diff --git a/hands_on_ja/chainer/begginers_hands_on/01_Chainer_basic_tutorial.ipynb b/hands_on_ja/chainer/begginers_hands_on/01_Chainer_basic_tutorial.ipynb
index fec731f..9d1d44c 100644
--- a/hands_on_ja/chainer/begginers_hands_on/01_Chainer_basic_tutorial.ipynb
+++ b/hands_on_ja/chainer/begginers_hands_on/01_Chainer_basic_tutorial.ipynb
@@ -6,9 +6,7 @@
"name": "01-Chainer-basic-tutorial.ipynb",
"version": "0.3.2",
"provenance": [],
- "collapsed_sections": [],
- "toc_visible": true,
- "include_colab_link": true
+ "collapsed_sections": []
},
"kernelspec": {
"name": "python3",
@@ -17,16 +15,6 @@
"accelerator": "GPU"
},
"cells": [
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "view-in-github",
- "colab_type": "text"
- },
- "source": [
- " "
- ]
- },
{
"metadata": {
"id": "-O-jqs_jY2W3",
@@ -34,11 +22,14 @@
},
"cell_type": "markdown",
"source": [
+ "\n",
+ "\n",
"# 01 Chainerの基本的な使い方を学んでみよう\n",
"\n",
"このNotebookの目的は以下の通りです。\n",
"\n",
"* 畳み込みニューラルネットワークについて学習すること\n",
+ "* 過学習・汎化性能を理解すること\n",
"* Chainerの機能について学習すること\n"
]
},
@@ -128,14 +119,13 @@
"colab": {
"base_uri": "https://localhost:8080/",
"height": 238
- },
- "outputId": "5a7c4f86-f987-4295-a7dd-5ec03118fe38"
+ }
},
"cell_type": "code",
"source": [
"!python -c 'import chainer; chainer.print_runtime_info()'"
],
- "execution_count": 2,
+ "execution_count": 0,
"outputs": [
{
"output_type": "stream",
@@ -219,7 +209,7 @@
"source": [
"!pip install chutil"
],
- "execution_count": 3,
+ "execution_count": 0,
"outputs": [
{
"output_type": "stream",
@@ -476,7 +466,7 @@
"train, test = get_fashion_mnist(withlabel=True, ndim=1)\n",
"train, validation = chainer.datasets.split_dataset_random(train, 50000, seed=0)"
],
- "execution_count": 5,
+ "execution_count": 0,
"outputs": [
{
"output_type": "stream",
@@ -656,7 +646,7 @@
"train_and_validate(\n",
" classifier_model, optimizer, train, validation, n_epoch, batchsize)"
],
- "execution_count": 8,
+ "execution_count": 0,
"outputs": [
{
"output_type": "stream",
@@ -715,7 +705,7 @@
"\n",
"show_test_performance(classifier_model, test)"
],
- "execution_count": 9,
+ "execution_count": 0,
"outputs": [
{
"output_type": "stream",
@@ -765,7 +755,7 @@
"\n",
"show_graph()"
],
- "execution_count": 10,
+ "execution_count": 0,
"outputs": [
{
"output_type": "display_data",
@@ -946,7 +936,9 @@
"\n",
"\n",
"\n",
- "cited from [3]"
+ "cited from [3]\n",
+ "\n",
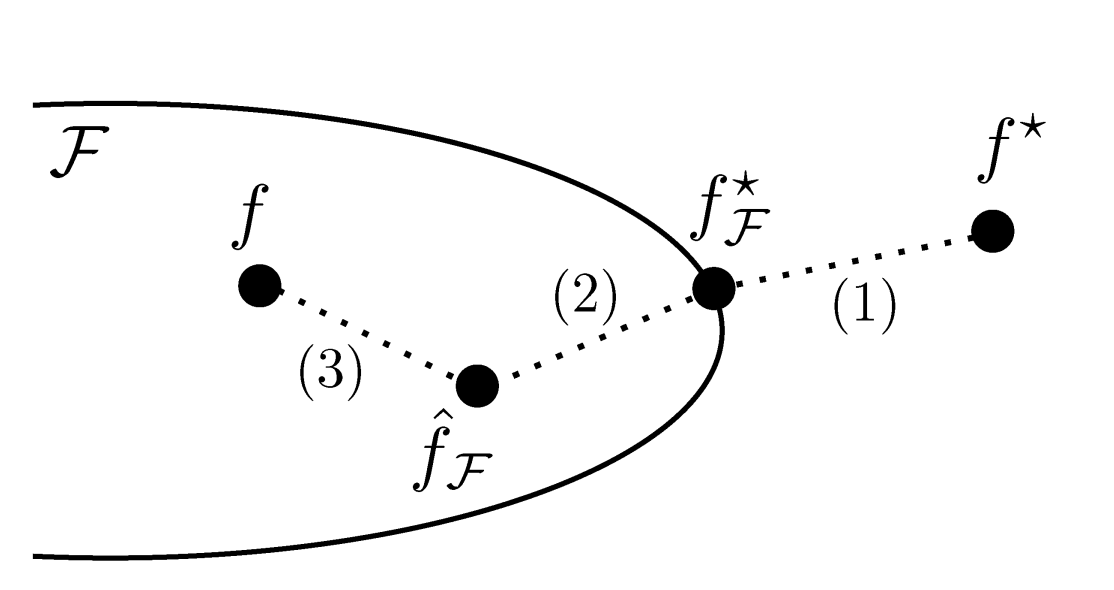
+ "過学習は2の誤差が大きい状況を言います。Deep Learningは層を積み重ねるなどネットワークを複雑にすることで$F$の範囲を大きくし(1)の誤差を小さくします。そして、大量のデータを用いることで(2)の誤差を小さくすることで求められる関数$f$をできるだけ$f^*$に近づけます。"
]
},
{
@@ -977,7 +969,7 @@
"#### 課題\n",
"* 下記コードにDropoutを追加して効果を確かめてみましょう。Dropoutの追加やパラメータの変更をすることで精度93%以上を達成しましょう。\n",
"\n",
- "```\n",
+ "```python\n",
"h = F.dropout(F.relu(self.fc5(h))) # add dropout\n",
"```\n",
"\n",
@@ -1148,7 +1140,7 @@
"source": [
"ちなみに下記のようなモデルを動かしてみると93%前後の性能が実現できました。\n",
"\n",
- "```\n",
+ "```python\n",
"class MyConvNet(Chain):\n",
" def __init__(self):\n",
" super(MyConvNet, self).__init__()\n",
@@ -1163,7 +1155,7 @@
" in_channels=None, out_channels=128, ksize=3, stride=1, pad=1)\n",
" self.fc5 = L.Linear(None, 2000) # 1000 -> 2000\n",
" self.fc6 = L.Linear(None, 10)\n",
- "\n",
+ " \n",
" def __call__(self, x):\n",
" h = F.dropout(F.relu(self.conv1(x.reshape((-1, 1, 28, 28)))), ratio=0.2) # add dropout\n",
" h = F.max_pooling_2d(h, ksize=2, stride=2)\n",
@@ -1253,72 +1245,102 @@
},
{
"metadata": {
- "id": "aia80uGnMA3X",
+ "id": "0VDvHAXDfIqT",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "### 1. cpu/gpuを決める\n",
+ "Chainerの各関数には`device`という引数を渡す関数が多く存在します。それに`-1`を与えるとcpuで動作し、0以上の値を指定すると、そのIDのGPUを使用することになります。"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "qHnMVI_5MMzC",
"colab_type": "text"
},
"cell_type": "markdown",
"source": [
- "### 2. Iteratorの作成\n",
+ "### 2. 最適化手法の選択\n",
+ "\n",
+ "学習時に用いる最適化の手法としてはいろいろな種類のものが提案されていますが、Chainerは多くの手法を同一のインターフェースで利用できるよう、`Optimizer`という機能でそれらを提供しています。`chainer.optimizers`モジュール以下に色々なものを見つけることができます。一覧はこちらにあります:\n",
"\n",
- "データセットの準備は完了しましたが、このままネットワークの学習に使うのは少し面倒です。なぜなら、ネットワークのパラメータ最適化手法として広く用いられているStochastic Gradient Descent (SGD)という手法では、一般的にいくつかのデータを束ねた**ミニバッチ**と呼ばれる単位でネットワークにデータを渡し、それに対する予測を作って、ラベルと比較するということを行います。そのため、**バッチサイズ分だけデータとラベルを束ねる作業が必要です。**\n",
+ "- [Chainerで使える最適化手法一覧](https://docs.chainer.org/en/stable/reference/optimizers.html)\n",
"\n",
- "そこで、**データセットから決まった数のデータとラベルを取得し、それらを束ねてミニバッチを作ってくれる機能を持った`Iterator`を使いましょう。**`Iterator`は、先程作ったデータセットオブジェクトを渡して初期化してやったあとは、`next()`メソッドで新しいミニバッチを返してくれます。内部ではデータセットを何周なめたか(`epoch`)などの情報がどうように記録されているおり、学習ループを書いていく際に便利です。\n",
+ "`Optimizer`のオブジェクトには、`setup`メソッドを使ってモデル(`Chain`オブジェクト)を渡します。こうすることで`Optimizer`に、何を最適化すればいいか把握させることができます。\n",
"\n",
- "データセットオブジェクトからイテレータを作るには、以下のようにします。"
+ "他にもいろいろな最適化手法が手軽に試せるので、色々と試してみて結果の変化を見てみてください。例えば、`chainer.optimizers.SGD`のうち`SGD`の部分を`MomentumSGD`, `RMSprop`, `Adam`などに変えるだけで、最適化手法の違いがどのような学習曲線(ロスカーブ)の違いを生むかなどを簡単に調べることができます。"
]
},
{
"metadata": {
- "id": "E2C0UTedMA_M",
+ "id": "8PTDwIuiMM5V",
"colab_type": "text"
},
"cell_type": "markdown",
"source": [
- "ここでは、学習に用いるデータセット用のイテレータ(`train_iter`)と、検証用のデータセット用のイテレータ(`valid_iter`)、および学習したネットワークの評価に用いるテストデータセット用のイテレータ(`test_iter`)の計3つを作成しています。ここで、`batchsize = 128`としているので、作成した3つの`Iterator`は、例えば`train_iter.next()`などとすると128枚の数字画像データを一括りにして返してくれます。"
+ "#### NOTE\n",
+ "\n",
+ "Optimizerのコンストラクタには`lr`という引数があります。この値は学習率として知られ、モデルをうまく訓練して良いパフォーマンスを発揮させるために調整する必要がある重要な**ハイパーパラメータ**として知られています。"
]
},
{
"metadata": {
- "id": "rVT8FNM0MMp5",
+ "id": "87-Tz4ixggjF",
"colab_type": "text"
},
"cell_type": "markdown",
"source": [
- "#### NOTE: `SerialIterator`について\n",
+ "#### NOTE\n",
+ "最近、それぞれのOptimizerがどのように収束するか直感的に表現したgif画像が話題になりました。参考にしてみてください。\n",
"\n",
- "Chainerがいくつか用意している`Iterator`の一種である`SerialIterator`は、データセットの中のデータを順番に取り出してくる最もシンプルな`Iterator`です。コンストラクタの引数にデータセットオブジェクトと、バッチサイズを取ります。このとき、渡したデータセットオブジェクトから、何周も何周もデータを繰り返し読み出す必要がある場合は`repeat`引数を`True`とし、1周が終わったらそれ以上データを取り出したくない場合はこれを`False`とします。これは、主にvalidation用のデータセットに対して使うフラグです。デフォルトでは、`True`になっています。また、`shuffle`引数に`True`を渡すと、データセットから取り出されてくるデータの順番をエポックごとにランダムに変更します。`SerialIterator`の他にも、マルチプロセスで高速にデータを処理できるようにした`MultiprocessIterator`や`MultithreadIterator`など、複数の`Iterator`が用意されています。詳しくは以下を見てください。\n",
+ "\n",
"\n",
- "- [Chainerで使えるIterator一覧](https://docs.chainer.org/en/stable/reference/iterators.html)"
+ "cited from [4]"
]
},
{
"metadata": {
- "id": "qHnMVI_5MMzC",
+ "id": "aia80uGnMA3X",
"colab_type": "text"
},
"cell_type": "markdown",
"source": [
- "### 3. 最適化手法の選択\n",
+ "### 3. Iteratorの作成\n",
"\n",
- "では、上で定義したネットワークをMNISTデータセットを使って訓練してみましょう。学習時に用いる最適化の手法としてはいろいろな種類のものが提案されていますが、Chainerは多くの手法を同一のインターフェースで利用できるよう、`Optimizer`という機能でそれらを提供しています。`chainer.optimizers`モジュール以下に色々なものを見つけることができます。一覧はこちらにあります:\n",
+ "データセットはが、このままネットワークの学習に使うのは少し面倒です。なぜなら、ネットワークのパラメータ最適化手法として広く用いられているStochastic Gradient Descent (SGD)という手法では、一般的にいくつかのデータを束ねた **ミニバッチ** と呼ばれる単位でネットワークにデータを渡し、それに対する予測を作って、ラベルと比較するということを行います。そのため、**バッチサイズ分だけデータとラベルを束ねる作業が必要です。**\n",
"\n",
- "- [Chainerで使える最適化手法一覧](https://docs.chainer.org/en/stable/reference/optimizers.html)\n",
- "\n",
- "ここでは最もシンプルな勾配降下法の手法である`optimizers.SGD`を用います。`Optimizer`のオブジェクトには、`setup`メソッドを使ってモデル(`Chain`オブジェクト)を渡します。こうすることで`Optimizer`に、何を最適化すればいいか把握させることができます。\n",
+ "そこで、**データセットから決まった数のデータとラベルを取得し、それらを束ねてミニバッチを作ってくれる機能を持ったIteratorを使いましょう。** `Iterator`は、先程作ったデータセットオブジェクトを渡して初期化してやったあとは、`next()`メソッドで新しいミニバッチを返してくれます。内部ではデータセットを何周なめたか(`epoch`)などの情報が記録されており、学習ループを書いていく際に便利です。\n",
"\n",
- "他にもいろいろな最適化手法が手軽に試せるので、色々と試してみて結果の変化を見てみてください。例えば、下の`chainer.optimizers.SGD`のうち`SGD`の部分を`MomentumSGD`, `RMSprop`, `Adam`などに変えるだけで、最適化手法の違いがどのような学習曲線(ロスカーブ)の違いを生むかなどを簡単に調べることができます。"
+ "```python\n",
+ "train_iter = chainer.iterators.SerialIterator(train, batchsize)\n",
+ "validation_iter = chainer.iterators.SerialIterator(\n",
+ " validation, batchsize, repeat=False, shuffle=False)\n",
+ "```"
]
},
{
"metadata": {
- "id": "8PTDwIuiMM5V",
+ "id": "E2C0UTedMA_M",
"colab_type": "text"
},
"cell_type": "markdown",
"source": [
- "#### NOTE\n",
+ "ここでは、学習に用いるデータセット用のイテレータ(`train_iter`)と、検証用のデータセット用のイテレータ(`validation_iter`)、の計2つを作成しています。ここで、`batchsize = 128`だったとすると、作成した2つの`Iterator`は、例えば`train_iter.next()`などとすると128枚の数字画像データを一括りにして返してくれます。"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "rVT8FNM0MMp5",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "#### NOTE: `SerialIterator`について\n",
+ "\n",
+ "Chainerがいくつか用意している`Iterator`の一種である`SerialIterator`は、データセットの中のデータを順番に取り出してくる最もシンプルな`Iterator`です。コンストラクタの引数にデータセットオブジェクトと、バッチサイズを取ります。このとき、渡したデータセットオブジェクトから、何周も何周もデータを繰り返し読み出す必要がある場合は`repeat`引数を`True`とし、1周が終わったらそれ以上データを取り出したくない場合はこれを`False`とします。これは、主にvalidation用のデータセットに対して使うフラグです。デフォルトでは、`True`になっています。また、`shuffle`引数に`True`を渡すと、データセットから取り出されてくるデータの順番をエポックごとにランダムに変更します。`SerialIterator`の他にも、マルチプロセスで高速にデータを処理できるようにした`MultiprocessIterator`や`MultithreadIterator`など、複数の`Iterator`が用意されています。詳しくは以下を見てください。\n",
"\n",
- "今回はSGDのコンストラクタの`lr`という引数に $0.01$ を与えました。この値は学習率として知られ、モデルをうまく訓練して良いパフォーマンスを発揮させるために調整する必要がある重要な**ハイパーパラメータ**として知られています。"
+ "- [Chainerで使えるIterator一覧](https://docs.chainer.org/en/stable/reference/iterators.html)"
]
},
{
@@ -1328,7 +1350,7 @@
},
"cell_type": "markdown",
"source": [
- "### 2. Updaterの準備\n",
+ "### 4-1. Updaterの準備\n",
"\n",
"ここからが学習ループを自分で書く場合と異なる部分です。ループを自分で書く場合には、データセットからバッチサイズ分のデータをとってきてミニバッチに束ねて、それをネットワークに入力して予測を作り、それを正解と比較し、ロスを計算してバックワード(誤差逆伝播)をして、`Optimizer`によってパラメータを更新する、というところまでを、以下のように書いていました。\n",
"\n",
@@ -1351,7 +1373,7 @@
"optimizer.update()\n",
"```\n",
"\n",
- "これらの処理を、まるっと`Updater`はまとめてくれます。これを行うために、**`Updater`には`Iterator`と`Optimizer`を渡してやります。** `Iterator`はデータセットオブジェクトを持っていて、そこからミニバッチを作り、`Optimizer`は最適化対象のネットワークを持っていて、それを使って前進計算とロスの計算・パラメータのアップデートをすることができます。そのため、この2つを渡しておけば、上記の処理を`Updater`内で全部行ってもらえるというわけです。では、`Updater`オブジェクトを作成してみましょう。"
+ "これらの処理を、まるっと`Updater`はまとめてくれます。これを行うために、**UpdaterにはIteratorとOptimizerを渡してやります。** `Iterator`はデータセットオブジェクトを持っていて、そこからミニバッチを作り、`Optimizer`は最適化対象のネットワークを持っていて、それを使って前進計算とロスの計算・パラメータのアップデートをすることができます。そのため、この2つを渡しておけば、上記の処理を`Updater`内で全部行ってもらえるというわけです。では、`Updater`オブジェクトを作成してみましょう。"
]
},
{
@@ -1363,7 +1385,7 @@
"source": [
"#### NOTE\n",
"\n",
- "ここでは、ネットワークを`L.Classifier`で包んでいます。`L.Classifier`は一種の`Chain`になっていて、渡されたネットワーク自体を`predictor`というattributeに持ち、**ロス計算を行う機能を追加してくれます。**こうすると、`net()`はデータ`x`だけでなくラベル`t`も取るようになり、まず渡されたデータを`predictor`に通して予測を作り、それを`t`と比較して**ロスの`Variable`を返すようになります。**ロス関数として何を用いるかはデフォルトでは`F.softmax_cross_entropy`となっていますが、`L.Classifier`の引数`lossfunc`にロス計算を行う関数を渡してやれば変更することができるため、Classifierという名前ながら回帰問題などのロス計算機能の追加にも使うことができます。(`L.Classifier(net, lossfun=L.mean_squared_error, compute_accuracy=False)`のようにする)\n",
+ "モデルを定義するときに、ネットワークを`L.Classifier`で包んでいます。`L.Classifier`は一種の`Chain`になっていて、渡されたネットワーク自体を`predictor`というattributeに持ち、**ロス計算を行う機能を追加してくれます。** こうすると、`net()`はデータ`x`だけでなくラベル`t`も取るようになり、まず渡されたデータを`predictor`に通して予測を作り、それを`t`と比較して**ロスのVariableを返すようになります。** ロス関数として何を用いるかはデフォルトでは`F.softmax_cross_entropy`となっていますが、`L.Classifier`の引数`lossfunc`にロス計算を行う関数を渡してやれば変更することができるため、Classifierという名前ながら回帰問題などのロス計算機能の追加にも使うことができます。(`L.Classifier(net, lossfun=L.mean_squared_error, compute_accuracy=False)`のようにする)\n",
"\n",
"`StandardUpdater`は前述のような`Updater`の担当する処理を遂行するための最もシンプルなクラスです。この他にも複数のGPUを用いるための`ParallelUpdater`などが用意されています。"
]
@@ -1375,7 +1397,7 @@
},
"cell_type": "markdown",
"source": [
- "### 3. Trainerの準備\n",
+ "### 4-2. Trainerの準備\n",
"\n",
"実際に学習ループ部分を隠蔽しているのは`Updater`なので、これがあればもう学習を始められそうですが、`Trainer`はさらに`Updater`を受け取って学習全体の管理を行う機能を提供しています。例えば、**データセットを何周したら学習を終了するか(stop_trigger)** や、**途中のロスの値をどのファイルに保存したいか**、**ロスカーブを可視化した画像ファイルを保存するかどうか**など、学習全体の設定として必須・もしくはあると便利な色々な機能を提供しています。\n",
"\n",
@@ -1405,7 +1427,7 @@
},
"cell_type": "markdown",
"source": [
- "### 4. TrainerにExtensionを追加する\n",
+ "### 5. TrainerにExtensionを追加する\n",
"\n",
"`Trainer`を使う利点として、\n",
"\n",
@@ -1462,6 +1484,112 @@
"- [ChainerのTrainer extension一覧](http://docs.chainer.org/en/stable/reference/extensions.html)"
]
},
+ {
+ "metadata": {
+ "id": "WNvCGRVkhijB",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "#### 課題\n",
+ "* 下記を変更してみて、Chainerの機能を体験してみましょう。"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "7PJoaxDYhsh1",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "def my_train_and_validate(\n",
+ " model, optimizer, train, validation, n_epoch, enable_cupy, batchsize):\n",
+ "\n",
+ " # 1. cpu/gpuを決める\n",
+ " device = -1\n",
+ " if enable_cupy:\n",
+ " device = 0\n",
+ " chainer.backends.cuda.get_device_from_id(device).use()\n",
+ " model.to_gpu()\n",
+ "\n",
+ " # 2. Optimizerを設定する\n",
+ " optimizer.setup(model)\n",
+ "\n",
+ " # 3. DatasetからIteratorを作成する\n",
+ " train_iter = chainer.iterators.SerialIterator(train, batchsize)\n",
+ " validation_iter = chainer.iterators.SerialIterator(\n",
+ " validation, batchsize, repeat=False, shuffle=False)\n",
+ "\n",
+ " # 4. Updater・Trainerを作成する\n",
+ " updater = training.StandardUpdater(train_iter, optimizer, device=device)\n",
+ " trainer = chainer.training.Trainer(updater, out='out')\n",
+ "\n",
+ " # 5. Trainerの機能を拡張する\n",
+ "\n",
+ " # 6. 訓練を開始する\n",
+ " trainer.run()"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "ZzkUNCCwhh9p",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "class MyConvNet(Chain):\n",
+ " def __init__(self):\n",
+ " super(MyConvNet, self).__init__()\n",
+ " with self.init_scope():\n",
+ " self.conv1 = L.Convolution2D(\n",
+ " in_channels=None, out_channels=32, ksize=3, stride=1, pad=1)\n",
+ " self.conv2 = L.Convolution2D(\n",
+ " in_channels=None, out_channels=64, ksize=3, stride=1, pad=1)\n",
+ " self.conv3 = L.Convolution2D(\n",
+ " in_channels=None, out_channels=128, ksize=3, stride=1, pad=1)\n",
+ " self.conv4 = L.Convolution2D(\n",
+ " in_channels=None, out_channels=128, ksize=3, stride=1, pad=1)\n",
+ " self.fc5 = L.Linear(None, 2000) # 1000 -> 2000\n",
+ " self.fc6 = L.Linear(None, 10)\n",
+ "\n",
+ " def __call__(self, x):\n",
+ " h = F.dropout(F.relu(self.conv1(x.reshape((-1, 1, 28, 28)))), ratio=0.2) # add dropout\n",
+ " h = F.max_pooling_2d(h, ksize=2, stride=2)\n",
+ " h = F.dropout(F.relu(self.conv2(h)), ratio=0.2) # add dropout\n",
+ " h = F.max_pooling_2d(h, ksize=2, stride=2)\n",
+ " h = F.dropout(F.relu(self.conv3(h)), ratio=0.2) # add dropout\n",
+ " h = F.max_pooling_2d(h, ksize=2, stride=2)\n",
+ " h = F.dropout(F.relu(self.conv4(h))) # add dropout\n",
+ " h = F.dropout(F.relu(self.fc5(h))) # add dropout\n",
+ " return self.fc6(h)"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "_IPnvIVFh0Ih",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "n_epoch = 5\n",
+ "batchsize = 128\n",
+ "\n",
+ "model = MyConvNet()\n",
+ "classifier_model = L.Classifier(model)\n",
+ "optimizer = optimizers.Adam()\n",
+ "my_train_and_validate(\n",
+ " classifier_model, optimizer, train, validation, n_epoch, batchsize)"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
{
"metadata": {
"id": "1Q_Ij1gE6Y52",
@@ -1690,8 +1818,22 @@
"## Reference\n",
"* [1] [Gradient-based learning applied to document recognition](http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf)\n",
"* [2] [Vincent Dumoulin, Francesco Visin - A guide to convolution arithmetic for deep learning](https://arxiv.org/abs/1603.07285)\n",
- "* [3] [最適化から見たディープラーニングの考え方](http://www.orsj.or.jp/archive2/or60-4/or60_4_191.pdf)"
+ "* [3] [最適化から見たディープラーニングの考え方](http://www.orsj.or.jp/archive2/or60-4/or60_4_191.pdf)\n",
+ "* [4] [CS231n](http://cs231n.github.io/neural-networks-3/)"
]
+ },
+ {
+ "metadata": {
+ "id": "2-ttm6w-hLju",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ ""
+ ],
+ "execution_count": 0,
+ "outputs": []
}
]
-}
+}
\ No newline at end of file
"
- ]
- },
{
"metadata": {
"id": "-O-jqs_jY2W3",
@@ -34,11 +22,14 @@
},
"cell_type": "markdown",
"source": [
+ "\n",
+ "\n",
"# 01 Chainerの基本的な使い方を学んでみよう\n",
"\n",
"このNotebookの目的は以下の通りです。\n",
"\n",
"* 畳み込みニューラルネットワークについて学習すること\n",
+ "* 過学習・汎化性能を理解すること\n",
"* Chainerの機能について学習すること\n"
]
},
@@ -128,14 +119,13 @@
"colab": {
"base_uri": "https://localhost:8080/",
"height": 238
- },
- "outputId": "5a7c4f86-f987-4295-a7dd-5ec03118fe38"
+ }
},
"cell_type": "code",
"source": [
"!python -c 'import chainer; chainer.print_runtime_info()'"
],
- "execution_count": 2,
+ "execution_count": 0,
"outputs": [
{
"output_type": "stream",
@@ -219,7 +209,7 @@
"source": [
"!pip install chutil"
],
- "execution_count": 3,
+ "execution_count": 0,
"outputs": [
{
"output_type": "stream",
@@ -476,7 +466,7 @@
"train, test = get_fashion_mnist(withlabel=True, ndim=1)\n",
"train, validation = chainer.datasets.split_dataset_random(train, 50000, seed=0)"
],
- "execution_count": 5,
+ "execution_count": 0,
"outputs": [
{
"output_type": "stream",
@@ -656,7 +646,7 @@
"train_and_validate(\n",
" classifier_model, optimizer, train, validation, n_epoch, batchsize)"
],
- "execution_count": 8,
+ "execution_count": 0,
"outputs": [
{
"output_type": "stream",
@@ -715,7 +705,7 @@
"\n",
"show_test_performance(classifier_model, test)"
],
- "execution_count": 9,
+ "execution_count": 0,
"outputs": [
{
"output_type": "stream",
@@ -765,7 +755,7 @@
"\n",
"show_graph()"
],
- "execution_count": 10,
+ "execution_count": 0,
"outputs": [
{
"output_type": "display_data",
@@ -946,7 +936,9 @@
"\n",
"\n",
"\n",
- "cited from [3]"
+ "cited from [3]\n",
+ "\n",
+ "過学習は2の誤差が大きい状況を言います。Deep Learningは層を積み重ねるなどネットワークを複雑にすることで$F$の範囲を大きくし(1)の誤差を小さくします。そして、大量のデータを用いることで(2)の誤差を小さくすることで求められる関数$f$をできるだけ$f^*$に近づけます。"
]
},
{
@@ -977,7 +969,7 @@
"#### 課題\n",
"* 下記コードにDropoutを追加して効果を確かめてみましょう。Dropoutの追加やパラメータの変更をすることで精度93%以上を達成しましょう。\n",
"\n",
- "```\n",
+ "```python\n",
"h = F.dropout(F.relu(self.fc5(h))) # add dropout\n",
"```\n",
"\n",
@@ -1148,7 +1140,7 @@
"source": [
"ちなみに下記のようなモデルを動かしてみると93%前後の性能が実現できました。\n",
"\n",
- "```\n",
+ "```python\n",
"class MyConvNet(Chain):\n",
" def __init__(self):\n",
" super(MyConvNet, self).__init__()\n",
@@ -1163,7 +1155,7 @@
" in_channels=None, out_channels=128, ksize=3, stride=1, pad=1)\n",
" self.fc5 = L.Linear(None, 2000) # 1000 -> 2000\n",
" self.fc6 = L.Linear(None, 10)\n",
- "\n",
+ " \n",
" def __call__(self, x):\n",
" h = F.dropout(F.relu(self.conv1(x.reshape((-1, 1, 28, 28)))), ratio=0.2) # add dropout\n",
" h = F.max_pooling_2d(h, ksize=2, stride=2)\n",
@@ -1253,72 +1245,102 @@
},
{
"metadata": {
- "id": "aia80uGnMA3X",
+ "id": "0VDvHAXDfIqT",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "### 1. cpu/gpuを決める\n",
+ "Chainerの各関数には`device`という引数を渡す関数が多く存在します。それに`-1`を与えるとcpuで動作し、0以上の値を指定すると、そのIDのGPUを使用することになります。"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "qHnMVI_5MMzC",
"colab_type": "text"
},
"cell_type": "markdown",
"source": [
- "### 2. Iteratorの作成\n",
+ "### 2. 最適化手法の選択\n",
+ "\n",
+ "学習時に用いる最適化の手法としてはいろいろな種類のものが提案されていますが、Chainerは多くの手法を同一のインターフェースで利用できるよう、`Optimizer`という機能でそれらを提供しています。`chainer.optimizers`モジュール以下に色々なものを見つけることができます。一覧はこちらにあります:\n",
"\n",
- "データセットの準備は完了しましたが、このままネットワークの学習に使うのは少し面倒です。なぜなら、ネットワークのパラメータ最適化手法として広く用いられているStochastic Gradient Descent (SGD)という手法では、一般的にいくつかのデータを束ねた**ミニバッチ**と呼ばれる単位でネットワークにデータを渡し、それに対する予測を作って、ラベルと比較するということを行います。そのため、**バッチサイズ分だけデータとラベルを束ねる作業が必要です。**\n",
+ "- [Chainerで使える最適化手法一覧](https://docs.chainer.org/en/stable/reference/optimizers.html)\n",
"\n",
- "そこで、**データセットから決まった数のデータとラベルを取得し、それらを束ねてミニバッチを作ってくれる機能を持った`Iterator`を使いましょう。**`Iterator`は、先程作ったデータセットオブジェクトを渡して初期化してやったあとは、`next()`メソッドで新しいミニバッチを返してくれます。内部ではデータセットを何周なめたか(`epoch`)などの情報がどうように記録されているおり、学習ループを書いていく際に便利です。\n",
+ "`Optimizer`のオブジェクトには、`setup`メソッドを使ってモデル(`Chain`オブジェクト)を渡します。こうすることで`Optimizer`に、何を最適化すればいいか把握させることができます。\n",
"\n",
- "データセットオブジェクトからイテレータを作るには、以下のようにします。"
+ "他にもいろいろな最適化手法が手軽に試せるので、色々と試してみて結果の変化を見てみてください。例えば、`chainer.optimizers.SGD`のうち`SGD`の部分を`MomentumSGD`, `RMSprop`, `Adam`などに変えるだけで、最適化手法の違いがどのような学習曲線(ロスカーブ)の違いを生むかなどを簡単に調べることができます。"
]
},
{
"metadata": {
- "id": "E2C0UTedMA_M",
+ "id": "8PTDwIuiMM5V",
"colab_type": "text"
},
"cell_type": "markdown",
"source": [
- "ここでは、学習に用いるデータセット用のイテレータ(`train_iter`)と、検証用のデータセット用のイテレータ(`valid_iter`)、および学習したネットワークの評価に用いるテストデータセット用のイテレータ(`test_iter`)の計3つを作成しています。ここで、`batchsize = 128`としているので、作成した3つの`Iterator`は、例えば`train_iter.next()`などとすると128枚の数字画像データを一括りにして返してくれます。"
+ "#### NOTE\n",
+ "\n",
+ "Optimizerのコンストラクタには`lr`という引数があります。この値は学習率として知られ、モデルをうまく訓練して良いパフォーマンスを発揮させるために調整する必要がある重要な**ハイパーパラメータ**として知られています。"
]
},
{
"metadata": {
- "id": "rVT8FNM0MMp5",
+ "id": "87-Tz4ixggjF",
"colab_type": "text"
},
"cell_type": "markdown",
"source": [
- "#### NOTE: `SerialIterator`について\n",
+ "#### NOTE\n",
+ "最近、それぞれのOptimizerがどのように収束するか直感的に表現したgif画像が話題になりました。参考にしてみてください。\n",
"\n",
- "Chainerがいくつか用意している`Iterator`の一種である`SerialIterator`は、データセットの中のデータを順番に取り出してくる最もシンプルな`Iterator`です。コンストラクタの引数にデータセットオブジェクトと、バッチサイズを取ります。このとき、渡したデータセットオブジェクトから、何周も何周もデータを繰り返し読み出す必要がある場合は`repeat`引数を`True`とし、1周が終わったらそれ以上データを取り出したくない場合はこれを`False`とします。これは、主にvalidation用のデータセットに対して使うフラグです。デフォルトでは、`True`になっています。また、`shuffle`引数に`True`を渡すと、データセットから取り出されてくるデータの順番をエポックごとにランダムに変更します。`SerialIterator`の他にも、マルチプロセスで高速にデータを処理できるようにした`MultiprocessIterator`や`MultithreadIterator`など、複数の`Iterator`が用意されています。詳しくは以下を見てください。\n",
+ "\n",
"\n",
- "- [Chainerで使えるIterator一覧](https://docs.chainer.org/en/stable/reference/iterators.html)"
+ "cited from [4]"
]
},
{
"metadata": {
- "id": "qHnMVI_5MMzC",
+ "id": "aia80uGnMA3X",
"colab_type": "text"
},
"cell_type": "markdown",
"source": [
- "### 3. 最適化手法の選択\n",
+ "### 3. Iteratorの作成\n",
"\n",
- "では、上で定義したネットワークをMNISTデータセットを使って訓練してみましょう。学習時に用いる最適化の手法としてはいろいろな種類のものが提案されていますが、Chainerは多くの手法を同一のインターフェースで利用できるよう、`Optimizer`という機能でそれらを提供しています。`chainer.optimizers`モジュール以下に色々なものを見つけることができます。一覧はこちらにあります:\n",
+ "データセットはが、このままネットワークの学習に使うのは少し面倒です。なぜなら、ネットワークのパラメータ最適化手法として広く用いられているStochastic Gradient Descent (SGD)という手法では、一般的にいくつかのデータを束ねた **ミニバッチ** と呼ばれる単位でネットワークにデータを渡し、それに対する予測を作って、ラベルと比較するということを行います。そのため、**バッチサイズ分だけデータとラベルを束ねる作業が必要です。**\n",
"\n",
- "- [Chainerで使える最適化手法一覧](https://docs.chainer.org/en/stable/reference/optimizers.html)\n",
- "\n",
- "ここでは最もシンプルな勾配降下法の手法である`optimizers.SGD`を用います。`Optimizer`のオブジェクトには、`setup`メソッドを使ってモデル(`Chain`オブジェクト)を渡します。こうすることで`Optimizer`に、何を最適化すればいいか把握させることができます。\n",
+ "そこで、**データセットから決まった数のデータとラベルを取得し、それらを束ねてミニバッチを作ってくれる機能を持ったIteratorを使いましょう。** `Iterator`は、先程作ったデータセットオブジェクトを渡して初期化してやったあとは、`next()`メソッドで新しいミニバッチを返してくれます。内部ではデータセットを何周なめたか(`epoch`)などの情報が記録されており、学習ループを書いていく際に便利です。\n",
"\n",
- "他にもいろいろな最適化手法が手軽に試せるので、色々と試してみて結果の変化を見てみてください。例えば、下の`chainer.optimizers.SGD`のうち`SGD`の部分を`MomentumSGD`, `RMSprop`, `Adam`などに変えるだけで、最適化手法の違いがどのような学習曲線(ロスカーブ)の違いを生むかなどを簡単に調べることができます。"
+ "```python\n",
+ "train_iter = chainer.iterators.SerialIterator(train, batchsize)\n",
+ "validation_iter = chainer.iterators.SerialIterator(\n",
+ " validation, batchsize, repeat=False, shuffle=False)\n",
+ "```"
]
},
{
"metadata": {
- "id": "8PTDwIuiMM5V",
+ "id": "E2C0UTedMA_M",
"colab_type": "text"
},
"cell_type": "markdown",
"source": [
- "#### NOTE\n",
+ "ここでは、学習に用いるデータセット用のイテレータ(`train_iter`)と、検証用のデータセット用のイテレータ(`validation_iter`)、の計2つを作成しています。ここで、`batchsize = 128`だったとすると、作成した2つの`Iterator`は、例えば`train_iter.next()`などとすると128枚の数字画像データを一括りにして返してくれます。"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "rVT8FNM0MMp5",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "#### NOTE: `SerialIterator`について\n",
+ "\n",
+ "Chainerがいくつか用意している`Iterator`の一種である`SerialIterator`は、データセットの中のデータを順番に取り出してくる最もシンプルな`Iterator`です。コンストラクタの引数にデータセットオブジェクトと、バッチサイズを取ります。このとき、渡したデータセットオブジェクトから、何周も何周もデータを繰り返し読み出す必要がある場合は`repeat`引数を`True`とし、1周が終わったらそれ以上データを取り出したくない場合はこれを`False`とします。これは、主にvalidation用のデータセットに対して使うフラグです。デフォルトでは、`True`になっています。また、`shuffle`引数に`True`を渡すと、データセットから取り出されてくるデータの順番をエポックごとにランダムに変更します。`SerialIterator`の他にも、マルチプロセスで高速にデータを処理できるようにした`MultiprocessIterator`や`MultithreadIterator`など、複数の`Iterator`が用意されています。詳しくは以下を見てください。\n",
"\n",
- "今回はSGDのコンストラクタの`lr`という引数に $0.01$ を与えました。この値は学習率として知られ、モデルをうまく訓練して良いパフォーマンスを発揮させるために調整する必要がある重要な**ハイパーパラメータ**として知られています。"
+ "- [Chainerで使えるIterator一覧](https://docs.chainer.org/en/stable/reference/iterators.html)"
]
},
{
@@ -1328,7 +1350,7 @@
},
"cell_type": "markdown",
"source": [
- "### 2. Updaterの準備\n",
+ "### 4-1. Updaterの準備\n",
"\n",
"ここからが学習ループを自分で書く場合と異なる部分です。ループを自分で書く場合には、データセットからバッチサイズ分のデータをとってきてミニバッチに束ねて、それをネットワークに入力して予測を作り、それを正解と比較し、ロスを計算してバックワード(誤差逆伝播)をして、`Optimizer`によってパラメータを更新する、というところまでを、以下のように書いていました。\n",
"\n",
@@ -1351,7 +1373,7 @@
"optimizer.update()\n",
"```\n",
"\n",
- "これらの処理を、まるっと`Updater`はまとめてくれます。これを行うために、**`Updater`には`Iterator`と`Optimizer`を渡してやります。** `Iterator`はデータセットオブジェクトを持っていて、そこからミニバッチを作り、`Optimizer`は最適化対象のネットワークを持っていて、それを使って前進計算とロスの計算・パラメータのアップデートをすることができます。そのため、この2つを渡しておけば、上記の処理を`Updater`内で全部行ってもらえるというわけです。では、`Updater`オブジェクトを作成してみましょう。"
+ "これらの処理を、まるっと`Updater`はまとめてくれます。これを行うために、**UpdaterにはIteratorとOptimizerを渡してやります。** `Iterator`はデータセットオブジェクトを持っていて、そこからミニバッチを作り、`Optimizer`は最適化対象のネットワークを持っていて、それを使って前進計算とロスの計算・パラメータのアップデートをすることができます。そのため、この2つを渡しておけば、上記の処理を`Updater`内で全部行ってもらえるというわけです。では、`Updater`オブジェクトを作成してみましょう。"
]
},
{
@@ -1363,7 +1385,7 @@
"source": [
"#### NOTE\n",
"\n",
- "ここでは、ネットワークを`L.Classifier`で包んでいます。`L.Classifier`は一種の`Chain`になっていて、渡されたネットワーク自体を`predictor`というattributeに持ち、**ロス計算を行う機能を追加してくれます。**こうすると、`net()`はデータ`x`だけでなくラベル`t`も取るようになり、まず渡されたデータを`predictor`に通して予測を作り、それを`t`と比較して**ロスの`Variable`を返すようになります。**ロス関数として何を用いるかはデフォルトでは`F.softmax_cross_entropy`となっていますが、`L.Classifier`の引数`lossfunc`にロス計算を行う関数を渡してやれば変更することができるため、Classifierという名前ながら回帰問題などのロス計算機能の追加にも使うことができます。(`L.Classifier(net, lossfun=L.mean_squared_error, compute_accuracy=False)`のようにする)\n",
+ "モデルを定義するときに、ネットワークを`L.Classifier`で包んでいます。`L.Classifier`は一種の`Chain`になっていて、渡されたネットワーク自体を`predictor`というattributeに持ち、**ロス計算を行う機能を追加してくれます。** こうすると、`net()`はデータ`x`だけでなくラベル`t`も取るようになり、まず渡されたデータを`predictor`に通して予測を作り、それを`t`と比較して**ロスのVariableを返すようになります。** ロス関数として何を用いるかはデフォルトでは`F.softmax_cross_entropy`となっていますが、`L.Classifier`の引数`lossfunc`にロス計算を行う関数を渡してやれば変更することができるため、Classifierという名前ながら回帰問題などのロス計算機能の追加にも使うことができます。(`L.Classifier(net, lossfun=L.mean_squared_error, compute_accuracy=False)`のようにする)\n",
"\n",
"`StandardUpdater`は前述のような`Updater`の担当する処理を遂行するための最もシンプルなクラスです。この他にも複数のGPUを用いるための`ParallelUpdater`などが用意されています。"
]
@@ -1375,7 +1397,7 @@
},
"cell_type": "markdown",
"source": [
- "### 3. Trainerの準備\n",
+ "### 4-2. Trainerの準備\n",
"\n",
"実際に学習ループ部分を隠蔽しているのは`Updater`なので、これがあればもう学習を始められそうですが、`Trainer`はさらに`Updater`を受け取って学習全体の管理を行う機能を提供しています。例えば、**データセットを何周したら学習を終了するか(stop_trigger)** や、**途中のロスの値をどのファイルに保存したいか**、**ロスカーブを可視化した画像ファイルを保存するかどうか**など、学習全体の設定として必須・もしくはあると便利な色々な機能を提供しています。\n",
"\n",
@@ -1405,7 +1427,7 @@
},
"cell_type": "markdown",
"source": [
- "### 4. TrainerにExtensionを追加する\n",
+ "### 5. TrainerにExtensionを追加する\n",
"\n",
"`Trainer`を使う利点として、\n",
"\n",
@@ -1462,6 +1484,112 @@
"- [ChainerのTrainer extension一覧](http://docs.chainer.org/en/stable/reference/extensions.html)"
]
},
+ {
+ "metadata": {
+ "id": "WNvCGRVkhijB",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "#### 課題\n",
+ "* 下記を変更してみて、Chainerの機能を体験してみましょう。"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "7PJoaxDYhsh1",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "def my_train_and_validate(\n",
+ " model, optimizer, train, validation, n_epoch, enable_cupy, batchsize):\n",
+ "\n",
+ " # 1. cpu/gpuを決める\n",
+ " device = -1\n",
+ " if enable_cupy:\n",
+ " device = 0\n",
+ " chainer.backends.cuda.get_device_from_id(device).use()\n",
+ " model.to_gpu()\n",
+ "\n",
+ " # 2. Optimizerを設定する\n",
+ " optimizer.setup(model)\n",
+ "\n",
+ " # 3. DatasetからIteratorを作成する\n",
+ " train_iter = chainer.iterators.SerialIterator(train, batchsize)\n",
+ " validation_iter = chainer.iterators.SerialIterator(\n",
+ " validation, batchsize, repeat=False, shuffle=False)\n",
+ "\n",
+ " # 4. Updater・Trainerを作成する\n",
+ " updater = training.StandardUpdater(train_iter, optimizer, device=device)\n",
+ " trainer = chainer.training.Trainer(updater, out='out')\n",
+ "\n",
+ " # 5. Trainerの機能を拡張する\n",
+ "\n",
+ " # 6. 訓練を開始する\n",
+ " trainer.run()"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "ZzkUNCCwhh9p",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "class MyConvNet(Chain):\n",
+ " def __init__(self):\n",
+ " super(MyConvNet, self).__init__()\n",
+ " with self.init_scope():\n",
+ " self.conv1 = L.Convolution2D(\n",
+ " in_channels=None, out_channels=32, ksize=3, stride=1, pad=1)\n",
+ " self.conv2 = L.Convolution2D(\n",
+ " in_channels=None, out_channels=64, ksize=3, stride=1, pad=1)\n",
+ " self.conv3 = L.Convolution2D(\n",
+ " in_channels=None, out_channels=128, ksize=3, stride=1, pad=1)\n",
+ " self.conv4 = L.Convolution2D(\n",
+ " in_channels=None, out_channels=128, ksize=3, stride=1, pad=1)\n",
+ " self.fc5 = L.Linear(None, 2000) # 1000 -> 2000\n",
+ " self.fc6 = L.Linear(None, 10)\n",
+ "\n",
+ " def __call__(self, x):\n",
+ " h = F.dropout(F.relu(self.conv1(x.reshape((-1, 1, 28, 28)))), ratio=0.2) # add dropout\n",
+ " h = F.max_pooling_2d(h, ksize=2, stride=2)\n",
+ " h = F.dropout(F.relu(self.conv2(h)), ratio=0.2) # add dropout\n",
+ " h = F.max_pooling_2d(h, ksize=2, stride=2)\n",
+ " h = F.dropout(F.relu(self.conv3(h)), ratio=0.2) # add dropout\n",
+ " h = F.max_pooling_2d(h, ksize=2, stride=2)\n",
+ " h = F.dropout(F.relu(self.conv4(h))) # add dropout\n",
+ " h = F.dropout(F.relu(self.fc5(h))) # add dropout\n",
+ " return self.fc6(h)"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "_IPnvIVFh0Ih",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "n_epoch = 5\n",
+ "batchsize = 128\n",
+ "\n",
+ "model = MyConvNet()\n",
+ "classifier_model = L.Classifier(model)\n",
+ "optimizer = optimizers.Adam()\n",
+ "my_train_and_validate(\n",
+ " classifier_model, optimizer, train, validation, n_epoch, batchsize)"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
{
"metadata": {
"id": "1Q_Ij1gE6Y52",
@@ -1690,8 +1818,22 @@
"## Reference\n",
"* [1] [Gradient-based learning applied to document recognition](http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf)\n",
"* [2] [Vincent Dumoulin, Francesco Visin - A guide to convolution arithmetic for deep learning](https://arxiv.org/abs/1603.07285)\n",
- "* [3] [最適化から見たディープラーニングの考え方](http://www.orsj.or.jp/archive2/or60-4/or60_4_191.pdf)"
+ "* [3] [最適化から見たディープラーニングの考え方](http://www.orsj.or.jp/archive2/or60-4/or60_4_191.pdf)\n",
+ "* [4] [CS231n](http://cs231n.github.io/neural-networks-3/)"
]
+ },
+ {
+ "metadata": {
+ "id": "2-ttm6w-hLju",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ ""
+ ],
+ "execution_count": 0,
+ "outputs": []
}
]
-}
+}
\ No newline at end of file