
Image recognition as it relates to machine learning and this project is the capability of software and hardware to identify objects within an image. This is usually accomplished by training a neural network with a particular set of images and then testing the accuracy of the model with a test set (i.e. image data set, live/prerecorded video, etc.) The potential for image recognition is vast with new applications being developed around the world and across industries (Tech Crunch).
This image recognition project is about object detection within images. The most basic idea of the first part of this project is to develop software that will utilize a camera feed to identify a very small set of images. Upon detection of one of the trained images the software will respond with an appropriate image or video response on a display. Think - ad on a digital billboard. This technology has applications from target-marketing to public health and safety.
As popular as computer vision is right now, image recognition has had some significant hurdles to overcome. The way a computer sees an image is as a series of pixels, each with a color code, not as an entire image. This can put significant strain on computational resources. In standard artificial neural networks each neuron would process each pixel. At small resolutions this wasn't a problem, but as images became larger, and in higher definition, the computational resources required grows exponentially and quickly becomes infeasible. Enter the convolutional neural network.
CNNs are structured differently than conventional neural networks. They are specifically designed for image classification, so they are able to operate with some generalizations about images that may not apply to broader applications of conventional neural networks. The biggest difference is the CNN will generalize that pixels of closer proximity to one another are more likely to related and this every single pixel doesn't need to be analyzed.
Convolution reduces the computational load by reducing the processes necessary to analyze an image. Much like the way the human eye works, a CNN will assign a small subset of the image (usually 5x5 or 3x3 pixels) to each neuron instead of each neuron analyzing each pixel (100x100 pixel image is 10,000 weights per neuron.) In effect, each neuron is only responsible for analyzing a small portion of the image much like the cortical neurons in the brain.
The small portion that each neuron is responsible for analyzing is known as it's receptive field. These receptive fields overlap with one another thus allowing complete analysis of the image with the least computational resources. Using CNNs it is possible to conduct object detection on high resolution images and video feeds previously not possible. The following image and breakdown from KDnuggets does a great job of explaining how a convolutional neural network operates:
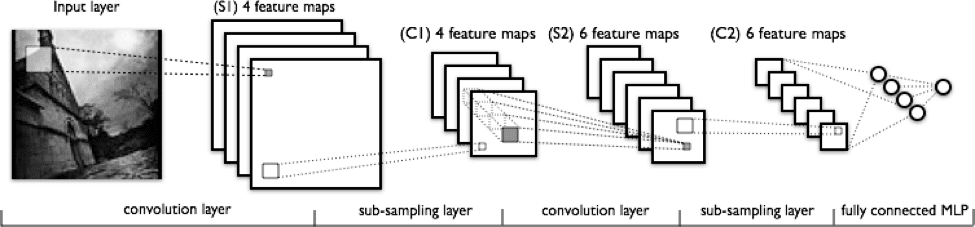
From left to right in the above image, you can observe:
- The real input image that is scanned for features. The filter that passes over it is the light rectangle.
- The activation maps are arranged in a stack on the top of one another, one for each filter you use. The larger rectangle is 1 patch to be downsampled.
- The activation maps are condensed via downsampling.
- A new group of activation maps generated by passing the filters over the stack that is downsampled first.
- The second downsampling – which condenses the second group of activation maps.
- A fully connected layer that designates output with 1 label per node.
An interesting concept to note, and one that greatly reduces computational load, is pooling. The basic concept behind pooling is to take the outputs of multiple neurons or neuron clusters and feed those outputs into a single neuron at the next subsampling layer. Another example of how the CNN use techniques to reduce the computational load for image recognition. The pooling and overlapping receptive fields produce a fully-connected neural network allowing for large image processing at minimal computational load.
http://www.cs.cmu.edu/~bhiksha/courses/deeplearning/Fall.2016/pdfs/Simard.pdfhttps://www.kdnuggets.com/2017/08/convolutional-neural-networks-image-recognition.html
https://techcrunch.com/2016/04/30/why-image-recognition-is-about-to-transform-business/