diff --git a/README.md b/README.md
index fae95d95..78017928 100644
--- a/README.md
+++ b/README.md
@@ -1,6 +1,6 @@
# optillm
-optillm is an OpenAI API compatible optimizing inference proxy which implements several state-of-the-art techniques that can improve the accuracy and performance of LLMs. The current focus is on implementing techniques that improve reasoning over coding, logical and mathematical queries.
+optillm is an OpenAI API compatible optimizing inference proxy which implements several state-of-the-art techniques that can improve the accuracy and performance of LLMs. The current focus is on implementing techniques that improve reasoning over coding, logical and mathematical queries.
It is possible to beat the frontier models using these techniques across diverse tasks by doing additional compute at inference time. A good example of how to combine such techniques together is the [CePO approach](optillm/cepo) from Cerebras.
@@ -14,7 +14,7 @@ It is possible to beat the frontier models using these techniques across diverse
```bash
pip install optillm
-optillm
+optillm
2024-10-22 07:45:05,612 - INFO - Loaded plugin: privacy
2024-10-22 07:45:06,293 - INFO - Loaded plugin: memory
2024-10-22 07:45:06,293 - INFO - Starting server with approach: auto
@@ -52,7 +52,7 @@ We support all major LLM providers and models for inference. You need to set the
| Provider | Required Environment Variables | Additional Notes |
|----------|-------------------------------|------------------|
-| OptiLLM | `OPTILLM_API_KEY` | Uses the inbuilt local server for inference, supports logprobs and decoding techniques like `cot_decoding` & `entropy_decoding` |
+| OptiLLM | `OPTILLM_API_KEY` | Uses the inbuilt local server for inference, supports logprobs and decoding techniques like `cot_decoding` & `entropy_decoding` |
| OpenAI | `OPENAI_API_KEY` | You can use this with any OpenAI compatible endpoint (e.g. OpenRouter) by setting the `base_url` |
| Cerebras | `CEREBRAS_API_KEY` | You can use this for fast inference with supported models, see [docs for details](https://inference-docs.cerebras.ai/introduction) |
| Azure OpenAI | `AZURE_OPENAI_API_KEY`
`AZURE_API_VERSION`
`AZURE_API_BASE` | - |
@@ -98,7 +98,7 @@ response = client.chat.completions.create(
print(response)
```
-The code above applies to both OpenAI and Azure OpenAI, just remember to populate the `OPENAI_API_KEY` env variable with the proper key.
+The code above applies to both OpenAI and Azure OpenAI, just remember to populate the `OPENAI_API_KEY` env variable with the proper key.
There are multiple ways to control the optimization techniques, they are applied in the follow order of preference:
- You can control the technique you use for optimization by prepending the slug to the model name `{slug}-model-name`. E.g. in the above code we are using `moa` or mixture of agents as the optimization approach. In the proxy logs you will see the following showing the `moa` is been used with the base model as `gpt-4o-mini`.
@@ -135,28 +135,28 @@ response = client.chat.completions.create(
> You can also combine different techniques either by using symbols `&` and `|`. When you use `&` the techniques are processed in the order from left to right in a pipeline
> with response from previous stage used as request to the next. While, with `|` we run all the requests in parallel and generate multiple responses that are returned as a list.
-Please note that the convention described above works only when the optillm server has been started with inference approach set to `auto`. Otherwise, the `model` attribute in the client request must be set with the model name only.
+Please note that the convention described above works only when the optillm server has been started with inference approach set to `auto`. Otherwise, the `model` attribute in the client request must be set with the model name only.
We now suport all LLM providers (by wrapping around the [LiteLLM sdk](https://docs.litellm.ai/docs/#litellm-python-sdk)). E.g. you can use the Gemini Flash model with `moa` by setting passing the api key in the environment variable `os.environ['GEMINI_API_KEY']` and then calling the model `moa-gemini/gemini-1.5-flash-002`. In the output you will then see that LiteLLM is being used to call the base model.
```bash
-9:43:21 - LiteLLM:INFO: utils.py:2952 -
+9:43:21 - LiteLLM:INFO: utils.py:2952 -
LiteLLM completion() model= gemini-1.5-flash-002; provider = gemini
-2024-09-29 19:43:21,011 - INFO -
+2024-09-29 19:43:21,011 - INFO -
LiteLLM completion() model= gemini-1.5-flash-002; provider = gemini
2024-09-29 19:43:21,481 - INFO - HTTP Request: POST https://generativelanguage.googleapis.com/v1beta/models/gemini-1.5-flash-002:generateContent?key=[redacted] "HTTP/1.1 200 OK"
19:43:21 - LiteLLM:INFO: utils.py:988 - Wrapper: Completed Call, calling success_handler
2024-09-29 19:43:21,483 - INFO - Wrapper: Completed Call, calling success_handler
-19:43:21 - LiteLLM:INFO: utils.py:2952 -
+19:43:21 - LiteLLM:INFO: utils.py:2952 -
LiteLLM completion() model= gemini-1.5-flash-002; provider = gemini
```
> [!TIP]
-> optillm is a transparent proxy and will work with any LLM API or provider that has an OpenAI API compatible chat completions endpoint, and in turn, optillm also exposes
+> optillm is a transparent proxy and will work with any LLM API or provider that has an OpenAI API compatible chat completions endpoint, and in turn, optillm also exposes
the same OpenAI API compatible chat completions endpoint. This should allow you to integrate it into any existing tools or frameworks easily. If the LLM you want to use
doesn't have an OpenAI API compatible endpoint (like Google or Anthropic) you can use [LiteLLM proxy server](https://docs.litellm.ai/docs/proxy/quick_start) that supports most LLMs.
-The following sequence diagram illustrates how the request and responses go through optillm.
+The following sequence diagram illustrates how the request and responses go through optillm.
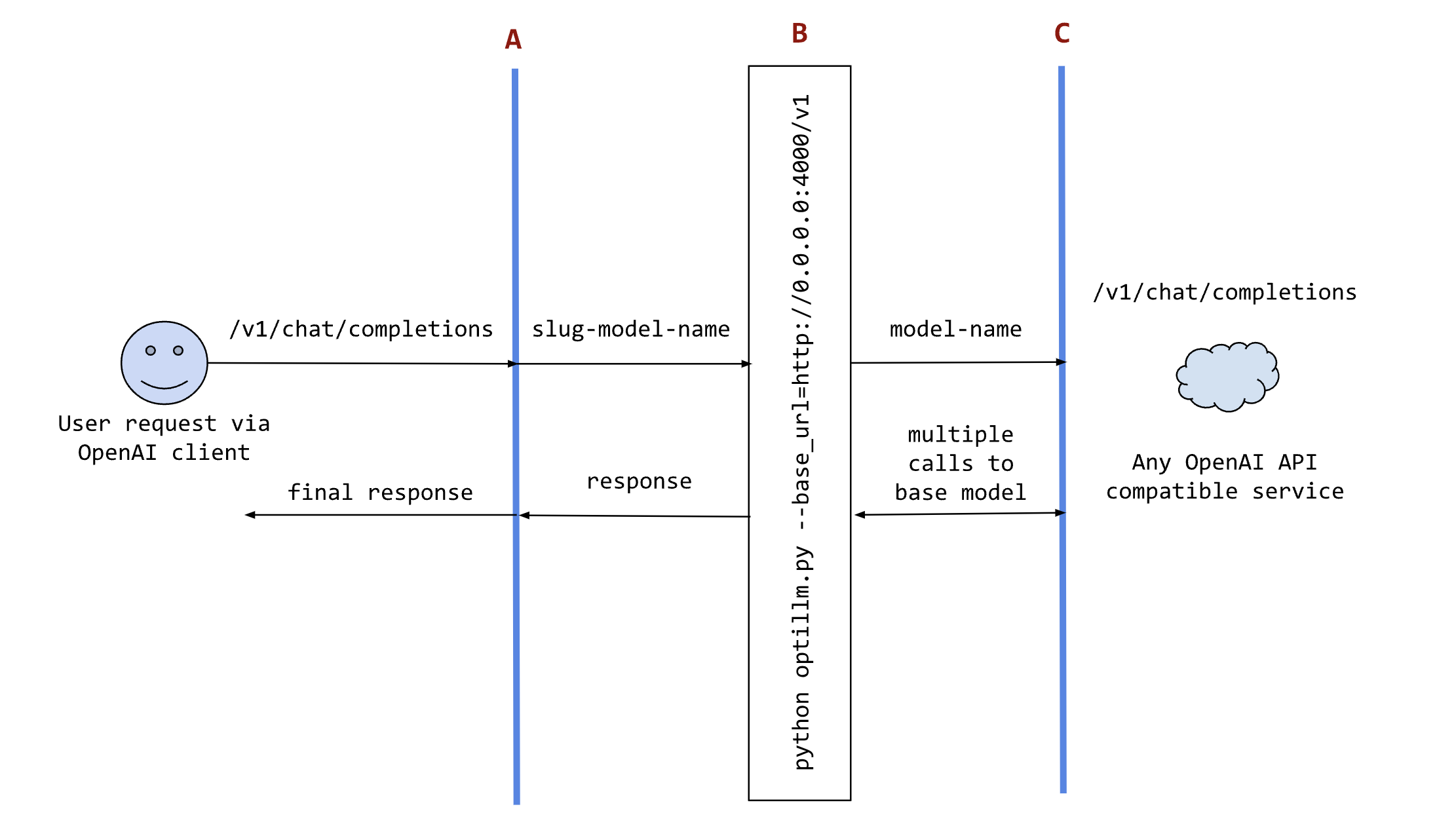
@@ -170,7 +170,7 @@ or your own code where you want to use the results from optillm. You can use it
We support loading any HuggingFace model or LoRA directly in optillm. To use the built-in inference server set the `OPTILLM_API_KEY` to any value (e.g. `export OPTILLM_API_KEY="optillm"`)
and then use the same in your OpenAI client. You can pass any HuggingFace model in model field. If it is a private model make sure you set the `HF_TOKEN` environment variable
-with your HuggingFace key. We also support adding any number of LoRAs on top of the model by using the `+` separator.
+with your HuggingFace key. We also support adding any number of LoRAs on top of the model by using the `+` separator.
E.g. The following code loads the base model `meta-llama/Llama-3.2-1B-Instruct` and then adds two LoRAs on top - `patched-codes/Llama-3.2-1B-FixVulns` and `patched-codes/Llama-3.2-1B-FastApply`.
You can specify which LoRA to use using the `active_adapter` param in `extra_args` field of OpenAI SDK client. By default we will load the last specified adapter.
@@ -343,7 +343,7 @@ Check this log file for connection issues, tool execution errors, and other diag
| Approach | Slug | Description |
| ------------------------------------ | ------------------ | ---------------------------------------------------------------------------------------------- |
-| Cerebras Planning and Optimimization | `cepo` | Combines Best of N, Chain-of-Thought, Self-Reflection, Self-Improvement, and various prompting techniques |
+| Cerebras Planning and Optimization | `cepo` | Combines Best of N, Chain-of-Thought, Self-Reflection, Self-Improvement, and various prompting techniques |
| CoT with Reflection | `cot_reflection` | Implements chain-of-thought reasoning with \, \ and \ sections |
| PlanSearch | `plansearch` | Implements a search algorithm over candidate plans for solving a problem in natural language |
| ReRead | `re2` | Implements rereading to improve reasoning by processing queries twice |
@@ -364,6 +364,7 @@ Check this log file for connection issues, tool execution errors, and other diag
| Plugin | Slug | Description |
| ----------------------- | ------------------ | ---------------------------------------------------------------------------------------------- |
+| Long-Context Cerebras Planning and Optimization | `longcepo` | Combines planning and divide-and-conquer processing of long documents to enable infinite context |
| MCP Client | `mcp` | Implements the model context protocol (MCP) client, enabling you to use any LLM with any MCP Server |
| Router | `router` | Uses the [optillm-modernbert-large](https://huggingface.co/codelion/optillm-modernbert-large) model to route requests to different approaches based on the user prompt |
| Chain-of-Code | `coc` | Implements a chain of code approach that combines CoT with code execution and LLM based code simulation |
@@ -491,10 +492,36 @@ Authorization: Bearer your_secret_api_key
| gemini-1.5-pro-002 | 20.00 |
| gemini-1.5-flash-002 | 16.67 |
+### LongCePO on LongBench v2 (Apr 2025)
+
+| Model¹ | Context window | Short samples (up to 32K words) | Medium samples (32–128K words) |
+|----------------------------------|----------------|------------------|----------------|
+| Llama 3.3 70B Instruct | 128K | 36.7 (45.0) | 27.0 (33.0) |
+| **LongCePO + Llama 3.3 70B Instruct** | **8K** | **36.8 ± 1.38** | **38.7 ± 2.574 (39.735)²** |
+| Mistral-Large-Instruct-2411 | 128K | 41.7 (46.1) | 30.7 (34.9) |
+| o1-mini-2024-09-12 | 128K | 48.6 (48.9) | 33.3 (32.9) |
+| Claude-3.5-Sonnet-20241022 | 200K | 46.1 (53.9) | 38.6 (41.9) |
+| Llama-4-Maverick-17B-128E-Instruct | 524K | 32.22 (50.56) | 28.84 (41.86) |
+
+ ¹ Performance numbers reported by LongBench v2 authors, except for LongCePO and Llama-4-Maverick results.
+
+ ² Numbers in parentheses for LongCePO indicate accuracy of majority voting from 5 runs.
+
+### LongCePO on HELMET - InfiniteBench En.MC, 128K length (Apr 2025)
+
+| Model | Accuracy (%) |
+|---------|---------------|
+| Llama 3.3 70B Instruct (full context) | 58.0 |
+| **LongCePO + Llama 3.3 70B Instruct (8K context)** | **71.6 ± 1.855 (73.0)¹** |
+| o1-mini-2024-09-12 (full context) | 58.0 |
+| gpt-4o-2024-08-06 (full context) | 74.0 |
+
+ ¹ Numbers in parentheses for LongCePO indicate accuracy of majority voting from 5 runs.
+
### readurls&memory-gpt-4o-mini on Google FRAMES Benchmark (Oct 2024)
-| Model | Accuracy |
+| Model | Accuracy |
| ----- | -------- |
-| readurls&memory-gpt-4o-mini | 61.29 |
+| readurls&memory-gpt-4o-mini | 61.29 |
| gpt-4o-mini | 50.61 |
| readurls&memory-Gemma2-9b | 30.1 |
| Gemma2-9b | 5.1 |
@@ -519,12 +546,13 @@ Authorization: Bearer your_secret_api_key
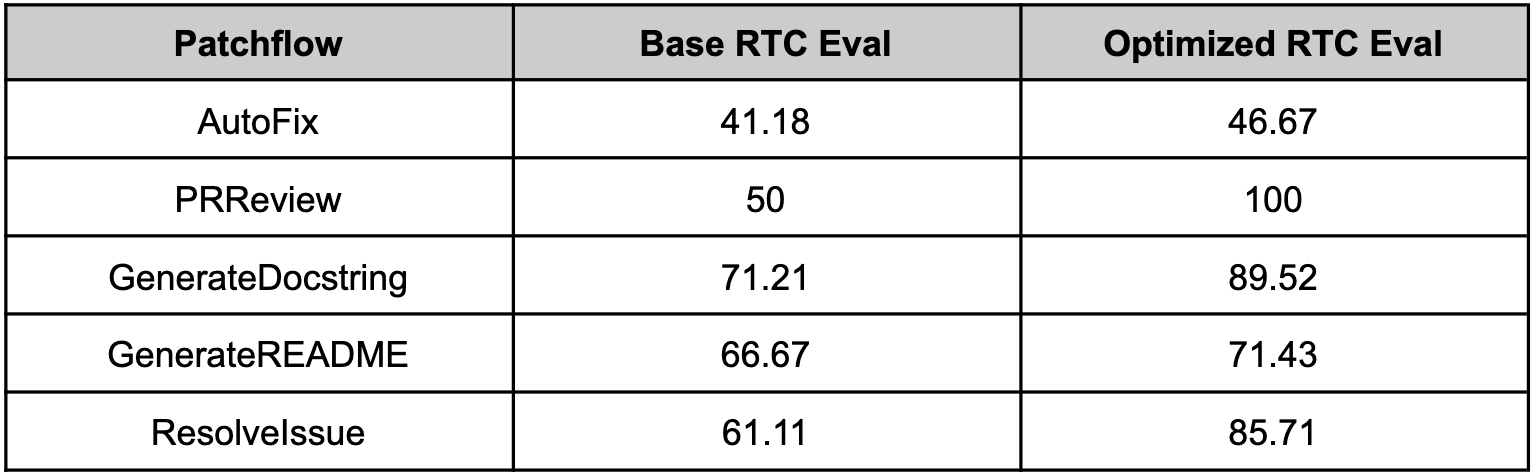
### optillm with Patchwork (July 2024)
Since optillm is a drop-in replacement for OpenAI API you can easily integrate it with existing tools and frameworks using the OpenAI client. We used optillm with [patchwork](https://github.com/patched-codes/patchwork) which is an open-source framework that automates development gruntwork like PR reviews, bug fixing, security patching using workflows
-called patchflows. We saw huge performance gains across all the supported patchflows as shown below when using the mixture of agents approach (moa).
