 +
+## Authors
+Written by [sameeksharl](https://www.github.com/sameeksharl)
+
+The project was built as a contribution during [GSSOC'21](https://gssoc.girlscript.tech/).
diff --git a/Address-Book/addressbook.py b/Address-Book/addressbook.py
new file mode 100644
index 0000000000..76ca9e2e69
--- /dev/null
+++ b/Address-Book/addressbook.py
@@ -0,0 +1,218 @@
+'''
+importing all the required libraries
+'''
+import sqlite3
+from sqlite3 import Error
+from tkinter import *
+import tkinter.messagebox
+root = Tk()
+root.geometry('600x370')
+list_of_names=[]
+root.title('AddressBook')
+Name = StringVar()
+Number = StringVar()
+
+""" creating a database connection to the SQLite database
+ specified by db_file
+ return: Connection object or None
+ """
+def create_connection(db_file):
+ conn = None
+ try:
+ conn = sqlite3.connect(db_file)
+ r_set=conn.execute('''SELECT * from tasks''');
+ for student in r_set:
+ list_of_names.append(student[1])
+ return conn
+ except Error as e:
+ print(e)
+ return conn
+
+""" create a table from the create_table_sql statement
+ conn: Connection object
+ create_table_sql: a CREATE TABLE statement
+ """
+def create_table(conn, create_table_sql):
+ try:
+ c = conn.cursor()
+ c.execute(create_table_sql)
+ except Error as e:
+ print(e)
+ return
+
+'''
+displaying added/deleted message
+'''
+def onClickAdded():
+ tkinter.messagebox.showinfo(" ",Name.get()+" got added")
+
+def onClickDeleted():
+ tkinter.messagebox.showinfo(" ",Name.get()+" got deleted")
+
+""" Create a new task (ie creating new row) for the given Name taking care of all conditions such as Name,phone no
+cannot be empty ,phone no should be 10 digits and also if Name already exist,then it cannot be inerted
+"""
+def create_task():
+ sql = ''' INSERT INTO tasks(name,status_id)
+ VALUES(?,?) '''
+ if(Name.get() not in list_of_names):
+
+ if((Name.get()=='') | (Number.get()=='') | (len(Number.get())!=10)):
+ top = Toplevel(root)
+ top.geometry('180x100')
+ if((Number.get()=='') | (len(Number.get())!=10)):
+ myLabel = Label(top, text="Phone no should be 10 digits\n")
+ else:
+ myLabel = Label(top, text="NAME IS EMPTY\n")
+ myLabel.pack()
+ mySubmitButton = Button(top, text=' Back ', command=top.destroy)
+ mySubmitButton.pack()
+ return
+ onClickAdded()
+ cur = conn.cursor()
+ cur.execute(sql, (Name.get(),Number.get()))
+ conn.commit()
+ return cur.lastrowid
+ else:
+ top = Toplevel(root)
+ top.geometry('180x100')
+ if(Name.get()==''):
+ myLabel = Label(top, text="NAME IS EMPTY\n")
+ elif((Number.get()=='') | (len(Number.get())!=10)):
+ myLabel = Label(top, text="Phone no should be 10 digits\n")
+ else:
+ myLabel = Label(top, text=Name.get()+" Already Exist\n")
+ myLabel.pack()
+ mySubmitButton = Button(top, text=' Back ', command=top.destroy)
+ mySubmitButton.pack()
+
+"""
+Query tasks by Name, if name not found then it gives a warning saying "NOT Found"
+"""
+def select_task_by_name():
+ cur = conn.cursor()
+ cur.execute("SELECT * FROM tasks WHERE name=?", (Name.get(),))
+ rows = cur.fetchall()
+ if(len(rows)==0):
+ inputDialog = MyDialog(root)
+ root.wait_window(inputDialog.top)
+ else:
+ Number.set(rows[0][2])
+
+"""
+Editing phone no, if name not found then it gives a warning saying "NOT Found"
+"""
+def update_task():
+ """
+ update priority, begin_date, and end date of a task
+ :param conn:
+ :param task:
+ :return: project id
+ """
+ sql = ''' UPDATE tasks
+ SET status_id = ?
+ WHERE name = ?'''
+ if((Name.get() not in list_of_names) | (Name.get()=='')):
+ inputDialog = MyDialog(root)
+ root.wait_window(inputDialog.top)
+ return
+ cur = conn.cursor()
+ cur.execute(sql, (Number.get(),Name.get()))
+ conn.commit()
+
+"""
+Delete a task by name.if not found ,gives a warning!!!
+"""
+def delete_task():
+ if((Name.get() not in list_of_names) | (Name.get()=='')):
+ inputDialog = MyDialog(root)
+ root.wait_window(inputDialog.top)
+ return
+ onClickDeleted()
+ sql = 'DELETE FROM tasks WHERE name=?'
+ cur = conn.cursor()
+ cur.execute(sql, (Name.get(),))
+ conn.commit()
+
+"""
+Get all rows in the tasks table
+"""
+def select_all_tasks():
+ r_set=conn.execute('''SELECT * from tasks''');
+ i=0
+ j=0
+ top = Toplevel(root)
+ for student in r_set:
+ list_of_names.append(student[1])
+ for j in range(len(student)):
+ e = Entry(top, width=11, fg='Gray20')
+ e.grid(row=i, column=j)
+ e.insert(END, student[j])
+ i=i+1
+ okButton= Button(top, text=' ok ', command=top.destroy)
+ if(j==0):
+ j=1
+ okButton.grid(row=i+3, column=j-1)
+
+'''
+Getting the path of database and defining the table to be created
+'''
+database = r"./Address-Book/addressbook.db"
+sql_create_tasks_table = """CREATE TABLE IF NOT EXISTS tasks (
+ id integer PRIMARY KEY,
+ name text NOT NULL,
+ status_id integer NOT NULL
+
+ );"""
+
+'''
+Creating connection and gives error message if connection failed
+'''
+conn = create_connection(database)
+if conn is not None:
+ create_table(conn, sql_create_tasks_table)
+else:
+ print("Error! cannot create the database connection.")
+
+'''
+creating dialog box for warnings!
+'''
+class MyDialog:
+ def __init__(self, parent):
+ top = self.top = Toplevel(parent)
+ self.myLabel = Label(top, text=Name.get().upper()+" NOT FOUND!")
+ self.myLabel.pack()
+ self.mySubmitButton = Button(top, text='Exit', command=self.send)
+ self.mySubmitButton.pack()
+
+ def send(self):
+ self.top.destroy()
+
+'''
+Exiting from the application
+'''
+def EXIT():
+ root.destroy()
+
+'''
+Resetting Name and phone no field
+'''
+def RESET():
+ Name.set('')
+ Number.set('')
+
+'''
+Creating UI for whole application
+'''
+Label(root, text = 'NAME', font='Times 15 bold').place(x= 130, y=20)
+Entry(root, textvariable = Name,width=42).place(x= 200, y=25)
+Label(root, text = 'PHONE NO ', font='Times 15 bold').place(x= 130, y=70)
+Entry(root, textvariable = Number,width=35).place(x= 242, y=73)
+Button(root,text=" ADD", font='Times 14 bold',bg='dark gray', command = create_task,width=8).place(x= 130, y=110)
+Button(root,text="EDIT", font='Times 14 bold',bg='dark gray',command = update_task,width=8).place(x= 260, y=108)
+Button(root,text="DELETE", font='Times 14 bold',bg='dark gray',command = delete_task,width=8).place(x= 390, y=107.5)
+Button(root,text="VIEW ALL", font='Times 14 bold',bg='dark gray', command = select_all_tasks,width=12).place(x= 160, y=191)
+Button(root,text="VIEW BY NAME", font='Times 14 bold',bg='dark gray', command = select_task_by_name,width=13).place(x= 330, y=190)
+Button(root,text="EXIT", font='Times 14 bold',bg='dark gray', command = EXIT,width=8).place(x= 200, y=280)
+Button(root,text="RESET", font='Times 14 bold',bg='dark gray', command = RESET,width=8).place(x= 320, y=280)
+root.mainloop()
diff --git a/Amazon-Price-Alert/requirements.txt b/Amazon-Price-Alert/requirements.txt
index 4cea477ee9..7d012dbdcd 100644
--- a/Amazon-Price-Alert/requirements.txt
+++ b/Amazon-Price-Alert/requirements.txt
@@ -16,6 +16,6 @@ requests-html==0.10.0
six==1.15.0
soupsieve==2.0.1
tqdm==4.49.0
-urllib3==1.25.10
+urllib3==1.26.5
w3lib==1.22.0
-websockets==8.1
+websockets==9.1
diff --git a/Audio_Steganography/Algos/Decrypt.py b/Audio_Steganography/Algos/Decrypt.py
new file mode 100644
index 0000000000..69576af4d3
--- /dev/null
+++ b/Audio_Steganography/Algos/Decrypt.py
@@ -0,0 +1,95 @@
+import os
+import wave
+import simpleaudio as sa
+import numpy as np
+from scipy.io import wavfile
+import binascii
+
+"""
+
+ [NOTE] In this decryption algorithm we simply read the path of the audio from the user and we
+ get a numpy array from the same. We then read the LSB of the binary representation of the data and get a string
+ of binary data. Finally we convert this string to ascii charecters and write it to a file.
+
+"""
+
+
+class Decrypt:
+
+ def __init__(self, audio_path):
+ self.audio_path = audio_path
+ self.audio_wave_obj = wave.open(audio_path)
+
+ """
+ This function is there for playing audio.
+ """
+
+ def play_audio(self) -> None:
+
+ playing = sa.WaveObject.from_wave_read(self.audio_wave_obj)
+ obj = playing.play()
+
+ if obj.is_playing():
+ print(f"Playing audio")
+
+ obj.wait_done()
+
+ """
+ The decryption is done here.
+ """
+
+ def decrypt_audio(self, output_dir: str, file_name: str, gen_file_status: bool) -> (str, bool):
+ if gen_file_status:
+ curr_dir_path = os.getcwd()
+ output_dir_path = os.path.join(curr_dir_path, output_dir)
+
+ try:
+ os.mkdir(output_dir_path)
+ except:
+ pass
+
+ print(f"This might take some while if your secret message is big and might contain some rubbish data.")
+
+ # Reading the data from the wav file
+ samplerate, data = wavfile.read(self.audio_path)
+ m, n = data.shape
+ # Reshaping it to make the data easier to handle
+ data_reshaped = data.reshape(m*n, 1)
+
+ s = ""
+ zeros = 0
+
+ # Getting the LSB from each number
+ for i in range(m*n):
+ t = str(data_reshaped[i][0] & 1)
+ if zeros < 9:
+ s += t
+ else:
+ break
+ if t == '0':
+ zeros += 1
+ if t == '1':
+ zeros = 0
+
+ # Making sure the bit-string is of length divisible by 8 as we have stored the input-secret as 8-bits only
+ s = s[:((len(s)//8)*8)]
+
+ # Converting bbinary string to utf-8
+ in_bin = int(s, 2)
+ byte_num = in_bin.bit_length() + 7 // 8
+ bin_arr = in_bin.to_bytes(byte_num, "big")
+ result = bin_arr.decode("utf-8", "ignore")
+
+ # Writing to output file if status was given true
+ if gen_file_status:
+ try:
+ with open(os.path.join(output_dir_path, file_name), "w", encoding="utf-8") as f:
+ f.write(result)
+ print("Success !!!")
+ return result, True
+ except:
+ print(("Error !!!"))
+ pass
+ return None, False
+ else:
+ return result, True
diff --git a/Audio_Steganography/Algos/Encrypt.py b/Audio_Steganography/Algos/Encrypt.py
new file mode 100644
index 0000000000..11b8ba2642
--- /dev/null
+++ b/Audio_Steganography/Algos/Encrypt.py
@@ -0,0 +1,120 @@
+import os
+import wave
+import simpleaudio as sa
+import numpy as np
+from scipy.io import wavfile
+
+
+"""
+ [NOTE] In this algorithm we make use of LSB Steganographic method of encoding. In this algorithm we have converted each charecter
+ of the secret text into 8-bit binary string and then we have stored it to a numpy array of size x*8 where x = no. of charecters.
+ After that we have copied the same into the LSB of the binary form of the audio file we have read.
+"""
+
+
+class Encrypt:
+
+ def __init__(self, message_audio_file_path: str, secret_message: str):
+ self.message_audio_file_path = message_audio_file_path
+ self.secret_message = secret_message
+
+ # For getting name of the file
+ self.message_filename = message_audio_file_path.split(os.sep)[-1]
+
+ # Reading the .wav audio file as a Wave obj - to be used later
+ self.message_audio = wave.open(message_audio_file_path)
+
+ # Getting the numpy array from the secret string.
+ self.secret_as_nparr = self.get_bin_npapp_from_path(
+ secret_message)
+
+ self.mess_as_nparr = None
+
+ """
+ This function is used as a helper function
+ """
+
+ def get_bin_npapp_from_path(self, secret: str) -> np.ndarray:
+
+ strings = ' '.join('{0:08b}'.format(ord(word), 'b')
+ for word in secret)
+ lst = []
+ for word in strings.split(" "):
+ # arr = np.fromstring(word, dtype="u1")-ord('0')
+ temp_lst = [int(i) for i in word]
+ lst.append(np.array(temp_lst))
+
+ return np.array(lst)
+
+ """
+ This function is there for playing audio.
+ """
+
+ def play_audio(self) -> None:
+
+ playing = sa.WaveObject.from_wave_read(self.message_audio)
+ obj = playing.play()
+
+ if obj.is_playing():
+ print(f"Playing audio : {self.message_filename}")
+
+ obj.wait_done()
+
+ """
+ This function is for encryption
+ """
+
+ def encrypt_using_lsb(self, output_dir: str, file_name: str) -> (np.ndarray, bool):
+
+ # Getting the ouput path
+ curr_dir_path = os.getcwd()
+ output_dir_path = os.path.join(curr_dir_path, output_dir)
+
+ try:
+ os.mkdir(output_dir_path)
+ except:
+ pass
+
+ print(f"This might take some while if either your audio file or your secret message is big")
+
+ # Reading shape of secret message and reshaping
+ m1, n1 = self.secret_as_nparr.shape
+ secret_reshape = self.secret_as_nparr.reshape(m1*n1, 1)
+
+ # Reading the .wav file
+ samplerate, self.mess_as_nparr = wavfile.read(
+ self.message_audio_file_path)
+
+ # Reading the shape of .wav file and reshaping
+ m2, n2 = self.mess_as_nparr.shape
+ message_reshape = self.mess_as_nparr.reshape(m2*n2, 1)
+
+ # Edge case
+ if m1*n1 > m2*n2:
+ print("Coudn't be done")
+ quit()
+
+ # Encryption part
+ k = 0
+ for i in range(m2*n2):
+ if k < m1*n1:
+ # This line is for copying the bit off the secret message to the LSB of the audio
+ message_reshape[i][0] = message_reshape[i][0] & 0xFE | secret_reshape[k][0]
+ k += 1
+ else:
+ message_reshape[i][0] = 0
+ break
+
+ # Reshaping back again
+ message_reshape = message_reshape.reshape(m2, n2)
+
+ try:
+ # Writing into ouput file
+ p = wavfile.write(os.path.join(output_dir_path, file_name),
+ samplerate, message_reshape.astype(message_reshape.dtype))
+ print("Success !!!")
+ return message_reshape, True
+ except:
+ print("Error !!!")
+ pass
+ return None, False
diff --git a/Audio_Steganography/Algos/__init__.py b/Audio_Steganography/Algos/__init__.py
new file mode 100644
index 0000000000..e69de29bb2
diff --git a/Audio_Steganography/Images/After.jpg b/Audio_Steganography/Images/After.jpg
new file mode 100644
index 0000000000..2dd65b989d
Binary files /dev/null and b/Audio_Steganography/Images/After.jpg differ
diff --git a/Audio_Steganography/Images/Before.jpg b/Audio_Steganography/Images/Before.jpg
new file mode 100644
index 0000000000..cf7dff22bb
Binary files /dev/null and b/Audio_Steganography/Images/Before.jpg differ
diff --git a/Audio_Steganography/README.md b/Audio_Steganography/README.md
new file mode 100644
index 0000000000..6cd1074752
--- /dev/null
+++ b/Audio_Steganography/README.md
@@ -0,0 +1,27 @@
+# Audio Steganography
+This is a package to encrypt a given message into a .wav audio file. It can decrypt from audio as well.
+- Encrypt : This is used for the encryption part. Can play the audio as well.
+- Decrypt : This is used for decryption part. Can play audio as well.
+
+## Setup instructions
+- It is recommended to install a virtualenv before you proceed. This can be done by ```virtualenv {name_of_virtualenv}```
+- Do
+ ```python3
+ pip install -r requirements.txt
+ ```
+- You can import Encrypt from Algos.Encrypt and decrypt from Algos.Decrpyt
+- The TestingCode.py file has an example implementation. Please refer to it if you face any issue.
+
+## Output
+- The code in TestingCode.py will produce 2 Directories as well as produce sound that is inside the .wav files that you have passed as a parameter to ```Encrypt```.
+- The Encryption and Decryption parts each will produce a directory with a name of your choice as well as file inside it containing the encrypted audio file or decrypted text file .
+- An Example of what you might expect :
+ - Before
+ 
+ - After
+ 
+
+- Dont worry if your decrypted sentence looks a bit funky-it is to be expected.
+
+## Author(s)
+[Trisanu Bhar](https://github.com/Trisanu-007)
diff --git a/Audio_Steganography/TestingCode.py b/Audio_Steganography/TestingCode.py
new file mode 100644
index 0000000000..0fa8aff1b1
--- /dev/null
+++ b/Audio_Steganography/TestingCode.py
@@ -0,0 +1,26 @@
+from Algos.Encrypt import Encrypt
+from Algos.Decrypt import Decrypt
+
+"""
+ [NOTE] Here we demostrate an use of the Encrypt and Decrypt algorithms
+ We also play the audio file as well.
+"""
+# You can try with Forest.wav as well
+message_path = input("Enter path of Audio file: ")
+secret = input("Enter secret message: ")
+
+# Using Encrypt
+en = Encrypt(message_path, secret)
+en.play_audio()
+res, status = en.encrypt_using_lsb("Encrypted", "encrypted.wav")
+
+if status:
+ print(res)
+
+# Using Decrypt
+dec = Decrypt("Encrypted\encrypted.wav")
+dec.play_audio()
+res, status = dec.decrypt_audio("Decrypted", "decrypted.txt", False)
+
+if status:
+ print(res)
diff --git a/Audio_Steganography/requirements.txt b/Audio_Steganography/requirements.txt
new file mode 100644
index 0000000000..ca79b8a91a
Binary files /dev/null and b/Audio_Steganography/requirements.txt differ
diff --git a/Beat-Board/README.md b/Beat-Board/README.md
new file mode 100644
index 0000000000..ea0a1e2328
--- /dev/null
+++ b/Beat-Board/README.md
@@ -0,0 +1,42 @@
+# Beat Board Script
+
+This program uses tkinter GUI to create a beat board in
+which the user can activate specific sounds based on the
+button or key pressed.
+
+The following keys correspond to the positions of the pads
+
+|Left Column |Middle Column | Right Column |
+|-- |---------- |-------- |
+|q |w |e |
+|a |s |d |
+|z |x |c |
+
+
+## Setup instructions
+
+This script uses the following modules:
+
+* tkinter
+* playsound
+ * To install module run the following command: `pip install playsound`
+* Thread from threading
+
+
+To run the script follow the following steps:
+
+1. Make sure you are within the Amazing-Python-Script directory
+2. Run the following command `python Beat-Board/beatBoard.py`
+
+## Detailed explanation of script, if needed
+
+This script uses a class-based approach to organize the different pads that
+can be seen in the GUI. This class contains the functions from the playsound module. The rest of the code is creating the buttons and linking the sounds with their respective objects.
+
+## Output
+
+Display images/gifs/videos of output/result of your script so that users can visualize it
+
+## Author
+
+Albert Paez
diff --git a/Beat-Board/Sounds/Kick.wav b/Beat-Board/Sounds/Kick.wav
new file mode 100644
index 0000000000..90e548e291
Binary files /dev/null and b/Beat-Board/Sounds/Kick.wav differ
diff --git a/Beat-Board/Sounds/Pad1.wav b/Beat-Board/Sounds/Pad1.wav
new file mode 100644
index 0000000000..f27dd8567f
Binary files /dev/null and b/Beat-Board/Sounds/Pad1.wav differ
diff --git a/Beat-Board/Sounds/Pad2.wav b/Beat-Board/Sounds/Pad2.wav
new file mode 100644
index 0000000000..04ea675132
Binary files /dev/null and b/Beat-Board/Sounds/Pad2.wav differ
diff --git a/Beat-Board/Sounds/Pad3.wav b/Beat-Board/Sounds/Pad3.wav
new file mode 100644
index 0000000000..8810709f45
Binary files /dev/null and b/Beat-Board/Sounds/Pad3.wav differ
diff --git a/Beat-Board/Sounds/Pad4.wav b/Beat-Board/Sounds/Pad4.wav
new file mode 100644
index 0000000000..82f1e904d7
Binary files /dev/null and b/Beat-Board/Sounds/Pad4.wav differ
diff --git a/Beat-Board/Sounds/Pad5.wav b/Beat-Board/Sounds/Pad5.wav
new file mode 100644
index 0000000000..f7b74fb3c1
Binary files /dev/null and b/Beat-Board/Sounds/Pad5.wav differ
diff --git a/Beat-Board/Sounds/Pad6.wav b/Beat-Board/Sounds/Pad6.wav
new file mode 100644
index 0000000000..53512bbf93
Binary files /dev/null and b/Beat-Board/Sounds/Pad6.wav differ
diff --git a/Beat-Board/Sounds/hiHat.wav b/Beat-Board/Sounds/hiHat.wav
new file mode 100644
index 0000000000..fe5216e5a0
Binary files /dev/null and b/Beat-Board/Sounds/hiHat.wav differ
diff --git a/Beat-Board/Sounds/snare.wav b/Beat-Board/Sounds/snare.wav
new file mode 100644
index 0000000000..16fb6f8409
Binary files /dev/null and b/Beat-Board/Sounds/snare.wav differ
diff --git a/Beat-Board/beatBoard.py b/Beat-Board/beatBoard.py
new file mode 100644
index 0000000000..6da0c34c06
--- /dev/null
+++ b/Beat-Board/beatBoard.py
@@ -0,0 +1,117 @@
+from tkinter import *
+from playsound import playsound
+from threading import Thread
+
+
+class padSound:
+ def __init__(self, soundLocation):
+ self.soundLocation = soundLocation
+
+ def given_sound(self):
+ playsound(self.soundLocation)
+
+ def play_sound(self,event):
+ sound = Thread(target=self.given_sound)
+ sound.start()
+
+
+# All the locations of the sounds
+kickLocation = './Beat-Board/Sounds/Kick.wav'
+hiHatLocation = './Beat-Board/Sounds/hiHat.wav'
+snareLocation = './Beat-Board/Sounds/snare.wav'
+pad1Location = './Beat-Board/Sounds/Pad1.wav'
+pad2Location = './Beat-Board/Sounds/Pad2.wav'
+pad3Location = './Beat-Board/Sounds/Pad3.wav'
+pad4Location = './Beat-Board/Sounds/Pad4.wav'
+pad5Location = './Beat-Board/Sounds/Pad5.wav'
+pad6Location = './Beat-Board/Sounds/Pad6.wav'
+
+# Create drum objects
+kickDrum = padSound(kickLocation)
+hiHatDrum = padSound(hiHatLocation)
+snareDrum = padSound(snareLocation)
+
+# Create pad objects
+pad1 = padSound(pad1Location)
+pad2 = padSound(pad2Location)
+pad3 = padSound(pad3Location)
+pad4 = padSound(pad4Location)
+pad5 = padSound(pad5Location)
+pad6 = padSound(pad6Location)
+
+def create_layout():
+
+ # Creates the Frame
+ frame_a = Frame(master=main_window, width=500, height=500, bg="black")
+ frame_a.grid(rowspan=3, columnspan=3)
+ frame_a.focus_set()
+
+ # Creates the Buttons
+ # ------------------------------------------------
+ # Kick Button
+ kickButton = Button(text="Kick", height=5, width=10)
+ frame_a.bind('q', kickDrum.play_sound)
+ kickButton.bind("
+
+## Authors
+Written by [sameeksharl](https://www.github.com/sameeksharl)
+
+The project was built as a contribution during [GSSOC'21](https://gssoc.girlscript.tech/).
diff --git a/Address-Book/addressbook.py b/Address-Book/addressbook.py
new file mode 100644
index 0000000000..76ca9e2e69
--- /dev/null
+++ b/Address-Book/addressbook.py
@@ -0,0 +1,218 @@
+'''
+importing all the required libraries
+'''
+import sqlite3
+from sqlite3 import Error
+from tkinter import *
+import tkinter.messagebox
+root = Tk()
+root.geometry('600x370')
+list_of_names=[]
+root.title('AddressBook')
+Name = StringVar()
+Number = StringVar()
+
+""" creating a database connection to the SQLite database
+ specified by db_file
+ return: Connection object or None
+ """
+def create_connection(db_file):
+ conn = None
+ try:
+ conn = sqlite3.connect(db_file)
+ r_set=conn.execute('''SELECT * from tasks''');
+ for student in r_set:
+ list_of_names.append(student[1])
+ return conn
+ except Error as e:
+ print(e)
+ return conn
+
+""" create a table from the create_table_sql statement
+ conn: Connection object
+ create_table_sql: a CREATE TABLE statement
+ """
+def create_table(conn, create_table_sql):
+ try:
+ c = conn.cursor()
+ c.execute(create_table_sql)
+ except Error as e:
+ print(e)
+ return
+
+'''
+displaying added/deleted message
+'''
+def onClickAdded():
+ tkinter.messagebox.showinfo(" ",Name.get()+" got added")
+
+def onClickDeleted():
+ tkinter.messagebox.showinfo(" ",Name.get()+" got deleted")
+
+""" Create a new task (ie creating new row) for the given Name taking care of all conditions such as Name,phone no
+cannot be empty ,phone no should be 10 digits and also if Name already exist,then it cannot be inerted
+"""
+def create_task():
+ sql = ''' INSERT INTO tasks(name,status_id)
+ VALUES(?,?) '''
+ if(Name.get() not in list_of_names):
+
+ if((Name.get()=='') | (Number.get()=='') | (len(Number.get())!=10)):
+ top = Toplevel(root)
+ top.geometry('180x100')
+ if((Number.get()=='') | (len(Number.get())!=10)):
+ myLabel = Label(top, text="Phone no should be 10 digits\n")
+ else:
+ myLabel = Label(top, text="NAME IS EMPTY\n")
+ myLabel.pack()
+ mySubmitButton = Button(top, text=' Back ', command=top.destroy)
+ mySubmitButton.pack()
+ return
+ onClickAdded()
+ cur = conn.cursor()
+ cur.execute(sql, (Name.get(),Number.get()))
+ conn.commit()
+ return cur.lastrowid
+ else:
+ top = Toplevel(root)
+ top.geometry('180x100')
+ if(Name.get()==''):
+ myLabel = Label(top, text="NAME IS EMPTY\n")
+ elif((Number.get()=='') | (len(Number.get())!=10)):
+ myLabel = Label(top, text="Phone no should be 10 digits\n")
+ else:
+ myLabel = Label(top, text=Name.get()+" Already Exist\n")
+ myLabel.pack()
+ mySubmitButton = Button(top, text=' Back ', command=top.destroy)
+ mySubmitButton.pack()
+
+"""
+Query tasks by Name, if name not found then it gives a warning saying "NOT Found"
+"""
+def select_task_by_name():
+ cur = conn.cursor()
+ cur.execute("SELECT * FROM tasks WHERE name=?", (Name.get(),))
+ rows = cur.fetchall()
+ if(len(rows)==0):
+ inputDialog = MyDialog(root)
+ root.wait_window(inputDialog.top)
+ else:
+ Number.set(rows[0][2])
+
+"""
+Editing phone no, if name not found then it gives a warning saying "NOT Found"
+"""
+def update_task():
+ """
+ update priority, begin_date, and end date of a task
+ :param conn:
+ :param task:
+ :return: project id
+ """
+ sql = ''' UPDATE tasks
+ SET status_id = ?
+ WHERE name = ?'''
+ if((Name.get() not in list_of_names) | (Name.get()=='')):
+ inputDialog = MyDialog(root)
+ root.wait_window(inputDialog.top)
+ return
+ cur = conn.cursor()
+ cur.execute(sql, (Number.get(),Name.get()))
+ conn.commit()
+
+"""
+Delete a task by name.if not found ,gives a warning!!!
+"""
+def delete_task():
+ if((Name.get() not in list_of_names) | (Name.get()=='')):
+ inputDialog = MyDialog(root)
+ root.wait_window(inputDialog.top)
+ return
+ onClickDeleted()
+ sql = 'DELETE FROM tasks WHERE name=?'
+ cur = conn.cursor()
+ cur.execute(sql, (Name.get(),))
+ conn.commit()
+
+"""
+Get all rows in the tasks table
+"""
+def select_all_tasks():
+ r_set=conn.execute('''SELECT * from tasks''');
+ i=0
+ j=0
+ top = Toplevel(root)
+ for student in r_set:
+ list_of_names.append(student[1])
+ for j in range(len(student)):
+ e = Entry(top, width=11, fg='Gray20')
+ e.grid(row=i, column=j)
+ e.insert(END, student[j])
+ i=i+1
+ okButton= Button(top, text=' ok ', command=top.destroy)
+ if(j==0):
+ j=1
+ okButton.grid(row=i+3, column=j-1)
+
+'''
+Getting the path of database and defining the table to be created
+'''
+database = r"./Address-Book/addressbook.db"
+sql_create_tasks_table = """CREATE TABLE IF NOT EXISTS tasks (
+ id integer PRIMARY KEY,
+ name text NOT NULL,
+ status_id integer NOT NULL
+
+ );"""
+
+'''
+Creating connection and gives error message if connection failed
+'''
+conn = create_connection(database)
+if conn is not None:
+ create_table(conn, sql_create_tasks_table)
+else:
+ print("Error! cannot create the database connection.")
+
+'''
+creating dialog box for warnings!
+'''
+class MyDialog:
+ def __init__(self, parent):
+ top = self.top = Toplevel(parent)
+ self.myLabel = Label(top, text=Name.get().upper()+" NOT FOUND!")
+ self.myLabel.pack()
+ self.mySubmitButton = Button(top, text='Exit', command=self.send)
+ self.mySubmitButton.pack()
+
+ def send(self):
+ self.top.destroy()
+
+'''
+Exiting from the application
+'''
+def EXIT():
+ root.destroy()
+
+'''
+Resetting Name and phone no field
+'''
+def RESET():
+ Name.set('')
+ Number.set('')
+
+'''
+Creating UI for whole application
+'''
+Label(root, text = 'NAME', font='Times 15 bold').place(x= 130, y=20)
+Entry(root, textvariable = Name,width=42).place(x= 200, y=25)
+Label(root, text = 'PHONE NO ', font='Times 15 bold').place(x= 130, y=70)
+Entry(root, textvariable = Number,width=35).place(x= 242, y=73)
+Button(root,text=" ADD", font='Times 14 bold',bg='dark gray', command = create_task,width=8).place(x= 130, y=110)
+Button(root,text="EDIT", font='Times 14 bold',bg='dark gray',command = update_task,width=8).place(x= 260, y=108)
+Button(root,text="DELETE", font='Times 14 bold',bg='dark gray',command = delete_task,width=8).place(x= 390, y=107.5)
+Button(root,text="VIEW ALL", font='Times 14 bold',bg='dark gray', command = select_all_tasks,width=12).place(x= 160, y=191)
+Button(root,text="VIEW BY NAME", font='Times 14 bold',bg='dark gray', command = select_task_by_name,width=13).place(x= 330, y=190)
+Button(root,text="EXIT", font='Times 14 bold',bg='dark gray', command = EXIT,width=8).place(x= 200, y=280)
+Button(root,text="RESET", font='Times 14 bold',bg='dark gray', command = RESET,width=8).place(x= 320, y=280)
+root.mainloop()
diff --git a/Amazon-Price-Alert/requirements.txt b/Amazon-Price-Alert/requirements.txt
index 4cea477ee9..7d012dbdcd 100644
--- a/Amazon-Price-Alert/requirements.txt
+++ b/Amazon-Price-Alert/requirements.txt
@@ -16,6 +16,6 @@ requests-html==0.10.0
six==1.15.0
soupsieve==2.0.1
tqdm==4.49.0
-urllib3==1.25.10
+urllib3==1.26.5
w3lib==1.22.0
-websockets==8.1
+websockets==9.1
diff --git a/Audio_Steganography/Algos/Decrypt.py b/Audio_Steganography/Algos/Decrypt.py
new file mode 100644
index 0000000000..69576af4d3
--- /dev/null
+++ b/Audio_Steganography/Algos/Decrypt.py
@@ -0,0 +1,95 @@
+import os
+import wave
+import simpleaudio as sa
+import numpy as np
+from scipy.io import wavfile
+import binascii
+
+"""
+
+ [NOTE] In this decryption algorithm we simply read the path of the audio from the user and we
+ get a numpy array from the same. We then read the LSB of the binary representation of the data and get a string
+ of binary data. Finally we convert this string to ascii charecters and write it to a file.
+
+"""
+
+
+class Decrypt:
+
+ def __init__(self, audio_path):
+ self.audio_path = audio_path
+ self.audio_wave_obj = wave.open(audio_path)
+
+ """
+ This function is there for playing audio.
+ """
+
+ def play_audio(self) -> None:
+
+ playing = sa.WaveObject.from_wave_read(self.audio_wave_obj)
+ obj = playing.play()
+
+ if obj.is_playing():
+ print(f"Playing audio")
+
+ obj.wait_done()
+
+ """
+ The decryption is done here.
+ """
+
+ def decrypt_audio(self, output_dir: str, file_name: str, gen_file_status: bool) -> (str, bool):
+ if gen_file_status:
+ curr_dir_path = os.getcwd()
+ output_dir_path = os.path.join(curr_dir_path, output_dir)
+
+ try:
+ os.mkdir(output_dir_path)
+ except:
+ pass
+
+ print(f"This might take some while if your secret message is big and might contain some rubbish data.")
+
+ # Reading the data from the wav file
+ samplerate, data = wavfile.read(self.audio_path)
+ m, n = data.shape
+ # Reshaping it to make the data easier to handle
+ data_reshaped = data.reshape(m*n, 1)
+
+ s = ""
+ zeros = 0
+
+ # Getting the LSB from each number
+ for i in range(m*n):
+ t = str(data_reshaped[i][0] & 1)
+ if zeros < 9:
+ s += t
+ else:
+ break
+ if t == '0':
+ zeros += 1
+ if t == '1':
+ zeros = 0
+
+ # Making sure the bit-string is of length divisible by 8 as we have stored the input-secret as 8-bits only
+ s = s[:((len(s)//8)*8)]
+
+ # Converting bbinary string to utf-8
+ in_bin = int(s, 2)
+ byte_num = in_bin.bit_length() + 7 // 8
+ bin_arr = in_bin.to_bytes(byte_num, "big")
+ result = bin_arr.decode("utf-8", "ignore")
+
+ # Writing to output file if status was given true
+ if gen_file_status:
+ try:
+ with open(os.path.join(output_dir_path, file_name), "w", encoding="utf-8") as f:
+ f.write(result)
+ print("Success !!!")
+ return result, True
+ except:
+ print(("Error !!!"))
+ pass
+ return None, False
+ else:
+ return result, True
diff --git a/Audio_Steganography/Algos/Encrypt.py b/Audio_Steganography/Algos/Encrypt.py
new file mode 100644
index 0000000000..11b8ba2642
--- /dev/null
+++ b/Audio_Steganography/Algos/Encrypt.py
@@ -0,0 +1,120 @@
+import os
+import wave
+import simpleaudio as sa
+import numpy as np
+from scipy.io import wavfile
+
+
+"""
+ [NOTE] In this algorithm we make use of LSB Steganographic method of encoding. In this algorithm we have converted each charecter
+ of the secret text into 8-bit binary string and then we have stored it to a numpy array of size x*8 where x = no. of charecters.
+ After that we have copied the same into the LSB of the binary form of the audio file we have read.
+"""
+
+
+class Encrypt:
+
+ def __init__(self, message_audio_file_path: str, secret_message: str):
+ self.message_audio_file_path = message_audio_file_path
+ self.secret_message = secret_message
+
+ # For getting name of the file
+ self.message_filename = message_audio_file_path.split(os.sep)[-1]
+
+ # Reading the .wav audio file as a Wave obj - to be used later
+ self.message_audio = wave.open(message_audio_file_path)
+
+ # Getting the numpy array from the secret string.
+ self.secret_as_nparr = self.get_bin_npapp_from_path(
+ secret_message)
+
+ self.mess_as_nparr = None
+
+ """
+ This function is used as a helper function
+ """
+
+ def get_bin_npapp_from_path(self, secret: str) -> np.ndarray:
+
+ strings = ' '.join('{0:08b}'.format(ord(word), 'b')
+ for word in secret)
+ lst = []
+ for word in strings.split(" "):
+ # arr = np.fromstring(word, dtype="u1")-ord('0')
+ temp_lst = [int(i) for i in word]
+ lst.append(np.array(temp_lst))
+
+ return np.array(lst)
+
+ """
+ This function is there for playing audio.
+ """
+
+ def play_audio(self) -> None:
+
+ playing = sa.WaveObject.from_wave_read(self.message_audio)
+ obj = playing.play()
+
+ if obj.is_playing():
+ print(f"Playing audio : {self.message_filename}")
+
+ obj.wait_done()
+
+ """
+ This function is for encryption
+ """
+
+ def encrypt_using_lsb(self, output_dir: str, file_name: str) -> (np.ndarray, bool):
+
+ # Getting the ouput path
+ curr_dir_path = os.getcwd()
+ output_dir_path = os.path.join(curr_dir_path, output_dir)
+
+ try:
+ os.mkdir(output_dir_path)
+ except:
+ pass
+
+ print(f"This might take some while if either your audio file or your secret message is big")
+
+ # Reading shape of secret message and reshaping
+ m1, n1 = self.secret_as_nparr.shape
+ secret_reshape = self.secret_as_nparr.reshape(m1*n1, 1)
+
+ # Reading the .wav file
+ samplerate, self.mess_as_nparr = wavfile.read(
+ self.message_audio_file_path)
+
+ # Reading the shape of .wav file and reshaping
+ m2, n2 = self.mess_as_nparr.shape
+ message_reshape = self.mess_as_nparr.reshape(m2*n2, 1)
+
+ # Edge case
+ if m1*n1 > m2*n2:
+ print("Coudn't be done")
+ quit()
+
+ # Encryption part
+ k = 0
+ for i in range(m2*n2):
+ if k < m1*n1:
+ # This line is for copying the bit off the secret message to the LSB of the audio
+ message_reshape[i][0] = message_reshape[i][0] & 0xFE | secret_reshape[k][0]
+ k += 1
+ else:
+ message_reshape[i][0] = 0
+ break
+
+ # Reshaping back again
+ message_reshape = message_reshape.reshape(m2, n2)
+
+ try:
+ # Writing into ouput file
+ p = wavfile.write(os.path.join(output_dir_path, file_name),
+ samplerate, message_reshape.astype(message_reshape.dtype))
+ print("Success !!!")
+ return message_reshape, True
+ except:
+ print("Error !!!")
+ pass
+ return None, False
diff --git a/Audio_Steganography/Algos/__init__.py b/Audio_Steganography/Algos/__init__.py
new file mode 100644
index 0000000000..e69de29bb2
diff --git a/Audio_Steganography/Images/After.jpg b/Audio_Steganography/Images/After.jpg
new file mode 100644
index 0000000000..2dd65b989d
Binary files /dev/null and b/Audio_Steganography/Images/After.jpg differ
diff --git a/Audio_Steganography/Images/Before.jpg b/Audio_Steganography/Images/Before.jpg
new file mode 100644
index 0000000000..cf7dff22bb
Binary files /dev/null and b/Audio_Steganography/Images/Before.jpg differ
diff --git a/Audio_Steganography/README.md b/Audio_Steganography/README.md
new file mode 100644
index 0000000000..6cd1074752
--- /dev/null
+++ b/Audio_Steganography/README.md
@@ -0,0 +1,27 @@
+# Audio Steganography
+This is a package to encrypt a given message into a .wav audio file. It can decrypt from audio as well.
+- Encrypt : This is used for the encryption part. Can play the audio as well.
+- Decrypt : This is used for decryption part. Can play audio as well.
+
+## Setup instructions
+- It is recommended to install a virtualenv before you proceed. This can be done by ```virtualenv {name_of_virtualenv}```
+- Do
+ ```python3
+ pip install -r requirements.txt
+ ```
+- You can import Encrypt from Algos.Encrypt and decrypt from Algos.Decrpyt
+- The TestingCode.py file has an example implementation. Please refer to it if you face any issue.
+
+## Output
+- The code in TestingCode.py will produce 2 Directories as well as produce sound that is inside the .wav files that you have passed as a parameter to ```Encrypt```.
+- The Encryption and Decryption parts each will produce a directory with a name of your choice as well as file inside it containing the encrypted audio file or decrypted text file .
+- An Example of what you might expect :
+ - Before
+ 
+ - After
+ 
+
+- Dont worry if your decrypted sentence looks a bit funky-it is to be expected.
+
+## Author(s)
+[Trisanu Bhar](https://github.com/Trisanu-007)
diff --git a/Audio_Steganography/TestingCode.py b/Audio_Steganography/TestingCode.py
new file mode 100644
index 0000000000..0fa8aff1b1
--- /dev/null
+++ b/Audio_Steganography/TestingCode.py
@@ -0,0 +1,26 @@
+from Algos.Encrypt import Encrypt
+from Algos.Decrypt import Decrypt
+
+"""
+ [NOTE] Here we demostrate an use of the Encrypt and Decrypt algorithms
+ We also play the audio file as well.
+"""
+# You can try with Forest.wav as well
+message_path = input("Enter path of Audio file: ")
+secret = input("Enter secret message: ")
+
+# Using Encrypt
+en = Encrypt(message_path, secret)
+en.play_audio()
+res, status = en.encrypt_using_lsb("Encrypted", "encrypted.wav")
+
+if status:
+ print(res)
+
+# Using Decrypt
+dec = Decrypt("Encrypted\encrypted.wav")
+dec.play_audio()
+res, status = dec.decrypt_audio("Decrypted", "decrypted.txt", False)
+
+if status:
+ print(res)
diff --git a/Audio_Steganography/requirements.txt b/Audio_Steganography/requirements.txt
new file mode 100644
index 0000000000..ca79b8a91a
Binary files /dev/null and b/Audio_Steganography/requirements.txt differ
diff --git a/Beat-Board/README.md b/Beat-Board/README.md
new file mode 100644
index 0000000000..ea0a1e2328
--- /dev/null
+++ b/Beat-Board/README.md
@@ -0,0 +1,42 @@
+# Beat Board Script
+
+This program uses tkinter GUI to create a beat board in
+which the user can activate specific sounds based on the
+button or key pressed.
+
+The following keys correspond to the positions of the pads
+
+|Left Column |Middle Column | Right Column |
+|-- |---------- |-------- |
+|q |w |e |
+|a |s |d |
+|z |x |c |
+
+
+## Setup instructions
+
+This script uses the following modules:
+
+* tkinter
+* playsound
+ * To install module run the following command: `pip install playsound`
+* Thread from threading
+
+
+To run the script follow the following steps:
+
+1. Make sure you are within the Amazing-Python-Script directory
+2. Run the following command `python Beat-Board/beatBoard.py`
+
+## Detailed explanation of script, if needed
+
+This script uses a class-based approach to organize the different pads that
+can be seen in the GUI. This class contains the functions from the playsound module. The rest of the code is creating the buttons and linking the sounds with their respective objects.
+
+## Output
+
+Display images/gifs/videos of output/result of your script so that users can visualize it
+
+## Author
+
+Albert Paez
diff --git a/Beat-Board/Sounds/Kick.wav b/Beat-Board/Sounds/Kick.wav
new file mode 100644
index 0000000000..90e548e291
Binary files /dev/null and b/Beat-Board/Sounds/Kick.wav differ
diff --git a/Beat-Board/Sounds/Pad1.wav b/Beat-Board/Sounds/Pad1.wav
new file mode 100644
index 0000000000..f27dd8567f
Binary files /dev/null and b/Beat-Board/Sounds/Pad1.wav differ
diff --git a/Beat-Board/Sounds/Pad2.wav b/Beat-Board/Sounds/Pad2.wav
new file mode 100644
index 0000000000..04ea675132
Binary files /dev/null and b/Beat-Board/Sounds/Pad2.wav differ
diff --git a/Beat-Board/Sounds/Pad3.wav b/Beat-Board/Sounds/Pad3.wav
new file mode 100644
index 0000000000..8810709f45
Binary files /dev/null and b/Beat-Board/Sounds/Pad3.wav differ
diff --git a/Beat-Board/Sounds/Pad4.wav b/Beat-Board/Sounds/Pad4.wav
new file mode 100644
index 0000000000..82f1e904d7
Binary files /dev/null and b/Beat-Board/Sounds/Pad4.wav differ
diff --git a/Beat-Board/Sounds/Pad5.wav b/Beat-Board/Sounds/Pad5.wav
new file mode 100644
index 0000000000..f7b74fb3c1
Binary files /dev/null and b/Beat-Board/Sounds/Pad5.wav differ
diff --git a/Beat-Board/Sounds/Pad6.wav b/Beat-Board/Sounds/Pad6.wav
new file mode 100644
index 0000000000..53512bbf93
Binary files /dev/null and b/Beat-Board/Sounds/Pad6.wav differ
diff --git a/Beat-Board/Sounds/hiHat.wav b/Beat-Board/Sounds/hiHat.wav
new file mode 100644
index 0000000000..fe5216e5a0
Binary files /dev/null and b/Beat-Board/Sounds/hiHat.wav differ
diff --git a/Beat-Board/Sounds/snare.wav b/Beat-Board/Sounds/snare.wav
new file mode 100644
index 0000000000..16fb6f8409
Binary files /dev/null and b/Beat-Board/Sounds/snare.wav differ
diff --git a/Beat-Board/beatBoard.py b/Beat-Board/beatBoard.py
new file mode 100644
index 0000000000..6da0c34c06
--- /dev/null
+++ b/Beat-Board/beatBoard.py
@@ -0,0 +1,117 @@
+from tkinter import *
+from playsound import playsound
+from threading import Thread
+
+
+class padSound:
+ def __init__(self, soundLocation):
+ self.soundLocation = soundLocation
+
+ def given_sound(self):
+ playsound(self.soundLocation)
+
+ def play_sound(self,event):
+ sound = Thread(target=self.given_sound)
+ sound.start()
+
+
+# All the locations of the sounds
+kickLocation = './Beat-Board/Sounds/Kick.wav'
+hiHatLocation = './Beat-Board/Sounds/hiHat.wav'
+snareLocation = './Beat-Board/Sounds/snare.wav'
+pad1Location = './Beat-Board/Sounds/Pad1.wav'
+pad2Location = './Beat-Board/Sounds/Pad2.wav'
+pad3Location = './Beat-Board/Sounds/Pad3.wav'
+pad4Location = './Beat-Board/Sounds/Pad4.wav'
+pad5Location = './Beat-Board/Sounds/Pad5.wav'
+pad6Location = './Beat-Board/Sounds/Pad6.wav'
+
+# Create drum objects
+kickDrum = padSound(kickLocation)
+hiHatDrum = padSound(hiHatLocation)
+snareDrum = padSound(snareLocation)
+
+# Create pad objects
+pad1 = padSound(pad1Location)
+pad2 = padSound(pad2Location)
+pad3 = padSound(pad3Location)
+pad4 = padSound(pad4Location)
+pad5 = padSound(pad5Location)
+pad6 = padSound(pad6Location)
+
+def create_layout():
+
+ # Creates the Frame
+ frame_a = Frame(master=main_window, width=500, height=500, bg="black")
+ frame_a.grid(rowspan=3, columnspan=3)
+ frame_a.focus_set()
+
+ # Creates the Buttons
+ # ------------------------------------------------
+ # Kick Button
+ kickButton = Button(text="Kick", height=5, width=10)
+ frame_a.bind('q', kickDrum.play_sound)
+ kickButton.bind(" +
+## 3. Draw Shapes
+In this, we will draw polygons (from triangles to decagons)in a continuous fashion.
+
+
+## 4. DrawDashedLine
+
+In this, we will draw a dashed line.
+
+
+
+## 5. Draw Spirograph
+
+In this , we will draw a spirograph.
+
+
+
+## 6. DrawSquare
+
+In this , we will draw a square.
+
+
+
+## 7. HirstSpotPainting
+
+In this , we will make a model of the famous Hirst spot painting.
+
+
+
+## 8. RandomColorWalk
+
+In this, we will generate a random walk using random colors.
+
+
+
+## 9. RandomWalk
+
+In this, we will generate a random walk using given colors.
+
+
\ No newline at end of file
diff --git a/Codes on Turtle Graphics/RandomColorWalk.png b/Codes on Turtle Graphics/RandomColorWalk.png
new file mode 100644
index 0000000000..76888f3c07
Binary files /dev/null and b/Codes on Turtle Graphics/RandomColorWalk.png differ
diff --git a/Codes on Turtle Graphics/RandomColorWalk.py b/Codes on Turtle Graphics/RandomColorWalk.py
new file mode 100644
index 0000000000..10e0cef8b7
--- /dev/null
+++ b/Codes on Turtle Graphics/RandomColorWalk.py
@@ -0,0 +1,15 @@
+import turtle as t
+import random
+
+ColorList = []
+tim = t.Turtle()
+t.colormode(255)
+tim.pensize(15)
+tim.speed("fastest")
+for i in range(300):
+ tim.forward(30)
+ # Choosing a random combination of colors
+ tim.color((random.randint(0, 255), random.randint(0, 255), random.randint(0, 255)))
+ tim.setheading(random.choice([0, 90, 180, 270]))
+scr = t.Screen()
+scr.exitonclick()
diff --git a/Codes on Turtle Graphics/RandomWalk.png b/Codes on Turtle Graphics/RandomWalk.png
new file mode 100644
index 0000000000..8463f829b7
Binary files /dev/null and b/Codes on Turtle Graphics/RandomWalk.png differ
diff --git a/Codes on Turtle Graphics/RandomWalk.py b/Codes on Turtle Graphics/RandomWalk.py
new file mode 100644
index 0000000000..d6f842c742
--- /dev/null
+++ b/Codes on Turtle Graphics/RandomWalk.py
@@ -0,0 +1,15 @@
+import turtle
+import turtle as t
+import random
+
+# Declaring colors
+ColorList = ["snow", "salmon", "pale turquoise", "lime green", "sandy brown"]
+tim = turtle.Turtle()
+tim.pensize(15)
+tim.speed("fastest")
+for i in range(300):
+ tim.forward(30)
+ tim.color(random.choice(ColorList))
+ tim.setheading(random.choice([0, 90, 180, 270]))
+scr = t.Screen()
+scr.exitonclick()
diff --git a/Codes on Turtle Graphics/Shapes.png b/Codes on Turtle Graphics/Shapes.png
new file mode 100644
index 0000000000..cd381f3de9
Binary files /dev/null and b/Codes on Turtle Graphics/Shapes.png differ
diff --git a/Codes on Turtle Graphics/Spirograph.png b/Codes on Turtle Graphics/Spirograph.png
new file mode 100644
index 0000000000..21b28c161e
Binary files /dev/null and b/Codes on Turtle Graphics/Spirograph.png differ
diff --git a/Codes on Turtle Graphics/Square.png b/Codes on Turtle Graphics/Square.png
new file mode 100644
index 0000000000..17d2ff156e
Binary files /dev/null and b/Codes on Turtle Graphics/Square.png differ
diff --git a/Codes on Turtle Graphics/image.jpg b/Codes on Turtle Graphics/image.jpg
new file mode 100644
index 0000000000..21853f1968
Binary files /dev/null and b/Codes on Turtle Graphics/image.jpg differ
diff --git a/Covid-19_Real-time_Notification/Covid.py b/Covid-19_Real-time_Notification/Covid.py
new file mode 100644
index 0000000000..c2332f533b
--- /dev/null
+++ b/Covid-19_Real-time_Notification/Covid.py
@@ -0,0 +1,44 @@
+from plyer import notification
+import requests
+from bs4 import BeautifulSoup
+import time
+from englisttohindi.englisttohindi import EngtoHindi
+
+def notify_user(title, message):
+ notification.notify(
+ title = title,
+ message = message,
+ app_icon = "./Covid-19_Real-time_Notification/Notify_icon.ico" ,
+ timeout = 5)
+
+def getInfo(url):
+ r = requests.get(url)
+ return r.text
+
+
+if __name__ == '__main__':
+ t = int(input("Enter interval in secs: "))
+ li = list(map(str, input("Enter name of states: ").split(",")))
+ states = []
+ for i in li:
+ states.append(i + " ( " + str(((EngtoHindi(i)).convert)) + " )")
+
+ while True:
+ HtmlData = getInfo('https://www.medtalks.in/live-corona-counter-india')
+ soup = BeautifulSoup(HtmlData, 'html.parser')
+
+ myData = ""
+ for tr in soup.find('tbody').find_all('tr'):
+ myData += tr.get_text()
+ myData = myData[1:]
+
+ itemList = myData.split("\n\n")
+ for item in itemList[:-2]:
+ dataList = item.split('\n')
+
+ if dataList[0] in states:
+ nTitle = 'Cases of Covid-19'
+ nText = f"State: {dataList[0]}: Total: {dataList[1]}\n Active: {dataList[2]}\n Death: {dataList[3]}"
+ notify_user(nTitle, nText)
+ time.sleep(2)
+ time.sleep(t)
\ No newline at end of file
diff --git a/Covid-19_Real-time_Notification/Notify_icon.ico b/Covid-19_Real-time_Notification/Notify_icon.ico
new file mode 100644
index 0000000000..50b30189f0
Binary files /dev/null and b/Covid-19_Real-time_Notification/Notify_icon.ico differ
diff --git a/Covid-19_Real-time_Notification/readME.md b/Covid-19_Real-time_Notification/readME.md
new file mode 100644
index 0000000000..75305aa17e
--- /dev/null
+++ b/Covid-19_Real-time_Notification/readME.md
@@ -0,0 +1,18 @@
+# REAL TIME COVID-19 OUTBREAK NOTIFICATION
+
+This is a notifier built with the use of BeautifulSoup, which will keep updating the user about the situation of covid in a particular state the user wants to know about after a particular interval of time.
+
+# What is the use ?
+
+In this time of crisis, it is needed to keep ourselves updated with the cases of covid for our own safety and benefit, and to get a better view of the situation.
+Everyone would like to have a system, that keeps them updated about the total cases, cured and deaths at an interval on its own. This script does exactly that for the user!
+
+# How to Use :
+
+Once the user starts the program, it will ask you about the state whose data you want to know, after it is entered, the notification system will do the work by itself and keep updating the user after an interval of an hour. The script will keep running in the background until the user exits it manually.
+
+# Development Status
+
+This script is at present complete. A future version may include a display of data of various states and also compare the new cases to cured cases, give updates on the vaccine distribution, etc.
+
+# Developed by [Sayantani Saha](https://github.com/sayantani11)
\ No newline at end of file
diff --git a/Covid-19_Real-time_Notification/requirements.txt b/Covid-19_Real-time_Notification/requirements.txt
new file mode 100644
index 0000000000..add756a9c3
--- /dev/null
+++ b/Covid-19_Real-time_Notification/requirements.txt
@@ -0,0 +1,5 @@
+Plyer
+requests
+bs4
+time
+englisttohindi
\ No newline at end of file
diff --git a/Crypto-price-checker/README.md b/Crypto-price-checker/README.md
new file mode 100644
index 0000000000..33e321c00d
--- /dev/null
+++ b/Crypto-price-checker/README.md
@@ -0,0 +1,38 @@
+# Cryptocurreny Price Checker GUI
+
+Running this Script would allow the user to fetch live top-100 cryptocurrency prices scraped from [cointracker.io](https://www.cointracker.io).
+
+## Setup instructions
+
+In order to run this script, you need to have Python and pip installed on your system. After you're done installing Python and pip, run the following command from your terminal to install the requirements from the same folder (directory) of the project.
+
+```
+pip install -r requirements.txt
+```
+
+As this script uses selenium, you will need to install the chrome webdriver from [this link](https://sites.google.com/a/chromium.org/chromedriver/downloads)
+
+After satisfying all the requirements for the project, Open the terminal in the project folder and run
+
+```
+python crypto.py
+```
+
+or
+
+```
+python3 crypto.py
+```
+
+depending upon the python version. Make sure that you are running the command from the same virtual environment in which the required modules are installed.
+
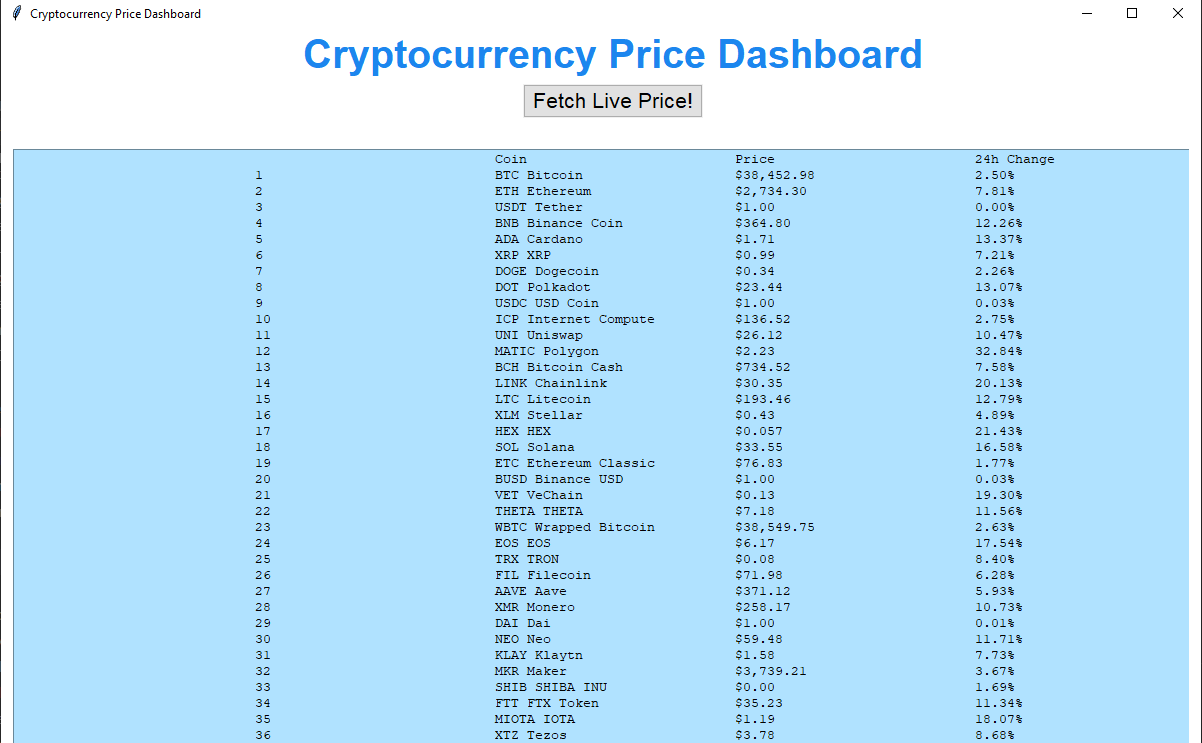
+## Output
+
+The top-100 cryptocurrencies are displayed along with some data about their performance
+
+
+
+
+## Author
+
+[Ayush Jain](https://github.com/Ayushjain2205)
diff --git a/Crypto-price-checker/crypto.py b/Crypto-price-checker/crypto.py
new file mode 100644
index 0000000000..0e0ca8b855
--- /dev/null
+++ b/Crypto-price-checker/crypto.py
@@ -0,0 +1,86 @@
+import requests
+from bs4 import BeautifulSoup
+import tkinter as tk
+from tkinter import ttk
+from tkinter import font as tkFont
+from selenium import webdriver
+from selenium.webdriver.common.keys import Keys
+import time
+
+driver_path = input('Enter chrome driver path: ')
+
+
+# Function to scrape stock data from generated URL
+def scraper():
+ url = 'https://www.cointracker.io/price'
+ driver = webdriver.Chrome(driver_path)
+ driver.get(url)
+
+ # Wait for results to load
+ time.sleep(5)
+ html = driver.page_source
+
+ # Start scraping resultant html data
+ soup = BeautifulSoup(html, 'html.parser')
+
+ # Find the crypto price table to scrape
+ results = soup.find("table", {"class": 'table mx-auto'})
+ rows = results.findChildren('tr')
+
+ table_data = []
+ row_values = []
+ # Append individual cryptocurrency data into a list
+ for row in rows:
+ cells = row.findChildren(['th', 'td'])
+ for cell in cells:
+ value = cell.text.strip()
+ value = " ".join(value.split())
+ row_values.append(value)
+ table_data.append(row_values)
+ row_values = []
+
+ # Formatting the cryptocurrency data stored in the list
+ stocks_data = ""
+ for stock in table_data:
+ single_record = ""
+ for cell in stock:
+ format_cell = "{:<30}"
+ single_record += format_cell.format(cell[:20])
+ single_record += "\n"
+ stocks_data += single_record
+
+ # Adding the formatted data into tkinter GUI
+ query_label.config(state=tk.NORMAL)
+ query_label.delete(1.0, "end")
+ query_label.insert(1.0, stocks_data)
+ query_label.config(state=tk.DISABLED)
+ driver.close()
+
+
+# Creating tkinter window
+window = tk.Tk()
+window.title('Cryptocurrency Price Checker')
+window.geometry('1200x1000')
+window.configure(bg='white')
+
+style = ttk.Style()
+style.configure('my.TButton', font=('Helvetica', 16))
+style.configure('my.TFrame', background='white')
+
+# label text for title
+ttk.Label(window, text="Cryptocurrency Price Checker",
+ background='white', foreground="DodgerBlue2",
+ font=("Helvetica", 30, 'bold')).grid(row=0, column=3, padx=300)
+
+submit_btn = ttk.Button(window, text="Fetch Live Price!",
+ style='my.TButton', command=scraper)
+submit_btn.grid(row=5, column=3, pady=5, padx=15, ipadx=5)
+
+frame = ttk.Frame(window, style='my.TFrame')
+frame.place(relx=0.50, rely=0.12, relwidth=0.98, relheight=0.90, anchor="n")
+
+# To display stock data
+query_label = tk.Text(frame, height="52", width="500", bg="lightskyblue1")
+query_label.grid(row=7, columnspan=2)
+
+window.mainloop()
diff --git a/Crypto-price-checker/requirements.txt b/Crypto-price-checker/requirements.txt
new file mode 100644
index 0000000000..b74b115ce7
--- /dev/null
+++ b/Crypto-price-checker/requirements.txt
@@ -0,0 +1,3 @@
+requests
+beautifulsoup4
+selenium
\ No newline at end of file
diff --git a/DNS verifier/main.py b/DNS verifier/main.py
new file mode 100644
index 0000000000..251c528b4b
--- /dev/null
+++ b/DNS verifier/main.py
@@ -0,0 +1,44 @@
+# DNS VERIFIER
+
+import json
+import sys
+from collections import OrderedDict
+
+import dns.resolver
+
+
+def checker(dns_val=None) -> OrderedDict:
+
+ ip_values = None
+ avail = False
+
+ if dns_val is None:
+ raise ValueError("Sorry DNS not found, DNS is needed")
+ if isinstance(dns_val, str) is False:
+ raise TypeError("Sorry, \'DNS\' must be type \'str\'")
+ try:
+ output = dns.resolver.resolve(dns_val, 'A')
+ ip_values = [ipval.to_text() for ipval in output]
+ except dns.resolver.NXDOMAIN:
+ avail = True
+
+ return OrderedDict([
+ ("DNS", dns_val),
+ ("IP", ip_values),
+ ("AVAIL", avail),
+ ])
+
+
+if __name__ == '__main__':
+ dns_val = None
+ option = None
+ print("Enter the DNS:")
+ dns_val=input()
+ try:
+ response = checker(dns_val=dns_val)
+ except Exception as err:
+ print(f"error: {err}")
+ sys.exit(1)
+
+ print(json.dumps(response, indent=4))
+ sys.exit(0)
\ No newline at end of file
diff --git a/DNS verifier/readme.MD b/DNS verifier/readme.MD
new file mode 100644
index 0000000000..2104ae565e
--- /dev/null
+++ b/DNS verifier/readme.MD
@@ -0,0 +1,39 @@
+# DNS VERIFIER
+## Description
+A Script to verify the Domain Name System.
+- This is useful to check for availability of DNS.
+
+## Language
+- [X] Python
+
+## Instructions to run this application
+
+ 1. Python 3 must be installed in your system.
+
+ - For first time, run this in terminal or powershell
+```
+pip3 install -r requirements.txt
+```
+ 2. It will download all the required modules
+
+ - Now run the below command
+
+Usage:
+
+```
+ python main.py
+```
+
+example:
+```
+ python main.py
+```
+
+Enter the DNS: gaana.com
+{
+ "DNS": "gaana.com",
+ "IP": [
+ "23.211.222.138"
+ ],
+ "AVAIL": false
+}
diff --git a/DNS verifier/requirements.txt b/DNS verifier/requirements.txt
new file mode 100644
index 0000000000..689e42ff8f
--- /dev/null
+++ b/DNS verifier/requirements.txt
@@ -0,0 +1 @@
+dnspython==2.0.0
\ No newline at end of file
diff --git a/Download-page-as-pdf/Readme.md b/Download-page-as-pdf/Readme.md
new file mode 100644
index 0000000000..b0ab79aa57
--- /dev/null
+++ b/Download-page-as-pdf/Readme.md
@@ -0,0 +1,24 @@
+# Download Page as PDF:
+
+Download a page as a PDF .
+
+ #### Required Modules :
+ - pyppdf
+ ```bash
+ pip3 install pyppdf
+ ```
+ - pyppyteer
+ ```bash
+ pip3 install pyppeteer
+ ```
+
+ #### Examples of use :
+ - Download a page:
+ ```bash
+ python download-page-as-pdf.py -l 'www.pudim.com.br'
+ ```
+
+ - Download a page and give a pdf name:
+ ```bash
+ python download-page-as-pdf.py -l 'http://www.pudim.com.br' -n 'pudim.pdf'
+ ```
diff --git a/Download-page-as-pdf/main.py b/Download-page-as-pdf/main.py
new file mode 100644
index 0000000000..5e26c87767
--- /dev/null
+++ b/Download-page-as-pdf/main.py
@@ -0,0 +1,42 @@
+#!/usr/bin/python
+# -*- coding: UTF-8 -*-
+
+import argparse
+import pyppdf
+import re
+from pyppeteer.errors import PageError, TimeoutError, NetworkError
+
+
+def main():
+ parser = argparse.ArgumentParser(description = 'Page Downloader as PDF')
+ parser.add_argument('--link', '-l', action = 'store', dest = 'link',
+ required = True, help = 'Inform the link to download.')
+ parser.add_argument('--name', '-n', action = 'store', dest = 'name',
+ required = False, help = 'Inform the name to save.')
+
+ arguments = parser.parse_args()
+
+ url = arguments.link
+
+ if not arguments.name:
+ name = re.sub(r'^\w+://', '', url.lower())
+ name = name.replace('/', '-')
+ else:
+ name = arguments.name
+
+ if not name.endswith('.pdf'):
+ name = name + '.pdf'
+
+ print(f'Name of the file: {name}')
+
+ try:
+ pyppdf.save_pdf(name, url)
+ except PageError:
+ print('URL could not be resolved.')
+ except TimeoutError:
+ print('Timeout.')
+ except NetworkError:
+ print('No access to the network.')
+
+if __name__ == '__main__':
+ main()
diff --git a/Download-page-as-pdf/requirements.txt b/Download-page-as-pdf/requirements.txt
new file mode 100644
index 0000000000..89960d9126
--- /dev/null
+++ b/Download-page-as-pdf/requirements.txt
@@ -0,0 +1,2 @@
+pyppdf==0.1.2
+pyppeteer==0.2.2
diff --git a/Email GUI/Readme.md b/Email GUI/Readme.md
new file mode 100644
index 0000000000..25ccb7f969
--- /dev/null
+++ b/Email GUI/Readme.md
@@ -0,0 +1,37 @@
+# Email GUI
+
+[](https://forthebadge.com)
+
+## Email GUI Functionalities : 🚀
+
+- **To send email the less security option of sender's email must be turned on.**
+- Enter all the details like sender's email, password, Recipient's Email and message.
+- The script logs into the gmail account and then sends the message.
+
+## Select Stocks by volume Increase Instructions: 👨🏻💻
+
+### Step 1:
+
+ Open Termnial 💻
+
+### Step 2:
+
+ Locate to the directory where python file is located 📂
+
+### Step 3:
+
+ Run the command: python script.py/python3 script.py 🧐
+
+### Step 4:
+
+ Sit back and Relax. Let the Script do the Job. ☕
+
+### Requirements
+
+- smtplib
+- tkinter
+
+## Author
+
+[Amit Kumar Mishra](https://github.com/Amit366)
+
diff --git a/Email GUI/script.py b/Email GUI/script.py
new file mode 100644
index 0000000000..c9e41a5bc9
--- /dev/null
+++ b/Email GUI/script.py
@@ -0,0 +1,76 @@
+import smtplib
+from tkinter import *
+
+
+def send_message():
+
+ address_info = address.get()
+
+ email_body_info = email_body.get()
+
+ sender_info = sender_address.get()
+
+ password_info = password.get()
+
+ server = smtplib.SMTP('smtp.gmail.com',587)
+
+ server.starttls()
+
+ server.login(sender_info,password_info)
+
+ print("Login successful")
+
+ server.sendmail(sender_info,address_info,email_body_info)
+
+ print("Message sent")
+
+ address_entry.delete(0,END)
+ email_body_entry.delete(0,END)
+ password_entry.delete(0,END)
+ sender_address_entry.delete(0,END)
+
+
+gui = Tk()
+
+gui.geometry("500x500")
+
+gui.title("Email Sender App")
+
+heading = Label(text="Email Sender App",bg="yellow",fg="black",font="10",width="500",height="3")
+
+heading.pack()
+gui.configure(background = "light blue")
+
+sender_address_field = Label(text="Sender's Email :")
+sender_address_field.place(x=15,y=70)
+
+sender_address = StringVar()
+sender_address_entry = Entry(textvariable=sender_address,width="30")
+sender_address_entry.place(x=15,y=100)
+
+sender_password_field = Label(text="Sender's Password :")
+sender_password_field.place(x=15,y=140)
+
+password = StringVar()
+password_entry = Entry(textvariable=password,width="30")
+password_entry.place(x=15,y=170)
+
+address_field = Label(text="Recipient Email :")
+address_field.place(x=15,y=210)
+
+address = StringVar()
+address_entry = Entry(textvariable=address,width="30")
+address_entry.place(x=15,y=240)
+
+email_body_field = Label(text="Message :")
+email_body_field.place(x=15,y=280)
+
+email_body = StringVar()
+email_body_entry = Entry(textvariable=email_body,width="30")
+email_body_entry.place(x=15,y=320,height="30")
+
+button = Button(gui,text="Send Message",command=send_message,width="30",height="2",bg="grey")
+
+button.place(x=15,y=400)
+
+mainloop()
diff --git a/Facebook-DP-Downloader/Readme.md b/Facebook-DP-Downloader/Readme.md
new file mode 100644
index 0000000000..6667fe2654
--- /dev/null
+++ b/Facebook-DP-Downloader/Readme.md
@@ -0,0 +1,16 @@
+# Facebook Profile Picture Downloader
+
+Download the profile picture of any public profile on Facebook by its Facebook id.
+
+
+## 3. Draw Shapes
+In this, we will draw polygons (from triangles to decagons)in a continuous fashion.
+
+
+## 4. DrawDashedLine
+
+In this, we will draw a dashed line.
+
+
+
+## 5. Draw Spirograph
+
+In this , we will draw a spirograph.
+
+
+
+## 6. DrawSquare
+
+In this , we will draw a square.
+
+
+
+## 7. HirstSpotPainting
+
+In this , we will make a model of the famous Hirst spot painting.
+
+
+
+## 8. RandomColorWalk
+
+In this, we will generate a random walk using random colors.
+
+
+
+## 9. RandomWalk
+
+In this, we will generate a random walk using given colors.
+
+
\ No newline at end of file
diff --git a/Codes on Turtle Graphics/RandomColorWalk.png b/Codes on Turtle Graphics/RandomColorWalk.png
new file mode 100644
index 0000000000..76888f3c07
Binary files /dev/null and b/Codes on Turtle Graphics/RandomColorWalk.png differ
diff --git a/Codes on Turtle Graphics/RandomColorWalk.py b/Codes on Turtle Graphics/RandomColorWalk.py
new file mode 100644
index 0000000000..10e0cef8b7
--- /dev/null
+++ b/Codes on Turtle Graphics/RandomColorWalk.py
@@ -0,0 +1,15 @@
+import turtle as t
+import random
+
+ColorList = []
+tim = t.Turtle()
+t.colormode(255)
+tim.pensize(15)
+tim.speed("fastest")
+for i in range(300):
+ tim.forward(30)
+ # Choosing a random combination of colors
+ tim.color((random.randint(0, 255), random.randint(0, 255), random.randint(0, 255)))
+ tim.setheading(random.choice([0, 90, 180, 270]))
+scr = t.Screen()
+scr.exitonclick()
diff --git a/Codes on Turtle Graphics/RandomWalk.png b/Codes on Turtle Graphics/RandomWalk.png
new file mode 100644
index 0000000000..8463f829b7
Binary files /dev/null and b/Codes on Turtle Graphics/RandomWalk.png differ
diff --git a/Codes on Turtle Graphics/RandomWalk.py b/Codes on Turtle Graphics/RandomWalk.py
new file mode 100644
index 0000000000..d6f842c742
--- /dev/null
+++ b/Codes on Turtle Graphics/RandomWalk.py
@@ -0,0 +1,15 @@
+import turtle
+import turtle as t
+import random
+
+# Declaring colors
+ColorList = ["snow", "salmon", "pale turquoise", "lime green", "sandy brown"]
+tim = turtle.Turtle()
+tim.pensize(15)
+tim.speed("fastest")
+for i in range(300):
+ tim.forward(30)
+ tim.color(random.choice(ColorList))
+ tim.setheading(random.choice([0, 90, 180, 270]))
+scr = t.Screen()
+scr.exitonclick()
diff --git a/Codes on Turtle Graphics/Shapes.png b/Codes on Turtle Graphics/Shapes.png
new file mode 100644
index 0000000000..cd381f3de9
Binary files /dev/null and b/Codes on Turtle Graphics/Shapes.png differ
diff --git a/Codes on Turtle Graphics/Spirograph.png b/Codes on Turtle Graphics/Spirograph.png
new file mode 100644
index 0000000000..21b28c161e
Binary files /dev/null and b/Codes on Turtle Graphics/Spirograph.png differ
diff --git a/Codes on Turtle Graphics/Square.png b/Codes on Turtle Graphics/Square.png
new file mode 100644
index 0000000000..17d2ff156e
Binary files /dev/null and b/Codes on Turtle Graphics/Square.png differ
diff --git a/Codes on Turtle Graphics/image.jpg b/Codes on Turtle Graphics/image.jpg
new file mode 100644
index 0000000000..21853f1968
Binary files /dev/null and b/Codes on Turtle Graphics/image.jpg differ
diff --git a/Covid-19_Real-time_Notification/Covid.py b/Covid-19_Real-time_Notification/Covid.py
new file mode 100644
index 0000000000..c2332f533b
--- /dev/null
+++ b/Covid-19_Real-time_Notification/Covid.py
@@ -0,0 +1,44 @@
+from plyer import notification
+import requests
+from bs4 import BeautifulSoup
+import time
+from englisttohindi.englisttohindi import EngtoHindi
+
+def notify_user(title, message):
+ notification.notify(
+ title = title,
+ message = message,
+ app_icon = "./Covid-19_Real-time_Notification/Notify_icon.ico" ,
+ timeout = 5)
+
+def getInfo(url):
+ r = requests.get(url)
+ return r.text
+
+
+if __name__ == '__main__':
+ t = int(input("Enter interval in secs: "))
+ li = list(map(str, input("Enter name of states: ").split(",")))
+ states = []
+ for i in li:
+ states.append(i + " ( " + str(((EngtoHindi(i)).convert)) + " )")
+
+ while True:
+ HtmlData = getInfo('https://www.medtalks.in/live-corona-counter-india')
+ soup = BeautifulSoup(HtmlData, 'html.parser')
+
+ myData = ""
+ for tr in soup.find('tbody').find_all('tr'):
+ myData += tr.get_text()
+ myData = myData[1:]
+
+ itemList = myData.split("\n\n")
+ for item in itemList[:-2]:
+ dataList = item.split('\n')
+
+ if dataList[0] in states:
+ nTitle = 'Cases of Covid-19'
+ nText = f"State: {dataList[0]}: Total: {dataList[1]}\n Active: {dataList[2]}\n Death: {dataList[3]}"
+ notify_user(nTitle, nText)
+ time.sleep(2)
+ time.sleep(t)
\ No newline at end of file
diff --git a/Covid-19_Real-time_Notification/Notify_icon.ico b/Covid-19_Real-time_Notification/Notify_icon.ico
new file mode 100644
index 0000000000..50b30189f0
Binary files /dev/null and b/Covid-19_Real-time_Notification/Notify_icon.ico differ
diff --git a/Covid-19_Real-time_Notification/readME.md b/Covid-19_Real-time_Notification/readME.md
new file mode 100644
index 0000000000..75305aa17e
--- /dev/null
+++ b/Covid-19_Real-time_Notification/readME.md
@@ -0,0 +1,18 @@
+# REAL TIME COVID-19 OUTBREAK NOTIFICATION
+
+This is a notifier built with the use of BeautifulSoup, which will keep updating the user about the situation of covid in a particular state the user wants to know about after a particular interval of time.
+
+# What is the use ?
+
+In this time of crisis, it is needed to keep ourselves updated with the cases of covid for our own safety and benefit, and to get a better view of the situation.
+Everyone would like to have a system, that keeps them updated about the total cases, cured and deaths at an interval on its own. This script does exactly that for the user!
+
+# How to Use :
+
+Once the user starts the program, it will ask you about the state whose data you want to know, after it is entered, the notification system will do the work by itself and keep updating the user after an interval of an hour. The script will keep running in the background until the user exits it manually.
+
+# Development Status
+
+This script is at present complete. A future version may include a display of data of various states and also compare the new cases to cured cases, give updates on the vaccine distribution, etc.
+
+# Developed by [Sayantani Saha](https://github.com/sayantani11)
\ No newline at end of file
diff --git a/Covid-19_Real-time_Notification/requirements.txt b/Covid-19_Real-time_Notification/requirements.txt
new file mode 100644
index 0000000000..add756a9c3
--- /dev/null
+++ b/Covid-19_Real-time_Notification/requirements.txt
@@ -0,0 +1,5 @@
+Plyer
+requests
+bs4
+time
+englisttohindi
\ No newline at end of file
diff --git a/Crypto-price-checker/README.md b/Crypto-price-checker/README.md
new file mode 100644
index 0000000000..33e321c00d
--- /dev/null
+++ b/Crypto-price-checker/README.md
@@ -0,0 +1,38 @@
+# Cryptocurreny Price Checker GUI
+
+Running this Script would allow the user to fetch live top-100 cryptocurrency prices scraped from [cointracker.io](https://www.cointracker.io).
+
+## Setup instructions
+
+In order to run this script, you need to have Python and pip installed on your system. After you're done installing Python and pip, run the following command from your terminal to install the requirements from the same folder (directory) of the project.
+
+```
+pip install -r requirements.txt
+```
+
+As this script uses selenium, you will need to install the chrome webdriver from [this link](https://sites.google.com/a/chromium.org/chromedriver/downloads)
+
+After satisfying all the requirements for the project, Open the terminal in the project folder and run
+
+```
+python crypto.py
+```
+
+or
+
+```
+python3 crypto.py
+```
+
+depending upon the python version. Make sure that you are running the command from the same virtual environment in which the required modules are installed.
+
+## Output
+
+The top-100 cryptocurrencies are displayed along with some data about their performance
+
+
+
+
+## Author
+
+[Ayush Jain](https://github.com/Ayushjain2205)
diff --git a/Crypto-price-checker/crypto.py b/Crypto-price-checker/crypto.py
new file mode 100644
index 0000000000..0e0ca8b855
--- /dev/null
+++ b/Crypto-price-checker/crypto.py
@@ -0,0 +1,86 @@
+import requests
+from bs4 import BeautifulSoup
+import tkinter as tk
+from tkinter import ttk
+from tkinter import font as tkFont
+from selenium import webdriver
+from selenium.webdriver.common.keys import Keys
+import time
+
+driver_path = input('Enter chrome driver path: ')
+
+
+# Function to scrape stock data from generated URL
+def scraper():
+ url = 'https://www.cointracker.io/price'
+ driver = webdriver.Chrome(driver_path)
+ driver.get(url)
+
+ # Wait for results to load
+ time.sleep(5)
+ html = driver.page_source
+
+ # Start scraping resultant html data
+ soup = BeautifulSoup(html, 'html.parser')
+
+ # Find the crypto price table to scrape
+ results = soup.find("table", {"class": 'table mx-auto'})
+ rows = results.findChildren('tr')
+
+ table_data = []
+ row_values = []
+ # Append individual cryptocurrency data into a list
+ for row in rows:
+ cells = row.findChildren(['th', 'td'])
+ for cell in cells:
+ value = cell.text.strip()
+ value = " ".join(value.split())
+ row_values.append(value)
+ table_data.append(row_values)
+ row_values = []
+
+ # Formatting the cryptocurrency data stored in the list
+ stocks_data = ""
+ for stock in table_data:
+ single_record = ""
+ for cell in stock:
+ format_cell = "{:<30}"
+ single_record += format_cell.format(cell[:20])
+ single_record += "\n"
+ stocks_data += single_record
+
+ # Adding the formatted data into tkinter GUI
+ query_label.config(state=tk.NORMAL)
+ query_label.delete(1.0, "end")
+ query_label.insert(1.0, stocks_data)
+ query_label.config(state=tk.DISABLED)
+ driver.close()
+
+
+# Creating tkinter window
+window = tk.Tk()
+window.title('Cryptocurrency Price Checker')
+window.geometry('1200x1000')
+window.configure(bg='white')
+
+style = ttk.Style()
+style.configure('my.TButton', font=('Helvetica', 16))
+style.configure('my.TFrame', background='white')
+
+# label text for title
+ttk.Label(window, text="Cryptocurrency Price Checker",
+ background='white', foreground="DodgerBlue2",
+ font=("Helvetica", 30, 'bold')).grid(row=0, column=3, padx=300)
+
+submit_btn = ttk.Button(window, text="Fetch Live Price!",
+ style='my.TButton', command=scraper)
+submit_btn.grid(row=5, column=3, pady=5, padx=15, ipadx=5)
+
+frame = ttk.Frame(window, style='my.TFrame')
+frame.place(relx=0.50, rely=0.12, relwidth=0.98, relheight=0.90, anchor="n")
+
+# To display stock data
+query_label = tk.Text(frame, height="52", width="500", bg="lightskyblue1")
+query_label.grid(row=7, columnspan=2)
+
+window.mainloop()
diff --git a/Crypto-price-checker/requirements.txt b/Crypto-price-checker/requirements.txt
new file mode 100644
index 0000000000..b74b115ce7
--- /dev/null
+++ b/Crypto-price-checker/requirements.txt
@@ -0,0 +1,3 @@
+requests
+beautifulsoup4
+selenium
\ No newline at end of file
diff --git a/DNS verifier/main.py b/DNS verifier/main.py
new file mode 100644
index 0000000000..251c528b4b
--- /dev/null
+++ b/DNS verifier/main.py
@@ -0,0 +1,44 @@
+# DNS VERIFIER
+
+import json
+import sys
+from collections import OrderedDict
+
+import dns.resolver
+
+
+def checker(dns_val=None) -> OrderedDict:
+
+ ip_values = None
+ avail = False
+
+ if dns_val is None:
+ raise ValueError("Sorry DNS not found, DNS is needed")
+ if isinstance(dns_val, str) is False:
+ raise TypeError("Sorry, \'DNS\' must be type \'str\'")
+ try:
+ output = dns.resolver.resolve(dns_val, 'A')
+ ip_values = [ipval.to_text() for ipval in output]
+ except dns.resolver.NXDOMAIN:
+ avail = True
+
+ return OrderedDict([
+ ("DNS", dns_val),
+ ("IP", ip_values),
+ ("AVAIL", avail),
+ ])
+
+
+if __name__ == '__main__':
+ dns_val = None
+ option = None
+ print("Enter the DNS:")
+ dns_val=input()
+ try:
+ response = checker(dns_val=dns_val)
+ except Exception as err:
+ print(f"error: {err}")
+ sys.exit(1)
+
+ print(json.dumps(response, indent=4))
+ sys.exit(0)
\ No newline at end of file
diff --git a/DNS verifier/readme.MD b/DNS verifier/readme.MD
new file mode 100644
index 0000000000..2104ae565e
--- /dev/null
+++ b/DNS verifier/readme.MD
@@ -0,0 +1,39 @@
+# DNS VERIFIER
+## Description
+A Script to verify the Domain Name System.
+- This is useful to check for availability of DNS.
+
+## Language
+- [X] Python
+
+## Instructions to run this application
+
+ 1. Python 3 must be installed in your system.
+
+ - For first time, run this in terminal or powershell
+```
+pip3 install -r requirements.txt
+```
+ 2. It will download all the required modules
+
+ - Now run the below command
+
+Usage:
+
+```
+ python main.py
+```
+
+example:
+```
+ python main.py
+```
+
+Enter the DNS: gaana.com
+{
+ "DNS": "gaana.com",
+ "IP": [
+ "23.211.222.138"
+ ],
+ "AVAIL": false
+}
diff --git a/DNS verifier/requirements.txt b/DNS verifier/requirements.txt
new file mode 100644
index 0000000000..689e42ff8f
--- /dev/null
+++ b/DNS verifier/requirements.txt
@@ -0,0 +1 @@
+dnspython==2.0.0
\ No newline at end of file
diff --git a/Download-page-as-pdf/Readme.md b/Download-page-as-pdf/Readme.md
new file mode 100644
index 0000000000..b0ab79aa57
--- /dev/null
+++ b/Download-page-as-pdf/Readme.md
@@ -0,0 +1,24 @@
+# Download Page as PDF:
+
+Download a page as a PDF .
+
+ #### Required Modules :
+ - pyppdf
+ ```bash
+ pip3 install pyppdf
+ ```
+ - pyppyteer
+ ```bash
+ pip3 install pyppeteer
+ ```
+
+ #### Examples of use :
+ - Download a page:
+ ```bash
+ python download-page-as-pdf.py -l 'www.pudim.com.br'
+ ```
+
+ - Download a page and give a pdf name:
+ ```bash
+ python download-page-as-pdf.py -l 'http://www.pudim.com.br' -n 'pudim.pdf'
+ ```
diff --git a/Download-page-as-pdf/main.py b/Download-page-as-pdf/main.py
new file mode 100644
index 0000000000..5e26c87767
--- /dev/null
+++ b/Download-page-as-pdf/main.py
@@ -0,0 +1,42 @@
+#!/usr/bin/python
+# -*- coding: UTF-8 -*-
+
+import argparse
+import pyppdf
+import re
+from pyppeteer.errors import PageError, TimeoutError, NetworkError
+
+
+def main():
+ parser = argparse.ArgumentParser(description = 'Page Downloader as PDF')
+ parser.add_argument('--link', '-l', action = 'store', dest = 'link',
+ required = True, help = 'Inform the link to download.')
+ parser.add_argument('--name', '-n', action = 'store', dest = 'name',
+ required = False, help = 'Inform the name to save.')
+
+ arguments = parser.parse_args()
+
+ url = arguments.link
+
+ if not arguments.name:
+ name = re.sub(r'^\w+://', '', url.lower())
+ name = name.replace('/', '-')
+ else:
+ name = arguments.name
+
+ if not name.endswith('.pdf'):
+ name = name + '.pdf'
+
+ print(f'Name of the file: {name}')
+
+ try:
+ pyppdf.save_pdf(name, url)
+ except PageError:
+ print('URL could not be resolved.')
+ except TimeoutError:
+ print('Timeout.')
+ except NetworkError:
+ print('No access to the network.')
+
+if __name__ == '__main__':
+ main()
diff --git a/Download-page-as-pdf/requirements.txt b/Download-page-as-pdf/requirements.txt
new file mode 100644
index 0000000000..89960d9126
--- /dev/null
+++ b/Download-page-as-pdf/requirements.txt
@@ -0,0 +1,2 @@
+pyppdf==0.1.2
+pyppeteer==0.2.2
diff --git a/Email GUI/Readme.md b/Email GUI/Readme.md
new file mode 100644
index 0000000000..25ccb7f969
--- /dev/null
+++ b/Email GUI/Readme.md
@@ -0,0 +1,37 @@
+# Email GUI
+
+[](https://forthebadge.com)
+
+## Email GUI Functionalities : 🚀
+
+- **To send email the less security option of sender's email must be turned on.**
+- Enter all the details like sender's email, password, Recipient's Email and message.
+- The script logs into the gmail account and then sends the message.
+
+## Select Stocks by volume Increase Instructions: 👨🏻💻
+
+### Step 1:
+
+ Open Termnial 💻
+
+### Step 2:
+
+ Locate to the directory where python file is located 📂
+
+### Step 3:
+
+ Run the command: python script.py/python3 script.py 🧐
+
+### Step 4:
+
+ Sit back and Relax. Let the Script do the Job. ☕
+
+### Requirements
+
+- smtplib
+- tkinter
+
+## Author
+
+[Amit Kumar Mishra](https://github.com/Amit366)
+
diff --git a/Email GUI/script.py b/Email GUI/script.py
new file mode 100644
index 0000000000..c9e41a5bc9
--- /dev/null
+++ b/Email GUI/script.py
@@ -0,0 +1,76 @@
+import smtplib
+from tkinter import *
+
+
+def send_message():
+
+ address_info = address.get()
+
+ email_body_info = email_body.get()
+
+ sender_info = sender_address.get()
+
+ password_info = password.get()
+
+ server = smtplib.SMTP('smtp.gmail.com',587)
+
+ server.starttls()
+
+ server.login(sender_info,password_info)
+
+ print("Login successful")
+
+ server.sendmail(sender_info,address_info,email_body_info)
+
+ print("Message sent")
+
+ address_entry.delete(0,END)
+ email_body_entry.delete(0,END)
+ password_entry.delete(0,END)
+ sender_address_entry.delete(0,END)
+
+
+gui = Tk()
+
+gui.geometry("500x500")
+
+gui.title("Email Sender App")
+
+heading = Label(text="Email Sender App",bg="yellow",fg="black",font="10",width="500",height="3")
+
+heading.pack()
+gui.configure(background = "light blue")
+
+sender_address_field = Label(text="Sender's Email :")
+sender_address_field.place(x=15,y=70)
+
+sender_address = StringVar()
+sender_address_entry = Entry(textvariable=sender_address,width="30")
+sender_address_entry.place(x=15,y=100)
+
+sender_password_field = Label(text="Sender's Password :")
+sender_password_field.place(x=15,y=140)
+
+password = StringVar()
+password_entry = Entry(textvariable=password,width="30")
+password_entry.place(x=15,y=170)
+
+address_field = Label(text="Recipient Email :")
+address_field.place(x=15,y=210)
+
+address = StringVar()
+address_entry = Entry(textvariable=address,width="30")
+address_entry.place(x=15,y=240)
+
+email_body_field = Label(text="Message :")
+email_body_field.place(x=15,y=280)
+
+email_body = StringVar()
+email_body_entry = Entry(textvariable=email_body,width="30")
+email_body_entry.place(x=15,y=320,height="30")
+
+button = Button(gui,text="Send Message",command=send_message,width="30",height="2",bg="grey")
+
+button.place(x=15,y=400)
+
+mainloop()
diff --git a/Facebook-DP-Downloader/Readme.md b/Facebook-DP-Downloader/Readme.md
new file mode 100644
index 0000000000..6667fe2654
--- /dev/null
+++ b/Facebook-DP-Downloader/Readme.md
@@ -0,0 +1,16 @@
+# Facebook Profile Picture Downloader
+
+Download the profile picture of any public profile on Facebook by its Facebook id.
++ +## How it works: + +* Just run the script by entering the Facebook id (valid Facebook-user-id) and get the profile-pictures stored in your local file. +* The Facebook id can be thought of as a unique Facebook-user-id of any profile existing on Facebook. +* This method allows to download profile pictures from only those profile, which are made public along with no profile picture guard set. +* The profiles begin to exist on Facebook from Facebook user id=4. No profile pictures will get downloaded for Facebook ids below 4, since there exists no such Facebook user id. +* The profile pictures will only get downloaded if the respective Facebook profile exists for the corresponding Facebook user id entered (the profile does may/may not exist for every numerical value). +* User-id-4 is for the Facebook id of [Mark Zuckerberg](https://en.wikipedia.org/wiki/Mark_Zuckerberg) +
+ +Script by [Anamika](https://github.com/noviicee) diff --git a/Facebook-DP-Downloader/fb_dp_downloader.py b/Facebook-DP-Downloader/fb_dp_downloader.py new file mode 100644 index 0000000000..b052957ecd --- /dev/null +++ b/Facebook-DP-Downloader/fb_dp_downloader.py @@ -0,0 +1,39 @@ +""" + Facebook-DP-Downloader + Download the profile picture of any public profile on Facebook + by just having it's Facebook id + +""" + +import os +import requests + +url="https://graph.facebook.com/{}/picture?type=large" + +""" This url is the url provided by the Facebook graph api +which helps to get to the profile picture of the corresponding Facebook id +{}==Facebook id +Facebook id denotes the unique user id of the Facebook profile +whose profile we are requesting +""" + +path = os.getcwd() +# get the path of the current working directory + +if not "fb_dps" in os.listdir(path): + os.mkdir("fb_dps") + +"""checks if the folder exists in the current working directory. +If it does not exist, then it gets created +""" + +fbid=int(input("Enter the Facebook-id to download it's profile picture: ")) +# the number should be a valid Facebook user id + +try: + result=requests.get(url.format(fbid)) + with open("fb_dps/{}_img.jpg".format(fbid),"wb") as file: + file.write(result.content) + +except: + print("There was some error") diff --git a/Facebook-DP-Downloader/requirements.txt b/Facebook-DP-Downloader/requirements.txt new file mode 100644 index 0000000000..b17731fd28 --- /dev/null +++ b/Facebook-DP-Downloader/requirements.txt @@ -0,0 +1,2 @@ +os +request \ No newline at end of file diff --git a/Facebook_Video_Downloader/Readme.md b/Facebook_Video_Downloader/Readme.md new file mode 100644 index 0000000000..79a6825259 --- /dev/null +++ b/Facebook_Video_Downloader/Readme.md @@ -0,0 +1,23 @@ +# Facebook Video Downloader + +A GUI downloader used to download Facebook video by providing URL of the Post + +## Installation + +> pip3 install -r requirements.txt + +## Usage +- Run command python3 script.py +- A GUI Will Appear +- Provide the URL of the Video in the field and click `Download`. + +## Output + +Downloaded video you desired in the same directory of the script. + +## Authors + +Written by [Sukriti-sood](https://www.github.com/Sukriti-sood). + + + diff --git a/Facebook_Video_Downloader/requirements.txt b/Facebook_Video_Downloader/requirements.txt new file mode 100644 index 0000000000..9d84d35885 --- /dev/null +++ b/Facebook_Video_Downloader/requirements.txt @@ -0,0 +1 @@ +requests==2.25.1 diff --git a/Facebook_Video_Downloader/script.py b/Facebook_Video_Downloader/script.py new file mode 100644 index 0000000000..24e6aad413 --- /dev/null +++ b/Facebook_Video_Downloader/script.py @@ -0,0 +1,139 @@ +# ALL Imports +import time +from tkinter.ttk import * +import tkinter as tk +from requests import get, HTTPError, ConnectionError +from re import findall +from urllib.parse import unquote +from threading import Thread +import queue +from queue import Empty + +def Invalid_Url(): + """ Sets Status bar label to error message """ + Status["text"] = "Invalid URL..." + Status["fg"] = "red" + +def get_downloadlink(url): + + url = url.replace("www", "mbasic") + try: + r = get(url, timeout=5, allow_redirects=True) + if r.status_code != 200: + raise HTTPError + a = findall("/video_redirect/", r.text) + if len(a) == 0: + print("[!] Video Not Found...") + exit(0) + else: + return unquote(r.text.split("?src=")[1].split('"')[0]) + except (HTTPError, ConnectionError): + print("[x] Invalid URL") + exit(1) + + + +def Download_vid(): + + # Validates Link and download Video + global Url_Val + url=Url_Val.get() + + Status["text"]="Downloading" + Status["fg"]="green" + + + # Validating Input + + if not "www.facebook.com" in url: + Invalid_Url() + return + + link=get_downloadlink(url) + + start_downloading() + + download_thread=VideoDownload(link) + download_thread.start() + monitor(download_thread) + + + +def monitor( download_thread): + """ Monitor the download thread """ + if download_thread.is_alive(): + + try: + bar["value"]=queue.get(0) + ld_window.after(10, lambda: monitor(download_thread)) + except Empty: + pass + + + +class VideoDownload(Thread): + + def __init__(self, url): + super().__init__() + + self.url = url + + def run(self): + """ download video""" + + # save the picture to a file + block_size = 1024 # 1kB + r = get(self.url, stream=True) + total_size = int(r.headers.get("content-length")) + + with open('video.mp4', 'wb') as file: + totaldata=0; + for data in r.iter_content(block_size): + totaldata+=len(data) + per_downloaded=totaldata*100/total_size + queue.put(per_downloaded) + bar['value'] = per_downloaded + file.write(data) + time.sleep(0.01) + file.close() + print("Download Finished") + + print("Download Complete !!!") + Status["text"] = "Finished!!" + Status["fg"] = "green" + + + +#start download +def start_downloading(): + bar["value"]=0; + +# GUI + +ld_window=tk.Tk() +ld_window.title("Facebook Video Downloader") +ld_window.geometry("400x300") + +# Label for URL Input +input_label= tk.Label(ld_window,text="Enter Facebook Video URL:") +input_label.pack() + +# Input of URL +Url_Val = tk.StringVar() +Url_Input = tk.Entry(ld_window, textvariable=Url_Val, font=("Calibri", 9)) +Url_Input.place( x=25,y=50, width=350) + +# Button for Download +Download_button = tk.Button(ld_window, text="Download", font=("Calibri", 9), command=Download_vid) +Download_button.place(x=100, y=100, width=200) + +# Progress Bar +bar = Progressbar(ld_window, length=350, style='grey.Horizontal.TProgressbar',mode='determinate') +bar.place(y=200,width=350,x=25) + +queue=queue.Queue() +# Text for Status of Downloading +Status = tk.Label(ld_window, text="Hello!! :D", fg="blue", font=("Calibri", 9), bd=1, relief=tk.SUNKEN, anchor=tk.W, padx=3) +Status.pack(side=tk.BOTTOM, fill=tk.X) + +ld_window.mainloop() \ No newline at end of file diff --git a/File Downloader/Readme.md b/File Downloader/Readme.md new file mode 100644 index 0000000000..6d92c60b14 --- /dev/null +++ b/File Downloader/Readme.md @@ -0,0 +1,29 @@ +# File Downloader + +This python script will help users to download any kind of files, irrespective of their size from the internet.
+You just need to have the url and you are good to go! + +## Setup instructions + +Just run the python script. +It will ask for the url of the file to be downloaded. +After providing the url, the corresponding file will be downloaded in no time. + +## Output + +You will be able to see the status of the file being downloaded. + + + + + + + + + + +The file will be stored locally after being downloaded. + +## Author(s) + +[Anamika](https://github.com/noviicee) diff --git a/File Downloader/file_downloader.py b/File Downloader/file_downloader.py new file mode 100644 index 0000000000..40940f0db7 --- /dev/null +++ b/File Downloader/file_downloader.py @@ -0,0 +1,40 @@ +""" + File Downloader + + This python script will help users to download any kind of files, irrespective of their size from the internet.
+ You just need to have the url and you are good to go! +""" +import os +import requests +from tqdm import tqdm +import math +import time + +url=input("Enter the url of the file you want to download: ") + +r=requests.get(url) +#receives data from the url + +file_size=int(r.headers['Content-Length']) +chunk_size=256 + +"""Chunk size is the +number of bytes downloaded at a time +""" + +r=requests.get(url,stream=True) + +"""streams=True ensures that +will not get data at once, but will get data one by one + +""" + +extension=(os.path.splitext(url))[-1] +file="file"+extension + +iterations=math.ceil(file_size/chunk_size) + +with open(file, "wb") as file: + for chunk in tqdm(r.iter_content(chunk_size=chunk_size),total=iterations): + time.sleep(0.5) + file.write(chunk) diff --git a/File Downloader/requirements.txt b/File Downloader/requirements.txt new file mode 100644 index 0000000000..0a9d8886f2 --- /dev/null +++ b/File Downloader/requirements.txt @@ -0,0 +1,5 @@ +os +requests +tqdm +math +time \ No newline at end of file diff --git a/FirebaseScripts/CredentialsHelper.py b/FirebaseScripts/CredentialsHelper.py new file mode 100644 index 0000000000..720b8c6137 --- /dev/null +++ b/FirebaseScripts/CredentialsHelper.py @@ -0,0 +1,53 @@ +import os + +from dotenv import load_dotenv + +dotenv_path = "./credentials.env" +load_dotenv(dotenv_path) + +firebaseConfig = { + "apiKey": "", + "authDomain": "", + "databaseURL": "", + "projectId": "", + "storageBucket": "", + "messagingSenderId": "", + "appId": "", + "measurementId": "" +} + + +def get_fireBase_credentials(): + try: + + # Accessing variables. + + apiKey = os.getenv('apiKey') + authDomain = os.getenv('authDomain') + databaseURL = os.getenv('databaseURL') + projectId = os.getenv('projectId') + storageBucket = os.getenv('storageBucket') + messagingSenderId = os.getenv('messagingSenderId') + appId = os.getenv('appId') + measurementId = os.getenv('measurementId') + credentials = [apiKey, authDomain, databaseURL, projectId, storageBucket, messagingSenderId, appId, + measurementId] + if any(not(credential) for credential in credentials): + raise ValueError("Value cannot be None ") + else: + firebaseConfig["apiKey"] = apiKey + firebaseConfig["authDomain"] = authDomain + firebaseConfig["databaseURL"] = databaseURL + firebaseConfig["projectId"] = projectId + firebaseConfig["storageBucket"] = storageBucket + firebaseConfig["messagingSenderId"] = messagingSenderId + firebaseConfig["appId"] = appId + firebaseConfig["measurementId"] = measurementId + + except: + print("error while getting the Keys ") + raise + + return firebaseConfig + +get_fireBase_credentials() \ No newline at end of file diff --git a/FirebaseScripts/Readme.md b/FirebaseScripts/Readme.md new file mode 100644 index 0000000000..f3e61eafb6 --- /dev/null +++ b/FirebaseScripts/Readme.md @@ -0,0 +1,66 @@ +## Script for Firebase Management for beginners + +This python script can be used to access or manage different features of firebase database by google. + +This provides features like : + +### Authentication + +1. Create new User +2. Sign In Used based on email or password +3. Authorize a new uer +4. email verification +5. reset password + +### Database : + +1. Create your Real Time Database +2. Retrieve Data from the Database +3. update Data +4. Delete Data + +Note : + +Firebase Real time database is an Non SQL based Database. + +### Storage : + +1. Retrieve Data +2. Send data +3. Download Data +4. Update / Delete Data + +Note : + +firebase Storage is used to store all the files/ non text based data in the Database. + +## Installation + +First of all install [python]("https://www.python.org/downloads/") on your system. +``` +pip install pyrebase4 +pip install firebase +``` +## Steps to Get your Firebase Credentials + +1. Go to [FireBase Console]("https://console.firebase.google.com/") +2. Sign in / Login with your Google Account or any other Account you prefer +3. after that in your window the option to create a new Project will be there go and create a new project +4. after that fill in the basic details like project name, etc +5. after that just go and click on add an App icon on the screen +6. in that select web app as the option +7. after that you will see some credentials that have been allocated by the Firebase Cloud service +8. just copy-paste them accordingly in credentials.env and Do + +## Learn more + +Learn more about firebase and its services [firebase]("https://firebase.google.com/") + +Learn more about pyrebase a wrapper framwork for firebase API's [pyrebase]("https://openbase.com/python/Pyrebase") + +### Made with ❤️ by Shantam Sultania + +You can find me at:- +[Linkedin](https://www.linkedin.com/in/shantam-sultania-737084175/) or [Github](https://github.com/shantamsultania) . + +Happy coding ❤️ . diff --git a/FirebaseScripts/credentials.env b/FirebaseScripts/credentials.env new file mode 100644 index 0000000000..7935b1a89b --- /dev/null +++ b/FirebaseScripts/credentials.env @@ -0,0 +1,9 @@ + +apiKey = "" +authDomain = "" +databaseURL = "" +projectId = "" +storageBucket = "" +messagingSenderId = "" +appId = "" +measurementId = "" diff --git a/FirebaseScripts/firebase_authentications.py b/FirebaseScripts/firebase_authentications.py new file mode 100644 index 0000000000..39c62d5dfd --- /dev/null +++ b/FirebaseScripts/firebase_authentications.py @@ -0,0 +1,53 @@ +import pyrebase + +import FirebaseScripts.CredentialsHelper as credentials + +firebase = pyrebase.initialize_app(credentials.get_fireBase_credentials()) + +auth = firebase.auth() + + +def create_user_with_token(): + token = auth.create_custom_token("enter the token here ") + print(token) + return token + + +def create_user_with_email(email, password): + user = auth.create_user_with_email_and_password(email, password) + print(user) + return user + + +def sign_in_user_with_email(email, password): + user = auth.sign_in_with_email_and_password(email=email, password=password) + print(user) + return user + + +def signIn_user_with_token(token): + user = auth.sign_in_with_custom_token(token) + print(user) + return user + + +def email_verifications(user): + verification = auth.send_email_verification(user["idToken"]) + print(verification) + return verification + + +def password_reset(email): + password_rest = auth.send_password_reset_email(email) + print(password_rest) + return password_rest + + +def get_user_account_info(user): + info = auth.get_account_info(user["idToken"]) + print(info) + return info + + +if __name__ == "__main__": + create_user_with_email("email here ", "password here ") diff --git a/FirebaseScripts/firebase_database.py b/FirebaseScripts/firebase_database.py new file mode 100644 index 0000000000..21a09f5a73 --- /dev/null +++ b/FirebaseScripts/firebase_database.py @@ -0,0 +1,55 @@ +import pyrebase + +import FirebaseScripts.CredentialsHelper as credentials + +firebase = pyrebase.initialize_app(credentials.get_fireBase_credentials()) + +database = firebase.database() + + +def create_data_path(): + response = database.child("testdata") + print(response) + return response + + +def add_data(data): + response = database.child("testdata").push(data) + print(response) + return response + + +def set_key_of_data(data): + response = database.child("testdata").child("newKey").set(data) + print(response) + return response + + +def update_data(updateData): + response = database.child("testdata").child("newKey").update(updateData) + print(response) + return response + + +def delete_data(key): + response = database.child("testdata").child(key).remove() + print(response) + return response + + +def retrieve_data(): + response = database.child("testdata").get() + print("data " + str(response)) + print("Keys : " + str(response.key())) + print("Values : " + str(response.val())) + return response + + +def print_all_data(): + for i in retrieve_data().each(): + print(i.key()) + print(i.val()) + + +if __name__ == "__main__": + print_all_data() diff --git a/FirebaseScripts/firebase_storage.py b/FirebaseScripts/firebase_storage.py new file mode 100644 index 0000000000..39742d480a --- /dev/null +++ b/FirebaseScripts/firebase_storage.py @@ -0,0 +1,29 @@ +import pyrebase + +import FirebaseScripts.CredentialsHelper as credentials + +firebase = pyrebase.initialize_app(credentials.get_fireBase_credentials()) + +storage = firebase.storage() + + +def send_file(firebase_path, source_path): + response = storage.child(firebase_path).put(source_path) + print(response) + return response + + +def delete_file(firebase_path, name_of_file_to_delete): + response = storage.child(firebase_path).delete(name_of_file_to_delete) + print(response) + return response + + +def download_file(firebase_path, file_name): + response = storage.child(firebase_path).download(path="./", filename=file_name) + print(response) + return response + + +if __name__ == "__main__": + download_file("enter your path here ", "enter your file name here ") diff --git a/FirebaseScripts/requirements.txt b/FirebaseScripts/requirements.txt new file mode 100644 index 0000000000..c26f5613e4 --- /dev/null +++ b/FirebaseScripts/requirements.txt @@ -0,0 +1,2 @@ +pyrebase4==4.4.3 +firebase=3.0.1 \ No newline at end of file diff --git a/GST Calculator/Readme.md b/GST Calculator/Readme.md new file mode 100644 index 0000000000..b2934e41b4 --- /dev/null +++ b/GST Calculator/Readme.md @@ -0,0 +1,40 @@ +# GST Calculator + +[](https://forthebadge.com) + +## GST Calculator Functionalities : 🚀 + +- This is a GST Calculator where the user enters the original price and net price and the script returns the GST percentage. + +## GST Calculator Instructions: 👨🏻💻 + +### Step 1: + + Open Termnial 💻 + +### Step 2: + + Locate to the directory where python file is located 📂 + +### Step 3: + + Run the command: python script.py/python3 script.py 🧐 + +### Step 4: + + Sit back and Relax. Let the Script do the Job. ☕ + +## Requirements + + - tkinter + +## DEMO + + +- re +- requests +- urllib.request + +## Author + +[Amit Kumar Mishra](https://github.com/Amit366) diff --git a/GST Calculator/script.py b/GST Calculator/script.py new file mode 100644 index 0000000000..20445e1a87 --- /dev/null +++ b/GST Calculator/script.py @@ -0,0 +1,72 @@ +from tkinter import * + +# Function for finding GST rate +def GST_Calc() : + + gst_percentField.delete(0, END) + + org_cost= int(original_priceField.get()) + + N_price = int(net_priceField.get()) + + gst_rate = ((N_price - org_cost) * 100) / org_cost; + + gst_percentField.insert(10, str(gst_rate) + " % ") + +def clearAll(): + + original_priceField.delete(0, END) + + net_priceField.delete(0, END) + + gst_percentField.delete(0, END) + + +# Driver Code +if __name__ == "__main__" : + + gui = Tk() + + gui.configure(background = "light blue") + + gui.title("GST Calculator") + + gui.geometry("500x500") + + original_price = Label(gui, text = "Original Price", + font=(None,18)) + + original_price.grid(row = 1, column = 1,padx = 10,pady = 10,sticky='w') + + original_priceField = Entry(gui) + + original_priceField.grid(row = 1, column = 2 ,padx = 10,pady = 10,sticky='w') + + + net_price = Label(gui, text = "Net Price", + font=(None,18)) + + net_price.grid(row = 2, column = 1, padx = 10, pady = 10,sticky='w') + net_priceField = Entry(gui) + net_priceField.grid(row = 2, column = 2, padx = 10,pady = 10,sticky='w') + + + find = Button(gui, text = "Find", fg = "Black", + bg = "light yellow", + command = GST_Calc) + find.grid(row = 3, column = 2,padx = 10,pady = 10,sticky='w') + + gst_percent = Label(gui, text = "Gst Rate", font=(None,18)) + gst_percent.grid(row = 4, column = 1,padx = 10, pady = 10,sticky='w') + gst_percentField = Entry(gui) + + gst_percentField.grid(row = 4, column = 2, padx = 10,pady = 10,sticky='w') + + clear = Button(gui, text = "Clear", fg = "Black", + bg = "light yellow", + command = clearAll) + + clear.grid(row = 5, column = 2, padx = 10, pady = 10,sticky='w') + + # Start the GUI + gui.mainloop() diff --git a/Github-User-Scraper/README.md b/Github-User-Scraper/README.md new file mode 100644 index 0000000000..c9682d8ae3 --- /dev/null +++ b/Github-User-Scraper/README.md @@ -0,0 +1,26 @@ +# Github Trending Users Fetcher +Running this Script would allow the user to fetch trending github users based on choice of language (Python, Java etc) or time frame (daily, monthly or weekly trending users) + +## Setup instructions +In order to run this script, you need to have Python and pip installed on your system. After you're done installing Python and pip, run the following command from your terminal to install the requirements from the same folder (directory) of the project. +``` +pip install -r requirements.txt +``` +After satisfying all the requirements for the project, Open the terminal in the project folder and run +``` +python scraper.py +``` +or +``` +python3 scraper.py +``` +depending upon the python version. Make sure that you are running the command from the same virtual environment in which the required modules are installed. + +## Output + +The user can choose the language they want to scrape trending users for and the time frame as well. + + + +## Author +[Ayush Jain](https://github.com/Ayushjain2205) \ No newline at end of file diff --git a/Github-User-Scraper/requirements.txt b/Github-User-Scraper/requirements.txt new file mode 100644 index 0000000000..a98ae430c4 --- /dev/null +++ b/Github-User-Scraper/requirements.txt @@ -0,0 +1,2 @@ +requests +beautifulsoup4 \ No newline at end of file diff --git a/Github-User-Scraper/scraper.py b/Github-User-Scraper/scraper.py new file mode 100644 index 0000000000..93b6715722 --- /dev/null +++ b/Github-User-Scraper/scraper.py @@ -0,0 +1,194 @@ +import requests +from bs4 import BeautifulSoup +import tkinter as tk +from tkinter import ttk +from tkinter import font as tkFont +from tkinter import messagebox, simpledialog +import sqlite3 +from sqlite3 import Error +import time +import datetime + +# Dictionary for date values +dates = {'Today':'daily','This week':'weekly','This month':'monthly'} + +# Function to connect to the SQL Database +def sql_connection(): + try: + con = sqlite3.connect('./Github-User-Scraper/githubUsers.db') + return con + except Error: + print(Error) + + +# Function to create table +def sql_table(con): + cursorObj = con.cursor() + cursorObj.execute( + "CREATE TABLE IF NOT EXISTS users(name text, profile_link text, date_range text, repo text, repo_lang text, repo_link text)") + con.commit() + +# Call functions to connect to database and create table +con = sql_connection() +sql_table(con) + +# Function to insert into table +def sql_insert(con, entities): + cursorObj = con.cursor() + cursorObj.execute( + 'INSERT INTO users(name, profile_link, date_range, repo, repo_lang, repo_link) VALUES(?, ?, ?, ?, ?, ?)', entities) + con.commit() + +# Function to fetch data from DB +def sql_fetch(con): + cursorObj = con.cursor() + try: + cursorObj.execute('SELECT DISTINCT * FROM users ORDER BY rowid DESC') # SQL search query + except Error: + print("Database empty... Fetch courses using fetcher script") + return + + rows = cursorObj.fetchall() + display_text = "" + + # Show messagebox incase of empty DB + if len(rows) == 0 : + messagebox.showinfo("Alert", "No users scraped yet!") + return " " + + first_row = "{:^30}".format("Name") + "{:^40}".format("Profile Link") + "{:^30}".format("Date Range") + "{:^30}".format("Top Repo") + "{:^20}".format("Repo Lang") + "{:^30}".format("Repo Link") + '\n' + display_text += first_row + + # Format rows + for row in rows: + name = "{:<30}".format(row[0]) + profile_link = "{:<40}".format( + row[1] if len(row[1]) < 30 else row[1][:26]+"...") + date_range = "{:<30}".format( + row[2] if len(row[2]) < 30 else row[2][:26]+"...") + repo = "{:<30}".format( + row[3] if len(row[3]) < 30 else row[3][:26]+"...") + repo_lang = "{:^20}".format( + row[4] if len(row[4]) < 30 else row[4][:26]+"...") + repo_link = "{:<30}".format( + row[5] if len(row[5]) < 30 else row[5][:26]+"...") + display_text += (name + profile_link + date_range + repo + repo_lang + repo_link + '\n') + + return display_text + + +# Function to generate URL based on choice +def get_URL(): + url_lang = language.get() + url_date = dates[date.get()] + url = 'https://github.com/trending/developers/{}?since={}'.format(url_lang.lower(), url_date) + return url + +def scrape_users(): + url_lang = language.get() + date_range = date_helper() + url = get_URL() + page = requests.get(url) + + # Start scraping resultant html data + soup = BeautifulSoup(page.content, 'html.parser') + users = soup.find_all('article', {'class': 'Box-row d-flex'}) + for user in users: + progress['value'] += 10 + window.update_idletasks() + name = user.find('h1', {'class': 'h3 lh-condensed'}).text.strip() + profile_link = 'https://github.com{}'.format(user.find('h1', {'class': 'h3 lh-condensed'}).find('a')['href']) + repo = user.find('h1', {'class': 'h4 lh-condensed'}).text.strip() + repo_link = 'https://github.com{}'.format(user.find('h1', {'class': 'h4 lh-condensed'}).find('a')['href']) + entities = (name, profile_link, date_range, repo, url_lang, repo_link) + sql_insert(con, entities) + + #set progress bar back to 0 + progress['value'] = 0 + window.update_idletasks() + messagebox.showinfo("Success!", "Users scrapped successfully!") + +def show_results(): + display_text = sql_fetch(con) + query_label.config(state=tk.NORMAL) + query_label.delete(1.0, "end") + query_label.insert(1.0, display_text) + query_label.config(state=tk.DISABLED) + +def date_helper(): + date_range_type = dates[date.get()] + today = datetime.date.today() + if date_range_type == 'daily': + formatted = today.strftime("%d/%m/%Y") + return formatted + elif date_range_type == 'weekly': + from_date = ( datetime.date.today() - datetime.timedelta(days = 7)) + formatted_today = today.strftime("%d/%m/%Y") + formatted_from_date = from_date.strftime("%d/%m/%Y") + return "{} - {}".format(formatted_from_date,formatted_today) + else: + month = today.strftime("%B") + return month + + +# Creating tkinter window +window = tk.Tk() +window.title('Github Trending User Fetcher') +window.geometry('1400x1000') +window.configure(bg='white') + +style = ttk.Style() +style.configure('my.TButton', font=('Helvetica', 16)) +style.configure('my.TFrame', background='white') + +# label text for title +ttk.Label(window, text="Trending Github Users", + background='white', foreground="Blue", + font=("Helvetica", 30, 'bold')).grid(row=0, column=1) + +# label for combobox +ttk.Label(window, text="Select Language:", background = 'white', + font=("Helvetica", 15)).grid(column=0, + row=5, padx=10, pady=25) +ttk.Label(window, text="Select Date range:", background = 'white', + font=("Helvetica", 15)).grid(column=2, + row=5, padx=10, pady=25) + +# Combobox creation +language = ttk.Combobox( + window, width=30, state='readonly', font="Helvetica 15") +date = ttk.Combobox( + window, width=20, state='readonly',font="Helvetica 15") + +# Button creation +scrape_btn = ttk.Button(window, text="Scrape Users!", style='my.TButton', command = scrape_users) + +display_btn = ttk.Button(window, text="Display from DB", style='my.TButton', command = show_results) + +# Adding combobox drop down list +language['values'] = ('C++', 'HTML', 'Java', 'Javascript', 'PHP', 'Python', 'Ruby', 'C#', 'C', 'Dockerfile', 'JSON', 'Julia', 'Dart' + 'Shell','Solidity','YAML') + +date['values'] = ('Today','This week','This month') + +# Progress bar +progress = ttk.Progressbar(window, orient="horizontal", length=200, mode="determinate") +progress.grid(row=5, column=5, pady=5, padx=15, ipadx=5) + +language.grid(column=1, row=5, padx=10) +language.current(0) + +date.grid(column=3, row=5, padx=10) +date.current(0) + +scrape_btn.grid(row=5, column=4, pady=5, padx=15, ipadx=5) +display_btn.grid(row=7, column=2, pady=5, padx=15, ipadx=5) + +frame = ttk.Frame(window, style='my.TFrame') +frame.place(relx=0.50, rely=0.18, relwidth=0.98, relheight=0.90, anchor="n") + +# To display stock data +query_label = tk.Text(frame ,height="52" ,width="500", bg="alice blue") +query_label.grid(row=10, columnspan=2) + +window.mainloop() diff --git a/Google-Classroom-Bot/requirements.txt b/Google-Classroom-Bot/requirements.txt index 3959f29ba7..dfd72186cb 100644 --- a/Google-Classroom-Bot/requirements.txt +++ b/Google-Classroom-Bot/requirements.txt @@ -1,2 +1,2 @@ selenium==3.141.0 -urllib3==1.25.10 +urllib3==1.26.5 diff --git a/Hashnode-Scraper/README.md b/Hashnode-Scraper/README.md new file mode 100644 index 0000000000..f1b017a1b3 --- /dev/null +++ b/Hashnode-Scraper/README.md @@ -0,0 +1,31 @@ +# Hashnode Scrapper +Running this Script would allow the user to scrape any number of blogs from [hashnode.com](https://hashnode.com/) from any category as per the user's choice + +## Setup instructions +In order to run this script, you need to have Python and pip installed on your system. After you're done installing Python and pip, run the following command from your terminal to install the requirements from the same folder (directory) of the project. +``` +pip install -r requirements.txt +``` +As this script uses selenium, you will need to install the chrome webdriver from [this link](https://sites.google.com/a/chromium.org/chromedriver/downloads) + +After satisfying all the requirements for the project, Open the terminal in the project folder and run +``` +python scraper.py +``` +or +``` +python3 scraper.py +``` +depending upon the python version. Make sure that you are running the command from the same virtual environment in which the required modules are installed. + +## Output +The user needs to enter Category and Number of blogs to scrape + + + +The scraped pdf files get saved in the folder in which the script is run + + + +## Author +[Ayush Jain](https://github.com/Ayushjain2205) \ No newline at end of file diff --git a/Hashnode-Scraper/requirements.txt b/Hashnode-Scraper/requirements.txt new file mode 100644 index 0000000000..e29506e0fe --- /dev/null +++ b/Hashnode-Scraper/requirements.txt @@ -0,0 +1,4 @@ +requests +beautifulsoup4 +selenium +fpdf \ No newline at end of file diff --git a/Hashnode-Scraper/scraper.py b/Hashnode-Scraper/scraper.py new file mode 100644 index 0000000000..d433c68c0d --- /dev/null +++ b/Hashnode-Scraper/scraper.py @@ -0,0 +1,86 @@ +import requests +from bs4 import BeautifulSoup +from selenium import webdriver +from selenium.webdriver.common.keys import Keys +import time +from fpdf import FPDF + +# Get input for category and number of articles +category = input("Enter category: ") +number_articles = int(input("Enter number of articles: ")) +driver_path = input('Enter chrome driver path: ') + +url = 'https://hashnode.com/search?q={}'.format(category) + +# initiating the webdriver. Parameter includes the path of the webdriver. +driver = webdriver.Chrome(driver_path) +driver.get(url) + +# this is just to ensure that the page is loaded +time.sleep(5) +html = driver.page_source + +# Now apply bs4 to html variable +soup = BeautifulSoup(html, "html.parser") +results_div = soup.find('div', {'class': 'pb-20'}) +blogs = results_div.find('div') + +# Getting articles from dev.to +count = 0 +for blog in blogs: + + # If div is not a blog then skip + check_blog = blog.find('a')['href'] + if check_blog[0] == '/': + continue + + # If div is blog then start scraping individual blogs + blog_link = blog.find('a', class_='items-start')['href'] + post_url = blog_link + driver.get(post_url) + time.sleep(5) + + post_html = driver.page_source + soup = BeautifulSoup(post_html, "html.parser") + title = soup.find('h1', itemprop = 'headline name').text + author = soup.find('span', itemprop = 'name').text + + # Post content found + blog_content_body = soup.find( + 'div', itemprop='text') + content_tags = blog_content_body.find_all(['p','h2','h3','h4']) + + title_string = (title.strip()).encode( + 'latin-1', 'replace').decode('latin-1') + author_string = ("By - {}".format(author.strip()) + ).encode('latin-1', 'replace').decode('latin-1') + + # Add a page + pdf = FPDF() + pdf.add_page() + # set style and size of font + pdf.set_font("Arial", size=12) + + # Blog Title cell + pdf.cell(200, 5, txt=title_string, ln=1, align='C') + # Blog Author cell + pdf.cell(200, 10, txt=author_string, ln=2, align='C') + + for tag in content_tags: + article_part = (tag.text.strip()).encode( + 'latin-1', 'replace').decode('latin-1') + # Add part of article to pdf + pdf.multi_cell(0, 5, txt=article_part, align='L') + + # Trim title + title = title if len(title) < 30 else title[:30] + + # save the pdf with name .pdf + pdf_title = ''.join(e for e in title if e.isalnum()) + pdf.output("{}.pdf".format(pdf_title)) + + count = count + 1 + if(count == number_articles): + break + +driver.close() # closing the webdriver diff --git a/Image Contrast Adjusting Filter/Image Contrast Adjusting Filter.py b/Image Contrast Adjusting Filter/Image Contrast Adjusting Filter.py new file mode 100644 index 0000000000..5b154bb497 --- /dev/null +++ b/Image Contrast Adjusting Filter/Image Contrast Adjusting Filter.py @@ -0,0 +1,67 @@ +import numpy as np +import matplotlib.pyplot as plt +from PIL import Image +import os.path + +img_path = input("Enter the path here: ") #example -> C:\Users\xyz\OneDrive\Desktop\project\image.jpg +img = Image.open(img_path) + +# convert our image into a numpy array +img = np.asarray(img) +#print(img.shape) +# put pixels in a 1D array by flattening out img array +flat = img.flatten() + +# create our own histogram function +def get_histogram(image, bins): + # array with size of bins, set to zeros + histogram = np.zeros(bins) + + # loop through pixels and sum up counts of pixels + for pixel in image: + histogram[pixel] += 1 + + # return our final result + return histogram + +# execute our histogram function +hist = get_histogram(flat, 256) + +# execute the fn +cs = np.cumsum(hist) + +# numerator & denomenator +nj = (cs - cs.min()) * 255 +N = cs.max() - cs.min() + +# re-normalize the cumsum +cs = nj / N + +# cast it back to uint8 since we can't use floating point values in images +cs = cs.astype('uint8') + +# get the value from cumulative sum for every index in flat, and set that as img_new +img_new = cs[flat] + +# put array back into original shape since we flattened it +img_new = np.reshape(img_new, img.shape) + +# set up side-by-side image display +fig = plt.figure() +fig.set_figheight(15) +fig.set_figwidth(15) + +# display the real image +fig.add_subplot(1,2,1) +plt.imshow(img, cmap='gray') +plt.title("Image 'Before' Contrast Adjustment") + +# display the new image +fig.add_subplot(1,2,2) +plt.imshow(img_new, cmap='gray') +plt.title("Image 'After' Contrast Adjustment") +filename = os.path.basename(img_path) + +plt.savefig("./Image Contrast Adjusting Filter/(Contrast Adjusted)"+filename) + +plt.show() diff --git a/Image Contrast Adjusting Filter/Images/Result.jpg b/Image Contrast Adjusting Filter/Images/Result.jpg new file mode 100644 index 0000000000..2966308a34 Binary files /dev/null and b/Image Contrast Adjusting Filter/Images/Result.jpg differ diff --git a/Image Contrast Adjusting Filter/README.md b/Image Contrast Adjusting Filter/README.md new file mode 100644 index 0000000000..e77252f87b --- /dev/null +++ b/Image Contrast Adjusting Filter/README.md @@ -0,0 +1,28 @@ +# Image Contrast Adjusting Filter + +Images captured in dim light mostly not have a much better contrast so an (Image Contrast Adjusting filter) filter helps accordingly to adjusts and increase its contrast and hence we are having a better version of the image. Hence this filter helps to get a high contrast image. + +## Libraries used +Firstly import the following python libraries +* Matplotlib, +* NumPy +* PIL +Save the image and your code in the same folder +Run the python code + +## Detailed explanation of the method used + +* Imported the required libraries ( Numpy, Matplotlib, PIL, IPython.display) +* Read the input image using Image from PIL library +* Converted the image into an array and then flatten it making it a 1d array +* Count the number of occurance of each pixel in the image and hence getting an array of frequency count of each pixels +* Then making cdf from the frequency count list +* Normalizing the cdf +* Converting the cdf shape into the shape of given image +* Finally converted the image into contrast adjusted image + +## Comparison With The Result +
 +
+## Author(s)
+[Akriti](https://github.com/A-kriti)
diff --git a/Image Contrast Adjusting Filter/requirements.txt b/Image Contrast Adjusting Filter/requirements.txt
new file mode 100644
index 0000000000..d5d0c5b6ff
--- /dev/null
+++ b/Image Contrast Adjusting Filter/requirements.txt
@@ -0,0 +1,3 @@
+numpy==1.18.5
+matplotlib==3.2.2
+Pillow==8.2.0
diff --git a/Image-scrape-download/README.md b/Image-scrape-download/README.md
new file mode 100644
index 0000000000..2315bf8eb8
--- /dev/null
+++ b/Image-scrape-download/README.md
@@ -0,0 +1,26 @@
+# Image viewer and downloader
+Running this Script would allow the user to search for any image by entering a search query, the image will then be scraped and displayed in the GUI, and providing an option to download the image as well
+
+## Setup instructions
+In order to run this script, you need to have Python and pip installed on your system. After you're done installing Python and pip, run the following command from your terminal to install the requirements from the same folder (directory) of the project.
+```
+pip install -r requirements.txt
+```
+After satisfying all the requirements for the project, Open the terminal in the project folder and run
+```
+python image.py
+```
+or
+```
+python3 image.py
+```
+depending upon the python version. Make sure that you are running the command from the same virtual environment in which the required modules are installed.
+
+## Output
+
+The user can enter the search query in the input box and then the image will be displayed as shown in the screenshot below
+
+
+
+## Author
+[Ayush Jain](https://github.com/Ayushjain2205)
\ No newline at end of file
diff --git a/Image-scrape-download/image.py b/Image-scrape-download/image.py
new file mode 100644
index 0000000000..e0f8842c24
--- /dev/null
+++ b/Image-scrape-download/image.py
@@ -0,0 +1,73 @@
+# Import Module
+from tkinter import *
+from tkhtmlview import HTMLLabel
+from tkinter import ttk
+from tkinter import font as tkFont
+import requests
+from bs4 import BeautifulSoup
+import urllib3
+import shutil
+
+# Function to save image to the users file system
+def saveImage():
+ file_name = search_box.get().replace(" ","")
+ image_file = getImage()
+ http = urllib3.PoolManager()
+ with open(file_name, 'wb') as out:
+ r = http.request('GET', image_file, preload_content=False)
+ shutil.copyfileobj(r, out)
+
+# Function to scrape image source from bing
+def getImage():
+ search = search_box.get()
+ url = "https://www.bing.com/images/search?q={}".format(search.replace(' ','?'))
+ page = requests.get(url)
+
+ # Start scraping resultant html data
+ soup = BeautifulSoup(page.content, 'html.parser')
+ images_div = soup.find('div',{'id':'mmComponent_images_2'})
+ images_ul = images_div.find('ul')
+
+ image = images_ul.find("li")
+ link = image.find('img').get('src')
+
+ return link
+
+# Function to show image in the GUI
+def showImage():
+ link = getImage()
+ str_value = '
+
+## Author(s)
+[Akriti](https://github.com/A-kriti)
diff --git a/Image Contrast Adjusting Filter/requirements.txt b/Image Contrast Adjusting Filter/requirements.txt
new file mode 100644
index 0000000000..d5d0c5b6ff
--- /dev/null
+++ b/Image Contrast Adjusting Filter/requirements.txt
@@ -0,0 +1,3 @@
+numpy==1.18.5
+matplotlib==3.2.2
+Pillow==8.2.0
diff --git a/Image-scrape-download/README.md b/Image-scrape-download/README.md
new file mode 100644
index 0000000000..2315bf8eb8
--- /dev/null
+++ b/Image-scrape-download/README.md
@@ -0,0 +1,26 @@
+# Image viewer and downloader
+Running this Script would allow the user to search for any image by entering a search query, the image will then be scraped and displayed in the GUI, and providing an option to download the image as well
+
+## Setup instructions
+In order to run this script, you need to have Python and pip installed on your system. After you're done installing Python and pip, run the following command from your terminal to install the requirements from the same folder (directory) of the project.
+```
+pip install -r requirements.txt
+```
+After satisfying all the requirements for the project, Open the terminal in the project folder and run
+```
+python image.py
+```
+or
+```
+python3 image.py
+```
+depending upon the python version. Make sure that you are running the command from the same virtual environment in which the required modules are installed.
+
+## Output
+
+The user can enter the search query in the input box and then the image will be displayed as shown in the screenshot below
+
+
+
+## Author
+[Ayush Jain](https://github.com/Ayushjain2205)
\ No newline at end of file
diff --git a/Image-scrape-download/image.py b/Image-scrape-download/image.py
new file mode 100644
index 0000000000..e0f8842c24
--- /dev/null
+++ b/Image-scrape-download/image.py
@@ -0,0 +1,73 @@
+# Import Module
+from tkinter import *
+from tkhtmlview import HTMLLabel
+from tkinter import ttk
+from tkinter import font as tkFont
+import requests
+from bs4 import BeautifulSoup
+import urllib3
+import shutil
+
+# Function to save image to the users file system
+def saveImage():
+ file_name = search_box.get().replace(" ","")
+ image_file = getImage()
+ http = urllib3.PoolManager()
+ with open(file_name, 'wb') as out:
+ r = http.request('GET', image_file, preload_content=False)
+ shutil.copyfileobj(r, out)
+
+# Function to scrape image source from bing
+def getImage():
+ search = search_box.get()
+ url = "https://www.bing.com/images/search?q={}".format(search.replace(' ','?'))
+ page = requests.get(url)
+
+ # Start scraping resultant html data
+ soup = BeautifulSoup(page.content, 'html.parser')
+ images_div = soup.find('div',{'id':'mmComponent_images_2'})
+ images_ul = images_div.find('ul')
+
+ image = images_ul.find("li")
+ link = image.find('img').get('src')
+
+ return link
+
+# Function to show image in the GUI
+def showImage():
+ link = getImage()
+ str_value = 'Markdown Viewer
") +result.pack(fill=BOTH, expand=1, side=RIGHT, padx=10, pady=10) + + +window.mainloop() diff --git a/Master Script/datastore.json b/Master Script/datastore.json index a9d6dad8f6..5efee3ebf4 100644 --- a/Master Script/datastore.json +++ b/Master Script/datastore.json @@ -1 +1 @@ -{"Calculators": {"Age calculator": ["Age-Calculator-GUI", "age_calc_gui.py", "none", "none", "mehabhalodiya", "users can type in their date of birth, and the app will calculate and display their age."], "BMI calculator": ["BMI-Calculator-GUI", "BMI_Calculator.py", "none", "none", "vybhav72954", "Calculates Your Body Mass Index for your health fitness."], "Binary calculator": ["Binary-Calculator-GUI", "script.py", "none", "none", "vybhav72954", "A GUI based Standard Binary number calculator."], "Calculator GUI": ["Calculator-GUI", "script.py", "none", "none", "vybhav72954", "It is GUI based calculator used to calculate any simple mathematical equation."], "Calculator CLI": ["Calculator", "Calcy.py", "none", "none", "vybhav72954", "A CLI that is used to calculate any simple mathematical equation."], "Distance calculator": ["Distance-Calculator-GUI", "main.py", "none", "Distance-Calculator-GUI/requirements.txt", "vybhav72954", "This app calculates distance between two geo-locations."], "Cryptocurrency Converter": ["Crypocurrency-Converter-GUI", "main.py", "none", "Crypocurrency-Converter-GUI/requirements.txt", "vybhav72954", "A script that converts Cryptocurrency to real currency using GUI"], "Currency Convertor": ["Currency Convertor - GUI based", "Currency_convertor_GUI.py", "none", "none", "MayankkumarTank", "GUI-based Currency Convertor using Tkinter in python"], "Currency Exchange Rates": ["Currency-Exchange-Rates", "exchange_rates.py", "none", "none", "vybhav72954", "A script that converts an entered currency number to many possible equivalents in other currencies"], "Distance Converter": ["Distance Conversion GUI", "distance_conversion.py", "none", "none", "tanvi355", "This is a distance unit converter using which we can convert the distance from one unit to other."], "Weight Converter": ["Weight-Converter-GUI", "weight_con_gui.py", "none", "none", "mehabhalodiya", "a GUI based weight converter that accepts a kilogram input value and converts that value to Carat, Gram, Ounce, Pound, Quintal and Tonne"], "Shortest-Path-Finder": ["Shortest-Path-Finder (GUI)", "Shortest Path Finder.py", "none", "none", "ImgBotApp", "Shortest Path finder is a GUI application which finds the shortest possible path between two points placed by the user on the board."], "Smart calcy": ["Smart calcy", "Smart_calcy.py", "none", "none", "Yuvraj-kadale", "Hey!! I am Smart calculator and my name is Genius. Genius is a Smart GUI calculator that can read English and perform the mathematical task given or simple word problems."], "Applying Bitwise Operations": ["Applying Bitwise Operations", "Applying Bitwise operations.py", "none", "none", "undetectablevirus", "Applying Bitwise Operations on two images using OpenCV"], "Calculate Distance": ["Calculate-distance", "manage.py", "none", "Calculate-distance/requirements.txt", "pritamp17", "App that can show distance between user's location and searched location on map."], "Geo Cordinate Locator": ["Geo-Cordinate-Locator", "script.py", "none", "Geo-Cordinate-Locator/requirements.txt", "NChechulin", "Gets you current Longitude and Latitude when you provide your address."], "Base_N Calculator": ["Base-N_Calc", "script.py", "none", "none", "XZANATOL", "A GUI that will allow you to convert a number of base-X to base-Y as long as X&Y > 1."]}, "AI/ML": {"Air pollution prediction": ["Air pollution prediction", "CodeAP.py", "none", "none", "Pranjal-2001", "This helps you find the levels of Air pollution plotted graphically with a provided dataset."], "Bag of words": ["Bag of words model", "bow.py", "none", "none", "zaverisanya", "tokenize the sentences taken from user, transforming text to vectors where each word and its count is a feature, Create dataframe where dataframe is an analogy to excel-spreadsheet"], "Body detection": ["Body Detection", "detection.py", "none", "none", "Avishake007", "Detect your Body in video"], "corona cases forecasting": ["corona cases forecasting", "main.py", "none", "corona cases forecasting/requirements.txt", "ImgBotApp", "This is a python script capable of Predicting number of covid 19 cases for next 21 days"], "Covid 19 Detection": ["Covid -19-Detection-Using-Chest-X-Ray", "test.py", "none", "none", "vybhav72954", "This Script is all about to check wether the person is suffering from the covid-19or not."], "Face mask detection": ["Face-Mask-Detection", "face_mask_detection_using_cnn.py", "none", "none", "ImgBotApp", "Face mask detection model using tensorflow"], "Facial expression recognition": ["Facial-Expression-Recognition", "face-crop.py", "none", "none", "Debashish-hub", "Facial expression recognition is a technology which detects emotions in human faces. More precisely, this technology is a sentiment analysis tool and is able to automatically detect the basic or universal expressions: happiness, sadness, anger, surprise, fear, and disgust etc."], "Heart Disease prediction": ["Heart Disease Prediction", "script.py", "none", "Heart Disease Prediction/requirements.txt", "aaadddiii", "This python script uses a machine learning model to predict whether a person has heart disease or not."], "Message spam detection": ["Message_Spam_Detection", "Message_Spam_Detection.py", "none", "none", "Nkap23", "The python code contains script for message spam detection based on Kaggle Dataset (dataset link inside the code)"], "Message spam": ["Message-Spam", "messagespam.py", "none", "none", "vybhav72954", "This Script is all about to check wether the entered message is a spam or not spam using machine learning algorithm"], "Plagiarism Checker": ["Plagiarism-Checker", "plagiarism.py", "none", "none", "Anupreetadas", "In order to compute the simlilarity between two text documents"], "Remove POS Hindi text": ["Remove_POS_hindi_text", "hindi_POS_tag_removal.py", "none", "none", "ImgBotApp", "A script to remove POS Hindi text"], "Salary predictor": ["Salary Predictor", "model.py", "none", "none", "shreyasZ10", "This is basically a python script used to predict the average annual salary of person."], "Text Summary": ["Text_Summary", "text_summary.py", "none", "Text_Summary/requirements.txt", "vybhav72954", "Text Summarization is an advanced project and comes under the umbrella of Natural Language Processing. There are multiple methods people use in order to summarize text."], "Traffic Sign Detection": ["Traffic-Sign-Detection", "traffic_sign_detection.py", "none", "Traffic-Sign-Detection/requirements.txt", "vybhav72954", "Using German Traffic Sign Recognition Benchmark, in this script I have used Data Augmentation and then passed the images to miniVGGNet (VGG 7) a famous architecture of Convolutional Neural Network (CNN)."], "Document summary creator": ["Document-Summary-Creator", "main.py", "none", "Document-Summary-Creator/requirements.txt", "vybhav72954", "A python script to create a sentence summary"], "Reddit flair detection": ["Reddit-Scraping-And-Flair-Detection", "WebScrapping and PreProcessing.ipynb", "none", "none", "vybhav72954", "Through taking input URL from the user, the model will predict and return actual + predicted flairs from Reddit"], "Movie Genre Prediction": ["Movie-Genre-Prediction-Chatbot", "Movie_recommendation_Sentance_Embedding.ipynb", "none", "none", "hritik5102", "Chatbot with deep learning"], "Dominant Color Extraction": ["Dominant-Color-Extraction", "Dominant color Extraction.ipynb", "none", "Dominant-Color-Extraction/requirements.txt", "aryangulati", "Finding Dominant Colour: Finding Colour with Kmeans and giving appropriate colors to the pixel/data points of the image, In addition to analyzing them using K-means."], "Malaria": ["Malaria", "main.py", "none", "Malaria\\requirements.txt", "ayush-raj8", "script that predicts malaria based on input of cell image"]}, "Scrappers": {"Wikipedia Infobox Scraper": ["Wiki_Infobox_Scraper", "main.py", "none", "requirements.txt", "RohiniRG", "The given python script uses beautiful soup to scrape Wikipedia pages according to the given user query and obtain data from its Wikipedia infobox. This information will be presented along with a GUI."], "Amazon price alert": ["Amazon-Price-Alert", "amazon_scraper.py", "none", "Amazon-Price-Alert/requirements.txt", "dependabot", "web-scraper built on BeautifulSoup that alerts you when the price of an amazon prduct falls within your budget!"], "Amazon price tracker": ["Amazon-Price-Tracker", "amazonprice.py", "none", "none", "vybhav72954", "Tracks the current given product price."], "Animer tracker": ["Anime-Tracker", "anime_tracker.py", "none", "none", "vybhav72954", "This is a python script for giving information about the anime like information about anime , number of episodes released till date, Years active, Tags related to it."], "Bitcoin price tracker": ["BITCOIN-price-tracker", "tracker.py", "none", "none", "vybhav72954", "Python script that show's BITCOIN Price"], "CodeChef scrapper": ["Codechef Scrapper", "codechef.py", "none", "Codechef Scrapper/requirements.txt", "smriti26raina", "This python script will let the user to scrape 'n' number of codechef problems from any category/difficulty in https://www.codechef.com/ ,as provided by the user."], "Dev.to scrapper": ["Dev.to Scraper", "scraper.py", "none", "Dev.to Scraper/requirements.txt", "Ayushjain2205", "Running this Script would allow the user to scrape any number of articles from dev.to from any category as per the user's choice"], "extracting emails from website": ["extracting-emails-from-website", "emails-from-website", "none", "none", "ankurg132", "Scrapper to extract emails from a website"], "Facebook autologin": ["Facebook-Autologin", "facebookAuto.py", "none", "Facebook-Autologin/requirements.txt", "vybhav72954", "This is a python script that automates the facebook login process"], "Flipkart price alert": ["Flipkart-price-alert", "track.py", "none", "Flipkart-price-alert/requirements.txt", "Jade9ja", "Checks for the price of a desired product periodically. If the price drops below the desired amount, notifies the user via email."], "Football player club info": ["Football-Player-Club-Info", "main.py", "none", "none", "vybhav72954", "Gets info of a football player"], "Github contributor list size": ["Github-Size-Contributor-List", "script.py", "none", "none", "vybhav72954", "Makes an API call to the, \"Github API\" in order to retrieve the information needed. It retrieves the size of the repository and the number of contributors the repo has"], "Google news scrapper": ["Google-News-Scraapper", "app.py", "none", "Google-News-Scraapper/requirements.txt", "vybhav72954", "A python Automation script that helps to scrape the google news articles."], "Google search newsletter": ["Google-Search-Newsletter", "google-search-newsletter.py", "none", "Google-Search-Newsletter/requirements.txt", "vybhav72954", "Performs google search of topic stated in config file"], "IMDB scrapper": ["IMDB-Scraper", "scraper.py", "none", "none", "priyanshu20", "Collects the information given on IMDB for the given title"], "Instagram auto login": ["Insta-Autologin", "main.py", "none", "none", "vybhav72954", "Autologin for Instagram"], "Insta Auto SendMsg": ["Insta-Bot-Follow-SendMsg", "instabot.py", "none", "none", "vivek-2000", "Given a username if the Instagram account is public , will auto-follow and send msg."], "Insatgram Profile Pics downloader": ["Instagram downloader", "downloader.py", "none", "none", "Sloth-Panda", "This python script is used to download profile pics that are on instagram."], "Instagram Liker bot": ["Instagram Liker Bot", "Instagram_Liker_Bot.py", "none", "none", "sayantani11", "Given a username if the Instagram account is public or the posts are accessible to the operator, will auto-like all the posts on behalf and exit."], "Internshala Scraper": ["Internshala-Scraper", "program.py", "none", "Internshala-Scraper/requirements.txt", "vybhav72954", "Select field, select number of pages and the script saves internships to a csv."], "LinkedIn connectinos scrapper": ["Linkedin_Connections_Scrapper", "script.py", "none", "h-e-p-s", "XZANATOL", "It's a script built to scrap LinkedIn connections list along with the skills of each connection if you want to."], "LinkedIn email scrapper": ["Linkedin-Email-Scraper", "main.py", "none", "Linkedin-Email-Scraper/requirements.txt", "vybhav72954", "a script to scrap names and their corresponding emails from a post"], "Live cricket score": ["Live-Cricket-Score", "live_score.py", "none", "Live-Cricket-Score/requirements.txt", "vybhav72954", "This python script will scrap cricbuzz.com to get live scores of the matches."], "MonsterJobs scraper": ["MonsterJobs Scraper", "scraper.py", "none", "MonsterJobs Scraper/requirements.txt", "Ayushjain2205", "Running this Script would allow the user to scrape job openings from Monster jobs, based on their choice of location, job role, company or designation."], "Movie Info telegram bot": ["Movie-Info-Telegram-Bot", "bot.py", "none", "Movie-Info-Telegram-Bot/requirements.txt", "aish2002", "A telegram Bot made using python which scrapes IMDb website"], "Move recommendation": ["Movie-Recommendation", "script.py", "none", "none", "vybhav72954", "The Movie Titles are scraped from the IMDb list by using BeautifulSoup Python Library to recommend to the user."], "News scraper": ["News_Scrapper", "scrapper.py", "none", "none", "paulamib123", "This Script is used to get top 10 headlines from India Today based on the category entered by user and stores it in a CSV file."], "Price comparison and checker": ["Price Comparison and Checker", "price_comparison.py", "none", "Price Comparison and Checker/Requirements.txt", "aashishah", "This python script can automatically search for an item across Amazon, Flipkart and other online shopping websites and after performing comparisons, find the cheapest price available."], "Reddit meme scrapper": ["Reddit-Meme-Scraper", "script.py", "none", "Reddit-Meme-Scraper/requirements.txt", "vybhav72954", "This script locates and downloads images from several subreddits (r/deepfriedmemes, r/surrealmemes, r/nukedmemes, r/bigbangedmemes, r/wackytictacs, r/bonehurtingjuice) into your local system."], "Search username": ["Search-Username", "search_user.py", "none", "none", "vybhav72954", "This script of code, using request module, will help to determine weather, a username exists on a platform or not."], "Slideshare downloader": ["Slideshare downloader", "slideshare_downloader.py", "none", "Slideshare downloader/requirements.txt", "vikashkumar2020", "A Script to download slides from Slideshare as pdf from URL."], "Social media links extractor": ["Social-Media-Links-From-Website", "script.py", "none", "none", "vybhav72954", "The code filters out all the social media links like youtube, instagram, linkedin etc. from the provided website url and displays as the output."], "Temporary sign-up tool": ["Temporary-Sign-Up-Tool", "temp_sign_up_tool.py", "none", "Temporary-Sign-Up-Tool/requirement.md", "chaitanyabisht", "This script can be used when you want to Register or Sign Up to annoying websites or when you don't want to give out your personal data. As it provides you with a temporary username, email, and password to make your registration easy."], "Unfollowers Insta": ["Unfollowers-Insta", "insta_bot_bb8.py", "none", "Unfollowers-Insta/requirements.txt", "vybhav72954", "bb8 is a cute name for a great bot to check for the people that you follow who don't follow you back on Instagram."], "Weather app": ["Weather-App", "weatherapp.py", "none", "none", "NChechulin", "Gets the weather in your current location"], "Youtube Trending Feed Scrapper": ["Youtube Trending Feed Scrapper", "youtube_scrapper.py", "h-c-m", "none", "XZANATOL", "It's a 2 scripts that is used to scrap and read the first 10 trending news in YouTube from any its available categories."], "Zoom auto attend": ["Zoom-Auto-Attend", "zoomzoom.py", "none", "Zoom-Auto-Attend/requirements.txt", "dependabot", "A zoom bot that automatically joins zoom calls for you and saves the meeting id and password."], "Udemy Scraper": ["Udemy Scraper", "fetcher.py", "none", "Udemy Scraper/requirements.txt", "Ayushjain2205", "This script is used to scrape course data from udemy based on the category entered as input by the user"], "IPL Statistics": ["IPL Statistics GUI", "ipl.py", "none", "IPL Statistics GUI/requirements.txt", "Ayushjain2205", "Running this Script would allow the user see IPL statistics from various categories like most runs , most wickets etc from all seasons (2008 - 2020)"], "Covid India Stats App": ["Covid India Stats App", "app.py", "none", "none", "dsg1320", "COVID19 stats app for indian states which works using api call"], "Twitter Scraper without API": ["Twitter_Scraper_without_API", "fetch_hashtags.py", "none", "Twitter_Scraper_without_API/requirements.txt", "RohiniRG", "we make use of snscrape to scrape tweets associated with a particular hashtag. Snscrape is a python library that scrapes twitter without the use of API keys."], "Coderforces Problem Scrapper": ["Coderforces_Problem_Scrapper", "Codeforces_problem_scrapper.py", "none", "Coderforces_Problem_Scrapper\\requirements.txt", "iamakkkhil", "This python script will let you download any number of Problem Statements from Codeforces and save them as a pdf file."], "LeetCode Scraper": ["LeetCode-Scrapper", "ques.py", "none", "LeetCode-Scrapper\\requirements.txt", "AshuKV", "script will let the user to scrape 'n' number of LeetCode problems from any category/difficulty in Leetcode"], "NSE Stocks": ["NSE Stocks GUI", "stocks.py", "none", "NSE Stocks GUI\\requirements.txt", "Ayushjain2205", "Script would allow the user to go through NSE Stock data scraped from NSE Website"], "Social_Media": {"Automate Facebook bot": ["Automate Facebook bot", "script.py", "none", "none", "Amit366", "On running the script it posts your message in the groups whose id is given by the user"], "Creating Emoji": ["Creating-Emoji-Using-Python", "program.py", "none", "none", "vybhav72954", "This is python program to create emojis"], "Discord bot": ["Discord-Bot", "main.py", "none", "none", "vybhav72954", "This is a Discord bot built with Python"], "DownTube": ["DownTube-Youtube-Downloader", "DownTube.py", "h-a-p-u-f", "none", "XZANATOL", "DownTube is an on-to-go downloader for any bundle of Youtube links you want to download."], "Facebook Auto login": ["Facebook-Autologin", "facebookAuto.py", "none", "Facebook-Autologin/requirements.txt", "vybhav72954", "This is a python script that automates the facebook login process"], "Google Classroom": ["Google-Classroom-Bot", "gmeet_bot.py", "none", "Google-Classroom-Bot/requirements.txt", "vybhav72954", "This bot joins your classes for you on time automatically using your google classroom schedule and account credentials."], "Google meet scheduler": ["Google-Meet-Scheduler", "script.py", "none", "Google-Meet-Scheduler/requirements.txt", "Tarun-Kamboj", "The script here allows you to schedule a google meeting with multiple guests using python."], "Instagram Auto login": ["Insta-Autologin", "main.py", "none", "none", "vybhav72954", "Autologin for Instagram"], "Insta follow sendmsg bot": ["Insta-Bot-Follow-SendMsg", "instabot.py", "none", "none", "vivek-2000", "Given a username if the Instagram account is public , will auto-follow and send msg."], "Instagram downloader": ["Instagram downloader", "downloader.py", "none", "none", "Sloth-Panda", "This python script is used to download profile pics that are on instagram."], "Instagram liker bot": ["Instagram Liker Bot", "Instagram_Liker_Bot.py", "none", "none", "sayantani11", "Given a username if the Instagram account is public or the posts are accessible to the operator, will auto-like all the posts on behalf and exit."], "Instagram Profile Pic Downloader": ["Instagram-Profile-Pic-Downloader", "Instagram Profile Pic Downloader.py", "none", "none", "vybhav72954", "Instagram Profile Pic Downloader"], "LinkedIn Connections Scrapper": ["Linkedin_Connections_Scrapper", "script.py", "h-e-p-s", "none", "XZANATOL", "A script to scrap LinkedIn connections list along with the skills of each connection if you want to."], "LinkedIn Email Scrapper": ["Linkedin-Email-Scraper", "main.py", "none", "Linkedin-Email-Scraper/requirements.txt", "vybhav72954", "a script to scrap names and their corresponding emails from a post"], "Movie info Telegram bot": ["Movie-Info-Telegram-Bot", "bot.py", "none", "Movie-Info-Telegram-Bot/requirements.txt", "aish2002", "A telegram Bot made using python which scrapes IMDb website"], "Reddit meme scrapper": ["Reddit-Meme-Scraper", "script.py", "none", "Reddit-Meme-Scraper/requirements.txt", "vybhav72954", "This script locates and downloads images from several subreddits (r/deepfriedmemes, r/surrealmemes, r/nukedmemes, r/bigbangedmemes, r/wackytictacs, r/bonehurtingjuice) into your local system."], "Search Username": ["Search-Username", "search_user.py", "none", "none", "vybhav72954", "This script of code, using request module, will help to determine weather, a username exists on a platform or not."], "Social media links extractor": ["Social-Media-Links-From-Website", "script.py", "none", "none", "vybhav72954", "The code filters out all the social media links like youtube, instagram, linkedin etc. from the provided website url and displays as the output."], "Telegram bot": ["Telegram-Bot", "TelegramBot.py", "none", "none", "vybhav72954", "Create a bot in telegram"], "Tweet fetcher": ["Tweet-Fetcher", "fetcher.py", "none", "Tweet-Fetcher/requirements.txt", "Ayushjain2205", "This script is used to fetch tweets by a user specified hashtags and then store these tweets in a SQL database"], "Unfollowers Insta": ["Unfollowers-Insta", "insta_bot_bb8.py", "none", "Unfollowers-Insta/requirements.txt", "vybhav72954", "bb8 is a cute name for a great bot to check for the people that you follow who don't follow you back on Instagram."], "Whatsapp COVID19 Bot": ["Whatsapp_COVID-19_Bot", "covid_bot.py", "none", "Whatsapp_COVID-19_Bot/requirements.txt", "vybhav72954", "A COVID-19 Bot build using `Twilio API`, that tracks the Number of Infected persons, Recovered Persons and Number of Total deaths along with the day-to-day increase in the statistics. The information is then updated via WhatsApp."], "Whatsapp Automation": ["Whatsapp-Automation", "whatsappAutomation.py", "none", "none", "vybhav72954", "Whatsapp automated message sender"], "Whatsapp auto messenger": ["WhatsApp-Auto-Messenger", "WhatsApp-Auto-Messenger.py", "none", "WhatsApp-Auto-Messenger/requirements.txt", "AnandD007", "Send and schedule a message in WhatsApp by only seven lines of Python Script."], "Youtube Trending Feed Scrapper": ["Youtube Trending Feed Scrapper", "youtube_scrapper.py", "h-c-m", "none", "XZANATOL", "It's a 2 scripts that is used to scrap and read the first 10 trending news in YouTube from any its available categories."], "Youtube Audio Downloader": ["Youtube-Audio-Downloader", "YouTubeAudioDownloader.py", "none", "Youtube-Audio-Downloader/requirements.txt", "vybhav72954", "Download Audio Of A YouTube Video"], "Youtube Video Downloader": ["YouTube-Video-Downloader", "youtube_vid_dl.py", "none", "none", "mehabhalodiya", "The objective of this project is to download any type of video in a fast and easy way from youtube in your device."], "Instagram Follow/NotFollow": ["Instagram Follow- NotFollow", "main.py", "none", "none", "nidhivanjare", "An Instagram chatbot to display people you follow and who do not follow you back."]}, "PDF": {"PDF Encryptor": ["PDF Encryption", "pdfEncryption.py", "none", "none", "vybhav72954", "The Python Script will let you encrypt the PDF with one OWNER and one USER password respectively."], "PDF2TXT": ["PDF2Text", "script.py", "none", "none", "Amit366", "Converts PDF file to a text file"], "PDF Delete Pages": ["PDF-Delete-Pages", "script.py", "none", "none", "vybhav72954", "Using this script you can delete the pages you don't want with just one click."], "PDF2Audio": ["PDF-To-Audio", "pdf_to_audio.py", "none", "none", "vybhav72954", "Add the possiblity to save .PDF to .MP3"], "PDF2CSV": ["PDF-To-CSV-Converter", "main.py", "none", "PDF-To-CSV-Converter/requirements.txt.txt", "vybhav72954", "Converts .PDF to .CSV"], "PDF Tools": ["PDF-Tools", "main.py", "none", "PDF-Tools/requirements.txt", "iamakkkhil", "Multiple functionalities involving PDFs which can be acessed using console menu"], "PDF Watermark": ["PDF-Watermark", "pdf-watermark.py", "none", "none", "vybhav72954", "Adds a watermark to the provided PDF."], "PDF arrange": ["Rearrange-PDF", "ReArrange.py", "none", "none", "vybhav72954", "This script can be helpful for re-arranging a pdf file which may have pages out of order."]}, "Image_Processing": {"Catooning Image": ["Cartooning Image", "cartooneffect.py", "none", "none", "aliya-rahmani", "Aim to transform images into its cartoon."], "Color Detection": ["Color_dectection", "Color_detection.py", "none", "none", "deepshikha007", "An application through which you can automatically get the name of the color by clicking on them."], "Convert2JPG": ["Convert-to-JPG", "convert2jpg.py", "none", "none", "vybhav72954", "This is a python script which converts photos to jpg format"], "Image editor": ["Image editor python script", "Image_editing_script.py", "none", "none", "Image_editing_script.py", "This menu-driven python script uses pillow library to make do some editing over the given image."], "Image processor": ["Image Processing", "ImgEnhancing.py", "none", "none", "Lakhankumawat", "Enchances a provided Image. Directory has 2 other scripts"], "Image Background Remover": ["Image_Background_Subtractor", "BG_Subtractor.py", "none", "Image_Background_Subtractor/requirements.txt", "iamakkkhil", "This python script lets you remove background form image by keeping only foreground in focus."], "Image viewer with GUI": ["Image_Viewing_GUI", "script.py", "none", "none", "Amit366", "script to see all the images one by one."], "IMG2SKETCH": ["ImageToSketch", "sketchScript.py", "none", "none", "vaishnavirshah", "Menu driven script- takes either the path of the image from the user or captures the image using webcam as per the user preference. The image is then converted to sketch."], "IMG2SPEECH": ["Imagetospeech", "image_to_speech.py", "none", "none", "Amit366", "The script converts an image to text and speech files."], "OCR Image to text": ["OCR-Image-To-Text", "ocr-img-to-txt.py", "none", "none", "vybhav72954", "A script that converts provided OCR Image to text"], "Screeshot": ["Screenshot", "screenshot.py", "none", "none", "vybhav72954", "A script that takes a screenshot of your current screen."], "Screenshot with GUI": ["Screenshot-GUI", "screenshot_gui.py", "none", "none", "vybhav72954", "A simple GUI script that allows you to capture a screenshot of your current screen."], "Text Extraction from Images": ["Text-Extract-Images", "text_extract.py", "none", "Text-Extract-Images/requirements.txt", "vybhav72954", "Text extraction form Images, OCR, Tesseract, Basic Image manipulation."], "Text on Image drawer": ["Text-On-Image.py", "text_on_image.py", "none", "none", "vybhav72954", "A script to draw text on an Image."], "Watermark maker on Image": ["Watermark Maker(On Image)", "Watermark_maker.py", "none", "none", "aishwaryachand", "User will be able to create a watermark on a given image."], "Photo2ASCII": ["Photo To Ascii", "photo_to_ascii.py", "none", "none", "Avishake007", "Convert your photo to ascii with it"], "Ghost filter": ["Ghost filter", "Ghost filter code.py", "none", "none", "A-kriti", "Converting an image into ghost/negative image"], "Invisibility Cloak": ["Invisibility_Cloak", "Invisibility_Cloak.py", "none", "none", "satyampgt4", "An invisibility cloak is a magical garment which renders whomever or whatever it covers invisible"], "Corner Detection": ["Fast Algorithm (Corner Detection)", "Fast_Algorithm.py", "none", "none", "ShubhamGupta577", "In this script, we implement the `Fast (Features from Accelerated Segment Test)` algorithm of `OpenCV` to detect the corners from any image."]}, "Video_Processing": {"Vid2Aud GUI": ["Video-Audio-Converter-GUI", "converter.py", "none", "none", "amrzaki2000", "This is a video to audio converter created with python."], "Vid2Aud CLI": ["Video-To-Audio(CLI-Ver)", "video_to_audio.py", "none", "none", "smriti1313", "Used to convert any type of video file to audio files using python."], "Video watermark adder": ["Video-Watermark", "watermark.py", "none", "Video-Watermark/requirements.txt", "vybhav72954", "This script can add watermark to a video with the given font."]}, "Games": {"Spaceship Game": ["Spaceship_Game", "main.py", "none", "requirements.txt", "iamakkkhil", "The python script makes use of Pygame, a popular GUI module, to develop an interactive Multiplayer Spaceship Game."], "Blackjack": ["Blackjack", "blackjack.py", "none", "none", "mehabhalodiya", "Blackjack (also known as 21) is a multiplayer card game, with fairly simple rules."], "Brick Breaker": ["Brick Breaker game", "brick_breaker.py", "none", "none", "Yuvraj-kadale", "Brick Breaker is a Breakout clonewhich the player must smash a wall of bricks by deflecting a bouncing ball with a paddle."], "Bubble Shooter": ["Bubble Shooter Game", "bubbleshooter.py", "none", "none", "syamala27", "A Bubble Shooter game built with Python and love."], "Turtle Graphics": ["Codes on Turtle Graphics", "Kaleido-spiral.py", "none", "none", "ricsin23", "_turtle_ is a pre installed library in Python that enables us to create pictures and shapes by providing them with a virtual canvas."], "Connect 4": ["Connect-4 game", "Connect-4.py", "none", "none", "syamala27", "Four consecutive balls should match of the same colour horizontally, vertically or diagonally"], "Flames": ["Flames-Game", "flames_game_gui.py", "none", "none", "vybhav72954", "Flames game"], "Guessing Game": ["Guessing_Game_GUI", "guessing_game_tkinter.py", "none", "none", "saidrishya", "A random number is generated between an upper and lower limit both entered by the user. The user has to enter a number and the algorithm checks if the number matches or not within three attempts."], "Hangman": ["Hangman-Game", "main.py", "none", "none", "madihamallick", "A simple Hangman game using Python"], "MineSweeper": ["MineSweeper", "minesweeper.py", "none", "none", "Ratnesh4193", "This is a python script MINESWEEPER game"], "Snake": ["Snake Game (GUI)", "game.py", "none", "none", "vybhav72954", "Snake game is an Arcade Maze Game which has been developed by Gremlin Industries. The player\u2019s objective in the game is to achieve maximum points as possible by collecting food or fruits. The player loses once the snake hits the wall or hits itself."], "Sudoku Solver and Visualizer": ["Sudoku-Solver-And-Vizualizer", "Solve_viz.py", "none", "none", "vybhav72954", "Sudoku Solver and Vizualizer"], "Terminal Hangman": ["Terminal Hangman", "T_hangman.py", "none", "none", "Yuvraj-kadale", "Guess the Word in less than 10 attempts"], "TicTacToe GUI": ["TicTacToe-GUI", "TicTacToe.py", "none", "none", "Lakhankumawat", "Our Tic Tac Toe is programmed in other to allow two users or players to play the game in the same time."], "TicTacToe using MinMax": ["Tictactoe-Using-Minmax", "main.py", "none", "none", "NChechulin", "Adversarial algorithm-Min-Max for Tic-Tac-Toe Game. An agent (Robot) will play Tic Tac Toe Game with Human."], "Typing Speed Test": ["Typing-Speed-Test", "speed_test.py", "none", "none", "dhriti987", "A program to test (hence improve) your typing speed"], "Tarot Reader": ["Tarot Reader", "tarot_card_reader.py", "none", "none", "Akshu-on-github", "This is a python script that draws three cards from a pack of 78 cards and gives fortunes for the same. As it was originally created as a command line game, it doesn't have a GUI"], "Stone Paper Scissors Game": ["Stone-Paper-Scissors-Game", "Rock-Paper-Scissors Game.py", "none", "none", "NChechulin", "Stone Paper Scissors Game"], "StonePaperScissor - GUI": ["StonePaperScissor - GUI", "StonePaperScissors.py", "none", "none", "Lakhankumawat", "Rock Paper and Scissor Game Using Tkinter"], "Guess the Countries": ["Guess the Countries", "main.py", "none", "none", "Shubhrima Jana", "Guess the name of the countries on the world map and score a point with every correct guess."], "Dice Roll Simulator": ["Dice-Roll-Simulator", "dice_roll_simulator.py", "none", "none", "mehabhalodiya", "It is making a computer model. Thus, a dice simulator is a simple computer model that can roll a dice for us."]}, "Networking": {"Browser": ["Broswer", "browser.py", "none", "none", "Sloth-Panda", "This is a simple web browser made using python with just functionality to have access to the complete gsuite(google suite) and the default search engine here is google."], "Get Wifi Password": ["Get-Wifi-Password", "finder.py", "none", "none", "pritamp17", "A Python Script Which,when excuted on target WINDOWS PC will send all the stored WIFI passwords in it through given email."], "HTTP Server": ["HTTP-Server", "httpServer.py", "none", "HTTP-Server/requirements.txt", "NChechulin", "This is the project based on http protocol that has been used in day to day life. All dimensions are considered according to rfc 2616"], "HTTP Sniffer": ["Http-Sniffer", "sniffer.py", "none", "none", "avinashkranjan", "python3 script to sniff data from the HTTP pages."], "Network Scanner": ["Network-Scanner", "network_scanner.py", "none", "none", "NChechulin", "This tool will show all the IP's on the same network and their respective MAC adresses"], "Network Troubleshooter": ["Network-troubleshooter", "ipreset.py", "none", "none", "geekymeeky", "A CLI tool to fix corrupt IP configuaration and other network socket related issue of your Windows PC."], "Phone Number Tracker": ["Phonenumber Tracker", "index.py", "none", "none", "Sloth-Panda", "This is a phonenumber tracker that uses phonenumbers library to get the country and service provider of the phone number and coded completely in python."], "Port Scanner": ["PortScanning", "portscanningscript.py", "none", "none", "Mafiaguy", "A python scripting which help to do port scanning of a particular ip."], "Wifi Password Saver": ["Save-Wifi-Password", "wifiPassword.py", "none", "none", "geekymeeky", "Find and write all your saved wifi passwords in a txt file"], "URL Shortner": ["URL-Shortener", "url-shortener.py", "none", "none", "NChechulin", "It shortens your given website URL."], "URL Shortner GUI": ["URL-Shortener-GUI", "url-shortener-gui.py", "none", "none", "NChechulin", "GUI based It shortens your given website URL."], "Website Status Checker": ["Website-Status-Checker", "website_status_checker.py", "none", "none", "avinashkranjan", "This script will check the status of the web address which you will input"], "Email Validator": ["Email-Validator", "email-verification.py", "none", "none", "saaalik", "A simple program which checks for Email Address Validity in three simple checks"]}, "OS_Utilities": {"Auto Backup": ["Auto_Backup", "Auto_Backup.py", "none", "t-s-c", "vybhav72954", "Automatic Backup and Compression of large file, sped up using Threading."], "Battery Notification": ["Battery-Notification", "Battery-Notification.py", "none", "none", "pankaj892", "This is a Python Script which shows the battery percentage left"], "CPU Temperature": ["CPU temperature", "temp.py", "none", "none", "atarax665", "This python script is used to get cpu temperature"], "Desktop News Notification": ["Desktop News Notifier", "script.py", "none", "none", "Amit366", "On running the script it gives a notification of top 10 news"], "Desktop drinkWater Notification": ["Desktop-drinkWater-Notification", "main.py", "none", "none", "viraldevpb", "This python script helps user to drink more water in a day as per her body needed and also this python script is executed in the background and every 30 minutes it notifies user to drink water."], "Desktop Voice Assistant": ["Desktop-Voice-assistant", "voice_assistant.py", "none", "Desktop-Voice-assistant/requirements.txt", "sayantani11", "It would be great to have a desktop voice assistant who could perform tasks like sending email, playing music, search wikipedia on its own when we ask it to."], "Digital Clock": ["Digital Clock", "Clock.py", "none", "none", "Dhanush2612", "A simple digital 12 hour clock."], "Duplicate File Finder": ["Duplicate-File-Finder", "file_finder.py", "argv", "Duplicate-File-Finder/requirements.txt", "vybhav72954", "This sweet and simple script helps you to compare various files in a directory, find the duplicate, list them out, and then even allows you to delete them."], "Email Sender": ["Email-Sender", "email-sender.py", "none", "none", "avinashkranjan", "A script to send Email using Python."], "File Change Listener": ["File-Change-Listen", "main.py", "none", "File-Change-Listen/requirements.txt", "antrikshmisri", "This is a python script that keeps track of all files change in the current working directory"], "File Mover": ["File-Mover", "fmover.py", "none", "File-Mover/requirements.txt", "NChechulin", "his is a small program that automatically moves and sorts files from chosen source to destination."], "Folder2Zip": ["Folder-To-Zip", "folder-to-zip.py", "none", "none", "NChechulin", "To convert folders into ZIP format"], "Get Wifi Password": ["Get-Wifi-Password", "finder.py", "none", "none", "pritamp17", "A Python Script Which,when excuted on target WINDOWS PC will send all the stored WIFI passwords in it through given email."], "Keylogger": ["Keylogger", "keylogger.py", "none", "none", "madihamallick", "A Keylogger script built using Python."], "Last Access": ["Last Access", "Last Access.py", "none", "none", "Bug-007", "It prints out when was the last the file in folder was accessed."], "Mini Google Assistant": ["Mini Google Assistant", "Mini google assistant.py", "none", "none", "A-kriti", "A mini google assistant using python which can help you to play song, tell time, tell joke, tell date as well as help you to capure a photo/video."], "Music Player": ["Music-Player-App", "main.py", "none", "none", "robin025", "A Python GUI Based Music Player"], "News Voice Assistant": ["News-Voice-Assistant", "news_assistant.py", "none", "News-Voice-Assistant/requirements.txt", "NChechulin", "Hear your favourite news in your computer!"], "Organise Files According To Their Extensions": ["Organise-Files-According-To-Their-Extensions", "script_dirs.py", "none", "none", "NChechulin", "Script to organise files according to their extensions"], "Paint App": ["Paint Application/", "paint.py", "none", "Paint Application/requirements.txt", "Ayushjain2205", "Running this Script would open up a Paint application GUI on which the user can draw using the brush tool."], "Password Generator": ["Password-Generator", "passowrd_gen.py", "none", "none", "NChechulin", "A Password Generator built using Python"], "Password Manager": ["Password-Manager-GUI", "passwords.py", "none", "none", "Ayushjain2205", "This script opens up a Password Manager GUI on execution."], "QR Code Generator": ["QR_Code_Generator", "main.py", "none", "none", "CharvyJain", "This script will generate the QR Code of the given link."], "QR code Gen": ["QR-code-Genrator", "main.py", "none", "QR-code-Genrator/requirement.txt", "Goheljay", "A simple GUI based qr code genrator application in Python that helps you to create the qr code based on user given data."], "Random Password Generator": ["Random Password Generator", "script.py", "none", "none", "tanvi355", "This is a random password generator."], "Random Email Generator": ["Random-Email-Generator", "random_email_generator.py", "none", "none", "pankaj892", "This is a Python Script which generates random email addresses"], "Run Script at a Particular Time": ["Run-Script-At-a-Particular-Time", "date_time.py", "none", "none", "avinashkranjan", "Runs a script at a particular time defined by a user"], "Screen Recorder": ["Screen-Recorder", "screen_recorder.py", "none", "none", "avinashkranjan", "It records the computer screen."], "Notepad": ["Simple Notepad", "SimpleNotepad.py", "none", "none", "Bug-007", "Using Tkinter GUI of simplenotepad is made."], "Python IDE": ["Simple Python IDE using Tkinter", "script.py", "none", "none", "Priyadarshan2000", "This is a Simple Python IDE using Tkinter."], "Site Blocker": ["Site-blocker", "web-blocker.py", "none", "none", "Sloth-Panda", "This is a script that aims to implement a website blocking utility for Windows-based systems."], "Speech to Text": ["Speech-To-Text", "speech-to-text.py", "none", "none", "avinashkranjan", "A script that converts speech to text"], "Text to Speech": ["Text-To-Speech", "text-to-speech.py", "none", "none", "mehabhalodiya", "Text to speech is a process to convert any text into voice."], "ToDo": ["ToDo-GUI", "todo.py", "none", "ToDo-GUI/requirements.txt", "a-k-r-a-k-r", "This project is about creating a ToDo App with simple to use GUI"], "Unzip File": ["Unzip file", "script.py", "none", "none", "Amit366", "Upload the zip file which is to be unzipped"], "Voice Assistant": ["Voice-Assistant", "test.py", "none", "none", "avinashkranjan", "It is a beginner-friendly script in python, where they can learn about the if-else conditions in python and different libraries."], "Bandwidth Monitor": ["Bandwidth-Monitor", "bandwidth_py3.py", "none", "none", "adarshkushwah", "A python script to keep a track of network usage and notify you if it exceeds a specified limit (only support for wifi right now)"], "Sticky Notes": ["sticky notes", "main.py", "none", "none", "vikashkumar2020", "A simple GUI based application in Python that helps you to create simple remember lists or sticky notes."], "Calendar": ["Calendar GUI", "Calendar_gui.py", "none", "none", "aishwaryachand", "Using this code you will be able to create a Calendar GUI where calendar of a specific year appears."], "Directory Tree Generator": ["Directory Tree Generator", "tree.py", "argv", "Directory Tree Generator/requirements.txt", "vikashkumar2020", "A Script useful for visualizing the relationship between files and directories and making their positioning easy."], "Stopwatch": ["Stopwatch GUI", "stopwatch_gui.py", "none", "none", "aishwaryachand", "This is a Stopwatch GUI using which user can measure the time elapsed using the start and pause button."], "Webcam Imgcap": ["Webcam-(imgcap)", "webcam-img-cap.py", "none", "none", "NChechulin", "Image Capture using Web Camera"], "Countdown clock and Timer": ["Countdown_clock_and_Timer", "countdown_clock_and_timer.py", "none", "none", "Ayush7614", "A simple timer that can be used to track runtime."], "Paint Application": ["Paint Application", "paint.py", "none", "Paint Application/requirements.txt", "Ayushjain2205", "Running this Script would open up a Paint application GUI on which the user can draw using the brush tool."], "Covid-19 Updater": ["Covid-19-Updater", "covid-19-updater_bot.py", "none", "none", "avinashkranjan", "Get hourly updates of Covid19 cases, deaths and recovered from coronavirus-19-api.herokuapp.com using a desktop app in Windows."], "Link Preview": ["Link-Preview", "linkPreview.py", "none", "Link-Preview/requirements.txt", "jhamadhav", "A script to provide the user with a preview of the link entered."]}, "Automation": {"Gmail Attachment Downloader": ["Attachment_Downloader", "attachment.py", "none", "none", "Kirtan17", "The script downloads gmail atttachment(s) in no time!"], "Auto Birthday Wisher": ["Auto Birthday Wisher", "Auto B'Day Wisher.py", "none", "none", "SpecTEviL", "An automatic birthday wisher via email makes one's life easy. It will send the birthday wishes to friends via email automatically via a server and using an excel sheet to store the data of friends and their birthdays along with email id."], "Auto Fill Google Forms": ["Auto-Fill-Google-Forms", "test.py", "none", "none", "NChechulin", "This is a python script which can helps you to fillout the google form automatically by bot."], "Automatic Certificate Generator": ["Automatic Certificate Generator", "main.py", "none", "none", "achalesh27022003", "This python script automatically generates certificate by using a certificate template and csv file which contains the list of names to be printed on certificate."], "Chrome Automation": ["Chrome-Automation", "chrome-automation.py", "none", "none", "NChechulin", "Automated script that opens chrome along with a couple of defined pages in tabs."], "Custom Bulk Email Sender": ["Custom-Bulk-Email-Sender", "customBulkEmailSender.py", "none", "none", "NChechulin", "he above script is capable of sending bulk custom congratulation emails which are listed in the .xlsx or .csv format."], "Github Automation": ["Github-Automation", "main.py", "none", "Github-Automation/requirements.txt", "antrikshmisri", "This script allows user to completely automate github workflow."], "SMS Automation": ["SMS Automation", "script.py", "none", "none", "Amit366", "Send SMS messages using Twilio"], "Send Twilio SMS": ["Send-Twilio-SMS", "main.py", "none", "none", "dhanrajdc7", "Python Script to Send SMS to any Mobile Number using Twilio"], "Spreadsheet Comparision Automation": ["Spreadsheet_Automation", "script.py", "none", "none", "Amit366", "Spreadsheet Automation Functionality to compare 2 datasets."], "HTML Email Sender": ["HTML-Email-Sender", "main.py", "none", "none", "dhanrajdc7", "This script helps to send HTML Mails to Bulk Emails"], "HTML to MD": ["HTML-To-MD", "html_to_md.py", "none", "none", "NChechulin", "Converts HTML file to MarkDown (MD) file"], "Censor word detector": ["Censor word detection", "censor_word_detection.py", "none", "none", "jeelnathani", "an application which can detect censor words."]}, "Cryptography": {"BitCoin Mining": ["BitCoin Mining", "BitCoin_Mining.py", "none", "none", "NEERAJAP2001", "A driver code with explains how BITCOIN is mined"], "Caesar Cipher": ["Caesar-Cipher", "caesar_cipher.py", "none", "none", "smriti1313", "It is a type of substitution cipher in which each letter in the plaintext is replaced by a letter some fixed number of positions down the alphabet."], "Morse Code Translator": ["Morse_Code_Translator", "Morse_Code_Translator.py", "none", "none", "aishwaryachand", "Morse code is a method used in telecommunication to encode text characters as standardized sequences of two different signal durations, called _dots_ and _dashes_."], "Steganography": ["Steganography", "steganography.py", "argv", "none", "dhriti987", "This Python Script Can hide text under image and can retrive from it with some simple commands"], "CRYPTOGRAPHY": ["Cryptography", "crypto.py", "none", "none", "codebuzzer01", "The objective of this project is to encode and decode messages using a common key."]}, "Computer_Vision": {"Color Detection": ["Color_detection", "Color_detection.py", "none", "none", "deepshikha007", "In this color detection Python project, we are going to build an application through which you can automatically get the name of the color by clicking on them."], "Contour Detection": ["Contour-Detection", "live_contour_det.py", "none", "none", "mehabhalodiya", "Contours can be explained simply as a curve joining all the continuous points (along the boundary), having same color or intensity."], "Document Word Detection": ["Document-Word-Detection", "Word_detection.py", "none", "none", "hritik5102", "Detect a word present in the document (pages) using OpenCV"], "Edge Detection": ["Edge Detection", "Edge_Detection.py", "none", "none", "ShubhamGupta577", "This script uses `OpenCV` for taking input and output for the image. In this we are using he `Canny algorithm` for the detection of the edge."], "Eye Detection": ["Eye Detection", "eyes.py", "none", "none", "Avishake007", "It is going to detect your eyes and count the number of eyes"], "Face Detection": ["Face-Detection", "face-detect.py", "none", "none", "Avishake007", "Face Detection script using Python Computer Vision"], "Corner Detection": ["Fast Algorithm (Corner Detection)", "Fast_Algorithm.py", "none", "none", "ShubhamGupta577", "In this script, we implement the `Fast (Features from Accelerated Segment Test)` algorithm of `OpenCV` to detect the corners from any image."], "Human Detection": ["Human-Detection", "script.py", "none", "none", "NChechulin", "Uses OpenCV to Detect Human using pre trained data."], "Num Plate Detector": ["Num-Plate-Detector", "number_plate.py", "none", "none", "mehabhalodiya", "License plate of the vehicle is detected using various features of image processing library openCV and recognizing the text on the license plate using python tool named as tesseract."], "Realtime Text Extraction": ["Realtime Text Extraction", "Realtime Text Extraction.py", "none", "none", "ShubhamGupta577", "In this script we are going to read a real-time captured image using a web cam or any other camera and extract the text from that image by removing noise from it."], "Virtual Paint": ["Virtual Paint", "virtual_paint.py", "none", "none", "mehabhalodiya", "It is an OpenCV application that can track an object\u2019s movement, using which a user can draw on the screen by moving the object around."], "ORB Algorithm": ["ORB Algorithm", "ORB_Algorithm.py", "none", "none", "ShubhamGupta577", "ORB Algorithm of `Open CV` for recognition and matching the features of image."]}, "Fun": {"Spiral Star": ["Spiral-Star", "program1.py", "none", "none", "avinashkranjan", "This is python programs to create a spiral star and colourful spiral star using python"], "Matrix Rain": ["Matrix-rain-code", "matrix-rain.py", "none", "none", "YashIndane", "Matrix Rain"], "Github Bomb Issues": ["Github_Bomb_Issues", "bomb-issues.py", "none", "Github_Bomb_Issues/requirements.txt", "Ayush7614", "This python script bombs specified number of issues on a Github Repository."], "Lyrics Genius API": ["Lyrics_Genius_API", "lyrics.py", "none", "none", "vybhav72954", "This script can be used to download lyrics of any number of songs, by any number of Artists, until the API Limit is met."], "Songs by Artist": ["Songs-By-Artist", "songs_of_artist.py", "none", "none", "NChechulin", "A music search application, using a few named technologies that allows users to search for the songs of their favorite Artists in a very less time."]}, "Others": {"Bubble Sort Visualization": ["Bubble-Sort-Visualization", "bubble_sort.py", "none", "none", "amrzaki2000", "This is a script that provides easy simulation to bubble sort algorithm."], "Select Stocks by volume Increase": ["Select Stocks by volume Increase", "script.py", "none", "none", "Amit366", "Select Stocks by volume Increase when provided by the number of days from the user."], "ZIP Function": ["ZIP-Function", "transpose.py", "none", "none", "avinashkranjan", "function creates an iterator that will aggregate elements from two or more iterables."], "Quiz GUI": ["Quiz-GUI", "quiztime.py", "none", "none", "soumyavemuri", "A quiz application created with Python's Tkinter GUI toolkit."], "Dictionary GUI": ["Dictionary-GUI", "dictionary.py", "none", "Dictionary-GUI/requirements.txt", "Ayushjain2205", "This script lets the user search for the meaning of words like a dictionary."], "Translator Script": ["Translator Script", "Translation.py", "none", "none", "NEERAJAP2001", "Running this Script would translate one language to another language"], "Translator GUI": ["Translator-GUI", "translator.py", "none", "Translator-GUI/requirements.txt", "Ayushjain2205", "Running this Script would open up a translator with GUI which can be used to translate one language to another."], "Gmplot Track the Route": ["Gmplot-Track the Route", "main.py", "none", "none", "Lakhankumawat", "track the whole route of a person by reading values of a provided CSV file on Google Maps and create an Image containing route or location."], "Health Log Book": ["Health_Log_Book", "main.py", "none", "none", "anuragmukherjee2001", "The script will contain the daily records of food and workouts of a person."], "Pagespeed API": ["Pagespeed-API", "test.py", "none", "none", "keshavbansal015", "This script generates the PageSpeed API results for a website."], "String Matching Scripts": ["String-Matching-Scripts", "string_matching.py", "none", "none", "avinashkranjan", "an efficient way of string matching script."], "Wikipedia Summary": ["Wikipedia-Summary-GUI", "summary.py", "none", "Wikipedia-Summary-GUI/requirements.txt", "Ayushjain2205", "Running this Script would open up a wikipedia summary generator GUI which can be used to get summary about any topic of the user's choice from wikipedia."], "Expense Tracker": ["Expense Tracker", "script.py", "none", "none", "Amit366", "This is used to store the daily expenses."], "Piglatin Translator": ["Piglatin_Translator", "piglatin.py", "none", "none", "archanagandhi", "A secret language formed from English by transferring the initial consonant or consonant cluster of each word to the end of the word and adding a vocalic syllable (usually /e\u026a/): so pig Latin would be igpay atinlay."], "TODO CLI": ["TODO (CLI-VER)", "todolist.py", "none", "none", "Avishake007", "List down your items in a Todolist so that you don't forget"], "Sentiment Detector": ["Script to check Sentiment", "script.py", "none", "none", "Amit366", "Sentiment Detector that checks sentiment in the provided sentence."]}}, "Others": {"Linear Search Visualizer": ["Linear Search Visualizer", "script.py", "none", "none", "tanvi355", "A GUI that allows you to see the linear search in action."]}} \ No newline at end of file +{"Calculators": {"Age calculator": ["Age-Calculator-GUI", "age_calc_gui.py", "none", "none", "mehabhalodiya", "users can type in their date of birth, and the app will calculate and display their age."], "BMI calculator": ["BMI-Calculator-GUI", "BMI_Calculator.py", "none", "none", "vybhav72954", "Calculates Your Body Mass Index for your health fitness."], "Binary calculator": ["Binary-Calculator-GUI", "script.py", "none", "none", "vybhav72954", "A GUI based Standard Binary number calculator."], "Calculator GUI": ["Calculator-GUI", "script.py", "none", "none", "vybhav72954", "It is GUI based calculator used to calculate any simple mathematical equation."], "Calculator CLI": ["Calculator", "Calcy.py", "none", "none", "vybhav72954", "A CLI that is used to calculate any simple mathematical equation."], "Distance calculator": ["Distance-Calculator-GUI", "main.py", "none", "Distance-Calculator-GUI/requirements.txt", "vybhav72954", "This app calculates distance between two geo-locations."], "Cryptocurrency Converter": ["Crypocurrency-Converter-GUI", "main.py", "none", "Crypocurrency-Converter-GUI/requirements.txt", "vybhav72954", "A script that converts Cryptocurrency to real currency using GUI"], "Currency Convertor": ["Currency Convertor - GUI based", "Currency_convertor_GUI.py", "none", "none", "MayankkumarTank", "GUI-based Currency Convertor using Tkinter in python"], "Currency Exchange Rates": ["Currency-Exchange-Rates", "exchange_rates.py", "none", "none", "vybhav72954", "A script that converts an entered currency number to many possible equivalents in other currencies"], "Distance Converter": ["Distance Conversion GUI", "distance_conversion.py", "none", "none", "tanvi355", "This is a distance unit converter using which we can convert the distance from one unit to other."], "Weight Converter": ["Weight-Converter-GUI", "weight_con_gui.py", "none", "none", "mehabhalodiya", "a GUI based weight converter that accepts a kilogram input value and converts that value to Carat, Gram, Ounce, Pound, Quintal and Tonne"], "Shortest-Path-Finder": ["Shortest-Path-Finder (GUI)", "Shortest Path Finder.py", "none", "none", "ImgBotApp", "Shortest Path finder is a GUI application which finds the shortest possible path between two points placed by the user on the board."], "Smart calcy": ["Smart calcy", "Smart_calcy.py", "none", "none", "Yuvraj-kadale", "Hey!! I am Smart calculator and my name is Genius. Genius is a Smart GUI calculator that can read English and perform the mathematical task given or simple word problems."], "Applying Bitwise Operations": ["Applying Bitwise Operations", "Applying Bitwise operations.py", "none", "none", "undetectablevirus", "Applying Bitwise Operations on two images using OpenCV"], "Calculate Distance": ["Calculate-distance", "manage.py", "none", "Calculate-distance/requirements.txt", "pritamp17", "App that can show distance between user's location and searched location on map."], "Geo Cordinate Locator": ["Geo-Cordinate-Locator", "script.py", "none", "Geo-Cordinate-Locator/requirements.txt", "NChechulin", "Gets you current Longitude and Latitude when you provide your address."], "Base_N Calculator": ["Base-N_Calc", "script.py", "none", "none", "XZANATOL", "A GUI that will allow you to convert a number of base-X to base-Y as long as X&Y > 1."], "Blood Content Alcohol": ["Blood Content Alcohol", "Blood_Alcohol_Content.py", "none", "none", "soumik2012 ", "Want to know how much amount of alcohol you drank? Well, the Blood alcohol content program will help you find out the alcohol intake."]}, "AI/ML": {"Air pollution prediction": ["Air pollution prediction", "CodeAP.py", "none", "none", "Pranjal-2001", "This helps you find the levels of Air pollution plotted graphically with a provided dataset."], "Bag of words": ["Bag of words model", "bow.py", "none", "none", "zaverisanya", "tokenize the sentences taken from user, transforming text to vectors where each word and its count is a feature, Create dataframe where dataframe is an analogy to excel-spreadsheet"], "Body detection": ["Body Detection", "detection.py", "none", "none", "Avishake007", "Detect your Body in video"], "corona cases forecasting": ["corona cases forecasting", "main.py", "none", "corona cases forecasting/requirements.txt", "ImgBotApp", "This is a python script capable of Predicting number of covid 19 cases for next 21 days"], "Covid 19 Detection": ["Covid -19-Detection-Using-Chest-X-Ray", "test.py", "none", "none", "vybhav72954", "This Script is all about to check wether the person is suffering from the covid-19or not."], "Face mask detection": ["Face-Mask-Detection", "face_mask_detection_using_cnn.py", "none", "none", "ImgBotApp", "Face mask detection model using tensorflow"], "Facial expression recognition": ["Facial-Expression-Recognition", "face-crop.py", "none", "none", "Debashish-hub", "Facial expression recognition is a technology which detects emotions in human faces. More precisely, this technology is a sentiment analysis tool and is able to automatically detect the basic or universal expressions: happiness, sadness, anger, surprise, fear, and disgust etc."], "Heart Disease prediction": ["Heart Disease Prediction", "script.py", "none", "Heart Disease Prediction/requirements.txt", "aaadddiii", "This python script uses a machine learning model to predict whether a person has heart disease or not."], "Message spam detection": ["Message_Spam_Detection", "Message_Spam_Detection.py", "none", "none", "Nkap23", "The python code contains script for message spam detection based on Kaggle Dataset (dataset link inside the code)"], "Message spam": ["Message-Spam", "messagespam.py", "none", "none", "vybhav72954", "This Script is all about to check wether the entered message is a spam or not spam using machine learning algorithm"], "Plagiarism Checker": ["Plagiarism-Checker", "plagiarism.py", "none", "none", "Anupreetadas", "In order to compute the simlilarity between two text documents"], "Remove POS Hindi text": ["Remove_POS_hindi_text", "hindi_POS_tag_removal.py", "none", "none", "ImgBotApp", "A script to remove POS Hindi text"], "Salary predictor": ["Salary Predictor", "model.py", "none", "none", "shreyasZ10", "This is basically a python script used to predict the average annual salary of person."], "Text Summary": ["Text_Summary", "text_summary.py", "none", "Text_Summary/requirements.txt", "vybhav72954", "Text Summarization is an advanced project and comes under the umbrella of Natural Language Processing. There are multiple methods people use in order to summarize text."], "Traffic Sign Detection": ["Traffic-Sign-Detection", "traffic_sign_detection.py", "none", "Traffic-Sign-Detection/requirements.txt", "vybhav72954", "Using German Traffic Sign Recognition Benchmark, in this script I have used Data Augmentation and then passed the images to miniVGGNet (VGG 7) a famous architecture of Convolutional Neural Network (CNN)."], "Document summary creator": ["Document-Summary-Creator", "main.py", "none", "Document-Summary-Creator/requirements.txt", "vybhav72954", "A python script to create a sentence summary"], "Reddit flair detection": ["Reddit-Scraping-And-Flair-Detection", "WebScrapping and PreProcessing.ipynb", "none", "none", "vybhav72954", "Through taking input URL from the user, the model will predict and return actual + predicted flairs from Reddit"], "Movie Genre Prediction": ["Movie-Genre-Prediction-Chatbot", "Movie_recommendation_Sentance_Embedding.ipynb", "none", "none", "hritik5102", "Chatbot with deep learning"], "Dominant Color Extraction": ["Dominant-Color-Extraction", "Dominant color Extraction.ipynb", "none", "Dominant-Color-Extraction/requirements.txt", "aryangulati", "Finding Dominant Colour: Finding Colour with Kmeans and giving appropriate colors to the pixel/data points of the image, In addition to analyzing them using K-means."], "Malaria": ["Malaria", "main.py", "none", "Malaria\\requirements.txt", "ayush-raj8", "script that predicts malaria based on input of cell image"]}, "Scrappers": {"Wikipedia Infobox Scraper": ["Wiki_Infobox_Scraper", "main.py", "none", "requirements.txt", "RohiniRG", "The given python script uses beautiful soup to scrape Wikipedia pages according to the given user query and obtain data from its Wikipedia infobox. This information will be presented along with a GUI."], "Amazon price alert": ["Amazon-Price-Alert", "amazon_scraper.py", "none", "Amazon-Price-Alert/requirements.txt", "dependabot", "web-scraper built on BeautifulSoup that alerts you when the price of an amazon prduct falls within your budget!"], "Amazon price tracker": ["Amazon-Price-Tracker", "amazonprice.py", "none", "none", "vybhav72954", "Tracks the current given product price."], "Animer tracker": ["Anime-Tracker", "anime_tracker.py", "none", "none", "vybhav72954", "This is a python script for giving information about the anime like information about anime , number of episodes released till date, Years active, Tags related to it."], "Bitcoin price tracker": ["BITCOIN-price-tracker", "tracker.py", "none", "none", "vybhav72954", "Python script that show's BITCOIN Price"], "CodeChef scrapper": ["Codechef Scrapper", "codechef.py", "none", "Codechef Scrapper/requirements.txt", "smriti26raina", "This python script will let the user to scrape 'n' number of codechef problems from any category/difficulty in https://www.codechef.com/ ,as provided by the user."], "Dev.to scrapper": ["Dev.to Scraper", "scraper.py", "none", "Dev.to Scraper/requirements.txt", "Ayushjain2205", "Running this Script would allow the user to scrape any number of articles from dev.to from any category as per the user's choice"], "extracting emails from website": ["extracting-emails-from-website", "emails-from-website", "none", "none", "ankurg132", "Scrapper to extract emails from a website"], "Facebook autologin": ["Facebook-Autologin", "facebookAuto.py", "none", "Facebook-Autologin/requirements.txt", "vybhav72954", "This is a python script that automates the facebook login process"], "Flipkart price alert": ["Flipkart-price-alert", "track.py", "none", "Flipkart-price-alert/requirements.txt", "Jade9ja", "Checks for the price of a desired product periodically. If the price drops below the desired amount, notifies the user via email."], "Football player club info": ["Football-Player-Club-Info", "main.py", "none", "none", "vybhav72954", "Gets info of a football player"], "Github contributor list size": ["Github-Size-Contributor-List", "script.py", "none", "none", "vybhav72954", "Makes an API call to the, \"Github API\" in order to retrieve the information needed. It retrieves the size of the repository and the number of contributors the repo has"], "Google news scrapper": ["Google-News-Scraapper", "app.py", "none", "Google-News-Scraapper/requirements.txt", "vybhav72954", "A python Automation script that helps to scrape the google news articles."], "Google search newsletter": ["Google-Search-Newsletter", "google-search-newsletter.py", "none", "Google-Search-Newsletter/requirements.txt", "vybhav72954", "Performs google search of topic stated in config file"], "IMDB scrapper": ["IMDB-Scraper", "scraper.py", "none", "none", "priyanshu20", "Collects the information given on IMDB for the given title"], "Instagram auto login": ["Insta-Autologin", "main.py", "none", "none", "vybhav72954", "Autologin for Instagram"], "Insta Auto SendMsg": ["Insta-Bot-Follow-SendMsg", "instabot.py", "none", "none", "vivek-2000", "Given a username if the Instagram account is public , will auto-follow and send msg."], "Insatgram Profile Pics downloader": ["Instagram downloader", "downloader.py", "none", "none", "Sloth-Panda", "This python script is used to download profile pics that are on instagram."], "Instagram Liker bot": ["Instagram Liker Bot", "Instagram_Liker_Bot.py", "none", "none", "sayantani11", "Given a username if the Instagram account is public or the posts are accessible to the operator, will auto-like all the posts on behalf and exit."], "Internshala Scraper": ["Internshala-Scraper", "program.py", "none", "Internshala-Scraper/requirements.txt", "vybhav72954", "Select field, select number of pages and the script saves internships to a csv."], "LinkedIn connectinos scrapper": ["Linkedin_Connections_Scrapper", "script.py", "none", "h-e-p-s", "XZANATOL", "It's a script built to scrap LinkedIn connections list along with the skills of each connection if you want to."], "LinkedIn email scrapper": ["Linkedin-Email-Scraper", "main.py", "none", "Linkedin-Email-Scraper/requirements.txt", "vybhav72954", "a script to scrap names and their corresponding emails from a post"], "Live cricket score": ["Live-Cricket-Score", "live_score.py", "none", "Live-Cricket-Score/requirements.txt", "vybhav72954", "This python script will scrap cricbuzz.com to get live scores of the matches."], "MonsterJobs scraper": ["MonsterJobs Scraper", "scraper.py", "none", "MonsterJobs Scraper/requirements.txt", "Ayushjain2205", "Running this Script would allow the user to scrape job openings from Monster jobs, based on their choice of location, job role, company or designation."], "Movie Info telegram bot": ["Movie-Info-Telegram-Bot", "bot.py", "none", "Movie-Info-Telegram-Bot/requirements.txt", "aish2002", "A telegram Bot made using python which scrapes IMDb website"], "Move recommendation": ["Movie-Recommendation", "script.py", "none", "none", "vybhav72954", "The Movie Titles are scraped from the IMDb list by using BeautifulSoup Python Library to recommend to the user."], "News scraper": ["News_Scrapper", "scrapper.py", "none", "none", "paulamib123", "This Script is used to get top 10 headlines from India Today based on the category entered by user and stores it in a CSV file."], "Price comparison and checker": ["Price Comparison and Checker", "price_comparison.py", "none", "Price Comparison and Checker/Requirements.txt", "aashishah", "This python script can automatically search for an item across Amazon, Flipkart and other online shopping websites and after performing comparisons, find the cheapest price available."], "Reddit meme scrapper": ["Reddit-Meme-Scraper", "script.py", "none", "Reddit-Meme-Scraper/requirements.txt", "vybhav72954", "This script locates and downloads images from several subreddits (r/deepfriedmemes, r/surrealmemes, r/nukedmemes, r/bigbangedmemes, r/wackytictacs, r/bonehurtingjuice) into your local system."], "Search username": ["Search-Username", "search_user.py", "none", "none", "vybhav72954", "This script of code, using request module, will help to determine weather, a username exists on a platform or not."], "Slideshare downloader": ["Slideshare downloader", "slideshare_downloader.py", "none", "Slideshare downloader/requirements.txt", "vikashkumar2020", "A Script to download slides from Slideshare as pdf from URL."], "Social media links extractor": ["Social-Media-Links-From-Website", "script.py", "none", "none", "vybhav72954", "The code filters out all the social media links like youtube, instagram, linkedin etc. from the provided website url and displays as the output."], "Temporary sign-up tool": ["Temporary-Sign-Up-Tool", "temp_sign_up_tool.py", "none", "Temporary-Sign-Up-Tool/requirement.md", "chaitanyabisht", "This script can be used when you want to Register or Sign Up to annoying websites or when you don't want to give out your personal data. As it provides you with a temporary username, email, and password to make your registration easy."], "Unfollowers Insta": ["Unfollowers-Insta", "insta_bot_bb8.py", "none", "Unfollowers-Insta/requirements.txt", "vybhav72954", "bb8 is a cute name for a great bot to check for the people that you follow who don't follow you back on Instagram."], "Weather app": ["Weather-App", "weatherapp.py", "none", "none", "NChechulin", "Gets the weather in your current location"], "Youtube Trending Feed Scrapper": ["Youtube Trending Feed Scrapper", "youtube_scrapper.py", "h-c-m", "none", "XZANATOL", "It's a 2 scripts that is used to scrap and read the first 10 trending news in YouTube from any its available categories."], "Zoom auto attend": ["Zoom-Auto-Attend", "zoomzoom.py", "none", "Zoom-Auto-Attend/requirements.txt", "dependabot", "A zoom bot that automatically joins zoom calls for you and saves the meeting id and password."], "Udemy Scraper": ["Udemy Scraper", "fetcher.py", "none", "Udemy Scraper/requirements.txt", "Ayushjain2205", "This script is used to scrape course data from udemy based on the category entered as input by the user"], "IPL Statistics": ["IPL Statistics GUI", "ipl.py", "none", "IPL Statistics GUI/requirements.txt", "Ayushjain2205", "Running this Script would allow the user see IPL statistics from various categories like most runs , most wickets etc from all seasons (2008 - 2020)"], "Covid India Stats App": ["Covid India Stats App", "app.py", "none", "none", "dsg1320", "COVID19 stats app for indian states which works using api call"], "Twitter Scraper without API": ["Twitter_Scraper_without_API", "fetch_hashtags.py", "none", "Twitter_Scraper_without_API/requirements.txt", "RohiniRG", "we make use of snscrape to scrape tweets associated with a particular hashtag. Snscrape is a python library that scrapes twitter without the use of API keys."], "Coderforces Problem Scrapper": ["Coderforces_Problem_Scrapper", "Codeforces_problem_scrapper.py", "none", "Coderforces_Problem_Scrapper\\requirements.txt", "iamakkkhil", "This python script will let you download any number of Problem Statements from Codeforces and save them as a pdf file."], "LeetCode Scraper": ["LeetCode-Scrapper", "ques.py", "none", "LeetCode-Scrapper\\requirements.txt", "AshuKV", "script will let the user to scrape 'n' number of LeetCode problems from any category/difficulty in Leetcode"], "NSE Stocks": ["NSE Stocks GUI", "stocks.py", "none", "NSE Stocks GUI\\requirements.txt", "Ayushjain2205", "Script would allow the user to go through NSE Stock data scraped from NSE Website"]}, "Social_Media": {"Automate Facebook bot": ["Automate Facebook bot", "script.py", "none", "none", "Amit366", "On running the script it posts your message in the groups whose id is given by the user"], "Creating Emoji": ["Creating-Emoji-Using-Python", "program.py", "none", "none", "vybhav72954", "This is python program to create emojis"], "Discord bot": ["Discord-Bot", "main.py", "none", "none", "vybhav72954", "This is a Discord bot built with Python"], "DownTube": ["DownTube-Youtube-Downloader", "DownTube.py", "h-a-p-u-f", "none", "XZANATOL", "DownTube is an on-to-go downloader for any bundle of Youtube links you want to download."], "Facebook Auto login": ["Facebook-Autologin", "facebookAuto.py", "none", "Facebook-Autologin/requirements.txt", "vybhav72954", "This is a python script that automates the facebook login process"], "Google Classroom": ["Google-Classroom-Bot", "gmeet_bot.py", "none", "Google-Classroom-Bot/requirements.txt", "vybhav72954", "This bot joins your classes for you on time automatically using your google classroom schedule and account credentials."], "Google meet scheduler": ["Google-Meet-Scheduler", "script.py", "none", "Google-Meet-Scheduler/requirements.txt", "Tarun-Kamboj", "The script here allows you to schedule a google meeting with multiple guests using python."], "Instagram Auto login": ["Insta-Autologin", "main.py", "none", "none", "vybhav72954", "Autologin for Instagram"], "Insta follow sendmsg bot": ["Insta-Bot-Follow-SendMsg", "instabot.py", "none", "none", "vivek-2000", "Given a username if the Instagram account is public , will auto-follow and send msg."], "Instagram downloader": ["Instagram downloader", "downloader.py", "none", "none", "Sloth-Panda", "This python script is used to download profile pics that are on instagram."], "Instagram liker bot": ["Instagram Liker Bot", "Instagram_Liker_Bot.py", "none", "none", "sayantani11", "Given a username if the Instagram account is public or the posts are accessible to the operator, will auto-like all the posts on behalf and exit."], "Instagram Profile Pic Downloader": ["Instagram-Profile-Pic-Downloader", "Instagram Profile Pic Downloader.py", "none", "none", "vybhav72954", "Instagram Profile Pic Downloader"], "LinkedIn Connections Scrapper": ["Linkedin_Connections_Scrapper", "script.py", "h-e-p-s", "none", "XZANATOL", "A script to scrap LinkedIn connections list along with the skills of each connection if you want to."], "LinkedIn Email Scrapper": ["Linkedin-Email-Scraper", "main.py", "none", "Linkedin-Email-Scraper/requirements.txt", "vybhav72954", "a script to scrap names and their corresponding emails from a post"], "Movie info Telegram bot": ["Movie-Info-Telegram-Bot", "bot.py", "none", "Movie-Info-Telegram-Bot/requirements.txt", "aish2002", "A telegram Bot made using python which scrapes IMDb website"], "Reddit meme scrapper": ["Reddit-Meme-Scraper", "script.py", "none", "Reddit-Meme-Scraper/requirements.txt", "vybhav72954", "This script locates and downloads images from several subreddits (r/deepfriedmemes, r/surrealmemes, r/nukedmemes, r/bigbangedmemes, r/wackytictacs, r/bonehurtingjuice) into your local system."], "Search Username": ["Search-Username", "search_user.py", "none", "none", "vybhav72954", "This script of code, using request module, will help to determine weather, a username exists on a platform or not."], "Social media links extractor": ["Social-Media-Links-From-Website", "script.py", "none", "none", "vybhav72954", "The code filters out all the social media links like youtube, instagram, linkedin etc. from the provided website url and displays as the output."], "Telegram bot": ["Telegram-Bot", "TelegramBot.py", "none", "none", "vybhav72954", "Create a bot in telegram"], "Tweet fetcher": ["Tweet-Fetcher", "fetcher.py", "none", "Tweet-Fetcher/requirements.txt", "Ayushjain2205", "This script is used to fetch tweets by a user specified hashtags and then store these tweets in a SQL database"], "Unfollowers Insta": ["Unfollowers-Insta", "insta_bot_bb8.py", "none", "Unfollowers-Insta/requirements.txt", "vybhav72954", "bb8 is a cute name for a great bot to check for the people that you follow who don't follow you back on Instagram."], "Whatsapp COVID19 Bot": ["Whatsapp_COVID-19_Bot", "covid_bot.py", "none", "Whatsapp_COVID-19_Bot/requirements.txt", "vybhav72954", "A COVID-19 Bot build using `Twilio API`, that tracks the Number of Infected persons, Recovered Persons and Number of Total deaths along with the day-to-day increase in the statistics. The information is then updated via WhatsApp."], "Whatsapp Automation": ["Whatsapp-Automation", "whatsappAutomation.py", "none", "none", "vybhav72954", "Whatsapp automated message sender"], "Whatsapp auto messenger": ["WhatsApp-Auto-Messenger", "WhatsApp-Auto-Messenger.py", "none", "WhatsApp-Auto-Messenger/requirements.txt", "AnandD007", "Send and schedule a message in WhatsApp by only seven lines of Python Script."], "Youtube Trending Feed Scrapper": ["Youtube Trending Feed Scrapper", "youtube_scrapper.py", "h-c-m", "none", "XZANATOL", "It's a 2 scripts that is used to scrap and read the first 10 trending news in YouTube from any its available categories."], "Youtube Audio Downloader": ["Youtube-Audio-Downloader", "YouTubeAudioDownloader.py", "none", "Youtube-Audio-Downloader/requirements.txt", "vybhav72954", "Download Audio Of A YouTube Video"], "Youtube Video Downloader": ["YouTube-Video-Downloader", "youtube_vid_dl.py", "none", "none", "mehabhalodiya", "The objective of this project is to download any type of video in a fast and easy way from youtube in your device."], "Instagram Follow/NotFollow": ["Instagram Follow- NotFollow", "main.py", "none", "none", "nidhivanjare", "An Instagram chatbot to display people you follow and who do not follow you back."]}, "PDF": {"PDF TO Word converter": ["PDFToWord", "main.py", "none", "requirements.txt", "dsrao711", "Takes the path of pdf from the user, The user can add a custom name to the word doc otherwise the same name of the pdf will be used."], "PDF Encryptor": ["PDF Encryption", "pdfEncryption.py", "none", "none", "vybhav72954", "The Python Script will let you encrypt the PDF with one OWNER and one USER password respectively."], "PDF2TXT": ["PDF2Text", "script.py", "none", "none", "Amit366", "Converts PDF file to a text file"], "PDF Delete Pages": ["PDF-Delete-Pages", "script.py", "none", "none", "vybhav72954", "Using this script you can delete the pages you don't want with just one click."], "PDF2Audio": ["PDF-To-Audio", "pdf_to_audio.py", "none", "none", "vybhav72954", "Add the possiblity to save .PDF to .MP3"], "PDF2CSV": ["PDF-To-CSV-Converter", "main.py", "none", "PDF-To-CSV-Converter/requirements.txt.txt", "vybhav72954", "Converts .PDF to .CSV"], "PDF Tools": ["PDF-Tools", "main.py", "none", "PDF-Tools/requirements.txt", "iamakkkhil", "Multiple functionalities involving PDFs which can be acessed using console menu"], "PDF Watermark": ["PDF-Watermark", "pdf-watermark.py", "none", "none", "vybhav72954", "Adds a watermark to the provided PDF."], "PDF arrange": ["Rearrange-PDF", "ReArrange.py", "none", "none", "vybhav72954", "This script can be helpful for re-arranging a pdf file which may have pages out of order."]}, "Image_Processing": {"Catooning Image": ["Cartooning Image", "cartooneffect.py", "none", "none", "aliya-rahmani", "Aim to transform images into its cartoon."], "Color Detection": ["Color_dectection", "Color_detection.py", "none", "none", "deepshikha007", "An application through which you can automatically get the name of the color by clicking on them."], "Convert2JPG": ["Convert-to-JPG", "convert2jpg.py", "none", "none", "vybhav72954", "This is a python script which converts photos to jpg format"], "Image editor": ["Image editor python script", "Image_editing_script.py", "none", "none", "asmita20aggarwal", "This menu-driven python script uses pillow library to make do some editing over the given image."], "Image processor": ["Image Processing", "ImgEnhancing.py", "none", "none", "Lakhankumawat", "Enchances a provided Image. Directory has 2 other scripts"], "Image Background Remover": ["Image_Background_Subtractor", "BG_Subtractor.py", "none", "Image_Background_Subtractor/requirements.txt", "iamakkkhil", "This python script lets you remove background form image by keeping only foreground in focus."], "Image viewer with GUI": ["Image_Viewing_GUI", "script.py", "none", "none", "Amit366", "script to see all the images one by one."], "IMG2SKETCH": ["ImageToSketch", "sketchScript.py", "none", "none", "vaishnavirshah", "Menu driven script- takes either the path of the image from the user or captures the image using webcam as per the user preference. The image is then converted to sketch."], "IMG2SPEECH": ["Imagetospeech", "image_to_speech.py", "none", "none", "Amit366", "The script converts an image to text and speech files."], "OCR Image to text": ["OCR-Image-To-Text", "ocr-img-to-txt.py", "none", "none", "vybhav72954", "A script that converts provided OCR Image to text"], "Screeshot": ["Screenshot", "screenshot.py", "none", "none", "vybhav72954", "A script that takes a screenshot of your current screen."], "Screenshot with GUI": ["Screenshot-GUI", "screenshot_gui.py", "none", "none", "vybhav72954", "A simple GUI script that allows you to capture a screenshot of your current screen."], "Text Extraction from Images": ["Text-Extract-Images", "text_extract.py", "none", "Text-Extract-Images/requirements.txt", "vybhav72954", "Text extraction form Images, OCR, Tesseract, Basic Image manipulation."], "Text on Image drawer": ["Text-On-Image.py", "text_on_image.py", "none", "none", "vybhav72954", "A script to draw text on an Image."], "Watermark maker on Image": ["Watermark Maker(On Image)", "Watermark_maker.py", "none", "none", "aishwaryachand", "User will be able to create a watermark on a given image."], "Photo2ASCII": ["Photo To Ascii", "photo_to_ascii.py", "none", "none", "Avishake007", "Convert your photo to ascii with it"], "Ghost filter": ["Ghost filter", "Ghost filter code.py", "none", "none", "A-kriti", "Converting an image into ghost/negative image"], "Invisibility Cloak": ["Invisibility_Cloak", "Invisibility_Cloak.py", "none", "none", "satyampgt4", "An invisibility cloak is a magical garment which renders whomever or whatever it covers invisible"], "Corner Detection": ["Fast Algorithm (Corner Detection)", "Fast_Algorithm.py", "none", "none", "ShubhamGupta577", "In this script, we implement the `Fast (Features from Accelerated Segment Test)` algorithm of `OpenCV` to detect the corners from any image."]}, "Video_Processing": {"Vid2Aud GUI": ["Video-Audio-Converter-GUI", "converter.py", "none", "none", "amrzaki2000", "This is a video to audio converter created with python."], "Vid2Aud CLI": ["Video-To-Audio(CLI-Ver)", "video_to_audio.py", "none", "none", "smriti1313", "Used to convert any type of video file to audio files using python."], "Video watermark adder": ["Video-Watermark", "watermark.py", "none", "Video-Watermark/requirements.txt", "vybhav72954", "This script can add watermark to a video with the given font."]}, "Games": {"Spaceship Game": ["Spaceship_Game", "main.py", "none", "requirements.txt", "iamakkkhil", "The python script makes use of Pygame, a popular GUI module, to develop an interactive Multiplayer Spaceship Game."], "Blackjack": ["Blackjack", "blackjack.py", "none", "none", "mehabhalodiya", "Blackjack (also known as 21) is a multiplayer card game, with fairly simple rules."], "Brick Breaker": ["Brick Breaker game", "brick_breaker.py", "none", "none", "Yuvraj-kadale", "Brick Breaker is a Breakout clonewhich the player must smash a wall of bricks by deflecting a bouncing ball with a paddle."], "Bubble Shooter": ["Bubble Shooter Game", "bubbleshooter.py", "none", "none", "syamala27", "A Bubble Shooter game built with Python and love."], "Turtle Graphics": ["Codes on Turtle Graphics", "Kaleido-spiral.py", "none", "none", "ricsin23", "_turtle_ is a pre installed library in Python that enables us to create pictures and shapes by providing them with a virtual canvas."], "Connect 4": ["Connect-4 game", "Connect-4.py", "none", "none", "syamala27", "Four consecutive balls should match of the same colour horizontally, vertically or diagonally"], "Flames": ["Flames-Game", "flames_game_gui.py", "none", "none", "vybhav72954", "Flames game"], "Guessing Game": ["Guessing_Game_GUI", "guessing_game_tkinter.py", "none", "none", "saidrishya", "A random number is generated between an upper and lower limit both entered by the user. The user has to enter a number and the algorithm checks if the number matches or not within three attempts."], "Hangman": ["Hangman-Game", "main.py", "none", "none", "madihamallick", "A simple Hangman game using Python"], "MineSweeper": ["MineSweeper", "minesweeper.py", "none", "none", "Ratnesh4193", "This is a python script MINESWEEPER game"], "Snake": ["Snake Game (GUI)", "game.py", "none", "none", "vybhav72954", "Snake game is an Arcade Maze Game which has been developed by Gremlin Industries. The player\u2019s objective in the game is to achieve maximum points as possible by collecting food or fruits. The player loses once the snake hits the wall or hits itself."], "Sudoku Solver and Visualizer": ["Sudoku-Solver-And-Vizualizer", "Solve_viz.py", "none", "none", "vybhav72954", "Sudoku Solver and Vizualizer"], "Terminal Hangman": ["Terminal Hangman", "T_hangman.py", "none", "none", "Yuvraj-kadale", "Guess the Word in less than 10 attempts"], "TicTacToe GUI": ["TicTacToe-GUI", "TicTacToe.py", "none", "none", "Lakhankumawat", "Our Tic Tac Toe is programmed in other to allow two users or players to play the game in the same time."], "TicTacToe using MinMax": ["Tictactoe-Using-Minmax", "main.py", "none", "none", "NChechulin", "Adversarial algorithm-Min-Max for Tic-Tac-Toe Game. An agent (Robot) will play Tic Tac Toe Game with Human."], "Typing Speed Test": ["Typing-Speed-Test", "speed_test.py", "none", "none", "dhriti987", "A program to test (hence improve) your typing speed"], "Tarot Reader": ["Tarot Reader", "tarot_card_reader.py", "none", "none", "Akshu-on-github", "This is a python script that draws three cards from a pack of 78 cards and gives fortunes for the same. As it was originally created as a command line game, it doesn't have a GUI"], "Stone Paper Scissors Game": ["Stone-Paper-Scissors-Game", "Rock-Paper-Scissors Game.py", "none", "none", "NChechulin", "Stone Paper Scissors Game"], "StonePaperScissor - GUI": ["StonePaperScissor - GUI", "StonePaperScissors.py", "none", "none", "Lakhankumawat", "Rock Paper and Scissor Game Using Tkinter"], "Guess the Countries": ["Guess the Countries", "main.py", "none", "none", "Shubhrima Jana", "Guess the name of the countries on the world map and score a point with every correct guess."], "Dice Roll Simulator": ["Dice-Roll-Simulator", "dice_roll_simulator.py", "none", "none", "mehabhalodiya", "It is making a computer model. Thus, a dice simulator is a simple computer model that can roll a dice for us."]}, "Networking": {"Browser": ["Broswer", "browser.py", "none", "none", "Sloth-Panda", "This is a simple web browser made using python with just functionality to have access to the complete gsuite(google suite) and the default search engine here is google."], "Get Wifi Password": ["Get-Wifi-Password", "finder.py", "none", "none", "pritamp17", "A Python Script Which,when excuted on target WINDOWS PC will send all the stored WIFI passwords in it through given email."], "HTTP Server": ["HTTP-Server", "httpServer.py", "none", "HTTP-Server/requirements.txt", "NChechulin", "This is the project based on http protocol that has been used in day to day life. All dimensions are considered according to rfc 2616"], "HTTP Sniffer": ["Http-Sniffer", "sniffer.py", "none", "none", "avinashkranjan", "python3 script to sniff data from the HTTP pages."], "Network Scanner": ["Network-Scanner", "network_scanner.py", "none", "none", "NChechulin", "This tool will show all the IP's on the same network and their respective MAC adresses"], "Network Troubleshooter": ["Network-troubleshooter", "ipreset.py", "none", "none", "geekymeeky", "A CLI tool to fix corrupt IP configuaration and other network socket related issue of your Windows PC."], "Phone Number Tracker": ["Phonenumber Tracker", "index.py", "none", "none", "Sloth-Panda", "This is a phonenumber tracker that uses phonenumbers library to get the country and service provider of the phone number and coded completely in python."], "Port Scanner": ["PortScanning", "portscanningscript.py", "none", "none", "Mafiaguy", "A python scripting which help to do port scanning of a particular ip."], "Wifi Password Saver": ["Save-Wifi-Password", "wifiPassword.py", "none", "none", "geekymeeky", "Find and write all your saved wifi passwords in a txt file"], "URL Shortner": ["URL-Shortener", "url-shortener.py", "none", "none", "NChechulin", "It shortens your given website URL."], "URL Shortner GUI": ["URL-Shortener-GUI", "url-shortener-gui.py", "none", "none", "NChechulin", "GUI based It shortens your given website URL."], "Website Status Checker": ["Website-Status-Checker", "website_status_checker.py", "none", "none", "avinashkranjan", "This script will check the status of the web address which you will input"], "Email Validator": ["Email-Validator", "email-verification.py", "none", "none", "saaalik", "A simple program which checks for Email Address Validity in three simple checks"]}, "OS_Utilities": {"Auto Backup": ["Auto_Backup", "Auto_Backup.py", "none", "t-s-c", "vybhav72954", "Automatic Backup and Compression of large file, sped up using Threading."], "Battery Notification": ["Battery-Notification", "Battery-Notification.py", "none", "none", "pankaj892", "This is a Python Script which shows the battery percentage left"], "CPU Temperature": ["CPU temperature", "temp.py", "none", "none", "atarax665", "This python script is used to get cpu temperature"], "Desktop News Notification": ["Desktop News Notifier", "script.py", "none", "none", "Amit366", "On running the script it gives a notification of top 10 news"], "Desktop drinkWater Notification": ["Desktop-drinkWater-Notification", "main.py", "none", "none", "viraldevpb", "This python script helps user to drink more water in a day as per her body needed and also this python script is executed in the background and every 30 minutes it notifies user to drink water."], "Desktop Voice Assistant": ["Desktop-Voice-assistant", "voice_assistant.py", "none", "Desktop-Voice-assistant/requirements.txt", "sayantani11", "It would be great to have a desktop voice assistant who could perform tasks like sending email, playing music, search wikipedia on its own when we ask it to."], "Digital Clock": ["Digital Clock", "Clock.py", "none", "none", "Dhanush2612", "A simple digital 12 hour clock."], "Duplicate File Finder": ["Duplicate-File-Finder", "file_finder.py", "argv", "Duplicate-File-Finder/requirements.txt", "vybhav72954", "This sweet and simple script helps you to compare various files in a directory, find the duplicate, list them out, and then even allows you to delete them."], "Email Sender": ["Email-Sender", "email-sender.py", "none", "none", "avinashkranjan", "A script to send Email using Python."], "File Change Listener": ["File-Change-Listen", "main.py", "none", "File-Change-Listen/requirements.txt", "antrikshmisri", "This is a python script that keeps track of all files change in the current working directory"], "File Mover": ["File-Mover", "fmover.py", "none", "File-Mover/requirements.txt", "NChechulin", "his is a small program that automatically moves and sorts files from chosen source to destination."], "Folder2Zip": ["Folder-To-Zip", "folder-to-zip.py", "none", "none", "NChechulin", "To convert folders into ZIP format"], "Get Wifi Password": ["Get-Wifi-Password", "finder.py", "none", "none", "pritamp17", "A Python Script Which,when excuted on target WINDOWS PC will send all the stored WIFI passwords in it through given email."], "Keylogger": ["Keylogger", "keylogger.py", "none", "none", "madihamallick", "A Keylogger script built using Python."], "Last Access": ["Last Access", "Last Access.py", "none", "none", "Bug-007", "It prints out when was the last the file in folder was accessed."], "Mini Google Assistant": ["Mini Google Assistant", "Mini google assistant.py", "none", "none", "A-kriti", "A mini google assistant using python which can help you to play song, tell time, tell joke, tell date as well as help you to capure a photo/video."], "Music Player": ["Music-Player-App", "main.py", "none", "none", "robin025", "A Python GUI Based Music Player"], "News Voice Assistant": ["News-Voice-Assistant", "news_assistant.py", "none", "News-Voice-Assistant/requirements.txt", "NChechulin", "Hear your favourite news in your computer!"], "Organise Files According To Their Extensions": ["Organise-Files-According-To-Their-Extensions", "script_dirs.py", "none", "none", "NChechulin", "Script to organise files according to their extensions"], "Paint App": ["Paint Application/", "paint.py", "none", "Paint Application/requirements.txt", "Ayushjain2205", "Running this Script would open up a Paint application GUI on which the user can draw using the brush tool."], "Password Generator": ["Password-Generator", "passowrd_gen.py", "none", "none", "NChechulin", "A Password Generator built using Python"], "Password Manager": ["Password-Manager-GUI", "passwords.py", "none", "none", "Ayushjain2205", "This script opens up a Password Manager GUI on execution."], "QR Code Generator": ["QR_Code_Generator", "main.py", "none", "none", "CharvyJain", "This script will generate the QR Code of the given link."], "QR code Gen": ["QR-code-Genrator", "main.py", "none", "QR-code-Genrator/requirement.txt", "Goheljay", "A simple GUI based qr code genrator application in Python that helps you to create the qr code based on user given data."], "Random Password Generator": ["Random Password Generator", "script.py", "none", "none", "tanvi355", "This is a random password generator."], "Random Email Generator": ["Random-Email-Generator", "random_email_generator.py", "none", "none", "pankaj892", "This is a Python Script which generates random email addresses"], "Run Script at a Particular Time": ["Run-Script-At-a-Particular-Time", "date_time.py", "none", "none", "avinashkranjan", "Runs a script at a particular time defined by a user"], "Screen Recorder": ["Screen-Recorder", "screen_recorder.py", "none", "none", "avinashkranjan", "It records the computer screen."], "Notepad": ["Simple Notepad", "SimpleNotepad.py", "none", "none", "Bug-007", "Using Tkinter GUI of simplenotepad is made."], "Python IDE": ["Simple Python IDE using Tkinter", "script.py", "none", "none", "Priyadarshan2000", "This is a Simple Python IDE using Tkinter."], "Site Blocker": ["Site-blocker", "web-blocker.py", "none", "none", "Sloth-Panda", "This is a script that aims to implement a website blocking utility for Windows-based systems."], "Speech to Text": ["Speech-To-Text", "speech-to-text.py", "none", "none", "avinashkranjan", "A script that converts speech to text"], "Text to Speech": ["Text-To-Speech", "text-to-speech.py", "none", "none", "mehabhalodiya", "Text to speech is a process to convert any text into voice."], "ToDo": ["ToDo-GUI", "todo.py", "none", "ToDo-GUI/requirements.txt", "a-k-r-a-k-r", "This project is about creating a ToDo App with simple to use GUI"], "Unzip File": ["Unzip file", "script.py", "none", "none", "Amit366", "Upload the zip file which is to be unzipped"], "Voice Assistant": ["Voice-Assistant", "test.py", "none", "none", "avinashkranjan", "It is a beginner-friendly script in python, where they can learn about the if-else conditions in python and different libraries."], "Bandwidth Monitor": ["Bandwidth-Monitor", "bandwidth_py3.py", "none", "none", "adarshkushwah", "A python script to keep a track of network usage and notify you if it exceeds a specified limit (only support for wifi right now)"], "Sticky Notes": ["sticky notes", "main.py", "none", "none", "vikashkumar2020", "A simple GUI based application in Python that helps you to create simple remember lists or sticky notes."], "Calendar": ["Calendar GUI", "Calendar_gui.py", "none", "none", "aishwaryachand", "Using this code you will be able to create a Calendar GUI where calendar of a specific year appears."], "Directory Tree Generator": ["Directory Tree Generator", "tree.py", "argv", "Directory Tree Generator/requirements.txt", "vikashkumar2020", "A Script useful for visualizing the relationship between files and directories and making their positioning easy."], "Stopwatch": ["Stopwatch GUI", "stopwatch_gui.py", "none", "none", "aishwaryachand", "This is a Stopwatch GUI using which user can measure the time elapsed using the start and pause button."], "Webcam Imgcap": ["Webcam-(imgcap)", "webcam-img-cap.py", "none", "none", "NChechulin", "Image Capture using Web Camera"], "Countdown clock and Timer": ["Countdown_clock_and_Timer", "countdown_clock_and_timer.py", "none", "none", "Ayush7614", "A simple timer that can be used to track runtime."], "Paint Application": ["Paint Application", "paint.py", "none", "Paint Application/requirements.txt", "Ayushjain2205", "Running this Script would open up a Paint application GUI on which the user can draw using the brush tool."], "Covid-19 Updater": ["Covid-19-Updater", "covid-19-updater_bot.py", "none", "none", "avinashkranjan", "Get hourly updates of Covid19 cases, deaths and recovered from coronavirus-19-api.herokuapp.com using a desktop app in Windows."], "Link Preview": ["Link-Preview", "linkPreview.py", "none", "Link-Preview/requirements.txt", "jhamadhav", "A script to provide the user with a preview of the link entered."]}, "Automation": {"Firebase Management Scripts": ["FirebaseScripts", "firebase_authentications.py ", "none", "requirements.txt", "shantamsultania ", "A set of Scripts that can be used to connect to different services provided by firebase cloud services "], "Gmail Attachment Downloader": ["Attachment_Downloader", "attachment.py", "none", "none", "Kirtan17", "The script downloads gmail atttachment(s) in no time!"], "Auto Birthday Wisher": ["Auto Birthday Wisher", "Auto B'Day Wisher.py", "none", "none", "SpecTEviL", "An automatic birthday wisher via email makes one's life easy. It will send the birthday wishes to friends via email automatically via a server and using an excel sheet to store the data of friends and their birthdays along with email id."], "Auto Fill Google Forms": ["Auto-Fill-Google-Forms", "test.py", "none", "none", "NChechulin", "This is a python script which can helps you to fillout the google form automatically by bot."], "Automatic Certificate Generator": ["Automatic Certificate Generator", "main.py", "none", "none", "achalesh27022003", "This python script automatically generates certificate by using a certificate template and csv file which contains the list of names to be printed on certificate."], "Chrome Automation": ["Chrome-Automation", "chrome-automation.py", "none", "none", "NChechulin", "Automated script that opens chrome along with a couple of defined pages in tabs."], "Custom Bulk Email Sender": ["Custom-Bulk-Email-Sender", "customBulkEmailSender.py", "none", "none", "NChechulin", "he above script is capable of sending bulk custom congratulation emails which are listed in the .xlsx or .csv format."], "Github Automation": ["Github-Automation", "main.py", "none", "Github-Automation/requirements.txt", "antrikshmisri", "This script allows user to completely automate github workflow."], "SMS Automation": ["SMS Automation", "script.py", "none", "none", "Amit366", "Send SMS messages using Twilio"], "Send Twilio SMS": ["Send-Twilio-SMS", "main.py", "none", "none", "dhanrajdc7", "Python Script to Send SMS to any Mobile Number using Twilio"], "Spreadsheet Comparision Automation": ["Spreadsheet_Automation", "script.py", "none", "none", "Amit366", "Spreadsheet Automation Functionality to compare 2 datasets."], "HTML Email Sender": ["HTML-Email-Sender", "main.py", "none", "none", "dhanrajdc7", "This script helps to send HTML Mails to Bulk Emails"], "HTML to MD": ["HTML-To-MD", "html_to_md.py", "none", "none", "NChechulin", "Converts HTML file to MarkDown (MD) file"], "Censor word detector": ["Censor word detection", "censor_word_detection.py", "none", "none", "jeelnathani", "an application which can detect censor words."]}, "Cryptography": {"BitCoin Mining": ["BitCoin Mining", "BitCoin_Mining.py", "none", "none", "NEERAJAP2001", "A driver code with explains how BITCOIN is mined"], "Caesar Cipher": ["Caesar-Cipher", "caesar_cipher.py", "none", "none", "smriti1313", "It is a type of substitution cipher in which each letter in the plaintext is replaced by a letter some fixed number of positions down the alphabet."], "Morse Code Translator": ["Morse_Code_Translator", "Morse_Code_Translator.py", "none", "none", "aishwaryachand", "Morse code is a method used in telecommunication to encode text characters as standardized sequences of two different signal durations, called _dots_ and _dashes_."], "Steganography": ["Steganography", "steganography.py", "argv", "none", "dhriti987", "This Python Script Can hide text under image and can retrive from it with some simple commands"], "CRYPTOGRAPHY": ["Cryptography", "crypto.py", "none", "none", "codebuzzer01", "The objective of this project is to encode and decode messages using a common key."]}, "Computer_Vision": {"Finger Counter using hand tracking": ["Finger-Counter", "finger_counter.py", "none", "requirements.txt", "mehabhalodiya", "A system that detects a human hand, segments the hand, counts the number of fingers being held up, and displays the finger count, from live video input."], "Color Detection": ["Color_detection", "Color_detection.py", "none", "none", "deepshikha007", "In this color detection Python project, we are going to build an application through which you can automatically get the name of the color by clicking on them."], "Contour Detection": ["Contour-Detection", "live_contour_det.py", "none", "none", "mehabhalodiya", "Contours can be explained simply as a curve joining all the continuous points (along the boundary), having same color or intensity."], "Document Word Detection": ["Document-Word-Detection", "Word_detection.py", "none", "none", "hritik5102", "Detect a word present in the document (pages) using OpenCV"], "Edge Detection": ["Edge Detection", "Edge_Detection.py", "none", "none", "ShubhamGupta577", "This script uses `OpenCV` for taking input and output for the image. In this we are using he `Canny algorithm` for the detection of the edge."], "Eye Detection": ["Eye Detection", "eyes.py", "none", "none", "Avishake007", "It is going to detect your eyes and count the number of eyes"], "Face Detection": ["Face-Detection", "face-detect.py", "none", "none", "Avishake007", "Face Detection script using Python Computer Vision"], "Corner Detection": ["Fast Algorithm (Corner Detection)", "Fast_Algorithm.py", "none", "none", "ShubhamGupta577", "In this script, we implement the `Fast (Features from Accelerated Segment Test)` algorithm of `OpenCV` to detect the corners from any image."], "Human Detection": ["Human-Detection", "script.py", "none", "none", "NChechulin", "Uses OpenCV to Detect Human using pre trained data."], "Num Plate Detector": ["Num-Plate-Detector", "number_plate.py", "none", "none", "mehabhalodiya", "License plate of the vehicle is detected using various features of image processing library openCV and recognizing the text on the license plate using python tool named as tesseract."], "Realtime Text Extraction": ["Realtime Text Extraction", "Realtime Text Extraction.py", "none", "none", "ShubhamGupta577", "In this script we are going to read a real-time captured image using a web cam or any other camera and extract the text from that image by removing noise from it."], "Virtual Paint": ["Virtual Paint", "virtual_paint.py", "none", "none", "mehabhalodiya", "It is an OpenCV application that can track an object\u2019s movement, using which a user can draw on the screen by moving the object around."], "ORB Algorithm": ["ORB Algorithm", "ORB_Algorithm.py", "none", "none", "ShubhamGupta577", "ORB Algorithm of `Open CV` for recognition and matching the features of image."]}, "Fun": {"Pygame-Buttons": ["Pygame-Buttons", "main.py", "none", "requirements.txt", "Lakhankumawat", " How to make design and animate buttons in python."], "Spiral Star": ["Spiral-Star", "program1.py", "none", "none", "avinashkranjan", "This is python programs to create a spiral star and colourful spiral star using python"], "Matrix Rain": ["Matrix-rain-code", "matrix-rain.py", "none", "none", "YashIndane", "Matrix Rain"], "Github Bomb Issues": ["Github_Bomb_Issues", "bomb-issues.py", "none", "Github_Bomb_Issues/requirements.txt", "Ayush7614", "This python script bombs specified number of issues on a Github Repository."], "Lyrics Genius API": ["Lyrics_Genius_API", "lyrics.py", "none", "none", "vybhav72954", "This script can be used to download lyrics of any number of songs, by any number of Artists, until the API Limit is met."], "Songs by Artist": ["Songs-By-Artist", "songs_of_artist.py", "none", "none", "NChechulin", "A music search application, using a few named technologies that allows users to search for the songs of their favorite Artists in a very less time."], "Beat_Board": ["Beat-Board", "beatBoard.py", "none", "requirements.txt", "albertzeap", "A small GUI program that allows the user to create custom sounds through mouse clicks or key presses."]}, "Others": {"Pwned or not": ["Pwned_or_not_GUI", "pwned_passwords_GUI.py", "none", "requirements.txt", "RohiniRG", "The python script helps users to know if their passwords were ever part of a data breach, and thus helping them stay aware and change their passwords accordingly. This information will be presented to users in a user-friendly GUI."], "Bubble Sort Visualization": ["Bubble-Sort-Visualization", "bubble_sort.py", "none", "none", "amrzaki2000", "This is a script that provides easy simulation to bubble sort algorithm."], "Select Stocks by volume Increase": ["Select Stocks by volume Increase", "script.py", "none", "none", "Amit366", "Select Stocks by volume Increase when provided by the number of days from the user."], "ZIP Function": ["ZIP-Function", "transpose.py", "none", "none", "avinashkranjan", "function creates an iterator that will aggregate elements from two or more iterables."], "Quiz GUI": ["Quiz-GUI", "quiztime.py", "none", "none", "soumyavemuri", "A quiz application created with Python's Tkinter GUI toolkit."], "Dictionary GUI": ["Dictionary-GUI", "dictionary.py", "none", "Dictionary-GUI/requirements.txt", "Ayushjain2205", "This script lets the user search for the meaning of words like a dictionary."], "Translator Script": ["Translator Script", "Translation.py", "none", "none", "NEERAJAP2001", "Running this Script would translate one language to another language"], "Translator GUI": ["Translator-GUI", "translator.py", "none", "Translator-GUI/requirements.txt", "Ayushjain2205", "Running this Script would open up a translator with GUI which can be used to translate one language to another."], "Gmplot Track the Route": ["Gmplot-Track the Route", "main.py", "none", "none", "Lakhankumawat", "track the whole route of a person by reading values of a provided CSV file on Google Maps and create an Image containing route or location."], "Health Log Book": ["Health_Log_Book", "main.py", "none", "none", "anuragmukherjee2001", "The script will contain the daily records of food and workouts of a person."], "Pagespeed API": ["Pagespeed-API", "test.py", "none", "none", "keshavbansal015", "This script generates the PageSpeed API results for a website."], "String Matching Scripts": ["String-Matching-Scripts", "string_matching.py", "none", "none", "avinashkranjan", "an efficient way of string matching script."], "Wikipedia Summary": ["Wikipedia-Summary-GUI", "summary.py", "none", "Wikipedia-Summary-GUI/requirements.txt", "Ayushjain2205", "Running this Script would open up a wikipedia summary generator GUI which can be used to get summary about any topic of the user's choice from wikipedia."], "Expense Tracker": ["Expense Tracker", "script.py", "none", "none", "Amit366", "This is used to store the daily expenses."], "Piglatin Translator": ["Piglatin_Translator", "piglatin.py", "none", "none", "archanagandhi", "A secret language formed from English by transferring the initial consonant or consonant cluster of each word to the end of the word and adding a vocalic syllable (usually /e\u026a/): so pig Latin would be igpay atinlay."], "TODO CLI": ["TODO (CLI-VER)", "todolist.py", "none", "none", "Avishake007", "List down your items in a Todolist so that you don't forget"], "Sentiment Detector": ["Script to check Sentiment", "script.py", "none", "none", "Amit366", "Sentiment Detector that checks sentiment in the provided sentence."], "Linear Search Visualizer": ["Linear Search Visualizer", "script.py", "none", "none", "tanvi355", "A GUI that allows you to see the linear search in action."]}} \ No newline at end of file diff --git a/Medium-Scraper/README.md b/Medium-Scraper/README.md new file mode 100644 index 0000000000..d7b693ec93 --- /dev/null +++ b/Medium-Scraper/README.md @@ -0,0 +1,31 @@ +# Medium Scrapper +Running this Script would allow the user to scrape any number of articles from [medium.com](https://medium.com/) from any category as per the user's choice + +## Setup instructions +In order to run this script, you need to have Python and pip installed on your system. After you're done installing Python and pip, run the following command from your terminal to install the requirements from the same folder (directory) of the project. +``` +pip install -r requirements.txt +``` +As this script uses selenium, you will need to install the chrome webdriver from [this link](https://sites.google.com/a/chromium.org/chromedriver/downloads) + +After satisfying all the requirements for the project, Open the terminal in the project folder and run +``` +python scraper.py +``` +or +``` +python3 scraper.py +``` +depending upon the python version. Make sure that you are running the command from the same virtual environment in which the required modules are installed. + +## Output +The user needs to enter Category and Number of articles + + + +The scraped pdf files get saved in the folder in which the script is run + + + +## Author +[Ayush Jain](https://github.com/Ayushjain2205) \ No newline at end of file diff --git a/Medium-Scraper/requirements.txt b/Medium-Scraper/requirements.txt new file mode 100644 index 0000000000..e29506e0fe --- /dev/null +++ b/Medium-Scraper/requirements.txt @@ -0,0 +1,4 @@ +requests +beautifulsoup4 +selenium +fpdf \ No newline at end of file diff --git a/Medium-Scraper/scraper.py b/Medium-Scraper/scraper.py new file mode 100644 index 0000000000..69293998c2 --- /dev/null +++ b/Medium-Scraper/scraper.py @@ -0,0 +1,80 @@ +import requests +from bs4 import BeautifulSoup +from selenium import webdriver +from selenium.webdriver.common.keys import Keys +import time +from fpdf import FPDF + +# Get input for category and number of articles +category = input("Enter category (Ex- Programming or javascript) : ") +number_articles = int(input("Enter number of articles: ")) +driver_path = input("Enter chrome driver path: ") + +url = 'https://medium.com/topic/{}'.format(category) + +# initiating the webdriver to run in incognito mode +chrome_options = webdriver.ChromeOptions() +chrome_options.add_argument("--incognito") +driver = webdriver.Chrome(driver_path, options=chrome_options) +driver.get(url) + +# this is just to ensure that the page is loaded +time.sleep(5) +html = driver.page_source + +# Now apply bs4 to html variable +soup = BeautifulSoup(html, "html.parser") +articles = soup.find_all('section') + +# Getting articles from medium +num = number_articles +for article in articles: + article_data = article.find('a')['href'] + if article_data[0] == '/': + article_data = 'https://medium.com' + article_data + + post_url = article_data + driver.get(post_url) + time.sleep(5) + + post_html = driver.page_source + soup = BeautifulSoup(post_html, "html.parser") + a_tags = soup.find_all('a') + + author = a_tags[2].text + + title = soup.find('h1').text.strip() + section = soup.find_all('section')[1] + p_tags = section.find_all('p') + + title_string = (title).encode( + 'latin-1', 'replace').decode('latin-1') + author_string = (author).encode('latin-1', 'replace').decode('latin-1') + + # Add a page in pdf + pdf = FPDF() + pdf.add_page() + # set style and size of font for pdf + pdf.set_font("Arial", size=12) + + # Title cell + pdf.cell(200, 5, txt=title_string, ln=1, align='C') + # Author cell + pdf.cell(200, 10, txt=author_string, ln=2, align='C') + + for p_tag in p_tags: + article_part = (p_tag.text.strip()).encode('latin-1', 'replace').decode('latin-1') + article_part += '\n' + # Add part of article to pdf + pdf.multi_cell(0, 5, txt=article_part, align='L') + + # save the pdf with name .pdf + pdf_title = ''.join(e for e in title if e.isalnum()) + pdf.output("{}.pdf".format(pdf_title)) + + num = num-1 + if(num == 0): + break + + +driver.close() # closing the webdriver diff --git a/Neon Effect Filter/Code.py b/Neon Effect Filter/Code.py new file mode 100644 index 0000000000..d3119ada51 --- /dev/null +++ b/Neon Effect Filter/Code.py @@ -0,0 +1,31 @@ +import numpy as np +import cv2 +import os.path +from matplotlib import pyplot as plt + +img_path = input("Enter the path of image: ") #example -> C:\Users\xyz\OneDrive\Desktop\project\image.jpg +img = cv2.imread(img_path) +image = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) + +img_small = cv2.pyrDown(image) +num_iter = 5 +for _ in range(num_iter): + img_small= cv2.bilateralFilter(img_small, d=9, sigmaColor=9, sigmaSpace=7) + +img_rgb = cv2.pyrUp(img_small) + +img_gray = cv2.cvtColor(img_rgb, cv2.COLOR_RGB2GRAY) +img_blur = cv2.medianBlur(img_gray, 7) +img_edge = cv2.adaptiveThreshold(img_blur, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 7, 2) + +img_edge = cv2.cvtColor(img_edge, cv2.COLOR_GRAY2RGB) +array = cv2.bitwise_and(image, img_edge) +array1 = cv2.bitwise_xor(array, image) +plt.figure(figsize= (10,10)) +plt.imshow(array1,cmap='gray') +plt.title("Neon Effect Filtered Photo") +plt.axis('off') +filename = os.path.basename(image_path) +plt.savefig("./Neon Effect Filter/Neon Effect Filter"+filename) #saved file name as (Filtered)image_name.jpg + +plt.show() diff --git a/Neon Effect Filter/Image/(Neon Effect Filter)image_.jpg b/Neon Effect Filter/Image/(Neon Effect Filter)image_.jpg new file mode 100644 index 0000000000..5799ad1ea1 Binary files /dev/null and b/Neon Effect Filter/Image/(Neon Effect Filter)image_.jpg differ diff --git a/Neon Effect Filter/Image/image_.jpg b/Neon Effect Filter/Image/image_.jpg new file mode 100644 index 0000000000..9cb7e57e85 Binary files /dev/null and b/Neon Effect Filter/Image/image_.jpg differ diff --git a/Neon Effect Filter/README.md b/Neon Effect Filter/README.md new file mode 100644 index 0000000000..66c6f697ae --- /dev/null +++ b/Neon Effect Filter/README.md @@ -0,0 +1,33 @@ + +# Neon Effect Filter + +Converting an image into an neon effect filtered image using some of the python libraries. + +## Libraries used +Firstly import the following python libraries +* OpenCv +* Os +* Matplotlib +* Numpy + +Taking path of the image/Real image as input using os and finally reading it using cv2 + +## Detailed explanation of the method used + +* Imported the required libraries ( Numpy, Matplotlib, OpenCv, Os) +* Read the input path of the image using Cv2 library +* Used Bilateral Filter +* Followed by Median Blur +* Followed by Adaptive Threshold +* Followed by Bitwise "and" between original image and edge image +* And at last used Bitwise "xor" between orginal and output of the above "bitwise and image" +* Finally converted the image into "Neon Effect Filtered" image + +## Original Image + +
+## Neon Effect Filtered Image
+
+
+## Neon Effect Filtered Image
+image_.jpg) +
+## Author(s)
+[Akriti](https://github.com/A-kriti)
diff --git a/Neon Effect Filter/requirements.txt b/Neon Effect Filter/requirements.txt
new file mode 100644
index 0000000000..7c3546d78b
--- /dev/null
+++ b/Neon Effect Filter/requirements.txt
@@ -0,0 +1,3 @@
+numpy==1.18.5
+opencv_python==4.5.1.48
+matplotlib==3.2.2
diff --git a/News-Voice-Assistant/requirements.txt b/News-Voice-Assistant/requirements.txt
index 00e83d1787..7aeb4ae075 100644
--- a/News-Voice-Assistant/requirements.txt
+++ b/News-Voice-Assistant/requirements.txt
@@ -9,6 +9,6 @@ newsapi-python==0.1.1
requests==2.24.0
six==1.15.0
soupsieve==2.0.1
-urllib3==1.25.11
+urllib3==1.26.5
pydub==0.24.1
simpleaudio==1.0.4
diff --git a/Noise Reduction Script/Audio/(Filtered_Audio)test_noise .wav b/Noise Reduction Script/Audio/(Filtered_Audio)test_noise .wav
new file mode 100644
index 0000000000..c331ce5b8e
Binary files /dev/null and b/Noise Reduction Script/Audio/(Filtered_Audio)test_noise .wav differ
diff --git a/Noise Reduction Script/Audio/test_noise.wav b/Noise Reduction Script/Audio/test_noise.wav
new file mode 100644
index 0000000000..1522ae4849
Binary files /dev/null and b/Noise Reduction Script/Audio/test_noise.wav differ
diff --git a/Noise Reduction Script/Graph/test_noise.wav(Spectral Subtraction graph).jpg b/Noise Reduction Script/Graph/test_noise.wav(Spectral Subtraction graph).jpg
new file mode 100644
index 0000000000..e0ed98da22
Binary files /dev/null and b/Noise Reduction Script/Graph/test_noise.wav(Spectral Subtraction graph).jpg differ
diff --git a/Noise Reduction Script/Noise Reduction Script.py b/Noise Reduction Script/Noise Reduction Script.py
new file mode 100644
index 0000000000..277f7a7523
--- /dev/null
+++ b/Noise Reduction Script/Noise Reduction Script.py
@@ -0,0 +1,50 @@
+# Spectral Subtraction: Method used for noise reduction
+import scipy.io.wavfile as wav
+import numpy as np
+import matplotlib.pyplot as plt
+
+file = input("Enter the file path: ")
+sr, data = wav.read(file)
+fl = 400 #frame_length
+frames = [] #empty list
+for i in range(0,int(len(data)/(int(fl/2))-1)):
+ arr = data[int(i*int(fl/2)):int(i*int(fl/2)+fl)]
+ frames.append(arr) #appending each array data into the frames list
+frames = np.array(frames) #converting the frames list into an array
+ham_window = np.hamming(fl) #using np.hamming
+windowed_frames = frames*ham_window #multiplying frames array with ham_window
+dft = [] #empty list containing fft of windowed_frames
+for i in windowed_frames:
+ dft.append(np.fft.fft(i)) #now taking the first fourier transform of each window
+dft = np.array(dft) #converting dft into array
+
+dft_mag_spec = np.abs(dft) #converting dft into absolute values
+dft_phase_spec = np.angle(dft) #finding dft angle
+noise_estimate = np.mean(dft_mag_spec,axis=0) #mean
+noise_estimate_mag = np.abs(noise_estimate) #absolute value
+
+estimate_mag = (dft_mag_spec-2*noise_estimate_mag) #subtraction method
+estimate_mag[estimate_mag<0]=0
+estimate = estimate_mag*np.exp(1j*dft_phase_spec) #calculating the final estimate
+ift = [] #taking ift as input list containing inverse fourier transform of estimate
+for i in estimate:
+ ift.append(np.fft.ifft(i)) #appending in ift list
+
+clean_data = []
+clean_data.extend(ift[0][:int(fl/2)]) #extending clean_data containg ift list
+for i in range(len(ift)-1):
+ clean_data.extend(ift[i][int(fl/2):]+ift[i+1][:int(fl/2)])
+clean_data.extend(ift[-1][int(fl/2):]) #extending clean_data containing ift list
+clean_data = np.array(clean_data) #converting it into array
+
+#finally plotting the graph showing the diffrence in the noise
+fig = plt.figure(figsize=(8,5))
+ax = plt.subplot(1,1,1)
+ax.plot(np.linspace(0,64000,64000),data,label='Original',color="orange")
+ax.plot(np.linspace(0,64000,64000),clean_data,label='Filtered',color="purple")
+ax.legend(fontsize=12)
+ax.set_title('Spectral Subtraction Method', fontsize=15)
+filename = os.path.basename(file)
+cleaned_file = "(Filtered_Audio)"+filename #final filtered audio
+wav.write(cleaned_file,rate=sr, data = clean_data.astype(np.int16))
+plt.savefig(filename+"(Spectral Subtraction graph).jpg") #saved file name as audio.wav(Spectral Subtraction graph).jpg
diff --git a/Noise Reduction Script/README.md b/Noise Reduction Script/README.md
new file mode 100644
index 0000000000..071e22c33b
--- /dev/null
+++ b/Noise Reduction Script/README.md
@@ -0,0 +1,25 @@
+# Noise Reduction Script
+Implementing a feature that helps to filter an audio file by reducing the background noise similar to "Audacity".
+
+## Libraries used
+Firstly import the following python libraries
+* NumPy
+* scipy.io.wavfile
+* Matplotlib
+* Os
+Save the audio files and your code in the same folder
+Run the python code
+
+## Detailed explanation of method used for "Noise Reduction Script"
+* Imported the required libraries (NumPy, scipy.io.wavfile, and Matplotlib)
+* Read the input audio file using scipy.io.wavfile library
+* Converting the audio file into an array containg all the information of the given audio file and intiallizing the frame value.
+* Calculating the first fourier transform of each window of the noisy audio file
+* Subtracting the noise spectral mean from input spectral, and istft (Inverse Short-Time Fourier Transform)
+* Finally getting an audio file with reduction in the background noise at a much higher extent
+
+## Output
+
+
+## Author(s)
+[Akriti](https://github.com/A-kriti)
diff --git a/Neon Effect Filter/requirements.txt b/Neon Effect Filter/requirements.txt
new file mode 100644
index 0000000000..7c3546d78b
--- /dev/null
+++ b/Neon Effect Filter/requirements.txt
@@ -0,0 +1,3 @@
+numpy==1.18.5
+opencv_python==4.5.1.48
+matplotlib==3.2.2
diff --git a/News-Voice-Assistant/requirements.txt b/News-Voice-Assistant/requirements.txt
index 00e83d1787..7aeb4ae075 100644
--- a/News-Voice-Assistant/requirements.txt
+++ b/News-Voice-Assistant/requirements.txt
@@ -9,6 +9,6 @@ newsapi-python==0.1.1
requests==2.24.0
six==1.15.0
soupsieve==2.0.1
-urllib3==1.25.11
+urllib3==1.26.5
pydub==0.24.1
simpleaudio==1.0.4
diff --git a/Noise Reduction Script/Audio/(Filtered_Audio)test_noise .wav b/Noise Reduction Script/Audio/(Filtered_Audio)test_noise .wav
new file mode 100644
index 0000000000..c331ce5b8e
Binary files /dev/null and b/Noise Reduction Script/Audio/(Filtered_Audio)test_noise .wav differ
diff --git a/Noise Reduction Script/Audio/test_noise.wav b/Noise Reduction Script/Audio/test_noise.wav
new file mode 100644
index 0000000000..1522ae4849
Binary files /dev/null and b/Noise Reduction Script/Audio/test_noise.wav differ
diff --git a/Noise Reduction Script/Graph/test_noise.wav(Spectral Subtraction graph).jpg b/Noise Reduction Script/Graph/test_noise.wav(Spectral Subtraction graph).jpg
new file mode 100644
index 0000000000..e0ed98da22
Binary files /dev/null and b/Noise Reduction Script/Graph/test_noise.wav(Spectral Subtraction graph).jpg differ
diff --git a/Noise Reduction Script/Noise Reduction Script.py b/Noise Reduction Script/Noise Reduction Script.py
new file mode 100644
index 0000000000..277f7a7523
--- /dev/null
+++ b/Noise Reduction Script/Noise Reduction Script.py
@@ -0,0 +1,50 @@
+# Spectral Subtraction: Method used for noise reduction
+import scipy.io.wavfile as wav
+import numpy as np
+import matplotlib.pyplot as plt
+
+file = input("Enter the file path: ")
+sr, data = wav.read(file)
+fl = 400 #frame_length
+frames = [] #empty list
+for i in range(0,int(len(data)/(int(fl/2))-1)):
+ arr = data[int(i*int(fl/2)):int(i*int(fl/2)+fl)]
+ frames.append(arr) #appending each array data into the frames list
+frames = np.array(frames) #converting the frames list into an array
+ham_window = np.hamming(fl) #using np.hamming
+windowed_frames = frames*ham_window #multiplying frames array with ham_window
+dft = [] #empty list containing fft of windowed_frames
+for i in windowed_frames:
+ dft.append(np.fft.fft(i)) #now taking the first fourier transform of each window
+dft = np.array(dft) #converting dft into array
+
+dft_mag_spec = np.abs(dft) #converting dft into absolute values
+dft_phase_spec = np.angle(dft) #finding dft angle
+noise_estimate = np.mean(dft_mag_spec,axis=0) #mean
+noise_estimate_mag = np.abs(noise_estimate) #absolute value
+
+estimate_mag = (dft_mag_spec-2*noise_estimate_mag) #subtraction method
+estimate_mag[estimate_mag<0]=0
+estimate = estimate_mag*np.exp(1j*dft_phase_spec) #calculating the final estimate
+ift = [] #taking ift as input list containing inverse fourier transform of estimate
+for i in estimate:
+ ift.append(np.fft.ifft(i)) #appending in ift list
+
+clean_data = []
+clean_data.extend(ift[0][:int(fl/2)]) #extending clean_data containg ift list
+for i in range(len(ift)-1):
+ clean_data.extend(ift[i][int(fl/2):]+ift[i+1][:int(fl/2)])
+clean_data.extend(ift[-1][int(fl/2):]) #extending clean_data containing ift list
+clean_data = np.array(clean_data) #converting it into array
+
+#finally plotting the graph showing the diffrence in the noise
+fig = plt.figure(figsize=(8,5))
+ax = plt.subplot(1,1,1)
+ax.plot(np.linspace(0,64000,64000),data,label='Original',color="orange")
+ax.plot(np.linspace(0,64000,64000),clean_data,label='Filtered',color="purple")
+ax.legend(fontsize=12)
+ax.set_title('Spectral Subtraction Method', fontsize=15)
+filename = os.path.basename(file)
+cleaned_file = "(Filtered_Audio)"+filename #final filtered audio
+wav.write(cleaned_file,rate=sr, data = clean_data.astype(np.int16))
+plt.savefig(filename+"(Spectral Subtraction graph).jpg") #saved file name as audio.wav(Spectral Subtraction graph).jpg
diff --git a/Noise Reduction Script/README.md b/Noise Reduction Script/README.md
new file mode 100644
index 0000000000..071e22c33b
--- /dev/null
+++ b/Noise Reduction Script/README.md
@@ -0,0 +1,25 @@
+# Noise Reduction Script
+Implementing a feature that helps to filter an audio file by reducing the background noise similar to "Audacity".
+
+## Libraries used
+Firstly import the following python libraries
+* NumPy
+* scipy.io.wavfile
+* Matplotlib
+* Os
+Save the audio files and your code in the same folder
+Run the python code
+
+## Detailed explanation of method used for "Noise Reduction Script"
+* Imported the required libraries (NumPy, scipy.io.wavfile, and Matplotlib)
+* Read the input audio file using scipy.io.wavfile library
+* Converting the audio file into an array containg all the information of the given audio file and intiallizing the frame value.
+* Calculating the first fourier transform of each window of the noisy audio file
+* Subtracting the noise spectral mean from input spectral, and istft (Inverse Short-Time Fourier Transform)
+* Finally getting an audio file with reduction in the background noise at a much higher extent
+
+## Output
+.jpg) +
+## Author(s)
+[Akriti](https://github.com/A-kriti)
diff --git a/Noise Reduction Script/requirements.txt b/Noise Reduction Script/requirements.txt
new file mode 100644
index 0000000000..d366d86ca6
--- /dev/null
+++ b/Noise Reduction Script/requirements.txt
@@ -0,0 +1,3 @@
+matplotlib==3.2.2
+numpy==1.18.5
+scipy==1.5.0
diff --git a/PDF Watermark Remover/PDF-Watermark-Remover.py b/PDF Watermark Remover/PDF-Watermark-Remover.py
new file mode 100644
index 0000000000..6e3a206e09
--- /dev/null
+++ b/PDF Watermark Remover/PDF-Watermark-Remover.py
@@ -0,0 +1,67 @@
+from skimage import io
+from PyPDF2 import PdfFileReader
+from pdf2image import convert_from_path
+import numpy as np
+import os
+from PIL import Image
+from fpdf import FPDF
+import shutil
+
+pdfFile = input('PDF file location: ')
+dirname = os.path.dirname(os.path.normpath(pdfFile))
+outputFile = os.path.basename(pdfFile)
+outputFile = os.path.splitext(outputFile)[0]
+pdf_reader = PdfFileReader(pdfFile)
+pages = pdf_reader.getNumPages()
+rang = int(pages) + 1
+
+# Select the pixel from the extracted images of pdf pages
+def select_pixel(r,g,b):
+ if r > 120 and r < 254 and g > 120 and g < 254 and b > 120 and b < 254:
+ return True
+ else:
+ return False
+
+# Handling of images for removing the watermark
+def handle(imgs):
+ for i in range(imgs.shape[0]):
+ for j in range(imgs.shape[1]):
+ if select_pixel(imgs[i][j][0],imgs[i][j][1],imgs[i][j][2]):
+ imgs[i][j][0] = imgs[i][j][1] = imgs[i][j][2] = 255
+ return imgs
+
+images = convert_from_path(pdfFile)
+
+try:
+ os.mkdir(dirname + '\img')
+except FileExistsError:
+ print('Folder exist')
+index = 0
+for img in images:
+ index += 1
+ img = np.array(img)
+ print(img.shape)
+ img = handle(img)
+ io.imsave(dirname + '\img\img' + str(index) + '.jpg', img)
+ print(index)
+
+# Merging images to a sigle PDF
+pdf = FPDF()
+sdir = dirname + "img/"
+w,h = 0,0
+
+for i in range(1, rang):
+ fname = sdir + "img%.0d.jpg" % i
+ if os.path.exists(fname):
+ if i == 1:
+ cover = Image.open(fname)
+ w,h = cover.size
+ pdf = FPDF(unit = "pt", format = [w,h])
+ image = fname
+ pdf.add_page()
+ pdf.image(image, 0, 0, w, h)
+ else:
+ print("File not found:", fname)
+ # print("processed %d" % i)
+pdf.output(dirname + outputFile + '_rw.pdf', "F")
+print("done")
\ No newline at end of file
diff --git a/PDF Watermark Remover/img1.jpg b/PDF Watermark Remover/img1.jpg
new file mode 100644
index 0000000000..76fc56d91b
Binary files /dev/null and b/PDF Watermark Remover/img1.jpg differ
diff --git a/PDF Watermark Remover/readme.md b/PDF Watermark Remover/readme.md
new file mode 100644
index 0000000000..10667cc9a8
--- /dev/null
+++ b/PDF Watermark Remover/readme.md
@@ -0,0 +1,28 @@
+# PDF-Watermark-Remover
+
+The script PDF-Watermark-Remover will remove the watermark from the PDF files. The watermark is selected based on ranges of RGB color and based on selected pixels it will remove the watermark from the pages.
+
+## Setup instructions
+
+1. Download the python script file ("PDF-Watermark-Remover.py")
+2. Open the cmd/powershell/shell and type below line & hit return
+ - For windows
+ ```
+ python
+
+## Author(s)
+[Akriti](https://github.com/A-kriti)
diff --git a/Noise Reduction Script/requirements.txt b/Noise Reduction Script/requirements.txt
new file mode 100644
index 0000000000..d366d86ca6
--- /dev/null
+++ b/Noise Reduction Script/requirements.txt
@@ -0,0 +1,3 @@
+matplotlib==3.2.2
+numpy==1.18.5
+scipy==1.5.0
diff --git a/PDF Watermark Remover/PDF-Watermark-Remover.py b/PDF Watermark Remover/PDF-Watermark-Remover.py
new file mode 100644
index 0000000000..6e3a206e09
--- /dev/null
+++ b/PDF Watermark Remover/PDF-Watermark-Remover.py
@@ -0,0 +1,67 @@
+from skimage import io
+from PyPDF2 import PdfFileReader
+from pdf2image import convert_from_path
+import numpy as np
+import os
+from PIL import Image
+from fpdf import FPDF
+import shutil
+
+pdfFile = input('PDF file location: ')
+dirname = os.path.dirname(os.path.normpath(pdfFile))
+outputFile = os.path.basename(pdfFile)
+outputFile = os.path.splitext(outputFile)[0]
+pdf_reader = PdfFileReader(pdfFile)
+pages = pdf_reader.getNumPages()
+rang = int(pages) + 1
+
+# Select the pixel from the extracted images of pdf pages
+def select_pixel(r,g,b):
+ if r > 120 and r < 254 and g > 120 and g < 254 and b > 120 and b < 254:
+ return True
+ else:
+ return False
+
+# Handling of images for removing the watermark
+def handle(imgs):
+ for i in range(imgs.shape[0]):
+ for j in range(imgs.shape[1]):
+ if select_pixel(imgs[i][j][0],imgs[i][j][1],imgs[i][j][2]):
+ imgs[i][j][0] = imgs[i][j][1] = imgs[i][j][2] = 255
+ return imgs
+
+images = convert_from_path(pdfFile)
+
+try:
+ os.mkdir(dirname + '\img')
+except FileExistsError:
+ print('Folder exist')
+index = 0
+for img in images:
+ index += 1
+ img = np.array(img)
+ print(img.shape)
+ img = handle(img)
+ io.imsave(dirname + '\img\img' + str(index) + '.jpg', img)
+ print(index)
+
+# Merging images to a sigle PDF
+pdf = FPDF()
+sdir = dirname + "img/"
+w,h = 0,0
+
+for i in range(1, rang):
+ fname = sdir + "img%.0d.jpg" % i
+ if os.path.exists(fname):
+ if i == 1:
+ cover = Image.open(fname)
+ w,h = cover.size
+ pdf = FPDF(unit = "pt", format = [w,h])
+ image = fname
+ pdf.add_page()
+ pdf.image(image, 0, 0, w, h)
+ else:
+ print("File not found:", fname)
+ # print("processed %d" % i)
+pdf.output(dirname + outputFile + '_rw.pdf', "F")
+print("done")
\ No newline at end of file
diff --git a/PDF Watermark Remover/img1.jpg b/PDF Watermark Remover/img1.jpg
new file mode 100644
index 0000000000..76fc56d91b
Binary files /dev/null and b/PDF Watermark Remover/img1.jpg differ
diff --git a/PDF Watermark Remover/readme.md b/PDF Watermark Remover/readme.md
new file mode 100644
index 0000000000..10667cc9a8
--- /dev/null
+++ b/PDF Watermark Remover/readme.md
@@ -0,0 +1,28 @@
+# PDF-Watermark-Remover
+
+The script PDF-Watermark-Remover will remove the watermark from the PDF files. The watermark is selected based on ranges of RGB color and based on selected pixels it will remove the watermark from the pages.
+
+## Setup instructions
+
+1. Download the python script file ("PDF-Watermark-Remover.py")
+2. Open the cmd/powershell/shell and type below line & hit return
+ - For windows
+ ```
+ python 📑 Introduction
@@ -42,7 +43,7 @@ You can refer to the following articles on **_basics of Git and Github and also✨ Contributors
-Thanks goes to these **Wonderful People** 👨🏻💻: 🚀 **Contributions** of any kind is welcome! +Thanks go to these **Wonderful People** 👨🏻💻: 🚀 **Contributions** of any kind are welcome! Avinash Ranjan+ |
+
+ Kaustubh Gupta+ |
+
+ Antriksh Misri+ |
+ Santushti Sharma+ |
+
+ Kushal Das |
+
+
Happy Coding 👨💻
diff --git a/Rain Alert Mail Sender/README.md b/Rain Alert Mail Sender/README.md new file mode 100644 index 0000000000..e22de0df89 --- /dev/null +++ b/Rain Alert Mail Sender/README.md @@ -0,0 +1,11 @@ +# Rain Alert Mail Sender + +An application that checks the weather condition for the next 12 hours and sends a message to the registered mail address number as to whether one should carry a sunglass (if it is sunny) , or an umbrella (if it rains).
+ +Libraries used : requests, smtp, time, datetime
+ + +
+
+# Author(s)
+Shubhrima Jana
diff --git a/Rain Alert Mail Sender/main.py b/Rain Alert Mail Sender/main.py
new file mode 100644
index 0000000000..4f19152e72
--- /dev/null
+++ b/Rain Alert Mail Sender/main.py
@@ -0,0 +1,56 @@
+import requests
+from smtplib import SMTP
+import os
+from dotenv import load_dotenv
+
+load_dotenv()
+
+def function():
+ """Go to Manage your Google(or any mail) account, and then headover to Security.\nTurn OFF the options 'Two Step Verification' and 'Use your phone to sign in' in the Signing in to Google section.\nTurn ON the Less secure apps section.
+ """
+ return 0
+print(function.__doc__)
+MY_MAIL= os.getenv('MAIL')
+MY_PASSWORD= os.getenv('PASSWORD')
+RECIEVER_MAIL = input('Send mail to (mail id): ')
+CITY = input('Enter your City: ')
+
+API_KEY = os.getenv('API')
+
+API_END_POINT ='https://nominatim.openstreetmap.org/search.php'
+PARAMETER_LOCATION ={
+ 'city' : CITY,
+ 'format': 'json',
+}
+response_location = requests.get(url = API_END_POINT, params=PARAMETER_LOCATION)
+data_location = response_location .json()
+LAT = data_location [0]['lat']
+LONG = data_location [0]['lon']
+PARAMETER= {
+ "lat": LAT,
+ "lon": LONG,
+ "appid" : API_KEY,
+ "exclude" : "current,minutely,daily",
+}
+api = requests.get(url="http://api.openweathermap.org/data/2.5/onecall",params=PARAMETER)
+data = api.json()
+
+bring_umbrella = False
+
+for i in range(0,12):
+ hourly_condition = data['hourly'][i]['weather'][0]['id']
+ if(hourly_condition<700):
+ bring_umbrella = True
+
+if (bring_umbrella == True):
+ MESSAGE=f"Subject: Rain Rain \n\nIt's going to rain today. Bring Umbrella "
+
+else:
+ MESSAGE = f"Subject: Sunny Day\n\nMay be a sunny day. Carry sunglasses. "
+
+with SMTP("smtp.gmail.com") as connection:
+ connection.starttls()
+ connection.login(user=MY_MAIL, password=MY_PASSWORD)
+ connection.sendmail(from_addr=MY_MAIL, to_addrs=RECIEVER_MAIL,
+ msg=MESSAGE)
+ print('Mail Sent')
diff --git a/Rain Alert Mail Sender/requirements.txt b/Rain Alert Mail Sender/requirements.txt
new file mode 100644
index 0000000000..b4f6d53390
--- /dev/null
+++ b/Rain Alert Mail Sender/requirements.txt
@@ -0,0 +1,2 @@
+requests==2.25.1
+dotenv==0.05
\ No newline at end of file
diff --git a/Real Estate Webscrapper/README.md b/Real Estate Webscrapper/README.md
new file mode 100644
index 0000000000..34e06a4b22
--- /dev/null
+++ b/Real Estate Webscrapper/README.md
@@ -0,0 +1,34 @@
+## Real Estate Webscrapper
+- It will take information from the real estate site and store it in the form of csv file making the data more organised and locally accessible.
+
+___
+
+## Requirements
+- BeautifulSoup
+- Pandas
+---
+## How To install
+> pip install pandas
+
+> pip install beautifulsoup
+---
+- Now run the real_estate_webscrapper.py file to create the output2.csv file.
+- Then output2.csv will be created in the same folder as real_estate_webscrapper.py file and it can be opened using Microsoft Excel.
+---
+### Step 1
+- Load the website https://www.magicbricks.com/ready-to-move-flats-in-new-delhi-pppfs in your code using requests.
+
+### Step 2
+- Use inspect in website to know which div contains the information that we need
+- Use beautiful soup to load the information in program and store it into a dictionary for each property
+
+### Step 3
+- Use pandas to convert the list of dictionaries to csv file
+---
+
+## Author
+[Himanshi2997](https://github.com/Himanshi2997)
+---
+
+## Output
+
diff --git a/Real Estate Webscrapper/real_estate_webscrapper.py b/Real Estate Webscrapper/real_estate_webscrapper.py
new file mode 100644
index 0000000000..dd6cd5a5fb
--- /dev/null
+++ b/Real Estate Webscrapper/real_estate_webscrapper.py
@@ -0,0 +1,75 @@
+import requests
+from bs4 import BeautifulSoup
+import pandas
+
+
+headers = {
+ 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:55.0) Gecko/20100101 Firefox/55.0',
+}
+
+r=requests.get("https://www.magicbricks.com/ready-to-move-flats-in-new-delhi-pppfs", headers=headers)
+c=r.content
+soup=BeautifulSoup(c,"html.parser")
+
+
+complete_dataset = []
+
+
+all_containers=soup.find_all("div",{"class":"flex relative clearfix m-srp-card__container"})
+for item in all_containers:
+ item_data={}
+ try:
+ Price=item.find("div",{"class":"m-srp-card__price"}).text.replace("\n","").replace(" ","").replace("₹","")
+ p=Price.split()
+ item_data["Price"]=p[0]
+
+ except:
+ Price=item.find("span",{"class":"luxury-srp-card__price"}).text.replace("\n","").replace(" ","").replace("₹","")
+ p=Price.split()
+ item_data["Price"]=p[0]
+
+
+ try:
+ Pricepersqft=item.find("div",{"class":"m-srp-card__area"}).text.replace("₹","")
+ pr=Pricepersqft.split()
+ item_data["Pricepersqft"]=pr[0]
+
+ except:
+ try:
+ Pricepersqft=item.find("span",{"class":"luxury-srp-card__sqft"}).text.replace("\n","").replace(" ","").replace("₹","")
+ pr=Pricepersqft.split()
+ item_data["Pricepersqft"]=pr[0]
+ except:
+ item_data["Pricepersqft"]=None
+
+ try:
+ item_data["Size"]=item.find("span",{"class":"m-srp-card__title__bhk"}).text.replace("\n","").strip()[0:5]
+ except:
+ item_data["Size"]=None
+
+
+ title=item.find("span",{"class":"m-srp-card__title"})
+
+ words=(title.text.replace("in","")).split()
+
+ for i in range(len(words)):
+ if words[i]=="sale" or words[i]=="Sale":
+ break
+ s=""
+ for word in range(i+1,len(words)):
+ s=s+words[word]+" "
+
+ item_data["Address"]=s
+
+ try:
+ item_data["Carpet Area"]=item.find("div",{"class":"m-srp-card__summary__info"}).text
+ except:
+ item_data["Carpet Area"]=item.find("div",{"class":"luxury-srp-card__area__value"}).text
+
+
+ complete_dataset.append(item_data)
+
+
+
+df=pandas.DataFrame(complete_dataset)
+df.to_csv("./Real Estate Webscrapper/scraped.csv")
diff --git a/Real Estate Webscrapper/requirements.txt b/Real Estate Webscrapper/requirements.txt
new file mode 100644
index 0000000000..96fc9b6a4f
--- /dev/null
+++ b/Real Estate Webscrapper/requirements.txt
@@ -0,0 +1,3 @@
+requests==2.25.1
+pandas==1.2.4
+beautifulsoup4==4.9.3
diff --git a/Reddit_Scraper_without_API/README.md b/Reddit_Scraper_without_API/README.md
new file mode 100644
index 0000000000..ec65d6c75c
--- /dev/null
+++ b/Reddit_Scraper_without_API/README.md
@@ -0,0 +1,27 @@
+# Reddit Scraper
+
+- Using BeautifulSoup, a python library useful for web scraping, this script helps to scrape a desired subreddit to obtain all relevant data regarding its posts.
+
+- In the `fetch_reddit.py` , we take user input for the subreddit name, tags and the maximum count of posts to be scraped, we fetch and store all this information in a database file.
+
+- In the `display_reddit.py` , we display the desired results from the database to the user.
+
+## Setup instructions
+
+- The requirements can be installed as follows:
+
+```shell
+ $ pip install -r requirements.txt
+```
+
+## Working screenshots
+
+
+
+#
+
+
+
+## Author
+[Rohini Rao](www.github.com/RohiniRG)
+
diff --git a/Reddit_Scraper_without_API/display_reddit.py b/Reddit_Scraper_without_API/display_reddit.py
new file mode 100644
index 0000000000..299475a23b
--- /dev/null
+++ b/Reddit_Scraper_without_API/display_reddit.py
@@ -0,0 +1,51 @@
+import sqlite3
+import os
+
+
+def sql_connection():
+ """
+ Establishes a connection to the SQL file database
+ :return connection object:
+ """
+ path = os.path.abspath('SubredditDatabase.db')
+ con = sqlite3.connect(path)
+ return con
+
+
+def sql_fetcher(con):
+ """
+ Fetches all the tweets with the given hashtag from our database
+ :param con:
+ :return:
+ """
+ subreddit = input("\nEnter subreddit to search: r/")
+ count = 0
+ cur = con.cursor()
+ cur.execute('SELECT * FROM posts') # SQL search query
+ rows = cur.fetchall()
+
+ for r in rows:
+ if subreddit in r:
+ count += 1
+ print(f'\nTAG: {r[1]}\nPOST TITLE: {r[2]}\nAUTHOR: {r[3]}\n'
+ f'TIME STAMP: {r[4]}\nUPVOTES: {r[5]}\nCOMMENTS: {r[6]}'
+ f'\nURL: {r[7]}\n')
+
+ if count:
+ print(f'{count} posts fetched from database\n')
+ else:
+ print('\nNo posts stored for this subreddit\n')
+
+
+con = sql_connection()
+
+while 1:
+ sql_fetcher(con)
+
+ ans = input('\nPress (y) to continue or any other key to exit: ').lower()
+ if ans == 'y':
+ continue
+ else:
+ print('\nExiting..\n')
+ break
+
diff --git a/Reddit_Scraper_without_API/fetch_reddit.py b/Reddit_Scraper_without_API/fetch_reddit.py
new file mode 100644
index 0000000000..1518f8af1c
--- /dev/null
+++ b/Reddit_Scraper_without_API/fetch_reddit.py
@@ -0,0 +1,159 @@
+import requests
+import csv
+import time
+import sqlite3
+from bs4 import BeautifulSoup
+
+
+def sql_connection():
+ """
+ Establishes a connection to the SQL file database
+ :return connection object:
+ """
+ con = sqlite3.connect('SubredditDatabase.db')
+ return con
+
+
+def sql_table(con):
+ """
+ Creates a table in the database (if it does not exist already)
+ to store the tweet info
+ :param con:
+ :return:
+ """
+ cur = con.cursor()
+ cur.execute("CREATE TABLE IF NOT EXISTS posts(SUBREDDIT text, TAG text, "
+ " TITLE text, AUTHOR text, TIMESTAMP text, UPVOTES int, "
+ " COMMENTS text, URL text)")
+ con.commit()
+
+
+def sql_insert_table(con, entities):
+ """
+ Inserts the desired data into the table to store tweet info
+ :param con:
+ :param entities:
+ :return:
+ """
+ cur = con.cursor()
+ cur.execute('INSERT INTO posts(SUBREDDIT, TAG, TITLE, AUTHOR, '
+ 'TIMESTAMP, UPVOTES, COMMENTS, URL) '
+ 'VALUES(?, ?, ?, ?, ?, ?, ?, ?)', entities)
+ con.commit()
+
+
+def scraper():
+ """
+ The function scrapes the post info from the desired subreddit and stores it
+ into the desired file.
+ :return:
+ """
+ con = sql_connection()
+ sql_table(con)
+
+ while 1:
+ subreddit = input('\n\nEnter the name of the subreddit: r/').lower()
+ max_count = int(input('Enter the maximum number of entries to collect: '))
+ select = int(input('Select tags to add for the search: \n1. hot\n2. new'
+ '\n3. rising\n4. controversial\n5. top\nMake your choice: '))
+
+ if select == 1:
+ tag = 'hot'
+ tag_url = '/'
+ elif select == 2:
+ tag = 'new'
+ tag_url = '/new/'
+ elif select == 3:
+ tag = 'rising'
+ tag_url = '/rising/'
+ elif select == 4:
+ tag = 'controversial'
+ tag_url = '/controversial/'
+ elif select == 5:
+ tag = 'top'
+ tag_url = '/top/'
+
+ # URL for the desired subreddit
+ url = 'https://old.reddit.com/r/' + subreddit
+
+ # Using a user-agent to mimic browser activity
+ headers = {'User-Agent': 'Mozilla/5.0'}
+
+ req = requests.get(url, headers=headers)
+
+ if req.status_code == 200:
+ soup = BeautifulSoup(req.text, 'html.parser')
+ print(f'\nCOLLECTING INFORMATION FOR r/{subreddit}....')
+
+ attrs = {'class': 'thing'}
+ counter = 1
+ full = 0
+ reddit_info = []
+ while 1:
+ for post in soup.find_all('div', attrs=attrs):
+ try:
+ # To obtain the post title
+ title = post.find('a', class_='title').text
+
+ # To get the username of the post author
+ author = post.find('a', class_='author').text
+
+ # To obtain the time of the post
+ time_stamp = post.time.attrs['title']
+
+ # To obtain the number of comments on the post
+ comments = post.find('a', class_='comments').text.split()[0]
+ if comments == 'comment':
+ comments = 0
+
+ # To get the number of comments on the post
+ upvotes = post.find('div', class_='score likes').text
+ if upvotes == '•':
+ upvotes = "None"
+
+ # To get the URL of the post
+ link = post.find('a', class_='title')['href']
+ link = 'www.reddit.com' + link
+
+ # Entering all the collected information into our database
+ entities = (subreddit, tag, title, author, time_stamp, upvotes,
+ comments, link)
+ sql_insert_table(con, entities)
+
+ if counter == max_count:
+ full = 1
+ break
+
+ counter += 1
+ except AttributeError:
+ continue
+
+ if full:
+ break
+
+ try:
+ # To go to the next page
+ next_button = soup.find('span', class_='next-button')
+ next_page_link = next_button.find('a').attrs['href']
+
+ time.sleep(2)
+
+ req = requests.get(next_page_link, headers=headers)
+ soup = BeautifulSoup(req.text, 'html.parser')
+ except:
+ break
+
+ print('DONE!\n')
+ ans = input('Press (y) to continue or any other key to exit: ').lower()
+ if ans == 'y':
+ continue
+ else:
+ print('Exiting..')
+ break
+ else:
+ print('Error fetching results.. Try again!')
+
+
+if __name__ == '__main__':
+ scraper()
+
diff --git a/Reddit_Scraper_without_API/requirements.txt b/Reddit_Scraper_without_API/requirements.txt
new file mode 100644
index 0000000000..b7a5bb209c
--- /dev/null
+++ b/Reddit_Scraper_without_API/requirements.txt
@@ -0,0 +1,7 @@
+beautifulsoup4==4.9.3
+certifi==2020.12.5
+chardet==4.0.0
+idna==2.10
+requests==2.25.1
+soupsieve==2.2.1
+urllib3==1.26.4
diff --git a/Speak-like-Yoda/README.md b/Speak-like-Yoda/README.md
new file mode 100644
index 0000000000..57188d650f
--- /dev/null
+++ b/Speak-like-Yoda/README.md
@@ -0,0 +1,24 @@
+# Speak-Like-Yoda
+
+## Description
+A python script that translates an input English sentence into Yoda-speak.
+
+## Usage
+Run ```python speak_like_yoda.py```. Type in your sentence to get it translated into Yoda-speak.
+
+## Requirements
+The script only uses Python's standard modules ```random``` and ```string```, so no additional installation is needed.
+
+## Output
+```
+Your English sentence:
+Avoiding failure is something we learn at some later point in life.
+
+Your Yodenglish sentence:
+Something is we point some failure learn avoiding later at in life
+
+```
+
+## Author(s)
+
+[Soumik Kumar Baithalu](https://www.github.com/soumik2012)
diff --git a/Speak-like-Yoda/Speak_Like_yoda.py b/Speak-like-Yoda/Speak_Like_yoda.py
new file mode 100644
index 0000000000..3e92e8d6df
--- /dev/null
+++ b/Speak-like-Yoda/Speak_Like_yoda.py
@@ -0,0 +1,23 @@
+import random
+import string
+
+def speak_like_yoda(sentence):
+ """
+ Translate the input sentence into Yoda-speak.
+
+ :param sentence: input string
+ :return: translation to Yoda-speak
+ """
+ sentence = sentence.lower()
+ for p in string.punctuation.replace("'", ''):
+ sentence = sentence.replace(p, '')
+ words = sentence.split()
+ random.shuffle(words)
+ new_sent = ' '.join(words)
+ print('\nYour Yodenglish sentence: ')
+ print(new_sent.capitalize())
+
+if __name__ == '__main__':
+ print('Your English sentence: ')
+ sentence = str(input())
+ speak_like_yoda(sentence)
diff --git a/Speak-like-Yoda/requirements.txt b/Speak-like-Yoda/requirements.txt
new file mode 100644
index 0000000000..d1357856c9
--- /dev/null
+++ b/Speak-like-Yoda/requirements.txt
@@ -0,0 +1,2 @@
+random
+string
diff --git a/Stack-overflow-scraper/README.md b/Stack-overflow-scraper/README.md
new file mode 100644
index 0000000000..0681571a06
--- /dev/null
+++ b/Stack-overflow-scraper/README.md
@@ -0,0 +1,26 @@
+# Stack overflow question scraper
+Running this Script would allow the user to scrape top questions from Stack overflow based on the question tag(python, java, etc) of their choice. The question, summary, link, votes and views will be stored in a local SQL DB.
+
+## Setup instructions
+In order to run this script, you need to have Python and pip installed on your system. After you're done installing Python and pip, run the following command from your terminal to install the requirements from the same folder (directory) of the project.
+```
+pip install -r requirements.txt
+```
+After satisfying all the requirements for the project, Open the terminal in the project folder and run
+```
+python scraper.py
+```
+or
+```
+python3 scraper.py
+```
+depending upon the python version. Make sure that you are running the command from the same virtual environment in which the required modules are installed.
+
+## Output
+
+The user can choose the question tag based on which they want to scrape top questions from Stack Overflow.
+
+
+
+## Author
+[Ayush Jain](https://github.com/Ayushjain2205)
\ No newline at end of file
diff --git a/Stack-overflow-scraper/requirements.txt b/Stack-overflow-scraper/requirements.txt
new file mode 100644
index 0000000000..a98ae430c4
--- /dev/null
+++ b/Stack-overflow-scraper/requirements.txt
@@ -0,0 +1,2 @@
+requests
+beautifulsoup4
\ No newline at end of file
diff --git a/Stack-overflow-scraper/scraper.py b/Stack-overflow-scraper/scraper.py
new file mode 100644
index 0000000000..2cb2588949
--- /dev/null
+++ b/Stack-overflow-scraper/scraper.py
@@ -0,0 +1,193 @@
+import requests
+from bs4 import BeautifulSoup
+import tkinter as tk
+from tkinter import messagebox, simpledialog
+from tkinter import ttk
+from tkinter import font as tkFont
+import time
+import sqlite3
+from sqlite3 import Error
+
+# Function to connect to the SQL Database
+def sql_connection():
+ try:
+ con = sqlite3.connect('./Stack-overflow-scraper/stackoverflow.db')
+ return con
+ except Error:
+ print(Error)
+
+# Function to create table
+def sql_table(con):
+ cursorObj = con.cursor()
+ cursorObj.execute(
+ "CREATE TABLE IF NOT EXISTS questions(question_text text, question_summary text, question_link text,votes integer, views integer )")
+ con.commit()
+
+# Call functions to connect to database and create table
+con = sql_connection()
+sql_table(con)
+
+# Function to insert into table
+def sql_insert(con, entities):
+ cursorObj = con.cursor()
+ cursorObj.execute(
+ 'INSERT INTO questions(question_text, question_summary, question_link, votes, views) VALUES(?, ?, ?, ?, ?)', entities)
+ con.commit()
+
+# Function to generate URL based on choice
+def get_URL():
+ tag = search_box.get()
+ if not tag:
+ messagebox.showinfo("Alert", "Please Enter tag!")
+ return
+ url = 'https://stackoverflow.com/questions/tagged/{}?sort=MostVotes&edited=true'.format(tag)
+ return url
+
+def number_questions():
+ questions = int(questions_box.get())
+ if type(questions) != int or questions > 15:
+ return 15
+ return questions
+
+def scrape_questions():
+ for count in range(5):
+ progress['value'] += 15
+ window.update_idletasks()
+ time.sleep(0.10)
+
+ question_count = number_questions()
+ count = 0
+
+ url = get_URL()
+ if url:
+ page = requests.get(url)
+ else:
+ clear_progress()
+ return
+
+ # Start scraping resultant html data
+ soup = BeautifulSoup(page.content, 'html.parser')
+ questions = soup.find_all('div', {'class': 'question-summary'})
+ if not questions:
+ messagebox.showinfo("Invalid", "Invalid search tag")
+ clear_progress()
+ return ""
+ for question in questions:
+ if count >= question_count:
+ break
+ question_text = question.find('a', {'class': 'question-hyperlink'}).text.strip()
+ question_summary = question.find('div', {'class': 'excerpt'}).text.strip()
+ question_summary = question_summary.replace('\n',' ')
+ question_link = 'https://stackoverflow.com{}'.format(question.find('a', {'class': 'question-hyperlink'})['href'])
+ votes = question.find('span', {'class': 'vote-count-post'}).text.strip()
+ views = question.find('div', {'class': 'views'}).text.strip().split()[0]
+ entities = (question_text, question_summary, question_link, votes, views)
+ sql_insert(con, entities)
+ count += 1
+
+ messagebox.showinfo("Success!", "Questions scrapped successfully!")
+ clear_progress()
+
+# Function to fetch stackoverflow questions from DB
+def sql_fetch(con):
+ cursorObj = con.cursor()
+ try:
+ cursorObj.execute('SELECT DISTINCT * FROM questions ORDER BY rowid DESC') # SQL search query
+ except Error:
+ print("Database empty... Fetch users using GUI")
+ return
+
+ rows = cursorObj.fetchall()
+ display_text = ""
+
+ # Show messagebox incase of empty DB
+ if len(rows) == 0 :
+ messagebox.showinfo("Alert", "No users scraped yet!")
+ return " "
+
+ first_row = "{:^65}".format("Question") + "{:^65}".format("Summary") + "{:^40}".format("Link") + "{:^15}".format("Votes") + "{:^15}".format("Views") + '\n'
+ display_text += first_row
+
+ # Format rows
+ for row in rows:
+ question_text = "{:<65}".format(
+ row[0] if len(row[0]) < 60 else row[0][:56]+"...")
+ question_summary = "{:<65}".format(
+ row[1] if len(row[1]) < 60 else row[1][:56]+"...")
+ question_link = "{:<40}".format(
+ row[2] if len(row[2]) < 30 else row[2][:36]+"...")
+ votes = "{:^15}".format(row[3])
+ views = "{:^15}".format(row[4])
+ display_text += (question_text + question_summary + question_link + votes + views +'\n')
+
+ return display_text
+
+def show_results():
+ display_text = sql_fetch(con)
+ query_label.config(state=tk.NORMAL)
+ query_label.delete(1.0, "end")
+ query_label.insert(1.0, display_text)
+ query_label.config(state=tk.DISABLED)
+
+def clear_progress():
+ #set progress bar back to 0
+ progress['value'] = 100
+ window.update_idletasks()
+ progress['value'] = 0
+ window.update_idletasks()
+
+# Creating tkinter window
+window = tk.Tk()
+window.title('Stack overflow question scraper')
+window.geometry('1200x1000')
+window.configure(bg='white')
+
+style = ttk.Style()
+style.theme_use('alt')
+style.map('my.TButton', background=[('active','white')])
+style.configure('my.TButton', font=('Helvetica', 16, 'bold'))
+style.configure('my.TButton', background='white')
+style.configure('my.TButton', foreground='orange')
+style.configure('my.TFrame', background='white')
+
+# label text for title
+ttk.Label(window, text="Stack overflow question scraper",
+ background='white', foreground="Orange",
+ font=("Helvetica", 30, 'bold')).grid(row=0, column=1)
+
+# label texts
+ttk.Label(window, text="Enter tag (ex - python):", background = 'white',
+ font=("Helvetica", 15)).grid(column=0,
+ row=5, padx=10, pady=25)
+
+ttk.Label(window, text="No of questions to scrape:", background = 'white',
+ font=("Helvetica", 15)).grid(column=0,
+ row=6, padx=10, pady=5)
+
+
+# Button creation
+scrape_btn = ttk.Button(window, text="Scrape questions!", style='my.TButton', command=scrape_questions)
+scrape_btn.grid(row=5, column=2, pady=5, padx=15, ipadx=5)
+
+display_btn = ttk.Button(window, text="Display from DB", style='my.TButton', command = show_results)
+display_btn.grid(row=6, column=2, pady=5, padx=15, ipadx=5)
+
+# Search Box
+search_box = tk.Entry(window, font=("Helvetica 15"), bd = 2, width=60)
+search_box.grid(row=5, column=1, pady=5, padx=15, ipadx=5)
+
+questions_box = tk.Entry(window, font=("Helvetica 15"), bd = 2, width=60)
+questions_box.grid(row=6, column=1, pady=5, padx=15, ipadx=5)
+
+frame = ttk.Frame(window, style='my.TFrame')
+frame.place(relx=0.50, rely=0.18, relwidth=0.98, relheight=0.90, anchor="n")
+
+# Progress bar
+progress = ttk.Progressbar(window, orient="horizontal", length=200, mode="determinate")
+progress.grid(row=5, column=5, pady=5, padx=15, ipadx=5)
+
+# To display questions data
+query_label = tk.Text(frame ,height="52" ,width="500", bg="alice blue")
+query_label.grid(row=10, columnspan=2)
+
+window.mainloop()
\ No newline at end of file
diff --git a/Stackoverflow-Tool/README.md b/Stackoverflow-Tool/README.md
new file mode 100644
index 0000000000..a7a86cc923
--- /dev/null
+++ b/Stackoverflow-Tool/README.md
@@ -0,0 +1,11 @@
+# Package/Script Name
+
+Stack Overflow Error Search Auto Tool
+
+- This script executes your python file.
+- And it opens up the related Stack Overflow threads in the browser if there's any error in the script.
+
+## Author(s)
+
+[Muskan Kalra](https://github.com/Muskan0)
+
diff --git a/Stackoverflow-Tool/requirements.txt b/Stackoverflow-Tool/requirements.txt
new file mode 100644
index 0000000000..4387b609b9
--- /dev/null
+++ b/Stackoverflow-Tool/requirements.txt
@@ -0,0 +1,3 @@
+subprocess
+requests
+webbrowser
diff --git a/Stackoverflow-Tool/script.py b/Stackoverflow-Tool/script.py
new file mode 100644
index 0000000000..d97f80dcdd
--- /dev/null
+++ b/Stackoverflow-Tool/script.py
@@ -0,0 +1,37 @@
+import subprocess
+import requests
+import webbrowser
+
+# take the input of the python file
+file=input("Enter the python file name(same directory) or enter the proper location\n")
+# executing a script and extracting the errors
+p = subprocess.run(['python', file], capture_output=True, text=True)
+s= p.stderr
+s=s.split("\n")
+s=s[-2]
+errorType= errorMessage= ""
+k=len(s)
+for i in range(k):
+ if s[i]==":":
+ break
+errorType=s[:i]
+errorMessage=s[i+1:]
+
+# using Stack Exchange API search feature
+# parsing the json and extracting the links
+URL="https://api.stackexchange.com/2.2/search"
+PARAMS= {'intitle': errorType, 'tagged': 'python', 'nottagged':errorMessage, 'sort': 'votes', 'site': 'stackoverflow'}
+r= requests.get(url= URL, params= PARAMS)
+data= r.json()
+
+links=[]
+for i in data['items']:
+ # get those question links which are answered
+ if i["is_answered"]==True:
+ links.append(i["link"])
+
+# opening links the web browser
+n1=len(links)
+for i in range(7):
+ if i
+
+
+# Author(s)
+Shubhrima Jana
diff --git a/Rain Alert Mail Sender/main.py b/Rain Alert Mail Sender/main.py
new file mode 100644
index 0000000000..4f19152e72
--- /dev/null
+++ b/Rain Alert Mail Sender/main.py
@@ -0,0 +1,56 @@
+import requests
+from smtplib import SMTP
+import os
+from dotenv import load_dotenv
+
+load_dotenv()
+
+def function():
+ """Go to Manage your Google(or any mail) account, and then headover to Security.\nTurn OFF the options 'Two Step Verification' and 'Use your phone to sign in' in the Signing in to Google section.\nTurn ON the Less secure apps section.
+ """
+ return 0
+print(function.__doc__)
+MY_MAIL= os.getenv('MAIL')
+MY_PASSWORD= os.getenv('PASSWORD')
+RECIEVER_MAIL = input('Send mail to (mail id): ')
+CITY = input('Enter your City: ')
+
+API_KEY = os.getenv('API')
+
+API_END_POINT ='https://nominatim.openstreetmap.org/search.php'
+PARAMETER_LOCATION ={
+ 'city' : CITY,
+ 'format': 'json',
+}
+response_location = requests.get(url = API_END_POINT, params=PARAMETER_LOCATION)
+data_location = response_location .json()
+LAT = data_location [0]['lat']
+LONG = data_location [0]['lon']
+PARAMETER= {
+ "lat": LAT,
+ "lon": LONG,
+ "appid" : API_KEY,
+ "exclude" : "current,minutely,daily",
+}
+api = requests.get(url="http://api.openweathermap.org/data/2.5/onecall",params=PARAMETER)
+data = api.json()
+
+bring_umbrella = False
+
+for i in range(0,12):
+ hourly_condition = data['hourly'][i]['weather'][0]['id']
+ if(hourly_condition<700):
+ bring_umbrella = True
+
+if (bring_umbrella == True):
+ MESSAGE=f"Subject: Rain Rain \n\nIt's going to rain today. Bring Umbrella "
+
+else:
+ MESSAGE = f"Subject: Sunny Day\n\nMay be a sunny day. Carry sunglasses. "
+
+with SMTP("smtp.gmail.com") as connection:
+ connection.starttls()
+ connection.login(user=MY_MAIL, password=MY_PASSWORD)
+ connection.sendmail(from_addr=MY_MAIL, to_addrs=RECIEVER_MAIL,
+ msg=MESSAGE)
+ print('Mail Sent')
diff --git a/Rain Alert Mail Sender/requirements.txt b/Rain Alert Mail Sender/requirements.txt
new file mode 100644
index 0000000000..b4f6d53390
--- /dev/null
+++ b/Rain Alert Mail Sender/requirements.txt
@@ -0,0 +1,2 @@
+requests==2.25.1
+dotenv==0.05
\ No newline at end of file
diff --git a/Real Estate Webscrapper/README.md b/Real Estate Webscrapper/README.md
new file mode 100644
index 0000000000..34e06a4b22
--- /dev/null
+++ b/Real Estate Webscrapper/README.md
@@ -0,0 +1,34 @@
+## Real Estate Webscrapper
+- It will take information from the real estate site and store it in the form of csv file making the data more organised and locally accessible.
+
+___
+
+## Requirements
+- BeautifulSoup
+- Pandas
+---
+## How To install
+> pip install pandas
+
+> pip install beautifulsoup
+---
+- Now run the real_estate_webscrapper.py file to create the output2.csv file.
+- Then output2.csv will be created in the same folder as real_estate_webscrapper.py file and it can be opened using Microsoft Excel.
+---
+### Step 1
+- Load the website https://www.magicbricks.com/ready-to-move-flats-in-new-delhi-pppfs in your code using requests.
+
+### Step 2
+- Use inspect in website to know which div contains the information that we need
+- Use beautiful soup to load the information in program and store it into a dictionary for each property
+
+### Step 3
+- Use pandas to convert the list of dictionaries to csv file
+---
+
+## Author
+[Himanshi2997](https://github.com/Himanshi2997)
+---
+
+## Output
+
diff --git a/Real Estate Webscrapper/real_estate_webscrapper.py b/Real Estate Webscrapper/real_estate_webscrapper.py
new file mode 100644
index 0000000000..dd6cd5a5fb
--- /dev/null
+++ b/Real Estate Webscrapper/real_estate_webscrapper.py
@@ -0,0 +1,75 @@
+import requests
+from bs4 import BeautifulSoup
+import pandas
+
+
+headers = {
+ 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:55.0) Gecko/20100101 Firefox/55.0',
+}
+
+r=requests.get("https://www.magicbricks.com/ready-to-move-flats-in-new-delhi-pppfs", headers=headers)
+c=r.content
+soup=BeautifulSoup(c,"html.parser")
+
+
+complete_dataset = []
+
+
+all_containers=soup.find_all("div",{"class":"flex relative clearfix m-srp-card__container"})
+for item in all_containers:
+ item_data={}
+ try:
+ Price=item.find("div",{"class":"m-srp-card__price"}).text.replace("\n","").replace(" ","").replace("₹","")
+ p=Price.split()
+ item_data["Price"]=p[0]
+
+ except:
+ Price=item.find("span",{"class":"luxury-srp-card__price"}).text.replace("\n","").replace(" ","").replace("₹","")
+ p=Price.split()
+ item_data["Price"]=p[0]
+
+
+ try:
+ Pricepersqft=item.find("div",{"class":"m-srp-card__area"}).text.replace("₹","")
+ pr=Pricepersqft.split()
+ item_data["Pricepersqft"]=pr[0]
+
+ except:
+ try:
+ Pricepersqft=item.find("span",{"class":"luxury-srp-card__sqft"}).text.replace("\n","").replace(" ","").replace("₹","")
+ pr=Pricepersqft.split()
+ item_data["Pricepersqft"]=pr[0]
+ except:
+ item_data["Pricepersqft"]=None
+
+ try:
+ item_data["Size"]=item.find("span",{"class":"m-srp-card__title__bhk"}).text.replace("\n","").strip()[0:5]
+ except:
+ item_data["Size"]=None
+
+
+ title=item.find("span",{"class":"m-srp-card__title"})
+
+ words=(title.text.replace("in","")).split()
+
+ for i in range(len(words)):
+ if words[i]=="sale" or words[i]=="Sale":
+ break
+ s=""
+ for word in range(i+1,len(words)):
+ s=s+words[word]+" "
+
+ item_data["Address"]=s
+
+ try:
+ item_data["Carpet Area"]=item.find("div",{"class":"m-srp-card__summary__info"}).text
+ except:
+ item_data["Carpet Area"]=item.find("div",{"class":"luxury-srp-card__area__value"}).text
+
+
+ complete_dataset.append(item_data)
+
+
+
+df=pandas.DataFrame(complete_dataset)
+df.to_csv("./Real Estate Webscrapper/scraped.csv")
diff --git a/Real Estate Webscrapper/requirements.txt b/Real Estate Webscrapper/requirements.txt
new file mode 100644
index 0000000000..96fc9b6a4f
--- /dev/null
+++ b/Real Estate Webscrapper/requirements.txt
@@ -0,0 +1,3 @@
+requests==2.25.1
+pandas==1.2.4
+beautifulsoup4==4.9.3
diff --git a/Reddit_Scraper_without_API/README.md b/Reddit_Scraper_without_API/README.md
new file mode 100644
index 0000000000..ec65d6c75c
--- /dev/null
+++ b/Reddit_Scraper_without_API/README.md
@@ -0,0 +1,27 @@
+# Reddit Scraper
+
+- Using BeautifulSoup, a python library useful for web scraping, this script helps to scrape a desired subreddit to obtain all relevant data regarding its posts.
+
+- In the `fetch_reddit.py` , we take user input for the subreddit name, tags and the maximum count of posts to be scraped, we fetch and store all this information in a database file.
+
+- In the `display_reddit.py` , we display the desired results from the database to the user.
+
+## Setup instructions
+
+- The requirements can be installed as follows:
+
+```shell
+ $ pip install -r requirements.txt
+```
+
+## Working screenshots
+
+
+
+#
+
+
+
+## Author
+[Rohini Rao](www.github.com/RohiniRG)
+
diff --git a/Reddit_Scraper_without_API/display_reddit.py b/Reddit_Scraper_without_API/display_reddit.py
new file mode 100644
index 0000000000..299475a23b
--- /dev/null
+++ b/Reddit_Scraper_without_API/display_reddit.py
@@ -0,0 +1,51 @@
+import sqlite3
+import os
+
+
+def sql_connection():
+ """
+ Establishes a connection to the SQL file database
+ :return connection object:
+ """
+ path = os.path.abspath('SubredditDatabase.db')
+ con = sqlite3.connect(path)
+ return con
+
+
+def sql_fetcher(con):
+ """
+ Fetches all the tweets with the given hashtag from our database
+ :param con:
+ :return:
+ """
+ subreddit = input("\nEnter subreddit to search: r/")
+ count = 0
+ cur = con.cursor()
+ cur.execute('SELECT * FROM posts') # SQL search query
+ rows = cur.fetchall()
+
+ for r in rows:
+ if subreddit in r:
+ count += 1
+ print(f'\nTAG: {r[1]}\nPOST TITLE: {r[2]}\nAUTHOR: {r[3]}\n'
+ f'TIME STAMP: {r[4]}\nUPVOTES: {r[5]}\nCOMMENTS: {r[6]}'
+ f'\nURL: {r[7]}\n')
+
+ if count:
+ print(f'{count} posts fetched from database\n')
+ else:
+ print('\nNo posts stored for this subreddit\n')
+
+
+con = sql_connection()
+
+while 1:
+ sql_fetcher(con)
+
+ ans = input('\nPress (y) to continue or any other key to exit: ').lower()
+ if ans == 'y':
+ continue
+ else:
+ print('\nExiting..\n')
+ break
+
diff --git a/Reddit_Scraper_without_API/fetch_reddit.py b/Reddit_Scraper_without_API/fetch_reddit.py
new file mode 100644
index 0000000000..1518f8af1c
--- /dev/null
+++ b/Reddit_Scraper_without_API/fetch_reddit.py
@@ -0,0 +1,159 @@
+import requests
+import csv
+import time
+import sqlite3
+from bs4 import BeautifulSoup
+
+
+def sql_connection():
+ """
+ Establishes a connection to the SQL file database
+ :return connection object:
+ """
+ con = sqlite3.connect('SubredditDatabase.db')
+ return con
+
+
+def sql_table(con):
+ """
+ Creates a table in the database (if it does not exist already)
+ to store the tweet info
+ :param con:
+ :return:
+ """
+ cur = con.cursor()
+ cur.execute("CREATE TABLE IF NOT EXISTS posts(SUBREDDIT text, TAG text, "
+ " TITLE text, AUTHOR text, TIMESTAMP text, UPVOTES int, "
+ " COMMENTS text, URL text)")
+ con.commit()
+
+
+def sql_insert_table(con, entities):
+ """
+ Inserts the desired data into the table to store tweet info
+ :param con:
+ :param entities:
+ :return:
+ """
+ cur = con.cursor()
+ cur.execute('INSERT INTO posts(SUBREDDIT, TAG, TITLE, AUTHOR, '
+ 'TIMESTAMP, UPVOTES, COMMENTS, URL) '
+ 'VALUES(?, ?, ?, ?, ?, ?, ?, ?)', entities)
+ con.commit()
+
+
+def scraper():
+ """
+ The function scrapes the post info from the desired subreddit and stores it
+ into the desired file.
+ :return:
+ """
+ con = sql_connection()
+ sql_table(con)
+
+ while 1:
+ subreddit = input('\n\nEnter the name of the subreddit: r/').lower()
+ max_count = int(input('Enter the maximum number of entries to collect: '))
+ select = int(input('Select tags to add for the search: \n1. hot\n2. new'
+ '\n3. rising\n4. controversial\n5. top\nMake your choice: '))
+
+ if select == 1:
+ tag = 'hot'
+ tag_url = '/'
+ elif select == 2:
+ tag = 'new'
+ tag_url = '/new/'
+ elif select == 3:
+ tag = 'rising'
+ tag_url = '/rising/'
+ elif select == 4:
+ tag = 'controversial'
+ tag_url = '/controversial/'
+ elif select == 5:
+ tag = 'top'
+ tag_url = '/top/'
+
+ # URL for the desired subreddit
+ url = 'https://old.reddit.com/r/' + subreddit
+
+ # Using a user-agent to mimic browser activity
+ headers = {'User-Agent': 'Mozilla/5.0'}
+
+ req = requests.get(url, headers=headers)
+
+ if req.status_code == 200:
+ soup = BeautifulSoup(req.text, 'html.parser')
+ print(f'\nCOLLECTING INFORMATION FOR r/{subreddit}....')
+
+ attrs = {'class': 'thing'}
+ counter = 1
+ full = 0
+ reddit_info = []
+ while 1:
+ for post in soup.find_all('div', attrs=attrs):
+ try:
+ # To obtain the post title
+ title = post.find('a', class_='title').text
+
+ # To get the username of the post author
+ author = post.find('a', class_='author').text
+
+ # To obtain the time of the post
+ time_stamp = post.time.attrs['title']
+
+ # To obtain the number of comments on the post
+ comments = post.find('a', class_='comments').text.split()[0]
+ if comments == 'comment':
+ comments = 0
+
+ # To get the number of comments on the post
+ upvotes = post.find('div', class_='score likes').text
+ if upvotes == '•':
+ upvotes = "None"
+
+ # To get the URL of the post
+ link = post.find('a', class_='title')['href']
+ link = 'www.reddit.com' + link
+
+ # Entering all the collected information into our database
+ entities = (subreddit, tag, title, author, time_stamp, upvotes,
+ comments, link)
+ sql_insert_table(con, entities)
+
+ if counter == max_count:
+ full = 1
+ break
+
+ counter += 1
+ except AttributeError:
+ continue
+
+ if full:
+ break
+
+ try:
+ # To go to the next page
+ next_button = soup.find('span', class_='next-button')
+ next_page_link = next_button.find('a').attrs['href']
+
+ time.sleep(2)
+
+ req = requests.get(next_page_link, headers=headers)
+ soup = BeautifulSoup(req.text, 'html.parser')
+ except:
+ break
+
+ print('DONE!\n')
+ ans = input('Press (y) to continue or any other key to exit: ').lower()
+ if ans == 'y':
+ continue
+ else:
+ print('Exiting..')
+ break
+ else:
+ print('Error fetching results.. Try again!')
+
+
+if __name__ == '__main__':
+ scraper()
+
diff --git a/Reddit_Scraper_without_API/requirements.txt b/Reddit_Scraper_without_API/requirements.txt
new file mode 100644
index 0000000000..b7a5bb209c
--- /dev/null
+++ b/Reddit_Scraper_without_API/requirements.txt
@@ -0,0 +1,7 @@
+beautifulsoup4==4.9.3
+certifi==2020.12.5
+chardet==4.0.0
+idna==2.10
+requests==2.25.1
+soupsieve==2.2.1
+urllib3==1.26.4
diff --git a/Speak-like-Yoda/README.md b/Speak-like-Yoda/README.md
new file mode 100644
index 0000000000..57188d650f
--- /dev/null
+++ b/Speak-like-Yoda/README.md
@@ -0,0 +1,24 @@
+# Speak-Like-Yoda
+
+## Description
+A python script that translates an input English sentence into Yoda-speak.
+
+## Usage
+Run ```python speak_like_yoda.py```. Type in your sentence to get it translated into Yoda-speak.
+
+## Requirements
+The script only uses Python's standard modules ```random``` and ```string```, so no additional installation is needed.
+
+## Output
+```
+Your English sentence:
+Avoiding failure is something we learn at some later point in life.
+
+Your Yodenglish sentence:
+Something is we point some failure learn avoiding later at in life
+
+```
+
+## Author(s)
+
+[Soumik Kumar Baithalu](https://www.github.com/soumik2012)
diff --git a/Speak-like-Yoda/Speak_Like_yoda.py b/Speak-like-Yoda/Speak_Like_yoda.py
new file mode 100644
index 0000000000..3e92e8d6df
--- /dev/null
+++ b/Speak-like-Yoda/Speak_Like_yoda.py
@@ -0,0 +1,23 @@
+import random
+import string
+
+def speak_like_yoda(sentence):
+ """
+ Translate the input sentence into Yoda-speak.
+
+ :param sentence: input string
+ :return: translation to Yoda-speak
+ """
+ sentence = sentence.lower()
+ for p in string.punctuation.replace("'", ''):
+ sentence = sentence.replace(p, '')
+ words = sentence.split()
+ random.shuffle(words)
+ new_sent = ' '.join(words)
+ print('\nYour Yodenglish sentence: ')
+ print(new_sent.capitalize())
+
+if __name__ == '__main__':
+ print('Your English sentence: ')
+ sentence = str(input())
+ speak_like_yoda(sentence)
diff --git a/Speak-like-Yoda/requirements.txt b/Speak-like-Yoda/requirements.txt
new file mode 100644
index 0000000000..d1357856c9
--- /dev/null
+++ b/Speak-like-Yoda/requirements.txt
@@ -0,0 +1,2 @@
+random
+string
diff --git a/Stack-overflow-scraper/README.md b/Stack-overflow-scraper/README.md
new file mode 100644
index 0000000000..0681571a06
--- /dev/null
+++ b/Stack-overflow-scraper/README.md
@@ -0,0 +1,26 @@
+# Stack overflow question scraper
+Running this Script would allow the user to scrape top questions from Stack overflow based on the question tag(python, java, etc) of their choice. The question, summary, link, votes and views will be stored in a local SQL DB.
+
+## Setup instructions
+In order to run this script, you need to have Python and pip installed on your system. After you're done installing Python and pip, run the following command from your terminal to install the requirements from the same folder (directory) of the project.
+```
+pip install -r requirements.txt
+```
+After satisfying all the requirements for the project, Open the terminal in the project folder and run
+```
+python scraper.py
+```
+or
+```
+python3 scraper.py
+```
+depending upon the python version. Make sure that you are running the command from the same virtual environment in which the required modules are installed.
+
+## Output
+
+The user can choose the question tag based on which they want to scrape top questions from Stack Overflow.
+
+
+
+## Author
+[Ayush Jain](https://github.com/Ayushjain2205)
\ No newline at end of file
diff --git a/Stack-overflow-scraper/requirements.txt b/Stack-overflow-scraper/requirements.txt
new file mode 100644
index 0000000000..a98ae430c4
--- /dev/null
+++ b/Stack-overflow-scraper/requirements.txt
@@ -0,0 +1,2 @@
+requests
+beautifulsoup4
\ No newline at end of file
diff --git a/Stack-overflow-scraper/scraper.py b/Stack-overflow-scraper/scraper.py
new file mode 100644
index 0000000000..2cb2588949
--- /dev/null
+++ b/Stack-overflow-scraper/scraper.py
@@ -0,0 +1,193 @@
+import requests
+from bs4 import BeautifulSoup
+import tkinter as tk
+from tkinter import messagebox, simpledialog
+from tkinter import ttk
+from tkinter import font as tkFont
+import time
+import sqlite3
+from sqlite3 import Error
+
+# Function to connect to the SQL Database
+def sql_connection():
+ try:
+ con = sqlite3.connect('./Stack-overflow-scraper/stackoverflow.db')
+ return con
+ except Error:
+ print(Error)
+
+# Function to create table
+def sql_table(con):
+ cursorObj = con.cursor()
+ cursorObj.execute(
+ "CREATE TABLE IF NOT EXISTS questions(question_text text, question_summary text, question_link text,votes integer, views integer )")
+ con.commit()
+
+# Call functions to connect to database and create table
+con = sql_connection()
+sql_table(con)
+
+# Function to insert into table
+def sql_insert(con, entities):
+ cursorObj = con.cursor()
+ cursorObj.execute(
+ 'INSERT INTO questions(question_text, question_summary, question_link, votes, views) VALUES(?, ?, ?, ?, ?)', entities)
+ con.commit()
+
+# Function to generate URL based on choice
+def get_URL():
+ tag = search_box.get()
+ if not tag:
+ messagebox.showinfo("Alert", "Please Enter tag!")
+ return
+ url = 'https://stackoverflow.com/questions/tagged/{}?sort=MostVotes&edited=true'.format(tag)
+ return url
+
+def number_questions():
+ questions = int(questions_box.get())
+ if type(questions) != int or questions > 15:
+ return 15
+ return questions
+
+def scrape_questions():
+ for count in range(5):
+ progress['value'] += 15
+ window.update_idletasks()
+ time.sleep(0.10)
+
+ question_count = number_questions()
+ count = 0
+
+ url = get_URL()
+ if url:
+ page = requests.get(url)
+ else:
+ clear_progress()
+ return
+
+ # Start scraping resultant html data
+ soup = BeautifulSoup(page.content, 'html.parser')
+ questions = soup.find_all('div', {'class': 'question-summary'})
+ if not questions:
+ messagebox.showinfo("Invalid", "Invalid search tag")
+ clear_progress()
+ return ""
+ for question in questions:
+ if count >= question_count:
+ break
+ question_text = question.find('a', {'class': 'question-hyperlink'}).text.strip()
+ question_summary = question.find('div', {'class': 'excerpt'}).text.strip()
+ question_summary = question_summary.replace('\n',' ')
+ question_link = 'https://stackoverflow.com{}'.format(question.find('a', {'class': 'question-hyperlink'})['href'])
+ votes = question.find('span', {'class': 'vote-count-post'}).text.strip()
+ views = question.find('div', {'class': 'views'}).text.strip().split()[0]
+ entities = (question_text, question_summary, question_link, votes, views)
+ sql_insert(con, entities)
+ count += 1
+
+ messagebox.showinfo("Success!", "Questions scrapped successfully!")
+ clear_progress()
+
+# Function to fetch stackoverflow questions from DB
+def sql_fetch(con):
+ cursorObj = con.cursor()
+ try:
+ cursorObj.execute('SELECT DISTINCT * FROM questions ORDER BY rowid DESC') # SQL search query
+ except Error:
+ print("Database empty... Fetch users using GUI")
+ return
+
+ rows = cursorObj.fetchall()
+ display_text = ""
+
+ # Show messagebox incase of empty DB
+ if len(rows) == 0 :
+ messagebox.showinfo("Alert", "No users scraped yet!")
+ return " "
+
+ first_row = "{:^65}".format("Question") + "{:^65}".format("Summary") + "{:^40}".format("Link") + "{:^15}".format("Votes") + "{:^15}".format("Views") + '\n'
+ display_text += first_row
+
+ # Format rows
+ for row in rows:
+ question_text = "{:<65}".format(
+ row[0] if len(row[0]) < 60 else row[0][:56]+"...")
+ question_summary = "{:<65}".format(
+ row[1] if len(row[1]) < 60 else row[1][:56]+"...")
+ question_link = "{:<40}".format(
+ row[2] if len(row[2]) < 30 else row[2][:36]+"...")
+ votes = "{:^15}".format(row[3])
+ views = "{:^15}".format(row[4])
+ display_text += (question_text + question_summary + question_link + votes + views +'\n')
+
+ return display_text
+
+def show_results():
+ display_text = sql_fetch(con)
+ query_label.config(state=tk.NORMAL)
+ query_label.delete(1.0, "end")
+ query_label.insert(1.0, display_text)
+ query_label.config(state=tk.DISABLED)
+
+def clear_progress():
+ #set progress bar back to 0
+ progress['value'] = 100
+ window.update_idletasks()
+ progress['value'] = 0
+ window.update_idletasks()
+
+# Creating tkinter window
+window = tk.Tk()
+window.title('Stack overflow question scraper')
+window.geometry('1200x1000')
+window.configure(bg='white')
+
+style = ttk.Style()
+style.theme_use('alt')
+style.map('my.TButton', background=[('active','white')])
+style.configure('my.TButton', font=('Helvetica', 16, 'bold'))
+style.configure('my.TButton', background='white')
+style.configure('my.TButton', foreground='orange')
+style.configure('my.TFrame', background='white')
+
+# label text for title
+ttk.Label(window, text="Stack overflow question scraper",
+ background='white', foreground="Orange",
+ font=("Helvetica", 30, 'bold')).grid(row=0, column=1)
+
+# label texts
+ttk.Label(window, text="Enter tag (ex - python):", background = 'white',
+ font=("Helvetica", 15)).grid(column=0,
+ row=5, padx=10, pady=25)
+
+ttk.Label(window, text="No of questions to scrape:", background = 'white',
+ font=("Helvetica", 15)).grid(column=0,
+ row=6, padx=10, pady=5)
+
+
+# Button creation
+scrape_btn = ttk.Button(window, text="Scrape questions!", style='my.TButton', command=scrape_questions)
+scrape_btn.grid(row=5, column=2, pady=5, padx=15, ipadx=5)
+
+display_btn = ttk.Button(window, text="Display from DB", style='my.TButton', command = show_results)
+display_btn.grid(row=6, column=2, pady=5, padx=15, ipadx=5)
+
+# Search Box
+search_box = tk.Entry(window, font=("Helvetica 15"), bd = 2, width=60)
+search_box.grid(row=5, column=1, pady=5, padx=15, ipadx=5)
+
+questions_box = tk.Entry(window, font=("Helvetica 15"), bd = 2, width=60)
+questions_box.grid(row=6, column=1, pady=5, padx=15, ipadx=5)
+
+frame = ttk.Frame(window, style='my.TFrame')
+frame.place(relx=0.50, rely=0.18, relwidth=0.98, relheight=0.90, anchor="n")
+
+# Progress bar
+progress = ttk.Progressbar(window, orient="horizontal", length=200, mode="determinate")
+progress.grid(row=5, column=5, pady=5, padx=15, ipadx=5)
+
+# To display questions data
+query_label = tk.Text(frame ,height="52" ,width="500", bg="alice blue")
+query_label.grid(row=10, columnspan=2)
+
+window.mainloop()
\ No newline at end of file
diff --git a/Stackoverflow-Tool/README.md b/Stackoverflow-Tool/README.md
new file mode 100644
index 0000000000..a7a86cc923
--- /dev/null
+++ b/Stackoverflow-Tool/README.md
@@ -0,0 +1,11 @@
+# Package/Script Name
+
+Stack Overflow Error Search Auto Tool
+
+- This script executes your python file.
+- And it opens up the related Stack Overflow threads in the browser if there's any error in the script.
+
+## Author(s)
+
+[Muskan Kalra](https://github.com/Muskan0)
+
diff --git a/Stackoverflow-Tool/requirements.txt b/Stackoverflow-Tool/requirements.txt
new file mode 100644
index 0000000000..4387b609b9
--- /dev/null
+++ b/Stackoverflow-Tool/requirements.txt
@@ -0,0 +1,3 @@
+subprocess
+requests
+webbrowser
diff --git a/Stackoverflow-Tool/script.py b/Stackoverflow-Tool/script.py
new file mode 100644
index 0000000000..d97f80dcdd
--- /dev/null
+++ b/Stackoverflow-Tool/script.py
@@ -0,0 +1,37 @@
+import subprocess
+import requests
+import webbrowser
+
+# take the input of the python file
+file=input("Enter the python file name(same directory) or enter the proper location\n")
+# executing a script and extracting the errors
+p = subprocess.run(['python', file], capture_output=True, text=True)
+s= p.stderr
+s=s.split("\n")
+s=s[-2]
+errorType= errorMessage= ""
+k=len(s)
+for i in range(k):
+ if s[i]==":":
+ break
+errorType=s[:i]
+errorMessage=s[i+1:]
+
+# using Stack Exchange API search feature
+# parsing the json and extracting the links
+URL="https://api.stackexchange.com/2.2/search"
+PARAMS= {'intitle': errorType, 'tagged': 'python', 'nottagged':errorMessage, 'sort': 'votes', 'site': 'stackoverflow'}
+r= requests.get(url= URL, params= PARAMS)
+data= r.json()
+
+links=[]
+for i in data['items']:
+ # get those question links which are answered
+ if i["is_answered"]==True:
+ links.append(i["link"])
+
+# opening links the web browser
+n1=len(links)
+for i in range(7):
+ if i