diff --git a/.clang-format b/.clang-format
new file mode 100644
index 0000000000..17de768cbe
--- /dev/null
+++ b/.clang-format
@@ -0,0 +1,7 @@
+---
+BasedOnStyle: LLVM
+---
+Language: Cpp
+# Force pointers to the type for C++.
+DerivePointerAlignment: false
+PointerAlignment: Left
diff --git a/.gitignore b/.gitignore
new file mode 100644
index 0000000000..503569b57a
--- /dev/null
+++ b/.gitignore
@@ -0,0 +1,5 @@
+*.pyc
+.idea
+horovod.egg-info
+dist
+build
diff --git a/LICENSE b/LICENSE
new file mode 100644
index 0000000000..f70e1e0f41
--- /dev/null
+++ b/LICENSE
@@ -0,0 +1,249 @@
+ Horovod
+ Copyright 2017 Uber Technologies, Inc.
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
+
+ Horovod includes:
+
+ FlatBuffers
+ Copyright (c) 2014 Google Inc.
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
+
+ baidu-research/tensorflow-allreduce
+ Copyright (c) 2015, The TensorFlow Authors.
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
+
+
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright [yyyy] [name of copyright owner]
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
\ No newline at end of file
diff --git a/MANIFEST.in b/MANIFEST.in
new file mode 100644
index 0000000000..e24a4c600f
--- /dev/null
+++ b/MANIFEST.in
@@ -0,0 +1,2 @@
+recursive-include * *.h *.cc
+include README.md
diff --git a/README.md b/README.md
new file mode 100644
index 0000000000..2f003bf6f8
--- /dev/null
+++ b/README.md
@@ -0,0 +1,289 @@
+# Horovod
+
+Horovod is a distributed training framework for TensorFlow. The goal of Horovod is to make distributed Deep Learning
+fast and easy to use.
+
+# Install
+
+To install Horovod:
+
+1. Install [Open MPI](https://www.open-mpi.org/).
+
+2. Install the `horovod` pip package.
+
+```bash
+$ pip install horovod
+```
+
+This basic installation is good for laptops and for getting to know Horovod.
+If you're installing Horovod on a server with GPUs, read the [Horovod on GPU](#gpu) section.
+
+# Concepts
+
+Horovod core principles are based on [MPI](http://mpi-forum.org/) concepts such as *size*, *rank*,
+*local rank*, *allreduce*, *allgather* and *broadcast*. These are best explained by example. Say we launched
+a training script on 4 servers, each having 4 GPUs. If we launched one copy of the script per GPU:
+
+1. *Size* would be the number of processes, in this case 16.
+
+2. *Rank* would be the unique process ID from 0 to 15 (*size* - 1).
+
+3. *Local rank* would be the unique process ID within the server from 0 to 3.
+
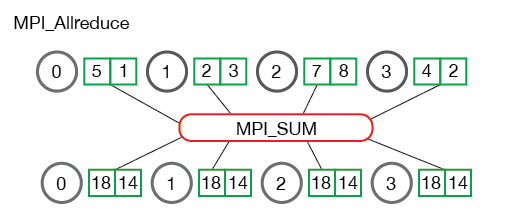
+4. *Allreduce* is an operation that aggregates data among multiple processes and distributes
+ results back to them. *Allreduce* is used to average dense tensors. Here's an illustration from the
+ [MPI Tutorial](http://mpitutorial.com/tutorials/mpi-reduce-and-allreduce/):
+
+ 
+
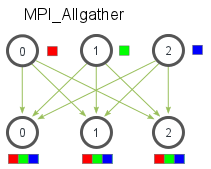
+5. *Allgather* is an operation that gathers data from all processes on every process. *Allgather* is used to collect
+ values of sparse tensors. Here's an illustration from the [MPI Tutorial](http://mpitutorial.com/tutorials/mpi-scatter-gather-and-allgather/):
+
+ 
+
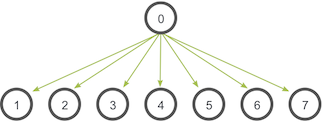
+6. *Broadcast* is an operation that broadcasts data from one process, identified by root rank, onto every other process.
+ Here's an illustration from the [MPI Tutorial](http://mpitutorial.com/tutorials/mpi-broadcast-and-collective-communication/):
+
+ 
+
+# Usage
+
+To use Horovod, make the following additions to your program:
+
+1. Run `hvd.init()`.
+
+2. Pin a server GPU to be used by this process using `config.gpu_options.visible_device_list`.
+ With the typical setup of one GPU per process, this can be set to *local rank*.
+
+3. Wrap optimizer in `hvd.DistributedOptimizer`. The distributed optimizer delegates gradient computation
+ to the original optimizer, averages gradients using *allreduce* or *allgather*, and then applies those averaged
+ gradients.
+
+4. Add `hvd.BroadcastGlobalVariablesHook(0)` to broadcast initial variable states from rank 0 to all other
+ processes. Alternatively, if you're not using `MonitoredTrainingSession`, you can simply execute the
+ `hvd.broadcast_global_variables` op after global variables have been initialized.
+
+Example (full MNIST training example is available [here](examples/tensorflow_mnist.py)):
+
+```python
+import tensorflow as tf
+import horovod.tensorflow as hvd
+
+
+# Initialize Horovod
+hvd.init()
+
+# Pin GPU to be used to process local rank (one GPU per process)
+config = tf.ConfigProto()
+config.gpu_options.visible_device_list = str(hvd.local_rank())
+
+# Build model...
+loss = ...
+opt = tf.train.AdagradOptimizer(0.01)
+
+# Add Horovod Distributed Optimizer
+opt = hvd.DistributedOptimizer(opt)
+
+# Add hook to broadcast variables from rank 0 to all other processes during
+# initialization.
+hooks = [hvd.BroadcastGlobalVariablesHook(0)]
+
+# Make training operation
+train_op = opt.minimize(loss)
+
+# The MonitoredTrainingSession takes care of session initialization,
+# restoring from a checkpoint, saving to a checkpoint, and closing when done
+# or an error occurs.
+with tf.train.MonitoredTrainingSession(checkpoint_dir="/tmp/train_logs",
+ config=config,
+ hooks=hooks) as mon_sess:
+ while not mon_sess.should_stop():
+ # Perform synchronous training.
+ mon_sess.run(train_op)
+```
+
+To run on a machine with 4 GPUs:
+
+```bash
+$ mpirun -np 4 python train.py
+```
+
+## Horovod on GPU
+
+To use Horovod on GPU, read the options below and see which one applies to you best.
+
+### Have GPUs?
+
+In most situations, using NCCL 2 will significantly improve performance over the CPU version. NCCL 2 provides the *allreduce*
+operation optimized for NVIDIA GPUs and a variety of networking devices, such as InfiniBand or RoCE.
+
+1. Install [NCCL 2](https://developer.nvidia.com/nccl).
+
+2. Install [Open MPI](https://www.open-mpi.org/).
+
+3. Install the `horovod` pip package.
+
+```bash
+$ HOROVOD_GPU_ALLREDUCE=NCCL pip install horovod
+```
+
+**Note**: Some networks with a high computation to communication ratio benefit from doing allreduce on CPU, even if a
+GPU version is available. Inception V3 is an example of such network. To force allreduce to happen on CPU, pass
+`device_dense='/cpu:0'` to `hvd.DistributedOptimizer`:
+
+```python
+opt = hvd.DistributedOptimizer(opt, device_dense='/cpu:0')
+```
+
+### Advanced: Have GPUs and networking with GPUDirect?
+
+[GPUDirect](https://developer.nvidia.com/gpudirect) allows GPUs to transfer memory among each other without CPU
+involvement, which significantly reduces latency and load on CPU. NCCL 2 is able to use GPUDirect automatically for
+*allreduce* operation if it detects it.
+
+Additionally, Horovod uses *allgather* and *broadcast* operations from MPI. They are used for averaging sparse tensors
+that are typically used for embeddings, and for broadcasting initial state. To speed these operations up with GPUDirect,
+make sure your MPI implementation supports CUDA and add `HOROVOD_GPU_ALLGATHER=MPI HOROVOD_GPU_BROADCAST=MPI` to the pip
+command.
+
+1. Install [NCCL 2](https://developer.nvidia.com/nccl).
+
+2. Install [Open MPI](https://www.open-mpi.org/).
+
+3. Install the `horovod` pip package.
+
+```bash
+$ HOROVOD_GPU_ALLREDUCE=NCCL HOROVOD_GPU_ALLGATHER=MPI HOROVOD_GPU_BROADCAST=MPI pip install horovod
+```
+
+**Note**: Allgather allocates an output tensor which is proportionate to the number of processes participating in the
+training. If you find yourself running out of GPU memory, you can force allreduce to happen on CPU by passing
+`device_sparse='/cpu:0'` to `hvd.DistributedOptimizer`:
+
+```python
+opt = hvd.DistributedOptimizer(opt, device_sparse='/cpu:0')
+```
+
+### Advanced: Have MPI optimized for your network?
+
+If you happen to have network hardware not supported by NCCL 2 or your MPI vendor's implementation on GPU is faster,
+you can also use the pure MPI version of *allreduce*, *allgather* and *broadcast* on GPU.
+
+1. Make sure your MPI implementation is installed.
+
+2. Install the `horovod` pip package.
+
+```bash
+$ HOROVOD_GPU_ALLREDUCE=MPI HOROVOD_GPU_ALLGATHER=MPI HOROVOD_GPU_BROADCAST=MPI pip install horovod
+```
+
+## Inference
+
+What about inference? Inference may be done outside of the Python script that was used to train the model. If you do this, it
+will not have references to the Horovod library.
+
+To run inference on a checkpoint generated by the Horovod-enabled training script you should optimize the graph and only
+keep operations necessary for a forward pass through network. The [Optimize for Inference](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/tools/optimize_for_inference.py)
+script from the TensorFlow repository will do that for you.
+
+If you want to convert your checkpoint to [Frozen Graph](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/tools/freeze_graph.py),
+you should do so after doing the optimization described above, otherwise the [Freeze Graph](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/tools/freeze_graph.py)
+script will fail to load Horovod op:
+
+```
+ValueError: No op named HorovodAllreduce in defined operations.
+```
+
+## Troubleshooting
+
+### Import TensorFlow failed during installation
+
+1. Is TensorFlow installed?
+
+If you see the error message below, it means that TensorFlow is not installed. Please install TensorFlow before installing
+Horovod.
+
+```
+error: import tensorflow failed, is it installed?
+
+Traceback (most recent call last):
+ File "/tmp/pip-OfE_YX-build/setup.py", line 29, in fully_define_extension
+ import tensorflow as tf
+ImportError: No module named tensorflow
+```
+
+2. Are the CUDA libraries available?
+
+If you see the error message below, it means that TensorFlow cannot be loaded. If you're installing Horovod into a container
+on a machine without GPUs, you may use CUDA stub drivers to work around the issue.
+
+```
+error: import tensorflow failed, is it installed?
+
+Traceback (most recent call last):
+ File "/tmp/pip-41aCq9-build/setup.py", line 29, in fully_define_extension
+ import tensorflow as tf
+ File "/usr/local/lib/python2.7/dist-packages/tensorflow/__init__.py", line 24, in
+ from tensorflow.python import *
+ File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/__init__.py", line 49, in
+ from tensorflow.python import pywrap_tensorflow
+ File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/pywrap_tensorflow.py", line 52, in
+ raise ImportError(msg)
+ImportError: Traceback (most recent call last):
+ File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/pywrap_tensorflow.py", line 41, in
+ from tensorflow.python.pywrap_tensorflow_internal import *
+ File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/pywrap_tensorflow_internal.py", line 28, in
+ _pywrap_tensorflow_internal = swig_import_helper()
+ File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/pywrap_tensorflow_internal.py", line 24, in swig_import_helper
+ _mod = imp.load_module('_pywrap_tensorflow_internal', fp, pathname, description)
+ImportError: libcuda.so.1: cannot open shared object file: No such file or directory
+```
+
+To use CUDA stub drivers:
+
+```bash
+# temporary add stub drivers to ld.so.cache
+$ ldconfig /usr/local/cuda/lib64/stubs
+
+# install Horovod, add other HOROVOD_* environment variables as necessary
+$ pip install horovod
+
+# revert to standard libraries
+$ ldconfig
+```
+
+### Running out of memory
+
+If you notice that your program is running out of GPU memory and multiple processes
+are being placed on the same GPU, it's likely that your program (or its dependencies)
+create a `tf.Session` that does not use the `config` that pins specific GPU.
+
+If possible, track down the part of program that uses these additional `tf.Session`s and pass
+the same configuration.
+
+Alternatively, you can place following snippet in the beginning of your program to ask TensorFlow
+to minimize the amount of memory it will pre-allocate on each GPU:
+
+```python
+small_cfg = tf.ConfigProto()
+small_cfg.gpu_options.allow_growth = True
+with tf.Session(config=small_cfg):
+ pass
+```
+
+As a last resort, you can **replace** setting `config.gpu_options.visible_device_list`
+with different code:
+
+```python
+# Pin GPU to be used
+import os
+os.environ['CUDA_VISIBLE_DEVICES'] = str(hvd.local_rank())
+```
+
+**Note**: Setting `CUDA_VISIBLE_DEVICES` is incompatible with `config.gpu_options.visible_device_list`.
+
+Setting `CUDA_VISIBLE_DEVICES` has additional disadvantage for GPU version - CUDA will not be able to use IPC, which
+will likely cause NCCL and MPI and to fail. In order to disable IPC in NCCL and MPI and allow it to fallback to shared
+memory, use:
+* `export NCCL_P2P_DISABLE=1` for NCCL.
+* `--mca btl_smcuda_use_cuda_ipc 0` flag for OpenMPI and similar flags for other vendors.
diff --git a/examples/tensorflow_mnist.py b/examples/tensorflow_mnist.py
new file mode 100644
index 0000000000..63795bf16a
--- /dev/null
+++ b/examples/tensorflow_mnist.py
@@ -0,0 +1,110 @@
+# Copyright 2017 Uber Technologies, Inc. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#!/usr/bin/env python
+
+import tensorflow as tf
+import horovod.tensorflow as hvd
+layers = tf.contrib.layers
+learn = tf.contrib.learn
+
+tf.logging.set_verbosity(tf.logging.INFO)
+
+
+def conv_model(feature, target, mode):
+ """2-layer convolution model."""
+ # Convert the target to a one-hot tensor of shape (batch_size, 10) and
+ # with a on-value of 1 for each one-hot vector of length 10.
+ target = tf.one_hot(tf.cast(target, tf.int32), 10, 1, 0)
+
+ # Reshape feature to 4d tensor with 2nd and 3rd dimensions being
+ # image width and height final dimension being the number of color channels.
+ feature = tf.reshape(feature, [-1, 28, 28, 1])
+
+ # First conv layer will compute 32 features for each 5x5 patch
+ with tf.variable_scope('conv_layer1'):
+ h_conv1 = layers.conv2d(
+ feature, 32, kernel_size=[5, 5], activation_fn=tf.nn.relu)
+ h_pool1 = tf.nn.max_pool(
+ h_conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
+
+ # Second conv layer will compute 64 features for each 5x5 patch.
+ with tf.variable_scope('conv_layer2'):
+ h_conv2 = layers.conv2d(
+ h_pool1, 64, kernel_size=[5, 5], activation_fn=tf.nn.relu)
+ h_pool2 = tf.nn.max_pool(
+ h_conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
+ # reshape tensor into a batch of vectors
+ h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64])
+
+ # Densely connected layer with 1024 neurons.
+ h_fc1 = layers.dropout(
+ layers.fully_connected(
+ h_pool2_flat, 1024, activation_fn=tf.nn.relu),
+ keep_prob=0.5,
+ is_training=mode == tf.contrib.learn.ModeKeys.TRAIN)
+
+ # Compute logits (1 per class) and compute loss.
+ logits = layers.fully_connected(h_fc1, 10, activation_fn=None)
+ loss = tf.losses.softmax_cross_entropy(target, logits)
+
+ return tf.argmax(logits, 1), loss
+
+
+def main(_):
+ # Initialize Horovod.
+ hvd.init()
+
+ # Download and load MNIST dataset.
+ mnist = learn.datasets.mnist.read_data_sets('MNIST-data-%d' % hvd.rank())
+
+ # Build model...
+ with tf.name_scope('input'):
+ image = tf.placeholder(tf.float32, [None, 784], name='image')
+ label = tf.placeholder(tf.float32, [None], name='label')
+ predict, loss = conv_model(image, label, tf.contrib.learn.ModeKeys.TRAIN)
+
+ opt = tf.train.RMSPropOptimizer(0.01)
+
+ # Add Horovod Distributed Optimizer.
+ opt = hvd.DistributedOptimizer(opt)
+
+ global_step = tf.contrib.framework.get_or_create_global_step()
+ train_op = opt.minimize(loss, global_step=global_step)
+
+ # BroadcastGlobalVariablesHook broadcasts variables from rank 0 to all other
+ # processes during initialization.
+ hooks = [hvd.BroadcastGlobalVariablesHook(0),
+ tf.train.StopAtStepHook(last_step=100),
+ tf.train.LoggingTensorHook(tensors={'step': global_step, 'loss': loss},
+ every_n_iter=10),
+ ]
+
+ # Pin GPU to be used to process local rank (one GPU per process)
+ config = tf.ConfigProto()
+ config.gpu_options.allow_growth = True
+ config.gpu_options.visible_device_list = str(hvd.local_rank())
+
+ # The MonitoredTrainingSession takes care of session initialization,
+ # restoring from a checkpoint, saving to a checkpoint, and closing when done
+ # or an error occurs.
+ with tf.train.SingularMonitoredSession(hooks=hooks, config=config) as mon_sess:
+ while not mon_sess.should_stop():
+ # Run a training step synchronously.
+ image_, label_ = mnist.train.next_batch(100)
+ mon_sess.run(train_op, feed_dict={image: image_, label: label_})
+
+
+if __name__ == "__main__":
+ tf.app.run()
diff --git a/examples/tensorflow_word2vec.py b/examples/tensorflow_word2vec.py
new file mode 100644
index 0000000000..bd4f2f9efa
--- /dev/null
+++ b/examples/tensorflow_word2vec.py
@@ -0,0 +1,245 @@
+# Copyright 2015 The TensorFlow Authors. All Rights Reserved.
+# Modifications copyright (C) 2017 Uber Technologies, Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Basic word2vec example."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import collections
+import math
+import os
+import random
+import zipfile
+
+import numpy as np
+from six.moves import urllib
+from six.moves import xrange # pylint: disable=redefined-builtin
+import tensorflow as tf
+import horovod.tensorflow as hvd
+
+# Initialize Horovod.
+hvd.init()
+
+
+# Step 1: Download the data.
+url = 'http://mattmahoney.net/dc/text8.zip'
+
+
+def maybe_download(filename, expected_bytes):
+ """Download a file if not present, and make sure it's the right size."""
+ if not os.path.exists(filename):
+ filename, _ = urllib.request.urlretrieve(url, filename)
+ statinfo = os.stat(filename)
+ if statinfo.st_size == expected_bytes:
+ print('Found and verified', filename)
+ else:
+ print(statinfo.st_size)
+ raise Exception(
+ 'Failed to verify ' + url + '. Can you get to it with a browser?')
+ return filename
+
+filename = maybe_download('text8-%d.zip' % hvd.rank(), 31344016)
+
+
+# Read the data into a list of strings.
+def read_data(filename):
+ """Extract the first file enclosed in a zip file as a list of words."""
+ with zipfile.ZipFile(filename) as f:
+ data = tf.compat.as_str(f.read(f.namelist()[0])).split()
+ return data
+
+vocabulary = read_data(filename)
+print('Data size', len(vocabulary))
+
+# Step 2: Build the dictionary and replace rare words with UNK token.
+vocabulary_size = 50000
+
+
+def build_dataset(words, n_words):
+ """Process raw inputs into a dataset."""
+ count = [['UNK', -1]]
+ count.extend(collections.Counter(words).most_common(n_words - 1))
+ dictionary = dict()
+ for word, _ in count:
+ dictionary[word] = len(dictionary)
+ data = list()
+ unk_count = 0
+ for word in words:
+ if word in dictionary:
+ index = dictionary[word]
+ else:
+ index = 0 # dictionary['UNK']
+ unk_count += 1
+ data.append(index)
+ count[0][1] = unk_count
+ reversed_dictionary = dict(zip(dictionary.values(), dictionary.keys()))
+ return data, count, dictionary, reversed_dictionary
+
+data, count, dictionary, reverse_dictionary = build_dataset(vocabulary,
+ vocabulary_size)
+del vocabulary # Hint to reduce memory.
+print('Most common words (+UNK)', count[:5])
+print('Sample data', data[:10], [reverse_dictionary[i] for i in data[:10]])
+
+
+# Step 3: Function to generate a training batch for the skip-gram model.
+def generate_batch(batch_size, num_skips, skip_window):
+ assert num_skips <= 2 * skip_window
+ # Adjust batch_size to match num_skips
+ batch_size = batch_size // num_skips * num_skips
+ span = 2 * skip_window + 1 # [ skip_window target skip_window ]
+ # Backtrack a little bit to avoid skipping words in the end of a batch
+ data_index = random.randint(0, len(data) - span - 1)
+ batch = np.ndarray(shape=(batch_size), dtype=np.int32)
+ labels = np.ndarray(shape=(batch_size, 1), dtype=np.int32)
+ buffer = collections.deque(maxlen=span)
+ for _ in range(span):
+ buffer.append(data[data_index])
+ data_index = (data_index + 1) % len(data)
+ for i in range(batch_size // num_skips):
+ target = skip_window # target label at the center of the buffer
+ targets_to_avoid = [skip_window]
+ for j in range(num_skips):
+ while target in targets_to_avoid:
+ target = random.randint(0, span - 1)
+ targets_to_avoid.append(target)
+ batch[i * num_skips + j] = buffer[skip_window]
+ labels[i * num_skips + j, 0] = buffer[target]
+ buffer.append(data[data_index])
+ data_index = (data_index + 1) % len(data)
+ return batch, labels
+
+batch, labels = generate_batch(batch_size=8, num_skips=2, skip_window=1)
+for i in range(8):
+ print(batch[i], reverse_dictionary[batch[i]],
+ '->', labels[i, 0], reverse_dictionary[labels[i, 0]])
+
+# Step 4: Build and train a skip-gram model.
+
+max_batch_size = 128
+embedding_size = 128 # Dimension of the embedding vector.
+skip_window = 1 # How many words to consider left and right.
+num_skips = 2 # How many times to reuse an input to generate a label.
+
+# We pick a random validation set to sample nearest neighbors. Here we limit the
+# validation samples to the words that have a low numeric ID, which by
+# construction are also the most frequent.
+valid_size = 16 # Random set of words to evaluate similarity on.
+valid_window = 100 # Only pick dev samples in the head of the distribution.
+valid_examples = np.random.choice(valid_window, valid_size, replace=False)
+num_sampled = 64 # Number of negative examples to sample.
+
+graph = tf.Graph()
+
+with graph.as_default():
+
+ # Input data.
+ train_inputs = tf.placeholder(tf.int32, shape=[None])
+ train_labels = tf.placeholder(tf.int32, shape=[None, 1])
+ valid_dataset = tf.constant(valid_examples, dtype=tf.int32)
+
+ # Look up embeddings for inputs.
+ embeddings = tf.Variable(
+ tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0))
+ embed = tf.nn.embedding_lookup(embeddings, train_inputs)
+
+ # Construct the variables for the NCE loss
+ nce_weights = tf.Variable(
+ tf.truncated_normal([vocabulary_size, embedding_size],
+ stddev=1.0 / math.sqrt(embedding_size)))
+ nce_biases = tf.Variable(tf.zeros([vocabulary_size]))
+
+ # Compute the average NCE loss for the batch.
+ # tf.nce_loss automatically draws a new sample of the negative labels each
+ # time we evaluate the loss.
+ loss = tf.reduce_mean(
+ tf.nn.nce_loss(weights=nce_weights,
+ biases=nce_biases,
+ labels=train_labels,
+ inputs=embed,
+ num_sampled=num_sampled,
+ num_classes=vocabulary_size))
+
+ # Construct the SGD optimizer using a learning rate of 1.0.
+ optimizer = tf.train.GradientDescentOptimizer(1.0)
+
+ # Add Horovod Distributed Optimizer.
+ optimizer = hvd.DistributedOptimizer(optimizer)
+
+ train_op = optimizer.minimize(loss)
+
+ # Compute the cosine similarity between minibatch examples and all embeddings.
+ norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims=True))
+ normalized_embeddings = embeddings / norm
+ valid_embeddings = tf.nn.embedding_lookup(
+ normalized_embeddings, valid_dataset)
+ similarity = tf.matmul(
+ valid_embeddings, normalized_embeddings, transpose_b=True)
+
+ # Add variable initializer.
+ init = tf.global_variables_initializer()
+
+ # Broadcast variables from rank 0 to all other processes.
+ bcast = hvd.broadcast_global_variables(0)
+
+# Step 5: Begin training.
+num_steps = 100001
+
+# Pin GPU to be used to process local rank (one GPU per process)
+config = tf.ConfigProto()
+config.gpu_options.allow_growth = True
+config.gpu_options.visible_device_list = str(hvd.local_rank())
+
+with tf.Session(graph=graph, config=config) as session:
+ # We must initialize all variables before we use them.
+ init.run()
+ bcast.run()
+ print('Initialized')
+
+ average_loss = 0
+ for step in xrange(num_steps):
+ # simulate various sentence length by randomization
+ batch_size = random.randint(max_batch_size // 2, max_batch_size)
+ batch_inputs, batch_labels = generate_batch(
+ batch_size, num_skips, skip_window)
+ feed_dict = {train_inputs: batch_inputs, train_labels: batch_labels}
+
+ # We perform one update step by evaluating the optimizer op (including it
+ # in the list of returned values for session.run()
+ _, loss_val = session.run([train_op, loss], feed_dict=feed_dict)
+ average_loss += loss_val
+
+ if step % 2000 == 0:
+ if step > 0:
+ average_loss /= 2000
+ # The average loss is an estimate of the loss over the last 2000 batches.
+ print('Average loss at step ', step, ': ', average_loss)
+ average_loss = 0
+
+ # Note that this is expensive (~20% slowdown if computed every 500 steps)
+ if step % 10000 == 0:
+ sim = similarity.eval()
+ for i in xrange(valid_size):
+ valid_word = reverse_dictionary[valid_examples[i]]
+ top_k = 8 # number of nearest neighbors
+ nearest = (-sim[i, :]).argsort()[1:top_k + 1]
+ log_str = 'Nearest to %s:' % valid_word
+ for k in xrange(top_k):
+ close_word = reverse_dictionary[nearest[k]]
+ log_str = '%s %s,' % (log_str, close_word)
+ print(log_str)
+ final_embeddings = normalized_embeddings.eval()
diff --git a/horovod/__init__.py b/horovod/__init__.py
new file mode 100644
index 0000000000..e69de29bb2
diff --git a/horovod/tensorflow/__init__.py b/horovod/tensorflow/__init__.py
new file mode 100644
index 0000000000..f859e01b95
--- /dev/null
+++ b/horovod/tensorflow/__init__.py
@@ -0,0 +1,214 @@
+# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
+# Modifications copyright (C) 2017 Uber Technologies, Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+# pylint: disable=g-short-docstring-punctuation
+"""## Communicating Between Processes with MPI
+
+TensorFlow natively provides inter-device communication through send and
+receive ops and inter-node communication through Distributed TensorFlow, based
+on the same send and receive abstractions. On HPC clusters where Infiniband or
+other high-speed node interconnects are available, these can end up being
+insufficient for synchronous data-parallel training (without asynchronous
+gradient descent). This module implements a variety of MPI ops which can take
+advantage of hardware-specific MPI libraries for efficient communication.
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import tensorflow as tf
+
+from horovod.tensorflow.mpi_ops import size
+from horovod.tensorflow.mpi_ops import rank
+from horovod.tensorflow.mpi_ops import local_rank
+from horovod.tensorflow.mpi_ops import allgather
+from horovod.tensorflow.mpi_ops import broadcast
+from horovod.tensorflow.mpi_ops import _allreduce
+from horovod.tensorflow.mpi_ops import init
+
+
+def allreduce(tensor, average=True, device_dense='', device_sparse=''):
+ """Perform an allreduce on a tf.Tensor or tf.IndexedSlices.
+
+ Arguments:
+ tensor: tf.Tensor, tf.Variable, or tf.IndexedSlices to reduce.
+ The shape of the input must be identical across all ranks.
+ average: If True, computes the average over all ranks.
+ Otherwise, computes the sum over all ranks.
+ device_dense: Device to be used for dense tensors. Uses GPU by default
+ if Horovod was build with HOROVOD_GPU_ALLREDUCE.
+ device_sparse: Device to be used for sparse tensors. Uses GPU by default
+ if Horovod was build with HOROVOD_GPU_ALLGATHER.
+
+ This function performs a bandwidth-optimal ring allreduce on the input
+ tensor. If the input is an tf.IndexedSlices, the function instead does an
+ allgather on the values and the indices, effectively doing an allreduce on
+ the represented tensor.
+ """
+ if isinstance(tensor, tf.IndexedSlices):
+ with tf.device(device_sparse):
+ # For IndexedSlices, do two allgathers intead of an allreduce.
+ horovod_size = tf.cast(size(), tensor.values.dtype)
+ values = allgather(tensor.values)
+ indices = allgather(tensor.indices)
+
+ # To make this operation into an average, divide all gathered values by
+ # the Horovod size.
+ new_values = tf.div(values, horovod_size) if average else values
+ return tf.IndexedSlices(new_values, indices,
+ dense_shape=tensor.dense_shape)
+ else:
+ with tf.device(device_dense):
+ horovod_size = tf.cast(size(), tensor.dtype)
+ summed_tensor = _allreduce(tensor)
+ new_tensor = (tf.div(summed_tensor, horovod_size)
+ if average else summed_tensor)
+ return new_tensor
+
+
+def broadcast_global_variables(root_rank):
+ """Broadcasts all global variables from root rank to all other processes.
+
+ Arguments:
+ root_rank: rank of the process from which global variables will be broadcasted
+ to all other processes.
+ """
+ return tf.group(*[tf.assign(var, broadcast(var, root_rank))
+ for var in tf.global_variables()])
+
+
+class BroadcastGlobalVariablesHook(tf.train.SessionRunHook):
+ """SessionRunHook that will broadcast all global variables from root rank
+ to all other processes during initialization."""
+
+ def __init__(self, root_rank, device=''):
+ """Construct a new BroadcastGlobalVariablesHook that will broadcast all
+ global variables from root rank to all other processes during initialization.
+
+ Args:
+ root_rank:
+ Rank that will send data, other ranks will receive data.
+ device:
+ Device to be used for broadcasting. Uses GPU by default
+ if Horovod was build with HOROVOD_GPU_BROADCAST.
+ """
+ self.root_rank = root_rank
+ self.bcast_op = None
+ self.device = device
+
+ def begin(self):
+ if not self.bcast_op:
+ with tf.device(self.device):
+ self.bcast_op = broadcast_global_variables(self.root_rank)
+
+ def after_create_session(self, session, coord):
+ session.run(self.bcast_op)
+
+
+class DistributedOptimizer(tf.train.Optimizer):
+ """An optimizer that wraps another tf.Optimizer, using an allreduce to
+ average gradient values before applying gradients to model weights."""
+
+ def __init__(self, optimizer, name=None, use_locking=False, device_dense='',
+ device_sparse=''):
+ """Construct a new DistributedOptimizer, which uses another optimizer
+ under the hood for computing single-process gradient values and
+ applying gradient updates after the gradient values have been averaged
+ across all the Horovod ranks.
+
+ Args:
+ optimizer:
+ Optimizer to use for computing gradients and applying updates.
+ name:
+ Optional name prefix for the operations created when applying
+ gradients. Defaults to "Distributed" followed by the provided
+ optimizer type.
+ use_locking:
+ Whether to use locking when updating variables.
+ See Optimizer.__init__ for more info.
+ device_dense:
+ Device to be used for dense tensors. Uses GPU by default
+ if Horovod was build with HOROVOD_GPU_ALLREDUCE.
+ device_sparse:
+ Device to be used for sparse tensors. Uses GPU by default
+ if Horovod was build with HOROVOD_GPU_ALLGATHER.
+ """
+ if name is None:
+ name = "Distributed{}".format(type(optimizer).__name__)
+
+ self._optimizer = optimizer
+ self._device_dense = device_dense
+ self._device_sparse = device_sparse
+ super(DistributedOptimizer, self).__init__(
+ name=name, use_locking=use_locking)
+
+ def compute_gradients(self, *args, **kwargs):
+ """Compute gradients of all trainable variables.
+
+ See Optimizer.compute_gradients() for more info.
+
+ In DistributedOptimizer, compute_gradients() is overriden to also
+ allreduce the gradients before returning them.
+ """
+ gradients = (super(DistributedOptimizer, self)
+ .compute_gradients(*args, **kwargs))
+ if size() > 1:
+ with tf.name_scope(self._name + "_Allreduce"):
+ return [(allreduce(gradient, device_dense=self._device_dense,
+ device_sparse=self._device_sparse), var)
+ for (gradient, var) in gradients]
+ else:
+ return gradients
+
+ def _apply_dense(self, *args, **kwargs):
+ """Calls this same method on the underlying optimizer."""
+ return self._optimizer._apply_dense(*args, **kwargs)
+
+ def _resource_apply_dense(self, *args, **kwargs):
+ """Calls this same method on the underlying optimizer."""
+ return self._optimizer._resource_apply_dense(*args, **kwargs)
+
+ def _resource_apply_sparse_duplicate_indices(self, *args, **kwargs):
+ """Calls this same method on the underlying optimizer."""
+ return self._optimizer._resource_apply_sparse_duplicate_indices(*args, **kwargs)
+
+ def _resource_apply_sparse(self, *args, **kwargs):
+ """Calls this same method on the underlying optimizer."""
+ return self._optimizer._resource_apply_sparse(*args, **kwargs)
+
+ def _apply_sparse_duplicate_indices(self, *args, **kwargs):
+ """Calls this same method on the underlying optimizer."""
+ return self._optimizer._apply_sparse_duplicate_indices(*args, **kwargs)
+
+ def _apply_sparse(self, *args, **kwargs):
+ """Calls this same method on the underlying optimizer."""
+ return self._optimizer._apply_sparse(*args, **kwargs)
+
+ def _prepare(self, *args, **kwargs):
+ """Calls this same method on the underlying optimizer."""
+ return self._optimizer._prepare(*args, **kwargs)
+
+ def _create_slots(self, *args, **kwargs):
+ """Calls this same method on the underlying optimizer."""
+ return self._optimizer._create_slots(*args, **kwargs)
+
+ def _valid_dtypes(self, *args, **kwargs):
+ """Calls this same method on the underlying optimizer."""
+ return self._optimizer._valid_dtypes(*args, **kwargs)
+
+ def _finish(self, *args, **kwargs):
+ """Calls this same method on the underlying optimizer."""
+ return self._optimizer._finish(*args, **kwargs)
diff --git a/horovod/tensorflow/hash_vector.h b/horovod/tensorflow/hash_vector.h
new file mode 100644
index 0000000000..b2d9f30565
--- /dev/null
+++ b/horovod/tensorflow/hash_vector.h
@@ -0,0 +1,38 @@
+// Copyright 2017 Uber Technologies, Inc. All Rights Reserved.
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+// =============================================================================
+
+#ifndef HOROVOD_HASH_VECTOR_H
+#define HOROVOD_HASH_VECTOR_H
+
+#include
+
+namespace std {
+
+template struct hash> {
+ typedef std::vector argument_type;
+ typedef std::size_t result_type;
+
+ result_type operator()(argument_type const& in) const {
+ size_t size = in.size();
+ size_t seed = 0;
+ for (size_t i = 0; i < size; i++)
+ seed ^= std::hash()(in[i]) + 0x9e3779b9 + (seed << 6) + (seed >> 2);
+ return seed;
+ }
+};
+
+} // namespace std
+
+#endif //HOROVOD_HASH_VECTOR_H
diff --git a/horovod/tensorflow/mpi_message.cc b/horovod/tensorflow/mpi_message.cc
new file mode 100644
index 0000000000..1a8d4d12b6
--- /dev/null
+++ b/horovod/tensorflow/mpi_message.cc
@@ -0,0 +1,246 @@
+// Copyright 2016 The TensorFlow Authors. All Rights Reserved.
+// Modifications copyright (C) 2017 Uber Technologies, Inc.
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+// =============================================================================
+
+#include "mpi_message.h"
+#include "wire/mpi_message_generated.h"
+#include
+
+namespace horovod {
+namespace tensorflow {
+
+const std::string& MPIDataType_Name(MPIDataType value) {
+ switch (value) {
+ case TF_MPI_UINT8:
+ static const std::string uint8("uint8");
+ return uint8;
+ case TF_MPI_INT8:
+ static const std::string int8("int8");
+ return int8;
+ case TF_MPI_UINT16:
+ static const std::string uint16("uint16");
+ return uint16;
+ case TF_MPI_INT16:
+ static const std::string int16("int16");
+ return int16;
+ case TF_MPI_INT32:
+ static const std::string int32("int32");
+ return int32;
+ case TF_MPI_INT64:
+ static const std::string int64("int64");
+ return int64;
+ case TF_MPI_FLOAT32:
+ static const std::string float32("float32");
+ return float32;
+ case TF_MPI_FLOAT64:
+ static const std::string float64("float64");
+ return float64;
+ default:
+ static const std::string unknown("");
+ return unknown;
+ }
+}
+
+const std::string& MPIRequest::RequestType_Name(RequestType value) {
+ switch (value) {
+ case RequestType::ALLREDUCE:
+ static const std::string allreduce("ALLREDUCE");
+ return allreduce;
+ case RequestType::ALLGATHER:
+ static const std::string allgather("ALLGATHER");
+ return allgather;
+ case RequestType::BROADCAST:
+ static const std::string broadcast("BROADCAST");
+ return broadcast;
+ default:
+ static const std::string unknown("");
+ return unknown;
+ }
+}
+
+int32_t MPIRequest::request_rank() const { return request_rank_; }
+
+void MPIRequest::set_request_rank(int32_t value) { request_rank_ = value; }
+
+MPIRequest::RequestType MPIRequest::request_type() const {
+ return request_type_;
+}
+
+void MPIRequest::set_request_type(RequestType value) { request_type_ = value; }
+
+MPIDataType MPIRequest::tensor_type() const { return tensor_type_; }
+
+void MPIRequest::set_tensor_type(MPIDataType value) { tensor_type_ = value; }
+
+const std::string& MPIRequest::tensor_name() const { return tensor_name_; }
+
+void MPIRequest::set_tensor_name(const std::string& value) {
+ tensor_name_ = value;
+}
+
+int32_t MPIRequest::root_rank() const { return root_rank_; }
+
+void MPIRequest::set_root_rank(int32_t value) { root_rank_ = value; }
+
+int32_t MPIRequest::device() const { return device_; }
+
+void MPIRequest::set_device(int32_t value) { device_ = value; }
+
+const std::vector& MPIRequest::tensor_shape() const {
+ return tensor_shape_;
+}
+
+void MPIRequest::set_tensor_shape(const std::vector& value) {
+ tensor_shape_ = value;
+}
+
+void MPIRequest::add_tensor_shape(int64_t value) {
+ tensor_shape_.push_back(value);
+}
+
+void MPIRequest::ParseFromString(MPIRequest& request,
+ const std::string& input) {
+ auto obj = flatbuffers::GetRoot((uint8_t*)input.c_str());
+ request.set_request_rank(obj->request_rank());
+ request.set_request_type((MPIRequest::RequestType)obj->request_type());
+ request.set_tensor_type((MPIDataType)obj->tensor_type());
+ request.set_tensor_name(obj->tensor_name()->str());
+ request.set_root_rank(obj->root_rank());
+ request.set_device(obj->device());
+ request.set_tensor_shape(std::vector(obj->tensor_shape()->begin(),
+ obj->tensor_shape()->end()));
+}
+
+void MPIRequest::SerializeToString(MPIRequest& request, std::string& output) {
+ flatbuffers::FlatBufferBuilder builder(1024);
+ wire::MPIRequestBuilder request_builder(builder);
+ request_builder.add_request_rank(request.request_rank());
+ request_builder.add_request_type(
+ (wire::MPIRequestType)request.request_type());
+ request_builder.add_tensor_type((wire::MPIDataType)request.tensor_type());
+ request_builder.add_tensor_name(builder.CreateString(request.tensor_name()));
+ request_builder.add_root_rank(request.root_rank());
+ request_builder.add_device(request.device());
+ request_builder.add_tensor_shape(
+ builder.CreateVector(request.tensor_shape()));
+ auto obj = request_builder.Finish();
+ builder.Finish(obj);
+
+ uint8_t* buf = builder.GetBufferPointer();
+ auto size = builder.GetSize();
+ output = std::string((char*)buf, size);
+}
+
+const std::string& MPIResponse::ResponseType_Name(ResponseType value) {
+ switch (value) {
+ case ResponseType::ALLREDUCE:
+ static const std::string allreduce("ALLREDUCE");
+ return allreduce;
+ case ResponseType::ALLGATHER:
+ static const std::string allgather("ALLGATHER");
+ return allgather;
+ case ResponseType::BROADCAST:
+ static const std::string broadcast("BROADCAST");
+ return broadcast;
+ case ResponseType::ERROR:
+ static const std::string error("ERROR");
+ return error;
+ case ResponseType::DONE:
+ static const std::string done("DONE");
+ return done;
+ case ResponseType::SHUTDOWN:
+ static const std::string shutdown("SHUTDOWN");
+ return shutdown;
+ default:
+ static const std::string unknown("");
+ return unknown;
+ }
+}
+
+MPIResponse::ResponseType MPIResponse::response_type() const {
+ return response_type_;
+}
+
+void MPIResponse::set_response_type(ResponseType value) {
+ response_type_ = value;
+}
+
+const std::string& MPIResponse::tensor_name() const { return tensor_name_; }
+
+void MPIResponse::set_tensor_name(const std::string& value) {
+ tensor_name_ = value;
+}
+
+const std::string& MPIResponse::error_message() const { return error_message_; }
+
+void MPIResponse::set_error_message(const std::string& value) {
+ error_message_ = value;
+}
+
+const std::vector& MPIResponse::devices() const { return devices_; }
+
+void MPIResponse::set_devices(const std::vector& value) {
+ devices_ = value;
+}
+
+void MPIResponse::add_devices(int32_t value) { devices_.push_back(value); }
+
+const std::vector& MPIResponse::tensor_sizes() const {
+ return tensor_sizes_;
+}
+
+void MPIResponse::set_tensor_sizes(const std::vector& value) {
+ tensor_sizes_ = value;
+}
+
+void MPIResponse::add_tensor_sizes(int64_t value) {
+ tensor_sizes_.push_back(value);
+}
+
+void MPIResponse::ParseFromString(MPIResponse& response,
+ const std::string& input) {
+ auto obj = flatbuffers::GetRoot((uint8_t*)input.c_str());
+ response.set_response_type((MPIResponse::ResponseType)obj->response_type());
+ response.set_tensor_name(obj->tensor_name()->str());
+ response.set_error_message(obj->error_message()->str());
+ response.set_devices(
+ std::vector(obj->devices()->begin(), obj->devices()->end()));
+ response.set_tensor_sizes(std::vector(obj->tensor_sizes()->begin(),
+ obj->tensor_sizes()->end()));
+}
+
+void MPIResponse::SerializeToString(MPIResponse& response,
+ std::string& output) {
+ flatbuffers::FlatBufferBuilder builder(1024);
+ wire::MPIResponseBuilder response_builder(builder);
+ response_builder.add_response_type(
+ (wire::MPIResponseType)response.response_type());
+ response_builder.add_tensor_name(
+ builder.CreateString(response.tensor_name()));
+ response_builder.add_error_message(
+ builder.CreateString(response.error_message()));
+ response_builder.add_devices(builder.CreateVector(response.devices()));
+ response_builder.add_tensor_sizes(
+ builder.CreateVector(response.tensor_sizes()));
+ auto obj = response_builder.Finish();
+ builder.Finish(obj);
+
+ uint8_t* buf = builder.GetBufferPointer();
+ auto size = builder.GetSize();
+ output = std::string((char*)buf, size);
+}
+
+} // namespace tensorflow
+} // namespace horovod
diff --git a/horovod/tensorflow/mpi_message.h b/horovod/tensorflow/mpi_message.h
new file mode 100644
index 0000000000..6da559219a
--- /dev/null
+++ b/horovod/tensorflow/mpi_message.h
@@ -0,0 +1,142 @@
+// Copyright 2016 The TensorFlow Authors. All Rights Reserved.
+// Modifications copyright (C) 2017 Uber Technologies, Inc.
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+// =============================================================================
+
+#ifndef HOROVOD_MPI_MESSAGE_H
+#define HOROVOD_MPI_MESSAGE_H
+
+#include
+#include
+
+namespace horovod {
+namespace tensorflow {
+
+enum MPIDataType {
+ TF_MPI_UINT8 = 0,
+ TF_MPI_INT8 = 1,
+ TF_MPI_UINT16 = 2,
+ TF_MPI_INT16 = 3,
+ TF_MPI_INT32 = 4,
+ TF_MPI_INT64 = 5,
+ TF_MPI_FLOAT32 = 6,
+ TF_MPI_FLOAT64 = 7
+};
+
+const std::string& MPIDataType_Name(MPIDataType value);
+
+// An MPIRequest is a message sent from a rank greater than zero to the
+// coordinator (rank zero), informing the coordinator of an operation that
+// the rank wants to do and the tensor that it wants to apply the operation to.
+class MPIRequest {
+public:
+ enum RequestType { ALLREDUCE = 0, ALLGATHER = 1, BROADCAST = 2 };
+
+ static const std::string& RequestType_Name(RequestType value);
+
+ // The request rank is necessary to create a consistent ordering of results,
+ // for example in the allgather where the order of outputs should be sorted
+ // by rank.
+ int32_t request_rank() const;
+ void set_request_rank(int32_t value);
+
+ RequestType request_type() const;
+ void set_request_type(RequestType value);
+
+ MPIDataType tensor_type() const;
+ void set_tensor_type(MPIDataType value);
+
+ const std::string& tensor_name() const;
+ void set_tensor_name(const std::string& value);
+
+ int32_t root_rank() const;
+ void set_root_rank(int32_t value);
+
+ int32_t device() const;
+ void set_device(int32_t value);
+
+ const std::vector& tensor_shape() const;
+ void set_tensor_shape(const std::vector& value);
+ void add_tensor_shape(int64_t value);
+
+ static void ParseFromString(MPIRequest& request, const std::string& input);
+ static void SerializeToString(MPIRequest& request, std::string& output);
+
+private:
+ int32_t request_rank_;
+ RequestType request_type_;
+ MPIDataType tensor_type_;
+ int32_t root_rank_;
+ int32_t device_;
+ std::string tensor_name_;
+ std::vector tensor_shape_;
+};
+
+// An MPIResponse is a message sent from the coordinator (rank zero) to a rank
+// greater than zero, informing the rank of an operation should be performed
+// now. If the operation requested would result in an error (for example, due
+// to a type or shape mismatch), then the MPIResponse can contain an error and
+// an error message instead. Finally, an MPIResponse can be a DONE message (if
+// there are no more tensors to reduce on this tick of the background loop) or
+// SHUTDOWN if all MPI processes should shut down.
+class MPIResponse {
+public:
+ enum ResponseType {
+ ALLREDUCE = 0,
+ ALLGATHER = 1,
+ BROADCAST = 2,
+ ERROR = 3,
+ DONE = 4,
+ SHUTDOWN = 5
+ };
+
+ static const std::string& ResponseType_Name(ResponseType value);
+
+ ResponseType response_type() const;
+ void set_response_type(ResponseType value);
+
+ // Empty if the type is DONE or SHUTDOWN.
+ const std::string& tensor_name() const;
+ void set_tensor_name(const std::string& value);
+
+ // Empty unless response_type is ERROR.
+ const std::string& error_message() const;
+ void set_error_message(const std::string& value);
+
+ const std::vector& devices() const;
+ void set_devices(const std::vector& value);
+ void add_devices(int32_t value);
+
+ // Empty unless response_type is ALLGATHER.
+ // These tensor sizes are the dimension zero sizes of all the input matrices,
+ // indexed by the rank.
+ const std::vector& tensor_sizes() const;
+ void set_tensor_sizes(const std::vector& value);
+ void add_tensor_sizes(int64_t value);
+
+ static void ParseFromString(MPIResponse& response, const std::string& input);
+ static void SerializeToString(MPIResponse& response, std::string& output);
+
+private:
+ ResponseType response_type_;
+ std::string tensor_name_;
+ std::string error_message_;
+ std::vector devices_;
+ std::vector tensor_sizes_;
+};
+
+} // namespace tensorflow
+} // namespace horovod
+
+#endif // HOROVOD_MPI_MESSAGE_H
diff --git a/horovod/tensorflow/mpi_ops.cc b/horovod/tensorflow/mpi_ops.cc
new file mode 100644
index 0000000000..27ee4b94b9
--- /dev/null
+++ b/horovod/tensorflow/mpi_ops.cc
@@ -0,0 +1,1451 @@
+// Copyright 2016 The TensorFlow Authors. All Rights Reserved.
+// Modifications copyright (C) 2017 Uber Technologies, Inc.
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+// =============================================================================
+
+#include
+#include
+#include
+
+#include "tensorflow/core/framework/op.h"
+#include "tensorflow/core/framework/op_kernel.h"
+#include "tensorflow/core/framework/shape_inference.h"
+
+#define EIGEN_USE_THREADS
+
+#if HAVE_CUDA
+#include "tensorflow/stream_executor/stream.h"
+#include
+#endif
+
+#if HAVE_NCCL
+#include
+#endif
+
+#define OMPI_SKIP_MPICXX
+#include "mpi.h"
+#include "mpi_message.h"
+#include "hash_vector.h"
+
+/*
+ * Allreduce, Allgather and Broadcast Ops for TensorFlow.
+ *
+ * TensorFlow natively provides inter-device communication through send and
+ * receive ops and inter-node communication through Distributed TensorFlow,
+ * based on the same send and receive abstractions. These end up being
+ * insufficient for synchronous data-parallel training on HPC clusters where
+ * Infiniband or other high-speed interconnects are available. This module
+ * implements MPI ops for allgather, allreduce and broadcast, which do
+ * optimized gathers, reductions and broadcasts and can take advantage of
+ * hardware-optimized communication libraries through the MPI implementation.
+ *
+ * The primary logic of the allreduce, allgather and broadcast are in MPI and
+ * NCCL implementations. The background thread which facilitates MPI operations
+ * is run in BackgroundThreadLoop(). The provided ops are:
+ * – HorovodAllreduce:
+ * Perform an allreduce on a Tensor, returning the sum
+ * across all MPI processes in the global communicator.
+ * – HorovodAllgather:
+ * Perform an allgather on a Tensor, returning the concatenation of
+ * the tensor on the first dimension across all MPI processes in the
+ * global communicator.
+ * - HorovodBroadcast:
+ * Perform a broadcast on a Tensor, broadcasting Tensor
+ * value from root rank to all other ranks.
+ *
+ * Additionally, this library provides C APIs to initialize Horovod and query
+ * rank, local rank and world size. These are used in Python directly through
+ * ctypes.
+ */
+
+using namespace tensorflow;
+
+namespace horovod {
+namespace tensorflow {
+
+namespace {
+
+// Device ID used for CPU.
+#define CPU_DEVICE_ID -1
+
+// Use void pointer for ready event if CUDA is not present to avoid linking
+// error.
+#if HAVE_CUDA
+#define GPU_EVENT_IF_CUDA perftools::gputools::Event*
+#else
+#define GPU_EVENT_IF_CUDA void*
+#endif
+
+// A callback to call after the MPI communication completes. Since the
+// allreduce and allgather ops are asynchronous, this callback is what resumes
+// computation after the reduction is completed.
+typedef std::function StatusCallback;
+
+// Table storing Tensors to be reduced, keyed by unique name.
+// This table contains everything necessary to do the reduction.
+typedef struct {
+ // Operation context.
+ OpKernelContext* context;
+ // Input tensor.
+ Tensor tensor;
+ // Pre-allocated output tensor.
+ Tensor* output;
+ // Root rank for broadcast operation.
+ int root_rank;
+ // Event indicating that data is ready.
+ GPU_EVENT_IF_CUDA ready_event;
+ // GPU to do reduction on, or CPU_DEVICE_ID in case of CPU.
+ int device;
+ // A callback to call with the status.
+ StatusCallback callback;
+} TensorTableEntry;
+typedef std::unordered_map TensorTable;
+
+// Table for storing Tensor metadata on rank zero. This is used for error
+// checking, stall checking and size calculations, as well as determining
+// when a reduction is ready to be done (when all nodes are ready to do it).
+typedef std::unordered_map<
+ std::string,
+ std::tuple, std::chrono::system_clock::time_point>>
+ MessageTable;
+
+// The global state required for the MPI ops.
+//
+// MPI is a library that stores a lot of global per-program state and often
+// requires running on a single thread. As a result, we have to have a single
+// background thread responsible for all MPI operations, and communicate with
+// that background thread through global state.
+struct HorovodGlobalState {
+ // An atomic boolean which is set to true when background thread is started.
+ // This ensures that only one background thread is spawned.
+ std::atomic_flag initialize_flag = ATOMIC_FLAG_INIT;
+
+ // A mutex that needs to be used whenever MPI operations are done.
+ std::mutex mutex;
+
+ // Tensors waiting to be allreduced or allgathered.
+ TensorTable tensor_table;
+
+ // Queue of MPI requests waiting to be sent to the coordinator node.
+ std::queue message_queue;
+
+ // Background thread running MPI communication.
+ std::thread background_thread;
+
+ // Whether the background thread should shutdown.
+ bool shut_down = false;
+
+ // Only exists on the coordinator node (rank zero). Maintains a count of
+ // how many nodes are ready to allreduce every tensor (keyed by tensor
+ // name) and time point when tensor started allreduce op.
+ std::unique_ptr message_table;
+
+ // Time point when coordinator last checked for stalled tensors.
+ std::chrono::system_clock::time_point last_stall_check;
+
+ // Whether MPI_Init has been completed on the background thread.
+ bool initialization_done = false;
+
+ // The MPI rank, local rank, and size.
+ int rank = 0;
+ int local_rank = 0;
+ int size = 1;
+
+// The CUDA stream used for data transfers and within-allreduce operations.
+// A naive implementation would use the TensorFlow StreamExecutor CUDA
+// stream. However, the allreduce and allgather require doing memory copies
+// and kernel executions (for accumulation of values on the GPU). However,
+// the subsequent operations must wait for those operations to complete,
+// otherwise MPI (which uses its own stream internally) will begin the data
+// transfers before the CUDA calls are complete. In order to wait for those
+// CUDA operations, if we were using the TensorFlow stream, we would have to
+// synchronize that stream; however, other TensorFlow threads may be
+// submitting more work to that stream, so synchronizing on it can cause the
+// allreduce to be delayed, waiting for compute totally unrelated to it in
+// other parts of the graph. Overlaying memory transfers and compute during
+// backpropagation is crucial for good performance, so we cannot use the
+// TensorFlow stream, and must use our own stream.
+#if HAVE_NCCL
+ std::unordered_map streams;
+ std::unordered_map, ncclComm_t> nccl_comms;
+#endif
+
+ ~HorovodGlobalState() {
+ // Make sure that the destructor of the background thread is safe to
+ // call. If a thread is still joinable (not detached or complete) its
+ // destructor cannot be called.
+ if (background_thread.joinable()) {
+ shut_down = true;
+ background_thread.join();
+ }
+ }
+};
+
+// All the Horovod state that must be stored globally per-process.
+static HorovodGlobalState horovod_global;
+
+// For clarify in argument lists.
+#define RANK_ZERO 0
+
+// A tag used for all coordinator messaging.
+#define TAG_NOTIFY 1
+
+// Stall-check warning time
+#define STALL_WARNING_TIME std::chrono::seconds(60)
+
+// Store the MPIRequest for a name, and return whether the total count of
+// MPIRequests for that tensor is now equal to the MPI size (and thus we are
+// ready to reduce the tensor).
+bool IncrementTensorCount(std::unique_ptr& message_table,
+ MPIRequest msg, int mpi_size) {
+ auto name = msg.tensor_name();
+ auto table_iter = message_table->find(name);
+ if (table_iter == message_table->end()) {
+ std::vector messages = {msg};
+ auto now = std::chrono::system_clock::now();
+ message_table->emplace(name, std::make_tuple(std::move(messages), now));
+ table_iter = message_table->find(name);
+ } else {
+ std::vector& messages = std::get<0>(table_iter->second);
+ messages.push_back(msg);
+ }
+
+ std::vector& messages = std::get<0>(table_iter->second);
+ int count = (int)messages.size();
+ return count == mpi_size;
+}
+
+// Once a tensor is ready to be reduced, the coordinator sends an MPIResponse
+// instructing all ranks to start the reduction to all ranks. The MPIResponse
+// also contains error messages in case the submitted MPIRequests were not
+// valid (for example, contained mismatched shapes or types).
+//
+// Constructing the MPIResponse, thus, requires a whole lot of error checking.
+MPIResponse ConstructMPIResponse(std::unique_ptr& message_table,
+ std::string name) {
+ bool error = false;
+ auto it = message_table->find(name);
+ assert(it != message_table->end());
+
+ std::vector& requests = std::get<0>(it->second);
+ assert(requests.size() > 0);
+
+ std::ostringstream error_message_stream;
+
+ // Check that all data types of tensors being reduced, gathered or broadcasted
+ // are identical.
+ auto data_type = requests[0].tensor_type();
+ for (unsigned int i = 1; i < requests.size(); i++) {
+ auto request_type = requests[i].tensor_type();
+ if (data_type != request_type) {
+ error = true;
+ error_message_stream << "Mismatched data types: One rank had type "
+ << MPIDataType_Name(data_type)
+ << ", but another rank had type "
+ << MPIDataType_Name(request_type) << ".";
+ break;
+ }
+ }
+
+ // Check that all requested operations are the same
+ auto message_type = requests[0].request_type();
+ for (unsigned int i = 1; i < requests.size(); i++) {
+ if (error) {
+ break;
+ }
+
+ auto request_type = requests[i].request_type();
+ if (message_type != request_type) {
+ error = true;
+ error_message_stream << "Mismatched MPI operations: One rank did an "
+ << MPIRequest::RequestType_Name(message_type)
+ << ", but another rank did an "
+ << MPIRequest::RequestType_Name(request_type) << ".";
+ break;
+ }
+ }
+
+ // If we are doing an allreduce or broadcast, check that all tensor shapes are
+ // identical.
+ if (message_type == MPIRequest::ALLREDUCE ||
+ message_type == MPIRequest::BROADCAST) {
+ TensorShape tensor_shape;
+ for (auto it = requests[0].tensor_shape().begin();
+ it != requests[0].tensor_shape().end(); it++) {
+ tensor_shape.AddDim(*it);
+ }
+ for (unsigned int i = 1; i < requests.size(); i++) {
+ if (error) {
+ break;
+ }
+
+ TensorShape request_shape;
+ for (auto it = requests[i].tensor_shape().begin();
+ it != requests[i].tensor_shape().end(); it++) {
+ request_shape.AddDim(*it);
+ }
+ if (tensor_shape != request_shape) {
+ error = true;
+ error_message_stream
+ << "Mismatched " << MPIRequest::RequestType_Name(message_type)
+ << " tensor shapes: One rank sent a tensor of shape "
+ << tensor_shape.DebugString()
+ << ", but another rank sent a tensor of shape "
+ << request_shape.DebugString() << ".";
+ break;
+ }
+ }
+ }
+
+ // If we are doing an allgather, make sure all but the first dimension are
+ // the same. The first dimension may be different and the output tensor is
+ // the sum of the first dimension. Collect the sizes by rank.
+ std::vector tensor_sizes(requests.size());
+ if (message_type == MPIRequest::ALLGATHER) {
+ TensorShape tensor_shape;
+ for (auto it = requests[0].tensor_shape().begin();
+ it != requests[0].tensor_shape().end(); it++) {
+ tensor_shape.AddDim(*it);
+ }
+
+ if (tensor_shape.dims() == 0) {
+ error = true;
+ error_message_stream << "Rank zero tried to "
+ << MPIRequest::RequestType_Name(message_type)
+ << " a rank-zero tensor.";
+ } else {
+ tensor_sizes[requests[0].request_rank()] =
+ size_t(tensor_shape.dim_size(0));
+ }
+
+ for (unsigned int i = 1; i < requests.size(); i++) {
+ if (error) {
+ break;
+ }
+
+ TensorShape request_shape;
+ for (auto it = requests[i].tensor_shape().begin();
+ it != requests[i].tensor_shape().end(); it++) {
+ request_shape.AddDim(*it);
+ }
+ if (tensor_shape.dims() != request_shape.dims()) {
+ error = true;
+ error_message_stream
+ << "Mismatched " << MPIRequest::RequestType_Name(message_type)
+ << " tensor shapes: One rank sent a tensor of rank "
+ << tensor_shape.dims()
+ << ", but another rank sent a tensor of rank "
+ << request_shape.dims() << ".";
+ break;
+ }
+
+ bool dim_mismatch = false;
+ for (int dim = 1; dim < tensor_shape.dims(); dim++) {
+ if (tensor_shape.dim_size(dim) != request_shape.dim_size(dim)) {
+ error = true;
+ error_message_stream
+ << "Mismatched " << MPIRequest::RequestType_Name(message_type)
+ << " tensor shapes: One rank sent a tensor with dimension " << dim
+ << " equal to " << tensor_shape.dim_size(dim)
+ << ", but another rank sent a tensor with dimension " << dim
+ << " equal to " << request_shape.dim_size(dim) << ".";
+ dim_mismatch = true;
+ break;
+ }
+ }
+ if (dim_mismatch) {
+ break;
+ }
+
+ tensor_sizes[requests[i].request_rank()] =
+ size_t(request_shape.dim_size(0));
+ }
+ }
+
+ // If we are doing a broadcast, check that all root ranks are identical.
+ if (message_type == MPIRequest::BROADCAST) {
+ int first_root_rank = requests[0].root_rank();
+ for (unsigned int i = 1; i < requests.size(); i++) {
+ if (error) {
+ break;
+ }
+
+ int this_root_rank = requests[i].root_rank();
+ if (first_root_rank != this_root_rank) {
+ error = true;
+ error_message_stream
+ << "Mismatched " << MPIRequest::RequestType_Name(message_type)
+ << " root ranks: One rank specified root rank " << first_root_rank
+ << ", but another rank specified root rank " << this_root_rank
+ << ".";
+ break;
+ }
+ }
+ }
+
+ bool first_device_is_cpu = requests[0].device() == CPU_DEVICE_ID;
+ for (unsigned int i = 1; i < requests.size(); i++) {
+ if (error) {
+ break;
+ }
+
+ bool this_device_is_cpu = requests[i].device() == CPU_DEVICE_ID;
+ if (first_device_is_cpu != this_device_is_cpu) {
+ error = true;
+ error_message_stream
+ << "Mismatched " << MPIRequest::RequestType_Name(message_type)
+ << " CPU/GPU device selection: One rank specified device "
+ << (first_device_is_cpu ? "CPU" : "GPU")
+ << ", but another rank specified device "
+ << (this_device_is_cpu ? "CPU" : "GPU") << ".";
+ break;
+ }
+ }
+ std::vector devices(requests.size());
+ for (auto it = requests.begin(); it != requests.end(); it++) {
+ devices[it->request_rank()] = it->device();
+ }
+
+ MPIResponse response;
+ response.set_tensor_name(name);
+ if (error) {
+ std::string error_message = error_message_stream.str();
+ response.set_response_type(MPIResponse::ERROR);
+ response.set_error_message(error_message);
+ } else if (message_type == MPIRequest::ALLGATHER) {
+ response.set_response_type(MPIResponse::ALLGATHER);
+ for (auto dim : tensor_sizes) {
+ response.add_tensor_sizes(dim);
+ }
+ } else if (message_type == MPIRequest::ALLREDUCE) {
+ response.set_response_type(MPIResponse::ALLREDUCE);
+ } else if (message_type == MPIRequest::BROADCAST) {
+ response.set_response_type(MPIResponse::BROADCAST);
+ }
+ response.set_devices(devices);
+
+ // Clear all queued up requests for this name. They are now taken care of
+ // by the constructed MPI response.
+ message_table->erase(it);
+
+ return response;
+}
+
+Status GetMPIDataType(const Tensor tensor, MPI_Datatype* dtype) {
+ switch (tensor.dtype()) {
+ case DT_UINT8:
+ *dtype = MPI_UINT8_T;
+ return Status::OK();
+ case DT_INT8:
+ *dtype = MPI_INT8_T;
+ return Status::OK();
+ case DT_UINT16:
+ *dtype = MPI_UINT16_T;
+ return Status::OK();
+ case DT_INT16:
+ *dtype = MPI_INT16_T;
+ return Status::OK();
+ case DT_INT32:
+ *dtype = MPI_INT32_T;
+ return Status::OK();
+ case DT_INT64:
+ *dtype = MPI_INT64_T;
+ return Status::OK();
+ case DT_FLOAT:
+ *dtype = MPI_FLOAT;
+ return Status::OK();
+ case DT_DOUBLE:
+ *dtype = MPI_DOUBLE;
+ return Status::OK();
+ default:
+ // This is not reachable normally since we specify acceptable
+ // data types in Op definition.
+ return errors::Internal("Invalid tensor type.");
+ }
+}
+
+#if HAVE_NCCL
+Status GetNCCLDataType(const Tensor tensor, ncclDataType_t* dtype) {
+ switch (tensor.dtype()) {
+ case DT_INT32:
+ *dtype = ncclInt32;
+ return Status::OK();
+ case DT_INT64:
+ *dtype = ncclInt64;
+ return Status::OK();
+ case DT_FLOAT:
+ *dtype = ncclFloat32;
+ return Status::OK();
+ case DT_DOUBLE:
+ *dtype = ncclFloat64;
+ return Status::OK();
+ default:
+ // This is not reachable normally since we specify acceptable
+ // data types in Op definition.
+ return errors::Internal("Invalid tensor type.");
+ }
+}
+#endif
+
+#define MPI_CHECK(e, op_name, op) \
+ { \
+ auto mpi_result = (op); \
+ if (mpi_result != MPI_SUCCESS) { \
+ e.callback( \
+ errors::Unknown(op_name, " failed, see MPI output for details.")); \
+ return; \
+ } \
+ }
+
+#define CUDA_CHECK(e, op_name, op) \
+ { \
+ auto cuda_result = (op); \
+ if (cuda_result != cudaSuccess) { \
+ e.callback(errors::Unknown( \
+ op_name, " failed: ", cudaGetErrorString(cuda_result))); \
+ return; \
+ } \
+ }
+
+#define NCCL_CHECK(e, op_name, op) \
+ { \
+ auto nccl_result = (op); \
+ if (nccl_result != ncclSuccess) { \
+ e.callback(errors::Unknown( \
+ op_name, " failed: ", ncclGetErrorString(nccl_result))); \
+ return; \
+ } \
+ }
+
+// Process an MPIResponse by doing a reduction, a gather, a broadcast, or
+// raising an error.
+void PerformOperation(TensorTable& tensor_table, MPIResponse response) {
+ TensorTableEntry e;
+ {
+ // Lock on the tensor table.
+ std::lock_guard guard(horovod_global.mutex);
+
+ // We should never fail at finding this key in the tensor table.
+ auto name = response.tensor_name();
+ auto iter = tensor_table.find(name);
+ assert(iter != tensor_table.end());
+
+ assert(response.response_type() == MPIResponse::ALLREDUCE ||
+ response.response_type() == MPIResponse::ALLGATHER ||
+ response.response_type() == MPIResponse::BROADCAST ||
+ response.response_type() == MPIResponse::ERROR);
+
+ e = iter->second;
+
+ // Clear the tensor table of this tensor and its callbacks; the rest of
+ // this function takes care of it.
+ tensor_table.erase(iter);
+ }
+
+#if HAVE_CUDA
+ // On GPU data readiness is signalled by ready_event.
+ if (e.ready_event != nullptr) {
+ while (e.ready_event->PollForStatus() ==
+ perftools::gputools::Event::Status::kPending) {
+ std::this_thread::sleep_for(std::chrono::nanoseconds(100));
+ }
+ }
+#endif
+
+ Status status;
+ if (response.response_type() == MPIResponse::ALLGATHER) {
+ // Copy tensor sizes from the MPI response into a vector of size_t
+ // and compute total size. This is size of first dimension.
+ std::vector tensor_sizes;
+ size_t total_dimension_size = 0;
+ for (auto it = response.tensor_sizes().begin();
+ it != response.tensor_sizes().end(); it++) {
+ tensor_sizes.push_back(size_t(*it));
+ total_dimension_size += size_t(*it);
+ }
+
+ // Every tensor participating in Allgather operation may have different
+ // first dimension size, but the rest of dimensions are same for all
+ // tensors. Here we get shape of tensor sliced by first dimension.
+ TensorShape single_slice_shape;
+ for (int i = 1; i < e.tensor.shape().dims(); i++) {
+ single_slice_shape.AddDim(e.tensor.dim_size(i));
+ }
+
+ // Allgather output will have shape of:
+ // (sum of first dimension of every tensor) x (tensor slice shape).
+ TensorShape output_shape;
+ output_shape.AddDim((int64)total_dimension_size);
+ output_shape.AppendShape(single_slice_shape);
+
+ status = e.context->allocate_output(0, output_shape, &e.output);
+ if (!status.ok()) {
+ e.callback(status);
+ return;
+ }
+
+#if HAVE_CUDA
+ // On GPU allocation is asynchronous, we need to wait for it to complete.
+ auto device_context = e.context->op_device_context();
+ if (device_context != nullptr) {
+ device_context->stream()->BlockHostUntilDone();
+ }
+#endif
+
+ MPI_Datatype dtype;
+ status = GetMPIDataType(e.tensor, &dtype);
+ if (!status.ok()) {
+ e.callback(status);
+ return;
+ }
+
+ // Tensors may have different first dimension, so we need to use
+ // MPI_Allgatherv API that supports gathering arrays of different length.
+ int* recvcounts = new int[tensor_sizes.size()];
+ int* displcmnts = new int[tensor_sizes.size()];
+ for (size_t i = 0; i < tensor_sizes.size(); i++) {
+ recvcounts[i] =
+ (int)(single_slice_shape.num_elements() * tensor_sizes[i]);
+ if (i == 0) {
+ displcmnts[i] = 0;
+ } else {
+ displcmnts[i] = recvcounts[i - 1] + displcmnts[i - 1];
+ }
+ }
+ auto result = MPI_Allgatherv((const void*)e.tensor.tensor_data().data(),
+ (int)e.tensor.NumElements(), dtype,
+ (void*)e.output->tensor_data().data(),
+ recvcounts, displcmnts, dtype, MPI_COMM_WORLD);
+ delete[] recvcounts;
+ delete[] displcmnts;
+ MPI_CHECK(e, "MPI_Allgatherv", result)
+
+ e.callback(Status::OK());
+
+ } else if (response.response_type() == MPIResponse::ALLREDUCE) {
+#if HOROVOD_GPU_ALLREDUCE == 'N' // 'N' stands for NCCL
+ bool on_gpu = e.device != CPU_DEVICE_ID;
+ if (on_gpu) {
+ CUDA_CHECK(e, "cudaSetDevice", cudaSetDevice(e.device))
+
+ // Ensure stream is in the map before executing reduction.
+ cudaStream_t& stream = horovod_global.streams[e.device];
+ if (stream == nullptr) {
+ CUDA_CHECK(e, "cudaStreamCreate", cudaStreamCreate(&stream))
+ }
+
+ // Ensure NCCL communicator is in the map before executing reduction.
+ ncclComm_t& nccl_comm = horovod_global.nccl_comms[response.devices()];
+ if (nccl_comm == nullptr) {
+ ncclUniqueId nccl_id;
+ if (horovod_global.rank == 0) {
+ NCCL_CHECK(e, "ncclGetUniqueId", ncclGetUniqueId(&nccl_id))
+ }
+
+ MPI_CHECK(e, "MPI_Bcast",
+ MPI_Bcast((void*)&nccl_id, sizeof(nccl_id), MPI_BYTE, 0,
+ MPI_COMM_WORLD));
+
+ NCCL_CHECK(e, "ncclCommInitRank",
+ ncclCommInitRank(&nccl_comm, horovod_global.size, nccl_id,
+ horovod_global.rank))
+
+ // TODO: Rohit (NVIDIA): figure out why we need this sleep
+ std::this_thread::sleep_for(std::chrono::seconds(1));
+ }
+
+ ncclDataType_t dtype;
+ status = GetNCCLDataType(e.tensor, &dtype);
+ if (!status.ok()) {
+ e.callback(status);
+ return;
+ }
+
+ NCCL_CHECK(e, "ncclAllReduce",
+ ncclAllReduce((const void*)e.tensor.tensor_data().data(),
+ (void*)e.output->tensor_data().data(),
+ (size_t)e.tensor.NumElements(), dtype, ncclSum,
+ nccl_comm, stream))
+
+ // Use completion marker via event because it's faster than
+ // cudaStreamSynchronize().
+ cudaEvent_t event;
+ CUDA_CHECK(e, "cudaEventCreateWithFlags",
+ cudaEventCreateWithFlags(&event, cudaEventBlockingSync |
+ cudaEventDisableTiming))
+ CUDA_CHECK(e, "cudaEventRecord",
+ cudaEventRecord(event, horovod_global.streams[e.device]))
+
+ // TODO: use thread pool or single thread for callbacks
+ std::thread finalizer_thread([e, event] {
+ CUDA_CHECK(e, "cudaSetDevice", cudaSetDevice(e.device))
+ CUDA_CHECK(e, "cudaEventSynchronize", cudaEventSynchronize(event))
+ e.callback(Status::OK());
+ cudaEventDestroy(event);
+ });
+ finalizer_thread.detach();
+ return;
+ }
+#endif
+
+ MPI_Datatype dtype;
+ status = GetMPIDataType(e.tensor, &dtype);
+ if (!status.ok()) {
+ e.callback(status);
+ return;
+ }
+
+ MPI_CHECK(e, "MPI_Allreduce",
+ MPI_Allreduce((const void*)e.tensor.tensor_data().data(),
+ (void*)e.output->tensor_data().data(),
+ (int)e.tensor.NumElements(), dtype, MPI_SUM,
+ MPI_COMM_WORLD))
+
+ e.callback(Status::OK());
+
+ } else if (response.response_type() == MPIResponse::BROADCAST) {
+ MPI_Datatype dtype;
+ status = GetMPIDataType(e.tensor, &dtype);
+ if (!status.ok()) {
+ e.callback(status);
+ return;
+ }
+
+ // On root rank, MPI_Bcast sends data, on other ranks it receives data.
+ void* data_ptr;
+ if (horovod_global.rank == e.root_rank) {
+ data_ptr = (void*)e.tensor.tensor_data().data();
+ } else {
+ data_ptr = (void*)e.output->tensor_data().data();
+ }
+
+ MPI_CHECK(e, "MPI_Bcast",
+ MPI_Bcast(data_ptr, (int)e.tensor.NumElements(), dtype,
+ e.root_rank, MPI_COMM_WORLD))
+
+ e.callback(Status::OK());
+
+ } else if (response.response_type() == MPIResponse::ERROR) {
+ status = errors::FailedPrecondition(response.error_message());
+ e.callback(status);
+ }
+}
+
+// Report Tensors that were submitted to be reduced, gathered or broadcasted by
+// some ranks but not others and are waiting for long time to get processed.
+void CheckForStalledTensors(HorovodGlobalState& state) {
+ bool preamble = false;
+ auto now = std::chrono::system_clock::now();
+ for (auto it = state.message_table->begin(); it != state.message_table->end();
+ it++) {
+ auto tensor_name = it->first;
+ std::vector& messages = std::get<0>(it->second);
+ std::chrono::system_clock::time_point start_at = std::get<1>(it->second);
+
+ if (now - start_at > STALL_WARNING_TIME) {
+ if (!preamble) {
+ std::cerr << "WARNING: One or more tensors were submitted to be "
+ "reduced, gathered or broadcasted by subset of ranks and "
+ "are waiting for remainder of ranks for more than "
+ << std::chrono::duration_cast(
+ STALL_WARNING_TIME)
+ .count()
+ << " seconds. ";
+ std::cerr << "This may indicate that different ranks are trying to "
+ "submit different tensors or that only subset of ranks is "
+ "submitting tensors, which will cause deadlock. ";
+ std::cerr << "Stalled ops: ";
+ preamble = true;
+ } else {
+ std::cerr << ", ";
+ }
+ std::cerr << tensor_name;
+ std::cerr << " [ready ranks:";
+ for (auto msg_iter = messages.begin(); msg_iter != messages.end();
+ msg_iter++) {
+ if (msg_iter == messages.begin()) {
+ std::cerr << " ";
+ } else {
+ std::cerr << ", ";
+ }
+ std::cerr << msg_iter->request_rank();
+ }
+ std::cerr << "]";
+ }
+ }
+ if (preamble) {
+ std::cerr << std::endl;
+ }
+}
+
+// The MPI background thread loop coordinates all the MPI processes and the
+// tensor reductions. The design of the communicator mechanism is limited by a
+// few considerations:
+//
+// 1. Some MPI implementations require all MPI calls to happen from a
+// single thread. Since TensorFlow may use several threads for graph
+// processing, this means we must have our own dedicated thread for dealing
+// with MPI.
+// 2. We want to gracefully handle errors, when MPI processes do not
+// properly agree upon what should happen (such as mismatched types or
+// shapes). To do so requires the MPI processes to know about the shapes
+// and types of the relevant tensors on the other processes.
+// 3. The MPI reductions and gathers should be able to happen in parallel
+// with other ongoing operations. This means that they cannot be blocking
+// ops, but rather must be async ops, the execution of which happens on a
+// separate thread.
+// 4. We cannot guarantee that all the MPI processes reduce their tensors
+// in the same order, so we cannot dispatch one thread per tensor,
+// otherwise we may end up dispatching many blocked threads and never make
+// progress if we have a thread pool limit.
+//
+// The coordinator currently follows a master-worker paradigm. Rank zero acts
+// as the master (the "coordinator"), whereas all other ranks are simply
+// workers. Each rank runs its own background thread which progresses in ticks.
+// In each tick, the following actions happen:
+//
+// a) The workers send an MPIRequest to the coordinator, indicating what
+// they would like to do (which tensor they would like to gather and
+// reduce, as well as their shape and type). They repeat this for every
+// tensor that they would like to operate on.
+//
+// b) The workers send an empty "DONE" message to the coordinator to
+// indicate that there are no more tensors they wish to operate on.
+//
+// c) The coordinator receives the MPIRequests from the workers, as well
+// as from its own TensorFlow ops, and stores them in a request table. The
+// coordinator continues to receive MPIRequest messages until it has
+// received MPI_SIZE number of empty "DONE" messages.
+//
+// d) The coordinator finds all tensors that are ready to be reduced,
+// gathered, or all operations that result in an error. For each of those,
+// it sends an MPIResponse to all the workers. When no more MPIResponses
+// are available, it sends a "DONE" response to the workers. If the process
+// is being shutdown, it instead sends a "SHUTDOWN" response.
+//
+// e) The workers listen for MPIResponse messages, processing each one by
+// doing the required reduce or gather, until they receive a "DONE"
+// response from the coordinator. At that point, the tick ends.
+// If instead of "DONE" they receive "SHUTDOWN", they exit their background
+// loop.
+void BackgroundThreadLoop(HorovodGlobalState& state) {
+ // Initialize MPI. This must happen on the background thread, since not all
+ // MPI implementations support being called from multiple threads.
+ MPI_Init(NULL, NULL);
+
+ // Get MPI rank to determine if we are rank zero.
+ int rank;
+ MPI_Comm_rank(MPI_COMM_WORLD, &rank);
+ bool is_coordinator = rank == 0;
+
+ // Get MPI size to determine how many tensors to wait for before reducing.
+ int size;
+ MPI_Comm_size(MPI_COMM_WORLD, &size);
+
+ // Determine local rank by querying the local communicator.
+ MPI_Comm local_comm;
+ MPI_Comm_split_type(MPI_COMM_WORLD, MPI_COMM_TYPE_SHARED, 0, MPI_INFO_NULL,
+ &local_comm);
+ int local_rank;
+ MPI_Comm_rank(local_comm, &local_rank);
+
+ state.rank = rank;
+ state.local_rank = local_rank;
+ state.size = size;
+ state.initialization_done = true;
+
+ // Initialize the tensor count table. No tensors are available yet.
+ if (is_coordinator) {
+ state.message_table = std::unique_ptr(new MessageTable());
+ }
+
+ // The coordinator sends a SHUTDOWN message to trigger shutdown.
+ bool should_shut_down = false;
+ do {
+ // This delay determines thread frequency and MPI message latency
+ std::this_thread::sleep_for(std::chrono::milliseconds(5));
+
+ // Copy the data structures from global state under this lock.
+ // However, don't keep the lock for the rest of the loop, so that
+ // enqueued stream callbacks can continue.
+ std::queue message_queue;
+ {
+ std::lock_guard guard(state.mutex);
+ while (!state.message_queue.empty()) {
+ MPIRequest message = state.message_queue.front();
+ state.message_queue.pop();
+ message_queue.push(message);
+ }
+ }
+
+ // Collect all tensors that are ready to be reduced. Record them in the
+ // tensor count table (rank zero) or send them to rank zero to be
+ // recorded (everyone else).
+ std::vector ready_to_reduce;
+ while (!message_queue.empty()) {
+ // Pop the first available message message
+ MPIRequest message = message_queue.front();
+ message_queue.pop();
+
+ if (is_coordinator) {
+ bool reduce = IncrementTensorCount(state.message_table, message, size);
+ if (reduce) {
+ ready_to_reduce.push_back(message.tensor_name());
+ }
+ } else {
+ std::string encoded_message;
+ MPIRequest::SerializeToString(message, encoded_message);
+ MPI_Send(encoded_message.c_str(), (int)encoded_message.length() + 1,
+ MPI_BYTE, RANK_ZERO, TAG_NOTIFY, MPI_COMM_WORLD);
+ }
+ }
+
+ // Rank zero has put all its own tensors in the tensor count table.
+ // Now, it should count all the tensors that are coming from other
+ // ranks at this tick. It should keep getting tensors until it gets a
+ // DONE message from all the other ranks.
+ if (is_coordinator) {
+ // Count of DONE messages. Keep receiving messages until the number
+ // of messages is equal to the number of processes. Initialize to
+ // one since the coordinator is effectively done.
+ int completed_ranks = 1;
+ while (completed_ranks != size) {
+ MPI_Status status;
+ MPI_Probe(MPI_ANY_SOURCE, TAG_NOTIFY, MPI_COMM_WORLD, &status);
+
+ // Find number of characters in message (including zero byte).
+ int source_rank = status.MPI_SOURCE;
+ int msg_length;
+ MPI_Get_count(&status, MPI_BYTE, &msg_length);
+
+ // If the length is zero, this is a DONE message.
+ if (msg_length == 0) {
+ completed_ranks++;
+ MPI_Recv(NULL, 0, MPI_BYTE, source_rank, TAG_NOTIFY, MPI_COMM_WORLD,
+ &status);
+ continue;
+ }
+
+ // Get tensor name from MPI into an std::string.
+ char* buffer = new char[msg_length];
+ MPI_Recv(buffer, msg_length, MPI_BYTE, source_rank, TAG_NOTIFY,
+ MPI_COMM_WORLD, &status);
+ std::string received_data(buffer, (size_t)msg_length);
+ delete[] buffer;
+
+ MPIRequest received_message;
+ MPIRequest::ParseFromString(received_message, received_data);
+ auto received_name = received_message.tensor_name();
+
+ bool reduce =
+ IncrementTensorCount(state.message_table, received_message, size);
+ if (reduce) {
+ ready_to_reduce.push_back(received_name);
+ }
+ }
+
+ // At this point, rank zero should have a fully updated tensor count
+ // table and should know all the tensors that need to be reduced or
+ // gathered, and everyone else should have sent all their information
+ // to rank zero. We can now do reductions and gathers; rank zero will
+ // choose which ones and in what order, and will notify the other ranks
+ // before doing each reduction.
+ for (size_t i = 0; i < ready_to_reduce.size(); i++) {
+ // Notify all nodes which tensor we'd like to reduce at this step.
+ auto name = ready_to_reduce[i];
+ MPIResponse response = ConstructMPIResponse(state.message_table, name);
+
+ std::string encoded_response;
+ MPIResponse::SerializeToString(response, encoded_response);
+ for (int r = 1; r < size; r++) {
+ MPI_Send(encoded_response.c_str(), (int)encoded_response.length() + 1,
+ MPI_BYTE, r, TAG_NOTIFY, MPI_COMM_WORLD);
+ }
+
+ // Perform the collective operation. All nodes should end up performing
+ // the same operation.
+ PerformOperation(state.tensor_table, response);
+ }
+
+ // Notify all nodes that we are done with the reductions for this tick.
+ MPIResponse done_response;
+ should_shut_down = state.shut_down;
+ done_response.set_response_type(should_shut_down ? MPIResponse::SHUTDOWN
+ : MPIResponse::DONE);
+ std::string encoded_response;
+ MPIResponse::SerializeToString(done_response, encoded_response);
+ for (int r = 1; r < size; r++) {
+ MPI_Send(encoded_response.c_str(), (int)encoded_response.length() + 1,
+ MPI_BYTE, r, TAG_NOTIFY, MPI_COMM_WORLD);
+ }
+
+ // Check for stalled tensors.
+ if (std::chrono::system_clock::now() - state.last_stall_check >
+ STALL_WARNING_TIME) {
+ CheckForStalledTensors(state);
+ state.last_stall_check = std::chrono::system_clock::now();
+ }
+ } else {
+ // Notify the coordinator that this node is done sending messages.
+ // A DONE message is encoded as a zero-length message.
+ MPI_Send(NULL, 0, MPI_BYTE, RANK_ZERO, TAG_NOTIFY, MPI_COMM_WORLD);
+
+ // Receive names for tensors to reduce from rank zero.
+ // Once we receive a empty DONE message, stop waiting for more names.
+ while (true) {
+ MPI_Status status;
+ MPI_Probe(0, TAG_NOTIFY, MPI_COMM_WORLD, &status);
+
+ // Find number of characters in message (including zero byte).
+ int msg_length;
+ MPI_Get_count(&status, MPI_BYTE, &msg_length);
+
+ // Get tensor name from MPI into an std::string.
+ char* buffer = new char[msg_length];
+ MPI_Recv(buffer, msg_length, MPI_BYTE, 0, TAG_NOTIFY, MPI_COMM_WORLD,
+ &status);
+ std::string received_message(buffer, (size_t)msg_length);
+ delete[] buffer;
+
+ MPIResponse response;
+ MPIResponse::ParseFromString(response, received_message);
+ if (response.response_type() == MPIResponse::DONE) {
+ // No more messages this tick
+ break;
+ } else if (response.response_type() == MPIResponse::SHUTDOWN) {
+ // No more messages this tick, and the background thread should shut
+ // down
+ should_shut_down = true;
+ break;
+ } else {
+ // Process the current message
+ PerformOperation(state.tensor_table, response);
+ }
+ }
+ }
+ } while (!should_shut_down);
+
+ // TODO: init.cu:645 WARN Cuda failure 'driver shutting down'
+ //#if HAVE_NCCL
+ // for (auto it = horovod_global.streams.begin();
+ // it != horovod_global.streams.end(); it++) {
+ // cudaStreamSynchronize(it->second);
+ // }
+ // for (auto it = horovod_global.nccl_comms.begin();
+ // it != horovod_global.nccl_comms.end(); it++) {
+ // ncclCommDestroy(it->second);
+ // }
+ //#endif
+ MPI_Finalize();
+}
+
+// Start Horovod background thread. Ensure that this is
+// only done once no matter how many times this function is called.
+void InitializeHorovodOnce() {
+ // Ensure background thread is only started once.
+ if (!horovod_global.initialize_flag.test_and_set()) {
+ horovod_global.background_thread =
+ std::thread(BackgroundThreadLoop, std::ref(horovod_global));
+ }
+
+ // Wait to ensure that the background thread has finished initializing MPI.
+ while (!horovod_global.initialization_done) {
+ std::this_thread::sleep_for(std::chrono::milliseconds(1));
+ }
+}
+
+// Check that Horovod is initialized.
+Status CheckInitialized() {
+ if (!horovod_global.initialization_done) {
+ return errors::FailedPrecondition(
+ "Horovod has not been initialized; use horovod.tensorflow.init().");
+ }
+ return Status::OK();
+}
+
+// C interface to initialize Horovod.
+extern "C" void horovod_tensorflow_init() { InitializeHorovodOnce(); }
+
+// C interface to get index of current Horovod process.
+// Returns -1 if Horovod is not initialized.
+extern "C" int horovod_tensorflow_rank() {
+ if (!horovod_global.initialization_done) {
+ return -1;
+ }
+ return horovod_global.rank;
+}
+
+// C interface to get index of current Horovod process in the node it is on..
+// Returns -1 if Horovod is not initialized.
+extern "C" int horovod_tensorflow_local_rank() {
+ if (!horovod_global.initialization_done) {
+ return -1;
+ }
+ return horovod_global.local_rank;
+}
+
+// C interface to return number of Horovod processes.
+// Returns -1 if Horovod is not initialized.
+extern "C" int horovod_tensorflow_size() {
+ if (!horovod_global.initialization_done) {
+ return -1;
+ }
+ return horovod_global.size;
+}
+
+// Convert a TensorFlow DataType to our MPIDataType.
+Status DataTypeToMPIType(DataType tf_dtype, MPIDataType* mpi_dtype) {
+ switch (tf_dtype) {
+ case DT_UINT8:
+ *mpi_dtype = TF_MPI_UINT8;
+ return Status::OK();
+ case DT_INT8:
+ *mpi_dtype = TF_MPI_INT8;
+ return Status::OK();
+ case DT_UINT16:
+ *mpi_dtype = TF_MPI_UINT16;
+ return Status::OK();
+ case DT_INT16:
+ *mpi_dtype = TF_MPI_INT16;
+ return Status::OK();
+ case DT_INT32:
+ *mpi_dtype = TF_MPI_INT32;
+ return Status::OK();
+ case DT_INT64:
+ *mpi_dtype = TF_MPI_INT64;
+ return Status::OK();
+ case DT_FLOAT:
+ *mpi_dtype = TF_MPI_FLOAT32;
+ return Status::OK();
+ case DT_DOUBLE:
+ *mpi_dtype = TF_MPI_FLOAT64;
+ return Status::OK();
+ default:
+ return errors::Internal("Invalid tensor type.");
+ }
+}
+
+// MPI must be initialized and the background thread must be running before
+// this function is called.
+void EnqueueTensorAllreduce(OpKernelContext* context, const Tensor& tensor,
+ Tensor* output, GPU_EVENT_IF_CUDA ready_event,
+ const std::string name, const int device,
+ StatusCallback callback) {
+ MPIDataType dtype;
+ Status status = DataTypeToMPIType(tensor.dtype(), &dtype);
+ if (!status.ok()) {
+ callback(status);
+ return;
+ }
+
+ int rank;
+ MPI_Comm_rank(MPI_COMM_WORLD, &rank);
+
+ MPIRequest message;
+ message.set_request_rank(rank);
+ message.set_tensor_name(name);
+ message.set_tensor_type(dtype);
+ message.set_device(device);
+ message.set_request_type(MPIRequest::ALLREDUCE);
+ for (int i = 0; i < tensor.shape().dims(); i++) {
+ message.add_tensor_shape(tensor.shape().dim_size(i));
+ }
+
+ TensorTableEntry e;
+ e.context = context;
+ e.tensor = tensor;
+ e.output = output;
+ e.ready_event = ready_event;
+ e.device = device;
+ e.callback = callback;
+
+ std::lock_guard guard(horovod_global.mutex);
+ horovod_global.tensor_table.emplace(name, std::move(e));
+ horovod_global.message_queue.push(message);
+}
+
+// MPI must be initialized and the background thread must be running before
+// this function is called.
+void EnqueueTensorAllgather(OpKernelContext* context, const Tensor& tensor,
+ GPU_EVENT_IF_CUDA ready_event,
+ const std::string name, const int device,
+ StatusCallback callback) {
+ MPIDataType dtype;
+ Status status = DataTypeToMPIType(tensor.dtype(), &dtype);
+ if (!status.ok()) {
+ callback(status);
+ return;
+ }
+
+ int rank;
+ MPI_Comm_rank(MPI_COMM_WORLD, &rank);
+
+ MPIRequest message;
+ message.set_request_rank(rank);
+ message.set_tensor_name(name);
+ message.set_tensor_type(dtype);
+ message.set_device(device);
+ message.set_request_type(MPIRequest::ALLGATHER);
+ for (int i = 0; i < tensor.shape().dims(); i++) {
+ message.add_tensor_shape(tensor.shape().dim_size(i));
+ }
+
+ TensorTableEntry e;
+ e.context = context;
+ e.tensor = tensor;
+ e.ready_event = ready_event;
+ e.device = device;
+ e.callback = callback;
+
+ std::lock_guard guard(horovod_global.mutex);
+ horovod_global.tensor_table.emplace(name, std::move(e));
+ horovod_global.message_queue.push(message);
+}
+
+// MPI must be initialized and the background thread must be running before
+// this function is called.
+void EnqueueTensorBroadcast(OpKernelContext* context, const Tensor& tensor,
+ Tensor* output, int root_rank,
+ GPU_EVENT_IF_CUDA ready_event,
+ const std::string name, const int device,
+ StatusCallback callback) {
+ MPIDataType dtype;
+ Status status = DataTypeToMPIType(tensor.dtype(), &dtype);
+ if (!status.ok()) {
+ callback(status);
+ return;
+ }
+
+ int rank;
+ MPI_Comm_rank(MPI_COMM_WORLD, &rank);
+
+ MPIRequest message;
+ message.set_request_rank(rank);
+ message.set_tensor_name(name);
+ message.set_tensor_type(dtype);
+ message.set_root_rank(root_rank);
+ message.set_device(device);
+ message.set_request_type(MPIRequest::BROADCAST);
+ for (int i = 0; i < tensor.shape().dims(); i++) {
+ message.add_tensor_shape(tensor.shape().dim_size(i));
+ }
+
+ TensorTableEntry e;
+ e.context = context;
+ e.tensor = tensor;
+ e.output = output;
+ e.root_rank = root_rank;
+ e.ready_event = ready_event;
+ e.device = device;
+ e.callback = callback;
+
+ std::lock_guard guard(horovod_global.mutex);
+ horovod_global.tensor_table.emplace(name, std::move(e));
+ horovod_global.message_queue.push(message);
+}
+
+int GetDeviceID(OpKernelContext* context) {
+ int device = CPU_DEVICE_ID;
+ if (context->device() != nullptr &&
+ context->device()->tensorflow_gpu_device_info() != nullptr) {
+ device = context->device()->tensorflow_gpu_device_info()->gpu_id;
+ }
+ return device;
+}
+
+// On GPU this event will signal that data is ready, and tensors are
+// allocated.
+GPU_EVENT_IF_CUDA RecordReadyEvent(OpKernelContext* context) {
+#if HAVE_CUDA
+ auto device_context = context->op_device_context();
+ if (device_context != nullptr) {
+ auto executor = device_context->stream()->parent();
+ GPU_EVENT_IF_CUDA ready_event = new perftools::gputools::Event(executor);
+ ready_event->Init();
+ device_context->stream()->ThenRecordEvent(ready_event);
+ return ready_event;
+ }
+#endif
+ return nullptr;
+}
+
+} // namespace tensorflow
+
+class HorovodAllreduceOp : public AsyncOpKernel {
+public:
+ explicit HorovodAllreduceOp(OpKernelConstruction* context)
+ : AsyncOpKernel(context) {}
+
+ void ComputeAsync(OpKernelContext* context, DoneCallback done) override {
+ OP_REQUIRES_OK(context, CheckInitialized());
+
+ auto node_name = name();
+ auto device = GetDeviceID(context);
+ auto tensor = context->input(0);
+ Tensor* output;
+ OP_REQUIRES_OK(context,
+ context->allocate_output(0, tensor.shape(), &output));
+ GPU_EVENT_IF_CUDA ready_event = RecordReadyEvent(context);
+ EnqueueTensorAllreduce(context, tensor, output, ready_event, node_name,
+ device, [context, done](const Status& status) {
+ context->SetStatus(status);
+ done();
+ });
+ }
+};
+
+REGISTER_KERNEL_BUILDER(Name("HorovodAllreduce").Device(DEVICE_CPU),
+ HorovodAllreduceOp);
+#if HOROVOD_GPU_ALLREDUCE
+REGISTER_KERNEL_BUILDER(Name("HorovodAllreduce").Device(DEVICE_GPU),
+ HorovodAllreduceOp);
+#endif
+
+REGISTER_OP("HorovodAllreduce")
+ .Attr("T: {int32, int64, float32, float64}")
+ .Input("tensor: T")
+ .Output("sum: T")
+ .SetShapeFn([](shape_inference::InferenceContext* c) {
+ c->set_output(0, c->input(0));
+ return Status::OK();
+ })
+ .Doc(R"doc(
+Perform an MPI Allreduce on a tensor. All other processes that do a reduction
+on a tensor with the same name must have the same dimension for that tensor.
+Tensors are reduced with other tensors that have the same node name for the
+allreduce.
+
+Arguments
+ tensor: A tensor to reduce.
+
+Output
+ sum: A tensor with the same shape as `tensor`, summed across all MPI processes.
+)doc");
+
+class HorovodAllgatherOp : public AsyncOpKernel {
+public:
+ explicit HorovodAllgatherOp(OpKernelConstruction* context)
+ : AsyncOpKernel(context) {}
+
+ void ComputeAsync(OpKernelContext* context, DoneCallback done) override {
+ OP_REQUIRES_OK(context, CheckInitialized());
+
+ auto node_name = name();
+ auto device = GetDeviceID(context);
+ auto tensor = context->input(0);
+ // We cannot pre-allocate output for allgather, since shape of result
+ // is only known after all ranks make a request.
+ GPU_EVENT_IF_CUDA ready_event = RecordReadyEvent(context);
+ EnqueueTensorAllgather(context, tensor, ready_event, node_name, device,
+ [context, done](const Status& status) {
+ context->SetStatus(status);
+ done();
+ });
+ }
+}; // namespace tensorflow
+
+REGISTER_KERNEL_BUILDER(Name("HorovodAllgather").Device(DEVICE_CPU),
+ HorovodAllgatherOp);
+#if HOROVOD_GPU_ALLGATHER
+REGISTER_KERNEL_BUILDER(Name("HorovodAllgather").Device(DEVICE_GPU),
+ HorovodAllgatherOp);
+#endif
+
+REGISTER_OP("HorovodAllgather")
+ .Attr("T: {uint8, int8, uint16, int16, int32, int64, float32, float64}")
+ .Input("tensor: T")
+ .Output("output: T")
+ .SetShapeFn([](shape_inference::InferenceContext* c) {
+ shape_inference::ShapeHandle output;
+ TF_RETURN_IF_ERROR(
+ c->ReplaceDim(c->input(0), 0, c->UnknownDim(), &output));
+ c->set_output(0, output);
+ return Status::OK();
+ })
+ .Doc(R"doc(
+Perform an MPI Allgather on a tensor. All other processes that do a gather on a
+tensor with the same name must have the same rank for that tensor, and have the
+same dimension on all but the first dimension.
+
+Arguments
+ tensor: A tensor to gather.
+
+Output
+ gathered: A tensor with the same shape as `tensor` except for the first dimension.
+)doc");
+
+class HorovodBroadcastOp : public AsyncOpKernel {
+public:
+ explicit HorovodBroadcastOp(OpKernelConstruction* context)
+ : AsyncOpKernel(context) {
+ OP_REQUIRES_OK(context, context->GetAttr("root_rank", &root_rank_));
+ }
+
+ void ComputeAsync(OpKernelContext* context, DoneCallback done) override {
+ OP_REQUIRES_OK(context, CheckInitialized());
+
+ auto node_name = name();
+ auto device = GetDeviceID(context);
+ auto tensor = context->input(0);
+ Tensor* output = nullptr;
+ if (horovod_global.rank == root_rank_) {
+ context->set_output(0, tensor);
+ } else {
+ OP_REQUIRES_OK(context,
+ context->allocate_output(0, tensor.shape(), &output));
+ }
+ GPU_EVENT_IF_CUDA ready_event = RecordReadyEvent(context);
+ EnqueueTensorBroadcast(context, tensor, output, root_rank_, ready_event,
+ node_name, device,
+ [context, done](const Status& status) {
+ context->SetStatus(status);
+ done();
+ });
+ }
+
+private:
+ int root_rank_;
+};
+
+REGISTER_KERNEL_BUILDER(Name("HorovodBroadcast").Device(DEVICE_CPU),
+ HorovodBroadcastOp);
+#if HOROVOD_GPU_BROADCAST
+REGISTER_KERNEL_BUILDER(Name("HorovodBroadcast").Device(DEVICE_GPU),
+ HorovodBroadcastOp);
+#endif
+
+REGISTER_OP("HorovodBroadcast")
+ .Attr("T: {uint8, int8, uint16, int16, int32, int64, float32, float64}")
+ .Attr("root_rank: int")
+ .Input("tensor: T")
+ .Output("output: T")
+ .SetShapeFn([](shape_inference::InferenceContext* c) {
+ c->set_output(0, c->input(0));
+ return Status::OK();
+ })
+ .Doc(R"doc(
+Perform an MPI Broadcast on a tensor. All other processes that do a broadcast
+on a tensor with the same name must have the same dimension for that tensor.
+
+Arguments
+ tensor: A tensor to broadcast.
+ root_rank: Rank that will send data, other ranks will receive data.
+
+Output
+ output: A tensor with the same shape as `tensor` and same value as
+ `tensor` on root rank.
+)doc");
+
+} // namespace tensorflow
+} // namespace horovod
diff --git a/horovod/tensorflow/mpi_ops.py b/horovod/tensorflow/mpi_ops.py
new file mode 100644
index 0000000000..8db0c9e387
--- /dev/null
+++ b/horovod/tensorflow/mpi_ops.py
@@ -0,0 +1,190 @@
+# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
+# Modifications copyright (C) 2017 Uber Technologies, Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# =============================================================================
+"""Inter-process communication using MPI."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import ctypes
+import re
+import sysconfig
+from tensorflow.python.framework import load_library
+from tensorflow.python.framework import ops
+from tensorflow.python.platform import resource_loader
+
+
+def _get_ext_suffix():
+ """Determine library extension for various versions of Python."""
+ ext_suffix = sysconfig.get_config_var('EXT_SUFFIX')
+ if ext_suffix:
+ return ext_suffix
+
+ ext_suffix = sysconfig.get_config_var('SO')
+ if ext_suffix:
+ return ext_suffix
+
+ return '.so'
+
+
+def _load_library(name, op_list=None):
+ """Loads a .so file containing the specified operators.
+
+ Args:
+ name: The name of the .so file to load.
+ op_list: A list of names of operators that the library should have. If None
+ then the .so file's contents will not be verified.
+
+ Raises:
+ NameError if one of the required ops is missing.
+ NotFoundError if were not able to load .so file.
+ """
+ filename = resource_loader.get_path_to_datafile(name)
+ library = load_library.load_op_library(filename)
+ for expected_op in (op_list or []):
+ for lib_op in library.OP_LIST.op:
+ if lib_op.name == expected_op:
+ break
+ else:
+ raise NameError(
+ 'Could not find operator %s in dynamic library %s' %
+ (expected_op, name))
+ return library
+
+
+def _load_ctypes_dll(name):
+ filename = resource_loader.get_path_to_datafile(name)
+ return ctypes.CDLL(filename, mode=ctypes.RTLD_GLOBAL)
+
+
+MPI_LIB = _load_library('mpi_lib' + _get_ext_suffix(),
+ ['HorovodAllgather', 'HorovodAllreduce'])
+
+
+MPI_LIB_CTYPES = _load_ctypes_dll('mpi_lib' + _get_ext_suffix())
+
+
+def init():
+ """A function which initializes Horovod.
+ """
+ return MPI_LIB_CTYPES.horovod_tensorflow_init()
+
+
+def size():
+ """A function which returns the number of Horovod processes.
+
+ Returns:
+ An integer scalar containing the number of Horovod processes.
+ """
+ size = MPI_LIB_CTYPES.horovod_tensorflow_size()
+ if size == -1:
+ raise ValueError(
+ 'Horovod has not been initialized; use horovod.tensorflow.init().')
+ return size
+
+
+def rank():
+ """A function which returns the Horovod rank of the calling process.
+
+ Returns:
+ An integer scalar with the Horovod rank of the calling process.
+ """
+ rank = MPI_LIB_CTYPES.horovod_tensorflow_rank()
+ if rank == -1:
+ raise ValueError(
+ 'Horovod has not been initialized; use horovod.tensorflow.init().')
+ return rank
+
+
+def local_rank():
+ """A function which returns the local Horovod rank of the calling process, within the
+ node that it is running on. For example, if there are seven processes running
+ on a node, their local ranks will be zero through six, inclusive.
+
+ Returns:
+ An integer scalar with the local Horovod rank of the calling process.
+ """
+ local_rank = MPI_LIB_CTYPES.horovod_tensorflow_local_rank()
+ if local_rank == -1:
+ raise ValueError(
+ 'Horovod has not been initialized; use horovod.tensorflow.init().')
+ return local_rank
+
+
+def _normalize_name(name):
+ """Normalizes operation name to TensorFlow rules."""
+ return re.sub('[^a-zA-Z0-9_]', '_', name)
+
+
+def _allreduce(tensor, name=None):
+ """An op which sums an input tensor over all the Horovod processes.
+
+ The reduction operation is keyed by the name of the op. The tensor type and
+ shape must be the same on all Horovod processes for a given name. The reduction
+ will not start until all processes are ready to send and receive the tensor.
+
+ Returns:
+ A tensor of the same shape and type as `tensor`, summed across all
+ processes.
+ """
+ if name is None:
+ name = 'HorovodAllreduce_%s' % _normalize_name(tensor.name)
+ return MPI_LIB.horovod_allreduce(tensor, name=name)
+
+
+ops.NotDifferentiable('HorovodAllreduce')
+
+
+def allgather(tensor, name=None):
+ """An op which concatenates the input tensor with the same input tensor on
+ all other Horovod processes.
+
+ The concatenation is done on the first dimension, so the input tensors on the
+ different processes must have the same rank and shape, except for the first
+ dimension, which is allowed to be different.
+
+ Returns:
+ A tensor of the same type as `tensor`, concatenated on dimension zero
+ across all processes. The shape is identical to the input shape, except for
+ the first dimension, which may be greater and is the sum of all first
+ dimensions of the tensors in different Horovod processes.
+ """
+ if name is None:
+ name = 'HorovodAllgather_%s' % _normalize_name(tensor.name)
+ return MPI_LIB.horovod_allgather(tensor, name=name)
+
+
+ops.NotDifferentiable('HorovodAllgather')
+
+
+def broadcast(tensor, root_rank, name=None):
+ """An op which broadcasts the input tensor on root rank to the same input tensor
+ on all other Horovod processes.
+
+ The broadcast operation is keyed by the name of the op. The tensor type and
+ shape must be the same on all Horovod processes for a given name. The broadcast
+ will not start until all processes are ready to send and receive the tensor.
+
+ Returns:
+ A tensor of the same shape and type as `tensor`, with the value broadcasted
+ from root rank.
+ """
+ if name is None:
+ name = 'HorovodBroadcast_%s' % _normalize_name(tensor.name)
+ return MPI_LIB.horovod_broadcast(tensor, name=name, root_rank=root_rank)
+
+
+ops.NotDifferentiable('HorovodBroadcast')
diff --git a/horovod/tensorflow/mpi_ops_test.py b/horovod/tensorflow/mpi_ops_test.py
new file mode 100644
index 0000000000..f12397ce6f
--- /dev/null
+++ b/horovod/tensorflow/mpi_ops_test.py
@@ -0,0 +1,462 @@
+# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
+# Modifications copyright (C) 2017 Uber Technologies, Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# =============================================================================
+
+"""Tests for horovod.tensorflow.mpi_ops."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import os.path
+import itertools
+
+import tensorflow as tf
+
+import horovod.tensorflow as hvd
+
+
+def mpi_env_rank_and_size():
+ """Get MPI rank and size from environment variables and return them as a
+ tuple of integers.
+
+ Most MPI implementations have an `mpirun` or `mpiexec` command that will
+ run an MPI executable and set up all communication necessary between the
+ different processors. As part of that set up, they will set environment
+ variables that contain the rank and size of the MPI_COMM_WORLD
+ communicator. We can read those environment variables from Python in order
+ to ensure that `hvd.rank()` and `hvd.size()` return the expected values.
+
+ Since MPI is just a standard, not an implementation, implementations
+ typically choose their own environment variable names. This function tries
+ to support several different implementation, but really it only needs to
+ support whatever implementation we want to use for the TensorFlow test
+ suite.
+
+ If this is not running under MPI, then defaults of rank zero and size one
+ are returned. (This is appropriate because when you call MPI_Init in an
+ application not started with mpirun, it will create a new independent
+ communicator with only one process in it.)
+ """
+ rank_env = "PMI_RANK OMPI_COMM_WORLD_RANK".split()
+ size_env = "PMI_SIZE OMPI_COMM_WORLD_SIZE".split()
+
+ for rank_var, size_var in zip(rank_env, size_env):
+ rank = os.environ.get(rank_var)
+ size = os.environ.get(size_var)
+ if rank is not None and size is not None:
+ return int(rank), int(size)
+
+ # Default to rank zero and size one if there are no environment variables
+ return 0, 1
+
+
+class MPITests(tf.test.TestCase):
+ """
+ Tests for ops in horovod.tensorflow.
+ """
+
+ def test_horovod_rank(self):
+ """Test that the rank returned by hvd.rank() is correct."""
+ true_rank, _ = mpi_env_rank_and_size()
+ hvd.init()
+ rank = hvd.rank()
+ self.assertEqual(true_rank, rank)
+
+ def test_horovod_size(self):
+ """Test that the size returned by hvd.size() is correct."""
+ _, true_size = mpi_env_rank_and_size()
+ hvd.init()
+ size = hvd.size()
+ self.assertEqual(true_size, size)
+
+ def test_horovod_allreduce_cpu(self):
+ """Test on CPU that the allreduce correctly sums 1D, 2D, 3D tensors."""
+ hvd.init()
+ size = hvd.size()
+ with self.test_session() as session:
+ dtypes = [tf.int32, tf.int64, tf.float32, tf.float64]
+ dims = [1, 2, 3]
+ for dtype, dim in itertools.product(dtypes, dims):
+ with tf.device("/cpu:0"):
+ tf.set_random_seed(1234)
+ tensor = tf.random_uniform([17] * dim, -100, 100, dtype=dtype)
+ summed = hvd.allreduce(tensor, average=False)
+ multiplied = tensor * size
+ max_difference = tf.reduce_max(tf.abs(summed - multiplied))
+
+ # Threshold for floating point equality depends on number of
+ # ranks, since we're comparing against precise multiplication.
+ if size <= 3:
+ threshold = 0
+ elif size < 10:
+ threshold = 1e-4
+ elif size < 15:
+ threshold = 5e-4
+ else:
+ break
+
+ diff = session.run(max_difference)
+ self.assertTrue(diff <= threshold,
+ "hvd.allreduce produces incorrect results")
+
+ def test_horovod_allreduce_gpu(self):
+ """Test that the allreduce works on GPUs.
+
+ This test will crash badly if used with an MPI implementation that does
+ not support GPU memory transfers directly, as it will call MPI_Send on
+ a GPU data pointer."""
+ # Only do this test if there are GPUs available.
+ if not tf.test.is_gpu_available(cuda_only=True):
+ return
+
+ hvd.init()
+ local_rank = hvd.local_rank()
+ size = hvd.size()
+
+ one_gpu = tf.GPUOptions(visible_device_list=str(local_rank))
+ gpu_config = tf.ConfigProto(gpu_options=one_gpu)
+ with self.test_session(config=gpu_config) as session:
+ dtypes = [tf.int32, tf.int64, tf.float32, tf.float64]
+ dims = [1, 2, 3]
+ for dtype, dim in itertools.product(dtypes, dims):
+ with tf.device("/gpu:0"):
+ tf.set_random_seed(1234)
+ tensor = tf.random_uniform(
+ [17] * dim, -100, 100, dtype=dtype)
+ summed = hvd.allreduce(tensor, average=False)
+ multiplied = tensor * size
+ max_difference = tf.reduce_max(tf.abs(summed - multiplied))
+
+ # Threshold for floating point equality depends on number of
+ # ranks, since we're comparing against precise multiplication.
+ if size <= 3:
+ threshold = 0
+ elif size < 10:
+ threshold = 1e-4
+ elif size < 15:
+ threshold = 5e-4
+ else:
+ return
+
+ diff = session.run(max_difference)
+ self.assertTrue(diff <= threshold,
+ "hvd.allreduce on GPU produces incorrect results")
+
+ def test_horovod_allreduce_multi_gpu(self):
+ """Test that the allreduce works on multiple GPUs.
+
+ This test will crash badly if used with an MPI implementation that does
+ not support GPU memory transfers directly, as it will call MPI_Send on
+ a GPU data pointer."""
+ # Only do this test if there are GPUs available.
+ if not tf.test.is_gpu_available(cuda_only=True):
+ return
+
+ hvd.init()
+ local_rank = hvd.local_rank()
+ size = hvd.size()
+
+ iter = 0
+ two_gpus = tf.GPUOptions(visible_device_list=('%d,%d' % (local_rank * 2, local_rank * 2 + 1)))
+ gpu_config = tf.ConfigProto(gpu_options=two_gpus)
+ with self.test_session(config=gpu_config) as session:
+ dtypes = [tf.int32, tf.int64, tf.float32, tf.float64]
+ dims = [1, 2, 3]
+ for dtype, dim in itertools.product(dtypes, dims):
+ iter += 1
+ with tf.device("/gpu:%d" % ((iter + local_rank) % 2)):
+ tf.set_random_seed(1234)
+ tensor = tf.random_uniform(
+ [17] * dim, -100, 100, dtype=dtype)
+ summed = hvd.allreduce(tensor, average=False)
+ multiplied = tensor * size
+ max_difference = tf.reduce_max(tf.abs(summed - multiplied))
+
+ # Threshold for floating point equality depends on number of
+ # ranks, since we're comparing against precise multiplication.
+ if size <= 3:
+ threshold = 0
+ elif size < 10:
+ threshold = 1e-4
+ elif size < 15:
+ threshold = 5e-4
+ else:
+ return
+
+ diff = session.run(max_difference)
+ self.assertTrue(diff <= threshold,
+ "hvd.allreduce on GPU produces incorrect results")
+
+ def test_horovod_allreduce_error(self):
+ """Test that the allreduce raises an error if different ranks try to
+ send tensors of different rank or dimension."""
+ hvd.init()
+ rank = hvd.rank()
+ size = hvd.size()
+
+ # This test does not apply if there is only one worker.
+ if size == 1:
+ return
+
+ with self.test_session() as session:
+ # Same rank, different dimension
+ tf.set_random_seed(1234)
+ dims = [17 + rank] * 3
+ tensor = tf.random_uniform(dims, -1.0, 1.0)
+ with self.assertRaises(tf.errors.FailedPreconditionError):
+ session.run(hvd.allreduce(tensor))
+
+ # Same number of elements, different rank
+ tf.set_random_seed(1234)
+ if rank == 0:
+ dims = [17, 23 * 57]
+ else:
+ dims = [17, 23, 57]
+ tensor = tf.random_uniform(dims, -1.0, 1.0)
+ with self.assertRaises(tf.errors.FailedPreconditionError):
+ session.run(hvd.allreduce(tensor))
+
+ def test_horovod_allreduce_type_error(self):
+ """Test that the allreduce raises an error if different ranks try to
+ send tensors of different type."""
+ hvd.init()
+ rank = hvd.rank()
+ size = hvd.size()
+
+ # This test does not apply if there is only one worker.
+ if size == 1:
+ return
+
+ with self.test_session() as session:
+ # Same rank, different dimension
+ dims = [17] * 3
+ tensor = tf.ones(dims,
+ dtype=tf.int32 if rank % 2 == 0 else tf.float32)
+ with self.assertRaises(tf.errors.FailedPreconditionError):
+ session.run(hvd.allreduce(tensor))
+
+ def test_horovod_allreduce_cpu_gpu_error(self):
+ """Test that the allreduce raises an error if different ranks try to
+ perform reduction on CPU and GPU."""
+ # Only do this test if there are GPUs available.
+ if not tf.test.is_gpu_available(cuda_only=True):
+ return
+
+ hvd.init()
+ local_rank = hvd.local_rank()
+ size = hvd.size()
+
+ # This test does not apply if there is only one worker.
+ if size == 1:
+ return
+
+ device = "/gpu:0" if local_rank % 2 == 0 else "/cpu:0"
+ one_gpu = tf.GPUOptions(visible_device_list=str(local_rank))
+ gpu_config = tf.ConfigProto(gpu_options=one_gpu)
+ with self.test_session(config=gpu_config) as session:
+ with tf.device(device):
+ # Same rank, different dimension
+ dims = [17] * 3
+ tensor = tf.ones(dims, dtype=tf.int32)
+ with self.assertRaises(tf.errors.FailedPreconditionError):
+ session.run(hvd.allreduce(tensor))
+
+ def test_horovod_allgather(self):
+ """Test that the allgather correctly gathers 1D, 2D, 3D tensors."""
+ hvd.init()
+ rank = hvd.rank()
+ size = hvd.size()
+
+ with self.test_session() as session:
+ dtypes = [tf.uint8, tf.int8, tf.uint16, tf.int16,
+ tf.int32, tf.int64, tf.float32, tf.float64]
+ dims = [1, 2, 3]
+ for dtype, dim in itertools.product(dtypes, dims):
+ tensor = tf.ones([17] * dim, dtype=dtype) * rank
+ gathered = hvd.allgather(tensor)
+
+ gathered_tensor = session.run(gathered)
+ self.assertEqual(list(gathered_tensor.shape),
+ [17 * size] + [17] * (dim - 1))
+
+ for i in range(size):
+ rank_tensor = tf.slice(gathered_tensor,
+ [i * 17] + [0] * (dim - 1),
+ [17] + [-1] * (dim - 1))
+ self.assertEqual(list(rank_tensor.shape), [17] * dim)
+ # tf.equal() does not support tf.uint16 as of TensorFlow 1.2,
+ # so need to cast rank_tensor to tf.int32.
+ self.assertTrue(
+ session.run(tf.reduce_all(
+ tf.equal(tf.cast(rank_tensor, tf.int32), i))),
+ "hvd.allgather produces incorrect gathered tensor")
+
+ def test_horovod_allgather_variable_size(self):
+ """Test that the allgather correctly gathers 1D, 2D, 3D tensors,
+ even if those tensors have different sizes along the first dim."""
+ hvd.init()
+ rank = hvd.rank()
+ size = hvd.size()
+
+ with self.test_session() as session:
+ dtypes = [tf.uint8, tf.int8, tf.uint16, tf.int16,
+ tf.int32, tf.int64, tf.float32, tf.float64]
+ dims = [1, 2, 3]
+ for dtype, dim in itertools.product(dtypes, dims):
+ # Support tests up to MPI Size of 35
+ if size > 35:
+ break
+
+ tensor_sizes = [17, 32, 81, 12, 15, 23, 22] * 5
+ tensor_sizes = tensor_sizes[:size]
+
+ tensor = tf.ones([tensor_sizes[rank]] + [17] * (dim - 1),
+ dtype=dtype) * rank
+ gathered = hvd.allgather(tensor)
+
+ gathered_tensor = session.run(gathered)
+ expected_size = sum(tensor_sizes)
+ self.assertEqual(list(gathered_tensor.shape),
+ [expected_size] + [17] * (dim - 1))
+
+ for i in range(size):
+ rank_size = [tensor_sizes[i]] + [17] * (dim - 1)
+ rank_tensor = tf.slice(
+ gathered, [sum(tensor_sizes[:i])] + [0] * (dim - 1),
+ rank_size)
+ self.assertEqual(list(rank_tensor.shape), rank_size)
+ # tf.equal() does not support tf.uint16 as of TensorFlow 1.2,
+ # so need to cast rank_tensor to tf.int32.
+ self.assertTrue(
+ session.run(tf.reduce_all(
+ tf.equal(tf.cast(rank_tensor, tf.int32), i))),
+ "hvd.allgather produces incorrect gathered tensor")
+
+ def test_horovod_allgather_error(self):
+ """Test that the allgather returns an error if any dimension besides
+ the first is different among the tensors being gathered."""
+ hvd.init()
+ rank = hvd.rank()
+ size = hvd.size()
+
+ # This test does not apply if there is only one worker.
+ if size == 1:
+ return
+
+ with self.test_session() as session:
+ tensor_size = [17] * 3
+ tensor_size[1] = 10 * (rank + 1)
+ tensor = tf.ones(tensor_size, dtype=tf.float32) * rank
+ with self.assertRaises(tf.errors.FailedPreconditionError):
+ session.run(hvd.allgather(tensor))
+
+ def test_horovod_allgather_type_error(self):
+ """Test that the allgather returns an error if the types being gathered
+ differ among the processes"""
+ hvd.init()
+ rank = hvd.rank()
+ size = hvd.size()
+
+ # This test does not apply if there is only one worker.
+ if size == 1:
+ return
+
+ with self.test_session() as session:
+ tensor_size = [17] * 3
+ dtype = tf.int32 if rank % 2 == 0 else tf.float32
+ tensor = tf.ones(tensor_size, dtype=dtype) * rank
+ with self.assertRaises(tf.errors.FailedPreconditionError):
+ session.run(hvd.allgather(tensor))
+
+ def test_horovod_broadcast(self):
+ """Test that the broadcast correctly broadcasts 1D, 2D, 3D tensors."""
+ hvd.init()
+ rank = hvd.rank()
+ size = hvd.size()
+
+ # This test does not apply if there is only one worker.
+ if size == 1:
+ return
+
+ with self.test_session() as session:
+ dtypes = [tf.uint8, tf.int8, tf.uint16, tf.int16,
+ tf.int32, tf.int64, tf.float32, tf.float64]
+ dims = [1, 2, 3]
+ root_ranks = list(range(size))
+ for dtype, dim, root_rank in itertools.product(dtypes, dims, root_ranks):
+ tensor = tf.ones([17] * dim, dtype=dtype) * rank
+ root_tensor = tf.ones([17] * dim, dtype=dtype) * root_rank
+ broadcasted_tensor = hvd.broadcast(tensor, root_rank)
+ self.assertTrue(
+ session.run(tf.reduce_all(tf.equal(
+ tf.cast(root_tensor, tf.int32), tf.cast(broadcasted_tensor, tf.int32)))),
+ "hvd.broadcast produces incorrect broadcasted tensor")
+
+ def test_horovod_broadcast_error(self):
+ """Test that the broadcast returns an error if any dimension besides
+ the first is different among the tensors being broadcasted."""
+ hvd.init()
+ rank = hvd.rank()
+ size = hvd.size()
+
+ # This test does not apply if there is only one worker.
+ if size == 1:
+ return
+
+ with self.test_session() as session:
+ tensor_size = [17] * 3
+ tensor_size[1] = 10 * (rank + 1)
+ tensor = tf.ones(tensor_size, dtype=tf.float32) * rank
+ with self.assertRaises(tf.errors.FailedPreconditionError):
+ session.run(hvd.broadcast(tensor, 0))
+
+ def test_horovod_broadcast_type_error(self):
+ """Test that the broadcast returns an error if the types being broadcasted
+ differ among the processes"""
+ hvd.init()
+ rank = hvd.rank()
+ size = hvd.size()
+
+ # This test does not apply if there is only one worker.
+ if size == 1:
+ return
+
+ with self.test_session() as session:
+ tensor_size = [17] * 3
+ dtype = tf.int32 if rank % 2 == 0 else tf.float32
+ tensor = tf.ones(tensor_size, dtype=dtype) * rank
+ with self.assertRaises(tf.errors.FailedPreconditionError):
+ session.run(hvd.broadcast(tensor, 0))
+
+ def test_horovod_broadcast_rank_error(self):
+ """Test that the broadcast returns an error if different ranks
+ specify different root rank."""
+ hvd.init()
+ rank = hvd.rank()
+ size = hvd.size()
+
+ # This test does not apply if there is only one worker.
+ if size == 1:
+ return
+
+ with self.test_session() as session:
+ tensor = tf.ones([17] * 3, dtype=tf.float32)
+ with self.assertRaises(tf.errors.FailedPreconditionError):
+ session.run(hvd.broadcast(tensor, rank))
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git a/horovod/tensorflow/wire/flatbuffers/flatbuffers.h b/horovod/tensorflow/wire/flatbuffers/flatbuffers.h
new file mode 100644
index 0000000000..a13921595f
--- /dev/null
+++ b/horovod/tensorflow/wire/flatbuffers/flatbuffers.h
@@ -0,0 +1,1852 @@
+/*
+ * Copyright 2014 Google Inc. All rights reserved.
+ *
+ * Licensed under the Apache License, Version 2.0 (the "License");
+ * you may not use this file except in compliance with the License.
+ * You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+#ifndef FLATBUFFERS_H_
+#define FLATBUFFERS_H_
+
+#include
+
+#include
+#include
+#include
+#include
+#include
+#include
+#include
+#include
+#include
+#include
+#include
+
+#ifdef _STLPORT_VERSION
+ #define FLATBUFFERS_CPP98_STL
+#endif
+#ifndef FLATBUFFERS_CPP98_STL
+ #include
+#endif
+
+/// @cond FLATBUFFERS_INTERNAL
+#if __cplusplus <= 199711L && \
+ (!defined(_MSC_VER) || _MSC_VER < 1600) && \
+ (!defined(__GNUC__) || \
+ (__GNUC__ * 10000 + __GNUC_MINOR__ * 100 + __GNUC_PATCHLEVEL__ < 40400))
+ #error A C++11 compatible compiler with support for the auto typing is \
+ required for FlatBuffers.
+ #error __cplusplus _MSC_VER __GNUC__ __GNUC_MINOR__ __GNUC_PATCHLEVEL__
+#endif
+
+#if !defined(__clang__) && \
+ defined(__GNUC__) && \
+ (__GNUC__ * 10000 + __GNUC_MINOR__ * 100 + __GNUC_PATCHLEVEL__ < 40600)
+ // Backwards compatability for g++ 4.4, and 4.5 which don't have the nullptr
+ // and constexpr keywords. Note the __clang__ check is needed, because clang
+ // presents itself as an older GNUC compiler.
+ #ifndef nullptr_t
+ const class nullptr_t {
+ public:
+ template inline operator T*() const { return 0; }
+ private:
+ void operator&() const;
+ } nullptr = {};
+ #endif
+ #ifndef constexpr
+ #define constexpr const
+ #endif
+#endif
+
+// The wire format uses a little endian encoding (since that's efficient for
+// the common platforms).
+#if !defined(FLATBUFFERS_LITTLEENDIAN)
+ #if defined(__GNUC__) || defined(__clang__)
+ #ifdef __BIG_ENDIAN__
+ #define FLATBUFFERS_LITTLEENDIAN 0
+ #else
+ #define FLATBUFFERS_LITTLEENDIAN 1
+ #endif // __BIG_ENDIAN__
+ #elif defined(_MSC_VER)
+ #if defined(_M_PPC)
+ #define FLATBUFFERS_LITTLEENDIAN 0
+ #else
+ #define FLATBUFFERS_LITTLEENDIAN 1
+ #endif
+ #else
+ #error Unable to determine endianness, define FLATBUFFERS_LITTLEENDIAN.
+ #endif
+#endif // !defined(FLATBUFFERS_LITTLEENDIAN)
+
+#define FLATBUFFERS_VERSION_MAJOR 1
+#define FLATBUFFERS_VERSION_MINOR 6
+#define FLATBUFFERS_VERSION_REVISION 0
+#define FLATBUFFERS_STRING_EXPAND(X) #X
+#define FLATBUFFERS_STRING(X) FLATBUFFERS_STRING_EXPAND(X)
+
+#if (!defined(_MSC_VER) || _MSC_VER > 1600) && \
+ (!defined(__GNUC__) || (__GNUC__ * 100 + __GNUC_MINOR__ >= 407))
+ #define FLATBUFFERS_FINAL_CLASS final
+#else
+ #define FLATBUFFERS_FINAL_CLASS
+#endif
+
+#if (!defined(_MSC_VER) || _MSC_VER >= 1900) && \
+ (!defined(__GNUC__) || (__GNUC__ * 100 + __GNUC_MINOR__ >= 406))
+ #define FLATBUFFERS_CONSTEXPR constexpr
+#else
+ #define FLATBUFFERS_CONSTEXPR
+#endif
+
+/// @endcond
+
+/// @file
+namespace flatbuffers {
+
+/// @cond FLATBUFFERS_INTERNAL
+// Our default offset / size type, 32bit on purpose on 64bit systems.
+// Also, using a consistent offset type maintains compatibility of serialized
+// offset values between 32bit and 64bit systems.
+typedef uint32_t uoffset_t;
+
+// Signed offsets for references that can go in both directions.
+typedef int32_t soffset_t;
+
+// Offset/index used in v-tables, can be changed to uint8_t in
+// format forks to save a bit of space if desired.
+typedef uint16_t voffset_t;
+
+typedef uintmax_t largest_scalar_t;
+
+// In 32bits, this evaluates to 2GB - 1
+#define FLATBUFFERS_MAX_BUFFER_SIZE ((1ULL << (sizeof(soffset_t) * 8 - 1)) - 1)
+
+// We support aligning the contents of buffers up to this size.
+#define FLATBUFFERS_MAX_ALIGNMENT 16
+
+#ifndef FLATBUFFERS_CPP98_STL
+// Pointer to relinquished memory.
+typedef std::unique_ptr>
+ unique_ptr_t;
+#endif
+
+// Wrapper for uoffset_t to allow safe template specialization.
+template struct Offset {
+ uoffset_t o;
+ Offset() : o(0) {}
+ Offset(uoffset_t _o) : o(_o) {}
+ Offset Union() const { return Offset(o); }
+};
+
+inline void EndianCheck() {
+ int endiantest = 1;
+ // If this fails, see FLATBUFFERS_LITTLEENDIAN above.
+ assert(*reinterpret_cast(&endiantest) == FLATBUFFERS_LITTLEENDIAN);
+ (void)endiantest;
+}
+
+template T EndianSwap(T t) {
+ #if defined(_MSC_VER)
+ #define FLATBUFFERS_BYTESWAP16 _byteswap_ushort
+ #define FLATBUFFERS_BYTESWAP32 _byteswap_ulong
+ #define FLATBUFFERS_BYTESWAP64 _byteswap_uint64
+ #else
+ #if defined(__GNUC__) && __GNUC__ * 100 + __GNUC_MINOR__ < 408
+ // __builtin_bswap16 was missing prior to GCC 4.8.
+ #define FLATBUFFERS_BYTESWAP16(x) \
+ static_cast(__builtin_bswap32(static_cast(x) << 16))
+ #else
+ #define FLATBUFFERS_BYTESWAP16 __builtin_bswap16
+ #endif
+ #define FLATBUFFERS_BYTESWAP32 __builtin_bswap32
+ #define FLATBUFFERS_BYTESWAP64 __builtin_bswap64
+ #endif
+ if (sizeof(T) == 1) { // Compile-time if-then's.
+ return t;
+ } else if (sizeof(T) == 2) {
+ auto r = FLATBUFFERS_BYTESWAP16(*reinterpret_cast(&t));
+ return *reinterpret_cast(&r);
+ } else if (sizeof(T) == 4) {
+ auto r = FLATBUFFERS_BYTESWAP32(*reinterpret_cast(&t));
+ return *reinterpret_cast(&r);
+ } else if (sizeof(T) == 8) {
+ auto r = FLATBUFFERS_BYTESWAP64(*reinterpret_cast(&t));
+ return *reinterpret_cast(&r);
+ } else {
+ assert(0);
+ }
+}
+
+template T EndianScalar(T t) {
+ #if FLATBUFFERS_LITTLEENDIAN
+ return t;
+ #else
+ return EndianSwap(t);
+ #endif
+}
+
+template T ReadScalar(const void *p) {
+ return EndianScalar(*reinterpret_cast(p));
+}
+
+template void WriteScalar(void *p, T t) {
+ *reinterpret_cast(p) = EndianScalar(t);
+}
+
+template size_t AlignOf() {
+ #ifdef _MSC_VER
+ return __alignof(T);
+ #else
+ #ifndef alignof
+ return __alignof__(T);
+ #else
+ return alignof(T);
+ #endif
+ #endif
+}
+
+// When we read serialized data from memory, in the case of most scalars,
+// we want to just read T, but in the case of Offset, we want to actually
+// perform the indirection and return a pointer.
+// The template specialization below does just that.
+// It is wrapped in a struct since function templates can't overload on the
+// return type like this.
+// The typedef is for the convenience of callers of this function
+// (avoiding the need for a trailing return decltype)
+template struct IndirectHelper {
+ typedef T return_type;
+ typedef T mutable_return_type;
+ static const size_t element_stride = sizeof(T);
+ static return_type Read(const uint8_t *p, uoffset_t i) {
+ return EndianScalar((reinterpret_cast(p))[i]);
+ }
+};
+template struct IndirectHelper> {
+ typedef const T *return_type;
+ typedef T *mutable_return_type;
+ static const size_t element_stride = sizeof(uoffset_t);
+ static return_type Read(const uint8_t *p, uoffset_t i) {
+ p += i * sizeof(uoffset_t);
+ return reinterpret_cast(p + ReadScalar(p));
+ }
+};
+template struct IndirectHelper {
+ typedef const T *return_type;
+ typedef T *mutable_return_type;
+ static const size_t element_stride = sizeof(T);
+ static return_type Read(const uint8_t *p, uoffset_t i) {
+ return reinterpret_cast(p + i * sizeof(T));
+ }
+};
+
+// An STL compatible iterator implementation for Vector below, effectively
+// calling Get() for every element.
+template
+struct VectorIterator
+ : public std::iterator {
+
+ typedef std::iterator super_type;
+
+public:
+ VectorIterator(const uint8_t *data, uoffset_t i) :
+ data_(data + IndirectHelper::element_stride * i) {}
+ VectorIterator(const VectorIterator &other) : data_(other.data_) {}
+ #ifndef FLATBUFFERS_CPP98_STL
+ VectorIterator(VectorIterator &&other) : data_(std::move(other.data_)) {}
+ #endif
+
+ VectorIterator &operator=(const VectorIterator &other) {
+ data_ = other.data_;
+ return *this;
+ }
+
+ VectorIterator &operator=(VectorIterator &&other) {
+ data_ = other.data_;
+ return *this;
+ }
+
+ bool operator==(const VectorIterator &other) const {
+ return data_ == other.data_;
+ }
+
+ bool operator!=(const VectorIterator &other) const {
+ return data_ != other.data_;
+ }
+
+ ptrdiff_t operator-(const VectorIterator &other) const {
+ return (data_ - other.data_) / IndirectHelper::element_stride;
+ }
+
+ typename super_type::value_type operator *() const {
+ return IndirectHelper::Read(data_, 0);
+ }
+
+ typename super_type::value_type operator->() const {
+ return IndirectHelper::Read(data_, 0);
+ }
+
+ VectorIterator &operator++() {
+ data_ += IndirectHelper::element_stride;
+ return *this;
+ }
+
+ VectorIterator operator++(int) {
+ VectorIterator temp(data_, 0);
+ data_ += IndirectHelper::element_stride;
+ return temp;
+ }
+
+ VectorIterator operator+(const uoffset_t &offset) {
+ return VectorIterator(data_ + offset * IndirectHelper::element_stride, 0);
+ }
+
+ VectorIterator& operator+=(const uoffset_t &offset) {
+ data_ += offset * IndirectHelper::element_stride;
+ return *this;
+ }
+
+ VectorIterator &operator--() {
+ data_ -= IndirectHelper::element_stride;
+ return *this;
+ }
+
+ VectorIterator operator--(int) {
+ VectorIterator temp(data_, 0);
+ data_ -= IndirectHelper::element_stride;
+ return temp;
+ }
+
+ VectorIterator operator-(const uoffset_t &offset) {
+ return VectorIterator(data_ - offset * IndirectHelper::element_stride, 0);
+ }
+
+ VectorIterator& operator-=(const uoffset_t &offset) {
+ data_ -= offset * IndirectHelper::element_stride;
+ return *this;
+ }
+
+private:
+ const uint8_t *data_;
+};
+
+// This is used as a helper type for accessing vectors.
+// Vector::data() assumes the vector elements start after the length field.
+template class Vector {
+public:
+ typedef VectorIterator::mutable_return_type>
+ iterator;
+ typedef VectorIterator::return_type>
+ const_iterator;
+
+ uoffset_t size() const { return EndianScalar(length_); }
+
+ // Deprecated: use size(). Here for backwards compatibility.
+ uoffset_t Length() const { return size(); }
+
+ typedef typename IndirectHelper::return_type return_type;
+ typedef typename IndirectHelper::mutable_return_type mutable_return_type;
+
+ return_type Get(uoffset_t i) const {
+ assert(i < size());
+ return IndirectHelper::Read(Data(), i);
+ }
+
+ return_type operator[](uoffset_t i) const { return Get(i); }
+
+ // If this is a Vector of enums, T will be its storage type, not the enum
+ // type. This function makes it convenient to retrieve value with enum
+ // type E.
+ template E GetEnum(uoffset_t i) const {
+ return static_cast(Get(i));
+ }
+
+ const void *GetStructFromOffset(size_t o) const {
+ return reinterpret_cast(Data() + o);
+ }
+
+ iterator begin() { return iterator(Data(), 0); }
+ const_iterator begin() const { return const_iterator(Data(), 0); }
+
+ iterator end() { return iterator(Data(), size()); }
+ const_iterator end() const { return const_iterator(Data(), size()); }
+
+ // Change elements if you have a non-const pointer to this object.
+ // Scalars only. See reflection.h, and the documentation.
+ void Mutate(uoffset_t i, const T& val) {
+ assert(i < size());
+ WriteScalar(data() + i, val);
+ }
+
+ // Change an element of a vector of tables (or strings).
+ // "val" points to the new table/string, as you can obtain from
+ // e.g. reflection::AddFlatBuffer().
+ void MutateOffset(uoffset_t i, const uint8_t *val) {
+ assert(i < size());
+ assert(sizeof(T) == sizeof(uoffset_t));
+ WriteScalar(data() + i,
+ static_cast(val - (Data() + i * sizeof(uoffset_t))));
+ }
+
+ // Get a mutable pointer to tables/strings inside this vector.
+ mutable_return_type GetMutableObject(uoffset_t i) const {
+ assert(i < size());
+ return const_cast(IndirectHelper::Read(Data(), i));
+ }
+
+ // The raw data in little endian format. Use with care.
+ const uint8_t *Data() const {
+ return reinterpret_cast(&length_ + 1);
+ }
+
+ uint8_t *Data() {
+ return reinterpret_cast(&length_ + 1);
+ }
+
+ // Similarly, but typed, much like std::vector::data
+ const T *data() const { return reinterpret_cast(Data()); }
+ T *data() { return reinterpret_cast(Data()); }
+
+ template return_type LookupByKey(K key) const {
+ void *search_result = std::bsearch(&key, Data(), size(),
+ IndirectHelper::element_stride, KeyCompare);
+
+ if (!search_result) {
+ return nullptr; // Key not found.
+ }
+
+ const uint8_t *element = reinterpret_cast(search_result);
+
+ return IndirectHelper::Read(element, 0);
+ }
+
+protected:
+ // This class is only used to access pre-existing data. Don't ever
+ // try to construct these manually.
+ Vector();
+
+ uoffset_t length_;
+
+private:
+ template static int KeyCompare(const void *ap, const void *bp) {
+ const K *key = reinterpret_cast(ap);
+ const uint8_t *data = reinterpret_cast(bp);
+ auto table = IndirectHelper::Read(data, 0);
+
+ // std::bsearch compares with the operands transposed, so we negate the
+ // result here.
+ return -table->KeyCompareWithValue(*key);
+ }
+};
+
+// Represent a vector much like the template above, but in this case we
+// don't know what the element types are (used with reflection.h).
+class VectorOfAny {
+public:
+ uoffset_t size() const { return EndianScalar(length_); }
+
+ const uint8_t *Data() const {
+ return reinterpret_cast(&length_ + 1);
+ }
+ uint8_t *Data() {
+ return reinterpret_cast(&length_ + 1);
+ }
+protected:
+ VectorOfAny();
+
+ uoffset_t length_;
+};
+
+// Convenient helper function to get the length of any vector, regardless
+// of wether it is null or not (the field is not set).
+template static inline size_t VectorLength(const Vector *v) {
+ return v ? v->Length() : 0;
+}
+
+struct String : public Vector {
+ const char *c_str() const { return reinterpret_cast(Data()); }
+ std::string str() const { return std::string(c_str(), Length()); }
+
+ bool operator <(const String &o) const {
+ return strcmp(c_str(), o.c_str()) < 0;
+ }
+};
+
+// Simple indirection for buffer allocation, to allow this to be overridden
+// with custom allocation (see the FlatBufferBuilder constructor).
+class simple_allocator {
+ public:
+ virtual ~simple_allocator() {}
+ virtual uint8_t *allocate(size_t size) const { return new uint8_t[size]; }
+ virtual void deallocate(uint8_t *p) const { delete[] p; }
+};
+
+// This is a minimal replication of std::vector functionality,
+// except growing from higher to lower addresses. i.e push_back() inserts data
+// in the lowest address in the vector.
+class vector_downward {
+ public:
+ explicit vector_downward(size_t initial_size,
+ const simple_allocator &allocator)
+ : reserved_((initial_size + sizeof(largest_scalar_t) - 1) &
+ ~(sizeof(largest_scalar_t) - 1)),
+ buf_(allocator.allocate(reserved_)),
+ cur_(buf_ + reserved_),
+ allocator_(allocator) {}
+
+ ~vector_downward() {
+ if (buf_)
+ allocator_.deallocate(buf_);
+ }
+
+ void clear() {
+ if (buf_ == nullptr)
+ buf_ = allocator_.allocate(reserved_);
+
+ cur_ = buf_ + reserved_;
+ }
+
+ #ifndef FLATBUFFERS_CPP98_STL
+ // Relinquish the pointer to the caller.
+ unique_ptr_t release() {
+ // Actually deallocate from the start of the allocated memory.
+ std::function deleter(
+ std::bind(&simple_allocator::deallocate, allocator_, buf_));
+
+ // Point to the desired offset.
+ unique_ptr_t retval(data(), deleter);
+
+ // Don't deallocate when this instance is destroyed.
+ buf_ = nullptr;
+ cur_ = nullptr;
+
+ return retval;
+ }
+ #endif
+
+ size_t growth_policy(size_t bytes) {
+ return (bytes / 2) & ~(sizeof(largest_scalar_t) - 1);
+ }
+
+ uint8_t *make_space(size_t len) {
+ if (len > static_cast(cur_ - buf_)) {
+ reallocate(len);
+ }
+ cur_ -= len;
+ // Beyond this, signed offsets may not have enough range:
+ // (FlatBuffers > 2GB not supported).
+ assert(size() < FLATBUFFERS_MAX_BUFFER_SIZE);
+ return cur_;
+ }
+
+ uoffset_t size() const {
+ assert(cur_ != nullptr && buf_ != nullptr);
+ return static_cast(reserved_ - (cur_ - buf_));
+ }
+
+ uint8_t *data() const {
+ assert(cur_ != nullptr);
+ return cur_;
+ }
+
+ uint8_t *data_at(size_t offset) const { return buf_ + reserved_ - offset; }
+
+ void push(const uint8_t *bytes, size_t num) {
+ auto dest = make_space(num);
+ memcpy(dest, bytes, num);
+ }
+
+ // Specialized version of push() that avoids memcpy call for small data.
+ template void push_small(T little_endian_t) {
+ auto dest = make_space(sizeof(T));
+ *reinterpret_cast(dest) = little_endian_t;
+ }
+
+ // fill() is most frequently called with small byte counts (<= 4),
+ // which is why we're using loops rather than calling memset.
+ void fill(size_t zero_pad_bytes) {
+ auto dest = make_space(zero_pad_bytes);
+ for (size_t i = 0; i < zero_pad_bytes; i++) dest[i] = 0;
+ }
+
+ // Version for when we know the size is larger.
+ void fill_big(size_t zero_pad_bytes) {
+ auto dest = make_space(zero_pad_bytes);
+ memset(dest, 0, zero_pad_bytes);
+ }
+
+ void pop(size_t bytes_to_remove) { cur_ += bytes_to_remove; }
+
+ private:
+ // You shouldn't really be copying instances of this class.
+ vector_downward(const vector_downward &);
+ vector_downward &operator=(const vector_downward &);
+
+ size_t reserved_;
+ uint8_t *buf_;
+ uint8_t *cur_; // Points at location between empty (below) and used (above).
+ const simple_allocator &allocator_;
+
+ void reallocate(size_t len) {
+ auto old_size = size();
+ auto largest_align = AlignOf();
+ reserved_ += (std::max)(len, growth_policy(reserved_));
+ // Round up to avoid undefined behavior from unaligned loads and stores.
+ reserved_ = (reserved_ + (largest_align - 1)) & ~(largest_align - 1);
+ auto new_buf = allocator_.allocate(reserved_);
+ auto new_cur = new_buf + reserved_ - old_size;
+ memcpy(new_cur, cur_, old_size);
+ cur_ = new_cur;
+ allocator_.deallocate(buf_);
+ buf_ = new_buf;
+ }
+};
+
+// Converts a Field ID to a virtual table offset.
+inline voffset_t FieldIndexToOffset(voffset_t field_id) {
+ // Should correspond to what EndTable() below builds up.
+ const int fixed_fields = 2; // Vtable size and Object Size.
+ return static_cast((field_id + fixed_fields) * sizeof(voffset_t));
+}
+
+// Computes how many bytes you'd have to pad to be able to write an
+// "scalar_size" scalar if the buffer had grown to "buf_size" (downwards in
+// memory).
+inline size_t PaddingBytes(size_t buf_size, size_t scalar_size) {
+ return ((~buf_size) + 1) & (scalar_size - 1);
+}
+
+template const T* data(const std::vector &v) {
+ return v.empty() ? nullptr : &v.front();
+}
+template T* data(std::vector &v) {
+ return v.empty() ? nullptr : &v.front();
+}
+
+/// @endcond
+
+/// @addtogroup flatbuffers_cpp_api
+/// @{
+/// @class FlatBufferBuilder
+/// @brief Helper class to hold data needed in creation of a FlatBuffer.
+/// To serialize data, you typically call one of the `Create*()` functions in
+/// the generated code, which in turn call a sequence of `StartTable`/
+/// `PushElement`/`AddElement`/`EndTable`, or the builtin `CreateString`/
+/// `CreateVector` functions. Do this is depth-first order to build up a tree to
+/// the root. `Finish()` wraps up the buffer ready for transport.
+class FlatBufferBuilder
+/// @cond FLATBUFFERS_INTERNAL
+FLATBUFFERS_FINAL_CLASS
+/// @endcond
+{
+ public:
+ /// @brief Default constructor for FlatBufferBuilder.
+ /// @param[in] initial_size The initial size of the buffer, in bytes. Defaults
+ /// to`1024`.
+ /// @param[in] allocator A pointer to the `simple_allocator` that should be
+ /// used. Defaults to `nullptr`, which means the `default_allocator` will be
+ /// be used.
+ explicit FlatBufferBuilder(uoffset_t initial_size = 1024,
+ const simple_allocator *allocator = nullptr)
+ : buf_(initial_size, allocator ? *allocator : default_allocator),
+ nested(false), finished(false), minalign_(1), force_defaults_(false),
+ dedup_vtables_(true), string_pool(nullptr) {
+ offsetbuf_.reserve(16); // Avoid first few reallocs.
+ vtables_.reserve(16);
+ EndianCheck();
+ }
+
+ ~FlatBufferBuilder() {
+ if (string_pool) delete string_pool;
+ }
+
+ /// @brief Reset all the state in this FlatBufferBuilder so it can be reused
+ /// to construct another buffer.
+ void Clear() {
+ buf_.clear();
+ offsetbuf_.clear();
+ nested = false;
+ finished = false;
+ vtables_.clear();
+ minalign_ = 1;
+ if (string_pool) string_pool->clear();
+ }
+
+ /// @brief The current size of the serialized buffer, counting from the end.
+ /// @return Returns an `uoffset_t` with the current size of the buffer.
+ uoffset_t GetSize() const { return buf_.size(); }
+
+ /// @brief Get the serialized buffer (after you call `Finish()`).
+ /// @return Returns an `uint8_t` pointer to the FlatBuffer data inside the
+ /// buffer.
+ uint8_t *GetBufferPointer() const {
+ Finished();
+ return buf_.data();
+ }
+
+ /// @brief Get a pointer to an unfinished buffer.
+ /// @return Returns a `uint8_t` pointer to the unfinished buffer.
+ uint8_t *GetCurrentBufferPointer() const { return buf_.data(); }
+
+ #ifndef FLATBUFFERS_CPP98_STL
+ /// @brief Get the released pointer to the serialized buffer.
+ /// @warning Do NOT attempt to use this FlatBufferBuilder afterwards!
+ /// @return The `unique_ptr` returned has a special allocator that knows how
+ /// to deallocate this pointer (since it points to the middle of an
+ /// allocation). Thus, do not mix this pointer with other `unique_ptr`'s, or
+ /// call `release()`/`reset()` on it.
+ unique_ptr_t ReleaseBufferPointer() {
+ Finished();
+ return buf_.release();
+ }
+ #endif
+
+ /// @brief get the minimum alignment this buffer needs to be accessed
+ /// properly. This is only known once all elements have been written (after
+ /// you call Finish()). You can use this information if you need to embed
+ /// a FlatBuffer in some other buffer, such that you can later read it
+ /// without first having to copy it into its own buffer.
+ size_t GetBufferMinAlignment() {
+ Finished();
+ return minalign_;
+ }
+
+ /// @cond FLATBUFFERS_INTERNAL
+ void Finished() const {
+ // If you get this assert, you're attempting to get access a buffer
+ // which hasn't been finished yet. Be sure to call
+ // FlatBufferBuilder::Finish with your root table.
+ // If you really need to access an unfinished buffer, call
+ // GetCurrentBufferPointer instead.
+ assert(finished);
+ }
+ /// @endcond
+
+ /// @brief In order to save space, fields that are set to their default value
+ /// don't get serialized into the buffer.
+ /// @param[in] bool fd When set to `true`, always serializes default values.
+ void ForceDefaults(bool fd) { force_defaults_ = fd; }
+
+ /// @brief By default vtables are deduped in order to save space.
+ /// @param[in] bool dedup When set to `true`, dedup vtables.
+ void DedupVtables(bool dedup) { dedup_vtables_ = dedup; }
+
+ /// @cond FLATBUFFERS_INTERNAL
+ void Pad(size_t num_bytes) { buf_.fill(num_bytes); }
+
+ void Align(size_t elem_size) {
+ if (elem_size > minalign_) minalign_ = elem_size;
+ buf_.fill(PaddingBytes(buf_.size(), elem_size));
+ }
+
+ void PushFlatBuffer(const uint8_t *bytes, size_t size) {
+ PushBytes(bytes, size);
+ finished = true;
+ }
+
+ void PushBytes(const uint8_t *bytes, size_t size) {
+ buf_.push(bytes, size);
+ }
+
+ void PopBytes(size_t amount) { buf_.pop(amount); }
+
+ template void AssertScalarT() {
+ #ifndef FLATBUFFERS_CPP98_STL
+ // The code assumes power of 2 sizes and endian-swap-ability.
+ static_assert(std::is_scalar::value
+ // The Offset type is essentially a scalar but fails is_scalar.
+ || sizeof(T) == sizeof(Offset),
+ "T must be a scalar type");
+ #endif
+ }
+
+ // Write a single aligned scalar to the buffer
+ template uoffset_t PushElement(T element) {
+ AssertScalarT();
+ T litle_endian_element = EndianScalar(element);
+ Align(sizeof(T));
+ buf_.push_small(litle_endian_element);
+ return GetSize();
+ }
+
+ template uoffset_t PushElement(Offset off) {
+ // Special case for offsets: see ReferTo below.
+ return PushElement(ReferTo(off.o));
+ }
+
+ // When writing fields, we track where they are, so we can create correct
+ // vtables later.
+ void TrackField(voffset_t field, uoffset_t off) {
+ FieldLoc fl = { off, field };
+ offsetbuf_.push_back(fl);
+ }
+
+ // Like PushElement, but additionally tracks the field this represents.
+ template void AddElement(voffset_t field, T e, T def) {
+ // We don't serialize values equal to the default.
+ if (e == def && !force_defaults_) return;
+ auto off = PushElement(e);
+ TrackField(field, off);
+ }
+
+ template void AddOffset(voffset_t field, Offset off) {
+ if (!off.o) return; // An offset of 0 means NULL, don't store.
+ AddElement(field, ReferTo(off.o), static_cast(0));
+ }
+
+ template void AddStruct(voffset_t field, const T *structptr) {
+ if (!structptr) return; // Default, don't store.
+ Align(AlignOf());
+ buf_.push_small(*structptr);
+ TrackField(field, GetSize());
+ }
+
+ void AddStructOffset(voffset_t field, uoffset_t off) {
+ TrackField(field, off);
+ }
+
+ // Offsets initially are relative to the end of the buffer (downwards).
+ // This function converts them to be relative to the current location
+ // in the buffer (when stored here), pointing upwards.
+ uoffset_t ReferTo(uoffset_t off) {
+ // Align to ensure GetSize() below is correct.
+ Align(sizeof(uoffset_t));
+ // Offset must refer to something already in buffer.
+ assert(off && off <= GetSize());
+ return GetSize() - off + static_cast(sizeof(uoffset_t));
+ }
+
+ void NotNested() {
+ // If you hit this, you're trying to construct a Table/Vector/String
+ // during the construction of its parent table (between the MyTableBuilder
+ // and table.Finish().
+ // Move the creation of these sub-objects to above the MyTableBuilder to
+ // not get this assert.
+ // Ignoring this assert may appear to work in simple cases, but the reason
+ // it is here is that storing objects in-line may cause vtable offsets
+ // to not fit anymore. It also leads to vtable duplication.
+ assert(!nested);
+ }
+
+ // From generated code (or from the parser), we call StartTable/EndTable
+ // with a sequence of AddElement calls in between.
+ uoffset_t StartTable() {
+ NotNested();
+ nested = true;
+ return GetSize();
+ }
+
+ // This finishes one serialized object by generating the vtable if it's a
+ // table, comparing it against existing vtables, and writing the
+ // resulting vtable offset.
+ uoffset_t EndTable(uoffset_t start, voffset_t numfields) {
+ // If you get this assert, a corresponding StartTable wasn't called.
+ assert(nested);
+ // Write the vtable offset, which is the start of any Table.
+ // We fill it's value later.
+ auto vtableoffsetloc = PushElement(0);
+ // Write a vtable, which consists entirely of voffset_t elements.
+ // It starts with the number of offsets, followed by a type id, followed
+ // by the offsets themselves. In reverse:
+ buf_.fill_big(numfields * sizeof(voffset_t));
+ auto table_object_size = vtableoffsetloc - start;
+ assert(table_object_size < 0x10000); // Vtable use 16bit offsets.
+ PushElement(static_cast(table_object_size));
+ PushElement(FieldIndexToOffset(numfields));
+ // Write the offsets into the table
+ for (auto field_location = offsetbuf_.begin();
+ field_location != offsetbuf_.end();
+ ++field_location) {
+ auto pos = static_cast(vtableoffsetloc - field_location->off);
+ // If this asserts, it means you've set a field twice.
+ assert(!ReadScalar(buf_.data() + field_location->id));
+ WriteScalar(buf_.data() + field_location->id, pos);
+ }
+ offsetbuf_.clear();
+ auto vt1 = reinterpret_cast(buf_.data());
+ auto vt1_size = ReadScalar(vt1);
+ auto vt_use = GetSize();
+ // See if we already have generated a vtable with this exact same
+ // layout before. If so, make it point to the old one, remove this one.
+ if (dedup_vtables_) {
+ for (auto it = vtables_.begin(); it != vtables_.end(); ++it) {
+ auto vt2 = reinterpret_cast(buf_.data_at(*it));
+ auto vt2_size = *vt2;
+ if (vt1_size != vt2_size || memcmp(vt2, vt1, vt1_size)) continue;
+ vt_use = *it;
+ buf_.pop(GetSize() - vtableoffsetloc);
+ break;
+ }
+ }
+ // If this is a new vtable, remember it.
+ if (vt_use == GetSize()) {
+ vtables_.push_back(vt_use);
+ }
+ // Fill the vtable offset we created above.
+ // The offset points from the beginning of the object to where the
+ // vtable is stored.
+ // Offsets default direction is downward in memory for future format
+ // flexibility (storing all vtables at the start of the file).
+ WriteScalar(buf_.data_at(vtableoffsetloc),
+ static_cast(vt_use) -
+ static_cast(vtableoffsetloc));
+
+ nested = false;
+ return vtableoffsetloc;
+ }
+
+ // This checks a required field has been set in a given table that has
+ // just been constructed.
+ template void Required(Offset table, voffset_t field) {
+ auto table_ptr = buf_.data_at(table.o);
+ auto vtable_ptr = table_ptr - ReadScalar(table_ptr);
+ bool ok = ReadScalar(vtable_ptr + field) != 0;
+ // If this fails, the caller will show what field needs to be set.
+ assert(ok);
+ (void)ok;
+ }
+
+ uoffset_t StartStruct(size_t alignment) {
+ Align(alignment);
+ return GetSize();
+ }
+
+ uoffset_t EndStruct() { return GetSize(); }
+
+ void ClearOffsets() { offsetbuf_.clear(); }
+
+ // Aligns such that when "len" bytes are written, an object can be written
+ // after it with "alignment" without padding.
+ void PreAlign(size_t len, size_t alignment) {
+ buf_.fill(PaddingBytes(GetSize() + len, alignment));
+ }
+ template void PreAlign(size_t len) {
+ AssertScalarT();
+ PreAlign(len, sizeof(T));
+ }
+ /// @endcond
+
+ /// @brief Store a string in the buffer, which can contain any binary data.
+ /// @param[in] str A const char pointer to the data to be stored as a string.
+ /// @param[in] len The number of bytes that should be stored from `str`.
+ /// @return Returns the offset in the buffer where the string starts.
+ Offset CreateString(const char *str, size_t len) {
+ NotNested();
+ PreAlign(len + 1); // Always 0-terminated.
+ buf_.fill(1);
+ PushBytes(reinterpret_cast(str), len);
+ PushElement(static_cast(len));
+ return Offset(GetSize());
+ }
+
+ /// @brief Store a string in the buffer, which is null-terminated.
+ /// @param[in] str A const char pointer to a C-string to add to the buffer.
+ /// @return Returns the offset in the buffer where the string starts.
+ Offset CreateString(const char *str) {
+ return CreateString(str, strlen(str));
+ }
+
+ /// @brief Store a string in the buffer, which can contain any binary data.
+ /// @param[in] str A const reference to a std::string to store in the buffer.
+ /// @return Returns the offset in the buffer where the string starts.
+ Offset CreateString(const std::string &str) {
+ return CreateString(str.c_str(), str.length());
+ }
+
+ /// @brief Store a string in the buffer, which can contain any binary data.
+ /// @param[in] str A const pointer to a `String` struct to add to the buffer.
+ /// @return Returns the offset in the buffer where the string starts
+ Offset CreateString(const String *str) {
+ return str ? CreateString(str->c_str(), str->Length()) : 0;
+ }
+
+ /// @brief Store a string in the buffer, which can contain any binary data.
+ /// If a string with this exact contents has already been serialized before,
+ /// instead simply returns the offset of the existing string.
+ /// @param[in] str A const char pointer to the data to be stored as a string.
+ /// @param[in] len The number of bytes that should be stored from `str`.
+ /// @return Returns the offset in the buffer where the string starts.
+ Offset CreateSharedString(const char *str, size_t len) {
+ if (!string_pool)
+ string_pool = new StringOffsetMap(StringOffsetCompare(buf_));
+ auto size_before_string = buf_.size();
+ // Must first serialize the string, since the set is all offsets into
+ // buffer.
+ auto off = CreateString(str, len);
+ auto it = string_pool->find(off);
+ // If it exists we reuse existing serialized data!
+ if (it != string_pool->end()) {
+ // We can remove the string we serialized.
+ buf_.pop(buf_.size() - size_before_string);
+ return *it;
+ }
+ // Record this string for future use.
+ string_pool->insert(off);
+ return off;
+ }
+
+ /// @brief Store a string in the buffer, which null-terminated.
+ /// If a string with this exact contents has already been serialized before,
+ /// instead simply returns the offset of the existing string.
+ /// @param[in] str A const char pointer to a C-string to add to the buffer.
+ /// @return Returns the offset in the buffer where the string starts.
+ Offset CreateSharedString(const char *str) {
+ return CreateSharedString(str, strlen(str));
+ }
+
+ /// @brief Store a string in the buffer, which can contain any binary data.
+ /// If a string with this exact contents has already been serialized before,
+ /// instead simply returns the offset of the existing string.
+ /// @param[in] str A const reference to a std::string to store in the buffer.
+ /// @return Returns the offset in the buffer where the string starts.
+ Offset CreateSharedString(const std::string &str) {
+ return CreateSharedString(str.c_str(), str.length());
+ }
+
+ /// @brief Store a string in the buffer, which can contain any binary data.
+ /// If a string with this exact contents has already been serialized before,
+ /// instead simply returns the offset of the existing string.
+ /// @param[in] str A const pointer to a `String` struct to add to the buffer.
+ /// @return Returns the offset in the buffer where the string starts
+ Offset CreateSharedString(const String *str) {
+ return CreateSharedString(str->c_str(), str->Length());
+ }
+
+ /// @cond FLATBUFFERS_INTERNAL
+ uoffset_t EndVector(size_t len) {
+ assert(nested); // Hit if no corresponding StartVector.
+ nested = false;
+ return PushElement(static_cast(len));
+ }
+
+ void StartVector(size_t len, size_t elemsize) {
+ NotNested();
+ nested = true;
+ PreAlign(len * elemsize);
+ PreAlign(len * elemsize, elemsize); // Just in case elemsize > uoffset_t.
+ }
+
+ // Call this right before StartVector/CreateVector if you want to force the
+ // alignment to be something different than what the element size would
+ // normally dictate.
+ // This is useful when storing a nested_flatbuffer in a vector of bytes,
+ // or when storing SIMD floats, etc.
+ void ForceVectorAlignment(size_t len, size_t elemsize, size_t alignment) {
+ PreAlign(len * elemsize, alignment);
+ }
+
+ uint8_t *ReserveElements(size_t len, size_t elemsize) {
+ return buf_.make_space(len * elemsize);
+ }
+ /// @endcond
+
+ /// @brief Serialize an array into a FlatBuffer `vector`.
+ /// @tparam T The data type of the array elements.
+ /// @param[in] v A pointer to the array of type `T` to serialize into the
+ /// buffer as a `vector`.
+ /// @param[in] len The number of elements to serialize.
+ /// @return Returns a typed `Offset` into the serialized data indicating
+ /// where the vector is stored.
+ template Offset> CreateVector(const T *v, size_t len) {
+ StartVector(len, sizeof(T));
+ for (auto i = len; i > 0; ) {
+ PushElement(v[--i]);
+ }
+ return Offset>(EndVector(len));
+ }
+
+ /// @brief Serialize a `std::vector` into a FlatBuffer `vector`.
+ /// @tparam T The data type of the `std::vector` elements.
+ /// @param v A const reference to the `std::vector` to serialize into the
+ /// buffer as a `vector`.
+ /// @return Returns a typed `Offset` into the serialized data indicating
+ /// where the vector is stored.
+ template Offset> CreateVector(const std::vector &v) {
+ return CreateVector(data(v), v.size());
+ }
+
+ // vector may be implemented using a bit-set, so we can't access it as
+ // an array. Instead, read elements manually.
+ // Background: https://isocpp.org/blog/2012/11/on-vectorbool
+ Offset> CreateVector(const std::vector &v) {
+ StartVector(v.size(), sizeof(uint8_t));
+ for (auto i = v.size(); i > 0; ) {
+ PushElement(static_cast(v[--i]));
+ }
+ return Offset>(EndVector(v.size()));
+ }
+
+ #ifndef FLATBUFFERS_CPP98_STL
+ /// @brief Serialize values returned by a function into a FlatBuffer `vector`.
+ /// This is a convenience function that takes care of iteration for you.
+ /// @tparam T The data type of the `std::vector` elements.
+ /// @param f A function that takes the current iteration 0..vector_size-1 and
+ /// returns any type that you can construct a FlatBuffers vector out of.
+ /// @return Returns a typed `Offset` into the serialized data indicating
+ /// where the vector is stored.
+ template Offset> CreateVector(size_t vector_size,
+ const std::function &f) {
+ std::vector elems(vector_size);
+ for (size_t i = 0; i < vector_size; i++) elems[i] = f(i);
+ return CreateVector(elems);
+ }
+ #endif
+
+ /// @brief Serialize a `std::vector` into a FlatBuffer `vector`.
+ /// This is a convenience function for a common case.
+ /// @param v A const reference to the `std::vector` to serialize into the
+ /// buffer as a `vector`.
+ /// @return Returns a typed `Offset` into the serialized data indicating
+ /// where the vector is stored.
+ Offset>> CreateVectorOfStrings(
+ const std::vector &v) {
+ std::vector> offsets(v.size());
+ for (size_t i = 0; i < v.size(); i++) offsets[i] = CreateString(v[i]);
+ return CreateVector(offsets);
+ }
+
+ /// @brief Serialize an array of structs into a FlatBuffer `vector`.
+ /// @tparam T The data type of the struct array elements.
+ /// @param[in] v A pointer to the array of type `T` to serialize into the
+ /// buffer as a `vector`.
+ /// @param[in] len The number of elements to serialize.
+ /// @return Returns a typed `Offset` into the serialized data indicating
+ /// where the vector is stored.
+ template Offset> CreateVectorOfStructs(
+ const T *v, size_t len) {
+ StartVector(len * sizeof(T) / AlignOf(), AlignOf());
+ PushBytes(reinterpret_cast(v), sizeof(T) * len);
+ return Offset>(EndVector(len));
+ }
+
+ #ifndef FLATBUFFERS_CPP98_STL
+ /// @brief Serialize an array of structs into a FlatBuffer `vector`.
+ /// @tparam T The data type of the struct array elements.
+ /// @param[in] f A function that takes the current iteration 0..vector_size-1
+ /// and a pointer to the struct that must be filled.
+ /// @return Returns a typed `Offset` into the serialized data indicating
+ /// where the vector is stored.
+ /// This is mostly useful when flatbuffers are generated with mutation
+ /// accessors.
+ template Offset> CreateVectorOfStructs(
+ size_t vector_size, const std::function &filler) {
+ StartVector(vector_size * sizeof(T) / AlignOf(), AlignOf());
+ T *structs = reinterpret_cast(buf_.make_space(vector_size * sizeof(T)));
+ for (size_t i = 0; i < vector_size; i++) {
+ filler(i, structs);
+ structs++;
+ }
+ return Offset>(EndVector(vector_size));
+ }
+ #endif
+
+ /// @brief Serialize a `std::vector` of structs into a FlatBuffer `vector`.
+ /// @tparam T The data type of the `std::vector` struct elements.
+ /// @param[in]] v A const reference to the `std::vector` of structs to
+ /// serialize into the buffer as a `vector`.
+ /// @return Returns a typed `Offset` into the serialized data indicating
+ /// where the vector is stored.
+ template Offset> CreateVectorOfStructs(
+ const std::vector &v) {
+ return CreateVectorOfStructs(data(v), v.size());
+ }
+
+ /// @cond FLATBUFFERS_INTERNAL
+ template
+ struct TableKeyComparator {
+ TableKeyComparator(vector_downward& buf) : buf_(buf) {}
+ bool operator()(const Offset &a, const Offset &b) const {
+ auto table_a = reinterpret_cast