/
dawid_skene.py
190 lines (147 loc) · 7.09 KB
/
dawid_skene.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
__all__ = ['DawidSkene']
from typing import List
import attr
import numpy as np
import pandas as pd
from .. import annotations
from ..annotations import manage_docstring, Annotation
from ..base import BaseClassificationAggregator
from .majority_vote import MajorityVote
from ..utils import get_most_probable_labels, named_series_attrib
_EPS = np.float_power(10, -10)
@attr.s
@manage_docstring
class DawidSkene(BaseClassificationAggregator):
r"""
Dawid-Skene aggregation model.
Probabilistic model that parametrizes workers' level of expertise through confusion matrices.
Let $e^w$ be a worker's confusion (error) matrix of size $K \times K$ in case of $K$ class classification,
$p$ be a vector of prior classes probabilities, $z_j$ be a true task's label, and $y^w_j$ be a worker's
answer for the task $j$. The relationships between these parameters are represented by the following latent
label model.
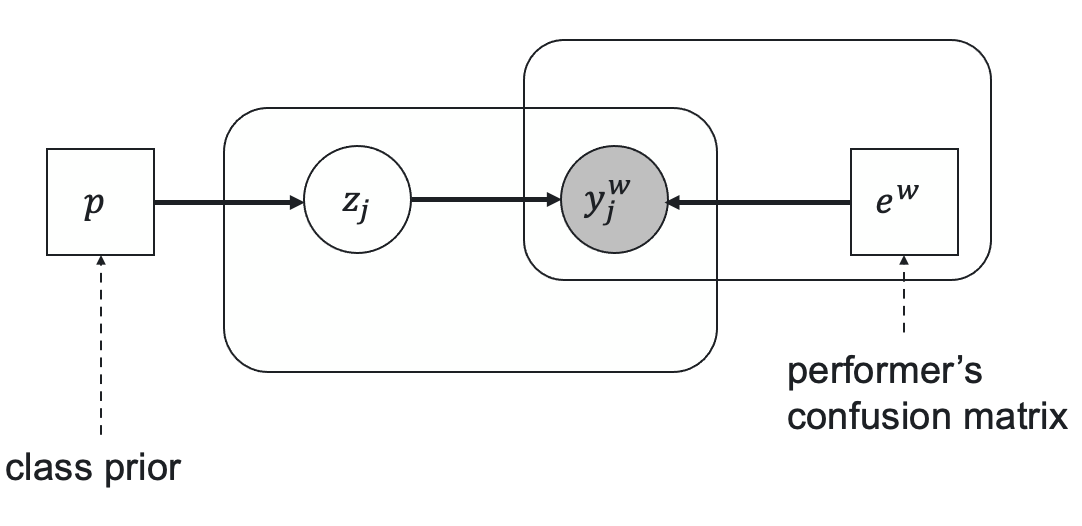
Here the prior true label probability is
$$
\operatorname{Pr}(z_j = c) = p[c],
$$
and the distribution on the worker's responses given the true label $c$ is represented by the
corresponding column of the error matrix:
$$
\operatorname{Pr}(y_j^w = k | z_j = c) = e^w[k, c].
$$
Parameters $p$ and $e^w$ and latent variables $z$ are optimized through the Expectation-Maximization algorithm.
A. Philip Dawid and Allan M. Skene. Maximum Likelihood Estimation of Observer Error-Rates Using the EM Algorithm.
*Journal of the Royal Statistical Society. Series C (Applied Statistics), Vol. 28*, 1 (1979), 20–28.
https://doi.org/10.2307/2346806
Args:
n_iter: The number of EM iterations.
Examples:
>>> from crowdkit.aggregation import DawidSkene
>>> from crowdkit.datasets import load_dataset
>>> df, gt = load_dataset('relevance-2')
>>> ds = DawidSkene(100)
>>> result = ds.fit_predict(df)
"""
n_iter: int = attr.ib(default=100)
tol: float = attr.ib(default=1e-5)
probas_: annotations.OPTIONAL_PROBAS = attr.ib(init=False)
priors_: annotations.OPTIONAL_PRIORS = named_series_attrib(name='prior')
# labels_
errors_: annotations.OPTIONAL_ERRORS = attr.ib(init=False)
loss_history_: List[float] = attr.ib(init=False)
@staticmethod
@manage_docstring
def _m_step(data: annotations.LABELED_DATA, probas: annotations.TASKS_LABEL_PROBAS) -> annotations.ERRORS:
"""Perform M-step of Dawid-Skene algorithm.
Given workers' answers and tasks' true labels probabilities estimates
worker's errors probabilities matrix.
"""
joined = data.join(probas, on='task')
joined.drop(columns=['task'], inplace=True)
errors = joined.groupby(['worker', 'label'], sort=False).sum()
errors.clip(lower=_EPS, inplace=True)
errors /= errors.groupby('worker', sort=False).sum()
return errors
@staticmethod
@manage_docstring
def _e_step(data: annotations.LABELED_DATA, priors: annotations.LABEL_PRIORS, errors: annotations.ERRORS) -> annotations.TASKS_LABEL_PROBAS:
"""
Perform E-step of Dawid-Skene algorithm.
Given worker's answers, labels' prior probabilities and worker's worker's
errors probabilities matrix estimates tasks' true labels probabilities.
"""
# We have to multiply lots of probabilities and such products are known to converge
# to zero exponentially fast. To avoid floating-point precision problems we work with
# logs of original values
joined = data.join(np.log2(errors), on=['worker', 'label'])
joined.drop(columns=['worker', 'label'], inplace=True)
log_likelihoods = np.log2(priors) + joined.groupby('task', sort=False).sum()
# Exponentiating log_likelihoods 'as is' may still get us beyond our precision.
# So we shift every row of log_likelihoods by a constant (which is equivalent to
# multiplying likelihoods rows by a constant) so that max log_likelihood in each
# row is equal to 0. This trick ensures proper scaling after exponentiating and
# does not affect the result of E-step
scaled_likelihoods = np.exp2(log_likelihoods.sub(log_likelihoods.max(axis=1), axis=0))
return scaled_likelihoods.div(scaled_likelihoods.sum(axis=1), axis=0)
def _evidence_lower_bound(
self,
data: annotations.LABELED_DATA, probas: annotations.TASKS_LABEL_PROBAS,
priors: annotations.LABEL_PRIORS, errors: annotations.ERRORS
):
# calculate joint probability log-likelihood expectation over probas
joined = data.join(np.log(errors), on=['worker', 'label'])
# escape boolean index/column names to prevent confusion between indexing by boolean array and iterable of names
joined = joined.rename(columns={True: 'True', False: 'False'}, copy=False)
priors = priors.rename(index={True: 'True', False: 'False'}, copy=False)
joined.loc[:, priors.index] = joined.loc[:, priors.index].add(np.log(priors))
joined.set_index(['task', 'worker'], inplace=True)
joint_expectation = (probas * joined).sum().sum()
entropy = -(np.log(probas) * probas).sum().sum()
return joint_expectation + entropy
@manage_docstring
def fit(self, data: annotations.LABELED_DATA) -> Annotation(type='DawidSkene', title='self'):
"""
Fit the model through the EM-algorithm.
"""
data = data[['task', 'worker', 'label']]
# Early exit
if not data.size:
self.probas_ = pd.DataFrame()
self.priors_ = pd.Series(dtype=float)
self.errors_ = pd.DataFrame()
self.labels_ = pd.Series(dtype=float)
return self
# Initialization
probas = MajorityVote().fit_predict_proba(data)
priors = probas.mean()
errors = self._m_step(data, probas)
loss = -np.inf
self.loss_history_ = []
# Updating proba and errors n_iter times
for _ in range(self.n_iter):
probas = self._e_step(data, priors, errors)
priors = probas.mean()
errors = self._m_step(data, probas)
new_loss = self._evidence_lower_bound(data, probas, priors, errors) / len(data)
self.loss_history_.append(new_loss)
if new_loss - loss < self.tol:
break
loss = new_loss
# Saving results
self.probas_ = probas
self.priors_ = priors
self.errors_ = errors
self.labels_ = get_most_probable_labels(probas)
return self
@manage_docstring
def fit_predict_proba(self, data: annotations.LABELED_DATA) -> annotations.TASKS_LABEL_PROBAS:
"""
Fit the model and return probability distributions on labels for each task.
"""
return self.fit(data).probas_
@manage_docstring
def fit_predict(self, data: annotations.LABELED_DATA) -> annotations.TASKS_LABELS:
"""
Fit the model and return aggregated results.
"""
return self.fit(data).labels_