diff --git a/docs/source/en/tutorials/fast_diffusion.md b/docs/source/en/tutorials/fast_diffusion.md
index 9338bb0a0f47..e758ea399b59 100644
--- a/docs/source/en/tutorials/fast_diffusion.md
+++ b/docs/source/en/tutorials/fast_diffusion.md
@@ -34,13 +34,10 @@ Install [PyTorch nightly](https://pytorch.org/) to benefit from the latest and f
pip3 install --pre torch --index-url https://download.pytorch.org/whl/nightly/cu121
```
-
-
-The results reported below are from a 80GB 400W A100 with its clock rate set to the maximum.
+> [!TIP]
+> The results reported below are from a 80GB 400W A100 with its clock rate set to the maximum.
+> If you're interested in the full benchmarking code, take a look at [huggingface/diffusion-fast](https://github.com/huggingface/diffusion-fast).
-If you're interested in the full benchmarking code, take a look at [huggingface/diffusion-fast](https://github.com/huggingface/diffusion-fast).
-
-
## Baseline
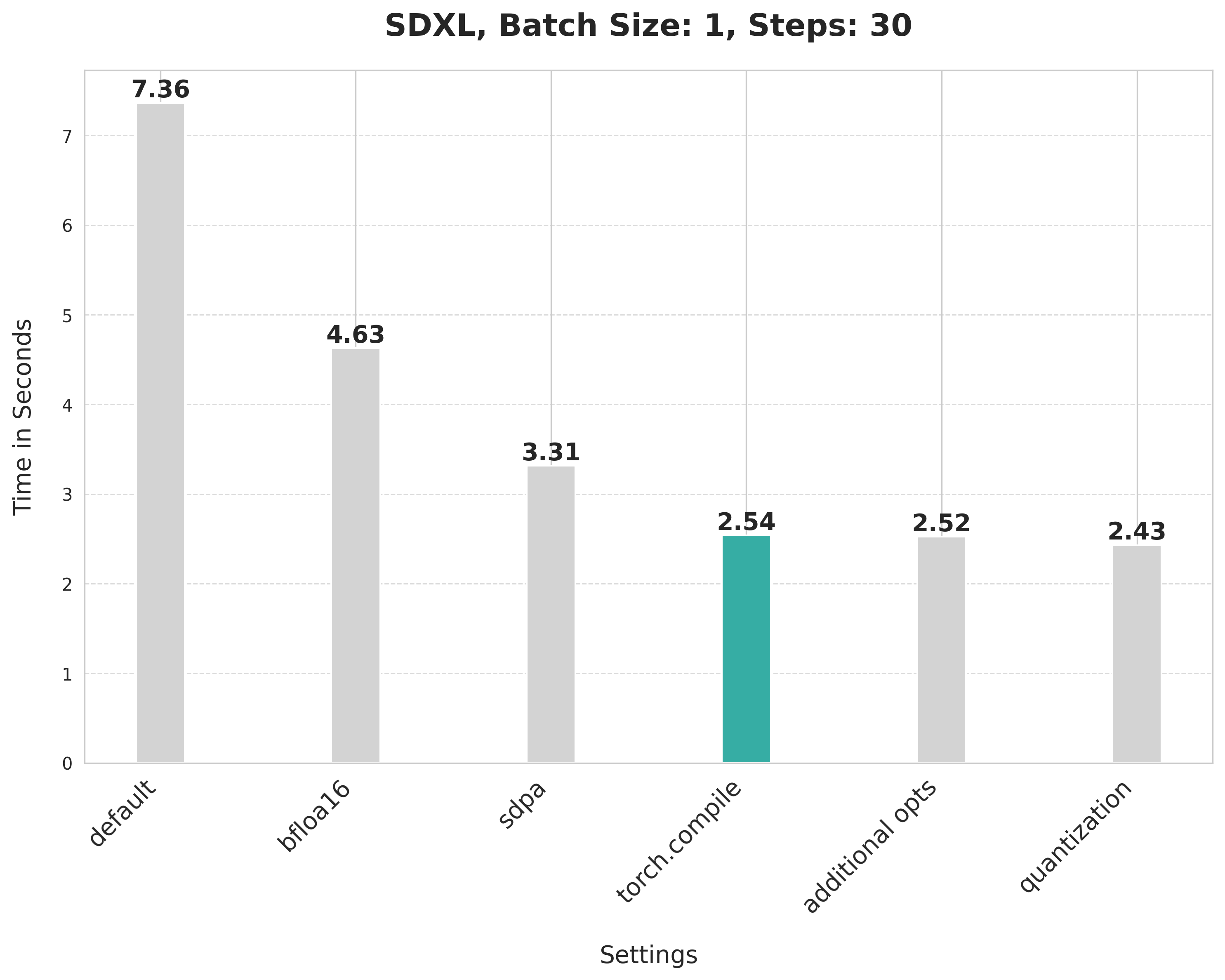
@@ -170,6 +167,9 @@ Using SDPA attention and compiling both the UNet and VAE cuts the latency from 3
 +> [!TIP]
+> From PyTorch 2.3.1, you can control the caching behavior of `torch.compile()`. This is particularly beneficial for compilation modes like `"max-autotune"` which performs a grid-search over several compilation flags to find the optimal configuration. Learn more in the [Compile Time Caching in torch.compile](https://pytorch.org/tutorials/recipes/torch_compile_caching_tutorial.html) tutorial.
+
### Prevent graph breaks
Specifying `fullgraph=True` ensures there are no graph breaks in the underlying model to take full advantage of `torch.compile` without any performance degradation. For the UNet and VAE, this means changing how you access the return variables.
+> [!TIP]
+> From PyTorch 2.3.1, you can control the caching behavior of `torch.compile()`. This is particularly beneficial for compilation modes like `"max-autotune"` which performs a grid-search over several compilation flags to find the optimal configuration. Learn more in the [Compile Time Caching in torch.compile](https://pytorch.org/tutorials/recipes/torch_compile_caching_tutorial.html) tutorial.
+
### Prevent graph breaks
Specifying `fullgraph=True` ensures there are no graph breaks in the underlying model to take full advantage of `torch.compile` without any performance degradation. For the UNet and VAE, this means changing how you access the return variables.