Compiling with Lottie Library enabled in LVGL configuration #8
Comments
|
Wanted to note that lv_lib_rlottie will compile and run on an ESP32 |
|
https://docs.lvgl.io/master/libs/rlottie.html Will try following this |
|
Took some hacky fixes, but full screen (240x320) lottie file running on ESP32S3 |


|
What is the difference so important between the ESP32 and the ESP32-S3 ? Is it just the LX7 vs LX6 architecture or is the LCD in your ESP-S3 board using multiple SPI lines (DIO/QIO/8IO) so transfers are faster ? |
|
Lottie files, per discussion in lv_lib_rlottie, consume a significant amount of memory in building the image buffer which is then used by rlottie to draw into (not discounting the amount of memory that then gets used by rlottie while drawing the buffer). The ESP32-Wrover has 4MB of PSRAM - this is enough to be able to load a 240x320 lottie file, but is in no way performant (at or below 1 FPS). LCD shown above vs early working lottie demos in lv_lib_rlottie is effectively the same. Single channel SPI interface to the display. A parallel interface (such as the one used in the ESP-BOX) could potentially get the lottie files running even smoother, but at the cost of IO (project dependent as to whether its affordable). I'd be intrigued to compare performance to an actual ESP-BOX devkit with the parallel interface I expect the LX7 is fundamentally improved over LX6, but the specific part (my belief) the ESP32-S3 has over the ESP32 (depending on config) is an octal spi interface to PSRAM, enabling significantly faster comms than on the WROVER to the same block of PSRAM - I believe this is one of the key enabling differences between the ESP32 and S3 in getting a full screen lottie animation to play. The ESP32, without PSRAM, doesnt have enough available memory to allocate the full buffer for a 240x320 lottie animation. 240x320x32/8 == ~300kb. DRAM segment ~256kb, before any chunks start to get eaten by freertos. Another possibility - rlottie uses a signifcant number of floating point calculations (vector graphics after all). ESP32, from my reading, uses a VFPU, documentation for the S3 seemed to point to this VFPU being improved over the ESP32, but I dont have hard numbers to back that up. |
|
For reference, here's a benchmark of ESP32s3 vs ESP32 on highly optimized FP32 code: For the PSRAM, if I follow what Espressif is saying, it shouldn't matter since the PSRAM loads 32kB in the CPU cache, and works from here. But, since the rlottie code is using a lot of classes containing pointers in their members, it might cross the 32kB boundary and cause the PSRAM to swap. Hard to know without measuring... I'll try to use the IRAM area for the rendering buffer, since, at least this one, is allocated from LVGL, access are 32 bits aligned and we have plenty left usually. On my ESP32 system, I couldn't get more than 12 fps on such animation, and I can't transfer the whole screen to the SPI LCD that fast. Even scrolling is slow on my system. |
|
Above link is accounting for 02 optimization, I have been unable to get rlottie to compile outside of debug compiler settings - is this something that you fixed in your fork of rlottie? I have not measured if it goes over 32kb, but would not surprise me on larger animations especially (maybe this is where smaller animations were performing better than larger ones?)
I assume the test on ESP32 with IRAM was using your partial rendering PR? I'd be curious to try this on an S3 Fwiw, I just got an S3 with 2mb psram and quad spi (vs 8mb psram and octal spi) yesterday. The octal spi part is performant and plays at 28-33 fps with 240x320 animations, the quad spi part is dropping to around 15-20fps (same code between the two, aside from the change in sdkconfig for quad spi vs octal spi). I haven't taken hard numbers, but I think this starts to support the improvement that octal vs quad vs single spi on PSRAM can have. Also would note that both the octal/quad chips are both connecting to a LAN and able to hit http end points for those devices, something that I was unable to ever get running alongside lottie on the ESP32 due to memory issues |

|
I've run a simple test on a ESP32 (first version) with different rendering buffers (either SPIRAM, IRAM or DRAM) and here are the results: To sum up, on DRAM, the rendering is 30% faster than SPIRAM and IRAM is 15% faster than SPIRAM (I guess because of the overhead of some 8 bit accesses on the 32bits IRAM that trap the CPU and must be emulated). |
|
The difference reduces to 25% when accounting for color conversion (DRAM is only 25% faster than SPIRAM). Couldn't test IRAM here, since color conversion code is doing unaligned access that's not supported by IRAM. The next step would be to have rlottie allocate all its structures in DRAM to test (a lot harder since it implies modifying the C++ allocator system wide not to use SPIRAM...). |
|
Ok, here's the last test, and it matches what you observed. In short, if the rlottie structures (result of parsing) are in SPIRAM, then rendering is 4x slower. Please ignore the IRAM advantage here, since there's no color conversion in this test for IRAM. |
|
For information, parsing the file takes 26333964 cycles (so 21.7x longer than rendering) in DRAM and 33590308 cycles (so 8.20x longer than rendering) in SPIRAM. |
|
This is fantastic info!!! Thanks for digging into this more, way more precise than what I was doing To your point of modifying rlotties allocator to be able for DRAM/IRAM/SPIRAM/wherever else it could go, at what point do you think its worthwhile for an official lottie plugin for LVGL, rather than relying upon rlottie and any nuance that comes with it? Presumably the main value would be in the embedded side, which is a niche of LVGL to begin with. Is something like a ThorVG port into LVGL a better route for rendering lottie than rlottie? Is lottie the ideal format for rendering pre-built animations from a file, as opposed to Rive, Gifs, etc. Re-invent the wheel vs square peg/round hole |
|
For the code, here it's: // We need types
#include "Logger.hpp"
// We need performance counter
#include <perfmon.h>
static const uint32_t counters[] = {
XTPERF_CNT_CYCLES, XTPERF_MASK_CYCLES, // total cycles
XTPERF_CNT_INSN, XTPERF_MASK_INSN_ALL, // total instructions
XTPERF_CNT_D_LOAD_U1, XTPERF_MASK_D_LOAD_LOCAL_MEM, // Mem read
XTPERF_CNT_D_STORE_U1, XTPERF_MASK_D_STORE_LOCAL_MEM, // Mem write
XTPERF_CNT_BUBBLES, XTPERF_MASK_BUBBLES_ALL &(~XTPERF_MASK_BUBBLES_R_HOLD_REG_DEP), // wait for other reasons
XTPERF_CNT_BUBBLES, XTPERF_MASK_BUBBLES_R_HOLD_REG_DEP, // Wait for register dependency
XTPERF_CNT_OVERFLOW, XTPERF_MASK_OVERFLOW, // Last test cycle
};
struct PerfCounter
{
static void dump(void *name, uint32_t select, uint32_t mask, uint32_t value)
{
Log(Logger::SystemInfo, "Bench (%s) s%u m%u v:%u", (const char*)name, select, mask, value);
}
static void benchmark(const char * name, void (*func)(void *), void * arg) {
xtensa_perfmon_config_t config;
Zero(config);
config.counters_size = ArrSz(counters);
config.select_mask = counters;
config.repeat_count = 200;
config.max_deviation = 1;
config.call_function = func;
config.call_params = arg;
config.callback = xtensa_perfmon_view_cb;
config.callback_params = stdout;
config.tracelevel = -1;
Log(Logger::SystemInfo, "Bench %s\n---------------------", name);
xtensa_perfmon_exec(&config);
}
};
#include <rlottie_capi.h>
#define renderSize 64
struct Lottie
{
Lottie_Animation * animation;
uint32 * renderingBuffer;
Lottie(const void * data, size_t len) : renderingBuffer(0) {
animation = lottie_animation_from_rodata((const char *)data, len, "");
if (!animation) {
Log(Logger::SystemError, "Can't open lottie");
}
// double fps = lottie_animation_get_framerate(animation);
// size_t duration = lottie_animation_get_totalframe(animation);
// Log(Logger::SystemInfo, "Opened animation %u frames %g", duration, fps);
}
static void convert_to_rgba5658(uint32_t * pix, uint8_t * dest, const size_t width, const size_t height)
{
/* rlottie draws in ARGB32 format, but LVGL only deal with RGB565 format with (optional 8 bit alpha channel)
so convert in place here the received buffer to LVGL format. */
uint32_t * src = pix;
for(size_t y = 0; y < height; y++) {
/* Convert a 4 bytes per pixel in format ARGB to R5G6B5A8 format
naive way:
r = ((c & 0xFF0000) >> 19)
g = ((c & 0xFF00) >> 10)
b = ((c & 0xFF) >> 3)
rgb565 = (r << 11) | (g << 5) | b
a = c >> 24;
That's 3 mask, 6 bitshift and 2 or operations
A bit better:
r = ((c & 0xF80000) >> 8)
g = ((c & 0xFC00) >> 5)
b = ((c & 0xFF) >> 3)
rgb565 = r | g | b
a = c >> 24;
That's 3 mask, 3 bitshifts and 2 or operations */
for(size_t x = 0; x < width; x++) {
uint32_t in = src[x];
#if LV_COLOR_16_SWAP == 0
uint16_t r = (uint16_t)(((in & 0xF80000) >> 8) | ((in & 0xFC00) >> 5) | ((in & 0xFF) >> 3));
#else
/* We want: rrrr rrrr GGGg gggg bbbb bbbb => gggb bbbb rrrr rGGG */
uint16_t r = (uint16_t)(((in & 0xF80000) >> 16) | ((in & 0xFC00) >> 13) | ((in & 0x1C00) << 3) | ((in & 0xF8) << 5));
#endif
memcpy(dest, &r, sizeof(r));
dest[sizeof(r)] = (uint8_t)(in >> 24);
dest += 3;
}
src += width;
}
}
void render(bool allowUnaligned = true) {
if (!renderingBuffer) return;
lottie_animation_render(animation, 12, renderingBuffer, renderSize, renderSize, renderSize * 4);
if (allowUnaligned) convert_to_rgba5658(renderingBuffer, (uint8_t*)renderingBuffer, renderSize, renderSize);
}
~Lottie() {
free0(renderingBuffer);
lottie_animation_destroy(animation);
}
};
void psramMode(void * obj) {
Lottie * lottie = (Lottie*)obj;
lottie->render();
}
void iramMode(void * obj) {
Lottie * lottie = (Lottie*)obj;
lottie->render(false);
}
void parserTime(void * obj) {
ROString * txt = (ROString *)obj;
Lottie lottie(txt->getData(), txt->getLength());
(void)lottie;
}
void dumpHeap() {
heap_caps_print_heap_info(MALLOC_CAP_SPIRAM);
heap_caps_print_heap_info(MALLOC_CAP_32BIT | MALLOC_CAP_INTERNAL);
heap_caps_print_heap_info(MALLOC_CAP_8BIT | MALLOC_CAP_INTERNAL);
}
enum TestMode
{
SPIRAM = 0,
IRAM = 1,
DRAM = 2,
};
static TestMode _testMode;
using namespace std;
void * _new(size_t size)
{
switch(_testMode) {
case SPIRAM: return heap_caps_aligned_alloc(4, size, MALLOC_CAP_SPIRAM);
case IRAM: return heap_caps_aligned_alloc(4, size, MALLOC_CAP_32BIT | MALLOC_CAP_INTERNAL);
case DRAM: return heap_caps_aligned_alloc(4, size, MALLOC_CAP_8BIT | MALLOC_CAP_INTERNAL);
default: return malloc(size);
}
}
void * operator new(size_t size)
{
return _new(size);
}
void * operator new[](size_t size)
{
return _new(size);
}
void operator delete(void * p)
{
free(p);
}
void operator delete[](void * p)
{
free(p);
}
void benchmarkRlottie(void*)
{
ROString iconData = efs.getFile("faucet.json");
/* {
_testMode = SPIRAM;
PerfCounter::benchmark("parser", &parserTime, &iconData);
}
*/
dumpHeap();
{
_testMode = SPIRAM;
Lottie lottie(iconData.getData(), iconData.getLength());
lottie.renderingBuffer = (uint32_t*)heap_caps_aligned_alloc(4, renderSize*4*renderSize, MALLOC_CAP_SPIRAM);
if (!lottie.renderingBuffer) {
Log(Logger::SystemError, "Can't allocate SPIRAM");
return;
}
memset(lottie.renderingBuffer, 0, renderSize*renderSize*4);
PerfCounter::benchmark("psram", &psramMode, &lottie);
dumpHeap();
}
// free0(lottie.renderingBuffer);
{
_testMode = DRAM;
Lottie lottie(iconData.getData(), iconData.getLength());
lottie.renderingBuffer = (uint32_t*)heap_caps_aligned_alloc(4, renderSize*4*renderSize, MALLOC_CAP_32BIT | MALLOC_CAP_INTERNAL);
if (!lottie.renderingBuffer) {
Log(Logger::SystemError, "Can't allocate SPIRAM");
return;
}
memset(lottie.renderingBuffer, 0, renderSize*renderSize*4);
PerfCounter::benchmark("iram", &iramMode, &lottie);
dumpHeap();
}
// lottie.renderingBuffer = (uint32_t*)heap_caps_aligned_alloc(4, renderSize*4*renderSize, MALLOC_CAP_32BIT);
// memset(lottie.renderingBuffer, 0, renderSize*renderSize*4);
// if (!lottie.renderingBuffer) {
// Log(Logger::SystemError, "Can't allocate IRAM");
// return;
// }
// PerfCounter::benchmark("iram", &iramMode, &lottie);
// free0(lottie.renderingBuffer);
{
_testMode = DRAM;
Lottie lottie(iconData.getData(), iconData.getLength());
lottie.renderingBuffer = (uint32_t*)heap_caps_aligned_alloc(4, renderSize*4*renderSize, MALLOC_CAP_8BIT | MALLOC_CAP_INTERNAL);
if (!lottie.renderingBuffer) {
Log(Logger::SystemError, "Can't allocate SPIRAM");
return;
}
memset(lottie.renderingBuffer, 0, renderSize*renderSize*4);
PerfCounter::benchmark("dram", &psramMode, &lottie);
dumpHeap();
}
// lottie.renderingBuffer = (uint32_t*)heap_caps_aligned_alloc(4, renderSize*4*renderSize, MALLOC_CAP_8BIT | MALLOC_CAP_INTERNAL);
// memset(lottie.renderingBuffer, 0, renderSize*renderSize*4);
// if (!lottie.renderingBuffer) {
// Log(Logger::SystemError, "Can't allocate IRAM");
// return;
// }
// PerfCounter::benchmark("dram", &psramMode, &lottie);
while(1) { delayMs(1000); }
} |
|
And for the other questions: I'm working on improving rlottie to consume less memory. Right now, I'm changing the code to defer to another vector class that's not using exponential-grow to allocate (so when allocating 17 elements, you don't pay for 32 elements like standard STL). This is not a huge work and it should hit my memshrink branch tomorrow. It'll be slower than the classical std::vector unless the code is modified to pre-reserve the expected size (I'm also looking at this, but the rlottie code is a bit convoluted). I'm sure the overhead will worth it, since the benchmark above show that a 12kB JSON file consumes 74kB heap memory for internal rlottie structures once parsed. The less memory it uses, the more compact it'll be in SPIRAM and it'll fit the 32KB cache better so it might be faster in the end (also, parsing is done once, but rendering is done for each frame). Then there's the possibility to change the allocator. Unfortunately, in C++, if you override operator new, it's global for all program (that's one of the historical dumbness of C++), or you need to overload per class (which is impossible to do for rlottie, too much work). Yet, I think I've found a solution that might help more people. My idea is to implement a render_rlottie() {
set_custom_allocator(DRAM);
lottie = lottie_animation_from_file(...); // This calls new in all structure and that'll be overridden above
set_custom_allocator(Default); // Back to default allocator
}
// Allocator
thread_local mode; // Either DRAM, IRAM, SPIRAM, whatever
void * operator new(size_t n) {
switch (mode) {
case Default: return ::malloc(n);
case DRAM: return ::heap_cap_malloc(DRAM, n);
...
}
[...]For LVGL, I think it'll need more work to implement a capability aware allocator (a smarter In short, for light interfaces with 3 animated icons, I think we can work with the DRAM heap (that's around 180kB) and gain a good 3 to 4x the performance instead of using the SPIRAM. Last possible solution to optimize more would be to change rlottie code to use hash instead of strings for its few I don't think ThorVG will be the panacea either. It has many advantages but a lot of cons for me:
|
|
I've tried with a vector class that's not using exponential growth and got these results: In short, it's slower (as expected), but consume more memory (unexpected) than standard It's in my memShrinkVector branch if you want to test. |
|
Ok, I've made some progress here on understanding why it takes more memory. The issue is not the consumed heap memory (which is lower by 4kB) but the overhead of the many small allocations in the heap itself. Here's the output of valgrind with massif on my vector class: vs the output with We see that the useful heap is smaller for my vector (12,174kiB vs 12,196kiB) but the overhead is much higher (103120 vs 102749). So I guess TLSF in ESP32 is even worst (I've no tool to measure) than my computer's heap algorithm. So in the end, it doesn't make sense to allocate with my vector here. I'm reverting the commit on the memShrink branch. |
|
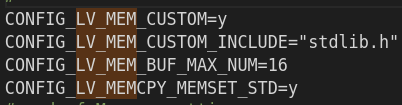
Re-run the test with adding |
Describe the bug
Compiling examples/rlottie fails x
To Reproduce
Compile latest LVGL on master with lottie library enabled in sdkconfig
lv_lib_rlottie added as a submodule under lvgl/lv_lib/lv_lib_rlottie
LVGL otherwise works as intended, but havent been able to get it to compile with the lottie option in the sdkconfig. Very interested in trying on the S3 specifically to see how large of a lottie animation can play on a 240x320 SPI TFT (ESP32 was not performant enough to play larger than 120x120 animations)
Expected behavior
Will not compile
rlottie_capi.h is a dependency from the full rlottie lib (also in lv_lib_rlottie)
Screenshots or video
The text was updated successfully, but these errors were encountered: