diff --git a/platform-api/legacy-api/aws.mdx b/api/legacy-api/aws.mdx
similarity index 99%
rename from platform-api/legacy-api/aws.mdx
rename to api/legacy-api/aws.mdx
index 54e40fd4..79db79ce 100644
--- a/platform-api/legacy-api/aws.mdx
+++ b/api/legacy-api/aws.mdx
@@ -314,7 +314,7 @@ For example, run one of the following, setting the following environment variabl
- Set `UNSTRUCTURED_API_URL` to `http://`, followed by your load balancer's DNS name, followed by `/general/v0/general`.
You can now use this value (`http://`, followed by your load balancer's DNS name, followed by `/general/v0/general`) in place of
- calling the [Unstructured Platform Partition Endpoint](/platform-api/partition-api/overview) URL as described elsewhere in the Unstructured API documentation.
+ calling the [Unstructured Partition Endpoint](/api/partition/overview) URL as described elsewhere in the Unstructured API documentation.
- Set `LOCAL_FILE_INPUT_DIR` to the path on your local machine to the files for the Unstructured API to process. If you do not have any input files available, you can download any of the ones from the [example-docs](https://github.com/Unstructured-IO/unstructured-ingest/tree/main/example-docs) folder in GitHub.
- Set `LOCAL_FILE_OUTPUT_DIR` to the path on your local machine for Unstructured API to send the processed output in JSON format:
diff --git a/platform-api/legacy-api/azure.mdx b/api/legacy-api/azure.mdx
similarity index 100%
rename from platform-api/legacy-api/azure.mdx
rename to api/legacy-api/azure.mdx
diff --git a/platform-api/legacy-api/free-api.mdx b/api/legacy-api/free-api.mdx
similarity index 82%
rename from platform-api/legacy-api/free-api.mdx
rename to api/legacy-api/free-api.mdx
index 72fddbc7..a5b5daa8 100644
--- a/platform-api/legacy-api/free-api.mdx
+++ b/api/legacy-api/free-api.mdx
@@ -5,7 +5,7 @@ title: Free Unstructured API
The Free Unstructured API is in the process of deprecation by April 4, 2025. It is no longer supported and is not being actively updated.
- Unstructured recommends that you use the [Unstructured Platform API](/platform-api/overview) instead, which provides new users with 14 days of free usage at up to 1000 pages per day during that period.
+ Unstructured recommends that you use the [Unstructured API](/api/overview) instead, which provides new users with 14 days of free usage at up to 1000 pages per day during that period.
This page is not being actively updated. It might contain out-of-date information. This page is provided for legacy reference purposes only.
@@ -32,7 +32,7 @@ The Free Unstructured API is designed for prototyping purposes, and not for prod
* Users of the Free Unstructured API do not get their own dedicated infrastructure.
* The data sent over the Free Unstructured API can be used for model training purposes, and other service improvements.
-If you require a production-ready API, consider using the [Unstructured Platform API](/platform-api/overview) instead.
+If you require a production-ready API, consider using the [Unstructured API](/api/overview) instead.
import SharedPagesBilling from '/snippets/general-shared-text/pages-billing.mdx';
@@ -55,7 +55,7 @@ To work with the Free Unstructured API by using the [Unstructured Ingest CLI](/i
- Set the `UNSTRUCTURED_API_KEY` environment variable to your Free Unstructured API key.
- Set the `UNSTRUCTURED_API_URL` environment variable to your Free Unstructured API URL, which is `https://api.unstructured.io/general/v0/general`
-- Have some compatible files on your local machine to be processed. [See the list of supported file types](/platform-api/supported-file-types). If you do not have any files available, you can download some from the [example-docs](https://github.com/Unstructured-IO/unstructured-ingest/tree/main/example-docs) folder in the Unstructured repo on GitHub.
+- Have some compatible files on your local machine to be processed. [See the list of supported file types](/api/supported-file-types). If you do not have any files available, you can download some from the [example-docs](https://github.com/Unstructured-IO/unstructured-ingest/tree/main/example-docs) folder in the Unstructured repo on GitHub.
Now, use the CLI to call the API, replacing:
@@ -93,7 +93,7 @@ To work with Unstructured by using the [Unstructured Python library](/ingestion/
[Get your API key and API URL](#get-started).
-- Have some compatible files on your local machine to be processed. [See the list of supported file types](/platform-api/supported-file-types). If you do not have any files available, you can download some from the [example-docs](https://github.com/Unstructured-IO/unstructured-ingest/tree/main/example-docs) folder in the Unstructured repo on GitHub. If you do not have any files available, you can download some from the [example-docs](https://github.com/Unstructured-IO/unstructured-ingest/tree/main/example-docs) folder in the Unstructured repo on GitHub.
+- Have some compatible files on your local machine to be processed. [See the list of supported file types](/api/supported-file-types). If you do not have any files available, you can download some from the [example-docs](https://github.com/Unstructured-IO/unstructured-ingest/tree/main/example-docs) folder in the Unstructured repo on GitHub. If you do not have any files available, you can download some from the [example-docs](https://github.com/Unstructured-IO/unstructured-ingest/tree/main/example-docs) folder in the Unstructured repo on GitHub.
Now, use the CLI to call the API, replacing:
diff --git a/platform-api/legacy-api/overview.mdx b/api/legacy-api/overview.mdx
similarity index 63%
rename from platform-api/legacy-api/overview.mdx
rename to api/legacy-api/overview.mdx
index 6f0d879b..b744304b 100644
--- a/platform-api/legacy-api/overview.mdx
+++ b/api/legacy-api/overview.mdx
@@ -4,15 +4,15 @@ title: Overview
Unstructured has deprecated the following APIs:
-- The [Free Unstructured API](/platform-api/legacy-api/free-api) is in the process of deprecation by April 4, 2025.
+- The [Free Unstructured API](/api/legacy-api/free-api) is in the process of deprecation by April 4, 2025.
It is no longer supported and is not being actively updated. Unstructured recommends that you use the
- [Unstructured Platform API](/platform-api/overview) instead, which provides new users with 14 days of free usage at up to
+ [Unstructured API](/api/overview) instead, which provides new users with 14 days of free usage at up to
1000 pages per day during that period.
-- The [Unstructured API on AWS](/platform-api/legacy-api/aws) is deprecated. It is no longer supported and is not being actively updated.
+- The [Unstructured API on AWS](/api/legacy-api/aws) is deprecated. It is no longer supported and is not being actively updated.
Unstructured is now available on the AWS Marketplace as a private offering. To explore supported options
for running Unstructured within your virtual private cloud (VPC), email Unstructured Sales at
[sales@unstructured.io](mailto:sales@unstructured.io).
-- The [Unstructured API on Azure](/platform-api/legacy-api/azure) is deprecated. It is no longer supported and is not being actively updated.
+- The [Unstructured API on Azure](/api/legacy-api/azure) is deprecated. It is no longer supported and is not being actively updated.
Unstructured is now available on the AWS Marketplace as a private offering. To explore supported options
for running Unstructured within your virtual private cloud (VPC), email Unstructured Sales at
[sales@unstructured.io](mailto:sales@unstructured.io).
diff --git a/platform-api/overview.mdx b/api/overview.mdx
similarity index 65%
rename from platform-api/overview.mdx
rename to api/overview.mdx
index 81065eb5..6eb9cec3 100644
--- a/platform-api/overview.mdx
+++ b/api/overview.mdx
@@ -2,21 +2,21 @@
title: Overview
---
-The Unstructured Platform API consists of two parts:
+The Unstructured API consists of two parts:
-- The [Unstructured Platform Workflow Endpoint](/platform-api/api/overview) enables a full range of partitioning, chunking, embedding, and
+- The [Unstructured Workflow Endpoint](/api/workflow/overview) enables a full range of partitioning, chunking, embedding, and
enrichment options for your files and data. It is designed to batch-process files and data in remote locations; send processed results to
various storage, databases, and vector stores; and use the latest and highest-performing models on the market today. It has built-in logic
- to deliver the highest quality results at the lowest cost. [Learn more](/platform-api/api/overview).
-- The [Unstructured Platform Partition Endpoint](/platform-api/partition-api/overview) is intended for rapid prototyping of Unstructured's
+ to deliver the highest quality results at the lowest cost. [Learn more](/api/workflow/overview).
+- The [Unstructured Partition Endpoint](/api/partition/overview) is intended for rapid prototyping of Unstructured's
various partitioning strategies, with limited support for chunking. It is designed to work only with processing of local files, one file
- at a time. Use the [Unstructured Platform Workflow Endpoint](/platform-api/api/overview) for production-level scenarios, file processing in
+ at a time. Use the [Unstructured Workflow Endpoint](/api/workflow/overview) for production-level scenarios, file processing in
batches, files and data in remote locations, generating embeddings, applying post-transform enrichments, using the latest and
- highest-performing models, and for the highest quality results at the lowest cost. [Learn more](/platform-api/partition-api/overview).
+ highest-performing models, and for the highest quality results at the lowest cost. [Learn more](/api/partition/overview).
# Benefits over open source
-The Unstructured Platform API provides the following benefits beyond the [Unstructured open source library](/open-source/introduction/overview) offering:
+The Unstructured API provides the following benefits beyond the [Unstructured open source library](/open-source/introduction/overview) offering:
* Designed for production scenarios.
* Significantly increased performance on document and table extraction.
@@ -33,4 +33,4 @@ The Unstructured Platform API provides the following benefits beyond the [Unstru
## Get support
-Should you require any assistance or have any questions regarding the Unstructured Platform API, please [contact us directly](https://unstructured.io/contact).
+Should you require any assistance or have any questions regarding the Unstructured API, please [contact us directly](https://unstructured.io/contact).
diff --git a/platform-api/partition-api/api-parameters.mdx b/api/partition/api-parameters.mdx
similarity index 92%
rename from platform-api/partition-api/api-parameters.mdx
rename to api/partition/api-parameters.mdx
index 3edfc586..d9e42370 100644
--- a/platform-api/partition-api/api-parameters.mdx
+++ b/api/partition/api-parameters.mdx
@@ -3,7 +3,7 @@ title: Platform Endpoint parameters
sidebarTitle: Endpoint parameters
---
-The Unstructured Platform Partition Endpoint provides parameters to customize the processing of documents. These parameters include:
+The Unstructured Partition Endpoint provides parameters to customize the processing of documents. These parameters include:
The only required parameter is `files` - the file you wish to process.
@@ -12,26 +12,26 @@ The only required parameter is `files` - the file you wish to process.
| POST, Python | JavaScript/TypeScript | Description |
|-------------------------------------------|------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| `files` (_shared.Files_) | `files` (_File_, _Blob_, _shared.Files_) | The file to process. |
-| `chunking_strategy` (_str_) | `chunkingStrategy` (_string_) | Use one of the supported strategies to chunk the returned elements after partitioning. When no chunking strategy is specified, no chunking is performed and any other chunking parameters provided are ignored. Supported strategies: `basic`, `by_title`, `by_page`, and `by_similarity`. [Learn more](/platform-api/partition-api/chunking). |
+| `chunking_strategy` (_str_) | `chunkingStrategy` (_string_) | Use one of the supported strategies to chunk the returned elements after partitioning. When no chunking strategy is specified, no chunking is performed and any other chunking parameters provided are ignored. Supported strategies: `basic`, `by_title`, `by_page`, and `by_similarity`. [Learn more](/api/partition/chunking). |
| `content_type` (_str_) | `contentType` (_string_) | A hint to Unstructured about the content type to use (such as `text/markdown`), when there are problems processing a specific file. This value is a MIME type in the format `type/subtype`. For available MIME types, see [model.py](https://github.com/Unstructured-IO/unstructured/blob/main/unstructured/file_utils/model.py). |
-| `coordinates` (_bool_) | `coordinates` (_boolean_) | True to return bounding box coordinates for each element extracted with OCR. Default: false. [Learn more](/platform-api/partition-api/examples#saving-bounding-box-coordinates). |
+| `coordinates` (_bool_) | `coordinates` (_boolean_) | True to return bounding box coordinates for each element extracted with OCR. Default: false. [Learn more](/api/partition/examples#saving-bounding-box-coordinates). |
| `encoding` (_str_) | `encoding` (_string_) | The encoding method used to decode the text input. Default: `utf-8`. |
-| `extract_image_block_types` (_List[str]_) | `extractImageBlockTypes` (_string[]_) | The types of elements to extract, for use in extracting image blocks as Base64 encoded data stored in element metadata fields, for example: `["Image","Table"]`. Supported filetypes are image and PDF. [Learn more](/platform-api/partition-api/extract-image-block-types). |
+| `extract_image_block_types` (_List[str]_) | `extractImageBlockTypes` (_string[]_) | The types of elements to extract, for use in extracting image blocks as Base64 encoded data stored in element metadata fields, for example: `["Image","Table"]`. Supported filetypes are image and PDF. [Learn more](/api/partition/extract-image-block-types). |
| `gz_uncompressed_content_type` (_str_) | `gzUncompressedContentType` (_string_) | If file is gzipped, use this content type after unzipping. Example: `application/pdf` |
-| `hi_res_model_name` (_str_) | `hiResModelName` (_string_) | The name of the inference model used when strategy is `hi_res`. Options are `layout_v1.1.0` and `yolox`. Default: `layout_v1.1.0`. [Learn more](/platform-api/partition-api/examples#changing-partition-strategy-for-a-pdf). |
+| `hi_res_model_name` (_str_) | `hiResModelName` (_string_) | The name of the inference model used when strategy is `hi_res`. Options are `layout_v1.1.0` and `yolox`. Default: `layout_v1.1.0`. [Learn more](/api/partition/examples#changing-partition-strategy-for-a-pdf). |
| `include_page_breaks` (_bool_) | `includePageBreaks` (_boolean_) | True for the output to include page breaks if the filetype supports it. Default: false. |
-| `languages` (_List[str]_) | `languages` (_string[]_) | The languages present in the document, for use in partitioning and OCR. [View the list of available languages](https://github.com/tesseract-ocr/tessdata). [Learn more](/platform-api/partition-api/examples#specifying-the-language-of-a-document-for-better-ocr-results). |
+| `languages` (_List[str]_) | `languages` (_string[]_) | The languages present in the document, for use in partitioning and OCR. [View the list of available languages](https://github.com/tesseract-ocr/tessdata). [Learn more](/api/partition/examples#specifying-the-language-of-a-document-for-better-ocr-results). |
| `output_format` (_str_) | `outputFormat` (_string_) | The format of the response. Supported formats are `application/json` and `text/csv`. Default: `application/json`. |
| `pdf_infer_table_structure` (_bool_) | `pdfInferTableStructure` (_boolean_) | **Deprecated!** If true and `strategy` is `hi_res`, any `Table` elements extracted from a PDF will include an additional metadata field, `text_as_html`, where the value (string) is a just a transformation of the data into an HTML table. |
| `skip_infer_table_types` (_List[str]_) | `skipInferTableTypes` (_string[]_) | The document types that you want to skip table extraction for. Default: `[]`. |
| `starting_page_number` (_int_) | `startingPageNumber` (_number_) | The page number to be be assigned to the first page in the document. This information will be included in elements' metadata and can be be especially useful when partitioning a document that is part of a larger document. |
-| `strategy` (_str_) | `strategy` (_string_) | The strategy to use for partitioning PDF and image files. Options are `auto`, `vlm`, `hi_res`, `fast`, and `ocr_only`. Default: `auto`. [Learn more](/platform-api/partition-api/partitioning). |
+| `strategy` (_str_) | `strategy` (_string_) | The strategy to use for partitioning PDF and image files. Options are `auto`, `vlm`, `hi_res`, `fast`, and `ocr_only`. Default: `auto`. [Learn more](/api/partition/partitioning). |
| `unique_element_ids` (_bool_) | `uniqueElementIds` (_boolean_) | True to assign UUIDs to element IDs, which guarantees their uniqueness (useful when using them as primary keys in database). Otherwise a SHA-256 of the element's text is used. Default: false. |
| `vlm_model` (_str_) | (Not yet available) | Applies only when `strategy` is `vlm`. The name of the vision language model (VLM) provider to use for partitioning. `vlm_model_provider` must also be specified. For a list of allowed values, see the end of this article. |
| `vlm_model_provider` (_str_) | (Not yet available) | Applies only when `strategy` is `vlm`. The name of the vision language model (VLM) to use for partitioning. `vlm_model` must also be specified. For a list of allowed values, see the end of this article. |
| `xml_keep_tags` (_bool_) | `xmlKeepTags` (_boolean_) | True to retain the XML tags in the output. Otherwise it will just extract the text from within the tags. Only applies to XML documents. |
-The following parameters only apply when a chunking strategy is specified. Otherwise, they are ignored. [Learn more](/platform-api/partition-api/chunking).
+The following parameters only apply when a chunking strategy is specified. Otherwise, they are ignored. [Learn more](/api/partition/chunking).
| POST, Python | JavaScript/TypeScript | Description |
|----------------------------------|-----------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
@@ -44,16 +44,16 @@ The following parameters only apply when a chunking strategy is specified. Other
| `overlap_all` (_bool_) | `overlapAll` (_boolean_) | True to have an overlap also applied to "normal" chunks formed by combining whole elements. Use with caution, as this can introduce noise into otherwise clean semantic units. Default: none. |
| `similarity_threshold` (_float_) | `similarityThreshold` (_number_) | Applies only when the chunking strategy is set to `by_similarity`. The minimum similarity text in consecutive elements must have to be included in the same chunk. Must be between 0.0 and 1.0, exclusive (0.01 to 0.99, inclusive). Default: 0.5. |
-The following parameters are specific to the Python and JavaScript/TypeScript clients and are not sent to the server. [Learn more](/platform-api/partition-api/sdk-python#page-splitting).
+The following parameters are specific to the Python and JavaScript/TypeScript clients and are not sent to the server. [Learn more](/api/partition/sdk-python#page-splitting).
| POST, Python | JavaScript/TypeScript | Description |
|---------------------------------------|---------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
-| `split_pdf_page` (_bool_) | `splitPdfPage` (_boolean_) | True to split the PDF file client-side. [Learn more](/platform-api/partition-api/sdk-python#page-splitting). |
+| `split_pdf_page` (_bool_) | `splitPdfPage` (_boolean_) | True to split the PDF file client-side. [Learn more](/api/partition/sdk-python#page-splitting). |
| `split_pdf_allow_failed` (_bool_) | `splitPdfAllowFailed` (_boolean_) | When `true`, a failed split request will not stop the processing of the rest of the document. The affected page range will be ignored in the results. When `false`, a failed split request will cause the entire document to fail. Default: `false`. |
| `split_pdf_concurrency_level` (_int_) | `splitPdfConcurrencyLevel` (_number_) | The number of split files to be sent concurrently. Default: 5. Maximum: 15. |
| `split_pdf_page_range` (_List[int]_) | `splitPdfPageRange` (_number[]_) | A list of 2 integers within the range `[1, length_of_pdf]`. When pdf splitting is enabled, this will send only the specified page range to the API. |
-Need help getting started? Check out the [Examples page](/platform-api/partition-api/examples) for some inspiration.
+Need help getting started? Check out the [Examples page](/api/partition/examples) for some inspiration.
Allowed values for `vlm_model_provider` and `vlm_model` pairs include the following:
diff --git a/platform-api/partition-api/api-validation-errors.mdx b/api/partition/api-validation-errors.mdx
similarity index 93%
rename from platform-api/partition-api/api-validation-errors.mdx
rename to api/partition/api-validation-errors.mdx
index 4afb0aab..f647b15a 100644
--- a/platform-api/partition-api/api-validation-errors.mdx
+++ b/api/partition/api-validation-errors.mdx
@@ -1,6 +1,6 @@
---
title: Endpoint validation errors
-description: This section details the structure of HTTP validation errors returned by the Unstructured Platform Partition Endpoint.
+description: This section details the structure of HTTP validation errors returned by the Unstructured Partition Endpoint.
---
## HTTPValidationError
diff --git a/platform-api/partition-api/chunking.mdx b/api/partition/chunking.mdx
similarity index 100%
rename from platform-api/partition-api/chunking.mdx
rename to api/partition/chunking.mdx
diff --git a/platform-api/partition-api/document-elements.mdx b/api/partition/document-elements.mdx
similarity index 100%
rename from platform-api/partition-api/document-elements.mdx
rename to api/partition/document-elements.mdx
diff --git a/platform-api/partition-api/examples.mdx b/api/partition/examples.mdx
similarity index 99%
rename from platform-api/partition-api/examples.mdx
rename to api/partition/examples.mdx
index e41ef17e..7921671e 100644
--- a/platform-api/partition-api/examples.mdx
+++ b/api/partition/examples.mdx
@@ -1,10 +1,10 @@
---
title: Examples
-description: This page provides some examples of accessing Unstructured Platform Partition Endpoint via different methods.
+description: This page provides some examples of accessing Unstructured Partition Endpoint via different methods.
---
To use these examples, you'll first need to set an environment variable named `UNSTRUCTURED_API_KEY`,
-representing your Unstructured API key. [Get your API key](/platform-api/partition-api/overview).
+representing your Unstructured API key. [Get your API key](/api/partition/overview).
For the POST and Unstructured JavaScript/TypeScript SDK examples, you'll also need to set an environment variable named `UNSTRUCTURED_API_URL` to the
value `https://api.unstructuredapp.io/general/v0/general`
diff --git a/platform-api/partition-api/extract-image-block-types.mdx b/api/partition/extract-image-block-types.mdx
similarity index 78%
rename from platform-api/partition-api/extract-image-block-types.mdx
rename to api/partition/extract-image-block-types.mdx
index 9e601f8b..110c64e9 100644
--- a/platform-api/partition-api/extract-image-block-types.mdx
+++ b/api/partition/extract-image-block-types.mdx
@@ -15,7 +15,7 @@ and then show it.
## To run this example
You will need a document that is one of the document types supported by the `extract_image_block_types` argument.
-See the `extract_image_block_types` entry in [API Parameters](/platform-api/partition-api/api-parameters).
+See the `extract_image_block_types` entry in [API Parameters](/api/partition/api-parameters).
This example uses a PDF file with embedded images and tables.
import SharedAPIKeyURL from '/snippets/general-shared-text/api-key-url.mdx';
@@ -23,11 +23,11 @@ import ExtractImageBlockTypesPy from '/snippets/how-to-api/extract_image_block_t
## Code
-For the [Unstructured Python SDK](/platform-api/partition-api/sdk-python), you'll need:
+For the [Unstructured Python SDK](/api/partition/sdk-python), you'll need:
## See also
-- [Extract text as HTML](/platform-api/partition-api/text-as-html)
+- [Extract text as HTML](/api/partition/text-as-html)
- [Table extraction from PDF](/examplecode/codesamples/apioss/table-extraction-from-pdf)
\ No newline at end of file
diff --git a/platform-api/partition-api/generate-schema.mdx b/api/partition/generate-schema.mdx
similarity index 100%
rename from platform-api/partition-api/generate-schema.mdx
rename to api/partition/generate-schema.mdx
diff --git a/platform-api/partition-api/get-chunked-elements.mdx b/api/partition/get-chunked-elements.mdx
similarity index 93%
rename from platform-api/partition-api/get-chunked-elements.mdx
rename to api/partition/get-chunked-elements.mdx
index efaee4d7..1990151c 100644
--- a/platform-api/partition-api/get-chunked-elements.mdx
+++ b/api/partition/get-chunked-elements.mdx
@@ -55,11 +55,11 @@ You will need to chunk a document during processing. This example uses a PDF fil
import GetChunkedElementsPy from '/snippets/how-to-api/get_chunked_elements.py.mdx';
import SharedAPIKeyURL from '/snippets/general-shared-text/api-key-url.mdx';
-For the [Unstructured Python SDK](/platform-api/partition-api/sdk-python), you'll need:
+For the [Unstructured Python SDK](/api/partition/sdk-python), you'll need:
## See also
- [Recovering chunk elements](/open-source/core-functionality/chunking#recovering-chunk-elements)
-- [Chunking strategies](/platform-api/partition-api/chunking)
\ No newline at end of file
+- [Chunking strategies](/api/partition/chunking)
\ No newline at end of file
diff --git a/platform-api/partition-api/get-elements.mdx b/api/partition/get-elements.mdx
similarity index 91%
rename from platform-api/partition-api/get-elements.mdx
rename to api/partition/get-elements.mdx
index 89e75afb..4c9d8593 100644
--- a/platform-api/partition-api/get-elements.mdx
+++ b/api/partition/get-elements.mdx
@@ -4,7 +4,7 @@ title: Get element contents
## Task
-You want to get, manipulate, and print or save, the contents of the [document elements and metadata](/platform-api/partition-api/document-elements) from the processed data that Unstructured returns.
+You want to get, manipulate, and print or save, the contents of the [document elements and metadata](/api/partition/document-elements) from the processed data that Unstructured returns.
## Approach
@@ -14,7 +14,7 @@ The programmatic approach you take to get these document elements will depend on
- For the [Unstructured Python SDK](/platform-api/partition-api/sdk-python), calling an `UnstructuredClient` object's `general.partition_async` method returns a `PartitionResponse` object.
+ For the [Unstructured Python SDK](/api/partition/sdk-python), calling an `UnstructuredClient` object's `general.partition_async` method returns a `PartitionResponse` object.
This `PartitionResponse` object's `elements` variable contains a list of key-value dictionaries (`List[Dict[str, Any]]`). For example:
@@ -78,7 +78,7 @@ The programmatic approach you take to get these document elements will depend on
```
- For the [Unstructured JavaScript/TypeScript SDK](/platform-api/partition-api/sdk-jsts), calling an `UnstructuredClient` object's `general.partition` method returns a `Promise` object.
+ For the [Unstructured JavaScript/TypeScript SDK](/api/partition/sdk-jsts), calling an `UnstructuredClient` object's `general.partition` method returns a `Promise` object.
This `PartitionResponse` object's `elements` property contains an `Array` of string-value objects (`{ [k: string]: any; }[]`). For example:
diff --git a/api/partition/output-bounding-box-coordinates.mdx b/api/partition/output-bounding-box-coordinates.mdx
new file mode 100644
index 00000000..98152117
--- /dev/null
+++ b/api/partition/output-bounding-box-coordinates.mdx
@@ -0,0 +1,4 @@
+---
+title: "Output bounding box coordinates"
+url: "/api/partition/examples#saving-bounding-box-coordinates"
+---
\ No newline at end of file
diff --git a/platform-api/partition-api/overview.mdx b/api/partition/overview.mdx
similarity index 83%
rename from platform-api/partition-api/overview.mdx
rename to api/partition/overview.mdx
index 43d6d50d..9ac9cfec 100644
--- a/platform-api/partition-api/overview.mdx
+++ b/api/partition/overview.mdx
@@ -2,15 +2,15 @@
title: Overview
---
-The Unstructured Platform Partition Endpoint, part of the [Unstructured Platform API](/platform-api/overview), is intended for rapid prototyping of Unstructured's
+The Unstructured Partition Endpoint, part of the [Unstructured API](/api/overview), is intended for rapid prototyping of Unstructured's
various partitioning strategies, with limited support for chunking. It is designed to work only with processing of local files, one file
-at a time. Use the [Unstructured Platform Workflow Endpoint](/platform-api/api/overview) for production-level scenarios, file processing in
+at a time. Use the [Unstructured Workflow Endpoint](/api/workflow/overview) for production-level scenarios, file processing in
batches, files and data in remote locations, generating embeddings, applying post-transform enrichments, using the latest and
highest-performing models, and for the highest quality results at the lowest cost.
## Get started
-To call the Unstructured Platform Partition Endpoint, you need an Unstructured account and an Unstructured API key:
+To call the Unstructured Partition Endpoint, you need an Unstructured account and an Unstructured API key:
@@ -29,8 +29,8 @@ To call the Unstructured Platform Partition Endpoint, you need an Unstructured a
To save money by switching from a pay-per-page to a subscribe-and-save plan, go to the
[Unstructured Subscribe & Save](https://unstructured.io/subscribeandsave) page and complete the on-screen instructions.
- By signing up for a pay-per-page or subscribe-and-save plan, your Unstructured account will run within the context of the Unstructured Platform on
- Unstructured's own hosted cloud resources. If you would rather run the Unstructured Platform within the context of your own virtual private cloud (VPC),
+ By signing up for a pay-per-page or subscribe-and-save plan, your Unstructured account will run within the context of the Unstructured API on
+ Unstructured's own hosted cloud resources. If you would rather run the Unstructured API within the context of your own virtual private cloud (VPC),
(or you want to save even more money by making a long-term billing commitment),
stop here and sign up through the [For Enterprise](https://unstructured.io/enterprise) page instead.
@@ -44,9 +44,9 @@ To call the Unstructured Platform Partition Endpoint, you need an Unstructured a
be different. For enterprise sign-in guidance, contact Unstructured Sales at [sales@unstructured.io](mailto:sales@unstructured.io).
- 1. After you have signed up for a pay-per-page plan, the Unstructured Platform sign-in page appears.
+ 1. After you have signed up for a pay-per-page plan, the Unstructured account sign-in page appears.
- 
+ 
2. Click **Google** or **GitHub** to sign in with the Google or GitHub account that you signed up with.
Or, enter the email address that you signed up with, and then click **Sign In**.
@@ -65,9 +65,9 @@ To call the Unstructured Platform Partition Endpoint, you need an Unstructured a
 - 
+ 
- 
+ 
1. Sign in to your Unstructured account, at [https://platform.unstructured.io](https://platform.unstructured.io).
2. At the bottom of the sidebar, click your user icon, and then click **Account Settings**.
@@ -89,11 +89,11 @@ If you signed up for a pay-per-page plan, you can enjoy a free 14-day trial with
At the end of the 14-day free trial, or if you need to go past the trial's page processing limits during the 14-day free trial, you must set up your billing information to keep using
-the Unstructured Platform Partition API:
+the Unstructured Partition Endpoint:
-
+
-
+
1. Sign in to your Unstructured account, at [https://platform.unstructured.io](https://platform.unstructured.io).
2. At the bottom of the sidebar, click your user icon, and then click **Account Settings**.
@@ -113,7 +113,7 @@ import SharedPagesBilling from '/snippets/general-shared-text/pages-billing.mdx'
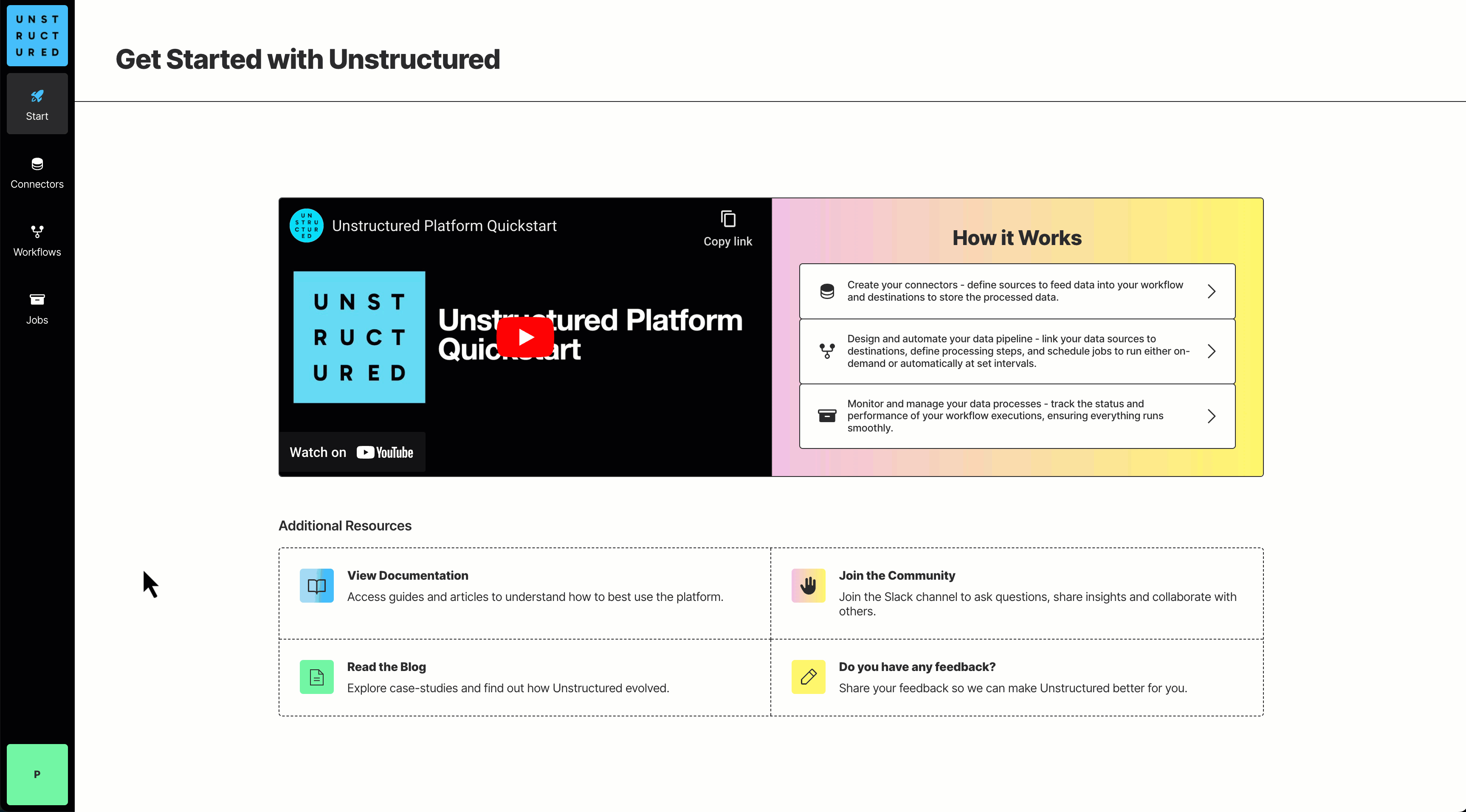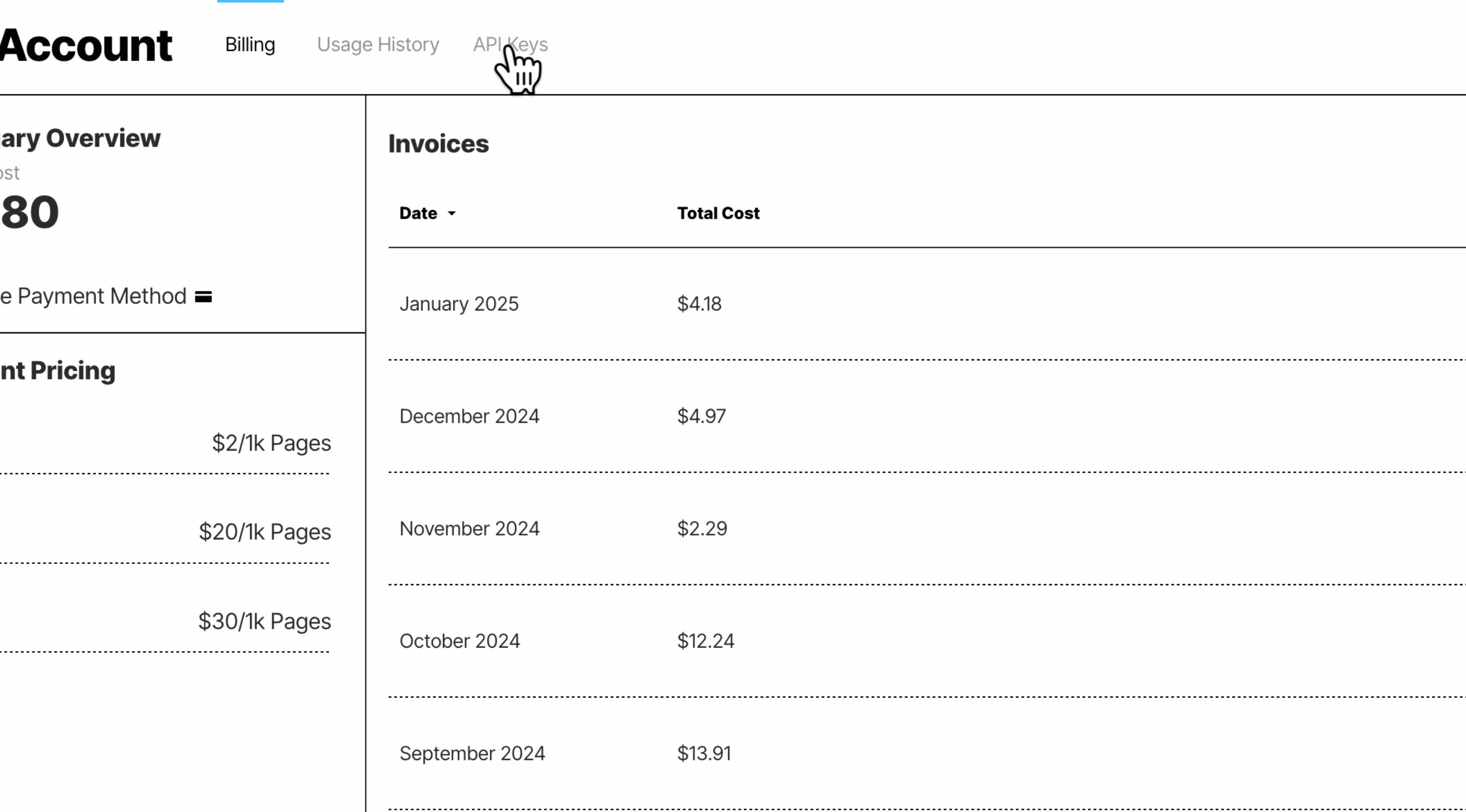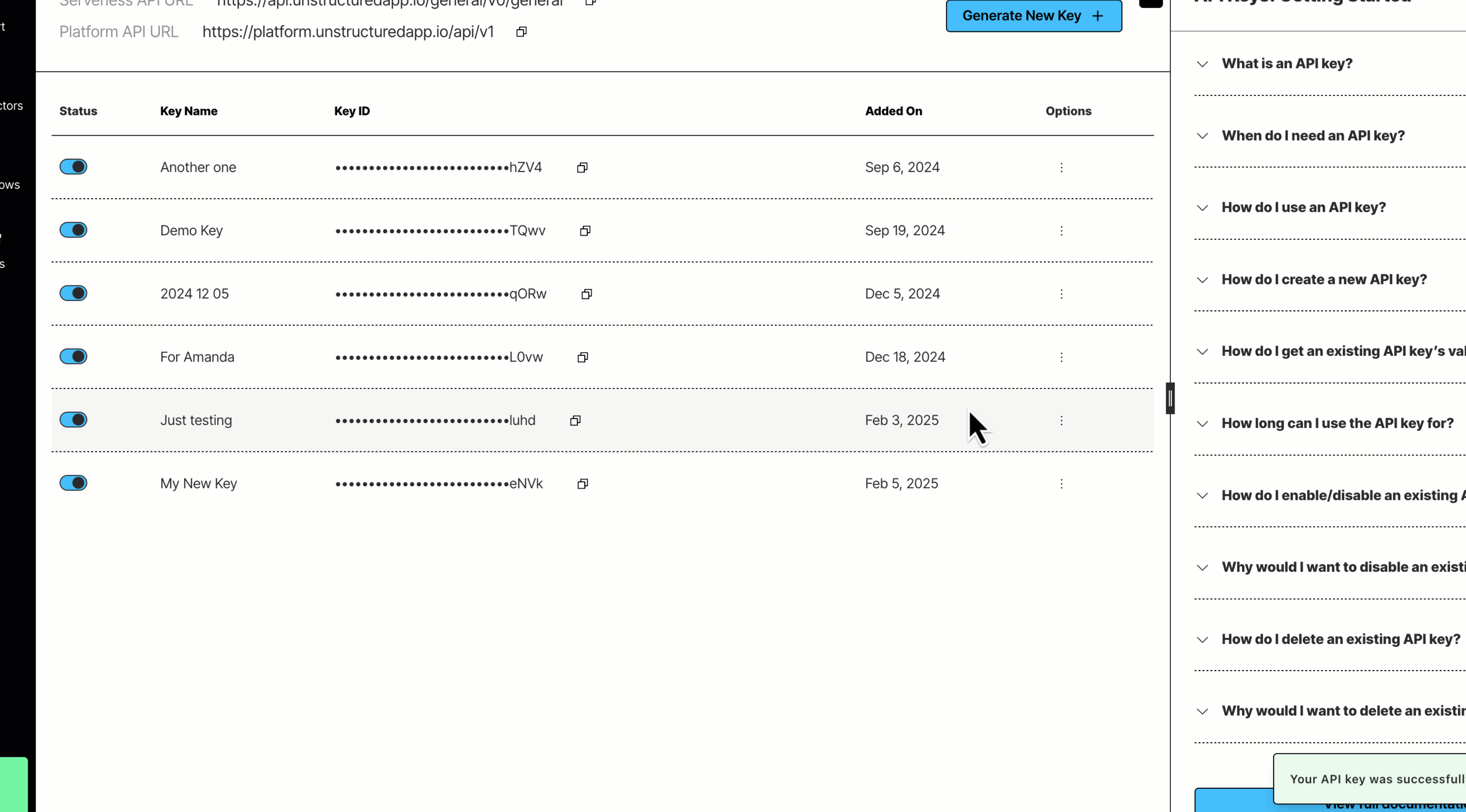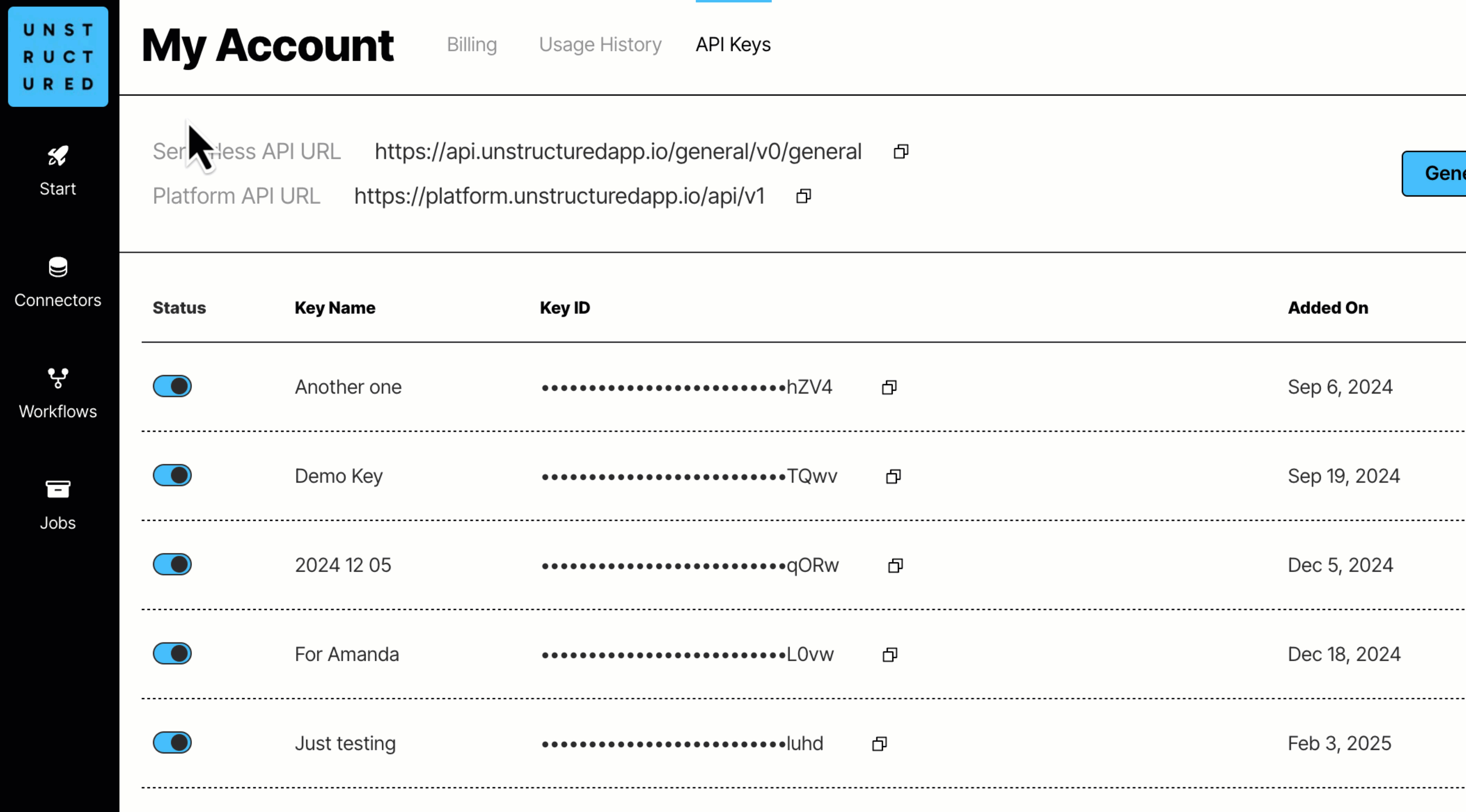
## Quickstart
-This example uses the [curl](https://curl.se/) utility on your local machine to call the Unstructured Platform Partition Endpoint. It sends a source (input) file from your local machine to the Unstructured Platform Partition Endpoint which then delivers the processed data to a destination (output) location, also on your local machine. Data is processed on Unstructured-hosted compute resources.
+This example uses the [curl](https://curl.se/) utility on your local machine to call the Unstructured Partition Endpoint. It sends a source (input) file from your local machine to the Unstructured Partition Endpoint which then delivers the processed data to a destination (output) location, also on your local machine. Data is processed on Unstructured-hosted compute resources.
If you do not have a source file readily available, you could use for example a sample PDF file containing the text of the United States Constitution,
available for download from [https://constitutioncenter.org/media/files/constitution.pdf](https://constitutioncenter.org/media/files/constitution.pdf).
@@ -122,7 +122,7 @@ available for download from [https://constitutioncenter.org/media/files/constitu
From your terminal or Command Prompt, set the following two environment variables.
- - Replace `` with the Unstructured Platform Partition Endpoint URL, which is `https://api.unstructuredapp.io/general/v0/general`
+ - Replace `` with the Unstructured Partition Endpoint URL, which is `https://api.unstructuredapp.io/general/v0/general`
- Replace `` with your Unstructured API key, which you generated earlier on this page.
```bash
@@ -159,7 +159,7 @@ available for download from [https://constitutioncenter.org/media/files/constitu
-You can also call the Unstructured Platform Partition Endpoint by using the [Unstructured Python SDK](/platform-api/partition-api/sdk-python) or the [Unstructured JavaScript/TypeScript SDK](/platform-api/partition-api/sdk-jsts).
+You can also call the Unstructured Partition Endpoint by using the [Unstructured Python SDK](/api/partition/sdk-python) or the [Unstructured JavaScript/TypeScript SDK](/api/partition/sdk-jsts).
## Telemetry
diff --git a/platform-api/partition-api/partitioning.mdx b/api/partition/partitioning.mdx
similarity index 100%
rename from platform-api/partition-api/partitioning.mdx
rename to api/partition/partitioning.mdx
diff --git a/platform-api/partition-api/pipeline-1.mdx b/api/partition/pipeline-1.mdx
similarity index 100%
rename from platform-api/partition-api/pipeline-1.mdx
rename to api/partition/pipeline-1.mdx
diff --git a/platform-api/partition-api/post-requests.mdx b/api/partition/post-requests.mdx
similarity index 82%
rename from platform-api/partition-api/post-requests.mdx
rename to api/partition/post-requests.mdx
index def219fe..253a9091 100644
--- a/platform-api/partition-api/post-requests.mdx
+++ b/api/partition/post-requests.mdx
@@ -3,17 +3,17 @@ title: Process an individual file by making a direct POST request
sidebarTitle: POST request
---
-To make POST requests to the Unstructured Platform Partition Endpoint, you will need:
+To make POST requests to the Unstructured Partition Endpoint, you will need:
import SharedAPIKeyURL from '/snippets/general-shared-text/api-key-url.mdx';
-[Get your API key](/platform-api/partition-api/overview).
+[Get your API key](/api/partition/overview).
The API URL is `https://api.unstructuredapp.io/general/v0/general`
-Let's start with a simple example in which you use [curl](https://curl.se/) to send a local PDF file (`*.pdf`) to partition via the Unstructured Platform Partition Endpoint.
+Let's start with a simple example in which you use [curl](https://curl.se/) to send a local PDF file (`*.pdf`) to partition via the Unstructured Partition Endpoint.
In this command, be sure to replace `` with the path to your local PDF file.
@@ -32,14 +32,14 @@ curl --request 'POST' \
```
In the example above we're representing the API endpoint with the environment variable `UNSTRUCTURED_API_URL`. Note, however, that you also need to authenticate yourself with
-your individual API Key, represented by the environment variable `UNSTRUCTURED_API_KEY`. Learn how to obtain an API URL and API key in the [Unstructured Platform Partition Endpoint guide](/platform-api/partition-api/overview).
+your individual API Key, represented by the environment variable `UNSTRUCTURED_API_KEY`. Learn how to obtain an API URL and API key in the [Unstructured Partition Endpoint guide](/api/partition/overview).
## Parameters & examples
-The API parameters are the same across all methods of accessing the Unstructured Platform Partition Endpoint.
+The API parameters are the same across all methods of accessing the Unstructured Partition Endpoint.
-* Refer to the [API parameters](/platform-api/partition-api/api-parameters) page for the full list of available parameters.
-* Refer to the [Examples](/platform-api/partition-api/examples) page for some inspiration on using the parameters.
+* Refer to the [API parameters](/api/partition/api-parameters) page for the full list of available parameters.
+* Refer to the [Examples](/api/partition/examples) page for some inspiration on using the parameters.
[//]: # (TODO: when we have the concepts page shared across products, link it from here for the users to learn about partition strategies, chunking strategies and other important shared concepts)
@@ -61,7 +61,7 @@ Unstructured offers a [Postman collection](https://learning.postman.com/docs/col
5. On the sidebar, click **Collections**.
6. Expand **Unstructured POST**.
-7. Click **(Platform Partition Endpoint) Basic Request**.
+7. Click **(Partition Endpoint) Basic Request**.
8. On the **Headers** tab, next to `unstructured-api-key`, enter your Unstructured API key in the **Value** column.
9. On the **Body** tab, next to `files`, click the **Select files** box in the **Value** column.
10. Click **New file from local machine**.
diff --git a/platform-api/partition-api/sdk-jsts.mdx b/api/partition/sdk-jsts.mdx
similarity index 95%
rename from platform-api/partition-api/sdk-jsts.mdx
rename to api/partition/sdk-jsts.mdx
index f5fead98..547bfc03 100644
--- a/platform-api/partition-api/sdk-jsts.mdx
+++ b/api/partition/sdk-jsts.mdx
@@ -2,10 +2,10 @@
title: JavaScript/TypeScript SDK
---
-The [Unstructured JavaScript/TypeScript SDK](https://github.com/Unstructured-IO/unstructured-js-client) client allows you to send one file at a time for processing by the Unstructured Platform Partition API.
+The [Unstructured JavaScript/TypeScript SDK](https://github.com/Unstructured-IO/unstructured-js-client) client allows you to send one file at a time for processing by the Unstructured Partition Endpoint.
To use the JavaScript/TypeScript SDK, you'll first need to set an environment variable named `UNSTRUCTURED_API_KEY`,
-representing your Unstructured API key. [Get your API key](/platform-api/partition-api/overview).
+representing your Unstructured API key. [Get your API key](/api/partition/overview).
## Installation
@@ -23,7 +23,7 @@ representing your Unstructured API key. [Get your API key](/platform-api/partiti
## Basics
- Let's start with a simple example in which you send a PDF document to the Unstructured Platform Parition Endpoint to be partitioned by Unstructured.
+ Let's start with a simple example in which you send a PDF document to the Unstructured Partition Endpoint to be partitioned by Unstructured.
The JavaScript/TypeScript SDK has the following breaking changes in v0.11.0:
@@ -286,6 +286,6 @@ The parameter names used in this document are for the JavaScript/TypeScript SDK,
convention. The Python SDK follows the `snake_case` convention. Other than this difference in naming convention,
the names used in the SDKs are the same across all methods.
-* Refer to the [API parameters](/platform-api/partition-api/api-parameters) page for the full list of available parameters.
-* Refer to the [Examples](/platform-api/partition-api/examples) page for some inspiration on using the parameters.
+* Refer to the [API parameters](/api/partition/api-parameters) page for the full list of available parameters.
+* Refer to the [Examples](/api/partition/examples) page for some inspiration on using the parameters.
diff --git a/platform-api/partition-api/sdk-python.mdx b/api/partition/sdk-python.mdx
similarity index 95%
rename from platform-api/partition-api/sdk-python.mdx
rename to api/partition/sdk-python.mdx
index 347eec8b..6553d820 100644
--- a/platform-api/partition-api/sdk-python.mdx
+++ b/api/partition/sdk-python.mdx
@@ -3,10 +3,10 @@ title: Python SDK
---
The [Unstructured Python SDK](https://github.com/Unstructured-IO/unstructured-python-client) client allows you to send one file at a time for processing by
-the [Unstructured Platform Partition Endpoint](/platform-api/partition-api/overview).
+the [Unstructured Partition Endpoint](/api/partition/overview).
To use the Python SDK, you'll first need to set an environment variable named `UNSTRUCTURED_API_KEY`,
-representing your Unstructured API key. [Get your API key](/platform-api/partition-api/overview).
+representing your Unstructured API key. [Get your API key](/api/partition/overview).
## Installation
@@ -23,7 +23,7 @@ representing your Unstructured API key. [Get your API key](/platform-api/partiti
## Basics
- Let's start with a simple example in which you send a PDF document to the Unstructured Platform Parition Endpoint to be partitioned by Unstructured.
+ Let's start with a simple example in which you send a PDF document to the Unstructured Partition Endpoint to be partitioned by Unstructured.
```python Python
import os, json
@@ -250,8 +250,8 @@ The parameter names used in this document are for the Python SDK, which follow s
convention. Other than this difference in naming convention,
the names used in the SDKs are the same across all methods.
-* Refer to the [API parameters](/platform-api/partition-api/api-parameters) page for the full list of available parameters.
-* Refer to the [Examples](/platform-api/partition-api/examples) page for some inspiration on using the parameters.
+* Refer to the [API parameters](/api/partition/api-parameters) page for the full list of available parameters.
+* Refer to the [Examples](/api/partition/examples) page for some inspiration on using the parameters.
## Migration guide
diff --git a/platform-api/partition-api/speed-up-large-files-batches.mdx b/api/partition/speed-up-large-files-batches.mdx
similarity index 82%
rename from platform-api/partition-api/speed-up-large-files-batches.mdx
rename to api/partition/speed-up-large-files-batches.mdx
index 9cd3704b..dcfedb6f 100644
--- a/platform-api/partition-api/speed-up-large-files-batches.mdx
+++ b/api/partition/speed-up-large-files-batches.mdx
@@ -4,13 +4,13 @@ title: Speed up processing of large files and batches
When you use Unstructured, here are some techniques that you can try to help speed up the processing of large files and large batches of files.
-Choose your partitioning strategy wisely. For example, if you have simple PDFs that don't have images and tables, you might be able to use the `fast` strategy. Try the `fast` strategy on a few of your documents before you try using the `hi_res` strategy. [Learn more](/platform-api/partition-api/partitioning).
+Choose your partitioning strategy wisely. For example, if you have simple PDFs that don't have images and tables, you might be able to use the `fast` strategy. Try the `fast` strategy on a few of your documents before you try using the `hi_res` strategy. [Learn more](/api/partition/partitioning).
-To speed up PDF file processing, the [Unstructured SDK for Python](/platform-api/partition-api/sdk-python) and the [Unstructured SDK for JavaScript/TypeScript](/platform-api/partition-api/sdk-jsts) provide the following parameters to help speed up processing a large PDF file:
+To speed up PDF file processing, the [Unstructured SDK for Python](/api/partition/sdk-python) and the [Unstructured SDK for JavaScript/TypeScript](/api/partition/sdk-jsts) provide the following parameters to help speed up processing a large PDF file:
- `split_pdf_page` (Python) or `splitPdfPage` (JavaScript/TypeScript), when set to true, splits the PDF file on the client side before sending it as batches to Unstructured for processing. The number of pages in each batch is determined internally. Batches can contain between 2 and 20 pages.
- `split_pdf_concurrency_level` (Python) or `splitPdfConcurrencyLevel` (JavaScript/TypeScript) is an integer that specifies the number of parallel requests. The default is 5. The maximum is 15. This behavior is ignored unless `split_pdf_page` (Python) or `splitPdfPage` (JavaScript/TypeScript) is also set to true.
- `split_pdf_allow_failed` (Python) or splitPdfAllowFailed` (JavaScript/TypeScript), when set to true, allows partitioning to continue even if some pages fail.
- `split_pdf_page_range` (Python only) is a list of two integers that specify the beginning and ending page numbers of the PDF file to be sent. A `ValueError` is raised if the specified range is not valid. This behavior is ignored unless `split_pdf_page` is also set to true.
-[Learn more](/platform-api/partition-api/sdk-python#page-splitting).
+[Learn more](/api/partition/sdk-python#page-splitting).
diff --git a/platform-api/partition-api/text-as-html.mdx b/api/partition/text-as-html.mdx
similarity index 84%
rename from platform-api/partition-api/text-as-html.mdx
rename to api/partition/text-as-html.mdx
index 82f83b70..4e4d45f6 100644
--- a/platform-api/partition-api/text-as-html.mdx
+++ b/api/partition/text-as-html.mdx
@@ -21,11 +21,11 @@ import ExtractTextAsHTMLPy from '/snippets/how-to-api/extract_text_as_html.py.md
## Code
-For the [Unstructured Python SDK](/platform-api/partition-api/sdk-python), you'll need:
+For the [Unstructured Python SDK](/api/partition/sdk-python), you'll need:
## See also
-- [Extract images and tables from documents](/platform-api/partition-api/extract-image-block-types)
+- [Extract images and tables from documents](/api/partition/extract-image-block-types)
- [Table Extraction from PDF](/examplecode/codesamples/apioss/table-extraction-from-pdf)
\ No newline at end of file
diff --git a/platform-api/partition-api/transform-schemas.mdx b/api/partition/transform-schemas.mdx
similarity index 100%
rename from platform-api/partition-api/transform-schemas.mdx
rename to api/partition/transform-schemas.mdx
diff --git a/platform-api/supported-file-types.mdx b/api/supported-file-types.mdx
similarity index 100%
rename from platform-api/supported-file-types.mdx
rename to api/supported-file-types.mdx
diff --git a/platform-api/troubleshooting/api-key-url.mdx b/api/troubleshooting/api-key-url.mdx
similarity index 76%
rename from platform-api/troubleshooting/api-key-url.mdx
rename to api/troubleshooting/api-key-url.mdx
index e47c06bc..c5f596e0 100644
--- a/platform-api/troubleshooting/api-key-url.mdx
+++ b/api/troubleshooting/api-key-url.mdx
@@ -1,11 +1,11 @@
---
-title: Troubleshooting Unstructured Platform API keys and URLs
+title: Troubleshooting Unstructured API keys and URLs
sidebarTitle: API keys and URLs
---
## Issue
-When you run script or code to call an Unstructured Platform API, you get one of the following warnings or errors:
+When you run script or code to call an Unstructured API, you get one of the following warnings or errors:
```
UserWarning: If intending to use the paid API, please define `server_url` in your request.
@@ -37,20 +37,20 @@ API error occurred: Status 404
For the API URL, note the following:
-- For the [Unstructured Platform Workflow Endpoint](/platform-api/api/overview), the API URL is typically `https://platform.unstructuredapp.io/api/v1`.
-- For the [Unstructured Platform Partition Endpoint](/platform-api/partition-api/overview), the API URL is typically `https://api.unstructuredapp.io/general/v0/general`.
+- For the [Unstructured Workflow Endpoint](/api/workflow/overview), the API URL is typically `https://platform.unstructuredapp.io/api/v1`.
+- For the [Unstructured Partition Endpoint](/api/partition/overview), the API URL is typically `https://api.unstructuredapp.io/general/v0/general`.
-For the API key, the same API key works for both the [Unstructured Platform Workflow Endpoint](/platform-api/api/overview) key or [Unstructured Platform Partition Endpoint](/platform-api/partition-api/overview). This API key is in your Unstructured account dashboard. To access your dashboard:
+For the API key, the same API key works for both the [Unstructured Workflow Endpoint](/api/workflow/overview) key or [Unstructured Partition Endpoint](/api/partition/overview). This API key is in your Unstructured account dashboard. To access your dashboard:
- 
+ 
1. Sign in to your Unstructured account, at [https://platform.unstructured.io](https://platform.unstructured.io).
2. At the bottom of the sidebar, click your user icon, and then click **Account Settings**.
3. On the **API Keys** tab, click the copy icon next to your key.
-For the API URL, note the value of the the Unstructured **Platform API URL** (for the Unstructured Platform Workflow Endpoint) or the Unstructured **Serverless API URL** (for the Unstructured Platform Partition Endpoint).
+For the API URL, note the value of the the Unstructured **API URL** (for the Unstructured Workflow Endpoint) or the Unstructured **Serverless API URL** (for the Unstructured Partition Endpoint).
- 
+ 
1. Sign in to your Unstructured account, at [https://platform.unstructured.io](https://platform.unstructured.io).
2. At the bottom of the sidebar, click your user icon, and then click **Account Settings**.
diff --git a/platform-api/api/destinations/astradb.mdx b/api/workflow/destinations/astradb.mdx
similarity index 100%
rename from platform-api/api/destinations/astradb.mdx
rename to api/workflow/destinations/astradb.mdx
diff --git a/platform-api/api/destinations/azure-ai-search.mdx b/api/workflow/destinations/azure-ai-search.mdx
similarity index 100%
rename from platform-api/api/destinations/azure-ai-search.mdx
rename to api/workflow/destinations/azure-ai-search.mdx
diff --git a/platform-api/api/destinations/couchbase.mdx b/api/workflow/destinations/couchbase.mdx
similarity index 100%
rename from platform-api/api/destinations/couchbase.mdx
rename to api/workflow/destinations/couchbase.mdx
diff --git a/platform-api/api/destinations/databricks-delta-table.mdx b/api/workflow/destinations/databricks-delta-table.mdx
similarity index 88%
rename from platform-api/api/destinations/databricks-delta-table.mdx
rename to api/workflow/destinations/databricks-delta-table.mdx
index 6cfb46da..8c512a12 100644
--- a/platform-api/api/destinations/databricks-delta-table.mdx
+++ b/api/workflow/destinations/databricks-delta-table.mdx
@@ -6,10 +6,10 @@ title: Delta Tables in Databricks
This article covers connecting Unstructured to Delta Tables in Databricks.
For information about connecting Unstructured to Delta Tables in Amazon S3 instead, see
- [Delta Tables in Amazon S3](/platform-api/api/destinations/delta-table).
+ [Delta Tables in Amazon S3](/api/workflow/destinations/delta-table).
For information about connecting Unstructured to Databricks Volumes instead, see
- [Databricks Volumes](/platform-api/api/destinations/databricks-volumes).
+ [Databricks Volumes](/api/workflow/destinations/databricks-volumes).
Send processed data from Unstructured to a Delta Table in Databricks.
diff --git a/platform-api/api/destinations/databricks-volumes.mdx b/api/workflow/destinations/databricks-volumes.mdx
similarity index 92%
rename from platform-api/api/destinations/databricks-volumes.mdx
rename to api/workflow/destinations/databricks-volumes.mdx
index 87ae3362..7170de5e 100644
--- a/platform-api/api/destinations/databricks-volumes.mdx
+++ b/api/workflow/destinations/databricks-volumes.mdx
@@ -6,7 +6,7 @@ title: Databricks Volumes
This article covers connecting Unstructured to Databricks Volumes.
For information about connecting Unstructured to Delta Tables in Databricks instead, see
- [Delta Tables in Databricks](/platform-api/api/destinations/databricks-delta-table).
+ [Delta Tables in Databricks](/api/workflow/destinations/databricks-delta-table).
Send processed data from Unstructured to Databricks Volumes.
diff --git a/platform-api/api/destinations/delta-table.mdx b/api/workflow/destinations/delta-table.mdx
similarity index 91%
rename from platform-api/api/destinations/delta-table.mdx
rename to api/workflow/destinations/delta-table.mdx
index ac968bd7..78e7eb42 100644
--- a/platform-api/api/destinations/delta-table.mdx
+++ b/api/workflow/destinations/delta-table.mdx
@@ -5,7 +5,7 @@ title: Delta Tables in Amazon S3
This article covers connecting Unstructured to Delta Tables in Amazon S3. For information about
connecting Unstructured to Delta Tables in Databricks instead, see
- [Delta Tables in Databricks](/platform-api/api/destinations/databricks-delta-table).
+ [Delta Tables in Databricks](/api/workflow/destinations/databricks-delta-table).
Send processed data from Unstructured to a Delta Table, stored in Amazon S3.
diff --git a/platform-api/api/destinations/elasticsearch.mdx b/api/workflow/destinations/elasticsearch.mdx
similarity index 100%
rename from platform-api/api/destinations/elasticsearch.mdx
rename to api/workflow/destinations/elasticsearch.mdx
diff --git a/platform-api/api/destinations/google-cloud.mdx b/api/workflow/destinations/google-cloud.mdx
similarity index 100%
rename from platform-api/api/destinations/google-cloud.mdx
rename to api/workflow/destinations/google-cloud.mdx
diff --git a/platform-api/api/destinations/kafka.mdx b/api/workflow/destinations/kafka.mdx
similarity index 100%
rename from platform-api/api/destinations/kafka.mdx
rename to api/workflow/destinations/kafka.mdx
diff --git a/platform-api/api/destinations/milvus.mdx b/api/workflow/destinations/milvus.mdx
similarity index 100%
rename from platform-api/api/destinations/milvus.mdx
rename to api/workflow/destinations/milvus.mdx
diff --git a/platform-api/api/destinations/mongodb.mdx b/api/workflow/destinations/mongodb.mdx
similarity index 100%
rename from platform-api/api/destinations/mongodb.mdx
rename to api/workflow/destinations/mongodb.mdx
diff --git a/platform-api/api/destinations/motherduck.mdx b/api/workflow/destinations/motherduck.mdx
similarity index 100%
rename from platform-api/api/destinations/motherduck.mdx
rename to api/workflow/destinations/motherduck.mdx
diff --git a/platform-api/api/destinations/neo4j.mdx b/api/workflow/destinations/neo4j.mdx
similarity index 100%
rename from platform-api/api/destinations/neo4j.mdx
rename to api/workflow/destinations/neo4j.mdx
diff --git a/platform-api/api/destinations/onedrive.mdx b/api/workflow/destinations/onedrive.mdx
similarity index 100%
rename from platform-api/api/destinations/onedrive.mdx
rename to api/workflow/destinations/onedrive.mdx
diff --git a/api/workflow/destinations/overview.mdx b/api/workflow/destinations/overview.mdx
new file mode 100644
index 00000000..64d296a0
--- /dev/null
+++ b/api/workflow/destinations/overview.mdx
@@ -0,0 +1,42 @@
+---
+title: Overview
+---
+
+To use the [Unstructured Workflow Endpoint](/api/workflow/overview) to manage destination connectors, do the following:
+
+- To get a list of available destination connectors, use the `UnstructuredClient` object's `destinations.list_destinations` function (for the Python SDK) or
+ the `GET` method to call the `/destinations` endpoint (for `curl` or Postman).. [Learn more](/api/workflow/overview#list-destination-connectors).
+- To get information about a destination connector, use the `UnstructuredClient` object's `destinations.get_destination` function (for the Python SDK) or
+ the `GET` method to call the `/destinations/` endpoint (for `curl` or Postman). [Learn more](/api/workflow/overview#get-a-destination-connector).
+- To create a destination connector, use the `UnstructuredClient` object's `destinations.create_destination` function (for the Python SDK) or
+ the `POST` method to call the `/destinations` endpoint (for `curl` or Postman). [Learn more](/api/workflow/overview#create-a-destination-connector).
+- To update a destination connector, use the `UnstructuredClient` object's `destinations.update_destination` function (for the Python SDK) or
+ the `PUT` method to call the `/destinations/` endpoint (for `curl` or Postman). [Learn more](/api/workflow/overview#update-a-destination-connector).
+- To delete a destination connector, use the `UnstructuredClient` object's `destinations.delete_destination` function (for the Python SDK) or
+ the `DELETE` method to call the `/destinations/` endpoint (for `curl` or Postman). [Learn more](/api/workflow/overview#delete-a-destination-connector).
+
+To create or update a destination connector, you must also provide settings that are specific to that connector.
+For the list of specific settings, see:
+
+- [Astra DB](/api/workflow/destinations/astradb) (`ASTRADB` for the Python SDK or `astradb` for `curl` or Postman)
+- [Azure AI Search](/api/workflow/destinations/azure-ai-search) (`AZURE_AI_SEARCH` for the Python SDK or `azure_ai_search` for `curl` or Postman)
+- [Couchbase](/api/workflow/destinations/couchbase) (`COUCHBASE` for the Python SDK or `couchbase` for `curl` or Postman)
+- [Databricks Volumes](/api/workflow/destinations/databricks-volumes) (`DATABRICKS_VOLUMES` for the Python SDK or `databricks_volumes` for `curl` or Postman)
+- [Delta Tables in Amazon S3](/api/workflow/destinations/delta-table) (`DELTA_TABLE` for the Python SDK or `delta_table` for `curl` or Postman)
+- [Delta Tables in Databricks](/api/workflow/destinations/databricks-delta-table) (`DATABRICKS_VOLUME_DELTA_TABLES` for the Python SDK or `databricks_volume_delta_tables` for `curl` or Postman)
+- [Elasticsearch](/api/workflow/destinations/elasticsearch) (`ELASTICSEARCH` for the Python SDK or `elasticsearch` for `curl` or Postman)
+- [Google Cloud Storage](/api/workflow/destinations/google-cloud) (`GCS` for the Python SDK or `gcs` for `curl` or Postman)
+- [Kafka](/api/workflow/destinations/kafka) (`KAFKA_CLOUD` for the Python SDK or `kafka-cloud` for `curl` or Postman)
+- [Milvus](/api/workflow/destinations/milvus) (`MILVUS` for the Python SDK or `milvus` for `curl` or Postman)
+- [MongoDB](/api/workflow/destinations/mongodb) (`MONGODB` for the Python SDK or `mongodb` for `curl` or Postman)
+- [MotherDuck](/api/workflow/destinations/motherduck) (`MOTHERDUCK` for the Python SDK or `motherduck` for `curl` or Postman)
+- [Neo4j](/api/workflow/destinations/neo4j) (`NEO4J` for the Python SDK or `neo4j` for `curl` or Postman)
+- [OneDrive](/api/workflow/destinations/onedrive) (`ONEDRIVE` for the Python SDK or `onedrive` for `curl` or Postman)
+- [Pinecone](/api/workflow/destinations/pinecone) (`PINECONE` for the Python SDK or `pinecone` for `curl` or Postman)
+- [PostgreSQL](/api/workflow/destinations/postgresql) (`POSTGRES` for the Python SDK or `postgres` for `curl` or Postman)
+- [Qdrant](/api/workflow/destinations/qdrant) (`QDRANT_CLOUD` for the Python SDK or `qdrant-cloud` for `curl` or Postman)
+- [Redis](/api/workflow/destinations/redis) (`REDIS` for the Python SDK or `redis` for `curl` or Postman)
+- [Snowflake](/api/workflow/destinations/snowflake) (`SNOWFLAKE` for the Python SDK or `snowflake` for `curl` or Postman)
+- [S3](/api/workflow/destinations/s3) (`S3` for the Python SDK or `s3` for `curl` or Postman)
+- [Weaviate](/api/workflow/destinations/weaviate) (`WEAVIATE` for the Python SDK or `weaviate` for `curl` or Postman)
+
diff --git a/platform-api/api/destinations/pinecone.mdx b/api/workflow/destinations/pinecone.mdx
similarity index 100%
rename from platform-api/api/destinations/pinecone.mdx
rename to api/workflow/destinations/pinecone.mdx
diff --git a/platform-api/api/destinations/postgresql.mdx b/api/workflow/destinations/postgresql.mdx
similarity index 100%
rename from platform-api/api/destinations/postgresql.mdx
rename to api/workflow/destinations/postgresql.mdx
diff --git a/platform-api/api/destinations/qdrant.mdx b/api/workflow/destinations/qdrant.mdx
similarity index 100%
rename from platform-api/api/destinations/qdrant.mdx
rename to api/workflow/destinations/qdrant.mdx
diff --git a/platform-api/api/destinations/redis.mdx b/api/workflow/destinations/redis.mdx
similarity index 100%
rename from platform-api/api/destinations/redis.mdx
rename to api/workflow/destinations/redis.mdx
diff --git a/platform-api/api/destinations/s3.mdx b/api/workflow/destinations/s3.mdx
similarity index 100%
rename from platform-api/api/destinations/s3.mdx
rename to api/workflow/destinations/s3.mdx
diff --git a/platform-api/api/destinations/snowflake.mdx b/api/workflow/destinations/snowflake.mdx
similarity index 100%
rename from platform-api/api/destinations/snowflake.mdx
rename to api/workflow/destinations/snowflake.mdx
diff --git a/platform-api/api/destinations/weaviate.mdx b/api/workflow/destinations/weaviate.mdx
similarity index 100%
rename from platform-api/api/destinations/weaviate.mdx
rename to api/workflow/destinations/weaviate.mdx
diff --git a/platform-api/api/jobs.mdx b/api/workflow/jobs.mdx
similarity index 59%
rename from platform-api/api/jobs.mdx
rename to api/workflow/jobs.mdx
index 2e065d14..5ddd8fdc 100644
--- a/platform-api/api/jobs.mdx
+++ b/api/workflow/jobs.mdx
@@ -2,13 +2,13 @@
title: Jobs
---
-To use the [Unstructured Platform Workflow Endpoint](/platform-api/api/overview) to manage jobs, do the following:
+To use the [Unstructured Workflow Endpoint](/api/workflow/overview) to manage jobs, do the following:
- To get a list of available jobs, use the `UnstructuredClient` object's `jobs.list_jobs` function (for the Python SDK) or
- the `GET` method to call the `/jobs` endpoint (for `curl` or Postman). [Learn more](/platform-api/api/overview#list-jobs).
+ the `GET` method to call the `/jobs` endpoint (for `curl` or Postman). [Learn more](/api/workflow/overview#list-jobs).
- To get information about a job, use the `UnstructuredClient` object's `jobs.get_job` function (for the Python SDK) or
- the `GET` method to call the `/jobs/` endpoint (for `curl` or Postman). [Learn more](/platform-api/api/overview#get-a-job).
-- A job is created automatically whenever a workflow runs on a schedule; see [Create a workflow](/platform-api/api/workflows#create-a-workflow).
- A job is also created whenever you run a workflow manually; see [Run a workflow](/platform-api/api/overview#run-a-workflow).
+ the `GET` method to call the `/jobs/` endpoint (for `curl` or Postman). [Learn more](/api/workflow/overview#get-a-job).
+- A job is created automatically whenever a workflow runs on a schedule; see [Create a workflow](/api/workflow/workflows#create-a-workflow).
+ A job is also created whenever you run a workflow manually; see [Run a workflow](/api/workflow/overview#run-a-workflow).
- To cancel a running job, use the `UnstructuredClient` object's `jobs.cancel_job` function (for the Python SDK) or
- the `POST` method to call the `/jobs//cancel` endpoint (for `curl` or Postman). [Learn more](/platform-api/api/overview#cancel-a-job).
\ No newline at end of file
+ the `POST` method to call the `/jobs//cancel` endpoint (for `curl` or Postman). [Learn more](/api/workflow/overview#cancel-a-job).
\ No newline at end of file
diff --git a/platform-api/api/overview.mdx b/api/workflow/overview.mdx
similarity index 96%
rename from platform-api/api/overview.mdx
rename to api/workflow/overview.mdx
index 4ecee2f4..decde5ef 100644
--- a/platform-api/api/overview.mdx
+++ b/api/workflow/overview.mdx
@@ -2,20 +2,20 @@
title: Overview
---
-The [Unstructured Platform UI](/platform/overview) features a no-code user interface for transforming your unstructured data into data that is ready
+The [Unstructured UI](/ui/overview) features a no-code user interface for transforming your unstructured data into data that is ready
for Retrieval Augmented Generation (RAG).
-The Unstructured Platform Workflow Endpoint, part of the [Unstructured Platform API](/platform-api/overview), enables a full range of partitioning, chunking, embedding, and
+The Unstructured Workflow Endpoint, part of the [Unstructured API](/api/overview), enables a full range of partitioning, chunking, embedding, and
enrichment options for your files and data. It is designed to batch-process files and data in remote locations; send processed results to
various storage, databases, and vector stores; and use the latest and highest-performing models on the market today. It has built-in logic
to deliver the highest quality results at the lowest cost.
-This page provides an overview of the Unstructured Platform Workflow Endpoint. This endpoint enables Unstructured Platform UI automation usage
+This page provides an overview of the Unstructured Workflow Endpoint. This endpoint enables Unstructured UI automation usage
scenarios as well as for documentation, reporting, and recovery needs.
## Getting started
-Choose one of the following options to get started with the Unstructured Platform Workflow Endpoint:
+Choose one of the following options to get started with the Unstructured Workflow Endpoint:
- Follow the [quickstart](#quickstart), which uses the Unstructured Python SDK from a remote hosted Google Collab notebook.
- Start using the [Unstructred Python SDK](#unstructured-python-sdk).
@@ -30,7 +30,7 @@ import SharedPlatformAPI from '/snippets/quickstarts/platform-api.mdx';
## Unstructured Python SDK
The [Unstructured Python SDK](https://github.com/Unstructured-IO/unstructured-python-client), beginning with version 0.30.6,
-allows you to call the Unstructured Platform Workflow Endpoint through standard Python code.
+allows you to call the Unstructured Workflow Endpoint through standard Python code.
To install the Unstructured Python SDK, run the following command from within your Python virtual environment:
@@ -62,7 +62,7 @@ To get your Unstructured API key, do the following:
5. Click the **Copy** icon for your new API key. The API key's value is copied to your system's clipboard.
Calls made by the Unstructured Python SDK's `unstructured_client` functions for creating, listing, updating,
-and deleting connectors, workflows, and jobs in the Unstructured Platform UI all use the Unstructured Platform Workflow Endpoint URL (`https://platform.unstructuredapp.io/api/v1`) by default. You do not need to
+and deleting connectors, workflows, and jobs in the Unstructured UI all use the Unstructured Workflow Endpoint URL (`https://platform.unstructuredapp.io/api/v1`) by default. You do not need to
use the `server_url` parameter to specify this API URL in your Python code for these particular functions.
@@ -74,8 +74,8 @@ use the `server_url` parameter to specify this API URL in your Python code for t
To specify an API URL in your code, set the `server_url` parameter in the `UnstructuredClient` constructor to the target API URL.
-The Unstructured Platform Workflow Endpoint enables you to work with [connectors](#connectors),
-[workflows](#workflows), and [jobs](#jobs) in the Unstructured Platform UI.
+The Unstructured Workflow Endpoint enables you to work with [connectors](#connectors),
+[workflows](#workflows), and [jobs](#jobs) in the Unstructured UI.
- A _source connector_ ingests files or data into Unstructured from a source location.
- A _destination connector_ sends the processed data from Unstructured to a destination location.
@@ -84,9 +84,9 @@ The Unstructured Platform Workflow Endpoint enables you to work with [connectors
For general information about these objects, see:
-- [Connectors](/platform/connectors)
-- [Workflows](/platform/workflows)
-- [Jobs](/platform/jobs)
+- [Connectors](/ui/connectors)
+- [Workflows](/ui/workflows)
+- [Jobs](/ui/jobs)
Skip ahead to start learning about how to use the Unstructured Python SDK to work with
[connectors](#connectors),
@@ -94,13 +94,13 @@ Skip ahead to start learning about how to use the Unstructured Python SDK to wor
## REST endpoints
-The Unstructured Platform Workflow Endpoint is callable from a set of Representational State Transfer (REST) endpoints, which you can call through standard REST-enabled
-utilities, tools, programming languages, packages, and libraries. The examples, shown later on this page and on related pages, describe how to call the Unstructured Platform Workflow Endpoint with
+The Unstructured Workflow Endpoint is callable from a set of Representational State Transfer (REST) endpoints, which you can call through standard REST-enabled
+utilities, tools, programming languages, packages, and libraries. The examples, shown later on this page and on related pages, describe how to call the Unstructured Workflow Endpoint with
`curl` and Postman. You can adapt this information as needed for your preferred programming languages and libraries, for example by using the
`requests` library with Python.
- You can also use the [Unstructured Platform Workflow Endpoint - Swagger UI](https://platform.unstructuredapp.io/docs) to call the REST endpoints
+ You can also use the [Unstructured Workflow Endpoint - Swagger UI](https://platform.unstructuredapp.io/docs) to call the REST endpoints
that are available through `https://platform.unstructuredapp.io`. To use the Swagger UI, you must provide your Unstructured API key with each call. To
get this API key, see the [quickstart](#quickstart), earlier on this page.
@@ -168,8 +168,8 @@ To get your Unstructured API key, do the following:
API URL throughout the following examples.
-The Unstructured Platform Workflow Endpoint enables you to work with [connectors](#connectors),
-[workflows](#workflows), and [jobs](#jobs) in the Unstructured Platform UI.
+The Unstructured Workflow Endpoint enables you to work with [connectors](#connectors),
+[workflows](#workflows), and [jobs](#jobs) in the Unstructured UI.
- A _source connector_ ingests files or data into Unstructured from a source location.
- A _destination connector_ sends the processed data from Unstructured to a destination location.
@@ -178,9 +178,9 @@ The Unstructured Platform Workflow Endpoint enables you to work with [connectors
For general information about these objects, see:
-- [Connectors](/platform/connectors)
-- [Workflows](/platform/workflows)
-- [Jobs](/platform/jobs)
+- [Connectors](/ui/connectors)
+- [Workflows](/ui/workflows)
+- [Jobs](/ui/jobs)
Skip ahead to start learning about how to use the REST endpoints to work with
[connectors](#connectors),
@@ -188,15 +188,15 @@ Skip ahead to start learning about how to use the REST endpoints to work with
## Restrictions
-The following Unstructured SDKs, tools, and libraries do _not_ work with the Unstructured Platform Workflow Endpoint:
+The following Unstructured SDKs, tools, and libraries do _not_ work with the Unstructured Workflow Endpoint:
-- The [Unstructured JavaScript/TypeScript SDK](/platform-api/partition-api/sdk-jsts)
-- [Local single-file POST requests](/platform-api/partition-api/sdk-jsts) to the Unstructured Platform Partition Endpoint
+- The [Unstructured JavaScript/TypeScript SDK](/api/partition/sdk-jsts)
+- [Local single-file POST requests](/api/partition/sdk-jsts) to the Unstructured Partition Endpoint
- The [Unstructured open source Python library](/open-source/introduction/overview)
- The [Unstructued Ingest CLI](/ingestion/ingest-cli)
- The [Unstructured Ingest Python library](/ingestion/python-ingest)
-The following Unstructured API URL is also _not_ supported: `https://api.unstructuredapp.io/general/v0/general` (the Unstructured Platform Partition Endpoint URL).
+The following Unstructured API URL is also _not_ supported: `https://api.unstructuredapp.io/general/v0/general` (the Unstructured Partition Endpoint URL).
## Connectors
@@ -211,7 +211,7 @@ You can also [list](#list-destination-connectors),
[update](#update-a-destination-connector),
and [delete](#delete-a-destination-connector) destination connectors.
-For general information, see [Connectors](/platform/connectors).
+For general information, see [Connectors](/ui/connectors).
### List source connectors
@@ -222,7 +222,7 @@ To filter the list of source connectors, use the `ListSourcesRequest` object's `
or the query parameter `source_type=` (for `curl` or Postman),
replacing `` with the source connector type's unique ID
(for example, for the Amazon S3 source connector type, `S3` for the Python SDK or `s3` for `curl` or Postman).
-To get this ID, see [Sources](/platform-api/api/sources/overview).
+To get this ID, see [Sources](/api/workflow/sources/overview).
@@ -418,10 +418,10 @@ the `POST` method to call the `/sources` endpoint (for `curl` or Postman).
In the `CreateSourceConnector` object (for the Python SDK) or
the request body (for `curl` or Postman),
specify the settings for the connector. For the specific settings to include, which differ by connector, see
-[Sources](/platform-api/api/sources/overview).
+[Sources](/api/workflow/sources/overview).
For the Python SDK, replace `` with the source connector type's unique ID (for example, for the Amazon S3 source connector type, `S3`).
-To get this ID, see [Sources](/platform-api/api/sources/overview).
+To get this ID, see [Sources](/api/workflow/sources/overview).
@@ -547,10 +547,10 @@ the `PUT` method to call the `/sources/` endpoint (for `curl` or P
In the `UpdateSourceConnector` object (for the Python SDK) or
the request body (for `curl` or Postman), specify the settings for the connector. For the specific settings to include, which differ by connector, see
-[Sources](/platform-api/api/sources/overview).
+[Sources](/api/workflow/sources/overview).
For the Python SDK, replace `` with the source connector type's unique ID (for example, for the Amazon S3 source connector type, `S3`).
-To get this ID, see [Sources](/platform-api/api/sources/overview).
+To get this ID, see [Sources](/api/workflow/sources/overview).
You must specify all of the settings for the connector, even for settings that are not changing.
@@ -753,7 +753,7 @@ To filter the list of destination connectors, use the `ListDestinationsRequest`
the query parameter `destination_type=` (for `curl` or Postman),
replacing `` with the destination connector type's unique ID
(for example, for the Amazon S3 source connector type, `S3` for the Python SDK or `s3` for `curl` or Postman).
-To get this ID, see [Destinations](/platform-api/api/destinations/overview).
+To get this ID, see [Destinations](/api/workflow/destinations/overview).
@@ -948,10 +948,10 @@ the `POST` method to call the `/destinations` endpoint (for `curl` or Postman).
In the `CreateDestinationConnector` object (for the Python SDK) or
the request body (for `curl` or Postman),
specify the settings for the connector. For the specific settings to include, which differ by connector, see
-[Destinations](/platform-api/api/destinations/overview).
+[Destinations](/api/workflow/destinations/overview).
For the Python SDK, replace `` with the destination connector type's unique ID (for example, for the Amazon S3 source connector type, `S3`).
-To get this ID, see [Destinations](/platform-api/api/destinations/overview).
+To get this ID, see [Destinations](/api/workflow/destinations/overview).
@@ -1076,7 +1076,7 @@ the `PUT` method to call the `/destinations/` endpoint (for `curl`
In the `UpdateDestinationConnector` object (for the Python SDK) or
the request body (for `curl` or Postman), specify the settings for the connector. For the specific settings to include, which differ by connector, see
-[Destinations](/platform-api/api/destinations/overview).
+[Destinations](/api/workflow/destinations/overview).
You must specify all of the settings for the connector, even for settings that are not changing.
@@ -1278,7 +1278,7 @@ You can [list](#list-workflows),
[update](#update-a-workflow),
and [delete](#delete-a-workflow) workflows.
-For general information, see [Workflows](/platform/workflows).
+For general information, see [Workflows](/ui/workflows).
### List workflows
@@ -1541,7 +1541,7 @@ the `POST` method to call the `/workflows` endpoint (for `curl` or Postman).
In the `CreateWorkflow` object (for the Python SDK) or
the request body (for `curl` or Postman),
specify the settings for the workflow. For the specific settings to include, see
-[Create a workflow](/platform-api/api/workflows#create-a-workflow).
+[Create a workflow](/api/workflow/workflows#create-a-workflow).
@@ -1757,7 +1757,7 @@ the `POST` method to call the `/workflows//run` endpoint (for `curl
To run a workflow on a schedule instead, specify the `schedule` setting in the request body when you create or update a
-workflow. See [Create a workflow](/platform-api/api/workflows#create-a-workflow) or [Update a workflow](/platform-api/api/workflows#update-a-workflow).
+workflow. See [Create a workflow](/api/workflow/workflows#create-a-workflow) or [Update a workflow](/api/workflow/workflows#update-a-workflow).
### Update a workflow
@@ -1767,7 +1767,7 @@ the `PUT` method to call the `/workflows/` endpoint (for `curl` or
In `UpdateWorkflow` object (for the Python SDK) or
the request body (for `curl` or Postman), specify the settings for the workflow. For the specific settings to include, see
-[Update a workflow](/platform-api/api/workflows#update-a-workflow).
+[Update a workflow](/api/workflow/workflows#update-a-workflow).
@@ -1993,7 +1993,7 @@ and [cancel](#cancel-a-job) jobs.
A job is created automatically whenever a workflow runs on a schedule; see [Create a workflow](#create-a-workflow).
A job is also created whenever you run a workflow; see [Run a workflow](#run-a-workflow).
-For general information, see [Jobs](/platform/jobs).
+For general information, see [Jobs](/ui/jobs).
### List jobs
diff --git a/platform-api/api/sources/azure-blob-storage.mdx b/api/workflow/sources/azure-blob-storage.mdx
similarity index 100%
rename from platform-api/api/sources/azure-blob-storage.mdx
rename to api/workflow/sources/azure-blob-storage.mdx
diff --git a/platform-api/api/sources/box.mdx b/api/workflow/sources/box.mdx
similarity index 100%
rename from platform-api/api/sources/box.mdx
rename to api/workflow/sources/box.mdx
diff --git a/platform-api/api/sources/confluence.mdx b/api/workflow/sources/confluence.mdx
similarity index 100%
rename from platform-api/api/sources/confluence.mdx
rename to api/workflow/sources/confluence.mdx
diff --git a/platform-api/api/sources/couchbase.mdx b/api/workflow/sources/couchbase.mdx
similarity index 100%
rename from platform-api/api/sources/couchbase.mdx
rename to api/workflow/sources/couchbase.mdx
diff --git a/platform-api/api/sources/databricks-volumes.mdx b/api/workflow/sources/databricks-volumes.mdx
similarity index 100%
rename from platform-api/api/sources/databricks-volumes.mdx
rename to api/workflow/sources/databricks-volumes.mdx
diff --git a/platform-api/api/sources/dropbox.mdx b/api/workflow/sources/dropbox.mdx
similarity index 100%
rename from platform-api/api/sources/dropbox.mdx
rename to api/workflow/sources/dropbox.mdx
diff --git a/platform-api/api/sources/elasticsearch.mdx b/api/workflow/sources/elasticsearch.mdx
similarity index 100%
rename from platform-api/api/sources/elasticsearch.mdx
rename to api/workflow/sources/elasticsearch.mdx
diff --git a/platform-api/api/sources/google-cloud.mdx b/api/workflow/sources/google-cloud.mdx
similarity index 100%
rename from platform-api/api/sources/google-cloud.mdx
rename to api/workflow/sources/google-cloud.mdx
diff --git a/platform-api/api/sources/google-drive.mdx b/api/workflow/sources/google-drive.mdx
similarity index 100%
rename from platform-api/api/sources/google-drive.mdx
rename to api/workflow/sources/google-drive.mdx
diff --git a/platform-api/api/sources/kafka.mdx b/api/workflow/sources/kafka.mdx
similarity index 100%
rename from platform-api/api/sources/kafka.mdx
rename to api/workflow/sources/kafka.mdx
diff --git a/platform-api/api/sources/mongodb.mdx b/api/workflow/sources/mongodb.mdx
similarity index 100%
rename from platform-api/api/sources/mongodb.mdx
rename to api/workflow/sources/mongodb.mdx
diff --git a/platform-api/api/sources/onedrive.mdx b/api/workflow/sources/onedrive.mdx
similarity index 100%
rename from platform-api/api/sources/onedrive.mdx
rename to api/workflow/sources/onedrive.mdx
diff --git a/platform-api/api/sources/outlook.mdx b/api/workflow/sources/outlook.mdx
similarity index 100%
rename from platform-api/api/sources/outlook.mdx
rename to api/workflow/sources/outlook.mdx
diff --git a/api/workflow/sources/overview.mdx b/api/workflow/sources/overview.mdx
new file mode 100644
index 00000000..bbee8b47
--- /dev/null
+++ b/api/workflow/sources/overview.mdx
@@ -0,0 +1,40 @@
+---
+title: Overview
+---
+
+To use the [Unstructured Workflow Endpoint](/api/workflow/overview) to manage source connectors, do the following:
+
+- To get a list of available source connectors, use the `UnstructuredClient` object's `sources.list_sources` function (for the Python SDK) or
+ the `GET` method to call the `/sources` endpoint (for `curl` or Postman). [Learn more](/api/workflow/overview#list-source-connectors).
+- To get information about a source connector, use the `UnstructuredClient` object's `sources.get_source` function (for the Python SDK) or
+ the `GET` method to call the `/sources/` endpoint (for `curl` or Postman). [Learn more](/api/workflow/overview#get-a-source-connector).
+- To create a source connector, use the `UnstructuredClient` object's `sources.create_source` function (for the Python SDK) or
+ the `POST` method to call the `/sources` endpoint (for `curl` or Postman). [Learn more](/api/workflow/overview#create-a-source-connector).
+- To update a source connector, use the `UnstructuredClient` object's `sources.update_source` function (for the Python SDK) or
+ the `PUT` method to call the `/sources/` endpoint (for `curl` or Postman). [Learn more](/api/workflow/overview#update-a-source-connector).
+- To delete a source connector, use the `UnstructuredClient` object's `sources.delete_source` function (for the Python SDK) or
+ the `DELETE` method to call the `/sources/` endpoint (for `curl` or Postman). [Learn more](/api/workflow/overview#delete-a-source-connector).
+
+To create or update a source connector, you must also provide settings that are specific to that connector.
+For the list of specific settings, see:
+
+- [Azure](/api/workflow/sources/azure-blob-storage) (`AZURE` for the Python SDK or `azure` for `curl` and Postman)
+- [Box](/api/workflow/sources/box) (`BOX` for the Python SDK or `box` for `curl` and Postman)
+- [Confluence](/api/workflow/sources/confluence) (`CONFLUENCE` for the Python SDK or `confluence` for `curl` and Postman)
+- [Couchbase](/api/workflow/sources/couchbase) (`COUCHBASE` for the Python SDK or `couchbase` for `curl` and Postman)
+- [Databricks Volumes](/api/workflow/sources/databricks-volumes) (`DATABRICKS_VOLUMES` for the Python SDK or `databricks_volumes` for `curl` and Postman)
+- [Dropbox](/api/workflow/sources/dropbox) (`DROPBOX` for the Python SDK or `dropbox` for `curl` and Postman)
+- [Elasticsearch](/api/workflow/sources/elasticsearch) (`ELASTICSEARCH` for the Python SDK or `elasticsearch` for `curl` and Postman)
+- [Google Cloud Storage](/api/workflow/sources/google-cloud) (`GCS` for the Python SDK or `gcs` for `curl` and Postman)
+- [Google Drive](/api/workflow/sources/google-drive) (`GOOGLE_DRIVE` for the Python SDK or `google_drive` for `curl` and Postman)
+- [Kafka](/api/workflow/sources/kafka) (`KAFKA_CLOUD` for the Python SDK or `kafka-cloud` for `curl` and Postman)
+- [MongoDB](/api/workflow/sources/mongodb) (`MONGODB` for the Python SDK or `mongodb` for `curl` and Postman)
+- [OneDrive](/api/workflow/sources/onedrive) (`ONEDRIVE` for the Python SDK or `onedrive` for `curl` and Postman)
+- [Outlook](/api/workflow/sources/outlook) (`OUTLOOK` for the Python SDK or `outlook` for `curl` and Postman)
+- [PostgreSQL](/api/workflow/sources/postgresql) (`POSTGRES` for the Python SDK or `postgres` for `curl` and Postman)
+- [S3](/api/workflow/sources/s3) (`S3` for the Python SDK or `s3` for `curl` and Postman)
+- [Salesforce](/api/workflow/sources/salesforce) (`SALESFORCE` for the Python SDK or `salesforce` for `curl` and Postman)
+- [SharePoint](/api/workflow/sources/sharepoint) (`SHAREPOINT` for the Python SDK or `sharepoint` for `curl` and Postman)
+- [Snowflake](/api/workflow/sources/snowflake) (`SNOWFLAKE` for the Python SDK or `snowflake` for `curl` and Postman)
+
+
diff --git a/platform-api/api/sources/postgresql.mdx b/api/workflow/sources/postgresql.mdx
similarity index 100%
rename from platform-api/api/sources/postgresql.mdx
rename to api/workflow/sources/postgresql.mdx
diff --git a/platform-api/api/sources/s3.mdx b/api/workflow/sources/s3.mdx
similarity index 100%
rename from platform-api/api/sources/s3.mdx
rename to api/workflow/sources/s3.mdx
diff --git a/platform-api/api/sources/salesforce.mdx b/api/workflow/sources/salesforce.mdx
similarity index 100%
rename from platform-api/api/sources/salesforce.mdx
rename to api/workflow/sources/salesforce.mdx
diff --git a/platform-api/api/sources/sharepoint.mdx b/api/workflow/sources/sharepoint.mdx
similarity index 100%
rename from platform-api/api/sources/sharepoint.mdx
rename to api/workflow/sources/sharepoint.mdx
diff --git a/platform-api/api/sources/snowflake.mdx b/api/workflow/sources/snowflake.mdx
similarity index 100%
rename from platform-api/api/sources/snowflake.mdx
rename to api/workflow/sources/snowflake.mdx
diff --git a/platform-api/api/workflows.mdx b/api/workflow/workflows.mdx
similarity index 96%
rename from platform-api/api/workflows.mdx
rename to api/workflow/workflows.mdx
index 16f86492..cd9bd1e5 100644
--- a/platform-api/api/workflows.mdx
+++ b/api/workflow/workflows.mdx
@@ -2,23 +2,23 @@
title: Workflows
---
-To use the [Unstructured Platform Workflow Endpoint](/platform-api/api/overview) to manage workflows, do the following:
+To use the [Unstructured Workflow Endpoint](/api/workflow/overview) to manage workflows, do the following:
- To get a list of available workflows, use the `UnstructuredClient` object's `workflows.list_workflows` function (for the Python SDK) or
- the `GET` method to call the `/workflows` endpoint (for `curl` or Postman). [Learn more](/platform-api/api/overview#list-workflows).
+ the `GET` method to call the `/workflows` endpoint (for `curl` or Postman). [Learn more](/api/workflow/overview#list-workflows).
- To get information about a workflow, use the `UnstructuredClient` object's `workflows.get_workflow` function (for the Python SDK) or
- the `GET` method to call the `/workflows/` endpoint (for `curl` or Postman)use the `GET` method to call the `/workflows/` endpoint. [Learn more](/platform-api/api/overview#get-a-workflow).
+ the `GET` method to call the `/workflows/` endpoint (for `curl` or Postman)use the `GET` method to call the `/workflows/` endpoint. [Learn more](/api/workflow/overview#get-a-workflow).
- To create a workflow, use the `UnstructuredClient` object's `workflows.create_workflow` function (for the Python SDK) or
the `POST` method to call the `/workflows` endpoint (for `curl` or Postman). [Learn more](#create-a-workflow).
- To run a workflow manually, use the `UnstructuredClient` object's `workflows.run_workflow` function (for the Python SDK) or
- the `POST` method to call the `/workflows//run` endpoint (for `curl` or Postman). [Learn more](/platform-api/api/overview#run-a-workflow).
+ the `POST` method to call the `/workflows//run` endpoint (for `curl` or Postman). [Learn more](/api/workflow/overview#run-a-workflow).
- To update a workflow, use the `UnstructuredClient` object's `workflows.update_workflow` function (for the Python SDK) or
the `PUT` method to call the `/workflows/` endpoint (for `curl` or Postman). [Learn more](#update-a-workflow).
- To delete a workflow, use the `UnstructuredClient` object's `workflows.delete_workflow` function (for the Python SDK) or
- the `DELETE` method to call the `/workflows/` endpoint (for `curl` or Postman). [Learn more](/platform-api/api/overview#delete-a-workflow).
+ the `DELETE` method to call the `/workflows/` endpoint (for `curl` or Postman). [Learn more](/api/workflow/overview#delete-a-workflow).
-The following examples assume that you have already met the [requirements](/platform-api/api/overview#requirements) and
-understand the [basics](/platform-api/api/overview#basics) of working with the Unstructured Platform Workflow Endpoint.
+The following examples assume that you have already met the [requirements](/api/workflow/overview#requirements) and
+understand the [basics](/api/workflow/overview#basics) of working with the Unstructured Workflow Endpoint.
## Create a workflow
@@ -269,10 +269,10 @@ Replace the preceding placeholders as follows:
- `` (_required_) - A unique name for this workflow.
- `` (_required_) - The ID of the target source connector. To get the ID,
use the `UnstructuredClient` object's `sources.list_sources` function (for the Python SDK) or
- the `GET` method to call the `/sources` endpoint (for `curl` or Postman). [Learn more](/platform-api/api/overview#list-source-connectors).
+ the `GET` method to call the `/sources` endpoint (for `curl` or Postman). [Learn more](/api/workflow/overview#list-source-connectors).
- `` (_required_) - The ID of the target destination connector. To get the ID,
use the `UnstructuredClient` object's `destinations.list_destinations` function (for the Python SDK) or
- the `GET` method to call the `/destinations` endpoint (for `curl` or Postman). [Learn more](/platform-api/api/overview#list-destination-connectors).
+ the `GET` method to call the `/destinations` endpoint (for `curl` or Postman). [Learn more](/api/workflow/overview#list-destination-connectors).
- `` (for the Python SDK) or `` (for `curl` or Postman) (_required_) - The workflow type. Available values include `CUSTOM` (for the Python SDK) and `custom` (for `curl` or Postman).
If `` is set to `CUSTOM` (for the Python SDK), or if `` is set to `custom` (for `curl` or Postman), you must add a `workflow_nodes` array. For instructions, see [Custom workflow DAG nodes](#custom-workflow-dag-nodes).
@@ -281,7 +281,7 @@ Replace the preceding placeholders as follows:
The previously-available workflow optimization types `ADVANCED`, `BASIC`, and `PLATINUM` (for the Python SDK) and
`advanced`, `basic`, and `platinum` (for `curl` or Postman) are non-operational and planned to be fully removed in a future release.
- The ability to create an [automatic workflow](/platform/workflows#create-an-automatic-workflow) type is currently not available but is planned to be added in a future release.
+ The ability to create an [automatic workflow](/ui/workflows#create-an-automatic-workflow) type is currently not available but is planned to be added in a future release.
- `` - The repeating automatic run schedule, specified as a predefined phrase. The available predefined phrases are:
@@ -307,7 +307,7 @@ the `PUT` method to call the `/workflows/` endpoint (for `curl` or
`` with the workflow's unique ID. To get this ID, see [List workflows](#list-workflows).
In the request body, specify the settings for the workflow. For the specific settings to include, see
-[Create a workflow](/platform-api/api/workflows#create-a-workflow).
+[Create a workflow](/api/workflow/workflows#create-a-workflow).
@@ -508,7 +508,7 @@ flowchart LR
A **Partitioner** node has a `type` of `WorkflowNodeType.PARTITION` (for the Python SDK) or `partition` (for `curl` and Postman).
-[Learn about the available partitioning strategies](/platform/partitioning).
+[Learn about the available partitioning strategies](/ui/partitioning).
#### Auto strategy
@@ -747,7 +747,7 @@ Allowed values for `provider` and `model` include:
A **Chunker** node has a `type` of `WorkflowNodeType.CHUNK` (for the Python SDK) or `chunk` (for `curl` and Postman).
-[Learn about the available chunking strategies](/platform/chunking).
+[Learn about the available chunking strategies](/ui/chunking).
#### Chunk by Character strategy
@@ -915,7 +915,7 @@ A **Chunker** node has a `type` of `WorkflowNodeType.CHUNK` (for the Python SDK)
An **Enrichment** node has a `type` of `WorkflowNodeType.PROMPTER` (for the Python SDK) or `prompter` (for `curl` and Postman).
-[Learn about the available enrichments](/platform/enriching/overview).
+[Learn about the available enrichments](/ui/enriching/overview).
#### Image Description task
@@ -1047,7 +1047,7 @@ Allowed values for `` include:
An **Embedder** node has a `type` of `WorkflowNodeType.EMBED` (for the Python SDK) or `embed` (for `curl` and Postman).
-[Learn about the available embedding providers and models](/platform/embedding).
+[Learn about the available embedding providers and models](/ui/embedding).
diff --git a/examplecode/codesamples/api/Unstructured-POST.postman_collection.json b/examplecode/codesamples/api/Unstructured-POST.postman_collection.json
index 0793aea1..06cdd379 100644
--- a/examplecode/codesamples/api/Unstructured-POST.postman_collection.json
+++ b/examplecode/codesamples/api/Unstructured-POST.postman_collection.json
@@ -7,7 +7,7 @@
},
"item": [
{
- "name": "(Platform Partition Endpoint) Basic Request",
+ "name": "(Partition Endpoint) Basic Request",
"request": {
"method": "POST",
"header": [
diff --git a/examplecode/codesamples/api/huggingchat.mdx b/examplecode/codesamples/api/huggingchat.mdx
index 992197c3..f4eef381 100644
--- a/examplecode/codesamples/api/huggingchat.mdx
+++ b/examplecode/codesamples/api/huggingchat.mdx
@@ -3,15 +3,15 @@ title: Query processed PDF with HuggingChat
---
This example uses the [Unstructured Ingest Python library](/ingestion/python-ingest) or the
-[Unstructured JavaScript/TypeScript SDK](/platform-api/partition-api/sdk-jsts) to send a PDF file to
-the [Unstructured Platform Partition Endpoint](/platform-api/partition-api/overview) for processing. Unstructured processes the PDF and extracts the PDF's content.
+[Unstructured JavaScript/TypeScript SDK](/api/partition/sdk-jsts) to send a PDF file to
+the [Unstructured Partition Endpoint](/api/partition/overview) for processing. Unstructured processes the PDF and extracts the PDF's content.
This example then sends some of the content to [HuggingChat](https://huggingface.co/chat/), Hugging Face's open-source AI chatbot,
along with some queries about this content.
To run this example, you'll need:
- The [hugchat](https://pypi.org/project/hugchat/) package for Python, or the [huggingface-chat](https://www.npmjs.com/package/huggingface-chat) package for JavaScript/TypeScript.
-- Your Unstructured API key and API URL. [Get an API key and API URL](/platform-api/partition-api/overview).
+- Your Unstructured API key and API URL. [Get an API key and API URL](/api/partition/overview).
- Your Hugging Face account's email address and account password. [Get an account](https://huggingface.co/join).
- A PDF file for Unstructured to process. This example uses a sample PDF file containing the text of the United States Constitution,
available for download from [https://constitutioncenter.org/media/files/constitution.pdf](https://constitutioncenter.org/media/files/constitution.pdf).
diff --git a/examplecode/codesamples/apioss/table-extraction-from-pdf.mdx b/examplecode/codesamples/apioss/table-extraction-from-pdf.mdx
index ba992f69..88525226 100644
--- a/examplecode/codesamples/apioss/table-extraction-from-pdf.mdx
+++ b/examplecode/codesamples/apioss/table-extraction-from-pdf.mdx
@@ -4,7 +4,7 @@ description: This section describes two methods for extracting tables from PDF f
---
-This sample code utilizes the [Unstructured Open Source](/open-source/introduction/overview "Open Source") library and also provides an alternative method the utilizing the [Unstructured Platform Partition Endpoint](/platform-api/partition-api/overview).
+This sample code utilizes the [Unstructured Open Source](/open-source/introduction/overview "Open Source") library and also provides an alternative method the utilizing the [Unstructured Partition Endpoint](/api/partition/overview).
## Method 1: Using partition\_pdf
@@ -33,7 +33,7 @@ print(tables[0].metadata.text_as_html)
## Method 2: Using Auto Partition or Unstructured API
-By default, table extraction from all file types is enabled. To extract tables from PDFs and images using [Auto Partition](/open-source/core-functionality/partitioning#partition) or [Unstructured API parameters](/platform-api/partition-api/api-parameters) simply set `strategy` parameter to `hi_res`.
+By default, table extraction from all file types is enabled. To extract tables from PDFs and images using [Auto Partition](/open-source/core-functionality/partitioning#partition) or [Unstructured API parameters](/api/partition/api-parameters) simply set `strategy` parameter to `hi_res`.
**Usage: Auto Partition**
diff --git a/examplecode/codesamples/oss/multi-files-api-processing.mdx b/examplecode/codesamples/oss/multi-files-api-processing.mdx
index 21bf7c20..83b52c6a 100644
--- a/examplecode/codesamples/oss/multi-files-api-processing.mdx
+++ b/examplecode/codesamples/oss/multi-files-api-processing.mdx
@@ -2,7 +2,7 @@
title: Multi-file API processing
---
-This sample code utilizes the [Unstructured Platform Partition Endpoint](/platform-api/partition-api/overview).
+This sample code utilizes the [Unstructured Partition Endpoint](/api/partition/overview).
## Introduction
diff --git a/examplecode/notebooks.mdx b/examplecode/notebooks.mdx
index d49c3fc3..cf72317f 100644
--- a/examplecode/notebooks.mdx
+++ b/examplecode/notebooks.mdx
@@ -8,9 +8,9 @@ description: "Notebooks contain complete working sample code for end-to-end solu
- 
+ 
- 
+ 
1. Sign in to your Unstructured account, at [https://platform.unstructured.io](https://platform.unstructured.io).
2. At the bottom of the sidebar, click your user icon, and then click **Account Settings**.
@@ -89,11 +89,11 @@ If you signed up for a pay-per-page plan, you can enjoy a free 14-day trial with
At the end of the 14-day free trial, or if you need to go past the trial's page processing limits during the 14-day free trial, you must set up your billing information to keep using
-the Unstructured Platform Partition API:
+the Unstructured Partition Endpoint:
-
+
-
+
1. Sign in to your Unstructured account, at [https://platform.unstructured.io](https://platform.unstructured.io).
2. At the bottom of the sidebar, click your user icon, and then click **Account Settings**.
@@ -113,7 +113,7 @@ import SharedPagesBilling from '/snippets/general-shared-text/pages-billing.mdx'
## Quickstart
-This example uses the [curl](https://curl.se/) utility on your local machine to call the Unstructured Platform Partition Endpoint. It sends a source (input) file from your local machine to the Unstructured Platform Partition Endpoint which then delivers the processed data to a destination (output) location, also on your local machine. Data is processed on Unstructured-hosted compute resources.
+This example uses the [curl](https://curl.se/) utility on your local machine to call the Unstructured Partition Endpoint. It sends a source (input) file from your local machine to the Unstructured Partition Endpoint which then delivers the processed data to a destination (output) location, also on your local machine. Data is processed on Unstructured-hosted compute resources.
If you do not have a source file readily available, you could use for example a sample PDF file containing the text of the United States Constitution,
available for download from [https://constitutioncenter.org/media/files/constitution.pdf](https://constitutioncenter.org/media/files/constitution.pdf).
@@ -122,7 +122,7 @@ available for download from [https://constitutioncenter.org/media/files/constitu
From your terminal or Command Prompt, set the following two environment variables.
- - Replace `` with the Unstructured Platform Partition Endpoint URL, which is `https://api.unstructuredapp.io/general/v0/general`
+ - Replace `` with the Unstructured Partition Endpoint URL, which is `https://api.unstructuredapp.io/general/v0/general`
- Replace `` with your Unstructured API key, which you generated earlier on this page.
```bash
@@ -159,7 +159,7 @@ available for download from [https://constitutioncenter.org/media/files/constitu
-You can also call the Unstructured Platform Partition Endpoint by using the [Unstructured Python SDK](/platform-api/partition-api/sdk-python) or the [Unstructured JavaScript/TypeScript SDK](/platform-api/partition-api/sdk-jsts).
+You can also call the Unstructured Partition Endpoint by using the [Unstructured Python SDK](/api/partition/sdk-python) or the [Unstructured JavaScript/TypeScript SDK](/api/partition/sdk-jsts).
## Telemetry
diff --git a/platform-api/partition-api/partitioning.mdx b/api/partition/partitioning.mdx
similarity index 100%
rename from platform-api/partition-api/partitioning.mdx
rename to api/partition/partitioning.mdx
diff --git a/platform-api/partition-api/pipeline-1.mdx b/api/partition/pipeline-1.mdx
similarity index 100%
rename from platform-api/partition-api/pipeline-1.mdx
rename to api/partition/pipeline-1.mdx
diff --git a/platform-api/partition-api/post-requests.mdx b/api/partition/post-requests.mdx
similarity index 82%
rename from platform-api/partition-api/post-requests.mdx
rename to api/partition/post-requests.mdx
index def219fe..253a9091 100644
--- a/platform-api/partition-api/post-requests.mdx
+++ b/api/partition/post-requests.mdx
@@ -3,17 +3,17 @@ title: Process an individual file by making a direct POST request
sidebarTitle: POST request
---
-To make POST requests to the Unstructured Platform Partition Endpoint, you will need:
+To make POST requests to the Unstructured Partition Endpoint, you will need:
import SharedAPIKeyURL from '/snippets/general-shared-text/api-key-url.mdx';
-[Get your API key](/platform-api/partition-api/overview).
+[Get your API key](/api/partition/overview).
The API URL is `https://api.unstructuredapp.io/general/v0/general`
-Let's start with a simple example in which you use [curl](https://curl.se/) to send a local PDF file (`*.pdf`) to partition via the Unstructured Platform Partition Endpoint.
+Let's start with a simple example in which you use [curl](https://curl.se/) to send a local PDF file (`*.pdf`) to partition via the Unstructured Partition Endpoint.
In this command, be sure to replace `` with the path to your local PDF file.
@@ -32,14 +32,14 @@ curl --request 'POST' \
```
In the example above we're representing the API endpoint with the environment variable `UNSTRUCTURED_API_URL`. Note, however, that you also need to authenticate yourself with
-your individual API Key, represented by the environment variable `UNSTRUCTURED_API_KEY`. Learn how to obtain an API URL and API key in the [Unstructured Platform Partition Endpoint guide](/platform-api/partition-api/overview).
+your individual API Key, represented by the environment variable `UNSTRUCTURED_API_KEY`. Learn how to obtain an API URL and API key in the [Unstructured Partition Endpoint guide](/api/partition/overview).
## Parameters & examples
-The API parameters are the same across all methods of accessing the Unstructured Platform Partition Endpoint.
+The API parameters are the same across all methods of accessing the Unstructured Partition Endpoint.
-* Refer to the [API parameters](/platform-api/partition-api/api-parameters) page for the full list of available parameters.
-* Refer to the [Examples](/platform-api/partition-api/examples) page for some inspiration on using the parameters.
+* Refer to the [API parameters](/api/partition/api-parameters) page for the full list of available parameters.
+* Refer to the [Examples](/api/partition/examples) page for some inspiration on using the parameters.
[//]: # (TODO: when we have the concepts page shared across products, link it from here for the users to learn about partition strategies, chunking strategies and other important shared concepts)
@@ -61,7 +61,7 @@ Unstructured offers a [Postman collection](https://learning.postman.com/docs/col
5. On the sidebar, click **Collections**.
6. Expand **Unstructured POST**.
-7. Click **(Platform Partition Endpoint) Basic Request**.
+7. Click **(Partition Endpoint) Basic Request**.
8. On the **Headers** tab, next to `unstructured-api-key`, enter your Unstructured API key in the **Value** column.
9. On the **Body** tab, next to `files`, click the **Select files** box in the **Value** column.
10. Click **New file from local machine**.
diff --git a/platform-api/partition-api/sdk-jsts.mdx b/api/partition/sdk-jsts.mdx
similarity index 95%
rename from platform-api/partition-api/sdk-jsts.mdx
rename to api/partition/sdk-jsts.mdx
index f5fead98..547bfc03 100644
--- a/platform-api/partition-api/sdk-jsts.mdx
+++ b/api/partition/sdk-jsts.mdx
@@ -2,10 +2,10 @@
title: JavaScript/TypeScript SDK
---
-The [Unstructured JavaScript/TypeScript SDK](https://github.com/Unstructured-IO/unstructured-js-client) client allows you to send one file at a time for processing by the Unstructured Platform Partition API.
+The [Unstructured JavaScript/TypeScript SDK](https://github.com/Unstructured-IO/unstructured-js-client) client allows you to send one file at a time for processing by the Unstructured Partition Endpoint.
To use the JavaScript/TypeScript SDK, you'll first need to set an environment variable named `UNSTRUCTURED_API_KEY`,
-representing your Unstructured API key. [Get your API key](/platform-api/partition-api/overview).
+representing your Unstructured API key. [Get your API key](/api/partition/overview).
## Installation
@@ -23,7 +23,7 @@ representing your Unstructured API key. [Get your API key](/platform-api/partiti
## Basics
- Let's start with a simple example in which you send a PDF document to the Unstructured Platform Parition Endpoint to be partitioned by Unstructured.
+ Let's start with a simple example in which you send a PDF document to the Unstructured Partition Endpoint to be partitioned by Unstructured.
The JavaScript/TypeScript SDK has the following breaking changes in v0.11.0:
@@ -286,6 +286,6 @@ The parameter names used in this document are for the JavaScript/TypeScript SDK,
convention. The Python SDK follows the `snake_case` convention. Other than this difference in naming convention,
the names used in the SDKs are the same across all methods.
-* Refer to the [API parameters](/platform-api/partition-api/api-parameters) page for the full list of available parameters.
-* Refer to the [Examples](/platform-api/partition-api/examples) page for some inspiration on using the parameters.
+* Refer to the [API parameters](/api/partition/api-parameters) page for the full list of available parameters.
+* Refer to the [Examples](/api/partition/examples) page for some inspiration on using the parameters.
diff --git a/platform-api/partition-api/sdk-python.mdx b/api/partition/sdk-python.mdx
similarity index 95%
rename from platform-api/partition-api/sdk-python.mdx
rename to api/partition/sdk-python.mdx
index 347eec8b..6553d820 100644
--- a/platform-api/partition-api/sdk-python.mdx
+++ b/api/partition/sdk-python.mdx
@@ -3,10 +3,10 @@ title: Python SDK
---
The [Unstructured Python SDK](https://github.com/Unstructured-IO/unstructured-python-client) client allows you to send one file at a time for processing by
-the [Unstructured Platform Partition Endpoint](/platform-api/partition-api/overview).
+the [Unstructured Partition Endpoint](/api/partition/overview).
To use the Python SDK, you'll first need to set an environment variable named `UNSTRUCTURED_API_KEY`,
-representing your Unstructured API key. [Get your API key](/platform-api/partition-api/overview).
+representing your Unstructured API key. [Get your API key](/api/partition/overview).
## Installation
@@ -23,7 +23,7 @@ representing your Unstructured API key. [Get your API key](/platform-api/partiti
## Basics
- Let's start with a simple example in which you send a PDF document to the Unstructured Platform Parition Endpoint to be partitioned by Unstructured.
+ Let's start with a simple example in which you send a PDF document to the Unstructured Partition Endpoint to be partitioned by Unstructured.
```python Python
import os, json
@@ -250,8 +250,8 @@ The parameter names used in this document are for the Python SDK, which follow s
convention. Other than this difference in naming convention,
the names used in the SDKs are the same across all methods.
-* Refer to the [API parameters](/platform-api/partition-api/api-parameters) page for the full list of available parameters.
-* Refer to the [Examples](/platform-api/partition-api/examples) page for some inspiration on using the parameters.
+* Refer to the [API parameters](/api/partition/api-parameters) page for the full list of available parameters.
+* Refer to the [Examples](/api/partition/examples) page for some inspiration on using the parameters.
## Migration guide
diff --git a/platform-api/partition-api/speed-up-large-files-batches.mdx b/api/partition/speed-up-large-files-batches.mdx
similarity index 82%
rename from platform-api/partition-api/speed-up-large-files-batches.mdx
rename to api/partition/speed-up-large-files-batches.mdx
index 9cd3704b..dcfedb6f 100644
--- a/platform-api/partition-api/speed-up-large-files-batches.mdx
+++ b/api/partition/speed-up-large-files-batches.mdx
@@ -4,13 +4,13 @@ title: Speed up processing of large files and batches
When you use Unstructured, here are some techniques that you can try to help speed up the processing of large files and large batches of files.
-Choose your partitioning strategy wisely. For example, if you have simple PDFs that don't have images and tables, you might be able to use the `fast` strategy. Try the `fast` strategy on a few of your documents before you try using the `hi_res` strategy. [Learn more](/platform-api/partition-api/partitioning).
+Choose your partitioning strategy wisely. For example, if you have simple PDFs that don't have images and tables, you might be able to use the `fast` strategy. Try the `fast` strategy on a few of your documents before you try using the `hi_res` strategy. [Learn more](/api/partition/partitioning).
-To speed up PDF file processing, the [Unstructured SDK for Python](/platform-api/partition-api/sdk-python) and the [Unstructured SDK for JavaScript/TypeScript](/platform-api/partition-api/sdk-jsts) provide the following parameters to help speed up processing a large PDF file:
+To speed up PDF file processing, the [Unstructured SDK for Python](/api/partition/sdk-python) and the [Unstructured SDK for JavaScript/TypeScript](/api/partition/sdk-jsts) provide the following parameters to help speed up processing a large PDF file:
- `split_pdf_page` (Python) or `splitPdfPage` (JavaScript/TypeScript), when set to true, splits the PDF file on the client side before sending it as batches to Unstructured for processing. The number of pages in each batch is determined internally. Batches can contain between 2 and 20 pages.
- `split_pdf_concurrency_level` (Python) or `splitPdfConcurrencyLevel` (JavaScript/TypeScript) is an integer that specifies the number of parallel requests. The default is 5. The maximum is 15. This behavior is ignored unless `split_pdf_page` (Python) or `splitPdfPage` (JavaScript/TypeScript) is also set to true.
- `split_pdf_allow_failed` (Python) or splitPdfAllowFailed` (JavaScript/TypeScript), when set to true, allows partitioning to continue even if some pages fail.
- `split_pdf_page_range` (Python only) is a list of two integers that specify the beginning and ending page numbers of the PDF file to be sent. A `ValueError` is raised if the specified range is not valid. This behavior is ignored unless `split_pdf_page` is also set to true.
-[Learn more](/platform-api/partition-api/sdk-python#page-splitting).
+[Learn more](/api/partition/sdk-python#page-splitting).
diff --git a/platform-api/partition-api/text-as-html.mdx b/api/partition/text-as-html.mdx
similarity index 84%
rename from platform-api/partition-api/text-as-html.mdx
rename to api/partition/text-as-html.mdx
index 82f83b70..4e4d45f6 100644
--- a/platform-api/partition-api/text-as-html.mdx
+++ b/api/partition/text-as-html.mdx
@@ -21,11 +21,11 @@ import ExtractTextAsHTMLPy from '/snippets/how-to-api/extract_text_as_html.py.md
## Code
-For the [Unstructured Python SDK](/platform-api/partition-api/sdk-python), you'll need:
+For the [Unstructured Python SDK](/api/partition/sdk-python), you'll need:
## See also
-- [Extract images and tables from documents](/platform-api/partition-api/extract-image-block-types)
+- [Extract images and tables from documents](/api/partition/extract-image-block-types)
- [Table Extraction from PDF](/examplecode/codesamples/apioss/table-extraction-from-pdf)
\ No newline at end of file
diff --git a/platform-api/partition-api/transform-schemas.mdx b/api/partition/transform-schemas.mdx
similarity index 100%
rename from platform-api/partition-api/transform-schemas.mdx
rename to api/partition/transform-schemas.mdx
diff --git a/platform-api/supported-file-types.mdx b/api/supported-file-types.mdx
similarity index 100%
rename from platform-api/supported-file-types.mdx
rename to api/supported-file-types.mdx
diff --git a/platform-api/troubleshooting/api-key-url.mdx b/api/troubleshooting/api-key-url.mdx
similarity index 76%
rename from platform-api/troubleshooting/api-key-url.mdx
rename to api/troubleshooting/api-key-url.mdx
index e47c06bc..c5f596e0 100644
--- a/platform-api/troubleshooting/api-key-url.mdx
+++ b/api/troubleshooting/api-key-url.mdx
@@ -1,11 +1,11 @@
---
-title: Troubleshooting Unstructured Platform API keys and URLs
+title: Troubleshooting Unstructured API keys and URLs
sidebarTitle: API keys and URLs
---
## Issue
-When you run script or code to call an Unstructured Platform API, you get one of the following warnings or errors:
+When you run script or code to call an Unstructured API, you get one of the following warnings or errors:
```
UserWarning: If intending to use the paid API, please define `server_url` in your request.
@@ -37,20 +37,20 @@ API error occurred: Status 404
For the API URL, note the following:
-- For the [Unstructured Platform Workflow Endpoint](/platform-api/api/overview), the API URL is typically `https://platform.unstructuredapp.io/api/v1`.
-- For the [Unstructured Platform Partition Endpoint](/platform-api/partition-api/overview), the API URL is typically `https://api.unstructuredapp.io/general/v0/general`.
+- For the [Unstructured Workflow Endpoint](/api/workflow/overview), the API URL is typically `https://platform.unstructuredapp.io/api/v1`.
+- For the [Unstructured Partition Endpoint](/api/partition/overview), the API URL is typically `https://api.unstructuredapp.io/general/v0/general`.
-For the API key, the same API key works for both the [Unstructured Platform Workflow Endpoint](/platform-api/api/overview) key or [Unstructured Platform Partition Endpoint](/platform-api/partition-api/overview). This API key is in your Unstructured account dashboard. To access your dashboard:
+For the API key, the same API key works for both the [Unstructured Workflow Endpoint](/api/workflow/overview) key or [Unstructured Partition Endpoint](/api/partition/overview). This API key is in your Unstructured account dashboard. To access your dashboard:
- 
+ 
1. Sign in to your Unstructured account, at [https://platform.unstructured.io](https://platform.unstructured.io).
2. At the bottom of the sidebar, click your user icon, and then click **Account Settings**.
3. On the **API Keys** tab, click the copy icon next to your key.
-For the API URL, note the value of the the Unstructured **Platform API URL** (for the Unstructured Platform Workflow Endpoint) or the Unstructured **Serverless API URL** (for the Unstructured Platform Partition Endpoint).
+For the API URL, note the value of the the Unstructured **API URL** (for the Unstructured Workflow Endpoint) or the Unstructured **Serverless API URL** (for the Unstructured Partition Endpoint).
- 
+ 
1. Sign in to your Unstructured account, at [https://platform.unstructured.io](https://platform.unstructured.io).
2. At the bottom of the sidebar, click your user icon, and then click **Account Settings**.
diff --git a/platform-api/api/destinations/astradb.mdx b/api/workflow/destinations/astradb.mdx
similarity index 100%
rename from platform-api/api/destinations/astradb.mdx
rename to api/workflow/destinations/astradb.mdx
diff --git a/platform-api/api/destinations/azure-ai-search.mdx b/api/workflow/destinations/azure-ai-search.mdx
similarity index 100%
rename from platform-api/api/destinations/azure-ai-search.mdx
rename to api/workflow/destinations/azure-ai-search.mdx
diff --git a/platform-api/api/destinations/couchbase.mdx b/api/workflow/destinations/couchbase.mdx
similarity index 100%
rename from platform-api/api/destinations/couchbase.mdx
rename to api/workflow/destinations/couchbase.mdx
diff --git a/platform-api/api/destinations/databricks-delta-table.mdx b/api/workflow/destinations/databricks-delta-table.mdx
similarity index 88%
rename from platform-api/api/destinations/databricks-delta-table.mdx
rename to api/workflow/destinations/databricks-delta-table.mdx
index 6cfb46da..8c512a12 100644
--- a/platform-api/api/destinations/databricks-delta-table.mdx
+++ b/api/workflow/destinations/databricks-delta-table.mdx
@@ -6,10 +6,10 @@ title: Delta Tables in Databricks
This article covers connecting Unstructured to Delta Tables in Databricks.
For information about connecting Unstructured to Delta Tables in Amazon S3 instead, see
- [Delta Tables in Amazon S3](/platform-api/api/destinations/delta-table).
+ [Delta Tables in Amazon S3](/api/workflow/destinations/delta-table).
For information about connecting Unstructured to Databricks Volumes instead, see
- [Databricks Volumes](/platform-api/api/destinations/databricks-volumes).
+ [Databricks Volumes](/api/workflow/destinations/databricks-volumes).
Send processed data from Unstructured to a Delta Table in Databricks.
diff --git a/platform-api/api/destinations/databricks-volumes.mdx b/api/workflow/destinations/databricks-volumes.mdx
similarity index 92%
rename from platform-api/api/destinations/databricks-volumes.mdx
rename to api/workflow/destinations/databricks-volumes.mdx
index 87ae3362..7170de5e 100644
--- a/platform-api/api/destinations/databricks-volumes.mdx
+++ b/api/workflow/destinations/databricks-volumes.mdx
@@ -6,7 +6,7 @@ title: Databricks Volumes
This article covers connecting Unstructured to Databricks Volumes.
For information about connecting Unstructured to Delta Tables in Databricks instead, see
- [Delta Tables in Databricks](/platform-api/api/destinations/databricks-delta-table).
+ [Delta Tables in Databricks](/api/workflow/destinations/databricks-delta-table).
Send processed data from Unstructured to Databricks Volumes.
diff --git a/platform-api/api/destinations/delta-table.mdx b/api/workflow/destinations/delta-table.mdx
similarity index 91%
rename from platform-api/api/destinations/delta-table.mdx
rename to api/workflow/destinations/delta-table.mdx
index ac968bd7..78e7eb42 100644
--- a/platform-api/api/destinations/delta-table.mdx
+++ b/api/workflow/destinations/delta-table.mdx
@@ -5,7 +5,7 @@ title: Delta Tables in Amazon S3
This article covers connecting Unstructured to Delta Tables in Amazon S3. For information about
connecting Unstructured to Delta Tables in Databricks instead, see
- [Delta Tables in Databricks](/platform-api/api/destinations/databricks-delta-table).
+ [Delta Tables in Databricks](/api/workflow/destinations/databricks-delta-table).
Send processed data from Unstructured to a Delta Table, stored in Amazon S3.
diff --git a/platform-api/api/destinations/elasticsearch.mdx b/api/workflow/destinations/elasticsearch.mdx
similarity index 100%
rename from platform-api/api/destinations/elasticsearch.mdx
rename to api/workflow/destinations/elasticsearch.mdx
diff --git a/platform-api/api/destinations/google-cloud.mdx b/api/workflow/destinations/google-cloud.mdx
similarity index 100%
rename from platform-api/api/destinations/google-cloud.mdx
rename to api/workflow/destinations/google-cloud.mdx
diff --git a/platform-api/api/destinations/kafka.mdx b/api/workflow/destinations/kafka.mdx
similarity index 100%
rename from platform-api/api/destinations/kafka.mdx
rename to api/workflow/destinations/kafka.mdx
diff --git a/platform-api/api/destinations/milvus.mdx b/api/workflow/destinations/milvus.mdx
similarity index 100%
rename from platform-api/api/destinations/milvus.mdx
rename to api/workflow/destinations/milvus.mdx
diff --git a/platform-api/api/destinations/mongodb.mdx b/api/workflow/destinations/mongodb.mdx
similarity index 100%
rename from platform-api/api/destinations/mongodb.mdx
rename to api/workflow/destinations/mongodb.mdx
diff --git a/platform-api/api/destinations/motherduck.mdx b/api/workflow/destinations/motherduck.mdx
similarity index 100%
rename from platform-api/api/destinations/motherduck.mdx
rename to api/workflow/destinations/motherduck.mdx
diff --git a/platform-api/api/destinations/neo4j.mdx b/api/workflow/destinations/neo4j.mdx
similarity index 100%
rename from platform-api/api/destinations/neo4j.mdx
rename to api/workflow/destinations/neo4j.mdx
diff --git a/platform-api/api/destinations/onedrive.mdx b/api/workflow/destinations/onedrive.mdx
similarity index 100%
rename from platform-api/api/destinations/onedrive.mdx
rename to api/workflow/destinations/onedrive.mdx
diff --git a/api/workflow/destinations/overview.mdx b/api/workflow/destinations/overview.mdx
new file mode 100644
index 00000000..64d296a0
--- /dev/null
+++ b/api/workflow/destinations/overview.mdx
@@ -0,0 +1,42 @@
+---
+title: Overview
+---
+
+To use the [Unstructured Workflow Endpoint](/api/workflow/overview) to manage destination connectors, do the following:
+
+- To get a list of available destination connectors, use the `UnstructuredClient` object's `destinations.list_destinations` function (for the Python SDK) or
+ the `GET` method to call the `/destinations` endpoint (for `curl` or Postman).. [Learn more](/api/workflow/overview#list-destination-connectors).
+- To get information about a destination connector, use the `UnstructuredClient` object's `destinations.get_destination` function (for the Python SDK) or
+ the `GET` method to call the `/destinations/` endpoint (for `curl` or Postman). [Learn more](/api/workflow/overview#get-a-destination-connector).
+- To create a destination connector, use the `UnstructuredClient` object's `destinations.create_destination` function (for the Python SDK) or
+ the `POST` method to call the `/destinations` endpoint (for `curl` or Postman). [Learn more](/api/workflow/overview#create-a-destination-connector).
+- To update a destination connector, use the `UnstructuredClient` object's `destinations.update_destination` function (for the Python SDK) or
+ the `PUT` method to call the `/destinations/` endpoint (for `curl` or Postman). [Learn more](/api/workflow/overview#update-a-destination-connector).
+- To delete a destination connector, use the `UnstructuredClient` object's `destinations.delete_destination` function (for the Python SDK) or
+ the `DELETE` method to call the `/destinations/` endpoint (for `curl` or Postman). [Learn more](/api/workflow/overview#delete-a-destination-connector).
+
+To create or update a destination connector, you must also provide settings that are specific to that connector.
+For the list of specific settings, see:
+
+- [Astra DB](/api/workflow/destinations/astradb) (`ASTRADB` for the Python SDK or `astradb` for `curl` or Postman)
+- [Azure AI Search](/api/workflow/destinations/azure-ai-search) (`AZURE_AI_SEARCH` for the Python SDK or `azure_ai_search` for `curl` or Postman)
+- [Couchbase](/api/workflow/destinations/couchbase) (`COUCHBASE` for the Python SDK or `couchbase` for `curl` or Postman)
+- [Databricks Volumes](/api/workflow/destinations/databricks-volumes) (`DATABRICKS_VOLUMES` for the Python SDK or `databricks_volumes` for `curl` or Postman)
+- [Delta Tables in Amazon S3](/api/workflow/destinations/delta-table) (`DELTA_TABLE` for the Python SDK or `delta_table` for `curl` or Postman)
+- [Delta Tables in Databricks](/api/workflow/destinations/databricks-delta-table) (`DATABRICKS_VOLUME_DELTA_TABLES` for the Python SDK or `databricks_volume_delta_tables` for `curl` or Postman)
+- [Elasticsearch](/api/workflow/destinations/elasticsearch) (`ELASTICSEARCH` for the Python SDK or `elasticsearch` for `curl` or Postman)
+- [Google Cloud Storage](/api/workflow/destinations/google-cloud) (`GCS` for the Python SDK or `gcs` for `curl` or Postman)
+- [Kafka](/api/workflow/destinations/kafka) (`KAFKA_CLOUD` for the Python SDK or `kafka-cloud` for `curl` or Postman)
+- [Milvus](/api/workflow/destinations/milvus) (`MILVUS` for the Python SDK or `milvus` for `curl` or Postman)
+- [MongoDB](/api/workflow/destinations/mongodb) (`MONGODB` for the Python SDK or `mongodb` for `curl` or Postman)
+- [MotherDuck](/api/workflow/destinations/motherduck) (`MOTHERDUCK` for the Python SDK or `motherduck` for `curl` or Postman)
+- [Neo4j](/api/workflow/destinations/neo4j) (`NEO4J` for the Python SDK or `neo4j` for `curl` or Postman)
+- [OneDrive](/api/workflow/destinations/onedrive) (`ONEDRIVE` for the Python SDK or `onedrive` for `curl` or Postman)
+- [Pinecone](/api/workflow/destinations/pinecone) (`PINECONE` for the Python SDK or `pinecone` for `curl` or Postman)
+- [PostgreSQL](/api/workflow/destinations/postgresql) (`POSTGRES` for the Python SDK or `postgres` for `curl` or Postman)
+- [Qdrant](/api/workflow/destinations/qdrant) (`QDRANT_CLOUD` for the Python SDK or `qdrant-cloud` for `curl` or Postman)
+- [Redis](/api/workflow/destinations/redis) (`REDIS` for the Python SDK or `redis` for `curl` or Postman)
+- [Snowflake](/api/workflow/destinations/snowflake) (`SNOWFLAKE` for the Python SDK or `snowflake` for `curl` or Postman)
+- [S3](/api/workflow/destinations/s3) (`S3` for the Python SDK or `s3` for `curl` or Postman)
+- [Weaviate](/api/workflow/destinations/weaviate) (`WEAVIATE` for the Python SDK or `weaviate` for `curl` or Postman)
+
diff --git a/platform-api/api/destinations/pinecone.mdx b/api/workflow/destinations/pinecone.mdx
similarity index 100%
rename from platform-api/api/destinations/pinecone.mdx
rename to api/workflow/destinations/pinecone.mdx
diff --git a/platform-api/api/destinations/postgresql.mdx b/api/workflow/destinations/postgresql.mdx
similarity index 100%
rename from platform-api/api/destinations/postgresql.mdx
rename to api/workflow/destinations/postgresql.mdx
diff --git a/platform-api/api/destinations/qdrant.mdx b/api/workflow/destinations/qdrant.mdx
similarity index 100%
rename from platform-api/api/destinations/qdrant.mdx
rename to api/workflow/destinations/qdrant.mdx
diff --git a/platform-api/api/destinations/redis.mdx b/api/workflow/destinations/redis.mdx
similarity index 100%
rename from platform-api/api/destinations/redis.mdx
rename to api/workflow/destinations/redis.mdx
diff --git a/platform-api/api/destinations/s3.mdx b/api/workflow/destinations/s3.mdx
similarity index 100%
rename from platform-api/api/destinations/s3.mdx
rename to api/workflow/destinations/s3.mdx
diff --git a/platform-api/api/destinations/snowflake.mdx b/api/workflow/destinations/snowflake.mdx
similarity index 100%
rename from platform-api/api/destinations/snowflake.mdx
rename to api/workflow/destinations/snowflake.mdx
diff --git a/platform-api/api/destinations/weaviate.mdx b/api/workflow/destinations/weaviate.mdx
similarity index 100%
rename from platform-api/api/destinations/weaviate.mdx
rename to api/workflow/destinations/weaviate.mdx
diff --git a/platform-api/api/jobs.mdx b/api/workflow/jobs.mdx
similarity index 59%
rename from platform-api/api/jobs.mdx
rename to api/workflow/jobs.mdx
index 2e065d14..5ddd8fdc 100644
--- a/platform-api/api/jobs.mdx
+++ b/api/workflow/jobs.mdx
@@ -2,13 +2,13 @@
title: Jobs
---
-To use the [Unstructured Platform Workflow Endpoint](/platform-api/api/overview) to manage jobs, do the following:
+To use the [Unstructured Workflow Endpoint](/api/workflow/overview) to manage jobs, do the following:
- To get a list of available jobs, use the `UnstructuredClient` object's `jobs.list_jobs` function (for the Python SDK) or
- the `GET` method to call the `/jobs` endpoint (for `curl` or Postman). [Learn more](/platform-api/api/overview#list-jobs).
+ the `GET` method to call the `/jobs` endpoint (for `curl` or Postman). [Learn more](/api/workflow/overview#list-jobs).
- To get information about a job, use the `UnstructuredClient` object's `jobs.get_job` function (for the Python SDK) or
- the `GET` method to call the `/jobs/` endpoint (for `curl` or Postman). [Learn more](/platform-api/api/overview#get-a-job).
-- A job is created automatically whenever a workflow runs on a schedule; see [Create a workflow](/platform-api/api/workflows#create-a-workflow).
- A job is also created whenever you run a workflow manually; see [Run a workflow](/platform-api/api/overview#run-a-workflow).
+ the `GET` method to call the `/jobs/` endpoint (for `curl` or Postman). [Learn more](/api/workflow/overview#get-a-job).
+- A job is created automatically whenever a workflow runs on a schedule; see [Create a workflow](/api/workflow/workflows#create-a-workflow).
+ A job is also created whenever you run a workflow manually; see [Run a workflow](/api/workflow/overview#run-a-workflow).
- To cancel a running job, use the `UnstructuredClient` object's `jobs.cancel_job` function (for the Python SDK) or
- the `POST` method to call the `/jobs//cancel` endpoint (for `curl` or Postman). [Learn more](/platform-api/api/overview#cancel-a-job).
\ No newline at end of file
+ the `POST` method to call the `/jobs//cancel` endpoint (for `curl` or Postman). [Learn more](/api/workflow/overview#cancel-a-job).
\ No newline at end of file
diff --git a/platform-api/api/overview.mdx b/api/workflow/overview.mdx
similarity index 96%
rename from platform-api/api/overview.mdx
rename to api/workflow/overview.mdx
index 4ecee2f4..decde5ef 100644
--- a/platform-api/api/overview.mdx
+++ b/api/workflow/overview.mdx
@@ -2,20 +2,20 @@
title: Overview
---
-The [Unstructured Platform UI](/platform/overview) features a no-code user interface for transforming your unstructured data into data that is ready
+The [Unstructured UI](/ui/overview) features a no-code user interface for transforming your unstructured data into data that is ready
for Retrieval Augmented Generation (RAG).
-The Unstructured Platform Workflow Endpoint, part of the [Unstructured Platform API](/platform-api/overview), enables a full range of partitioning, chunking, embedding, and
+The Unstructured Workflow Endpoint, part of the [Unstructured API](/api/overview), enables a full range of partitioning, chunking, embedding, and
enrichment options for your files and data. It is designed to batch-process files and data in remote locations; send processed results to
various storage, databases, and vector stores; and use the latest and highest-performing models on the market today. It has built-in logic
to deliver the highest quality results at the lowest cost.
-This page provides an overview of the Unstructured Platform Workflow Endpoint. This endpoint enables Unstructured Platform UI automation usage
+This page provides an overview of the Unstructured Workflow Endpoint. This endpoint enables Unstructured UI automation usage
scenarios as well as for documentation, reporting, and recovery needs.
## Getting started
-Choose one of the following options to get started with the Unstructured Platform Workflow Endpoint:
+Choose one of the following options to get started with the Unstructured Workflow Endpoint:
- Follow the [quickstart](#quickstart), which uses the Unstructured Python SDK from a remote hosted Google Collab notebook.
- Start using the [Unstructred Python SDK](#unstructured-python-sdk).
@@ -30,7 +30,7 @@ import SharedPlatformAPI from '/snippets/quickstarts/platform-api.mdx';
## Unstructured Python SDK
The [Unstructured Python SDK](https://github.com/Unstructured-IO/unstructured-python-client), beginning with version 0.30.6,
-allows you to call the Unstructured Platform Workflow Endpoint through standard Python code.
+allows you to call the Unstructured Workflow Endpoint through standard Python code.
To install the Unstructured Python SDK, run the following command from within your Python virtual environment:
@@ -62,7 +62,7 @@ To get your Unstructured API key, do the following:
5. Click the **Copy** icon for your new API key. The API key's value is copied to your system's clipboard.
Calls made by the Unstructured Python SDK's `unstructured_client` functions for creating, listing, updating,
-and deleting connectors, workflows, and jobs in the Unstructured Platform UI all use the Unstructured Platform Workflow Endpoint URL (`https://platform.unstructuredapp.io/api/v1`) by default. You do not need to
+and deleting connectors, workflows, and jobs in the Unstructured UI all use the Unstructured Workflow Endpoint URL (`https://platform.unstructuredapp.io/api/v1`) by default. You do not need to
use the `server_url` parameter to specify this API URL in your Python code for these particular functions.
@@ -74,8 +74,8 @@ use the `server_url` parameter to specify this API URL in your Python code for t
To specify an API URL in your code, set the `server_url` parameter in the `UnstructuredClient` constructor to the target API URL.
-The Unstructured Platform Workflow Endpoint enables you to work with [connectors](#connectors),
-[workflows](#workflows), and [jobs](#jobs) in the Unstructured Platform UI.
+The Unstructured Workflow Endpoint enables you to work with [connectors](#connectors),
+[workflows](#workflows), and [jobs](#jobs) in the Unstructured UI.
- A _source connector_ ingests files or data into Unstructured from a source location.
- A _destination connector_ sends the processed data from Unstructured to a destination location.
@@ -84,9 +84,9 @@ The Unstructured Platform Workflow Endpoint enables you to work with [connectors
For general information about these objects, see:
-- [Connectors](/platform/connectors)
-- [Workflows](/platform/workflows)
-- [Jobs](/platform/jobs)
+- [Connectors](/ui/connectors)
+- [Workflows](/ui/workflows)
+- [Jobs](/ui/jobs)
Skip ahead to start learning about how to use the Unstructured Python SDK to work with
[connectors](#connectors),
@@ -94,13 +94,13 @@ Skip ahead to start learning about how to use the Unstructured Python SDK to wor
## REST endpoints
-The Unstructured Platform Workflow Endpoint is callable from a set of Representational State Transfer (REST) endpoints, which you can call through standard REST-enabled
-utilities, tools, programming languages, packages, and libraries. The examples, shown later on this page and on related pages, describe how to call the Unstructured Platform Workflow Endpoint with
+The Unstructured Workflow Endpoint is callable from a set of Representational State Transfer (REST) endpoints, which you can call through standard REST-enabled
+utilities, tools, programming languages, packages, and libraries. The examples, shown later on this page and on related pages, describe how to call the Unstructured Workflow Endpoint with
`curl` and Postman. You can adapt this information as needed for your preferred programming languages and libraries, for example by using the
`requests` library with Python.
- You can also use the [Unstructured Platform Workflow Endpoint - Swagger UI](https://platform.unstructuredapp.io/docs) to call the REST endpoints
+ You can also use the [Unstructured Workflow Endpoint - Swagger UI](https://platform.unstructuredapp.io/docs) to call the REST endpoints
that are available through `https://platform.unstructuredapp.io`. To use the Swagger UI, you must provide your Unstructured API key with each call. To
get this API key, see the [quickstart](#quickstart), earlier on this page.
@@ -168,8 +168,8 @@ To get your Unstructured API key, do the following:
API URL throughout the following examples.
-The Unstructured Platform Workflow Endpoint enables you to work with [connectors](#connectors),
-[workflows](#workflows), and [jobs](#jobs) in the Unstructured Platform UI.
+The Unstructured Workflow Endpoint enables you to work with [connectors](#connectors),
+[workflows](#workflows), and [jobs](#jobs) in the Unstructured UI.
- A _source connector_ ingests files or data into Unstructured from a source location.
- A _destination connector_ sends the processed data from Unstructured to a destination location.
@@ -178,9 +178,9 @@ The Unstructured Platform Workflow Endpoint enables you to work with [connectors
For general information about these objects, see:
-- [Connectors](/platform/connectors)
-- [Workflows](/platform/workflows)
-- [Jobs](/platform/jobs)
+- [Connectors](/ui/connectors)
+- [Workflows](/ui/workflows)
+- [Jobs](/ui/jobs)
Skip ahead to start learning about how to use the REST endpoints to work with
[connectors](#connectors),
@@ -188,15 +188,15 @@ Skip ahead to start learning about how to use the REST endpoints to work with
## Restrictions
-The following Unstructured SDKs, tools, and libraries do _not_ work with the Unstructured Platform Workflow Endpoint:
+The following Unstructured SDKs, tools, and libraries do _not_ work with the Unstructured Workflow Endpoint:
-- The [Unstructured JavaScript/TypeScript SDK](/platform-api/partition-api/sdk-jsts)
-- [Local single-file POST requests](/platform-api/partition-api/sdk-jsts) to the Unstructured Platform Partition Endpoint
+- The [Unstructured JavaScript/TypeScript SDK](/api/partition/sdk-jsts)
+- [Local single-file POST requests](/api/partition/sdk-jsts) to the Unstructured Partition Endpoint
- The [Unstructured open source Python library](/open-source/introduction/overview)
- The [Unstructued Ingest CLI](/ingestion/ingest-cli)
- The [Unstructured Ingest Python library](/ingestion/python-ingest)
-The following Unstructured API URL is also _not_ supported: `https://api.unstructuredapp.io/general/v0/general` (the Unstructured Platform Partition Endpoint URL).
+The following Unstructured API URL is also _not_ supported: `https://api.unstructuredapp.io/general/v0/general` (the Unstructured Partition Endpoint URL).
## Connectors
@@ -211,7 +211,7 @@ You can also [list](#list-destination-connectors),
[update](#update-a-destination-connector),
and [delete](#delete-a-destination-connector) destination connectors.
-For general information, see [Connectors](/platform/connectors).
+For general information, see [Connectors](/ui/connectors).
### List source connectors
@@ -222,7 +222,7 @@ To filter the list of source connectors, use the `ListSourcesRequest` object's `
or the query parameter `source_type=` (for `curl` or Postman),
replacing `` with the source connector type's unique ID
(for example, for the Amazon S3 source connector type, `S3` for the Python SDK or `s3` for `curl` or Postman).
-To get this ID, see [Sources](/platform-api/api/sources/overview).
+To get this ID, see [Sources](/api/workflow/sources/overview).
@@ -418,10 +418,10 @@ the `POST` method to call the `/sources` endpoint (for `curl` or Postman).
In the `CreateSourceConnector` object (for the Python SDK) or
the request body (for `curl` or Postman),
specify the settings for the connector. For the specific settings to include, which differ by connector, see
-[Sources](/platform-api/api/sources/overview).
+[Sources](/api/workflow/sources/overview).
For the Python SDK, replace `` with the source connector type's unique ID (for example, for the Amazon S3 source connector type, `S3`).
-To get this ID, see [Sources](/platform-api/api/sources/overview).
+To get this ID, see [Sources](/api/workflow/sources/overview).
@@ -547,10 +547,10 @@ the `PUT` method to call the `/sources/` endpoint (for `curl` or P
In the `UpdateSourceConnector` object (for the Python SDK) or
the request body (for `curl` or Postman), specify the settings for the connector. For the specific settings to include, which differ by connector, see
-[Sources](/platform-api/api/sources/overview).
+[Sources](/api/workflow/sources/overview).
For the Python SDK, replace `` with the source connector type's unique ID (for example, for the Amazon S3 source connector type, `S3`).
-To get this ID, see [Sources](/platform-api/api/sources/overview).
+To get this ID, see [Sources](/api/workflow/sources/overview).
You must specify all of the settings for the connector, even for settings that are not changing.
@@ -753,7 +753,7 @@ To filter the list of destination connectors, use the `ListDestinationsRequest`
the query parameter `destination_type=` (for `curl` or Postman),
replacing `` with the destination connector type's unique ID
(for example, for the Amazon S3 source connector type, `S3` for the Python SDK or `s3` for `curl` or Postman).
-To get this ID, see [Destinations](/platform-api/api/destinations/overview).
+To get this ID, see [Destinations](/api/workflow/destinations/overview).
@@ -948,10 +948,10 @@ the `POST` method to call the `/destinations` endpoint (for `curl` or Postman).
In the `CreateDestinationConnector` object (for the Python SDK) or
the request body (for `curl` or Postman),
specify the settings for the connector. For the specific settings to include, which differ by connector, see
-[Destinations](/platform-api/api/destinations/overview).
+[Destinations](/api/workflow/destinations/overview).
For the Python SDK, replace `` with the destination connector type's unique ID (for example, for the Amazon S3 source connector type, `S3`).
-To get this ID, see [Destinations](/platform-api/api/destinations/overview).
+To get this ID, see [Destinations](/api/workflow/destinations/overview).
@@ -1076,7 +1076,7 @@ the `PUT` method to call the `/destinations/` endpoint (for `curl`
In the `UpdateDestinationConnector` object (for the Python SDK) or
the request body (for `curl` or Postman), specify the settings for the connector. For the specific settings to include, which differ by connector, see
-[Destinations](/platform-api/api/destinations/overview).
+[Destinations](/api/workflow/destinations/overview).
You must specify all of the settings for the connector, even for settings that are not changing.
@@ -1278,7 +1278,7 @@ You can [list](#list-workflows),
[update](#update-a-workflow),
and [delete](#delete-a-workflow) workflows.
-For general information, see [Workflows](/platform/workflows).
+For general information, see [Workflows](/ui/workflows).
### List workflows
@@ -1541,7 +1541,7 @@ the `POST` method to call the `/workflows` endpoint (for `curl` or Postman).
In the `CreateWorkflow` object (for the Python SDK) or
the request body (for `curl` or Postman),
specify the settings for the workflow. For the specific settings to include, see
-[Create a workflow](/platform-api/api/workflows#create-a-workflow).
+[Create a workflow](/api/workflow/workflows#create-a-workflow).
@@ -1757,7 +1757,7 @@ the `POST` method to call the `/workflows//run` endpoint (for `curl
To run a workflow on a schedule instead, specify the `schedule` setting in the request body when you create or update a
-workflow. See [Create a workflow](/platform-api/api/workflows#create-a-workflow) or [Update a workflow](/platform-api/api/workflows#update-a-workflow).
+workflow. See [Create a workflow](/api/workflow/workflows#create-a-workflow) or [Update a workflow](/api/workflow/workflows#update-a-workflow).
### Update a workflow
@@ -1767,7 +1767,7 @@ the `PUT` method to call the `/workflows/` endpoint (for `curl` or
In `UpdateWorkflow` object (for the Python SDK) or
the request body (for `curl` or Postman), specify the settings for the workflow. For the specific settings to include, see
-[Update a workflow](/platform-api/api/workflows#update-a-workflow).
+[Update a workflow](/api/workflow/workflows#update-a-workflow).
@@ -1993,7 +1993,7 @@ and [cancel](#cancel-a-job) jobs.
A job is created automatically whenever a workflow runs on a schedule; see [Create a workflow](#create-a-workflow).
A job is also created whenever you run a workflow; see [Run a workflow](#run-a-workflow).
-For general information, see [Jobs](/platform/jobs).
+For general information, see [Jobs](/ui/jobs).
### List jobs
diff --git a/platform-api/api/sources/azure-blob-storage.mdx b/api/workflow/sources/azure-blob-storage.mdx
similarity index 100%
rename from platform-api/api/sources/azure-blob-storage.mdx
rename to api/workflow/sources/azure-blob-storage.mdx
diff --git a/platform-api/api/sources/box.mdx b/api/workflow/sources/box.mdx
similarity index 100%
rename from platform-api/api/sources/box.mdx
rename to api/workflow/sources/box.mdx
diff --git a/platform-api/api/sources/confluence.mdx b/api/workflow/sources/confluence.mdx
similarity index 100%
rename from platform-api/api/sources/confluence.mdx
rename to api/workflow/sources/confluence.mdx
diff --git a/platform-api/api/sources/couchbase.mdx b/api/workflow/sources/couchbase.mdx
similarity index 100%
rename from platform-api/api/sources/couchbase.mdx
rename to api/workflow/sources/couchbase.mdx
diff --git a/platform-api/api/sources/databricks-volumes.mdx b/api/workflow/sources/databricks-volumes.mdx
similarity index 100%
rename from platform-api/api/sources/databricks-volumes.mdx
rename to api/workflow/sources/databricks-volumes.mdx
diff --git a/platform-api/api/sources/dropbox.mdx b/api/workflow/sources/dropbox.mdx
similarity index 100%
rename from platform-api/api/sources/dropbox.mdx
rename to api/workflow/sources/dropbox.mdx
diff --git a/platform-api/api/sources/elasticsearch.mdx b/api/workflow/sources/elasticsearch.mdx
similarity index 100%
rename from platform-api/api/sources/elasticsearch.mdx
rename to api/workflow/sources/elasticsearch.mdx
diff --git a/platform-api/api/sources/google-cloud.mdx b/api/workflow/sources/google-cloud.mdx
similarity index 100%
rename from platform-api/api/sources/google-cloud.mdx
rename to api/workflow/sources/google-cloud.mdx
diff --git a/platform-api/api/sources/google-drive.mdx b/api/workflow/sources/google-drive.mdx
similarity index 100%
rename from platform-api/api/sources/google-drive.mdx
rename to api/workflow/sources/google-drive.mdx
diff --git a/platform-api/api/sources/kafka.mdx b/api/workflow/sources/kafka.mdx
similarity index 100%
rename from platform-api/api/sources/kafka.mdx
rename to api/workflow/sources/kafka.mdx
diff --git a/platform-api/api/sources/mongodb.mdx b/api/workflow/sources/mongodb.mdx
similarity index 100%
rename from platform-api/api/sources/mongodb.mdx
rename to api/workflow/sources/mongodb.mdx
diff --git a/platform-api/api/sources/onedrive.mdx b/api/workflow/sources/onedrive.mdx
similarity index 100%
rename from platform-api/api/sources/onedrive.mdx
rename to api/workflow/sources/onedrive.mdx
diff --git a/platform-api/api/sources/outlook.mdx b/api/workflow/sources/outlook.mdx
similarity index 100%
rename from platform-api/api/sources/outlook.mdx
rename to api/workflow/sources/outlook.mdx
diff --git a/api/workflow/sources/overview.mdx b/api/workflow/sources/overview.mdx
new file mode 100644
index 00000000..bbee8b47
--- /dev/null
+++ b/api/workflow/sources/overview.mdx
@@ -0,0 +1,40 @@
+---
+title: Overview
+---
+
+To use the [Unstructured Workflow Endpoint](/api/workflow/overview) to manage source connectors, do the following:
+
+- To get a list of available source connectors, use the `UnstructuredClient` object's `sources.list_sources` function (for the Python SDK) or
+ the `GET` method to call the `/sources` endpoint (for `curl` or Postman). [Learn more](/api/workflow/overview#list-source-connectors).
+- To get information about a source connector, use the `UnstructuredClient` object's `sources.get_source` function (for the Python SDK) or
+ the `GET` method to call the `/sources/` endpoint (for `curl` or Postman). [Learn more](/api/workflow/overview#get-a-source-connector).
+- To create a source connector, use the `UnstructuredClient` object's `sources.create_source` function (for the Python SDK) or
+ the `POST` method to call the `/sources` endpoint (for `curl` or Postman). [Learn more](/api/workflow/overview#create-a-source-connector).
+- To update a source connector, use the `UnstructuredClient` object's `sources.update_source` function (for the Python SDK) or
+ the `PUT` method to call the `/sources/` endpoint (for `curl` or Postman). [Learn more](/api/workflow/overview#update-a-source-connector).
+- To delete a source connector, use the `UnstructuredClient` object's `sources.delete_source` function (for the Python SDK) or
+ the `DELETE` method to call the `/sources/` endpoint (for `curl` or Postman). [Learn more](/api/workflow/overview#delete-a-source-connector).
+
+To create or update a source connector, you must also provide settings that are specific to that connector.
+For the list of specific settings, see:
+
+- [Azure](/api/workflow/sources/azure-blob-storage) (`AZURE` for the Python SDK or `azure` for `curl` and Postman)
+- [Box](/api/workflow/sources/box) (`BOX` for the Python SDK or `box` for `curl` and Postman)
+- [Confluence](/api/workflow/sources/confluence) (`CONFLUENCE` for the Python SDK or `confluence` for `curl` and Postman)
+- [Couchbase](/api/workflow/sources/couchbase) (`COUCHBASE` for the Python SDK or `couchbase` for `curl` and Postman)
+- [Databricks Volumes](/api/workflow/sources/databricks-volumes) (`DATABRICKS_VOLUMES` for the Python SDK or `databricks_volumes` for `curl` and Postman)
+- [Dropbox](/api/workflow/sources/dropbox) (`DROPBOX` for the Python SDK or `dropbox` for `curl` and Postman)
+- [Elasticsearch](/api/workflow/sources/elasticsearch) (`ELASTICSEARCH` for the Python SDK or `elasticsearch` for `curl` and Postman)
+- [Google Cloud Storage](/api/workflow/sources/google-cloud) (`GCS` for the Python SDK or `gcs` for `curl` and Postman)
+- [Google Drive](/api/workflow/sources/google-drive) (`GOOGLE_DRIVE` for the Python SDK or `google_drive` for `curl` and Postman)
+- [Kafka](/api/workflow/sources/kafka) (`KAFKA_CLOUD` for the Python SDK or `kafka-cloud` for `curl` and Postman)
+- [MongoDB](/api/workflow/sources/mongodb) (`MONGODB` for the Python SDK or `mongodb` for `curl` and Postman)
+- [OneDrive](/api/workflow/sources/onedrive) (`ONEDRIVE` for the Python SDK or `onedrive` for `curl` and Postman)
+- [Outlook](/api/workflow/sources/outlook) (`OUTLOOK` for the Python SDK or `outlook` for `curl` and Postman)
+- [PostgreSQL](/api/workflow/sources/postgresql) (`POSTGRES` for the Python SDK or `postgres` for `curl` and Postman)
+- [S3](/api/workflow/sources/s3) (`S3` for the Python SDK or `s3` for `curl` and Postman)
+- [Salesforce](/api/workflow/sources/salesforce) (`SALESFORCE` for the Python SDK or `salesforce` for `curl` and Postman)
+- [SharePoint](/api/workflow/sources/sharepoint) (`SHAREPOINT` for the Python SDK or `sharepoint` for `curl` and Postman)
+- [Snowflake](/api/workflow/sources/snowflake) (`SNOWFLAKE` for the Python SDK or `snowflake` for `curl` and Postman)
+
+
diff --git a/platform-api/api/sources/postgresql.mdx b/api/workflow/sources/postgresql.mdx
similarity index 100%
rename from platform-api/api/sources/postgresql.mdx
rename to api/workflow/sources/postgresql.mdx
diff --git a/platform-api/api/sources/s3.mdx b/api/workflow/sources/s3.mdx
similarity index 100%
rename from platform-api/api/sources/s3.mdx
rename to api/workflow/sources/s3.mdx
diff --git a/platform-api/api/sources/salesforce.mdx b/api/workflow/sources/salesforce.mdx
similarity index 100%
rename from platform-api/api/sources/salesforce.mdx
rename to api/workflow/sources/salesforce.mdx
diff --git a/platform-api/api/sources/sharepoint.mdx b/api/workflow/sources/sharepoint.mdx
similarity index 100%
rename from platform-api/api/sources/sharepoint.mdx
rename to api/workflow/sources/sharepoint.mdx
diff --git a/platform-api/api/sources/snowflake.mdx b/api/workflow/sources/snowflake.mdx
similarity index 100%
rename from platform-api/api/sources/snowflake.mdx
rename to api/workflow/sources/snowflake.mdx
diff --git a/platform-api/api/workflows.mdx b/api/workflow/workflows.mdx
similarity index 96%
rename from platform-api/api/workflows.mdx
rename to api/workflow/workflows.mdx
index 16f86492..cd9bd1e5 100644
--- a/platform-api/api/workflows.mdx
+++ b/api/workflow/workflows.mdx
@@ -2,23 +2,23 @@
title: Workflows
---
-To use the [Unstructured Platform Workflow Endpoint](/platform-api/api/overview) to manage workflows, do the following:
+To use the [Unstructured Workflow Endpoint](/api/workflow/overview) to manage workflows, do the following:
- To get a list of available workflows, use the `UnstructuredClient` object's `workflows.list_workflows` function (for the Python SDK) or
- the `GET` method to call the `/workflows` endpoint (for `curl` or Postman). [Learn more](/platform-api/api/overview#list-workflows).
+ the `GET` method to call the `/workflows` endpoint (for `curl` or Postman). [Learn more](/api/workflow/overview#list-workflows).
- To get information about a workflow, use the `UnstructuredClient` object's `workflows.get_workflow` function (for the Python SDK) or
- the `GET` method to call the `/workflows/` endpoint (for `curl` or Postman)use the `GET` method to call the `/workflows/` endpoint. [Learn more](/platform-api/api/overview#get-a-workflow).
+ the `GET` method to call the `/workflows/` endpoint (for `curl` or Postman)use the `GET` method to call the `/workflows/` endpoint. [Learn more](/api/workflow/overview#get-a-workflow).
- To create a workflow, use the `UnstructuredClient` object's `workflows.create_workflow` function (for the Python SDK) or
the `POST` method to call the `/workflows` endpoint (for `curl` or Postman). [Learn more](#create-a-workflow).
- To run a workflow manually, use the `UnstructuredClient` object's `workflows.run_workflow` function (for the Python SDK) or
- the `POST` method to call the `/workflows//run` endpoint (for `curl` or Postman). [Learn more](/platform-api/api/overview#run-a-workflow).
+ the `POST` method to call the `/workflows//run` endpoint (for `curl` or Postman). [Learn more](/api/workflow/overview#run-a-workflow).
- To update a workflow, use the `UnstructuredClient` object's `workflows.update_workflow` function (for the Python SDK) or
the `PUT` method to call the `/workflows/` endpoint (for `curl` or Postman). [Learn more](#update-a-workflow).
- To delete a workflow, use the `UnstructuredClient` object's `workflows.delete_workflow` function (for the Python SDK) or
- the `DELETE` method to call the `/workflows/` endpoint (for `curl` or Postman). [Learn more](/platform-api/api/overview#delete-a-workflow).
+ the `DELETE` method to call the `/workflows/` endpoint (for `curl` or Postman). [Learn more](/api/workflow/overview#delete-a-workflow).
-The following examples assume that you have already met the [requirements](/platform-api/api/overview#requirements) and
-understand the [basics](/platform-api/api/overview#basics) of working with the Unstructured Platform Workflow Endpoint.
+The following examples assume that you have already met the [requirements](/api/workflow/overview#requirements) and
+understand the [basics](/api/workflow/overview#basics) of working with the Unstructured Workflow Endpoint.
## Create a workflow
@@ -269,10 +269,10 @@ Replace the preceding placeholders as follows:
- `` (_required_) - A unique name for this workflow.
- `` (_required_) - The ID of the target source connector. To get the ID,
use the `UnstructuredClient` object's `sources.list_sources` function (for the Python SDK) or
- the `GET` method to call the `/sources` endpoint (for `curl` or Postman). [Learn more](/platform-api/api/overview#list-source-connectors).
+ the `GET` method to call the `/sources` endpoint (for `curl` or Postman). [Learn more](/api/workflow/overview#list-source-connectors).
- `` (_required_) - The ID of the target destination connector. To get the ID,
use the `UnstructuredClient` object's `destinations.list_destinations` function (for the Python SDK) or
- the `GET` method to call the `/destinations` endpoint (for `curl` or Postman). [Learn more](/platform-api/api/overview#list-destination-connectors).
+ the `GET` method to call the `/destinations` endpoint (for `curl` or Postman). [Learn more](/api/workflow/overview#list-destination-connectors).
- `` (for the Python SDK) or `` (for `curl` or Postman) (_required_) - The workflow type. Available values include `CUSTOM` (for the Python SDK) and `custom` (for `curl` or Postman).
If `` is set to `CUSTOM` (for the Python SDK), or if `` is set to `custom` (for `curl` or Postman), you must add a `workflow_nodes` array. For instructions, see [Custom workflow DAG nodes](#custom-workflow-dag-nodes).
@@ -281,7 +281,7 @@ Replace the preceding placeholders as follows:
The previously-available workflow optimization types `ADVANCED`, `BASIC`, and `PLATINUM` (for the Python SDK) and
`advanced`, `basic`, and `platinum` (for `curl` or Postman) are non-operational and planned to be fully removed in a future release.
- The ability to create an [automatic workflow](/platform/workflows#create-an-automatic-workflow) type is currently not available but is planned to be added in a future release.
+ The ability to create an [automatic workflow](/ui/workflows#create-an-automatic-workflow) type is currently not available but is planned to be added in a future release.
- `` - The repeating automatic run schedule, specified as a predefined phrase. The available predefined phrases are:
@@ -307,7 +307,7 @@ the `PUT` method to call the `/workflows/` endpoint (for `curl` or
`` with the workflow's unique ID. To get this ID, see [List workflows](#list-workflows).
In the request body, specify the settings for the workflow. For the specific settings to include, see
-[Create a workflow](/platform-api/api/workflows#create-a-workflow).
+[Create a workflow](/api/workflow/workflows#create-a-workflow).
@@ -508,7 +508,7 @@ flowchart LR
A **Partitioner** node has a `type` of `WorkflowNodeType.PARTITION` (for the Python SDK) or `partition` (for `curl` and Postman).
-[Learn about the available partitioning strategies](/platform/partitioning).
+[Learn about the available partitioning strategies](/ui/partitioning).
#### Auto strategy
@@ -747,7 +747,7 @@ Allowed values for `provider` and `model` include:
A **Chunker** node has a `type` of `WorkflowNodeType.CHUNK` (for the Python SDK) or `chunk` (for `curl` and Postman).
-[Learn about the available chunking strategies](/platform/chunking).
+[Learn about the available chunking strategies](/ui/chunking).
#### Chunk by Character strategy
@@ -915,7 +915,7 @@ A **Chunker** node has a `type` of `WorkflowNodeType.CHUNK` (for the Python SDK)
An **Enrichment** node has a `type` of `WorkflowNodeType.PROMPTER` (for the Python SDK) or `prompter` (for `curl` and Postman).
-[Learn about the available enrichments](/platform/enriching/overview).
+[Learn about the available enrichments](/ui/enriching/overview).
#### Image Description task
@@ -1047,7 +1047,7 @@ Allowed values for `` include:
An **Embedder** node has a `type` of `WorkflowNodeType.EMBED` (for the Python SDK) or `embed` (for `curl` and Postman).
-[Learn about the available embedding providers and models](/platform/embedding).
+[Learn about the available embedding providers and models](/ui/embedding).
diff --git a/examplecode/codesamples/api/Unstructured-POST.postman_collection.json b/examplecode/codesamples/api/Unstructured-POST.postman_collection.json
index 0793aea1..06cdd379 100644
--- a/examplecode/codesamples/api/Unstructured-POST.postman_collection.json
+++ b/examplecode/codesamples/api/Unstructured-POST.postman_collection.json
@@ -7,7 +7,7 @@
},
"item": [
{
- "name": "(Platform Partition Endpoint) Basic Request",
+ "name": "(Partition Endpoint) Basic Request",
"request": {
"method": "POST",
"header": [
diff --git a/examplecode/codesamples/api/huggingchat.mdx b/examplecode/codesamples/api/huggingchat.mdx
index 992197c3..f4eef381 100644
--- a/examplecode/codesamples/api/huggingchat.mdx
+++ b/examplecode/codesamples/api/huggingchat.mdx
@@ -3,15 +3,15 @@ title: Query processed PDF with HuggingChat
---
This example uses the [Unstructured Ingest Python library](/ingestion/python-ingest) or the
-[Unstructured JavaScript/TypeScript SDK](/platform-api/partition-api/sdk-jsts) to send a PDF file to
-the [Unstructured Platform Partition Endpoint](/platform-api/partition-api/overview) for processing. Unstructured processes the PDF and extracts the PDF's content.
+[Unstructured JavaScript/TypeScript SDK](/api/partition/sdk-jsts) to send a PDF file to
+the [Unstructured Partition Endpoint](/api/partition/overview) for processing. Unstructured processes the PDF and extracts the PDF's content.
This example then sends some of the content to [HuggingChat](https://huggingface.co/chat/), Hugging Face's open-source AI chatbot,
along with some queries about this content.
To run this example, you'll need:
- The [hugchat](https://pypi.org/project/hugchat/) package for Python, or the [huggingface-chat](https://www.npmjs.com/package/huggingface-chat) package for JavaScript/TypeScript.
-- Your Unstructured API key and API URL. [Get an API key and API URL](/platform-api/partition-api/overview).
+- Your Unstructured API key and API URL. [Get an API key and API URL](/api/partition/overview).
- Your Hugging Face account's email address and account password. [Get an account](https://huggingface.co/join).
- A PDF file for Unstructured to process. This example uses a sample PDF file containing the text of the United States Constitution,
available for download from [https://constitutioncenter.org/media/files/constitution.pdf](https://constitutioncenter.org/media/files/constitution.pdf).
diff --git a/examplecode/codesamples/apioss/table-extraction-from-pdf.mdx b/examplecode/codesamples/apioss/table-extraction-from-pdf.mdx
index ba992f69..88525226 100644
--- a/examplecode/codesamples/apioss/table-extraction-from-pdf.mdx
+++ b/examplecode/codesamples/apioss/table-extraction-from-pdf.mdx
@@ -4,7 +4,7 @@ description: This section describes two methods for extracting tables from PDF f
---
-This sample code utilizes the [Unstructured Open Source](/open-source/introduction/overview "Open Source") library and also provides an alternative method the utilizing the [Unstructured Platform Partition Endpoint](/platform-api/partition-api/overview).
+This sample code utilizes the [Unstructured Open Source](/open-source/introduction/overview "Open Source") library and also provides an alternative method the utilizing the [Unstructured Partition Endpoint](/api/partition/overview).
## Method 1: Using partition\_pdf
@@ -33,7 +33,7 @@ print(tables[0].metadata.text_as_html)
## Method 2: Using Auto Partition or Unstructured API
-By default, table extraction from all file types is enabled. To extract tables from PDFs and images using [Auto Partition](/open-source/core-functionality/partitioning#partition) or [Unstructured API parameters](/platform-api/partition-api/api-parameters) simply set `strategy` parameter to `hi_res`.
+By default, table extraction from all file types is enabled. To extract tables from PDFs and images using [Auto Partition](/open-source/core-functionality/partitioning#partition) or [Unstructured API parameters](/api/partition/api-parameters) simply set `strategy` parameter to `hi_res`.
**Usage: Auto Partition**
diff --git a/examplecode/codesamples/oss/multi-files-api-processing.mdx b/examplecode/codesamples/oss/multi-files-api-processing.mdx
index 21bf7c20..83b52c6a 100644
--- a/examplecode/codesamples/oss/multi-files-api-processing.mdx
+++ b/examplecode/codesamples/oss/multi-files-api-processing.mdx
@@ -2,7 +2,7 @@
title: Multi-file API processing
---
-This sample code utilizes the [Unstructured Platform Partition Endpoint](/platform-api/partition-api/overview).
+This sample code utilizes the [Unstructured Partition Endpoint](/api/partition/overview).
## Introduction
diff --git a/examplecode/notebooks.mdx b/examplecode/notebooks.mdx
index d49c3fc3..cf72317f 100644
--- a/examplecode/notebooks.mdx
+++ b/examplecode/notebooks.mdx
@@ -8,9 +8,9 @@ description: "Notebooks contain complete working sample code for end-to-end solu
- Build RAG with Databricks Vector Search with context preprocessed from multiple sources by Unstructured Platform.
+ Build RAG with Databricks Vector Search with context preprocessed from multiple sources by Unstructured.
- ``Unstructured Platform`` ``Databricks`` ``Introductory notebook``
+ ``Databricks`` ``Introductory notebook``
@@ -18,21 +18,21 @@ description: "Notebooks contain complete working sample code for end-to-end solu
Build Agentic RAG with `smolagents` library and compare the results with Vanilla RAG in pure Python
- ``Unstructured Platform UI`` ``GPT-4o`` ``smolagents`` ``Agents`` ``DataStax`` ``S3`` ``Advanced notebook``
+ ``GPT-4o`` ``smolagents`` ``Agents`` ``DataStax`` ``S3`` ``Advanced notebook``
- Evaluate Llama3.2 for your RAG system with Unstructured Platform, GPT-4o, Ragas, and LangChain
+ Evaluate Llama3.2 for your RAG system with Unstructured, GPT-4o, Ragas, and LangChain
- ``Unstructured Platform UI`` ``GPT-4o`` ``Ragas`` ``LangChain`` ``Llama3.2`` ``Pinecone`` ``S3`` ``Advanced notebook``
+ ``GPT-4o`` ``Ragas`` ``LangChain`` ``Llama3.2`` ``Pinecone`` ``S3`` ``Advanced notebook``
- Process a file in S3 with Unstructured Platform and return images in your RAG output
+ Process a file in S3 with Unstructured and return images in your RAG output
- ``Unstructured Platform UI`` ``S3`` ``FAISS`` ``GPT-4o-mini`` ``Advanced notebook``
+ ``S3`` ``FAISS`` ``GPT-4o-mini`` ``Advanced notebook``
diff --git a/examplecode/tools/langflow.mdx b/examplecode/tools/langflow.mdx
index d86a8f32..0b921b10 100644
--- a/examplecode/tools/langflow.mdx
+++ b/examplecode/tools/langflow.mdx
@@ -21,7 +21,7 @@ Also:
- [Sign up for an OpenAI account](https://platform.openai.com/signup), and [get your OpenAI API key](https://help.openai.com/en/articles/4936850-where-do-i-find-my-openai-api-key).
- [Sign up for a free Langflow account](https://astra.datastax.com/signup?type=langflow).
-- [Get your Unstructured Platform Partition Endpoint key](/platform-api/partition-api/overview).
+- [Get your Unstructured Partition Endpoint key](/api/partition/overview).
## Create and run the demonstration project
@@ -32,7 +32,7 @@ Also:
3. Click **Blank Flow**.
- In this step, you add a component that instructs the Unstructured Platform Partition Endpoint to process a local file that you specify.
+ In this step, you add a component that instructs the Unstructured Partition Endpoint to process a local file that you specify.
1. On the sidebar, expand **Experimental (Beta)**, and then expand **Loaders**.
2. Drag the **Unstructured** component onto the designer area.
@@ -233,14 +233,14 @@ such as processing multiple files or using a different vector store.
In this demonstration, you pass to Unstructured a single local file. To pass multiple local or
non-local files to Unstructured instead, you can use the
-[Unstructured Platform](/platform/overview) or
+[Unstructured UI](/ui/overview) or the [Unstructured API](/api/overview) or
[Unstructured Ingest](/ingestion/overview) outside of Langflow.
To do this, you can:
-- [Use the Unstructured Platform to create a workflow](/platform/quickstart) that relies on any available
- [source connector](/platform/sources/overview) to connect to
- [Astra DB](/platform/destinations/astradb). Run this workflow outside of Langflow anytime you have new documents in that source location that
+- [Use the Unstructured UI to create a workflow](/ui/quickstart) that relies on any available
+ [source connector](/ui/sources/overview) to connect to
+ [Astra DB](/ui/destinations/astradb). Run this workflow outside of Langflow anytime you have new documents in that source location that
you want Unstructured to process and then insert the new processed data into Astra DB. Then, back in the Langflow project,
use the **Playground** to ask additional questions, which will now include the new data when generating answers.
@@ -256,13 +256,13 @@ In this demonstration, you use Astra DB as the vector store. Langflow and Unstru
To do this, you can:
-[Use the Unstructured Platform to create a workflow](/platform/quickstart) that relies on any available
-[source connector](/platform/sources/overview) to connect to
+[Use the Unstructured UI to create a workflow](/ui/quickstart) that relies on any available
+[source connector](/ui/sources/overview) to connect to
one of the following available vector stores that Langflow also supports:
-- [Milvus](/platform/destinations/milvus)
-- [MongoDB](/platform/destinations/mongodb)
-- [Pinecone](/platform/destinations/pinecone)
+- [Milvus](/ui/destinations/milvus)
+- [MongoDB](/ui/destinations/mongodb)
+- [Pinecone](/ui/destinations/pinecone)
Run this workflow outside of Langflow anytime you have new documents in the source location that
you want Unstructured to process and then insert the new processed data into the vector store. Then, back in the Langflow project,
diff --git a/examplecode/tools/vectorshift.mdx b/examplecode/tools/vectorshift.mdx
index 488cc748..525bf054 100644
--- a/examplecode/tools/vectorshift.mdx
+++ b/examplecode/tools/vectorshift.mdx
@@ -43,20 +43,20 @@ Also:
- [Sign up for an OpenAI account](https://platform.openai.com/signup), and [get your OpenAI API key](https://help.openai.com/en/articles/4936850-where-do-i-find-my-openai-api-key).
- [Sign up for a VectorShift Starter account](https://app.vectorshift.ai/api/signup).
-- [Sign up for an Unstructured Platform account through the For Developers page](/platform/quickstart).
+- [Sign up for an Unstructured account through the For Developers page](/ui/quickstart).
## Create and run the demonstration project
- Although you can use any [supported file type](/platform/supported-file-types) or data in any
- [supported source type](/platform/sources/overview) for the input into Pinecone, this demonstration uses [the text of the United States Constitution in PDF format](https://constitutioncenter.org/media/files/constitution.pdf).
-
- 1. Sign in to your Unstructured Platform account.
- 2. [Create a source connector](/platform/sources/overview), if you do not already have one, to connect Unstructured to the source location where the PDF file is stored.
- 3. [Create a Pinecone destination connector](/platform/destinations/pinecone), if you do not already have one, to connect Unstructured to your Pinecone serverless index.
- 4. [Create a workflow](/platform/workflows#create-a-workflow) that references this source connector and destination connector.
- 5. [Run the workflow](/platform/workflows#edit-delete-or-run-a-workflow).
+ Although you can use any [supported file type](/ui/supported-file-types) or data in any
+ [supported source type](/ui/sources/overview) for the input into Pinecone, this demonstration uses [the text of the United States Constitution in PDF format](https://constitutioncenter.org/media/files/constitution.pdf).
+
+ 1. Sign in to your Unstructured account.
+ 2. [Create a source connector](/ui/sources/overview), if you do not already have one, to connect Unstructured to the source location where the PDF file is stored.
+ 3. [Create a Pinecone destination connector](/ui/destinations/pinecone), if you do not already have one, to connect Unstructured to your Pinecone serverless index.
+ 4. [Create a workflow](/ui/workflows#create-a-workflow) that references this source connector and destination connector.
+ 5. [Run the workflow](/ui/workflows#edit-delete-or-run-a-workflow).
1. Sign in to your VectorShift account dashboard.
diff --git a/img/platform/APIKeyOnly.png b/img/ui/APIKeyOnly.png
similarity index 100%
rename from img/platform/APIKeyOnly.png
rename to img/ui/APIKeyOnly.png
diff --git a/img/platform/APIKeyURL.png b/img/ui/APIKeyURL.png
similarity index 100%
rename from img/platform/APIKeyURL.png
rename to img/ui/APIKeyURL.png
diff --git a/img/platform/AccountBilling.png b/img/ui/AccountBilling.png
similarity index 100%
rename from img/platform/AccountBilling.png
rename to img/ui/AccountBilling.png
diff --git a/img/platform/AccountBillingPayPerPage.png b/img/ui/AccountBillingPayPerPage.png
similarity index 100%
rename from img/platform/AccountBillingPayPerPage.png
rename to img/ui/AccountBillingPayPerPage.png
diff --git a/img/platform/AccountBillingPaymentMethod.png b/img/ui/AccountBillingPaymentMethod.png
similarity index 100%
rename from img/platform/AccountBillingPaymentMethod.png
rename to img/ui/AccountBillingPaymentMethod.png
diff --git a/img/platform/AccountBillingSubscribeAndSave.png b/img/ui/AccountBillingSubscribeAndSave.png
similarity index 100%
rename from img/platform/AccountBillingSubscribeAndSave.png
rename to img/ui/AccountBillingSubscribeAndSave.png
diff --git a/img/platform/AccountSettings.png b/img/ui/AccountSettings.png
similarity index 100%
rename from img/platform/AccountSettings.png
rename to img/ui/AccountSettings.png
diff --git a/img/platform/AccountSettingsNeedHelp.png b/img/ui/AccountSettingsNeedHelp.png
similarity index 100%
rename from img/platform/AccountSettingsNeedHelp.png
rename to img/ui/AccountSettingsNeedHelp.png
diff --git a/img/platform/AccountSettingsSidebar.png b/img/ui/AccountSettingsSidebar.png
similarity index 100%
rename from img/platform/AccountSettingsSidebar.png
rename to img/ui/AccountSettingsSidebar.png
diff --git a/img/platform/AccountSettingsSidebarMessageUs.png b/img/ui/AccountSettingsSidebarMessageUs.png
similarity index 100%
rename from img/platform/AccountSettingsSidebarMessageUs.png
rename to img/ui/AccountSettingsSidebarMessageUs.png
diff --git a/img/platform/AccountUsage.png b/img/ui/AccountUsage.png
similarity index 100%
rename from img/platform/AccountUsage.png
rename to img/ui/AccountUsage.png
diff --git a/img/platform/Choose-Workflow-Type.png b/img/ui/Choose-Workflow-Type.png
similarity index 100%
rename from img/platform/Choose-Workflow-Type.png
rename to img/ui/Choose-Workflow-Type.png
diff --git a/img/platform/Destinations-Sidebar.png b/img/ui/Destinations-Sidebar.png
similarity index 100%
rename from img/platform/Destinations-Sidebar.png
rename to img/ui/Destinations-Sidebar.png
diff --git a/img/platform/GoToPlatform.png b/img/ui/GoToPlatform.png
similarity index 100%
rename from img/platform/GoToPlatform.png
rename to img/ui/GoToPlatform.png
diff --git a/img/platform/Job-Complete.png b/img/ui/Job-Complete.png
similarity index 100%
rename from img/platform/Job-Complete.png
rename to img/ui/Job-Complete.png
diff --git a/img/platform/Job-Failed.png b/img/ui/Job-Failed.png
similarity index 100%
rename from img/platform/Job-Failed.png
rename to img/ui/Job-Failed.png
diff --git a/img/platform/Job-Finished-Fully.png b/img/ui/Job-Finished-Fully.png
similarity index 100%
rename from img/platform/Job-Finished-Fully.png
rename to img/ui/Job-Finished-Fully.png
diff --git a/img/platform/Job-Finished-Partially.png b/img/ui/Job-Finished-Partially.png
similarity index 100%
rename from img/platform/Job-Finished-Partially.png
rename to img/ui/Job-Finished-Partially.png
diff --git a/img/platform/Job-In-Progress.png b/img/ui/Job-In-Progress.png
similarity index 100%
rename from img/platform/Job-In-Progress.png
rename to img/ui/Job-In-Progress.png
diff --git a/img/platform/Job-Pending.png b/img/ui/Job-Pending.png
similarity index 100%
rename from img/platform/Job-Pending.png
rename to img/ui/Job-Pending.png
diff --git a/img/platform/Jobs-Sidebar.png b/img/ui/Jobs-Sidebar.png
similarity index 100%
rename from img/platform/Jobs-Sidebar.png
rename to img/ui/Jobs-Sidebar.png
diff --git a/img/platform/Node-Usage-Hints.png b/img/ui/Node-Usage-Hints.png
similarity index 100%
rename from img/platform/Node-Usage-Hints.png
rename to img/ui/Node-Usage-Hints.png
diff --git a/img/platform/PlatformAPIURL.png b/img/ui/PlatformAPIURL.png
similarity index 100%
rename from img/platform/PlatformAPIURL.png
rename to img/ui/PlatformAPIURL.png
diff --git a/img/platform/Python-Workflow-Code-Partial.png b/img/ui/Python-Workflow-Code-Partial.png
similarity index 100%
rename from img/platform/Python-Workflow-Code-Partial.png
rename to img/ui/Python-Workflow-Code-Partial.png
diff --git a/img/platform/Select-Job.png b/img/ui/Select-Job.png
similarity index 100%
rename from img/platform/Select-Job.png
rename to img/ui/Select-Job.png
diff --git a/img/platform/ServerlessAPIURL.png b/img/ui/ServerlessAPIURL.png
similarity index 100%
rename from img/platform/ServerlessAPIURL.png
rename to img/ui/ServerlessAPIURL.png
diff --git a/img/platform/ServerlessPlatformAPIURL.png b/img/ui/ServerlessPlatformAPIURL.png
similarity index 100%
rename from img/platform/ServerlessPlatformAPIURL.png
rename to img/ui/ServerlessPlatformAPIURL.png
diff --git a/img/platform/Signin.png b/img/ui/Signin.png
similarity index 100%
rename from img/platform/Signin.png
rename to img/ui/Signin.png
diff --git a/img/platform/Sources-Sidebar.png b/img/ui/Sources-Sidebar.png
similarity index 100%
rename from img/platform/Sources-Sidebar.png
rename to img/ui/Sources-Sidebar.png
diff --git a/img/platform/Start-Screen-Partial.png b/img/ui/Start-Screen-Partial.png
similarity index 100%
rename from img/platform/Start-Screen-Partial.png
rename to img/ui/Start-Screen-Partial.png
diff --git a/img/platform/Start-Screen.png b/img/ui/Start-Screen.png
similarity index 100%
rename from img/platform/Start-Screen.png
rename to img/ui/Start-Screen.png
diff --git a/img/platform/Workflow-Add-Node.png b/img/ui/Workflow-Add-Node.png
similarity index 100%
rename from img/platform/Workflow-Add-Node.png
rename to img/ui/Workflow-Add-Node.png
diff --git a/img/platform/Workflow-Designer.png b/img/ui/Workflow-Designer.png
similarity index 100%
rename from img/platform/Workflow-Designer.png
rename to img/ui/Workflow-Designer.png
diff --git a/img/platform/Workflow-Details.png b/img/ui/Workflow-Details.png
similarity index 100%
rename from img/platform/Workflow-Details.png
rename to img/ui/Workflow-Details.png
diff --git a/img/platform/Workflows-Sidebar.png b/img/ui/Workflows-Sidebar.png
similarity index 100%
rename from img/platform/Workflows-Sidebar.png
rename to img/ui/Workflows-Sidebar.png
diff --git a/ingestion/how-to/extract-image-block-types.mdx b/ingestion/how-to/extract-image-block-types.mdx
index 76741bd9..df700d97 100644
--- a/ingestion/how-to/extract-image-block-types.mdx
+++ b/ingestion/how-to/extract-image-block-types.mdx
@@ -15,7 +15,7 @@ and then show it.
## To run this example
You will need a document that is one of the document types supported by the `extract_image_block_types` argument.
-See the `extract_image_block_types` entry in [API Parameters](/platform-api/partition-api/api-parameters).
+See the `extract_image_block_types` entry in [API Parameters](/api/partition/api-parameters).
This example uses a PDF file with embedded images and tables.
import SharedAPIKeyURL from '/snippets/general-shared-text/api-key-url.mdx';
diff --git a/ingestion/ingest-cli.mdx b/ingestion/ingest-cli.mdx
index 7b5d2696..c475239c 100644
--- a/ingestion/ingest-cli.mdx
+++ b/ingestion/ingest-cli.mdx
@@ -6,9 +6,9 @@ sidebarTitle: Ingest CLI
The Unstructured Ingest CLI enables you to use command-line scripts to send files in batches to Unstructured for processing, and to tell Unstructured where to deliver the processed data. [Learn more](/ingestion/overview#unstructured-ingest-cli).
- The Unstructured Ingest CLI does not work with the Unstructured Platform API.
+ The Unstructured Ingest CLI does not work with the Unstructured API.
- For information about the Unstructured Platform API, see the [Unstructured Platform API Overview](/platform-api/api/overview).
+ For information about the Unstructured API, see the [Unstructured API Overview](/api/workflow/overview).
## Installation
diff --git a/ingestion/overview.mdx b/ingestion/overview.mdx
index fc1483c3..f5c2d1e4 100644
--- a/ingestion/overview.mdx
+++ b/ingestion/overview.mdx
@@ -3,14 +3,14 @@ title: Overview
---
- Unstructured recommends that you use the [Unstructured Platform API](/platform-api/overview) instead of the
+ Unstructured recommends that you use the [Unstructured API](/api/overview) instead of the
Unstructured Ingest CLI or the Unstructured Ingest Python library.
- The Unstructured Platform API provides a full range of partitioning, chunking, embedding, and enrichment options for your files and data.
+ The Unstructured API provides a full range of partitioning, chunking, embedding, and enrichment options for your files and data.
It also uses the latest and highest-performing models on the market today, and it has built-in logic to deliver the highest quality results
at the lowest cost.
- The Unstructured Ingest CLI and the Unstructured Ingest Python library are not being actively updated to include these and other Unstructured Platform API features.
+ The Unstructured Ingest CLI and the Unstructured Ingest Python library are not being actively updated to include these and other Unstructured API features.
You can send multiple files in batches to be ingested by Unstructured for processing.
@@ -131,5 +131,5 @@ import GeneratePythonCodeExamples from '/snippets/ingestion/code-generator.mdx';
## See also
-- The [Unstructured Platform UI](/platform/overview) enables you to send batches to Unstructured from remote locations, and to have Unstructured send the processed data to remote locations, all without using code or a CLI.
+- The [Unstructured UI](/ui/overview) enables you to send batches to Unstructured from remote locations, and to have Unstructured send the processed data to remote locations, all without using code or a CLI.
diff --git a/ingestion/python-ingest.mdx b/ingestion/python-ingest.mdx
index 3f1fe85f..6c5d3fcd 100644
--- a/ingestion/python-ingest.mdx
+++ b/ingestion/python-ingest.mdx
@@ -6,9 +6,9 @@ sidebarTitle: Ingest Python library
The Unstructured Ingest Python library enables you to use Python code to send files in batches to Unstructured for processing, and to tell Unstructured where to deliver the processed data.
- The Unstructured Ingest Python library does not work with the Unstructured Platform API.
+ The Unstructured Ingest Python library does not work with the Unstructured API.
- For information about the Unstructured Platform API, see the [Unstructured Platform API Overview](/platform-api/api/overview).
+ For information about the Unstructured API, see the [Unstructured API Overview](/api/workflow/overview).
The following 3-minute video shows how to use the Unstructured Ingest Python library to send multiple PDFs from a local directory in batches to be ingested by Unstructured for processing:
diff --git a/mint.json b/mint.json
index e84bec83..b2c93f98 100644
--- a/mint.json
+++ b/mint.json
@@ -74,12 +74,12 @@
},
"tabs": [
{
- "name": "Platform UI",
- "url": "platform"
+ "name": "UI",
+ "url": "ui"
},
{
- "name": "Platform API",
- "url": "platform-api"
+ "name": "API",
+ "url": "api"
},
{
"name": "Example code",
@@ -165,199 +165,199 @@
]
},
{
- "group": "Unstructured Platform UI",
+ "group": "Unstructured UI",
"pages": [
- "platform/overview",
- "platform/supported-file-types",
- "platform/connectors"
+ "ui/overview",
+ "ui/supported-file-types",
+ "ui/connectors"
]
},
{
- "group": "Getting started with Platform",
+ "group": "Getting started with the UI",
"pages": [
- "platform/quickstart"
+ "ui/quickstart"
]
},
{
- "group": "Using Platform",
+ "group": "Using the UI",
"pages": [
{
"group": "Sources",
"pages": [
- "platform/sources/overview",
- "platform/sources/azure-blob-storage",
- "platform/sources/box",
- "platform/sources/confluence",
- "platform/sources/couchbase",
- "platform/sources/databricks-volumes",
- "platform/sources/dropbox",
- "platform/sources/elasticsearch",
- "platform/sources/google-cloud",
- "platform/sources/google-drive",
- "platform/sources/kafka",
- "platform/sources/mongodb",
- "platform/sources/onedrive",
- "platform/sources/outlook",
- "platform/sources/postgresql",
- "platform/sources/s3",
- "platform/sources/salesforce",
- "platform/sources/sharepoint",
- "platform/sources/snowflake"
+ "ui/sources/overview",
+ "ui/sources/azure-blob-storage",
+ "ui/sources/box",
+ "ui/sources/confluence",
+ "ui/sources/couchbase",
+ "ui/sources/databricks-volumes",
+ "ui/sources/dropbox",
+ "ui/sources/elasticsearch",
+ "ui/sources/google-cloud",
+ "ui/sources/google-drive",
+ "ui/sources/kafka",
+ "ui/sources/mongodb",
+ "ui/sources/onedrive",
+ "ui/sources/outlook",
+ "ui/sources/postgresql",
+ "ui/sources/s3",
+ "ui/sources/salesforce",
+ "ui/sources/sharepoint",
+ "ui/sources/snowflake"
]
},
{
"group": "Destinations",
"pages": [
- "platform/destinations/overview",
- "platform/destinations/astradb",
- "platform/destinations/azure-ai-search",
- "platform/destinations/couchbase",
- "platform/destinations/databricks-volumes",
- "platform/destinations/delta-table",
- "platform/destinations/databricks-delta-table",
- "platform/destinations/elasticsearch",
- "platform/destinations/google-cloud",
- "platform/destinations/kafka",
- "platform/destinations/milvus",
- "platform/destinations/mongodb",
- "platform/destinations/motherduck",
- "platform/destinations/neo4j",
- "platform/destinations/onedrive",
- "platform/destinations/pinecone",
- "platform/destinations/postgresql",
- "platform/destinations/qdrant",
- "platform/destinations/redis",
- "platform/destinations/s3",
- "platform/destinations/snowflake",
- "platform/destinations/weaviate"
+ "ui/destinations/overview",
+ "ui/destinations/astradb",
+ "ui/destinations/azure-ai-search",
+ "ui/destinations/couchbase",
+ "ui/destinations/databricks-volumes",
+ "ui/destinations/delta-table",
+ "ui/destinations/databricks-delta-table",
+ "ui/destinations/elasticsearch",
+ "ui/destinations/google-cloud",
+ "ui/destinations/kafka",
+ "ui/destinations/milvus",
+ "ui/destinations/mongodb",
+ "ui/destinations/motherduck",
+ "ui/destinations/neo4j",
+ "ui/destinations/onedrive",
+ "ui/destinations/pinecone",
+ "ui/destinations/postgresql",
+ "ui/destinations/qdrant",
+ "ui/destinations/redis",
+ "ui/destinations/s3",
+ "ui/destinations/snowflake",
+ "ui/destinations/weaviate"
]
},
- "platform/workflows",
- "platform/jobs",
- "platform/billing"
+ "ui/workflows",
+ "ui/jobs",
+ "ui/billing"
]
},
{
"group": "Concepts",
"pages": [
- "platform/document-elements",
- "platform/partitioning",
- "platform/chunking",
+ "ui/document-elements",
+ "ui/partitioning",
+ "ui/chunking",
{
"group": "Enriching",
"pages": [
- "platform/enriching/overview",
- "platform/enriching/image-descriptions",
- "platform/enriching/table-descriptions",
- "platform/enriching/table-to-html",
- "platform/enriching/ner"
+ "ui/enriching/overview",
+ "ui/enriching/image-descriptions",
+ "ui/enriching/table-descriptions",
+ "ui/enriching/table-to-html",
+ "ui/enriching/ner"
]
},
- "platform/embedding"
+ "ui/embedding"
]
},
{
- "group": "Unstructured Platform API",
+ "group": "Unstructured API",
"pages": [
- "platform-api/overview",
- "platform-api/supported-file-types"
+ "api/overview",
+ "api/supported-file-types"
]
},
{
"group": "Workflow Endpoint",
"pages": [
- "platform-api/api/overview",
+ "api/workflow/overview",
{
"group": "Sources",
"pages": [
- "platform-api/api/sources/overview",
- "platform-api/api/sources/azure-blob-storage",
- "platform-api/api/sources/box",
- "platform-api/api/sources/confluence",
- "platform-api/api/sources/couchbase",
- "platform-api/api/sources/databricks-volumes",
- "platform-api/api/sources/dropbox",
- "platform-api/api/sources/elasticsearch",
- "platform-api/api/sources/google-cloud",
- "platform-api/api/sources/google-drive",
- "platform-api/api/sources/kafka",
- "platform-api/api/sources/mongodb",
- "platform-api/api/sources/onedrive",
- "platform-api/api/sources/outlook",
- "platform-api/api/sources/postgresql",
- "platform-api/api/sources/s3",
- "platform-api/api/sources/salesforce",
- "platform-api/api/sources/sharepoint",
- "platform-api/api/sources/snowflake"
+ "api/workflow/sources/overview",
+ "api/workflow/sources/azure-blob-storage",
+ "api/workflow/sources/box",
+ "api/workflow/sources/confluence",
+ "api/workflow/sources/couchbase",
+ "api/workflow/sources/databricks-volumes",
+ "api/workflow/sources/dropbox",
+ "api/workflow/sources/elasticsearch",
+ "api/workflow/sources/google-cloud",
+ "api/workflow/sources/google-drive",
+ "api/workflow/sources/kafka",
+ "api/workflow/sources/mongodb",
+ "api/workflow/sources/onedrive",
+ "api/workflow/sources/outlook",
+ "api/workflow/sources/postgresql",
+ "api/workflow/sources/s3",
+ "api/workflow/sources/salesforce",
+ "api/workflow/sources/sharepoint",
+ "api/workflow/sources/snowflake"
]
},
{
"group": "Destinations",
"pages": [
- "platform-api/api/destinations/overview",
- "platform-api/api/destinations/astradb",
- "platform-api/api/destinations/azure-ai-search",
- "platform-api/api/destinations/couchbase",
- "platform-api/api/destinations/databricks-volumes",
- "platform-api/api/destinations/delta-table",
- "platform-api/api/destinations/databricks-delta-table",
- "platform-api/api/destinations/elasticsearch",
- "platform-api/api/destinations/google-cloud",
- "platform-api/api/destinations/kafka",
- "platform-api/api/destinations/milvus",
- "platform-api/api/destinations/mongodb",
- "platform-api/api/destinations/motherduck",
- "platform-api/api/destinations/neo4j",
- "platform-api/api/destinations/onedrive",
- "platform-api/api/destinations/pinecone",
- "platform-api/api/destinations/postgresql",
- "platform-api/api/destinations/qdrant",
- "platform-api/api/destinations/redis",
- "platform-api/api/destinations/s3",
- "platform-api/api/destinations/snowflake",
- "platform-api/api/destinations/weaviate"
+ "api/workflow/destinations/overview",
+ "api/workflow/destinations/astradb",
+ "api/workflow/destinations/azure-ai-search",
+ "api/workflow/destinations/couchbase",
+ "api/workflow/destinations/databricks-volumes",
+ "api/workflow/destinations/delta-table",
+ "api/workflow/destinations/databricks-delta-table",
+ "api/workflow/destinations/elasticsearch",
+ "api/workflow/destinations/google-cloud",
+ "api/workflow/destinations/kafka",
+ "api/workflow/destinations/milvus",
+ "api/workflow/destinations/mongodb",
+ "api/workflow/destinations/motherduck",
+ "api/workflow/destinations/neo4j",
+ "api/workflow/destinations/onedrive",
+ "api/workflow/destinations/pinecone",
+ "api/workflow/destinations/postgresql",
+ "api/workflow/destinations/qdrant",
+ "api/workflow/destinations/redis",
+ "api/workflow/destinations/s3",
+ "api/workflow/destinations/snowflake",
+ "api/workflow/destinations/weaviate"
]
},
- "platform-api/api/workflows",
- "platform-api/api/jobs"
+ "api/workflow/workflows",
+ "api/workflow/jobs"
]
},
{
"group": "Partition Endpoint",
"pages": [
- "platform-api/partition-api/overview",
- "platform-api/partition-api/post-requests",
- "platform-api/partition-api/sdk-python",
- "platform-api/partition-api/sdk-jsts",
- "platform-api/partition-api/api-parameters",
- "platform-api/partition-api/api-validation-errors",
- "platform-api/partition-api/examples",
- "platform-api/partition-api/document-elements",
- "platform-api/partition-api/partitioning",
- "platform-api/partition-api/chunking",
- "platform-api/partition-api/speed-up-large-files-batches",
- "platform-api/partition-api/get-elements",
- "platform-api/partition-api/text-as-html",
- "platform-api/partition-api/extract-image-block-types",
- "platform-api/partition-api/get-chunked-elements",
- "platform-api/partition-api/transform-schemas",
- "platform-api/partition-api/generate-schema",
- "platform-api/partition-api/pipeline-1"
+ "api/partition/overview",
+ "api/partition/post-requests",
+ "api/partition/sdk-python",
+ "api/partition/sdk-jsts",
+ "api/partition/api-parameters",
+ "api/partition/api-validation-errors",
+ "api/partition/examples",
+ "api/partition/document-elements",
+ "api/partition/partitioning",
+ "api/partition/chunking",
+ "api/partition/speed-up-large-files-batches",
+ "api/partition/get-elements",
+ "api/partition/text-as-html",
+ "api/partition/extract-image-block-types",
+ "api/partition/get-chunked-elements",
+ "api/partition/transform-schemas",
+ "api/partition/generate-schema",
+ "api/partition/pipeline-1"
]
},
{
"group": "Legacy APIs",
"pages": [
- "platform-api/legacy-api/overview",
- "platform-api/legacy-api/free-api",
- "platform-api/legacy-api/aws",
- "platform-api/legacy-api/azure"
+ "api/legacy-api/overview",
+ "api/legacy-api/free-api",
+ "api/legacy-api/aws",
+ "api/legacy-api/azure"
]
},
{
"group": "Troubleshooting",
"pages": [
- "platform-api/troubleshooting/api-key-url"
+ "api/troubleshooting/api-key-url"
]
},
{
@@ -513,43 +513,43 @@
"redirects": [
{
"source": "/api-reference/api-services/accessing-unstructured-api",
- "destination": "/platform-api/overview"
+ "destination": "/api/overview"
},
{
"source": "/api-reference/api-services/api-parameters",
- "destination": "/platform-api/partition-api/api-parameters"
+ "destination": "/api/partition/api-parameters"
},
{
"source": "/api-reference/api-services/api-validation-errors",
- "destination": "/platform-api/partition-api/api-validation-errors"
+ "destination": "/api/partition/api-validation-errors"
},
{
"source": "/api-reference/api-services/aws",
- "destination": "/platform-api/legacy-api/aws"
+ "destination": "/api/legacy-api/aws"
},
{
"source": "/api-reference/api-services/azure",
- "destination": "/platform-api/legacy-api/azure"
+ "destination": "/api/legacy-api/azure"
},
{
"source": "/api-reference/api-services/chunking",
- "destination": "/platform-api/partition-api/chunking"
+ "destination": "/api/partition/chunking"
},
{
"source": "/api-reference/api-services/document-elements",
- "destination": "/platform-api/partition-api/document-elements"
+ "destination": "/api/partition/document-elements"
},
{
"source": "/api-reference/api-services/examples",
- "destination": "/platform-api/partition-api/examples"
+ "destination": "/api/partition/examples"
},
{
"source": "/api-reference/api-services/free-api",
- "destination": "/platform-api/legacy-api/free-api"
+ "destination": "/api/legacy-api/free-api"
},
{
"source": "/api-reference/api-services/overview",
- "destination": "/platform-api/overview"
+ "destination": "/api/overview"
},
{
"source": "/api-reference/api-services/partition-via-api",
@@ -557,39 +557,39 @@
},
{
"source": "/api-reference/api-services/partitioning",
- "destination": "/platform-api/partition-api/partitioning"
+ "destination": "/api/partition/partitioning"
},
{
"source": "/api-reference/api-services/post-requests",
- "destination": "/platform-api/partition-api/post-requests"
+ "destination": "/api/partition/post-requests"
},
{
"source": "/api-reference/api-services/saas-api-development-guide",
- "destination": "/platform-api/overview"
+ "destination": "/api/overview"
},
{
"source": "/api-reference/api-services/sdk-jsts",
- "destination": "/platform-api/partition-api/sdk-jsts"
+ "destination": "/api/partition/sdk-jsts"
},
{
"source": "/api-reference/api-services/sdk-python",
- "destination": "platform-api/partition-api/sdk-python"
+ "destination": "/api/partition/sdk-python"
},
{
"source": "/api-reference/api-services/supported-file-types",
- "destination": "/platform-api/supported-file-types"
+ "destination": "/api/supported-file-types"
},
{
"source": "/api-reference/best-practices/speed-up-large-files-batches",
- "destination": "/platform-api/partition-api/speed-up-large-files-batches"
+ "destination": "/api/partition/speed-up-large-files-batches"
},
{
"source": "/api-reference/general/pipeline-1",
- "destination": "/platform-api/partition-api/pipeline-1"
+ "destination": "/api/partition/pipeline-1"
},
{
"source": "/api-reference/how-to/:slug*",
- "destination": "/platform-api/partition-api/:slug*"
+ "destination": "/api/partition/:slug*"
},
{
"source": "/api-reference/ingest/:slug*",
@@ -597,7 +597,7 @@
},
{
"source": "/api-reference/troubleshooting/api-key-url",
- "destination": "/platform-api/troubleshooting/api-key-url"
+ "destination": "/api/troubleshooting/api-key-url"
},
{
"source": "/glossary/glossary",
@@ -607,26 +607,42 @@
"source": "/open-source/ingest/:slug*",
"destination": "/ingestion/:slug*"
},
+ {
+ "source": "/platform/:slug*",
+ "destination": "/ui/:slug*"
+ },
{
"source": "/platform/api/:slug*",
- "destination": "/platform-api/api/:slug*"
+ "destination": "/api/workflow/:slug*"
+ },
+ {
+ "source": "/platform-api/api/:slug*",
+ "destination": "/api/workflow/:slug*"
+ },
+ {
+ "source": "/platform-api/legacy-api/:slug*",
+ "destination": "/api/legacy-api/:slug*"
},
{
"source": "/platform-api/partition-api/choose-hi-res-model",
- "destination": "/platform-api/partition-api/partitioning"
+ "destination": "/api/partition/partitioning"
},
{
"source": "/platform-api/partition-api/choose-partitioning-strategy",
- "destination": "/platform-api/partition-api/partitioning"
+ "destination": "/api/partition/partitioning"
},
{
"source": "/platform-api/partition-api/embedding",
- "destination": "/ingestion/how-to/embedding"
+ "destination": "/api/partition/embedding"
},
{
"source": "/platform-api/partition-api/filter-files",
"destination": "/ingestion/how-to/filter-files"
- }
+ },
+ {
+ "source": "/platform-api/partition-api/:slug*",
+ "destination": "/api/partition/:slug*"
+ }
],
"analytics": {
"ga4": {
diff --git a/open-source/core-functionality/partitioning.mdx b/open-source/core-functionality/partitioning.mdx
index 2ddad7b0..9fbbd758 100644
--- a/open-source/core-functionality/partitioning.mdx
+++ b/open-source/core-functionality/partitioning.mdx
@@ -692,7 +692,7 @@ elements = partition_via_api(
```
-If you are using the [Unstructured Platform Partition Endpoint](/platform-api/partition-api/overview), you can use the `api_url` kwarg to point the `partition_via_api` function at your Unstructured Platform Partition URL.
+If you are using the [Unstructured Partition Endpoint](/api/partition/overview), you can use the `api_url` kwarg to point the `partition_via_api` function at your Unstructured Partition URL.
```python
import os
diff --git a/open-source/introduction/overview.mdx b/open-source/introduction/overview.mdx
index 84da4a7f..5cbb4f8d 100644
--- a/open-source/introduction/overview.mdx
+++ b/open-source/introduction/overview.mdx
@@ -3,7 +3,7 @@ title: Unstructured Open Source
sidebarTitle: Overview
---
-The `unstructured` open source library is designed as a starting point for quick prototyping and has [limits](#limits). For production scenarios, see the [Unstructured Platform API](/platform-api/overview) instead.
+The `unstructured` open source library is designed as a starting point for quick prototyping and has [limits](#limits). For production scenarios, see the [Unstructured API](/api/overview) instead.
The `unstructured` [library](https://github.com/Unstructured-IO/unstructured) offers an open-source toolkit
designed to simplify the ingestion and pre-processing of diverse data formats, including images and text-based documents
@@ -44,7 +44,7 @@ and use cases.
## Limits
-The open source library has the following limits as compared to [Unstructured Platform API](/platform-api/overview) and the [Unstructured Platform](/platform/overview):
+The open source library has the following limits as compared to the [Unstructured UI](/ui/overview) and the [Unstructured API](/api/overview):
* Not designed for production scenarios.
* Significantly decreased performance on document and table extraction.
@@ -62,7 +62,7 @@ The open source library has the following limits as compared to [Unstructured Pl
## Telemetry
-The open source library allows you to make calls to the Unstructured Platform Partition Endpoint. If you do plan to make such calls, please note:
+The open source library allows you to make calls to the Unstructured Partition Endpoint. If you do plan to make such calls, please note:
import SharedTelemetry from '/snippets/general-shared-text/telemetry.mdx';
diff --git a/openapi.json b/openapi.json
index 687b9b9a..ff0a2def 100644
--- a/openapi.json
+++ b/openapi.json
@@ -7,7 +7,7 @@
"servers": [
{
"url": "https://api.unstructuredapp.io",
- "description": "Platform Partition Endpoint",
+ "description": "Partition Endpoint",
"x-speakeasy-server-id": "saas-api"
},
{
diff --git a/platform-api/api/destinations/overview.mdx b/platform-api/api/destinations/overview.mdx
deleted file mode 100644
index 483f262b..00000000
--- a/platform-api/api/destinations/overview.mdx
+++ /dev/null
@@ -1,42 +0,0 @@
----
-title: Overview
----
-
-To use the [Unstructured Platform Workflow Endpoint](/platform-api/api/overview) to manage destination connectors, do the following:
-
-- To get a list of available destination connectors, use the `UnstructuredClient` object's `destinations.list_destinations` function (for the Python SDK) or
- the `GET` method to call the `/destinations` endpoint (for `curl` or Postman).. [Learn more](/platform-api/api/overview#list-destination-connectors).
-- To get information about a destination connector, use the `UnstructuredClient` object's `destinations.get_destination` function (for the Python SDK) or
- the `GET` method to call the `/destinations/` endpoint (for `curl` or Postman). [Learn more](/platform-api/api/overview#get-a-destination-connector).
-- To create a destination connector, use the `UnstructuredClient` object's `destinations.create_destination` function (for the Python SDK) or
- the `POST` method to call the `/destinations` endpoint (for `curl` or Postman). [Learn more](/platform-api/api/overview#create-a-destination-connector).
-- To update a destination connector, use the `UnstructuredClient` object's `destinations.update_destination` function (for the Python SDK) or
- the `PUT` method to call the `/destinations/` endpoint (for `curl` or Postman). [Learn more](/platform-api/api/overview#update-a-destination-connector).
-- To delete a destination connector, use the `UnstructuredClient` object's `destinations.delete_destination` function (for the Python SDK) or
- the `DELETE` method to call the `/destinations/` endpoint (for `curl` or Postman). [Learn more](/platform-api/api/overview#delete-a-destination-connector).
-
-To create or update a destination connector, you must also provide settings that are specific to that connector.
-For the list of specific settings, see:
-
-- [Astra DB](/platform-api/api/destinations/astradb) (`ASTRADB` for the Python SDK or `astradb` for `curl` or Postman)
-- [Azure AI Search](/platform-api/api/destinations/azure-ai-search) (`AZURE_AI_SEARCH` for the Python SDK or `azure_ai_search` for `curl` or Postman)
-- [Couchbase](/platform-api/api/destinations/couchbase) (`COUCHBASE` for the Python SDK or `couchbase` for `curl` or Postman)
-- [Databricks Volumes](/platform-api/api/destinations/databricks-volumes) (`DATABRICKS_VOLUMES` for the Python SDK or `databricks_volumes` for `curl` or Postman)
-- [Delta Tables in Amazon S3](/platform-api/api/destinations/delta-table) (`DELTA_TABLE` for the Python SDK or `delta_table` for `curl` or Postman)
-- [Delta Tables in Databricks](/platform-api/api/destinations/databricks-delta-table) (`DATABRICKS_VOLUME_DELTA_TABLES` for the Python SDK or `databricks_volume_delta_tables` for `curl` or Postman)
-- [Elasticsearch](/platform-api/api/destinations/elasticsearch) (`ELASTICSEARCH` for the Python SDK or `elasticsearch` for `curl` or Postman)
-- [Google Cloud Storage](/platform-api/api/destinations/google-cloud) (`GCS` for the Python SDK or `gcs` for `curl` or Postman)
-- [Kafka](/platform-api/api/destinations/kafka) (`KAFKA_CLOUD` for the Python SDK or `kafka-cloud` for `curl` or Postman)
-- [Milvus](/platform-api/api/destinations/milvus) (`MILVUS` for the Python SDK or `milvus` for `curl` or Postman)
-- [MongoDB](/platform-api/api/destinations/mongodb) (`MONGODB` for the Python SDK or `mongodb` for `curl` or Postman)
-- [MotherDuck](/platform-api/api/destinations/motherduck) (`MOTHERDUCK` for the Python SDK or `motherduck` for `curl` or Postman)
-- [Neo4j](/platform-api/api/destinations/neo4j) (`NEO4J` for the Python SDK or `neo4j` for `curl` or Postman)
-- [OneDrive](/platform-api/api/destinations/onedrive) (`ONEDRIVE` for the Python SDK or `onedrive` for `curl` or Postman)
-- [Pinecone](/platform-api/api/destinations/pinecone) (`PINECONE` for the Python SDK or `pinecone` for `curl` or Postman)
-- [PostgreSQL](/platform-api/api/destinations/postgresql) (`POSTGRES` for the Python SDK or `postgres` for `curl` or Postman)
-- [Qdrant](/platform-api/api/destinations/qdrant) (`QDRANT_CLOUD` for the Python SDK or `qdrant-cloud` for `curl` or Postman)
-- [Redis](/platform-api/api/destinations/redis) (`REDIS` for the Python SDK or `redis` for `curl` or Postman)
-- [Snowflake](/platform-api/api/destinations/snowflake) (`SNOWFLAKE` for the Python SDK or `snowflake` for `curl` or Postman)
-- [S3](/platform-api/api/destinations/s3) (`S3` for the Python SDK or `s3` for `curl` or Postman)
-- [Weaviate](/platform-api/api/destinations/weaviate) (`WEAVIATE` for the Python SDK or `weaviate` for `curl` or Postman)
-
diff --git a/platform-api/api/sources/overview.mdx b/platform-api/api/sources/overview.mdx
deleted file mode 100644
index fed53173..00000000
--- a/platform-api/api/sources/overview.mdx
+++ /dev/null
@@ -1,40 +0,0 @@
----
-title: Overview
----
-
-To use the [Unstructured Platform Workflow Endpoint](/platform-api/api/overview) to manage source connectors, do the following:
-
-- To get a list of available source connectors, use the `UnstructuredClient` object's `sources.list_sources` function (for the Python SDK) or
- the `GET` method to call the `/sources` endpoint (for `curl` or Postman). [Learn more](/platform-api/api/overview#list-source-connectors).
-- To get information about a source connector, use the `UnstructuredClient` object's `sources.get_source` function (for the Python SDK) or
- the `GET` method to call the `/sources/` endpoint (for `curl` or Postman). [Learn more](/platform-api/api/overview#get-a-source-connector).
-- To create a source connector, use the `UnstructuredClient` object's `sources.create_source` function (for the Python SDK) or
- the `POST` method to call the `/sources` endpoint (for `curl` or Postman). [Learn more](/platform-api/api/overview#create-a-source-connector).
-- To update a source connector, use the `UnstructuredClient` object's `sources.update_source` function (for the Python SDK) or
- the `PUT` method to call the `/sources/` endpoint (for `curl` or Postman). [Learn more](/platform-api/api/overview#update-a-source-connector).
-- To delete a source connector, use the `UnstructuredClient` object's `sources.delete_source` function (for the Python SDK) or
- the `DELETE` method to call the `/sources/` endpoint (for `curl` or Postman). [Learn more](/platform-api/api/overview#delete-a-source-connector).
-
-To create or update a source connector, you must also provide settings that are specific to that connector.
-For the list of specific settings, see:
-
-- [Azure](/platform-api/api/sources/azure-blob-storage) (`AZURE` for the Python SDK or `azure` for `curl` and Postman)
-- [Box](/platform-api/api/sources/box) (`BOX` for the Python SDK or `box` for `curl` and Postman)
-- [Confluence](/platform-api/api/sources/confluence) (`CONFLUENCE` for the Python SDK or `confluence` for `curl` and Postman)
-- [Couchbase](/platform-api/api/sources/couchbase) (`COUCHBASE` for the Python SDK or `couchbase` for `curl` and Postman)
-- [Databricks Volumes](/platform-api/api/sources/databricks-volumes) (`DATABRICKS_VOLUMES` for the Python SDK or `databricks_volumes` for `curl` and Postman)
-- [Dropbox](/platform-api/api/sources/dropbox) (`DROPBOX` for the Python SDK or `dropbox` for `curl` and Postman)
-- [Elasticsearch](/platform-api/api/sources/elasticsearch) (`ELASTICSEARCH` for the Python SDK or `elasticsearch` for `curl` and Postman)
-- [Google Cloud Storage](/platform-api/api/sources/google-cloud) (`GCS` for the Python SDK or `gcs` for `curl` and Postman)
-- [Google Drive](/platform-api/api/sources/google-drive) (`GOOGLE_DRIVE` for the Python SDK or `google_drive` for `curl` and Postman)
-- [Kafka](/platform-api/api/sources/kafka) (`KAFKA_CLOUD` for the Python SDK or `kafka-cloud` for `curl` and Postman)
-- [MongoDB](/platform-api/api/sources/mongodb) (`MONGODB` for the Python SDK or `mongodb` for `curl` and Postman)
-- [OneDrive](/platform-api/api/sources/onedrive) (`ONEDRIVE` for the Python SDK or `onedrive` for `curl` and Postman)
-- [Outlook](/platform-api/api/sources/outlook) (`OUTLOOK` for the Python SDK or `outlook` for `curl` and Postman)
-- [PostgreSQL](/platform-api/api/sources/postgresql) (`POSTGRES` for the Python SDK or `postgres` for `curl` and Postman)
-- [S3](/platform-api/api/sources/s3) (`S3` for the Python SDK or `s3` for `curl` and Postman)
-- [Salesforce](/platform-api/api/sources/salesforce) (`SALESFORCE` for the Python SDK or `salesforce` for `curl` and Postman)
-- [SharePoint](/platform-api/api/sources/sharepoint) (`SHAREPOINT` for the Python SDK or `sharepoint` for `curl` and Postman)
-- [Snowflake](/platform-api/api/sources/snowflake) (`SNOWFLAKE` for the Python SDK or `snowflake` for `curl` and Postman)
-
-
diff --git a/platform-api/partition-api/output-bounding-box-coordinates.mdx b/platform-api/partition-api/output-bounding-box-coordinates.mdx
deleted file mode 100644
index e53a9763..00000000
--- a/platform-api/partition-api/output-bounding-box-coordinates.mdx
+++ /dev/null
@@ -1,4 +0,0 @@
----
-title: "Output bounding box coordinates"
-url: "/platform-api/partition-api/examples#saving-bounding-box-coordinates"
----
\ No newline at end of file
diff --git a/platform/connectors.mdx b/platform/connectors.mdx
deleted file mode 100644
index 3f55e6ac..00000000
--- a/platform/connectors.mdx
+++ /dev/null
@@ -1,66 +0,0 @@
----
-title: Supported connectors
----
-
-The Unstructured Platform supports connecting to the following source and destination types.
-
-```mermaid
- flowchart LR
- Sources-->Unstructured-->Destinations
-```
-
-## Sources
-
-- [Azure](/platform/sources/azure-blob-storage)
-- [Box](/platform/sources/box)
-- [Confluence](/platform/sources/confluence)
-- [Couchbase](/platform/sources/couchbase)
-- [Databricks Volumes](/platform/sources/databricks-volumes)
-- [Dropbox](/platform/sources/dropbox)
-- [Elasticsearch](/platform/sources/elasticsearch)
-- [Google Cloud Storage](/platform/sources/google-cloud)
-- [Google Drive](/platform/sources/google-drive)
-- [Kafka](/platform/sources/kafka)
-- [MongoDB](/platform/sources/mongodb)
-- [OneDrive](/platform/sources/onedrive)
-- [Outlook](/platform/sources/outlook)
-- [PostgreSQL](/platform/sources/postgresql)
-- [S3](/platform/sources/s3)
-- [Salesforce](/platform/sources/salesforce)
-- [SharePoint](/platform/sources/sharepoint)
-- [Snowflake](/platform/sources/snowflake)
-
-If your source is not listed here, you might still be able to connect Unstructured to it through scripts or code by using the
-[Unstructured Ingest CLI](/ingestion/overview#unstructured-ingest-cli) or the
-[Unstructured Ingest Python library](/ingestion/python-ingest).
-[Learn more](/ingestion/source-connectors/overview).
-
-## Destinations
-
-- [Astra DB](/platform/destinations/astradb)
-- [Azure AI Search](/platform/destinations/azure-ai-search)
-- [Couchbase](/platform/destinations/couchbase)
-- [Databricks Volumes](/platform/destinations/databricks-volumes)
-- [Delta Tables in Amazon S3](/platform/destinations/delta-table)
-- [Delta Tables in Databricks](/platform/destinations/databricks-delta-table)
-- [Elasticsearch](/platform/destinations/elasticsearch)
-- [Google Cloud Storage](/platform/destinations/google-cloud)
-- [Kafka](/platform/destinations/kafka)
-- [Milvus](/platform/destinations/milvus)
-- [MotherDuck](/platform/destinations/motherduck)
-- [MongoDB](/platform/destinations/mongodb)
-- [Neo4j](/platform/destinations/neo4j)
-- [OneDrive](/platform/destinations/onedrive)
-- [Pinecone](/platform/destinations/pinecone)
-- [PostgreSQL](/platform/destinations/postgresql)
-- [Qdrant](/platform/destinations/qdrant)
-- [Redis](/platform/destinations/redis)
-- [S3](/platform/destinations/s3)
-- [Snowflake](/platform/destinations/snowflake)
-- [Weaviate](/platform/destinations/weaviate)
-
-If your destination is not listed here, you might still be able to connect Unstructured to it through scripts or code by using the
-[Unstructured Ingest CLI](/ingestion/overview#unstructured-ingest-cli) or the
-[Unstructured Ingest Python library](/ingestion/python-ingest).
-[Learn more](/ingestion/destination-connectors/overview).
-
diff --git a/platform/destinations/overview.mdx b/platform/destinations/overview.mdx
deleted file mode 100644
index cedc6dd5..00000000
--- a/platform/destinations/overview.mdx
+++ /dev/null
@@ -1,43 +0,0 @@
----
-title: Overview
-description: Destination connectors in the Unstructured Platform are designed to specify the endpoint for data processed within the platform. These connectors ensure that the transformed and analyzed data is securely and efficiently transferred to a storage system for future use, often to a vector database for tasks that involve high-speed retrieval and advanced data analytics operations.
----
-
-
-
-To see your existing destination connectors, on the sidebar, click **Connectors**, and then click **Destinations**.
-
-To create a destination connector:
-
-1. In the sidebar, click **Connectors**.
-2. Click **Destinations**.
-3. Cick **New** or **Create Connector**.
-4. For **Name**, enter some unique name for this connector.
-5. In the **Provider** area, click the destination location type that matches yours.
-6. Click **Continue**.
-7. Fill in the fields according to your connector type. To learn how, click your connector type in the following list:
-
- - [Astra DB](/platform/destinations/astradb)
- - [Azure AI Search](/platform/destinations/azure-ai-search)
- - [Couchbase](/platform/destinations/couchbase)
- - [Databricks Volumes](/platform/destinations/databricks-volumes)
- - [Delta Tables in Amazon S3](/platform/destinations/delta-table)
- - [Delta Tables in Databricks](/platform/destinations/databricks-delta-table)
- - [Elasticsearch](/platform/destinations/elasticsearch)
- - [Google Cloud Storage](/platform/destinations/google-cloud)
- - [Kafka](/platform/destinations/kafka)
- - [Milvus](/platform/destinations/milvus)
- - [MongoDB](/platform/destinations/mongodb)
- - [MotherDuck](/platform/destinations/motherduck)
- - [Neo4j](/platform/destinations/neo4j)
- - [OneDrive](/platform/destinations/onedrive)
- - [Pinecone](/platform/destinations/pinecone)
- - [PostgreSQL](/platform/destinations/postgresql)
- - [Qdrant](/platform/destinations/qdrant)
- - [Redis](/platform/destinations/redis)
- - [S3](/platform/destinations/s3)
- - [Snowflake](/platform/destinations/snowflake)
- - [Weaviate](/platform/destinations/weaviate)
-
-8. If a **Continue** button appears, click it, and fill in any additional settings fields.
-9. Click **Save and Test**.
\ No newline at end of file
diff --git a/snippets/general-shared-text/azure-ai-search.mdx b/snippets/general-shared-text/azure-ai-search.mdx
index c89dbd07..6ef5080a 100644
--- a/snippets/general-shared-text/azure-ai-search.mdx
+++ b/snippets/general-shared-text/azure-ai-search.mdx
@@ -942,4 +942,4 @@ Here are some more details about these requirements:
- [Search indexes in Azure AI Search](https://learn.microsoft.com/azure/search/search-what-is-an-index)
- [Schema of a search index](https://learn.microsoft.com/azure/search/search-what-is-an-index#schema-of-a-search-index)
- [Example index schema](https://learn.microsoft.com/rest/api/searchservice/create-index#examples)
- - [Unstructured document elements and metadata](/platform-api/partition-api/document-elements)
\ No newline at end of file
+ - [Unstructured document elements and metadata](/api/partition/document-elements)
\ No newline at end of file
diff --git a/snippets/general-shared-text/couchbase.mdx b/snippets/general-shared-text/couchbase.mdx
index de581cea..b62bbe97 100644
--- a/snippets/general-shared-text/couchbase.mdx
+++ b/snippets/general-shared-text/couchbase.mdx
@@ -1,4 +1,4 @@
-- For the [Unstructured Platform](/platform/overview), only Couchbase Capella clusters are supported.
+- For the [Unstructured UI](/ui/overview) or the [Unstructured API](/api/overview), only Couchbase Capella clusters are supported.
- For [Unstructured Ingest](/ingestion/overview), Couchbase Capella clusters and local Couchbase server deployments are supported.
-Unstructured offers the Unstructured Platform user interface (UI) and the Unstructured Platform API. Read on to learn more.
+Unstructured offers the Unstructured user interface (UI) and the Unstructured API. Read on to learn more.
-## Unstructured Platform user interface (UI)
+## Unstructured user interface (UI)
-No-code UI. Production-ready. Pay as you go. [Learn more](/platform/overview).
+No-code UI. Production-ready. Pay as you go. [Learn more](/ui/overview).
-Here is a screenshot of the Unstructured Platform UI **Start** page:
+Here is a screenshot of the Unstructured UI **Start** page:
-
+
-This 90-second video provides a brief overview of the Unstructured Platform UI:
+This 90-second video provides a brief overview of the Unstructured UI:
Unstructured Platform API
+## Unstructured API
-Use scripts or code. Production-ready. Pay as you go. [Learn more](/platform-api/overview).
+Use scripts or code. Production-ready. Pay as you go. [Learn more](/api/overview).
-The Unstructured Platform API consists of two parts:
+The Unstructured API consists of two parts:
-- The [Unstructured Platform Workflow Endpoint](/platform-api/api/overview) enables a full range of partitioning, chunking, embedding, and
+- The [Unstructured Workflow Endpoint](/api/overview) enables a full range of partitioning, chunking, embedding, and
enrichment options for your files and data. It is designed to batch-process files and data in remote locations; send processed results to
various storage, databases, and vector stores; and use the latest and highest-performing models on the market today. It has built-in logic
- to deliver the highest quality results at the lowest cost. [Learn more](/platform-api/api/overview).
-- The [Unstructured Platform Partition Endpoint](platform-api/partition-api/overview) is intended for rapid prototyping of Unstructured's
+ to deliver the highest quality results at the lowest cost. [Learn more](/api/overview).
+- The [Unstructured Partition Endpoint](/api/partition/overview) is intended for rapid prototyping of Unstructured's
various partitioning strategies, with limited support for chunking. It is designed to work only with processing of local files, one file
- at a time. Use the [Unstructured Platform Workflow Endpoint](/platform-api/api/overview) for production-level scenarios, file processing in
+ at a time. Use the [Unstructured Workflow Endpoint](/api/overview) for production-level scenarios, file processing in
batches, files and data in remote locations, generating embeddings, applying post-transform enrichments, using the latest and
- highest-performing models, and for the highest quality results at the lowest cost. [Learn more](/platform-api/partition-api/overview).
+ highest-performing models, and for the highest quality results at the lowest cost. [Learn more](/api/partition/overview).
-Here is a screenshot of some Python code that calls the Unstructured Platform Workflow Endpoint:
+Here is a screenshot of some Python code that calls the Unstructured Workflow Endpoint:
-
+
-To start using the Unstructured Platform Workflow Endpoint right away, skip ahead to the [quickstart](#quickstart-unstructured-platform-endpoint).
+To start using the Unstructured Workflow Endpoint right away, skip ahead to the [quickstart](#unstructured-workflow-endpoint-quickstart).
---
@@ -85,26 +85,26 @@ import SupportedFileTypes from '/snippets/general-shared-text/supported-file-typ
---
-## Quickstart: Unstructured Platform UI
+## Unstructured UI quickstart
import SharedPlatformUI from '/snippets/quickstarts/platform.mdx';
-[Learn more about the Unstructured Platform UI](/platform/overview).
+[Learn more about the Unstructured UI](/ui/overview).
---
import LocalToLocalPythonIngestLibrary from '/snippets/ingestion/local-to-local.v2.py.mdx';
import AdditionalIngestDependencies from '/snippets/general-shared-text/ingest-dependencies.mdx';
-## Quickstart: Unstructured Platform Workflow Endpoint
+## Unstructured Workflow Endpoint quickstart
import SharedPlatformAPI from '/snippets/quickstarts/platform-api.mdx';
-[Learn more about the Unstructured Platform API](/platform-api/overview).
+[Learn more about the Unstructured API](/api/overview).
---