Adaptive compression often wrongly locks at high compression levels #2200
Comments
|
I've made a quick proof-of-concept that uses
The poor man's plot shows that it's performing a better than the current algorithm but still worse than static level. I suppose this could still be improved by someone who knows what he's doing. The proof-of-concept diff: diff --git a/programs/fileio.c b/programs/fileio.c
index e0f7fde..aef44b5 100644
--- a/programs/fileio.c
+++ b/programs/fileio.c
@@ -20,6 +20,8 @@
# define _POSIX_SOURCE 1 /* disable %llu warnings with MinGW on Windows */
#endif
+#define EXPERIMENTAL_ADAPTIVE_CPUTIME 1
+
/*-*************************************
* Includes
***************************************/
@@ -33,6 +35,9 @@
#include <limits.h> /* INT_MAX */
#include <signal.h>
#include "timefn.h" /* UTIL_getTime, UTIL_clockSpanMicro */
+#if EXPERIMENTAL_ADAPTIVE_CPUTIME
+#include <time.h>
+#endif
#if defined (_MSC_VER)
# include <sys/stat.h>
@@ -1172,6 +1177,15 @@ FIO_compressLz4Frame(cRess_t* ress,
#endif
+#if EXPERIMENTAL_ADAPTIVE_CPUTIME
+double timespec_subtract(struct timespec t1, struct timespec t2)
+{
+ double nsec = t1.tv_nsec - t2.tv_nsec;
+ return t1.tv_sec - t2.tv_sec + nsec/1000000000.;
+}
+#endif
+
+
static unsigned long long
FIO_compressZstdFrame(FIO_prefs_t* const prefs,
const cRess_t* ressPtr,
@@ -1193,6 +1207,11 @@ FIO_compressZstdFrame(FIO_prefs_t* const prefs,
unsigned inputPresented = 0;
unsigned inputBlocked = 0;
unsigned lastJobID = 0;
+#if EXPERIMENTAL_ADAPTIVE_CPUTIME
+ struct timespec prevWallTime, prevCpuTime;
+ speedChange_e prevSpeedChange = noChange;
+ int speedChangeCount = 0;
+#endif
DISPLAYLEVEL(6, "compression using zstd format \n");
@@ -1274,6 +1293,38 @@ FIO_compressZstdFrame(FIO_prefs_t* const prefs,
assert(zfp.produced >= previous_zfp_update.produced);
assert(prefs->nbWorkers >= 1);
+#if EXPERIMENTAL_ADAPTIVE_CPUTIME
+ struct timespec wallTime, cpuTime;
+ double cpuUse;
+
+ clock_gettime(CLOCK_MONOTONIC, &wallTime);
+ clock_gettime(CLOCK_PROCESS_CPUTIME_ID, &cpuTime);
+ cpuUse =
+ timespec_subtract(cpuTime, prevCpuTime) /
+ timespec_subtract(wallTime, prevWallTime) /
+ prefs->nbWorkers;
+
+ if (cpuUse > 0.95)
+ speedChange = faster;
+ else if (cpuUse < 0.8)
+ speedChange = slower;
+
+ /* avoid very rapid speed changes */
+ if (speedChange == prevSpeedChange) {
+ if (++speedChangeCount < 10)
+ speedChange = noChange;
+ else
+ speedChangeCount = 0;
+ } else {
+ prevSpeedChange = speedChange;
+ speedChange = noChange;
+ speedChangeCount = 0;
+ }
+
+ prevWallTime = wallTime;
+ prevCpuTime = cpuTime;
+#else
+
/* test if compression is blocked
* either because output is slow and all buffers are full
* or because input is slow and no job can start while waiting for at least one buffer to be filled.
@@ -1328,6 +1379,7 @@ FIO_compressZstdFrame(FIO_prefs_t* const prefs,
inputBlocked = 0;
inputPresented = 0;
}
+#endif
if (speedChange == slower) {
DISPLAYLEVEL(6, "slower speed , higher compression \n") |

|
In case it isn't clear, the main question is whether you'd be interested in doing this or having me work on it? If the latter, I'd use some tips on how to do it. In particular, it'd be platform-specific, so whether it should be implemented as a new option specific to some platforms. The |
|
Thanks @mgorny , the issue described is correct : The logic has even more difficulties to keep up when using a lot of threads, because a lot of work is already piped in worker threads, and by the time it can realize that it has targeted a too slow speed, there is a huge latency to come back from. Anyway, I totally agree that the current logic is perfectible, and could be improved. Thanks for your great measurements. It's helpful, and also shows that your proposal can offer sensible improvements for this use case. It's also nicely done, with logic concentrated in a few places. Using time instead of buffer fill rate seems like a good idea, but it also introduces portability issues. I suspect your suggested approach is to make your solution platform-specific, reverting back to existing logic for other unsupported platforms. It's both interesting, making it possible to directly compare the 2 logics and measure the differences, and a bit scary from a maintenance perspective. To be more complete, my own preference would be to improve the fill-rate buffer methodology so that it handles these scenarios better, due to its inherent portability advantages. But given that my availability is very limited, I don't plan to work on it soon, making this preference a moot point. |
|
Adaptive compression is a way of investing more compute cycles as profitable. Perhaps it's only stable when modulated by something like an idle time goal. |
|
Are there any known workarounds? perhaps limiting the bounds to 0.5x and 1.5x the link bandwidth will prevent wild swings for example |
Describe the bug
In my experience, adaptive compression sometimes increases compression level throughout low entropy data and afterwards fails to decrease it even though CPU becomes the bottleneck. I've aborted the compression after it lasted for a minute or two, so I don't think if it'd eventually manage to reduce it.
To Reproduce
Most recently, I've reproduced while making a backup to a slower HDD, so...
Steps to reproduce the behavior:
tar -c / | zstd -v --adapt -T12 > /mnt/backup/foo.tar.zstdExpected behavior
I expected the compression level to be adapted to achieve best throughput with CPU utilization close to 100%.
Screenshots and charts
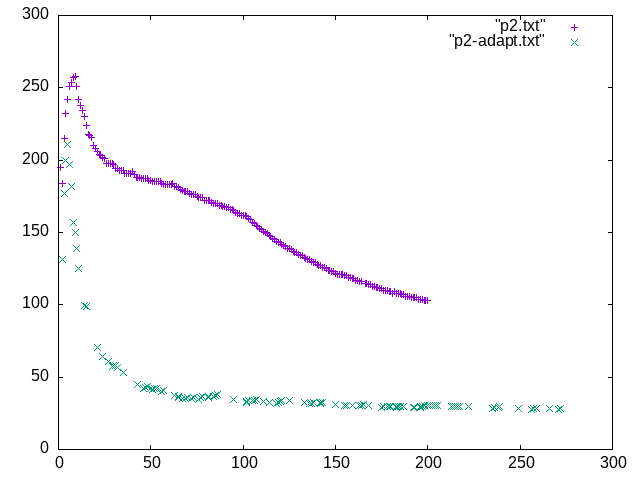
This is a very rough benchmark of input rate vs time.
p2.txtis constant compression level that keeps CPU utilization low, so it's entirely I/O bound.p2-adapt.txtis adaptive compression. There's a visible peak due to I/O caching but still, it's quite clearly visible that adaptive compression is doing very badly here.Desktop (please complete the following information):
-march=znver2 --param l1-cache-size=32 --param l1-cache-line-size=64 -O2 -pipeAdditional context
Maybe it'd be better to make adaptation work based on perceived CPU utilization rather than I/O conditions? I think that'd yield more stable results and avoid instability caused by buffering. I don't know what other use cases are for adaptive compression but in my case, the primary goal would be to achieve realtime compression, and only secondary to achieve strongest compression possible while at it.
The text was updated successfully, but these errors were encountered: