Source: Solve HLAE recording bottlenecking on one thread for potentially non-required format conversion #295
Comments
|
branch: https://github.com/advancedfx/advancedfx/tree/faster-recording-295 improvements already implemented:
planned improvements (not implemented yet!):
breaking changes:
TestingIf you only have time / motivation to test a subset of the tests, that's ok too.
A: Single stream performance
B: Multi stream performance
|
|
TL;DR: MSAA is preventing streams from being recorded. 1) My usual mm cfg w/ highest quality settings (8x MSAA) and huffyuv ffmpeg recording, basefx & depth stream test:
2) Did not execute my mm cfg, tried A: Single stream performance w/ afxFfmpeg (8x MSAA)
Disabling MSAA seems to have solved it. 3) B: multi stream performance w/ afxFfmpeg (8x MSAA) Same as before, MSAA prevented the streams that use it from being recorded, while depth worked. I didn't test the speed yet as I wanted to focus on this MSAA issue first. |
|
Thanks to @DuKeM-CSGO and @Dechno1337 we fixed crash upon recording due to out of bound reads on the transforming thread(s) and MSAA not working: For desired testing see my previous post. |
|
Compared the speed with 2 streams:
( |
|
Single stream performance (SSD):
Single stream performance (HDD):
Most likely a HDD bottleneck when the performance is basically the same. |


|
Test Settings and results are listed below. There are about 50% Speed Improvment. Hardware13700K 5G+4.1G Config// Basic Settings
sv_cheats 1
mirv_campath enabled 1
cl_clock_correction 0
mirv_fix playerAnimState 1
mirv_fix blockObserverTarget 1
mirv_fov handlezoom enabled 1
mirv_streams record name "D:\benchmark"
sv_disablefreezecam 1
sv_nomvp 1
sv_nonemesis 1
sv_holiday_mode 0
fog_override 1
net_graph 0
mat_postprocess_enable 0
mp_display_kill_assists 0
cl_showpos 0
cl_show_observer_crosshair 0
cl_spec_follow_grenade_key 2
cl_updaterate 128
host_syncfps 1
hud_showtargetid 0
hud_drawhistory_time 0
engine_no_focus_sleep 0
mirv_cvar_unhide_all
demo_pause
fps_max 0
spec_cameraman_disable_with_user_control 1;spec_cameraman_ui 0;spec_cameraman_xray 0;spec_cameraman_set_xray 0;
mirv_exec alias continue "demo_resume";
mirv_exec alias rec "HlaeRecord;demo_timescale 1;mirv_snd_timescale 1;host_timescale 0;fps_max 0;mirv_streams record start;echo {QUOTE}>>> HLAE录制开始{QUOTE}";
mirv_exec alias rec_end "host_framerate 0;host_timescale 1;mirv_streams record end;echo {QUOTE}>>> HLAE录制结束{QUOTE}";
// Stream
mirv_streams add baseFx raw;mirv_streams edit raw drawHud -1;mirv_streams edit raw record 1;
// Recording
mirv_streams settings add ffmpeg p422 "-c:v prores -profile:v 2 -pix_fmt yuv422p10le {QUOTE}{AFX_STREAM_PATH}.mov{QUOTE}"
mirv_streams settings add ffmpeg p4444 "-c:v prores -profile:v 4 {QUOTE}{AFX_STREAM_PATH}.mov{QUOTE}"
mirv_streams settings add ffmpeg p0pro "-c:v libx264 -preset 0 -qp 0 -g 300 -keyint_min 300 -pix_fmt yuv422p10le {QUOTE}{AFX_STREAM_PATH}.mp4{QUOTE}"
mirv_streams settings add ffmpeg p1 "-c:v libx264 -preset 1 -crf 2 -qmax 20 -g 300 -keyint_min 300 -x264-params ref=3:me=hex:subme=3:merange=12:b-adapt=1:aq-mode=2:aq-strength=0.9:no-fast-pskip=1 {QUOTE}{AFX_STREAM_PATH}.mp4{QUOTE}"
mirv_streams settings add ffmpeg x265 "-c:v libx265 -preset 1 -crf 8 -g 300 -pix_fmt yuv422p10le {QUOTE}{AFX_STREAM_PATH}.mp4{QUOTE}"
mirv_streams settings add ffmpeg n0 "-c:v h264_nvenc -g 300 -tune lossless -pix_fmt yuv444p {QUOTE}{AFX_STREAM_PATH}.mp4{QUOTE}"
mirv_streams settings add ffmpeg n1 "-c:v h264_nvenc -g 300 -preset medium -tune hq -rc constqp -qp 12 -pix_fmt yuv444p {QUOTE}{AFX_STREAM_PATH}.mp4{QUOTE}"
mirv_streams settings add ffmpeg n2 "-c:v hevc_nvenc -g 300 -preset medium -tune hq -rc constqp -qp 14 -pix_fmt yuv444p {QUOTE}{AFX_STREAM_PATH}.mp4{QUOTE}"
mirv_exec alias tga "mirv_streams settings edit afxDefault settings afxClassic;echo;echo {QUOTE}Current Record Setting: afxClassic{QUOTE};echo;";
mirv_exec alias p422 "mirv_streams settings edit afxDefault settings p422 ;echo;echo {QUOTE}Current Record Setting: Prores 422{QUOTE};echo;";
mirv_exec alias p4444 "mirv_streams settings edit afxDefault settings p4444;echo;echo {QUOTE}Current Record Setting: Prores 4444{QUOTE};echo;";
mirv_exec alias p0pro "mirv_streams settings edit afxDefault settings p0pro;echo;echo {QUOTE}Current Record Setting: p0pro{QUOTE};echo;";
mirv_exec alias p1 "mirv_streams settings edit afxDefault settings p1 ;echo;echo {QUOTE}Current Record Setting: p1 {QUOTE};echo;";
mirv_exec alias x265 "mirv_streams settings edit afxDefault settings x265 ;echo;echo {QUOTE}Current Record Setting: x265 {QUOTE};echo;";
mirv_exec alias n0 "mirv_streams settings edit afxDefault settings n0;echo;echo {QUOTE}Current Record Setting: n0 - h264_nvenc lossess{QUOTE};echo;";
mirv_exec alias n1 "mirv_streams settings edit afxDefault settings n1;echo;echo {QUOTE}Current Record Setting: n1 - h264_nvenc cqp 12 yuv444{QUOTE};echo;";
mirv_exec alias n2 "mirv_streams settings edit afxDefault settings n2;echo;echo {QUOTE}Current Record Setting: n2 - h265_nvenc cqp 14 yuv444{QUOTE};echo;";
// jump to tick
demo_gototick 163900;
alias go "demo_gototick 163900"
// Fixed Start/End Tick
mirv_cmd addAtTick 164320 rec;
mirv_cmd addAtTick 168160 rec_end; // 30s
// mirv_cmd addAtTick 172000 rec_end; // 60sSetting
Result
|
|
new dll doesn't work with alpha layers |
|
Using most of settings as #295 (comment), except the following though: Hardwarei7-6700HQ 2.60GHz ConfigSame. SettingsSame except resolution is 1920 * 850. Result
|

Can confirm. I tried huffyuv / afxFfmpegHuffyuv, but I guess it's not related to the FFMPEG presets/settings. |
Regerding #295 - Fixed matte stream with new recording. - Made matte stream merging parallel Todo: - make TwinStream parallel - Test OpenExr / depth24 - make Sampling parallel - stop wasting a frame
|
Dec requested a new dll: This one has the matte stream fixed and optimized (parallel CPU threads) and has all features of the "upcoming" milestone as of today. Stil left todo for me:
|
|
515a499 Fixed mirv_streams capture types depthF, depthFZIP, depth24, depth24ZIP (Don't recommend to retest.) |
|
Stop wasting a GPU frame when recording This is the last bigger change planned before pre-release (TwinStream optimization and Sampling System optimization I consider smaller things). This one has heavy stream recording logic changes and tries to be as optimal as possible in terms of not wasting GPU frames. You can use The following properities are known to have a relevant influence upon the test results and optimization:
As a rule of thumb, the optimization will be best if you put the mainStream (default = first stream see above) also into preview or if it's a truly normal stream, in that case you will get the lowest possible number of GPU frame render passes. (On fast GPUs the optimization might be not very notable, it will only be notable if GPU bottle-necked like my setup.) |
|
The last version has a bug and loses MSAA under certain conditions due to a shortcut I took 🤦 |
|
(Not doing 1. of #194 as part of this feature request, because it's a can of worms on it's own.) |
commit 4345557 Author: Dominik Tugend <dominik@matrixstorm.com> Date: Sat Jan 21 07:33:32 2023 +0100 Optimize TwinStreams commit 3b92d5c Author: Dominik Tugend <dominik@matrixstorm.com> Date: Thu Jan 19 22:25:07 2023 +0100 Fix missing MSAA in certain conditions - Addresses #295 commit 3b46279 Author: Dominik Tugend <dominik@matrixstorm.com> Date: Wed Jan 18 21:03:00 2023 +0100 Stop wasting a GPU frame when recording - Addresses #295 commit 515a499 Author: Dominik Tugend <dominik@matrixstorm.com> Date: Mon Jan 16 06:14:30 2023 +0100 Fix mirv_streams capture types depthF(ZIP), depth24(ZIP) commit e86c0e1 Author: Dominik Tugend <dominik@matrixstorm.com> Date: Sat Jan 14 11:18:14 2023 +0100 Fix + optimize + todo Regerding #295 - Fixed matte stream with new recording. - Made matte stream merging parallel Todo: - make TwinStream parallel - Test OpenExr / depth24 - make Sampling parallel - stop wasting a frame commit 3ebad81 Merge: 7251ff9 29679d6 Author: Dominik Tugend <dominik@matrixstorm.com> Date: Sat Jan 14 07:29:07 2023 +0100 Merge branch 'main' into faster-recording-295 commit 7251ff9 Merge: 7d52c88 cb11366 Author: Dominik Tugend <dominik@matrixstorm.com> Date: Sat Jan 7 12:58:36 2023 +0100 Merge branch 'main' into faster-recording-295 commit 7d52c88 Author: Dominik Tugend <dominik@matrixstorm.com> Date: Sat Jan 7 12:54:05 2023 +0100 Fix MSAA recording not working Thanks for testing @Dechno1337 commit 5dea86c Author: Dominik Tugend <dominik@matrixstorm.com> Date: Sat Jan 7 12:53:01 2023 +0100 Fix out of bounds memory access in transform threads Thanks for testing @DuKeM-CSGO commit d15e263 Author: Dominik Tugend <dominik@matrixstorm.com> Date: Fri Jan 6 13:59:09 2023 +0100 Backup commit 658ed31 Author: Dominik Tugend <dominik@matrixstorm.com> Date: Tue Jan 3 00:15:24 2023 +0100 Backup (doesn't work yet ;) commit 41c342a Author: Dominik Tugend <dominik@matrixstorm.com> Date: Fri Dec 30 14:07:09 2022 +0100 Backup (work in progress) Will not compile or work. commit bafdd2b Author: Dominik Tugend <dominik@matrixstorm.com> Date: Sat Dec 24 16:22:21 2022 +0100 WIP (will not compile), see #295
|
d74215a This should have most problems fixed. I need to test:
|
|
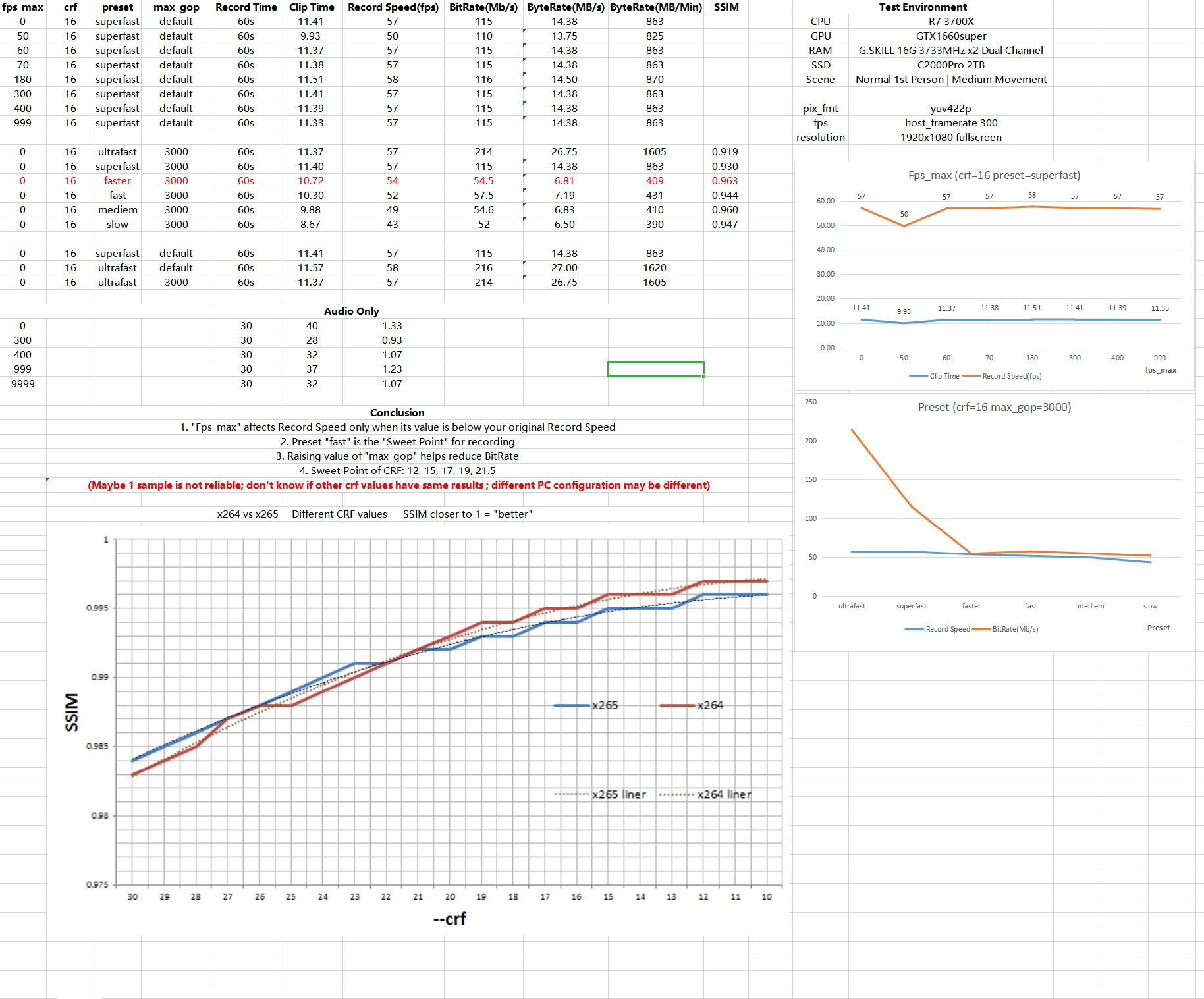
Final graph with the official HLAE 2.144.2 version.
Testing methodology:Each session in CS:GO I would record the same scene (set up with I used a stopwatch to count the time it would take to record the scene, but I would round it to the nearest half second, and then average all three passes. For the final graph numbers, I averaged the results for each stream setup. After each session I would close CS:GO, check the recorded footage to see if it was intact, and then delete it. After I had tested all four presets for a specific amount of streams I would restart my PC. In hindsight I should've restarted my PC after each game session, but ultimately I don't think it would have mattered. I forgot to mention that hardware-accelerated GPU scheduling was also turned on for both versions. When I tested earlier builds it was disabled and I noticed that it helped with the recording speeds in most cases when enabled. Raw data: |

we are simply hitting the single-threaded CPU throughput limit here:
I am guessing the main culprit is HLAE itself here, since it converts rgb to bgr on CPU after downloading it from GPU on the drawing thread, meaning on one single thread:
https://github.com/advancedfx/advancedfx/blob/main/AfxHookSource/AfxStreams.cpp#L739
Edit: There's also unneeded conversion by CS:GO's readpixels itself (e.g. removing padding).
Edit2: The bottle neck is probably RAM frequency and not CPU.
Image by @Purple-CSGO:
Cancelled:
Related:
The text was updated successfully, but these errors were encountered: