Performance degradation dotnet core 2.1.300 TieredCompilation #10470
Comments
|
cc @noahfalk |
|
@mrange - Thanks for letting us know! The extra jmp is a known part of the implementation at the moment at least. I had done some theorizing in the past on how we might eliminate it, but thus far in our testing scenarios it wasn't showing up as a significant perf issue so other aspects of the tiered compilation work took priority and we had left this as-is. Let me take a little time to inspect what you've got and share it with some other perf experts and then we can take it from there. |
|
In 2.1 tiered jitting won't give you performance above and beyond what you get with normal jitting. It can improve performance for apps that rely on prejitted code. We are still laying the groundwork to allow tiered jitting to be more aggressive or more adaptive than normal jitting. So keep an eye on things over the next couple of months as we start working towards that. I wasn't sure which method you were talking about above, so I just picked one to look at after doing a bit of profiling. While jitting Devirtualization currently runs very early as we want it upstream of inlining (which also runs very early). So the jit has not yet run any dataflow analysis to determine that a sequence like the above does not actually modify arg2. If the language compiler could eliminate those same-value assignments then devirtualization would kick in. But it will do so both in normal jitting and in tiered rejitting, so it won't offer the latter any advantage over the former. Another alternative (which might not be viable) is to mark types like |
|
Hmm thanks for very interesting input @AndyAyersMS. I will try to reimplement this in C# to see if I can get the IL close to what you describe. If that improves performance then I think this could form the case for a PR to F# compiler. I |
|
We're going to keep looking at this too -- while we don't expect tiering to improve perf, we also don't want to see it degrade perf. |
|
Using my homegrown instruction retired explorer tool, I see the following profile breakdown (per-method counts are exclusive instructions retired). So it looks like the rejitted code is getting run and the tier0 code gets swapped out, but there are a bunch of IP hits in code blocks that do not map to any managed method or native image, so perhaps those are the prestubs? |
|
Somewhat offtopic but I am trying to recreate the push streams in C# in order to test your feedback that the F# IL code eliminated the possibility for the jitter to inline virtual calls. My theory is that I could get the C# compiler IL closer something that could be inlined. However, I can't get the performance numbers even close to F# when trying to replicate the the push streams in C# (3x slower). Looking at the IL code the jitter has inlined even less. This can be because F# compiler tries to inline small lambdas and using I totally respect if you are too busy with other tasks to look at this: This is my C# code (which is a replicate of the F# code) I tried using abstract classes for the receivers, it gave a performance boost but a minor one. Hmm, since I just want to test jitter here perhaps I should just decompile the F# code into C#, clean it up and run C# on it. |
|
It's probably easier for me to prototype this in the jit. The relevant check is here, where the jit is trying to evaluate what it knows about the actual type of an argument when inlining: |
|
Hmm, turns out to be not all that interesting on its own -- devirtualization kicks in but inlining is blocked because the jit won't inline methods with Inlines into 06000011 trivialTest@67-1:Invoke(ref):ref:this
[1 IL=0007 TR=000010 0600000E] [below ALWAYS_INLINE size] trivialTest@67-2:.ctor(ref):this
[2 IL=0001 TR=000026 06000150] [below ALWAYS_INLINE size] Microsoft.FSharp.Core.FSharpFunc`2[Int64,__Canon][System.Int64,System.__Canon]:.ctor():this
[3 IL=0001 TR=000034 06000191] [below ALWAYS_INLINE size] System.Object:.ctor():this
[4 IL=0012 TR=000018 06000005] [below ALWAYS_INLINE size] PerformanceTests:arg@1(int,ref)
[5 IL=0003 TR=000050 0600000C] [below ALWAYS_INLINE size] trivialTest@66:.ctor(ref):this
[6 IL=0001 TR=000063 06000150] [below ALWAYS_INLINE size] Microsoft.FSharp.Core.FSharpFunc`2[Int32,__Canon][System.Int32,System.__Canon]:.ctor():this
[7 IL=0001 TR=000071 0600018A] [below ALWAYS_INLINE size] System.Object:.ctor():this
[8 IL=0009 TR=000055 0600005A] [profitable inline] Loop:range(int,int,ref,int)
- [0 IL=0006 TR=000089 0600014F] [FAILED: target not direct] Microsoft.FSharp.Core.FSharpFunc`2[Int32,__Canon][System.Int32,System.__Canon]:Invoke(int):ref:this
+ [0 IL=0006 TR=000089 0600000D] [FAILED: explicit tail prefix in callee] trivialTest@66:Invoke(int):ref:this...and trying to alter that aspect of jit behavior is not so simple. It is probably worth re-examining the jit's logic for inlining in the presence of explicit tail calls (#18406). Local measurements for just the |
|
A bit more hacking and I can get Perf improves slightly: Odd tiering perf might be from using a CHK jit -- it will be slower to rejit and so the faster tier1 code won't get patched in quite as quickly. Will need to redo with a release build . |
|
Interesting. I remember seeing some code in improved |
|
Tried applying From your comments I thought I would perhaps see calls inlined but perhaps I did something wrong. FYI; trivial stream with |
|
Clarification; .NET 4.7.1 and dotnet core shows the same behavior when surpressing tail calls. With tail calls: Tail calls surpressed |
|
The tail call stuff was done on top of the hack to get devirtualization working. I haven't looked at it in isolation (and it's currently even more hacky than the devirt change, so not even worth sharing out yet). |
|
If I have understood you correctly tiered compilation doesn't improve sustained performance compared to the default setting then the purpose for tiered compilation is improve startup performance? For a "large" program (10+ MiB) what kind of improvements have you seen? |
|
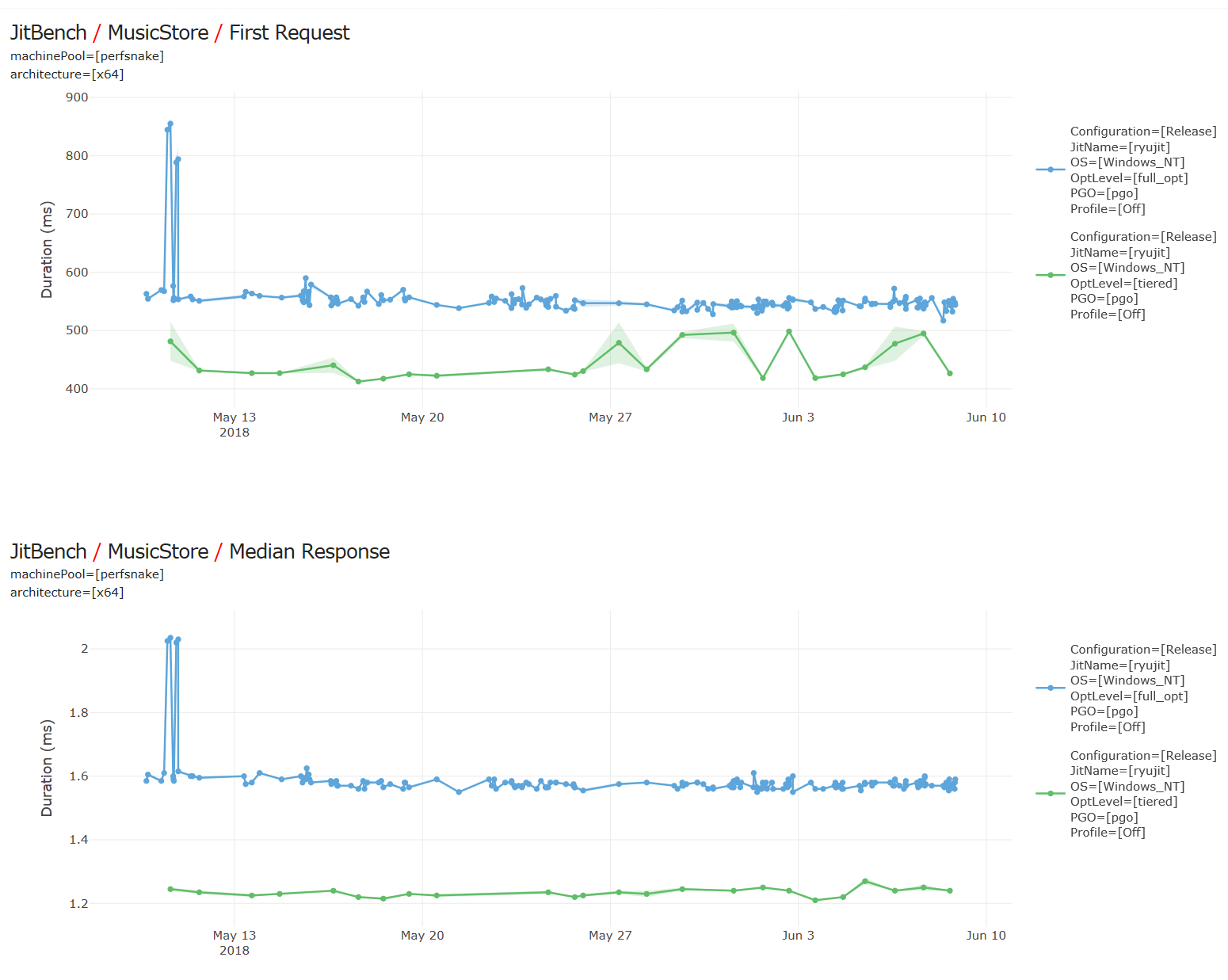
Apps that rely heavily on prejitted code will see faster startup and better steady state performance. For example, on the ASP.Net sample music store app, about 20% faster first response, and 20% better overall throughput. In charts below, lower is better (y axis is time), and green line/dots are from runs with tiered jitting enabled. |
|
To tidy up one of the loose ends above, the unresolved addresses in the analysis of instruction retired events do look like Precode jmp instructions. In case anyone else needs to repeat the analysis what I did was:
|
|
Could we get the runtime to emit some kind of ETL record for the precode and similar? I noticed we have something like this under |
|
Yeah, I don't see why not other than someone needs to set aside some time to work through it. I just created dotnet/coreclr#18428 there to track it. |
|
So does this summary seem accurate?
If there is always going to be some additional call overhead in Tier1 then we should consider making the jit inline more aggressively. But in this case it would not help to simply turn up the dial; we need new capabilities in the jit and perhaps some IL level modifications from FSC. I opened dotnet/coreclr#18406 to look at making inlining more effective in the presence of explicit tail calls. Elsewhere I think we're looking at options to avoid or reduce the cost of precode, since we are going to encounter more cases like this that put a premium on call overhead. |
|
Yeah, that feels like a good summary to me.
I don't think of it as tier1 has to have extra overhead, more that getting rid of that overhead entirely is non-trivial and likely won't give results that are as good as jit inlining. If the jit inlining is sufficiently hard and the scenarios are common/important for real world apps then I'd say we should invest. I hope jit inlining can be our 1st choice of solution though and reducing tier 1 call overhead is the fallback position. |
|
We will certainly look at making the inliner more aggressive overall in Tier1, but I think we also need to make the inliner more capable. Relatively soon I hope to start having the inliner take advantage of profile feedback, whether synthetic, via IBC or similar off-line channels, or from some in-process measurement. And after that we will likely need to work on guarded speculation for indirect calls, possibly also informed by in-process feedback. |
|
Just to give some context from my point of view: WRT to high call to work that was the intention of my performance test to begin with. I compare the impact of datapipelines. For non-trivial "work" the overhead of the datapipelines disappears. I was hoping with tiered compilation to see more code being devirtualized and inlined and thus reduce the overhead of the datapipeline abstractions. Just to give even more context: I have tinkered with datapipelines in C++ (https://github.com/mrange/cpplinq) and Java as well. Because of how C++ lambdas works more information is "easily" available to the compiler and is capable of eliminating the overhead almost entirely (auto vectorizer never seems to work with datapipelines and end of loop conditions placed sub-optimally). In Java that has supported (AFAIK) tiered compilation for a long time. Java Streams seems to perform much better than what I am able to do in .NET. OFC this requires me to use the specialized *Streams in order to remove the overhead of boxing. I don't have any assembly code available but from what I remember Java jitter did a better job on devirtualization and inlining. Because of the tiered compilation in Java the first tiers were doing worse than .NET but the latter ones were doing better. Obviously since I am having a soft spot for .NET I am hoping that .NET will catchup and out-perform the competitors. WRT to F# |
|
Would be addressed by fix for https://github.com/dotnet/coreclr/issues/19752 |
I am very excited about Tiered Compilation in dotnet core so I decided to take it for a spin. Unfortunately in my case I found a performance degradation from 370 ms to 540 ms
My dotnet version:
My use-case
I am tinkering with a push stream in F#. Push streams are faster than Pull streams (like LINQ). One area where .NET JIT loses against JVM JIT is that .NET JIT is less keen on inlining. With Tiered Compilation I was hoping to see improved inlining improving performance.
Essentially the degradation seems to boil down to that there is an extra jmp in the call chain (as far as I understood this is due to the new jitter introducing an level stub to track stats). I was expected this jmp being eliminated after warmup phase. As the stub don't do any stats tracking it seems to be the final optimized stub to me.
Finally time for some assembly code:
So with Tiered compilation I was hoping for the virtual call to be eliminated (as is the case in JVM JIT) instead I got a performance degradation from 370 ms to 540 ms.
Perhaps I should wait for some more detailed posts on Tiered Compilation as promised here: https://blogs.msdn.microsoft.com/dotnet/2018/05/30/announcing-net-core-2-1/
However, I am quite excited about Tiered Compilation so I wanted to get an early start. Hopefully you tell me I made a mistake.
My F# code:
The text was updated successfully, but these errors were encountered: