This issue was moved to a discussion.
You can continue the conversation there. Go to discussion →
为什么 MongoDB 使用 B 树 · Why's THE Design? · /whys-the-design-mongodb-b-tree #167
Comments
|
大多数 OLTP 的数据库面对的都是读多写少的场景 ==> 这里是不是说 OLAP |
绝大多数的场景下都是读多写少的,我还是把 OLTP 和 OLAP 去掉吧... |
|
可以讲讲postgre吗?与mysql比较下 |
可以啊,不过你有什么具体的问题想比较.. |
没,对两个数据库其实都不是特别清楚,如果大佬想写的话请自由发挥吧 |
|
"MongoDB更合适的做法其实是使用嵌入文档",突然想到这岂不是跟graphql很配? |
我的体验是 GraphQL 是前端技术 https://draveness.me/graphql-microservice |
|
我感觉只讲读多写少一个原因是没办法解释 MongoDB 为什么使用 B-tree 而不是 LSM 的,因为按照这个逻辑,OLTP 数据库就不应该用 LSM,而现实是 TiDB 和 CockroachDB 之类的数据库都选择了 LSM。 TiDB 解释说 LSM 写放大、空间放大要相比 B-Tree 好一些,另外 RocksDB 本身牛逼(社区、接口等),还提到说使用缓存提高读性能要比提高写性能简单。 CockroachDB 直接就说选 RocksDB 跟它用 LSM 关系不大,主要是 RocksDB 本身牛逼。 但是如果 LSM 的读性能像 WiredTiger 说的那么不堪的话,可能也没法大规模用起来,WiredTiger 是用 LevelDB 来测试的,可能 LevelDB 比 RocksDB 差很多或者 B-tree 比 B+ tree 性能高很多? |
确实是这样,读多写少单独没法解释这个原因,但是读多写少和 WiredTiger 对读写性能的基准测试应该可以解释它做出这种选择的原因。
这两个参考链接质量都挺高,TiDB 对比的是 B+ 树和 LSM 树,B 树和 B+ 树还是有些区别『使用缓存提高读性能要比提高写性能简单』
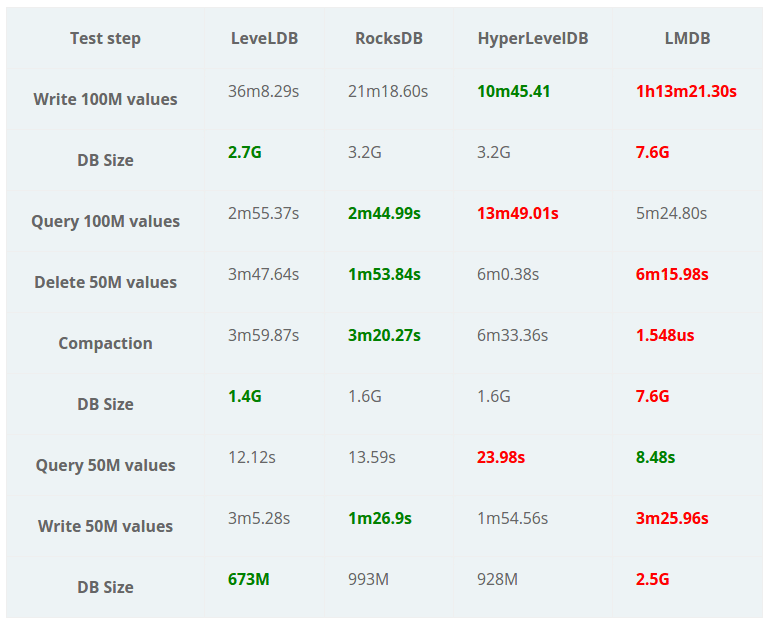
Influxdata 做了一个 LevelDB 和 RocksDB 的基准测试1,结果表明 LevelDB 在磁盘磁盘空间利用率方面有优势,而 RocksDB 在读写上都优于 LevelDB,其中 RocksDB 的写入比 LevelDB 好很多,从这个结果来看 RocksDB 确实比 LevelDB 牛逼,不过正向文中说的,基准测试不够可靠,尤其是别人做的基准测试...
HackerNews 的讨论中说 WiredTiger 跑的 Benchmark 目前已经过时了2,但是我还没有找到其他来源的可靠 Benchmark。
WiredTiger 也不是没有用 LSM 树,只是在默认情况下使用 B 树,其他的数据库选择 LSM 应该也有自己的考虑,毕竟数据结构除了读写性能之外还有其他方面的差异,这可能是其他存储系统选择 LSM 的原因。 这个问题感觉非常有价值,我应该会在深入研究一下,感谢! Footnotes |
|
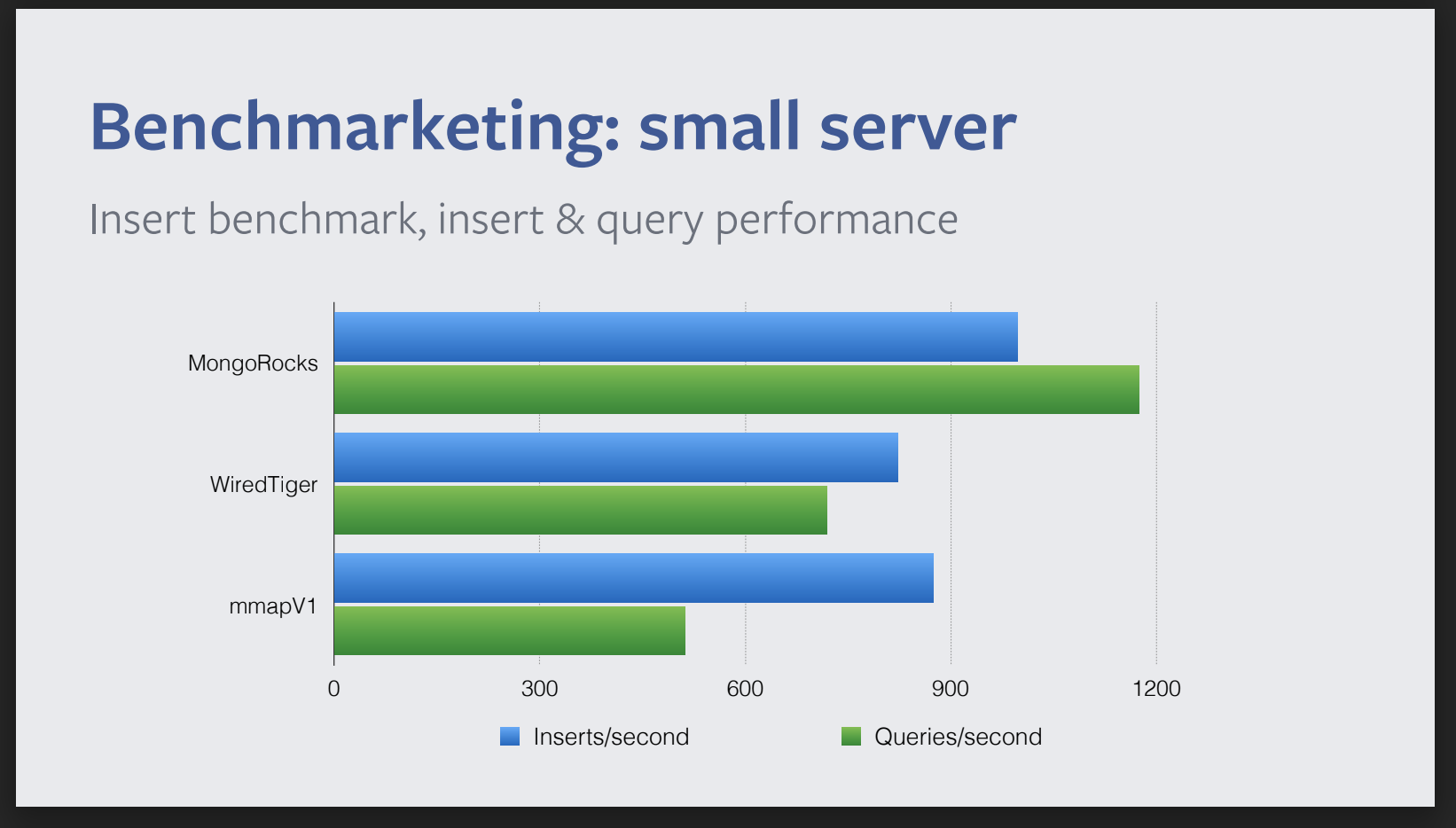
@leafduo 找到了这个 Benchmark,看来 RocksDB 是真的牛逼...
https://drive.google.com/file/d/1pgYC62oT87js8po55qpYT9GEsrKG2SDM/view |
|
MongoDB官方版本中,WiredTiger仅会使用B-Tree(我用作者给的createCollection做了试验,用stats看到存储结构仍旧是B-Tree)。 仅有Percona Server for MongoDB的个别版本对WiredTiger开启了LSM,以及支持了另一个用LSM-Tree的RocksDB引擎,这里提到:https://www.percona.com/blog/2015/12/23/percona-server-for-mongodb-storage-engines-in-iibench-insert-workload/ |
感谢,这个问题我重新确认一下,如果有问题的话我会加上标注。 |
读写比例并不是决定存储引擎采用什么底层结构的主要因素。HBase 采用 LSM-Tree 可能主要是 HDFS 的限制:无法随机写。 这里可以展开一个问题:HDFS 上是否能设计一个 B-Tree 的存储引擎? |
我又确定了一下这个问题,使用的是最新版本的 MongoDB, > db.posts.stats()
{
"ns" : "test.posts",
"size" : 0,
"count" : 0,
"storageSize" : 0,
"capped" : false,
"wiredTiger" : {
"metadata" : {
"formatVersion" : 1
},
"creationString" : "access_pattern_hint=none,allocation_size=4KB,app_metadata=(formatVersion=1),assert=(commit_timestamp=none,durable_timestamp=none,read_timestamp=none),block_allocation=best,block_compressor=snappy,cache_resident=false,checksum=on,colgroups=,collator=,columns=,dictionary=0,encryption=(keyid=,name=),exclusive=false,extractor=,format=btree,huffman_key=,huffman_value=,ignore_in_memory_cache_size=false,immutable=false,internal_item_max=0,internal_key_max=0,internal_key_truncate=true,internal_page_max=4KB,key_format=q,key_gap=10,leaf_item_max=0,leaf_key_max=0,leaf_page_max=32KB,leaf_value_max=64MB,log=(enabled=true),lsm=(auto_throttle=true,bloom=true,bloom_bit_count=16,bloom_config=,bloom_hash_count=8,bloom_oldest=false,chunk_count_limit=0,chunk_max=5GB,chunk_size=10MB,merge_custom=(prefix=,start_generation=0,suffix=),merge_max=15,merge_min=0),memory_page_image_max=0,memory_page_max=10m,os_cache_dirty_max=0,os_cache_max=0,prefix_compression=false,prefix_compression_min=4,source=,split_deepen_min_child=0,split_deepen_per_child=0,split_pct=90,type=lsm,value_format=u",
"type" : "lsm",
"uri" : "statistics:table:collection-8-4681929244516766022",
...
}$ mongo
MongoDB shell version v4.2.2
... |
这里也没有提它是主要因素,没有用过这个词,MongoDB 本身的设计是这里的主要因素。当其他因素被放大的时候,读写比例确实可能会变成次要因素。
可以,我之后来看看 |
我用的是阿里云的MongoDB 3.4.6,细看 我有空的话会做个大数据量测试,看下究竟是B-Tree还是LSM-Tree。 另外,一篇关于LSM的文章提到,MongoDB的WiredTiger并未支持LSM: |
我用的 4.2.2 版本的 MongoDB,所有 btree 的值都是 0...
当我向类型为 $ ls -al /usr/local/var/mongodb
...
-rw------- 1 draven admin collection-13-4681929244516766022-000002.lsm
...但是向默认的类型的集合中插入数据不会创建该文件。 除此之外,我又尝试执行了如下所示的命令,尝试创建 > db.createCollection("posts",{ storageEngine: { wiredTiger: {configString: "type=unknown"}}})
{
"ok" : 0,
"errmsg" : "45: Operation not supported",
"code" : 8,
"codeName" : "UnknownError"
}
> db.createCollection("posts",{ storageEngine: { wiredTiger: {configString: "type=lsm"}}})
{ "ok" : 1 }所以看来 MongoDB 确实是支持类型为 |
我用本地MongoDB 3.4.21也看到这个lsm文件了。不过,当你给这个集合加数据时、建索索引时,它却会多出几个后缀是.wt的文件, 个人猜测:集合数据是保存在lsm文件中(用Snappy压缩),而索引是保存在wt文件中(B树,前缀压缩)。 |
|
感谢你的文章。“非关系型”这一节中的最后一张配图,标题里的“DATASTRUCTURES”好像是拼写错了? |
好像没错啊 |
"STRUCTURES" vs "SRUCTURES",你的少了一个 "T" |
确实是,我改一下 |
|
{% include related/whys-the-design.md %} |
|
大多数的数据库面对的都是读多写少的场景,B 树与 LSM 树在该场景下有更大的优势; |
没太懂你的问题,不过 B 树和 LSM 树现在的性能不好说,很多情况下 LSM 树在实现数据库性能会好一些,要看具体实现。 |
|
问下,B树的非叶子结点是直接存放数据本身,还是存放指向数据的指针呢? |
肯定不是记录本身啊 |
这种查询也会受益于 MySQL B+ 树相互连接的叶节点,因为它能减少磁盘的随机 IO 次数。 文中关于这块不太理解,希望解解惑。post_id看起来不是主键,那么以post_id构建的索引实际上是二级索引,是不存储数据,存储的是主键的值。而Mongo和MySQL原始数据如果是有序的应该也是按主键排序的。这里找
考虑第一步中获取的主键值是离散的,那MySQL和Mongo的随机I/O次数应该都是一样的吧? |
你要在 postid 索引中遍历所有满足的记录 |
|
本文说的不太对。现在mongo默认使用WiredTiger作为存储引擎。 WiredTiger实际是用B+树。http://source.wiredtiger.com/3.2.1/tune_page_size_and_comp.html 描述了"WiredTiger maintains a table's data in memory using a data structure called a B-Tree ( B+ Tree to be specific)"。 本文参考文档9 "Btree vs LSM https://github.com/wiredtiger/wiredtiger/wiki/Btree-vs-LSM" 写到"The benchmarks on this page aim to demonstrate the strengths and weaknesses of Log Structured Merge trees and Btree table types. WiredTiger supports both LSM and Btree based tables.",这里的"Btree"链接也是维基百科的B+树链接。 |
你给的链接都没有问题,我之后会重新 Review 这篇文章,然后做出修改,感谢 |
|
博客链接好像 404 了 |
|
这篇文章404打不开了 |
1 similar comment
|
这篇文章404打不开了 |
This issue was moved to a discussion.
You can continue the conversation there. Go to discussion →
https://draveness.me/whys-the-design-mongodb-b-tree
The text was updated successfully, but these errors were encountered: