diff --git a/docs/CSS/_category_.json b/docs/CSS/_category_.json
index 553c5ddbb..6da1ba5e6 100644
--- a/docs/CSS/_category_.json
+++ b/docs/CSS/_category_.json
@@ -1,6 +1,6 @@
{
"label": "CSS",
- "position": 20,
+ "position": 3,
"link": {
"type": "generated-index",
"description": "In this section, you will learn about the CSS."
diff --git a/docs/Computer Networks/_category_.json b/docs/Computer Networks/_category_.json
deleted file mode 100644
index aeb009c52..000000000
--- a/docs/Computer Networks/_category_.json
+++ /dev/null
@@ -1,9 +0,0 @@
-{
- "label": "Computer Networks",
- "position":3 ,
- "link": {
- "type": "generated-index",
- "description": "Computer Networks is the practice of connecting computers and other devices to share resources and information. This section covers fundamental concepts, protocols, and technologies that form the backbone of network communication."
- }
- }
-
\ No newline at end of file
diff --git a/docs/Computer Networks/common_network_protocols.md b/docs/Computer Networks/common_network_protocols.md
deleted file mode 100644
index 295f05f78..000000000
--- a/docs/Computer Networks/common_network_protocols.md
+++ /dev/null
@@ -1,97 +0,0 @@
----
-id: common_network_protocols
-title: Common Network Protocols
-sidebar_label: Common Network Protocols
-sidebar_position: 13
-tags: [computer_networks, networks, communication]
-description: Network protocols are the rules and conventions for communication between network devices. They ensure that data is transmitted accurately and efficiently across networks. This document covers some of the most common network protocols are HTTP/HTTPS, FTP, DNS, DHCP, and SMTP.
----
-# Common Network Protocols
-
-## Introduction
-Network protocols are the rules and conventions for communication between network devices. They ensure that data is transmitted accurately and efficiently across networks. This document covers some of the most common network protocols: HTTP/HTTPS, FTP, DNS, DHCP, and SMTP.
-
-## HTTP/HTTPS (HyperText Transfer Protocol / HyperText Transfer Protocol Secure)
-### HTTP
-HTTP is the protocol used for transferring web pages on the internet. It operates at the application layer of the OSI model.
-
-#### Functions of HTTP
-- **Request-Response Protocol**: HTTP works on a request-response model where a client (e.g., a web browser) sends a request to a server, which then responds with the requested resource (e.g., a web page).
-- **Stateless Protocol**: Each HTTP request is independent, meaning the server does not retain information about previous requests.
-
-#### Components of HTTP
-- **URL (Uniform Resource Locator)**: The address of a resource on the internet.
-- **Methods**: Common HTTP methods include GET (retrieve data), POST (send data), PUT (update data), DELETE (remove data).
-- **Status Codes**: HTTP responses include status codes indicating the result of the request (e.g., 200 OK, 404 Not Found).
-
-### HTTPS
-HTTPS is the secure version of HTTP. It uses SSL/TLS to encrypt data transmitted between the client and server, ensuring privacy and integrity.
-
-#### Functions of HTTPS
-- **Encryption**: HTTPS encrypts data to protect it from interception and tampering.
-- **Authentication**: HTTPS verifies the identity of the server to prevent man-in-the-middle attacks.
-
-## FTP (File Transfer Protocol)
-FTP is a standard protocol for transferring files between computers over a TCP/IP network. It operates at the application layer of the OSI model.
-
-### Functions of FTP
-- **File Transfer**: FTP allows users to upload and download files to and from a server.
-- **File Management**: FTP supports basic file management operations such as creating directories, deleting files, and renaming files.
-
-### Components of FTP
-- **FTP Client**: The software used to connect to an FTP server (e.g., FileZilla).
-- **FTP Server**: The server that hosts the files and handles client requests.
-- **Commands**: FTP uses commands like USER (username), PASS (password), STOR (upload file), and RETR (download file).
-
-### FTP Modes
-- **Active Mode**: The client opens a port and waits for the server to connect to it.
-- **Passive Mode**: The server opens a port and waits for the client to connect to it, improving compatibility with firewalls.
-
-## DNS (Domain Name System)
-DNS is the system that translates human-readable domain names (e.g., www.example.com) into IP addresses (e.g., 192.168.1.1). It operates at the application layer of the OSI model.
-
-### Functions of DNS
-- **Name Resolution**: DNS converts domain names into IP addresses, allowing users to access websites using easy-to-remember names.
-- **Distributed Database**: DNS is a distributed database, with multiple servers worldwide handling domain name resolutions.
-
-### Components of DNS
-- **DNS Resolver**: The client-side component that initiates DNS queries.
-- **DNS Server**: The server that responds to DNS queries. There are several types, including root servers, top-level domain (TLD) servers, and authoritative name servers.
-- **DNS Records**: Entries in a DNS database, such as A (address) records, MX (mail exchange) records, and CNAME (canonical name) records.
-
-## DHCP (Dynamic Host Configuration Protocol)
-DHCP is a network management protocol used to automatically assign IP addresses and other network configuration parameters to devices on a network. It operates at the application layer of the OSI model.
-
-### Functions of DHCP
-- **IP Address Assignment**: DHCP dynamically assigns IP addresses to devices, reducing the need for manual configuration.
-- **Configuration Distribution**: DHCP can also provide other configuration information, such as the subnet mask, default gateway, and DNS server addresses.
-
-### Components of DHCP
-- **DHCP Server**: The server that assigns IP addresses and configuration information.
-- **DHCP Client**: The device that requests an IP address and configuration information.
-- **DHCP Lease**: The period during which an IP address is assigned to a device.
-
-### DHCP Process
-1. **Discover**: The client broadcasts a DHCPDISCOVER message to locate a DHCP server.
-2. **Offer**: The server responds with a DHCPOFFER message, offering an IP address.
-3. **Request**: The client replies with a DHCPREQUEST message, requesting the offered address.
-4. **Acknowledge**: The server sends a DHCPACK message, confirming the IP address assignment.
-
-## SMTP (Simple Mail Transfer Protocol)
-SMTP is the protocol used for sending and receiving email. It operates at the application layer of the OSI model.
-
-### Functions of SMTP
-- **Email Transmission**: SMTP transfers email from the sender's mail server to the recipient's mail server.
-- **Email Relaying**: SMTP can relay email through multiple servers before it reaches the final destination.
-
-### Components of SMTP
-- **SMTP Client**: The component that sends email (e.g., an email client or mail server).
-- **SMTP Server**: The server that receives and forwards email.
-
-### SMTP Process
-1. **Mail Submission**: The email client submits the email to the SMTP server.
-2. **Mail Relay**: The SMTP server may relay the email to other SMTP servers.
-3. **Mail Delivery**: The final SMTP server delivers the email to the recipient's mail server.
-
-## Summary
-Understanding common network protocols like HTTP/HTTPS, FTP, DNS, DHCP, and SMTP is essential for anyone working with networks. These protocols facilitate communication, file transfer, domain name resolution, IP address assignment, and email transmission, forming the backbone of modern networking.
\ No newline at end of file
diff --git a/docs/Computer Networks/crc.md b/docs/Computer Networks/crc.md
deleted file mode 100644
index df03f1df4..000000000
--- a/docs/Computer Networks/crc.md
+++ /dev/null
@@ -1,121 +0,0 @@
-# Cyclic Redundancy Check
-
-CRC or Cyclic Redundancy Check is a method of detecting accidental changes/errors in the communication channel.
-
-```java
-
-import java.util.Arrays;
-class Program {
-
-
- static String Xor(String a, String b)
- {
-
-
- String result = "";
- int n = b.length();
-
- for (int i = 1; i < n; i++) {
- if (a.charAt(i) == b.charAt(i))
- result += "0";
- else
- result += "1";
- }
- return result;
- }
- static String Mod2Div(String dividend, String divisor)
- {
-
- int pick = divisor.length();
-
-
- String tmp = dividend.substring(0, pick);
-
- int n = dividend.length();
-
- while (pick < n) {
- if (tmp.charAt(0) == '1')
-
- tmp = Xor(divisor, tmp)
- + dividend.charAt(pick);
- else
-
-
- tmp = Xor(new String(new char[pick])
- .replace("\0", "0"),
- tmp)
- + dividend.charAt(pick);
-
-
- pick += 1;
- }
-
-
- if (tmp.charAt(0) == '1')
- tmp = Xor(divisor, tmp);
- else
- tmp = Xor(new String(new char[pick])
- .replace("\0", "0"),
- tmp);
-
- return tmp;
- }
-
-
- static void EncodeData(String data, String key)
- {
- int l_key = key.length();
-
- String appended_data
- = (data
- + new String(new char[l_key - 1])
- .replace("\0", "0"));
-
- String remainder = Mod2Div(appended_data, key);
-
-
- String codeword = data + remainder;
- System.out.println("Remainder : " + remainder);
- System.out.println(
- "Encoded Data (Data + Remainder) :" + codeword
- + "\n");
- }
- static void Receiver(String data, String key)
- {
- String currxor
- = Mod2Div(data.substring(0, key.length()), key);
- int curr = key.length();
- while (curr != data.length()) {
- if (currxor.length() != key.length()) {
- currxor += data.charAt(curr++);
- }
- else {
- currxor = Mod2Div(currxor, key);
- }
- }
- if (currxor.length() == key.length()) {
- currxor = Mod2Div(currxor, key);
- }
- if (currxor.contains("1")) {
- System.out.println(
- "there is some error in data");
- }
- else {
- System.out.println("correct message received");
- }
- }
-
- public static void main(String[] args)
- {
- String data = "100100";
- String key = "1101";
- System.out.println("\nSender side...");
- EncodeData(data, key);
-
- System.out.println("Receiver side...");
- Receiver(data+Mod2Div(data+new String(new char[key.length() - 1])
- .replace("\0", "0"),key),key);
- }
-}
-
-```
diff --git a/docs/Computer Networks/internet_tcp_ip_model.md b/docs/Computer Networks/internet_tcp_ip_model.md
deleted file mode 100644
index 51d77cf07..000000000
--- a/docs/Computer Networks/internet_tcp_ip_model.md
+++ /dev/null
@@ -1,115 +0,0 @@
----
-id: internet_tcp_ip_model
-title: The Internet and TCP/IP Model
-sidebar_label: The Internet and TCP/IP Model
-sidebar_position: 10
-tags: [computer_networks, networks, communication]
-description: The Internet is a global network of interconnected computers and other devices that communicate with each other using standardized protocols.The TCP/IP model (Transmission Control Protocol/Internet Protocol) is a conceptual framework used to understand and implement networking protocols in four layers.
----
-# The Internet and TCP/IP Model
-
-## What is the Internet?
-
-The **Internet** is a global network of interconnected computers and other devices that communicate with each other using standardized protocols. It enables the exchange of data and access to information, services, and resources from anywhere in the world.
-
-### Key Components of the Internet
-
-1. **Clients and Servers**: Clients are devices that request information or services, while servers provide these services or information.
-2. **Routers and Switches**: Routers direct data packets between networks, and switches connect multiple devices within the same network.
-3. **Protocols**: Rules and standards that define how data is transmitted and received over the Internet.
-
-### Services Provided by the Internet
-
-1. **World Wide Web (WWW)**: A system of interlinked hypertext documents accessed through web browsers.
-2. **Email**: Electronic mail services for communication.
-3. **File Transfer Protocol (FTP)**: Used for transferring files between devices.
-4. **Voice over IP (VoIP)**: Enables voice communication over the Internet.
-5. **Streaming Media**: Services like video and audio streaming.
-
-## The TCP/IP Model
-
-The **TCP/IP model** (Transmission Control Protocol/Internet Protocol) is a conceptual framework used to understand and implement networking protocols in four layers. It is the foundation of the Internet and most modern networks. The TCP/IP model predates and inspired the OSI model.
-
-### Layers of the TCP/IP Model
-
-1. **Network Interface Layer**
-2. **Internet Layer**
-3. **Transport Layer**
-4. **Application Layer**
-
-#### 1. Network Interface Layer
-
-The **Network Interface Layer** (also known as the Link Layer) corresponds to the OSI model's Physical and Data Link layers. It handles the physical transmission of data over a network medium.
-
-- **Functions**:
- - Defines how data is physically sent through the network.
- - Manages physical addressing and access to the network medium.
- - Ensures error-free delivery of data between devices on the same network.
-
-- **Examples**:
- - Ethernet, Wi-Fi, and other LAN technologies.
- - Network Interface Cards (NICs) and device drivers.
-
-#### 2. Internet Layer
-
-The **Internet Layer** is responsible for logical addressing, routing, and packet forwarding. It corresponds to the OSI model's Network layer.
-
-- **Functions**:
- - Logical addressing using IP addresses.
- - Routing of data packets between different networks.
- - Fragmentation and reassembly of packets.
-
-- **Examples**:
- - IP (Internet Protocol) - IPv4 and IPv6.
- - ICMP (Internet Control Message Protocol) for error and diagnostic messages.
- - ARP (Address Resolution Protocol) for mapping IP addresses to MAC addresses.
-
-#### 3. Transport Layer
-
-The **Transport Layer** provides end-to-end communication services for applications. It corresponds to the OSI model's Transport layer.
-
-- **Functions**:
- - Reliable data transfer with error detection and correction.
- - Flow control and data segmentation.
- - Multiplexing and demultiplexing of data streams.
-
-- **Examples**:
- - TCP (Transmission Control Protocol): Provides reliable, connection-oriented communication.
- - UDP (User Datagram Protocol): Provides unreliable, connectionless communication.
-
-#### 4. Application Layer
-
-The **Application Layer** provides network services directly to user applications. It corresponds to the OSI model's Application, Presentation, and Session layers.
-
-- **Functions**:
- - Provides protocols and services for various applications.
- - Facilitates communication between software applications and lower-layer network services.
-
-- **Examples**:
- - HTTP (Hypertext Transfer Protocol) for web communication.
- - FTP (File Transfer Protocol) for file transfers.
- - SMTP (Simple Mail Transfer Protocol) for email.
- - DNS (Domain Name System) for resolving domain names to IP addresses.
-
-## Comparison Between OSI and TCP/IP Models
-
-| Feature | OSI Model | TCP/IP Model |
-|-----------------------------|--------------------------------|--------------------------|
-| Layers | 7 | 4 |
-| Development | Developed by ISO | Developed by DARPA |
-| Layer Names | Physical, Data Link, Network, Transport, Session, Presentation, Application | Network Interface, Internet, Transport, Application |
-| Protocol Specification | Protocol-independent | Protocol-specific (TCP/IP)|
-| Usage | Primarily theoretical and educational | Widely used and practical |
-
-## Importance of the TCP/IP Model
-
-The TCP/IP model is crucial for the functioning of the Internet and modern networking due to its:
-
-1. **Standardization**: Provides a standardized set of protocols for data transmission, ensuring interoperability between different devices and networks.
-2. **Scalability**: Designed to accommodate growth, allowing the Internet to expand and support a vast number of devices and users.
-3. **Flexibility**: Adapts to various types of networks and devices, making it suitable for a wide range of applications.
-4. **Robustness**: Ensures reliable data transfer and communication even in the presence of network failures or congestion.
-
-## Conclusion
-
-The Internet and the TCP/IP model are foundational elements of modern networking. The TCP/IP model, with its four layers, provides a practical and efficient framework for data communication, enabling the vast and diverse services of the Internet. Understanding the TCP/IP model is essential for networking professionals and anyone involved in the design, implementation, and maintenance of networked systems.
\ No newline at end of file
diff --git a/docs/Computer Networks/intro_to_cn.md b/docs/Computer Networks/intro_to_cn.md
deleted file mode 100644
index 83f7c01c3..000000000
--- a/docs/Computer Networks/intro_to_cn.md
+++ /dev/null
@@ -1,61 +0,0 @@
----
-id: computer_networks
-title: Computer Networks
-sidebar_label: Computer Networks
-sidebar_position: 6
-tags: [computer_networks, networks, communication]
-description: Computer Networks is the practice of connecting computers and other devices to share resources and information. This section covers fundamental concepts, protocols, and technologies that form the backbone of network communication.
----
-# Introduction to Computer Networks
-
-## What Are Computer Networks?
-
-A **computer network** is a collection of interconnected devices that communicate with each other to share resources and information. These devices can include computers, servers, smartphones, and networking hardware like routers and switches.
-
-### Key Components of a Network
-
-1. **Nodes**: These are the devices connected to the network, such as computers, smartphones, printers, and servers.
-2. **Links**: These are the communication pathways that connect nodes. They can be physical (cables) or wireless (radio waves).
-3. **Switches**: Devices that connect multiple devices within a LAN and use MAC addresses to forward data to the correct destination.
-4. **Routers**: Devices that connect different networks together and use IP addresses to route data between networks.
-5. **Protocols**: Sets of rules and conventions that determine how data is transmitted and received across the network (e.g., TCP/IP, HTTP).
-
-### Types of Networks
-
-1. **Local Area Network (LAN)**: Covers a small geographic area, like a home, office, or building.
-2. **Wide Area Network (WAN)**: Spans a large geographic area, such as a city, country, or even globally.
-3. **Metropolitan Area Network (MAN)**: Covers a larger geographic area than a LAN but smaller than a WAN, such as a city.
-4. **Personal Area Network (PAN)**: Involves a network for personal devices, typically within a range of a few meters, like a Bluetooth connection.
-5. **Wireless Networks (WLAN, WWAN)**: Utilizes wireless connections, such as Wi-Fi or cellular networks, to connect devices.
-
-## Why Are Computer Networks Important?
-
-Computer networks are vital in today's digital age for several reasons:
-
-### 1. **Resource Sharing**
-
-Networks allow for the sharing of resources such as files, applications, and hardware (e.g., printers, scanners). This improves efficiency and reduces costs by enabling multiple users to access shared resources.
-
-### 2. **Communication and Collaboration**
-
-Networks facilitate communication through email, instant messaging, video conferencing, and social media platforms. They enable collaboration among users regardless of their physical location, enhancing productivity and innovation.
-
-### 3. **Data Management and Access**
-
-Networks enable centralized data storage and management, making it easier to backup, secure, and access data. This ensures data integrity and availability, crucial for business operations and decision-making.
-
-### 4. **Scalability and Flexibility**
-
-Networks can be scaled up or down based on the organization's needs. This flexibility allows businesses to adapt to changing demands without significant infrastructure changes.
-
-### 5. **Enhanced Security**
-
-Networks provide mechanisms for implementing security measures such as firewalls, encryption, and access controls. These measures protect sensitive data from unauthorized access and cyber threats.
-
-### 6. **Cost Efficiency**
-
-By enabling resource sharing and efficient communication, networks reduce operational costs. They eliminate the need for redundant hardware and streamline processes, leading to cost savings.
-
-## Conclusion
-
-Computer networks are the backbone of modern communication and information sharing. They are essential for businesses, educational institutions, governments, and individuals to function efficiently and effectively in a connected world.
\ No newline at end of file
diff --git a/docs/Computer Networks/ip_addressing.md b/docs/Computer Networks/ip_addressing.md
deleted file mode 100644
index f0c13b9ca..000000000
--- a/docs/Computer Networks/ip_addressing.md
+++ /dev/null
@@ -1,82 +0,0 @@
----
-id: ip_addressing
-title: IP Addressing
-sidebar_label: IP Addressing
-sidebar_position: 11
-tags: [computer_networks, networks, communication]
-description: An IP (Internet Protocol) address is a unique identifier assigned to each device connected to a network. It allows devices to locate and communicate with each other on the network.
----
-# IP Addressing
-
-## What is an IP Address?
-An IP (Internet Protocol) address is a unique identifier assigned to each device connected to a network. It allows devices to locate and communicate with each other on the network. There are two main versions of IP addresses in use today: IPv4 and IPv6.
-
-## IPv4 Addresses
-IPv4 addresses are 32-bit numbers, typically represented in decimal format as four octets separated by dots, e.g., `192.168.1.1`.
-
-### IPv4 Address Structure
-- **Network Part**: Identifies the specific network.
-- **Host Part**: Identifies the specific device within the network.
-
-### Classes of IPv4 Addresses
-IPv4 addresses are divided into five classes (A, B, C, D, E) based on the leading bits. Classes A, B, and C are used for unicast addresses, while classes D and E are reserved for multicast and experimental purposes, respectively.
-
-| Class | Starting Address | Ending Address | Default Subnet Mask |
-|-------|-------------------|----------------|----------------------|
-| A | 0.0.0.0 | 127.255.255.255| 255.0.0.0 |
-| B | 128.0.0.0 | 191.255.255.255| 255.255.0.0 |
-| C | 192.0.0.0 | 223.255.255.255| 255.255.255.0 |
-| D | 224.0.0.0 | 239.255.255.255| N/A |
-| E | 240.0.0.0 | 255.255.255.255| N/A |
-
-### Private IPv4 Addresses
-Certain address ranges are reserved for private networks and cannot be routed on the public Internet. These ranges include:
-- Class A: `10.0.0.0` to `10.255.255.255`
-- Class B: `172.16.0.0` to `172.31.255.255`
-- Class C: `192.168.0.0` to `192.168.255.255`
-
-### IPv4 Subnetting
-Subnetting divides a network into smaller subnetworks, allowing for better management and utilization of IP addresses.
-
-#### Calculating Subnets
-To calculate subnets, extend the network part by borrowing bits from the host part. For example, using a Class C address `192.168.1.0/24`, borrowing 2 bits for subnetting would result in `192.168.1.0/26`, creating 4 subnets.
-
-### Subnet Mask
-A subnet mask is a 32-bit number that masks an IP address, dividing it into network and host parts. For example, the subnet mask `255.255.255.0` is equivalent to `/24`.
-
-## IPv6 Addresses
-IPv6 addresses are 128-bit numbers, represented in hexadecimal format as eight groups of four hex digits, separated by colons, e.g., `2001:0db8:85a3:0000:0000:8a2e:0370:7334`.
-
-### IPv6 Address Structure
-- **Global Routing Prefix**: Identifies the network.
-- **Subnet ID**: Identifies the subnet within the network.
-- **Interface ID**: Identifies the specific device.
-
-### Types of IPv6 Addresses
-- **Unicast**: A single unique address identifying a specific device.
-- **Multicast**: An address representing a group of devices, where data sent to this address is received by all group members.
-- **Anycast**: An address assigned to multiple devices, where data is routed to the nearest device with that address.
-
-### IPv6 Address Notation
-- **Full Notation**: `2001:0db8:85a3:0000:0000:8a2e:0370:7334`
-- **Compressed Notation**: `2001:db8:85a3::8a2e:370:7334` (zeros are omitted)
-
-## Subnetting in IPv6
-IPv6 subnetting works similarly to IPv4 but is more flexible due to the larger address space. The standard subnet prefix length is `/64`, leaving 64 bits for device addresses within the subnet.
-
-## CIDR (Classless Inter-Domain Routing)
-CIDR is a method for allocating IP addresses and routing that replaces the old system of class-based networks. It allows for more efficient use of IP address space.
-
-### CIDR Notation
-CIDR notation specifies an IP address and its associated network prefix. For example, `192.168.1.0/24` indicates that the first 24 bits are the network part, and the remaining 8 bits are the host part.
-
-## NAT (Network Address Translation)
-NAT is a technique used to remap one IP address space into another. It modifies the IP address information in packet headers while in transit, enabling multiple devices on a local network to share a single public IP address.
-
-### Types of NAT
-- **Static NAT**: Maps a private IP address to a public IP address on a one-to-one basis.
-- **Dynamic NAT**: Maps a private IP address to a public IP address from a pool of available addresses.
-- **PAT (Port Address Translation)**: Also known as NAT overload, it maps multiple private IP addresses to a single public IP address using different ports.
-
-## Summary
-IP addressing is fundamental for network communication. Understanding IPv4 and IPv6 addresses, subnetting, CIDR, and NAT helps in designing and managing networks efficiently. This knowledge is essential for anyone working in networking and IT fields.
\ No newline at end of file
diff --git a/docs/Computer Networks/network_devices.md b/docs/Computer Networks/network_devices.md
deleted file mode 100644
index 352ddb24e..000000000
--- a/docs/Computer Networks/network_devices.md
+++ /dev/null
@@ -1,61 +0,0 @@
----
-id: basic_network_devices
-title: Basic Network Devices
-sidebar_label: Basic Network Devices
-sidebar_position: 12
-tags: [computer_networks, networks, communication]
-description: Understanding the functions of basic network devices such as routers, switches, hubs, modems, and access points is essential for designing and managing effective networks.
----
-# Basic Network Devices
-
-## Routers
-Routers are devices that connect different networks and direct data packets between them. They operate at the network layer (Layer 3) of the OSI model and use IP addresses to determine the best path for data to travel.
-
-### Functions of Routers
-- **Packet Forwarding**: Routers receive data packets and forward them to their destination based on IP addresses.
-- **Routing**: Routers maintain routing tables and use routing protocols (e.g., OSPF, BGP) to determine the best path for data packets.
-- **Network Segmentation**: Routers can divide large networks into smaller, more manageable subnets.
-- **Network Address Translation (NAT)**: Routers can perform NAT, allowing multiple devices on a local network to share a single public IP address.
-- **Firewall**: Many routers have built-in firewalls to filter traffic and enhance security.
-
-## Switches
-Switches are devices that connect devices within a local area network (LAN) and operate at the data link layer (Layer 2) of the OSI model. They use MAC addresses to forward data to the correct destination.
-
-### Functions of Switches
-- **Frame Forwarding**: Switches receive frames and forward them to the appropriate device based on MAC addresses.
-- **MAC Address Learning**: Switches maintain a MAC address table to keep track of the devices connected to each port.
-- **Segmentation**: Switches create separate collision domains, reducing network congestion and improving performance.
-- **VLANs (Virtual LANs)**: Switches can create VLANs to segment network traffic logically, enhancing security and management.
-
-## Hubs
-Hubs are basic network devices that connect multiple Ethernet devices, making them act as a single network segment. They operate at the physical layer (Layer 1) of the OSI model.
-
-### Functions of Hubs
-- **Data Transmission**: Hubs receive data from one device and broadcast it to all other connected devices.
-- **Signal Amplification**: Hubs can amplify signals to extend the distance that data can travel.
-- **Network Expansion**: Hubs can be used to connect multiple devices in a simple network.
-
-### Limitations of Hubs
-- **No Data Filtering**: Hubs do not filter data or direct it to specific devices, leading to unnecessary network traffic.
-- **Single Collision Domain**: All devices connected to a hub share the same collision domain, which can lead to data collisions and network inefficiency.
-
-## Modems
-Modems are devices that modulate and demodulate analog signals for digital data transmission over telephone lines or cable systems. They enable internet connectivity by converting digital data from a computer into analog signals for transmission and vice versa.
-
-### Functions of Modems
-- **Signal Modulation**: Modems convert digital data into analog signals for transmission over telephone or cable lines.
-- **Signal Demodulation**: Modems convert incoming analog signals back into digital data for the computer to process.
-- **Internet Connectivity**: Modems establish and maintain a connection to the internet service provider (ISP).
-- **Error Detection and Correction**: Modems can detect and correct errors that occur during data transmission.
-
-## Access Points
-Access Points (APs) are devices that allow wireless devices to connect to a wired network using Wi-Fi. They extend the range of a wired network and provide wireless connectivity.
-
-### Functions of Access Points
-- **Wireless Connectivity**: APs provide Wi-Fi access to wireless devices, enabling them to connect to a wired network.
-- **Network Extension**: APs extend the coverage area of a network, allowing devices to connect from a greater distance.
-- **Roaming Support**: APs enable seamless roaming, allowing devices to move between different APs without losing connectivity.
-- **Security**: APs can implement wireless security protocols (e.g., WPA2, WPA3) to protect the network from unauthorized access.
-
-## Summary
-Understanding the functions of basic network devices such as routers, switches, hubs, modems, and access points is essential for designing and managing effective networks. Each device plays a specific role in ensuring efficient data transmission, network connectivity, and security.
diff --git a/docs/Computer Networks/network_security.md b/docs/Computer Networks/network_security.md
deleted file mode 100644
index d8660055e..000000000
--- a/docs/Computer Networks/network_security.md
+++ /dev/null
@@ -1,89 +0,0 @@
----
-id: network_security
-title: Network Security
-sidebar_label: Network Security
-sidebar_position: 15
-tags: [computer_networks, networks, communication]
-description: Network security is a critical aspect of information technology that ensures the integrity, confidentiality, and availability of data as it is transmitted and received across networks
----
-# Network Security Basics
-
-## Introduction
-Network security is a critical aspect of information technology that ensures the integrity, confidentiality, and availability of data as it is transmitted and received across networks. Effective network security involves a combination of hardware, software, policies, and procedures designed to defend against threats and unauthorized access. This document covers the importance of network security, firewalls, antivirus software, and best practices in detail.
-
-## Importance of Network Security
-Network security is vital for protecting sensitive data, maintaining privacy, and ensuring the reliability of communications. Key reasons for its importance include:
-
-- **Protection of Sensitive Data**: Safeguarding personal information, financial data, and intellectual property from unauthorized access and breaches.
-- **Prevention of Cyber Attacks**: Defending against malware, phishing, ransomware, and other cyber threats that can disrupt operations and cause financial loss.
-- **Compliance with Regulations**: Adhering to legal and regulatory requirements for data protection, such as GDPR, HIPAA, and PCI-DSS.
-- **Maintaining Trust**: Ensuring customers and stakeholders have confidence in the security measures in place, which is essential for maintaining a good reputation and business continuity.
-- **Ensuring Network Availability**: Preventing network downtime and ensuring continuous access to critical services and resources.
-
-## Firewalls
-Firewalls are network security devices that monitor and control incoming and outgoing network traffic based on predetermined security rules. They act as a barrier between trusted internal networks and untrusted external networks.
-
-### Types of Firewalls
-- **Packet-Filtering Firewalls**: Inspect packets and allow or deny them based on source and destination IP addresses, ports, and protocols.
-- **Stateful Inspection Firewalls**: Monitor the state of active connections and make decisions based on the context of traffic, ensuring that only legitimate packets are allowed.
-- **Proxy Firewalls**: Act as intermediaries between end-users and the internet, providing additional security by inspecting and filtering content at the application layer.
-- **Next-Generation Firewalls (NGFW)**: Combine traditional firewall capabilities with advanced features like intrusion prevention, deep packet inspection, and application awareness.
-
-### Functions of Firewalls
-- **Traffic Filtering**: Allowing or blocking traffic based on security rules.
-- **Intrusion Detection and Prevention**: Identifying and stopping malicious activities.
-- **Network Segmentation**: Dividing a network into smaller segments to improve security and performance.
-- **VPN Support**: Enabling secure remote access to the network through virtual private networks.
-
-## Antivirus Software
-Antivirus software is designed to detect, prevent, and remove malware, including viruses, worms, trojans, and other malicious programs. It plays a crucial role in protecting individual devices and networks from cyber threats.
-
-### Functions of Antivirus Software
-- **Malware Detection**: Scanning files and systems for known malware signatures and behaviors.
-- **Real-Time Protection**: Continuously monitoring for malicious activities and blocking threats as they occur.
-- **Quarantine and Removal**: Isolating and removing infected files to prevent further spread of malware.
-- **System Scanning**: Performing regular and on-demand scans to ensure the system is free of malware.
-
-### Types of Malware Detected by Antivirus
-- **Viruses**: Malicious programs that attach themselves to legitimate files and spread to other files and systems.
-- **Worms**: Self-replicating malware that spreads across networks without user intervention.
-- **Trojans**: Malicious software disguised as legitimate programs, which can create backdoors for unauthorized access.
-- **Spyware**: Software that secretly collects user information and sends it to a remote attacker.
-- **Ransomware**: Malware that encrypts files and demands payment for their release.
-
-## Best Practices for Network Security
-Implementing best practices for network security helps to mitigate risks and protect against threats. Key best practices include:
-
-1. **Regular Software Updates**
- - Keep all software, including operating systems and applications, up to date with the latest security patches.
-
-2. **Strong Password Policies**
- - Enforce the use of complex passwords and regular password changes.
- - Implement multi-factor authentication (MFA) for additional security.
-
-3. **Network Segmentation**
- - Divide the network into segments to limit the spread of attacks and improve performance.
-
-4. **Data Encryption**
- - Use encryption to protect sensitive data both in transit and at rest.
-
-5. **Security Awareness Training**
- - Educate employees on security best practices and how to recognize phishing and other social engineering attacks.
-
-6. **Regular Security Audits**
- - Conduct regular security assessments and vulnerability scans to identify and address weaknesses.
-
-7. **Access Control**
- - Implement strict access controls to ensure that only authorized users have access to sensitive information and systems.
-
-8. **Backup and Recovery**
- - Regularly back up data and have a disaster recovery plan in place to quickly restore operations in the event of an attack.
-
-9. **Intrusion Detection and Prevention Systems (IDPS)**
- - Use IDPS to monitor network traffic for suspicious activities and take action to prevent potential threats.
-
-10. **Secure Configuration**
- - Ensure that all network devices and systems are securely configured according to best practices and industry standards.
-
-## Summary
-Network security is essential for protecting data, maintaining privacy, and ensuring the reliability of communications. Firewalls and antivirus software play critical roles in defending against cyber threats. By implementing best practices, organizations can significantly enhance their network security posture and mitigate risks.
\ No newline at end of file
diff --git a/docs/Computer Networks/network_topologies.md b/docs/Computer Networks/network_topologies.md
deleted file mode 100644
index df8552287..000000000
--- a/docs/Computer Networks/network_topologies.md
+++ /dev/null
@@ -1,157 +0,0 @@
----
-id: network_topologies
-title: Network Topologies
-sidebar_label: Network Topologies
-sidebar_position: 8
-tags: [computer_networks, networks, communication]
-description: A network topology is the arrangement of different elements (links, nodes, etc.) in a computer network.
----
-# Network Topologies
-
-## What is a Network Topology?
-
-A **network topology** is the arrangement of different elements (links, nodes, etc.) in a computer network. It is the structure or layout of a network and how different nodes in a network are connected and communicate with each other. The choice of topology affects the network's performance and scalability.
-
-### Types of Network Topologies
-
-1. **Bus Topology**
-2. **Star Topology**
-3. **Ring Topology**
-4. **Mesh Topology**
-5. **Tree Topology**
-6. **Hybrid Topology**
-
-#### 1. Bus Topology
-
-In a **bus topology**, all the devices are connected to a single central cable, known as the bus or backbone. Data sent from a node is broadcast to all devices on the network, but only the intended recipient accepts and processes the data.
-
-- **Characteristics**:
- - Simple and easy to install.
- - Uses a single cable for data transmission.
- - Suitable for small networks.
-
-- **Advantages**:
- - Cost-effective due to minimal cabling.
- - Easy to add new devices to the network.
- - Requires less cable than some other topologies.
-
-- **Disadvantages**:
- - Limited cable length and number of devices.
- - If the main cable (bus) fails, the entire network goes down.
- - Performance degrades as more devices are added.
-
-- **Examples**:
- - Early Ethernet networks.
- - Small office or home networks where cost is a primary concern.
-
-#### 2. Star Topology
-
-In a **star topology**, all devices are connected to a central hub or switch. The hub acts as a repeater for data flow.
-
-- **Characteristics**:
- - Each device has a dedicated connection to the central hub.
- - The hub manages and controls all functions of the network.
-
-- **Advantages**:
- - Easy to install and manage.
- - Failure of one device does not affect the others.
- - Simple to add new devices without disrupting the network.
-
-- **Disadvantages**:
- - If the central hub fails, the entire network goes down.
- - Requires more cable than bus topology.
- - Hub can become a bottleneck if too many devices are connected.
-
-- **Examples**:
- - Modern Ethernet networks.
- - Office environments with a centralized management hub.
-
-#### 3. Ring Topology
-
-In a **ring topology**, each device is connected to two other devices, forming a circular data path. Data travels in one direction (or in some cases, both directions) around the ring until it reaches its destination.
-
-- **Characteristics**:
- - Each device has exactly two neighbors for communication.
- - Data travels in a circular fashion.
-
-- **Advantages**:
- - Data packets travel at high speed.
- - Easy to install and reconfigure.
- - Better performance than bus topology under heavy load.
-
-- **Disadvantages**:
- - Failure of a single device can disrupt the entire network.
- - Troubleshooting can be difficult.
- - Adding or removing devices can disrupt the network.
-
-- **Examples**:
- - Token Ring networks.
- - Some metropolitan area networks (MANs).
-
-#### 4. Mesh Topology
-
-In a **mesh topology**, every device is connected to every other device in the network. This provides high redundancy and reliability.
-
-- **Characteristics**:
- - Full mesh: Every device is connected to every other device.
- - Partial mesh: Some devices are connected to multiple devices, but not all.
-
-- **Advantages**:
- - Provides high redundancy and reliability.
- - Failure of one link does not affect the entire network.
- - Excellent for large networks where reliability is crucial.
-
-- **Disadvantages**:
- - Expensive due to the large amount of cabling and network interfaces required.
- - Complex to install and manage.
-
-- **Examples**:
- - Military networks.
- - High-reliability networks in financial institutions.
-
-#### 5. Tree Topology
-
-A **tree topology** is a combination of star and bus topologies. It consists of groups of star-configured networks connected to a linear bus backbone.
-
-- **Characteristics**:
- - Hierarchical structure with root nodes and leaf nodes.
- - Combines characteristics of both bus and star topologies.
-
-- **Advantages**:
- - Scalable and easy to add new devices.
- - Fault isolation is easier.
- - Supports future expansion of network segments.
-
-- **Disadvantages**:
- - If the backbone line fails, the entire segment goes down.
- - Requires more cable than bus topology.
-
-- **Examples**:
- - Corporate networks with departmental segmentation.
- - School campus networks.
-
-#### 6. Hybrid Topology
-
-A **hybrid topology** is a combination of two or more different types of topologies. It aims to leverage the advantages of each of the component topologies.
-
-- **Characteristics**:
- - Combines features of multiple topologies.
- - Can be tailored to meet specific needs.
-
-- **Advantages**:
- - Flexible and scalable.
- - Optimized performance based on specific requirements.
- - Fault tolerance can be enhanced by combining robust topologies.
-
-- **Disadvantages**:
- - Can be complex and expensive to design and implement.
- - Managing and maintaining the network can be challenging.
-
-- **Examples**:
- - Large enterprise networks with multiple departmental networks using different topologies.
- - Campus networks with a combination of star and mesh configurations.
-
-## Conclusion
-
-Understanding network topologies is essential for designing efficient and reliable networks. Each topology has its own set of advantages and disadvantages, making them suitable for different scenarios and requirements. Selecting the appropriate topology can significantly impact the performance, scalability, and resilience of the network.
-
diff --git a/docs/Computer Networks/osi_model.md b/docs/Computer Networks/osi_model.md
deleted file mode 100644
index 24ba8057d..000000000
--- a/docs/Computer Networks/osi_model.md
+++ /dev/null
@@ -1,130 +0,0 @@
----
-id: osi-model
-title: The OSI Model
-sidebar_label: The OSI Model
-sidebar_position: 9
-tags: [computer_networks, networks, communication]
-description: The Open Systems Interconnection (OSI) model is a conceptual framework used to understand and implement network protocols in seven layers.
----
-
-# The OSI Model
-
-## What is the OSI Model?
-
-The **Open Systems Interconnection (OSI) model** is a conceptual framework used to understand and implement network protocols in seven layers. It was developed by the International Organization for Standardization (ISO) to standardize networking protocols and ensure different systems can communicate with each other. Each layer serves a specific function and communicates with the layers directly above and below it.
-
-### The Seven Layers of the OSI Model
-
-1. **Physical Layer (Layer 1)**
-2. **Data Link Layer (Layer 2)**
-3. **Network Layer (Layer 3)**
-4. **Transport Layer (Layer 4)**
-5. **Session Layer (Layer 5)**
-6. **Presentation Layer (Layer 6)**
-7. **Application Layer (Layer 7)**
-
-#### 1. Physical Layer (Layer 1)
-
-The **Physical Layer** is responsible for the physical connection between devices. It deals with the transmission and reception of raw bitstreams over a physical medium.
-
-- **Functions**:
- - Defines the hardware elements involved in the network, including cables, switches, and NICs (Network Interface Cards).
- - Specifies the electrical, mechanical, and procedural interface to the transmission medium.
- - Converts data into signals appropriate for the transmission medium.
-
-- **Examples**:
- - Ethernet cables, fiber optics, and wireless radio frequencies.
- - Standards like RS-232, RJ45, and IEEE 802.11.
-
-#### 2. Data Link Layer (Layer 2)
-
-The **Data Link Layer** provides node-to-node data transfer and handles error detection and correction from the Physical Layer. It is divided into two sublayers: Logical Link Control (LLC) and Media Access Control (MAC).
-
-- **Functions**:
- - Establishes and terminates a logical link between nodes.
- - Frame traffic control and flow control.
- - Error detection and correction.
- - Physical addressing (MAC addresses).
-
-- **Examples**:
- - Ethernet, Wi-Fi (IEEE 802.11), and PPP (Point-to-Point Protocol).
- - Switches and bridges operating at this layer.
-
-#### 3. Network Layer (Layer 3)
-
-The **Network Layer** is responsible for packet forwarding, including routing through intermediate routers.
-
-- **Functions**:
- - Logical addressing (IP addresses).
- - Routing and forwarding of data packets.
- - Fragmentation and reassembly of packets.
- - Handling of packet switching and congestion control.
-
-- **Examples**:
- - IP (Internet Protocol), ICMP (Internet Control Message Protocol), and OSPF (Open Shortest Path First).
- - Routers operate at this layer.
-
-#### 4. Transport Layer (Layer 4)
-
-The **Transport Layer** ensures complete data transfer. It provides reliable data transfer services to the upper layers.
-
-- **Functions**:
- - Establishment, maintenance, and termination of a connection.
- - Error detection and recovery.
- - Flow control and data segmentation.
- - Multiplexing of multiple communication streams.
-
-- **Examples**:
- - TCP (Transmission Control Protocol) and UDP (User Datagram Protocol).
- - Port numbers and sockets.
-
-#### 5. Session Layer (Layer 5)
-
-The **Session Layer** manages sessions between applications. It establishes, maintains, and terminates connections between applications.
-
-- **Functions**:
- - Session establishment, maintenance, and termination.
- - Synchronization of data exchange.
- - Dialog control, managing two-way communications.
-
-- **Examples**:
- - RPC (Remote Procedure Call) and NetBIOS.
- - Management of connections in client-server applications.
-
-#### 6. Presentation Layer (Layer 6)
-
-The **Presentation Layer** translates data between the application layer and the network format. It is responsible for data encoding, compression, and encryption.
-
-- **Functions**:
- - Data translation and encoding.
- - Data compression.
- - Data encryption and decryption.
-
-- **Examples**:
- - JPEG, GIF, PNG (image formats).
- - SSL/TLS (encryption protocols).
-
-#### 7. Application Layer (Layer 7)
-
-The **Application Layer** provides network services directly to end-users. It facilitates communication between software applications and lower-layer network services.
-
-- **Functions**:
- - Network process to application.
- - Provides protocols and services for email, file transfer, and other network software services.
- - End-user services such as web browsers, email clients, and file sharing applications.
-
-- **Examples**:
- - HTTP, FTP, SMTP, and DNS.
- - Applications like web browsers (Chrome, Firefox), email clients (Outlook, Gmail), and file sharing tools (Dropbox).
-
-## Importance of the OSI Model
-
-The OSI model is crucial for understanding and designing interoperable network systems. It:
-
-- **Standardizes Networking Protocols**: Provides a universal set of guidelines to ensure different network devices and protocols can work together.
-- **Facilitates Troubleshooting**: Helps network administrators diagnose and fix network issues by breaking down the problem into specific layers.
-- **Encourages Modular Engineering**: Promotes the design of network systems in modular layers, making it easier to upgrade or replace specific components without affecting the entire system.
-
-## Conclusion
-
-The OSI model is a foundational concept in networking that helps us understand how different network protocols and devices interact. By breaking down the complex process of network communication into seven distinct layers, it provides a clear framework for network design, implementation, and troubleshooting.
\ No newline at end of file
diff --git a/docs/Computer Networks/types-of-networks.md b/docs/Computer Networks/types-of-networks.md
deleted file mode 100644
index 25d751b8e..000000000
--- a/docs/Computer Networks/types-of-networks.md
+++ /dev/null
@@ -1,85 +0,0 @@
----
-id: types_of_networks
-title: Types of Networks
-sidebar_label: Types Of Networks
-sidebar_position: 7
-tags: [computer_networks, networks, communication]
-description: Computer networks can be categorized based on their size, range, and structure. The most common types are listed in this section.
-
----
-# Types of Networks
-Computer networks can be categorized based on their size, range, and structure. The most common types are:
-
-#### 1. Local Area Network (LAN)
-
-A **Local Area Network (LAN)** is a network that covers a small geographic area, typically a single building or a campus. LANs are commonly used to connect computers and devices within an office, school, or home environment.
-
-- **Characteristics**:
- - High data transfer rates (typically from 100 Mbps to 10 Gbps).
- - Limited geographic range, usually within a single building or a group of buildings.
- - Owned, managed, and maintained by a single organization or individual.
-
-- **Uses**:
- - Sharing files, printers, and other resources among connected devices.
- - Enabling communication through email and instant messaging within the network.
- - Supporting collaborative work environments with shared applications and data storage.
-
-- **Examples**:
- - A home network connecting a few computers, smartphones, and a printer.
- - An office network connecting workstations, servers, and other network devices.
-
-#### 2. Wide Area Network (WAN)
-
-A **Wide Area Network (WAN)** spans a large geographic area, such as a city, country, or even the globe. WANs are used to connect multiple LANs that are geographically dispersed.
-
-- **Characteristics**:
- - Lower data transfer rates compared to LANs (ranging from 56 Kbps to several Gbps).
- - Covers large geographic areas, often using leased telecommunication lines.
- - Can be public (the internet) or private (a company's intranet).
-
-- **Uses**:
- - Connecting remote offices of a business, allowing data sharing and communication across long distances.
- - Enabling internet access for users and organizations.
- - Supporting global communication and information exchange.
-
-- **Examples**:
- - The internet is the largest WAN, connecting millions of private, public, academic, and government networks.
- - A company's intranet connecting its headquarters with branch offices around the world.
-
-#### 3. Metropolitan Area Network (MAN)
-
-A **Metropolitan Area Network (MAN)** covers a larger geographic area than a LAN but smaller than a WAN, such as a city or a large campus. MANs are used to connect multiple LANs within a metropolitan area.
-
-- **Characteristics**:
- - Intermediate data transfer rates (typically between 10 Mbps and 1 Gbps).
- - Spans a city or a large campus.
- - Can be owned and operated by a single organization or a consortium of organizations.
-
-- **Uses**:
- - Connecting multiple LANs within a city, providing high-speed data transfer and communication.
- - Enabling efficient resource sharing and data exchange within a metropolitan area.
- - Supporting public services such as city-wide Wi-Fi networks and municipal services.
-
-- **Examples**:
- - A city-wide network connecting various government offices, libraries, and public facilities.
- - A university campus network connecting different departments and buildings.
-
-#### 4. Personal Area Network (PAN)
-
-A **Personal Area Network (PAN)** involves a network for personal devices, typically within a range of a few meters. PANs are used to connect personal electronic devices such as smartphones, tablets, laptops, and wearable devices.
-
-- **Characteristics**:
- - Short-range communication (typically within 10 meters).
- - Low data transfer rates compared to LANs and WANs.
- - Usually wireless, but can also include wired connections.
-
-- **Uses**:
- - Connecting personal devices for data synchronization and file sharing.
- - Enabling communication between wearable devices and smartphones.
- - Facilitating the use of personal wireless peripherals such as Bluetooth headphones and keyboards.
-
-- **Examples**:
- - A Bluetooth connection between a smartphone and a wireless headset.
- - A Wi-Fi network connecting a laptop and a printer within a home.
-
-Understanding the different types of networks is crucial for designing and implementing effective networking solutions. Each type of network serves specific purposes and is suited for different scenarios based on geographic scope, data transfer requirements, and user needs.
diff --git a/docs/Computer Networks/wireless_networking.md b/docs/Computer Networks/wireless_networking.md
deleted file mode 100644
index a4aed9716..000000000
--- a/docs/Computer Networks/wireless_networking.md
+++ /dev/null
@@ -1,87 +0,0 @@
----
-id: wireless_networking
-title: Wireless Networking
-sidebar_label: Wireless Networking
-sidebar_position: 14
-tags: [computer_networks, networks, communication]
-description: Wireless networking allows devices to connect and communicate without physical cables, using radio frequency signals.
----
-# Wireless Networking
-
-## Introduction
-Wireless networking allows devices to connect and communicate without physical cables, using radio frequency signals. Two common wireless technologies are Wi-Fi and Bluetooth, each serving different purposes and use cases. This document covers the basics of Wi-Fi and Bluetooth, and provides detailed information on Wi-Fi security.
-
-## Basics of Wi-Fi
-Wi-Fi (Wireless Fidelity) is a wireless networking technology that allows devices to connect to a local area network (LAN) and access the internet without physical cables. It operates within the IEEE 802.11 standards.
-
-### How Wi-Fi Works
-- **Access Points (APs)**: Devices, such as routers, that broadcast Wi-Fi signals and connect wireless devices to a wired network.
-- **Wi-Fi Adapters**: Hardware in devices (e.g., laptops, smartphones) that receive and send Wi-Fi signals.
-- **Frequency Bands**: Wi-Fi typically operates on 2.4 GHz and 5 GHz frequency bands.
-- **Channels**: Frequency bands are divided into channels to minimize interference.
-
-### Wi-Fi Standards
-- **802.11a**: Operates at 5 GHz, supports up to 54 Mbps.
-- **802.11b**: Operates at 2.4 GHz, supports up to 11 Mbps.
-- **802.11g**: Operates at 2.4 GHz, supports up to 54 Mbps.
-- **802.11n**: Operates at 2.4 GHz and 5 GHz, supports up to 600 Mbps.
-- **802.11ac**: Operates at 5 GHz, supports up to several Gbps.
-- **802.11ax (Wi-Fi 6)**: Operates at 2.4 GHz and 5 GHz, supports higher data rates and improved performance in congested environments.
-
-## Basics of Bluetooth
-Bluetooth is a wireless technology for short-range communication between devices. It operates at 2.4 GHz and is widely used for connecting peripherals, such as keyboards, mice, headphones, and smart devices.
-
-### How Bluetooth Works
-- **Pairing**: The process of establishing a connection between two Bluetooth devices.
-- **Profiles**: Define specific Bluetooth functions and applications (e.g., A2DP for audio streaming, HID for input devices).
-- **Range**: Typically up to 10 meters for most devices, though some classes can reach up to 100 meters.
-
-### Bluetooth Versions
-- **Bluetooth 1.0-1.2**: Basic features with data rates up to 1 Mbps.
-- **Bluetooth 2.0-2.1**: Enhanced data rates up to 3 Mbps.
-- **Bluetooth 3.0**: High-Speed data transfer using Wi-Fi.
-- **Bluetooth 4.0-4.2**: Low Energy (LE) for power-efficient communication.
-- **Bluetooth 5.0**: Improved range, speed, and broadcast capacity.
-
-## Wi-Fi Security
-Securing a Wi-Fi network is crucial to protect data and prevent unauthorized access. Various security protocols and practices help achieve this.
-
-### Wi-Fi Security Protocols
-- **WEP (Wired Equivalent Privacy)**: An older security protocol that provides weak protection due to vulnerabilities.
-- **WPA (Wi-Fi Protected Access)**: Improved security over WEP with dynamic key encryption.
-- **WPA2 (Wi-Fi Protected Access II)**: Uses AES encryption for stronger security and is widely used today.
-- **WPA3 (Wi-Fi Protected Access III)**: The latest security protocol offering improved encryption and protection against brute-force attacks.
-
-### Common Wi-Fi Security Measures
-1. **Change Default SSID and Password**
- - **SSID (Service Set Identifier)**: The name of your Wi-Fi network. Change the default SSID to a unique name.
- - **Password**: Use a strong, unique password for your Wi-Fi network.
-
-2. **Enable Network Encryption**
- - Use WPA3 if supported; otherwise, use WPA2.
-
-3. **Disable SSID Broadcasting**
- - Hides your Wi-Fi network from casual discovery. Devices must know the SSID to connect.
-
-4. **Enable MAC Address Filtering**
- - Restrict network access to devices with specific MAC addresses.
-
-5. **Use a Guest Network**
- - Set up a separate network for guests to keep your primary network secure.
-
-6. **Regularly Update Router Firmware**
- - Keep your router's firmware up to date to protect against security vulnerabilities.
-
-7. **Implement Network Firewalls**
- - Use built-in router firewalls and consider additional software firewalls on connected devices.
-
-8. **Disable Remote Management**
- - Turn off remote management features unless specifically needed.
-
-### Advanced Wi-Fi Security Practices
-- **VPN (Virtual Private Network)**: Use a VPN to encrypt internet traffic and protect data privacy.
-- **Network Segmentation**: Create separate networks for different device types (e.g., IoT devices on a separate network).
-- **Intrusion Detection Systems (IDS)**: Monitor network traffic for suspicious activity.
-
-## Summary
-Wireless networking, through technologies like Wi-Fi and Bluetooth, enables convenient and flexible connectivity. Understanding the basics of these technologies and implementing robust Wi-Fi security measures is essential for protecting data and ensuring reliable communication in both personal and professional environments.
\ No newline at end of file
diff --git a/docs/DBMS/Entity-Relational Model/_category.json b/docs/DBMS/Entity-Relational Model/_category.json
deleted file mode 100644
index 78b19ec4a..000000000
--- a/docs/DBMS/Entity-Relational Model/_category.json
+++ /dev/null
@@ -1,9 +0,0 @@
-{
- "label": "Entity-Relational Model",
- "position": 1,
- "link": {
- "type": "generated-index",
- "description": "In this section, you will learn about the Entity-Relational Model in DBMS, a fundamental concept for conceptual design of databases. We will cover the basics of entities, relationships, attributes, and constraints, and how they are used to create a structured database schema."
- }
- }
-
\ No newline at end of file
diff --git a/docs/DBMS/Entity-Relational Model/dbms-generalization-and-aggregation.md b/docs/DBMS/Entity-Relational Model/dbms-generalization-and-aggregation.md
deleted file mode 100644
index 1356900f6..000000000
--- a/docs/DBMS/Entity-Relational Model/dbms-generalization-and-aggregation.md
+++ /dev/null
@@ -1,101 +0,0 @@
----
-id: dbms-generalization-and-aggregation
-title: DBMS - Generalization and Aggregation
-sidebar_label: Generalization and Aggregation
-sidebar_position: 3
-description: Learn about the concepts of Generalization and Aggregation in DBMS, which allow expressing database entities in a conceptual hierarchical manner.
-tags:
- - DBMS
- - Generalization
- - Aggregation
- - Database Design
----
-
-# DBMS - Generalization and Aggregation
-
-The ER Model has the power of expressing database entities in a conceptual hierarchical manner. As the hierarchy goes up, it generalizes the view of entities, and as we go deep in the hierarchy, it gives us the detail of every entity included.
-
-Going up in this structure is called generalization, where entities are clubbed together to represent a more generalized view. For example, a particular student named Mira can be generalized along with all the students. The entity shall be a student, and further, the student is a person. The reverse is called specialization where a person is a student, and that student is Mira.
-
-## Generalization
-
-As mentioned above, the process of generalizing entities, where the generalized entities contain the properties of all the generalized entities, is called generalization. In generalization, a number of entities are brought together into one generalized entity based on their similar characteristics. For example, pigeon, house sparrow, crow, and dove can all be generalized as Birds.
-
-### Example of Generalization
-
-| Specific Entities | Generalized Entity |
-|-------------------|---------------------|
-| Pigeon | Bird |
-| House Sparrow | Bird |
-| Crow | Bird |
-| Dove | Bird |
-
-```mermaid
----
-title: Generalization Example
----
-erDiagram
- PIGEON }|..|{ BIRD : generalizes
- HOUSE_SPARROW }|..|{ BIRD : generalizes
- CROW }|..|{ BIRD : generalizes
- DOVE }|..|{ BIRD : generalizes
-```
-
-## Specialization
-
-Specialization is the opposite of generalization. In specialization, a group of entities is divided into sub-groups based on their characteristics. Take a group ‘Person’ for example. A person has a name, date of birth, gender, etc. These properties are common in all persons, human beings. But in a company, persons can be identified as employee, employer, customer, or vendor, based on what role they play in the company.
-
-### Example of Specialization
-
-| General Entity | Specialized Entities |
-|----------------|--------------------------|
-| Person | Employee, Employer, Customer, Vendor |
-
-```mermaid
----
-title: Specialization Example
----
-erDiagram
- PERSON ||--o{ EMPLOYEE : specializes
- PERSON ||--o{ EMPLOYER : specializes
- PERSON ||--o{ CUSTOMER : specializes
- PERSON ||--o{ VENDOR : specializes
-```
-
-Similarly, in a school database, persons can be specialized as teacher, student, or a staff, based on what role they play in school as entities.
-
-## Inheritance
-
-We use all the above features of ER-Model in order to create classes of objects in object-oriented programming. The details of entities are generally hidden from the user; this process is known as abstraction.
-
-Inheritance is an important feature of Generalization and Specialization. It allows lower-level entities to inherit the attributes of higher-level entities.
-
-### Example of Inheritance
-
-| Higher-level Entity | Attributes | Lower-level Entities |
-|---------------------|-----------------------------|------------------------|
-| Person | Name, Age, Gender | Student, Teacher |
-
-```mermaid
----
-title: Inheritance Example
----
-erDiagram
- PERSON {
- string name
- int age
- string gender
- }
- STUDENT {
- string school
- string grade
- }
- TEACHER {
- string subject
- string department
- }
- PERSON ||--o{ STUDENT : inherits
- PERSON ||--o{ TEACHER : inherits
-```
-
-For example, the attributes of a Person class such as name, age, and gender can be inherited by lower-level entities such as Student or Teacher.
\ No newline at end of file
diff --git a/docs/DBMS/Entity-Relational Model/er-diagram-representation.md b/docs/DBMS/Entity-Relational Model/er-diagram-representation.md
deleted file mode 100644
index 73b97600f..000000000
--- a/docs/DBMS/Entity-Relational Model/er-diagram-representation.md
+++ /dev/null
@@ -1,181 +0,0 @@
----
-id: er-diagram-representation
-title: DBMS ER Diagram Representation
-sidebar_label: ER Diagram Representation
-sidebar_position: 2
-description: Learn how to represent the Entity-Relationship (ER) Model using ER diagrams, including entities, attributes, relationships, and cardinality.
-tags:
- - DBMS
- - ER Diagram
- - Database Design
----
-
-# DBMS - ER Diagram Representation
-
-Let us now learn how the ER Model is represented by means of an ER diagram. Any object, for example, entities, attributes of an entity, relationship sets, and attributes of relationship sets, can be represented with the help of an ER diagram.
-
-## Entity
-
-Entities are represented by means of rectangles. Rectangles are named with the entity set they represent.
-
-```mermaid
----
-title: Entity Representation
----
-erDiagram
- ENTITY {
- string attribute1
- int attribute2
- }
-```
-
-## Attributes
-
-### Simple Attributes
-
-Attributes are the properties of entities. Attributes are represented by means of ellipses. Every ellipse represents one attribute and is directly connected to its entity (rectangle).
-
-```mermaid
----
-title: Simple Attributes
----
-erDiagram
- ENTITY {
- string attribute1
- }
-```
-
-### Composite Attributes
-
-If the attributes are composite, they are further divided in a tree-like structure. Every node is then connected to its attribute. Composite attributes are represented by ellipses that are connected with an ellipse.
-
-```mermaid
----
-title: Composite Attributes
----
-erDiagram
- ENTITY {
- string attribute1
- }
- attribute1 {
- string sub_attribute1
- string sub_attribute2
- }
- ENTITY ||--o{ attribute1 : has
-```
-
-### Multivalued Attributes
-
-Multivalued attributes are depicted by double ellipses.
-
-```mermaid
----
-title: Multivalued Attributes
----
-erDiagram
- ENTITY {
- string attribute1
- int attribute2
- string[] multivalued_attribute
- }
- ENTITY ||--o{ multivalued_attribute : has
-```
-
-### Derived Attributes
-
-Derived attributes are depicted by dashed ellipses.
-
-```mermaid
----
-title: Derived Attributes
----
-erDiagram
- ENTITY {
- string attribute1
- int attribute2
- int derived_attribute
- }
- ENTITY ||--o{ derived_attribute : derives
-```
-
-## Relationship
-
-Relationships are represented by diamond-shaped boxes. The name of the relationship is written inside the diamond-box. All the entities (rectangles) participating in a relationship are connected to it by a line.
-
-### Binary Relationship and Cardinality
-
-A relationship where two entities are participating is called a binary relationship. Cardinality is the number of instances of an entity from a relation that can be associated with the relation.
-
-#### One-to-One
-
-When only one instance of an entity is associated with the relationship, it is marked as '1:1'. The following image reflects that only one instance of each entity should be associated with the relationship. It depicts one-to-one relationship.
-
-```mermaid
----
-title: One-to-One Relationship
----
-erDiagram
- ENTITY1 ||--|| ENTITY2 : relationship
-```
-
-#### One-to-Many
-
-When more than one instance of an entity is associated with a relationship, it is marked as '1:N'. The following image reflects that only one instance of entity on the left and more than one instance of an entity on the right can be associated with the relationship. It depicts one-to-many relationship.
-
-```mermaid
----
-title: One-to-Many Relationship
----
-erDiagram
- ENTITY1 ||--o{ ENTITY2 : relationship
-```
-
-#### Many-to-One
-
-When more than one instance of entity is associated with the relationship, it is marked as 'N:1'. The following image reflects that more than one instance of an entity on the left and only one instance of an entity on the right can be associated with the relationship. It depicts many-to-one relationship.
-
-```mermaid
----
-title: Many-to-One Relationship
----
-erDiagram
- ENTITY1 }o--|| ENTITY2 : relationship
-```
-
-#### Many-to-Many
-
-The following image reflects that more than one instance of an entity on the left and more than one instance of an entity on the right can be associated with the relationship. It depicts many-to-many relationship.
-
-```mermaid
----
-title: Many-to-Many Relationship
----
-erDiagram
- ENTITY1 }o--o{ ENTITY2 : relationship
-```
-
-### Participation Constraints
-
-#### Total Participation
-
-Each entity is involved in the relationship. Total participation is represented by double lines.
-
-```mermaid
----
-title: Total Participation
----
-erDiagram
- ENTITY1 ||--|| ENTITY2 : relationship
-```
-
-#### Partial Participation
-
-Not all entities are involved in the relationship. Partial participation is represented by single lines.
-
-```mermaid
----
-title: Partial Participation
----
-erDiagram
- ENTITY1 }o--|| ENTITY2 : relationship
-```
diff --git a/docs/DBMS/Entity-Relational Model/er-model-basics-concepts.md b/docs/DBMS/Entity-Relational Model/er-model-basics-concepts.md
deleted file mode 100644
index d36a7cae0..000000000
--- a/docs/DBMS/Entity-Relational Model/er-model-basics-concepts.md
+++ /dev/null
@@ -1,81 +0,0 @@
----
-id: er-model-basics-concepts
-title: DBMS ER Model Basic Concepts
-sidebar_label: ER Model Basic Concepts
-sidebar_position: 1
-description: Learn about the Entity-Relationship (ER) model, its basic concepts, entities, attributes, and relationships that form the foundation of database design.
-tags:
- - DBMS
- - ER Model
- - Database Design
----
-
-# DBMS - ER Model Basic Concepts
-
-The ER model defines the conceptual view of a database. It works around real-world entities and the associations among them. At view level, the ER model is considered a good option for designing databases.
-
-## Entity
-
-An entity can be a real-world object, either animate or inanimate, that can be easily identifiable. For example, in a school database, students, teachers, classes, and courses offered can be considered as entities. All these entities have some attributes or properties that give them their identity.
-
-An entity set is a collection of similar types of entities. An entity set may contain entities with attribute sharing similar values. For example, a Students set may contain all the students of a school; likewise, a Teachers set may contain all the teachers of a school from all faculties. Entity sets need not be disjoint.
-
-## Attributes
-
-Entities are represented by means of their properties, called attributes. All attributes have values. For example, a student entity may have name, class, and age as attributes.
-
-There exists a domain or range of values that can be assigned to attributes. For example, a student's name cannot be a numeric value. It has to be alphabetic. A student's age cannot be negative, etc.
-
-### Types of Attributes
-
-| Type | Description |
-| ---------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------- |
-| Simple attribute | Atomic values, which cannot be divided further. Example: a student's phone number is an atomic value of 10 digits. |
-| Composite attribute | Made of more than one simple attribute. Example: a student's complete name may have first_name and last_name. |
-| Derived attribute | Attributes that do not exist in the physical database, but their values are derived from other attributes. Example: average_salary in a department. |
-| Single-value attribute | Contain a single value. Example: Social_Security_Number. |
-| Multi-value attribute | May contain more than one value. Example: a person can have more than one phone number, email_address, etc. |
-
-These attribute types can come together in a way like −
-
-- Simple single-valued attributes
-- Simple multi-valued attributes
-- Composite single-valued attributes
-- Composite multi-valued attributes
-
-## Entity-Set and Keys
-
-Key is an attribute or collection of attributes that uniquely identifies an entity among an entity set.
-
-For example, the roll_number of a student makes him/her identifiable among students.
-
-- **Super Key** − A set of attributes (one or more) that collectively identifies an entity in an entity set.
-- **Candidate Key** − A minimal super key is called a candidate key. An entity set may have more than one candidate key.
-- **Primary Key** − A primary key is one of the candidate keys chosen by the database designer to uniquely identify the entity set.
-
-## Relationship
-
-The association among entities is called a relationship. For example, an employee works_at a department, a student enrolls in a course. Here, Works_at and Enrolls are called relationships.
-
-### Relationship Set
-
-A set of relationships of similar type is called a relationship set. Like entities, a relationship too can have attributes. These attributes are called descriptive attributes.
-
-### Degree of Relationship
-
-The number of participating entities in a relationship defines the degree of the relationship.
-
-- Binary = degree 2
-- Ternary = degree 3
-- n-ary = degree n
-
-### Mapping Cardinalities
-
-Cardinality defines the number of entities in one entity set, which can be associated with the number of entities of another set via a relationship set.
-
-| Cardinality | Diagram | Description |
-| ------------ | ------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
-| One-to-one |  | One entity from entity set A can be associated with at most one entity of entity set B and vice versa. |
-| One-to-many |  | One entity from entity set A can be associated with more than one entities of entity set B; however, an entity from entity set B can be associated with at most one entity. |
-| Many-to-one |  | More than one entities from entity set A can be associated with at most one entity of entity set B; however, an entity from entity set B can be associated with more than one entity from entity set A. |
-| Many-to-many |  | One entity from entity set A can be associated with more than one entity from entity set B and vice versa. |
diff --git a/docs/DBMS/Indexing And Hashing/_category.json b/docs/DBMS/Indexing And Hashing/_category.json
deleted file mode 100644
index db7e16bb7..000000000
--- a/docs/DBMS/Indexing And Hashing/_category.json
+++ /dev/null
@@ -1,8 +0,0 @@
-{
- "label": "Indexing and Hashing",
- "position": 5,
- "link": {
- "type": "generated-index",
- "description": "Explore various indexing techniques and hashing methods in DBMS."
- }
-}
\ No newline at end of file
diff --git a/docs/DBMS/Indexing And Hashing/hashing.md b/docs/DBMS/Indexing And Hashing/hashing.md
deleted file mode 100644
index 68ae87520..000000000
--- a/docs/DBMS/Indexing And Hashing/hashing.md
+++ /dev/null
@@ -1,107 +0,0 @@
----
-id: dbms-hashing
-title: DBMS - Hashing
-sidebar_label: Hashing
-sidebar_position: 2
-description: Learn about different types of hashing in database management systems, their structures, and operations.
----
-
-DBMS - Hashing
-===
-
-For a huge database structure, it can be almost next to impossible to search all the index values through all its levels and then reach the destination data block to retrieve the desired data. Hashing is an effective technique to calculate the direct location of a data record on the disk without using an index structure.
-
-Hashing uses hash functions with search keys as parameters to generate the address of a data record.
-
-Hash Organization
----
-
-- **Bucket:** A hash file stores data in bucket format. A bucket is considered a unit of storage and typically stores one complete disk block, which in turn can store one or more records.
-- **Hash Function:** A hash function, h, is a mapping function that maps all the set of search-keys K to the address where actual records are placed. It is a function from search keys to bucket addresses.
-
-### Static Hashing
-
-In static hashing, when a search-key value is provided, the hash function always computes the same address. For example, if a mod-4 hash function is used, then it shall generate only 5 values. The output address shall always be the same for that function. The number of buckets provided remains unchanged at all times.
-
-#### Operation
-- **Insertion:** When a record is required to be entered using static hash, the hash function h computes the bucket address for search key K, where the record will be stored.
- - Bucket address = h(K)
-- **Search:** When a record needs to be retrieved, the same hash function can be used to retrieve the address of the bucket where the data is stored.
-- **Delete:** This is simply a search followed by a deletion operation.
-
-```mermaid
-graph TD;
- A[Static Hashing] --> B[Insertion]
- A --> C[Search]
- A --> D[Deletion]
- B --> E[Compute Bucket Address]
- C --> F[Retrieve Bucket Address]
- D --> G[Locate and Delete Record]
-```
-
-#### Bucket Overflow
-The condition of bucket overflow is known as a collision. This is a critical state for any static hash function. In this case, overflow chaining can be used.
-
-- **Overflow Chaining:** When buckets are full, a new bucket is allocated for the same hash result and is linked after the previous one. This mechanism is called Closed Hashing.
-- **Linear Probing:** When a hash function generates an address at which data is already stored, the next free bucket is allocated to it. This mechanism is called Open Hashing.
-
-```mermaid
-graph TD;
- A[Bucket Overflow] --> B[Overflow Chaining]
- A --> C[Linear Probing]
- B --> D[New Bucket Allocation]
- C --> E[Next Free Bucket]
-```
-
-### Dynamic Hashing
-
-The problem with static hashing is that it does not expand or shrink dynamically as the size of the database grows or shrinks. Dynamic hashing provides a mechanism in which data buckets are added and removed dynamically and on-demand. Dynamic hashing is also known as extended hashing.
-
-#### Organization
-The prefix of an entire hash value is taken as a hash index. Only a portion of the hash value is used for computing bucket addresses. Every hash index has a depth value to signify how many bits are used for computing a hash function. These bits can address $(2^n)$ buckets. When all these bits are consumed, that is, when all the buckets are full, then the depth value is increased linearly and twice the buckets are allocated.
-
-```mermaid
-graph TD;
- A[Dynamic Hashing] --> B[Hash Index]
- B --> C[Depth Value]
- C --> D[Compute Bucket Addresses]
- D --> E[Increase Depth and Allocate More Buckets]
-```
-
-#### Operation
-- **Querying:** Look at the depth value of the hash index and use those bits to compute the bucket address.
-- **Update:** Perform a query as above and update the data.
-- **Deletion:** Perform a query to locate the desired data and delete the same.
-- **Insertion:** Compute the address of the bucket.
- - If the bucket is already full:
- - Add more buckets.
- - Add additional bits to the hash value.
- - Re-compute the hash function.
- - Else:
- - Add data to the bucket.
- - If all the buckets are full, perform the remedies of static hashing.
-
-```mermaid
-graph TD;
- A[Dynamic Hashing Operation] --> B[Querying]
- A --> C[Update]
- A --> D[Deletion]
- A --> E[Insertion]
- E --> F[Compute Bucket Address]
- F --> G{Bucket Full?}
- G --> H[Add More Buckets]
- G --> I[Add Data to Bucket]
- H --> J[Add Bits to Hash Value]
- H --> K[Re-compute Hash Function]
-```
-
-### Comparison Table
-
-| Feature | Static Hashing | Dynamic Hashing |
-|--------------------|---------------------------|----------------------------|
-| Bucket Expansion | Fixed number of buckets | Buckets expand/shrink dynamically |
-| Collision Handling | Overflow chaining, linear probing | Overflow chaining, linear probing |
-| Performance | Good for small databases | Better for large, dynamic databases |
-| Flexibility | Less flexible | Highly flexible |
-
-Hashing is not favorable when the data is organized in some ordering and the queries require a range of data. When data is discrete and random, hashing performs the best. Hashing algorithms have higher complexity than indexing. All hash operations are done in constant time.
diff --git a/docs/DBMS/Indexing And Hashing/indexing.md b/docs/DBMS/Indexing And Hashing/indexing.md
deleted file mode 100644
index 64c55a8a2..000000000
--- a/docs/DBMS/Indexing And Hashing/indexing.md
+++ /dev/null
@@ -1,135 +0,0 @@
----
-id: dbms-indexing
-title: DBMS - Indexing
-sidebar_label: Indexing
-sidebar_position: 1
-description: Learn about different types of indexing in database management systems, their structures, and operations.
----
-
-DBMS - Indexing
-===
-
-We know that data is stored in the form of records. Every record has a key field, which helps it to be recognized uniquely.
-
-Indexing is a data structure technique to efficiently retrieve records from the database files based on some attributes on which the indexing has been done. Indexing in database systems is similar to what we see in books.
-
-Indexing Types
----
-
-Indexing is defined based on its indexing attributes. Indexing can be of the following types:
-
-### Primary Index
-- **Description:** Defined on an ordered data file. The data file is ordered on a key field, generally the primary key of the relation.
-
-### Secondary Index
-- **Description:** May be generated from a field which is a candidate key and has a unique value in every record, or a non-key with duplicate values.
-
-### Clustering Index
-- **Description:** Defined on an ordered data file. The data file is ordered on a non-key field.
-
-Ordered Indexing Types
----
-
-Ordered Indexing can be of two types:
-
-### Dense Index
-- **Description:** There is an index record for every search key value in the database.
-- **Characteristics:** Faster searching but requires more space to store index records.
-- **Structure:**
- - Index records contain search key value and a pointer to the actual record on the disk.
-
-```mermaid
-graph TD;
- A[Dense Index] --> B[Search Key 1]
- A --> C[Search Key 2]
- A --> D[Search Key 3]
- B --> E[Record Pointer 1]
- C --> F[Record Pointer 2]
- D --> G[Record Pointer 3]
-```
-
-### Sparse Index
-- **Description:** Index records are not created for every search key.
-- **Characteristics:** Contains a search key and an actual pointer to the data on the disk.
-- **Structure:**
- - To search a record, proceed by index record and reach the actual location of the data. If not found, start sequential search until the desired data is found.
-
-```mermaid
-graph TD;
- A[Sparse Index] --> B[Search Key 1]
- A --> C[Search Key 2]
- A --> D[Search Key 3]
- B --> E[Record Pointer 1]
- C --> F[Record Pointer 2]
- D --> G[Record Pointer 3]
-```
-
-### Multilevel Index
-- **Description:** Index records comprise search-key values and data pointers. Stored on disk along with the actual database files.
-- **Characteristics:** As the database size grows, so does the size of the indices.
-- **Structure:**
- - Break down the index into several smaller indices to make the outermost level so small that it can be saved in a single disk block.
-
-```mermaid
-graph TD;
- A[Multilevel Index] --> B[Level 1 Index]
- B --> C[Level 2 Index 1]
- B --> D[Level 2 Index 2]
- C --> E[Data Pointer 1]
- C --> F[Data Pointer 2]
- D --> G[Data Pointer 3]
- D --> H[Data Pointer 4]
-```
-
-### B+ Tree
-- **Description:** A balanced binary search tree that follows a multi-level index format. Leaf nodes denote actual data pointers.
-- **Characteristics:** Ensures all leaf nodes remain at the same height, thus balanced. Supports random access and sequential access.
-
-```mermaid
-graph TD;
- A[B+ Tree] --> B[Internal Node]
- B --> C[Leaf Node 1]
- B --> D[Leaf Node 2]
- C --> E[Data Pointer 1]
- C --> F[Data Pointer 2]
- D --> G[Data Pointer 3]
- D --> H[Data Pointer 4]
- H --> I[Next Leaf Node]
-```
-
-#### Structure of B+ Tree
-- **Internal Nodes:**
- - Contain at least $⌈n/2⌉$ pointers, except the root node.
- - At most, an internal node can contain n pointers.
-
-- **Leaf Nodes:**
- - Contain at least $⌈n/2⌉$ record pointers and $⌈n/2⌉$ key values.
- - At most, a leaf node can contain n record pointers and n key values.
- - Every leaf node contains one block pointer P to point to the next leaf node, forming a linked list.
-
-#### B+ Tree Insertion
-1. **Insertion at Leaf Node:**
- - If a leaf node overflows, split node into two parts.
- - Partition at $i = ⌊(m+1)/2⌋$.
- - First i entries are stored in one node.
- - Rest of the entries (i+1 onwards) are moved to a new node.
- - ith key is duplicated at the parent of the leaf.
-
-2. **Insertion at Non-leaf Node:**
- - Split node into two parts.
- - Partition the node at $i = ⌊(m+1)/2⌋$.
- - Entries up to i are kept in one node.
- - Rest of the entries are moved to a new node.
-
-#### B+ Tree Deletion
-1. **Deletion at Leaf Node:**
- - The target entry is searched and deleted.
- - If it is an internal node, delete and replace it with the entry from the left position.
- - After deletion, check for underflow.
-
-2. **Handling Underflow:**
- - If underflow occurs, distribute the entries from the nodes left to it.
- - If distribution is not possible from the left, distribute from the nodes right to it.
- - If distribution is not possible from left or right, merge the node with left and right nodes.
-
-In summary, indexing in DBMS is a crucial technique to enhance the speed and efficiency of data retrieval. Different indexing methods and structures are suited to various data and query types, ensuring optimized performance for diverse database operations.
diff --git a/docs/DBMS/Relational Database Design/_category.json b/docs/DBMS/Relational Database Design/_category.json
deleted file mode 100644
index ca74a0112..000000000
--- a/docs/DBMS/Relational Database Design/_category.json
+++ /dev/null
@@ -1,8 +0,0 @@
-{
- "label": "Relational Database Design",
- "position": 3,
- "link": {
- "type": "generated-index",
- "description": "Explore relational database design concepts, including the Relational Model, ER modeling, normalization, and more."
- }
-}
\ No newline at end of file
diff --git a/docs/DBMS/Relational Database Design/dbms-joins.md b/docs/DBMS/Relational Database Design/dbms-joins.md
deleted file mode 100644
index 565e31ef6..000000000
--- a/docs/DBMS/Relational Database Design/dbms-joins.md
+++ /dev/null
@@ -1,123 +0,0 @@
----
-id: dbms-joins
-title: DBMS - Joins
-sidebar_label: DBMS Joins
-sidebar_position: 2
-description: Explore different types of joins in database management systems and their applications.
----
-
-DBMS - Joins
----
-
-Joins in database management systems allow us to combine data from multiple tables based on specified conditions. Let's explore various types of joins:
-
-Theta (θ) Join
----
-
-Theta join combines tuples from different relations based on a given theta condition denoted by the symbol θ. It can use various comparison operators.
-
-```mermaid
-graph TD;
- A[Student] -->|Std| B[Subjects]
- B -->|Class| C[Student_Detail]
-```
-
-Example of Theta Join:
-```plaintext
-Student
-SID Name Std
-101 Alex 10
-102 Maria 11
-
-Subjects
-Class Subject
-10 Math
-10 English
-11 Music
-11 Sports
-
-Student_Detail
-SID Name Std Class Subject
-101 Alex 10 10 Math
-101 Alex 10 10 English
-102 Maria 11 11 Music
-102 Maria 11 11 Sports
-```
-
-Equijoin
----
-
-Equijoin is a type of theta join where only equality comparison operators are used. It matches tuples based on equal values of attributes.
-
-Natural Join (⋈)
----
-
-Natural join combines tuples from two relations based on common attributes with the same name and domain. It does not use any comparison operator.
-
-Example of Natural Join:
-```mermaid
-graph TD;
- A[Courses] -->|Dept| B[HoD]
-```
-
-Result of Natural Join:
-```plaintext
-Courses ⋈ HoD
-Dept CID Course Head
-CS CS01 Database Alex
-ME ME01 Mechanics Maya
-EE EE01 Electronics Mira
-```
-
-Outer Joins
----
-
-Outer joins include all tuples from participating relations, even if there are no matching tuples.
-
-Left Outer Join (R Left Outer Join S)
----
-
-```plaintext
-Left
-A B
-100 Database
-101 Mechanics
-102 Electronics
-
-Right
-A B
-100 Alex
-102 Maya
-104 Mira
-
-Courses Left Outer Join HoD
-A B C D
-100 Database 100 Alex
-101 Mechanics --- ---
-102 Electronics 102 Maya
-```
-
-Right Outer Join (R Right Outer Join S)
----
-
-```plaintext
-Courses Right Outer Join HoD
-A B C D
-100 Database 100 Alex
-102 Electronics 102 Maya
---- --- 104 Mira
-```
-
-Full Outer Join (R Full Outer Join S)
----
-
-```plaintext
-Courses Full Outer Join HoD
-A B C D
-100 Database 100 Alex
-101 Mechanics --- ---
-102 Electronics 102 Maya
---- --- 104 Mira
-```
-
-These joins are crucial for combining data effectively from multiple tables in database systems.
\ No newline at end of file
diff --git a/docs/DBMS/Relational Database Design/dbms-normalization.md b/docs/DBMS/Relational Database Design/dbms-normalization.md
deleted file mode 100644
index ace18f8e1..000000000
--- a/docs/DBMS/Relational Database Design/dbms-normalization.md
+++ /dev/null
@@ -1,115 +0,0 @@
----
-id: dbms-normalization
-title: DBMS - Normalization
-sidebar_label: Normalization
-sidebar_position: 1
-description: Learn about Functional Dependency, Normalization, and different Normal Forms in Database Management Systems (DBMS).
----
-
-# DBMS - Normalization
-
-## Functional Dependency
-
-Functional dependency (FD) is a set of constraints between two attributes in a relation. Functional dependency says that if two tuples have the same values for attributes A1, A2,..., An, then those two tuples must have the same values for attributes B1, B2, ..., Bn.
-
-Functional dependency is represented by an arrow sign (→) that is, $X \rightarrow Y$, where X functionally determines Y. The left-hand side attributes determine the values of attributes on the right-hand side.
-
-### Armstrong's Axioms
-
-If F is a set of functional dependencies then the closure of F, denoted as F+, is the set of all functional dependencies logically implied by F. Armstrong's Axioms are a set of rules, that when applied repeatedly, generates a closure of functional dependencies.
-
-```mermaid
-graph TD;
- A["alpha"] -->|is_subset_of| B["beta"]
- B -->|alpha holds beta| C["alpha holds beta"]
- A -->|augmentation rule| D["ay → by also holds"]
- C -->|transitivity rule| E["a → c also holds"]
-```
-
-## Trivial Functional Dependency
-
-- **Trivial:** If a functional dependency (FD) X → Y holds, where Y is a subset of X, then it is called a trivial FD. Trivial FDs always hold.
-
-- **Non-trivial:** If an FD X → Y holds, where Y is not a subset of X, then it is called a non-trivial FD.
-
-- **Completely non-trivial:** If an FD X → Y holds, where x intersect Y = Φ, it is said to be a completely non-trivial FD.
-
-## Normalization
-
-If a database design is not perfect, it may contain anomalies, which are like a bad dream for any database administrator. Managing a database with anomalies is next to impossible.
-
-- **Update anomalies** − If data items are scattered and are not linked to each other properly, then it could lead to strange situations. For example, when we try to update one data item having its copies scattered over several places, a few instances get updated properly while a few others are left with old values. Such instances leave the database in an inconsistent state.
-
-- **Deletion anomalies** − We tried to delete a record, but parts of it was left undeleted because of unawareness, the data is also saved somewhere else.
-
-- **Insert anomalies** − We tried to insert data in a record that does not exist at all.
-
-Normalization is a method to remove all these anomalies and bring the database to a consistent state.
-
-```mermaid
-graph TD;
- A[Update anomalies] -->|Inconsistent state| B[Database]
- C[Deletion anomalies] -->|Left undeleted parts| B
- D[Insert anomalies] -->|Insert data in non-existing record| B
-```
-
-## First Normal Form (1NF)
-
-First Normal Form is defined in the definition of relations (tables) itself. This rule defines that all the attributes in a relation must have atomic domains. The values in an atomic domain are indivisible units.
-
-unorganized relation
-
-```mermaid
-graph TD;
- A["Relation"] -->|Unorganized| B["1NF"]
-```
-
-Each attribute must contain only a single value from its pre-defined domain.
-
-## Second Normal Form (2NF)
-
-Before we learn about the second normal form, we need to understand the following −
-
-- **Prime attribute :** An attribute, which is a part of the candidate-key, is known as a prime attribute.
-
-- **Non-prime attribute :** An attribute, which is not a part of the prime-key, is said to be a non-prime attribute.
-
-```mermaid
-graph TD;
- A["Candidate Key"] -->|Part of| B["Prime Attribute"]
- C["Non-Prime Attribute"] -->|Not part of| A
- D["X → A holds"] -->|No subset Y → A| E["Second Normal Form"]
-```
-
-## Third Normal Form (3NF)
-
-For a relation to be in Third Normal Form, it must be in Second Normal form and the following must satisfy −
-
-No non-prime attribute is transitively dependent on the prime key attribute.
-
-```mermaid
-graph TD;
- A["X → A"] -->|Superkey or A is prime| B["Third Normal Form"]
- C["Transitive Dependency"] -->|Stu_ID → Zip → City| D["Relation not in 3NF"]
-```
-
-## Boyce-Codd Normal Form (BCNF)
-
-BCNF is an extension of Third Normal Form on strict terms. BCNF states that −
-
-For any non-trivial functional dependency, X → A, X must be a super-key.
-
-```mermaid
-graph TD;
- A["X → A"] -->|X is super-key| B["BCNF"]
-```
-
-In the above image, Stu_ID is the super-key in the relation Student_Detail and Zip is the super-key in the relation ZipCodes. So,
-```
-Stu_ID → Stu_Name, Zip
-```
-and
-```
-Zip → City
-```
-Which confirms that both the relations are in BCNF.
\ No newline at end of file
diff --git a/docs/DBMS/Relational-Model/_category.json b/docs/DBMS/Relational-Model/_category.json
deleted file mode 100644
index 2fa6bd3c9..000000000
--- a/docs/DBMS/Relational-Model/_category.json
+++ /dev/null
@@ -1,9 +0,0 @@
-{
- "label": "Relational Model",
- "position": 2,
- "link": {
- "type": "generated-index",
- "description": "Explore the Relational Model in DBMS, its concepts, and its applications."
- }
- }
-
\ No newline at end of file
diff --git a/docs/DBMS/Relational-Model/codd's-rule.md b/docs/DBMS/Relational-Model/codd's-rule.md
deleted file mode 100644
index 538c8a801..000000000
--- a/docs/DBMS/Relational-Model/codd's-rule.md
+++ /dev/null
@@ -1,116 +0,0 @@
----
-id: codd-s-12-rules
-title: Codd's 12 Rules
-sidebar_label: Codd's 12 Rules
-sidebar_position: 1
-description: Explore Dr. Edgar F. Codd's 12 Rules for true relational databases with examples and diagrams.
----
-
-# DBMS - Codd's 12 Rules
-
-Dr. Edgar F. Codd, after his extensive research on the Relational Model of database systems, came up with twelve rules of his own, which according to him, a database must obey in order to be regarded as a true relational database.
-
-## Rule 1: Information Rule
-
-The data stored in a database, may it be user data or metadata, must be a value of some table cell. Everything in a database must be stored in a table format.
-
-### Example:
-
-Consider a database for a library. The Information Rule ensures that every piece of data, like the title of a book or the name of an author, is stored within a specific table cell, such as the 'Book Title' attribute in the 'Books' table.
-
-## Rule 2: Guaranteed Access Rule
-
-Every single data element (value) is guaranteed to be accessible logically with a combination of table-name, primary-key (row value), and attribute-name (column value). No other means, such as pointers, can be used to access data.
-
-### Example:
-
-In a customer database, the Guaranteed Access Rule ensures that you can access a specific customer's details using their unique customer ID, such as querying "SELECT \* FROM Customers WHERE CustomerID = '123'".
-
-## Rule 3: Systematic Treatment of NULL Values
-
-The NULL values in a database must be given a systematic and uniform treatment. This is a very important rule because a NULL can be interpreted as one of the following − data is missing, data is not known, or data is not applicable.
-
-### Example:
-
-In an employee database, the Systematic Treatment of NULL Values ensures that if an employee's middle name is unknown or not applicable, it's represented as NULL in the database rather than an empty string or a placeholder.
-
-## Rule 4: Active Online Catalog
-
-The structure description of the entire database must be stored in an online catalog, known as data dictionary, which can be accessed by authorized users. Users can use the same query language to access the catalog which they use to access the database itself.
-
-### Example:
-
-An Active Online Catalog provides metadata about the database schema. For instance, it includes information about tables, columns, data types, and relationships, allowing users to understand and query the database structure.
-
-```mermaid
-erDiagram
- CAT_TABLE ||--o{ DB_TABLE : has
- CAT_TABLE ||--o{ COLUMN : has
- DB_TABLE ||--o{ COLUMN : contains
- DB_TABLE }|..|{ DATA : stores
-```
-
-## Rule 5: Comprehensive Data Sub-Language Rule
-
-A database can only be accessed using a language having linear syntax that supports data definition, data manipulation, and transaction management operations. This language can be used directly or by means of some application. If the database allows access to data without any help of this language, then it is considered as a violation.
-
-### Example:
-
-SQL (Structured Query Language) is a comprehensive data sub-language that fulfills the requirements of data definition, manipulation, and transaction management. It allows users to interact with the database through standard commands like SELECT, INSERT, UPDATE, DELETE, and COMMIT.
-
-## Rule 6: View Updating Rule
-
-All the views of a database, which can theoretically be updated, must also be updatable by the system.
-
-### Example:
-
-Consider a view that combines data from multiple tables for reporting purposes. The View Updating Rule ensures that if the view includes columns from a single base table, those columns can be updated through the view.
-
-## Rule 7: High-Level Insert, Update, and Delete Rule
-
-A database must support high-level insertion, updation, and deletion. This must not be limited to a single row, that is, it must also support union, intersection and minus operations to yield sets of data records.
-
-### Example:
-
-The High-Level Insert, Update, and Delete Rule allows you to insert, update, or delete multiple rows at once. For instance, you can use an SQL statement like "DELETE FROM Employees WHERE Salary < 50000" to delete all employees with a salary below $50,000.
-
-## Rule 8: Physical Data Independence
-
-The data stored in a database must be independent of the applications that access the database. Any change in the physical structure of a database must not have any impact on how the data is being accessed by external applications.
-
-### Example:
-
-Physical Data Independence allows you to modify the storage structures (like changing indexes or file organization) without affecting how users and applications interact with the data. This ensures that applications remain functional even if the database undergoes structural changes.
-
-## Rule 9: Logical Data Independence
-
-The logical data in a database must be independent of its user’s view (application). Any change in logical data must not affect the applications using it. For example, if two tables are merged or one is split into two different tables, there should be no impact or change on the user application. This is one of the most difficult rules to apply.
-
-### Example:
-
-Imagine merging two tables 'Customers' and 'Suppliers' into a single table 'Partners'. Logical Data Independence ensures that existing applications accessing 'Customers' or 'Suppliers' continue to function seamlessly after the merge.
-
-## Rule 10: Integrity Independence
-
-A database must be independent of the application that uses it. All its integrity constraints can be independently modified without the need of any change in the application. This rule makes a database independent of the front-end application and its interface.
-
-### Example:
-
-Integrity constraints like primary keys, foreign keys, and unique constraints can be modified or added without affecting how applications interact with the database. This allows for changes in data validation rules without altering application logic.
-
-## Rule 11: Distribution Independence
-
-The end-user must not be able to see that the data is distributed over various locations. Users should always get the impression that the data is located at one site only. This rule has been regarded as the foundation of distributed database systems.
-
-### Example:
-
-In a distributed database, data may be stored across multiple physical locations. Distribution Independence ensures that users perceive and interact with the data as if it's stored in a single location, regardless of its actual distribution.
-
-## Rule 12: Non-Subversion Rule
-
-If a system has an interface that provides access to low-level records, then the interface must not be able to subvert the system and bypass security and integrity constraints.
-
-### Example:
-
-The Non-Subversion Rule prevents unauthorized access to low-level records or system components that could compromise security or integrity. It ensures that access controls and security measures are enforced, even through direct interfaces.
-
\ No newline at end of file
diff --git a/docs/DBMS/Relational-Model/convert-er-model-to-relational-model.md b/docs/DBMS/Relational-Model/convert-er-model-to-relational-model.md
deleted file mode 100644
index 50538b1ff..000000000
--- a/docs/DBMS/Relational-Model/convert-er-model-to-relational-model.md
+++ /dev/null
@@ -1,96 +0,0 @@
----
-id: convert-er-model-to-relational-model
-title: Convert ER Model to Relational Model
-sidebar_label: Convert ER Model to Relational Model
-sidebar_position: 4
-description: Learn how to convert an ER (Entity-Relationship) model into a relational model, including mapping entities, relationships, weak entity sets, and hierarchical entities.
----
-
-# Convert ER Model to Relational Model
-
-ER Model, when conceptualized into diagrams, gives a good overview of entity-relationship, which is easier to understand. ER diagrams can be mapped to a relational schema, meaning it is possible to create a relational schema using an ER diagram. Although not all ER constraints can be imported into the relational model, an approximate schema can be generated.
-
-## Mapping Entity
-
-An entity is a real-world object with some attributes.
-
-### Mapping Process (Algorithm)
-
-1. Create a table for each entity.
-2. Entity's attributes should become fields of tables with their respective data types.
-3. Declare the primary key.
-
-```mermaid
-graph TD;
- A[Entity] -- Mapping --> B[Table]
- B -- Fields --> C[Attributes]
- C -- Data Types --> D[Field Types]
- B -- Primary Key --> E[Primary Key Constraint]
-```
-
-## Mapping Relationship
-
-A relationship is an association among entities.
-
-### Mapping Process
-
-1. Create a table for a relationship.
-2. Add the primary keys of all participating entities as fields of the table with their respective data types.
-3. If the relationship has any attributes, add each attribute as a field of the table.
-4. Declare a primary key composing all the primary keys of participating entities.
-5. Declare all foreign key constraints.
-
-```mermaid
-graph TD;
- A[Relationship] -- Mapping --> B[Table]
- B -- Primary Keys --> C[Participating Entities]
- C -- Data Types --> D[Field Types]
- B -- Attributes --> E[Attributes]
- E -- Field Types --> F[Attribute Data Types]
- B -- Primary Key --> G[Primary Key Constraint]
- B -- Foreign Key Constraints --> H[Foreign Key Constraints]
-```
-
-## Mapping Weak Entity Sets
-
-A weak entity set is one which does not have any primary key associated with it.
-
-### Mapping Process
-
-1. Create a table for the weak entity set.
-2. Add all its attributes to the table as fields.
-3. Add the primary key of the identifying entity set.
-4. Declare all foreign key constraints.
-
-```mermaid
-graph TD;
- A[Weak Entity Set] -- Mapping --> B[Table]
- B -- Attributes --> C[Attributes]
- C -- Field Types --> D[Attribute Data Types]
- B -- Primary Key of Identifying Entity Set --> E[Primary Key Constraint]
- B -- Foreign Key Constraints --> F[Foreign Key Constraints]
-```
-
-## Mapping Hierarchical Entities
-
-ER specialization or generalization comes in the form of hierarchical entity sets.
-
-### Mapping Process
-
-1. Create tables for all higher-level entities.
-2. Create tables for lower-level entities.
-3. Add primary keys of higher-level entities in the table of lower-level entities.
-4. In lower-level tables, add all other attributes of lower-level entities.
-5. Declare the primary key of the higher-level table and the primary key for the lower-level table.
-6. Declare foreign key constraints.
-
-```mermaid
-graph TD;
- A[Higher-Level Entity] -- Mapping --> B[Higher-Level Table]
- C[Lower-Level Entity] -- Mapping --> D[Lower-Level Table]
- D -- Primary Key of Higher-Level Entity --> E[Foreign Key Constraint]
- D -- Attributes of Lower-Level Entity --> F[Attributes]
- B -- Primary Key --> G[Primary Key Constraint]
- F -- Field Types --> H[Attribute Data Types]
- G -- Foreign Key Constraints --> I[Foreign Key Constraints]
-```
diff --git a/docs/DBMS/Relational-Model/relational-algebra.md b/docs/DBMS/Relational-Model/relational-algebra.md
deleted file mode 100644
index db9983f1f..000000000
--- a/docs/DBMS/Relational-Model/relational-algebra.md
+++ /dev/null
@@ -1,109 +0,0 @@
----
-id: relational-algebra
-title: DBMS - Relational Algebra
-sidebar_label: Relational Algebra
-sidebar_position: 3
-description: Learn about relational algebra, a procedural query language for relational database systems, including fundamental operations and examples.
----
-
-# DBMS - Relational Algebra
-
-Relational database systems are expected to be equipped with a query language that can assist its users to query the database instances. There are two kinds of query languages − relational algebra and relational calculus.
-
-## Relational Algebra
-
-Relational algebra is a procedural query language that takes instances of relations as input and yields instances of relations as output. It uses operators to perform queries. An operator can be either unary or binary. They accept relations as their input and yield relations as their output. Relational algebra is performed recursively on a relation, and intermediate results are also considered relations.
-
-```mermaid
-graph TD;
- A[Relation] -- Unary --> B[Operation]
- A -- Binary --> C[Operation]
- B -- Output --> D[Relation]
- C -- Output --> E[Relation]
-```
-
-The fundamental operations of relational algebra are as follows:
-
-- **Select**: $σ_p(r)$
-- **Project**: $∏_{A1, A2, An} (r)$
-- **Union**: $r ∪ s$
-- **Set Difference**: $r - s$
-- **Cartesian Product**: $r Χ s$
-- **Rename**: $ρ_x (E)$
-
-### Select Operation (σ)
-
-It selects tuples that satisfy the given predicate from a relation.
-
-**Notation**: $σ_p(r)$
-
-1. $σ_{subject = "database"}(Books)$
- - Selects tuples from books where subject is 'database'.
-2. $σ_{subject = "database" and price = "450"}(Books)$
- - Selects tuples from books where subject is 'database' and price is 450.
-3. $σ_{subject = "database" and price = "450" or year > "2010"}(Books)$
- - Selects tuples from books where subject is 'database' and price is 450 or those books published after 2010.
-
-### Project Operation (∏)
-
-It projects columns that satisfy a given predicate.
-
-**Notation**: $∏_{subject, author} (Books)$
-
-- $∏_{subject, author} (Books)$
- - Selects and projects columns named subject and author from the relation Books.
-
-### Union Operation (∪)
-
-It performs binary union between two given relations.
-
-**Notation**: $r ∪ s$
-
-- $∏_{author} (Books) ∪ ∏_{author} (Articles)$
- - Projects the names of the authors who have either written a book or an article or both.
-
-### Set Difference (-)
-
-The result of set difference operation is tuples present in one relation but not in the second relation.
-
-**Notation**: $r - s$
-
-- $∏_{author} (Books) - ∏_{author} (Articles)$
- - Provides the names of authors who have written books but not articles.
-
-### Cartesian Product (Χ)
-
-Combines information of two different relations into one.
-
-**Notation**: $r Χ s$
-
-- $σ_{author = 'tutorialspoint'}(Books Χ Articles)$
- - Yields a relation showing all the books and articles written by tutorialspoint.
-
-### Rename Operation (ρ)
-
-The results of relational algebra are relations without any name. The rename operation allows us to rename the output relation.
-
-**Notation**: $ρ_x (E)$
-
-- $ρ_x (Books ∏_{author})$
- - Renames the output relation of Books ∏ author to x.
-
-Additional operations include Set Intersection, Assignment, and Natural Join.
-
-## Relational Calculus
-
-Relational calculus is a non-procedural query language, that is, it tells what to do but never explains how to do it. It exists in two forms:
-
-- Tuple Relational Calculus (TRC)
-- Domain Relational Calculus (DRC)
-
-TRC and DRC involve quantifiers and relational operators to define queries.
-
-```mermaid
-graph TD;
- A[Query] -- TRC --> B[Tuple Relational Calculus]
- A -- DRC --> C[Domain Relational Calculus]
-```
-
-> **NOTE:** TRC and DRC allow specifying conditions and constraints on the result sets without specifying how to retrieve the data.
diff --git a/docs/DBMS/Relational-Model/relational-data-model.md b/docs/DBMS/Relational-Model/relational-data-model.md
deleted file mode 100644
index 46c3ff37d..000000000
--- a/docs/DBMS/Relational-Model/relational-data-model.md
+++ /dev/null
@@ -1,79 +0,0 @@
----
-id: relational-data-model
-title: DBMS - Relational Data Model
-sidebar_label: Relational Data Model
-sidebar_position: 2
-description: Explore the primary data model used widely for data storage and processing - the Relational Data Model.
----
-
-# DBMS - Relational Data Model
-
-The relational data model is the primary data model used widely around the world for data storage and processing. This model is simple and has all the properties and capabilities required to process data with storage efficiency.
-
-## Concepts
-
-### Tables
-
-In the relational data model, relations are saved in the format of Tables. This format stores the relation among entities. A table has rows and columns, where rows represent records and columns represent attributes.
-
-```mermaid
- erDiagram
- CUSTOMER ||--o{ ORDERS : places
- CUSTOMER ||--o{ PAYMENTS : makes
- ORDERS ||--|{ ORDER_ITEMS : contains
-```
-
-### Tuple
-
-A single row of a table, which contains a single record for that relation, is called a tuple.
-
-### Relation Instance
-
-A finite set of tuples in the relational database system represents a relation instance. Relation instances do not have duplicate tuples.
-
-### Relation Schema
-
-A relation schema describes the relation name (table name), attributes, and their names.
-
-### Relation Key
-
-Each row has one or more attributes, known as a relation key, which can identify the row in the relation (table) uniquely.
-
-### Attribute Domain
-
-Every attribute has some predefined value scope, known as an attribute domain.
-
-## Constraints
-
-Every relation has some conditions that must hold for it to be a valid relation. These conditions are called Relational Integrity Constraints. There are three main integrity constraints −
-
-1. **Key Constraints**
-2. **Domain Constraints**
-3. **Referential Integrity Constraints**
-
-### Key Constraints
-
-There must be at least one minimal subset of attributes in the relation, which can identify a tuple uniquely. This minimal subset of attributes is called a key for that relation. If there are more than one such minimal subsets, these are called candidate keys.
-
-Key constraints force that −
-
-- In a relation with a key attribute, no two tuples can have identical values for key attributes.
-- A key attribute cannot have NULL values.
-
-Key constraints are also referred to as Entity Constraints.
-
-### Domain Constraints
-
-Attributes have specific values in real-world scenarios. For example, age can only be a positive integer. The same constraints have been tried to employ on the attributes of a relation. Every attribute is bound to have a specific range of values. For example, age cannot be less than zero, and telephone numbers cannot contain a digit outside 0-9.
-
-### Referential Integrity Constraints
-
-Referential integrity constraints work on the concept of Foreign Keys. A foreign key is a key attribute of a relation that can be referred to in another relation.
-
-Referential integrity constraint states that if a relation refers to a key attribute of a different or same relation, then that key element must exist.
-
-| Constraint Type | Description |
-| --------------------- | -------------------------------------------------------------------------------------- |
-| Key Constraints | Ensure uniqueness of key attributes and disallow NULL values. |
-| Domain Constraints | Define allowable values for attributes based on their data types and real-world rules. |
-| Referential Integrity | Enforce relationships between tables, ensuring that references remain valid. |
diff --git a/docs/DBMS/Storage And File Structure/_category.json b/docs/DBMS/Storage And File Structure/_category.json
deleted file mode 100644
index 431f50bba..000000000
--- a/docs/DBMS/Storage And File Structure/_category.json
+++ /dev/null
@@ -1,8 +0,0 @@
-{
- "label": "Storage and Joins",
- "position": 4,
- "link": {
- "type": "generated-index",
- "description": "Explore various storage techniques and join operations in DBMS."
- }
-}
\ No newline at end of file
diff --git a/docs/DBMS/Storage And File Structure/dbms-file-structure.md b/docs/DBMS/Storage And File Structure/dbms-file-structure.md
deleted file mode 100644
index 3b0edafa8..000000000
--- a/docs/DBMS/Storage And File Structure/dbms-file-structure.md
+++ /dev/null
@@ -1,95 +0,0 @@
----
-id: dbms-file-structure
-title: DBMS - File Structure
-sidebar_label: File Structure
-sidebar_position: 2
-description: Explore the different types of file structures in database management, including file organization methods and file operations.
----
-
-DBMS - File Structure
----
-
-Relative data and information are stored collectively in file formats. A file is a sequence of records stored in binary format. A disk drive is formatted into several blocks that can store records. File records are mapped onto those disk blocks.
-
-File Organization
----
-
-File Organization defines how file records are mapped onto disk blocks. We have four types of File Organization to organize file records:
-
-### Heap File Organization
-- **Description:** When a file is created using Heap File Organization, the Operating System allocates memory area to that file without any further accounting details. File records can be placed anywhere in that memory area.
-- **Characteristics:** No ordering, sequencing, or indexing.
-- **Responsibility:** Software manages the records.
-
-### Sequential File Organization
-- **Description:** Records are placed in the file in some sequential order based on a unique key field or search key.
-- **Characteristics:** Practically, not all records can be stored sequentially in physical form.
-- **Example:** Library cataloging system where books are stored based on a unique identifier.
-
-### Hash File Organization
-- **Description:** Uses Hash function computation on some fields of the records. The output of the hash function determines the location of the disk block where the records are to be placed.
-- **Characteristics:** Efficient for retrieval when the search is based on the hashed attribute.
-- **Example:** Student records where student ID is used to determine storage location.
-
-### Clustered File Organization
-- **Description:** Related records from one or more relations are kept in the same disk block.
-- **Characteristics:** Not based on primary key or search key.
-- **Use Case:** Used when accessing related data together.
-
-```mermaid
-graph TD;
- A[File Organization] --> B[Heap File Organization]
- A --> C[Sequential File Organization]
- A --> D[Hash File Organization]
- A --> E[Clustered File Organization]
-```
-
-File Operations
----
-
-Operations on database files can be broadly classified into two categories:
-
-1. **Update Operations**
- - **Description:** Change data values by insertion, deletion, or update.
-
-2. **Retrieval Operations**
- - **Description:** Retrieve data without altering it, potentially with optional conditional filtering.
-
-### Common File Operations
-- **Open:**
- - **Modes:** Read mode (data is read-only) and Write mode (data modification allowed).
- - **Characteristics:** Files in read mode can be shared; files in write mode cannot be shared.
-
-- **Locate:**
- - **Description:** File pointer tells the current position where data is to be read or written.
- - **Function:** Can be moved forward or backward using find (seek) operation.
-
-- **Read:**
- - **Description:** By default, the file pointer points to the beginning of the file when opened in read mode.
- - **Characteristics:** User can specify where to locate the file pointer.
-
-- **Write:**
- - **Description:** Enables editing file contents, including deletion, insertion, or modification.
- - **Characteristics:** File pointer can be dynamically changed if allowed by the operating system.
-
-- **Close:**
- - **Description:** Crucial for the operating system.
- - **Function:**
- 1. Removes all locks if in shared mode.
- 2. Saves data to secondary storage if altered.
- 3. Releases all buffers and file handlers associated with the file.
-
-```mermaid
-graph TD;
- A[File Operations] --> B[Update Operations]
- A --> C[Retrieval Operations]
- B --> D[Insert]
- B --> E[Delete]
- B --> F[Update]
- C --> G[Select]
- C --> H[Filter]
-```
-
-The organization of data inside a file plays a major role in how efficiently these operations can be performed. The method used to locate the file pointer to a desired record inside a file varies based on whether the records are arranged sequentially or clustered.
-
-In summary, understanding the various file structures and their operations is crucial for efficient database management, ensuring optimal performance and reliability.
diff --git a/docs/DBMS/Storage And File Structure/dbms-storage-system.md b/docs/DBMS/Storage And File Structure/dbms-storage-system.md
deleted file mode 100644
index 74baf4580..000000000
--- a/docs/DBMS/Storage And File Structure/dbms-storage-system.md
+++ /dev/null
@@ -1,114 +0,0 @@
----
-id: dbms-storage-system
-title: DBMS - Storage System
-sidebar_label: Storage System
-sidebar_position: 1
-description: Understand the various storage systems in database management, including memory types, memory hierarchy, magnetic disks, and RAID technology.
----
-
-# DBMS - Storage System
----
-
-Databases are stored in various file formats and devices, each serving different purposes and performance requirements. Let's explore the different types of storage systems and their hierarchical organization.
-
-## Memory Types
-
-1. **Primary Storage**
-
- - **Description:** Directly accessible to the CPU.
- - **Examples:** CPU's internal memory (registers), cache, main memory (RAM).
- - **Characteristics:** Ultra-fast, volatile, requires continuous power.
-
-2. **Secondary Storage**
-
- - **Description:** Used for future data use or backup.
- - **Examples:** Magnetic disks, optical disks (DVD, CD), hard disks, flash drives, magnetic tapes.
- - **Characteristics:** Non-volatile, slower than primary storage, larger capacity.
-
-3. **Tertiary Storage**
- - **Description:** Used for storing huge volumes of data.
- - **Examples:** Optical disks, magnetic tapes.
- - **Characteristics:** Slowest in speed, used for system backups.
-
-## Memory Hierarchy
-
-A computer system's memory hierarchy ranges from the fastest, smallest, and most expensive types to the slowest, largest, and least expensive.
-
-```mermaid
-graph TD;
- A[Primary Memory] --> B[Secondary Memiry]
- B --> C[Tertiary Memory]
-```
-
-- **Registers:** Fastest access time, smallest capacity, highest cost.
-- **Cache Memory:** Faster access time than RAM, used to store frequently accessed data.
-- **Main Memory (RAM):** Directly accessible by the CPU, larger capacity than cache.
-- **Secondary Storage:** Larger capacity, slower access time, used for data storage and backup.
-- **Tertiary Storage:** Largest capacity, slowest access time, used for extensive backups.
-
-## Magnetic Disks
-
-Hard disk drives (HDDs) are the most common secondary storage devices, using magnetization to store information.
-
-```mermaid
-graph TD;
- A[Hard Disk] --> B[Spindle]
- B --> C[Read/Write Head]
- C --> D[Magnetizable Disks]
-```
-
-- **Structure:** Consists of metal disks coated with magnetizable material, placed on a spindle.
-- **Operation:** A read/write head magnetizes or de-magnetizes spots to represent data bits (0 or 1).
-- **Organization:** Disks have concentric circles (tracks), each divided into sectors (typically 512 bytes).
-
-## Redundant Array of Independent Disks (RAID)
-
-RAID technology connects multiple secondary storage devices to function as a single unit, enhancing performance and data redundancy.
-
-1. **RAID 0:**
-
- - **Description:** Striped array of disks.
- - **Features:** Enhances speed and performance, no parity or backup.
-
-2. **RAID 1:**
-
- - **Description:** Mirroring technique.
- - **Features:** Provides 100% redundancy, copies data to all disks.
-
-3. **RAID 2:**
-
- - **Description:** Uses Error Correction Code (ECC) with Hamming distance.
- - **Features:** Stripes data bits and ECC codes, high cost and complexity.
-
-4. **RAID 3:**
-
- - **Description:** Stripes data with parity bit on a separate disk.
- - **Features:** Overcomes single disk failures.
-
-5. **RAID 4:**
-
- - **Description:** Block-level striping with dedicated parity disk.
- - **Features:** Requires at least three disks, similar to RAID 3 but with block-level striping.
-
-6. **RAID 5:**
-
- - **Description:** Block-level striping with distributed parity.
- - **Features:** Distributes parity bits among all data disks.
-
-7. **RAID 6:**
- - **Description:** Extension of RAID 5 with dual parity.
- - **Features:** Provides additional fault tolerance, requires at least four disks.
-
-```mermaid
-graph LR;
- A[RAID 0] --> B[RAID 1]
-
- B --> C[RAID 2]
- C --> D[RAID 3]
- D --> E[RAID 4]
- E --> F[RAID 5]
- F --> G[RAID 6]
-
-```
-
-Each RAID level serves specific needs, balancing between performance, data redundancy, and fault tolerance.
diff --git a/docs/DBMS/Structured Query Language/DDL.md b/docs/DBMS/Structured Query Language/DDL.md
deleted file mode 100644
index c6465d009..000000000
--- a/docs/DBMS/Structured Query Language/DDL.md
+++ /dev/null
@@ -1,56 +0,0 @@
-# Data Definition Language (DDL)
-
-Data Definition Language (DDL) is a subset of SQL used to define, modify, and delete database objects such as tables, indexes, views, and constraints. DDL statements enable users to create and manage the structure of the database schema.
-
-## Key DDL Commands
-
-### 1. CREATE
-
-- `CREATE TABLE`: Defines a new table in the database.
- ```sql
- CREATE TABLE table_name (
- column1 datatype,
- column2 datatype,
- ...
- );
-- `CREATE INDEX`: Creates an index on a table to improve data retrieval performance.
-
-```sql
-CREATE INDEX index_name ON table_name (column1, column2, ...);
-```
-- `CREATE VIEW`: Defines a virtual table based on the result set of a `SELECT` query.
-
-```sql
-CREATE VIEW view_name AS
-SELECT column1, column2 FROM table_name WHERE condition;
-```
-
-### 2. ALTER
-
-- `ALTER TABLE` : Modifies the structure of an existing table.
- - Add a new column
- ```sql
- ALTER TABLE table_name ADD column_name datatype;
- ```
- - Modify column definition
- ```sql
- ALTER TABLE table_name MODIFY column_name datatype;
- ````
- - Drop a column
- ```sql
- ALTER TABLE table_name DROP COLUMN column_name;
- ```
-
-### 3. DROP
-- `DROP TABLE`: Deletes a table and its data from the database.
- ```sql
- DROP TABLE table_name;
- ```
-- `DROP INDEX`: Removes an index from the database.
- ```sql
- DROP INDEX index_name;
- ```
-- `DROP VIEW`: Deletes a view from the database.
- ```sql
- DROP VIEW view_name;
- ```
diff --git a/docs/DBMS/Structured Query Language/_category.json b/docs/DBMS/Structured Query Language/_category.json
deleted file mode 100644
index 817e9b142..000000000
--- a/docs/DBMS/Structured Query Language/_category.json
+++ /dev/null
@@ -1,8 +0,0 @@
-{
- "label": "SQL",
- "position": 8,
- "link": {
- "type": "generated-index",
- "description": "Explore SQL in DBMS."
- }
-}
\ No newline at end of file
diff --git a/docs/DBMS/Structured Query Language/dml.md b/docs/DBMS/Structured Query Language/dml.md
deleted file mode 100644
index 3b3698561..000000000
--- a/docs/DBMS/Structured Query Language/dml.md
+++ /dev/null
@@ -1,78 +0,0 @@
-# Data Manipulation Language
-
-DML is used for performing non-structural updates to a database. For example, adding a row to an existing table, retrieving data from a table, etc.
-
-### DML commands include:
-- Select
-- Insert
-- Update
-- Delete
-
-Let's see each command in detail:
-
-## select
-
-This command is used to retrieve data from the database. It is generally followed by from and where clauses.
-
-Example:
-```sql
-select * from customers;
-```
-This query will return all the rows from the table customers including all attributes (columns).
-
-```sql
-select *
-from customers
-where address="India";
-```
-This query will return all the rows where the address of the customer is India.
-
-```sql
-select name,address
-from customers;
-```
-This type of query returns only the name and address of the customers, i.e. the required information, instead of returning all the information.
-
-## insert
-
-The insert command is used to add rows to a table in the database.
-
-Example:
-```sql
-insert into customers values("Riya","India");
-```
-We can also insert multiple rows at a time:
-```sql
-insert into customers values
-("Riya","India")
-("Aditya","India")
-("Chris","Germany");
-```
-
-## update
-
-This command is used to update a certain row, given some information about that row.
-
-Example:
-```sql
-update customers
-set name="Tanisha"
-where customer_id=125;
-```
-This query would update the name of the customer with id=125 to Tanisha.
-
-## delete
-
-Delete command is used to delete some rows in the table.
-
-Example:
-```sql
-delete from customers where customer_id=125;
-```
-This will delete all the information of customer with id=125.
-
-We can also delete multiple rows at a time:
-```sql
-delete from customers where address="India";
-```
-This query would delete information of all customers from India.
diff --git a/docs/DBMS/Structured Query Language/sql-aggregate-functions.md b/docs/DBMS/Structured Query Language/sql-aggregate-functions.md
deleted file mode 100644
index 914ef38d5..000000000
--- a/docs/DBMS/Structured Query Language/sql-aggregate-functions.md
+++ /dev/null
@@ -1,85 +0,0 @@
----
-id: sql-aggregate-function
-title: DBMS - SQL Aggregate Functions
-sidebar_label: Aggregate Functions
-sidebar_position: 3
-description: Learn about the SQL Aggregate Functions.
-tags:
- - DBMS
- - SQL
- - SQL-Functions
- - Database Design
----
-
-# DBMS - SQL Aggregate Functions
-
-Aggregate functions in SQL are used to perform calculations on multiple rows of a table's column and return a single value. These functions are essential for data analysis and reporting as they help in summarizing large datasets.
-
-## COMMON AGGREGATE FUNCTIONS
-
-1. **COUNT():** The COUNT() function returns the number of rows that match a specified condition. This query returns the total number of rows in the table.
- ```sql
- SELECT COUNT(*) AS total_rows
- FROM table_name;
- ```
-
-2. **SUM():** The SUM() function returns the total sum of a numeric column. This query calculates the sum of all values in column_name.
- ```sql
- SELECT SUM(column_name) AS total_sum
- FROM table_name;
- ```
-
-3. **AVG():** The AVG() function returns the average value of a numeric column. This query calculates the average value of column_name.
- ```sql
- SELECT AVG(column_name) AS average_value
- FROM table_name;
- ```
-
-4. **MIN():** The MIN() function returns the smallest value in a specified column. This query finds the smallest value in column_name.
- ```sql
- SELECT MIN(column_name) AS minimum_value
- FROM table_name;
- ```
-
-5. **MAX():** The MAX() function returns the largest value in a specified column. This query finds the largest value in column_name.
- ```sql
- SELECT MAX(column_name) AS maximum_value
- FROM table_name;
- ```
-
-## AGGREGATE FUNCTIONS WITH GROUP BY
-
-Aggregate functions are often used in conjunction with the GROUP BY clause to group the result set by one or more columns and perform the calculation on each group.
- ```sql
- SELECT department, COUNT(*) AS total_employees
- FROM employees
- GROUP BY department;
- ```
- This query groups the employees by their department and returns the number of employees in each department.
-
- ```sql
- SELECT department, COUNT(*) AS total_employees, AVG(salary) AS average_salary, MAX(salary) AS highest_salary
- FROM employees
- GROUP BY department;
- ```
- This query groups the employees by their department and returns the total number of employees, average salary, and highest salary in each department.
-
-## AGGREGATE FUNCTIONS USING HAVING
-
-The HAVING clause is used to filter groups based on the result of aggregate functions. It is similar to the WHERE clause, but WHERE cannot be used with aggregate functions.
- ```sql
- SELECT department, COUNT(*) AS total_employees
- GROUP BY department
- HAVING COUNT(*) > 10;
- ```
- This query groups the employees by their department and returns the departments that have more than 10 employees.
-
-You can combine multiple aggregate functions in a single query to perform various calculations.
- ```sql
- SELECT COUNT(*) AS total_rows, SUM(column_name) AS total_sum, AVG(column_name) AS average_value
- FROM table_name;
- ```
- This query returns the total number of rows, the sum of column_name, and the average value of column_name.
-
-Aggregate functions are powerful tools in SQL for summarizing and analyzing data. By mastering these functions, you can perform complex data analysis and gain valuable insights from your database.
-
diff --git a/docs/DBMS/Structured Query Language/sql-basic-concepts.md b/docs/DBMS/Structured Query Language/sql-basic-concepts.md
deleted file mode 100644
index 4811cea15..000000000
--- a/docs/DBMS/Structured Query Language/sql-basic-concepts.md
+++ /dev/null
@@ -1,71 +0,0 @@
----
-id: sql-basic-concepts
-title: DBMS - SQL Basic Concepts
-sidebar_label: Basic Concepts
-sidebar_position: 1
-description: Learn about the Structured Query language (SQL), its basic concepts, data types, operators, and commands that form the foundation of database manipulation.
-tags:
- - DBMS
- - SQL
- - Database Design
----
-
-# DBMS - SQL Basic Concepts
-
-SQL stands for Structured Query Language. It is used to access and manipulate data in databases. By executing queries SQL can *create*, *update*, *delete*, and *retrieve* data in databases like MySQL, Oracle, PostgreSQL, etc. Overall, SQL is a query language that communicates with databases.
-
-## Why SQL?
-SQL helps to easily get information from data with high efficiency. Best Part? Without a lot of coding knowledge, we can manage a database with SQL. Anyone who knows English can master SQL queries in no time.
-When we are executing the command of SQL on any Relational database managemnet system, then the system automatically finds the best routine to carry out our requests, and the SQL engine determines how to interpret the particular command.
-
-
-## SQL DATABASE
-The very first step is to store the information in database, hence, we will first create a database.
-
-1. **CREATE:**
- To create a new database in SQL we use this command. Note that blank spaces are not allowed in the name and is case-insenitive.
- ```sql
- CREATE DATABASE database_name;
-2. **SHOW:**
- To view all the databases, we can use the keyword show. It returns a list of all the databases that exist in our system.
- ```sql
- SHOW DATABASE;
-3. **USE:**
- To change the database or select another database, we use the command:
- ```sql
- USE database_name;
-4. **DROP:**
- It is used to remove the entire database from the system. Once deleted, it can not be retrieved.
- We can use the if exists clause to avoid any errors.
- ```sql
- DROP DATABASE database_name;
- DROP DATABASE IF EXISTS database_name;
-5. **RENAME:**
- It is used to rename the database.
- ```sql
- RENAME DATABASE former_database_name TO new_database_name;
-
-## SQL TABLES
-Now we have created the database. We will create tables inside our database. They are very similar to spreadsheets, which store data in very organized grid format. We can create as many tables as we require.
-1. **CREATE:**
- To create a new table in database we use this command. We define the structure of table and the datatypes of columns.
- ```sql
- CREATE table Employee(
- EmployeeID INT PRIMARY KEY,
- FirstName VARCHAR(50),
- LastName VARCHAR(50),
- Department VARCHAR(50),
- Salary DECIMAL(10, 2)
- );
-2. **DELETE:**
- It is used to delete data in a database. We selectively remove records from a database table based on certain conditions.
- ```sql
- DELETE FROM table_name WHERE some_condition;
-3. **DROP:**
- It is used to delete data and structure of the table from the database permanently.
- ```sql
- DROP TABLE table_name;
-4. **ALTER:**
- It is used to rename the table.
- ```sql
- ALTER TABLE former_table_name RENAME TO new_table_name;
diff --git a/docs/DBMS/Structured Query Language/sql-clauses-operators.md b/docs/DBMS/Structured Query Language/sql-clauses-operators.md
deleted file mode 100644
index 5a8c80454..000000000
--- a/docs/DBMS/Structured Query Language/sql-clauses-operators.md
+++ /dev/null
@@ -1,203 +0,0 @@
----
-id: sql-clauses-operators
-title: DBMS - SQL Clauses & Operators
-sidebar_label: Clauses & Operators
-sidebar_position: 2
-description: Learn about the SQL clauses and operators.
-tags:
- - DBMS
- - SQL-Operators
- - SQL
- - Database Design
----
-
-# DBMS - SQL Clauses & Operators
-
-In SQL, clauses and operators play a crucial role in forming queries that manipulate and retrieve data from databases. Understanding these elements is essential for effective database management and query execution.
-
-## SQL Clauses
-
-SQL clauses are used to specify various conditions and constraints in SQL statements. Here are some of the most commonly used clauses:
-
-1. **SELECT:**
- The SELECT clause is used to retrieve data from a database.
- ```sql
- SELECT column1, column2, ...
- FROM table_name;
-2. **WHERE:**
- The WHERE clause is used to filter records based on a specified condition.
- ```sql
- SELECT column1, column2, ...
- FROM table_name
- WHERE condition;
-3. **ORDER BY:**
- The ORDER BY clause is used to sort the result set in ascending or descending order.
- ```sql
- SELECT column1, column2, ...
- FROM table_name
- ORDER BY column1 ASC | DESC;
-4. **GROUP BY:**
- The GROUP BY clause is used to group rows that have the same values into summary rows.
- ```sql
- SELECT column1, COUNT(*)
- FROM table_name
- GROUP BY column1;
-5. **HAVING:**
- The HAVING clause is used to filter groups based on a specified condition, often used with GROUP BY.
- ```sql
- SELECT column1, COUNT(*)
- FROM table_name
- GROUP BY column1
- HAVING condition;
-6. **JOIN:**
- The JOIN clause is used to combine rows from two or more tables based on a related column.
- - **INNER JOIN:**
- ```sql
- SELECT columns
- FROM table1
- INNER JOIN table2
- ON table1.column = table2.column;
- - **LEFT JOIN (or LEFT OUTER JOIN):**
- ```sql
- SELECT columns
- FROM table1
- LEFT JOIN table2
- ON table1.column = table2.column;
- - **RIGHT JOIN (or RIGHT OUTER JOIN):**
- ```sql
- SELECT columns
- FROM table1
- RIGHT JOIN table2
- ON table1.column = table2.column;
- - **FULL JOIN (or FULL OUTER JOIN):**
- ```sql
- SELECT columns
- FROM table1
- FULL JOIN table2
- ON table1.column = table2.column;
- ```
-
-## SQL Operators
-
-SQL operators are used to perform operations on data. Here are some of the most commonly used operators:
-
-1. **ARITHMETIC OPERATORS:**
- Arithmetic operators are used to perform arithmetic operations on numeric data.
-
- - **ADDITION:**
- ```sql
- SELECT column1 + column2 AS result
- FROM table_name;
- ```
- - **SUBTRACTION:**
- ```sql
- SELECT column1 - column2 AS result
- FROM table_name;
- ```
- - **MULTIPLICATION:**
- ```sql
- SELECT column1 * column2 AS result
- FROM table_name;
- ```
- - **DIVISION:**
- ```sql
- SELECT column1 / column2 AS result
- FROM table_name;
- ```
-
-2. **COMPARISON OPERATORS:**
- Comparison operators are used to compare two values.
-
- - **EQUAL TO:**
- ```sql
- SELECT columns
- FROM table_name
- WHERE column = value;
- ```
- - **NOT EQUAL TO:**
- ```sql
- SELECT columns
- FROM table_name
- WHERE column <> value;
- ```
- - **GREATER THAN:**
- ```sql
- SELECT columns
- FROM table_name
- WHERE column > value;
- ```
- - **LESS THAN:**
- ```sql
- SELECT columns
- FROM table_name
- WHERE column < value;
- ```
- - **GREATER THAN OR EQUAL TO:**
- ```sql
- SELECT columns
- FROM table_name
- WHERE column >= value;
- ```
- - **LESS THAN OR EQUAL TO:**
- ```sql
- SELECT columns
- FROM table_name
- WHERE column <= value;
- ```
-
-3. **LOGICAL OPERATORS:**
- Logical operators are used to combine two or more conditions.
-
- - **AND:**
- ```sql
- SELECT columns
- FROM table_name
- WHERE condition1 AND condition2;
- ```
- - **OR:**
- ```sql
- SELECT columns
- FROM table_name
- WHERE condition1 OR condition2;
- ```
- - **NOT:**
- ```sql
- SELECT columns
- FROM table_name
- WHERE NOT condition;
- ```
-
-4. **OTHER USEFUL OPERATORS:**
-
- - **BETWEEN:** The BETWEEN operator selects values within a given range.
- ```sql
- SELECT columns
- FROM table_name
- WHERE column BETWEEN value1 AND value2;
- ```
- - **IN:** The IN operator allows you to specify multiple values in a WHERE clause.
- ```sql
- SELECT columns
- FROM table_name
- WHERE column IN (value1, value2, ...);
- ```
- - **LIKE:** The LIKE operator is used to search for a specified pattern in a column.
- ```sql
- SELECT columns
- FROM table_name
- WHERE column LIKE pattern;
- ```
- - **IS NULL:** The IS NULL operator is used to test for empty values (NULL).
- ```sql
- SELECT columns
- FROM table_name
- WHERE column IS NULL;
- ```
- - **IS NOT NULL:** The IS NOT NULL operator is used to test for non-empty values.
- ```sql
- SELECT columns
- FROM table_name
- WHERE column IS NOT NULL;
- ```
-
-This covers the basic SQL clauses and operators, which are essential for writing effective SQL queries. By mastering these elements, you can perform complex data manipulations and retrieve valuable insights from your database.
\ No newline at end of file
diff --git a/docs/DBMS/Structured Query Language/sql-data-types.md b/docs/DBMS/Structured Query Language/sql-data-types.md
deleted file mode 100644
index 8550981c5..000000000
--- a/docs/DBMS/Structured Query Language/sql-data-types.md
+++ /dev/null
@@ -1,55 +0,0 @@
----
-id: sql-data-types
-title: DBMS - SQL data-types
-sidebar_label: Data-Types
-sidebar_position: 5
-description: SQL data-types
-tags:
- - DBMS
- - SQL
- - Data Types
----
-
-## Introduction:
-Varios datatypes are supported in SQL. They include numeric data types, string data types and date and time.
-
-## Numeric data types
-
-1. int- For integer data.
-eg:
-```sql
-create table temp(
- age int
-);
-```
-2. tinyint- For very small values.
-3. smallint- For small values.
-4. mediumint- For medium vakues.
-5. bigint- Upto 20 digits.
-6. float- Used for decimals. It has 2 arguments, length and the number of digits after decimals.
-eg:
-```sql
-create table temp(
- cash float(10,2)
-);
-```
-7. double- Similar to float but can denote much larger numbers.
-
-
-## String data types
-
-1. char- Used if the length of string is fixed. Has an argument, the length.
-2. varchar- Used for variable length strings. It also has an argument, the maximum possible length.
-eg:
-```sql
-create table temp(
- name varchar(50)
-);
-```
-
-## Date and Time
-
-1. date
-2. time
-3. datetime
-4. timestamnp
\ No newline at end of file
diff --git a/docs/DBMS/Structured Query Language/sql-sub-queries.md b/docs/DBMS/Structured Query Language/sql-sub-queries.md
deleted file mode 100644
index bb90f1c1e..000000000
--- a/docs/DBMS/Structured Query Language/sql-sub-queries.md
+++ /dev/null
@@ -1,107 +0,0 @@
----
-id: sql-sub-queries
-title: DBMS - SQL Sub-Queries
-sidebar_label: Sub-Queries
-sidebar_position: 4
-description: Learn with an example.
-tags:
- - DBMS
- - SQL
- - SQL-Queries
- - Database Design
----
-
-# DBMS - SQL Sub-Queries
-
-Subqueries, also known as inner queries or nested queries, are queries within a query. They are used to perform operations that require multiple steps, providing intermediate results for the outer query to process. Subqueries can be essential for complex data retrieval and manipulation, allowing you to break down complex queries into manageable parts.
-
-## WHY USE SUBQUERIES?
-
-1. **Modularity:** Break down complex queries into simpler parts.
-2. **Reusability:** Use results from subqueries in multiple parts of the main query.
-3. **Isolation:** Encapsulate logic to ensure clarity and correctness.
-4. **Flexibility:** Perform operations like filtering, aggregating, and joining in a more readable way.
-
-## SYNTAX OF SUBQUERY
-
-A subquery is enclosed within parentheses and can be used in various parts of an SQL statement, such as the `SELECT`, `FROM`, `WHERE`, and `HAVING` clauses.
-```sql
-SELECT column1, column2
-FROM table1
-WHERE column3 = (SELECT column1 FROM table2 WHERE condition);
-```
-
-
-## TYPES OF SUBQUERIES
-1. **SCALAR:** These return a single value and are often used in SELECT or WHERE clauses.
- ```sql
- SELECT first_name, last_name
- FROM employees
- WHERE salary > (SELECT AVG(salary) FROM employees);
- ```
- This query selects employees whose salary is above the average salary.
-
-2. **COLUMN:** These return a single column of values and can be used with IN or ANY.
- ```sql
- SELECT first_name, last_name
- FROM employees
- WHERE department_id IN (SELECT department_id FROM departments WHERE department_name = 'IT');
- ```
- This query selects employees who work in the IT department.
-
-3. **ROW:** These return a single row of values and are used in comparisons involving multiple columns.
- ```sql
- SELECT first_name, last_name
- FROM employees
- WHERE (department_id, salary) = (SELECT department_id, MAX(salary) FROM employees);
- ```
- This query selects the employee with the highest salary in each department.
-
-4. **TABLE:** These return a result set that can be used as a temporary table in the FROM clause.
- ```sql
- SELECT department_id, AVG(salary)
- FROM (SELECT department_id, salary FROM employees WHERE salary > 50000) AS high_salaries
- GROUP BY department_id;
- ```
- This query calculates the average salary for employees earning more than 50,000, grouped by department.
-
-
-## SUBQUERIES IN DIFFERENT CLAUSES
-1. **SELECT Clause:** Used to return a value for each row selected by the outer query.
- ```sql
- SELECT first_name, last_name, (SELECT department_name FROM departments WHERE departments.department_id = employees.department_id) AS department
- FROM employees;
- ```
- This query retrieves the department name for each employee.
-
-2. **FROM Clause:** Used to create a temporary table for the outer query to use.
- ```sql
- SELECT temp.department_id, AVG(temp.salary) AS avg_salary
- FROM (SELECT department_id, salary FROM employees WHERE salary > 50000) AS temp
- GROUP BY temp.department_id;
- ```
- This query calculates the average salary of employees earning more than 50,000, grouped by department.
-
-3. **WHERE Clause:** Used to filter rows based on the result of the subquery.
- ```sql
- SELECT first_name, last_name
- FROM employees
- WHERE department_id = (SELECT department_id FROM departments WHERE department_name = 'HR');
- ```
- This query selects employees working in the HR department.
-
-4. **HAVING Clause:** Used to filter groups based on the result of the subquery.
- ```sql
- SELECT department_id, COUNT(*) AS num_employees
- FROM employees
- GROUP BY department_id
- HAVING COUNT(*) > (SELECT AVG(num_employees) FROM (SELECT department_id, COUNT(*) AS num_employees FROM employees GROUP BY department_id) AS sub);
- ```
- This query selects departments with a number of employees greater than the average number of employees per department.
-
-## TIPS FOR USING SUBQUERIES
-1. **Performance:** Subqueries can be less efficient than joins, especially for large datasets. Optimize where possible.
-2. **Readability:** Use subqueries to simplify complex queries, but ensure they remain readable.
-3. **Testing:** Test subqueries separately to ensure they return the expected results before integrating them into the main query.
-
-Subqueries are powerful tools for SQL query formulation, allowing for modular, reusable, and flexible query structures. Mastering subqueries can significantly enhance your ability to manipulate and retrieve data effectively.
\ No newline at end of file
diff --git a/docs/DBMS/Transaction and Concurrency/_category.json b/docs/DBMS/Transaction and Concurrency/_category.json
deleted file mode 100644
index b0eac087a..000000000
--- a/docs/DBMS/Transaction and Concurrency/_category.json
+++ /dev/null
@@ -1,8 +0,0 @@
-{
- "label": "Transaction",
- "position": 4,
- "link": {
- "type": "generated-index",
- "description": "Explore transactions, ACID properties, concurrency control, and serializability in DBMS."
- }
-}
\ No newline at end of file
diff --git a/docs/DBMS/Transaction and Concurrency/dbms-concurrency-control.md b/docs/DBMS/Transaction and Concurrency/dbms-concurrency-control.md
deleted file mode 100644
index 88a6b5538..000000000
--- a/docs/DBMS/Transaction and Concurrency/dbms-concurrency-control.md
+++ /dev/null
@@ -1,64 +0,0 @@
----
-id: dbms-concurrency-control
-title: DBMS - Concurrency Control
-sidebar_label: Concurrency Control
-sidebar_position: 3
-description: Explore concurrency control protocols in database management, including lock-based protocols and timestamp-based protocols, ensuring atomicity, isolation, and serializability of transactions.
----
-
-# DBMS - Concurrency Control
-
-In a multi-transaction environment, managing concurrency is vital to ensure the atomicity, isolation, and serializability of transactions. Concurrency control protocols play a crucial role in achieving these objectives and maintaining data integrity.
-
-## Lock-based Protocols
-
-Lock-based protocols restrict access to data items using locks, ensuring that transactions acquire appropriate locks before reading or writing data. There are two types of locks:
-
-- **Binary Locks:** Data items can be either locked or unlocked.
-- **Shared/Exclusive Locks:** Differentiates locks based on their use (read or write).
-
-### Types of Lock-based Protocols
-
-#### Simplistic Lock Protocol
-
-Transactions acquire locks on data items before performing write operations and release them afterward.
-
-#### Pre-claiming Lock Protocol
-
-Transactions pre-determine the locks they need, request all locks before execution, and roll back if all locks are not granted.
-
-#### Two-Phase Locking (2PL)
-
-Divides transaction execution into two phases: growing phase (acquiring locks) and shrinking phase (releasing locks).
-
-#### Strict Two-Phase Locking (Strict-2PL)
-
-Similar to 2PL but holds all locks until the commit point, releasing them simultaneously.
-
-## Timestamp-based Protocols
-
-Timestamp-based protocols use timestamps (system time or logical counter) to manage concurrency and ordering of transactions.
-
-Every transaction and data item has associated timestamps for read and write operations.
-
-### Timestamp Ordering Protocol
-
-Ensures serializability among conflicting read and write operations based on transaction timestamps.
-
-#### Rules
-
-- Read(X) operation:
- - $TS(Ti) < W-timestamp(X)$: Rejected.
- - $TS(Ti) >= W-timestamp(X)$: Executed, update timestamps.
-- Write(X) operation:
- - $TS(Ti) < R-timestamp(X)$: Rejected.
- - $TS(Ti) < W-timestamp(X)$: Rejected, rollback.
- - Otherwise: Executed.
-
-#### Thomas' Write Rule
-
-If $TS(Ti) < W-timestamp(X)$, the write operation is rejected, and Ti is rolled back.
-
-## Summary
-
-Concurrency control protocols, whether lock-based or timestamp-based, are essential for managing transactions effectively in a database system. They ensure transactions are executed in a controlled manner, maintaining data consistency and integrity.
diff --git a/docs/DBMS/Transaction and Concurrency/transaction.md b/docs/DBMS/Transaction and Concurrency/transaction.md
deleted file mode 100644
index d49ba2ed5..000000000
--- a/docs/DBMS/Transaction and Concurrency/transaction.md
+++ /dev/null
@@ -1,112 +0,0 @@
----
-id: dbms-transaction
-title: DBMS - Transaction
-sidebar_label: Transaction
-sidebar_position: 2
-description: Learn about transactions in database management, their properties (ACID), states, and the importance of serializability in ensuring data integrity.
----
-
-# DBMS - Transactions
-
-A transaction in a Database Management System (DBMS) is defined as a group of tasks that together form a single unit of work. Each task in a transaction is the smallest processing unit that cannot be divided further. Transactions are crucial in ensuring data integrity and consistency within a database.
-
-## Example of a Transaction
-
-Consider a bank transaction where Rs 500 is transferred from A's account to B's account. This transaction involves the following tasks:
-
-**A's Account:**
-1. Open_Account(A)
-2. Old_Balance = A.balance
-3. New_Balance = Old_Balance - 500
-4. A.balance = New_Balance
-5. Close_Account(A)
-
-**B's Account:**
-1. Open_Account(B)
-2. Old_Balance = B.balance
-3. New_Balance = Old_Balance + 500
-4. B.balance = New_Balance
-5. Close_Account(B)
-
-## ACID Properties
-
-Transactions must satisfy the ACID properties to ensure accuracy, completeness, and data integrity.
-
-- **Atomicity:** Ensures that all operations within the transaction are completed; if not, the transaction is aborted.
-- **Consistency:** Ensures that the database remains in a consistent state before and after the transaction.
-- **Isolation:** Ensures that transactions are executed in isolation, without interference from other transactions.
-- **Durability:** Ensures that the results of a committed transaction are permanently stored in the database, even in the case of a system failure.
-
-## Serializability
-
-Serializability ensures that the transactions produce the same results as if they were executed serially, one after the other. This is crucial in a multi-transaction environment.
-
-### Types of Schedules
-
-- **Serial Schedule:** Transactions are executed one after the other, without overlapping.
-- **Equivalence Schedules:** Schedules that are considered equivalent if they satisfy certain properties.
-
-#### Equivalence Schedules Types
-
-- **Result Equivalence:** Schedules that produce the same result after execution.
-
-- **View Equivalence:** Schedules where transactions perform similar actions in a similar manner.
-
-##### Example
-
-- If T reads the initial data in S1, then it also reads the initial data in S2.
-
-- If T reads the value written by J in S1, then it also reads the value written by J in S2.
-
-- If T performs the final write on the data value in S1, then it also performs the final write on the data value in S2.
-
-- **Conflict Equivalence:** Schedules with conflicting operations that access the same data item, where at least one operation is a write.
-
-Two schedules would be conflicting if they have the following properties −
-
-- Both belong to separate transactions.
-- Both accesses the same data item.
-- At least one of them is "write" operation.
-
-Two schedules having multiple transactions with conflicting operations are said to be conflict equivalent if and only if −
-
-- Both the schedules contain the same set of Transactions.
-- The order of conflicting pairs of operation is maintained in both the schedules.
-
-> **Note :** View equivalent schedules are view serializable and conflict equivalent schedules are conflict serializable. All conflict serializable schedules are view serializable too.
-
-## Equivalence Types Comparison Table
-
-| Equivalence Type | Description | Significance |
-|------------------|-------------|--------------|
-| Result Equivalence | Produces the same result after execution. | Not generally significant due to variable results. |
-| View Equivalence | Transactions perform similar actions in a similar manner. | Ensures transactions read and write similar values. |
-| Conflict Equivalence | Transactions have conflicting operations accessing the same data item. | Ensures conflicting operations maintain order. |
-
-## States of Transactions
-
-A transaction in a database can be in one of the following states:
-
-- **Active:** The transaction is being executed.
-- **Partially Committed:** The transaction has executed its final operation but not yet committed.
-- **Failed:** The transaction has encountered an error and cannot proceed.
-- **Aborted:** The transaction has been rolled back to its original state.
-- **Committed:** The transaction has successfully completed and its changes are permanently applied to the database.
-
-
-### Transaction States Diagram
-
-```mermaid
-stateDiagram-v2
- [*] --> Active
- Active --> PartiallyCommitted : Final operation
- PartiallyCommitted --> Committed : Commit
- Active --> Failed : Error
- Failed --> Aborted : Rollback
- Aborted --> [*]
- Committed --> [*]
-```
-
-## Summary
-
-Transactions are vital for maintaining data integrity and consistency in DBMS. By adhering to the ACID properties, transactions ensure reliable and accurate database operations. Understanding transaction states and serializability helps in managing and optimizing concurrent transactions effectively.
\ No newline at end of file
diff --git a/docs/DBMS/_category.json b/docs/DBMS/_category.json
deleted file mode 100644
index aa94290b4..000000000
--- a/docs/DBMS/_category.json
+++ /dev/null
@@ -1,8 +0,0 @@
-{
- "label": "DBMS",
- "position": 5,
- "link": {
- "type": "generated-index",
- "description": "Database Management Systems (DBMS) are software systems designed to manage databases. They provide an interface for users and applications to interact with data efficiently and securely. DBMSs support various types of databases, such as relational, NoSQL, and distributed databases, each serving different purposes and use cases. Relational databases use structured query language (SQL) for defining and manipulating data, while NoSQL databases are designed for specific data models and scalability. Key features of DBMS include data integrity, concurrency control, transaction management, and data security. Examples of popular DBMS include MySQL, PostgreSQL, MongoDB, and Oracle Database."
- }
-}
\ No newline at end of file
diff --git a/docs/DBMS/data-independence-dbms.md b/docs/DBMS/data-independence-dbms.md
deleted file mode 100644
index a5289c66c..000000000
--- a/docs/DBMS/data-independence-dbms.md
+++ /dev/null
@@ -1,34 +0,0 @@
----
-id: data-independence-dbms
-title: DBMS Data Independence
-sidebar_label: Data Independence
-sidebar_position: 6
-tags: [dbms, data independence]
-description: Understand data independence in DBMS, including logical and physical data independence, and their importance in maintaining flexibility and scalability.
----
-
-# DBMS - Data Independence
-
-If a database system is not multi-layered, then it becomes difficult to make any changes in the database system. Database systems are designed in multi-layers as we learned earlier.
-
-## Data Independence
-
-A database system normally contains a lot of data in addition to users’ data. For example, it stores data about data, known as metadata, to locate and retrieve data easily. It is rather difficult to modify or update a set of metadata once it is stored in the database. But as a DBMS expands, it needs to change over time to satisfy the requirements of the users. If the entire data is dependent, it would become a tedious and highly complex job.
-
-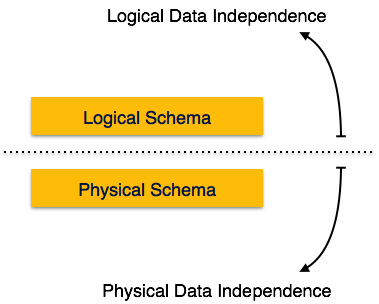
-
-### Data Independence
-
-Metadata itself follows a layered architecture, so that when we change data at one layer, it does not affect the data at another level. This data is independent but mapped to each other.
-
-### Logical Data Independence
-
-Logical data is data about the database, that is, it stores information about how data is managed inside. For example, a table (relation) stored in the database and all its constraints, applied to that relation.
-
-Logical data independence is a kind of mechanism, which liberalizes itself from actual data stored on the disk. If we make some changes to the table format, it should not change the data residing on the disk.
-
-### Physical Data Independence
-
-All the schemas are logical, and the actual data is stored in bit format on the disk. Physical data independence is the power to change the physical data without impacting the schema or logical data.
-
-For example, if we want to change or upgrade the storage system itself − suppose we want to replace hard disks with SSDs − it should not have any impact on the logical data or schemas.
\ No newline at end of file
diff --git a/docs/DBMS/data-models.md b/docs/DBMS/data-models.md
deleted file mode 100644
index e9f45520e..000000000
--- a/docs/DBMS/data-models.md
+++ /dev/null
@@ -1,90 +0,0 @@
----
-id: data-models-dbms
-title: DBMS Data Models
-sidebar_label: Data Models
-sidebar_position: 4
-tags: [dbms, data models]
-description: Learn about different data models in DBMS, including flat data models, Entity-Relationship models, and relational models, and understand how data is structured, processed, and stored.
----
-
-# DBMS - Data Models
-
-Data models define the logical structure of a database and introduce abstraction in a DBMS. They specify how data is connected, processed, and stored within the system.
-
-## Flat Data Models
-
-Flat data models were the earliest, where all data was kept on the same plane. However, they were prone to duplication and update anomalies due to their non-scientific nature.
-
-## Entity-Relationship Model (ER Model)
-
-The Entity-Relationship (ER) Model is based on real-world entities and their relationships. It creates entity sets, relationship sets, attributes, and constraints, making it suitable for conceptual database design.
-
-```mermaid
----
-title: ER Model Example
----
-erDiagram
- STUDENT {
- string name
- int age
- string class
- }
- TEACHER {
- string name
- string subject
- }
- COURSE {
- string name
- int credits
- }
- STUDENT ||--o{ COURSE : enrolls
- TEACHER ||--o{ COURSE : teaches
-```
-
-### Concepts of ER Model
-
-- **Entity**: A real-world entity with attributes defined by a domain. For example, in a school database, a student is an entity with attributes like name, age, and class.
-- **Relationship**: Logical associations between entities, defined by mapping cardinalities such as one-to-one, one-to-many, many-to-one, and many-to-many.
-
-## Relational Model
-
-The Relational Model is the most popular data model in DBMS, based on first-order predicate logic. It defines a table as an n-ary relation.
-
-```mermaid
----
-title: Relational Model Table Example
----
-erDiagram
- CUSTOMER {
- int id
- string name
- string address
- }
- ORDER {
- int id
- date orderDate
- float amount
- }
- LINE_ITEM {
- int id
- int quantity
- float price
- }
- CUSTOMER ||--o{ ORDER : places
- ORDER ||--|{ LINE_ITEM : contains
- CUSTOMER }|..|{ DELIVERY_ADDRESS : uses
- DELIVERY_ADDRESS {
- int id
- string street
- string city
- string zip
- }
-```
-
-### Highlights of Relational Model
-
-- Data stored in tables (relations).
-- Relations can be normalized.
-- Normalized relations contain atomic values.
-- Each row in a relation has a unique value.
-- Columns in a relation contain values from the same domain.
\ No newline at end of file
diff --git a/docs/DBMS/data-schema.md b/docs/DBMS/data-schema.md
deleted file mode 100644
index 181554ade..000000000
--- a/docs/DBMS/data-schema.md
+++ /dev/null
@@ -1,34 +0,0 @@
----
-id: data-schema-dbms
-title: DBMS Data Schemas
-sidebar_label: Data Schemas
-sidebar_position: 5
-tags: [dbms, data schemas]
-description: Learn about database schemas, including physical and logical schemas, and understand their role in defining the structure and constraints of a database.
----
-
-# DBMS - Data Schemas
-
-A database schema is the skeleton structure that represents the logical view of the entire database. It defines how the data is organized and how the relations among them are associated. It formulates all the constraints that are to be applied to the data.
-
-## Database Schema
-
-A database schema defines its entities and the relationship among them. It contains a descriptive detail of the database, which can be depicted by means of schema diagrams. It’s the database designers who design the schema to help programmers understand the database and make it useful.
-
-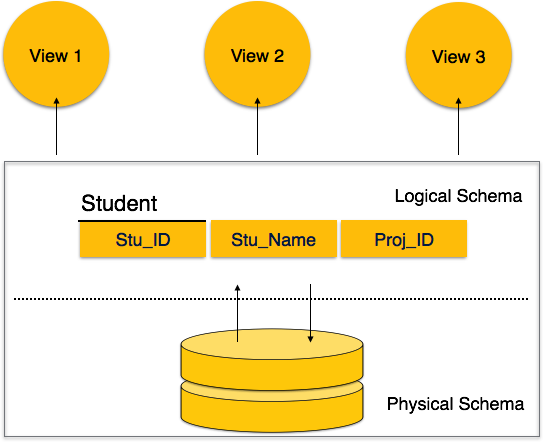
-
-### Categories of Database Schema
-
-A database schema can be divided broadly into two categories:
-
-- **Physical Database Schema**: This schema pertains to the actual storage of data and its form of storage like files, indices, etc. It defines how the data will be stored in a secondary storage.
-
-- **Logical Database Schema**: This schema defines all the logical constraints that need to be applied to the data stored. It defines tables, views, and integrity constraints.
-
-## Database Instance
-
-> **Note:** It is important to distinguish these two terms individually:
-
-- **Database Schema**: The skeleton of the database, designed before the database is created. Once the database is operational, it is very difficult to make any changes to it. A database schema does not contain any data or information.
-
-- **Database Instance**: A state of the operational database with data at any given time. It contains a snapshot of the database. Database instances tend to change with time. A DBMS ensures that every instance (state) is valid by diligently following all the validations, constraints, and conditions that the database designers have imposed.
diff --git a/docs/DBMS/dbms-architecture.md b/docs/DBMS/dbms-architecture.md
deleted file mode 100644
index e0a01aa67..000000000
--- a/docs/DBMS/dbms-architecture.md
+++ /dev/null
@@ -1,34 +0,0 @@
----
-id: architecture-dbms
-title: DBMS Architecture
-sidebar_label: DBMS Architecture
-sidebar_position: 3
-tags: [dbms, architecture]
-description: Learn about the architecture of Database Management Systems (DBMS) including single-tier, two-tier, and three-tier architectures.
----
-
-# DBMS - Architecture
-
-The design of a DBMS depends on its architecture, which can be centralized, decentralized, or hierarchical. The architecture can also be classified as single-tier or multi-tier.
-
-## Single-Tier Architecture
-
-In a single-tier architecture, the DBMS is the sole entity where the user directly interacts with and uses it. Any changes made here directly affect the DBMS itself. However, this architecture lacks convenient tools for end-users, making it more suitable for database designers and programmers.
-
-## Two-Tier Architecture
-
-A two-tier architecture involves an application through which the DBMS is accessed. Programmers use this architecture to access the DBMS via an application, with the application tier operating independently of the database in terms of operation, design, and programming.
-
-## Three-Tier Architecture
-
-The three-tier architecture is the most widely used to design a DBMS, as it separates tiers based on user complexity and data usage:
-
-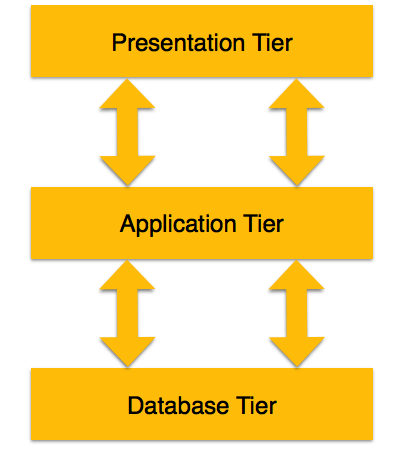
-
-- **Database (Data) Tier**: This tier houses the database along with query processing languages and data relations.
-
-- **Application (Middle) Tier**: Here, the application server and programs that access the database reside. This tier presents an abstracted view of the database to end-users, acting as a mediator between them and the database.
-
-- **User (Presentation) Tier**: End-users operate on this tier, unaware of the database's existence beyond this layer. The application can provide multiple views of the database, generated by applications in the application tier.
-
-The multiple-tier database architecture is highly modifiable, as its components are independent and can be changed independently.
diff --git a/docs/DBMS/dbms-types-of-languages.md b/docs/DBMS/dbms-types-of-languages.md
deleted file mode 100644
index 063136560..000000000
--- a/docs/DBMS/dbms-types-of-languages.md
+++ /dev/null
@@ -1,198 +0,0 @@
----
-id: database-languages
-title: DBMS Database Languages
-sidebar_label: Database Languages
-sidebar_position: 7
-tags: [dbms]
-description: Learn about different types of languages in DBMS.
----
-
-There are 4 types of database languages:
-- DDL (Data Definition Language)
-- DML (Data Manipulation Language)
-- DCL (Data Control Language)
-- TCL (Transaction Control Language)
-
-## DDL - Data Definition Language
-
-DDL commands result in structural changes in the database.
-
-These commands include:
-- create
-- alter
-- truncate
-- drop
-- comment
-- rename
-
-1. ### Create
-create command can be used to create a database or a table.
-
-Example:
-```sql
-create table customers(
- name varchar(50),
- age int
-);
-```
-This command would create a new table 'customers' with two columns, name and age.
-
-2. ### Alter
-
-Alter command can be used for different purposes, such as adding a column, dropping a column, modifying a column name,etc.
-
-Example:
-
-```sql
-alter table customers
-add column city varchar(20);
-```
-This command would add a new coulum 'city' of type varchar to the table customers. Since alter is a ddl command, it cannot be used to delete a row!
-
-
-3. ### Truncate
-
-The 'truncate' command is used to remove all the current data from a table, without deleting the table.
-
-Consider the table below:
-------------------
-| name | age |
-|---------|------|
-| Siya | 24 |
-| Dipti | 45 |
-| Aditya | 18 |
-| Lakshya | 51 |
-------------------
-
-Now, lets use the truncate command:
-
-```sql
-truncate table customers;
-
-/* Output:
-mysql> select * from customers;
-Empty set (0.00 sec)
-*/
-```
-As expected, the command deletes all the rows from the table.
-
-4. ### Rename
-
-The 'rename' command is used to change the name of the table or a column.
-
-example:
-```sql
-alter table customers
-rename to cust;
-
-```
-This example would rename the table 'customers' to 'cust'.
-
-5. Drop
-
-Drop command is used to delete a column or to to delete a table, or even a database.
-
-example:
-```sql
-drop table cust;
-```
-This example would drop the table 'cust' from the database.
-
-## DML - Data Manipulation Language
-
-DML commands modify / retrieve the data in the database and do not result in any structural changes.
-
-These command include:
-- insert
-- select
-- delete
-- update
-
-1. ### Insert
-
-The insert command is used to add data, a row, in a table.
-
-example.
-```sql
- insert into customers values
- ("Siya",24),
- ("Dipti",45),
- ("Aditya",18),
- ("Lakshya",51);
-```
-Thsi query would insert 4 rows in the 'customers' table.
-
-2. ### Select
-
-Data is retrieved using this command.
-example:
-```sql
- select * from customers;
-
- /* Output:
- +---------+------+
-| name | age |
-+---------+------+
-| Siya | 24 |
-| Dipti | 45 |
-| Aditya | 18 |
-| Lakshya | 51 |
-+---------+------+
- */
-```
-3. ### Update
-
-This DML command is used to update values in a table.
-
-example:
-```sql
-update customers
-set age=28
-where name="Siya";
-
-/* Output:
-mysql> select age from customers where name="Siya";
-+------+
-| age |
-+------+
-| 28 |
-+------+
-1 row in set (0.00 sec)
-*/
-```
-
-4. ### Delete
-
-This command is used to delete a row from the table.
-example:
-```sql
-delete from customers
-where name="Siya";
-
-/* Output:
-mysql> select age from customers where name="Siya";
-Empty set (0.00 sec)
-*/
-```
-
-## DCL - Data Control Language
-
-DCL commands are used to control the accessto the database.
-
-These command include:
-- grant
-- revoke
-
-The grant command grants the access to the database. Revoke, on the other hamd, revokes the access to the database.
-
-### TCL - Transaction Control Language
-
-TCL commands include:
-- Commit
-- Rollback
-
-Commit command saves the state after a transaction is complete.
-Rollback command retrieves the original state of the database, i.e. the state before any operations of that transaction are performed.
-
-### Conclusion:
-In this tutorial, we learnt about the different types of database languages, how to execute various commands and their results.
diff --git a/docs/DBMS/home.md b/docs/DBMS/home.md
deleted file mode 100644
index ce495b107..000000000
--- a/docs/DBMS/home.md
+++ /dev/null
@@ -1,54 +0,0 @@
----
-id: dbms-home
-title: Database Management System Tutorial Home
-sidebar_label: Home
-sidebar_position: 1
-tags: [dbms, overview]
-description: In this tutorial, you will learn about Database Management Systems (DBMS), their architecture, data models, applications, and importance in modern computing.
----
-
-# Database Management System Tutorial
-
-## Discussion
-
-Database Management System or DBMS in short refers to the technology of storing and retrieving users' data with utmost efficiency along with appropriate security measures. This tutorial explains the basics of DBMS such as its architecture, data models, data schemas, data independence, E-R model, relation model, relational database design, and storage and file structure and much more.
-
-## Why to Learn DBMS?
-
-Traditionally, data was organized in file formats. DBMS was a new concept then, and all the research was done to make it overcome the deficiencies in traditional style of data management. A modern DBMS has the following characteristics −
-
-- **Real-world entity** − A modern DBMS is more realistic and uses real-world entities to design its architecture. It uses the behavior and attributes too. For example, a school database may use students as an entity and their age as an attribute.
-
-- **Relation-based tables** − DBMS allows entities and relations among them to form tables. A user can understand the architecture of a database just by looking at the table names.
-
-- **Isolation of data and application** − A database system is entirely different than its data. A database is an active entity, whereas data is said to be passive, on which the database works and organizes. DBMS also stores metadata, which is data about data, to ease its own process.
-
-- **Less redundancy** − DBMS follows the rules of normalization, which splits a relation when any of its attributes is having redundancy in values. Normalization is a mathematically rich and scientific process that reduces data redundancy.
-
-- **Consistency** − Consistency is a state where every relation in a database remains consistent. There exist methods and techniques, which can detect attempt of leaving database in inconsistent state. A DBMS can provide greater consistency as compared to earlier forms of data storing applications like file-processing systems.
-
-- **Query Language** − DBMS is equipped with query language, which makes it more efficient to retrieve and manipulate data. A user can apply as many and as different filtering options as required to retrieve a set of data. Traditionally it was not possible where file-processing system was used.
-
-## Applications of DBMS
-
-Database is a collection of related data and data is a collection of facts and figures that can be processed to produce information.
-
-Mostly data represents recordable facts. Data aids in producing information, which is based on facts. For example, if we have data about marks obtained by all students, we can then conclude about toppers and average marks.
-
-A database management system stores data in such a way that it becomes easier to retrieve, manipulate, and produce information. Following are the important characteristics and applications of DBMS.
-
-- **ACID Properties** − DBMS follows the concepts of Atomicity, Consistency, Isolation, and Durability (normally shortened as ACID). These concepts are applied on transactions, which manipulate data in a database. ACID properties help the database stay healthy in multi-transactional environments and in case of failure.
-
-- **Multiuser and Concurrent Access** − DBMS supports multi-user environment and allows them to access and manipulate data in parallel. Though there are restrictions on transactions when users attempt to handle the same data item, but users are always unaware of them.
-
-- **Multiple views** − DBMS offers multiple views for different users. A user who is in the Sales department will have a different view of database than a person working in the Production department. This feature enables the users to have a concentrate view of the database according to their requirements.
-
-- **Security** − Features like multiple views offer security to some extent where users are unable to access data of other users and departments. DBMS offers methods to impose constraints while entering data into the database and retrieving the same at a later stage. DBMS offers many different levels of security features, which enables multiple users to have different views with different features. For example, a user in the Sales department cannot see the data that belongs to the Purchase department. Additionally, it can also be managed how much data of the Sales department should be displayed to the user. Since a DBMS is not saved on the disk as traditional file systems, it is very hard for miscreants to break the code.
-
-## Audience
-
-This DBMS tutorial will especially help computer science graduates in understanding the basic-to-advanced concepts related to Database Management Systems.
-
-## Prerequisites
-
-Before you start proceeding with this tutorial, it is recommended that you have a good understanding of basic computer concepts such as primary memory, secondary memory, and data structures and algorithms.
diff --git a/docs/DBMS/overview.md b/docs/DBMS/overview.md
deleted file mode 100644
index 2a1afad5e..000000000
--- a/docs/DBMS/overview.md
+++ /dev/null
@@ -1,38 +0,0 @@
----
-id: overview-dbms
-title: DBMS Overview
-sidebar_label: Overview
-sidebar_position: 2
-tags: [dbms, overview]
-description: In this tutorial, you will learn about Database Management Systems (DBMS), their architecture, data models, applications, and importance in modern computing.
----
-
-# DBMS - Overview
-
-## Database Overview
-
-A database is a collection of related data, consisting of facts and figures that can be processed to produce information. Data often represents recordable facts and aids in producing meaningful information. For instance, data about student marks enables conclusions about top performers and average scores. A database management system (DBMS) stores data efficiently, facilitating retrieval, manipulation, and information generation.
-
-## Characteristics of DBMS
-
-Traditionally, data was organized in file formats. DBMS emerged to overcome deficiencies in traditional data management. Modern DBMS possess several key characteristics:
-
-- **Real-world entity**: DBMS uses real-world entities with their attributes and behavior. For instance, in a school database, students are entities with attributes like age.
-- **Relation-based tables**: Entities and relations among them form tables, simplifying database architecture understanding.
-
-- **Isolation of data and application**: DBMS separates data from the application, utilizing metadata for its processes.
-- **Less redundancy**: DBMS follows normalization rules, reducing data redundancy and ensuring data integrity.
-- **Consistency**: DBMS maintains consistency across relations, detecting and preventing inconsistencies.
-- **Query Language**: Equipped with query languages, DBMS efficiently retrieves and manipulates data with various filtering options.
-- **ACID Properties**: DBMS follows Atomicity, Consistency, Isolation, and Durability (ACID) principles, ensuring transactional integrity.
-- **Multiuser and Concurrent Access**: Supports multi-user environments with concurrent data access, maintaining data integrity.
-- **Multiple Views**: Offers different views for users based on their roles and requirements.
-- **Security**: Implements security features to restrict data access based on user roles and ensure data confidentiality and integrity.
-
-## Users of DBMS
-
-A typical DBMS has users with different rights and permissions:
-
-- **Administrators**: Maintain and administer the DBMS, creating user access profiles and managing system resources.
-- **Designers**: Work on designing the database structure, including entities, relations, constraints, and views.
-- **End Users**: Utilize the DBMS for various purposes, from viewing data to conducting sophisticated analyses.
diff --git a/docs/Deep Learning/Activation Function/Activation Function.md b/docs/Deep Learning/Activation Function/Activation Function.md
deleted file mode 100644
index f952e202e..000000000
--- a/docs/Deep Learning/Activation Function/Activation Function.md
+++ /dev/null
@@ -1,107 +0,0 @@
-# Activation Functions in Deep Learning: LaTeX Equations and Python Implementation
-
-## Overview
-
-This project provides LaTeX equations, explanations, and Python implementations for various activation functions used in Artificial Neural Networks (ANN) and Deep Learning. Our goal is to offer clear, visually appealing mathematical representations and practical implementations of these functions for educational and reference purposes.
-
-## Contents
-
-1. [Introduction to Activation Functions](#introduction-to-activation-functions)
-2. [Activation Functions](#activation-functions)
-3. [Mathematical Equations](#mathematical-equations)
-4. [Python Implementations](#python-implementations)
-5. [Jupyter Notebook](#jupyter-notebook)
-7. [Comparison of Activation Functions](#comparison-of-activation-functions)
-8. [How to Use This Repository](#how-to-use-this-repository)
-
-
-## Introduction to Activation Functions
-
-Activation functions are crucial components in neural networks, introducing non-linearity to the model and allowing it to learn complex patterns. They determine the output of a neural network node, given an input or set of inputs.
-
-## Activation Functions
-
-This project covers the following activation functions:
-
-### Non-Linear Activation Functions
-Non-linear activation functions introduce non-linearity into the model, enabling the network to learn and represent complex patterns.
-
-- Essential for deep learning models as they introduce the non-linearity needed to capture complex patterns and relationships in the data.
-
-- Here are some common non-linear activation functions:
-1. Sigmoid
-2. Hyperbolic Tangent (tanh)
-3. Rectified Linear Unit (ReLU)
-
-### Linear Activation Functions
-A linear activation function is a function where the output is directly proportional to the input.
-
-- **Linearity:** The function does not introduce any non-linearity. The output is just a scaled version of the input.
-- **Derivative:** The derivative of the function is constant, which means it does not vary with the input.
-
-- Here are some common linear activation functions:
-
-1. Identity
-2. Step Function
-
-## Mathematical Equations
-
-We provide LaTeX equations for each activation function. For example:
-
-1. Sigmoid: $\sigma(x) = \frac{1}{1 + e^{-x}}$
-2. Hyperbolic Tangent: $\tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}}$
-3. ReLU: $f(x) = \max(0, x)$
-4. Linear : $f(x) = x$
-5. Step :
-
-$$
-f(x) =
-\begin{cases}
-0 & \text{if } x < \text{threshold} \\
-1 & \text{if } x \geq \text{threshold}
-\end{cases}
-$$
-
-
-## Python Implementations
-
-Here are the Python implementations of the activation functions:
-
-```python
-import numpy as np
-
-# Non-Linear activation functions
-def sigmoid(x):
- return 1 / (1 + np.exp(-x))
-
-def tanh(x):
- return (np.exp(x) - np.exp(-x)) / (np.exp(x) + np.exp(-x))
-
-def reLu(x):
- return np.maximum(x, 0)
-
-# Linear activation functions
-def identity(x):
- return x
-
-def step(x, thres):
- return np.where(x >= thres, 1, 0)
-```
-
-
-## How to Use This Repository
-
-- Clone this repository to your local machine.
-
-```bash
- git clone https://github.com/CodeHarborHub/codeharborhub.github.io/tree/main/docs/Deep%20Learning/Activation function
-```
-- For Python implementations and visualizations:
-
-1. Ensure you have Jupyter Notebook installed
-
-```bash
- pip install jupyter
-```
-2. Navigate to the project directory in your terminal.
-3. Open activation_functions.ipynb.
diff --git a/docs/Deep Learning/Ann.md b/docs/Deep Learning/Ann.md
deleted file mode 100644
index 8686cdc20..000000000
--- a/docs/Deep Learning/Ann.md
+++ /dev/null
@@ -1,163 +0,0 @@
----
-id: artificial-neural-networks
-title: Artificial Neural Networks
-sidebar_label: Artificial Neural Networks
-sidebar_position: 2
-tags: [Deep Learning, Artificial Neural Networks]
-
----
-
-Artificial Neural Networks (ANNs) are computing systems inspired by the biological neural networks that constitute animal brains. They are a key component of deep learning and machine learning. ANNs consist of interconnected layers of nodes, called neurons, which process and transmit information. These networks are capable of learning from data, making them powerful tools for various applications.
-
-### **Structure of ANNs**
-
-
-
-1. **Input Layer**: The input layer receives the initial data and passes it to the subsequent layers.
-2. **Hidden Layers**: These layers perform computations and feature extraction. There can be one or multiple hidden layers, making the network deeper and more capable of handling complex tasks.
-3. **Output Layer**: The final layer produces the output, which can be a classification, prediction, or any other result based on the input data.
-
-The learning process of Artificial Neural Networks (ANNs) involves several key steps, starting from initializing the network to adjusting its parameters based on data. Here’s a detailed breakdown:
-
-### 1. Initialization
-- **Architecture Design**: Choose the number of layers and the number of neurons in each layer. The architecture can be shallow (few layers) or deep (many layers).
-- **Weight Initialization**: Assign initial values to the weights and biases in the network. This can be done randomly or using specific strategies like Xavier or He initialization.
-
-#### Example
-- **Architecture**: 1 input layer (2 neurons), 1 hidden layer (3 neurons), 1 output layer (1 neuron).
-- **Weights and Biases**: Randomly initialized.
-
-### 2. Forward Propagation
-- **Input Layer**: The input layer receives the raw data. Each neuron in this layer represents an input feature.
-- **Hidden Layers**: Each neuron in a hidden layer computes a weighted sum of its inputs, adds a bias term, and applies an activation function (e.g., ReLU, Sigmoid, Tanh) to introduce non-linearity.
-- **Output Layer**: The final layer produces the network's output. The activation function in this layer depends on the task (e.g., Softmax for classification, linear for regression).
-
-### 3. Loss Computation
-- **Loss Function**: Calculate the loss (or error) which quantifies the difference between the predicted output and the actual target. Common loss functions include Mean Squared Error (MSE) for regression and Cross-Entropy Loss for classification.
-
-### 4. Backpropagation
-- **Gradient Computation**: Calculate the gradient of the loss function with respect to each weight and bias in the network using the chain rule of calculus. This involves computing the partial derivatives of the loss with respect to each parameter.
-- **Weight Update**: Adjust the weights and biases using a gradient-based optimization algorithm. The most common method is Stochastic Gradient Descent (SGD) and its variants (e.g., Adam, RMSprop). The update rule typically looks like:
-
- 
-
-### 5. Epochs and Iterations
-- **Epoch**: One full pass through the entire training dataset.
-- **Iteration**: One update of the network's weights, usually after processing a mini-batch of data.
-
-### 6. Convergence
-- **Stopping Criteria**: Training continues for a predefined number of epochs or until the loss converges to a satisfactory level. Early stopping can be used to halt training when performance on a validation set starts to degrade, indicating overfitting.
-
-
-The learning process of ANNs involves initializing the network, propagating inputs forward to compute outputs, calculating loss, backpropagating errors to update weights, and iterating until the model converges. Each step is crucial for the network to learn and make accurate predictions on new, unseen data.
-
-### **Types of ANNs**
-
-Artificial Neural Networks (ANNs) come in various types, each designed to address specific tasks and data structures. Here’s a detailed overview of the most common types of ANNs:
-
-### 1. Feedforward Neural Networks (FNN)
-- The simplest type of ANN, where the data moves in only one direction—from the input layer through hidden layers to the output layer.
-- **Use Cases**: Basic pattern recognition, regression, and classification tasks.
-- **Example**: A neural network for predicting house prices based on features like size, location, and number of rooms.
-
-### 2. Convolutional Neural Networks (CNN)
-- Specialized for processing grid-like data such as images. They use convolutional layers that apply filters to the input data to capture spatial hierarchies.
-- **Components**:
- - **Convolutional Layers**: Extract features from input data.
- - **Pooling Layers**: Reduce dimensionality and retain important information.
- - **Fully Connected Layers**: Perform classification based on extracted features.
-- **Use Cases**: Image and video recognition, object detection, and medical image analysis.
-- **Example**: A CNN for classifying handwritten digits (MNIST dataset).
-
-### 3. Recurrent Neural Networks (RNN)
- - Designed for sequential data. They have connections that form directed cycles, allowing information to persist.
-- **Components**:
- - **Hidden State**: Carries information across sequence steps.
- - **Loop Connections**: Enable memory of previous inputs.
-- **Use Cases**: Time series prediction, natural language processing, and speech recognition.
-- **Example**: An RNN for predicting the next word in a sentence.
-
-### 4. Long Short-Term Memory Networks (LSTM)
-- A type of RNN that addresses the vanishing gradient problem with a special architecture that allows it to remember information for long periods.
-- **Components**:
- - **Cell State**: Manages the flow of information.
- - **Gates**: Control the cell state (input, forget, and output gates).
-- **Use Cases**: Long-term dependency tasks like language modeling, machine translation, and speech synthesis.
-- **Example**: An LSTM for translating text from one language to another.
-
-### 5. Gated Recurrent Units (GRU)
-- A simplified version of LSTM with fewer gates, making it computationally more efficient while still handling the vanishing gradient problem.
-- **Components**:
- - **Update Gate**: Decides how much past information to keep.
- - **Reset Gate**: Determines how much past information to forget.
-- **Use Cases**: Similar to LSTM, used for time series prediction and NLP tasks.
-- **Example**: A GRU for predicting stock prices.
-
-### 6. Autoencoders
-- Neural networks used to learn efficient representations of data, typically for dimensionality reduction or denoising.
-- **Components**:
- - **Encoder**: Compresses the input into a latent-space representation.
- - **Decoder**: Reconstructs the input from the latent representation.
-- **Use Cases**: Anomaly detection, image denoising, and data compression.
-- **Example**: An autoencoder for reducing the dimensionality of a dataset while preserving its structure.
-
-### 7. Variational Autoencoders (VAE)
- : A type of autoencoder that generates new data points by learning the probability distribution of the input data.
-- **Components**:
- - **Encoder**: Maps input data to a distribution.
- - **Decoder**: Generates data from the distribution.
-- **Use Cases**: Generative tasks like image and text generation.
-- **Example**: A VAE for generating new faces based on a dataset of human faces.
-
-### 8. Generative Adversarial Networks (GAN)
-- Consists of two networks (generator and discriminator) that compete against each other. The generator creates data, and the discriminator evaluates it.
-- **Components**:
- - **Generator**: Generates new data instances.
- - **Discriminator**: Distinguishes between real and generated data.
-- **Use Cases**: Image generation, style transfer, and data augmentation.
-- **Example**: A GAN for generating realistic images of landscapes.
-
-### 9. Radial Basis Function Networks (RBFN)
-- Uses radial basis functions as activation functions. Typically consists of three layers: input, hidden (with RBF activation), and output.
-- **Use Cases**: Function approximation, time-series prediction, and control systems.
-- **Example**: An RBFN for approximating complex nonlinear functions.
-
-### 10. Self-Organizing Maps (SOM)
-- An unsupervised learning algorithm that produces a low-dimensional (typically 2D) representation of the input space, preserving topological properties.
-- **Use Cases**: Data visualization, clustering, and feature mapping.
-- **Example**: A SOM for visualizing high-dimensional data like customer purchase behavior.
-
-### 11. Transformer Networks
-- A model architecture that relies on self-attention mechanisms to process input sequences in parallel rather than sequentially.
-- **Key Components**:
- - **Self-Attention Mechanism**: Computes the relationship between different positions in the input sequence.
- - **Feedforward Layers**: Process the self-attention outputs.
-- **Use Cases**: Natural language processing tasks like translation, summarization, and question answering.
-- **Example**: The Transformer model for language translation (e.g., Google Translate).
-
-
-Each type of ANN has its own strengths and is suited for different types of tasks. The choice of ANN depends on the specific problem at hand, the nature of the data, and the desired outcome. Understanding these various architectures allows for better design and implementation of neural networks to solve complex real-world problems.
-
-### **Applications**
-
-1. **Image and Video Recognition**: ANNs can identify objects, faces, and actions in images and videos.
-2. **Natural Language Processing (NLP)**: Used for tasks like language translation, sentiment analysis, and chatbots.
-3. **Speech Recognition**: Convert spoken language into text.
-4. **Predictive Analytics**: Forecasting future trends based on historical data.
-5. **Autonomous Systems**: Control systems in self-driving cars, robots, and drones.
-
-### **Advantages**
-
-1. **Adaptability**: ANNs can learn and adapt to new data.
-2. **Versatility**: Applicable to a wide range of tasks.
-3. **Efficiency**: Capable of processing large amounts of data quickly.
-
-### **Challenges**
-
-1. **Complexity**: Designing and training large neural networks can be complex and computationally intensive.
-2. **Data Requirements**: ANNs often require large amounts of labeled data for training.
-3. **Interpretability**: Understanding how a trained neural network makes decisions can be difficult.
-
-### **Conclusion**
-
-Artificial Neural Networks are a foundational technology in the field of artificial intelligence and machine learning. Their ability to learn from data and adapt to new situations makes them invaluable for a wide range of applications, from image recognition to autonomous systems. Despite their complexity and data requirements, the advancements in computational power and algorithms continue to enhance their capabilities and broaden their applications.
diff --git a/docs/Deep Learning/Backpropogation in ANN.md b/docs/Deep Learning/Backpropogation in ANN.md
deleted file mode 100644
index 442040f78..000000000
--- a/docs/Deep Learning/Backpropogation in ANN.md
+++ /dev/null
@@ -1,120 +0,0 @@
-
-# Backpropagation in Neural Networks
-
-## Overview
-
-Backpropagation is a fundamental algorithm used for training artificial neural networks. It computes the gradient of the loss function with respect to each weight by the chain rule, efficiently propagating errors backward through the network. This allows for the adjustment of weights to minimize the loss function, ultimately improving the performance of the neural network.
-
-
-
-
-# How Backpropagation Works
-
-## Forward propogation
-
-- Input Layer: The input data is fed into the network.
-- Hidden Layers: Each layer performs computations using weights and biases to transform the input data.
-- Output Layer: The final transformation produces the output, which is compared to the actual target to calculate the loss.
-
-### Mathematical Formulation
-$$
-a_i^l = f\left(z_i^l\right) = f\left(\sum_j w_{ij}^l a_j^{l-1} + b_i^l\right)
-$$
-
-
-where f is the activation function, zᵢˡ is the net input of neuron i in layer l, wᵢⱼˡ is the connection weight between neuron j in layer l — 1 and neuron i in layer l, and bᵢˡ is the bias of neuron i in layer l.
-
-## Backward propogation
-
-- Compute Loss: Calculate the error (loss) using a loss function (e.g., Mean Squared Error, Cross-Entropy Loss).
-- Error Propagation: Propagate the error backward through the network, layer by layer.
-- Gradient Calculation: Compute the gradient of the loss with respect to each weight using the chain rule.
-- Weight Update: Adjust the weights by subtracting the gradient multiplied by the learning rate.
-
-### Mathematical Formulation
-
-- The loss function measures how well the neural network's output matches the target values. Common loss functions include:
-1) **Mean Squared Error (MSE):**
-
-$$
-L = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2
-$$
-1) **Cross-Entropy Loss:**
-
-$$
-L = -\frac{1}{n} \sum_{i=1}^{n} \left[ y_i \log(\hat{y}_i) + (1 - y_i) \log(1 - \hat{y}_i) \right]
-$$
-
-
-- For each weight 𝑤 in the network, the gradient of the loss L with respect to w is computed as:
-
-$$
-\frac{\partial L}{\partial w} = \frac{\partial L}{\partial \hat{y}} \cdot \frac{\partial \hat{y}}{\partial w}
-$$
-
-
-- Weights are updated using the gradient descent algorithm:
-
-$$
-w \leftarrow w - \eta \frac{\partial L}{\partial w}
-$$
-
-# Backpropogation from scratch
-
-
-
-```bash
- import numpy as np
-
-def sigmoid(x):
- return 1 / (1 + np.exp(-x))
-
-def sigmoid_derivative(x):
- return x * (1 - x)
-
-# Input data
-X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
-y = np.array([[0], [1], [1], [0]])
-
-# Initialize weights and biases
-np.random.seed(42)
-weights_input_hidden = np.random.rand(2, 2)
-weights_hidden_output = np.random.rand(2, 1)
-bias_hidden = np.random.rand(1, 2)
-bias_output = np.random.rand(1, 1)
-learning_rate = 0.1
-
-# Training
-
-for epoch in range(10000):
-
- # Forward pass
- hidden_input = np.dot(X, weights_input_hidden) + bias_hidden
- hidden_output = sigmoid(hidden_input)
- final_input = np.dot(hidden_output, weights_hidden_output) + bias_output
- final_output = sigmoid(final_input)
-
- # Error
- error = y - final_output
- d_output = error * sigmoid_derivative(final_output)
-
- # Backward Propogation ( gradient decent)
- error_hidden = d_output.dot(weights_hidden_output.T)
- d_hidden = error_hidden * sigmoid_derivative(hidden_output)
-
- # Update weights and biases
- weights_hidden_output += hidden_output.T.dot(d_output) * learning_rate
- bias_output += np.sum(d_output, axis=0, keepdims=True) * learning_rate
- weights_input_hidden += X.T.dot(d_hidden) * learning_rate
- bias_hidden += np.sum(d_hidden, axis=0) * learning_rate
-
-print("Training complete")
-print("Output after training:")
-print(final_output)
-
-```
-
-
-## Conclusion
-
-Backpropagation is a powerful technique for training neural networks(ANN), enabling them to learn complex patterns and make accurate predictions. Understanding the mechanics and mathematics behind it is essential to Understand inner woking of an ANN.
diff --git a/docs/Deep Learning/CNN.md b/docs/Deep Learning/CNN.md
deleted file mode 100644
index 27ca48807..000000000
--- a/docs/Deep Learning/CNN.md
+++ /dev/null
@@ -1,164 +0,0 @@
----
-id: convolutional-neural-networks
-title: Convolutional Neural Networks
-sidebar_label: Introduction to Convolutional Neural Networks
-sidebar_position: 1
-tags: [CNN, Convolutional Neural Networks, deep learning, machine learning, classification algorithm, data analysis, data science, neural networks, image recognition, feature extraction, pattern recognition]
-description: In this tutorial, you will learn about Convolutional Neural Networks (CNNs), their importance, what CNNs are, why learn CNNs, how to use CNNs, steps to start using CNNs, and more.
----
-
-### Introduction to Convolutional Neural Networks
-Convolutional Neural Networks (CNNs) are a class of deep learning algorithms designed primarily for image processing and pattern recognition tasks. They leverage convolutional layers to automatically and adaptively learn spatial hierarchies of features from input images, making them powerful tools for visual data analysis.
-
-### What is a Convolutional Neural Network?
-Convolutional Neural Networks involve several key components and layers:
-
-- **Convolutional Layers**: These layers apply convolution operations to the input, using a set of learnable filters (kernels) to produce feature maps. Convolution helps in extracting local features from the input image.
-
-- **Pooling Layers**: These layers downsample the feature maps to reduce their spatial dimensions and computational load. Common pooling operations include max pooling and average pooling.
-
-- **Fully Connected Layers**: After several convolutional and pooling layers, the network usually transitions to fully connected layers, where each neuron is connected to every neuron in the previous layer, enabling high-level reasoning.
-
-- **Activation Functions**: Non-linear functions like ReLU (Rectified Linear Unit) are applied to introduce non-linearity into the model, allowing it to learn more complex patterns.
-
-
-
-### Example:
-Consider using a CNN for handwritten digit recognition. The network might learn edges and simple shapes in early layers and complex digit shapes in deeper layers. This hierarchical learning enables accurate classification of handwritten digits.
-
-### Advantages of Convolutional Neural Networks
-CNNs offer several advantages:
-
-- **Automatic Feature Extraction**: CNNs automatically learn relevant features from raw input images, reducing the need for manual feature engineering.
-- **Parameter Sharing**: Convolutional layers share parameters across spatial locations, significantly reducing the number of parameters and computational complexity.
-- **Translation Invariance**: CNNs are robust to translations of the input image, making them effective for recognizing objects regardless of their position.
-
-### Example:
-In medical imaging, CNNs can classify MRI scans to detect tumors by learning relevant features from the scans without manual intervention, aiding in accurate diagnosis.
-
-### Disadvantages of Convolutional Neural Networks
-Despite their advantages, CNNs have limitations:
-
-- **Data-Intensive**: CNNs typically require large amounts of labeled data for training to achieve good performance.
-- **Computationally Expensive**: Training CNNs can be computationally intensive, often requiring specialized hardware like GPUs.
-- **Black Box Nature**: The learned features and decision-making process in CNNs can be difficult to interpret and understand.
-
-### Example:
-In real-time video analysis, the computational requirements of CNNs can be a bottleneck, necessitating efficient implementations and hardware acceleration.
-
-### Practical Tips for Using Convolutional Neural Networks
-To maximize the effectiveness of CNNs:
-
-- **Data Augmentation**: Use techniques like rotation, scaling, and flipping to artificially increase the size of the training dataset.
-- **Transfer Learning**: Utilize pre-trained models and fine-tune them on your specific dataset to leverage learned features from large-scale datasets.
-- **Regularization**: Apply dropout and weight regularization techniques to prevent overfitting and improve generalization.
-
-### Example:
-In facial recognition systems, data augmentation helps create diverse training samples, improving the model's ability to generalize to unseen faces.
-
-### Real-World Examples
-
-#### Autonomous Driving
-CNNs are used in self-driving cars for tasks like object detection and lane detection. They process images from cameras mounted on the car to recognize pedestrians, vehicles, traffic signs, and road lanes, enabling safe navigation.
-
-#### Image Captioning
-CNNs are combined with Recurrent Neural Networks (RNNs) to generate captions for images. The CNN extracts features from the image, and the RNN generates a sequence of words describing the image, producing coherent and meaningful captions.
-
-### Difference Between CNN and Traditional Neural Networks
-| Feature | Convolutional Neural Networks (CNN) | Traditional Neural Networks (NN) |
-|---------------------------------|-------------------------------------|----------------------------------|
-| Feature Extraction | Automatically extracts features using convolutional layers. | Requires manual feature extraction or flattened input. |
-| Parameter Sharing | Yes, reduces the number of parameters significantly. | No, each neuron has its own parameters. |
-| Spatial Hierarchies | Learns spatial hierarchies of features from images. | Typically does not capture spatial hierarchies. |
-
-### Implementation
-To implement and train a Convolutional Neural Network, you can use libraries such as TensorFlow or PyTorch in Python. Below are the steps to install the necessary libraries and train a CNN model.
-
-#### Libraries to Download
-- `TensorFlow` or `PyTorch`: Essential for building and training neural networks.
-- `numpy`: Essential for numerical operations.
-- `matplotlib`: Useful for visualizing data and model performance.
-
-You can install these libraries using pip:
-
-```bash
-pip install tensorflow numpy matplotlib
-```
-
-#### Training a Convolutional Neural Network
-Here’s a step-by-step guide to training a CNN model using TensorFlow:
-
-**Import Libraries:**
-
-```python
-import tensorflow as tf
-from tensorflow.keras import layers, models
-import numpy as np
-import matplotlib.pyplot as plt
-```
-
-**Load and Prepare Data:**
-Assuming you are using the MNIST dataset of handwritten digits:
-
-```python
-# Load the dataset
-(X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data()
-
-# Normalize the pixel values
-X_train, X_test = X_train / 255.0, X_test / 255.0
-
-# Add a channel dimension (required by Conv2D)
-X_train = X_train[..., np.newaxis]
-X_test = X_test[..., np.newaxis]
-```
-
-**Define the Convolutional Neural Network:**
-
-```python
-model = models.Sequential([
- layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
- layers.MaxPooling2D((2, 2)),
- layers.Conv2D(64, (3, 3), activation='relu'),
- layers.MaxPooling2D((2, 2)),
- layers.Conv2D(64, (3, 3), activation='relu'),
- layers.Flatten(),
- layers.Dense(64, activation='relu'),
- layers.Dense(10, activation='softmax')
-])
-```
-
-**Compile the Model:**
-
-```python
-model.compile(optimizer='adam',
- loss='sparse_categorical_crossentropy',
- metrics=['accuracy'])
-```
-
-**Train the Model:**
-
-```python
-history = model.fit(X_train, y_train, epochs=5,
- validation_data=(X_test, y_test))
-```
-
-**Evaluate the Model:**
-
-```python
-test_loss, test_acc = model.evaluate(X_test, y_test, verbose=2)
-print(f'\nTest accuracy: {test_acc:.2f}')
-```
-
-This example demonstrates loading data, defining a CNN architecture, training the model, and evaluating its performance using TensorFlow. Adjust parameters and preprocessing steps based on your specific dataset and requirements.
-
-### Performance Considerations
-
-#### Computational Efficiency
-- **Hardware Acceleration**: Utilize GPUs or TPUs to accelerate training and inference processes.
-- **Batch Processing**: Train the model using mini-batches to efficiently utilize computational resources.
-
-### Example:
-In real-time video processing, leveraging GPUs ensures timely analysis and response, critical for applications like surveillance and autonomous driving.
-
-### Conclusion
-Convolutional Neural Networks are a versatile and powerful tool for image analysis and pattern recognition. By understanding their architecture, advantages, limitations, and implementation, practitioners can effectively apply CNNs to a wide range of computer vision tasks in data science and machine learning projects.
diff --git a/docs/Deep Learning/Intro.md b/docs/Deep Learning/Intro.md
deleted file mode 100644
index a009858b2..000000000
--- a/docs/Deep Learning/Intro.md
+++ /dev/null
@@ -1,62 +0,0 @@
----
-id: introducation-to-deep-learning
-title: Introducation to Deep Learning
-sidebar_label: Introducation to Deep Learning
-sidebar_position: 1
-tags: [Deep Learning]
-
----
-
-Deep learning is a subset of machine learning and artificial intelligence (AI) that mimics the workings of the human brain in processing data and creating patterns for use in decision-making. It uses neural networks with many layers (hence "deep") to analyze various factors of data.
-
-In a fully connected Deep neural network, there is an input layer and one or more hidden layers connected one after the other. Each neuron receives input from the previous layer neurons or the input layer. The output of one neuron becomes the input to other neurons in the next layer of the network, and this process continues until the final layer produces the output of the network. The layers of the neural network transform the input data through a series of nonlinear transformations, allowing the network to learn complex representations of the input data.
-
-
-
-Today Deep learning AI has become one of the most popular and visible areas of machine learning, due to its success in a variety of applications, such as computer vision, natural language processing, and Reinforcement learning.
-
-Deep learning AI can be used for supervised, unsupervised, and reinforcement machine learning, each utilizing different methods for processing data.
-
-**Supervised Machine Learning**: In supervised machine learning, the neural network learns to make predictions or classify data based on labeled datasets. We provide both input features and target outcomes. The neural network learns by minimizing the error between predicted and actual targets through a process called backpropagation. Deep learning algorithms like Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) are used for tasks such as image classification, sentiment analysis, and language translation.
-
-**Unsupervised Machine Learning**: In unsupervised machine learning, the neural network discovers patterns or clusters within unlabeled datasets, meaning there are no target variables. The machine identifies hidden patterns or relationships within the data. Deep learning algorithms like autoencoders and generative models are used for tasks such as clustering, dimensionality reduction, and anomaly detection.
-
-**Reinforcement Machine Learning**: In reinforcement machine learning, an agent learns to make decisions in an environment to maximize a reward signal. The agent takes actions, observes the results, and receives rewards. Deep learning helps the agent learn policies, or sets of actions, that maximize cumulative rewards over time. Algorithms like Deep Q Networks (DQNs) and Deep Deterministic Policy Gradient (DDPG) are used for tasks like robotics and game playing.
-
-## **Core Concept**
-- **Artificial Neural Networks (ANNs)** : Inspired by the structure and function of the human brain, ANNs consist of interconnected nodes (artificial neurons) that process information.
-
-- **Hidden Layers**: Unlike simpler neural networks, deep learning models have multiple hidden layers between the input and output layers. These layers allow the network to learn increasingly complex features from the data.
-- **Learning Process**: Deep learning models learn through a process called backpropagation. This involves adjusting the connections between neurons based on the difference between the model's predictions and the actual data.
-
-## **Key Characteristics of Deep Learning**
-
-- **High Capacity**: Deep neural networks can learn intricate relationships within data due to their multiple layers and numerous connections.
-- **Unsupervised vs. Supervised Learning**: Deep learning can be applied in both supervised learning (models trained with labeled data) and unsupervised learning (models identify patterns in unlabeled data).
-- **Representation Learning**: Deep learning models can automatically learn features (representations) from the data, eliminating the need for manual feature engineering in many cases.
-
-## **Benefits of Deep Learning**
-
-- **Superior Performance**: Deep learning models have achieved state-of-the-art performance in various tasks, including image recognition, natural language processing, and speech recognition.
-- **Automating Feature Extraction**: Deep learning reduces the need for manual feature engineering, a time-consuming and domain-specific task.
-- **Handling Complex Data**: Deep learning can effectively handle complex data types like images, audio, and text, making it well-suited for modern applications.
-
-## **Disadvantages of Deep Learning**
-- **High computational requirements**: Deep Learning AI models require large amounts of data and computational resources to train and optimize.
-Requires large amounts of labeled data: Deep Learning models often require a large amount of labeled data for training, which can be expensive and time- consuming to acquire.
-- **Interpretability**: Deep Learning models can be challenging to interpret, making it difficult to understand how they make decisions.
-- **Overfitting**: Deep Learning models can sometimes overfit to the training data, resulting in poor performance on new and unseen data.
-Black-box nature: Deep Learning models are often treated as black boxes, making it difficult to understand how they work and how they arrived at their predictions.
-
-## **Applications of Deep Learning**
-
-- **Computer Vision**: Image recognition, object detection, facial recognition, medical image analysis.
-- **Natural Language Processing**: Machine translation, sentiment analysis, text summarization, chatbots.
-- **Speech Recognition and Synthesis**: Voice assistants, automatic transcription, language learning apps.
-- **Recommender Systems**: Personalization of recommendations for products, music, movies, etc.
-- **Anomaly Detection**: Identifying unusual patterns or events in data for fraud detection, network security, etc.
-## **Challenges of Deep Learning**
-
-- **Computational Cost**: Training deep learning models often requires significant computational resources and large datasets.
-- **Data Requirements**: Deep learning models can be data-hungry, and performance can suffer with limited data availability.
-- **Explainability**: Understanding how deep learning models arrive at their decisions can be challenging, limiting interpretability in some applications.
diff --git a/docs/Deep Learning/Learning rule in ANN/Learning-Rules.md b/docs/Deep Learning/Learning rule in ANN/Learning-Rules.md
deleted file mode 100644
index b9bbadbb8..000000000
--- a/docs/Deep Learning/Learning rule in ANN/Learning-Rules.md
+++ /dev/null
@@ -1,106 +0,0 @@
-# Learning Rules in Artificial Neural Networks (ANN)
-
-## Introduction
-
-Learning rules are essential components of Artificial Neural Networks (ANNs) that govern how the network updates its weights and biases. This document focuses on two fundamental learning rules: Hebbian Learning and Adaline (Adaptive Linear Neuron) Learning.
-
-## 1. Hebbian Learning
-
-Hebbian Learning, proposed by Donald Hebb in 1949, is one of the earliest and simplest learning rules in neural networks. It is based on the principle that neurons that fire together, wire together.
-
-### Basic Principle
-
-The strength of a connection between two neurons increases if both neurons are activated simultaneously.
-
-### Mathematical Formulation
-
-For neurons $i$ and $j$ with activation values $x_i$ and $x_j$, the weight update $\Delta w_{ij}$ is given by:
-
-$$ \Delta w_{ij} = \eta x_i x_j $$
-
-Where:
-- $\Delta w_{ij}$ is the change in weight between neurons $i$ and $j$
-- $\eta$ is the learning rate
-- $x_i$ is the output of the presynaptic neuron
-- $x_j$ is the output of the postsynaptic neuron
-
-### Variations
-
-1. **Oja's Rule**: A modification of Hebbian learning that includes weight normalization:
-
- $$\Delta w_{ij} = \eta(x_i x_j - \alpha y_j^2 w_{ij})$$
-
- Where $y_j$ is the output of neuron $j$ and $\alpha$ is a forgetting factor.
-
-2. **Generalized Hebbian Algorithm (GHA)**: Extends Oja's rule to multiple outputs:
-
- $$\Delta W = \eta(xy^T - \text{lower}(Wy^Ty))$$
-
- Where $\text{lower}()$ denotes the lower triangular part of a matrix.
-
-## 2. Adaline Learning (Widrow-Hoff Learning Rule)
-
-Adaline (Adaptive Linear Neuron) Learning, developed by Bernard Widrow and Marcian Hoff in 1960, is a single-layer neural network that uses linear activation functions.
-
-### Basic Principle
-
-Adaline learning aims to minimize the mean squared error between the desired output and the actual output of the neuron.
-
-### Mathematical Formulation
-
-For an input vector $\mathbf{x}$ and desired output $d$, the weight update is given by:
-
-$$ \Delta \mathbf{w} = \eta(d - y)\mathbf{x} $$
-
-Where:
-- $\Delta \mathbf{w}$ is the change in weight vector
-- $\eta$ is the learning rate
-- $d$ is the desired output
-- $y = \mathbf{w}^T\mathbf{x}$ is the actual output
-- $\mathbf{x}$ is the input vector
-
-### Learning Process
-
-1. Initialize weights randomly
-2. For each training example:
-
- a. Calculate the output:
-
- $y = \mathbf{w}^T\mathbf{x}$
-
- b. Update weights:
-
- $$w_{new} = w_{old} + \eta(d - y)x$$
-
-4. Repeat step 2 until convergence or a maximum number of epochs is reached
-
-### Comparison with Perceptron Learning
-
-While similar to the perceptron learning rule, Adaline uses the actual output value for weight updates, not just the sign of the output. This allows for more precise weight adjustments.
-
-## Conclusion
-
-Both Hebbian and Adaline learning rules play crucial roles in the development of neural network theory:
-
-- Hebbian Learning provides a biological inspiration for neural learning and is fundamental in unsupervised learning scenarios.
-- Adaline Learning introduces the concept of minimizing error, which is a cornerstone of many modern learning algorithms, including backpropagation in deep neural networks.
-
-Understanding these basic learning rules provides insight into more complex learning algorithms used in deep learning and helps in appreciating the historical development of neural network theory.
-
-
-## How to Use This Repository
-
-- Clone this repository to your local machine.
-
-```bash
- git clone https://github.com/CodeHarborHub/codeharborhub.github.io/tree/main/docs/Deep%20Learning/Learning Rule IN ANN
-```
-- For Python implementations and visualizations:
-
-1. Ensure you have Jupyter Notebook installed
-
-```bash
- pip install jupyter
-```
-2. Navigate to the project directory in your terminal.
-3. Open learning_rules.ipynb.
diff --git a/docs/Deep Learning/Long Short-Term Memory (LSTM).md b/docs/Deep Learning/Long Short-Term Memory (LSTM).md
deleted file mode 100644
index 7d1abd455..000000000
--- a/docs/Deep Learning/Long Short-Term Memory (LSTM).md
+++ /dev/null
@@ -1,161 +0,0 @@
----
-id: long-short-term-memory
-title: Long Short-Term Memory (LSTM) Networks
-sidebar_label: Introduction to LSTM Networks
-sidebar_position: 1
-tags: [LSTM, long short-term memory, deep learning, neural networks, sequence modeling, time series, machine learning, predictive modeling, RNN, recurrent neural networks, data science, AI]
-description: In this tutorial, you will learn about Long Short-Term Memory (LSTM) networks, their importance, what LSTM is, why learn LSTM, how to use LSTM, steps to start using LSTM, and more.
----
-
-### Introduction to Long Short-Term Memory (LSTM) Networks
-Long Short-Term Memory (LSTM) networks are a type of recurrent neural network (RNN) designed to handle and predict sequences of data. They are particularly effective in capturing long-term dependencies and patterns in sequential data, making them widely used in deep learning and time series analysis.
-
-### What is Long Short-Term Memory (LSTM)?
-A **Long Short-Term Memory (LSTM)** network is a specialized RNN architecture capable of learning and retaining information over long periods. Unlike traditional RNNs, LSTMs address the problem of vanishing gradients by incorporating memory cells that maintain and update information through gates.
-
-- **Recurrent Neural Networks (RNNs)**: Neural networks designed for processing sequential data, where connections between nodes form a directed graph along a temporal sequence.
-
-- **Memory Cells**: Components of LSTM networks that store information across time steps, helping the network remember previous inputs.
-
-- **Gates**: Mechanisms in LSTMs (input, forget, and output gates) that regulate the flow of information, determining which data to keep, update, or discard.
-
-**Vanishing Gradients**: A challenge in training RNNs where gradients become exceedingly small, hindering the learning of long-term dependencies.
-
-**Sequential Data**: Data that is ordered and dependent on previous data points, such as time series, text, or speech.
-
-### Example:
-Consider LSTM for predicting stock prices. The algorithm processes historical stock prices, learning patterns and trends over time to make accurate future predictions.
-
-### Advantages of Long Short-Term Memory (LSTM) Networks
-LSTM networks offer several advantages:
-
-- **Capturing Long-term Dependencies**: Effectively learn and remember long-term patterns in sequential data.
-- **Handling Sequential Data**: Suitable for tasks involving time series, text, and speech data.
-- **Preventing Vanishing Gradients**: Overcome the vanishing gradient problem, ensuring better training performance.
-
-### Example:
-In natural language processing, LSTM networks can accurately generate text by understanding the context and dependencies between words over long sequences.
-
-### Disadvantages of Long Short-Term Memory (LSTM) Networks
-Despite its advantages, LSTM networks have limitations:
-
-- **Computationally Intensive**: Training LSTM models can be resource-intensive and time-consuming.
-- **Complexity**: Designing and tuning LSTM networks can be complex, requiring careful selection of hyperparameters.
-- **Overfitting**: LSTM networks can overfit the training data if not properly regularized, especially with limited data.
-
-### Example:
-In speech recognition, LSTM networks might overfit if trained on a small dataset, leading to poor performance on new speech samples.
-
-### Practical Tips for Using Long Short-Term Memory (LSTM) Networks
-To maximize the effectiveness of LSTM networks:
-
-- **Hyperparameter Tuning**: Carefully tune hyperparameters such as learning rate, number of layers, and units per layer to optimize performance.
-- **Regularization**: Use techniques like dropout to prevent overfitting and improve generalization.
-- **Sequence Padding**: Properly pad sequences to ensure uniform input lengths, facilitating efficient training.
-
-### Example:
-In weather forecasting, LSTM networks can predict future temperatures by learning patterns from historical weather data, ensuring accurate predictions through proper tuning and regularization.
-
-### Real-World Examples
-
-#### Sentiment Analysis
-LSTM networks analyze customer reviews and social media posts to determine sentiment, providing valuable insights into customer opinions and market trends.
-
-#### Anomaly Detection
-In industrial systems, LSTM networks monitor sensor data to detect anomalies and predict equipment failures, enabling proactive maintenance.
-
-### Difference Between LSTM and GRU
-| Feature | Long Short-Term Memory (LSTM) | Gated Recurrent Unit (GRU) |
-|---------------------------------|-------------------------------|----------------------------|
-| Architecture | More complex with three gates (input, forget, output) | Simpler with two gates (reset, update) |
-| Training Speed | Slower due to complexity | Faster due to simplicity |
-| Performance | Handles longer sequences better | Often performs comparably with fewer parameters |
-
-### Implementation
-To implement and train an LSTM network, you can use libraries such as TensorFlow or Keras in Python. Below are the steps to install the necessary library and train an LSTM model.
-
-#### Libraries to Download
-
-- `tensorflow`: Essential for building and training neural networks, including LSTM.
-- `pandas`: Useful for data manipulation and analysis.
-- `numpy`: Essential for numerical operations.
-
-You can install these libraries using pip:
-
-```bash
-pip install tensorflow pandas numpy
-```
-
-#### Training a Long Short-Term Memory (LSTM) Model
-Here’s a step-by-step guide to training an LSTM model:
-
-**Import Libraries:**
-
-```python
-import pandas as pd
-import numpy as np
-import tensorflow as tf
-from tensorflow.keras.models import Sequential
-from tensorflow.keras.layers import LSTM, Dense, Dropout
-from sklearn.model_selection import train_test_split
-```
-
-**Load and Prepare Data:**
-Assuming you have a time series dataset in a CSV file:
-
-```python
-# Load the dataset
-data = pd.read_csv('your_dataset.csv')
-
-# Prepare features (X) and target variable (y)
-X = data.drop('target_column', axis=1).values # Replace 'target_column' with your target variable name
-y = data['target_column'].values
-```
-
-**Reshape Data for LSTM:**
-
-```python
-# Reshape data to 3D array [samples, timesteps, features]
-X_reshaped = X.reshape((X.shape[0], 1, X.shape[1]))
-```
-
-**Split Data into Training and Testing Sets:**
-
-```python
-X_train, X_test, y_train, y_test = train_test_split(X_reshaped, y, test_size=0.2, random_state=42)
-```
-
-**Initialize and Train the LSTM Model:**
-
-```python
-model = Sequential()
-model.add(LSTM(50, return_sequences=True, input_shape=(X_train.shape[1], X_train.shape[2])))
-model.add(Dropout(0.2))
-model.add(LSTM(50))
-model.add(Dropout(0.2))
-model.add(Dense(1))
-
-model.compile(optimizer='adam', loss='mean_squared_error')
-model.fit(X_train, y_train, epochs=50, batch_size=32, validation_data=(X_test, y_test))
-```
-
-**Evaluate the Model:**
-
-```python
-loss = model.evaluate(X_test, y_test)
-print(f'Loss: {loss:.2f}')
-```
-
-This example demonstrates loading data, preparing features, training an LSTM model, and evaluating its performance using TensorFlow/Keras. Adjust parameters and preprocessing steps based on your specific dataset and requirements.
-
-### Performance Considerations
-
-#### Computational Efficiency
-- **Sequence Length**: LSTMs can handle long sequences but may require significant computational resources.
-- **Model Complexity**: Proper tuning of hyperparameters can balance model complexity and computational efficiency.
-
-### Example:
-In financial forecasting, LSTM networks help predict stock prices by analyzing historical data, ensuring accurate predictions through efficient computational use.
-
-### Conclusion
-Long Short-Term Memory (LSTM) networks are powerful for sequence modeling and time series analysis. By understanding their architecture, advantages, and implementation steps, practitioners can effectively leverage LSTM networks for a variety of predictive modeling tasks in deep learning and data science projects.
diff --git a/docs/Deep Learning/Multilayer Perceptron (MLP).md b/docs/Deep Learning/Multilayer Perceptron (MLP).md
deleted file mode 100644
index 6b3128be6..000000000
--- a/docs/Deep Learning/Multilayer Perceptron (MLP).md
+++ /dev/null
@@ -1,129 +0,0 @@
----
-id: multilayer-perceptron-in-deep-learning
-title: Multilayer Perceptron in Deep Learning
-sidebar_label: Introduction to Multilayer Perceptron (MLP)
-sidebar_position: 5
-tags: [Multilayer Perceptron, MLP, deep learning, neural networks, machine learning, supervised learning, classification, regression]
-description: In this tutorial, you will learn about Multilayer Perceptron (MLP), its architecture, its applications in deep learning, and how to implement MLP models effectively for various tasks.
----
-
-### Introduction to Multilayer Perceptron (MLP)
-A Multilayer Perceptron (MLP) is a type of artificial neural network used in deep learning. It consists of multiple layers of neurons, including an input layer, one or more hidden layers, and an output layer. MLPs are capable of learning complex patterns and are used for various tasks, including classification and regression.
-
-### Architecture of Multilayer Perceptron
-An MLP is composed of:
-
-- **Input Layer**: The first layer that receives the input features. Each neuron in this layer corresponds to a feature in the input data.
-- **Hidden Layers**: Intermediate layers between the input and output layers. Each hidden layer contains neurons that apply activation functions to the weighted sum of inputs.
-- **Output Layer**: The final layer that produces the predictions. The number of neurons in this layer corresponds to the number of classes (for classification) or the number of output values (for regression).
-
-**Activation Functions**: Non-linear functions applied to the weighted sum of inputs in each neuron. Common activation functions include ReLU (Rectified Linear Unit), sigmoid, and tanh.
-
-**Forward Propagation**: The process of passing input data through the network to obtain predictions.
-
-**Backpropagation**: The process of updating weights in the network based on the error of predictions, using gradient descent or its variants.
-
-### Example Applications of MLP
-- **Image Classification**: Classifying images into different categories (e.g., identifying objects in photos).
-- **Text Classification**: Categorizing text into predefined classes (e.g., spam detection).
-- **Regression Tasks**: Predicting continuous values (e.g., house prices based on features).
-
-### Advantages of Multilayer Perceptron
-- **Ability to Learn Non-Linear Relationships**: Through activation functions and multiple layers, MLPs can model complex non-linear relationships.
-- **Flexibility**: Can be used for both classification and regression tasks.
-- **Generalization**: Capable of generalizing well to new, unseen data when properly trained.
-
-### Disadvantages of Multilayer Perceptron
-- **Training Time**: MLPs can be computationally expensive and require significant time and resources to train, especially with large datasets and many layers.
-- **Overfitting**: Risk of overfitting, especially with complex models and limited data. Regularization techniques like dropout and weight decay can help mitigate this.
-- **Vanishing Gradient Problem**: During backpropagation, gradients can become very small, slowing down learning. This issue is lessened with modern activation functions and architectures.
-
-### Practical Tips for Implementing MLP
-
-- **Feature Scaling**: Normalize or standardize input features to improve the convergence of the training process.
-- **Network Architecture**: Experiment with the number of hidden layers and neurons per layer to find the optimal network architecture for your task.
-- **Regularization**: Use dropout, L2 regularization, and early stopping to prevent overfitting and improve generalization.
-- **Hyperparameter Tuning**: Adjust learning rates, batch sizes, and other hyperparameters to enhance model performance.
-
-### Example Workflow for Implementing an MLP
-
-1. **Data Preparation**:
- - Load and preprocess data (e.g., normalization, handling missing values).
- - Split data into training and testing sets.
-
-2. **Define the MLP Model**:
- - Specify the number of layers and neurons in each layer.
- - Choose activation functions for hidden layers and output layers.
-
-3. **Compile the Model**:
- - Select an optimizer (e.g., Adam, SGD) and a loss function (e.g., cross-entropy for classification, mean squared error for regression).
- - Define evaluation metrics (e.g., accuracy, F1 score).
-
-4. **Train the Model**:
- - Fit the model to the training data, specifying the number of epochs and batch size.
- - Monitor training and validation performance to prevent overfitting.
-
-5. **Evaluate the Model**:
- - Assess model performance on the testing set.
- - Generate predictions and analyze results.
-
-6. **Tune and Optimize**:
- - Adjust hyperparameters and model architecture based on performance.
- - Use techniques like grid search or random search for hyperparameter optimization.
-
-### Implementation Example
-
-Here’s a basic example of how to implement an MLP using TensorFlow and Keras in Python:
-
-```python
-import numpy as np
-import tensorflow as tf
-from tensorflow.keras.models import Sequential
-from tensorflow.keras.layers import Dense
-from sklearn.model_selection import train_test_split
-from sklearn.preprocessing import StandardScaler
-from sklearn.datasets import load_iris
-
-# Load and prepare data
-data = load_iris()
-X = data.data
-y = data.target
-
-# Standardize features
-scaler = StandardScaler()
-X_scaled = scaler.fit_transform(X)
-
-# Split data
-X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
-
-# Define MLP model
-model = Sequential([
- Dense(64, activation='relu', input_shape=(X_train.shape[1],)),
- Dense(32, activation='relu'),
- Dense(3, activation='softmax') # Number of classes in the output layer
-])
-
-# Compile the model
-model.compile(optimizer='adam',
- loss='sparse_categorical_crossentropy',
- metrics=['accuracy'])
-
-# Train the model
-model.fit(X_train, y_train, epochs=50, batch_size=32, validation_split=0.2)
-
-# Evaluate the model
-loss, accuracy = model.evaluate(X_test, y_test)
-print(f'Test Accuracy: {accuracy:.2f}')
-```
-
-### Performance Considerations
-
-#### Computational Resources
-- **Training Time**: Training MLPs can be time-consuming, especially with large datasets and complex models. Using GPUs or TPUs can accelerate training.
-- **Memory Usage**: Large networks and datasets may require significant memory. Ensure your hardware can handle the computational load.
-
-#### Model Complexity
-- **Number of Layers and Neurons**: More layers and neurons can increase model capacity but may also lead to overfitting. Find a balance that suits your data and task.
-
-### Conclusion
-Multilayer Perceptrons (MLPs) are fundamental to deep learning, providing powerful capabilities for learning complex patterns in data. By understanding MLP architecture, advantages, and practical implementation tips, you can effectively apply MLPs to various tasks in machine learning and deep learning projects.
diff --git a/docs/Deep Learning/Optimizers in Deep Learning/AdaGard.md b/docs/Deep Learning/Optimizers in Deep Learning/AdaGard.md
deleted file mode 100644
index e9e67cfd0..000000000
--- a/docs/Deep Learning/Optimizers in Deep Learning/AdaGard.md
+++ /dev/null
@@ -1,109 +0,0 @@
-# Add AdaGrad in Deep Learning Optimizers
-
-This section contains an explanation and implementation of the AdaGrad optimization algorithm used in deep learning. AdaGrad is known for its ability to adapt the learning rate based on the frequency of updates for each parameter.
-
-## Table of Contents
-- [Introduction](#introduction)
-- [Mathematical Explanation](#mathematical-explanation)
- - [AdaGrad in Gradient Descent](#adagrad-in-gradient-descent)
- - [Update Rule](#update-rule)
-- [Implementation in Keras](#implementation-in-keras)
-- [Usage](#usage)
-- [Results](#results)
-- [Advantages of AdaGrad](#advantages-of-adagrad)
-- [Limitations of AdaGrad](#limitations-of-adagrad)
-- [What Next](#what-next)
-
-## Introduction
-
-AdaGrad (Adaptive Gradient Algorithm) is an optimization method that adjusts the learning rate for each parameter individually based on the accumulated squared gradients. This allows the algorithm to perform well in scenarios where sparse features are involved, as it effectively scales down the learning rate for frequently updated parameters.
-
-## Mathematical Explanation
-
-### AdaGrad in Gradient Descent
-
-AdaGrad modifies the standard gradient descent algorithm by adjusting the learning rate for each parameter based on the sum of the squares of the past gradients.
-
-### Update Rule
-
-The update rule for AdaGrad is as follows:
-
-1. Accumulate the squared gradients:
-
- $$
- G_t = G_{t-1} + g_t^2
- $$
-
-2. Update the parameters:
-
-
-$$η = \theta_{t-1} - \frac{\eta}{\sqrt{G_t} + \epsilon} \cdot g_t$$
-
-where:
-- $G_t$ is the accumulated sum of squares of gradients up to time step $t$
-- $g_t$ is the gradient at time step $t$
-- $\eta$ is the learning rate
-- $\epsilon$ is a small constant to prevent division by zero
-
-## Implementation in Keras
-
-Here is a simple implementation of the AdaGrad optimizer using Keras:
-
-```python
-import numpy as np
-from keras.models import Sequential
-from keras.layers import Dense
-from keras.optimizers import Adagrad
-
-# Generate dummy data
-X_train = np.random.rand(1000, 20)
-y_train = np.random.randint(2, size=(1000, 1))
-
-# Define a simple model
-model = Sequential()
-model.add(Dense(64, activation='relu', input_dim=20))
-model.add(Dense(1, activation='sigmoid'))
-
-# Compile the model with AdaGrad optimizer
-optimizer = Adagrad(learning_rate=0.01)
-model.compile(optimizer=optimizer, loss='binary_crossentropy', metrics=['accuracy'])
-
-# Train the model
-model.fit(X_train, y_train, epochs=50, batch_size=32)
-```
-
-In this example:
-- We generate some dummy data for training.
-- We define a simple neural network model with one hidden layer.
-- We compile the model using the AdaGrad optimizer with a learning rate of 0.01.
-- We train the model for 50 epochs with a batch size of 32.
-
-## Usage
-
-To use this implementation, ensure you have the required dependencies installed:
-
-```bash
-pip install numpy keras
-```
-
-Then, you can run the provided script to train a model using the AdaGrad optimizer.
-
-## Results
-
-The results of the training process, including the loss and accuracy, will be displayed after each epoch. You can adjust the learning rate and other hyperparameters to see how they affect the training process.
-
-## Advantages of AdaGrad
-
-1. **Adaptive Learning Rates**: AdaGrad adapts the learning rate for each parameter, making it effective for dealing with sparse data and features.
-2. **No Need for Manual Learning Rate Decay**: Since AdaGrad automatically decays the learning rate, it eliminates the need to manually set learning rate schedules.
-3. **Good for Sparse Data**: AdaGrad performs well on problems with sparse features, such as natural language processing and computer vision tasks.
-
-## Limitations of AdaGrad
-
-1. **Aggressive Learning Rate Decay**: The accumulated gradient sum can grow very large, causing the learning rate to become very small and eventually stopping the learning process.
-2. **Not Suitable for Non-Sparse Data**: For dense data, AdaGrad’s aggressive learning rate decay can slow down convergence, making it less effective.
-3. **Memory Usage**: AdaGrad requires storing the sum of squared gradients for each parameter, which can be memory-intensive for large models.
-
-## What Next
-
-To address these issues, various optimization algorithms have been developed, such as Adam, which incorporate techniques. Which we'll see in next section .
diff --git a/docs/Deep Learning/Optimizers in Deep Learning/Adam.md b/docs/Deep Learning/Optimizers in Deep Learning/Adam.md
deleted file mode 100644
index 74d9df09b..000000000
--- a/docs/Deep Learning/Optimizers in Deep Learning/Adam.md
+++ /dev/null
@@ -1,116 +0,0 @@
-# Add Adam in Deep Learning Optimizers
-
-This Section contains an explanation and implementation of the Adam optimization algorithm used in deep learning. Adam (Adaptive Moment Estimation) is a popular optimizer that combines the benefits of two other widely used methods: AdaGrad and RMSProp.
-
-## Table of Contents
-- [Introduction](#introduction)
-- [Mathematical Explanation](#mathematical-explanation)
- - [Adam in Gradient Descent](#adam-in-gradient-descent)
- - [Update Rule](#update-rule)
-- [Implementation in Keras](#implementation-in-keras)
-- [Results](#results)
-- [Advantages of Adam](#advantages-of-adam)
-- [Limitations of Adam](#limitations-of-adam)
-
-
-## Introduction
-
-Adam is an optimization algorithm that computes adaptive learning rates for each parameter. It combines the advantages of the AdaGrad and RMSProp algorithms by using estimates of the first and second moments of the gradients. Adam is widely used in deep learning due to its efficiency and effectiveness.
-
-## Mathematical Explanation
-
-### Adam in Gradient Descent
-
-Adam optimizes the stochastic gradient descent by calculating individual adaptive learning rates for each parameter based on the first and second moments of the gradients.
-
-### Update Rule
-
-The update rule for Adam is as follows:
-
-1. Compute the first moment estimate (mean of gradients):
-
-$$
-m_t = \beta_1 m_{t-1} + (1 - \beta_1) g_t
-$$
-
-2. Compute the second moment estimate (uncentered variance of gradients):
-
-$$
-v_t = \beta_2 v_{t-1} + (1 - \beta_2) g_t^2
-$$
-
-3. Correct the bias for the first moment estimate:
-
-$$
-\hat{m}_t = \frac{m_t}{1 - \beta_1^t}
-$$
-
-4. Correct the bias for the second moment estimate:
-
-$$
-\hat{v}_t = \frac{v_t}{1 - \beta_2^t}
-$$
-
-5. Update the parameters:
-
-$$
-\theta_t = \theta_{t-1} - \frac{\eta}{\sqrt{\hat{v}_t} + \epsilon} \hat{m}_t
-$$
-
-where:
-- $\theta$ are the model parameters
-- $\eta$ is the learning rate
-- $\beta_1$ and $\beta_2$ are the exponential decay rates for the moment estimates
-- $\epsilon$ is a small constant to prevent division by zero
-- $g_t$ is the gradient at time step $t$
-
-## Implementation in Keras
-
-Simple implementation of the Adam optimizer using Keras:
-
-```python
-import numpy as np
-from keras.models import Sequential
-from keras.layers import Dense
-from keras.optimizers import Adam
-
-# Generate data
-X_train = np.random.rand(1000, 20)
-y_train = np.random.randint(2, size=(1000, 1))
-
-# Define a model
-model = Sequential()
-model.add(Dense(64, activation='relu', input_dim=20))
-model.add(Dense(1, activation='sigmoid'))
-
-# Compile the model with Adam optimizer
-optimizer = Adam(learning_rate=0.001)
-model.compile(optimizer=optimizer, loss='binary_crossentropy', metrics=['accuracy'])
-
-# Train the model
-model.fit(X_train, y_train, epochs=50, batch_size=32)
-```
-
-In this example:
-- We generate some dummy data for training.
-- We define a simple neural network model with one hidden layer.
-- We compile the model using the Adam optimizer with a learning rate of 0.001.
-- We train the model for 50 epochs with a batch size of 32.
-
-
-## Results
-
-The results of the training process, including the loss and accuracy, will be displayed after each epoch. You can adjust the learning rate and other hyperparameters to see how they affect the training process.
-
-## Advantages of Adam
-
-1. **Adaptive Learning Rates**: Adam computes adaptive learning rates for each parameter, which helps in faster convergence.
-2. **Momentum**: Adam includes momentum, which helps in smoothing the optimization path and avoiding local minima.
-3. **Bias Correction**: Adam includes bias correction, improving convergence in the early stages of training.
-4. **Robustness**: Adam works well in practice for a wide range of problems, including those with noisy gradients or sparse data.
-
-## Limitations of Adam
-
-1. **Hyperparameter Sensitivity**: The performance of Adam is sensitive to the choice of hyperparameters ($\beta_1$, $\beta_2$, $\eta$), which may require careful tuning.
-2. **Memory Usage**: Adam requires additional memory to store the first and second moments, which can be significant for large models.
-3. **Generalization**: Models trained with Adam might not generalize as well as those trained with simpler optimizers like SGD in certain cases.
diff --git a/docs/Deep Learning/Optimizers in Deep Learning/Gradient Decent.md b/docs/Deep Learning/Optimizers in Deep Learning/Gradient Decent.md
deleted file mode 100644
index bdb7ee6d5..000000000
--- a/docs/Deep Learning/Optimizers in Deep Learning/Gradient Decent.md
+++ /dev/null
@@ -1,131 +0,0 @@
-
-# Gradient Descent in Deep Learning Optimizers
-
-This repository contains an in-depth explanation and implementation of Gradient Descent, a fundamental optimization algorithm used in deep learning. Gradient Descent is used to minimize the loss function of a model by iteratively updating its parameters.
-
-## Table of Contents
-- [Introduction](#introduction)
-- [Mathematical Explanation](#mathematical-explanation)
- - [Gradient in Gradient Descent](#gradient-in-gradient-descent)
- - [Basic Gradient Descent](#basic-gradient-descent)
- - [Stochastic Gradient Descent (SGD)](#stochastic-gradient-descent-sgd)
- - [Mini-Batch Gradient Descent](#mini-batch-gradient-descent)
- - [Comparison](#comparison)
-- [Implementation in Keras](#implementation-in-keras)
-- [Usage](#usage)
-- [Limation of Gradient Descent](#problems-with-gradient-descent-as-a-deep-learning-optimizer)
-- [Results](#results)
-
-
-## Introduction
-
-Gradient Descent is an optimization algorithm used for minimizing the loss function in machine learning and deep learning models. It works by iteratively adjusting the model parameters in the opposite direction of the gradient of the loss function with respect to the parameters.
-
-## Mathematical Explanation
-
-### Gradient in Gradient Descent
-
-The gradient of a function measures the steepness and direction of the function at a given point. In the context of Gradient Descent, the gradient of the loss function with respect to the parameters indicates how the loss function will change if the parameters are changed.
-
-Mathematically, the gradient is a vector of partial derivatives:
-
-$$∇J(θ)=[∂J(θ)∂θ1,∂J(θ)∂θ2,…,∂J(θ)∂θn]$$
-
-### Basic Gradient Descent
-
-The update rule for the parameters $θ$ in basic gradient descent is:
-
-$$θ = θ - η∇J(θ)$$
-
-where:
-- $θ$ are the model parameters
-- $η$ is the learning rate, a small positive number
-- $∇J(θ)$ is the gradient of the loss function with respect to the parameters
-
-### Stochastic Gradient Descent (SGD)
-
-In Stochastic Gradient Descent, the parameters are updated for each training example rather than after calculating the gradient over the entire dataset.
-
-$$θ = θ - η∇J(θ; x^(i); y^(i))$$
-
-where $x^(i); y^(i)$ represents the $i$-th training example.
-
-### Mini-Batch Gradient Descent
-
-Mini-Batch Gradient Descent is a compromise between Batch Gradient Descent and Stochastic Gradient Descent. It updates the parameters after computing the gradient on a mini-batch of the training data.
-
-$$θ = θ - η∇J(θ; x^mini-batch; y^mini-batch)$$
-
-### Comparison
-
-| Method | Description | Update Frequency | Pros | Cons |
-|---------------------------|--------------------------------------------------------------|-----------------------------|----------------------------------|--------------------------------------|
-| Batch Gradient Descent | Computes gradient over entire dataset | Once per epoch | Stable convergence | Slow for large datasets |
-| Stochastic Gradient Descent (SGD) | Computes gradient for each training example | Once per training example | Faster updates, can escape local minima | Noisy updates, may not converge |
-| Mini-Batch Gradient Descent | Computes gradient over small batches of the dataset | Once per mini-batch | Balance between speed and stability | Requires tuning of mini-batch size |
-
-## Implementation in Keras
-
-Here is a simple implementation of Gradient Descent using Keras:
-
-```python
-import numpy as np
-from keras.models import Sequential
-from keras.layers import Dense
-from keras.optimizers import SGD
-
-# load data
-X_train = np.random.rand(1000, 20)
-y_train = np.random.randint(2, size=(1000, 1))
-
-# Define model
-model = Sequential()
-model.add(Dense(64, activation='relu', input_dim=20))
-model.add(Dense(1, activation='sigmoid'))
-
-# Stochastic Gradient Descent (SGD)
-optimizer = SGD(learning_rate=0.01)
-model.compile(optimizer=optimizer, loss='binary_crossentropy', metrics=['accuracy'])
-
-# finally Train the model
-model.fit(X_train, y_train, epochs=50, batch_size=32)
-```
-
-In this example:
-- We generate some dummy data for training.
-- We define a simple neural network model with one hidden layer.
-- We compile the model using the SGD optimizer with a learning rate of 0.01.
-- We train the model for 50 epochs with a batch size of 32.
-
-## Usage
-
-To use this implementation, ensure you have the required dependencies installed:
-
-```bash
-pip install numpy keras
-```
-
-Then, you can run the provided script to train a model using Gradient Descent.
-
-## Problems with Gradient Descent as a Deep Learning Optimizer
-
-Gradient descent, while a fundamental optimization algorithm, faces several challenges in the context of deep learning:
-
-### 1. Vanishing and Exploding Gradients
-* **Problem:** In deep neural networks, gradients can become extremely small (vanishing) or large (exploding) as they propagate through multiple layers.
-* **Impact:** This hinders the training process, making it difficult for the network to learn from earlier layers.
-
-### 2. Saddle Points and Local Minima
-* **Problem:** The optimization landscape of deep neural networks often contains numerous saddle points (points where the gradient is zero but not a minimum or maximum) and local minima.
-* **Impact:** Gradient descent can easily get stuck at these points, preventing it from finding the global minimum.
-
-### 3. Slow Convergence
-* **Problem:** Gradient descent can be slow to converge, especially for large datasets and complex models.
-* **Impact:** This increases training time and computational costs.
-
-To address these issues, various optimization algorithms have been developed, such as Adam, and Adagrad, which incorporate techniques like momentum Which we'll see in next section .
-
-
-## Results
-
-The results of the training process, including the loss and accuracy, will be displayed after each epoch. You can adjust the learning rate and other hyperparameters to see how they affect the training process.
diff --git a/docs/Deep Learning/Optimizers in Deep Learning/Introduction.md b/docs/Deep Learning/Optimizers in Deep Learning/Introduction.md
deleted file mode 100644
index 57e1a49ce..000000000
--- a/docs/Deep Learning/Optimizers in Deep Learning/Introduction.md
+++ /dev/null
@@ -1,132 +0,0 @@
-# Deep Learning Optimizers
-
-This repository contains implementations and explanations of various optimization algorithms used in deep learning. Each optimizer is explained with its mathematical equations and includes a small code example using Keras.
-
-## Table of Contents
-- [Introduction](#introduction)
-- [Optimizers](#optimizers)
- - [Gradient Descent](#gradient-descent)
- - [Stochastic Gradient Descent (SGD)](#stochastic-gradient-descent-sgd)
- - [Momentum](#momentum)
- - [AdaGrad](#adagrad)
- - [RMSprop](#rmsprop)
- - [Adam](#adam)
-- [Usage](#usage)
-
-
-## Introduction
-
-Optimizers are algorithms or methods used to change the attributes of your neural network such as weights and learning rate to reduce the losses. Optimization algorithms help to minimize (or maximize) an objective function by adjusting the weights of the network.
-
-## Optimizers
-
-### Gradient Descent
-
-Gradient Descent is the most basic but most used optimization algorithm. It is an iterative optimization algorithm to find the minimum of a function.
-
-**Mathematical Equation:**
-
-$$ \theta = \theta - \eta \nabla J(\theta) $$
-
-**Keras Code:**
-
-```python
-from keras.optimizers import SGD
-
-model.compile(optimizer=SGD(learning_rate=0.01), loss='mse')
-```
-
-### Stochastic Gradient Descent (SGD)
-
-SGD updates the weights for each training example, rather than at the end of each epoch.
-
-**Mathematical Equation:**
-
-$$\theta = \theta - \eta \nabla J(\theta; x^{(i)}; y^{(i)})$$
-
-**Keras Code:**
-
-```python
-from keras.optimizers import SGD
-
-model.compile(optimizer=SGD(learning_rate=0.01), loss='mse')
-```
-
-### Momentum
-
-Momentum helps accelerate gradients vectors in the right directions, thus leading to faster converging.
-
-**Mathematical Equation:**
-
-$$ v_t = \gamma v_{t-1} + \eta \nabla J(\theta) $$
-$$ \theta = \theta - v_t $$
-
-**Keras Code:**
-
-```python
-from keras.optimizers import SGD
-
-model.compile(optimizer=SGD(learning_rate=0.01, momentum=0.9), loss='mse')
-```
-
-### AdaGrad
-
-AdaGrad adapts the learning rate to the parameters, performing larger updates for infrequent and smaller updates for frequent parameters.
-
-**Mathematical Equation:**
-
-$$ \theta = \theta - \frac{\eta}{\sqrt{G_{ii} + \epsilon}} \nabla J(\theta) $$
-
-**Keras Code:**
-
-```python
-from keras.optimizers import Adagrad
-
-model.compile(optimizer=Adagrad(learning_rate=0.01), loss='mse')
-```
-
-### RMSprop
-
-RMSprop modifies AdaGrad to perform better in the non-convex setting by changing the gradient accumulation into an exponentially weighted moving average.
-
-**Mathematical Equation:**
-
-$$\theta = \theta - \frac{\eta}{\sqrt{E[g^2]_t + \epsilon}} \nabla J(\theta)$$
-
-**Keras Code:**
-
-```python
-from keras.optimizers import RMSprop
-
-model.compile(optimizer=RMSprop(learning_rate=0.001), loss='mse')
-```
-
-### Adam
-
-Adam combines the advantages of two other extensions of SGD: AdaGrad and RMSprop.
-
-**Mathematical Equation:**
-
-$$ m_t = \beta_1 m_{t-1} + (1 - \beta_1) g_t $$
-$$ v_t = \beta_2 v_{t-1} + (1 - \beta_2) g_t^2 $$
-$$ \hat{m_t} = \frac{m_t}{1 - \beta_1^t} $$
-$$ \hat{v_t} = \frac{v_t}{1 - \beta_2^t} $$
-$$ \theta = \theta - \eta \frac{\hat{m_t}}{\sqrt{\hat{v_t}} + \epsilon} $$
-
-**Keras Code:**
-
-```python
-from keras.optimizers import Adam
-
-model.compile(optimizer=Adam(learning_rate=0.001), loss='mse')
-```
-
-## Usage
-
-To use these optimizers, simply include the relevant Keras code snippet in your model compilation step. For example:
-
-```python
-model.compile(optimizer=Adam(learning_rate=0.001), loss='categorical_crossentropy', metrics=['accuracy'])
-model.fit(X_train, y_train, epochs=10, batch_size=32, validation_data=(X_test, y_test))
-```
-
diff --git a/docs/Deep Learning/Optimizers in Deep Learning/Momentum.md b/docs/Deep Learning/Optimizers in Deep Learning/Momentum.md
deleted file mode 100644
index 3c1b82b18..000000000
--- a/docs/Deep Learning/Optimizers in Deep Learning/Momentum.md
+++ /dev/null
@@ -1,109 +0,0 @@
-# Add Momentum in Deep Learning Optimizers
-
-This repository contains an explanation and implementation of the Momentum optimization algorithm used in deep learning. Momentum helps accelerate the convergence of the gradient descent algorithm by adding a fraction of the previous update to the current update.
-
-## Table of Contents
-- [Introduction](#introduction)
-- [Mathematical Explanation](#mathematical-explanation)
- - [Momentum in Gradient Descent](#momentum-in-gradient-descent)
- - [Update Rule](#update-rule)
-- [Implementation in Keras](#implementation-in-keras)
-- [Usage](#usage)
-- [Results](#results)
-- [Advantages of Momentum](#advantages-of-momentum)
-- [Limitations of Momentum](#limitations-of-momentum)
-- [What Next](#what-next)
-
-## Introduction
-
-Momentum is an optimization algorithm that builds upon the standard gradient descent algorithm. It helps accelerate gradients vectors in the right directions, thereby leading to faster converging.
-
-## Mathematical Explanation
-
-### Momentum in Gradient Descent
-
-Momentum adds a fraction of the previous update to the current update, which helps in smoothing the optimization path and accelerates convergence. This is especially useful in cases where the gradient descent is slow due to small gradients.
-
-### How it works:
-
-1. Momentum builds up a "velocity" term based on previous updates.
-2. This velocity helps to overcome local minima and reduce oscillations.
-
-3. Momentum can lead to faster convergence, especially in cases with noisy gradients or shallow gradients.
-
-### Update Rule
-
-The update rule for gradient descent with momentum is as follows:
-
-$$v_t = γ v_{t-1} + η ∇J(θ)$$
-$$θ = θ - v_t$$
-
-where:
-
-- $v_t$: Velocity (or momentum) at time step t.
-- $γ$ (gamma): Momentum coefficient (usually between 0.5 and 0.9).
-- $η$ (eta): Learning rate.
-- $∇J(θ):$$ Gradient of the loss function with respect to the parameters.
-
-## Implementation in Keras
-
-Here is a simple implementation of Gradient Descent with Momentum using Keras:
-
-```python
-import numpy as np
-from keras.models import Sequential
-from keras.layers import Dense
-from keras.optimizers import SGD
-
-# Generate data
-X_train = np.random.rand(1000, 20)
-y_train = np.random.randint(2, size=(1000, 1))
-
-# Define model
-model = Sequential()
-model.add(Dense(64, activation='relu', input_dim=20))
-model.add(Dense(1, activation='sigmoid'))
-
-# Compile the model
-optimizer = SGD(learning_rate=0.01, momentum=0.9)
-model.compile(optimizer=optimizer, loss='binary_crossentropy', metrics=['accuracy'])
-
-# Train model
-model.fit(X_train, y_train, epochs=50, batch_size=32)
-```
-
-In this example:
-- We generate some dummy data for training.
-- We define a simple neural network model with one hidden layer.
-- We compile the model using the SGD optimizer with a learning rate of 0.01 and a momentum coefficient of 0.9.
-- We train the model for 50 epochs with a batch size of 32.
-
-## Usage
-
-To use this implementation, ensure you have the required dependencies installed:
-
-```bash
-pip install numpy keras
-```
-
-Then, you can run the provided script to train a model using Gradient Descent with Momentum.
-
-## Results
-
-The results of the training process, including the loss and accuracy, will be displayed after each epoch. You can adjust the learning rate, momentum coefficient, and other hyperparameters to see how they affect the training process.
-
-## Advantages of Momentum
-
-1. **Faster Convergence**: By accelerating gradients vectors in the right directions, Momentum helps the model converge faster than standard Gradient Descent.
-2. **Smoothing Effect**: Momentum helps in smoothing the optimization path, which can be particularly useful in navigating the optimization landscape with noisy gradients.
-3. **Avoiding Local Minima**: Momentum can help the optimization process to escape local minima and continue to explore the solution space.
-
-## Limitations of Momentum
-
-1. **Hyperparameter Tuning**: The performance of Momentum heavily depends on the choice of the momentum coefficient $γ$ and the learning rate $η$. These hyperparameters require careful tuning.
-2. **Overshooting**: With a high momentum coefficient, there is a risk of overshooting the minimum, causing the optimization to oscillate around the minimum rather than converge smoothly.
-3. **Increased Computational Cost**: The additional computation of the momentum term slightly increases the computational cost per iteration compared to standard Gradient Descent.
-
-## What Next
-
-To address these issues, various optimization algorithms have been developed, such as Adam, and Adagrad, which incorporate techniques. Which we'll see in next section .
diff --git a/docs/Deep Learning/Recurrent Neural Networks/Recurrent-Neural-Networks.md b/docs/Deep Learning/Recurrent Neural Networks/Recurrent-Neural-Networks.md
deleted file mode 100644
index 0924066e9..000000000
--- a/docs/Deep Learning/Recurrent Neural Networks/Recurrent-Neural-Networks.md
+++ /dev/null
@@ -1,153 +0,0 @@
-# Recurrent Neural Networks (RNNs) in Deep Learning
-
-## Introduction
-
-Recurrent Neural Networks (RNNs) are a class of artificial neural networks designed to work with sequential data. Unlike traditional feedforward neural networks, RNNs can use their internal state (memory) to process sequences of inputs, making them particularly suited for tasks such as natural language processing, speech recognition, and time series analysis.
-
-## Basic Structure
-
-An RNN processes a sequence of inputs $(x_1, x_2, ..., x_T)$ and produces a sequence of outputs $(y_1, y_2, ..., y_T)$. At each time step $t$, the network updates its hidden state $h_t$ based on the current input $x_t$ and the previous hidden state $h_{t-1}$.
-
-## The different types of RNN are:
-- **One to One RNN**
-- **One to Many RNN**
-- **Many to One RNN**
-- **Many to Many RNN**
-
-![alt text]()
-
-### One to One RNN
-One to One RNN (Tx=Ty=1) is the most basic and traditional type of Neural network giving a single output for a single input, as can be seen in the above image.It is also known as Vanilla Neural Network. It is used to solve regular machine learning problems.
-
-### One to Many
-One to Many (Tx=1,Ty>1) is a kind of RNN architecture is applied in situations that give multiple output for a single input. A basic example of its application would be Music generation. In Music generation models, RNN models are used to generate a music piece(multiple output) from a single musical note(single input).
-
-### Many to One
-Many-to-one RNN architecture (Tx>1,Ty=1) is usually seen for sentiment analysis model as a common example. As the name suggests, this kind of model is used when multiple inputs are required to give a single output.
-
-Take for example The Twitter sentiment analysis model. In that model, a text input (words as multiple inputs) gives its fixed sentiment (single output). Another example could be movie ratings model that takes review texts as input to provide a rating to a movie that may range from 1 to 5.
-
-### Many-to-Many
-As is pretty evident, Many-to-Many RNN (Tx>1,Ty>1) Architecture takes multiple input and gives multiple output, but Many-to-Many models can be two kinds as represented above:
-
-1. Tx=Ty:
-
-This refers to the case when input and output layers have the same size. This can be also understood as every input having a output, and a common application can be found in Named entity Recognition.
-
-2. Tx!=Ty:
-
-Many-to-Many architecture can also be represented in models where input and output layers are of different size, and the most common application of this kind of RNN architecture is seen in Machine Translation. For example, “I Love you”, the 3 magical words of the English language translates to only 2 in Spanish, “te amo”. Thus, machine translation models are capable of returning words more or less than the input string because of a non-equal Many-to-Many RNN architecture works in the background.
-
-## Mathematical Formulation
-
-**Simplified Architecture Of RNN**
-
-
-
-The basic RNN can be described by the following equations:
-
-1. Hidden state update:
-
- $$h_t = f(W_{hh}h_{t-1} + W_{xh}x_t + b_h)$$
-
-3. Output calculation:
-
- $$y_t = g(W_{hy}h_t + b_y)$$
-
-Where:
-- $h_t$ is the hidden state at time $t$
-- $x_t$ is the input at time $t$
-- $y_t$ is the output at time $t$
-- $W_{hh}$, $W_{xh}$, and $W_{hy}$ are weight matrices
-- $b_h$ and $b_y$ are bias vectors
-- $f$ and $g$ are activation functions (often tanh or ReLU for $f$, and softmax for $g$ in classification tasks)
-
-
-
-## Backpropagation Through Time (BPTT)
-
-RNNs are trained using Backpropagation Through Time (BPTT), an extension of the standard backpropagation algorithm. The loss is calculated at each time step and propagated backwards through the network:
-
-$$\frac{\partial L}{\partial W} = \sum_{t=1}^T \frac{\partial L_t}{\partial W}$$
-
-Where $L$ is the total loss and $L_t$ is the loss at time step $t$.
-
-
-
-## Variants of RNNs
-### Long Short-Term Memory (LSTM)
-
-LSTMs address the vanishing gradient problem in standard RNNs by introducing a memory cell and gating mechanisms. The LSTM architecture contains three gates and a memory cell:
-
-$$f_t = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f)$$
-
-$$i_t = \sigma(W_i \cdot [h_{t-1}, x_t] + b_i)$$
-
-$$C_t = f_t * C_{t-1} + i_t * \tilde{C}_t$$
-
-$$o_t = \sigma(W_o \cdot [h_{t-1}, x_t] + b_o)$$
-
-$$h_t = o_t * \tanh(C_t)$$
-
-Where:
-- $f_t$, $i_t$, and $o_t$ are the forget, input, and output gates respectively
-- $C_t$ is the cell state
-- $h_t$ is the hidden state
-- $\sigma$ is the sigmoid function
-- $*$ denotes element-wise multiplication
-
-**This is how an LSTM Architecture looks like:**
-
-
-#### Gate Descriptions:
-
-1. **Forget Gate** $(f_t)$:
- - Purpose: Decides what information to discard from the cell state.
- - Operation: Takes $h_{t-1}$ and $x_t$ as input and outputs a number between 0 and 1 for each number in the cell state $C_{t-1}$.
- - Interpretation: 1 means "keep this" while 0 means "forget this".
- - This is how as forget gate look like:
-
- ![alt text]()
-
-2. **Input Gate** $(i_t)$:
- - Purpose: Decides which new information to store in the cell state.
- - Operation:
- - $i_t$: Decides which values we'll update.
- - $\tilde{C}_t$: Creates a vector of new candidate values that could be added to the state.
- - This is how as Input gate look like:
- ![alt text]()
-
-3. **Cell State Update**:
- - Purpose: Updates the old cell state, $C_{t-1}$, into the new cell state $C_t$.
- - Operation:
- - Multiply the old state by $f_t$, forgetting things we decided to forget earlier.
- - Add $i_t * \tilde{C}_t$. This is the new candidate values, scaled by how much we decided to update each state value.
- -
-
-4. **Output Gate** $(o_t)$:
- - Purpose: Decides what parts of the cell state we're going to output.
- - Operation:
- - $o_t$: Decides what parts of the cell state we're going to output.
- - Multiply it by a tanh of the cell state to push the values to be between -1 and 1.
-
-The power of LSTMs lies in their ability to selectively remember or forget information over long sequences, mitigating the vanishing gradient problem that plagues simple RNNs.
-
-## Applications
-
-1. Natural Language Processing (NLP)
-2. Speech Recognition
-3. Machine Translation
-4. Time Series Prediction
-5. Sentiment Analysis
-6. Music Generation
-
-## Challenges and Considerations
-
-1. Vanishing and Exploding Gradients
-2. Long-term Dependencies
-3. Computational Complexity
-4. Choosing the Right Architecture (LSTM vs GRU vs Simple RNN)
-
-## Conclusion
-
-RNNs and their variants like LSTM are powerful tools for processing sequential data. They have revolutionized many areas of machine learning, particularly in tasks involving time-dependent or sequential information. Understanding their structure, mathematics, and applications is crucial for effectively applying them to real-world problems.
diff --git a/docs/Deep Learning/Recurrent Neural Networks/images/LSTM.webp b/docs/Deep Learning/Recurrent Neural Networks/images/LSTM.webp
deleted file mode 100644
index 9112ab5f1..000000000
Binary files a/docs/Deep Learning/Recurrent Neural Networks/images/LSTM.webp and /dev/null differ
diff --git a/docs/Deep Learning/Recurrent Neural Networks/images/basic_rnn_arch.webp b/docs/Deep Learning/Recurrent Neural Networks/images/basic_rnn_arch.webp
deleted file mode 100644
index c9eaa350a..000000000
Binary files a/docs/Deep Learning/Recurrent Neural Networks/images/basic_rnn_arch.webp and /dev/null differ
diff --git a/docs/Deep Learning/Recurrent Neural Networks/images/forget gate.webp b/docs/Deep Learning/Recurrent Neural Networks/images/forget gate.webp
deleted file mode 100644
index 06765aae5..000000000
Binary files a/docs/Deep Learning/Recurrent Neural Networks/images/forget gate.webp and /dev/null differ
diff --git a/docs/Deep Learning/Recurrent Neural Networks/images/input gate.webp b/docs/Deep Learning/Recurrent Neural Networks/images/input gate.webp
deleted file mode 100644
index b6f33163e..000000000
Binary files a/docs/Deep Learning/Recurrent Neural Networks/images/input gate.webp and /dev/null differ
diff --git a/docs/Deep Learning/Recurrent Neural Networks/images/types of rnn.webp b/docs/Deep Learning/Recurrent Neural Networks/images/types of rnn.webp
deleted file mode 100644
index 916f5a10e..000000000
Binary files a/docs/Deep Learning/Recurrent Neural Networks/images/types of rnn.webp and /dev/null differ
diff --git a/docs/Deep Learning/_category.json b/docs/Deep Learning/_category.json
deleted file mode 100644
index fe0ca6e0a..000000000
--- a/docs/Deep Learning/_category.json
+++ /dev/null
@@ -1,8 +0,0 @@
-{
- "label": "Deep Learning",
- "position": 6,
- "link": {
- "type": "generated-index",
- "description": "In this section, you will learn about Deep Learning"
- }
- }
\ No newline at end of file
diff --git a/docs/Deep Learning/img.png b/docs/Deep Learning/img.png
deleted file mode 100644
index 942707eb8..000000000
Binary files a/docs/Deep Learning/img.png and /dev/null differ
diff --git a/docs/Deep Learning/img2.png b/docs/Deep Learning/img2.png
deleted file mode 100644
index 236e08a83..000000000
Binary files a/docs/Deep Learning/img2.png and /dev/null differ
diff --git a/docs/Deep Learning/img3.png b/docs/Deep Learning/img3.png
deleted file mode 100644
index 05965b575..000000000
Binary files a/docs/Deep Learning/img3.png and /dev/null differ
diff --git a/docs/Deep Learning/img4.png b/docs/Deep Learning/img4.png
deleted file mode 100644
index b6b57bb77..000000000
Binary files a/docs/Deep Learning/img4.png and /dev/null differ
diff --git a/docs/Django/AdminInterface.md b/docs/Django/AdminInterface.md
deleted file mode 100644
index 92512c17f..000000000
--- a/docs/Django/AdminInterface.md
+++ /dev/null
@@ -1,97 +0,0 @@
----
-id: admin-interface-in-django
-title: Admin Interface
-sidebar_label: Admin Interface
-sidebar_position: 6
-tags: [python,Django Introduction,Admin Interface,Framework]
-description: Admin Interface.
----
-
-In Django, the admin interface is a powerful built-in feature that automatically generates a user-friendly interface for managing and interacting with your application's data models. It's particularly useful for developers and administrators to perform CRUD (Create, Read, Update, Delete) operations on data without writing custom views or templates. Here’s a comprehensive overview of the Django admin interface:
-
-### Key Features of Django Admin Interface:
-
-1. **Automatic Interface Generation**:
- - Django automatically creates an admin interface based on your defined models (`django.db.models.Model` subclasses).
- - Each model registered with the admin interface is represented as a list view (showing all instances), a detail view (showing a single instance), and an edit view (for updating instances).
-
-2. **Customization Options**:
- - **ModelAdmin Class**: You can customize the behavior and appearance of models in the admin interface using a `ModelAdmin` class. This allows you to specify fields to display, search and filter options, fieldsets, readonly fields, etc.
-
- ```python
- from django.contrib import admin
- from .models import Product
-
- @admin.register(Product)
- class ProductAdmin(admin.ModelAdmin):
- list_display = ('name', 'price', 'created_at')
- search_fields = ('name',)
- list_filter = ('created_at',)
- ```
-
- - **Inline Editing**: You can edit related objects directly on the model’s edit page using inline models (`InlineModelAdmin`).
-
- ```python
- from django.contrib import admin
- from .models import Order, OrderItem
-
- class OrderItemInline(admin.TabularInline):
- model = OrderItem
- extra = 1
-
- @admin.register(Order)
- class OrderAdmin(admin.ModelAdmin):
- inlines = (OrderItemInline,)
- ```
-
- - **Actions**: Admin actions allow bulk updates or deletions of objects directly from the list view.
-
- ```python
- from django.contrib import admin
- from .models import Product
-
- @admin.register(Product)
- class ProductAdmin(admin.ModelAdmin):
- actions = ['make_published']
-
- def make_published(self, request, queryset):
- queryset.update(status='published')
- make_published.short_description = "Mark selected products as published"
- ```
-
-3. **Authentication and Authorization**:
- - The admin interface integrates with Django’s authentication system (`django.contrib.auth`) to control access based on user permissions.
- - You can define which users or groups have access to specific models or admin actions using permissions and groups.
-
-4. **Custom Dashboard**:
- - You can create a custom admin dashboard by overriding Django admin templates (`admin/base_site.html` and others) to provide a tailored experience for administrators.
-
-5. **Integration with Django Apps**:
- - Django admin can be extended by integrating third-party packages (`django-admin-tools`, `django-suit`, etc.) to further customize the admin interface's appearance and functionality.
-
-6. **Internationalization (i18n)**:
- - The admin interface supports internationalization and localization, allowing you to display the admin interface in different languages based on user preferences.
-
-### How to Use the Django Admin Interface:
-
-1. **Registering Models**:
- - To make a model editable in the admin interface, register it in the `admin.py` file of your app using the `admin.site.register()` function or the `@admin.register()` decorator.
-
- ```python title="products/admin.py"
- from django.contrib import admin
- from .models import Product
-
- admin.site.register(Product)
- ```
-
-2. **Accessing the Admin Interface**:
- - To access the admin interface during development, run your Django server (`manage.py runserver`) and navigate to `/admin/` in your web browser.
- - You'll be prompted to log in with a user account that has appropriate permissions.
-
-3. **Managing Data**:
- - Once logged in, you can view, add, edit, and delete instances of registered models directly through the admin interface.
-
-4. **Customization**:
- - Customize the admin interface by defining custom `ModelAdmin` classes, configuring list views, detail views, form layouts, and more in your app’s `admin.py` file.
-
-The Django admin interface significantly speeds up the development process by providing a ready-made interface for managing data models. It's highly customizable and integrates seamlessly with Django’s ORM and authentication system, making it an essential tool for building and maintaining Django-based web applications.
diff --git a/docs/Django/Forms.md b/docs/Django/Forms.md
deleted file mode 100644
index 94c4d4918..000000000
--- a/docs/Django/Forms.md
+++ /dev/null
@@ -1,114 +0,0 @@
----
-id: forms-in-django
-title: Forms in Django
-sidebar_label: Forms in Django
-sidebar_position: 2
-tags: [python,Django Introduction,Forms in Django,Framework]
-description: Forms in Django.
----
-
-In Django, forms play a crucial role in handling user input, validating data, and interacting with models. They simplify the process of collecting and processing user-submitted data in web applications. Here's a comprehensive guide to understanding and using forms in Django:
-
-### 1. **Form Basics**
-
-Django forms are Python classes that represent HTML forms. They can be used to:
-- Display HTML forms in templates.
-- Validate user input.
-- Handle form submission (processing data submitted by users).
-
-### 2. **Creating a Form Class**
-
-To define a form in Django, you typically create a form class that inherits from `django.forms.Form` or `django.forms.ModelForm`:
-
-- **`Form` Class**: Used for creating custom forms that are not necessarily tied to models.
-
- ```python title="forms.py"
- from django import forms
-
- class ContactForm(forms.Form):
- name = forms.CharField(max_length=100)
- email = forms.EmailField()
- message = forms.CharField(widget=forms.Textarea)
- ```
-
-- **`ModelForm` Class**: Used to create forms that are directly tied to models, simplifying tasks such as saving form data to the database.
-
- ```python title="forms.py"
- from django import forms
- from .models import Product
-
- class ProductForm(forms.ModelForm):
- class Meta:
- model = Product
- fields = ['name', 'price', 'description']
- ```
-
-### 3. **Rendering Forms in Templates**
-
-Forms can be rendered in HTML templates using Django's form rendering capabilities. This includes rendering form fields, handling form errors, and displaying form labels and widgets:
-
-- **Rendering a Form in a Template**:
-
- ```html title="template.html
-
- ```
-
- - **`{{ form.as_p }}`**: Renders the form fields as paragraphs (`
` tags). Other methods include `{{ form.as_ul }}` (unordered list) and `{{ form.as_table }}` (HTML table).
-
-### 4. **Handling Form Submission**
-
-When a form is submitted, Django handles the submitted data in views. Views validate the form data, process it, and decide what action to take (e.g., saving to the database, redirecting):
-
-- **Handling Form Submission in Views**:
-
- ```python title="views.py"
- from django.shortcuts import render, redirect
- from .forms import ContactForm
-
- def contact_view(request):
- if request.method == 'POST':
- form = ContactForm(request.POST)
- if form.is_valid():
- # Process form data
- name = form.cleaned_data['name']
- email = form.cleaned_data['email']
- message = form.cleaned_data['message']
- # Additional processing (e.g., sending email)
- return redirect('success_page')
- else:
- form = ContactForm()
-
- return render(request, 'contact.html', {'form': form})
- ```
-
- - **`form.is_valid()`**: Checks if the submitted data is valid according to the form’s field validations (e.g., required fields, email format).
- - **`form.cleaned_data`**: Contains cleaned and validated data after calling `is_valid()`, accessible as Python dictionaries.
-
-### 5. **Form Validation**
-
-Django provides built-in form validation to ensure that data entered by users is correct and meets specified criteria (e.g., required fields, email format):
-
-- **Validation Rules**: Defined in form field definitions (e.g., `required=True`, `max_length=100`, `min_value=0`).
-
-### 6. **Customizing Forms**
-
-You can customize forms by:
-- **Adding Custom Validation**: Implementing `clean_()` methods in form classes to perform additional validation.
-- **Customizing Form Widgets**: Specifying widgets (e.g., `forms.Textarea`, `forms.Select`) to control how data is displayed and collected in HTML.
-
-### 7. **Formsets and Inline Formsets**
-
-Django supports formsets and inline formsets for handling multiple forms on the same page or managing related objects (e.g., adding multiple instances of related objects):
-
-- **Formsets**: Handle multiple instances of a form (e.g., multiple products in an order form).
-- **Inline Formsets**: Edit related objects inline within a single form (e.g., order items in an order form).
-
-### 8. **Testing Forms**
-
-Django provides testing tools (`unittest` or `pytest` frameworks) for writing and executing tests to validate form behavior, ensuring that forms validate correctly and handle data as expected.
-
-Forms in Django are integral to creating interactive web applications that collect and process user input efficiently. They provide a structured way to handle data validation and interaction with models, enhancing the security and usability of Django-powered websites.
diff --git a/docs/Django/Introduction.md b/docs/Django/Introduction.md
deleted file mode 100644
index 5729d9d0b..000000000
--- a/docs/Django/Introduction.md
+++ /dev/null
@@ -1,30 +0,0 @@
----
-id: django-introduction
-title: Django Introduction
-sidebar_label: Introduction
-sidebar_position: 1
-tags: [python,Django Introduction,Framework]
-description: Django Introduction.
----
-
-Django is a high-level Python web framework that allows developers to create robust web applications quickly. It follows the Model-View-Controller (MVC) architectural pattern, but in Django's case, it's more accurately described as Model-View-Template (MVT). Here's a breakdown of some key concepts and explanations you'll encounter when learning Django:
-
-1. **Models**: Models in Django are Python classes that define the structure of your data. Each model class corresponds to a database table, and attributes of the class represent fields of the table. Django provides an Object-Relational Mapping (ORM) layer that lets you interact with your database using Python code, without writing SQL queries directly.
-
-2. **Views**: Views are Python functions or classes that receive web requests and return web responses. They contain the business logic of your application and determine what content is displayed to the user. Views typically interact with models to retrieve data and templates to render HTML.
-
-3. **Templates**: Templates are HTML files that contain the presentation layer of your application. They are used to generate dynamic HTML content by combining static HTML with Django template language (DTL). Templates can include variables, tags, and filters provided by DTL to render data passed from views.
-
-4. **URL Dispatcher**: Django uses a URL dispatcher to map URL patterns to views. It allows you to define URL patterns in a central location (usually in `urls.py` files) and specify which view function or class should handle each pattern.
-
-5. **Admin Interface**: Django provides a built-in admin interface that allows administrators to manage site content without writing any views or templates. It's automatically generated from your models and can be extensively customized to suit your application's needs.
-
-6. **Forms**: Django forms allow you to create HTML forms that can validate user input and handle form submission. They simplify the process of collecting and processing user data, and they can be used in views to create, update, or delete objects in the database.
-
-7. **Middleware**: Middleware is a framework of hooks into Django’s request/response processing. It’s a lightweight, low-level plugin system for globally altering Django’s input or output.
-
-8. **Sessions and Authentication**: Django provides built-in support for user authentication, sessions, and authorization. It includes a flexible authentication system that allows you to manage user accounts and permissions easily.
-
-9. **Static files**: Django allows you to manage static files (e.g., CSS, JavaScript, images) using its built-in `staticfiles` app. It provides tools to collect, store, and serve static files during development and deployment.
-
-10. **Settings**: Django settings are configuration parameters that control the behavior of your Django application. Settings are typically stored in a `settings.py` file and include things like database configuration, static files settings, middleware configuration, etc.
\ No newline at end of file
diff --git a/docs/Django/Middleware.md b/docs/Django/Middleware.md
deleted file mode 100644
index 5c18335f4..000000000
--- a/docs/Django/Middleware.md
+++ /dev/null
@@ -1,74 +0,0 @@
----
-id: middleware-introduction
-title: Middleware
-sidebar_label: Important of Middleware
-sidebar_position: 8
-tags: [python,Django Introduction,Middleware,Framework]
-description: Middleware.
----
-
-
-Middleware in Django is a fundamental concept that allows you to process requests and responses globally before they reach the view layer or after the view layer has processed them. Middleware sits between the request and the view, providing a way to modify incoming requests or outgoing responses, handle exceptions, authenticate users, perform content filtering, and more. Here’s a detailed explanation of middleware in Django:
-
-### How Middleware Works
-
-1. **Order of Execution**:
- - Middleware components are executed in the order they are defined in the `MIDDLEWARE` setting in your Django project’s settings file (`settings.py`).
- - Each middleware component can process requests before passing them to the next middleware or view, and can process responses after they are generated by the view but before they are sent to the client.
-
-2. **Middleware Components**:
- - Middleware components are Python classes or functions that implement at least one of the following methods:
- - `process_request(request)`: Executes before the view is called; can modify the `request` object or return an `HttpResponse` object to shortcut the processing.
- - `process_view(request, view_func, view_args, view_kwargs)`: Called before calling the view function; receives the view function and its arguments.
- - `process_response(request, response)`: Executes just before Django sends the response to the client; can modify the `response` object.
- - `process_exception(request, exception)`: Called when a view raises an exception; handles exceptions and returns an `HttpResponse` object or `None`.
-
-3. **Built-in Middleware**:
- - Django includes several built-in middleware components for common tasks, such as:
- - `django.middleware.security.SecurityMiddleware`: Adds security enhancements to HTTP headers.
- - `django.middleware.common.CommonMiddleware`: Provides various HTTP-related helpers.
- - `django.middleware.csrf.CsrfViewMiddleware`: Adds CSRF protection to forms.
- - `django.contrib.sessions.middleware.SessionMiddleware`: Manages sessions across requests.
- - `django.contrib.auth.middleware.AuthenticationMiddleware`: Handles user authentication.
- - `django.contrib.messages.middleware.MessageMiddleware`: Enables the passing of messages between views.
-
- These middleware components are included by default in the `MIDDLEWARE` setting.
-
-4. **Custom Middleware**:
- - You can create custom middleware classes to implement application-specific logic.
- - To create a custom middleware, define a class with methods that correspond to the desired middleware behavior, then add the middleware class to the `MIDDLEWARE` setting.
-
- ```python title="myapp/middleware.py"
- class MyCustomMiddleware:
- def __init__(self, get_response):
- self.get_response = get_response
-
- def __call__(self, request):
- # Code to be executed for each request before the view (process_request)
- response = self.get_response(request)
- # Code to be executed for each response after the view (process_response)
- return response
- ```
-
- ```python title="settings.py"
- MIDDLEWARE = [
- 'django.middleware.security.SecurityMiddleware',
- 'django.middleware.common.CommonMiddleware',
- 'django.middleware.csrf.CsrfViewMiddleware',
- 'django.contrib.sessions.middleware.SessionMiddleware',
- 'django.middleware.auth.AuthenticationMiddleware',
- 'django.contrib.messages.middleware.MessageMiddleware',
- 'myapp.middleware.MyCustomMiddleware', # Custom middleware
- ]
- ```
-
-5. **Middleware Execution Flow**:
- - When a request comes into Django, it passes through each middleware component in the order defined.
- - Middleware can modify request attributes (like adding data to the request object) or decide to shortcut further processing by returning a response directly.
- - After the view processes the request and generates a response, the response passes back through the middleware in reverse order. Each middleware can then modify or inspect the response before it is sent to the client.
-
-6. **Debugging Middleware**:
- - Middleware can be instrumental in debugging and profiling applications by logging requests, inspecting headers, or capturing errors.
- - It’s essential to ensure that middleware components are efficient and do not introduce unnecessary overhead that could affect performance.
-
-Middleware in Django provides a flexible mechanism for intercepting and processing requests and responses at various stages of the request-response cycle. Understanding how to leverage middleware effectively allows you to add cross-cutting concerns, security features, and custom behavior to your Django applications seamlessly.
diff --git a/docs/Django/Models.md b/docs/Django/Models.md
deleted file mode 100644
index ea6173256..000000000
--- a/docs/Django/Models.md
+++ /dev/null
@@ -1,65 +0,0 @@
----
-id: models-in-django
-title: Models In Django
-sidebar_label: Models In Django
-sidebar_position: 2
-tags: [python,Django Introduction,Models In Django,Framework]
-description: Models In Django.
----
-
-In Django, models are at the heart of your application's data structure. They define the entities (or tables) in your database and encapsulate the fields and behaviors of those entities. Here's a detailed explanation of the key aspects of models in Django:
-
-### 1. **Defining Models**
- - **Model Class**: A Django model is typically defined as a Python class that subclasses `django.db.models.Model`. This class represents a database table, and each instance of the class corresponds to a row in that table.
- - **Fields**: Class attributes of the model represent fields in the database table. Django provides various field types (`CharField`, `IntegerField`, `DateTimeField`, etc.) to define the type of data each field can store.
-
- ```python
- from django.db import models
-
- class Product(models.Model):
- name = models.CharField(max_length=100)
- price = models.DecimalField(max_digits=10, decimal_places=2)
- description = models.TextField()
- created_at = models.DateTimeField(auto_now_add=True)
- ```
-
-### 2. **ORM (Object-Relational Mapping)**
- - Django's ORM translates Python code into SQL queries, allowing you to interact with your database using Python without writing raw SQL.
- - You can perform database operations (create, read, update, delete) using methods provided by model instances or managers (`objects`).
-
- ```python
- # Creating a new instance of the model
- product = Product(name='Laptop', price=999.99, description='Powerful laptop')
- product.save() # Saves the instance to the database
-
- # Querying data
- products = Product.objects.all() # Retrieves all Product objects
- ```
-
-### 3. **Fields and Options**
- - **Field Options**: Fields can have various options (`max_length`, `default`, `null`, `blank`, etc.) that control how they behave and how data is stored in the database.
- - **Meta Options**: The `Meta` class inside a model allows you to specify metadata such as ordering, database table name, and unique constraints.
-
- ```python
- class Meta:
- ordering = ['name']
- verbose_name_plural = 'Products'
- ```
-
-### 4. **Relationships**
- - **ForeignKey and Many-to-One**: Represents a many-to-one relationship where each instance of a model can be associated with one instance of another model.
- - **ManyToManyField**: Represents a many-to-many relationship where each instance of a model can be associated with multiple instances of another model.
-
- ```python
- class Order(models.Model):
- customer = models.ForeignKey(Customer, on_delete=models.CASCADE)
- products = models.ManyToManyField(Product)
- ```
-
-### 5. **Database Schema Migration**
- - Django's migration system (`manage.py makemigrations` and `manage.py migrate`) manages changes to your models over time, keeping your database schema up-to-date with your model definitions.
-
-### 6. **Admin Interface**
- - Django automatically generates an admin interface based on your models. It allows you to perform CRUD operations on your data without writing custom views or forms.
-
-Models in Django provide a powerful way to define and manage your application's data structure, abstracting away much of the complexity of database interactions and allowing for rapid development of database-driven web applications. Understanding models is crucial for effective Django development, as they form the basis for interacting with and manipulating data in your application.
\ No newline at end of file
diff --git a/docs/Django/SessionsAndAuthentication.md b/docs/Django/SessionsAndAuthentication.md
deleted file mode 100644
index 5809f7a75..000000000
--- a/docs/Django/SessionsAndAuthentication.md
+++ /dev/null
@@ -1,128 +0,0 @@
----
-id: session-and-authentication
-title: Sessions And Authentication
-sidebar_label: Sessions And Authentication
-sidebar_position: 9
-tags: [python,Django Introduction,Sessions And Authentication,Framework]
-description: Sessions And Authentication.
----
-
-Sessions and authentication are critical components in web development, and Django provides robust built-in tools to manage user authentication and handle session management efficiently. Here’s a detailed explanation of sessions and authentication in Django:
-
-### Sessions in Django
-
-Sessions in Django allow you to store and retrieve arbitrary data per visitor across multiple page requests. They enable stateful behavior in otherwise stateless HTTP protocol. Here’s how sessions work in Django:
-
-1. **Session Framework**:
- - Django uses a session framework (`django.contrib.sessions`) to manage sessions.
- - Sessions are implemented using cookies, and by default, Django stores session data in a database table (`django_session`) but can also use other storage backends like cache or files.
-
-2. **Enabling Sessions**:
- - Sessions are enabled by default in Django projects. To use sessions, ensure that `django.contrib.sessions.middleware.SessionMiddleware` is included in the `MIDDLEWARE` setting.
-
- ```python title="settings.py"
- MIDDLEWARE = [
- 'django.middleware.security.SecurityMiddleware',
- 'django.contrib.sessions.middleware.SessionMiddleware',
- # Other middleware
- ]
- ```
-
-3. **Using Sessions**:
- - Sessions are accessed through the `request.session` attribute, which acts like a dictionary.
- - You can store data in the session, retrieve it later, and delete items from the session.
-
- ```python title="views.py"
- def my_view(request):
- # Set session data
- request.session['username'] = 'john_doe'
-
- # Get session data
- username = request.session.get('username', 'Guest')
-
- # Delete session data
- del request.session['username']
- ```
-
-4. **Session Configuration**:
- - Configure session settings in `settings.py`, such as session expiration, cookie attributes, and storage backend.
-
- ```python title="settings.py"
- SESSION_EXPIRE_AT_BROWSER_CLOSE = True # Session expires when the browser is closed
- SESSION_COOKIE_AGE = 3600 # Session cookie expires in 1 hour (in seconds)
- ```
-
-5. **Session Security**:
- - Ensure that sensitive data stored in sessions is protected.
- - Use HTTPS to secure session cookies in transit.
-
-### Authentication in Django
-
-Authentication in Django manages user authentication and authorization using built-in components provided by `django.contrib.auth`. It includes user authentication, permissions, groups, and integration with session management. Here’s how authentication works in Django:
-
-1. **User Authentication**:
- - Django provides a user authentication system (`django.contrib.auth.models.User`) that handles user registration, login, logout, and password management.
-
-2. **Authentication Middleware**:
- - Include `django.contrib.auth.middleware.AuthenticationMiddleware` in the `MIDDLEWARE` setting to manage user authentication across requests.
-
- ```python title="settings.py"
- MIDDLEWARE = [
- 'django.middleware.security.SecurityMiddleware',
- 'django.contrib.sessions.middleware.SessionMiddleware',
- 'django.middleware.common.CommonMiddleware',
- 'django.middleware.csrf.CsrfViewMiddleware',
- 'django.contrib.auth.middleware.AuthenticationMiddleware',
- 'django.contrib.messages.middleware.MessageMiddleware',
- 'django.middleware.clickjacking.XFrameOptionsMiddleware',
- ]
- ```
-
-3. **Login and Logout Views**:
- - Django provides built-in views (`django.contrib.auth.views.LoginView`, `django.contrib.auth.views.LogoutView`) for handling user login and logout.
-
- ```python title="urls.py"
- from django.urls import path
- from django.contrib.auth import views as auth_views
-
- urlpatterns = [
- path('login/', auth_views.LoginView.as_view(), name='login'),
- path('logout/', auth_views.LogoutView.as_view(), name='logout'),
- ]
- ```
-
-4. **User Permissions and Groups**:
- - Django allows you to define permissions and assign users to groups (`django.contrib.auth.models.Group`) to manage access control.
-
- ```python title="views.py"
- from django.contrib.auth.decorators import login_required, permission_required
-
- @login_required
- def my_view(request):
- # Authenticated user
- ...
-
- @permission_required('myapp.can_publish')
- def publish_article(request):
- # User with specific permission
- ...
- ```
-
-5. **Custom User Models**:
- - Customize the user model (`AUTH_USER_MODEL`) to extend or modify user fields as per project requirements.
-
- ```python title="settings.py"
- AUTH_USER_MODEL = 'myapp.CustomUser'
- ```
-
-6. **Authentication Backends**:
- - Customize authentication behavior by defining custom authentication backends (`AUTHENTICATION_BACKENDS`) to authenticate users against different sources (e.g., LDAP, OAuth).
-
- ```python title="settings.py"
- AUTHENTICATION_BACKENDS = [
- 'myapp.backends.MyCustomAuthBackend',
- 'django.contrib.auth.backends.ModelBackend',
- ]
- ```
-
-Authentication and sessions are fundamental to building secure and user-friendly web applications with Django. They provide mechanisms to handle user identity, manage user sessions, and control access to application resources effectively. Understanding how to configure and use these components is essential for developing robust Django applications.
diff --git a/docs/Django/Settings.md b/docs/Django/Settings.md
deleted file mode 100644
index 75f6c61c1..000000000
--- a/docs/Django/Settings.md
+++ /dev/null
@@ -1,175 +0,0 @@
----
-id: settings-in-django
-title: Settings In Django
-sidebar_label: Settings
-sidebar_position: 11
-tags: [python,Django Introduction,Settings in Django,Framework]
-description: Settings In Django.
----
-
-In Django, settings play a crucial role in configuring and controlling the behavior of your web application. The `settings.py` file in your Django project contains all the configuration settings that Django uses to operate. Here’s a comprehensive overview of the `settings.py` file and the key settings you should be familiar with:
-
-### Structure of `settings.py`
-
-The `settings.py` file is typically located in the main project directory (`project_name/settings.py`). It contains Python code that configures Django's settings. Here’s a simplified structure of a `settings.py` file:
-
-```python
-# project_name/settings.py
-
-import os
-
-# Build paths inside the project like this: os.path.join(BASE_DIR, ...)
-BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
-
-# Quick-start development settings - unsuitable for production
-# See https://docs.djangoproject.com/en/4.0/howto/deployment/checklist/
-
-# SECURITY WARNING: keep the secret key used in production secret!
-SECRET_KEY = 'your_secret_key_here'
-
-# SECURITY WARNING: don't run with debug turned on in production!
-DEBUG = True
-
-ALLOWED_HOSTS = []
-
-# Application definition
-
-INSTALLED_APPS = [
- 'django.contrib.admin',
- 'django.contrib.auth',
- 'django.contrib.contenttypes',
- 'django.contrib.sessions',
- 'django.contrib.messages',
- 'django.contrib.staticfiles',
- 'myapp', # Replace with your app name
-]
-
-MIDDLEWARE = [
- 'django.middleware.security.SecurityMiddleware',
- 'django.contrib.sessions.middleware.SessionMiddleware',
- 'django.middleware.common.CommonMiddleware',
- 'django.middleware.csrf.CsrfViewMiddleware',
- 'django.contrib.auth.middleware.AuthenticationMiddleware',
- 'django.contrib.messages.middleware.MessageMiddleware',
- 'django.middleware.clickjacking.XFrameOptionsMiddleware',
-]
-
-ROOT_URLCONF = 'project_name.urls'
-
-TEMPLATES = [
- {
- 'BACKEND': 'django.template.backends.django.DjangoTemplates',
- 'DIRS': [],
- 'APP_DIRS': True,
- 'OPTIONS': {
- 'context_processors': [
- 'django.template.context_processors.debug',
- 'django.template.context_processors.request',
- 'django.contrib.auth.context_processors.auth',
- 'django.contrib.messages.context_processors.messages',
- ],
- },
- },
-]
-
-WSGI_APPLICATION = 'project_name.wsgi.application'
-
-# Database
-# https://docs.djangoproject.com/en/4.0/ref/settings/#databases
-
-DATABASES = {
- 'default': {
- 'ENGINE': 'django.db.backends.sqlite3',
- 'NAME': BASE_DIR / 'db.sqlite3',
- }
-}
-
-# Password validation
-# https://docs.djangoproject.com/en/4.0/ref/settings/#auth-password-validators
-
-AUTH_PASSWORD_VALIDATORS = [
- {
- 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator',
- },
- {
- 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator',
- },
- {
- 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator',
- },
- {
- 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator',
- },
-]
-
-# Internationalization
-# https://docs.djangoproject.com/en/4.0/topics/i18n/
-
-LANGUAGE_CODE = 'en-us'
-
-TIME_ZONE = 'UTC'
-
-USE_I18N = True
-
-USE_L10N = True
-
-USE_TZ = True
-
-# Static files (CSS, JavaScript, Images)
-# https://docs.djangoproject.com/en/4.0/howto/static-files/
-
-STATIC_URL = '/static/'
-
-# Default primary key field type
-# https://docs.djangoproject.com/en/4.0/ref/settings/#std:setting-DEFAULT_AUTO_FIELD
-
-DEFAULT_AUTO_FIELD = 'django.db.models.BigAutoField'
-```
-
-### Key Settings Explained
-
-1. **Secret Key (`SECRET_KEY`)**:
- - A secret cryptographic key used for hashing, signing cookies, and other security-related mechanisms. Keep this value secret and never share it publicly.
-
-2. **Debug Mode (`DEBUG`)**:
- - Controls whether Django runs in debug mode (`True` for development, `False` for production). Enable debug mode during development to display detailed error pages and debug information.
-
-3. **Allowed Hosts (`ALLOWED_HOSTS`)**:
- - A list of strings representing the host/domain names that this Django site can serve. Set this to your domain names in production.
-
-4. **Installed Apps (`INSTALLED_APPS`)**:
- - A list of strings representing all Django applications installed and enabled for use in the project.
-
-5. **Middleware (`MIDDLEWARE`)**:
- - A list of middleware classes that process requests and responses. Middlewares are applied in the order they are listed.
-
-6. **Database Configuration (`DATABASES`)**:
- - Specifies the database connection details. By default, Django uses SQLite for development (`'sqlite3'`), but you can configure other databases like MySQL, PostgreSQL, etc.
-
-7. **Templates (`TEMPLATES`)**:
- - Configuration for template engines used in Django. By default, it uses Django’s built-in template engine (`'django.template.backends.django.DjangoTemplates'`).
-
-8. **Static Files (`STATIC_URL`)**:
- - URL prefix for serving static files during development (`'/static/'` by default). Static files are served by Django’s development server.
-
-9. **Internationalization and Localization (`LANGUAGE_CODE`, `TIME_ZONE`, etc.)**:
- - Settings related to language translation (`LANGUAGE_CODE`), timezone (`TIME_ZONE`), and other internationalization features.
-
-10. **Password Validation (`AUTH_PASSWORD_VALIDATORS`)**:
- - A list of validators that validate the strength of user passwords.
-
-11. **Default Primary Key (`DEFAULT_AUTO_FIELD`)**:
- - The type of auto-incrementing primary key used for models created without specifying a primary key type (`'django.db.models.BigAutoField'` by default).
-
-### Additional Settings
-
-- **Logging Configuration**: Configure logging to capture and manage application logs.
-- **Email Configuration**: Configure SMTP email settings for sending emails from Django.
-- **Security Settings**: Configure security-related settings such as CSRF protection, session security, etc.
-- **Cache Settings**: Configure caching backends for caching data to improve performance.
-
-### Customizing Settings
-
-- You can override default settings or define custom settings as per your project requirements. Ensure to follow Django's documentation and best practices when modifying settings to maintain application stability and security.
-
-Understanding and configuring `settings.py` correctly is essential for building and deploying Django applications effectively. It provides the foundational configuration needed to run your Django project in various environments, from development to production.
\ No newline at end of file
diff --git a/docs/Django/StaticFiles.md b/docs/Django/StaticFiles.md
deleted file mode 100644
index 6ca5032d4..000000000
--- a/docs/Django/StaticFiles.md
+++ /dev/null
@@ -1,130 +0,0 @@
----
-id: static-files
-title: Static Files
-sidebar_label: Important of Static Files
-sidebar_position: 10
-tags: [python,Django Introduction,Important of Static Files,Framework]
-description: Important of Static Files.
----
-
-Static files in Django refer to files like CSS, JavaScript, images, and other assets that are served directly to clients without any processing by Django’s backend. Handling static files efficiently is crucial for building responsive and visually appealing web applications. Here’s a comprehensive guide to working with static files in Django:
-
-### 1. **Configuring Static Files**
-
-1. **Directory Structure**:
- - Create a directory named `static` in each Django app where you store static files specific to that app.
- - Additionally, create a project-level `static` directory to store static files shared across multiple apps.
-
- ```
- project/
- ├── manage.py
- ├── project/
- │ ├── settings.py
- │ ├── urls.py
- │ ├── wsgi.py
- ├── myapp/
- │ ├── static/
- │ │ ├── myapp/
- │ │ │ ├── css/
- │ │ │ │ └── style.css
- │ │ │ ├── js/
- │ │ │ ├── img/
- │ │ ├── other_app_static/
- │ │ │ └── ...
- ├── static/
- │ ├── admin/
- │ │ └── ...
- │ ├── css/
- │ ├── js/
- │ ├── img/
- │ └── ...
- ```
-
-2. **Configuring Settings**:
- - Define the `STATIC_URL` and `STATICFILES_DIRS` settings in `settings.py`.
-
- ```python title="settings.py"
- STATIC_URL = '/static/'
-
- STATICFILES_DIRS = [
- os.path.join(BASE_DIR, 'static'),
- ]
- ```
-
- - `STATIC_URL`: URL prefix for serving static files during development (`/static/` by default).
- - `STATICFILES_DIRS`: List of directories where Django looks for static files.
-
-3. **Collecting Static Files for Deployment**:
- - In production, run `collectstatic` to gather all static files from individual apps and the project’s `static` directory into a single location (`STATIC_ROOT`).
-
- ```bash
- python manage.py collectstatic
- ```
-
- - `STATIC_ROOT`: Directory where `collectstatic` collects static files for deployment.
-
- ```python title="settings.py"
- STATIC_ROOT = os.path.join(BASE_DIR, 'staticfiles')
- ```
-
-### 2. **Using Static Files in Templates**
-
-1. **Load Static Files**:
- - Load static files in templates using the `{% static %}` template tag.
-
- ```html title="template.html"
-
-
-
-
- My Page
-
-
-
-
-
-
-
- ```
-
- - `{% static 'path/to/static/file' %}`: Generates the URL for the static file based on `STATIC_URL`.
-
-### 3. **Using Static Files in Views**
-
-1. **Accessing Static Files in Views**:
- - In views or any Python code, use `django.templatetags.static.static()` to generate URLs for static files.
-
- ```python
- from django.templatetags.static import static
-
- def my_view(request):
- css_url = static('css/style.css')
- js_url = static('js/script.js')
- # Use URLs as needed
- ...
- ```
-
-### 4. **Static Files in Development vs. Production**
-
-1. **Development**:
- - Django serves static files automatically from the `STATICFILES_DIRS` during development when `DEBUG=True`.
-
-2. **Production**:
- - In production, serve static files using a web server like Nginx or Apache for better performance.
- - Set up `STATIC_ROOT` and run `collectstatic` to gather all static files into a single directory for deployment.
-
-### 5. **Static File Caching and Compression**
-
-1. **Caching**:
- - Use cache headers (`Cache-Control`, `Expires`) to control caching behavior for static files in production.
-
- ```python title="settings.py"
- STATICFILES_STORAGE = 'django.contrib.staticfiles.storage.ManifestStaticFilesStorage'
- ```
-
-2. **Compression**:
- - Django supports automatic compression of static files (CSS, JavaScript) using tools like `django-compressor` or `whitenoise` for serving compressed files efficiently.
-
-### Summary
-
-Handling static files in Django involves configuring settings, organizing directories, using template tags, and managing static files across development and production environments. Proper management ensures efficient delivery of assets and enhances the performance and aesthetics of Django applications.
diff --git a/docs/Django/Template.md b/docs/Django/Template.md
deleted file mode 100644
index c85991b5c..000000000
--- a/docs/Django/Template.md
+++ /dev/null
@@ -1,131 +0,0 @@
----
-id: template-in-django
-title: Template In Django
-sidebar_label: Template In Django
-sidebar_position: 4
-tags: [python,Django Introduction,Template In Django,Framework]
-description: Template In Django.
----
-
-In Django, templates are used to generate dynamic HTML content by combining static HTML with Django Template Language (DTL) syntax. Templates provide a way to separate the design (HTML structure) from the logic (Python code in views) of your web application. Here’s a comprehensive overview of templates in Django:
-
-### 1. **Template Structure**
-
-Django templates are HTML files that can include special syntax and tags provided by DTL. They are typically stored in the `templates` directory within each Django app or in a project-level `templates` directory.
-
-Example template (`product_list.html`):
-
-```html
-
-
-
-
- Product List
-
-
-
Products
-
- {% for product in products %}
-
{{ product.name }} - ${{ product.price }}
- {% endfor %}
-
-
-
-```
-
-### 2. **Django Template Language (DTL)**
-
-DTL is a lightweight template language provided by Django for rendering templates dynamically. It includes variables, tags, and filters that allow you to manipulate and display data from views.
-
-- **Variables**: Enclosed in double curly braces (`{{ variable }}`), used to output values passed from views to templates.
-
- ```html
-
Welcome, {{ user.username }}!
- ```
-
-- **Tags**: Enclosed in curly braces with percent signs (`{% tag %}`), control the logic flow and processing within templates (e.g., `for` loops, `if` statements).
-
- ```html
- {% for product in products %}
-
{{ product.name }} - ${{ product.price }}
- {% endfor %}
- ```
-
-- **Filters**: Modify the output of variables before they are displayed (e.g., date formatting, string manipulation).
-
- ```html
- {{ product.created_at | date:'F j, Y' }}
- ```
-
-### 3. **Template Inheritance**
-
-Django supports template inheritance, allowing you to create base templates that define the common structure and layout of your pages. Child templates can then override specific blocks or extend the base template.
-
-- **Base Template (`base.html`)**:
-
- ```html
-
-
-
-
- {% block title %}My Site{% endblock %}
-
-
-
-
{% block header %}Welcome to My Site{% endblock %}
- {% endblock %}
- ```
-
-### 4. **Including Templates**
-
-You can include one template within another using the `{% include %}` tag, allowing you to reuse common HTML snippets across multiple templates.
-
-```html
-{% include 'includes/header.html' %}
-
Content goes here
-{% include 'includes/footer.html' %}
-```
-
-### 5. **Static Files**
-
-Templates can reference static files (CSS, JavaScript, images) using the `{% static %}` tag, which generates the URL to the static file as defined in your `STATIC_URL` setting.
-
-```html
-
-```
-
-### 6. **Template Loading**
-
-Django automatically searches for templates within each app’s `templates` directory and the project-level `templates` directory. You can customize template loading by configuring the `TEMPLATES` setting in your Django project settings.
-
-### 7. **Testing Templates**
-
-Django provides testing tools to ensure templates render correctly and display expected content. Tests can verify the presence of specific HTML elements or content in rendered templates.
-
-Templates in Django play a crucial role in separating presentation logic from application logic, promoting code reusability, and enhancing maintainability. Understanding how to structure and utilize templates effectively is essential for building scalable and responsive web applications with Django.
\ No newline at end of file
diff --git a/docs/Django/UrlDispatcher.md b/docs/Django/UrlDispatcher.md
deleted file mode 100644
index 70de62bbc..000000000
--- a/docs/Django/UrlDispatcher.md
+++ /dev/null
@@ -1,116 +0,0 @@
----
-id: url-dispatcher-introduction
-title: Django URL Dispatcher
-sidebar_label: Django URL Dispatcher
-sidebar_position: 5
-tags: [python,Django Introduction,Django URL Dispatcher,Framework]
-description: Django URL Dispatcher.
----
-
-In Django, the URL dispatcher is a core component that maps URL patterns to views. It determines which view function or class-based view should handle an incoming HTTP request based on the requested URL. Here's a detailed explanation of how the URL dispatcher works and how you can configure it:
-
-### 1. **URL Patterns**
-
-URL patterns are defined in Django using regular expressions (regex) or simple strings to match specific URL patterns. These patterns are typically configured in the `urls.py` files within your Django apps or project.
-
-#### Example of `urls.py` in an App:
-
-```python title="urls.py"
-from django.urls import path
-from . import views
-
-urlpatterns = [
- path('', views.index, name='index'),
- path('about/', views.about, name='about'),
- path('products//', views.product_detail, name='product_detail'),
-]
-```
-
-- **`path()` Function**: Defines a URL pattern along with the corresponding view function (`views.index`, `views.about`, etc.) that will handle the request.
-- **Named URL Patterns**: Each URL pattern can have a name (`name='index'`, `name='about'`, etc.), which allows you to refer to them in templates or in other parts of your code without hardcoding URLs.
-
-### 2. **Regular Expressions in URL Patterns**
-
-You can use regular expressions to capture dynamic parts of URLs, such as numeric IDs or slugs, and pass them as parameters to your view functions.
-
-```python
-from django.urls import path
-from . import views
-
-urlpatterns = [
- path('products//', views.product_detail, name='product_detail'),
- path('blog//', views.blog_post_detail, name='blog_post_detail'),
-]
-```
-
-- **``**: Matches a numeric integer (`product_id`) and passes it as an argument to the `product_detail` view.
-- **``**: Matches a slug (typically a URL-friendly string) and passes it as an argument to the `blog_post_detail` view.
-
-### 3. **Include() Function**
-
-The `include()` function allows you to modularize your URL configuration by including patterns from other `urls.py` modules. This helps organize your URL patterns into smaller, manageable units.
-
-#### Example of Including URLs:
-
-```python
-from django.urls import path, include
-
-urlpatterns = [
- path('admin/', admin.site.urls),
- path('accounts/', include('accounts.urls')), # Include URLs from 'accounts' app
- path('products/', include('products.urls')), # Include URLs from 'products' app
-]
-```
-
-### 4. **Namespace**
-
-You can define a namespace for your URL patterns using the `namespace` parameter in the `include()` function or in the app's `urls.py`. This helps differentiate URL patterns from different apps that might have the same URL names.
-
-#### Example of Namespace:
-
-```python title="accounts/urls.py"
-from django.urls import path
-from . import views
-
-app_name = 'accounts'
-urlpatterns = [
- path('login/', views.login, name='login'),
- path('logout/', views.logout, name='logout'),
-]
-
-# project/urls.py
-from django.urls import path, include
-
-urlpatterns = [
- path('accounts/', include('accounts.urls', namespace='accounts')),
-]
-```
-
-### 5. **URL Reverse**
-
-Django provides a `reverse()` function and `{% url %}` template tag to generate URLs based on their name and optional parameters defined in your URL configuration. This avoids hardcoding URLs in your codebase and makes it easier to update URL patterns later.
-
-#### Example of URL Reverse in Views:
-
-```python
-from django.shortcuts import reverse, redirect
-
-def redirect_to_index(request):
- return redirect(reverse('index'))
-```
-
-#### Example of URL Reverse in Templates:
-
-```html
-Home
-```
-
-### 6. **Testing URLs**
-
-Django provides testing utilities to verify that URL patterns resolve correctly to the expected views. This ensures that all defined URLs in your application are correctly configured and accessible.
-
-### 7. **Middleware**
-
-URL patterns are processed by Django's middleware framework, which intercepts incoming requests and determines which view should handle them based on the configured URL patterns.
-
-Understanding and effectively using the URL dispatcher in Django is crucial for designing clean and maintainable URL structures in your web applications. It helps organize your codebase, facilitate URL navigation, and promote code reuse through modularization.
diff --git a/docs/Django/Views.md b/docs/Django/Views.md
deleted file mode 100644
index 6aa6f4755..000000000
--- a/docs/Django/Views.md
+++ /dev/null
@@ -1,118 +0,0 @@
----
-id: views-in-django
-title: Views In Django
-sidebar_label: Views In Django
-sidebar_position: 3
-tags: [python,Django Introduction, Views In Django,Framework]
-description: Views In Django.
----
-
-In Django, views are Python functions or classes that receive web requests and return web responses. They contain the logic that processes the user's request, retrieves data from the database using models, and renders HTML content using templates. Here's a comprehensive explanation of views in Django:
-
-### 1. **Function-Based Views**
-
-Function-based views are defined as Python functions that accept an `HttpRequest` object as the first argument and return an `HttpResponse` object or a subclass of `HttpResponse`.
-
-```python
-from django.shortcuts import render
-from django.http import HttpResponse
-from .models import Product
-
-def product_list(request):
- products = Product.objects.all()
- context = {'products': products}
- return render(request, 'products/product_list.html', context)
-```
-
-- **HttpRequest**: Represents an incoming HTTP request from the user's browser. It contains metadata about the request (e.g., headers, method, user session).
-- **HttpResponse**: Represents the HTTP response that will be sent back to the user's browser. It typically contains rendered HTML content or redirects.
-
-### 2. **Class-Based Views (CBVs)**
-
-Class-based views are Django classes that inherit from Django's `View` class or one of its subclasses. They provide an object-oriented way to organize view code and encapsulate related behavior into reusable components.
-
-```python
-from django.views import View
-from django.shortcuts import render
-from .models import Product
-
-class ProductListView(View):
- def get(self, request):
- products = Product.objects.all()
- context = {'products': products}
- return render(request, 'products/product_list.html', context)
-```
-
-- **HTTP Methods**: Class-based views define methods (`get`, `post`, `put`, `delete`, etc.) corresponding to HTTP methods. The appropriate method is called based on the type of request received.
-
-### 3. **Rendering Templates**
-
-Views typically render HTML templates to generate dynamic content that is sent back to the user's browser. The `render` function is commonly used to render templates with context data.
-
-```python
-from django.shortcuts import render
-
-def product_list(request):
- products = Product.objects.all()
- context = {'products': products}
- return render(request, 'products/product_list.html', context)
-```
-
-- **Context**: Data passed to the template for rendering. It can include objects retrieved from the database, form data, or any other information needed to generate the HTML content.
-
-### 4. **Handling Forms and Data**
-
-Views are responsible for processing form submissions, validating input, and saving data to the database. Django provides form handling mechanisms (`forms.ModelForm`, `forms.Form`) that integrate seamlessly with views.
-
-```python
-from django.shortcuts import render, redirect
-from .forms import ProductForm
-
-def add_product(request):
- if request.method == 'POST':
- form = ProductForm(request.POST)
- if form.is_valid():
- form.save()
- return redirect('product_list')
- else:
- form = ProductForm()
-
- return render(request, 'products/add_product.html', {'form': form})
-```
-
-- **Redirects**: After processing a request (e.g., form submission), views often redirect users to another URL or view to prevent resubmission of form data and maintain clean URL patterns.
-
-### 5. **Context Data**
-
-Views can pass data to templates using context dictionaries. This data is used to dynamically generate HTML content based on the current state of the application or user input.
-
-```python
-def product_detail(request, product_id):
- product = Product.objects.get(id=product_id)
- context = {'product': product}
- return render(request, 'products/product_detail.html', context)
-```
-
-- **Dynamic URLs**: Views can accept parameters from the URL (e.g., `product_id` in the example above) to fetch specific data from the database and render it in the template.
-
-### 6. **Middleware and Decorators**
-
-Views can be enhanced with middleware (functions that run before or after a view is executed) and decorators (functions that modify the behavior of views). These mechanisms provide additional functionality such as authentication, caching, or logging.
-
-```python
-from django.contrib.auth.decorators import login_required
-from django.utils.decorators import method_decorator
-
-@method_decorator(login_required, name='dispatch')
-class MyProtectedView(View):
- def get(self, request):
- return HttpResponse('This is a protected view.')
-```
-
-- **Authentication**: Django provides built-in decorators like `login_required` to restrict access to views based on user authentication status.
-
-### 7. **Testing Views**
-
-Django includes testing tools (`unittest` or `pytest` frameworks) for writing and executing tests that verify the behavior of views. Tests can simulate HTTP requests and verify the correctness of view responses.
-
-Views in Django play a central role in handling user interactions, processing data, and generating HTML content. Understanding how to create and organize views effectively is essential for building robust and maintainable web applications with Django.
\ No newline at end of file
diff --git a/docs/Django/_category_.json b/docs/Django/_category_.json
deleted file mode 100644
index 65887a6f4..000000000
--- a/docs/Django/_category_.json
+++ /dev/null
@@ -1,8 +0,0 @@
-{
- "label": "Django",
- "position": 7,
- "link": {
- "type": "generated-index",
- "description": "Django is a high-level Python web framework that allows developers to create robust web applications quickly."
- }
-}
\ No newline at end of file
diff --git a/docs/Flask/01-Introduction.md b/docs/Flask/01-Introduction.md
deleted file mode 100644
index 94558b420..000000000
--- a/docs/Flask/01-Introduction.md
+++ /dev/null
@@ -1,23 +0,0 @@
----
-id: introduction-to-flask
-title: Introduction to Flask
-sidebar_label: Introduction to Flask
-sidebar_position: 1
-tags: [flask, python, web development]
-description: In this tutorial, you will learn about Flask, a lightweight WSGI web application framework written in Python.
----
-
-Flask is a lightweight WSGI web application framework written in Python. It is widely used for building web applications and APIs due to its simplicity and flexibility. Flask is designed to make getting started quick and easy, with the ability to scale up to complex applications. This tutorial will guide you through the basics of Flask, helping you get started with building web applications.
-
-### Key Features of Flask
-
-1. **Lightweight and Modular:** Flask is easy to set up and use, providing the essentials for web development while allowing you to add extensions as needed.
-
-2. **Flexible:** Flask provides a simple interface for routing, templating, and handling requests, giving you the flexibility to customize your application.
-
-3. **Extensible:** Flask supports a wide range of extensions for database integration, form handling, authentication, and more.
-
-
-### Conclusion
-
-Flask is a powerful and flexible framework for building web applications and APIs. Its simplicity and ease of use make it a popular choice among developers. Understanding the basics of Flask is the first step towards creating robust and scalable web applications.
\ No newline at end of file
diff --git a/docs/Flask/02-Installing.md b/docs/Flask/02-Installing.md
deleted file mode 100644
index 90e6de48a..000000000
--- a/docs/Flask/02-Installing.md
+++ /dev/null
@@ -1,29 +0,0 @@
----
-id: installing-flask
-title: Installing Flask
-sidebar_label: Installing Flask
-sidebar_position: 2
-tags: [flask, python, installation]
-description: In this tutorial, you will learn how to install Flask, a lightweight WSGI web application framework written in Python.
----
-
-To start using Flask, you need to install it on your system. Flask can be installed using Python's package manager, pip.
-
-### Prerequisites
-**Python:** Ensure you have Python installed on your system. You can download it from the official website.
-
-### Installing Flask
-1. **Using pip:**
-Open your terminal or command prompt and run the following command:
-```
-pip install Flask
-```
-2. **Verifying Installation:**
-To verify that Flask is installed correctly, you can run:
-```
-python -m flask --version
-```
-
-### Conclusion
-
-Installing Flask is a straightforward process using pip. Once installed, you can start building your web applications and exploring the various features and functionalities that Flask offers.
\ No newline at end of file
diff --git a/docs/Flask/03-SettingUp-newProject.md b/docs/Flask/03-SettingUp-newProject.md
deleted file mode 100644
index 80884bad8..000000000
--- a/docs/Flask/03-SettingUp-newProject.md
+++ /dev/null
@@ -1,43 +0,0 @@
----
-id: setting-up-a-new-flask-project
-title: Setting up a New Flask Project
-sidebar_label: Setting up a New Flask Project
-sidebar_position: 3
-tags: [flask, python, project setup]
-description: In this tutorial, you will learn how to set up a new Flask project.
----
-
-Setting up a new Flask project involves creating a basic project structure and initializing the Flask application.
-
-### Project Structure
-
-1. **Create a Project Directory:**
-mkdir my_flask_app
-cd my_flask_app
-
-2. **Create a Virtual Environment:**
-python -m venv venv
-source venv/bin/activate # On Windows, use `venv\Scripts\activate`
-
-3. **Install Flask:**
-pip install Flask
-
-### Initializing the Flask Application
-
-**Create `app.py`:**
-```python
-from flask import Flask
-
-app = Flask(__name__)
-
-@app.route('/')
-def home():
- return "Hello, Flask!"
-
-if __name__ == '__main__':
- app.run(debug=True)
-```
-
-### Conclusion
-
-Flask is a powerful and flexible framework for building web applications and APIs. Its simplicity and ease of use make it a popular choice among developers. Understanding the basics of Flask is the first step towards creating robust and scalable web applications.
\ No newline at end of file
diff --git a/docs/Flask/04-Routing.md b/docs/Flask/04-Routing.md
deleted file mode 100644
index e453bb628..000000000
--- a/docs/Flask/04-Routing.md
+++ /dev/null
@@ -1,50 +0,0 @@
----
-id: flask-routing-and-request-handling
-title: Flask Routing and Request Handling
-sidebar_label: Flask Routing and Request Handling
-sidebar_position: 4
-tags: [flask, python, routing, request handling]
-description: In this tutorial, you will learn about routing and request handling in Flask.
----
-
-Routing in Flask is used to map URLs to functions (views). Each view function is responsible for handling requests to a specific URL.
-
-### Defining Routes
-Routes are defined using the `@app.route` decorator. Here's a simple example:
-```python
-from flask import Flask
-
-app = Flask(__name__)
-
-@app.route('/')
-def home():
- return "Hello, Flask!"
-
-@app.route('/about')
-def about():
- return "About Page"
-
-if __name__ == '__main__':
- app.run(debug=True)
-```
-
-### Handling Requests
-Flask provides support for handling different types of HTTP requests. By default, routes handle `GET` requests, but you can specify other methods like `POST`, `PUT`, `DELETE`, etc.
-```python
-from flask import Flask, request
-
-app = Flask(__name__)
-
-@app.route('/submit', methods=['POST'])
-def submit():
- data = request.form['data']
- return f"Received: {data}"
-
-if __name__ == '__main__':
- app.run(debug=True)
-```
-
-### Conclusion
-
-Understanding routing and request handling in Flask is crucial for creating dynamic web applications. By defining routes and handling different types of requests, you can build responsive and interactive web applications.
-
diff --git a/docs/Flask/05-Templates.md b/docs/Flask/05-Templates.md
deleted file mode 100644
index f18b37971..000000000
--- a/docs/Flask/05-Templates.md
+++ /dev/null
@@ -1,50 +0,0 @@
----
-id: using-templates-with-jinja2
-title: Using Templates with Jinja2
-sidebar_label: Using Templates with Jinja2
-sidebar_position: 5
-tags: [flask, python, templates, jinja2]
-description: In this tutorial, you will learn about using templates with Jinja2 in Flask.
----
-
-Flask uses the Jinja2 templating engine to render HTML templates. This allows you to create dynamic web pages by embedding Python code within HTML.
-
-### Creating a Template
-1. **Create a Templates Directory:**
-mkdir templates
-
-2. **Create `index.html`:**
-
-```html
-
-
-
-
- Flask App
-
-
-
{{ title }}
-
{{ message }}
-
-
-```
-
-### Rendering the Template
-**Update `app.py:`**
-```python
-from flask import Flask, render_template
-
-app = Flask(__name__)
-
-@app.route('/')
-def home():
- return render_template('index.html', title="Welcome to Flask", message="This is a dynamic web page.")
-
-if __name__ == '__main__':
- app.run(debug=True)
-```
-
-### Conclusion
-
-Using templates with Jinja2 in Flask allows you to create dynamic and reusable web pages. By rendering templates, you can pass data from your Flask application to the HTML templates, making your web application more interactive and efficient.
-
diff --git a/docs/Flask/06-HandlingForms.md b/docs/Flask/06-HandlingForms.md
deleted file mode 100644
index fc14f036b..000000000
--- a/docs/Flask/06-HandlingForms.md
+++ /dev/null
@@ -1,76 +0,0 @@
----
-id: handling-forms-and-user-input
-title: Handling Forms and User Input
-sidebar_label: Handling Forms and User Input
-sidebar_position: 6
-tags: [flask, python, forms, user input]
-description: In this tutorial, you will learn how to handle forms and user input in Flask.
----
-
-Flask is a lightweight WSGI web application framework written in Python. It is widely used for building web applications and APIs due to its simplicity and flexibility. Flask is designed to make getting started quick and easy, with the ability to scale up to complex applications. This tutorial will guide you through the basics of Flask, helping you get started with building web applications.
-
-### Handling forms and user input is a common requirement in web applications. Flask-WTF is an extension that integrates Flask with WTForms to provide form handling and validation.
-
-### Installing Flask-WTF
-First, you need to install Flask-WTF:
-
-pip install Flask-WTF
-
-### Creating a Simple Form
-1. **Create `forms.py`:**
-
-```python
-from flask_wtf import FlaskForm
-from wtforms import StringField, SubmitField
-from wtforms.validators import DataRequired
-
-class MyForm(FlaskForm):
- name = StringField('Name', validators=[DataRequired()])
- submit = SubmitField('Submit')
-```
-
-2. **Update `app.py`:**
-```python
-from flask import Flask, render_template, redirect, url_for
-from forms import MyForm
-
-app = Flask(__name__)
-app.config['SECRET_KEY'] = 'your_secret_key'
-
-@app.route('/', methods=['GET', 'POST'])
-def index():
- form = MyForm()
- if form.validate_on_submit():
- name = form.name.data
- return redirect(url_for('success', name=name))
- return render_template('index.html', form=form)
-
-@app.route('/success/')
-def success(name):
- return f"Hello, {name}!"
-
-if __name__ == '__main__':
- app.run(debug=True)
-```
-
-3. **Create `templates/index.html`:**
-```html
-
-
-
-
- Flask Form
-
-
-
-
-
-```
-
-### Conclusion
-
-Handling forms and user input in Flask is straightforward with Flask-WTF. This integration allows you to create forms, validate user input, and process form data efficiently.
\ No newline at end of file
diff --git a/docs/Flask/07-Database.md b/docs/Flask/07-Database.md
deleted file mode 100644
index 7b651f5b3..000000000
--- a/docs/Flask/07-Database.md
+++ /dev/null
@@ -1,70 +0,0 @@
----
-id: working-with-databases
-title: Working with Databases (SQLAlchemy)
-sidebar_label: Working with Databases (SQLAlchemy)
-sidebar_position: 7
-tags: [flask, python, databases, sqlalchemy]
-description: In this tutorial, you will learn how to work with databases using SQLAlchemy in Flask.
----
-
-Flask-SQLAlchemy is an extension that simplifies database interactions in Flask applications. It provides an ORM (Object Relational Mapper) for managing database records as Python objects.
-
-### Installing Flask-SQLAlchemy
-First, install Flask-SQLAlchemy:
-```sh
-pip install Flask-SQLAlchemy
-```
-
-### Setting Up the Database
-1. **Update `app.py:`**
-
-```python
-from flask import Flask
-from flask_sqlalchemy import SQLAlchemy
-
-app = Flask(__name__)
-app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///site.db'
-db = SQLAlchemy(app)
-
-class User(db.Model):
- id = db.Column(db.Integer, primary_key=True)
- username = db.Column(db.String(150), nullable=False, unique=True)
-
- def __repr__(self):
- return f"User('{self.username}')"
-
-@app.route('/')
-def index():
- return "Welcome to Flask-SQLAlchemy"
-
-if __name__ == '__main__':
- app.run(debug=True)
-```
-
-2. **Creating the Database:**
-```python
->>> from app import db
->>> db.create_all()
-```
-
-### Performing CRUD Operations
-
-1. **Adding Records:**
-
-```python
-from app import db, User
-user1 = User(username='john_doe')
-db.session.add(user1)
-db.session.commit()
-```
-
-2. **Querying Records:**
-
-```python
-users = User.query.all()
-print(users)
-```
-
-### Conclusion
-
-Working with databases in Flask is made easy with Flask-SQLAlchemy. It provides an ORM to interact with the database using Python objects, allowing for efficient and organized database management.
\ No newline at end of file
diff --git a/docs/Flask/08-Blueprints.md b/docs/Flask/08-Blueprints.md
deleted file mode 100644
index a62a1f467..000000000
--- a/docs/Flask/08-Blueprints.md
+++ /dev/null
@@ -1,52 +0,0 @@
----
-id: flask-blueprints-and-application-structure
-title: Flask Blueprints and Application Structure
-sidebar_label: Flask Blueprints and Application Structure
-sidebar_position: 8
-tags: [flask, python, blueprints, application structure]
-description: In this tutorial, you will learn about Flask Blueprints and how to structure your application.
----
-
-Flask Blueprints allow you to organize your application into smaller, reusable components. This is especially useful for larger applications.
-
-### Setting Up Blueprints
-
-1. **Create a Blueprint:**
-
-```python
-# myapp/blueprints/main.py
-from flask import Blueprint, render_template
-
-main = Blueprint('main', __name__)
-
-@main.route('/')
-def home():
- return render_template('index.html')
-```
-
-2. **Register the Blueprint:**
-
-```python
-from flask import Flask
-from blueprints.main import main
-
-app = Flask(__name__)
-app.register_blueprint(main)
-
-if __name__ == '__main__':
- app.run(debug=True)
-```
-
-### Project Structure
-
-myapp/
-├── app.py
-├── blueprints/
-│ └── main.py
-├── templates/
-│ └── index.html
-└── static/
-
-### Conclusion
-
-Using Flask Blueprints helps in organizing your application into modular components, making the application structure more manageable and reusable.
diff --git a/docs/Flask/09-Error-and-Debugging.md b/docs/Flask/09-Error-and-Debugging.md
deleted file mode 100644
index aab24ffcf..000000000
--- a/docs/Flask/09-Error-and-Debugging.md
+++ /dev/null
@@ -1,66 +0,0 @@
----
-id: error-handling-and-debugging
-title: Error Handling and Debugging
-sidebar_label: Error Handling and Debugging
-sidebar_position: 9
-tags: [flask, python, error handling, debugging]
-description: In this tutorial, you will learn about error handling and debugging in Flask.
----
-
-Handling errors gracefully and debugging effectively are crucial for developing robust Flask applications.
-
-### Handling Errors
-1. **Custom Error Pages:**
-
-```python
-from flask import Flask, render_template
-
-app = Flask(__name__)
-
-@app.errorhandler(404)
-def page_not_found(e):
- return render_template('404.html'), 404
-
-if __name__ == '__main__':
- app.run(debug=True)
-```
-
-2. **Creating `404.html`:**
-
-```html
-
-
-
-
- Page Not Found
-
-
-
404 - Page Not Found
-
The page you are looking for does not exist.
-
-
-```
-
-### Debugging
-1. **Using the Debugger:**
-Set debug=True in your app.run() to enable the debugger:
-
-```python
-if __name__ == '__main__':
- app.run(debug=True)
-```
-
-2. **Logging Errors:**
-```python
-import logging
-from logging.handlers import RotatingFileHandler
-
-if not app.debug:
- handler = RotatingFileHandler('error.log', maxBytes=10000, backupCount=1)
- handler.setLevel(logging.ERROR)
- app.logger.addHandler(handler)
-```
-
-### Conclusion
-
-Flask is a powerful and flexible framework for building web applications and APIs. Its simplicity and ease of use make it a popular choice among developers. Understanding the basics of Flask is the first step towards creating robust and scalable web applications.
\ No newline at end of file
diff --git a/docs/Flask/10.Deployment.md b/docs/Flask/10.Deployment.md
deleted file mode 100644
index 67ddbd749..000000000
--- a/docs/Flask/10.Deployment.md
+++ /dev/null
@@ -1,103 +0,0 @@
----
-id: deployment-options-and-best-practices
-title: Deployment Options and Best Practices
-sidebar_label: Deployment Options and Best Practices
-sidebar_position: 10
-tags: [flask, python, deployment, best practices]
-description: In this tutorial, you will learn about deployment options and best practices for Flask applications.
----
-
-Deploying Flask applications to production requires careful planning and following best practices to ensure reliability and scalability.
-
-
-### Deployment Options
-1. **Using WSGI Servers:**
-
-- **Gunicorn:**
-Gunicorn is a Python WSGI HTTP Server for UNIX. It's a pre-fork worker model, which means it forks multiple worker processes to handle requests.
-```sh
-pip install gunicorn
-gunicorn -w 4 app:app
-```
-
-- **uWSGI:**
-uWSGI is a versatile WSGI server with lots of features. It is capable of serving Python web applications through the WSGI interface.
-```sh
-pip install uwsgi
-uwsgi --http :5000 --wsgi-file app.py --callable app
-```
-
-2. **Platform as a Service (PaaS):**
-
-- **Heroku:**
-Heroku is a cloud platform that lets companies build, deliver, monitor, and scale apps. It's the fastest way to go from idea to URL, bypassing all those infrastructure headaches.
-```sh
-heroku create
-git push heroku main
-heroku open
-```
-
-3. **Containerization:**
-
-- **Docker:**
-Docker is a tool designed to make it easier to create, deploy, and run applications by using containers. Containers allow a developer to package up an application with all parts it needs, such as libraries and other dependencies, and ship it all out as one package.
-
-```dockerfile
-FROM python:3.8-slim
-WORKDIR /app
-COPY . /app
-RUN pip install -r requirements.txt
-CMD ["gunicorn", "-w", "4", "app:app"]
-```
-
-### Best Practices
-1. **Use Environment Variables:**
-Store configuration and secrets in environment variables rather than hardcoding them in your code.
-
-```python
-import os
-SECRET_KEY = os.getenv('SECRET_KEY', 'default_secret_key')
-```
-
-2. **Enable Logging:**
-Proper logging is essential for monitoring and troubleshooting your application.
-
-```python
-import logging
-from logging.handlers import RotatingFileHandler
-
-if not app.debug:
- handler = RotatingFileHandler('error.log', maxBytes=10000, backupCount=1)
- handler.setLevel(logging.ERROR)
- app.logger.addHandler(handler)
-```
-
-3. **Use a Reverse Proxy:**
-Use a reverse proxy server (e.g., Nginx) in front of your Flask application to handle client requests and serve static files efficiently.
-
-```
-server {
- listen 80;
- server_name example.com;
-
- location / {
- proxy_pass http://127.0.0.1:8000;
- proxy_set_header Host $host;
- proxy_set_header X-Real-IP $remote_addr;
- proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
- proxy_set_header X-Forwarded-Proto $scheme;
- }
-}
-```
-4. **Automate Deployments:**
-Use CI/CD pipelines to automate the deployment process, ensuring consistency and reducing the potential for human error.
-
-5. **Security Considerations:**
-
-- Always use HTTPS to encrypt data between the client and server.
-- Regularly update your dependencies to patch security vulnerabilities.
-- Implement proper input validation and sanitization to prevent common attacks like SQL injection and XSS.
-
-### Conclusion
-
-Deploying Flask applications requires careful consideration of various deployment options and best practices. By using WSGI servers, PaaS platforms, or containerization, and following best practices such as using environment variables, enabling logging, using a reverse proxy, automating deployments, and prioritizing security, you can ensure your Flask application is robust, scalable, and secure.
\ No newline at end of file
diff --git a/docs/Flask/11-Flask app on Heroku.md b/docs/Flask/11-Flask app on Heroku.md
deleted file mode 100644
index 930016f58..000000000
--- a/docs/Flask/11-Flask app on Heroku.md
+++ /dev/null
@@ -1,50 +0,0 @@
----
-id: Deploy Python Flask App on Heroku
-title: how to deploy a flask app on Heroku
-sidebar_label: Flask App on Heroku
-sidebar_position: 11
-tags: [flask, python, heroku ]
-description: In this tutorial, you will learn about deployment offlask app on Heroku.
----
-
- Flask is based on the Werkzeug WSGI toolkit and Jinja2 template engine. Both are Pocco projects. This article revolves around how to deploy a flask app on Heroku. To demonstrate this, we are first going to create a sample application for a better understanding of the process.
-
-The Prerequisites are-
-1.Python
-2.pip
-3.Heroku CLI
-4.Git
-
-### Deploying Flask App on Heroku
-
-Let’s create a simple flask application first and then it can be deployed to heroku. Create a folder named “eflask” and open the command line and cd inside the “eflask” directory. Follow the following steps to create the sample application for this tutorial.
-
- # STEP 1 :
- Create a virtual environment with pipenv and install Flask and Gunicorn .
-
- # STEP 2 :
- Create a “Procfile” and write the following code.
-
- # STEP 3 :
- Create “runtime.txt” and write the following code.
-
- # STEP 4 :
- Create a folder named “app” and enter the folder
-
- # STEP 5 :
- Create a python file, “main.py” and enter the sample code.
-
- # STEP 6 :
- Get back to the previous directory “eflask”.Create a file“wsgi.py” and insert the following code.
-
- # STEP 7 :
- Run the virtual environment.
-
-# STEP 8 :
- Initialize an empty repo, add the files in the repo and commit all the changes.
-
-# STEP 9 :
-Login to heroku CLI
-
-# STEP 10 :
-Push your code from local to the heroku remote.
diff --git a/docs/Flask/_category_.json b/docs/Flask/_category_.json
deleted file mode 100644
index da6dd51c5..000000000
--- a/docs/Flask/_category_.json
+++ /dev/null
@@ -1,8 +0,0 @@
-{
- "label": "Flask",
- "position": 29,
- "link": {
- "type": "generated-index",
- "description": " In this tutorial, you'll learn about Flask, a lightweight and flexible web application framework in Python, and understand its core concepts and features."
- }
-}
\ No newline at end of file
diff --git a/docs/Flutter/_category_.json b/docs/Flutter/_category_.json
deleted file mode 100644
index 76e372b33..000000000
--- a/docs/Flutter/_category_.json
+++ /dev/null
@@ -1,8 +0,0 @@
-{
- "label": "Flutter",
- "position": 9,
- "link": {
- "type": "generated-index",
- "description": "Flutter is an open-source UI framework developed by Google for building natively compiled applications for mobile, web, and desktop using a single codebase."
- }
-}
\ No newline at end of file
diff --git a/docs/Flutter/flutter-architecture.md b/docs/Flutter/flutter-architecture.md
deleted file mode 100644
index 7909af7d3..000000000
--- a/docs/Flutter/flutter-architecture.md
+++ /dev/null
@@ -1,43 +0,0 @@
----
-id: flutter-architecture
-title: Flutter Architecture
-sidebar_label: Flutter Architecture
-sidebar_position: 3
-tags: [introduction, Flutter, App development]
-description: Flutter Architecture
----
-
-In this chapter, we will discuss the architecture of the Flutter framework.
-
-Widgets
-The core concept of Flutter is that everything is a widget. Widgets are the building blocks of the user interface in Flutter.
-
-In Flutter, the application itself is a widget. The application is the top-level widget and its UI is created using one or more children widgets. This composability feature allows us to create user interfaces of any complexity.
-
-For example, the widget hierarchy of the hello world application (created in the previous chapter) is as follows:
-
-- MyApp is the user-created widget, built using the Flutter native widget, MaterialApp.
-- MaterialApp has a home property that specifies the user interface of the home page, which is another user-created widget, MyHomePage.
-- MyHomePage is built using another Flutter native widget, Scaffold.
-- Scaffold has two properties - body and appBar.
-- The body property is used to specify the main user interface, and the appBar property is used to specify the header user interface.
-- The header UI is built using the Flutter native widget, AppBar, and the body UI is built using the Center widget.
-- The Center widget has a child property that refers to the actual content, which is built using the Text widget.
-
-Gestures
-Flutter widgets support interaction through the GestureDetector widget. GestureDetector is an invisible widget that can capture user interactions such as tapping and dragging. Many native widgets in Flutter support interaction through the use of GestureDetector. We can also add interactive features to existing widgets by composing them with the GestureDetector widget. We will cover gestures in more detail in upcoming chapters.
-
-State Concept
-Flutter widgets support state maintenance through the use of the StatefulWidget widget. Widgets need to be derived from the StatefulWidget widget to support state maintenance, and all other widgets should be derived from StatefulWidget. Flutter widgets are reactive, similar to ReactJS, and the StatefulWidget will be automatically re-rendered whenever its internal state changes. The re-rendering process is optimized by only rendering the necessary changes between the old and new widget UI.
-
-Layers
-The most important concept in the Flutter framework is that it is organized into layers of decreasing complexity. Each layer is built using the layer immediately below it. The topmost layer is specific to Android and iOS, followed by the Flutter native widgets layer. The next layer is the Rendering layer, which is a low-level renderer component that renders everything in the Flutter app. These layers go down to the core platform-specific code.
-
-Here is a general overview of the layers in Flutter:
-
-- Flutter follows a widget-based architecture, where complex widgets are composed of existing widgets.
-- Interactive features can be added using the GestureDetector widget.
-- State can be maintained using the StatefulWidget widget.
-- Flutter offers a layered design approach, allowing different layers to be programmed based on the complexity of the task.
-
-We will discuss these concepts in more detail in the upcoming chapters.
diff --git a/docs/Flutter/flutter-installation.md b/docs/Flutter/flutter-installation.md
deleted file mode 100644
index 35c0d60d0..000000000
--- a/docs/Flutter/flutter-installation.md
+++ /dev/null
@@ -1,71 +0,0 @@
----
-id: flutter-installation
-title: Flutter Installation
-sidebar_label: Flutter Installation
-sidebar_position: 2
-tags: [introduction,Flutter,App development]
-description: Flutter Installation
----
-
-This chapter provides a detailed guide on how to install Flutter on your local computer.
-
-## Installation in Windows
-
-To install Flutter SDK and its requirements on a Windows system, follow these steps:
-
-1. Go to [https://flutter.dev/docs/get-started/install/windows](https://flutter.dev/docs/get-started/install/windows) and download the latest Flutter SDK (version 1.2.1 as of April 2019) from the provided URL.
-
-2. Unzip the downloaded zip archive into a folder, for example, `C:\flutter\`.
-
-3. Update the system path to include the Flutter bin directory.
-
-4. Run the command `flutter doctor` to check if all the requirements for Flutter development are met. The command will analyze the system and provide a report.
-
-5. If the report shows any issues, such as a missing Android SDK or Android Studio, follow the instructions to install the required components.
-
-6. Connect an Android device through USB or start an Android emulator to resolve the "No devices available" issue.
-
-7. Install the latest Android SDK and Android Studio if reported by `flutter doctor`.
-
-8. Install the Flutter and Dart plugin for Android Studio by following these steps:
- - Open Android Studio.
- - Click on File → Settings → Plugins.
- - Select the Flutter plugin and click Install.
- - Click Yes when prompted to install the Dart plugin.
- - Restart Android Studio.
-
-## Installation in MacOS
-
-To install Flutter on MacOS, follow these steps:
-
-1. Go to [https://flutter.dev/docs/get-started/install/macos](https://flutter.dev/docs/get-started/install/macos) and download the latest Flutter SDK (version 1.2.1 as of April 2019) from the provided URL.
-
-2. Unzip the downloaded zip archive into a folder, for example, `/path/to/flutter`.
-
-3. Update the system path to include the Flutter bin directory by adding the following line to the `~/.bashrc` file:
- ```
- export PATH="$PATH:/path/to/flutter/bin"
- ```
-
-4. Enable the updated path in the current session by running the following commands:
- ```
- source ~/.bashrc
- source $HOME/.bash_profile
- echo $PATH
- ```
-
-5. Run the command `flutter doctor` to check if all the requirements for Flutter development are met.
-
-6. If the report shows any issues, such as a missing XCode or Android SDK, follow the instructions to install the required components.
-
-7. Start an Android emulator or connect a real Android device to the system for Android application development.
-
-8. Open the iOS simulator or connect a real iPhone device to the system for iOS application development.
-
-9. Install the Flutter and Dart plugin for Android Studio by following these steps:
- - Open Android Studio.
- - Click on Preferences → Plugins.
- - Select the Flutter plugin and click Install.
- - Click Yes when prompted to install the Dart plugin.
- - Restart Android Studio.
-
diff --git a/docs/Flutter/flutter-introduction.md b/docs/Flutter/flutter-introduction.md
deleted file mode 100644
index 91b226ed3..000000000
--- a/docs/Flutter/flutter-introduction.md
+++ /dev/null
@@ -1,62 +0,0 @@
----
-id: flutter-introduction
-title: Flutter Introduction
-sidebar_label: Flutter Introduction
-sidebar_position: 1
-tags: [introduction,Flutter,App development]
-description: Flutter Introduction
----
-
-
-
-
-
-Flutter is an open-source UI software development kit created by Google. It allows developers to build beautiful and fast native applications for mobile, web, and desktop platforms using a single codebase. With Flutter, you can write code once and deploy it on multiple platforms, saving time and effort.
-
-One of the key features of Flutter is its use of a reactive framework, which enables developers to create highly responsive and interactive user interfaces. Flutter uses a widget-based architecture, where everything is a widget, from buttons and text fields to entire screens. This makes it easy to build complex UI layouts and customize the look and feel of your app.
-
-Flutter also comes with a rich set of pre-designed widgets, called the Flutter Material Design and Cupertino libraries, which provide a consistent and native-like experience across different platforms. These widgets are highly customizable and can be easily styled to match your app's branding.
-
-Another advantage of Flutter is its performance. Flutter apps are compiled to native code, which allows them to run directly on the device's hardware, resulting in fast and smooth animations and transitions. Additionally, Flutter uses a hot reload feature, which allows developers to see the changes they make to the code in real-time, without having to restart the app.
-
-Flutter has a strong and active community, with a wide range of packages and plugins available through its package manager, called Pub. These packages provide additional functionality and can be easily integrated into your app, saving development time.
-
-In conclusion, Flutter is a powerful and versatile framework for building cross-platform applications. Its reactive framework, extensive widget library, performance optimizations, and active community make it a popular choice among developers. Whether you are a beginner or an experienced developer, Flutter provides the tools and resources you need to create stunning and high-performing apps.
-
-
-
-## Advantages of Flutter
-
-1. **Single Codebase**: Flutter allows developers to write code once and deploy it on multiple platforms, including mobile, web, and desktop. This significantly reduces development time and effort.
-
-2. **Fast Development**: Flutter's hot reload feature enables developers to see the changes they make to the code in real-time, without having to restart the app. This speeds up the development process and enhances productivity.
-
-3. **Reactive Framework**: Flutter uses a reactive framework, which enables developers to create highly responsive and interactive user interfaces. This ensures a smooth and engaging user experience.
-
-4. **Rich Widget Library**: Flutter comes with a rich set of pre-designed widgets, such as the Flutter Material Design and Cupertino libraries. These widgets provide a consistent and native-like experience across different platforms and can be easily customized to match your app's branding.
-
-5. **Performance Optimization**: Flutter apps are compiled to native code, allowing them to run directly on the device's hardware. This results in fast and smooth animations and transitions, providing a high-performance user experience.
-
-6. **Active Community**: Flutter has a strong and active community, with a wide range of packages and plugins available through its package manager, Pub. These packages provide additional functionality and can be easily integrated into your app, saving development time.
-
-## Disadvantages of Flutter
-
-1. **Learning Curve**: Flutter has its own programming language called Dart, which developers need to learn in order to build Flutter apps. This may require some initial time and effort to become proficient in Dart.
-
-2. **Limited Native Functionality**: Although Flutter provides a rich set of pre-designed widgets, there may be cases where you need to access native platform features that are not readily available in Flutter. In such cases, you may need to write platform-specific code or use third-party plugins.
-
-3. **App Size**: Flutter apps tend to have a larger file size compared to native apps, as they include the Flutter engine and framework. This may result in longer download and installation times for users.
-
-## Applications of Flutter
-
-1. **Mobile App Development**: Flutter is widely used for developing mobile applications for both Android and iOS platforms. Its ability to create a single codebase that runs on multiple platforms makes it a popular choice for mobile app development.
-
-2. **Web Development**: Flutter can also be used for building web applications. With the introduction of Flutter for web, developers can leverage their existing Flutter knowledge to create responsive and visually appealing web interfaces.
-
-3. **Desktop App Development**: Flutter's support for desktop platforms, such as Windows, macOS, and Linux, allows developers to build cross-platform desktop applications using Flutter's single codebase approach.
-
-4. **UI Prototyping**: Flutter's hot reload feature and extensive widget library make it an excellent choice for rapid prototyping of user interfaces. It allows designers and developers to quickly iterate and experiment with different UI designs.
-
-5. **Game Development**: Flutter's performance optimizations and support for animations make it suitable for developing simple games and interactive experiences.
-
-In summary, Flutter offers advantages such as a single codebase, fast development, reactive framework, rich widget library, performance optimization, and an active community. However, it also has disadvantages like a learning curve, limited native functionality, and larger app size. Flutter finds applications in mobile app development, web development, desktop app development, UI prototyping, and game development.
\ No newline at end of file
diff --git a/docs/Flutter/image.png b/docs/Flutter/image.png
deleted file mode 100644
index 9e2423e8d..000000000
Binary files a/docs/Flutter/image.png and /dev/null differ
diff --git a/docs/Flutter/intro-to-dart.md b/docs/Flutter/intro-to-dart.md
deleted file mode 100644
index 83b008343..000000000
--- a/docs/Flutter/intro-to-dart.md
+++ /dev/null
@@ -1,142 +0,0 @@
----
-id: flutter-dart-introduction
-title: Flutter - Introduction to Dart Programming
-sidebar_label: Flutter - Introduction to Dart Programming
-sidebar_position: 4
-tags: [introduction, Flutter, App development]
-description: Introduction to Dart Programming
-
----
-
-Dart is an open-source general-purpose programming language developed by Google. It is an object-oriented language with C-style syntax. Dart supports programming concepts like interfaces and classes. However, unlike other programming languages, Dart doesn't support arrays. Instead, Dart collections can be used to replicate data structures such as arrays, generics, and optional typing.
-
-Here is a simple Dart program:
-
-```dart
-void main() {
- print("Dart language is easy to learn");
-}
-```
-
-## Variables and Data Types
-
-In Dart, variables are named storage locations, and data types refer to the type and size of data associated with variables and functions.
-
-Dart uses the `var` keyword to declare variables. For example:
-
-```dart
-var name = 'Dart';
-```
-
-The `final` and `const` keywords are used to declare constants. For example:
-
-```dart
-void main() {
- final a = 12;
- const pi = 3.14;
- print(a);
- print(pi);
-}
-```
-
-Dart language supports the following data types:
-
-- Numbers: Used to represent numeric literals, such as integers and doubles.
-- Strings: Represents a sequence of characters. String values are specified in either single or double quotes.
-- Booleans: Dart uses the `bool` keyword to represent Boolean values, `true` and `false`.
-- Lists and Maps: Used to represent a collection of objects. For example:
-
-```dart
-void main() {
- var list = [1, 2, 3, 4, 5];
- print(list);
-}
-```
-
-The above code produces the output: `[1, 2, 3, 4, 5]`.
-
-Map can be defined as shown here:
-
-```dart
-void main() {
- var mapping = {'id': 1, 'name': 'Dart'};
- print(mapping);
-}
-```
-
-The above code produces the output: `{'id': 1, 'name': 'Dart'}`.
-
-Dynamic: If the variable type is not defined, then its default type is dynamic. For example:
-
-```dart
-void main() {
- dynamic name = "Dart";
- print(name);
-}
-```
-
-## Decision Making and Loops
-
-Dart supports decision-making statements like `if`, `if..else`, and `switch`. It also supports loops like `for`, `for..in`, `while`, and `do..while`. Here's an example:
-
-```dart
-void main() {
- for (var i = 1; i <= 10; i++) {
- if (i % 2 == 0) {
- print(i);
- }
- }
-}
-```
-
-The above code prints the even numbers from 1 to 10.
-
-## Functions
-
-A function is a group of statements that together performs a specific task. Here's an example of a simple function in Dart:
-
-```dart
-void main() {
- add(3, 4);
-}
-
-void add(int a, int b) {
- int c;
- c = a + b;
- print(c);
-}
-```
-
-The above function adds two values and produces the output: `7`.
-
-## Object-Oriented Programming
-
-Dart is an object-oriented language that supports features like classes and interfaces. A class is a blueprint for creating objects and includes fields, getters and setters, constructors, and functions. Here's an example:
-
-```dart
-class Employee {
- String name;
-
- // Getter method
- String get emp_name {
- return name;
- }
-
- // Setter method
- void set emp_name(String name) {
- this.name = name;
- }
-
- // Function definition
- void result() {
- print(name);
- }
-}
-
-void main() {
- // Object creation
- Employee emp = new Employee();
- emp.name = "employee1";
- emp.result(); // Function call
-}
-```
diff --git a/docs/Git-Github/Branched-in-git.md b/docs/Git-Github/Branched-in-git.md
deleted file mode 100644
index aee938ad0..000000000
--- a/docs/Git-Github/Branched-in-git.md
+++ /dev/null
@@ -1,81 +0,0 @@
-# Branches in Git
-
-## Branches in Git
-
-Branches are a way to work on different versions of a project at the same time. They allow you to create a separate line of development that can be worked on independently of the main branch. This can be useful when you want to make changes to a project without affecting the main branch or when you want to work on a new feature or bug fix.
-
-
-
-Some developers can work on Header, some can work on Footer, some can work on Content, and some can work on Layout. This is a good example of how branches can be used in Git.
-
-## HEAD in Git
-
-The HEAD is a pointer to the current branch that you are working on. It points to the latest commit in the current branch. When you create a new branch, it is automatically set as the HEAD of that branch.
-
-> The default branch used to be master, but it is now called main. There is nothing special about main, it is just a convention.
-
-## Creating a New Branch
-
-To create a new branch, you can use the following command:
-
-```bash
-git branch
-git branch bug-fix
-git switch bug-fix
-git log
-git switch master
-git switch -c dark-mode
-git checkout orange-mode
-```
-
-Some points to note:
-
-- `git branch` - This command lists all the branches in the current repository.
-- `git branch bug-fix` - This command creates a new branch called `bug-fix`.
-- `git switch bug-fix` - This command switches to the `bug-fix` branch.
-- `git log` - This command shows the commit history for the current branch.
-- `git switch master` - This command switches to the `master` branch.
-- `git switch -c dark-mode` - This command creates and switches to a new branch called `dark-mode`. The `-c` flag is used to create a new branch.
-- `git checkout orange-mode` - This command switches to the `orange-mode` branch.
-
-> - Commit before switching to a branch
-> - Go to the .git folder and check the HEAD file
-
-## Rename a Branch
-
-You can rename a branch using the following command:
-
-```bash
-git branch -m
-```
-
-## Delete a Branch
-
-You can delete a branch using the following command:
-
-```bash
-git branch -d
-```
-
-## Checkout a Branch
-
-You can checkout a branch using the following command:
-
-```bash
-git checkout
-```
-
-Checkout a branch means that you are going to work on that branch. You can checkout any branch you want.
-
-## List All Branches
-
-You can list all branches using the following command:
-
-```bash
-git branch
-```
-
-Listing all branches means that you are going to see all the branches in your repository.
-
-
-[Author: @root-0101](https://github.com/root-0101)
diff --git a/docs/Git-Github/Getting-started-with-Github.md b/docs/Git-Github/Getting-started-with-Github.md
deleted file mode 100644
index 643786f97..000000000
--- a/docs/Git-Github/Getting-started-with-Github.md
+++ /dev/null
@@ -1,180 +0,0 @@
-# Getting Started with GitHub
-
-## What is GitHub?
-
-GitHub is a web-based Git repository hosting service. It is a popular platform for developers to collaborate on projects and share code. GitHub provides a user-friendly interface for managing and tracking changes to your code, as well as a platform for hosting and sharing your projects with others.
-
-Some other alternatives to GitHub are:
-
-- GitLab
-- Bitbucket
-- Azure Repos
-- Gitea
-
-But the mainstream popular tool these days is GitHub.
-
-## GitHub Account
-
-Creating a GitHub account is free and easy. You can create an account by visiting the [GitHub website](https://github.com/) and clicking on the "Sign up" button. You will be prompted to enter your email address and password, and then you will be redirected to the GitHub homepage.
-
-Once you have created an account, you can start using GitHub to host and collaborate on your projects. GitHub provides a variety of features and tools that make it easy to manage and track your code, including issues, pull requests, and code reviews.
-
-## Configure Your Config File
-
-If you haven't done it already, you need to configure your git config file. You can do this by running the following command:
-
-```bash
-git config --global user.email "your-email@example.com"
-git config --global user.name "Your Name"
-```
-
-This will set your email and name as your global settings. You can change these settings later by running the following command:
-
-```bash
-git config --global user.email "your-email@example.com"
-git config --global user.name "Your Name"
-```
-
-Now you can check your config settings:
-
-```bash
-git config --list
-```
-
-This will show you all the settings that you have changed.
-
-## Setup SSH Key and Add to GitHub
-
-If you haven't done it already, you need to set up an SSH key and add it to your GitHub account. You can do this by following the instructions on the [GitHub website](https://docs.github.com/en/authentication/connecting-to-github-with-ssh/generating-a-new-ssh-key-and-adding-it-to-the-ssh-agent).
-
-You can find the exact steps on the website for both Windows and macOS. The steps are the same for both; only Apple users need to add the SSH key to their keychain.
-
-### Step 1: Generate a New SSH Key
-
-To generate a new SSH key, open the terminal and run the following command:
-
-```bash
-ssh-keygen -t ed25519 -C "your-email@code.com"
-```
-
-Here, `ed25519` is the type of key that you are generating. This creates a new SSH key, using the provided email as a label.
-
-### Save the Key
-
-After generating the key, you need to save it to your computer. You can do this by running the following command:
-
-> Enter a file in which to save the key (/Users/YOU/.ssh/id_ALGORITHM): [Press enter]
-
-At the prompt, you can enter a passphrase for the key or leave it blank. If you leave it blank, the key will be saved without a passphrase.
-
-### Add Key to Your SSH-Agent
-
-After saving the key, you need to add it to your SSH-agent. You can do this by running the following command:
-
-Here it is best to refer to the above link for more information, as GitHub has a lot of information on this. There is no point in repeating it here.
-
-### Add Key to GitHub
-
-Use the web UI to add the key to your GitHub account. You can do this by following the instructions on the [GitHub website](https://docs.github.com/en/authentication/connecting-to-github-with-ssh/adding-a-new-ssh-key-to-your-github-account?tool=webui).
-
-## Adding Code to Remote Repository
-
-Now that you have set up your SSH key and added it to your GitHub account, you can start pushing your code to the remote repository.
-
-Create a new repository on your system first, add some code, and commit it.
-
-```bash
-git init
-git add
-git commit -m "commit message"
-```
-
-### Check Remote URL Setting
-
-You can check the remote URL setting by running the following command:
-
-```bash
-git remote -v
-```
-
-This will show you the remote URL of your repository.
-
-### Add Remote Repository
-
-You can add a remote repository by running the following command:
-
-```bash
-git remote add origin
-```
-
-Here, `` is the URL of the remote repository that you want to add, and `origin` is the name of the remote repository. This origin is used to refer to the remote repository in the future.
-
-```bash
-git remote add origin https://github.com/username/something.git
-```
-
-### Push Code to Remote Repository
-
-```bash
-git push origin main
-```
-
-Here, `origin` is the name of the remote repository that you want to push to, and `main` is the name of the branch that you want to push.
-
-### Setup an Upstream Remote
-
-Setting up an upstream remote is useful when you want to keep your local repository up to date with the remote repository. It allows you to fetch and merge changes from the remote repository into your local repository.
-
-To set up an upstream remote, you can use the following command:
-
-```bash
-git remote add upstream
-```
-
-or you can use the shorthand:
-
-```bash
-git remote add -u
-```
-
-You can do this at the time of pushing your code to the remote repository.
-
-```bash
-git push -u origin main
-```
-
-This will set up an upstream remote and push your code to the remote repository. This will allow you to run future commands like `git pull` and `git push` without specifying the remote name.
-
-## Get Code from Remote Repository
-
-There are two ways to get code from a remote repository:
-
-- Fetch the code
-- Pull the code
-
-Fetching the code means that you are going to download the code from the remote repository to your local repository. Pulling the code means that you are going to download the code from the remote repository and merge it with your local repository.
-
-
-
-### Fetch Code
-
-To fetch code from a remote repository, you can use the following command:
-
-```bash
-git fetch
-```
-
-Here, `` is the name of the remote repository that you want to fetch from.
-
-### Pull Code
-
-To pull code from a remote repository, you can use the following command:
-
-```bash
-git pull
-git pull origin main
-```
-
-Here, `` is the name of the remote repository that you want to pull from, and `` is the name of the branch that you want to pull.
-
-[Author: @root-0101](https://github.com/root-0101)
\ No newline at end of file
diff --git a/docs/Git-Github/Terminology.md b/docs/Git-Github/Terminology.md
deleted file mode 100644
index 4e4be4cf0..000000000
--- a/docs/Git-Github/Terminology.md
+++ /dev/null
@@ -1,87 +0,0 @@
-# Terminology
-
-# Repository
-
-A repository is a collection of files and directories that are stored together. It is a way to store and manage your code. A repository is like a folder on your computer, but it is more than just a folder. It can contain other files, folders, and even other repositories. You can think of a repository as a container that holds all your code.
-
-There is a difference between software on your system and tracking a particular folder on your system. At any point, you can run the following command to see the current state of your repository:
-
-```bash
-git status
-```
-
-## Your Config Settings
-
-GitHub has a lot of settings that you can change. You can change your username, email, and other settings. Whenever you checkpoint your changes, Git will add some information about you, such as your username and email, to the commit. There is a git config file that stores all the settings that you have changed. You can make settings like what editor you would like to use, etc. There are some global settings and some repository-specific settings.
-
-Let's set up your email and username in this config file. I would recommend you create an account on GitHub and then use the email and username that you have created.
-
-```bash
-git config --global user.email "your-email@example.com"
-git config --global user.name "Your Name"
-```
-
-Now you can check your config settings:
-
-```bash
-git config --list
-```
-
-This will show you all the settings that you have changed.
-
-## Creating a Repository
-
-Creating a repository is a process of creating a new folder on your system and initializing it as a Git repository. It's just a regular folder to code your project; you are just asking Git to track it. To create a repository, you can use the following command:
-
-```bash
-git status
-git init
-```
-
-The `git status` command will show you the current state of your repository. The `git init` command will create a new folder on your system and initialize it as a Git repository. This adds a hidden `.git` folder to your project.
-
-## Commit
-
-A commit is a way to save your changes to your repository. It is a way to record your changes and make them permanent. You can think of a commit as a snapshot of your code at a particular point in time. When you commit your changes, you are telling Git to save them in a permanent way. This way, you can always go back to that point in time and see what you changed.
-
-## Stage
-
-Staging is a way to tell Git to track a particular file or folder. You can use the following command to stage a file:
-
-```bash
-git add
-git status
-```
-
-Here we are initializing the repository and adding a file to the repository. Then we can see that the file is now being tracked by Git. Currently, our files are in the staging area; this means that we have not yet committed the changes but are ready to be committed.
-
-## Commit
-
-```bash
-git commit -m "commit message"
-git status
-```
-
-Here we are committing the changes to the repository. We can see that the changes are now committed to the repository. The `-m` flag is used to add a message to the commit. This message is a short description of the changes that were made. You can use this message to remember what the changes were. Missing the `-m` flag will result in an action that opens your default settings editor, which is usually VIM. We will change this to VSCode in the next section.
-
-## Logs
-
-```bash
-git log
-```
-
-This command will show you the history of your repository. It will show you all the commits that were made to the repository. You can use the `--oneline` flag to show only the commit message. This will make the output more compact and easier to read.
-
-## gitignore
-
-`.gitignore` is a file that tells Git which files and folders to ignore. It is a way to prevent Git from tracking certain files or folders. You can create a `.gitignore` file and add a list of files and folders to ignore by using the following example:
-
-Example `.gitignore` file:
-
-```
-node_modules
-.env
-.vscode
-```
-
-[Author: @root-0101](https://github.com/root-0101)
diff --git a/docs/Git-Github/_category_.json b/docs/Git-Github/_category_.json
deleted file mode 100644
index bc03ea8ba..000000000
--- a/docs/Git-Github/_category_.json
+++ /dev/null
@@ -1,8 +0,0 @@
-{
- "label": "Git and Github",
- "position": 14,
- "link": {
- "type": "generated-index",
- "description": "git and github"
- }
-}
\ No newline at end of file
diff --git a/docs/Git-Github/git-github-basic.md b/docs/Git-Github/git-github-basic.md
deleted file mode 100644
index e3981909b..000000000
--- a/docs/Git-Github/git-github-basic.md
+++ /dev/null
@@ -1,27 +0,0 @@
----
-id: git-github-basic
-title: Introduction to git and github
-sidebar_label: Basics of git and github
-sidebar_position: 9
-tags: [git, github]
-description: "Learn Basics of git and github"
----
-
-
-# Git and GitHub
-
-Let's start with the basics. Git is a version control system that allows you to track changes to your files and collaborate with others. It is used to manage the history of your code and to merge changes from different branches. Terms like version control, branches, and merges might be unfamiliar now, but don't worry—we will learn them in this tutorial.
-
-## Git and GitHub are Different
-
-Git is a version control system used to track changes to your files. It is free, open-source software available for Windows, macOS, and Linux. Remember, Git is software that can be installed on your computer.
-
-GitHub is a web-based hosting service for Git repositories. It is an online platform that allows you to store and share your code with others. It is popular for developers to collaborate on projects and share code. While GitHub is one of the most popular providers of Git repositories, it is not the only one.
-
-## A Little on Version Control Systems
-
-Version control systems manage the history of your code. They allow you to track changes to your files and collaborate with others. Version control systems are essential for software development. Consider version control as a checkpoint in a game: you can move to any time in the game and always go back to a previous checkpoint. This is the same concept in software development.
-
-Before Git became mainstream, developers used version control systems to manage their code. These were called SCCS (Source Code Control System). SCCS was proprietary software used to manage the history of code. It was expensive and not very user-friendly. Git was created to replace SCCS and make version control more accessible and user-friendly. Some common version control systems are Subversion (SVN), CVS, and Perforce.
-
-[Author: @root-0101](https://github.com/root-0101)
\ No newline at end of file
diff --git a/docs/Go/Concurrency.md b/docs/Go/Concurrency.md
deleted file mode 100644
index 7cf8b7c90..000000000
--- a/docs/Go/Concurrency.md
+++ /dev/null
@@ -1,89 +0,0 @@
----
-id: go-concurrency
-title: Go Concurrency
-sidebar_label: Go concurrency
-sidebar_position: 2
-tags: [introduction,Go,concurrency,open-source,programming language]
-description: Go Concept of Concurrency
----
-
-Concurrency in Go is one of its standout features, designed to make it easier to write programs that effectively utilize multicore processors and handle large numbers of simultaneous tasks. Here's a detailed explanation of concurrency in Go:
-
-### Goroutines
-
-Goroutines are lightweight, independently executing functions managed by the Go runtime. They are analogous to threads but are more efficient in terms of memory usage and management by the operating system. Goroutines enable concurrent execution of functions without the overhead typically associated with threads.
-
-To create a goroutine, you simply prefix a function call with the `go` keyword:
-
-```go
-package main
-
-import (
- "fmt"
- "time"
-)
-
-func sayHello() {
- for i := 0; i < 5; i++ {
- fmt.Println("Hello")
- time.Sleep(100 * time.Millisecond)
- }
-}
-
-func main() {
- go sayHello() // Start a new goroutine
- time.Sleep(500 * time.Millisecond) // Give the goroutine some time to execute
- fmt.Println("Main function")
-}
-```
-
-In this example, `sayHello` is executed concurrently as a goroutine while the `main` function continues to execute independently. The `time.Sleep` functions are used to demonstrate the concurrent execution.
-
-### Channels
-
-Channels are a core mechanism in Go for communication and synchronization between goroutines. They allow goroutines to send and receive values to and from each other. Channels are typed, meaning they carry a specific type of data.
-
-Here's an example of using channels to synchronize goroutines:
-
-```go
-package main
-
-import (
- "fmt"
- "time"
-)
-
-func sendMessages(ch chan string) {
- messages := []string{"message1", "message2", "message3"}
- for _, msg := range messages {
- ch <- msg // Send a message to the channel
- time.Sleep(1 * time.Second)
- }
- close(ch) // Close the channel when done sending messages
-}
-
-func main() {
- ch := make(chan string) // Create a channel of strings
- go sendMessages(ch) // Start sending messages concurrently
-
- // Receive messages from the channel
- for msg := range ch {
- fmt.Println("Received:", msg)
- }
-}
-```
-
-In this example:
-- `sendMessages` sends messages to the channel `ch` with a delay between each message.
-- The `main` function receives messages from the channel `ch` using a `for` loop that ranges over the channel until it's closed.
-
-### Benefits of Concurrency in Go
-
-1. **Efficient Use of Resources:** Goroutines are lightweight and use less memory compared to traditional threads, making it feasible to create thousands of them in a single application.
-
-2. **Simplified Synchronization:** Channels provide a clear and safe way to synchronize data access between goroutines without the pitfalls of traditional shared memory concurrency.
-
-3. **Scalability:** Go's concurrency model is designed to scale well with multicore processors, allowing applications to take full advantage of modern hardware.
-
-4. **Cleaner Code:** Goroutines and channels promote a clear and structured approach to concurrent programming, reducing the complexity of managing concurrency manually.
-
\ No newline at end of file
diff --git a/docs/Go/ErrorHandling.md b/docs/Go/ErrorHandling.md
deleted file mode 100644
index cbfc1625c..000000000
--- a/docs/Go/ErrorHandling.md
+++ /dev/null
@@ -1,94 +0,0 @@
----
-id: go-error-handling
-title: Error Handling
-sidebar_label: Error Handling
-sidebar_position: 7
-tags: [introduction,Go,Garbage Collection,Packages and Imports,Error Handling,open-source,Types and Interfaces,programming language]
-description: Go concept of Error Handling.
----
-
-Error handling in Go is designed to be explicit and straightforward, emphasizing the importance of handling errors directly where they occur rather than relying on exceptions or runtime errors. Here's a detailed explanation of how error handling works in Go:
-
-### Returning Errors
-
-In Go, functions that can produce an error typically return an error as the last return value (often of type `error`). It's a common practice to return `nil` (indicating no error) when the function succeeds, and a non-nil `error` when it fails.
-
-```go
-package main
-
-import (
- "errors"
- "fmt"
-)
-
-func divide(x, y float64) (float64, error) {
- if y == 0 {
- return 0, errors.New("division by zero")
- }
- return x / y, nil
-}
-
-func main() {
- result, err := divide(10, 2)
- if err != nil {
- fmt.Println("Error:", err)
- } else {
- fmt.Println("Result:", result)
- }
-
- result, err = divide(10, 0)
- if err != nil {
- fmt.Println("Error:", err)
- } else {
- fmt.Println("Result:", result)
- }
-}
-```
-
-In this example:
-- The `divide` function returns a `float64` result and an `error`. It checks if `y` is zero and returns an error if true.
-- In `main`, we call `divide` twice with different arguments. We check if `err` is `nil` to determine if an error occurred.
-
-### Error Handling Patterns
-
-1. **Check Errors Immediately:** Always check errors immediately after calling a function that can return an error. This ensures errors are handled promptly.
-
-2. **Error Propagation:** Functions can propagate errors up the call stack by returning them to the caller. Each layer of the call stack can add context or handle the error accordingly.
-
-3. **Error Wrapping:** Go supports error wrapping using `fmt.Errorf` or `errors.Wrap` from the `errors` package to add context to errors while preserving the original error information.
-
-```go
-package main
-
-import (
- "errors"
- "fmt"
- "github.com/pkg/errors"
-)
-
-func openFile(filename string) error {
- _, err := os.Open(filename)
- if err != nil {
- return errors.Wrap(err, "failed to open file")
- }
- return nil
-}
-
-func main() {
- err := openFile("nonexistent.txt")
- if err != nil {
- fmt.Println("Error:", err)
- // Extract the underlying error message
- fmt.Println("Underlying error:", errors.Unwrap(err))
- }
-}
-```
-
-### Error Handling Best Practices
-
-- **Avoid Panic:** In Go, panicking should be reserved for unrecoverable errors, like out-of-memory conditions or unrecoverable state.
-
-- **Contextual Error Messages:** Provide clear and meaningful error messages that help developers understand the cause of the error.
-
-- **Handle Errors Appropriately:** Decide whether to handle an error locally or propagate it to the caller based on the application's needs and the context in which the error occurred.
-
\ No newline at end of file
diff --git a/docs/Go/FunctionsAsFirst-ClassCitizens.md b/docs/Go/FunctionsAsFirst-ClassCitizens.md
deleted file mode 100644
index b9efbef2a..000000000
--- a/docs/Go/FunctionsAsFirst-ClassCitizens.md
+++ /dev/null
@@ -1,131 +0,0 @@
----
-id: functions-as-first-class-citizens
-title: Functions as First-Class Citizens
-sidebar_label: Functions as First-Class Citizens
-sidebar_position: 4
-tags: [introduction,Go,open-source,programming language]
-description: Go Concept of Functions as First-Class Citizens.
----
-
-In Go (or Golang), functions are treated as first-class citizens, which means they can be treated like any other variable. This includes passing functions as arguments to other functions, returning functions as values from other functions, assigning functions to variables, and storing functions in data structures.
-
-Here are a few ways functions are treated as first-class citizens in Go:
-
-### 1. Assigning Functions to Variables
-
-In Go, you can assign functions to variables just like you would assign integers, strings, or any other data type.
-
-```go
-package main
-
-import "fmt"
-
-func add(a, b int) int {
- return a + b
-}
-
-func main() {
- var sumFunc func(int, int) int // Declare a variable of function type
- sumFunc = add // Assign the add function to sumFunc
-
- result := sumFunc(3, 5) // Call the function using the variable
- fmt.Println("Sum:", result)
-}
-```
-
-### 2. Passing Functions as Arguments
-
-Functions can be passed as arguments to other functions in Go, allowing for powerful abstractions and higher-order functions.
-
-```go
-package main
-
-import "fmt"
-
-func apply(f func(int, int) int, a, b int) int {
- return f(a, b)
-}
-
-func add(a, b int) int {
- return a + b
-}
-
-func multiply(a, b int) int {
- return a * b
-}
-
-func main() {
- result1 := apply(add, 3, 5) // Pass add function as an argument
- result2 := apply(multiply, 3, 5) // Pass multiply function as an argument
-
- fmt.Println("Addition result:", result1)
- fmt.Println("Multiplication result:", result2)
-}
-```
-
-### 3. Returning Functions from Functions
-
-Functions can also return other functions as values, allowing for functional programming techniques such as closures.
-
-```go
-package main
-
-import "fmt"
-
-func makeGreeter(greeting string) func(string) string {
- return func(name string) string {
- return fmt.Sprintf("%s, %s!", greeting, name)
- }
-}
-
-func main() {
- englishGreeter := makeGreeter("Hello")
- spanishGreeter := makeGreeter("Hola")
-
- fmt.Println(englishGreeter("Alice"))
- fmt.Println(spanishGreeter("Carlos"))
-}
-```
-
-In this example, `makeGreeter` returns a function that takes a `name` argument and returns a greeting string. This demonstrates how functions can be used to encapsulate behavior and create reusable components.
-
-### 4. Functions in Data Structures
-
-You can store functions in data structures such as slices, maps, or structs.
-
-```go
-package main
-
-import "fmt"
-
-type mathFunc func(int, int) int
-
-func add(a, b int) int {
- return a + b
-}
-
-func multiply(a, b int) int {
- return a * b
-}
-
-func main() {
- mathFuncs := map[string]mathFunc{
- "add": add,
- "multiply": multiply,
- }
-
- result1 := mathFuncs["add"](3, 5)
- result2 := mathFuncs["multiply"](3, 5)
-
- fmt.Println("Addition result:", result1)
- fmt.Println("Multiplication result:", result2)
-}
-```
-
-Here, `mathFunc` is a type that represents functions with a specific signature. Functions `add` and `multiply` are stored in a map and called based on their keys.
-
-### Benefits of First-Class Functions in Go
-
-- **Higher-order functions**: Functions that can accept functions as arguments or return functions enable flexible and expressive programming.
-- **Closures**: Functions can access variables defined in their lexical scope, allowing for powerful encapsulation of state.
-- **Modularity**: Functions can be easily composed and reused, enhancing code maintainability and readability.
diff --git a/docs/Go/GarbageCollection.md b/docs/Go/GarbageCollection.md
deleted file mode 100644
index 26939e45e..000000000
--- a/docs/Go/GarbageCollection.md
+++ /dev/null
@@ -1,47 +0,0 @@
----
-id: go-garbage-collection
-title: Garbage Collection
-sidebar_label: Garbage Collection
-sidebar_position: 5
-tags: [introduction,Go,Garbage Collection,open-source,Types and Interfaces,programming language]
-description: Go concept of Garbage Collection.
----
-
-Garbage collection (GC) is an essential aspect of memory management in modern programming languages, including Go (Golang). Here’s an explanation of what garbage collection is, why it’s important, and how it works in Go:
-
-### What is Garbage Collection?
-
-Garbage collection is an automatic memory management technique where the programming language runtime system automatically deallocates memory that is no longer in use by the program. The primary goal of garbage collection is to free up memory occupied by objects that are no longer reachable or needed by the program, thus preventing memory leaks and ensuring efficient use of memory.
-
-### Why is Garbage Collection Important?
-
-Manual memory management, where developers explicitly allocate and deallocate memory, can lead to several issues such as:
-
-- **Memory leaks**: Memory that is allocated but never deallocated, leading to wasted resources and potential program crashes.
-- **Dangling pointers**: Pointers that reference memory locations that have been deallocated, resulting in undefined behavior.
-- **Complexity**: Manual memory management adds complexity to the code, making it harder to maintain and debug.
-
-Garbage collection automates memory management, relieving developers from the burden of managing memory explicitly and reducing the likelihood of memory-related bugs.
-
-### Garbage Collection in Go (Golang)
-
-Go uses a concurrent, tri-color mark-and-sweep garbage collector. Here are the key features and aspects of garbage collection in Go:
-
-1. **Concurrency**: Go's garbage collector runs concurrently with the application's goroutines (lightweight threads), which means it can reclaim memory while the program is still executing.
-
-2. **Tri-Color Mark-and-Sweep Algorithm**:
- - **Mark Phase**: The garbage collector traverses the object graph starting from known root objects (e.g., global variables, stacks of goroutines) and marks all reachable objects as alive.
- - **Sweep Phase**: It sweeps through the entire heap, freeing memory for objects that are not marked (i.e., not reachable) and reclaiming that memory for reuse.
-
-3. **Generational**: Go's garbage collector is generational, meaning it categorizes objects by their age (how long they have been allocated). Younger objects (recently allocated) are collected more frequently than older objects.
-
-4. **Memory Heaps**: Go manages memory in heaps, which are divided into small fixed-size segments called spans. Spans can be either used for allocating objects or reserved for specific types of objects (e.g., large objects).
-
-### Controlling Garbage Collection in Go
-
-While Go's garbage collector is designed to work efficiently without manual intervention, there are a few mechanisms available to control its behavior:
-
-- **`runtime.GC()`**: This function can be used to trigger garbage collection manually, although it's generally not recommended for normal application use.
-
-- **Environment Variables**: Go provides environment variables like `GOGC` which allows tuning of garbage collection behavior. For example, setting `GOGC=100` may increase the aggressiveness of garbage collection.
-
\ No newline at end of file
diff --git a/docs/Go/Introduction.md b/docs/Go/Introduction.md
deleted file mode 100644
index 70a786c73..000000000
--- a/docs/Go/Introduction.md
+++ /dev/null
@@ -1,55 +0,0 @@
----
-id: intro-go
-title: Introduction of GO Language
-sidebar_label: Introduction of GO Language
-sidebar_position: 1
-tags: [introduction,Go,open-source,programming language]
-description: Go is an open-source programming language created by Google in 2007 and released to the public in 2009.
----
-
-**Go Language Overview:**
-Go is an open-source programming language created by Google in 2007 and released to the public in 2009. It was designed by Robert Griesemer, Rob Pike, and Ken Thompson and aims to be simple, efficient, and reliable. Go is statically typed and has a syntax that is similar to C, but it also includes features from other languages like Python and JavaScript. It's known for its strong support for concurrent programming and its garbage collection capabilities.
-
-### Key Concepts in Go:
-
-1. **Concurrency:** Go has built-in support for concurrency using goroutines and channels. Goroutines are lightweight threads managed by the Go runtime, allowing concurrent execution of functions. Channels facilitate communication and synchronization between goroutines, making it easier to write concurrent programs.
-
-2. **Types and Interfaces:** Go is statically typed, meaning variables always have a specific type which is known at compile time. It supports user-defined types and interfaces, allowing abstraction and polymorphism.
-
-3. **Functions as First-Class Citizens:** Functions in Go are first-class citizens, meaning they can be assigned to variables, passed as arguments to other functions, and returned as values from functions.
-
-4. **Garbage Collection:** Go has a garbage collector that automatically manages memory allocation and deallocation, reducing the burden on developers to manage memory manually.
-
-5. **Packages and Imports:** Go programs are organized into packages, which are collections of Go source files that together provide a set of related functionalities. Packages can be imported and reused in other programs using the `import` keyword.
-
-6. **Error Handling:** Go encourages explicit error handling. Functions can return multiple values, allowing functions to return both results and error indicators. This helps developers handle errors effectively without resorting to exceptions.
-
-7. **Structs and Methods:** Go supports struct types, which are collections of fields. Methods can be associated with structs, providing an object-oriented way to define behaviors for types.
-
-8. **Tooling:** Go comes with a comprehensive set of tools, including a powerful build system (`go build`), package management (`go mod`), testing (`go test`), and profiling (`go profile`).
-
-### Example of a Simple Go Program:
-
-```go
-package main
-
-import "fmt"
-
-func main() {
- fmt.Println("Hello, World!")
-}
-```
-
-In this example:
-- `package main`: Indicates that this Go file belongs to the `main` package, which is required for executable commands.
-- `import "fmt"`: Imports the `fmt` package, which contains functions for formatting input and output.
-- `func main() {...}`: Defines the `main` function, which is the entry point of the program. It calls `fmt.Println` to print "Hello, World!" to the console.
-
-### Why Use Go?
-
-- **Simplicity**: Go has a simple and clean syntax that is easy to learn and read.
-- **Concurrency**: Goroutines and channels make it easy to write concurrent programs.
-- **Performance**: Go compiles to machine code, providing performance comparable to statically-typed languages like C and C++.
-- **Scalability**: Go is designed for scalability, making it suitable for building large-scale systems.
-- **Community and Support**: Being backed by Google and having a growing community ensures good support and continuous improvement.
-
\ No newline at end of file
diff --git a/docs/Go/PackagesAndImports.md b/docs/Go/PackagesAndImports.md
deleted file mode 100644
index bdd65daa6..000000000
--- a/docs/Go/PackagesAndImports.md
+++ /dev/null
@@ -1,61 +0,0 @@
----
-id: go-packages-and-imports
-title: Packages and Imports
-sidebar_label: Packages and Imports
-sidebar_position: 6
-tags: [introduction,Go,Garbage Collection,Packages and Imports,open-source,Types and Interfaces,programming language]
-description: Go concept of Packages and Imports.
----
-
-In Go (Golang), packages and imports play crucial roles in organizing and reusing code. Here’s a comprehensive explanation of packages, imports, and their usage in Go:
-
-### Packages
-
-A package in Go is a collection of Go source files that reside in the same directory and have the same package declaration at the top of each file. Packages provide modularity and namespace separation, allowing code to be organized into manageable units. Key points about packages include:
-
-- **Package Declaration**: Every Go file starts with a `package` declaration, specifying the name of the package to which the file belongs. For example, `package main` indicates that the file belongs to the `main` package, which is required for executable programs.
-
-- **Package Naming**: By convention, packages are named after the last element of their import path. For example, the package `fmt` is imported with `import "fmt"`, where `"fmt"` is the import path and `fmt` is the package name.
-
-- **Visibility**: Go uses capitalized names to indicate whether an identifier (function, variable, etc.) is exported (public) or unexported (private) from a package. Exported identifiers are visible and accessible from outside the package, while unexported identifiers are restricted to the package they are defined in.
-
-### Imports
-
-Imports in Go allow you to use code defined in other packages. They enable code reuse and dependency management. Key points about imports include:
-
-- **Import Declaration**: Imports are declared using the `import` keyword followed by the package path in double quotes (`"`). For example, `import "fmt"` imports the `fmt` package.
-
-- **Alias**: You can optionally specify an alias for an imported package using the `import` keyword followed by a dot (`.`) and the alias name. For example, `import fm "fmt"` imports the `fmt` package and allows you to refer to it as `fm` within your code.
-
-- **Blank Identifier**: If you import a package solely for its side effects (such as initialization), you can use the blank identifier (`_`) to discard the package name. For example, `import _ "database/sql"` imports the `database/sql` package without explicitly using it.
-
-### Example Usage
-
-Here’s a simple example demonstrating how packages and imports work together in Go:
-
-```go
-// File: main.go
-package main
-
-import (
- "fmt"
- "math/rand"
-)
-
-func main() {
- fmt.Println("Random number:", rand.Intn(100)) // Using function from the rand package
-}
-```
-
-In this example:
-- `main.go` belongs to the `main` package.
-- `import "fmt"` imports the `fmt` package for formatted I/O operations.
-- `import "math/rand"` imports the `rand` package for generating random numbers.
-
-### Organizing Packages
-
-Go encourages organizing code into packages based on functionality and purpose. Common practices include:
-- **Single Responsibility**: Each package should have a clear and specific responsibility.
-- **Separation of Concerns**: Packages should be designed to minimize dependencies between different parts of the codebase.
-- **Clear Interfaces**: Define clear interfaces between packages to promote reusability and maintainability.
-
\ No newline at end of file
diff --git a/docs/Go/StructsAndMethods.md b/docs/Go/StructsAndMethods.md
deleted file mode 100644
index 3b537da4a..000000000
--- a/docs/Go/StructsAndMethods.md
+++ /dev/null
@@ -1,111 +0,0 @@
----
-id: go-structs-and-methods
-title: Structs and Methods
-sidebar_label: Structs and Methods
-sidebar_position: 8
-tags: [introduction,Go,open-source,Structs and Methods,programming language]
-description: Go Concept of Structs and Methods
----
-
-In Go (Golang), structs and methods are fundamental concepts used to define custom data types and associated behaviors. Let's delve into structs and methods, their definitions, usage, and examples.
-
-### Structs
-
-A struct is a composite data type that groups together zero or more named fields of possibly different types into a single unit. Structs are used to create complex data structures that can represent real-world entities in a program. Key points about structs include:
-
-- **Definition**: Structs are defined using the `type` and `struct` keywords followed by a list of fields inside curly braces `{}`.
-- **Fields**: Each field in a struct has a name and a type.
-- **Initialization**: Structs can be initialized with field values using a struct literal.
-
-#### Example of Structs:
-
-```go
-package main
-
-import "fmt"
-
-// Define a struct type
-type Person struct {
- FirstName string
- LastName string
- Age int
-}
-
-func main() {
- // Create a new instance of Person struct
- person := Person{
- FirstName: "John",
- LastName: "Doe",
- Age: 30,
- }
-
- // Accessing struct fields
- fmt.Println("First Name:", person.FirstName)
- fmt.Println("Last Name:", person.LastName)
- fmt.Println("Age:", person.Age)
-}
-```
-
-In this example:
-- `Person` is a struct type with three fields: `FirstName`, `LastName`, and `Age`.
-- An instance `person` of type `Person` is created using a struct literal with initial values.
-
-### Methods
-
-Methods in Go are functions that are associated with a particular type. They allow you to define behavior (functions) for your custom types (structs or any other types). Methods can either be associated with a struct type (`receiver`) or a non-struct type.
-
-#### Receiver Syntax:
-
-- **Pointer Receiver (`*T`)**: Modifies the value pointed to by the receiver. Changes are visible to the caller.
-- **Value Receiver (`T`)**: Operates on a copy of the receiver. Changes are not visible to the caller unless the receiver is a struct or array and is not defined as a pointer.
-
-#### Example of Methods:
-
-```go
-package main
-
-import "fmt"
-
-// Define a struct type
-type Rectangle struct {
- Width float64
- Height float64
-}
-
-// Method with value receiver
-func (r Rectangle) Area() float64 {
- return r.Width * r.Height
-}
-
-// Method with pointer receiver
-func (r *Rectangle) Scale(factor float64) {
- r.Width *= factor
- r.Height *= factor
-}
-
-func main() {
- // Create a new instance of Rectangle struct
- rectangle := Rectangle{
- Width: 10.0,
- Height: 5.0,
- }
-
- // Call methods
- fmt.Println("Area:", rectangle.Area()) // Calling method with value receiver
- rectangle.Scale(2.0) // Calling method with pointer receiver
- fmt.Println("Scaled Width:", rectangle.Width)
- fmt.Println("Scaled Height:", rectangle.Height)
-}
-```
-
-In this example:
-- `Rectangle` is a struct type with `Width` and `Height` fields.
-- `Area()` is a method with a value receiver `Rectangle`. It calculates and returns the area of the rectangle.
-- `Scale()` is a method with a pointer receiver `*Rectangle`. It scales the dimensions of the rectangle by a given factor.
-
-### When to Use Methods vs Functions
-
-- **Methods** are used to associate behavior with a specific type (struct or non-struct). They enhance code readability and maintainability by keeping related operations grouped together with the data they operate on.
-
-- **Functions** are used for generic computations or operations that don't necessarily need to be associated with a specific type.
-
\ No newline at end of file
diff --git a/docs/Go/Tooling.md b/docs/Go/Tooling.md
deleted file mode 100644
index 6d2a14aae..000000000
--- a/docs/Go/Tooling.md
+++ /dev/null
@@ -1,59 +0,0 @@
----
-id: go-tooling
-title: Tooling
-sidebar_label: Tooling
-sidebar_position: 9
-tags: [introduction,Go,open-source,Structs and Methods,Tooling,programming language]
-description: Go Concept of Tooling
----
-
-In the context of Go (Golang), tooling refers to the set of software tools and utilities that aid in various aspects of Go development, including writing, testing, managing dependencies, and deploying applications. Here’s an overview of some essential tools and utilities commonly used in Go development:
-
-### 1. **go command**
-The `go` command is the official tool for managing Go source code. It provides functionalities such as compiling, testing, installing packages, and managing dependencies. Common subcommands include:
-- `go build`: Compiles packages and dependencies.
-- `go run`: Compiles and runs a Go program.
-- `go test`: Runs tests associated with a package.
-- `go get`: Downloads and installs packages and dependencies.
-
-### 2. **go mod**
-`go mod` is the Go module system introduced in Go 1.11 to manage dependencies. It allows for versioned dependency management outside of the traditional `$GOPATH` structure.
-
-- `go mod init`: Initializes a new module (creates a `go.mod` file).
-- `go mod tidy`: Ensures that `go.mod` and `go.sum` reflect the correct set of dependencies.
-- `go mod vendor`: Copies dependencies into a local `vendor` directory.
-- `go mod download`: Downloads modules needed to build and test packages.
-
-### 3. **gofmt**
-`gofmt` is a tool that formats Go source code according to Go's style guidelines (`gofmt` stands for "Go format"). It ensures consistent formatting across different codebases and helps maintain readability.
-
-- `gofmt -w file.go`: Formats a single file and overwrites it with the formatted version.
-- `gofmt -l .`: Lists files whose formatting differs from `gofmt`'s style.
-
-### 4. **golint**
-`golint` is a linter for Go code that provides suggestions for improving Go code quality based on the official Go style guide and best practices.
-
-- Install: `go install golang.org/x/lint/golint`
-- Usage: `golint path/to/package` to lint a specific package.
-
-### 5. **go vet**
-`go vet` is a tool for analyzing Go source code for suspicious constructs and potential errors that `gofmt` and `golint` might miss.
-
-- Usage: `go vet path/to/package` to analyze a specific package.
-
-### 6. **godoc**
-`godoc` is a tool for displaying Go package documentation. It serves as a web server that presents Go package documentation as HTML pages.
-
-- `godoc -http=:6060`: Starts a local web server serving Go documentation at `http://localhost:6060`.
-
-### 7. **Testing Tools**
-Go has built-in support for testing with the `go test` command. Testing tools include:
-- **Testing Package (`testing`)**: Standard package for writing unit tests in Go.
-- **Benchmarking (`testing.B`)**: Allows measuring performance of code.
-- **Coverage (`go test -cover`)**: Measures test coverage of packages.
-
-### 8. **Third-party Tools**
-Besides built-in tools, many third-party tools and libraries enhance Go development, including:
-- **Dependency Managers**: `dep`, `godep`, `vgo`, and now the built-in `go mod`.
-- **IDEs and Editors**: VS Code, IntelliJ IDEA with Go plugin, Atom with Go-Plus package, etc.
-- **Code Editors**: Vim with plugins like vim-go, Emacs with go-mode, etc.
\ No newline at end of file
diff --git a/docs/Go/TypesandInterfaces.md b/docs/Go/TypesandInterfaces.md
deleted file mode 100644
index 4aae50170..000000000
--- a/docs/Go/TypesandInterfaces.md
+++ /dev/null
@@ -1,103 +0,0 @@
----
-id: go-types-and-interfaces
-title: Types and Interfaces
-sidebar_label: Types and Interfaces
-sidebar_position: 3
-tags: [introduction,Go,open-source,Types and Interfaces,programming language]
-description: Go concept of Types and Interfaces.
----
-
-In Go (Golang), types and interfaces are fundamental concepts that facilitate robust and flexible code design. Let's explore each of these concepts in detail:
-
-### Types
-
-In Go, a type defines the blueprint for a set of values. It specifies the representation of data and the operations that can be performed on that data. Types in Go include basic types (like `int`, `float64`, `string`), composite types (like `struct`, `array`, `slice`, `map`), and user-defined types (created using `type` keyword).
-
-#### Example of Types:
-
-```go
-package main
-
-import "fmt"
-
-// Define a new type using type alias
-type Celsius float64
-
-// Define a struct type
-type Person struct {
- Name string
- Age int
-}
-
-func main() {
- // Using basic types
- var age int = 30
- var temperature Celsius = 20.5
-
- // Using composite types
- var john Person
- john.Name = "John Doe"
- john.Age = 40
-
- fmt.Printf("Age: %d\n", age)
- fmt.Printf("Temperature: %.1f°C\n", temperature)
- fmt.Printf("Person: %+v\n", john)
-}
-```
-
-In this example:
-- `Celsius` is a user-defined type alias for `float64`.
-- `Person` is a struct type with fields `Name` and `Age`.
-- Instances of these types (`age`, `temperature`, `john`) demonstrate different uses of types in Go.
-
-### Interfaces
-
-Interfaces in Go provide a way to specify behavior—what a type can do—without specifying how it does it. An interface is a collection of method signatures that a type can implement. Unlike some languages, interfaces in Go are implicit; a type automatically satisfies an interface if it implements all the methods defined by that interface.
-
-#### Example of Interfaces:
-
-```go
-package main
-
-import "fmt"
-
-// Define an interface
-type Shape interface {
- Area() float64
-}
-
-// Define a struct type implementing the Shape interface
-type Rectangle struct {
- Width float64
- Height float64
-}
-
-// Method to calculate area of Rectangle
-func (r Rectangle) Area() float64 {
- return r.Width * r.Height
-}
-
-func main() {
- // Create an instance of Rectangle
- rectangle := Rectangle{Width: 10, Height: 5}
-
- // The Rectangle type satisfies the Shape interface
- var shape Shape
- shape = rectangle
-
- // Call Area method via Shape interface
- fmt.Printf("Area of rectangle: %.2f square units\n", shape.Area())
-}
-```
-
-In this example:
-- `Shape` is an interface with a single method `Area()` that returns a `float64`.
-- `Rectangle` struct implements the `Shape` interface by defining its `Area()` method.
-- The `rectangle` instance of type `Rectangle` is assigned to `shape` of type `Shape`, demonstrating interface assignment and method invocation.
-
-### Key Points and Benefits
-
-- **Type Safety**: Go's type system ensures compile-time type checking, reducing runtime errors.
-- **Abstraction and Flexibility**: Interfaces allow decoupling of code by specifying behavior rather than implementation details, promoting code reusability and modularity.
-- **Polymorphism**: Interfaces enable polymorphic behavior where different types can be used interchangeably based on shared methods.
-
\ No newline at end of file
diff --git a/docs/Go/_category_.json b/docs/Go/_category_.json
deleted file mode 100644
index 7f5ca38b9..000000000
--- a/docs/Go/_category_.json
+++ /dev/null
@@ -1,8 +0,0 @@
-{
- "label": "GO",
- "position": 21,
- "link": {
- "type": "generated-index",
- "description": "Go is an open-source programming language."
- }
- }
\ No newline at end of file
diff --git a/docs/Jekyll/01-Introduction.md b/docs/Jekyll/01-Introduction.md
deleted file mode 100644
index b61ffdc76..000000000
--- a/docs/Jekyll/01-Introduction.md
+++ /dev/null
@@ -1,25 +0,0 @@
----
-id: introduction-to-jekyll
-title: Introduction to Jekyll
-sidebar_label: Introduction to Jekyll
-sidebar_position: 1
-tags: [jekyll, static site generator]
-description: Learn about Jekyll, a static site generator used for creating fast and secure websites with ease.
----
-
-Jekyll is a static site generator written in Ruby. It takes a directory of templates, content files, and configuration, and produces a static website. Jekyll is commonly used for blogs and project websites because of its simplicity and efficiency.
-
-### Key Features of Flask
-
-1. **Static Site Generation:** Jekyll generates static HTML pages, which are fast to load and secure.
-
-2. **Markdown Support:** Write content in Markdown, and Jekyll will convert it to HTML.
-
-3. **Template System:** Use Liquid templates to create dynamic content.
-
-4. **Plugins:** Extend Jekyll's functionality with plugins.
-
-
-### Conclusion
-
-Jekyll is an excellent choice for creating simple, fast, and secure static websites. Its features make it suitable for personal blogs, project documentation, and more. Whether you're a developer looking to build a portfolio or a content creator needing a reliable blogging platform, Jekyll offers the tools and flexibility needed to create a professional and efficient website.
\ No newline at end of file
diff --git a/docs/Jekyll/02-Installation.md b/docs/Jekyll/02-Installation.md
deleted file mode 100644
index 5a62a783d..000000000
--- a/docs/Jekyll/02-Installation.md
+++ /dev/null
@@ -1,30 +0,0 @@
----
-id: installing-jekyll
-title: Installing Jekyll
-sidebar_label: Installing Jekyll
-sidebar_position: 2
-tags: [jekyll, installation]
-description: Learn how to install Jekyll on your local machine and get started quickly.
----
-
-Installing Jekyll is straightforward, especially if you have Ruby installed on your system. Jekyll requires a few dependencies and can be set up with simple commands.
-
-### Prerequisites
-**Ruby:** Ensure you have Ruby installed. You can check by running `ruby -v` in your terminal.
-
-**RubyGems:** This is usually installed with Ruby. Check with `gem -v`.
-
-### Installation Steps
-
-1. **Install Jekyll and Bundler:**
-```sh
-gem install jekyll bundler
-```
-
-2. **Verify the Installation:**
-```sh
-jekyll -v
-```
-### Conclusion
-
-By following these steps, you should have Jekyll installed on your system, ready to create and manage static websites. With Jekyll and Bundler set up, you can efficiently handle dependencies and ensure your site builds consistently across different environments.
\ No newline at end of file
diff --git a/docs/Jekyll/03-Setting-Up.md b/docs/Jekyll/03-Setting-Up.md
deleted file mode 100644
index 87a044946..000000000
--- a/docs/Jekyll/03-Setting-Up.md
+++ /dev/null
@@ -1,28 +0,0 @@
----
-id: setting-up-a-new-jekyll-site
-title: Setting up a new Jekyll site
-sidebar_label: Setting up a new Jekyll site
-sidebar_position: 3
-tags: [jekyll, setup, new site]
-description: Learn how to set up a new Jekyll site from scratch, including creating and structuring your project.
----
-
-Setting up a new Jekyll site is simple and quick, allowing you to get started with your static website in no time. Jekyll provides a default structure that you can easily customize.
-
-### Steps
-
-1. **Create a New Jekyll Site:**
-```sh
-jekyll new my-awesome-site
-cd my-awesome-site
-```
-
-2. **Build the Site and Serve Locally:**
-```sh
-bundle exec jekyll serve
-```
-Visit `http://localhost:4000` to see your new site.
-
-### Conclusion
-
-With these steps, you've created a new Jekyll site and served it locally, ready for customization and content addition. Jekyll's default structure includes folders for posts, pages, assets, and configuration, making it easy to organize and manage your site effectively.
\ No newline at end of file
diff --git a/docs/Jekyll/04-Configuration.md b/docs/Jekyll/04-Configuration.md
deleted file mode 100644
index 837670eb2..000000000
--- a/docs/Jekyll/04-Configuration.md
+++ /dev/null
@@ -1,33 +0,0 @@
----
-id: jekyll-configuration
-title: Jekyll Configuration
-sidebar_label: Jekyll Configuration
-sidebar_position: 4
-tags: [jekyll, configuration]
-description: Learn how to configure your Jekyll site using the `_config.yml` file to customize settings and behavior.
----
-
-Jekyll uses a `_config.yml` file for configuration, where you can set various options for your site. This file is essential for customizing your site's behavior, appearance, and functionality.
-
-### Key Configuration Options
-
-1. **Site Settings:**
-``yaml
-title: My Awesome Site
-description: >- # this means to ignore newlines until "baseurl:"
- This is my awesome website built with Jekyll.
-baseurl: "" # the subpath of your site, e.g. /blog
-url: "http://example.com" # the base hostname & protocol for your site
-```
-
-2. **Build Settings:**
-```yaml
-markdown: kramdown
-theme: minima
-plugins:
- - jekyll-feed
-```
-
-### Conclusion
-
-The `_config.yml` file is crucial for customizing your Jekyll site. By modifying this file, you can easily change the behavior and appearance of your site. Whether you need to update the site title, add plugins, or adjust markdown settings,` _config.yml` provides a centralized location for these configurations, simplifying site management and customization.
\ No newline at end of file
diff --git a/docs/Jekyll/05-Pages-and-Post.md b/docs/Jekyll/05-Pages-and-Post.md
deleted file mode 100644
index 6e695d925..000000000
--- a/docs/Jekyll/05-Pages-and-Post.md
+++ /dev/null
@@ -1,62 +0,0 @@
----
-id: creating-pages-and-posts
-title: Creating Pages and Posts
-sidebar_label: Creating Pages and Posts
-sidebar_position: 5
-tags: [jekyll, pages, posts]
-description: Learn how to create pages and posts in Jekyll to add content to your site.
----
-
-Creating content in Jekyll involves creating pages and posts. Pages are used for static content, while posts are typically used for blog entries.
-
-### Creating Pages
-
-1. **Create a New Page:**
-```sh
-touch about.md
-```
-- Add the following front matter to the page:
-
-markdown
----
-layout: page
-title: About
-permalink: /about/
----
-
-
-2. **Add Content:**
-
-markdown
-# About Me
-This is the about page of my Jekyll site.
-
-
-### Creating Posts
-
-1. **Create a New Post:**
-```sh
-touch _posts/2024-07-20-my-first-post.md
-```
-
-- Add the following front matter to the post:
-
-```markdown
----
-layout: post
-title: "My First Post"
-date: 2024-07-20 12:00:00 -0400
-categories: blog
----
-```
-
-2. **Add Content:**
-
-```markdown
-# Welcome
-This is my first blog post on my new Jekyll site.
-```
-
-### Conclusion
-
-Creating pages and posts in Jekyll is straightforward. By using the appropriate front matter, you can easily add and organize content on your site. Whether you're building a blog, a portfolio, or a documentation site, Jekyll's simple file-based structure makes content management intuitive and efficient.
\ No newline at end of file
diff --git a/docs/Jekyll/06-Themes.md b/docs/Jekyll/06-Themes.md
deleted file mode 100644
index 6e8f59535..000000000
--- a/docs/Jekyll/06-Themes.md
+++ /dev/null
@@ -1,34 +0,0 @@
----
-id: using-themes
-title: Using Themes
-sidebar_label: Using Themes
-sidebar_position: 6
-tags: [jekyll, themes]
-description: Learn how to use and customize themes in Jekyll to enhance the look and feel of your site.
----
-
-Jekyll themes allow you to quickly change the appearance of your site without having to design it from scratch. Themes provide a consistent look and feel across all pages and posts.
-
-### Steps to Use a Theme
-
-1. **Choose a Theme:** Browse themes on Jekyll Themes or GitHub.
-
-2. **Add the Theme to Your Site:**
-
-```yaml
-# _config.yml
-theme: jekyll-theme-minimal
-```
-
-3. **Install the Theme:**
-```sh
-bundle install
-```
-
-### Customizing a Theme
-
-To customize a theme, you can override theme files by copying them into your site’s directory. For example, to customize the `_layouts/default.html` layout, copy it from the theme's gem to your local `_layouts` directory.
-
-### Conclusion
-
-Using themes in Jekyll simplifies the process of styling your site. You can quickly implement a professional design and further customize it to meet your needs, ensuring your site looks unique and polished.
\ No newline at end of file
diff --git a/docs/Jekyll/07-Layouts-and-Includes.md b/docs/Jekyll/07-Layouts-and-Includes.md
deleted file mode 100644
index 457cc86bc..000000000
--- a/docs/Jekyll/07-Layouts-and-Includes.md
+++ /dev/null
@@ -1,66 +0,0 @@
----
-id: working-with-layouts-and-includes
-title: Working with Layouts and Includes
-sidebar_label: Working with Layouts and Includes
-sidebar_position: 7
-tags: [jekyll, layouts, includes]
-description: Learn how to use layouts and includes in Jekyll to structure your site efficiently.
----
-
-Layouts and includes in Jekyll help you manage the structure and reuse components across your site. They enable you to maintain a consistent design and avoid redundancy.
-
-### Using Layouts
-
-1. **Define a Layout:**
-
-```html
-
-
-
-
-
- {{ page.title }}
-
-
- {{ content }}
-
-
-```
-
-2. **Apply the Layout:**
-```yaml
----
-layout: default
-title: My Page
----
-```
-
-### Using Includes
-
-1. **Create an Include:**
-
-```html
-
-
\\\\...
-
-
-Now, let's use the index in a query:
-```sql
-EXPLAIN ANALYZE SELECT * FROM film
-WHERE title = 'Shawshank Redemption';
-```
-
-If you look at the log of this query, "Index lookup on film using idx_film_title_release" is printed. If we remove the index and run the above query again, we can see that the time in executing the query is different. In case where indexing is not used, it takes more time to execute and more rows are searched to find the title.
-
diff --git a/docs/SQL/07-transactions.md b/docs/SQL/07-transactions.md
deleted file mode 100644
index d674f5e46..000000000
--- a/docs/SQL/07-transactions.md
+++ /dev/null
@@ -1,205 +0,0 @@
-# Transaction
-
-## Agenda
-
- - Need for concurrency
- - Problems that arise with concurrency
- - Introduction to transactions
- - Commit / Rollback
- - ACID
- - Is ACID boolean
- - Durability levels
- - Isolation levels
-
-
-## Need for concurrency
-
-Till now, all our SQL queries were written with the assumption that there is no interference from any other operation on the machine.
-Basically, all operations are being run sequentially.
-
-That's however like there being only one queue in immigration. Leads to things being slow and large wait time for someone in the queue.
-In such a case, what do you do?
-Correct. Open multiple counters so that there are multiple *parallel* lines.
-
-Very similarily, in a database, there could be multiple people trying to run their queries at the same time. If DB chooses to run them sequentially, it will become really slow. Machines have multi-core CPUs. So, Database can think of running multiple queries concurrently which will increase it's throughput and reduce the wait time for people trying to run their queries.
-
-## Problems that arise with concurrency
-
-However, concurrency is not all good. It can lead to some issues around data integrity and unexpected behavior. Let's explore one such case.
-
-Imagine we have a database for a bank.
-What's one common transaction in a bank? Transfer money from person X to person Y.
-
-What would be steps of doing that money transaction (let's say transfer 500 INR from X to Y):
-
-```
- 1. Read balA = current balance of user X.
- 2. If balA >= 500:
- 3. update current balane of user X to be (balA - 500)
- 4. Read balB = current balance of user Y
- 5. update current balance of user Y to be (balB + 500)
-
-```
-
-
-Let's imagine there are 2 money transactions happening at the same time - Person A transferring 700 INR to Person B, and Person A transferring 800 INR to Person C.
-Assume current balance of A is 1000, B is 5000, C is 2000.
-
-It is possible that Step 1 (`Read balA = current balance of A`) gets exectuted for both money transaction at the same time. So, both money transaction find balA = 1000. And hence step 2 (balance being larger than the money being transferred) passes for both. Then step 3 gets executed for both money transactions (let's say). A's balance will be updated to 300 by money transaction 1 and then to 200 by money transaction 2.
-A's balance at the end will be 200, with both B and C getting the money and ending at 5700 and 2800 respectively.
-
-Total sum of money does not add up. Seems like the bank owes more money now.
-If you see, if both money transactions had happened one after another (after first had completely finished), then this issue would not have occurred.
-How do we avoid this?
-
-## Introduction to transactions.
-
-Let's understand the solution to the above in 2 parts.
-
- 1. What guidelines does the database management system give to the end user to be able to solve the above. Basically, what should I do as the end user, and the guarantees provided by my database.
- 2. How does the DB really solve it internally? What's happening behind the scene.
-
-Let's first look at 1. What tools does the DBMS give to me to be able to avoid situations like the above.
-
-In the above case, doing a money transaction involved 5 steps (multiple SQL queries).
-Database says why don't you group these tasks into a single unit called **Transactions**.
-
-Formally, Transactions group a set of tasks into a single execution unit. Each transaction begins with a specific task and ends when all the tasks in the group successfully complete. If any of the tasks fail, the transaction fails. Therefore, a transaction has only two results: success or failure.
-
-For example, a transaction example could be:
-
-```sql
-BEGIN TRANSACTION
-
-UPDATE film SET title = "TempTitle1" WHERE id = 10;
-UPDATE film SET title = "TempTitle2" WHERE id = 100;
-
-COMMIT
-```
-
-The above transaction has 2 SQL statements. These statements do not get finalized on the disk until commit command is executed. If any statement fails, all updates are rolled back (like undo operation).
-You can also explicitly write `ROLLBACK` which undoes all operations till the last commit.
-
-Database basically indicates that if you want a group of operations to happen together and you want database to handle all concurrency, put them in a single transaction and then send it to the database.
-If you do so, database promises the following.
-
-## ACID
-
-If you send a transaction to a DBMS, it sets the following expectations to you:
-
- - **ATOMICITY:** All or none. Either all operations in the transactions will succeed or none will.
- - **CONSISTENCY:** Correctness / Validity. All operations will be executed correctly and will leave the database in a consistent state before and after the transaction. For example, in the money transfer example, consistency was violated because the money amount sum should have stayed the same, but it was not.
- - **ISOLATION:** Multiple transactions can be executed concurrently without interfering with each other. Isolation is one of the factors helping with consistency.
- - **DURABILITY:** Updates/Writes to the database are permanent and will not be lost. They are persisted.
-
-
-However, there is one caveat to the above. Atomicity is boolean - all transactions are definitely atomic.
-But all the remaining parameters are not really boolean but have levels. That is so, because there is a tradeoff. To make my database support highest amount of isolation and consistency, I will have to compromise performance which we will see later. So, based on your application requirement, your DBMS lets you configure the level of isolation or durability. Let's discuss them one by one.
-
-### Durability levels
-
-The most basic form of durability is writing updates to disk. However, someone can argue that what if my hard disk has a failure which causes me to loose information stored on the hard disk.
-I can choose then to have replica and all commits are forwarded to replicas as well. That has cost of latency and cost of additional machines.
-We will discuss more about master slave and replication during system design classes.
-
-## Isolation Levels
-
-Before we explore isolation levels, let's understand how would database handle concurrency between multiple transactions happening at the same time.
-Typically, you would take locks to block other operations from interfering with your current transactions. [You'll study more about locks during concurrency class].
-When you take a lock on a table row for example, any other transaction which also might be trying to access the same row would wait for you to complete. Which means with a lot of locks, overall transactions become slower, as they may be spending a lot of time waiting for locks to be released.
-
-Locks are of 2 kinds:
- - Shared Locks: Which means multiple transactions could be reading the same entity at the same time. However, a transaction that intends to write, will have to wait for ongoing reads to finish, and then would have to block all other reads and writes when it is writing/updating the entity.
- - Exclusive Locks: Exclusive lock when taken blocks all reads and writes from other transaction. They have to wait till this transaction is complete.
-There are other kind of locks as well, but not relevant to this discussion for now.
-
-A database can use a combination of the above to achieve isolation during multiple transactions happening at the same time.
-Note that the locks are acquired on rows of the table instead of the entire table. More granular the lock, better it is for performance.
-
-As we can see that locks interfere with performance, database lets you choose isolation levels. Lower the level, more the performance, but lower the isolation/consistency levels.
-
-The isolation levels are the following:
-
-### Read uncommitted.
-
-This is most relaxed isolation level. In READ UNCOMMITTED isolation level, there isn’t much isolation present between the transactions at all, ie ., No locks.
-This is the lowest level of isolation, and does almost nothing. It means that transactions can read data being worked with by other transactions, even if the changes aren’t committed yet. This means the performance is going to be really fast.
-
-However, there are major challenges to consistency.
-Let's consider a case.
-
-| Time | Transaction 1 | Transaction 2 |
-| --- | ------------- | ------------- |
-| 1 | Update row #1, balance updated from 500 to 1000 | |
-| 2 | | Select row #1, gets value as 1000 |
-| 3 | Rollback (balance reverted to 500) | |
-
-T1 reverts the balance to 500. However, T2 is still using the balance as 1000 because it read a value which was not committed yet. This is also called as `dirty read`.
-`Read uncommitted` has the problem of dirty reads when concurrent transactions are happening.
-
-**Example usecase:** Imagine you wanted to maintain count of live users on hotstar live match. You want very high performance, and you don't really care about the exact count. If count is off by a little, you don't mind. So, you won't mind compromising consistency for performance. Hence, read uncommitted is the right isolation level for such a use case.
-
-### Read committed
-
-The next level of isolation is READ_COMMITTED, which adds a little locking into the equation to avoid dirty reads. In READ_COMMITTED, transactions can only read data once writes have been committed. Let’s use our two transactions, but change up the order a bit: T2 is going to read data after T1 has written to it, but then T1 gets rolled back (for some reason).
-
-| Time | Transaction 1 | Transaction 2 |
-| --- | ------------- | ------------- |
-| 1 | Selects row #1 | |
-| 2 | Updates row #1, acquires lock | |
-| 3 | | Tries to select row #1, but blocked by T1’s lock |
-| 4 | Rolls back transaction | |
-| 5 | | Selects row #1 |
-
-READ_COMMITTED helps avoid a dirty read here: if T2 was allowed to read row #1 at Time 3, that read would be invalid; T1 ended up getting rolled back, so the data that T2 read was actually wrong. Because of the lock acquired at Time 2 (thanks READ_COMMITTED!), everything works smoothly and T2 waits to execute its SELECT query.
-
-**This is the default isolation levels in some DBMS like Postgres.**
-
-However, this isolation level has a problem of **Non-repeatable reads.** Let's understand what that is.
-
-Consider the following.
-
-| Time | Transaction 1 | Transaction 2 |
-| --- | ------------- | ------------- |
-| 1 | Selects emails with low psp | |
-| 2 | | update some low psp users with a better psp, acquires lock |
-| 3 | | commit, lock released |
-| 4 | Select emails with low psp again | |
-
-At timestamp 4, I might want to read the emails again because I might want to update the status of having scheduled reminder emails to them. However, I will get a different set of emails in the same transaction (timestamp 1 vs timestamp 4). This issues is called non-repeatable reads and can happen in the current isolation level.
-
-### Repeatable reads
-
-The third isolation level is repeatable reads. This is the default isolation levels in many DBMS including MySQL.
-
-The primary difference in repeable reads is the following:
- - Every transaction reads all the committed rows required for executing reads and writes before the start of the transaction and stores it locally in memory as a snapshot. That way, if you read the same information multiple times in the same transaction, you will get the same entries.
- - Locking mechanism:
- - Writes acquire exclusive locks (same as read committed)
- - Reads with write intent (SELECT FOR UPDATE) acquire exclusive locks.
-
-Further reading: https://ssudan16.medium.com/database-isolation-levels-explained-61429c4b1e31
-
-| Time | Transaction 1 | Transaction 2 |
-| ---- | ------------- | ------------- |
-| 1 | Selects row #1 **for update**, acquires lock on row #1 | |
-| 2 | | Tries to update row #1, but is blocked by T1’s lock |
-| 3 | updates row #1, commits transaction | |
-| 4 | | Updates row #1 |
-
-The first example we took of money transfer could work if select for update is properly used in transactions with this isolation level.
-However, this still has the following issue:
- - Normal reads do not take any lock. So, it is possible while I have a local copy in my snapshot, the real values in DB have changed. Reads are not strongly consistent.
- - Phantom reads: A very corner case, but the table might change if there are new rows inserted while the transaction is ongoing. Since new rows were not part of the snapshot, it might cause inconsistency in new writes, reads or updates.
-
-### Serializable Isolation level
-
-This is the strictest isolation level in a DB. It's the same as repeatable reads with the following differences:
- - All reads acquire a shared lock. So, they don't let updates happen till they are completed.
- - No snapshots required anymore.
- - Range locking - To avoid phantom reads, this isolation level also locks a few entries in the range close to what is being read.
-
-**Example usecase:** This is the isolation levels that banks use because they want strong consistency with every single piece of their information.
-However, systems that do not require as strict isolation levels (like Scaler or Facebook) would then use Read Committed OR Repeatable Reads.
-
-
diff --git a/docs/SQL/08-schema-design1.md b/docs/SQL/08-schema-design1.md
deleted file mode 100644
index 77a16dbc0..000000000
--- a/docs/SQL/08-schema-design1.md
+++ /dev/null
@@ -1,257 +0,0 @@
-# Schema design
-
-## Agenda
-
-- What is Schema Design
-- What can go wrong
-- Normalisation
-- How to approach Schema Design
-- Cardinality
- - How to find cardinality in relations
- - How to represent different cardinalities
-- Nuances when representing relations
-
-## What is Schema Design
-
-Let's understand what Schema is. Schema refers to the structure of the database. Broadly speaking, schema gives information about the following:
-- Structure of a database
-- Tables in a database
-- Columns in a table
-- Primary Key
-- Foreign Key
-- Index
-- Pictorial representation of how the DB is structured.
-
-In general, 'Design' refers to the pictorial reference for solving how should something be formed considering the constraints. Prototyping, blueprinting or a plan, or structuring how something should exist is called Design.
-
-Before any table or database is created for a software, a design document is formed consisting:
-- Schema
-- Class Diagram
-- Architectural Diagram
-
-## What can go wrong
-
-
-#### Example 1:
-Let's say Flipkart has a table for t-shirts. T-shirt has a column named color.
-Some t-shirts could have multiple colors. What do you put in the color column then? Maybe I put all the colors comma separated.
-
-So, something like,
-
-| tshirt_id | collar_type | size | color |
-|-----------|-------------|------|-------|
-| 1 | Round | M | red |
-| 2 | Round | L | red, green |
-| 3 | Round | L | blue, red |
-
-How do you find all t-shirts of color red here.
-
-```sql
-SELECT * FROM tshirt WHERE color LIKE "%red%"
-```
-
-The above query is going to do full-text search on color. You'll not be able to make it fast as it cannot leverage the power of indexing.
-And for that reason, some of your queries will always be slow.
-
-
-#### Example 2:
-
-Let's say we want to store classes and their instructor. Instead of creating 2 separate tables, I choose to put all information in one single table.
-
-
-| class_id | topic | instructor_id | instructor_name | Instructor_email |
-|----------|-------|---------------|-----------------|----------------|
-| 1 | Transactions | 4 | Anshuman | abcd@abcd.com |
-| 2 | Indexing | 4 | Anshuman | abcd@abcd.com |
-| 3 | Schema Design | 4 | Anshuman | abcd@abcd.com |
-| 4 | SQL-1 | 6 | Ayush | ayush@abcd.com |
-
-This has the following problems:
- - Update problem: If name for Anshuman needs to be updated, it has to be updated in all 3 rows containing Anshuman. Missing even a single row causes inconsistency.
- - Delete problem: If you delete the class #4, you end up loosing all infomation about the instructor Ayush.
- - Insert problem: If a new instructor has been onboarded, there is no way to record their information. I cannot create a row with dummy entries. The only way to save their information is when they have a class assigned.
-
-Bad design.
-As you can see, if you start with bad design, it causes tons of issues around performance, data integrity in the future. If you design your schema well, 50% of the battle is won. Let's see principles used for good schema design.
-
-## Normalisation
-
-Normalization is the process to eliminate data redundancy and enhance data integrity in the table. It is a systematic technique of decomposing tables to eliminate data redundancy (repetition) and undesirable characteristics like Insertion, Update, and Deletion anomalies.
-
-To understand, if we are using the technique properly, various normalized forms are defined. Let's look at them one by one.
-
-### 1-NF
-
-A table is referred to as being in its First Normal Form if atomicity of the table is 1.
-Here, atomicity states that a single cell cannot hold multiple values. It must hold only a single-valued attribute.
-The First normal form disallows the multi-valued attribute, composite attribute, and their combinations.
-
-So, example 1 above is not in 1-NF form.
-However, if all your table columns contain atomic values, then your schema satisfies 1-NF form.
-
-How do you solve example 1 to make it 1-NF?
-Create another table called tshirt_color and have a unique row for every tshirt-id, color combination.
-
-### 2-NF
-
-A table is said to be in the second normal form if and only if:
- - The table is already in 1-NF form.
- - If the proper subset of candidate key determines non-prime attribute, it is called partial dependency. A table should not have partial dependencies.
-
-Let's see with an example (Example 2).
-
-
-| class_id | topic | instructor_id | instructor_name | Instructor_email |
-|----------|-------|---------------|-----------------|----------------|
-| 1 | Transactions | 4 | Anshuman | abcd@abcd.com |
-| 2 | Indexing | 4 | Anshuman | abcd@abcd.com |
-| 3 | Schema Design | 4 | Anshuman | abcd@abcd.com |
-| 4 | SQL-1 | 6 | Ayush | ayush@abcd.com |
-
-Here, instructor_name cannot alone decide the class_id or the topic or instructor_id. Various instructors could have the same name with different instructor ID. Hence, instructor_name is a non prime attribute.
-instructor_name can be derived from instructor_id which is a proper subset of the key (instructor_id alone cannot be the key). Hence, the above table violates 2-NF form.
-
-How do you solve to make it 2-NF?
-Only keep instructor_id in the table. Move all other instructor relalted parameters like instructor_name, instructor_email to another table where you have one entry for every unique instructor.
-
-
-## How to approach Schema Design
-
-Let's learn about this using a familiar example. You are asked to build a software for Scaler which can handle some base requirements.
-
-The requirements are as follows:
-1. Scaler will have multiple batches.
-2. For each batch, we need to store the name, start month and current instructor.
-3. Each batch of Scaler will have multiple students.
-4. Each batch has multiple classes.
-5. For each class, store the name, date and time, instructor of the class.
-6. For every student, we store their name, graduation year, University name, email, phone number.
-7. Every student has a buddy, who is also a student.
-8. A student may move from one batch to another.
-9. For each batch a student moves to, the date of starting is stored.
-10. Every student has a mentor.
-11. For every mentor, we store their name and current company name.
-12. Store information about all mentor sessions (time, duration, student, mentor, student rating, mentor rating).
-13. For every batch, store if it is an Academy-batch or a DSML-batch.
-
-Representation of schema doesn't matter. What matters is that you have all the tables needed to satisfy the requirements. Considering above requirements, how will you design a schema? Let's see the steps involved in creating the schema design.
-
-Steps:
-1. **Create the tables:** For this we need to identify the tables needed. To identify the tables,
- - Find all the nouns that are present in requirements.
- - For each noun, ask if you need to store data about that entity in your DB.
- - If yes, create the table; otherwise, move ahead.
-
- Here, such nouns are batches, instructors (if we just need to store instructor name then it will be a column in batches table. But if we need to store information about instructor then we need to make a separate table), students, classes, mentor, mentor session.
-
- Note that, a good convention about names:
-Name of a table should be plural, because it is storing multiple values. Eg. 'mentor_sessions'. Name of a column is singular and in snake-case.
-
-2. **Add primary key (id) and all the attributes** about that entity in all the tables created above.
-
- Expectation with the primary key is that:
- - It should rarely change. Because indexing is done on PK (primary key) and the data on disk is sorted according to PK. Hence, these are updated with every change in primary key.
- - It should ideally be a datatype which is easy to sort and has smaller size. Have a separate integer/big integer column called 'id' as a primary key. For eg. twitter's algorithm ([Snowflake](https://blog.twitter.com/engineering/en_us/a/2010/announcing-snowflake)) to generate the key (id) for every tweet.
- - A good convention to name keys is \\id. For example, 'batch_id'.
-
- Now, for writing attributes of each table, just see which attributes are of that entity itself. For `batches`, coulmns will be `name`, `start_month`. `current_instructor` will not be a column as we don't just want to store the name of current instructor but their details as well. So, it is not just one attribute, there will be a relation between `batches` and `instructors` table for this. So we will get these tables:
-
-`batches`
-| batch_id | name | start_month |
-|----------|------|-------------|
-
-`instructors`
-| instructor_id | name | email | avg_rating |
-|---------------|------|-------|------------|
-
-`students`
-| student_id | name | email | phone_number | grad_year | univ_name |
-|------------|------|-------|--------------|-----------|-----------|
-
-`classes`
-| class_id | name | schedule_time |
-|----------|------|---------------|
-
-`mentors`
-| mentor_id | name | company_name |
-|-----------|------|--------------|
-
-`mentor_sessions`
-| mentor_session_id | time | duration | student_rating | mentor_rating |
-|-------------------|------|----------|----------------|---------------|
-
-3. **Representing relations:** For understanding this step, we need to look into cardinality.
-
-## Cardinality
-
-When two entities are related to each other, there is a questions: how many of one are related to how many of the other.
-
-For example, for two tables students and batches, cardinality represents how many students are related to how many batches and vice versa.
-
-- 1:1 cardinality means 1 student belongs to only 1 batch and 1 batch has only 1 students.
-- 1:m cardinality means 1 student can belong to multiple batches and 1 batch has only 1 student.
-- m:1 cardinality means 1 student belongs to only 1 batch and 1 batch can have multiple students.
-- m:m cardinality means multiple students can belong to multiple batches, and vice versa.
-
-In cardinality, `1` means an entity can be associated to 1 instance at max, [0, 1]. `m` means an entity can be associated with zero or more instances, [0, 1, 2, ... inf]
-
-### Steps to calculate cardinality
-
-If you want to calculate relationship between `noun1` and `noun2`, then you can do the following:
- - *Step 1:* If you take one example of `noun2`, how many noun1 are related to this example object. Output : Either `1` or `many`
- - *Step 2:* If you take one example of `noun1`, how many noun2 are related to this example object. Output : Either `1` or `many`
-
-Take output from step1 (o1) and output from step2 (o2). o1:o2 is your relationship.
-
-Let's take an example.
-What is the cardinality between employee and department. Assume that an employee can be part of only one department.
-
- - Step 1: Example of department: Finance. How many employees can be part of Finance. Answer: **many**
- - Step 2: Example of employee: Sudhanshu. How many department can Sudhanshu be part of? Answer: **one**
-
-So, answer = **many-to-one**
-
-**Example 2:** What is the cardinality between ticket and seat in apps like bookMyShow?
-
-In one ticket, we can book multiple seats.
-One seat can be booked in only 1 ticket.
-
-So, the final cardinality between ticket and seat is **one-to-many**
-
-**Example 3:** Consider a monogamous community. What is the cardinality between husband and wife?
-
-| husband | --- married to --- | wife |
-| ------- | ------------------ | ---- |
-| 1 | > | 1 |
-| 1 | < | 1 |
-
-
-In a monogamous community, 1 man is married to 1 woman and vice versa. Hence, the cardinality is **one-to-one**
-
-**Example 4:** What is the cardinality between class and current instructor at Scaler?
-Answer: many-to-one
-
-## How to represent different cardinalities
-
-When we have a 1:1 cardinality, the `id` column of any one relation can be used as an attribute in another relation. It is not suggested to include the both the respective `id` column of the two relations in each other because it may cause update anomaly in future transactions.
-
-For 1:m and m:1 cardinalities, the `id` column of `1` side relation is included as an attribute in `m` side relation.
-
-For m:m cardinalities, create a new table called a **mapping table** or **lookup table** which stores the ids of both tables according to their associations.
-
-For example, for tables `orders` and `products` in previous quiz have m:m cardinality. So, we will create a new table `orders_products` to accomodate the relation between order ids and products ids.
-
-`orders_products`
-| order_id | product_id |
-| -------- | ---------- |
-| 1 | 1 |
-| 1 | 2 |
-| 1 | 3 |
-| 2 | 2 |
-| 2 | 4 |
-| 3 | 1 |
-| 3 | 5 |
-| 4 | 5 |
-
-
-We will cover case studies for the next class - applying the principles learnt.
diff --git a/docs/SQL/10-views-and-window-function.md b/docs/SQL/10-views-and-window-function.md
deleted file mode 100644
index 54a75c8a6..000000000
--- a/docs/SQL/10-views-and-window-function.md
+++ /dev/null
@@ -1,358 +0,0 @@
-# Views & window function
-
-## Agenda
-
- - Views
- - Window function
-
-## Views
-
-Imagine in sakillaDB, I frequently have queries of the following type:
- - Given an actor, give me the name of all films they have acted in.
- - Given a film, give me the name of all actors who have acted in it.
-
-Getting the above requires a join across 3 tables, `film`, `film_actor` and `actor`.
-
-Why is that an issue?
- - Writing these queries time after time is cumbersome. Infact imagine queries that are even more complex - requiring joins across a lot of tables with complex conditions. Writing those everytime with 100% accuracy is difficult and time-taking.
- - Not every team would understand the schema really well to pull data with ease. And understanding the entire schema for a large, complicated system would be hard and would slow down teams.
-
-So, what's the solution?
-Databases allow for creation of views. Think of views as an alias which when referred is replaced by the query you store with the view.
-
-So, a query like the following:
-
-```sql
-CREATE OR REPLACE view actor_film_name AS
-
-SELECT
- concat(a.first_name, a.last_name) AS actor_name,
- f.title AS file_name
-FROM actor a
- JOIN film_actor fa
- ON fa.actor_id = a.actor_id
- JOIN film f
- ON f.film_id = fa.film_id
-```
-
-
-**Note that a view is not a table.** It runs the query on the go, and hence data redundancy is not a problem.
-
-### Operating with views
-
-Once a view is created, you can use it in queries like a table. Note that in background the view is replaced by the query itself with view name as alias.
-Let's see with an example.
-
-```sql
-SELECT film_name FROM
-actor_film_name WHERE actor_name = "JOE SWANK"
-```
-
-OR
-
-```sql
-SELECT actor_name FROM
-actor_file_name WHERE film_name = "AGENT TRUMAN"
-```
-
-If you see, with views it's super simple to write queries that I write frequently. Lesser chances to make an error.
-Note that however, actor_file_name above is not a separate table but more of an alias.
-
-An easy way to understand that is that assume every occurrence of `actor_file_name` is replaced by
-
-```sql
-(SELECT
- concat(a.first_name, a.last_name) AS actor_name,
- f.title AS file_name
-FROM actor a
- JOIN film_actor fa
- ON fa.actor_id = a.actor_id
- JOIN film f
- ON f.film_id = fa.film_id) AS actor_file_name
-```
-
-**Caveat:** Certain DBMS natively support materialised views. Materialised views are views with a difference that the views also store results of the query. This means there is redundancy and can lead to inconsistency / performance concerns with too many views. But it helps drastically improve the performance of queries using views. MySQL for example does not support materialised views. Materialised views are tricky and should not be created unless absolutely necessary for
-performance.
-
-#### How to best leverage views
-
-Imagine there is an enterprise team at Scaler which helps with placements of the students.
-Should they learn about the entire Scaler schema? Not really. They are only concerned with student details, their resume, Module wise PSP, Module wise Mock Interview clearance, companies details and student status in the companies where they have applied.
-
-In such a case, can we create views which gets all of the information in 1 or 2 tables? If we can, then they need to only understand those 2 tables and can work with that.
-
-#### More operations on views
-
-**How to get all views in the database:**
-
-```sql
-SHOW FULL TABLES WHERE table_type = 'VIEW';
-```
-
-**Dropping a view**
-
-```sql
-DROP VIEW actor_file_name;
-```
-
-**Updating a view**
-
-```sql
-ALTER view actor_film_name AS
-
- SELECT
- concat(a.first_name, a.last_name) AS actor_name,
- f.title AS file_name
- FROM actor a
- JOIN film_actor fa
- ON fa.actor_id = a.actor_id
- JOIN film f
- ON f.film_id = fa.film_id
-```
-
-**Note:** Not recommended to run update on views to update the data in the underlying tables. Best practice to use views for reading information.
-
-**See the original create statement for a view**
-
-```sql
-SHOW CREATE TABLE actor_film_name
-```
-
-## Window Function
-
-Imagine you have an `employees` table with the following columns.
-
-```sql
-employees
-emp_no | department | salary
- 1 | Tech | 60,000
- 2 | Tech | 50,000
- 3 | HR | 40,000
- 4 | HR | 60,000
-```
-
-If I ask you to fetch the average salary for every department, what would you do?
-Yes, you would use a group_by to fetch the avg salary in a department.
-
-```sql
-SELECT department, AVG(salary)
-FROM employees
-GROUP BY department
-```
-
-which will print
-
-```
-department | AVG(salary)
- Tech | 55000
- HR | 50000
-```
-
-However, what if I ask you to print every row in the employees table along with the avg salary of the department.
-You can use WINDOW function for that. Window function is exactly like group by, just that it prints it's output for every row.
-
-**Syntax:**
-
-```sql
-SELECT
- emp_no,
- department,
- salary,
- AVG(salary) OVER (PARTITION BY department) AS dept_avg
-FROM employees
-```
-
-The term `OVER` indicates that I am using a window function.
-Just like group by, window function would need to define what is a group like. For that, it uses PARTITION BY. `PARTITION BY department` creates 2 groups/windows - one for Tech, one for HR.
-In each group, you calculate the aggregate function specified before `OVER`.
-
-So, the above query yields:
-
-```sql
-employees
-emp_no | department | salary | dept_avg
- 1 | Tech | 60,000 | 55000
- 2 | Tech | 50,000 | 55000
- 3 | HR | 40,000 | 50000
- 4 | HR | 60,000 | 50000
-```
-
-What happens if there is no Partition by? What's the group then?
-Correct. The entire table becomes the group.
-
-So, the following query:
-
-```sql
-SELECT
- emp_no,
- department,
- salary,
- AVG(salary) OVER () AS dept_avg
-FROM employees
-```
-
-yields
-
-
-```sql
-employees
-emp_no | department | salary | dept_avg
- 1 | Tech | 60,000 | 52500
- 2 | Tech | 50,000 | 52500
- 3 | HR | 40,000 | 52500
- 4 | HR | 60,000 | 52500
-```
-
-You can have multiple window function in the same SQL statement. For example, how do I print MAX, MIN and AVG salary in every department along with the employee?
-
-```sql
-SELECT
- emp_no,
- department,
- salary,
- AVG(salary) OVER (PARTITION BY department) AS dept_avg,
- MAX(salary) OVER (PARTITION BY department) AS dept_max,
- MIN(salary) OVER (PARTITION BY department) AS dept_min
-FROM employees
-```
-
-This would yield:
-
-```sql
-employees
-emp_no | department | salary | dept_avg | dept_max | dept_min
- 1 | Tech | 60,000 | 55000 | 60000 | 50000
- 2 | Tech | 50,000 | 55000 | 60000 | 50000
- 3 | HR | 40,000 | 50000 | 60000 | 40000
- 4 | HR | 60,000 | 50000 | 60000 | 40000
-```
-
-*You can have multiple window functions with different partition by in a SQL query. Just that it would do more work - twice as expensive. It would create different groups / windows in parallel and then calculate the aggregate value.*
-
-Window function also allows you to order entries in a certain order within a group / partition / window. For example, if I wanted that within a single department, entries are sorted based on salary in descending order, I can write:
-
-
-```sql
-SELECT
- emp_no,
- department,
- salary,
- AVG(salary) OVER (PARTITION BY department ORDER BY salary DESC) AS dept_avg
-FROM employees
-```
-
-which would yield:
-
-```sql
-employees
-emp_no | department | salary | dept_avg
- 1 | Tech | 60,000 | 55000
- 2 | Tech | 50,000 | 55000
- 4 | HR | 60,000 | 50000
- 3 | HR | 40,000 | 50000
-```
-
-### Aggregate function which work only with Window function.
-
-**RANK()** - Gives the rank of every entry in the group/window/partition it belongs to. It is recommended to specify a order by clause in window function when using rank(). Ranking is done based on the ordering of entries within a partitio.
-Imagine I wanted to print all employees along with their department rank based on salary.
-
-```sql
-SELECT
- emp_no,
- department,
- salary,
- RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS dept_rank
-FROM employees
-```
-
-which yields
-
-
-```sql
-employees
-emp_no | department | salary | dept_rank
- 1 | Tech | 60,000 | 1
- 2 | Tech | 50,000 | 2
- 4 | HR | 60,000 | 1
- 3 | HR | 40,000 | 2
-```
-
-In the absence of partition by, the entire table becomes one large group and hence salaries are ranked in the entire company.
-
-```sql
-SELECT
- emp_no,
- department,
- salary,
- RANK() OVER (ORDER BY salary DESC) AS company_rank
-FROM employees
-```
-
-yields
-
-
-```sql
-employees
-emp_no | department | salary | company_rank
- 1 | Tech | 60,000 | 1
- 4 | HR | 60,000 | 1
- 2 | Tech | 50,000 | 3
- 3 | HR | 40,000 | 4
-```
-
-Note that 2 entries with the same salary got the same rank. How do I know that I need to compare salaries (because that's whats specified in order by clause). Conflicting entries get the same rank. And next entry (after the duplicate/conflicting entries) gets a number which it would have gotten had the entries been different.
-If you want the next entry to get the next natural number, then you can use the **dense_rank()** function which works exactly like the rank() function with the only difference being how the next entry is assigned a rank in case of duplicate values.
-
-**DENSE_RANK()** - Explained above.
-
-**ROW_NUMBER()** - Imagine in the above rank() example, you don't want same ranks assigned to entries with the same value. In that case, you can use row_number().
-
-```sql
-SELECT
- emp_no,
- department,
- salary,
- ROW_NUMBER() OVER (ORDER BY salary DESC) AS company_rank
-FROM employees
-```
-
-yields
-
-```sql
-employees
-emp_no | department | salary | company_rank
- 1 | Tech | 60,000 | 1
- 4 | HR | 60,000 | 2
- 2 | Tech | 50,000 | 3
- 3 | HR | 40,000 | 4
-```
-
-
-**LAG(column) / LEAD(column)**: Imagine in the above context, I wanted to print the value from the previous row in the group, or the next row in the group, then I use the lead or lag functions.
-LAG(column) - As the name indicates, it prints the column value from the previous row in the group.
-LEAD(column) - column value from the next row in the group.
-For example, what if I wanted to print the next higher salary than me in the department (or the next lower) along with my rank.
-
-```sql
-SELECT
- emp_no,
- department,
- salary,
- RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS dept_rank,
- LAG(salary) OVER (PARTITION BY department ORDER BY salary DESC) AS next_higher_salary
-FROM employees
-```
-
-yields
-
-```sql
-employees
-emp_no | department | salary | dept_rank | next_higher_salary
- 1 | Tech | 60,000 | 1 | NULL
- 2 | Tech | 50,000 | 2 | 60000
- 4 | HR | 60,000 | 1 | NULL
- 3 | HR | 40,000 | 2 | 60000
-```
-
-
diff --git a/docs/SQL/SQL-Aggregrate-Function.md b/docs/SQL/SQL-Aggregrate-Function.md
deleted file mode 100644
index be2192684..000000000
--- a/docs/SQL/SQL-Aggregrate-Function.md
+++ /dev/null
@@ -1,90 +0,0 @@
----
-id: sql-aggregrate-function
-title: Aggregate Functions in SQL
-sidebar_label: Aggregate Functions
-sidebar_position: 9
-tags: [sql, database, functions]
-description: In this tutorial, you will learn how to Aggregate Functions in the SQL.
----
-
-SQL aggregate functions perform a calculation on a set of values and return a single value. They are commonly used with the GROUP BY clause of the SELECT statement.
-
-
-## The most commonly used SQL aggregate functions are:
-
-- MIN() - returns the smallest value within the selected column.
-- MAX() - returns the largest value within the selected column.
-- COUNT() - returns the number of rows in a set.
-- SUM() - returns the total sum of a numerical column.
-- AVG() - returns the average value of a numerical column.
-
-**Aggregate functions ignore null values (except for COUNT()).**
-Aggregate functions are often used with the GROUP BY clause of the SELECT statement. The GROUP BY clause splits the result-set into groups of values and the aggregate function can be used to return a single value for each group.
-
-## Advantages of SQL Aggregate Functions
-
-**1. Data Summarization**
-Aggregate functions allow you to summarize and gain insights from your data efficiently. For example, you can quickly find out the total sales, average price, or number of transactions.
-
-**2. Reduced Data Retrieval**
-Instead of retrieving and processing all individual records in an application, you can use aggregate functions to perform calculations directly in the database. This reduces the amount of data transferred and processed outside the database, improving performance.
-
-**3. Simplified Queries**
-Aggregate functions can simplify complex data analysis tasks. For example, calculating the average, sum, or maximum value in SQL is straightforward compared to doing the same in application code.
-
-**4. Improved Performance**
-Databases are optimized for executing aggregate functions, often using indexes and other internal mechanisms to perform calculations efficiently. This can result in better performance compared to processing data in the application layer.
-## Examples of Aggregate Function in SQL
-
-#### Count()
-Description : Counts the number of rows in a set.
-Syntax :
-```sql
-SELECT COUNT(*)
-FROM table_name;
-```
-#### SUM()
-
-- Description: Adds up the values in a numeric column.
-- Syntax :
-```sql
-SELECT SUM(column_name)
-FROM table_name;
-```
-### AVG()
-
-- Description: Calculates the average value of a numeric column.
-- Syntax :
-```sql
-SELECT AVG(column_name)
-FROM table_name;
-```
-### MIN()
-
-- Description: Returns the minimum value in a set.
-- Syntax :
-```sql
-SELECT MIN(column_name)
-FROM table_name;
-```
-### MAX()
-
-- Description: Returns the maximum value in a set.
-- Syntax :
-```sql
-SELECT MAX(column_name)
-FROM table_name;
-```
-
-## Conclusion
-SQL aggregate functions are powerful and efficient tools for data summarization, reporting, and analysis. They allow you to perform calculations directly within the database, which improves performance, simplifies queries, and reduces the amount of data transferred between the database and the application. By leveraging these functions, you can gain valuable insights from your data with minimal effort and enhanced performance, making them indispensable for any data-intensive application or analysis task. Whether you're calculating totals, averages, or other statistical measures, aggregate functions help you achieve your goals quickly and effectively.
-
----
-
-## Authors:
-
-
- {['Damini2004'].map(username => (
-
- ))}
-
diff --git a/docs/SQL/SQL-Between-Operator.md b/docs/SQL/SQL-Between-Operator.md
deleted file mode 100644
index 0cd2e3e06..000000000
--- a/docs/SQL/SQL-Between-Operator.md
+++ /dev/null
@@ -1,81 +0,0 @@
----
-id: sql-between-operator
-title: Between Operator in SQL
-sidebar_label: Between Operator
-sidebar_position: 10
-tags: [sql, database, operator]
-description: In this tutorial, you will learn how to Between Operator in the SQL.
----
-
-The BETWEEN operator in SQL is used to filter the result set within a certain range. It selects values within a given range, inclusive of the start and end values. The BETWEEN operator can be used with numeric values, text values, and dates.
-
-
-## Advantages of SQL Aggregate Functions
-
-**1. Readability and Simplicity**
-The BETWEEN operator makes SQL queries more readable and easier to write. Instead of using multiple comparison operators, you can express a range condition concisely.
-
-**2. Inclusive Range**
-The BETWEEN operator is inclusive, meaning it includes both the start and end values of the range. This simplifies the logic when you want to include boundary values in your results.
-
-**3. Versatility**
-The BETWEEN operator works with different data types, including numbers, dates, and strings, making it a versatile tool for various use cases.
-
-**4. Performance**
-In many cases, using the BETWEEN operator can be more efficient than using multiple AND conditions. Database engines often optimize range queries, especially if indexes are in place.
-
-### Examples
-**Numeric Range**
-Suppose you have a table named employees with a column salary and you want to select employees with a salary between 30000 and 50000.
-
-```
-sql
-SELECT * FROM employees
-WHERE salary BETWEEN 30000 AND 50000;```
-
-**Date Range**
- If you have a table named orders with a column order_date and you want to select orders placed between January 1, 2023, and June 30, 2023.
-
-```sql
-SELECT * FROM orders
-WHERE order_date BETWEEN '2023-01-01' AND '2023-06-30';
-```
-
-**Text Range**
-For a table named products with a column product_name, to select products with names between 'Apple' and 'Orange':
-
-```sql
-SELECT * FROM products
-WHERE product_name BETWEEN 'Apple' AND 'Orange';
-```
-
-
-#### Equivalent BETWEEN with Comparison Operators
-The BETWEEN operator can also be written using comparison operators:
-
-```sql
-SELECT * FROM employees
-WHERE salary >= 30000 AND salary <= 50000;
-```
-### Using NOT BETWEEN
-To select values outside a specified range, you can use the NOT BETWEEN operator.
-
-```sql
-SELECT * FROM employees
-WHERE salary NOT BETWEEN 30000 AND 50000;
-```
-### Combining with Other Conditions
-You can combine the BETWEEN operator with other conditions using AND or OR.
-
-```sql
-SELECT * FROM employees
-WHERE salary BETWEEN 30000 AND 50000 AND department_id = 10;
-```
-### Conclusion
-The BETWEEN operator enhances the clarity, conciseness, and efficiency of SQL queries when filtering data within a range. Its inclusive nature, versatility, and ease of maintenance make it a preferred choice for range-based conditions in SQL queries.
-
-
-
-
-
-
diff --git a/docs/SQL/SQL-Delete-Statement.md b/docs/SQL/SQL-Delete-Statement.md
deleted file mode 100644
index 00f7081e8..000000000
--- a/docs/SQL/SQL-Delete-Statement.md
+++ /dev/null
@@ -1,77 +0,0 @@
----
-id: sql-delete-statement
-title: Delete Statement in SQL
-sidebar_label: Where Clause
-sidebar_position: 8
-tags: [sql, database, statement]
-description: In this tutorial, you will learn how to delete the data,rows,colums,table in the SQL.
----
-
-The DELETE statement in SQL is used to remove one or more rows from a table. It is a Data Manipulation Language (DML) command, which means it is used to manage and modify the data within database tables. The DELETE statement allows for both targeted deletions, where specific rows are removed based on a condition, and bulk deletions, where multiple rows or even all rows in a table can be removed.
-
-
-## Syntax
-```sql
-DELETE FROM table_name
-WHERE condition;
-
-```
-
-## Advantages of SQL WHERE Clause
-
-**1.Targeted Data Removal:**
-The DELETE statement allows you to remove specific records based on conditions specified in the WHERE clause. This precision helps in maintaining data accuracy and relevance.
-
-**2.Flexibility:**
-You can delete one or multiple records using a single DELETE statement, depending on the criteria provided. This flexibility is useful for various data cleanup and maintenance tasks.
-
-**3.Conditional Deletion:**
-The DELETE statement supports complex conditions using logical operators, subqueries, and joins, allowing for sophisticated data removal strategies.
-
-**4.Maintaining Data Integrity:**
-By using transactions, you can ensure that deletions are only finalized if they meet certain conditions, preserving data integrity and allowing rollback in case of errors.
-
-**5.Improving Database Performance:**
-Regular use of the DELETE statement to remove outdated or irrelevant data can improve database performance by reducing the amount of data the database needs to handle.
-
-## Examples of Delete Statement in SQL
-
-#### Deleting a Single Record
-Description - To delete a specific record where id is 1:
-Example -
-```sql
-DELETE FROM employees
-WHERE id = 1;
-```
-### Deleting Multiple Records
-Description - To delete all employees in the 'Sales' department:
-Example -
-```sql
-DELETE FROM employees
-WHERE department = 'Sales';
-```
-### Deleting All Records
-Description - To delete all records from the employees table (but keep the table structure intact):
-Example -
-```sql
-DELETE FROM employees;
-```
-### Using Subqueries
-Description - You can use a subquery in the WHERE clause to specify records to delete. For example, deleting employees who have a low performance score from another table:
-Example -
-```sql
-DELETE FROM employees
-WHERE id IN (SELECT employee_id FROM performance WHERE score < 50);
-```
-## Conclusion
-The DELETE statement is a fundamental command in SQL for removing data from tables. It provides flexibility to delete specific records based on conditions, and it can handle both small-scale and large-scale deletions. However, it must be used with caution to avoid unintentional data loss. Using the WHERE clause, transactions, and backup strategies ensures that deletions are performed safely and effectively, maintaining the integrity and reliability of the database.
-
----
-
-## Authors:
-
-
- {['Damini2004'].map(username => (
-
- ))}
-
diff --git a/docs/SQL/SQL-Inner-Join.md b/docs/SQL/SQL-Inner-Join.md
deleted file mode 100644
index e36953f0b..000000000
--- a/docs/SQL/SQL-Inner-Join.md
+++ /dev/null
@@ -1,88 +0,0 @@
----
-id: sql-inner-join
-title: Inner Join in SQL
-sidebar_label: Inner Join
-sidebar_position: 14
-tags: [sql, database, operation]
-description: In this tutorial, we will learn about inner joins in sql.
----
-
-## What is an inner join?
-An inner join of 2 tables, say table_1 and table_2 on a column would return all rows with same values in common columns.An inner join may or may not have an 'on' clause. An inner join without an 'on' clause returns the cross join of the tables.
-
-## Syntax
-
-```sql
-select *
-from table_1 inner join table_2
-on table_1.col=table_2.col;
-```
-
-##### Note that the columns of table_1 and table_2 in the on clause must be the same attribute.
-
-## Example
-
-Consider the following tables:
-
-```sql
-select * from students;
-+---------+-----------+
-| stud_id | stud_name |
-+---------+-----------+
-| 101 | Shreeya |
-| 102 | Aakash |
-| 103 | Mansi |
-| 104 | Aditya |
-+---------+-----------+
-
- select * from grades;
-+---------+-------+
-| stud_id | grade |
-+---------+-------+
-| 101 | A |
-| 104 | A+ |
-+---------+-------+
-```
-
-Now , lets try to obtain a result using inner join with and without the on clause.
-
-##### With 'on' clause:
-```sql
-select s.stud_id, s.stud_name, g.grade
-from students s inner join grades g
-on s.stud_id=g.stud_id;
-
-Output:
-+---------+-----------+-------+
-| stud_id | stud_name | grade |
-+---------+-----------+-------+
-| 101 | Shreeya | A |
-| 104 | Aditya | A+ |
-+---------+-----------+-------+
-```
-We can observe that only the rows with matching values in common column (stud_id) are returned.
-
-##### Without 'on' clause:
-```sql
-select s.stud_id, s.stud_name, g.grade
-from students s inner join grades g;
-
-Output:
-+---------+-----------+-------+
-| stud_id | stud_name | grade |
-+---------+-----------+-------+
-| 101 | Shreeya | A |
-| 101 | Shreeya | A+ |
-| 102 | Aakash | A |
-| 102 | Aakash | A+ |
-| 103 | Mansi | A |
-| 103 | Mansi | A+ |
-| 104 | Aditya | A |
-| 104 | Aditya | A+ |
-+---------+-----------+-------+
-```
-Here we can see that the output is the cross join of both the tables.
-
-## Conclusion
-In this tutorial, we learnt how to use the inner join with and without the 'on' clause.
-Inner joins are used when we want to retrieve all the rows with same values in common column(s).
\ No newline at end of file
diff --git a/docs/SQL/SQL-Insert-Into.md b/docs/SQL/SQL-Insert-Into.md
deleted file mode 100644
index f9c8f7799..000000000
--- a/docs/SQL/SQL-Insert-Into.md
+++ /dev/null
@@ -1,96 +0,0 @@
----
-id: sql-not-operator
-title: Not Operator in SQL
-sidebar_label: Not Operator
-sidebar_position: 5
-tags: [sql, database, operator]
-description: In this tutorial, you will learn how to build queries with Negations to get the desired output.
----
-
-
-In SQL, the NOT operator is used to negate a condition in a WHERE clause or other SQL statement. Its primary function is to reverse the logical meaning of the condition that follows it.
-
-## Syntax
-```sql
-SELECT column1, column2, ...
-FROM table_name
-WHERE NOT condition;
-
-```
-
-## Operators Used in the WHERE Clause
-1. `=` : Equal
-2. `>` : Greater than
-3. `<` : Less than
-4. `>=` : Greater than or equal
-5. `<=` : Less than or equal
-6. `<>` : Not equal (Note: In some versions of SQL, this operator may be written as `!=`)
-7. `BETWEEN` : Between a certain range
-8. `LIKE` : Search for a pattern
-9. `IN` : To specify multiple possible values for a column
-
-## Advantages of SQL WHERE Clause
-
-**1.Enhanced Query Flexibility:**
-- Allows for the creation of more complex and precise queries by enabling the exclusion of specific conditions.
-- Facilitates the implementation of complex logical expressions by negating conditions.
-**2.Filtering Specific Data:**
-- Useful for filtering out unwanted records from query results. For example, it can be used to exclude records that meet certain criteria, such as records with a specific status or value.
-- Helps in scenarios where you need to select records that do not match a particular condition, enhancing the specificity of your data retrieval.
-**3.Handling NULL Values:**
-- Effective in checking for non-NULL values in a dataset. Using NOT NULL helps in ensuring data completeness and integrity by filtering out rows with missing values.
-- For instance, WHERE column IS NOT NULL is a common usage pattern to exclude rows with NULL values from the results.
-**4.Simplifying Logical Expressions:**
-- Allows for straightforward negation of conditions, making SQL queries easier to read and understand.
-- By using NOT, you can avoid complex nested conditions, making the query logic clearer.
-**5.Compatibility with Other SQL Operators:**
-- Works seamlessly with other SQL logical operators such as AND and OR, enabling the construction of more refined and targeted queries.
-- Enhances the expressiveness of SQL statements when combined with these operators.
-
-## Examples of Not Operator in SQL
-
-### NOT LIKE
-```sql
-SELECT * FROM Customers
-WHERE CustomerName NOT LIKE 'A%';
-```
-
-### NOT BETWEEN
-```sql
-SELECT * FROM Customers
-WHERE CustomerID NOT BETWEEN 10 AND 60;
-```
-
-### NOT IN
-```sql
-SELECT * FROM Customers
-WHERE City NOT IN ('Paris', 'London');
-```
-
-### NOT Greater Than
-```sql
-SELECT * FROM Customers
-WHERE NOT CustomerID > 50;
-```
-
-### NOT Less Than
-```sql
-SELECT * FROM Customers
-WHERE NOT CustomerId < 50;
-```
-
-
-## Conclusion
-The NOT operator in SQL provides a straightforward way to negate conditions in SQL queries, allowing for more flexible and precise data retrieval. Understanding its usage is crucial for crafting effective SQL statements, particularly when dealing with complex filtering requirements.
-
----
-
-## Authors:
-
-
- {['Damini2004'].map(username => (
-
- ))}
-
-
-
diff --git a/docs/SQL/SQL-Joins.md b/docs/SQL/SQL-Joins.md
deleted file mode 100644
index 71d68df40..000000000
--- a/docs/SQL/SQL-Joins.md
+++ /dev/null
@@ -1,62 +0,0 @@
----
-id: sql-joins
-title: Joins in SQL
-sidebar_label: Joins
-sidebar_position: 11
-tags: [sql, database, operation]
-description: In this tutorial, you will learn how to Joins in the SQL.
----
-
-Understanding and effectively using SQL joins can be challenging for many users. This often leads to inefficient queries or incorrect data retrieval, causing frustration and hindering productivity.
-
-### Syntax
-```sql
-SELECT columns
-FROM table1
-INNER JOIN table2
-ON table1.common_column = table2.common_column;
-```
-
-## Advantages of SQL Aggregate Functions
-
-**1. Readability and Simplicity**
-The BETWEEN operator makes SQL queries more readable and easier to write. Instead of using multiple comparison operators, you can express a range condition concisely.
-
-**2. Inclusive Range**
-The BETWEEN operator is inclusive, meaning it includes both the start and end values of the range. This simplifies the logic when you want to include boundary values in your results.
-
-**3. Versatility**
-The BETWEEN operator works with different data types, including numbers, dates, and strings, making it a versatile tool for various use cases.
-
-**4. Performance**
-In many cases, using the BETWEEN operator can be more efficient than using multiple AND conditions. Database engines often optimize range queries, especially if indexes are in place.
-
-### Types of Joins
-**1.Right Join**
-A RIGHT JOIN returns all rows from the right table (table2) and the matched rows from the left table (table1). If no match is found, NULL values are returned for columns from the left table.
-
-
-**2.Left Join**
-A LEFT JOIN returns all rows from the left table (table1) and the matched rows from the right table (table2). If no match is found, NULL values are returned for columns from the right table.
-
-**3.Inner Join**
-An INNER JOIN returns rows that have matching values in both tables.
-**4.Full Join**
-A FULL JOIN returns all rows when there is a match in either table. If there is no match, the result is NULL on the side where there is no match.
-
-
-
-### Conclusion
-Joins are fundamental in SQL for combining data from multiple tables. Understanding the different types of joins and their use cases is essential for effective database querying and data manipulation.
-
-
-
-
-
-
-
-
-
-
-
-
diff --git a/docs/SQL/SQL-Left-Join.md b/docs/SQL/SQL-Left-Join.md
deleted file mode 100644
index fc6d4a5e5..000000000
--- a/docs/SQL/SQL-Left-Join.md
+++ /dev/null
@@ -1,68 +0,0 @@
----
-id: sql-left-join
-title: Left Join in SQL
-sidebar_label: Left Join
-sidebar_position: 13
-tags: [sql, database, operation]
-description: In this tutorial, we will learn about left joins in sql.
----
-
-## What is a left join?
-A left join of two tables, say table 1 and table 2, would return all the rows from the left table and matched values from table 2. If for a particular row in table 1 there is no matching entry in table 2, 'null' is returned.
-
-## Syntax
-
-```sql
-select *
-from table_1 left join table_2
-on table_1.col=table_2.col;
-```
-
-##### Note that the columns of table_1 and table_2 in the on clause must be the same attribute.
-
-## Example
-
-Consider the following tables:
-
-```sql
-select * from students;
-+---------+-----------+
-| stud_id | stud_name |
-+---------+-----------+
-| 101 | Shreeya |
-| 102 | Aakash |
-| 103 | Mansi |
-| 104 | Aditya |
-+---------+-----------+
-
- select * from grades;
-+---------+-------+
-| stud_id | grade |
-+---------+-------+
-| 101 | A |
-| 104 | A+ |
-+---------+-------+
-```
-
-Now , lets try to obtain a result using left join.
-
-```sql
-select s.stud_id, s.stud_name, g.grade
-from students s left outer join grades g
-on s.stud_id=g.stud_id;
-
-Output:
-+---------+-----------+-------+
-| stud_id | stud_name | grade |
-+---------+-----------+-------+
-| 101 | Shreeya | A |
-| 102 | Aakash | NULL |
-| 103 | Mansi | NULL |
-| 104 | Aditya | A+ |
-+---------+-----------+-------+
-```
-Here we can see that the output contains the entry of student id's 102 and 103 even though they are not assigned any grade, i.e., they are not present in the 'grades' table.
-
-## Conclusion
-In this tutorial, we learnt how to use the left outer join with an example.
-Left outer joins are used when we want to retrieve all the rows from the left(1st) table, irrespective of it being in the right(2nd) table.
\ No newline at end of file
diff --git a/docs/SQL/SQL-Not-Operator.md b/docs/SQL/SQL-Not-Operator.md
deleted file mode 100644
index 1e6e8f997..000000000
--- a/docs/SQL/SQL-Not-Operator.md
+++ /dev/null
@@ -1,101 +0,0 @@
----
-id: not-operator-in-sql
-title: Not Operator in SQL
-sidebar_label: Not Operator
-sidebar_position: 5
-tags: [sql, database, operator]
-description: In this tutorial, you will learn how to build queries with Negations to get the desired output.
----
-
-In SQL, the NOT operator is used to negate a condition in a WHERE clause or other SQL statement. Its primary function is to reverse the logical meaning of the condition that follows it.
-
-## Syntax
-
-```sql
-SELECT column1, column2, ...
-FROM table_name
-WHERE NOT condition;
-
-```
-
-## Operators Used in the WHERE Clause
-
-1. `=` : Equal
-2. `>` : Greater than
-3. `<` : Less than
-4. `>=` : Greater than or equal
-5. `<=` : Less than or equal
-6. `<>` : Not equal (Note: In some versions of SQL, this operator may be written as `!=`)
-7. `BETWEEN` : Between a certain range
-8. `LIKE` : Search for a pattern
-9. `IN` : To specify multiple possible values for a column
-
-## Advantages of SQL WHERE Clause
-
-**1.Enhanced Query Flexibility:**
-
-- Allows for the creation of more complex and precise queries by enabling the exclusion of specific conditions.
-- Facilitates the implementation of complex logical expressions by negating conditions.
- **2.Filtering Specific Data:**
-- Useful for filtering out unwanted records from query results. For example, it can be used to exclude records that meet certain criteria, such as records with a specific status or value.
-- Helps in scenarios where you need to select records that do not match a particular condition, enhancing the specificity of your data retrieval.
- **3.Handling NULL Values:**
-- Effective in checking for non-NULL values in a dataset. Using NOT NULL helps in ensuring data completeness and integrity by filtering out rows with missing values.
-- For instance, WHERE column IS NOT NULL is a common usage pattern to exclude rows with NULL values from the results.
- **4.Simplifying Logical Expressions:**
-- Allows for straightforward negation of conditions, making SQL queries easier to read and understand.
-- By using NOT, you can avoid complex nested conditions, making the query logic clearer.
- **5.Compatibility with Other SQL Operators:**
-- Works seamlessly with other SQL logical operators such as AND and OR, enabling the construction of more refined and targeted queries.
-- Enhances the expressiveness of SQL statements when combined with these operators.
-
-## Examples of Not Operator in SQL
-
-### NOT LIKE
-
-```sql
-SELECT * FROM Customers
-WHERE CustomerName NOT LIKE 'A%';
-```
-
-### NOT BETWEEN
-
-```sql
-SELECT * FROM Customers
-WHERE CustomerID NOT BETWEEN 10 AND 60;
-```
-
-### NOT IN
-
-```sql
-SELECT * FROM Customers
-WHERE City NOT IN ('Paris', 'London');
-```
-
-### NOT Greater Than
-
-```sql
-SELECT * FROM Customers
-WHERE NOT CustomerID > 50;
-```
-
-### NOT Less Than
-
-```sql
-SELECT * FROM Customers
-WHERE NOT CustomerId < 50;
-```
-
-## Conclusion
-
-The NOT operator in SQL provides a straightforward way to negate conditions in SQL queries, allowing for more flexible and precise data retrieval. Understanding its usage is crucial for crafting effective SQL statements, particularly when dealing with complex filtering requirements.
-
----
-
-## Authors:
-
-
- {['Damini2004'].map(username => (
-
- ))}
-
diff --git a/docs/SQL/SQL-OR-Operator.md b/docs/SQL/SQL-OR-Operator.md
deleted file mode 100644
index a8607f0aa..000000000
--- a/docs/SQL/SQL-OR-Operator.md
+++ /dev/null
@@ -1,47 +0,0 @@
----
-id: sql-or-operator
-title: OR Operator in SQL
-sidebar_label: OR Operator
-sidebar_position: 5
-tags: [sql, database, operator ]
-description: In this tutorial, you will learn how to add OR operator in the query to get desired output.
----
-
-The OR operator in SQL is used to combine multiple conditions in a WHERE clause, returning rows that satisfy at least one of the conditions specified.
-
-# Syntax
-`SELECT column1, column2, ... FROM table_name WHERE condition1 OR condition2 OR condition3 ...;`
-
-# Advantage of SQL WHERE Clause
-
-**1.Order of Evaluation:**
-SQL evaluates conditions combined with AND before those combined with OR. Use parentheses to explicitly define the order of evaluation.
-
-**2.Performance:**
-The performance of queries using OR can be influenced by the presence of indexes on the columns involved in the conditions. Proper indexing can significantly speed up query execution.
-
-# Example of Order By Clause in SQL
-
-**1.Selecting rows based on multiple conditions:**
-- Example : `SELECT * FROM Employees WHERE Age < 25 OR Department = 'HR';`
-- Description : Suppose you have a table called Employees with columns EmployeeID, FirstName, LastName, Age, and Department.This query selects all employees who are either younger than 25 or work in the HR department.
-
-**2.Using OR with other operators:**
-- Example : `SELECT * FROM Employees WHERE Age < 25 OR Age > 50 OR Department = 'Sales';`
-- Description : You can combine OR with other comparison operators like `=`, `!=`, `<`, `>`, `<=`, `>=`.This query selects all employees who are either younger than 25, older than 50, or work in the Sales department.
-
-**3.Combining OR with AND:**
-- Example : `SELECT * FROM Employees WHERE (Age < 25 AND Department = 'Marketing') OR (Age > 50 AND Department = 'Sales');`
-- Descriptiom : When combining OR with AND, you often use parentheses to ensure the correct order of evaluation.This query selects employees who are either younger than 25 and work in Marketing or older than 50 and work in Sales.
-
-# Conclusion
-The OR operator in SQL is essential for retrieving rows that meet at least one of several conditions within a WHERE clause. Understanding and effectively using the OR operator enhances your ability to filter data according to complex criteria. Proper use of parentheses ensures the correct logical evaluation, and indexing relevant columns can improve query performance. For further insights, refer to the documentation specific to your SQL database system.
-
-
-## Authors:
-
-
diff --git a/docs/SQL/SQL-Right-Join.md b/docs/SQL/SQL-Right-Join.md
deleted file mode 100644
index 3a1315241..000000000
--- a/docs/SQL/SQL-Right-Join.md
+++ /dev/null
@@ -1,53 +0,0 @@
----
-id: sql-Right-join
-title: Right Join in SQL
-sidebar_label: Right Join
-sidebar_position: 12
-tags: [sql, database, operation]
-description: In this tutorial, you will learn how to build queries with Right Join to get the desired output.
----
-
-Certainly! A RIGHT JOIN (or RIGHT OUTER JOIN) in SQL is used to return all rows from the right table (table2), and the matched rows from the left table (table1). If there is no match, NULL values are returned for columns from the left table.
-
-### Syntax
-```sql
-SELECT columns
-FROM table1
-RIGHT JOIN table2
-ON table1.common_column = table2.common_column;
-```
-### Example
-Consider two tables, employees and departments:
-
-**employees Table:**
-employee_id name department_id
-1 John 10
-2 Jane 20
-3 Mike 30
-**departments Table:**
-department_id department_name
-10 HR
-20 Finance
-40 Marketing
-
-To perform a RIGHT JOIN to get all departments and their corresponding employees:
-
-```sql
-SELECT employees.employee_id, employees.name, departments.department_name
-FROM employees
-RIGHT JOIN departments
-ON employees.department_id = departments.department_id;
-```
-**Result:**
-employee_id name department_name
-1 John HR
-2 Jane Finance
-NULL NULL Marketing
-
-**Explanation**
-- Row 1: The employee with ID 1 (John) works in the HR department.
-- Row 2: The employee with ID 2 (Jane) works in the Finance department.
-- Row 3: There are no employees assigned to the Marketing department, so NULL values are returned for employee_id and name.
-
-### Conclusion
-A RIGHT JOIN retrieves all records from the right table (table2) and matched records from the left table (table1). It ensures that every row from the right table is returned, even if there are no matching rows in the left table, in which case NULL values are used. This type of join is useful when you want to include all records from the right table, ensuring no data is left out from that side of the join operation.
diff --git a/docs/SQL/SQL-Update-Statement.md b/docs/SQL/SQL-Update-Statement.md
deleted file mode 100644
index a76f71b66..000000000
--- a/docs/SQL/SQL-Update-Statement.md
+++ /dev/null
@@ -1,100 +0,0 @@
----
-id: sql-update-statement
-title: Update Statement
-sidebar_label: Update Statement
-sidebar_position: 7
-tags: [sql, database, statement]
-description: In this tutorial, you will learn how to Update the data into the database.
----
-
-
-The UPDATE statement in SQL is used to modify the existing records in a table. Below is a comprehensive overview of the UPDATE statement, including syntax, usage, and examples.
-
-
-## Syntax
-```sql
-UPDATE table_name
-SET column1 = value1, column2 = value2, ...
-WHERE condition;
-
-
-```
-
-## Advantages of SQL Update into Statement
-
-**1.Efficient Data Modification:**
-The UPDATE statement allows you to efficiently modify existing records without the need to delete and reinsert them. This can save time and reduce the risk of errors.
-
-**2.Targeted Updates:**
-You can update specific records using the WHERE clause, ensuring that only the desired rows are affected. This precision helps maintain data integrity and prevents unintended changes.
-
-**3.Bulk Updates:**
-The UPDATE statement can be used to modify multiple records at once, which is particularly useful for batch updates and maintaining large datasets.
-
-**4.Conditional Updates:**
-With the WHERE clause, you can apply conditions to update only those records that meet certain criteria. This flexibility allows for dynamic and context-specific data modifications.
-
-**5.Use of Expressions and Functions:**
-You can incorporate SQL expressions and functions in the SET clause to perform complex updates. For example, you can calculate new values based on existing data.
-
-## Examples of Update Into in SQL
-
-### Updating a Single Column
-Description - Let's assume we have a table called employees with the following columns: id, name, position, and salary.
-To update the salary of an employee with id 1:
-Example -
-```sql
-UPDATE employees
-SET salary = 75000
-WHERE id = 1;
-```
-
-### Updating Multiple Columns
-Description - To update both the position and salary of an employee with id 2:
-Example -
-```sql
-UPDATE employees
-SET position = 'Senior Data Analyst', salary = 70000
-WHERE id = 2;
-```
-### Updating Multiple Rows
-Description - To increase the salary of all employees in the 'Sales' department by 5000:
-Example -
-```sql
-UPDATE employees
-SET salary = salary + 5000
-WHERE department = 'Sales';
-```
-### Updating All Rows
-Description - To set the default department to 'General' for all employees:
-
-Example -
-```sql
-UPDATE employees
-SET department = 'General';
-```
-
-Note: Be careful when omitting the WHERE clause, as this will update all rows in the table.
-
-### Conditional Update Using Subquery
-Description - To update the salary of employees based on their performance score stored in another table:
-Example -
-
-```sql
-UPDATE employees
-SET salary = salary + 5000
-WHERE id IN (SELECT employee_id FROM performance WHERE score > 90);
-```
-
-## Conclusion
-In conclusion, the UPDATE statement in SQL is a powerful and essential tool for database management. Its advantages include efficient data modification, targeted updates, the ability to handle bulk and conditional updates, and the use of expressions and functions to perform complex operations. The UPDATE statement also enhances data consistency and integrity, improves performance, and is easy to use, making it a fundamental part of any database administrator's toolkit.
----
-
-## Authors:
-
-
- {['Damini2004'].map(username => (
-
- ))}
-
-Footer
diff --git a/docs/SQL/SQL-Where-Clause.md b/docs/SQL/SQL-Where-Clause.md
deleted file mode 100644
index 047e38456..000000000
--- a/docs/SQL/SQL-Where-Clause.md
+++ /dev/null
@@ -1,86 +0,0 @@
----
-id: sql-where-clause
-title: Where Clause in SQL
-sidebar_label: Where Clause
-sidebar_position: 3
-tags: [sql, database, clause]
-description: In this tutorial, you will learn how to build queries with conditions to get the desired output.
----
-
-The WHERE clause in SQL is used to filter records from a result set. It specifies the conditions that must be met for the rows to be included in the result. The WHERE clause is often used in SELECT, UPDATE, DELETE, and other SQL statements to narrow down the data returned or affected.
-
-## Syntax
-```sql
-SELECT column1, column2, ...
-FROM table_name
-WHERE condition;
-```
-
-## Operators Used in the WHERE Clause
-1. `=` : Equal
-2. `>` : Greater than
-3. `<` : Less than
-4. `>=` : Greater than or equal
-5. `<=` : Less than or equal
-6. `<>` : Not equal (Note: In some versions of SQL, this operator may be written as `!=`)
-7. `BETWEEN` : Between a certain range
-8. `LIKE` : Search for a pattern
-9. `IN` : To specify multiple possible values for a column
-
-## Advantages of SQL WHERE Clause
-
-1. **Filtering Rows:** The WHERE clause evaluates each row in the table to determine if it meets the specified condition(s). Only rows that satisfy the condition are included in the result set.
-2. **Conditions:** Conditions in the WHERE clause can use comparison operators like `=`, `<>` (not equal), `>`, `<`, `>=`, `<=`. Logical operators such as `AND`, `OR`, and `NOT` can be used to combine multiple conditions.
-3. **Pattern Matching:** The LIKE operator can be used for pattern matching. For example, `LIKE 'A%'` matches any string that starts with the letter 'A'.
-4. **Range Checks:** The BETWEEN operator checks if a value is within a range of values. For example, `BETWEEN 10 AND 20`.
-5. **Null Values:** The `IS NULL` and `IS NOT NULL` operators are used to filter records with null values.
-
-## Examples of WHERE Clause in SQL
-
-### Basic Select Query
-```sql
-SELECT * FROM Students WHERE marks > 50;
-```
-
-### WHERE Clause in UPDATE Statement
-```sql
-UPDATE employees SET salary = salary * 1.10
-WHERE performance_rating = 'Excellent';
-```
-
-### WHERE Clause in DELETE Statement
-```sql
-DELETE FROM employees
-WHERE last_login < '2023-01-01';
-```
-
-### WHERE Clause with LIKE Statement
-```sql
-SELECT * FROM customers
-WHERE name LIKE 'J%';
-```
-
-### WHERE Clause with BETWEEN Statement
-```sql
-SELECT * FROM orders
-WHERE order_date BETWEEN '2023-01-01' AND '2023-12-31';
-```
-
-### WHERE Clause with IS NULL Statement
-```sql
-SELECT * FROM employees
-WHERE manager_id IS NULL;
-```
-
-## Conclusion
-The WHERE clause in SQL is a powerful tool for filtering data in various SQL statements. It allows you to specify conditions that rows must meet to be included in the result set, thereby enabling precise data retrieval and manipulation. By using comparison operators, logical operators, pattern matching, range checks, and handling null values, you can create complex queries tailored to your specific data requirements. Mastering the WHERE clause is essential for efficient database management and analysis, providing the ability to focus on relevant data and perform targeted updates and deletions.
-
----
-
-## Authors:
-
-
diff --git a/docs/SQL/_category_.json b/docs/SQL/_category_.json
deleted file mode 100644
index a60eafbfd..000000000
--- a/docs/SQL/_category_.json
+++ /dev/null
@@ -1,8 +0,0 @@
-{
- "label": "SQL",
- "position": 24,
- "link": {
- "type": "generated-index",
- "description": "in this tutorial you will learn about SQL "
- }
-}
\ No newline at end of file
diff --git a/docs/SQL/image-1.png b/docs/SQL/image-1.png
deleted file mode 100644
index 4ce468609..000000000
Binary files a/docs/SQL/image-1.png and /dev/null differ
diff --git a/docs/SQL/index.md b/docs/SQL/index.md
deleted file mode 100644
index ee0168731..000000000
--- a/docs/SQL/index.md
+++ /dev/null
@@ -1,372 +0,0 @@
-# Introduction to SQL
-
-SQL (Structured Query Language) is a powerful language used for managing and manipulating relational databases. Developed initially in the 1970s, SQL has become the standard language for interacting with databases across various platforms and environments. It provides a structured approach to defining, querying, updating, and managing data stored in relational database management systems (RDBMS) such as MySQL, PostgreSQL, Oracle, SQL Server, and SQLite.
-
-SQL operates through a set of declarative commands that enable users to perform essential operations such as retrieving data with `SELECT` statements, inserting new records with `INSERT INTO`, updating existing records with `UPDATE`, and deleting records with `DELETE FROM`. These commands form the foundation for creating, modifying, and maintaining database schemas and ensuring data integrity.
-
-Beyond basic CRUD (Create, Read, Update, Delete) operations, SQL supports advanced capabilities including:
-
-- **Aggregation functions** (`SUM`, `AVG`, `COUNT`, etc.) for data analysis
-- **Joins** to combine data from multiple tables
-- **Transaction management** for ensuring data consistency and reliability
-- **Indexing** for optimizing query performance
-- **Views, stored procedures, and triggers** for encapsulating complex logic within the database
-
-SQL’s versatility and standardized syntax make it indispensable in various domains such as software development, data analysis, business intelligence, and system administration. Its ability to handle both simple and complex queries efficiently makes SQL a cornerstone of modern data management practices.
-
-# Wide Operations in SQL
-
-## Data Retrieval
-- **Retrieve specific data from databases using `SELECT` statements.**
-
-## Data Manipulation
-- **Insert, update, and delete records with `INSERT INTO`, `UPDATE`, and `DELETE` statements.**
-
-## Data Definition
-- **Define and modify database schemas, tables, indexes, and constraints.**
-
-## Advanced Capabilities
-- **Joins**: Combine data from multiple tables using `INNER JOIN`, `LEFT JOIN`, etc.
-- **Aggregation**: Perform calculations on grouped data using functions like `SUM`, `AVG`, `COUNT`, etc.
-- **Transactions**: Ensure data consistency and integrity by grouping operations into atomic units.
-- **Stored Procedures and Functions**: Store and execute reusable procedural logic directly in the database.
-
-## SQL Commands
-
-### Extract and Transform Data
-- **SELECT**: Extracts data from a database.
- - **Syntax**:
- ```sql
- SELECT column1, column2, ... FROM table_name;
- ```
- - **Example**:
- ```sql
- SELECT * FROM Customers;
- ```
-
-### Modify Existing Data
-- **UPDATE**: Updates data in a database.
- - **Syntax**:
- ```sql
- UPDATE table_name
- SET column1 = value1, column2 = value2, ...
- WHERE condition;
- ```
- - **Example**:
- ```sql
- UPDATE Customers
- SET ContactName = 'Alfred Schmidt'
- WHERE CustomerID = 1;
- ```
-
-### Remove Unnecessary Data
-- **DELETE**: Deletes data from a database.
- - **Syntax**:
- ```sql
- DELETE FROM table_name
- WHERE condition;
- ```
- - **Example**:
- ```sql
- DELETE FROM Customers
- WHERE CustomerID = 1;
- ```
-
-### Add New Entries
-- **INSERT INTO**: Inserts new data into a database.
- - **Syntax**:
- ```sql
- INSERT INTO table_name (column1, column2, column3, ...)
- VALUES (value1, value2, value3, ...);
- ```
- - **Example**:
- ```sql
- INSERT INTO Customers (CustomerName, ContactName)
- VALUES ('Cardinal', 'Tom B. Erichsen');
- ```
-
-### Database Management
-- **CREATE DATABASE**: Creates a new database.
- - **Syntax**:
- ```sql
- CREATE DATABASE database_name;
- ```
- - **Example**:
- ```sql
- CREATE DATABASE myDatabase;
- ```
-
-- **ALTER DATABASE**: Modifies a database.
- - **Syntax**:
- ```sql
- ALTER DATABASE database_name [MODIFY
 -
-
-## Theory
-
-### Bayes' Theorem
-
-The foundation of Naive Bayes is Bayes' theorem, which describes the probability of an event based on prior knowledge of conditions that might be related to the event.
-
-
-$$ P(A|B) = \frac{P(B|A) \cdot P(A)}{P(B)} $$
-
-Where:
-- $P(A|B)$ is the posterior probability
-- $P(B|A)$ is the likelihood
-- $P(A)$ is the prior probability
-- $P(B)$ is the marginal likelihood
-
-
-
-
-## Theory
-
-### Bayes' Theorem
-
-The foundation of Naive Bayes is Bayes' theorem, which describes the probability of an event based on prior knowledge of conditions that might be related to the event.
-
-
-$$ P(A|B) = \frac{P(B|A) \cdot P(A)}{P(B)} $$
-
-Where:
-- $P(A|B)$ is the posterior probability
-- $P(B|A)$ is the likelihood
-- $P(A)$ is the prior probability
-- $P(B)$ is the marginal likelihood
-
- -
-
-### Naive Bayes Classifier
-
-The Naive Bayes classifier extends this to classify data points into categories. It assumes that the presence of a particular feature in a class is unrelated to the presence of any other feature (the "naive" assumption).
-
-For a data point $X = (x_1, x_2, ..., x_n)$ and a class variable :
-
-$$ P(C|X) = \frac{P(X|C) \cdot P(C)}{P(X)} $$
-
-The classifier chooses the class with the highest posterior probability:
-
-$$ C^* = \underset{c \in C}{argmax} P(X|c) \cdot P(c) $$
-
-### Mathematical Formulation
-
-For a given set of features $(x_1, x_2, ..., x_n)$:
-
-$$ P(C|x_1, x_2, ..., x_n) \propto P(C) \cdot P(x_1|C) \cdot P(x_2|C) \cdot ... \cdot P(x_n|C) $$
-
-Where:
-- $P(C|x_1, x_2, ..., x_n)$ is the posterior probability of class $C$ given the features
-- $P(C)$ is the prior probability of class $C$
-- $P(x_i|C)$ is the likelihood of feature $x_i$ given class $C$
-
-## Types of Naive Bayes Classifiers
-
-1. **Gaussian Naive Bayes**: Assumes continuous values associated with each feature are distributed according to a Gaussian distribution.
-
-2. **Multinomial Naive Bayes**: Typically used for discrete counts, like word counts in text classification.
-
-3. **Bernoulli Naive Bayes**: Used for binary feature models (0s and 1s).
-
-## Example: Gaussian Naive Bayes in scikit-learn
-
-Here's a simple example of using Gaussian Naive Bayes in scikit-learn:
-
-```python
-from sklearn.naive_bayes import GaussianNB
-from sklearn.datasets import load_iris
-from sklearn.model_selection import train_test_split
-from sklearn.metrics import accuracy_score
-
-# Load the iris dataset
-iris = load_iris()
-X, y = iris.data, iris.target
-
-# Split the data into training and testing sets
-X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
-
-# Initialize and train
-gnb = GaussianNB()
-gnb.fit(X_train, y_train)
-
-# Predictions
-y_pred = gnb.predict(X_test)
-
-# Accuracy
-accuracy = accuracy_score(y_test, y_pred)
-print(f"Accuracy: {accuracy:.2f}")
-
-```
-
-## Applications of Naive Bayes Algorithm
-- Real-time Prediction.
-- Multi-class Prediction.
-- Text classification/ Spam Filtering/ Sentiment Analysis.
-- Recommendation Systems.
diff --git a/docs/Machine Learning/Principal Component Analysis.md b/docs/Machine Learning/Principal Component Analysis.md
deleted file mode 100644
index 8e03e03f8..000000000
--- a/docs/Machine Learning/Principal Component Analysis.md
+++ /dev/null
@@ -1,168 +0,0 @@
----
-id: principal-component-analysis
-title: Principal Component Analysis
-sidebar_label: Introduction to Principal Component Analysis
-sidebar_position: 1
-tags: [Principal Component Analysis, PCA, machine learning, dimensionality reduction, data analysis, data science, feature extraction, unsupervised learning, data preprocessing, variance, eigenvectors, eigenvalues]
-description: In this tutorial, you will learn about Principal Component Analysis (PCA), its importance, what PCA is, why learn PCA, how to use PCA, steps to start using PCA, and more.
----
-
-### Introduction to Principal Component Analysis
-Principal Component Analysis (PCA) is a powerful unsupervised learning algorithm used for dimensionality reduction. It transforms high-dimensional data into a lower-dimensional form while retaining as much variability as possible. PCA is widely used in data preprocessing, visualization, and noise reduction, making it an essential tool for data scientists and machine learning practitioners.
-
-### What is Principal Component Analysis?
-Principal Component Analysis (PCA) is a powerful unsupervised learning algorithm used for dimensionality reduction. It transforms high-dimensional data into a lower-dimensional form while retaining as much variability as possible. PCA achieves this by identifying the directions, called principal components, along which the data varies the most. These principal components are new orthogonal axes where the original data can be projected, effectively reducing its dimensionality.
-
-PCA is widely used in data preprocessing, visualization, and noise reduction tasks, making it an essential tool for data scientists and machine learning practitioners.
-
-Principal Component Analysis involves identifying the principal components that capture the most variance in the data:
-
-**Principal Components:** Orthogonal vectors that represent directions of maximum variance in the data. These components are linear combinations of the original features.
-
-**Eigenvectors:** Represent the direction of the principal components.
-
-**Eigenvalues:** Represent the magnitude of the variance captured by each principal component.
-
-**Transformation:** Projects the original data onto the new subspace defined by the principal components.
-
-**Variance:** Measures the spread of the data points. PCA aims to maximize the variance in the projected subspace.
-
-**Covariance Matrix:** A matrix representing the covariance between pairs of features. PCA uses the covariance matrix to identify principal components.
-
-**Linear Correlation:** Two variables are linearly correlated if a linear function of one variable can be used to predict the other variable. Understanding linear correlation is crucial as PCA relies on these relationships to identify the principal components that best summarize the data's variance.
-
-**Example:**
-Consider PCA for image compression. The algorithm reduces the dimensionality of image data by finding principal components that capture the most significant features, allowing for efficient storage and transmission of images with minimal loss of quality.
-### Advantages of Principal Component Analysis
-Principal Component Analysis offers several advantages:
-
-- **Dimensionality Reduction**: Reduces the number of features while retaining the most important information, making data easier to visualize and analyze.
-- **Noise Reduction**: Removes noise and redundant features, improving the performance of machine learning models.
-- **Data Visualization**: Projects high-dimensional data into 2D or 3D spaces for easier visualization and interpretation.
-
-### Example:
-In genetics, PCA can reduce the dimensionality of gene expression data, allowing researchers to visualize and identify patterns in genetic variations across different populations.
-
-### Disadvantages of Principal Component Analysis
-Despite its advantages, Principal Component Analysis has limitations:
-
-- **Loss of Interpretability**: Transformed features (principal components) are linear combinations of original features, making them harder to interpret.
-- **Assumes Linearity**: PCA assumes linear relationships between features, which may not hold in all datasets.
-- **Sensitive to Scaling**: Features with different scales can disproportionately influence the principal components, requiring careful preprocessing.
-
-### Example:
-In finance, PCA might struggle with non-linear relationships between stock prices and economic indicators, limiting its effectiveness in some predictive modeling tasks.
-
-### Practical Tips for Using Principal Component Analysis
-To maximize the effectiveness of Principal Component Analysis:
-
-- **Standardize Features**: Scale features to have zero mean and unit variance before applying PCA to ensure all features contribute equally.
-- **Choose the Right Number of Components**: Use techniques like the explained variance ratio to determine the optimal number of principal components to retain.
-- **Interpret Results with Caution**: While PCA simplifies data, interpreting the transformed features requires understanding their linear combinations.
-
-### Example:
-In face recognition, PCA can reduce the dimensionality of facial image data, identifying key features that distinguish different faces. Standardizing pixel values ensures that variations in lighting and contrast do not distort the analysis.
-
-### Real-World Examples
-
-#### Image Compression
-PCA is used to compress images by reducing the number of pixels while retaining essential visual information. This technique is widely applied in image storage, transmission, and processing.
-
-#### Market Segmentation
-In marketing analytics, PCA helps identify key factors that influence customer behavior, allowing businesses to segment their customer base and tailor marketing strategies effectively.
-
-### Difference Between PCA and LDA
-| Feature | Principal Component Analysis (PCA) | Linear Discriminant Analysis (LDA) |
-|---------------------------------|------------------------------------|-----------------------------------|
-| Purpose | Dimensionality reduction by maximizing variance. | Dimensionality reduction by maximizing class separability. |
-| Data Type | Unsupervised learning. | Supervised learning. |
-| Use Cases | Suitable for feature extraction and noise reduction. | Suitable for classification tasks with labeled data. |
-
-### Implementation
-To implement and apply Principal Component Analysis, you can use libraries such as scikit-learn in Python. Below are the steps to install the necessary library and apply PCA.
-
-#### Libraries to Download
-- `scikit-learn`: Essential for machine learning tasks, including PCA implementation.
-- `pandas`: Useful for data manipulation and analysis.
-- `numpy`: Essential for numerical operations.
-
-You can install these libraries using pip:
-
-```bash
-pip install scikit-learn pandas numpy
-```
-
-#### Applying Principal Component Analysis
-Here’s a step-by-step guide to applying PCA:
-
-**Import Libraries:**
-
-```python
-import pandas as pd
-import numpy as np
-from sklearn.decomposition import PCA
-from sklearn.preprocessing import StandardScaler
-```
-
-**Load and Prepare Data:**
-Assuming you have a dataset in a CSV file:
-
-```python
-# Load the dataset
-data = pd.read_csv('your_dataset.csv')
-
-# Prepare features (X)
-X = data.drop('target_column', axis=1) # Replace 'target_column' with your target variable name
-```
-
-**Feature Scaling:**
-
-```python
-# Standardize the features
-scaler = StandardScaler()
-X_scaled = scaler.fit_transform(X)
-```
-
-**Initialize and Apply PCA:**
-
-```python
-# Initialize PCA
-pca = PCA(n_components=2) # Adjust the number of components as needed
-
-# Fit and transform the data
-X_pca = pca.fit_transform(X_scaled)
-```
-
-**Evaluate Explained Variance:**
-
-```python
-# Print explained variance ratio
-print(f'Explained variance ratio: {pca.explained_variance_ratio_}')
-```
-
-**Visualize the Transformed Data:**
-
-```python
-import matplotlib.pyplot as plt
-
-# Scatter plot of the first two principal components
-plt.scatter(X_pca[:, 0], X_pca[:, 1])
-plt.xlabel('Principal Component 1')
-plt.ylabel('Principal Component 2')
-plt.title('PCA of Dataset')
-plt.show()
-```
-
-This example demonstrates loading data, scaling features, applying PCA, and visualizing the transformed data using scikit-learn and matplotlib. Adjust parameters and preprocessing steps based on your specific dataset and requirements.
-
-### Performance Considerations
-
-#### Computational Efficiency
-- **Feature Dimensionality**: PCA is computationally efficient for moderate-sized datasets but may become intensive with very high-dimensional data.
-- **Number of Components**: Selecting the right number of components balances computational efficiency and information retention.
-
-### Example:
-In climate science, PCA helps reduce the dimensionality of climate model outputs, allowing researchers to analyze and interpret climate patterns efficiently.
-
-### Conclusion
-Principal Component Analysis is a versatile and powerful technique for dimensionality reduction and data visualization. By understanding its assumptions, advantages, and implementation steps, practitioners can effectively leverage PCA for various data science and machine learning tasks.
diff --git a/docs/Machine Learning/Random-Forest.md b/docs/Machine Learning/Random-Forest.md
deleted file mode 100644
index a0c76ab8d..000000000
--- a/docs/Machine Learning/Random-Forest.md
+++ /dev/null
@@ -1,162 +0,0 @@
-# Random Forest
-
-## Introduction to Random Forest
-
-Random Forest is an ensemble learning method that builds multiple decision trees on random subsets of data and features, then combines their predictions for more accurate and robust results. It is effective for both classification and regression tasks, handling large datasets, managing missing values, and providing feature importance insights. This versatility makes it popular in fields like finance, healthcare, and marketing.
-
-## Random Forest Overview
-
-Random Forest is an ensemble learning method that builds multiple decision trees and combines their outputs to improve predictive accuracy and control overfitting. Each tree is constructed from a random subset of the data and features, promoting diversity and robustness in the model. This technique is effective for both classification and regression tasks and provides reliable predictions and feature importance metrics. Due to its versatility and effectiveness, Random Forest is widely used in various domains such as finance, healthcare, and marketing.
-
-### Example:
-
-Consider a Random Forest model for predicting customer churn in a telecom company. The model might use multiple decision trees, each splitting customers based on contract type, usage patterns, and demographics. The final prediction on whether a customer is likely to churn is derived from the aggregated outputs of all the trees.
-
-## Advantages of Random Forest
-
-Random Forests offer several advantages:
-
-- **Improved Accuracy:** By averaging the predictions of multiple trees, Random Forests typically achieve higher accuracy than individual decision trees.
-
-- **Reduced Overfitting:** The aggregation of multiple trees helps mitigate overfitting, making the model generalize better to new data.
-
-- **Feature Importance:** Random Forests provide insights into feature importance, helping identify the most influential features in the dataset.
-
-- **Versatility:** They can handle both numerical and categorical data and are effective with large datasets.
-
-### Example:
-
-In a healthcare setting, Random Forests can predict patient outcomes by analyzing a mix of medical history, demographics, and treatment options, providing accurate and interpretable insights for clinicians.
-
-## Disadvantages of Random Forest
-
-Despite their advantages, Random Forests have limitations:
-
-- **Computational Complexity:** Training multiple trees can be computationally expensive and time-consuming, especially with large datasets.
-
-- **Less Interpretability:** The combined model is less interpretable than a single decision tree, making it harder to understand individual predictions.
-
-- **Need for Tuning:** Hyperparameters like the number of trees and tree depth require tuning to optimize performance.
-
-### Example:
-
-In financial markets, predicting stock prices using Random Forests might require significant computational resources and careful hyperparameter tuning to handle high volatility and complex relationships between market factors.
-
-## Practical Tips for Using Random Forest
-
-To maximize the effectiveness of Random Forest:
-
-- **Hyperparameter Tuning:** Experiment with parameters like the number of trees, maximum depth, and minimum samples per leaf to optimize model performance.
-
-- **Feature Selection:** Use feature importance scores to select and focus on the most relevant features, improving model efficiency.
-
-- **Parallel Processing:** Utilize parallel processing techniques to speed up training and prediction times.
-
-### Example:
-
-In e-commerce, Random Forests can enhance personalized product recommendations by analyzing customer behavior and purchase history, improving user satisfaction and sales through accurate predictions.
-
-## Real-World Examples
-
-### Customer Segmentation in Retail
-
-Random Forests are extensively used in retail for customer segmentation. By analyzing customer demographics, purchase history, and behavior, retailers can create targeted marketing campaigns and personalize customer experiences.
-
-### Medical Diagnosis
-
-In healthcare, Random Forests assist in medical diagnosis by analyzing patient symptoms, medical history, and test results to classify diseases or conditions, aiding healthcare professionals in making informed decisions.
-
-## Implementation
-
-To implement and train a Random Forest model, you need to use a machine learning library such as `scikit-learn`. Below are the steps to install the necessary library and train a Random Forest model.
-
-### Libraries to Download
-
-1. **scikit-learn**: This is the primary library for machine learning in Python, including the Random Forest implementation.
-2. **pandas**: Useful for data manipulation and analysis.
-3. **numpy**: Useful for numerical operations.
-
-You can install these libraries using pip:
-
-```sh
-pip install scikit-learn pandas numpy
-```
-
-### Training a Random Forest Model
-
-Here’s a step-by-step guide to training a Random Forest model:
-
-1. **Import Libraries**:
-
-```python
-import pandas as pd
-import numpy as np
-from sklearn.model_selection import train_test_split
-from sklearn.ensemble import RandomForestClassifier
-from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
-```
-
-2. **Load and Prepare Data**:
-
-Assuming you have a dataset in a CSV file:
-
-```python
-# Load the dataset
-data = pd.read_csv('your_dataset.csv')
-
-# Prepare features (X) and target (y)
-X = data.drop('target_column', axis=1) # replace 'target_column' with the name of your target column
-y = data['target_column']
-```
-
-3. **Split Data into Training and Testing Sets**:
-
-```python
-X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
-```
-
-4. **Initialize and Train the Random Forest Model**:
-
-```python
-# Initialize the Random Forest model
-rf_model = RandomForestClassifier(n_estimators=100, random_state=42)
-
-# Train the model
-rf_model.fit(X_train, y_train)
-```
-
-5. **Make Predictions and Evaluate the Model**:
-
-```python
-# Make predictions
-y_pred = rf_model.predict(X_test)
-
-# Evaluate the model
-accuracy = accuracy_score(y_test, y_pred)
-conf_matrix = confusion_matrix(y_test, y_pred)
-class_report = classification_report(y_test, y_pred)
-
-print(f'Accuracy: {accuracy}')
-print('Confusion Matrix:')
-print(conf_matrix)
-print('Classification Report:')
-print(class_report)
-```
-
-This example demonstrates how to load data, prepare features and target variables, split the data, train a Random Forest model, and evaluate its performance. You can adjust parameters and the dataset as needed for your specific use case.
-
-## Performance Considerations
-
-### Scalability and Computational Efficiency
-
-- **Large Datasets:** Random Forests can become computationally intensive with large datasets due to the need to train multiple trees.
-
-- **Algorithmic Complexity:** Techniques like reducing the number of features considered at each split and limiting tree depth can improve scalability.
-
-### Example:
-
-In financial analytics, Random Forests are used to analyze market trends and predict stock movements. Optimizing Random Forest algorithms for large-scale data processing ensures timely and accurate predictions, critical for financial decision-making.
-
-## Conclusion
-
-Random Forests are a valuable tool in machine learning, offering a balance of predictive power and robustness. Understanding their structure, strengths, and weaknesses is essential for effectively applying them to diverse real-world problems.
diff --git a/docs/Machine Learning/Reinforcement Learning.md b/docs/Machine Learning/Reinforcement Learning.md
deleted file mode 100644
index 1caf2162f..000000000
--- a/docs/Machine Learning/Reinforcement Learning.md
+++ /dev/null
@@ -1,139 +0,0 @@
----
-id: reinforcement-learning
-title: Reinforcement Learning
-sidebar_label: Introduction to Reinforcement Learning
-sidebar_position: 1
-tags: [Reinforcement Learning, RL, machine learning, data analysis, data science, artificial intelligence, agent-based modeling, decision-making, dynamic environments, policy learning]
-description: In this tutorial, you will learn about Reinforcement Learning (RL), its importance, what RL is, why learn RL, how to use RL, steps to start using RL, and more.
----
-
-### Introduction to Reinforcement Learning
-Reinforcement Learning (RL) is a type of machine learning where an agent learns to make decisions by performing actions in an environment to maximize cumulative rewards. RL is well-suited for problems where an agent interacts with a dynamic environment, making it a powerful tool for tasks requiring sequential decision-making.
-
-### What is Reinforcement Learning?
-Reinforcement Learning involves several key components:
-
-- **Agent**: The learner or decision maker that interacts with the environment.
-- **Environment**: The external system with which the agent interacts.
-- **State**: A representation of the current situation or configuration of the environment.
-- **Action**: The set of all possible moves the agent can make.
-- **Reward**: The feedback from the environment based on the agent's actions.
-- **Policy**: A strategy used by the agent to determine the next action based on the current state.
-- **Value Function**: Estimates the expected return (cumulative reward) of states or state-action pairs.
-
-### Example:
-Consider using RL for training a robotic arm to pick up objects. The robot (agent) observes its surroundings (state), decides how to move its arm (action), and receives feedback (reward) based on whether it successfully picks up an object.
-
-### Advantages of Reinforcement Learning
-Reinforcement Learning offers several advantages:
-
-- **Dynamic Learning**: Adapts to changes in the environment, making it suitable for real-time decision-making.
-- **Sequential Decision Making**: Excels at tasks that require a series of actions to achieve a goal.
-- **Exploration and Exploitation**: Balances exploring new actions and exploiting known actions to maximize rewards.
-
-### Example:
-In video games, RL can train agents to learn optimal strategies by interacting with the game environment, leading to intelligent non-player characters (NPCs) that enhance gameplay.
-
-### Disadvantages of Reinforcement Learning
-Despite its advantages, RL has limitations:
-
-- **Sample Inefficiency**: Requires a large number of interactions with the environment to learn effectively.
-- **Computational Complexity**: Can be computationally expensive, especially for environments with large state and action spaces.
-- **Reward Design**: Designing an appropriate reward function can be challenging and significantly impacts learning performance.
-
-### Example:
-In autonomous driving, RL agents need extensive simulation and real-world interactions to learn safe and efficient driving policies, which can be time-consuming and resource-intensive.
-
-### Practical Tips for Using Reinforcement Learning
-To maximize the effectiveness of Reinforcement Learning:
-
-- **Reward Shaping**: Carefully design reward functions to guide the agent towards desired behaviors.
-- **Exploration Strategies**: Use techniques like epsilon-greedy or softmax to balance exploration and exploitation.
-- **Environment Simulation**: Utilize simulated environments to accelerate training and reduce real-world risks.
-
-### Example:
-In stock trading, RL agents can be trained in simulated markets to develop trading strategies before being deployed in live markets, minimizing financial risk during training.
-
-### Real-World Examples
-
-#### Robotics
-RL is used in robotics to enable robots to learn tasks such as walking, grasping, and navigating. By continuously interacting with their environment, robots improve their performance and adapt to new tasks.
-
-#### Healthcare
-In personalized medicine, RL can optimize treatment plans by learning the most effective interventions for individual patients based on historical data and ongoing feedback.
-
-### Difference Between RL and Supervised Learning
-| Feature | Reinforcement Learning (RL) | Supervised Learning |
-|---------------------------------|-----------------------------|---------------------|
-| Learning Paradigm | Learns by interacting with the environment and receiving feedback. | Learns from labeled data provided by a supervisor. |
-| Feedback Type | Receives rewards or penalties based on actions. | Receives explicit labels for input-output pairs. |
-| Use Cases | Suitable for sequential decision-making problems. | Suitable for classification and regression tasks. |
-
-### Implementation
-To implement and train a Reinforcement Learning model, you can use libraries such as TensorFlow, PyTorch, or specialized RL libraries like OpenAI Gym and Stable Baselines3. Below are the steps to install the necessary libraries and train an RL agent.
-
-#### Libraries to Download
-- `TensorFlow` or `PyTorch`: Essential for building and training neural networks.
-- `gym`: A toolkit for developing and comparing RL algorithms.
-- `stable-baselines3`: A set of reliable implementations of RL algorithms.
-
-You can install these libraries using pip:
-
-```bash
-pip install tensorflow gym stable-baselines3
-```
-
-#### Training a Reinforcement Learning Agent
-Here’s a step-by-step guide to training an RL agent using Stable Baselines3:
-
-**Import Libraries:**
-
-```python
-import gym
-from stable_baselines3 import PPO
-```
-
-**Create and Initialize the Environment:**
-
-```python
-# Create the environment
-env = gym.make('CartPole-v1')
-```
-
-**Define and Train the RL Model:**
-
-```python
-# Initialize the PPO agent
-model = PPO('MlpPolicy', env, verbose=1)
-
-# Train the agent
-model.learn(total_timesteps=10000)
-```
-
-**Evaluate the Model:**
-
-```python
-# Evaluate the trained agent
-obs = env.reset()
-for _ in range(1000):
- action, _states = model.predict(obs)
- obs, rewards, dones, info = env.step(action)
- env.render()
- if dones:
- obs = env.reset()
-env.close()
-```
-
-This example demonstrates setting up an RL environment, defining a PPO agent, training the agent, and evaluating its performance using Stable Baselines3. Adjust parameters and algorithms based on your specific problem and requirements.
-
-### Performance Considerations
-
-#### Computational Efficiency
-- **Hardware Acceleration**: Utilize GPUs to accelerate the training of deep RL models.
-- **Parallel Training**: Run multiple environment instances in parallel to improve sample efficiency.
-
-### Example:
-In real-time strategy games, parallel training with multiple game instances allows RL agents to quickly learn and adapt strategies, improving their performance in complex environments.
-
-### Conclusion
-Reinforcement Learning is a versatile and powerful tool for solving problems that require dynamic and sequential decision-making. By understanding its components, advantages, limitations, and implementation, practitioners can effectively apply RL to a wide range of applications in data science and machine learning projects.
diff --git a/docs/Machine Learning/SVM Algorithm.md b/docs/Machine Learning/SVM Algorithm.md
deleted file mode 100644
index b3713eaaf..000000000
--- a/docs/Machine Learning/SVM Algorithm.md
+++ /dev/null
@@ -1,159 +0,0 @@
-# Support Vector Machine (SVM)
-
-## Introduction to Support Vector Machine
-
-Support Vector Machine (SVM) is a supervised machine learning algorithm that is primarily used for classification tasks, although it can also be applied to regression problems. SVM works by finding the optimal hyperplane that best separates different classes in the feature space. This algorithm is particularly effective for high-dimensional data and situations where the number of dimensions exceeds the number of samples.
-
-## SVM Overview
-
-Support Vector Machine aims to create a decision boundary (hyperplane) that maximizes the margin between different classes. The data points that are closest to the hyperplane and influence its position are called support vectors. SVM can handle both linear and non-linear classification tasks using different kernel functions, which transform the data into higher dimensions to make it separable.
-
-### Example:
-
-Consider an SVM model for classifying emails as spam or non-spam. The model identifies the optimal hyperplane based on features like word frequency, email length, and presence of certain keywords, effectively separating spam from non-spam emails.
-
-## Advantages of SVM
-
-SVMs offer several advantages:
-
-- **Effective in High Dimensions:** SVM is highly effective in high-dimensional spaces and scenarios where the number of dimensions is greater than the number of samples.
-
-- **Robustness to Overfitting:** SVMs are robust to overfitting, especially in high-dimensional space, due to the regularization parameter that controls the trade-off between maximizing the margin and minimizing classification error.
-
-- **Versatility with Kernels:** SVMs can handle non-linear classification through kernel functions (e.g., polynomial, radial basis function), making them versatile for various datasets.
-
-### Example:
-
-In image classification, SVMs can distinguish between different objects (e.g., cats vs. dogs) by transforming the pixel intensity features into a higher-dimensional space using a radial basis function (RBF) kernel.
-
-## Disadvantages of SVM
-
-Despite their advantages, SVMs have limitations:
-
-- **Computationally Intensive:** Training an SVM can be computationally expensive, particularly with large datasets and complex kernel functions.
-
-- **Choice of Kernel:** Selecting the appropriate kernel function and tuning its parameters (e.g., the cost parameter, kernel coefficient) is crucial for optimal performance but can be challenging.
-
-- **Less Interpretability:** The decision boundary and support vectors in high-dimensional space can make the model less interpretable compared to simpler algorithms.
-
-### Example:
-
-In natural language processing, using SVM to classify text documents (e.g., sentiment analysis) can be computationally demanding due to the high-dimensional nature of textual data and the need to fine-tune kernel parameters for best performance.
-
-## Practical Tips for Using SVM
-
-To maximize the effectiveness of SVM:
-
-- **Hyperparameter Tuning:** Experiment with different kernel functions (linear, polynomial, RBF) and tune parameters like C (regularization) and gamma (kernel coefficient) to optimize model performance.
-
-- **Feature Scaling:** Ensure that features are scaled (e.g., using StandardScaler) as SVMs are sensitive to the scale of input data.
-
-- **Cross-Validation:** Use cross-validation techniques to select the best model parameters and prevent overfitting.
-
-### Example:
-
-In finance, SVMs can predict credit risk by analyzing customer data such as credit history and financial transactions. Properly tuning the model’s parameters and scaling features ensures accurate and reliable predictions.
-
-## Real-World Examples
-
-### Handwriting Recognition
-
-SVMs are widely used in handwriting recognition, where they classify handwritten digits based on pixel intensity features. The model transforms the features into a higher-dimensional space, enabling accurate classification of digits.
-
-### Bioinformatics
-
-In bioinformatics, SVMs classify proteins based on their amino acid sequences and structural features. By using appropriate kernels, SVMs handle the complex, high-dimensional data inherent in biological sequences.
-
-## Implementation
-
-To implement and train an SVM model, you can use a machine learning library such as `scikit-learn`. Below are the steps to install the necessary library and train an SVM model.
-
-### Libraries to Download
-
-1. **scikit-learn**: This is the primary library for machine learning in Python, including the SVM implementation.
-2. **pandas**: Useful for data manipulation and analysis.
-3. **numpy**: Useful for numerical operations.
-
-You can install these libraries using pip:
-
-```sh
-pip install scikit-learn pandas numpy
-```
-
-### Training an SVM Model
-
-Here’s a step-by-step guide to training an SVM model:
-
-1. **Import Libraries**:
-
-```python
-import pandas as pd
-import numpy as np
-from sklearn.model_selection import train_test_split
-from sklearn.svm import SVC
-from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
-```
-
-2. **Load and Prepare Data**:
-
-Assuming you have a dataset in a CSV file:
-
-```python
-# Load the dataset
-data = pd.read_csv('your_dataset.csv')
-
-# Prepare features (X) and target (y)
-X = data.drop('target_column', axis=1) # replace 'target_column' with the name of your target column
-y = data['target_column']
-```
-
-3. **Split Data into Training and Testing Sets**:
-
-```python
-X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
-```
-
-4. **Initialize and Train the SVM Model**:
-
-```python
-# Initialize the SVM model
-svm_model = SVC(kernel='rbf', C=1.0, gamma='scale', random_state=42)
-
-# Train the model
-svm_model.fit(X_train, y_train)
-```
-
-5. **Make Predictions and Evaluate the Model**:
-
-```python
-# Make predictions
-y_pred = svm_model.predict(X_test)
-
-# Evaluate the model
-accuracy = accuracy_score(y_test, y_pred)
-conf_matrix = confusion_matrix(y_test, y_pred)
-class_report = classification_report(y_test, y_pred)
-
-print(f'Accuracy: {accuracy}')
-print('Confusion Matrix:')
-print(conf_matrix)
-print('Classification Report:')
-print(class_report)
-```
-
-This example demonstrates how to load data, prepare features and target variables, split the data, train an SVM model, and evaluate its performance. You can adjust parameters and the dataset as needed for your specific use case.
-
-## Performance Considerations
-
-### Scalability and Computational Efficiency
-
-- **Large Datasets:** SVMs can be computationally intensive with large datasets, especially when using non-linear kernels.
-- **Algorithmic Complexity:** Techniques such as reducing feature dimensions through Principal Component Analysis (PCA) and using linear kernels for large datasets can improve scalability.
-
-### Example:
-
-In text classification, SVMs are used to categorize documents into predefined classes (e.g., news articles into topics). Optimizing SVM algorithms for large-scale text data ensures efficient processing and accurate classifications.
-
-## Conclusion
-
-Support Vector Machines are powerful tools in machine learning, especially for classification tasks involving high-dimensional data. Understanding their structure, strengths, and limitations is crucial for effectively applying them to various real-world problems. By carefully tuning parameters and selecting appropriate kernels, SVMs can achieve high accuracy and robustness in diverse applications.
diff --git a/docs/Machine Learning/Scikit-Learn.md b/docs/Machine Learning/Scikit-Learn.md
deleted file mode 100644
index af5d1f27c..000000000
--- a/docs/Machine Learning/Scikit-Learn.md
+++ /dev/null
@@ -1,229 +0,0 @@
-# Scikit-Learn
-
-> Unlock the Power of Machine Learning with Scikit-learn: Simplifying Complexity, Empowering Discovery
-
-
-**Supervised Learning**
-- Linear Models
-
-- Support Vector Machines
-
-- Data Preprocessing
-
-1. Linear Models
-
-The following are a set of
-methods intended for regression in which the target value is expected to
-be a linear combination of the features. In mathematical notation, if
-$\hat{y}$ is the predicted value.
-
-$$
-\hat{y}(w, x) = w_0 + w_1 + \ldots + w_p
-$$
-
-Across the module, we designate the vector w =
-$(w_0, w_1, \ldots, w_n)$ as `coef_` and $w_0$ as `intercept_`.
-
-
-- *Linear Regression*
- Linear Regression fits a linear model with coefficients w = $(w_0 ,w_1 ,
-...w_n)$ to minimize the residual sum of squares between the observed
-targets in the dataset, and the targets predicted by the linear
-approximation. Mathematically it solves a problem of the form:
-
- $\min_{w} || X w - y||_2^2$
-
-``` python
-from sklearn import linear_model
-reg = linear_model.LinearRegression() #To Use Linear Regression
-reg.fit([[0, 0], [1, 1], [2, 2]], [0, 1, 2])
-coefficients = reg.coef_
-intercept = reg.intercept_
-
-print("Coefficients:", coefficients)
-print("Intercept:", intercept)
-```
-
-Output:
-
- Coefficients: [0.5 0.5]
- Intercept: 1.1102230246251565e-16
-
-
-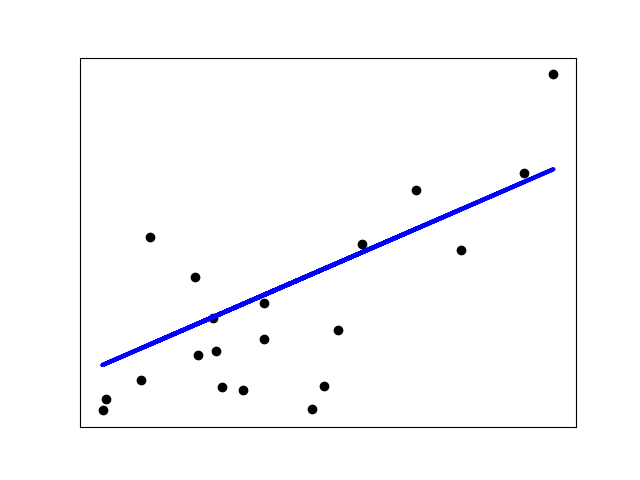
-
-This is how the Linear Regression fits the line .
-
-
-- Support Vector Machines
- Support vector machines (SVMs) are a set of supervised learning methods
-used for classification, regression and outliers detection.
-
-*The advantages of support vector machines are:*
-
-Effective in high dimensional spaces.
-
-Still effective in cases where number of dimensions is greater than the
-number of samples.
-
-Uses a subset of training points in the decision function (called
-support vectors), so it is also memory efficient.
-
-Versatile: different Kernel functions can be specified for the decision
-function. Common kernels are provided, but it is also possible to
-specify custom kernels.
-
-*The disadvantages of support vector machines include:*
-
-If the number of features is much greater than the number of samples,
-avoid over-fitting in choosing Kernel functions and regularization term
-is crucial.
-
-SVMs do not directly provide probability estimates, these are calculated
-using an expensive five-fold cross-validation (see Scores and
-probabilities, below).
-
-The support vector machines in scikit-learn support both dense
-(numpy.ndarray and convertible to that by numpy.asarray) and sparse (any
-scipy.sparse) sample vectors as input. However, to use an SVM to make
-predictions for sparse data, it must have been fit on such data. For
-optimal performance, use C-ordered numpy.ndarray (dense) or
-scipy.sparse.csr_matrix (sparse) with dtype=float64
-
-**Linear Kernel:**
-
-Function: 𝐾 ( 𝑥 , 𝑦 ) = 𝑥 𝑇 𝑦
-
-Parameters: No additional parameters.
-
-**Polynomial Kernel:**
-
-Function: 𝐾 ( 𝑥 , 𝑦 ) = ( 𝛾 𝑥 𝑇 𝑦 𝑟 ) 𝑑
-
-Parameters:
-
-γ (gamma): Coefficient for the polynomial term. Higher values increase
-the influence of high-degree polynomials.
-
-r: Coefficient for the constant term.
-
-d: Degree of the polynomial.
-
-**Radial Basis Function (RBF) Kernel:**
-
-Function: 𝐾 ( 𝑥 , 𝑦 ) = exp ( − 𝛾 ∣ ∣ 𝑥 − 𝑦 ∣ ∣ 2 )
-
-Parameters: 𝛾 γ (gamma): Controls the influence of each training
-example. Higher values result in a more complex decision boundary.
-
-**Sigmoid Kernel:**
-
-Function: 𝐾 ( 𝑥 , 𝑦 ) = tanh ( 𝛾 𝑥 𝑇 𝑦 𝑟 )
-
-Parameters:
-
-γ (gamma): Coefficient for the sigmoid term.
-
-r: Coefficient for the constant term.
-
-
-``` python
-import numpy as np
-import matplotlib.pyplot as plt
-from sklearn import svm, datasets
-
-# Load example dataset (Iris dataset)
-iris = datasets.load_iris()
-X = iris.data[:, :2] # We only take the first two features
-y = iris.target
-
-# Define the SVM model with RBF kernel
-C = 1.0 # Regularization parameter
-gamma = 0.7 # Kernel coefficient
-svm_model = svm.SVC(kernel='rbf', C=C, gamma=gamma)
-
-# Train the SVM model
-svm_model.fit(X, y)
-
-# Plot the decision boundary
-x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
-y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
-xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
- np.arange(y_min, y_max, 0.02))
-Z = svm_model.predict(np.c_[xx.ravel(), yy.ravel()])
-Z = Z.reshape(xx.shape)
-
-plt.contourf(xx, yy, Z, cmap=plt.cm.Paired, alpha=0.8)
-
-# Plot the training points
-plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Paired)
-plt.xlabel('Sepal length')
-plt.ylabel('Sepal width')
-plt.title('SVM with RBF Kernel')
-plt.show()
-```
-
-
-- Data Preprocessing
- Data preprocessing is a crucial step in the machine learning pipeline
-that involves transforming raw data into a format suitable for training
-a model. Here are some fundamental techniques in data preprocessing
-using scikit-learn:
-
-**Handling Missing Values:**
-
-Imputation: Replace missing values with a calculated value (e.g., mean,
-median, mode) using SimpleImputer. Removal: Remove rows or columns with
-missing values using dropna.
-
-**Feature Scaling:**
-
-Standardization: Scale features to have a mean of 0 and a standard
-deviation of 1 using StandardScaler.
-
-Normalization: Scale features to a range between 0 and 1 using
-MinMaxScaler. Encoding Categorical Variables:
-
-One-Hot Encoding: Convert categorical variables into binary vectors
-using OneHotEncoder.
-
-Label Encoding: Encode categorical variables as integers using
-LabelEncoder.
-
-**Feature Transformation:**
-
-Polynomial Features: Generate polynomial features up to a specified
-degree using PolynomialFeatures.
-
-Log Transformation: Transform features using the natural logarithm to
-handle skewed distributions.
-
-**Handling Outliers:**
-
-Detection: Identify outliers using statistical methods or domain
-knowledge. Transformation: Apply transformations (e.g., winsorization)
-or remove outliers based on a threshold.
-
-**Handling Imbalanced Data:**
-
-Resampling: Over-sample minority class or under-sample majority class to
-balance the dataset using techniques like RandomOverSampler or
-RandomUnderSampler.
-
-Synthetic Sampling: Generate synthetic samples for the minority class
-using algorithms like Synthetic Minority Over-sampling Technique
-(SMOTE). Feature Selection:
-
-Univariate Feature Selection: Select features based on statistical tests
-like ANOVA using SelectKBest or SelectPercentile.
-
-Recursive Feature Elimination: Select features recursively by
-considering smaller and smaller sets of features using RFECV.
-
-**Splitting Data:**
-
-Train-Test Split: Split the dataset into training and testing sets using
-train_test_split.
-
-Cross-Validation: Split the dataset into multiple folds for
-cross-validation using KFold or StratifiedKFold.
diff --git a/docs/Machine Learning/Stochastic Gradient Descent model.md b/docs/Machine Learning/Stochastic Gradient Descent model.md
deleted file mode 100644
index 050510df5..000000000
--- a/docs/Machine Learning/Stochastic Gradient Descent model.md
+++ /dev/null
@@ -1,145 +0,0 @@
----
-id: stochastic-gradient-descent
-title: Stochastic Gradient Descent
-sidebar_label: Introduction to Stochastic Gradient Descent
-sidebar_position: 1
-tags: [stochastic gradient descent, machine learning, optimization algorithm, deep learning, gradient descent, data science, model training, stochastic optimization, neural networks, supervised learning, gradient descent variants, iterative optimization, parameter tuning]
-description: In this tutorial, you will learn about Stochastic Gradient Descent (SGD), its importance, what SGD is, why learn SGD, how to use SGD, steps to start using SGD, and more.
----
-
-### Introduction to Stochastic Gradient Descent
-Stochastic Gradient Descent (SGD) is a fundamental optimization algorithm widely used in machine learning and deep learning for training models. It belongs to the family of gradient descent methods and is particularly suited for large-scale datasets and complex models due to its efficiency and iterative nature.
-
-### What is Stochastic Gradient Descent?
-Stochastic Gradient Descent is an optimization technique that updates model parameters iteratively to minimize a loss function by taking small steps in the direction of the steepest gradient calculated from a subset (batch) of training data at each iteration. Unlike traditional Gradient Descent, which computes gradients using the entire dataset (batch gradient descent), SGD processes data in smaller batches, making it faster and more suitable for online learning and dynamic environments.
-
--**Batch Size**: Number of data points used in each iteration to compute the gradient and update parameters.
-
--**Learning Rate**: Step size that controls the magnitude of parameter updates in each iteration.
-
-
-### Example:
-Consider training a deep neural network (DNN) for image classification using SGD. Instead of computing gradients over the entire dataset in one go, SGD updates model weights incrementally after processing each batch of images. This stochastic process helps in navigating complex optimization landscapes efficiently.
-
-### Advantages of Stochastic Gradient Descent
-Stochastic Gradient Descent offers several advantages:
-
-- **Efficiency**: It processes data in mini-batches, reducing computational requirements compared to batch gradient descent, especially with large datasets.
-- **Convergence Speed**: SGD often converges faster than batch methods because it quickly adjusts model parameters using frequent updates.
-- **Scalability**: Suitable for large-scale datasets and online learning scenarios where data arrives sequentially or in streams.
-
-### Example:
-In natural language processing (NLP), SGD is used to train models for text classification tasks. By processing text data in batches and updating weights iteratively, SGD enables efficient training of models to classify documents into categories such as spam vs. non-spam emails.
-
-### Disadvantages of Stochastic Gradient Descent
-Despite its advantages, SGD has limitations:
-
-- **Noisy Updates**: The stochastic nature of SGD introduces noise due to mini-batch sampling, which can lead to fluctuations in training loss and convergence.
-- **Learning Rate Tuning**: Requires careful tuning of the learning rate and batch size to achieve optimal convergence and stability.
-- **Potential for Overshooting**: In some cases, SGD can overshoot the optimal solution, especially when the learning rate is too high or batch size is too small.
-
-### Example:
-In financial modeling, using SGD for predicting stock prices may require careful tuning of batch size and learning rate to mitigate noise and ensure accurate predictions amidst market volatility.
-
-### Practical Tips for Using Stochastic Gradient Descent
-To effectively apply SGD in model training:
-
-- **Learning Rate Schedule**: Implement learning rate schedules (e.g., decay or adaptive learning rates) to dynamically adjust the learning rate during training.
-- **Batch Size Selection**: Experiment with different batch sizes to find a balance between computational efficiency and model stability.
-- **Regularization**: Incorporate regularization techniques (e.g., L2 regularization) to prevent overfitting and improve generalization.
-
-### Example:
-In recommender systems, SGD is employed to optimize matrix factorization models for personalized recommendations. Fine-tuning batch sizes and learning rates ensures that the model efficiently learns user preferences from large-scale interaction data.
-
-### Real-World Examples
-
-#### Deep Learning Training
-Stochastic Gradient Descent is extensively used in training deep learning models, including convolutional neural networks (CNNs) for image recognition and recurrent neural networks (RNNs) for sequence modeling. Its efficiency in handling large volumes of training data and complex model architectures makes it indispensable in modern AI applications.
-
-#### Online Learning
-In online advertising, SGD enables real-time updates of ad recommendation models based on user interactions and behavioral data. By processing new data streams in mini-batches, SGD continuously refines model predictions to adapt to evolving user preferences.
-
-### Difference Between Stochastic Gradient Descent and Batch Gradient Descent
-
-| Feature | Stochastic Gradient Descent | Batch Gradient Descent |
-|---------------------------------|--------------------------------------|-----------------------------------|
-| Processing | Mini-batches of data points | Entire dataset |
-| Gradient Calculation | Subset of data at each iteration | Entire dataset |
-| Convergence Speed | Faster due to frequent updates | Slower, requires full dataset |
-| Noise Sensitivity | More sensitive due to mini-batch sampling | Smoother due to full dataset |
-| Use Cases | Large-scale datasets, online learning | Small to medium-sized datasets |
-
-### Implementation
-To implement Stochastic Gradient Descent in Python, you can use libraries such as TensorFlow, PyTorch, or scikit-learn, depending on your specific model and application requirements. Below is a basic example using scikit-learn for linear regression:
-
-#### Libraries to Download
-- `scikit-learn`: Provides various machine learning algorithms and utilities in Python.
-
-Install scikit-learn using pip:
-
-```bash
-pip install scikit-learn
-```
-
-#### Training a Model with SGD
-Here’s a simplified example of training a linear regression model using SGD with scikit-learn:
-
-**Import Libraries:**
-
-```python
-from sklearn.linear_model import SGDRegressor
-from sklearn.datasets import make_regression
-from sklearn.model_selection import train_test_split
-from sklearn.preprocessing import StandardScaler
-import numpy as np
-import matplotlib.pyplot as plt
-```
-
-**Generate Synthetic Data:**
-
-```python
-# Generate synthetic data
-X, y = make_regression(n_samples=1000, n_features=10, noise=0.1, random_state=42)
-
-# Split data into training and testing sets
-X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
-
-# Standardize features
-scaler = StandardScaler()
-X_train_scaled = scaler.fit_transform(X_train)
-X_test_scaled = scaler.transform(X_test)
-```
-
-**Initialize and Train SGD Model:**
-
-```python
-# Initialize SGDRegressor
-sgd = SGDRegressor(max_iter=1000, tol=1e-3, random_state=42)
-
-# Train the model
-sgd.fit(X_train_scaled, y_train)
-```
-
-**Evaluate the Model:**
-
-```python
-# Evaluate model performance
-train_score = sgd.score(X_train_scaled, y_train)
-test_score = sgd.score(X_test_scaled, y_test)
-print(f"Training R2 Score: {train_score:.2f}")
-print(f"Testing R2 Score: {test_score:.2f}")
-```
-
-This example demonstrates how to train a linear regression model using SGD with scikit-learn, including data preprocessing, model initialization, training, and evaluation. Adjust parameters and data handling based on your specific use case and dataset characteristics.
-
-### Performance Considerations
-
-#### Convergence and Hyperparameter Tuning
-- **Learning Rate**: Optimize learning rate selection to balance convergence speed and stability.
-- **Mini-Batch Size**: Experiment with different batch sizes to find an optimal balance between noise sensitivity and computational efficiency.
-
-### Example:
-In climate modeling, SGD is applied to optimize complex simulation models based on atmospheric data. Efficiently training these models using SGD enables accurate prediction and analysis of climate patterns and phenomena.
-
-### Conclusion
-Stochastic Gradient Descent is a versatile and efficient optimization algorithm crucial for training machine learning models, especially in scenarios involving large datasets and complex model architectures. By understanding its principles, advantages, and implementation strategies, practitioners can effectively leverage SGD to enhance model performance and scalability across various domains of artificial intelligence and data science.
diff --git a/docs/Machine Learning/Support Vector Regression.md b/docs/Machine Learning/Support Vector Regression.md
deleted file mode 100644
index 2c828cb6c..000000000
--- a/docs/Machine Learning/Support Vector Regression.md
+++ /dev/null
@@ -1,157 +0,0 @@
----
-
-id: support-vector-regression
-title: Support Vector Regression
-sidebar_label: Introduction to Support Vector Regression
-sidebar_position: 1
-tags: [Support Vector Regression, SVR, machine learning, regression algorithm, data analysis, data science, supervised learning, predictive modeling, feature importance]
-description: In this tutorial, you will learn about Support Vector Regression (SVR), its importance, what SVR is, why learn SVR, how to use SVR, steps to start using SVR, and more.
-
----
-
-### Introduction to Support Vector Regression
-Support Vector Regression (SVR) is a machine learning algorithm used for predicting continuous values. It extends the Support Vector Machine (SVM) algorithm, which is typically used for classification, to handle regression tasks.
-
-### What is Support Vector Regression?
-**Support Vector Regression (SVR)** is a type of Support Vector Machine (SVM) used for predicting continuous outcomes. SVR finds a line (or hyperplane) that best fits the data points while keeping most of them within a specified margin of error.
-
-- **Support Vectors**: Data points that are closest to the line and influence its position.
-
-- **Epsilon-insensitive Loss Function**: A method that ignores small errors within a specified range (epsilon).
-
-**Hyperplane**: The line or boundary that SVR tries to find, which best fits the data within the allowed error margin.
-
-**Kernel Trick**: A technique to transform data into a higher-dimensional space, allowing SVR to handle complex, non-linear relationships.
-
-### Example:
-For predicting house prices, SVR can create a model that finds the relationship between various features (like size, number of rooms) and the price, fitting the data within a margin of error.
-
-### Advantages of Support Vector Regression
-- **Robust to Outliers**: Focuses on the most important data points (support vectors), making it less sensitive to outliers.
-- **Flexible with Kernels**: Can handle non-linear relationships using different kernel functions.
-- **Effective in High Dimensions**: Works well even when there are many features.
-
-### Example:
-In predicting stock prices, SVR can handle noisy data and complex relationships between market indicators and prices.
-
-### Disadvantages of Support Vector Regression
-- **Computationally Intensive**: Training SVR can be slow, especially with large datasets.
-- **Needs Careful Tuning**: Performance depends on selecting the right parameters (like C, epsilon, and kernel type).
-- **Complex Interpretation**: The resulting model can be hard to interpret, especially with non-linear kernels.
-
-### Example:
-In forecasting energy usage, SVR might be slow with large datasets, requiring good computational resources.
-
-### Practical Tips for Using Support Vector Regression
-- **Tune Parameters**: Adjust parameters like C, epsilon, and kernel type for better performance.
-- **Scale Features**: Normalize features to improve model performance and convergence.
-- **Choose Kernels Wisely**: Select an appropriate kernel function based on your data.
-
-### Example:
-In medical diagnostics, SVR can predict patient outcomes. Proper feature scaling and kernel selection improve prediction accuracy.
-
-### Real-World Examples
-
-#### Weather Forecasting
-SVR is used to predict temperature and rainfall based on historical data, helping in accurate weather forecasting.
-
-#### Demand Forecasting
-In supply chain management, SVR predicts product demand, helping businesses optimize inventory and reduce costs.
-
-### Difference Between SVR and Linear Regression
-| Feature | Support Vector Regression (SVR) | Linear Regression |
-|---------------------------------|---------------------------------|-------------------|
-| Loss Function | Epsilon-insensitive | Mean squared error |
-| Flexibility | Can model non-linear relationships | Assumes linear relationships |
-| Robustness to Outliers | More robust to outliers | Sensitive to outliers |
-
-### Implementation
-To implement SVR, you can use Python libraries like scikit-learn. Here are the steps:
-
-#### Libraries to Download
-
-- `scikit-learn`: For machine learning tasks, including SVR.
-- `pandas`: For data manipulation.
-- `numpy`: For numerical operations.
-
-Install these using pip:
-
-```bash
-pip install scikit-learn pandas numpy
-```
-
-#### Training a Support Vector Regression Model
-
-**Import Libraries:**
-
-```
-
-```python
-import pandas as pd
-import numpy as np
-from sklearn.svm import SVR
-from sklearn.model_selection import train_test_split
-from sklearn.preprocessing import StandardScaler
-```
-
-**Load and Prepare Data:**
-Assuming you have a dataset in a CSV file:
-
-```python
-# Load the dataset
-data = pd.read_csv('your_dataset.csv')
-
-# Prepare features (X) and target variable (y)
-X = data.drop('target_column', axis=1) # Replace 'target_column' with your target variable name
-y = data['target_column']
-```
-
-**Feature Scaling:**
-
-```python
-# Perform feature scaling
-scaler = StandardScaler()
-X_scaled = scaler.fit_transform(X)
-```
-
-**Split Data into Training and Testing Sets:**
-
-```python
-X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
-```
-
-**Initialize and Train the Support Vector Regression Model:**
-
-```python
-svr = SVR(kernel='rbf')
-svr.fit(X_train, y_train)
-```
-
-**Evaluate the Model:**
-
-```python
-from sklearn.metrics import mean_squared_error, r2_score
-
-# Predict on test data
-y_pred = svr.predict(X_test)
-
-# Evaluate performance
-mse = mean_squared_error(y_test, y_pred)
-r2 = r2_score(y_test, y_pred)
-print(f'Mean Squared Error: {mse:.2f}')
-print(f'R^2 Score: {r2:.2f}')
-```
-
-This example demonstrates loading data, preparing features, training an SVR model, and evaluating its performance using scikit-learn. Adjust parameters and preprocessing steps based on your specific dataset and requirements.
-
-### Performance Considerations
-
-#### Computational Efficiency
-- **Kernel Choice**: The choice of kernel affects both the computational efficiency and the performance of SVR.
-- **Model Complexity**: Proper tuning of hyperparameters can balance model complexity and computational efficiency.
-
-### Example:
-In financial forecasting, SVR helps predict future asset prices based on historical data. Choosing the right kernel and tuning hyperparameters ensures accurate and efficient predictions.
-
-### Conclusion
-Support Vector Regression is a versatile and powerful algorithm for regression tasks. By understanding its assumptions, advantages, and implementation steps, practitioners can effectively leverage SVR for a variety of predictive modeling tasks in data science and machine learning projects.
diff --git a/docs/Machine Learning/Transfer Learning.md b/docs/Machine Learning/Transfer Learning.md
deleted file mode 100644
index bc462ecdd..000000000
--- a/docs/Machine Learning/Transfer Learning.md
+++ /dev/null
@@ -1,169 +0,0 @@
----
-id: transfer-learning
-title: Transfer Learning
-sidebar_label: Introduction to Transfer Learning
-sidebar_position: 1
-tags: [Transfer Learning, neural networks, machine learning, data science, deep learning, pre-trained models, fine-tuning, feature extraction]
-description: In this tutorial, you will learn about Transfer Learning, its importance, what Transfer Learning is, why learn Transfer Learning, how to use Transfer Learning, steps to start using Transfer Learning, and more.
-
----
-
-### Introduction to Transfer Learning
-Transfer Learning is a machine learning technique where a model developed for one task is reused as the starting point for a model on a second task. This approach leverages pre-trained models, often trained on large datasets, to improve performance on a related task with less data and computation. Transfer Learning is particularly powerful in deep learning, enabling rapid progress and improved performance across various applications.
-
-### What is Transfer Learning?
-**Transfer Learning** involves taking a pre-trained model and adapting it to a new, often related, task. This can be done in several ways:
-
-- **Feature Extraction**: Using the pre-trained model's layers as feature extractors. The learned features are fed into a new model for the specific task.
-- **Fine-Tuning**: Starting with the pre-trained model and fine-tuning its weights on the new task. This involves retraining some or all of the layers.
-
-Pre-trained models are typically trained on large datasets like ImageNet, which contains millions of images and thousands of classes, providing a rich feature space.
-
-:::info
-**Feature Extraction**: Utilizes the representations learned by a pre-trained model to extract features from new data. Often involves freezing the layers of the pre-trained model.
-
-**Fine-Tuning**: Involves retraining some or all of the pre-trained model's layers to adapt them to the new task. This can improve performance but requires more computational resources.
-:::
-
-### Example:
-Consider using a pre-trained model like VGG16 for image classification. You can use the convolutional base of VGG16 to extract features from your dataset and train a new classifier on top of these features, significantly reducing the amount of data and training time needed.
-
-### Advantages of Transfer Learning
-Transfer Learning offers several advantages:
-
-- **Reduced Training Time**: By leveraging pre-trained models, you can reduce the time required to train a new model.
-- **Improved Performance**: Pre-trained models have learned rich feature representations, which can enhance performance on related tasks.
-- **Less Data Required**: Transfer Learning can achieve good performance even with limited data for the new task.
-
-### Example:
-In medical image analysis, where annotated data is scarce, Transfer Learning allows practitioners to build accurate models by starting with pre-trained models trained on general image datasets.
-
-### Disadvantages of Transfer Learning
-Despite its advantages, Transfer Learning has limitations:
-
-- **Compatibility Issues**: The pre-trained model needs to be somewhat relevant to the new task for effective transfer.
-- **Computational Resources**: Fine-tuning a pre-trained model can be computationally expensive, requiring significant resources.
-
-### Example:
-In natural language processing, using a pre-trained model trained on general text data might not transfer well to domain-specific tasks without significant fine-tuning.
-
-### Practical Tips for Using Transfer Learning
-To maximize the effectiveness of Transfer Learning:
-
-- **Choose the Right Model**: Select a pre-trained model that is closely related to your task. For image tasks, models like ResNet, VGG, or Inception are popular choices.
-- **Freeze Layers Appropriately**: Start by freezing the early layers of the pre-trained model and only train the new layers. Gradually unfreeze layers and fine-tune as needed.
-- **Use Appropriate Data Augmentation**: Apply data augmentation techniques to increase the diversity of your training data and improve the model's robustness.
-
-### Example:
-In sentiment analysis, using a pre-trained language model like BERT can significantly improve performance. Fine-tuning BERT on a small annotated dataset can yield state-of-the-art results.
-
-### Real-World Examples
-
-#### Image Classification
-Transfer Learning is widely used in image classification tasks. Pre-trained models on ImageNet can be fine-tuned for specific tasks like medical image diagnosis, wildlife classification, and more.
-
-#### Natural Language Processing
-In NLP, models like BERT, GPT, and ELMo are pre-trained on large text corpora and fine-tuned for tasks such as sentiment analysis, named entity recognition, and machine translation.
-
-### Difference Between Transfer Learning and Traditional Machine Learning
-
-| Feature | Transfer Learning | Traditional Machine Learning |
-|----------------------------------|------------------------------------------|-----------------------------------------|
-| Training Time | Reduced due to pre-trained models | Longer, as models are trained from scratch |
-| Data Requirements | Requires less data for the new task | Requires large amounts of task-specific data |
-| Performance | Often higher due to rich pre-trained features | Depends heavily on the size and quality of the dataset |
-| Use Cases | Image classification, NLP, medical imaging | General machine learning tasks |
-
-### Implementation
-To implement Transfer Learning, you can use libraries such as TensorFlow, Keras, or PyTorch in Python. Below are the steps to install the necessary libraries and apply Transfer Learning.
-
-#### Libraries to Download
-
-- `TensorFlow` or `PyTorch`: Essential for building and training models.
-- `numpy`: Useful for numerical operations.
-- `matplotlib`: Useful for visualizing training progress and results.
-
-You can install these libraries using pip:
-
-```bash
-pip install tensorflow numpy matplotlib
-```
-
-#### Applying Transfer Learning
-Here’s a step-by-step guide to applying Transfer Learning using TensorFlow and Keras:
-
-**Import Libraries:**
-
-```python
-import numpy as np
-import matplotlib.pyplot as plt
-import tensorflow as tf
-from tensorflow.keras.layers import Dense, GlobalAveragePooling2D
-from tensorflow.keras.models import Model
-from tensorflow.keras.applications import VGG16
-from tensorflow.keras.preprocessing.image import ImageDataGenerator
-```
-
-**Load Pre-trained Model and Prepare Data:**
-
-```python
-# Load VGG16 model with pre-trained weights
-base_model = VGG16(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
-
-# Freeze the layers of the pre-trained model
-for layer in base_model.layers:
- layer.trainable = False
-
-# Prepare data generators
-train_datagen = ImageDataGenerator(rescale=1./255, horizontal_flip=True, zoom_range=0.2, rotation_range=20)
-train_generator = train_datagen.flow_from_directory('path_to_train_data', target_size=(224, 224), batch_size=32, class_mode='binary')
-
-validation_datagen = ImageDataGenerator(rescale=1./255)
-validation_generator = validation_datagen.flow_from_directory('path_to_validation_data', target_size=(224, 224), batch_size=32, class_mode='binary')
-```
-
-**Add Custom Layers and Compile Model:**
-
-```python
-# Add custom layers on top of the pre-trained base
-x = base_model.output
-x = GlobalAveragePooling2D()(x)
-x = Dense(1024, activation='relu')(x)
-predictions = Dense(1, activation='sigmoid')(x)
-
-# Define the new model
-model = Model(inputs=base_model.input, outputs=predictions)
-
-# Compile the model
-model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
-```
-
-**Train the Model:**
-
-```python
-# Train the model
-history = model.fit(train_generator, epochs=10, validation_data=validation_generator)
-
-# Plot training and validation accuracy
-plt.plot(history.history['accuracy'], label='train accuracy')
-plt.plot(history.history['val_accuracy'], label='validation accuracy')
-plt.title('Training and Validation Accuracy')
-plt.xlabel('Epochs')
-plt.ylabel('Accuracy')
-plt.legend()
-plt.show()
-```
-
-This example demonstrates how to load a pre-trained VGG16 model, add custom layers, and train it on a new dataset using TensorFlow and Keras. Adjust the model architecture, hyperparameters, and dataset as needed for your specific use case.
-
-### Performance Considerations
-
-#### Fine-Tuning Strategy
-- **Gradual Unfreezing**: Start by training only the custom layers. Gradually unfreeze and fine-tune the upper layers of the pre-trained model to adapt them to your task.
-- **Learning Rate**: Use a lower learning rate for fine-tuning the pre-trained layers to prevent large updates that could destroy the learned features.
-
-### Example:
-In fine-tuning a pre-trained model for object detection, starting with a low learning rate and gradually unfreezing layers can lead to improved performance and stability.
-
-### Conclusion
-Transfer Learning is a powerful technique that leverages pre-trained models to improve performance and reduce training time for new tasks. By understanding the principles, advantages, and practical implementation steps, practitioners can effectively apply Transfer Learning to various machine learning challenges, enhancing their models' efficiency and effectiveness.
diff --git a/docs/Machine Learning/linear_regression.md b/docs/Machine Learning/linear_regression.md
deleted file mode 100644
index 9cfd2277f..000000000
--- a/docs/Machine Learning/linear_regression.md
+++ /dev/null
@@ -1,128 +0,0 @@
-# Linear Regression
-
-### Introduction to Linear Regression
-
-Linear regression is a fundamental and widely used statistical technique for predicting numeric outcomes based on one or more independent variables. This document provides an overview of linear regression, including its principles, advantages, disadvantages, and practical considerations for application.
-
-### Overview of Linear Regression Model
-
-Linear regression models the relationship between a dependent variable (target) and one or more independent variables (predictors) by fitting a linear equation to observed data.
-
-### Formula:
-
-$$Y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \beta_3 x_3 + \cdots + \beta_n x_n + \epsilon$$
-
-
-#### y: Dependent variable (target)
-
-#### 𝛽0 : Intercept
-
-#### 𝛽i : Coefficients for each predictor 𝑥𝑖(Independent variables)
-
-
-#### ϵ: Error term (residuals)
-
-
-### Example:
-
-In predicting house prices, linear regression may model the relationship between house size, number of bedrooms, and location to estimate the sale price of a property.
-
-### Code:
-```python
-#import libraries
-from matplotlib import pyplot as plt
-import pandas as pd
-from sklearn.model_selection import train_test_split
-from sklearn.linear_model import LinearRegression
-from sklearn.metrics import r2_score
-
-#read the file
-df=pd.read_csv("data.csv")
-
-#assign x(independent variable) and y(dependent variable) from the dataset
-y=df['A']
-x=df['B']
-
-#split the data into training and testing sets
-X_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.25,random_state=50)
-
-#object
-linreg=LinearRegression()
-linreg.fit(X_train,y_train)
-
-#predict for test data
-y_pred=linreg.predict(x_test)
-
-#regression line
-plt.xlabel("B")
-plt.ylabel("A")
-plt.plot(x_test,y_pred)
-plt.scatter(x_test,y_test)
-
-#evaluation of model
-print("r2 score : ",r2_score(y_test,y_pred))
-```
-
-### Advantages of Linear Regression
-
-#### Linear regression offers several advantages:
-
-- Interpretability: Coefficients indicate the strength and direction of relationships between predictors and the target variable.
-
-- Simple to Implement: The model is straightforward to implement and understand, making it accessible for beginners and useful for quick insights.
-
-- Efficient Computation: Training and predicting with linear regression are computationally efficient even with large datasets.
-
-#### Example:
-
-In marketing, linear regression helps analyze the impact of advertising spend on sales revenue, guiding budget allocation decisions for optimal ROI.
-
-### Disadvantages of Linear Regression
-
-Despite its advantages, linear regression has limitations:
-
-- Assumption of Linearity: Linear regression assumes a linear relationship between predictors and the target, which may not hold true for complex real-world data.
-
-- Sensitive to Outliers: Outliers can disproportionately influence the regression coefficients and predictions.
-
-- Limited Flexibility: Linear regression may underperform with nonlinear relationships, requiring transformations or more complex models.
-
-#### Example:
-In economic forecasting, linear regression may struggle to predict GDP growth during periods of economic volatility due to nonlinear factors influencing economic performance.
-
-### Practical Tips for Using Linear Regression
-
-#### To maximize the effectiveness of linear regression:
-
-- Feature Engineering: Select relevant predictors and consider transformations to improve model performance.
-
-- Residual Analysis: Evaluate residuals to check model assumptions and identify outliers or patterns that could impact predictions.
-
-- Regularization: Apply regularization techniques (e.g., Ridge, Lasso regression) to handle multicollinearity and improve model robustness.
-
-#### Example:
-
-In healthcare analytics, linear regression assists in predicting patient readmission rates based on demographic factors and medical history, facilitating resource allocation and patient care planning.
-
-### Real-World Applications
-
-#### Sales Forecasting in Retail
-
-Linear regression is widely applied in retail for sales forecasting. By analyzing historical sales data and economic indicators, retailers can predict future sales trends and optimize inventory management.
-
-#### Academic Performance Prediction
-
-In education, linear regression helps predict student performance based on factors such as attendance, study hours, and socioeconomic background, enabling targeted interventions to improve educational outcomes.
-
-### Performance Considerations
-
-- Model Complexity and Scalability
-Large Datasets: Linear regression remains efficient for large datasets but may require regularization techniques to handle high-dimensional data.
-
-- Computational Resources: Model training and inference are generally fast, but scalability can be impacted by the number of predictors and data volume.
-
-#### Example:
-In environmental science, linear regression models are used to analyze the relationship between pollution levels, weather patterns, and health outcomes, guiding public health policies and interventions.
-
-### Conclusion
-Linear regression is a versatile and widely used statistical technique that provides valuable insights into relationships between variables. Understanding its principles and limitations is essential for leveraging its predictive power effectively across various domains and applications.
diff --git a/docs/Machine Learning/t-Distributed Stochastic Neighbor Embedding.md b/docs/Machine Learning/t-Distributed Stochastic Neighbor Embedding.md
deleted file mode 100644
index aea9fdb08..000000000
--- a/docs/Machine Learning/t-Distributed Stochastic Neighbor Embedding.md
+++ /dev/null
@@ -1,141 +0,0 @@
----
-id: t-distributed-stochastic-neighbor-embedding
-title: t-Distributed Stochastic Neighbor Embedding
-sidebar_label: Introduction to t-Distributed Stochastic Neighbor Embedding
-sidebar_position: 2
-tags: [t-Distributed Stochastic Neighbor Embedding, t-SNE, dimensionality reduction, data visualization, machine learning, data science, non-linear dimensionality reduction, feature reduction]
-description: In this tutorial, you will learn about t-Distributed Stochastic Neighbor Embedding (t-SNE), its significance, what t-SNE is, why learn t-SNE, how to use t-SNE, steps to start using t-SNE, and more.
----
-
-### Introduction to t-Distributed Stochastic Neighbor Embedding
-t-Distributed Stochastic Neighbor Embedding (t-SNE) is a popular dimensionality reduction technique used to visualize high-dimensional data in a lower-dimensional space, typically 2D or 3D. It is particularly effective in preserving the local structure of the data, making it an invaluable tool for exploring and understanding complex datasets.
-
-### What is t-Distributed Stochastic Neighbor Embedding?
-t-SNE works by converting high-dimensional data into a probability distribution that captures pairwise similarities between data points. It then maps these points to a lower-dimensional space while preserving these similarities.
-
-- **High-Dimensional Data**: Data is represented in a high-dimensional space with complex structures.
-- **Probability Distribution**: t-SNE calculates the similarity between data points using conditional probabilities.
-- **Low-Dimensional Mapping**: The algorithm minimizes the divergence between the high-dimensional and low-dimensional probability distributions, resulting in a 2D or 3D representation.
-
-**Similarity Measurement**: Uses Gaussian distribution to measure similarity in high-dimensional space and Student’s t-distribution for low-dimensional space.
-
-### Example:
-Consider using t-SNE to visualize clusters in a dataset of handwritten digits. By reducing the data to 2D, you can observe how different digits group together, revealing underlying patterns and clusters.
-
-### Advantages of t-Distributed Stochastic Neighbor Embedding
-t-SNE offers several advantages:
-
-- **Preserves Local Structure**: Maintains the local relationships between data points, making clusters and patterns more apparent.
-- **Non-Linear Mapping**: Capable of capturing complex, non-linear structures in the data.
-- **Intuitive Visualization**: Produces intuitive and interpretable visualizations of high-dimensional data.
-
-### Example:
-In bioinformatics, t-SNE can be used to visualize gene expression profiles, revealing patterns and relationships between different genes or samples.
-
-### Disadvantages of t-Distributed Stochastic Neighbor Embedding
-Despite its strengths, t-SNE has limitations:
-
-- **Computational Complexity**: Can be computationally intensive, especially with large datasets.
-- **Parameter Sensitivity**: Results can be sensitive to hyperparameters, such as perplexity and learning rate.
-- **Global Structure**: May not preserve global structures or distances well, focusing more on local relationships.
-
-### Example:
-In large-scale image datasets, t-SNE might struggle to maintain meaningful global relationships between images, potentially making it less effective for certain types of analysis.
-
-### Practical Tips for Using t-Distributed Stochastic Neighbor Embedding
-To get the most out of t-SNE:
-
-- **Choose Perplexity Wisely**: Perplexity is a key parameter that controls the balance between local and global aspects of the data. Experiment with different values to find the best representation.
-- **Normalize Data**: Preprocess and normalize data to ensure that t-SNE operates on well-conditioned inputs.
-- **Use Dimensionality Reduction Preprocessing**: Apply initial dimensionality reduction (e.g., PCA) to reduce the computational burden and improve the performance of t-SNE.
-
-### Example:
-In a text analysis project, you can preprocess word embeddings using t-SNE to visualize and cluster similar words or documents based on their semantic content.
-
-### Real-World Examples
-
-#### Image Analysis
-t-SNE is often used in computer vision to visualize the clusters of similar images in a dataset, helping to understand and evaluate image classification algorithms.
-
-#### Customer Segmentation
-In marketing analytics, t-SNE can visualize customer segments based on purchasing behavior, aiding in the development of targeted marketing strategies.
-
-### Difference Between t-SNE and PCA
-| Feature | t-Distributed Stochastic Neighbor Embedding (t-SNE) | Principal Component Analysis (PCA) |
-|---------------------------------|------------------------------------------------------|-----------------------------------|
-| Linear vs Non-Linear | Non-linear dimensionality reduction. | Linear dimensionality reduction. |
-| Preserved Structure | Preserves local structure; may distort global structure. | Preserves global structure; may not capture local nuances. |
-| Computational Cost | Computationally intensive with large datasets. | Generally faster and more scalable. |
-
-### Implementation
-To implement and visualize data using t-SNE, you can use libraries such as scikit-learn in Python. Below are the steps to install the necessary library and apply t-SNE.
-
-#### Libraries to Download
-- scikit-learn: Provides the implementation of t-SNE.
-- matplotlib: Useful for data visualization.
-- pandas: Useful for data manipulation and analysis.
-- numpy: Essential for numerical operations.
-
-You can install these libraries using pip:
-
-```bash
-pip install scikit-learn matplotlib pandas numpy
-```
-
-#### Applying t-Distributed Stochastic Neighbor Embedding
-Here’s a step-by-step guide to applying t-SNE:
-
-**Import Libraries:**
-
-```python
-import pandas as pd
-import numpy as np
-from sklearn.manifold import TSNE
-import matplotlib.pyplot as plt
-```
-
-**Load and Prepare Data:**
-Assuming you have a dataset in a CSV file:
-
-```python
-# Load the dataset
-data = pd.read_csv('your_dataset.csv')
-
-# Prepare features (X)
-X = data.drop('target_column', axis=1) # Replace 'target_column' with any non-feature columns
-```
-
-**Apply t-SNE:**
-
-```python
-# Initialize t-SNE
-tsne = TSNE(n_components=2, random_state=42)
-
-# Fit and transform the data
-X_tsne = tsne.fit_transform(X)
-```
-
-**Visualize the Results:**
-
-```python
-# Plot t-SNE results
-plt.figure(figsize=(10, 8))
-plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c=data['target_column'], cmap='viridis', alpha=0.7)
-plt.colorbar()
-plt.title('t-SNE Visualization')
-plt.xlabel('Component 1')
-plt.ylabel('Component 2')
-plt.show()
-```
-
-### Performance Considerations
-
-#### Computational Efficiency
-- **Dataset Size**: t-SNE can be slow for very large datasets. Consider using a subset of the data or combining it with other dimensionality reduction techniques (e.g., PCA) to speed up the process.
-- **Hyperparameters**: Proper tuning of hyperparameters, such as perplexity, can affect both the quality of the results and the computational cost.
-
-### Example:
-In a large-scale text dataset, combining t-SNE with PCA for initial dimensionality reduction can make the visualization process more manageable and faster.
-
-### Conclusion
-t-Distributed Stochastic Neighbor Embedding is a powerful technique for visualizing and understanding high-dimensional data. By grasping its strengths, limitations, and implementation, practitioners can effectively leverage t-SNE to gain insights and make sense of complex datasets in various data science and machine learning projects.
diff --git a/docs/Operating System/_category_.json b/docs/Operating System/_category_.json
deleted file mode 100644
index 5ab9f65df..000000000
--- a/docs/Operating System/_category_.json
+++ /dev/null
@@ -1,8 +0,0 @@
-{
- "label": "Operating System",
- "position": 18,
- "link": {
- "type": "generated-index",
- "description": "Operating System lies in the category of system software. It basically manages all the resources of the computer"
- }
-}
diff --git a/docs/Operating System/device_management.md b/docs/Operating System/device_management.md
deleted file mode 100644
index 025662ded..000000000
--- a/docs/Operating System/device_management.md
+++ /dev/null
@@ -1,92 +0,0 @@
----
-id: device-management
-title: device-management
-sidebar_label: Device Management
-sidebar_position: 12
-tags: [operating_system, create database, commands]
-description: Device management is a crucial function of an operating system that handles the communication and control of hardware devices.
----
-# Device Management
-
-## Introduction
-Device management is a crucial function of an operating system that handles the communication and control of hardware devices. It ensures that hardware resources are used efficiently and provides a way for software applications to interact with hardware devices.
-
-## Key Concepts
-
-### 1. Device Types
-Devices can be broadly categorized into two types:
-- **Block Devices**: These devices store data in fixed-size blocks, each with its own address. Examples include hard drives and CD-ROMs.
-- **Character Devices**: These devices transmit data as a stream of bytes. Examples include keyboards, mice, and serial ports.
-
-### 2. Device Controllers
-A device controller is a hardware component that manages a specific type of device. It communicates with the CPU and the device it controls. Each device controller has registers to store commands, status, and data.
-
-### 3. Device Drivers
-Device drivers are software programs that act as an interface between the operating system and hardware devices. They translate high-level commands from the OS into device-specific operations.
-
-## Device Management Functions
-
-### 1. Device Allocation
-The operating system allocates devices to processes as needed. This involves:
-- **Exclusive Allocation**: Some devices can be allocated to only one process at a time.
-- **Shared Allocation**: Some devices can be shared among multiple processes.
-
-### 2. Device Scheduling
-The OS schedules access to devices to ensure efficient and fair use. This is similar to CPU scheduling but with different algorithms tailored to the specific device.
-
-### 3. Device Queues
-Each device has a queue to manage the requests from processes. The OS uses different scheduling algorithms to process these queues.
-
-## I/O Control Methods
-
-### 1. Programmed I/O
-The CPU is responsible for executing I/O operations, constantly checking the device's status, and transferring data as needed. This method is simple but inefficient as the CPU is tied up during I/O operations.
-
-### 2. Interrupt-Driven I/O
-The device generates an interrupt when it is ready for the next part of the I/O operation, allowing the CPU to execute other instructions between interrupts. This method improves CPU utilization.
-
-### 3. Direct Memory Access (DMA)
-DMA allows devices to transfer data directly to or from memory without involving the CPU for each byte of transfer. The CPU sets up the DMA controller, which then handles the data transfer independently, significantly improving efficiency.
-
-## Device Management Techniques
-
-### 1. Buffering
-Buffering involves using memory areas to temporarily hold data while it is being transferred between devices or between a device and an application. It helps to accommodate speed differences between the producer and consumer of the data.
-
-### 2. Caching
-Caching involves keeping copies of frequently accessed data in a faster storage medium to reduce access time. This is commonly used for disk I/O operations.
-
-### 3. Spooling
-Spooling (Simultaneous Peripheral Operations On-line) is a technique where data is written to an intermediate storage (usually a disk) to be processed later. This is commonly used for managing printer queues.
-
-## Device Drivers
-
-### 1. Device Driver Structure
-A typical device driver consists of:
-- **Initialization Code**: Sets up the device and registers it with the OS.
-- **I/O Operations**: Handles read and write operations.
-- **Interrupt Handling**: Manages device interrupts.
-- **Cleanup Code**: Frees resources when the device is no longer needed.
-
-### 2. Writing Device Drivers
-Writing device drivers requires understanding the device's hardware interface and the operating system's driver interface. Drivers must be efficient and handle errors gracefully.
-
-## Device Management in Modern Operating Systems
-
-### 1. Plug and Play (PnP)
-Modern operating systems support Plug and Play, allowing devices to be automatically detected, configured, and used without manual intervention. PnP involves:
-- **Device Detection**: Identifying the presence of a new device.
-- **Resource Allocation**: Assigning system resources like IRQs and memory addresses to the device.
-- **Driver Installation**: Loading the appropriate device driver.
-
-### 2. Power Management
-Device management also involves managing the power state of devices to conserve energy. Techniques include:
-- **Power States**: Devices can be in different power states (e.g., active, standby, sleep).
-- **Dynamic Power Management**: Adjusting power usage based on device activity.
-
-## Conclusion
-Device management is essential for the efficient and effective use of hardware resources in an operating system. It involves allocating devices, scheduling access, handling I/O operations, and ensuring smooth communication between hardware and software. Understanding device management helps in optimizing system performance and enhancing user experience.
-
----
-
-Efficient device management is a cornerstone of modern operating systems, enabling seamless interaction between software applications and hardware components, and ensuring optimal resource utilization and system performance.
diff --git a/docs/Operating System/distributed_systems.md b/docs/Operating System/distributed_systems.md
deleted file mode 100644
index 7b41bc355..000000000
--- a/docs/Operating System/distributed_systems.md
+++ /dev/null
@@ -1,94 +0,0 @@
----
-id: distributed-systems
-title: distributed-systems
-sidebar_label: Distributed Systems
-sidebar_position: 14
-tags: [operating_system, create database, commands]
-description: A distributed system is a collection of independent computers that appear to the users of the system as a single coherent system.
----
-# Distributed Systems
-
-## Introduction
-A distributed system is a collection of independent computers that appear to the users of the system as a single coherent system. These systems collaborate to achieve a common goal, sharing resources and communicating over a network.
-
-## Key Concepts
-
-### 1. Characteristics of Distributed Systems
-- **Resource Sharing**: Resources such as files, printers, and data are shared among multiple systems.
-- **Openness**: The system is open if it is easy to add new components and to expand existing services.
-- **Concurrency**: Multiple processes run concurrently, accessing shared resources.
-- **Scalability**: The system can handle the addition of users, resources, and services without performance degradation.
-- **Fault Tolerance**: The system can continue to operate, possibly at a reduced level, when part of the system fails.
-- **Transparency**: The complexity of the distributed nature of the system is hidden from users.
-
-### 2. Types of Distributed Systems
-- **Client-Server Systems**: Clients request services, and servers provide them. Examples include web services and database systems.
-- **Peer-to-Peer Systems**: Each node acts as both a client and a server. Examples include file-sharing networks and blockchain.
-- **Distributed Computing Systems**: Multiple computers work together on a single task. Examples include grid computing and cloud computing.
-
-## Distributed System Models
-
-### 1. Architectural Models
-- **Layered Architecture**: The system is organized into layers, each providing services to the layer above and consuming services of the layer below.
-- **Object-Based Architecture**: The system is composed of objects that interact with each other. Examples include CORBA and DCOM.
-- **Data-Centered Architecture**: Data is shared among multiple clients through a central repository. Examples include distributed databases and shared filesystems.
-- **Event-Based Architecture**: Components communicate by broadcasting and receiving events. Examples include publish-subscribe systems.
-
-### 2. Interaction Models
-- **Synchronous Communication**: The sender waits for the receiver to acknowledge receipt of the message.
-- **Asynchronous Communication**: The sender does not wait for the receiver to acknowledge receipt of the message.
-- **Remote Procedure Calls (RPC)**: A function call that is executed on a remote server.
-- **Message Passing**: Components communicate by sending and receiving messages.
-
-## Challenges in Distributed Systems
-
-### 1. Network Issues
-- **Latency**: The time taken for a message to travel from sender to receiver.
-- **Bandwidth**: The capacity of the network to transmit data.
-- **Jitter**: Variation in the time taken for messages to travel.
-
-### 2. Security
-- **Authentication**: Verifying the identity of users and systems.
-- **Authorization**: Ensuring users have permission to access resources.
-- **Encryption**: Protecting data from unauthorized access during transmission.
-
-### 3. Fault Tolerance
-- **Redundancy**: Duplicating critical components to ensure availability.
-- **Replication**: Copying data across multiple systems to prevent data loss.
-- **Checkpointing**: Saving the state of a system at intervals to enable recovery.
-
-### 4. Synchronization
-- **Clock Synchronization**: Ensuring all systems have a consistent view of time.
-- **Coordination**: Managing the execution order of processes in different systems.
-
-## Distributed Algorithms
-
-### 1. Consensus Algorithms
-- **Paxos**: A protocol for achieving consensus in a network of unreliable processors.
-- **Raft**: A consensus algorithm designed to be understandable and easier to implement than Paxos.
-
-### 2. Distributed Hash Tables (DHT)
-- **Chord**: A protocol and algorithm for a peer-to-peer distributed hash table.
-- **Kademlia**: A distributed hash table for decentralized peer-to-peer computer networks.
-
-### 3. Leader Election Algorithms
-- **Bully Algorithm**: A process elects itself as the leader if it has the highest process ID.
-- **Ring Algorithm**: Processes are arranged in a logical ring, and election messages are passed around the ring.
-
-## Case Studies
-
-### 1. Google File System (GFS)
-A scalable distributed file system designed for large data-intensive applications. It provides fault tolerance and high throughput.
-
-### 2. Hadoop Distributed File System (HDFS)
-A distributed file system designed to run on commodity hardware. It is highly fault-tolerant and designed for large-scale data processing.
-
-### 3. Amazon DynamoDB
-A highly available and scalable distributed data store. It uses a combination of techniques like consistent hashing, replication, and versioning to achieve high availability and scalability.
-
-## Conclusion
-Distributed systems offer numerous benefits, including resource sharing, scalability, and fault tolerance. However, they also pose significant challenges, such as ensuring security, synchronization, and fault tolerance. Understanding the key concepts, models, and algorithms of distributed systems is crucial for designing and managing efficient and robust systems.
-
----
-
-By leveraging the principles and techniques of distributed systems, organizations can build scalable, reliable, and efficient systems that meet the demands of modern applications.
diff --git a/docs/Operating System/file_systems.md b/docs/Operating System/file_systems.md
deleted file mode 100644
index 467202963..000000000
--- a/docs/Operating System/file_systems.md
+++ /dev/null
@@ -1,109 +0,0 @@
----
-id: file_systems
-title: file_systems
-sidebar_label: File Systems
-sidebar_position: 11
-tags: [operating_system, create database, commands]
-description: A file system is a method and data structure that the operating system uses to control how data is stored and retrieved.
----
-
-# File Systems
-
-## Introduction
-A file system is a method and data structure that the operating system uses to control how data is stored and retrieved. Without a file system, information placed in a storage medium would be one large body of data with no way to tell where one piece of information stops and the next begins.
-
-## Key Concepts
-
-### 1. File
-A file is a collection of related information that is recorded on secondary storage. A file can contain programs, data, or both.
-
-### 2. Directory
-A directory is a special type of file that contains a list of files and other directories. Directories help in organizing files into a hierarchical structure.
-
-### 3. Path
-The path specifies the location of a file or directory in the file system. Paths can be absolute (starting from the root directory) or relative (starting from the current directory).
-
-## File Attributes
-Files have attributes that provide additional information about the file:
-- **Name**: The human-readable name of the file.
-- **Type**: The type of the file (e.g., text, binary, executable).
-- **Location**: The location of the file on the storage medium.
-- **Size**: The size of the file in bytes.
-- **Protection**: Access control information (e.g., read, write, execute permissions).
-- **Timestamps**: Information about the file's creation, modification, and last access times.
-
-## File Operations
-Common file operations include:
-- **Create**: Creating a new file.
-- **Open**: Opening an existing file for reading or writing.
-- **Close**: Closing an open file.
-- **Read**: Reading data from a file.
-- **Write**: Writing data to a file.
-- **Delete**: Deleting a file.
-- **Rename**: Changing the name of a file.
-
-## Directory Structure
-
-### Single-Level Directory
-All files are contained in a single directory. This simple structure can lead to name conflicts and is not scalable for larger systems.
-
-### Two-Level Directory
-There is a separate directory for each user. This structure solves the name conflict issue but still has limitations in organizing a large number of files.
-
-### Tree-Structured Directory
-Directories are organized in a tree structure, allowing for a hierarchical organization of files. Each directory can contain files and subdirectories.
-
-### Acyclic-Graph Directory
-Directories form an acyclic graph, allowing shared subdirectories and files. This structure enables better organization and sharing but requires handling of link deletion and cycles.
-
-### General Graph Directory
-Allows for arbitrary links between directories and files, creating a general graph structure. This structure offers maximum flexibility but requires sophisticated algorithms to manage.
-
-## File Allocation Methods
-
-### Contiguous Allocation
-Files are stored in contiguous blocks of memory. This method is simple and efficient for sequential access but can lead to fragmentation and difficulty in file size extension.
-
-### Linked Allocation
-Files are stored as linked lists of blocks. Each block contains a pointer to the next block. This method eliminates fragmentation but can be inefficient for direct access.
-
-### Indexed Allocation
-An index block is created, which contains pointers to the actual data blocks of the file. This method supports both sequential and direct access but requires extra space for the index block.
-
-## Free Space Management
-
-### Bit Vector
-A bit vector is used to represent the free and allocated blocks. Each bit in the vector represents a block; 0 indicates free and 1 indicates allocated.
-
-### Linked List
-Free blocks are linked together, forming a list. Each free block contains a pointer to the next free block.
-
-### Grouping
-Similar to linked list but with a group of free blocks stored together. The first block of the group points to the next group of free blocks.
-
-### Counting
-Stores the address of the first free block and the number of free contiguous blocks that follow it.
-
-## Disk Scheduling Algorithms
-
-### First-Come, First-Served (FCFS)
-Processes disk requests in the order they arrive. Simple but can lead to inefficient use of the disk.
-
-### Shortest Seek Time First (SSTF)
-Selects the request that is closest to the current head position. Reduces seek time but can lead to starvation of some requests.
-
-### SCAN (Elevator Algorithm)
-The disk arm moves in one direction, fulfilling requests until it reaches the end, then reverses direction. Provides a more uniform wait time.
-
-### C-SCAN (Circular SCAN)
-Similar to SCAN, but when the disk arm reaches the end, it returns to the beginning and starts again. Provides a more uniform wait time.
-
-### LOOK and C-LOOK
-Similar to SCAN and C-SCAN but the disk arm only goes as far as the last request in each direction before reversing or restarting.
-
-## Conclusion
-File systems are a critical component of operating systems, providing a structured way to store, manage, and retrieve data. Understanding the various aspects of file systems, including file operations, directory structures, allocation methods, and disk scheduling algorithms, is essential for efficient data management and system performance.
-
----
-
-A well-designed file system ensures efficient storage, quick access, and effective management of data, contributing significantly to the overall performance and usability of an operating system.
diff --git a/docs/Operating System/function_of_OS.md b/docs/Operating System/function_of_OS.md
deleted file mode 100644
index 0ef406daf..000000000
--- a/docs/Operating System/function_of_OS.md
+++ /dev/null
@@ -1,184 +0,0 @@
----
-id: function-of-operating-system
-title: function-of-operating-system
-sidebar_label: Function of Operating System
-sidebar_position: 7
-tags: [operating_system, create database, commands]
-description: An Operating System acts as a communication bridge (interface) between the user and computer hardware.
----
-
-# Functions of Operating System
-
-An Operating System acts as a communication bridge (interface) between the user and computer hardware. The purpose of an operating system is to provide a platform on which a user can execute programs conveniently and efficiently.
-
-An operating system is a piece of software that manages the allocation of Computer Hardware. The coordination of the hardware must be appropriate to ensure the correct working of the computer system and to prevent user programs from interfering with the proper working of the system.
-
-The main goal of the Operating System is to make the computer environment more convenient to use and the secondary goal is to use the resources most efficiently.
-
-## What is an Operating System?
-
-An operating system is a program that manages a computer’s hardware. It also provides a basis for application programs and acts as an intermediary between the computer user and computer hardware. The main task an operating system carries out is the allocation of resources and services, such as the allocation of memory, devices, processors, and information. The operating system also includes programs to manage these resources, such as a traffic controller, a scheduler, a memory management module, I/O programs, and a file system. The operating system simply provides an environment within which other programs can do useful work.
-
-## Why are Operating Systems Used?
-
-Operating System is used as a communication channel between the computer hardware and the user. It works as an intermediate between system hardware and end-user. Operating System handles the following responsibilities:
-
-- It controls all the computer resources.
-
-- It provides valuable services to user programs.
-
-- It coordinates the execution of user programs.
-
-- It provides resources for user programs.
-
-- It provides an interface (virtual machine) to the user.
-
-- It hides the complexity of software.
-
-- It supports multiple execution modes.
-
-- It monitors the execution of user programs to prevent errors.
-
-## Functions of an Operating System
-
-### Memory Management
-
-The operating system manages the Primary Memory or Main Memory. Main memory is fast storage and it can be accessed directly by the CPU. For a program to be executed, it should be first loaded in the main memory. An operating system manages the allocation and deallocation of memory to various processes and ensures that the other process does not consume the memory allocated to one process. An Operating System performs the following activities for Memory Management:
-
-- It keeps track of primary memory, i.e., which bytes of memory are used by which user program.
-
-- In multiprogramming, the OS decides the order in which processes are granted memory access, and for how long.
-
-- It allocates the memory to a process when the process requests it and deallocates the memory when the process has terminated or is performing an I/O operation.
-
- 
-
-### Processor Management
-
-In a multi-programming environment, the OS decides the order in which processes have access to the processor, and how much processing time each process has. This function of OS is called Process Scheduling. An Operating System performs the following activities for Processor Management:
-
-- Manages the processor’s work by allocating various jobs to it and ensuring that each process receives enough time from the processor to function properly.
-
-- Keeps track of the status of processes. The program which performs this task is known as a traffic controller.
-
-- Allocates the CPU (processor) to a process.
-
-- Deallocates the processor when a process is no longer required.
-
- 
-
-### Device Management
-
-An OS manages device communication via its respective drivers. It performs the following activities for device management:
-
-- Keeps track of all devices connected to the system. Designates a program responsible for every device known as the Input/Output controller.
-
-- Decides which process gets access to a certain device and for how long.
-
-- Allocates devices effectively and efficiently.
-
-- Deallocates devices when they are no longer required.
-
-- Controls the working of input-output devices, receives requests from these devices, performs specific tasks, and communicates back to the requesting process.
-
-### File Management
-
-A file system is organized into directories for efficient or easy navigation and usage. These directories may contain other directories and other files. An Operating System carries out the following file management activities:
-
-- Keeps track of where information is stored, user access settings, the status of every file, and more. These facilities are collectively known as the file system.
-
-- Keeps track of information regarding the creation, deletion, transfer, copy, and storage of files in an organized way.
-
-- Maintains the integrity of the data stored in these files, including the file directory structure, by protecting against unauthorized access.
-
- 
-
-### User Interface or Command Interpreter
-
-The user interacts with the computer system through the operating system. Hence OS acts as an interface between the user and the computer hardware. This user interface is offered through a set of commands or a graphical user interface (GUI). Through this interface, the user interacts with the applications and the machine hardware.
-
- 
-
-### Booting the Computer
-
-The process of starting or restarting the computer is known as booting. If the computer is switched off completely and if turned on then it is called cold booting. Warm booting is a process of using the operating system to restart the computer.
-
-### Security
-
-The operating system uses password protection to protect user data and similar other techniques. It also prevents unauthorized access to programs and user data. The operating system provides various techniques which assure the integrity and confidentiality of user data:
-
-- Protection against unauthorized access through login.
-
-- Protection against intrusion by keeping the firewall active.
-
-- Protecting the system memory against malicious access.
-
-- Displaying messages related to system vulnerabilities.
-
-### Control Over System Performance
-
-Operating systems play a pivotal role in controlling and optimizing system performance. They act as intermediaries between hardware and software, ensuring that computing resources are efficiently utilized. One fundamental aspect is resource allocation, where the OS allocates CPU time, memory, and I/O devices to different processes, striving to provide fair and optimal resource utilization. Process scheduling, a critical function, helps decide which processes or threads should run when, preventing any single task from monopolizing the CPU and enabling effective multitasking.
-
- 
-
-### Job Accounting
-
-The operating system keeps track of time and resources used by various tasks and users. This information can be used to track resource usage for a particular user or group of users. In a multitasking OS where multiple programs run simultaneously, the OS determines which applications should run in which order and how time should be allocated to each application.
-
-### Error-Detecting Aids
-
-The operating system constantly monitors the system to detect errors and avoid malfunctioning computer systems. From time to time, the operating system checks the system for any external threat or malicious software activity. It also checks the hardware for any type of damage. This process displays several alerts to the user so that the appropriate action can be taken against any damage caused to the system.
-
-### Coordination Between Other Software and Users
-
-Operating systems also coordinate and assign interpreters, compilers, assemblers, and other software to the various users of the computer systems. In simpler terms, think of the operating system as the traffic cop of your computer. It directs and manages how different software programs can share your computer’s resources without causing chaos. It ensures that when you want to use a program, it runs smoothly without crashing or causing problems for others.
-
-### Performs Basic Computer Tasks
-
-The management of various peripheral devices such as the mouse, keyboard, and printer is carried out by the operating system. Today most operating systems are plug-and-play. These operating systems automatically recognize and configure the devices with no user interference.
-
-### Network Management
-
-- **Network Communication:** Operating systems help computers talk to each other and the internet. They manage how data is packaged and sent over the network, making sure it arrives safely and in the right order.
-
-- **Settings and Monitoring:** They let you set up your network connections, like Wi-Fi or Ethernet, and keep an eye on how your network is doing. They make sure your computer is using the network efficiently and securely, like adjusting the speed of your internet or protecting your computer from online threats.
-
-## Services Provided by an Operating System
-
-The Operating System provides certain services to the users which can be listed in the following manner:
-
-- **User Interface:** Almost all operating systems have a user interface (UI). This interface can take several forms such as command-line interface (CLI), batch interface, or graphical user interface (GUI).
-
-- **Program Execution:** Responsible for the execution of all types of programs whether it be user programs or system programs.
-
-- **Handling Input/Output Operations:** Responsible for handling all sorts of inputs, i.e., from the keyboard, mouse, desktop, etc.
-
-- **Manipulation of File System:** Responsible for making decisions regarding the storage of all types of data or files.
-
-- **Resource Allocation:** Ensures the proper use of all the resources available by deciding which resource to be used by whom for how much time.
-
-- **Accounting:** Tracks an account of all the functionalities taking place in the computer system at a time.
-
-- **Information and Resource Protection:** Uses all the information and resources available on the machine in the most protected way.
-
-- **Communication:** Implements communication between one process to another process to exchange information.
-
-- **System Services:** Provides various system services, such as printing, time and date management, and event logging.
-
-- **Error Detection:** Needs to detect and correct errors constantly to ensure correct and consistent computing.
-
-## Characteristics of Operating System
-
-- **Virtualization:** Provides virtualization capabilities, allowing multiple operating systems or instances of an operating system to run on a single physical machine.
-
-- **Networking:** Provides networking capabilities, allowing the computer system to connect to other systems and devices over a network.
-
-- **Scheduling:** Provides scheduling algorithms that determine the order in which tasks are executed on the system.
-
-- **Interprocess Communication:** Provides mechanisms for applications to communicate with each other, allowing them to share data and coordinate their activities.
-
-- **Performance Monitoring:** Provides tools for monitoring system performance, including CPU usage, memory usage, disk usage, and network activity.
-
-- **Backup and Recovery:** Provides backup and recovery mechanisms to protect data in the event of system failure or data loss.
-
-- **Debugging:** Provides
diff --git a/docs/Operating System/image-1.png b/docs/Operating System/image-1.png
deleted file mode 100644
index ad0257ffc..000000000
Binary files a/docs/Operating System/image-1.png and /dev/null differ
diff --git a/docs/Operating System/image-10.png b/docs/Operating System/image-10.png
deleted file mode 100644
index 6943aef0e..000000000
Binary files a/docs/Operating System/image-10.png and /dev/null differ
diff --git a/docs/Operating System/image-11.png b/docs/Operating System/image-11.png
deleted file mode 100644
index ea9968ace..000000000
Binary files a/docs/Operating System/image-11.png and /dev/null differ
diff --git a/docs/Operating System/image-12.png b/docs/Operating System/image-12.png
deleted file mode 100644
index 7a0b932f5..000000000
Binary files a/docs/Operating System/image-12.png and /dev/null differ
diff --git a/docs/Operating System/image-2.png b/docs/Operating System/image-2.png
deleted file mode 100644
index bb1b079fd..000000000
Binary files a/docs/Operating System/image-2.png and /dev/null differ
diff --git a/docs/Operating System/image-3.png b/docs/Operating System/image-3.png
deleted file mode 100644
index b1d3a34d1..000000000
Binary files a/docs/Operating System/image-3.png and /dev/null differ
diff --git a/docs/Operating System/image-4.png b/docs/Operating System/image-4.png
deleted file mode 100644
index e954f063c..000000000
Binary files a/docs/Operating System/image-4.png and /dev/null differ
diff --git a/docs/Operating System/image-5.png b/docs/Operating System/image-5.png
deleted file mode 100644
index a16e8dfc0..000000000
Binary files a/docs/Operating System/image-5.png and /dev/null differ
diff --git a/docs/Operating System/image-6.png b/docs/Operating System/image-6.png
deleted file mode 100644
index 271c161c8..000000000
Binary files a/docs/Operating System/image-6.png and /dev/null differ
diff --git a/docs/Operating System/image-7.png b/docs/Operating System/image-7.png
deleted file mode 100644
index 6aed8089a..000000000
Binary files a/docs/Operating System/image-7.png and /dev/null differ
diff --git a/docs/Operating System/image-8.png b/docs/Operating System/image-8.png
deleted file mode 100644
index b3267089d..000000000
Binary files a/docs/Operating System/image-8.png and /dev/null differ
diff --git a/docs/Operating System/image-9.png b/docs/Operating System/image-9.png
deleted file mode 100644
index cbbbd8f88..000000000
Binary files a/docs/Operating System/image-9.png and /dev/null differ
diff --git a/docs/Operating System/image.png b/docs/Operating System/image.png
deleted file mode 100644
index 5446f3352..000000000
Binary files a/docs/Operating System/image.png and /dev/null differ
diff --git a/docs/Operating System/intro_to_OS.md b/docs/Operating System/intro_to_OS.md
deleted file mode 100644
index fedf2bf7d..000000000
--- a/docs/Operating System/intro_to_OS.md
+++ /dev/null
@@ -1,116 +0,0 @@
----
-id: operating_system
-title: operating_system
-sidebar_label: Operating System
-sidebar_position: 6
-tags: [operating_system, create database, commands]
-description: An operating system acts as an interface between the software and different parts of the computer or the computer hardware.
----
-
-# What is an Operating System?
-
-Operating System lies in the category of system software. It basically manages all the resources of the computer. An operating system acts as an interface between the software and different parts of the computer or the computer hardware. The operating system is designed in such a way that it can manage the overall resources and operations of the computer.
-
-Operating System is a fully integrated set of specialized programs that handle all the operations of the computer. It controls and monitors the execution of all other programs that reside in the computer, which also includes application programs and other system software of the computer. Examples of Operating Systems are Windows, Linux, Mac OS, etc.
-
-An Operating System (OS) is a collection of software that manages computer hardware resources and provides common services for computer programs. The operating system is the most important type of system software in a computer system.
-
-## What is an Operating System Used for?
-
-The operating system helps in improving the computer software as well as hardware. Without OS, it became very difficult for any application to be user-friendly. The Operating System provides a user with an interface that makes any application attractive and user-friendly. The operating System comes with a large number of device drivers that make OS services reachable to the hardware environment. Each and every application present in the system requires the Operating System. The operating system works as a communication channel between system hardware and system software. The operating system helps an application with the hardware part without knowing about the actual hardware configuration. It is one of the most important parts of the system and hence it is present in every device, whether large or small device.
-
- 
-
-## Functions of the Operating System
-
-- **Resource Management**: The operating system manages and allocates memory, CPU time, and other hardware resources among the various programs and processes running on the computer.
-
-- **Process Management**: The operating system is responsible for starting, stopping, and managing processes and programs. It also controls the scheduling of processes and allocates resources to them
- .
-- **Memory Management**: The operating system manages the computer’s primary memory and provides mechanisms for optimizing memory usage.
-
-- **Security**: The operating system provides a secure environment for the user, applications, and data by implementing security policies and mechanisms such as access controls and encryption.
-
-- **Job Accounting**: It keeps track of time and resources used by various jobs or users.
-
-- **File Management**: The operating system is responsible for organizing and managing the file system, including the creation, deletion, and manipulation of files and directories.
-
-- **Device Management**: The operating system manages input/output devices such as printers, keyboards, mice, and displays. It provides the necessary drivers and interfaces to enable communication between the devices and the computer.
-
-- **Networking**: The operating system provides networking capabilities such as establishing and managing network connections, handling network protocols, and sharing resources such as printers and files over a network.
-
-- **User Interface**: The operating system provides a user interface that enables users to interact with the computer system. This can be a Graphical User Interface (GUI), a Command-Line Interface (CLI), or a combination of both.
-
-- **Backup and Recovery**: The operating system provides mechanisms for backing up data and recovering it in case of system failures, errors, or disasters.
-
-- **Virtualization**: The operating system provides virtualization capabilities that allow multiple operating systems or applications to run on a single physical machine. This can enable efficient use of resources and flexibility in managing workloads.
-
-- **Performance Monitoring**: The operating system provides tools for monitoring and optimizing system performance, including identifying bottlenecks, optimizing resource usage, and analyzing system logs and metrics.
-
-- **Time-Sharing**: The operating system enables multiple users to share a computer system and its resources simultaneously by providing time-sharing mechanisms that allocate resources fairly and efficiently.
-
-- **System Calls**: The operating system provides a set of system calls that enable applications to interact with the operating system and access its resources. System calls provide a standardized interface between applications and the operating system, enabling portability and compatibility across different hardware and software platforms.
-
-- **Error-detecting Aids**: These contain methods that include the production of dumps, traces, error messages, and other debugging and error-detecting methods.
-
-## Objectives of Operating Systems
-
-Let us now see some of the objectives of the operating system, which are mentioned below.
-
-- **Convenient to use**: One of the objectives is to make the computer system more convenient to use in an efficient manner.
-
-- **User Friendly**: To make the computer system more interactive with a more convenient interface for the users.
-
-- **Easy Access**: To provide easy access to users for using resources by acting as an intermediary between the hardware and its users.
-
-- **Management of Resources**: For managing the resources of a computer in a better and faster way.
-
-- **Controls and Monitoring**: By keeping track of who is using which resource, granting resource requests, and mediating conflicting requests from different programs and users.
-
-- **Fair Sharing of Resources**: Providing efficient and fair sharing of resources between the users and programs.
-
-## Types of Operating Systems
-
-- **Batch Operating System**: A Batch Operating System is a type of operating system that does not interact with the computer directly. There is an operator who takes similar jobs having the same requirements and groups them into batches.
-
-- **Time-sharing Operating System**: Time-sharing Operating System is a type of operating system that allows many users to share computer resources (maximum utilization of the resources).
-
-- **Distributed Operating System**: Distributed Operating System is a type of operating system that manages a group of different computers and makes appear to be a single computer. These operating systems are designed to operate on a network of computers. They allow multiple users to access shared resources and communicate with each other over the network. Examples include Microsoft Windows Server and various distributions of Linux designed for servers.
-
-- **Network Operating System**: Network Operating System is a type of operating system that runs on a server and provides the capability to manage data, users, groups, security, applications, and other networking functions.
-
-- **Real-time Operating System**: Real-time Operating System is a type of operating system that serves a real-time system and the time interval required to process and respond to inputs is very small. These operating systems are designed to respond to events in real time. They are used in applications that require quick and deterministic responses, such as embedded systems, industrial control systems, and robotics.
-
-- **Multiprocessing Operating System**: Multiprocessor Operating Systems are used in operating systems to boost the performance of multiple CPUs within a single computer system. Multiple CPUs are linked together so that a job can be divided and executed more quickly.
-
-- **Single-User Operating Systems**: Single-User Operating Systems are designed to support a single user at a time. Examples include Microsoft Windows for personal computers and Apple macOS.
-
-- **Multi-User Operating Systems**: Multi-User Operating Systems are designed to support multiple users simultaneously. Examples include Linux and Unix.
-
-- **Embedded Operating Systems**: Embedded Operating Systems are designed to run on devices with limited resources, such as smartphones, wearable devices, and household appliances. Examples include Google’s Android and Apple’s iOS.
-
-- **Cluster Operating Systems**: Cluster Operating Systems are designed to run on a group of computers, or a cluster, to work together as a single system. They are used for high-performance computing and for applications that require high availability and reliability. Examples include Rocks Cluster Distribution and OpenMPI.
-
-## How to Check the Operating System?
-
-There are so many factors to be considered while choosing the best Operating System for our use. These factors are mentioned below.
-
-- **Price Factor**: Price is one of the factors to choose the correct Operating System as there are some OS that is free, like Linux, but there is some more OS that is paid like Windows and macOS.
-
-- **Accessibility Factor**: Some Operating Systems are easy to use like macOS and iOS, but some OS are a little bit complex to understand like Linux. So, you must choose the Operating System in which you are more accessible.
-
-- **Compatibility Factor**: Some Operating Systems support very less applications whereas some Operating Systems supports more application. You must choose the OS, which supports the applications which are required by you.
-
-- **Security Factor**: The security Factor is also a factor in choosing the correct OS, as macOS provide some additional security while Windows has little fewer security features.
-
-## Examples of Operating Systems
-
-- **Windows**: GUI-based, PC
-
-- **GNU/Linux**: Personal, Workstations, ISP, File, and print server, Three-tier client/Server
-
-- **macOS**: Used for Apple’s personal computers and workstations (MacBook, iMac)
-
-- **Android**: Google’s Operating System for smartphones/tablets/smartwatches
-
-- **iOS**: Apple’s OS for iPhone, iPad, and iPod Touch
diff --git a/docs/Operating System/memory_management.md b/docs/Operating System/memory_management.md
deleted file mode 100644
index 4c1f0bb91..000000000
--- a/docs/Operating System/memory_management.md
+++ /dev/null
@@ -1,88 +0,0 @@
----
-id: memory-management
-title: memory-management
-sidebar_label: Memory Management
-sidebar_position: 10
-tags: [operating_system, create database, commands]
-description: Memory management is a crucial function of the operating system that handles or manages primary memory.
----
-# Memory Management
-
-## Introduction
-Memory management is a crucial function of the operating system that handles or manages primary memory. It keeps track of each byte in a computer’s memory and is responsible for allocating and deallocating memory spaces as needed by various programs.
-
-## Key Concepts
-
-### 1. Memory Allocation
-Memory allocation is the process of assigning blocks of memory to various programs while ensuring efficient use of memory. There are two types of memory allocation:
-- **Static Allocation**: Memory is allocated at compile time.
-- **Dynamic Allocation**: Memory is allocated at runtime.
-
-### 2. Contiguous vs Non-Contiguous Allocation
-- **Contiguous Allocation**: Each process is allocated a single contiguous block of memory.
-- **Non-Contiguous Allocation**: Memory is allocated in different blocks scattered throughout memory.
-
-### 3. Paging
-Paging is a memory management scheme that eliminates the need for contiguous allocation of physical memory. It divides memory into fixed-sized pages. When a process is executed, its pages are loaded into any available memory frames.
-
-#### Steps in Paging:
-1. **Divide the Process**: The process is divided into pages of equal size.
-2. **Divide Physical Memory**: Physical memory is divided into frames of the same size as the pages.
-3. **Load Pages into Frames**: Pages are loaded into available frames in physical memory.
-4. **Page Table**: A page table maintains the mapping between the process's pages and physical memory frames.
-
-### 4. Segmentation
-Segmentation divides a program into different segments such as code, data, stack, etc. Each segment can be placed in different parts of memory. This allows logical grouping of data and code, enhancing protection and sharing.
-
-#### Steps in Segmentation:
-1. **Divide the Program**: The program is divided into logical segments.
-2. **Map Segments to Memory**: Segments are mapped to different parts of physical memory.
-3. **Segment Table**: A segment table maintains the mapping between the segments and physical memory addresses.
-
-### 5. Virtual Memory
-Virtual memory allows the execution of processes that may not be completely in the physical memory. It extends the available memory on a system by using disk space to simulate additional RAM. Techniques used include paging and segmentation.
-
-### 6. Memory Allocation Techniques
-
-#### Fixed Partitioning
-Memory is divided into fixed-sized partitions. Each partition can hold one process. However, this leads to inefficient memory use and internal fragmentation.
-
-#### Dynamic Partitioning
-Memory is divided into partitions dynamically, based on the size of the process. This reduces internal fragmentation but can lead to external fragmentation.
-
-#### Buddy System
-The buddy system is a memory allocation and management algorithm that divides memory into blocks of size 2^k. It is a compromise between fixed and dynamic partitioning.
-
-## Swapping
-Swapping is a technique where a process can be temporarily swapped out of memory to a backing store and then brought back into memory for continued execution. This allows more processes to be executed than can fit in memory at one time.
-
-### Steps in Swapping:
-1. **Process Suspension**: The process is suspended and its state is saved.
-2. **Transfer to Backing Store**: The process is copied to the backing store (disk).
-3. **Loading into Memory**: When the process is to be resumed, it is copied back into memory.
-
-## Fragmentation
-
-### Internal Fragmentation
-Occurs when fixed-sized memory blocks are allocated and the memory assigned to a process is slightly larger than the memory requested. This leads to wasted space.
-
-### External Fragmentation
-Occurs when free memory is split into small blocks and is interspersed by allocated memory. Compaction can help reduce external fragmentation.
-
-## Memory Management Algorithms
-
-### First Fit
-Allocates the first block of free memory that is large enough for the process.
-
-### Best Fit
-Allocates the smallest block of memory that is sufficient for the process. This reduces wasted space but can lead to external fragmentation.
-
-### Worst Fit
-Allocates the largest block of free memory. This helps to reduce the chances of small unusable fragments.
-
-## Conclusion
-Memory management is essential for the efficient operation of an operating system. By understanding various memory management techniques and algorithms, we can ensure that memory is used effectively and processes are executed smoothly.
-
----
-
-Memory management is a complex but crucial aspect of operating systems, ensuring optimal use of memory resources and enabling multitasking and efficient process management.
diff --git a/docs/Operating System/os_development.md b/docs/Operating System/os_development.md
deleted file mode 100644
index 32cc560fb..000000000
--- a/docs/Operating System/os_development.md
+++ /dev/null
@@ -1,96 +0,0 @@
----
-id: os-development
-title: os-development
-sidebar_label: OS Development
-sidebar_position: 18
-tags: [operating_system, create database, commands]
-description: Operating system (OS) development involves designing and implementing the core software that manages hardware resources and provides services for application programs.
----
-# Operating System Development
-
-## Introduction
-Operating system (OS) development involves designing and implementing the core software that manages hardware resources and provides services for application programs. It is a complex and challenging field that requires a deep understanding of computer architecture, systems programming, and software engineering principles.
-
-## Key Concepts
-
-### 1. Kernel
-The kernel is the core component of an operating system. It manages system resources, including CPU, memory, and I/O devices, and provides essential services such as process scheduling, memory management, and device management.
-
-### 2. Bootloader
-A bootloader is a small program that initializes the hardware and loads the kernel into memory during the system startup process. Examples include GRUB (Grand Unified Bootloader) and UEFI (Unified Extensible Firmware Interface).
-
-### 3. System Calls
-System calls are the interface between user programs and the operating system kernel. They allow programs to request services from the kernel, such as file operations, process control, and inter-process communication.
-
-### 4. Process Management
-Process management involves creating, scheduling, and terminating processes. It ensures efficient use of the CPU and provides mechanisms for process synchronization and communication.
-
-### 5. Memory Management
-Memory management involves allocating and deallocating memory for processes and ensuring efficient use of memory resources. It includes techniques such as paging, segmentation, and virtual memory.
-
-### 6. File Systems
-File systems manage the storage and retrieval of data on disk. They provide a hierarchical structure for organizing files and directories and handle tasks such as file creation, deletion, reading, and writing.
-
-### 7. Device Drivers
-Device drivers are specialized programs that enable the operating system to communicate with hardware devices. They provide a standard interface for accessing and controlling devices such as keyboards, mice, and storage devices.
-
-## Development Process
-
-### 1. Setting Up the Development Environment
-- **Cross-Compiler**: A cross-compiler is required to compile code for the target architecture. GCC (GNU Compiler Collection) is commonly used.
-- **Emulator**: An emulator, such as QEMU, allows you to test the OS without needing physical hardware.
-- **Version Control**: Using a version control system like Git helps manage code changes and collaboration.
-
-### 2. Writing the Bootloader
-The bootloader initializes the hardware, sets up the memory map, and loads the kernel into memory. It typically involves low-level programming in assembly language.
-
-### 3. Developing the Kernel
-- **Kernel Initialization**: Setting up the kernel environment, including memory management structures and hardware initialization.
-- **Process Management**: Implementing process creation, scheduling, and context switching.
-- **Memory Management**: Setting up the virtual memory system, including page tables and memory allocation.
-- **File System**: Developing the file system structure, including inode management and directory operations.
-- **Device Drivers**: Writing drivers for essential hardware components, such as the keyboard, display, and disk storage.
-
-### 4. Implementing System Calls
-System calls provide the interface for user programs to interact with the kernel. Implementing system calls involves defining the API, handling parameters, and performing the requested operations in the kernel.
-
-### 5. Developing User Space Programs
-User space programs run outside the kernel and interact with it via system calls. Developing basic utilities, such as a shell, text editor, and file manager, is part of OS development.
-
-## Tools and Resources
-
-### 1. Development Tools
-- **GCC**: A cross-compiler for building the OS.
-- **QEMU**: An emulator for testing the OS.
-- **GDB**: A debugger for debugging the OS.
-- **Make**: A build automation tool for managing the compilation process.
-
-### 2. Documentation and Tutorials
-- **OSDev.org**: A community-driven resource for OS development, including tutorials and documentation.
-- **The Linux Kernel**: Reading and understanding the source code of the Linux kernel can provide valuable insights into OS design and implementation.
-- **Books**: Recommended books include "Operating Systems: Design and Implementation" by Andrew S. Tanenbaum and "Modern Operating Systems" by Andrew S. Tanenbaum.
-
-### 3. Sample Projects
-- **MINIX**: A small, educational operating system designed for teaching OS principles.
-- **XV6**: A modern re-implementation of Unix Version 6, used in MIT's operating systems course.
-
-## Challenges in OS Development
-
-### 1. Complexity
-OS development is inherently complex, requiring knowledge of computer architecture, low-level programming, and concurrent programming.
-
-### 2. Debugging
-Debugging kernel code is challenging due to the lack of standard debugging tools and the need to work with raw hardware interfaces.
-
-### 3. Performance
-Ensuring efficient resource utilization and low latency is critical in OS development, particularly for real-time and high-performance systems.
-
-### 4. Security
-Implementing robust security mechanisms, such as access control, encryption, and secure communication, is essential to protect the OS from attacks.
-
-## Conclusion
-Operating system development is a challenging but rewarding field that requires a deep understanding of computer systems and software engineering. By mastering key concepts, tools, and techniques, developers can build robust, efficient, and secure operating systems.
-
----
-
-Operating system development involves creating the core software that manages hardware resources and provides services for application programs. It requires a deep understanding of computer architecture, systems programming, and software engineering principles.
diff --git a/docs/Operating System/process_management.md b/docs/Operating System/process_management.md
deleted file mode 100644
index e9a4a070b..000000000
--- a/docs/Operating System/process_management.md
+++ /dev/null
@@ -1,76 +0,0 @@
----
-id: process-management
-title: process-management
-sidebar_label: Process Management
-sidebar_position: 9
-tags: [operating_system, create database, commands]
-description: Process management is a fundamental concept in operating systems that deals with the creation, scheduling, and termination of processes.
----
-# Process Management
-
-## Introduction
-Process management is a fundamental concept in operating systems that deals with the creation, scheduling, and termination of processes. It ensures that the CPU is utilized efficiently and that processes are executed smoothly without conflicts.
-
-## Key Concepts
-
-### 1. Process
-A process is a program in execution. It consists of the program code, current activity, and associated resources. Each process has a unique Process ID (PID).
-
-### 2. Process States
-Processes typically go through a series of states during their lifecycle:
-- **New**: The process is being created.
-- **Ready**: The process is waiting to be assigned to a processor.
-- **Running**: Instructions are being executed.
-- **Waiting**: The process is waiting for some event to occur.
-- **Terminated**: The process has finished execution.
-
-### 3. Process Control Block (PCB)
-The PCB is a data structure used by the operating system to store all the information about a process. This includes the process state, program counter, CPU registers, memory management information, and accounting information.
-
-### 4. Context Switching
-Context switching is the process of storing the state of a currently running process and restoring the state of the next process to be executed. It allows multiple processes to share a single CPU.
-
-### 5. Scheduling
-Process scheduling is the activity of the process manager that handles the removal of the running process from the CPU and the selection of another process. There are different types of scheduling algorithms:
-- **First-Come, First-Served (FCFS)**
-- **Shortest Job Next (SJN)**
-- **Priority Scheduling**
-- **Round Robin (RR)**
-- **Multilevel Queue Scheduling**
-
-## Process Creation and Termination
-
-### Process Creation
-Processes can be created using system calls like `fork()` in Unix-based systems. A new process, called the child process, is created as a copy of the parent process.
-
-#### Steps in Process Creation:
-1. **Forking**: The operating system creates a new process by duplicating the parent process.
-2. **Execution**: The child process starts executing. It can run a different program using the `exec` system call.
-3. **Address Space Allocation**: The operating system allocates memory for the new process.
-
-### Process Termination
-A process terminates when it finishes execution or is explicitly killed. System calls like `exit()` are used for normal termination, while `kill()` can be used to terminate a process forcefully.
-
-#### Reasons for Process Termination:
-1. **Normal Completion**: The process finishes its task.
-2. **Errors**: Errors occur during execution.
-3. **Resource Unavailability**: Required resources are not available.
-4. **User Request**: The user requests the termination of the process.
-5. **Parent Termination**: The parent process is terminated.
-
-## Inter-Process Communication (IPC)
-IPC mechanisms allow processes to communicate and synchronize their actions. Common IPC methods include:
-- **Pipes**: Unidirectional communication channels between processes.
-- **Message Queues**: A linked list of messages stored within the kernel.
-- **Shared Memory**: Multiple processes can access the same memory space.
-- **Semaphores**: Used to control access to a common resource by multiple processes.
-
-### Synchronization
-Synchronization is essential to ensure that processes do not interfere with each other while sharing resources. Techniques include:
-- **Mutexes**: Locks that ensure mutual exclusion.
-- **Condition Variables**: Used to block a process until a particular condition is met.
-- **Monitors**: High-level synchronization constructs.
-
-## Conclusion
-Process management is crucial for the efficient operation of an operating system. It ensures that processes are executed in a manner that maximizes CPU utilization and minimizes conflicts. By understanding process management, we gain insight into how operating systems handle multitasking and ensure that multiple processes can run smoothly and efficiently.
-
diff --git a/docs/Operating System/real_time_systems.md b/docs/Operating System/real_time_systems.md
deleted file mode 100644
index bf564f65c..000000000
--- a/docs/Operating System/real_time_systems.md
+++ /dev/null
@@ -1,85 +0,0 @@
----
-id: real-time-systems
-title: real-time-systems
-sidebar_label: Real Time Systems
-sidebar_position: 15
-tags: [operating_system, create database, commands]
-description: Real-time systems are computing systems that must respond to inputs and deliver outputs within a specified time frame.
----
-# Real-Time Systems
-
-## Introduction
-Real-time systems are computing systems that must respond to inputs and deliver outputs within a specified time frame. These systems are used in environments where timing is critical, such as embedded systems, industrial control systems, and aerospace applications.
-
-## Key Concepts
-
-### 1. Hard vs. Soft Real-Time Systems
-- **Hard Real-Time Systems**: Systems where missing a deadline can lead to catastrophic consequences. Examples include airbag systems in cars and pacemakers.
-- **Soft Real-Time Systems**: Systems where deadlines are important but missing them does not result in catastrophic failure, although it may degrade system performance. Examples include video streaming and online transaction processing.
-
-### 2. Determinism
-Determinism in real-time systems refers to the predictability of system behavior. A deterministic system guarantees response within a known time limit.
-
-### 3. Latency
-Latency is the time taken from the occurrence of an event to the start of the response. Minimizing latency is crucial in real-time systems.
-
-### 4. Jitter
-Jitter is the variability in response time. In real-time systems, low jitter is desirable to ensure consistent performance.
-
-## Real-Time Operating Systems (RTOS)
-
-### 1. Characteristics of RTOS
-- **Preemptive Multitasking**: Allows the RTOS to interrupt tasks to ensure high-priority tasks get CPU time.
-- **Priority-Based Scheduling**: Tasks are assigned priorities, and the scheduler ensures that high-priority tasks are executed first.
-- **Inter-task Communication**: Mechanisms such as message queues, semaphores, and events for tasks to communicate and synchronize.
-- **Minimal Interrupt Latency**: Ensures that the system responds quickly to interrupts.
-- **Resource Management**: Efficient management of CPU, memory, and other resources to meet timing requirements.
-
-### 2. Common RTOS Examples
-- **FreeRTOS**: An open-source RTOS used in embedded systems.
-- **VxWorks**: A commercial RTOS used in aerospace and defense applications.
-- **RTEMS**: A free RTOS designed for real-time embedded systems.
-- **QNX**: A commercial RTOS known for its microkernel architecture.
-
-## Real-Time Scheduling Algorithms
-
-### 1. Rate Monotonic Scheduling (RMS)
-A fixed-priority algorithm where tasks with shorter periods are assigned higher priorities. It is optimal for preemptive, fixed-priority scheduling.
-
-### 2. Earliest Deadline First (EDF)
-A dynamic scheduling algorithm where tasks closest to their deadlines are given the highest priority. It is optimal for both preemptive and non-preemptive scheduling.
-
-### 3. Least Laxity First (LLF)
-A dynamic scheduling algorithm where tasks with the least laxity (slack time) are given the highest priority. Laxity is the difference between the time remaining until the deadline and the remaining execution time.
-
-### 4. Priority Inheritance Protocol
-A protocol to handle priority inversion by temporarily elevating the priority of a task holding a resource that a higher-priority task needs.
-
-## Real-Time Communication
-
-### 1. Time-Triggered Protocol (TTP)
-A communication protocol where messages are transmitted at predefined times. It is used in applications requiring high reliability and predictability.
-
-### 2. Controller Area Network (CAN)
-A robust vehicle bus standard designed to allow microcontrollers and devices to communicate with each other without a host computer.
-
-### 3. Time-Sensitive Networking (TSN)
-A set of standards for time-sensitive transmission of data over Ethernet networks. It is used in industrial automation and automotive applications.
-
-## Case Studies
-
-### 1. Automotive Systems
-Modern cars use real-time systems for engine control, braking systems, and airbag deployment. These systems require precise timing and reliability to ensure safety.
-
-### 2. Industrial Control Systems
-Real-time systems control manufacturing processes, robotics, and assembly lines. They ensure timely and synchronized operations to maintain productivity and safety.
-
-### 3. Aerospace Systems
-Real-time systems are used in avionics for navigation, flight control, and communication systems. They require high reliability and low latency to ensure passenger safety.
-
-## Conclusion
-Real-time systems are essential in applications where timing is critical. They require specialized operating systems and scheduling algorithms to ensure timely and predictable responses. Understanding the principles of real-time systems is crucial for designing systems that meet the stringent timing and reliability requirements of various industries.
-
----
-
-Real-time systems play a vital role in ensuring the correct and timely operation of critical applications. Their design and implementation require a thorough understanding of timing constraints, scheduling algorithms, and communication protocols.
diff --git a/docs/Operating System/security_and_protection.md b/docs/Operating System/security_and_protection.md
deleted file mode 100644
index 405a70b25..000000000
--- a/docs/Operating System/security_and_protection.md
+++ /dev/null
@@ -1,85 +0,0 @@
----
-id: security-and-protection
-title: security-and-protection
-sidebar_label: Security and Protection
-sidebar_position: 13
-tags: [operating_system, create database, commands]
-description: Security and protection are critical aspects of operating systems, ensuring that the system's resources are used as intended and protecting against unauthorized access, misuse, and harm.
----
-# Security and Protection
-
-## Introduction
-Security and protection are critical aspects of operating systems, ensuring that the system's resources are used as intended and protecting against unauthorized access, misuse, and harm. These mechanisms are designed to safeguard data integrity, confidentiality, and availability.
-
-## Key Concepts
-
-### 1. Security vs. Protection
-- **Security**: Refers to defending the system against external threats such as viruses, malware, and hackers.
-- **Protection**: Refers to internal mechanisms that control access to system resources, ensuring that programs and users can access only the resources they are authorized to.
-
-### 2. Threats and Attacks
-- **Threat**: A potential cause of an unwanted incident, which may result in harm to a system or organization.
-- **Attack**: An action taken to exploit a vulnerability in the system.
-
-### 3. Types of Attacks
-- **Passive Attacks**: Attempts to learn or make use of information from the system but do not affect system resources (e.g., eavesdropping).
-- **Active Attacks**: Attempts to alter system resources or affect their operation (e.g., viruses, worms).
-
-## Security Measures
-
-### 1. Authentication
-Authentication is the process of verifying the identity of a user or process. Methods include:
-- **Passwords**: Secret words or phrases used to verify identity.
-- **Biometrics**: Using physical characteristics like fingerprints or retina scans.
-- **Two-Factor Authentication (2FA)**: Combining two different methods for higher security.
-
-### 2. Authorization
-Authorization determines what an authenticated user or process is allowed to do. It involves setting permissions and access rights.
-
-### 3. Encryption
-Encryption transforms readable data into an unreadable format to protect it from unauthorized access. Types include:
-- **Symmetric Encryption**: The same key is used for both encryption and decryption.
-- **Asymmetric Encryption**: Different keys are used for encryption and decryption (public key and private key).
-
-### 4. Intrusion Detection Systems (IDS)
-IDS monitor network or system activities for malicious actions or policy violations. They can be:
-- **Host-Based IDS (HIDS)**: Installed on individual devices to monitor local activities.
-- **Network-Based IDS (NIDS)**: Monitor network traffic for suspicious activities.
-
-### 5. Firewalls
-Firewalls control incoming and outgoing network traffic based on predetermined security rules. They can be hardware-based or software-based.
-
-## Protection Mechanisms
-
-### 1. Access Control
-Access control mechanisms determine who can access what resources in the system. Models include:
-- **Discretionary Access Control (DAC)**: Access rights are assigned by the owner of the resource.
-- **Mandatory Access Control (MAC)**: Access rights are assigned based on fixed policies set by the administrator.
-- **Role-Based Access Control (RBAC)**: Access rights are assigned based on user roles within an organization.
-
-### 2. Protection Domains
-A protection domain defines the set of resources that a process can access. Each process operates within its own domain.
-
-### 3. Capability-Based Systems
-Capabilities are tokens or keys that grant a process specific access rights to objects. They simplify access control by binding access rights to the object.
-
-### 4. Language-Based Protection
-Programming languages can enforce protection by using language constructs to define access rights. For example, Java provides access control modifiers like private, protected, and public.
-
-## Security Policies
-
-### 1. Principle of Least Privilege
-Users and processes should operate with the minimum set of privileges necessary to complete their tasks. This minimizes the potential damage from accidents or malicious activities.
-
-### 2. Defense in Depth
-Multiple layers of security controls and defenses are used to protect the system. If one layer fails, others still provide protection.
-
-### 3. Separation of Duties
-Responsibilities are divided among multiple individuals or systems to prevent fraud and errors. No single user should have control over all aspects of any critical function.
-
-## Conclusion
-Security and protection are vital for maintaining the integrity, confidentiality, and availability of system resources. By implementing robust security measures and protection mechanisms, operating systems can defend against a wide range of threats and ensure that resources are used appropriately and securely.
-
----
-
-A well-secured operating system not only defends against external threats but also ensures proper usage of resources internally, maintaining the overall health and functionality of the system.
diff --git a/docs/Operating System/system_calls.md b/docs/Operating System/system_calls.md
deleted file mode 100644
index bd3cb1310..000000000
--- a/docs/Operating System/system_calls.md
+++ /dev/null
@@ -1,114 +0,0 @@
----
-id: system-calls
-title: system-calls
-sidebar_label: System calls
-sidebar_position: 17
-tags: [operating_system, create database, commands]
-description: System calls are the interface between a running program and the operating system.
----
-# System Calls
-
-## Introduction
-System calls are the interface between a running program and the operating system. They allow user-level processes to request services from the kernel, such as file manipulation, process control, and communication.
-
-## Key Concepts
-
-### 1. Definition
-A system call is a function that provides the programmatic interface to the services provided by the operating system.
-
-### 2. User Mode vs. Kernel Mode
-- **User Mode**: The mode in which user applications run. Limited access to system resources.
-- **Kernel Mode**: The mode in which the operating system runs. Full access to all system resources.
-
-### 3. System Call Interface
-The system call interface acts as a boundary between user programs and the operating system kernel. It provides a set of services that programs can use to perform operations.
-
-## Types of System Calls
-
-### 1. Process Control
-- **fork()**: Creates a new process by duplicating the calling process.
-- **exec()**: Replaces the current process image with a new process image.
-- **exit()**: Terminates the calling process.
-- **wait()**: Waits for a child process to terminate.
-
-### 2. File Management
-- **open()**: Opens a file.
-- **close()**: Closes a file descriptor.
-- **read()**: Reads data from a file.
-- **write()**: Writes data to a file.
-- **lseek()**: Repositions the read/write file offset.
-- **unlink()**: Removes a directory entry.
-
-### 3. Device Management
-- **ioctl()**: Controls device parameters.
-- **read()**: Reads data from a device.
-- **write()**: Writes data to a device.
-
-### 4. Information Maintenance
-- **getpid()**: Gets the process ID.
-- **alarm()**: Sets an alarm clock for delivery of a signal.
-- **sleep()**: Suspends execution for an interval of time.
-- **gettimeofday()**: Gets the current time.
-
-### 5. Communication
-- **pipe()**: Creates a unidirectional data channel.
-- **shmget()**: Allocates a shared memory segment.
-- **shmat()**: Attaches a shared memory segment.
-- **semget()**: Gets a semaphore set identifier.
-
-## System Call Implementation
-
-### 1. System Call Handler
-When a system call is invoked, control is transferred to the system call handler in the kernel, which performs the requested service and returns control to the user program.
-
-### 2. Software Interrupt
-System calls are typically implemented using software interrupts or traps. This involves an interrupt instruction that switches the CPU to kernel mode and transfers control to a predefined interrupt handler.
-
-### 3. Parameter Passing
-Parameters for system calls can be passed in several ways:
-- **Registers**: Parameters are passed via CPU registers.
-- **Stack**: Parameters are pushed onto the stack.
-- **Memory**: Parameters are stored in a memory block, and the address of the block is passed.
-
-## Examples of System Calls
-
-### 1. Linux
-- **fork()**: Creates a new process.
-- **execve()**: Executes a program.
-- **mmap()**: Maps files or devices into memory.
-- **kill()**: Sends a signal to a process.
-
-### 2. Windows
-- **CreateProcess()**: Creates a new process.
-- **ReadFile()**: Reads data from a file.
-- **WriteFile()**: Writes data to a file.
-- **CreateFile()**: Opens a file.
-
-## System Call Optimization
-
-### 1. System Call Batching
-Combining multiple system calls into a single call to reduce overhead.
-
-### 2. Fast System Calls
-Using specialized CPU instructions to reduce the overhead of switching between user mode and kernel mode.
-
-### 3. Asynchronous System Calls
-Allowing system calls to be non-blocking, so a process can continue execution without waiting for the system call to complete.
-
-## Security Considerations
-
-### 1. Access Control
-Ensuring that only authorized processes can make certain system calls.
-
-### 2. Input Validation
-Validating parameters passed to system calls to prevent buffer overflows and other vulnerabilities.
-
-### 3. Privilege Escalation
-Preventing unauthorized processes from gaining elevated privileges through system calls.
-
-## Conclusion
-System calls are a critical aspect of operating system functionality, providing the necessary interface between user programs and the kernel. Understanding how system calls work and how they are implemented is essential for system programming and OS development.
-
----
-
-System calls are the bridge between user applications and the operating system, enabling programs to perform essential operations and interact with hardware.
diff --git a/docs/Operating System/types_of_OS.md b/docs/Operating System/types_of_OS.md
deleted file mode 100644
index 88bf8d0f4..000000000
--- a/docs/Operating System/types_of_OS.md
+++ /dev/null
@@ -1,227 +0,0 @@
----
-id: types-of-operating_system
-title: types-of-operating_system
-sidebar_label: Types of Operating System
-sidebar_position: 8
-tags: [operating_system, create database, commands]
-description: An Operating System performs all the basic tasks like managing files, processes, and memory. .
----
-
-# Types of Operating Systems
-
-## Pre-Requisite: What is an Operating System?
-
-An Operating System performs all the basic tasks like managing files, processes, and memory. Thus operating system acts as the manager of all the resources, i.e. resource manager. Thus, the operating system becomes an interface between the user and the machine. It is one of the most required software that is present in the device.
-
-Operating System is a type of software that works as an interface between the system program and the hardware. There are several types of Operating Systems, many of which are mentioned below. Let’s have a look at them.
-
-## Types of Operating Systems
-
-There are several types of Operating Systems which are mentioned below.
-
-1. [Batch Operating System](#batch-operating-system)
-
-2. [Multi-Programming System](#multi-programming-operating-system)
-
-3. [Multi-Processing System](#multi-processing-operating-system)
-
-4. [Multi-Tasking Operating System](#multi-tasking-operating-system)
-
-5. [Time-Sharing Operating System](#time-sharing-operating-system)
-
-6. [Distributed Operating System](#distributed-operating-system)
-
-7. [Network Operating System](#network-operating-system)
-
-8. [Real-Time Operating System](#real-time-operating-system)
-
-### Batch Operating System
-
-This type of operating system does not interact with the computer directly. There is an operator which takes similar jobs having the same requirement and groups them into batches. It is the responsibility of the operator to sort jobs with similar needs.
-
- 
-
-#### Advantages of Batch Operating System
-
-- Multiple users can share the batch systems.
-
-- The idle time for the batch system is very less.
-
-- It is easy to manage large work repeatedly in batch systems.
-
-#### Disadvantages of Batch Operating System
-
-- The computer operators should be well known with batch systems.
-
-- Batch systems are hard to debug.
-
-- It is sometimes costly.
-
-- The other jobs will have to wait for an unknown time if any job fails.
-
-- In batch operating system the processing time for jobs is commonly difficult to accurately predict while they are in the queue.
-
-- It is difficult to accurately predict the exact time required for a job to complete while it is in the queue.
-
-#### Examples of Batch Operating Systems
-
-- Payroll Systems, Bank Statements, etc.
-
-### Multi-Programming Operating System
-
-Multiprogramming Operating Systems can be simply illustrated as more than one program is present in the main memory and any one of them can be kept in execution. This is basically used for better execution of resources.
-
- 
-
-#### Advantages of Multi-Programming Operating System
-
-- Multi Programming increases the Throughput of the System.
-
-- It helps in reducing the response time.
-
-#### Disadvantages of Multi-Programming Operating System
-
-- There is not any facility for user interaction of system resources with the system.
-
-### Multi-Processing Operating System
-
-Multi-Processing Operating System is a type of Operating System in which more than one CPU is used for the execution of resources. It betters the throughput of the System.
-
- 
-
-#### Advantages of Multi-Processing Operating System
-
-- It increases the throughput of the system.
-
-- As it has several processors, so, if one processor fails, we can proceed with another processor.
-
-#### Disadvantages of Multi-Processing Operating System
-
-- Due to the multiple CPU, it can be more complex and somehow difficult to understand.
-
-### Multi-Tasking Operating System
-
-Multitasking Operating System is simply a multiprogramming Operating System with having facility of a Round-Robin Scheduling Algorithm. It can run multiple programs simultaneously.
-
- 
-
-#### Types of Multi-Tasking Systems
-
-- Preemptive Multi-Tasking
-
-- Cooperative Multi-Tasking
-
-#### Advantages of Multi-Tasking Operating System
-
-- Multiple Programs can be executed simultaneously in Multi-Tasking Operating System.
-
-- It comes with proper memory management.
-
-#### Disadvantages of Multi-Tasking Operating System
-
-- The system gets heated in case of heavy programs multiple times.
-
-### Time-Sharing Operating System
-
-Each task is given some time to execute so that all the tasks work smoothly. Each user gets the time of the CPU as they use a single system. These systems are also known as Multitasking Systems. The task can be from a single user or different users also. The time that each task gets to execute is called quantum. After this time interval is over OS switches over to the next task.
-
- 
-
-#### Advantages of Time-Sharing OS
-
-- Each task gets an equal opportunity.
-
-- Fewer chances of duplication of software.
-
-- CPU idle time can be reduced.
-
-- Resource Sharing: Time-sharing systems allow multiple users to share hardware resources such as the CPU, memory, and peripherals, reducing the cost of hardware and increasing efficiency.
-
-- Improved Productivity: Time-sharing allows users to work concurrently, thereby reducing the waiting time for their turn to use the computer. This increased productivity translates to more work getting done in less time.
-
-- Improved User Experience: Time-sharing provides an interactive environment that allows users to communicate with the computer in real time, providing a better user experience than batch processing.
-
-#### Disadvantages of Time-Sharing OS
-
-- Reliability problem.
-
-- One must have to take care of the security and integrity of user programs and data.
-
-- Data communication problem.
-
-- High Overhead: Time-sharing systems have a higher overhead than other operating systems due to the need for scheduling, context switching, and other overheads that come with supporting multiple users.
-
-- Complexity: Time-sharing systems are complex and require advanced software to manage multiple users simultaneously. This complexity increases the chance of bugs and errors.
-
-- Security Risks: With multiple users sharing resources, the risk of security breaches increases. Time-sharing systems require careful management of user access, authentication, and authorization to ensure the security of data and software.
-
-#### Examples of Time-Sharing OS with explanation
-
-- **IBM VM/CMS**: IBM VM/CMS is a time-sharing operating system that was first introduced in 1972. It is still in use today, providing a virtual machine environment that allows multiple users to run their own instances of operating systems and applications.
-
-- **TSO (Time Sharing Option)**: TSO is a time-sharing operating system that was first introduced in the 1960s by IBM for the IBM System/360 mainframe computer. It allowed multiple users to access the same computer simultaneously, running their own applications.
-
-- **Windows Terminal Services**: Windows Terminal Services is a time-sharing operating system that allows multiple users to access a Windows server remotely. Users can run their own applications and access shared resources, such as printers and network storage, in real-time.
-
-### Distributed Operating System
-
-These types of operating system is a recent advancement in the world of computer technology and are being widely accepted all over the world and, that too, at a great pace. Various autonomous interconnected computers communicate with each other using a shared communication network. Independent systems possess their own memory unit and CPU. These are referred to as loosely coupled systems or distributed systems. These systems’ processors differ in size and function. The major benefit of working with these types of the operating system is that it is always possible that one user can access the files or software which are not actually present on his system but some other system connected within this network i.e., remote access is enabled within the devices connected in that network.
-
- 
-
-#### Advantages of Distributed Operating System
-
-- Failure of one will not affect the other network communication, as all systems are independent of each other.
-- Electronic mail increases the data exchange speed.
-- Since resources are being shared, computation is highly fast and durable.
-- Load on host computer reduces.
-- These systems are easily scalable as many systems can be easily added to the network.
-- Delay in data processing reduces.
-
-#### Disadvantages of Distributed Operating System
-
-- Failure of the main network will stop the entire communication.
-- To establish distributed systems the language is used not well-defined yet.
-- These types of systems are not readily available as they are very expensive. Not only that the underlying software is highly complex and not understood well yet.
-
-#### Examples of Distributed Operating Systems
-
-- LOCUS, etc.
-
-#### Issues in Distributed OS
-
-- Networking causes delays in the transfer of data between nodes of a distributed system. Such delays may lead to an inconsistent view of data located in different nodes, and make it difficult to know the chronological order in which events occurred in the system.
-- Control functions like scheduling, resource allocation, and deadlock detection have to be performed in several nodes to achieve computation speedup and provide reliable operation when computers or networking components fail.
-- Messages exchanged by processes present in different nodes may travel over public networks and pass through computer systems that are not controlled by the distributed operating system. An intruder may exploit this feature to tamper with messages, or create fake messages to fool the authentication procedure and masquerade as a user of the system.
-
-### Network Operating System
-
-These systems run on a server and provide the capability to manage data, users, groups, security, applications, and other networking functions. These types of operating systems allow shared access to files, printers, security, applications, and other networking functions over a small private network. One more important aspect of Network Operating Systems is that all the users are well aware of the underlying configuration, of all other users within the network, their individual connections, etc. and that’s why these computers are popularly known as tightly coupled systems.
-
- 
-
-#### Advantages of Network Operating System
-
-- Highly stable centralized servers.
-
-- Security concerns are handled through servers.
-
-- New technologies and hardware up-gradation are easily integrated into the system.
-
-- Server access is possible remotely from different locations and types of systems.
-
-#### Disadvantages of Network Operating System
-
-- Servers are costly.
-
-- User has to depend on a central location for most operations.
-
-- Maintenance and updates are required regularly.
-
-#### Examples of Network Operating Systems
-
-- Microsoft Windows Server 2003, Microsoft Windows Server 2008, UNIX, Linux, Mac OS X, Novell NetWare, BSD, etc.
-
-### Real-Time Operating System
-
-These types of OSs serve real-time systems
diff --git a/docs/Operating System/virtualization.md b/docs/Operating System/virtualization.md
deleted file mode 100644
index 826e5952d..000000000
--- a/docs/Operating System/virtualization.md
+++ /dev/null
@@ -1,91 +0,0 @@
----
-id: virtualization
-title: virtualization
-sidebar_label: Virtualization
-sidebar_position: 16
-tags: [operating_system, create database, commands]
-description: Virtualization is a technology that allows a single physical machine to run multiple virtual machines (VMs), each with its own operating system and applications.
----
-# Virtualization
-
-## Introduction
-Virtualization is a technology that allows a single physical machine to run multiple virtual machines (VMs), each with its own operating system and applications. This abstraction layer separates the hardware from the software, enabling efficient resource utilization, isolation, and flexibility.
-
-## Key Concepts
-
-### 1. Virtual Machines (VMs)
-A virtual machine is a software emulation of a physical computer. Each VM runs its own operating system and applications, behaving like an independent computer.
-
-### 2. Hypervisor
-A hypervisor, also known as a virtual machine monitor (VMM), is software that creates and manages VMs by allocating hardware resources to them. Hypervisors can be classified into two types:
-- **Type 1 (Bare-Metal Hypervisors)**: Run directly on the physical hardware. Examples include VMware ESXi, Microsoft Hyper-V, and Xen.
-- **Type 2 (Hosted Hypervisors)**: Run on a host operating system that provides virtualization services. Examples include VMware Workstation and Oracle VirtualBox.
-
-### 3. Host and Guest
-- **Host**: The physical machine on which the hypervisor runs.
-- **Guest**: The virtual machines running on the hypervisor.
-
-## Benefits of Virtualization
-
-### 1. Resource Efficiency
-Virtualization allows multiple VMs to share the same physical resources, leading to higher utilization of CPU, memory, and storage.
-
-### 2. Isolation
-Each VM is isolated from others, ensuring that issues in one VM do not affect others. This isolation also enhances security.
-
-### 3. Flexibility and Scalability
-Virtualization enables easy scaling by adding or removing VMs based on demand. It also allows for rapid provisioning and deployment of new services.
-
-### 4. Disaster Recovery
-Virtualization simplifies backup and recovery processes. VMs can be easily backed up and restored, and they can be moved between physical machines without downtime.
-
-## Types of Virtualization
-
-### 1. Hardware Virtualization
-Emulates hardware devices, allowing VMs to run different operating systems. This includes full virtualization and paravirtualization.
-- **Full Virtualization**: VMs are completely isolated from the host. Examples include VMware and Hyper-V.
-- **Paravirtualization**: VMs are aware of the virtualization layer, allowing for optimized performance. Examples include Xen and KVM.
-
-### 2. Operating System Virtualization
-Enables multiple isolated user-space instances (containers) to run on a single OS kernel. Examples include Docker and LXC (Linux Containers).
-
-### 3. Network Virtualization
-Abstracts physical network resources into multiple virtual networks, each with its own topology and policies. Examples include VLANs (Virtual Local Area Networks) and SDN (Software-Defined Networking).
-
-### 4. Storage Virtualization
-Combines multiple physical storage devices into a single logical storage unit, providing flexible storage management. Examples include SAN (Storage Area Network) and NAS (Network-Attached Storage).
-
-## Virtualization Techniques
-
-### 1. Emulation
-The hypervisor emulates the complete hardware environment for the guest OS. This allows any OS to run on any hardware but can be slow due to overhead.
-
-### 2. Binary Translation
-The hypervisor translates sensitive instructions from the guest OS into safe instructions on the fly. This improves performance compared to emulation.
-
-### 3. Hardware-Assisted Virtualization
-Modern CPUs provide virtualization extensions (e.g., Intel VT-x, AMD-V) that allow the hypervisor to run VMs more efficiently by executing certain instructions directly on the hardware.
-
-### 4. Containerization
-Containers share the host OS kernel and run as isolated processes. They are lightweight and provide fast startup times compared to VMs. Examples include Docker and Kubernetes.
-
-## Virtualization in Cloud Computing
-Virtualization is a foundational technology for cloud computing. It enables the creation of scalable, on-demand infrastructure services such as Infrastructure as a Service (IaaS) and Platform as a Service (PaaS).
-
-## Case Studies
-
-### 1. VMware vSphere
-A comprehensive virtualization platform that provides powerful tools for managing and automating VMs, including vMotion for live VM migration and DRS (Distributed Resource Scheduler) for load balancing.
-
-### 2. Docker
-A platform for developing, shipping, and running applications in containers. Docker simplifies application deployment by packaging all dependencies into a single container image.
-
-### 3. Amazon EC2
-A cloud computing service that provides scalable virtual servers (instances) on demand. Users can choose from various instance types optimized for different workloads.
-
-## Conclusion
-Virtualization is a transformative technology that enhances resource utilization, provides flexibility, and simplifies management. Understanding virtualization concepts and techniques is essential for modern IT infrastructure, enabling efficient and scalable deployment of applications and services.
-
----
-
-Virtualization is a key enabler for cloud computing and modern data centers, offering significant benefits in terms of efficiency, scalability, and management.
diff --git a/docs/Pandas/Pandas-gettingstarted.md b/docs/Pandas/Pandas-gettingstarted.md
deleted file mode 100644
index ba5cb6892..000000000
--- a/docs/Pandas/Pandas-gettingstarted.md
+++ /dev/null
@@ -1,53 +0,0 @@
----
-id: Pandas-GettingStarted
-title: Pandas Getting Started
-sidebar_label: Pandas Getting Started
-sidebar_position: 2
-tags: [Python-library, Pandas , Machine-learning]
-description: Learn how to install and use Pandas, a powerful Python library for data manipulation and analysis.
----
-
-
-
-
-
-## Installation of Pandas
-
-If you already have Python and PIP installed on your system, installing Pandas is straightforward. Simply run the following command:
-
-```
-pip install pandas
-```
-
-If the command fails, consider using a Python distribution that already includes Pandas, such as Anaconda or Spyder.
-
-## Importing Pandas
-
-Once Pandas is installed, you can import it into your applications using the `import` keyword:
-
-```python
-import pandas
-```
-
-Now, Pandas is imported and ready to be used.
-
-## Example
-
-Here's a simple example that demonstrates the usage of Pandas:
-
-```python
-import pandas
-
-mydataset = {
- 'cars': ["BMW", "Volvo", "Ford"],
- 'passings': [3, 7, 2]
-}
-
-myvar = pandas.DataFrame(mydataset)
-
-print(myvar)
-```
-
-This example creates a DataFrame using a dictionary and prints its contents.
-
-Pandas is a versatile library that provides powerful tools for data manipulation and analysis in Python. By learning how to install and use Pandas, you can enhance your data processing capabilities and streamline your data analysis workflows.
\ No newline at end of file
diff --git a/docs/Pandas/Read-files.md b/docs/Pandas/Read-files.md
deleted file mode 100644
index 58722f4f5..000000000
--- a/docs/Pandas/Read-files.md
+++ /dev/null
@@ -1,255 +0,0 @@
----
-id: Pandas-Readfiles
-title: Pandas Read Files
-sidebar_label: Pandas Read Files
-sidebar_position: 6
-tags: [Python-library, Pandas ,Pandas-files, Machine-learning]
-description: Read CSV files , JSON files in PANDAS.
----
-
-
-### Read CSV Files
-A simple way to store big data sets is to use CSV files (comma separated files).
-
-CSV files contain plain text and are a well-known format that can be read by everyone, including Pandas.
-
-In our examples, we will be using a CSV file called 'data.csv'.
-
-Download data.csv or Open data.csv
-
-**Example: Get your own Python Server**
-
-Load the CSV into a DataFrame:
-
-```python
-import pandas as pd
-
-df = pd.read_csv('data.csv')
-
-print(df.to_string())
-```
-
-**Tip:** Use `to_string()` to print the entire DataFrame.
-
-If you have a large DataFrame with many rows, Pandas will only return the first 5 rows and the last 5 rows:
-
-**Example:**
-Print the DataFrame without the `to_string()` method:
-
-```python
-import pandas as pd
-
-df = pd.read_csv('data.csv')
-
-print(df)
-```
-
-### max_rows
-The number of rows returned is defined in Pandas option settings.
-
-You can check your system's maximum rows with the `pd.options.display.max_rows` statement.
-
-**Example:**
-Check the number of maximum returned rows:
-
-```python
-import pandas as pd
-
-print(pd.options.display.max_rows)
-```
-
-In my system, the number is 60, which means that if the DataFrame contains more than 60 rows, the `print(df)` statement will return only the headers and the first and last 5 rows.
-
-You can change the maximum rows number with the same statement.
-
-**Example:**
-Increase the maximum number of rows to display the entire DataFrame:
-
-```python
-import pandas as pd
-
-pd.options.display.max_rows = 9999
-
-df = pd.read_csv('data.csv')
-
-print(df)
-```
-
-## Pandas Read JSON
-### Read JSON
-Big data sets are often stored or extracted as JSON.
-
-JSON is plain text but has the format of an object and is well-known in the world of programming, including Pandas.
-
-In our examples, we will be using a JSON file called 'data.json'.
-
-Open data.json.
-
-**Example: Get your own Python Server**
-
-Load the JSON file into a DataFrame:
-
-```python
-import pandas as pd
-
-df = pd.read_json('data.json')
-
-print(df.to_string())
-```
-
-**Tip:** Use `to_string()` to print the entire DataFrame.
-
-### Dictionary as JSON
-JSON = Python Dictionary
-
-JSON objects have the same format as Python dictionaries.
-
-If your JSON code is not in a file but in a Python Dictionary, you can load it into a DataFrame directly:
-
-**Example:**
-Load a Python Dictionary into a DataFrame:
-
-```python
-import pandas as pd
-
-data = {
- "Duration":{
- "0":60,
- "1":60,
- "2":60,
- "3":45,
- "4":45,
- "5":60
- },
- "Pulse":{
- "0":110,
- "1":117,
- "2":103,
- "3":109,
- "4":117,
- "5":102
- },
- "Maxpulse":{
- "0":130,
- "1":145,
- "2":135,
- "3":175,
- "4":148,
- "5":127
- },
- "Calories":{
- "0":409,
- "1":479,
- "2":340,
- "3":282,
- "4":406,
- "5":300
- }
-}
-
-df = pd.DataFrame(data)
-
-print(df)
-```
-
-## Pandas - Analyzing DataFrames
-### Viewing the Data
-One of the most used methods for getting a quick overview of the DataFrame is the `head()` method.
-
-The `head()` method returns the headers and a specified number of rows, starting from the top.
-
-**Example: Get your own Python Server**
-Get a quick overview by printing the first 10 rows of the DataFrame:
-
-```python
-import pandas as pd
-
-df = pd.read_csv('data.csv')
-
-print(df.head(10))
-```
-
-In our examples, we will be using a CSV file called 'data.csv'.
-
-Download data.csv or open data.csv in your browser.
-
-**Note:** If the number of rows is not specified, the `head()` method will return the top 5 rows.
-
-**Example:**
-Print the first 5 rows of the DataFrame:
-
-```python
-import pandas as pd
-
-df = pd.read_csv('data.csv')
-
-print(df.head())
-```
-
-There is also a `tail()` method for viewing the last rows of the DataFrame.
-
-The `tail()` method returns the headers and a specified number of rows, starting from the bottom.
-
-**Example:**
-Print the last 5 rows of the DataFrame:
-
-```python
-print(df.tail())
-```
-
-**w3schools CERTIFIED.2022**
-Get Certified!
-Complete the Pandas modules, do the exercises, take the exam, and you will become w3schools certified!
-
-### Info About the Data
-The DataFrame object has a method called `info()`, which gives you more information about the dataset.
-
-**Example:**
-Print information about the data:
-
-```python
-print(df.info())
-```
-
-**Result:**
-
-```
-
-
-
-### Naive Bayes Classifier
-
-The Naive Bayes classifier extends this to classify data points into categories. It assumes that the presence of a particular feature in a class is unrelated to the presence of any other feature (the "naive" assumption).
-
-For a data point $X = (x_1, x_2, ..., x_n)$ and a class variable :
-
-$$ P(C|X) = \frac{P(X|C) \cdot P(C)}{P(X)} $$
-
-The classifier chooses the class with the highest posterior probability:
-
-$$ C^* = \underset{c \in C}{argmax} P(X|c) \cdot P(c) $$
-
-### Mathematical Formulation
-
-For a given set of features $(x_1, x_2, ..., x_n)$:
-
-$$ P(C|x_1, x_2, ..., x_n) \propto P(C) \cdot P(x_1|C) \cdot P(x_2|C) \cdot ... \cdot P(x_n|C) $$
-
-Where:
-- $P(C|x_1, x_2, ..., x_n)$ is the posterior probability of class $C$ given the features
-- $P(C)$ is the prior probability of class $C$
-- $P(x_i|C)$ is the likelihood of feature $x_i$ given class $C$
-
-## Types of Naive Bayes Classifiers
-
-1. **Gaussian Naive Bayes**: Assumes continuous values associated with each feature are distributed according to a Gaussian distribution.
-
-2. **Multinomial Naive Bayes**: Typically used for discrete counts, like word counts in text classification.
-
-3. **Bernoulli Naive Bayes**: Used for binary feature models (0s and 1s).
-
-## Example: Gaussian Naive Bayes in scikit-learn
-
-Here's a simple example of using Gaussian Naive Bayes in scikit-learn:
-
-```python
-from sklearn.naive_bayes import GaussianNB
-from sklearn.datasets import load_iris
-from sklearn.model_selection import train_test_split
-from sklearn.metrics import accuracy_score
-
-# Load the iris dataset
-iris = load_iris()
-X, y = iris.data, iris.target
-
-# Split the data into training and testing sets
-X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
-
-# Initialize and train
-gnb = GaussianNB()
-gnb.fit(X_train, y_train)
-
-# Predictions
-y_pred = gnb.predict(X_test)
-
-# Accuracy
-accuracy = accuracy_score(y_test, y_pred)
-print(f"Accuracy: {accuracy:.2f}")
-
-```
-
-## Applications of Naive Bayes Algorithm
-- Real-time Prediction.
-- Multi-class Prediction.
-- Text classification/ Spam Filtering/ Sentiment Analysis.
-- Recommendation Systems.
diff --git a/docs/Machine Learning/Principal Component Analysis.md b/docs/Machine Learning/Principal Component Analysis.md
deleted file mode 100644
index 8e03e03f8..000000000
--- a/docs/Machine Learning/Principal Component Analysis.md
+++ /dev/null
@@ -1,168 +0,0 @@
----
-id: principal-component-analysis
-title: Principal Component Analysis
-sidebar_label: Introduction to Principal Component Analysis
-sidebar_position: 1
-tags: [Principal Component Analysis, PCA, machine learning, dimensionality reduction, data analysis, data science, feature extraction, unsupervised learning, data preprocessing, variance, eigenvectors, eigenvalues]
-description: In this tutorial, you will learn about Principal Component Analysis (PCA), its importance, what PCA is, why learn PCA, how to use PCA, steps to start using PCA, and more.
----
-
-### Introduction to Principal Component Analysis
-Principal Component Analysis (PCA) is a powerful unsupervised learning algorithm used for dimensionality reduction. It transforms high-dimensional data into a lower-dimensional form while retaining as much variability as possible. PCA is widely used in data preprocessing, visualization, and noise reduction, making it an essential tool for data scientists and machine learning practitioners.
-
-### What is Principal Component Analysis?
-Principal Component Analysis (PCA) is a powerful unsupervised learning algorithm used for dimensionality reduction. It transforms high-dimensional data into a lower-dimensional form while retaining as much variability as possible. PCA achieves this by identifying the directions, called principal components, along which the data varies the most. These principal components are new orthogonal axes where the original data can be projected, effectively reducing its dimensionality.
-
-PCA is widely used in data preprocessing, visualization, and noise reduction tasks, making it an essential tool for data scientists and machine learning practitioners.
-
-Principal Component Analysis involves identifying the principal components that capture the most variance in the data:
-
-**Principal Components:** Orthogonal vectors that represent directions of maximum variance in the data. These components are linear combinations of the original features.
-
-**Eigenvectors:** Represent the direction of the principal components.
-
-**Eigenvalues:** Represent the magnitude of the variance captured by each principal component.
-
-**Transformation:** Projects the original data onto the new subspace defined by the principal components.
-
-**Variance:** Measures the spread of the data points. PCA aims to maximize the variance in the projected subspace.
-
-**Covariance Matrix:** A matrix representing the covariance between pairs of features. PCA uses the covariance matrix to identify principal components.
-
-**Linear Correlation:** Two variables are linearly correlated if a linear function of one variable can be used to predict the other variable. Understanding linear correlation is crucial as PCA relies on these relationships to identify the principal components that best summarize the data's variance.
-
-**Example:**
-Consider PCA for image compression. The algorithm reduces the dimensionality of image data by finding principal components that capture the most significant features, allowing for efficient storage and transmission of images with minimal loss of quality.
-### Advantages of Principal Component Analysis
-Principal Component Analysis offers several advantages:
-
-- **Dimensionality Reduction**: Reduces the number of features while retaining the most important information, making data easier to visualize and analyze.
-- **Noise Reduction**: Removes noise and redundant features, improving the performance of machine learning models.
-- **Data Visualization**: Projects high-dimensional data into 2D or 3D spaces for easier visualization and interpretation.
-
-### Example:
-In genetics, PCA can reduce the dimensionality of gene expression data, allowing researchers to visualize and identify patterns in genetic variations across different populations.
-
-### Disadvantages of Principal Component Analysis
-Despite its advantages, Principal Component Analysis has limitations:
-
-- **Loss of Interpretability**: Transformed features (principal components) are linear combinations of original features, making them harder to interpret.
-- **Assumes Linearity**: PCA assumes linear relationships between features, which may not hold in all datasets.
-- **Sensitive to Scaling**: Features with different scales can disproportionately influence the principal components, requiring careful preprocessing.
-
-### Example:
-In finance, PCA might struggle with non-linear relationships between stock prices and economic indicators, limiting its effectiveness in some predictive modeling tasks.
-
-### Practical Tips for Using Principal Component Analysis
-To maximize the effectiveness of Principal Component Analysis:
-
-- **Standardize Features**: Scale features to have zero mean and unit variance before applying PCA to ensure all features contribute equally.
-- **Choose the Right Number of Components**: Use techniques like the explained variance ratio to determine the optimal number of principal components to retain.
-- **Interpret Results with Caution**: While PCA simplifies data, interpreting the transformed features requires understanding their linear combinations.
-
-### Example:
-In face recognition, PCA can reduce the dimensionality of facial image data, identifying key features that distinguish different faces. Standardizing pixel values ensures that variations in lighting and contrast do not distort the analysis.
-
-### Real-World Examples
-
-#### Image Compression
-PCA is used to compress images by reducing the number of pixels while retaining essential visual information. This technique is widely applied in image storage, transmission, and processing.
-
-#### Market Segmentation
-In marketing analytics, PCA helps identify key factors that influence customer behavior, allowing businesses to segment their customer base and tailor marketing strategies effectively.
-
-### Difference Between PCA and LDA
-| Feature | Principal Component Analysis (PCA) | Linear Discriminant Analysis (LDA) |
-|---------------------------------|------------------------------------|-----------------------------------|
-| Purpose | Dimensionality reduction by maximizing variance. | Dimensionality reduction by maximizing class separability. |
-| Data Type | Unsupervised learning. | Supervised learning. |
-| Use Cases | Suitable for feature extraction and noise reduction. | Suitable for classification tasks with labeled data. |
-
-### Implementation
-To implement and apply Principal Component Analysis, you can use libraries such as scikit-learn in Python. Below are the steps to install the necessary library and apply PCA.
-
-#### Libraries to Download
-- `scikit-learn`: Essential for machine learning tasks, including PCA implementation.
-- `pandas`: Useful for data manipulation and analysis.
-- `numpy`: Essential for numerical operations.
-
-You can install these libraries using pip:
-
-```bash
-pip install scikit-learn pandas numpy
-```
-
-#### Applying Principal Component Analysis
-Here’s a step-by-step guide to applying PCA:
-
-**Import Libraries:**
-
-```python
-import pandas as pd
-import numpy as np
-from sklearn.decomposition import PCA
-from sklearn.preprocessing import StandardScaler
-```
-
-**Load and Prepare Data:**
-Assuming you have a dataset in a CSV file:
-
-```python
-# Load the dataset
-data = pd.read_csv('your_dataset.csv')
-
-# Prepare features (X)
-X = data.drop('target_column', axis=1) # Replace 'target_column' with your target variable name
-```
-
-**Feature Scaling:**
-
-```python
-# Standardize the features
-scaler = StandardScaler()
-X_scaled = scaler.fit_transform(X)
-```
-
-**Initialize and Apply PCA:**
-
-```python
-# Initialize PCA
-pca = PCA(n_components=2) # Adjust the number of components as needed
-
-# Fit and transform the data
-X_pca = pca.fit_transform(X_scaled)
-```
-
-**Evaluate Explained Variance:**
-
-```python
-# Print explained variance ratio
-print(f'Explained variance ratio: {pca.explained_variance_ratio_}')
-```
-
-**Visualize the Transformed Data:**
-
-```python
-import matplotlib.pyplot as plt
-
-# Scatter plot of the first two principal components
-plt.scatter(X_pca[:, 0], X_pca[:, 1])
-plt.xlabel('Principal Component 1')
-plt.ylabel('Principal Component 2')
-plt.title('PCA of Dataset')
-plt.show()
-```
-
-This example demonstrates loading data, scaling features, applying PCA, and visualizing the transformed data using scikit-learn and matplotlib. Adjust parameters and preprocessing steps based on your specific dataset and requirements.
-
-### Performance Considerations
-
-#### Computational Efficiency
-- **Feature Dimensionality**: PCA is computationally efficient for moderate-sized datasets but may become intensive with very high-dimensional data.
-- **Number of Components**: Selecting the right number of components balances computational efficiency and information retention.
-
-### Example:
-In climate science, PCA helps reduce the dimensionality of climate model outputs, allowing researchers to analyze and interpret climate patterns efficiently.
-
-### Conclusion
-Principal Component Analysis is a versatile and powerful technique for dimensionality reduction and data visualization. By understanding its assumptions, advantages, and implementation steps, practitioners can effectively leverage PCA for various data science and machine learning tasks.
diff --git a/docs/Machine Learning/Random-Forest.md b/docs/Machine Learning/Random-Forest.md
deleted file mode 100644
index a0c76ab8d..000000000
--- a/docs/Machine Learning/Random-Forest.md
+++ /dev/null
@@ -1,162 +0,0 @@
-# Random Forest
-
-## Introduction to Random Forest
-
-Random Forest is an ensemble learning method that builds multiple decision trees on random subsets of data and features, then combines their predictions for more accurate and robust results. It is effective for both classification and regression tasks, handling large datasets, managing missing values, and providing feature importance insights. This versatility makes it popular in fields like finance, healthcare, and marketing.
-
-## Random Forest Overview
-
-Random Forest is an ensemble learning method that builds multiple decision trees and combines their outputs to improve predictive accuracy and control overfitting. Each tree is constructed from a random subset of the data and features, promoting diversity and robustness in the model. This technique is effective for both classification and regression tasks and provides reliable predictions and feature importance metrics. Due to its versatility and effectiveness, Random Forest is widely used in various domains such as finance, healthcare, and marketing.
-
-### Example:
-
-Consider a Random Forest model for predicting customer churn in a telecom company. The model might use multiple decision trees, each splitting customers based on contract type, usage patterns, and demographics. The final prediction on whether a customer is likely to churn is derived from the aggregated outputs of all the trees.
-
-## Advantages of Random Forest
-
-Random Forests offer several advantages:
-
-- **Improved Accuracy:** By averaging the predictions of multiple trees, Random Forests typically achieve higher accuracy than individual decision trees.
-
-- **Reduced Overfitting:** The aggregation of multiple trees helps mitigate overfitting, making the model generalize better to new data.
-
-- **Feature Importance:** Random Forests provide insights into feature importance, helping identify the most influential features in the dataset.
-
-- **Versatility:** They can handle both numerical and categorical data and are effective with large datasets.
-
-### Example:
-
-In a healthcare setting, Random Forests can predict patient outcomes by analyzing a mix of medical history, demographics, and treatment options, providing accurate and interpretable insights for clinicians.
-
-## Disadvantages of Random Forest
-
-Despite their advantages, Random Forests have limitations:
-
-- **Computational Complexity:** Training multiple trees can be computationally expensive and time-consuming, especially with large datasets.
-
-- **Less Interpretability:** The combined model is less interpretable than a single decision tree, making it harder to understand individual predictions.
-
-- **Need for Tuning:** Hyperparameters like the number of trees and tree depth require tuning to optimize performance.
-
-### Example:
-
-In financial markets, predicting stock prices using Random Forests might require significant computational resources and careful hyperparameter tuning to handle high volatility and complex relationships between market factors.
-
-## Practical Tips for Using Random Forest
-
-To maximize the effectiveness of Random Forest:
-
-- **Hyperparameter Tuning:** Experiment with parameters like the number of trees, maximum depth, and minimum samples per leaf to optimize model performance.
-
-- **Feature Selection:** Use feature importance scores to select and focus on the most relevant features, improving model efficiency.
-
-- **Parallel Processing:** Utilize parallel processing techniques to speed up training and prediction times.
-
-### Example:
-
-In e-commerce, Random Forests can enhance personalized product recommendations by analyzing customer behavior and purchase history, improving user satisfaction and sales through accurate predictions.
-
-## Real-World Examples
-
-### Customer Segmentation in Retail
-
-Random Forests are extensively used in retail for customer segmentation. By analyzing customer demographics, purchase history, and behavior, retailers can create targeted marketing campaigns and personalize customer experiences.
-
-### Medical Diagnosis
-
-In healthcare, Random Forests assist in medical diagnosis by analyzing patient symptoms, medical history, and test results to classify diseases or conditions, aiding healthcare professionals in making informed decisions.
-
-## Implementation
-
-To implement and train a Random Forest model, you need to use a machine learning library such as `scikit-learn`. Below are the steps to install the necessary library and train a Random Forest model.
-
-### Libraries to Download
-
-1. **scikit-learn**: This is the primary library for machine learning in Python, including the Random Forest implementation.
-2. **pandas**: Useful for data manipulation and analysis.
-3. **numpy**: Useful for numerical operations.
-
-You can install these libraries using pip:
-
-```sh
-pip install scikit-learn pandas numpy
-```
-
-### Training a Random Forest Model
-
-Here’s a step-by-step guide to training a Random Forest model:
-
-1. **Import Libraries**:
-
-```python
-import pandas as pd
-import numpy as np
-from sklearn.model_selection import train_test_split
-from sklearn.ensemble import RandomForestClassifier
-from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
-```
-
-2. **Load and Prepare Data**:
-
-Assuming you have a dataset in a CSV file:
-
-```python
-# Load the dataset
-data = pd.read_csv('your_dataset.csv')
-
-# Prepare features (X) and target (y)
-X = data.drop('target_column', axis=1) # replace 'target_column' with the name of your target column
-y = data['target_column']
-```
-
-3. **Split Data into Training and Testing Sets**:
-
-```python
-X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
-```
-
-4. **Initialize and Train the Random Forest Model**:
-
-```python
-# Initialize the Random Forest model
-rf_model = RandomForestClassifier(n_estimators=100, random_state=42)
-
-# Train the model
-rf_model.fit(X_train, y_train)
-```
-
-5. **Make Predictions and Evaluate the Model**:
-
-```python
-# Make predictions
-y_pred = rf_model.predict(X_test)
-
-# Evaluate the model
-accuracy = accuracy_score(y_test, y_pred)
-conf_matrix = confusion_matrix(y_test, y_pred)
-class_report = classification_report(y_test, y_pred)
-
-print(f'Accuracy: {accuracy}')
-print('Confusion Matrix:')
-print(conf_matrix)
-print('Classification Report:')
-print(class_report)
-```
-
-This example demonstrates how to load data, prepare features and target variables, split the data, train a Random Forest model, and evaluate its performance. You can adjust parameters and the dataset as needed for your specific use case.
-
-## Performance Considerations
-
-### Scalability and Computational Efficiency
-
-- **Large Datasets:** Random Forests can become computationally intensive with large datasets due to the need to train multiple trees.
-
-- **Algorithmic Complexity:** Techniques like reducing the number of features considered at each split and limiting tree depth can improve scalability.
-
-### Example:
-
-In financial analytics, Random Forests are used to analyze market trends and predict stock movements. Optimizing Random Forest algorithms for large-scale data processing ensures timely and accurate predictions, critical for financial decision-making.
-
-## Conclusion
-
-Random Forests are a valuable tool in machine learning, offering a balance of predictive power and robustness. Understanding their structure, strengths, and weaknesses is essential for effectively applying them to diverse real-world problems.
diff --git a/docs/Machine Learning/Reinforcement Learning.md b/docs/Machine Learning/Reinforcement Learning.md
deleted file mode 100644
index 1caf2162f..000000000
--- a/docs/Machine Learning/Reinforcement Learning.md
+++ /dev/null
@@ -1,139 +0,0 @@
----
-id: reinforcement-learning
-title: Reinforcement Learning
-sidebar_label: Introduction to Reinforcement Learning
-sidebar_position: 1
-tags: [Reinforcement Learning, RL, machine learning, data analysis, data science, artificial intelligence, agent-based modeling, decision-making, dynamic environments, policy learning]
-description: In this tutorial, you will learn about Reinforcement Learning (RL), its importance, what RL is, why learn RL, how to use RL, steps to start using RL, and more.
----
-
-### Introduction to Reinforcement Learning
-Reinforcement Learning (RL) is a type of machine learning where an agent learns to make decisions by performing actions in an environment to maximize cumulative rewards. RL is well-suited for problems where an agent interacts with a dynamic environment, making it a powerful tool for tasks requiring sequential decision-making.
-
-### What is Reinforcement Learning?
-Reinforcement Learning involves several key components:
-
-- **Agent**: The learner or decision maker that interacts with the environment.
-- **Environment**: The external system with which the agent interacts.
-- **State**: A representation of the current situation or configuration of the environment.
-- **Action**: The set of all possible moves the agent can make.
-- **Reward**: The feedback from the environment based on the agent's actions.
-- **Policy**: A strategy used by the agent to determine the next action based on the current state.
-- **Value Function**: Estimates the expected return (cumulative reward) of states or state-action pairs.
-
-### Example:
-Consider using RL for training a robotic arm to pick up objects. The robot (agent) observes its surroundings (state), decides how to move its arm (action), and receives feedback (reward) based on whether it successfully picks up an object.
-
-### Advantages of Reinforcement Learning
-Reinforcement Learning offers several advantages:
-
-- **Dynamic Learning**: Adapts to changes in the environment, making it suitable for real-time decision-making.
-- **Sequential Decision Making**: Excels at tasks that require a series of actions to achieve a goal.
-- **Exploration and Exploitation**: Balances exploring new actions and exploiting known actions to maximize rewards.
-
-### Example:
-In video games, RL can train agents to learn optimal strategies by interacting with the game environment, leading to intelligent non-player characters (NPCs) that enhance gameplay.
-
-### Disadvantages of Reinforcement Learning
-Despite its advantages, RL has limitations:
-
-- **Sample Inefficiency**: Requires a large number of interactions with the environment to learn effectively.
-- **Computational Complexity**: Can be computationally expensive, especially for environments with large state and action spaces.
-- **Reward Design**: Designing an appropriate reward function can be challenging and significantly impacts learning performance.
-
-### Example:
-In autonomous driving, RL agents need extensive simulation and real-world interactions to learn safe and efficient driving policies, which can be time-consuming and resource-intensive.
-
-### Practical Tips for Using Reinforcement Learning
-To maximize the effectiveness of Reinforcement Learning:
-
-- **Reward Shaping**: Carefully design reward functions to guide the agent towards desired behaviors.
-- **Exploration Strategies**: Use techniques like epsilon-greedy or softmax to balance exploration and exploitation.
-- **Environment Simulation**: Utilize simulated environments to accelerate training and reduce real-world risks.
-
-### Example:
-In stock trading, RL agents can be trained in simulated markets to develop trading strategies before being deployed in live markets, minimizing financial risk during training.
-
-### Real-World Examples
-
-#### Robotics
-RL is used in robotics to enable robots to learn tasks such as walking, grasping, and navigating. By continuously interacting with their environment, robots improve their performance and adapt to new tasks.
-
-#### Healthcare
-In personalized medicine, RL can optimize treatment plans by learning the most effective interventions for individual patients based on historical data and ongoing feedback.
-
-### Difference Between RL and Supervised Learning
-| Feature | Reinforcement Learning (RL) | Supervised Learning |
-|---------------------------------|-----------------------------|---------------------|
-| Learning Paradigm | Learns by interacting with the environment and receiving feedback. | Learns from labeled data provided by a supervisor. |
-| Feedback Type | Receives rewards or penalties based on actions. | Receives explicit labels for input-output pairs. |
-| Use Cases | Suitable for sequential decision-making problems. | Suitable for classification and regression tasks. |
-
-### Implementation
-To implement and train a Reinforcement Learning model, you can use libraries such as TensorFlow, PyTorch, or specialized RL libraries like OpenAI Gym and Stable Baselines3. Below are the steps to install the necessary libraries and train an RL agent.
-
-#### Libraries to Download
-- `TensorFlow` or `PyTorch`: Essential for building and training neural networks.
-- `gym`: A toolkit for developing and comparing RL algorithms.
-- `stable-baselines3`: A set of reliable implementations of RL algorithms.
-
-You can install these libraries using pip:
-
-```bash
-pip install tensorflow gym stable-baselines3
-```
-
-#### Training a Reinforcement Learning Agent
-Here’s a step-by-step guide to training an RL agent using Stable Baselines3:
-
-**Import Libraries:**
-
-```python
-import gym
-from stable_baselines3 import PPO
-```
-
-**Create and Initialize the Environment:**
-
-```python
-# Create the environment
-env = gym.make('CartPole-v1')
-```
-
-**Define and Train the RL Model:**
-
-```python
-# Initialize the PPO agent
-model = PPO('MlpPolicy', env, verbose=1)
-
-# Train the agent
-model.learn(total_timesteps=10000)
-```
-
-**Evaluate the Model:**
-
-```python
-# Evaluate the trained agent
-obs = env.reset()
-for _ in range(1000):
- action, _states = model.predict(obs)
- obs, rewards, dones, info = env.step(action)
- env.render()
- if dones:
- obs = env.reset()
-env.close()
-```
-
-This example demonstrates setting up an RL environment, defining a PPO agent, training the agent, and evaluating its performance using Stable Baselines3. Adjust parameters and algorithms based on your specific problem and requirements.
-
-### Performance Considerations
-
-#### Computational Efficiency
-- **Hardware Acceleration**: Utilize GPUs to accelerate the training of deep RL models.
-- **Parallel Training**: Run multiple environment instances in parallel to improve sample efficiency.
-
-### Example:
-In real-time strategy games, parallel training with multiple game instances allows RL agents to quickly learn and adapt strategies, improving their performance in complex environments.
-
-### Conclusion
-Reinforcement Learning is a versatile and powerful tool for solving problems that require dynamic and sequential decision-making. By understanding its components, advantages, limitations, and implementation, practitioners can effectively apply RL to a wide range of applications in data science and machine learning projects.
diff --git a/docs/Machine Learning/SVM Algorithm.md b/docs/Machine Learning/SVM Algorithm.md
deleted file mode 100644
index b3713eaaf..000000000
--- a/docs/Machine Learning/SVM Algorithm.md
+++ /dev/null
@@ -1,159 +0,0 @@
-# Support Vector Machine (SVM)
-
-## Introduction to Support Vector Machine
-
-Support Vector Machine (SVM) is a supervised machine learning algorithm that is primarily used for classification tasks, although it can also be applied to regression problems. SVM works by finding the optimal hyperplane that best separates different classes in the feature space. This algorithm is particularly effective for high-dimensional data and situations where the number of dimensions exceeds the number of samples.
-
-## SVM Overview
-
-Support Vector Machine aims to create a decision boundary (hyperplane) that maximizes the margin between different classes. The data points that are closest to the hyperplane and influence its position are called support vectors. SVM can handle both linear and non-linear classification tasks using different kernel functions, which transform the data into higher dimensions to make it separable.
-
-### Example:
-
-Consider an SVM model for classifying emails as spam or non-spam. The model identifies the optimal hyperplane based on features like word frequency, email length, and presence of certain keywords, effectively separating spam from non-spam emails.
-
-## Advantages of SVM
-
-SVMs offer several advantages:
-
-- **Effective in High Dimensions:** SVM is highly effective in high-dimensional spaces and scenarios where the number of dimensions is greater than the number of samples.
-
-- **Robustness to Overfitting:** SVMs are robust to overfitting, especially in high-dimensional space, due to the regularization parameter that controls the trade-off between maximizing the margin and minimizing classification error.
-
-- **Versatility with Kernels:** SVMs can handle non-linear classification through kernel functions (e.g., polynomial, radial basis function), making them versatile for various datasets.
-
-### Example:
-
-In image classification, SVMs can distinguish between different objects (e.g., cats vs. dogs) by transforming the pixel intensity features into a higher-dimensional space using a radial basis function (RBF) kernel.
-
-## Disadvantages of SVM
-
-Despite their advantages, SVMs have limitations:
-
-- **Computationally Intensive:** Training an SVM can be computationally expensive, particularly with large datasets and complex kernel functions.
-
-- **Choice of Kernel:** Selecting the appropriate kernel function and tuning its parameters (e.g., the cost parameter, kernel coefficient) is crucial for optimal performance but can be challenging.
-
-- **Less Interpretability:** The decision boundary and support vectors in high-dimensional space can make the model less interpretable compared to simpler algorithms.
-
-### Example:
-
-In natural language processing, using SVM to classify text documents (e.g., sentiment analysis) can be computationally demanding due to the high-dimensional nature of textual data and the need to fine-tune kernel parameters for best performance.
-
-## Practical Tips for Using SVM
-
-To maximize the effectiveness of SVM:
-
-- **Hyperparameter Tuning:** Experiment with different kernel functions (linear, polynomial, RBF) and tune parameters like C (regularization) and gamma (kernel coefficient) to optimize model performance.
-
-- **Feature Scaling:** Ensure that features are scaled (e.g., using StandardScaler) as SVMs are sensitive to the scale of input data.
-
-- **Cross-Validation:** Use cross-validation techniques to select the best model parameters and prevent overfitting.
-
-### Example:
-
-In finance, SVMs can predict credit risk by analyzing customer data such as credit history and financial transactions. Properly tuning the model’s parameters and scaling features ensures accurate and reliable predictions.
-
-## Real-World Examples
-
-### Handwriting Recognition
-
-SVMs are widely used in handwriting recognition, where they classify handwritten digits based on pixel intensity features. The model transforms the features into a higher-dimensional space, enabling accurate classification of digits.
-
-### Bioinformatics
-
-In bioinformatics, SVMs classify proteins based on their amino acid sequences and structural features. By using appropriate kernels, SVMs handle the complex, high-dimensional data inherent in biological sequences.
-
-## Implementation
-
-To implement and train an SVM model, you can use a machine learning library such as `scikit-learn`. Below are the steps to install the necessary library and train an SVM model.
-
-### Libraries to Download
-
-1. **scikit-learn**: This is the primary library for machine learning in Python, including the SVM implementation.
-2. **pandas**: Useful for data manipulation and analysis.
-3. **numpy**: Useful for numerical operations.
-
-You can install these libraries using pip:
-
-```sh
-pip install scikit-learn pandas numpy
-```
-
-### Training an SVM Model
-
-Here’s a step-by-step guide to training an SVM model:
-
-1. **Import Libraries**:
-
-```python
-import pandas as pd
-import numpy as np
-from sklearn.model_selection import train_test_split
-from sklearn.svm import SVC
-from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
-```
-
-2. **Load and Prepare Data**:
-
-Assuming you have a dataset in a CSV file:
-
-```python
-# Load the dataset
-data = pd.read_csv('your_dataset.csv')
-
-# Prepare features (X) and target (y)
-X = data.drop('target_column', axis=1) # replace 'target_column' with the name of your target column
-y = data['target_column']
-```
-
-3. **Split Data into Training and Testing Sets**:
-
-```python
-X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
-```
-
-4. **Initialize and Train the SVM Model**:
-
-```python
-# Initialize the SVM model
-svm_model = SVC(kernel='rbf', C=1.0, gamma='scale', random_state=42)
-
-# Train the model
-svm_model.fit(X_train, y_train)
-```
-
-5. **Make Predictions and Evaluate the Model**:
-
-```python
-# Make predictions
-y_pred = svm_model.predict(X_test)
-
-# Evaluate the model
-accuracy = accuracy_score(y_test, y_pred)
-conf_matrix = confusion_matrix(y_test, y_pred)
-class_report = classification_report(y_test, y_pred)
-
-print(f'Accuracy: {accuracy}')
-print('Confusion Matrix:')
-print(conf_matrix)
-print('Classification Report:')
-print(class_report)
-```
-
-This example demonstrates how to load data, prepare features and target variables, split the data, train an SVM model, and evaluate its performance. You can adjust parameters and the dataset as needed for your specific use case.
-
-## Performance Considerations
-
-### Scalability and Computational Efficiency
-
-- **Large Datasets:** SVMs can be computationally intensive with large datasets, especially when using non-linear kernels.
-- **Algorithmic Complexity:** Techniques such as reducing feature dimensions through Principal Component Analysis (PCA) and using linear kernels for large datasets can improve scalability.
-
-### Example:
-
-In text classification, SVMs are used to categorize documents into predefined classes (e.g., news articles into topics). Optimizing SVM algorithms for large-scale text data ensures efficient processing and accurate classifications.
-
-## Conclusion
-
-Support Vector Machines are powerful tools in machine learning, especially for classification tasks involving high-dimensional data. Understanding their structure, strengths, and limitations is crucial for effectively applying them to various real-world problems. By carefully tuning parameters and selecting appropriate kernels, SVMs can achieve high accuracy and robustness in diverse applications.
diff --git a/docs/Machine Learning/Scikit-Learn.md b/docs/Machine Learning/Scikit-Learn.md
deleted file mode 100644
index af5d1f27c..000000000
--- a/docs/Machine Learning/Scikit-Learn.md
+++ /dev/null
@@ -1,229 +0,0 @@
-# Scikit-Learn
-
-> Unlock the Power of Machine Learning with Scikit-learn: Simplifying Complexity, Empowering Discovery
-
-
-**Supervised Learning**
-- Linear Models
-
-- Support Vector Machines
-
-- Data Preprocessing
-
-1. Linear Models
-
-The following are a set of
-methods intended for regression in which the target value is expected to
-be a linear combination of the features. In mathematical notation, if
-$\hat{y}$ is the predicted value.
-
-$$
-\hat{y}(w, x) = w_0 + w_1 + \ldots + w_p
-$$
-
-Across the module, we designate the vector w =
-$(w_0, w_1, \ldots, w_n)$ as `coef_` and $w_0$ as `intercept_`.
-
-
-- *Linear Regression*
- Linear Regression fits a linear model with coefficients w = $(w_0 ,w_1 ,
-...w_n)$ to minimize the residual sum of squares between the observed
-targets in the dataset, and the targets predicted by the linear
-approximation. Mathematically it solves a problem of the form:
-
- $\min_{w} || X w - y||_2^2$
-
-``` python
-from sklearn import linear_model
-reg = linear_model.LinearRegression() #To Use Linear Regression
-reg.fit([[0, 0], [1, 1], [2, 2]], [0, 1, 2])
-coefficients = reg.coef_
-intercept = reg.intercept_
-
-print("Coefficients:", coefficients)
-print("Intercept:", intercept)
-```
-
-Output:
-
- Coefficients: [0.5 0.5]
- Intercept: 1.1102230246251565e-16
-
-
-
-
-This is how the Linear Regression fits the line .
-
-
-- Support Vector Machines
- Support vector machines (SVMs) are a set of supervised learning methods
-used for classification, regression and outliers detection.
-
-*The advantages of support vector machines are:*
-
-Effective in high dimensional spaces.
-
-Still effective in cases where number of dimensions is greater than the
-number of samples.
-
-Uses a subset of training points in the decision function (called
-support vectors), so it is also memory efficient.
-
-Versatile: different Kernel functions can be specified for the decision
-function. Common kernels are provided, but it is also possible to
-specify custom kernels.
-
-*The disadvantages of support vector machines include:*
-
-If the number of features is much greater than the number of samples,
-avoid over-fitting in choosing Kernel functions and regularization term
-is crucial.
-
-SVMs do not directly provide probability estimates, these are calculated
-using an expensive five-fold cross-validation (see Scores and
-probabilities, below).
-
-The support vector machines in scikit-learn support both dense
-(numpy.ndarray and convertible to that by numpy.asarray) and sparse (any
-scipy.sparse) sample vectors as input. However, to use an SVM to make
-predictions for sparse data, it must have been fit on such data. For
-optimal performance, use C-ordered numpy.ndarray (dense) or
-scipy.sparse.csr_matrix (sparse) with dtype=float64
-
-**Linear Kernel:**
-
-Function: 𝐾 ( 𝑥 , 𝑦 ) = 𝑥 𝑇 𝑦
-
-Parameters: No additional parameters.
-
-**Polynomial Kernel:**
-
-Function: 𝐾 ( 𝑥 , 𝑦 ) = ( 𝛾 𝑥 𝑇 𝑦 𝑟 ) 𝑑
-
-Parameters:
-
-γ (gamma): Coefficient for the polynomial term. Higher values increase
-the influence of high-degree polynomials.
-
-r: Coefficient for the constant term.
-
-d: Degree of the polynomial.
-
-**Radial Basis Function (RBF) Kernel:**
-
-Function: 𝐾 ( 𝑥 , 𝑦 ) = exp ( − 𝛾 ∣ ∣ 𝑥 − 𝑦 ∣ ∣ 2 )
-
-Parameters: 𝛾 γ (gamma): Controls the influence of each training
-example. Higher values result in a more complex decision boundary.
-
-**Sigmoid Kernel:**
-
-Function: 𝐾 ( 𝑥 , 𝑦 ) = tanh ( 𝛾 𝑥 𝑇 𝑦 𝑟 )
-
-Parameters:
-
-γ (gamma): Coefficient for the sigmoid term.
-
-r: Coefficient for the constant term.
-
-
-``` python
-import numpy as np
-import matplotlib.pyplot as plt
-from sklearn import svm, datasets
-
-# Load example dataset (Iris dataset)
-iris = datasets.load_iris()
-X = iris.data[:, :2] # We only take the first two features
-y = iris.target
-
-# Define the SVM model with RBF kernel
-C = 1.0 # Regularization parameter
-gamma = 0.7 # Kernel coefficient
-svm_model = svm.SVC(kernel='rbf', C=C, gamma=gamma)
-
-# Train the SVM model
-svm_model.fit(X, y)
-
-# Plot the decision boundary
-x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
-y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
-xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
- np.arange(y_min, y_max, 0.02))
-Z = svm_model.predict(np.c_[xx.ravel(), yy.ravel()])
-Z = Z.reshape(xx.shape)
-
-plt.contourf(xx, yy, Z, cmap=plt.cm.Paired, alpha=0.8)
-
-# Plot the training points
-plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Paired)
-plt.xlabel('Sepal length')
-plt.ylabel('Sepal width')
-plt.title('SVM with RBF Kernel')
-plt.show()
-```
-
-
-- Data Preprocessing
- Data preprocessing is a crucial step in the machine learning pipeline
-that involves transforming raw data into a format suitable for training
-a model. Here are some fundamental techniques in data preprocessing
-using scikit-learn:
-
-**Handling Missing Values:**
-
-Imputation: Replace missing values with a calculated value (e.g., mean,
-median, mode) using SimpleImputer. Removal: Remove rows or columns with
-missing values using dropna.
-
-**Feature Scaling:**
-
-Standardization: Scale features to have a mean of 0 and a standard
-deviation of 1 using StandardScaler.
-
-Normalization: Scale features to a range between 0 and 1 using
-MinMaxScaler. Encoding Categorical Variables:
-
-One-Hot Encoding: Convert categorical variables into binary vectors
-using OneHotEncoder.
-
-Label Encoding: Encode categorical variables as integers using
-LabelEncoder.
-
-**Feature Transformation:**
-
-Polynomial Features: Generate polynomial features up to a specified
-degree using PolynomialFeatures.
-
-Log Transformation: Transform features using the natural logarithm to
-handle skewed distributions.
-
-**Handling Outliers:**
-
-Detection: Identify outliers using statistical methods or domain
-knowledge. Transformation: Apply transformations (e.g., winsorization)
-or remove outliers based on a threshold.
-
-**Handling Imbalanced Data:**
-
-Resampling: Over-sample minority class or under-sample majority class to
-balance the dataset using techniques like RandomOverSampler or
-RandomUnderSampler.
-
-Synthetic Sampling: Generate synthetic samples for the minority class
-using algorithms like Synthetic Minority Over-sampling Technique
-(SMOTE). Feature Selection:
-
-Univariate Feature Selection: Select features based on statistical tests
-like ANOVA using SelectKBest or SelectPercentile.
-
-Recursive Feature Elimination: Select features recursively by
-considering smaller and smaller sets of features using RFECV.
-
-**Splitting Data:**
-
-Train-Test Split: Split the dataset into training and testing sets using
-train_test_split.
-
-Cross-Validation: Split the dataset into multiple folds for
-cross-validation using KFold or StratifiedKFold.
diff --git a/docs/Machine Learning/Stochastic Gradient Descent model.md b/docs/Machine Learning/Stochastic Gradient Descent model.md
deleted file mode 100644
index 050510df5..000000000
--- a/docs/Machine Learning/Stochastic Gradient Descent model.md
+++ /dev/null
@@ -1,145 +0,0 @@
----
-id: stochastic-gradient-descent
-title: Stochastic Gradient Descent
-sidebar_label: Introduction to Stochastic Gradient Descent
-sidebar_position: 1
-tags: [stochastic gradient descent, machine learning, optimization algorithm, deep learning, gradient descent, data science, model training, stochastic optimization, neural networks, supervised learning, gradient descent variants, iterative optimization, parameter tuning]
-description: In this tutorial, you will learn about Stochastic Gradient Descent (SGD), its importance, what SGD is, why learn SGD, how to use SGD, steps to start using SGD, and more.
----
-
-### Introduction to Stochastic Gradient Descent
-Stochastic Gradient Descent (SGD) is a fundamental optimization algorithm widely used in machine learning and deep learning for training models. It belongs to the family of gradient descent methods and is particularly suited for large-scale datasets and complex models due to its efficiency and iterative nature.
-
-### What is Stochastic Gradient Descent?
-Stochastic Gradient Descent is an optimization technique that updates model parameters iteratively to minimize a loss function by taking small steps in the direction of the steepest gradient calculated from a subset (batch) of training data at each iteration. Unlike traditional Gradient Descent, which computes gradients using the entire dataset (batch gradient descent), SGD processes data in smaller batches, making it faster and more suitable for online learning and dynamic environments.
-
--**Batch Size**: Number of data points used in each iteration to compute the gradient and update parameters.
-
--**Learning Rate**: Step size that controls the magnitude of parameter updates in each iteration.
-
-
-### Example:
-Consider training a deep neural network (DNN) for image classification using SGD. Instead of computing gradients over the entire dataset in one go, SGD updates model weights incrementally after processing each batch of images. This stochastic process helps in navigating complex optimization landscapes efficiently.
-
-### Advantages of Stochastic Gradient Descent
-Stochastic Gradient Descent offers several advantages:
-
-- **Efficiency**: It processes data in mini-batches, reducing computational requirements compared to batch gradient descent, especially with large datasets.
-- **Convergence Speed**: SGD often converges faster than batch methods because it quickly adjusts model parameters using frequent updates.
-- **Scalability**: Suitable for large-scale datasets and online learning scenarios where data arrives sequentially or in streams.
-
-### Example:
-In natural language processing (NLP), SGD is used to train models for text classification tasks. By processing text data in batches and updating weights iteratively, SGD enables efficient training of models to classify documents into categories such as spam vs. non-spam emails.
-
-### Disadvantages of Stochastic Gradient Descent
-Despite its advantages, SGD has limitations:
-
-- **Noisy Updates**: The stochastic nature of SGD introduces noise due to mini-batch sampling, which can lead to fluctuations in training loss and convergence.
-- **Learning Rate Tuning**: Requires careful tuning of the learning rate and batch size to achieve optimal convergence and stability.
-- **Potential for Overshooting**: In some cases, SGD can overshoot the optimal solution, especially when the learning rate is too high or batch size is too small.
-
-### Example:
-In financial modeling, using SGD for predicting stock prices may require careful tuning of batch size and learning rate to mitigate noise and ensure accurate predictions amidst market volatility.
-
-### Practical Tips for Using Stochastic Gradient Descent
-To effectively apply SGD in model training:
-
-- **Learning Rate Schedule**: Implement learning rate schedules (e.g., decay or adaptive learning rates) to dynamically adjust the learning rate during training.
-- **Batch Size Selection**: Experiment with different batch sizes to find a balance between computational efficiency and model stability.
-- **Regularization**: Incorporate regularization techniques (e.g., L2 regularization) to prevent overfitting and improve generalization.
-
-### Example:
-In recommender systems, SGD is employed to optimize matrix factorization models for personalized recommendations. Fine-tuning batch sizes and learning rates ensures that the model efficiently learns user preferences from large-scale interaction data.
-
-### Real-World Examples
-
-#### Deep Learning Training
-Stochastic Gradient Descent is extensively used in training deep learning models, including convolutional neural networks (CNNs) for image recognition and recurrent neural networks (RNNs) for sequence modeling. Its efficiency in handling large volumes of training data and complex model architectures makes it indispensable in modern AI applications.
-
-#### Online Learning
-In online advertising, SGD enables real-time updates of ad recommendation models based on user interactions and behavioral data. By processing new data streams in mini-batches, SGD continuously refines model predictions to adapt to evolving user preferences.
-
-### Difference Between Stochastic Gradient Descent and Batch Gradient Descent
-
-| Feature | Stochastic Gradient Descent | Batch Gradient Descent |
-|---------------------------------|--------------------------------------|-----------------------------------|
-| Processing | Mini-batches of data points | Entire dataset |
-| Gradient Calculation | Subset of data at each iteration | Entire dataset |
-| Convergence Speed | Faster due to frequent updates | Slower, requires full dataset |
-| Noise Sensitivity | More sensitive due to mini-batch sampling | Smoother due to full dataset |
-| Use Cases | Large-scale datasets, online learning | Small to medium-sized datasets |
-
-### Implementation
-To implement Stochastic Gradient Descent in Python, you can use libraries such as TensorFlow, PyTorch, or scikit-learn, depending on your specific model and application requirements. Below is a basic example using scikit-learn for linear regression:
-
-#### Libraries to Download
-- `scikit-learn`: Provides various machine learning algorithms and utilities in Python.
-
-Install scikit-learn using pip:
-
-```bash
-pip install scikit-learn
-```
-
-#### Training a Model with SGD
-Here’s a simplified example of training a linear regression model using SGD with scikit-learn:
-
-**Import Libraries:**
-
-```python
-from sklearn.linear_model import SGDRegressor
-from sklearn.datasets import make_regression
-from sklearn.model_selection import train_test_split
-from sklearn.preprocessing import StandardScaler
-import numpy as np
-import matplotlib.pyplot as plt
-```
-
-**Generate Synthetic Data:**
-
-```python
-# Generate synthetic data
-X, y = make_regression(n_samples=1000, n_features=10, noise=0.1, random_state=42)
-
-# Split data into training and testing sets
-X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
-
-# Standardize features
-scaler = StandardScaler()
-X_train_scaled = scaler.fit_transform(X_train)
-X_test_scaled = scaler.transform(X_test)
-```
-
-**Initialize and Train SGD Model:**
-
-```python
-# Initialize SGDRegressor
-sgd = SGDRegressor(max_iter=1000, tol=1e-3, random_state=42)
-
-# Train the model
-sgd.fit(X_train_scaled, y_train)
-```
-
-**Evaluate the Model:**
-
-```python
-# Evaluate model performance
-train_score = sgd.score(X_train_scaled, y_train)
-test_score = sgd.score(X_test_scaled, y_test)
-print(f"Training R2 Score: {train_score:.2f}")
-print(f"Testing R2 Score: {test_score:.2f}")
-```
-
-This example demonstrates how to train a linear regression model using SGD with scikit-learn, including data preprocessing, model initialization, training, and evaluation. Adjust parameters and data handling based on your specific use case and dataset characteristics.
-
-### Performance Considerations
-
-#### Convergence and Hyperparameter Tuning
-- **Learning Rate**: Optimize learning rate selection to balance convergence speed and stability.
-- **Mini-Batch Size**: Experiment with different batch sizes to find an optimal balance between noise sensitivity and computational efficiency.
-
-### Example:
-In climate modeling, SGD is applied to optimize complex simulation models based on atmospheric data. Efficiently training these models using SGD enables accurate prediction and analysis of climate patterns and phenomena.
-
-### Conclusion
-Stochastic Gradient Descent is a versatile and efficient optimization algorithm crucial for training machine learning models, especially in scenarios involving large datasets and complex model architectures. By understanding its principles, advantages, and implementation strategies, practitioners can effectively leverage SGD to enhance model performance and scalability across various domains of artificial intelligence and data science.
diff --git a/docs/Machine Learning/Support Vector Regression.md b/docs/Machine Learning/Support Vector Regression.md
deleted file mode 100644
index 2c828cb6c..000000000
--- a/docs/Machine Learning/Support Vector Regression.md
+++ /dev/null
@@ -1,157 +0,0 @@
----
-
-id: support-vector-regression
-title: Support Vector Regression
-sidebar_label: Introduction to Support Vector Regression
-sidebar_position: 1
-tags: [Support Vector Regression, SVR, machine learning, regression algorithm, data analysis, data science, supervised learning, predictive modeling, feature importance]
-description: In this tutorial, you will learn about Support Vector Regression (SVR), its importance, what SVR is, why learn SVR, how to use SVR, steps to start using SVR, and more.
-
----
-
-### Introduction to Support Vector Regression
-Support Vector Regression (SVR) is a machine learning algorithm used for predicting continuous values. It extends the Support Vector Machine (SVM) algorithm, which is typically used for classification, to handle regression tasks.
-
-### What is Support Vector Regression?
-**Support Vector Regression (SVR)** is a type of Support Vector Machine (SVM) used for predicting continuous outcomes. SVR finds a line (or hyperplane) that best fits the data points while keeping most of them within a specified margin of error.
-
-- **Support Vectors**: Data points that are closest to the line and influence its position.
-
-- **Epsilon-insensitive Loss Function**: A method that ignores small errors within a specified range (epsilon).
-
-**Hyperplane**: The line or boundary that SVR tries to find, which best fits the data within the allowed error margin.
-
-**Kernel Trick**: A technique to transform data into a higher-dimensional space, allowing SVR to handle complex, non-linear relationships.
-
-### Example:
-For predicting house prices, SVR can create a model that finds the relationship between various features (like size, number of rooms) and the price, fitting the data within a margin of error.
-
-### Advantages of Support Vector Regression
-- **Robust to Outliers**: Focuses on the most important data points (support vectors), making it less sensitive to outliers.
-- **Flexible with Kernels**: Can handle non-linear relationships using different kernel functions.
-- **Effective in High Dimensions**: Works well even when there are many features.
-
-### Example:
-In predicting stock prices, SVR can handle noisy data and complex relationships between market indicators and prices.
-
-### Disadvantages of Support Vector Regression
-- **Computationally Intensive**: Training SVR can be slow, especially with large datasets.
-- **Needs Careful Tuning**: Performance depends on selecting the right parameters (like C, epsilon, and kernel type).
-- **Complex Interpretation**: The resulting model can be hard to interpret, especially with non-linear kernels.
-
-### Example:
-In forecasting energy usage, SVR might be slow with large datasets, requiring good computational resources.
-
-### Practical Tips for Using Support Vector Regression
-- **Tune Parameters**: Adjust parameters like C, epsilon, and kernel type for better performance.
-- **Scale Features**: Normalize features to improve model performance and convergence.
-- **Choose Kernels Wisely**: Select an appropriate kernel function based on your data.
-
-### Example:
-In medical diagnostics, SVR can predict patient outcomes. Proper feature scaling and kernel selection improve prediction accuracy.
-
-### Real-World Examples
-
-#### Weather Forecasting
-SVR is used to predict temperature and rainfall based on historical data, helping in accurate weather forecasting.
-
-#### Demand Forecasting
-In supply chain management, SVR predicts product demand, helping businesses optimize inventory and reduce costs.
-
-### Difference Between SVR and Linear Regression
-| Feature | Support Vector Regression (SVR) | Linear Regression |
-|---------------------------------|---------------------------------|-------------------|
-| Loss Function | Epsilon-insensitive | Mean squared error |
-| Flexibility | Can model non-linear relationships | Assumes linear relationships |
-| Robustness to Outliers | More robust to outliers | Sensitive to outliers |
-
-### Implementation
-To implement SVR, you can use Python libraries like scikit-learn. Here are the steps:
-
-#### Libraries to Download
-
-- `scikit-learn`: For machine learning tasks, including SVR.
-- `pandas`: For data manipulation.
-- `numpy`: For numerical operations.
-
-Install these using pip:
-
-```bash
-pip install scikit-learn pandas numpy
-```
-
-#### Training a Support Vector Regression Model
-
-**Import Libraries:**
-
-```
-
-```python
-import pandas as pd
-import numpy as np
-from sklearn.svm import SVR
-from sklearn.model_selection import train_test_split
-from sklearn.preprocessing import StandardScaler
-```
-
-**Load and Prepare Data:**
-Assuming you have a dataset in a CSV file:
-
-```python
-# Load the dataset
-data = pd.read_csv('your_dataset.csv')
-
-# Prepare features (X) and target variable (y)
-X = data.drop('target_column', axis=1) # Replace 'target_column' with your target variable name
-y = data['target_column']
-```
-
-**Feature Scaling:**
-
-```python
-# Perform feature scaling
-scaler = StandardScaler()
-X_scaled = scaler.fit_transform(X)
-```
-
-**Split Data into Training and Testing Sets:**
-
-```python
-X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
-```
-
-**Initialize and Train the Support Vector Regression Model:**
-
-```python
-svr = SVR(kernel='rbf')
-svr.fit(X_train, y_train)
-```
-
-**Evaluate the Model:**
-
-```python
-from sklearn.metrics import mean_squared_error, r2_score
-
-# Predict on test data
-y_pred = svr.predict(X_test)
-
-# Evaluate performance
-mse = mean_squared_error(y_test, y_pred)
-r2 = r2_score(y_test, y_pred)
-print(f'Mean Squared Error: {mse:.2f}')
-print(f'R^2 Score: {r2:.2f}')
-```
-
-This example demonstrates loading data, preparing features, training an SVR model, and evaluating its performance using scikit-learn. Adjust parameters and preprocessing steps based on your specific dataset and requirements.
-
-### Performance Considerations
-
-#### Computational Efficiency
-- **Kernel Choice**: The choice of kernel affects both the computational efficiency and the performance of SVR.
-- **Model Complexity**: Proper tuning of hyperparameters can balance model complexity and computational efficiency.
-
-### Example:
-In financial forecasting, SVR helps predict future asset prices based on historical data. Choosing the right kernel and tuning hyperparameters ensures accurate and efficient predictions.
-
-### Conclusion
-Support Vector Regression is a versatile and powerful algorithm for regression tasks. By understanding its assumptions, advantages, and implementation steps, practitioners can effectively leverage SVR for a variety of predictive modeling tasks in data science and machine learning projects.
diff --git a/docs/Machine Learning/Transfer Learning.md b/docs/Machine Learning/Transfer Learning.md
deleted file mode 100644
index bc462ecdd..000000000
--- a/docs/Machine Learning/Transfer Learning.md
+++ /dev/null
@@ -1,169 +0,0 @@
----
-id: transfer-learning
-title: Transfer Learning
-sidebar_label: Introduction to Transfer Learning
-sidebar_position: 1
-tags: [Transfer Learning, neural networks, machine learning, data science, deep learning, pre-trained models, fine-tuning, feature extraction]
-description: In this tutorial, you will learn about Transfer Learning, its importance, what Transfer Learning is, why learn Transfer Learning, how to use Transfer Learning, steps to start using Transfer Learning, and more.
-
----
-
-### Introduction to Transfer Learning
-Transfer Learning is a machine learning technique where a model developed for one task is reused as the starting point for a model on a second task. This approach leverages pre-trained models, often trained on large datasets, to improve performance on a related task with less data and computation. Transfer Learning is particularly powerful in deep learning, enabling rapid progress and improved performance across various applications.
-
-### What is Transfer Learning?
-**Transfer Learning** involves taking a pre-trained model and adapting it to a new, often related, task. This can be done in several ways:
-
-- **Feature Extraction**: Using the pre-trained model's layers as feature extractors. The learned features are fed into a new model for the specific task.
-- **Fine-Tuning**: Starting with the pre-trained model and fine-tuning its weights on the new task. This involves retraining some or all of the layers.
-
-Pre-trained models are typically trained on large datasets like ImageNet, which contains millions of images and thousands of classes, providing a rich feature space.
-
-:::info
-**Feature Extraction**: Utilizes the representations learned by a pre-trained model to extract features from new data. Often involves freezing the layers of the pre-trained model.
-
-**Fine-Tuning**: Involves retraining some or all of the pre-trained model's layers to adapt them to the new task. This can improve performance but requires more computational resources.
-:::
-
-### Example:
-Consider using a pre-trained model like VGG16 for image classification. You can use the convolutional base of VGG16 to extract features from your dataset and train a new classifier on top of these features, significantly reducing the amount of data and training time needed.
-
-### Advantages of Transfer Learning
-Transfer Learning offers several advantages:
-
-- **Reduced Training Time**: By leveraging pre-trained models, you can reduce the time required to train a new model.
-- **Improved Performance**: Pre-trained models have learned rich feature representations, which can enhance performance on related tasks.
-- **Less Data Required**: Transfer Learning can achieve good performance even with limited data for the new task.
-
-### Example:
-In medical image analysis, where annotated data is scarce, Transfer Learning allows practitioners to build accurate models by starting with pre-trained models trained on general image datasets.
-
-### Disadvantages of Transfer Learning
-Despite its advantages, Transfer Learning has limitations:
-
-- **Compatibility Issues**: The pre-trained model needs to be somewhat relevant to the new task for effective transfer.
-- **Computational Resources**: Fine-tuning a pre-trained model can be computationally expensive, requiring significant resources.
-
-### Example:
-In natural language processing, using a pre-trained model trained on general text data might not transfer well to domain-specific tasks without significant fine-tuning.
-
-### Practical Tips for Using Transfer Learning
-To maximize the effectiveness of Transfer Learning:
-
-- **Choose the Right Model**: Select a pre-trained model that is closely related to your task. For image tasks, models like ResNet, VGG, or Inception are popular choices.
-- **Freeze Layers Appropriately**: Start by freezing the early layers of the pre-trained model and only train the new layers. Gradually unfreeze layers and fine-tune as needed.
-- **Use Appropriate Data Augmentation**: Apply data augmentation techniques to increase the diversity of your training data and improve the model's robustness.
-
-### Example:
-In sentiment analysis, using a pre-trained language model like BERT can significantly improve performance. Fine-tuning BERT on a small annotated dataset can yield state-of-the-art results.
-
-### Real-World Examples
-
-#### Image Classification
-Transfer Learning is widely used in image classification tasks. Pre-trained models on ImageNet can be fine-tuned for specific tasks like medical image diagnosis, wildlife classification, and more.
-
-#### Natural Language Processing
-In NLP, models like BERT, GPT, and ELMo are pre-trained on large text corpora and fine-tuned for tasks such as sentiment analysis, named entity recognition, and machine translation.
-
-### Difference Between Transfer Learning and Traditional Machine Learning
-
-| Feature | Transfer Learning | Traditional Machine Learning |
-|----------------------------------|------------------------------------------|-----------------------------------------|
-| Training Time | Reduced due to pre-trained models | Longer, as models are trained from scratch |
-| Data Requirements | Requires less data for the new task | Requires large amounts of task-specific data |
-| Performance | Often higher due to rich pre-trained features | Depends heavily on the size and quality of the dataset |
-| Use Cases | Image classification, NLP, medical imaging | General machine learning tasks |
-
-### Implementation
-To implement Transfer Learning, you can use libraries such as TensorFlow, Keras, or PyTorch in Python. Below are the steps to install the necessary libraries and apply Transfer Learning.
-
-#### Libraries to Download
-
-- `TensorFlow` or `PyTorch`: Essential for building and training models.
-- `numpy`: Useful for numerical operations.
-- `matplotlib`: Useful for visualizing training progress and results.
-
-You can install these libraries using pip:
-
-```bash
-pip install tensorflow numpy matplotlib
-```
-
-#### Applying Transfer Learning
-Here’s a step-by-step guide to applying Transfer Learning using TensorFlow and Keras:
-
-**Import Libraries:**
-
-```python
-import numpy as np
-import matplotlib.pyplot as plt
-import tensorflow as tf
-from tensorflow.keras.layers import Dense, GlobalAveragePooling2D
-from tensorflow.keras.models import Model
-from tensorflow.keras.applications import VGG16
-from tensorflow.keras.preprocessing.image import ImageDataGenerator
-```
-
-**Load Pre-trained Model and Prepare Data:**
-
-```python
-# Load VGG16 model with pre-trained weights
-base_model = VGG16(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
-
-# Freeze the layers of the pre-trained model
-for layer in base_model.layers:
- layer.trainable = False
-
-# Prepare data generators
-train_datagen = ImageDataGenerator(rescale=1./255, horizontal_flip=True, zoom_range=0.2, rotation_range=20)
-train_generator = train_datagen.flow_from_directory('path_to_train_data', target_size=(224, 224), batch_size=32, class_mode='binary')
-
-validation_datagen = ImageDataGenerator(rescale=1./255)
-validation_generator = validation_datagen.flow_from_directory('path_to_validation_data', target_size=(224, 224), batch_size=32, class_mode='binary')
-```
-
-**Add Custom Layers and Compile Model:**
-
-```python
-# Add custom layers on top of the pre-trained base
-x = base_model.output
-x = GlobalAveragePooling2D()(x)
-x = Dense(1024, activation='relu')(x)
-predictions = Dense(1, activation='sigmoid')(x)
-
-# Define the new model
-model = Model(inputs=base_model.input, outputs=predictions)
-
-# Compile the model
-model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
-```
-
-**Train the Model:**
-
-```python
-# Train the model
-history = model.fit(train_generator, epochs=10, validation_data=validation_generator)
-
-# Plot training and validation accuracy
-plt.plot(history.history['accuracy'], label='train accuracy')
-plt.plot(history.history['val_accuracy'], label='validation accuracy')
-plt.title('Training and Validation Accuracy')
-plt.xlabel('Epochs')
-plt.ylabel('Accuracy')
-plt.legend()
-plt.show()
-```
-
-This example demonstrates how to load a pre-trained VGG16 model, add custom layers, and train it on a new dataset using TensorFlow and Keras. Adjust the model architecture, hyperparameters, and dataset as needed for your specific use case.
-
-### Performance Considerations
-
-#### Fine-Tuning Strategy
-- **Gradual Unfreezing**: Start by training only the custom layers. Gradually unfreeze and fine-tune the upper layers of the pre-trained model to adapt them to your task.
-- **Learning Rate**: Use a lower learning rate for fine-tuning the pre-trained layers to prevent large updates that could destroy the learned features.
-
-### Example:
-In fine-tuning a pre-trained model for object detection, starting with a low learning rate and gradually unfreezing layers can lead to improved performance and stability.
-
-### Conclusion
-Transfer Learning is a powerful technique that leverages pre-trained models to improve performance and reduce training time for new tasks. By understanding the principles, advantages, and practical implementation steps, practitioners can effectively apply Transfer Learning to various machine learning challenges, enhancing their models' efficiency and effectiveness.
diff --git a/docs/Machine Learning/linear_regression.md b/docs/Machine Learning/linear_regression.md
deleted file mode 100644
index 9cfd2277f..000000000
--- a/docs/Machine Learning/linear_regression.md
+++ /dev/null
@@ -1,128 +0,0 @@
-# Linear Regression
-
-### Introduction to Linear Regression
-
-Linear regression is a fundamental and widely used statistical technique for predicting numeric outcomes based on one or more independent variables. This document provides an overview of linear regression, including its principles, advantages, disadvantages, and practical considerations for application.
-
-### Overview of Linear Regression Model
-
-Linear regression models the relationship between a dependent variable (target) and one or more independent variables (predictors) by fitting a linear equation to observed data.
-
-### Formula:
-
-$$Y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \beta_3 x_3 + \cdots + \beta_n x_n + \epsilon$$
-
-
-#### y: Dependent variable (target)
-
-#### 𝛽0 : Intercept
-
-#### 𝛽i : Coefficients for each predictor 𝑥𝑖(Independent variables)
-
-
-#### ϵ: Error term (residuals)
-
-
-### Example:
-
-In predicting house prices, linear regression may model the relationship between house size, number of bedrooms, and location to estimate the sale price of a property.
-
-### Code:
-```python
-#import libraries
-from matplotlib import pyplot as plt
-import pandas as pd
-from sklearn.model_selection import train_test_split
-from sklearn.linear_model import LinearRegression
-from sklearn.metrics import r2_score
-
-#read the file
-df=pd.read_csv("data.csv")
-
-#assign x(independent variable) and y(dependent variable) from the dataset
-y=df['A']
-x=df['B']
-
-#split the data into training and testing sets
-X_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.25,random_state=50)
-
-#object
-linreg=LinearRegression()
-linreg.fit(X_train,y_train)
-
-#predict for test data
-y_pred=linreg.predict(x_test)
-
-#regression line
-plt.xlabel("B")
-plt.ylabel("A")
-plt.plot(x_test,y_pred)
-plt.scatter(x_test,y_test)
-
-#evaluation of model
-print("r2 score : ",r2_score(y_test,y_pred))
-```
-
-### Advantages of Linear Regression
-
-#### Linear regression offers several advantages:
-
-- Interpretability: Coefficients indicate the strength and direction of relationships between predictors and the target variable.
-
-- Simple to Implement: The model is straightforward to implement and understand, making it accessible for beginners and useful for quick insights.
-
-- Efficient Computation: Training and predicting with linear regression are computationally efficient even with large datasets.
-
-#### Example:
-
-In marketing, linear regression helps analyze the impact of advertising spend on sales revenue, guiding budget allocation decisions for optimal ROI.
-
-### Disadvantages of Linear Regression
-
-Despite its advantages, linear regression has limitations:
-
-- Assumption of Linearity: Linear regression assumes a linear relationship between predictors and the target, which may not hold true for complex real-world data.
-
-- Sensitive to Outliers: Outliers can disproportionately influence the regression coefficients and predictions.
-
-- Limited Flexibility: Linear regression may underperform with nonlinear relationships, requiring transformations or more complex models.
-
-#### Example:
-In economic forecasting, linear regression may struggle to predict GDP growth during periods of economic volatility due to nonlinear factors influencing economic performance.
-
-### Practical Tips for Using Linear Regression
-
-#### To maximize the effectiveness of linear regression:
-
-- Feature Engineering: Select relevant predictors and consider transformations to improve model performance.
-
-- Residual Analysis: Evaluate residuals to check model assumptions and identify outliers or patterns that could impact predictions.
-
-- Regularization: Apply regularization techniques (e.g., Ridge, Lasso regression) to handle multicollinearity and improve model robustness.
-
-#### Example:
-
-In healthcare analytics, linear regression assists in predicting patient readmission rates based on demographic factors and medical history, facilitating resource allocation and patient care planning.
-
-### Real-World Applications
-
-#### Sales Forecasting in Retail
-
-Linear regression is widely applied in retail for sales forecasting. By analyzing historical sales data and economic indicators, retailers can predict future sales trends and optimize inventory management.
-
-#### Academic Performance Prediction
-
-In education, linear regression helps predict student performance based on factors such as attendance, study hours, and socioeconomic background, enabling targeted interventions to improve educational outcomes.
-
-### Performance Considerations
-
-- Model Complexity and Scalability
-Large Datasets: Linear regression remains efficient for large datasets but may require regularization techniques to handle high-dimensional data.
-
-- Computational Resources: Model training and inference are generally fast, but scalability can be impacted by the number of predictors and data volume.
-
-#### Example:
-In environmental science, linear regression models are used to analyze the relationship between pollution levels, weather patterns, and health outcomes, guiding public health policies and interventions.
-
-### Conclusion
-Linear regression is a versatile and widely used statistical technique that provides valuable insights into relationships between variables. Understanding its principles and limitations is essential for leveraging its predictive power effectively across various domains and applications.
diff --git a/docs/Machine Learning/t-Distributed Stochastic Neighbor Embedding.md b/docs/Machine Learning/t-Distributed Stochastic Neighbor Embedding.md
deleted file mode 100644
index aea9fdb08..000000000
--- a/docs/Machine Learning/t-Distributed Stochastic Neighbor Embedding.md
+++ /dev/null
@@ -1,141 +0,0 @@
----
-id: t-distributed-stochastic-neighbor-embedding
-title: t-Distributed Stochastic Neighbor Embedding
-sidebar_label: Introduction to t-Distributed Stochastic Neighbor Embedding
-sidebar_position: 2
-tags: [t-Distributed Stochastic Neighbor Embedding, t-SNE, dimensionality reduction, data visualization, machine learning, data science, non-linear dimensionality reduction, feature reduction]
-description: In this tutorial, you will learn about t-Distributed Stochastic Neighbor Embedding (t-SNE), its significance, what t-SNE is, why learn t-SNE, how to use t-SNE, steps to start using t-SNE, and more.
----
-
-### Introduction to t-Distributed Stochastic Neighbor Embedding
-t-Distributed Stochastic Neighbor Embedding (t-SNE) is a popular dimensionality reduction technique used to visualize high-dimensional data in a lower-dimensional space, typically 2D or 3D. It is particularly effective in preserving the local structure of the data, making it an invaluable tool for exploring and understanding complex datasets.
-
-### What is t-Distributed Stochastic Neighbor Embedding?
-t-SNE works by converting high-dimensional data into a probability distribution that captures pairwise similarities between data points. It then maps these points to a lower-dimensional space while preserving these similarities.
-
-- **High-Dimensional Data**: Data is represented in a high-dimensional space with complex structures.
-- **Probability Distribution**: t-SNE calculates the similarity between data points using conditional probabilities.
-- **Low-Dimensional Mapping**: The algorithm minimizes the divergence between the high-dimensional and low-dimensional probability distributions, resulting in a 2D or 3D representation.
-
-**Similarity Measurement**: Uses Gaussian distribution to measure similarity in high-dimensional space and Student’s t-distribution for low-dimensional space.
-
-### Example:
-Consider using t-SNE to visualize clusters in a dataset of handwritten digits. By reducing the data to 2D, you can observe how different digits group together, revealing underlying patterns and clusters.
-
-### Advantages of t-Distributed Stochastic Neighbor Embedding
-t-SNE offers several advantages:
-
-- **Preserves Local Structure**: Maintains the local relationships between data points, making clusters and patterns more apparent.
-- **Non-Linear Mapping**: Capable of capturing complex, non-linear structures in the data.
-- **Intuitive Visualization**: Produces intuitive and interpretable visualizations of high-dimensional data.
-
-### Example:
-In bioinformatics, t-SNE can be used to visualize gene expression profiles, revealing patterns and relationships between different genes or samples.
-
-### Disadvantages of t-Distributed Stochastic Neighbor Embedding
-Despite its strengths, t-SNE has limitations:
-
-- **Computational Complexity**: Can be computationally intensive, especially with large datasets.
-- **Parameter Sensitivity**: Results can be sensitive to hyperparameters, such as perplexity and learning rate.
-- **Global Structure**: May not preserve global structures or distances well, focusing more on local relationships.
-
-### Example:
-In large-scale image datasets, t-SNE might struggle to maintain meaningful global relationships between images, potentially making it less effective for certain types of analysis.
-
-### Practical Tips for Using t-Distributed Stochastic Neighbor Embedding
-To get the most out of t-SNE:
-
-- **Choose Perplexity Wisely**: Perplexity is a key parameter that controls the balance between local and global aspects of the data. Experiment with different values to find the best representation.
-- **Normalize Data**: Preprocess and normalize data to ensure that t-SNE operates on well-conditioned inputs.
-- **Use Dimensionality Reduction Preprocessing**: Apply initial dimensionality reduction (e.g., PCA) to reduce the computational burden and improve the performance of t-SNE.
-
-### Example:
-In a text analysis project, you can preprocess word embeddings using t-SNE to visualize and cluster similar words or documents based on their semantic content.
-
-### Real-World Examples
-
-#### Image Analysis
-t-SNE is often used in computer vision to visualize the clusters of similar images in a dataset, helping to understand and evaluate image classification algorithms.
-
-#### Customer Segmentation
-In marketing analytics, t-SNE can visualize customer segments based on purchasing behavior, aiding in the development of targeted marketing strategies.
-
-### Difference Between t-SNE and PCA
-| Feature | t-Distributed Stochastic Neighbor Embedding (t-SNE) | Principal Component Analysis (PCA) |
-|---------------------------------|------------------------------------------------------|-----------------------------------|
-| Linear vs Non-Linear | Non-linear dimensionality reduction. | Linear dimensionality reduction. |
-| Preserved Structure | Preserves local structure; may distort global structure. | Preserves global structure; may not capture local nuances. |
-| Computational Cost | Computationally intensive with large datasets. | Generally faster and more scalable. |
-
-### Implementation
-To implement and visualize data using t-SNE, you can use libraries such as scikit-learn in Python. Below are the steps to install the necessary library and apply t-SNE.
-
-#### Libraries to Download
-- scikit-learn: Provides the implementation of t-SNE.
-- matplotlib: Useful for data visualization.
-- pandas: Useful for data manipulation and analysis.
-- numpy: Essential for numerical operations.
-
-You can install these libraries using pip:
-
-```bash
-pip install scikit-learn matplotlib pandas numpy
-```
-
-#### Applying t-Distributed Stochastic Neighbor Embedding
-Here’s a step-by-step guide to applying t-SNE:
-
-**Import Libraries:**
-
-```python
-import pandas as pd
-import numpy as np
-from sklearn.manifold import TSNE
-import matplotlib.pyplot as plt
-```
-
-**Load and Prepare Data:**
-Assuming you have a dataset in a CSV file:
-
-```python
-# Load the dataset
-data = pd.read_csv('your_dataset.csv')
-
-# Prepare features (X)
-X = data.drop('target_column', axis=1) # Replace 'target_column' with any non-feature columns
-```
-
-**Apply t-SNE:**
-
-```python
-# Initialize t-SNE
-tsne = TSNE(n_components=2, random_state=42)
-
-# Fit and transform the data
-X_tsne = tsne.fit_transform(X)
-```
-
-**Visualize the Results:**
-
-```python
-# Plot t-SNE results
-plt.figure(figsize=(10, 8))
-plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c=data['target_column'], cmap='viridis', alpha=0.7)
-plt.colorbar()
-plt.title('t-SNE Visualization')
-plt.xlabel('Component 1')
-plt.ylabel('Component 2')
-plt.show()
-```
-
-### Performance Considerations
-
-#### Computational Efficiency
-- **Dataset Size**: t-SNE can be slow for very large datasets. Consider using a subset of the data or combining it with other dimensionality reduction techniques (e.g., PCA) to speed up the process.
-- **Hyperparameters**: Proper tuning of hyperparameters, such as perplexity, can affect both the quality of the results and the computational cost.
-
-### Example:
-In a large-scale text dataset, combining t-SNE with PCA for initial dimensionality reduction can make the visualization process more manageable and faster.
-
-### Conclusion
-t-Distributed Stochastic Neighbor Embedding is a powerful technique for visualizing and understanding high-dimensional data. By grasping its strengths, limitations, and implementation, practitioners can effectively leverage t-SNE to gain insights and make sense of complex datasets in various data science and machine learning projects.
diff --git a/docs/Operating System/_category_.json b/docs/Operating System/_category_.json
deleted file mode 100644
index 5ab9f65df..000000000
--- a/docs/Operating System/_category_.json
+++ /dev/null
@@ -1,8 +0,0 @@
-{
- "label": "Operating System",
- "position": 18,
- "link": {
- "type": "generated-index",
- "description": "Operating System lies in the category of system software. It basically manages all the resources of the computer"
- }
-}
diff --git a/docs/Operating System/device_management.md b/docs/Operating System/device_management.md
deleted file mode 100644
index 025662ded..000000000
--- a/docs/Operating System/device_management.md
+++ /dev/null
@@ -1,92 +0,0 @@
----
-id: device-management
-title: device-management
-sidebar_label: Device Management
-sidebar_position: 12
-tags: [operating_system, create database, commands]
-description: Device management is a crucial function of an operating system that handles the communication and control of hardware devices.
----
-# Device Management
-
-## Introduction
-Device management is a crucial function of an operating system that handles the communication and control of hardware devices. It ensures that hardware resources are used efficiently and provides a way for software applications to interact with hardware devices.
-
-## Key Concepts
-
-### 1. Device Types
-Devices can be broadly categorized into two types:
-- **Block Devices**: These devices store data in fixed-size blocks, each with its own address. Examples include hard drives and CD-ROMs.
-- **Character Devices**: These devices transmit data as a stream of bytes. Examples include keyboards, mice, and serial ports.
-
-### 2. Device Controllers
-A device controller is a hardware component that manages a specific type of device. It communicates with the CPU and the device it controls. Each device controller has registers to store commands, status, and data.
-
-### 3. Device Drivers
-Device drivers are software programs that act as an interface between the operating system and hardware devices. They translate high-level commands from the OS into device-specific operations.
-
-## Device Management Functions
-
-### 1. Device Allocation
-The operating system allocates devices to processes as needed. This involves:
-- **Exclusive Allocation**: Some devices can be allocated to only one process at a time.
-- **Shared Allocation**: Some devices can be shared among multiple processes.
-
-### 2. Device Scheduling
-The OS schedules access to devices to ensure efficient and fair use. This is similar to CPU scheduling but with different algorithms tailored to the specific device.
-
-### 3. Device Queues
-Each device has a queue to manage the requests from processes. The OS uses different scheduling algorithms to process these queues.
-
-## I/O Control Methods
-
-### 1. Programmed I/O
-The CPU is responsible for executing I/O operations, constantly checking the device's status, and transferring data as needed. This method is simple but inefficient as the CPU is tied up during I/O operations.
-
-### 2. Interrupt-Driven I/O
-The device generates an interrupt when it is ready for the next part of the I/O operation, allowing the CPU to execute other instructions between interrupts. This method improves CPU utilization.
-
-### 3. Direct Memory Access (DMA)
-DMA allows devices to transfer data directly to or from memory without involving the CPU for each byte of transfer. The CPU sets up the DMA controller, which then handles the data transfer independently, significantly improving efficiency.
-
-## Device Management Techniques
-
-### 1. Buffering
-Buffering involves using memory areas to temporarily hold data while it is being transferred between devices or between a device and an application. It helps to accommodate speed differences between the producer and consumer of the data.
-
-### 2. Caching
-Caching involves keeping copies of frequently accessed data in a faster storage medium to reduce access time. This is commonly used for disk I/O operations.
-
-### 3. Spooling
-Spooling (Simultaneous Peripheral Operations On-line) is a technique where data is written to an intermediate storage (usually a disk) to be processed later. This is commonly used for managing printer queues.
-
-## Device Drivers
-
-### 1. Device Driver Structure
-A typical device driver consists of:
-- **Initialization Code**: Sets up the device and registers it with the OS.
-- **I/O Operations**: Handles read and write operations.
-- **Interrupt Handling**: Manages device interrupts.
-- **Cleanup Code**: Frees resources when the device is no longer needed.
-
-### 2. Writing Device Drivers
-Writing device drivers requires understanding the device's hardware interface and the operating system's driver interface. Drivers must be efficient and handle errors gracefully.
-
-## Device Management in Modern Operating Systems
-
-### 1. Plug and Play (PnP)
-Modern operating systems support Plug and Play, allowing devices to be automatically detected, configured, and used without manual intervention. PnP involves:
-- **Device Detection**: Identifying the presence of a new device.
-- **Resource Allocation**: Assigning system resources like IRQs and memory addresses to the device.
-- **Driver Installation**: Loading the appropriate device driver.
-
-### 2. Power Management
-Device management also involves managing the power state of devices to conserve energy. Techniques include:
-- **Power States**: Devices can be in different power states (e.g., active, standby, sleep).
-- **Dynamic Power Management**: Adjusting power usage based on device activity.
-
-## Conclusion
-Device management is essential for the efficient and effective use of hardware resources in an operating system. It involves allocating devices, scheduling access, handling I/O operations, and ensuring smooth communication between hardware and software. Understanding device management helps in optimizing system performance and enhancing user experience.
-
----
-
-Efficient device management is a cornerstone of modern operating systems, enabling seamless interaction between software applications and hardware components, and ensuring optimal resource utilization and system performance.
diff --git a/docs/Operating System/distributed_systems.md b/docs/Operating System/distributed_systems.md
deleted file mode 100644
index 7b41bc355..000000000
--- a/docs/Operating System/distributed_systems.md
+++ /dev/null
@@ -1,94 +0,0 @@
----
-id: distributed-systems
-title: distributed-systems
-sidebar_label: Distributed Systems
-sidebar_position: 14
-tags: [operating_system, create database, commands]
-description: A distributed system is a collection of independent computers that appear to the users of the system as a single coherent system.
----
-# Distributed Systems
-
-## Introduction
-A distributed system is a collection of independent computers that appear to the users of the system as a single coherent system. These systems collaborate to achieve a common goal, sharing resources and communicating over a network.
-
-## Key Concepts
-
-### 1. Characteristics of Distributed Systems
-- **Resource Sharing**: Resources such as files, printers, and data are shared among multiple systems.
-- **Openness**: The system is open if it is easy to add new components and to expand existing services.
-- **Concurrency**: Multiple processes run concurrently, accessing shared resources.
-- **Scalability**: The system can handle the addition of users, resources, and services without performance degradation.
-- **Fault Tolerance**: The system can continue to operate, possibly at a reduced level, when part of the system fails.
-- **Transparency**: The complexity of the distributed nature of the system is hidden from users.
-
-### 2. Types of Distributed Systems
-- **Client-Server Systems**: Clients request services, and servers provide them. Examples include web services and database systems.
-- **Peer-to-Peer Systems**: Each node acts as both a client and a server. Examples include file-sharing networks and blockchain.
-- **Distributed Computing Systems**: Multiple computers work together on a single task. Examples include grid computing and cloud computing.
-
-## Distributed System Models
-
-### 1. Architectural Models
-- **Layered Architecture**: The system is organized into layers, each providing services to the layer above and consuming services of the layer below.
-- **Object-Based Architecture**: The system is composed of objects that interact with each other. Examples include CORBA and DCOM.
-- **Data-Centered Architecture**: Data is shared among multiple clients through a central repository. Examples include distributed databases and shared filesystems.
-- **Event-Based Architecture**: Components communicate by broadcasting and receiving events. Examples include publish-subscribe systems.
-
-### 2. Interaction Models
-- **Synchronous Communication**: The sender waits for the receiver to acknowledge receipt of the message.
-- **Asynchronous Communication**: The sender does not wait for the receiver to acknowledge receipt of the message.
-- **Remote Procedure Calls (RPC)**: A function call that is executed on a remote server.
-- **Message Passing**: Components communicate by sending and receiving messages.
-
-## Challenges in Distributed Systems
-
-### 1. Network Issues
-- **Latency**: The time taken for a message to travel from sender to receiver.
-- **Bandwidth**: The capacity of the network to transmit data.
-- **Jitter**: Variation in the time taken for messages to travel.
-
-### 2. Security
-- **Authentication**: Verifying the identity of users and systems.
-- **Authorization**: Ensuring users have permission to access resources.
-- **Encryption**: Protecting data from unauthorized access during transmission.
-
-### 3. Fault Tolerance
-- **Redundancy**: Duplicating critical components to ensure availability.
-- **Replication**: Copying data across multiple systems to prevent data loss.
-- **Checkpointing**: Saving the state of a system at intervals to enable recovery.
-
-### 4. Synchronization
-- **Clock Synchronization**: Ensuring all systems have a consistent view of time.
-- **Coordination**: Managing the execution order of processes in different systems.
-
-## Distributed Algorithms
-
-### 1. Consensus Algorithms
-- **Paxos**: A protocol for achieving consensus in a network of unreliable processors.
-- **Raft**: A consensus algorithm designed to be understandable and easier to implement than Paxos.
-
-### 2. Distributed Hash Tables (DHT)
-- **Chord**: A protocol and algorithm for a peer-to-peer distributed hash table.
-- **Kademlia**: A distributed hash table for decentralized peer-to-peer computer networks.
-
-### 3. Leader Election Algorithms
-- **Bully Algorithm**: A process elects itself as the leader if it has the highest process ID.
-- **Ring Algorithm**: Processes are arranged in a logical ring, and election messages are passed around the ring.
-
-## Case Studies
-
-### 1. Google File System (GFS)
-A scalable distributed file system designed for large data-intensive applications. It provides fault tolerance and high throughput.
-
-### 2. Hadoop Distributed File System (HDFS)
-A distributed file system designed to run on commodity hardware. It is highly fault-tolerant and designed for large-scale data processing.
-
-### 3. Amazon DynamoDB
-A highly available and scalable distributed data store. It uses a combination of techniques like consistent hashing, replication, and versioning to achieve high availability and scalability.
-
-## Conclusion
-Distributed systems offer numerous benefits, including resource sharing, scalability, and fault tolerance. However, they also pose significant challenges, such as ensuring security, synchronization, and fault tolerance. Understanding the key concepts, models, and algorithms of distributed systems is crucial for designing and managing efficient and robust systems.
-
----
-
-By leveraging the principles and techniques of distributed systems, organizations can build scalable, reliable, and efficient systems that meet the demands of modern applications.
diff --git a/docs/Operating System/file_systems.md b/docs/Operating System/file_systems.md
deleted file mode 100644
index 467202963..000000000
--- a/docs/Operating System/file_systems.md
+++ /dev/null
@@ -1,109 +0,0 @@
----
-id: file_systems
-title: file_systems
-sidebar_label: File Systems
-sidebar_position: 11
-tags: [operating_system, create database, commands]
-description: A file system is a method and data structure that the operating system uses to control how data is stored and retrieved.
----
-
-# File Systems
-
-## Introduction
-A file system is a method and data structure that the operating system uses to control how data is stored and retrieved. Without a file system, information placed in a storage medium would be one large body of data with no way to tell where one piece of information stops and the next begins.
-
-## Key Concepts
-
-### 1. File
-A file is a collection of related information that is recorded on secondary storage. A file can contain programs, data, or both.
-
-### 2. Directory
-A directory is a special type of file that contains a list of files and other directories. Directories help in organizing files into a hierarchical structure.
-
-### 3. Path
-The path specifies the location of a file or directory in the file system. Paths can be absolute (starting from the root directory) or relative (starting from the current directory).
-
-## File Attributes
-Files have attributes that provide additional information about the file:
-- **Name**: The human-readable name of the file.
-- **Type**: The type of the file (e.g., text, binary, executable).
-- **Location**: The location of the file on the storage medium.
-- **Size**: The size of the file in bytes.
-- **Protection**: Access control information (e.g., read, write, execute permissions).
-- **Timestamps**: Information about the file's creation, modification, and last access times.
-
-## File Operations
-Common file operations include:
-- **Create**: Creating a new file.
-- **Open**: Opening an existing file for reading or writing.
-- **Close**: Closing an open file.
-- **Read**: Reading data from a file.
-- **Write**: Writing data to a file.
-- **Delete**: Deleting a file.
-- **Rename**: Changing the name of a file.
-
-## Directory Structure
-
-### Single-Level Directory
-All files are contained in a single directory. This simple structure can lead to name conflicts and is not scalable for larger systems.
-
-### Two-Level Directory
-There is a separate directory for each user. This structure solves the name conflict issue but still has limitations in organizing a large number of files.
-
-### Tree-Structured Directory
-Directories are organized in a tree structure, allowing for a hierarchical organization of files. Each directory can contain files and subdirectories.
-
-### Acyclic-Graph Directory
-Directories form an acyclic graph, allowing shared subdirectories and files. This structure enables better organization and sharing but requires handling of link deletion and cycles.
-
-### General Graph Directory
-Allows for arbitrary links between directories and files, creating a general graph structure. This structure offers maximum flexibility but requires sophisticated algorithms to manage.
-
-## File Allocation Methods
-
-### Contiguous Allocation
-Files are stored in contiguous blocks of memory. This method is simple and efficient for sequential access but can lead to fragmentation and difficulty in file size extension.
-
-### Linked Allocation
-Files are stored as linked lists of blocks. Each block contains a pointer to the next block. This method eliminates fragmentation but can be inefficient for direct access.
-
-### Indexed Allocation
-An index block is created, which contains pointers to the actual data blocks of the file. This method supports both sequential and direct access but requires extra space for the index block.
-
-## Free Space Management
-
-### Bit Vector
-A bit vector is used to represent the free and allocated blocks. Each bit in the vector represents a block; 0 indicates free and 1 indicates allocated.
-
-### Linked List
-Free blocks are linked together, forming a list. Each free block contains a pointer to the next free block.
-
-### Grouping
-Similar to linked list but with a group of free blocks stored together. The first block of the group points to the next group of free blocks.
-
-### Counting
-Stores the address of the first free block and the number of free contiguous blocks that follow it.
-
-## Disk Scheduling Algorithms
-
-### First-Come, First-Served (FCFS)
-Processes disk requests in the order they arrive. Simple but can lead to inefficient use of the disk.
-
-### Shortest Seek Time First (SSTF)
-Selects the request that is closest to the current head position. Reduces seek time but can lead to starvation of some requests.
-
-### SCAN (Elevator Algorithm)
-The disk arm moves in one direction, fulfilling requests until it reaches the end, then reverses direction. Provides a more uniform wait time.
-
-### C-SCAN (Circular SCAN)
-Similar to SCAN, but when the disk arm reaches the end, it returns to the beginning and starts again. Provides a more uniform wait time.
-
-### LOOK and C-LOOK
-Similar to SCAN and C-SCAN but the disk arm only goes as far as the last request in each direction before reversing or restarting.
-
-## Conclusion
-File systems are a critical component of operating systems, providing a structured way to store, manage, and retrieve data. Understanding the various aspects of file systems, including file operations, directory structures, allocation methods, and disk scheduling algorithms, is essential for efficient data management and system performance.
-
----
-
-A well-designed file system ensures efficient storage, quick access, and effective management of data, contributing significantly to the overall performance and usability of an operating system.
diff --git a/docs/Operating System/function_of_OS.md b/docs/Operating System/function_of_OS.md
deleted file mode 100644
index 0ef406daf..000000000
--- a/docs/Operating System/function_of_OS.md
+++ /dev/null
@@ -1,184 +0,0 @@
----
-id: function-of-operating-system
-title: function-of-operating-system
-sidebar_label: Function of Operating System
-sidebar_position: 7
-tags: [operating_system, create database, commands]
-description: An Operating System acts as a communication bridge (interface) between the user and computer hardware.
----
-
-# Functions of Operating System
-
-An Operating System acts as a communication bridge (interface) between the user and computer hardware. The purpose of an operating system is to provide a platform on which a user can execute programs conveniently and efficiently.
-
-An operating system is a piece of software that manages the allocation of Computer Hardware. The coordination of the hardware must be appropriate to ensure the correct working of the computer system and to prevent user programs from interfering with the proper working of the system.
-
-The main goal of the Operating System is to make the computer environment more convenient to use and the secondary goal is to use the resources most efficiently.
-
-## What is an Operating System?
-
-An operating system is a program that manages a computer’s hardware. It also provides a basis for application programs and acts as an intermediary between the computer user and computer hardware. The main task an operating system carries out is the allocation of resources and services, such as the allocation of memory, devices, processors, and information. The operating system also includes programs to manage these resources, such as a traffic controller, a scheduler, a memory management module, I/O programs, and a file system. The operating system simply provides an environment within which other programs can do useful work.
-
-## Why are Operating Systems Used?
-
-Operating System is used as a communication channel between the computer hardware and the user. It works as an intermediate between system hardware and end-user. Operating System handles the following responsibilities:
-
-- It controls all the computer resources.
-
-- It provides valuable services to user programs.
-
-- It coordinates the execution of user programs.
-
-- It provides resources for user programs.
-
-- It provides an interface (virtual machine) to the user.
-
-- It hides the complexity of software.
-
-- It supports multiple execution modes.
-
-- It monitors the execution of user programs to prevent errors.
-
-## Functions of an Operating System
-
-### Memory Management
-
-The operating system manages the Primary Memory or Main Memory. Main memory is fast storage and it can be accessed directly by the CPU. For a program to be executed, it should be first loaded in the main memory. An operating system manages the allocation and deallocation of memory to various processes and ensures that the other process does not consume the memory allocated to one process. An Operating System performs the following activities for Memory Management:
-
-- It keeps track of primary memory, i.e., which bytes of memory are used by which user program.
-
-- In multiprogramming, the OS decides the order in which processes are granted memory access, and for how long.
-
-- It allocates the memory to a process when the process requests it and deallocates the memory when the process has terminated or is performing an I/O operation.
-
- 
-
-### Processor Management
-
-In a multi-programming environment, the OS decides the order in which processes have access to the processor, and how much processing time each process has. This function of OS is called Process Scheduling. An Operating System performs the following activities for Processor Management:
-
-- Manages the processor’s work by allocating various jobs to it and ensuring that each process receives enough time from the processor to function properly.
-
-- Keeps track of the status of processes. The program which performs this task is known as a traffic controller.
-
-- Allocates the CPU (processor) to a process.
-
-- Deallocates the processor when a process is no longer required.
-
- 
-
-### Device Management
-
-An OS manages device communication via its respective drivers. It performs the following activities for device management:
-
-- Keeps track of all devices connected to the system. Designates a program responsible for every device known as the Input/Output controller.
-
-- Decides which process gets access to a certain device and for how long.
-
-- Allocates devices effectively and efficiently.
-
-- Deallocates devices when they are no longer required.
-
-- Controls the working of input-output devices, receives requests from these devices, performs specific tasks, and communicates back to the requesting process.
-
-### File Management
-
-A file system is organized into directories for efficient or easy navigation and usage. These directories may contain other directories and other files. An Operating System carries out the following file management activities:
-
-- Keeps track of where information is stored, user access settings, the status of every file, and more. These facilities are collectively known as the file system.
-
-- Keeps track of information regarding the creation, deletion, transfer, copy, and storage of files in an organized way.
-
-- Maintains the integrity of the data stored in these files, including the file directory structure, by protecting against unauthorized access.
-
- 
-
-### User Interface or Command Interpreter
-
-The user interacts with the computer system through the operating system. Hence OS acts as an interface between the user and the computer hardware. This user interface is offered through a set of commands or a graphical user interface (GUI). Through this interface, the user interacts with the applications and the machine hardware.
-
- 
-
-### Booting the Computer
-
-The process of starting or restarting the computer is known as booting. If the computer is switched off completely and if turned on then it is called cold booting. Warm booting is a process of using the operating system to restart the computer.
-
-### Security
-
-The operating system uses password protection to protect user data and similar other techniques. It also prevents unauthorized access to programs and user data. The operating system provides various techniques which assure the integrity and confidentiality of user data:
-
-- Protection against unauthorized access through login.
-
-- Protection against intrusion by keeping the firewall active.
-
-- Protecting the system memory against malicious access.
-
-- Displaying messages related to system vulnerabilities.
-
-### Control Over System Performance
-
-Operating systems play a pivotal role in controlling and optimizing system performance. They act as intermediaries between hardware and software, ensuring that computing resources are efficiently utilized. One fundamental aspect is resource allocation, where the OS allocates CPU time, memory, and I/O devices to different processes, striving to provide fair and optimal resource utilization. Process scheduling, a critical function, helps decide which processes or threads should run when, preventing any single task from monopolizing the CPU and enabling effective multitasking.
-
- 
-
-### Job Accounting
-
-The operating system keeps track of time and resources used by various tasks and users. This information can be used to track resource usage for a particular user or group of users. In a multitasking OS where multiple programs run simultaneously, the OS determines which applications should run in which order and how time should be allocated to each application.
-
-### Error-Detecting Aids
-
-The operating system constantly monitors the system to detect errors and avoid malfunctioning computer systems. From time to time, the operating system checks the system for any external threat or malicious software activity. It also checks the hardware for any type of damage. This process displays several alerts to the user so that the appropriate action can be taken against any damage caused to the system.
-
-### Coordination Between Other Software and Users
-
-Operating systems also coordinate and assign interpreters, compilers, assemblers, and other software to the various users of the computer systems. In simpler terms, think of the operating system as the traffic cop of your computer. It directs and manages how different software programs can share your computer’s resources without causing chaos. It ensures that when you want to use a program, it runs smoothly without crashing or causing problems for others.
-
-### Performs Basic Computer Tasks
-
-The management of various peripheral devices such as the mouse, keyboard, and printer is carried out by the operating system. Today most operating systems are plug-and-play. These operating systems automatically recognize and configure the devices with no user interference.
-
-### Network Management
-
-- **Network Communication:** Operating systems help computers talk to each other and the internet. They manage how data is packaged and sent over the network, making sure it arrives safely and in the right order.
-
-- **Settings and Monitoring:** They let you set up your network connections, like Wi-Fi or Ethernet, and keep an eye on how your network is doing. They make sure your computer is using the network efficiently and securely, like adjusting the speed of your internet or protecting your computer from online threats.
-
-## Services Provided by an Operating System
-
-The Operating System provides certain services to the users which can be listed in the following manner:
-
-- **User Interface:** Almost all operating systems have a user interface (UI). This interface can take several forms such as command-line interface (CLI), batch interface, or graphical user interface (GUI).
-
-- **Program Execution:** Responsible for the execution of all types of programs whether it be user programs or system programs.
-
-- **Handling Input/Output Operations:** Responsible for handling all sorts of inputs, i.e., from the keyboard, mouse, desktop, etc.
-
-- **Manipulation of File System:** Responsible for making decisions regarding the storage of all types of data or files.
-
-- **Resource Allocation:** Ensures the proper use of all the resources available by deciding which resource to be used by whom for how much time.
-
-- **Accounting:** Tracks an account of all the functionalities taking place in the computer system at a time.
-
-- **Information and Resource Protection:** Uses all the information and resources available on the machine in the most protected way.
-
-- **Communication:** Implements communication between one process to another process to exchange information.
-
-- **System Services:** Provides various system services, such as printing, time and date management, and event logging.
-
-- **Error Detection:** Needs to detect and correct errors constantly to ensure correct and consistent computing.
-
-## Characteristics of Operating System
-
-- **Virtualization:** Provides virtualization capabilities, allowing multiple operating systems or instances of an operating system to run on a single physical machine.
-
-- **Networking:** Provides networking capabilities, allowing the computer system to connect to other systems and devices over a network.
-
-- **Scheduling:** Provides scheduling algorithms that determine the order in which tasks are executed on the system.
-
-- **Interprocess Communication:** Provides mechanisms for applications to communicate with each other, allowing them to share data and coordinate their activities.
-
-- **Performance Monitoring:** Provides tools for monitoring system performance, including CPU usage, memory usage, disk usage, and network activity.
-
-- **Backup and Recovery:** Provides backup and recovery mechanisms to protect data in the event of system failure or data loss.
-
-- **Debugging:** Provides
diff --git a/docs/Operating System/image-1.png b/docs/Operating System/image-1.png
deleted file mode 100644
index ad0257ffc..000000000
Binary files a/docs/Operating System/image-1.png and /dev/null differ
diff --git a/docs/Operating System/image-10.png b/docs/Operating System/image-10.png
deleted file mode 100644
index 6943aef0e..000000000
Binary files a/docs/Operating System/image-10.png and /dev/null differ
diff --git a/docs/Operating System/image-11.png b/docs/Operating System/image-11.png
deleted file mode 100644
index ea9968ace..000000000
Binary files a/docs/Operating System/image-11.png and /dev/null differ
diff --git a/docs/Operating System/image-12.png b/docs/Operating System/image-12.png
deleted file mode 100644
index 7a0b932f5..000000000
Binary files a/docs/Operating System/image-12.png and /dev/null differ
diff --git a/docs/Operating System/image-2.png b/docs/Operating System/image-2.png
deleted file mode 100644
index bb1b079fd..000000000
Binary files a/docs/Operating System/image-2.png and /dev/null differ
diff --git a/docs/Operating System/image-3.png b/docs/Operating System/image-3.png
deleted file mode 100644
index b1d3a34d1..000000000
Binary files a/docs/Operating System/image-3.png and /dev/null differ
diff --git a/docs/Operating System/image-4.png b/docs/Operating System/image-4.png
deleted file mode 100644
index e954f063c..000000000
Binary files a/docs/Operating System/image-4.png and /dev/null differ
diff --git a/docs/Operating System/image-5.png b/docs/Operating System/image-5.png
deleted file mode 100644
index a16e8dfc0..000000000
Binary files a/docs/Operating System/image-5.png and /dev/null differ
diff --git a/docs/Operating System/image-6.png b/docs/Operating System/image-6.png
deleted file mode 100644
index 271c161c8..000000000
Binary files a/docs/Operating System/image-6.png and /dev/null differ
diff --git a/docs/Operating System/image-7.png b/docs/Operating System/image-7.png
deleted file mode 100644
index 6aed8089a..000000000
Binary files a/docs/Operating System/image-7.png and /dev/null differ
diff --git a/docs/Operating System/image-8.png b/docs/Operating System/image-8.png
deleted file mode 100644
index b3267089d..000000000
Binary files a/docs/Operating System/image-8.png and /dev/null differ
diff --git a/docs/Operating System/image-9.png b/docs/Operating System/image-9.png
deleted file mode 100644
index cbbbd8f88..000000000
Binary files a/docs/Operating System/image-9.png and /dev/null differ
diff --git a/docs/Operating System/image.png b/docs/Operating System/image.png
deleted file mode 100644
index 5446f3352..000000000
Binary files a/docs/Operating System/image.png and /dev/null differ
diff --git a/docs/Operating System/intro_to_OS.md b/docs/Operating System/intro_to_OS.md
deleted file mode 100644
index fedf2bf7d..000000000
--- a/docs/Operating System/intro_to_OS.md
+++ /dev/null
@@ -1,116 +0,0 @@
----
-id: operating_system
-title: operating_system
-sidebar_label: Operating System
-sidebar_position: 6
-tags: [operating_system, create database, commands]
-description: An operating system acts as an interface between the software and different parts of the computer or the computer hardware.
----
-
-# What is an Operating System?
-
-Operating System lies in the category of system software. It basically manages all the resources of the computer. An operating system acts as an interface between the software and different parts of the computer or the computer hardware. The operating system is designed in such a way that it can manage the overall resources and operations of the computer.
-
-Operating System is a fully integrated set of specialized programs that handle all the operations of the computer. It controls and monitors the execution of all other programs that reside in the computer, which also includes application programs and other system software of the computer. Examples of Operating Systems are Windows, Linux, Mac OS, etc.
-
-An Operating System (OS) is a collection of software that manages computer hardware resources and provides common services for computer programs. The operating system is the most important type of system software in a computer system.
-
-## What is an Operating System Used for?
-
-The operating system helps in improving the computer software as well as hardware. Without OS, it became very difficult for any application to be user-friendly. The Operating System provides a user with an interface that makes any application attractive and user-friendly. The operating System comes with a large number of device drivers that make OS services reachable to the hardware environment. Each and every application present in the system requires the Operating System. The operating system works as a communication channel between system hardware and system software. The operating system helps an application with the hardware part without knowing about the actual hardware configuration. It is one of the most important parts of the system and hence it is present in every device, whether large or small device.
-
- 
-
-## Functions of the Operating System
-
-- **Resource Management**: The operating system manages and allocates memory, CPU time, and other hardware resources among the various programs and processes running on the computer.
-
-- **Process Management**: The operating system is responsible for starting, stopping, and managing processes and programs. It also controls the scheduling of processes and allocates resources to them
- .
-- **Memory Management**: The operating system manages the computer’s primary memory and provides mechanisms for optimizing memory usage.
-
-- **Security**: The operating system provides a secure environment for the user, applications, and data by implementing security policies and mechanisms such as access controls and encryption.
-
-- **Job Accounting**: It keeps track of time and resources used by various jobs or users.
-
-- **File Management**: The operating system is responsible for organizing and managing the file system, including the creation, deletion, and manipulation of files and directories.
-
-- **Device Management**: The operating system manages input/output devices such as printers, keyboards, mice, and displays. It provides the necessary drivers and interfaces to enable communication between the devices and the computer.
-
-- **Networking**: The operating system provides networking capabilities such as establishing and managing network connections, handling network protocols, and sharing resources such as printers and files over a network.
-
-- **User Interface**: The operating system provides a user interface that enables users to interact with the computer system. This can be a Graphical User Interface (GUI), a Command-Line Interface (CLI), or a combination of both.
-
-- **Backup and Recovery**: The operating system provides mechanisms for backing up data and recovering it in case of system failures, errors, or disasters.
-
-- **Virtualization**: The operating system provides virtualization capabilities that allow multiple operating systems or applications to run on a single physical machine. This can enable efficient use of resources and flexibility in managing workloads.
-
-- **Performance Monitoring**: The operating system provides tools for monitoring and optimizing system performance, including identifying bottlenecks, optimizing resource usage, and analyzing system logs and metrics.
-
-- **Time-Sharing**: The operating system enables multiple users to share a computer system and its resources simultaneously by providing time-sharing mechanisms that allocate resources fairly and efficiently.
-
-- **System Calls**: The operating system provides a set of system calls that enable applications to interact with the operating system and access its resources. System calls provide a standardized interface between applications and the operating system, enabling portability and compatibility across different hardware and software platforms.
-
-- **Error-detecting Aids**: These contain methods that include the production of dumps, traces, error messages, and other debugging and error-detecting methods.
-
-## Objectives of Operating Systems
-
-Let us now see some of the objectives of the operating system, which are mentioned below.
-
-- **Convenient to use**: One of the objectives is to make the computer system more convenient to use in an efficient manner.
-
-- **User Friendly**: To make the computer system more interactive with a more convenient interface for the users.
-
-- **Easy Access**: To provide easy access to users for using resources by acting as an intermediary between the hardware and its users.
-
-- **Management of Resources**: For managing the resources of a computer in a better and faster way.
-
-- **Controls and Monitoring**: By keeping track of who is using which resource, granting resource requests, and mediating conflicting requests from different programs and users.
-
-- **Fair Sharing of Resources**: Providing efficient and fair sharing of resources between the users and programs.
-
-## Types of Operating Systems
-
-- **Batch Operating System**: A Batch Operating System is a type of operating system that does not interact with the computer directly. There is an operator who takes similar jobs having the same requirements and groups them into batches.
-
-- **Time-sharing Operating System**: Time-sharing Operating System is a type of operating system that allows many users to share computer resources (maximum utilization of the resources).
-
-- **Distributed Operating System**: Distributed Operating System is a type of operating system that manages a group of different computers and makes appear to be a single computer. These operating systems are designed to operate on a network of computers. They allow multiple users to access shared resources and communicate with each other over the network. Examples include Microsoft Windows Server and various distributions of Linux designed for servers.
-
-- **Network Operating System**: Network Operating System is a type of operating system that runs on a server and provides the capability to manage data, users, groups, security, applications, and other networking functions.
-
-- **Real-time Operating System**: Real-time Operating System is a type of operating system that serves a real-time system and the time interval required to process and respond to inputs is very small. These operating systems are designed to respond to events in real time. They are used in applications that require quick and deterministic responses, such as embedded systems, industrial control systems, and robotics.
-
-- **Multiprocessing Operating System**: Multiprocessor Operating Systems are used in operating systems to boost the performance of multiple CPUs within a single computer system. Multiple CPUs are linked together so that a job can be divided and executed more quickly.
-
-- **Single-User Operating Systems**: Single-User Operating Systems are designed to support a single user at a time. Examples include Microsoft Windows for personal computers and Apple macOS.
-
-- **Multi-User Operating Systems**: Multi-User Operating Systems are designed to support multiple users simultaneously. Examples include Linux and Unix.
-
-- **Embedded Operating Systems**: Embedded Operating Systems are designed to run on devices with limited resources, such as smartphones, wearable devices, and household appliances. Examples include Google’s Android and Apple’s iOS.
-
-- **Cluster Operating Systems**: Cluster Operating Systems are designed to run on a group of computers, or a cluster, to work together as a single system. They are used for high-performance computing and for applications that require high availability and reliability. Examples include Rocks Cluster Distribution and OpenMPI.
-
-## How to Check the Operating System?
-
-There are so many factors to be considered while choosing the best Operating System for our use. These factors are mentioned below.
-
-- **Price Factor**: Price is one of the factors to choose the correct Operating System as there are some OS that is free, like Linux, but there is some more OS that is paid like Windows and macOS.
-
-- **Accessibility Factor**: Some Operating Systems are easy to use like macOS and iOS, but some OS are a little bit complex to understand like Linux. So, you must choose the Operating System in which you are more accessible.
-
-- **Compatibility Factor**: Some Operating Systems support very less applications whereas some Operating Systems supports more application. You must choose the OS, which supports the applications which are required by you.
-
-- **Security Factor**: The security Factor is also a factor in choosing the correct OS, as macOS provide some additional security while Windows has little fewer security features.
-
-## Examples of Operating Systems
-
-- **Windows**: GUI-based, PC
-
-- **GNU/Linux**: Personal, Workstations, ISP, File, and print server, Three-tier client/Server
-
-- **macOS**: Used for Apple’s personal computers and workstations (MacBook, iMac)
-
-- **Android**: Google’s Operating System for smartphones/tablets/smartwatches
-
-- **iOS**: Apple’s OS for iPhone, iPad, and iPod Touch
diff --git a/docs/Operating System/memory_management.md b/docs/Operating System/memory_management.md
deleted file mode 100644
index 4c1f0bb91..000000000
--- a/docs/Operating System/memory_management.md
+++ /dev/null
@@ -1,88 +0,0 @@
----
-id: memory-management
-title: memory-management
-sidebar_label: Memory Management
-sidebar_position: 10
-tags: [operating_system, create database, commands]
-description: Memory management is a crucial function of the operating system that handles or manages primary memory.
----
-# Memory Management
-
-## Introduction
-Memory management is a crucial function of the operating system that handles or manages primary memory. It keeps track of each byte in a computer’s memory and is responsible for allocating and deallocating memory spaces as needed by various programs.
-
-## Key Concepts
-
-### 1. Memory Allocation
-Memory allocation is the process of assigning blocks of memory to various programs while ensuring efficient use of memory. There are two types of memory allocation:
-- **Static Allocation**: Memory is allocated at compile time.
-- **Dynamic Allocation**: Memory is allocated at runtime.
-
-### 2. Contiguous vs Non-Contiguous Allocation
-- **Contiguous Allocation**: Each process is allocated a single contiguous block of memory.
-- **Non-Contiguous Allocation**: Memory is allocated in different blocks scattered throughout memory.
-
-### 3. Paging
-Paging is a memory management scheme that eliminates the need for contiguous allocation of physical memory. It divides memory into fixed-sized pages. When a process is executed, its pages are loaded into any available memory frames.
-
-#### Steps in Paging:
-1. **Divide the Process**: The process is divided into pages of equal size.
-2. **Divide Physical Memory**: Physical memory is divided into frames of the same size as the pages.
-3. **Load Pages into Frames**: Pages are loaded into available frames in physical memory.
-4. **Page Table**: A page table maintains the mapping between the process's pages and physical memory frames.
-
-### 4. Segmentation
-Segmentation divides a program into different segments such as code, data, stack, etc. Each segment can be placed in different parts of memory. This allows logical grouping of data and code, enhancing protection and sharing.
-
-#### Steps in Segmentation:
-1. **Divide the Program**: The program is divided into logical segments.
-2. **Map Segments to Memory**: Segments are mapped to different parts of physical memory.
-3. **Segment Table**: A segment table maintains the mapping between the segments and physical memory addresses.
-
-### 5. Virtual Memory
-Virtual memory allows the execution of processes that may not be completely in the physical memory. It extends the available memory on a system by using disk space to simulate additional RAM. Techniques used include paging and segmentation.
-
-### 6. Memory Allocation Techniques
-
-#### Fixed Partitioning
-Memory is divided into fixed-sized partitions. Each partition can hold one process. However, this leads to inefficient memory use and internal fragmentation.
-
-#### Dynamic Partitioning
-Memory is divided into partitions dynamically, based on the size of the process. This reduces internal fragmentation but can lead to external fragmentation.
-
-#### Buddy System
-The buddy system is a memory allocation and management algorithm that divides memory into blocks of size 2^k. It is a compromise between fixed and dynamic partitioning.
-
-## Swapping
-Swapping is a technique where a process can be temporarily swapped out of memory to a backing store and then brought back into memory for continued execution. This allows more processes to be executed than can fit in memory at one time.
-
-### Steps in Swapping:
-1. **Process Suspension**: The process is suspended and its state is saved.
-2. **Transfer to Backing Store**: The process is copied to the backing store (disk).
-3. **Loading into Memory**: When the process is to be resumed, it is copied back into memory.
-
-## Fragmentation
-
-### Internal Fragmentation
-Occurs when fixed-sized memory blocks are allocated and the memory assigned to a process is slightly larger than the memory requested. This leads to wasted space.
-
-### External Fragmentation
-Occurs when free memory is split into small blocks and is interspersed by allocated memory. Compaction can help reduce external fragmentation.
-
-## Memory Management Algorithms
-
-### First Fit
-Allocates the first block of free memory that is large enough for the process.
-
-### Best Fit
-Allocates the smallest block of memory that is sufficient for the process. This reduces wasted space but can lead to external fragmentation.
-
-### Worst Fit
-Allocates the largest block of free memory. This helps to reduce the chances of small unusable fragments.
-
-## Conclusion
-Memory management is essential for the efficient operation of an operating system. By understanding various memory management techniques and algorithms, we can ensure that memory is used effectively and processes are executed smoothly.
-
----
-
-Memory management is a complex but crucial aspect of operating systems, ensuring optimal use of memory resources and enabling multitasking and efficient process management.
diff --git a/docs/Operating System/os_development.md b/docs/Operating System/os_development.md
deleted file mode 100644
index 32cc560fb..000000000
--- a/docs/Operating System/os_development.md
+++ /dev/null
@@ -1,96 +0,0 @@
----
-id: os-development
-title: os-development
-sidebar_label: OS Development
-sidebar_position: 18
-tags: [operating_system, create database, commands]
-description: Operating system (OS) development involves designing and implementing the core software that manages hardware resources and provides services for application programs.
----
-# Operating System Development
-
-## Introduction
-Operating system (OS) development involves designing and implementing the core software that manages hardware resources and provides services for application programs. It is a complex and challenging field that requires a deep understanding of computer architecture, systems programming, and software engineering principles.
-
-## Key Concepts
-
-### 1. Kernel
-The kernel is the core component of an operating system. It manages system resources, including CPU, memory, and I/O devices, and provides essential services such as process scheduling, memory management, and device management.
-
-### 2. Bootloader
-A bootloader is a small program that initializes the hardware and loads the kernel into memory during the system startup process. Examples include GRUB (Grand Unified Bootloader) and UEFI (Unified Extensible Firmware Interface).
-
-### 3. System Calls
-System calls are the interface between user programs and the operating system kernel. They allow programs to request services from the kernel, such as file operations, process control, and inter-process communication.
-
-### 4. Process Management
-Process management involves creating, scheduling, and terminating processes. It ensures efficient use of the CPU and provides mechanisms for process synchronization and communication.
-
-### 5. Memory Management
-Memory management involves allocating and deallocating memory for processes and ensuring efficient use of memory resources. It includes techniques such as paging, segmentation, and virtual memory.
-
-### 6. File Systems
-File systems manage the storage and retrieval of data on disk. They provide a hierarchical structure for organizing files and directories and handle tasks such as file creation, deletion, reading, and writing.
-
-### 7. Device Drivers
-Device drivers are specialized programs that enable the operating system to communicate with hardware devices. They provide a standard interface for accessing and controlling devices such as keyboards, mice, and storage devices.
-
-## Development Process
-
-### 1. Setting Up the Development Environment
-- **Cross-Compiler**: A cross-compiler is required to compile code for the target architecture. GCC (GNU Compiler Collection) is commonly used.
-- **Emulator**: An emulator, such as QEMU, allows you to test the OS without needing physical hardware.
-- **Version Control**: Using a version control system like Git helps manage code changes and collaboration.
-
-### 2. Writing the Bootloader
-The bootloader initializes the hardware, sets up the memory map, and loads the kernel into memory. It typically involves low-level programming in assembly language.
-
-### 3. Developing the Kernel
-- **Kernel Initialization**: Setting up the kernel environment, including memory management structures and hardware initialization.
-- **Process Management**: Implementing process creation, scheduling, and context switching.
-- **Memory Management**: Setting up the virtual memory system, including page tables and memory allocation.
-- **File System**: Developing the file system structure, including inode management and directory operations.
-- **Device Drivers**: Writing drivers for essential hardware components, such as the keyboard, display, and disk storage.
-
-### 4. Implementing System Calls
-System calls provide the interface for user programs to interact with the kernel. Implementing system calls involves defining the API, handling parameters, and performing the requested operations in the kernel.
-
-### 5. Developing User Space Programs
-User space programs run outside the kernel and interact with it via system calls. Developing basic utilities, such as a shell, text editor, and file manager, is part of OS development.
-
-## Tools and Resources
-
-### 1. Development Tools
-- **GCC**: A cross-compiler for building the OS.
-- **QEMU**: An emulator for testing the OS.
-- **GDB**: A debugger for debugging the OS.
-- **Make**: A build automation tool for managing the compilation process.
-
-### 2. Documentation and Tutorials
-- **OSDev.org**: A community-driven resource for OS development, including tutorials and documentation.
-- **The Linux Kernel**: Reading and understanding the source code of the Linux kernel can provide valuable insights into OS design and implementation.
-- **Books**: Recommended books include "Operating Systems: Design and Implementation" by Andrew S. Tanenbaum and "Modern Operating Systems" by Andrew S. Tanenbaum.
-
-### 3. Sample Projects
-- **MINIX**: A small, educational operating system designed for teaching OS principles.
-- **XV6**: A modern re-implementation of Unix Version 6, used in MIT's operating systems course.
-
-## Challenges in OS Development
-
-### 1. Complexity
-OS development is inherently complex, requiring knowledge of computer architecture, low-level programming, and concurrent programming.
-
-### 2. Debugging
-Debugging kernel code is challenging due to the lack of standard debugging tools and the need to work with raw hardware interfaces.
-
-### 3. Performance
-Ensuring efficient resource utilization and low latency is critical in OS development, particularly for real-time and high-performance systems.
-
-### 4. Security
-Implementing robust security mechanisms, such as access control, encryption, and secure communication, is essential to protect the OS from attacks.
-
-## Conclusion
-Operating system development is a challenging but rewarding field that requires a deep understanding of computer systems and software engineering. By mastering key concepts, tools, and techniques, developers can build robust, efficient, and secure operating systems.
-
----
-
-Operating system development involves creating the core software that manages hardware resources and provides services for application programs. It requires a deep understanding of computer architecture, systems programming, and software engineering principles.
diff --git a/docs/Operating System/process_management.md b/docs/Operating System/process_management.md
deleted file mode 100644
index e9a4a070b..000000000
--- a/docs/Operating System/process_management.md
+++ /dev/null
@@ -1,76 +0,0 @@
----
-id: process-management
-title: process-management
-sidebar_label: Process Management
-sidebar_position: 9
-tags: [operating_system, create database, commands]
-description: Process management is a fundamental concept in operating systems that deals with the creation, scheduling, and termination of processes.
----
-# Process Management
-
-## Introduction
-Process management is a fundamental concept in operating systems that deals with the creation, scheduling, and termination of processes. It ensures that the CPU is utilized efficiently and that processes are executed smoothly without conflicts.
-
-## Key Concepts
-
-### 1. Process
-A process is a program in execution. It consists of the program code, current activity, and associated resources. Each process has a unique Process ID (PID).
-
-### 2. Process States
-Processes typically go through a series of states during their lifecycle:
-- **New**: The process is being created.
-- **Ready**: The process is waiting to be assigned to a processor.
-- **Running**: Instructions are being executed.
-- **Waiting**: The process is waiting for some event to occur.
-- **Terminated**: The process has finished execution.
-
-### 3. Process Control Block (PCB)
-The PCB is a data structure used by the operating system to store all the information about a process. This includes the process state, program counter, CPU registers, memory management information, and accounting information.
-
-### 4. Context Switching
-Context switching is the process of storing the state of a currently running process and restoring the state of the next process to be executed. It allows multiple processes to share a single CPU.
-
-### 5. Scheduling
-Process scheduling is the activity of the process manager that handles the removal of the running process from the CPU and the selection of another process. There are different types of scheduling algorithms:
-- **First-Come, First-Served (FCFS)**
-- **Shortest Job Next (SJN)**
-- **Priority Scheduling**
-- **Round Robin (RR)**
-- **Multilevel Queue Scheduling**
-
-## Process Creation and Termination
-
-### Process Creation
-Processes can be created using system calls like `fork()` in Unix-based systems. A new process, called the child process, is created as a copy of the parent process.
-
-#### Steps in Process Creation:
-1. **Forking**: The operating system creates a new process by duplicating the parent process.
-2. **Execution**: The child process starts executing. It can run a different program using the `exec` system call.
-3. **Address Space Allocation**: The operating system allocates memory for the new process.
-
-### Process Termination
-A process terminates when it finishes execution or is explicitly killed. System calls like `exit()` are used for normal termination, while `kill()` can be used to terminate a process forcefully.
-
-#### Reasons for Process Termination:
-1. **Normal Completion**: The process finishes its task.
-2. **Errors**: Errors occur during execution.
-3. **Resource Unavailability**: Required resources are not available.
-4. **User Request**: The user requests the termination of the process.
-5. **Parent Termination**: The parent process is terminated.
-
-## Inter-Process Communication (IPC)
-IPC mechanisms allow processes to communicate and synchronize their actions. Common IPC methods include:
-- **Pipes**: Unidirectional communication channels between processes.
-- **Message Queues**: A linked list of messages stored within the kernel.
-- **Shared Memory**: Multiple processes can access the same memory space.
-- **Semaphores**: Used to control access to a common resource by multiple processes.
-
-### Synchronization
-Synchronization is essential to ensure that processes do not interfere with each other while sharing resources. Techniques include:
-- **Mutexes**: Locks that ensure mutual exclusion.
-- **Condition Variables**: Used to block a process until a particular condition is met.
-- **Monitors**: High-level synchronization constructs.
-
-## Conclusion
-Process management is crucial for the efficient operation of an operating system. It ensures that processes are executed in a manner that maximizes CPU utilization and minimizes conflicts. By understanding process management, we gain insight into how operating systems handle multitasking and ensure that multiple processes can run smoothly and efficiently.
-
diff --git a/docs/Operating System/real_time_systems.md b/docs/Operating System/real_time_systems.md
deleted file mode 100644
index bf564f65c..000000000
--- a/docs/Operating System/real_time_systems.md
+++ /dev/null
@@ -1,85 +0,0 @@
----
-id: real-time-systems
-title: real-time-systems
-sidebar_label: Real Time Systems
-sidebar_position: 15
-tags: [operating_system, create database, commands]
-description: Real-time systems are computing systems that must respond to inputs and deliver outputs within a specified time frame.
----
-# Real-Time Systems
-
-## Introduction
-Real-time systems are computing systems that must respond to inputs and deliver outputs within a specified time frame. These systems are used in environments where timing is critical, such as embedded systems, industrial control systems, and aerospace applications.
-
-## Key Concepts
-
-### 1. Hard vs. Soft Real-Time Systems
-- **Hard Real-Time Systems**: Systems where missing a deadline can lead to catastrophic consequences. Examples include airbag systems in cars and pacemakers.
-- **Soft Real-Time Systems**: Systems where deadlines are important but missing them does not result in catastrophic failure, although it may degrade system performance. Examples include video streaming and online transaction processing.
-
-### 2. Determinism
-Determinism in real-time systems refers to the predictability of system behavior. A deterministic system guarantees response within a known time limit.
-
-### 3. Latency
-Latency is the time taken from the occurrence of an event to the start of the response. Minimizing latency is crucial in real-time systems.
-
-### 4. Jitter
-Jitter is the variability in response time. In real-time systems, low jitter is desirable to ensure consistent performance.
-
-## Real-Time Operating Systems (RTOS)
-
-### 1. Characteristics of RTOS
-- **Preemptive Multitasking**: Allows the RTOS to interrupt tasks to ensure high-priority tasks get CPU time.
-- **Priority-Based Scheduling**: Tasks are assigned priorities, and the scheduler ensures that high-priority tasks are executed first.
-- **Inter-task Communication**: Mechanisms such as message queues, semaphores, and events for tasks to communicate and synchronize.
-- **Minimal Interrupt Latency**: Ensures that the system responds quickly to interrupts.
-- **Resource Management**: Efficient management of CPU, memory, and other resources to meet timing requirements.
-
-### 2. Common RTOS Examples
-- **FreeRTOS**: An open-source RTOS used in embedded systems.
-- **VxWorks**: A commercial RTOS used in aerospace and defense applications.
-- **RTEMS**: A free RTOS designed for real-time embedded systems.
-- **QNX**: A commercial RTOS known for its microkernel architecture.
-
-## Real-Time Scheduling Algorithms
-
-### 1. Rate Monotonic Scheduling (RMS)
-A fixed-priority algorithm where tasks with shorter periods are assigned higher priorities. It is optimal for preemptive, fixed-priority scheduling.
-
-### 2. Earliest Deadline First (EDF)
-A dynamic scheduling algorithm where tasks closest to their deadlines are given the highest priority. It is optimal for both preemptive and non-preemptive scheduling.
-
-### 3. Least Laxity First (LLF)
-A dynamic scheduling algorithm where tasks with the least laxity (slack time) are given the highest priority. Laxity is the difference between the time remaining until the deadline and the remaining execution time.
-
-### 4. Priority Inheritance Protocol
-A protocol to handle priority inversion by temporarily elevating the priority of a task holding a resource that a higher-priority task needs.
-
-## Real-Time Communication
-
-### 1. Time-Triggered Protocol (TTP)
-A communication protocol where messages are transmitted at predefined times. It is used in applications requiring high reliability and predictability.
-
-### 2. Controller Area Network (CAN)
-A robust vehicle bus standard designed to allow microcontrollers and devices to communicate with each other without a host computer.
-
-### 3. Time-Sensitive Networking (TSN)
-A set of standards for time-sensitive transmission of data over Ethernet networks. It is used in industrial automation and automotive applications.
-
-## Case Studies
-
-### 1. Automotive Systems
-Modern cars use real-time systems for engine control, braking systems, and airbag deployment. These systems require precise timing and reliability to ensure safety.
-
-### 2. Industrial Control Systems
-Real-time systems control manufacturing processes, robotics, and assembly lines. They ensure timely and synchronized operations to maintain productivity and safety.
-
-### 3. Aerospace Systems
-Real-time systems are used in avionics for navigation, flight control, and communication systems. They require high reliability and low latency to ensure passenger safety.
-
-## Conclusion
-Real-time systems are essential in applications where timing is critical. They require specialized operating systems and scheduling algorithms to ensure timely and predictable responses. Understanding the principles of real-time systems is crucial for designing systems that meet the stringent timing and reliability requirements of various industries.
-
----
-
-Real-time systems play a vital role in ensuring the correct and timely operation of critical applications. Their design and implementation require a thorough understanding of timing constraints, scheduling algorithms, and communication protocols.
diff --git a/docs/Operating System/security_and_protection.md b/docs/Operating System/security_and_protection.md
deleted file mode 100644
index 405a70b25..000000000
--- a/docs/Operating System/security_and_protection.md
+++ /dev/null
@@ -1,85 +0,0 @@
----
-id: security-and-protection
-title: security-and-protection
-sidebar_label: Security and Protection
-sidebar_position: 13
-tags: [operating_system, create database, commands]
-description: Security and protection are critical aspects of operating systems, ensuring that the system's resources are used as intended and protecting against unauthorized access, misuse, and harm.
----
-# Security and Protection
-
-## Introduction
-Security and protection are critical aspects of operating systems, ensuring that the system's resources are used as intended and protecting against unauthorized access, misuse, and harm. These mechanisms are designed to safeguard data integrity, confidentiality, and availability.
-
-## Key Concepts
-
-### 1. Security vs. Protection
-- **Security**: Refers to defending the system against external threats such as viruses, malware, and hackers.
-- **Protection**: Refers to internal mechanisms that control access to system resources, ensuring that programs and users can access only the resources they are authorized to.
-
-### 2. Threats and Attacks
-- **Threat**: A potential cause of an unwanted incident, which may result in harm to a system or organization.
-- **Attack**: An action taken to exploit a vulnerability in the system.
-
-### 3. Types of Attacks
-- **Passive Attacks**: Attempts to learn or make use of information from the system but do not affect system resources (e.g., eavesdropping).
-- **Active Attacks**: Attempts to alter system resources or affect their operation (e.g., viruses, worms).
-
-## Security Measures
-
-### 1. Authentication
-Authentication is the process of verifying the identity of a user or process. Methods include:
-- **Passwords**: Secret words or phrases used to verify identity.
-- **Biometrics**: Using physical characteristics like fingerprints or retina scans.
-- **Two-Factor Authentication (2FA)**: Combining two different methods for higher security.
-
-### 2. Authorization
-Authorization determines what an authenticated user or process is allowed to do. It involves setting permissions and access rights.
-
-### 3. Encryption
-Encryption transforms readable data into an unreadable format to protect it from unauthorized access. Types include:
-- **Symmetric Encryption**: The same key is used for both encryption and decryption.
-- **Asymmetric Encryption**: Different keys are used for encryption and decryption (public key and private key).
-
-### 4. Intrusion Detection Systems (IDS)
-IDS monitor network or system activities for malicious actions or policy violations. They can be:
-- **Host-Based IDS (HIDS)**: Installed on individual devices to monitor local activities.
-- **Network-Based IDS (NIDS)**: Monitor network traffic for suspicious activities.
-
-### 5. Firewalls
-Firewalls control incoming and outgoing network traffic based on predetermined security rules. They can be hardware-based or software-based.
-
-## Protection Mechanisms
-
-### 1. Access Control
-Access control mechanisms determine who can access what resources in the system. Models include:
-- **Discretionary Access Control (DAC)**: Access rights are assigned by the owner of the resource.
-- **Mandatory Access Control (MAC)**: Access rights are assigned based on fixed policies set by the administrator.
-- **Role-Based Access Control (RBAC)**: Access rights are assigned based on user roles within an organization.
-
-### 2. Protection Domains
-A protection domain defines the set of resources that a process can access. Each process operates within its own domain.
-
-### 3. Capability-Based Systems
-Capabilities are tokens or keys that grant a process specific access rights to objects. They simplify access control by binding access rights to the object.
-
-### 4. Language-Based Protection
-Programming languages can enforce protection by using language constructs to define access rights. For example, Java provides access control modifiers like private, protected, and public.
-
-## Security Policies
-
-### 1. Principle of Least Privilege
-Users and processes should operate with the minimum set of privileges necessary to complete their tasks. This minimizes the potential damage from accidents or malicious activities.
-
-### 2. Defense in Depth
-Multiple layers of security controls and defenses are used to protect the system. If one layer fails, others still provide protection.
-
-### 3. Separation of Duties
-Responsibilities are divided among multiple individuals or systems to prevent fraud and errors. No single user should have control over all aspects of any critical function.
-
-## Conclusion
-Security and protection are vital for maintaining the integrity, confidentiality, and availability of system resources. By implementing robust security measures and protection mechanisms, operating systems can defend against a wide range of threats and ensure that resources are used appropriately and securely.
-
----
-
-A well-secured operating system not only defends against external threats but also ensures proper usage of resources internally, maintaining the overall health and functionality of the system.
diff --git a/docs/Operating System/system_calls.md b/docs/Operating System/system_calls.md
deleted file mode 100644
index bd3cb1310..000000000
--- a/docs/Operating System/system_calls.md
+++ /dev/null
@@ -1,114 +0,0 @@
----
-id: system-calls
-title: system-calls
-sidebar_label: System calls
-sidebar_position: 17
-tags: [operating_system, create database, commands]
-description: System calls are the interface between a running program and the operating system.
----
-# System Calls
-
-## Introduction
-System calls are the interface between a running program and the operating system. They allow user-level processes to request services from the kernel, such as file manipulation, process control, and communication.
-
-## Key Concepts
-
-### 1. Definition
-A system call is a function that provides the programmatic interface to the services provided by the operating system.
-
-### 2. User Mode vs. Kernel Mode
-- **User Mode**: The mode in which user applications run. Limited access to system resources.
-- **Kernel Mode**: The mode in which the operating system runs. Full access to all system resources.
-
-### 3. System Call Interface
-The system call interface acts as a boundary between user programs and the operating system kernel. It provides a set of services that programs can use to perform operations.
-
-## Types of System Calls
-
-### 1. Process Control
-- **fork()**: Creates a new process by duplicating the calling process.
-- **exec()**: Replaces the current process image with a new process image.
-- **exit()**: Terminates the calling process.
-- **wait()**: Waits for a child process to terminate.
-
-### 2. File Management
-- **open()**: Opens a file.
-- **close()**: Closes a file descriptor.
-- **read()**: Reads data from a file.
-- **write()**: Writes data to a file.
-- **lseek()**: Repositions the read/write file offset.
-- **unlink()**: Removes a directory entry.
-
-### 3. Device Management
-- **ioctl()**: Controls device parameters.
-- **read()**: Reads data from a device.
-- **write()**: Writes data to a device.
-
-### 4. Information Maintenance
-- **getpid()**: Gets the process ID.
-- **alarm()**: Sets an alarm clock for delivery of a signal.
-- **sleep()**: Suspends execution for an interval of time.
-- **gettimeofday()**: Gets the current time.
-
-### 5. Communication
-- **pipe()**: Creates a unidirectional data channel.
-- **shmget()**: Allocates a shared memory segment.
-- **shmat()**: Attaches a shared memory segment.
-- **semget()**: Gets a semaphore set identifier.
-
-## System Call Implementation
-
-### 1. System Call Handler
-When a system call is invoked, control is transferred to the system call handler in the kernel, which performs the requested service and returns control to the user program.
-
-### 2. Software Interrupt
-System calls are typically implemented using software interrupts or traps. This involves an interrupt instruction that switches the CPU to kernel mode and transfers control to a predefined interrupt handler.
-
-### 3. Parameter Passing
-Parameters for system calls can be passed in several ways:
-- **Registers**: Parameters are passed via CPU registers.
-- **Stack**: Parameters are pushed onto the stack.
-- **Memory**: Parameters are stored in a memory block, and the address of the block is passed.
-
-## Examples of System Calls
-
-### 1. Linux
-- **fork()**: Creates a new process.
-- **execve()**: Executes a program.
-- **mmap()**: Maps files or devices into memory.
-- **kill()**: Sends a signal to a process.
-
-### 2. Windows
-- **CreateProcess()**: Creates a new process.
-- **ReadFile()**: Reads data from a file.
-- **WriteFile()**: Writes data to a file.
-- **CreateFile()**: Opens a file.
-
-## System Call Optimization
-
-### 1. System Call Batching
-Combining multiple system calls into a single call to reduce overhead.
-
-### 2. Fast System Calls
-Using specialized CPU instructions to reduce the overhead of switching between user mode and kernel mode.
-
-### 3. Asynchronous System Calls
-Allowing system calls to be non-blocking, so a process can continue execution without waiting for the system call to complete.
-
-## Security Considerations
-
-### 1. Access Control
-Ensuring that only authorized processes can make certain system calls.
-
-### 2. Input Validation
-Validating parameters passed to system calls to prevent buffer overflows and other vulnerabilities.
-
-### 3. Privilege Escalation
-Preventing unauthorized processes from gaining elevated privileges through system calls.
-
-## Conclusion
-System calls are a critical aspect of operating system functionality, providing the necessary interface between user programs and the kernel. Understanding how system calls work and how they are implemented is essential for system programming and OS development.
-
----
-
-System calls are the bridge between user applications and the operating system, enabling programs to perform essential operations and interact with hardware.
diff --git a/docs/Operating System/types_of_OS.md b/docs/Operating System/types_of_OS.md
deleted file mode 100644
index 88bf8d0f4..000000000
--- a/docs/Operating System/types_of_OS.md
+++ /dev/null
@@ -1,227 +0,0 @@
----
-id: types-of-operating_system
-title: types-of-operating_system
-sidebar_label: Types of Operating System
-sidebar_position: 8
-tags: [operating_system, create database, commands]
-description: An Operating System performs all the basic tasks like managing files, processes, and memory. .
----
-
-# Types of Operating Systems
-
-## Pre-Requisite: What is an Operating System?
-
-An Operating System performs all the basic tasks like managing files, processes, and memory. Thus operating system acts as the manager of all the resources, i.e. resource manager. Thus, the operating system becomes an interface between the user and the machine. It is one of the most required software that is present in the device.
-
-Operating System is a type of software that works as an interface between the system program and the hardware. There are several types of Operating Systems, many of which are mentioned below. Let’s have a look at them.
-
-## Types of Operating Systems
-
-There are several types of Operating Systems which are mentioned below.
-
-1. [Batch Operating System](#batch-operating-system)
-
-2. [Multi-Programming System](#multi-programming-operating-system)
-
-3. [Multi-Processing System](#multi-processing-operating-system)
-
-4. [Multi-Tasking Operating System](#multi-tasking-operating-system)
-
-5. [Time-Sharing Operating System](#time-sharing-operating-system)
-
-6. [Distributed Operating System](#distributed-operating-system)
-
-7. [Network Operating System](#network-operating-system)
-
-8. [Real-Time Operating System](#real-time-operating-system)
-
-### Batch Operating System
-
-This type of operating system does not interact with the computer directly. There is an operator which takes similar jobs having the same requirement and groups them into batches. It is the responsibility of the operator to sort jobs with similar needs.
-
- 
-
-#### Advantages of Batch Operating System
-
-- Multiple users can share the batch systems.
-
-- The idle time for the batch system is very less.
-
-- It is easy to manage large work repeatedly in batch systems.
-
-#### Disadvantages of Batch Operating System
-
-- The computer operators should be well known with batch systems.
-
-- Batch systems are hard to debug.
-
-- It is sometimes costly.
-
-- The other jobs will have to wait for an unknown time if any job fails.
-
-- In batch operating system the processing time for jobs is commonly difficult to accurately predict while they are in the queue.
-
-- It is difficult to accurately predict the exact time required for a job to complete while it is in the queue.
-
-#### Examples of Batch Operating Systems
-
-- Payroll Systems, Bank Statements, etc.
-
-### Multi-Programming Operating System
-
-Multiprogramming Operating Systems can be simply illustrated as more than one program is present in the main memory and any one of them can be kept in execution. This is basically used for better execution of resources.
-
- 
-
-#### Advantages of Multi-Programming Operating System
-
-- Multi Programming increases the Throughput of the System.
-
-- It helps in reducing the response time.
-
-#### Disadvantages of Multi-Programming Operating System
-
-- There is not any facility for user interaction of system resources with the system.
-
-### Multi-Processing Operating System
-
-Multi-Processing Operating System is a type of Operating System in which more than one CPU is used for the execution of resources. It betters the throughput of the System.
-
- 
-
-#### Advantages of Multi-Processing Operating System
-
-- It increases the throughput of the system.
-
-- As it has several processors, so, if one processor fails, we can proceed with another processor.
-
-#### Disadvantages of Multi-Processing Operating System
-
-- Due to the multiple CPU, it can be more complex and somehow difficult to understand.
-
-### Multi-Tasking Operating System
-
-Multitasking Operating System is simply a multiprogramming Operating System with having facility of a Round-Robin Scheduling Algorithm. It can run multiple programs simultaneously.
-
- 
-
-#### Types of Multi-Tasking Systems
-
-- Preemptive Multi-Tasking
-
-- Cooperative Multi-Tasking
-
-#### Advantages of Multi-Tasking Operating System
-
-- Multiple Programs can be executed simultaneously in Multi-Tasking Operating System.
-
-- It comes with proper memory management.
-
-#### Disadvantages of Multi-Tasking Operating System
-
-- The system gets heated in case of heavy programs multiple times.
-
-### Time-Sharing Operating System
-
-Each task is given some time to execute so that all the tasks work smoothly. Each user gets the time of the CPU as they use a single system. These systems are also known as Multitasking Systems. The task can be from a single user or different users also. The time that each task gets to execute is called quantum. After this time interval is over OS switches over to the next task.
-
- 
-
-#### Advantages of Time-Sharing OS
-
-- Each task gets an equal opportunity.
-
-- Fewer chances of duplication of software.
-
-- CPU idle time can be reduced.
-
-- Resource Sharing: Time-sharing systems allow multiple users to share hardware resources such as the CPU, memory, and peripherals, reducing the cost of hardware and increasing efficiency.
-
-- Improved Productivity: Time-sharing allows users to work concurrently, thereby reducing the waiting time for their turn to use the computer. This increased productivity translates to more work getting done in less time.
-
-- Improved User Experience: Time-sharing provides an interactive environment that allows users to communicate with the computer in real time, providing a better user experience than batch processing.
-
-#### Disadvantages of Time-Sharing OS
-
-- Reliability problem.
-
-- One must have to take care of the security and integrity of user programs and data.
-
-- Data communication problem.
-
-- High Overhead: Time-sharing systems have a higher overhead than other operating systems due to the need for scheduling, context switching, and other overheads that come with supporting multiple users.
-
-- Complexity: Time-sharing systems are complex and require advanced software to manage multiple users simultaneously. This complexity increases the chance of bugs and errors.
-
-- Security Risks: With multiple users sharing resources, the risk of security breaches increases. Time-sharing systems require careful management of user access, authentication, and authorization to ensure the security of data and software.
-
-#### Examples of Time-Sharing OS with explanation
-
-- **IBM VM/CMS**: IBM VM/CMS is a time-sharing operating system that was first introduced in 1972. It is still in use today, providing a virtual machine environment that allows multiple users to run their own instances of operating systems and applications.
-
-- **TSO (Time Sharing Option)**: TSO is a time-sharing operating system that was first introduced in the 1960s by IBM for the IBM System/360 mainframe computer. It allowed multiple users to access the same computer simultaneously, running their own applications.
-
-- **Windows Terminal Services**: Windows Terminal Services is a time-sharing operating system that allows multiple users to access a Windows server remotely. Users can run their own applications and access shared resources, such as printers and network storage, in real-time.
-
-### Distributed Operating System
-
-These types of operating system is a recent advancement in the world of computer technology and are being widely accepted all over the world and, that too, at a great pace. Various autonomous interconnected computers communicate with each other using a shared communication network. Independent systems possess their own memory unit and CPU. These are referred to as loosely coupled systems or distributed systems. These systems’ processors differ in size and function. The major benefit of working with these types of the operating system is that it is always possible that one user can access the files or software which are not actually present on his system but some other system connected within this network i.e., remote access is enabled within the devices connected in that network.
-
- 
-
-#### Advantages of Distributed Operating System
-
-- Failure of one will not affect the other network communication, as all systems are independent of each other.
-- Electronic mail increases the data exchange speed.
-- Since resources are being shared, computation is highly fast and durable.
-- Load on host computer reduces.
-- These systems are easily scalable as many systems can be easily added to the network.
-- Delay in data processing reduces.
-
-#### Disadvantages of Distributed Operating System
-
-- Failure of the main network will stop the entire communication.
-- To establish distributed systems the language is used not well-defined yet.
-- These types of systems are not readily available as they are very expensive. Not only that the underlying software is highly complex and not understood well yet.
-
-#### Examples of Distributed Operating Systems
-
-- LOCUS, etc.
-
-#### Issues in Distributed OS
-
-- Networking causes delays in the transfer of data between nodes of a distributed system. Such delays may lead to an inconsistent view of data located in different nodes, and make it difficult to know the chronological order in which events occurred in the system.
-- Control functions like scheduling, resource allocation, and deadlock detection have to be performed in several nodes to achieve computation speedup and provide reliable operation when computers or networking components fail.
-- Messages exchanged by processes present in different nodes may travel over public networks and pass through computer systems that are not controlled by the distributed operating system. An intruder may exploit this feature to tamper with messages, or create fake messages to fool the authentication procedure and masquerade as a user of the system.
-
-### Network Operating System
-
-These systems run on a server and provide the capability to manage data, users, groups, security, applications, and other networking functions. These types of operating systems allow shared access to files, printers, security, applications, and other networking functions over a small private network. One more important aspect of Network Operating Systems is that all the users are well aware of the underlying configuration, of all other users within the network, their individual connections, etc. and that’s why these computers are popularly known as tightly coupled systems.
-
- 
-
-#### Advantages of Network Operating System
-
-- Highly stable centralized servers.
-
-- Security concerns are handled through servers.
-
-- New technologies and hardware up-gradation are easily integrated into the system.
-
-- Server access is possible remotely from different locations and types of systems.
-
-#### Disadvantages of Network Operating System
-
-- Servers are costly.
-
-- User has to depend on a central location for most operations.
-
-- Maintenance and updates are required regularly.
-
-#### Examples of Network Operating Systems
-
-- Microsoft Windows Server 2003, Microsoft Windows Server 2008, UNIX, Linux, Mac OS X, Novell NetWare, BSD, etc.
-
-### Real-Time Operating System
-
-These types of OSs serve real-time systems
diff --git a/docs/Operating System/virtualization.md b/docs/Operating System/virtualization.md
deleted file mode 100644
index 826e5952d..000000000
--- a/docs/Operating System/virtualization.md
+++ /dev/null
@@ -1,91 +0,0 @@
----
-id: virtualization
-title: virtualization
-sidebar_label: Virtualization
-sidebar_position: 16
-tags: [operating_system, create database, commands]
-description: Virtualization is a technology that allows a single physical machine to run multiple virtual machines (VMs), each with its own operating system and applications.
----
-# Virtualization
-
-## Introduction
-Virtualization is a technology that allows a single physical machine to run multiple virtual machines (VMs), each with its own operating system and applications. This abstraction layer separates the hardware from the software, enabling efficient resource utilization, isolation, and flexibility.
-
-## Key Concepts
-
-### 1. Virtual Machines (VMs)
-A virtual machine is a software emulation of a physical computer. Each VM runs its own operating system and applications, behaving like an independent computer.
-
-### 2. Hypervisor
-A hypervisor, also known as a virtual machine monitor (VMM), is software that creates and manages VMs by allocating hardware resources to them. Hypervisors can be classified into two types:
-- **Type 1 (Bare-Metal Hypervisors)**: Run directly on the physical hardware. Examples include VMware ESXi, Microsoft Hyper-V, and Xen.
-- **Type 2 (Hosted Hypervisors)**: Run on a host operating system that provides virtualization services. Examples include VMware Workstation and Oracle VirtualBox.
-
-### 3. Host and Guest
-- **Host**: The physical machine on which the hypervisor runs.
-- **Guest**: The virtual machines running on the hypervisor.
-
-## Benefits of Virtualization
-
-### 1. Resource Efficiency
-Virtualization allows multiple VMs to share the same physical resources, leading to higher utilization of CPU, memory, and storage.
-
-### 2. Isolation
-Each VM is isolated from others, ensuring that issues in one VM do not affect others. This isolation also enhances security.
-
-### 3. Flexibility and Scalability
-Virtualization enables easy scaling by adding or removing VMs based on demand. It also allows for rapid provisioning and deployment of new services.
-
-### 4. Disaster Recovery
-Virtualization simplifies backup and recovery processes. VMs can be easily backed up and restored, and they can be moved between physical machines without downtime.
-
-## Types of Virtualization
-
-### 1. Hardware Virtualization
-Emulates hardware devices, allowing VMs to run different operating systems. This includes full virtualization and paravirtualization.
-- **Full Virtualization**: VMs are completely isolated from the host. Examples include VMware and Hyper-V.
-- **Paravirtualization**: VMs are aware of the virtualization layer, allowing for optimized performance. Examples include Xen and KVM.
-
-### 2. Operating System Virtualization
-Enables multiple isolated user-space instances (containers) to run on a single OS kernel. Examples include Docker and LXC (Linux Containers).
-
-### 3. Network Virtualization
-Abstracts physical network resources into multiple virtual networks, each with its own topology and policies. Examples include VLANs (Virtual Local Area Networks) and SDN (Software-Defined Networking).
-
-### 4. Storage Virtualization
-Combines multiple physical storage devices into a single logical storage unit, providing flexible storage management. Examples include SAN (Storage Area Network) and NAS (Network-Attached Storage).
-
-## Virtualization Techniques
-
-### 1. Emulation
-The hypervisor emulates the complete hardware environment for the guest OS. This allows any OS to run on any hardware but can be slow due to overhead.
-
-### 2. Binary Translation
-The hypervisor translates sensitive instructions from the guest OS into safe instructions on the fly. This improves performance compared to emulation.
-
-### 3. Hardware-Assisted Virtualization
-Modern CPUs provide virtualization extensions (e.g., Intel VT-x, AMD-V) that allow the hypervisor to run VMs more efficiently by executing certain instructions directly on the hardware.
-
-### 4. Containerization
-Containers share the host OS kernel and run as isolated processes. They are lightweight and provide fast startup times compared to VMs. Examples include Docker and Kubernetes.
-
-## Virtualization in Cloud Computing
-Virtualization is a foundational technology for cloud computing. It enables the creation of scalable, on-demand infrastructure services such as Infrastructure as a Service (IaaS) and Platform as a Service (PaaS).
-
-## Case Studies
-
-### 1. VMware vSphere
-A comprehensive virtualization platform that provides powerful tools for managing and automating VMs, including vMotion for live VM migration and DRS (Distributed Resource Scheduler) for load balancing.
-
-### 2. Docker
-A platform for developing, shipping, and running applications in containers. Docker simplifies application deployment by packaging all dependencies into a single container image.
-
-### 3. Amazon EC2
-A cloud computing service that provides scalable virtual servers (instances) on demand. Users can choose from various instance types optimized for different workloads.
-
-## Conclusion
-Virtualization is a transformative technology that enhances resource utilization, provides flexibility, and simplifies management. Understanding virtualization concepts and techniques is essential for modern IT infrastructure, enabling efficient and scalable deployment of applications and services.
-
----
-
-Virtualization is a key enabler for cloud computing and modern data centers, offering significant benefits in terms of efficiency, scalability, and management.
diff --git a/docs/Pandas/Pandas-gettingstarted.md b/docs/Pandas/Pandas-gettingstarted.md
deleted file mode 100644
index ba5cb6892..000000000
--- a/docs/Pandas/Pandas-gettingstarted.md
+++ /dev/null
@@ -1,53 +0,0 @@
----
-id: Pandas-GettingStarted
-title: Pandas Getting Started
-sidebar_label: Pandas Getting Started
-sidebar_position: 2
-tags: [Python-library, Pandas , Machine-learning]
-description: Learn how to install and use Pandas, a powerful Python library for data manipulation and analysis.
----
-
-
-
-
-
-## Installation of Pandas
-
-If you already have Python and PIP installed on your system, installing Pandas is straightforward. Simply run the following command:
-
-```
-pip install pandas
-```
-
-If the command fails, consider using a Python distribution that already includes Pandas, such as Anaconda or Spyder.
-
-## Importing Pandas
-
-Once Pandas is installed, you can import it into your applications using the `import` keyword:
-
-```python
-import pandas
-```
-
-Now, Pandas is imported and ready to be used.
-
-## Example
-
-Here's a simple example that demonstrates the usage of Pandas:
-
-```python
-import pandas
-
-mydataset = {
- 'cars': ["BMW", "Volvo", "Ford"],
- 'passings': [3, 7, 2]
-}
-
-myvar = pandas.DataFrame(mydataset)
-
-print(myvar)
-```
-
-This example creates a DataFrame using a dictionary and prints its contents.
-
-Pandas is a versatile library that provides powerful tools for data manipulation and analysis in Python. By learning how to install and use Pandas, you can enhance your data processing capabilities and streamline your data analysis workflows.
\ No newline at end of file
diff --git a/docs/Pandas/Read-files.md b/docs/Pandas/Read-files.md
deleted file mode 100644
index 58722f4f5..000000000
--- a/docs/Pandas/Read-files.md
+++ /dev/null
@@ -1,255 +0,0 @@
----
-id: Pandas-Readfiles
-title: Pandas Read Files
-sidebar_label: Pandas Read Files
-sidebar_position: 6
-tags: [Python-library, Pandas ,Pandas-files, Machine-learning]
-description: Read CSV files , JSON files in PANDAS.
----
-
-
-### Read CSV Files
-A simple way to store big data sets is to use CSV files (comma separated files).
-
-CSV files contain plain text and are a well-known format that can be read by everyone, including Pandas.
-
-In our examples, we will be using a CSV file called 'data.csv'.
-
-Download data.csv or Open data.csv
-
-**Example: Get your own Python Server**
-
-Load the CSV into a DataFrame:
-
-```python
-import pandas as pd
-
-df = pd.read_csv('data.csv')
-
-print(df.to_string())
-```
-
-**Tip:** Use `to_string()` to print the entire DataFrame.
-
-If you have a large DataFrame with many rows, Pandas will only return the first 5 rows and the last 5 rows:
-
-**Example:**
-Print the DataFrame without the `to_string()` method:
-
-```python
-import pandas as pd
-
-df = pd.read_csv('data.csv')
-
-print(df)
-```
-
-### max_rows
-The number of rows returned is defined in Pandas option settings.
-
-You can check your system's maximum rows with the `pd.options.display.max_rows` statement.
-
-**Example:**
-Check the number of maximum returned rows:
-
-```python
-import pandas as pd
-
-print(pd.options.display.max_rows)
-```
-
-In my system, the number is 60, which means that if the DataFrame contains more than 60 rows, the `print(df)` statement will return only the headers and the first and last 5 rows.
-
-You can change the maximum rows number with the same statement.
-
-**Example:**
-Increase the maximum number of rows to display the entire DataFrame:
-
-```python
-import pandas as pd
-
-pd.options.display.max_rows = 9999
-
-df = pd.read_csv('data.csv')
-
-print(df)
-```
-
-## Pandas Read JSON
-### Read JSON
-Big data sets are often stored or extracted as JSON.
-
-JSON is plain text but has the format of an object and is well-known in the world of programming, including Pandas.
-
-In our examples, we will be using a JSON file called 'data.json'.
-
-Open data.json.
-
-**Example: Get your own Python Server**
-
-Load the JSON file into a DataFrame:
-
-```python
-import pandas as pd
-
-df = pd.read_json('data.json')
-
-print(df.to_string())
-```
-
-**Tip:** Use `to_string()` to print the entire DataFrame.
-
-### Dictionary as JSON
-JSON = Python Dictionary
-
-JSON objects have the same format as Python dictionaries.
-
-If your JSON code is not in a file but in a Python Dictionary, you can load it into a DataFrame directly:
-
-**Example:**
-Load a Python Dictionary into a DataFrame:
-
-```python
-import pandas as pd
-
-data = {
- "Duration":{
- "0":60,
- "1":60,
- "2":60,
- "3":45,
- "4":45,
- "5":60
- },
- "Pulse":{
- "0":110,
- "1":117,
- "2":103,
- "3":109,
- "4":117,
- "5":102
- },
- "Maxpulse":{
- "0":130,
- "1":145,
- "2":135,
- "3":175,
- "4":148,
- "5":127
- },
- "Calories":{
- "0":409,
- "1":479,
- "2":340,
- "3":282,
- "4":406,
- "5":300
- }
-}
-
-df = pd.DataFrame(data)
-
-print(df)
-```
-
-## Pandas - Analyzing DataFrames
-### Viewing the Data
-One of the most used methods for getting a quick overview of the DataFrame is the `head()` method.
-
-The `head()` method returns the headers and a specified number of rows, starting from the top.
-
-**Example: Get your own Python Server**
-Get a quick overview by printing the first 10 rows of the DataFrame:
-
-```python
-import pandas as pd
-
-df = pd.read_csv('data.csv')
-
-print(df.head(10))
-```
-
-In our examples, we will be using a CSV file called 'data.csv'.
-
-Download data.csv or open data.csv in your browser.
-
-**Note:** If the number of rows is not specified, the `head()` method will return the top 5 rows.
-
-**Example:**
-Print the first 5 rows of the DataFrame:
-
-```python
-import pandas as pd
-
-df = pd.read_csv('data.csv')
-
-print(df.head())
-```
-
-There is also a `tail()` method for viewing the last rows of the DataFrame.
-
-The `tail()` method returns the headers and a specified number of rows, starting from the bottom.
-
-**Example:**
-Print the last 5 rows of the DataFrame:
-
-```python
-print(df.tail())
-```
-
-**w3schools CERTIFIED.2022**
-Get Certified!
-Complete the Pandas modules, do the exercises, take the exam, and you will become w3schools certified!
-
-### Info About the Data
-The DataFrame object has a method called `info()`, which gives you more information about the dataset.
-
-**Example:**
-Print information about the data:
-
-```python
-print(df.info())
-```
-
-**Result:**
-
-```
-