都没答好,是不是挂了(结果真的是) )
+
+### 小结
+
+头条的面试确实很专业,每次面试官会提前给你发一个视频链接,然后准点开始面试,而且考察的点都比较全。
+
+面试官都有一个特点,会抓住一个值得深入的点或者你没说清楚的点深入下去直到你把这个点讲清楚,不然面试官会觉得你并没有真正理解。二面面试官给了我一点建议,研究技术的时候一定要去研究产生的背景,弄明白在什么场景解决什么特定的问题,其实很多技术内部都是相通的。很诚恳,还是很感谢这位面试官大大。
+
+## 总结
+
+从年前开始面试到头条面完大概一个多月的时间,真的有点身心俱疲的感觉。最后拿到了拼多多、蚂蚁的offer,还是蛮幸运的。头条的面试对我帮助很大,再次感谢面试官对我的诚恳建议,以及拼多多的HR对我的啰嗦的问题详细解答。
+
+这里要说的是面试前要做好两件事:简历和自我介绍,简历要好好回顾下自己做的一些项目,然后挑几个亮点项目。自我介绍基本每轮面试都有,所以最好提前自己练习下,想好要讲哪些东西,分别怎么讲。此外,简历提到的技术一定是自己深入研究过的,没有深入研究也最好找点资料预热下,不打无准备的仗。
+
+**这些年看过的书**:
+
+《Effective Java》、《现代操作系统》、《TCP/IP详解:卷一》、《代码整洁之道》、《重构》、《Java程序性能优化》、《Spring实战》、《Zookeeper》、《高性能MySQL》、《亿级网站架构核心技术》、《可伸缩服务架构》、《Java编程思想》
+
+说实话这些书很多只看了一部分,我通常会带着问题看书,不然看着看着就睡着了,简直是催眠良药😅。
+
+
+最后,附一张自己面试前准备的脑图:
+
+链接:https://pan.baidu.com/s/1o2l1tuRakBEP0InKEh4Hzw 密码:300d
+
+全文完。
diff --git a/docs/essential-content-for-interview/BATJrealInterviewExperience/2020-zijietiaodong.md b/docs/essential-content-for-interview/BATJrealInterviewExperience/2020-zijietiaodong.md
new file mode 100644
index 00000000000..0e63008bc27
--- /dev/null
+++ b/docs/essential-content-for-interview/BATJrealInterviewExperience/2020-zijietiaodong.md
@@ -0,0 +1,61 @@
+
+
+> 本文来自读者 Boyn 投稿!恭喜这位粉丝拿到了含金量极高的字节跳动实习 offer!赞!
+
+## 基本条件
+
+本人是底层 211 本科,现在大三,无科研经历,但是有一些项目经历,在国内监控行业某头部企业做过一段时间的实习。想着投一下字节,可以积累一下面试经验和为春招做准备.投了简历之后,过了一段时间,HR 就打电话跟我约时间,在年后进行远程面。
+
+说明一下,我投的是北京 office。
+
+## 一面
+
+面试官很和蔼,由于疫情的原因,大家都在家里面进行远程面试
+
+开头没有自我介绍,直接开始问项目了,问了比如
+
+- 常用的 Web 组件有哪些(回答了自己经常用到的 SpringBoot,Redis,Mysql 等等,字节这边基本没有用 Java 的后台,所以感觉面试官不大会问 Spring,Java 这些东西,反倒是对数据库和中间件比较感兴趣)
+- Kafka 相关,如何保证不会重复消费,Kafka 消费组结构等等(这个只是凭着感觉和面试官说了,因为 Kafka 自己确实准备得不充分,但是心态稳住了)
+- **Mysql 索引,B+树(必考嗷同学们)**
+
+还有一些项目中的细节,这些因人而异,就不放上来了,提示一点就是要在项目中介绍一些亮眼的地方,比如用了什么牛逼的数据结构,架构上有什么特点,并发量大小还有怎么去 hold 住并发量
+
+后面就是算法题了,一共做了两道
+
+1. 判断平衡二叉树(这道题总体来说并不难,但是面试官在中间穿插了垃圾回收的知识,这就很难受了,具体的就是大家要判断一下对象在什么时候会回收,可达性分析什么时候对这个对象来说是不可达的,还有在递归函数中内存如何变化,这个是让我们来对这个函数进行执行过程的建模,只看栈帧大小变化的话,应该有是两个峰值,中间会有抖动的情况)
+2. 二分查找法的变种题,给定`target`和一个升序的数组,寻找下一个比数组大的数.这道题也不难,靠大家对二分查找法的熟悉程度,当然,这边还有一个优化的点,可以看看[我的博客](https://boyn.top/2019/11/09/%E7%AE%97%E6%B3%95%E4%B8%8E%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/%E6%B7%B1%E5%85%A5%E7%90%86%E8%A7%A3%E4%BA%8C%E5%88%86%E6%9F%A5%E6%89%BE%E6%B3%95/)找找灵感
+
+完成了之后,面试官让我等一会有二面,大概 10 分钟左右吧,休息了一会就继续了
+
+## 二面
+
+二面一上来就是先让我自我介绍,当然还是同样的套路,同样的香脆
+
+然后问了我一些关于 Redis 的问题,比如 **zset 的实现(跳表,这个高频)** ,键的过期策略,持久化等等,这些在大多数 Redis 的介绍中都可以找到,就不细说了
+
+还有一些数据结构的问题,比如说问了哈希表是什么,给面试官详细说了一下`java.util.HashMap`是怎么实现(当然里面就穿插着红黑树了,多看看红黑树是有什么特点之类的)的,包括说为什么要用链地址法来避免冲突,探测法有哪些,链地址法和探测法的优劣对比
+
+后面还跟我讨论了很久的项目,所以说大家的项目一定要做好,要有亮点的地方,在这里跟面试官讨论了很多项目优化的地方,还有什么不足,还有什么地方可以新增功能等等,同样不细说了
+
+一边讨论的时候劈里啪啦敲了很多,应该是对个人的面试评价一类的
+
+后面就是字节的传统艺能手撕算法了,一共做了三道
+
+- 一二道是连在一起的.给定一个规则`S_0 = {1} S_1={1,2,1} S_2 = {1,2,1,3,1,2,1} S_n = {S_n-1 , n + 1, S_n-1}`.第一个问题是他们的个数有什么关系(1 3 7 15... 2 的 n 次方-1,用位运算解决).第二个问题是给定数组个数下标 n 和索引 k,让我们求出 S_n(k)所指的数,假如`S_2(2) = 1`,我在做的时候没有什么好的思路,如果有的话大家可以分享一下
+- 第三道是下一个排列:[https://leetcode-cn.com/problems/next-permutation](https://leetcode-cn.com/problems/next-permutation) 的题型,不过做了一些修改,数组大小`10000
+
+如果还有什么问题欢迎给我留言!如果文章有什么问题的话,也劳烦指出,Guide 哥感激不尽!
+
+后面的文章我会介绍:
+
+- [ ] Java8 对日期的支持以及为啥不能用 SimpleDateFormat。
+- [ ] SpringBoot 中如何实际使用(JPA 为例)
\ No newline at end of file
diff --git "a/docs/database/\346\225\260\346\215\256\345\272\223\347\264\242\345\274\225.md" "b/docs/database/\346\225\260\346\215\256\345\272\223\347\264\242\345\274\225.md"
new file mode 100644
index 00000000000..568ba833fab
--- /dev/null
+++ "b/docs/database/\346\225\260\346\215\256\345\272\223\347\264\242\345\274\225.md"
@@ -0,0 +1,225 @@
+## 什么是索引?
+**索引是一种用于快速查询和检索数据的数据结构。常见的索引结构有: B树, B+树和Hash。**
+
+索引的作用就相当于目录的作用。打个比方: 我们在查字典的时候,如果没有目录,那我们就只能一页一页的去找我们需要查的那个字,速度很慢。如果有目录了,我们只需要先去目录里查找字的位置,然后直接翻到那一页就行了。
+
+## 为什么要用索引?索引的优缺点分析
+
+### 索引的优点
+**可以大大加快 数据的检索速度(大大减少的检索的数据量), 这也是创建索引的最主要的原因。毕竟大部分系统的读请求总是大于写请求的。 ** 另外,通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
+
+### 索引的缺点
+1. **创建索引和维护索引需要耗费许多时间**:当对表中的数据进行增删改的时候,如果数据有索引,那么索引也需要动态的修改,会降低SQL执行效率。
+2. **占用物理存储空间** :索引需要使用物理文件存储,也会耗费一定空间。
+
+## B树和B+树区别
+
+* B树的所有节点既存放 键(key) 也存放 数据(data);而B+树只有叶子节点存放 key 和 data,其他内节点只存放key。
+* B树的叶子节点都是独立的;B+树的叶子节点有一条引用链指向与它相邻的叶子节点。
+* B树的检索的过程相当于对范围内的每个节点的关键字做二分查找,可能还没有到达叶子节点,检索就结束了。而B+树的检索效率就很稳定了,任何查找都是从根节点到叶子节点的过程,叶子节点的顺序检索很明显。
+
+
+
+## Hash索引和 B+树索引优劣分析
+
+**Hash索引定位快**
+
+Hash索引指的就是Hash表,最大的优点就是能够在很短的时间内,根据Hash函数定位到数据所在的位置,这是B+树所不能比的。
+
+**Hash冲突问题**
+
+知道HashMap或HashTable的同学,相信都知道它们最大的缺点就是Hash冲突了。不过对于数据库来说这还不算最大的缺点。
+
+**Hash索引不支持顺序和范围查询(Hash索引不支持顺序和范围查询是它最大的缺点。**
+
+试想一种情况:
+
+````text
+SELECT * FROM tb1 WHERE id < 500;
+````
+
+B+树是有序的,在这种范围查询中,优势非常大,直接遍历比500小的叶子节点就够了。而Hash索引是根据hash算法来定位的,难不成还要把 1 - 499的数据,每个都进行一次hash计算来定位吗?这就是Hash最大的缺点了。
+
+---
+
+## 索引类型
+
+### 主键索引(Primary Key)
+**数据表的主键列使用的就是主键索引。**
+
+**一张数据表有只能有一个主键,并且主键不能为null,不能重复。**
+
+**在mysql的InnoDB的表中,当没有显示的指定表的主键时,InnoDB会自动先检查表中是否有唯一索引的字段,如果有,则选择该字段为默认的主键,否则InnoDB将会自动创建一个6Byte的自增主键。**
+
+### 二级索引(辅助索引)
+**二级索引又称为辅助索引,是因为二级索引的叶子节点存储的数据是主键。也就是说,通过二级索引,可以定位主键的位置。**
+
+唯一索引,普通索引,前缀索引等索引属于二级索引。
+
+**PS:不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,也可以自行搜索。**
+
+1. **唯一索引(Unique Key)** :唯一索引也是一种约束。**唯一索引的属性列不能出现重复的数据,但是允许数据为NULL,一张表允许创建多个唯一索引。**建立唯一索引的目的大部分时候都是为了该属性列的数据的唯一性,而不是为了查询效率。
+2. **普通索引(Index)** :**普通索引的唯一作用就是为了快速查询数据,一张表允许创建多个普通索引,并允许数据重复和NULL。**
+3. **前缀索引(Prefix)** :前缀索引只适用于字符串类型的数据。前缀索引是对文本的前几个字符创建索引,相比普通索引建立的数据更小,
+ 因为只取前几个字符。
+4. **全文索引(Full Text)** :全文索引主要是为了检索大文本数据中的关键字的信息,是目前搜索引擎数据库使用的一种技术。Mysql5.6之前只有MYISAM引擎支持全文索引,5.6之后InnoDB也支持了全文索引。
+
+二级索引:
+.png)
+
+## 聚集索引与非聚集索引
+
+### 聚集索引
+**聚集索引即索引结构和数据一起存放的索引。主键索引属于聚集索引。**
+
+在 Mysql 中,InnoDB引擎的表的 `.ibd`文件就包含了该表的索引和数据,对于 InnoDB 引擎表来说,该表的索引(B+树)的每个非叶子节点存储索引,叶子节点存储索引和索引对应的数据。
+
+#### 聚集索引的优点
+聚集索引的查询速度非常的快,因为整个B+树本身就是一颗多叉平衡树,叶子节点也都是有序的,定位到索引的节点,就相当于定位到了数据。
+
+#### 聚集索引的缺点
+1. **依赖于有序的数据** :因为B+树是多路平衡树,如果索引的数据不是有序的,那么就需要在插入时排序,如果数据是整型还好,否则类似于字符串或UUID这种又长又难比较的数据,插入或查找的速度肯定比较慢。
+2. **更新代价大** : 如果对索引列的数据被修改时,那么对应的索引也将会被修改,
+ 而且况聚集索引的叶子节点还存放着数据,修改代价肯定是较大的,
+ 所以对于主键索引来说,主键一般都是不可被修改的。
+
+### 非聚集索引
+
+**非聚集索引即索引结构和数据分开存放的索引。**
+
+**二级索引属于非聚集索引。**
+
+>MYISAM引擎的表的.MYI文件包含了表的索引,
+>该表的索引(B+树)的每个叶子非叶子节点存储索引,
+>叶子节点存储索引和索引对应数据的指针,指向.MYD文件的数据。
+>
+**非聚集索引的叶子节点并不一定存放数据的指针,
+因为二级索引的叶子节点就存放的是主键,根据主键再回表查数据。**
+
+#### 非聚集索引的优点
+**更新代价比聚集索引要小** 。非聚集索引的更新代价就没有聚集索引那么大了,非聚集索引的叶子节点是不存放数据的
+
+#### 非聚集索引的缺点
+1. 跟聚集索引一样,非聚集索引也依赖于有序的数据
+2. **可能会二次查询(回表)** :这应该是非聚集索引最大的缺点了。 当查到索引对应的指针或主键后,可能还需要根据指针或主键再到数据文件或表中查询。
+
+这是Mysql的表的文件截图:
+
+
+
+聚集索引和非聚集索引:
+
+
+
+### 非聚集索引一定回表查询吗(覆盖索引)?
+**非聚集索引不一定回表查询。**
+
+>试想一种情况,用户准备使用SQL查询用户名,而用户名字段正好建立了索引。
+
+````text
+ SELECT name FROM table WHERE username='guang19';
+````
+
+>那么这个索引的key本身就是name,查到对应的name直接返回就行了,无需回表查询。
+
+**即使是MYISAM也是这样,虽然MYISAM的主键索引确实需要回表,
+因为它的主键索引的叶子节点存放的是指针。但是如果SQL查的就是主键呢?**
+
+```text
+SELECT id FROM table WHERE id=1;
+```
+
+主键索引本身的key就是主键,查到返回就行了。这种情况就称之为覆盖索引了。
+
+## 覆盖索引
+
+如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为“覆盖索引”。我们知道在InnoDB存储引擎中,如果不是主键索引,叶子节点存储的是主键+列值。最终还是要“回表”,也就是要通过主键再查找一次。这样就会比较慢覆盖索引就是把要查询出的列和索引是对应的,不做回表操作!
+
+**覆盖索引即需要查询的字段正好是索引的字段,那么直接根据该索引,就可以查到数据了,
+而无需回表查询。**
+
+>如主键索引,如果一条SQL需要查询主键,那么正好根据主键索引就可以查到主键。
+>
+>再如普通索引,如果一条SQL需要查询name,name字段正好有索引,
+>那么直接根据这个索引就可以查到数据,也无需回表。
+
+覆盖索引:
+
+
+---
+
+## 索引创建原则
+
+### 单列索引
+单列索引即由一列属性组成的索引。
+
+### 联合索引(多列索引)
+联合索引即由多列属性组成索引。
+
+### 最左前缀原则
+
+假设创建的联合索引由三个字段组成:
+
+```text
+ALTER TABLE table ADD INDEX index_name (num,name,age)
+```
+
+那么当查询的条件有为:num / (num AND name) / (num AND name AND age)时,索引才生效。所以在创建联合索引时,尽量把查询最频繁的那个字段作为最左(第一个)字段。查询的时候也尽量以这个字段为第一条件。
+
+> 但可能由于版本原因(我的mysql版本为8.0.x),我创建的联合索引,相当于在联合索引的每个字段上都创建了相同的索引:
+
+.png)
+
+无论是否符合最左前缀原则,每个字段的索引都生效:
+
+
+
+## 索引创建注意点
+
+### 最左前缀原则
+
+虽然我目前的Mysql版本较高,好像不遵守最左前缀原则,索引也会生效。
+但是我们仍应遵守最左前缀原则,以免版本更迭带来的麻烦。
+
+### 选择合适的字段
+
+#### 1.不为NULL的字段
+
+索引字段的数据应该尽量不为NULL,因为对于数据为NULL的字段,数据库较难优化。如果字段频繁被查询,但又避免不了为NULL,建议使用0,1,true,false这样语义较为清晰的短值或短字符作为替代。
+
+#### 2.被频繁查询的字段
+
+我们创建索引的字段应该是查询操作非常频繁的字段。
+
+#### 3.被作为条件查询的字段
+
+被作为WHERE条件查询的字段,应该被考虑建立索引。
+
+#### 4.被经常频繁用于连接的字段
+
+经常用于连接的字段可能是一些外键列,对于外键列并不一定要建立外键,只是说该列涉及到表与表的关系。对于频繁被连接查询的字段,可以考虑建立索引,提高多表连接查询的效率。
+
+### 不合适创建索引的字段
+
+#### 1.被频繁更新的字段应该慎重建立索引
+
+虽然索引能带来查询上的效率,但是维护索引的成本也是不小的。
+如果一个字段不被经常查询,反而被经常修改,那么就更不应该在这种字段上建立索引了。
+
+#### 2.不被经常查询的字段没有必要建立索引
+
+#### 3.尽可能的考虑建立联合索引而不是单列索引
+
+因为索引是需要占用磁盘空间的,可以简单理解为每个索引都对应着一颗B+树。如果一个表的字段过多,索引过多,那么当这个表的数据达到一个体量后,索引占用的空间也是很多的,且修改索引时,耗费的时间也是较多的。如果是联合索引,多个字段在一个索引上,那么将会节约很大磁盘空间,且修改数据的操作效率也会提升。
+
+#### 4.注意避免冗余索引
+
+冗余索引指的是索引的功能相同,能够命中 就肯定能命中 ,那么 就是冗余索引如(name,city )和(name )这两个索引就是冗余索引,能够命中后者的查询肯定是能够命中前者的 在大多数情况下,都应该尽量扩展已有的索引而不是创建新索引。
+
+#### 5.考虑在字符串类型的字段上使用前缀索引代替普通索引
+
+前缀索引仅限于字符串类型,较普通索引会占用更小的空间,所以可以考虑使用前缀索引带替普通索引。
+
+### 使用索引一定能提高查询性能吗?
+
+大多数情况下,索引查询都是比全表扫描要快的。但是如果数据库的数据量不大,那么使用索引也不一定能够带来很大提升。
\ No newline at end of file
diff --git "a/docs/database/\346\225\260\346\215\256\345\272\223\350\277\236\346\216\245\346\261\240.md" "b/docs/database/\346\225\260\346\215\256\345\272\223\350\277\236\346\216\245\346\261\240.md"
new file mode 100644
index 00000000000..3e84dfc8efd
--- /dev/null
+++ "b/docs/database/\346\225\260\346\215\256\345\272\223\350\277\236\346\216\245\346\261\240.md"
@@ -0,0 +1,21 @@
+- 公众号和Github待发文章:[数据库:数据库连接池原理详解与自定义连接池实现](https://www.fangzhipeng.com/javainterview/2019/07/15/mysql-connector-pool.html)
+- [基于JDBC的数据库连接池技术研究与应用](http://blog.itpub.net/9403012/viewspace-111794/)
+- [数据库连接池技术详解](https://juejin.im/post/5b7944c6e51d4538c86cf195)
+
+数据库连接本质就是一个 socket 的连接。数据库服务端还要维护一些缓存和用户权限信息之类的 所以占用了一些内存
+
+连接池是维护的数据库连接的缓存,以便将来需要对数据库的请求时可以重用这些连接。为每个用户打开和维护数据库连接,尤其是对动态数据库驱动的网站应用程序的请求,既昂贵又浪费资源。**在连接池中,创建连接后,将其放置在池中,并再次使用它,因此不必建立新的连接。如果使用了所有连接,则会建立一个新连接并将其添加到池中。**连接池还减少了用户必须等待建立与数据库的连接的时间。
+
+操作过数据库的朋友应该都知道数据库连接池这个概念,它几乎每天都在和我们打交道,但是你真的了解 **数据库连接池** 吗?
+
+### 没有数据库连接池之前
+
+我相信你一定听过这样一句话:**Java语言中,JDBC(Java DataBase Connection)是应用程序与数据库沟通的桥梁**。
+
+
+
+
+
+
+
+
diff --git "a/docs/database/\351\230\277\351\207\214\345\267\264\345\267\264\345\274\200\345\217\221\346\211\213\345\206\214\346\225\260\346\215\256\345\272\223\351\203\250\345\210\206\347\232\204\344\270\200\344\272\233\346\234\200\344\275\263\345\256\236\350\267\265.md" "b/docs/database/\351\230\277\351\207\214\345\267\264\345\267\264\345\274\200\345\217\221\346\211\213\345\206\214\346\225\260\346\215\256\345\272\223\351\203\250\345\210\206\347\232\204\344\270\200\344\272\233\346\234\200\344\275\263\345\256\236\350\267\265.md"
new file mode 100644
index 00000000000..abd9331d6f7
--- /dev/null
+++ "b/docs/database/\351\230\277\351\207\214\345\267\264\345\267\264\345\274\200\345\217\221\346\211\213\345\206\214\346\225\260\346\215\256\345\272\223\351\203\250\345\210\206\347\232\204\344\270\200\344\272\233\346\234\200\344\275\263\345\256\236\350\267\265.md"
@@ -0,0 +1,41 @@
+# 阿里巴巴Java开发手册数据库部分的一些最佳实践总结
+
+## 模糊查询
+
+对于模糊查询阿里巴巴开发手册这样说到:
+
+> 【强制】页面搜索严禁左模糊或者全模糊,如果需要请走搜索引擎来解决。
+>
+> 说明:索引文件具有 B-Tree 的最左前缀匹配特性,如果左边的值未确定,那么无法使用此索引。
+
+## 外键和级联
+
+对于外键和级联,阿里巴巴开发手册这样说到:
+
+>【强制】不得使用外键与级联,一切外键概念必须在应用层解决。
+>
+>说明:以学生和成绩的关系为例,学生表中的 student_id 是主键,那么成绩表中的 student_id 则为外键。如果更新学生表中的 student_id,同时触发成绩表中的 student_id 更新,即为级联更新。外键与级联更新适用于单机低并发,不适合分布式、高并发集群;级联更新是强阻塞,存在数据库更新风暴的风 险;外键影响数据库的插入速度
+
+为什么不要用外键呢?大部分人可能会这样回答:
+
+> 1. **增加了复杂性:** a.每次做DELETE 或者UPDATE都必须考虑外键约束,会导致开发的时候很痛苦,测试数据极为不方便;b.外键的主从关系是定的,假如那天需求有变化,数据库中的这个字段根本不需要和其他表有关联的话就会增加很多麻烦。
+> 2. **增加了额外工作**: 数据库需要增加维护外键的工作,比如当我们做一些涉及外键字段的增,删,更新操作之后,需要触发相关操作去检查,保证数据的的一致性和正确性,这样会不得不消耗资源;(个人觉得这个不是不用外键的原因,因为即使你不使用外键,你在应用层面也还是要保证的。所以,我觉得这个影响可以忽略不计。)
+> 3. 外键还会因为需要请求对其他表内部加锁而容易出现死锁情况;
+> 4. **对分库分表不友好** :因为分库分表下外键是无法生效的。
+> 5. ......
+
+我个人觉得上面这种回答不是特别的全面,只是说了外键存在的一个常见的问题。实际上,我们知道外键也是有很多好处的,比如:
+
+1. 保证了数据库数据的一致性和完整性;
+2. 级联操作方便,减轻了程序代码量;
+3. ......
+
+所以说,不要一股脑的就抛弃了外键这个概念,既然它存在就有它存在的道理,如果系统不涉及分不分表,并发量不是很高的情况还是可以考虑使用外键的。
+
+我个人是不太喜欢外键约束,比较喜欢在应用层去进行相关操作。
+
+## 关于@Transactional注解
+
+对于`@Transactional`事务注解,阿里巴巴开发手册这样说到:
+
+>【参考】@Transactional事务不要滥用。事务会影响数据库的QPS,另外使用事务的地方需要考虑各方面的回滚方案,包括缓存回滚、搜索引擎回滚、消息补偿、统计修正等。
diff --git a/docs/essential-content-for-interview/BATJrealInterviewExperience/2019alipay-pinduoduo-toutiao.md b/docs/essential-content-for-interview/BATJrealInterviewExperience/2019alipay-pinduoduo-toutiao.md
new file mode 100644
index 00000000000..183a1852a90
--- /dev/null
+++ b/docs/essential-content-for-interview/BATJrealInterviewExperience/2019alipay-pinduoduo-toutiao.md
@@ -0,0 +1,294 @@
+作者: rhwayfun,原文地址:https://mp.weixin.qq.com/s/msYty4vjjC0PvrwasRH5Bw ,JavaGuide 已经获得作者授权并对原文进行了重新排版。
+
+
+- [写在2019年后的蚂蚁、头条、拼多多的面试总结](#写在2019年后的蚂蚁头条拼多多的面试总结)
+ - [准备过程](#准备过程)
+ - [蚂蚁金服](#蚂蚁金服)
+ - [一面](#一面)
+ - [二面](#二面)
+ - [三面](#三面)
+ - [四面](#四面)
+ - [五面](#五面)
+ - [小结](#小结)
+ - [拼多多](#拼多多)
+ - [面试前](#面试前)
+ - [一面](#一面-1)
+ - [二面](#二面-1)
+ - [三面](#三面-1)
+ - [小结](#小结-1)
+ - [字节跳动](#字节跳动)
+ - [面试前](#面试前-1)
+ - [一面](#一面-2)
+ - [二面](#二面-2)
+ - [小结](#小结-2)
+ - [总结](#总结)
+
+
+
+# 2019年蚂蚁金服、头条、拼多多的面试总结
+
+文章有点长,请耐心看完,绝对有收获!不想听我BB直接进入面试分享:
+
+- 准备过程
+- 蚂蚁金服面试分享
+- 拼多多面试分享
+- 字节跳动面试分享
+- 总结
+
+说起来开始进行面试是年前倒数第二周,上午9点,我还在去公司的公交上,突然收到蚂蚁的面试电话,其实算不上真正的面试。面试官只是和我聊了下他们在做的事情(主要是做双十一这里大促的稳定性保障,偏中间件吧),说的很详细,然后和我沟通了下是否有兴趣,我表示有兴趣,后面就收到正式面试的通知,最后没选择去蚂蚁表示抱歉。
+
+当时我自己也准备出去看看机会,顺便看看自己的实力。当时我其实挺纠结的,一方面现在部门也正需要我,还是可以有一番作为的,另一方面觉得近一年来进步缓慢,没有以前飞速进步的成就感了,而且业务和技术偏于稳定,加上自己也属于那种比较懒散的人,骨子里还是希望能够突破现状,持续在技术上有所精进。
+
+在开始正式的总结之前,还是希望各位同仁能否听我继续发泄一会,抱拳!
+
+我翻开自己2018年初立的flag,觉得甚是惭愧。其中就有一条是保持一周写一篇博客,奈何中间因为各种原因没能坚持下去。细细想来,主要是自己没能真正静下来心认真投入到技术的研究和学习,那么为什么会这样?说白了还是因为没有确定目标或者目标不明确,没有目标或者目标不明确都可能导致行动的失败。
+
+那么问题来了,目标是啥?就我而言,短期目标是深入研究某一项技术,比如最近在研究mysql,那么深入研究一定要动手实践并且有所产出,这就够了么?还需要我们能够举一反三,结合实际开发场景想一想日常开发要注意什么,这中间有没有什么坑?可以看出,要进步真的不是一件简单的事,这种反人类的行为需要我们克服自我的弱点,逐渐形成习惯。真正牛逼的人,从不觉得认真学习是一件多么难的事,因为这已经形成了他的习惯,就喝早上起床刷牙洗脸那么自然简单。
+
+扯了那么多,开始进入正题,先后进行了蚂蚁、拼多多和字节跳动的面试。
+
+## 准备过程
+
+先说说我自己的情况,我2016先在蚂蚁实习了将近三个月,然后去了我现在的老东家,2.5年工作经验,可以说毕业后就一直老老实实在老东家打怪升级,虽说有蚂蚁的实习经历,但是因为时间太短,还是有点虚的。所以面试官看到我简历第一个问题绝对是这样的。
+
+“哇,你在蚂蚁待过,不错啊”,面试官笑嘻嘻地问到。“是的,还好”,我说。“为啥才三个月?”,面试官脸色一沉问到。“哗啦啦解释一通。。。”,我解释道。“哦,原来如此,那我们开始面试吧”,面试官一本正经说到。
+
+尼玛,早知道不写蚂蚁的实习经历了,后面仔细一想,当初写上蚂蚁不就给简历加点料嘛。
+
+言归正传,准备过程其实很早开始了(当然这不是说我工作时老想着跳槽,因为我明白现在的老东家并不是终点,我还需要不断提升),具体可追溯到从蚂蚁离职的时候,当时出来也面了很多公司,没啥大公司,面了大概5家公司,都拿到offer了。
+
+工作之余常常会去额外研究自己感兴趣的技术以及工作用到的技术,力求把原理搞明白,并且会自己实践一把。此外,买了N多书,基本有时间就会去看,补补基础,什么操作系统、数据结构与算法、MySQL、JDK之类的源码,基本都好好温习了(文末会列一下自己看过的书和一些好的资料)。**我深知基础就像“木桶效应”的短板,决定了能装多少水。**
+
+此外,在正式决定看机会之前,我给自己列了一个提纲,主要包括Java要掌握的核心要点,有不懂的就查资料搞懂。我给自己定位还是Java工程师,所以Java体系是一定要做到心中有数的,很多东西没有常年的积累面试的时候很容易露馅,学习要对得起自己,不要骗人。
+
+剩下的就是找平台和内推了,除了蚂蚁,头条和拼多多都是找人内推的,感谢蚂蚁面试官对我的欣赏,以后说不定会去蚂蚁咯😄。
+
+平台:脉脉、GitHub、v2
+
+## 蚂蚁金服
+
+
+
+- 一面
+- 二面
+- 三面
+- 四面
+- 五面
+- 小结
+
+### 一面
+
+一面就做了一道算法题,要求两小时内完成,给了长度为N的有重复元素的数组,要求输出第10大的数。典型的TopK问题,快排算法搞定。
+
+算法题要注意的是合法性校验、边界条件以及异常的处理。另外,如果要写测试用例,一定要保证测试覆盖场景尽可能全。加上平时刷刷算法题,这种考核应该没问题的。
+
+### 二面
+
+- 自我介绍下呗
+- 开源项目贡献过代码么?(Dubbo提过一个打印accesslog的bug算么)
+- 目前在部门做什么,业务简单介绍下,内部有哪些系统,作用和交互过程说下
+- Dubbo踩过哪些坑,分别是怎么解决的?(说了异常处理时业务异常捕获的问题,自定义了一个异常拦截器)
+- 开始进入正题,说下你对线程安全的理解(多线程访问同一个对象,如果不需要考虑额外的同步,调用对象的行为就可以获得正确的结果就是线程安全)
+- 事务有哪些特性?(ACID)
+- 怎么理解原子性?(同一个事务下,多个操作要么成功要么失败,不存在部分成功或者部分失败的情况)
+- 乐观锁和悲观锁的区别?(悲观锁假定会发生冲突,访问的时候都要先获得锁,保证同一个时刻只有线程获得锁,读读也会阻塞;乐观锁假设不会发生冲突,只有在提交操作的时候检查是否有冲突)这两种锁在Java和MySQL分别是怎么实现的?(Java乐观锁通过CAS实现,悲观锁通过synchronize实现。mysql乐观锁通过MVCC,也就是版本实现,悲观锁可以通过select... for update加上排它锁)
+- HashMap为什么不是线程安全的?(多线程操作无并发控制,顺便说了在扩容的时候多线程访问时会造成死锁,会形成一个环,不过扩容时多线程操作形成环的问题再JDK1.8已经解决,但多线程下使用HashMap还会有一些其他问题比如数据丢失,所以多线程下不应该使用HashMap,而应该使用ConcurrentHashMap)怎么让HashMap变得线程安全?(Collections的synchronize方法包装一个线程安全的Map,或者直接用ConcurrentHashMap)两者的区别是什么?(前者直接在put和get方法加了synchronize同步,后者采用了分段锁以及CAS支持更高的并发)
+- jdk1.8对ConcurrentHashMap做了哪些优化?(插入的时候如果数组元素使用了红黑树,取消了分段锁设计,synchronize替代了Lock锁)为什么这样优化?(避免冲突严重时链表多长,提高查询效率,时间复杂度从O(N)提高到O(logN))
+- redis主从机制了解么?怎么实现的?
+- 有过GC调优的经历么?(有点虚,答得不是很好)
+- 有什么想问的么?
+
+### 三面
+
+- 简单自我介绍下
+- 监控系统怎么做的,分为哪些模块,模块之间怎么交互的?用的什么数据库?(MySQL)使用什么存储引擎,为什么使用InnnoDB?(支持事务、聚簇索引、MVCC)
+- 订单表有做拆分么,怎么拆的?(垂直拆分和水平拆分)
+- 水平拆分后查询过程描述下
+- 如果落到某个分片的数据很大怎么办?(按照某种规则,比如哈希取模、range,将单张表拆分为多张表)
+- 哈希取模会有什么问题么?(有的,数据分布不均,扩容缩容相对复杂 )
+- 分库分表后怎么解决读写压力?(一主多从、多主多从)
+- 拆分后主键怎么保证惟一?(UUID、Snowflake算法)
+- Snowflake生成的ID是全局递增唯一么?(不是,只是全局唯一,单机递增)
+- 怎么实现全局递增的唯一ID?(讲了TDDL的一次取一批ID,然后再本地慢慢分配的做法)
+- Mysql的索引结构说下(说了B+树,B+树可以对叶子结点顺序查找,因为叶子结点存放了数据结点且有序)
+- 主键索引和普通索引的区别(主键索引的叶子结点存放了整行记录,普通索引的叶子结点存放了主键ID,查询的时候需要做一次回表查询)一定要回表查询么?(不一定,当查询的字段刚好是索引的字段或者索引的一部分,就可以不用回表,这也是索引覆盖的原理)
+- 你们系统目前的瓶颈在哪里?
+- 你打算怎么优化?简要说下你的优化思路
+- 有什么想问我么?
+
+### 四面
+
+- 介绍下自己
+- 为什么要做逆向?
+- 怎么理解微服务?
+- 服务治理怎么实现的?(说了限流、压测、监控等模块的实现)
+- 这个不是中间件做的事么,为什么你们部门做?(当时没有单独的中间件团队,微服务刚搞不久,需要进行监控和性能优化)
+- 说说Spring的生命周期吧
+- 说说GC的过程(说了young gc和full gc的触发条件和回收过程以及对象创建的过程)
+- CMS GC有什么问题?(并发清除算法,浮动垃圾,短暂停顿)
+- 怎么避免产生浮动垃圾?(记得有个VM参数设置可以让扫描新生代之前进行一次young gc,但是因为gc是虚拟机自动调度的,所以不保证一定执行。但是还有参数可以让虚拟机强制执行一次young gc)
+- 强制young gc会有什么问题?(STW停顿时间变长)
+- 知道G1么?(了解一点 )
+- 回收过程是怎么样的?(young gc、并发阶段、混合阶段、full gc,说了Remember Set)
+- 你提到的Remember Set底层是怎么实现的?
+- 有什么想问的么?
+
+### 五面
+
+五面是HRBP面的,和我提前预约了时间,主要聊了之前在蚂蚁的实习经历、部门在做的事情、职业发展、福利待遇等。阿里面试官确实是具有一票否决权的,很看重你的价值观是否match,一般都比较喜欢皮实的候选人。HR面一定要诚实,不要说谎,只要你说谎HR都会去证实,直接cut了。
+
+- 之前蚂蚁实习三个月怎么不留下来?
+- 实习的时候主管是谁?
+- 实习做了哪些事情?(尼玛这种也问?)
+- 你对技术怎么看?平时使用什么技术栈?(阿里HR真的是既当爹又当妈,😂)
+- 最近有在研究什么东西么
+- 你对SRE怎么看
+- 对待遇有什么预期么
+
+最后HR还对我说目前稳定性保障部挺缺人的,希望我尽快回复。
+
+### 小结
+
+蚂蚁面试比较重视基础,所以Java那些基本功一定要扎实。蚂蚁的工作环境还是挺赞的,因为我面的是稳定性保障部门,还有许多单独的小组,什么三年1班,很有青春的感觉。面试官基本水平都比较高,基本都P7以上,除了基础还问了不少架构设计方面的问题,收获还是挺大的。
+
+## 拼多多
+
+
+
+- 面试前
+- 一面
+- 二面
+- 三面
+- 小结
+
+### 面试前
+
+面完蚂蚁后,早就听闻拼多多这个独角兽,决定也去面一把。首先我在脉脉找了一个拼多多的HR,加了微信聊了下,发了简历便开始我的拼多多面试之旅。这里要非常感谢拼多多HR小姐姐,从面试内推到offer确认一直都在帮我,人真的很nice。
+
+### 一面
+
+- 为啥蚂蚁只待了三个月?没转正?(转正了,解释了一通。。。)
+- Java中的HashMap、TreeMap解释下?(TreeMap红黑树,有序,HashMap无序,数组+链表)
+- TreeMap查询写入的时间复杂度多少?(O(logN))
+- HashMap多线程有什么问题?(线程安全,死锁)怎么解决?( jdk1.8用了synchronize + CAS,扩容的时候通过CAS检查是否有修改,是则重试)重试会有什么问题么?(CAS(Compare And Swap)是比较和交换,不会导致线程阻塞,但是因为重试是通过自旋实现的,所以仍然会占用CPU时间,还有ABA的问题)怎么解决?(超时,限定自旋的次数,ABA可以通过原理变量AtomicStampedReference解决,原理利用版本号进行比较)超过重试次数如果仍然失败怎么办?(synchronize互斥锁)
+- CAS和synchronize有什么区别?都用synchronize不行么?(CAS是乐观锁,不需要阻塞,硬件级别实现的原子性;synchronize会阻塞,JVM级别实现的原子性。使用场景不同,线程冲突严重时CAS会造成CPU压力过大,导致吞吐量下降,synchronize的原理是先自旋然后阻塞,线程冲突严重仍然有较高的吞吐量,因为线程都被阻塞了,不会占用CPU
+)
+- 如果要保证线程安全怎么办?(ConcurrentHashMap)
+- ConcurrentHashMap怎么实现线程安全的?(分段锁)
+- get需要加锁么,为什么?(不用,volatile关键字)
+- volatile的作用是什么?(保证内存可见性)
+- 底层怎么实现的?(说了主内存和工作内存,读写内存屏障,happen-before,并在纸上画了线程交互图)
+- 在多核CPU下,可见性怎么保证?(思考了一会,总线嗅探技术)
+- 聊项目,系统之间是怎么交互的?
+- 系统并发多少,怎么优化?
+- 给我一张纸,画了一个九方格,都填了数字,给一个M*N矩阵,从1开始逆时针打印这M*N个数,要求时间复杂度尽可能低(内心OS:之前貌似碰到过这题,最优解是怎么实现来着)思考中。。。
+- 可以先说下你的思路(想起来了,说了什么时候要变换方向的条件,向右、向下、向左、向上,依此循环)
+- 有什么想问我的?
+
+### 二面
+
+- 自我介绍下
+- 手上还有其他offer么?(拿了蚂蚁的offer)
+- 部门组织结构是怎样的?(这轮不是技术面么,不过还是老老实实说了)
+- 系统有哪些模块,每个模块用了哪些技术,数据怎么流转的?(面试官有点秃顶,一看级别就很高)给了我一张纸,我在上面简单画了下系统之间的流转情况
+- 链路追踪的信息是怎么传递的?(RpcContext的attachment,说了Span的结构:parentSpanId + curSpanId)
+- SpanId怎么保证唯一性?(UUID,说了下内部的定制改动)
+- RpcContext是在什么维度传递的?(线程)
+- Dubbo的远程调用怎么实现的?(讲了读取配置、拼装url、创建Invoker、服务导出、服务注册以及消费者通过动态代理、filter、获取Invoker列表、负载均衡等过程(哗啦啦讲了10多分钟),我可以喝口水么)
+- Spring的单例是怎么实现的?(单例注册表)
+- 为什么要单独实现一个服务治理框架?(说了下内部刚搞微服务不久,主要对服务进行一些监控和性能优化)
+- 谁主导的?内部还在使用么?
+- 逆向有想过怎么做成通用么?
+- 有什么想问的么?
+
+### 三面
+
+二面老大面完后就直接HR面了,主要问了些职业发展、是否有其他offer、以及入职意向等问题,顺便说了下公司的福利待遇等,都比较常规啦。不过要说的是手上有其他offer或者大厂经历会有一定加分。
+
+### 小结
+
+拼多多的面试流程就简单许多,毕竟是一个成立三年多的公司。面试难度中规中矩,只要基础扎实应该不是问题。但不得不说工作强度很大,开始面试前HR就提前和我确认能否接受这样强度的工作,想来的老铁还是要做好准备
+
+## 字节跳动
+
+
+
+- 面试前
+- 一面
+- 二面
+- 小结
+
+### 面试前
+
+头条的面试是三家里最专业的,每次面试前有专门的HR和你约时间,确定OK后再进行面试。每次都是通过视频面试,因为都是之前都是电话面或现场面,所以视频面试还是有点不自然。也有人觉得视频面试体验很赞,当然萝卜青菜各有所爱。最坑的二面的时候对方面试官的网络老是掉线,最后很冤枉的挂了(当然有一些点答得不好也是原因之一)。所以还是有点遗憾的。
+
+### 一面
+
+- 先自我介绍下
+- 聊项目,逆向系统是什么意思
+- 聊项目,逆向系统用了哪些技术
+- 线程池的线程数怎么确定?
+- 如果是IO操作为主怎么确定?
+- 如果计算型操作又怎么确定?
+- Redis熟悉么,了解哪些数据结构?(说了zset) zset底层怎么实现的?(跳表)
+- 跳表的查询过程是怎么样的,查询和插入的时间复杂度?(说了先从第一层查找,不满足就下沉到第二层找,因为每一层都是有序的,写入和插入的时间复杂度都是O(logN))
+- 红黑树了解么,时间复杂度?(说了是N叉平衡树,O(logN))
+- 既然两个数据结构时间复杂度都是O(logN),zset为什么不用红黑树(跳表实现简单,踩坑成本低,红黑树每次插入都要通过旋转以维持平衡,实现复杂)
+- 点了点头,说下Dubbo的原理?(说了服务注册与发布以及消费者调用的过程)踩过什么坑没有?(说了dubbo异常处理的和打印accesslog的问题)
+- CAS了解么?(说了CAS的实现)还了解其他同步机制么?(说了synchronize以及两者的区别,一个乐观锁,一个悲观锁)
+- 那我们做一道题吧,数组A,2*n个元素,n个奇数、n个偶数,设计一个算法,使得数组奇数下标位置放置的都是奇数,偶数下标位置放置的都是偶数
+- 先说下你的思路(从0下标开始遍历,如果是奇数下标判断该元素是否奇数,是则跳过,否则从该位置寻找下一个奇数)
+- 下一个奇数?怎么找?(有点懵逼,思考中。。)
+- 有思路么?(仍然是先遍历一次数组,并对下标进行判断,如果下标属性和该位置元素不匹配从当前下标的下一个遍历数组元素,然后替换)
+- 你这样时间复杂度有点高,如果要求O(N)要怎么做(思考一会,答道“定义两个指针,分别从下标0和1开始遍历,遇见奇数位是是偶数和偶数位是奇数就停下,交换内容”)
+- 时间差不多了,先到这吧。你有什么想问我的?
+
+### 二面
+
+- 面试官和蔼很多,你先介绍下自己吧
+- 你对服务治理怎么理解的?
+- 项目中的限流怎么实现的?(Guava ratelimiter,令牌桶算法)
+- 具体怎么实现的?(要点是固定速率且令牌数有限)
+- 如果突然很多线程同时请求令牌,有什么问题?(导致很多请求积压,线程阻塞)
+- 怎么解决呢?(可以把积压的请求放到消息队列,然后异步处理)
+- 如果不用消息队列怎么解决?(说了RateLimiter预消费的策略)
+- 分布式追踪的上下文是怎么存储和传递的?(ThreadLocal + spanId,当前节点的spanId作为下个节点的父spanId)
+- Dubbo的RpcContext是怎么传递的?(ThreadLocal)主线程的ThreadLocal怎么传递到线程池?(说了先在主线程通过ThreadLocal的get方法拿到上下文信息,在线程池创建新的ThreadLocal并把之前获取的上下文信息设置到ThreadLocal中。这里要注意的线程池创建的ThreadLocal要在finally中手动remove,不然会有内存泄漏的问题)
+- 你说的内存泄漏具体是怎么产生的?(说了ThreadLocal的结构,主要分两种场景:主线程仍然对ThreadLocal有引用和主线程不存在对ThreadLocal的引用。第一种场景因为主线程仍然在运行,所以还是有对ThreadLocal的引用,那么ThreadLocal变量的引用和value是不会被回收的。第二种场景虽然主线程不存在对ThreadLocal的引用,且该引用是弱引用,所以会在gc的时候被回收,但是对用的value不是弱引用,不会被内存回收,仍然会造成内存泄漏)
+- 线程池的线程是不是必须手动remove才可以回收value?(是的,因为线程池的核心线程是一直存在的,如果不清理,那么核心线程的threadLocals变量会一直持有ThreadLocal变量)
+- 那你说的内存泄漏是指主线程还是线程池?(主线程 )
+- 可是主线程不是都退出了,引用的对象不应该会主动回收么?(面试官和内存泄漏杠上了),沉默了一会。。。
+- 那你说下SpringMVC不同用户登录的信息怎么保证线程安全的?(刚才解释的有点懵逼,一下没反应过来,居然回答成锁了。大脑有点晕了,此时已经一个小时过去了,感觉情况不妙。。。)
+- 这个直接用ThreadLocal不就可以么,你见过SpringMVC有锁实现的代码么?(有点晕菜。。。)
+- 我们聊聊mysql吧,说下索引结构(说了B+树)
+- 为什么使用B+树?( 说了查询效率高,O(logN),可以充分利用磁盘预读的特性,多叉树,深度小,叶子结点有序且存储数据)
+- 什么是索引覆盖?(忘记了。。。 )
+- Java为什么要设计双亲委派模型?
+- 什么时候需要自定义类加载器?
+- 我们做一道题吧,手写一个对象池
+- 有什么想问我的么?(感觉我很多点都没答好,是不是挂了(结果真的是) )
+
+### 小结
+
+头条的面试确实很专业,每次面试官会提前给你发一个视频链接,然后准点开始面试,而且考察的点都比较全。
+
+面试官都有一个特点,会抓住一个值得深入的点或者你没说清楚的点深入下去直到你把这个点讲清楚,不然面试官会觉得你并没有真正理解。二面面试官给了我一点建议,研究技术的时候一定要去研究产生的背景,弄明白在什么场景解决什么特定的问题,其实很多技术内部都是相通的。很诚恳,还是很感谢这位面试官大大。
+
+## 总结
+
+从年前开始面试到头条面完大概一个多月的时间,真的有点身心俱疲的感觉。最后拿到了拼多多、蚂蚁的offer,还是蛮幸运的。头条的面试对我帮助很大,再次感谢面试官对我的诚恳建议,以及拼多多的HR对我的啰嗦的问题详细解答。
+
+这里要说的是面试前要做好两件事:简历和自我介绍,简历要好好回顾下自己做的一些项目,然后挑几个亮点项目。自我介绍基本每轮面试都有,所以最好提前自己练习下,想好要讲哪些东西,分别怎么讲。此外,简历提到的技术一定是自己深入研究过的,没有深入研究也最好找点资料预热下,不打无准备的仗。
+
+**这些年看过的书**:
+
+《Effective Java》、《现代操作系统》、《TCP/IP详解:卷一》、《代码整洁之道》、《重构》、《Java程序性能优化》、《Spring实战》、《Zookeeper》、《高性能MySQL》、《亿级网站架构核心技术》、《可伸缩服务架构》、《Java编程思想》
+
+说实话这些书很多只看了一部分,我通常会带着问题看书,不然看着看着就睡着了,简直是催眠良药😅。
+
+
+最后,附一张自己面试前准备的脑图:
+
+链接:https://pan.baidu.com/s/1o2l1tuRakBEP0InKEh4Hzw 密码:300d
+
+全文完。
diff --git a/docs/essential-content-for-interview/BATJrealInterviewExperience/2020-zijietiaodong.md b/docs/essential-content-for-interview/BATJrealInterviewExperience/2020-zijietiaodong.md
new file mode 100644
index 00000000000..0e63008bc27
--- /dev/null
+++ b/docs/essential-content-for-interview/BATJrealInterviewExperience/2020-zijietiaodong.md
@@ -0,0 +1,61 @@
+
+
+> 本文来自读者 Boyn 投稿!恭喜这位粉丝拿到了含金量极高的字节跳动实习 offer!赞!
+
+## 基本条件
+
+本人是底层 211 本科,现在大三,无科研经历,但是有一些项目经历,在国内监控行业某头部企业做过一段时间的实习。想着投一下字节,可以积累一下面试经验和为春招做准备.投了简历之后,过了一段时间,HR 就打电话跟我约时间,在年后进行远程面。
+
+说明一下,我投的是北京 office。
+
+## 一面
+
+面试官很和蔼,由于疫情的原因,大家都在家里面进行远程面试
+
+开头没有自我介绍,直接开始问项目了,问了比如
+
+- 常用的 Web 组件有哪些(回答了自己经常用到的 SpringBoot,Redis,Mysql 等等,字节这边基本没有用 Java 的后台,所以感觉面试官不大会问 Spring,Java 这些东西,反倒是对数据库和中间件比较感兴趣)
+- Kafka 相关,如何保证不会重复消费,Kafka 消费组结构等等(这个只是凭着感觉和面试官说了,因为 Kafka 自己确实准备得不充分,但是心态稳住了)
+- **Mysql 索引,B+树(必考嗷同学们)**
+
+还有一些项目中的细节,这些因人而异,就不放上来了,提示一点就是要在项目中介绍一些亮眼的地方,比如用了什么牛逼的数据结构,架构上有什么特点,并发量大小还有怎么去 hold 住并发量
+
+后面就是算法题了,一共做了两道
+
+1. 判断平衡二叉树(这道题总体来说并不难,但是面试官在中间穿插了垃圾回收的知识,这就很难受了,具体的就是大家要判断一下对象在什么时候会回收,可达性分析什么时候对这个对象来说是不可达的,还有在递归函数中内存如何变化,这个是让我们来对这个函数进行执行过程的建模,只看栈帧大小变化的话,应该有是两个峰值,中间会有抖动的情况)
+2. 二分查找法的变种题,给定`target`和一个升序的数组,寻找下一个比数组大的数.这道题也不难,靠大家对二分查找法的熟悉程度,当然,这边还有一个优化的点,可以看看[我的博客](https://boyn.top/2019/11/09/%E7%AE%97%E6%B3%95%E4%B8%8E%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/%E6%B7%B1%E5%85%A5%E7%90%86%E8%A7%A3%E4%BA%8C%E5%88%86%E6%9F%A5%E6%89%BE%E6%B3%95/)找找灵感
+
+完成了之后,面试官让我等一会有二面,大概 10 分钟左右吧,休息了一会就继续了
+
+## 二面
+
+二面一上来就是先让我自我介绍,当然还是同样的套路,同样的香脆
+
+然后问了我一些关于 Redis 的问题,比如 **zset 的实现(跳表,这个高频)** ,键的过期策略,持久化等等,这些在大多数 Redis 的介绍中都可以找到,就不细说了
+
+还有一些数据结构的问题,比如说问了哈希表是什么,给面试官详细说了一下`java.util.HashMap`是怎么实现(当然里面就穿插着红黑树了,多看看红黑树是有什么特点之类的)的,包括说为什么要用链地址法来避免冲突,探测法有哪些,链地址法和探测法的优劣对比
+
+后面还跟我讨论了很久的项目,所以说大家的项目一定要做好,要有亮点的地方,在这里跟面试官讨论了很多项目优化的地方,还有什么不足,还有什么地方可以新增功能等等,同样不细说了
+
+一边讨论的时候劈里啪啦敲了很多,应该是对个人的面试评价一类的
+
+后面就是字节的传统艺能手撕算法了,一共做了三道
+
+- 一二道是连在一起的.给定一个规则`S_0 = {1} S_1={1,2,1} S_2 = {1,2,1,3,1,2,1} S_n = {S_n-1 , n + 1, S_n-1}`.第一个问题是他们的个数有什么关系(1 3 7 15... 2 的 n 次方-1,用位运算解决).第二个问题是给定数组个数下标 n 和索引 k,让我们求出 S_n(k)所指的数,假如`S_2(2) = 1`,我在做的时候没有什么好的思路,如果有的话大家可以分享一下
+- 第三道是下一个排列:[https://leetcode-cn.com/problems/next-permutation](https://leetcode-cn.com/problems/next-permutation) 的题型,不过做了一些修改,数组大小`10000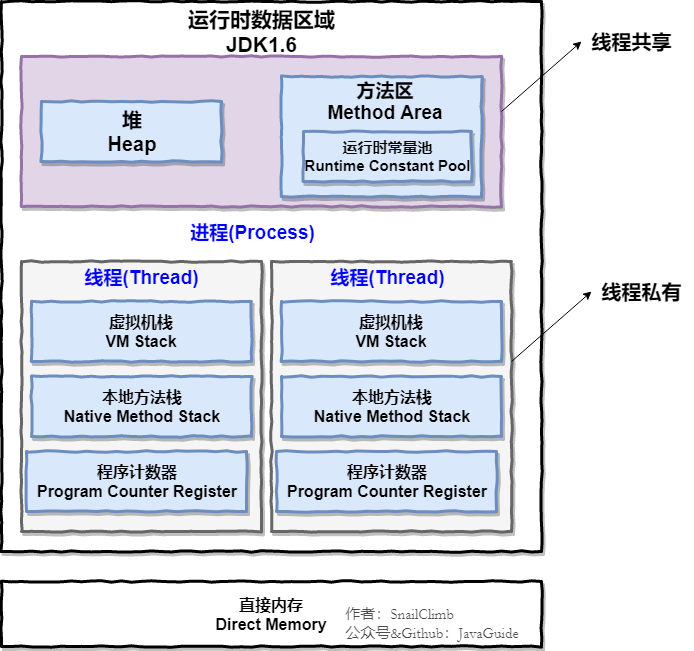 +
+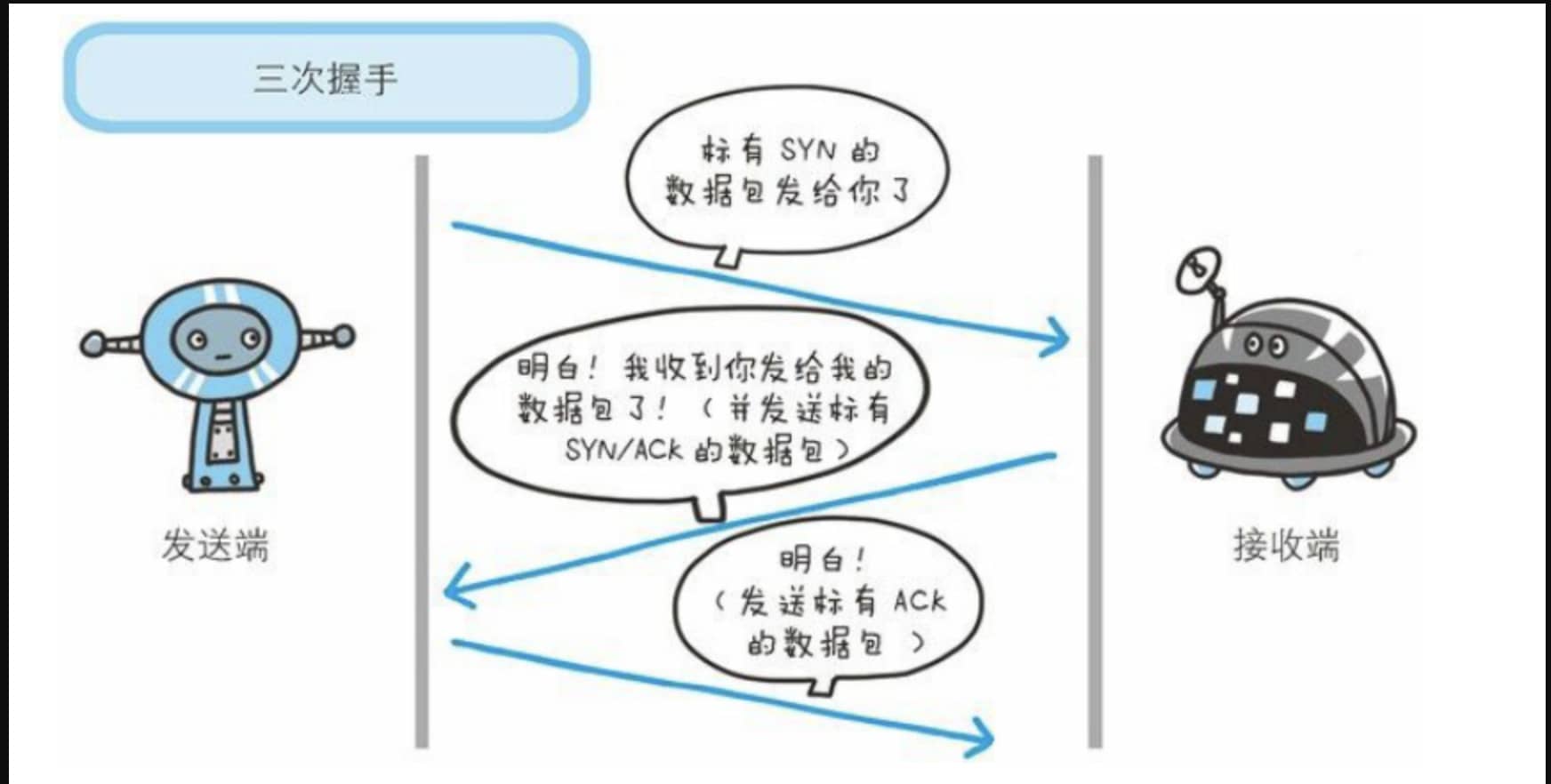 +
+**简单示意图:**
+
+
+**简单示意图:**
+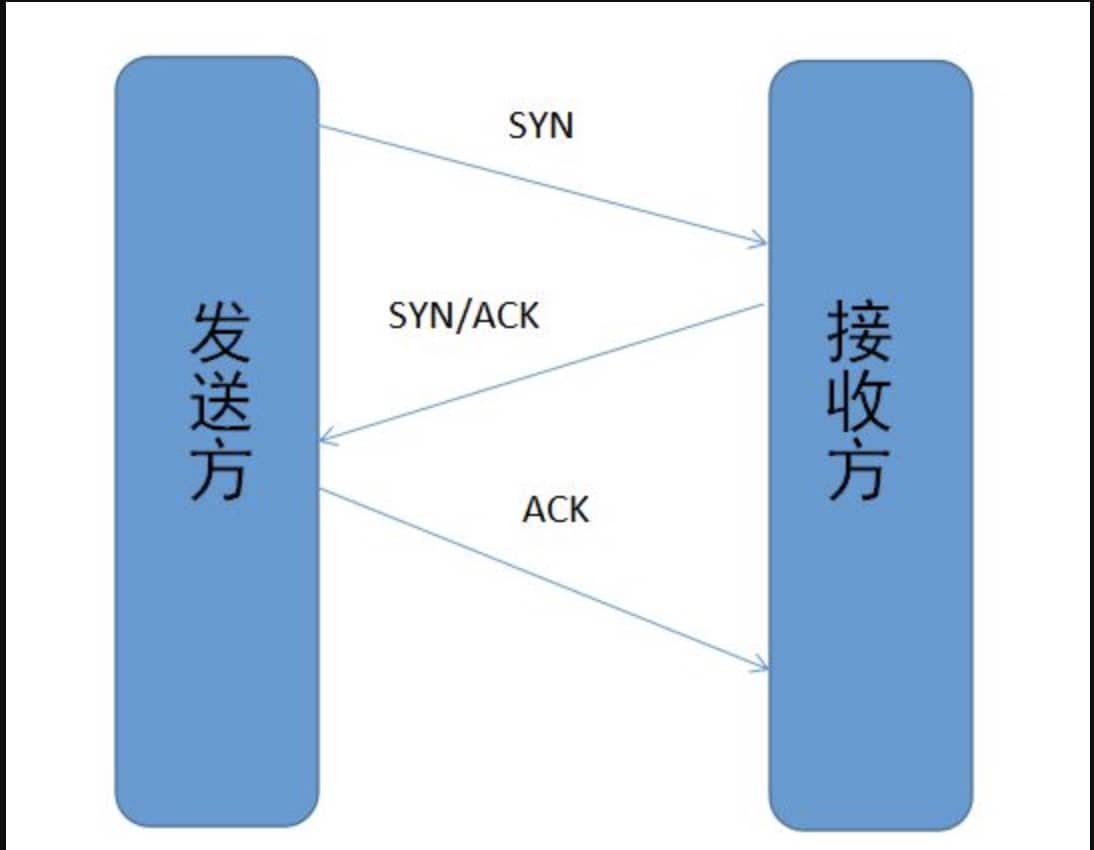 +
+- 客户端–发送带有 SYN 标志的数据包–一次握手–服务端
+- 服务端–发送带有 SYN/ACK 标志的数据包–二次握手–客户端
+- 客户端–发送带有带有 ACK 标志的数据包–三次握手–服务端
+
+#### 为什么要三次握手
+
+**三次握手的目的是建立可靠的通信信道,说到通讯,简单来说就是数据的发送与接收,而三次握手最主要的目的就是双方确认自己与对方的发送与接收是正常的。**
+
+第一次握手:Client 什么都不能确认;Server 确认了对方发送正常,自己接收正常。
+
+第二次握手:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:自己接收正常,对方发送正常
+
+第三次握手:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:自己发送、接收正常,对方发送、接收正常
+
+所以三次握手就能确认双发收发功能都正常,缺一不可。
+
+#### 为什么要传回 SYN
+
+接收端传回发送端所发送的 SYN 是为了告诉发送端,我接收到的信息确实就是你所发送的信号了。
+
+> SYN 是 TCP/IP 建立连接时使用的握手信号。在客户机和服务器之间建立正常的 TCP 网络连接时,客户机首先发出一个 SYN 消息,服务器使用 SYN-ACK 应答表示接收到了这个消息,最后客户机再以 ACK(Acknowledgement[汉译:确认字符 ,在数据通信传输中,接收站发给发送站的一种传输控制字符。它表示确认发来的数据已经接受无误。 ])消息响应。这样在客户机和服务器之间才能建立起可靠的 TCP 连接,数据才可以在客户机和服务器之间传递。
+
+#### 传了 SYN,为啥还要传 ACK
+
+双方通信无误必须是两者互相发送信息都无误。传了 SYN,证明发送方(主动关闭方)到接收方(被动关闭方)的通道没有问题,但是接收方到发送方的通道还需要 ACK 信号来进行验证。
+
+断开一个 TCP 连接则需要“四次挥手”:
+
+- 客户端-发送一个 FIN,用来关闭客户端到服务器的数据传送
+- 服务器-收到这个 FIN,它发回一 个 ACK,确认序号为收到的序号加 1 。和 SYN 一样,一个 FIN 将占用一个序号
+- 服务器-关闭与客户端的连接,发送一个 FIN 给客户端
+- 客户端-发回 ACK 报文确认,并将确认序号设置为收到序号加 1
+
+#### 为什么要四次挥手
+
+任何一方都可以在数据传送结束后发出连接释放的通知,待对方确认后进入半关闭状态。当另一方也没有数据再发送的时候,则发出连接释放通知,对方确认后就完全关闭了 TCP 连接。
+
+举个例子:A 和 B 打电话,通话即将结束后,A 说“我没啥要说的了”,B 回答“我知道了”,但是 B 可能还会有要说的话,A 不能要求 B 跟着自己的节奏结束通话,于是 B 可能又巴拉巴拉说了一通,最后 B 说“我说完了”,A 回答“知道了”,这样通话才算结束。
+
+上面讲的比较概括,推荐一篇讲的比较细致的文章:[https://blog.csdn.net/qzcsu/article/details/72861891](https://blog.csdn.net/qzcsu/article/details/72861891 "https://blog.csdn.net/qzcsu/article/details/72861891")
+
+## 5. IP 地址与 MAC 地址的区别
+
+参考:[https://blog.csdn.net/guoweimelon/article/details/50858597](https://blog.csdn.net/guoweimelon/article/details/50858597 "https://blog.csdn.net/guoweimelon/article/details/50858597")
+
+IP 地址是指互联网协议地址(Internet Protocol Address)IP Address 的缩写。IP 地址是 IP 协议提供的一种统一的地址格式,它为互联网上的每一个网络和每一台主机分配一个逻辑地址,以此来屏蔽物理地址的差异。
+
+MAC 地址又称为物理地址、硬件地址,用来定义网络设备的位置。网卡的物理地址通常是由网卡生产厂家写入网卡的,具有全球唯一性。MAC 地址用于在网络中唯一标示一个网卡,一台电脑会有一或多个网卡,每个网卡都需要有一个唯一的 MAC 地址。
+
+## 6. HTTP 请求,响应报文格式
+
+HTTP 请求报文主要由请求行、请求头部、请求正文 3 部分组成
+
+HTTP 响应报文主要由状态行、响应头部、响应正文 3 部分组成
+
+详细内容可以参考:[https://blog.csdn.net/a19881029/article/details/14002273](https://blog.csdn.net/a19881029/article/details/14002273 "https://blog.csdn.net/a19881029/article/details/14002273")
+
+## 7. 为什么要使用索引?索引这么多优点,为什么不对表中的每一个列创建一个索引呢?索引是如何提高查询速度的?说一下使用索引的注意事项?Mysql 索引主要使用的两种数据结构?什么是覆盖索引?
+
+**为什么要使用索引?**
+
+1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
+2. 可以大大加快 数据的检索速度(大大减少的检索的数据量), 这也是创建索引的最主要的原因。
+3. 帮助服务器避免排序和临时表
+4. 将随机 IO 变为顺序 IO
+5. 可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
+
+**索引这么多优点,为什么不对表中的每一个列创建一个索引呢?**
+
+1. 当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
+2. 索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
+3. 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
+
+**索引是如何提高查询速度的?**
+
+将无序的数据变成相对有序的数据(就像查目录一样)
+
+**说一下使用索引的注意事项**
+
+1. 避免 where 子句中对字段施加函数,这会造成无法命中索引。
+2. 在使用 InnoDB 时使用与业务无关的自增主键作为主键,即使用逻辑主键,而不要使用业务主键。
+3. 将打算加索引的列建议设置为 NOT NULL ,因为 NULL 比空字符串需要更多的存储空间(不仅仅是索引列,普通的列如果业务允许都建议设置为 NOT NULL)
+4. 删除长期未使用的索引,不用的索引的存在会造成不必要的性能损耗 MySQL 5.7 可以通过查询 sys 库的 schema_unused_indexes 视图来查询哪些索引从未被使用
+5. 在使用 limit offset 查询缓慢时,可以借助索引来提高性能
+
+**Mysql 索引主要使用的哪两种数据结构?**
+
+- 哈希索引:对于哈希索引来说,底层的数据结构就是哈希表,因此在绝大多数需求为单条记录查询的时候,可以选择哈希索引,查询性能最快;其余大部分场景,建议选择 BTree 索引。
+- BTree 索引:Mysql 的 BTree 索引使用的是 B 树中的 B+Tree。但对于主要的两种存储引擎(MyISAM 和 InnoDB)的实现方式是不同的。
+
+更多关于索引的内容可以查看我的这篇文章:[【思维导图-索引篇】搞定数据库索引就是这么简单](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484486&idx=1&sn=215450f11e042bca8a58eac9f4a97686&chksm=fd985227caefdb3117b8375f150676f5824aa20d1ebfdbcfb93ff06e23e26efbafae6cf6b48e&token=1990180468&lang=zh_CN#rd)
+
+**什么是覆盖索引?**
+
+如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称
+之为“覆盖索引”。我们知道在 InnoDB 存储引擎中,如果不是主键索引,叶子节点存储的是主键+列值。最终还是要“回表”,也就是要通过主键再查找一次,这样就会比较慢。覆盖索引就是把要查询出的列和索引是对应的,不做回表操作!
+
+## 8. 进程与线程的区别是什么?进程间的几种通信方式说一下?线程间的几种通信方式知道不?
+
+**进程与线程的区别是什么?**
+
+线程与进程相似,但线程是一个比进程更小的执行单位。一个进程在其执行的过程中可以产生多个线程。与进程不同的是同类的多个线程共享同一块内存空间和一组系统资源,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。另外,也正是因为共享资源,所以线程中执行时一般都要进行同步和互斥。总的来说,进程和线程的主要差别在于它们是不同的操作系统资源管理方式。
+
+**进程间的几种通信方式说一下?**
+
+1. **管道(pipe)**:管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有血缘关系的进程间使用。进程的血缘关系通常指父子进程关系。管道分为 pipe(无名管道)和 fifo(命名管道)两种,有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间通信。
+2. **信号量(semophore)**:信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它通常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
+3. **消息队列(message queue)**:消息队列是由消息组成的链表,存放在内核中 并由消息队列标识符标识。消息队列克服了信号传递信息少,管道只能承载无格式字节流以及缓冲区大小受限等缺点。消息队列与管道通信相比,其优势是对每个消息指定特定的消息类型,接收的时候不需要按照队列次序,而是可以根据自定义条件接收特定类型的消息。
+4. **信号(signal)**:信号是一种比较复杂的通信方式,用于通知接收进程某一事件已经发生。
+5. **共享内存(shared memory)**:共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问,共享内存是最快的 IPC 方式,它是针对其他进程间的通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量配合使用,来实现进程间的同步和通信。
+6. **套接字(socket)**:socket,即套接字是一种通信机制,凭借这种机制,客户/服务器(即要进行通信的进程)系统的开发工作既可以在本地单机上进行,也可以跨网络进行。也就是说它可以让不在同一台计算机但通过网络连接计算机上的进程进行通信。也因为这样,套接字明确地将客户端和服务器区分开来。
+
+**线程间的几种通信方式知道不?**
+
+1、锁机制
+
+- 互斥锁:提供了以排它方式阻止数据结构被并发修改的方法。
+- 读写锁:允许多个线程同时读共享数据,而对写操作互斥。
+- 条件变量:可以以原子的方式阻塞进程,直到某个特定条件为真为止。对条件测试是在互斥锁的保护下进行的。条件变量始终与互斥锁一起使用。
+
+2、信号量机制:包括无名线程信号量与有名线程信号量
+
+3、信号机制:类似于进程间的信号处理。
+
+线程间通信的主要目的是用于线程同步,所以线程没有象进程通信中用于数据交换的通信机制。
+
+## 9. 为什么要用单例模式?手写几种线程安全的单例模式?
+
+**简单来说使用单例模式可以带来下面几个好处:**
+
+- 对于频繁使用的对象,可以省略创建对象所花费的时间,这对于那些重量级对象而言,是非常可观的一笔系统开销;
+- 由于 new 操作的次数减少,因而对系统内存的使用频率也会降低,这将减轻 GC 压力,缩短 GC 停顿时间。
+
+**懒汉式(双重检查加锁版本)**
+
+```java
+public class Singleton {
+
+ //volatile保证,当uniqueInstance变量被初始化成Singleton实例时,多个线程可以正确处理uniqueInstance变量
+ private volatile static Singleton uniqueInstance;
+ private Singleton() {
+ }
+ public static Singleton getInstance() {
+ //检查实例,如果不存在,就进入同步代码块
+ if (uniqueInstance == null) {
+ //只有第一次才彻底执行这里的代码
+ synchronized(Singleton.class) {
+ //进入同步代码块后,再检查一次,如果仍是null,才创建实例
+ if (uniqueInstance == null) {
+ uniqueInstance = new Singleton();
+ }
+ }
+ }
+ return uniqueInstance;
+ }
+}
+```
+
+**静态内部类方式**
+
+静态内部实现的单例是懒加载的且线程安全。
+
+只有通过显式调用 getInstance 方法时,才会显式装载 SingletonHolder 类,从而实例化 instance(只有第一次使用这个单例的实例的时候才加载,同时不会有线程安全问题)。
+
+```java
+public class Singleton {
+ private static class SingletonHolder {
+ private static final Singleton INSTANCE = new Singleton();
+ }
+ private Singleton (){}
+ public static final Singleton getInstance() {
+ return SingletonHolder.INSTANCE;
+ }
+}
+```
+
+## 10. 简单介绍一下 bean;知道 Spring 的 bean 的作用域与生命周期吗?
+
+在 Spring 中,那些组成应用程序的主体及由 Spring IOC 容器所管理的对象,被称之为 bean。简单地讲,bean 就是由 IOC 容器初始化、装配及管理的对象,除此之外,bean 就与应用程序中的其他对象没有什么区别了。而 bean 的定义以及 bean 相互间的依赖关系将通过配置元数据来描述。
+
+Spring 中的 bean 默认都是单例的,这些单例 Bean 在多线程程序下如何保证线程安全呢? 例如对于 Web 应用来说,Web 容器对于每个用户请求都创建一个单独的 Sevlet 线程来处理请求,引入 Spring 框架之后,每个 Action 都是单例的,那么对于 Spring 托管的单例 Service Bean,如何保证其安全呢? Spring 的单例是基于 BeanFactory 也就是 Spring 容器的,单例 Bean 在此容器内只有一个,Java 的单例是基于 JVM,每个 JVM 内只有一个实例。
+
+
+
+Spring 的 bean 的生命周期以及更多内容可以查看:[一文轻松搞懂 Spring 中 bean 的作用域与生命周期](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484400&idx=2&sn=7201eb365102fce017f89cb3527fb0bc&chksm=fd985591caefdc872a2fac897288119f94c345e4e12150774f960bf5f816b79e4b9b46be3d7f&token=1990180468&lang=zh_CN#rd)
+
+## 11. Spring 中的事务传播行为了解吗?TransactionDefinition 接口中哪五个表示隔离级别的常量?
+
+#### 事务传播行为
+
+事务传播行为(为了解决业务层方法之间互相调用的事务问题):
+当事务方法被另一个事务方法调用时,必须指定事务应该如何传播。例如:方法可能继续在现有事务中运行,也可能开启一个新事务,并在自己的事务中运行。在 TransactionDefinition 定义中包括了如下几个表示传播行为的常量:
+
+**支持当前事务的情况:**
+
+- TransactionDefinition.PROPAGATION_REQUIRED: 如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。
+- TransactionDefinition.PROPAGATION_SUPPORTS: 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
+- TransactionDefinition.PROPAGATION_MANDATORY: 如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。(mandatory:强制性)
+
+**不支持当前事务的情况:**
+
+- TransactionDefinition.PROPAGATION_REQUIRES_NEW: 创建一个新的事务,如果当前存在事务,则把当前事务挂起。
+- TransactionDefinition.PROPAGATION_NOT_SUPPORTED: 以非事务方式运行,如果当前存在事务,则把当前事务挂起。
+- TransactionDefinition.PROPAGATION_NEVER: 以非事务方式运行,如果当前存在事务,则抛出异常。
+
+**其他情况:**
+
+- TransactionDefinition.PROPAGATION_NESTED: 如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于 TransactionDefinition.PROPAGATION_REQUIRED。
+
+#### 隔离级别
+
+TransactionDefinition 接口中定义了五个表示隔离级别的常量:
+
+- **TransactionDefinition.ISOLATION_DEFAULT:** 使用后端数据库默认的隔离级别,Mysql 默认采用的 REPEATABLE_READ 隔离级别 Oracle 默认采用的 READ_COMMITTED 隔离级别.
+- **TransactionDefinition.ISOLATION_READ_UNCOMMITTED:** 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读
+- **TransactionDefinition.ISOLATION_READ_COMMITTED:** 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生
+- **TransactionDefinition.ISOLATION_REPEATABLE_READ:** 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
+- **TransactionDefinition.ISOLATION_SERIALIZABLE:** 最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
+
+## 12. SpringMVC 原理了解吗?
+
+
+
+客户端发送请求-> 前端控制器 DispatcherServlet 接受客户端请求 -> 找到处理器映射 HandlerMapping 解析请求对应的 Handler-> HandlerAdapter 会根据 Handler 来调用真正的处理器处理请求,并处理相应的业务逻辑 -> 处理器返回一个模型视图 ModelAndView -> 视图解析器进行解析 -> 返回一个视图对象->前端控制器 DispatcherServlet 渲染数据(Model)->将得到视图对象返回给用户
+
+关于 SpringMVC 原理更多内容可以查看我的这篇文章:[SpringMVC 工作原理详解](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484496&idx=1&sn=5472ffa687fe4a05f8900d8ee6726de4&chksm=fd985231caefdb27fc75b44ecf76b6f43e4617e0b01b3c040f8b8fab32e51dfa5118eed1d6ad&token=1990180468&lang=zh_CN#rd)
+
+## 13. Spring AOP IOC 实现原理
+
+过了秋招挺长一段时间了,说实话我自己也忘了如何简要概括 Spring AOP IOC 实现原理,就在网上找了一个较为简洁的答案,下面分享给各位。
+
+**IOC:** 控制反转也叫依赖注入。IOC 利用 java 反射机制,AOP 利用代理模式。IOC 概念看似很抽象,但是很容易理解。说简单点就是将对象交给容器管理,你只需要在 spring 配置文件中配置对应的 bean 以及设置相关的属性,让 spring 容器来生成类的实例对象以及管理对象。在 spring 容器启动的时候,spring 会把你在配置文件中配置的 bean 都初始化好,然后在你需要调用的时候,就把它已经初始化好的那些 bean 分配给你需要调用这些 bean 的类。
+
+**AOP:** 面向切面编程。(Aspect-Oriented Programming) 。AOP 可以说是对 OOP 的补充和完善。OOP 引入封装、继承和多态性等概念来建立一种对象层次结构,用以模拟公共行为的一个集合。实现 AOP 的技术,主要分为两大类:一是采用动态代理技术,利用截取消息的方式,对该消息进行装饰,以取代原有对象行为的执行;二是采用静态织入的方式,引入特定的语法创建“方面”,从而使得编译器可以在编译期间织入有关“方面”的代码,属于静态代理。
+
+# 二 进阶篇
+
+## 1 消息队列 MQ 的套路
+
+消息队列/消息中间件应该是 Java 程序员必备的一个技能了,如果你之前没接触过消息队列的话,建议先去百度一下某某消息队列入门,然后花 2 个小时就差不多可以学会任何一种消息队列的使用了。如果说仅仅学会使用是万万不够的,在实际生产环境还要考虑消息丢失等等情况。关于消息队列面试相关的问题,推荐大家也可以看一下视频《Java 工程师面试突击第 1 季-中华石杉老师》,如果大家没有资源的话,可以在我的公众号“Java 面试通关手册”后台回复关键字“1”即可!
+
+### 1.1 介绍一下消息队列 MQ 的应用场景/使用消息队列的好处
+
+面试官一般会先问你这个问题,预热一下,看你知道消息队列不,一般在第一面的时候面试官可能只会问消息队列 MQ 的应用场景/使用消息队列的好处、使用消息队列会带来什么问题、消息队列的技术选型这几个问题,不会太深究下去,在后面的第二轮/第三轮技术面试中可能会深入问一下。
+
+**《大型网站技术架构》第四章和第七章均有提到消息队列对应用性能及扩展性的提升。**
+
+#### 1)通过异步处理提高系统性能
+
+
+如上图,**在不使用消息队列服务器的时候,用户的请求数据直接写入数据库,在高并发的情况下数据库压力剧增,使得响应速度变慢。但是在使用消息队列之后,用户的请求数据发送给消息队列之后立即 返回,再由消息队列的消费者进程从消息队列中获取数据,异步写入数据库。由于消息队列服务器处理速度快于数据库(消息队列也比数据库有更好的伸缩性),因此响应速度得到大幅改善。**
+
+通过以上分析我们可以得出**消息队列具有很好的削峰作用的功能**——即**通过异步处理,将短时间高并发产生的事务消息存储在消息队列中,从而削平高峰期的并发事务。** 举例:在电子商务一些秒杀、促销活动中,合理使用消息队列可以有效抵御促销活动刚开始大量订单涌入对系统的冲击。如下图所示:
+
+因为**用户请求数据写入消息队列之后就立即返回给用户了,但是请求数据在后续的业务校验、写数据库等操作中可能失败**。因此使用消息队列进行异步处理之后,需要**适当修改业务流程进行配合**,比如**用户在提交订单之后,订单数据写入消息队列,不能立即返回用户订单提交成功,需要在消息队列的订单消费者进程真正处理完该订单之后,甚至出库后,再通过电子邮件或短信通知用户订单成功**,以免交易纠纷。这就类似我们平时手机订火车票和电影票。
+
+#### 2)降低系统耦合性
+
+我们知道模块分布式部署以后聚合方式通常有两种:1.**分布式消息队列**和 2.**分布式服务**。
+
+> **先来简单说一下分布式服务:**
+
+目前使用比较多的用来构建**SOA(Service Oriented Architecture 面向服务体系结构)**的**分布式服务框架**是阿里巴巴开源的**Dubbo**。如果想深入了解 Dubbo 的可以看我写的关于 Dubbo 的这一篇文章:**《高性能优秀的服务框架-dubbo 介绍》**:[https://juejin.im/post/5acadeb1f265da2375072f9c](https://juejin.im/post/5acadeb1f265da2375072f9c "https://juejin.im/post/5acadeb1f265da2375072f9c")
+
+> **再来谈我们的分布式消息队列:**
+
+我们知道如果模块之间不存在直接调用,那么新增模块或者修改模块就对其他模块影响较小,这样系统的可扩展性无疑更好一些。
+
+我们最常见的**事件驱动架构**类似生产者消费者模式,在大型网站中通常用利用消息队列实现事件驱动结构。如下图所示:
+
+
+**消息队列使利用发布-订阅模式工作,消息发送者(生产者)发布消息,一个或多个消息接受者(消费者)订阅消息。** 从上图可以看到**消息发送者(生产者)和消息接受者(消费者)之间没有直接耦合**,消息发送者将消息发送至分布式消息队列即结束对消息的处理,消息接受者从分布式消息队列获取该消息后进行后续处理,并不需要知道该消息从何而来。**对新增业务,只要对该类消息感兴趣,即可订阅该消息,对原有系统和业务没有任何影响,从而实现网站业务的可扩展性设计**。
+
+消息接受者对消息进行过滤、处理、包装后,构造成一个新的消息类型,将消息继续发送出去,等待其他消息接受者订阅该消息。因此基于事件(消息对象)驱动的业务架构可以是一系列流程。
+
+**另外为了避免消息队列服务器宕机造成消息丢失,会将成功发送到消息队列的消息存储在消息生产者服务器上,等消息真正被消费者服务器处理后才删除消息。在消息队列服务器宕机后,生产者服务器会选择分布式消息队列服务器集群中的其他服务器发布消息。**
+
+**备注:** 不要认为消息队列只能利用发布-订阅模式工作,只不过在解耦这个特定业务环境下是使用发布-订阅模式的,**比如在我们的 ActiveMQ 消息队列中还有点对点工作模式**,具体的会在后面的文章给大家详细介绍,这一篇文章主要还是让大家对消息队列有一个更透彻的了解。
+
+> 这个问题一般会在上一个问题问完之后,紧接着被问到。“使用消息队列会带来什么问题?”这个问题要引起重视,一般我们都会考虑使用消息队列会带来的好处而忽略它带来的问题!
+
+### 1.2 那么使用消息队列会带来什么问题?考虑过这些问题吗?
+
+- **系统可用性降低:** 系统可用性在某种程度上降低,为什么这样说呢?在加入 MQ 之前,你不用考虑消息丢失或者说 MQ 挂掉等等的情况,但是,引入 MQ 之后你就需要去考虑了!
+- **系统复杂性提高:** 加入 MQ 之后,你需要保证消息没有被重复消费、处理消息丢失的情况、保证消息传递的顺序性等等问题!
+- **一致性问题:** 我上面讲了消息队列可以实现异步,消息队列带来的异步确实可以提高系统响应速度。但是,万一消息的真正消费者并没有正确消费消息怎么办?这样就会导致数据不一致的情况了!
+
+> 了解下面这个问题是为了我们更好的进行技术选型!该部分摘自:《Java 工程师面试突击第 1 季-中华石杉老师》,如果大家没有资源的话,可以在我的公众号“Java 面试通关手册”后台回复关键字“1”即可!
+
+### 1.3 介绍一下你知道哪几种消息队列,该如何选择呢?
+
+| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
+| :----------------------- | -----------------------------------------------------------: | -----------------------------------------------------------: | -----------------------------------------------------------: | -----------------------------------------------------------: |
+| 单机吞吐量 | 万级,吞吐量比 RocketMQ 和 Kafka 要低了一个数量级 | 万级,吞吐量比 RocketMQ 和 Kafka 要低了一个数量级 | 10 万级,RocketMQ 也是可以支撑高吞吐的一种 MQ | 10 万级别,这是 kafka 最大的优点,就是吞吐量高。一般配合大数据类的系统来进行实时数据计算、日志采集等场景 |
+| topic 数量对吞吐量的影响 | | | topic 可以达到几百,几千个的级别,吞吐量会有较小幅度的下降这是 RocketMQ 的一大优势,在同等机器下,可以支撑大量的 topic | topic 从几十个到几百个的时候,吞吐量会大幅度下降。所以在同等机器下,kafka 尽量保证 topic 数量不要过多。如果要支撑大规模 topic,需要增加更多的机器资源 |
+| 可用性 | 高,基于主从架构实现高可用性 | 高,基于主从架构实现高可用性 | 非常高,分布式架构 | 非常高,kafka 是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 |
+| 消息可靠性 | 有较低的概率丢失数据 | | 经过参数优化配置,可以做到 0 丢失 | 经过参数优化配置,消息可以做到 0 丢失 |
+| 时效性 | ms 级 | 微秒级,这是 rabbitmq 的一大特点,延迟是最低的 | ms 级 | 延迟在 ms 级以内 |
+| 功能支持 | MQ 领域的功能极其完备 | 基于 erlang 开发,所以并发能力很强,性能极其好,延时很低 | MQ 功能较为完善,还是分布式的,扩展性好 | 功能较为简单,主要支持简单的 MQ 功能,在大数据领域的实时计算以及日志采集被大规模使用,是事实上的标准 |
+| 优劣势总结 | 非常成熟,功能强大,在业内大量的公司以及项目中都有应用。偶尔会有较低概率丢失消息,而且现在社区以及国内应用都越来越少,官方社区现在对 ActiveMQ 5.x 维护越来越少,几个月才发布一个版本而且确实主要是基于解耦和异步来用的,较少在大规模吞吐的场景中使用 | erlang 语言开发,性能极其好,延时很低;吞吐量到万级,MQ 功能比较完备而且开源提供的管理界面非常棒,用起来很好用。社区相对比较活跃,几乎每个月都发布几个版本分在国内一些互联网公司近几年用 rabbitmq 也比较多一些但是问题也是显而易见的,RabbitMQ 确实吞吐量会低一些,这是因为他做的实现机制比较重。而且 erlang 开发,国内有几个公司有实力做 erlang 源码级别的研究和定制?如果说你没这个实力的话,确实偶尔会有一些问题,你很难去看懂源码,你公司对这个东西的掌控很弱,基本职能依赖于开源社区的快速维护和修复 bug。而且 rabbitmq 集群动态扩展会很麻烦,不过这个我觉得还好。其实主要是 erlang 语言本身带来的问题。很难读源码,很难定制和掌控。 | 接口简单易用,而且毕竟在阿里大规模应用过,有阿里品牌保障。日处理消息上百亿之多,可以做到大规模吞吐,性能也非常好,分布式扩展也很方便,社区维护还可以,可靠性和可用性都是 ok 的,还可以支撑大规模的 topic 数量,支持复杂 MQ 业务场景。而且一个很大的优势在于,阿里出品都是 java 系的,我们可以自己阅读源码,定制自己公司的 MQ,可以掌控。社区活跃度相对较为一般,不过也还可以,文档相对来说简单一些,然后接口这块不是按照标准 JMS 规范走的有些系统要迁移需要修改大量代码。还有就是阿里出台的技术,你得做好这个技术万一被抛弃,社区黄掉的风险,那如果你们公司有技术实力我觉得用 RocketMQ 挺好的 | kafka 的特点其实很明显,就是仅仅提供较少的核心功能,但是提供超高的吞吐量,ms 级的延迟,极高的可用性以及可靠性,而且分布式可以任意扩展。同时 kafka 最好是支撑较少的 topic 数量即可,保证其超高吞吐量。而且 kafka 唯一的一点劣势是有可能消息重复消费,那么对数据准确性会造成极其轻微的影响,在大数据领域中以及日志采集中,这点轻微影响可以忽略这个特性天然适合大数据实时计算以及日志收集。 |
+
+> 这部分内容,我这里不给出答案,大家可以自行根据自己学习的消息队列查阅相关内容,我可能会在后面的文章中介绍到这部分内容。另外,下面这些问题在视频《Java 工程师面试突击第 1 季-中华石杉老师》中都有提到,如果大家没有资源的话,可以在我的公众号“Java 面试通关手册”后台回复关键字“1”即可!
+
+### 1.4 关于消息队列其他一些常见的问题展望
+
+1. 引入消息队列之后如何保证高可用性?
+2. 如何保证消息不被重复消费呢?
+3. 如何保证消息的可靠性传输(如何处理消息丢失的问题)?
+4. 我该怎么保证从消息队列里拿到的数据按顺序执行?
+5. 如何解决消息队列的延时以及过期失效问题?消息队列满了以后该怎么处理?有几百万消息持续积压几小时,说说怎么解决?
+6. 如果让你来开发一个消息队列中间件,你会怎么设计架构?
+
+## 2 谈谈 InnoDB 和 MyIsam 两者的区别
+
+### 2.1 两者的对比
+
+1. **count 运算上的区别:** 因为 MyISAM 缓存有表 meta-data(行数等),因此在做 COUNT(\*)时对于一个结构很好的查询是不需要消耗多少资源的。而对于 InnoDB 来说,则没有这种缓存
+2. **是否支持事务和崩溃后的安全恢复:** MyISAM 强调的是性能,每次查询具有原子性,其执行速度比 InnoDB 类型更快,但是不提供事务支持。但是 InnoDB 提供事务支持,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
+3. **是否支持外键:** MyISAM 不支持,而 InnoDB 支持。
+
+### 2.2 关于两者的总结
+
+MyISAM 更适合读密集的表,而 InnoDB 更适合写密集的表。 在数据库做主从分离的情况下,经常选择 MyISAM 作为主库的存储引擎。
+
+一般来说,如果需要事务支持,并且有较高的并发读取频率(MyISAM 的表锁的粒度太大,所以当该表写并发量较高时,要等待的查询就会很多了),InnoDB 是不错的选择。如果你的数据量很大(MyISAM 支持压缩特性可以减少磁盘的空间占用),而且不需要支持事务时,MyISAM 是最好的选择。
+
+## 3 聊聊 Java 中的集合吧!
+
+### 3.1 Arraylist 与 LinkedList 有什么不同?(注意加上从数据结构分析的内容)
+
+- **1. 是否保证线程安全:** ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;
+- **2. 底层数据结构:** Arraylist 底层使用的是 Object 数组;LinkedList 底层使用的是双向链表数据结构(注意双向链表和双向循环链表的区别:);
+- **3. 插入和删除是否受元素位置的影响:** ① **ArrayList 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。** 比如:执行`add(E e)`方法的时候, ArrayList 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是 O(1)。但是如果要在指定位置 i 插入和删除元素的话(`add(int index, E element)`)时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。 ② **LinkedList 采用链表存储,所以插入,删除元素时间复杂度不受元素位置的影响,都是近似 O(1) 而数组为近似 O(n) 。**
+- **4. 是否支持快速随机访问:** LinkedList 不支持高效的随机元素访问,而 ArrayList 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于`get(int index)`方法)。
+- **5. 内存空间占用:** ArrayList 的空 间浪费主要体现在在 list 列表的结尾会预留一定的容量空间,而 LinkedList 的空间花费则体现在它的每一个元素都需要消耗比 ArrayList 更多的空间(因为要存放直接后继和直接前驱以及数据)。
+
+**补充内容:RandomAccess 接口**
+
+```java
+public interface RandomAccess {
+}
+```
+
+查看源码我们发现实际上 RandomAccess 接口中什么都没有定义。所以,在我看来 RandomAccess 接口不过是一个标识罢了。标识什么? 标识实现这个接口的类具有随机访问功能。
+
+在 binarySearch() 方法中,它要判断传入的 list 是否 RamdomAccess 的实例,如果是,调用 indexedBinarySearch() 方法,如果不是,那么调用 iteratorBinarySearch() 方法
+
+```java
+ public static
+
+- 客户端–发送带有 SYN 标志的数据包–一次握手–服务端
+- 服务端–发送带有 SYN/ACK 标志的数据包–二次握手–客户端
+- 客户端–发送带有带有 ACK 标志的数据包–三次握手–服务端
+
+#### 为什么要三次握手
+
+**三次握手的目的是建立可靠的通信信道,说到通讯,简单来说就是数据的发送与接收,而三次握手最主要的目的就是双方确认自己与对方的发送与接收是正常的。**
+
+第一次握手:Client 什么都不能确认;Server 确认了对方发送正常,自己接收正常。
+
+第二次握手:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:自己接收正常,对方发送正常
+
+第三次握手:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:自己发送、接收正常,对方发送、接收正常
+
+所以三次握手就能确认双发收发功能都正常,缺一不可。
+
+#### 为什么要传回 SYN
+
+接收端传回发送端所发送的 SYN 是为了告诉发送端,我接收到的信息确实就是你所发送的信号了。
+
+> SYN 是 TCP/IP 建立连接时使用的握手信号。在客户机和服务器之间建立正常的 TCP 网络连接时,客户机首先发出一个 SYN 消息,服务器使用 SYN-ACK 应答表示接收到了这个消息,最后客户机再以 ACK(Acknowledgement[汉译:确认字符 ,在数据通信传输中,接收站发给发送站的一种传输控制字符。它表示确认发来的数据已经接受无误。 ])消息响应。这样在客户机和服务器之间才能建立起可靠的 TCP 连接,数据才可以在客户机和服务器之间传递。
+
+#### 传了 SYN,为啥还要传 ACK
+
+双方通信无误必须是两者互相发送信息都无误。传了 SYN,证明发送方(主动关闭方)到接收方(被动关闭方)的通道没有问题,但是接收方到发送方的通道还需要 ACK 信号来进行验证。
+
+断开一个 TCP 连接则需要“四次挥手”:
+
+- 客户端-发送一个 FIN,用来关闭客户端到服务器的数据传送
+- 服务器-收到这个 FIN,它发回一 个 ACK,确认序号为收到的序号加 1 。和 SYN 一样,一个 FIN 将占用一个序号
+- 服务器-关闭与客户端的连接,发送一个 FIN 给客户端
+- 客户端-发回 ACK 报文确认,并将确认序号设置为收到序号加 1
+
+#### 为什么要四次挥手
+
+任何一方都可以在数据传送结束后发出连接释放的通知,待对方确认后进入半关闭状态。当另一方也没有数据再发送的时候,则发出连接释放通知,对方确认后就完全关闭了 TCP 连接。
+
+举个例子:A 和 B 打电话,通话即将结束后,A 说“我没啥要说的了”,B 回答“我知道了”,但是 B 可能还会有要说的话,A 不能要求 B 跟着自己的节奏结束通话,于是 B 可能又巴拉巴拉说了一通,最后 B 说“我说完了”,A 回答“知道了”,这样通话才算结束。
+
+上面讲的比较概括,推荐一篇讲的比较细致的文章:[https://blog.csdn.net/qzcsu/article/details/72861891](https://blog.csdn.net/qzcsu/article/details/72861891 "https://blog.csdn.net/qzcsu/article/details/72861891")
+
+## 5. IP 地址与 MAC 地址的区别
+
+参考:[https://blog.csdn.net/guoweimelon/article/details/50858597](https://blog.csdn.net/guoweimelon/article/details/50858597 "https://blog.csdn.net/guoweimelon/article/details/50858597")
+
+IP 地址是指互联网协议地址(Internet Protocol Address)IP Address 的缩写。IP 地址是 IP 协议提供的一种统一的地址格式,它为互联网上的每一个网络和每一台主机分配一个逻辑地址,以此来屏蔽物理地址的差异。
+
+MAC 地址又称为物理地址、硬件地址,用来定义网络设备的位置。网卡的物理地址通常是由网卡生产厂家写入网卡的,具有全球唯一性。MAC 地址用于在网络中唯一标示一个网卡,一台电脑会有一或多个网卡,每个网卡都需要有一个唯一的 MAC 地址。
+
+## 6. HTTP 请求,响应报文格式
+
+HTTP 请求报文主要由请求行、请求头部、请求正文 3 部分组成
+
+HTTP 响应报文主要由状态行、响应头部、响应正文 3 部分组成
+
+详细内容可以参考:[https://blog.csdn.net/a19881029/article/details/14002273](https://blog.csdn.net/a19881029/article/details/14002273 "https://blog.csdn.net/a19881029/article/details/14002273")
+
+## 7. 为什么要使用索引?索引这么多优点,为什么不对表中的每一个列创建一个索引呢?索引是如何提高查询速度的?说一下使用索引的注意事项?Mysql 索引主要使用的两种数据结构?什么是覆盖索引?
+
+**为什么要使用索引?**
+
+1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
+2. 可以大大加快 数据的检索速度(大大减少的检索的数据量), 这也是创建索引的最主要的原因。
+3. 帮助服务器避免排序和临时表
+4. 将随机 IO 变为顺序 IO
+5. 可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
+
+**索引这么多优点,为什么不对表中的每一个列创建一个索引呢?**
+
+1. 当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
+2. 索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
+3. 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
+
+**索引是如何提高查询速度的?**
+
+将无序的数据变成相对有序的数据(就像查目录一样)
+
+**说一下使用索引的注意事项**
+
+1. 避免 where 子句中对字段施加函数,这会造成无法命中索引。
+2. 在使用 InnoDB 时使用与业务无关的自增主键作为主键,即使用逻辑主键,而不要使用业务主键。
+3. 将打算加索引的列建议设置为 NOT NULL ,因为 NULL 比空字符串需要更多的存储空间(不仅仅是索引列,普通的列如果业务允许都建议设置为 NOT NULL)
+4. 删除长期未使用的索引,不用的索引的存在会造成不必要的性能损耗 MySQL 5.7 可以通过查询 sys 库的 schema_unused_indexes 视图来查询哪些索引从未被使用
+5. 在使用 limit offset 查询缓慢时,可以借助索引来提高性能
+
+**Mysql 索引主要使用的哪两种数据结构?**
+
+- 哈希索引:对于哈希索引来说,底层的数据结构就是哈希表,因此在绝大多数需求为单条记录查询的时候,可以选择哈希索引,查询性能最快;其余大部分场景,建议选择 BTree 索引。
+- BTree 索引:Mysql 的 BTree 索引使用的是 B 树中的 B+Tree。但对于主要的两种存储引擎(MyISAM 和 InnoDB)的实现方式是不同的。
+
+更多关于索引的内容可以查看我的这篇文章:[【思维导图-索引篇】搞定数据库索引就是这么简单](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484486&idx=1&sn=215450f11e042bca8a58eac9f4a97686&chksm=fd985227caefdb3117b8375f150676f5824aa20d1ebfdbcfb93ff06e23e26efbafae6cf6b48e&token=1990180468&lang=zh_CN#rd)
+
+**什么是覆盖索引?**
+
+如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称
+之为“覆盖索引”。我们知道在 InnoDB 存储引擎中,如果不是主键索引,叶子节点存储的是主键+列值。最终还是要“回表”,也就是要通过主键再查找一次,这样就会比较慢。覆盖索引就是把要查询出的列和索引是对应的,不做回表操作!
+
+## 8. 进程与线程的区别是什么?进程间的几种通信方式说一下?线程间的几种通信方式知道不?
+
+**进程与线程的区别是什么?**
+
+线程与进程相似,但线程是一个比进程更小的执行单位。一个进程在其执行的过程中可以产生多个线程。与进程不同的是同类的多个线程共享同一块内存空间和一组系统资源,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。另外,也正是因为共享资源,所以线程中执行时一般都要进行同步和互斥。总的来说,进程和线程的主要差别在于它们是不同的操作系统资源管理方式。
+
+**进程间的几种通信方式说一下?**
+
+1. **管道(pipe)**:管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有血缘关系的进程间使用。进程的血缘关系通常指父子进程关系。管道分为 pipe(无名管道)和 fifo(命名管道)两种,有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间通信。
+2. **信号量(semophore)**:信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它通常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
+3. **消息队列(message queue)**:消息队列是由消息组成的链表,存放在内核中 并由消息队列标识符标识。消息队列克服了信号传递信息少,管道只能承载无格式字节流以及缓冲区大小受限等缺点。消息队列与管道通信相比,其优势是对每个消息指定特定的消息类型,接收的时候不需要按照队列次序,而是可以根据自定义条件接收特定类型的消息。
+4. **信号(signal)**:信号是一种比较复杂的通信方式,用于通知接收进程某一事件已经发生。
+5. **共享内存(shared memory)**:共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问,共享内存是最快的 IPC 方式,它是针对其他进程间的通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量配合使用,来实现进程间的同步和通信。
+6. **套接字(socket)**:socket,即套接字是一种通信机制,凭借这种机制,客户/服务器(即要进行通信的进程)系统的开发工作既可以在本地单机上进行,也可以跨网络进行。也就是说它可以让不在同一台计算机但通过网络连接计算机上的进程进行通信。也因为这样,套接字明确地将客户端和服务器区分开来。
+
+**线程间的几种通信方式知道不?**
+
+1、锁机制
+
+- 互斥锁:提供了以排它方式阻止数据结构被并发修改的方法。
+- 读写锁:允许多个线程同时读共享数据,而对写操作互斥。
+- 条件变量:可以以原子的方式阻塞进程,直到某个特定条件为真为止。对条件测试是在互斥锁的保护下进行的。条件变量始终与互斥锁一起使用。
+
+2、信号量机制:包括无名线程信号量与有名线程信号量
+
+3、信号机制:类似于进程间的信号处理。
+
+线程间通信的主要目的是用于线程同步,所以线程没有象进程通信中用于数据交换的通信机制。
+
+## 9. 为什么要用单例模式?手写几种线程安全的单例模式?
+
+**简单来说使用单例模式可以带来下面几个好处:**
+
+- 对于频繁使用的对象,可以省略创建对象所花费的时间,这对于那些重量级对象而言,是非常可观的一笔系统开销;
+- 由于 new 操作的次数减少,因而对系统内存的使用频率也会降低,这将减轻 GC 压力,缩短 GC 停顿时间。
+
+**懒汉式(双重检查加锁版本)**
+
+```java
+public class Singleton {
+
+ //volatile保证,当uniqueInstance变量被初始化成Singleton实例时,多个线程可以正确处理uniqueInstance变量
+ private volatile static Singleton uniqueInstance;
+ private Singleton() {
+ }
+ public static Singleton getInstance() {
+ //检查实例,如果不存在,就进入同步代码块
+ if (uniqueInstance == null) {
+ //只有第一次才彻底执行这里的代码
+ synchronized(Singleton.class) {
+ //进入同步代码块后,再检查一次,如果仍是null,才创建实例
+ if (uniqueInstance == null) {
+ uniqueInstance = new Singleton();
+ }
+ }
+ }
+ return uniqueInstance;
+ }
+}
+```
+
+**静态内部类方式**
+
+静态内部实现的单例是懒加载的且线程安全。
+
+只有通过显式调用 getInstance 方法时,才会显式装载 SingletonHolder 类,从而实例化 instance(只有第一次使用这个单例的实例的时候才加载,同时不会有线程安全问题)。
+
+```java
+public class Singleton {
+ private static class SingletonHolder {
+ private static final Singleton INSTANCE = new Singleton();
+ }
+ private Singleton (){}
+ public static final Singleton getInstance() {
+ return SingletonHolder.INSTANCE;
+ }
+}
+```
+
+## 10. 简单介绍一下 bean;知道 Spring 的 bean 的作用域与生命周期吗?
+
+在 Spring 中,那些组成应用程序的主体及由 Spring IOC 容器所管理的对象,被称之为 bean。简单地讲,bean 就是由 IOC 容器初始化、装配及管理的对象,除此之外,bean 就与应用程序中的其他对象没有什么区别了。而 bean 的定义以及 bean 相互间的依赖关系将通过配置元数据来描述。
+
+Spring 中的 bean 默认都是单例的,这些单例 Bean 在多线程程序下如何保证线程安全呢? 例如对于 Web 应用来说,Web 容器对于每个用户请求都创建一个单独的 Sevlet 线程来处理请求,引入 Spring 框架之后,每个 Action 都是单例的,那么对于 Spring 托管的单例 Service Bean,如何保证其安全呢? Spring 的单例是基于 BeanFactory 也就是 Spring 容器的,单例 Bean 在此容器内只有一个,Java 的单例是基于 JVM,每个 JVM 内只有一个实例。
+
+
+
+Spring 的 bean 的生命周期以及更多内容可以查看:[一文轻松搞懂 Spring 中 bean 的作用域与生命周期](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484400&idx=2&sn=7201eb365102fce017f89cb3527fb0bc&chksm=fd985591caefdc872a2fac897288119f94c345e4e12150774f960bf5f816b79e4b9b46be3d7f&token=1990180468&lang=zh_CN#rd)
+
+## 11. Spring 中的事务传播行为了解吗?TransactionDefinition 接口中哪五个表示隔离级别的常量?
+
+#### 事务传播行为
+
+事务传播行为(为了解决业务层方法之间互相调用的事务问题):
+当事务方法被另一个事务方法调用时,必须指定事务应该如何传播。例如:方法可能继续在现有事务中运行,也可能开启一个新事务,并在自己的事务中运行。在 TransactionDefinition 定义中包括了如下几个表示传播行为的常量:
+
+**支持当前事务的情况:**
+
+- TransactionDefinition.PROPAGATION_REQUIRED: 如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。
+- TransactionDefinition.PROPAGATION_SUPPORTS: 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
+- TransactionDefinition.PROPAGATION_MANDATORY: 如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。(mandatory:强制性)
+
+**不支持当前事务的情况:**
+
+- TransactionDefinition.PROPAGATION_REQUIRES_NEW: 创建一个新的事务,如果当前存在事务,则把当前事务挂起。
+- TransactionDefinition.PROPAGATION_NOT_SUPPORTED: 以非事务方式运行,如果当前存在事务,则把当前事务挂起。
+- TransactionDefinition.PROPAGATION_NEVER: 以非事务方式运行,如果当前存在事务,则抛出异常。
+
+**其他情况:**
+
+- TransactionDefinition.PROPAGATION_NESTED: 如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于 TransactionDefinition.PROPAGATION_REQUIRED。
+
+#### 隔离级别
+
+TransactionDefinition 接口中定义了五个表示隔离级别的常量:
+
+- **TransactionDefinition.ISOLATION_DEFAULT:** 使用后端数据库默认的隔离级别,Mysql 默认采用的 REPEATABLE_READ 隔离级别 Oracle 默认采用的 READ_COMMITTED 隔离级别.
+- **TransactionDefinition.ISOLATION_READ_UNCOMMITTED:** 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读
+- **TransactionDefinition.ISOLATION_READ_COMMITTED:** 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生
+- **TransactionDefinition.ISOLATION_REPEATABLE_READ:** 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
+- **TransactionDefinition.ISOLATION_SERIALIZABLE:** 最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
+
+## 12. SpringMVC 原理了解吗?
+
+
+
+客户端发送请求-> 前端控制器 DispatcherServlet 接受客户端请求 -> 找到处理器映射 HandlerMapping 解析请求对应的 Handler-> HandlerAdapter 会根据 Handler 来调用真正的处理器处理请求,并处理相应的业务逻辑 -> 处理器返回一个模型视图 ModelAndView -> 视图解析器进行解析 -> 返回一个视图对象->前端控制器 DispatcherServlet 渲染数据(Model)->将得到视图对象返回给用户
+
+关于 SpringMVC 原理更多内容可以查看我的这篇文章:[SpringMVC 工作原理详解](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484496&idx=1&sn=5472ffa687fe4a05f8900d8ee6726de4&chksm=fd985231caefdb27fc75b44ecf76b6f43e4617e0b01b3c040f8b8fab32e51dfa5118eed1d6ad&token=1990180468&lang=zh_CN#rd)
+
+## 13. Spring AOP IOC 实现原理
+
+过了秋招挺长一段时间了,说实话我自己也忘了如何简要概括 Spring AOP IOC 实现原理,就在网上找了一个较为简洁的答案,下面分享给各位。
+
+**IOC:** 控制反转也叫依赖注入。IOC 利用 java 反射机制,AOP 利用代理模式。IOC 概念看似很抽象,但是很容易理解。说简单点就是将对象交给容器管理,你只需要在 spring 配置文件中配置对应的 bean 以及设置相关的属性,让 spring 容器来生成类的实例对象以及管理对象。在 spring 容器启动的时候,spring 会把你在配置文件中配置的 bean 都初始化好,然后在你需要调用的时候,就把它已经初始化好的那些 bean 分配给你需要调用这些 bean 的类。
+
+**AOP:** 面向切面编程。(Aspect-Oriented Programming) 。AOP 可以说是对 OOP 的补充和完善。OOP 引入封装、继承和多态性等概念来建立一种对象层次结构,用以模拟公共行为的一个集合。实现 AOP 的技术,主要分为两大类:一是采用动态代理技术,利用截取消息的方式,对该消息进行装饰,以取代原有对象行为的执行;二是采用静态织入的方式,引入特定的语法创建“方面”,从而使得编译器可以在编译期间织入有关“方面”的代码,属于静态代理。
+
+# 二 进阶篇
+
+## 1 消息队列 MQ 的套路
+
+消息队列/消息中间件应该是 Java 程序员必备的一个技能了,如果你之前没接触过消息队列的话,建议先去百度一下某某消息队列入门,然后花 2 个小时就差不多可以学会任何一种消息队列的使用了。如果说仅仅学会使用是万万不够的,在实际生产环境还要考虑消息丢失等等情况。关于消息队列面试相关的问题,推荐大家也可以看一下视频《Java 工程师面试突击第 1 季-中华石杉老师》,如果大家没有资源的话,可以在我的公众号“Java 面试通关手册”后台回复关键字“1”即可!
+
+### 1.1 介绍一下消息队列 MQ 的应用场景/使用消息队列的好处
+
+面试官一般会先问你这个问题,预热一下,看你知道消息队列不,一般在第一面的时候面试官可能只会问消息队列 MQ 的应用场景/使用消息队列的好处、使用消息队列会带来什么问题、消息队列的技术选型这几个问题,不会太深究下去,在后面的第二轮/第三轮技术面试中可能会深入问一下。
+
+**《大型网站技术架构》第四章和第七章均有提到消息队列对应用性能及扩展性的提升。**
+
+#### 1)通过异步处理提高系统性能
+
+
+如上图,**在不使用消息队列服务器的时候,用户的请求数据直接写入数据库,在高并发的情况下数据库压力剧增,使得响应速度变慢。但是在使用消息队列之后,用户的请求数据发送给消息队列之后立即 返回,再由消息队列的消费者进程从消息队列中获取数据,异步写入数据库。由于消息队列服务器处理速度快于数据库(消息队列也比数据库有更好的伸缩性),因此响应速度得到大幅改善。**
+
+通过以上分析我们可以得出**消息队列具有很好的削峰作用的功能**——即**通过异步处理,将短时间高并发产生的事务消息存储在消息队列中,从而削平高峰期的并发事务。** 举例:在电子商务一些秒杀、促销活动中,合理使用消息队列可以有效抵御促销活动刚开始大量订单涌入对系统的冲击。如下图所示:
+
+因为**用户请求数据写入消息队列之后就立即返回给用户了,但是请求数据在后续的业务校验、写数据库等操作中可能失败**。因此使用消息队列进行异步处理之后,需要**适当修改业务流程进行配合**,比如**用户在提交订单之后,订单数据写入消息队列,不能立即返回用户订单提交成功,需要在消息队列的订单消费者进程真正处理完该订单之后,甚至出库后,再通过电子邮件或短信通知用户订单成功**,以免交易纠纷。这就类似我们平时手机订火车票和电影票。
+
+#### 2)降低系统耦合性
+
+我们知道模块分布式部署以后聚合方式通常有两种:1.**分布式消息队列**和 2.**分布式服务**。
+
+> **先来简单说一下分布式服务:**
+
+目前使用比较多的用来构建**SOA(Service Oriented Architecture 面向服务体系结构)**的**分布式服务框架**是阿里巴巴开源的**Dubbo**。如果想深入了解 Dubbo 的可以看我写的关于 Dubbo 的这一篇文章:**《高性能优秀的服务框架-dubbo 介绍》**:[https://juejin.im/post/5acadeb1f265da2375072f9c](https://juejin.im/post/5acadeb1f265da2375072f9c "https://juejin.im/post/5acadeb1f265da2375072f9c")
+
+> **再来谈我们的分布式消息队列:**
+
+我们知道如果模块之间不存在直接调用,那么新增模块或者修改模块就对其他模块影响较小,这样系统的可扩展性无疑更好一些。
+
+我们最常见的**事件驱动架构**类似生产者消费者模式,在大型网站中通常用利用消息队列实现事件驱动结构。如下图所示:
+
+
+**消息队列使利用发布-订阅模式工作,消息发送者(生产者)发布消息,一个或多个消息接受者(消费者)订阅消息。** 从上图可以看到**消息发送者(生产者)和消息接受者(消费者)之间没有直接耦合**,消息发送者将消息发送至分布式消息队列即结束对消息的处理,消息接受者从分布式消息队列获取该消息后进行后续处理,并不需要知道该消息从何而来。**对新增业务,只要对该类消息感兴趣,即可订阅该消息,对原有系统和业务没有任何影响,从而实现网站业务的可扩展性设计**。
+
+消息接受者对消息进行过滤、处理、包装后,构造成一个新的消息类型,将消息继续发送出去,等待其他消息接受者订阅该消息。因此基于事件(消息对象)驱动的业务架构可以是一系列流程。
+
+**另外为了避免消息队列服务器宕机造成消息丢失,会将成功发送到消息队列的消息存储在消息生产者服务器上,等消息真正被消费者服务器处理后才删除消息。在消息队列服务器宕机后,生产者服务器会选择分布式消息队列服务器集群中的其他服务器发布消息。**
+
+**备注:** 不要认为消息队列只能利用发布-订阅模式工作,只不过在解耦这个特定业务环境下是使用发布-订阅模式的,**比如在我们的 ActiveMQ 消息队列中还有点对点工作模式**,具体的会在后面的文章给大家详细介绍,这一篇文章主要还是让大家对消息队列有一个更透彻的了解。
+
+> 这个问题一般会在上一个问题问完之后,紧接着被问到。“使用消息队列会带来什么问题?”这个问题要引起重视,一般我们都会考虑使用消息队列会带来的好处而忽略它带来的问题!
+
+### 1.2 那么使用消息队列会带来什么问题?考虑过这些问题吗?
+
+- **系统可用性降低:** 系统可用性在某种程度上降低,为什么这样说呢?在加入 MQ 之前,你不用考虑消息丢失或者说 MQ 挂掉等等的情况,但是,引入 MQ 之后你就需要去考虑了!
+- **系统复杂性提高:** 加入 MQ 之后,你需要保证消息没有被重复消费、处理消息丢失的情况、保证消息传递的顺序性等等问题!
+- **一致性问题:** 我上面讲了消息队列可以实现异步,消息队列带来的异步确实可以提高系统响应速度。但是,万一消息的真正消费者并没有正确消费消息怎么办?这样就会导致数据不一致的情况了!
+
+> 了解下面这个问题是为了我们更好的进行技术选型!该部分摘自:《Java 工程师面试突击第 1 季-中华石杉老师》,如果大家没有资源的话,可以在我的公众号“Java 面试通关手册”后台回复关键字“1”即可!
+
+### 1.3 介绍一下你知道哪几种消息队列,该如何选择呢?
+
+| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
+| :----------------------- | -----------------------------------------------------------: | -----------------------------------------------------------: | -----------------------------------------------------------: | -----------------------------------------------------------: |
+| 单机吞吐量 | 万级,吞吐量比 RocketMQ 和 Kafka 要低了一个数量级 | 万级,吞吐量比 RocketMQ 和 Kafka 要低了一个数量级 | 10 万级,RocketMQ 也是可以支撑高吞吐的一种 MQ | 10 万级别,这是 kafka 最大的优点,就是吞吐量高。一般配合大数据类的系统来进行实时数据计算、日志采集等场景 |
+| topic 数量对吞吐量的影响 | | | topic 可以达到几百,几千个的级别,吞吐量会有较小幅度的下降这是 RocketMQ 的一大优势,在同等机器下,可以支撑大量的 topic | topic 从几十个到几百个的时候,吞吐量会大幅度下降。所以在同等机器下,kafka 尽量保证 topic 数量不要过多。如果要支撑大规模 topic,需要增加更多的机器资源 |
+| 可用性 | 高,基于主从架构实现高可用性 | 高,基于主从架构实现高可用性 | 非常高,分布式架构 | 非常高,kafka 是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 |
+| 消息可靠性 | 有较低的概率丢失数据 | | 经过参数优化配置,可以做到 0 丢失 | 经过参数优化配置,消息可以做到 0 丢失 |
+| 时效性 | ms 级 | 微秒级,这是 rabbitmq 的一大特点,延迟是最低的 | ms 级 | 延迟在 ms 级以内 |
+| 功能支持 | MQ 领域的功能极其完备 | 基于 erlang 开发,所以并发能力很强,性能极其好,延时很低 | MQ 功能较为完善,还是分布式的,扩展性好 | 功能较为简单,主要支持简单的 MQ 功能,在大数据领域的实时计算以及日志采集被大规模使用,是事实上的标准 |
+| 优劣势总结 | 非常成熟,功能强大,在业内大量的公司以及项目中都有应用。偶尔会有较低概率丢失消息,而且现在社区以及国内应用都越来越少,官方社区现在对 ActiveMQ 5.x 维护越来越少,几个月才发布一个版本而且确实主要是基于解耦和异步来用的,较少在大规模吞吐的场景中使用 | erlang 语言开发,性能极其好,延时很低;吞吐量到万级,MQ 功能比较完备而且开源提供的管理界面非常棒,用起来很好用。社区相对比较活跃,几乎每个月都发布几个版本分在国内一些互联网公司近几年用 rabbitmq 也比较多一些但是问题也是显而易见的,RabbitMQ 确实吞吐量会低一些,这是因为他做的实现机制比较重。而且 erlang 开发,国内有几个公司有实力做 erlang 源码级别的研究和定制?如果说你没这个实力的话,确实偶尔会有一些问题,你很难去看懂源码,你公司对这个东西的掌控很弱,基本职能依赖于开源社区的快速维护和修复 bug。而且 rabbitmq 集群动态扩展会很麻烦,不过这个我觉得还好。其实主要是 erlang 语言本身带来的问题。很难读源码,很难定制和掌控。 | 接口简单易用,而且毕竟在阿里大规模应用过,有阿里品牌保障。日处理消息上百亿之多,可以做到大规模吞吐,性能也非常好,分布式扩展也很方便,社区维护还可以,可靠性和可用性都是 ok 的,还可以支撑大规模的 topic 数量,支持复杂 MQ 业务场景。而且一个很大的优势在于,阿里出品都是 java 系的,我们可以自己阅读源码,定制自己公司的 MQ,可以掌控。社区活跃度相对较为一般,不过也还可以,文档相对来说简单一些,然后接口这块不是按照标准 JMS 规范走的有些系统要迁移需要修改大量代码。还有就是阿里出台的技术,你得做好这个技术万一被抛弃,社区黄掉的风险,那如果你们公司有技术实力我觉得用 RocketMQ 挺好的 | kafka 的特点其实很明显,就是仅仅提供较少的核心功能,但是提供超高的吞吐量,ms 级的延迟,极高的可用性以及可靠性,而且分布式可以任意扩展。同时 kafka 最好是支撑较少的 topic 数量即可,保证其超高吞吐量。而且 kafka 唯一的一点劣势是有可能消息重复消费,那么对数据准确性会造成极其轻微的影响,在大数据领域中以及日志采集中,这点轻微影响可以忽略这个特性天然适合大数据实时计算以及日志收集。 |
+
+> 这部分内容,我这里不给出答案,大家可以自行根据自己学习的消息队列查阅相关内容,我可能会在后面的文章中介绍到这部分内容。另外,下面这些问题在视频《Java 工程师面试突击第 1 季-中华石杉老师》中都有提到,如果大家没有资源的话,可以在我的公众号“Java 面试通关手册”后台回复关键字“1”即可!
+
+### 1.4 关于消息队列其他一些常见的问题展望
+
+1. 引入消息队列之后如何保证高可用性?
+2. 如何保证消息不被重复消费呢?
+3. 如何保证消息的可靠性传输(如何处理消息丢失的问题)?
+4. 我该怎么保证从消息队列里拿到的数据按顺序执行?
+5. 如何解决消息队列的延时以及过期失效问题?消息队列满了以后该怎么处理?有几百万消息持续积压几小时,说说怎么解决?
+6. 如果让你来开发一个消息队列中间件,你会怎么设计架构?
+
+## 2 谈谈 InnoDB 和 MyIsam 两者的区别
+
+### 2.1 两者的对比
+
+1. **count 运算上的区别:** 因为 MyISAM 缓存有表 meta-data(行数等),因此在做 COUNT(\*)时对于一个结构很好的查询是不需要消耗多少资源的。而对于 InnoDB 来说,则没有这种缓存
+2. **是否支持事务和崩溃后的安全恢复:** MyISAM 强调的是性能,每次查询具有原子性,其执行速度比 InnoDB 类型更快,但是不提供事务支持。但是 InnoDB 提供事务支持,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
+3. **是否支持外键:** MyISAM 不支持,而 InnoDB 支持。
+
+### 2.2 关于两者的总结
+
+MyISAM 更适合读密集的表,而 InnoDB 更适合写密集的表。 在数据库做主从分离的情况下,经常选择 MyISAM 作为主库的存储引擎。
+
+一般来说,如果需要事务支持,并且有较高的并发读取频率(MyISAM 的表锁的粒度太大,所以当该表写并发量较高时,要等待的查询就会很多了),InnoDB 是不错的选择。如果你的数据量很大(MyISAM 支持压缩特性可以减少磁盘的空间占用),而且不需要支持事务时,MyISAM 是最好的选择。
+
+## 3 聊聊 Java 中的集合吧!
+
+### 3.1 Arraylist 与 LinkedList 有什么不同?(注意加上从数据结构分析的内容)
+
+- **1. 是否保证线程安全:** ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;
+- **2. 底层数据结构:** Arraylist 底层使用的是 Object 数组;LinkedList 底层使用的是双向链表数据结构(注意双向链表和双向循环链表的区别:);
+- **3. 插入和删除是否受元素位置的影响:** ① **ArrayList 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。** 比如:执行`add(E e)`方法的时候, ArrayList 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是 O(1)。但是如果要在指定位置 i 插入和删除元素的话(`add(int index, E element)`)时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。 ② **LinkedList 采用链表存储,所以插入,删除元素时间复杂度不受元素位置的影响,都是近似 O(1) 而数组为近似 O(n) 。**
+- **4. 是否支持快速随机访问:** LinkedList 不支持高效的随机元素访问,而 ArrayList 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于`get(int index)`方法)。
+- **5. 内存空间占用:** ArrayList 的空 间浪费主要体现在在 list 列表的结尾会预留一定的容量空间,而 LinkedList 的空间花费则体现在它的每一个元素都需要消耗比 ArrayList 更多的空间(因为要存放直接后继和直接前驱以及数据)。
+
+**补充内容:RandomAccess 接口**
+
+```java
+public interface RandomAccess {
+}
+```
+
+查看源码我们发现实际上 RandomAccess 接口中什么都没有定义。所以,在我看来 RandomAccess 接口不过是一个标识罢了。标识什么? 标识实现这个接口的类具有随机访问功能。
+
+在 binarySearch() 方法中,它要判断传入的 list 是否 RamdomAccess 的实例,如果是,调用 indexedBinarySearch() 方法,如果不是,那么调用 iteratorBinarySearch() 方法
+
+```java
+ public static  +
+做过分布式电商系统的一定很熟悉上面的架构图(目前比较流行的是微服务架构,但是如果你有分布式开发经验也是非常加分的!)。
+
+**面试官:** 简单介绍一下你做的这个系统吧!
+
+**我:** 我一本正经的对着我刚刚画的商城架构图开始了满嘴造火箭的讲起来:
+
+> 本系统主要分为展示层、服务层和持久层这三层。表现层顾名思义主要就是为了用来展示,比如我们的后台管理系统的页面、商城首页的页面、搜索系统的页面等等,这一层都只是作为展示,并没有提供任何服务。
+>
+> 展示层和服务层一般是部署在不同的机器上来提高并发量和扩展性,那么展示层和服务层怎样才能交互呢?在本系统中我们使用 Dubbo 来进行服务治理。Dubbo 是一款高性能、轻量级的开源 Java RPC 框架。Dubbo 在本系统的主要作用就是提供远程 RPC 调用。在本系统中服务层的信息通过 Dubbo 注册给 ZooKeeper,表现层通过 Dubbo 去 ZooKeeper 中获取服务的相关信息。Zookeeper 的作用仅仅是存放提供服务的服务器的地址和一些服务的相关信息,实现 RPC 远程调用功能的还是 Dubbo。如果需要引用到某个服务的时候,我们只需要在配置文件中配置相关信息就可以在代码中直接使用了,就像调用本地方法一样。假如说某个服务的使用量增加时,我们只用为这单个服务增加服务器,而不需要为整个系统添加服务。
+>
+> 另外,本系统的数据库使用的是常用的 MySQL,并且用到了数据库中间件 MyCat。另外,本系统还用到 redis 内存数据库来作为缓存来提高系统的反应速度。假如用户第一次访问数据库中的某些数据,这个过程会比较慢,因为是从硬盘上读取的。将该用户访问的数据存在数缓存中,这样下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。
+>
+> 系统还用到了 Elasticsearch 来提供搜索功能。使用 Elasticsearch 我们可以非常方便的为我们的商城系统添加必备的搜索功能,并且使用 Elasticsearch 还能提供其它非常实用的功能,并且很容易扩展。
+
+**面试官:** 我看你的系统里面还用到了消息队列,能说说为什么要用它吗?
+
+**我:**
+
+> 使用消息队列主要是为了:
+>
+> 1. 减少响应所需时间和削峰。
+> 2. 降低系统耦合性(解耦/提升系统可扩展性)。
+
+**面试官:** 你这说的太简单了!能不能稍微详细一点,最好能画图给我解释一下。
+
+**我:** 内心 os:"都 2019 年了,大部分面试者都能对消息队列的为系统带来的这两个好处倒背如流了,如果你想走的更远就要别别人懂的更深一点!"
+
+> 当我们不使用消息队列的时候,所有的用户的请求会直接落到服务器,然后通过数据库或者缓存响应。假如在高并发的场景下,如果没有缓存或者数据库承受不了这么大的压力的话,就会造成响应速度缓慢,甚至造成数据库宕机。但是,在使用消息队列之后,用户的请求数据发送给了消息队列之后就可以立即返回,再由消息队列的消费者进程从消息队列中获取数据,异步写入数据库,不过要确保消息不被重复消费还要考虑到消息丢失问题。由于消息队列服务器处理速度快于数据库,因此响应速度得到大幅改善。
+>
+> 文字 is too 空洞,直接上图吧!下图展示了使用消息前后系统处理用户请求的对比(ps:我自己都被我画的这个图美到了,如果你也觉得这张图好看的话麻烦来个素质三连!)。
+>
+> 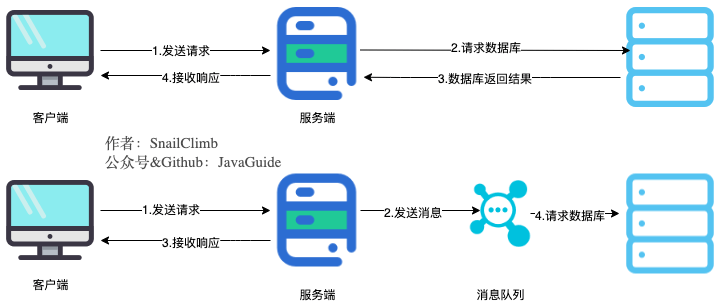
+>
+> 通过以上分析我们可以得出**消息队列具有很好的削峰作用的功能**——即**通过异步处理,将短时间高并发产生的事务消息存储在消息队列中,从而削平高峰期的并发事务。** 举例:在电子商务一些秒杀、促销活动中,合理使用消息队列可以有效抵御促销活动刚开始大量订单涌入对系统的冲击。如下图所示:
+>
+> 
+>
+> 使用消息队列还可以降低系统耦合性。我们知道如果模块之间不存在直接调用,那么新增模块或者修改模块就对其他模块影响较小,这样系统的可扩展性无疑更好一些。还是直接上图吧:
+>
+> 
+>
+> 生产者(客户端)发送消息到消息队列中去,接受者(服务端)处理消息,需要消费的系统直接去消息队列取消息进行消费即可而不需要和其他系统有耦合, 这显然也提高了系统的扩展性。
+
+**面试官:** 你觉得它有什么缺点吗?或者说怎么考虑用不用消息队列?
+
+**我:** 内心 os: "面试官真鸡贼!这不是勾引我上钩么?还好我准备充分。"
+
+> 我觉得可以从下面几个方面来说:
+>
+> 1. **系统可用性降低:** 系统可用性在某种程度上降低,为什么这样说呢?在加入 MQ 之前,你不用考虑消息丢失或者说 MQ 挂掉等等的情况,但是,引入 MQ 之后你就需要去考虑了!
+> 2. **系统复杂性提高:** 加入 MQ 之后,你需要保证消息没有被重复消费、处理消息丢失的情况、保证消息传递的顺序性等等问题!
+> 3. **一致性问题:** 我上面讲了消息队列可以实现异步,消息队列带来的异步确实可以提高系统响应速度。但是,万一消息的真正消费者并没有正确消费消息怎么办?这样就会导致数据不一致的情况了!
+
+**面试官**:做项目的过程中遇到了什么问题吗?解决了吗?如果解决的话是如何解决的呢?
+
+**我** : 内心 os: "做的过程中好像也没有遇到什么问题啊!怎么办?怎么办?突然想到可以说我在使用 Redis 过程中遇到的问题,毕竟我对 Redis 还算熟悉嘛,**把面试官往这个方向吸引**,准没错。"
+
+> 我在使用 Redis 对常用数据进行缓冲的过程中出现了缓存穿透问题。然后,我通过谷歌搜索相关的解决方案来解决的。
+
+**面试官:** 你还知道缓存穿透啊?不错啊!来说说什么是缓存穿透以及你最后的解决办法。
+
+**我:** 我先来谈谈什么是缓存穿透吧!
+
+> 缓存穿透说简单点就是大量请求的 key 根本不存在于缓存中,导致请求直接到了数据库上,根本没有经过缓存这一层。举个例子:某个黑客故意制造我们缓存中不存在的 key 发起大量请求,导致大量请求落到数据库。
+>
+> 总结一下就是:
+>
+> 1. 缓存层不命中。
+> 2. 存储层不命中,不将空结果写回缓存。
+> 3. 返回空结果给客户端。
+>
+> 一般 MySQL 默认的最大连接数在 150 左右,这个可以通过 `show variables like '%max_connections%';`命令来查看。最大连接数一个还只是一个指标,cpu,内存,磁盘,网络等物理条件都是其运行指标,这些指标都会限制其并发能力!所以,一般 3000 的并发请求就能打死大部分数据库了。
+
+**面试官:** 小伙子不错啊!还准备问你:“为什么 3000 的并发能把支持最大连接数 4000 数据库压死?”想不到你自己就提前回答了!不错!
+
+**我:** 别夸了!别夸了!我再来说说我知道的一些解决办法以及我最后采用的方案吧!您帮忙看看有没有问题。
+
+> 最基本的就是首先做好参数校验,一些不合法的参数请求直接抛出异常信息返回给客户端。比如查询的数据库 id 不能小于 0、传入的邮箱格式不对的时候直接返回错误消息给客户端等等。
+>
+> 参数校验通过的情况还是会出现缓存穿透,我们还可以通过以下几个方案来解决这个问题:
+>
+> **1)缓存无效 key** : 如果缓存和数据库都查不到某个 key 的数据就写一个到 redis 中去并设置过期时间,具体命令如下:`SET key value EX 10086`。这种方式可以解决请求的 key 变化不频繁的情况,如何黑客恶意攻击,每次构建的不同的请求 key,会导致 redis 中缓存大量无效的 key 。很明显,这种方案并不能从根本上解决此问题。如果非要用这种方式来解决穿透问题的话,尽量将无效的 key 的过期时间设置短一点比如 1 分钟。
+>
+> 另外,这里多说一嘴,一般情况下我们是这样设计 key 的: `表名:列名:主键名:主键值`。
+>
+> **2)布隆过滤器:** 布隆过滤器是一个非常神奇的数据结构,通过它我们可以非常方便地判断一个给定数据是否存在于海量数据中。我们需要的就是判断 key 是否合法,有没有感觉布隆过滤器就是我们想要找的那个“人”。
+
+**面试官:** 不错不错!你还知道布隆过滤器啊!来给我谈一谈。
+
+**我:** 内心 os:“如果你准备过海量数据处理的面试题,你一定对:“如何确定一个数字是否在于包含大量数字的数字集中(数字集很大,5 亿以上!)?”这个题目很了解了!解决这道题目就要用到布隆过滤器。”
+
+> 布隆过滤器在针对海量数据去重或者验证数据合法性的时候非常有用。**布隆过滤器的本质实际上是 “位(bit)数组”,也就是说每一个存入布隆过滤器的数据都只占一位。相比于我们平时常用的的 List、Map 、Set 等数据结构,它占用空间更少并且效率更高,但是缺点是其返回的结果是概率性的,而不是非常准确的。**
+>
+> **当一个元素加入布隆过滤器中的时候,会进行如下操作:**
+>
+> 1. 使用布隆过滤器中的哈希函数对元素值进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。
+> 2. 根据得到的哈希值,在位数组中把对应下标的值置为 1。
+>
+> **当我们需要判断一个元素是否存在于布隆过滤器的时候,会进行如下操作:**
+>
+> 1. 对给定元素再次进行相同的哈希计算;
+> 2. 得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
+>
+> 举个简单的例子:
+>
+> 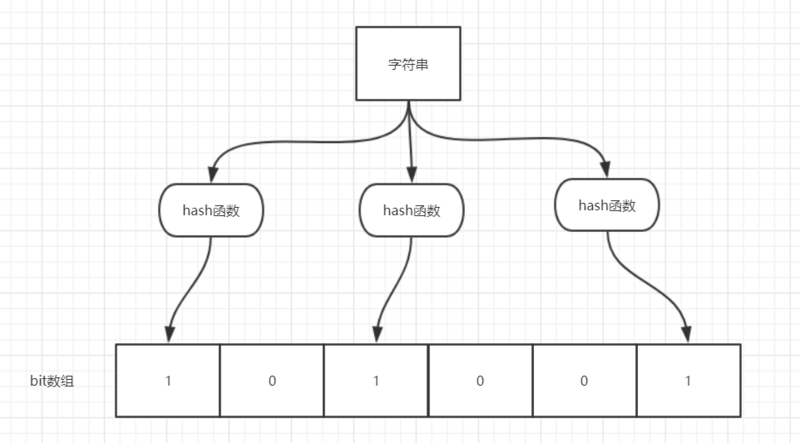
+>
+> 如图所示,当字符串存储要加入到布隆过滤器中时,该字符串首先由多个哈希函数生成不同的哈希值,然后在对应的位数组的下表的元素设置为 1(当位数组初始化时 ,所有位置均为 0)。当第二次存储相同字符串时,因为先前的对应位置已设置为 1,所以很容易知道此值已经存在(去重非常方便)。
+>
+> 如果我们需要判断某个字符串是否在布隆过滤器中时,只需要对给定字符串再次进行相同的哈希计算,得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
+>
+> **不同的字符串可能哈希出来的位置相同,这种情况我们可以适当增加位数组大小或者调整我们的哈希函数。**
+>
+> 综上,我们可以得出:**布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。**
+
+**面试官:** 看来你对布隆过滤器了解的还挺不错的嘛!那你快说说你最后是怎么利用它来解决缓存穿透的。
+
+**我:** 知道了布隆过滤器的原理就之后就很容易做了。我是利用 Redis 布隆过滤器来做的。我把所有可能存在的请求的值都存放在布隆过滤器中,当用户请求过来,我会先判断用户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才会走下面的流程。总结一下就是下面这张图(这张图片不是我画的,为了省事直接在网上找的):
+
+
+
+做过分布式电商系统的一定很熟悉上面的架构图(目前比较流行的是微服务架构,但是如果你有分布式开发经验也是非常加分的!)。
+
+**面试官:** 简单介绍一下你做的这个系统吧!
+
+**我:** 我一本正经的对着我刚刚画的商城架构图开始了满嘴造火箭的讲起来:
+
+> 本系统主要分为展示层、服务层和持久层这三层。表现层顾名思义主要就是为了用来展示,比如我们的后台管理系统的页面、商城首页的页面、搜索系统的页面等等,这一层都只是作为展示,并没有提供任何服务。
+>
+> 展示层和服务层一般是部署在不同的机器上来提高并发量和扩展性,那么展示层和服务层怎样才能交互呢?在本系统中我们使用 Dubbo 来进行服务治理。Dubbo 是一款高性能、轻量级的开源 Java RPC 框架。Dubbo 在本系统的主要作用就是提供远程 RPC 调用。在本系统中服务层的信息通过 Dubbo 注册给 ZooKeeper,表现层通过 Dubbo 去 ZooKeeper 中获取服务的相关信息。Zookeeper 的作用仅仅是存放提供服务的服务器的地址和一些服务的相关信息,实现 RPC 远程调用功能的还是 Dubbo。如果需要引用到某个服务的时候,我们只需要在配置文件中配置相关信息就可以在代码中直接使用了,就像调用本地方法一样。假如说某个服务的使用量增加时,我们只用为这单个服务增加服务器,而不需要为整个系统添加服务。
+>
+> 另外,本系统的数据库使用的是常用的 MySQL,并且用到了数据库中间件 MyCat。另外,本系统还用到 redis 内存数据库来作为缓存来提高系统的反应速度。假如用户第一次访问数据库中的某些数据,这个过程会比较慢,因为是从硬盘上读取的。将该用户访问的数据存在数缓存中,这样下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。
+>
+> 系统还用到了 Elasticsearch 来提供搜索功能。使用 Elasticsearch 我们可以非常方便的为我们的商城系统添加必备的搜索功能,并且使用 Elasticsearch 还能提供其它非常实用的功能,并且很容易扩展。
+
+**面试官:** 我看你的系统里面还用到了消息队列,能说说为什么要用它吗?
+
+**我:**
+
+> 使用消息队列主要是为了:
+>
+> 1. 减少响应所需时间和削峰。
+> 2. 降低系统耦合性(解耦/提升系统可扩展性)。
+
+**面试官:** 你这说的太简单了!能不能稍微详细一点,最好能画图给我解释一下。
+
+**我:** 内心 os:"都 2019 年了,大部分面试者都能对消息队列的为系统带来的这两个好处倒背如流了,如果你想走的更远就要别别人懂的更深一点!"
+
+> 当我们不使用消息队列的时候,所有的用户的请求会直接落到服务器,然后通过数据库或者缓存响应。假如在高并发的场景下,如果没有缓存或者数据库承受不了这么大的压力的话,就会造成响应速度缓慢,甚至造成数据库宕机。但是,在使用消息队列之后,用户的请求数据发送给了消息队列之后就可以立即返回,再由消息队列的消费者进程从消息队列中获取数据,异步写入数据库,不过要确保消息不被重复消费还要考虑到消息丢失问题。由于消息队列服务器处理速度快于数据库,因此响应速度得到大幅改善。
+>
+> 文字 is too 空洞,直接上图吧!下图展示了使用消息前后系统处理用户请求的对比(ps:我自己都被我画的这个图美到了,如果你也觉得这张图好看的话麻烦来个素质三连!)。
+>
+> 
+>
+> 通过以上分析我们可以得出**消息队列具有很好的削峰作用的功能**——即**通过异步处理,将短时间高并发产生的事务消息存储在消息队列中,从而削平高峰期的并发事务。** 举例:在电子商务一些秒杀、促销活动中,合理使用消息队列可以有效抵御促销活动刚开始大量订单涌入对系统的冲击。如下图所示:
+>
+> 
+>
+> 使用消息队列还可以降低系统耦合性。我们知道如果模块之间不存在直接调用,那么新增模块或者修改模块就对其他模块影响较小,这样系统的可扩展性无疑更好一些。还是直接上图吧:
+>
+> 
+>
+> 生产者(客户端)发送消息到消息队列中去,接受者(服务端)处理消息,需要消费的系统直接去消息队列取消息进行消费即可而不需要和其他系统有耦合, 这显然也提高了系统的扩展性。
+
+**面试官:** 你觉得它有什么缺点吗?或者说怎么考虑用不用消息队列?
+
+**我:** 内心 os: "面试官真鸡贼!这不是勾引我上钩么?还好我准备充分。"
+
+> 我觉得可以从下面几个方面来说:
+>
+> 1. **系统可用性降低:** 系统可用性在某种程度上降低,为什么这样说呢?在加入 MQ 之前,你不用考虑消息丢失或者说 MQ 挂掉等等的情况,但是,引入 MQ 之后你就需要去考虑了!
+> 2. **系统复杂性提高:** 加入 MQ 之后,你需要保证消息没有被重复消费、处理消息丢失的情况、保证消息传递的顺序性等等问题!
+> 3. **一致性问题:** 我上面讲了消息队列可以实现异步,消息队列带来的异步确实可以提高系统响应速度。但是,万一消息的真正消费者并没有正确消费消息怎么办?这样就会导致数据不一致的情况了!
+
+**面试官**:做项目的过程中遇到了什么问题吗?解决了吗?如果解决的话是如何解决的呢?
+
+**我** : 内心 os: "做的过程中好像也没有遇到什么问题啊!怎么办?怎么办?突然想到可以说我在使用 Redis 过程中遇到的问题,毕竟我对 Redis 还算熟悉嘛,**把面试官往这个方向吸引**,准没错。"
+
+> 我在使用 Redis 对常用数据进行缓冲的过程中出现了缓存穿透问题。然后,我通过谷歌搜索相关的解决方案来解决的。
+
+**面试官:** 你还知道缓存穿透啊?不错啊!来说说什么是缓存穿透以及你最后的解决办法。
+
+**我:** 我先来谈谈什么是缓存穿透吧!
+
+> 缓存穿透说简单点就是大量请求的 key 根本不存在于缓存中,导致请求直接到了数据库上,根本没有经过缓存这一层。举个例子:某个黑客故意制造我们缓存中不存在的 key 发起大量请求,导致大量请求落到数据库。
+>
+> 总结一下就是:
+>
+> 1. 缓存层不命中。
+> 2. 存储层不命中,不将空结果写回缓存。
+> 3. 返回空结果给客户端。
+>
+> 一般 MySQL 默认的最大连接数在 150 左右,这个可以通过 `show variables like '%max_connections%';`命令来查看。最大连接数一个还只是一个指标,cpu,内存,磁盘,网络等物理条件都是其运行指标,这些指标都会限制其并发能力!所以,一般 3000 的并发请求就能打死大部分数据库了。
+
+**面试官:** 小伙子不错啊!还准备问你:“为什么 3000 的并发能把支持最大连接数 4000 数据库压死?”想不到你自己就提前回答了!不错!
+
+**我:** 别夸了!别夸了!我再来说说我知道的一些解决办法以及我最后采用的方案吧!您帮忙看看有没有问题。
+
+> 最基本的就是首先做好参数校验,一些不合法的参数请求直接抛出异常信息返回给客户端。比如查询的数据库 id 不能小于 0、传入的邮箱格式不对的时候直接返回错误消息给客户端等等。
+>
+> 参数校验通过的情况还是会出现缓存穿透,我们还可以通过以下几个方案来解决这个问题:
+>
+> **1)缓存无效 key** : 如果缓存和数据库都查不到某个 key 的数据就写一个到 redis 中去并设置过期时间,具体命令如下:`SET key value EX 10086`。这种方式可以解决请求的 key 变化不频繁的情况,如何黑客恶意攻击,每次构建的不同的请求 key,会导致 redis 中缓存大量无效的 key 。很明显,这种方案并不能从根本上解决此问题。如果非要用这种方式来解决穿透问题的话,尽量将无效的 key 的过期时间设置短一点比如 1 分钟。
+>
+> 另外,这里多说一嘴,一般情况下我们是这样设计 key 的: `表名:列名:主键名:主键值`。
+>
+> **2)布隆过滤器:** 布隆过滤器是一个非常神奇的数据结构,通过它我们可以非常方便地判断一个给定数据是否存在于海量数据中。我们需要的就是判断 key 是否合法,有没有感觉布隆过滤器就是我们想要找的那个“人”。
+
+**面试官:** 不错不错!你还知道布隆过滤器啊!来给我谈一谈。
+
+**我:** 内心 os:“如果你准备过海量数据处理的面试题,你一定对:“如何确定一个数字是否在于包含大量数字的数字集中(数字集很大,5 亿以上!)?”这个题目很了解了!解决这道题目就要用到布隆过滤器。”
+
+> 布隆过滤器在针对海量数据去重或者验证数据合法性的时候非常有用。**布隆过滤器的本质实际上是 “位(bit)数组”,也就是说每一个存入布隆过滤器的数据都只占一位。相比于我们平时常用的的 List、Map 、Set 等数据结构,它占用空间更少并且效率更高,但是缺点是其返回的结果是概率性的,而不是非常准确的。**
+>
+> **当一个元素加入布隆过滤器中的时候,会进行如下操作:**
+>
+> 1. 使用布隆过滤器中的哈希函数对元素值进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。
+> 2. 根据得到的哈希值,在位数组中把对应下标的值置为 1。
+>
+> **当我们需要判断一个元素是否存在于布隆过滤器的时候,会进行如下操作:**
+>
+> 1. 对给定元素再次进行相同的哈希计算;
+> 2. 得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
+>
+> 举个简单的例子:
+>
+> 
+>
+> 如图所示,当字符串存储要加入到布隆过滤器中时,该字符串首先由多个哈希函数生成不同的哈希值,然后在对应的位数组的下表的元素设置为 1(当位数组初始化时 ,所有位置均为 0)。当第二次存储相同字符串时,因为先前的对应位置已设置为 1,所以很容易知道此值已经存在(去重非常方便)。
+>
+> 如果我们需要判断某个字符串是否在布隆过滤器中时,只需要对给定字符串再次进行相同的哈希计算,得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
+>
+> **不同的字符串可能哈希出来的位置相同,这种情况我们可以适当增加位数组大小或者调整我们的哈希函数。**
+>
+> 综上,我们可以得出:**布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。**
+
+**面试官:** 看来你对布隆过滤器了解的还挺不错的嘛!那你快说说你最后是怎么利用它来解决缓存穿透的。
+
+**我:** 知道了布隆过滤器的原理就之后就很容易做了。我是利用 Redis 布隆过滤器来做的。我把所有可能存在的请求的值都存放在布隆过滤器中,当用户请求过来,我会先判断用户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才会走下面的流程。总结一下就是下面这张图(这张图片不是我画的,为了省事直接在网上找的):
+
+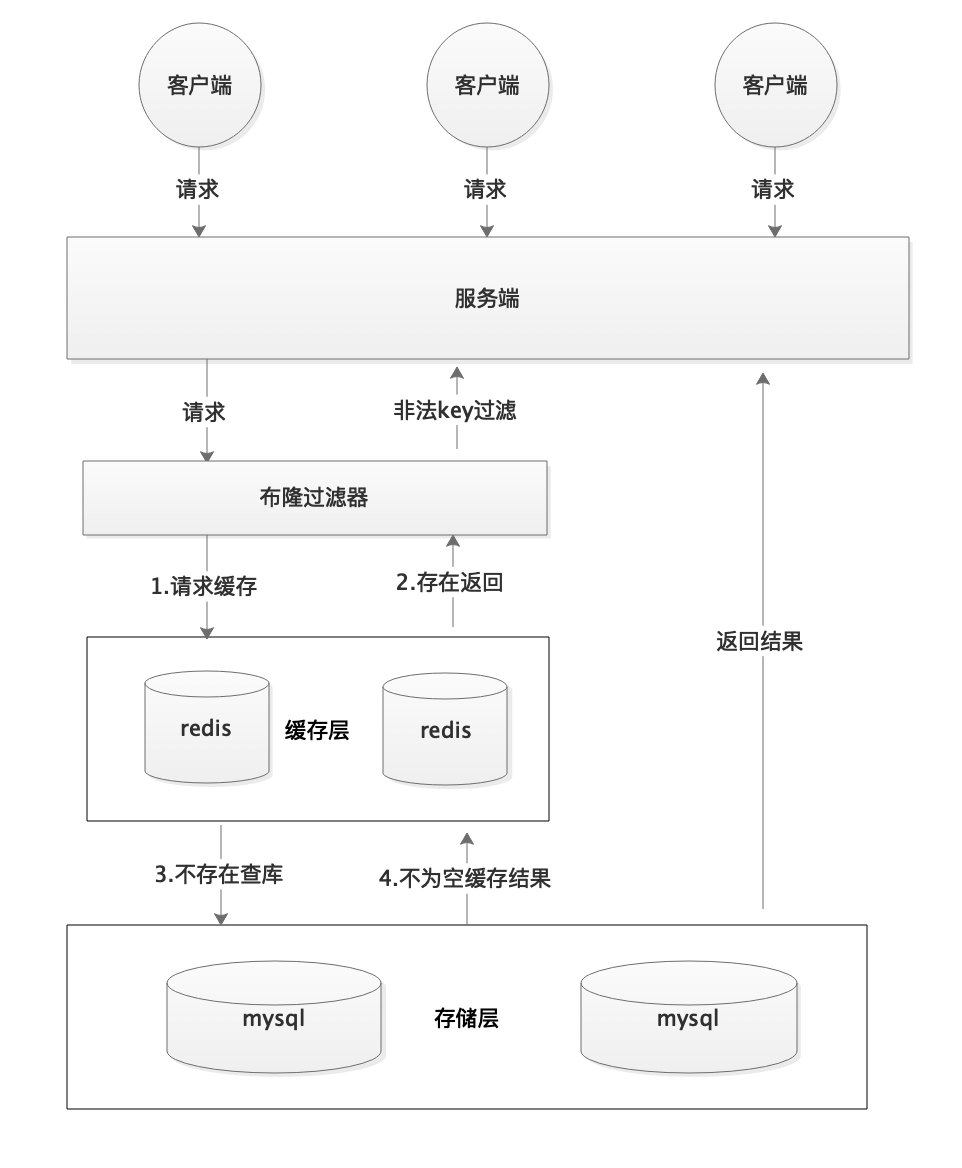 +
+更多关于布隆过滤器的内容可以看我的这篇原创:[《不了解布隆过滤器?一文给你整的明明白白!》](https://github.com/Snailclimb/JavaGuide/blob/master/docs/dataStructures-algorithms/data-structure/bloom-filter.md "《不了解布隆过滤器?一文给你整的明明白白!》") ,强烈推荐,个人感觉网上应该找不到总结的这么明明白白的文章了。
+
+**面试官:** 好了好了。项目就暂时问到这里吧!下面有一些比较基础的问题我简单地问一下你。内心 os: 难不成这家伙满口高并发,连最基础的东西都不会吧!
+
+**我:** 好的好的!没问题!
+
+**面试官:** 浏览器输入 URL 发生了什么?
+
+**我:** 内心 os:“很常问的一个问题,建议拿小本本记好了!另外,百度好像最喜欢问这个问题,去百度面试可要提前备好这道题的功课哦!相似问题:打开一个网页,整个过程会使用哪些协议?”。
+
+> 图解(图片来源:《图解 HTTP》):
+>
+>
+
+更多关于布隆过滤器的内容可以看我的这篇原创:[《不了解布隆过滤器?一文给你整的明明白白!》](https://github.com/Snailclimb/JavaGuide/blob/master/docs/dataStructures-algorithms/data-structure/bloom-filter.md "《不了解布隆过滤器?一文给你整的明明白白!》") ,强烈推荐,个人感觉网上应该找不到总结的这么明明白白的文章了。
+
+**面试官:** 好了好了。项目就暂时问到这里吧!下面有一些比较基础的问题我简单地问一下你。内心 os: 难不成这家伙满口高并发,连最基础的东西都不会吧!
+
+**我:** 好的好的!没问题!
+
+**面试官:** 浏览器输入 URL 发生了什么?
+
+**我:** 内心 os:“很常问的一个问题,建议拿小本本记好了!另外,百度好像最喜欢问这个问题,去百度面试可要提前备好这道题的功课哦!相似问题:打开一个网页,整个过程会使用哪些协议?”。
+
+> 图解(图片来源:《图解 HTTP》):
+>
+> 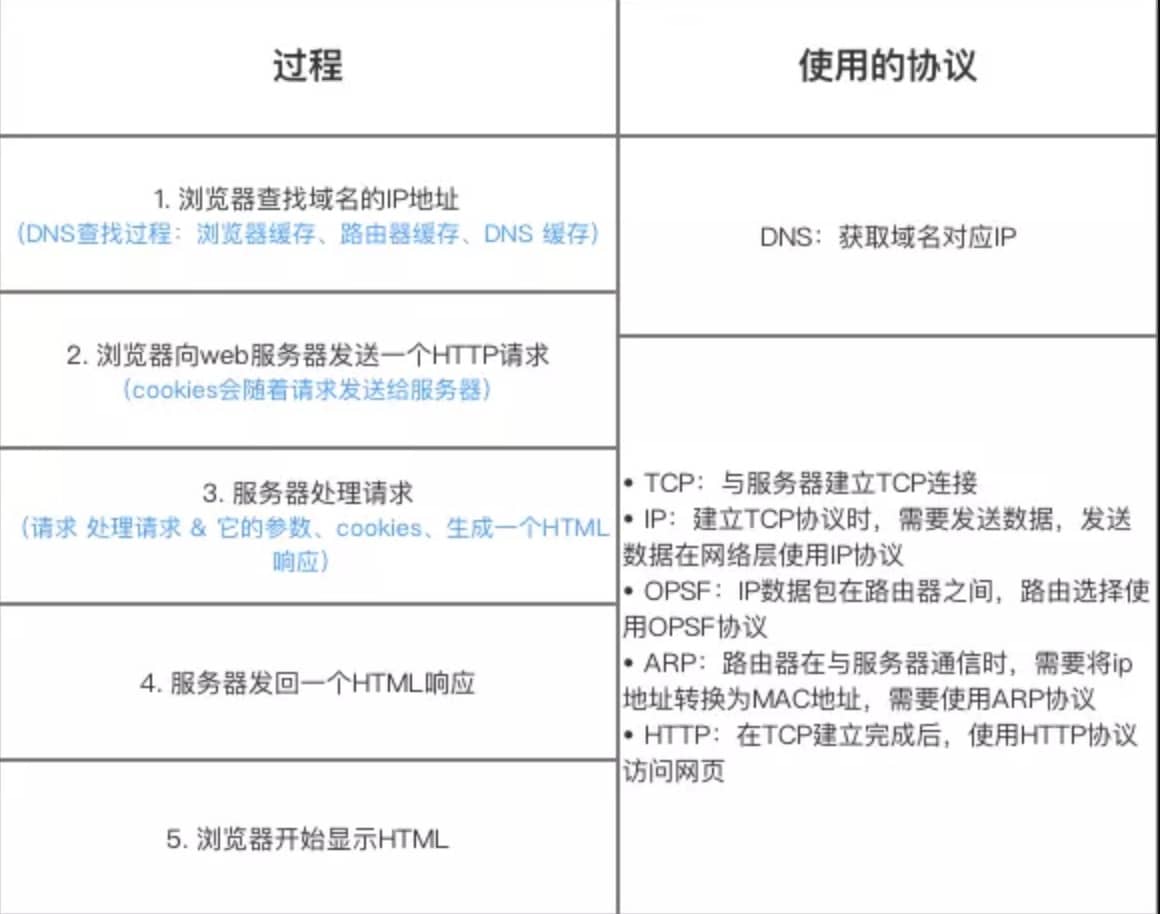 +>
+> 总体来说分为以下几个过程:
+>
+> 1. DNS 解析
+> 2. TCP 连接
+> 3. 发送 HTTP 请求
+> 4. 服务器处理请求并返回 HTTP 报文
+> 5. 浏览器解析渲染页面
+> 6. 连接结束
+>
+> 具体可以参考下面这篇文章:
+>
+> - [https://segmentfault.com/a/1190000006879700](https://segmentfault.com/a/1190000006879700 "https://segmentfault.com/a/1190000006879700")
+
+**面试官:** TCP 和 UDP 区别?
+
+**我:**
+
+> 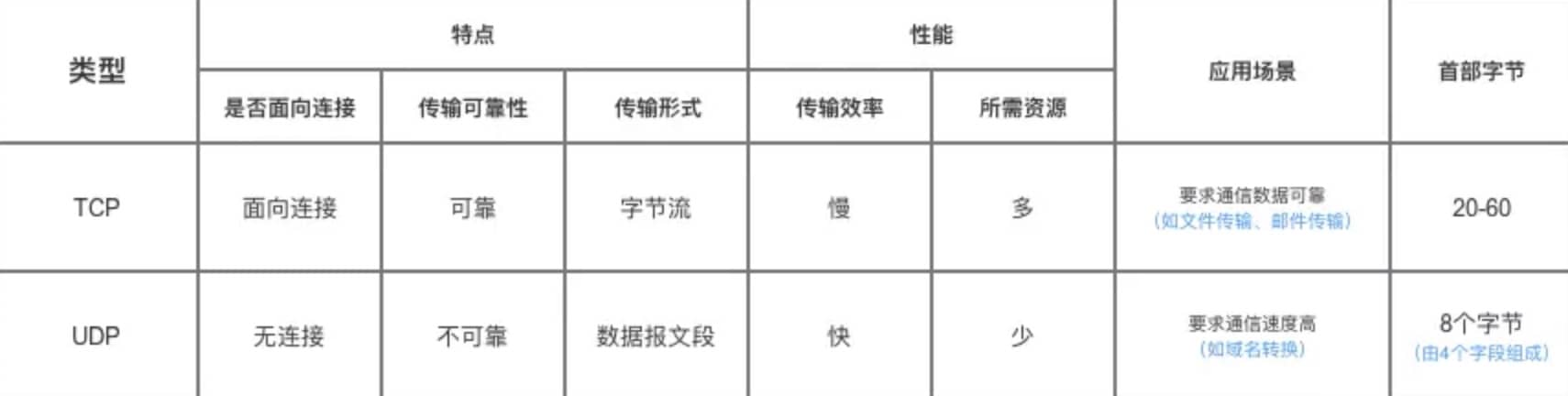
+>
+> UDP 在传送数据之前不需要先建立连接,远地主机在收到 UDP 报文后,不需要给出任何确认。虽然 UDP 不提供可靠交付,但在某些情况下 UDP 确是一种最有效的工作方式(一般用于即时通信),比如: QQ 语音、 QQ 视频 、直播等等
+>
+> TCP 提供面向连接的服务。在传送数据之前必须先建立连接,数据传送结束后要释放连接。 TCP 不提供广播或多播服务。由于 TCP 要提供可靠的,面向连接的传输服务(TCP 的可靠体现在 TCP 在传递数据之前,会有三次握手来建立连接,而且在数据传递时,有确认、窗口、重传、拥塞控制机制,在数据传完后,还会断开连接用来节约系统资源),这一难以避免增加了许多开销,如确认,流量控制,计时器以及连接管理等。这不仅使协议数据单元的首部增大很多,还要占用许多处理机资源。TCP 一般用于文件传输、发送和接收邮件、远程登录等场景。
+
+**面试官:** TCP 如何保证传输可靠性?
+
+**我:**
+
+> 1. 应用数据被分割成 TCP 认为最适合发送的数据块。
+> 2. TCP 给发送的每一个包进行编号,接收方对数据包进行排序,把有序数据传送给应用层。
+> 3. **校验和:** TCP 将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP 将丢弃这个报文段和不确认收到此报文段。
+> 4. TCP 的接收端会丢弃重复的数据。
+> 5. **流量控制:** TCP 连接的每一方都有固定大小的缓冲空间,TCP 的接收端只允许发送端发送接收端缓冲区能接纳的数据。当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。TCP 使用的流量控制协议是可变大小的滑动窗口协议。 (TCP 利用滑动窗口实现流量控制)
+> 6. **拥塞控制:** 当网络拥塞时,减少数据的发送。
+> 7. **ARQ 协议:** 也是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认。在收到确认后再发下一个分组。
+> 8. **超时重传:** 当 TCP 发出一个段后,它启动一个定时器,等待目的端确认收到这个报文段。如果不能及时收到一个确认,将重发这个报文段。
+
+**面试官:** 我再来问你一些 Java 基础的问题吧!小伙子。
+
+**我:** 好的。(内心 os:“你尽管来!”)
+
+**面试官:** 既然有了字节流,为什么还要有字符流?
+
+我:内心 os :“问题本质想问:**不管是文件读写还是网络发送接收,信息的最小存储单元都是字节,那为什么 I/O 流操作要分为字节流操作和字符流操作呢?**”
+
+> 字符流是由 Java 虚拟机将字节转换得到的,问题就出在这个过程还算是非常耗时,并且,如果我们不知道编码类型就很容易出现乱码问题。所以, I/O 流就干脆提供了一个直接操作字符的接口,方便我们平时对字符进行流操作。如果音频文件、图片等媒体文件用字节流比较好,如果涉及到字符的话使用字符流比较好。
+
+**面试官**:深拷贝 和 浅拷贝有啥区别呢?
+
+**我:**
+
+> 1. **浅拷贝**:对基本数据类型进行值传递,对引用数据类型进行引用传递般的拷贝,此为浅拷贝。
+> 2. **深拷贝**:对基本数据类型进行值传递,对引用数据类型,创建一个新的对象,并复制其内容,此为深拷贝。
+>
+> 
+
+**面试官:** 好的!面试结束。小伙子可以的!回家等通知吧!
+
+**我:** 好的好的!辛苦您了!
diff --git "a/\351\235\242\350\257\225\345\277\205\345\244\207/\346\211\213\346\212\212\346\211\213\346\225\231\344\275\240\347\224\250Markdown\345\206\231\344\270\200\344\273\275\351\253\230\350\264\250\351\207\217\347\232\204\347\256\200\345\216\206.md" "b/docs/essential-content-for-interview/\346\211\213\346\212\212\346\211\213\346\225\231\344\275\240\347\224\250Markdown\345\206\231\344\270\200\344\273\275\351\253\230\350\264\250\351\207\217\347\232\204\347\256\200\345\216\206.md"
similarity index 100%
rename from "\351\235\242\350\257\225\345\277\205\345\244\207/\346\211\213\346\212\212\346\211\213\346\225\231\344\275\240\347\224\250Markdown\345\206\231\344\270\200\344\273\275\351\253\230\350\264\250\351\207\217\347\232\204\347\256\200\345\216\206.md"
rename to "docs/essential-content-for-interview/\346\211\213\346\212\212\346\211\213\346\225\231\344\275\240\347\224\250Markdown\345\206\231\344\270\200\344\273\275\351\253\230\350\264\250\351\207\217\347\232\204\347\256\200\345\216\206.md"
diff --git "a/\351\235\242\350\257\225\345\277\205\345\244\207/\347\256\200\345\216\206\346\250\241\346\235\277.md" "b/docs/essential-content-for-interview/\347\256\200\345\216\206\346\250\241\346\235\277.md"
similarity index 100%
rename from "\351\235\242\350\257\225\345\277\205\345\244\207/\347\256\200\345\216\206\346\250\241\346\235\277.md"
rename to "docs/essential-content-for-interview/\347\256\200\345\216\206\346\250\241\346\235\277.md"
diff --git "a/\351\235\242\350\257\225\345\277\205\345\244\207/\351\235\242\350\257\225\345\277\205\345\244\207\344\271\213\344\271\220\350\247\202\351\224\201\344\270\216\346\202\262\350\247\202\351\224\201.md" "b/docs/essential-content-for-interview/\351\235\242\350\257\225\345\277\205\345\244\207\344\271\213\344\271\220\350\247\202\351\224\201\344\270\216\346\202\262\350\247\202\351\224\201.md"
similarity index 84%
rename from "\351\235\242\350\257\225\345\277\205\345\244\207/\351\235\242\350\257\225\345\277\205\345\244\207\344\271\213\344\271\220\350\247\202\351\224\201\344\270\216\346\202\262\350\247\202\351\224\201.md"
rename to "docs/essential-content-for-interview/\351\235\242\350\257\225\345\277\205\345\244\207\344\271\213\344\271\220\350\247\202\351\224\201\344\270\216\346\202\262\350\247\202\351\224\201.md"
index b6f40fbc31b..00aaecd8c5b 100644
--- "a/\351\235\242\350\257\225\345\277\205\345\244\207/\351\235\242\350\257\225\345\277\205\345\244\207\344\271\213\344\271\220\350\247\202\351\224\201\344\270\216\346\202\262\350\247\202\351\224\201.md"
+++ "b/docs/essential-content-for-interview/\351\235\242\350\257\225\345\277\205\345\244\207\344\271\213\344\271\220\350\247\202\351\224\201\344\270\216\346\202\262\350\247\202\351\224\201.md"
@@ -1,3 +1,22 @@
+点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
+
+
+
+- [何谓悲观锁与乐观锁](#何谓悲观锁与乐观锁)
+ - [悲观锁](#悲观锁)
+ - [乐观锁](#乐观锁)
+ - [两种锁的使用场景](#两种锁的使用场景)
+- [乐观锁常见的两种实现方式](#乐观锁常见的两种实现方式)
+ - [1. 版本号机制](#1-版本号机制)
+ - [2. CAS算法](#2-cas算法)
+- [乐观锁的缺点](#乐观锁的缺点)
+ - [1 ABA 问题](#1-aba-问题)
+ - [2 循环时间长开销大](#2-循环时间长开销大)
+ - [3 只能保证一个共享变量的原子操作](#3-只能保证一个共享变量的原子操作)
+- [CAS与synchronized的使用情景](#cas与synchronized的使用情景)
+
+
+
### 何谓悲观锁与乐观锁
> 乐观锁对应于生活中乐观的人总是想着事情往好的方向发展,悲观锁对应于生活中悲观的人总是想着事情往坏的方向发展。这两种人各有优缺点,不能不以场景而定说一种人好于另外一种人。
@@ -64,8 +83,6 @@ JDK 1.5 以后的 `AtomicStampedReference 类`就提供了此种能力,其中
CAS 只对单个共享变量有效,当操作涉及跨多个共享变量时 CAS 无效。但是从 JDK 1.5开始,提供了`AtomicReference类`来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行 CAS 操作.所以我们可以使用锁或者利用`AtomicReference类`把多个共享变量合并成一个共享变量来操作。
-
-
### CAS与synchronized的使用情景
> **简单的来说CAS适用于写比较少的情况下(多读场景,冲突一般较少),synchronized适用于写比较多的情况下(多写场景,冲突一般较多)**
@@ -73,10 +90,17 @@ CAS 只对单个共享变量有效,当操作涉及跨多个共享变量时 CAS
1. 对于资源竞争较少(线程冲突较轻)的情况,使用synchronized同步锁进行线程阻塞和唤醒切换以及用户态内核态间的切换操作额外浪费消耗cpu资源;而CAS基于硬件实现,不需要进入内核,不需要切换线程,操作自旋几率较少,因此可以获得更高的性能。
2. 对于资源竞争严重(线程冲突严重)的情况,CAS自旋的概率会比较大,从而浪费更多的CPU资源,效率低于synchronized。
-
补充: Java并发编程这个领域中synchronized关键字一直都是元老级的角色,很久之前很多人都会称它为 **“重量级锁”** 。但是,在JavaSE 1.6之后进行了主要包括为了减少获得锁和释放锁带来的性能消耗而引入的 **偏向锁** 和 **轻量级锁** 以及其它**各种优化**之后变得在某些情况下并不是那么重了。synchronized的底层实现主要依靠 **Lock-Free** 的队列,基本思路是 **自旋后阻塞**,**竞争切换后继续竞争锁**,**稍微牺牲了公平性,但获得了高吞吐量**。在线程冲突较少的情况下,可以获得和CAS类似的性能;而线程冲突严重的情况下,性能远高于CAS。
+## 公众号
+
+如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
+
+**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"面试突击"** 即可免费领取!
+
+**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
+
diff --git a/docs/github-trending/2018-12.md b/docs/github-trending/2018-12.md
new file mode 100644
index 00000000000..3637e93ea0c
--- /dev/null
+++ b/docs/github-trending/2018-12.md
@@ -0,0 +1,78 @@
+本文数据统计于 1.1 号凌晨,由 SnailClimb 整理。
+
+### 1. JavaGuide
+
+- **Github地址**: [https://github.com/Snailclimb/JavaGuide](https://github.com/Snailclimb/JavaGuide)
+- **star**: 18.2k
+- **介绍**: 【Java学习+面试指南】 一份涵盖大部分Java程序员所需要掌握的核心知识。
+
+### 2. mall
+
+- **Github地址**: [https://github.com/macrozheng/mall](https://github.com/macrozheng/mall)
+- **star**: 3.3k
+- **介绍**: mall项目是一套电商系统,包括前台商城系统及后台管理系统,基于SpringBoot+MyBatis实现。 前台商城系统包含首页门户、商品推荐、商品搜索、商品展示、购物车、订单流程、会员中心、客户服务、帮助中心等模块。 后台管理系统包含商品管理、订单管理、会员管理、促销管理、运营管理、内容管理、统计报表、财务管理、权限管理、设置等模块。
+
+### 3. advanced-java
+
+- **Github地址**:[https://github.com/doocs/advanced-java](https://github.com/doocs/advanced-java)
+- **star**: 3.3k
+- **介绍**: 互联网 Java 工程师进阶知识完全扫盲
+
+### 4. matrix
+
+- **Github地址**:[https://github.com/Tencent/matrix](https://github.com/Tencent/matrix)
+- **star**: 2.5k
+- **介绍**: Matrix 是一款微信研发并日常使用的 APM(Application Performance Manage),当前主要运行在 Android 平台上。 Matrix 的目标是建立统一的应用性能接入框架,通过各种性能监控方案,对性能监控项的异常数据进行采集和分析,输出相应的问题分析、定位与优化建议,从而帮助开发者开发出更高质量的应用。
+
+### 5. miaosha
+
+- **Github地址**:[https://github.com/qiurunze123/miaosha](https://github.com/qiurunze123/miaosha)
+- **star**: 2.4k
+- **介绍**: 高并发大流量如何进行秒杀架构,我对这部分知识做了一个系统的整理,写了一套系统。
+
+### 6. arthas
+
+- **Github地址**:[https://github.com/alibaba/arthas](https://github.com/alibaba/arthas)
+- **star**: 8.2k
+- **介绍**: Arthas 是Alibaba开源的Java诊断工具,深受开发者喜爱。
+
+### 7 spring-boot
+
+- **Github地址**: [https://github.com/spring-projects/spring-boot](https://github.com/spring-projects/spring-boot)
+- **star:** 32.6k
+- **介绍**: 虽然Spring的组件代码是轻量级的,但它的配置却是重量级的(需要大量XML配置),不过Spring Boot 让这一切成为了过去。 另外Spring Cloud也是基于Spring Boot构建的,我个人非常有必要学习一下。
+
+ **关于Spring Boot官方的介绍:**
+
+ > Spring Boot makes it easy to create stand-alone, production-grade Spring based Applications that you can “just run”…Most Spring Boot applications need very little Spring configuration.(Spring Boot可以轻松创建独立的生产级基于Spring的应用程序,只要通过 “just run”(可能是run ‘Application’或java -jar 或 tomcat 或 maven插件run 或 shell脚本)便可以运行项目。大部分Spring Boot项目只需要少量的配置即可)
+
+### 8. tutorials
+
+- **Github地址**:[https://github.com/eugenp/tutorials](https://github.com/eugenp/tutorials)
+- **star**: 10k
+- **介绍**: 该项目是一系列小而专注的教程 - 每个教程都涵盖Java生态系统中单一且定义明确的开发领域。 当然,它们的重点是Spring Framework - Spring,Spring Boot和Spring Securiyt。 除了Spring之外,还有以下技术:核心Java,Jackson,HttpClient,Guava。
+
+### 9. qmq
+
+- **Github地址**:[https://github.com/qunarcorp/qmq](https://github.com/qunarcorp/qmq)
+- **star**: 1.1k
+- **介绍**: QMQ是去哪儿网内部广泛使用的消息中间件,自2012年诞生以来在去哪儿网所有业务场景中广泛的应用,包括跟交易息息相关的订单场景; 也包括报价搜索等高吞吐量场景。
+
+
+### 10. symphony
+
+- **Github地址**:[https://github.com/b3log/symphony](https://github.com/b3log/symphony)
+- **star**: 9k
+- **介绍**: 一款用 Java 实现的现代化社区(论坛/BBS/社交网络/博客)平台。
+
+### 11. incubator-dubbo
+
+- **Github地址**:[https://github.com/apache/incubator-dubbo](https://github.com/apache/incubator-dubbo)
+- **star**: 23.6k
+- **介绍**: 阿里开源的一个基于Java的高性能开源RPC框架。
+
+### 12. apollo
+
+- **Github地址**:[https://github.com/ctripcorp/apollo](https://github.com/ctripcorp/apollo)
+- **star**: 10k
+- **介绍**: Apollo(阿波罗)是携程框架部门研发的分布式配置中心,能够集中化管理应用不同环境、不同集群的配置,配置修改后能够实时推送到应用端,并且具备规范的权限、流程治理等特性,适用于微服务配置管理场景。
diff --git a/docs/github-trending/2019-1.md b/docs/github-trending/2019-1.md
new file mode 100644
index 00000000000..aa1de92f623
--- /dev/null
+++ b/docs/github-trending/2019-1.md
@@ -0,0 +1,76 @@
+### 1. JavaGuide
+
+- **Github地址**: [https://github.com/Snailclimb/JavaGuide](https://github.com/Snailclimb/JavaGuide)
+- **star**: 22.8k
+- **介绍**: 【Java学习+面试指南】 一份涵盖大部分Java程序员所需要掌握的核心知识。
+
+### 2. advanced-java
+
+- **Github地址**:[https://github.com/doocs/advanced-java](https://github.com/doocs/advanced-java)
+- **star**: 7.9k
+- **介绍**: 互联网 Java 工程师进阶知识完全扫盲
+
+### 3. fescar
+
+- **Github地址**:[https://github.com/alibaba/fescar](https://github.com/alibaba/fescar)
+- **star**: 4.6k
+- **介绍**: 具有 **高性能** 和 **易用性** 的 **微服务架构** 的 **分布式事务** 的解决方案。(特点:高性能且易于使用,旨在实现简单并快速的事务提交与回滚。
+
+### 4. mall
+
+- **Github地址**: [https://github.com/macrozheng/mall](https://github.com/macrozheng/mall)
+- **star**: 5.6 k
+- **介绍**: mall项目是一套电商系统,包括前台商城系统及后台管理系统,基于SpringBoot+MyBatis实现。 前台商城系统包含首页门户、商品推荐、商品搜索、商品展示、购物车、订单流程、会员中心、客户服务、帮助中心等模块。 后台管理系统包含商品管理、订单管理、会员管理、促销管理、运营管理、内容管理、统计报表、财务管理、权限管理、设置等模块。
+
+### 5. miaosha
+
+- **Github地址**:[https://github.com/qiurunze123/miaosha](https://github.com/qiurunze123/miaosha)
+- **star**: 4.4k
+- **介绍**: 高并发大流量如何进行秒杀架构,我对这部分知识做了一个系统的整理,写了一套系统。
+
+### 6. flink
+
+- **Github地址**:[https://github.com/apache/flink](https://github.com/apache/flink)
+- **star**: 7.1 k
+- **介绍**: Apache Flink是一个开源流处理框架,具有强大的流和批处理功能。
+
+### 7. cim
+
+- **Github地址**:[https://github.com/crossoverJie/cim](https://github.com/crossoverJie/cim)
+- **star**: 1.8 k
+- **介绍**: cim(cross IM) 适用于开发者的即时通讯系统。
+
+### 8. symphony
+
+- **Github地址**:[https://github.com/b3log/symphony](https://github.com/b3log/symphony)
+- **star**: 10k
+- **介绍**: 一款用 Java 实现的现代化社区(论坛/BBS/社交网络/博客)平台。
+
+### 9. spring-boot
+
+- **Github地址**: [https://github.com/spring-projects/spring-boot](https://github.com/spring-projects/spring-boot)
+- **star:** 32.6k
+- **介绍**: 虽然Spring的组件代码是轻量级的,但它的配置却是重量级的(需要大量XML配置),不过Spring Boot 让这一切成为了过去。 另外Spring Cloud也是基于Spring Boot构建的,我个人非常有必要学习一下。
+
+ **关于Spring Boot官方的介绍:**
+
+ > Spring Boot makes it easy to create stand-alone, production-grade Spring based Applications that you can “just run”…Most Spring Boot applications need very little Spring configuration.(Spring Boot可以轻松创建独立的生产级基于Spring的应用程序,只要通过 “just run”(可能是run ‘Application’或java -jar 或 tomcat 或 maven插件run 或 shell脚本)便可以运行项目。大部分Spring Boot项目只需要少量的配置即可)
+
+### 10. arthas
+
+- **Github地址**:[https://github.com/alibaba/arthas](https://github.com/alibaba/arthas)
+- **star**: 9.5k
+- **介绍**: Arthas 是Alibaba开源的Java诊断工具。
+
+**概览:**
+
+当你遇到以下类似问题而束手无策时,`Arthas`可以帮助你解决:
+
+0. 这个类从哪个 jar 包加载的?为什么会报各种类相关的 Exception?
+1. 我改的代码为什么没有执行到?难道是我没 commit?分支搞错了?
+2. 遇到问题无法在线上 debug,难道只能通过加日志再重新发布吗?
+3. 线上遇到某个用户的数据处理有问题,但线上同样无法 debug,线下无法重现!
+4. 是否有一个全局视角来查看系统的运行状况?
+5. 有什么办法可以监控到JVM的实时运行状态?
+
+`Arthas`支持JDK 6+,支持Linux/Mac/Winodws,采用命令行交互模式,同时提供丰富的 `Tab` 自动补全功能,进一步方便进行问题的定位和诊断。
diff --git a/docs/github-trending/2019-12.md b/docs/github-trending/2019-12.md
new file mode 100644
index 00000000000..9a8f79ed6e8
--- /dev/null
+++ b/docs/github-trending/2019-12.md
@@ -0,0 +1,144 @@
+# 年末将至,值得你关注的16个Java 开源项目!
+
+Star 的数量统计于 2019-12-29。
+
+### 1.JavaGuide
+
+Guide 哥大三开始维护的,目前算是纯 Java 类型项目中 Star 数量最多的项目了。但是,本仓库的价值远远(+N次 )比不上像 Spring Boot、Elasticsearch 等等这样非常非常非常优秀的项目。希望以后我也有能力为这些项目贡献一些有价值的代码。
+
+- **Github 地址**:
+>
+> 总体来说分为以下几个过程:
+>
+> 1. DNS 解析
+> 2. TCP 连接
+> 3. 发送 HTTP 请求
+> 4. 服务器处理请求并返回 HTTP 报文
+> 5. 浏览器解析渲染页面
+> 6. 连接结束
+>
+> 具体可以参考下面这篇文章:
+>
+> - [https://segmentfault.com/a/1190000006879700](https://segmentfault.com/a/1190000006879700 "https://segmentfault.com/a/1190000006879700")
+
+**面试官:** TCP 和 UDP 区别?
+
+**我:**
+
+> 
+>
+> UDP 在传送数据之前不需要先建立连接,远地主机在收到 UDP 报文后,不需要给出任何确认。虽然 UDP 不提供可靠交付,但在某些情况下 UDP 确是一种最有效的工作方式(一般用于即时通信),比如: QQ 语音、 QQ 视频 、直播等等
+>
+> TCP 提供面向连接的服务。在传送数据之前必须先建立连接,数据传送结束后要释放连接。 TCP 不提供广播或多播服务。由于 TCP 要提供可靠的,面向连接的传输服务(TCP 的可靠体现在 TCP 在传递数据之前,会有三次握手来建立连接,而且在数据传递时,有确认、窗口、重传、拥塞控制机制,在数据传完后,还会断开连接用来节约系统资源),这一难以避免增加了许多开销,如确认,流量控制,计时器以及连接管理等。这不仅使协议数据单元的首部增大很多,还要占用许多处理机资源。TCP 一般用于文件传输、发送和接收邮件、远程登录等场景。
+
+**面试官:** TCP 如何保证传输可靠性?
+
+**我:**
+
+> 1. 应用数据被分割成 TCP 认为最适合发送的数据块。
+> 2. TCP 给发送的每一个包进行编号,接收方对数据包进行排序,把有序数据传送给应用层。
+> 3. **校验和:** TCP 将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP 将丢弃这个报文段和不确认收到此报文段。
+> 4. TCP 的接收端会丢弃重复的数据。
+> 5. **流量控制:** TCP 连接的每一方都有固定大小的缓冲空间,TCP 的接收端只允许发送端发送接收端缓冲区能接纳的数据。当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。TCP 使用的流量控制协议是可变大小的滑动窗口协议。 (TCP 利用滑动窗口实现流量控制)
+> 6. **拥塞控制:** 当网络拥塞时,减少数据的发送。
+> 7. **ARQ 协议:** 也是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认。在收到确认后再发下一个分组。
+> 8. **超时重传:** 当 TCP 发出一个段后,它启动一个定时器,等待目的端确认收到这个报文段。如果不能及时收到一个确认,将重发这个报文段。
+
+**面试官:** 我再来问你一些 Java 基础的问题吧!小伙子。
+
+**我:** 好的。(内心 os:“你尽管来!”)
+
+**面试官:** 既然有了字节流,为什么还要有字符流?
+
+我:内心 os :“问题本质想问:**不管是文件读写还是网络发送接收,信息的最小存储单元都是字节,那为什么 I/O 流操作要分为字节流操作和字符流操作呢?**”
+
+> 字符流是由 Java 虚拟机将字节转换得到的,问题就出在这个过程还算是非常耗时,并且,如果我们不知道编码类型就很容易出现乱码问题。所以, I/O 流就干脆提供了一个直接操作字符的接口,方便我们平时对字符进行流操作。如果音频文件、图片等媒体文件用字节流比较好,如果涉及到字符的话使用字符流比较好。
+
+**面试官**:深拷贝 和 浅拷贝有啥区别呢?
+
+**我:**
+
+> 1. **浅拷贝**:对基本数据类型进行值传递,对引用数据类型进行引用传递般的拷贝,此为浅拷贝。
+> 2. **深拷贝**:对基本数据类型进行值传递,对引用数据类型,创建一个新的对象,并复制其内容,此为深拷贝。
+>
+> 
+
+**面试官:** 好的!面试结束。小伙子可以的!回家等通知吧!
+
+**我:** 好的好的!辛苦您了!
diff --git "a/\351\235\242\350\257\225\345\277\205\345\244\207/\346\211\213\346\212\212\346\211\213\346\225\231\344\275\240\347\224\250Markdown\345\206\231\344\270\200\344\273\275\351\253\230\350\264\250\351\207\217\347\232\204\347\256\200\345\216\206.md" "b/docs/essential-content-for-interview/\346\211\213\346\212\212\346\211\213\346\225\231\344\275\240\347\224\250Markdown\345\206\231\344\270\200\344\273\275\351\253\230\350\264\250\351\207\217\347\232\204\347\256\200\345\216\206.md"
similarity index 100%
rename from "\351\235\242\350\257\225\345\277\205\345\244\207/\346\211\213\346\212\212\346\211\213\346\225\231\344\275\240\347\224\250Markdown\345\206\231\344\270\200\344\273\275\351\253\230\350\264\250\351\207\217\347\232\204\347\256\200\345\216\206.md"
rename to "docs/essential-content-for-interview/\346\211\213\346\212\212\346\211\213\346\225\231\344\275\240\347\224\250Markdown\345\206\231\344\270\200\344\273\275\351\253\230\350\264\250\351\207\217\347\232\204\347\256\200\345\216\206.md"
diff --git "a/\351\235\242\350\257\225\345\277\205\345\244\207/\347\256\200\345\216\206\346\250\241\346\235\277.md" "b/docs/essential-content-for-interview/\347\256\200\345\216\206\346\250\241\346\235\277.md"
similarity index 100%
rename from "\351\235\242\350\257\225\345\277\205\345\244\207/\347\256\200\345\216\206\346\250\241\346\235\277.md"
rename to "docs/essential-content-for-interview/\347\256\200\345\216\206\346\250\241\346\235\277.md"
diff --git "a/\351\235\242\350\257\225\345\277\205\345\244\207/\351\235\242\350\257\225\345\277\205\345\244\207\344\271\213\344\271\220\350\247\202\351\224\201\344\270\216\346\202\262\350\247\202\351\224\201.md" "b/docs/essential-content-for-interview/\351\235\242\350\257\225\345\277\205\345\244\207\344\271\213\344\271\220\350\247\202\351\224\201\344\270\216\346\202\262\350\247\202\351\224\201.md"
similarity index 84%
rename from "\351\235\242\350\257\225\345\277\205\345\244\207/\351\235\242\350\257\225\345\277\205\345\244\207\344\271\213\344\271\220\350\247\202\351\224\201\344\270\216\346\202\262\350\247\202\351\224\201.md"
rename to "docs/essential-content-for-interview/\351\235\242\350\257\225\345\277\205\345\244\207\344\271\213\344\271\220\350\247\202\351\224\201\344\270\216\346\202\262\350\247\202\351\224\201.md"
index b6f40fbc31b..00aaecd8c5b 100644
--- "a/\351\235\242\350\257\225\345\277\205\345\244\207/\351\235\242\350\257\225\345\277\205\345\244\207\344\271\213\344\271\220\350\247\202\351\224\201\344\270\216\346\202\262\350\247\202\351\224\201.md"
+++ "b/docs/essential-content-for-interview/\351\235\242\350\257\225\345\277\205\345\244\207\344\271\213\344\271\220\350\247\202\351\224\201\344\270\216\346\202\262\350\247\202\351\224\201.md"
@@ -1,3 +1,22 @@
+点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
+
+
+
+- [何谓悲观锁与乐观锁](#何谓悲观锁与乐观锁)
+ - [悲观锁](#悲观锁)
+ - [乐观锁](#乐观锁)
+ - [两种锁的使用场景](#两种锁的使用场景)
+- [乐观锁常见的两种实现方式](#乐观锁常见的两种实现方式)
+ - [1. 版本号机制](#1-版本号机制)
+ - [2. CAS算法](#2-cas算法)
+- [乐观锁的缺点](#乐观锁的缺点)
+ - [1 ABA 问题](#1-aba-问题)
+ - [2 循环时间长开销大](#2-循环时间长开销大)
+ - [3 只能保证一个共享变量的原子操作](#3-只能保证一个共享变量的原子操作)
+- [CAS与synchronized的使用情景](#cas与synchronized的使用情景)
+
+
+
### 何谓悲观锁与乐观锁
> 乐观锁对应于生活中乐观的人总是想着事情往好的方向发展,悲观锁对应于生活中悲观的人总是想着事情往坏的方向发展。这两种人各有优缺点,不能不以场景而定说一种人好于另外一种人。
@@ -64,8 +83,6 @@ JDK 1.5 以后的 `AtomicStampedReference 类`就提供了此种能力,其中
CAS 只对单个共享变量有效,当操作涉及跨多个共享变量时 CAS 无效。但是从 JDK 1.5开始,提供了`AtomicReference类`来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行 CAS 操作.所以我们可以使用锁或者利用`AtomicReference类`把多个共享变量合并成一个共享变量来操作。
-
-
### CAS与synchronized的使用情景
> **简单的来说CAS适用于写比较少的情况下(多读场景,冲突一般较少),synchronized适用于写比较多的情况下(多写场景,冲突一般较多)**
@@ -73,10 +90,17 @@ CAS 只对单个共享变量有效,当操作涉及跨多个共享变量时 CAS
1. 对于资源竞争较少(线程冲突较轻)的情况,使用synchronized同步锁进行线程阻塞和唤醒切换以及用户态内核态间的切换操作额外浪费消耗cpu资源;而CAS基于硬件实现,不需要进入内核,不需要切换线程,操作自旋几率较少,因此可以获得更高的性能。
2. 对于资源竞争严重(线程冲突严重)的情况,CAS自旋的概率会比较大,从而浪费更多的CPU资源,效率低于synchronized。
-
补充: Java并发编程这个领域中synchronized关键字一直都是元老级的角色,很久之前很多人都会称它为 **“重量级锁”** 。但是,在JavaSE 1.6之后进行了主要包括为了减少获得锁和释放锁带来的性能消耗而引入的 **偏向锁** 和 **轻量级锁** 以及其它**各种优化**之后变得在某些情况下并不是那么重了。synchronized的底层实现主要依靠 **Lock-Free** 的队列,基本思路是 **自旋后阻塞**,**竞争切换后继续竞争锁**,**稍微牺牲了公平性,但获得了高吞吐量**。在线程冲突较少的情况下,可以获得和CAS类似的性能;而线程冲突严重的情况下,性能远高于CAS。
+## 公众号
+
+如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
+
+**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"面试突击"** 即可免费领取!
+
+**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
+
diff --git a/docs/github-trending/2018-12.md b/docs/github-trending/2018-12.md
new file mode 100644
index 00000000000..3637e93ea0c
--- /dev/null
+++ b/docs/github-trending/2018-12.md
@@ -0,0 +1,78 @@
+本文数据统计于 1.1 号凌晨,由 SnailClimb 整理。
+
+### 1. JavaGuide
+
+- **Github地址**: [https://github.com/Snailclimb/JavaGuide](https://github.com/Snailclimb/JavaGuide)
+- **star**: 18.2k
+- **介绍**: 【Java学习+面试指南】 一份涵盖大部分Java程序员所需要掌握的核心知识。
+
+### 2. mall
+
+- **Github地址**: [https://github.com/macrozheng/mall](https://github.com/macrozheng/mall)
+- **star**: 3.3k
+- **介绍**: mall项目是一套电商系统,包括前台商城系统及后台管理系统,基于SpringBoot+MyBatis实现。 前台商城系统包含首页门户、商品推荐、商品搜索、商品展示、购物车、订单流程、会员中心、客户服务、帮助中心等模块。 后台管理系统包含商品管理、订单管理、会员管理、促销管理、运营管理、内容管理、统计报表、财务管理、权限管理、设置等模块。
+
+### 3. advanced-java
+
+- **Github地址**:[https://github.com/doocs/advanced-java](https://github.com/doocs/advanced-java)
+- **star**: 3.3k
+- **介绍**: 互联网 Java 工程师进阶知识完全扫盲
+
+### 4. matrix
+
+- **Github地址**:[https://github.com/Tencent/matrix](https://github.com/Tencent/matrix)
+- **star**: 2.5k
+- **介绍**: Matrix 是一款微信研发并日常使用的 APM(Application Performance Manage),当前主要运行在 Android 平台上。 Matrix 的目标是建立统一的应用性能接入框架,通过各种性能监控方案,对性能监控项的异常数据进行采集和分析,输出相应的问题分析、定位与优化建议,从而帮助开发者开发出更高质量的应用。
+
+### 5. miaosha
+
+- **Github地址**:[https://github.com/qiurunze123/miaosha](https://github.com/qiurunze123/miaosha)
+- **star**: 2.4k
+- **介绍**: 高并发大流量如何进行秒杀架构,我对这部分知识做了一个系统的整理,写了一套系统。
+
+### 6. arthas
+
+- **Github地址**:[https://github.com/alibaba/arthas](https://github.com/alibaba/arthas)
+- **star**: 8.2k
+- **介绍**: Arthas 是Alibaba开源的Java诊断工具,深受开发者喜爱。
+
+### 7 spring-boot
+
+- **Github地址**: [https://github.com/spring-projects/spring-boot](https://github.com/spring-projects/spring-boot)
+- **star:** 32.6k
+- **介绍**: 虽然Spring的组件代码是轻量级的,但它的配置却是重量级的(需要大量XML配置),不过Spring Boot 让这一切成为了过去。 另外Spring Cloud也是基于Spring Boot构建的,我个人非常有必要学习一下。
+
+ **关于Spring Boot官方的介绍:**
+
+ > Spring Boot makes it easy to create stand-alone, production-grade Spring based Applications that you can “just run”…Most Spring Boot applications need very little Spring configuration.(Spring Boot可以轻松创建独立的生产级基于Spring的应用程序,只要通过 “just run”(可能是run ‘Application’或java -jar 或 tomcat 或 maven插件run 或 shell脚本)便可以运行项目。大部分Spring Boot项目只需要少量的配置即可)
+
+### 8. tutorials
+
+- **Github地址**:[https://github.com/eugenp/tutorials](https://github.com/eugenp/tutorials)
+- **star**: 10k
+- **介绍**: 该项目是一系列小而专注的教程 - 每个教程都涵盖Java生态系统中单一且定义明确的开发领域。 当然,它们的重点是Spring Framework - Spring,Spring Boot和Spring Securiyt。 除了Spring之外,还有以下技术:核心Java,Jackson,HttpClient,Guava。
+
+### 9. qmq
+
+- **Github地址**:[https://github.com/qunarcorp/qmq](https://github.com/qunarcorp/qmq)
+- **star**: 1.1k
+- **介绍**: QMQ是去哪儿网内部广泛使用的消息中间件,自2012年诞生以来在去哪儿网所有业务场景中广泛的应用,包括跟交易息息相关的订单场景; 也包括报价搜索等高吞吐量场景。
+
+
+### 10. symphony
+
+- **Github地址**:[https://github.com/b3log/symphony](https://github.com/b3log/symphony)
+- **star**: 9k
+- **介绍**: 一款用 Java 实现的现代化社区(论坛/BBS/社交网络/博客)平台。
+
+### 11. incubator-dubbo
+
+- **Github地址**:[https://github.com/apache/incubator-dubbo](https://github.com/apache/incubator-dubbo)
+- **star**: 23.6k
+- **介绍**: 阿里开源的一个基于Java的高性能开源RPC框架。
+
+### 12. apollo
+
+- **Github地址**:[https://github.com/ctripcorp/apollo](https://github.com/ctripcorp/apollo)
+- **star**: 10k
+- **介绍**: Apollo(阿波罗)是携程框架部门研发的分布式配置中心,能够集中化管理应用不同环境、不同集群的配置,配置修改后能够实时推送到应用端,并且具备规范的权限、流程治理等特性,适用于微服务配置管理场景。
diff --git a/docs/github-trending/2019-1.md b/docs/github-trending/2019-1.md
new file mode 100644
index 00000000000..aa1de92f623
--- /dev/null
+++ b/docs/github-trending/2019-1.md
@@ -0,0 +1,76 @@
+### 1. JavaGuide
+
+- **Github地址**: [https://github.com/Snailclimb/JavaGuide](https://github.com/Snailclimb/JavaGuide)
+- **star**: 22.8k
+- **介绍**: 【Java学习+面试指南】 一份涵盖大部分Java程序员所需要掌握的核心知识。
+
+### 2. advanced-java
+
+- **Github地址**:[https://github.com/doocs/advanced-java](https://github.com/doocs/advanced-java)
+- **star**: 7.9k
+- **介绍**: 互联网 Java 工程师进阶知识完全扫盲
+
+### 3. fescar
+
+- **Github地址**:[https://github.com/alibaba/fescar](https://github.com/alibaba/fescar)
+- **star**: 4.6k
+- **介绍**: 具有 **高性能** 和 **易用性** 的 **微服务架构** 的 **分布式事务** 的解决方案。(特点:高性能且易于使用,旨在实现简单并快速的事务提交与回滚。
+
+### 4. mall
+
+- **Github地址**: [https://github.com/macrozheng/mall](https://github.com/macrozheng/mall)
+- **star**: 5.6 k
+- **介绍**: mall项目是一套电商系统,包括前台商城系统及后台管理系统,基于SpringBoot+MyBatis实现。 前台商城系统包含首页门户、商品推荐、商品搜索、商品展示、购物车、订单流程、会员中心、客户服务、帮助中心等模块。 后台管理系统包含商品管理、订单管理、会员管理、促销管理、运营管理、内容管理、统计报表、财务管理、权限管理、设置等模块。
+
+### 5. miaosha
+
+- **Github地址**:[https://github.com/qiurunze123/miaosha](https://github.com/qiurunze123/miaosha)
+- **star**: 4.4k
+- **介绍**: 高并发大流量如何进行秒杀架构,我对这部分知识做了一个系统的整理,写了一套系统。
+
+### 6. flink
+
+- **Github地址**:[https://github.com/apache/flink](https://github.com/apache/flink)
+- **star**: 7.1 k
+- **介绍**: Apache Flink是一个开源流处理框架,具有强大的流和批处理功能。
+
+### 7. cim
+
+- **Github地址**:[https://github.com/crossoverJie/cim](https://github.com/crossoverJie/cim)
+- **star**: 1.8 k
+- **介绍**: cim(cross IM) 适用于开发者的即时通讯系统。
+
+### 8. symphony
+
+- **Github地址**:[https://github.com/b3log/symphony](https://github.com/b3log/symphony)
+- **star**: 10k
+- **介绍**: 一款用 Java 实现的现代化社区(论坛/BBS/社交网络/博客)平台。
+
+### 9. spring-boot
+
+- **Github地址**: [https://github.com/spring-projects/spring-boot](https://github.com/spring-projects/spring-boot)
+- **star:** 32.6k
+- **介绍**: 虽然Spring的组件代码是轻量级的,但它的配置却是重量级的(需要大量XML配置),不过Spring Boot 让这一切成为了过去。 另外Spring Cloud也是基于Spring Boot构建的,我个人非常有必要学习一下。
+
+ **关于Spring Boot官方的介绍:**
+
+ > Spring Boot makes it easy to create stand-alone, production-grade Spring based Applications that you can “just run”…Most Spring Boot applications need very little Spring configuration.(Spring Boot可以轻松创建独立的生产级基于Spring的应用程序,只要通过 “just run”(可能是run ‘Application’或java -jar 或 tomcat 或 maven插件run 或 shell脚本)便可以运行项目。大部分Spring Boot项目只需要少量的配置即可)
+
+### 10. arthas
+
+- **Github地址**:[https://github.com/alibaba/arthas](https://github.com/alibaba/arthas)
+- **star**: 9.5k
+- **介绍**: Arthas 是Alibaba开源的Java诊断工具。
+
+**概览:**
+
+当你遇到以下类似问题而束手无策时,`Arthas`可以帮助你解决:
+
+0. 这个类从哪个 jar 包加载的?为什么会报各种类相关的 Exception?
+1. 我改的代码为什么没有执行到?难道是我没 commit?分支搞错了?
+2. 遇到问题无法在线上 debug,难道只能通过加日志再重新发布吗?
+3. 线上遇到某个用户的数据处理有问题,但线上同样无法 debug,线下无法重现!
+4. 是否有一个全局视角来查看系统的运行状况?
+5. 有什么办法可以监控到JVM的实时运行状态?
+
+`Arthas`支持JDK 6+,支持Linux/Mac/Winodws,采用命令行交互模式,同时提供丰富的 `Tab` 自动补全功能,进一步方便进行问题的定位和诊断。
diff --git a/docs/github-trending/2019-12.md b/docs/github-trending/2019-12.md
new file mode 100644
index 00000000000..9a8f79ed6e8
--- /dev/null
+++ b/docs/github-trending/2019-12.md
@@ -0,0 +1,144 @@
+# 年末将至,值得你关注的16个Java 开源项目!
+
+Star 的数量统计于 2019-12-29。
+
+### 1.JavaGuide
+
+Guide 哥大三开始维护的,目前算是纯 Java 类型项目中 Star 数量最多的项目了。但是,本仓库的价值远远(+N次 )比不上像 Spring Boot、Elasticsearch 等等这样非常非常非常优秀的项目。希望以后我也有能力为这些项目贡献一些有价值的代码。
+
+- **Github 地址**: