Figure 3. list of KV cache blocks
@@ -238,7 +238,7 @@ Forward-pass step itself has two execution modes:
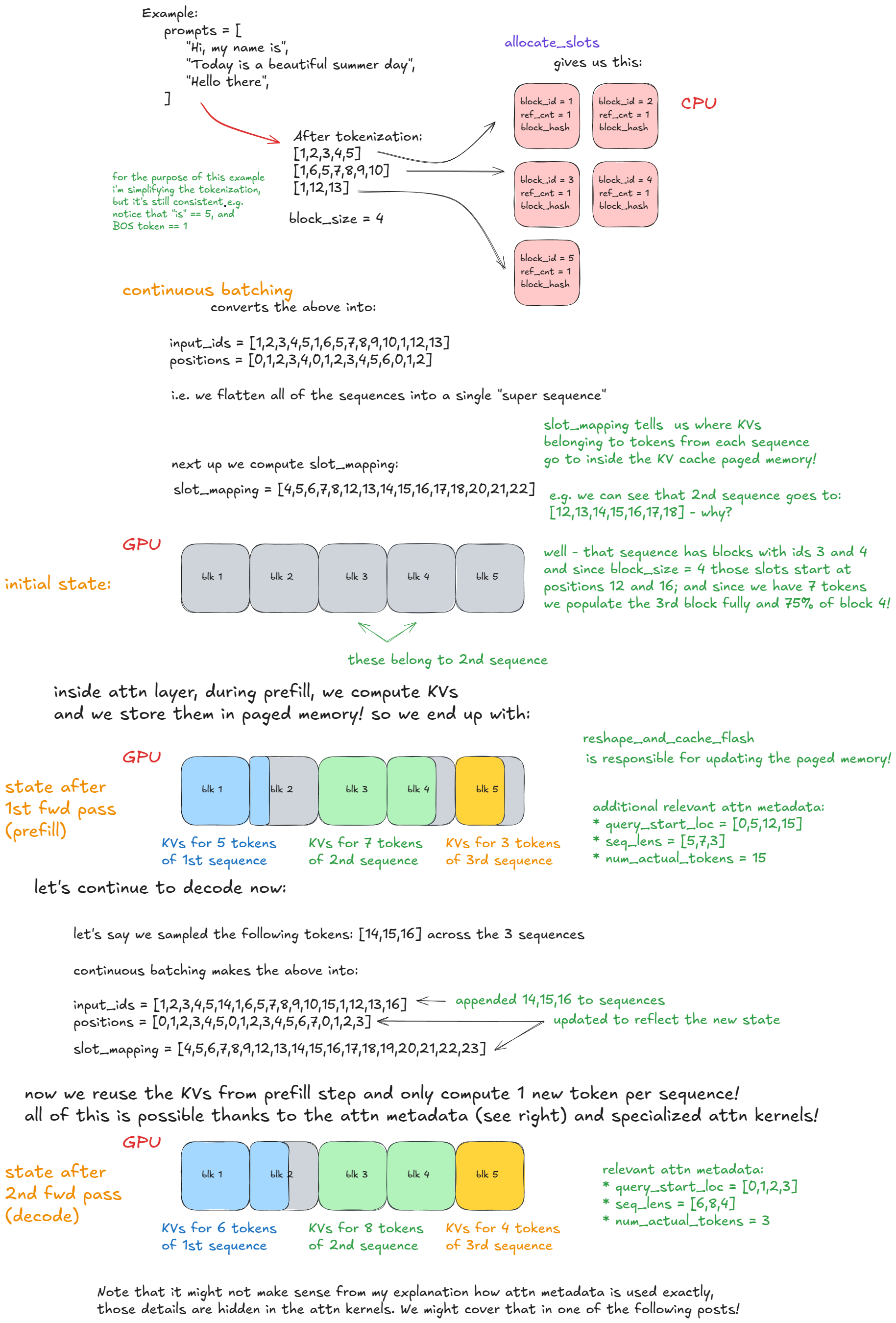
Here is a concrete example that should make continuous batching and paged attention clear:
-
+
Figure 4. Forward pass: continuous batching and paged attention
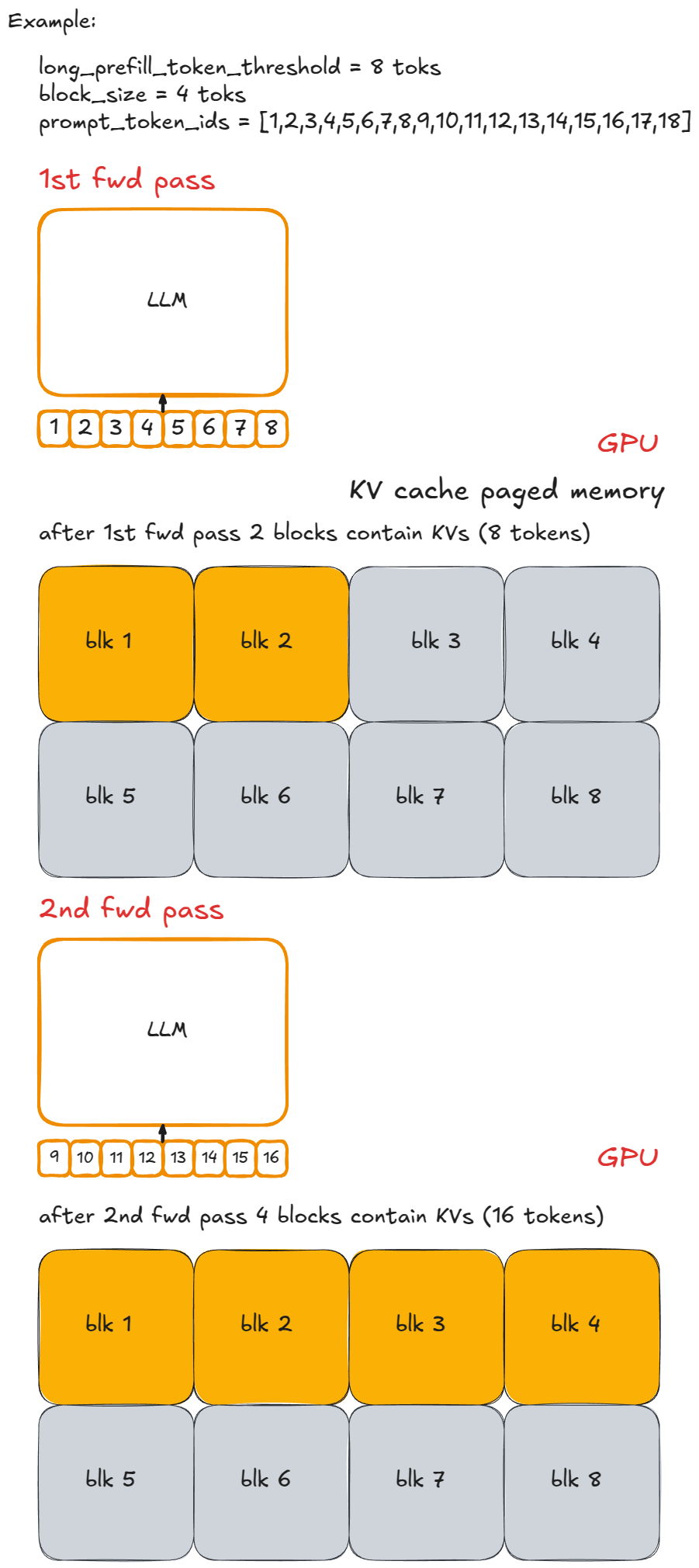
@@ -266,7 +266,7 @@ For example, let each chunk contain `n` (=8) tokens, labeled with lowercase lett
Here is that same example visually:
-
+
Implementation is straightforward: cap the number of new tokens per step. If the requested number exceeds `long_prefill_token_threshold`, reset it to exactly that value. The underlying indexing logic (described earlier) takes care of the rest.
@@ -327,7 +327,7 @@ The list is stored in `self.req_to_block_hashes[request_id]`.
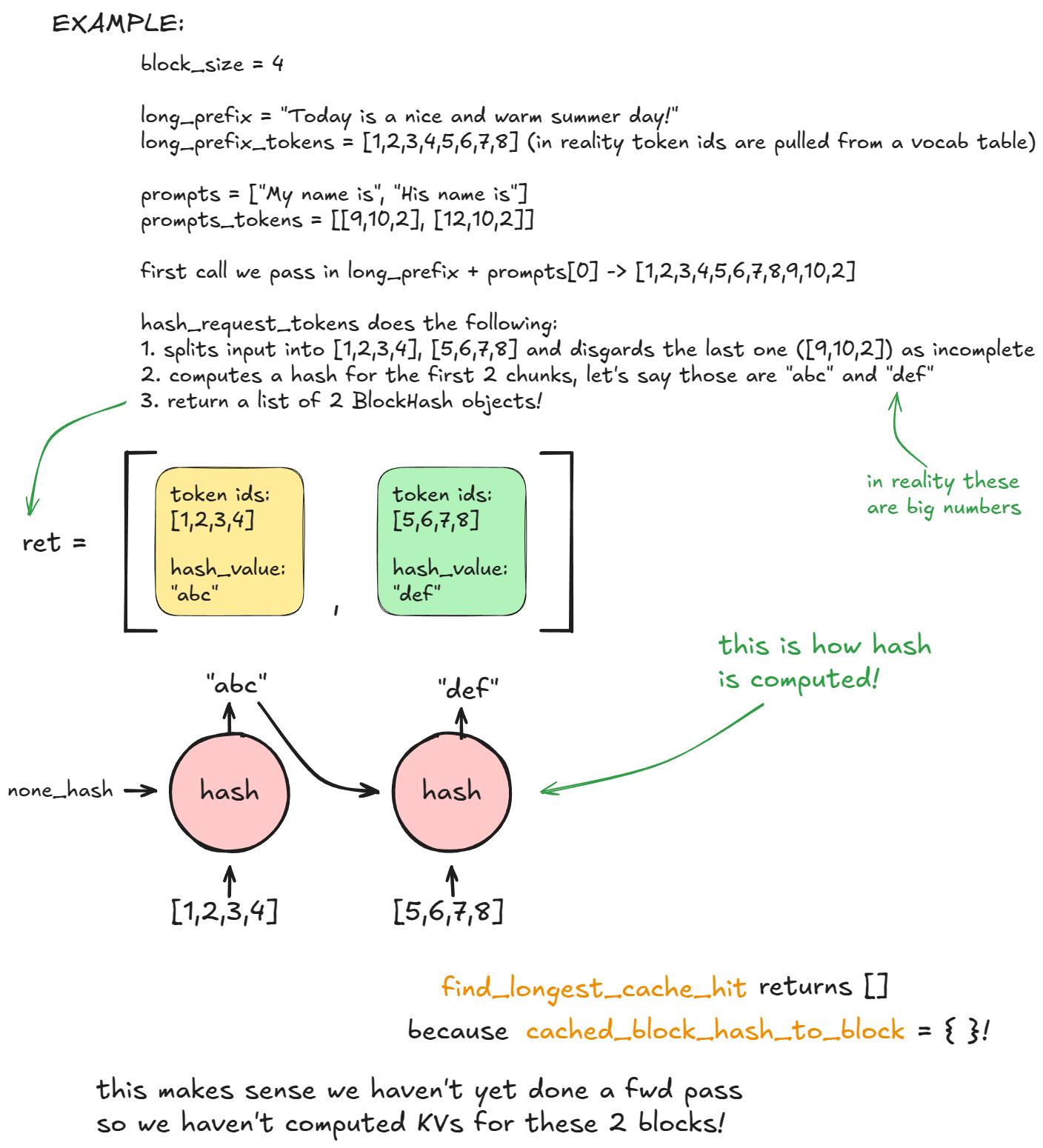
Next, the engine calls `find_longest_cache_hit` to check if any of these hashes already exist in `cached_block_hash_to_block`. On the first request, no hits are found.
-
+
Then we call `allocate_slots` which calls `coordinator.cache_blocks`, which associates the new `BlockHash` entries with allocated KV blocks and records them in `cached_block_hash_to_block`.
@@ -337,13 +337,13 @@ Afterwards, the forward pass will populate KVs in paged KV cache memory correspo
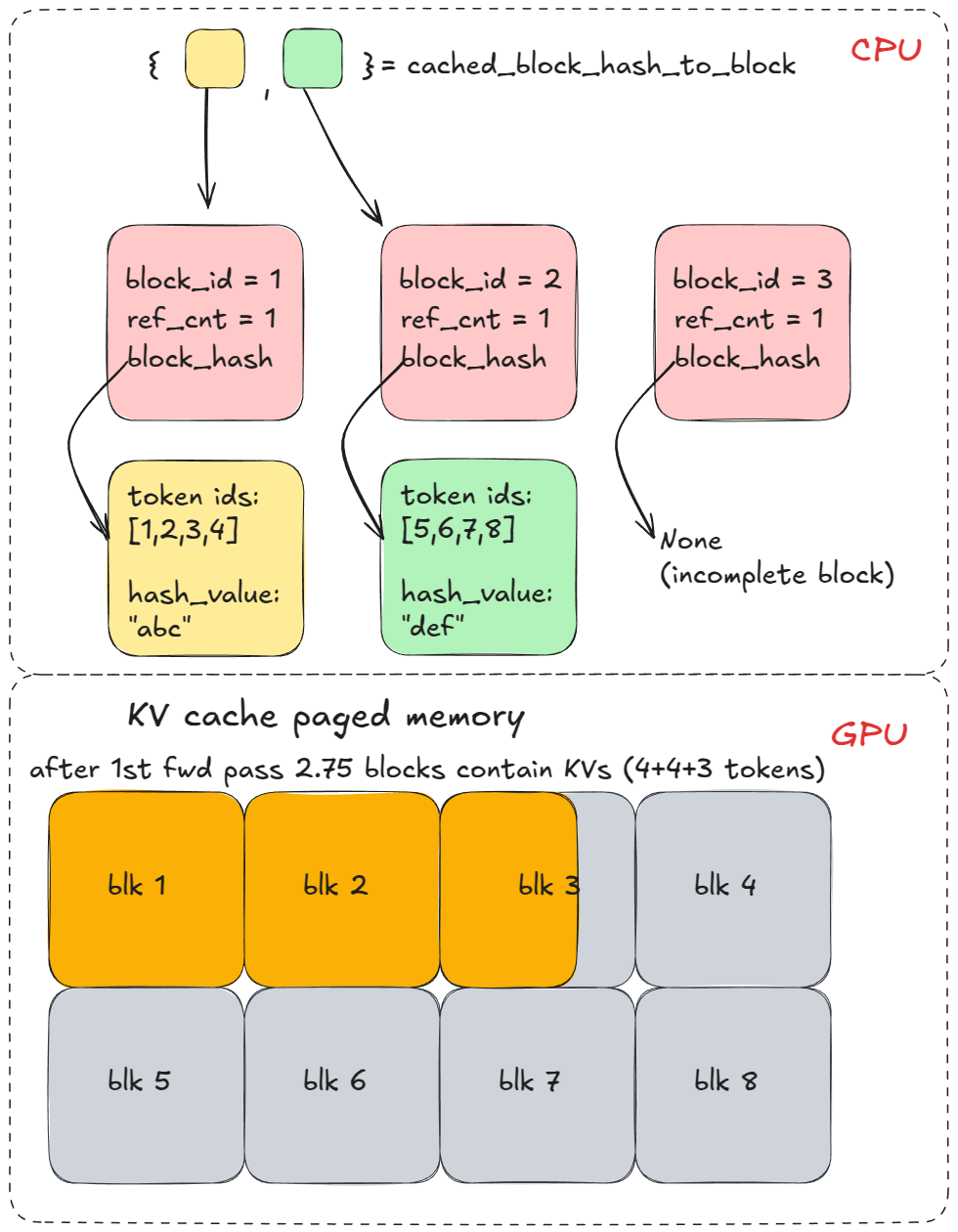
After many engine steps it'll allocate more KV cache blocks but it doesn't matter for our example because the prefix has diverged immediately after `long_prefix`.
-
+
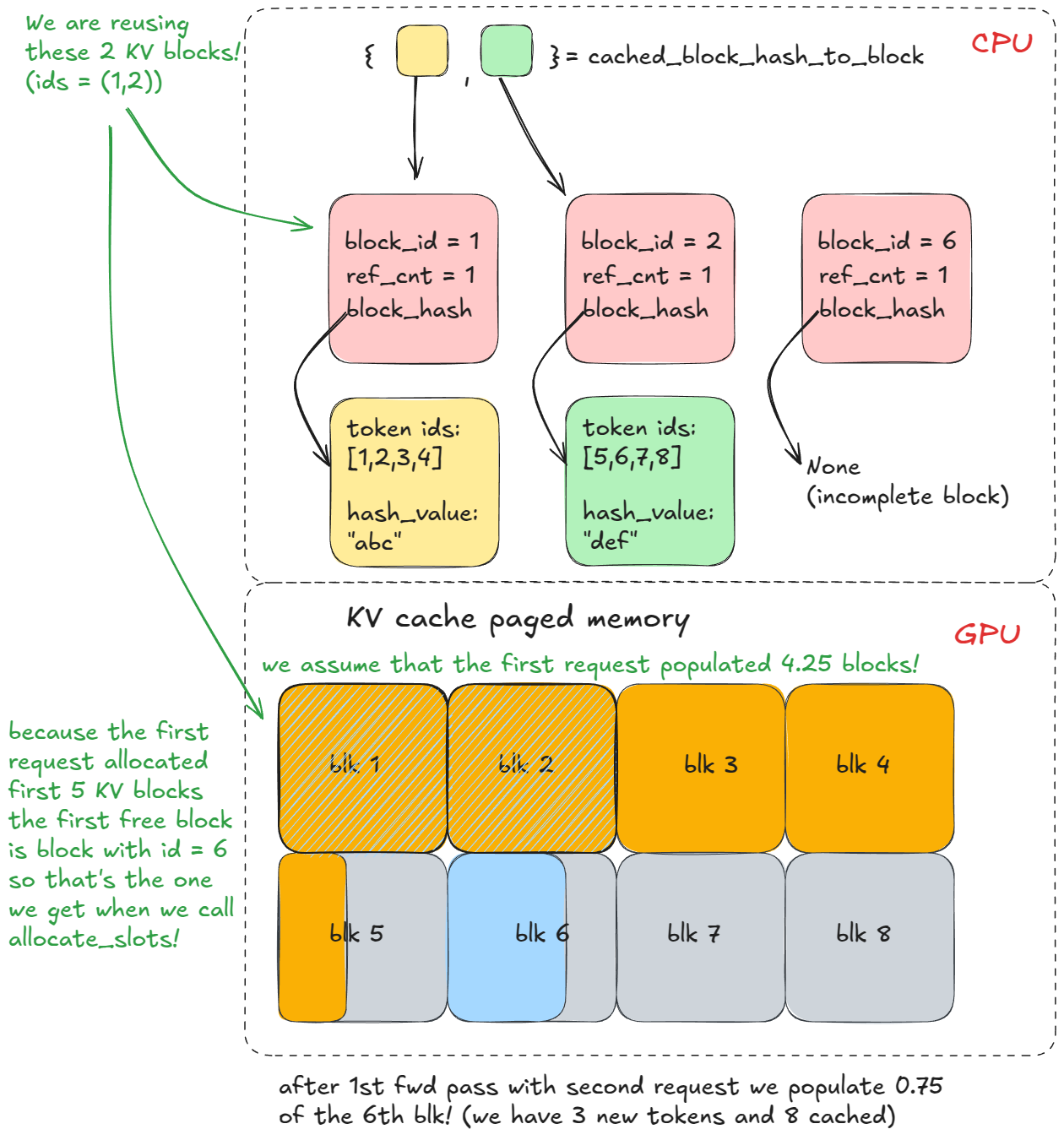
On a second `generate` call with the same prefix, steps 1-3 repeat, but now `find_longest_cache_hit` finds matches for all `n` blocks (via linear search). The engine can reuse those KV blocks directly.
-
+
-If the original request were still alive, the reference count for those blocks would increment (e.g. to 2). In this example, the first request has already completed, so the blocks were freed back to the pool and their reference counts set back to 0. Because we were able to retrieve them from `cached_block_hash_to_block` we know they're valid (the logic of the KV cache manager is setup in such a way), so we just remove them from `free_block_queue` again.
+If the original request were still alive, the reference count for those blocks would increment (e.g. to 2). In this example, the first request has already completed, so the blocks were freed back to the pool and their reference counts set back to 0. Because we were able to retrieve them from `cached_block_hash_to_block` we know they're valid (the logic of the KV cache manager is to set up in such a way), so we just remove them from `free_block_queue` again.
!!! note "Advanced note:"
@@ -388,7 +388,7 @@ if __name__ == "__main__":
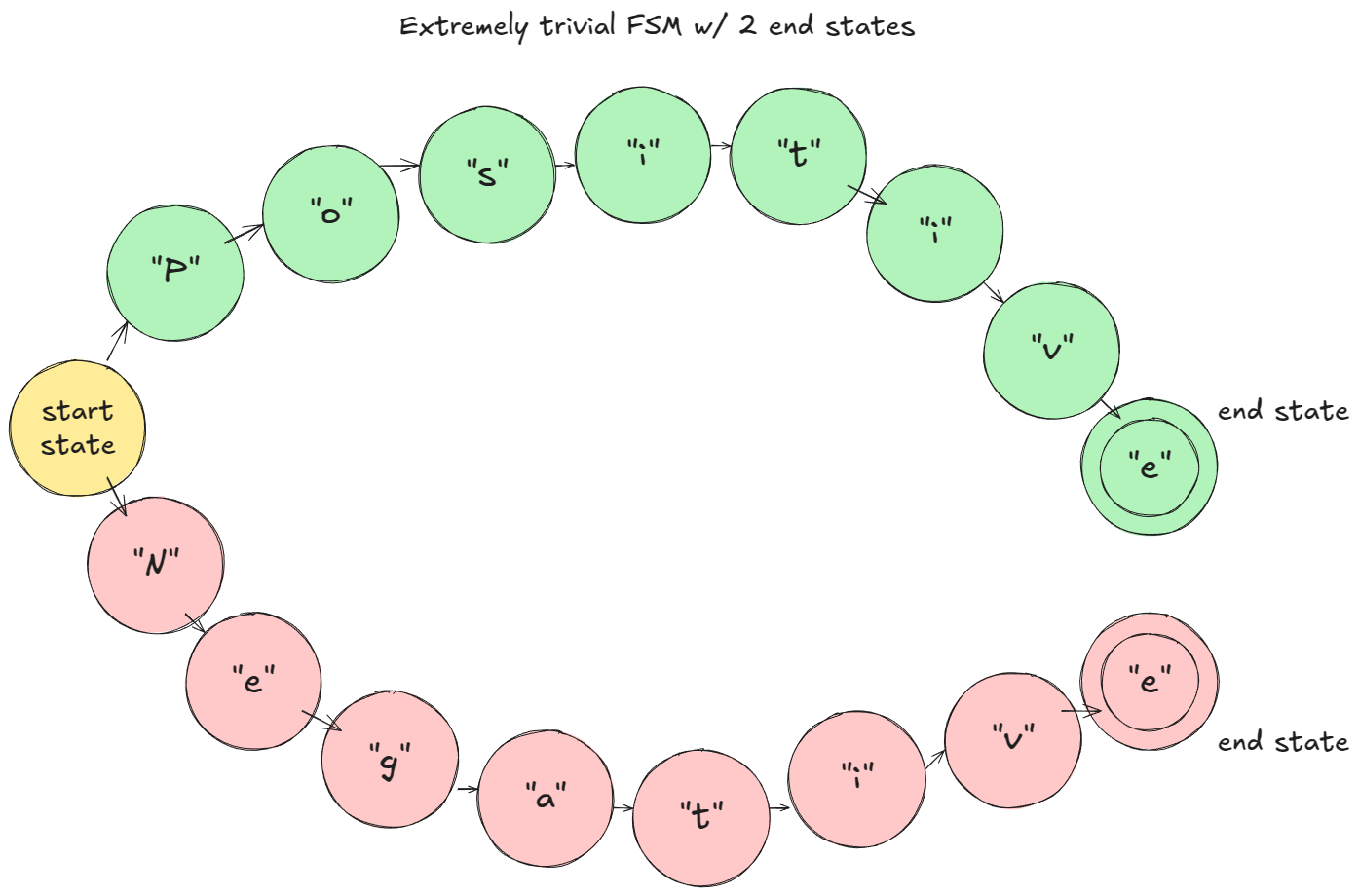
In the toy example I gave (assume character-level tokenization): at prefill, the FSM masks logits so only "P" or "N" are viable. If "P" is sampled, the FSM moves to the "Positive" branch; next step only "o" is allowed, and so on.
-
+
Figure 5. Toy example FSM
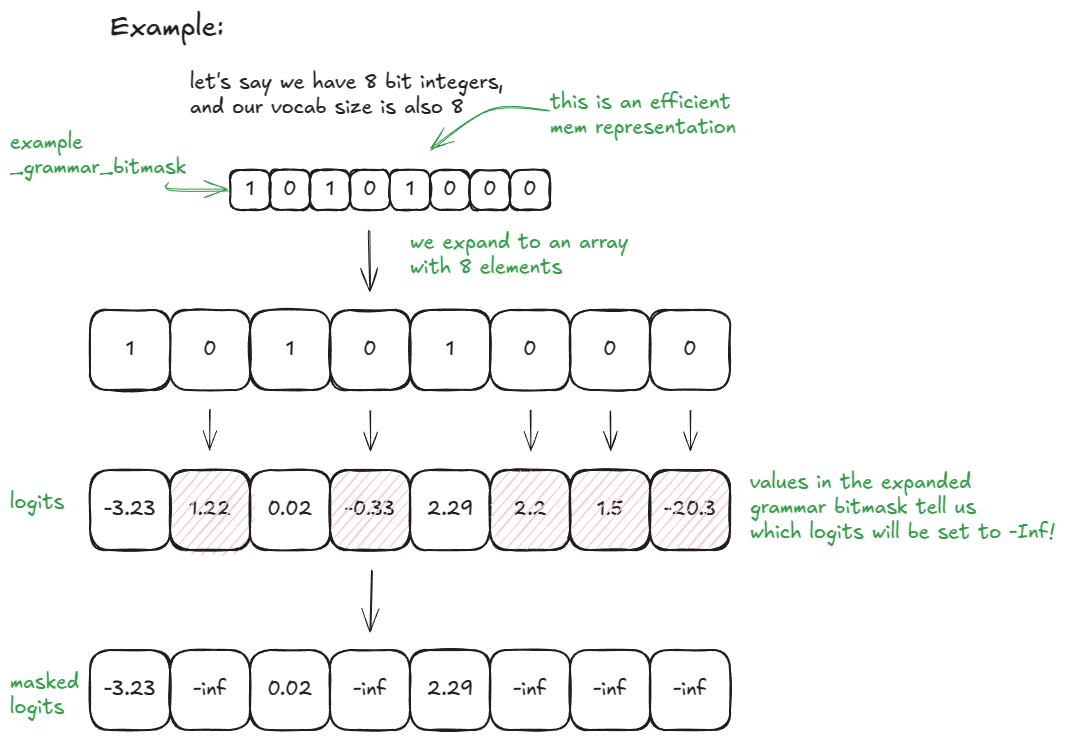
@@ -414,7 +414,7 @@ If `vocab_size = 32`, `_grammar_bitmask` is a single integer; its binary represe
Here is an even simpler example with vocab_size = 8 and 8-bit integers (for those of you who like my visuals):
-
+
Figure 6. Toy example
@@ -510,9 +510,9 @@ How does this work in vLLM?
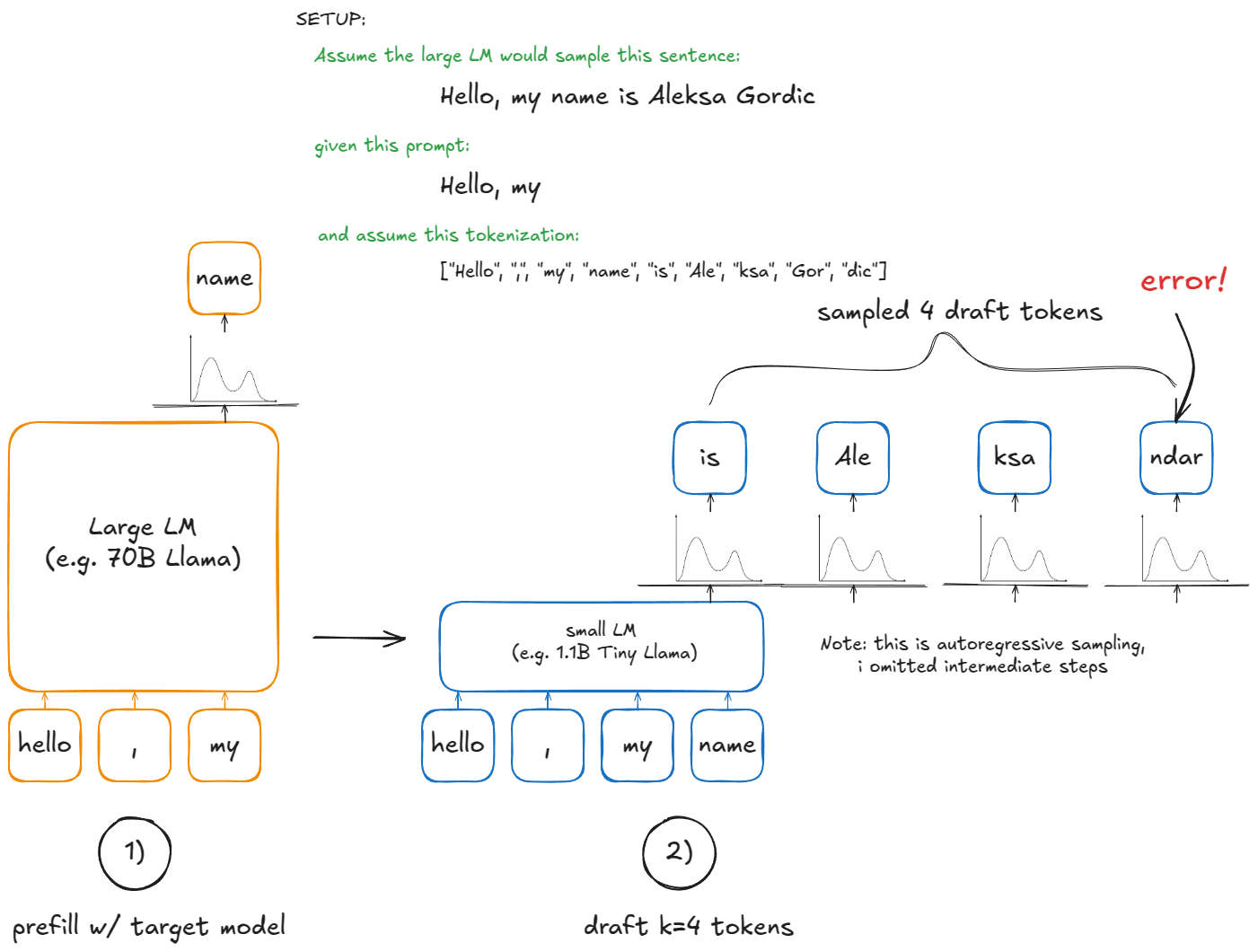
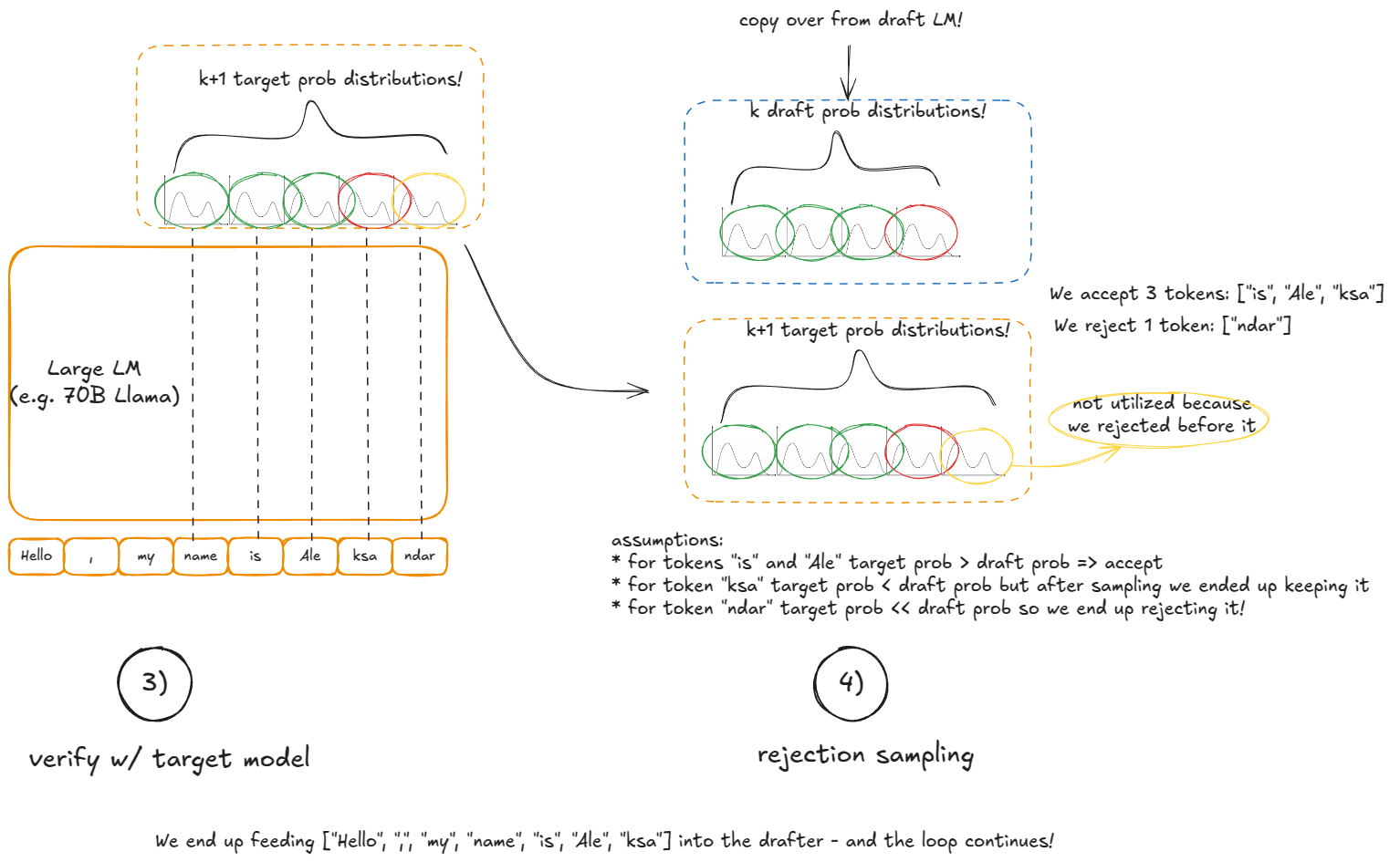
The best way to internalize this is to fire up your debugger and step through the codebase, but this section hopefully gives you a taste for it. This as well:
-
+
-
+
### Disaggregated P/D
@@ -627,7 +627,7 @@ These are the steps in vLLM:
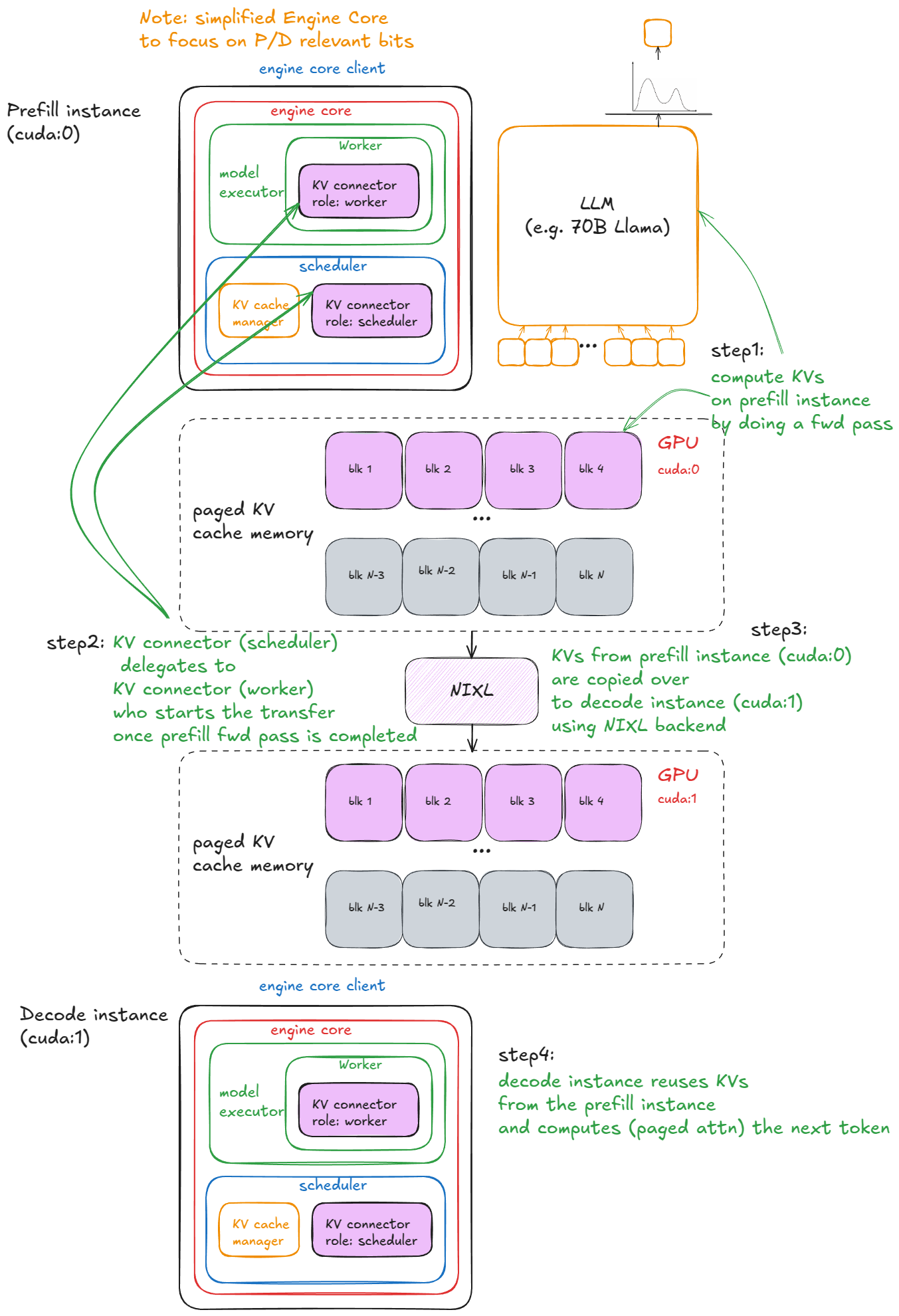
Here is a visual example:
-
+
Figure 7. disaggregated P/D
@@ -654,7 +654,7 @@ The first option is to shard the model across multiple GPUs on the same node usi
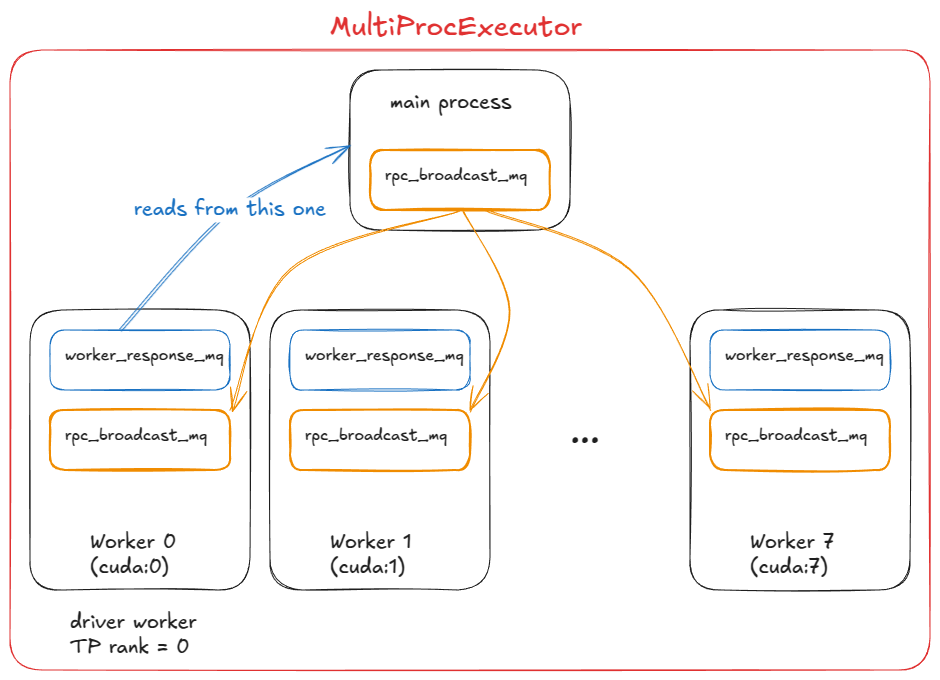
At this stage, we need multiple GPU processes (workers) and an orchestration layer to coordinate them. That's exactly what `MultiProcExecutor` provides.
-
+
Figure 8. MultiProcExecutor in a TP=8 setting (driver worker being rank 0)
@@ -690,7 +690,7 @@ There are many ways to set up serving infrastructure, but to stay concrete, here
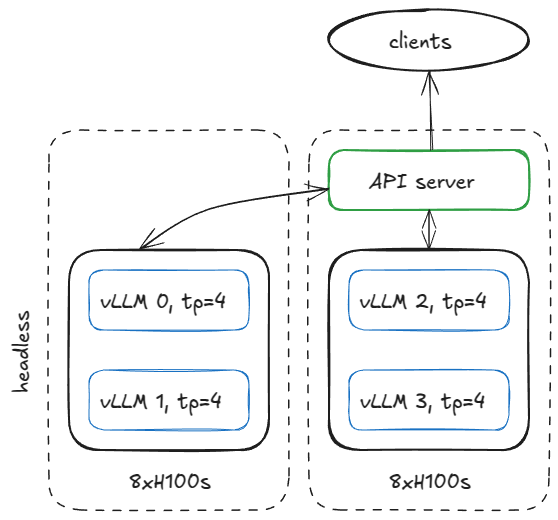
If the model requires `TP=4`, we can configure the nodes like this.
-
+
Figure 9. server configuration with 2 8xH100 nodes (1 headless, 1 api server)
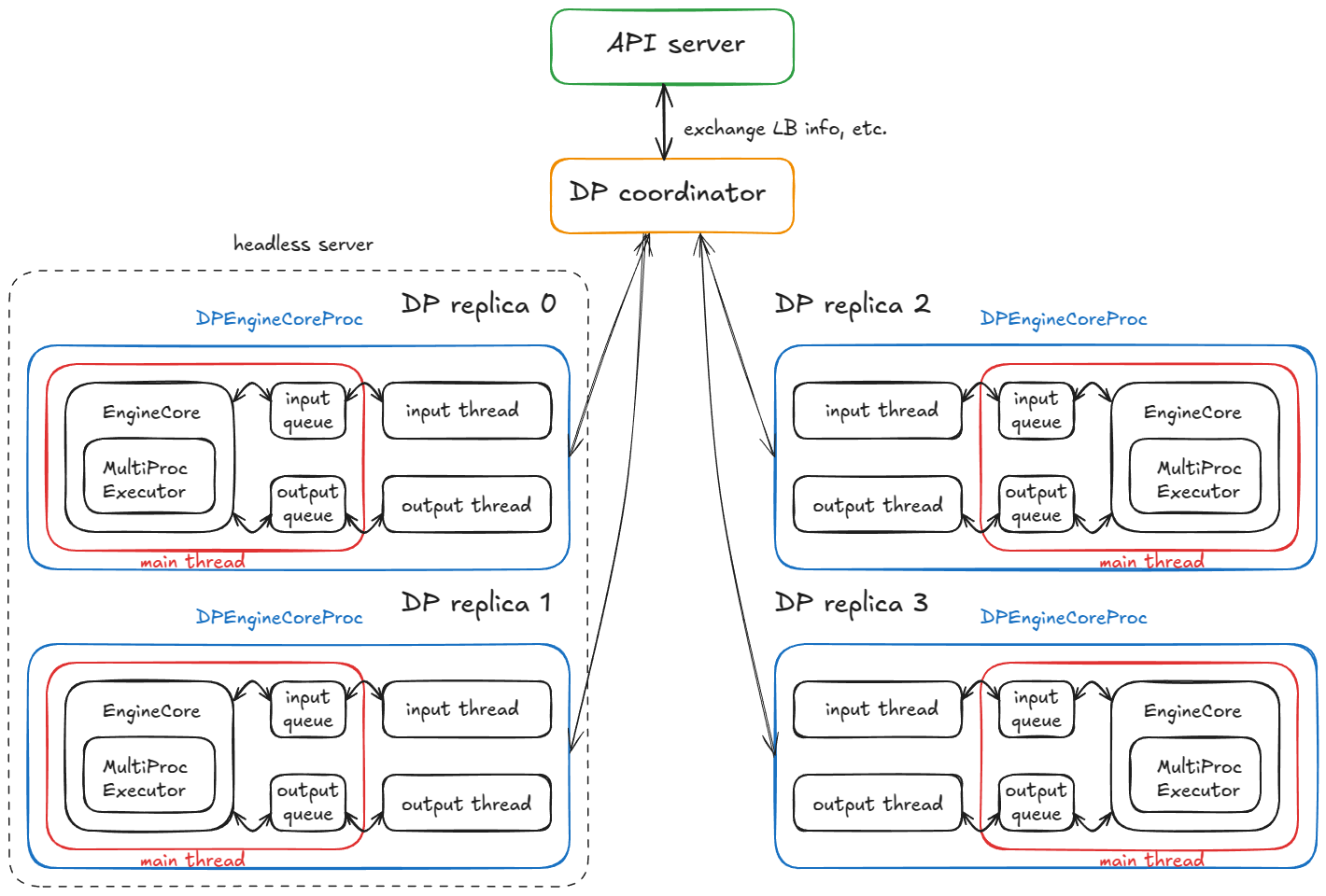
@@ -748,7 +748,7 @@ On the headless node, a `CoreEngineProcManager` launches 2 processes (per `--dat
TL;DR: We end up with 4 child processes (one per DP replica), each running a main, input, and output thread. They complete a coordination handshake with the DP coordinator and frontend, then all three threads per process run in steady-state busy loops.
-
+
Figure 10. distributed system with 4 DP replicas running 4 DPEngineCoreProc
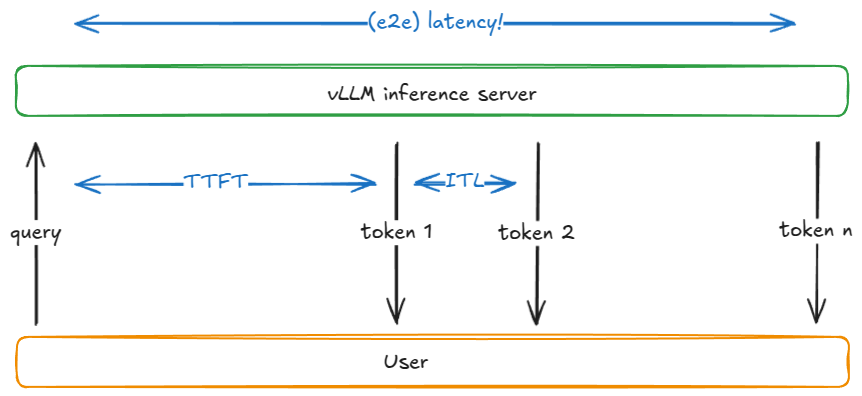
@@ -868,7 +868,7 @@ Before explaining why latency and throughput compete, let's define a few common
| `Throughput` | Total tokens processed per second (input, output, or both), or alternatively requests per second |
| `Goodput` | Throughput that meets service-level objectives (SLOs) such as max TTFT, TPOT, or e2e latency. For example, only tokens from requests meeting those SLOs are counted |
-
+
Figure 11. ttft, itl, e2e latency
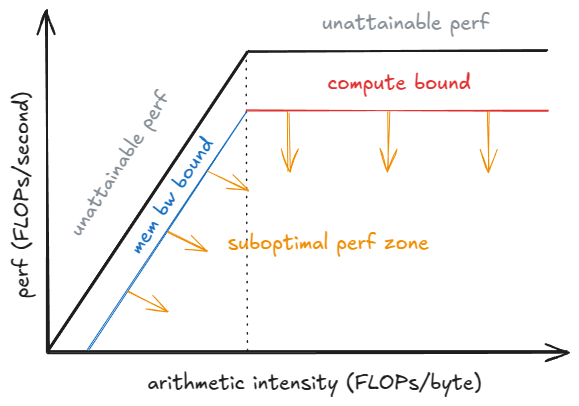
@@ -884,7 +884,7 @@ The tradeoff becomes clear when looking at how batch size `B` affects a single d
A roofline model helps with understanding here: below a saturation batch `B_sat`, the step time is dominated by HBM bandwidth (streaming weights layer-by-layer into on-chip memory), so step latency is nearly flat—computing 1 vs 10 tokens can take a similar time. Beyond `B_sat`, the kernels become compute-bound and step time grows roughly with `B`; each extra token adds to ITL.
-
+
Figure 12. roofline perf model