Nomad CSI plugin seems healthy but controller is now working properly #10030
Comments
|
Hi @carlosrbcunha! So for starters, the order of running the controller vs node plugin definitely should not matter at all. I think that's just surfacing some other issue here. I can't find where it's documented in the If you take a magnifying glass 😁 and compare their k8s manifests for the Controller vs the Node I think the controller shouldn't have the So if that's the case, then when the controller is getting placed before the node, it's registering itself as a node plugin but Nomad is expecting it to be a controller. So Nomad is mounting its control socket in a location that assumes it's a controller, and then the node plugin on that client can't take the same control socket location. All the behaviors you're describing could be the result of that. Also, does the output of |
|
Hi @tgross , thanks for answering. I agree with you, the order should not matter but in this case its impacting, in the incorrect status only node seems to be working and not the controller. You that see that the nomad job has a csi stanza that states the type of plugin. I did not encounter a argument for the command that had this distinction. The My code only works with node first , wait some seconds so that all nodes come up and then start the controllers. If I invert the order or remove the sleep timer, it start to show both but in the end it will only show the nodes. I will try to talk with the developer in charge of the driver and see if I have more guidance. Can you try and help me from your end ? With some examples maybe ? |
That tells Nomad the type of plugin. It doesn't tell the plugin whether it should be acting as a controller or node. Try deploying with that |
|
I tested that and the result is still the same, not stable. |
|
Ok, can you provide the results of |
|
Hi, nomad status output Node logs controller logs Plugin status page |
You should run one node plugin (as a system job) on every client where you want to mount volumes. You should run at least one controller plugin. It's definitely possible the Azure plugin doesn't properly handle the HA case where there's more than one controller. That won't impact plugin counts for Nomad but it'll could cause confusion for the controller. Here's a relevant bit of the node log. Note that the node plugin is running the controller services, which you don't want.
If we look at the
Now, Nomad is only hitting it with Node RPCs, but that doesn't mean it's not confusing the plugin counts. It's going to be very challenging and not very useful to try to debug why we're getting the wrong counts for plugins if the plugins aren't reporting correctly to Nomad. Then we continue a bit to where you've tried to claim a volume, and that's throwing errors. I'm not super familiar with Azure but it looks like you're trying to claim something for a VM that either doesn't exist or that the client doesn't have authorization for (depending on how the Azure API surfaces that):
The controller plugin logs show that it's running the node service, so that's also a problem with the plugin config. But we don't see any Node RPCs hitting it so I think we're ok in terms of whether Nomad thinks it's a controller.
But I only ever see the validate volume capabilities RPCs getting hit on the controller. This implies that the plugin doesn't implement much of the controller RPC API; this sort of makes sense with what we're seeing in the logs: a lot of plugins with controllers do attachment in the controller RPC but it's actually a better workflow in my opinion to do that in the node RPC. So this part looks healthy.
|
This is because the node Plugin at first uses the name of the container and then it uses the node name to try match with the corresponding VM. I use a prefix and a suffix for my VM objects that is not present in the hostname of the client, that's why my parameter --nodeid its
Regarding the node and controller starting advertising both capabilities, I will try to sort that out in the driver's GitHub page. I tested this setup (1 controller + x nodes) and it won't start flawlessly every time I runned it. But if I restarted the controller node at the end, it will became healthy. Also with the sleep timer in the terraform , making sure that the nodes started, it became much more stable and worked 10/10 times I tested. PS. I finished co-hosting a Hashitalks2021 presentation regarding this topic , hopefully we got people excited and will have more people using this. Thanks for the help ! |
|
It occurs to me that because the azuredisk plugin doesn't implement the controller attach RPC, it might be possible to run it in |
|
Haven't heard back on this one in a while, so I'm going to close it out. If you have new information on this specific issue, feel free to reopen. Otherwise go ahead and open a new issue. Thanks! |
|
I'm going to lock this issue because it has been closed for 120 days ⏳. This helps our maintainers find and focus on the active issues. |
We have setup CSI on our nomad cluster and choose to start node and controller by hand (nomad cli) and not use terraform to do this. We also believed that controller workload should start first than node (also there is no clear guidance on this topic as we suspect that order has an impact in the health and ability to CSI to perform without problems).
In our recent tests we noticed that there might be a correlation regarding the errors that we got randomly and the start order of the nodes and controllers.
Nomad version
Nomad v1.0.3 (08741d9)
Operating system and Environment details
Ubuntu 20.04.2 LTS running in a Azure VM
Issue
Nomad CSI plugin seems healthy but controller is now working properly
Reproduction steps
Start nomad node and controller via terraform
Job file (if appropriate)
Node job
Controller job
Bad behaviour


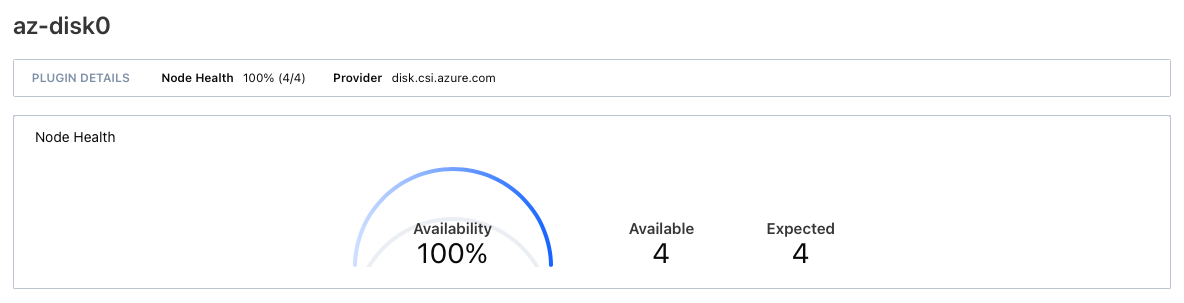
If I start the node and the controller without any time gap between the two I get this state
Everything seems ok but if we drill down to the status it shows ...
Only node info in available, no controller !! . As the result of this, the jobs requiring CSI fail with this message.
Expected behaviour

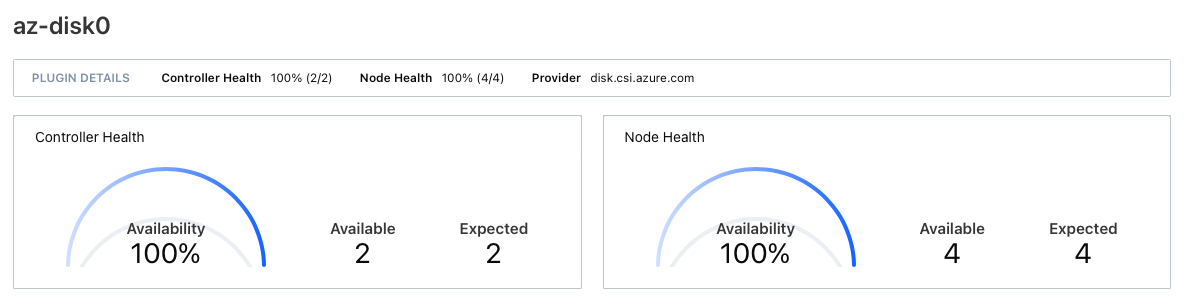
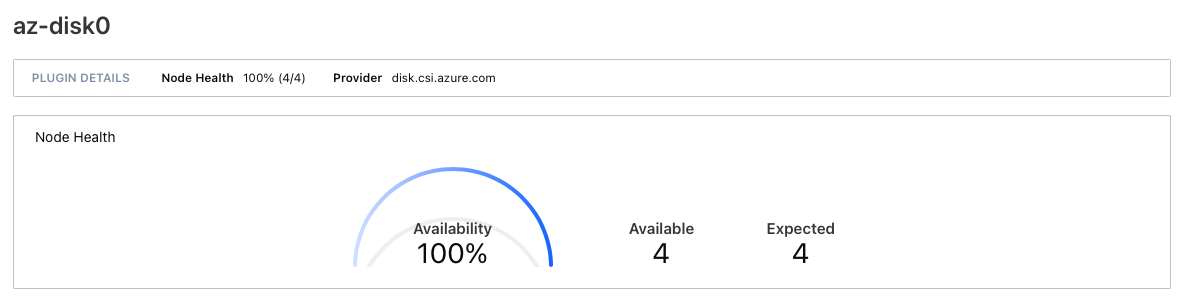
If I start the node and then add a time gap of, for instance, 10 seconds. The node and controllers start but in the end I see different result.
This time with controller and node data stating 100% across the board.
In this case, all workloads start and work without any issue.
Analysing the data that we have, we identified a different setting when querying the API in this 2 states.
In the 'bad behaviour' setting when we query via (
curl http://<nomad_ip>:4646/v1/plugin/csi/az-disk0) , the json response hadControllerRequired": falsewhereas the expected behaviour hadControllerRequired": trueIs there any guidance on the order of workloads to start (node and controller) ? We only located a terraform registry KristophUK/terraform-nomad-aws-ebs-csi-plugin as an example with node first but without timer between workloads.
Is there some way we can track the status of the plugin and make the controller and node be more resilient ? Sometimes out of the blue things start failing with errors and all seams OK in the controller and node health status.
The text was updated successfully, but these errors were encountered: