Branch 2.3 #20957
Closed
Branch 2.3 #20957
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
…LevelDB. The code was sorting "0" as "less than" negative values, which is a little wrong. Fix is simple, most of the changes are the added test and related cleanup. Author: Marcelo Vanzin <vanzin@cloudera.com> Closes #20284 from vanzin/SPARK-23103. (cherry picked from commit aa3a127) Signed-off-by: Imran Rashid <irashid@cloudera.com>
This follows the behavior of 2.2: only named accumulators with a value are rendered. Screenshot:  Author: Marcelo Vanzin <vanzin@cloudera.com> Closes #20299 from vanzin/SPARK-23135. (cherry picked from commit f6da41b) Signed-off-by: Sameer Agarwal <sameerag@apache.org>
{kind=link}
## What changes were proposed in this pull request? Once a meta hive client is created, it generates its SessionState which creates a lot of session related directories, some deleteOnExit, some does not. if a hive client is useless we may not create it at the very start. ## How was this patch tested? N/A cc hvanhovell cloud-fan Author: Kent Yao <11215016@zju.edu.cn> Closes #18983 from yaooqinn/patch-1. (cherry picked from commit 793841c) Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request? Narrow bound on approx quantile test to epsilon from 2*epsilon to match paper ## How was this patch tested? Existing tests. Author: Sean Owen <sowen@cloudera.com> Closes #20324 from srowen/SPARK-23091. (cherry picked from commit 396cdfb) Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request? Fix spelling in quick-start doc. ## How was this patch tested? Doc only. Author: Shashwat Anand <me@shashwat.me> Closes #20336 from ashashwat/SPARK-23165. (cherry picked from commit 84a076e) Signed-off-by: gatorsmile <gatorsmile@gmail.com>
…rk.sql.orc.compression.codec' configuration doesn't take effect on hive table writing [SPARK-21786][SQL] The 'spark.sql.parquet.compression.codec' and 'spark.sql.orc.compression.codec' configuration doesn't take effect on hive table writing What changes were proposed in this pull request? Pass ‘spark.sql.parquet.compression.codec’ value to ‘parquet.compression’. Pass ‘spark.sql.orc.compression.codec’ value to ‘orc.compress’. How was this patch tested? Add test. Note: This is the same issue mentioned in #19218 . That branch was deleted mistakenly, so make a new pr instead. gatorsmile maropu dongjoon-hyun discipleforteen Author: fjh100456 <fu.jinhua6@zte.com.cn> Author: Takeshi Yamamuro <yamamuro@apache.org> Author: Wenchen Fan <wenchen@databricks.com> Author: gatorsmile <gatorsmile@gmail.com> Author: Yinan Li <liyinan926@gmail.com> Author: Marcelo Vanzin <vanzin@cloudera.com> Author: Juliusz Sompolski <julek@databricks.com> Author: Felix Cheung <felixcheung_m@hotmail.com> Author: jerryshao <sshao@hortonworks.com> Author: Li Jin <ice.xelloss@gmail.com> Author: Gera Shegalov <gera@apache.org> Author: chetkhatri <ckhatrimanjal@gmail.com> Author: Joseph K. Bradley <joseph@databricks.com> Author: Bago Amirbekian <bago@databricks.com> Author: Xianjin YE <advancedxy@gmail.com> Author: Bruce Robbins <bersprockets@gmail.com> Author: zuotingbing <zuo.tingbing9@zte.com.cn> Author: Kent Yao <yaooqinn@hotmail.com> Author: hyukjinkwon <gurwls223@gmail.com> Author: Adrian Ionescu <adrian@databricks.com> Closes #20087 from fjh100456/HiveTableWriting. (cherry picked from commit 00d1691) Signed-off-by: gatorsmile <gatorsmile@gmail.com>
…on is false/null ## What changes were proposed in this pull request? CheckCartesianProduct raises an AnalysisException also when the join condition is always false/null. In this case, we shouldn't raise it, since the result will not be a cartesian product. ## How was this patch tested? added UT Author: Marco Gaido <marcogaido91@gmail.com> Closes #20333 from mgaido91/SPARK-23087. (cherry picked from commit 121dc96) Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request? streaming programming guide changes ## How was this patch tested? manually Author: Felix Cheung <felixcheung_m@hotmail.com> Closes #20340 from felixcheung/rstreamdoc. (cherry picked from commit 2239d7a) Signed-off-by: Felix Cheung <felixcheung@apache.org>
## What changes were proposed in this pull request? The clean up logic on the worker perviously determined the liveness of a particular applicaiton based on whether or not it had running executors. This would fail in the case that a directory was made for a driver running in cluster mode if that driver had no running executors on the same machine. To preserve driver directories we consider both executors and running drivers when checking directory liveness. ## How was this patch tested? Manually started up two node cluster with a single core on each node. Turned on worker directory cleanup and set the interval to 1 second and liveness to one second. Without the patch the driver directory is removed immediately after the app is launched. With the patch it is not ### Without Patch ``` INFO 2018-01-05 23:48:24,693 Logging.scala:54 - Asked to launch driver driver-20180105234824-0000 INFO 2018-01-05 23:48:25,293 Logging.scala:54 - Changing view acls to: cassandra INFO 2018-01-05 23:48:25,293 Logging.scala:54 - Changing modify acls to: cassandra INFO 2018-01-05 23:48:25,294 Logging.scala:54 - Changing view acls groups to: INFO 2018-01-05 23:48:25,294 Logging.scala:54 - Changing modify acls groups to: INFO 2018-01-05 23:48:25,294 Logging.scala:54 - SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(cassandra); groups with view permissions: Set(); users with modify permissions: Set(cassandra); groups with modify permissions: Set() INFO 2018-01-05 23:48:25,330 Logging.scala:54 - Copying user jar file:/home/automaton/writeRead-0.1.jar to /var/lib/spark/worker/driver-20180105234824-0000/writeRead-0.1.jar INFO 2018-01-05 23:48:25,332 Logging.scala:54 - Copying /home/automaton/writeRead-0.1.jar to /var/lib/spark/worker/driver-20180105234824-0000/writeRead-0.1.jar INFO 2018-01-05 23:48:25,361 Logging.scala:54 - Launch Command: "/usr/lib/jvm/jdk1.8.0_40//bin/java" .... **** INFO 2018-01-05 23:48:56,577 Logging.scala:54 - Removing directory: /var/lib/spark/worker/driver-20180105234824-0000 ### << Cleaned up **** -- One minute passes while app runs (app has 1 minute sleep built in) -- WARN 2018-01-05 23:49:58,080 ShuffleSecretManager.java:73 - Attempted to unregister application app-20180105234831-0000 when it is not registered INFO 2018-01-05 23:49:58,081 ExternalShuffleBlockResolver.java:163 - Application app-20180105234831-0000 removed, cleanupLocalDirs = false INFO 2018-01-05 23:49:58,081 ExternalShuffleBlockResolver.java:163 - Application app-20180105234831-0000 removed, cleanupLocalDirs = false INFO 2018-01-05 23:49:58,082 ExternalShuffleBlockResolver.java:163 - Application app-20180105234831-0000 removed, cleanupLocalDirs = true INFO 2018-01-05 23:50:00,999 Logging.scala:54 - Driver driver-20180105234824-0000 exited successfully ``` With Patch ``` INFO 2018-01-08 23:19:54,603 Logging.scala:54 - Asked to launch driver driver-20180108231954-0002 INFO 2018-01-08 23:19:54,975 Logging.scala:54 - Changing view acls to: automaton INFO 2018-01-08 23:19:54,976 Logging.scala:54 - Changing modify acls to: automaton INFO 2018-01-08 23:19:54,976 Logging.scala:54 - Changing view acls groups to: INFO 2018-01-08 23:19:54,976 Logging.scala:54 - Changing modify acls groups to: INFO 2018-01-08 23:19:54,976 Logging.scala:54 - SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(automaton); groups with view permissions: Set(); users with modify permissions: Set(automaton); groups with modify permissions: Set() INFO 2018-01-08 23:19:55,029 Logging.scala:54 - Copying user jar file:/home/automaton/writeRead-0.1.jar to /var/lib/spark/worker/driver-20180108231954-0002/writeRead-0.1.jar INFO 2018-01-08 23:19:55,031 Logging.scala:54 - Copying /home/automaton/writeRead-0.1.jar to /var/lib/spark/worker/driver-20180108231954-0002/writeRead-0.1.jar INFO 2018-01-08 23:19:55,038 Logging.scala:54 - Launch Command: ...... INFO 2018-01-08 23:21:28,674 ShuffleSecretManager.java:69 - Unregistered shuffle secret for application app-20180108232000-0000 INFO 2018-01-08 23:21:28,675 ExternalShuffleBlockResolver.java:163 - Application app-20180108232000-0000 removed, cleanupLocalDirs = false INFO 2018-01-08 23:21:28,675 ExternalShuffleBlockResolver.java:163 - Application app-20180108232000-0000 removed, cleanupLocalDirs = false INFO 2018-01-08 23:21:28,681 ExternalShuffleBlockResolver.java:163 - Application app-20180108232000-0000 removed, cleanupLocalDirs = true INFO 2018-01-08 23:21:31,703 Logging.scala:54 - Driver driver-20180108231954-0002 exited successfully ***** INFO 2018-01-08 23:21:32,346 Logging.scala:54 - Removing directory: /var/lib/spark/worker/driver-20180108231954-0002 ### < Happening AFTER the Run completes rather than during it ***** ``` Author: Russell Spitzer <Russell.Spitzer@gmail.com> Closes #20298 from RussellSpitzer/SPARK-22976-master. (cherry picked from commit 11daeb8) Signed-off-by: jerryshao <sshao@hortonworks.com>
…ttributes ## What changes were proposed in this pull request? This PR fixes the wrong comment on `org.apache.spark.sql.parquet.row.attributes` which is useful for UDTs like Vector/Matrix. Please see [SPARK-22320](https://issues.apache.org/jira/browse/SPARK-22320) for the usage. Originally, [SPARK-19411](bf49368#diff-ee26d4c4be21e92e92a02e9f16dbc285L314) left this behind during removing optional column metadatas. In the same PR, the same comment was removed at line 310-311. ## How was this patch tested? N/A (This is about comments). Author: Dongjoon Hyun <dongjoon@apache.org> Closes #20346 from dongjoon-hyun/minor_comment_parquet. (cherry picked from commit 8142a3b) Signed-off-by: hyukjinkwon <gurwls223@gmail.com>
The race in the code is because the handle might update its state to the wrong state if the connection handling thread is still processing incoming data; so the handle needs to wait for the connection to finish up before checking the final state. The race in the test is because when waiting for a handle to reach a final state, the waitFor() method needs to wait until all handle state is updated (which also includes waiting for the connection thread above to finish). Otherwise, waitFor() may return too early, which would cause a bunch of different races (like the listener not being yet notified of the state change, or being in the middle of being notified, or the handle not being properly disposed and causing postChecks() to assert). On top of that I found, by code inspection, a couple of potential races that could make a handle end up in the wrong state when being killed. The original version of this fix introduced the flipped version of the first race described above; the connection closing might override the handle state before the handle might have a chance to do cleanup. The fix there is to only dispose of the handle from the connection when there is an error, and let the handle dispose itself in the normal case. The fix also caused a bug in YarnClusterSuite to be surfaced; the code was checking for a file in the classpath that was not expected to be there in client mode. Because of the above issues, the error was not propagating correctly and the (buggy) test was incorrectly passing. Tested by running the existing unit tests a lot (and not seeing the errors I was seeing before). Author: Marcelo Vanzin <vanzin@cloudera.com> Closes #20297 from vanzin/SPARK-23020. (cherry picked from commit ec22897) Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request? The example jar file is now in ./examples/jars directory of Spark distribution. Author: Arseniy Tashoyan <tashoyan@users.noreply.github.com> Closes #20349 from tashoyan/patch-1. (cherry picked from commit 60175e9) Signed-off-by: jerryshao <sshao@hortonworks.com>
## What changes were proposed in this pull request? This PR is to update the docs for UDF registration ## How was this patch tested? N/A Author: gatorsmile <gatorsmile@gmail.com> Closes #20348 from gatorsmile/testUpdateDoc. (cherry picked from commit 7328116) Signed-off-by: gatorsmile <gatorsmile@gmail.com>
…and optimizer rules ## What changes were proposed in this pull request? Dump the statistics of effective runs of analyzer and optimizer rules. ## How was this patch tested? Do a manual run of TPCDSQuerySuite ``` === Metrics of Analyzer/Optimizer Rules === Total number of runs: 175899 Total time: 25.486559948 seconds Rule Effective Time / Total Time Effective Runs / Total Runs org.apache.spark.sql.catalyst.optimizer.ColumnPruning 1603280450 / 2868461549 761 / 1877 org.apache.spark.sql.catalyst.analysis.Analyzer$CTESubstitution 2045860009 / 2056602674 37 / 788 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveAggregateFunctions 440719059 / 1693110949 38 / 1982 org.apache.spark.sql.catalyst.optimizer.Optimizer$OptimizeSubqueries 1429834919 / 1446016225 39 / 285 org.apache.spark.sql.catalyst.optimizer.PruneFilters 33273083 / 1389586938 3 / 1592 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveReferences 821183615 / 1266668754 616 / 1982 org.apache.spark.sql.catalyst.optimizer.ReorderJoin 775837028 / 866238225 132 / 1592 org.apache.spark.sql.catalyst.analysis.DecimalPrecision 550683593 / 748854507 211 / 1982 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveSubquery 513075345 / 634370596 49 / 1982 org.apache.spark.sql.catalyst.analysis.Analyzer$FixNullability 33475731 / 606406532 12 / 742 org.apache.spark.sql.catalyst.analysis.TypeCoercion$ImplicitTypeCasts 193144298 / 545403925 86 / 1982 org.apache.spark.sql.catalyst.optimizer.BooleanSimplification 18651497 / 495725004 7 / 1592 org.apache.spark.sql.catalyst.optimizer.PushPredicateThroughJoin 369257217 / 489934378 709 / 1592 org.apache.spark.sql.catalyst.optimizer.RemoveRedundantAliases 3707000 / 468291609 9 / 1592 org.apache.spark.sql.catalyst.optimizer.InferFiltersFromConstraints 410155900 / 435254175 192 / 285 org.apache.spark.sql.execution.datasources.FindDataSourceTable 348885539 / 371855866 233 / 1982 org.apache.spark.sql.catalyst.optimizer.NullPropagation 11307645 / 307531225 26 / 1592 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveFunctions 120324545 / 304948785 294 / 1982 org.apache.spark.sql.catalyst.analysis.TypeCoercion$FunctionArgumentConversion 92323199 / 286695007 38 / 1982 org.apache.spark.sql.catalyst.optimizer.PushDownPredicate 230084193 / 265845972 785 / 1592 org.apache.spark.sql.catalyst.analysis.TypeCoercion$PromoteStrings 45938401 / 265144009 40 / 1982 org.apache.spark.sql.catalyst.analysis.TypeCoercion$InConversion 14888776 / 261499450 1 / 1982 org.apache.spark.sql.catalyst.analysis.TypeCoercion$CaseWhenCoercion 113796384 / 244913861 29 / 1982 org.apache.spark.sql.catalyst.optimizer.ConstantFolding 65008069 / 236548480 126 / 1592 org.apache.spark.sql.catalyst.analysis.Analyzer$ExtractGenerator 0 / 226338929 0 / 1982 org.apache.spark.sql.catalyst.analysis.ResolveTimeZone 98134906 / 221323770 417 / 1982 org.apache.spark.sql.catalyst.optimizer.ReorderAssociativeOperator 0 / 208421703 0 / 1592 org.apache.spark.sql.catalyst.optimizer.OptimizeIn 8762534 / 199351958 16 / 1592 org.apache.spark.sql.catalyst.analysis.TypeCoercion$DateTimeOperations 11980016 / 190779046 27 / 1982 org.apache.spark.sql.catalyst.optimizer.SimplifyBinaryComparison 0 / 188887385 0 / 1592 org.apache.spark.sql.catalyst.optimizer.SimplifyConditionals 0 / 186812106 0 / 1592 org.apache.spark.sql.catalyst.optimizer.SimplifyCaseConversionExpressions 0 / 183885230 0 / 1592 org.apache.spark.sql.catalyst.optimizer.SimplifyCasts 17128295 / 182901910 69 / 1592 org.apache.spark.sql.catalyst.analysis.TypeCoercion$Division 14579110 / 180309340 8 / 1982 org.apache.spark.sql.catalyst.analysis.TypeCoercion$BooleanEquality 0 / 176740516 0 / 1982 org.apache.spark.sql.catalyst.analysis.TypeCoercion$IfCoercion 0 / 170781986 0 / 1982 org.apache.spark.sql.catalyst.optimizer.LikeSimplification 771605 / 164136736 1 / 1592 org.apache.spark.sql.catalyst.optimizer.RemoveDispensableExpressions 0 / 155958962 0 / 1592 org.apache.spark.sql.catalyst.analysis.ResolveCreateNamedStruct 0 / 151222943 0 / 1982 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveWindowOrder 7534632 / 146596355 14 / 1982 org.apache.spark.sql.catalyst.analysis.TypeCoercion$EltCoercion 0 / 144488654 0 / 1982 org.apache.spark.sql.catalyst.analysis.TypeCoercion$ConcatCoercion 0 / 142403338 0 / 1982 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveWindowFrame 12067635 / 141500665 21 / 1982 org.apache.spark.sql.catalyst.analysis.TimeWindowing 0 / 140431958 0 / 1982 org.apache.spark.sql.catalyst.analysis.TypeCoercion$WindowFrameCoercion 0 / 125471960 0 / 1982 org.apache.spark.sql.catalyst.optimizer.EliminateOuterJoin 14226972 / 124922019 11 / 1592 org.apache.spark.sql.catalyst.analysis.TypeCoercion$StackCoercion 0 / 123613887 0 / 1982 org.apache.spark.sql.catalyst.optimizer.RewriteCorrelatedScalarSubquery 8491071 / 121179056 7 / 1592 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveGroupingAnalytics 55526073 / 120290529 11 / 1982 org.apache.spark.sql.catalyst.optimizer.ConstantPropagation 0 / 113886790 0 / 1592 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveDeserializer 52383759 / 107160222 148 / 1982 org.apache.spark.sql.catalyst.analysis.CleanupAliases 52543524 / 102091518 344 / 1086 org.apache.spark.sql.catalyst.optimizer.RemoveRedundantProject 40682895 / 94403652 342 / 1877 org.apache.spark.sql.catalyst.analysis.Analyzer$ExtractWindowExpressions 38473816 / 89740578 23 / 1982 org.apache.spark.sql.catalyst.optimizer.CollapseProject 46806090 / 83315506 281 / 1877 org.apache.spark.sql.catalyst.optimizer.FoldablePropagation 0 / 78750087 0 / 1592 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveAliases 13742765 / 77227258 47 / 1982 org.apache.spark.sql.catalyst.optimizer.CombineFilters 53386729 / 76960344 448 / 1592 org.apache.spark.sql.execution.datasources.DataSourceAnalysis 68034341 / 75724186 24 / 742 org.apache.spark.sql.catalyst.analysis.Analyzer$LookupFunctions 0 / 71151084 0 / 750 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveMissingReferences 12139848 / 67599140 8 / 1982 org.apache.spark.sql.catalyst.optimizer.PullupCorrelatedPredicates 45017938 / 65968777 23 / 285 org.apache.spark.sql.execution.datasources.v2.PushDownOperatorsToDataSource 0 / 60937767 0 / 285 org.apache.spark.sql.catalyst.optimizer.CollapseRepartition 0 / 59897237 0 / 1592 org.apache.spark.sql.catalyst.optimizer.PushProjectionThroughUnion 8547262 / 53941370 10 / 1592 org.apache.spark.sql.catalyst.analysis.Analyzer$HandleNullInputsForUDF 0 / 52735976 0 / 742 org.apache.spark.sql.catalyst.analysis.TypeCoercion$WidenSetOperationTypes 9797713 / 52401665 9 / 1982 org.apache.spark.sql.catalyst.analysis.Analyzer$PullOutNondeterministic 0 / 51741500 0 / 742 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveRelations 28614911 / 51061186 233 / 1990 org.apache.spark.sql.execution.datasources.PruneFileSourcePartitions 0 / 50621510 0 / 285 org.apache.spark.sql.catalyst.optimizer.CombineUnions 2777800 / 50262112 17 / 1877 org.apache.spark.sql.catalyst.analysis.Analyzer$GlobalAggregates 1640641 / 49633909 46 / 1982 org.apache.spark.sql.catalyst.optimizer.DecimalAggregates 20198374 / 48488419 100 / 385 org.apache.spark.sql.catalyst.optimizer.LimitPushDown 0 / 45052523 0 / 1592 org.apache.spark.sql.catalyst.optimizer.CombineLimits 0 / 44719443 0 / 1592 org.apache.spark.sql.catalyst.optimizer.EliminateSorts 0 / 44216930 0 / 1592 org.apache.spark.sql.catalyst.optimizer.RewritePredicateSubquery 36235699 / 44165786 148 / 285 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveNewInstance 0 / 42750307 0 / 1982 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveUpCast 0 / 41811748 0 / 1982 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveOrdinalInOrderByAndGroupBy 3819476 / 41776562 4 / 1982 org.apache.spark.sql.catalyst.optimizer.ComputeCurrentTime 0 / 40527808 0 / 285 org.apache.spark.sql.catalyst.optimizer.CollapseWindow 0 / 36832538 0 / 1592 org.apache.spark.sql.catalyst.optimizer.EliminateSerialization 0 / 36120667 0 / 1592 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveAggAliasInGroupBy 0 / 32435826 0 / 1982 org.apache.spark.sql.execution.datasources.PreprocessTableCreation 0 / 32145218 0 / 742 org.apache.spark.sql.execution.datasources.ResolveSQLOnFile 0 / 30295614 0 / 1982 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolvePivot 0 / 30111655 0 / 1982 org.apache.spark.sql.catalyst.expressions.codegen.package$ExpressionCanonicalizer$CleanExpressions 59930 / 28038201 26 / 8280 org.apache.spark.sql.catalyst.analysis.ResolveInlineTables 0 / 27808108 0 / 1982 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveSubqueryColumnAliases 0 / 27066690 0 / 1982 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveGenerate 0 / 26660210 0 / 1982 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveNaturalAndUsingJoin 0 / 25255184 0 / 1982 org.apache.spark.sql.catalyst.analysis.ResolveTableValuedFunctions 0 / 24663088 0 / 1990 org.apache.spark.sql.catalyst.analysis.SubstituteUnresolvedOrdinals 9709079 / 24450670 4 / 788 org.apache.spark.sql.catalyst.analysis.ResolveHints$ResolveBroadcastHints 0 / 23776535 0 / 750 org.apache.spark.sql.catalyst.optimizer.ReplaceExpressions 0 / 22697895 0 / 285 org.apache.spark.sql.catalyst.optimizer.CheckCartesianProducts 0 / 22523798 0 / 285 org.apache.spark.sql.catalyst.optimizer.ReplaceDistinctWithAggregate 988593 / 21535410 15 / 300 org.apache.spark.sql.catalyst.optimizer.EliminateMapObjects 0 / 20269996 0 / 285 org.apache.spark.sql.catalyst.optimizer.RewriteDistinctAggregates 0 / 19388592 0 / 285 org.apache.spark.sql.catalyst.analysis.EliminateSubqueryAliases 17675532 / 18971185 215 / 285 org.apache.spark.sql.catalyst.optimizer.GetCurrentDatabase 0 / 18271152 0 / 285 org.apache.spark.sql.catalyst.optimizer.PropagateEmptyRelation 2077097 / 17190855 3 / 288 org.apache.spark.sql.catalyst.analysis.EliminateBarriers 0 / 16736359 0 / 1086 org.apache.spark.sql.execution.OptimizeMetadataOnlyQuery 0 / 16669341 0 / 285 org.apache.spark.sql.catalyst.analysis.UpdateOuterReferences 0 / 14470235 0 / 742 org.apache.spark.sql.catalyst.optimizer.ReplaceExceptWithAntiJoin 6715625 / 12190561 1 / 300 org.apache.spark.sql.catalyst.optimizer.ReplaceIntersectWithSemiJoin 3451793 / 11431432 7 / 300 org.apache.spark.sql.execution.python.ExtractPythonUDFFromAggregate 0 / 10810568 0 / 285 org.apache.spark.sql.catalyst.optimizer.RemoveRepetitionFromGroupExpressions 344198 / 10475276 1 / 286 org.apache.spark.sql.catalyst.analysis.Analyzer$WindowsSubstitution 0 / 10386630 0 / 788 org.apache.spark.sql.catalyst.analysis.EliminateUnions 0 / 10096526 0 / 788 org.apache.spark.sql.catalyst.analysis.AliasViewChild 0 / 9991706 0 / 742 org.apache.spark.sql.catalyst.optimizer.ConvertToLocalRelation 0 / 9649334 0 / 288 org.apache.spark.sql.catalyst.analysis.ResolveHints$RemoveAllHints 0 / 8739109 0 / 750 org.apache.spark.sql.execution.datasources.PreprocessTableInsertion 0 / 8420889 0 / 742 org.apache.spark.sql.catalyst.analysis.EliminateView 0 / 8319134 0 / 285 org.apache.spark.sql.catalyst.optimizer.RemoveLiteralFromGroupExpressions 0 / 7392627 0 / 286 org.apache.spark.sql.catalyst.optimizer.ReplaceExceptWithFilter 0 / 7170516 0 / 300 org.apache.spark.sql.catalyst.optimizer.SimplifyCreateArrayOps 0 / 7109643 0 / 1592 org.apache.spark.sql.catalyst.optimizer.SimplifyCreateStructOps 0 / 6837590 0 / 1592 org.apache.spark.sql.catalyst.optimizer.SimplifyCreateMapOps 0 / 6617848 0 / 1592 org.apache.spark.sql.catalyst.optimizer.CombineConcats 0 / 5768406 0 / 1592 org.apache.spark.sql.catalyst.optimizer.ReplaceDeduplicateWithAggregate 0 / 5349831 0 / 285 org.apache.spark.sql.catalyst.optimizer.CombineTypedFilters 0 / 5186642 0 / 285 org.apache.spark.sql.catalyst.optimizer.EliminateDistinct 0 / 2427686 0 / 285 org.apache.spark.sql.catalyst.optimizer.CostBasedJoinReorder 0 / 2420436 0 / 285 ``` Author: gatorsmile <gatorsmile@gmail.com> Closes #20342 from gatorsmile/reportExecution. (cherry picked from commit 7880188) Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request? Revert the unneeded test case changes we made in SPARK-23000 Also fixes the test suites that do not call `super.afterAll()` in the local `afterAll`. The `afterAll()` of `TestHiveSingleton` actually reset the environments. ## How was this patch tested? N/A Author: gatorsmile <gatorsmile@gmail.com> Closes #20341 from gatorsmile/testRelated. (cherry picked from commit 896e45a) Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request? Several improvements: * provide a default implementation for the batch get methods * rename `getChildColumn` to `getChild`, which is more concise * remove `getStruct(int, int)`, it's only used to simplify the codegen, which is an internal thing, we should not add a public API for this purpose. ## How was this patch tested? existing tests Author: Wenchen Fan <wenchen@databricks.com> Closes #20277 from cloud-fan/column-vector. (cherry picked from commit 5d680ca) Signed-off-by: Wenchen Fan <wenchen@databricks.com>
… streaming apps ## What changes were proposed in this pull request? The allJobs and the job pages attempt to use stage attempt and DAG visualization from the store, but for long running jobs they are not guaranteed to be retained, leading to exceptions when these pages are rendered. To fix it `store.lastStageAttempt(stageId)` and `store.operationGraphForJob(jobId)` are wrapped in `store.asOption` and default values are used if the info is missing. ## How was this patch tested? Manual testing of the UI, also using the test command reported in SPARK-23121: ./bin/spark-submit --class org.apache.spark.examples.streaming.HdfsWordCount ./examples/jars/spark-examples_2.11-2.4.0-SNAPSHOT.jar /spark Closes #20287 Author: Sandor Murakozi <smurakozi@gmail.com> Closes #20330 from smurakozi/SPARK-23121. (cherry picked from commit 446948a) Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request? a new interface which allows data source to report partitioning and avoid shuffle at Spark side. The design is pretty like the internal distribution/partitioing framework. Spark defines a `Distribution` interfaces and several concrete implementations, and ask the data source to report a `Partitioning`, the `Partitioning` should tell Spark if it can satisfy a `Distribution` or not. ## How was this patch tested? new test Author: Wenchen Fan <wenchen@databricks.com> Closes #20201 from cloud-fan/partition-reporting. (cherry picked from commit 51eb750) Signed-off-by: gatorsmile <gatorsmile@gmail.com>
…rtitioner when defaultParallelism is set ## What changes were proposed in this pull request? #20002 purposed a way to safe check the default partitioner, however, if `spark.default.parallelism` is set, the defaultParallelism still could be smaller than the proper number of partitions for upstreams RDDs. This PR tries to extend the approach to address the condition when `spark.default.parallelism` is set. The requirements where the PR helps with are : - Max partitioner is not eligible since it is atleast an order smaller, and - User has explicitly set 'spark.default.parallelism', and - Value of 'spark.default.parallelism' is lower than max partitioner - Since max partitioner was discarded due to being at least an order smaller, default parallelism is worse - even though user specified. Under the rest cases, the changes should be no-op. ## How was this patch tested? Add corresponding test cases in `PairRDDFunctionsSuite` and `PartitioningSuite`. Author: Xingbo Jiang <xingbo.jiang@databricks.com> Closes #20091 from jiangxb1987/partitioner. (cherry picked from commit 96cb60b) Signed-off-by: Mridul Muralidharan <mridul@gmail.com>
…octet_length ## What changes were proposed in this pull request? We need to override the prettyName for bit_length and octet_length for getting the expected auto-generated alias name. ## How was this patch tested? The existing tests Author: gatorsmile <gatorsmile@gmail.com> Closes #20358 from gatorsmile/test2.3More. (cherry picked from commit ee572ba) Signed-off-by: hyukjinkwon <gurwls223@gmail.com>
## What changes were proposed in this pull request?
The hint of the plan segment is lost, if the plan segment is replaced by the cached data.
```Scala
val df1 = spark.createDataFrame(Seq((1, "4"), (2, "2"))).toDF("key", "value")
val df2 = spark.createDataFrame(Seq((1, "1"), (2, "2"))).toDF("key", "value")
df2.cache()
val df3 = df1.join(broadcast(df2), Seq("key"), "inner")
```
This PR is to fix it.
## How was this patch tested?
Added a test
Author: gatorsmile <gatorsmile@gmail.com>
Closes #20365 from gatorsmile/fixBroadcastHintloss.
(cherry picked from commit 613c290)
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
The broadcast hint of the cached plan is lost if we cache the plan. This PR is to correct it.
```Scala
val df1 = spark.createDataFrame(Seq((1, "4"), (2, "2"))).toDF("key", "value")
val df2 = spark.createDataFrame(Seq((1, "1"), (2, "2"))).toDF("key", "value")
broadcast(df2).cache()
df2.collect()
val df3 = df1.join(df2, Seq("key"), "inner")
```
## How was this patch tested?
Added a test.
Author: gatorsmile <gatorsmile@gmail.com>
Closes #20368 from gatorsmile/cachedBroadcastHint.
(cherry picked from commit 44cc4da)
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request? Increased timeout from 50 ms to 300 ms (50 ms was really too low). ## How was this patch tested? Multiple rounds of tests. Author: Tathagata Das <tathagata.das1565@gmail.com> Closes #20371 from tdas/SPARK-23197. (cherry picked from commit 15adcc8) Signed-off-by: Tathagata Das <tathagata.das1565@gmail.com>
…SparkR DataFrame ## What changes were proposed in this pull request? A fix to https://issues.apache.org/jira/browse/SPARK-21727, "Operating on an ArrayType in a SparkR DataFrame throws error" ## How was this patch tested? - Ran tests at R\pkg\tests\run-all.R (see below attached results) - Tested the following lines in SparkR, which now seem to execute without error: ``` indices <- 1:4 myDf <- data.frame(indices) myDf$data <- list(rep(0, 20)) mySparkDf <- as.DataFrame(myDf) collect(mySparkDf) ``` [2018-01-22 SPARK-21727 Test Results.txt](https://github.com/apache/spark/files/1653535/2018-01-22.SPARK-21727.Test.Results.txt) felixcheung yanboliang sun-rui shivaram _The contribution is my original work and I license the work to the project under the project’s open source license_ Author: neilalex <neil@neilalex.com> Closes #20352 from neilalex/neilalex-sparkr-arraytype. (cherry picked from commit f54b65c) Signed-off-by: Felix Cheung <felixcheung@apache.org>
This reverts commit a23f6b1.
… from aggregate
## What changes were proposed in this pull request?
We extract Python UDFs in logical aggregate which depends on aggregate expression or grouping key in ExtractPythonUDFFromAggregate rule. But Python UDFs which don't depend on above expressions should also be extracted to avoid the issue reported in the JIRA.
A small code snippet to reproduce that issue looks like:
```python
import pyspark.sql.functions as f
df = spark.createDataFrame([(1,2), (3,4)])
f_udf = f.udf(lambda: str("const_str"))
df2 = df.distinct().withColumn("a", f_udf())
df2.show()
```
Error exception is raised as:
```
: org.apache.spark.sql.catalyst.errors.package$TreeNodeException: Binding attribute, tree: pythonUDF0#50
at org.apache.spark.sql.catalyst.errors.package$.attachTree(package.scala:56)
at org.apache.spark.sql.catalyst.expressions.BindReferences$$anonfun$bindReference$1.applyOrElse(BoundAttribute.scala:91)
at org.apache.spark.sql.catalyst.expressions.BindReferences$$anonfun$bindReference$1.applyOrElse(BoundAttribute.scala:90)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$2.apply(TreeNode.scala:267)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$2.apply(TreeNode.scala:267)
at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:70)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:266)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$transformDown$1.apply(TreeNode.scala:272)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$transformDown$1.apply(TreeNode.scala:272)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$4.apply(TreeNode.scala:306)
at org.apache.spark.sql.catalyst.trees.TreeNode.mapProductIterator(TreeNode.scala:187)
at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:304)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:272)
at org.apache.spark.sql.catalyst.trees.TreeNode.transform(TreeNode.scala:256)
at org.apache.spark.sql.catalyst.expressions.BindReferences$.bindReference(BoundAttribute.scala:90)
at org.apache.spark.sql.execution.aggregate.HashAggregateExec$$anonfun$38.apply(HashAggregateExec.scala:514)
at org.apache.spark.sql.execution.aggregate.HashAggregateExec$$anonfun$38.apply(HashAggregateExec.scala:513)
```
This exception raises because `HashAggregateExec` tries to bind the aliased Python UDF expression (e.g., `pythonUDF0#50 AS a#44`) to grouping key.
## How was this patch tested?
Added test.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes #20379 from viirya/SPARK-23177-backport-2.3.
## What changes were proposed in this pull request?
We should provide customized canonicalize plan for `InMemoryRelation` and `InMemoryTableScanExec`. Otherwise, we can wrongly treat two different cached plans as same result. It causes wrongly reused exchange then.
For a test query like this:
```scala
val cached = spark.createDataset(Seq(TestDataUnion(1, 2, 3), TestDataUnion(4, 5, 6))).cache()
val group1 = cached.groupBy("x").agg(min(col("y")) as "value")
val group2 = cached.groupBy("x").agg(min(col("z")) as "value")
group1.union(group2)
```
Canonicalized plans before:
First exchange:
```
Exchange hashpartitioning(none#0, 5)
+- *(1) HashAggregate(keys=[none#0], functions=[partial_min(none#1)], output=[none#0, none#4])
+- *(1) InMemoryTableScan [none#0, none#1]
+- InMemoryRelation [x#4253, y#4254, z#4255], true, 10000, StorageLevel(disk, memory, deserialized, 1 replicas)
+- LocalTableScan [x#4253, y#4254, z#4255]
```
Second exchange:
```
Exchange hashpartitioning(none#0, 5)
+- *(3) HashAggregate(keys=[none#0], functions=[partial_min(none#1)], output=[none#0, none#4])
+- *(3) InMemoryTableScan [none#0, none#1]
+- InMemoryRelation [x#4253, y#4254, z#4255], true, 10000, StorageLevel(disk, memory, deserialized, 1 replicas)
+- LocalTableScan [x#4253, y#4254, z#4255]
```
You can find that they have the canonicalized plans are the same, although we use different columns in two `InMemoryTableScan`s.
Canonicalized plan after:
First exchange:
```
Exchange hashpartitioning(none#0, 5)
+- *(1) HashAggregate(keys=[none#0], functions=[partial_min(none#1)], output=[none#0, none#4])
+- *(1) InMemoryTableScan [none#0, none#1]
+- InMemoryRelation [none#0, none#1, none#2], true, 10000, StorageLevel(memory, 1 replicas)
+- LocalTableScan [none#0, none#1, none#2]
```
Second exchange:
```
Exchange hashpartitioning(none#0, 5)
+- *(3) HashAggregate(keys=[none#0], functions=[partial_min(none#1)], output=[none#0, none#4])
+- *(3) InMemoryTableScan [none#0, none#2]
+- InMemoryRelation [none#0, none#1, none#2], true, 10000, StorageLevel(memory, 1 replicas)
+- LocalTableScan [none#0, none#1, none#2]
```
## How was this patch tested?
Added unit test.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes #20831 from viirya/SPARK-23614.
(cherry picked from commit b2edc30)
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
The lint failure bugged me:
```R
R/SQLContext.R:715:97: style: Trailing whitespace is superfluous.
#' file-based streaming data source. \code{timeZone} to indicate a timezone to be used to
^
tests/fulltests/test_streaming.R:239:45: style: Commas should always have a space after.
expect_equal(times[order(times$eventTime),][1, 2], 2)
^
lintr checks failed.
```
and I actually saw https://amplab.cs.berkeley.edu/jenkins/job/spark-master-test-sbt-hadoop-2.6-ubuntu-test/500/console too. If I understood correctly, there is a try about moving to Unbuntu one.
## How was this patch tested?
Manually tested by `./dev/lint-r`:
```
...
lintr checks passed.
```
Author: hyukjinkwon <gurwls223@apache.org>
Closes #20879 from HyukjinKwon/minor-r-lint.
(cherry picked from commit 92e9525)
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
…tyle check ## What changes were proposed in this pull request? We re-enabled the Scalastyle checker on a line of code. It was previously disabled, but it does not violate any of the rules. So there's no reason to disable the Scalastyle checker here. ## How was this patch tested? We tested this by running `build/mvn scalastyle:check` after removing the comments that disable the checker. This check passed with no errors or warnings for Spark Core ``` [INFO] [INFO] ------------------------------------------------------------------------ [INFO] Building Spark Project Core 2.4.0-SNAPSHOT [INFO] ------------------------------------------------------------------------ [INFO] [INFO] --- scalastyle-maven-plugin:1.0.0:check (default-cli) spark-core_2.11 --- Saving to outputFile=<path to local dir>/spark/core/target/scalastyle-output.xml Processed 485 file(s) Found 0 errors Found 0 warnings Found 0 infos ``` We did not run all tests (with `dev/run-tests`) since this Scalastyle check seemed sufficient. ## Co-contributors: chialun-yeh Hrayo712 vpourquie Author: arucard21 <arucard21@gmail.com> Closes #20880 from arucard21/scalastyle_util. (cherry picked from commit 6ac4fba) Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request? Fixes SPARK-23759 by moving connector.start() after connector.setHost() Problem was created due connector.setHost(hostName) call was after connector.start() ## How was this patch tested? Patch was tested after build and deployment. This patch requires SPARK_LOCAL_IP environment variable to be set on spark-env.sh Author: bag_of_tricks <falbani@hortonworks.com> Closes #20883 from felixalbani/SPARK-23759. (cherry picked from commit 8b56f16) Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request? The serializability test uses the same MemoryStream instance for 3 different queries. If any of those queries ask it to commit before the others have run, the rest will see empty dataframes. This can fail the test if q3 is affected. We should use one instance per query instead. ## How was this patch tested? Existing unit test. If I move q2.processAllAvailable() before starting q3, the test always fails without the fix. Author: Jose Torres <torres.joseph.f+github@gmail.com> Closes #20896 from jose-torres/fixrace. (cherry picked from commit 816a549) Signed-off-by: Shixiong Zhu <zsxwing@gmail.com>
## What changes were proposed in this pull request? This patch adds a UUID generator from Pseudo-Random Numbers. We can use it later to have deterministic `UUID()` expression. ## How was this patch tested? Added unit tests. Author: Liang-Chi Hsieh <viirya@gmail.com> Closes #20817 from viirya/SPARK-23599. (cherry picked from commit 4de638c) Signed-off-by: Herman van Hovell <hvanhovell@databricks.com>
…f memory, got 224631 ## What changes were proposed in this pull request? https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/88263/testReport https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/88260/testReport https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/88257/testReport https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/88224/testReport These tests all failed: ``` org.apache.spark.memory.SparkOutOfMemoryError: Unable to acquire 262144 bytes of memory, got 224631 at org.apache.spark.memory.MemoryConsumer.throwOom(MemoryConsumer.java:157) at org.apache.spark.memory.MemoryConsumer.allocateArray(MemoryConsumer.java:98) at org.apache.spark.unsafe.map.BytesToBytesMap.allocate(BytesToBytesMap.java:787) at org.apache.spark.unsafe.map.BytesToBytesMap.<init>(BytesToBytesMap.java:204) at org.apache.spark.unsafe.map.BytesToBytesMap.<init>(BytesToBytesMap.java:219) ... ``` This PR ignore this test. ## How was this patch tested? N/A Author: Yuming Wang <yumwang@ebay.com> Closes #20835 from wangyum/SPARK-23598. (cherry picked from commit 15c3c98) Signed-off-by: Herman van Hovell <hvanhovell@databricks.com>
…ord args
## What changes were proposed in this pull request?
Add documentation about the limitations of `pandas_udf` with keyword arguments and related concepts, like `functools.partial` fn objects.
NOTE: intermediate commits on this PR show some of the steps that can be taken to fix some (but not all) of these pain points.
### Survey of problems we face today:
(Initialize) Note: python 3.6 and spark 2.4snapshot.
```
from pyspark.sql import SparkSession
import inspect, functools
from pyspark.sql.functions import pandas_udf, PandasUDFType, col, lit, udf
spark = SparkSession.builder.getOrCreate()
print(spark.version)
df = spark.range(1,6).withColumn('b', col('id') * 2)
def ok(a,b): return a+b
```
Using a keyword argument at the call site `b=...` (and yes, *full* stack trace below, haha):
```
---> 14 df.withColumn('ok', pandas_udf(f=ok, returnType='bigint')('id', b='id')).show() # no kwargs
TypeError: wrapper() got an unexpected keyword argument 'b'
```
Using partial with a keyword argument where the kw-arg is the first argument of the fn:
*(Aside: kind of interesting that lines 15,16 work great and then 17 explodes)*
```
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-9-e9f31b8799c1> in <module>()
15 df.withColumn('ok', pandas_udf(f=functools.partial(ok, 7), returnType='bigint')('id')).show()
16 df.withColumn('ok', pandas_udf(f=functools.partial(ok, b=7), returnType='bigint')('id')).show()
---> 17 df.withColumn('ok', pandas_udf(f=functools.partial(ok, a=7), returnType='bigint')('id')).show()
/Users/stu/ZZ/spark/python/pyspark/sql/functions.py in pandas_udf(f, returnType, functionType)
2378 return functools.partial(_create_udf, returnType=return_type, evalType=eval_type)
2379 else:
-> 2380 return _create_udf(f=f, returnType=return_type, evalType=eval_type)
2381
2382
/Users/stu/ZZ/spark/python/pyspark/sql/udf.py in _create_udf(f, returnType, evalType)
54 argspec.varargs is None:
55 raise ValueError(
---> 56 "Invalid function: 0-arg pandas_udfs are not supported. "
57 "Instead, create a 1-arg pandas_udf and ignore the arg in your function."
58 )
ValueError: Invalid function: 0-arg pandas_udfs are not supported. Instead, create a 1-arg pandas_udf and ignore the arg in your function.
```
Author: Michael (Stu) Stewart <mstewart141@gmail.com>
Closes #20900 from mstewart141/udfkw2.
(cherry picked from commit 087fb31)
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
…ession ## What changes were proposed in this pull request? As stated in Jira, there are problems with current `Uuid` expression which uses `java.util.UUID.randomUUID` for UUID generation. This patch uses the newly added `RandomUUIDGenerator` for UUID generation. So we can make `Uuid` deterministic between retries. This backports SPARK-23599 to Spark 2.3. ## How was this patch tested? Added tests. Author: Liang-Chi Hsieh <viirya@gmail.com> Closes #20903 from viirya/SPARK-23599-2.3.
… with dynamic allocation ## What changes were proposed in this pull request? ignore errors when you are waiting for a broadcast.unpersist. This is handling it the same way as doing rdd.unpersist in https://issues.apache.org/jira/browse/SPARK-22618 ## How was this patch tested? Patch was tested manually against a couple jobs that exhibit this behavior, with the change the application no longer dies due to this and just prints the warning. Please review http://spark.apache.org/contributing.html before opening a pull request. Author: Thomas Graves <tgraves@unharmedunarmed.corp.ne1.yahoo.com> Closes #20924 from tgravescs/SPARK-23806. (cherry picked from commit 641aec6) Signed-off-by: Wenchen Fan <wenchen@databricks.com>
…tion before setting state ## What changes were proposed in this pull request? Changed `LauncherBackend` `set` method so that it checks if the connection is open or not before writing to it (uses `isConnected`). ## How was this patch tested? None Author: Sahil Takiar <stakiar@cloudera.com> Closes #20893 from sahilTakiar/master. (cherry picked from commit 491ec11) Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
…SQL CLI ## What changes were proposed in this pull request? In SparkSQLCLI, SessionState generates before SparkContext instantiating. When we use --proxy-user to impersonate, it's unable to initializing a metastore client to talk to the secured metastore for no kerberos ticket. This PR use real user ugi to obtain token for owner before talking to kerberized metastore. ## How was this patch tested? Manually verified with kerberized hive metasotre / hdfs. Author: Kent Yao <yaooqinn@hotmail.com> Closes #20784 from yaooqinn/SPARK-23639. (cherry picked from commit a7755fd) Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
…ons. ## What changes were proposed in this pull request? Set default Spark session in the TestSparkSession and TestHiveSparkSession constructors. ## How was this patch tested? new unit tests Author: Jose Torres <torres.joseph.f+github@gmail.com> Closes #20926 from jose-torres/test3. (cherry picked from commit b348901) Signed-off-by: gatorsmile <gatorsmile@gmail.com>
…f connection before setting state" This reverts commit 0bfbcaf.
…partitioned into specific number of partitions ## What changes were proposed in this pull request? Currently, the requiredChildDistribution does not specify the partitions. This can cause the weird corner cases where the child's distribution is `SinglePartition` which satisfies the required distribution of `ClusterDistribution(no-num-partition-requirement)`, thus eliminating the shuffle needed to repartition input data into the required number of partitions (i.e. same as state stores). That can lead to "file not found" errors on the state store delta files as the micro-batch-with-no-shuffle will not run certain tasks and therefore not generate the expected state store delta files. This PR adds the required constraint on the number of partitions. ## How was this patch tested? Modified test harness to always check that ANY stateful operator should have a constraint on the number of partitions. As part of that, the existing opt-in checks on child output partitioning were removed, as they are redundant. Author: Tathagata Das <tathagata.das1565@gmail.com> Closes #20941 from tdas/SPARK-23827. (cherry picked from commit 15298b9) Signed-off-by: Tathagata Das <tathagata.das1565@gmail.com>
…fle reader Backport #20449 and #20920 to branch-2.3 --- ## What changes were proposed in this pull request? Before this commit, a non-interruptible iterator is returned if aggregator or ordering is specified. This commit also ensures that sorter is closed even when task is cancelled(killed) in the middle of sorting. ## How was this patch tested? Add a unit test in JobCancellationSuite Author: Xianjin YE <advancedxy@gmail.com> Author: Xingbo Jiang <xingbo.jiang@databricks.com> Closes #20954 from jiangxb1987/SPARK-23040-2.3.
|
Can one of the admins verify this patch? |
|
@rameshch16, seems mistakenly open. mind closing this please? |
These tests can fail with a timeout if the remote repos are not responding, or slow. The tests don't need anything from those repos, so use an empty ivy config file to avoid setting up the defaults. The tests are passing reliably for me locally now, and failing more often than not today without this change since http://dl.bintray.com/spark-packages/maven doesn't seem to be loading from my machine. Author: Marcelo Vanzin <vanzin@cloudera.com> Closes #20916 from vanzin/SPARK-19964. (cherry picked from commit 441d0d0) Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request? Easy fix in the markdown. ## How was this patch tested? jekyII build test manually. Please review http://spark.apache.org/contributing.html before opening a pull request. Author: lemonjing <932191671@qq.com> Closes #20897 from Lemonjing/master. (cherry picked from commit 8020f66) Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request? Address #20924 (comment), show block manager id when remove RDD/Broadcast fails. ## How was this patch tested? N/A Author: Xingbo Jiang <xingbo.jiang@databricks.com> Closes #20960 from jiangxb1987/bmid. (cherry picked from commit 7cf9fab) Signed-off-by: hyukjinkwon <gurwls223@apache.org>
…esolved state ## What changes were proposed in this pull request? Add cast to nulls introduced by PropagateEmptyRelation so in cases they're part of coalesce they will not break its type checking rules ## How was this patch tested? Added unit test Author: Robert Kruszewski <robertk@palantir.com> Closes #20914 from robert3005/rk/propagate-empty-fix. (cherry picked from commit 5cfd5fa) Signed-off-by: gatorsmile <gatorsmile@gmail.com>
… SQL tab ## What changes were proposed in this pull request? A running SQL query would appear as completed in the Spark UI:  We can see the query in "Completed queries", while in in the job page we see it's still running Job 132. 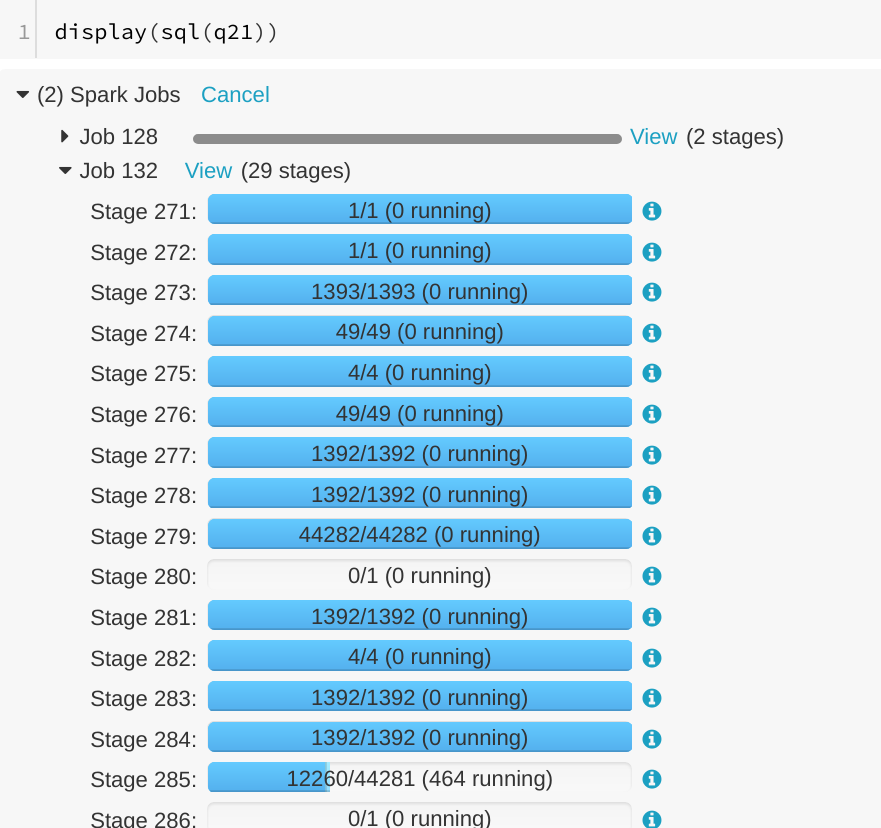 After some time in the query still appears in "Completed queries" (while it's still running), but the "Duration" gets increased.  To reproduce, we can run a query with multiple jobs. E.g. Run TPCDS q6. The reason is that updates from executions are written into kvstore periodically, and the job start event may be missed. ## How was this patch tested? Manually run the job again and check the SQL Tab. The fix is pretty simple. Author: Gengliang Wang <gengliang.wang@databricks.com> Closes #20955 from gengliangwang/jobCompleted. (cherry picked from commit d8379e5) Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
{kind=link}
{kind=link}
{kind=link}
…tor is killed multiple times. ## What changes were proposed in this pull request? `YarnAllocator` uses `numExecutorsRunning` to track the number of running executor. `numExecutorsRunning` is used to check if there're executors missing and need to allocate more. In current code, `numExecutorsRunning` can be negative when driver asks to kill a same idle executor multiple times. ## How was this patch tested? UT added Author: jinxing <jinxing6042@126.com> Closes #20781 from jinxing64/SPARK-23637. (cherry picked from commit d3bd043) Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
Fixes https://issues.apache.org/jira/browse/SPARK-23823 Keep origin for all the methods using transformExpression ## What changes were proposed in this pull request? Keep origin in transformExpression ## How was this patch tested? Manually tested that this fixes https://issues.apache.org/jira/browse/SPARK-23823 and columns have correct origins after Analyzer.analyze Author: JiahuiJiang <jjiang@palantir.com> Author: Jiahui Jiang <jjiang@palantir.com> Closes #20961 from JiahuiJiang/jj/keep-origin. (cherry picked from commit d65e531) Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request? This pull request tries to improve the error message for spark while reading parquet files with different schemas, e.g. One with a STRING column and the other with a INT column. A new ParquetSchemaColumnConvertNotSupportedException is added to replace the old UnsupportedOperationException. The Exception is again wrapped in FileScanRdd.scala to throw a more a general QueryExecutionException with the actual parquet file name which trigger the exception. ## How was this patch tested? Unit tests added to check the new exception and verify the error messages. Also manually tested with two parquet with different schema to check the error message. <img width="1125" alt="screen shot 2018-03-30 at 4 03 04 pm" src="https://user-images.githubusercontent.com/37087310/38156580-dd58a140-3433-11e8-973a-b816d859fbe1.png"> Author: Yuchen Huo <yuchen.huo@databricks.com> Closes #20953 from yuchenhuo/SPARK-23822. (cherry picked from commit 9452401) Signed-off-by: gatorsmile <gatorsmile@gmail.com>
{kind=link}
…OrCreate This backports #20927 to branch-2.3 ## What changes were proposed in this pull request? Currently, the active spark session is set inconsistently (e.g., in createDataFrame, prior to query execution). Many places in spark also incorrectly query active session when they should be calling activeSession.getOrElse(defaultSession) and so might get None even if a Spark session exists. The semantics here can be cleaned up if we also set the active session when the default session is set. Related: https://github.com/apache/spark/pull/20926/files ## How was this patch tested? Unit test, existing test. Note that if #20926 merges first we should also update the tests there. Author: Eric Liang <ekl@databricks.com> Closes #20971 from ericl/backport-23809.
…uptible iterator of shuffle reader" ## What changes were proposed in this pull request? The test case JobCancellationSuite."interruptible iterator of shuffle reader" has been flaky because `KillTask` event is handled asynchronously, so it can happen that the semaphore is released but the task is still running. Actually we only have to check if the total number of processed elements is less than the input elements number, so we know the task get cancelled. ## How was this patch tested? The new test case still fails without the purposed patch, and succeeded in current master. Author: Xingbo Jiang <xingbo.jiang@databricks.com> Closes #20993 from jiangxb1987/JobCancellationSuite. (cherry picked from commit d81f29e) Signed-off-by: gatorsmile <gatorsmile@gmail.com>
SPARK-19276 ensured that FetchFailures do not get swallowed by other layers of exception handling, but it also meant that a killed task could look like a fetch failure. This is particularly a problem with speculative execution, where we expect to kill tasks as they are reading shuffle data. The fix is to ensure that we always check for killed tasks first. Added a new unit test which fails before the fix, ran it 1k times to check for flakiness. Full suite of tests on jenkins. Author: Imran Rashid <irashid@cloudera.com> Closes #20987 from squito/SPARK-23816. (cherry picked from commit 10f45bb) Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
What changes were proposed in this pull request?
(Please fill in changes proposed in this fix)
How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.