cuTT is a high performance tensor transpose library for NVIDIA GPUs. It works with Kepler (SM 3.0) and above GPUs.
Copyright (c) 2016 Antti-Pekka Hynninen
Copyright (c) 2016 Oak Ridge National Laboratory (UT-Batelle)
Version 1.1
Software requirements:
- C++ compiler with C++11 compitability
- CUDA compiler
Hardware requirements:
- Kepler (SM 3.0) or above NVIDIA GPU
To compile cuTT library as well as test cases and benchmarks, simply do
make
This will create the library itself:
- include/cutt.h
- lib/libcutt.a
as well as the test and benchmarks
- bin/cutt_test
- bin/cutt_bench
In order to use cuTT, you only need the include (include/cutt.h) and the library (lib/libcutt.a) files.
Tests and benchmark executables are in the bin/ directory and they can be run without any options. Options to the test executable lets you choose the device ID on which to run:
cutt_test [options] Options: -device gpuid : use GPU with ID gpuid
For the benchmark executable, we have an additional option that lets you run the benchmarks using plans that are chosen optimally by measuring the performance of every possible implementation and choosing the best one.
cutt_bench [options] Options: -device gpuid : use GPU with ID gpuid -measure : use cuttPlanMeasure (default is cuttPlan)
cuTT was designed with performance as the main goal. Here are performance benchmarks for a random set of tensors with 200M double elements with ranks 2 to 7. The benchmarks were run with the measurement flag on
(cutt_bench -measure)
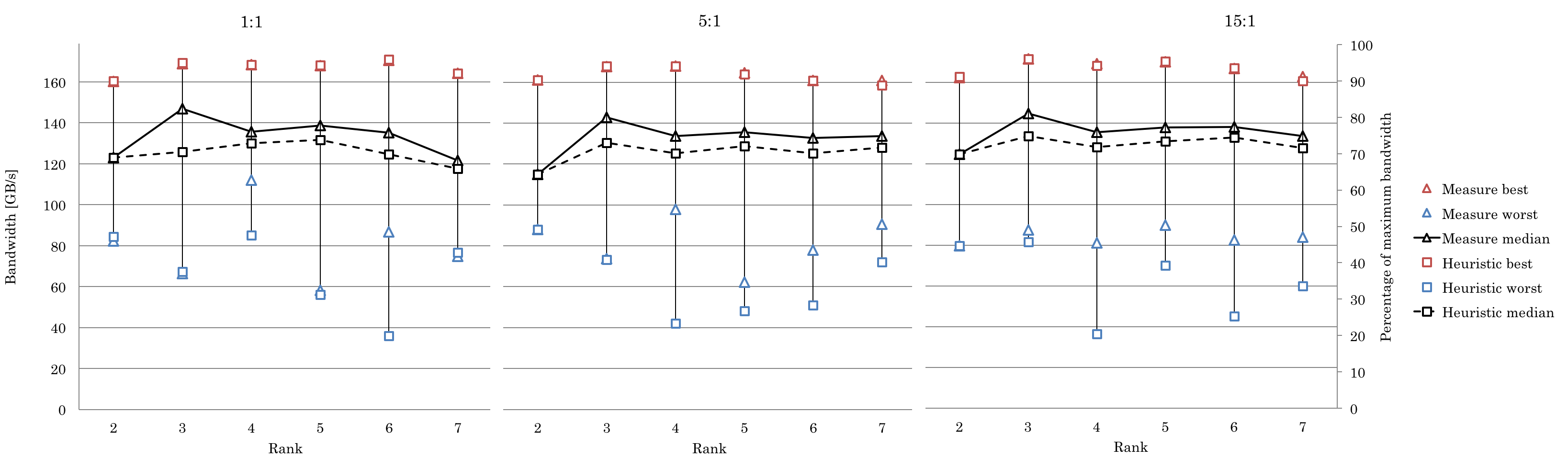
cuTT uses a "plan structure" similar to FFTW and cuFFT libraries, where the user first creates a plan for the transpose and then executes that plan. Here is an example code.
#include <cutt.h>
//
// Error checking wrapper for cutt
//
#define cuttCheck(stmt) do { \
cuttResult err = stmt; \
if (err != CUTT_SUCCESS) { \
fprintf(stderr, "%s in file %s, function %s\n", #stmt,__FILE__,__FUNCTION__); \
exit(1); \
} \
} while(0)
int main() {
// Four dimensional tensor
// Transpose (31, 549, 2, 3) -> (3, 31, 2, 549)
int dim[4] = {31, 549, 2, 3};
int permutation[4] = {3, 0, 2, 1};
.... input and output data is setup here ...
// double* idata : size product(dim)
// double* odata : size product(dim)
// Option 1: Create plan on NULL stream and choose implementation based on heuristics
cuttHandle plan;
cuttCheck(cuttPlan(&plan, 4, dim, permutation, sizeof(double), 0));
// Option 2: Create plan on NULL stream and choose implementation based on performance measurements
// cuttCheck(cuttPlanMeasure(&plan, 4, dim, permutation, sizeof(double), 0, idata, odata));
// Execute plan
cuttCheck(cuttExecute(plan, idata, odata));
... do stuff with your output and deallocate data ...
// Destroy plan
cuttCheck(cuttDestroy(plan));
return 0;
}Input (idata) and output (odata) data are both in GPU memory and must point to different memory areas for correct operation. That is, cuTT only currently supports out-of-place transposes. Note that using Option 2 to create the plan can take up some time especially for high-rank tensors.
//
// Create plan
//
// Parameters
// handle = Returned handle to cuTT plan
// rank = Rank of the tensor
// dim[rank] = Dimensions of the tensor
// permutation[rank] = Transpose permutation
// sizeofType = Size of the elements of the tensor in bytes (=4 or 8)
// stream = CUDA stream (0 if no stream is used)
//
// Returns
// Success/unsuccess code
//
cuttResult cuttPlan(cuttHandle* handle, int rank, int* dim, int* permutation, size_t sizeofType,
cudaStream_t stream);
//
// Create plan and choose implementation by measuring performance
//
// Parameters
// handle = Returned handle to cuTT plan
// rank = Rank of the tensor
// dim[rank] = Dimensions of the tensor
// permutation[rank] = Transpose permutation
// sizeofType = Size of the elements of the tensor in bytes (=4 or 8)
// stream = CUDA stream (0 if no stream is used)
// idata = Input data size product(dim)
// odata = Output data size product(dim)
//
// Returns
// Success/unsuccess code
//
cuttResult cuttPlanMeasure(cuttHandle* handle, int rank, int* dim, int* permutation, size_t sizeofType,
cudaStream_t stream, void* idata, void* odata);
//
// Destroy plan
//
// Parameters
// handle = Handle to the cuTT plan
//
// Returns
// Success/unsuccess code
//
cuttResult cuttDestroy(cuttHandle handle);
//
// Execute plan out-of-place
//
// Parameters
// handle = Returned handle to cuTT plan
// idata = Input data size product(dim)
// odata = Output data size product(dim)
//
// Returns
// Success/unsuccess code
//
cuttResult cuttExecute(cuttHandle handle, void* idata, void* odata);- Benchmarks sometime fail due to the stupid algorithm I have now to create random tensors with fixed volume.
- Make "tiled" method work with sets of ranks (where ranks in M_m and M_k remain in same order)
MIT License
Copyright (c) 2016 Antti-Pekka Hynninen
Copyright (c) 2016 Oak Ridge National Laboratory (UT-Batelle)
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.