Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
[ZEPPELIN-2753] Basic Implementation of IPython Interpreter
### What is this PR for? This is the first step for implement IPython Interpreter in Zeppelin. I just use the jupyter_client to create and manage the ipython kernel. We don't need to care about python compilation and execution, all the things are delegated to ipython kernel. Ideally all the features of ipython should be available in Zeppelin as well. For now, user can use %python.ipython for IPython Interpreter. And if ipython is available, the default python interpreter will use ipython. But user can still set `zeppelin.python.useIPython` as false to enforce to use the old implementation of python interpreter. Main features: * IPython interpreter support ** All the ipython features are available, including visualization, ipython magics. * ZeppelinContext support * Streaming output support * Support Ipython in PySpark Regarding the visualization, ideally all the visualization libraries work in jupyter should also work here. In unit test, I only verify the following 3 popular visualization library. could add more later. * matplotlib * bokeh * ggplot ### What type of PR is it? [Feature ] ### Todos * [ ] - Task ### What is the Jira issue? * https://issues.apache.org/jira/browse/ZEPPELIN-2753 ### How should this be tested? Unit test is added. ### Screenshots (if appropriate) Verify bokeh in IPython Interpreter 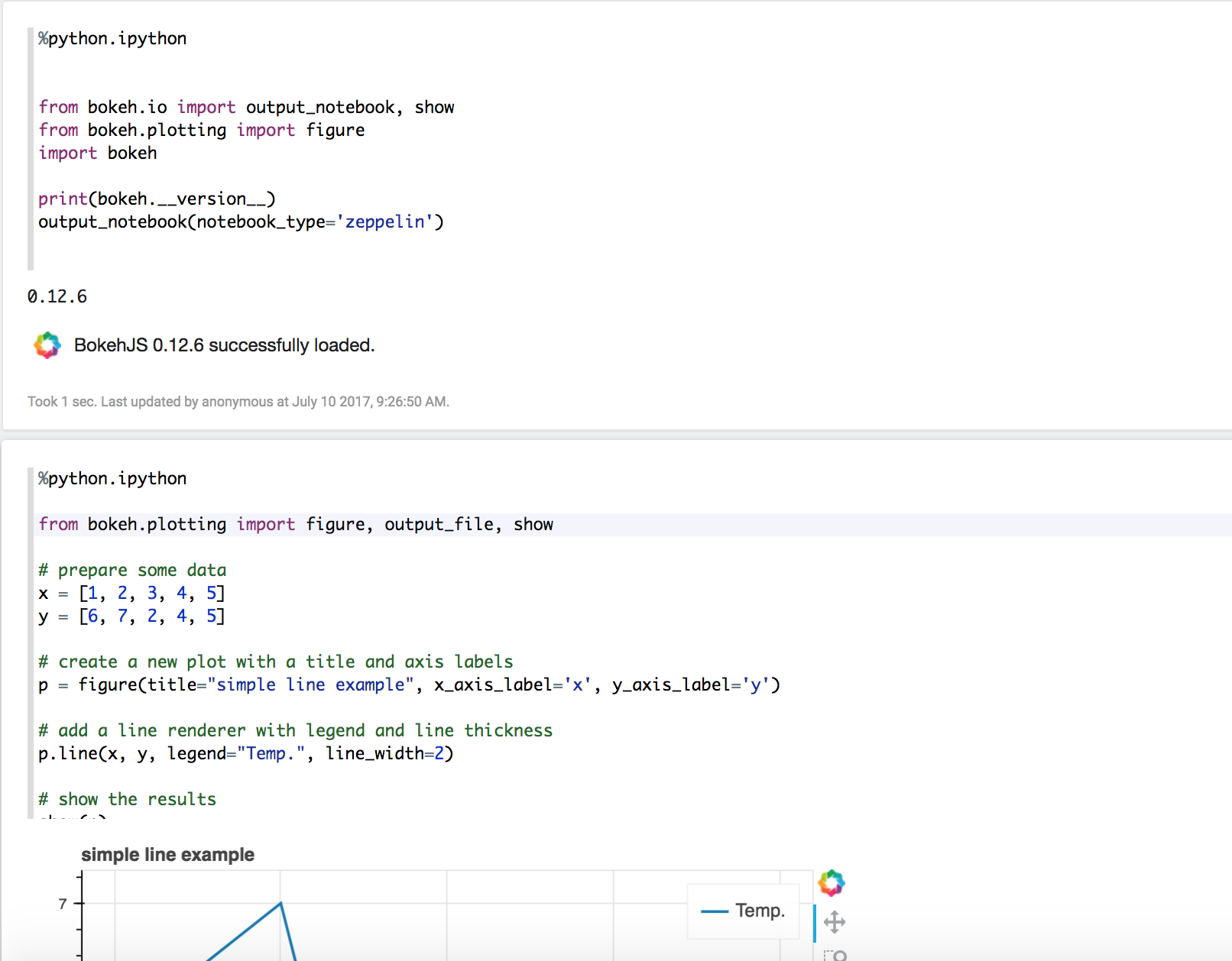 Verify matplotlib  Verify ZeppelinContext  Verify Streaming  ### Questions: * Does the licenses files need update? No * Is there breaking changes for older versions? No * Does this needs documentation? No Author: Jeff Zhang <zjffdu@apache.org> Closes #2474 from zjffdu/ZEPPELIN-2753 and squashes the following commits: e869f31 [Jeff Zhang] address comments b0b5c95 [Jeff Zhang] [ZEPPELIN-2753] Basic Implementation of IPython Interpreter
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Loading branch information
Showing
48 changed files
with
3,257 additions
and
95 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Oops, something went wrong.