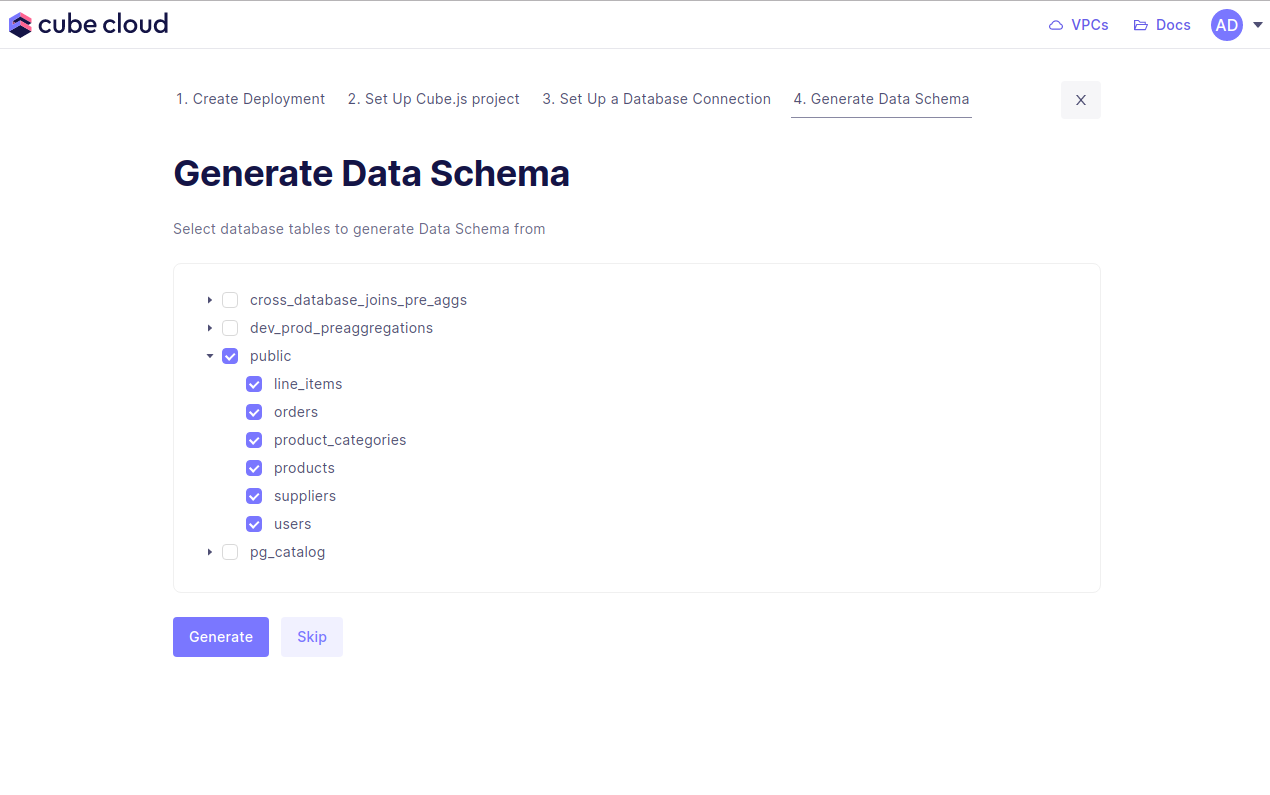
+
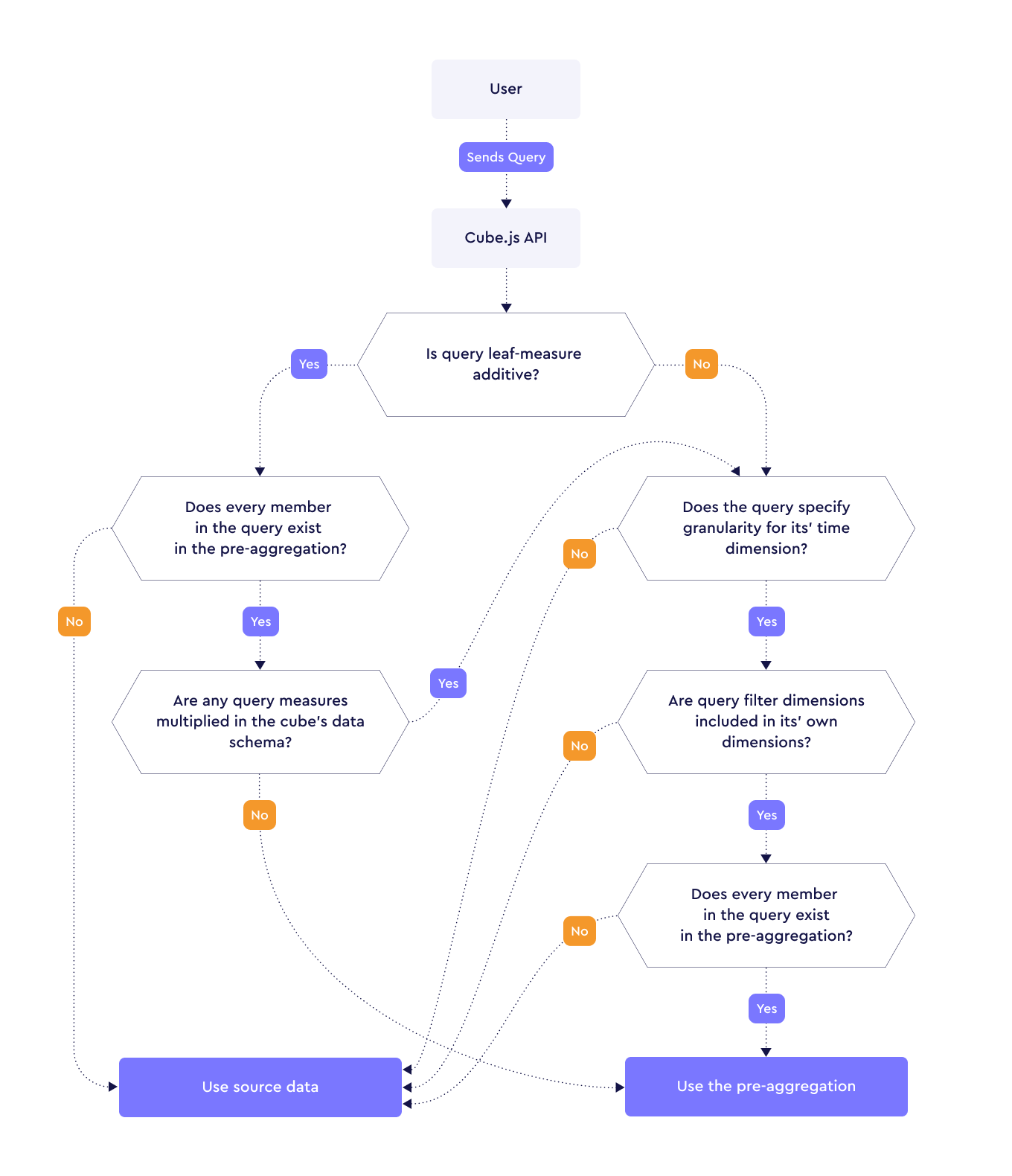 @@ -470,7 +468,7 @@ Some extra considerations for pre-aggregation selection:
`['2020-01-01T00:00:00.000', '2020-01-01T23:59:59.999']`. Date ranges are
inclusive, and the minimum granularity is `second`.
-- The order in which pre-aggregations are defined in schemas matter; the first
+- The order in which pre-aggregations are defined in models matter; the first
matching pre-aggregation for a query is the one that is used. Both the
measures and dimensions of any cubes specified in the query are checked to
find a matching `rollup`.
diff --git a/docs/content/Caching/Overview.mdx b/docs/content/Caching/Overview.mdx
index 01f5a4dffb5ca..faad5e3fce000 100644
--- a/docs/content/Caching/Overview.mdx
+++ b/docs/content/Caching/Overview.mdx
@@ -49,8 +49,8 @@ more about read-only support and pre-aggregation build strategies.
-Pre-aggregations are defined in the data schema. You can learn more about
-defining pre-aggregations in [schema reference][ref-schema-ref-preaggs].
+Pre-aggregations are defined in the data model. You can learn more about
+defining pre-aggregations in [data modeling reference][ref-schema-ref-preaggs].
```javascript
cube(`Orders`, {
@@ -142,10 +142,9 @@ The default values for `refreshKey` are
- `every: '10 second'` for all other databases.
+You can use a custom SQL query to check if a refresh is required by changing
-the [`refreshKey`][ref-schema-ref-cube-refresh-key] property in a cube's Data
-Schema. Often, a `MAX(updated_at_timestamp)` for OLTP data is a viable option,
-or examining a metadata table for whatever system is managing the data to see
-when it last ran.
+the [`refreshKey`][ref-schema-ref-cube-refresh-key] property in a cube. Often, a
+`MAX(updated_at_timestamp)` for OLTP data is a viable option, or examining a
+metadata table for whatever system is managing the data to see when it last ran.
### <--{"id" : "In-memory Cache"}--> Disabling the cache
diff --git a/docs/content/Caching/Using-Pre-Aggregations.mdx b/docs/content/Caching/Using-Pre-Aggregations.mdx
index f3b13d61db3e8..92ae7f3883376 100644
--- a/docs/content/Caching/Using-Pre-Aggregations.mdx
+++ b/docs/content/Caching/Using-Pre-Aggregations.mdx
@@ -7,7 +7,8 @@ menuOrder: 3
Pre-aggregations is a powerful way to speed up your Cube queries. There are many
configuration options to consider. Please make sure to also check [the
-Pre-Aggregations reference in the data schema section][ref-schema-ref-preaggs].
+Pre-Aggregations reference in the data modeling
+section][ref-schema-ref-preaggs].
## Refresh Strategy
diff --git a/docs/content/Configuration/Advanced/Multitenancy.mdx b/docs/content/Configuration/Advanced/Multitenancy.mdx
index b0875731dd3cc..36d41ab35824b 100644
--- a/docs/content/Configuration/Advanced/Multitenancy.mdx
+++ b/docs/content/Configuration/Advanced/Multitenancy.mdx
@@ -6,7 +6,7 @@ subCategory: Advanced
menuOrder: 3
---
-Cube supports multitenancy out of the box, both on database and data schema
+Cube supports multitenancy out of the box, both on database and data model
levels. Multiple drivers are also supported, meaning that you can have one
customer’s data in MongoDB and others in Postgres with one Cube instance.
@@ -34,7 +34,7 @@ combinations of these configuration options.
### <--{"id" : "Multitenancy"}--> Multitenancy vs Multiple Data Sources
-In cases where your Cube schema is spread across multiple different data
+In cases where your Cube data model is spread across multiple different data
sources, consider using the [`dataSource` cube property][ref-cube-datasource]
instead of multitenancy. Multitenancy is designed for cases where you need to
serve different datasets for multiple users, or tenants which aren't related to
@@ -169,7 +169,7 @@ cube(`Products`, {
### <--{"id" : "Multitenancy"}--> Running in Production
Each unique id generated by `contextToAppId` or `contextToOrchestratorId` will
-generate a dedicated set of resources, including schema compile cache, SQL
+generate a dedicated set of resources, including data model compile cache, SQL
compile cache, query queues, in-memory result caching, etc. Depending on your
data model complexity and usage patterns, those resources can have a pretty
sizable memory footprint ranging from single-digit MBs on the lower end and
@@ -219,7 +219,7 @@ module.exports = {
};
```
-## Multiple DB Instances with Same Schema
+## Multiple DB Instances with Same Data Model
Let's consider an example where we store data for different users in different
databases, but on the same Postgres host. The database name format is
@@ -249,12 +249,12 @@ select the database, based on the `appId` and `userId`:
@@ -470,7 +468,7 @@ Some extra considerations for pre-aggregation selection:
`['2020-01-01T00:00:00.000', '2020-01-01T23:59:59.999']`. Date ranges are
inclusive, and the minimum granularity is `second`.
-- The order in which pre-aggregations are defined in schemas matter; the first
+- The order in which pre-aggregations are defined in models matter; the first
matching pre-aggregation for a query is the one that is used. Both the
measures and dimensions of any cubes specified in the query are checked to
find a matching `rollup`.
diff --git a/docs/content/Caching/Overview.mdx b/docs/content/Caching/Overview.mdx
index 01f5a4dffb5ca..faad5e3fce000 100644
--- a/docs/content/Caching/Overview.mdx
+++ b/docs/content/Caching/Overview.mdx
@@ -49,8 +49,8 @@ more about read-only support and pre-aggregation build strategies.
-Pre-aggregations are defined in the data schema. You can learn more about
-defining pre-aggregations in [schema reference][ref-schema-ref-preaggs].
+Pre-aggregations are defined in the data model. You can learn more about
+defining pre-aggregations in [data modeling reference][ref-schema-ref-preaggs].
```javascript
cube(`Orders`, {
@@ -142,10 +142,9 @@ The default values for `refreshKey` are
- `every: '10 second'` for all other databases.
+You can use a custom SQL query to check if a refresh is required by changing
-the [`refreshKey`][ref-schema-ref-cube-refresh-key] property in a cube's Data
-Schema. Often, a `MAX(updated_at_timestamp)` for OLTP data is a viable option,
-or examining a metadata table for whatever system is managing the data to see
-when it last ran.
+the [`refreshKey`][ref-schema-ref-cube-refresh-key] property in a cube. Often, a
+`MAX(updated_at_timestamp)` for OLTP data is a viable option, or examining a
+metadata table for whatever system is managing the data to see when it last ran.
### <--{"id" : "In-memory Cache"}--> Disabling the cache
diff --git a/docs/content/Caching/Using-Pre-Aggregations.mdx b/docs/content/Caching/Using-Pre-Aggregations.mdx
index f3b13d61db3e8..92ae7f3883376 100644
--- a/docs/content/Caching/Using-Pre-Aggregations.mdx
+++ b/docs/content/Caching/Using-Pre-Aggregations.mdx
@@ -7,7 +7,8 @@ menuOrder: 3
Pre-aggregations is a powerful way to speed up your Cube queries. There are many
configuration options to consider. Please make sure to also check [the
-Pre-Aggregations reference in the data schema section][ref-schema-ref-preaggs].
+Pre-Aggregations reference in the data modeling
+section][ref-schema-ref-preaggs].
## Refresh Strategy
diff --git a/docs/content/Configuration/Advanced/Multitenancy.mdx b/docs/content/Configuration/Advanced/Multitenancy.mdx
index b0875731dd3cc..36d41ab35824b 100644
--- a/docs/content/Configuration/Advanced/Multitenancy.mdx
+++ b/docs/content/Configuration/Advanced/Multitenancy.mdx
@@ -6,7 +6,7 @@ subCategory: Advanced
menuOrder: 3
---
-Cube supports multitenancy out of the box, both on database and data schema
+Cube supports multitenancy out of the box, both on database and data model
levels. Multiple drivers are also supported, meaning that you can have one
customer’s data in MongoDB and others in Postgres with one Cube instance.
@@ -34,7 +34,7 @@ combinations of these configuration options.
### <--{"id" : "Multitenancy"}--> Multitenancy vs Multiple Data Sources
-In cases where your Cube schema is spread across multiple different data
+In cases where your Cube data model is spread across multiple different data
sources, consider using the [`dataSource` cube property][ref-cube-datasource]
instead of multitenancy. Multitenancy is designed for cases where you need to
serve different datasets for multiple users, or tenants which aren't related to
@@ -169,7 +169,7 @@ cube(`Products`, {
### <--{"id" : "Multitenancy"}--> Running in Production
Each unique id generated by `contextToAppId` or `contextToOrchestratorId` will
-generate a dedicated set of resources, including schema compile cache, SQL
+generate a dedicated set of resources, including data model compile cache, SQL
compile cache, query queues, in-memory result caching, etc. Depending on your
data model complexity and usage patterns, those resources can have a pretty
sizable memory footprint ranging from single-digit MBs on the lower end and
@@ -219,7 +219,7 @@ module.exports = {
};
```
-## Multiple DB Instances with Same Schema
+## Multiple DB Instances with Same Data Model
Let's consider an example where we store data for different users in different
databases, but on the same Postgres host. The database name format is
@@ -249,12 +249,12 @@ select the database, based on the `appId` and `userId`:
The App ID (the result of [`contextToAppId`][ref-config-ctx-to-appid]) is used
-as a caching key for various in-memory structures like schema compilation
+as a caching key for various in-memory structures like data model compilation
results, connection pool. The Orchestrator ID (the result of
[`contextToOrchestratorId`][ref-config-ctx-to-orch-id]) is used as a caching key
for database connections, execution queues and pre-aggregation table caches. Not
-declaring these properties will result in unexpected caching issues such as
-schema or data of one tenant being used for another.
+declaring these properties will result in unexpected caching issues such as the
+data model or data of one tenant being used for another.
@@ -292,7 +292,7 @@ module.exports = {
};
```
-## Multiple Schema and Drivers
+## Multiple Data Models and Drivers
What if for application with ID 3, the data is stored not in Postgres, but in
MongoDB?
@@ -301,9 +301,9 @@ We can instruct Cube to connect to MongoDB in that case, instead of Postgres. To
do this, we'll use the [`driverFactory`][ref-config-driverfactory] option to
dynamically set database type. We will also need to modify our
[`securityContext`][ref-config-security-ctx] to determine which tenant is
-requesting data. Finally, we want to have separate data schemas for every
+requesting data. Finally, we want to have separate data models for every
application. We can use the [`repositoryFactory`][ref-config-repofactory] option
-to dynamically set a repository with schema files depending on the `appId`:
+to dynamically set a repository with data model files depending on the `appId`:
**cube.js:**
diff --git a/docs/content/Configuration/Downstream/Superset.mdx b/docs/content/Configuration/Downstream/Superset.mdx
index 96d07014d32cd..cceadf81fbf28 100644
--- a/docs/content/Configuration/Downstream/Superset.mdx
+++ b/docs/content/Configuration/Downstream/Superset.mdx
@@ -69,7 +69,7 @@ a new database:
Your cubes will be exposed as tables, where both your measures and dimensions
are columns.
-Let's use the following Cube data schema:
+Let's use the following Cube data model:
```javascript
cube(`Orders`, {
@@ -124,7 +124,7 @@ a time grain of `month`.
The `COUNT(*)` aggregate function is being mapped to a measure of type
[count](/schema/reference/types-and-formats#measures-types-count) in Cube's
-**Orders** schema file.
+**Orders** data model file.
## Additional Configuration
diff --git a/docs/content/Deployment/Cloud/Continuous-Deployment.mdx b/docs/content/Deployment/Cloud/Continuous-Deployment.mdx
index 2c732f823ad8b..1be39559ad056 100644
--- a/docs/content/Deployment/Cloud/Continuous-Deployment.mdx
+++ b/docs/content/Deployment/Cloud/Continuous-Deployment.mdx
@@ -56,8 +56,11 @@ Cube Cloud will automatically deploy from the specified production branch
-Enabling this option will cause the Schema page to display the last known state of a Git-based codebase (if available), instead of reflecting the latest modifications made.
-It is important to note that the logic will still be updated in both the API and the Playground.
+Enabling this option will cause the Data Model page to display the
+last known state of a Git-based codebase (if available), instead of reflecting
+the latest modifications made. It is important to note that the logic will still
+be updated in both the API and the Playground.
+
You can use the CLI to set up continuous deployment for a Git repository. You
@@ -65,7 +68,7 @@ can also use the CLI to manually deploy changes without continuous deployment.
### <--{"id" : "Deploy with CLI"}--> Manual Deploys
-You can deploy your Cube project manually. This method uploads data schema and
+You can deploy your Cube project manually. This method uploads data models and
configuration files directly from your local project directory.
You can obtain Cube Cloud deploy token from your deployment **Settings** page.
diff --git a/docs/content/Deployment/Overview.mdx b/docs/content/Deployment/Overview.mdx
index c1b8f17f03e9d..f257cd6c606ae 100644
--- a/docs/content/Deployment/Overview.mdx
+++ b/docs/content/Deployment/Overview.mdx
@@ -42,7 +42,7 @@ API instances.
API instances and Refresh Workers can be configured via [environment
variables][ref-config-env] or the [`cube.js` configuration file][ref-config-js].
-They also need access to the data schema files. Cube Store clusters can be
+They also need access to the data model files. Cube Store clusters can be
configured via environment variables.
You can find an example Docker Compose configuration for a Cube deployment in
@@ -57,21 +57,22 @@ requests between multiple API instances.
The [Cube Docker image][dh-cubejs] is used for API Instance.
-API instance needs to be configured via environment variables, cube.js file and
-has access to the data schema files.
+API instances can be configured via environment variables or the `cube.js`
+configuration file, and **must** have access to the data model files (as
+specified by [`schemaPath`][ref-conf-ref-schemapath].
## Refresh Worker
A Refresh Worker updates pre-aggregations and invalidates the in-memory cache in
-the background. They also keep the refresh keys up-to-date for all defined
-schemas and pre-aggregations. Please note that the in-memory cache is just
-invalidated but not populated by Refresh Worker. In-memory cache is populated
-lazily during querying. On the other hand, pre-aggregations are eagerly
-populated and kept up-to-date by Refresh Worker.
+the background. They also keep the refresh keys up-to-date for all data models
+and pre-aggregations. Please note that the in-memory cache is just invalidated
+but not populated by Refresh Worker. In-memory cache is populated lazily during
+querying. On the other hand, pre-aggregations are eagerly populated and kept
+up-to-date by Refresh Worker.
-[Cube Docker image][dh-cubejs] can be used for creating Refresh Workers; to make
-the service act as a Refresh Worker, `CUBEJS_REFRESH_WORKER=true` should be set
-in the environment variables.
+The [Cube Docker image][dh-cubejs] can be used for creating Refresh Workers; to
+make the service act as a Refresh Worker, `CUBEJS_REFRESH_WORKER=true` should be
+set in the environment variables.
## Cube Store
@@ -275,6 +276,7 @@ guide][blog-migration-guide].
[ref-deploy-docker]: /deployment/platforms/docker
[ref-config-env]: /reference/environment-variables
[ref-config-js]: /config
+[ref-conf-ref-schemapath]: /config#options-reference-schema-path
[redis]: https://redis.io
[ref-config-redis]: /reference/environment-variables#cubejs-redis-password
[blog-details]: https://cube.dev/blog/how-you-win-by-using-cube-store-part-1
diff --git a/docs/content/Deployment/Production-Checklist.mdx b/docs/content/Deployment/Production-Checklist.mdx
index b866f0e9d1c32..4c95d8ade4bd1 100644
--- a/docs/content/Deployment/Production-Checklist.mdx
+++ b/docs/content/Deployment/Production-Checklist.mdx
@@ -97,37 +97,45 @@ deployment's health and be alerted to any issues.
## Appropriate cluster sizing
-There's no one-size-fits-all when it comes to sizing Cube cluster, and its resources.
-Resources required by Cube depend a lot on the amount of traffic Cube needs to serve and the amount of data it needs to process.
-The following sizing estimates are based on default settings and are very generic, which may not fit your Cube use case, so you should always tweak resources based on consumption patterns you see.
+There's no one-size-fits-all when it comes to sizing a Cube cluster and its
+resources. Resources required by Cube significantly depend on the amount of
+traffic Cube needs to serve and the amount of data it needs to process. The
+following sizing estimates are based on default settings and are very generic,
+which may not fit your Cube use case, so you should always tweak resources based
+on consumption patterns you see.
### <--{"id" : "Appropriate cluster sizing"}--> Memory and CPU
-Each Cube cluster should contain at least 2 Cube API instances.
-Every Cube API instance should have at least 3GB of RAM and 2 CPU cores allocated for it.
+Each Cube cluster should contain at least 2 Cube API instances. Every Cube API
+instance should have at least 3GB of RAM and 2 CPU cores allocated for it.
-Refresh workers tend to be much more CPU and memory intensive, so at least 6GB of RAM is recommended.
-Please note that to take advantage of all available RAM, the Node.js heap size should be adjusted accordingly
-by using the [`--max-old-space-size` option][node-heap-size]:
+Refresh workers tend to be much more CPU and memory intensive, so at least 6GB
+of RAM is recommended. Please note that to take advantage of all available RAM,
+the Node.js heap size should be adjusted accordingly by using the
+[`--max-old-space-size` option][node-heap-size]:
```sh
NODE_OPTIONS="--max-old-space-size=6144"
```
-[node-heap-size]: https://nodejs.org/api/cli.html#--max-old-space-sizesize-in-megabytes
+[node-heap-size]:
+ https://nodejs.org/api/cli.html#--max-old-space-sizesize-in-megabytes
-The Cube Store router node should have at least 6GB of RAM and 4 CPU cores allocated for it.
-Every Cube Store worker node should have at least 8GB of RAM and 4 CPU cores allocated for it.
-The Cube Store cluster should have at least two worker nodes.
+The Cube Store router node should have at least 6GB of RAM and 4 CPU cores
+allocated for it. Every Cube Store worker node should have at least 8GB of RAM
+and 4 CPU cores allocated for it. The Cube Store cluster should have at least
+two worker nodes.
### <--{"id" : "Appropriate cluster sizing"}--> RPS and data volume
-Depending on schema size, every Core Cube API instance can serve 1 to 10 requests per second.
-Every Core Cube Store router node can serve 50-100 queries per second.
-As a rule of thumb, you should provision 1 Cube Store worker node per one Cube Store partition or 1M of rows scanned in a query.
-For example if your queries scan 16M of rows per query, you should have at least 16 Cube Store worker nodes provisioned.
-`EXPLAIN ANALYZE` can be used to see partitions involved in a Cube Store query.
-Cube Cloud ballpark performance numbers can differ as it has different Cube runtime.
+Depending on data model size, every Core Cube API instance can serve 1 to 10
+requests per second. Every Core Cube Store router node can serve 50-100 queries
+per second. As a rule of thumb, you should provision 1 Cube Store worker node
+per one Cube Store partition or 1M of rows scanned in a query. For example if
+your queries scan 16M of rows per query, you should have at least 16 Cube Store
+worker nodes provisioned. `EXPLAIN ANALYZE` can be used to see partitions
+involved in a Cube Store query. Cube Cloud ballpark performance numbers can
+differ as it has different Cube runtime.
[blog-migrate-to-cube-cloud]:
https://cube.dev/blog/migrating-from-self-hosted-to-cube-cloud/
diff --git a/docs/content/Examples-Tutorials-Recipes/Examples.mdx b/docs/content/Examples-Tutorials-Recipes/Examples.mdx
index 8b967ea40416b..3a768105ff28f 100644
--- a/docs/content/Examples-Tutorials-Recipes/Examples.mdx
+++ b/docs/content/Examples-Tutorials-Recipes/Examples.mdx
@@ -41,13 +41,13 @@ The following tutorials cover advanced concepts of Cube:
Learn more about prominent features of Cube:
-| Feature | Story | Demo |
-| :-------------------------------------------------------------------------------------- | :------------------------------------------------------------------------------------------------------------------- | :------------------------------------------------ |
-| [Drill downs](https://cube.dev/docs/schema/fundamentals/additional-concepts#drilldowns) | [Introducing a drill down table API](https://cube.dev/blog/introducing-a-drill-down-table-api-in-cubejs/) | [Demo](https://drill-downs-demo.cube.dev) |
-| [Compare date range](https://cube.dev/docs/query-format#time-dimensions-format) | [Comparing data over different time periods](https://cube.dev/blog/comparing-data-over-different-time-periods/) | [Demo](https://compare-date-range-demo.cube.dev) |
-| [Data blending](https://cube.dev/docs/recipes/data-blending) | [Introducing data blending API](https://cube.dev/blog/introducing-data-blending-api/) | [Demo](https://data-blending-demo.cube.dev) |
-| [Real-time data fetch](https://cube.dev/docs/real-time-data-fetch) | [Real-time dashboard guide](https://real-time-dashboard.cube.dev) | [Demo](https://real-time-dashboard-demo.cube.dev) |
-| [Dynamic schema creation](https://cube.dev/docs/dynamic-schema-creation) | [Using asyncModule to generate schemas](https://github.com/cube-js/cube/tree/master/examples/async-module-simple) | — |
+| Feature | Story | Demo |
+| :-------------------------------------------------------------------------------------- | :---------------------------------------------------------------------------------------------------------------- | :------------------------------------------------ |
+| [Drill downs](https://cube.dev/docs/schema/fundamentals/additional-concepts#drilldowns) | [Introducing a drill down table API](https://cube.dev/blog/introducing-a-drill-down-table-api-in-cubejs/) | [Demo](https://drill-downs-demo.cube.dev) |
+| [Compare date range](https://cube.dev/docs/query-format#time-dimensions-format) | [Comparing data over different time periods](https://cube.dev/blog/comparing-data-over-different-time-periods/) | [Demo](https://compare-date-range-demo.cube.dev) |
+| [Data blending](https://cube.dev/docs/recipes/data-blending) | [Introducing data blending API](https://cube.dev/blog/introducing-data-blending-api/) | [Demo](https://data-blending-demo.cube.dev) |
+| [Real-time data fetch](https://cube.dev/docs/real-time-data-fetch) | [Real-time dashboard guide](https://real-time-dashboard.cube.dev) | [Demo](https://real-time-dashboard-demo.cube.dev) |
+| [Dynamic data model](https://cube.dev/docs/dynamic-schema-creation) | [Using asyncModule to generate schemas](https://github.com/cube-js/cube/tree/master/examples/async-module-simple) | — |
| [Authentication](https://cube.dev/docs/security#using-json-web-key-sets-jwks) | [Auth0 integration](https://github.com/cube-js/cube/tree/master/examples/auth0) | — |
| [Authentication](https://cube.dev/docs/security#using-json-web-key-sets-jwks) | [AWS Cognito integration](https://github.com/cube-js/cube/tree/master/examples/cognito) | — |
diff --git a/docs/content/Examples-Tutorials-Recipes/Recipes.mdx b/docs/content/Examples-Tutorials-Recipes/Recipes.mdx
index d782c90945335..f489da4423add 100644
--- a/docs/content/Examples-Tutorials-Recipes/Recipes.mdx
+++ b/docs/content/Examples-Tutorials-Recipes/Recipes.mdx
@@ -31,12 +31,12 @@ These recipes will show you the best practices of using Cube.
- [Using SSL connections to a data source](/recipes/enable-ssl-connections-to-database)
- [Joining data from multiple data sources](/recipes/joining-multiple-data-sources)
-### <--{"id" : "Recipes"}--> Data schema
+### <--{"id" : "Recipes"}--> Data modeling
- [Calculating average and percentiles](https://cube.dev/docs/recipes/percentiles)
- [Implementing data snapshots](/recipes/snapshots)
- [Implementing Entity-Attribute-Value model](/recipes/entity-attribute-value)
-- [Using different schemas for tenants](/recipes/using-different-schemas-for-tenants)
+- [Using different data models for tenants](/recipes/using-different-schemas-for-tenants)
- [Using dynamic measures](/recipes/referencing-dynamic-measures)
- [Using dynamic union tables](/recipes/dynamically-union-tables)
diff --git a/docs/content/Examples-Tutorials-Recipes/Recipes/Auth/AWS-Cognito.mdx b/docs/content/Examples-Tutorials-Recipes/Recipes/Auth/AWS-Cognito.mdx
index 2c3675e8c70a3..e6d0d729e9c6a 100644
--- a/docs/content/Examples-Tutorials-Recipes/Recipes/Auth/AWS-Cognito.mdx
+++ b/docs/content/Examples-Tutorials-Recipes/Recipes/Auth/AWS-Cognito.mdx
@@ -183,8 +183,8 @@ Save button.
/>
-Close the popup and use the Developer Playground to make a request. Any schemas
-using the [Security Context][ref-sec-ctx] should now work as expected.
+Close the popup and use the Developer Playground to make a request. Any data
+models using the [Security Context][ref-sec-ctx] should now work as expected.
[link-aws-cognito-hosted-ui]:
https://docs.aws.amazon.com/cognito/latest/developerguide/cognito-user-pools-app-integration.html#cognito-user-pools-create-an-app-integration
diff --git a/docs/content/Examples-Tutorials-Recipes/Recipes/Auth/Auth0-Guide.mdx b/docs/content/Examples-Tutorials-Recipes/Recipes/Auth/Auth0-Guide.mdx
index 5d13f3c3a12bd..7e1223d2ac259 100644
--- a/docs/content/Examples-Tutorials-Recipes/Recipes/Auth/Auth0-Guide.mdx
+++ b/docs/content/Examples-Tutorials-Recipes/Recipes/Auth/Auth0-Guide.mdx
@@ -222,8 +222,8 @@ button.
/>
-Close the popup and use the Developer Playground to make a request. Any schemas
-using the [Security Context][ref-sec-ctx] should now work as expected.
+Close the popup and use the Developer Playground to make a request. Any data
+models using the [Security Context][ref-sec-ctx] should now work as expected.
## Example
diff --git a/docs/content/Examples-Tutorials-Recipes/Recipes/active-users.mdx b/docs/content/Examples-Tutorials-Recipes/Recipes/active-users.mdx
index 08feac532539d..e84977e6977f3 100644
--- a/docs/content/Examples-Tutorials-Recipes/Recipes/active-users.mdx
+++ b/docs/content/Examples-Tutorials-Recipes/Recipes/active-users.mdx
@@ -13,7 +13,7 @@ redirect_from:
We want to know the customer engagement of our store. To do this, we need to use
an [Active Users metric](https://en.wikipedia.org/wiki/Active_users).
-## Data schema
+## Data modeling
Daily, weekly, and monthly active users are commonly referred to as DAU, WAU,
MAU. To get these metrics, we need to use a rolling time frame to calculate a
diff --git a/docs/content/Examples-Tutorials-Recipes/Recipes/column-based-access.mdx b/docs/content/Examples-Tutorials-Recipes/Recipes/column-based-access.mdx
index f3007302c6ed4..e830614deb7df 100644
--- a/docs/content/Examples-Tutorials-Recipes/Recipes/column-based-access.mdx
+++ b/docs/content/Examples-Tutorials-Recipes/Recipes/column-based-access.mdx
@@ -12,7 +12,7 @@ We want to manage user access to different data depending on a database
relationship. In the recipe below, we will manage supplier access to their
products. A supplier can't see other supplier's products.
-## Data schema
+## Data modeling
To implement column-based access, we will use supplier's email from a
[JSON Web Token](https://cube.dev/docs/security), and the
diff --git a/docs/content/Examples-Tutorials-Recipes/Recipes/controlling-access-to-cubes-and-views.mdx b/docs/content/Examples-Tutorials-Recipes/Recipes/controlling-access-to-cubes-and-views.mdx
index 127f39645c6b7..3c62bbec915b8 100644
--- a/docs/content/Examples-Tutorials-Recipes/Recipes/controlling-access-to-cubes-and-views.mdx
+++ b/docs/content/Examples-Tutorials-Recipes/Recipes/controlling-access-to-cubes-and-views.mdx
@@ -28,7 +28,7 @@ module.exports = {
};
```
-## Data schema
+## Data modeling
```javascript
// Orders.js
diff --git a/docs/content/Examples-Tutorials-Recipes/Recipes/dynamic-union-tables.mdx b/docs/content/Examples-Tutorials-Recipes/Recipes/dynamic-union-tables.mdx
index 8117619128dae..effec32eb3029 100644
--- a/docs/content/Examples-Tutorials-Recipes/Recipes/dynamic-union-tables.mdx
+++ b/docs/content/Examples-Tutorials-Recipes/Recipes/dynamic-union-tables.mdx
@@ -2,7 +2,7 @@
title: Using Dynamic Union Tables
permalink: /recipes/dynamically-union-tables
category: Examples & Tutorials
-subCategory: Data schema
+subCategory: Data modeling
menuOrder: 4
redirect_from:
- /dynamically-union-tables
diff --git a/docs/content/Examples-Tutorials-Recipes/Recipes/entity-attribute-value.mdx b/docs/content/Examples-Tutorials-Recipes/Recipes/entity-attribute-value.mdx
index 364d5b7413e88..08b9fe0e34984 100644
--- a/docs/content/Examples-Tutorials-Recipes/Recipes/entity-attribute-value.mdx
+++ b/docs/content/Examples-Tutorials-Recipes/Recipes/entity-attribute-value.mdx
@@ -2,7 +2,7 @@
title: Implementing Entity-Attribute-Value Model (EAV)
permalink: /recipes/entity-attribute-value
category: Examples & Tutorials
-subCategory: Data schema
+subCategory: Data modeling
menuOrder: 4
---
@@ -16,7 +16,7 @@ same set of associated attributes, thus making the entity-attribute-value
relation a sparse matrix. In the cube, we'd like every attribute to be modeled
as a dimension.
-## Data schema
+## Data modeling
Let's explore the `Users` cube that contains the entities:
@@ -95,7 +95,7 @@ their orders in any of these statuses. In terms of the EAV model:
Let's explore some possible ways to model that.
-### <--{"id" : "Data schema"}--> Static attributes
+### <--{"id" : "Data modeling"}--> Static attributes
We already know that the following statuses are present in the dataset:
`completed`, `processing`, and `shipped`. Let's assume this set of statuses is
@@ -179,7 +179,7 @@ The drawback is that when the set of statuses changes, we'll need to amend the
cube definition in several places: update selected values and joins in SQL as
well as update the dimensions. Let's see how to work around that.
-### <--{"id" : "Data schema"}--> Static attributes, DRY version
+### <--{"id" : "Data modeling"}--> Static attributes, DRY version
We can embrace the
[Don't Repeat Yourself](https://en.wikipedia.org/wiki/Don%27t_repeat_yourself)
@@ -240,7 +240,7 @@ The new `UsersStatuses_DRY` cube is functionally identical to the
data. However, there's still a static list of statuses present in the cube's
source code. Let's work around that next.
-### <--{"id" : "Data schema"}--> Dynamic attributes
+### <--{"id" : "Data modeling"}--> Dynamic attributes
We can eliminate the list of statuses from the cube's code by loading this list
from an external source, e.g., the data source. Here's the code from the
@@ -276,7 +276,7 @@ exports.fetchStatuses = async () => {
In the cube file, we will use the `fetchStatuses` function to load the list of
statuses. We will also wrap the cube definition with the `asyncModule` built-in
-function that allows the data schema to be created
+function that allows the data model to be created
[dynamically](https://cube.dev/docs/schema/advanced/dynamic-schema-creation).
```javascript
diff --git a/docs/content/Examples-Tutorials-Recipes/Recipes/event-analytics.mdx b/docs/content/Examples-Tutorials-Recipes/Recipes/event-analytics.mdx
index 7e06ef77b93a7..c3a69d9f692e1 100644
--- a/docs/content/Examples-Tutorials-Recipes/Recipes/event-analytics.mdx
+++ b/docs/content/Examples-Tutorials-Recipes/Recipes/event-analytics.mdx
@@ -22,11 +22,11 @@ This tutorial walks through how to transform raw event data into sessions. Many
they work as a “black box.” It doesn’t give the user either insight into or
control how these sessions defined and work.
-With Cube SQL-based sessions schema, you’ll have full control over how these
+With Cube SQL-based sessions data model, you’ll have full control over how these
metrics are defined. It will give you great flexibility when designing sessions
and events to your unique business use case.
-A few question we’ll answer with our sessions schema:
+A few question we’ll answer with our sessions data model:
- How do we measure session duration?
- What is our bounce rate?
@@ -430,7 +430,7 @@ cube('Sessions', {
});
```
-That was our final step in building a foundation for sessions schema.
+That was our final step in building a foundation for a sessions data model.
Congratulations on making it here! Now we’re ready to add some advanced metrics
on top of it.
diff --git a/docs/content/Examples-Tutorials-Recipes/Recipes/getting-unique-values-for-a-field.mdx b/docs/content/Examples-Tutorials-Recipes/Recipes/getting-unique-values-for-a-field.mdx
index 17ae7c325ab51..2bbd181fb0589 100644
--- a/docs/content/Examples-Tutorials-Recipes/Recipes/getting-unique-values-for-a-field.mdx
+++ b/docs/content/Examples-Tutorials-Recipes/Recipes/getting-unique-values-for-a-field.mdx
@@ -13,7 +13,7 @@ them by city. To do so, we need to display all unique values for cities in the
dropdown. In the recipe below, we'll learn how to get unique values for
[dimensions](https://cube.dev/docs/schema/reference/dimensions).
-## Data schema
+## Data modeling
To filter users by city, we need to define the appropriate dimension:
diff --git a/docs/content/Examples-Tutorials-Recipes/Recipes/incrementally-building-pre-aggregations-for-a-date-range.mdx b/docs/content/Examples-Tutorials-Recipes/Recipes/incrementally-building-pre-aggregations-for-a-date-range.mdx
index b260616ea6e58..16dc70f3afe42 100644
--- a/docs/content/Examples-Tutorials-Recipes/Recipes/incrementally-building-pre-aggregations-for-a-date-range.mdx
+++ b/docs/content/Examples-Tutorials-Recipes/Recipes/incrementally-building-pre-aggregations-for-a-date-range.mdx
@@ -19,7 +19,7 @@ This is most beneficial when using data warehouses with partitioning support
(such as [AWS Athena][self-config-aws-athena] and [Google
BigQuery][self-config-google-bigquery]).
-## Data schema
+## Data modeling
Let's use an example of a cube with a nested SQL query:
diff --git a/docs/content/Examples-Tutorials-Recipes/Recipes/joining-multiple-data-sources.mdx b/docs/content/Examples-Tutorials-Recipes/Recipes/joining-multiple-data-sources.mdx
index b08e5da981a5a..f6d7f277ae64f 100644
--- a/docs/content/Examples-Tutorials-Recipes/Recipes/joining-multiple-data-sources.mdx
+++ b/docs/content/Examples-Tutorials-Recipes/Recipes/joining-multiple-data-sources.mdx
@@ -49,7 +49,7 @@ module.exports = {
};
```
-## Data schema
+## Data modeling
First, we'll define
[rollup](https://cube.dev/docs/schema/reference/pre-aggregations#parameters-type-rollup)
diff --git a/docs/content/Examples-Tutorials-Recipes/Recipes/multiple-sources-same-schema.mdx b/docs/content/Examples-Tutorials-Recipes/Recipes/multiple-sources-same-schema.mdx
index 1c1830921d0b7..adbe0f43defa9 100644
--- a/docs/content/Examples-Tutorials-Recipes/Recipes/multiple-sources-same-schema.mdx
+++ b/docs/content/Examples-Tutorials-Recipes/Recipes/multiple-sources-same-schema.mdx
@@ -10,14 +10,14 @@ menuOrder: 3
We need to access the data from different data sources for different tenants.
For example, we are the platform for the online website builder, and each client
-can only view their data. The same data schema is used for all clients.
+can only view their data. The same data model is used for all clients.
## Configuration
Each client has its own database. In this recipe, the `Mango Inc` tenant keeps
its data in the remote `ecom` database while the `Avocado Inc` tenant works with
the local database (bootstrapped in the `docker-compose.yml` file) which has the
-same schema.
+same data model.
To enable multitenancy, use the
[`contextToAppId`](https://cube.dev/docs/config#options-reference-context-to-app-id)
@@ -69,8 +69,8 @@ module.exports = {
## Query
To get users for different tenants, we will send two identical requests with
-different JWTs. Also we send a query with unknown tenant to show that he cannot
-access to the data schema of other tenants.
+different JWTs. Also, we send a query with unknown tenant to show that he cannot
+access to the data model of other tenants.
```javascript
// JWT payload for "Avocado Inc"
diff --git a/docs/content/Examples-Tutorials-Recipes/Recipes/non-additivity.mdx b/docs/content/Examples-Tutorials-Recipes/Recipes/non-additivity.mdx
index 9322ca718f6a8..87bf2e895096b 100644
--- a/docs/content/Examples-Tutorials-Recipes/Recipes/non-additivity.mdx
+++ b/docs/content/Examples-Tutorials-Recipes/Recipes/non-additivity.mdx
@@ -20,7 +20,7 @@ Pre-aggregations with such measures are less likely to be
[selected](https://cube.dev/docs/caching/pre-aggregations/getting-started#ensuring-pre-aggregations-are-targeted-by-queries-selecting-the-pre-aggregation)
to accelerate a query. However, there are a few ways to work around that.
-## Data schema
+## Data modeling
Let's explore the `Users` cube that contains various measures describing users'
age:
@@ -94,7 +94,7 @@ accelerated:
Let's explore some possible workarounds.
-### <--{"id" : "Data schema"}--> Replacing with approximate additive measures
+### <--{"id" : "Data modeling"}--> Replacing with approximate additive measures
Often, non-additive `countDistinct` measures can be changed to have the
[`countDistinctApprox` type](https://cube.dev/docs/schema/reference/types-and-formats#measures-types-count-distinct-approx)
@@ -117,7 +117,7 @@ For example, the `distinctAges` measure can be rewritten as follows:
},
```
-### <--{"id" : "Data schema"}--> Decomposing into a formula with additive measures
+### <--{"id" : "Data modeling"}--> Decomposing into a formula with additive measures
Non-additive `avg` measures can be rewritten as
[calculated measures](https://cube.dev/docs/schema/reference/measures#calculated-measures)
@@ -142,7 +142,7 @@ For example, the `avgAge` measure can be rewritten as follows:
},
```
-### <--{"id" : "Data schema"}--> Providing multiple pre-aggregations
+### <--{"id" : "Data modeling"}--> Providing multiple pre-aggregations
If the two workarounds described above don't apply to your use case, feel free
to create additional pre-aggregations with definitions that fully match your
diff --git a/docs/content/Examples-Tutorials-Recipes/Recipes/pagination.mdx b/docs/content/Examples-Tutorials-Recipes/Recipes/pagination.mdx
index b1fc7c7ca942e..3a68f2bb1651d 100644
--- a/docs/content/Examples-Tutorials-Recipes/Recipes/pagination.mdx
+++ b/docs/content/Examples-Tutorials-Recipes/Recipes/pagination.mdx
@@ -13,9 +13,9 @@ easier to digest and to improve the performance of the query, we'll use
pagination. With the recipe below, we'll get the orders list sorted by the order
number. Every page will have 5 orders.
-## Data schema
+## Data modeling
-We have the following data schema.
+We have the following data model:
```javascript
cube(`Orders`, {
diff --git a/docs/content/Examples-Tutorials-Recipes/Recipes/passing-dynamic-parameters-in-a-query.mdx b/docs/content/Examples-Tutorials-Recipes/Recipes/passing-dynamic-parameters-in-a-query.mdx
index e65e5523c7a44..6005bf1712640 100644
--- a/docs/content/Examples-Tutorials-Recipes/Recipes/passing-dynamic-parameters-in-a-query.mdx
+++ b/docs/content/Examples-Tutorials-Recipes/Recipes/passing-dynamic-parameters-in-a-query.mdx
@@ -2,7 +2,7 @@
title: Passing Dynamic Parameters in a Query
permalink: /recipes/passing-dynamic-parameters-in-a-query
category: Examples & Tutorials
-subCategory: Data schema
+subCategory: Data modeling
menuOrder: 4
---
@@ -14,7 +14,7 @@ filter. The trick is to get the value of the city from the user and use it in
the calculation. In the recipe below, we can learn how to join the data table
with itself and reshape the dataset!
-## Data schema
+## Data modeling
Let's explore the `Users` cube data that contains various information about
users, including city and gender:
diff --git a/docs/content/Examples-Tutorials-Recipes/Recipes/percentiles.mdx b/docs/content/Examples-Tutorials-Recipes/Recipes/percentiles.mdx
index 6a6878e5f02da..53d9ecc822224 100644
--- a/docs/content/Examples-Tutorials-Recipes/Recipes/percentiles.mdx
+++ b/docs/content/Examples-Tutorials-Recipes/Recipes/percentiles.mdx
@@ -2,7 +2,7 @@
title: Calculating Average and Percentiles
permalink: /recipes/percentiles
category: Examples & Tutorials
-subCategory: Data schema
+subCategory: Data modeling
menuOrder: 4
---
@@ -24,7 +24,7 @@ as the 50th percentile (`n = 0.5`), and it can be casually thought of as "the
middle" value. 2.5 and 0 are the medians of `(1, 2, 3, 4)` and `(0, 0, 0, 10)`,
respectively.
-## Data schema
+## Data modeling
Let's explore the data in the `Users` cube that contains various demographic
information about users, including their age:
diff --git a/docs/content/Examples-Tutorials-Recipes/Recipes/schema-generation.mdx b/docs/content/Examples-Tutorials-Recipes/Recipes/schema-generation.mdx
index a791f579d3b6f..e5dd32af6ed32 100644
--- a/docs/content/Examples-Tutorials-Recipes/Recipes/schema-generation.mdx
+++ b/docs/content/Examples-Tutorials-Recipes/Recipes/schema-generation.mdx
@@ -8,9 +8,10 @@ redirect_from:
- /schema-generation
---
-Cube Schema is Javascript code, which means the full power of this language can
-be used to configure your schema definitions. In this guide we generate several
-measure definitions based on an array of strings.
+Cube supports two ways to define data model files: with YAML or JavaScript
+syntax. If you opt for JavaScript syntax, you can use the full power of this
+programming language to configure your data model. In this guide we generate
+several measure definitions based on an array of strings.
One example, based on a real world scenario, is when you have a single `events`
table containing an `event_type` and `user_id` column. Based on this table you
@@ -59,5 +60,5 @@ code. This configuration can be reused using
Please refer to
[asyncModule](/schema/reference/execution-environment#async-module)
-documentation to learn how to use databases and other data sources for schema
-generation.
+documentation to learn how to use databases and other data sources for data
+model generation.
diff --git a/docs/content/Examples-Tutorials-Recipes/Recipes/snapshots.mdx b/docs/content/Examples-Tutorials-Recipes/Recipes/snapshots.mdx
index 5967aa1d1ac33..26aa7c308e5d9 100644
--- a/docs/content/Examples-Tutorials-Recipes/Recipes/snapshots.mdx
+++ b/docs/content/Examples-Tutorials-Recipes/Recipes/snapshots.mdx
@@ -2,7 +2,7 @@
title: Implementing Data Snapshots
permalink: /recipes/snapshots
category: Examples & Tutorials
-subCategory: Data schema
+subCategory: Data modeling
menuOrder: 4
---
@@ -17,12 +17,12 @@ date for a cube with `Product Id`, `Status`, and `Changed At` dimensions.
We can consider the status property to be a
[slowly changing dimension](https://en.wikipedia.org/wiki/Slowly_changing_dimension)
-(SCD) of type 2. Modeling data schemas with slowly changing dimensions is an
+(SCD) of type 2. Modeling data with slowly changing dimensions is an
essential part of the data engineering skillset.