V2 Microarchitecture Changes
This repository contains the second generation microarchitecture, which was completely redesigned (the last change containing the first generation is tagged in git as 'v1_uarch'). Here is a diagram of the version 1 microarchitecture:
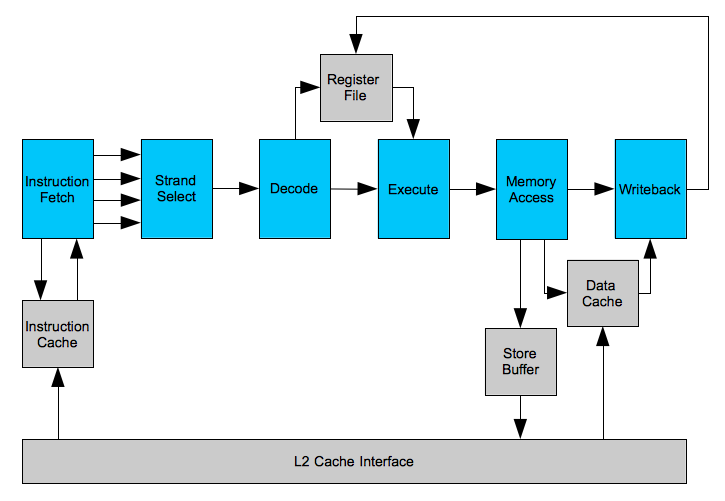
And here is the version 2:
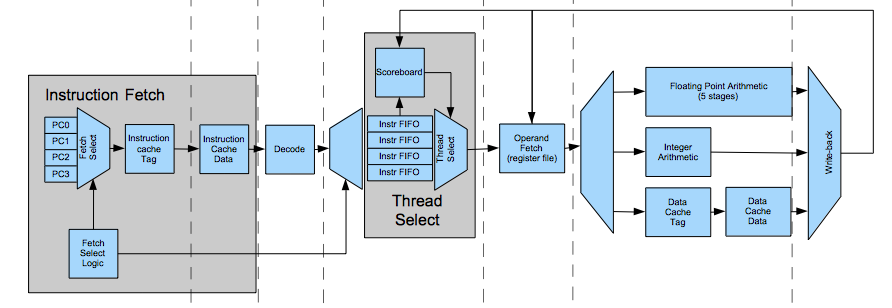
Here is a list of differences between the V1 and V2 architectures:
- The instruction and data caches now have two stages--one to check the tag and one to fetch the data. The data fetch stage now knows the way index when it fetches the data. The previous implementation had four banks of cache data memory that it fetched in parallel with tag lookup. It used a wide mux to pull the appropriate line. Since the way index is known when data is fetched in the new architecture, it can use only one bank of memory and fetch only one line. This improves clock speed and reduces area. It also addresses some issues with implementing TLBs in the old design.
- The floating point arithmetic pipeline has five stages instead of four, and it now registers the last stage. There are extra rounding stages to support proper IEEE 754 round-towards-nearest mode. The pipeline supports higher a clock rate.
- Result forwarding logic has been removed in the new architecture. This was a timing critical path in the previous design. Because the arithmetic and memory stages are now parallel, there is no place where an intermediate result can be forwarded anyway.
- A scoreboard now tracks RAW and WAW dependencies. The previous implementation stalled a thread whenever it issued a long latency instruction. Now, all instructions are effectively long latency. The scoreboard only stalls when there is a dependency. This improves pipeline utilization. The scoreboard also makes it easier to add more stages or change the structure of the backend of the pipeline. The pipeline no longer assumes it must be able to issue dependent instructions back-to-back.
- The arithmetic and memory pipelines are parallel instead of end-to-end. The pipelines merge at the writeback stage instead of before the memory access stage, and the last stage of the pipeline registers the result rather than multiplexing combinationally at the end of the execute stage.
- As a result, there is now only one point where the pipeline dispatches rollbacks (the writeback stage). The rollback logic no longer needs to reconcile simultaneous rollbacks for multiple threads. There is a 'rollback_thread' signal that goes to all stages. Each checks the current thread against it and rollback if there is a match. This reduces combinational delay.
- The central coherence cache directory has been removed from the L2. Instead, each core snoops broadcasts from the L2 cache via a second read port on its tag memory. This potentially reduces area depending on the technology (having one triple ported SRAM instead of two dual ported). It also allows allocate-on-fill instead of allocate-on-miss. This should improve cache hit rate by using more recent LRU information.
- There is no longer branch prediction in this design, because of the way the fetch pipeline is implemented.
- The store buffer supports write combining in the new design
As a result, when synthesized for a Cyclone IV FPGA, the design is 22% smaller in terms of logic cells (~90k elements -> ~72k) and the Fmax is 60% faster (~30 MHz -> 52 Mhz).