Summarization Fine Tuning #4406
Comments
|
First thing you can try is fine-tune T5/BART for summarization on your corpus and see how it performs. |
|
@patil-suraj where can I find a guide to this? I'm a bit confused by the documentation. |
|
Here's the official example which fine-tunes BART on CNN/DM, you can just replace the cnn/dm dataset with your own summerization dataset. |
|
@patil-suraj Thanks for the example. I'm wondering if there is any simpler way to get started since I'm planning on training it in a Kaggle notebook due to GPU constraints, because otherwise I may need to copy paste entire folder into a Kaggle notebook. |
|
@kevinlu1248 |
|
@patil-suraj Thanks, I'll look into it. |
Hi @patil-suraj, I am following that example and have my data in that format, and I can see the process using GPU/CPU, but I can't get tensorboard working. Do you have any hints? I am happy to contribute to documentation once I get it working. |
|
@sam-qordoba lightning handles logging itself and by default the tensorboard logs are saved in lightning_logs directory. So you should be able see the logs by passing lightning_logs as the logdir to tensorboard command. |
|
Thanks @patil-suraj |
|
Hey @patil-suraj, I had OOM issues on Colab, so moved to a VM with 56GB RAM, and the behaviour is the same as on Colab: memory usage grows, until it uses up everything available (I even added 32GB of swap, so, it's a really impressive amount of memory usage), until I get locked out of the machine... and the only time it writes to jupyter@pytorch-20200529-155153:~/lightning_logs$ tree
.
└── version_0
├── events.out.tfevents.1590794134.pytorch-20200529-155753.8733.0
└── hparams.yaml
1 directory, 2 files
The cell Sorry to keep bothering you, but do you have any hints? It's hard to know what's going on because it doesn't seem to log |
|
It shouldn't take that much memory, did you try reducing the batch size ? Also seems that you are using fp16 here. I haven't tried it with fp16 yet. tagging @sshleifer |
|
Ok, I tried fp16 as a "maybe this will use less memory" experiment, I will try without. I tried batch size of 4, could go lower I guess. Should I just double the learning rate each time I halve the batch size, or are other changes needed? |
|
Could somebody who has fine-tuned BART give me an estimate of how long it takes / how many epochs until convergence? Also any tricks to speed it up (weight freezing etc)? 1 epoch takes c. 150 hrs for my dataset so wondering how many I need... |
|
Sounds like you have a huge dataset? I have had to go down to batch size=1 or 2 on some occasions. @sam-qordoba is your |
|
You can also freeze the You can also use |
|
@sshleifer thanks for coming back with this- all very helpful. Yes- essentially I am just trying out using BART to for longer docs (arXiv/PubMed) as a baseline to compare more sophisticated methods against. This means training set has 300k samples and only 1 sample fits on the GPU at once (12Gb- using 1,024 input length). Lots for me to play around with and see what works well. Thanks for your help. |
@alexgaskell10 If you are interested in using BART for long documents then keep an eye here. I'm trying to convert BART to it's long version using longformer's sliding-window attention. I've been able to replace BART encoder's gradient checkpointing and fp16 with '02' opt level should allow to use larger batch size |
|
@patil-suraj thanks for this- adapting BART for LongformerSelfAttention was actually something I was going to start looking into over the next couple of weeks. Thanks for sharing- I'll be sure to give it a go soon. |
|
Hey @patil-suraj, any updates on your latest progress on LongBART? Thinking about diving into a similar block of work: expanding BART via Longformer |
|
Hi @virattt , I've been able to replace bart encoder's self attention with sliding window attention. Also added gradient checkpoiting in the encoder. Gradient checkpoiting in decoder is not working so going to remove it for now. Will update the repo this weekend and will put some instructions in the readme. |
|
Sounds great, thanks @patil-suraj |
|
Would love to hear |
|
@sshleifer I have been playing around with The best result so far is ROUGE-1 = 36.8 (for comparison, fine-tuning vanilla
Let me know if there is anything you would like to see and I'll try to schedule it in. |
|
Hi @alexgaskell10 , did you use the code as it is ? I think we'll need to train the embeddings for few epochs then we can freeze it. @sshleifer do you have any ideas why this might be happening ? It went well till 60% of first epoch then OOM. Batch size was 1 and max_seq_len 4096 ? @alexgaskell10 can you share more details, how many epochs, batch size, fp16 or not ? |
|
Yes, I used the code as is (minor changes to integrate with hf finetune.py script). I agree that the embeddings and encoder should not be frozen from the beginning but I couldn't fit it on my 12Gb GPU. Once I get setup on the cluster I'll try this. More details on all my runs so far can be found in my wandb project. To answer your question, max a couple epochs so far, batch size between 4 and 16 depending on what fits, not fp16 so far (haven't set up yet but will do soon). |
|
Thanks @alexgaskell10 , I think you'll be able to use bart-base with fp16 and max 2048 seq len without frezzing embdddings on 12GB GPU |
|
I ran the benchmark scripts for each version: Latest Version 2.11.0 ( |
|
I also tested the differences before and after d697b6c ([Longformer] Major Refactor (#5219)). Training time changes: Before d697b6c (at commit e0d58dd): After d697b6c (at commit d697b6c): |
|
@patrickvonplaten @alexgaskell10 @ibeltagy The training time increased from tags/v2.11.0 (0.361s) to right before d697b6c (at commit e0d58dd) (1.445s) by 1.084s. The training time increased from right before d697b6c (at commit e0d58dd) (1.445s) to directly after d697b6c (at commit d697b6c) (2.121s) by 0.676s. I ran the benchmarks twice and got similar results both times. |
|
nice finding. Thanks, @HHousen. @patrickvonplaten, we can check the refactoring more carefully to find the reason for the second slowdown. Any thoughts on what could be the reason for the first one? It is a span of 270 commits!! |
|
Thanks a lot for running the benchmark @HHousen ! Very interesting indeed! I will take a look tomorrow. |
|
@patrickvonplaten You're correct about the first training time increase. I tracked down the time change to commit fa0be6d. At 18a0150 (right before fa0be6d) the training time is about 0.35s. But at fa0be6d it's about 1.4s. So the first time increase can be safely ignored because it was caused by a change in the benchmark scripts. The second time increase, caused by d697b6c seems to be the main issue. |
|
I just ran the same benchmarking scripts on different versions and I can confirm that there is quite a drastic slow-down at master. My results for results for It was probably caused by me, when I did the major longformer refactoring... => will investigate more tomorrow! I guess we should have tests that automatically check if the PR causes a significant slow down. (also @sshleifer , @thomwolf, @mfuntowicz ) |
|
@patrickvonplaten I ran the benchmark on master and the speeds do look to be normal again. The training speeds are 1.328s, 1.378s, 1.457s, and 1.776s for sequences of length 8, 32, 128, 512 respectively, which is similar to the speeds before the major refactor at d697b6c. Inference speeds are 0.326s, 0.343s, 0.348s, and 0.367s, which are appear to be back to normal. |
|
@ibeltagy Should you merge ibeltagy/transformers@longformer_encoder_decoder into huggingface/transformers@master yet to add gradient checkpointing to BART? Or are you waiting for the final LongformerEncoderDecoder implementation to be completed? |
|
@HHousen, I had to disable certain features of the model here to implement gradient checkpointing, so merging it will require more work. |
I modified this example to adapt to the BART. And only use |
|
@WangHexie , not sure. One suggestion, with BART you won't need to manually add at the end as the BART tokenizer automatically add the |
|
@patil-suraj Thanks to your prompt. These models' behaviour is quite different, the problem is solved by shifting decoder input to the right manually. |
|
@alexgaskell10, @HHousen, the |
|
@alexgaskell10, you are right. Just pushed a fix for that one as well. |
|
@ibeltagy it still isn't working correctly for me (even at bsz=1). On some runs and at random points training the training becomes corrupted as per the image below. Taking a look into this now but not really sure where to start as it only happens sometimes and at random points during training so I haven't got much to work with. Any ideas?
|
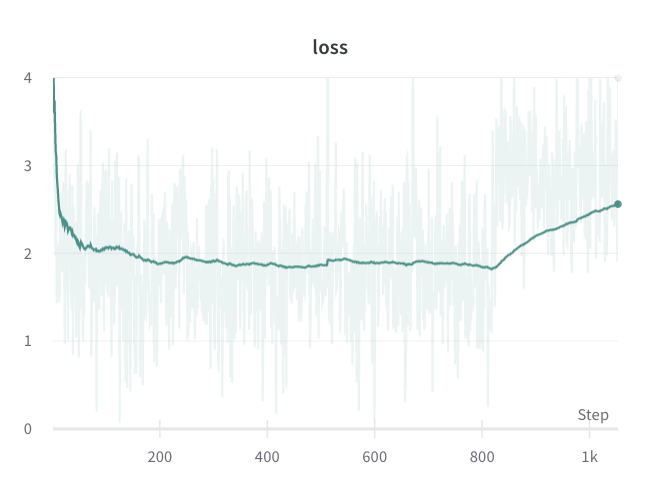
|
|
Thanks for the suggestions- a couple of good thoughts. I have only been using small bsz so far (< 4) so I think that is somewhere to start alongside playing with the LR. Thanks!
|
|
oh, sorry, I meant plotting learning rate curve vs. steps. |
Hello @patil-suraj Can you help me please @alexgaskell10? Thank you so much. |
Just adding that I get the same error for It doesn't appear immediately, but a little way into the warm-up phase of the training. |
|
I had the same problem with FunnelTransformer. But it seems resolved after I set WANDB_WATCH=false or disable --fp16. You can try if it works for you.
|
|
@patil-suraj what is the best way to save the fine tune model in order to reuse it again with |
|
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions. |
❓ Questions & Help
Details
I tried using T5 and Bart but the abstraction summarization on scientific texts does not seem to give the results I want since I think they are both trained on news corpora. I have scraped all of the free PMC articles and I am thinking about fine-tuning a seq2seq model between the articles and their abstracts to make an abstractive summarizer for scientific texts. This Medium article (https://medium.com/huggingface/encoder-decoders-in-transformers-a-hybrid-pre-trained-architecture-for-seq2seq-af4d7bf14bb8) provides a bit of an introduction to how to approach this but does not quite go into detail so I am wondering how to approach this.
I'm not really asking for help being stuck but I just don't really know how to approach this problem.
A link to original question on Stack Overflow:
https://stackoverflow.com/questions/61826443/train-custom-seq2seq-transformers-model
The text was updated successfully, but these errors were encountered: