diff --git a/guides/ipynb/keras_nlp/getting_started.ipynb b/guides/ipynb/keras_nlp/getting_started.ipynb
new file mode 100644
index 0000000000..74768ae8bb
--- /dev/null
+++ b/guides/ipynb/keras_nlp/getting_started.ipynb
@@ -0,0 +1,911 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "# Getting Started with KerasNLP\n",
+ "\n",
+ "**Author:** [jbischof](https://github.com/jbischof)
\n",
+ "**Date created:** 2022/12/15
\n",
+ "**Last modified:** 2022/12/15
\n",
+ "**Description:** An introduction to the KerasNLP API."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "## Introduction\n",
+ "\n",
+ "KerasNLP is a natural language processing library that supports users through\n",
+ "their entire development cycle. Our workflows are built from modular components\n",
+ "that have state-of-the-art preset weights and architectures when used\n",
+ "out-of-the-box and are easily customizable when more control is needed. We\n",
+ "emphasize in-graph computation for all workflows so that developers can expect\n",
+ "easy productionization using the TensorFlow ecosystem.\n",
+ "\n",
+ "This library is an extension of the core Keras API; all high level modules are\n",
+ "[`Layers`](/api/layers/) or [`Models`](/api/models/). If you are familiar with Keras,\n",
+ "congratulations! You already understand most of KerasNLP.\n",
+ "\n",
+ "This guide demonstrates our modular approach using a sentiment analysis example at six\n",
+ "levels of complexity:\n",
+ "\n",
+ "* Inference with a pretrained classifier\n",
+ "* Fine tuning a pretrained backbone\n",
+ "* Fine tuning with user-controlled preprocessing\n",
+ "* Fine tuning a custom model\n",
+ "* Pretraining a backbone model\n",
+ "* Build and train your own transformer from scratch\n",
+ "\n",
+ "Throughout our guide we use Professor Keras, the official Keras mascot, as a visual\n",
+ "reference for the complexity of the material:\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "import keras_nlp\n",
+ "import tensorflow as tf\n",
+ "from tensorflow import keras\n",
+ "\n",
+ "# Use mixed precision for optimal performance\n",
+ "keras.mixed_precision.set_global_policy(\"mixed_float16\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "## API quickstart\n",
+ "\n",
+ "Our highest level API is `keras_nlp.models`. These symbols cover the complete user\n",
+ "journey of converting strings to tokens, tokens to dense features, and dense features to\n",
+ "task-specific output. For each `XX` architecture (e.g., `Bert`), we offer the following\n",
+ "modules:\n",
+ "\n",
+ "* **Tokenizer**: `keras_nlp.models.XXTokenizer`\n",
+ " * **What it does**: Converts strings to `tf.RaggedTensor`s of token ids.\n",
+ " * **Why it's important**: The raw bytes of a string are too high dimensional to be useful\n",
+ " features so we first map them to a small number of tokens, for example `\"The quick brown\n",
+ " fox\"` to `[\"the\", \"qu\", \"##ick\", \"br\", \"##own\", \"fox\"]`.\n",
+ " * **Inherits from**: `keras.layers.Layer`.\n",
+ "* **Preprocessor**: `keras_nlp.models.XXPreprocessor`\n",
+ " * **What it does**: Converts strings to a dictonary of preprocessed tensors consumed by\n",
+ " the backbone, starting with tokenization.\n",
+ " * **Why it's important**: Each model uses special tokens and extra tensors to understand\n",
+ " the input such as deliminting input segments and identifying padding tokens. Padding each\n",
+ " sequence to the same length improves computational efficiency.\n",
+ " * **Has a**: `XXTokenizer`.\n",
+ " * **Inherits from**: `keras.layers.Layer`.\n",
+ "* **Backbone**: `keras_nlp.models.XXBackbone`\n",
+ " * **What it does**: Converts preprocessed tensors to dense features. *Does not handle\n",
+ " strings; call the preprocessor first.*\n",
+ " * **Why it's important**: The backbone distills the input tokens into dense features that\n",
+ " can be used in downstream tasks. It is generally pretrained on a language modeling task\n",
+ " using massive amounts of unlabeled data. Transfering this information to a new task is a\n",
+ " major breakthrough in modern NLP.\n",
+ " * **Inherits from**: `keras.Model`.\n",
+ "* **Task**: e.g., `keras_nlp.models.XXClassifier`\n",
+ " * **What it does**: Converts strings to task-specific output (e.g., classification\n",
+ " probabilities).\n",
+ " * **Why it's important**: Task models combine string preprocessing and the backbone model\n",
+ " with task-specific `Layers` to solve a problem such as sentence classification, token\n",
+ " classification, or text generation. The additional `Layers` must be fine-tuned on labeled\n",
+ " data.\n",
+ " * **Has a**: `XXBackbone` and `XXPreprocessor`.\n",
+ " * **Inherits from**: `keras.Model`.\n",
+ "\n",
+ "Here is the modular hierarchy for `BertClassifier` (all relationships are compositional):\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "import keras_nlp\n",
+ "import tensorflow as tf\n",
+ "from tensorflow import keras\n",
+ "\n",
+ "# Use mixed precision for optimal performance\n",
+ "keras.mixed_precision.set_global_policy(\"mixed_float16\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "## API quickstart\n",
+ "\n",
+ "Our highest level API is `keras_nlp.models`. These symbols cover the complete user\n",
+ "journey of converting strings to tokens, tokens to dense features, and dense features to\n",
+ "task-specific output. For each `XX` architecture (e.g., `Bert`), we offer the following\n",
+ "modules:\n",
+ "\n",
+ "* **Tokenizer**: `keras_nlp.models.XXTokenizer`\n",
+ " * **What it does**: Converts strings to `tf.RaggedTensor`s of token ids.\n",
+ " * **Why it's important**: The raw bytes of a string are too high dimensional to be useful\n",
+ " features so we first map them to a small number of tokens, for example `\"The quick brown\n",
+ " fox\"` to `[\"the\", \"qu\", \"##ick\", \"br\", \"##own\", \"fox\"]`.\n",
+ " * **Inherits from**: `keras.layers.Layer`.\n",
+ "* **Preprocessor**: `keras_nlp.models.XXPreprocessor`\n",
+ " * **What it does**: Converts strings to a dictonary of preprocessed tensors consumed by\n",
+ " the backbone, starting with tokenization.\n",
+ " * **Why it's important**: Each model uses special tokens and extra tensors to understand\n",
+ " the input such as deliminting input segments and identifying padding tokens. Padding each\n",
+ " sequence to the same length improves computational efficiency.\n",
+ " * **Has a**: `XXTokenizer`.\n",
+ " * **Inherits from**: `keras.layers.Layer`.\n",
+ "* **Backbone**: `keras_nlp.models.XXBackbone`\n",
+ " * **What it does**: Converts preprocessed tensors to dense features. *Does not handle\n",
+ " strings; call the preprocessor first.*\n",
+ " * **Why it's important**: The backbone distills the input tokens into dense features that\n",
+ " can be used in downstream tasks. It is generally pretrained on a language modeling task\n",
+ " using massive amounts of unlabeled data. Transfering this information to a new task is a\n",
+ " major breakthrough in modern NLP.\n",
+ " * **Inherits from**: `keras.Model`.\n",
+ "* **Task**: e.g., `keras_nlp.models.XXClassifier`\n",
+ " * **What it does**: Converts strings to task-specific output (e.g., classification\n",
+ " probabilities).\n",
+ " * **Why it's important**: Task models combine string preprocessing and the backbone model\n",
+ " with task-specific `Layers` to solve a problem such as sentence classification, token\n",
+ " classification, or text generation. The additional `Layers` must be fine-tuned on labeled\n",
+ " data.\n",
+ " * **Has a**: `XXBackbone` and `XXPreprocessor`.\n",
+ " * **Inherits from**: `keras.Model`.\n",
+ "\n",
+ "Here is the modular hierarchy for `BertClassifier` (all relationships are compositional):\n",
+ "\n",
+ " \n",
+ "\n",
+ "All modules can be used independently and have a `from_preset()` method in addition to\n",
+ "the standard constructor that instantiates the class with **preset** architecture and\n",
+ "weights (see examples below)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "## Data\n",
+ "\n",
+ "We will use a running example of sentiment analysis of IMDB movie reviews. In this task,\n",
+ "we use the text to predict whether the review was positive (`label = 1`) or negative\n",
+ "(`label = 0`).\n",
+ "\n",
+ "We load the data using `keras.utils.text_dataset_from_directory`, which utilizes the\n",
+ "powerful `tf.data.Dataset` format for examples."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "!curl -O https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz\n",
+ "!tar -xf aclImdb_v1.tar.gz\n",
+ "!# Remove unsupervised examples\n",
+ "!rm -r aclImdb/train/unsup"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "BATCH_SIZE = 16\n",
+ "imdb_train = tf.keras.preprocessing.text_dataset_from_directory(\n",
+ " \"aclImdb/train\",\n",
+ " batch_size=BATCH_SIZE,\n",
+ ")\n",
+ "imdb_test = tf.keras.preprocessing.text_dataset_from_directory(\n",
+ " \"aclImdb/test\",\n",
+ " batch_size=BATCH_SIZE,\n",
+ ")\n",
+ "\n",
+ "# Inspect first review\n",
+ "# Format is (review text tensor, label tensor)\n",
+ "print(imdb_train.unbatch().take(1).get_single_element())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "## Inference with a pretrained classifier\n",
+ "\n",
+ "
\n",
+ "\n",
+ "All modules can be used independently and have a `from_preset()` method in addition to\n",
+ "the standard constructor that instantiates the class with **preset** architecture and\n",
+ "weights (see examples below)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "## Data\n",
+ "\n",
+ "We will use a running example of sentiment analysis of IMDB movie reviews. In this task,\n",
+ "we use the text to predict whether the review was positive (`label = 1`) or negative\n",
+ "(`label = 0`).\n",
+ "\n",
+ "We load the data using `keras.utils.text_dataset_from_directory`, which utilizes the\n",
+ "powerful `tf.data.Dataset` format for examples."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "!curl -O https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz\n",
+ "!tar -xf aclImdb_v1.tar.gz\n",
+ "!# Remove unsupervised examples\n",
+ "!rm -r aclImdb/train/unsup"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "BATCH_SIZE = 16\n",
+ "imdb_train = tf.keras.preprocessing.text_dataset_from_directory(\n",
+ " \"aclImdb/train\",\n",
+ " batch_size=BATCH_SIZE,\n",
+ ")\n",
+ "imdb_test = tf.keras.preprocessing.text_dataset_from_directory(\n",
+ " \"aclImdb/test\",\n",
+ " batch_size=BATCH_SIZE,\n",
+ ")\n",
+ "\n",
+ "# Inspect first review\n",
+ "# Format is (review text tensor, label tensor)\n",
+ "print(imdb_train.unbatch().take(1).get_single_element())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "## Inference with a pretrained classifier\n",
+ "\n",
+ " \n",
+ "\n",
+ "The highest level module in KerasNLP is a **task**. A **task** is a `keras.Model`\n",
+ "consisting of a (generally pretrained) **backbone** model and task-specific layers.\n",
+ "Here's an example using `keras_nlp.models.BertClassifier`.\n",
+ "\n",
+ "**Note**: Outputs are the logits per class (e.g., `[0, 0]` is 50% chance of positive)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "classifier = keras_nlp.models.BertClassifier.from_preset(\"bert_tiny_en_uncased_sst2\")\n",
+ "# Note: batched inputs expected so must wrap string in iterable\n",
+ "classifier.predict([\"I love modular workflows in keras-nlp!\"])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "All **tasks** have a `from_preset` method that constructs a `keras.Model` instance with\n",
+ "preset preprocessing, architecture and weights. This means that we can pass raw strings\n",
+ "in any format accepted by a `keras.Model` and get output specific to our task.\n",
+ "\n",
+ "This particular **preset** is a `\"bert_tiny_uncased_en\"` **backbone** fine-tuned on\n",
+ "`sst2`, another movie review sentiment analysis (this time from Rotten Tomatoes). We use\n",
+ "the `tiny` architecture for demo purposes, but larger models are recommended for SoTA\n",
+ "performance. For all the task-specific presets available for `BertClassifier`, see\n",
+ "our keras.io [models page](https://keras.io/api/keras_nlp/models/).\n",
+ "\n",
+ "Let's evaluate our classifier on the IMDB dataset. We first need to compile the\n",
+ "`keras.Model`. The output is `[loss, accuracy]`,\n",
+ "\n",
+ "**Note**: We don't need an optimizer since we're not training the model."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "classifier.compile(\n",
+ " loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n",
+ " metrics=keras.metrics.SparseCategoricalAccuracy(),\n",
+ " jit_compile=True,\n",
+ ")\n",
+ "\n",
+ "classifier.evaluate(imdb_test)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "Our result is 78% accuracy without training anything. Not bad!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "## Fine tuning a pretrained BERT backbone\n",
+ "\n",
+ "
\n",
+ "\n",
+ "The highest level module in KerasNLP is a **task**. A **task** is a `keras.Model`\n",
+ "consisting of a (generally pretrained) **backbone** model and task-specific layers.\n",
+ "Here's an example using `keras_nlp.models.BertClassifier`.\n",
+ "\n",
+ "**Note**: Outputs are the logits per class (e.g., `[0, 0]` is 50% chance of positive)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "classifier = keras_nlp.models.BertClassifier.from_preset(\"bert_tiny_en_uncased_sst2\")\n",
+ "# Note: batched inputs expected so must wrap string in iterable\n",
+ "classifier.predict([\"I love modular workflows in keras-nlp!\"])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "All **tasks** have a `from_preset` method that constructs a `keras.Model` instance with\n",
+ "preset preprocessing, architecture and weights. This means that we can pass raw strings\n",
+ "in any format accepted by a `keras.Model` and get output specific to our task.\n",
+ "\n",
+ "This particular **preset** is a `\"bert_tiny_uncased_en\"` **backbone** fine-tuned on\n",
+ "`sst2`, another movie review sentiment analysis (this time from Rotten Tomatoes). We use\n",
+ "the `tiny` architecture for demo purposes, but larger models are recommended for SoTA\n",
+ "performance. For all the task-specific presets available for `BertClassifier`, see\n",
+ "our keras.io [models page](https://keras.io/api/keras_nlp/models/).\n",
+ "\n",
+ "Let's evaluate our classifier on the IMDB dataset. We first need to compile the\n",
+ "`keras.Model`. The output is `[loss, accuracy]`,\n",
+ "\n",
+ "**Note**: We don't need an optimizer since we're not training the model."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "classifier.compile(\n",
+ " loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n",
+ " metrics=keras.metrics.SparseCategoricalAccuracy(),\n",
+ " jit_compile=True,\n",
+ ")\n",
+ "\n",
+ "classifier.evaluate(imdb_test)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "Our result is 78% accuracy without training anything. Not bad!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "## Fine tuning a pretrained BERT backbone\n",
+ "\n",
+ " \n",
+ "\n",
+ "When labeled text specific to our task is available, fine-tuning a custom classifier can\n",
+ "improve performance. If we want to predict IMDB review sentiment, using IMDB data should\n",
+ "perform better than Rotten Tomatoes data! And for many tasks no relevant pretrained model\n",
+ "will be available (e.g., categorizing customer reviews).\n",
+ "\n",
+ "The workflow for fine-tuning is almost identical to above, except that we request a\n",
+ "**preset** for the **backbone**-only model rather than the entire classifier. When passed\n",
+ "a **backone** **preset**, a **task** `Model` will randomly initialize all task-specific\n",
+ "layers in preparation for training. For all the **backbone** presets available for\n",
+ "`BertClassifier`, see our keras.io [models page](https://keras.io/api/keras_nlp/models/).\n",
+ "\n",
+ "To train your classifier, use `Model.compile()` and `Model.fit()` as with any other\n",
+ "`keras.Model`. Since preprocessing is included in all **tasks** by default, we again pass\n",
+ "the raw data."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "classifier = keras_nlp.models.BertClassifier.from_preset(\n",
+ " \"bert_tiny_en_uncased\",\n",
+ " num_classes=2,\n",
+ ")\n",
+ "classifier.compile(\n",
+ " loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n",
+ " optimizer=keras.optimizers.experimental.AdamW(5e-5),\n",
+ " metrics=keras.metrics.SparseCategoricalAccuracy(),\n",
+ " jit_compile=True,\n",
+ ")\n",
+ "classifier.fit(\n",
+ " imdb_train,\n",
+ " validation_data=imdb_test,\n",
+ " epochs=1,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "Here we see significant lift in validation accuracy (0.78 -> 0.87) with a single epoch of\n",
+ "training even though the IMDB dataset is much smaller than `sst2`."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "## Fine tuning with user-controlled preprocessing\n",
+ "
\n",
+ "\n",
+ "When labeled text specific to our task is available, fine-tuning a custom classifier can\n",
+ "improve performance. If we want to predict IMDB review sentiment, using IMDB data should\n",
+ "perform better than Rotten Tomatoes data! And for many tasks no relevant pretrained model\n",
+ "will be available (e.g., categorizing customer reviews).\n",
+ "\n",
+ "The workflow for fine-tuning is almost identical to above, except that we request a\n",
+ "**preset** for the **backbone**-only model rather than the entire classifier. When passed\n",
+ "a **backone** **preset**, a **task** `Model` will randomly initialize all task-specific\n",
+ "layers in preparation for training. For all the **backbone** presets available for\n",
+ "`BertClassifier`, see our keras.io [models page](https://keras.io/api/keras_nlp/models/).\n",
+ "\n",
+ "To train your classifier, use `Model.compile()` and `Model.fit()` as with any other\n",
+ "`keras.Model`. Since preprocessing is included in all **tasks** by default, we again pass\n",
+ "the raw data."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "classifier = keras_nlp.models.BertClassifier.from_preset(\n",
+ " \"bert_tiny_en_uncased\",\n",
+ " num_classes=2,\n",
+ ")\n",
+ "classifier.compile(\n",
+ " loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n",
+ " optimizer=keras.optimizers.experimental.AdamW(5e-5),\n",
+ " metrics=keras.metrics.SparseCategoricalAccuracy(),\n",
+ " jit_compile=True,\n",
+ ")\n",
+ "classifier.fit(\n",
+ " imdb_train,\n",
+ " validation_data=imdb_test,\n",
+ " epochs=1,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "Here we see significant lift in validation accuracy (0.78 -> 0.87) with a single epoch of\n",
+ "training even though the IMDB dataset is much smaller than `sst2`."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "## Fine tuning with user-controlled preprocessing\n",
+ " \n",
+ "\n",
+ "For some advanced training scenarios, users might prefer direct control over\n",
+ "preprocessing. For large datasets, examples can be preprocessed in advance and saved to\n",
+ "disk or preprocessed by a separate worker pool using `tf.data.experimental.service`. In\n",
+ "other cases, custom preprocessing is needed to handle the inputs.\n",
+ "\n",
+ "Pass `preprocessor=None` to the constructor of a **task** `Model` to skip automatic\n",
+ "preprocessing or pass a custom `BertPreprocessor` instead."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "### Separate preprocessing from the same preset\n",
+ "\n",
+ "Each model architecture has a parallel **preprocessor** `Layer` with its own\n",
+ "`from_preset` constructor. Using the same **preset** for this `Layer` will return the\n",
+ "matching **preprocessor** as the **task**.\n",
+ "\n",
+ "In this workflow we train the model over three epochs using `tf.data.Dataset.cache()`,\n",
+ "which computes the preprocessing once and caches the result before fitting begins.\n",
+ "\n",
+ "**Note:** this code only works if your data fits in memory. If not, pass a `filename` to\n",
+ "`cache()`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "preprocessor = keras_nlp.models.BertPreprocessor.from_preset(\n",
+ " \"bert_tiny_en_uncased\",\n",
+ " sequence_length=512,\n",
+ ")\n",
+ "\n",
+ "imdb_train_cached = (\n",
+ " imdb_train.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)\n",
+ ")\n",
+ "imdb_test_cached = (\n",
+ " imdb_test.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)\n",
+ ")\n",
+ "\n",
+ "classifier = keras_nlp.models.BertClassifier.from_preset(\n",
+ " \"bert_tiny_en_uncased\",\n",
+ " preprocessor=None,\n",
+ ")\n",
+ "classifier.compile(\n",
+ " loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n",
+ " optimizer=keras.optimizers.experimental.AdamW(5e-5),\n",
+ " metrics=keras.metrics.SparseCategoricalAccuracy(),\n",
+ " jit_compile=True,\n",
+ ")\n",
+ "classifier.fit(\n",
+ " imdb_train_cached,\n",
+ " validation_data=imdb_test_cached,\n",
+ " epochs=3,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "After three epochs, our validation accuracy has only increased to 0.88. This is both a\n",
+ "function of the small size of our dataset and our model. To exceed 90% accuracy, try\n",
+ "larger **presets** such as `\"bert_base_en_uncased\"`. For all the **backbone** presets\n",
+ "available for `BertClassifier`, see our keras.io [models page](https://keras.io/api/keras_nlp/models/)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "### Custom preprocessing\n",
+ "\n",
+ "In cases where custom preprocessing is required, we offer direct access to the\n",
+ "`Tokenizer` class that maps raw strings to tokens. It also has a `from_preset()`\n",
+ "constructor to get the vocabulary matching pretraining.\n",
+ "\n",
+ "**Note:** `BertTokenizer` does not pad sequences by default, so the output is\n",
+ "a `tf.RaggedTensor`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "tokenizer = keras_nlp.models.BertTokenizer.from_preset(\"bert_tiny_en_uncased\")\n",
+ "tokenizer([\"I love modular workflows!\", \"Libraries over frameworks!\"])\n",
+ "\n",
+ "# Write your own packer or use one our `Layers`\n",
+ "packer = keras_nlp.layers.MultiSegmentPacker(\n",
+ " start_value=tokenizer.cls_token_id,\n",
+ " end_value=tokenizer.sep_token_id,\n",
+ " # Note: This cannot be longer than the preset's `sequence_length`, and there\n",
+ " # is no check for a custom preprocessor!\n",
+ " sequence_length=64,\n",
+ ")\n",
+ "\n",
+ "\n",
+ "def preprocessor(x, y):\n",
+ " token_ids, segment_ids = packer(tokenizer(x))\n",
+ " x = {\n",
+ " \"token_ids\": token_ids,\n",
+ " \"segment_ids\": segment_ids,\n",
+ " \"padding_mask\": token_ids != 0,\n",
+ " }\n",
+ " return x, y\n",
+ "\n",
+ "\n",
+ "imbd_train_preprocessed = imdb_train.map(preprocessor, tf.data.AUTOTUNE).prefetch(\n",
+ " tf.data.AUTOTUNE\n",
+ ")\n",
+ "imdb_test_preprocessed = imdb_test.map(preprocessor, tf.data.AUTOTUNE).prefetch(\n",
+ " tf.data.AUTOTUNE\n",
+ ")\n",
+ "\n",
+ "# Preprocessed example\n",
+ "print(imbd_train_preprocessed.unbatch().take(1).get_single_element())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "## Fine tuning with a custom model\n",
+ "\n",
+ "\n",
+ "For more advanced applications, an appropriate **task** `Model` may not be available. In\n",
+ "this case we provide direct access to the **backbone** `Model`, which has its own\n",
+ "`from_preset` constructor and can be composed with custom `Layer`s. Detailed examples can\n",
+ "be found at our [transfer learning guide](https://keras.io/guides/transfer_learning/).\n",
+ "\n",
+ "A **backbone** `Model` does not include automatic preprocessing but can be paired with a\n",
+ "matching **preprocessor** using the same **preset** as shown in the previous workflow.\n",
+ "\n",
+ "In this workflow we experiment with freezing our backbone model and adding two trainable\n",
+ "transfomer layers to adapt to the new input.\n",
+ "\n",
+ "**Note**: We can igonore the warning about gradients for the `pooled_dense` layer because\n",
+ "we are using BERT's sequence output."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "preprocessor = keras_nlp.models.BertPreprocessor.from_preset(\"bert_tiny_en_uncased\")\n",
+ "backbone = keras_nlp.models.BertBackbone.from_preset(\"bert_tiny_en_uncased\")\n",
+ "\n",
+ "imdb_train_preprocessed = (\n",
+ " imdb_train.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)\n",
+ ")\n",
+ "imdb_test_preprocessed = (\n",
+ " imdb_test.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)\n",
+ ")\n",
+ "\n",
+ "backbone.trainable = False\n",
+ "inputs = backbone.input\n",
+ "sequence = backbone(inputs)[\"sequence_output\"]\n",
+ "for _ in range(2):\n",
+ " sequence = keras_nlp.layers.TransformerEncoder(\n",
+ " num_heads=2,\n",
+ " intermediate_dim=512,\n",
+ " dropout=0.1,\n",
+ " )(sequence)\n",
+ "# Use [CLS] token output to classify\n",
+ "outputs = keras.layers.Dense(2)(sequence[:, backbone.cls_token_index, :])\n",
+ "\n",
+ "model = keras.Model(inputs, outputs)\n",
+ "model.compile(\n",
+ " loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n",
+ " optimizer=keras.optimizers.experimental.AdamW(5e-5),\n",
+ " metrics=keras.metrics.SparseCategoricalAccuracy(),\n",
+ " jit_compile=True,\n",
+ ")\n",
+ "model.summary()\n",
+ "model.fit(\n",
+ " imdb_train_preprocessed,\n",
+ " validation_data=imdb_test_preprocessed,\n",
+ " epochs=3,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "This model achieves reasonable accuracy despite having only 10% the trainable parameters\n",
+ "of our `BertClassifier` model. Each training step takes about 1/3 of the time---even\n",
+ "accounting for cached preprocessing."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "## Pretraining a backbone model\n",
+ "
\n",
+ "\n",
+ "For some advanced training scenarios, users might prefer direct control over\n",
+ "preprocessing. For large datasets, examples can be preprocessed in advance and saved to\n",
+ "disk or preprocessed by a separate worker pool using `tf.data.experimental.service`. In\n",
+ "other cases, custom preprocessing is needed to handle the inputs.\n",
+ "\n",
+ "Pass `preprocessor=None` to the constructor of a **task** `Model` to skip automatic\n",
+ "preprocessing or pass a custom `BertPreprocessor` instead."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "### Separate preprocessing from the same preset\n",
+ "\n",
+ "Each model architecture has a parallel **preprocessor** `Layer` with its own\n",
+ "`from_preset` constructor. Using the same **preset** for this `Layer` will return the\n",
+ "matching **preprocessor** as the **task**.\n",
+ "\n",
+ "In this workflow we train the model over three epochs using `tf.data.Dataset.cache()`,\n",
+ "which computes the preprocessing once and caches the result before fitting begins.\n",
+ "\n",
+ "**Note:** this code only works if your data fits in memory. If not, pass a `filename` to\n",
+ "`cache()`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "preprocessor = keras_nlp.models.BertPreprocessor.from_preset(\n",
+ " \"bert_tiny_en_uncased\",\n",
+ " sequence_length=512,\n",
+ ")\n",
+ "\n",
+ "imdb_train_cached = (\n",
+ " imdb_train.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)\n",
+ ")\n",
+ "imdb_test_cached = (\n",
+ " imdb_test.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)\n",
+ ")\n",
+ "\n",
+ "classifier = keras_nlp.models.BertClassifier.from_preset(\n",
+ " \"bert_tiny_en_uncased\",\n",
+ " preprocessor=None,\n",
+ ")\n",
+ "classifier.compile(\n",
+ " loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n",
+ " optimizer=keras.optimizers.experimental.AdamW(5e-5),\n",
+ " metrics=keras.metrics.SparseCategoricalAccuracy(),\n",
+ " jit_compile=True,\n",
+ ")\n",
+ "classifier.fit(\n",
+ " imdb_train_cached,\n",
+ " validation_data=imdb_test_cached,\n",
+ " epochs=3,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "After three epochs, our validation accuracy has only increased to 0.88. This is both a\n",
+ "function of the small size of our dataset and our model. To exceed 90% accuracy, try\n",
+ "larger **presets** such as `\"bert_base_en_uncased\"`. For all the **backbone** presets\n",
+ "available for `BertClassifier`, see our keras.io [models page](https://keras.io/api/keras_nlp/models/)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "### Custom preprocessing\n",
+ "\n",
+ "In cases where custom preprocessing is required, we offer direct access to the\n",
+ "`Tokenizer` class that maps raw strings to tokens. It also has a `from_preset()`\n",
+ "constructor to get the vocabulary matching pretraining.\n",
+ "\n",
+ "**Note:** `BertTokenizer` does not pad sequences by default, so the output is\n",
+ "a `tf.RaggedTensor`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "tokenizer = keras_nlp.models.BertTokenizer.from_preset(\"bert_tiny_en_uncased\")\n",
+ "tokenizer([\"I love modular workflows!\", \"Libraries over frameworks!\"])\n",
+ "\n",
+ "# Write your own packer or use one our `Layers`\n",
+ "packer = keras_nlp.layers.MultiSegmentPacker(\n",
+ " start_value=tokenizer.cls_token_id,\n",
+ " end_value=tokenizer.sep_token_id,\n",
+ " # Note: This cannot be longer than the preset's `sequence_length`, and there\n",
+ " # is no check for a custom preprocessor!\n",
+ " sequence_length=64,\n",
+ ")\n",
+ "\n",
+ "\n",
+ "def preprocessor(x, y):\n",
+ " token_ids, segment_ids = packer(tokenizer(x))\n",
+ " x = {\n",
+ " \"token_ids\": token_ids,\n",
+ " \"segment_ids\": segment_ids,\n",
+ " \"padding_mask\": token_ids != 0,\n",
+ " }\n",
+ " return x, y\n",
+ "\n",
+ "\n",
+ "imbd_train_preprocessed = imdb_train.map(preprocessor, tf.data.AUTOTUNE).prefetch(\n",
+ " tf.data.AUTOTUNE\n",
+ ")\n",
+ "imdb_test_preprocessed = imdb_test.map(preprocessor, tf.data.AUTOTUNE).prefetch(\n",
+ " tf.data.AUTOTUNE\n",
+ ")\n",
+ "\n",
+ "# Preprocessed example\n",
+ "print(imbd_train_preprocessed.unbatch().take(1).get_single_element())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "## Fine tuning with a custom model\n",
+ "\n",
+ "\n",
+ "For more advanced applications, an appropriate **task** `Model` may not be available. In\n",
+ "this case we provide direct access to the **backbone** `Model`, which has its own\n",
+ "`from_preset` constructor and can be composed with custom `Layer`s. Detailed examples can\n",
+ "be found at our [transfer learning guide](https://keras.io/guides/transfer_learning/).\n",
+ "\n",
+ "A **backbone** `Model` does not include automatic preprocessing but can be paired with a\n",
+ "matching **preprocessor** using the same **preset** as shown in the previous workflow.\n",
+ "\n",
+ "In this workflow we experiment with freezing our backbone model and adding two trainable\n",
+ "transfomer layers to adapt to the new input.\n",
+ "\n",
+ "**Note**: We can igonore the warning about gradients for the `pooled_dense` layer because\n",
+ "we are using BERT's sequence output."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "preprocessor = keras_nlp.models.BertPreprocessor.from_preset(\"bert_tiny_en_uncased\")\n",
+ "backbone = keras_nlp.models.BertBackbone.from_preset(\"bert_tiny_en_uncased\")\n",
+ "\n",
+ "imdb_train_preprocessed = (\n",
+ " imdb_train.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)\n",
+ ")\n",
+ "imdb_test_preprocessed = (\n",
+ " imdb_test.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)\n",
+ ")\n",
+ "\n",
+ "backbone.trainable = False\n",
+ "inputs = backbone.input\n",
+ "sequence = backbone(inputs)[\"sequence_output\"]\n",
+ "for _ in range(2):\n",
+ " sequence = keras_nlp.layers.TransformerEncoder(\n",
+ " num_heads=2,\n",
+ " intermediate_dim=512,\n",
+ " dropout=0.1,\n",
+ " )(sequence)\n",
+ "# Use [CLS] token output to classify\n",
+ "outputs = keras.layers.Dense(2)(sequence[:, backbone.cls_token_index, :])\n",
+ "\n",
+ "model = keras.Model(inputs, outputs)\n",
+ "model.compile(\n",
+ " loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n",
+ " optimizer=keras.optimizers.experimental.AdamW(5e-5),\n",
+ " metrics=keras.metrics.SparseCategoricalAccuracy(),\n",
+ " jit_compile=True,\n",
+ ")\n",
+ "model.summary()\n",
+ "model.fit(\n",
+ " imdb_train_preprocessed,\n",
+ " validation_data=imdb_test_preprocessed,\n",
+ " epochs=3,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "This model achieves reasonable accuracy despite having only 10% the trainable parameters\n",
+ "of our `BertClassifier` model. Each training step takes about 1/3 of the time---even\n",
+ "accounting for cached preprocessing."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "## Pretraining a backbone model\n",
+ " \n",
+ "\n",
+ "Do you have access to large unlabeled datasets in your domain? Are they are around the\n",
+ "same size as used to train popular backbones such as BERT, RoBERTa, or GPT2 (XX+ GiB)? If\n",
+ "so, you might benefit from domain-specific pretraining of your own backbone models.\n",
+ "\n",
+ "NLP models are generally pretrained on a language modeling task, predicting masked words\n",
+ "given the visible words in an input sentence. For example, given the input\n",
+ "`\"The fox [MASK] over the [MASK] dog\"`, the model might be asked to predict `[\"jumped\", \"lazy\"]`.\n",
+ "The lower layers of this model are then packaged as a **backbone** to be combined with\n",
+ "layers relating to a new task.\n",
+ "\n",
+ "The KerasNLP library offers SoTA **backbones** and **tokenizers** to be trained from\n",
+ "scratch without presets.\n",
+ "\n",
+ "In this workflow we pretrain a BERT **backbone** using our IMDB review text. We skip the\n",
+ "\"next sentence prediction\" (NSP) loss because it adds significant complexity to the data\n",
+ "processing and was dropped by later models like RoBERTa. See our e2e [BERT pretraining\n",
+ "example](https://github.com/keras-team/keras-nlp/tree/master/examples/bert) for\n",
+ "step-by-step details on how to replicate the original paper."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "### Preprocessing"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "# All BERT `en` models have the same vocabulary, so reuse preprocessor from\n",
+ "# \"bert_tiny_en_uncased\"\n",
+ "preprocessor = keras_nlp.models.BertPreprocessor.from_preset(\n",
+ " \"bert_tiny_en_uncased\",\n",
+ " sequence_length=256,\n",
+ ")\n",
+ "packer = preprocessor.packer\n",
+ "tokenizer = preprocessor.tokenizer\n",
+ "\n",
+ "# keras.Layer to replace some input tokens with the \"[MASK]\" token\n",
+ "masker = keras_nlp.layers.MaskedLMMaskGenerator(\n",
+ " vocabulary_size=tokenizer.vocabulary_size(),\n",
+ " mask_selection_rate=0.25,\n",
+ " mask_selection_length=64,\n",
+ " mask_token_id=tokenizer.token_to_id(\"[MASK]\"),\n",
+ " unselectable_token_ids=[\n",
+ " tokenizer.token_to_id(x) for x in [\"[CLS]\", \"[PAD]\", \"[SEP]\"]\n",
+ " ],\n",
+ ")\n",
+ "\n",
+ "\n",
+ "def preprocess(inputs, label):\n",
+ " inputs = preprocessor(inputs)\n",
+ " masked_inputs = masker(inputs[\"token_ids\"])\n",
+ " # Split the masking layer outputs into a (features, labels, and weights)\n",
+ " # tuple that we can use with keras.Model.fit().\n",
+ " features = {\n",
+ " \"token_ids\": masked_inputs[\"token_ids\"],\n",
+ " \"segment_ids\": inputs[\"segment_ids\"],\n",
+ " \"padding_mask\": inputs[\"padding_mask\"],\n",
+ " \"mask_positions\": masked_inputs[\"mask_positions\"],\n",
+ " }\n",
+ " labels = masked_inputs[\"mask_ids\"]\n",
+ " weights = masked_inputs[\"mask_weights\"]\n",
+ " return features, labels, weights\n",
+ "\n",
+ "\n",
+ "pretrain_ds = imdb_train.map(preprocess, num_parallel_calls=tf.data.AUTOTUNE).prefetch(\n",
+ " tf.data.AUTOTUNE\n",
+ ")\n",
+ "pretrain_val_ds = imdb_test.map(\n",
+ " preprocess, num_parallel_calls=tf.data.AUTOTUNE\n",
+ ").prefetch(tf.data.AUTOTUNE)\n",
+ "\n",
+ "# Tokens with ID 103 are \"masked\"\n",
+ "print(pretrain_ds.unbatch().take(1).get_single_element())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "### Pretraining model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "# BERT backbone\n",
+ "backbone = keras_nlp.models.BertBackbone(\n",
+ " vocabulary_size=tokenizer.vocabulary_size(),\n",
+ " num_layers=2,\n",
+ " num_heads=2,\n",
+ " hidden_dim=128,\n",
+ " intermediate_dim=512,\n",
+ ")\n",
+ "\n",
+ "# Language modeling head\n",
+ "mlm_head = keras_nlp.layers.MaskedLMHead(\n",
+ " embedding_weights=backbone.token_embedding.embeddings,\n",
+ ")\n",
+ "\n",
+ "inputs = {\n",
+ " \"token_ids\": keras.Input(shape=(None,), dtype=tf.int32),\n",
+ " \"segment_ids\": keras.Input(shape=(None,), dtype=tf.int32),\n",
+ " \"padding_mask\": keras.Input(shape=(None,), dtype=tf.int32),\n",
+ " \"mask_positions\": keras.Input(shape=(None,), dtype=tf.int32),\n",
+ "}\n",
+ "\n",
+ "# Encoded token sequence\n",
+ "sequence = backbone(inputs)[\"sequence_output\"]\n",
+ "\n",
+ "# Predict an output word for each masked input token.\n",
+ "# We use the input token embedding to project from our encoded vectors to\n",
+ "# vocabulary logits, which has been shown to improve training efficiency.\n",
+ "outputs = mlm_head(sequence, mask_positions=inputs[\"mask_positions\"])\n",
+ "\n",
+ "# Define and compile our pretraining model.\n",
+ "pretraining_model = keras.Model(inputs, outputs)\n",
+ "pretraining_model.summary()\n",
+ "pretraining_model.compile(\n",
+ " loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n",
+ " optimizer=keras.optimizers.experimental.AdamW(learning_rate=5e-4),\n",
+ " weighted_metrics=keras.metrics.SparseCategoricalAccuracy(),\n",
+ " jit_compile=True,\n",
+ ")\n",
+ "\n",
+ "# Pretrain on IMDB dataset\n",
+ "pretraining_model.fit(\n",
+ " pretrain_ds,\n",
+ " validation_data=pretrain_val_ds,\n",
+ " epochs=3, # Increase to 6 for higher accuracy\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "After pretraining save your `backbone` submodel to use in a new task!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "## Build and train your own transformer from scratch\n",
+ "\n",
+ "\n",
+ "Want to implement a novel transformer architecture? The KerasNLP library offers all the\n",
+ "low-level modules used to build SoTA architectures in our `models` API. This includes the\n",
+ "`keras_nlp.tokenizers` API which allows you to train your own subword tokenizer using\n",
+ "`WordPieceTokenizer`, `BytePairTokenizer`, or `SentencePieceTokenizer`.\n",
+ "\n",
+ "In this workflow we train a custom tokenizer on the IMDB data and design a backbone with\n",
+ "custom transformer architecture. For simplicity we then train directly on the\n",
+ "classification task. Interested in more details? We wrote an entire guide to pretraining\n",
+ "and finetuning a custom transformer on\n",
+ "[keras.io](https://keras.io/guides/keras_nlp/transformer_pretraining/),"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "### Train custom vocabulary from IMBD data"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "vocab = keras_nlp.tokenizers.compute_word_piece_vocabulary(\n",
+ " imdb_train.map(lambda x, y: x),\n",
+ " vocabulary_size=20_000,\n",
+ " lowercase=True,\n",
+ " strip_accents=True,\n",
+ " reserved_tokens=[\"[PAD]\", \"[START]\", \"[END]\", \"[MASK]\", \"[UNK]\"],\n",
+ ")\n",
+ "tokenizer = keras_nlp.tokenizers.WordPieceTokenizer(\n",
+ " vocabulary=vocab,\n",
+ " lowercase=True,\n",
+ " strip_accents=True,\n",
+ " oov_token=\"[UNK]\",\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "### Preprocess data with custom tokenizer"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "packer = keras_nlp.layers.StartEndPacker(\n",
+ " start_value=tokenizer.token_to_id(\"[START]\"),\n",
+ " end_value=tokenizer.token_to_id(\"[END]\"),\n",
+ " pad_value=tokenizer.token_to_id(\"[PAD]\"),\n",
+ " sequence_length=512,\n",
+ ")\n",
+ "\n",
+ "\n",
+ "def preprocess(x, y):\n",
+ " token_ids = packer(tokenizer(x))\n",
+ " return token_ids, y\n",
+ "\n",
+ "\n",
+ "imdb_preproc_train_ds = imdb_train.map(\n",
+ " preprocess, num_parallel_calls=tf.data.AUTOTUNE\n",
+ ").prefetch(tf.data.AUTOTUNE)\n",
+ "imdb_preproc_val_ds = imdb_test.map(\n",
+ " preprocess, num_parallel_calls=tf.data.AUTOTUNE\n",
+ ").prefetch(tf.data.AUTOTUNE)\n",
+ "\n",
+ "print(imdb_preproc_train_ds.unbatch().take(1).get_single_element())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "### Design a tiny transformer"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "token_id_input = keras.Input(\n",
+ " shape=(None,),\n",
+ " dtype=\"int32\",\n",
+ " name=\"token_ids\",\n",
+ ")\n",
+ "outputs = keras_nlp.layers.TokenAndPositionEmbedding(\n",
+ " vocabulary_size=len(vocab),\n",
+ " sequence_length=packer.sequence_length,\n",
+ " embedding_dim=64,\n",
+ ")(token_id_input)\n",
+ "outputs = keras_nlp.layers.TransformerEncoder(\n",
+ " num_heads=2,\n",
+ " intermediate_dim=128,\n",
+ " dropout=0.1,\n",
+ ")(outputs)\n",
+ "# Use \"[START]\" token to classify\n",
+ "outputs = keras.layers.Dense(2)(outputs[:, 0, :])\n",
+ "model = keras.Model(\n",
+ " inputs=token_id_input,\n",
+ " outputs=outputs,\n",
+ ")\n",
+ "\n",
+ "model.summary()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "### Train the transformer directly on the classification objective"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "model.compile(\n",
+ " loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n",
+ " optimizer=keras.optimizers.experimental.AdamW(5e-5),\n",
+ " metrics=keras.metrics.SparseCategoricalAccuracy(),\n",
+ " jit_compile=True,\n",
+ ")\n",
+ "model.fit(\n",
+ " imdb_preproc_train_ds,\n",
+ " validation_data=imdb_preproc_val_ds,\n",
+ " epochs=3,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "Excitingly, our custom classifier is similar to the performance of fine-tuning\n",
+ "`\"bert_tiny_en_uncased\"`! To see the advantages of pretraining and exceed 90% accuracy we\n",
+ "would need to use larger **presets** such as `\"bert_base_en_uncased\"`."
+ ]
+ }
+ ],
+ "metadata": {
+ "accelerator": "GPU",
+ "colab": {
+ "collapsed_sections": [],
+ "name": "getting_started",
+ "private_outputs": false,
+ "provenance": [],
+ "toc_visible": true
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.0"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
\ No newline at end of file
diff --git a/guides/keras_nlp/getting_started.py b/guides/keras_nlp/getting_started.py
new file mode 100644
index 0000000000..1ac2140423
--- /dev/null
+++ b/guides/keras_nlp/getting_started.py
@@ -0,0 +1,619 @@
+"""
+Title: Getting Started with KerasNLP
+Author: [jbischof](https://github.com/jbischof)
+Date created: 2022/12/15
+Last modified: 2022/12/15
+Description: An introduction to the KerasNLP API.
+Accelerator: GPU
+"""
+"""
+## Introduction
+
+KerasNLP is a natural language processing library that supports users through
+their entire development cycle. Our workflows are built from modular components
+that have state-of-the-art preset weights and architectures when used
+out-of-the-box and are easily customizable when more control is needed. We
+emphasize in-graph computation for all workflows so that developers can expect
+easy productionization using the TensorFlow ecosystem.
+
+This library is an extension of the core Keras API; all high level modules are
+[`Layers`](/api/layers/) or [`Models`](/api/models/). If you are familiar with Keras,
+congratulations! You already understand most of KerasNLP.
+
+This guide demonstrates our modular approach using a sentiment analysis example at six
+levels of complexity:
+
+* Inference with a pretrained classifier
+* Fine tuning a pretrained backbone
+* Fine tuning with user-controlled preprocessing
+* Fine tuning a custom model
+* Pretraining a backbone model
+* Build and train your own transformer from scratch
+
+Throughout our guide we use Professor Keras, the official Keras mascot, as a visual
+reference for the complexity of the material:
+
+
\n",
+ "\n",
+ "Do you have access to large unlabeled datasets in your domain? Are they are around the\n",
+ "same size as used to train popular backbones such as BERT, RoBERTa, or GPT2 (XX+ GiB)? If\n",
+ "so, you might benefit from domain-specific pretraining of your own backbone models.\n",
+ "\n",
+ "NLP models are generally pretrained on a language modeling task, predicting masked words\n",
+ "given the visible words in an input sentence. For example, given the input\n",
+ "`\"The fox [MASK] over the [MASK] dog\"`, the model might be asked to predict `[\"jumped\", \"lazy\"]`.\n",
+ "The lower layers of this model are then packaged as a **backbone** to be combined with\n",
+ "layers relating to a new task.\n",
+ "\n",
+ "The KerasNLP library offers SoTA **backbones** and **tokenizers** to be trained from\n",
+ "scratch without presets.\n",
+ "\n",
+ "In this workflow we pretrain a BERT **backbone** using our IMDB review text. We skip the\n",
+ "\"next sentence prediction\" (NSP) loss because it adds significant complexity to the data\n",
+ "processing and was dropped by later models like RoBERTa. See our e2e [BERT pretraining\n",
+ "example](https://github.com/keras-team/keras-nlp/tree/master/examples/bert) for\n",
+ "step-by-step details on how to replicate the original paper."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "### Preprocessing"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "# All BERT `en` models have the same vocabulary, so reuse preprocessor from\n",
+ "# \"bert_tiny_en_uncased\"\n",
+ "preprocessor = keras_nlp.models.BertPreprocessor.from_preset(\n",
+ " \"bert_tiny_en_uncased\",\n",
+ " sequence_length=256,\n",
+ ")\n",
+ "packer = preprocessor.packer\n",
+ "tokenizer = preprocessor.tokenizer\n",
+ "\n",
+ "# keras.Layer to replace some input tokens with the \"[MASK]\" token\n",
+ "masker = keras_nlp.layers.MaskedLMMaskGenerator(\n",
+ " vocabulary_size=tokenizer.vocabulary_size(),\n",
+ " mask_selection_rate=0.25,\n",
+ " mask_selection_length=64,\n",
+ " mask_token_id=tokenizer.token_to_id(\"[MASK]\"),\n",
+ " unselectable_token_ids=[\n",
+ " tokenizer.token_to_id(x) for x in [\"[CLS]\", \"[PAD]\", \"[SEP]\"]\n",
+ " ],\n",
+ ")\n",
+ "\n",
+ "\n",
+ "def preprocess(inputs, label):\n",
+ " inputs = preprocessor(inputs)\n",
+ " masked_inputs = masker(inputs[\"token_ids\"])\n",
+ " # Split the masking layer outputs into a (features, labels, and weights)\n",
+ " # tuple that we can use with keras.Model.fit().\n",
+ " features = {\n",
+ " \"token_ids\": masked_inputs[\"token_ids\"],\n",
+ " \"segment_ids\": inputs[\"segment_ids\"],\n",
+ " \"padding_mask\": inputs[\"padding_mask\"],\n",
+ " \"mask_positions\": masked_inputs[\"mask_positions\"],\n",
+ " }\n",
+ " labels = masked_inputs[\"mask_ids\"]\n",
+ " weights = masked_inputs[\"mask_weights\"]\n",
+ " return features, labels, weights\n",
+ "\n",
+ "\n",
+ "pretrain_ds = imdb_train.map(preprocess, num_parallel_calls=tf.data.AUTOTUNE).prefetch(\n",
+ " tf.data.AUTOTUNE\n",
+ ")\n",
+ "pretrain_val_ds = imdb_test.map(\n",
+ " preprocess, num_parallel_calls=tf.data.AUTOTUNE\n",
+ ").prefetch(tf.data.AUTOTUNE)\n",
+ "\n",
+ "# Tokens with ID 103 are \"masked\"\n",
+ "print(pretrain_ds.unbatch().take(1).get_single_element())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "### Pretraining model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "# BERT backbone\n",
+ "backbone = keras_nlp.models.BertBackbone(\n",
+ " vocabulary_size=tokenizer.vocabulary_size(),\n",
+ " num_layers=2,\n",
+ " num_heads=2,\n",
+ " hidden_dim=128,\n",
+ " intermediate_dim=512,\n",
+ ")\n",
+ "\n",
+ "# Language modeling head\n",
+ "mlm_head = keras_nlp.layers.MaskedLMHead(\n",
+ " embedding_weights=backbone.token_embedding.embeddings,\n",
+ ")\n",
+ "\n",
+ "inputs = {\n",
+ " \"token_ids\": keras.Input(shape=(None,), dtype=tf.int32),\n",
+ " \"segment_ids\": keras.Input(shape=(None,), dtype=tf.int32),\n",
+ " \"padding_mask\": keras.Input(shape=(None,), dtype=tf.int32),\n",
+ " \"mask_positions\": keras.Input(shape=(None,), dtype=tf.int32),\n",
+ "}\n",
+ "\n",
+ "# Encoded token sequence\n",
+ "sequence = backbone(inputs)[\"sequence_output\"]\n",
+ "\n",
+ "# Predict an output word for each masked input token.\n",
+ "# We use the input token embedding to project from our encoded vectors to\n",
+ "# vocabulary logits, which has been shown to improve training efficiency.\n",
+ "outputs = mlm_head(sequence, mask_positions=inputs[\"mask_positions\"])\n",
+ "\n",
+ "# Define and compile our pretraining model.\n",
+ "pretraining_model = keras.Model(inputs, outputs)\n",
+ "pretraining_model.summary()\n",
+ "pretraining_model.compile(\n",
+ " loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n",
+ " optimizer=keras.optimizers.experimental.AdamW(learning_rate=5e-4),\n",
+ " weighted_metrics=keras.metrics.SparseCategoricalAccuracy(),\n",
+ " jit_compile=True,\n",
+ ")\n",
+ "\n",
+ "# Pretrain on IMDB dataset\n",
+ "pretraining_model.fit(\n",
+ " pretrain_ds,\n",
+ " validation_data=pretrain_val_ds,\n",
+ " epochs=3, # Increase to 6 for higher accuracy\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "After pretraining save your `backbone` submodel to use in a new task!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "## Build and train your own transformer from scratch\n",
+ "\n",
+ "\n",
+ "Want to implement a novel transformer architecture? The KerasNLP library offers all the\n",
+ "low-level modules used to build SoTA architectures in our `models` API. This includes the\n",
+ "`keras_nlp.tokenizers` API which allows you to train your own subword tokenizer using\n",
+ "`WordPieceTokenizer`, `BytePairTokenizer`, or `SentencePieceTokenizer`.\n",
+ "\n",
+ "In this workflow we train a custom tokenizer on the IMDB data and design a backbone with\n",
+ "custom transformer architecture. For simplicity we then train directly on the\n",
+ "classification task. Interested in more details? We wrote an entire guide to pretraining\n",
+ "and finetuning a custom transformer on\n",
+ "[keras.io](https://keras.io/guides/keras_nlp/transformer_pretraining/),"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "### Train custom vocabulary from IMBD data"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "vocab = keras_nlp.tokenizers.compute_word_piece_vocabulary(\n",
+ " imdb_train.map(lambda x, y: x),\n",
+ " vocabulary_size=20_000,\n",
+ " lowercase=True,\n",
+ " strip_accents=True,\n",
+ " reserved_tokens=[\"[PAD]\", \"[START]\", \"[END]\", \"[MASK]\", \"[UNK]\"],\n",
+ ")\n",
+ "tokenizer = keras_nlp.tokenizers.WordPieceTokenizer(\n",
+ " vocabulary=vocab,\n",
+ " lowercase=True,\n",
+ " strip_accents=True,\n",
+ " oov_token=\"[UNK]\",\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "### Preprocess data with custom tokenizer"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "packer = keras_nlp.layers.StartEndPacker(\n",
+ " start_value=tokenizer.token_to_id(\"[START]\"),\n",
+ " end_value=tokenizer.token_to_id(\"[END]\"),\n",
+ " pad_value=tokenizer.token_to_id(\"[PAD]\"),\n",
+ " sequence_length=512,\n",
+ ")\n",
+ "\n",
+ "\n",
+ "def preprocess(x, y):\n",
+ " token_ids = packer(tokenizer(x))\n",
+ " return token_ids, y\n",
+ "\n",
+ "\n",
+ "imdb_preproc_train_ds = imdb_train.map(\n",
+ " preprocess, num_parallel_calls=tf.data.AUTOTUNE\n",
+ ").prefetch(tf.data.AUTOTUNE)\n",
+ "imdb_preproc_val_ds = imdb_test.map(\n",
+ " preprocess, num_parallel_calls=tf.data.AUTOTUNE\n",
+ ").prefetch(tf.data.AUTOTUNE)\n",
+ "\n",
+ "print(imdb_preproc_train_ds.unbatch().take(1).get_single_element())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "### Design a tiny transformer"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "token_id_input = keras.Input(\n",
+ " shape=(None,),\n",
+ " dtype=\"int32\",\n",
+ " name=\"token_ids\",\n",
+ ")\n",
+ "outputs = keras_nlp.layers.TokenAndPositionEmbedding(\n",
+ " vocabulary_size=len(vocab),\n",
+ " sequence_length=packer.sequence_length,\n",
+ " embedding_dim=64,\n",
+ ")(token_id_input)\n",
+ "outputs = keras_nlp.layers.TransformerEncoder(\n",
+ " num_heads=2,\n",
+ " intermediate_dim=128,\n",
+ " dropout=0.1,\n",
+ ")(outputs)\n",
+ "# Use \"[START]\" token to classify\n",
+ "outputs = keras.layers.Dense(2)(outputs[:, 0, :])\n",
+ "model = keras.Model(\n",
+ " inputs=token_id_input,\n",
+ " outputs=outputs,\n",
+ ")\n",
+ "\n",
+ "model.summary()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "### Train the transformer directly on the classification objective"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "model.compile(\n",
+ " loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n",
+ " optimizer=keras.optimizers.experimental.AdamW(5e-5),\n",
+ " metrics=keras.metrics.SparseCategoricalAccuracy(),\n",
+ " jit_compile=True,\n",
+ ")\n",
+ "model.fit(\n",
+ " imdb_preproc_train_ds,\n",
+ " validation_data=imdb_preproc_val_ds,\n",
+ " epochs=3,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "Excitingly, our custom classifier is similar to the performance of fine-tuning\n",
+ "`\"bert_tiny_en_uncased\"`! To see the advantages of pretraining and exceed 90% accuracy we\n",
+ "would need to use larger **presets** such as `\"bert_base_en_uncased\"`."
+ ]
+ }
+ ],
+ "metadata": {
+ "accelerator": "GPU",
+ "colab": {
+ "collapsed_sections": [],
+ "name": "getting_started",
+ "private_outputs": false,
+ "provenance": [],
+ "toc_visible": true
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.0"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
\ No newline at end of file
diff --git a/guides/keras_nlp/getting_started.py b/guides/keras_nlp/getting_started.py
new file mode 100644
index 0000000000..1ac2140423
--- /dev/null
+++ b/guides/keras_nlp/getting_started.py
@@ -0,0 +1,619 @@
+"""
+Title: Getting Started with KerasNLP
+Author: [jbischof](https://github.com/jbischof)
+Date created: 2022/12/15
+Last modified: 2022/12/15
+Description: An introduction to the KerasNLP API.
+Accelerator: GPU
+"""
+"""
+## Introduction
+
+KerasNLP is a natural language processing library that supports users through
+their entire development cycle. Our workflows are built from modular components
+that have state-of-the-art preset weights and architectures when used
+out-of-the-box and are easily customizable when more control is needed. We
+emphasize in-graph computation for all workflows so that developers can expect
+easy productionization using the TensorFlow ecosystem.
+
+This library is an extension of the core Keras API; all high level modules are
+[`Layers`](/api/layers/) or [`Models`](/api/models/). If you are familiar with Keras,
+congratulations! You already understand most of KerasNLP.
+
+This guide demonstrates our modular approach using a sentiment analysis example at six
+levels of complexity:
+
+* Inference with a pretrained classifier
+* Fine tuning a pretrained backbone
+* Fine tuning with user-controlled preprocessing
+* Fine tuning a custom model
+* Pretraining a backbone model
+* Build and train your own transformer from scratch
+
+Throughout our guide we use Professor Keras, the official Keras mascot, as a visual
+reference for the complexity of the material:
+
+ +"""
+
+import keras_nlp
+import tensorflow as tf
+from tensorflow import keras
+
+# Use mixed precision for optimal performance
+keras.mixed_precision.set_global_policy("mixed_float16")
+
+"""
+## API quickstart
+
+Our highest level API is `keras_nlp.models`. These symbols cover the complete user
+journey of converting strings to tokens, tokens to dense features, and dense features to
+task-specific output. For each `XX` architecture (e.g., `Bert`), we offer the following
+modules:
+
+* **Tokenizer**: `keras_nlp.models.XXTokenizer`
+ * **What it does**: Converts strings to `tf.RaggedTensor`s of token ids.
+ * **Why it's important**: The raw bytes of a string are too high dimensional to be useful
+ features so we first map them to a small number of tokens, for example `"The quick brown
+ fox"` to `["the", "qu", "##ick", "br", "##own", "fox"]`.
+ * **Inherits from**: `keras.layers.Layer`.
+* **Preprocessor**: `keras_nlp.models.XXPreprocessor`
+ * **What it does**: Converts strings to a dictonary of preprocessed tensors consumed by
+ the backbone, starting with tokenization.
+ * **Why it's important**: Each model uses special tokens and extra tensors to understand
+ the input such as deliminting input segments and identifying padding tokens. Padding each
+ sequence to the same length improves computational efficiency.
+ * **Has a**: `XXTokenizer`.
+ * **Inherits from**: `keras.layers.Layer`.
+* **Backbone**: `keras_nlp.models.XXBackbone`
+ * **What it does**: Converts preprocessed tensors to dense features. *Does not handle
+ strings; call the preprocessor first.*
+ * **Why it's important**: The backbone distills the input tokens into dense features that
+ can be used in downstream tasks. It is generally pretrained on a language modeling task
+ using massive amounts of unlabeled data. Transfering this information to a new task is a
+ major breakthrough in modern NLP.
+ * **Inherits from**: `keras.Model`.
+* **Task**: e.g., `keras_nlp.models.XXClassifier`
+ * **What it does**: Converts strings to task-specific output (e.g., classification
+ probabilities).
+ * **Why it's important**: Task models combine string preprocessing and the backbone model
+ with task-specific `Layers` to solve a problem such as sentence classification, token
+ classification, or text generation. The additional `Layers` must be fine-tuned on labeled
+ data.
+ * **Has a**: `XXBackbone` and `XXPreprocessor`.
+ * **Inherits from**: `keras.Model`.
+
+Here is the modular hierarchy for `BertClassifier` (all relationships are compositional):
+
+
+"""
+
+import keras_nlp
+import tensorflow as tf
+from tensorflow import keras
+
+# Use mixed precision for optimal performance
+keras.mixed_precision.set_global_policy("mixed_float16")
+
+"""
+## API quickstart
+
+Our highest level API is `keras_nlp.models`. These symbols cover the complete user
+journey of converting strings to tokens, tokens to dense features, and dense features to
+task-specific output. For each `XX` architecture (e.g., `Bert`), we offer the following
+modules:
+
+* **Tokenizer**: `keras_nlp.models.XXTokenizer`
+ * **What it does**: Converts strings to `tf.RaggedTensor`s of token ids.
+ * **Why it's important**: The raw bytes of a string are too high dimensional to be useful
+ features so we first map them to a small number of tokens, for example `"The quick brown
+ fox"` to `["the", "qu", "##ick", "br", "##own", "fox"]`.
+ * **Inherits from**: `keras.layers.Layer`.
+* **Preprocessor**: `keras_nlp.models.XXPreprocessor`
+ * **What it does**: Converts strings to a dictonary of preprocessed tensors consumed by
+ the backbone, starting with tokenization.
+ * **Why it's important**: Each model uses special tokens and extra tensors to understand
+ the input such as deliminting input segments and identifying padding tokens. Padding each
+ sequence to the same length improves computational efficiency.
+ * **Has a**: `XXTokenizer`.
+ * **Inherits from**: `keras.layers.Layer`.
+* **Backbone**: `keras_nlp.models.XXBackbone`
+ * **What it does**: Converts preprocessed tensors to dense features. *Does not handle
+ strings; call the preprocessor first.*
+ * **Why it's important**: The backbone distills the input tokens into dense features that
+ can be used in downstream tasks. It is generally pretrained on a language modeling task
+ using massive amounts of unlabeled data. Transfering this information to a new task is a
+ major breakthrough in modern NLP.
+ * **Inherits from**: `keras.Model`.
+* **Task**: e.g., `keras_nlp.models.XXClassifier`
+ * **What it does**: Converts strings to task-specific output (e.g., classification
+ probabilities).
+ * **Why it's important**: Task models combine string preprocessing and the backbone model
+ with task-specific `Layers` to solve a problem such as sentence classification, token
+ classification, or text generation. The additional `Layers` must be fine-tuned on labeled
+ data.
+ * **Has a**: `XXBackbone` and `XXPreprocessor`.
+ * **Inherits from**: `keras.Model`.
+
+Here is the modular hierarchy for `BertClassifier` (all relationships are compositional):
+
+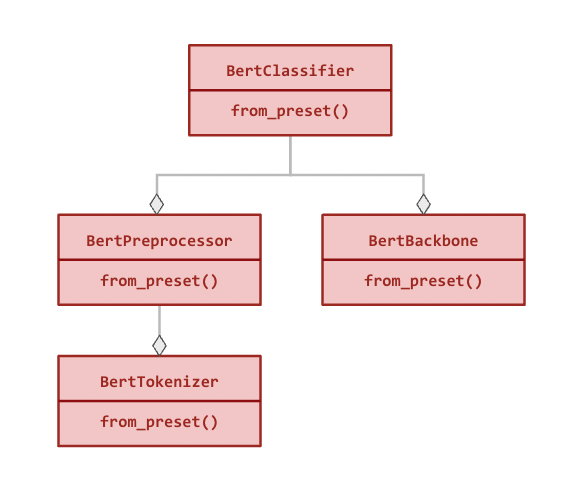 +
+All modules can be used independently and have a `from_preset()` method in addition to
+the standard constructor that instantiates the class with **preset** architecture and
+weights (see examples below).
+"""
+
+"""
+## Data
+
+We will use a running example of sentiment analysis of IMDB movie reviews. In this task,
+we use the text to predict whether the review was positive (`label = 1`) or negative
+(`label = 0`).
+
+We load the data using `keras.utils.text_dataset_from_directory`, which utilizes the
+powerful `tf.data.Dataset` format for examples.
+"""
+
+"""shell
+curl -O https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
+tar -xf aclImdb_v1.tar.gz
+# Remove unsupervised examples
+rm -r aclImdb/train/unsup
+"""
+
+BATCH_SIZE = 16
+imdb_train = tf.keras.preprocessing.text_dataset_from_directory(
+ "aclImdb/train",
+ batch_size=BATCH_SIZE,
+)
+imdb_test = tf.keras.preprocessing.text_dataset_from_directory(
+ "aclImdb/test",
+ batch_size=BATCH_SIZE,
+)
+
+# Inspect first review
+# Format is (review text tensor, label tensor)
+print(imdb_train.unbatch().take(1).get_single_element())
+
+"""
+## Inference with a pretrained classifier
+
+
+
+All modules can be used independently and have a `from_preset()` method in addition to
+the standard constructor that instantiates the class with **preset** architecture and
+weights (see examples below).
+"""
+
+"""
+## Data
+
+We will use a running example of sentiment analysis of IMDB movie reviews. In this task,
+we use the text to predict whether the review was positive (`label = 1`) or negative
+(`label = 0`).
+
+We load the data using `keras.utils.text_dataset_from_directory`, which utilizes the
+powerful `tf.data.Dataset` format for examples.
+"""
+
+"""shell
+curl -O https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
+tar -xf aclImdb_v1.tar.gz
+# Remove unsupervised examples
+rm -r aclImdb/train/unsup
+"""
+
+BATCH_SIZE = 16
+imdb_train = tf.keras.preprocessing.text_dataset_from_directory(
+ "aclImdb/train",
+ batch_size=BATCH_SIZE,
+)
+imdb_test = tf.keras.preprocessing.text_dataset_from_directory(
+ "aclImdb/test",
+ batch_size=BATCH_SIZE,
+)
+
+# Inspect first review
+# Format is (review text tensor, label tensor)
+print(imdb_train.unbatch().take(1).get_single_element())
+
+"""
+## Inference with a pretrained classifier
+
+ +
+The highest level module in KerasNLP is a **task**. A **task** is a `keras.Model`
+consisting of a (generally pretrained) **backbone** model and task-specific layers.
+Here's an example using `keras_nlp.models.BertClassifier`.
+
+**Note**: Outputs are the logits per class (e.g., `[0, 0]` is 50% chance of positive).
+"""
+
+classifier = keras_nlp.models.BertClassifier.from_preset("bert_tiny_en_uncased_sst2")
+# Note: batched inputs expected so must wrap string in iterable
+classifier.predict(["I love modular workflows in keras-nlp!"])
+
+"""
+All **tasks** have a `from_preset` method that constructs a `keras.Model` instance with
+preset preprocessing, architecture and weights. This means that we can pass raw strings
+in any format accepted by a `keras.Model` and get output specific to our task.
+
+This particular **preset** is a `"bert_tiny_uncased_en"` **backbone** fine-tuned on
+`sst2`, another movie review sentiment analysis (this time from Rotten Tomatoes). We use
+the `tiny` architecture for demo purposes, but larger models are recommended for SoTA
+performance. For all the task-specific presets available for `BertClassifier`, see
+our keras.io [models page](https://keras.io/api/keras_nlp/models/).
+
+Let's evaluate our classifier on the IMDB dataset. We first need to compile the
+`keras.Model`. The output is `[loss, accuracy]`,
+
+**Note**: We don't need an optimizer since we're not training the model.
+"""
+
+classifier.compile(
+ loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
+ metrics=keras.metrics.SparseCategoricalAccuracy(),
+ jit_compile=True,
+)
+
+classifier.evaluate(imdb_test)
+
+"""
+Our result is 78% accuracy without training anything. Not bad!
+"""
+
+"""
+## Fine tuning a pretrained BERT backbone
+
+
+
+The highest level module in KerasNLP is a **task**. A **task** is a `keras.Model`
+consisting of a (generally pretrained) **backbone** model and task-specific layers.
+Here's an example using `keras_nlp.models.BertClassifier`.
+
+**Note**: Outputs are the logits per class (e.g., `[0, 0]` is 50% chance of positive).
+"""
+
+classifier = keras_nlp.models.BertClassifier.from_preset("bert_tiny_en_uncased_sst2")
+# Note: batched inputs expected so must wrap string in iterable
+classifier.predict(["I love modular workflows in keras-nlp!"])
+
+"""
+All **tasks** have a `from_preset` method that constructs a `keras.Model` instance with
+preset preprocessing, architecture and weights. This means that we can pass raw strings
+in any format accepted by a `keras.Model` and get output specific to our task.
+
+This particular **preset** is a `"bert_tiny_uncased_en"` **backbone** fine-tuned on
+`sst2`, another movie review sentiment analysis (this time from Rotten Tomatoes). We use
+the `tiny` architecture for demo purposes, but larger models are recommended for SoTA
+performance. For all the task-specific presets available for `BertClassifier`, see
+our keras.io [models page](https://keras.io/api/keras_nlp/models/).
+
+Let's evaluate our classifier on the IMDB dataset. We first need to compile the
+`keras.Model`. The output is `[loss, accuracy]`,
+
+**Note**: We don't need an optimizer since we're not training the model.
+"""
+
+classifier.compile(
+ loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
+ metrics=keras.metrics.SparseCategoricalAccuracy(),
+ jit_compile=True,
+)
+
+classifier.evaluate(imdb_test)
+
+"""
+Our result is 78% accuracy without training anything. Not bad!
+"""
+
+"""
+## Fine tuning a pretrained BERT backbone
+
+ +
+When labeled text specific to our task is available, fine-tuning a custom classifier can
+improve performance. If we want to predict IMDB review sentiment, using IMDB data should
+perform better than Rotten Tomatoes data! And for many tasks no relevant pretrained model
+will be available (e.g., categorizing customer reviews).
+
+The workflow for fine-tuning is almost identical to above, except that we request a
+**preset** for the **backbone**-only model rather than the entire classifier. When passed
+a **backone** **preset**, a **task** `Model` will randomly initialize all task-specific
+layers in preparation for training. For all the **backbone** presets available for
+`BertClassifier`, see our keras.io [models page](https://keras.io/api/keras_nlp/models/).
+
+To train your classifier, use `Model.compile()` and `Model.fit()` as with any other
+`keras.Model`. Since preprocessing is included in all **tasks** by default, we again pass
+the raw data.
+"""
+
+classifier = keras_nlp.models.BertClassifier.from_preset(
+ "bert_tiny_en_uncased",
+ num_classes=2,
+)
+classifier.compile(
+ loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
+ optimizer=keras.optimizers.experimental.AdamW(5e-5),
+ metrics=keras.metrics.SparseCategoricalAccuracy(),
+ jit_compile=True,
+)
+classifier.fit(
+ imdb_train,
+ validation_data=imdb_test,
+ epochs=1,
+)
+
+"""
+Here we see significant lift in validation accuracy (0.78 -> 0.87) with a single epoch of
+training even though the IMDB dataset is much smaller than `sst2`.
+"""
+
+"""
+## Fine tuning with user-controlled preprocessing
+
+
+When labeled text specific to our task is available, fine-tuning a custom classifier can
+improve performance. If we want to predict IMDB review sentiment, using IMDB data should
+perform better than Rotten Tomatoes data! And for many tasks no relevant pretrained model
+will be available (e.g., categorizing customer reviews).
+
+The workflow for fine-tuning is almost identical to above, except that we request a
+**preset** for the **backbone**-only model rather than the entire classifier. When passed
+a **backone** **preset**, a **task** `Model` will randomly initialize all task-specific
+layers in preparation for training. For all the **backbone** presets available for
+`BertClassifier`, see our keras.io [models page](https://keras.io/api/keras_nlp/models/).
+
+To train your classifier, use `Model.compile()` and `Model.fit()` as with any other
+`keras.Model`. Since preprocessing is included in all **tasks** by default, we again pass
+the raw data.
+"""
+
+classifier = keras_nlp.models.BertClassifier.from_preset(
+ "bert_tiny_en_uncased",
+ num_classes=2,
+)
+classifier.compile(
+ loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
+ optimizer=keras.optimizers.experimental.AdamW(5e-5),
+ metrics=keras.metrics.SparseCategoricalAccuracy(),
+ jit_compile=True,
+)
+classifier.fit(
+ imdb_train,
+ validation_data=imdb_test,
+ epochs=1,
+)
+
+"""
+Here we see significant lift in validation accuracy (0.78 -> 0.87) with a single epoch of
+training even though the IMDB dataset is much smaller than `sst2`.
+"""
+
+"""
+## Fine tuning with user-controlled preprocessing
+ +
+For some advanced training scenarios, users might prefer direct control over
+preprocessing. For large datasets, examples can be preprocessed in advance and saved to
+disk or preprocessed by a separate worker pool using `tf.data.experimental.service`. In
+other cases, custom preprocessing is needed to handle the inputs.
+
+Pass `preprocessor=None` to the constructor of a **task** `Model` to skip automatic
+preprocessing or pass a custom `BertPreprocessor` instead.
+"""
+
+"""
+### Separate preprocessing from the same preset
+
+Each model architecture has a parallel **preprocessor** `Layer` with its own
+`from_preset` constructor. Using the same **preset** for this `Layer` will return the
+matching **preprocessor** as the **task**.
+
+In this workflow we train the model over three epochs using `tf.data.Dataset.cache()`,
+which computes the preprocessing once and caches the result before fitting begins.
+
+**Note:** this code only works if your data fits in memory. If not, pass a `filename` to
+`cache()`.
+"""
+
+preprocessor = keras_nlp.models.BertPreprocessor.from_preset(
+ "bert_tiny_en_uncased",
+ sequence_length=512,
+)
+
+imdb_train_cached = (
+ imdb_train.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
+)
+imdb_test_cached = (
+ imdb_test.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
+)
+
+classifier = keras_nlp.models.BertClassifier.from_preset(
+ "bert_tiny_en_uncased",
+ preprocessor=None,
+)
+classifier.compile(
+ loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
+ optimizer=keras.optimizers.experimental.AdamW(5e-5),
+ metrics=keras.metrics.SparseCategoricalAccuracy(),
+ jit_compile=True,
+)
+classifier.fit(
+ imdb_train_cached,
+ validation_data=imdb_test_cached,
+ epochs=3,
+)
+
+"""
+After three epochs, our validation accuracy has only increased to 0.88. This is both a
+function of the small size of our dataset and our model. To exceed 90% accuracy, try
+larger **presets** such as `"bert_base_en_uncased"`. For all the **backbone** presets
+available for `BertClassifier`, see our keras.io [models page](https://keras.io/api/keras_nlp/models/).
+"""
+
+"""
+### Custom preprocessing
+
+In cases where custom preprocessing is required, we offer direct access to the
+`Tokenizer` class that maps raw strings to tokens. It also has a `from_preset()`
+constructor to get the vocabulary matching pretraining.
+
+**Note:** `BertTokenizer` does not pad sequences by default, so the output is
+a `tf.RaggedTensor`.
+"""
+
+tokenizer = keras_nlp.models.BertTokenizer.from_preset("bert_tiny_en_uncased")
+tokenizer(["I love modular workflows!", "Libraries over frameworks!"])
+
+# Write your own packer or use one our `Layers`
+packer = keras_nlp.layers.MultiSegmentPacker(
+ start_value=tokenizer.cls_token_id,
+ end_value=tokenizer.sep_token_id,
+ # Note: This cannot be longer than the preset's `sequence_length`, and there
+ # is no check for a custom preprocessor!
+ sequence_length=64,
+)
+
+
+def preprocessor(x, y):
+ token_ids, segment_ids = packer(tokenizer(x))
+ x = {
+ "token_ids": token_ids,
+ "segment_ids": segment_ids,
+ "padding_mask": token_ids != 0,
+ }
+ return x, y
+
+
+imbd_train_preprocessed = imdb_train.map(preprocessor, tf.data.AUTOTUNE).prefetch(
+ tf.data.AUTOTUNE
+)
+imdb_test_preprocessed = imdb_test.map(preprocessor, tf.data.AUTOTUNE).prefetch(
+ tf.data.AUTOTUNE
+)
+
+# Preprocessed example
+print(imbd_train_preprocessed.unbatch().take(1).get_single_element())
+
+"""
+## Fine tuning with a custom model
+
+
+For more advanced applications, an appropriate **task** `Model` may not be available. In
+this case we provide direct access to the **backbone** `Model`, which has its own
+`from_preset` constructor and can be composed with custom `Layer`s. Detailed examples can
+be found at our [transfer learning guide](https://keras.io/guides/transfer_learning/).
+
+A **backbone** `Model` does not include automatic preprocessing but can be paired with a
+matching **preprocessor** using the same **preset** as shown in the previous workflow.
+
+In this workflow we experiment with freezing our backbone model and adding two trainable
+transfomer layers to adapt to the new input.
+
+**Note**: We can igonore the warning about gradients for the `pooled_dense` layer because
+we are using BERT's sequence output.
+"""
+
+preprocessor = keras_nlp.models.BertPreprocessor.from_preset("bert_tiny_en_uncased")
+backbone = keras_nlp.models.BertBackbone.from_preset("bert_tiny_en_uncased")
+
+imdb_train_preprocessed = (
+ imdb_train.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
+)
+imdb_test_preprocessed = (
+ imdb_test.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
+)
+
+backbone.trainable = False
+inputs = backbone.input
+sequence = backbone(inputs)["sequence_output"]
+for _ in range(2):
+ sequence = keras_nlp.layers.TransformerEncoder(
+ num_heads=2,
+ intermediate_dim=512,
+ dropout=0.1,
+ )(sequence)
+# Use [CLS] token output to classify
+outputs = keras.layers.Dense(2)(sequence[:, backbone.cls_token_index, :])
+
+model = keras.Model(inputs, outputs)
+model.compile(
+ loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
+ optimizer=keras.optimizers.experimental.AdamW(5e-5),
+ metrics=keras.metrics.SparseCategoricalAccuracy(),
+ jit_compile=True,
+)
+model.summary()
+model.fit(
+ imdb_train_preprocessed,
+ validation_data=imdb_test_preprocessed,
+ epochs=3,
+)
+
+"""
+This model achieves reasonable accuracy despite having only 10% the trainable parameters
+of our `BertClassifier` model. Each training step takes about 1/3 of the time---even
+accounting for cached preprocessing.
+"""
+
+"""
+## Pretraining a backbone model
+
+
+For some advanced training scenarios, users might prefer direct control over
+preprocessing. For large datasets, examples can be preprocessed in advance and saved to
+disk or preprocessed by a separate worker pool using `tf.data.experimental.service`. In
+other cases, custom preprocessing is needed to handle the inputs.
+
+Pass `preprocessor=None` to the constructor of a **task** `Model` to skip automatic
+preprocessing or pass a custom `BertPreprocessor` instead.
+"""
+
+"""
+### Separate preprocessing from the same preset
+
+Each model architecture has a parallel **preprocessor** `Layer` with its own
+`from_preset` constructor. Using the same **preset** for this `Layer` will return the
+matching **preprocessor** as the **task**.
+
+In this workflow we train the model over three epochs using `tf.data.Dataset.cache()`,
+which computes the preprocessing once and caches the result before fitting begins.
+
+**Note:** this code only works if your data fits in memory. If not, pass a `filename` to
+`cache()`.
+"""
+
+preprocessor = keras_nlp.models.BertPreprocessor.from_preset(
+ "bert_tiny_en_uncased",
+ sequence_length=512,
+)
+
+imdb_train_cached = (
+ imdb_train.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
+)
+imdb_test_cached = (
+ imdb_test.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
+)
+
+classifier = keras_nlp.models.BertClassifier.from_preset(
+ "bert_tiny_en_uncased",
+ preprocessor=None,
+)
+classifier.compile(
+ loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
+ optimizer=keras.optimizers.experimental.AdamW(5e-5),
+ metrics=keras.metrics.SparseCategoricalAccuracy(),
+ jit_compile=True,
+)
+classifier.fit(
+ imdb_train_cached,
+ validation_data=imdb_test_cached,
+ epochs=3,
+)
+
+"""
+After three epochs, our validation accuracy has only increased to 0.88. This is both a
+function of the small size of our dataset and our model. To exceed 90% accuracy, try
+larger **presets** such as `"bert_base_en_uncased"`. For all the **backbone** presets
+available for `BertClassifier`, see our keras.io [models page](https://keras.io/api/keras_nlp/models/).
+"""
+
+"""
+### Custom preprocessing
+
+In cases where custom preprocessing is required, we offer direct access to the
+`Tokenizer` class that maps raw strings to tokens. It also has a `from_preset()`
+constructor to get the vocabulary matching pretraining.
+
+**Note:** `BertTokenizer` does not pad sequences by default, so the output is
+a `tf.RaggedTensor`.
+"""
+
+tokenizer = keras_nlp.models.BertTokenizer.from_preset("bert_tiny_en_uncased")
+tokenizer(["I love modular workflows!", "Libraries over frameworks!"])
+
+# Write your own packer or use one our `Layers`
+packer = keras_nlp.layers.MultiSegmentPacker(
+ start_value=tokenizer.cls_token_id,
+ end_value=tokenizer.sep_token_id,
+ # Note: This cannot be longer than the preset's `sequence_length`, and there
+ # is no check for a custom preprocessor!
+ sequence_length=64,
+)
+
+
+def preprocessor(x, y):
+ token_ids, segment_ids = packer(tokenizer(x))
+ x = {
+ "token_ids": token_ids,
+ "segment_ids": segment_ids,
+ "padding_mask": token_ids != 0,
+ }
+ return x, y
+
+
+imbd_train_preprocessed = imdb_train.map(preprocessor, tf.data.AUTOTUNE).prefetch(
+ tf.data.AUTOTUNE
+)
+imdb_test_preprocessed = imdb_test.map(preprocessor, tf.data.AUTOTUNE).prefetch(
+ tf.data.AUTOTUNE
+)
+
+# Preprocessed example
+print(imbd_train_preprocessed.unbatch().take(1).get_single_element())
+
+"""
+## Fine tuning with a custom model
+
+
+For more advanced applications, an appropriate **task** `Model` may not be available. In
+this case we provide direct access to the **backbone** `Model`, which has its own
+`from_preset` constructor and can be composed with custom `Layer`s. Detailed examples can
+be found at our [transfer learning guide](https://keras.io/guides/transfer_learning/).
+
+A **backbone** `Model` does not include automatic preprocessing but can be paired with a
+matching **preprocessor** using the same **preset** as shown in the previous workflow.
+
+In this workflow we experiment with freezing our backbone model and adding two trainable
+transfomer layers to adapt to the new input.
+
+**Note**: We can igonore the warning about gradients for the `pooled_dense` layer because
+we are using BERT's sequence output.
+"""
+
+preprocessor = keras_nlp.models.BertPreprocessor.from_preset("bert_tiny_en_uncased")
+backbone = keras_nlp.models.BertBackbone.from_preset("bert_tiny_en_uncased")
+
+imdb_train_preprocessed = (
+ imdb_train.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
+)
+imdb_test_preprocessed = (
+ imdb_test.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
+)
+
+backbone.trainable = False
+inputs = backbone.input
+sequence = backbone(inputs)["sequence_output"]
+for _ in range(2):
+ sequence = keras_nlp.layers.TransformerEncoder(
+ num_heads=2,
+ intermediate_dim=512,
+ dropout=0.1,
+ )(sequence)
+# Use [CLS] token output to classify
+outputs = keras.layers.Dense(2)(sequence[:, backbone.cls_token_index, :])
+
+model = keras.Model(inputs, outputs)
+model.compile(
+ loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
+ optimizer=keras.optimizers.experimental.AdamW(5e-5),
+ metrics=keras.metrics.SparseCategoricalAccuracy(),
+ jit_compile=True,
+)
+model.summary()
+model.fit(
+ imdb_train_preprocessed,
+ validation_data=imdb_test_preprocessed,
+ epochs=3,
+)
+
+"""
+This model achieves reasonable accuracy despite having only 10% the trainable parameters
+of our `BertClassifier` model. Each training step takes about 1/3 of the time---even
+accounting for cached preprocessing.
+"""
+
+"""
+## Pretraining a backbone model
+ +
+Do you have access to large unlabeled datasets in your domain? Are they are around the
+same size as used to train popular backbones such as BERT, RoBERTa, or GPT2 (XX+ GiB)? If
+so, you might benefit from domain-specific pretraining of your own backbone models.
+
+NLP models are generally pretrained on a language modeling task, predicting masked words
+given the visible words in an input sentence. For example, given the input
+`"The fox [MASK] over the [MASK] dog"`, the model might be asked to predict `["jumped", "lazy"]`.
+The lower layers of this model are then packaged as a **backbone** to be combined with
+layers relating to a new task.
+
+The KerasNLP library offers SoTA **backbones** and **tokenizers** to be trained from
+scratch without presets.
+
+In this workflow we pretrain a BERT **backbone** using our IMDB review text. We skip the
+"next sentence prediction" (NSP) loss because it adds significant complexity to the data
+processing and was dropped by later models like RoBERTa. See our e2e [BERT pretraining
+example](https://github.com/keras-team/keras-nlp/tree/master/examples/bert) for
+step-by-step details on how to replicate the original paper.
+"""
+
+"""
+### Preprocessing
+"""
+
+# All BERT `en` models have the same vocabulary, so reuse preprocessor from
+# "bert_tiny_en_uncased"
+preprocessor = keras_nlp.models.BertPreprocessor.from_preset(
+ "bert_tiny_en_uncased",
+ sequence_length=256,
+)
+packer = preprocessor.packer
+tokenizer = preprocessor.tokenizer
+
+# keras.Layer to replace some input tokens with the "[MASK]" token
+masker = keras_nlp.layers.MaskedLMMaskGenerator(
+ vocabulary_size=tokenizer.vocabulary_size(),
+ mask_selection_rate=0.25,
+ mask_selection_length=64,
+ mask_token_id=tokenizer.token_to_id("[MASK]"),
+ unselectable_token_ids=[
+ tokenizer.token_to_id(x) for x in ["[CLS]", "[PAD]", "[SEP]"]
+ ],
+)
+
+
+def preprocess(inputs, label):
+ inputs = preprocessor(inputs)
+ masked_inputs = masker(inputs["token_ids"])
+ # Split the masking layer outputs into a (features, labels, and weights)
+ # tuple that we can use with keras.Model.fit().
+ features = {
+ "token_ids": masked_inputs["token_ids"],
+ "segment_ids": inputs["segment_ids"],
+ "padding_mask": inputs["padding_mask"],
+ "mask_positions": masked_inputs["mask_positions"],
+ }
+ labels = masked_inputs["mask_ids"]
+ weights = masked_inputs["mask_weights"]
+ return features, labels, weights
+
+
+pretrain_ds = imdb_train.map(preprocess, num_parallel_calls=tf.data.AUTOTUNE).prefetch(
+ tf.data.AUTOTUNE
+)
+pretrain_val_ds = imdb_test.map(
+ preprocess, num_parallel_calls=tf.data.AUTOTUNE
+).prefetch(tf.data.AUTOTUNE)
+
+# Tokens with ID 103 are "masked"
+print(pretrain_ds.unbatch().take(1).get_single_element())
+
+"""
+### Pretraining model
+"""
+
+# BERT backbone
+backbone = keras_nlp.models.BertBackbone(
+ vocabulary_size=tokenizer.vocabulary_size(),
+ num_layers=2,
+ num_heads=2,
+ hidden_dim=128,
+ intermediate_dim=512,
+)
+
+# Language modeling head
+mlm_head = keras_nlp.layers.MaskedLMHead(
+ embedding_weights=backbone.token_embedding.embeddings,
+)
+
+inputs = {
+ "token_ids": keras.Input(shape=(None,), dtype=tf.int32),
+ "segment_ids": keras.Input(shape=(None,), dtype=tf.int32),
+ "padding_mask": keras.Input(shape=(None,), dtype=tf.int32),
+ "mask_positions": keras.Input(shape=(None,), dtype=tf.int32),
+}
+
+# Encoded token sequence
+sequence = backbone(inputs)["sequence_output"]
+
+# Predict an output word for each masked input token.
+# We use the input token embedding to project from our encoded vectors to
+# vocabulary logits, which has been shown to improve training efficiency.
+outputs = mlm_head(sequence, mask_positions=inputs["mask_positions"])
+
+# Define and compile our pretraining model.
+pretraining_model = keras.Model(inputs, outputs)
+pretraining_model.summary()
+pretraining_model.compile(
+ loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
+ optimizer=keras.optimizers.experimental.AdamW(learning_rate=5e-4),
+ weighted_metrics=keras.metrics.SparseCategoricalAccuracy(),
+ jit_compile=True,
+)
+
+# Pretrain on IMDB dataset
+pretraining_model.fit(
+ pretrain_ds,
+ validation_data=pretrain_val_ds,
+ epochs=3, # Increase to 6 for higher accuracy
+)
+
+"""
+After pretraining save your `backbone` submodel to use in a new task!
+"""
+
+"""
+## Build and train your own transformer from scratch
+
+
+Want to implement a novel transformer architecture? The KerasNLP library offers all the
+low-level modules used to build SoTA architectures in our `models` API. This includes the
+`keras_nlp.tokenizers` API which allows you to train your own subword tokenizer using
+`WordPieceTokenizer`, `BytePairTokenizer`, or `SentencePieceTokenizer`.
+
+In this workflow we train a custom tokenizer on the IMDB data and design a backbone with
+custom transformer architecture. For simplicity we then train directly on the
+classification task. Interested in more details? We wrote an entire guide to pretraining
+and finetuning a custom transformer on
+[keras.io](https://keras.io/guides/keras_nlp/transformer_pretraining/),
+"""
+
+"""
+### Train custom vocabulary from IMBD data
+"""
+
+vocab = keras_nlp.tokenizers.compute_word_piece_vocabulary(
+ imdb_train.map(lambda x, y: x),
+ vocabulary_size=20_000,
+ lowercase=True,
+ strip_accents=True,
+ reserved_tokens=["[PAD]", "[START]", "[END]", "[MASK]", "[UNK]"],
+)
+tokenizer = keras_nlp.tokenizers.WordPieceTokenizer(
+ vocabulary=vocab,
+ lowercase=True,
+ strip_accents=True,
+ oov_token="[UNK]",
+)
+
+"""
+### Preprocess data with custom tokenizer
+"""
+
+packer = keras_nlp.layers.StartEndPacker(
+ start_value=tokenizer.token_to_id("[START]"),
+ end_value=tokenizer.token_to_id("[END]"),
+ pad_value=tokenizer.token_to_id("[PAD]"),
+ sequence_length=512,
+)
+
+
+def preprocess(x, y):
+ token_ids = packer(tokenizer(x))
+ return token_ids, y
+
+
+imdb_preproc_train_ds = imdb_train.map(
+ preprocess, num_parallel_calls=tf.data.AUTOTUNE
+).prefetch(tf.data.AUTOTUNE)
+imdb_preproc_val_ds = imdb_test.map(
+ preprocess, num_parallel_calls=tf.data.AUTOTUNE
+).prefetch(tf.data.AUTOTUNE)
+
+print(imdb_preproc_train_ds.unbatch().take(1).get_single_element())
+
+"""
+
+### Design a tiny transformer
+"""
+
+token_id_input = keras.Input(
+ shape=(None,),
+ dtype="int32",
+ name="token_ids",
+)
+outputs = keras_nlp.layers.TokenAndPositionEmbedding(
+ vocabulary_size=len(vocab),
+ sequence_length=packer.sequence_length,
+ embedding_dim=64,
+)(token_id_input)
+outputs = keras_nlp.layers.TransformerEncoder(
+ num_heads=2,
+ intermediate_dim=128,
+ dropout=0.1,
+)(outputs)
+# Use "[START]" token to classify
+outputs = keras.layers.Dense(2)(outputs[:, 0, :])
+model = keras.Model(
+ inputs=token_id_input,
+ outputs=outputs,
+)
+
+model.summary()
+
+"""
+### Train the transformer directly on the classification objective
+"""
+
+model.compile(
+ loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
+ optimizer=keras.optimizers.experimental.AdamW(5e-5),
+ metrics=keras.metrics.SparseCategoricalAccuracy(),
+ jit_compile=True,
+)
+model.fit(
+ imdb_preproc_train_ds,
+ validation_data=imdb_preproc_val_ds,
+ epochs=3,
+)
+
+"""
+Excitingly, our custom classifier is similar to the performance of fine-tuning
+`"bert_tiny_en_uncased"`! To see the advantages of pretraining and exceed 90% accuracy we
+would need to use larger **presets** such as `"bert_base_en_uncased"`.
+"""
diff --git a/guides/md/keras_nlp/getting_started.md b/guides/md/keras_nlp/getting_started.md
new file mode 100644
index 0000000000..f62f724d92
--- /dev/null
+++ b/guides/md/keras_nlp/getting_started.md
@@ -0,0 +1,992 @@
+# Getting Started with KerasNLP
+
+**Author:** [jbischof](https://github.com/jbischof)
+
+Do you have access to large unlabeled datasets in your domain? Are they are around the
+same size as used to train popular backbones such as BERT, RoBERTa, or GPT2 (XX+ GiB)? If
+so, you might benefit from domain-specific pretraining of your own backbone models.
+
+NLP models are generally pretrained on a language modeling task, predicting masked words
+given the visible words in an input sentence. For example, given the input
+`"The fox [MASK] over the [MASK] dog"`, the model might be asked to predict `["jumped", "lazy"]`.
+The lower layers of this model are then packaged as a **backbone** to be combined with
+layers relating to a new task.
+
+The KerasNLP library offers SoTA **backbones** and **tokenizers** to be trained from
+scratch without presets.
+
+In this workflow we pretrain a BERT **backbone** using our IMDB review text. We skip the
+"next sentence prediction" (NSP) loss because it adds significant complexity to the data
+processing and was dropped by later models like RoBERTa. See our e2e [BERT pretraining
+example](https://github.com/keras-team/keras-nlp/tree/master/examples/bert) for
+step-by-step details on how to replicate the original paper.
+"""
+
+"""
+### Preprocessing
+"""
+
+# All BERT `en` models have the same vocabulary, so reuse preprocessor from
+# "bert_tiny_en_uncased"
+preprocessor = keras_nlp.models.BertPreprocessor.from_preset(
+ "bert_tiny_en_uncased",
+ sequence_length=256,
+)
+packer = preprocessor.packer
+tokenizer = preprocessor.tokenizer
+
+# keras.Layer to replace some input tokens with the "[MASK]" token
+masker = keras_nlp.layers.MaskedLMMaskGenerator(
+ vocabulary_size=tokenizer.vocabulary_size(),
+ mask_selection_rate=0.25,
+ mask_selection_length=64,
+ mask_token_id=tokenizer.token_to_id("[MASK]"),
+ unselectable_token_ids=[
+ tokenizer.token_to_id(x) for x in ["[CLS]", "[PAD]", "[SEP]"]
+ ],
+)
+
+
+def preprocess(inputs, label):
+ inputs = preprocessor(inputs)
+ masked_inputs = masker(inputs["token_ids"])
+ # Split the masking layer outputs into a (features, labels, and weights)
+ # tuple that we can use with keras.Model.fit().
+ features = {
+ "token_ids": masked_inputs["token_ids"],
+ "segment_ids": inputs["segment_ids"],
+ "padding_mask": inputs["padding_mask"],
+ "mask_positions": masked_inputs["mask_positions"],
+ }
+ labels = masked_inputs["mask_ids"]
+ weights = masked_inputs["mask_weights"]
+ return features, labels, weights
+
+
+pretrain_ds = imdb_train.map(preprocess, num_parallel_calls=tf.data.AUTOTUNE).prefetch(
+ tf.data.AUTOTUNE
+)
+pretrain_val_ds = imdb_test.map(
+ preprocess, num_parallel_calls=tf.data.AUTOTUNE
+).prefetch(tf.data.AUTOTUNE)
+
+# Tokens with ID 103 are "masked"
+print(pretrain_ds.unbatch().take(1).get_single_element())
+
+"""
+### Pretraining model
+"""
+
+# BERT backbone
+backbone = keras_nlp.models.BertBackbone(
+ vocabulary_size=tokenizer.vocabulary_size(),
+ num_layers=2,
+ num_heads=2,
+ hidden_dim=128,
+ intermediate_dim=512,
+)
+
+# Language modeling head
+mlm_head = keras_nlp.layers.MaskedLMHead(
+ embedding_weights=backbone.token_embedding.embeddings,
+)
+
+inputs = {
+ "token_ids": keras.Input(shape=(None,), dtype=tf.int32),
+ "segment_ids": keras.Input(shape=(None,), dtype=tf.int32),
+ "padding_mask": keras.Input(shape=(None,), dtype=tf.int32),
+ "mask_positions": keras.Input(shape=(None,), dtype=tf.int32),
+}
+
+# Encoded token sequence
+sequence = backbone(inputs)["sequence_output"]
+
+# Predict an output word for each masked input token.
+# We use the input token embedding to project from our encoded vectors to
+# vocabulary logits, which has been shown to improve training efficiency.
+outputs = mlm_head(sequence, mask_positions=inputs["mask_positions"])
+
+# Define and compile our pretraining model.
+pretraining_model = keras.Model(inputs, outputs)
+pretraining_model.summary()
+pretraining_model.compile(
+ loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
+ optimizer=keras.optimizers.experimental.AdamW(learning_rate=5e-4),
+ weighted_metrics=keras.metrics.SparseCategoricalAccuracy(),
+ jit_compile=True,
+)
+
+# Pretrain on IMDB dataset
+pretraining_model.fit(
+ pretrain_ds,
+ validation_data=pretrain_val_ds,
+ epochs=3, # Increase to 6 for higher accuracy
+)
+
+"""
+After pretraining save your `backbone` submodel to use in a new task!
+"""
+
+"""
+## Build and train your own transformer from scratch
+
+
+Want to implement a novel transformer architecture? The KerasNLP library offers all the
+low-level modules used to build SoTA architectures in our `models` API. This includes the
+`keras_nlp.tokenizers` API which allows you to train your own subword tokenizer using
+`WordPieceTokenizer`, `BytePairTokenizer`, or `SentencePieceTokenizer`.
+
+In this workflow we train a custom tokenizer on the IMDB data and design a backbone with
+custom transformer architecture. For simplicity we then train directly on the
+classification task. Interested in more details? We wrote an entire guide to pretraining
+and finetuning a custom transformer on
+[keras.io](https://keras.io/guides/keras_nlp/transformer_pretraining/),
+"""
+
+"""
+### Train custom vocabulary from IMBD data
+"""
+
+vocab = keras_nlp.tokenizers.compute_word_piece_vocabulary(
+ imdb_train.map(lambda x, y: x),
+ vocabulary_size=20_000,
+ lowercase=True,
+ strip_accents=True,
+ reserved_tokens=["[PAD]", "[START]", "[END]", "[MASK]", "[UNK]"],
+)
+tokenizer = keras_nlp.tokenizers.WordPieceTokenizer(
+ vocabulary=vocab,
+ lowercase=True,
+ strip_accents=True,
+ oov_token="[UNK]",
+)
+
+"""
+### Preprocess data with custom tokenizer
+"""
+
+packer = keras_nlp.layers.StartEndPacker(
+ start_value=tokenizer.token_to_id("[START]"),
+ end_value=tokenizer.token_to_id("[END]"),
+ pad_value=tokenizer.token_to_id("[PAD]"),
+ sequence_length=512,
+)
+
+
+def preprocess(x, y):
+ token_ids = packer(tokenizer(x))
+ return token_ids, y
+
+
+imdb_preproc_train_ds = imdb_train.map(
+ preprocess, num_parallel_calls=tf.data.AUTOTUNE
+).prefetch(tf.data.AUTOTUNE)
+imdb_preproc_val_ds = imdb_test.map(
+ preprocess, num_parallel_calls=tf.data.AUTOTUNE
+).prefetch(tf.data.AUTOTUNE)
+
+print(imdb_preproc_train_ds.unbatch().take(1).get_single_element())
+
+"""
+
+### Design a tiny transformer
+"""
+
+token_id_input = keras.Input(
+ shape=(None,),
+ dtype="int32",
+ name="token_ids",
+)
+outputs = keras_nlp.layers.TokenAndPositionEmbedding(
+ vocabulary_size=len(vocab),
+ sequence_length=packer.sequence_length,
+ embedding_dim=64,
+)(token_id_input)
+outputs = keras_nlp.layers.TransformerEncoder(
+ num_heads=2,
+ intermediate_dim=128,
+ dropout=0.1,
+)(outputs)
+# Use "[START]" token to classify
+outputs = keras.layers.Dense(2)(outputs[:, 0, :])
+model = keras.Model(
+ inputs=token_id_input,
+ outputs=outputs,
+)
+
+model.summary()
+
+"""
+### Train the transformer directly on the classification objective
+"""
+
+model.compile(
+ loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
+ optimizer=keras.optimizers.experimental.AdamW(5e-5),
+ metrics=keras.metrics.SparseCategoricalAccuracy(),
+ jit_compile=True,
+)
+model.fit(
+ imdb_preproc_train_ds,
+ validation_data=imdb_preproc_val_ds,
+ epochs=3,
+)
+
+"""
+Excitingly, our custom classifier is similar to the performance of fine-tuning
+`"bert_tiny_en_uncased"`! To see the advantages of pretraining and exceed 90% accuracy we
+would need to use larger **presets** such as `"bert_base_en_uncased"`.
+"""
diff --git a/guides/md/keras_nlp/getting_started.md b/guides/md/keras_nlp/getting_started.md
new file mode 100644
index 0000000000..f62f724d92
--- /dev/null
+++ b/guides/md/keras_nlp/getting_started.md
@@ -0,0 +1,992 @@
+# Getting Started with KerasNLP
+
+**Author:** [jbischof](https://github.com/jbischof)
+**Date created:** 2022/12/15
+**Last modified:** 2022/12/15
+**Description:** An introduction to the KerasNLP API.
+
+
+ [**View in Colab**](https://colab.research.google.com/github/keras-team/keras-io/blob/master/guides/ipynb/keras_nlp/getting_started.ipynb) •
[**View in Colab**](https://colab.research.google.com/github/keras-team/keras-io/blob/master/guides/ipynb/keras_nlp/getting_started.ipynb) • [**GitHub source**](https://github.com/keras-team/keras-io/blob/master/guides/keras_nlp/getting_started.py)
+
+
+
+---
+## Introduction
+
+KerasNLP is a natural language processing library that supports users through
+their entire development cycle. Our workflows are built from modular components
+that have state-of-the-art preset weights and architectures when used
+out-of-the-box and are easily customizable when more control is needed. We
+emphasize in-graph computation for all workflows so that developers can expect
+easy productionization using the TensorFlow ecosystem.
+
+This library is an extension of the core Keras API; all high level modules are
+[`Layers`](/api/layers/) or [`Models`](/api/models/). If you are familiar with Keras,
+congratulations! You already understand most of KerasNLP.
+
+This guide demonstrates our modular approach using a sentiment analysis example at six
+levels of complexity:
+
+* Inference with a pretrained classifier
+* Fine tuning a pretrained backbone
+* Fine tuning with user-controlled preprocessing
+* Fine tuning a custom model
+* Pretraining a backbone model
+* Build and train your own transformer from scratch
+
+Throughout our guide we use Professor Keras, the official Keras mascot, as a visual
+reference for the complexity of the material:
+
+
+
+
+```python
+import keras_nlp
+import tensorflow as tf
+from tensorflow import keras
+
+# Use mixed precision for optimal performance
+keras.mixed_precision.set_global_policy("mixed_float16")
+```
+
+
[**GitHub source**](https://github.com/keras-team/keras-io/blob/master/guides/keras_nlp/getting_started.py)
+
+
+
+---
+## Introduction
+
+KerasNLP is a natural language processing library that supports users through
+their entire development cycle. Our workflows are built from modular components
+that have state-of-the-art preset weights and architectures when used
+out-of-the-box and are easily customizable when more control is needed. We
+emphasize in-graph computation for all workflows so that developers can expect
+easy productionization using the TensorFlow ecosystem.
+
+This library is an extension of the core Keras API; all high level modules are
+[`Layers`](/api/layers/) or [`Models`](/api/models/). If you are familiar with Keras,
+congratulations! You already understand most of KerasNLP.
+
+This guide demonstrates our modular approach using a sentiment analysis example at six
+levels of complexity:
+
+* Inference with a pretrained classifier
+* Fine tuning a pretrained backbone
+* Fine tuning with user-controlled preprocessing
+* Fine tuning a custom model
+* Pretraining a backbone model
+* Build and train your own transformer from scratch
+
+Throughout our guide we use Professor Keras, the official Keras mascot, as a visual
+reference for the complexity of the material:
+
+
+
+
+```python
+import keras_nlp
+import tensorflow as tf
+from tensorflow import keras
+
+# Use mixed precision for optimal performance
+keras.mixed_precision.set_global_policy("mixed_float16")
+```
+
+
+```
+INFO:tensorflow:Mixed precision compatibility check (mixed_float16): OK
+
+```
+
+---
+## API quickstart
+
+Our highest level API is `keras_nlp.models`. These symbols cover the complete user
+journey of converting strings to tokens, tokens to dense features, and dense features to
+task-specific output. For each `XX` architecture (e.g., `Bert`), we offer the following
+modules:
+
+* **Tokenizer**: `keras_nlp.models.XXTokenizer`
+ * **What it does**: Converts strings to `tf.RaggedTensor`s of token ids.
+ * **Why it's important**: The raw bytes of a string are too high dimensional to be useful
+ features so we first map them to a small number of tokens, for example `"The quick brown
+ fox"` to `["the", "qu", "##ick", "br", "##own", "fox"]`.
+ * **Inherits from**: `keras.layers.Layer`.
+* **Preprocessor**: `keras_nlp.models.XXPreprocessor`
+ * **What it does**: Converts strings to a dictonary of preprocessed tensors consumed by
+ the backbone, starting with tokenization.
+ * **Why it's important**: Each model uses special tokens and extra tensors to understand
+ the input such as deliminting input segments and identifying padding tokens. Padding each
+ sequence to the same length improves computational efficiency.
+ * **Has a**: `XXTokenizer`.
+ * **Inherits from**: `keras.layers.Layer`.
+* **Backbone**: `keras_nlp.models.XXBackbone`
+ * **What it does**: Converts preprocessed tensors to dense features. *Does not handle
+ strings; call the preprocessor first.*
+ * **Why it's important**: The backbone distills the input tokens into dense features that
+ can be used in downstream tasks. It is generally pretrained on a language modeling task
+ using massive amounts of unlabeled data. Transfering this information to a new task is a
+ major breakthrough in modern NLP.
+ * **Inherits from**: `keras.Model`.
+* **Task**: e.g., `keras_nlp.models.XXClassifier`
+ * **What it does**: Converts strings to task-specific output (e.g., classification
+ probabilities).
+ * **Why it's important**: Task models combine string preprocessing and the backbone model
+ with task-specific `Layers` to solve a problem such as sentence classification, token
+ classification, or text generation. The additional `Layers` must be fine-tuned on labeled
+ data.
+ * **Has a**: `XXBackbone` and `XXPreprocessor`.
+ * **Inherits from**: `keras.Model`.
+
+Here is the modular hierarchy for `BertClassifier` (all relationships are compositional):
+
+
+
+All modules can be used independently and have a `from_preset()` method in addition to
+the standard constructor that instantiates the class with **preset** architecture and
+weights (see examples below).
+
+---
+## Data
+
+We will use a running example of sentiment analysis of IMDB movie reviews. In this task,
+we use the text to predict whether the review was positive (`label = 1`) or negative
+(`label = 0`).
+
+We load the data using `keras.utils.text_dataset_from_directory`, which utilizes the
+powerful `tf.data.Dataset` format for examples.
+
+
+```python
+!curl -O https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
+!tar -xf aclImdb_v1.tar.gz
+!# Remove unsupervised examples
+!rm -r aclImdb/train/unsup
+```
+
+```python
+BATCH_SIZE = 16
+imdb_train = tf.keras.preprocessing.text_dataset_from_directory(
+ "aclImdb/train",
+ batch_size=BATCH_SIZE,
+)
+imdb_test = tf.keras.preprocessing.text_dataset_from_directory(
+ "aclImdb/test",
+ batch_size=BATCH_SIZE,
+)
+
+# Inspect first review
+# Format is (review text tensor, label tensor)
+print(imdb_train.unbatch().take(1).get_single_element())
+```
+
+```
+ % Total % Received % Xferd Average Speed Time Time Time Current
+ Dload Upload Total Spent Left Speed
+100 80.2M 100 80.2M 0 0 91.2M 0 --:--:-- --:--:-- --:--:-- 91.2M
+
+Found 25000 files belonging to 2 classes.
+Found 25000 files belonging to 2 classes.
+(, )
+
+```
+
+---
+## Inference with a pretrained classifier
+
+
+
+The highest level module in KerasNLP is a **task**. A **task** is a `keras.Model`
+consisting of a (generally pretrained) **backbone** model and task-specific layers.
+Here's an example using `keras_nlp.models.BertClassifier`.
+
+**Note**: Outputs are the logits per class (e.g., `[0, 0]` is 50% chance of positive).
+
+
+```python
+classifier = keras_nlp.models.BertClassifier.from_preset("bert_tiny_en_uncased_sst2")
+# Note: batched inputs expected so must wrap string in iterable
+classifier.predict(["I love modular workflows in keras-nlp!"])
+```
+
+
+```
+1/1 [==============================] - 1s 1s/step
+
+array([[-1.54 , 1.543]], dtype=float16)
+
+```
+
+All **tasks** have a `from_preset` method that constructs a `keras.Model` instance with
+preset preprocessing, architecture and weights. This means that we can pass raw strings
+in any format accepted by a `keras.Model` and get output specific to our task.
+
+This particular **preset** is a `"bert_tiny_uncased_en"` **backbone** fine-tuned on
+`sst2`, another movie review sentiment analysis (this time from Rotten Tomatoes). We use
+the `tiny` architecture for demo purposes, but larger models are recommended for SoTA
+performance. For all the task-specific presets available for `BertClassifier`, see
+our keras.io [models page](https://keras.io/api/keras_nlp/models/).
+
+Let's evaluate our classifier on the IMDB dataset. We first need to compile the
+`keras.Model`. The output is `[loss, accuracy]`,
+
+**Note**: We don't need an optimizer since we're not training the model.
+
+
+```python
+classifier.compile(
+ loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
+ metrics=keras.metrics.SparseCategoricalAccuracy(),
+ jit_compile=True,
+)
+
+classifier.evaluate(imdb_test)
+```
+
+
+```
+1563/1563 [==============================] - 16s 10ms/step - loss: 0.4630 - sparse_categorical_accuracy: 0.7837
+
+[0.4629555940628052, 0.7836800217628479]
+
+```
+
+Our result is 78% accuracy without training anything. Not bad!
+
+---
+## Fine tuning a pretrained BERT backbone
+
+
+
+When labeled text specific to our task is available, fine-tuning a custom classifier can
+improve performance. If we want to predict IMDB review sentiment, using IMDB data should
+perform better than Rotten Tomatoes data! And for many tasks no relevant pretrained model
+will be available (e.g., categorizing customer reviews).
+
+The workflow for fine-tuning is almost identical to above, except that we request a
+**preset** for the **backbone**-only model rather than the entire classifier. When passed
+a **backone** **preset**, a **task** `Model` will randomly initialize all task-specific
+layers in preparation for training. For all the **backbone** presets available for
+`BertClassifier`, see our keras.io [models page](https://keras.io/api/keras_nlp/models/).
+
+To train your classifier, use `Model.compile()` and `Model.fit()` as with any other
+`keras.Model`. Since preprocessing is included in all **tasks** by default, we again pass
+the raw data.
+
+
+```python
+classifier = keras_nlp.models.BertClassifier.from_preset(
+ "bert_tiny_en_uncased",
+ num_classes=2,
+)
+classifier.compile(
+ loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
+ optimizer=keras.optimizers.experimental.AdamW(5e-5),
+ metrics=keras.metrics.SparseCategoricalAccuracy(),
+ jit_compile=True,
+)
+classifier.fit(
+ imdb_train,
+ validation_data=imdb_test,
+ epochs=1,
+)
+```
+
+
+```
+1563/1563 [==============================] - 183s 113ms/step - loss: 0.4156 - sparse_categorical_accuracy: 0.8085 - val_loss: 0.3088 - val_sparse_categorical_accuracy: 0.8687
+
+
+
+```
+
+Here we see significant lift in validation accuracy (0.78 -> 0.87) with a single epoch of
+training even though the IMDB dataset is much smaller than `sst2`.
+
+---
+## Fine tuning with user-controlled preprocessing
+
+
+For some advanced training scenarios, users might prefer direct control over
+preprocessing. For large datasets, examples can be preprocessed in advance and saved to
+disk or preprocessed by a separate worker pool using `tf.data.experimental.service`. In
+other cases, custom preprocessing is needed to handle the inputs.
+
+Pass `preprocessor=None` to the constructor of a **task** `Model` to skip automatic
+preprocessing or pass a custom `BertPreprocessor` instead.
+
+### Separate preprocessing from the same preset
+
+Each model architecture has a parallel **preprocessor** `Layer` with its own
+`from_preset` constructor. Using the same **preset** for this `Layer` will return the
+matching **preprocessor** as the **task**.
+
+In this workflow we train the model over three epochs using `tf.data.Dataset.cache()`,
+which computes the preprocessing once and caches the result before fitting begins.
+
+**Note:** this code only works if your data fits in memory. If not, pass a `filename` to
+`cache()`.
+
+
+```python
+preprocessor = keras_nlp.models.BertPreprocessor.from_preset(
+ "bert_tiny_en_uncased",
+ sequence_length=512,
+)
+
+imdb_train_cached = (
+ imdb_train.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
+)
+imdb_test_cached = (
+ imdb_test.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
+)
+
+classifier = keras_nlp.models.BertClassifier.from_preset(
+ "bert_tiny_en_uncased",
+ preprocessor=None,
+)
+classifier.compile(
+ loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
+ optimizer=keras.optimizers.experimental.AdamW(5e-5),
+ metrics=keras.metrics.SparseCategoricalAccuracy(),
+ jit_compile=True,
+)
+classifier.fit(
+ imdb_train_cached,
+ validation_data=imdb_test_cached,
+ epochs=3,
+)
+```
+
+
+```
+Epoch 1/3
+1563/1563 [==============================] - 172s 106ms/step - loss: 0.4133 - sparse_categorical_accuracy: 0.8096 - val_loss: 0.3109 - val_sparse_categorical_accuracy: 0.8690
+Epoch 2/3
+1563/1563 [==============================] - 153s 98ms/step - loss: 0.2666 - sparse_categorical_accuracy: 0.8948 - val_loss: 0.2932 - val_sparse_categorical_accuracy: 0.8792
+Epoch 3/3
+1563/1563 [==============================] - 154s 99ms/step - loss: 0.1961 - sparse_categorical_accuracy: 0.9255 - val_loss: 0.3505 - val_sparse_categorical_accuracy: 0.8664
+
+
+
+```
+
+After three epochs, our validation accuracy has only increased to 0.88. This is both a
+function of the small size of our dataset and our model. To exceed 90% accuracy, try
+larger **presets** such as `"bert_base_en_uncased"`. For all the **backbone** presets
+available for `BertClassifier`, see our keras.io [models page](https://keras.io/api/keras_nlp/models/).
+
+### Custom preprocessing
+
+In cases where custom preprocessing is required, we offer direct access to the
+`Tokenizer` class that maps raw strings to tokens. It also has a `from_preset()`
+constructor to get the vocabulary matching pretraining.
+
+**Note:** `BertTokenizer` does not pad sequences by default, so the output is
+a `tf.RaggedTensor`.
+
+
+```python
+tokenizer = keras_nlp.models.BertTokenizer.from_preset("bert_tiny_en_uncased")
+tokenizer(["I love modular workflows!", "Libraries over frameworks!"])
+
+# Write your own packer or use one our `Layers`
+packer = keras_nlp.layers.MultiSegmentPacker(
+ start_value=tokenizer.cls_token_id,
+ end_value=tokenizer.sep_token_id,
+ # Note: This cannot be longer than the preset's `sequence_length`, and there
+ # is no check for a custom preprocessor!
+ sequence_length=64,
+)
+
+
+def preprocessor(x, y):
+ token_ids, segment_ids = packer(tokenizer(x))
+ x = {
+ "token_ids": token_ids,
+ "segment_ids": segment_ids,
+ "padding_mask": token_ids != 0,
+ }
+ return x, y
+
+
+imbd_train_preprocessed = imdb_train.map(preprocessor, tf.data.AUTOTUNE).prefetch(
+ tf.data.AUTOTUNE
+)
+imdb_test_preprocessed = imdb_test.map(preprocessor, tf.data.AUTOTUNE).prefetch(
+ tf.data.AUTOTUNE
+)
+
+# Preprocessed example
+print(imbd_train_preprocessed.unbatch().take(1).get_single_element())
+```
+
+
+```
+({'token_ids': , 'segment_ids': , 'padding_mask': }, )
+
+```
+
+---
+## Fine tuning with a custom model
+
+
+For more advanced applications, an appropriate **task** `Model` may not be available. In
+this case we provide direct access to the **backbone** `Model`, which has its own
+`from_preset` constructor and can be composed with custom `Layer`s. Detailed examples can
+be found at our [transfer learning guide](https://keras.io/guides/transfer_learning/).
+
+A **backbone** `Model` does not include automatic preprocessing but can be paired with a
+matching **preprocessor** using the same **preset** as shown in the previous workflow.
+
+In this workflow we experiment with freezing our backbone model and adding two trainable
+transfomer layers to adapt to the new input.
+
+**Note**: We can igonore the warning about gradients for the `pooled_dense` layer because
+we are using BERT's sequence output.
+
+
+```python
+preprocessor = keras_nlp.models.BertPreprocessor.from_preset("bert_tiny_en_uncased")
+backbone = keras_nlp.models.BertBackbone.from_preset("bert_tiny_en_uncased")
+
+imdb_train_preprocessed = (
+ imdb_train.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
+)
+imdb_test_preprocessed = (
+ imdb_test.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
+)
+
+backbone.trainable = False
+inputs = backbone.input
+sequence = backbone(inputs)["sequence_output"]
+for _ in range(2):
+ sequence = keras_nlp.layers.TransformerEncoder(
+ num_heads=2,
+ intermediate_dim=512,
+ dropout=0.1,
+ )(sequence)
+# Use [CLS] token output to classify
+outputs = keras.layers.Dense(2)(sequence[:, backbone.cls_token_index, :])
+
+model = keras.Model(inputs, outputs)
+model.compile(
+ loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
+ optimizer=keras.optimizers.experimental.AdamW(5e-5),
+ metrics=keras.metrics.SparseCategoricalAccuracy(),
+ jit_compile=True,
+)
+model.summary()
+model.fit(
+ imdb_train_preprocessed,
+ validation_data=imdb_test_preprocessed,
+ epochs=3,
+)
+```
+
+
+```
+Model: "model"
+__________________________________________________________________________________________________
+ Layer (type) Output Shape Param # Connected to
+==================================================================================================
+ padding_mask (InputLayer) [(None, None)] 0 []
+
+ segment_ids (InputLayer) [(None, None)] 0 []
+
+ token_ids (InputLayer) [(None, None)] 0 []
+
+ bert_backbone_3 (BertBackbone) {'sequence_output': 4385920 ['padding_mask[0][0]',
+ (None, None, 128), 'segment_ids[0][0]',
+ 'pooled_output': ( 'token_ids[0][0]']
+ None, 128)}
+
+ transformer_encoder (Transform (None, None, 128) 198272 ['bert_backbone_3[0][1]']
+ erEncoder)
+
+ transformer_encoder_1 (Transfo (None, None, 128) 198272 ['transformer_encoder[0][0]']
+ rmerEncoder)
+
+ tf.__operators__.getitem_4 (Sl (None, 128) 0 ['transformer_encoder_1[0][0]']
+ icingOpLambda)
+
+ dense (Dense) (None, 2) 258 ['tf.__operators__.getitem_4[0][0
+ ]']
+
+==================================================================================================
+Total params: 4,782,722
+Trainable params: 396,802
+Non-trainable params: 4,385,920
+__________________________________________________________________________________________________
+Epoch 1/3
+1563/1563 [==============================] - 34s 17ms/step - loss: 0.5811 - sparse_categorical_accuracy: 0.6941 - val_loss: 0.5046 - val_sparse_categorical_accuracy: 0.7554
+Epoch 2/3
+1563/1563 [==============================] - 18s 11ms/step - loss: 0.4859 - sparse_categorical_accuracy: 0.7686 - val_loss: 0.4235 - val_sparse_categorical_accuracy: 0.8056
+Epoch 3/3
+1563/1563 [==============================] - 17s 11ms/step - loss: 0.4405 - sparse_categorical_accuracy: 0.7947 - val_loss: 0.3994 - val_sparse_categorical_accuracy: 0.8198
+
+
+
+```
+
+This model achieves reasonable accuracy despite having only 10% the trainable parameters
+of our `BertClassifier` model. Each training step takes about 1/3 of the time---even
+accounting for cached preprocessing.
+
+---
+## Pretraining a backbone model
+
+
+Do you have access to large unlabeled datasets in your domain? Are they are around the
+same size as used to train popular backbones such as BERT, RoBERTa, or GPT2 (XX+ GiB)? If
+so, you might benefit from domain-specific pretraining of your own backbone models.
+
+NLP models are generally pretrained on a language modeling task, predicting masked words
+given the visible words in an input sentence. For example, given the input
+`"The fox [MASK] over the [MASK] dog"`, the model might be asked to predict `["jumped", "lazy"]`.
+The lower layers of this model are then packaged as a **backbone** to be combined with
+layers relating to a new task.
+
+The KerasNLP library offers SoTA **backbones** and **tokenizers** to be trained from
+scratch without presets.
+
+In this workflow we pretrain a BERT **backbone** using our IMDB review text. We skip the
+"next sentence prediction" (NSP) loss because it adds significant complexity to the data
+processing and was dropped by later models like RoBERTa. See our e2e [BERT pretraining
+example](https://github.com/keras-team/keras-nlp/tree/master/examples/bert) for
+step-by-step details on how to replicate the original paper.
+
+### Preprocessing
+
+
+```python
+# All BERT `en` models have the same vocabulary, so reuse preprocessor from
+# "bert_tiny_en_uncased"
+preprocessor = keras_nlp.models.BertPreprocessor.from_preset(
+ "bert_tiny_en_uncased",
+ sequence_length=256,
+)
+packer = preprocessor.packer
+tokenizer = preprocessor.tokenizer
+
+# keras.Layer to replace some input tokens with the "[MASK]" token
+masker = keras_nlp.layers.MaskedLMMaskGenerator(
+ vocabulary_size=tokenizer.vocabulary_size(),
+ mask_selection_rate=0.25,
+ mask_selection_length=64,
+ mask_token_id=tokenizer.token_to_id("[MASK]"),
+ unselectable_token_ids=[
+ tokenizer.token_to_id(x) for x in ["[CLS]", "[PAD]", "[SEP]"]
+ ],
+)
+
+
+def preprocess(inputs, label):
+ inputs = preprocessor(inputs)
+ masked_inputs = masker(inputs["token_ids"])
+ # Split the masking layer outputs into a (features, labels, and weights)
+ # tuple that we can use with keras.Model.fit().
+ features = {
+ "token_ids": masked_inputs["token_ids"],
+ "segment_ids": inputs["segment_ids"],
+ "padding_mask": inputs["padding_mask"],
+ "mask_positions": masked_inputs["mask_positions"],
+ }
+ labels = masked_inputs["mask_ids"]
+ weights = masked_inputs["mask_weights"]
+ return features, labels, weights
+
+
+pretrain_ds = imdb_train.map(preprocess, num_parallel_calls=tf.data.AUTOTUNE).prefetch(
+ tf.data.AUTOTUNE
+)
+pretrain_val_ds = imdb_test.map(
+ preprocess, num_parallel_calls=tf.data.AUTOTUNE
+).prefetch(tf.data.AUTOTUNE)
+
+# Tokens with ID 103 are "masked"
+print(pretrain_ds.unbatch().take(1).get_single_element())
+```
+
+
+```
+({'token_ids': , 'segment_ids': , 'padding_mask': , 'mask_positions': }, , )
+
+```
+
+### Pretraining model
+
+
+```python
+# BERT backbone
+backbone = keras_nlp.models.BertBackbone(
+ vocabulary_size=tokenizer.vocabulary_size(),
+ num_layers=2,
+ num_heads=2,
+ hidden_dim=128,
+ intermediate_dim=512,
+)
+
+# Language modeling head
+mlm_head = keras_nlp.layers.MaskedLMHead(
+ embedding_weights=backbone.token_embedding.embeddings,
+)
+
+inputs = {
+ "token_ids": keras.Input(shape=(None,), dtype=tf.int32),
+ "segment_ids": keras.Input(shape=(None,), dtype=tf.int32),
+ "padding_mask": keras.Input(shape=(None,), dtype=tf.int32),
+ "mask_positions": keras.Input(shape=(None,), dtype=tf.int32),
+}
+
+# Encoded token sequence
+sequence = backbone(inputs)["sequence_output"]
+
+# Predict an output word for each masked input token.
+# We use the input token embedding to project from our encoded vectors to
+# vocabulary logits, which has been shown to improve training efficiency.
+outputs = mlm_head(sequence, mask_positions=inputs["mask_positions"])
+
+# Define and compile our pretraining model.
+pretraining_model = keras.Model(inputs, outputs)
+pretraining_model.summary()
+pretraining_model.compile(
+ loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
+ optimizer=keras.optimizers.experimental.AdamW(learning_rate=5e-4),
+ weighted_metrics=keras.metrics.SparseCategoricalAccuracy(),
+ jit_compile=True,
+)
+
+# Pretrain on IMDB dataset
+pretraining_model.fit(
+ pretrain_ds,
+ validation_data=pretrain_val_ds,
+ epochs=3, # Increase to 6 for higher accuracy
+)
+```
+
+
+```
+Model: "model_1"
+__________________________________________________________________________________________________
+ Layer (type) Output Shape Param # Connected to
+==================================================================================================
+ input_4 (InputLayer) [(None, None)] 0 []
+
+ input_3 (InputLayer) [(None, None)] 0 []
+
+ input_2 (InputLayer) [(None, None)] 0 []
+
+ input_1 (InputLayer) [(None, None)] 0 []
+
+ bert_backbone_4 (BertBackbone) {'sequence_output': 4385920 ['input_4[0][0]',
+ (None, None, 128), 'input_3[0][0]',
+ 'pooled_output': ( 'input_2[0][0]',
+ None, 128)} 'input_1[0][0]']
+
+ masked_lm_head (MaskedLMHead) (None, None, 30522) 3954106 ['bert_backbone_4[0][1]',
+ 'input_4[0][0]']
+
+==================================================================================================
+Total params: 4,433,210
+Trainable params: 4,433,210
+Non-trainable params: 0
+__________________________________________________________________________________________________
+
+/home/matt/miniconda3/envs/keras-io/lib/python3.9/site-packages/keras/engine/functional.py:638: UserWarning: Input dict contained keys ['mask_positions'] which did not match any model input. They will be ignored by the model.
+ inputs = self._flatten_to_reference_inputs(inputs)
+
+Epoch 1/3
+WARNING:tensorflow:Gradients do not exist for variables ['pooled_dense/kernel:0', 'pooled_dense/bias:0'] when minimizing the loss. If you're using `model.compile()`, did you forget to provide a `loss` argument?
+WARNING:tensorflow:Gradients do not exist for variables ['pooled_dense/kernel:0', 'pooled_dense/bias:0'] when minimizing the loss. If you're using `model.compile()`, did you forget to provide a `loss` argument?
+1563/1563 [==============================] - 68s 39ms/step - loss: 5.2595 - sparse_categorical_accuracy: 0.0866 - val_loss: 4.9751 - val_sparse_categorical_accuracy: 0.1144
+Epoch 2/3
+1563/1563 [==============================] - 58s 37ms/step - loss: 4.9573 - sparse_categorical_accuracy: 0.1244 - val_loss: 4.8743 - val_sparse_categorical_accuracy: 0.1310
+Epoch 3/3
+1563/1563 [==============================] - 57s 37ms/step - loss: 4.8230 - sparse_categorical_accuracy: 0.1440 - val_loss: 4.6139 - val_sparse_categorical_accuracy: 0.1837
+
+
+
+```
+
+After pretraining save your `backbone` submodel to use in a new task!
+
+---
+## Build and train your own transformer from scratch
+
+
+Want to implement a novel transformer architecture? The KerasNLP library offers all the
+low-level modules used to build SoTA architectures in our `models` API. This includes the
+`keras_nlp.tokenizers` API which allows you to train your own subword tokenizer using
+`WordPieceTokenizer`, `BytePairTokenizer`, or `SentencePieceTokenizer`.
+
+In this workflow we train a custom tokenizer on the IMDB data and design a backbone with
+custom transformer architecture. For simplicity we then train directly on the
+classification task. Interested in more details? We wrote an entire guide to pretraining
+and finetuning a custom transformer on
+[keras.io](https://keras.io/guides/keras_nlp/transformer_pretraining/),
+
+### Train custom vocabulary from IMBD data
+
+
+```python
+vocab = keras_nlp.tokenizers.compute_word_piece_vocabulary(
+ imdb_train.map(lambda x, y: x),
+ vocabulary_size=20_000,
+ lowercase=True,
+ strip_accents=True,
+ reserved_tokens=["[PAD]", "[START]", "[END]", "[MASK]", "[UNK]"],
+)
+tokenizer = keras_nlp.tokenizers.WordPieceTokenizer(
+ vocabulary=vocab,
+ lowercase=True,
+ strip_accents=True,
+ oov_token="[UNK]",
+)
+```
+
+### Preprocess data with custom tokenizer
+
+
+```python
+packer = keras_nlp.layers.StartEndPacker(
+ start_value=tokenizer.token_to_id("[START]"),
+ end_value=tokenizer.token_to_id("[END]"),
+ pad_value=tokenizer.token_to_id("[PAD]"),
+ sequence_length=512,
+)
+
+
+def preprocess(x, y):
+ token_ids = packer(tokenizer(x))
+ return token_ids, y
+
+
+imdb_preproc_train_ds = imdb_train.map(
+ preprocess, num_parallel_calls=tf.data.AUTOTUNE
+).prefetch(tf.data.AUTOTUNE)
+imdb_preproc_val_ds = imdb_test.map(
+ preprocess, num_parallel_calls=tf.data.AUTOTUNE
+).prefetch(tf.data.AUTOTUNE)
+
+print(imdb_preproc_train_ds.unbatch().take(1).get_single_element())
+```
+
+
+```
+(, )
+
+```
+
+### Design a tiny transformer
+
+
+```python
+token_id_input = keras.Input(
+ shape=(None,),
+ dtype="int32",
+ name="token_ids",
+)
+outputs = keras_nlp.layers.TokenAndPositionEmbedding(
+ vocabulary_size=len(vocab),
+ sequence_length=packer.sequence_length,
+ embedding_dim=64,
+)(token_id_input)
+outputs = keras_nlp.layers.TransformerEncoder(
+ num_heads=2,
+ intermediate_dim=128,
+ dropout=0.1,
+)(outputs)
+# Use "[START]" token to classify
+outputs = keras.layers.Dense(2)(outputs[:, 0, :])
+model = keras.Model(
+ inputs=token_id_input,
+ outputs=outputs,
+)
+
+model.summary()
+```
+
+
+```
+Model: "model_2"
+_________________________________________________________________
+ Layer (type) Output Shape Param #
+=================================================================
+ token_ids (InputLayer) [(None, None)] 0
+
+ token_and_position_embeddin (None, None, 64) 1259648
+ g (TokenAndPositionEmbeddin
+ g)
+
+ transformer_encoder_2 (Tran (None, None, 64) 33472
+ sformerEncoder)
+
+ tf.__operators__.getitem_6 (None, 64) 0
+ (SlicingOpLambda)
+
+ dense_1 (Dense) (None, 2) 130
+
+=================================================================
+Total params: 1,293,250
+Trainable params: 1,293,250
+Non-trainable params: 0
+_________________________________________________________________
+
+```
+
+### Train the transformer directly on the classification objective
+
+
+```python
+model.compile(
+ loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
+ optimizer=keras.optimizers.experimental.AdamW(5e-5),
+ metrics=keras.metrics.SparseCategoricalAccuracy(),
+ jit_compile=True,
+)
+model.fit(
+ imdb_preproc_train_ds,
+ validation_data=imdb_preproc_val_ds,
+ epochs=3,
+)
+```
+
+
+```
+Epoch 1/3
+1563/1563 [==============================] - 81s 50ms/step - loss: 0.6350 - sparse_categorical_accuracy: 0.6133 - val_loss: 0.4307 - val_sparse_categorical_accuracy: 0.8206
+Epoch 2/3
+1563/1563 [==============================] - 77s 49ms/step - loss: 0.3256 - sparse_categorical_accuracy: 0.8674 - val_loss: 0.3166 - val_sparse_categorical_accuracy: 0.8699
+Epoch 3/3
+1563/1563 [==============================] - 77s 49ms/step - loss: 0.2482 - sparse_categorical_accuracy: 0.9009 - val_loss: 0.2934 - val_sparse_categorical_accuracy: 0.8816
+
+
+
+```
+
+Excitingly, our custom classifier is similar to the performance of fine-tuning
+`"bert_tiny_en_uncased"`! To see the advantages of pretraining and exceed 90% accuracy we
+would need to use larger **presets** such as `"bert_base_en_uncased"`.
diff --git a/scripts/guides_master.py b/scripts/guides_master.py
index 9d36a1b81e..7208b3cdf2 100644
--- a/scripts/guides_master.py
+++ b/scripts/guides_master.py
@@ -28,6 +28,10 @@
"title": "KerasNLP",
"toc": True,
"children": [
+ {
+ "path": "getting_started",
+ "title": "Getting Started with KerasNLP",
+ },
{
"path": "transformer_pretraining",
"title": "Pretraining a Transformer from scratch with KerasNLP",
diff --git a/templates/keras_nlp/index.md b/templates/keras_nlp/index.md
index 1f859b67ea..785047af93 100644
--- a/templates/keras_nlp/index.md
+++ b/templates/keras_nlp/index.md
@@ -31,9 +31,10 @@ check out our
---
## Guides
-* [Getting Started with KerasNLP](/guides/keras-nlp/getting_started/)
+* [Getting Started with KerasNLP](/guides/keras_nlp/getting_started/)
* [Pretraining a Transformer from scratch](/guides/keras_nlp/transformer_pretraining/)
+
---
## Examples