Job execution calculation not displayed if an integration alert delivered (or a job runs long) #219
Comments
|
Yep, the run times are not shown in the UI if the job takes longer than 1 hour to run: https://github.com/healthchecks/healthchecks/blob/master/hc/front/views.py#L415 A couple of reasons for this:
I'm thinking, raising the limit from 1 hour to 24 hours (so for long jobs UI would show "X h Y min Z sec") would probably be enough, right? |
|
Point number 1 makes sense (as does number 2 😉 ). I know at least personally that 24h would be more than enough. Perhaps use the Grace Time setting in determining when (a) a ping is the end of a currently executing job or (b) a newly-started job? This way you avoid arbitrarily opening up the window so wide, while at the same time using concrete settings that play well with this functionality. For example, with these long-running jobs I've set their Grace Time to be 200 minutes (3h20m). I think it's a good indicator, while at the same time minimizing the likelihood of point number 1. Perhaps make it |
|
Thanks, these are good ideas. I went with your suggested |
|
Sweet! I already retroactively see the change in logic:
Something I just considered, and I don't expect the need to use it, but should a job ever radically become faster in execution time--and I decrease the grace time--the older ones with longer grace times may disappear if the grace time is not persistent data associated with the particular execution of the job. This would be true if it's being stored as a high-level property or descriptive attribute of the job that applies to every runtime of a job, past, present, and future. I don't know if this is the case or not as I haven't read through the code very thoroughly. Storing the current grace time value at the time of the execution, if not already being done, along with the job execution results would address this. I mention this only as a consideration, as I know it will increase the complexity, and I don't see the urgency. It's more like one of those back-of-the-mind quirks that you know about. |
|
That's a good point – changing the grace time can make the historic execution times flip on and off.
Will keep this in mind. In future we might build new features that require more data to be stored with each ping. At that time it would make sense to improve this area as well. |
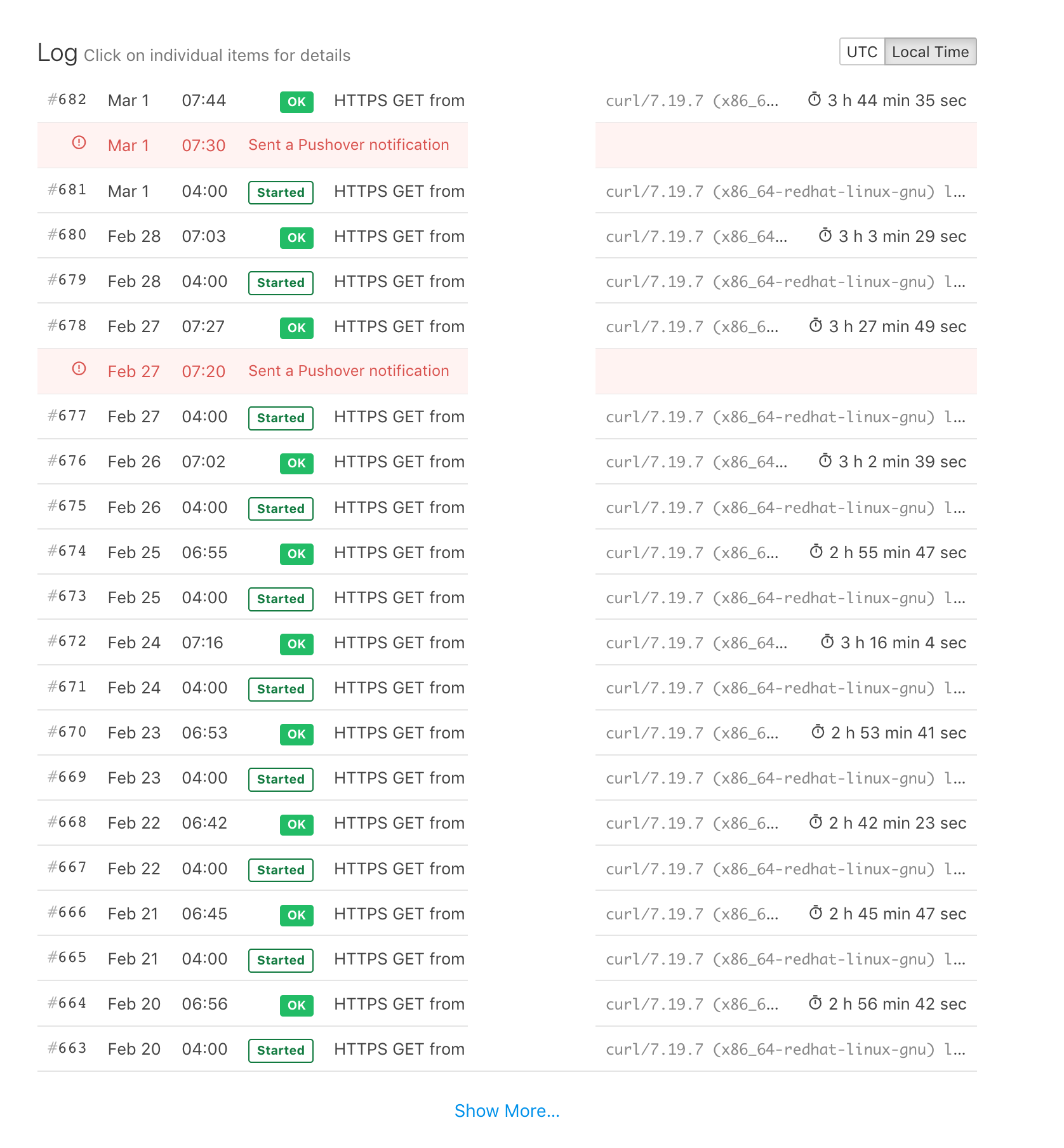
In the log for job executions, if one uses the
/startendpoint, the next request will display the job execution time:However, if a notification or alert is sent between the "Started" and "OK" requests, the job's execution time is not displayed.
Edit:
Now I'm thinking it just has to do with a job that runs long. I've been adjusting some jobs that have moved to slower disks, and they now take about three hours to run, so the grace time was adjusted for this, so alerts are no longer being triggered.
Have a look at the last few dozen logs:
The text was updated successfully, but these errors were encountered: