Delivery and continous integration
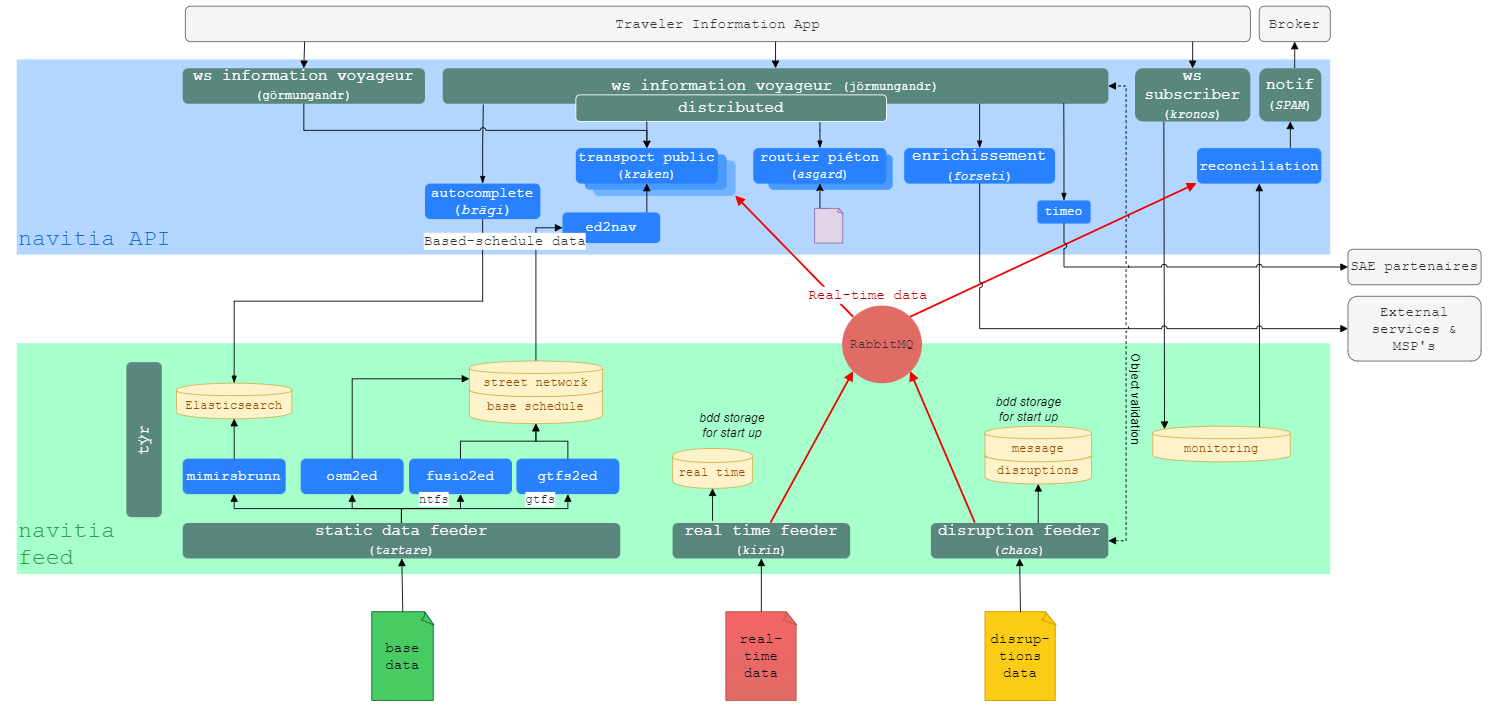
In order to understand the tests organization, you need to have a reminder of the Navitia architecture.
after every pull request (only merged when including a brief message and some unit tests from the author...)
- we build a new version
- then launch the unit tests
- then launch the integration tests
And every 2 weeks, the delivery on our platforms starts...
- every 2 mondays, our quality-team tests the new version in real condition during 2 days
- after that, Kisio Digital customers can test this new version on our customer platform, with their front-end applications
- then our dream-devops-team deliver our little baby on api.navitia.io after 1 week of real condition testing
- so every 2 thursday (pair week), api.navitia.io is up-to-date with newer github release branch
Of course, hotfix are delivered more frequently and in a quickest way.
Navitia has a micro service oriented architecture (not "micro" everywhere yet, but we aim to).
- Each service is tested with unit test/whole service tests.
- The integration between some services is tested by integration tests.
- The whole system is tested by non regression tests (Artemis).
Unit tests should test really simple functionality to avoid side-effects when adding feature. We are looking carefully on that point when merging a new pull request.
When using unit tests is not enough, whole service tests are available. They test the output of a service with a given input.
And after all these tests, integration tests check that several services can work together. The last layer of test is Artemis, our non regression tests. Artemis tests the whole Navitia architecture, starting from several data-sets and testing non regression through the API.
When running tests (make test), all the tests but Artemis are run. Artemis is in a separate repository and is run continuously on the navitia repository since it's duration is quite important.
https://codecov.io/gh/CanalTP/navitia
We use boost unit test for the c++ unit test framework and nose test as the python test framework. When possible we use doc test as functions documentation.
Nothing much to say here.
Those tests check whole logical components. Each component is tested in a different way, but sometimes there are helpers to ease the tests creation.
The core of Navitia is it's public transport routing algorithm, thus it's the most tested component of the lot.
The creation of a test data-set can be a pain, so data-set builders have been developed.
The main one is the public transport data-set builder.
The build helper can be found in source/ed/build_helper.h.
The aim is to have a very simple way to create sample data-set.
Here is a self explanatory code snippet:
ed::builder b("20150531"); // creation of the builder, with a validity period starting from a given data
b.vj("A") // creation of a vehicle journey A (and by cascade since they do not exists a line:A and a route:A
("stop1", "8:00"_t, "8:05"_t) // the vj will be arriving in stop1 at 8:00 and leaving at 8:05
("stop2", "8:20"_t, "8:23"_t) // then it'll go to stop2
("stop3", "9:00"_t); // and finish in stop3
// We add a second line to our data set, visiting stop4 -> stop2 -> stop5
b.vj("B")("stop4", "8:10"_t, "8:10"_t)("stop5", "8:15"_t, "8:30"_t)("stop6", "8:50"_t);
// we add a connection between stop5 and stop6
b.connection("stop5", "stop6", "2"_min);Please refer to source/ed/build_helper.h for all of the builder capabilities. Lots of used examples can be found in source/routing/tests/
The same kind of builder have been made to build street network routing graph. It can be found in source/georef/tests/builder.h. It has been made with the same parenthesis operator logic.
Sample:
GraphBuilder b;
/*
* _________
* / \
* o------o------o
* a b c
*/
// we add 3 nodes to the data-set, with their coordinates
b("a", 1, 0)("b", 2, 0)("c", 3, 0);
// add the edges on the graph
b("a", "b", 10_s) // 10 seconds to go from a to b
("b", "c", 20_s) // 20 seconds to go from b to c
("c", "a", 1_min); // 1 minute to go from c to aThe interactions between Jörmungandr (the python front end) and kraken (the c++ core) are essential in Navitia, so we created a test mechanism to check those parts.
The aim of those tests are to check the API call for some given krakens.
The general idea is that several krakens are poped with tests data-set. The krakens can be found in source/tests.
The data-set are mainly created using both previously seen data-set builders.
The Jörmungandr counter parts contains the tests mechanism and can be found in source/jormungandr/tests.
Of course you will need all the Jörmungandr requirements installed.
The tests are grouped by fixtures. Each fixture depends on some data-sets that match the build-in kraken's names.
The krakens are poped once by feature and killed at the end of all the fixture tests.
For one fixture several tests method can be added. The classic test method consist on one or more API call, followed by some asserts on the API response. Some generic response structure checkers are available in source/jormungandr/tests/check_utils.py (is_valid_stop_area, is_valid_date, ...).
Note: remember that the tests need to be independent, no side effects in the tests!
To understand the mechanisms, let's look at a test:
@dataset(["main_routing_test", "empty_routing_test"]) # -> krakens to load for this test fixture
class TestOverlappingCoverage(AbstractTestFixture): # -> all test fixtures must inherit from this class
def test_journeys(self):
""" # -> Note: it's important to add a comment explaining the purpose of the test
journey query with 2 overlapping coverage.
main_routing_test is free
empty_routing_test is not free but without data (and with the same bounding shape than main_routing_test)
the empty region should be chosen first and after having returned no journey the real region should be called
==> ie we must have a journey in the end
"""
response = self.query("/v1/{q}".format(q=journey_basic_query)) # -> call to the journey api
is_valid_journey_response(response, self.tester, journey_basic_query) # -> check that the response is a valid journey response (with some journeys in it)
def test_journeys_on_empty(self):
"""
explicit call to the empty region should not work
"""
response, error_code = self.query_no_assert("/v1/coverage/empty_routing_test/{q}".format(q=journey_basic_query), display=False)
# -> asserts on the response
assert not 'journeys' in response or len(response['journeys']) == 0
assert error_code == 404
assert 'error' in response
#impossible to project the starting/ending point
assert response['error']['id'] == 'no_origin_nor_destination'The data integration (the ED part) cannot be tested without a database. We thus use docker to provide a temporary database.
The Ed integration tests can be run with a custom cmake target (we currently don't want to make the use of docker mandatory):
make docker_test
This will read different data sets, load them into the ED database, export them with ed2nav.
Some tests are then done on the exported file.
At the very end of the test process are the non regression tests, Artemis.
Note: Artemis is not free software yet because of some data-set licenses.
Artemis check non regression on the whole navitia architecture. It starts from some data sets (Gtfs, Ntfs, OSM, POIs, ...) and check the stability of the API responses.
Due to it's broad test responsibility, the Artemis tests are quite long and quite difficult to analyse on error. You really want to add as many unit tests/integration tests as you can not to have too many failing Artemis tests!
The architecture of Artemis is quite close to the Kraken/Jörmungandr integration tests with test fixture representing data-sets and test methods on those.
At the setup of the test fixture the whole Navitia integration process is run (osm2ed/fusio2ed/gtfs2ed/...) and a kraken poped with the data.
Each API call in a test function will be stored as json and compared to a reference. The comparison will be done only on a subset of the response field to limit the update of the tests references for minor API modifications.
If the API call is different than the reference the test is marked as in error and a user has to analyse the differences. The user can then either correct the code if it is an error or update the reference if the new behaviour is correct.