 +- [ECS Monitoring on EC2 with AWS-Managed Open Source](https://aws-observability.github.io/terraform-aws-observability-accelerator/ecs/ecs-monitoring-on-ec2/) - Collect metrics, traces, and logs for ECS on EC2 and send them to a Managed Prometheus workspace , X-Ray, and CloudWatch Logs. Includes pre-built Grafana dashboards for key metrics and logs.
+- [Managed Prometheus Monitoring](https://aws-observability.github.io/terraform-aws-observability-accelerator/workloads/managed-prometheus/) - This module sets up automated observability for Amazon Managed Service for Prometheus workspaces, including a Grafana dashboard, CloudWatch monitoring, and service quota alarms.
-Check the the [complete example](./examples/existing-cluster-with-base-and-infra/)
## Motivation
@@ -156,9 +54,8 @@ Grafana and Amazon OpenSearch.
AWS customers have asked for best-practices and guidance to collect metrics, logs
and traces from their containerized applications and microservices with ease of
deployment. Customers can use the AWS Observability Accelerator to configure their
-metrics and traces collection, leveraging [AWS Distro for OpenTelemetry](https://aws-otel.github.io/),
-to have opinionated dashboards and alerts available in only minutes.
-
+metrics and traces collection to have opinionated dashboards and alerts
+available in only minutes.
## Support & Feedback
@@ -173,59 +70,6 @@ section of this GitHub repo.
If you are interested in contributing, see the
[Contribution guide](https://github.com/aws-observability/terraform-aws-observability-accelerator/blob/main/CONTRIBUTING.md).
----
-
-
-## Requirements
-
-| Name | Version |
-|------|---------|
-| [terraform](#requirement\_terraform) | >= 1.1.0 |
-| [aws](#requirement\_aws) | >= 4.0.0 |
-| [awscc](#requirement\_awscc) | >= 0.24.0 |
-
-## Providers
-
-| Name | Version |
-|------|---------|
-| [aws](#provider\_aws) | >= 4.0.0 |
-
-## Modules
-
-No modules.
-
-## Resources
-
-| Name | Type |
-|------|------|
-| [aws_prometheus_alert_manager_definition.this](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/prometheus_alert_manager_definition) | resource |
-| [aws_prometheus_workspace.this](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/prometheus_workspace) | resource |
-| [aws_grafana_workspace.this](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/data-sources/grafana_workspace) | data source |
-| [aws_region.current](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/data-sources/region) | data source |
-
-## Inputs
-
-| Name | Description | Type | Default | Required |
-|------|-------------|------|---------|:--------:|
-| [aws\_region](#input\_aws\_region) | AWS Region | `string` | n/a | yes |
-| [enable\_alertmanager](#input\_enable\_alertmanager) | Creates Amazon Managed Service for Prometheus AlertManager for all workloads | `bool` | `false` | no |
-| [enable\_managed\_prometheus](#input\_enable\_managed\_prometheus) | Creates a new Amazon Managed Service for Prometheus Workspace | `bool` | `true` | no |
-| [managed\_grafana\_workspace\_id](#input\_managed\_grafana\_workspace\_id) | Amazon Managed Grafana Workspace ID | `string` | n/a | yes |
-| [managed\_prometheus\_workspace\_id](#input\_managed\_prometheus\_workspace\_id) | Amazon Managed Service for Prometheus Workspace ID | `string` | `""` | no |
-| [managed\_prometheus\_workspace\_region](#input\_managed\_prometheus\_workspace\_region) | Region where Amazon Managed Service for Prometheus is deployed | `string` | `null` | no |
-| [tags](#input\_tags) | Additional tags (e.g. `map('BusinessUnit`,`XYZ`) | `map(string)` | `{}` | no |
-
-## Outputs
-
-| Name | Description |
-|------|-------------|
-| [aws\_region](#output\_aws\_region) | AWS Region |
-| [managed\_grafana\_workspace\_endpoint](#output\_managed\_grafana\_workspace\_endpoint) | Amazon Managed Grafana workspace endpoint |
-| [managed\_prometheus\_workspace\_endpoint](#output\_managed\_prometheus\_workspace\_endpoint) | Amazon Managed Prometheus workspace endpoint |
-| [managed\_prometheus\_workspace\_id](#output\_managed\_prometheus\_workspace\_id) | Amazon Managed Prometheus workspace ID |
-| [managed\_prometheus\_workspace\_region](#output\_managed\_prometheus\_workspace\_region) | Amazon Managed Prometheus workspace region |
-
-
## Contributing
See [CONTRIBUTING](CONTRIBUTING.md#security-issue-notifications) for more information.
diff --git a/docs/concepts.md b/docs/concepts.md
index 1a4c4641..9633c2a4 100644
--- a/docs/concepts.md
+++ b/docs/concepts.md
@@ -44,7 +44,6 @@ We have setup a [GitRepository](https://fluxcd.io/flux/components/source/gitrepo
We have placed our declarative code snippet to create an Amazon Managed Service For Promethes datasource and Grafana Dashboard in Amazon Managed Grafana in our [AWS Observabiity Accelerator GitHub Repository](https://github.com/aws-observability/aws-observability-accelerator). We have setup a GitRepository to point to the AWS Observabiity Accelerator GitHub Repository and `Kustomization` for flux to sync Git Repository with artifacts in `./artifacts/grafana-operator-manifests/*` path in the AWS Observabiity Accelerator GitHub Repository. You can use this extension of our solution to point your own Kubernetes manifests to create Grafana Datasources and personified Grafana Dashboards of your choice using GitOps with Grafana Operator and Flux in Kubernetes native way with altering and redeploying this solution for changes to Grafana resources.
-
## Release notes
We encourage you to use our [release versions](https://github.com/aws-observability/terraform-aws-observability-accelerator/releases)
@@ -57,82 +56,19 @@ module "eks_monitoring" {
}
```
+## Modules
-## Base module
-
-The base module allows you to configure the AWS Observability services for your cluster and
-the AWS Distro for OpenTelemetry (ADOT) Operator as the signals collection mechanism.
-
-This is the minimum configuration to have a new Amazon Managed Service for Prometheus Workspace
-and ADOT Operator deployed for you and ready to receive your data.
-The base module serve as an anchor to the workload modules and cannot run on its own.
-
-```hcl
-module "aws_observability_accelerator" {
- # use release tags and check for the latest versions
- # https://github.com/aws-observability/terraform-aws-observability-accelerator/releases
- source = "github.com/aws-observability/terraform-aws-observability-accelerator?ref=v1.6.1"
-
- aws_region = "eu-west-1"
- eks_cluster_id = "my-eks-cluster"
-
- # As Grafana shares a different lifecycle, we recommend using an existing workspace.
- managed_grafana_workspace_id = var.managed_grafana_workspace_id
-}
-```
-
-You can optionally reuse an existing Amazon Managed Service for Prometheus Workspace:
-
-```hcl
-module "aws_observability_accelerator" {
- # use release tags and check for the latest versions
- # https://github.com/aws-observability/terraform-aws-observability-accelerator/releases
- source = "github.com/aws-observability/terraform-aws-observability-accelerator?ref=v1.6.1"
-
- aws_region = "eu-west-1"
- eks_cluster_id = "my-eks-cluster"
-
- # prevents creation of a new Amazon Managed Prometheus workspace
- enable_managed_prometheus = false
-
- # reusing existing Amazon Managed Prometheus Workspace
- managed_prometheus_workspace_id = "ws-abcd123..."
-
- managed_grafana_workspace_id = "g-abcdef123"
-}
-```
-
-View all the configuration options in the [module's documentation](https://github.com/aws-observability/terraform-aws-observability-accelerator#requirements)
-
-## Workload modules
-
-Workloads modules are focused Terraform modules provided in this repository. They essentially provide curated metrics collection, alerts and Grafana dashboards according to the use case. Most of those modules require the base module.
-
-You can check the full workload modules list and their documentation [here](https://github.com/aws-observability/terraform-aws-observability-accelerator/tree/main/modules/).
-
+[Modules](https://github.com/aws-observability/terraform-aws-observability-accelerator/tree/main/modules/)
+are set of functionalities (ex: Managed Open-Source EKS monitoring, CloudWatch Container Insights, ...)
+packaged together that can be used to add Observability to your environments.
All the modules come with end-to-end deployable examples.
## Examples
-[Examples](https://github.com/aws-observability/terraform-aws-observability-accelerator/tree/main/examples) put modules together in a ready to deploy terraform configuration as a starting point. With little to no configuration, you can run `terraform apply` and use the deployed resources on your AWS Account.
+[Examples](https://github.com/aws-observability/terraform-aws-observability-accelerator/tree/main/examples) put [modules](https://github.com/aws-observability/terraform-aws-observability-accelerator/tree/main/modules/) together in a ready to deploy terraform configuration as a starting point. With little to no configuration, you can run `terraform apply` and use the deployed resources on your AWS Account.
You can find **workload** examples like [Amazon EKS infrastructure monitoring](https://aws-observability.github.io/terraform-aws-observability-accelerator/eks/) or [monitoring your Amazon Managed Service for Prometheus workspace](https://aws-observability.github.io/terraform-aws-observability-accelerator/workloads/managed-prometheus/) and more.
-```mermaid
-classDiagram
- Example <|-- Base Module
- Example <|-- Workload Module
- class Base Module{
- Amazon Managed Prometheus
- Amazon Managed Grafana Data Sources
- }
- class Workload Module{
- Amazon Distro for Open Telemetry Config
- Amazon Managed Prometheus Alerts
- Amazon Managed Grafana Dashboards
- }
-```
-
## Getting started with AWS Observability services
diff --git a/docs/contributors.md b/docs/contributors.md
index 8e742837..0c893128 100644
--- a/docs/contributors.md
+++ b/docs/contributors.md
@@ -14,11 +14,8 @@ The core team include the following people:
* Jerome DECQ
* Kevin Lewin
* Michael Hausenblas
-* Munish Dabra
* Rodrigue Koffi
* Toshal Dudhwala
-* Vara Bonthu
-* Vikram Venkataraman
We welcome the wider open source community and thank [those who contribute](https://github.com/aws-observability/terraform-aws-observability-accelerator/graphs/contributors)
to this project.
diff --git a/docs/index.md b/docs/index.md
index 4407a022..e8c44840 100644
--- a/docs/index.md
+++ b/docs/index.md
@@ -8,11 +8,7 @@ AWS-managed observability services such as Amazon Managed Service for Prometheus
Amazon Managed Grafana, AWS Distro for OpenTelemetry (ADOT) and Amazon CloudWatch.
We provide curated metrics, logs, traces collection, alerting rules and Grafana
-dashboards for your EKS infrastructure, Java/JMX, NGINX based workloads and
-your custom applications.
-
-You also can monitor your Amazon Managed Service for Prometheus workspaces ingestion,
-costs, active series with [this module](https://aws-observability.github.io/terraform-aws-observability-accelerator/workloads/managed-prometheus/).
+dashboards for your AWS infrastructure and custom applications.
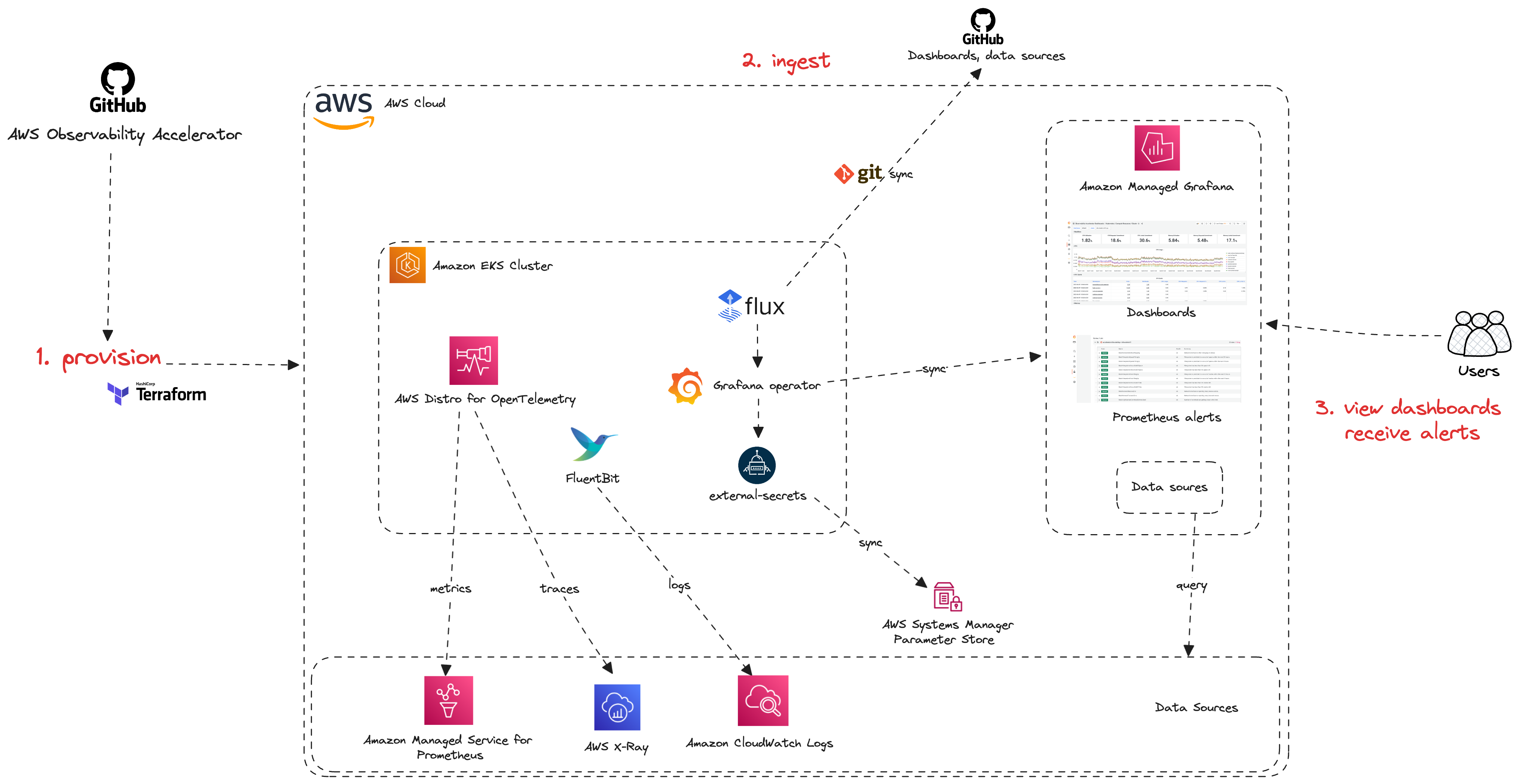
@@ -21,12 +17,13 @@ costs, active series with [this module](https://aws-observability.github.io/terr
This project provides a set of Terraform modules to enable metrics, logs and
traces collection, dashboards and alerts for monitoring:
-- Amazon EKS clusters infrastructure and applications
-- NGINX workloads (running on Amazon EKS)
-- Java/JMX workloads (running on Amazon EKS)
-- Amazon Managed Service for Prometheus workspaces with Amazon CloudWatch
-- [Grafana Operator](https://github.com/grafana-operator/grafana-operator) and [Flux CD](https://fluxcd.io/) to manage Grafana contents (AWS data sources, Grafana Dashboards) with GitOps
-- External Secrets Operator to retrieve and sync the Grafana API keys
+- [EKS Monitoring with AWS-Managed Open Source](https://aws-observability.github.io/terraform-aws-observability-accelerator/eks/) - Get Prometheus metrics, CloudWatch logs collection, and X-Ray traces (with OTLP support) for your EKS cluster. Visualize key metrics and logs with provided Grafana dashboards and get pre-built alerting rules.
+
+- [EKS Monitoring with Enhanced CloudWatch Container Insights](https://aws-observability.github.io/terraform-aws-observability-accelerator/container-insights/eks/) - Get deep visibility into EKS using Amazon CloudWatch for metrics collection, aggregation, and insights summaries. Includes support for [CloudWatch Application Signals (preview)](https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/CloudWatch-Application-Monitoring-Sections.html).
+
+- [ECS Monitoring on EC2 with AWS-Managed Open Source](https://aws-observability.github.io/terraform-aws-observability-accelerator/ecs/ecs-monitoring-on-ec2/) - Collect metrics, traces, and logs for ECS on EC2 and send them to a Managed Prometheus workspace , X-Ray, and CloudWatch Logs. Includes pre-built Grafana dashboards for key metrics and logs.
+
+- [Managed Prometheus Monitoring](https://aws-observability.github.io/terraform-aws-observability-accelerator/workloads/managed-prometheus/) - This module sets up automated observability for Amazon Managed Service for Prometheus workspaces, including a Grafana dashboard, CloudWatch monitoring, and service quota alarms.
These modules can be directly configured in your existing Terraform
configurations or ready to be deployed in our packaged
diff --git a/examples/eks-cross-account-with-central-amp/data.tf b/examples/eks-cross-account-with-central-amp/data.tf
index e87543fa..88c91c4d 100644
--- a/examples/eks-cross-account-with-central-amp/data.tf
+++ b/examples/eks-cross-account-with-central-amp/data.tf
@@ -17,3 +17,8 @@ data "aws_eks_cluster" "eks_two" {
name = var.cluster_two.name
provider = aws.eks_cluster_two
}
+
+data "aws_grafana_workspace" "this" {
+ workspace_id = var.monitoring.managed_grafana_id
+ provider = aws.eks_cluster_one
+}
diff --git a/examples/eks-cross-account-with-central-amp/main.tf b/examples/eks-cross-account-with-central-amp/main.tf
index 9c608b45..d48f8cbc 100644
--- a/examples/eks-cross-account-with-central-amp/main.tf
+++ b/examples/eks-cross-account-with-central-amp/main.tf
@@ -6,7 +6,7 @@ locals {
# EKS Monitoring Addon for cluster one #
###########################################################################
module "eks_monitoring_one" {
- source = "../../modules/eks-monitoring"
+ source = "../..//modules/eks-monitoring"
# source = "github.com/aws-observability/terraform-aws-observability-accelerator//modules/eks-monitoring?ref=v2.0.0"
providers = {
aws = aws.eks_cluster_one
@@ -36,11 +36,15 @@ module "eks_monitoring_one" {
grafana_api_key = aws_grafana_workspace_api_key.key.key
target_secret_name = "grafana-admin-credentials"
target_secret_namespace = "grafana-operator"
- grafana_url = module.aws_observability_accelerator.managed_grafana_workspace_endpoint
+ grafana_url = "https://${data.aws_grafana_workspace.this.endpoint}"
- managed_prometheus_workspace_id = module.aws_observability_accelerator.managed_prometheus_workspace_id
- managed_prometheus_workspace_endpoint = module.aws_observability_accelerator.managed_prometheus_workspace_endpoint
- managed_prometheus_workspace_region = module.aws_observability_accelerator.managed_prometheus_workspace_region
+
+ # prevents the module to create a workspace
+ enable_managed_prometheus = false
+
+ managed_prometheus_workspace_id = module.managed_service_prometheus.workspace_id
+ managed_prometheus_workspace_endpoint = module.managed_service_prometheus.workspace_prometheus_endpoint
+ managed_prometheus_workspace_region = var.cluster_one.region
managed_prometheus_cross_account_role = aws_iam_role.cross_account_amp_role.arn
irsa_iam_additional_policies = [aws_iam_policy.irsa_assume_role_policy_one.arn]
@@ -51,10 +55,6 @@ module "eks_monitoring_one" {
}
enable_logs = true
-
- depends_on = [
- module.aws_observability_accelerator
- ]
}
@@ -63,7 +63,7 @@ module "eks_monitoring_one" {
###########################################################################
module "eks_monitoring_two" {
- source = "../../modules/eks-monitoring"
+ source = "../..//modules/eks-monitoring"
# source = "github.com/aws-observability/terraform-aws-observability-accelerator//modules/eks-monitoring?ref=v2.0.0"
providers = {
aws = aws.eks_cluster_two
@@ -91,11 +91,15 @@ module "eks_monitoring_two" {
grafana_api_key = aws_grafana_workspace_api_key.key.key
target_secret_name = "grafana-admin-credentials"
target_secret_namespace = "grafana-operator"
- grafana_url = module.aws_observability_accelerator.managed_grafana_workspace_endpoint
+ grafana_url = "https://${data.aws_grafana_workspace.this.endpoint}"
+
+ # prevents the module to create a workspace
+ enable_managed_prometheus = false
+
+ managed_prometheus_workspace_id = module.managed_service_prometheus.workspace_id
+ managed_prometheus_workspace_endpoint = module.managed_service_prometheus.workspace_prometheus_endpoint
+ managed_prometheus_workspace_region = var.cluster_two.region
- managed_prometheus_workspace_id = module.aws_observability_accelerator.managed_prometheus_workspace_id
- managed_prometheus_workspace_endpoint = module.aws_observability_accelerator.managed_prometheus_workspace_endpoint
- managed_prometheus_workspace_region = module.aws_observability_accelerator.managed_prometheus_workspace_region
managed_prometheus_cross_account_role = aws_iam_role.cross_account_amp_role.arn
irsa_iam_additional_policies = [aws_iam_policy.irsa_assume_role_policy_two.arn]
@@ -106,10 +110,6 @@ module "eks_monitoring_two" {
}
enable_logs = true
-
- depends_on = [
- module.aws_observability_accelerator
- ]
}
###########################################################################
@@ -133,17 +133,3 @@ module "managed_service_prometheus" {
workspace_alias = local.amp_workspace_alias
}
-
-module "aws_observability_accelerator" {
- source = "../../../terraform-aws-observability-accelerator"
- aws_region = var.monitoring.region
- enable_managed_prometheus = false
- enable_alertmanager = false
- managed_prometheus_workspace_region = var.monitoring.region
- managed_prometheus_workspace_id = module.managed_service_prometheus.workspace_id
- managed_grafana_workspace_id = var.monitoring.managed_grafana_id
-
- providers = {
- aws = aws.central_monitoring
- }
-}
diff --git a/examples/eks-istio/README.md b/examples/eks-istio/README.md
index 873b4a0d..3a88dd41 100644
--- a/examples/eks-istio/README.md
+++ b/examples/eks-istio/README.md
@@ -1,4 +1,4 @@
-# Existing Cluster with the AWS Observability accelerator base module, Tetrate Istio Add-on and Istio monitoring
+# Existing Cluster with Tetrate Istio Add-on and Istio monitoring
View the full documentation for this example [here](https://aws-observability.github.io/terraform-aws-observability-accelerator/eks/istio)
@@ -23,7 +23,6 @@ View the full documentation for this example [here](https://aws-observability.gi
| Name | Source | Version |
|------|--------|---------|
-| [aws\_observability\_accelerator](#module\_aws\_observability\_accelerator) | ../../ | n/a |
| [eks\_blueprints\_kubernetes\_addons](#module\_eks\_blueprints\_kubernetes\_addons) | github.com/aws-ia/terraform-aws-eks-blueprints//modules/kubernetes-addons | v4.32.1 |
| [eks\_monitoring](#module\_eks\_monitoring) | ../../modules/eks-monitoring | n/a |
@@ -33,6 +32,7 @@ View the full documentation for this example [here](https://aws-observability.gi
|------|------|
| [aws_eks_cluster.this](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/data-sources/eks_cluster) | data source |
| [aws_eks_cluster_auth.this](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/data-sources/eks_cluster_auth) | data source |
+| [aws_grafana_workspace.this](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/data-sources/grafana_workspace) | data source |
## Inputs
@@ -49,9 +49,9 @@ View the full documentation for this example [here](https://aws-observability.gi
| Name | Description |
|------|-------------|
-| [aws\_region](#output\_aws\_region) | AWS Region |
| [eks\_cluster\_id](#output\_eks\_cluster\_id) | EKS Cluster Id |
| [eks\_cluster\_version](#output\_eks\_cluster\_version) | EKS Cluster version |
| [managed\_prometheus\_workspace\_endpoint](#output\_managed\_prometheus\_workspace\_endpoint) | Amazon Managed Prometheus workspace endpoint |
| [managed\_prometheus\_workspace\_id](#output\_managed\_prometheus\_workspace\_id) | Amazon Managed Prometheus workspace ID |
+| [managed\_prometheus\_workspace\_region](#output\_managed\_prometheus\_workspace\_region) | AWS Region |
diff --git a/examples/eks-istio/main.tf b/examples/eks-istio/main.tf
index 4d63ca9a..138887ce 100644
--- a/examples/eks-istio/main.tf
+++ b/examples/eks-istio/main.tf
@@ -10,6 +10,10 @@ data "aws_eks_cluster" "this" {
name = var.eks_cluster_id
}
+data "aws_grafana_workspace" "this" {
+ workspace_id = var.managed_grafana_workspace_id
+}
+
provider "kubernetes" {
host = local.eks_cluster_endpoint
cluster_ca_certificate = base64decode(data.aws_eks_cluster.this.certificate_authority[0].data)
@@ -33,28 +37,6 @@ locals {
}
}
-# deploys the base module
-module "aws_observability_accelerator" {
- source = "../../"
- # source = "github.com/aws-observability/terraform-aws-observability-accelerator?ref=v2.0.0"
-
- aws_region = var.aws_region
-
- # creates a new Amazon Managed Prometheus workspace, defaults to true
- enable_managed_prometheus = local.create_new_workspace
-
- # reusing existing Amazon Managed Prometheus if specified
- managed_prometheus_workspace_id = var.managed_prometheus_workspace_id
-
- # sets up the Amazon Managed Prometheus alert manager at the workspace level
- enable_alertmanager = true
-
- # reusing existing Amazon Managed Grafana workspace
- managed_grafana_workspace_id = var.managed_grafana_workspace_id
-
- tags = local.tags
-}
-
module "eks_blueprints_kubernetes_addons" {
source = "github.com/aws-ia/terraform-aws-eks-blueprints//modules/kubernetes-addons?ref=v4.32.1"
@@ -95,15 +77,13 @@ module "eks_monitoring" {
grafana_api_key = var.grafana_api_key
target_secret_name = "grafana-admin-credentials"
target_secret_namespace = "grafana-operator"
- grafana_url = module.aws_observability_accelerator.managed_grafana_workspace_endpoint
+ grafana_url = "https://${data.aws_grafana_workspace.this.endpoint}"
# control the publishing of dashboards by specifying the boolean value for the variable 'enable_dashboards', default is 'true'
enable_dashboards = var.enable_dashboards
- managed_prometheus_workspace_id = module.aws_observability_accelerator.managed_prometheus_workspace_id
-
- managed_prometheus_workspace_endpoint = module.aws_observability_accelerator.managed_prometheus_workspace_endpoint
- managed_prometheus_workspace_region = module.aws_observability_accelerator.managed_prometheus_workspace_region
+ enable_managed_prometheus = local.create_new_workspace
+ managed_prometheus_workspace_id = var.managed_prometheus_workspace_id
# optional, defaults to 60s interval and 15s timeout
prometheus_config = {
@@ -114,8 +94,4 @@ module "eks_monitoring" {
enable_logs = true
tags = local.tags
-
- depends_on = [
- module.aws_observability_accelerator
- ]
}
diff --git a/examples/eks-istio/outputs.tf b/examples/eks-istio/outputs.tf
index ad1c3405..e14427e3 100644
--- a/examples/eks-istio/outputs.tf
+++ b/examples/eks-istio/outputs.tf
@@ -1,16 +1,16 @@
-output "aws_region" {
+output "managed_prometheus_workspace_region" {
description = "AWS Region"
- value = module.aws_observability_accelerator.aws_region
+ value = module.eks_monitoring.managed_prometheus_workspace_region
}
output "managed_prometheus_workspace_endpoint" {
description = "Amazon Managed Prometheus workspace endpoint"
- value = module.aws_observability_accelerator.managed_prometheus_workspace_endpoint
+ value = module.eks_monitoring.managed_prometheus_workspace_endpoint
}
output "managed_prometheus_workspace_id" {
description = "Amazon Managed Prometheus workspace ID"
- value = module.aws_observability_accelerator.managed_prometheus_workspace_id
+ value = module.eks_monitoring.managed_prometheus_workspace_id
}
output "eks_cluster_version" {
diff --git a/examples/eks-multicluster/data.tf b/examples/eks-multicluster/data.tf
index acc5d558..2a25fd5e 100644
--- a/examples/eks-multicluster/data.tf
+++ b/examples/eks-multicluster/data.tf
@@ -17,3 +17,13 @@ data "aws_eks_cluster" "eks_cluster_2" {
name = var.eks_cluster_2_id
provider = aws.eks_cluster_2
}
+
+data "aws_grafana_workspace" "this" {
+ workspace_id = var.managed_grafana_workspace_id
+ provider = aws.eks_cluster_1
+}
+
+data "aws_prometheus_workspace" "this" {
+ workspace_id = local.managed_prometheus_workspace_id
+ provider = aws.eks_cluster_1
+}
diff --git a/examples/eks-multicluster/main.tf b/examples/eks-multicluster/main.tf
index 8e3034b5..d5b8e72c 100644
--- a/examples/eks-multicluster/main.tf
+++ b/examples/eks-multicluster/main.tf
@@ -1,19 +1,9 @@
-module "aws_observability_accelerator" {
- source = "../../../terraform-aws-observability-accelerator"
- aws_region = var.eks_cluster_1_region
- enable_managed_prometheus = false
- enable_alertmanager = true
- managed_prometheus_workspace_region = null
- managed_prometheus_workspace_id = var.managed_prometheus_workspace_id
- managed_grafana_workspace_id = var.managed_grafana_workspace_id
-
- providers = {
- aws = aws.eks_cluster_1
- }
+locals {
+ create_new_workspace = var.managed_prometheus_workspace_id == "" ? true : false
+ managed_prometheus_workspace_id = local.create_new_workspace ? module.managed_service_prometheus[0].workspace_id : var.managed_prometheus_workspace_id
}
-
module "eks_cluster_1_monitoring" {
- source = "../../../terraform-aws-observability-accelerator//modules/eks-monitoring"
+ source = "../..//modules/eks-monitoring"
eks_cluster_id = var.eks_cluster_1_id
enable_amazon_eks_adot = true
enable_cert_manager = true
@@ -31,11 +21,15 @@ module "eks_cluster_1_monitoring" {
enable_apiserver_monitoring = true
enable_adotcollector_metrics = true
- grafana_api_key = var.grafana_api_key
- managed_prometheus_workspace_id = module.aws_observability_accelerator.managed_prometheus_workspace_id
- managed_prometheus_workspace_endpoint = module.aws_observability_accelerator.managed_prometheus_workspace_endpoint
- managed_prometheus_workspace_region = module.aws_observability_accelerator.managed_prometheus_workspace_region
- grafana_url = module.aws_observability_accelerator.managed_grafana_workspace_endpoint
+ grafana_api_key = var.grafana_api_key
+ grafana_url = "https://${data.aws_grafana_workspace.this.endpoint}"
+
+ # prevents the module to create a workspace
+ enable_managed_prometheus = false
+
+ managed_prometheus_workspace_id = local.managed_prometheus_workspace_id
+ managed_prometheus_workspace_endpoint = data.aws_prometheus_workspace.this.prometheus_endpoint
+ managed_prometheus_workspace_region = var.eks_cluster_1_region
prometheus_config = {
global_scrape_interval = "60s"
@@ -48,14 +42,10 @@ module "eks_cluster_1_monitoring" {
kubernetes = kubernetes.eks_cluster_1
helm = helm.eks_cluster_1
}
-
- depends_on = [
- module.aws_observability_accelerator
- ]
}
module "eks_cluster_2_monitoring" {
- source = "../../../terraform-aws-observability-accelerator//modules/eks-monitoring"
+ source = "../..//modules/eks-monitoring"
eks_cluster_id = var.eks_cluster_2_id
enable_amazon_eks_adot = true
enable_cert_manager = true
@@ -73,9 +63,12 @@ module "eks_cluster_2_monitoring" {
enable_apiserver_monitoring = false
enable_adotcollector_metrics = false
- managed_prometheus_workspace_id = module.aws_observability_accelerator.managed_prometheus_workspace_id
- managed_prometheus_workspace_endpoint = module.aws_observability_accelerator.managed_prometheus_workspace_endpoint
- managed_prometheus_workspace_region = module.aws_observability_accelerator.managed_prometheus_workspace_region
+ # prevents the module to create a workspace
+ enable_managed_prometheus = false
+
+ managed_prometheus_workspace_id = var.managed_prometheus_workspace_id
+ managed_prometheus_workspace_endpoint = data.aws_prometheus_workspace.this.prometheus_endpoint
+ managed_prometheus_workspace_region = var.eks_cluster_1_region
prometheus_config = {
global_scrape_interval = "60s"
@@ -88,8 +81,15 @@ module "eks_cluster_2_monitoring" {
kubernetes = kubernetes.eks_cluster_2
helm = helm.eks_cluster_2
}
+}
+
+module "managed_service_prometheus" {
+ count = local.create_new_workspace ? 1 : 0
+ source = "terraform-aws-modules/managed-service-prometheus/aws"
+ version = "~> 2.2.2"
+ providers = {
+ aws = aws.eks_cluster_1
+ }
- depends_on = [
- module.aws_observability_accelerator
- ]
+ workspace_alias = "aws-observability-accelerator-multicluster"
}
diff --git a/examples/existing-cluster-java/README.md b/examples/existing-cluster-java/README.md
index 571fa68e..1b1e08b2 100644
--- a/examples/existing-cluster-java/README.md
+++ b/examples/existing-cluster-java/README.md
@@ -207,7 +207,6 @@ terraform destroy -var-file=terraform.tfvars
| Name | Source | Version |
|------|--------|---------|
-| [aws\_observability\_accelerator](#module\_aws\_observability\_accelerator) | ../../ | n/a |
| [eks\_monitoring](#module\_eks\_monitoring) | ../../modules/eks-monitoring | n/a |
## Resources
@@ -216,6 +215,7 @@ terraform destroy -var-file=terraform.tfvars
|------|------|
| [aws_eks_cluster.this](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/data-sources/eks_cluster) | data source |
| [aws_eks_cluster_auth.this](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/data-sources/eks_cluster_auth) | data source |
+| [aws_grafana_workspace.this](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/data-sources/grafana_workspace) | data source |
## Inputs
@@ -232,9 +232,9 @@ terraform destroy -var-file=terraform.tfvars
| Name | Description |
|------|-------------|
-| [aws\_region](#output\_aws\_region) | AWS Region |
| [eks\_cluster\_id](#output\_eks\_cluster\_id) | EKS Cluster Id |
| [eks\_cluster\_version](#output\_eks\_cluster\_version) | EKS Cluster version |
| [managed\_prometheus\_workspace\_endpoint](#output\_managed\_prometheus\_workspace\_endpoint) | Amazon Managed Prometheus workspace endpoint |
| [managed\_prometheus\_workspace\_id](#output\_managed\_prometheus\_workspace\_id) | Amazon Managed Prometheus workspace ID |
+| [managed\_prometheus\_workspace\_region](#output\_managed\_prometheus\_workspace\_region) | AWS Region |
diff --git a/examples/existing-cluster-java/main.tf b/examples/existing-cluster-java/main.tf
index 302b4ced..7a3af6d7 100644
--- a/examples/existing-cluster-java/main.tf
+++ b/examples/existing-cluster-java/main.tf
@@ -10,6 +10,10 @@ data "aws_eks_cluster" "this" {
name = var.eks_cluster_id
}
+data "aws_grafana_workspace" "this" {
+ workspace_id = var.managed_grafana_workspace_id
+}
+
provider "kubernetes" {
host = local.eks_cluster_endpoint
cluster_ca_certificate = base64decode(data.aws_eks_cluster.this.certificate_authority[0].data)
@@ -33,25 +37,6 @@ locals {
}
}
-# deploys the base module
-module "aws_observability_accelerator" {
- source = "../../"
- # source = "github.com/aws-observability/terraform-aws-observability-accelerator?ref=v2.0.0"
-
- aws_region = var.aws_region
-
- # creates a new Amazon Managed Prometheus workspace, defaults to true
- enable_managed_prometheus = local.create_new_workspace
-
- # reusing existing Amazon Managed Prometheus if specified
- managed_prometheus_workspace_id = var.managed_prometheus_workspace_id
-
- # reusing existing Amazon Managed Grafana workspace
- managed_grafana_workspace_id = var.managed_grafana_workspace_id
-
- tags = local.tags
-}
-
module "eks_monitoring" {
source = "../../modules/eks-monitoring"
# source = "github.com/aws-observability/terraform-aws-observability-accelerator//modules/eks-monitoring?ref=v2.0.0"
@@ -64,17 +49,15 @@ module "eks_monitoring" {
grafana_api_key = var.grafana_api_key
target_secret_name = "grafana-admin-credentials"
target_secret_namespace = "grafana-operator"
- grafana_url = module.aws_observability_accelerator.managed_grafana_workspace_endpoint
+ grafana_url = "https://${data.aws_grafana_workspace.this.endpoint}"
eks_cluster_id = var.eks_cluster_id
# control the publishing of dashboards by specifying the boolean value for the variable 'enable_dashboards', default is 'true'
enable_dashboards = var.enable_dashboards
- managed_prometheus_workspace_id = module.aws_observability_accelerator.managed_prometheus_workspace_id
-
- managed_prometheus_workspace_endpoint = module.aws_observability_accelerator.managed_prometheus_workspace_endpoint
- managed_prometheus_workspace_region = module.aws_observability_accelerator.managed_prometheus_workspace_region
+ enable_managed_prometheus = local.create_new_workspace
+ managed_prometheus_workspace_id = var.managed_prometheus_workspace_id
# optional, defaults to 60s interval and 15s timeout
prometheus_config = {
@@ -86,8 +69,4 @@ module "eks_monitoring" {
enable_logs = true
tags = local.tags
-
- depends_on = [
- module.aws_observability_accelerator
- ]
}
diff --git a/examples/existing-cluster-java/outputs.tf b/examples/existing-cluster-java/outputs.tf
index ad1c3405..e14427e3 100644
--- a/examples/existing-cluster-java/outputs.tf
+++ b/examples/existing-cluster-java/outputs.tf
@@ -1,16 +1,16 @@
-output "aws_region" {
+output "managed_prometheus_workspace_region" {
description = "AWS Region"
- value = module.aws_observability_accelerator.aws_region
+ value = module.eks_monitoring.managed_prometheus_workspace_region
}
output "managed_prometheus_workspace_endpoint" {
description = "Amazon Managed Prometheus workspace endpoint"
- value = module.aws_observability_accelerator.managed_prometheus_workspace_endpoint
+ value = module.eks_monitoring.managed_prometheus_workspace_endpoint
}
output "managed_prometheus_workspace_id" {
description = "Amazon Managed Prometheus workspace ID"
- value = module.aws_observability_accelerator.managed_prometheus_workspace_id
+ value = module.eks_monitoring.managed_prometheus_workspace_id
}
output "eks_cluster_version" {
diff --git a/examples/existing-cluster-nginx/README.md b/examples/existing-cluster-nginx/README.md
index 066734c0..dad16832 100644
--- a/examples/existing-cluster-nginx/README.md
+++ b/examples/existing-cluster-nginx/README.md
@@ -218,7 +218,6 @@ add this `managed_prometheus_region=xxx` and `managed_prometheus_workspace_id=ws
| Name | Source | Version |
|------|--------|---------|
-| [aws\_observability\_accelerator](#module\_aws\_observability\_accelerator) | ../../ | n/a |
| [eks\_monitoring](#module\_eks\_monitoring) | ../../modules/eks-monitoring | n/a |
## Resources
@@ -227,6 +226,7 @@ add this `managed_prometheus_region=xxx` and `managed_prometheus_workspace_id=ws
|------|------|
| [aws_eks_cluster.this](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/data-sources/eks_cluster) | data source |
| [aws_eks_cluster_auth.this](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/data-sources/eks_cluster_auth) | data source |
+| [aws_grafana_workspace.this](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/data-sources/grafana_workspace) | data source |
## Inputs
@@ -243,9 +243,9 @@ add this `managed_prometheus_region=xxx` and `managed_prometheus_workspace_id=ws
| Name | Description |
|------|-------------|
-| [aws\_region](#output\_aws\_region) | AWS Region |
| [eks\_cluster\_id](#output\_eks\_cluster\_id) | EKS Cluster Id |
| [eks\_cluster\_version](#output\_eks\_cluster\_version) | EKS Cluster version |
| [managed\_prometheus\_workspace\_endpoint](#output\_managed\_prometheus\_workspace\_endpoint) | Amazon Managed Prometheus workspace endpoint |
| [managed\_prometheus\_workspace\_id](#output\_managed\_prometheus\_workspace\_id) | Amazon Managed Prometheus workspace ID |
+| [managed\_prometheus\_workspace\_region](#output\_managed\_prometheus\_workspace\_region) | AWS Region |
diff --git a/examples/existing-cluster-nginx/main.tf b/examples/existing-cluster-nginx/main.tf
index 987e18b1..659dbb21 100644
--- a/examples/existing-cluster-nginx/main.tf
+++ b/examples/existing-cluster-nginx/main.tf
@@ -10,6 +10,10 @@ data "aws_eks_cluster" "this" {
name = var.eks_cluster_id
}
+data "aws_grafana_workspace" "this" {
+ workspace_id = var.managed_grafana_workspace_id
+}
+
provider "kubernetes" {
host = local.eks_cluster_endpoint
cluster_ca_certificate = base64decode(data.aws_eks_cluster.this.certificate_authority[0].data)
@@ -34,24 +38,6 @@ locals {
}
}
-module "aws_observability_accelerator" {
- source = "../../"
- # source = "github.com/aws-observability/terraform-aws-observability-accelerator?ref=v2.0.0"
-
- aws_region = var.aws_region
-
- # creates a new AMP workspace, defaults to true
- enable_managed_prometheus = local.create_new_workspace
-
- # reusing existing AMP if specified
- managed_prometheus_workspace_id = var.managed_prometheus_workspace_id
-
- # reusing existing Amazon Managed Grafana workspace
- managed_grafana_workspace_id = var.managed_grafana_workspace_id
-
- tags = local.tags
-}
-
module "eks_monitoring" {
source = "../../modules/eks-monitoring"
# source = "github.com/aws-observability/terraform-aws-observability-accelerator//modules/eks-monitoring?ref=v2.0.0"
@@ -66,21 +52,15 @@ module "eks_monitoring" {
grafana_api_key = var.grafana_api_key
target_secret_name = "grafana-admin-credentials"
target_secret_namespace = "grafana-operator"
- grafana_url = module.aws_observability_accelerator.managed_grafana_workspace_endpoint
+ grafana_url = "https://${data.aws_grafana_workspace.this.endpoint}"
# control the publishing of dashboards by specifying the boolean value for the variable 'enable_dashboards', default is 'true'
enable_dashboards = var.enable_dashboards
- managed_prometheus_workspace_id = module.aws_observability_accelerator.managed_prometheus_workspace_id
-
- managed_prometheus_workspace_endpoint = module.aws_observability_accelerator.managed_prometheus_workspace_endpoint
- managed_prometheus_workspace_region = module.aws_observability_accelerator.managed_prometheus_workspace_region
+ enable_managed_prometheus = local.create_new_workspace
+ managed_prometheus_workspace_id = var.managed_prometheus_workspace_id
enable_logs = true
tags = local.tags
-
- depends_on = [
- module.aws_observability_accelerator
- ]
}
diff --git a/examples/existing-cluster-nginx/outputs.tf b/examples/existing-cluster-nginx/outputs.tf
index ad1c3405..e14427e3 100644
--- a/examples/existing-cluster-nginx/outputs.tf
+++ b/examples/existing-cluster-nginx/outputs.tf
@@ -1,16 +1,16 @@
-output "aws_region" {
+output "managed_prometheus_workspace_region" {
description = "AWS Region"
- value = module.aws_observability_accelerator.aws_region
+ value = module.eks_monitoring.managed_prometheus_workspace_region
}
output "managed_prometheus_workspace_endpoint" {
description = "Amazon Managed Prometheus workspace endpoint"
- value = module.aws_observability_accelerator.managed_prometheus_workspace_endpoint
+ value = module.eks_monitoring.managed_prometheus_workspace_endpoint
}
output "managed_prometheus_workspace_id" {
description = "Amazon Managed Prometheus workspace ID"
- value = module.aws_observability_accelerator.managed_prometheus_workspace_id
+ value = module.eks_monitoring.managed_prometheus_workspace_id
}
output "eks_cluster_version" {
diff --git a/examples/existing-cluster-with-base-and-infra/README.md b/examples/existing-cluster-with-base-and-infra/README.md
index 3b06c870..a2a22630 100644
--- a/examples/existing-cluster-with-base-and-infra/README.md
+++ b/examples/existing-cluster-with-base-and-infra/README.md
@@ -1,4 +1,4 @@
-# Existing Cluster with the AWS Observability accelerator base module and Infrastructure monitoring
+# Existing Cluster with the AWS Observability accelerator EKS Infrastructure monitoring
This example demonstrates how to use the AWS Observability Accelerator Terraform
modules with Infrastructure monitoring enabled.
@@ -35,7 +35,6 @@ View the full documentation for this example [here](https://aws-observability.gi
| Name | Source | Version |
|------|--------|---------|
-| [aws\_observability\_accelerator](#module\_aws\_observability\_accelerator) | ../../ | n/a |
| [eks\_monitoring](#module\_eks\_monitoring) | ../../modules/eks-monitoring | n/a |
## Resources
@@ -44,6 +43,7 @@ View the full documentation for this example [here](https://aws-observability.gi
|------|------|
| [aws_eks_cluster.this](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/data-sources/eks_cluster) | data source |
| [aws_eks_cluster_auth.this](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/data-sources/eks_cluster_auth) | data source |
+| [aws_grafana_workspace.this](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/data-sources/grafana_workspace) | data source |
## Inputs
@@ -60,7 +60,9 @@ View the full documentation for this example [here](https://aws-observability.gi
| Name | Description |
|------|-------------|
-| [aws\_region](#output\_aws\_region) | AWS Region |
| [eks\_cluster\_id](#output\_eks\_cluster\_id) | EKS Cluster Id |
| [eks\_cluster\_version](#output\_eks\_cluster\_version) | EKS Cluster version |
+| [managed\_prometheus\_workspace\_endpoint](#output\_managed\_prometheus\_workspace\_endpoint) | Amazon Managed Prometheus workspace endpoint |
+| [managed\_prometheus\_workspace\_id](#output\_managed\_prometheus\_workspace\_id) | Amazon Managed Prometheus workspace ID |
+| [managed\_prometheus\_workspace\_region](#output\_managed\_prometheus\_workspace\_region) | AWS Region |
diff --git a/examples/existing-cluster-with-base-and-infra/main.tf b/examples/existing-cluster-with-base-and-infra/main.tf
index eccd94a1..a00df02f 100644
--- a/examples/existing-cluster-with-base-and-infra/main.tf
+++ b/examples/existing-cluster-with-base-and-infra/main.tf
@@ -10,6 +10,10 @@ data "aws_eks_cluster" "this" {
name = var.eks_cluster_id
}
+data "aws_grafana_workspace" "this" {
+ workspace_id = var.managed_grafana_workspace_id
+}
+
provider "kubernetes" {
host = local.eks_cluster_endpoint
cluster_ca_certificate = base64decode(data.aws_eks_cluster.this.certificate_authority[0].data)
@@ -33,28 +37,6 @@ locals {
}
}
-# deploys the base module
-module "aws_observability_accelerator" {
- source = "../../"
- # source = "github.com/aws-observability/terraform-aws-observability-accelerator?ref=v2.0.0"
-
- aws_region = var.aws_region
-
- # creates a new Amazon Managed Prometheus workspace, defaults to true
- enable_managed_prometheus = local.create_new_workspace
-
- # reusing existing Amazon Managed Prometheus if specified
- managed_prometheus_workspace_id = var.managed_prometheus_workspace_id
-
- # sets up the Amazon Managed Prometheus alert manager at the workspace level
- enable_alertmanager = true
-
- # reusing existing Amazon Managed Grafana workspace
- managed_grafana_workspace_id = var.managed_grafana_workspace_id
-
- tags = local.tags
-}
-
module "eks_monitoring" {
source = "../../modules/eks-monitoring"
# source = "github.com/aws-observability/terraform-aws-observability-accelerator//modules/eks-monitoring?ref=v2.0.0"
@@ -75,15 +57,17 @@ module "eks_monitoring" {
grafana_api_key = var.grafana_api_key
target_secret_name = "grafana-admin-credentials"
target_secret_namespace = "grafana-operator"
- grafana_url = module.aws_observability_accelerator.managed_grafana_workspace_endpoint
+ grafana_url = "https://${data.aws_grafana_workspace.this.endpoint}"
# control the publishing of dashboards by specifying the boolean value for the variable 'enable_dashboards', default is 'true'
enable_dashboards = var.enable_dashboards
- managed_prometheus_workspace_id = module.aws_observability_accelerator.managed_prometheus_workspace_id
+ # creates a new Amazon Managed Prometheus workspace, defaults to true
+ enable_managed_prometheus = local.create_new_workspace
+ managed_prometheus_workspace_id = var.managed_prometheus_workspace_id
- managed_prometheus_workspace_endpoint = module.aws_observability_accelerator.managed_prometheus_workspace_endpoint
- managed_prometheus_workspace_region = module.aws_observability_accelerator.managed_prometheus_workspace_region
+ # sets up the Amazon Managed Prometheus alert manager at the workspace level
+ enable_alertmanager = true
# optional, defaults to 60s interval and 15s timeout
prometheus_config = {
@@ -94,8 +78,4 @@ module "eks_monitoring" {
enable_logs = true
tags = local.tags
-
- depends_on = [
- module.aws_observability_accelerator
- ]
}
diff --git a/examples/existing-cluster-with-base-and-infra/outputs.tf b/examples/existing-cluster-with-base-and-infra/outputs.tf
index f8b4d584..e14427e3 100644
--- a/examples/existing-cluster-with-base-and-infra/outputs.tf
+++ b/examples/existing-cluster-with-base-and-infra/outputs.tf
@@ -1,6 +1,16 @@
-output "aws_region" {
+output "managed_prometheus_workspace_region" {
description = "AWS Region"
- value = module.aws_observability_accelerator.aws_region
+ value = module.eks_monitoring.managed_prometheus_workspace_region
+}
+
+output "managed_prometheus_workspace_endpoint" {
+ description = "Amazon Managed Prometheus workspace endpoint"
+ value = module.eks_monitoring.managed_prometheus_workspace_endpoint
+}
+
+output "managed_prometheus_workspace_id" {
+ description = "Amazon Managed Prometheus workspace ID"
+ value = module.eks_monitoring.managed_prometheus_workspace_id
}
output "eks_cluster_version" {
diff --git a/locals.tf b/locals.tf
deleted file mode 100644
index 8e823659..00000000
--- a/locals.tf
+++ /dev/null
@@ -1,17 +0,0 @@
-data "aws_region" "current" {}
-
-data "aws_grafana_workspace" "this" {
- workspace_id = var.managed_grafana_workspace_id
-}
-
-
-locals {
- # if region is not passed, we assume the current one
- amp_ws_region = coalesce(var.managed_prometheus_workspace_region, data.aws_region.current.name)
- amp_ws_id = var.enable_managed_prometheus ? aws_prometheus_workspace.this[0].id : var.managed_prometheus_workspace_id
- amp_ws_endpoint = "https://aps-workspaces.${local.amp_ws_region}.amazonaws.com/workspaces/${local.amp_ws_id}/"
-
- amg_ws_endpoint = "https://${data.aws_grafana_workspace.this.endpoint}"
-
- name = "aws-observability-accelerator"
-}
diff --git a/main.tf b/main.tf
deleted file mode 100644
index d7e7ae62..00000000
--- a/main.tf
+++ /dev/null
@@ -1,20 +0,0 @@
-resource "aws_prometheus_workspace" "this" {
- count = var.enable_managed_prometheus ? 1 : 0
-
- alias = local.name
- tags = var.tags
-}
-
-resource "aws_prometheus_alert_manager_definition" "this" {
- count = var.enable_alertmanager ? 1 : 0
-
- workspace_id = local.amp_ws_id
-
- definition = <
+- [ECS Monitoring on EC2 with AWS-Managed Open Source](https://aws-observability.github.io/terraform-aws-observability-accelerator/ecs/ecs-monitoring-on-ec2/) - Collect metrics, traces, and logs for ECS on EC2 and send them to a Managed Prometheus workspace , X-Ray, and CloudWatch Logs. Includes pre-built Grafana dashboards for key metrics and logs.
+- [Managed Prometheus Monitoring](https://aws-observability.github.io/terraform-aws-observability-accelerator/workloads/managed-prometheus/) - This module sets up automated observability for Amazon Managed Service for Prometheus workspaces, including a Grafana dashboard, CloudWatch monitoring, and service quota alarms.
-Check the the [complete example](./examples/existing-cluster-with-base-and-infra/)
## Motivation
@@ -156,9 +54,8 @@ Grafana and Amazon OpenSearch.
AWS customers have asked for best-practices and guidance to collect metrics, logs
and traces from their containerized applications and microservices with ease of
deployment. Customers can use the AWS Observability Accelerator to configure their
-metrics and traces collection, leveraging [AWS Distro for OpenTelemetry](https://aws-otel.github.io/),
-to have opinionated dashboards and alerts available in only minutes.
-
+metrics and traces collection to have opinionated dashboards and alerts
+available in only minutes.
## Support & Feedback
@@ -173,59 +70,6 @@ section of this GitHub repo.
If you are interested in contributing, see the
[Contribution guide](https://github.com/aws-observability/terraform-aws-observability-accelerator/blob/main/CONTRIBUTING.md).
----
-
-
-## Requirements
-
-| Name | Version |
-|------|---------|
-| [terraform](#requirement\_terraform) | >= 1.1.0 |
-| [aws](#requirement\_aws) | >= 4.0.0 |
-| [awscc](#requirement\_awscc) | >= 0.24.0 |
-
-## Providers
-
-| Name | Version |
-|------|---------|
-| [aws](#provider\_aws) | >= 4.0.0 |
-
-## Modules
-
-No modules.
-
-## Resources
-
-| Name | Type |
-|------|------|
-| [aws_prometheus_alert_manager_definition.this](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/prometheus_alert_manager_definition) | resource |
-| [aws_prometheus_workspace.this](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/prometheus_workspace) | resource |
-| [aws_grafana_workspace.this](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/data-sources/grafana_workspace) | data source |
-| [aws_region.current](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/data-sources/region) | data source |
-
-## Inputs
-
-| Name | Description | Type | Default | Required |
-|------|-------------|------|---------|:--------:|
-| [aws\_region](#input\_aws\_region) | AWS Region | `string` | n/a | yes |
-| [enable\_alertmanager](#input\_enable\_alertmanager) | Creates Amazon Managed Service for Prometheus AlertManager for all workloads | `bool` | `false` | no |
-| [enable\_managed\_prometheus](#input\_enable\_managed\_prometheus) | Creates a new Amazon Managed Service for Prometheus Workspace | `bool` | `true` | no |
-| [managed\_grafana\_workspace\_id](#input\_managed\_grafana\_workspace\_id) | Amazon Managed Grafana Workspace ID | `string` | n/a | yes |
-| [managed\_prometheus\_workspace\_id](#input\_managed\_prometheus\_workspace\_id) | Amazon Managed Service for Prometheus Workspace ID | `string` | `""` | no |
-| [managed\_prometheus\_workspace\_region](#input\_managed\_prometheus\_workspace\_region) | Region where Amazon Managed Service for Prometheus is deployed | `string` | `null` | no |
-| [tags](#input\_tags) | Additional tags (e.g. `map('BusinessUnit`,`XYZ`) | `map(string)` | `{}` | no |
-
-## Outputs
-
-| Name | Description |
-|------|-------------|
-| [aws\_region](#output\_aws\_region) | AWS Region |
-| [managed\_grafana\_workspace\_endpoint](#output\_managed\_grafana\_workspace\_endpoint) | Amazon Managed Grafana workspace endpoint |
-| [managed\_prometheus\_workspace\_endpoint](#output\_managed\_prometheus\_workspace\_endpoint) | Amazon Managed Prometheus workspace endpoint |
-| [managed\_prometheus\_workspace\_id](#output\_managed\_prometheus\_workspace\_id) | Amazon Managed Prometheus workspace ID |
-| [managed\_prometheus\_workspace\_region](#output\_managed\_prometheus\_workspace\_region) | Amazon Managed Prometheus workspace region |
-
-
## Contributing
See [CONTRIBUTING](CONTRIBUTING.md#security-issue-notifications) for more information.
diff --git a/docs/concepts.md b/docs/concepts.md
index 1a4c4641..9633c2a4 100644
--- a/docs/concepts.md
+++ b/docs/concepts.md
@@ -44,7 +44,6 @@ We have setup a [GitRepository](https://fluxcd.io/flux/components/source/gitrepo
We have placed our declarative code snippet to create an Amazon Managed Service For Promethes datasource and Grafana Dashboard in Amazon Managed Grafana in our [AWS Observabiity Accelerator GitHub Repository](https://github.com/aws-observability/aws-observability-accelerator). We have setup a GitRepository to point to the AWS Observabiity Accelerator GitHub Repository and `Kustomization` for flux to sync Git Repository with artifacts in `./artifacts/grafana-operator-manifests/*` path in the AWS Observabiity Accelerator GitHub Repository. You can use this extension of our solution to point your own Kubernetes manifests to create Grafana Datasources and personified Grafana Dashboards of your choice using GitOps with Grafana Operator and Flux in Kubernetes native way with altering and redeploying this solution for changes to Grafana resources.
-
## Release notes
We encourage you to use our [release versions](https://github.com/aws-observability/terraform-aws-observability-accelerator/releases)
@@ -57,82 +56,19 @@ module "eks_monitoring" {
}
```
+## Modules
-## Base module
-
-The base module allows you to configure the AWS Observability services for your cluster and
-the AWS Distro for OpenTelemetry (ADOT) Operator as the signals collection mechanism.
-
-This is the minimum configuration to have a new Amazon Managed Service for Prometheus Workspace
-and ADOT Operator deployed for you and ready to receive your data.
-The base module serve as an anchor to the workload modules and cannot run on its own.
-
-```hcl
-module "aws_observability_accelerator" {
- # use release tags and check for the latest versions
- # https://github.com/aws-observability/terraform-aws-observability-accelerator/releases
- source = "github.com/aws-observability/terraform-aws-observability-accelerator?ref=v1.6.1"
-
- aws_region = "eu-west-1"
- eks_cluster_id = "my-eks-cluster"
-
- # As Grafana shares a different lifecycle, we recommend using an existing workspace.
- managed_grafana_workspace_id = var.managed_grafana_workspace_id
-}
-```
-
-You can optionally reuse an existing Amazon Managed Service for Prometheus Workspace:
-
-```hcl
-module "aws_observability_accelerator" {
- # use release tags and check for the latest versions
- # https://github.com/aws-observability/terraform-aws-observability-accelerator/releases
- source = "github.com/aws-observability/terraform-aws-observability-accelerator?ref=v1.6.1"
-
- aws_region = "eu-west-1"
- eks_cluster_id = "my-eks-cluster"
-
- # prevents creation of a new Amazon Managed Prometheus workspace
- enable_managed_prometheus = false
-
- # reusing existing Amazon Managed Prometheus Workspace
- managed_prometheus_workspace_id = "ws-abcd123..."
-
- managed_grafana_workspace_id = "g-abcdef123"
-}
-```
-
-View all the configuration options in the [module's documentation](https://github.com/aws-observability/terraform-aws-observability-accelerator#requirements)
-
-## Workload modules
-
-Workloads modules are focused Terraform modules provided in this repository. They essentially provide curated metrics collection, alerts and Grafana dashboards according to the use case. Most of those modules require the base module.
-
-You can check the full workload modules list and their documentation [here](https://github.com/aws-observability/terraform-aws-observability-accelerator/tree/main/modules/).
-
+[Modules](https://github.com/aws-observability/terraform-aws-observability-accelerator/tree/main/modules/)
+are set of functionalities (ex: Managed Open-Source EKS monitoring, CloudWatch Container Insights, ...)
+packaged together that can be used to add Observability to your environments.
All the modules come with end-to-end deployable examples.
## Examples
-[Examples](https://github.com/aws-observability/terraform-aws-observability-accelerator/tree/main/examples) put modules together in a ready to deploy terraform configuration as a starting point. With little to no configuration, you can run `terraform apply` and use the deployed resources on your AWS Account.
+[Examples](https://github.com/aws-observability/terraform-aws-observability-accelerator/tree/main/examples) put [modules](https://github.com/aws-observability/terraform-aws-observability-accelerator/tree/main/modules/) together in a ready to deploy terraform configuration as a starting point. With little to no configuration, you can run `terraform apply` and use the deployed resources on your AWS Account.
You can find **workload** examples like [Amazon EKS infrastructure monitoring](https://aws-observability.github.io/terraform-aws-observability-accelerator/eks/) or [monitoring your Amazon Managed Service for Prometheus workspace](https://aws-observability.github.io/terraform-aws-observability-accelerator/workloads/managed-prometheus/) and more.
-```mermaid
-classDiagram
- Example <|-- Base Module
- Example <|-- Workload Module
- class Base Module{
- Amazon Managed Prometheus
- Amazon Managed Grafana Data Sources
- }
- class Workload Module{
- Amazon Distro for Open Telemetry Config
- Amazon Managed Prometheus Alerts
- Amazon Managed Grafana Dashboards
- }
-```
-
## Getting started with AWS Observability services
diff --git a/docs/contributors.md b/docs/contributors.md
index 8e742837..0c893128 100644
--- a/docs/contributors.md
+++ b/docs/contributors.md
@@ -14,11 +14,8 @@ The core team include the following people:
* Jerome DECQ
* Kevin Lewin
* Michael Hausenblas
-* Munish Dabra
* Rodrigue Koffi
* Toshal Dudhwala
-* Vara Bonthu
-* Vikram Venkataraman
We welcome the wider open source community and thank [those who contribute](https://github.com/aws-observability/terraform-aws-observability-accelerator/graphs/contributors)
to this project.
diff --git a/docs/index.md b/docs/index.md
index 4407a022..e8c44840 100644
--- a/docs/index.md
+++ b/docs/index.md
@@ -8,11 +8,7 @@ AWS-managed observability services such as Amazon Managed Service for Prometheus
Amazon Managed Grafana, AWS Distro for OpenTelemetry (ADOT) and Amazon CloudWatch.
We provide curated metrics, logs, traces collection, alerting rules and Grafana
-dashboards for your EKS infrastructure, Java/JMX, NGINX based workloads and
-your custom applications.
-
-You also can monitor your Amazon Managed Service for Prometheus workspaces ingestion,
-costs, active series with [this module](https://aws-observability.github.io/terraform-aws-observability-accelerator/workloads/managed-prometheus/).
+dashboards for your AWS infrastructure and custom applications.

@@ -21,12 +17,13 @@ costs, active series with [this module](https://aws-observability.github.io/terr
This project provides a set of Terraform modules to enable metrics, logs and
traces collection, dashboards and alerts for monitoring:
-- Amazon EKS clusters infrastructure and applications
-- NGINX workloads (running on Amazon EKS)
-- Java/JMX workloads (running on Amazon EKS)
-- Amazon Managed Service for Prometheus workspaces with Amazon CloudWatch
-- [Grafana Operator](https://github.com/grafana-operator/grafana-operator) and [Flux CD](https://fluxcd.io/) to manage Grafana contents (AWS data sources, Grafana Dashboards) with GitOps
-- External Secrets Operator to retrieve and sync the Grafana API keys
+- [EKS Monitoring with AWS-Managed Open Source](https://aws-observability.github.io/terraform-aws-observability-accelerator/eks/) - Get Prometheus metrics, CloudWatch logs collection, and X-Ray traces (with OTLP support) for your EKS cluster. Visualize key metrics and logs with provided Grafana dashboards and get pre-built alerting rules.
+
+- [EKS Monitoring with Enhanced CloudWatch Container Insights](https://aws-observability.github.io/terraform-aws-observability-accelerator/container-insights/eks/) - Get deep visibility into EKS using Amazon CloudWatch for metrics collection, aggregation, and insights summaries. Includes support for [CloudWatch Application Signals (preview)](https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/CloudWatch-Application-Monitoring-Sections.html).
+
+- [ECS Monitoring on EC2 with AWS-Managed Open Source](https://aws-observability.github.io/terraform-aws-observability-accelerator/ecs/ecs-monitoring-on-ec2/) - Collect metrics, traces, and logs for ECS on EC2 and send them to a Managed Prometheus workspace , X-Ray, and CloudWatch Logs. Includes pre-built Grafana dashboards for key metrics and logs.
+
+- [Managed Prometheus Monitoring](https://aws-observability.github.io/terraform-aws-observability-accelerator/workloads/managed-prometheus/) - This module sets up automated observability for Amazon Managed Service for Prometheus workspaces, including a Grafana dashboard, CloudWatch monitoring, and service quota alarms.
These modules can be directly configured in your existing Terraform
configurations or ready to be deployed in our packaged
diff --git a/examples/eks-cross-account-with-central-amp/data.tf b/examples/eks-cross-account-with-central-amp/data.tf
index e87543fa..88c91c4d 100644
--- a/examples/eks-cross-account-with-central-amp/data.tf
+++ b/examples/eks-cross-account-with-central-amp/data.tf
@@ -17,3 +17,8 @@ data "aws_eks_cluster" "eks_two" {
name = var.cluster_two.name
provider = aws.eks_cluster_two
}
+
+data "aws_grafana_workspace" "this" {
+ workspace_id = var.monitoring.managed_grafana_id
+ provider = aws.eks_cluster_one
+}
diff --git a/examples/eks-cross-account-with-central-amp/main.tf b/examples/eks-cross-account-with-central-amp/main.tf
index 9c608b45..d48f8cbc 100644
--- a/examples/eks-cross-account-with-central-amp/main.tf
+++ b/examples/eks-cross-account-with-central-amp/main.tf
@@ -6,7 +6,7 @@ locals {
# EKS Monitoring Addon for cluster one #
###########################################################################
module "eks_monitoring_one" {
- source = "../../modules/eks-monitoring"
+ source = "../..//modules/eks-monitoring"
# source = "github.com/aws-observability/terraform-aws-observability-accelerator//modules/eks-monitoring?ref=v2.0.0"
providers = {
aws = aws.eks_cluster_one
@@ -36,11 +36,15 @@ module "eks_monitoring_one" {
grafana_api_key = aws_grafana_workspace_api_key.key.key
target_secret_name = "grafana-admin-credentials"
target_secret_namespace = "grafana-operator"
- grafana_url = module.aws_observability_accelerator.managed_grafana_workspace_endpoint
+ grafana_url = "https://${data.aws_grafana_workspace.this.endpoint}"
- managed_prometheus_workspace_id = module.aws_observability_accelerator.managed_prometheus_workspace_id
- managed_prometheus_workspace_endpoint = module.aws_observability_accelerator.managed_prometheus_workspace_endpoint
- managed_prometheus_workspace_region = module.aws_observability_accelerator.managed_prometheus_workspace_region
+
+ # prevents the module to create a workspace
+ enable_managed_prometheus = false
+
+ managed_prometheus_workspace_id = module.managed_service_prometheus.workspace_id
+ managed_prometheus_workspace_endpoint = module.managed_service_prometheus.workspace_prometheus_endpoint
+ managed_prometheus_workspace_region = var.cluster_one.region
managed_prometheus_cross_account_role = aws_iam_role.cross_account_amp_role.arn
irsa_iam_additional_policies = [aws_iam_policy.irsa_assume_role_policy_one.arn]
@@ -51,10 +55,6 @@ module "eks_monitoring_one" {
}
enable_logs = true
-
- depends_on = [
- module.aws_observability_accelerator
- ]
}
@@ -63,7 +63,7 @@ module "eks_monitoring_one" {
###########################################################################
module "eks_monitoring_two" {
- source = "../../modules/eks-monitoring"
+ source = "../..//modules/eks-monitoring"
# source = "github.com/aws-observability/terraform-aws-observability-accelerator//modules/eks-monitoring?ref=v2.0.0"
providers = {
aws = aws.eks_cluster_two
@@ -91,11 +91,15 @@ module "eks_monitoring_two" {
grafana_api_key = aws_grafana_workspace_api_key.key.key
target_secret_name = "grafana-admin-credentials"
target_secret_namespace = "grafana-operator"
- grafana_url = module.aws_observability_accelerator.managed_grafana_workspace_endpoint
+ grafana_url = "https://${data.aws_grafana_workspace.this.endpoint}"
+
+ # prevents the module to create a workspace
+ enable_managed_prometheus = false
+
+ managed_prometheus_workspace_id = module.managed_service_prometheus.workspace_id
+ managed_prometheus_workspace_endpoint = module.managed_service_prometheus.workspace_prometheus_endpoint
+ managed_prometheus_workspace_region = var.cluster_two.region
- managed_prometheus_workspace_id = module.aws_observability_accelerator.managed_prometheus_workspace_id
- managed_prometheus_workspace_endpoint = module.aws_observability_accelerator.managed_prometheus_workspace_endpoint
- managed_prometheus_workspace_region = module.aws_observability_accelerator.managed_prometheus_workspace_region
managed_prometheus_cross_account_role = aws_iam_role.cross_account_amp_role.arn
irsa_iam_additional_policies = [aws_iam_policy.irsa_assume_role_policy_two.arn]
@@ -106,10 +110,6 @@ module "eks_monitoring_two" {
}
enable_logs = true
-
- depends_on = [
- module.aws_observability_accelerator
- ]
}
###########################################################################
@@ -133,17 +133,3 @@ module "managed_service_prometheus" {
workspace_alias = local.amp_workspace_alias
}
-
-module "aws_observability_accelerator" {
- source = "../../../terraform-aws-observability-accelerator"
- aws_region = var.monitoring.region
- enable_managed_prometheus = false
- enable_alertmanager = false
- managed_prometheus_workspace_region = var.monitoring.region
- managed_prometheus_workspace_id = module.managed_service_prometheus.workspace_id
- managed_grafana_workspace_id = var.monitoring.managed_grafana_id
-
- providers = {
- aws = aws.central_monitoring
- }
-}
diff --git a/examples/eks-istio/README.md b/examples/eks-istio/README.md
index 873b4a0d..3a88dd41 100644
--- a/examples/eks-istio/README.md
+++ b/examples/eks-istio/README.md
@@ -1,4 +1,4 @@
-# Existing Cluster with the AWS Observability accelerator base module, Tetrate Istio Add-on and Istio monitoring
+# Existing Cluster with Tetrate Istio Add-on and Istio monitoring
View the full documentation for this example [here](https://aws-observability.github.io/terraform-aws-observability-accelerator/eks/istio)
@@ -23,7 +23,6 @@ View the full documentation for this example [here](https://aws-observability.gi
| Name | Source | Version |
|------|--------|---------|
-| [aws\_observability\_accelerator](#module\_aws\_observability\_accelerator) | ../../ | n/a |
| [eks\_blueprints\_kubernetes\_addons](#module\_eks\_blueprints\_kubernetes\_addons) | github.com/aws-ia/terraform-aws-eks-blueprints//modules/kubernetes-addons | v4.32.1 |
| [eks\_monitoring](#module\_eks\_monitoring) | ../../modules/eks-monitoring | n/a |
@@ -33,6 +32,7 @@ View the full documentation for this example [here](https://aws-observability.gi
|------|------|
| [aws_eks_cluster.this](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/data-sources/eks_cluster) | data source |
| [aws_eks_cluster_auth.this](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/data-sources/eks_cluster_auth) | data source |
+| [aws_grafana_workspace.this](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/data-sources/grafana_workspace) | data source |
## Inputs
@@ -49,9 +49,9 @@ View the full documentation for this example [here](https://aws-observability.gi
| Name | Description |
|------|-------------|
-| [aws\_region](#output\_aws\_region) | AWS Region |
| [eks\_cluster\_id](#output\_eks\_cluster\_id) | EKS Cluster Id |
| [eks\_cluster\_version](#output\_eks\_cluster\_version) | EKS Cluster version |
| [managed\_prometheus\_workspace\_endpoint](#output\_managed\_prometheus\_workspace\_endpoint) | Amazon Managed Prometheus workspace endpoint |
| [managed\_prometheus\_workspace\_id](#output\_managed\_prometheus\_workspace\_id) | Amazon Managed Prometheus workspace ID |
+| [managed\_prometheus\_workspace\_region](#output\_managed\_prometheus\_workspace\_region) | AWS Region |
diff --git a/examples/eks-istio/main.tf b/examples/eks-istio/main.tf
index 4d63ca9a..138887ce 100644
--- a/examples/eks-istio/main.tf
+++ b/examples/eks-istio/main.tf
@@ -10,6 +10,10 @@ data "aws_eks_cluster" "this" {
name = var.eks_cluster_id
}
+data "aws_grafana_workspace" "this" {
+ workspace_id = var.managed_grafana_workspace_id
+}
+
provider "kubernetes" {
host = local.eks_cluster_endpoint
cluster_ca_certificate = base64decode(data.aws_eks_cluster.this.certificate_authority[0].data)
@@ -33,28 +37,6 @@ locals {
}
}
-# deploys the base module
-module "aws_observability_accelerator" {
- source = "../../"
- # source = "github.com/aws-observability/terraform-aws-observability-accelerator?ref=v2.0.0"
-
- aws_region = var.aws_region
-
- # creates a new Amazon Managed Prometheus workspace, defaults to true
- enable_managed_prometheus = local.create_new_workspace
-
- # reusing existing Amazon Managed Prometheus if specified
- managed_prometheus_workspace_id = var.managed_prometheus_workspace_id
-
- # sets up the Amazon Managed Prometheus alert manager at the workspace level
- enable_alertmanager = true
-
- # reusing existing Amazon Managed Grafana workspace
- managed_grafana_workspace_id = var.managed_grafana_workspace_id
-
- tags = local.tags
-}
-
module "eks_blueprints_kubernetes_addons" {
source = "github.com/aws-ia/terraform-aws-eks-blueprints//modules/kubernetes-addons?ref=v4.32.1"
@@ -95,15 +77,13 @@ module "eks_monitoring" {
grafana_api_key = var.grafana_api_key
target_secret_name = "grafana-admin-credentials"
target_secret_namespace = "grafana-operator"
- grafana_url = module.aws_observability_accelerator.managed_grafana_workspace_endpoint
+ grafana_url = "https://${data.aws_grafana_workspace.this.endpoint}"
# control the publishing of dashboards by specifying the boolean value for the variable 'enable_dashboards', default is 'true'
enable_dashboards = var.enable_dashboards
- managed_prometheus_workspace_id = module.aws_observability_accelerator.managed_prometheus_workspace_id
-
- managed_prometheus_workspace_endpoint = module.aws_observability_accelerator.managed_prometheus_workspace_endpoint
- managed_prometheus_workspace_region = module.aws_observability_accelerator.managed_prometheus_workspace_region
+ enable_managed_prometheus = local.create_new_workspace
+ managed_prometheus_workspace_id = var.managed_prometheus_workspace_id
# optional, defaults to 60s interval and 15s timeout
prometheus_config = {
@@ -114,8 +94,4 @@ module "eks_monitoring" {
enable_logs = true
tags = local.tags
-
- depends_on = [
- module.aws_observability_accelerator
- ]
}
diff --git a/examples/eks-istio/outputs.tf b/examples/eks-istio/outputs.tf
index ad1c3405..e14427e3 100644
--- a/examples/eks-istio/outputs.tf
+++ b/examples/eks-istio/outputs.tf
@@ -1,16 +1,16 @@
-output "aws_region" {
+output "managed_prometheus_workspace_region" {
description = "AWS Region"
- value = module.aws_observability_accelerator.aws_region
+ value = module.eks_monitoring.managed_prometheus_workspace_region
}
output "managed_prometheus_workspace_endpoint" {
description = "Amazon Managed Prometheus workspace endpoint"
- value = module.aws_observability_accelerator.managed_prometheus_workspace_endpoint
+ value = module.eks_monitoring.managed_prometheus_workspace_endpoint
}
output "managed_prometheus_workspace_id" {
description = "Amazon Managed Prometheus workspace ID"
- value = module.aws_observability_accelerator.managed_prometheus_workspace_id
+ value = module.eks_monitoring.managed_prometheus_workspace_id
}
output "eks_cluster_version" {
diff --git a/examples/eks-multicluster/data.tf b/examples/eks-multicluster/data.tf
index acc5d558..2a25fd5e 100644
--- a/examples/eks-multicluster/data.tf
+++ b/examples/eks-multicluster/data.tf
@@ -17,3 +17,13 @@ data "aws_eks_cluster" "eks_cluster_2" {
name = var.eks_cluster_2_id
provider = aws.eks_cluster_2
}
+
+data "aws_grafana_workspace" "this" {
+ workspace_id = var.managed_grafana_workspace_id
+ provider = aws.eks_cluster_1
+}
+
+data "aws_prometheus_workspace" "this" {
+ workspace_id = local.managed_prometheus_workspace_id
+ provider = aws.eks_cluster_1
+}
diff --git a/examples/eks-multicluster/main.tf b/examples/eks-multicluster/main.tf
index 8e3034b5..d5b8e72c 100644
--- a/examples/eks-multicluster/main.tf
+++ b/examples/eks-multicluster/main.tf
@@ -1,19 +1,9 @@
-module "aws_observability_accelerator" {
- source = "../../../terraform-aws-observability-accelerator"
- aws_region = var.eks_cluster_1_region
- enable_managed_prometheus = false
- enable_alertmanager = true
- managed_prometheus_workspace_region = null
- managed_prometheus_workspace_id = var.managed_prometheus_workspace_id
- managed_grafana_workspace_id = var.managed_grafana_workspace_id
-
- providers = {
- aws = aws.eks_cluster_1
- }
+locals {
+ create_new_workspace = var.managed_prometheus_workspace_id == "" ? true : false
+ managed_prometheus_workspace_id = local.create_new_workspace ? module.managed_service_prometheus[0].workspace_id : var.managed_prometheus_workspace_id
}
-
module "eks_cluster_1_monitoring" {
- source = "../../../terraform-aws-observability-accelerator//modules/eks-monitoring"
+ source = "../..//modules/eks-monitoring"
eks_cluster_id = var.eks_cluster_1_id
enable_amazon_eks_adot = true
enable_cert_manager = true
@@ -31,11 +21,15 @@ module "eks_cluster_1_monitoring" {
enable_apiserver_monitoring = true
enable_adotcollector_metrics = true
- grafana_api_key = var.grafana_api_key
- managed_prometheus_workspace_id = module.aws_observability_accelerator.managed_prometheus_workspace_id
- managed_prometheus_workspace_endpoint = module.aws_observability_accelerator.managed_prometheus_workspace_endpoint
- managed_prometheus_workspace_region = module.aws_observability_accelerator.managed_prometheus_workspace_region
- grafana_url = module.aws_observability_accelerator.managed_grafana_workspace_endpoint
+ grafana_api_key = var.grafana_api_key
+ grafana_url = "https://${data.aws_grafana_workspace.this.endpoint}"
+
+ # prevents the module to create a workspace
+ enable_managed_prometheus = false
+
+ managed_prometheus_workspace_id = local.managed_prometheus_workspace_id
+ managed_prometheus_workspace_endpoint = data.aws_prometheus_workspace.this.prometheus_endpoint
+ managed_prometheus_workspace_region = var.eks_cluster_1_region
prometheus_config = {
global_scrape_interval = "60s"
@@ -48,14 +42,10 @@ module "eks_cluster_1_monitoring" {
kubernetes = kubernetes.eks_cluster_1
helm = helm.eks_cluster_1
}
-
- depends_on = [
- module.aws_observability_accelerator
- ]
}
module "eks_cluster_2_monitoring" {
- source = "../../../terraform-aws-observability-accelerator//modules/eks-monitoring"
+ source = "../..//modules/eks-monitoring"
eks_cluster_id = var.eks_cluster_2_id
enable_amazon_eks_adot = true
enable_cert_manager = true
@@ -73,9 +63,12 @@ module "eks_cluster_2_monitoring" {
enable_apiserver_monitoring = false
enable_adotcollector_metrics = false
- managed_prometheus_workspace_id = module.aws_observability_accelerator.managed_prometheus_workspace_id
- managed_prometheus_workspace_endpoint = module.aws_observability_accelerator.managed_prometheus_workspace_endpoint
- managed_prometheus_workspace_region = module.aws_observability_accelerator.managed_prometheus_workspace_region
+ # prevents the module to create a workspace
+ enable_managed_prometheus = false
+
+ managed_prometheus_workspace_id = var.managed_prometheus_workspace_id
+ managed_prometheus_workspace_endpoint = data.aws_prometheus_workspace.this.prometheus_endpoint
+ managed_prometheus_workspace_region = var.eks_cluster_1_region
prometheus_config = {
global_scrape_interval = "60s"
@@ -88,8 +81,15 @@ module "eks_cluster_2_monitoring" {
kubernetes = kubernetes.eks_cluster_2
helm = helm.eks_cluster_2
}
+}
+
+module "managed_service_prometheus" {
+ count = local.create_new_workspace ? 1 : 0
+ source = "terraform-aws-modules/managed-service-prometheus/aws"
+ version = "~> 2.2.2"
+ providers = {
+ aws = aws.eks_cluster_1
+ }
- depends_on = [
- module.aws_observability_accelerator
- ]
+ workspace_alias = "aws-observability-accelerator-multicluster"
}
diff --git a/examples/existing-cluster-java/README.md b/examples/existing-cluster-java/README.md
index 571fa68e..1b1e08b2 100644
--- a/examples/existing-cluster-java/README.md
+++ b/examples/existing-cluster-java/README.md
@@ -207,7 +207,6 @@ terraform destroy -var-file=terraform.tfvars
| Name | Source | Version |
|------|--------|---------|
-| [aws\_observability\_accelerator](#module\_aws\_observability\_accelerator) | ../../ | n/a |
| [eks\_monitoring](#module\_eks\_monitoring) | ../../modules/eks-monitoring | n/a |
## Resources
@@ -216,6 +215,7 @@ terraform destroy -var-file=terraform.tfvars
|------|------|
| [aws_eks_cluster.this](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/data-sources/eks_cluster) | data source |
| [aws_eks_cluster_auth.this](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/data-sources/eks_cluster_auth) | data source |
+| [aws_grafana_workspace.this](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/data-sources/grafana_workspace) | data source |
## Inputs
@@ -232,9 +232,9 @@ terraform destroy -var-file=terraform.tfvars
| Name | Description |
|------|-------------|
-| [aws\_region](#output\_aws\_region) | AWS Region |
| [eks\_cluster\_id](#output\_eks\_cluster\_id) | EKS Cluster Id |
| [eks\_cluster\_version](#output\_eks\_cluster\_version) | EKS Cluster version |
| [managed\_prometheus\_workspace\_endpoint](#output\_managed\_prometheus\_workspace\_endpoint) | Amazon Managed Prometheus workspace endpoint |
| [managed\_prometheus\_workspace\_id](#output\_managed\_prometheus\_workspace\_id) | Amazon Managed Prometheus workspace ID |
+| [managed\_prometheus\_workspace\_region](#output\_managed\_prometheus\_workspace\_region) | AWS Region |
diff --git a/examples/existing-cluster-java/main.tf b/examples/existing-cluster-java/main.tf
index 302b4ced..7a3af6d7 100644
--- a/examples/existing-cluster-java/main.tf
+++ b/examples/existing-cluster-java/main.tf
@@ -10,6 +10,10 @@ data "aws_eks_cluster" "this" {
name = var.eks_cluster_id
}
+data "aws_grafana_workspace" "this" {
+ workspace_id = var.managed_grafana_workspace_id
+}
+
provider "kubernetes" {
host = local.eks_cluster_endpoint
cluster_ca_certificate = base64decode(data.aws_eks_cluster.this.certificate_authority[0].data)
@@ -33,25 +37,6 @@ locals {
}
}
-# deploys the base module
-module "aws_observability_accelerator" {
- source = "../../"
- # source = "github.com/aws-observability/terraform-aws-observability-accelerator?ref=v2.0.0"
-
- aws_region = var.aws_region
-
- # creates a new Amazon Managed Prometheus workspace, defaults to true
- enable_managed_prometheus = local.create_new_workspace
-
- # reusing existing Amazon Managed Prometheus if specified
- managed_prometheus_workspace_id = var.managed_prometheus_workspace_id
-
- # reusing existing Amazon Managed Grafana workspace
- managed_grafana_workspace_id = var.managed_grafana_workspace_id
-
- tags = local.tags
-}
-
module "eks_monitoring" {
source = "../../modules/eks-monitoring"
# source = "github.com/aws-observability/terraform-aws-observability-accelerator//modules/eks-monitoring?ref=v2.0.0"
@@ -64,17 +49,15 @@ module "eks_monitoring" {
grafana_api_key = var.grafana_api_key
target_secret_name = "grafana-admin-credentials"
target_secret_namespace = "grafana-operator"
- grafana_url = module.aws_observability_accelerator.managed_grafana_workspace_endpoint
+ grafana_url = "https://${data.aws_grafana_workspace.this.endpoint}"
eks_cluster_id = var.eks_cluster_id
# control the publishing of dashboards by specifying the boolean value for the variable 'enable_dashboards', default is 'true'
enable_dashboards = var.enable_dashboards
- managed_prometheus_workspace_id = module.aws_observability_accelerator.managed_prometheus_workspace_id
-
- managed_prometheus_workspace_endpoint = module.aws_observability_accelerator.managed_prometheus_workspace_endpoint
- managed_prometheus_workspace_region = module.aws_observability_accelerator.managed_prometheus_workspace_region
+ enable_managed_prometheus = local.create_new_workspace
+ managed_prometheus_workspace_id = var.managed_prometheus_workspace_id
# optional, defaults to 60s interval and 15s timeout
prometheus_config = {
@@ -86,8 +69,4 @@ module "eks_monitoring" {
enable_logs = true
tags = local.tags
-
- depends_on = [
- module.aws_observability_accelerator
- ]
}
diff --git a/examples/existing-cluster-java/outputs.tf b/examples/existing-cluster-java/outputs.tf
index ad1c3405..e14427e3 100644
--- a/examples/existing-cluster-java/outputs.tf
+++ b/examples/existing-cluster-java/outputs.tf
@@ -1,16 +1,16 @@
-output "aws_region" {
+output "managed_prometheus_workspace_region" {
description = "AWS Region"
- value = module.aws_observability_accelerator.aws_region
+ value = module.eks_monitoring.managed_prometheus_workspace_region
}
output "managed_prometheus_workspace_endpoint" {
description = "Amazon Managed Prometheus workspace endpoint"
- value = module.aws_observability_accelerator.managed_prometheus_workspace_endpoint
+ value = module.eks_monitoring.managed_prometheus_workspace_endpoint
}
output "managed_prometheus_workspace_id" {
description = "Amazon Managed Prometheus workspace ID"
- value = module.aws_observability_accelerator.managed_prometheus_workspace_id
+ value = module.eks_monitoring.managed_prometheus_workspace_id
}
output "eks_cluster_version" {
diff --git a/examples/existing-cluster-nginx/README.md b/examples/existing-cluster-nginx/README.md
index 066734c0..dad16832 100644
--- a/examples/existing-cluster-nginx/README.md
+++ b/examples/existing-cluster-nginx/README.md
@@ -218,7 +218,6 @@ add this `managed_prometheus_region=xxx` and `managed_prometheus_workspace_id=ws
| Name | Source | Version |
|------|--------|---------|
-| [aws\_observability\_accelerator](#module\_aws\_observability\_accelerator) | ../../ | n/a |
| [eks\_monitoring](#module\_eks\_monitoring) | ../../modules/eks-monitoring | n/a |
## Resources
@@ -227,6 +226,7 @@ add this `managed_prometheus_region=xxx` and `managed_prometheus_workspace_id=ws
|------|------|
| [aws_eks_cluster.this](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/data-sources/eks_cluster) | data source |
| [aws_eks_cluster_auth.this](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/data-sources/eks_cluster_auth) | data source |
+| [aws_grafana_workspace.this](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/data-sources/grafana_workspace) | data source |
## Inputs
@@ -243,9 +243,9 @@ add this `managed_prometheus_region=xxx` and `managed_prometheus_workspace_id=ws
| Name | Description |
|------|-------------|
-| [aws\_region](#output\_aws\_region) | AWS Region |
| [eks\_cluster\_id](#output\_eks\_cluster\_id) | EKS Cluster Id |
| [eks\_cluster\_version](#output\_eks\_cluster\_version) | EKS Cluster version |
| [managed\_prometheus\_workspace\_endpoint](#output\_managed\_prometheus\_workspace\_endpoint) | Amazon Managed Prometheus workspace endpoint |
| [managed\_prometheus\_workspace\_id](#output\_managed\_prometheus\_workspace\_id) | Amazon Managed Prometheus workspace ID |
+| [managed\_prometheus\_workspace\_region](#output\_managed\_prometheus\_workspace\_region) | AWS Region |
diff --git a/examples/existing-cluster-nginx/main.tf b/examples/existing-cluster-nginx/main.tf
index 987e18b1..659dbb21 100644
--- a/examples/existing-cluster-nginx/main.tf
+++ b/examples/existing-cluster-nginx/main.tf
@@ -10,6 +10,10 @@ data "aws_eks_cluster" "this" {
name = var.eks_cluster_id
}
+data "aws_grafana_workspace" "this" {
+ workspace_id = var.managed_grafana_workspace_id
+}
+
provider "kubernetes" {
host = local.eks_cluster_endpoint
cluster_ca_certificate = base64decode(data.aws_eks_cluster.this.certificate_authority[0].data)
@@ -34,24 +38,6 @@ locals {
}
}
-module "aws_observability_accelerator" {
- source = "../../"
- # source = "github.com/aws-observability/terraform-aws-observability-accelerator?ref=v2.0.0"
-
- aws_region = var.aws_region
-
- # creates a new AMP workspace, defaults to true
- enable_managed_prometheus = local.create_new_workspace
-
- # reusing existing AMP if specified
- managed_prometheus_workspace_id = var.managed_prometheus_workspace_id
-
- # reusing existing Amazon Managed Grafana workspace
- managed_grafana_workspace_id = var.managed_grafana_workspace_id
-
- tags = local.tags
-}
-
module "eks_monitoring" {
source = "../../modules/eks-monitoring"
# source = "github.com/aws-observability/terraform-aws-observability-accelerator//modules/eks-monitoring?ref=v2.0.0"
@@ -66,21 +52,15 @@ module "eks_monitoring" {
grafana_api_key = var.grafana_api_key
target_secret_name = "grafana-admin-credentials"
target_secret_namespace = "grafana-operator"
- grafana_url = module.aws_observability_accelerator.managed_grafana_workspace_endpoint
+ grafana_url = "https://${data.aws_grafana_workspace.this.endpoint}"
# control the publishing of dashboards by specifying the boolean value for the variable 'enable_dashboards', default is 'true'
enable_dashboards = var.enable_dashboards
- managed_prometheus_workspace_id = module.aws_observability_accelerator.managed_prometheus_workspace_id
-
- managed_prometheus_workspace_endpoint = module.aws_observability_accelerator.managed_prometheus_workspace_endpoint
- managed_prometheus_workspace_region = module.aws_observability_accelerator.managed_prometheus_workspace_region
+ enable_managed_prometheus = local.create_new_workspace
+ managed_prometheus_workspace_id = var.managed_prometheus_workspace_id
enable_logs = true
tags = local.tags
-
- depends_on = [
- module.aws_observability_accelerator
- ]
}
diff --git a/examples/existing-cluster-nginx/outputs.tf b/examples/existing-cluster-nginx/outputs.tf
index ad1c3405..e14427e3 100644
--- a/examples/existing-cluster-nginx/outputs.tf
+++ b/examples/existing-cluster-nginx/outputs.tf
@@ -1,16 +1,16 @@
-output "aws_region" {
+output "managed_prometheus_workspace_region" {
description = "AWS Region"
- value = module.aws_observability_accelerator.aws_region
+ value = module.eks_monitoring.managed_prometheus_workspace_region
}
output "managed_prometheus_workspace_endpoint" {
description = "Amazon Managed Prometheus workspace endpoint"
- value = module.aws_observability_accelerator.managed_prometheus_workspace_endpoint
+ value = module.eks_monitoring.managed_prometheus_workspace_endpoint
}
output "managed_prometheus_workspace_id" {
description = "Amazon Managed Prometheus workspace ID"
- value = module.aws_observability_accelerator.managed_prometheus_workspace_id
+ value = module.eks_monitoring.managed_prometheus_workspace_id
}
output "eks_cluster_version" {
diff --git a/examples/existing-cluster-with-base-and-infra/README.md b/examples/existing-cluster-with-base-and-infra/README.md
index 3b06c870..a2a22630 100644
--- a/examples/existing-cluster-with-base-and-infra/README.md
+++ b/examples/existing-cluster-with-base-and-infra/README.md
@@ -1,4 +1,4 @@
-# Existing Cluster with the AWS Observability accelerator base module and Infrastructure monitoring
+# Existing Cluster with the AWS Observability accelerator EKS Infrastructure monitoring
This example demonstrates how to use the AWS Observability Accelerator Terraform
modules with Infrastructure monitoring enabled.
@@ -35,7 +35,6 @@ View the full documentation for this example [here](https://aws-observability.gi
| Name | Source | Version |
|------|--------|---------|
-| [aws\_observability\_accelerator](#module\_aws\_observability\_accelerator) | ../../ | n/a |
| [eks\_monitoring](#module\_eks\_monitoring) | ../../modules/eks-monitoring | n/a |
## Resources
@@ -44,6 +43,7 @@ View the full documentation for this example [here](https://aws-observability.gi
|------|------|
| [aws_eks_cluster.this](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/data-sources/eks_cluster) | data source |
| [aws_eks_cluster_auth.this](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/data-sources/eks_cluster_auth) | data source |
+| [aws_grafana_workspace.this](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/data-sources/grafana_workspace) | data source |
## Inputs
@@ -60,7 +60,9 @@ View the full documentation for this example [here](https://aws-observability.gi
| Name | Description |
|------|-------------|
-| [aws\_region](#output\_aws\_region) | AWS Region |
| [eks\_cluster\_id](#output\_eks\_cluster\_id) | EKS Cluster Id |
| [eks\_cluster\_version](#output\_eks\_cluster\_version) | EKS Cluster version |
+| [managed\_prometheus\_workspace\_endpoint](#output\_managed\_prometheus\_workspace\_endpoint) | Amazon Managed Prometheus workspace endpoint |
+| [managed\_prometheus\_workspace\_id](#output\_managed\_prometheus\_workspace\_id) | Amazon Managed Prometheus workspace ID |
+| [managed\_prometheus\_workspace\_region](#output\_managed\_prometheus\_workspace\_region) | AWS Region |
diff --git a/examples/existing-cluster-with-base-and-infra/main.tf b/examples/existing-cluster-with-base-and-infra/main.tf
index eccd94a1..a00df02f 100644
--- a/examples/existing-cluster-with-base-and-infra/main.tf
+++ b/examples/existing-cluster-with-base-and-infra/main.tf
@@ -10,6 +10,10 @@ data "aws_eks_cluster" "this" {
name = var.eks_cluster_id
}
+data "aws_grafana_workspace" "this" {
+ workspace_id = var.managed_grafana_workspace_id
+}
+
provider "kubernetes" {
host = local.eks_cluster_endpoint
cluster_ca_certificate = base64decode(data.aws_eks_cluster.this.certificate_authority[0].data)
@@ -33,28 +37,6 @@ locals {
}
}
-# deploys the base module
-module "aws_observability_accelerator" {
- source = "../../"
- # source = "github.com/aws-observability/terraform-aws-observability-accelerator?ref=v2.0.0"
-
- aws_region = var.aws_region
-
- # creates a new Amazon Managed Prometheus workspace, defaults to true
- enable_managed_prometheus = local.create_new_workspace
-
- # reusing existing Amazon Managed Prometheus if specified
- managed_prometheus_workspace_id = var.managed_prometheus_workspace_id
-
- # sets up the Amazon Managed Prometheus alert manager at the workspace level
- enable_alertmanager = true
-
- # reusing existing Amazon Managed Grafana workspace
- managed_grafana_workspace_id = var.managed_grafana_workspace_id
-
- tags = local.tags
-}
-
module "eks_monitoring" {
source = "../../modules/eks-monitoring"
# source = "github.com/aws-observability/terraform-aws-observability-accelerator//modules/eks-monitoring?ref=v2.0.0"
@@ -75,15 +57,17 @@ module "eks_monitoring" {
grafana_api_key = var.grafana_api_key
target_secret_name = "grafana-admin-credentials"
target_secret_namespace = "grafana-operator"
- grafana_url = module.aws_observability_accelerator.managed_grafana_workspace_endpoint
+ grafana_url = "https://${data.aws_grafana_workspace.this.endpoint}"
# control the publishing of dashboards by specifying the boolean value for the variable 'enable_dashboards', default is 'true'
enable_dashboards = var.enable_dashboards
- managed_prometheus_workspace_id = module.aws_observability_accelerator.managed_prometheus_workspace_id
+ # creates a new Amazon Managed Prometheus workspace, defaults to true
+ enable_managed_prometheus = local.create_new_workspace
+ managed_prometheus_workspace_id = var.managed_prometheus_workspace_id
- managed_prometheus_workspace_endpoint = module.aws_observability_accelerator.managed_prometheus_workspace_endpoint
- managed_prometheus_workspace_region = module.aws_observability_accelerator.managed_prometheus_workspace_region
+ # sets up the Amazon Managed Prometheus alert manager at the workspace level
+ enable_alertmanager = true
# optional, defaults to 60s interval and 15s timeout
prometheus_config = {
@@ -94,8 +78,4 @@ module "eks_monitoring" {
enable_logs = true
tags = local.tags
-
- depends_on = [
- module.aws_observability_accelerator
- ]
}
diff --git a/examples/existing-cluster-with-base-and-infra/outputs.tf b/examples/existing-cluster-with-base-and-infra/outputs.tf
index f8b4d584..e14427e3 100644
--- a/examples/existing-cluster-with-base-and-infra/outputs.tf
+++ b/examples/existing-cluster-with-base-and-infra/outputs.tf
@@ -1,6 +1,16 @@
-output "aws_region" {
+output "managed_prometheus_workspace_region" {
description = "AWS Region"
- value = module.aws_observability_accelerator.aws_region
+ value = module.eks_monitoring.managed_prometheus_workspace_region
+}
+
+output "managed_prometheus_workspace_endpoint" {
+ description = "Amazon Managed Prometheus workspace endpoint"
+ value = module.eks_monitoring.managed_prometheus_workspace_endpoint
+}
+
+output "managed_prometheus_workspace_id" {
+ description = "Amazon Managed Prometheus workspace ID"
+ value = module.eks_monitoring.managed_prometheus_workspace_id
}
output "eks_cluster_version" {
diff --git a/locals.tf b/locals.tf
deleted file mode 100644
index 8e823659..00000000
--- a/locals.tf
+++ /dev/null
@@ -1,17 +0,0 @@
-data "aws_region" "current" {}
-
-data "aws_grafana_workspace" "this" {
- workspace_id = var.managed_grafana_workspace_id
-}
-
-
-locals {
- # if region is not passed, we assume the current one
- amp_ws_region = coalesce(var.managed_prometheus_workspace_region, data.aws_region.current.name)
- amp_ws_id = var.enable_managed_prometheus ? aws_prometheus_workspace.this[0].id : var.managed_prometheus_workspace_id
- amp_ws_endpoint = "https://aps-workspaces.${local.amp_ws_region}.amazonaws.com/workspaces/${local.amp_ws_id}/"
-
- amg_ws_endpoint = "https://${data.aws_grafana_workspace.this.endpoint}"
-
- name = "aws-observability-accelerator"
-}
diff --git a/main.tf b/main.tf
deleted file mode 100644
index d7e7ae62..00000000
--- a/main.tf
+++ /dev/null
@@ -1,20 +0,0 @@
-resource "aws_prometheus_workspace" "this" {
- count = var.enable_managed_prometheus ? 1 : 0
-
- alias = local.name
- tags = var.tags
-}
-
-resource "aws_prometheus_alert_manager_definition" "this" {
- count = var.enable_alertmanager ? 1 : 0
-
- workspace_id = local.amp_ws_id
-
- definition = <object({
create_namespace = bool
k8s_namespace = string
helm_chart_name = string
helm_chart_version = string
helm_release_name = string
helm_repo_url = string
helm_settings = map(string)
helm_values = map(any)
}) | {
"create_namespace": true,
"helm_chart_name": "flux2",
"helm_chart_version": "2.12.2",
"helm_release_name": "observability-fluxcd-addon",
"helm_repo_url": "https://fluxcd-community.github.io/helm-charts",
"helm_settings": {},
"helm_values": {},
"k8s_namespace": "flux-system"
} | no |
@@ -127,6 +129,7 @@ See examples using this Terraform modules in the **Amazon EKS** section of [this
| [managed\_prometheus\_workspace\_region](#input\_managed\_prometheus\_workspace\_region) | Amazon Managed Prometheus Workspace's Region | `string` | `null` | no |
| [ne\_config](#input\_ne\_config) | Node exporter configuration | object({
create_namespace = bool
k8s_namespace = string
helm_chart_name = string
helm_chart_version = string
helm_release_name = string
helm_repo_url = string
helm_settings = map(string)
helm_values = map(any)
scrape_interval = string
scrape_timeout = string
}) | {
"create_namespace": true,
"helm_chart_name": "prometheus-node-exporter",
"helm_chart_version": "4.24.0",
"helm_release_name": "prometheus-node-exporter",
"helm_repo_url": "https://prometheus-community.github.io/helm-charts",
"helm_settings": {},
"helm_values": {},
"k8s_namespace": "prometheus-node-exporter",
"scrape_interval": "60s",
"scrape_timeout": "60s"
} | no |
| [nginx\_config](#input\_nginx\_config) | Configuration object for NGINX monitoring | object({
enable_alerting_rules = bool
enable_recording_rules = bool
enable_dashboards = bool
scrape_sample_limit = number
flux_gitrepository_name = string
flux_gitrepository_url = string
flux_gitrepository_branch = string
flux_kustomization_name = string
flux_kustomization_path = string
grafana_dashboard_url = string
prometheus_metrics_endpoint = string
}) | `null` | no |
+| [nvidia\_monitoring\_config](#input\_nvidia\_monitoring\_config) | Config object for nvidia monitoring | object({
flux_gitrepository_name = string
flux_gitrepository_url = string
flux_gitrepository_branch = string
flux_kustomization_name = string
flux_kustomization_path = string
}) | `null` | no |
| [prometheus\_config](#input\_prometheus\_config) | Controls default values such as scrape interval, timeouts and ports globally | object({
global_scrape_interval = string
global_scrape_timeout = string
}) | {
"global_scrape_interval": "120s",
"global_scrape_timeout": "15s"
} | no |
| [tags](#input\_tags) | Additional tags (e.g. `map('BusinessUnit`,`XYZ`) | `map(string)` | `{}` | no |
| [target\_secret\_name](#input\_target\_secret\_name) | Target secret in Kubernetes to store the Grafana API Key Secret | `string` | `"grafana-admin-credentials"` | no |
diff --git a/modules/eks-monitoring/dashboards.tf b/modules/eks-monitoring/dashboards.tf
index 6ad13f33..d130e80d 100644
--- a/modules/eks-monitoring/dashboards.tf
+++ b/modules/eks-monitoring/dashboards.tf
@@ -95,6 +95,26 @@ YAML
depends_on = [module.external_secrets]
}
+# nvidia dashboards
+resource "kubectl_manifest" "nvidia_monitoring_dashboards" {
+ yaml_body = <