+called patchflows. We saw huge performance gains across all the supported patchflows as shown below when using the mixture of agents approach (moa).
## References
- [CePO: Empowering Llama with Reasoning using Test-Time Compute](https://cerebras.ai/blog/cepo) - [Implementation](optillm/cepo)
+- [LongCePO: Empowering LLMs to efficiently leverage infinite context](https://cerebras.ai/blog/longcepo) - [Implementation](optillm/plugins/longcepo/main.py)
- [Chain of Code: Reasoning with a Language Model-Augmented Code Emulator](https://arxiv.org/abs/2312.04474) - [Inspired the implementation of coc plugin](optillm/plugins/coc_plugin.py)
- [Entropy Based Sampling and Parallel CoT Decoding](https://github.com/xjdr-alt/entropix) - [Implementation](optillm/entropy_decoding.py)
- [Fact, Fetch, and Reason: A Unified Evaluation of Retrieval-Augmented Generation](https://arxiv.org/abs/2409.12941) - [Evaluation script](scripts/eval_frames_benchmark.py)
diff --git a/optillm/plugins/longcepo.py b/optillm/plugins/longcepo.py
new file mode 100644
index 00000000..55d42062
--- /dev/null
+++ b/optillm/plugins/longcepo.py
@@ -0,0 +1,15 @@
+"""The Long-Context Cerebras Planning and Optimization (LongCePO) Method
+
+LongCePO is an inference-time computation method designed to provide LLMs with the capability to work with infinite context such as external knowledge bases that can run into millions of tokens. We achieve this goal through a combination of multiple strategies including planning (query decomposition) and divide-and-conquer long-context processing. This approach enables to use a limited context window (e.g. 8K) and outperform full-context processing with the same base model in many question-answering tasks.
+
+If you have any questions or want to contribute, please reach out to us on [cerebras.ai/discord](https://cerebras.ai/discord).
+"""
+
+from typing import Tuple
+from optillm.plugins.longcepo.main import run_longcepo
+
+
+SLUG = "longcepo"
+
+def run(system_prompt: str, initial_query: str, client, model: str) -> Tuple[str, int]:
+ return run_longcepo(system_prompt, initial_query, client, model)
diff --git a/optillm/plugins/longcepo/README.md b/optillm/plugins/longcepo/README.md
new file mode 100644
index 00000000..64534ba2
--- /dev/null
+++ b/optillm/plugins/longcepo/README.md
@@ -0,0 +1,89 @@
+# The Long-Context Cerebras Planning and Optimization (LongCePO) Method
+
+LongCePO is an inference-time computation method designed to provide LLMs with the capability to work with infinite context such as external knowledge bases that can run into millions of tokens. We achieve this goal through a combination of multiple strategies including planning (query decomposition) and divide-and-conquer long-context processing. This approach enables to use a limited context window (e.g. 8K) and outperform full-context processing with the same base model in many question-answering tasks.
+
+If you have any questions or want to contribute, please reach out to us on [cerebras.ai/discord](https://cerebras.ai/discord).
+
+## Usage
+
+Start the optillm proxy server with directory to plugins specified in the command line:
+
+```bash
+python optillm.py --base-url https://api.cerebras.ai/v1 --port --plugins-dir ./optillm/plugins
+```
+
+Now, you can send requests to the proxy using model name `longcepo-{model_name}` (e.g. `longcepo-llama-3.3-70b`) using the following format of the user message: `{context}{query}`. The `` delimiter string is used to split the user message into the (long) context and the user's query, respectively. This delimiter string can be changed (along with other LongCePO parameters) in the [config file](./config.py).
+
+
+## LongCePO Results
+
+LongCePO excels at tasks with long context (128K tokens and more) which is demonstrated below on LongBench v2 and HELMET benchmarks in comparison to frontier models. We additionally provide data points for tasks with shorter context that still exceeds the context window of 8K (HotpotQA and MuSiQue samples of 12-16K length). For our evaluations, we report mean and standard deviation of the target metric over 5 runs below.
+
+### LongBench v2
+
+| Model¹ | Context window | Short samples (up to 32K words) | Medium samples (32–128K words) |
+|----------------------------------|----------------|------------------|----------------|
+| Llama 3.3 70B Instruct | 128K | 36.7 (45.0) | 27.0 (33.0) |
+| **LongCePO + Llama 3.3 70B Instruct** | **8K** | **36.8 ± 1.38** | **38.7 ± 2.574 (39.735)²** |
+| Mistral-Large-Instruct-2411 | 128K | 41.7 (46.1) | 30.7 (34.9) |
+| o1-mini-2024-09-12 | 128K | 48.6 (48.9) | 33.3 (32.9) |
+| Claude-3.5-Sonnet-20241022 | 200K | 46.1 (53.9) | 38.6 (41.9) |
+| Llama-4-Maverick-17B-128E-Instruct | 524K | 32.22 (50.56) | 28.84 (41.86) |
+
+ ¹ Performance numbers reported by LongBench v2 authors, except for LongCePO and Llama-4-Maverick results.
+
+ ² Numbers in parentheses for LongCePO indicate accuracy of majority voting from 5 runs.
+
+### HELMET (InfiniteBench En.MC, 128K length)
+
+| Model | Accuracy (%) |
+|---------|---------------|
+| Llama 3.3 70B Instruct (full context) | 58.0 |
+| **LongCePO + Llama 3.3 70B Instruct (8K context)** | **71.6 ± 1.855 (73.0)¹** |
+| o1-mini-2024-09-12 (full context) | 58.0 |
+| gpt-4o-2024-08-06 (full context) | 74.0 |
+
+ ¹ Numbers in parentheses for LongCePO indicate accuracy of majority voting from 5 runs.
+
+### LongBench v1 (HotpotQA, 12K+ length - 124 samples)
+
+| Model | F1 Metric (%) | LLM-as-a-judge accuracy (%) |
+|---------|---------------|-----------------------------|
+| Llama 3.3 70B Instruct (full context) | 63.372 ± 0.269 | 77.903 ± 0.822 |
+| **LongCePO + Llama 3.3 70B Instruct (8K context)** | **64.842 ± 1.295** | **79.355 ± 1.66** |
+
+### LongBench v1 (MuSiQue, 12K+ length - 191 samples)
+
+| Model | F1 Metric (%) | LLM-as-a-judge accuracy (%) |
+|---------|---------------|-----------------------------|
+| Llama 3.3 70B Instruct (full context) | 48.481 ± 0.641 | 49.424 ± 0.71 |
+| **LongCePO + Llama 3.3 70B Instruct (8K context)** | **54.076 ± 2.059** | **60.628 ± 2.156** |
+
+
+## LongCePO Methodology
+
+LongCePO is based on the [LLM×MapReduce](https://arxiv.org/abs/2410.09342) approach to long document processing, adding a planning layer on top of a map-reduce-based question-answering engine. We also improve upon the map-reduce approach itself by (i) adding query-aware summaries of neighboring document chunks during the map stage of the processing, (ii) reducing the collapse (merging) stage to a minimum required number of collapse iterations by using a sliding window to iteratively merge pairs of summaries, (iii) using a customized system prompt produced with an [OPRO-like](https://arxiv.org/abs/2309.03409) optimization approach to enhance question-anwering performance. Given a user query, a plan consisting of sub-queries is generated from a normalized query; a map-reduce question-answering engine is then run for each sub-query consecutively, conditioned on the answers to previous sub-queries. Finally, the answer to original user's query is produced via map-reduce conditioned on answers to the whole plan. Similarly to [LLM×MapReduce](https://arxiv.org/abs/2410.09342), we retain the structured information protocol for producing document chunk summaries. We find that splitting the document into chunks of size smaller than the available context window (e.g. chunks of 4K size with available context window of 8K) leads to better performance, and use the remaning context budget to incorporate summaries from neighboring chunks into the map stage for each respective chunks, leading to a further boost in overall performance.
+
+## LongCePO Current Status
+
+This project is a work in progress, and the provided code is in an early experimental stage. While the proposed approach works well across the benchmarks we tested, further improvements can be achieved through a smart organization of the external knowledge base as well as customization of the plan generation to different tasks. For updates on LongCePO, [follow us on X](https://x.com/cerebrassystems) and join our [Discord](https://cerebras.ai/discord)!
+
+
+## References
+
+1. Zhou, Zihan, et al. *LLM×MapReduce: Simplified Long-Sequence Processing using Large Language Models.* arXiv preprint arXiv:2410.09342 (2024).
+
+2. Yang, Chengrun, et al. *Large language models as optimizers.* arXiv preprint arXiv:2309.03409 (2023).
+
+## Citing LongCePO
+
+```bibtex
+@misc{
+ cerebras2025longcepo,
+ author = {Lazarevich, Ivan and Hassanpour, Mohammad and Venkatesh, Ganesh},
+ title = {LongCePO: Empowering LLMs to efficiently leverage infinite context},
+ month = March,
+ year = 2025,
+ howpublished = {\url{https://cerebras.ai/blog/longcepo}, }
+}
+```
\ No newline at end of file
diff --git a/optillm/plugins/longcepo/__init__.py b/optillm/plugins/longcepo/__init__.py
new file mode 100644
index 00000000..e69de29b
diff --git a/optillm/plugins/longcepo/chunking.py b/optillm/plugins/longcepo/chunking.py
new file mode 100644
index 00000000..56f941b9
--- /dev/null
+++ b/optillm/plugins/longcepo/chunking.py
@@ -0,0 +1,248 @@
+# Code modified from https://github.com/thunlp/LLMxMapReduce under Apache 2.0
+
+import re
+from typing import List
+
+from optillm.plugins.longcepo.utils import logger
+
+
+def get_prompt_length(prompt: str, tokenizer, no_special_tokens=False, **kwargs) -> int:
+ """
+ Returns the token length of a prompt using the given tokenizer.
+ """
+ if isinstance(prompt, list):
+ prompt = "\n\n".join(prompt)
+ if no_special_tokens:
+ kwargs["add_special_tokens"] = False
+ return len(tokenizer.encode(prompt, **kwargs))
+
+
+def chunk_context(doc: str, chunk_size: int, tokenizer, separator="\n",) -> List[str]:
+ """
+ Splits a long document into token-limited chunks based on a separator, ensuring each chunk fits within `chunk_size`.
+
+ Uses a greedy approach to accumulate text segments (split by `separator`) into chunks that fit within the
+ token limit. If a segment alone exceeds the limit, it is recursively broken down using sentence-level
+ splitting. Attempts to preserve natural boundaries while minimizing excessive chunking.
+
+ Args:
+ doc (str): Input document to split.
+ chunk_size (int): Maximum number of tokens allowed per chunk.
+ tokenizer: Tokenizer instance with `.encode()` method to compute token length.
+ separator (str): Delimiter to split initial segments (default: newline).
+
+ Returns:
+ List[str]: List of non-empty, token-constrained document chunks.
+ """
+ paragraphs = doc.split(separator)
+ paragraphs = [paragraph for paragraph in paragraphs if paragraph]
+ separator_len = get_prompt_length(separator, tokenizer, no_special_tokens=True)
+
+ docs = []
+ current_doc = []
+ total = 0
+ for paragraph in paragraphs:
+ plen = get_prompt_length(paragraph, tokenizer, no_special_tokens=True)
+ if total + plen + (separator_len if len(current_doc) > 0 else 0) > chunk_size:
+ if total > chunk_size:
+ logger.info(
+ f"Created a chunk of size {total}, "
+ f"which is longer than the specified {chunk_size}"
+ )
+ # If single chunk is too long, split into more granular
+ if len(current_doc) == 1:
+ split_again = split_into_granular_chunks(
+ current_doc[0], chunk_size, tokenizer
+ )
+ docs.extend(split_again)
+ current_doc = []
+ total = 0
+
+ if len(current_doc) > 0:
+ doc = separator.join(current_doc)
+ if doc is not None:
+ docs.append(doc)
+ while total > 0 or (
+ total + plen + (separator_len if len(current_doc) > 0 else 0)
+ > chunk_size
+ and total > 0
+ ):
+ total -= get_prompt_length(
+ current_doc[0], tokenizer, no_special_tokens=True
+ ) + (separator_len if len(current_doc) > 1 else 0)
+ current_doc = current_doc[1:]
+
+ current_doc.append(paragraph)
+ total += plen + (separator_len if len(current_doc) > 1 else 0)
+ # Check if the last one exceeds
+ if (
+ get_prompt_length(current_doc[-1], tokenizer, no_special_tokens=True)
+ > chunk_size
+ and len(current_doc) == 1
+ ):
+ split_again = split_into_granular_chunks(current_doc[0], chunk_size, tokenizer)
+ docs.extend(split_again)
+ current_doc = []
+ else:
+ doc = separator.join(current_doc)
+ if doc is not None:
+ docs.append(doc)
+
+ return [doc for doc in docs if doc.strip()]
+
+
+def split_sentences(text: str, spliter: str):
+ """
+ Splits text into sentences or segments based on a given delimiter while preserving punctuation.
+
+ For punctuation-based splitters (e.g., ".", "!", "。"), it interleaves text and punctuation.
+ For space-based splitting, it preserves trailing spaces.
+
+ Args:
+ text (str): The input text to split.
+ spliter (str): Delimiter regex pattern (e.g., r"([.!?])", r"(。)", or " ").
+
+ Returns:
+ List[str]: List of split sentence-like segments with punctuation retained.
+ """
+
+ # Split by punctuation and keep punctuation
+ text = text.strip()
+ sentence_list = re.split(spliter, text)
+
+ # Rearrange sentences and punctuation
+ if spliter != " ":
+ sentences = ["".join(i) for i in zip(sentence_list[0::2], sentence_list[1::2])]
+ if len(sentence_list) % 2 != 0 and sentence_list[-1] != "":
+ sentences.append(sentence_list[-1])
+ else:
+ sentences = [i + " " for i in sentence_list if i != ""]
+ sentences[-1] = sentences[-1].strip()
+ return sentences
+
+
+def split_into_granular_chunks(
+ text: str, chunk_size: int, tokenizer, spliter=r"([。!?;.?!;])",
+) -> List[str]:
+ """
+ Splits long text into granular, token-length-constrained chunks using sentence boundaries.
+
+ Sentences are first extracted using a delimiter pattern (`spliter`), then grouped into chunks such that
+ each chunk does not exceed the specified `chunk_size` (in tokens). If a chunk still exceeds the limit,
+ it is recursively broken down further using whitespace as a fallback.
+
+ Ensures that the final chunks are balanced: if the last chunk is too small, it redistributes the last two
+ chunks more evenly by re-splitting and re-allocating their sentences.
+
+ Args:
+ text (str): Input text to be chunked.
+ chunk_size (int): Maximum number of tokens per chunk.
+ tokenizer: Tokenizer instance with `.encode()` method to compute token length.
+ spliter (str): Regex pattern to split sentences.
+
+ Returns:
+ List[str]: List of token-limited chunks, each composed of one or more sentences.
+ """
+ sentences = split_sentences(text, spliter)
+
+ chunks = []
+ current_chunk = ""
+
+ for sentence in sentences:
+ sentence_length = get_prompt_length(sentence, tokenizer)
+
+ if get_prompt_length(current_chunk, tokenizer) + sentence_length <= chunk_size:
+ current_chunk += sentence
+ else:
+ if current_chunk:
+ if get_prompt_length(current_chunk, tokenizer) <= chunk_size:
+ chunks.append(current_chunk)
+ else:
+ if spliter != " ": # Avoid infinite loops
+ chunks.extend(
+ split_into_granular_chunks(
+ current_chunk,
+ chunk_size=chunk_size,
+ tokenizer=tokenizer,
+ spliter=" ",
+ )
+ )
+ current_chunk = sentence
+
+ if current_chunk != "":
+ if get_prompt_length(current_chunk, tokenizer) <= chunk_size:
+ chunks.append(current_chunk)
+ else:
+ if spliter != " ": # Avoid infinite loops
+ chunks.extend(
+ split_into_granular_chunks(
+ current_chunk,
+ chunk_size=chunk_size,
+ tokenizer=tokenizer,
+ spliter=" ",
+ )
+ )
+
+ # If last chunk too short, re-balance the last two chunks
+ if len(chunks) > 1 and get_prompt_length(chunks[-1], tokenizer) < chunk_size // 2:
+ last_chunk = chunks.pop()
+ penultimate_chunk = chunks.pop()
+ combined_text = penultimate_chunk + last_chunk
+
+ new_sentences = split_sentences(combined_text, spliter)
+
+ # Reallocate sentence using double pointer
+ new_penultimate_chunk = ""
+ new_last_chunk = ""
+ start, end = 0, len(new_sentences) - 1
+
+ while start <= end and len(new_sentences) != 1:
+ flag = False
+ if (
+ get_prompt_length(
+ new_penultimate_chunk + new_sentences[start], tokenizer
+ )
+ <= chunk_size
+ ):
+ flag = True
+ new_penultimate_chunk += new_sentences[start]
+ if start == end:
+ break
+ start += 1
+ if (
+ get_prompt_length(new_last_chunk + new_sentences[end], tokenizer)
+ <= chunk_size
+ ):
+ new_last_chunk = new_sentences[end] + new_last_chunk
+ end -= 1
+ flag = True
+ if flag == False:
+ break
+ if start < end:
+ # If there is any unallocated part, split it by punctuation or space and then allocate it
+ remaining_sentences = new_sentences[start : end + 1]
+ if remaining_sentences:
+ remaining_text = "".join(remaining_sentences)
+ words = remaining_text.split(" ")
+ end_index = len(words) - 1
+ for index, w in enumerate(words):
+ if (
+ get_prompt_length(
+ " ".join([new_penultimate_chunk, w]), tokenizer
+ )
+ <= chunk_size
+ ):
+ new_penultimate_chunk = " ".join([new_penultimate_chunk, w])
+ else:
+ end_index = index
+ break
+ if end_index != len(words) - 1:
+ new_last_chunk = " ".join(words[end_index:]) + " " + new_last_chunk
+ if len(new_sentences) == 1:
+ chunks.append(penultimate_chunk)
+ chunks.append(last_chunk)
+ else:
+ chunks.append(new_penultimate_chunk)
+ chunks.append(new_last_chunk)
+
+ return chunks
diff --git a/optillm/plugins/longcepo/config.py b/optillm/plugins/longcepo/config.py
new file mode 100644
index 00000000..7f0027fe
--- /dev/null
+++ b/optillm/plugins/longcepo/config.py
@@ -0,0 +1,36 @@
+from dataclasses import dataclass
+
+from optillm.plugins.longcepo.prompts import (
+ MAPREDUCE_SYSTEM_PROMPT,
+ QUERY_FORMAT_PROMPT,
+ PLANNING_SYSTEM_PROMPT,
+ MAP_PROMPT,
+ REDUCE_PROMPT,
+ COLLAPSE_PROMPT,
+ SUMMARY_PROMPT,
+)
+
+
+@dataclass
+class LongCepoConfig:
+ temperature_plan: float = 0.7 # Temperature for planning stage
+ temperature_map: float = 0.7 # Temperature for map stage
+ temperature_collapse: float = 0.7 # Temperature for collapse stage
+ temperature_reduce: float = 0.7 # Temperature for reduce stage
+
+ chunk_size: int = 4096 # Max tokens per chunk when splitting context
+ max_output_tokens: int = 1024 # Max output tokens per LLM API call (except for summary generation)
+ max_context_window: int = 8192 # Total model context window available
+ max_output_tokens_summary: int = 300 # Max output tokens per LLM API call (summary generation)
+ num_neighbor_summaries: int = 5 # Number of adjacent summaries from before/after in the context included in mapping stage
+
+ system_prompt: str = MAPREDUCE_SYSTEM_PROMPT # System prompt used in map/collapse/reduce stages
+ summary_prompt: str = SUMMARY_PROMPT # Prompt template for generating summaries in map phase
+ map_prompt: str = MAP_PROMPT # Prompt template for map stage
+ collapse_prompt: str = COLLAPSE_PROMPT # Prompt template for collapse stage
+ reduce_prompt: str = REDUCE_PROMPT # Prompt template for reduce stage
+ query_format_prompt: str = QUERY_FORMAT_PROMPT # Query normalization step prompt
+ planning_system_prompt: str = PLANNING_SYSTEM_PROMPT # Planning stage prompt
+
+ context_query_delimiter: str = "" # Delimiter used to split initial input into context and query
+ tokenizer_name: str = "meta-llama/Llama-3.3-70B-Instruct" # Tokenizer to use to determine token lengths
diff --git a/optillm/plugins/longcepo/main.py b/optillm/plugins/longcepo/main.py
new file mode 100644
index 00000000..9f87163c
--- /dev/null
+++ b/optillm/plugins/longcepo/main.py
@@ -0,0 +1,109 @@
+import re
+from typing import Tuple
+from functools import partial
+
+from optillm.plugins.longcepo.mapreduce import mapreduce
+from optillm.plugins.longcepo.utils import (
+ get_prompt_response,
+ logger,
+ longcepo_init,
+ loop_until_match,
+)
+
+
+def run_longcepo(
+ system_prompt: str, initial_query: str, client, model: str
+) -> Tuple[str, int]:
+ """
+ Executes the full LongCePO multi-stage pipeline to answer a complex query from long context.
+
+ The pipeline includes:
+ - Normalizing the format of the original query
+ - Generating a plan of sub-questions
+ - Iteratively answering each sub-question using a MapReduce-style question-answering engine
+ - Aggregating QA history and producing a final answer with MapReduce
+
+ Args:
+ system_prompt (str): System prompt string.
+ initial_query (str): Raw input string containing context and query separated by delimiter string.
+ client: LLM API client instance.
+ model (str): Base model name.
+
+ Returns:
+ Tuple[str, int]: Final answer and total number of tokens used across the pipeline.
+ """
+ context, query, tokenizer, cb_log, longcepo_config = longcepo_init(initial_query)
+
+ # Normalize query
+ normalized_query, upd_log = get_prompt_response(
+ client,
+ model,
+ longcepo_config.query_format_prompt.format(full_query=query),
+ system_prompt,
+ max_tokens=longcepo_config.max_output_tokens,
+ )
+ cb_log.update(upd_log)
+ logger.info(f"Normalized query: {normalized_query}")
+
+ # Planning stage
+ prompt = f"The question is: {normalized_query}"
+ gen_fn = partial(
+ get_prompt_response,
+ client=client,
+ model=model,
+ prompt=prompt,
+ system_prompt=longcepo_config.planning_system_prompt,
+ max_tokens=longcepo_config.max_output_tokens,
+ )
+ planning_response, upd_log = loop_until_match(
+ gen_fn, pattern_list=("",)
+ )
+ logger.info(f"Planning stage output:\n\n{planning_response}")
+ questions = (
+ re.findall(
+ r"\s*(.*?)\s*", planning_response, re.DOTALL
+ )[0]
+ .strip()
+ .splitlines()
+ )
+
+ # Loop to answer sub-queries from the plan
+ qa_system_prompt = (
+ longcepo_config.system_prompt
+ if longcepo_config.system_prompt is not None
+ else system_prompt
+ )
+ qa_history = ""
+ for question in questions:
+ if not question:
+ continue
+ question = re.sub(r"^\d+\.", "", question)
+ answer, cb_log = mapreduce(
+ qa_system_prompt,
+ question,
+ context,
+ qa_history,
+ client,
+ model,
+ tokenizer,
+ longcepo_config=longcepo_config,
+ cb_log=cb_log,
+ )
+ qa_history += f"- Previous question: {question}\n\n"
+ answer = re.sub(r"^:+", "", answer)
+ qa_history += f"- Previous answer: {answer}\n\n"
+ logger.info(f"QA history:\n\n{qa_history}")
+
+ # Final answer generation
+ answer, cb_log = mapreduce(
+ qa_system_prompt,
+ query,
+ context,
+ qa_history,
+ client,
+ model,
+ tokenizer,
+ longcepo_config=longcepo_config,
+ cb_log=cb_log,
+ )
+ return answer, cb_log["total_tokens"]
diff --git a/optillm/plugins/longcepo/mapreduce.py b/optillm/plugins/longcepo/mapreduce.py
new file mode 100644
index 00000000..8fdcfffb
--- /dev/null
+++ b/optillm/plugins/longcepo/mapreduce.py
@@ -0,0 +1,277 @@
+from functools import partial
+from typing import Tuple, List
+
+from optillm.plugins.longcepo.utils import (
+ CBLog,
+ LongCepoConfig,
+ get_prompt_response,
+ concurrent_map,
+ logger,
+ loop_until_match,
+)
+from optillm.plugins.longcepo.chunking import (
+ chunk_context,
+ get_prompt_length,
+)
+
+format_chunk_list = lambda chunk_list: [
+ f"Information of Chunk {index}:\n{doc}\n" for index, doc in enumerate(chunk_list)
+]
+
+
+def remove_chunks(chunks: List[str], irrelevance_tags: Tuple[str]) -> List[str]:
+ """
+ Filter out chunks that contain at least one of irrelevance tags.
+ """
+ new_chunks = []
+ for chunk in chunks:
+ flag = False
+ for tag in irrelevance_tags:
+ if tag.upper() in chunk.upper():
+ flag = True
+ break
+ if not flag:
+ new_chunks.append(chunk)
+ return new_chunks
+
+
+def mapreduce(
+ system_prompt: str,
+ query: str,
+ context: str,
+ qa_history: str,
+ client,
+ model: str,
+ tokenizer,
+ longcepo_config: LongCepoConfig,
+ cb_log: CBLog,
+ answer_tags: Tuple[str] = ("Answer:", "**Answer**:", "**Answer**"),
+ irrelevance_tags: Tuple[str] = ("[NO INFORMATION]",),
+) -> Tuple[str, CBLog]:
+ """
+ Executes a MapReduce-style inference pipeline to answer a query from long context.
+
+ The function splits the input context into chunks, summarizes and evaluates each with the model (Map),
+ collapses intermediate answers to reduce redundancy, and then generates a final answer (Reduce).
+ Irrelevant responses are filtered based on `irrelevance_tags`.
+
+ Args:
+ system_prompt (str): System prompt string.
+ query (str): User query.
+ context (str): Long-form input context to process.
+ qa_history (str): QA history string for prompt injection.
+ client: LLM API client.
+ model (str): Base model name.
+ tokenizer: Tokenizer to compute token lengths.
+ longcepo_config (LongCepoConfig): Config with hyper-parameters and token limits.
+ cb_log (CBLog): Log object for tracking model calls.
+ answer_tags (Tuple[str]): Tags used to extract the final answer from model output.
+ irrelevance_tags (Tuple[str]): Tags used to identify and remove irrelevant outputs.
+
+ Returns:
+ Tuple[str, CBLog]: Final extracted answer and updated log object.
+ """
+
+ logger.info(f"MapReduce query: {query}")
+
+ qa_history_stub = (
+ f"\n\nAnswers to related questions:\n\n{qa_history}" if qa_history else ""
+ )
+
+ context_chunks = chunk_context(context, longcepo_config.chunk_size, tokenizer)
+
+ # Get short summaries of each chunk
+ def fetch_chunk_summary(client, model, chunk, query, system_prompt):
+ return get_prompt_response(
+ client,
+ model,
+ longcepo_config.summary_prompt.format(question=query, context=chunk),
+ system_prompt,
+ max_tokens=longcepo_config.max_output_tokens_summary,
+ temperature=longcepo_config.temperature_map,
+ )
+
+ summaries, cb_log = concurrent_map(
+ fetch_chunk_summary,
+ client,
+ model,
+ context_chunks,
+ query,
+ system_prompt,
+ cb_log,
+ )
+ num_summaries = longcepo_config.num_neighbor_summaries
+ # For each chunk position, get a neighborhood of `num_summaries` before and after the position
+ summaries_per_chunk = [
+ "\n\n".join(
+ summaries[
+ max(0, (summary_idx - num_summaries)) : min(
+ len(summaries) - 1, (summary_idx + num_summaries)
+ )
+ ]
+ )
+ for summary_idx in range(len(summaries))
+ ]
+
+ # Map stage
+ def fetch_map_response(client, model, chunk, query, system_prompt, summary):
+ return get_prompt_response(
+ client,
+ model,
+ longcepo_config.map_prompt.format(
+ question=query,
+ context=chunk,
+ summary=summary,
+ qa_history_stub=qa_history_stub,
+ ),
+ system_prompt,
+ max_tokens=longcepo_config.max_output_tokens,
+ temperature=longcepo_config.temperature_map,
+ )
+
+ result, cb_log = concurrent_map(
+ fetch_map_response,
+ client,
+ model,
+ context_chunks,
+ query,
+ system_prompt,
+ cb_log,
+ summaries_per_chunk=summaries_per_chunk,
+ )
+ result = remove_chunks(result, irrelevance_tags)
+ if not result:
+ return "No information", cb_log
+
+ logger.info(
+ f"Removed {len(context_chunks) - len(result)} chunks from total {len(context_chunks)} chunks"
+ )
+
+ # Collapse stage
+ result, cb_log = collapse_chunks(
+ client,
+ model,
+ result,
+ query,
+ system_prompt,
+ qa_history_stub,
+ tokenizer,
+ cb_log,
+ longcepo_config,
+ )
+ result = remove_chunks(result, irrelevance_tags)
+ if not result:
+ return "No information", cb_log
+
+ # Reduce stage
+ prompt = longcepo_config.reduce_prompt.format(
+ question=query,
+ context=format_chunk_list(result),
+ qa_history_stub=qa_history_stub,
+ )
+ gen_fn = partial(
+ get_prompt_response,
+ client=client,
+ model=model,
+ prompt=prompt,
+ system_prompt=system_prompt,
+ max_tokens=longcepo_config.max_output_tokens,
+ temperature=longcepo_config.temperature_reduce,
+ )
+ reduce_result, upd_log = loop_until_match(gen_fn, answer_tags,)
+ cb_log.update(upd_log)
+
+ final_answer = reduce_result
+ for answer_tag in answer_tags:
+ if answer_tag in reduce_result:
+ final_answer = reduce_result.split(answer_tag)[-1].strip()
+ break
+
+ return final_answer, cb_log
+
+
+def collapse_chunks(
+ client,
+ model: str,
+ context_chunks: List[str],
+ query: str,
+ system_prompt: str,
+ qa_history_stub: str,
+ tokenizer,
+ cb_log: CBLog,
+ longcepo_config: LongCepoConfig,
+) -> Tuple[List[str], CBLog]:
+ """
+ Collapses context chunk pairs in sliding window until the total token count fits within the context window.
+
+ Args:
+ client: LLM API client.
+ model (str): Base model name.
+ context_chunks (List[str]): Input context chunks.
+ query (str): User query.
+ system_prompt (str): System prompt string.
+ qa_history_stub (str): QA history prefix.
+ tokenizer: Tokenizer to compute token lengths.
+ cb_log (CBLog): Log object for tracking model calls.
+ longcepo_config (LongCepoConfig): Config with hyper-parameters and token limits.
+
+ Returns:
+ Tuple[List[str], CBLog]: Final context chunks and updated logs.
+ """
+ num_tokens = get_prompt_length(format_chunk_list(context_chunks), tokenizer)
+ token_budget = (
+ longcepo_config.max_context_window
+ - get_prompt_length(longcepo_config.collapse_prompt, tokenizer)
+ - longcepo_config.max_output_tokens
+ )
+ logger.info(f"Pre-collapse length of chunks {num_tokens}, allowed {token_budget}")
+
+ def fetch_collapse_response(client, model, docs, query, system_prompt):
+ if len(docs) == 1:
+ return docs[0], CBLog()
+ return get_prompt_response(
+ client,
+ model,
+ longcepo_config.collapse_prompt.format(
+ question=query,
+ context="\n\n".join(docs),
+ qa_history_stub=qa_history_stub,
+ ),
+ system_prompt,
+ max_tokens=longcepo_config.max_output_tokens,
+ temperature=longcepo_config.temperature_collapse,
+ )
+
+ merge_pair_idx = 0
+ collapse_step = 0
+ while num_tokens is not None and num_tokens > token_budget:
+ logger.info(f"Length at collapse stage {collapse_step}: {collapse_step}")
+
+ if len(context_chunks) == 1:
+ logger.info(f"Post-collapse length of chunks {num_tokens}")
+ return context_chunks, cb_log
+
+ # Merge chunk pair in a sliding window (merge_pair_idx:merge_pair_idx+2)
+ chunk_groups = (
+ [(context_chunks[i],) for i in range(merge_pair_idx)]
+ + [(context_chunks[merge_pair_idx], context_chunks[merge_pair_idx + 1])]
+ + [
+ (context_chunks[i],)
+ for i in range(merge_pair_idx + 2, len(context_chunks))
+ ]
+ )
+ context_chunks, cb_log = concurrent_map(
+ fetch_collapse_response,
+ client,
+ model,
+ chunk_groups,
+ query,
+ system_prompt,
+ cb_log,
+ )
+ merge_pair_idx = (merge_pair_idx + 1) % max(len(context_chunks) - 1, 1)
+ num_tokens = get_prompt_length(format_chunk_list(context_chunks), tokenizer)
+ collapse_step += 1
+
+ logger.info(f"Post-collapse length of chunks {num_tokens}")
+ return context_chunks, cb_log
diff --git a/optillm/plugins/longcepo/prompts.py b/optillm/plugins/longcepo/prompts.py
new file mode 100644
index 00000000..8a1b039e
--- /dev/null
+++ b/optillm/plugins/longcepo/prompts.py
@@ -0,0 +1,15 @@
+# Code (Map/Collapse/Reduce prompts) modified from https://github.com/thunlp/LLMxMapReduce under Apache 2.0
+
+MAPREDUCE_SYSTEM_PROMPT = """You are globally celebrated as a preeminent expert in the field of digital document analysis and synthesis, known for your unmatched precision in transforming fragmented texts into comprehensive and insightful responses. Always respond in the user\'s language, ensuring every interaction is informed by all preceding exchanges for complete contextual understanding.\n\nIn your initial message, confidently declare your credentials with a phrase such as: "As a world-renowned specialist in [specific field], honored with the [real prestigious local award]," replacing placeholders with authentic information from your domain.\n\nAdhere strictly to these principles with each document segment or query:\n\n1. Extract every critical piece of information, nuance, and context with meticulous attention to detail.\n2. Organize your analysis methodically, presenting specific examples, data, and verifiable facts clearly and logically.\n3. Cease your response abruptly if approaching character limits, awaiting the user\'s "continue" instruction to carry on.\n4. Anchor every insight and conclusion in provided content or universally accepted truths, strictly avoiding speculation or unfounded statements.\n5. Communicate with a professional yet approachable tone, reflecting profound expertise and clarity.\n\nRecognize the real-world impact of your insights; ensure each response is seamlessly integrated, richly detailed, and impeccably reliable. Rigorously observe these guidelines to offer authoritative and precise analysis and synthesis."""
+
+QUERY_FORMAT_PROMPT = """Given the below blurb, can you help identify only the question we want to answer? The blurb might contain other information such as -- format for final answer, multiple choices for the final answer, context, general directions about how to behave as an AI assistant etc. Please remove all of that and just faithfully copy out the question. The blurb is:\n\n{full_query}.\n\nDo not attempt to answer the question, ignore formatting instructions in the blurb, if any."""
+
+SUMMARY_PROMPT = """You are provided with a portion of an article and a question. Read the article portion and follow my instructions to process it.\n\nArticle:\nThe article begins as follows:\n{context}\nThe article concludes here.\n\nQuestion:\n{question}\n\nInstructions: Please just write a 2-3 sentence summary for the provided passage. Do not answer the question or write anything else."""
+
+PLANNING_SYSTEM_PROMPT = """As an intelligent assistant, your primary objective is to answer a user question as accurately as possible given a long article. The full article is too long to fit in your context window, and to facilitate your answering objective, a reading agent has been created that can process the article chunk by chunk and answer question about it. You can ask the reading agent any question you need to answer the user's question or to use it for clarification. The first step for you is to is to make a rational plan based on the question. The plan should consist of sub-questions you should ask to the reading agent that you need to know the answers to in order to answer the user's question. This plan should outline the step-by-step process to resolve the question and specify the key information required to formulate a comprehensive answer. The reader agent can make mistakes.\nExample:\n#####\nUser: Who had a longer tennis career, Danny or Alice?\nAssistant: In order to answer this question, we need to ask the following sub-questions:\n\n1. What is the length of Danny’s tennis career (their start and retirement)?\n2. What is the length of Alice’s tennis career (their start and retirement)?\n\n#####\nPlease strictly follow the above format. You must include the tags. Let’s begin."""
+
+MAP_PROMPT = """You are provided with a portion of an article, short summaries of related portions if any, and a question. Read the article portion and follow my instructions to process it.\n\nArticle:\nThe article begins as follows:\n{context}\nThe article concludes here.\n\nPrevious portion summaries:{summary}{qa_history_stub}\n\nQuestion:\n{question}\n\nInstructions:\n\nPlease extract information from the provided passage to try and answer the given question. Note that you only have a part of the entire text, so the information you obtain might not fully answer the question. Therefore, provide your rationale for using the extracted information to answer the question and include a confidence score. The following is some assigning scoring cases: . Follow these steps:\n\n1. Extract Relevant Information: Identify and highlight the key pieces of information from the passage that are relevant to the given question.\n2. Provide a Rationale: Analyze the extracted information and explain how it can be used to address the question. If the information is incomplete, discuss any assumptions or inferences you need to make.\n3. Answer the Question: Based on your rationale, provide the best possible answer to the question. If, after providing your rationale, you believe the passage does not contain any information to solve the question, output "[NO INFORMATION]" as the answer.\n4. Assign a Confidence Score: Assign a confidence score (out of 5) to your answer based on the completeness and reliability of the extracted information and your rationale process.\nPlease follow this format:\n\nExtracted Information:\nRationale:\nAnswer:\nConfidence Score:"""
+
+COLLAPSE_PROMPT = """You need to process a task with a long context that greatly exceeds your context limit. The only feasible way to handle this is by processing the long context chunk by chunk. You are provided with a question and some information extracted from each chunk. Each piece of information contains Extracted Information, Rationale, Answer, and a Confidence Score. The following is some assigning scoring cases: . Read the information and follow my instructions to process it.\n\nExtracted Information:\nThe extracted information begins as follows:\n{context}\nThe extracted information concludes here.{qa_history_stub}\n\nQuestion:\n{question}\n\nInstruction:\n\nIntegrate the extracted information and then reason through the following steps:\n\n1. Integrate Extracted Information: Collect and summarize all the evidence relevant to solving the question. Consider the confidence scores of each piece of extracted information to weigh their reliability. Higher confidence scores should be given more importance in your summary.\n2. Analyze: Re-analyze the question based on the summarized information. Use the confidence scores to determine the reliability of different pieces of information, giving more weight to information with higher confidence scores.\n3. Answer the Question: Provide the best possible answer based on the updated information. If, after providing your rationale, you believe the passage does not contain any information to solve the question, output "[NO INFORMATION]" as the answer. Use the confidence scores to support the reliability of your final answer, prioritizing higher confidence information.\n4. Assign Confidence Score: Give a confidence score (out of 5) for your final answer based on the completeness and reliability of the updated information and your rationale process.\nConsider the initial confidence scores of the integrated information to determine your final confidence score.\nPlease follow this format:\n\nExtracted Information:\nRationale:\nAnswer:\nConfidence Score:"""
+
+REDUCE_PROMPT = """You need to process a task with a long context that greatly exceeds your context limit. The only feasible way to handle this is by processing the long context chunk by chunk. You are provided with a question and some information extracted from each chunk. Each piece of information contains Extracted Information, Rationale, Answer, and a Confidence Score. The following is some assigning scoring cases: . Read the information and follow my instructions to process it.{qa_history_stub}\n\nQuestion:\n{question}\n\nInformation from chunks:\n{context}\n\nEach chunk provides extracted information related to the same question, but due to partial data, conclusions from each chunk might vary. Your role is to integrate and reason through this information, weighing confidence scores to resolve any inconsistencies. Then provide the final answer.\n\nPlease follow this format:\n\nRationale:\nAnswer:"""
diff --git a/optillm/plugins/longcepo/utils.py b/optillm/plugins/longcepo/utils.py
new file mode 100644
index 00000000..15efa9ec
--- /dev/null
+++ b/optillm/plugins/longcepo/utils.py
@@ -0,0 +1,191 @@
+import logging
+from typing import Callable, List, Optional, Tuple
+from concurrent.futures import ThreadPoolExecutor, as_completed
+
+from transformers import AutoTokenizer, PreTrainedTokenizerBase
+from optillm.plugins.longcepo.config import LongCepoConfig
+
+logger = logging.getLogger(__name__)
+
+
+class CBLog(dict):
+ """Object for logging the number of LLM calls and tokens used in the pipeline"""
+
+ __allowed_keys__ = {"total_tokens", "completion_tokens", "llm_calls"}
+
+ def __init__(self, *args, **kwargs):
+ super().__init__()
+ self.update(*args, **kwargs)
+
+ def __setitem__(self, key, value):
+ if key not in self.__allowed_keys__:
+ raise KeyError(
+ f"Key '{key}' not allowed. Allowed keys: {self.__allowed_keys__}"
+ )
+ if not isinstance(value, int):
+ raise TypeError(
+ f"Value for '{key}' must be int, got {type(value).__name__}"
+ )
+ super().__setitem__(key, value)
+
+ def update(self, other=None, **kwargs):
+ updates = {}
+ if other:
+ if isinstance(other, dict):
+ updates.update(other)
+ else:
+ updates.update(dict(other))
+ updates.update(kwargs)
+
+ for key, value in updates.items():
+ if key not in self.__allowed_keys__:
+ raise KeyError(
+ f"Key '{key}' not allowed. Allowed keys: {self.__allowed_keys__}"
+ )
+ if not isinstance(value, int):
+ raise TypeError(
+ f"Value for '{key}' must be int, got {type(value).__name__}"
+ )
+ self[key] = self.get(key, 0) + value
+
+
+def concurrent_map(
+ gen_function: Callable,
+ client,
+ model: str,
+ context_chunks: List[str],
+ query: str,
+ system_prompt: str,
+ cb_log: CBLog,
+ summaries_per_chunk: Optional[List[str]] = None,
+ workers: int = 16,
+) -> Tuple[List[str], CBLog]:
+ """
+ Runs `gen_function` concurrently over a list of context chunks.
+
+ Args:
+ gen_function (Callable): Function to call with each chunk and associated arguments.
+ client: LLM API client.
+ model (str): Base model name.
+ context_chunks (List[str]): Input context chunks.
+ query (str): User query.
+ system_prompt (str): System prompt string.
+ cb_log (CBLog): Log object for tracking model calls.
+ summaries_per_chunk (Optional[List[str]]): Concatenated neighbor summaries for each chunk.
+ workers (int): Number of threads to use.
+
+ Returns:
+ Tuple[List[str], CBLog]: List of responses (in original order) and updated log object.
+ """
+ result = [None] * len(context_chunks)
+ wrapped_gen_function = lambda index, *args: (index, gen_function(*args))
+ with ThreadPoolExecutor(max_workers=workers) as executor:
+ future_to_idx = {}
+ for idx, chunk in enumerate(context_chunks):
+ args = [client, model, chunk, query, system_prompt]
+ if summaries_per_chunk is not None:
+ args.append(summaries_per_chunk[idx])
+ future_to_idx[executor.submit(wrapped_gen_function, idx, *args)] = idx
+
+ for future in as_completed(future_to_idx):
+ try:
+ index, (response, upd_log) = future.result()
+ result[index] = response
+ cb_log.update(upd_log)
+ except Exception as e:
+ logger.error(f"Error processing chunk: {e}")
+ return result, cb_log
+
+
+def get_prompt_response(
+ client,
+ model: str,
+ prompt: str,
+ system_prompt: str,
+ max_tokens: int,
+ temperature: float = 0.7,
+ top_p: float = 0.7,
+):
+ """
+ Helper function that sends a prompt to the chat-based LLM API and returns the generated response along with usage logging.
+
+ Args:
+ client: LLM API client.
+ model (str): Base model name.
+ prompt (str): The user prompt to send.
+ system_prompt (str): System prompt string.
+ max_tokens (int): Maximum number of tokens in the response.
+ temperature (float): Sampling temperature for randomness (default: 0.7).
+ top_p (float): Cumulative probability cutoff for token selection (default: 0.7).
+
+ Returns:
+ Tuple[str, CBLog]: The model's response text and a CBLog object tracking token usage.
+ """
+ messages = [
+ {"role": "system", "content": system_prompt},
+ {"role": "user", "content": prompt},
+ ]
+ response = client.chat.completions.create(
+ model=model,
+ messages=messages,
+ max_tokens=max_tokens,
+ top_p=top_p,
+ temperature=temperature,
+ stream=False,
+ )
+ upd_log = CBLog(
+ llm_calls=1,
+ total_tokens=response.usage.total_tokens,
+ completion_tokens=response.usage.completion_tokens,
+ )
+ return response.choices[0].message.content, upd_log
+
+
+def loop_until_match(
+ function: Callable, pattern_list: Tuple[str], num_attempts: int = 10
+):
+ """
+ Repeatedly calls a function until its output matches one of the given patterns or max attempts is reached.
+
+ Args:
+ function (Callable): Function returning (answer: str, cb_log).
+ pattern_list (Tuple[str]): Patterns to match in the answer.
+ num_attempts (int): Max number of attempts (default: 10).
+
+ Returns:
+ Tuple[str, Any]: The matching answer and its corresponding log object.
+ """
+ correct_format = False
+ for _ in range(num_attempts):
+ answer, cb_log = function()
+
+ for pattern in pattern_list:
+ if pattern in answer:
+ correct_format = True
+
+ if correct_format:
+ break
+
+ logger.info("Wrong output formatting, retrying...")
+
+ return answer, cb_log
+
+
+def longcepo_init(
+ initial_query: str,
+) -> Tuple[str, str, PreTrainedTokenizerBase, CBLog, LongCepoConfig]:
+ """
+ Initializes context, query, tokenizer, logging, and config from an input string.
+
+ Args:
+ initial_query (str): Input string containing context and query separated by a delimiter string.
+
+ Returns:
+ Tuple[str, str, PreTrainedTokenizerBase, CBLog, LongCepoConfig]:
+ Parsed context, query, tokenizer instance, log object, and LongCePO config.
+ """
+ cb_log = CBLog()
+ config = LongCepoConfig()
+ context, query = initial_query.split(config.context_query_delimiter)
+ tokenizer = AutoTokenizer.from_pretrained(config.tokenizer_name)
+ return context.strip(), query.strip(), tokenizer, cb_log, config