` elements, you would use the `p` selector. + +```js +const paragraphs = document.querySelectorAll('p'); +``` + +### Class selector + +This is used to select elements by their class attribute. For example, to select all elements with the class of `highlight`, you would use the `.highlight` selector. + +```js +const highlightedElements = document.querySelectorAll('.highlight'); +``` + +### ID selector + +This is used to select an element by its `id` attribute. For example, to select an element with the id of `header`, you would use the `#header` selector. + +```js +const header = document.querySelector(`#header`); +``` + +### Attribute selector + +This is used to select elements based on the value of an attribute. For example, to select all elements with the attribute `data-custom` whose value is `yes`, you would use the `[data-custom="yes"]` selector. + +```js +const customElements = document.querySelectorAll('[data-custom="yes"]'); +``` + +### Chaining selectors + +You can also chain multiple selectors together to select elements more precisely. For example, to select an element with the class `highlight` that is inside a `
` element, you would use the `p.highlight` selector. + +```js +const highlightedParagraph = document.querySelectorAll('p.highlight'); +``` + +## CSS selectors in web scraping + +CSS selectors are important for web scraping because they allow you to target specific elements on a web page and extract their data. When scraping a web page, you typically want to extract specific pieces of information from the page, such as text, images, or links. CSS selectors allow you to locate these elements on the page, so you can extract the data that you need. + +For example, if you wanted to scrape a list of all the titles of blog posts on a website, you could use a CSS selector to select all the elements that contain the title text. Once you have selected these elements, you can extract the text from them and use it for your scraping project. + +Additionally, when web scraping it is important to understand the structure of the website and CSS selectors can help you to navigate it. With them, you can select specific elements and their children, siblings, or parent elements. This allows you to extract data that is nested within other elements, or to navigate through the page structure to find the data you need. + +## Resources + +- Find all the available CSS selectors and their syntax on the [MDN CSS Selectors page](https://developer.mozilla.org/en-US/docs/Web/CSS/CSS_Selectors). +
`, ``, or `
+Include variations, e.g. Airbnb API, Airbnb data, Airbnb data scraper, Airbnb rentals, Airbnb listings + - No-code scraping tool to extract Airbnb data: host info, prices, dates, location, and reviews. + - Scrape Airbnb listings without official Airbnb API! +- _Scraping/automation process variations_:
+Use terms, e.g. crawl, crawler, scraping tool, finder, scraper, data extraction tool, extract data, get data + - Scrape XYZ data, scraped data, data scraper, data crawler. + +### Choose how to start your sentences 📝 + +- _Noun-first (descriptive)_: + - Data extraction tool to extract Airbnb data: host info, prices, dates, location, and reviews. +- _Imperative-first (motivating)_: + - Try a free web scraping tool to extract Airbnb data: host info, prices, dates, location, and reviews. + + +### Keep it short and SEO-focused ✂️ + +- _Be concise and direct_: clearly state what your Actor does. Avoid unnecessary fluff and boilerplate text. + - ✅ Scrapes job listings from Indeed and gathers... + - ❌ *This Actor scrapes job listings from Indeed in order to gather... +- _Optimize for search engines_: include popular keywords related to your Actor’s functionality that users might search for. + - ✅ This Indeed scraper helps you collect job data efficiently. Use the tool to gather... + - ❌ This tool will search through job listings on Indeed and offers you... + + +### List the data your Actor works with 📝 + +- Data extraction tool to extract Airbnb data: host info, prices, dates, location, and reviews. +- Get hashtags, usernames, mentions, URLs, comments, images, likes, locations without the official Instagram API. + +### Use keywords or the language of the target website 🗣️ + +- Extract data from hundreds of Airbnb home rentals in seconds. +- Extract data from chosen tik-toks. Just add a TikTok URL and get TikTok video and profile data: URLs, numbers of shares, followers, hashtags, hearts, video, and music metadata. +- Scrape Booking with this hotels scraper and get data about accommodation on Booking.com. + +### Highlight your strong suits 🌟 + +- Ease of use, no coding, user-friendly: + - Easy scraping tool to extract Airbnb data. +- Fast and scalable: + - Scrape whole cities or extract data from hundreds of Airbnb rentals in seconds. +- Free (only if the trial run can cover $5 free credits): + - Try a free scraping tool to extract Airbnb data: host info, prices, dates, location, and reviews. + - Extract host information, locations, availability, stars, reviews, images, and host/guest details for free. +- Available platform features (various formats, API, integrations, scheduling): + - Export scraped data in formats like HTML, JSON, and Excel. +- Additional tips: + - Avoid ending lists with etc. + - Consider adding relevant emojis for visual appeal. + +### Break it down 🔠 + +Descriptions typically fit into 2-3 sentences. Don't try to jam everything into one. + +Examples: + +1. Scrape whole cities or extract data from hundreds of Airbnb rentals in seconds. +1. Extract host information, addresses, locations, prices, availability, stars, reviews, images, and host/guest details. +1. Export scraped data, run the scraper via API, schedule and monitor runs, or integrate with other tools. + +## FAQ + +#### Can the Actor's meta description and description be the same? + +Yes, they can, as long as they have the same (shorter) length (under 150 characters). But they can also be different - there's no harm in that. + +#### How different can description and meta description be? + +They can be vastly different and target different angles of your Actor. You can experiment by setting up different SEO descriptions for a period of time and seeing if the click-through rate rises. + +#### I set a custom SEO description but Google doesn't show it + +Sometimes Google picks up a part of the README as the SEO description. It's heavily dependent on the search query. Sometimes what you see on Google might look differently compared to how you set the SEO description. It's all a part of how Google customizes search results. +
+ Faster than full-browser solutions
+ Ideal for light scripting | Not for heavy dynamic JavaScript, executes server-side code only, depends on pre-installed NPM modules | Speedy scraping with light client-side JS | +| 🍲 BeautifulSoup Scraper | Python-based, HTTP requests + BeautifulSoup parser | Python-based, supports recursive crawling and URL lists | No full-featured web browser, not suitable for dynamic JavaScript-rendered pages | Python users needing simple, recursive crawling | + +### How do I choose the right universal web scraper to start with? + +🎯 Decision points: + +- Use 🌐 [Web Scraper](https://apify.com/apify/web-scraper) if you need simplicity with full browser capabilities and client-side JavaScript rendering. +- Use 🍩 [Cheerio Scraper](https://apify.com/apify/cheerio-scraper) for fast, cost-effective scraping of static pages with simple server-side JavaScript execution. +- Use 🎭 [Playwright Scraper](https://apify.com/apify/playwright-scraper) when cross-browser compatibility is crucial. +- Use 👐 [Puppeteer Scraper](https://apify.com/apify/puppeteer-scraper) for advanced, powerful scraping where you need both client-side and server-side JavaScript handling. +- Use ⚠️ [JSDOM Scraper](https://apify.com/apify/jsdom-scraper) for lightweight, speedy scraping with minimal client-side JavaScript requirements. +- Use 🍲 [BeautifulSoup Scraper](https://apify.com/apify/beautifulsoup-scraper) for Python-based scraping, especially with recursive crawling and processing URL lists. + + +To make it easier, here's a short questionnaire that guides you on selecting the best scraper based on your specific use case: + +
Questionnaire
+ 1. Is the website content rendered with a lot of client-side JavaScript? + - Yes: + - Do you need full browser capabilities? + - Yes: use Web Scraper or Playwright Scraper + - No, but I still want advanced features: use Puppeteer Scraper + - No: + - Do you prioritize speed and cost-effectiveness? + - Yes: use Cheerio Scraper + - No: use JSDOM Scraper + 2. Do you need cross-browser support for scraping? + - Yes:** use Playwright Scraper + - No:** continue to the next step. + 3. Is your preferred scripting language Python?** + - Yes:** use BeautifulSoup Scraper + - No:** continue to the next step. + 4. Are you dealing with static pages or lightweight client-side JavaScript?** + - Static pages: use Cheerio Scraper or BeautifulSoup Scraper + - Light client-side JavaScript: + - Do you want a balance between speed and client-side JavaScript handling? + - Yes: use JSDOM Scraper + - No: use Web Scraper or Puppeteer Scraper + 5. Do you need to support recursive crawling or process lists of URLs? + - Yes, and I prefer Python: use BeautifulSoup Scraper + - Yes, and I prefer JavaScript: use Web Scraper or Cheerio Scraper + - No: choose based on other criteria above. + +This should help you navigate through the options and choose the right scraper based on the website’s complexity, your scripting language preference, and your need for speed or advanced features. + ++ Check out the [Ideas page](https://apify.com/ideas) to find ideas that interest you. Look for ideas that align with your skills and the kind of Actor you want to build. +2. _Select an idea_
+ Once you’ve found a promising idea, review the details and requirements provided. If you see an idea you want to develop, make sure to check its current status. If it’s marked as **Open to develop**, you’re good to go. +3. _Develop your Actor_
+ Start building your Actor based on the idea. You don’t need to notify Apify about your development process. Focus on creating a functional and well-documented tool. +4. _Prepare for launch_
+ Once your Actor is ready, ensure it meets all quality standards and has a comprehensive README. This documentation should include installation instructions, usage details, and any other relevant information. +5. _Publish your Actor_
+ Deploy your Actor on Apify Store. Make sure it’s live and accessible for users. +6. _Claim your idea_
+ After your Actor is published, email [ideas@apify.com](mailto:ideas@apify.com) with the URL of your Actor and the original idea. This will allow us to tag the idea as Completed and link it to your new Actor, giving you credit and visibility. +7. _Monitor and optimize_
+ Make sure to monitor your Actor’s performance and user feedback. Use this information to make improvements and keep your Actor up to date. + +By following these steps, you’ll be able to contribute to the community while also gaining recognition for your work. + +## Criteria for claiming an idea + +To claim an idea, ensure that: + +1. Your Actor is functional. +2. Your README contains relevant information. +3. Your Actor closely aligns with the original idea. + +## Giving back to the Ideas page + +The Ideas page at Apify offers a variety of concepts for scrapers, integrations, and automations, and is a great place to find inspiration or solutions. It’s also a platform where you can contribute your own ideas to drive innovation and growth in our community. + +1. _Submit your Ideas_
+ Got a great Actor concept? Share it with us through the [Ideas form](https://apify.typeform.com/to/BNON8poB#source=ideas). Provide clear details about what your tool should do and how it should work. +2. _Engage with the community_
+ Upvote ideas you find intriguing. The more support an idea receives, the more likely it is to catch a developer’s eye and move forward. +3. _Don’t forget to claim your idea_
+ Once your Actor is up and running, claim your idea by emailing [ideas@apify.com](mailto:ideas@apify.com) with your Actor's URL and the original idea. We’ll mark your idea as **Completed** and link it to your Actor - a signal to the other developers that this tool already exists on Apify Store. + +## Multiple developers for one idea + +No problem! Apify Store can host multiple Actors with similar functions. However, we go by the “first come - first served” rule, so the first developer to claim an idea will receive the **Completed** tag and a link from the Ideas page. + +Remember that Apify Store is just like any other marketplace. We believe that competition helps developers thrive and improve upon their code, especially when there are similar scrapers on the horizon! You can still build the Actor, but try to be imaginative when it comes to its set of features. +
+Ready to grow your presence on the Apify platform? Check out our guide to [publishing your first Actor](/platform/actors/publishing). +
Example - rental pricing model
+ +You make your Actor rental with 7 days free trial and then $30/month. During the first calendar month, three users start to use your Actor: + +1. First user, on Apify paid plan, starts the free trial on 15th +2. Second user, on Apify paid plan, starts the free trial on 25th +3. Third user, on Apify free plan, start the free trial on 20th + +The first user pays their first rent 7 days after the free trial, i.e., on 22nd. The second user only starts paying the rent next month. The third user is on Apify free plan, so after the free trial ends on 27th, they are not charged and cannot use the Actor further until they get a paid plan. Your profit is computed only from the first user. They were charged $30, so 80% of this goes to you, i.e., _0.8 * 30 = $24_. +Example - pay-per-result pricing model
+ +You make your Actor pay-per-result and set price to be $1/1,000 results. During the first month, two users on Apify paid plans use your Actor to get 50,000 and 20,000 results, costing them $50 and $20 respectively. Let's say the underlying platform usage for the first user is $5 and for the second $2. Third user, this time on Apify free plan, uses the Actor to get 5,000 results, with underlying platform usage $0.5. + +Your profit is computed only from the first two users, since they are on Apify paid plans. The revenue for the first user is $50 and for the second $20, i.e., total revenue is $70. The total underlying cost is _$5 + $2 = $7_. Since your profit is 80% of the revenue minus the cost, it would be _0.8 * 70 - 7 = $49_. ++ ${url} + +
+ ${url} + +
` tag, as titles should be.
+Maybe surprisingly, we find that there are actually two `` tags on the detail page. This should get us thinking.
+Is there any parent element that includes our `` tag, but not the other ones? Yes, there is! A ``
+element that we can use to select only the heading we're interested in.
+
+> Remember that you can press CTRL+F (CMD+F) in the Elements tab of DevTools to open the search bar where you can quickly search for elements using
+> their selectors. And always make sure to use the DevTools to verify your scraping process and assumptions. It's faster than changing the crawler
+> code all the time.
+
+To get the title we need to find it using a `header h1` selector, which selects all `` elements that have a `` ancestor.
+And as we already know, there's only one.
+
+```js
+// Using Cheerio.
+async function pageFunction(context) {
+ const { $ } = context;
+ // ... rest of your code can come here
+ return {
+ title: $('header h1').text(),
+ };
+}
+```
+
+### Description
+
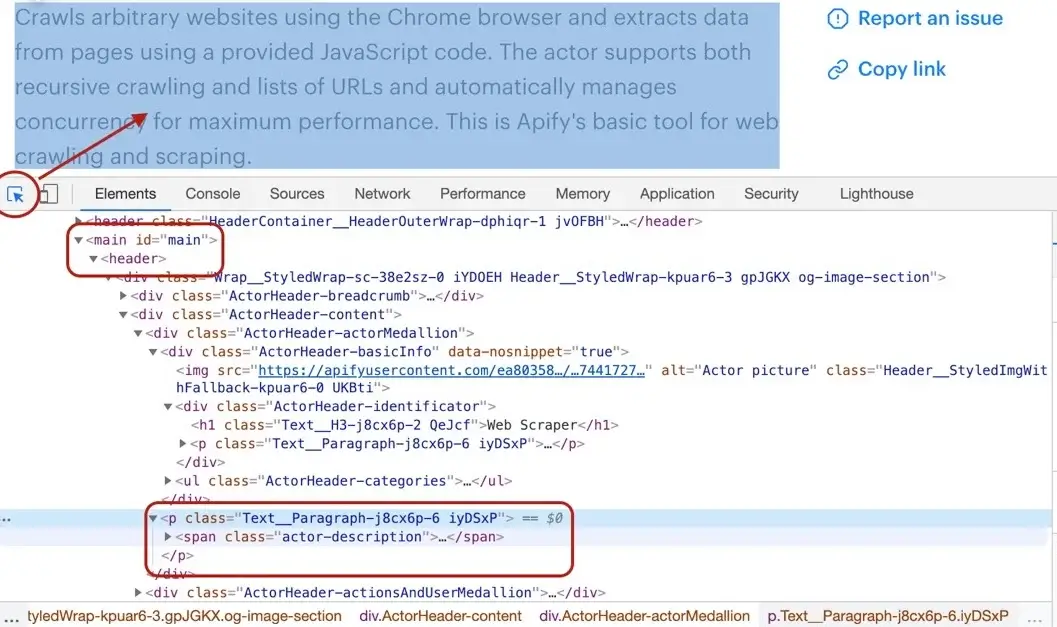
+Getting the Actor's description is a little more involved, but still pretty straightforward. We cannot search for a `` tag, because there's a lot of them in the page. We need to narrow our search down a little. Using the DevTools we find that the Actor description is nested within
+the `` element too, same as the title. Moreover, the actual description is nested inside a `` tag with a class `actor-description`.
+
+
+
+```js
+async function pageFunction(context) {
+ const { $ } = context;
+ // ... rest of your code can come here
+ return {
+ title: $('header h1').text(),
+ description: $('header span.actor-description').text(),
+ };
+}
+```
+
+### Modified date
+
+The DevTools tell us that the `modifiedDate` can be found in a `
` tag, but not the other ones? Yes, there is! A ``
+element that we can use to select only the heading we're interested in.
+
+> Remember that you can press CTRL+F (CMD+F) in the Elements tab of DevTools to open the search bar where you can quickly search for elements using
+> their selectors. And always make sure to use the DevTools to verify your scraping process and assumptions. It's faster than changing the crawler
+> code all the time.
+
+To get the title we need to find it using a `header h1` selector, which selects all `` elements that have a `` ancestor.
+And as we already know, there's only one.
+
+```js
+// Using Cheerio.
+async function pageFunction(context) {
+ const { $ } = context;
+ // ... rest of your code can come here
+ return {
+ title: $('header h1').text(),
+ };
+}
+```
+
+### Description
+
+Getting the Actor's description is a little more involved, but still pretty straightforward. We cannot search for a `` tag, because there's a lot of them in the page. We need to narrow our search down a little. Using the DevTools we find that the Actor description is nested within
+the `` element too, same as the title. Moreover, the actual description is nested inside a `` tag with a class `actor-description`.
+
+
+
+```js
+async function pageFunction(context) {
+ const { $ } = context;
+ // ... rest of your code can come here
+ return {
+ title: $('header h1').text(),
+ description: $('header span.actor-description').text(),
+ };
+}
+```
+
+### Modified date
+
+The DevTools tell us that the `modifiedDate` can be found in a `
` elements that have a `` ancestor.
+And as we already know, there's only one.
+
+```js
+// Using Cheerio.
+async function pageFunction(context) {
+ const { $ } = context;
+ // ... rest of your code can come here
+ return {
+ title: $('header h1').text(),
+ };
+}
+```
+
+### Description
+
+Getting the Actor's description is a little more involved, but still pretty straightforward. We cannot search for a `` tag, because there's a lot of them in the page. We need to narrow our search down a little. Using the DevTools we find that the Actor description is nested within
+the `` element too, same as the title. Moreover, the actual description is nested inside a `` tag with a class `actor-description`.
+
+
+
+```js
+async function pageFunction(context) {
+ const { $ } = context;
+ // ... rest of your code can come here
+ return {
+ title: $('header h1').text(),
+ description: $('header span.actor-description').text(),
+ };
+}
+```
+
+### Modified date
+
+The DevTools tell us that the `modifiedDate` can be found in a `
` tag, because there's a lot of them in the page. We need to narrow our search down a little. Using the DevTools we find that the Actor description is nested within
+the `
Hello World
' + ], +]); +$parsedResponse = \json_decode($response->getBody(), true); +$data = $parsedResponse['data']; + +echo \json_encode($data, JSON_PRETTY_PRINT); +``` + +Keep track of the returned run ID. + +Similar to datasets, we can get overall info about the default key-value store. + +```php +// ReplaceHi World
' + ], + // Pass in how long we want to wait, in seconds + 'query' => [ 'waitForFinish' => 60 ] +]); +$parsedResponse = \json_decode($response->getBody(), true); +$data = $parsedResponse['data']; + +echo \json_encode($data, JSON_PRETTY_PRINT); + +$runId = $data['id']; +$response = $client->get(sprintf('actor-runs/%s/key-value-store/records/OUTPUT', $runId)); +file_put_contents(__DIR__ . '/hi-world.pdf', $response->getBody()); +``` + +## Webhooks + +For Actors that take longer to run, we can use [webhooks](/platform/integrations/webhooks). A webhook is an HTML POST request that is sent to a specified URL when an Actor's status changes. We can use them as a kind of notification that is sent when your run finishes. You can set them up using query parameters. If we used webhooks in the example above, it would look like this: + +```php +// Webhooks need to be passed as a base64-encoded JSON string +$webhooks = \base64_encode(\json_encode([ + [ + // The webhook can be sent on multiple events + // this one fires when the run succeeds + 'eventTypes' => ['ACTOR.RUN.SUCCEEDED'], + // Set this to some url that you can react to + // To see what is sent to the URL, + // you can set up a temporary request bin at https://requestbin.com/r + 'requestUrl' => 'Hello World
' + ], + 'query' => [ 'webhooks' => $webhooks ] +]); +``` + +## How to use Apify Proxy + +Let's use another important feature: [proxy](/platform/proxy). If you want to make sure that your server's IP address won't get blocked somewhere when making requests, you can use the automatic proxy selection mode. + +```php +$client = new \GuzzleHttp\Client([ + // Replace+ +### 1. More reliable + +Since the data is coming directly from the site's API, as opposed to the parsing of HTML content based on CSS selectors, it can be relied on more, as it is less likely to change. Typically, websites change their APIs much less frequently than they change the structure/selectors of their pages. + +### 2. Configurable + +Most APIs accept query parameters such as `maxPosts` or `fromCountry`. These parameters can be mapped to the configuration options of the scraper, which makes creating a scraper that supports various requirements and use-cases much easier. They can also be utilized to filter and/or limit data results. + +### 3. Fast and efficient + +Especially for [dynamic sites](https://blog.apify.com/what-is-a-dynamic-page/), in which a headless browser would otherwise be required (it can sometimes be slow and cumbersome), scraping their API can prove to be much quicker and more efficient. + +### 4. Easy on the target website + +Depending on the website, sending large amounts of requests to their pages could result in a slight performance decrease on their end. By using their API instead, not only does your scraper run better, but it is less demanding of the target website. + +## Disadvantages of API Scraping {#disadvantages} + +
+ +### 1. Sometimes requires special tokens + +Many APIs will require the session cookie, an API key, or some other special value to be included within the header of the request in order to receive any data back. For certain projects, this can be a challenge. + +### 2. Potential overhead + +For complex APIs that require certain headers and/or payloads in order to make a successful request, return encoded data, have rate limits, or that use GraphQL, there can be a slight overhead in figuring out how to utilize them in a scraper. + + + +## Extra challenges {#extra-challenges} + +
+ +### 1. Different data formats + +APIs come in all different shapes and sizes. That means every API will vary in not only the quality of the data that it returns, but also the format that it is in. The two most common formats are JSON and HTML. + +JSON responses are ideal, as they can be manipulated in JavaScript code. In general, no serious parsing is necessary, and the data can be filtered and formatted to fit a scraper's dataset schema. + +APIs which output HTML generally return the raw HTML of a small component of the page which is already hydrated with data. In these cases, it is still worth using the API, as it is still more efficient than making a request to the entire page; even though the data does still need to be parsed from the HTML response. + +### 2. Encoded data + +Sometimes, a response will look something like this: + +```json +{ + "title": "Scraping Academy Message", + "message": "SGVsbG8hIFlvdSBoYXZlIHN1Y2Nlc3NmdWxseSBkZWNvZGVkIHRoaXMgYmFzZTY0IGVuY29kZWQgbWVzc2FnZSEgV2UgaG9wZSB5b3UncmUgbGVhcm5pbmcgYSBsb3QgZnJvbSB0aGUgQXBpZnkgU2NyYXBpbmcgQWNhZGVteSE=" +} +``` + +Or some other encoding format. This example's `message` has some data encoded in [Base64](https://en.wikipedia.org/wiki/Base64), which is one of the most common encoding types. For testing out Base64 encoding and decoding, you can use [base64encode.org](https://www.base64encode.org/) and [base64decode.org](https://www.base64decode.org/). Within a project where base64 decoding/encoding is necessary, the [Node.js Buffer Class](https://nodejs.org/api/buffer.html) can be used like so: + + +```js +const value = 'SGVsbG8hIFlvdSBoYXZlIHN1Y2Nlc3NmdWxseSBkZWNvZGVkIHRoaXMgYmFzZTY0IGVuY29kZWQgbWVzc2FnZSEgV2UgaG9wZSB5b3UncmUgbGVhcm5pbmcgYSBsb3QgZnJvbSB0aGUgQXBpZnkgU2NyYXBpbmcgQWNhZGVteSE='; + +const decoded = Buffer.from(value, 'base64').toString('utf-8'); + +console.log(decoded); +``` + +## First up {#first} + +Get started with this course by learning some general knowledge about API scraping in the [General API Scraping](./general_api_scraping/index.md) section! This section will teach you everything you need to know about scraping APIs before moving into more complex sections. +